Embed Size (px)
Citation preview

S.E.P. S.E.I.T. D.G.I.T.
CENTRO DE ENFORMACION
CENTRO NACIONAL, DE INVESTIGACIÓN Y DESARROLLO TECNOLÓGICO
cenidet
DETECCIÓN Y REGISTRO DE EVENTOS RELEVANTES PARA EL DISEÑO ADAPTABLE
DE BASES DE DATOS DISTRIBUIDAS EMPLEANDO REGLAS ECA
T E S I S QUE PARA OBTENER EL GRADO DE:
MAESTRO EN CIENCIAS EN CIENCIAS COMPUTACIONALES
P R E S E N T A : ROCIO ALEJANDRA KAUFFMANN MIRELES
CUERNAVACA, MORELOS FEBRERO 2000

Centro Nacional de Investigación y Desarrollo Tecnológico FORMA C3
REVISION DE TESIS
M.C. Máximo López Sánchez Presidente de la Academia de Ciencias Computacionales Presente
Nos es grato comunicarle, que conforme a los lineamientos para la obtención del grado de Maestro en Ciencias de este Centro, y después de haber sometido a revisión académica la tesis denominada: Detección y Registro de ,Eventos Relevantes para el Diseño Adaptable de Bases de Datos Distribuidas Empleando Reglas ECA, realizada por la C. Rocío Alejandra Kauffmann Mireles, y habiendo cumplido con todas las correcciones que le fueron indicadas, acordamos no tener objeción para que se le conceda la autorización de impresión de la tesis.
Sin otro particular, quedamos de usted.
'Atentamente
La comisión de revisión de tesis
H. &c' (L'L
M .C Mario Guillén Rodriguez
, Dr. Joaíjíh Pérez Ortega
Director de tesis
C.C.P. Dr. Javier Ortiz HernándezíJefe del Departamento de Ciencias Computacionales
INTERIOR INTERNADO PALMIRA S/N. CUERNAVACA. MOR. MÉXICO APARTADO POSTAL 5-164 CP 62050. CUERNAVACA. TELS.173112 2314.12 7 6 1 3 . 1 8 7741 ,FAX(73)12 2434 EMAIL O m caddetedu.mx

Centro Nacional de Investigación y Desarrollo Tecnológico FORMA C4
AUTORIZACION DE IMPRESIÓN DE TESIS
C. Rocio Alejandra Kauffmann Mireles Candidata al grado de Maestro en Ciencias en Ciencias Computacionales Presente
Después de haber atendido las indicaciones sugeridas por la Comisión Revisora de la Academia de Ciencias Computacionales en relación a su trabajo de tesis: Detección y Registro de Eventos Relevantes para el Diseño Adaptable de Bases de Datos Distribuidas Empleando Reglas ECA, me es grato comunicarle, que conforme a los lineamientos establecidos para la obtención del grado de Maestro en Ciencias en este Centro, se le concede la autorización para que proceda con la impresión de su tesis.
Atentamente /
INTERIOR INTERNADO PALMIRA S/N, CUERNAVACA. MOR. MÉXICO APARTADO POSTAL 5-164 CP 62050, CUERNAVACA. TELS.(73)12 2314.12 7613 ,18 7741,FAX(73) 12 2434 C L A A H nrii7fiArpnirlnt nrlii my

A mis padres Juanitay Algandm. A mis hermanos
Maná Fernanday Juan Carhs. A mi abue HerLnda.
1

Agradecimientos Gracias Padre por permitirme conocerte más en este tiempo,
realmente has sido mi roca.. . A mi familia, por ser el aliento para realizar este esfuerzo.
Gracias por su apoyo y su amor, por tener confianza en mi.
A mi asesor, Dr. Joaquín Pérez, por el tiempo dedicado, por su ayuda e interés en el desarrollo de este trabajo.
Al Centro Nacional de Investigación y Desarrollo Tecnológico por brindarme la oportunidad de realizar mis estudios de maestría.
A m i s revisores de tesis, Dr. Rodolfo A. Pazos, Dr. Javier Ortiz, M.C. Mario Guillén y M.C. Humberto Hemández. Gracias por sus valiosos comentarios para el
mejoramiento de la misma.
A todos mis maestros por transmitirme conocimientos que me hicieron mejor. Gracias maestro José Luis Alcántara.
A las personas que compartieron momentos especiales conmigo y que me brindaron su amistad, de manera especial a Sofía Ruiz, Nadira Rodriguez, Nancy Vizako, Claudia
Ibarra, Sinuhé Ramírez, Armando Ruu y Gustavo Alarcón ... ya saben cuanto los quiero.
Gracias Alex por hacer especiales muchos momentos.
Al pastor Raymundo y a su esposa Vicky, quienes me brindaron su amistad y se preocuparon por mí.
A la Sra. Lili Vázquez y a Flor Morales, por abrirme las puertas de su casa ... gracias por su confianza.
Fernando, gracias por apoyarme y darme tu amor.., por enseñarme a crecer como persona.
A mis amigos de siempre Gaby Martínez, Ana Ilián Muñoz, Usler Román, Joel Martínez, O h i a Fernández, Oscar Ibarra, Pablo Cano, Alfred0 Adriano, Manuel
Gomáiez y Rodolfo Luna, que a pesar de la distancia stguen a mi lado.
A todos m i s compañeros de generación: Sofía, Nadira, Roger, Paty, Fabi, Isaac, Santiago, May, Javier, Magda, Alberto, Agustín, José y Edson ... de cada uno aprendí aigo para bien. Gracias por las experiencias compartidas y por las muestras de afecto
que no cambio por nada.
Que Dios los bendiga a todos1
11

TABLA DE CONTENIDO
páp .CAPITULO 1 INTRODUCCI~N ...................................................................................... 1
1.1MetodologÍa Tradicional de Diseño de BDD's ............................. 2 1.1.1 Análisis de Requerimientos 4
1.1.1.1 Análisis de Requerimientos de Distribución ................... 4 1.1.2 Diseño Conceptual Global ........................................................ 4 1.1.3 Diseño Lógico Global ............................................................... 5 I . 1.4 Diseño de la Distribucibn ........ ; 1.1.5 Diseño Físico
1.2 El Diseño de la Distribución .. ......................................................... 6 1.2.1 Fragmentación ..... 1.2.2 Problema de Ubic ....................
_ . . 1.3 Motivación .: : ........................................................................................ 8
1.4 Descripción del Problema ............... : .............................................. 10
1.5 Objetivo .............................................................................................. 14
1.6 Propuesta de Solncion ..................................................................... 15
1.7 Alcances ............................................................................................. 15
. I
1.8 Organización del Documento ........................................................ 16
CAPITULO 2 .BASES DE DATOS ACTIVAS ............................................................... 19
2.1 Historia ............................................................................................. 21
2.2 Enfoques Alternos .......................................................................... 22 2.2.1 Modificación del Código ............... ............................ 22 2.2.2 Verificación Periódica .................. ............... 23
2.3 Reglas ECA ...................................................................................... 23
2.4 Estado del Arte ................................................................................ 26 2.4.1 ARIEL 2.4.2 MARIPOSA 2.4.3 Chimera ................................................................................... 31
... 111

2.4.4 SAMOS!.;. ....; .... : ............. ; ....................................... : ................. 32 . . . , . r 5% ,! ,"s ). , ;$e , ' . , . ,
CAPITULO 3 LENGUAJE DE REGLAS ECA ............................................................. 35 3.1 Gramática del Lenguaje de Reglas ECA ........................................ 37
3.1.1 RegiaECA 3.1.2 Eventos ..... 3.1.3 Condicione ...................................... 38 3.1.4 Acciones ._._.! ............................................................................ 39 3.1.5 Variables ................................................................................... 39
3.1:7 Elementos C,omunes 3.1.8 Val , - Co1umn.a 3.1.9 Valor-Where. 3.1.1O~Valor-Ti
3.2.1 Acciones Se 3.2.2 Acciones Se
I
'3:1.6 Operadores .... ............. .............. . . . . . . . . . .
3.2 Acciones Semánticas ...........
CAPITULO 4 W L E M E N T A C I O
4.1 Diseiio General del Sistema de Reglas ....................................... 63
4.2 Tipos de Datos ................................................................................. 64
4.3 Enfoque Orientado a Objetos ...................................................... 64
4.4 Precompilador ................................................................................. 66 4:4.i 'Interface01 " .................................... 66
. . . . . . . , c ,
. .
. ,
, .
................................... 73
, 4.5 Intérprete .................................................................................... 73 4.5.1 Detector de Evento
. , . 4.5.1.1 EventosDete
~ 4.5.2 Procesador de Reg1 4.5.1.2 Integración con el SiMBaDD ......
.
4.5.3 Módulo Trdnsformador de Consu1tas.a Forma Canónica .. 79 4.5.4 Integrad ................................... 81 4.5.5 Base de .................................................. 4.5.6 Base de Consultas: ................... :..'._._: 4.5.7 Datos Estadísticos de Explotación ....................................... 83 4.5.8 Módulo Identi ficador de Consultac' Básicas.. ...... 4.5.9 Interfaz de Consulta .....
84 ............................... 85
, . .
iv

CAPITULO 5 PRUEBAS ................................................................................................. 87
5.1 Objetivo de las Pruebas ................................................................. 87
5.2 Lista de Pruebas .............................................................................. 87
5.3 Descripción del Ambiente de Pruebas ........................................ 88 5.3.1 Esquema Relaciona1 de la Base de Datos de Prueba .......... 89 5.3.2 Herramientas Auxiliares ........................................................ 89
5.4 Resultados Obtenidos .................................................................... 90 5.4.1 Prueba 1: Altas y Bajas de Reglas ECA ... 5.4.2 Prueba 2: Definición de Reglas ECA .... 5.4.3 Prueba 3: Definición de la Condición de la Regla ECA ..'.. 92 5.4.4 Prueba 4: Registro de Datos Estadísticos de Explotación . 94 5.4.5 Prueba 5: Incremento de Frecuencia ......... 5.4.6 Prueba 6: Distintos Clientes .................................................. 97 5.4.7 Prueba 7: Control de Concurrencia ...................................... 97 5.4.8 Prueba 8: Equivalencia Semántica de Consultas 98 5.4.8 Prueba 9: Integración de Datos Estadísticos y
Obtención de Archivo de Datos .......................... 98
CAPITULO 6 CONCLUSIONES .................................................................................. 103
6.1 Trabajos Futuros .............................................................................. 104
6.2 Beneficios ........................................................................................... 104
REFERENCIAS ............................................................................................................... 107 APENDICE A ESTANDARES EN BDA .................................................. : ................... 111
A.l Restricciones de Integridad en el Estándar SQL-92 ............ 112
A.2 Aserciones y Disparadores en SQL3 ......................................... 114
APENDICE B CARACTERISTICAS ACTIVAS DEL MODULO IMPLEMENTADO .................................................. 117
B1 . Caracterrsticas ................................................................................. 117
B.2 Comparación con Algunos Prototipos .......................................... 121
B.3 Comparación con los Disparadores de Estándar SQL3 .............. 125
. .
APENDICE C PUBLICACIONES RECOMENDADAS ............................................. 129
V

LISTA DE FIGURAS
'li
;í
Figura 1-7: Migración de'Datos - Tabla 11 A
Figura 1-1: Metodología Tradicional de:Diseño deBDDs Figura 1-2: Automatización del Proceso'de Diseño de Distribución de Datos Figura 1-3: Sitios de la Red Figura 1-4: Esquema de Distribución de:!los Datos Figura 1-5: Patrones Originales de Explotación de los Datos Figura 1-6: Nuevos Patrones de Explotación de los Datos
Figura 1-8: Migración de Datos - Tabla B Figura 1-9: Esquema de Distribución de IoSDatos Adaptado a Patrones de
Figura 2-1: Taxonomía deBases de Daios , . en Cuanto a su Capacidad Activa Figura 2-2: Origen de las Bases de Datos Activas Figura 2-3: Algoritmo de Procesamiento de Reglas en L4 Figura 2-4: Algoritmo de Procesamiento' de Reglas ECA
Figura 2-6: Arquitectura de Mariposa Figura 2-7: Arquitectura de SAMOS Figura 3-1: Acciones Semánticas al Tiempo de Definición y Procesamiento de
Figura 3-2: Flujo de Control del Procesamiento de las Reglas ECA Figura 3-3: Generación de Acciones Sedánticas Figura 4-1: Diseño General del ~. Sistema ,. de . Reglas Figura 4-2: Arquitectura del P~écompilador Figura 4-3: Componentes de la Interfaz para la Definición de Reglas ECA Figura 4-4: Autómata para la Gramática'idel Valor Where Figura 4-5: Autómata para , el . . Análisis . . . . Léxico del Valor Tiempo Figura 4-6: Pseudocódigo para la Validación del Valor Tiempo Figura 4-7: Arquitectura del Intérprete I/: Figura 4-8: Autómata para el Reconocimiento de los Argumentos Referentes a
Figura 4-9: Interacción entre el SiMBaDD y el Módulo de Detección y
Figura 4-10: Generación de Procesos de Atención a Eventos
;I Explotación
Figura 2-5: Arquitectura de ~. Ariel , I . ,. >.
il
. . Reglas ECA .I
un Evento Detectado ' '
Registro de Eventos Relevantes I
Pág. 3 10 11 11 11 11 12 12
12 20 24 24 25 27 29 34
36 37 42 63 65 66 70 71 72 74
75
78 79

Figura 4-11: Ejemplo de Conversión de Consultas a Forma Canónica Figura 4-12: Tareas del Módulo Integrador Figura 5-1: Esquema de Distribución del Sistema Figura 5-2: Esquema Relaciona1 de la BD de Prueba
81 82 88 89

LISTA DE TABLAS
Tabla 3-1: Nombre de los Parámetros para Cada Evento Tabla 4-1: Tipos de Datos Correspondientes a las Variables ‘Definidas Tabla 4-2: Ejemplos de Condiciones, Tabla 6 3 : Ejemplos de Cláusulas Where Tabla 4-4: Eventos y Argumentos Tabla 4-5: Ejemplos de Reglas ECA Tabla 4-6: Información que se Almacena como Datos Estadísticos de
Explotación Tabla 5-1: Reglas ECA Aceptadas y!Almacenadas Tabla 5-2: Condiciones de Reglas Definidas y Resulta de Validación Tabla 5-3: Consultas de la Prueba 4 Tabla 5-4 Datos Estadísticos de Explotación en el sitio cad12 Tabla 5-5: Datos Estadísticos de Explotación en el sitio cad13 Tabla 5-6: Datos Estadísticos de Explotación en el sitio cad14
‘1
Pág. 52 64 69 71 76 83
84 92 93 95 95 95 96
Tabla 5-7: Datos Estadísticos de Explotación para la misma Consulta desde Distinto Cliente 97
Tabla B-1: Tabla Comparativa sobre las Características de Prototipos de 122 11 Sistemas Administradorfs de Bases de Datos Activas
Tabla E-2: Tabla Comparativa del Lenguaje de Reglas ECA y Disparadores 126

LISTA DE ABREVIATURAS
ABD BD BDA DD DML ECA FURD 1A SABDA SABDD SD SiMBaDD SQL SR WAN
Administrador de la Base de Datos Base de Datos Bases de Datos Activas Diccionario de Datos Lenguaje de Manipulación de Datos (Data Manipulation Language) Evento-Condición- Acción Fragmentación Ubicación y Reubicación Dinámica Inteligencia Artificial Sistema Administrador de Bases de Datos Activas Sistema Administrador de Bases de Datos Distribuidas Sistema Distribuido Sistema Manejador de Bases de Datos Distribuidas Lenguaje Estructurado de Consultas (Structure Queiy Language) Sistema de Reglas Red de Area Amplia (Wide Area Network)
ix

Resumen
Este trabajo de tesis es uno I i de varios esfuerzos encaminados hacia la
I explotación de los datos.

Capítulo 1 Introducción
Capítulo 1
Actualmente la tendencia en cuanto a la administración y almacenamiento de la
información en las grandes organizaciones son los sistemas distribuidos. Cada vez
son más los organismos que a partir de su naturaleza descentralizada, aplican el
esquema distribuido a través de oficinas y lugares de trabajo geográficamente
dispersos. Factores que han propiciado este hecho son los avances en la tecnología
de comunicaciones y el uso, cada vez más generalizado, de las redes de
computadoras.
,~
Algunas de las empresas más grandes de México, como Petróleos Mexicanos y
Comisión Federal de Electricidad, tienen este patrón de organización, y demandan
para sus procesos de toma de decisiones el intercambio eficiente de información
entre las unidades de la corporación. Esto obedece a nuevos conceptos
administrativos que exigen una disponibilidad de los datos que cumpla con la
siguiente premisa: “la persona adecuada debe recibir la información adecuada en el
momento adecuado”.
Es importante que en un sistema cuya información se encuentra distribuida, el
desempeño no se vea afectado por causa de los accesos remotos a la información.
Para lograr lo anterior se debe mantener una adecuada relación entre el esquema de
distribución de los datos y los patrones de explotación en el sistema. Éste es un
1

introducción I Capitulo 1
proceso innovador conocido como diseño adaptable y forma parte del proceso de
diseño de una base de datos.
Hasta la fecha, es tarea del administrador de la base de datos mantener un diseño
de la distribución de los datos corresbondiente a los patrones de explotación. Para la
realización de esta tarea, el administrador se basa en la experiencia que tiene sobre
la explotación de los datos, debido a que no existe un SABDD que genere la
información estadística necesarial'para la determinación del diseño de la distribución.
Este trabajo es una contribución al diseño adaptable de bases de datos
distribuidas, ya que mediante el empleo de principios de bases de datos activas, se
añade a un SABDD la capacidad activa de obtener la información estadística sobre
el uso de los datos para el establecimiento de esquemas de distribución apropiados.
11
!. ' . . . I1
!i
2 ,
Dado que el trabajo de tesis tiene como marco contextual el diseño de la
disfribución de una base de datos, kn la siguiente sección se presentan ,las fases
correspondientes a un proceso más general: el diseño de una base de datos I/
distribuida. :I, I.
I
1.1 Metodología Tradicional de Diseño de BDDs /I
El diseño de la distribuci,Ón ((es aún un problema presente en SABDDs
comerciales. Su objetivo es determinar las unidades de datos adecuadas para
almacenar, ya sean fragmentos o relaciones completas; y su ubicación a través de los
nodos, en este mismo orden. Dado que los accesos a los datos en una BDD,
representan costos de transmisión defiendientes de la ubicación física de los mismos,
el diseño de la distribución es un factor relevante en el desempeño de los sistemas
distribuidos, ya que influye directamente en la eficiencia del procesamiento de las
consultas. Pero el diseño de la diktribución es sólo una parte del diseño de Úna BDD.
SI
L
I I

Esquema Conceptual
Global
i
Definrción de Transacciones
Globales
Tablas de 0 Tablas de Frecuencia Esquema ugico GIobal Criierios de Acceso
Lógico Fragmentación
FRAGMENTACI~N HORIZONTAL
FRAGMENT ACIÓN
I
UBICACI~N Y REPLIC ACIÓN
DISENO DE DISENO LÓGICO LA DISllUBUCI6N
e ‘0” 9 5 E 8 U
4 Distribución del Esquema Global de Daios en Esquemas Lógicos Globales
DISENO FISICO LOCAL 1 Implantación del Esquema
Figura 1-1 Merodologia Tradicional de Diseño de BDDs
3

Introducción Capítulo 1
1 El proceso de diseño de una base de datos centralizada incluye análisis de
requerimientos, diseño conceptual, diseño lógico y diseño físico. Este proceso es la
plataforma para la realización del diseño de una base de datos distribuida mediante
la adición de dos fases: análisis de 'requerimientos histribuidos y diseño de la
distribución. A continuación se desbribe cada una de las fases de la metodología
tradicional de diseño incluyendo el diseño de la distribución.
i1 . "
'1 En la Figura 1-1 se presenta de manera esquemática la ubicación del trabajo que
se presenta,'en el contexto del proceso de diseño de bases de datos distribuidas', así
como su interacción con la fase de diseño de la distribución.
1
4
~. 1.1.1 Análisis de Requerimientos II En esta fase se lleva a cabo la recolección de los requerimientos del usuario, es
decir, se obtiene la información referente a las expectativas del usuario. Se analizan
los objetivos estratégicos de la orga(nización, con base en ellos se determinan los
requerimientos de información que los satisfagan, y posteriormente se determinan
los sistemas necesarios que proporcionen dicha información. li
I . 1.1.1 Análisis de Requerimientos de Distribución
. . I/
¡I '.
,
En esta fase se obtiene la frecuendia con la que las aplicaciones se ejecutan desde
cada uno de los sitios, y se recolecta,la información necesaria para la determinación
de la fragmentación sobre la base de datos. i
ii
1.1.2 Diseño Conceptual Global
El objetivo de esta fase es traslahar los requerimientos del usuario a un modelo
formal, independiente del SABD empleado. En esta fase se integran los
I Para mayor detalle consultar [Vé197] i
4
I

Capítulo 1 introducción
requerimientos de transacciones globales que describen operaciones que el sistema
ejecuta sobre los datos, así como información estadística sobre estas operaciones’.
Como resultado se obtiene el esquema conceptual global y el esquema de
transacciones globales.
1.1.3 Diseño Lógico Global
En esta fase se lleva a cabo el mapeo del esquema conceptual global hacia el
SABD empleado, ya sea relacional, de red o jerárquico. Se realiza la normalización
del modelo de datos, se definen todas las restricciones de integridad, se optimiza el
esquema de datos para soportar las transacciones más importantes y críticas, y se
especifican las consultas que soporta el SABD. Su salida es el esquema de datos
lógico y el acceso lógico a tablas.
1.1.4 Diseño de la Distribución
En esta fase se determinan las unidades de información en que se dividirá la base
de datos (fragmentos), así como la ubicación de cada una de ellas a través de los
sitios. Esta fase se ha desarrollado normalmente en dos pasos seriados: la
fragmentación y la ubicación de fragmentos. En la Figura 1-1 se puede apreciar que
esta fase recibe una entrada a partir de la base de datos operando. La entrada
consiste en información estadística sobre el uso de los datos, la cual es obtenida por
medio del Módulo de Detección y Registro de Eventos Relevantes, presentado en
este documento.
1.1.5 Diseño Físico
En esta fase se establece el mapeo de los esquemas locales al almacenamiento
La información estadística hace referencia a la ffecuencia de ejecución de las aplicaciones y al volumen de información requerida por estas.
5

