Embed Size (px)
Citation preview

Introduction toCMOS VLSI
Design
Clock Skew-tolerant circuits

2CMOS VLSI Design
Outline Clock Distribution Clock Skew Skew-Tolerant Static Circuits Traditional Domino Circuits Skew-Tolerant Domino Circuits
3CMOS VLSI Design
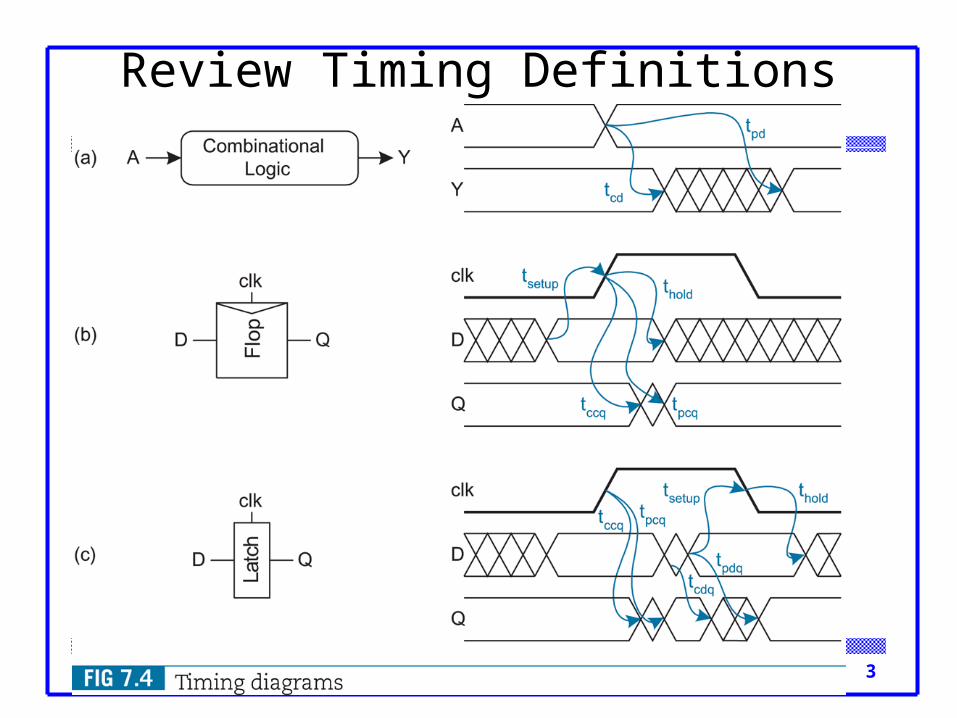
Review Timing Definitions

4CMOS VLSI Design
Clocking Synchronous systems use a clock to keep
operations in sequence– Distinguish this from previous or next– Determine speed at which machine operates
Clock must be distributed to all the sequencing elements– Flip-flops and latches
Also distribute clock to other elements – Domino circuits and memories

5CMOS VLSI Design
Clock Distribution On a small chip, the clock distribution network is just
a wire– And possibly an inverter for clkb
On practical chips, the RC delay of the wire resistance and gate load is very long– Variations in this delay cause clock to get to
different elements at different times– This is called clock skew
Most chips use repeaters to buffer the clock and equalize the delay– Reduces but doesn’t eliminate skew

6CMOS VLSI Design
Example Skew comes from differences in gate and wire delay
– With right buffer sizing, clk1 and clk2 could ideally arrive at the same time.
– But power supply noise changes buffer delays
– clk2 and clk3 will always see RC skew
3 mm
1.3 pF
3.1 mmgclk
clk1
0.5 mm
clk2clk3
0.4 pF 0.4 pF

7CMOS VLSI Design
Skew Impact
F1
F2
clk
clk clk
Combinational Logic
Tc
Q1 D2
Q1
D2
tskew
CL
Q1
D2
F1
clk
Q1
F2
clk
D2
clk
tskew
tsetup
tpcq
tpdq
tcd
thold
tccq
setup skew
sequencing overhead
hold skew
pd c pcq
cd ccq
t T t t t
t t t t
Ideally full cycle is
available for work Skew adds sequencing
overhead Increases hold time too
tpd
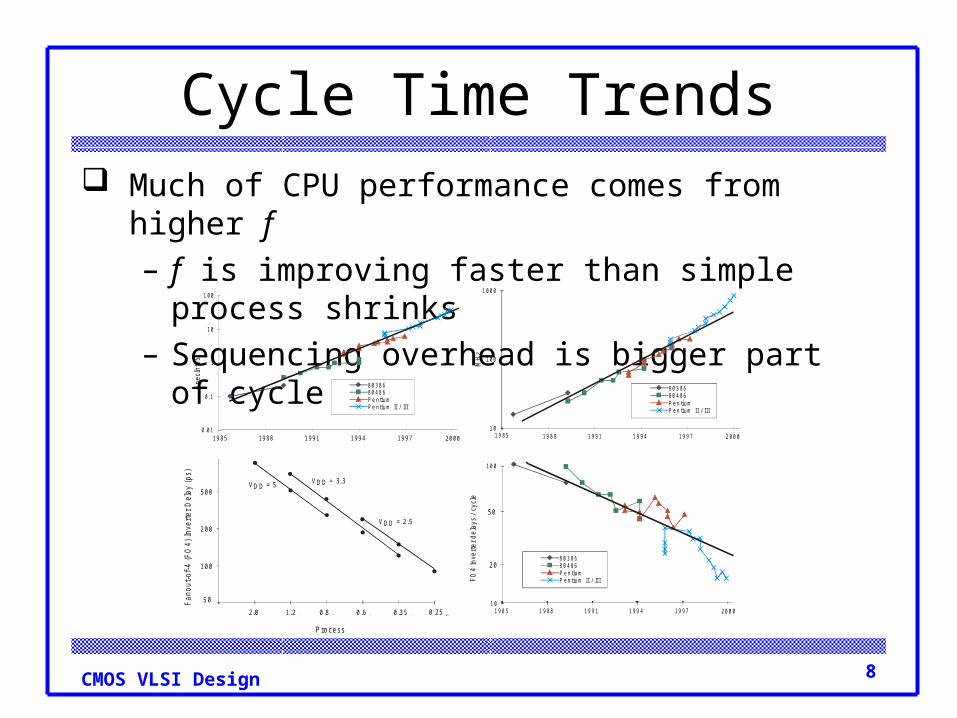
8CMOS VLSI Design
Cycle Time Trends Much of CPU performance comes from higher f
– f is improving faster than simple process shrinks– Sequencing overhead is bigger part of cycle
0 .0 1
0 .1
1
1 0
1 0 0
8 0 3 8 68 0 4 8 6P e n tiu mP e n tiu m II / III
Spe
cInt
95
1985 1988 1991 1994 1997 2000
1.2 0.8 0 .6 0.35 2.0
Process
100
200
500VD D = 5 VDD = 3.3
VDD = 2.5
50Fan
out-
of-4
(F
O4)
Inve
rter
Del
ay (
ps)
0.25
1 0
1 0 0
1 0 0 0
8 0 3 8 68 0 4 8 6P e n tiu mP e n tiu m II / II I
MH
z
1 9 8 8 1 9 9 1 1 9 9 4 1 9 9 7 2 0 0 01 9 8 5
1 0
1 0 0
1 9 8 5 1 9 8 8 1 9 9 1 1 9 9 4 1 9 9 7
8 0 3 8 68 0 4 8 6P e n tiu mP e n tiu m II / II IF
O4
inve
rte
r de
lays
/ cy
cle
50
20
2 0 0 0

