Embed Size (px)
Citation preview

CAPITOLO 1.
La rappresentazione dell’informazione
Il corso affronta i concetti fondamentali dell’informazione e della codifica,
necessari per comprendere come le tecniche di codifiche si sono evolute
seguendo i principi fondamentali, compatibilmente con i vincoli di complessità
realizzativi.
In particolare sono due gli argomenti che verranno affrontati :
• RAPPRESENTAZIONE DELL’INFORMAZIONE
• ELABORAZIONE DELL’INFORMAZIONE
I due argomenti sono strettamente correlati tra di loro: infatti se non so come
rappresentare determinate informazioni non so nemmeno come elaborale, quindi
data una determinata rappresentazione dell’informazione, esistono dei criteri di
elaborazione.
Tali criteri dovranno essere i più semplici possibili: dovranno essere cioè
meccanici, matematici
Prima di passare affrontare il primo argomento, e cioè la rappresentazione del
informazione, si da un breve accenno sui termini tecnologie e principi.
Si tratta di due concetti che vanno abbastanza indipendenti l’uno dall’altro: ad
esempio all’interno di un oggetto tecnologicamente avanzato ci possono essere
gli stessi principi di funzionamento che si trovavano in un calcolatore degli anni
50. Questo per dire che i principi sono gli enunciati, i concetti che stanno alla
base del funzionamento dei moderni sistemi di comunicazione, mentre le
tecnologie sono i mezzi attraverso i quali vengono attuati i principi e che
rispetto a questi ultimi, si evolvono continuamente.
Il corso si focalizza sui principi e in parte sui vari modi di rappresentare
l’informazione: questo argomento è trattato dalla teoria dell’informazione che è la
teoria fondamentale dietro tutto lo sviluppo della comunicazione digitale.
Il primo concetto fondamentale da cui partire è capire che cosa significa dare
un informazione a qualcuno.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
2
La teoria dell’informazione, considera l’informazione una selezione di
uno di tanti possibili concetti, oggetti o elementi già posseduti nel
patrimonio del ricevente.
La cosa importante da tenere presente, è dunque l’esistenza di uno spazio di
oggetti, di idee, elementi che a priori stanno nel ricevente: il passaggio
dell’informazione non è dire una cosa nuova, ma è dire una cosa che ci si poteva
aspettare, in quanto faceva parte di una delle conoscenze che potevo avere tra le
tante possibilità.
Possiamo rappresentare le tante informazioni di base che già possedute in questo
modo:
N := (s1, s
2 ......... s
n-1 )
Un numero finito di elementi ovvero informazioni che stanno nel patrimonio del
ricevente: questo insieme lo chiamiamo INSIEME INFORMATIVO e che
indichiamo con N.
L’informazione consiste dunque nel selezionare uno specifico elemento
tra questi n-1 possibili elementi si posseduti dal ricevente.1
Consideriamo un esempio di come può avvenire una selezione anche avendo
come interlocutore anziché una macchina una persona, supponiamo di voler
comunicare o trasmettere una parola della lingua italiana; in questo caso una
prima selezione che attua, tra tutto l’insieme informativo già posseduto, è
quella di eliminare tutte le parole che non sono italiane (quindi si è già eliminato
una incertezza). A questo punto, si può aggiungere un altra informazione dicendo
che la parola italiana inizia per E, questo riduce ulteriormente l’insieme
informativo in quanto si escludono tutte le parole che non iniziano per E. Ogni
volta dunque che si aggiunge una lettera come ulteriore informazione, si riduce
sempre di più l’incertezza operando un’esclusione di tutto ciò che non rientra
nell’informazione data.
Pertanto ad ogni informazione si attua una selezione sempre più precisa degli
elementi dell’insieme informativo di partenza fino a che non si arriva a ad
individuare con esattezza quell’unico elemento del patrimonio informativo N.
11 Nella mente umana non è semplice quantificare il numero delle informazione che si possono detenere, in quanto queste sono una continua evoluzione
dovuta all’esperienza di vario tipo che una persona fa nel corso della propria vita.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
3
Nell’ esempio considerato ogni lettera aggiunta, quindi ogni passaggio
dell’informazione, è un meccanismo formale di riduzione dell’incertezza su N.
E’ importante sottolineare la gradualità dei passaggi: supponiamo ad esempio
che lo spazio informativo N sia costituito dai 4 punti cardinali:
S0 S1 S2 S3
Nord Sud Est Ovest
ossia di avere un incertezza limitata a 4 elementi . Si richiede un meccanismo
che, dall’ incertezza che copre tutti i quattro possibili elementi, ce ne selezioni
solamente uno.
Si potrebbe numerare queste 4 possibilità e stabilire che l’informazione che si
passa è la 1° o la 2° o la 3° o la 4°. Tuttavia questo passaggio non tiene conto
che l’informazione può essere data con selezioni successive: nell’esempio si è
costretto a ridurre l’incertezza da 4 a 1 immediatamente.
Il modo per graduare la riduzione dell’informazione è quella di scomporre la
selezione in altre 2 selezioni. Possiamo rappresentare il tutto come segue:
A
AB
B
A B
N S E W
Figura 1.1
Il grafico così come è stato costruito, individua con il percorso AA l’elemento S0.:
si è scomposta la selezione con una prima selezione a valle e un altra selezione a
monte, questo perché l’informazione per sua natura è incrementale e ci sono
tanti criteri per ridurre l’insieme dell’incertezza.