Introducción Capítulo 1
físico disponible en el sitio, tomando en cuenta las características y capacidades del
SABD empleado. Se definen las estructuras físicas para la implementación de la
base de datos y su salida es el lenguaje de definición de datos.
1
1.2 El Diseño de la Distribución I En esta sección se presentan con mayor detalle los aspectos referentes a las
etapas, que de manera separada, dan lugar al diseño de la distribución, es decir,
fragmentación y ubicación de fragmentos.
1.2.1 Fragmentación 'I
La fragmentación de los dates se ha sugerido en la bibliografía como una forma
de mejorar el desempeño de los sistemas administradores de bases de datos. Se
argumenta que una relación compieta no es una unidad de distribución de datos
adecuada considerando que (1) generalmente las aplicaciones están definidas sobre
sólo una parte de la relación y (2) cuando se accede a una misma relación desde
diferentes sitios pueden suceder dos cosas. Por un lado, todos los sitios que realicen
el acceso, excepto el que almacenafla relación, pueden generar un gran volumen de
transferencia de datos (el caso extremo es la transferencia de la relación completa).
Por otro lado, se puede replicar la relación completa dando lugar a un gran volumen
de datos adicionales (aquellos que no son requeridos por la aplicación). Con la
finalidad de obtener las unidades de datos adecuadas para su distribución, las
relaciones se pueden dividir de manera horizontal o de manera vertical.
J
I En el caso de la fragmentación horizontal la relación R se divide en varios
subconjuntos rl, r2, ,.., r,, donde cada subconjunto tiene el esquema de la
relación original, es decir, cada fragmento tiene los mismos atributos que la
relación original R. Los fragmentos se determinan con base en un predicado que
11
6 I/

introducción Capitulo 1
distingue a las tuplas del fragmento, asignándoles el máximo potencial de
localidad con respecto a las aplicaciones, es decir, cada fragmento contiene las
tuplas más explotadas en el sitio de almacenamiento
I En la fragmentación vertical, también llamada partición de atributos, la relación
R es dividida en varios subconjuntos R I , R2, ..., R,, donde cada fragmento’ es
resultado de una proyección sobre la relación original. En este caso, cada
fragmento debe incluir la llave primaria de la relación original. El objetivo de
este tipo de fragmentación es agrupar aquellos atributos que son utilizados juntos
con frecuencia.
I Existe un tercer tipo de fragmentación, la fragmentación mixta. En este caso se
realizan n fragmentos, donde cada uno se obtiene alternando la fragmentación
horizontal y vertical sobre la relación original o sobre un fragmento previo.
1.2.2 Problema de Ubicación de Datos
La segunda etapa en el diseño de la distribución es la ubicación de los datos. Esta
etapa implica el siguiente problema: si se tiene un conjunto de fragmentos F = Fl ,
F2, ..., F n , y una red de comunicaciones con un conjunto de sitios S = SI, S2, .,.,
S, y un conjunto de aplicaciones Q = Ql, Q2, ..., en, cuál es la ubicación óptima
de F e n S de manera que el procesamiento de las consultas Q sea más eficiente.
La ubicación de datos es un problema complejo y su solución no es trivial debido
al número de parámetros que intervienen en el modelado y a la complejidad de la
solución, ya que el espacio de soluciones es muy amplio aún para problemas de
tamaño pequeño. Es decir, si no se considera el hecho de que pueden existir réplicas
de los fragmentos, el número de ubicaciones posibles paraffragmentos en s sitios
está dado por d mientras que si se considera la replicación, el número de

Introducción Capítulo 1 'I
posibilidades se incrementa considerhblemente a ($)/,".
11 Se ha presentado el contexto de desarrollo de la tesis. En la siguiente sección se
I1 procede a la exposición de los aspectos que lo motivaron.
,' .
il
1.3 Motivación .I1
A la fecha, los SABDs comerciales existentes son capaces de generar
información estadística, tal e s el caso de Sybase [Syb97a][Syb97b] y Oracle
[Ora99a][Ora99b]. Sin embargo, dicha información estadística no es útil para la
determinación del diseño de la distribución, o bien, no es suficiente. En el caso de
SQL Server 7.0 de Microsof, la inkormación estadística se genera en las etapas de
análisis y optimización de la consulta. En la etapa de análisis, las estadísticas se
refieren al número de exploraciones (iteraciones), número de lecturas lógicas (a
memoria caché), número de lecturas físicas (almacenamiento físico) y número de
lecturas anticipadas. En la etapa de optimización se mantiene un registro estadístico
sobre la distribución de datos,dentro de una columna, la cual puede o no ser índice.
Esta información es utilizada por el optimizador para elegir una columna índice, por
medio de la cual se optimice el procesamiento de la consulta. Otras estadísticas son
el tiempo de CPU total y el tiempo de ejecución de la consulta, así como la
selectividad y el número real de ejecuciones de cada paso en su procesamiento
[BM99].
'1
'1
.:. ,
'1
11
/I
1 Ili. ,.!
:I
't
0
11,
$1 'ill
La información anterior no es suficiente para determinar un esquema de
distribución de los datos, considerando que la selectividad si es un dato Útil pero no
suficiente. Por ejemplo, no se sabe cuál es el sitio que realiza la consulta, o bien, la
frecuencia de procesamiento de las consultas. I 1: ,
I '
11 Por otra parte, en la gran 'mayoría de los trabajos de investigación referentes al
il
8

Capítulo 1 Introducción
diseño de la distribución, la información sobre el uso de los datos, se proporciona
con base en la experiencia o en el conocimiento de la aplicación3 [MR95], [CPW87],
[NCW84]. Sin embargo, hasta ahora los datos no han sido obtenidos con base en la
explotación real de un SABDD. Esto presenta desventajas evidentes, como el hecho
de que los esquemas obtenidos de distribución de los datos no sean correspondientes
con la realidad, y en consecuencia el establecimiento de un esquema de distribución
inadecuado puede propiciar la degradación en el desempeño del sistema en lugar de
optimizarlo.
Una de las finalidades de este trabajo es llegar a conocer de forma cuantitativa
los patrones de uso de una base de datos en explotación, de tal manera que se pueda
obtener información estadística útil en la determinación del diseño de la distribución
de los datos.
El trabajo de tesis es uno de varios esfuerzos encaminados hacia la
automatización del diseño de la distribución en una base de datos distribuida, basada
en la utilización de un modelo de programación lineal entera 0-1 denominado FURD
(Fragmentación Ubicación y Reubicación Dinámica). Con este modelo se optimiza
el diseño de la fragmentación vertical y la ubicación de los fragmentos a través de la
base de datos distribuida [PPR98].
Hasta ahora la información requerida por el modelo para la determinación del
diseño de la distribución, había sido obtenida de manera aislada al sistema en
explotación y basada en la experiencia. En particular, el trabajo presentado consiste
en la automatización del proceso de captura de la información estadística requerida
por el modelo FURD. Dicha información estadística representa patrones de
’ En el primer caso, a través del tiempo el administrador ha adquirido la experiencia para determinar de forma aproximada los patrones de explotación. En el segundo caso, conoce la aplicación y en consecuencia puede conocer su comportamiento.
9

introducción Capítulo 1
I!
explotación de los datos a partir de las consultas relevantes en el sistema. En la
Figura 1-2 se muestra la interacción que tiene esta tesis con otros trabajos cuyo
objetivo, en conjunto, es la automatlzación del proceso de diseño de la distribución,
en particular con el modelo matemático FURD.
't
Obtentión Automatizada de "Información Estadística sobre el uso de los Datos
información Estadística
Distribución
Figura 1-2 Automatización del Proceso de Disefio de Distribución de Datos
11 1.4 Descripción del Problema
11
El siguiente ejemplo muestra gráficamente el proceso de diseño adaptable para
una BDD. En la Figura 1-3 se presenta un sistema formado por tres sitios. Para
efectos de este trabajo, no es relevante conocer la topología de la red, y es suficiente
conocer que los sitios están interconectados. El esquema de distribución de los datos
inicial está dado de la siguiente manera: Se almacena la Tabla A en el sitio SI y la
Tabla B en el sitio SZ (ver Figura i-4). Una vez que el sistema entra en operación, se
pueden identificar los patrones de acceso a los datos (ver Figura 1-5). Como se
observa, el esquema inicial de distribución de los datos tiene correspondencia con
los patrones de explotación iniciales, es decir, los datos están almacenados en los
sitios donde. su-explotación ,. , es,,mayor.
il
t
¡I
/I
I1
;/ :I
./I !I
10
II

Capítulo 1 Introducción
Tabla B
I I
r------
1 1 1
Figura 1-3 Siiios de la Red Figura 1-4 Esquema de Distribución de los Datos
Figura 1-5 Patrones Iniciales de Exploiación de los Daios
I Figum 1-6 Nuevos Patrones de Explotación de los Daios
A través del tiempo los patrones de explotación se van modificando según los
requerimientos de información desde los distintos sitios (ver Figura 1-6).
0 0 - 0 0 5 6
1 1

Capítulo 1 Introduccion I1
'1
Figura 1-7 Migración de Dalos - Tabla A
1 I
Figura I!8 Migración de Daios - Tabla B
1 Figura 1-9 Esquema de Dishi8ucidn de los Datos Adaptado a Pairones de Explotación
.I
Ante estos cambios en los patfones de acceso a los datos, un sistema ideal debe
evitar la degradación en su desempeño, modificando el esquema de distribución de iJ

Introducción Capitulo 1
los datos, adaptándolo a los nuevos requerimientos de información. En la Figura 1-7
se muestra la migración esperada de la información referente a los datos de la Tabla
A , de tal forma que los datos se lleven al sitio donde son más solicitados. Podemos
suponer que el mismo proceso se repite para los datos de la Tabla B (Figura 1-8).

introducción Capítulo 1
!!
!I cambios en los requerimientos de la información, podemos afirmar que el proceso de
diseño de una BDD se ha convertido en una tarea difícil para el administrador de la
base de datos y por lo tanto, se puede pensar, que el mismo sistema tuviera la
capacidad de realizar todo el proceso 'de forma dinámica.
. .,
I!
El problema particular de este'trabajo de tesis consiste en lo siguiente: I¡ '
I Determinar la frecuencia de procesamiento de las consultas, en un mismo
sitio del sistema y por un mismo cliente. Se debe obtener información
adicional, Útil para determinar el diseño de la distribución de los datos. Esta ,/
información incluye lo siguiente: cliente emisor de la consulta, selectividad
promedio de la consulta procesada, columnas . y tablas involucrados en la
1
0
consulta y predicado4. I/ Ill
Por otro lado, también es necesario identificar aquellas consultas con
diferencias sintácticas. El lenguaje de consulta SQL es flexible, por lo que
permite definir una misma consulta de variadas maneras, es decir, se puede
obtener el mismo resultado mediante consultas que aparentemente son
diferentes. Para .efectos de este trabajo, es necesario identificar este tipo de
consultas, ya que sólo así se podrá mantener un registro real de la frecuencia
de procesamiento de las consultas.
' I1 ,
1)
Il:
!j
/I 1 ,
1.5 Objetivo
El objetivo del trabajo de tesis consiste en desarrollar un módulo que obtenga
de manera automatizada información estadística de la explotación de una base de
datos distribuida mediante el uso ,de trincipios de bases de datos activas. 'I
dl
I1
Cabe mencionar que a lo largo del documento se hará mención a la frecuencia, como el número de veces que 4
una consulta es detectada en el sistema, esto es, dentro del periodo fijado por el ABD para realizar el monitoreo. En el caso de la selectividad, ésta se refiere al número de tuplas de una relación.
14

Introducción Capítulo 1
I 1.6 Propuesta de Solución
Para obtener'la información estadística sobre el uso de los datos, es necesario
monitorear el desempeño del sistema, así cuando se procesa una consulta, el sistema
puede detectarla y registrar la in formhón correspondiente a dicha consulta. I
Mediante el enfoque de bases de,datos activas se realizó un módulo que forma
parte del SABDD utilizado, añadiendo así la capacidad activa al mismo. Este I
módulo consta de dos partes: un Precomprlador útil en la definición de las Reglas
ECA, las cuales son el mecanismo mediante el cual se define el comportamiento
activo y, un Intérprete encargado del procesamiento de dichas reglas.
La implementación de los submódulos antes mencionados, fue especificada
formalmente mediante una gramática libre de contexto correspondiente a la
definición de un Lenguaje de Reglas ,ECA. En dicha gramática se especifican tanto
las acciones semánticas al tiempo de interpretación como al tiempo de 71
precompiiación. II
1.7 Alcances : 4
Como alcance de este trabajo se establecieron los siguientes puntos:
I implementar un módulo computacional para monitorear el desempeño del
sistema en cuanto a la explotación que se hace de los datos. Esto es con la
finalidad de registrar la información estadística requerida para la
determinación del diseño de la'distribución de los datos. Dicho módulo se
integró a un SABDD experimental denominado SiMBaDD.
La información estadística generada es la requerida por el modelo matemático
FURD descrito en [PPR98]: i,
!! 'I,
I,
i l l
\ I
1

Capítulo 1 .. > II
Introducción
. I , ,
1 I Nodos desde los cuales se.realiza$a consulta. . : , * , , , . I I
t. 1 II ' ,~ /I1 I Columnas accedidos.
I Tablas accedidas. 1 '4 I1
4 I Frecuencia de ejecución de las cdnsultas. . , , . (1) '; I , , . . . / I ,
I Selectividad promedio por consulta. I " I
Se consideran sólo operaciones de consulta para el registro deillos datos .>., .
!
111
En el trabajo de tesis no se desarrollarái,la ejecución del modelo matemático,
ni la ubicación dinámica de los/ datos. El objetivo del trabajo propuesto es
hacer disponible la información estadística nepesaria para reali'zar dichos
II II
II 11
. . dl . . I 8 1 .~
procesos. li
Para dar solución a la problemát,ica que'se presenta, se emplean los principios
de bases de datos activas. Esto permite dotar de 'la propiedad de dinamismo al 'li I1
II módulo de generación de inform'ación estadística. i).
,I 1 1.8 Organización del Documento I
El Capítulo 2 aborda los aspectos a los principios de Bases de Datos I
Activas. Se presenta desde:la historia,ldel enfoque activo, pasando por e¡ ,I estado del
arte correspondiente .a los prototipos1 que utilizan ,esta metodología, así como lo il 11 referente al mecanismo de Reglas ECA en el que se basan las BDAs.
I!
1 1
11 Ill ill i il
En el Capítulo 3 se presentan, los requerimientos para la implementación
computacional que da solución al problema que se aborda. Dichos requerimientos se
presentan en el sentido de una gramática independiente de contexto correspondiente II II
al Lenguaje de Reglas ECA diseñado, para el establecimiento del comportamiento
't
il
I! '!

Capitulo 1 Introducción
activo. Dicha gramática incluye las acciones semánticas al tiempo de definición y de
procesamiento.
La implementación del Lenguaje de Reglas ECA diseñado, se muestra en el
Capítulo 4. Primero se presenta la arquitectura del Precompilador empleado para la
definición de las Reglas ECA, y finalmente la parte correspondiente al Intérprete
que procesa dichas reglas.
En el Capítulo 5 se presentan las pruebas realizadas al módulo de Detección y
Registro de Eventos Relevantes, así como los resultados obtenidos.
Finalmente, en el Capítulo 6 se presentan las conclusiones del trabajo de tesis,
incluyendo la propuesta de trabajos futuros relacionados y los beneficios obtenidos.
El Apéndice A aborda los esfuerzos realizados por estandarizar el mecanismo de
disparadores, empleado en la mayoría de los SABDs comerciales de manera poco
uniforme.
Las características referentes a las bases de datos activas se presentan en el
Apéndice B. Así mismo se incluyen dos tablas comparativas de dichas
características entre el trabajo presentado en este documento y (1) otros SABDAs, y
(2) la definición del estándar SQW.
En el Apéndice C se presenta una lista de publicaciones recomendadas en el área
de BDA.
i 'I 17

Introducción Capítulo 1 I ~
., .. 'I I,
. , < , . , . . .
i I
'I . , . . ' !I. I. i l
II j :I
18

Capítulo 2 Bases de Datos Activas
Capítulo 2
BASES DE D A ' ~ O S ACTIVAS
. , !I
Puesto que las bases de datos activas! son una tecnología emergente, los
investigadores aún no han llegadoba un consenso en cuanto a la definición de un
concepto claro y uniforme para un sistema que pueda ser considerado a ~ t i v o . ~ '!
'I Por esta razón, dentro del contexto de este documento, basaremos el concepto de
capacidad activa de un SABD en e1"conjunto .de Eventos y Acciones con que cuente
el sistema. En esta sección sólo se delimitará el concepto de un sistema de bases de
datos activas así como el de un sistyma de bases de datos convencional o pasivo. En
secciones posteriores se abordará 18 referente a las Reglas ECA, incluyendo eventos
y acciones.
11
,'I
1
Después de analizar distintas definiciones referentes a un sistema activo, se
determinó el siguiente concepto deiun sistema de bases de datos activas: sistema
que por s í mismo es capaz de lidesarrollar operaciones automiíticamente, en
respuesta a la ocurrencia de ciertos eventos o al cumplimiento de ciertas
condiciones. Tanto Eventos como Acciones van más allá de las operaciones de
manipulación de daios. aunque también las incluyen.
81 11.
;I
d l Ahora bien, un sistema de base de datos convencional puede contar con algunas
propiedades de los sistemas activos, es decir, puede o no tener la capacidad de
presentar un comportamiento reactivo ante ciertos eventos o ante el cumplimiento de
t
Algunas de estas definiciones se pueden encontrar en PGG951, PHW951. 5
I 19
I I

Bases de Datos Activas Capítulo 2
I i
I! . .
!I 11 'I
I . ciertas condiciones. En este caso, Eventos y Acciones están limitados a operaciones
de manipulación de datos. Bajo la definicibn anterior, queda clarojl que un
subconjunto del total de los sistemas convencionales, también llamados pasivos,
presentan cierto grado de capacidad activa, la cual está limitada. Este suhonjunto
.,I.
'I I/ I/
está dado por los sistemas de bases de datos con mecanismo de disparadores, los
cuales sólo responden a eventos de manjpulacion de datos y reaccionan midiante la
ejecución de operaciones del mismo tipo. La Figura 2-1 ejemplifica la taxonomía
determinada por el umbral de operaciones descrito.
i II n !I .
It
Mayor Capacidzd
Activa
U
Menor Capacidad
Activa
Figura 2-1 Taxonomía de Bases de Datos en cuanto a su CapacidadAcfiva
I¡ I
11
II I1 Una vez presentados los conceptos básicos se enumeran algunas ventajas de los
sistemas activos sobre los pasivos6: ,( 111 I1
!I . t
111 ' 'I( 'I
(1) Pueden desarrollar funciones que en SABDs pasivos deben ser codificadas en
aplicaciones, por ejemplo restricciones de integridad general y disparadores.
(2) Facilitan el desarrollo de aplicaciones pertenecientes al alcance de los propios
Para mayor detalle de las funciones involucradas en cada uno de los puntos ver [wC96]. , . ,
. .
20
~~ .- . . . . .. . .., .. . ._ - ... .. .

Bases de Datos Activas Capítulo 2
SABDs pasivos, como son manejo de “workflow” y sistemas expertos para
cantidades masivas de datos.
(3) Pueden desempeñar tareas que requieran subsistemas de propósito especial en
SABDs pasivos: restriccionej de integridad simple, autorización, generación
de estadísticas y vistas materializadas. I \
En la siguiente sección se presentan los primeros indicios del enfoque activo y .I
cómo se fueron sentando las bases para los sistemas activos.
2.1 Antecedentes
El área de las BDAs fue realmente reconocida hasta mediados de los 80s con la
aparición del. primer sistema administrador de BDAs: el proyecto HiPAC. Sin
embargo, algunas características dei este enfoque fueron apareciendo desde los 70s
[WC96].
.I
I,!
A inicios de los 70s aparece un lenguaje de manipulación de datos (CODASYL)
que incluía un mecanismo para la invocación automática de procedimientos en
respuesta a operaciones específicas sobre la BD. La sintaxis empleada es la
siguiente: ON <command list > CAhL <procedure> I
8 1
El símbolo <procedure> especifica el procedimiento especifico y <command
list> especifica uno o más de los’iomandos INSERT, REMOVE, FIND, STORE,
DELETE, MODIFY y GET. I1
A mediados de los 70s aparde un QBE (Query-by-Example) que incluía la .I . . . facilidad de los disparadores para la verificación de restricciones de integridad.
~
Finalmente, a finales de los 70s, el Sistema R sugirió un subsistema de
SEP CEWIIDET. DGlT CENTRO DE lNFORMACION
I 1 21 i I 1

Bases de Datos Activas Capitulo 2
i I
disparadores, sin llegar a ser implementado-en sds productos. /I 'I I
2.2 Enfoques Alternos II 'I/! ili El empleo de BDA permite monitorear deterpinados eventos de interés. Con la
8 1
finalidad de comparar las ventajas de las I Bases de Datos Activas, en esta sección se ¡I 3 ¡I
periódicamente el estado del sistema. '11 I1 !I i(
describen métodos alternos, por medio de los cuales se puede realizar el rionitoreo
en sistemas pasivos: modificando el Código de las aplicaciones o verificando
I
2.2.1 Modificación del Código II
En el primer método, el desarrollaaor incluye condiciones de monhoreo en
lugares apropiados en el código de los programas, es decir, en los lugares donde
existe la posibilidad de ejecutarse un evento de interés. Esta solución'result: fácil de
implementar y no implica modificar el SABD.
I 11
Los principales problemas que se presentan 11. son Y los siguientes: iJl, 'I , I 'i I .
II ' . . /I !I i) El desarrollador de la aplicación :tiene que conocer y tomar en cuenta las
condiciones ha ser monitorear y entonces,,codificarlas como parte de la aplicación.
~
!
ii) El código de las condiciones de monitoreo ,no es mantenido o manejado por el
propio SABD y por lo tanto no puede ser compartido por otras aplicaciones, es por
ello que dicho código se repite en cada una de ellas.
I/ II 11
!
II iii) El software de mantenimiento de?los programas de aplicación del SABD es
muy complicado debido a la falta de modularidad y reusabilidad de código [Cha92]. 111, !
It I1
22

I
i
i
i i
! I
I I I 1 i i
Capítulo 2 Bases de Datos Activas
It 2.2.2 Verificación Periódica
Si se realiza la verificación periódica del estado del sistema, cada condición es
verificada temporalmente, y si dicha condición se cumple entonces se ejecutan las
acciones apropiadas. Sin embargo, la frecuencia de verificación debe ser
determinada considerando la complejidad de las condiciones. En general, esto puede
ser una carga para el administrador de la base de datos, ya que tiene que indicar
explícitamente la frecuencia de verificación.
I !i
;I !I .(I
I): . Esta técnica no es apropiada para sistemas con restricciones de tiempo, debido a
que si la frecuencia de la verificación es alta, entonces el desempeño del sistema se
ve afectado, ya que debe detener su ejecución para dar paso a la aplicación que
realizará la verificación. Por el contrario, si la frecuencia de verificación es baja, no
podemos detectar todos los eventos a tiempo. De ahí las desventajas de este método
de solución.
4L
I1
!I I!. ,i.
I ti.
!! 2.3 Reglas ECA
Las Reglas ECA son el mecanisino mediante el cual se define el comportamiento
activo en BDA. Los lenguajes de reglas ECA tienen su origen en los lenguajes de
reglas de producción de Inteligencia Artificial. Dicho paradigma ha sido adaptado al
contexto de BDAs, de tal forma que las reglas puedan responder a las operaciones
propias de un sistema de bases de datos (ver Figura 2-2).
t i
11
La forma general de las reglas en IA es la siguiente: Patrón-tAcción. Estas
reglas son llamadas basudus en parrones. Su procesamiento se basa en un ciclo (Ver
el algoritmo en la Figura 2-3). La fase de correspondencia identifica las reglas cuya
condición se cumple sobre el estado de la base de datos, y las agrega al conjunto de .I/
conflicto, representado por una cola del conjunto de reglas disparadas.
. 'P
II
23 il

Bases de Datos Activas 11 i! Capitulo 2
I I \\I
Inteligencia Artificial
I¡
I I' II
'I/ ,v d
di Ill I' it
¡I i/ 11.
li Ill
Figura 2-2 Origen de ?as Bares &e Aciivas 'I 'I
La fase de resolución del conflicto selecdiona una regla del conjunto de reilas en la
cola del conjunto de conflicto para ser procesada, y en la fase acción, se ejecuta la I1
parte de la acción de la regla 'se¡eccionada. El patrón' puede ser un predicaho o una
condición. En este tipo de reglas el evento está implícito, y esta dado por el cambio
en los valores de los datos en la memoria de trabajo, una vez que éstos enbuentran
correspondencia con el patrón definido en la regla [HW93].
. .
t 8 ,
correspondencia mientras (el conjunto de cahflicto no este vacio) hacer
jC j/ solución del conflicto acción correspondencia
fin-wbile I1 ~~
I/ Figura 2-3 Algoritmo de l+&samlento de Reglas en IA
ic La diferencia principal entre el lengdje de reglas de IA y el lenguaje de reglas
de bases de datos es la definición explícita en el último caso del evento. +a forma general de estas reglas es la siguiente: li, Ill il
,e
I On evento ,If condición Then acción '11 'li
Esta forma permite que las reglas sea; disparadas por eventos en el sistema, por
ejemplo, operaciones sobre la base de datos. Cuando un evento de interés ;curre, la s1, 11

I
I
Capítulo 2 Bases de Datos Activas
condición es evaluada contra la base de datos; si la condición se cumple, se ejecuta
la parte de la acción de la regla. Ver el algoritmo en la Figura 2-4. Ir
I mientras (haya reglas disparadas) hacer evalúa la condición de la regla si (la con&ción es verdadera) hacer
ejecuta la acción de la regla fin-mientras
Figura 2-4 AIgori&o de Procesamienio de Reglas ECA II
El evento representa cualquier vsituación . de interés, capaz de disparar alguna
regla ECA. Los eventos pueden set primitivos o compuestos. Ejemplos de eventos .'1 primitivos son modificación de datos, recuperación de datos, eventos de tiempo, y I! eventos indicados por una aplicación. It ' 1
La cláusula if especifica la condición a ser evaluada una vez que la regla ha sido
seleccionada. Se considera que la cbndición representa el contexto dentro del cual el
evento es detectado.
I
I!
La cláusula then especifica una o más acciones a ejecutar cuando la condición en
la regla se cumple.
En cuanto a las ventajas de emplear este mecanismo podemos mencionar las
siguientes [SHP96]: II
it I Las reglas tienen una descripción declarativa, la cual incluye la condición
donde se usa la regla.
I Las reglas tienen una descripción modular. Cada regia representa una parte de
la extensión.
il.
I/i
Como se puede apreciar, los principios de bases activas se apegan a la naturaleza
dinámica del problema que se aborda en esta'tesis y facilitan su implementación.

