Embed Size (px)
Citation preview

계량정보분석을 한 로그래 활용사례연구
- PERL을 심으로 -
원동규
이방래
정용일
이
한국과학기술정보연구원
(KISTI)

머 리 말
21세기는 지식과 정보가 그 국가의 경쟁력을 좌우하는 지식기반 산
업사회로 나아가고 있으며, 최고가 아니면 살아남을 수 없는 무한 경
쟁시 가 되어가고 있습니다. 우리나라가 이러한 변화 속에서 생존하
기 해서는 기술 신을 통한 국가경쟁력 강화가 필수불가결한 것으
로 인식되고 있으며, 이를 해서는 선진국형 고부가가치산업 국가
략기술의 육성이 실히 요구되고 있습니다.
이러한 시 요구 속에서 한국과학기술정보연구원에서는 우리나
라가 지식기반 산업사회를 선도해 나갈 수 있도록 계량정보분석을 이
용한 보고서를 제공하고 있으며, 이를 통해 숨겨진 지식을 발견하고
이를 확산시켜 궁극 으로 국제경쟁력을 향상시키기 해 노력하고
있습니다.
계량정보분석을 통해 지식을 발견하기 해서는 데이터 산에서의
채굴과정(data mining)이 필요한데, 이것이 단순히 주어진 데이터를
통계분석하는 것과 가장 큰 차이라고 할 수 있습니다. 하지만 고
스러워지는 통계분석방법론과는 달리 이의 근간을 이루고 있는 데
이터 채굴과정에 해서는 기존의 거 로그램에 의존하는 경향으
로 세 한 분석에 한 맞춤형 데이터 생성이 어려운 실정에 있는 것

한국과학기술정보연구원
원장
이 사실입니다. 이에 이번 우리 연구원의 신인 라 연구실에서 열악
한 조건에도 불구하고, 펄(Perl) 로그램을 이용한 계량정보분석 기반
에 한 연구는 우리나라 정보분석연구에 긴요한 선구자 연구가 될
수 있을 것으로 생각합니다.
끝으로 본 연구에 참여한 원동규, 이방래, 정용일, 이 등 연구원
들의 노고에 감사드리며, 수록된 내용은 한국과학기술정보연구원의 공
식 인 견해가 아님을 밝 두고자 합니다.
2005년 12월

i
목 차
제1장 들어가는 말 ············································································1
제1절 계량정보분석 분야에서 프로그래밍의 필요성 ·················· 2
제2절 계량정보분석을 위한 펄 ·················································· 3
제2장 PERL의 문법 ······································································9
제1절 준비하기 ············································································ 10
제2절 변수와 스칼라 ··································································· 11
제3절 배열 ··················································································· 18
제4절 제어문 ··············································································· 23
제5절 해시 ··················································································· 26
제6절 기본 입출력 ······································································ 29
제7절 정규표현식 ········································································ 30
제8절 함 수 ················································································· 38
제9절 기타 제어구조 ··································································· 41
제10절 파일핸들과 파일 테스트 ················································· 44

ii
제11절 포맷 ················································································· 48
제12절 디렉토리 액세스 ····························································· 56
제13절 파일과 디렉토리 조작 ···················································· 57
제14절 다른 데이터 변환 ··························································· 59
제15절 CGI ·················································································· 66
제3장 활용하기 ··············································································71
제1절 co-word 분석의 전략맵 도출 ·········································· 71
제2절 한국특허의 지역별 발명자수 분포 도출 ························· 88
제4장 결 론 ··················································································101
참고문헌 ·······················································································103

iii
표 목차
<표 3-1> 키워드 동시출현행렬 ··············································································· 73
<표 3-2> 키워드의 클러스터명 ··············································································· 73
<표 3-3> 계산된 Strength 매트릭스 ······································································ 81
<표 3-4> 계산된 centrality와 density ·································································· 87
<표 3-5> 한국특허의 지역별 발명자수 분포 ························································· 90
그림 목차
<그림 1-1> 펄 프로그램 무료 배포처 ······································································ 8
<그림 1-2> 터미널 프로그램(cmd.exe) 화면 ··························································· 8
<그림 2-1> 프로그래밍 오류잡는 방법 ·································································· 17
<그림 2-2> APM_Setup 5 설정화면 ······································································ 67
<그림 2-3> APM_Setup 5 실행화면 ······································································ 69
<그림 3-1> 전략맵 도출 프로세스 ·········································································· 72
<그림 3-2> 키워드1의 density와 centrality ··························································· 74
<그림 3-3> 로봇기술분야의 전략맵 ········································································ 75
<그림 3-4> 전략맵 소스코드(1-16라인) ································································· 76
<그림 3-5> 전략맵 소스코드(19-35라인) ······························································· 77
<그림 3-6> 키워드 동시출현행렬(@matrix) ··························································· 79
<그림 3-7> 전략맵 소스코드(36-45라인) ······························································· 81
<그림 3-8> 전략맵 소스코드(46-54라인) ······························································· 82
<그림 3-9> 전략맵 소스코드(55-71라인) ······························································· 83
<그림 3-10> 전략맵 소스코드(72-81라인) ······························································ 85
<그림 3-11> 전략맵 소스코드(82-91라인) ······························································ 86

iv
<그림 3-12> 전략맵 소스코드(92-95라인) ······························································ 88
<그림 3-13> 한국특허의 지역별 발명자수 추출 소스코드(1-6라인) ···················· 91
<그림 3-14> 한국특허의 지역별 발명자수 추출 소스코드(9-17라인) ·················· 92
<그림 3-15> 한국특허의 지역별 발명자수 추출 소스코드(19-30라인) ················· 93
<그림 3-16> 한국특허의 지역별 발명자수 추출 소스코드(32-43라인) ················· 95
<그림 3-17> 한국특허의 지역별 발명자수 추출 소스코드(44-61라인) ················· 97
<그림 3-18> 한국특허의 지역별 발명자수 추출 소스코드(62-79라인) ················· 97
<그림 3-19> 한국특허의 지역별 발명자수 추출 소스코드(80-97라인) ················· 98
<그림 3-20> 한국특허의 지역별 발명자수 추출 소스코드(99-108라인) ··············· 99

제1장 들어가는 말 1
제 1장
들어가는 말
본 보고서는 계량정보분석을 해서는 로그래 기술이 필요하다
는 것을 인식하고나서, 펄(Perl) 로그램을 학습하고 실제연구에 용
한 것이 계기가 되어서 나오게 되었다. 한국과학기술정보연구원 신
인 라연구실에서는 내부세미나를 통해서 펄 로그램에 하여 략
으로 학습하 고, 연구수행에 직 용하 으며, 이러한 학습과 실
습에 련된 내용을 재정리하여 본 보고서를 작성하 다. 제1장에서는
계량정보분석 분야에서 로그래 이 필요한 이유와 펄 로그램의
특징 이용방법에 해서 살펴보고 있다. 제2장에서는 펄의 문법을
설명하고 있는데, “이명 경 스쿨(http://www.emh. co.kr/tech.pl)”과
“Perl 제 로 배우기(김 식ㆍ강윤석 역, 한빛미디어)”를 학습하면서
계량정보분석에 꼭 필요한 내용을 주로 재정리 하 다. 제3장에서는
계량정보분석에 직 활용한 사례를 가지고 소스코드를 설명하는 형
태로 구성되었고, 제4장에서는 결론을 짓고 있다.

2 계량정보분석을 한 로그래 활용사례연구
제1절 계량정보분석 분야에서 프로그래밍의 필요성
오늘날은 컴퓨터와 인터넷의 발달로 수많은 정보들이 도처에 려
있고, 한 이를 이용하고 있다. 그러나 고 정보들까지도 쉽게 구할
수 있는 것은 아니다. 많은 정보를 할 수는 있지만 우리가 꼭 필요
로 하는 정보를 찾는 것이 어려운 경우가 종종 있다. 한 인터넷은
인터넷 정보제공자가 제공하고자 하는 정보만을 제공하고 있다. 인터
넷이 정보의 바다라고 하지만, 결국 제 로 정보를 찾을 수 있는 기술
을 가지고 있어야만 인터넷에서 많은 정보를 얻을 수가 있는 것이다.
만약 우리가 로그래 기술을 가지고 있다면 인터넷이나 데이터베
이스에 있는 수많은 정보로부터 새로운 지식을 발견할 수 있을 것이
다. 그러한 분야가 바로 Webometrics 분야이다.
한 연구원들은 연구결과를 토 로 필요한 툴이나 시스템을 개발
하게 되는데, 이러한 경우 실제 시스템 개발은 여러 가지 이유로 인해
서 문개발업체에게 맡기는 경우가 종종 있다. 그 지만 툴이나 시스
템 개발은 정확한 스펙을 설정해서 할 수 밖에 없다. 이를 해서는
연구결과에 한 합성 검증을 연구자 본인이 할 수 있어야 한다. 이
러한 연구결과에 한 합성 검증 과정에서 로그래 기술이 좋은
도구가 된다.
연구를 진행하다 보면, 필요한 데이터를 정보가공을 통해서 얻는 경
우가 왕왕 있다. 마이크로소 트사의 엑셀 로그램을 종종 이용하는
데, 엑셀 로그램이 만능은 아니다. 이러한 경우에도 로그래 기
술을 가지고 있다면, 필요한 데이터를 연구자 본인이 직 만들어 낼
수 있다. 한 이러한 간단한 작업을 문개발업체에게 의뢰하는 것은

제1장 들어가는 말 3
바람직한 모습이 아닌 것으로 생각된다.
한편 정보를 이용한 계량분석분야에서 분석툴에 상당히 많이 의존
하는 경향을 보이고 있는데, 이것도 큰 문제 으로 볼 수 있다. 연구
자들은 본인이 심 있어 하는 분야에서 자유롭게 연구하고 그 결과
를 자신의 방법으로 제시할 수 있어야 하는데, 툴에 의존하다 보면 상
당한 제한 이 따르기 때문이다. 분석툴은 그 것을 만든 업체나 연구
자의 목 에 맞게 설계되어 있기 때문에 모든 것을 다루기는 근본
으로 불가능하다. 결과 으로 연구자 본인이 자신의 연구결과를 보여
주기 해서는 분석툴을 직 만들어야 되는 경우가 발생한다. 그러나
분석툴을 직 개발하는 것은 시간 경제 이유로 인해서 쉽지 않
은 경우가 많다. 이러한 경우에 로그래 기술을 가지고 있다면, 분
석툴에 의존하지 않고 자유롭게 자신의 연구를 수행해 나갈 수 있다.
제2절 계량정보분석을 위한 펄
1. 펄을 선택한 이유
계량정보분석을 해서 로그래 기술을 익힌다면, 과연 어떤
로그래 언어가 합할까? 로그래 언어를 선택하는 것은 다양한
로그래 언어를 사용해 본 문가에게 문의하는 것이 가장 합할
것이다. 그러나 문제는 계량정보분석 분야에서의 로그래 문가는
찾기가 어렵다는 것이다. 다행히도 외국의 계량정보분석 연구자들은
펄을 배우기를 권장하고 있다1). 특히 텍스트 일에 한 패턴일치를

4 계량정보분석을 한 로그래 활용사례연구
이용하여 다양한 분석을 하는 계량정보분석 분야에서는 펄이 다른
로그래 언어보다도 훨씬 합한 선택이 될 것이다. J. S. KATZ 가
펄에 해서 언 한 내용을 소개해 보겠다.
데이터베이스 언어는 비록 간단한 텍스트처리에는 이상
이지만, 수학 인 문제를 다루기는 어렵다. 를들면, 계
형 데이터베이스의 SQL을 이용하면 동시출 매트릭스를
만드는 과정을 만들기가 어렵다. 한편 통 인 언어는 수
학 연산을 다루기에는 이상 이지만 문자열을 다루는
능력은 부족하다. 1980년 후반에 NASA에 근무하는
Larry Wall이 문자를 출력하는 언어를 개발하 는데, 이를
Perl(Practical Extraction and Report Language)이라고
한다. 이 언어는 규모 일을 다루기 해 개발되었고,
유닉스 시스템에서 문자열 루틴을 만드는데 많이 사용되
었다. 이제 Perl은 텍스트를 다루는 사람, 웹사이트 리자
개발자들이 필수 으로 알아야 할 언어가 되었다. Perl
은 착성을 갖는데, 다시말하면 독립 으로 사용될 수도
있고, C, Fortran과 함께 사용하여 Oracle, Microsoft
Access와 같은 데이터베이스에도 이용될 수 있다. Perl은
텍스트 조정함수, 패턴일치, 배열 데이터베이스 리 함
수에 한 많은 자료가 있다. 상세한 기술 인 것은 놔두
고 Perl의 다목 성을 서지분석에 활용한 를 통해 설명
해 보겠다. ...( 략)
1) J. S. KATZ, D. HICKS, "Desktop scientometrics", Scientometrics, Vol.38,
No.1(1997), pp.141-153

제1장 들어가는 말 5
참고로 개발자들이 특정 로그래 언어를 선택하는 기 을 살펴보
면 다음과 같다2). 번개같이 빠른 속력이 필요할 때는 순수 C를 선택
한다. 배포 크기를 도우용으로 최소화해야 한다면 정 으로 링크
한 MFC와 함께 C++를 선택한다. 맥, 도우, 리 스에서 돌아갈 GUI
가 필요할 때는 자바를 선택한다. 작업시간이 별로 없지만 멋지게 보
이는 GUI를 만들어야 할 때는 비주얼베이직을 선호한다. 속력에 무
하며 어떤 유닉스 기계에서도 돌아가는 명령행 도구가 필요하다면
Perl을 선택한다. 웹 라우 내부에서 동작해야 한다면 자바스크립
트를 선택한다. SQL 내장 로시 부문에서는 몇몇 회사에서 제공하는
독 인 SQL 생버 을 이용해야 한다. .NET 은 사용자가 어떤 언
어를 선택하거나 동일한 방식으로 움직이는 기반구조를 가지고 있다.
본 보고서에서는 펄의 용법과 활용사례를 주로 설명하고 있다. 참
고로 펄을 해커들이 주로 사용한다고도 하니 펄이 강력한 언어임에는
틀림없는 것 같다.
2. 펄의 특징
NASA에 근무하던 Larry Wall이 개발한 Perl은 Practical Extraction
and Report Language의 약칭이다. 이름에서도 알 수 있듯이 Perl은
데이터로부터 정보를 추출하여 이를 보고서 형태로 만들어내는 언어
이다. 실제로 펄의 가장 형 인 사용은 텍스트 일에서 정보를 추
출하거나, 그 것을 다른 형태로 변경해서 리포트를 생성하는 것이다.
2) 조엘 스폴스키 지음, 박재호ㆍ이해영 옭김, “조엘 온 스프트웨어 - 유쾌한 오프라인 블로그”, 에이콘, 2005.

6 계량정보분석을 한 로그래 활용사례연구
따라서 텍스트 데이터를 이용해서 지식을 찾아내는 계량정보분석분야
에서 펄은 매우 강력하게 그 효용가치를 보여 수 있다.
Larry Wall이 Perl을 개발할 당시에 Perl은 유닉스 시스템을 해서
개발되었다. 그러나 오늘날에는 리 스, 여러 종류의 유닉스, 도우즈,
매킨토시, 등 거의 부분의 운 체계로 포 가능한 언어이다.
다른 로그래 언어와 다른 을 보자면 Larry Wall 자신이 심
있어 하는 산학, 언어학, 종교, 술 등을 함께 집 성하여 Perl을
만들었기 때문에 조 은 문학 인 체취를 느낄 수 있다. 이는 종종 명
령문의 구조가 어문장의 형태로 이루어진다는 것을 보면 알 수 있
다.
계량정보분석 분야에서는 텍스트에 한 패턴일치를 이용한 작업을
많이 필요로 하는데, 이 분야에서 Perl 만큼 강력한 언어는 없다. 기존
의 C언어와 같은 것은 수학 연산에는 강력하지만 문자열의 처리에
는 약 을 갖고 있다. 그러나 Perl은 개발당시부터 이러한 목 을 가
지고 개발되었기 때문에 계량정보분석 분야에서 리 활용될 수 있다.
요즘은 웹 로그래 언어로서도 각 을 받고 있다. HTML과 같은
문서를 다루는데 아주 강력한 기능을 가지고 있으므로 CGI구 을
한 최 의 언어라 할 수 있다.
Perl로 작성된 코드는 다른 언어보다 간결하다. 다른 언어로 작성하
고자 하면 여러 이 되는 것을 Perl로 만들면 한두 로 끝나는 경우
가 많다. 한 우리가 작성한 코드를 기계어로 변환하기 해서 특별
한 컴 일러를 필요로 하지 않기 때문에 단히 실용 이다.
Perl은 C언어의 특징을 많이 따왔기 때문에 상 벨 로그램의
능력과 유연성을 가지고 있다. 이러한 특징을 가지고 있으므로 C언어

제1장 들어가는 말 7
를 알고 있는 사람이라면 펄을 배우는 것이 더욱 쉬운 일이 될 것이
다.
Perl의 가장 큰 장 은 무료로 구할 수 있다는 이다. 한 CPAN
(씨팬)이라는 공간에 상상할 수 있는 거의 모든 기능들이 이미 모듈
형태로 공개되어 있어서 필요한 모듈을 이용하여 우리가 원하는 작업
을 손쉽게 구 할 수 있다.
그러나 펄도 단 을 갖고 있다. 첫째로 속도를 목표로 개발된 언어
가 아니어서 C언어보다는 속도가 느리다. 두 번째는 메모리 요구량이
많다. 한 로그램을 이진 일로 컴 일하지 않은 인터 리터 언어
이므로 소스 코드가 공개되어져 상업용 로그램에는 합하지 않다.
3. 펄 프로그램 설치 및 이용방법
도우 사용자의 경우에 www.activestate.com에서 ActivePerl 로
그램을 다운로드 하여 설치하는데, 컴퓨터의 C 디 토리에 다운받아
서 C 디 토리에 설치하여야 한다. 만약 C 디 토리에 다운받지 않으
면 종종 컴퓨터의 티션 설정으로 인해서 설치가 제 로 되지 않는
경우가 있다.
다음에는 터미 로그램(cmd.exe)을 컴퓨터에서 검색하여 펄 디
토리(C:\Perl) 내에 복사한다. 실제로는 터미 로그램을 우리가
작성해서 실행할 소스코드와 동일한 디 토리에 치시키면 된다.
로그램 코드 작성은 리웨어로 구할 수 있는 텍스트에디터 로그램
을 이용하는 것이 편리하다. 일이름은 확장자가 pl로 되도록 장하
고, 터미 로그램에서 일이름을 입력하여 실행한다. <그림 1-1>
8 계량정보분석을 한 로그래 활용사례연구
<그림 1-1> 펄 프로그램 무료 배포처
<그림 1-2> 터미널 프로그램(cmd.exe) 화면
은 펄 로그램을 구할 수 있는 www.activestate.com을 보여주고 있
고, <그림 1-2>는 터미 로그램에서 펄 소스코드(filename.pl)를 실
행하는 것을 보여주고 있는데, 색반 을 시킨 후의 화면이다.

