Embed Size (px)
Citation preview

Appendici Matematica

Ap
pe
nd
ice
ATeoria dell’informazione
Dovresti chiamarla entropia, per due ragioni. Innanzitutto latua funzione di incertezza è già nota in meccanica statisticacon quel nome. In secondo luogo, ancora più importante,nessuno sa cosa sia con certezza l’entropia, così in unadiscussione avrai sarai sempre in vantaggio.
J. von Neumann, in risposta a C. Shannon
La teoria dell’informazione (Information Theory) è una branca della matema-tica applicata nata alla fine degli anni ’40, grazie al lavoro di Shannon [Sha48]Una Teoria Matematica della Comunicazione pubblicato sulla rivista tecnicadei laboratori Bell. La ricerca di Shannon riguardava principalmente il proble-ma della compressione dell’informazione e, più in generale, della memorizzazio-ne e della comunicazione digitale. I suoi risultati hanno gettato le basi per unavera e propria disciplina, con applicazioni in crittografia, statistica, biologia, emolti altri settori.
Guida per il lettore. Questa appendice riassume alcuni concetti di baseusati in diverse parti del testo. Nel Paragrafo A.1 richiameremo il concettodi variabile aleatoria e di distanza statistica tra variabili aleatorie. Nel Pa-ragrafo A.2 enunceremo (e dimostreremo) alcune disuguaglianze fondamentaliin teoria della probabilità, in particolare il limite di Chernoff. Infine, nel Pa-ragrafo A.3, presenteremo una breve panoramica sui concetti di entropia e diinformazione mutua.
Per un’introduzione alla teoria delle probabilità si vedano ad esempio [Tij04;Gut05], per approfondire i concetti di teoria dell’informazione si suggerisce unalettura di [CK97; CT06].
Venturi D.: Crittografia nel Paese delle MeraviglieDOI 10.1007/978-88-470-2481-6 15, c© Springer-Verlag Italia 2012

426 A Teoria dell’informazione
A.1 Variabili aleatorie
Una variabile aleatoria (random variable) può essere pensata come l’outputdi un esperimento del quale non si può predire con certezza il risultato. Aseconda di come è descritto l’output dell’esperimento parleremo di variabilialeatorie discrete o di variabili aleatorie continue. Nel seguito ci soffermia-mo solo sulle prime. La nostra trattazione sarà principalmente informale; siraccomanda [Bil79] per un approccio rigoroso.
Variabili aleatorie discrete. Essenzialmente una variabile aleatoria discre-ta X mappa un evento E in un valore di un insieme numerabile X (ad esempiol’insieme dei numeri interi); ciascun valore ha associata una quantità — dettaprobabilità — maggiore o uguale di zero e minore o uguale di 1. In questo modo,si associa ad ogni variabile aleatoria discreta una distribuzione di probabilità,detta anche densità discreta o funzione di massa di probabilità.
Consideriamo, ad esempio, l’evento E che descrive il lancio di un dado (nontruccato e con sei facce). Dato l’insieme X = {1, 2, 3, 4, 5, 6}, la variabilealeatoria X associa ad ogni possibile risultato del lancio del dado un elementodell’insieme X :
X =
⎧⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎩
1 se esce ,2 se esce ,3 se esce ,4 se esce ,5 se esce ,6 se esce .
La densità discreta sarà quindi
PX(x) =
{1/6 se x = 1, . . . , 6
0 altrimenti.
Più in generale, data una variabile aleatoria aleatoria X definita su un’insie-me numerabile X , la sua densità discreta nel punto x ∈ X è la probabilità cheX assuma il valore x. In simboli:
PX(x) = P [X = x] ∀x ∈ X .
Siccome la somma delle probabilità di tutti gli eventi è l’evento certo, si hasempre
∑x∈X PX(x) = 1.

A.1 Variabili aleatorie 427
Indipendenza statistica. Quando si ha a che fare con due variabili aleatoriecontemporaneamente, in genere non è sufficiente conoscere i valori di proba-bilità delle singole variabili. Intuitivamente il motivo è che le due variabilialeatorie possono essere in qualche modo “correlate”. In questo senso, la coppia(X,Y ) ∈ X ×Y è essa stessa una variabile aleatoria caratterizzata dalla densitàdiscreta (detta congiunta):
PX,Y (X,Y ) = P [X = x ∧ Y = y] .
Le densità discrete delle singole variabili aleatorie componenti, cosiddette mar-ginali, si ottengono per saturazione della congiunta:
PX(x) =∑y∈Y
PX,Y (x, y) (A.1)
PY (y) =∑x∈X
PX,Y (x, y). (A.2)
Possiamo esprimere il rapporto tra densità congiunta e marginale attraver-so il concetto di densità discreta condizionata. La probabilità dell’evento E1condizionata all’evento E2 è la probabilità che l’evento E1 si verifichi condizio-natamente al fatto che si verifichi E2. Ad esempio, tornando all’esempio deldado, la probabilità che esca sapendo che il risultato del lancio sarà ,oppure è 1/3. Formalmente, abbiamo:
P [E1 | E2] =P [E1 ∧ E2]
P [E2].
Due eventi si dicono statisticamente indipendenti quando P [E1 | E2] = P [E1](ovvero quando la probabilità che E1 si verifichi dato che si verifica E2 è ugua-le alla probabilità che E1 si verifichi a priori). La relazione tra P [E1 | E2] eP [E2 | E1] è data dal teorema di Bayes, espresso dalla seguente equazione:
P [E2 | E1] = P [E1 | E2] ·P [E2]P [E1]
. (A.3)
Passando alle densità, date due variabile aleatorie X ∈ X ed Y ∈ Y, laprobabilità condizionata di Y = y dato X = x è:
P [Y = y | X = x] =P [X = x ∧ Y = y]
P [X = x]
(A.3)=
P [Y = y|X = x]P [Y = y]
P [X = x].

