Embed Size (px)
Citation preview

1
BAZE PODATAKA Pretraživanje informacija
Mladen Varga
1
Slabo strukturirani / strukturirani podaci
Više od 80% podataka u organizacijama su slabo strukturirani
Takvi su tekstovi, bilješke, e-poruke, slike ….
2
1996. 2006.
Pretraživanje informacija
Pretraživanje informacija (engl. Information Retrieval -IR) je pronalaženje materijala (dokumenata) nestrukturiranog oblika (obično tekst) u velikoj kolekciji (na računalu u bazi dokumenata) koji odgovara informacijskoj potrebi
E-knjiga: http://www-csli.stanford.edu/~hinrich/information-retrieval-book.html
Information retrieval (IR)
http://en.wikipedia.org/wiki/Information_retrieval
Information retrieval wiki
http://ir.dcs.gla.ac.uk/wiki/
3 4
Ciljevi pretraživanja informacija
pronadi sve važne (relevantne) informacije (dokumente) za traženu temu potpun obuhvat
pronadi samo relevantne informacije za zadani upit potpuna preciznost
rangirati pronađene informacije po važnosti (relevantnosti) rang
Rezultati pretraživanja različito su važni
Oni leže na kontinuiranoj skali i teško je odrediti točnu granicu važno/nevažno
5
Mjere pretraživanja
a+b - relevantni objekti b+c - pronađeni objekti
obuhvat = b/(a+b)
preciznost = b/(b+c)
Raspon njihovih vrijednosti je 0,0-1,0 ili 0-100%
a b c
Obuhvat i preciznost
Kriva je pretpostavka da se pretraživanjem dobiva
potpun obuhvat (sve relevantno je pronađeno, a=)
potpuna preciznost (sve pronađeno je relevantno, c= )
Nažalost, praksa pokazuje da su mjere kontradiktorne
ako se jedna povedava, druga se smanjuje
Zahtjevi kvalitetnog pretraživanja (u praksi):
Visok obuhvat
Što veda preciznost, bez žrtvovanja obuhvata
Praksa na webu: dobar obuhvat ali loša preciznost
6

2
Tipičan odnos preciznosti i obuhvata
7
pre
ciz
nost
obuhvat
Preciznost na n dokumenata
Ako se pronađeni dokumenti rangiraju po relevantnosti, preciznost varira o broju ispisanih dokumenata
Ako je prvih 10 dokumenata relevantno, a sljededih 10 nerelevantno:
Preciznost je 100% u prvih 10 dokumenata, i 50 % u prvih 20 dokumenata
Preciznost na n dokumenata je stvarni broj relevantnih u odnosu na broj ispisanih dokumenata (hitlist)
Prosječna preciznost je suma preciznosti za svaki relevantni ispisani dokument (“hitlist”) podijeljena s ukupnim brojem relevantnih dokumenata u kolekciji
8
9
Problem pretraživanja informacija
1. primjer iz hrpe časopisa pronadi sve članke (dokumente) o Hrvatskoj čovjek zna koncept Hrvatska, pa ne čita svaki članak od riječi
do riječi, nego gleda naslov, podnaslov, ili dijelove članaka, da ustanovi ima članak veze s temom
konceptualno pretraživanje (temelji se na poznavanju koncepta Hrvatska i kontekstualnom znanju kako je uređen časopis)
2. primjer iz hrpe matematičkih časopisa pronadi sve članke o De
Morganovom pravilu čovjek ne zna koncept De Morganovo pravilo, pa čita svaki
članak od riječi do riječi i traži riječi De Morgan mehaničko pretraživanje (ne temelji se na poznavanju
koncepta)
Problem pretraživanja informacija - zaključak
konceptualno pretraživanje kvalitetnije i brže tako radi čovjek, jer ima znanje o konceptu (konceptualno
znanje)
mehaničko pretraživanje manje kvalitetno i sporo tako radi računalo, jer nema znanje o konceptu
Ostaje neriješen problem kako opisati konceptualno znanje, tj. kako riječima opisati koncept – pojam pretraživanja
10
Kako poboljšati računalno pretraživanje
Umjesto mehaničkog pretraživanja uvoditi “konceptualno” pretraživanje