제2장 PERL의 문법 9
제 2 장
PERL의 문법
제2장은 “이명 경 스쿨(http://www.emh.co.kr/tech.pl)”과 “Perl
제 로 배우기(김 식․강윤석 역, 한빛미디어)”를 학습하고 나서 재
정리한 내용이다. 따라서 제2장 내용을 더 잘 이해하고자 한다면, 웹
사이트도 참고하면서, “Perl 제 로 배우기”를 구입해서 보는 것을 권
장한다. 한 “Perl 제 로 배우기”교재를 보면서 이해할 수 있도록 해
당 페이지 번호를 제의 일이름에 사용하 다. Perl이 무엇인지도
모르는 상태에서 “이명 경 스쿨(http://www.emh.co.kr/tech.pl)”은
마치 유치원에서 놀이형태로 한 을 배우는 것처럼 아주 쉽게 Perl을
‘이야기’하고 있었다. 한 로그램을 잘 모르는 사람이 Perl 로그
램에 입문하는 단계에서 당한 학습교재를 찾던 , 무 부담을 주
지 않으면서 필요한 것은 부분 다루고 있는 교재로 “Perl 제 로 배
우기”가 에 들어왔고, 쉽게 설명이 되어 있어서 많은 도움이 되었다.

10 계량정보분석을 한 로그래 활용사례연구
제1절 준비하기
□ 연습문제 받기
“Perl 제 로 배우기”의 연습문제를 다운로드 받을 수 있다. 인터넷 주
소창에서 ftp://ftp.oreilly.com/로 속한 후에 published/oreilly/ nutshell/
learning_perl. win32 로 이동하여 다운로드받는다. 한 각 일의 확장
자가 plx로 되어 있는 것을 pl로 변경하면 바로 이용할 수 있다.
□ 유즈넷 뉴스그룹 이용하기
뉴스그룹 등을 이용하면 perl 로그래 에 한 여러가지 도움말을
참고할 수 있다. 아웃룩익스 스를 사용하고 있다면 뉴스그룹을 활
용해 볼 수 있다.
- 아웃룩익스 스에서 뉴스서버 설정하는 것은 천리안 유즈넷
사용법(http://user.chollian.net/~driveway/usenet1.htm)을 참고
하면 될 것이다.
- 뉴스서버 설정은 통신회사(KT, 하나로통신, 두루넷 등)가 제공
하는 뉴스서버(NNTP)를 기입하면 되는데, 한국통신은 news.
kornet.net, 하나로통신은 news.hananet.net, 두루넷은 news.thrunet.
net을 사용한다.
Perl 로그래 의 한 뉴스그룹은 han.comp.lang.perl 인데 활성화
가 안되어 있다. 해외 뉴스그룹 comp.lang.perl.misc은 활성화 되어
있으므로 로그램 작성시 난 에 부딪혔을 때 문의하면 종종 답변을
얻을 수 있을 것이다.

제2장 PERL의 문법 11
제2절 변수와 스칼라
□ 변수의 종류
펄에는 크게 스칼라, 배열, 해시 등의 세가지 변수가 있는데, 변수
형 용이 다른 로그램 언어보다 자유로워서 사용하기 편리하다.
- 스칼라는 하나의 무엇이며 주로 숫자와 문자열을 말한다. 복
수는 배열(array)로 나타내며, 해시변수는 키-값의 인데 아
이디-패스워드라고 생각하면 쉽다.
- 변수 이름을 만들 때는, 앞에 특수기호 ($, @, %)를 붙이고,
그 뒤에 문자가 오고, 그 뒤에 문자, 숫자, _ 을 조합하여 사
용한다. 한 소문자를 구별한다.
- 스칼라 변수는 $로 시작한다.
$a = 10; # 10을 스칼라 변수 $a 에 할당함(# 이하는 주석문)
$b = 'abc'; # 문자 abc 를 스칼라 변수 $b에 할당함,
# 문자는 작은따옴표(‘’)로 묶어 다.
- 복수는 배열(Array)로 처리하는데 배열변수는 @로 시작한다.
- 해시는 키-값의 을 처리하는데, 해시변수는 %로 시작한다.
@abc = (1, 2); # 1과 2를 배열변수 @abc 에 할당
%bbb = (홍길동, 123, 이순신, 456)
# 홍길동-123 , 이순신-456 을 해시변수 %bbb에 할당

12 계량정보분석을 한 로그래 활용사례연구
□ 구문의 구분과 주석문 처리
- 변수에 값을 할당한 후에는 반드시 끝에 세미콜론(;)을 붙여야
한다. 이는 펄이 구문을 구분할 때 세미콜론으로 하기 때문이
다. 종종 이 것을 하지 않아서 오류가 뜨곤 한다.
- 주석문은 # 으로 시작하는데, 만약 여러 을 주석문으로 처리
할 경우에는 각 마다 # 기호를 앞부분에 붙여주어야 한다.
□ 숫자
펄은 숫자를 내부 으로 배정 도 부동소수 (double‐precision) 값
으로 다루는데 신경 안 써도 알아서 처리해 다.
□ 단일 인용부호(작은따옴표) 문자열
문자열을 작은따옴표로 묶어서 하나의 스칼라 변수에 장한다. 그
러나 특수기호를 문자열 내에 포함할 경우에는 백슬래쉬를 이용해야
한다.
- : 작은따옴표를 문자열 내에 사용해야 할 경우 (can’t 를
‘can\’t’ 로 표시)
□ 이 인용부호(큰따옴표) 문자열
이 인용부호 안에서 백슬래쉬는 여러가지 다른 의미로 사용되는
데 일반 으로 백슬래쉬 이스 이 라고 부른다.
- 뉴라인(\n), 리턴(\r), 탭(\t), 소문자(\l), 문자(\u) 등이
있다. 자세한 것은 다른 펄 서 을 참고 바란다.

제2장 PERL의 문법 13
□ 숫자를 한 연산자
사칙연산 (+, -, *, /), 승 연산자(**), 나머지 연산자(%), 비교연산
자( ==, !=, <, >, <=, >=) 등이 있다.
2**3= 2*2*2 = 8 (2의 3승)
4%3 = 1 ( 4를 3으로 나 어서 나머지 1을 결과값으로 함)
3>2 (3이 2보다 크므로 참(1)을 결과값으로 함, 거짓인 경우는 0)
□ 문자열을 한 연산자
연결연산자 ( . )와 문자열 반복연산자 ( ⅹ )가 있다.
$a = "good" . " morning";
print $a;
# $a는 "good morning"; 와 동일
- 문자열 반복연산자 : x
$temp = 'ok';
$b = $temp x 2;
print $b; # $b는 'okok'가 된다.(숫자 곱셈은 *이지 x가 아님을 주의)
□ 할당연산자
- = 는 연산자 오른쪽의 값을 왼쪽에 있는 변수에 단순하게
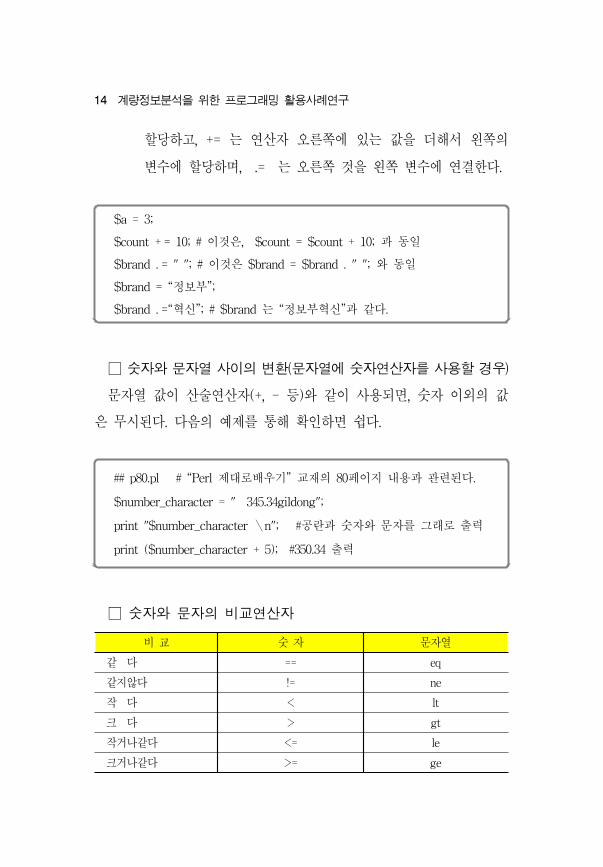
14 계량정보분석을 한 로그래 활용사례연구
할당하고, += 는 연산자 오른쪽에 있는 값을 더해서 왼쪽의
변수에 할당하며, .= 는 오른쪽 것을 왼쪽 변수에 연결한다.
$a = 3;
$count + = 10; # 이것은, $count = $count + 10; 과 동일
$brand . = " "; # 이것은 $brand = $brand . " "; 와 동일
$brand = “정보부”;
$brand . =“ 신”; # $brand 는 “정보부 신”과 같다.
□ 숫자와 문자열 사이의 변환(문자열에 숫자연산자를 사용할 경우)
문자열 값이 산술연산자(+, - 등)와 같이 사용되면, 숫자 이외의 값
은 무시된다. 다음의 제를 통해 확인하면 쉽다.
## p80.pl # “Perl 제 로배우기” 교재의 80페이지 내용과 련된다.
$number_character = " 345.34gildong";
print "$number_character \n"; #공란과 숫자와 문자를 그래로 출력
print ($number_character + 5); #350.34 출력
□ 숫자와 문자의 비교연산자
비 교 숫 자 문자열
같 다 == eq
같지않다 != ne
작 다 < lt
크 다 > gt
작거나같다 <= le
크거나같다 >= ge

제2장 PERL의 문법 15
□ 자동증가(++)와 자동감소(--), 치 후치 연산
자동증가(++)은 1만큼 증가하는 것이고, 자동감소(--)는 1만큼 감소
하는 것이다. 한 변수의 뒤에 사용하면 후치연산이고, 변수의 앞에
사용하면 치연산이다.
## p84.pl
$a = 11;
$b = $a++; # $b는 11이지만, $a는 12로 바뀜
print "$a \n$b";
# print $a \n$b; 큰따옴표로 안묶어주면 에러남
$c = 5;
$d = ++$c;
print "\n$c \n$d"; # $d와 $c 가 모두 6
□ 연산자 우선순
연산자 우선순 에 한 자세한 내용은 다른 교재를 참고하자. 일반
으로 자동증감(++, --), 승(**), 논리부정, 일치․비일치(=~, !~),
곱셈․나눗셈․나머지․문자열복사(*, /, %, x), 덧셈․뺄셈․문자열
연결(+, -, .), 논리연산자 등의 순서로 우선순 를 이룬다.
2**2**3 # 2**(2**3) = 2의 8승
2*3**4/2+5%2 # (2*(3**4))/2 + (5%2) = 162/2 + 1 = 82
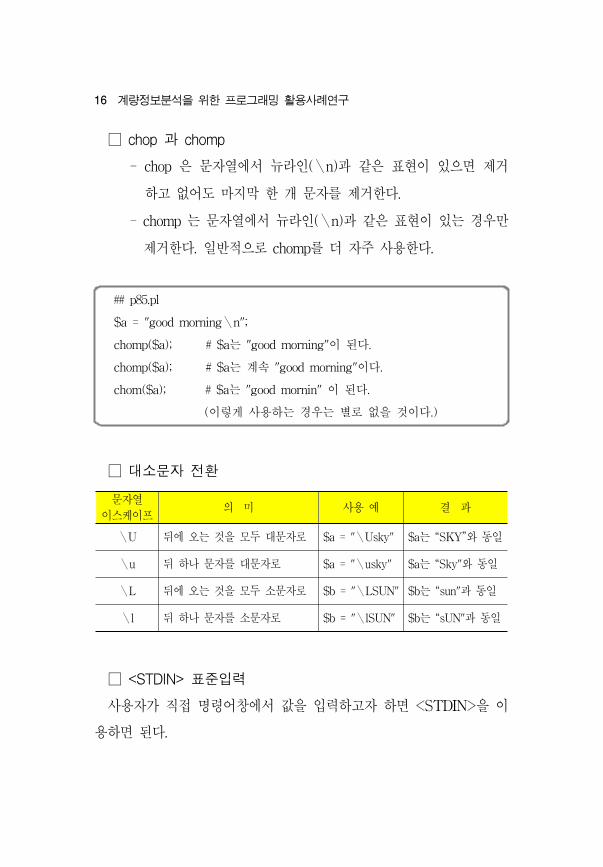
16 계량정보분석을 한 로그래 활용사례연구
□ chop 과 chomp
- chop 은 문자열에서 뉴라인(\n)과 같은 표 이 있으면 제거
하고 없어도 마지막 한 개 문자를 제거한다.
- chomp 는 문자열에서 뉴라인(\n)과 같은 표 이 있는 경우만
제거한다. 일반 으로 chomp를 더 자주 사용한다.
## p85.pl
$a = "good morning\n";
chomp($a); # $a는 "good morning"이 된다.
chomp($a); # $a는 계속 "good morning"이다.
chom($a); # $a는 "good mornin" 이 된다.
(이 게 사용하는 경우는 별로 없을 것이다.)
□ 소문자 환
문자열이스케이프
의 미 사용 예 결 과
\U 뒤에 오는 것을 모두 대문자로 $a = "\Usky" $a는 “SKY”와 동일
\u 뒤 하나 문자를 대문자로 $a = "\usky" $a는 “Sky"와 동일
\L 뒤에 오는 것을 모두 소문자로 $b = "\LSUN" $b는 “sun"과 동일
\l 뒤 하나 문자를 소문자로 $b = "\lSUN" $b는 “sUN"과 동일
□ <STDIN> 표 입력
사용자가 직 명령어창에서 값을 입력하고자 하면 <STDIN>을 이
용하면 된다.

제2장 PERL의 문법 17
chomp($a = <STDIN>);
## 명령어창에서 입력하고 입력을 마치려면 키보드에서 엔터키를 치게 되
는데, 엔터키는 바꿈(\n)으로 인식된다. 따라서 키보드에서 sky와 엔터키
를 치면 $a는 "sky\n"으로 입력된다. 그러나 보통 "sky" 만을 원하므로
chomp 명령어를 사용해서 엔터키를 제거한다.
□ undef 와 -w
- 연산자가 인수 범 를 벗어나거나 의미가 없는 경우에는
undef 를 리턴한다.
- 로그래 오류를 잡는 방법 : 명령 롬 트(cmd.exe)에서 소
스코드 일이름(*.pl)을 입력하고 그 뒤에 “–w” 입력하면
로그램 실행 에러가 있을 경우 경고문을 얻을 수 있다.
<그림 2-1> 프로그래밍 오류잡는 방법

18 계량정보분석을 한 로그래 활용사례연구
제3절 배열
□ 리스트, 배열, 리스트 리터럴
1, 2, 3 과 같이 순서가 있는 숫자들을 리스트라 하고, 이 것을 호
로 감싸고 쉼표로 구분하여 (1, 2, 3) 과 같이 나타내면 이 것을 리스
트 리터럴이 된다. 이 값을 하나의 변수에 담는다면 그 변수는 배열변
수가 된다.
@number = (1, 2, 3) ## 리스트 리터럴 (1, 2, 3)을 배열변수 @number
에 할당
- 배열 변수가 스칼라 변수에 할당되면 배열의 길이가 스칼라
변수에 할당된다.
@number = (1,2,3);
$a = @number; #$a 에는 @number 의 길이인 3이 할당됨
($a1) = @number; #$a1 에는 첫벗째 요소인 1이 할당됨
- 두개를 이용한 (1..5)는 (1,2,3,4,5)와 같다(순서 로이며
거꾸로는 안됨).
- 문자열을 다루는 변수의 경우에 qw를 슬래쉬 등과 함께 사용
하면 배열 안의 따옴표를 안써줘도 되므로 편리하다.