428 A Teoria dell’informazione
Quindi,PX,Y (x, y) = PY |X(y|x)PX(x) = PX|Y (x|y)PY (y).
Analogamente a quanto visto per gli eventi, due variabile aleatorie si diconostatisticamente indipendenti se PX,Y (x, y) = PX(x)PY (y).
Valore atteso e varianza. La densità discreta di una variabile aleatoriaX è caratterizzata da diversi parametri. In alcuni casi può essere sufficienteconoscere quale valore assume la variabile aleatoria in media; si definisce quindiil valore atteso di X come:
μ = E [X] =∑x∈X
xPX(x).
Non è difficile mostrare che il valore atteso è un operatore lineare: il valoreatteso della somma di più variabili aleatorie altro non è che la somma deisingoli valori attesi. Riportiamo il caso di due variabili aleatorie; l’estensioneal caso generale è un semplice esercizio (cf. Esercizio A.2).
Lemma A.1 (Linearità del valore atteso). Siano X ed Y due variabilealeatorie discrete definite (rispettivamente) su due insiemi X ed Y. Per ogniα, β ∈ R abbiamo E [αX + βY ] = αE [X] + βE [Y ].
Dimostrazione. La dimostrazione segue direttamente dalla definizione di den-sità congiunta:
E [αX + βY ] =∑x∈X
∑y∈Y
(αx+ βy)P [X = x ∧ Y = y]
= α∑x∈X
x∑y∈Y
P [X = x ∧ Y = y] + β∑y∈Y
y∑x∈X
P [X = x ∧ Y = y]
= [usando l’Eq. (A.1) e l’Eq. (A.2)]
= α∑x∈X
x · P [X = x] + β∑y∈Y
y · P [Y = y]
= αE [X] + βE [Y ] .
Anche quando è noto il valore medio, è lecito chiedersi quanto i valori di X(tipicamente) si allontanano da E [X]; a tale scopo si definisce la varianza diuna variabile aleatoria come:
σ2 = V [X] = E[(X − μ)2
].

A.1 Variabili aleatorie 429
La quantità σ =√σ2 è detta deviazione standard. Un semplice calcolo mostra:
V [X] = E[(X − μ)2
]= E
[X2 − 2μX + μ2
]= [per la linearità del valore atteso (cf. Lemma A.1)]
= E[X2]− 2μ2 + μ2
= E[X2]− (E [X])2.
La varianza (in generale) non è lineare. In alcuni casi particolari però laproprietà di linearità è soddisfatta. Di particolare interesse è il caso di variabilialeatorie indipendenti a coppie. Diremo che n variabili aleatorie X1, . . . , Xn
definite sull’insieme X sono indipendenti a coppie, se per ogni i, j ∈ [n] (coni = j) e per ogni a, b ∈ R, risulta:
P [Xi = a ∧Xj = b] = P [Xi = a] · P [Xj = b] .
Nel caso in cui l’indipendenza a coppie è soddisfatta la varianza della variabilealeatoria somma coincide con la somma delle singole varianze:
Lemma A.2 (Linearità della varianza). Siano X1, . . . , Xn variabili alea-torie indipendenti a coppie; poniamo X =
∑ni=1 Xi. Allora:
V [X] =
n∑i=1
V [Xi] .
Dimostrazione. Basta applicare la definizione e sfruttare la proprietà di linea-rità del valore atteso:
V [X] = E
[(X1 + . . .+Xn)
2]− (E [X1 + . . .+Xn])
2
= E [(X1 + . . .+Xn) · (X1 + . . .+Xn)]− (E [X1 + . . .+Xn])2
= E
⎡⎣∑i,j
XiXj
⎤⎦−∑i,j
E [Xi] · E [Xj ]
= [dalla linearità del valore atteso]
=∑i,j
E [Xi ·Xj ]−∑i,j
E [Xi] · E [Xj ]
=∑i
E[X2
i
]+∑i�=j
E [Xi ·Xj ]−∑i
(E [Xi])2 −∑i�=j
E [Xi] · E [Xj ]

430 A Teoria dell’informazione
=∑i
(E[X2
i
]− (E [Xi])
2)+∑i�=j
(E [Xi ·Xj ]− E [Xi] · E [Xj ])
=∑i
V [Xi] +∑i�=j
(E [Xi ·Xj ]− E [Xi] · E [Xj ]) .
Siccome le variabili aleatorie X1, . . . , Xn sono indipendenti a coppie, l’ultimasommatoria è nulla.
Spazi metrici e distanza statistica. Dato uno spazio, possiamo dotarlo diuna struttura arricchendolo con una metrica (detta anche distanza). In questomodo gli elementi dello spazio sono luoghi geometrici che (quando non identici)hanno distanza positiva.
Definizione A.1 (Metrica su uno spazio X ). Si definisce metrica unafunzione d : X × X → R+ che soddisfa le seguenti proprietà:
• Definita positiva. d(x, y) ≥ 0, ∀ x, y ∈ X e d(x, y) = 0 se e solo se x = y.
• Simmetria. d(x, y) = d(y, x), ∀ x, y ∈ X .
• Disuguaglianza triangolare. d(x, z) ≤ d(x, y) + d(y, z), ∀ x, y, z ∈ X .
�
In genere la scelta non è univoca, ed infatti esistono tante metriche. Unesempio classico è costituito dallo spazio delle stringhe binarie a lunghezza n(detto anche spazio di Hamming ed indicato con {0, 1}n), dove si definisce ladistanza di Hamming.
Definizione A.2 (Distanza di Hamming). Date due stringhe binarie x,y ∈{0, 1}n la loro distanza di Hamming dH : {0, 1}n × {0, 1}n → R+ è definitacome:
dH(x,y) = # {i : xi = yi, ∀ i = 1, 2, . . . , n} .�
Non è complesso verificare che la distanza di Hamming è una metrica. Ineffetti ciò deriva dal fatto che
dH(x,y) =n∑
i=1
|xi − yi| ;

A.1 Variabili aleatorie 431
pertanto, siccome la funzione valore assoluto è una metrica, anche la distanzadi Hamming lo è. Si definisce il peso di Hamming di una stringa binaria x ∈{0, 1}n come il numero di valori “1” in x. Più precisamente wH(x) = dH(x,0),dove 0 = (0, . . . , 0) è il vettore tutto nullo in {0, 1}n.
Un secondo esempio è quello dello spazio euclideo Rn. Dato un vettorex = (x1, . . . , xn) ∈ Rn, sia
‖x‖1 =n∑
i=1
|xi|
la sua norma l-1. È immediato verificare che la mappa d(x,y) = ‖x − y‖1 èuna metrica. Analogamente, se consideriamo la norma l-2:
‖x‖2 =
√√√√ n∑i=1
|xi|2, (A.4)
è banale verificare che la mappa d(x,y) = ‖x − y‖2 è una metrica.87 (Questanon è altro che la familiare distanza euclidea definita dal teorema di Pitagoranel piano Cartesiano.) Osserviamo che, per ogni vettore x ∈ Rn, risulta:
‖x‖1 ≤√n‖x‖2. (A.5)
Generalizzando questi esempi, è possibile definire una distanza tra distribu-zioni di probabilità discrete. Tale distanza è detta distanza statistica.
Definizione A.3 (Distanza statistica). Date due variabili aleatorie X0, X1
con valori in X , la loro distanza statistica è:
Δ(X0, X1) =1
2
∑x∈X
|P [X0 = x]− P [X1 = x]| .
(Notare che Δ(X0, X1) = 1/2‖X0 −X1‖1.) �
Sia Un la distribuzione uniforme su {0, 1}n. In genere, quando X assumevalori in X = {0, 1}n, si è soliti indicare con d(X) = Δ(X,Un) la distanza87Più in generale, per ogni p > 0, data la norma l-p:
‖x‖p = p
√√√√ n∑i=1
|xi|p,
la mappa d(x,y) = ‖x− y‖p è una metrica.