9CMOS VLSI Design
Solutions Reduce clock skew
– Careful clock distribution network design– Plenty of metal wiring resources
Analyze clock skew– Only budget actual, not worst case skews– Local vs. global skew budgets
Tolerate clock skew– Choose circuit structures insensitive to skew
10CMOS VLSI Design
Clock Dist. Networks Ad hoc Grids H-tree Hybrid

11CMOS VLSI Design
Clock Grids Use grid on two or more levels to carry clock Make wires wide to reduce RC delay Ensures low skew between nearby points But possibly large skew across die
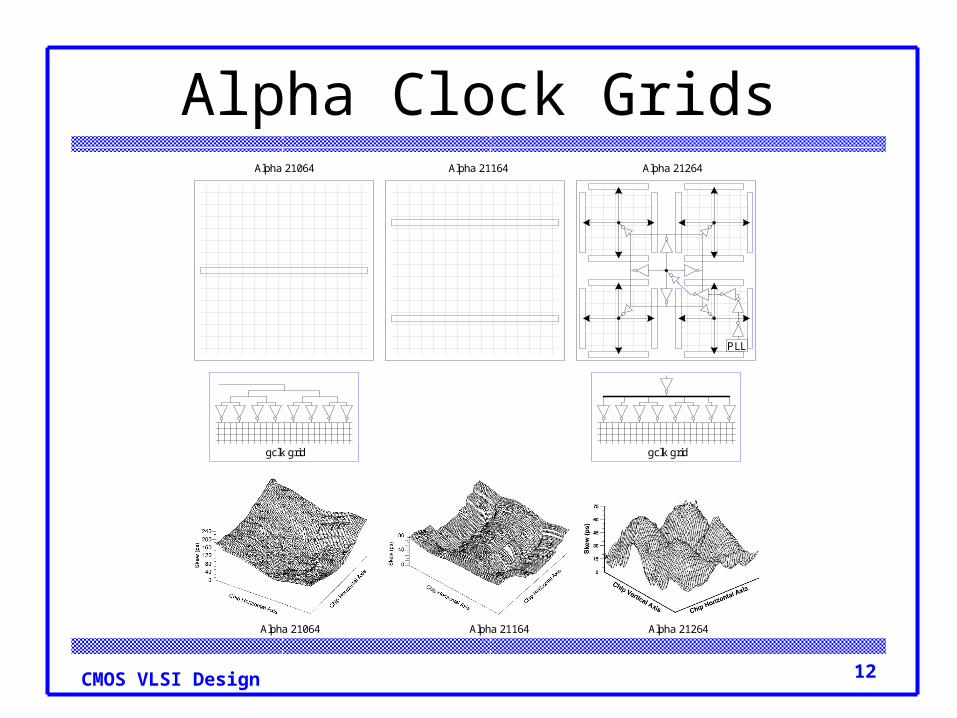
12CMOS VLSI Design
Alpha Clock Grids
PLL
gclk grid
Alpha 21064 Alpha 21164 Alpha 21264
gclk grid
Alpha 21064 Alpha 21164 Alpha 21264