제2장 PERL의 문법 19
("a","b","c"); # 아래의 표 들도 모두 동일한 내용을 표시
qw # a b c #;
qw ! a b c !;
qw { a b c };
qw [ a b c ];
qw/a b c /;
□ 배열 요소 액세스
- 배열의 각 요소는 0부터 시작하여 1씩 증가한다.
- 배열의 각 요소는 하나의 스칼라 값이므로 $로 시작하며 [ ]안
에 요소의 순서를 표시한다. 아래의 를 참고하자.
@number = (1,2,3) # $number[0] = 1, $number[1]=2 …
@number[0,1]; # ($number[0], $number1]) 과 동일한 의미
@number[0,1,2] = @number[1,1,1]; # 3요소를 모두 2번째 요소로 만듬
- 배열은 자동으로 확장되고, 어들어서 길이를 미리 할당할 필
요가 없다.
## p97.pl
@temp = (1,2,3);
$temp[3] = “hi”; $temp[7]=”haha”;
## @temp는 (1,2,3,”hi”,undef,undef,undef, “haha”)

20 계량정보분석을 한 로그래 활용사례연구
- 배열의 마지막 요소의 인덱스 값을 얻으려면 shebang($#)을
이용하면 된다.
- 배열의 마지막 요소의 인덱스 값으로 첨자 "-1"을 사용해도
된다 (마지막에서 두번째는 -2를 사용).
@temp = qw(sun mon thu wen thir fri sat);
## @temp의 요소가 7개이고 마지막 인덱스는 6이므로 $#temp는 6을 나
타낸다. $temp[-1] 과 $temp[$#temp] 는 모두 마지막 요소인 “sat” 을 나타
낸다.
□ push, pop
- push : 배열의 오른쪽에서 뭔가를 집어넣을때 사용한다.
- pop : 배열의 오른쪽에서 뭔가를 뺄 때 사용한다.
push(@temp, $new_value); # @temp = (@temp, $new_value)와 동일
$old_value = pop(@temp);
## $old_value 에는 $new_value 가 할당되고, @temp 에는 마지막 값
인 $new_value 가 없어진다.
@array = (1..100);
$last = pop(@array); # $last에는 100 이 담기고, @array는 (1..99)
push(@array,200); # @array 는 (1..99,200)

제2장 PERL의 문법 21
□ shift, unshift
리스트의 왼쪽에서 push, pop 기능을 수행한다.
- 배열의 왼쪽에서 뭔가를 빼내는 것은 shift 집어넣는 것은
unshift 를 사용한다.
@shifting = ('a'..'z');
$first = shift(@shifting);
# $first 스 일라 변수에는 'a'가 담기게 되고
# @shifting 배열은 ('b'..'z')
unshift(@shifting, "zzz");
□ reverse
배열을 역순으로 재배열 한다.
@b = (1,2,3);
@b = reverse(@b); ## 이제 @b는 (3,2,1)로 바 다.
## 단순히 reverse(@b) 하면 역순으로 되지 않는다.
□ sort
ASCII 상에서 오름차순으로 문자열 순으로 정렬한다. 숫자순으로
오름차순되는 것이 아니다.

22 계량정보분석을 한 로그래 활용사례연구
## p99.pl
@x = sort(qw(young old tall short));
print @x;
@y = sort(1,34, 4, 5, 13, 7, 67);
print "\n@y";
# 숫자 오름차순으로는 정렬 안되는데, 뒷부분에서 서 루틴 활용하여
정렬할 수 있다.
□ chomp 함수
chomp 는 스칼라 변수뿐만 아니라 배열 변수에서도 코드 구분자
(\n, \t 등)를 제거한다.
@temp = qw(small\n large\t medium\n);
chomp(@temp); ## @temp 는 qw(small large medium) 과 동일하다.
□ 배열에서의 <STDIN>
배열 요소를 하나씩 입력하고 엔터키 치고, 마지막에는 CTRL+Z(D)
를 르고 나서 엔터키를 친다. OS 시스템에 따라서 CTRL+Z 가 맞
을 수도 있고, CTRL+D 가 맞을 수도 있다.
@a = <STDIN> ;

제2장 PERL의 문법 23
□ 컨텍스트
- 펄은 같은 변수라도 상황에 따라서 다르게 취 될 수 있다.
즉 스칼라로 취 할 문맥이면 스칼라로 취 하고, 리스트로 취
할 분 기면 리스트로 취 한다.
- 10 + temp # + 가 스칼라 연산자니까 temp 는 스칼라로 취
된다.
- sort temp # sort 가 리스트 연산자니까 temp 는 리스트로
취 된다.
제4절 제어문
□ if / unless 문
if (조건문) { 실행문1 } ## 조건문을 만족하면 실행문1을 실행하고
else { 실행문2 } ## 아니면 실행문2을 실행한다.
## 조건문이 공백문자열(“”), 숫자값 0, undef 일 때는 거짓이므로 실행문
1을 수행하지 않는다(조건문이 숫자 00 일 때는 수행함).
if (조건문1) { 실행문1 }
elsif (조건문2) { 실행문2 }
elsif (조건문3) { 실행문3 }
else { 실행문 4 }
## elsif 는 무제한 추가가능하며, elseif가 아님을 주의한다.

24 계량정보분석을 한 로그래 활용사례연구
unless (조건문) { 실행문 } # 조건문이 거짓이면 실행문을 수행한다.
□ while / until 문
while (조건문) {실행문} # 조건문이 참이면 실행문을 무한 반복한다.
## p107. pl
print "올해 나이가 어 되시요?";
chomp($age = <STDIN>);
while ($age > 0) {
print "당신은 에 나이가 $age 이었다. \n";
$a--;
}
## 나이를 입력하면 1살이 나올때까지 계속 문장을 린트 한다.
until (조건문) {실행문} # 조건문이 거짓이면 실행문을 무한 반복한다.
□ do {} while / until 문
do { 실행문 } while 조건문
# 실행문을 먼 수행하고, 조건문이 거짓이 되면 종료하고, 참이
면 계속 실행문을 수행한다.

제2장 PERL의 문법 25
do { 실행문 } until 조건문 # 조건문이 거짓이면 실행문을 계속 수행한다.
□ for 문
for ( 기값 ; 조건문 ; 재 기화 ) { 실행문 }
## p109.pl
for ($i = 1; $i <= 10; $i++) {
print "$i 는 10이하입니다.\n";
} ## $i 를 1부터 10까지 1씩 증가시키면서
## “$i 는 10이하입니다.”를 출력함
□ foreach 문
foreach 루 는 for 루 와 거의 같지만, foreach는 재 몇 번째에
해당되는 작업인지를 알 수가 없다. 만약 순서를 알아야 하는 경우에
는 for 문을 사용해야 한다. 그러나 foreach는 실행속도가 for 루 보
다 빠르다.
foreach 스칼라변수 (리스트) { 실행문 }
## 리스트 값을 하나씩 받아서 스칼라 변수에 할당하고 실행문을 수행

26 계량정보분석을 한 로그래 활용사례연구
## p110.pl
@array = (1..5);
foreach $one (@array) {
print $one += 2;
} ## 배열 @array 의 각 원소들을 $one 변수로 가져와서 2를 더한
다음 린트한다.
제5절 해시
해시는 키와 값의 을 말하는데, 쉽게 생각하면 아이디와 패스워드
의 으로 생각할 수 있다. 배열에서는 값의 순서가 있고 제어할 수
있지만, 해시의 순서는 제어할 수 없다.
□ 해시변수와 리터럴 표
- 해시변수는 %로 시작하는데, % 뒤에 문자, 그 뒤에 문자
숫자 언더스코어가 온다.
- 키-값 의 순서는 제어할 수 없다.
- reverse 를 이용하면 키와 값이 교환된 해시를 만들 수 있다.
- 해시에서 복된 키는 있을 수 없지만 복된 값은 있을 수
있는데, 마치 아이디는 복 안되지만 비 번호는 복될 수
있는 것과 유사하다.

제2장 PERL의 문법 27
## p114.pl
%temp = ("gildong", 123, "sunshin", 234);
$temp{"aaa"} = 333; ## 키는 “aaa”, 값은 333을 생성
print %temp; # 이제 %temp는 ("gildong", 123, "sunshin", 234,"aaa", 333)
## 해쉬의 키-값 의 순서는 무작 이며 제어안된다.
- 해시변수를 배열변수로 복사하여 사용하면 편리한 경우가 있다.
@temp_list = %temp; @temp_list 는 (키1, 값1, 키2, 값2, …)이다.
□ 해시 함수 keys
해시를 한 함수 keys 함수는 해시의 키만을 리턴한다.
keys(%name)은 해시 %name의 모든 키 리스트를 리턴한다.
@list = keys(%temp); # @list에는 (키1, 키2, …)가 할당된다.
while(keys(%some) < 100) { 실행문 } ## 스칼라 구문
# 스칼라 구문에서 keys함수는 키를 리턴하는 것이 아니고 키 -값
의 개수를 리턴한다.
□ 해시함수 values
values 함수는 해시의 값만을 리턴한다. values(%name)을 통해서
%name의 값만이 리스트로 리턴된다.

28 계량정보분석을 한 로그래 활용사례연구
## p116.pl
%temp = ("gildong", 123, "sunshin", 234);
print @list = values(%temp); ## 값 123과 234가 @list로 할당된다.
□ 해시함수 each
해시함수 each는 each(해시변수명) 형태로 사용되며, 해시의 키-값
을 리턴한다.
□ 해시함수 delete
해시함수 delete는 delete(해시변수명) 형태로 쓰이며, 여기서 호는
옵션이다. 키-값 을 제거하는데 이용된다.
## p117.pl
%id_pw = qw ( 홍길동 hgd
손오공 sog
팔계 jpg
사오정 soj
);
delete ($id_pw{"홍길동"}); # 홍길동 - hgd 이 삭제됨
while ( ($id, $pw) = each(%id_pw) ) {
# 키-값 이 $id 와 $pw 로 리턴됨
print "The password of $id is $password \n";
}

제2장 PERL의 문법 29
제6절 기본 입출력
□ <STDIN> 표 입력
사용자가 명령어 창에서 값을 입력할 때는 표 입력 <STDIN>을
이용한다.
$one = <STDIN>; # 스칼라, 한 입력받음
@array = <STDIN>; # 여러 행을 리스트로 입력받음
while( <STDIN> ) { ## 입력값이 있으면
chomp; ## 엔터키를 제거하고 입력받아라
}
□ 일반출력 print, 포맷된 출력 printf
일반 으로 출력할 때는 print를 사용하고, 특정한 포맷형태로 출력
할 때는 printf를 이용한다.
$ss = "student"; $nn = 123; $rr = 12345.3456;
printf "%15s %5d %10.2f\n", $ss, $nn, $rr;
# %15s 는 $ss를 15문자 역으로,
# %5d는 $nn을 5문자 10진수로,
# %10.2f는 $rr을 10문자 역에서 소수 이하 2자리 실수로 출력

30 계량정보분석을 한 로그래 활용사례연구
제7절 정규표현식
정규표 식은 문자데이터를 가공하는 작업을 할 때 매우 유용하게
사용할 수 있다.
□ 정규표 식은 패턴이다.
- 문자열을 슬래쉬(/문자열/)로 둘러싸서 정규표 식으로 사용가
능하다.
- 치환 s/ab*c/def/; # ab*c를 def로 치환함, 여기서 b의 개
수는 0개이상이다.
- 임의의 단일문자 일치는 마침표(.)를 사용한다. 뉴라인과 일치
되지는 않는다.
/a./ # a와 다른 하나의 문자로 구성된 문자와 일치 ( : ab, as, af …)
- 패턴일치 클래스 : [일치할 문자패턴] 으로 표
[0123456789] # 임의의 한 숫자와 일치
[0 - 9] # 임의의 한 숫자와 일치
[0 - 9\-] # 임의 한 개의 숫자 마이 스와 일치(마이 스 기호를
사용하려면 마이 스 기호 앞에 백슬래쉬를 사용함)
[a-zA-Z0-9] #임의의 한 개의 소 문자 임의의 숫자와 일치

제2장 PERL의 문법 31
- 부정문자 클래스 : [^문자패턴] 으로 표 #문자패턴을 포함
하지 않는 것과 일치한다.
[^0 - 9] #숫자가 아닌 임의의 한 문자와 일치
- 정의된 단축 문자클래스
코 드 부정코드
\d #한 숫자 [0 - 9]와 일치 \D #숫자가 아닌 것
\w #한 문자 \W #문자가 아닌 것
\s #공백문자 \S #공백이 아닌 것
□ 그룹화
- 연속 # abc 는 세문자가 연속된 것이다.
- 배수기 : ?, *, + 기호
물음표(?) : 물음표(?) 앞에 오는 문자가 하나이거나 없거나임
별표(*) : 별표(*) 앞에 오는 문자가 0개 이상
러스 기호(+) : 러스 기호(+) 앞에 오는 문자가 하나 이상임
## p131.pl
print $_="Let's Gooooooooooooo";
s/o+/o/; # o가 하나 이상인 것을 o으로 치환
# 여기서 디폴트변수인 $_ 에 해서 수행함
print "\n$_"; # $_ 는 “Let's Go" 로 치환되어 출력됨

32 계량정보분석을 한 로그래 활용사례연구
- 자 개수 한정
/x{10,20}/ #x의 개수가 10개에서 20개 사이
/x{10,}/ #x의 개수가 10개 이상
/x{10}/ #x의 개수가 정확히 10개
/x{0,10}/ #x의 개수가 10개 이하
/a.{10}b/ #a와 b 사이에 임의의 10개 문자
□ 메모리로서의 호( )
호 친 것을 왼쪽에서부터 \1, \2… 로 지정한다.
## p134.pl
$_ = "abcdefghcggggg";
if ($_ =~ /ab(c)def(g)h\1\2/){
# 호친 c와 g 가 각각 \1, \2로 기억됨, 패턴이 일치하는지 검
사하여 일치하면 “패턴일치”를 출력한다. =~는 일치연산자로
뒷부분에서 설명한다.
print "패턴일치";
}else{
print "패턴 불일치";
}
□ 선택 /a|b|c/ : a , b, c 들 하나와 일치한다.

제2장 PERL의 문법 33
□ 앵커화 패턴
- \b : 단어 경계표시
/star\b/ # star와 일치하나 starter 와는 불일치
/\bstar/ # star와 일치하나 treckstar와는 불일치
- \B : 단어 경계 없음을 표시
/\bstar\B/ # starcraft 와 일치하나 star wars 와는 일치 안함
- 캐럿(^) : 문자열의 시작문자 일치
^s 는 s가 문자열의 첫번째 문자이다.
- $ : 문자열의 끝을 고정
r$ 는 문자열의 끝에 r 이 있을 때 일치
□ 정규표 식 우선순
호, 배수기, 연속과 앵커화, 선택 순이다. 자세한 것은 다른 교재
를 참고하기 바란다.

34 계량정보분석을 한 로그래 활용사례연구
□ 다른 목표의 선택(=~ 연산자)
- 연산자의 오른쪽에 정규표 식을 받아서 연산자의 왼쪽에 있
는 변수를 목표로 선택한다. 어떤 문자를 포함하고 있는지
검색하는데 사용할 수 있다.
$a = “good morning”;
$a =~ /^go/; # 참
@a = qw/서울특별시 부산직할시 경기도/;
foreach $word (@a) { ## 하나씩 단어를 $word 로 가져오고
if($word =~ /서울/){ ## 만약 $word 에 “서울”이 있으면
print "서울ok\n";
}
else{
print "서울아님\n";
}
}
□ 소문자 무시
- / 패턴/i # 슬래쉬 뒤에 소문자 i를 써주면 소문자가 무시된다.
if(<STDIN> =~ /^o/i { # 입력이 o로 시작하는가? 그 다면 실행문을
수행하라.
# 실행문
}

제2장 PERL의 문법 35
□ 변수삽입
$word = “time”;
$sentence = “time out”;
if($sentence =~ /\b$word/){ # $sentence 에 $word 가 있는지 검
print “문장에 $word 가 있다.\n”;
}
□ 특별한 읽기 용 변수
$_ = “we are researchers”;
($one, $two) = /(\w+)\W+(\w+)/; # 처음의 두 단어를 일치시킴
# $one 은 “we” 이고 $two 는 “are” 이다.
# (\w+) 는 한 개 이상의 문자이고, \W+ 는 한 개 이상의 문자아닌 것
- $ ̀ 은 일치 문자열, $& 은 일치된 문자열, $’ 은 일치된
뒤의 문자열을 표시한다.
## p140.pl
$_ = "this is a interesting book";
/int.*ng/; # 문자열 내의 "interesting"과 일치
# $ ̀ 은 "this is a " , $& 은 "interesting" , $' 은 " book"
과 일치함
printf "일치되기 문자열은 %s, \n
일치된 문자열은 %s, \n
일치된 뒤의 문자열은 %s 입니다.", $`, $&, $' ;

36 계량정보분석을 한 로그래 활용사례연구
□ 치환
- 간단한 치환방식 : s/치환할 문자열/새로운 문자열/
- 가능한 모든 일치에 한 치환은 정규표 식 뒤에 g 를 붙인다.
## p141.pl
$_ = "간장 공장 공장장은 간공장장인가 공장공장장인가?";
s/공/된/g; # $_ 는 "간장 된장 된장장은 간된장장인가 된장된장장인
가?" 로 바뀜, 여기서 치환의 상을 언 안해도 디폴트
변수인 $_에 해서 치환이 이루어진다.
print $_;
- 치환식에서 슬래쉬(/) 신에 다른 구분기호(# 등)를 사용해도
되는데, 다른 목표의 선택연산자( =~ )를 사용해도 된다.
## p141_1.pl
$sentence = "나는 학생이다.";
$sentence =~ s/학생/직장인/; # 이제 $sentence 는 "나는 직장인이다."
로 바뀜
print $sentence;
□ split 문자열 분리함수
- 배열명 = split(/구분자/, 문자열변수) 형태로 사용

제2장 PERL의 문법 37
## p142.pl
$sentence = "Hello!, Could you show me the way to go to the hotel?";
@array = split(/(\w+)/, $sentence); #문장을 단어단 로 쪼개서 배열로 장
## 단어, 기호(! , 등), 공란이 모두 하나씩 배열요소를 차지함
foreach $word (@array){ # 배열요소를 하나씩 린트
print "$word \n";
}
□ join 문자열 결합함수
- join(결합어, 리스트); # 결합할 리스트(배열) 요소 사이를
결합어로 결합시킨다.
- join(결합어, “”, 리스트); # “”와 리스트 사이에도 결합어를 둔다
- join(결합어, 리스트, “”); # 리스트의 마지막요소 뒤에도 결합
어를 둔다.
## p143.pl
@array = qw(하늘 바람 별 시);
$big_string = join("과 ", @array);
# $big_string 은 "하늘과 바람과 별과 시"(여기서 “과” 뒤에 빈칸 있다.)
print $big_string;
$big_string_front = join("가을","", @array);
# "가을하늘가을바람가을별가을시"
print "\n$big_string_front";
$big_string_back = join("님 ", @array,""); # "하늘님 바람님 별님 시님"
print "\n$big_string_back";

38 계량정보분석을 한 로그래 활용사례연구
제8절 함수
고 로그래머일수록 자신만의 함수를 잘 만들어 사용한다. 한
이 게 만들어 놓은 함수는 다른 로그램에 재사용하는 경우가 많다.
어떤 로그래머는 라인이 2 이 넘는 것은 거의 항상 함수로 만들어
사용한다고도 한다.
□ 사용자함수의 정의
- 사용자 편의 로 만들어서 나 에 호출하여 사용하는 서 루
틴이다.
- sub 사용자함수명 { 실행문 } 형태
- 서 루틴(사용자함수)은 일의 끝부분에 치하는 것이 미
상 편리하다.
- 서 루틴 정의는 역 (global)이다. 즉 특정 사용자함수명은
로그램 소스코드 체에서 한 번만 사용해야 한다.
- 서 루틴 본문 내에서 메인 로그램에서 공유되는 역변수
를 엑세스 할 수 있다.
□ 사용자 함수의 호출 / 리턴
- 서 루틴의 리턴값은 서 루틴의 마지막 표 식이다.
- return 반환값 형태를 띤다.