432 A Teoria dell’informazione
statistica tra X e la distribuzione uniforme su {0, 1}n. Quando d(X) ≤ ε sidice che X è ε-vicina alla distribuzione uniforme. Analogamente:
Δ(X0, X1|Y ) = Δ((X0, Y ), (X1, Y ))
d(X|Y ) = Δ((X,Y ), (Un, Y )).
Si può dimostrare che la distanza statistica è una metrica (cf. Definizione A.1).
A.2 Alcune disuguaglianze
In questo paragrafo studieremo alcune disuguaglianze molto importanti in teo-ria della probabilità. La seguente disuguaglianza di Markov collega probabilitàe valori attesi.
Lemma A.3 (Disuguaglianza di Markov). Ogni variabile aleatoria X nonnegativa soddisfa:
P [X ≥ n] ≤ E [X]
n.
Dimostrazione. Possiamo scrivere:
E [X] =∑x≥0
x · P [X = x] ≥∑
0≤x<n
P [X = x] · 0 +∑x≥n
P [X = x] · n
= P [X ≥ n] · n.
La disuguaglianza di Chebyshev garantisce che, per ogni variabile aleatoria,quasi tutti i valori sono “vicini alla media”.
Lemma A.4 (Disuguaglianza di Chebyshev). Sia X una variabile alea-toria con varianza σ2. Per ogni n > 0, risulta:
P [|X − E [X]| ≥ n] ≤ σ2
n2.
Dimostrazione. Definiamo la variabile aleatoria non negativa Y = (X−E [X])2
ed applichiamo la disuguaglianza di Markov ad Y :
P [|X − E [X]| ≥ n] ≤ P[(X − E [X])2 ≥ n2
]= P
[Y ≥ n2
]≤ E [Y ]
n2=
E[(X − E [X])2
]n2
=σ2
n2.

A.2 Alcune disuguaglianze 433
La stima fornita dalla disequazione di Chebyshev è in un certo senso grosso-lana. Il seguente teorema di Chernoff, consente una caratterizzazione più fine(cf. Esercizio A.6).
Teorema A.5 (Limite di Chernoff). Siano X1, X2, . . . , Xn, variabili alea-torie mutuamente indipendenti su {0, 1} e sia μ =
∑ni=1 E [Xi]. Allora:
(I) ∀ δ > 0,
P
[n∑
i=1
Xi ≥ (1 + δ)μ
]≤(
eδ
(1 + δ)1+δ
)μ
;
(II) ∀ 0 < δ ≤ 1,
P
[n∑
i=1
Xi ≥ (1 + δ)μ
]≤ e−μδ2/3;
(III) ∀ c ≥ 6μ,
P
[n∑
i=1
Xi ≥ c
]≤ 2−c.
Dimostrazione. Definiamo X =∑n
i=1 Xi. Posto pi = P [Xi = 1], si ha μ =∑ni=1 pi. Introduciamo un parametro t il cui ruolo sarà noto a breve; per ogni
t > 0, possiamo scrivere:
P [X > (1 + δ)μ] = P
[etX > et(1+δ)μ
].
Applicando la disuguaglianza di Markov al secondo membro, otteniamo:
P [X > (1 + δ)μ] ≤ E[etX]
et(1+δ)μ. (A.6)
Notare che, siccome le variabili aleatorie Xi sono mutuamente indipendenti,abbiamo:
E[etX]= E
[et
∑ni=1 Xi
]= E
[n∏
i=1
etXi
]=
n∏i=1
E[etXi
]. (A.7)
Possiamo inoltre limitare superiormente il termine etXi sfruttando il fatto cheex > 1 + x e che Xi ∈ {0, 1}:
E[etXi
]= pie
t + (1− pi) = 1 + (et − 1)pi ≤ e(et−1)pi .

434 A Teoria dell’informazione
Ma allora, sostituendo nell’Eq. (A.7), si ottiene:
E[etX]<
n∏i=1
e(et−1)pi = e
∑ni=1(e
t−1)pi = e(et−1)μ.
Sostituendo quest’ultima espressione nell’Eq. (A.6), infine, otteniamo:
P [X > (1 + δ)μ] ≤ E[etX]
et(1+δ)μ<
e(et−1)μ
et(1+δ)μ=(ee
t−1−t(1+δ))μ
.
L’ultima espressione è valida per ogni t > 0. Per ottenere l’asserto non ciresta che trovare il t ottimo, che rende la disuguaglianza stretta: vogliamo cioèminimizzare et − 1− t(1 + δ). Posto
d
dt(et − 1− t(1 + δ)) = et − 1− δ
!= 0,
si ottiene la soluzione unica t = ln(1 + δ). Quindi:
P [X > (1 + δ)μ] <(eδ−(1+δ) ln(1+δ)
)μ=
(eδ
(1 + δ)1+δ
)μ
,
che è esattamente l’espressione in (I).Per dimostrare la (II) scriviamo l’espansione in serie di Mclaurin88 del ter-
mine ln(1 + δ), ovvero:
(1 + δ) ln(1 + δ) = (1 + δ)∑i≥1
(−1)i+1 δi
i= δ +
∑i≥2
(−1)iδi(
1
i− 1− 1
i
).
88In analisi matematica, un risultato di Taylor consente di approssimare una funzione (diffe-renziabile) attorno ad un dato punto attraverso alcuni polinomi, detti polinomi di Taylor, i cuicoefficienti dipendono solo dalle derivate della funzione nel punto. In particolare sia f : [a, b] → Rn
una funzione differenziabile n volte nell’intervallo [a, b] e sia x0 ∈ [a, b]. Allora:
f(x) =
∞∑i=0
f (i)(x0)
i!(x− x0)
i,
dove con f (i)(x0) si intende la derivata i-sima di f calcolata nel punto x0. Quando x0 = 0 siparla anche di serie di Mclaurin. Un semplice calcolo mostra:
ln(1 + x) =
∞∑i=1
(−1)i+1 xi
iquando −1 < x ≤ 1.