Bases de Datos Activas Capítulo 2 ~
II I1 i:
I1 !
i
I .
2.4 Estado del Arte
Actualmente existen varios SABDAS 111, tanto experimentales 11 (POSTGRES!'[SJG90], I
Ariel [Han91], Starburst [Wid92], SAh4OS [GGJb95], Mariposa [SAP97], Ffamboise
[FGD98], Sentinel [CKT94], etc.) ~ coho comerciales (Oracle [Ora99]; Sybase
[Syb97], Ingres [WC96], etc.).
'11 I/
li 4 '
,I llil I)
'11
La capacidad activa se considera un mecanismo que soporta un gran numero de
I/ :I1
funciones del mismo SABD, .tales como :I mantenimiento de seguridad e . in.fegridad,
mantenimiento de vistas materializadas, manejo de restricciones e inferenci. basada
en reglas. Pero a la fecha ninguno de los SkBDs mencionados anteriormente
aprovechan su capacidad activa para la generación de información estadística útil
para el diseño de [a distribución de los datos en el sistema.
:I! 1 ll I
nii
' : I , !/I lib ' '' JL A continuación se presenta una breve descripción de la arquitectura del algunos
I/ I1 .
de estos SABDAs con la finalidad de visualizar los distintos aspectos que han Y
I
implementado en su parte activa. ii I1 ,I
.,
2.4.1 ARIEL
Este SABD fue desarrollado en la Uniuersidad;jde Florida por el investigaclor Eric
N. Hanson. La parte más relevante de la arquitectura en Ariel es un módulo que I1 .
genera una Red de Discriminación, mecanismo empleado para la evaluación de la !I ' .I/ .
condición de la regla. Dicho mecanismo se considera eficiente dado que mantiene en
memoria una parte de los resultados de ?a condición procesada, 'agilizando así su
/I
I/
II \ procesamiento. ij
I
II /I Los componentes de la arquitectura de Ariel ''[Han911 son los siguientes: Lado
Frontal (Analizador Léxico, Analizadhr Sintactico, Analizador Semá;ntico y
Optimizador de Consultas); Lado Posterior (Ejecutor del Plan de Consulta); 1 1
26 il I

Bases de Datos Activas Capítulo 2
Discriminación
Sistema de Reglas (Catálogo de ;Reglas, Red de Discriminación, Monitor de
Ejecución y Planificador de la Acción de las Reglas).
Léxico / Sintáctico Arbol
Sintáctico
A continuación se presenta la descripción de los componentes, del Sistema de
Activación 11 de la Regia
Reglas de Ariel:
Catálogo de Procesador de Reglas Consultas
4
!I
Monitor de Ejecución de
Regias
Comandos en SOL , IActualización
de tupias
Regia ~ Planeador de *'+ la Acción de
I' la Regla
Red de Discriminación: Ariel ¡cuenta con una red para la evaluación de las
condiciones de las reglas, la cuál está diseñada para aumentar la velocidad en el
procesamiento de las reglas en un ambiente de bases de datos y para reducir los
requerimientos de almacenamiento de la misma red. La Red de Discriminación
permite seleccionar la forma de evaluación de la condición, según convenga.
Y j i
F

Bases de Datos Activas 6 fi 1 Capítulo2
! II II; .
I
Monitor de Ejecución de Reglas: Mantiene !ma agenda de reglas por prioridades I !I l8 11 I1 1
y está basado en tres métodos:
addRule. Llamado por la Red de Discriminación. Agrega una regla a la agenda,
si no está ya incluida, cuando la condición de la misma se cumple, indicando que I1 I1 li
I1 dicha regla se encuentra activada,, I en este momento se genera la red de
I1
discriminación. También se almacenan las tuplas que cumplen la condición en
una estructura temporal p-nodo. 11, ; I II
, I
removeRule. Llamado por la Red de Discriminación. Elimina la regla de la I, I/
agenda cuando la condición ya no se cumple.
runRules. Llamado por el ejecutor. de consultas al final de una transición, para
disparar la última regla activada de mayoq prioridad a ser ejecutada por el
II 11
1 I
Planeador de Acción de Reglas. I
il /I I! III
Pianeador de la Acción de la Regla:, ste módulo se encarga de realizar el plan
de consulta para obtener las tuplas involucradas en la parte de la acción della regla.
Tiene dos opciones para hacerlo: por uh lado, cuando en la acción aparece una
r" I
variable tupla que también aparece, i en la condición, recorre la4 tuplas
correspondientes sobre la estructura temporal (p-nodo) que ya las contiede; de lo
contrario se emplea un indice para actuar sobre la relación directamente. . , 'Ir. lib '111
! 4 II
Autonomía Implementada: El tiempo en el que se construye el plan del'consulta
es muy importante para el desempefio dkl sistema, y Ariel soporta sobre 'SU parte
activa una técnica llamada "reoptimiza siempre" con la que el plan de consulta se
genera en el momento de disparo de la regla.
*I ;I\. '11 111
.i/ .It 4 ..
li I !
',

Capítulo 2 Bases de Datos Activas
2.4.2 MARIPOSA it
Mariposa [SAP97, SAD941 es un SABDD para redes WAN, en el que cada sitio
es autónomo. Este proyecto se encuentra bajo la dirección de Michael Stonebracker
en la Universidad de Berkeley.
Jil
Ili
111;
4s
11
Todos los sitios tienen una cuenta con el banco de la red. Un usuario proporciona
un presupuesto en la moneda del banco a cada consulta. De esta manera cada sitio
Mariposa realiza decisiones para comprar o vender un fragmento de información.
INTERMEDIARIO
Fragmentador
Agente
Coordinador ,'I
MODULO DE EJECUCIÓN
LOCAL
Parte activa
Figura 2-6 Arquitecíura de Mariposa [SAP971 4
La arquitectura del SABD es como sigue:
INTERMEDIARIO "k
Analizador Sintáctico: Maneja ia consulta en forma de árbol sintáctico. Elige el
servidor más adecuado para cada 'tabla invoiucrada basándose en los precios que
ofrecen los servidores, el presupuesto disponible y algún sistema de reglas definido
'I
11 29
II I!

Bases de Datos Activas ~ , Capítulo 2 I1 I 11
localmente que asigne prioridades a estos 'I factores. , ' l j :
II I/ II
íl 11
'I I/ il !I
. , I !
1 I1 /I
.~
Optimizador de' Sitio Único: Genera un plan de ejecución para la consulta i 1 ill! , ' 1) .I/. suponiendo que todos los fragmentos están almacenados en el sitio local.
I*
Fragmentador: Descompone el plan producido por el módulo anterior en un plan
de consúlta fragmentada. El resultado es una consulta por cada fragmento:/referido.
Se agrupan las consultas que se pueden realizar en paralelo para mejorar el
desempeño. ' ! I
Agente: Toma los planes de la consulta fragmentada y envía los requerimientos a
los distintos servidores para'recibir de ellos sus ofertas, notificando a los que hayan
sido aceptados. Finalmente se encarga de que io; resultados de las consulta& lleguen
al Coordinador.
dk
II. !I
I i:
Coordinador: Ensambla los resultados de las consultas parciales y regresa el II I¡ I
resultado al proceso usuario.
ll 'I
M ~ D U L O DE E J E C U C I ~ N LOCAL ;I /j
Postor: Es el módulo encargado de formular su oferta en respueda a los II requerimientos recibidos por parte de otro servidor. Para ,proporcionar su ;espuesta I 1 I1
se basa en los recursos locales (CPU, almacenamiento disponible, disco, etc.). Si no
cuenta con el fragmento solicitado puedellrechazar la petición o intentar comprarlo a otro sitio. I1 i
II I1
Ejecutor: Cada sito Mariposa tiene un número de módulos de ejecución local
que controla el grado de multiprocesami'ento. Ai cada ejecutor ocioso se . . le asigna 'I una subconsulta y después envía el resultado al sitio que procesará la siguiente
parte, o bien, al Coordinador.
. .
iII ./I '.
'I I

I!
Bases de Datos Activas Capitulo 2
Administrador de Almacenamiento: Determina la renta generada por los
fragmentos almacenados. Basado en espacio y consideraciones de renta, este módulo
!I
I.
negocia con otros sitios la compra y venta de fragmentos. ',
Autonomía Implementada: Los tres componentes del Ejecutor Local (Postor,
Ejecutor y Administrador de Almacenamiento) están codificados sobre la parte
activa de Mariposa, por lo que la autonomía del SABD está orientada
principalmente al manejo óptimo del almacenamiento de los fragmentos.
,'I . ..
Además Mariposa cuenta con una serie de Eventos Definidos para restricciones
de procesamiento, balance de cargalen el sistema y restricciones de dependencia de
datos. También cuenta con Acciones Construidas para enviar y recibir un fragmento,
para contactar un determinado sitiory solicitar un fragmento o para liberar un evento
a una serie de sitios (empleado pantrabajo cooperativo).
1,
i)
,'I
2.4.3 Chimera
Chimera (Politécnico de M i l a d , Stefan0 Ceri) es el nombre de un modelo de
datos conceptual orientado a objetos (Chimera Model, CM) y del sublenguaje de
base de datos correspondiente (Chimera Language, CL). Este último provee
definición de datos, consultas declarativas, primitivas para la manipulación de la '1
base de datos, así como varias formas de regias y restricciones [CM93a].
Los componentes de su arquitectura son los siguientes:
lade: Herramienta CASE que recolecta las especificaciones del esquema.
Produce como salida dos archivos Chimera: definición del esquema de restricciones
y disparadores para mantener la integridad del esquema.
.I1
'i
11
Argonaut: Soporta la generación de reglas activas provenientes de la

I3 1 Bases de Datos Activas Capitulo 2
I I II I1 II
especificación de las restricciones de intkgridad y vistas. . . . i/: I1 i1 Jj
II! 111 Ill
, .: , , . , . , '. . . Arachne.. Analiza la terminación del tiempo de compilación' de un conjunto de
,
reglas activas de Chimera. Determina las causas que originan ejecuciones infinitas. I I 41 11, 111
Algres: Es el ambiente de ejecución para un prototipo rápido1 de una especificación de diseño Chimera. '11 11 .I1
I I I1
di '1 ,I
Pandora: Traduce una aplicación Chimera a Oracle 7.2 I
II I1 I, Autonomía Implementada: Bajo Chimera los disparadores son conciderados
como reglas activas y las implementacidnes que se han desarrollado con ellos son
II 'I1 II los siguientes:
I 11 !I Verificación de restricciones de infegridad estática, es decir, a través de
disparadores se mantiene la integridad de la base. de datos al final ide cada
transición.
Verificación de restricciones, de integridad dinámica. Se determina si,l algunas
secuencias de eventos pueden violar .la integiidad, aún cuando separados no lo
I! i t
I1 .I
: I1 I, ii I/
'I
hagan.
1 I1 11
Materialización de vistas o de datos \derivados mediante reglas que se activan
inmediatamente. li 1
I
2.4.4 SAMOS ii il
'I Los eventos que maneja'SAMUS, SABD desarrollado en la Universidad de
Zurich por Stela Gatziu, pueden ser primitivos o compuestos. Dentro! de los
primitivos se tienen eventos de tiempo (los cuales ocurren en un punto específico en
el tiempo o periódicamente), eventos de/envio úe mensajes (ocurren al in/'cio o al
11, II :ll
I1 I1 .I/
'!
32

I!
'I
Bases de Datos Activas Capítulo 2
final de la ejecución de un método), eventos.de valor (ocurren al inicio o final de
una operación de modificación de datos), eventos de transacción (ocurren antes O
después de una operación de transacción) o eventos abstractos (los cuales no son
detectados por SAMOS pero han sido señalados explícitamente por una aplicación o
por un usuario). Los eventos compuqstos se construyen a partir de eventosprimitivos
o por otros eventos compuestos.
21.
9)
8 : '
El prototipo está constituido porbtres bloques: (a) un SABD orientado a objetos
llamado ObjectStore, (b) una capa sobre el SABD que representa la capacidad activa
formada por una serie de componentes como el Administrador de Reglas, el
Detector de Eventos Compuestos y:.un Componente de Ejecución, y ( c ) un conjunto
de herramientas compuesto por un compilador, un analizador, un editor y un
visuolizador de reglas.
!l.
.I1
il
iI
i!
Para comprender el funcionamiento de la arquitectura de SAMOS [Gat971
veremos cómo se realiza el procesamiento de las reglas:
Fase de Señalamiento: Después de haber recibido un mensaje de evento
sucedido por parte del Detector de Eventos Primitivos, se recupera el objeto del
evento apropiado y se mantiene su historial (registros de las ocurrencias del .evento).
El Administrador de Reglas verifica si el evento pertenece a uno compuesto, de ser
así se informa al Detector de Eventos Compuestos.
I
'I.
Fase de Disparo: Se procesa la historia del evento, es decir, se disparan las
reglas asociadas a los eventos señalados en la fase anterior. Finalmente se determina
un conjunto de reglas disparadas. I)
't Fase de Planeación: Una regla se selecciona del conjunto de reglas disparadas.
Las reglas se seleccionan en el o!den en que sus eventos fueron insertados en la
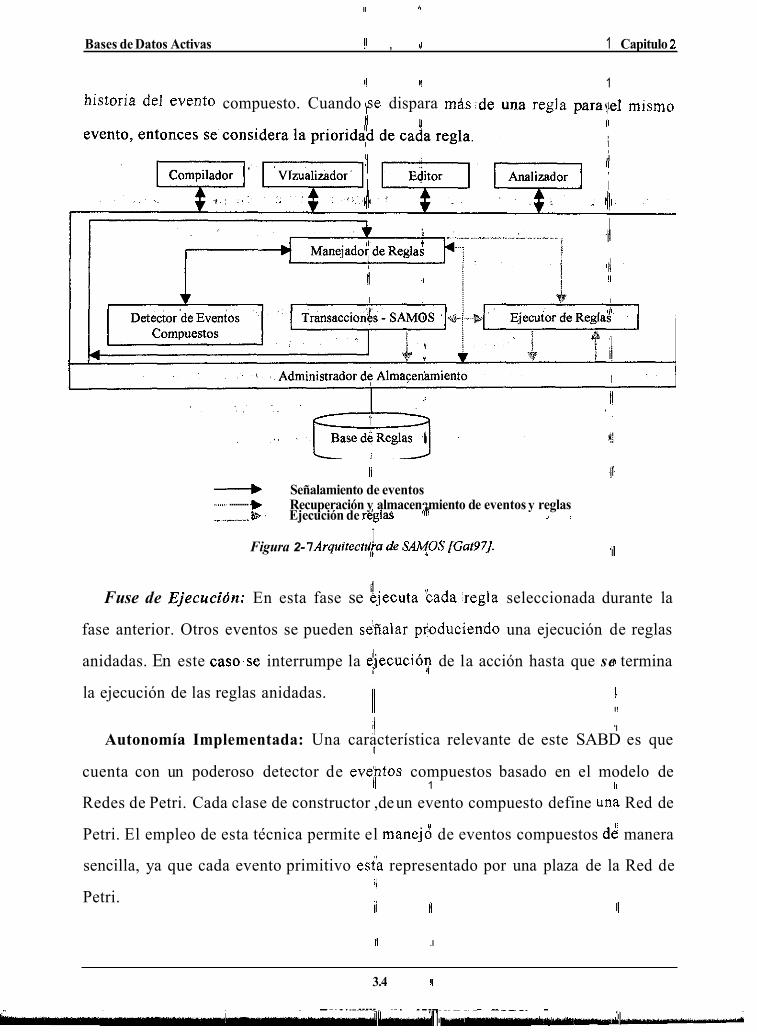
Bases de Datos Activas !I , I1 1 Capitulo 2 I
I! I! 1 historia del evento compuesto. Cuando Npe dispara miis :de una regla paravpl mismo
II
li 4 Señalamiento de eventos
.......... * Recuperación y almacenamiento de eventos y reglas 61. Ejecución de réglgias 'b - ,
'/I I Figura 2- 7 ArquiteduLa de S@OS rGat97J
Fuse de Ejecucidn: En esta fase se kjecuta 'bada .regla seleccionada durante la
fase anterior. Otros eventos se pueden s&aIar ptoduciendo una ejecución de reglas
anidadas. En este caso.se interrumpe la djecución de la acción hasta que se ' Y termina
la ejecución de las reglas anidadas. I/ 4
'I I!
'I
II '11 Autonomía Implementada: Una característica relevante de este SABD es que
cuenta con un poderoso detector de evehtos compuestos basado en el modelo de
Redes de Petri. Cada clase de constructor ,de un evento compuesto define una Red de
Petri. El empleo de esta técnica permite el manej8 de eventos compuestos de manera
sencilla, ya que cada evento primitivo est'a representado por una plaza de la Red de '1
Petri.
1)
/I 1 I,
~
I¡ I1 11
II .I
3.4 !I
..... ~~. . ~ ~ . .

Capítulo 3 Lenguaje de Reglas ECA
Capítulo 3
LENGUAJE DE REGLAS ECA (1 it.
Tradicionalmente se ha tratado la parte referente al lenguaje de definición de las
Reglas ECA de manera informal como en [Wid92], [Gat971 y [Han91]. Sólo en el
caso de algunos SABDAs se representa formalmente el lenguaje de definición de las
Reglas ECA empleado, tal es el CASO de Chimera [CM93], Framboise [FGD98] y
Snoop [CM93b].
11
Ill
'r r
11
En la mayoría de los SABDAs el lenguaje de definición empleado es una
extensión del lenguaje propio del. sistema, como puede ser SQL'. A manera de
ejemplo están Postgres y Ariel que extienden el lenguaje de consultas POSTQUEL,
o bien, Starburst que extiende el SQL. En particular, el lenguaje definido en este
trabajo es independiente de SQL, aunque en trabajos futuros se puede ampliar para
incluir predicados o consultas en dicho lenguaje, como parte de la definición de la
condición o de la acción en la regla.
i
!I
41 La importancia del lenguaje de Reglas ECA radica en que por medio de él se
define el comportamiento activo del sistema ante determinados eventos. La
especificación del lenguaje definido en este trabajo, se basa en los requerimientos de
procesamiento y definición de las Reglas ECA necesarias para la obtención de
nuestro objetivo: monitorear el desempeño del sistema.
' Este también es el caso de los SABD comerciales con mecanismo de disparadores que, aunque los consideramos patie de SABD convencionales? cuentan con una capacidad activa limitada.
ii I I
fJ
1,
li 35
1
II I/ 1
Lenguaje de Reglas ECA ' Capítulo 3 II !! I1
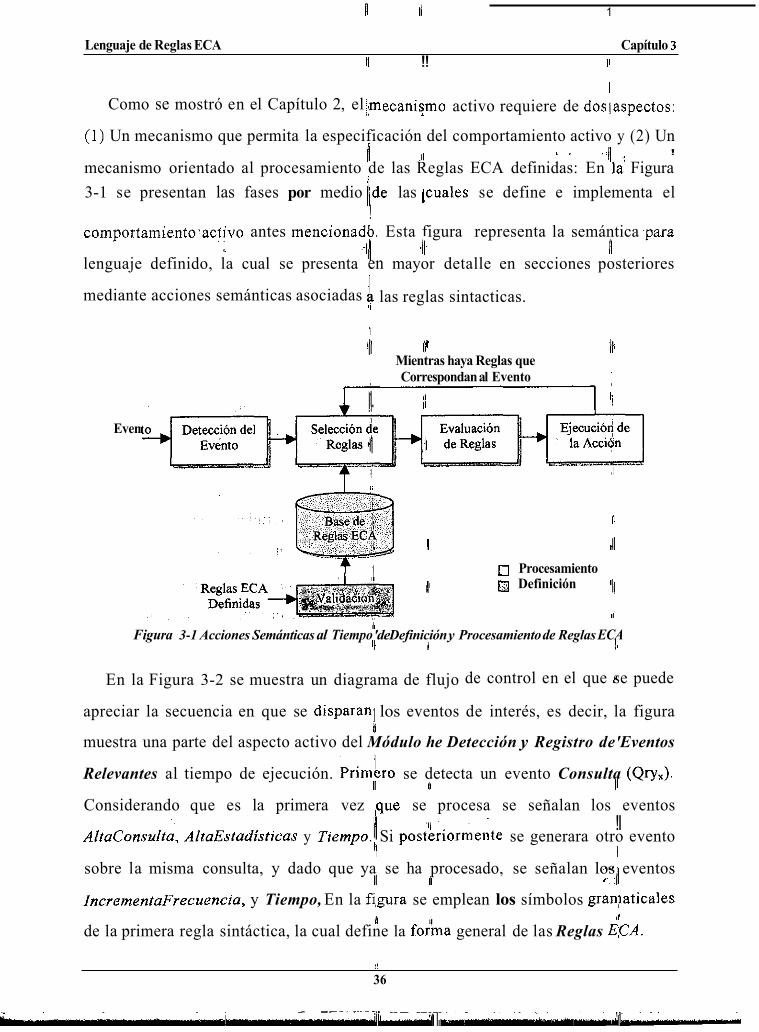
I I Como se mostró en el Capítulo 2, el ecanismo activo requiere de doslaspectos:
( I ) Un mecanismo que permita la especificación del comportamiento activo y (2) Un , . .:/I !
mecanismo orientado al procesamiento de las Reglas ECA definidas: En la' Figura /I I1
I 3-1 se presentan las fases por medio I Ide las llcuales se define e implementa el !
comportamiento.activo antes mencionadb., Esta figura representa la semántica 'para
lenguaje definido, la cual se presenta en mayor detalle en secciones posteriores
mediante acciones semánticas asociadas
6 .-I11 .¡l. I1
las reglas sintacticas.
'I
I 'lb Correspondan al Evento I
Mientras haya Reglas que !/I
Even
II
I AI
)(I 0 Procesamiento ~
pj Definición I/!
'11 81
Figura 3-1 Acciones Semánticas al Tiempo 'de Definición y Procesamiento de Reglas ECA
En la Figura 3-2 se muestra un diagrama de flujo 1 de control en el que se ,' puede
apreciar la secuencia en que se disparan'i los eventos de interés, es decir, la figura ¡I
muestra una parte del aspecto activo del Módulo he Detección y Registro de' Eventos
11 I/ I,
Relevantes al tiempo de ejecución. PrimLro se detecta un evento Consulta (Qry,). II 1) I1
Considerando que es la primera vez pue se procesa se señalan los eventos
AltaConsulta, AltaEstadísticas y Tiempo.11 Si poshormente se generara otro evento !I
It 11
II I1 c 1
sobre la misma consulta, y dado que ya se ha procesado, se señalan los eventos
IncrementaFrecuencia, y Tiempo, En la fiigura se emplean los símbolos granlaticales ,I I!
de la primera regla sintáctica, la cual define la forma general de las Reglas E,CA.
.! 36
.