Da questo esempio si deduce che l’unica informazione che non possiamo
scomporre in altre selezioni, è quella elementare: cioè quella tra due elementi
non essendo possibili ulteriori selezioni.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
4
Si arriva dunque al concetto di UNITÀ INFORMATIVA, ossia l’elemento
informativo elementare (o minimo) che non si può scomporre ulteriormente in
parti più elementari e che mi seleziona una tra due possibilità.
Si definisce unità informativa l’elemento che permette di selezionare tra
il minimo numero di casi possibili che è due; selezionare tra due elementi
significa quindi individuare uno solo di questi. Un modo per rappresentare l’unità
informativa ad esempio, è quella di prendere due numeri naturali 0 e 1 con i quali
individuare la possibilità zero e la possibilità 1.
Alla luce di quanto è stato detto possiamo dire che questo principio di
selezione dell’informazione (selezione di un elemento informativo) operata
attraverso il passaggio graduale dell’informazione, si realizza attraverso
un meccanismo che misuriamo in BIT2.
Si definisce BIT l'unità di informazione intesa come la scelta effettuata
fra due soli eventi, simboleggiati di norma, dalle cifre binarie 0 e 1.
L’unità informativa che consente dunque di selezionare una tra due possibilità e
quindi di partizionare lo spazio delle informazioni è il BIT.
Ritornando all’esempio delle parole italiane, si è visto che attuando una prima
selezione, si arrivava ad escludere tutto quello che non era parola non italiana,
abbiamo dato quindi un primo bit di informazione che ha partizionato l’iniziale
sistema informativo in due parti: le parole italiane e tutto il resto. Aggiungendo
un altro bit di informazione, ad esempio stabilendo che la parola italiana inizia per
E; si operava un'altra selezione: si escludevano tutte le parole che non iniziavano
per E.
Detto questo, vediamo come è possibile arrivare all’informazione finale attraverso
i bit. Nell’esempio di prima dei quattro punti cardinali, già con due bit, quindi due
unità informative elementari, riuscivo a identificare 4 possibilità, volendo ora
generalizzare il discorso a n-1 possibilità possiamo osservare la seguente figura:
2 Binary Digit

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
5
?
Sn/2Sn/4S 0 S3n/4 S N -1
Figura 1.2
Sia N l’ insieme informativo che rappresentiamo in una retta indicando gli n-1
elementi.
Intuitivamente possiamo pensare ai bit come degli indicatori di direzione, che di
fronte ad un bivio, quindi una scelta da effettuare, mi indichino la strada da
percorrere: o a destra o a sinistra (sinistra=0; destra=1). Nel grafico sopra,
ipotizziamo che la prima selezione procurataci dal bit sia zero: questo come
conseguenza mi porta ad escludere la metà dell’insieme informativo di partenza,
il che significa che l’elemento che io cerco si trova alla sinistra di N, escludendo
così tutta la parte destra.
Si tratta di un risultato non indifferente poiché già dalla prima selezione, abbiamo
escluso, nella migliore delle ipotesi, metà delle possibilità: con riferimento alla
figura, questo fa si che l’informazione che mi interessa si trovi sicuramente ed
esattamente tra la prima metà a sinistra (S0 ……Sn/2) del mio insieme informativo:
quindi il primo bit mi ha indicato la giusta direzione di dove posso recuperare
l’informazione. Andando avanti con le selezioni e quindi aggiungendo un altro bit,
faccio un'altra selezione che dimezza ulteriormente l’insieme informativo a sua
volta selezionato dal primo bit.
Questo esempio serve a capire che in un insieme di possibilità che hanno tutte
la stessa probabilità di verificarsi, ogni selezione mi dimezza l’incertezza
attraverso un solo bit di informazione.
Si può vedere con un altro esempio che cosa succede ogni volta che si effettua
una selezione. Sia il seguente grafico ad albero:

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
6
0
01
1
0 1
A B C D
1’ bit di selezione
2’ bit di selezione
3’ bit di selezione
AA BB CC DD EE FF GG HH
0 0 0 01 1 1 1
Figura 1.3
Come si vede dalla figura 1.3 alla prima incertezza si individuano 2 possibilità,
alla seconda, se ne individuano 4, alla terza 8 e così via. Se pensiamo a queste
diramazioni (che da monte a valle riducono maggiormente l’incertezza) come ad
un continuo avere informazioni su qual è la direzione giusta, quindi ad ogni
diramazione o bivio si associa un bit informativo in più, capisco il potere che
hanno i bit: cioè una sequenza di bit mi fa crescere esponenzialmente la capacità
di selezionare una precisa informazioni tra tutte quelle contenute nell’ insieme
informativo N: un solo bit mi permette di selezionare un elemento tra due, due
bit di selezionare uno tra quattro, tre bit uno tra otto, 4 bit selezionano uno tra
16, eccetera.
Con riferimento alla figura 1.3, la sola sequenza di 4 bit: 1011 individua
quell’unico elemento su uno spazio di 32 elementi.