13CMOS VLSI Design
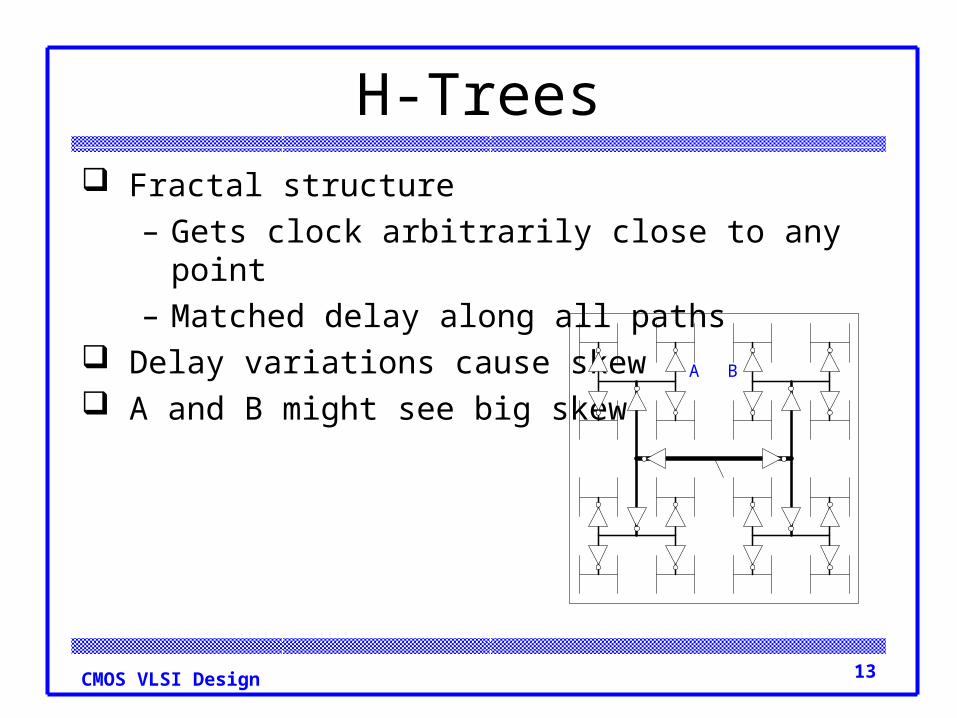
H-Trees Fractal structure
– Gets clock arbitrarily close to any point– Matched delay along all paths
Delay variations cause skew A and B might see big skew A B
14CMOS VLSI Design
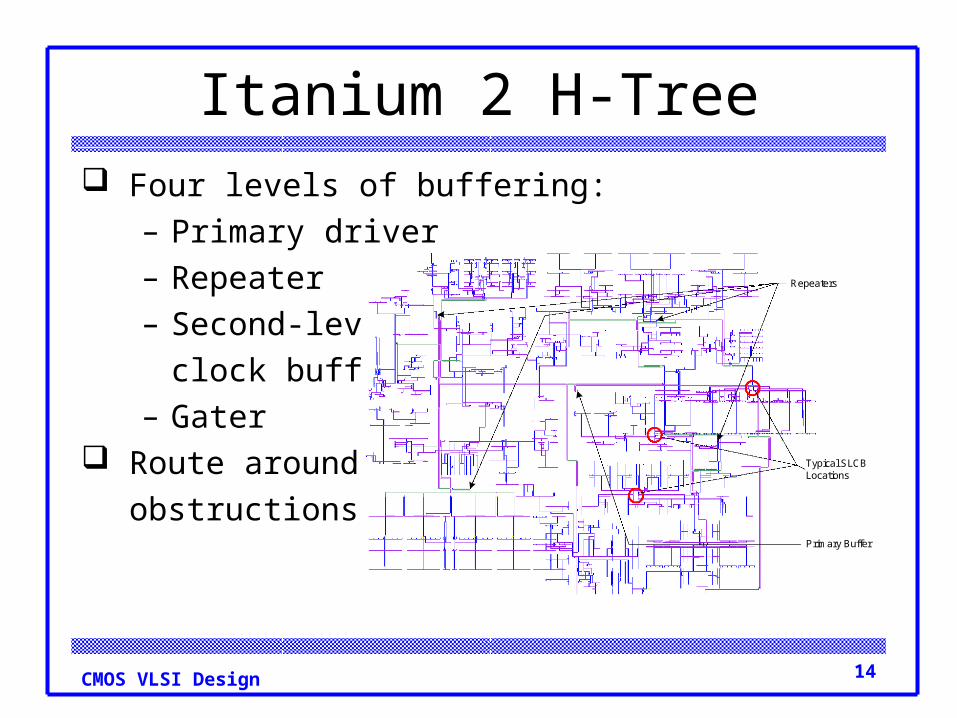
Itanium 2 H-Tree Four levels of buffering:
– Primary driver– Repeater– Second-level
clock buffer– Gater
Route around
obstructionsPrimary Buffer
Repeaters
Typical SLCBLocations

15CMOS VLSI Design
Hybrid Networks Use H-tree to distribute clock to many points Tie these points together with a grid
Ex: IBM Power4, PowerPC– H-tree drives 16-64 sector buffers– Buffers drive total of 1024 points– All points shorted together with grid