Capítulo 3 Lenguaje de Reglas ECA
Evento-AltaConsulta Condición-AltaConsulta Acción-AltaConsulta
,
Figura 3-2 Flujo de Control del Procesamienio de las Reglas ECA
En este trabajo se formalizó el lenguaje de Regglas ECA, mediante la definición
de su gramática. En la sección siguiente se presenta la gramática a través del empleo
de la notación Bakus Naur Form (BNF). 'I
3.1 Gramática del Lenguaje de Regias ECA :I1
La notación empleada para la definición de la gramática es BNF extendida. La
extensión consiste de los símbolos y que denotan cero o más ocurrencias de
determinada unidad Iéxica. Además los símbolos no terminales se escribirán en
minúsculas y los terminales con mayúsculas.
I'
'!
3.1.1 Regia ECA
Función: Especifica las distintas Reglas ECA que se pueden definir a partir de los
conjuntos de eventos, condiciones acciones.
ReglaECA : := Evento-IncrementoFrecuencia Condición - Numérica Acción-Numérica !I

I/ i!
Lenguaje de Reglas ECA ,I ! Capítulo 3
!I I I!
1 ,- 4
I1 . . t I
I Evento - Consulta True Acción Consulta
, I! 1 Evento - AltaConsulta Condición-AltaConsulta Acción-AltaConsulta 1 Evento AitaEstadisticas Condición-Ihnérica Acción-Numérica 1
I/ .I
I Evento - . Tiempo Condición -. l;Tiempo kcción-Tiempo !I 'I
- .I1
' t
3.1.2 Eventos Ill I1 I1 . I
Los siguientes símbolos gramaticales especifican el conjunto de eventos. lI I1 ,I/
Evento - IncrementoFrecuencia : := INCRE¡&NTO-DE-FRECUENCIA Evento-Consulta ::= CONSULTA ,ii. 111 111
! II
'). I Evento - Tiempo ::= TIEMPO
Evento-Altaconsulta : := ALTA-BASE-DE-CONSdTAS ' '
Evento - AltaEstadísticas ::= ALTA-DATOS~ES?ADISTICOS-DE-EXPLOTACI6N Ili I1
3.1.3 Condiciones
Los siguientes símbolos gramaticales esdecifican' conjuntos de condiciones %on base
en el tipo de los valores involucrados. 1 I1 Ir
II I Condición-Numérica * . : . ( I y, I
Función: Especifica Condición de tipo numérica.
Condición-Numérica ::=' V&able-Num Op Valir-Num I TRUE Ill' ill
. . , ' I 11 !I
li
I Condición-Tiempo II Función: Especifica Condición de tipo tiempo.
1 Condición-Tiempo : := Variable-Tiempo Op Valor-Tiempo
II
I I Condición-AltaConsulta
lj.
Función: Especifica Condición de tipo alfanumérica. I/ 11 I! Condición-Aifanumérica ::= Variable-Id Op Valor-Num
I Ill I / 'I;

Lenguaje de Reglas ECA 11 Capítu'03
1 Vaiable-Tabla Op Tabla I Variable-Columna Op Valor - Columna I Vanable-Where Op Valor-Where 1 Variable-Cliente Op Valor - Alfanum
I
I TRUE
I, " 1 3.1.4 Acciones
Los siguientes símbolos gramaticales 'constituyen el conjunto de acciones.
Acción - Numérica ::= PASA-QRY-A-RELEVANTES 1 AVISA-DBA I ' I
# , I: '1 EJECUTA-INTEGRADOR
Acción - Consulta ::= LLEVA-ESTADISTICAS I AVISA-DBA
Acción-Tiempo ::= AVISA-DBA 1 EJECmA-INTEGRADOR Acción Altaconsulta ::= AVISA-DBA u -
\ 3.1.5 Variables
Los siguientes símbolos gramaticales conforman el conjunto de variables.
1 Variable-Nun ::= IDENTIFICADOR 1 FRECUENCIA I SELECTIVIDAD
!I Variable-Tabla ::= TABLA 1 Variable-Colma ::= COLUMNA I I Variable-Where ::= WHERE 1 Variable - Cliente ::=CLIENTE I Variable-Identificador ::= IDENTIFICADOR 1,
Variable-Tiempo ::= TIEMPO ,I
:i I\
I
t .
1 3.1.6 Operadores
1 Los siguientes símbolos gramaticales especifican operadores.
II II 39

1 !I l Capítulo3 Lenguaje de Reglas ECA , ,I
I! I/
I :
3.1.7 Elementos Comunes
Valor-Nun ::= Dígito Dígito 1
Dígito::= 1 1 2 1 3 1 4 1 5 ( 6 / 7 1 8 1 9 / 0 , :,
Valor - Alfanum ::= letra letra I dígito 11 letra ::= letra-minúscula I letra-mayfwuia'
1 1
I1
I1 I¡
'. 111 .I1 :I1 , , ti
!I . , 1
::. .' Ib 4 * iL
, . . , .,
3.1.8 Val-Columna. I
Función: Especificación de Valor-Coiumna dl II
Valor-Columna ::= Tabla. Columna Tabla ::= Valor-Alfanum Columna ::= Valor-Alfanum ' . t
!I II
I 'i 3.1.9 Valor - Where
, I II Función: Especificación de Valor-Wliere
1' !i 4 II
I .
Valor-Where ::= Valor-Columna Op Valor-Nd ;l. . .
I Valor-columna o p VJor-Mfanum
4 II !!
3.1.10 Valor-Tiempo I li
'b Función: Especificación de Valor-Tiempo . ,
Valor-Tiempo : := Constante-Año,Constante-Mds,Constante-Día, li
1 ? . * '
I1
I Constante-Hora,Constante-Minuto
'I/ I / , , I . " Constante-Día ::= Valor-Nun I1 !I Constante - Hora ::= Valor-Nun
Constante - Año ::= Valor-Num Constante-Mes := Valor-Num
I
. . . . . . . ,I ~ .,,.

Capitulo 3 Lenguaje de Reglas ECA
111 Constante-Minuto = Valor-Num
TERMINALES = INCREMENTO-DE-FRECUENCIA, CONSULTA, TEMPO, ALTA-BASE-DE-CONSULTAS, ALTA-DATOS-ESTAD~STICOS-DE-
WEGRADOR, LLEVA-ESTADISTI~AS, IDENTIFICADOR, FRECUENCIA,
I\
EXF'LOTACIÓN, TRUE, PASA-QRY'A-RELEVANTES, AVISA-DBA, EJECUTA-
SELECTIVDAD, TIEMPO, TABLA, COLUMNA, WHERE, CLIENTE, =, <, >, O, <=,
>=, 1 ,2 ,3 ,4 ,5 ,6 ,7 , 8,9, O, a, b, c, d, e, f, g, h, i,j, k, I, m, n, o, P, es s, t, u,v, w, x, Y, 2, A, B, C,D,E, F, G,H, I, J, K, L,M,N,'O,P, Q,R, S, T, U, V, W, X, Y, Z)
3.2 Acciones Semánticas 4 . En esta sección se indican las acciones semánticas asociadas a la sintaxis del
Lenguaje de Reglas ECA. Una p ide de estas acciones se ejecuta al tiempo de
definición de las Reglas ECA y 1a.otra al tiempo de procesamiento de las mismas . (ver Figura 3-3). 1
3.2.1 Acciones Semánticas ai Tiempo de Definición 11
,l. Las acciones semánticas de esta etapa están enfocadas a la validación en la
definición de las Reglas ECA. A este tipo de validaciones se le denomina
verificación estática. [I
#I . .
I/
Las validaciones al tiempo de definición son las siguientes:
a) Verificar que el tipo de los valores asignados en una condición sean
correctos; por ejemplo, que ,para la variable Identificador de la gramática el
valor asignado sea del tipo numérico. 11
b) Verificar que los valores "de variables correspondientes a elementos del
diccionario de datos, tales como tablas, columnas y clientes sean válidos, es
decir, que realmente .. formeniparte del sistema.

Lenguaje de Reglas ECA 1 Capitulo 3 I II I1 1
Verificar que el valor definido por el administrador de la base de datos no sea II 11
I
11 I
'1
Constatar ;que el,, formato del ,ralor Fzempo sea correcto, así ,licorno los
parámetros asignados a la parte del a@, r e s , día, hora y minuto. I/.
I,\.
I 1, I 1
'~1
I ENTRADA I SALIDA II I 1
'I Figura 3-3 Generation de Acciones Semániicns
I( I/
Los errores que se .generen a partir/de Jas ,,yalidaciones ,antes mencionadas se
manejan a través de mensajes al administrador que indican el error detectado. .!I: Como II. lb
resultado de estas acciones semánticas no se permite el almacenamiento de alguna /I 'Ii 1
regla que no cumpla con las validaciones manejadas. I1 :r
Enseguida se presentan las acciones semánticas asociadas a la gramática, 111 Y! 'I"
correspondientes al tiempo de definición de las Reglas ECA. Cabe mencionar que se li ha empleado la siguiente convención: "
j ! il I
il
q? .I1 ? I
. . II , .
El símbolo ::= representa una asignación al igual que en la gramática IBNF.
La extensión .val hace referencia! ai valor de una variable utilizada en la
acción semántica.
Los símbolos entre comillas son cdkstanteskasignadas al valor de un simbolo.
I.
11. 'I ..
. < < i1 I! .il , . . ' ! I , I
111.
II I1
42 I1 I1

I I
2. ConvierteACanÓnica(Va1or~ Where). Esta función aplica la función de
conversión a forma canónica al ValorWhere definido.
3 . DiuValidoParaMes(Constanrepia, Constante-Mes). Este método valida
que el número de día definido sea permitido para el mes definido. I

3.2.1.1 Regla ECA Función: Especifica l a s distintas Reglas E C A que se pueden definir a partir de los conjuntos de eventos, condiciones y acciones
I EventoConsulta True Acción-Consulta
I EventoTiempo Condición-Tiempo AcciónTiempo
Evento-IncrementoFrecuencia Condición-Numérica Acción-Numérica
GenCod (ReglaECAval + “\n”)
ReglaECA.val : := Evento-Consulta.val 1‘‘*”11 TRUE I/’”’’ll Acción-Consulta.va1
GenCod (ReglaECA.val + “W)
ReglaECA.val ::= Evento-Tiempo.va1 \“*”I/ Condición-Tiempo.val111<*”/1
Acción-Tiempo.va1
Evento-1ncrementoFrecuencia.val I(LL*”II Condición-Numerica.vaI
I‘‘*”ll Acción-Numérica.val
- - -. ~.
_= ~~ -- ~~~ ~ ~
1 EventoAltaConsulta Condición-AltaConsulta Acción-AltaConsulta
- .. ._ .. . - .. .- . - -.
I EventoAltaEstadistics Condición-Numérica Acción-Numérica
. . - -. .- ~~. GenCod.(ReglaECA.vaI+ ‘W) ~~.
ReglaECAval ::= Evento_AltaConsulta.valI1<L*”ll Condición-AltaConsulta.val -~
/‘‘*’‘I1 Acción-AltaConsulta.val ~=~ . -- .- I
~ ~ . . = ‘i.-=’. . GenCod (ReglaEKval + “\n”) ReglaECA.val : := Evento-AltaEstadísticas.val (‘‘*”/I Condición-Numerica.val Il“*’’/
Acción-Numérica.va1
GenCod (ReglaECA.val + “\n”)
Evento-Consulta : := CONSULTA
EventoTiempo ::= TIEMPO Evento-Altaconsulta ::= ALTA-BASE-DE-CONSULTAS
3.2.1.2 Eventos Los siguientes símbolos gramaticales especifican el conjunto de eventos.
EventoConsulta.va1 : := ‘Consulta’
EventoTiempo.val : := ‘Tiempo’
Evento-AltaConsulta.va1 : := ‘ AltaBaseDeConsultas’

. ~~ - __ __ - , - ~ __=~ 7~ - -7~ ~
. ~ .. . _--- =~ _I I Evento-AltaEstadisticas : := ALTA-DATOS-ESTADISTICOS-DE- I Evento-AltaEstadisticas.va1 ::= ' AltaDatosEstadísticsDeExplotación'
Variable-Id Op Valor-Num I Variable-Tabla Op Tabla 1 Variable-Columna Op Valor-Columna
I Variable-Where Op Valor-Where
I EXPLOTACI~N I I
Condición-AltaConsulta.val ::= Variable-1d.val Ir "11 0p.val Ir "11 Valor-Nurn.val
Condición-AltaConsulta.val ::= Variable-Tabla.val111< "I/ Op.val111< ''11 Tabla.val Condición-AltaConsulta.va1 ::= Variable-Columna.val 1111 ''11 Op.val /Ijl ''11
Valor-Columna.val
Condición-AltaConsulta.val ::= Variable-Where.val 1'' ''11 Op.val 1111 ''11
3.2.1.3 Condiciones
3.2.1.3.1 Condición-Numirica Función: Especifica Condición de tipo numérica
3.2.1.3.2 Condición-Tiempo Función: Especifica Condición de tipo tiempo. ~~~ ~
~ ~ - ~~~ ~~~ .~
~ - ~ - p_ --'- - ~~ ~~
- -
3.2.1.3.3 Condición-AliaConsulta Función: Especifica Condición de tipo alfanumérica.
I I Valor-Where. val I

I Variable-Cliente Op Valor-Alfanum
I TRUE
________--- ___. . ':: , . <. Acciones Semanticas' :
= 'Identifiador'
Condición-AltaConsulta.val ::= Variable-Cliente.val Ir "11 0p.val (I" "(1 Valor-Cliente.val
Condición-AltaConsulta.val : := 'True'
I FRECUENCIA 1 SELECTiVIDAD
- -~ - %riable-Tiempo ::=-TIEMPO~ = .-
Variable Tabla ::= TABLA Variable Columna ::= COLUMNA
Var¡able.val= 'Columna'
Variable-Num.val : := 'Frecuencia'
Variable-Num.vai ::= 'Selectividad'
Variable-Tiempo.val ::= 'Tiempo' Variable-Tabla.val : := 'Tabla' Variable-Columna.val : := 'Columna'
- - -~ ~~
~~
~ -. - - ~~ .- ~~

Variable Where ::= WHERE
Variable Cliente ::=CLIENTE
Variable -Identiticador ::= DENTIFICADOR
3.2.1.6 Operadores Los siguientes símbolos gramaticales especifican operadores.
Variable-Where.val ::= ‘Where’ Vanable.val = ‘Where’ Variable-Cliente.val : := ‘Cliente’ Variable.va1 = ‘Cliente’ Var-Identificador.va1 ::= ‘Identificador’ Variabkvai = ‘Identiticador’
“P ::= = 0p.val ::= ‘=’
I < 0p.val ::=Y’
I’ 0p.val ::=‘Y
10 0p.val ::= ‘0’
I <= 0p.val ::= ‘<=’ 1 % 0p.val ::= ‘<=’
-
3.2.1.7 Elementos Comunes
Dígito ::= 1
... 19
Si (Valor-Num.val< O) entonces ERROR(“Va1or inválido”) Dígito.va1 ::= ‘I’
...
Dígito val ::= ‘9’

10
Si (Variable.val = ‘Cliente’) OR (Variable.va1 = ‘Tabla’) Si (Val-Alfanum val no existe en el Diccionario de Datos) entonces
ERROR (‘Variable.val no existe”)
Digito.val ::= ‘O’
letra ::= letra-minúscula I ietra.vai ::= ietra-minúscuia.vai
- ...
12
I
1 letra mayúscula 1 ietra.vai ::= ietra-mayúscuia.vai
... letra-minúscula.va1 : := ‘2’
.. . .-.. . . - . I
letra minúscula ::=a I ietra-minúscuia.vai ::= ‘a’
letra-mayúscula ::= A
... I Z
letra- mayúscula.val ::= ‘A‘
...
letra-mayúscula.val ::= ‘Z’
.-
3.2.1.8 Val - Columna Función: . . Especificación del Valor-Columna

1 Columna ::E Vai-Aifmum I Coiumna.vai :: = Vai-Aifanum.vai Si (Columna.val no existe en el Diccionario de Datos) entonces
ERROR (Tolurnna inválido”)
3.2.1.9 Valor- Where Función: Especificación de Valor-Where
I Valor-Columna Op Valor-Aifanum
Si (Valor-Num.tipo i= Valor-Columna.tipo) entonces
ERROR(“E1 valor asignado no corresponde al tipo de dato de la columna”) Sino ConvierteACanónica (Valor-Where.val)
Valor-Where.val ::= Valor-Colurnna.valII 0p.val 11 Valor-Alfanumval Si (Valor-Alfanum.tipo j= Valor-Columna.tipo) entonces
ERRORCEI valor asignado no corresponde al tipo de dato de la columna”) Sino ConvierteACanónica (Valor Where.va1)
3.2. I . I O Valor- Tiempo Función: Especificación de Valor-Tiempo
Constante-Día,Constante-Hora, Constante-Día.val111>.”11 Constante-Hora.va1 111>.”11 Constante-Minuto.val Constante-Minuto
Si (Constante-Aao.val > 9999) OR (Constante-Año.val< 1800) entonces ERRORC‘Año fuera de rango”)

- Constante-Mes : := Valor-Num Constante-Mes.val ::= Valor-Num.val
Si (Constante-Mes.val >12) OR (Constante-Mes.val< 01) entonces
ERROR("Mes fuera de rango")
I I Si (iDiaValidoParaMes(Constante-Dia.val, Constante-Mes.val )) entonces
- Constante-Día ::= Valor-Num Constante-Dia.val : := Valor-Num.val
Si (Constante-Día.val>3 I) OR (Constante-Día.val < 01) entonces
ERROR("E1 .. . . día no se puede asignar,al - mes seleccionado") 1 ERRORkDia fuera de rango")
Constante-Minuto : := Valor-Num
I 1 Constante-Hora.va1 ::= Valor-Num.val Constante-Hora ::= Valor-Num Si (Constante-Hora.val > 23) OR (Constante-Hora.val < 00) entonces
ERRORcHora fuera de rango")
Constante-Minuto.val : := Valor-Num.val
Si (Constante-Minuto.val > 59) OR (Constante-Minuto.vaI< 00) entonces ERROR("Minut0 fuera de rango")

Capitulo 3 tenguaje de Reglas ECA
3.2.2 Acciones Semánticas al Tiempo de Procesamiento
Mientras el SABDD se encuentra en ejecución, el Procesador de Reglas ECA
realiza el procesamiento de todas las reglas asociadas con los eventos presentados en
el sistema. Cuando una regla es disparada, se ejecutan una serie de acciones
semánticas relacionadas can la evaluación de la condición, con la ejecución de la
acción y con el maneja de los errores.
El conjunto de acciones semánticas indicadas explícitamente por las reglas son
las siguientes:
LPevaEstadisticas: Realiza el registro de los datos estadísticos cuando se detecta
una consulta procesada en el sitio local. Los parámetros que maneja son el nombre
del archivo que contiene la consulta, el nombre del archivo que contiene el resultado
de la consulta y el nombre del archivo que contiene el nombre cliente que emitió la
consulta.
AvisaDBA: Presenta un aviso al administrador de la base de datos. El aviso
indica la información referente al evento detectado como son el nombre del evento,
la fecha y hora en que se presentó, y cuál fue el contexto en el que se presentó dicho
evento, es decir, cuál fue la condición que se cumplió.
RegistraQryEnRelevantes: Registra los datos estadísticos de explotación
correspondientes a determinada consulta que el administrador de la base de datos
considera relevante. Para ello el administrador especifica por medio de una Regla
ECA las condiciones que debe cumplir dicha consulta.
Ejecutalntegrador: lniegra los datos estadísticos de explotación de los distintos
sitios del sistema en un solo sitio, generando un archivo de datos que es la entrada al
51

I 'I I Capítulo 3 Lenguaje de Regias ECA ii !I
'I con los patrones de explotación identificados.
11 I
.!b
1 I Jli
II
I!'
t
I ParámetroTablas
ParámetroCoiumnas ParámetroWhere I/
11 Tabla 3-1 Nombres de los Parametros para Cada Evento ?I Valores Asignados II Evento
-___ .I
INCREMENTO-DE-FRECUENCl A
CONSULTA
ParámetroIdentificador ParámetroFrecuencia
Parámetrociiente ParámetroSelectividad
Parám'etrociiente /¡ ParámetroConsulta ParámetroSelectividad 4
I jl I I .I!
~~
!I 11. EVENTO representa el nombre del evento disparado. /I I
I