Kako riječima opisati koncept ostaje neriješen problem pa preostaju polovična rješenja:
Strukturiranje dokumenata – definiranje atributa koji pobliže opisuju dokument
Uvođenje atributa kojim se dokumenti klasificiraju prema konceptima – klasifikacija sadržaja
Uvođenje metoda “konceptualnog” pretraživanja potpomognuta statističkim tehnikama
11 12
Problem klasifikacije
Klasificiranje sadržaja je prvi i najjednostavniji način poboljšanja pretraživanja sadržaja
Primjer u knjižnici (ili bazi podataka) pronadi dokumente (knjige ili članke) o WTO
(World Trade Organization)
traženje po ključnim riječima ili klasifikaciji (npr. UDK) – uz pomod kataloga (indeksa) pronalazimo
postoji sustav klasificiranja dokumenata
Zaključak pretraživanje je toliko kvalitetno koliko je kvalitetan sustav klasificiranja
dokumenata Ali !!!, univerzalne klasifikacije (npr. UDK – univerzalna decimalna
klasifikacija, koristi se u knjižnicama) su preopdenite gledajudi sa stanovišta pojedine struke
pojedine struke klasificiraju dokumente prema svojim potrebama
baze dokumenata obavezno se koriste klasifikacijskim sustavom

3
13
CIP - Katalogizacija u publikaciji
Nacionalna i sveučilišna knjižnica,
Zagreb
UDK 681.3
POSLOVNO računarstvo / urednici
VLATKO Čerić… [et al.]; - Zagreb:
Znak, 1998. - xx, 588 str.:ilustr.; 24 cm.
Kazalo.
ISBN 953-189-096-X
1. Varga, Mladen
2. Birolla, Hugo
Načini klasificiranja dokumenata
klasifikacijski sustavi (UDK, BSO, …)
hijerarhijska višerazinska podjela
ključne riječi (ili deskriptori)
riječi iz teksta dokumenta, koji konceptualno opisuju sadržaj dokumenta
tezaurus – sređeni skup pojmova (ključnih riječi)
Rudarenje podataka
Autor(i)
Sažetak (Abstract): xxxxxxxx
Ključne riječi (keywords):
rudarenje podataka, otkrivanje
znanja, …
Tekst xxxxxxxxxxxxxxxxxxxx
Pretraživanje knjižničnih kataloga
Knjižnica Ekonomskog fakulteta http://www.efzg.hr/default.aspx?id=267
Nacionalna i sveučilišna knjižnica http://www.nsk.hr/DigitalLib.aspx?id=8
Europske nacionalne knjižnice http://search.theeuropeanlibrary.org
14
15
Primjer pretraživanja po klasifikacijskim podacima
16
Primjer pretraživanja po klasifikacijskim podacima (2)
17
Metode pretraživanja informacija
Pretraživanje po riječima
Riječ opisuje koncept ili pojam (engl. term)
Pretraživanje se temelji na tehnikama uparivanja i brojanja pojmova u dokumentu
nedostaju modeli za stvarno opisivanje sadržaja teksta (za konceptualno pretraživanje)
Metode pretraživanja informacija
Metode Booleovog pretraživanja
Modeli vektorskog prostora
Probabilistički modeli
Dokumente rangiraju prema vjerojatnosti relevantnosti u odnosu na postavljeni upit
Modeli (ima ih više) različito procjenjuju tu vjerojatnost
Metode modifikacije upita
Ostale metode
Klasteriranje – pretpostavka da su dokumenti u klasteru slični (slične relevantnosti za korisnika)
Obrada prirodnog jezika
18

4
Booleovo pretraživanje
Informacijska potreba se opisuje upitom, koji se sastoji od riječi povezanih Booleovim (logičkim) operatorima I (AND), OR (ILI), NE (NOT)
Informacijski AND (sustav OR sistem)
Ako dokument odgovara upitu, dokument je pronađen selekcija: NE (0) ili DA (1)
Pronađeni dokumenti nisu rangirani, jer ne postoji mjera sličnosti upita i dokumenta
Potrebno je umijede dobrog formuliranja upita
Mnogi profesionalni korisnici ga koriste iako je slabije od metoda s rangiranjem dokumenata
19
Booleovo pretraživanje