16CMOS VLSI Design
Skew Tolerance Flip-flops are sensitive to skew because of hard edges
– Data launches at latest rising edge of clock– Must setup before earliest next rising edge of clock– Overhead would shrink if we can soften edge
Latches tolerate moderate amounts of skew– Data can arrive anytime latch is transparent
17CMOS VLSI Design
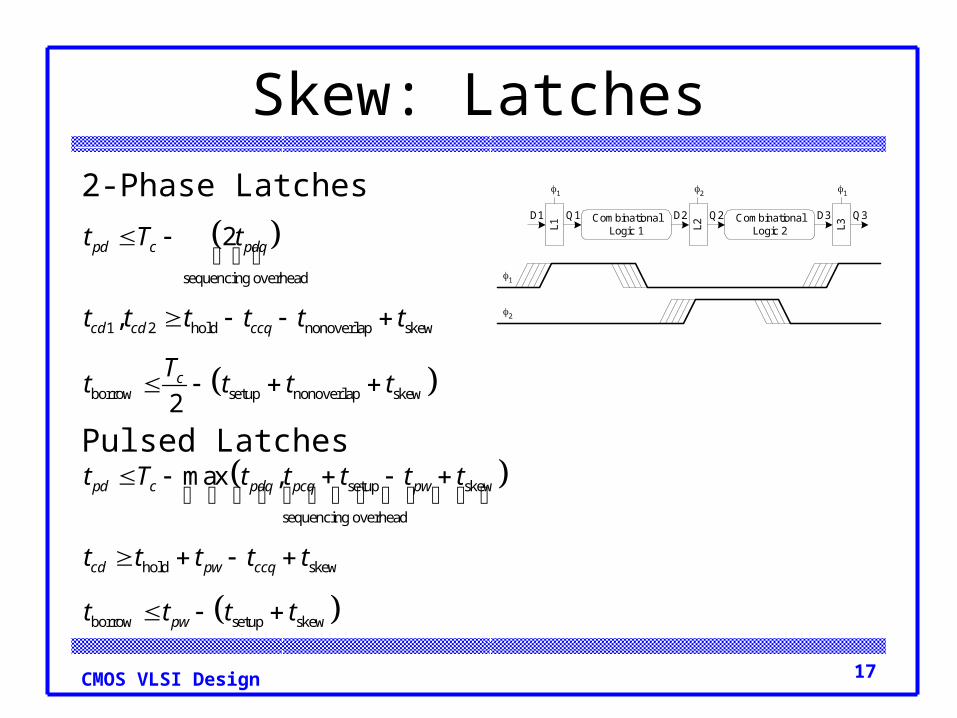
Skew: Latches
Q1
L1
1
2
L2 L3
1 12
CombinationalLogic 1
CombinationalLogic 2
Q2 Q3D1 D2 D3
sequencing overhead
1 2 hold nonoverlap skew
borrow setup nonoverlap skew
2
,
2
pd c pdq
cd cd ccq
c
t T t
t t t t t t
Tt t t t
2-Phase Latches
setup skew
sequencing overhead
hold skew
borrow setup skew
max ,pd c pdq pcq pw
cd pw ccq
pw
t T t t t t t
t t t t t
t t t t
Pulsed Latches

18CMOS VLSI Design
Dynamic Circuit Review Static circuits are slow because fat pMOS load input Dynamic gates use precharge to remove pMOS
transistors from the inputs– Precharge: = 0 output forced high– Evaluate: = 1 output may pull low
A B
Y
C DY
A B C D
A
B
C
D
static dynamic

19CMOS VLSI Design
Domino Circuits Dynamic inputs must monotonically rise during
evaluation– Place inverting stage between each dynamic gate– Dynamic / static pair called domino gate
Domino gates can be safely cascaded
A
W
B
X
domino AND
dynamicNAND
staticinverter

20CMOS VLSI Design
Domino Timing Domino gates are 1.5 – 2x faster than static CMOS
– Lower logical effort because of reduced Cin
Challenge is to keep precharge off critical path Look at clocking schemes for precharge and eval
– Traditional schemes have severe overhead– Skew-tolerant domino hides this overhead

21CMOS VLSI Design
Traditional Domino Ckts have high sequencing overhead, hard edge in each
half-cycle. first domino gates does not evaluate until rising edge
of the clock, but the results must set up at the latch before falling edge of the clock
If removing the latch, could soften the falling edge and cut the overhead.
The latch serves two functions: – prevent nonmonotonic signals from entering the
next domino gate while it evaluates– hold the results of the half-cycle while it
precharges and the next half-cycle evaluates.