Lenguaje de Reglas ECA Capitulo 3
111.
IV.
V.
VI.
VI1
Acción se refiere a la acción indicada en la Regla que se procesa
Parámetros es una variable de tipo arreglo que almacena los datos requeridos
para la ejecución de la acción. Dichos datos se obtienen al momento de
detección del evento.
Reglaseñalada es una variable que indica si la regla seleccionada
corresponde al evento disparado.
ValorAITiempoDeEjecuciÓn se utiliza para evaluar la condición de la regla
disparada. Almacena el valor de uno de los parámetros en la detección del
evento que corresponde a la variable definida en la parte de la condición de la
regla.
Para implementar las acciones seinánticas se emplearon las siguientes
funciones:
1 . EvalúaCondiciónNumérica (ValorAITiempoDeEjecuciÓn~ Operador,
ValorEnLaRegla). Esta función realiza la evaluación de la parte de la
condición de la regla y se aplica a condiciones sobre valores numéricos.
2. EvalúaCondiciónTiempo (ValorAITiempoDeEjecuciÓn, Operador,
VaIorEnLaRegla). Esta función realiza la evaluación de la parte de la
condición de la regla y se aplica a condiciones sobre valores de tipo tiempo.
3. EvalúaCondición (ValorAlliempoDeEjecución, Operador,
VaIorEnLaRegla). Esta función realiza la evaluación de la parte de la
condición de la regla y se aplica a condiciones sobre valores de tipo
alfanuméricos.
4. EjecutaAcción (Acción, Parámetros). Esta función ejecuta la parte de la

Lenguaje de Reglas ECA I , Capítulo 3
5. LeeSiguienteRegla(.). Lee ' la siguiente!
Cuando esta función se ejecuta, se inicia cbn
semánticas.
i
acción de la regla disparada
Regla ECA de la base de reglas.
el procesamiento de lasiacciones I/ . .
VIII.
asignado a la variable Res. :ji

3.2.2.1 Regla ECA Función: Especifica las distintas Reglas ECA que se pueden definir a partir de los conjuntos de eventos, condiciones y acciones
Evento-IncrementoFreniencia Condición-Numérica Acción-Numérica
I Evento-Consulta True Acción-Consulta [ Evento-Tiempo Condición-Tiempo Acción-Tiempo
I Evento-AltaConsulta Condición-AitaConsulta Acción-AltaConsulta
I Evento-AltaEstadisticas Condición_"mérica Acción Numérica
3.2.2.2 Eventos Los siguientes símbolos gramaticales especifican el conjunto de eventos.
Evento-Consulta : := CONSULTA
Evento-Tiempo ::=TIEMPO
Evento-AltaConsulta : := ALTA-BASE-DE-CONSULTAS
Evento-AltaEstadísticas ::= ALTA-DATOS-ESTADISTICOS-DE,
ReglaSeñalada.va1 = 1 Sino ReglaSeñalada.va1 = O
Si (Evento- Consulta.val = EVENTO.val) entonces ReglaSeñalada.va1 = 1
Sino ReglaSeñalada.va1 = O
Si (Evento- Tiempo.val = EVENTO.vd) entonces RegiaSeñalada.val = 1
Sino ReglaSeñalada.va1 = O
Si (Evento- AltaConsulta.val = EVENTO.val) entonces ReglaSeñalada.va1 = 1
Sino Reglaseñalada val = O
Si (Evento- AltaEstadísticas.va1 = EVENTO.val) entonces

EXPLOTACION Sino ReglaSeñalada.va1 = O
3.2.2.3 Condiciones
ReglaSeñalada.va1 = 1
3.2.2.3. I Condición-Numérica Función: Especifica Condición de tipo numérica.
I TRUE
Res.va1 = EvalúaCondiciónNuméca (ValorAlTiempoDeEjecución.val , Op.val, Valor-Nurn.val)
Si (Res.val = 1) EjecutaAcción (Acción.val, Parhetros.val)
LeeSiguienteRegla( )
Condición.val ::= ‘‘ ” EjecutaAcción (Acción.va1, Parametros.val)
LeeSiguienteRegla( )
i2.2:3.> CondicGn-Tiempo Función: Especifica Condición de tipo tiempo.
Valor-Tiempo.val
Res.val = EvalÚaCondiciónTiempo (Op.val, Valor-Tiempo.val )
Si (Res.val = I) EjecutaAcción (Acción.val, Parámetros.val)
3.2.2.3.3 Condición-AltaConsulta Función: Especifica Condición de tipo alfanumérica.
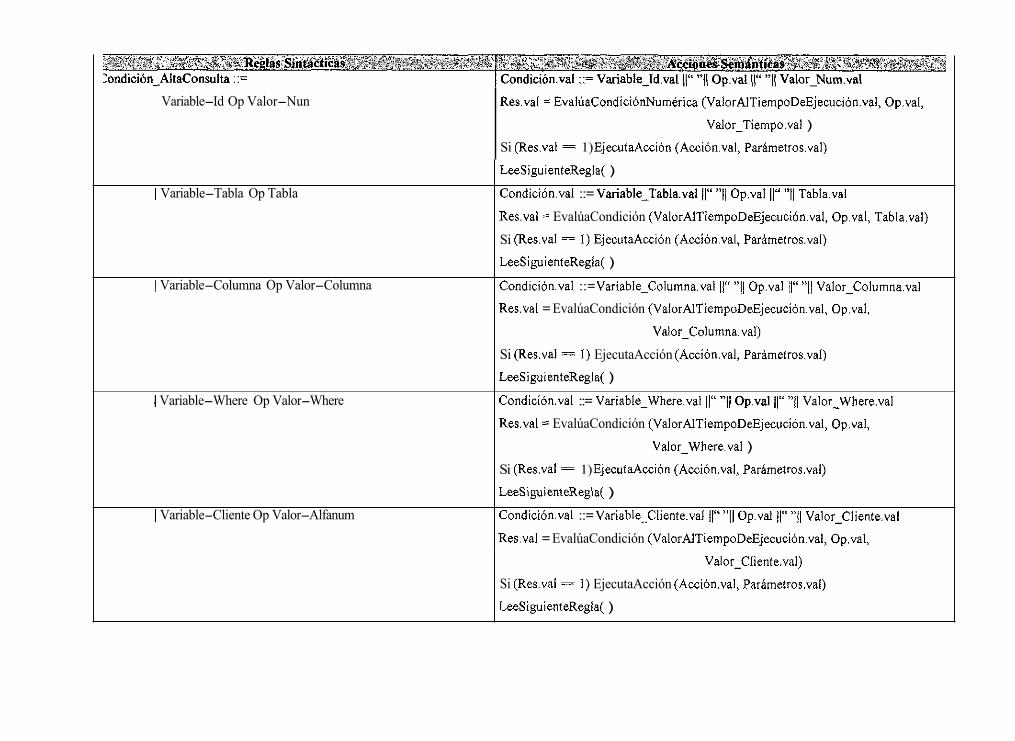
Variable-Id Op Valor-Nun
I Variable-Tabla Op Tabla
I Variable-Columna Op Valor-Columna
I Variable-Where Op Valor-Where
I Variable-Cliente Op Valor-Alfanum
Res.val = EvalúaCondiciónNuméca (ValorAITiempoDeEjecuciÓn.val, Op.val, Valor-Tiempo.val )
Si (Res.val = 1) EjecutaAcción (Acción.val, Parámetros.val) LeeSiguienteRegla( )
Condición.val ::= Variable-Tabla.val1111"l1 Op.val I(LL ''11 Tabla.val Res.val = EvalúaCondición (ValorAlTiempoDeEjec¡Ón.val, Op.val, Tabla.val) Si (Res.val = I) EjecutaAcción (Acción.val, Parámetros.val) LeeSiyienteRegla( )
Condición.val ::= Variable-Columna.val lllj ''11 0p.val /y ''11 Valor-Columna.val Res.val = EvalúaCondición (ValorAiTiempoDeEjecución.val, Op.val,
Valor-Columna.val) Si (Res.val = I) EjecutaAcción (Acción.val, Parámetros.val) LeeSiguienteRegla( )
Condición.val ::= Variable-Where.val II<L ''11 Op.val11" "11 Valor-Where.val Res.val EvalúaCondición (ValorAlTiempoDeEjecución.val, Op.val,
Valor-Where.val )
Si (Res.val = 1) EjecutaAcción (Acción.val, Parámetros.val) LeeSiguieníeRegla( )
Condición.val ::= Variable-Cliente.val I/" "11 0p.val Res.val = EvalúaCondición (ValorAlTiempoDeEjecución.val, Op.val,
''11 Valor-Cliente.val
Valor-Cliente.val) Si (Res.val = I ) EjecutaAcción (Acción.val, Parámetros.val) LeeSiguienteRegia( )

I TRUE
3.2.2.4 Acciones Los siguientes símbolos gramaticales constituyen el conjunto de acciones.
Condición.val ::= “ ”
EjecutaAcción (Acción.val, Parámetros.val) LeeSiguienteRegla( )
Parámetros[O] : := ParámetroIdentificador Parámetros[ 11 ::= ParámetroFrecuencia P%áiiiSos[2] : := PaiámetToCiiente Parámetros[3] : := ParámetroSelectividad
- ~ ~- .. ... - - . . ._ ~~
- ~ ~ -
~
~ - __
I AVISA-DBA Acción.val ::= ‘AvisaDBA’ Parámetros[O] : := EVENTO.va1 Parámetros[ I ] ::= Condición.val Acción.val : := ‘EjecutaIntegrador’ Acción.val ::= ‘LlevaEstadisticas’
I EJECUTA-INTEGRADOR Acción-Consulta: := LLEVA-ESTADISTICAS
- .... .
Parámetros[Z] ::= ParámetroSelectividad

I AVISA-DBA
Acción-Tiempo::= AVISA-DBA
Acción.val ::= ' AvisaDBA' Parámetros[O] ::= EVENTO.va1 Parámetros[l] : := Condición.vai Acción.val ::= 'AvisaDBA' Parámetros[OJ ::= EVENTO.val
Parámetros[O] : := EVENTO.val Parámetros[ 11 ::= Condición.val
I EJECUTA-INTEGRADOR Acción-AltaConsulta: := AVISA-DBA
3.2.2.5 Variables -tos siguientes símbolos gramaticales constituyen el conjunto de variables. ~
- ~
-
Parámetros[ 1 1 ::= Condición.val
Acción-val ::= 'Ejecutaintegrador' Acción.va1 ::= 'AvisaDBA'
I.V... ,-. . . = ParámetroSelectividad.va1
Variable-Tabla ::= TABLA Variable-Columna ::= COLUMNA Variable-Where ::=WHERE Variable-Cliente ::= CLIENTE Variable-Identificador ::= IDENTEFICADOR
ValorAlTiernpoDeEjecución.val : := ParámetroTabla .val ValorAlTiempoDeEjecución.val : := ParámetroColumna.va1
ValorAlTiempoDeEjecución.val ::= ParámetroWhere.val ValorAlTiempoDeEjecución.val : := ParámetroCiiente.vai VaiorAlTiempoDeEjecución.va1 : := ParámetroIdentificador.va1

op ::= =
I < I’ , ’
10
I <=
I >=
. .
3.2.2.7 Elementos Comunes
0p.val ::= ‘=’
0p.val ::= ‘<’
0p.val ::= ‘>’
0p.val ::=‘o’
0p.val ::= ‘<=’ Op.val ::= ‘<=’
Si (Valor-Num.val < O) entonces ERROR(“Va1or invalido”)
Diaito ::= 1 1 Digito.val ::= ‘ I ’
I ... I
... ...
I Z I ietra-mayúscuia.vai ::= ‘z’

3.2.2.8 Val - Columna Función: Especificación de Valor-Columna
Tabla ::= Val-Aifanum
Columna : := Val-Alfanurn
Valor Columna.tipo ::= OhtenTipoColurnna(Va1-Colurnna.val) //usado en Valor-Where Tahla.val ::= Val- Aifanurn.val Si (Tabla.va1 no existe en el Diccionario de Datos) entonces
ERROR (“Tabla inválida”) Coiumna.val :: = Val- Aifanurn.val Si (Columna.val no existe en el Diccionario de Datos) entonces
ERROR (“Columna inválido”)
__ -3.2.2.9-Valor- m e r e - ~~
- Función: Especificación de V a l o r w h e r e
3.2.2.10 Valor - Tiempo Función: Especificación de Valor-Tiempo
Constante-Dia,Constante-Hora, )y,”)) Constante-Hora.va1 JI<L,”/I Constante-Minuto.va1 Constante-Minuto


Capítulo 4 I Implementación del Sistema de Reglas
Capítulo 4
IMPLEMENTACION DEL SISTEMA'DE REGLAS
. .
En este capítulo se presentan la implementación y la arquitectura de los módulos
necesarios para la definición y el procesamiento de las Reglas ECA definidas a
partir del Lenguaje de Definición de Reglas ECA presentado en el capítulo anterior.
El conjunto de dichos módulos constituye lo que llamaremos el Sistema de Reglas
(SR) del SABD, es decir, la parte activa del mismo..
I
. .
i
*
, . , ! 4.1 Diseño General del Sistema de Reglas
. ,
En la Figura 4-1 se presenta el diseño general del Sistema de Reglas
implemeniado. Éste está construido por un precompilador y un iniérprefe. Las
acciones semánticas definidas en el 'Capítulo 3 correspondientes al tiempo de
definición, son ejecutadas por'el módulo precompilador, y las correspondientes al
tiempo de procesamiento son ejecutadas por el módulo intérprete.
Figura 4-1 Diseño Genejal del Sistema de Reglar

Implementación del Sistema de Reglas ,i Capítulo 4 'i
I( 4.4 Precompilador , ri
./I I(
.I1
Un precompilador es un programa de software que recibe como entrada un
código fuente en determinado lenguaje y lo traduce a un lenguaje semánti'camente
equivalente [ASUSS]. La salida del precompilador es código de alto nivel. En la
Figura 4-2 se muestran las clases y métodos.im@ementados para soportar"1a tarea
del precompilador en este trabajo.
11
11
4.4.1 Interface01 . !I / j
Es el constructor de la clase InterfaceOl. En este constructor se &atiza la
definición de todos los componentes de 1a.interfaz gráfica. En la Figura 4-3 se :e
I, I
presenta el diseño de dicha interfaz. llr ,i *. I
~ . , . . "...
ReglasECADelinIdas' .
". ". .'k Opciones de Acciones
Figura 4-3 Componentes de la Inierfaz para la Defrnicidn de Reglas ECA 1
2. ,I!? /I - La interfaz está disefiada para permitir al ahministrador de la base de datos la
selección de la mayoría de los componentes de ida Regla ECA definida, esto se hace
mediante objetos de la clase Choice aplicados a la selección de Eventos, Variables,
Signos y Acciones. El único componente de la'regla que el ABD define es el valor
de la condición, es decir, el operando derecho de la misma. Esto lo hace mediante un
objeto TextField, que captura el valor definido,por el ABD. En un objeto de la clase
4 ./I
'I

I
Implementacibn del Sistema de Reglas I Capitulo 4 1
I
I
Lrst se muestran las Reglas ECA ya definidas y finalmente mediante ejemplos de la
clase bottom se presenta al ABD la opción de “Salir” de la interfaz, “Borrar” una
regla y “Aceptar” una regla definida
4.4.2 Clase Action
En esta clase se realiza toda la fase de análisis de las Reglas ECA definidas. A
continuación se muestran las clases implementadas y sus métodos respectivos.
4.4.2.1 Clase AccedeDD Esta clase contiene 10s métodos necesarios correspondientes a las acciones
semánticas, para la validación de valores en la parte de la condición de la regla que
hagan referencia a información del DD. Dicha información corresponde a clientes,
tablas, columnas y tipos de datos de las columnas. A continuación se presentan los
metodos que componen esta clase. Se indica la entrada y salida de cada uno de ellos.
4.4.2.1.1 Método ObtieneNodos
Entrada: Ninguna. Salida: Vector de nodos del sistema.
Obtiene un vector con el nombre de los nodos en el sistema, mediante el acceso al
archivo NODOS.BD1 del diccionario de datos, el cual mantiene la definición de los
nodos dados de alta en el sistema.
4.4.2.1.2 Método ObtieneRutas
Entrada: Vector de nodos del sistema. Salida: Vector de rutas correspondientes a los nodos.
Obtiene las rutas correspondientes a los nodos que constituyen el sistema, mediante

Capítulo 4 Implementación del Sistema de Reglas
'I 1
el acceso al archivo NODOS.BDI.
4.4.2.1.3 Método ObtieneAttsDeTabla
I
Entrada: Nombre de la tabla, ruta del nodo que
Salida: Vector de las columnas de la tabla.
Accede al DD para obtener las columnas de una tabla. JI !I I 4.4.2.1.4 Mitodo EvisteTabla
Entrada: Nombre de la tabla, vector de rutas de nodoh del sistema,
Salida: Ruta donde se encontró la tabla, en caso regresa null.
Busca una tabla en el diccionario de datos.
4.4.2.i.5 Mitodo Existe&
Entrada: Nombre de la tabla, nombre de la columna, ru\a del sitio de la tabla.
Salida: Tipo de dato de la columna, si la columna no exjste regresa -1.
',
'I!
'I li; Busca una columna determinada conociendo la rutdmque almacena la ,tabla allla
' Y t
Y1
que pertenece y obtiene el tipo de dato de dicha columna. I
4.4.2.2 Clase Utilerías 1 li 1 En esta clase se han definido una serie de métodoskpara la precompilación del I¡,
Lenguaje de Reglas ECA. Cabe mencionar que algunos métodos no participan en el I ,
proceso de precompilación, pero son necesarios para el funcionamiento de la
interfaz. A continuación se presenta cada uno de los métodos indicando la fase de ,J
.I\
¡I It
'4,
11
precompilación que ejecuta.
4.4.2.2.1 Mérodo MuestraRegIm
Entrada: Ninguna.

Capítulo 4 Implementación del Sistema de Reglas
Salida: Ninguna.
Método encargado de la actualización de la interfaz en cuanto al objeto List que
muestra las reglas definidas. Se ejecuta cada vez que se crea una Regla ECA.
4.4.2.2.2 Método AltaReglaECA
Entrada: Regla ECA. Salida: Ninguna.
Este método tiene la función de almacenar la Regla ECA definida correctamente
en una extensión al DD. Corresponde a la fase de generación de código del
precopilador. Cuando la variable elegida en la parte de la condición es Where, se
verifica que el predicado correspondiente se almacene bajo una forma canónica
basada en el ordenamiento alfabético de sus operandos. En los demás casos de
variables, la transformación consiste en convertir el valor de la condición a
mayúsculas cuando el tipo de dato de la variable es Alfanumérico. La Tabla 4-2
muestra ejemplos de transformaciones de condiciones a una forma canónica.
Tabla 4-2 Ejemplos de Condiciones
Condición Condición en Forma Canónica Tabla=sp Tabla = SP
Clienteecad 12 Cliente 0 CAD12 Where = p a r k 0 s.city Where = S.CITY 0 PARIS
4.4.2.2.3 Método BajaReglaEcA
Entrada: Regla ECA seleccionada por el ABD.
Salida: ninguna.
Realiza la eliminación de la regla seleccionada de la Base de Reglas en el
Diccionario de Datos.
69

Implementación del Sistema de Reglas ¡I Capítulo 4 /I II
Entrada: Valor tipo Where. !(I Salida: 1 si el predicado es correcto. En casolde indica. 1
,/l.
error regresa el mensaje que 10
I1
I verificando su validez.
'I i
1:
I/ ! '
validar la existencia de la columna y de la tabla. 1 1
! i '

Capítulo 4 Irnplementación del Sistema de Reglas
En la Tabla 4-3 se muestran dos ejemplos donde se pueden apreciar los errores
que el algoritmo verifica.
Tabla 4-3 Ejemplos de Cláumlm Where
Cláusula Válida Cláusula Inválida %City < ‘Paris’
P.Pno = 100 %City < 104
P.Pno = Londres
En ambos casos se asigna un valor cuyo tipo de dato es diferente al definido en el
diccionario de datos para la columna.
4.4.2.2.5 Método VuliduTiempo
Entrada: Valor tipo Tiempo. Salida: 1 si el valor es correcto. En caso de error regresa el mensaje que lo indica.
En el caso del valor Tiempo, se debe reconocer la secuencia de caracteres
mostrada en el autómata de la Figura 4-5. En dicha figura se muestra el análisis
basta la parte del mes, posteriormente se repite el análisis para la parte del día, hora
y minuto, es decir, cada uno está formado por dos dígitos, excepto el año.
La Figura 4-6, presenta el pseudocódigo requerido para la validación del valor
correspondiente a la variable Tiempo. Se consideran los rangos referentes a cada
componente de la variable, es decir, año, mes, día, hora, minuto.
... Figura 4-5 Automata para el Análisis Léxico del Valor Tiempo
71

Implementación del Sistema de Reglas
,. , . /I Si ((año >= 1800) y (año <= 9999)) entona
Si ((mes >= I) y (mes <= 12)) entonce I / Según el número de días de cada I irsi ((dia es permitido para mes)) ento
Si ((hora >=O) y (hora <= 23)) en Si ((minuto >= O) y (minuto
regresa verdadero; sino regresa falso;
sino regresa falso; sino regresa falso;
sino regresa falso; sino regresa falso; .
Figura 4-6 Pseud#códig#paru la Vu1
4.4.2.2.6 Método Validdtt
Entrada: Columna. Salida: El tipo de dato de la columna. En ca indica.
Éste método "terifica l a ' existencia en el
definida en la condición.
4.4.2.2.7 Método ValidaNumérico
Entrada: Valor tipo numérico. Salida: 1 si es correcto, O en caso de error.
.~
Verifica que el valor sea numérico, no ne
ejecuta cuando 'la variable seleccionada pa
Identificador, Frecuencia o Selectividad.
',I
4.4.2.2.8 Método Validdlfanumérico
Entrada: Valor tipo alfanumérico. Salida: 1 si es correcto, O en caso de error.
Verifica que el valor sea alfanuméric
Caoitulo 4
S ces 9)) entonces
cion del Valor Tiempo
.i iII . de error regresa el mensaje que lo
li ccionario d& datos de la columna
:,I
11 tivo o igual a cero. Estd método se
la definición de la condicibn es All1
Ill
,It
y se ejecuta cuando variable

Capítulo 4 Implementación del Sistema de Reglas
seleccionada es Tabla o Cliente.
4.4.2.3 CIase SimpIeDiaIogError
Entrada: Mensaje de Error. Salida: Ninguna.
En el precompilador, el manejo de los errores consiste básicamente en el envío
de mensajes al administrador, indicando el error en la definición de la Regla ECA,
principalmente en cuanto a tipos de datos.
4.4.3 Clase handleEvent
Esta clase presenta una función de salida que la clase Frame entiende.
Específicamente, maneja el evento de destrucción de la ventana de manera normal.
4.5 Intérprete
La siguiente es la definición de un intérprete: Herramienta de software que
ejecuta las operaciones indicadas por el código fuente recibido. Para el caso en
particular de este trabajo, mediante el intérprete del lenguaje de Reglas ECA se
llevan a cabo un conjunto de acciones semánticas cuya finalidad básica es el
procesamiento de las Reglas ECA. Dicho módulo es activado por los eventos
detectados cuando el sistema se encuentra en explotación. Este intérprete ejecuta las
acciones semánticas señaladas en las Regla ECA que procesa y no contiene en sus
etapas la generación de código, a diferencia de un precompilador. k
En términos de BDA, las etapas que componen el proceso de interpretación para
el lenguaje de Reglas ECA, han sido implementadas en este trabajo mediante un
módulo Procesador de Reglas ECA y otros módulos complementarios, los cuales son
necesarios para añadir al SABDD la capacidad activa.

