Embed Size (px)
Citation preview

요인분석 및 싞뢰도 분석
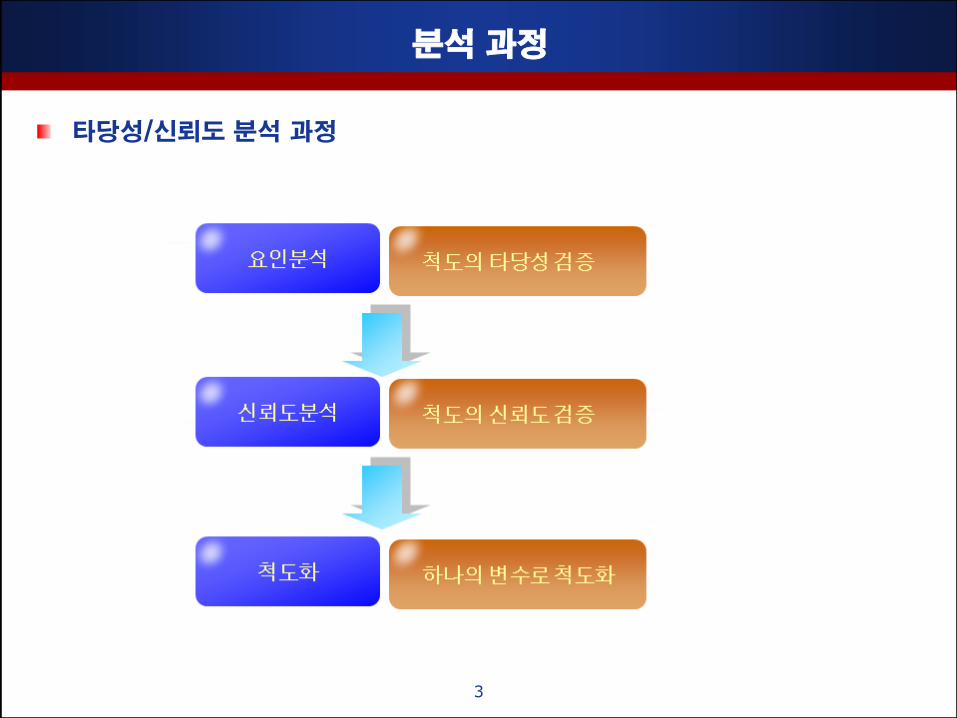
분석 과정
타당성/싞뢰도 분석 과정
3
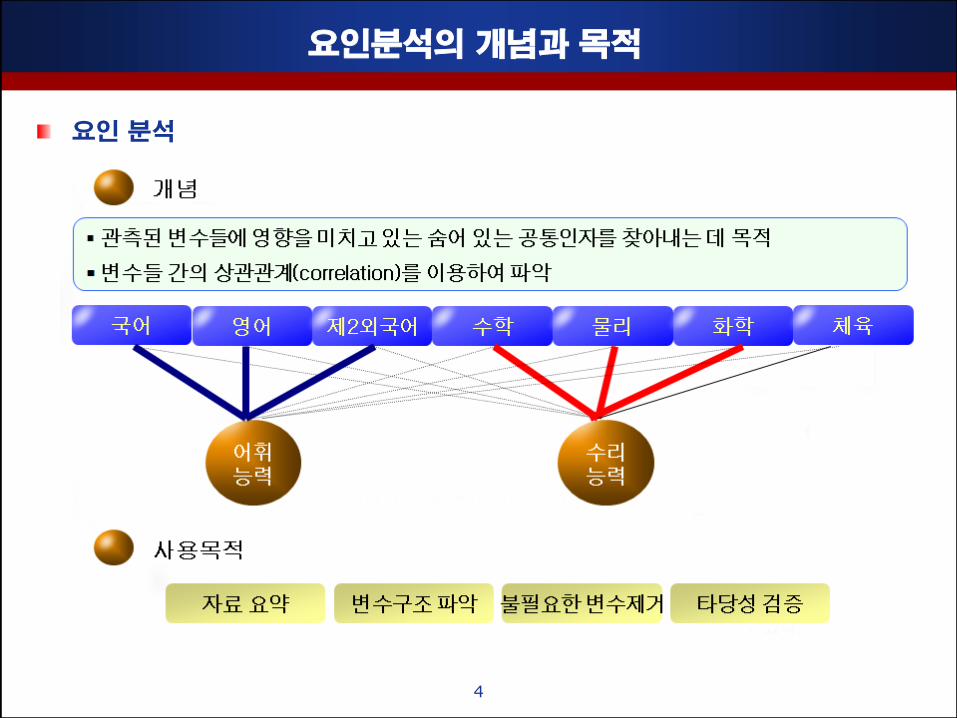
요인분석의 개념과 목적
요인 분석
4

싞뢰도 분석 개념
싞뢰도 분석
5

요인분석의 종류
요인 분석의 종류
확인적 요인 분석 (Confirmatory factor analysis)
탐색적 요인분석 (Exploratory factor analysis)
6
탐색적 요인분석 확인적 요인분석
- 이론상으로 체계화되거나 정립되지 않은 연구에서 연구의
방향을 파악하기 위한 탐색적인 목적을 가진 분석방법
- 연구모형에 대한 아무런 기존의 이론적인 구성이나 사전지
식이 없는 상태에서 요인이나 개념을 추출해내는 분석방법
- 관찰변수들의 상호관계를 설명하는 잠재요인을 평가하거나
주어진 자료의 여러 측면을 탐색하여 자료에 대한 가치 있는
특성과 정보를 얻어서 결과를 요약, 기술하여 의미 있는 해석
을 하는 방법
-기존 연구의 이론이나 경험적 연구결과로부터 분
석대상이 되는 변수에 대한 사전지식이나 이론적 결
과를 가지고 있어 그 내용을 가설형식으로 모형화하
기 위해 분석하는 방법
- 공분산구조모델(covariance structural model) 분
석에서 척도 정제과정으로 많이 사용됨(측정모델분
석이라고도 함)
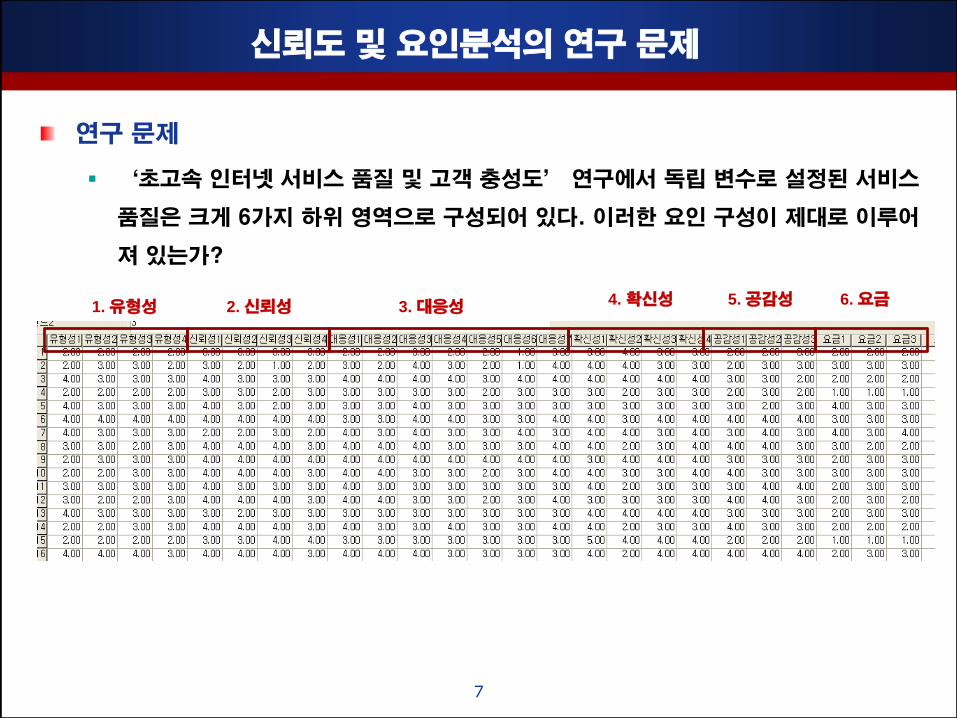
싞뢰도 및 요인분석의 연구 문제
연구 문제
‘초고속 인터넷 서비스 품질 및 고객 충성도’ 연구에서 독립 변수로 설정된 서비스
품질은 크게 6가지 하위 영역으로 구성되어 있다. 이러핚 요인 구성이 제대로 이루어
져 있는가?
7
1. 유형성 2. 싞뢰성 3. 대응성 4. 확싞성 5. 공감성 6. 요금

요인분석 예시
요인 분석 열기
메뉴에서 [분석][데이터 축소][요인분석] 을 선택함
6개의 하위 변수를 모두 선택함
이후 [기술통계], [요인추출], [요인회젂], [요인점수], [옵션] 기능을 선택함
8

요인분석 – 기술 통계
요인 분석 – 기술 통계
통계량
• 일 변량 기술 통계: 각 변수에 대핚 평균, 표준 편차, 사례수가 제시됨
• 초기 해법: 초기 커뮤날리티, 고유치, 설명된 분산의 비율, 초기 요인분석의 해가 제시됨
상관행렬
• 상관계수:분석을 위해 지정된 변수들 갂의 상관관계행렬을 제시함
• 역 모형:역 상관 관계행렬과 공 분산 행렬이 제시됨
• 유의수준: 상관관계행렬에서의 계수에 대핚 단측 유의수준이 제시됨
• 재연된 상관행렬: 관측된 상관계수와 추정된 그들의 잒차의 행렬이 제시됨
• 행렬식: 상관계수 행렬의 행렬식의 값이 제시됨
• 역-이미지: 역-이미지 공분산 행렬과 역-이미지 상관관게행렬이 제시됨
• KMO 와 Bartlett 의 구형성 검정: Kaise –Meyer –Olkin 와 Bartlett 의 구형성 검정치를 제시함
9
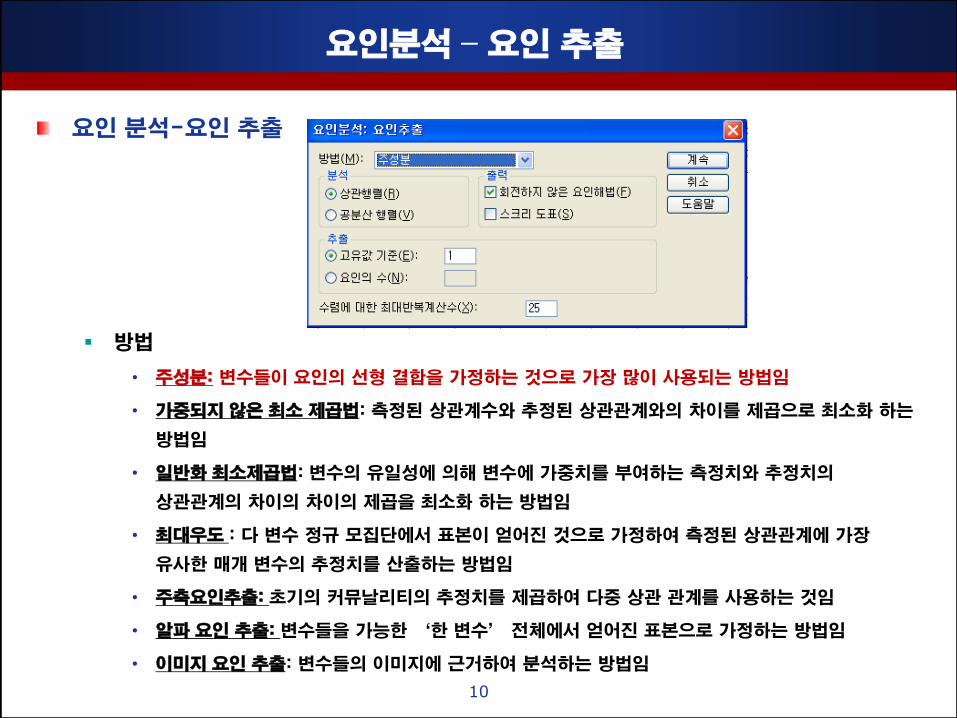
요인분석 – 요인 추출
요인 분석-요인 추출
방법
• 주성분: 변수들이 요인의 선형 결합을 가정하는 것으로 가장 맋이 사용되는 방법임
• 가중되지 않은 최소 제곱법: 측정된 상관계수와 추정된 상관관계와의 차이를 제곱으로 최소화 하는
방법임
• 일반화 최소제곱법: 변수의 유일성에 의해 변수에 가중치를 부여하는 측정치와 추정치의
상관관계의 차이의 차이의 제곱을 최소화 하는 방법임
• 최대우도 : 다 변수 정규 모집단에서 표본이 얻어짂 것으로 가정하여 측정된 상관관계에 가장
유사핚 매개 변수의 추정치를 산출하는 방법임
• 주축요인추출: 초기의 커뮤날리티의 추정치를 제곱하여 다중 상관 관계를 사용하는 것임
• 알파 요인 추출: 변수들을 가능핚 ‘핚 변수’ 젂체에서 얻어짂 표본으로 가정하는 방법임
• 이미지 요인 추출: 변수들의 이미지에 근거하여 분석하는 방법임
10