A.2 Alcune disuguaglianze 435
Se 0 ≤ δ < 1 possiamo ignorare i termini di ordine superiore, ottenendo:
(1 + δ) ln(1 + δ) > δ +δ2
2− δ3
6≥ δ − δ2
3;
quindi
P [X > (1 + δ)μ] <(eδ−(1+δ) ln(1+δ)
)μ≤ e−
δ2μ3 (0 ≤ δ < 1),
come desiderato.Per quanto riguarda la (III), infine, sia c = (1+δ)μ. Quando c ≥ 6μ abbiamo
δ = c/μ− 1 ≥ 5, quindi usando quanto dimostrato in (I):
P [X ≥ c] ≤(
eδ
(1 + δ)1+δ
)μ
≤(
e
1 + δ
)(1+δ)μ
≤(e6
)c≤ 2−c.
Si possono considerare alcune varianti, discusse brevemente di seguito. Unprocedimento simile a quello usato nella dimostrazione del Teorema A.5 mostrala validità delle seguenti disuguaglianze:
(I’) ∀ 0 < δ < 1,
P
[n∑
i=1
Xi ≤ (1− δ)μ
]≤(
e−δ
(1− δ)1−δ
)μ
;
(II’) ∀ 0 < δ < 1,
P
[n∑
i=1
Xi ≤ (1− δ)μ
]≤ e−μδ2/2.
In particolare, la seconda disuguaglianza afferma che la probabilità che l’outputdi n esperimenti indipendenti sia δ-lontano dal valore atteso (per 0 ≤ δ < 1), èdell’ordine di e−Ω(nδ2).

436 A Teoria dell’informazione
A.3 Entropia
Il termine entropia fa riferimento all’uso che ne ha fatto per primo Shannonin [Sha48]. Data una variabile aleatoria X ∈ X , definiamo la sua entropia(detta appunto di Shannon) come:
H(X) = −∑x∈X
PX(x) logPX(x).
Intuitivamente, l’entropia di una variabile aleatoria può essere vista come unamisura del contenuto informativo associato alla variabile aleatoria stessa; in al-tri termini la quantità H(X) rappresenta la quantità d’informazione contenutain X.
Consideriamo ad esempio un lancio di moneta, non necessariamente bilan-ciata, dove sono note le probabilità che esca “testa” oppure “croce”. L’entropiadell’esito del prossimo lancio è massima se la moneta non è truccata, cioèquando “testa” e “croce” hanno la stessa probabilità (pari a 1/2) di verificarsi.Questa è infatti la massima situazione di incertezza, in quanto è più difficileprevedere se uscirà “testa” oppure “croce”. D’altra parte, quando la moneta ètruccata uno degli esiti avrà una probabilità maggiore di verificarsi e quindi c’èmeno incertezza, che si riflette in una minore entropia. Il caso estremo è quelloin cui la moneta ha lo stesso simbolo su entrambe le facce: in questo caso nonc’è incertezza e l’entropia è zero (cf. Fig. A.1).
L’estensione della definizione di entropia al caso di due variabili aleatorie èpressoché immediata:
H(X,Y ) = −∑x∈X
∑y∈Y
PX,Y (x, y) logPX,Y (x, y).
Intuitivamente saremmo portati a dire che la quantità d’informazione associataad X ed Y (congiuntamente) è sempre maggiore della quantità d’informazioneassociata alla sola X. In effetti, applicando le definizione, non è complessoverificare che H(X,Y ) ≥ H(X) per ogni coppia di variabili aleatorie X ∈ Xed Y ∈ Y (cf. Esercizio A.9). Se alla quantità H(X,Y ) sottraiamo il contenutoinformativo associato ad X otteniamo la quantità d’informazione residua in Y“dopo aver visto X”. Tale quantità è detta entropia condizionata di Y dato X edè definita come H(Y |X) = H(X,Y )−H(X). Seguendo il significato intuitivo dientropia, date n variabili aleatorie X1, . . . , Xn a valori in X , saremmo portati apensare che la loro entropia congiunta è esattamente il contenuto d’informazio-ne in X1 più il contributo di X2 dopo aver visto X1 (cioè H(X2|X1)), più il con-tributo di X3 dopo aver visto X1, X2 (cioè H(X3|X1, X2)), e così via. In effetti

A.3 Entropia 437
si dimostra che, per ogni scelta delle variabili aleatorie X1, . . . , Xn, si ha esat-tamente H(X1, . . . , Xn) = H(X1) +
∑ni=2 H(Xi|X1, . . . , Xi−1). Quest’ultima
uguaglianza è detta regola della catena (chain rule, cf. Esercizio A.10).
Fig. A.1. Entropia H(X)di un lancio di moneta (mi-surata in bit) al variare delbilanciamento della moneta
Una metafora per l’entropia. Possiamorendere più esplicita la metafora di “entropiacome contenuto informativo associato ad unavariabile aleatoria” attraverso il concetto di mi-sura additiva su insiemi. Sia μ(X ) una mi-sura associata all’insieme X (ad esempio lasua cardinalità). Associamo μ(X ) all’entropiaH(X) (cf. anche Fig. A.2). Dati due insiemiX ed Y la misura dell’unione non è altro chela misura di X più la misura di Y \ X , ovve-ro μ(X ∪ Y) = μ(X ) + μ(Y \ X ). Allo stes-so modo H(X,Y ) = H(X) + H(Y |X). Con-tinuando a seguire questa metafora, ci aspet-tiamo che la misura associata ad Y sia sempremaggiore di quella associata ad Y \ X , ovveroμ(Y) ≥ μ(Y \ X ). In effetti, si può dimostra-re che H(Y ) − H(Y |X) ≥ 0 ed in particolarel’uguaglianza è valida se e solo se le variabilialeatorie X ed Y sono statisticamente indipendenti. La quantità:
I(X ∧ Y ) = H(Y )−H(Y |X) = H(X)−H(X|Y ) ≥ 0,
è detta informazione mutua delle variabili aleatorie X ed Y e nella nostrametafora rappresenta la misura dell’intersezione μ(X ∩ Y).89
Mettendo insieme quest’ultima disuguaglianza con le definizioni precedenti,
89Sebbene questa metafora aiuti a visualizzare molti concetti, bisogna utilizzarla con accortezza.Ecco un controesempio. Si definisce informazione mutua condizionata la quantità I(X ∧ Y |Z) =H(X|Z)+H(Y |X)−H(X,Y |Z). La nostra metafora ci porta a dire che I(X∧Y ) ≥ I(X∧Y |Z),perché tale quantità corrisponde alla misura dell’intersezione μ(X ∩ Y ∩ Z). Purtroppo ciò nonsempre è verificato, in particolare esistono casi in cui I(X ∧ Y ) ≥ I(X ∧ Y |Z) ed altri casi in cuiI(X ∧ Y ) < I(X ∧ Y |Z) (cf. Esercizio A.11).