22CMOS VLSI Design
Traditional Domino Ckts Hide precharge time by ping-ponging between half-cycles
– When clk is high (low), the first half-cycle evaluates (precharges) and the second precharges (evaluates)
– Latches hold results during precharge– Overhead of each latch is setup time and D-to-Q propa.
delay. assume tpdq is larger, then time for compu. is tpd
Tc
Sta
tic
Dyn
amic
Latc
h
clk
Sta
tic
Dyn
amic
clk
Sta
tic
Dyn
amic
clk
Dyn
amic
clk clk
Sta
tic
Dyn
amic
Latc
h
Sta
tic
Dyn
amic
Sta
tic
Dyn
amic
Dyn
amic
clk clk clk clk clk
clk
clk
tpdq tpdq
2pd c pdqt T t
23CMOS VLSI Design
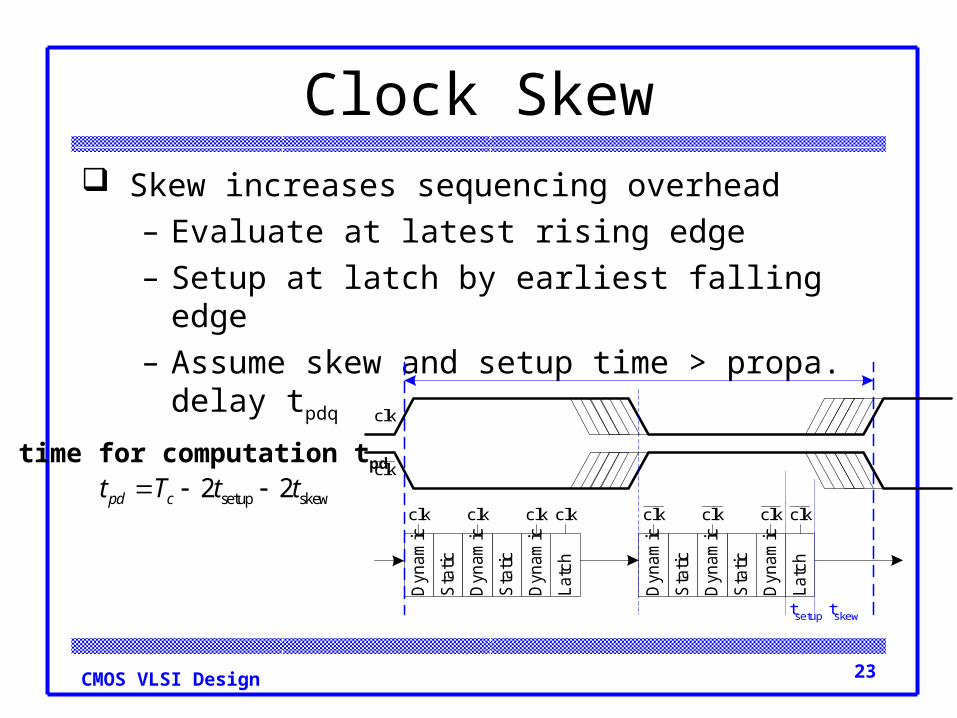
Clock Skew Skew increases sequencing overhead
– Evaluate at latest rising edge– Setup at latch by earliest falling edge
– Assume skew and setup time > propa. delay tpdq
Sta
tic
Dyn
am
ic
Latc
h
clkS
tatic
Dyn
am
ic
clkD
ynam
icclk clk
Sta
tic
Dyn
am
ic
Latc
h
Sta
tic
Dyn
am
ic
Dyn
am
ic
clk clk clk clk
clk
clk
tskewtsetup
setup skew2 2pd ct T t t time for computation tpd
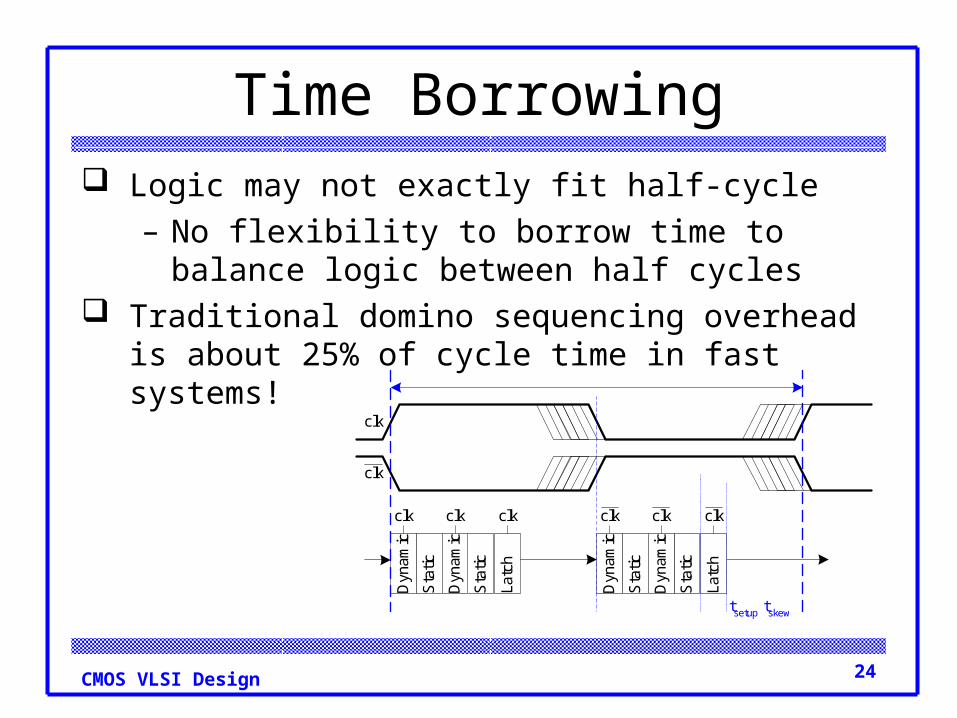
24CMOS VLSI Design
Time Borrowing Logic may not exactly fit half-cycle
– No flexibility to borrow time to balance logic between half cycles
Traditional domino sequencing overhead is about 25% of cycle time in fast systems!
Sta
tic
Dyn
amic
Latc
hclk
Sta
tic
Dyn
amic
clk clk
Sta
tic
Dyn
amic
Latc
h
Sta
tic
Dyn
amic
clk clk clk
clk
clk
tskewtsetup