Riječi se kombiniraju log. operacijama I, ILI, NE (AND, OR, NOT)
find (traži) nafta – pronalaženje članaka s rječju nafta
find nafta I ugljen – pronalaženje članaka u kojima se istodobno pojavljuju riječi nafta i ugljen
find nafta ILI ugljen – pronalaženje članaka u kojima se spominju ili samo nafta ili samo ugljen ili istovremeno obje
find naft* – pronalaženje članaka u kojima se pojavljuju riječi koje počinju s naft, npr. nafta, nafte, nafti, naftom, naftni, naftaši
find “naftna industrija” – pronalaženje članaka u kojima su riječi naftna i industrija tvore frazu (izričaj) “naftna industrija”
find predsjednik NEAR republike – pronalaženje članaka u kojima su riječi predsjednik i republike bliske, ali ne moraju biti i susjedne
20
Primjer Booleovog pretraživanja
Baza dokumenata (podataka) EconLit
Dostup preko
On-line sustav koji nudi pristup velikom broju full-text i bibliografskih baza. Može se pretraživati gotovo 3000 full-text časopisa i više od 5000 publikacija koje nude sažetke, novinske preglede, enciklopedijske podatke. Sadrži baze: Business source premier, Academic source premier, Econlit, Business source complete, Regional business news, ERIC, LISTA, SOCindex, Newspaper source, Clinical pharmacology, Health source, PsycINFO.
21 22
23 24

5
25 26
27
Modeli vektorskog prostora
Koristi se matematički pojam vektora
U vektor ulaze pojmovi: riječi ili fraze (izričaji)
Svaki pojam (riječ) postaje dimenzijom u vektorskom prostoru, vektori se smatraju neovisnim (ortogonalnim)
Bilo koji tekst se reprezentira vektorom
Ako tekst sadrži pojam (riječ), dobiva ne-nula vrijednost u dimenziji kojoj pojam pripada
Kako svaki tekst ima ograničen skup pojmova (riječi), a vokabular može imati i milijun pojmova, vedina vektora je slabo popunjena
28
Primjer vektorskog modela
Vokabular ima 10 riječi: ekonomska, društvena, tehnička, prirodna, znanost, jest, nije, nikako, pripada, uvijek
Dokument ima sljededi tekst: “Ekonomska znanost jest društvena znanost”
Vektor dokumenta: {1,1,0,0,1,1,0,0,0,0}
29 30
Pretraživanje u modelu vektorskog prostora
Popis pojmova (riječi) po kojima se pretražuje tvori vektor upita Q
Izračunava se udaljenost između vektora upita Q i vektora svakog dokumenta u bazi dokumenata
Ispisuju se dokumenti čija je udaljenost od upita manja od zadanog praga P
Dokumenti se rangiraju po relevantnosti (najprije se ispisuju relevantni dokumenti, bliži upitu)

6
31
Pretraživanje u modelu vektorskog prostora
Neka je skup pojmova za pretraživanje pj, 1≤j≤P (tezaurus)
Za svaki dokument Di, 1≤i≤N definira se vektor pojmova Di=(di1, di2, …, dip), gdje je dij pojava j-tog pojma u i-tom dokumentu, a ima težinsku vrijednost: broj pojavljivanja j-tog pojma u i-tom dokumentu,
tzv. FP-frekvencija pojmova (TF-term frequency); mjera ima slabu snagu ako se pojam učestalo pojavljuje u puno dokumenata
logaritam inverza dijela kojeg pojam j ima u cjelini: log (N/nj); tzv. IFD-inverzna frekvencija dokumenata (IDF-inverse document frequency)
FP-IFD shema (TF-IDF) je umnožak vrijednosti FP i IFD
32
Pretraživanje u modelu vektorskog prostora
Izračunava se udaljenost između vektora upita Q=(q1, q2, …, qp) i vektora pojedinih dokumenata Di=(di1, di2, …, dip) Kosinus (kosinusna udaljenost, korelacija) dvaju vektora
Kosinus ima svojstvo da vrijednost 1,0 imaju identični vektori, a 0,0 imaju ortogonalni (potpuno različiti) vektori
33
Primjer