438 A Teoria dell’informazione
Fig. A.2. Entropia e misura di insiemi
troviamo:
I(X ∧ Y ) = H(Y )−H(Y |X)
= H(Y )− (H(X,Y )−H(X))
= H(X) +H(Y )−H(X,Y )
≥ 0,
ed il segno uguale si verifica quando e solo quando X ed Y sono statisticamenteindipendenti. Ciò significa che l’informazione associata ad X ed Y (se corre-late), è maggiore della somma dei contributi informativi associati ad X ed Yprese singolarmente.
Entropia minima. L’entropia di Rényi [Rén61], è una generalizzazione del-l’entropia di Shannon, utile a quantificare diversi gradi di incertezza associatiad una variabile aleatoria generica.
Definizione A.4 (Entropia di Rényi). Sia X una variabile aleatoria suX = {x1, . . . , xn}. L’entropia di Rényi di ordine α, con α ≥ 0, è definita come:
Hα(X) =1
1− αlog
(n∑
i=1
pαi
),
essendo pi = P [X = xi]. �
Alcuni casi particolari sono riportati di seguito.

A.3 Entropia 439
• α = 0. Abbiamo H0(X) = log n = log |X |, che è il logaritmo della cardinalitàdi X , a volte detto entropia di Hartley.
• α→ 1. Nel limite per α che tende ad 1, abbiamo:
H1(X) = limα→1
Hα(X) = −n∑
i=1
pi log pi,
che è l’entropia di Shannon H(X).
• α→∞. Nel limite per α→∞ si parla di entropia minima (min-entropy):
H∞(X) = limα→∞Hα(X) = − log sup
i=1,...,npi = − logmax
x∈XP [X = x] ,
così detta perché è il valore più piccolo di Hα.
L’entropia minima misura la quantità di randomicità in X. Infatti la quantitàmaxx∈X P [X = x] = 2−H∞(X) rappresenta la massima probabilità di predirecorrettamente X; in questo senso, l’entropia minima misura quanto è difficilepredire X.

Esercizi
Esercizio A.1. Sia A un algoritmo che prende come input una stringa binariax ∈ {0, 1}n e restituisce 1 se e solo se i primi 3 bit di x sono 1. Sia (Enc,Dec)il cifrario OTP del Crittosistema 2.1. Calcolare:
P
[A (c) = 1 : k
$← {0, 1}n , c← Enck(1n)].
Esercizio A.2. Estendere il Lemma A.1 al caso di n > 2 variabili aleatorie.
Esercizio A.3. La legge debole dei grandi numeri dice che se X1, X2, X3, . . .sono variabili aleatorie indipendenti ed identicamente distribuite, con valoreatteso μ e deviazione standard σ, allora per ogni ε > 0 si ha:
limn→∞P
[∣∣∣∣X1 +X2 + . . .+Xn
n− μ
∣∣∣∣ > ε
]= 0.
Dimostrare la legge debole dei grandi numeri, utilizzando il seguente schema:
1. Sia X∗ = X1+X2+...+Xn
n . Calcolare μ∗ = E[X].
2. Calcolare σ∗ = V[X] e mostrare che per ogni costante ε > 0 si ha ε ≥σ/n =
√nσ∗ per n sufficientemente grande.
3. Applicare la disuguaglianza di Chebyshev usando i valori determinati aipassi precedenti.
Esercizio A.4. Consideriamo n variabili aleatorie Bernoulliane Xi$← Berτ ,
ovvero P[Xi = 1] = τ per ogni i ∈ [n]. Determinare la probabilità che∑ni=1 Xi > n · τ ′, per una costante τ < τ ′ < n.
Esercizio A.5. Consideriamo n variabili aleatorie Xi$← {0, 1}. Determinare
la probabilità che∑n
i=1 Xi ≤ n · τ ′, per una costante τ < τ ′ < 1/2.
Esercizio A.6. Sia X la variabile aleatoria che rappresenta il numero di va-lori “testa” in n lanci di moneta indipendenti. Applicare la disuguaglianza diChebyshev per limitare la probabilità che X sia più piccola di n/4 e più grandedi 3n/4. Confrontare il risultato con lo stesso limite ottenuto applicando ilteorema di Chernoff.
Esercizio A.7. Una moneta non truccata è lanciata fintanto che non si ottiene“testa”. Sia X il numero di lanci; determinare H(X).

Esercizi 441
Esercizio A.8. Consideriamo le variabili aleatorie binarie X,Y , con distribu-zione di probabilità congiunta determinata dalle equazioni:
PXY (0, 0) = 1/6 PXY (0, 1) = 1/6
PXY (1, 0) = 1/2 PXY (1, 1) = 1/6.
Calcolare H(X), H(Y ), H(X|Y ), H(Y |X), H(X,Y ), H(Y )−H(Y |X) ed I(X∧Y ).
Esercizio A.9. Dimostrare che per ogni coppia di variabili aleatorie X,Y ,definite su due insiemi X , Y, si ha H(X,Y ) ≥ H(X).(Suggerimento: applicare la definizione, quindi usare la regola di Bayes.)
Esercizio A.10. Dimostrare la regola della catena, ovvero:
H(X1, . . . , Xn) = H(X1) +
n∑i=2
H(Xi|X1, . . . , Xi+1).
(Suggerimento: usare ricorsivamente l’uguaglianza H(A,B) = H(A)+H(B|A),cominciando dal caso A = (X1, . . . , Xn−1), B = Xn.)
Esercizio A.11. Questo esercizio mostra che non è possibile stabilire unordinamento generale per le quantità I(X ∧ Y ) ed I(X ∧ Y |Z).
1. Sia X = Y = Z, con H(X) > 0. Mostrare che I(X∧Y )−I(X∧Y |Z) > 0.
2. Siano X, Y variabili aleatorie binarie indipendenti ed uniformementedistribuite, e Z = X ⊕ Y . Mostrare che I(X ∧ Y )− I(X ∧ Y |Z) < 0.
Esercizio A.12. Sia X una variabile aleatoria su un insieme X . Mostrareche per ogni scelta della distribuzione di probabilità PX , risulta H∞(X) ≤log(#X ).