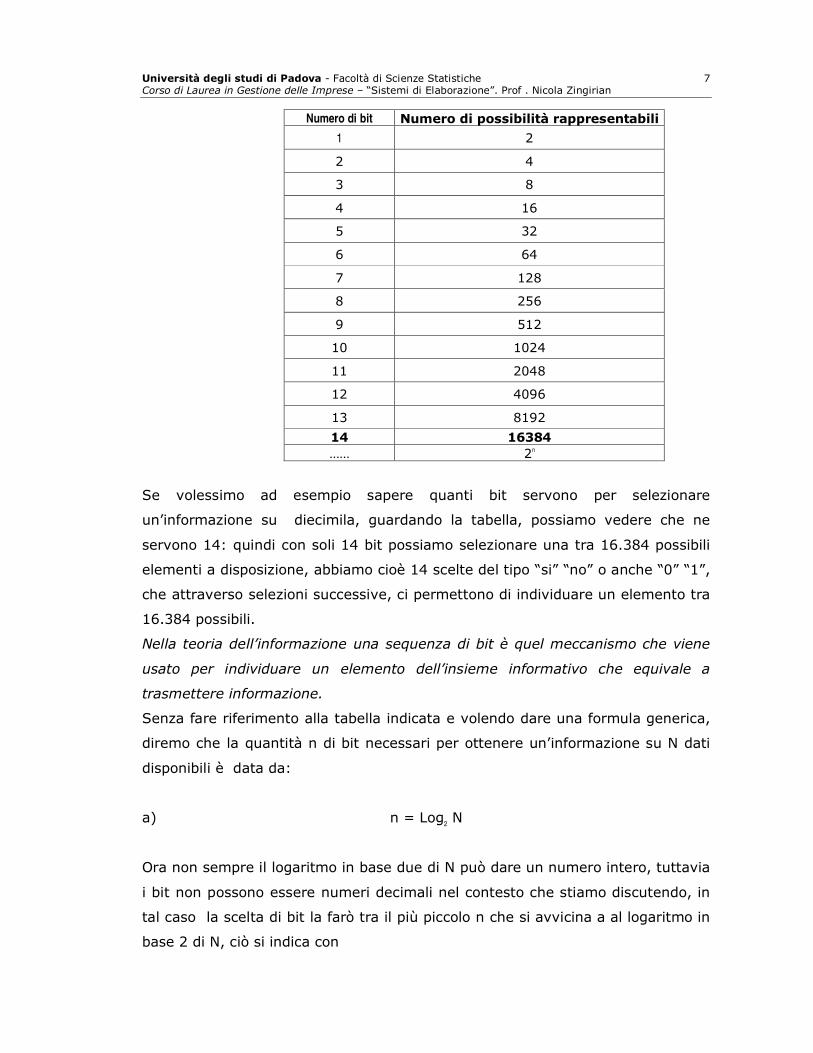
Questo porta a concludere che n bit permettono di selezionare un elemento
su 2n possibili elementi dell’insieme informativo. La capacità selettiva dei
bit è data dalla legge esponenziale 2n che a titolo rappresentativo possiamo
riportare nella seguente tabella:
Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
7
Numero di bit Numero di possibilità rappresentabili
1 2
2 4
3 8
4 16
5 32
6 64
7 128
8 256
9 512
10 1024
11 2048
12 4096
13 8192
14 16384
…… 2n
Se volessimo ad esempio sapere quanti bit servono per selezionare
un’informazione su diecimila, guardando la tabella, possiamo vedere che ne
servono 14: quindi con soli 14 bit possiamo selezionare una tra 16.384 possibili
elementi a disposizione, abbiamo cioè 14 scelte del tipo “si” “no” o anche “0” “1”,
che attraverso selezioni successive, ci permettono di individuare un elemento tra
16.384 possibili.
Nella teoria dell’informazione una sequenza di bit è quel meccanismo che viene
usato per individuare un elemento dell’insieme informativo che equivale a
trasmettere informazione.
Senza fare riferimento alla tabella indicata e volendo dare una formula generica,
diremo che la quantità n di bit necessari per ottenere un’informazione su N dati
disponibili è data da:
a) n = Log2 N
Ora non sempre il logaritmo in base due di N può dare un numero intero, tuttavia
i bit non possono essere numeri decimali nel contesto che stiamo discutendo, in
tal caso la scelta di bit la farò tra il più piccolo n che si avvicina a al logaritmo in
base 2 di N, ciò si indica con

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
8
b) n Log2 N
E si legge n estremo superiore (o soffitto) del logaritmo in base 2 di N. Individuo
cioè il numero minimo n di bit tale che:
c) Log2 N <= n
da cui consegue:
d) N < 2N
il numero delle possibilità facenti parte dell’insieme informativo N deve essere
inferiore o al più coincidere con 2n.
Ritornando infatti all’esempio di prima, per sapere quanti bit servono per
selezionare un elemento su 10.000, applicando la b) avremo
n = Log2 10000 = 13,28771238 =14
Si è arrotondato per eccesso il logaritmo in base due di 10.0000.
Quindi i bit che si individuano e che vanno a coprire l’insieme informativo N =
10000, è 14: infatti 214 =16384 che è maggiore di 10.000:
N =10000 < 214 = 16384
Si è detto che nella rappresentazione dell’informazione, i bit combinati tra loro,
cioè messi in sequenza l’uno all’altro, permettono di individuare spazi informativi
sempre più vasti fino a che non si arriva al numero di bit necessario, dato lo
spazio informativo prescelto.
1.3 Codici e codifica
Con riferimento alla figura 1.3, si è visto che la sequenza di bit 101 individua
l’elemento FF. La selezione porta con se una corrispondenza tra sequenza di bit e
oggetto che si vuole rappresentare, nell’esempio appena descritto l’elemento FF è
univocamente identificato con la sequenza di bit 101, analogamente gli altri

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
9
oggetti saranno individuati con altre diverse sequenze di bit, l’una diversa
dall’altra.