제2장 PERL의 문법 39
## p149.pl
$a = 1; $b = 2;
$c = sum(); # 서 루틴을 호출하여 리턴된 값을 $c 에 할당
print $c;
sub sum{
return $a + $b; # 역변수 $a, $b 를 사용하여 합하고
그 값을 반환
}
□ 인수
- 서 루틴에 인수(arguments)를 달하면 자동으로 @_ 특수변
수에 할당된다.
## p151.pl
say("YES", "KISTI"); # "YES" 와 "KISTI" 를 인수로 서 루틴에 달
sub say{
print "$_[0], $_[1]! \n" # $_[0]과 $_[1] 은 @_ 특수배열의 요소
}
□ my : 사용자 함수 내의 변수를 지역변수로 만들기
- my(변수명) 형태로 사용하는데, 동일한 이름의 역변수와 구
분하기 해 사용한다. 지역변수는 사용자 함수 내에서만 유효
한 함수이다.

40 계량정보분석을 한 로그래 활용사례연구
## p153.pl
print bigger_than(5, 1..10); print "\n"; # 1부터 10까지 에서 5보다
큰 것 출력
print bigger_than(10, 5..20);
sub bigger_than{
my($n, @values) = @_; # 인수로 받은 @_ 값을 $n과 @value로 분리
하고 지역변수로 만든다.
my(@result); # @result를 지역변수로 만든다.
foreach $_ (@values){ # @values 의 인수를 하나씩 $_ 로 할당하여
if($_ >$n){ # $_ 값이 $n 보다 크면
push(@result, $_); # @result 에 $_를 추가한다.
}
}
return @result; # 결과를 사용자 함수의 결과로 리턴한다.
}
□ local : 사설 변수 만들기
- 사용자함수 내에서 사용되지만 외면상 실제로는 역변수이다.
역변수의 값은 장되고, 지역 으로 선언된 값은 임시 으
로 치된다.
□ 일 벨 my() 변수
- 변수선언을 강제하여 로그램 실행 속도를 높이고자 할 때
사용한다.
- use strict; my 변수명 형태로 사용한다.

제2장 PERL의 문법 41
- use strict( 라그마) 를 일 시작부에 두면 my() 를 이용해
서 선언된 변수만 사용가능하다.
- 일반변수 $x 는 실제로는 $main :: x 이다.
- 일반변수보다 my 로 생성된 변수가 더 빨리 액세스된다.
## p155.pl
use strict; # 라그마 이용해서 변수선언 강제를 목 으로 함
my @b = qw(brown daddy mommy);
push @b, qw(william);
# print @c = sort @b; # @c 가 선언되지 않았으므로 실행
안됨(에러)
print sort @b; 정렬되어 출력된다.
제9절 기타 제어구조
제어구조에 유용하게 사용되는 것을 살펴보면, last, next, last 등이
있는데, 이들은 BLOCK( 호로 묶여있는 코드) 내에서만 유효하다.
즉, for, foreach, while, until, 는 자체블록으로 만들어진 블록에서만
유효하다. BLOCK 이 없는 구문에서는 필요하다면 BLOCK을 만들어
서 사용해야 한다. 블록이 없는 do{} while/until, if와 else 에서는 실
행 안된다. if 문 블록은 루 블록으로 취 되지 않는다는 것을 유의해
야 한다. 사용자 정의함수 sub { } 에서 특히 많이 사용된다.
□ last 문 : 제어문 구조에서 루 블록을 탈출할 때 사용한다.

42 계량정보분석을 한 로그래 활용사례연구
while (조건문1) { 실행문1;
if(조건문2){ 실행문2;
last; # while 루 를 빠져나감
}
실행문3;
}
# last 는 while 루 를 빠져나와서 이 곳으로 온다.
□ next 문 : next는 하던 작업을 멈추고 다음 번 루 를 돌아라
는 의미이다.
while (조건문1) { 실행문1;
if(조건문2){ 실행문2;
next;
}
실행문3;
# next 는 이 곳으로 온다.
}
□ redo 문 : 블록의 시작부로 이동한다.
while (조건문1) {
# redo 는 이 곳으로 온다.
실행문1;
if(조건문2){ 실행문2;
redo;
}
실행문3;
}

제2장 PERL의 문법 43
□ 라벨 붙은 블록
- 블록에 라벨을 붙여서 last, next, redo 사용한다. 라벨은 문
자로 하며, 블록을 포함하는 문 바로 앞뒤의 라벨에 콜론(:)을
붙여서 치시킨다.
SOMELABEL: while(조건문1){ 실행문
if(조건문2){
last SOMELABEL;
}
}
□ 표 식 수정자
- 실행문 if 조건문 형태 # if (조건문) {실행문} 형태의 다른 표
이다.
- if/unless/while/until 문 등에 사용한다.
□ 제어구조에 사용되는 && 와 ||
- 조건문 && 실행문 # if(조건문) {실행문} 의 다른 표
- 조건문 || 실행문 # unless (조건문) { 실행문 } 의 다른 표
- && 와 || 는 논리연산자 AND , OR 로도 사용된다.
□ (조건문1)? a : (조건문2)? b : (조건문3)? c : d;
- 조건문1을 만족하면 a, 조건문2를 만족하면 b, .. 앞에 만족하
는 조건이 없으면 d라는 의미이다.

44 계량정보분석을 한 로그래 활용사례연구
제10절 파일핸들과 파일 테스트
일핸들은 펄 로세스와 외부세계와의 I/O 연결을 말한다. 여기
서 외부세계라는 것은 하드디스크 등에 장된 일을 말할 수 있다.
즉 우리가 컴퓨터에 장해 놓고 있는 일을 펄로 가져와서 어떠한
연산을 수행하고자 하면 일핸들을 사용해야 한다. 앞서 배운
STDIN은 표 입력을 담당하는 일핸들이고, 표 출력을 해서는
STDOUT이라는 일핸들이 있다.
- 일핸들은 다른 변수와 달리 앞에 붙는 문자 ($, @, %)가 없
고, 사용상의 혼돈을 피하기 해 문자로 표기한다.
□ 일핸들 열고 닫기( 일 읽기와 쓰기)
- 추가 인 일핸들을 열 때 open 함수를 이용하며, 습 으
로 일핸들은 문자로 표기한다. 일핸들을 닫을 때는
close 함수를 사용한다.
- 일핸들은 읽기, 쓰기, 덧붙이기, 읽기쓰기 모드로 사용할 수
있다.
- 읽기모드는 일을 읽어오는데 사용하고, 쓰기모드는 새로운
일을 만들거나, 기존의 동일한 일의 내용을 제거하고 새
로운 내용으로 만들고자 할 때 사용하고, 덧붙이기 모드는 기
존의 일내용 끝에 내용을 추가할 때 사용한다. 읽기쓰기모
드의 경우 기존에 일이 없는 경우 새로운 일을 만들지는
못한다.

제2장 PERL의 문법 45
open(FILEHANDLE, “input.txt”); # input.txt 일을 FILEHANDLE 이
라는 일핸들로 ‘읽기모드’로 연다.
open(OUT, “>out.txt”); # out.txt를 작성하고자 OUT 일핸
들을 쓰기모드로 연다.
open(ABC, “>>temp.txt”); # temp.txt을 덧붙이기 하려고, ABC
일핸들을 덧붙이기 모드로 연다.
open(ABC, "+<temp.txt"); # 일이 기존에 있는 경우에만 사
용한다.
close(ABC); # 일핸들을 닫는다.
□ die / warn
- 일을 열고 닫을 때 에러가 발생하면 경고문을 제공하기
해서 이용한다. 다시 말하면 open() 이 성공했는지 아닌지를
확인할 필요가 있을 때 사용하며, 실패하면 로그램 실행을
단한다.
open(IN, “input.txt”) || die “Sorry, can't open input file\n” ;
open(LOG, “>>temp.txt”) || warn “cannot append: $!” ;
# $! 변수는 가장 최근의 운 체제 에러를 설명하는 에러문자열을 포함한다.
# warn은 에러메시지를 표시하며, die 보다 시간이 게 걸린다.

46 계량정보분석을 한 로그래 활용사례연구
## p169.pl, p169_input.txt
print "What file? ";
chomp($inputfile = <STDIN>);
open(IN, "$inputfile") || die "cannot open $inputfile: $!";
open(OUT, ">p169_output.txt") || die "cannot creat output file :$!";
while(<IN>){
push(@array, $_); ## 한 행씩 @array배열로 가져옴
print STDOUT $_; ## STDOUT 은 표 출력 일핸들임
}
print OUT @array;
close(IN) || die "can't close $inputfile: $!";
close(OUT) || die "can't close output file : $!";
□ 표 입력으로부터 여러 을 입력받을 때
while(defined($one_line=<STDIN>)) {
print $one_line;
}
- defined 라는 것은 변수에 어떤 값이 할당되어 있으면 1 을 리
턴하고 그 지 않으면 0 을 리턴하는 함수이다.
□ 일 테스트
표 인 일 테스트만 소개하며, 자세한 것은 다른 교재를 참고
바란다.

제2장 PERL의 문법 47
## p170.pl
print "print input file name \n";
chomp($input = <STDIN>);
if(-r $input && -w $input){ ## 일이 존재하고 읽고 쓸 수 있다면
print "$input 은 읽기 쓰기가 가능함"
}
- if 다음에 일테스트문을 붙여서 사용한다.
‐-r 파일명(디렉토리명) 파일 또는 디렉토리가 읽기 가능한지 테스트
‐-w 파일명(디렉토리명) 파일 또는 디렉토리가 쓰기 가능한지 테스트
‐-x 파일명(디렉토리명) 파일 또는 디렉토리가 실행 가능한지 테스트
‐-e 파일명(디렉토리명) 파일 또는 디렉토리가 존재하는지 테스트
‐-M 파일명 파일이 마지막으로 수정된 이후의 날 수
‐-A 파일명 파일이 마지막으로 액세스된 이후의 날 수
… …
□ 일지우기와 이름바꾸기
- unlink : 일지우기
- rename : 일이름 바꾸기
unlink "temp.txt"; ## temp.txt 일을 지우기
rename "filename" , "new_name"; ## "filename"를 "new_name"으로
일이름 바꾸기

48 계량정보분석을 한 로그래 활용사례연구
format 포맷이름 =
필드라인 필드홀더
값 행
필드라인 필드홀더
값 행
.
format LABEL =
| @<<<<<<<<<<<<<<<<<<<<<<<<<<<<< | # 필드라인, 필드홀더
$name # 값 행
| @<<<<<<<<<<<<<<<<<<<<<<<<<<<<< |
$address
| @<<<<<<<<<<<<<<<<<<<<<<<, @< @<<<<<<< |
$city, $state, $zip
.
제11절 포맷
Perl의 형 인 사용이 텍스트 데이터로부터 정보를 추출하여 보고
서로 작성하는 것인데, 보고서 작성에 해당하는 부분이 포맷이다.
□ 포맷정의는 일 끝부분에 서 루틴의 앞에 하는 경향을 보
이며, 다음과 같은 형태이다.
- 필드홀더 @<<<<<<<<<<< 는 @ 와 < 의 개수만큼의 문자
로 이루어지고, 왼쪽맞춤을 의미한다.
- 필드홀더 아래에 $name 값이 @<<<<<<<<<<< 로 치된다.
- 포맷의 처음과 끝에 있는 등호기호의 행(================)
은 필드를 가지고 있지 않으므로 값 행이 없다.

제2장 PERL의 문법 49
## p178.pl addresses.txt
open(LABEL, ">address_print.txt") || die "can't create";
open(ADDRESSES, "addresses.txt") || die "cannot open addresses";
while(<ADDRESSES>){
chomp;
($name, $address, $city, $state, $zip) = split(/:/);
write(LABEL);
}
format LABEL =
=============================================
| @<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< |
$name
| @<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< |
$address
| @<<<<<<<<<<<<<<<<<, @<<<<<<< @<<<<<<< |
$city, $state, $zip
===============================================
.
- 값 행 내의 여백은 무시되고, 단지 보기 편하게 하기 해서
필드라인 형태와 비슷하게 작성한다.
- 마지막은 마침표( . ) 로 끝난다.
□ 포맷의 호출 : write 함수 이용
- write(포맷이름) 형태로 포맷을 호출한다.
- 문을 살펴보면, addresses.txt 일을 입력받아서 구분기호(:)를
기 으로 데이터를 분리하여(split), 각 값을 $name, $address,
$city, $state, $zip 에 할당하여 LABEL 포맷을 호출(write)하고,
결과가 address_print.txt 로 장되는 로그램이다.

50 계량정보분석을 한 로그래 활용사례연구
## addresses.txt
김서울: 구 종로동:서울시: 한민국:130-042
홍길동:함흥동:함경북도:조선왕조:000-000
## address_print.txt
=============================================
| 김서울 |
| 구 종로동 |
| 서울시 , 한민국 130-042 |
===============================================
=============================================
| 홍길동 |
| 함흥동 |
| 함경북도 , 조선왕조 000-000 |
===============================================
□ 텍스트 필드
- 필드홀더는 @ 로 시작한다.
- @ 와 뒤에 오는 문자의 수는 필드의 폭을 나타낸다.
- <<<< 는 왼쪽정렬, >>>> 는 오른쪽정렬, ||||| 는 가운데정
렬이다.
□ 산술필드(고정-정 도 숫자필드) : 재무리포트에 유용하다.
- @ 뒤에 #이 한개 이상 치한다. 마침표도 올 수 있다.
- ) @####.## : 소수 왼쪽에 다섯자리, 오른쪽에 2자리 형태

제2장 PERL의 문법 51
□ 복수행 필드
@* : 복수행의 필드홀더를 나타낸다.
## p181.pl
format STDOUT =
Text
@*
$long_string
Text after.
.
$long_string = "삼순이\n 순이\n이순신\n";
write;
□ 충 필드
- ^<<<<<< : 충 필드는 캐럿(^)으로 시작하며, 단어 경계에
서 편리한 크기의 행으로 나 다.
- 충 필드에 응하는 값은 텍스트를 담고 있는 스칼라변수여
야 한다.
- 틸더(~)문자를 포함하는 행은 빈 행으로 출력되는 경우에 출력
되지 않는다.
- 틸더가 2개(~~) 인 행은 그 결과가 완 히 공백 행이 될 때까
지 자동으로 반복되며, 빈 행은 출력되지 않는다.
- 문을 설명하면, 처음에 NEWS 포맷을 정의하고 있는데, 왼
쪽에 $event를 써주고, 오른쪽에 $comment를 써주는데, 틸더
2개(~~)를 사용하여 $comment를 계속 써 다. while 문 안에
서는 SOMENEWS 로 가져온 것을 $comment 변수로 모두 연
결시켜 다.

52 계량정보분석을 한 로그래 활용사례연구
## p183.pl
format NEWS = ### 포맷 정의하기
Event: @<<<<<<<<<<<< Contents: ^<<<<<<<<<<<<<<<<<<<<<<
$event, $comment
~~ ^<<<<<<<<<<<<<<<<<<<<<<<<<
$comment
.
open(SOMENEWS, "news_in.txt") || die "can't open";
open(NEWS, ">news_out.txt") || die "can't create";
$event = "박지성 뉴스";
while(chomp($one_line = <SOMENEWS>)){
$comment .= $one_line;
}
write(NEWS); ### 포맷 호출하기
close(SOMENEWS);
close(NEWS);
## news_out.txt
Event: 박지성 뉴스 Contents: [마이데일리 = 김 기 기자] 맨체스터
유나이티드의 박지성(24)이 유니폼
을 입고처음으로 경기에 출장, 좋은
모습을선보 다.박지성은 16일 오후(이
하 한국시간)스코틀랜드 로드우드스
타디움에서 열린스코틀랜드 2부리그
소속의 클라이드FC와 가진 리시즌
첫 경기에 나서 반 45분을 뛰었다.