Letture consigliate
[Bil79] Patrick Billingsley. Probability and Measure. John Wiley e Sons, 1979.
[CK97] Imre Csiszár e János Körner. Information Theory: Coding Theorems forDiscrete Memoryless Systems. Second. Akademiai Kiado, 1997.
[CT06] Thomas M. Cover e Joy A. Thomas. Elements of Information Theory.Second. New York: Wiley-Interscience, 2006.
[Gut05] Allan Gut. Probability: A Graduate Course. Springer-Verlang, 2005.
[Rén61] Alfréd Rényi. “On Measures of Information and Entropy”. In: Proceedingsof the 4th Berkeley Symposium on Mathematics, Statistics and Probability.1961, pp. 547–561.
[Sha48] Claude E. Shannon. “A mathematical theory of communication”. In: BellSys. Tech. J. 27 (1948), pp. 623–656.
[Tij04] Henk Tijms. Understanding Probability: Chance Rules in Everyday Life.Cambridge University Press, 2004.

Ap
pe
nd
ice
BTeoria dei numeri
Cubum autem in duos cubos, aut quadratoquadratum in duos quadratoquadratos,et generaliter nullam in infinitum ultra quadratum potestatem in duos eiusdemnominis fas est dividere cuius rei demonstrationem mirabilem sane detexi. Hancmarginis exiguitas non caperet.
Pierre de Fermat (ai margini di una copia dell’Arithmetica di Diofanto)
La teoria dei numeri riguarda lo studio delle proprietà dei numeri interi. Laformulazione di molti dei problemi tipici della materia può essere facilmen-te compresa anche da un non-matematico; tuttavia la soluzione degli stessiproblemi è spesso complessa, e richiede tecniche non banali.
La teoria dei numeri nasce nell’antica Grecia, con lo studio dei criteri di di-visibilità degli interi (da parte di Euclide ad esempio). Più avanti (nel XVIIsecolo) fu Pierre de Fermat ad iniziare uno studio più sistematico. Il matema-tico Francese, in particolare, enunciò numerose congetture, senza fornire peresse una dimostrazione.90 I contributi successivi, ad opera di Eulero, Lagrangee Gauss, hanno quindi dato inizio alla teoria dei numeri moderna.
Guida per il lettore. Questa appendice richiama alcuni risultati di base inteoria dei numeri, usati in diverse parti del testo. Nel Paragrafo B.1 studieremoi criteri di divisibilità e l’algoritmo euclideo di divisione. Compiremo quindiun viaggio nel mondo dell’aritmetica modulare, studiando le congruenze (nelParagrafo B.2) e le proprietà dei residui quadratici (nel Paragrafo B.3). nelParagrafo B.4 ci soffermeremo, infine, sullo studio delle curve ellittiche su uncampo finito, che hanno diverse applicazioni in crittografia.
Per un’introduzione più rigorosa alla teoria “classica” dei numeri, si rimandaa [JJ05].90La più famosa di queste è senz’altro il famoso “ultimo teorema”, che afferma che non esistono
soluzioni intere all’equazione Xn + Y n = Zn per n > 2. La soluzione dell’enigma di Fermat havisto impegnate, senza fortuna, intere generazioni di matematici. La congettura è stata dimostratada Andrew Wiles [Wil95], nel 1994. L’avvincente storia della congettura è raccontata in [Sin97].
Venturi D.: Crittografia nel Paese delle MeraviglieDOI 10.1007/978-88-470-2481-6 16, c© Springer-Verlag Italia 2012

444 B Teoria dei numeri
B.1 Algoritmo euclideo
Cominciamo introducendo i concetti fondamentali di quoziente e resto di unadivisione.
Lemma B.1 (Quoziente e resto). Se a e b sono interi, con b > 0, alloraesiste un’unica coppia di interi (q, r) tali che a = qb+ r e 0 ≤ r < b.
Dimostrazione. La dimostrazione è costituita da due parti: nella prima partemostreremo che la coppia (q, r) esiste e nella seconda parte che essa è unica.
Definiamo l’insieme S = {a−nb : n ∈ Z}. Affermiamo che S contiene almenoun elemento non-negativo. Infatti se a > 0, allora possiamo scegliere n = 0 ea ∈ S. Se invece a < 0, possiamo scegliere n = a da cui a− ab = a(1− b) ∈ S.Siccome per ipotesi b > 0, abbiamo che (1 − b) è negativo e quindi a(1 − b) èun numero positivo oppure nullo (quando b = 1). In entrambi i casi comunquea− ab ∈ S è non-negativo.
Sia dunque r il minimo intero non negativo contenuto in S. Osserviamo cher = a − qb per un qualche q ∈ Z, da cui a = r + qb. Resta da mostrare che0 ≤ r < b. Siccome r ∈ S è non-negativo per definizione, dobbiamo solamentemostrare che r < b. Supponiamo che r ≥ b, allora:
r′ = a− (q + 1)b = a− qb− b = r − b ≥ 0,
contraddicendo il fatto che r sia il minimo elemento non-negativo di S.Per mostrare che la coppia (q, r) è unica, supponiamo che esistano due coppie
distinte (q, r) e (q′, r′) tali che a = qb+r ed a = q′b+r′. Segue r−r′ = b(q′−q),ovvero b divide r − r′. Siccome però 0 ≤ r, r′ < b, deve essere −b < −r′ ≤r − r′ < r < b; pertanto il divisore b è più grande (in valore assoluto) delnumero r − r′ che divide, il che è possibile solo se r − r′ = 0 ovvero r = r′.
Sostituendo in qb+ r = q′b+ r′, troviamo qb = q′b da cui segue q = q′.
Il resto della divisione è indicato con a mod b = r. Quando r = 0, si èsoliti dire che b divide a (oppure che b è un divisore di a) e si scrive b|a. Undivisore comune di a e b è un intero che divide sia a che b. Si definisce massimocomun divisore (greatest common divisor) di a e b — indicato con gcd(a, b) —il massimo tra i divisori comuni di a e b. (La definizione è ben posta perchél’insieme dei divisori comuni ad a e b è non vuoto (1 ne fa sempre parte) ed èfinito; quindi ha senso parlare di massimo.) Quando gcd(a, b) = 1 si dice che ae b sono coprimi.
Descriviamo ora l’algoritmo euclideo per il calcolo del massimo comun divi-sore tra a e b. L’ingrediente fondamentale è il seguente:

B.1 Algoritmo euclideo 445
Lemma B.2 (Algoritmo di Euclide). Siano a e b due interi tali che a ≥b > 0. Allora gcd(a, b) = gcd(b, a mod b).
Dimostrazione. È sufficiente mostrare che i divisori comuni ad a e b sono glistessi comuni a b ed a mod b. Per il Lemma B.1 possiamo sempre scriverea = qb + a mod b, dove q =
⌊ab
⌋e a mod b è il resto della divisione tra a e b.
Pertanto, un divisore comune ad a e b divide anche a− qb = a mod b.D’altra parte, un divisore comune di b ed a mod b divide anche a = qb +
a mod b; quindi l’asserto.
L’algoritmo euclideo sfrutta il lemma precedente in modo iterativo. In primoluogo se b = 0 abbiamo immediatamente gcd(a, 0) = 0. Se invece b = 0possiamo usare il Lemma B.2 e concludere gcd(a, b) = gcd(b, a mod b), conb > a mod b ≥ 0, in quanto a mod b è il resto della divisione tra a e b. A questopunto applichiamo ricorsivamente il Lemma B.2 agli elementi (b, a mod b): adogni passo il secondo termine del gcd diminuisce fino a diventare 0. A quelpunto:
gcd(a, b) = gcd(b, a mod b) = · · · = gcd(d, 0) = d,
ed abbiamo calcolato d = gcd(a, b).Un esempio chiarisce immediatamente le idee. Sia a = 185 e b = 40.
Applicando iterativamente il Lemma B.2, troviamo:
gcd(185, 40) = gcd(40, 25) = gcd(25, 15) = gcd(15, 10)
= gcd(10, 5) = gcd(5, 0) = 5.
Complessità. Vogliamo ora mostrare che l’algoritmo di Euclide è efficiente.Per fare questo dobbiamo innanzitutto discutere la complessità computazionaleassociata alle operazioni elementari di somma, prodotto e divisione. Sia O(1)il costo relativo alla somma di due bit ed indichiamo con sa la lunghezza dia (in binario), ovvero sa = �log a� + 1. (Un’espressione identica vale per sbrelativamente a b.) È banale verificare che (cf. Esercizio B.1):
• somma e sottrazione hanno complessità O(max {sa, sb});
• la moltiplicazione costa O(sa · sb);
• la divisione costa O(sq · sb), essendo q è il quoziente della divisione tra a e b.

446 B Teoria dei numeri
Osserviamo inoltre che lo spazio richiesto in memoria è O(sa + sb).Per poter valutare la complessità dell’algoritmo di Euclide, dobbiamo in
qualche modo limitare il numero di iterazioni necessarie fino al termine dell’al-goritmo stesso. Per fare ciò ci serviremo dei numeri di Fibonacci, introdotti perla prima volta dal matematico italiano Leonardo Fibonacci (nel XIII secolo)per studiare la velocità di riproduzione di una famiglia di conigli.
Definizione B.1 (Numeri di Fibonacci). La sequenza di interi {Fn}+∞n=0,
definita dalle relazioni F0 = 0, F1 = 1, Fn+2 = Fn + Fn+1, è detta sequenza diFibonacci. �
I primi elementi della sequenza di Fibonacci sono 0, 1, 1, 2, 3, 5, 8, 13, 21, . . ..La sequenza soddisfa alcune proprietà interessanti:
Lemma B.3 (Proprietà della sequenza di Fibonacci). Sia Θ = (1+√5)/2
il rapporto aureo. Per ogni numero naturale n ∈ N è valido quanto segue:
(i)Θn+2 = Θn +Θn+1 (ii)(1−Θ)n+2 = (1−Θ)n + (1−Θ)n+1
(iii)Fn =1√5(Θn − (1−Θ)n) (iv)Fn+1 <Θn < Fn+2.
Dimostrazione. Per dimostrare (i) e (ii) basta osservare che Θ e (1 − Θ) sonosoluzione dell’equazione di secondo grado X2 = X +1. Pertanto Θ2 = Θ+1 e(1−Θ)2 = (1−Θ) + 1. L’asserto segue moltiplicando ambo i membri per Θn
ed (1−Θ)2 (rispettivamente).La (iii) è anche detta formula di Binet (perché mostrata indipendentemente
da Binet). Dimostreremo l’espressione per induzione su n. Il caso base si hain corrispondenza dei valori F0 ed F1, ovvero quando n = 0 ed n = 1:
F0 =1√5(1− 1) = 0 F1 =
1√5(Θ− 1 + Θ).
Assumiamo ora che la formula sia valida per ogni intero < n e mostriamo checiò implica che essa sia valida anche per n:
Fn = Fn−1 + Fn−2 =1√5(Θn−1 − (1−Θ)n−1 +Θn−2 − (1−Θ)n−2)
=1√5(Θn−1 +Θn−2︸ ︷︷ ︸
Θn
− (1−Θ)n−1 + (1−Θ)n−2︸ ︷︷ ︸(1−Θ)n
)
=1√5(Θn − (1−Θ)n).