Riprendiamo l’ esempio dei quattro punti cardinali del paragrafo 1.1, N =4 , Il
grafico ad albero diventa:
0
01
1
01
N S E W
1’ bit di selezione
2’ bit di selezione
Figura 1.4
Le possibili combinazioni di bit rappresentate dal grafico, si possono organizzare
in una tabella che mi evidenzia una corrispondenza biunivoca tra la sequenza dei
bit e gli elementi da essi individuati. Ottengo così il seguente codice:
Tabella di codifica
Numero di bit Oggetto insieme informativo
00 N
01 S
10 E
11 W
ogni sequenza di due bit individua in maniera univoca un solo elemento
dell’insieme, e viceversa: ad ogni elemento di N, è associata una sola sequenza
di bit.
L’abbinamento biunivoco tra informazione e sequenza binaria è detta
codifica. Quindi il codice è una particolare codifica di un insieme di
informazione con sequenze binarie.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
10
Nella rappresentazione dell’informazione il meccanismo di codifica funziona nel
modo seguente:
S0
S3
S2
Sn - 1
Si
CODIFICA B1 b2 b3…Bn-1 DECODIFICA
Figura 1.5
Definiamo S:= {s1, s2, s3, ...sn-1}, l’insieme di informazione che si vuole
rappresentare, e con si gli elementi che lo compongono, si fissa una regola di
corrispondenza (detta anche mapping) tra gli elementi di S e le sequenze di bit
attraverso tabelle di codifica: a questo punto l’informazione così codificata per
essere utilizzata dall’uomo (che poi è il destinatario finale dell’informazione) deve
essere a sua volta codificata al contrario mediante un sistema decodifica che mi
porta all’elemento iniziale si di S.
{N,S,E,W}.
E’ importante notare che alla base della codifica e della decodifica ci deve essere
la stessa tabella rappresentativa delle informazioni, ossia devono valere le
stesse regole altrimenti non riusciremmo a risalire alle informazioni originali3 o
andrei a recuperare informazioni non esatte.
Vale la pena sottolineare che i codici così come sono stati individuati dagli esempi
che abbiamo fatto, possono non essere gli unici codici, perché il fatto di aver
valorizzato con 0 e 1 le possibilità di selezione è solo una convenzione. Si
potevano scegliere altri numeri, oppure dei simboli, quindi una volta determinato
il numero di bit necessari ad individuare un elemento informativo, la scelta con
cui rappresentare i bit può essere arbitraria. Questo richiama l’esigenza di creare
codici standard che siano universalmente riconosciuti3.
1.4. Codici a lunghezza fissa. Codice A.S.C.I.I.
Si definisce lunghezza del codice il numero dei bit necessari ad individuare
l’unità informativa
3questo è un aspetto molto importante da tenere presente in quanto spesso sta alla base di problemi di unificazione di modi di rappresentare le informazioni.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
11
L’esempio riportato utilizza per ogni elemento informativo, una sequenza di due
bit, pertanto il codice individuato ha lunghezza 2.
Un codice viene detto a lunghezza fissa quando viene usato sempre lo stesso
numero di cifre per la rappresentazione di qualunque valore.
Nell’esempio dei quattro punti cardinali del paragrafo 1.1,essendo N = 4,
applicando la c) otteniamo:
N = Log2 4 = 2 = n
Dove n indica la lunghezza del codice.
Se il codice fosse di tre bit, quindi avesse lunghezza 3, le possibilità che fanno
parte dell’insieme informativo aumentano passando da 22 a 23, per cui
considerando sempre l’esempio dei punti cardinali, le possibili combinazioni di
sequenze di tre bit raddoppiano rispetto a quelle di prima che erano di due bit.
Graficamente avremmo:
0
01
1
01
N S E W
1° bit di selezione
2° bit di selezione
3° bit di selezione
N NE E SE S SW W NW
Figura 1.6
ottenendo la seguente tabella di codifica:
bit oggetto insieme informativo 000 N 001 NE
010 E
011 SE
100 S
101 SW
110 W
111 NW

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
12
Un primo esempio di unificazione di modi di rappresentazione dell’informazione, è
stato il codice ASCII la cui sigla sta per: "American Standard Code for
Information Interchange", cioe' "Standard americano per lo scambio di
informazioni". Il codice ASCII è rappresentazione numerica dei caratteri di una
telescrivente dati dalle lettere dell’alfabeto maiuscole e minuscole più una serie di
simboli e caratteri particolari. Tale codice fu inventato molti anni fa per le
comunicazioni fra telescriventi (infatti ci sono dei codici di comandi specifici che
sono quasi incomprensibili, ma al tempo avevano la loro funzione), poi man mano
e' diventato uno standard mondiale.