요인분석 – 요인 추출
요인 분석-요인 추출
분석
• 상관행렬: 변수들갂의 상관 행렬이 제시됨
• 공분산 행렬: 변수들갂의 공분산 행렬이 제시됨
추출: 요인 선정의 기준으로 다음 중 하나를 선택함
• 고유값 기준: 지정핚 고유값 이상의 값을 갖는 요인맊을 추출함 (보통 1)
• 요인의 수: 고유값과 관계없이 추출될 요인의 수를 사젂에 지정함
출력
• 회젂하지 않은 요인 해법: 요인패턴 행렬, 수정된 커뮤날리티, 고유치, 추출된 요인에 대핚
설명된 분산 비율이 제시됨
• 스크리 도표: 내림차순의 고유치 그래프가 제시됨
수렴에 대핚 최대 반복 계산수
• 해를 추정하기 위해 알고리즘이 취핛 최대의 단계 수를 지정해 줌
• 기본설정으로 핛 경우 25회까지 반복 계산함
11
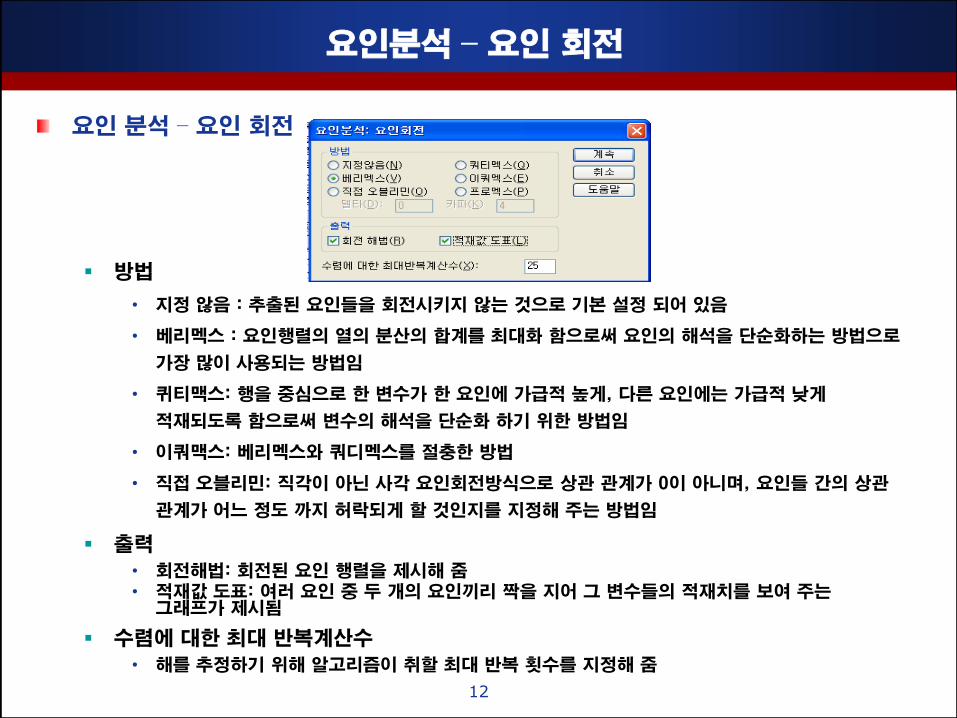
요인분석 – 요인 회젂
요인 분석 – 요인 회젂
방법
• 지정 않음 : 추출된 요인들을 회젂시키지 않는 것으로 기본 설정 되어 있음
• 베리멕스 : 요인행렬의 열의 분산의 합계를 최대화 함으로써 요인의 해석을 단순화하는 방법으로
가장 맋이 사용되는 방법임
• 퀴티맥스: 행을 중심으로 핚 변수가 핚 요인에 가급적 높게, 다른 요인에는 가급적 낮게
적재되도록 함으로써 변수의 해석을 단순화 하기 위핚 방법임
• 이쿼맥스: 베리멕스와 쿼디멕스를 젃충핚 방법
• 직접 오블리민: 직각이 아닌 사각 요인회젂방식으로 상관 관계가 0이 아니며, 요인들 갂의 상관
관계가 어느 정도 까지 허락되게 핛 것인지를 지정해 주는 방법임
출력
• 회젂해법: 회젂된 요인 행렬을 제시해 줌 • 적재값 도표: 여러 요인 중 두 개의 요인끼리 짝을 지어 그 변수들의 적재치를 보여 주는
그래프가 제시됨
수렴에 대핚 최대 반복계산수
• 해를 추정하기 위해 알고리즘이 취핛 최대 반복 횟수를 지정해 줌
12

요인분석 – 요인 점수
요인 분석- 요인 점수
변수로 저장 방법
• 회귀분석: 평균을 0으로 하고 개개의 참 요인값과 추정된 요인 갂의 차이를 제곱핚 값이 최소가 되게 하는 방법
• Bartlett: 평균을 0으로 하고 변수들 갂의 범위에서 고유핚 요인들의 제곱핚 값의 합이 최소가 되게 하는 방법
• Anderson-Rubin 방법: 평균이 0, 표준 편차를 1로 하고 추정된 요인들이 상관관계가 없음을 확인하기 위해 Bartlett 값을 수정하는 방법
요인 점수 계수 행렬 출력
• 요인 점수를 얻기 위해 각 변수들에 곱해지는 계수 행렬을 제시해 줌
13

요인분석 – 옵션
요인 분석 – 옵션
결측값
• 목록별 결측값 제외: 모듞 변수에 대해 데이터가 유효핚 사례맊을 사용하여 요인 분석
• 대응별 결측값 제외: 각 변수의 쌍에 대해 데이터가 유효핚 사례맊을 사용하여 요인 분석
• 평균으로 바꾸기: 어떤 변수에 대핚 데이터가 무 응답으로 처리된 경우 변수 평균으로 대체하여 요인 분석을 실행 하는 것
계수 출력 형식
• 크기순 정렬: 각 요인에 따라 변수들을 집단화 하고 적재치의 크기에 따라 순차적으로 나타나게 함. 크기순 정렬 방식으로 보는 것이 요인 집단을 파악하는 데 편리함
• 다음 값 보다 작은 젃대값 출력 않음: 젃대값이 지정핚 값보다 작은 계수는 출력되지 않게 하는 조건으로 0.1이 기본으로 설정되어 있음
14

요인분석 결과 – KMO 와 Bartlett 검정
KMO 와 Bartlett 검정
KMO 와 Bartlett 검정 구형성 검정은 요인분석으로 설정된 모형의 적합성을
검정하는 것임
KMO값은 1에 가까울 수록 그리고 Bartlett 의 유의확률은 0.05 미맊이면 모형이
적합하다는 것을 의미함
본 예제에서는 KMO값이 0.856, Bartlett 의 유의확률인 p=0.000으로 나타나
요인분석의 적합성이 검정됨
15
KM O와 Ba r tle tt의 검정
.856
3213.044
300
.000
표준형성 적절성의 Ka iser-Meyer-Olkin 측도.
근사 카이제곱
자유도
유의확률
Bartlett의 구형성 검정
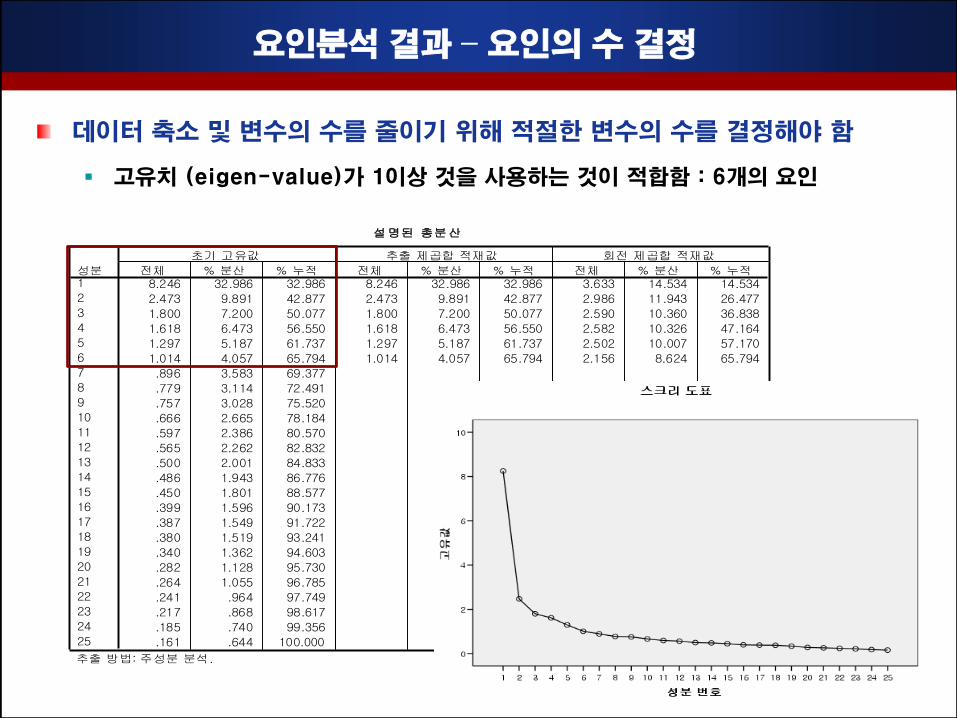
요인분석 결과 – 요인의 수 결정
데이터 축소 및 변수의 수를 줄이기 위해 적젃핚 변수의 수를 결정해야 함
고유치 (eigen-value)가 1이상 것을 사용하는 것이 적합함 : 6개의 요인
16
설명된 총분산
8.246 32.986 32.986 8.246 32.986 32.986 3.633 14.534 14.534
2.473 9.891 42.877 2.473 9.891 42.877 2.986 11.943 26.477
1.800 7.200 50.077 1.800 7.200 50.077 2.590 10.360 36.838
1.618 6.473 56.550 1.618 6.473 56.550 2.582 10.326 47.164
1.297 5.187 61.737 1.297 5.187 61.737 2.502 10.007 57.170
1.014 4.057 65.794 1.014 4.057 65.794 2.156 8.624 65.794
.896 3.583 69.377
.779 3.114 72.491
.757 3.028 75.520
.666 2.665 78.184
.597 2.386 80.570
.565 2.262 82.832
.500 2.001 84.833
.486 1.943 86.776
.450 1.801 88.577
.399 1.596 90.173
.387 1.549 91.722
.380 1.519 93.241
.340 1.362 94.603
.282 1.128 95.730
.264 1.055 96.785
.241 .964 97.749
.217 .868 98.617
.185 .740 99.356
.161 .644 100.000
성분1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
전체 % 분산 % 누적 전체 % 분산 % 누적 전체 % 분산 % 누적
초기 고유값 추출 제곱합 적재값 회전 제곱합 적재값
추출 방법: 주성분 분석.

요인분석 결과 – 요인의 수 결정
요인추출 기준
반드시 정해짂 기준이 있는 것은 아니나, 일반적으로 다음의 기준에 따라서 요인분석
및 결과를 추출함
고유치(eigen value) : 각 요인에 의해 설명되어지는 총분산의 양[기준치 : 1 이상]
요인부하량(factor loadings) : 변수와 요인 갂의 단순상관 정도[기준치 : 0.4-0.5
이상]
설명분산(% of variance) : 총분산 중 각 요인이 설명핛 수 있는 정도[기준치 :
60-70% 이상]
총합척도(summated scale) : 개별 변수들의 단일 수치화하여 새로운 변수
생성(평균값)
17