제2장 PERL의 문법 53
□ Top of Page 포맷
- 포맷이름 끝에 _TOP 이 붙은 일핸들 이름을 사용한다.
- $% : 특정 일핸들에 해 top‐of‐page 포맷이 호출된 수
로 정의하므로 페이지 번호로 사용할 수 있다.
format LABEL_TOP =
Addresses ‐‐ Page @<
$%
.
□ select() 를 이용한 일핸들 바꾸기
- print, write 에 한 STDOUT 일핸들은 재 선택된 일
의 디폴트 일핸들이다.
- select 연산으로 일핸들을 선택하고 나면, 다음 번 select 까
지 일핸들을 유지한다.
- select( 일핸들); 형태로 사용
□ 포맷이름 바꾸기
- 특정 일핸들에 해서 디폴트 포맷이름은 일핸들과 같다.
- $~ 특별변수에 새로운 포맷이름을 설정할 수 있다.
## REPORT 일핸들에 해 포맷을 SUMMARY 로 설정하길 원할 때
$oldhandle = select REPORT;
$~ = "SUMMARY";
select ($oldhandle);
write(REPORT);

54 계량정보분석을 한 로그래 활용사례연구
□ Top of page 포맷이름 바꾸기
- 포맷이름 바꾸기와 동일하게 $ ̂ 변수를 이용하여 변경한다.
□ 페이지 길이 변경
- 페이지 길이의 디폴트는 60행이다. 즉 write가 마지막 60번째
행에 맞게 들어가지 않으면 텍스트가 출력되기 에 top‐of‐
page 포맷이 자동으로 호출된다.
- $= 변수를 설정하여 페이지 길이를 변경할 수 있다.
$old = select LOG;
$= = 40; ### 디폴트 값을 40 행으로 변경
select $old;

제2장 PERL의 문법 55
## p186.pl
format NEWS = ### 포맷 정의하기
Event: @<<<<<<<<<<<<< Contents: ^<<<<<<<<<<<<<<<<<<<<<<
$event, $comment
~~ ^<<<<<<<<<<<<<<<<<<<<<<<<<<
$comment
.
format NEWS_FORM = ### 포맷 정의하기
Event: @<<<<<<<<<<<<<
$event
Contents: ^<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$comment
~~ ^<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
$comment
.
open(SOMENEWS, "news_in.txt") || die "can't open";
open(NEWS, ">news_out.txt") || die "can't create";
open(NEWS, ">news_outform.txt") || die "can't create";
$event = "박지성 뉴스";
while(chomp($one_line = <SOMENEWS>)){
$comment .= $one_line;
}
#write(NEWS); ### 포맷 호출하기
$oldhandle = select NEWS;
$~ = "NEWS_FORM"; ### 포맷 바꾸기
select ($oldhandle); ### 이 의 일핸들을 선택
write(NEWS); ### NEWS 일핸들에 NEWS_FORM 형식을 이용
해서 write 수행
close(SOMENEWS);
close(NEWS);
close(NEWS_FORM);

56 계량정보분석을 한 로그래 활용사례연구
□ 페이지에서 치변경
- Perl은 write 이외의 어떤 것에 해서도 행을 헤아리지 않는
다.
- $변수 : 재 페이지에 남은 행의 수를 표시한다.
- write 명령 이후, 마지막 행에 도달하면 $‐ 변수값은 0 이 되
고, 다시 top‐of‐page 가 호출되어 페이지길이($=) 값이 $‐
값으로 된다.
제12절 디렉토리 액세스
□ 디 토리 트리에서의 이동
- chdir(변경해 갈 디 토리명) : 디 토리 명으로 로세스를
변경한다.
□ 로빙 : 특정 유형의 일이름을 수집할 때 사용한다.
- glob 함수를 이용한다.
## p190.pl
#print @a = glob("c:/Perl/실습/p*");
print @a = glob("p*");##p로 시작되는 모든 일의 리스트를 출력한다.
□ 디 토리 핸들
- 일핸들과 디 토리 핸들은 련이 없으며, 디 토리 핸들은
데이터를 읽기보다 디 토리 내에 있는 일이름의 리스트를

제2장 PERL의 문법 57
읽는데 사용한다. 한 디 토리 핸들은 항상 읽기 용으로
열려진다.
□ 디 토리 핸들 열고 닫기
- opendir(), closedir() 를 이용한다.
□ 디 토리 핸들 읽기
- 디 토리 핸들을 열고나면, readdir() 로 일이름의 리스트를
읽을 수 있다.
## p193.pl
opendir(POSITION, "c:/Perl/실습") || die "no 실습 ?: $!";
## 디 토리 치 선정
foreach $name (sort readdir(POSITION)){ ## 모든 일 이름을 정렬함
print "$name \n";
}
close(POSITION);
제13절 파일과 디렉토리 조작
□ 일 제거
- unlink( 일이름) 함수로 일을 제거한다.
- 제거될 이름들의 리스트를 인수로 받을 수도 있다.

58 계량정보분석을 한 로그래 활용사례연구
□ 일 이름 변경
- rename($old, $new) 로 변경한다.
- rename(“file”, “some‐directory/file”);
□ 링킹 : 일에 한 다른 이름 생성
- 하드링크 : 일로의 모든 하드링크는 같은 디스크 상에 존재
해야 한다.
- 소 트링크(심링크, 심볼릭링크) : 재 일 시스템 밖에 있는
경로를 가리킬 수도 있다.
- 모든 시스템에서 지원되는 것은 아니다.
- link(이 일이름, 새로운 이름) # 하드링크
- symlink(이 일이름, 새로운 이름) # 심링크
□ 디 토리 생성과 제거 : mkdir(), rmdir
- mkdir(디 토리명, 모드); : 디 토리를 생성하며, 모드는 내
부 허가권에 향을 미치는 숫자이다. 0777을 모드로 사용하면
모든 것이 동작한다.
- rmdir(디 도리명); : 디 토리를 제거한다.
□ 허가권 변경
- chmod(모드, 일명);
- 모드는 8진수이며, 사용자, 그룹, 타사용자순으로 읽기(4), 쓰기
(2), 실행(1) 권한을 정의하며, 권한 값을 더해서 나타낸다.
- ) 사용자에게 모든권한, 그룹과 타사용자에게는 읽기만 가능하
도록 하는 모드는 0744 로 표 되며, 유닉스 표 은 rwxrr이다.

제2장 PERL의 문법 59
제14절 다른 데이터 변환
이 은 정규표 식과 함께 사용하면 도움이 많이 되는 부분이다.
□ 서 문자열 찾기
- $x = index($string, $substring) : $string 에서 $substring을
찾아서 왼쪽에서부터의 치를 반환한다. 치는 0 부터 시작
하는 정수이고, 찾는 값이 없으면 -1을 리턴한다.
## p219.pl
print $position = index("I am a student", "stu");
# "stu" 의 문자열 치 7를 리턴
print "\n";
print $position = index("I am a studentg", "sstu"); # -1을 리턴
print "\n";
print $position = index("I am a studentg", "a");
# 처음나타난 am 의 치 2를 리턴
- $x = index("good morning", "o", 4); # 4번 치 이후부터
찾아서 "o"의 치 6을 반환
- rindex 는 오른쪽에서부터 탐색한다.

60 계량정보분석을 한 로그래 활용사례연구
## p220.pl
print $position = index("good morning", "o", 5);
# 5번 치부터 시작하여 "o"의 치 6
print "\n";
print $position = rindex("good morning", "o"); # 가장 오른쪽 "o" 의
치는 6
print "\n";
print $position = rindex("good morning", "o", 5); # 5이 의 오른쪽
"o" 의 치는 2
□ 서 문자열의 추출과 체
- $s = substr(문자열, 시작 치, 길이) : 문자열에서 시작 치
로부터 길이만큼의 문자열을 추출하여 $s에 할당한다.
- 길이 값을 무 크게 해도 문자열의 끝까지만 추출하고 끝낸다.
- 시작 치가 음수이면 문자열 오른쪽에서부터의 치이다.
- 시작 치가 아주 큰 음수여서 문자열 길이를 넘어서면, 문자열
의 시작(0)이 시작 치이다.
- 시작 치가 아주 큰 양수여서 문자열 길이를 넘어서면 항상
빈 문자열이 리턴된다.
## p221.pl
print $extraction = substr("good morning", 6, 20);
print "\n", $extraction = substr("여름날씨가 덥다", 4, 4);
# 한 은 한 자에 2자리 차지
print "\n", $extraction = substr("good morning", -5, 5);
# 오른쪽에서 5번째부터 시작하여 추출

제2장 PERL의 문법 61
- substr(스칼라변수, 시작 치, 길이) = 체문자열 : 스칼라
변수를 체문자열만큼 변경한다.
## p222.pl
$gm = "good morning!";
substr($gm, 5, 20) = "afternoon"; # $gm = good afternoon 로 바뀜
print $gm;
□ sprintf() 로 데이터 포맷 하기
- 문자열 데이터 포맷
## p223.pl
$y = 123;
print $format = sprintf("X%07d", $y); ## X0000123
# X 뒤 7자리에 $y 값을 채우되 가운데 빈자리는 0으로 채움
□ 고 정렬 : sort 고 활용
- sort 는 아스키 순서 로 정렬한다(숫자순서가 아님).
- <=> 우주선연산자는 숫자비교의 결과를 -1, 0, 1 로 리턴한다.
- 배열명 = sort { $a <=> $b } 원배열명 : 원배열명의 값들을
비교하여 숫자크기 순서 로 정렬하여 배열명에 할당한다.
- 문자배열명 = sort { $a cmp $b } 원문자배열명 : 원문자배열
명의 값들을 비교하여 문자순으로 정렬하고, 문자배열명에 할
당한다.
- ($a <=> $b) || ($a cmp $b) : 숫자순서와 문자순서의 혼합에
사용한다.

62 계량정보분석을 한 로그래 활용사례연구
## p225.pl
@wronglist = (1,2,4,325,16,24,32,64,129,225);
@rightlist = sort {$a <=> $b} @wronglist; #숫자순 정열
foreach $list (@rightlist){ print "$list \t"; }
print "\n";
@literal_list = qw(student, desk, hat, watch, sky, school, road);
@result = sort { $a cmp $b } @literal_list; # 문자순 정열
foreach $list (@result){ print "$list \t"; }
print "\n\n";
@somelist = (1, 2, 45, 23, 125, " ", "여름", "가을", "겨울", "boy", "girl",
"animal");
@result_mix = sort by_mostly_numeric @somelist; # 숫자와 문자순
정열
foreach $list (@result_mix){ print "$list \t"; }
sub by_mostly_numeric { ## 사용자 정의함수
($a <=> $b) || ($a cmp $b); ## 숫자와 문자순 정렬의 혼합
}
- 해시에 한 정렬 : 키(로그인 이름) – 값(실제이름)의 %
names 해시에 해 값(실제이름)의 순서로 키‐값을 정렬하
고 싶은 경우

제2장 PERL의 문법 63
## p226.pl
%names = qw(lkkr, janggilsan, # 해시는 키‐값의 이며, 동일한 키는
없으나
golr, honggildong, # 동일한 값은 가능함
wert, samsuni, # 키(로그인 이름) ‐값(실제이름)
ttui, yisunsin
ijfy, yisunsin);
@sortedkeys = sort by_names keys(%names);
# 해시 %names 의 키를 정렬하여 @sortedkeys 에 할당하는데,
# 비교는 서 루틴 by_names 에서 수행하며
# by_names 에서는 해시의 값(실제이름)을 우선 으로 비교하고
# 동일한 값일 경우에는 키(로그인 이름)를 비교하여 정렬함
sub by_names {
($names{$a} cmp $names{$b}) || ($a cmp $b);
}
foreach (@sortedkeys){
print "$_ has a real name of $names{$_}\n";
}
□ 변환
- tr/ab/ba/; # 모든 a 는 b로, 모든 b 는 a 로 변환
- tr/abcde/ABCDE/;
- tr/a-z/A-Z/ # 소문자를 문자로 변환

64 계량정보분석을 한 로그래 활용사례연구
- tr/a-z/A-E/; # 응되는 것이 없으면 마지막 문자(E)로
변환
- tr/a-z/A-E/d; # 응되는 것이 없으면 삭제함
- tr/a-z//; # 새로운 리스트가 없고, d옵션도 없으면 새로
운 리스트는 옛날 것과 동일
- tr/// # 연산자의 리턴값은 옛날 문자열에 의해 일치
된 문자의 수
- $count = tr/a-z//c; # $_는 변화없고, $count 는 a - z 이외
의 문자수
- tr/a-z/_/c; # 비문자(a - z 이외의 문자)를 _ 로 변
환
- tr/a-z//cd; # 먼 보집합(complement)을 구하고 제
거함(delete)

제2장 PERL의 문법 65
## p228.pl
$_ = "nice to meet you!";
tr/a - e/A - E/; # 변환
print; print "\n";
$_ = "nice to meet you!";
tr/a - z/A - E/; # 응되는 것이 없으면 마지막 문자로 변환
print; print "\n";
$_ = "nice to meet you!";
tr/a-z/A-E/d; # 응되는 것이 없으면 삭제함
print; print "\n"; # $_ 는 "CE EE !" 로 됨
$_ = "nice to meet you!";
$count = tr/a-z//;
# 새로운 리스트가 없고, d옵션도 없으면 새로운 리스트는 옛날 것과 동일
# $_ 는 변화가 없으나, $count 는 문자의 수(13)가 됨
print; print "$count \n";
$_ = "nice to meet you!";
$count = tr/a-z//c; # $_는 변화없고, $count 는 a-z 이외의 문자수 4
print; print " $count \t";
tr/a-z/_/c; # 비문자(a-z 이외의 문자)를 _ 로 변환
# $_는 "nice_to_meeet_you_"
print; print "\t";
tr/a-z//cd; # 먼 보집합(complement)을 구하고 그 것을
제거함(delete)
print; print "\n"; # $_는 "nicetomeetyou"

66 계량정보분석을 한 로그래 활용사례연구
- 옵션 s : 변환된 결과문자에서 연속되는 동일문자를 하나로
압축한다.
- =~ 연산자 : 변환된 다른 문자열을 목표로 할 때 사용한다.
## p229.pl
$_ = "nice to meet you!, ??, no answer!";
tr/a - n/Z/s; # a‐n 사이의 문자는 Z 로 바 는데, 연속되면 Z를 한번만 사용함
print; print "\n";
$_ = "nice to meet you!, ??, no answer!";
tr/a - z/_/cs; # a‐z 이외의 문자는 언더바로 바 는데,
#모든 연속 인 비문자의 묶음(!, ??, )이 하나의 _ 로 바뀜
print; print "\n";
$sentence = "nice to meet you!, ??, no answer!";
$sentence =~ tr/a - z/X/s; # a - z 문자를 X 로 바꾸며, 압축함
print $sentence;
제15절 CGI
□ CGI ( common gateway interface )
CGI는 common gateway interface의 약자로써, 서버 컴퓨터에 존재
하는 여러 데이터와 로그램으로의 공통된(common) 게이트웨이를
만들어주는 인터페이스이다. 웹페이지를 단순히 HTML로 만든 것 보
다 CGI로 만드는 것이 훨씬 더 많은 효과를 가져다 다.
제2장 PERL의 문법 67
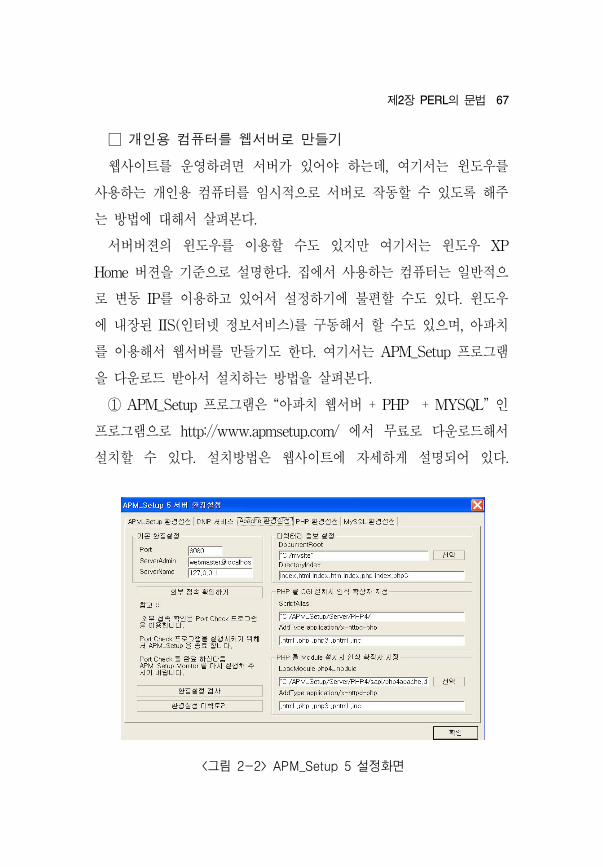
<그림 2-2> APM_Setup 5 설정화면
□ 개인용 컴퓨터를 웹서버로 만들기
웹사이트를 운 하려면 서버가 있어야 하는데, 여기서는 도우를
사용하는 개인용 컴퓨터를 임시 으로 서버로 작동할 수 있도록 해주
는 방법에 해서 살펴본다.
서버버젼의 도우를 이용할 수도 있지만 여기서는 도우 XP
Home 버젼을 기 으로 설명한다. 집에서 사용하는 컴퓨터는 일반 으
로 변동 IP를 이용하고 있어서 설정하기에 불편할 수도 있다. 도우
에 내장된 IIS(인터넷 정보서비스)를 구동해서 할 수도 있으며, 아 치
를 이용해서 웹서버를 만들기도 한다. 여기서는 APM_Setup 로그램
을 다운로드 받아서 설치하는 방법을 살펴본다.
① APM_Setup 로그램은 “아 치 웹서버 + PHP + MYSQL” 인
로그램으로 http://www.apmsetup.com/ 에서 무료로 다운로드해서
설치할 수 있다. 설치방법은 웹사이트에 자세하게 설명되어 있다.