Il codice ASCI standard ha lunghezza 7 bit, per cui è in grado di codificare 27 =
128 caratteri, viene anche definito ASCII7. (si riporta in appendice la tabella
ASCII7). La tabella ASCII mi codifica in maniera univoca dunque, ogni singolo
elemento dato da un tasto della tastiera di una telescrivente. Pertanto se
dovessimo rappresentare in codice ASCII7 un qualsiasi testo, ad esempio il testo
“caro prof”, seguendo le indicazioni della tabella, ogni singolo carattere sarebbe
così rappresentato:
carattere C A R O P R O F Sequenza
di bit 1000011 1000001 1010010 1001111 1010000 1010010 1001111 1000110
Ciò significa che sapendo che il codice è di lunghezza 7, se si riceve una
sequenza di bit di questo tipo:
100001110000011010010100111110011111001111100111110100101001111100011
0
Data la tabella ASCII, si è in grado di decodificare l’informazione semplicemente
estraendo da tale stringa, sequenze di bit a blocchi di 7 ricuperando in questo
modo l’informazione iniziale.
Il codice ASCII standard è stato successivamente ampliato portando i bit da 7 a 8
e la semplice aggiunta di un bit ha raddoppiato il numero dei caratteri del codice.
I codici ASCII estesi hanno il bit 7=1.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
13
1.5. Codici a lunghezza variabile
I codice a lunghezza variabile traggono origine da un’idea che ebbe nel 1837
Samuel Finley Breese Morse, l’inventore del famoso codice Morse e del telegrafo
elettrico: apparecchio in grado di mandare una tensione elettrica tramite un
semplice contatto, inviando così dei segnali che uniti appropriatamente, formano
tutte le lettere dell'alfabeto. I due segni sono la linea (che corrisponde ad un
suono lungo) ed il punto (che invece e' un suono breve).
Morse codificando questi impulsi, ideò un sistema di comunicazione che ha
segnato la storia delle comunicazioni a distanza. (viene riportata in appendice ll
codice Morse)
A differenza del codice ASCII, Morse ebbe l’intuizione di codificare le informazioni
o caratteri, con un codice non a lunghezza fissa, ma con una lunghezza che
variasse a seconda dell’elemento considerato facendo dipendere la variabilità,
dalla frequenza con cui veniva usato un determinato carattere: più precisamente,
attribuendo dei segnali più corti ai caratteri maggiormente usati, e dei segnali più
lunghi ai caratteri meno frequenti.
Il problema è che volendo applicare l’idea di Morse ai bit, ed essendo i bit
immagazzinati in un elaboratore, ogni volta che ci si trova di fronte ad una
sequenza di bit sufficientemente lunga, e non potendo estrarre sequenze a
blocchi fissi di n bit, la macchina non è più in grado di risalire in maniera univoca
all’informazione.
Supponiamo per esempio di tradurre in bit il codice Morse valorizzando con 0, il
punto, e con 1 la linea, otteniamo un codice a lunghezza variabile, ossia un
codice la cui sequenza di bit varia da carattere a carattere:
carattere bit morse A 01 • — B 1000 — • • • C 1010 — • — • D 100 — • • E 0 •
Se rappresentiamo in bit caratteri ABC della tabella, otteniamo la seguente
sequenza di bit:
0110001010

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
14
tuttavia, questa sequenza, dovendo essere letta da un elaboratore, questo non è
in grado di identificare in maniera univoca i singoli caratteri, poiché tra di essi
non esiste alcuna separazione fissa: cioè a seconda di dove si mettono i
separatori nella sequenza, si ottengono lettere diverse. Questo fa si che il codice
sia ambiguo.
Morse risolse questo problema, separando la sequenza con un piccolo intervallo
di tempo durante il quale veniva interrotto il segnale di trasmissione.
Resta comunque fondamentale che l’idea di codifica di Morse, era quella di
impiegare meno bit possibili nella rappresentazione delle informazioni, mediante
un codice variabile la cui lunghezza dipendesse dalle frequenze con cui i singoli
caratteri venivano impiegati.
1.6. La codifica di Huffmann
L’idea di Morse fu tradotta in bit qualche anno più tardi da David A. Huffman, che
risolse così il problema dell’ambiguità individuando un metodo di determinazione
del codice ottimo che garantisce l’impiego del minor numero di bit possibile per la
sua codifica. I codici Huffman sono codici a lunghezza variabile, cioè codici
che attribuiscono sequenze più brevi di bit ai caratteri che hanno più probabilità
di verificarsi.
A differenza del codice ASCII a lunghezza fissa, governato dalla legge N>=Log2N,
Huffman codifica i simboli più probabili usando per essi meno bit di quelli
impiegati per rappresentare simboli meno probabili.
Trattandosi di codici a lunghezza variabile, non ha più senso parlare della
lunghezza del codice, proprio perché ciascuna informazione è codificata da un
diverso numero di bit in sequenza.
1.7. Lunghezza media nei codici a lunghezza variabile.
Un primo problema che si presenta nei codici a lunghezza variabile, è quello di
individuare la lunghezza del codice.
Una grandezza rappresentativa della dimensione del codice a lunghezza variabile,
è quella di usare la media dei bit ponderata con la lunghezza dei bit associati a
ciascun carattere. Per comprendere meglio, supponiamo di aver codificato un
insieme di 4 caratteri con il seguente codice a lunghezza variabile secondo
quanto riportato dalla tabella

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
15
Carattere Bit Lunghezza A 0 Lunghezza 1 B 10 Lunghezza 2 C 110 Lunghezza 3
D 111 Lunghezza 4
Se prendessimo solo la media delle lunghezze di ciascuna sequenza di bit per
ogni elemento, il risultato che si ottiene non è indicativo della lunghezza del
codice perché non tiene conto della frequenza con cui si manifestano i vari
simboli. Così facendo infatti peseremmo tutti i simboli allo stesso modo, dando
per scontato che un determinato contesto tutti si manifestano con la stessa
frequenza o probabilità in.