I/ I/
1,
I! Implementación del Sistema de Reglas Capítulo 4
Enseguida se trata a detalle la referente a la betapa de
desarrollados para tal interpretación mediante una serie de
fin. En la Figura 4-7 se presenta la
la cual aparece la parte antes ir (Interfaz de Definición de Reglas ECA). !i
Modelo PURü I
............. ........................ ......
Sitios Remotos
Sistema Loca! 'I _ .......................................... Figuro 4-7 Arquit~chdra del Intérprete
¡)I Ir
4.5.1 Detector de Eventos ,j 1/1
Salida: Ninguna. II
Entrada: Identificador del evento presentado, argumentos necesarios para el procesamiento del evento. 11 !I
('1 11
, !ill '!
I
Este módulo detecta la activación de los' eqentos asociados con las Reglas ECA, y
I 74 ; !
~~
I . -,: ..._. . .

Capítulo 4 implementación del Sistema de Regias
señala al Procesador de Reglas la ocurrencia de los mismos. Cuando un evento de
interés es detectado por el sistema, la información necesaria para su procesamiento,
así como el identificador del evento, son enviados al Procesador de Reglas, para lo
cual, se analiza la información recibida en formato cadena, con la finalidad de
almacenarla en una estructura que facilite su manejo. El autómata de la Figura 4-8
muestra este proceso de reconocimiento de los parámetros correspondientes a cada
evento de interés. El número de argumentos varía con respecto al evento detectado.
1 O Evenio 1 @ 2 Arg, # ...
Figuru 4-8 Automara para el Reconocimiento de los Argumentos Referentes a un Evento Detectado
4.5.1.1 Eventos Detectables
Los eventos se detectan por medio de un proceso cliente que es un ejemplar dela
clase ClienteProcesador. Este cliente se comunica con un proceso servidor (clase
ServidorProcesador) que se encuentra en espera de la notificación de los eventos
ocurridos para iniciar el procesamiento de las Reglas ECA.
Se han implementado cinco eventos de interés, los cuales se muestran en la Tabla
4-4. También se presentan los argumentos respectivos a cada uno de ellos, indicando
el orden en que son reconocidos por el ServidorProcesador.
En el caso del evento Consulta, el módulo toma como entrada una consulta
definida originalmente en SQL. El resto de los eventos de interés es generado a
partir de éste, así, el evento Incremento de Frecuencia se presenta cuando una
consulta ya se ha procesado con anterioridad en el sitio.
1 5

Implementación del Sistema de Reglas Capitulo 4
I Tabla 4-4 Eventos y Argtrmenios
Evento Identificador - __.- AW 4 Arg4
c Archivo Cliente , Archivo !i
.I/
' Ir Incremento IF Identificador Nodo Selectividad Frecuencia , .
Consulta
Alta Base de AüDC ldentiíicador 1 Tabla Columna Where
Ilk Consultas I
1
Alta Datos ADEE Identificador Frecuencia Nodo ISelectividad Estadísticos de
Explotación ;I li
I¡
Tiempo T - 11 - - i'
Los eventos Alia de Datos Estadístico: de Explotación y Altalen Base de
Consultas, se presentan cuando no existe l,un registro previo sobre la consulta
detectada, por lo que se realiza el redistro de la información estadística
correspondiente a dicha consulta, así como de la definición de la misma (columnas,
!I I
!I i.
tablas involucradas y predicado). 1 I!
i, Otro evento útil, es el evento Tiempo, mediante el cual, el admikstrador de la
base de datos tiene la herramienta para poder tomar decisiones con base en el
cumplimiento, de una fecha determinada. Este evento puede servirle al administrador
para realizar la integración de la información estadística,de los distintos sitios del
sistema, con la finalidad de verificar si, en un momento dado en':el tiempo, los
patrones de explotación corresponden al esquema de distribución actual de los datos.
En todos los casos, la información que :;acompaña al nombre del evento, es la que
se tiene disponible al momento de la detección y es útil para el procksamiento de las
Reglas ECA, es decir, la evaluación de la condición y la ejecución de la acción.
I(
Ij !I l.
,I I1
:I 111
li. SI . .
I( !I
1111 I I
'1
I
1

Capitulo 4 Implernentación del Sistema de Regias
4.5.1.2 Integración con el SiMBaDD , <
El Sistema de Reglas fue implementado sobre un SABDD experimental
denominado SiMBaDD. En lo que se refiere al intérprete (procesamiento de Regias
ECA), dentro de las BDAs, el tipo de integración realizada se denomina construído-
en, lo cual implica que se tiene acceso al código del SABD y que éste puede ser
modificado con la finalidad de integrar la parte activa.
Una vez que se inicia el servidor de consultas del SiMBaDD, se ejecuta un
servidor denominado ServidorProcesador. Dicho servidor permanece en espera de
los eventos que se presentan en el sistema, con la finalidad de antenderlos mediante
el procesamiento de las Reglas ECA definidas.
Una segunda interacción entre el Módulo de Detección y Registro de Eventos y el
SiMBaDD, se realiza después de que el servidor de consultas del SABD ha
procesado exitosamente una consulta (ver Figura 4-9). Es entonces cuando se ejecuta
un proceso cliente que emite el señalamiento de la ocurrencia del evento consulta a
un módulo encargado del procesamiento de las Reglas ECA definidas en el sistema.
Sólo el evento consulta genera la comunicación entre el servidor de consultas del
SiMBaDD y el Módulo de Detección y Registro de Eventos Relevantes. El resto de
los eventos se generan a partir de la obtención de la información estadística sobre el
uso de los datos.
Ante el señalamiento del evento consulta, el proceso cliente que avisa de la
ocurrencia del evento es el encargado del envio de la información referente a la
consulta, dicha información hace referencia a la consulta presentada, a su
selectividad y al cliente emisor de la consulta.
77

11 , Capitulo4 Implementación del Sistema de Reglas
I1 Figura 4-9 Iníeracción entre el SiMBaDD y elM&lo de Detección y Regisho de Evenios Relevantes
II 'I I
,381 I 4.5.2 Procesador de Reglas ECA ¡I Nr
Entrada: Identificador del evento y argumentos necesarios para eI procesamiento del evento. Salida: Ninguna.
.I1 1
I*
/I Este módulo coordina la activación y procesamiento de las Reglas ECA asociadas It
con los eventos que las disparan, es deci;, selecciona las reglas relacionadas con el il evento dado en el sistema, evalúa la :I parte de la condicibn: de cada regla
4 1 1 I1
seleccionada, y cuando ésta se cumple manda ejecutar la acción correspondiente a la
regla procesada. /I# ocurrido, se genera un ejemplar del Cuando se recibe una señalización
I1 . módulo Procesador de Reglas de ECA mediante la clase ServidorProcesador. Dicho 11
ejemplar se ejecuta sobre un proceso hilo. La clase ServidorProcesador se encarga /I

Capítulo 4 Implementación del Sistema de Reglas
- Detecfor Proceso
del Evento ServidorProcesador
de generar los procesos hilos necesarios, es decir, uno por cada evento detectado. De
esta forma se atienden de manera concurrente los eventos detectados en un sitio (ver
Figura 4-10).
Evento Consulta,
Evento Tiempo
Evento Consultal
Atiende el Evento Consulta, . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ... . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .
Y Ejemplares del
Procewdor de Reglas ECA 1
Figura 4-1 O Generación de Procesos de Aiencidn a Eventos
En este sentido se presenta una ventaja, el proceso de selección de las reglas
relacionadas con el evento detectado, así como el procesamiento de las mismas, se
agiliza mediante la generación procesos ligeros que realizan la misma tarea de
manera concurrente. De otra forma, el procesamiento secuenciai de los eventos
detectados retrasaría el tiempo de atención a los mismos.
4.5.3 Módulo Transformador de Consultas a Forma Can6nica
Entrada: Consulta procesada. Salida: Consulta en Forma Canbnica.
La frecuencia con la que se presenta una consulta es un factor determinante para
efectuar el diseño de la distribución en el sistema. Esto se debe a que el costo de la
consulta, aunado a su frecuencia de procesamiento desde un mismo cliente,
79

Implementación del Sistema de Reglas 1 Capítulo 4
1
/I
permitirá determinar si.la reubicación es o no conveniente, es decir, aún &ando el
I' costo de procesamiento de una consulta sea elevado, 11
l. su frecuencia de procesamiento
/ será un factor que determine si los datos solicitados se reubican o no.
!J
I Por lo anterior, es necesario establecer la uni,cidad semántica entre consultas que
sintácticamente son distintas. A este respecto se,presenta un problema mayor, ya que
el análisis semántico de consultas tiene ya, por sí solo, su propia probllmática, la
cual está relacionada con la optimización de consultas.
'I ¡I
J i I1 I'
il 'I I
// !I /I ¡I
:I/ I "
'1
.,I
8 ;
El Módulo de Conversión de Consultas u Forma Canónica, es el encargado de
establecer la unicidad semántica entre las consultas procesadas. Los siguientes son
los aspectos considerados para este'efecto:
I El análisis se encuentra limitado a un subconjunto de la gramátiia del SQL.
Se determina la unicidad semántica entre consultas que involucran en la parte
del predicado algún operador de compa%ación.
I En la cláusula selecf se puede contar
I En la cláu;isula>iom se puede contar coti n tablas.
En el caso de la cláusula select, cuando en la definición de la conshta se utiliza
el operador *, en la forma canónica resultante se incluyen todas las columnas de la
tablaaccedida: ' ' ' .
11
I 'I 1:
n columnas o con el operador *.
(11 ?I
11 y; * 'I
iJ
~1 ii! I
'11 Ill
V i l
I
1' I
I i , Cuando se presentan varias columnas o iitablas en la 'cláusula select o from, se
emplea un algoritmo de ordenación léxica, para realizar el establecimiento de la (Y unicidad semántica entre consultas. ,Iii *
En la cláusula where también se emplea'iun algoritmo de ordenación Iéxica sobre
ambos operadores de la cláusula. En la Fgura 4-11 se muestra unmaejemplo de la . ,y . :If
c

Capitulo 4 Impiementación del Sistema de Reglas
forma canónica resultante para dos consultas con estas diferencias sintácticas
Forma Canónica para Consultal y Consulta2
Select SCity, SSname, S.Sno, S.status
Where Londres = S.City;
Figura 4-11 Ejemplo de Conversión de Consulías a Forma Canónica
Como se puede apreciar, en la cláusula where de la consulta, se ha aplicado la
ordenación léxica para los dos operandos del predicado.
4.5.4 Integrador
Entrada: Archivos necesarios para realizar la migración. Salida: Ninguna.
Es el encargado de reunir la información estadística de los distintos nodos del
sistema y de almacenarla localmente en el nodo en el que se disparó la regla cuya
acción genera la ejecución de este módulo.
Este módulo accede al diccionario de datos para obtener la información necesaria
sobre la configuración del sistema, es decir, sitios que componen el sistema, rutas de
acceso a dichos sitios, tablas que componen la base de datos, así como atributos de
cada tabla. Mediante el acceso al diccionario de datos se puede adaptar fácilmente
este proceso a cualquier configuración del sistema o a otra base de datos.
Además de migrar la información al sitio que procesó la regla, se realiza un
81

ii
/I Implementación del Sistema de Reglas I1 1Capítuio 4
It I/
1 por la implementación computacional del modelo
I
proceso de homogeneización de la información reunida. /I Este último paso se refiere a 11
I.
matemático que determinará el
4.5.5 Base de Reglas '!
En la Base de RegZas están almacenadas todas las TReglas ECA por medio de las
cuales, el administrador de la base de datos determina &l tratamiento que le desea, dar
a eventos de interés, asímismo, puede establecer el ,contexto dentro del cual se
considerará el evento detectado, es decir, la condición. La definición de las Reglas
!I
I1
! I!!
1 1
!I
'U . .
82
' -
_. - . ~ .. .._~_.. .

Capítulo 4 Implementación del Sistema de Reglas
ECA se realiza mediante el proceso de precompilación presentado en la Sección 4.3.
En la Tabla 4-5 se muestran algunos de ejemplos de Reglas ECA que se pueden
definir.
En la parte de la condición, se tiene la opción de definir una no-condición, es
decir, se tiene la opción de ejecutar determinada acción ante un evento, sin importar
su contexto. El operador True se utiliza para este fin y se puede emplear en la
definición de cualquier regla.
Tabla 4-5 Ejemplos de Reglas ECA
Evento Condición Acción
Consulta True LlevaEstadísticas incremento de Frecuencia Frecuencia > 500 RegistraEnRelevantes Tiempo Tiempo >= 99sep27 AvisaDBA
4.5.6 Base de Consultas
La Base de Consultas es una relación de las consultas que se han ejecutado por lo
menos una vez en el sistema local. Almacena la siguiente información referente a
una Consulta, como identificador Único, tablas y columnas involucradas, así como la
condición de la cláusula Where en su forma canónica.
I 4.5.7 Datos Estadísticos de Explotación
Esta información hace referencia a los patrones de explotación de los datos que
el modelo matemático requiere de entrada. Uno de los parámetros que se almacena
es el identificador único de la consulta detectada, con lo que se mantiene la relación
con la Base de Consultas. La información que se almacena se muestra en la Tabla I
I 4-6.
83

Implementación del Sistema de Reglas 'I ,Capítulo 4
11 I
Id
fk
N
s k
.,,' .'r Identificador de consulta relevante detectada al menos una vez
I1 Frecuencia de emisión de la consulta k
)I
'1
Nodo que originó la consulta k
Selegtividad promedio de la consulta'!
111 4
I
!
I l(1 ' II
4.5.8 Módulo Identificador de Consultas Básicas .. '11.
(I I
~ i li II II 41.
11
,I
Entrada: Consulta procesada. Salida: 1 si la consulta es aceptada, O en caso contrario.
!I
Este módulo &aliza un proceso de filtrado de consultas, ion la finalidad de
registrar sólo aquellas consultas que pueden ser reconocidas por el Convertidor de
Consulras a Forma Canónica. Recibe todas las consultas que se procesan en el 7 8 1
SABDD y realiza un análisis sobre ellas con 1 la finalidad de identificar las que
cumplan con el subconjunto de definiciones de la gramática del SQL conliderada en
este trabajo. ' /
1:
# i Se consideran aquellas consultas que tienen en la cláusula where un predicado
i;L con una sola comparación sobre alguna columnh. La ventaja de este enfoque se basa
111. ' . . & I , A en la estrategia de procesamiento del SABGD, la cual consiste en 'analizar la
consulta original y dividirla en subconsultas, siempre que sea posible, d l tal manera
que se generen consultas sencillas, como las ,que se identifican con este módulo.
Dichas subconsultas son procesadas independientemente en el sitio queicontiene la
información involucrada. Es por esta razón, que el hecho de que ¡a consulta original
II
fi I ( I ' '
' 4': ,,
I r 11 #I
1 1 I/ I
1 I .!I
I( 81
/I) 1,
sea tan compleja .I como se desee no representatmayor 4 problema para el propósito de
este trabajo.
Cabe mencionar que algunas definiciones de consultas originales nb se pueden
dividir en subconsultas. Esto Io determina la ,misma definición de la consulta, pero
84

se considera que son procesadas con menor frecuencia.
4.5.9 Interfaz de Consulta
También se ha integrado como parte de este prototipo una interfaz que permita al
administrador de la base de datos verificar los cambios en el registro de los Datos
Emdísticos de Explotación y, si el ABD lo especifica, las consultas relevantes ad
hoc.
t
i

Capítulo 5 Pniebas
Capítulo 5
PRUEB~AS
En este capítulo se presentan los resultados obtenidos con la aplicación de un
conjunto de pruebas al Sistema de Reglas implementado
. . 5.1 Objetivo de las Pruebas
I .. El objetivo del conjunto de pruebas que se presentan en las secciones sucesivas,
es demostrar que el Sistema de Reglas implementado cumple con los requerimientos,
esto es, que a partir del Lenguaje de Reglas ECA se ejecuta un conjunto de acciones
semánticas equivalentes.
5.2 Lista de Pruebas
Pruebas al Precompilador:
1. Altas y Bajas de Reglas ECA
2. Definición de Reglas ECA.
3. Asignación de valores a las variables en la parte de la condición.
Pruebas al Intérprete
4. Registro del cliente y la selectividad correctos, así como de la frecuencia inicial.
81

Pruebas
5 . Incremento adecuado de la frecuencia de 1
6 . Registro correcto en el caso de emisión clientes.
7. Control de concurrencia.
8. Establecimiento de la equivalencia semái sintácticas
9. Integración correcta de la información de
10. Correspondencia entre el archivo de matemático y la información estadística e
1, - ,, ,
5.3 Descripción del Ambiente de PI 2 . ' .,¡I
Las. pruebas fueron realizadas sobre una, rec
sistema operativo ,+Solaris 2.4. En la Figuri
distribución de las tablas a través del sistema.
, . ,
Siüo A
Figura 5-1 Esquema de Dishib* !'I, , A
88
capítulo 5
.esamiento. "I
la misma consulta por distintos '
I
11
!I . * , i entre consultas con diferencias
os los nodos.
tos obtenido para el modelo rada por el SABDD. ,;
I/ 1 1
'1 .
, . *. :, : [Ii;; I , . ' . P
3
-1,
'I 1, i :bas
.I
: estaciones ,de trabajo SUN con
-1 se muestra el esquema de . :
! i .,
. 1,
. .
del Sistema

Capitulo 5 Pruebas
El administrador de la base de datos es el encargado de ejecutar el servidor de
consultas del SiMüaDD en cada sitio que contenga al menos una tabla almacenada,
para que dicho sitio pueda fungir como servidor. También es necesario tener
instalada la versión 1.16 del JDK en cada sitio del sistema.
5.3.1 Esquema Relaciona1 de la Base de Datos de Prueba
Con la finalidad de comprobar el correcto funcionamiento del módulo
desarrollado, se utilizó la base de datos que aparece en [Dat95]. En la Figura 5-2 se
muestra el esquema relaciona] de dicha base de datos compuesta por las tablas de
Proveedores, Partes y Embarques.
SZ JAIMES 10 PARIS S3 BERNAL 30 PARIS S4 CORONA 20 LONDRES C5 ALDANA 30 ATENAS
P - :?W ;:PNOMBRE;'CüiOR .PESO ..,;ClWAO?,; ,.., :.:<.J.'.:. , I.. :,. ..,. . , , ; - L . ,..~.~.~~.., PI TUERCA RCl.0 12 LOhDRES P2 PERNO VERDE 17 PARIS P3 BIRLO AZUL 10 ROMA P4 BIRLO ROJO 14 LONDRES P5 LEVA AZUL 12 PARIS PB ENGFlANE ROJO 18 LONDRES
SP
$1 P2 m s1 P3 400 s1 P4 m s1 P5 1W S1 P6 1 O0 sz Pl 3w
52 I P2 400. 5 1 P 2 m s4 P2 m s4 P4 m s 4 P 5 400
Figum 5-2 Esquema Relacionalde la BD de Prueba
. . 5.3.2 Herramientas Auxiliares
Para la ejecución de pruebas en las que era necesario ejecutar una serie de
consultas desde distintos sitios, se implementó un programa en lenguaje C, el cual
realiza una serie de llamadas System, cada una realiza una petición de consulta a un
sitio determinado. En cada sitio' se ejecuta uno de estos programas con consultas
89

I
I diferentes y hacia diferentes clientes. "I
para verificar el resultado de la prueba. I ' , '. iI' 1
I
AI ejecutar el servidor aparece un
botón en pantalla con la leyenda "Visualizar Estadística" y otro con la
leyenda "Visualizar Consultas obtiene las consultas
registradas como consultas ,
I! correctamente sobre la Base de Reglas. ; '
'I Procedimiento: Se definió una Regla ECAfly
'1
1 ACEPTAR. La regla definida fue la siguiente:
_ . 5.4 Resultados.Obtenidos ,. . , ...
Enseguida se presentan las pruebas indicando el objetivo, el
I
después se presionó el botón
la interfaz, y se presionó el botón BORRAR.'. 1 , , ' I I
,I

Capítulo 5 Pruebas
Resultado: Satisfactorio. Se verificó que, aparte de que la regla apareciera en la
lista de reglas definidas de la interfaz de Edición de Reglas ECA, también existiera
en la Base de Reglas. Después de dar de alta la regla definida y de haberla
eliminado, se comprobó que no existiera en la Base de Reglas, tampoco aparece más
como una regla definida.
5.4.2 Prueba 2: Definición de Reglas ECA
Objetivo: Comprobar que las reglas definidas con base en el Lenguaje de Reglas
ECA sean reconocidas y almacenadas. 1
Procedimiento: Para realizar el proceso de validación se definió un conjunto de
reglas que fueran una muestra representativa de las que se pueden definir mediante
el Lenguaje de Reglas ECA.
Haciendo uso de la Interfaz de Edición de Reglas ECA se procedió a la definición
del conjunto representativo de reglas.
Resultado: Satisfactorio. Durante el proceso de selección de eventos, variables y
acciones, la interfaz guía al administrador en la selección de sólo componentes
válidos, por lo que sólo se aceptan Reglas ECA definidas correctamente. Eso se debe
a que, ante la selección de un evento, se hace disponible el conjunto de variables y
acciones permitidas para dicho evento, y el administrador sÓ10 puede seleccionar de
las opciones presentadas. La Tabla 5-1 muestra los resultados.

'I Pruebas . . 11 Capítulo 5
I . :.
!i Resultado
True LlevgEstadísticas Aceptada Consulta IncrementoFrecuencia Frecuencia > 1000 PasaQiy ARelevantes Aceptada
Aceptada AltaBaseDeConsultas Tabla = 'S'
1 Tabla 5-1 Reglas ECA Aceptadas y Almacenadas
Evento Condici6n , ,; 11 Acción
' , !I IF
'I) AvisaDBA 1
AltaDatosEstadísticos Cliente <> 'cadl2' AvisbBA DeExplotaciÓn 'i
: I ' Tiempo = 2000,01,01, .! Ejecutahtegrador Tiempo ., . 00,oo
IncrementoFrecuencia Selectividad > 200 .: AvisaDBA ,I
Aceptada
Aceptada ~
, >
Aceptada AltaBaseDeConsultas Where = S.sno = 'sl ' l AviSaDBA Aceptada
Aceptada IncrementoFrecuencia Identificador = 293 PasaQry ARelevantes 11
5.4.3 Prueba 3: Definición de la Condición de la Regla ECA' ,I I/ Objetivo: Comprobar que la definición de:la condición de las Reglas ECA se
II ,I I il
I ! i
encuentre validada.
I / / Las validaciones consideradas en esta prueba, se refieren a la parte de la
condición de las reglas, no importando el evento o acción involucrados, ya que
están validados desde la propia Interfaz de Edición @ Reglas ECA.
Procedimiento: Se definieron Reglas ECA.con las condiciones que aparecen en
la Tabla 5-2. Después de haber definido cada regla se presionó el botón "Aceptar"
para que el preprocesador iniciara las validaciones pertinentes en cada caso,
i1. I1

Capítulo 5 Pruebas
Tabla 5-2 Condiciones de Reglas Definidas y Resultado de la Valiaizción
Condición de la Regla ECA Resul tad0
Variable Tiempo
Tiempo
Tabla
Where
Identificador
Selectividad
Frecuencia
Cliente
Valor 1999,13,iZ,OO,OO
1999-12-03
‘Usuarios.BD1’
S.Sname >= 1000
Uno
-1
Asd
‘Cad156’
Error en la definición del valor Tiempo
Error en la definición del valor Tiempo. El Formato debe ser aaaa.mm.dd.hh.mm
La Tabla no existe en el DD
Error en la definición del valor Where. El Valor no corresponde
al tipo de dato de la columna Valor inválido
Valor inválido
Valor inválido
El Cliente no existe en el DD
Resultado: Satisfactorio. Una vez que se aceptó la Regla ECA definida, los
mensajes de manejo de errores se presentaron mediante una ventana de aviso
indicando el tipo de error. Ninguna regla fue aceptada. Los mensajes
correspondientes a cada definición aparecen también en la Tabla 5-2 y son
explicados a continuación para cada caso:
1. En este caso, la validación corresponde a la semántica del valor Tiempo. El
rango para el mes es de 1 a 12.
2. El formato utilizado para el valor del tiempo es incorrecto.
3. Cuando se definen condiciones sobre elementos del diccionario de datos, se
valida su existencia. En este caso, la condición de la Regla ECA se hizo sobre
una tabla que no forma parte del sistema.
4. En el caso de la variable Where, el administrador de la base de datos define
93

I 1
Frecuencia.
6 . La Selectividad, así como Identificador y
I 7. Es el mismo error que en el caso (5).
sistema.
Frecbencia no pueden ser negativos.
correctamente. 1' I I.