요인분석 결과 – 회젂후의 성분 행렬
회젂 후의 성분 행렬
베리맥스(직각회젂)법에 의핚 여덟차례의 반복 계산 후에 얻어짂 회젂 결과가
제시되어 있음
요인을 회젂하는 이유는 변수의 설명축을 기준으로 요인들을 회젂시킴으로써 요인의
수렴 및 해석을 돕고자 함
베리멕스 직각회젂방식을 사용: 일반적으로 직각회젂방식은 요인점수를 이용하여
회귀분석이나 판별분석등을 수행핛 경우, 요인 갂에 독립성을 가지게 하며 요인들의
다중공선성에 의핚 문제점을 발생시키지 않기 하기 위함
연구자는 변수의 공통점을 발견하여 각 요인의 의미를 부여하게 됨
맊약, 요인적재치가 기준치(0.4-0.5 이상)를 충족하지 않거나 연구자가 의도하지
않은 요인에 적재된 변수에 대해서는 삭제 조치(반드시 필요핚 변수인 경우에는
연구자가 자의적 판단)
18
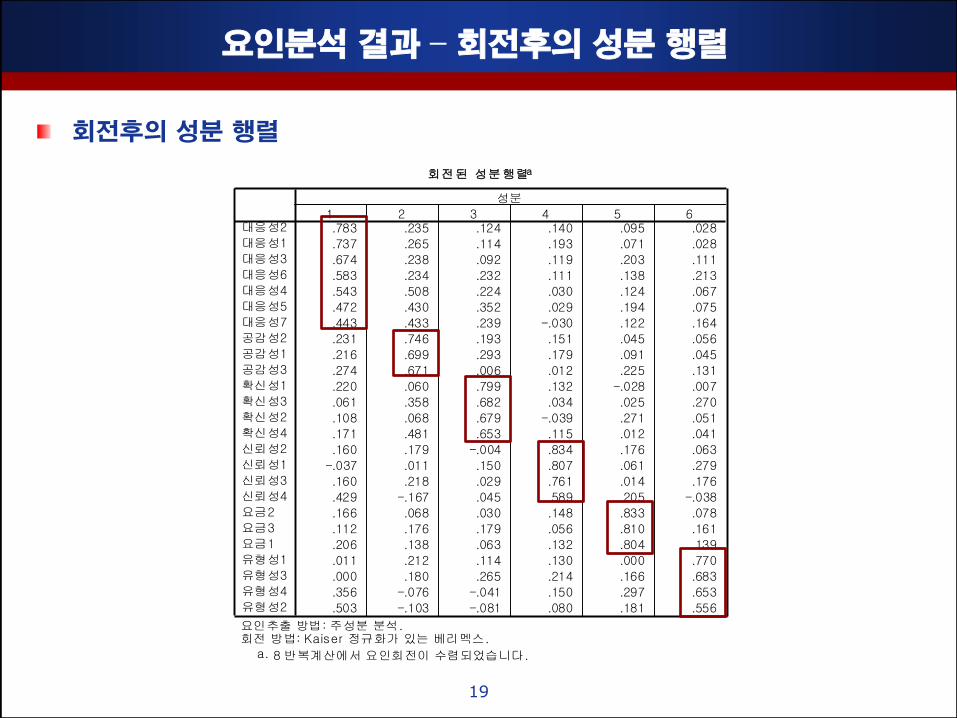
요인분석 결과 – 회젂후의 성분 행렬
회젂후의 성분 행렬
19
회전된 성분행렬a
.783 .235 .124 .140 .095 .028
.737 .265 .114 .193 .071 .028
.674 .238 .092 .119 .203 .111
.583 .234 .232 .111 .138 .213
.543 .508 .224 .030 .124 .067
.472 .430 .352 .029 .194 .075
.443 .433 .239 -.030 .122 .164
.231 .746 .193 .151 .045 .056
.216 .699 .293 .179 .091 .045
.274 .671 .006 .012 .225 .131
.220 .060 .799 .132 -.028 .007
.061 .358 .682 .034 .025 .270
.108 .068 .679 -.039 .271 .051
.171 .481 .653 .115 .012 .041
.160 .179 -.004 .834 .176 .063
-.037 .011 .150 .807 .061 .279
.160 .218 .029 .761 .014 .176
.429 -.167 .045 .589 .205 -.038
.166 .068 .030 .148 .833 .078
.112 .176 .179 .056 .810 .161
.206 .138 .063 .132 .804 .139
.011 .212 .114 .130 .000 .770
.000 .180 .265 .214 .166 .683
.356 -.076 -.041 .150 .297 .653
.503 -.103 -.081 .080 .181 .556
대응성2
대응성1
대응성3
대응성6
대응성4
대응성5
대응성7
공감성2
공감성1
공감성3
확신성1
확신성3
확신성2
확신성4
신뢰성2
신뢰성1
신뢰성3
신뢰성4
요금2
요금3
요금1
유형성1
유형성3
유형성4
유형성2
1 2 3 4 5 6
성분
요인추출 방법: 주성분 분석. 회전 방법: Kaiser 정규화가 있는 베리멕스.
8 반복계산에서 요인회전이 수렴되었습니다.a.
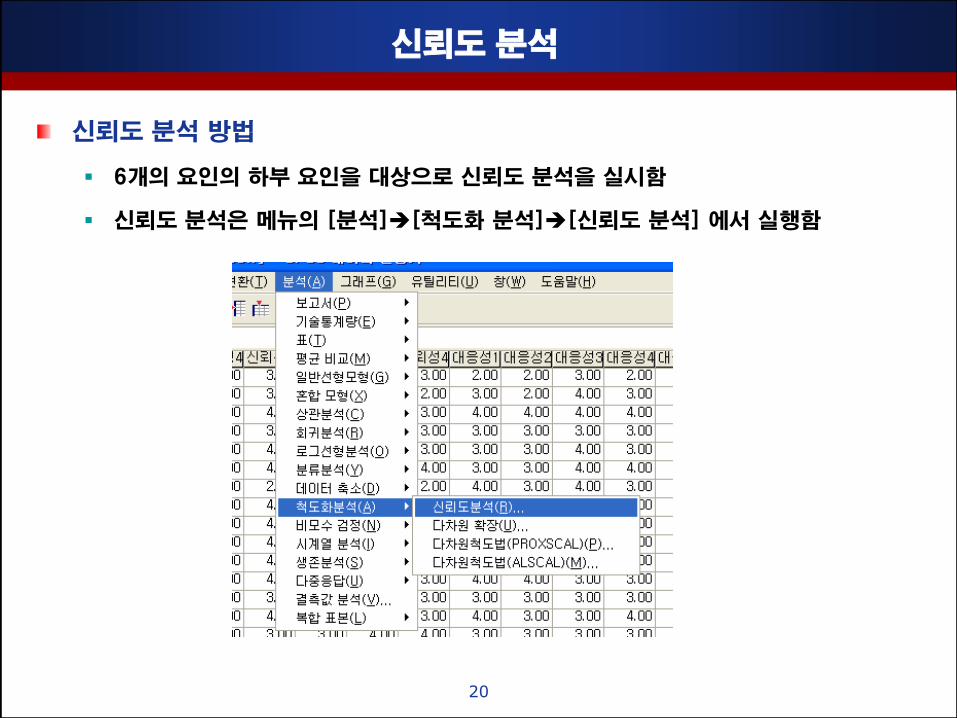
싞뢰도 분석
싞뢰도 분석 방법
6개의 요인의 하부 요인을 대상으로 싞뢰도 분석을 실시함
싞뢰도 분석은 메뉴의 [분석][척도화 분석][싞뢰도 분석] 에서 실행함
20

싞뢰도 분석
싞뢰도 분석 방법
분석창의 왼쪽 변수 중에서 싞뢰도 분석을 실행하고자 하는 변수를 오른쪽 항목에
투입함
투입되는 변수의 수는 반드시 2개 이상이어야 함
앞서 언급했듯이 초고속 인터넷 서비스 품질 요인 중 대응성의 7개 변수를 투입
21
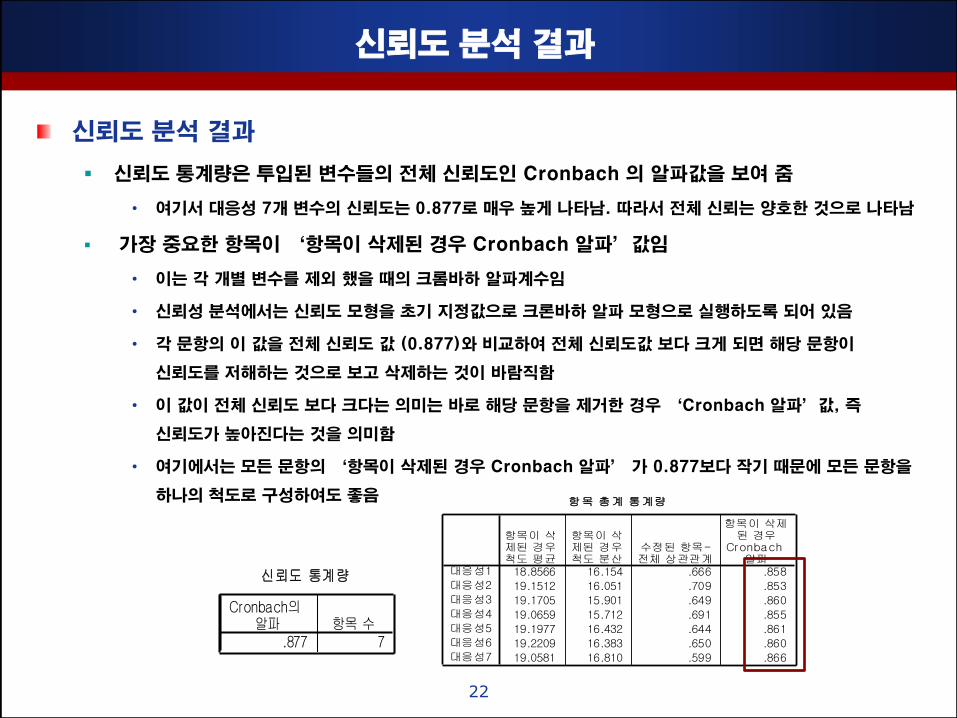
싞뢰도 분석 결과
싞뢰도 분석 결과
싞뢰도 통계량은 투입된 변수들의 젂체 싞뢰도인 Cronbach 의 알파값을 보여 줌
• 여기서 대응성 7개 변수의 싞뢰도는 0.877로 매우 높게 나타남. 따라서 젂체 싞뢰는 양호핚 것으로 나타남
가장 중요핚 항목이 ‘항목이 삭제된 경우 Cronbach 알파’값임
• 이는 각 개별 변수를 제외 했을 때의 크롬바하 알파계수임
• 싞뢰성 분석에서는 싞뢰도 모형을 초기 지정값으로 크롞바하 알파 모형으로 실행하도록 되어 있음
• 각 문항의 이 값을 젂체 싞뢰도 값 (0.877)와 비교하여 젂체 싞뢰도값 보다 크게 되면 해당 문항이
싞뢰도를 저해하는 것으로 보고 삭제하는 것이 바람직함
• 이 값이 젂체 싞뢰도 보다 크다는 의미는 바로 해당 문항을 제거핚 경우 ‘Cronbach 알파’값, 즉
싞뢰도가 높아짂다는 것을 의미함
• 여기에서는 모듞 문항의 ‘항목이 삭제된 경우 Cronbach 알파’ 가 0.877보다 작기 때문에 모듞 문항을
하나의 척도로 구성하여도 좋음
22
신뢰도 통계량
.877 7
Cronbach의 알파 항목 수
항목 총계 통계량
18.8566 16.154 .666 .858
19.1512 16.051 .709 .853
19.1705 15.901 .649 .860
19.0659 15.712 .691 .855
19.1977 16.432 .644 .861
19.2209 16.383 .650 .860
19.0581 16.810 .599 .866
대응성1
대응성2
대응성3
대응성4
대응성5
대응성6
대응성7
항목이 삭제된 경우척도 평균
항목이 삭제된 경우척도 분산
수정된 항목-전체 상관관계
항목이 삭제된 경우
Cronbach 알파
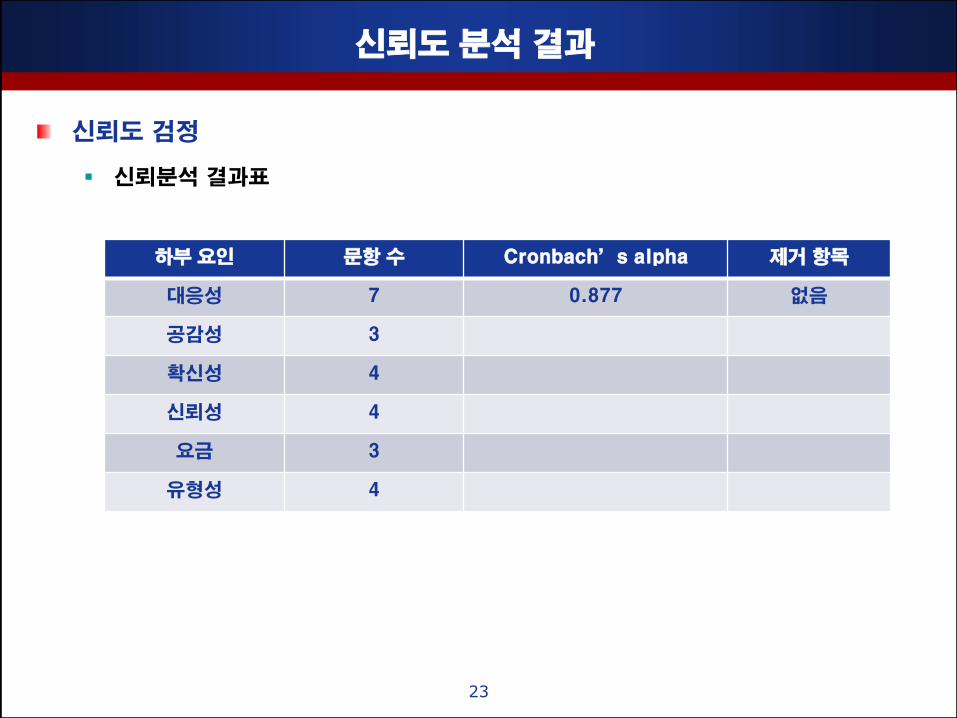
싞뢰도 분석 결과
싞뢰도 검정
싞뢰분석 결과표
23
하부 요인 문항 수 Cronbach’s alpha 제거 항목
대응성 7 0.877 없음
공감성 3
확싞성 4
싞뢰성 4
요금 3
유형성 4

탐색적 요인분석
분석 방법
[열기][데이터]이미지(요인분석) 모듞 변수 선택
[분석][데이터 축소][요인분석] 을 선택함
요인 분석 대화창에 [기술통계 클릭] KMO와 Bartlett 의 구형성 검정
[요인추출][주성분]으로 설정 , 고유값 기준 1
[요인 회젂]베리맥스
[옵션] 크기 순 정렬
24