Supponiamo ora di voler codificare una sorgente informativa rappresentata dal
seguente testo composto da 15 simboli o caratteri:
carattere A A B A A B C A A B A A B C D Bit 0 0 10 0 0 10 110 0 0 10 0 0 10 110 111
Lunghezza 1 1 2 1 1 2 3 1 1 2 1 1 2 3 3
Se per ogni lettera del testo, sommiamo il numero dei bit che codificano ogni
singolo carattere, otteniamo il numero totale dei bit necessari per rappresentare
tutto il testo considerato: ossia 25 bit per trasmettere 15 simboli. Dividendo il
totale dei bit del testo per il numero di simboli, otteniamo la media ponderata
della lunghezza del codice che rappresenta il testo:
Numero totale di bit 25 = 1,666 Numero totale di caratteri del testo 15
In media ciascun simbolo ha richiesto 1,66 bit per.
Il risultato che abbiamo ottenuto non è altro che la media della lunghezza di ogni
singolo carattere “pesata” con il numero di volte in cui compare il carattere
stesso.
Se per rappresentare ciascun carattere del testo avessimo usato con un codice a
lunghezza fissa, con n=4 caratteri da rappresentare, avremmo avuto bisogno di 2
bit contro 1,66 bit impiegati dal codice a lunghezza variabile. Ciò significa che
abbiamo risparmiato circa il 40% dei bit da utilizzare come rappresentazione
dell’informazione, ottenendo un risultato importante in termini di riduzione della
la memoria.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
16
Data una statistica rappresentata dalle frequenze, e dato un codice a lunghezza
variabile, per quel codice si è allora in grado di calcolare il numero di bit per
simbolo.
Sempre con riferimento al testo preso ad esempio, riscriviamo il conteggio della
media ponderata, evidenziando per ciascun carattere, il numero di volte in cui
esso compare nel testo:
(8x1) + (4x2) + (2x3) + (1x 3) 25 = 1,666 15 15
Ossia raggruppando:
066,115
253*
15
13*
15
22*
15
41*
15
8 ==
+
+
+
Quanto indicato sopra non ha fatto altro che evidenziare per ciascun carattere del
testo, la frequenza relativa con cui si manifesta il carattere stesso: ossia il
numero di volte con cui compare un singolo carattere rapportato al totale(15) dei
caratteri presenti nel testo.
La frazione che così si ottiene, può essere indifferentemente espressa anche in
percentuale, dal momento che il risultato non cambia: infatti:
8/15 = 53,3%
4/15 = 26,6%
2/15 = 13,3%
1/15 = 6,6%
L’esempio considera però un testo piccolo e quindi gestibile da un punto di vista
della misurazione delle frequenze, ma generalmente si ha a che fare con insiemi
informativi molto più vasti di quello considerato e se la statistica è stata fatta con
un numero sufficiente di volte, Le frequenze relative così come sono state
definite e calcolate nell’esempio, rappresentano nient’altro che la probabilità
che ha un singolo carattere di verificarsi.
Ora con riferimento all’esempio, indicano con pa, pb, pc, pd rispettivamente le
probabilità di ciascun elemento A,B,C,D ed con na , nb ,nc, nd i numero di bit

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
17
attribuiti ai singoli caratteri, il calcolo scritto sopra può essere generalizzato in
questo modo:
n = (pa*na) + (pb*nb)+(pc*nc)+ (pd*nd) = 066115
253
15
13
15
22
15
41
15
8,==
+
+
+
xxxx
dove n rappresenta la lunghezza media del codice, ossia il numero medio di
bit per singolo carattere. Quindi n fornisce una misura del contenuto medio di
informazione associato ad ognuno dei simboli emessi dalla sorgente in questo
esempio rappresentata da un testo di 15 caratteri
In generale indicando con:
S = s0, s1, s2, ........., sn-1
l’insieme informativo, con ni il numero di bit individuati dal codice attribuiti al
generico elemento si, e con pi la probabilità di uscita del simbolo si: allora la
lunghezza media del codice sarà cosi definita:
f) ∑−
=•=
1
0
n
iii
pnn
1.8. Ambiguità
Il fatto di aver individuato un metodo con cui calcolare la lunghezza media di un
codice a lunghezza variabile, ci pone il problema di trovare il codice migliore che
mi individua univocamente le informazioni. Infatti una volta determinata una
codifica, può essere che esistano altri codici più o meno efficienti a seconda della
combinazione che c’è tra le lunghezze e le frequenze.
Sempre con riferimento all’esempio del paragrafo precedente, supponiamo che
per i quattro caratteri così come sono stati codificati, sia stata individuata un'altra
tabella di codifica come la seguente:
bit caratteri
0 A 1 B 10 C 11 D

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
18
Riducendo ulteriormente il numero di bit associati ai vari caratteri, istintivamente
viene da pensare che il codice della tabella appena prodotta, sia migliore di quello
della tabella precedente, perché è stato costruito utilizzando meno bit. Tuttavia,
possiamo facilmente verificare che questo codice ha uno ambiguità: se
consideriamo infatti la sequenza di bit {10}, notiamo che la stessa sequenza
rappresenta indifferentemente i caratteri A o B o C. E’ presente dunque un
ambiguità perché, essendo il codice a lunghezza variabile, la macchina non è in
grado di riconoscere in modo univoco le informazione codificate dai bit4.