Capítulo 5 Pruebas
Tabla 5-3 Consultas de ia Prueba 4 '
id I Consulta Cliente Servidor Original Original
1 Select S.City, S.Sname Cad12 Cadi3 From S Where S.Ciiy = 'Paris';
2 Select SP. PNo, SP.Qiy Cad13 Cad 12 From SP Where SP. SNo = 'S2';
3 Select * From P;
Cad12 Cad14
4 Select P. Weight Cad13 Cad12 From P Where P.Pname = 'Tuerca';
5 Select P.Pname From P Where P.Color = 'Rojo';
Cad14 Cad13
Resultado: Satisfactorio. Luego de ejecutar repetidas veces el mismo conjunto
de consultas, los Datos Estadísticos de Explotación obtenidos en cada sitio son los
presentados en las Tablas 5-4, 5-5 y 5-6.
Tabla 5-4 Datos Estadísticos de Explofación en el sitio cadi2
Id Cliente Frecuencia Selectividad
1 Cad13 1 3 _-
Tabla 5-5 Datos Estadísticos de Explotación en el sitio cadI3
Id Cliente Frecuencia Selectividad
3 Cad14 1 3 4 Cad12 1 6 ' 5 Cad14 1 3
95

I/ Pruebas I Capítulo 5
! petición original.
Ij Tublu 5-6 Datos Estadísticos de Explotacion en el sitio cad14
~~ ~ ~~ ~
I ' " ' Ciiente Frecuencia! Selectividad - Id
2 Cad14 1 4 5 11
5.4.5 Prueba 5: Incremento de Frecuencia. 'I ;i
Objetivo: Verificar que la actualización he los Datos Estadísticos de
Exploiación se realiza de forma adecuada.
!I Procedimiento: Se ejecutaron las consultas de la Tabla 5-3 de manera repetitiva.
Resultado: Satisfactorio. Se verificó que a través de cada corrida el registro de la ' 1 I
selectividad se fuera'manteniendo en el promedio. ?I Respecto a la frecuencia, ésta se 11
'I incrementó en cada corrida sobre el registro 'de cada consulta y el cliente registrado
se mantuvo adecuadamente.

Capítulo 5 Pruebas
5.4.6 Prueba 6: Distintos Clientes
Objetivo: Comprobar que se genera un registro estadístico diferente para la
misma consulta desde distinto cliente.
Procedimiento: Se emitió la misma consulta (consulta 1 de la Tabla 5-3) desde
dos clientes hacia el servidor en cad12 con diferente frecuencia: 3 veces desde el
sitio cadi4 y 2 veces desde el sitio cadi3.
Resultado: Satisfactorio. El registro de los Datos Estadísticos de i%plolación en
el sitio cadi2 fue el siguiente:
Tabla 5-7Datos Estadisticos de Exploiaciónpara la Mima Constrlta I desde Disiinia Cliente
Id Cliente Frecuencia Selectividad
1 cad14 3 3 1 Cad13 2 3
. .
Como se muestra en la Tabla 5-7, se generó un registro para el cliente que emitió
la misma consulta. El promedio de selectividad se mantiene puesto que no hubo
actualizaciones a la Tabla S y el registro de la frecuencia fue correcto
5.4.7 Prueba 7: Control de Concurrencia
Objetivo: Comprobar que no existe colisión en el ServidorProcesador cuando
recibe múltiples señalamientos de eventos de manera simultánea, y que éstas son
atendidas en forma concurrente. La prueba se basó en los eventos implementados.
Procedimiento: Empleando el esquema de distribución de datos y sitios
presentado en la Figura 5-2, se emitieron consultas desde los tres sitios hacia el
servidor cadi2.
Resultado: Satisfactorio. Dado que el servidor de consultas en cad12 recibió las
97

Pruebas '1 Capitulo 5
~
" 1 también fueron atendidos de forma concurrente. I
El orden en que el servidorProcesador recibio los I
/señalamientos varió de corrida I '
, ,
Objetivo: Comprobar que se establece unicidad!'
II Procedimiento: Se emitieron dos consultas hacia el mismo servidor de consultas,
según lo siguiente:
semántica sobre las consultas
From s 1 Where s.sname = 'JIMENEZ'
2 Select * From S Where 'Jirnenez' = s.sname
I
'I 98
:'

Capítulo 5 Pruebas
incremento en la frecuencia de procesamiento. La forma canónica generada para la
consulta es la siguiente:
Select S.CITY, S.NAME, S.SNO, S.STATUS From S Where ‘JIMENEZ’ =
S.SNAME
5.4.9 Prueba 9: Integración de Datos Estadísticos y Obtención del Archivo de Datos para el Modelo Matemático
Objetivo: Comprobar que el proceso de integración de los datos estadísticos, así
como la generación de los archivos de datos, requeridos por el modelo matemático
FURD, se realiza correctamente. Se considera que la información estadística ya ha
sido migrada al sitio local.
Procedimiento: Esta prueba se realiza en un solo paso mediante la ejecución de la
acción Ejecutuintegrudor por medio de la definición de una regla ECA, la cuál se
puede definir sobre un evento de tiempo. Sin embargo, la prueba será dividida en
dos partes con la finalidad de analizar los resultados obtenidos, primero la parte de
integración de datos y después la obtención de los archivos de datos.
PARTE 1: En cuanto a la integración, al momento de disparo de la regla que
ejecuta la acción de integración, la información estadística en los distintos nodos es
la siguiente:
NODO cad12
332 S S.CITY S.SNAME PARIS = S.CITY 333 s S .CITY BERN= = S.NAME 334 s S.CITY S.SNAME LONDRES = S.CITY
332 cad14 1 2 333 cad13 2 2 333 cad14 2 2 334 cad12 3 6
99

Pruebas - 1 Capítulo 5
I/
J 180 cad13 5 2 18 1' cad14 5 2 ,)I
I '~
NODO cad14 I
1 SP 'SP.PNO .. i' S21;= SP. QTY I S1'= 2 SP
3. ' ~ S P ' .b..CP.PNO SP.QTY 2 Cl!
,I 1 . . cad14 7 .2 2 cad13 8 4 3 cad12 9 , 5 2 ~ ' cad12 8 4
'' ! !;I,
. .
#
II
SP.SNO SP.SN0
= SP.CNO
1 I. < . Datos Integrados
1 ' S ' 2 S 3 C 4 P 5 P 6 SP 7 CP 8 SP
S.CITY C.SNAME S.CITY S.CITY S.SNAME P.CITY P.WEIGHT
SP.QTY SP.PNO SP.QTY
SP . PNO t
PGIS = S.CITY BERNAL = C.NAME LONDRES = S.CITY PYIS = P.CITY 20 = P.WEIGHT C2 = SP.SON S1 = SP.SON S1' = SP.SN0
I I/
1 cad14 1 2 I1 2 cad13 2 2 2 cad14 2 2 3 cad12 3 6 4 cad13 5 2 5 cad14 5 2 6 cadí4 7 2 7 cad13 8 4 7 cad12 8 4
i 8 cad12 9 5 I
I
/I ' O 0 I I

Capítulo 5 Pruebas
PARTE 2: Respecto a la obtención del archivo de datos, se parte de la
información integrada en la primera parte de la prueba. Como se mencionó, la
misma acción realiza de manera sucesiva ambas partes.
Es importante mencionar que el formato de los archivos que el modelo
matemático recibe, contienen la información estadística sobre una tabla a la vez.
Resultado Parte 2: Satisfactorio. A continuación se presentan los archivos de datos
resultantes de la integración. En cuanto al formato de dichos archivos, se trata
básicamente de matrices. En cuanto al tipo de consultas, el valor asignado es el O en
todos los casos de las consultas registradas.
La matriz de uso de atributos tiene por columnas los atributos de la tabla
correspondiente en el orden en que son definidos en el diccionario de datos, los
renglones son las consultas procesadas. En cuanto a la matriz de frecuencias, las
columnas representan los sitios en el sistema y los renglones siguen siendo las
consultas. Finalmente, cada elemento en el vector de selectividades corresponde a
cada consulta registrada
Archivo de D a t o s para T a b l a P //Tipo de las consultas O o, o //Matriz de uso de atributos o, o, o, o, 1 o, o, o, 1, o //Matriz de frecuencias 0 , 5 , 0 O, O , 5 //Vector de Selectividades 2,2
Archivo de Datos para T a b l a SP //Tipo de las consultas o, o, o //Matriz de uso de atributos o, 1,1 0,1,0 o, o, 1 //Matriz de frecuencias 7 , o, o 888 , O 9, o, o //Vector de Selectividades 2,4,5
Archivo de D a t o s p a r a T a b l a S //Tipo de las consultas O o, o, 0 //Matriz de uso de atributos o, 1, o, 1 0,0,0,1 o, 1, o, 1 //Matriz de frecuencias o, o, 1 o, 2,2 3, O, O //Vector de Selectividades 2,2,6

Capítulo 6 Conclusiones
Capítulo 6
CONCLUSIONES
Este trabajo consiste en la automatización del proceso de captura de información
estadística requerida para el establecimiento de esquemas de distribución de los
datos en un sistema de bases de datos distribuidas. Dicha información representa
patrones de explotación de los datos a partir de las consultas relevantes en el
sistema.
A continuación se describen los resultados obtenidos a partir del desarrollo del
presente trabajo:
I Se muestra, cómo mediante el empleo de principios de Bases de Datos Activas, es factible determinar cuantitativamente patrones de frecuencia sobre el uso de los datos en un SABDD.
I Se presenta un enfoque innovador, Buses de Datos Activas, para la obtención
de Datos Estadísticos de Explotación, de manera automatizada.
I El prototipo desarrollado puede formar parte de un módulo en un SABDD, cuya función principal sea la ubicación de datos de forma optimizada, ante los cambios en los patrones de explotación.
I En este trabajo se exploró el problema de unicidad semántica de las consultas definidas en SQL. Como resultado se propone un método para la identificación de consultas equivalentes, basado en un subconjunto de la gramática del SQL.
103

Conclusiones I Capítulo 6
I Al incorporar este trabajo como parte de un sistema administrador de bases de datos experimental, se validó la factibilidadl de automatizar el proceso de
diseño adaptable de bases de datos distribuidas!
I Mediante un conjunto de pruebas se pudo comprobar la funcionalidad del
I I I
11 ,I
'I 1 las más importantes:
módulo implementado.
6.1 Trabajos Futuros
I1
i Procesador de Reglas ECA.
t
:
I
I
I
I I
I
restricciones o integridad de datos. ~ 11
'!
Incrementar el número de tipos de acciones.
6.2 Beneficios 1!
'I
41 Y
La obtención del objetivo fijado para esta tesis, es decir, la obtención de la I¡
104

Capítulo 6 Conclusiones
información estadística sobre el uso de los datos de manera automática, permite
contribuir a la automatización del proceso de diseño de la distribución de los datos.
De lo anterior se deriva el hecho de que la realización de este trabajo permitió
avanzar y obtener experiencia en el diseño automatizado de bases de datos
distribuidas.
Por otra parte, la utilización del lenguaje de programación Java para el desarrollo
de este trabajo, permite la integración del módulo sobre distintas plataformas
computacionales. Esto es aplicable dado que se cuenta con dos versiones del sistema
administrador utilizado (SiMBaDD), plataforma unix y Windows.
Finalmente, la integración de los principios de BDA, constituye la plataforma a
partir de la cual, se pueden soportar otras funciones propias del manejador,
aprovechando las ventajas de este enfoque. Una de dichas ventajas es que la
funcionalidad del módulo implementado se puede extender con facilidad, ya que las
extensiones se realizan de forma modular mediante la definición de Reglas ECA,
facilitando el mantenimiento del sistema.
105

Referencias
REFERENCIAS
[PPR98] Joaquín Pérez, Rodolfo A. Pazos, Guillermo Rodriguez O., Juan Fraustro S., Sandra Ramirez P. y F. Reyes S., “Un Modelo para la Fragmentación Vertical y Reubicación Dinámica de Bases de Datos Distribuidas”. VI Convención y Feria Internacional INFORMATICA ’98, La Habana, Cuba, 1998.
[Han911 Eric N. Hanson, “The Design and Implementation of the Ariel Active Database Rule System”, Technical Report UF-CIS-TR-92- 018, University of Florida, September 1992.
[CM93a] Stefan0 Ceri, Rainer Manthey, “Consolidated Specification of Chimera (CM and CL)”, Technical Report IDEA.DD2P.004, Politécnico di Milano, June 1993.
[Gat971 Stella Gatziu, “The SAMOS Active DBMS Prototype”, Switzerland, 6Ih Hellenic Conference in Informatics, Athens Greece, December 1997.
[Dat95] C. J. Date. An Introduction to Database Systems. Vol 1, 6‘h ed.; The Systems Programming Series; E.U.A.: Addison Wesley Publishing Company, 1995.
[HW93] Eric N. Hanson, Jennifer Widom, “An Overview of Produccion Rules in Databases Systems”, The Knowledge Engineering Revrew, Vol. 8 , No. 2, 1993.
[WC96] J. Widom, S. Ceri, Active Database Systems, la ed.; Sn. Francisco California: Morgan Kaufmann Publishers, inc., 1996)

~
Referencias
[PD99]
[SAP971
[SAD941
[SHP96]
[Cha92]
[PDW94]
[SJG90]
[FGD98]
Norman W. Paton, O. Díaz, ‘:Actiye !I Database Systems”, ÁCM Computing Surveys, Vol. 31, NÓ.l, 1999.
NI
M. Stonebraker, A Wide-Area International Conference on 1997.
I/
M.Stonbraker, “Mariposa: A New IEEE IOth International Conference on February 1994.
M. Stonebraker, E. Hanson and S. Potamianos, “The Postgres Rule
No. 7, 1996. Manager”, IEEE Transactions Engineering, Vol. 14,
S. Chakravarthy, Techniques for Active Databases: UF-CIS-TR- 92-041, University of Florida, 1992.
N. Paton, O. Díaz, M. H. et. al., “Dimensions of Active Behavior”, Is‘ on Rules in Database Systems, 1994.
M. Stonebraker, A. Goh, and S. Potaminos. “On Rules, Procedures, Views in Database Systems”, ACMSIGMOND International Conference of Data, May 1990.
,’; 4)
H. Fritschi, S. Gatziu, K. Dittrikh, “FRAMBOISE- an Approach to Framework-based Active Ibatabases Management System ~onstruction”, Proc. 7Ih Interdktionaí Conference on Information and Knowledge Managemen¡:’ (CIKM ‘98), Washington, D.C., November 1998. di
;i , I /
li

- ~
Referencias
[CM9 3 b]
[CKT94]
[DGG95]
[GGD95]
[Wid921
[Vé197]
tMR951
[CPW87]
S. Chakravarthy, D. Mishra, “Snoop: An Expressive Event Specification Language for Active Databases”, Technical Report UF-CIS-TR-93-007, Universidad de Florida, E.U.A., 1993.
S. Chakravarthy, V. Krishnaprasad, A. Tamizuddin, R. H. Badani, “ECA Rules Integration into an OODBMS: Architecture and Implementation”. Technical Report UF-CIS-TR-94-023, Universidad de Florida, E.U.A., 1994.
K. Dittrich, S. Gatziu, A. Gepert, “The ADBMS Manifesto: A Rulebase of ADBMS Features”, Proc. 2”d Workshop on Rules in Databases (RIDS), Athens, Greece, September 1995.
A. Geppert, S. Gatziu, K. R. Dittrich, “Rulebase Evolution in Active Object-Oriented Database Systems: Adapting the Past to Future Needs”. Technical Report 95.13, Universidad Zurich, 1995.
J. Widom, “The Starburst Rule System: Language Design, Implementation and Applications”, IEEE Boletín del Comité Técnico de Ingeniería de Dalos, Vol. 15 No.1-4, 1992.
Ana Vélez Chong, “Ubicación Optima de Datos en Aplicaciones de Bases de Datos Distribuidas”, Maestría en Ciencias en Ciencias Computacionales, Cuernavaca, Mor. Centro Nacional de Investigación y Desarrollo Tecnológico, 1997.
S. T. March, S. Rho. “Allocating Data and Operations on Nodes in Distributed Database Design”, Transactions on Knowledge and Dura Enginnering, Vol. 7, No. 2, 1995.
S. Ceri, B. Pernici, y G. Wiederhold. “Distributed Database Design Methodologies”, Proceeding IEEE, Vol. 75, No. 5, 1987.
109

Referencias ,‘I j
: [ASU88] ~ A. V. Aho, ~ R. Principles,
[NCW84] S . Navathe, S. J. Dou, “Vertical
Techniques and .Tools,
’ . Partitioning~ Algorithms for D a t a b l e Design’’, ACM Trans. On Database Systems, Vol. 9,. No.’ 4, 1984.
, :.
[POP971 Joaquín Pérez, Miguel Rodolfo A. Pazos, “Procesamiento en Paralelo de Consultas en SQL en Bases de Datos ‘Distribuidas”, Memorias de la Conferencia Internacional CIMAF:97, La Habana, Cuba. 1997.
. . . : ,; : . .
. ,: I I ,I I i

-
Apéndice A Estándares en BDA
Apéndice A
ESTANDARES EN BDA
En este apéndice se presentan los esfuerzos realizados por atacar uno de los
problemas importantes en los SABDA comerciales, que es la falta de
estandarización tanto en el aspecto de sintaxis como en lo referente a su semántica
de ejecución.
Algunos SABD comerciales soportan reglas de BDA, y hacen referencia a ellas
como disparadores. Su funcionalidad es muy limitada en comparación con los
prototipos de investigación desarrollados (Ver Capítulo 2), y sin embargo, es
suficiente para proveerles de un comportamiento activo relativamente complejo. Las
principales carencias de los SABDA comerciales respecto a los prototipos son las
siguientes:
1. Falta de estandarización en cuanto la sintaxis y a la semántica de ejecución de
los disparadores. Esto dificulta el uso de disparadores a través de distintos
SABDA comerciales.
2. Falta de una definición clara de la semántica de ejecución.
3. Falta de características avanzadas que los prototipos sí proporcionan (P.e.
eventos compuestos, eventos de aplicación específica).
4. Incorporan un número de restricciones (número de disparadores definidos).
111

Estándares en BDA Apéndice A
" I I Enseguida se presentan los avances obtenidos en la,'iestandarización respecto a los
disparadores por parte de IS0 y ANSI. Primeramente, cabe mencionar que los
disparadores no son integrados sino hasta el Último estándar SQL3, tomando como
base las restricciones de integridad del SQL-92. Así 'que en las siguientes secciones
se abordarán primero las restricciones de integridad en SQL-92 y después los
'i li 1
¡I
disparadores en SQL3. 1 I
I
A.l Restricciones de Integridad en eliEstándar SQL-92 i
1
La contribución más importante del estándar SQL-92 es la definición de una gran
cantidad de restricciones de integridad. Estas se,;clasifican en: restricciones sobre
tabla, de integridad referencia1 y aserciones genkrales. Se explica brevemente cada
tipo de restricción ya que son el marco de referenlia para los disparadores en SQL3.
y :I
'\
1 . Restricciones sobre Tabla: Permite establecer valores determinados sobre
los datos de una tabla mediante un CREATE TABLE. Incluye modificadores
como UNIQUE y NOT NULL para llaves primarias, así como la cláusula
CHECK, mediante la cual se especifica una condición que involucra una
columna cuyos valores son restringidos y la restricción es válida si la
condición resulta verdadera para cada tqpla de la tabla.
2. Restricciones de Integridad Refereneial: La definición de este tipo de
restricciones involucra dos tablas: una; tabla que hace referencia y una tabla
que es referenciada. La cláusula empleada es FOREIGN KEY en la sentencia
CREATE TABLE. En este caso, la restricción es violada por una tupla en la
tabla que hace referencia cuando las 'columnas de tupla representan un valor
que no aparece también en las columiias respectivas de la tabla referenciada
Un aspecto importante en este estándar, es que las actualizaciones y
'i ' Y / I1 11
1 I
:' I iI i . . I
i " fl
I 'I ir
1 12 !I . . !I - . . ~.