68 계량정보분석을 한 로그래 활용사례연구
APM_Setup 로그램이 작동되는 동안은 내 컴퓨터가 웹서버로 작용
한다.
② APM_Setup 을 설치한 후에는 내 웹써버의 문서 루트를 c:\mysite
로 생성한다. 그리고 CGI 일을 넣을 디 토리를 c:\mysite\cgi-bin
으로 생성한다.
③ APM_Setup 로그램 설치후 C:\APM_Setup\Server\Apache\conf
에서 "httpd.conf"를 텍스트 에디터로 열어서 편집을 다음과 같이 한다.
- DocumentRoot "C:/Program Files/Apache Group/ Apache/
htdoc"을 찾는다. 없으면 유사한 것을 찾는다. 이것을 DocumentRoot"
C:/mysite" 로 수정한다.
- 그 에 조 더 내려가보면, <Directory "C:/Program Files/
Apache Group/Apache/htdoc">가 나온다. 없으면 유사한 것을
찾는다. 이것은 의 DocumentRoot와 같이 맞춰줘야 하므
로 <Directory "C:/mysite">로 바꾼다.
- 그 다음 요한 것이 나오는데, <IfModule mod_alias.c>를 찾
아서 내부에 다음의 문장을 추가한다.
<Directory "C:/mysite">
AllowOverride None
Options ExecCGI
AddHandler cgi‐script .pl .cgi
Order allow,deny
Allow from all
</Directory>
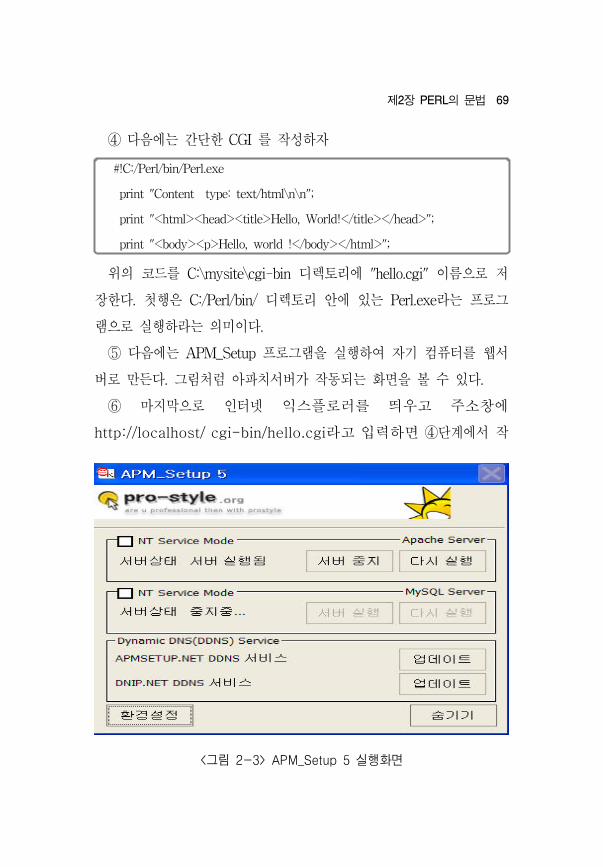
제2장 PERL의 문법 69
<그림 2-3> APM_Setup 5 실행화면
④ 다음에는 간단한 CGI 를 작성하자
#!C:/Perl/bin/Perl.exe
print "Content‐type: text/html\n\n";
print "<html><head><title>Hello, World!</title></head>";
print "<body><p>Hello, world !</body></html>";
의 코드를 C:\mysite\cgi-bin 디 토리에 "hello.cgi" 이름으로
장한다. 첫행은 C:/Perl/bin/ 디 토리 안에 있는 Perl.exe라는 로그
램으로 실행하라는 의미이다.
⑤ 다음에는 APM_Setup 로그램을 실행하여 자기 컴퓨터를 웹서
버로 만든다. 그림처럼 아 치서버가 작동되는 화면을 볼 수 있다.
⑥ 마지막으로 인터넷 익스플로러를 띄우고 주소창에
http://localhost/ cgi-bin/hello.cgi라고 입력하면 ④단계에서 작

70 계량정보분석을 한 로그래 활용사례연구
성한 CGI를 볼 수 있다. Hello, Wolrd!라고 뜬다면 성공한 것이
다. 다른 컴퓨터에서 확인해 보려면 인터넷 주소창에 localhost 신
CGI를 제공하는 컴퓨터의 IP 주소를 입력하여 확인해 볼 수 있다.
기본 펄 배포 에서 최근에는 CGI를 사용할 수 있는 CGI.pm 모듈
을 제공하고 있으므로 모듈 활용법만 익히면 쉽게 CGI를 만들 수 있
을 것이다.

제3장 활용하기 71
제 3 장
활용하기
제3장에서는 앞 장에서 소개한 펄 로그래 문법을 종합 으
로 용한 펄 로그램 소스코드를 통해서 실제로 어떻게 로그래
을 하는지 살펴보기로 한다. 이 장에서 소개할 소스코드는 2가지
이며 그 하나는 “계량정보분석을 통한 지식의 Mapping과 활용
(한국과학기술정보연구원, 2005)”에서 소개하고 있는 로 기술의
략맵을 다루고 있다. 다른 하나는 한국특허 록데이터로부터 발
명자의 지역별 분포를 도출하는 것이다.
제1절 co-word 분석의 전략맵 도출
1. co-word 분석의 전략맵 도출 과정
“계량정보분석을 통한 지식의 Mapping과 활용(한국과학기술정
보연구원, 2005)” 보고서에서 략맵의 도출과정을 보면 <그림
3-1> 과 같다. 자세히 살펴보면 데이터를 선정하고 나서 키워드를
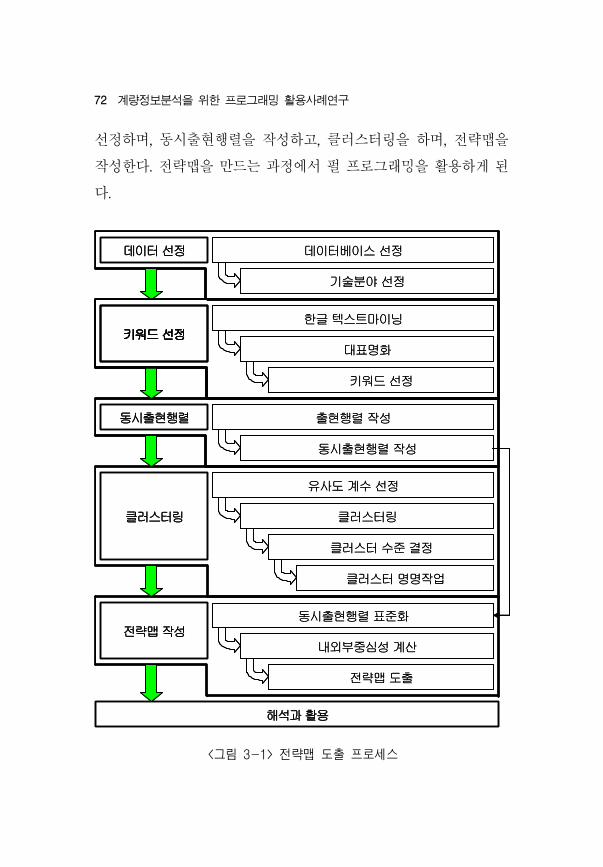
72 계량정보분석을 한 로그래 활용사례연구
선정하며, 동시출 행렬을 작성하고, 클러스터링을 하며, 략맵을
작성한다. 략맵을 만드는 과정에서 펄 로그래 을 활용하게 된
다.
<그림 3-1> 전략맵 도출 프로세스
데이터선정 데이터베이스선정
기술분야선정
한글텍스트마이닝
대표명화
키워드선정
출현행렬작성
동시출현행렬작성
유사도계수선정
클러스터링
클러스터수준결정
클러스터명명작업
동시출현행렬표준화
내외부중심성계산
전략맵도출
해석과활용
키워드선정
동시출현행렬
클러스터링
키워드선정
전략맵작성
데이터선정 데이터베이스선정
기술분야선정
한글텍스트마이닝
대표명화
키워드선정
출현행렬작성
동시출현행렬작성
유사도계수선정
클러스터링
클러스터수준결정
클러스터명명작업
동시출현행렬표준화
내외부중심성계산
전략맵도출
해석과활용
키워드선정
동시출현행렬
클러스터링
키워드선정
전략맵작성

제3장 활용하기 73
략맵 과정 에 필요한 것은 선정된 키워드의 클러스터명(숫자
값)과 동시출 행렬값이다. 를 들면 <표 3-1>은 키워드간 동시
출 행렬을 나타내고 있고, <표 3-2>는 각 키워드의 클러스터명
(숫자값)을 나타내고 있다. 이들을 텍스트 일로 펄 로그램에서
입력받아서 략맵을 한 데이터를 만든다.
<표 3-1> 키워드 동시출현행렬
구분 시스템 제어 기능 설계 형태 인식 정보 제작 자동화 ⋯
시스템 73 54 34 39 31 32 36 30 32
제어 54 65 33 38 30 29 28 34 25
기능 34 33 49 24 27 23 23 23 16
설계 39 38 24 48 25 23 19 29 16
형태 31 30 27 25 44 25 18 19 12
인식 32 29 23 23 25 39 22 16 14
정보 36 28 23 19 18 22 38 12 14
제작 30 34 23 29 19 16 12 36 11
자동화 32 25 16 16 12 14 14 11 36
⋮
<표 3-2> 키워드의 클러스터명
키워드 7 군집
시스템 1
제어 1
기능 1
설계 1
형태 1
인식 1
정보 1
제작 1
자동화 1
⋮ ⋮

74 계량정보분석을 한 로그래 활용사례연구
키워드1의 density = (d1+d2)/(3-1)
키워드1의 centrality = (c1+c2+c3)/(8-3)
<그림 3-2> 키워드1의 density와 centrality
클러스터1
클러스터3
클러스터2
키워드1
키워드2
키워드3
d1d2
d3
c1
c2
c3
클러스터1
클러스터3
클러스터2
키워드1
키워드2
키워드3
d1d2
d3
c1
c2
c3
표 화된 동시출 행렬의 값을 보통 Equivalence index,
e-coefficient, Strength 라고 말한다. 만약 출 행렬의 각 키워드의
빈도수를 C 라 할때, 표 화된 값은 Eij =
=
로 계산
된다. 이 게 계산된 행렬을 표 화된 동시출 행렬로 둔다.
략맵을 도출하기 해서는 각 키워드가 클러스터 내외부에 존
재하는 다른 키워드와 얼마나 계를 맺고 있는가에 한 정보를
계산해야 한다. Strength 매트릭스로 부터 내외부 심성을 계산하
는데, 보통 내부 심성을 density라고 말하며, 외부 심성을
centrality라고 말한다. density와 centrality 계산방법은 연구자에
따라 다르며 여기서는 독자 으로 정의한 내외부 심성을 사용한
다. 본 보고서에서 각 키워드의 내부 심성(density)은 클러스터
내에서의 키워드간 Eij 의 합을 클러스터 내의 자유도(n-1)로 나
값으로 정의한다. 한편 각 키워드의 외부 심성(centrality)은 클러
스터 외부에 연결된 키워드와의 Eij 의 합을 클러스터 외부의 자유
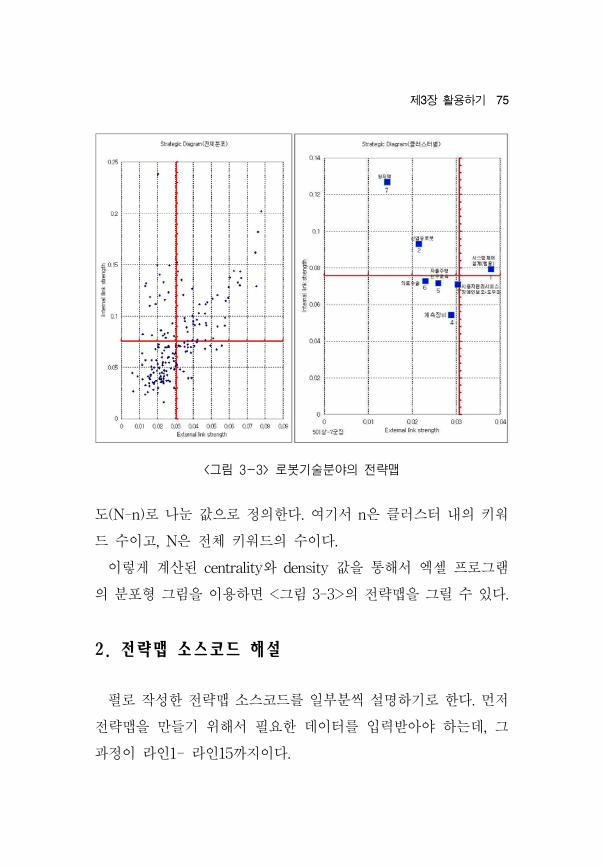
제3장 활용하기 75
<그림 3-3> 로봇기술분야의 전략맵
도(N-n)로 나 값으로 정의한다. 여기서 n은 클러스터 내의 키워
드 수이고, N은 체 키워드의 수이다.
이 게 계산된 centrality와 density 값을 통해서 엑셀 로그램
의 분포형 그림을 이용하면 <그림 3-3>의 략맵을 그릴 수 있다.
2. 전략맵 소스코드 해설
펄로 작성한 략맵 소스코드를 일부분씩 설명하기로 한다. 먼
략맵을 만들기 해서 필요한 데이터를 입력받아야 하는데, 그
과정이 라인1- 라인15까지이다.

76 계량정보분석을 한 로그래 활용사례연구
<그림 3-4> 전략맵 소스코드(1-16라인)
∙ 1라인에서는 #으로 시작하면서 주석을 달고 있는데, 로그램에
한 소개를 하고 있다.
∙ 2라인에서는 입출력에 계된 주석문이다.
∙ 3라인에서는 print 문을 이용하여 사용자에게 키워드의 동시출
행렬 일을 입력하라는 메시지를 쓰고 있다. 마지막의 “\n”
은 바꿈 기호이다. 실제 로그램을 실행할 때, “Type your
text file name ... " 가 명령어 실행창에 나타나면 텍스트로 된
동시출 행렬을 입력하면 된다.
∙ 4라인에서는 chomp 명령을 사용하고 있는데, 키워드의 동시출
행렬 일이름을 입력하고 마지막에는 엔터키를 칠 수 밖에
없고 이것은 일이름에 불필요한 “\n” 를 추가하게 된다. 표
입력 <STDIN> 으로 입력받은 입력 일이름에서 “\n” 를
제거할 수 있는 명령이 chomp 명령어이다. 이 게 제거된 후의
일이름이 $inputfile 이라는 변수에 장된다.
∙ 6라인에서는 if 문을 사용하고 있는데, $inputfile에 값이 있으면

제3장 활용하기 77
다음 과정을 수행하기 해서다.
∙ 7라인에서는 키워드의 클러스터명을 나타내는 텍스트 일의 이
름을 입력하라는 메시지를 나타낸다.
∙ 8라인에서 첫번째 if 문은 종료된다.
∙ 9라인에서는 4라인과 동일하게 불필요한 바꿈 기호를 제거하
고 클러스터 일이름을 $cluster_name 이라는 변수에 장한
다.
∙ 11라인부터 15라인까지는 open 함수를 사용하고 있는데, 일핸
들을 이용하여 입출력용 일이름을 다루고 있다. 11라인은
$inputfile을 IN이라는 일핸들로 읽기모드로 읽는다. 만약 읽
을 수 없다면(||), "cannot open $inputfile: $!";메시지를 나타내
면서 로그램 실행이 단된다.
∙ 12라인은 $cluster_name 을 CLUSTERNAME이라는 일핸들
로 읽기모드로 읽는다.
∙ 13라인부터 15라인까지는 각각 STRENGTH, CENTRALITY,
DENSITIY라는 일핸들을 이용하여, 쓰기모드로 이용한다. 즉
생성될 일이름은 각각 strength.txt, centrality.txt, denstiy.txt
가 된다.

78 계량정보분석을 한 로그래 활용사례연구
<그림 3-5> 전략맵 소스코드(19-35라인)
∙ 19라인은 주석이고, 20라인은 테스트용으로 사용했던 불필요한
것이다.
∙ 21라인은 <표 3-1> 의 형태로 입력받은 키워드간 동시출 행
렬 일을 일핸들 IN으로 가져와서 한 행씩 $one_line 으로
가져온다. 한, 한 행의 마지막에 있는 엔터키(\n)를 chomp
명령어로 제거하는데, while 문을 사용하여 모든 행이 끝날때까
지 계속한다.
∙ 22라인은 $one_line으로 가져온 한 행의 값을 탭간격으로 분리
하여, 분리된 데이터를 배열 @matrix_temp에 장하는 것이다.
키워드간 동시출 행렬은 다른 로그램(엑셀도 활용)에서 만
들어서 탭간격으로 구분된 텍스트 일로 만든 것이다.
∙ 23라인은 한 행씩 분리되어 장된 배열 @matrix_temp 값을
@matrix 배열에 추가하는 것이다. 이 것은 모든 행의 값을
@matrix 의 요소값으로 장하는 것이다. 실제 로 기술분야에

제3장 활용하기 79
해서 분석할 때 선정된 키워드는 176개 다. 따라서 동시출
행렬은 제목셀까지 포함하여 177×177 매트릭스가 되므로
@matrix 배열의 요소수는 177×177 = 31,329개이다. 펄은 매트
릭스를 직 처리할 수 없다는 단 이 있어서 배열로 처리했지
만, 기존에 만들어진 수학 모듈을 사용할 수도 있을 것이다.
∙ 24라인에서는 while 문을 닫고 있다.
∙ 25라인은 행의 수를 계산하여 $rows 로 할당한다. 배열명의 앞
에 $#를 붙인$#matrix 는 배열 @matrix 의 마지막 요소의 순번
을 나타낸다. 그러나 배열 요소는 0부터 시작하므로 마지막 요
소의 순번은 177×177 = 31,329가 아닌, 31,328이 된다. 따라서
$#matrix에 1을 더해 값을 제곱근(sqrt) 취하면 정사각 매트
릭스의 행의 수가 계산된다.
∙ 27라인부터 34라인은 동시출 행렬을 표 화한 strength 매트릭
스를 생성한다. strength 매트릭스는 @strength 배열로 값을
장하는데, square 매트릭스이고, @matrix 와 처음 행과 처음 열
은 모두 키워드로 채워진 동일한 값이므로 @matrix 를
@strength 로 복사하 다. 처음 행과 처음 열만 제외하고 나머
지를 다음 라인부터 수정할 것이다. <그림 3-6>은 @matrix를
보여주고 있다. 첫번째 요소는 “구분”이며 요소 순번은 0이다.
∙ 두번째 행의 첫 요소인 “시스템”의 순번은 $rows 이다. 28라인
에서는 행의 수를 2행부터 행의 마지막인 $rows 까지 한 행씩
증가시킨다는 의미이다.
∙ 29라인은 둘째열부터 마지막열인 $rows 까지 한 열씩 증가시킨
다는 의미이다. 따라서 <그림 3-6>에 음 으로 표신된 숫자값
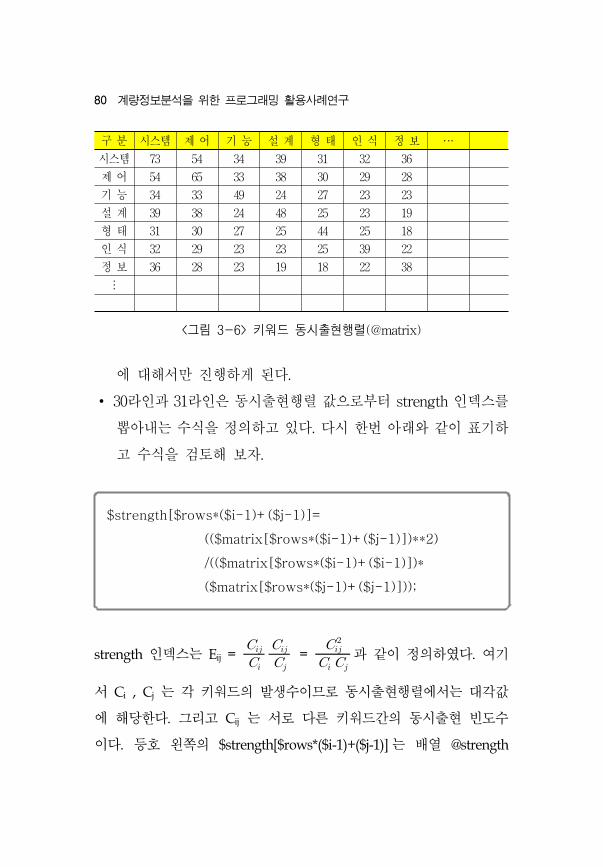
80 계량정보분석을 한 로그래 활용사례연구
<그림 3-6> 키워드 동시출현행렬(@matrix)
구 분 시스템 제 어 기 능 설 계 형 태 인 식 정 보 ⋯
시스템 73 54 34 39 31 32 36
제 어 54 65 33 38 30 29 28
기 능 34 33 49 24 27 23 23
설 계 39 38 24 48 25 23 19
형 태 31 30 27 25 44 25 18
인 식 32 29 23 23 25 39 22
정 보 36 28 23 19 18 22 38
⋮
에 해서만 진행하게 된다.
∙ 30라인과 31라인은 동시출 행렬 값으로부터 strength 인덱스를
뽑아내는 수식을 정의하고 있다. 다시 한번 아래와 같이 표기하
고 수식을 검토해 보자.
$strength[$rows*($i-1)+($j-1)]=
(($matrix[$rows*($i-1)+($j-1)])**2)
/(($matrix[$rows*($i-1)+($i-1)])*
($matrix[$rows*($j-1)+($j-1)]));
strength 인덱스는 Eij =
=
과 같이 정의하 다. 여기
서 Ci , Cj 는 각 키워드의 발생수이므로 동시출 행렬에서는 각값
에 해당한다. 그리고 Cij 는 서로 다른 키워드간의 동시출 빈도수
이다. 등호 왼쪽의 $strength[$rows*($i-1)+($j-1)] 는 배열 @strength