Per ovviare a questa ambiguità, è necessario fare in modo che se ad esempio si
decide di codificare il carattere A attribuendogli come primo bit il valore zero,
allora nessun altro carattere può essere codificato avendo il bit zero come primo
bit, ossia, per tutti i restanti caratteri della sorgente informativa, si devono
escludere tutte le possibili combinazioni di codici che iniziano con zero.
Infatti avendo attribuito ad A il bit zero si è escluso metà dello spazio
informativo, obbligando così gli altri caratteri ad usare 2, 3 o più bit.
Con una semplice rappresentazione grafica riusciamo subito a capire se un codice
è ambiguo o meno. Costruiamo il grafico ad albero della tabella:
BIT CARATTERI
0 A
1 B 10 C 11 D
0
0
1
1
D C
1’ bit di selezione
2’ bit di selezione
A B
Figura.1.7
4 Nei codici a lunghezza fissa come il codice ASCII, il problema non si presenta perché la lunga stringa dei bit viene catturata a blocchi di 7 per cui
l’informazione viene automaticamente codificata dalla macchina.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
19
Dalla figura 1.6 notiamo che c’è un anomalia: il primo bit di partenza seleziona
indifferentemente sia alla lettera A che alla lettera B; questo significa che per
arrivare a selezionare la C per esempio, si transita in un passaggio che seleziona
anche il carattere B, è evidente che a questo punto non siamo in grado di sapere
in maniera univoca se è stato selezionato il carattere C o il carattere B;
In altre parole si può dire che c’è un simbolo la cui rappresentazione è un
sottoinsieme, o un prefisso dei bit di un’altra rappresentazione: in figura 1.6. la
rappresentazione della lettere B è un prefisso della rappresentazione della
lettera C.
1.9. Il codice ottimo di Huffman
Il problema dell’ambiguità è stato risolto da Huffman, il quale ha fornito il criterio
con cui individuare un codice ottimo per codificare le informazioni: in particolare,
dato un codice a lunghezza variabile per l’insieme informativo in cui il generico
elemento si ha probabilità di pi di verificarsi, si dice ottimo, quando attribuisce
ni bit al simbolo si, tali che la lunghezza media del codice n è minima; ossia il
codice ottimo di Huffman è tale che:
g) ∑−
=•=
1
0
n
iii pnn = minima
pertanto, data una sequenza di oggetti facenti parte dell’insieme
informativo, quando la lunghezza media del codice n è minima, allora il
codice ottimo garantisce l’impiego del minor numero di bit per la sua
codifica. Inoltre non esiste alcun altro codice con altri ni che trova un
valore più basso di n individuato dal codice stesso.
Il codice individuato secondo il metodo di Hufman è quello ottimo.
Il codice di Huffman è un codice univocamente decodificabile a prefisso e ottimo.
Questo significa che nessuna parola del codice è il prefisso di un'altra parola del
codice stesso, e che il processo di decodifica è univoco; l’univoca decodificabilità
è un requisito irrinunciabile per ogni codice, mentre il fatto che un codice sia a
prefisso è molto comodo perché, in fase di decodifica, consente di evitare perdite
di tempo.
I Codici di Huffman sono codici a lunghezza variabile che attribuiscono le parole
codici più brevi ai simboli a cui risultano associate le frequenze più elevate.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
20
Con riferimento all’esempio del paragrafo 1.6., se avessimo codificato il testo con
un codice a lunghezza fissa, essendo ciascun carattere codificato con ni=2 bit,
applicando la g) otteniamo una lunghezza media pari a :
∑ ∑−
=
−
=•==•=
1
1
1
1
1222n
i
n
iii
ppn
perché
11
1
=∑−
=
n
iip
N
nP i
i=
infatti pi rappresentano le frequenze relative con cui ciascun carattere si
manifesta.
Riprendendo l’esempio del paragrafo 1.6, riportiamo la seguente tabella di
codifica:
Elemento Carattere Frequenza Probabilità Probabilità
pi Lunghezza codice
Lunghezza codice ni
s0 A 56% 8/15 pa 1 na
S1 B 28% 4/15 pb 2 nb
S2 C 8% 2/15 pc 3 nc
S3 D 8% 1/15 pd 3 nd
Data questa tabella di distribuzione delle probabilità dei singoli caratteri, il criterio
per individuare il codice ottimo secondo quanto stabilito da Huffman si realizza
attraverso il procedimento rappresentato dal seguente grafico:
Figura 1.8 Processo di riduzione nella costruzione di un codice di Huffman
Tale grafico si ottiene distribuendo su un asse le probabilità di ciascun carattere
ordinate in modo decrescente.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
21
Si prendono i primi due caratteri con minor probabilità, si marcano, e si
accorpano creando un nuovo simbolo con probabilità uguale alla somma delle
probabilità dei caratteri così individuati: nel grafico della figura 1.7, si osserva
che i primi due caratteri a più bassa probabilità sono le lettere C e D: in tal caso
si segnano e si accorpano in un unico simbolo V0 facendo la somma delle loro
probabilità che è pari a 3/15.
Accorpando i due caratteri C e D, si è così individuato un nuovo simbolo indicato
con V0 che li identifica con probabilità pari a 3/15 e che si sostituisce a loro in
modo tale da non considerarli più nella creazione del codice. Rimangono allora i
caratteri A, B e V0.