Pojmovi: p1=baza, p2=podataka, p3=SQL, p4=regresija, p5=vjerojatnost, p6=linearna
Dokumenti: d1-d10
Vektor pojmova p1 p2 p3 p4 p5 p6
d1 24 21 9 0 0 3
d2 32 10 5 0 3 0
d3 12 16 5 0 0 0
d4 6 7 2 0 0 0
d5 43 31 20 0 3 0
d6 2 0 0 18 7 16
d7 0 0 1 32 12 0
d8 3 0 0 22 4 2
d9 1 0 0 34 27 25
d10 6 0 0 17 4 23 34
Primjer (2)
Vektor upita: Q=(1,0,1,0,0,0) pokazuje pretraživanje po pojmovima “baza” i “SQL”
Po FP (TF) shemi najbolji je dokument d7
Po FP-IFD (TF-IDF) shemi najbolji je d2
Dokument FP (TF)
udaljenost
FP-IFD
(TF-IDF)
udaljenost
d1 0,70 0,32
d2 0,77 0,51
d3 0,58 0,24
d4 0,60 0,23
d5 0,79 0,43
d6 0,14 0,02
d7 0,06 0,01
d8 0,02 0,02
d9 0,09 0,01
d10 0,01 0,00
35
Metode modifikacije upita
Latentno semantičko indeksiranje (Latent Semantic Indexing - LSI) obično pretraživanje po riječima:
dokument sadrži traženu riječ ili ne (nema sredine)
LSI ispituje dokument kao cjelinu: gleda koji drugi dokumenti imaju iste riječi
(dokumenti koji imaju puno istih riječi su semantički slični)
u semantički sličnim dokumentima pronalazi i druge riječi po kojima pretražuje
ovaj jednostavan pristup korelira s načinom ljudskog pristupa – Iako LSI algoritam ne razumije sadržaj, daje dojam inteligentnog pronalaženja sličnih dokumenata.
Primjer: traženje po riječima De Morganovo pravilo daje dokumente koji sadrže tu
frazu (kao obično pretraživanje)
pronalazi i druge slične dokumente, jer se uz De Morganovo pravilo našlo da su i riječi logička varijabla semantički bliske, pa su pronađeni i dokumenti s tim riječima
Implementacija
Vedina sustava pretraživanja koristi invertirane liste Pi<da,…>,<db,…>, …<dn,…> i-ti pojam se nalazi u dokumentima da,db, …dn i može sadržavati dodatne informacije (broj pojavljivanja pojma u dokumentu)
Postupak izrade invertiranih lista je indeksiranje kojim se formira invertirani indeks
36

7
Implementacija
Vedina sustava uzima pojedine riječi kao pojmove
Neinformativne riječi (npr. a, ali, … the, of, a …) se ne indeksiraju – nazivaju se stop-riječima
Korjenovanje (engl. stemming) je uzimanje korijena riječi u indeks
Isti korijen se koristi u srodnim riječima – korijen naft se koristi u riječima nafta, naftaši, naftna …
Pretraživanje po korijenu riječi je efikasnije (naročito u flektivnim jezicima kakav je hrvatski jezik)
Indeksirati se mogu fraze (izričaji) npr. “informacijski sustav” ili “information retrieval”
37 38
SMART - sustav za pretraživanje dokumenata
Jedan od prvih i najboljih sustava za pretraživanje dokumenata, razvijen na Cornell University (Gerard Salton)
Koristi model vektorskog prostora
Obavlja automatsko indeksiranje:
najprije izbacuje stop-riječi (uz pomod pripremljene liste stop-riječi),
pronalazi i uzima korijen riječi,
dodjeljuje težinsku vrijednost
Zadani upit prevodi u vektor, a zatim ispituje njegovu sličnost (udaljenost) prema dokumentima u vektorskom prostoru
Rangira dokumente te ispisuje prvih n dokumenata (n određuje korisnik)
Može koristiti povratnu vezu, kojom korigira prvotno zadani upit
39
O'Neill Criticizes Europe on Grants PITTSBURGH (AP)
Treasury Secretary Paul O'Neill expressed irritation Wednesday that European countries have refused to go along with a U.S. proposal to boost the amount of direct grants rich nations offer poor countries. The Bush administration is pushing a plan to increase the amount of direct grants the World Bank provides the poorest nations to 50 percent of assistance, reducing use of loans to these nations.