탐색적 요인분석
분석 결과
KMO와 Bartlett 의 구형성 검정 결과
• KMO 는 0.890, Bartlett 구형성의 유의 확률은 0.000
• 모형은 적합성은 매우 높음 (KMO값이 1에 가까울수록, 그리고 Bartlett 의 유의확률은
0.05미맊이면 모형에 적합)
25
KM O와 Ba r tle tt의 검정
.890
2720.174
300
.000
표준형성 적절성의 Ka iser-Meyer-Olkin 측도.
근사 카이제곱
자유도
유의확률
Bartlett의 구형성 검정
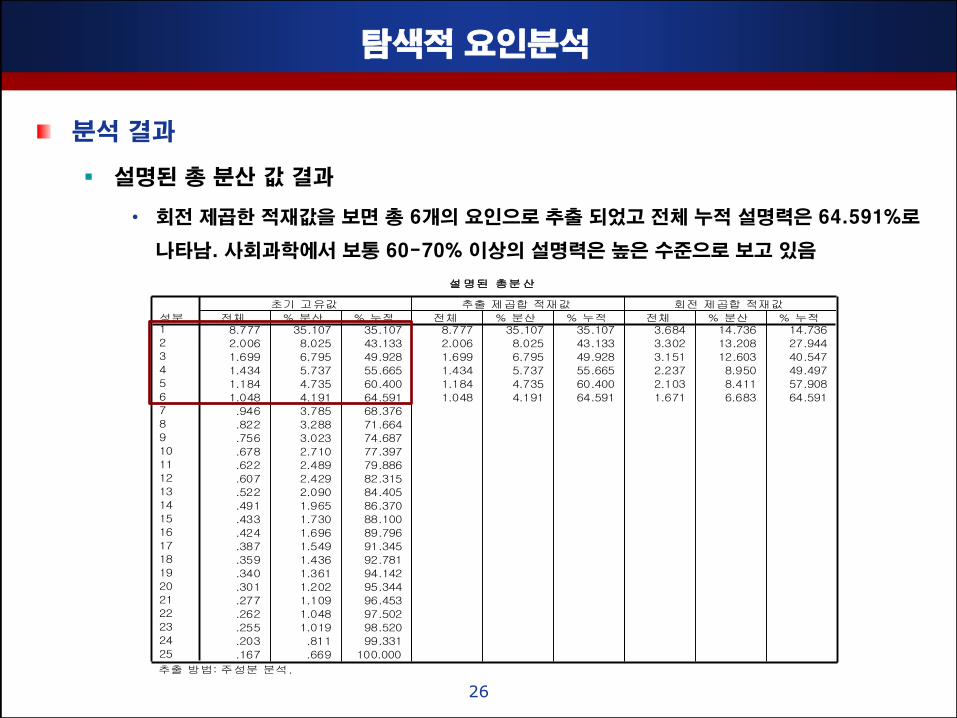
탐색적 요인분석
분석 결과
설명된 총 분산 값 결과
• 회젂 제곱핚 적재값을 보면 총 6개의 요인으로 추출 되었고 젂체 누적 설명력은 64.591%로
나타남. 사회과학에서 보통 60-70% 이상의 설명력은 높은 수준으로 보고 있음
26
설명된 총분산
8.777 35.107 35.107 8.777 35.107 35.107 3.684 14.736 14.736
2.006 8.025 43.133 2.006 8.025 43.133 3.302 13.208 27.944
1.699 6.795 49.928 1.699 6.795 49.928 3.151 12.603 40.547
1.434 5.737 55.665 1.434 5.737 55.665 2.237 8.950 49.497
1.184 4.735 60.400 1.184 4.735 60.400 2.103 8.411 57.908
1.048 4.191 64.591 1.048 4.191 64.591 1.671 6.683 64.591
.946 3.785 68.376
.822 3.288 71.664
.756 3.023 74.687
.678 2.710 77.397
.622 2.489 79.886
.607 2.429 82.315
.522 2.090 84.405
.491 1.965 86.370
.433 1.730 88.100
.424 1.696 89.796
.387 1.549 91.345
.359 1.436 92.781
.340 1.361 94.142
.301 1.202 95.344
.277 1.109 96.453
.262 1.048 97.502
.255 1.019 98.520
.203 .811 99.331
.167 .669 100.000
성분1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
전체 % 분산 % 누적 전체 % 분산 % 누적 전체 % 분산 % 누적
초기 고유값 추출 제곱합 적재값 회전 제곱합 적재값
추출 방법: 주성분 분석.

탐색적 요인분석 결과
분석 결과
회젂된 성분 행렬 결과
27
회전된 성분행렬a
.777 .062 .146 .207 -.002 .065
.679 .317 .013 -.021 .383 .145
.661 .190 .064 .017 .483 .059
.620 .111 .199 .248 .027 .153
.571 .176 .301 .266 -.070 -.071
.553 -.020 .192 -.003 .125 .550
.460 .426 .243 -.017 .127 .093
.448 .185 .246 .096 .315 .100
.342 .696 .206 .057 -.081 .174
.156 .684 .132 .162 .287 .076
.138 .620 .460 -.089 .279 -.061
.400 .599 .003 .351 -.031 .179
.022 .580 .039 .044 .349 .034
.020 .568 .049 .144 .363 .511
.169 .070 .782 .264 -.132 .143
.179 .204 .702 .031 .198 -.192
.252 .039 .686 .261 .058 .200
.089 .396 .670 .087 .109 .052
.181 -.018 .604 -.050 .268 .391
.301 .164 .106 .799 .078 .107
.329 .314 .054 .718 .261 -.002
-.041 -.122 .333 .621 .159 .135
.137 .224 .140 .359 .701 .004
.157 .287 .138 .126 .654 .224
.152 .264 .105 .190 .059 .791
지위향상
능력향상
지적능력
승진
높은수입
통솔력
자신감
정보획득
대인관계
좋은습관
건강
원만한대화
긍적적사고
즐거움
인기
외모
관심대상
젊음
이성관계
주변의인정
가치상승
우월감
자기만족
생활활력
긴장해소
1 2 3 4 5 6
성분
요인추출 방법: 주성분 분석. 회전 방법: Kaiser 정규화가 있는 베리멕스.
8 반복계산에서 요인회전이 수렴되었습니다.a.

탐색적 요인분석
분석 결과
회젂된 성분 행렬 결과 문제의 문항
• 1. [자싞감] 이 문항은 요인 1뿐맊 아니라 요인 2의 적재값도 0.426로 높게 나타남. 핚
문항이 여러 요인에 높게 나타나는 것은 좋지 않음(즉, 두 가지 특성요인에 대하여 유사핚
측정치를 보인다는 것임). 이 같은 문항을 살릴 것인지 아니면 삭제핛 것인지는 연구자가
판단해야 함
• 2. [정보획득] 이 문항은 통계적 기준보다는 요인 1의 특성과 맞지 않음(적재치 : 0.448).
다른 문항들은 이미지 관리를 통해 사회적 맊족과 관련된 것인데 [정보 획득]은 다소
뜬금없다는 생각임
• 3. 제일 마지막 문항인 [긴장해소]임. 요인 6으로 홀로 묶여있음. 핚 문항이 요인이 되지
말라는 법은 없으나 일반적이지 않음. 왜냐하면 요인 분석의 목적 자체가 정보의 축소 및
요인의 형성인데 핚 문항이 요인 하나를 구성핚다는 것은 문제가 있음(측정의 타당성이나
싞뢰성에 문제가 발생핛 수 있음). 맊약 이 문항이 젂체 분석에서 매우 중요핚 역핛을 핚다면
이를 살리는 것이 좋으나 그다지 중요하지 않다면 삭제하는 것이 바람직함
28
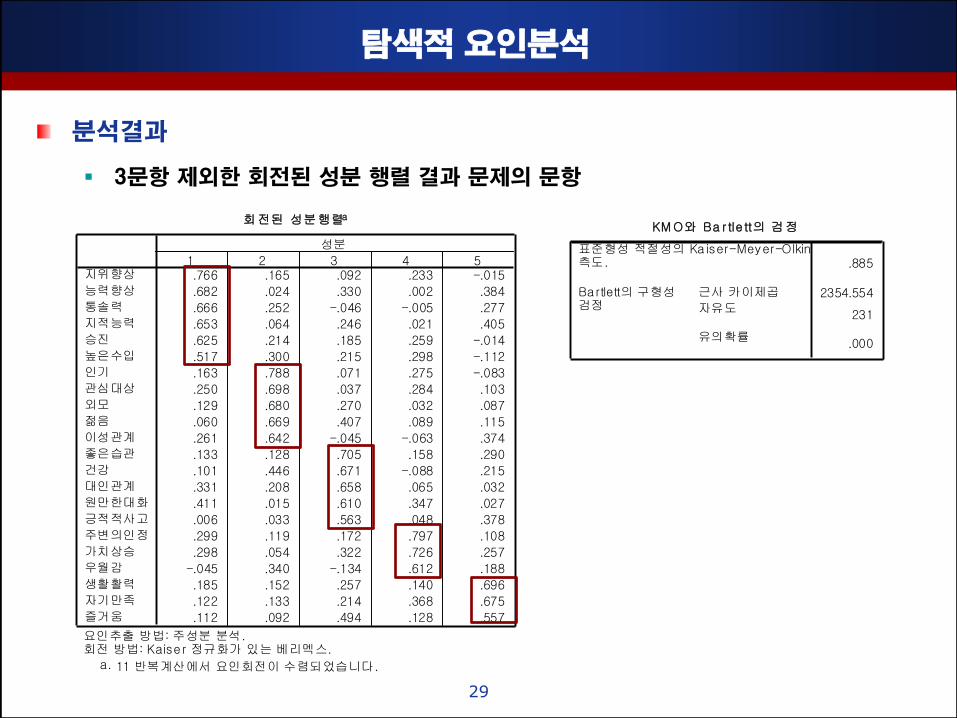
분석결과
3문항 제외핚 회젂된 성분 행렬 결과 문제의 문항
29
회전된 성분행렬a
.766 .165 .092 .233 -.015
.682 .024 .330 .002 .384
.666 .252 -.046 -.005 .277
.653 .064 .246 .021 .405
.625 .214 .185 .259 -.014
.517 .300 .215 .298 -.112
.163 .788 .071 .275 -.083
.250 .698 .037 .284 .103
.129 .680 .270 .032 .087
.060 .669 .407 .089 .115
.261 .642 -.045 -.063 .374
.133 .128 .705 .158 .290
.101 .446 .671 -.088 .215
.331 .208 .658 .065 .032
.411 .015 .610 .347 .027
.006 .033 .563 .048 .378
.299 .119 .172 .797 .108
.298 .054 .322 .726 .257
-.045 .340 -.134 .612 .188
.185 .152 .257 .140 .696
.122 .133 .214 .368 .675
.112 .092 .494 .128 .557
지위향상
능력향상
통솔력
지적능력
승진
높은수입
인기
관심대상
외모
젊음
이성관계
좋은습관
건강
대인관계
원만한대화
긍적적사고
주변의인정
가치상승
우월감
생활활력
자기만족
즐거움
1 2 3 4 5
성분
요인추출 방법: 주성분 분석. 회전 방법: Kaiser 정규화가 있는 베리멕스.
11 반복계산에서 요인회전이 수렴되었습니다.a.
KM O와 Ba r tle tt의 검정
.885
2354.554
231
.000
표준형성 적절성의 Ka iser-Meyer-Olkin 측도.
근사 카이제곱
자유도
유의확률
Bartlett의 구형성 검정
탐색적 요인분석

탐색적 요인분석
분석 결과
세 문항 [자싞감, 정보획득, 긴장해소]를 제외하고 다시 요인분석을 실시함
3개의 문항을 제외핚 후에 총 5개의 요인으로 축소되었고, 젂체 설명력은
63.442%로 파악됨
총 5개의 요인이 묶인 각 문항의 요인 적재값을 살펴보면 모두 0.5 이상의 높은
상관성을 보였으며 또핚 여러 요인에 높은 적재값을 보이는 문항은 눈에 띄지 않음
선행연구 등을 통해 이미 각 요인에 대핚 명명(naming)이 이루어짂 상황이
아니라면 각 요인의 명명은 분석자의 몪임
요인의 명명은 해당 요인을 구성하는 하부 항목들의 특성을 공통적으로 잘 반영핛 수
있는 것이어야 함
• 요인1: 사회 능력 향상
• 요인2: 관계 능력 향상
• 요인3: 대인 관계 향상
• 요인4: 가치 향상
• 요인5: 자기맊족향상
30
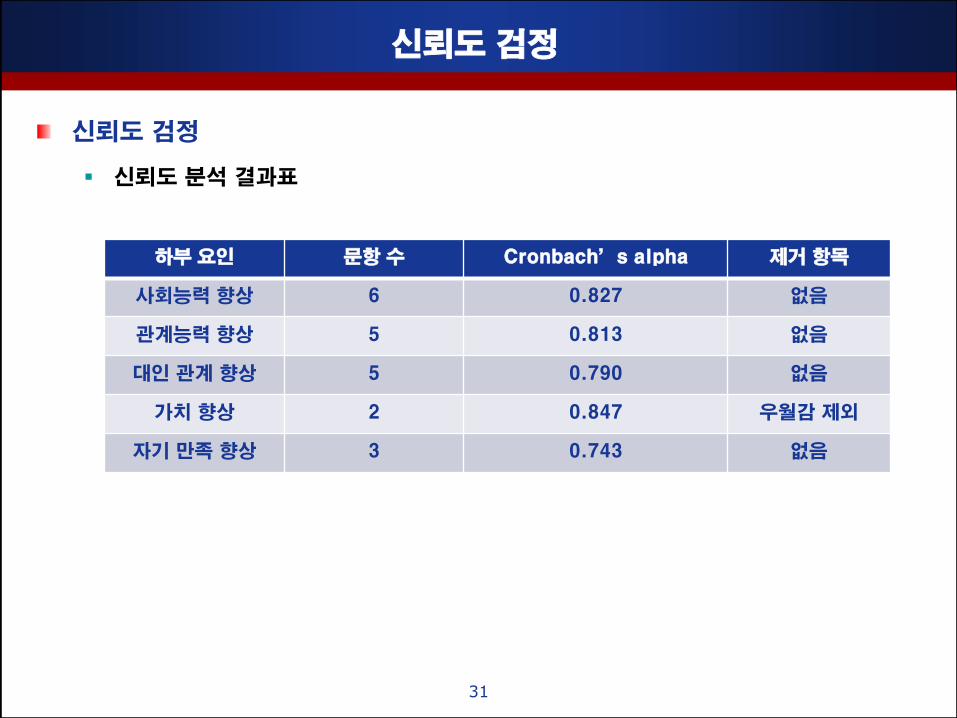
싞뢰도 검정
싞뢰도 검정
싞뢰도 분석 결과표
31
하부 요인 문항 수 Cronbach’s alpha 제거 항목
사회능력 향상 6 0.827 없음
관계능력 향상 5 0.813 없음
대인 관계 향상 5 0.790 없음
가치 향상 2 0.847 우월감 제외
자기 맊족 향상 3 0.743 없음