A questo punto, si ripete la stessa operazione di prima: tra i caratteri A, B e V05
si cercano i due con minore probabilità individuando in questo secondo
passaggio, i caratteri V0 e B, si marcano e si uniscono costruendo un nuovo
simbolo V1 con probabilità pari alla somma delle probabilità di V0 e B (7/15).
Analogamente si conclude la costruzione del codice accorpando V1 e A.
L’albero costruito secondo il metodo di Huffman ci consente a questo punto di
ricavare il codice ottimo che, mettendo per convenzione lo zero a destra e 1 a
sinistra, sarà dato dalla seguente tabella di codifica:
carattere Bit
A 0 B 10
C 110
D 111
Questo codice individuato secondo il metodo di Huffmann, garantisce di essere
quello migliore tra tutti i possibili codici, poiché è quello che contiene lunghezze ni
di sequenze di bit che minimizzano la lunghezza media dei bit necessari a
rappresentare un singolo elemento si dell’insieme informativo.
Se avessimo impiegato un codice a lunghezza fissa, con quattro oggetti da
codificare, avremmo dovuto usare 2 bit applicando la formula:
n Log2 4 = 2
5Si è definito impropriamente V0 carattere per semplificare il procedimento, in realtà V0 è solo un un accorpamento a cui è stato dato un valore (3/15) ai fini di
poter spiegare il passo successivo da seguire nella costruzione del codice ottimo.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
22
I codici individuati secondo l’algoritmo di Huffman sono un risultato notevole
anche da un punto di vista economico, se si pensa al risparmio che si realizza in
termini di costi di trasmissione dell’informazioni.
Riassumendo quanto detto sopra, passi dunque da seguire nella costruzione del
codice ottimo secondo il metodo di Huffman possono essere così riassunti dal
seguente algoritmo:
1. si individuano i due simboli (virtuali o reali) non ancora marcati con probabilità
più bassa;
2. si marco i simboli individuati;
3. si crea un simbolo virtuale con probabilità pari alla somma delle probabilità due
simboli individuati;
4. se ci sono simboli non marcati, si ritorna al passo 1.
L’algoritmo finisce quando i simboli sono stati marcati tutti.
Notiamo che il criterio del codice ottimo di Huffman, indicato dalla g), è stata
vista fino ad ora descritto come una proprietà intrinseca del codice: cioè si
individua un codice che trova una determinata sequenza di bit per singolo
elemento informativo.
Tuttavia il fatto che esista un codice ottimo che minimizza la g) vuol dire che non
esiste nessuna codifica che rappresenti l’informazione con una lunghezza media
inferiore di quella calcolata.
Esiste dunque un limite fisico che non è più dato dal numero degli elementi
informativi contenuti nella sorgente informativa di partenza, ma delle probabilità
che ciascun elemento della sorgente ha di verificarsi.
Infatti, negli esempi riportati, si può notare che i codici realizzati secondo il
metodo di Huffmann, sono stati individuati a partire dalle singole probabilità di
ciascun elemento informativo, senza utilizzare nessun altra grandezza: cioè a
partire dalle singole pi di ciascun elemento della sorgente informativa, abbiamo
individuato la lunghezza media minima n .
Ciò significa che n , non dipende dal codice, ma solamente dalle probabilità dei
singoli elementi che compongono la sorgente, per cui dato un insieme
informativo e data la distribuzione di probabilità di ciascun elemento, il codice di
Huffman viene automaticamente determinato e ci permette di sapere quanti bit
sono necessari per codificare ogni singolo elemento.

Università degli studi di Padova - Facoltà di Scienze Statistiche Corso di Laurea in Gestione delle Imprese – “Sistemi di Elaborazione”. Prof . Nicola Zingirian
23
Ora il fatto che a priori si sappia già che determinati simboli abbiano più
probabilità di verificarsi e altri meno, discostandoci da una condizione di
equiprobabilità6, ha come conseguenza che la sorgente informativa non è più
significativamente informativa in termini di riduzione dell’incertezza.
Infatti più la distribuzione delle probabilità di ciascun elemento informativo è
sbilanciata, discostandoci così da una situazione di equiprobabilità, minori
saranno i bit necessari per codificare in modo automatico nonché ottimale, i vari
elementi dell’insieme informativo: in questo caso infatti, la sorgente è, a priori,
meno informativa. Pertanto la grande informazione che scaturisce dalla sorgente,
si ha quando la distribuzione delle probabilità di ciascun elemento della sorgente
stessa, presenta una forte variabilità, ossia quando c’è la massima incertezza.
Massima incertezza significa che tutti i simboli si sono equiprobabili.
Il fatto che gli elementi siano equiprobabili, non da nessun vantaggio rispetto al
codice a lunghezza variabile.
Quanto detto lo possiamo facilmente verificare con questo banale esempio;
1
1/8 1/8 1/8 1/8 1/8 1/81/8 1/8
2/8 2/8 2/8 2/8
4/8 4/8
1
Figura 1.9.
alla base del grafico abbiamo riportato le probabilità di ciascun elemento che è
pari ad 1/8. Seguendo il metodo di Huffman arriviamo a costruire un codice a
lunghezza fissa 3. La sorgente da dunque 3 bit per simbolo.
6Ciascun elemento dunque ha lo stesso grado di probabilità di verificarsi; si è dunque in una condizione di massimo grado di indeterminatezza.





