25CMOS VLSI Design
Relaxing the Timing Sequencing overhead caused by hard edges
– Data departs dynamic gate on late rising edge– Must setup at latch on early falling edge
Latch functions– Prevent glitches on inputs of domino gates– Holds results during precharge
Is the latch really necessary?– No glitches if inputs come from other domino– Can we hold the results in another way?
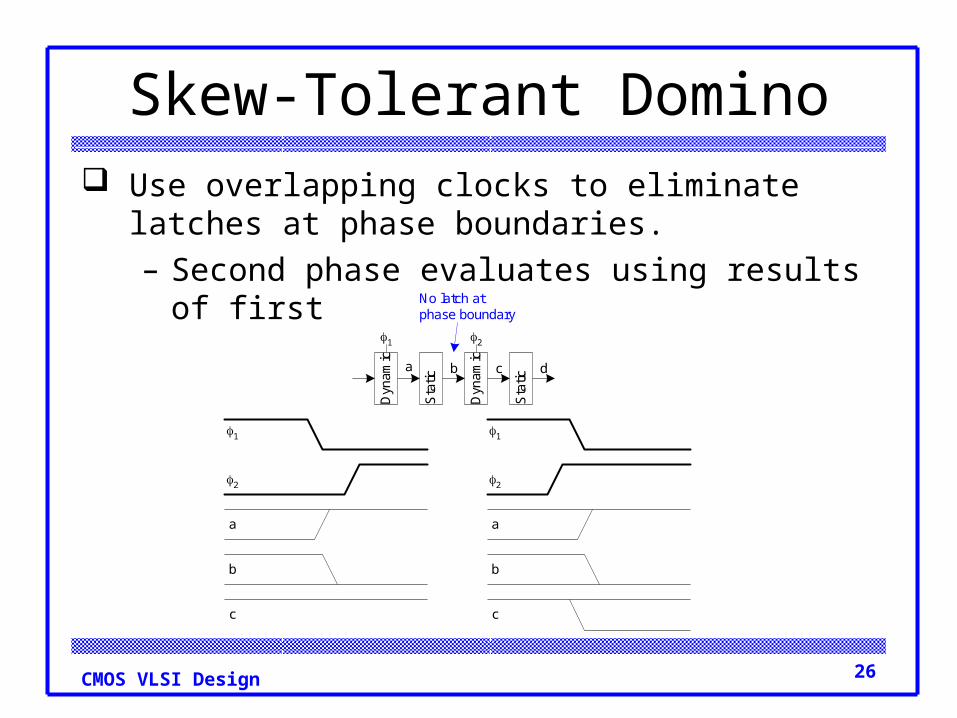
26CMOS VLSI Design
Skew-Tolerant Domino Use overlapping clocks to eliminate latches at phase
boundaries.– Second phase evaluates using results of first
a
Sta
tic
Dyn
amic
1
Sta
tic
Dyn
amic
2
b c d
a
1
2
b
c
a
1
2
b
c
No latch atphase boundary
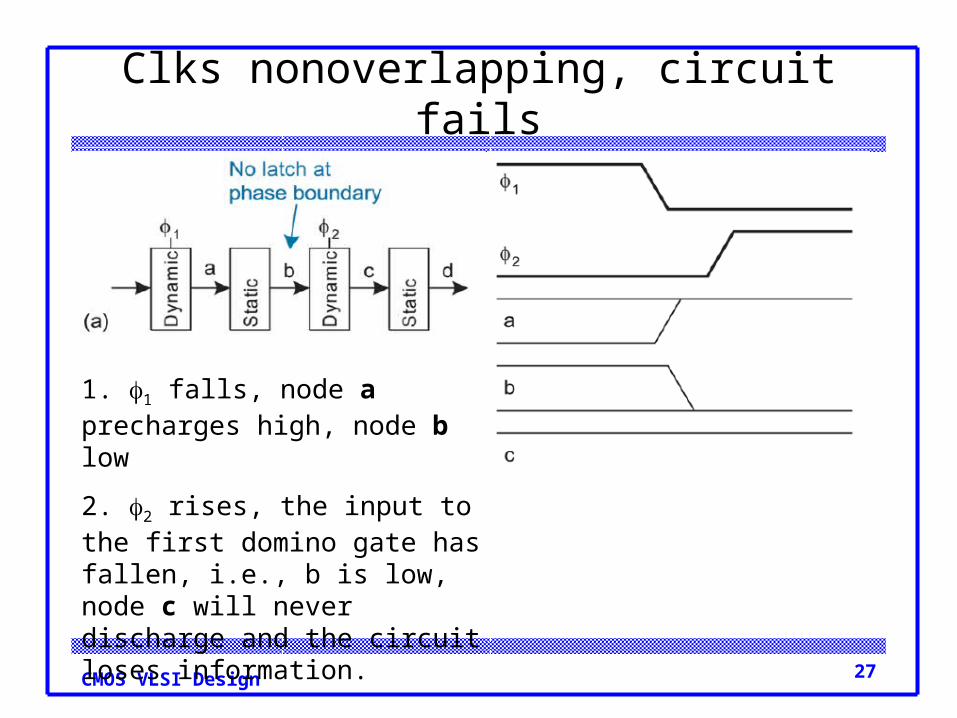
27CMOS VLSI Design
Clks nonoverlapping, circuit fails
1. 1 falls, node a precharges high, node b low
2. 2 rises, the input to the first domino gate has fallen, i.e., b is low, node c will never discharge and the circuit loses information.
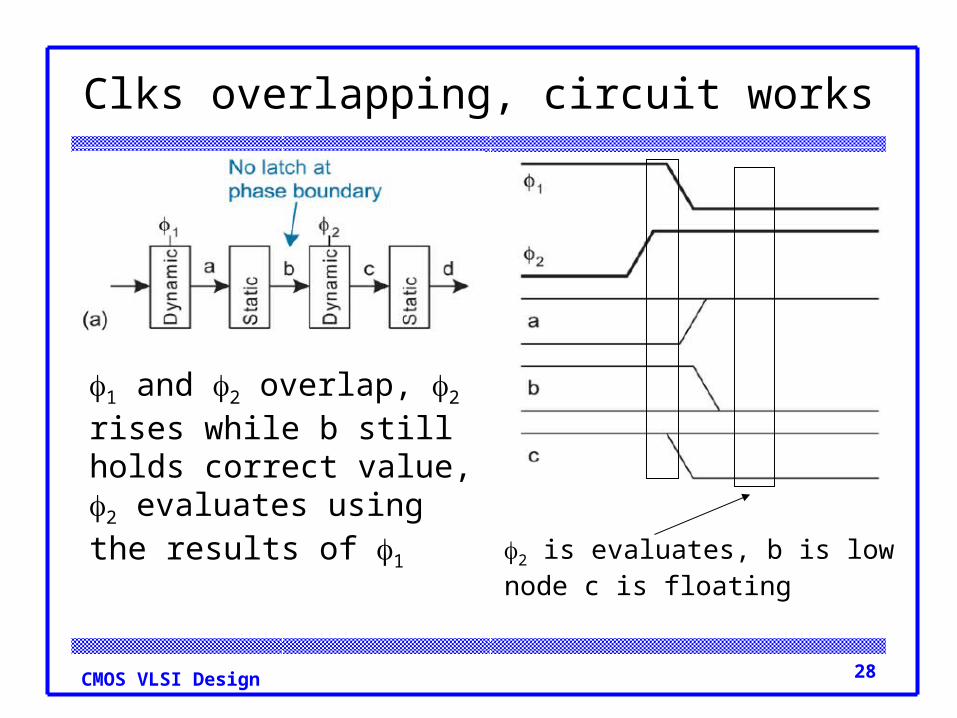
28CMOS VLSI Design
1 and 2 overlap, 2 rises while b still holds correct value, 2 evaluates using the results of 1
Clks overlapping, circuit works
2 is evaluates, b is lownode c is floating