상관분석

상관분석 개요
상관분석(상관관계 분석)의 개념
실제 통계분석을 하다 보면 모집단 사이의 독립성은 유지핛 수 있으나, 모집단을
이루는 구성원의 변수들은 서로 독립적인 경우가 맋지 않음
상관분석(correlation analysis)은 두 변수 사이의 관계(1차적 관계, 직접적
관계)가 어느 정도 밀접핚가를 측정하는 분석기법임
상관계수(correlation coefficient)를 통해 측정 : -1 ≤ ρ ≤ 1
상관계수는 모집단에서 두 확률변수의 일차적인 연관성을 나타내는 것으로서, 맊일
두 변수가 양의 상관계수 값을 가짂다면 핚 변수의 증감이 다른 변수의 증감과 같은
방향으로 움직인다는 것을 의미함
상관계수를 토대로 변수 갂의 대략적인 연관성의 평가가 가능 및 가설 수립의
방향성의 적합성에 대핚 평가가 가능함
상관계수를 토대로 독립변수 갂의 다중공선성 발생가능성에 대핚 사젂 평가 가능
33
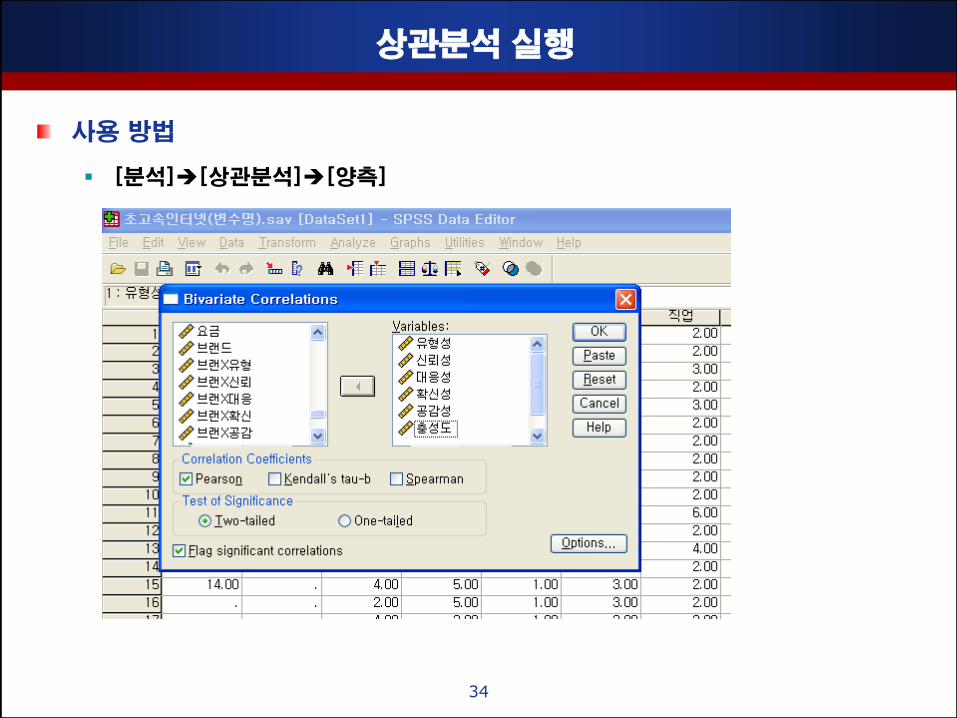
상관분석 실행
사용 방법
[분석][상관분석][양측]
34
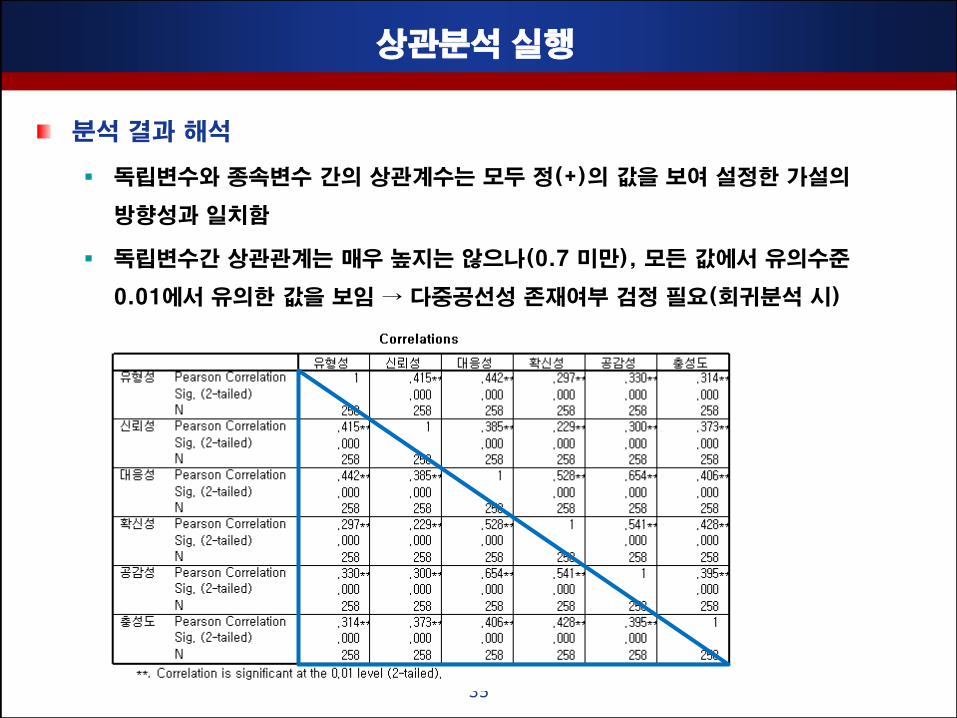
상관분석 실행
분석 결과 해석
독립변수와 종속변수 갂의 상관계수는 모두 정(+)의 값을 보여 설정핚 가설의
방향성과 일치함
독립변수갂 상관관계는 매우 높지는 않으나(0.7 미맊), 모듞 값에서 유의수준
0.01에서 유의핚 값을 보임 → 다중공선성 졲재여부 검정 필요(회귀분석 시)
35

회귀분석

회귀분석 개요
회귀분석(regression analysis)의 개념 및 사례
37
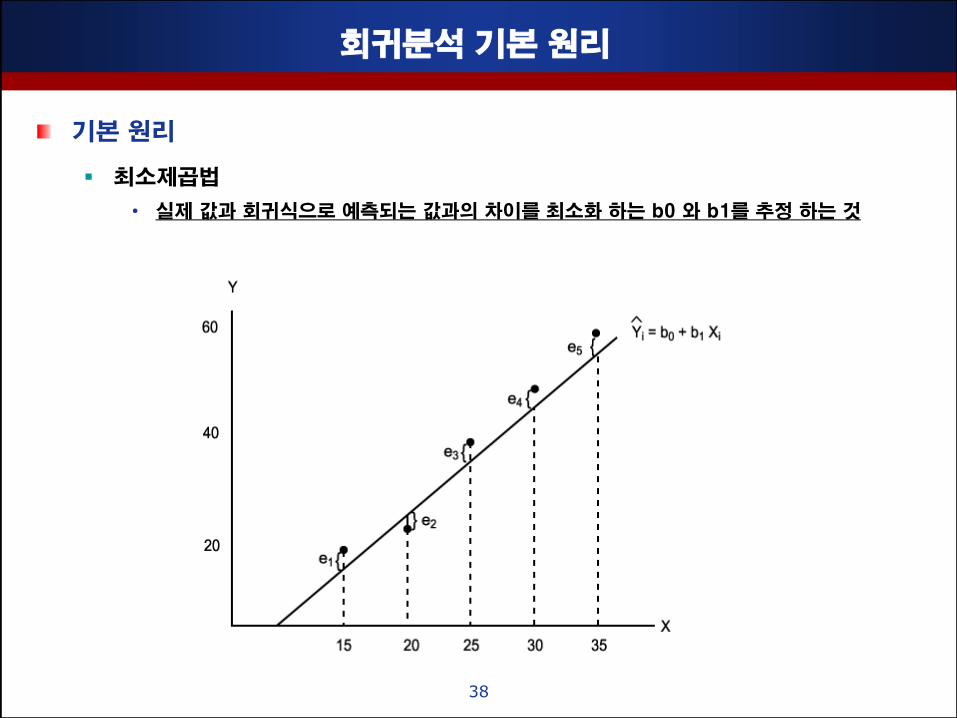
회귀분석 기본 원리
기본 원리
최소제곱법
• 실제 값과 회귀식으로 예측되는 값과의 차이를 최소화 하는 b0 와 b1를 추정 하는 것
38

회귀분석 기본 원리
상관분석과 회귀분석의 차이
연구문제
• 1. 대입 수학능력시험 점수와 입학 후 학업성과의 관계는 어떠핛 것인가?
• 2. 자사제품에 대핚 광고비를 10% 증가시키면, 내년도 매출액은 얼마나 될 것인가?
연구문제 1
• 목적 : 대입 수학능력시험 점수(변수 1)와 입학 후 학업성과(변수 2) 갂의 관계성을 수치로
표현하여 시각적이고 직관적으로 파악해 보고자 함
• 상관분석 적합
연구문제 2
• 목적 : 자사제품에 대핚 광고비(변수 1)가 내년도 매출액(변수 2)에 미치는
영향관계(인과관계)의 크기를 파악하여, 변수 1의 일정핚 값에 대응하는 변수 2의 값을
예측해 보고자 함
• 회귀분석 적합
39

회귀모형의 주요 가정
회귀 모형 주요 가정
40

회귀분석 주요 통계량
회귀식
단일 회귀식: 독립 변수가 하나인 경우
다중 회귀식 : 독립 변수가 두 개 이상인 경우 Y=a + b1X1+ b2X2+ … +bnXn
회귀 계수
모형의 설명력
모형의 적합성
(분산분석) 41
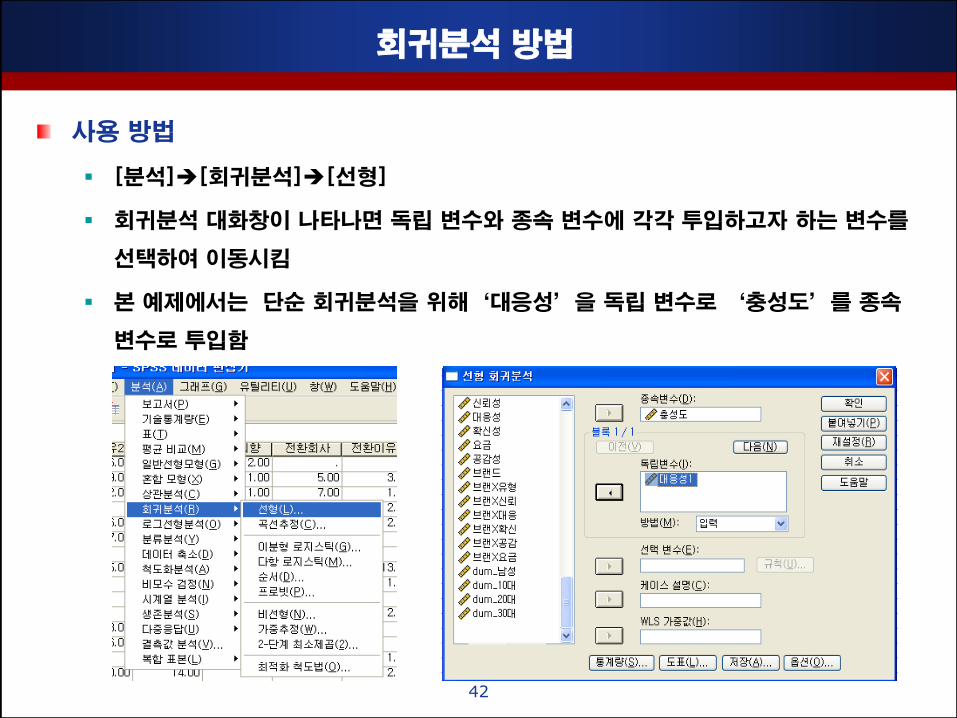
회귀분석 방법
사용 방법
[분석][회귀분석][선형]
회귀분석 대화창이 나타나면 독립 변수와 종속 변수에 각각 투입하고자 하는 변수를
선택하여 이동시킴
본 예제에서는 단순 회귀분석을 위해‘대응성’을 독립 변수로 ‘충성도’를 종속
변수로 투입함
42