제3장 활용하기 81
<그림 3-7> 전략맵 소스코드(36-45라인)
의 각각의 요소를 나타낸다. 즉 이 값이 Eij 이다. 맨 처음 값은 2행
2열($i = 2, $j = 2)에 있는 값이 된다. 등호의 오른쪽은 키워드 동시
출 행렬 @matrix 에서 strength 인덱스를 계산하는 수식이다. 즉
에 해당하는 부분이다.
∙ 33-34라인은 두 개의 for 문을 닫고 있다.
∙ 36-41라인은 계산된 strength 인덱스 값들을 출력 일로 출력하
는 것이다.
∙ 36라인에서는 행을 1행부터 마지막행($rows)까지 1행씩 증가시
킨다.
∙ 37라인은 1열부터 마지막열까지 증가시킨다.
∙ 38라인은 배열 @strength 에 장된 각각의 값인 $strength 를
하나씩 일핸들 STRENGTH 로 출력하는 것이다. 하나씩 출
력하되, 탭간격(\t)으로 띄우면서 장한다. 이 게 하면 나
에 엑셀 등에서 작업하기가 편리한다.
∙ 39라인에서는 열이 마지막열까지 도착하면 for문을 종료한다.
∙ 40라인에서 바꿈을 하기 해서 바꿈(\n)을 출력한다.
82 계량정보분석을 한 로그래 활용사례연구
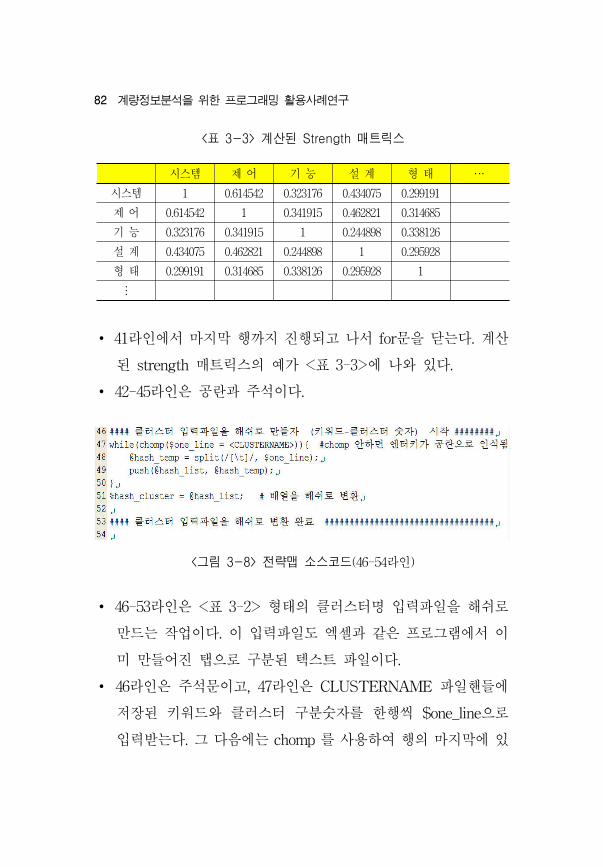
<표 3-3> 계산된 Strength 매트릭스
시스템 제 어 기 능 설 계 형 태 ⋯
시스템 1 0.614542 0.323176 0.434075 0.299191
제 어 0.614542 1 0.341915 0.462821 0.314685
기 능 0.323176 0.341915 1 0.244898 0.338126
설 계 0.434075 0.462821 0.244898 1 0.295928
형 태 0.299191 0.314685 0.338126 0.295928 1
⋮
<그림 3-8> 전략맵 소스코드(46-54라인)
∙ 41라인에서 마지막 행까지 진행되고 나서 for문을 닫는다. 계산
된 strength 매트릭스의 가 <표 3-3>에 나와 있다.
∙ 42-45라인은 공란과 주석이다.
∙ 46-53라인은 <표 3-2> 형태의 클러스터명 입력 일을 해쉬로
만드는 작업이다. 이 입력 일도 엑셀과 같은 로그램에서 이
미 만들어진 탭으로 구분된 텍스트 일이다.
∙ 46라인은 주석문이고, 47라인은 CLUSTERNAME 일핸들에
장된 키워드와 클러스터 구분숫자를 한행씩 $one_line으로
입력받는다. 그 다음에는 chomp 를 사용하여 행의 마지막에 있

제3장 활용하기 83
<그림 3-9> 전략맵 소스코드(55-71라인)
는 엔터키를 제거한다. 이것을 while 문을 이용하여 일의 끝
까지 진행한다.
∙ 48라인은 $one_line 에 장된 한 행(키워드-클러스터 구분숫
자)을 탭간격을 기 으로 split 을 이용하여 분리하고, 이를 각
각 배열 @hash_temp 에 장한다.
∙ 49라인은 @hash_temp 에 장된 키워드-클러스터 구분숫자
을 배열 @hash_list 에 push 명령을 이용하여 차곡차곡 쌓아둔
다.
∙ 50라인에서 while 문을 닫음으로 해서 클러스터 입력 일의 모
든 값은 배열 @hash_list에 배열 형태로 장된다.
∙ 51라인에서 @hash_list을 해쉬 %hash_cluster 로 변환함으로써
키워드-클러스터 구분 숫자 이 해쉬로 변한다. 해쉬는 이제
키워드의 순서는 상 없이 키워드와 클러스터 구분숫자의 만
의미있는 계가 된다. 마치 웹사이트의 로그인과 패스워드의
계가 된다.

84 계량정보분석을 한 로그래 활용사례연구
∙ 56라인부터 80라인까지는 strength 매트릭스 값을 이용하여
centrality 와 density를 계산하는데, 먼 56-71라인을 살펴보자.
∙ 56라인은 주석이고, 57라인은 행의 수를 2행부터 마지막행까지
한 행씩 증가시킨다.
∙ 58라인은 행이 바뀔 때마다 값을 기화 하는 작업이 필요해서
각 값을 0으로 기화 했다.
∙ 59라인은 열을 2열부터 마지막 열까지 한 열씩 증가시킨다.
∙ 60라인을 살펴보면, strength 매트릭스의 각선 값은 계산과정
에서 제외하기 때문에 행과 열이 같지 않을 경우에만(!= 연산
자) 진행함을 보여 다.
∙ 61라인은 각 키워드의 클러스터 구분숫자가 서로 같은지를 보는
것이다. 이는 같은 클러스터 구분숫자를 가진다면 동일한 클러
스터이고 이때는 내부 심성(density)을 계산하기 해서다.
등호의 왼쪽 $hash_cluster{$strength[$rows*($i-1)]} 은 첫번
째 열의 키워드 $strength[$rows*($i-1)] 에 한 해쉬의 값인
클러스터 구분 숫자를 나타낸다. 이는 각 행의 첫열에 해당하는
키워드들의 클러스터 구분숫자이다. 이 것을 첫 행에 있는 키워
드들의 클러스터 구분숫자와 비교하자는 것이다. 그래서 등호
의 오른쪽인 $hash_cluster{$strength[$j-1]} 는 첫 행에 있는
키워드 $strength[$j-1] 의 해쉬 값인 클러스터 구분 숫자이다.
∙ 62라인은 주석이고, 63라인은 키워드의 클러스터가 서로 일치하
는 경우에 있어서, 각각의 strength 인텍스 값을 모두 더해서
$sum_den 에 장한다. 그리고 앞서 각선 값은 제외했으므
로 동일한 클러스터 내의 다른 키워드의 수를 계산해서

제3장 활용하기 85
<그림 3-10> 전략맵 소스코드(72-81라인)
$num_den 에 장한다. density의 계산방법은 한 키워드가 동
일한 클러스터내에 있는 다른 키워드와의 연결 계 합을 최
연결가능한 키워드 수(자유도, n-1)로 나 값으로 정의한다.
여기서 n은 동일한 클러스터 내부의 키워드 숫자이다. density
계산은 나 으로 미루기로 하고 아직까지는 비만 했다.
∙ 65라인은 if 문을 닫고, 66라인은 키워드의 클러스터 구분숫자가
다른 경우를 시작하고 있다. 이러한 경우에는 centrality를 계산
한다.
∙ 67라인은 클러스터 외부에 연결된 키워드들의 strength 인덱스
값들을 += 연산자를 이용해서 해서 그 결과를 $sum_cen
에 장한다.
∙ 68라인은 ++ 연산자를 이용하여 클러스터 외부의 키워드 숫자
를 계산하여 $num_cen에 장한다. 이는 클러스터 외부의 최
연결가능한 키워드의 수(자유도, N-n)에 해당한다. 여기서 N
은 체 키워드의 숫자이다.
∙ 69-71라인은 안쪽부터 if 문 2개와 for 문 하나를 닫는다.
∙ 72라인은 테스트용으로 사용한 불필요한 문장이다. 그러나 실제

86 계량정보분석을 한 로그래 활용사례연구
<그림 3-11> 전략맵 소스코드(82-91라인)
로그램 개발시에는 간 간에 계속 으로 테스트를 해보면
서 코드를 작성하는 것이 가장 빠른 방법이다. 모두 작성한 이
후에 테스트 하면 어디에서 에러가 났는지 찾기가 매우 어렵다.
∙ 74라인은 앞서 계산된 $sum_den 을 클러스터 내부 자유도(n-1)
인 $num_dem 로 나 어서(/) 이 값을 density 값($density)으
로 정한다.
∙ 75라인은 마찬가지로 $sum_cen 값을 외부 자유도(N-n)인
$num_cen으로 나 어서 이 값을 centrality 로 정하고
$centrality 에 할당한다. 이는 하나의 행에 해서 계산한 것인데,
각 행의 첫 열에 있는 키워드에 을 두고 계산한 방식이다.
∙ 78라인과 79라인에서는 계산된 centrality와 density 값을 각 키
워드의 해쉬 값으로 할당하고 있다. 즉 키워드와 centraliry의
을 해쉬로 만들고, 키워드와 density의 을 해쉬로 만들기
함이다.
∙ 80라인에서는 centraliry와 density 계산과정을 종료하고 있다.
∙ 82-91라인은 계산된 centrality와 density 를 나 에 엑셀에서

제3장 활용하기 87
열기 해서 일단 탭간격으로 구분된 텍스트 일을 만드는
과정이다. 83라인은 centrality 일의 첫행을 일핸들
CENTRALITY를 이용하여 쓰고 있다.
∙ 84-86라인은 키워드와 centrality의 으로 구성된 해쉬
%cen_hash에서 keys 함수를 이용하여 키워드만을 뽑아내고 이
것을 $word 변수로 가져온다. 이 과정을 %cen_hash의 모든 값
에 해서 진행한다.
∙ 85라인에서는CENTRALITY 일핸들을 이용하여 키워드인
$word를 먼 출력하고 탭간격(\t)만큼 띄운 다음, 키워드와
매치되는 해쉬값인 centrality 값을 출력한다. 그리고 을 바꾼
다(\n).
∙ 86라인에서는 foreach 문을 닫고 있다.
∙ 87-90라인의 과정은 83-86라인과 동일하며 단지 density 에
해서 한다는 만 다르다. 이 게 출력된 centrality와 density
의 가 <표 3-4>와 같다.
<표 3-4> 계산된 centrality와 density
키워드 centrality
표 면 0.023896
다 양 0.059315
제 거 0.019492
정 보 0.059833
표 준 0.020852
병 렬 0.020309
관 리 0.018192
좌 표 0.015493
자동화 0.042049
⋮
키워드 density
표 면 0.041398
다 양 0.118063
제 거 0.056996
정 보 0.128283
표 준 0.049658
병 렬 0.069823
관 리 0.033747
좌 표 0.03181
자동화 0.0964
⋮

88 계량정보분석을 한 로그래 활용사례연구
<그림 3-12> 전략맵 소스코드(92-95라인)
∙ 92-95라인은 지 까지 사용했던 일핸들을 모두 닫는 과정이
다. 이 과정은 로그램 진행 에 일핸들을 열고 닫을 필요
가 있는 경우에는 반드시 필요한 과정이지만 보통은 로그램
종료와 동시에 일핸들이 자동으로 종료되므로 사용하지 않아
도 되는 과정이다. 그러나 로그래 습 상 일핸들을 닫는
것이 좋을 듯하여 close 문을 사용하여 일핸들을 닫았다.
제2절 한국특허의 지역별 발명자수 분포 도출
1. 도출과정
지방자치제가 확 되고, 지역균형발 을 강조하고 있는 시 에
서 특허정보를 통한 지역의 산업발 정도 는 지역간 력 황
등을 알고자 하는 연구들이 수행되고 있다. 이에 본 연구는 한국특
허 데이터베이스에 나타난 특허로부터 발명자의 지역별 분포를 도
출해 보고자 하 다.
실제 분석에서 이용한 한국특허 데이터베이스는 한국과학기술정
보연구원에서 이용할 수 있는 록정보이고, 그 형태는 다음과 같

제3장 활용하기 89
< 한국특허 초록 데이터 샘플>
Document 158
국가코드:KR
특허구분:20, P
출원번호:2019930006103
출원일:19930415
발명의명칭(국문):변색도료를이용한장식유리
IPC:C03C 25/68;
ICC Ver.:6
출원인(국문명):이영섭;남영우;
출원인(영문명):;;
출원인식별기호:419951002473
출원인주소:서울 강남구 역삼1동 743번지;서울 동작구 본동 410번지;
대표출원인명:;;
발명자(국문):남영우;이영섭;다가하시마사루;
발명자(영문):;;;
발명자식별기호:419980061778;419951002473;;
발명자우편번호:156-813
발명자주소:서울 동작구 본동 410번지;서울 강남구 역삼1동 743번지;일본국시즈오
가켄슨도군나가이츠미죠시모도가리1434;
요약:[청구범위] 유리(1)의 표면에 표현코저 하는 무늬(2)를 엠보싱가공처리하여
엠보싱면(3)으로형성하고, 그 엠보싱면(3)에 온도의 변화에 의해 변색되는 변색 도
료를 도착한 변색층(4)을 형성함을 특징으로 하는 변색 도료를 이용한 장식유리.
청구항 수:1
공개번호:2019940024797
공개일:19941117
대리인(국문명):최인술;
대리인(영문명):CHOI, In Sool;
대리인식별코드:919980005553
대리인주소:서울 강남구 역삼동 636-16 덕성빌딩 3층 동방국제특허법률사무소;
대표대리인명:;
90 계량정보분석을 한 로그래 활용사례연구
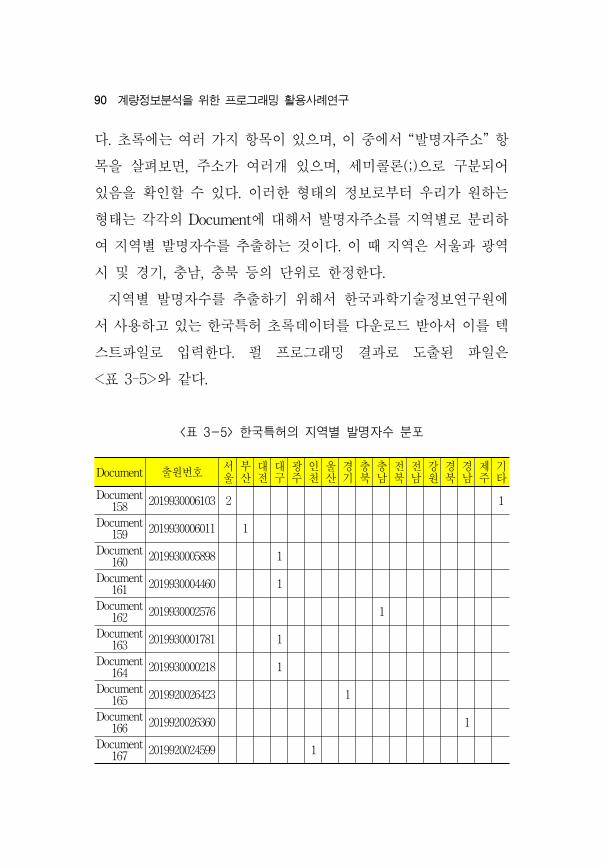
<표 3-5> 한국특허의 지역별 발명자수 분포
Document 출원번호 서울
부산
대전
대구
광주
인천
울산
경기
충북
충남
전북
전남
강원
경북
경남
제주
기타
Document 158 2019930006103 2 1
Document 159 2019930006011 1
Document 160 2019930005898 1
Document 161 2019930004460 1
Document 162 2019930002576 1
Document 163 2019930001781 1
Document 164 2019930000218 1
Document 165 2019920026423 1
Document 166 2019920026360 1
Document 167 2019920024599 1
다. 록에는 여러 가지 항목이 있으며, 이 에서 “발명자주소” 항
목을 살펴보면, 주소가 여러개 있으며, 세미콜론(;)으로 구분되어
있음을 확인할 수 있다. 이러한 형태의 정보로부터 우리가 원하는
형태는 각각의 Document에 해서 발명자주소를 지역별로 분리하
여 지역별 발명자수를 추출하는 것이다. 이 때 지역은 서울과 역
시 경기, 충남, 충북 등의 단 로 한정한다.
지역별 발명자수를 추출하기 해서 한국과학기술정보연구원에
서 사용하고 있는 한국특허 록데이터를 다운로드 받아서 이를 텍
스트 일로 입력한다. 펄 로그래 결과로 도출된 일은
<표 3-5>와 같다.