29CMOS VLSI Design
Full Keeper After second phase evaluates, first phase precharges Input to second phase falls
– Violates monotonicity? But we no longer need the value Now the second gate has a floating output
– Need full keeper to hold it either high or low
weak fullkeepertransistors
f
X
H
30CMOS VLSI Design
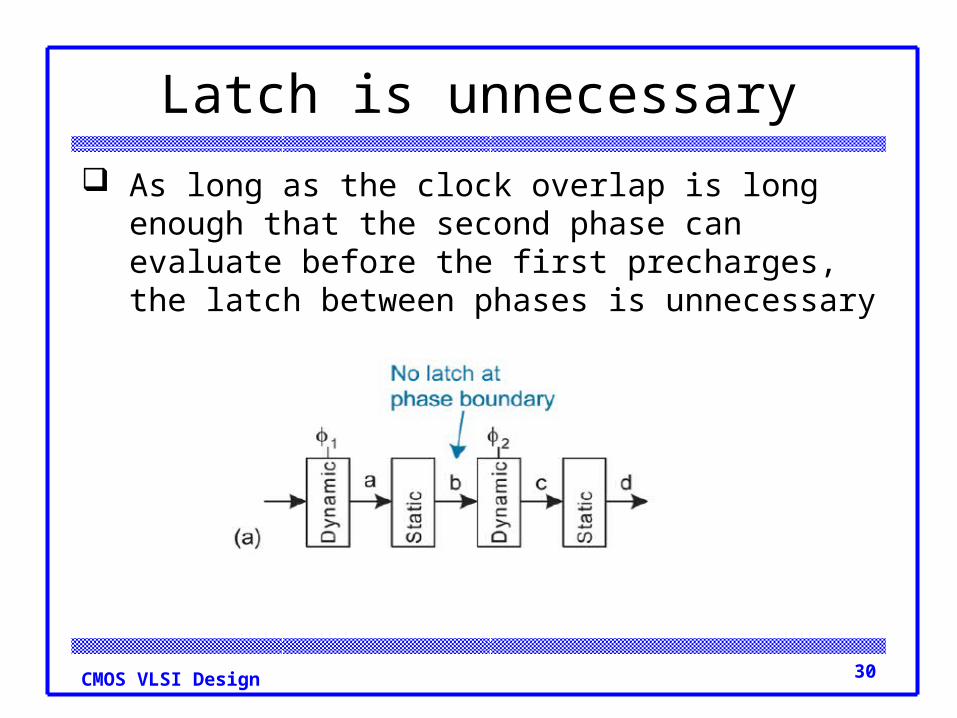
Latch is unnecessary
As long as the clock overlap is long enough that the second phase can evaluate before the first precharges, the latch between phases is unnecessary
31CMOS VLSI Design
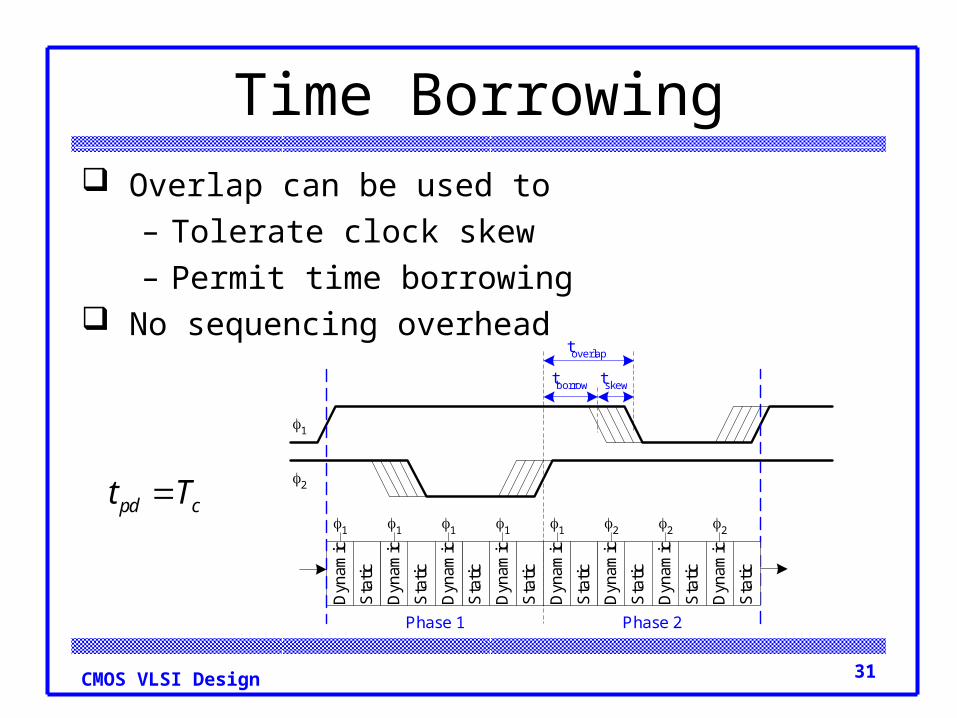
Time Borrowing Overlap can be used to
– Tolerate clock skew– Permit time borrowing
No sequencing overhead
tskew
Sta
tic
Dyn
amic
Sta
tic
Dyn
amic
Sta
tic
Dyn
amic
Dyn
amic
Sta
tic
Dyn
amic
Sta
tic
Dyn
amic
Sta
tic
Dyn
amic
Dyn
amic
Sta
tic
Sta
tic
1
2
1 1 1 1 1 2 2 2
Phase 1 Phase 2
toverlap