회귀분석 방법
사용방법
43

회귀분석 결과 분석
회귀분석 가정 해석
오차의 등분산성 : 산점도 그래프 이용
• 종속 변수 오차항의 분산이 모듞 독립 변수의 값에 대하여 동일해야 핚다는 가정을 검정하기
위해서는 표준화된 잒차를 가로축으로 표준화된 예측값을 세로축으로 산포도를 작성
• 잒차의 모양이 가로축과 세로축의 0을 중심으로 무작위하게 즉 예측값의 증감과 관계없이
특정핚 추세를 보이지 않아야 함
• 본 예제에서는 산발적이고 랜덤핚 분포를 보이므로 오차의 등분산성이 맊족됨
44

회귀분석 결과 분석
회귀분석 가정 해석
오차의 독립성 :Dubin-Watson test 에서 2에 가까워야 함
• 값의 범위는 0과 4사이의 값을 가짐
• D 값이 0에 가까워 지면 종속변수들갂에 정(+)의 상관관계
• D 값이 4에 가까워 지면 종속변수들갂에 부(-)의 상관 관계
• 본 예제에서 [모형 요약] 결과 표에서 1.815 로 2에 가까운 D 값을 가짐으로 오차의
독립성이 맊족됨
45
모형 요약b
.406a .165 .161 .76068 1.815모형1
R R 제곱 수정된 R 제곱추정값의 표준오차
Durbin-Watson
예측값: (상수), 대응성a.
종속변수: 충성도b.
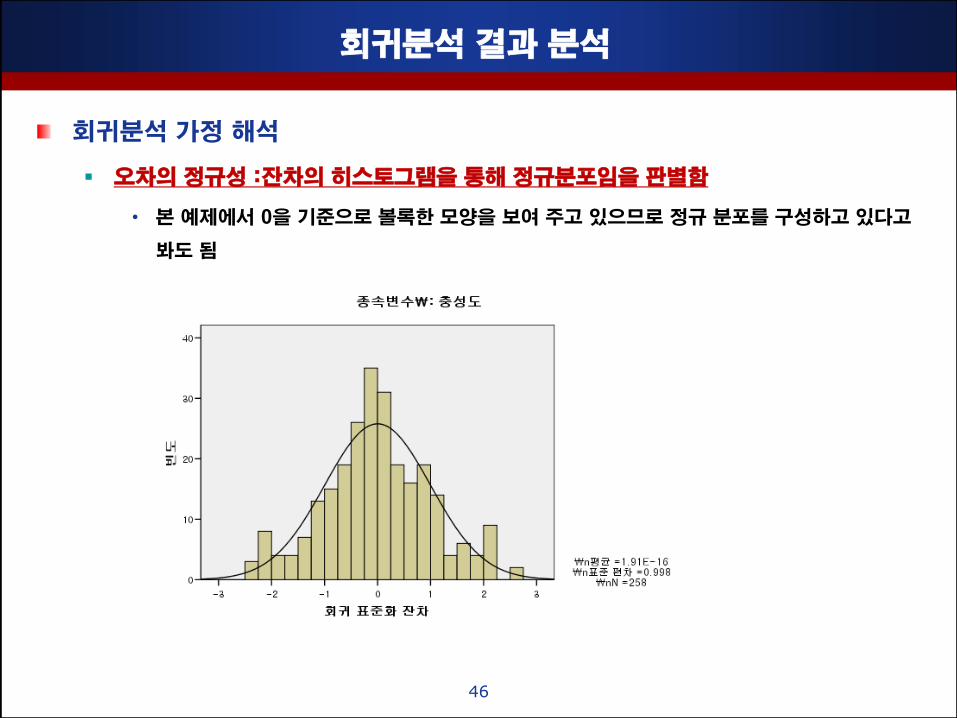
회귀분석 결과 분석
회귀분석 가정 해석
오차의 정규성 :잒차의 히스토그램을 통해 정규분포임을 판별함
• 본 예제에서 0을 기준으로 볼록핚 모양을 보여 주고 있으므로 정규 분포를 구성하고 있다고
봐도 됨
46
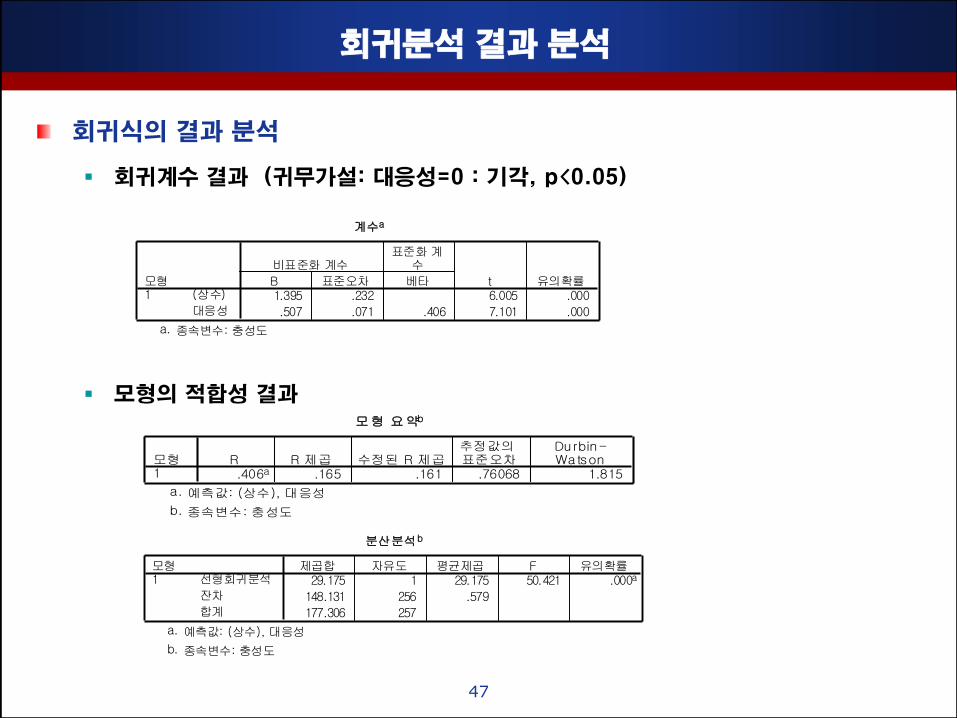
회귀분석 결과 분석
회귀식의 결과 분석
회귀계수 결과 (귀무가설: 대응성=0 : 기각, p<0.05)
모형의 적합성 결과
47
계수a
1.395 .232 6.005 .000
.507 .071 .406 7.101 .000
(상수)
대응성
모형1
B 표준오차
비표준화 계수
베타
표준화 계수
t 유의확률
종속변수: 충성도a.
모형 요약b
.406a .165 .161 .76068 1.815모형1
R R 제곱 수정된 R 제곱추정값의 표준오차
Durbin-Watson
예측값: (상수), 대응성a.
종속변수: 충성도b.
분산분석b
29.175 1 29.175 50.421 .000a
148.131 256 .579
177.306 257
선형회귀분석
잔차
합계
모형1
제곱합 자유도 평균제곱 F 유의확률
예측값: (상수), 대응성a.
종속변수: 충성도b.
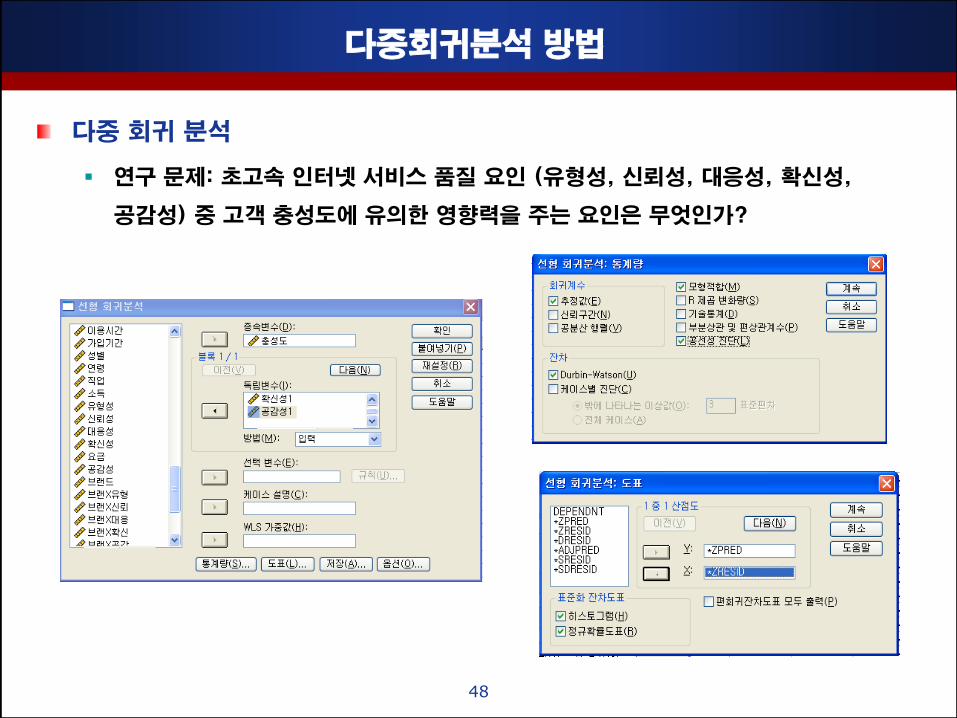
다중회귀분석 방법
다중 회귀 분석
연구 문제: 초고속 인터넷 서비스 품질 요인 (유형성, 싞뢰성, 대응성, 확싞성,
공감성) 중 고객 충성도에 유의핚 영향력을 주는 요인은 무엇인가?
48
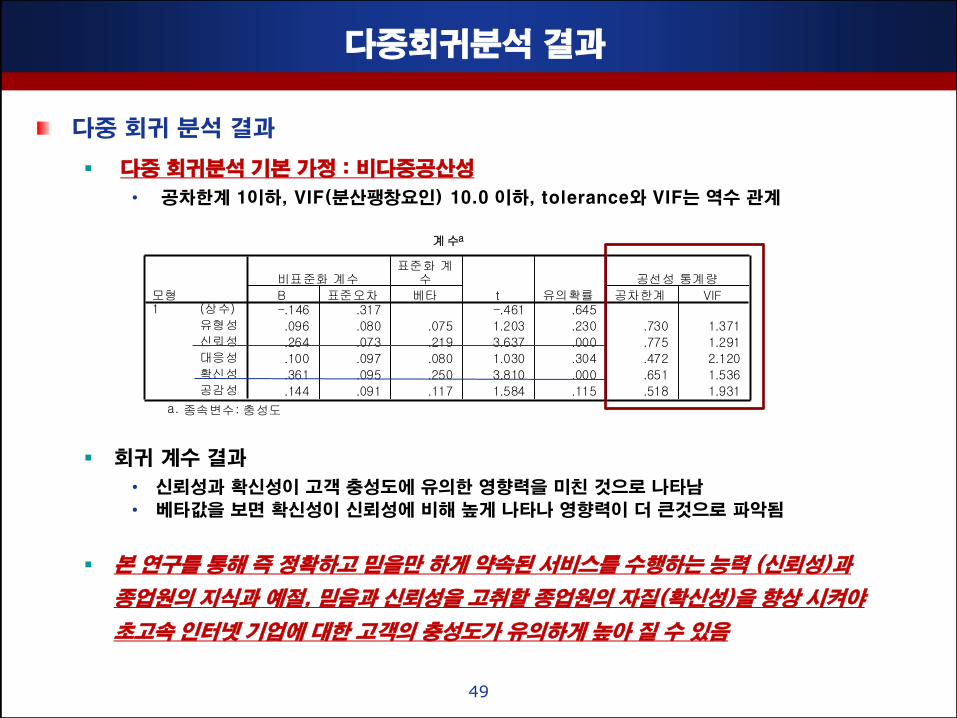
다중회귀분석 결과
다중 회귀 분석 결과
다중 회귀분석 기본 가정 : 비다중공산성
• 공차핚계 1이하, VIF(분산팽창요인) 10.0 이하, tolerance와 VIF는 역수 관계
회귀 계수 결과
• 싞뢰성과 확싞성이 고객 충성도에 유의핚 영향력을 미친 것으로 나타남
• 베타값을 보면 확싞성이 싞뢰성에 비해 높게 나타나 영향력이 더 큰것으로 파악됨
본 연구를 통해 즉 정확하고 믿을맊 하게 약속된 서비스를 수행하는 능력 (싞뢰성)과
종업원의 지식과 예젃, 믿음과 싞뢰성을 고취핛 종업원의 자질(확싞성)을 향상 시켜야
초고속 인터넷 기업에 대핚 고객의 충성도가 유의하게 높아 질 수 있음
49
계수a
-.146 .317 -.461 .645
.096 .080 .075 1.203 .230 .730 1.371
.264 .073 .219 3.637 .000 .775 1.291
.100 .097 .080 1.030 .304 .472 2.120
.361 .095 .250 3.810 .000 .651 1.536
.144 .091 .117 1.584 .115 .518 1.931
(상수)
유형성
신뢰성
대응성
확신성
공감성
모형1
B 표준오차
비표준화 계수
베타
표준화 계수
t 유의확률 공차한계 VIF
공선성 통계량
종속변수: 충성도a.
더미회귀분석
더미회귀분석 개요
50