o'neill criticizes europe on grants treasury secretary paul o'neill expressed irritation wednesday that european countries have refused to go along with a us proposal to boost the amount of direct grants rich nations offer poor countries the bush administration is pushing a plan to increase the amount of direct grants the world bank provides the poorest nations to 50 percent of assistance reducing use of loans to these nations
original
deformatiranje
o'neill criticizes europe on grants treasury secretary paul o'neill expressed irritation wednesday that european countries have refused to go along with a US proposal to boost the amount of direct grants rich nations offer poor countries the bush administration is pushing a plan to increase the amount of direct grants the world bank provides the poorest nations to 50 percent of assistance reducing use of loans to these nations
stop riječi
40
o'neill criticizes europe grants treasury secretary paul o'neill expressed irritation european countries refused US proposal boost direct grants rich nations poor countries bush administration pushing plan increase amount direct grants world bank poorest nations assistance loans nations o'neill criticizes europe grants treasury secretary
paul o'neill expressed irritation european countries refused US proposal boost direct grants rich nations poor countries bush administration pushing plan increase amount direct grants world bank poorest nations assistance loans nations
bez stop riječi
uzimanje korijena
administrat amount assist bank boost bush countr (2) direct europ express grant (2)
increas irritat loan nation (3) o'neill paul plan poor (2) propos push
refus rich secretar treasur US world
konačan popis riječi
Druge primjene pretraživanja informacija
Filtriranje poruka e-pošte: eliminacija nepoželjnih poruka ili pronalaženje specifičnih poruka
Media clipping usluge: pronalaženje značajnih dokumenata po nekom kriteriju i njihovo predstavljanje krajnjem korisniku
…
41
Web kao kolekcija (baza) dokumenata
Struktura dokumenata nije propisana Distribuirano stvaranje i povezivanje
sadržaja demokratizira publiciranje informacija