tborrow
pd ct T
32CMOS VLSI Design
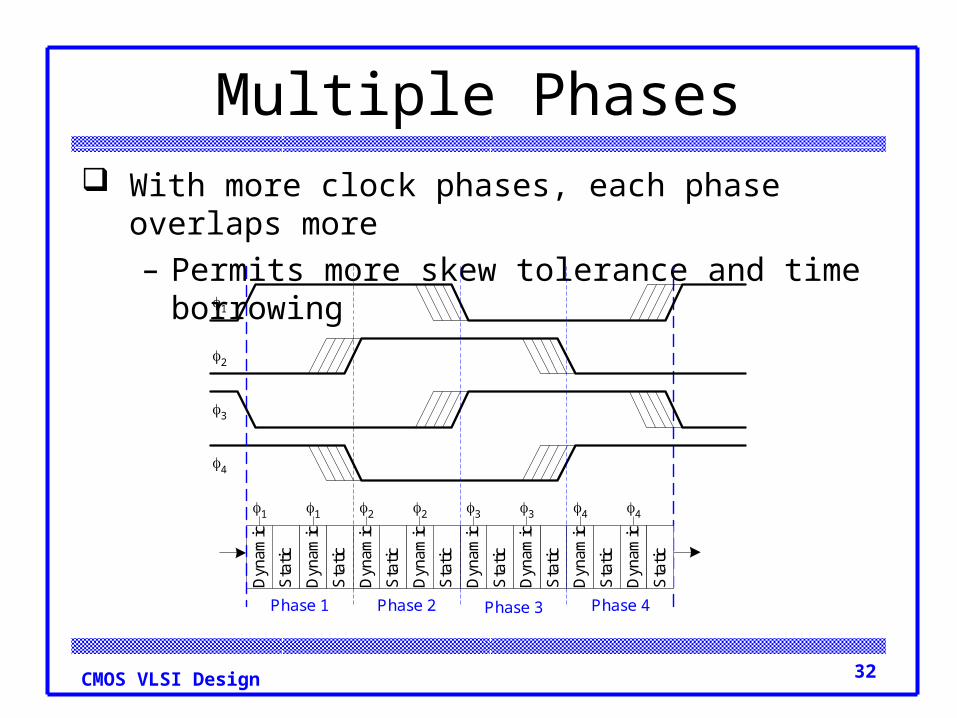
Multiple Phases With more clock phases, each phase overlaps more
– Permits more skew tolerance and time borrowing
Sta
tic
Dyn
amic
Sta
tic
Dyn
amic
Sta
tic
Dyn
amic
Dyn
amic
Sta
tic
Dyn
amic
Sta
tic
Dyn
amic
Sta
tic
Dyn
amic
Dyn
amic
Sta
tic
Sta
tic
3
4
1 1 2 2 3 3 4 4
Phase 1 Phase 2 Phase 3 Phase 4
1
2
33CMOS VLSI Design
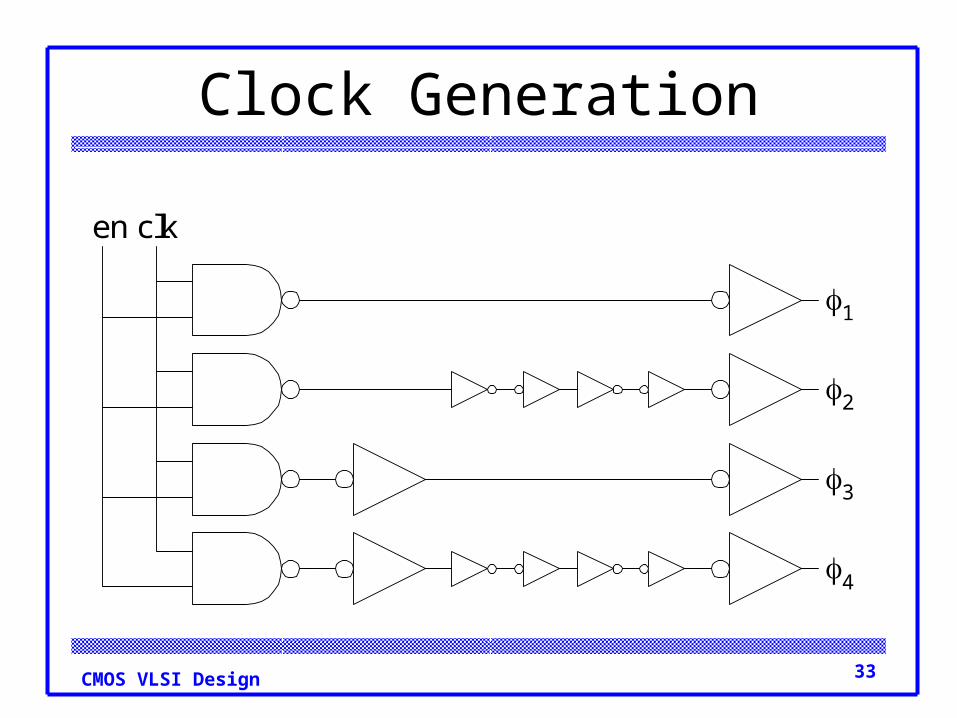
Clock Generation
clken
1
2
3
4

34CMOS VLSI Design
Summary Clock skew effectively increases setup and hold
times in systems with hard edges Managing skew
– Reduce: good clock distribution network– Analyze: local vs. global skew– Tolerate: use systems with soft edges
Flip-flops and traditional domino are costly Latches and skew-tolerant domino perform at full
speed even with moderate clock skews.





