제3장 활용하기 91
<그림 3-13> 한국특허의 지역별 발명자수 추출 소스코드(1-6라인)
2. 지역별 발명자수 추출 소스코드 해설
펄로 작성한 한국특허 록의 지역별 발명자수 추출 로그램에
해서 살펴보자. 먼 일 입출력에 해당하는 부분이 나오는 데
1~6라인에 해당한다.
∙ 1라인은 입력 일을 타이핑 하라는 메시지이다. 메시지가 나타
나면, patent.txt 는 patent.cap 처럼 일명을 명령어창에 입
력하면 된다.
∙ 2라인은 입렵 일명을 표 입력 <STDIN> 으로 입력받아서
$inputfile 로 일명을 받는데, 입력 일명을 타이핑하고 마지
막에 엔터키를 르는 것을 chomp 명령으로 없애는 것이다.
∙ 4라인은 입력 일을 일핸들 IN으로 여는 것이다. 일핸들로
가져오면 입력 일을 펄 로세스에서 자유자재로 다룰 수가
있다. 만약 열지 못했으면 에러메시지를 보내는 것이다.
∙ 5라인은 계산된 결과를 address.txt 일로 장하기 해서
일핸들 OUT 을 쓰기모드로 만드는 과정이다. 여기서도 일핸

92 계량정보분석을 한 로그래 활용사례연구
들을 열지 못하면 에러메시지를 die 명령을 통해서 보낸다.
<그림 3-14> 한국특허의 지역별 발명자수 추출 소스코드(9-17라인)
∙ 앞에 나온 <표 3-5>가 우리가 원하는 출력정보인데, 배열
@address 에 값을 할당할 것이다. 9-10라인에서는 <표 3-5>의
첫행을 할당하고 있다. 여기서 한 명령을 을 바꾸어서 했는
데, 명령문의 구분은 세미콜론(;)으로 하므로 을 옮긴 것은 명
령문을 인식하는데 아무런 지장이 없다.
∙ 11라인에서 while 문을 사용하고 있다. 입력 일이 있으면
<IN> 에 값이 있을 것이고, 한 행씩 변수 $one_line 으로 가져
온다. 그리고, 한 행의 마지막에 있는 엔터키(\n)를 제거하기
해 chomp 명령을 사용한다. 이러한 작업은 입력 일이 끝날때
까지 while 문을 이용하여 계속 진행된다.
∙ 12라인에서 하나의 Document를 인식하고 있다. 한국특허의
록 데이터 샘 을 보면, 각각의 특허 록은 Document 로 시작
하고 Document 자 앞에 공란이 7개 있으며, 그 뒤에 다시 공
란이 존재한다. 단어구분은 "\b" 를 이용한다. 한 행을 나타내는

제3장 활용하기 93
<그림 3-15> 한국특허의 지역별 발명자수 추출 소스코드(19-30라인)
$one_line 이 =~ 연산자의 왼쪽에 나타난 패턴일치문과 일치하
면 하나의 특허 록 Document가 시작되는 것을 알 수 있다.
∙ 13라인은 하나의 특허 록 Document가 인식될 때마다 $doc 를
1씩 증가시켜서 Document의 수를 계산한다.
∙ 14라인은 Document의 번호를 배열 @address 에 할당하는 과정
이다. 즉 <표 3-5>에서 1열 값을 뽑아내는 과정이다. substr
($one_line, 7, 100) 은 $one_line 에 할당된 한 행의 값에서 7번
째 치부터 길이 100 의 데이터를 뽑아낸다는 의미이다. 이 값
을 각 행의 첫열에 할당한다. 한 행은 Document 번호, 출원번
호, 서울, 경기, …, 기타까지 19열로 되어 있다. 따라서 각 행의
첫열은 $doc*19 번째이다.
∙ 17라인은 if 문을 닫고 있다.
∙ 19라인에서는 출원번호를 뽑아내고 있다. 한국특허 록 데이터
샘 을 보면 “출원번호:2019930006103”와 같이 구성되어 있는
데, 한 행에 이 값이 있는 지 확인하는 과정이다.

94 계량정보분석을 한 로그래 활용사례연구
∙ 20라인은 “출원번호”와 실제 출원번호 숫자( : 2019930006103)
를 콜론(:)을 구분자로 하여 split 명령을 이용하여 구분하며, 구
분된 것을 배열 @temp 에 장한다. 그러면 “출원번호”는
$temp[0] 에 담기고, 실제 출원번호 숫자는 $temp[1]에 장된
다.
∙ 21라인에서는 실제출원번호인 $temp[1] 값을 제2열에 장하기
해서 $address[$doc*19+1]에 할당하 다.
∙ 22라인은 if문을 닫고 있다.
∙ 24라인은 $one_line 에 장된 값에 “발명자주소:”로 시작하는
것이 있는지 조사하는 것이다. “발명자주소”가 나타나면 그 아
래에 있는 명령을 수행하게 된다. 여기서부터 발명자주소를 가
지고 지역별 발명자수를 추출하게 된다.
∙ 26라인은 “발명자주소”와 실제 주소를 분리하는 것이다. 발명자
주소 뒤에 콜론(:)이 나오므로 이 것을 구분자로 하여 split 명령
을 이용하여 분리하여 배열 @temp1에 장한다. 그 게 되면
$temp1[0] 에는 “발명자주소”가 할당되고, $temp1[1]에는 실제
발명자 주소( : 서울시 동 문구 ... )가 할당된다. 여기서 배열
@temp1 의 각각의 원소는 스칼라이므로 $temp1[0] 등으로 표
기한다.
∙ 27라인은 실제 발명자주소인 $temp1[1] 을 $temp_address 에
할당하고 있다.
∙ 28라인은 테스트용으로 만든 것인데 #을 앞부분에 사용하여 주
석처리 했다.
∙ 29라인은 발명자주소가 여러개인 경우 세미콜론(;)으로 구분되

제3장 활용하기 95
<그림 3-16> 한국특허의 지역별 발명자수 추출 소스코드(32-43라인)
어 있으므로 이 것을 분리하여 배열 @temp2 에 장하는 것이
다.
∙ 30라인도 테스트용으로 주석처리했다.
∙ 앞부분에서 여러개 있는 주소를 @temp2에 장했는데, 32라인
에서는 각각의 주소를 하나씩 $one_address 로 불러들어와서
foreach 문 안에 있는 실행문을 수행한다. foreach 문 내부에서
지역이 어디에 속하는지 구분하는 작업을 수행한다.
∙ 33라인은 각각의 발명자 주소에서 일부만 추출하는 과정이다.
우리나라의 주소는 서울특별시, 부산 역시, 경기도 등에서와
같이 처음 단어가 최 한 5 자이다. 더욱 상세한 주소는
필요없으므로 한 5 자만 주소에서 추출하는 과정이 33라인
이다. substr($one_address, 0, 10)은 $one_address 에 담긴 하
나의 주소에서 시작 치 0부터 길이 10만큼 추출한다는 의미
이다. 그런데 한 은 자 하나에 2만큼의 크기를 차지한다. 한
5 자를 주소에서 추출하여 그 값을 변수 $address_cut 에

96 계량정보분석을 한 로그래 활용사례연구
할당한다.
∙ 35라인은 한 5 자 내부에 공란이 존재하는지를 알아보기
함이다. 만약 추출해 낸 주소가 “경기 성남”이라면 공란 뒷부분
은 필요없는 부분이 된다. 따라서 공란의 치를 계산하고자 한
다. index($address_cut, " ") 은 $address_cut 에서 공란의
치를 앞에서부터 계산한다. 계산된 공란의 치를 $space 에 할
당한다. 만약 공란이 없으면 이 라인은 아무런 실행을 하지 않
는다. 그리고 공란이 없는 경우에 index 명령은 “-1”을 $space
에 할당한다.
∙ 37라인은 공란이 존재하는가를 확인하는 과정이다. 공란이 존재
하면 $space 값이 “-1” 이 아닌 값이 된다. 따라서 != 연산자를
사용하여 “-1”이 아닌지를 검한다.
∙ 39라인은 주소에 공란이 존재하는 경우, 공란의 앞부분까지만
다시 추출하는 과정이다. substr($address_cut, 0, $space) 는
$address_cut 에서 0 치부터 시작해서 $space 길이만큼 추출
하는 것이다. 여기서 공란의 치가 $space 고, 추출할 부분은
공란의 바로 앞부분까지이므로 길이가 $space 가 된다. 공란 앞
부분까지 추출한 값을 다시 $address_cut 에 할당한다.
∙ 40라인은 공란이 존재하는지의 if문을 닫고 있다.
∙ 41라인은 추출된 하나의 주소 $address_cut 에서 “서울”이 있는
지 확인하는 것이다.
∙ 42라인은 “서울”이라는 자가 있으면, 각 행의 서울에 해당하
는 값을 1만큼 증가시킨다는 의미이다.
∙ 43라인은 “서울”이 주소에 존재하는지의 if문을 닫고 있다.

제3장 활용하기 97
<그림 3-17> 한국특허의 지역별 발명자수
추출 소스코드(44-61라인)
<그림 3-18> 한국특허의 지역별 발명자수 추출 소스코드(62-79라인)
∙ 44-61라인은 부산, , 구, 주, 인천, 울산에 해당하는 주
소가 있는지 확인하고 있다면 각각의 열 값을 1씩 증가하는 것
이다. 주의할 은 여기서 elsif 를 반드시 사용하여야 하며, 만
약 각각을 별도의 if문을 이용하여 처리하게 되면 모든 경우를
다루지 못하고 에러값을 출력하게 된다.

98 계량정보분석을 한 로그래 활용사례연구
<그림 3-19> 한국특허의 지역별 발명자수 추출 소스코드(80-97라인)
∙ 62-67라인은 경기도에 해당하는 부분인데, 패턴일치를 /경기/
형식으로 사용하지 않고, 선택 /a|b|c/ 형태를 이용하 다. 선택
형태는 아무것이나 선택할 수 있다는 의미이다. 만약 특허 록
데이터에 있는 모든 경기도 내의 주소정보가 “경기도”로 시작
한다면 선택형태를 이용할 필요가 없는데, 어떤 경우에는 “경기
도”로 시작하지 않고, “성남시”로 시작하는 형태가 있었다. 그
러한 경우를 제 로 분류하기 해서 각 도단 내에 있는 시단
도시명을 모두 정규표 식에 사용하 다.
∙ 68-79라인은 충북, 충남, 북, 남에 한 부분이다.
∙ 80-91라인은 강원, 경북, 경남, 제주에 해당하는 부분이다.
∙ 92라인은 그외 분류안된 것을 찾는 것인데, 이 부분에 해당하는
주소는 주로 해외 발명자의 주소가 기록된다. 한 다른 에러
가 혹시 있다면 마지막 열(기타)에서 검해 보고자 하 다.
∙ 94-97라인은 여러개의 루 를 닫고 있다.

제3장 활용하기 99
<그림 3-20> 한국특허의 지역별 발명자수 추출
소스코드(99-108라인)
∙ 99-105라인은 배열 @address 에 장된 지역별 발명자수 데이
터를 일핸들 0UT 을 이용해서 출력하는 과정이다. 99라인에
서는 문서수(Document의 수)인 $doc 보다 하나 많게 행의 수
를 설정하고 있는데, 이는 <표 3-5>에서와 같이 첫행을 고려했
기 때문이다.
∙ 101라인은 열의 개수를 19개까지 한다는 것을 보여주고 있다.
∙ 102라인은 각각의 $address[] 값을 일핸들 OUT 을 이용하여
출력하는 명령이다. 한 각각의 값은 탭간격(\t)을 기 으로 구
분되어 출력된다.
∙ 103라인은 한 행이 끝났음을 나타내고, 104라인은 한 행이 끝나
고 나서 행을 구분하기 해서 바꿈(\n)을 이용하고 있다.
∙ 107-108라인은 일핸들 IN 과 OUT 을 닫고 있다. 만약 닺지
못하면 에러코드를 출력한다.
∙ 로그램이 실행된 이후에 출력되는 일은 address.txt 이고,
그 형태는 <표 3-5>와 같다.
이번 장에서 로 든 로그램 제는 펄 로그램을 사용했지만

100 계량정보분석을 한 로그래 활용사례연구
펄을 처음 학습한 입장에서 작성했기 때문에 펄다운 코드 형태로
만들지는 못했고 오히려 C 언어 형태로 만들었다.

제4장 결 론 101
제 4 장
결 론
본 보고서는 계량정보분석을 해서 로그래 언어를 습득하
는 것이 많은 도움을 것이라는 단 하에 작성하게 되었다. 펄
로그램은 계량정보분석을 해서 로그래 언어 탁월한 선
택이 될 것이며, 실험 인 연구를 진행하는데 있어서 많은 도움을
것이다.
“이명 경 스쿨(http://www.emh.co.kr/tech.pl)”에서 펄에 한
략 인 소개를 받을 수 있었고, 이를 통해서 펄을 배우는 것이
그리 어려운 것은 아니라는 확신을 갖게 되었다. 그 이후에 “Perl
제 로 배우기(김 식ㆍ강윤석 역, 한빛미디어)”를 통해서 계량정
보분석을 해 필요한 로그래 언어로서의 펄을 부분 학습할
수 있었다. 한 실제 연구사업을 수행하면서 로 기술분야 략맵
을 작성하기 해서 필요한 데이터를 펄을 이용하여 만들어 낼 수
있었다.
연구자가 분석툴에만 의존하게 된다면, 연구내용은 제한될 수 밖
에 없다. 로그래 기술이 없었다면, 략맵을 작성할 수 있는 기
존의 분석툴을 알지 못하므로 연구사업은 난 에 부딪힐 수도 있었

102 계량정보분석을 한 로그래 활용사례연구
을 것이다. 그리하여 연구방향을 기존의 툴을 활용해서 결과를 도
출할 수 있는 방향으로 변경했을 수도 있었을 것이다.
본 보고서에서 를 들고 있는 로그램은 단순히 데이터를 뽑아
내는 것까지만 했지만, 그래픽으로 처리하는 것도 향후에는 가능할
것이다. 최근에는 연구성과를 보여주기 해서 아무래도 좋은 그림
형태로 보여주는 것이 추세인 것 같다. 그 정도까지 하기 해서는
문개발업체에게 맡기는 것이 여러 가지 여건상 합리 일 수 있
다. 그러나 기 데이터를 뽑아내거나 기 형태의 그림을 만드는
것은 펄 로그램으로도 가능하다. 한 씨팬(www.perl.com/
CPAN/)에 가면, 이미 만들어진 펄 로그램들이 모듈형태로 제공
되고 있으므로 연구자들은 펄에 한 기본 인 문법만 익히고 나서
그냥 가져다 사용하면 된다. 이것은 다른 로그래 언어와 비교
했을 때 매우 강력한 장 이라고 할 수 있다.
본 보고서를 하신 연구자들은 시간이 허락된다면 펄 로그래
언어를 배우기를 권장한다. 특히 계량정보분석을 통해서 지식을
발견하는 작업을 수행하는 연구자들에게 더욱 권장하고 싶다.

참고문헌 103
참고문헌
1. 국내문헌
∙David Till , 최용호 역, “21일 완성 PERL5", 성안당,
∙Larry Wall, Tom Christiansen, Randal L. Schwarz , 김 식
ㆍ강윤석ㆍ박제 역, “Perl 로그래 ”, 한빛미디어
∙Randal L. Schwarz, Tom Christiansen , 김 식ㆍ강윤석 역,
“펄 제 로 배우기”, 한빛미디어
∙임백 , “임백 의 소 트웨어 산책”, 한빛미디어, 2005
∙조엘 스폴스키 , 박재호ㆍ이해 역, “조엘 온 소 트웨어 -
유쾌한 오 라인 블로그”, 에이콘, 2005.
2. 외국문헌
∙J. S. KATS, D. HICKS, "Desktop scientometrics", Sciento-
metrics, Vol.38, No.1(1997) pp.141-153
∙Johannes Stegmann et. al., "Hypothesis generation guided by
co-word clustering", Scientometrics, Vol.56, No.1(2003)
pp.111-135

104 계량정보분석을 한 로그래 활용사례연구
3. 웹사이트
∙ActiveState(http://www.activestate.com)
∙ST Server for Windows(http://www.apmsetup.com/)
∙씨팬(http://www.perl.com/CPAN)
∙이명 경 스쿨(http://www.emh.co.kr/tech.pl)
∙천리안유즈넷사용법(http://user.chollian.net/~driveway/
usenet1.htm)
∙펄 홈페이지(http://www.perl.org)





