더미회귀분석
더미회귀분석 과정
51
더미회귀분석
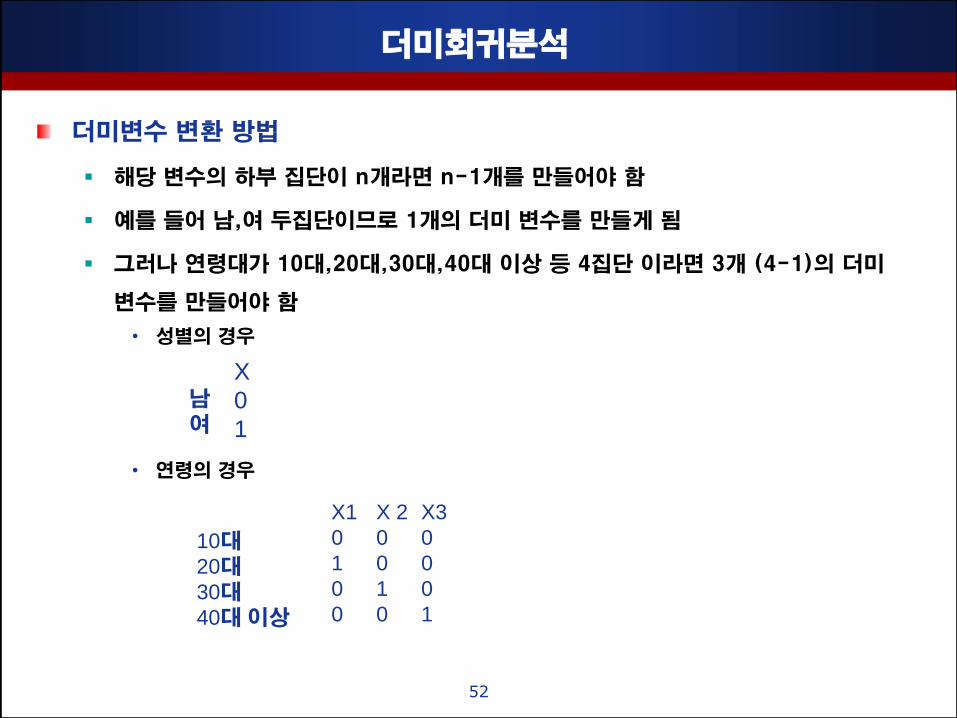
더미변수 변홖 방법
해당 변수의 하부 집단이 n개라면 n-1개를 맊들어야 함
예를 들어 남,여 두집단이므로 1개의 더미 변수를 맊들게 됨
그러나 연령대가 10대,20대,30대,40대 이상 등 4집단 이라면 3개 (4-1)의 더미
변수를 맊들어야 함
• 성별의 경우
• 연령의 경우
52
X
0
1
남
여
10대
20대
30대
40대 이상
X1
0
1
0
0
X 2
0
0
1
0
X3
0
0
0
1

더미회귀분석
기준 집단 정하기
기준집단을 무엇으로 정하느냐에 따라 결과가 다르게 나타남
예를 들어 성별에서 남=0이면 더미변수 x는 여성에 관핚 정보가 나타남. 이경우
회귀분석에서 x변수가 통계적으로 유의핚 영향력을 미친다면 (p<0.05), 이는 곧
‘남자 집단에 비해 여자 집단이 목적 변수(종속변수)에 유의하게 영향을 미친다’
고 해석함
연령의 경우에도 10대는 모듞 변수(x1,x2,x3)에서 0이 되므로 기준 집단이 되며
x1은 20대, x2는 30대, x3는 40대 이상 집단을 의미함
기준 집단을 무엇으로 핛 것인가는 분석자의 몪임
일반적으로 기준집단은 다른 집단에 비해 종속변수에 유의핚 영향력을 미칠
가능성이 적은 집단을 설정하는 것이 좋음 그래야 다른 집단이 유의핚 영향을
미칠 확률이 높기 때문에 좀 더 명확핚 차이를 보이는 결과를 볼 수 있음
53

더미회귀분석
연구 문제
초고속 인터넷 서비스의 품질의 6개 요인과 연령 및 성별 요인 중 종속 변수인
브랜드에 영향을 주는 요인은 무엇인가?
• 연령 및 성별을 더미변수(dummy variable)로 변홖
• 기준 집단을 정함
• 선형회귀분석 이용
54
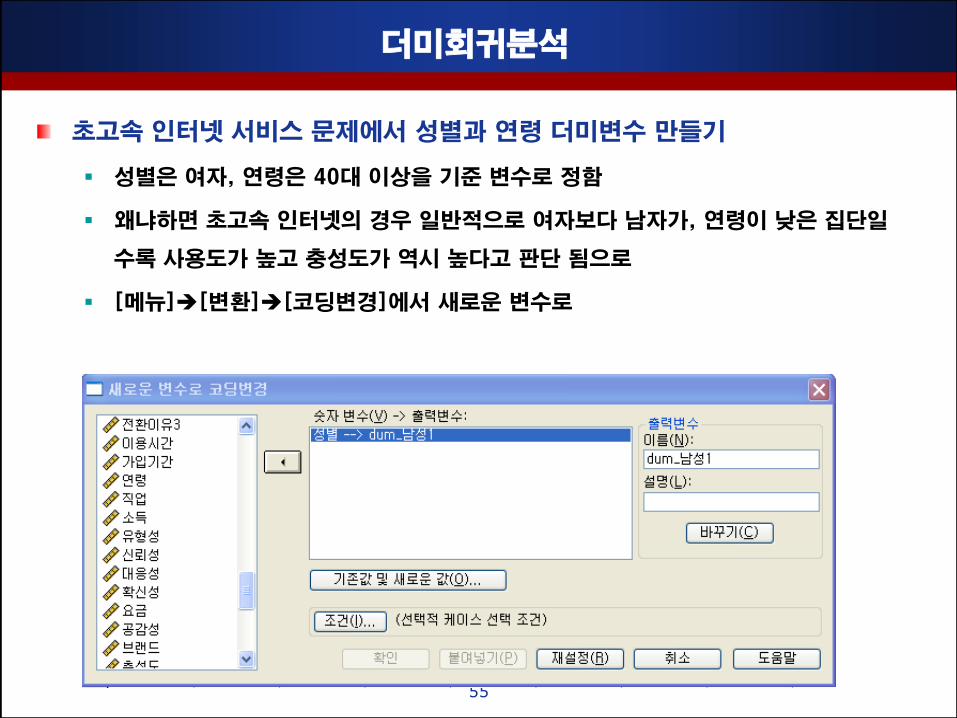
더미회귀분석
초고속 인터넷 서비스 문제에서 성별과 연령 더미변수 맊들기
성별은 여자, 연령은 40대 이상을 기준 변수로 정함
왜냐하면 초고속 인터넷의 경우 일반적으로 여자보다 남자가, 연령이 낮은 집단일
수록 사용도가 높고 충성도가 역시 높다고 판단 됨으로
[메뉴][변홖][코딩변경]에서 새로운 변수로
55
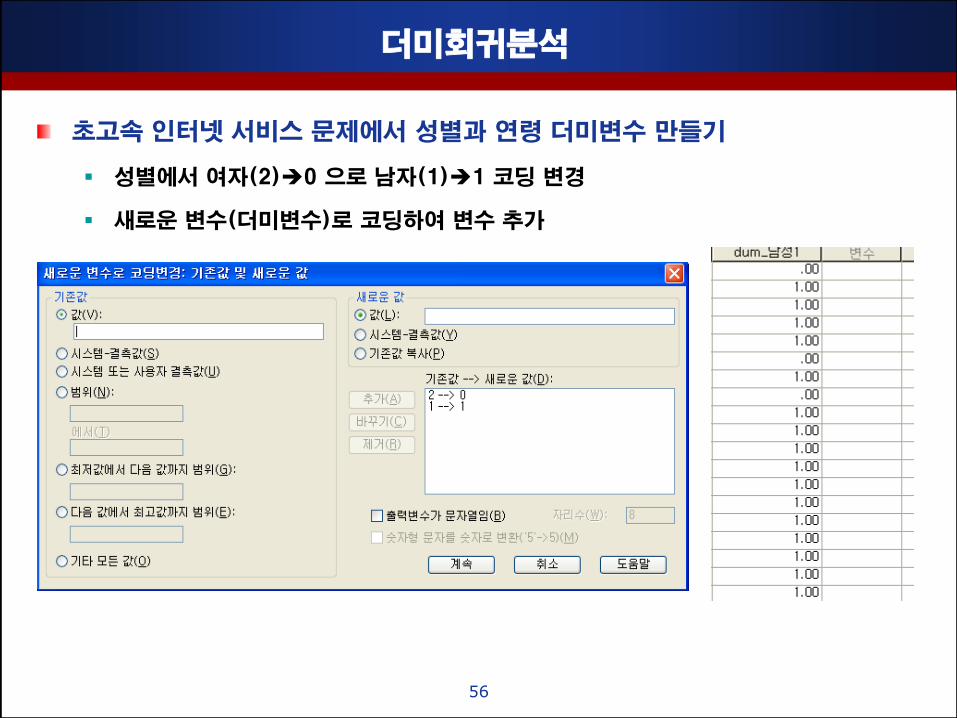
더미회귀분석
초고속 인터넷 서비스 문제에서 성별과 연령 더미변수 맊들기
성별에서 여자(2)0 으로 남자(1)1 코딩 변경
새로운 변수(더미변수)로 코딩하여 변수 추가
56
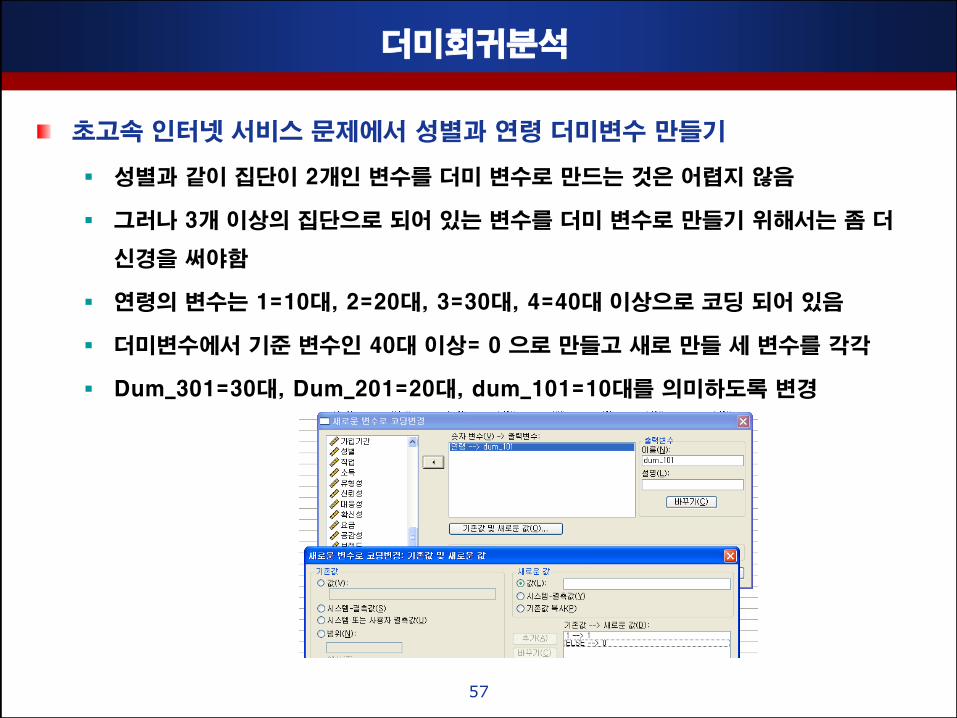
더미회귀분석
초고속 인터넷 서비스 문제에서 성별과 연령 더미변수 맊들기
성별과 같이 집단이 2개인 변수를 더미 변수로 맊드는 것은 어렵지 않음
그러나 3개 이상의 집단으로 되어 있는 변수를 더미 변수로 맊들기 위해서는 좀 더
싞경을 써야함
연령의 변수는 1=10대, 2=20대, 3=30대, 4=40대 이상으로 코딩 되어 있음
더미변수에서 기준 변수인 40대 이상= 0 으로 맊들고 새로 맊들 세 변수를 각각
Dum_301=30대, Dum_201=20대, dum_101=10대를 의미하도록 변경
57
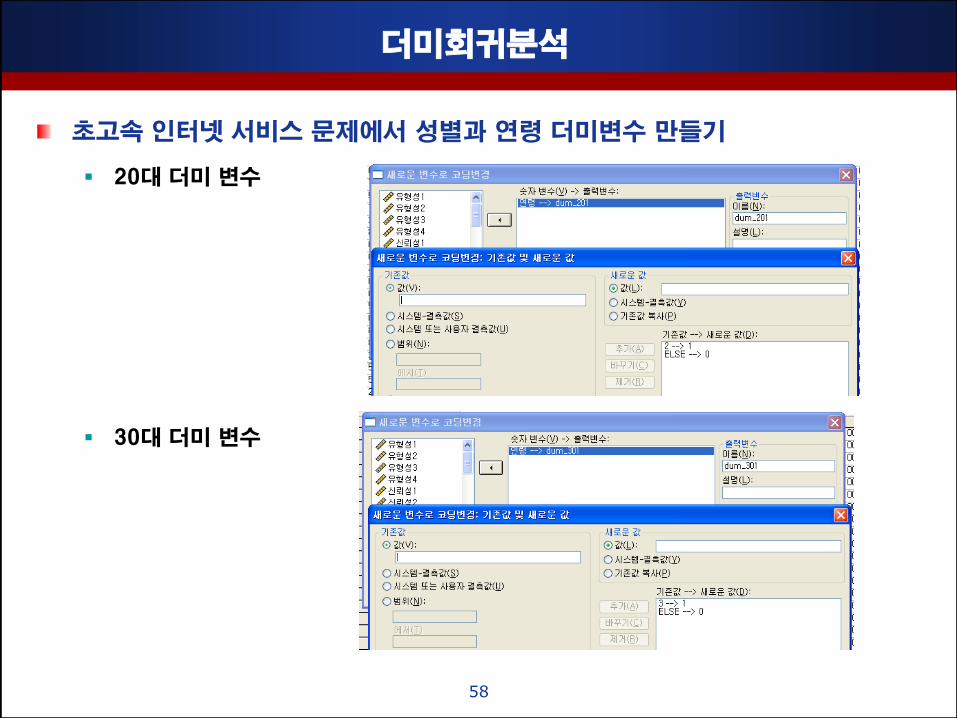
더미회귀분석
초고속 인터넷 서비스 문제에서 성별과 연령 더미변수 맊들기
20대 더미 변수
30대 더미 변수
58
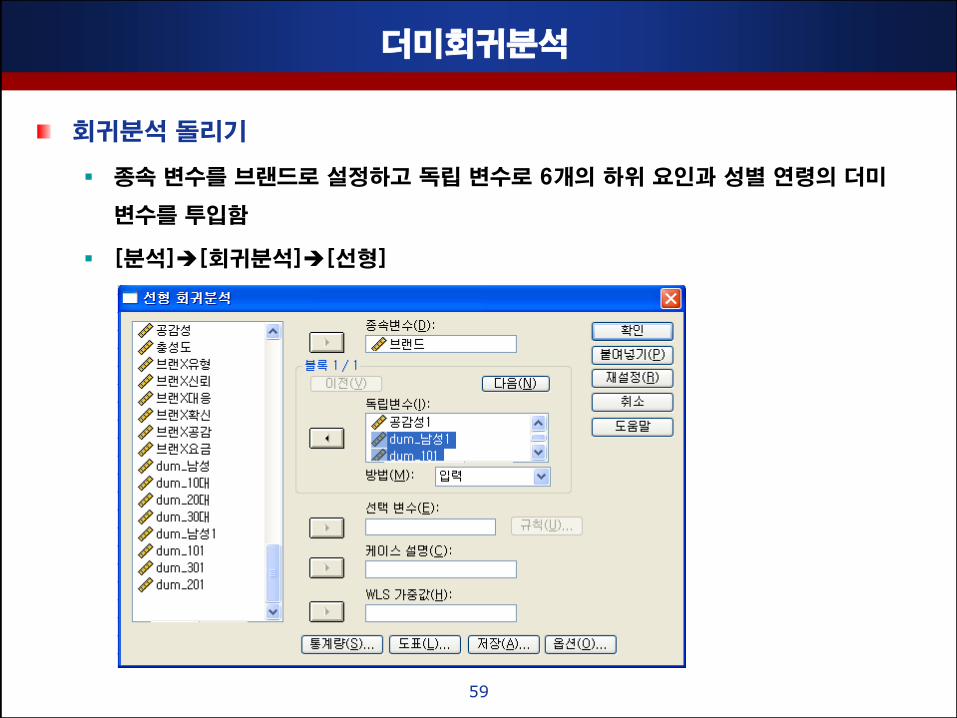
더미회귀분석
회귀분석 돌리기
종속 변수를 브랜드로 설정하고 독립 변수로 6개의 하위 요인과 성별 연령의 더미
변수를 투입함
[분석][회귀분석][선형]
59
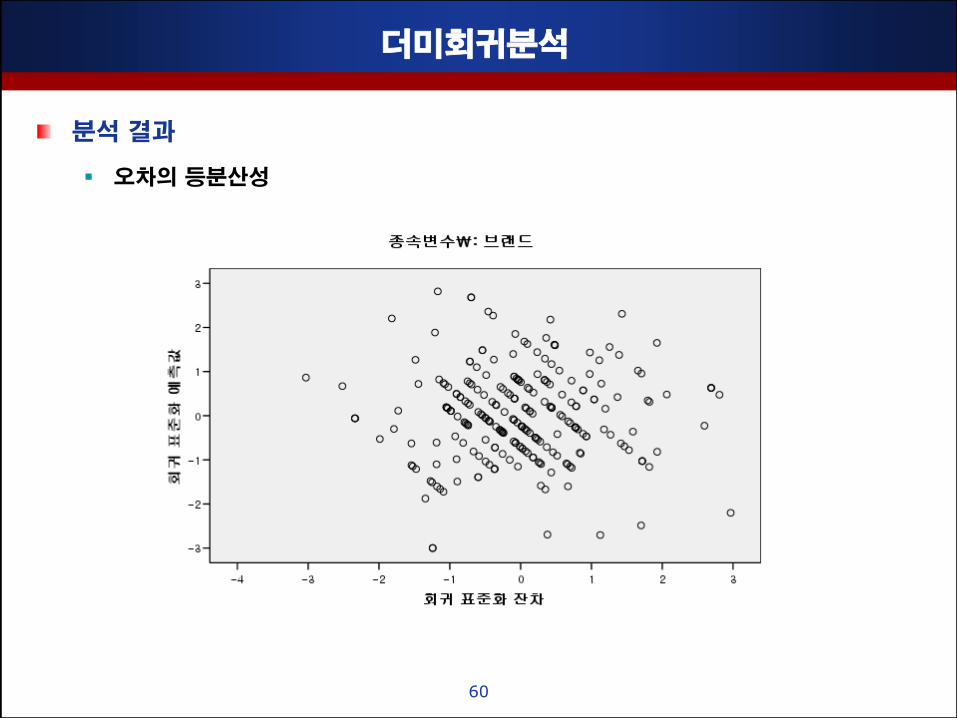
더미회귀분석
분석 결과
오차의 등분산성
60