Sadržaj varira od znanstvene istine do namjerne laži, informacije mogu biti kontradiktorne, zastarjele, …
Sadržaj je nestrukturiran (slike, tekst, html …), polustrukturiran (XML, označene slike), strukturiran (baze dokumenata)…
Dokumenti mogu biti dinamički generirani (ne postoje kao samostalne jedinice, stvaraju se iz drugih podataka) Web
8
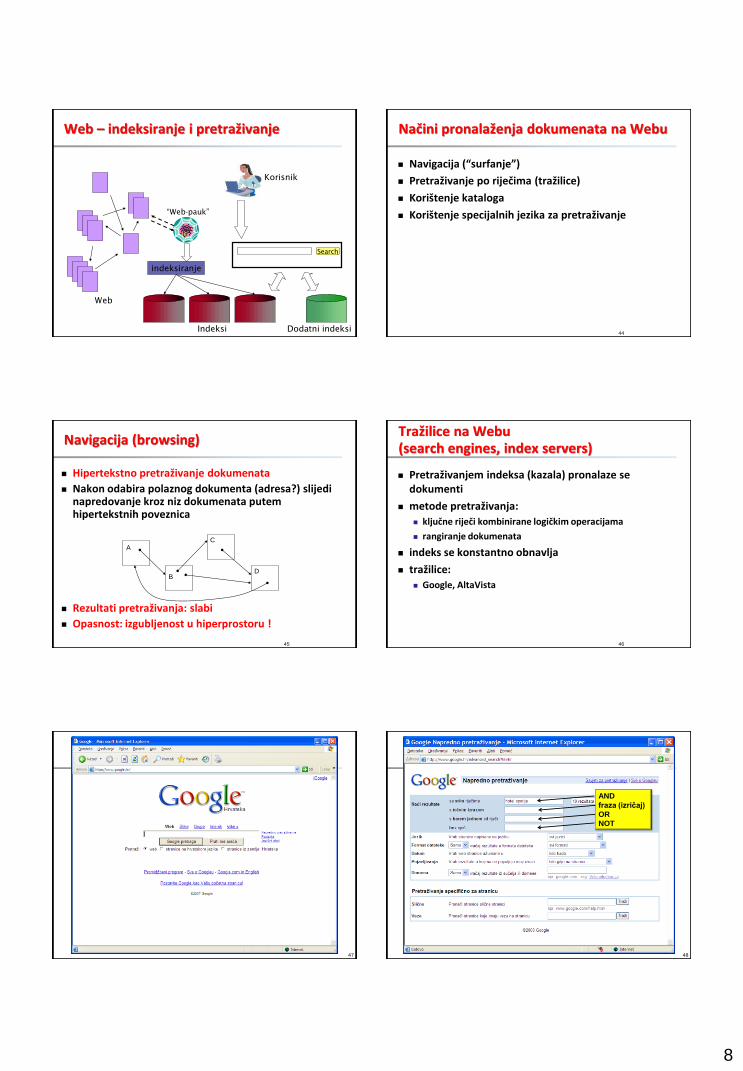
Web – indeksiranje i pretraživanje
Web
Dodatni indeksi
“Web-pauk”
indeksiranje
Indeksi
Search
Korisnik
44
Načini pronalaženja dokumenata na Webu
Navigacija (“surfanje”)
Pretraživanje po riječima (tražilice)
Korištenje kataloga
Korištenje specijalnih jezika za pretraživanje
45
Navigacija (browsing)
Hipertekstno pretraživanje dokumenata
Nakon odabira polaznog dokumenta (adresa?) slijedi napredovanje kroz niz dokumenata putem hipertekstnih poveznica
Rezultati pretraživanja: slabi
Opasnost: izgubljenost u hiperprostoru !
A C
B D
46
Tražilice na Webu (search engines, index servers)
Pretraživanjem indeksa (kazala) pronalaze se dokumenti
metode pretraživanja:
ključne riječi kombinirane logičkim operacijama
rangiranje dokumenata
indeks se konstantno obnavlja
tražilice:
Google, AltaVista
47 48
AND
fraza (izričaj)
OR
NOT

9
49 50
51
Rangiranje u Googleu – algoritam PageRank
PageRank je algoritam analize povezanosti hipertekstnih dokumenata (nazvan po Larry Pageu)
Dodjeljuje numeričku vrijednost svakom dokumentu u skupu hipertekstnih dokumenata (npr. webu) kojom opisuje relativnu važnost dokumenta u skupu
Može se primijeniti u bilo kojem skupu dokumenata koji se međusobno referenciraju (povezuju)
Numerička vrijednost dokumenta E je PageRank of E ili PR(E)
52
PageRank
Umjesto brojanja izravnih veza, PageRank tumači vezu sa stranice A na stranicu B kao glas stranice A za stranicu B
PageRank uzima u obzir i važnost svake stranice koja daje glas (glasovi nekih stranica su vredniji) na taj način dajudi povezanoj stranici vedu vrijednost
Važne stranice dobivaju viši PageRank i pojavljuju se na vrhu rezultata pretraživanja
53
PageRank
54
http://en.wikipedia.org/wiki/PageRank

10
55 56
57
Katalozi na Webu (subject trees, directories)
hijerarhijski uređeni katalozi Web dokumenata
katalozi:
Yahoo!