Apéndice A Estándares en BDA
eliminaciones sobre la tabla referenciada, son manejadas por medio de
“acciones de trigger referencia]”. La siguiente es su sintaxis: , I -
.I. *‘<foreign key action> ::= <event> <action> 8 ,
I <event> ::= ON UPDATE I ON DELETE .
’ <action> ::= CASCADE I SET DEFAULT I SET NCJLL 1 NO ACTION ., I . .
Como se puede observar, la definición anterior se ubica dentro del paradigma .: . .
evento-condición-acción de BDA. El evento es el que causa la violación de - .. . . ” . ’ .
integridad, la condición es la restricción misma y la acción es la encargada de
reparar la violación de la restricción.
Respecto a las acciones, CASCADE propaga la actualización o la eliminación
de las columnas de la tabla referenciada hacia las llaves foráneas o tuplas (en
el caso de eliminación),correspondientes ‘de todas las tablas que r e f e r d a h .
.. SET NüLL.pone a nulo el valor de las llaves foráneas.de las tuplas cuyo
valor sea menor que su correspondiente en la tabla referenciada. .SET
DEFAULT tiene la misma función que SET NULL, sólo que pone los valores
‘de las llave; foráneas su vaior p i r default. NO ACTION deshabiiita las
eliminaciones o actualizaciones hacia la tabla referenciada que causa la
violación de . integridad referencial.
+ I , ; f .
. ‘
I . -
0 ;
I , . . ! >i . , L
3. Aserciones: Permiten definir restricciones general& sobre múltiples I .
tablas. Su sintaxis es la siguiente:
<SQL92 assertion> ::= CREATE ASSERTION <constraint name> .. ,: ,
CHECK (<condition>) - < , _ .
[<constraint evaluation>] -
<constraint evaluation> ::= [NOT] DEFERRABLE ,

t I I
Características Activas del Módulo Implementado Apéndice B
'$ 11
semántica de ejecución: I/ 1 I,/ B
'; --I/ . Ya que se tiene ahora un panorama general con relación a las características de
otros prototipos de investigación, a continuac:ión se presentan las ventajas que
proporciona el Lenguaje de Reglas ECA implementado en esta tesis, así como su
.I/
,!,
I En cuanto a las fuentes que originan los e?/entos, el Sislemo de Reglas
implementado soporta operaciones sobre estructura (SELECT), tiempo absoluto I
' 'I
I .#., . y abstracto. . I
',< .í/ I En cuanto a la definición de la condiciónFse emplea el enfoque de opcional. En
todos lo SABDA relacionales se presentgla misma opción y sólo'en el caso de
los SABDA orientados a objetos se obliga a definir una condición. Nuestro
lenguaje tiene la flexibilidad de permitir al 'ABD definir reglas ECA con una condición True, es decir, no condición. " 11
a li I La política de ciclo empleada es de tipo recursivo, y la ventaja que presenta es
que las reglas asociadas a los eventos señalados son procesadas de forma
inmediata, es decir, una vez que se presenta el evento la regla es procesada.
I En cuanto a la planificación de varias reglaiECA disparadas al.mismo tiempo, el
modelo de ejecución del trabajo presentado,, implementa la ejecución en paralelo
de dichas reglas, a diferencia del procesamiento secuencia1 que se presenta en la
mayoría de los prototipos presentados en la Tabla B-l. En este aspecto se
aprovecharon las facilidades del lenguaje empleado en la implementación (Java),
ya que mediante la utilización del mecanismo de hilos cada regla es ejecutada de . #/I
manera paralela sobre procesos ligeros
Para la definición de las Reglas ECA en este trabajo, se emplea el lenguaje de
programación definido en el Capitulo 3.:Una ventaja del lenguaje es que permite
I. '1
I / .
/I ,I:
I
I 124

, ‘T‘
Apéndice A Estándares en BDA
I eliminaciones sobre la tabla referenciada, son manejadas por medio de
“acciones de trigger referencial”. La siguiente es su sintaxis:
<foreign key action> ::= <event> <action>
<event> ::= ON UPDATE I ON DELETE
<action> ::= CASCADE I SET DEFAULT I SET NULL I NO ACTION
Como se puede observar, la definición anterior se ubica dentro del paradigma
evento-condición-acción de BDA. El evento es el que causa la violación de
integridad, la condición es la restricción misma y la acción es la encargada de
reparar la violación de la restricción
Respecto a las acciones, CASCADE propaga la actualización o la eliminación
de las columnas de la tabla referenciada hacia las llaves foráneas o tuplas (en
el caso de eliminación) correspondientes de todas las tablas que referencían.
SET NULL pone a nulo el valor de las llaves foráneas de las tuplas cuyo
valor sea menor que su correspondiente en la tabla referenciada. SET
DEFAULT tiene la misma función que SET NULL, sólo que pone los valores
de las llaves foráieas a su valor por default. NO ACTION deshabilita las
eliminaciones o actualizaciones hacia la tabla referenciada que causa la
violación de integridad referencial.
3. Aserciones: Permiten definir restricciones generales sobre múltiples
tablas. Su sintaxis es la siguiente:
4 Q L 9 2 assertion> ::= CREATE ASSERTION <constraint name>
CHECK (<condition>)
I [<constraint evaluation>]
<constraint evaluation> ::= [NOT] DEFERRABLE ,

Estándares en BDA Apéndice A
1 evaluación diferida). ,111
t .; I
. . ,
1 ,
[INITIALL~ DEFERRED I 1: I\
1 1
!! .I¡
generales del SQL-92 son: +
INMEDIATE]
1 1 disparadores del mismo estándar y su sintaxis es:.
En este caso la aserción se satisface si '!a condición en la cláusula CHECK
resulta verdadera. La evaluación de la restricción es inmediata si se evalúa
después de cada sentencia SQL que puede violar la restricción, y es diferida si
la restricción se verifica hasta que la transacción ha efectuado el commit. A
diferencia de los tip& de restricciones 'anteriores, las aserciones permiten
I,i II, I
11. . It
diferir la evaluación de la restricción. Cuando la aserción es violada, se
de la restricción.
2. Introducción de la evaluación en el ámbito de tupla, es decir, la restricción se
evalúa para cada tupla modificada de la tabla dada, en lugar de para la tabla vi II
completa
1/ 1 114

Apéndice A Estándares en BDA
CHECK (<condition>)
[FOR [EACH ROW OF] <table name>]
<constraint evaluation>
<assertion event> ::= INSERT 1 DELETE I UPDATE [OF <colum names>]
ON <table name>
En SQL3 cada trigger reacciona ante operaciones específicas de modificación de
datos sobre tablas específicas. Los disparadores siguen el paradigma evento-
condición-acción de BDA, como se muestra en su sintaxis:
G Q L 3 trigger> ::= CREATE TRIGGER <trigger name>
BEFORE 1 AFTER I INSTEAD OF <trigger event>
ON <table name>
[ORDER corder value>]
[REFERENCING <references>]
WHEN (<condition>)
<SQL procedure statement>
FOR EACH ROW I STATEMENT j
i itrigger event> ::= INSERT 1 DELETE I UPDATE [OF <column name>]
<reference> ::= OLD AS <old value tuple name> I !
NEW AS <new value tuple name> 1 OLD-TABLE AS <old value table name> j
NEW - TABLE AS <new value table name>
I ,
En esta definición se puede observar que existe la posibilidad de definir el
tiempo de ejecución de un trigger, ya sea antes, después o en lugar de la operación
I 115 I

Estándares en BDA il Apéndice A
4 Para hacer referencia a los va1ores"de 10,s datos antes y después de la operación 4
. , Id
! d . . .
disparadora se emplean los valores old y new de la cláusula REFERENCING. '\
Además se cuenta con la cláusula ORDER, por medio de la cual se especifica el
orden en que se ejecutan dos o más disparadores que se disparan al mismo tiempo y
que están definidos sobre la misma tabla. Si 'no se especifica un orden, entonces la
secuencia de ejecución se basa en el tiempo de definición de los disparadores. 1
;i Finalmente, la definición de SQL3 para los disparadores, también proporciona
1: \I . ,
una sentencia para la eliminación de los disparidores:
! ~ '
5
<drop trigger> ::= DROP TRIGGER <trigger name> 1

Apéndice B Caractensticas Activas del M6dulo Implementado
Apéndice B
CARACTERISTICAS ACTIVAS DEL MODULO IMPLEMENTADO
En este Apéndice se presentan las propiedades que caracterizan a un SABDA.
Posteriormente se expone una comparación entre las características del Módulo de
Detección y Registro de Eventos Relevantes implementado y algunos prototipos, así
como con el estándar SQL3.
B.l Características
Las características de los SABDAs se agrupan bajo tres aspectos: El modelo de
conocimiento, el modelo de ejecución y la administración de las reglas. En las
siguientes secciones se presentan de manera general las características referentes a
cada aspecto.
B.l. l Modelo de Conocimiento
El modelo de conocimiento de un sistema activo abarca todo lo que se puede
decir acerca de las Reglas ECA. A continuación se presentan los atributos
correspondientes a cada parte de la regla.

Características Activas del Módulo Implementado I\ Apéndice B
B.1.I.I Evento
Fuente: Es la generadora del evento. Una fuente puede ser una operación sobre
las estructuras de la base de datos (insert, update, select), la invocación de un
comportarnienfo (operaciones indicada por el usuario), una transacción (por
~ '1
ejemplo: el señalamiento explícito
de un evento desde una excepción, de reloj
presentado es señalado por un suceso ? , .! .,
(un punto en el.tiempo), externa (el
externo al sistema).
Granuiaridad del Evento: Indica es definido sobre un conjunto, un ¡I i],
" \\, . miembro especifico o un subconjunto. Por ejemplo, un evento puede ser
detectado sólo cuando actúe sobre un svbconjunto de las tuplas de una relación.
Tipo: Los eventos pueden ser primitivosio compuestos. Los primitivos son
disparados por las fuentes antes presentadas, y los compuestos por
I 1 combinaciones de los primitivos. a
:I il Rol: Indica si el evento es obligatorio, opcion,al o si no se especrfica en la regla.
B.1.1.2 Condición :I
Rol: Indica si la condición es obligatoriaj opclonal o si no se especifica.
Contexto: Se refiere al estado de la base de' datos en el que la condición es
evaluada. Por ejemplo, al inicio de una'transacción o al .momento en que se
¡\
il d
presentó el evento
B.1.1.3 Acción
a
Opción: Se refiere al tipo de acciones que se implementar: invocación de
comportamiento, llamada externa, un administrador, aborto de

Apéndice B Características Activas del Módulo lmplementado
i
i I i I
i I i ~
I
transacción o una operación usando un comando hacer-en-lugar-de.
Contexto: Al igual que en la condición, se trata del estado en el que se encuentra
la base de datos al momento en que se ejecuta la acción.
B.1.2 Modelo de Ejecución
El modelo de ejecución se refiere a como son tratadas las regias al tiempo de
ejecución. Las siguientes son las características que corresponden a este aspecto.
Modo de Acoplamiento: Se refiere a los modos de acoplamiento entre el evento
y la condición, y entre la condición y la acción, es decir, en que momento se
evalúa la condición con respecto al evento, y en que momento se ejecuta la
acción con respecto a la condición. Los modos se determinan con respecto a la
transacción y pueden ser: inmediato (en la misma transacción de manera
inmediata), diferido (misma transacción, pero no de manera inmediata) o aislado
(en distinta transacción).
Granularidad de la Transición: Indica si la relación entre los eventos ocurridos
y las instancias de reglas disparadas es 1:l o muchos:l. Puede ser a nivel tuplu
cuando la ocurrencia de cada evento dispara una regla, o bien, a nivel conjunto
cuando un grupo de eventos dispara una sola regla.
Política de Efecto Neto: Indica si se considera el efecto neto de varias
ocurrencias de un mismo evento, o si cada ocurrencia se considera de manera
aislada. Por ejemplo, el efecto neto de varias actualizaciones sobre un mismo
dato es una actualización.
Política de Ciclo: Indica el tipo de algoritmo que se sigue cuando un evento es
señalado a partir de la evaluación de la condición o de la ejecución de la acción
119

j
Características Activas del Módulo Implementado 4 Apéndice B 1 'h de la regla. En un ciclo irerativo el ''procesamiento de la Condición o de la acción
nunca se suspende, es decir, los eventos disparados durante estas actividades son
atendidos hasta que dichas actividades I finalizan. En un ciclo recursivo los
eventos presentados provocan que dichas actividades sean suspendidas dando
lugar al procesamiento inmediato de las reglas correspondientes.
I . :~ J
1 1 . ¡I
I\ Prioridades: Cuando se disparan varias reglas al mismo tiempo, la elección de
cuál regla se ejecutará, se puede basarjen un criterio de prioridades. Las
prioridades pueden ser dinámicas (basadas en el tiempo de ocurrencia del
evento), numéricas (valores absolutos), relativas (con relación a la ejecución de
otras reglas), o bien, ninguna (no tiene impacto el orden de ejecución).
Calendarización: Especifica la for+ es que se procesan varias reglas
disparadas a la vez. Las opciones son: secuencralmente, en paralelo, algunas
reglas antes que cualquier otra o disparar sÓ1; algunas de todas reglas,
Manejo de Errores: La mayoría de los sistemas abortan la transacción ante la
'l. . \
i. ¡I
I ~ '1
11
'\
'I
presencia de errores al momento de ejecución. 1 ,Otros mecanismos son: ignorar la 1 l .
! ': 1s
regla que produce el error, deshacer las modificaciones, o manejar un mecanismo
de contingencia para la recuperación del error piesentado.
I' f B.1.3 Administración de las Reglas ' '1
Las características bajo este aspecto se refieren a las facilidades que proporciona
el sistema para el manejo de las reglas.
Descripción: Se refiere a la forma como son expresadas las Reglas ECA, es
decir, por medio de un lenguaje de programación, utilizando un lenguaje de
consultas o por medio de objetos. Estas categorías:no son exclusivas.
1 I\

Apéndice E Caractensti,cas Activas del Módulo Implementado
Operaciones: La operación obligatoria que se aplica a las reglas es la de
creación. Otras operaciones opcionales son: activación, desactivación (permite al
ABD inhabilitar el procesamiento de reglas, sin eliminarlas de la base de reglas)
y sefiaiamienio (se refiere a eventos externos señalados por la aplicación).
Adaptabilidad: Esta característica depende del procedimiento que se tiene que
seguir para que las reglas definidas puedan ser consideradas o reconocidas por el
sistema. La opción de compilación se utiliza cuando es necesaria la compilación
de la aplicación para el reconocimiento del comportamiento definido por medio
de las reglas. AI contrario de esta opción se tiene la denominada al tiempo de
corrida, bajo la cuál no es necesaria la compilación de la aplicación.
Modelo de Datos: Este es el modelo con el que el sistema activo es asociado y
puede ser: Relacional, Relacional Extendido, Deductivo u Orientado a Objetos.
B.2 Comparación con Algunos Prototipos
En la Tabla B-1 se muestran algunas de las características tanto de SABDAs
relacionales como orientados a objetos [PDW94]. Todos son prototipos de
investigación. Así mismo, se pueden observar las diferencias entre el ambiente
activo implementado en esta tesis con respecto a los SABDAs incluidos en la misma
I 1 I
i Tabla.
Cabe mencionar que algunos de los sistemas incluidos también aparecen en el
estudio del estado del arte realizado, el cuál aparece en el Capítulo 2.
I 121

Tabla E1 Tabla Comparativa sobre las Caracterislicas de Prototipos de Sisiemas Administradores de Bases de Datos Activas [PD99]
~ ~-


Apéndice B Características Activas del Módulo Implementado :\
5 . 1 Ya que se tiene ahora un panorama'. general con relación a las características de
otros prototipos de investigación, a continuación se presentan las ventajas que
proporciona el Lenguaje de Reglas ECA implementado en esta tesis, así como su
f I\ 1
" , \ \
¡\
1
semántica de ejecución: ,
I En cuanto a las fuentes que originan "los eventos, el Sistema de Reglas
implementado soporta operaciones sobre estructura (SELECT), tiempo absoluto
y abstracto.
En cuanto a la definición de la condicih;se, emplea el enfoque de opcional. En
todos lo SABDA relacionales se presenta lalimisma opción y sólo en el caso de
los SABDA orientados a objetos se obliga', a definir. una condición. Nuestro
lenguaje tiene la flexibilidad de .permitir al !ABD definir reglas ECA con una
condición True, es decir, no condición.
La política de ciclo empleada es de tipo recwsivo, y la ventaja que presenta es
que las reglas asociadas a los eventos señalados son procesadas de forma
inmediata, es decir, una vez que se presenta el evento la regla es procesada.
En cuanto a la planificación de varias regla ECA disparadas al mismo tiempo, el
modelo de ejecución del trabajo presentado,' implementa la ejecución en paralelo
de dichas reglas, a diferencia del procesamiento secuencia1 que se presenta en la
mayoría de los prototipos 'presentados en la Tabla B-l. En este aspecto se
aprovecharon las facilidades del lenguaje empleado en la implementación (Java),
\ , .
I ~ \\
1 1
I 21 1.
" 1 \I i1 11 I1
! \ I
ya que mediante la utilización del mecanismo cada regla es ejecutada de
manera paralela sobre procesos ligeros.
l. I Para la definición de las Reglas ECA en este trabajo, se emplea el lenguaje de
programación definido en el Capítulo 3 . Una lenguaje es que permite

Apéndice B Caractensticas Activas del Módulo implementado
añadir eventos o acciones definidas como métodos. De esta manera se pueden
incluir componentes para la definición de las reglas con la sola restricción de que
dichos componentes sean un método que pueda ser llamado.
I Respecto a las herramientas proporcionadas por el trabajo realizado, para la
administración de las Reglas ECA, se cuenta con una interfaz gráfica que permite
visualizar las reglas definidas al momento. El resto de los sistemas relacionales
de la tabla no presentan ninguna facilidad.
B.3 Comparación con los Disparadores de Estándar SQL3
En esta sección sólo se mencionarán las diferencias entre el lenguaje de
definición de reglas ECA implementado y los disparadores. Para ver la definición
formal de los disparadores, del estándar más reciente a la fecha, consultar el
Apéndice A.
En la Tabla B-2 aparece la relación de las características correspondientes al
comportamiento activo del SQL3 y el módulo activo implementado.
Una ventaja importante se presenta en cuanto a la fuente del evento. La
definición del SQL3 sólo detecta como eventos las operaciones de actualización
sobre la base de datos (UPDATE, DELETE e INSERT), en cambio el lenguaje
definido en este trabajo soporta una mayor gama de eventos: Recuperación de datos,
eventos de tiempo y actualización de datos (estadísticas).
~
! I
Debido a que se emplea un lenguaje de programación para la definición de las
reglas ECA y no una extensión al lenguaje de consultas SQL, es posible integrar
como acciones definidas métodos de programación. Con esto se puede definir una
amplia gama de acciones.
I 125 1

Características Activas del Módulo Implementado '1 Apéndice B
\I . Tabla B-2 Tabla Comparativa del Lenguaje de Reglas ECA y Disparadores'
c ~ I\
1 iI 'I
La planificación de las Reglas ECA disparadas a la vez, en el caso de este
trabajo, se realiza de forma paralela. El ..estándar SQL3 utiliza el tipo de
planificación secuencia] que presenta desventajas obvias. Por ejemplo, si se
considera que la acción de una regla involucra uno o más procesos extensos, el
procesamiento de las regias sucesivas se podría ver afectado '> 11:
d La información contenida en esta tabla, referente al SQL3, ha sido extraída de VD991 9
I/

Apéndice B Características Activas del Módulo Implementado
Finalmente, en este trabajo se proporciona una herramienta gráfica que le permite
al ABD la consulta de las reglas ECA definidas en el sistema.
Como se puede apreciar en la Tabla B-2. el estándar SQL3 cuenta en su
definición con muchas características que los prototipos de investigación han
implementado como parte de su comportamiento activo. Sin embargo, los SABDA
comerciales que se basan en el mecanismo de disparadores han implementado sólo
algunas capacidades de las definidas en el estándar SQL3.

Apéndice C Publicaciones Recomendadas
Apéndice C
PUBLICACIONES RECOMENDADAS
Es este apéndice se presenta una relación de las publicaciones más relevantes en
el área de las bases de datos activas. También se da una breve explicación del
contenido de cada referencia.
I S. Ceri, R. Manthey, “Consolidated Specijication of Chimera (CM and CL) ”,
Reporte Técnico IDEA.DD2P. 004, Politécnico di Milano, Italy. Junio I993
Este reporte técnico contiene la especificación del lenguaje conceptual
Chimera, perteneciente al proyecto IDEA, es decir, especificación de valores,
objetos, restricciones, vistas, disparadores, reglas pasivas, reglas activas,
consultas, actualizaciones, transacciones, así como la gramática completa del
lenguaje.
I Norman W. Paton, O. Díaz, “Active Database Systems”. ACM Computing
Surveys, Vol. 31, Ntím. I , Marzo 1999
Este artículo presenta un enfoque muy completo sobre las BDAs. Incluye la
descripción de las características fundamentales de los sistemas activos, un
panorama general de varios SABDAs, algunos aspectos referentes a la
arquitectura y finalmente avances actuales en el desarrollo de herramientas
129

Publicaciones Recomendadas Apéndice C
1 il útiles para el diseño de aplicaciones activas.
U. Jaeger, J. C. Freytag, “Annotate,d Bibliograpiy on, Active Databases”,
Alemania 1996
Representa un concentrado de laibiblibgrafía disponible sobre bases de datos
activas y SABDAs
li 1
‘ I ; .. i “i\ ’ ~
M. Stonebraker, “The Integration of Rule Systems and Database Systems”,
IEEE Transactions on Knowledge and Data Engineering, 4(5):415-423,
Octubre 1992
En este artícu1o’:se abordan los aspectos de integración de un sistema de
reglas y un sistema de bases de datos.
K. Dittrich, S. ‘Gatziu, A. Gepert, “The ADBMS Manifesto: A Rulebase of
ADBMS Features”. University of Zurich, Proc. 2nd Workshop on Rules in
Databases (RIDS)), Atenas, Grecia, Septiembre 1995
La funcionalidad que un SABD debe soportar para ser considerado activo, así
como aquellas características’ deseables son aspecto presentados ‘en este
artículo.
S. Gatziu, “The SAMOS Active DBMS Prototype ”, Departament of Computer
Science, Universidad de Zurich, ’ Suiza, 6th Hellenic Conference in
informatics, Atenas Grecia, Diciembie 29917
I 1
” 1, 1
’: \
1 I1
4 ’I 9
‘1 i r
‘I. il.
El artículo presenta una’ descripción acerca del prototipo SAMOS de
la Universidad de Zurich.
J. Widom, S. Ceri, ‘Yctive Systems”, Morgan Kaufmann

Apéndice C Publicaciones Recomendadas
Publishers, inc., Sn. Francisco California 1996, ISBN 1-55860-304-2
Este libro es un compendio amplio acerca de los sistemas de bases de datos
activas. Se presentan todos los aspectos relacionados al diseño y la
implementación de los SABDAs. También se abordan de manera general
tanto los prototipos de investigación como SABDs comerciales que soportan
mecanismos de disparadores. Otro aspecto importante que se incluye en este
libro es la parte referente a las aplicaciones soportadas por los sistemas de
este tipo.
I S. Ceri, P. Fraternali, “Designing Database Applications with Objects and
Rules”, Addison- Wesley, ISBN 0-201-40369 2, 1997
Este libro trata de la metodología IDEA, la cual abarca componentes para
análisis, diseño, prototipo e implementación en sistemas de bases de datos.
Una parte importante de esta metodología es Chimera, un lenguaje conceptual
para la definición del modelo dinámico, es decir, de reglas activas.
I C. Bauzer Medeiros, M. J. Andrade, “Implementing Integrity Control in
Active Data Bases”, Journal Systems Sofmare, Campinas, Brazil, 1994
Se presenta una metodología para convertir restricciones sobre la base de
datos en reglas de producción, bajo el enfoque de bases de datos activas.
I K. R. Dittrich, A. M. Kotz, J. A. Mulle, ‘An EveniiTrigger Mechanism to
Enforce Complex Consistency Constraints in Design Databases”, SIGMOND
RECORD Vol. 15. No. 3, Septiembre 1986
El artículo contiene los aspectos de implementación de un mecanismo basado
en disparadores para controlar las restricciones en el diseño de bases de datos.

![Bogan Turism Urban 2019 - editurauniversitara.ro · 7xulvpxo gh furd]lhu 7xulvpxo lqgxvwuldo 7xulvpxo ihuryldu](https://img.pdfslide.tips/doc/110x75/5e444d70ec78d05a7669a152/bogan-turism-urban-2019-7xulvpxo-gh-furdlhu-7xulvpxo-lqgxvwuldo-7xulvpxo-ihuryldu.jpg)