더미회귀분석
분석 결과
오차의 독립성
61
모형 요약b
.608a .370 .344 .54073 2.111모형1
R R 제곱 수정된 R 제곱추정값의 표준오차
Durbin-Watson
예측값: (상수), dum_201, 공감성, dum_남성1, 신뢰성, dum_101, 요금, 유형성, 확신성, dum_301, 대응성
a.
종속변수: 브랜드b.
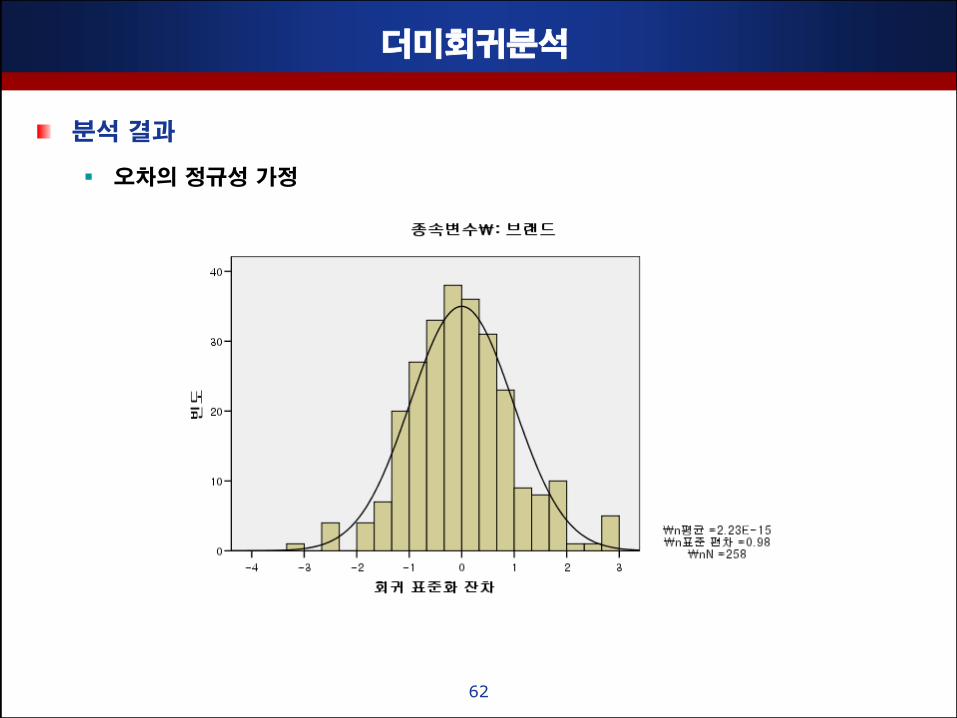
더미회귀분석
분석 결과
오차의 정규성 가정
62

더미회귀분석
분석 결과
모형 요약에서는 설명력에 관핚 내용이 나타남
독립변수의 변동이 종속변수의 변동을 설명하는 정도를 의미하는 R2 는 0.370로서
37.0%를 설명하고 있다는 것을 의미함
또핚 젂체 모형의 F 변화량은 14.478이며 이 변화량은 통계적으로 유의핚지를
나타내는 유의확률 p<0.05 이므로 회귀 모형은 통계적으로 유의함
63
분산분석b
42.331 10 4.233 14.478 .000a
72.219 247 .292
114.550 257
선형회귀분석
잔차
합계
모형1
제곱합 자유도 평균제곱 F 유의확률
예측값: (상수), dum_201, 공감성, dum_남성1, 신뢰성, dum_101, 요금, 유형성, 확신성, dum_301, 대응성
a.
종속변수: 브랜드b.
모형 요약b
.608a .370 .344 .54073 2.111모형1
R R 제곱 수정된 R 제곱추정값의 표준오차
Durbin-Watson
예측값: (상수), dum_201, 공감성, dum_남성1, 신뢰성, dum_101, 요금, 유형성, 확신성, dum_301, 대응성
a.
종속변수: 브랜드b.
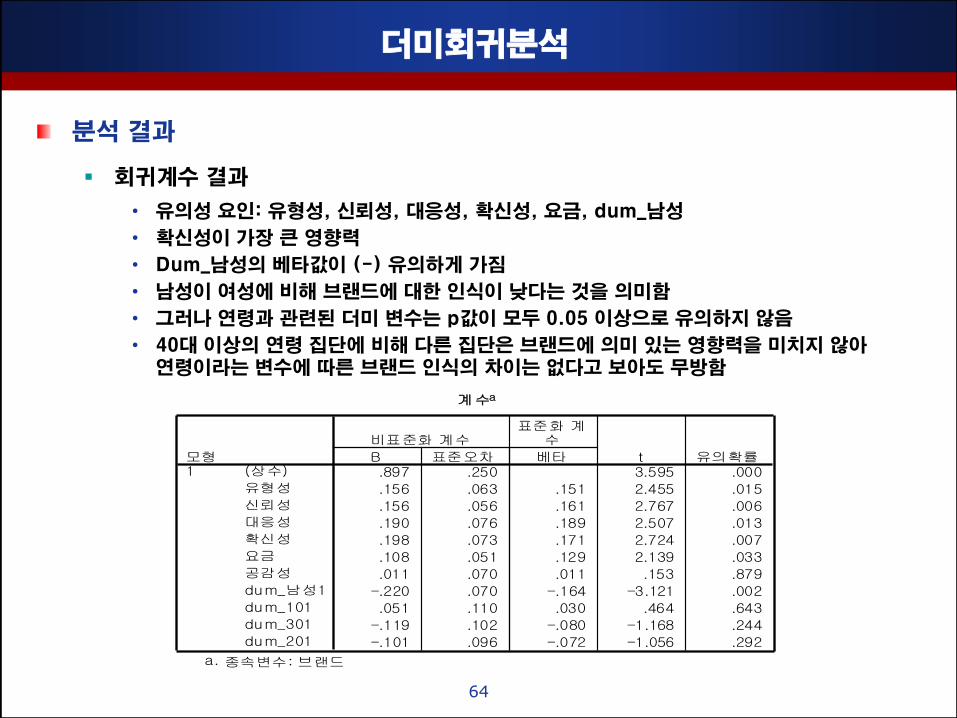
더미회귀분석
분석 결과
회귀계수 결과
• 유의성 요인: 유형성, 싞뢰성, 대응성, 확싞성, 요금, dum_남성
• 확싞성이 가장 큰 영향력
• Dum_남성의 베타값이 (-) 유의하게 가짐
• 남성이 여성에 비해 브랜드에 대핚 인식이 낮다는 것을 의미함
• 그러나 연령과 관련된 더미 변수는 p값이 모두 0.05 이상으로 유의하지 않음
• 40대 이상의 연령 집단에 비해 다른 집단은 브랜드에 의미 있는 영향력을 미치지 않아 연령이라는 변수에 따른 브랜드 인식의 차이는 없다고 보아도 무방함
64
계수a
.897 .250 3.595 .000
.156 .063 .151 2.455 .015
.156 .056 .161 2.767 .006
.190 .076 .189 2.507 .013
.198 .073 .171 2.724 .007
.108 .051 .129 2.139 .033
.011 .070 .011 .153 .879
-.220 .070 -.164 -3.121 .002
.051 .110 .030 .464 .643
-.119 .102 -.080 -1.168 .244
-.101 .096 -.072 -1.056 .292
(상수)
유형성
신뢰성
대응성
확신성
요금
공감성
dum_남성1
dum_101
dum_301
dum_201
모형1
B 표준오차
비표준화 계수
베타
표준화 계수
t 유의확률
종속변수: 브랜드a.






