58
Yahoo
59
Pretraživanje nestrukturiranih slikovnih i zvučnih podataka
Pretraživanje po primjerima (query-by-example) korisnik postavlja upit definiranjem vrijednosti atributa traženih objekata
baza dokumenata (multimedijskih objekata) vrada listu rangiranih pronađenih objekata
korisnik pregledava (ocjenjuje) listu, po potrebi korigira i ponovno postavlja upit
Primjer: QBIC (Query By Image Content) tvrtke IBM pretražuje baze slika po svojstvima: postotak boje, raspored boje,
tekstura slike
informacije: wwwqbic.almaden.ibm.com
primjer upotrebe: www.hermitagemuseum.org (St Petersburg) http://www.hermitagemuseum.org/fcgi-bin/db2www/qbicSearch.mac/qbic?selLang=English
Razvoj weba
60

11
Web 1.0 web 3.0 (semantički web)
U postojedem webu dokumenti su opisani HTML-om koji označava grafičke i neke sadržajne elemente
Ne postoji sadržajna označenost jedino čitatelj razumije sadržaj, ali ne i stroj
Semantički web unosi u dokument značenjske (semantičke) oznake sadržaj razumije i stroj
XML kao pogodan jezik
61
Semantički web: XML
<?xml version="1.0" encoding="UTF-8"?>
<poruka>
<primatelj>[email protected]</primatelj >
<pošiljatelj>[email protected]</pošiljatelj>
<predmet>Pozdrav</predmet>
<sadržaj>Dobro jutro!</sadržaj>
</poruka>
62
Semantički web: elementi
XML
RDF (Resource Description Framework)
OWL (Web Ontology Language)
63
Semantički web: RDF
RDF-om se opisuju resursi na webu, primjerice dokument na webu
Resurs je sve što može imati URI (Uniform Resource Identifier)
RDF identificira resurs navodedi web-identifikator, svojstvo resursa i vrijednost svojstva
Resurs-svojstvo-vrijednost čini tvrdnju oblika subjekt-predikat-objekt
64
Semantički web: RDF
Primjer: resurs je „http://www.efzg.hr/mvarga“, svojstvo „autor“, vrijednost „Mladen Varga“
<?xml version="1.0"?>
<RDF>
<Description about="http://www.efzg.hr/mvarga">
<autor>Mladen Varga</autor>
<pocetnastr>http://www.efzg.hr</pocetnastr>
</Description>
</RDF>
65
Semantički web: ontologija
Da bi ljudi (strojevi) mogli komunicirati trebaju se služiti zajedničkim vokabularom
Formalni vokabular koji definira klase pojmova, njihova svojstva i odnose naziva se ontologijom
Primjeri ontologija
Friend of a Friend (ontologija za opis osoba i odnosa prema drugim ljudima i objektima)
WordNet (leksički referentni sustav)
Gene Ontology (genska ontologija)
DublinCore (ontologija dokumenata)
66

12
Semantički web: ontologija DublinCore
vokabular od 15 svojstava resursa: contributor, coverage, creator, format, date, description, identifier, language, publisher, relation, rights, source, subject, title, type
ISO Standard 15836:2009
Koristi se u imenskom prostoru dc: http://purl.org/dc/elements/1.1/ ili dcterms: http://purl.org/dc/terms/
67
Semantički web: ontologija DublinCore
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc= "http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://www.efzg.hr">
<dc:description>Portal Ekonomskog fakulteta</dc:description>
<dc:publisher>Ekonomski fakultet - Zagreb</dc:publisher>
<dc:type>web-portal</dc:type>
</rdf:Description>
</rdf:RDF>
68
SPARQL: upitni jezik za RDF
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT ?title
WHERE { <http://example.org/book/book1> dc:title ?title }
69 70
Sustav za upravljanje sadržajem - Content Management System (CMS)
kombinacija baza podataka, baza dokumenata (datoteka) i softvera za pohranjivanje i pronalaženje velikih količina podataka
razlikuje se od transakcijskih baza podataka, jer sadrži i indeksira tekst, audio, video – pronalaženje podataka uz pomod ključnih riječi ( information retrieval)
koristi se za kreiranje portala, za obradu elektroničkih i web-dokumenata
71
Sudionici upravljanja sadržajem
Urednik sadržaja određuje koji de se sadržaj i gdje publicirati
Publicist sadržaja publicira sadržaj
Autor(i) sadržaja stvara sadržaj