B.1 Algoritmo euclideo 447
Dimostreremo la (iv) sempre per induzione su n. Quando n = 1 abbiamo ineffetti F1 = 1 < Θ < F2 = 2. Assumendo che l’espressione sia verificata perogni intero < n, possiamo scrivere:
Fn−1 < Θn−2 < Fn Fn < Θn−1 < Fn+1.
Ma allora:
Fn−1 + Fn = Fn+1 < Θn−2 +Θn−1 = Θn < Fn + Fn+1 = Fn+2,
come volevasi dimostrare.
Il seguente teorema, collega il numero di iterazioni dell’algoritmo di Euclidecon la sequenza di Fibonacci.
Teorema B.4 (Teorema di Lamè). Sia a ≥ b > 0 ed indichiamo con E(a, b)il numero di passi nell’algoritmo euclideo. Allora per ogni numero naturalen ∈ N abbiamo E(a, b) < n ogni volta che b < Fn+1 oppure a < Fn+2.
Dimostrazione. È sufficiente dimostrare che ogni volta in cui E(a, b) ≥ n, deveaversi b ≥ Fn+1 ed anche a ≥ Fn+2. Procediamo per induzione su n. Nel casobanale in cui n = 0, l’asserto diventa:
E(a, b) ≥ 0 ⇒ b ≥ F1 = 1 e a ≥ F2 = 2,
il che è sicuramente vero in quanto per ipotesi a ≥ b > 0.Supponiamo ora che E(a, b) ≥ k implichi b ≥ Fk+1 e a ≥ Fk+2, per ogni
intero k ≤ n; mostreremo che ciò implica l’asserto per ogni k ≥ n + 1. Inaltri termini dobbiamo dimostrare che se E(a, b) ≥ n + 1, allora a ≥ Fn+3
e b ≥ Fn+2. Sia E(a, b) ≥ n + 1; usando il Lemma B.2 possiamo scriveregcd(a, b) = gcd(b, a mod b) ed il calcolo di gcd(b, a mod b) richiede esattamenteE(a, b)−1 iterazioni. Siccome E(b, a mod b) = E(a, b)−1 ≥ n, possiamo usarel’ipotesi induttiva per concludere che b ≥ Fn+2 e a mod b ≥ Fn+1. Pertantoresta da mostrare che a ≥ Fn+3; ma a = qb + a mod b ≥ b + a mod b, da cuia ≥ b+ a mod b ≥ Fn+2 + Fn+1 = Fn+3. Questo conclude la prova.
Il Teorema di Lamè ci consente di calcolare la complessità dell’algoritmoeuclideo.
Corollario B.5 (Complessità dell’algoritmo di Euclide). Poniamo n =max {a, b}. La complessità dell’algoritmo di Euclide è O(log3 n).

448 B Teoria dei numeri
Dimostrazione. Sia b = b0 > 0 fissato, e concentriamoci su t = E(a, b0). IlTeorema B.4 implica a ≥ Ft+2. D’altra parte, per il Lemma B.3, sappiamo cheFt+2 > Θt e quindi a > Θt; pertanto:
logΘ a > t ⇒ t < log(a) < log(n).
Siccome ogni iterazione dell’algoritmo prevede una divisione (costo O(log2 n)),la complessità è O(log3 n).
Versione estesa. Possiamo definire una versione estesa dell’algoritmo di Eu-clide, utile per trovare soluzioni intere ad equazioni della forma aX + bY =gcd(a, b). La seguente espressione, dovuta a Bézout, ci assicura che una solu-zione esiste sempre:
Teorema B.6 (Identità di Bézout). Se a e b sono interi (non entrambinulli), allora esistono sempre due interi u, v tali che:
gcd(a, b) = a · u+ b · v.
Dimostrazione. Si tratta semplicemente di scrivere le relazioni dell’algoritmodi Euclide alla rovescia. Sia d = gcd(a, b) = rt l’ultimo resto non-nullodell’algoritmo di Euclide (ovvero rt+1 = 0). Possiamo scrivere:
rt = rt−2 − qt−1rt−1,
esprimendo così d in funzione di rt−2 ed rt−1. D’altra parte, al passo precedentedell’algoritmo, si deve avere:
rt−1 = rt−3 − qt−2rt−2,
e se sostituiamo rt−1 nell’espressione per rt, abbiamo espresso d in funzionedi rt−2 e di rt−3. Se proseguiamo a ritroso fino al primo passo dell’algoritmo,possiamo esprimere d come somma di un multiplo di r0 = a ed un multiplo dir1 = b, cioè:
gcd(a, b) = a · u+ b · v.
Più in generale è possibile mostrare che ogni equazione del tipo aX+ bY = cammette soluzione se e solo se c è un multiplo di gcd(a, b). È facile vedere chei valori di u e v non sono unici; comunque essi possono essere visti come unasoluzione dell’equazione aX + bY = gcd(a, b). Per calcolare tale soluzione, sipuò usare l’algoritmo esteso di Euclide:

B.1 Algoritmo euclideo 449
Lemma B.7 (Algoritmo di Euclide esteso). Definiamo le quantità:
xk+1 = qkxk + xk−1 x0 = 1, x1 = 0
yk+1 = qkxk + yk−1 y0 = 0, y1 = 1,
avendo indicato con qk il k-simo quoziente dell’algoritmo di Euclide applicatoagli interi a ≥ b > 0 (per ogni k = 1, · · · , t). Possiamo scrivere:
rk = (−1)kxka+ (−1)k+1ykb k = 0, 1, · · · , t,dove rk è il k-simo resto nell’algoritmo euclideo, dato da rk−2 = rk−1qk−1+ rkper ogni k = 2, 3, · · · , t. (Al solito r0 = a, r1 = b ed rt = d = gcd(a, b).)
Dimostrazione. Per induzione su k. Il caso base (k = 0 e k = 1) è verificato,in quanto:
k = 0 ⇒ r0 = (−1)0x0a+ (−1)1y0b = a
k = 1 ⇒ r1 = (−1)1x1a+ (−1)2y1b = b.
Supponiamo ora che l’asserto sia valido per ogni intero < k e mostriamo chequesto ne implica la validità per gli interi ≥ k. Usando l’ipotesi induttivapossiamo concludere:
rk = rk−2 − rk−1qk−1
= (−1)k−2xk−2a+ (−1)k−1yk−2b− qk−1
[(−1)k−1xk−1a+ (−1)kyk−1b
]= (−1)ka(xk−2 + qk−1xk−1) + (−1)k+1b(yk−2 + qk−1yk−1)
= (−1)kxka+ (−1)k+1ykb.
Siccome in particolare
rt = gcd(a, b) = (−1)txta+ (−1)t+1ytb,
segue che x = (−1)txt ed y = (−1)t+1yt sono soluzioni di aX+ bY = gcd(a, b).Supponiamo ad esempio di voler risolvere 185X + 40Y = 5. Applichiamo
prima l’algoritmo di Euclide ad a = 185 e b = 40, ottenendo le relazioni
185 = 40 · 4 + 25 ⇒ q1 = 4, r2 = 25
40 = 25 · 1 + 15 ⇒ q2 = 1, r3 = 15
25 = 15 · 1 + 10 ⇒ q3 = 1, r4 = 10
15 = 10 · 1 + 5 ⇒ q4 = 1, r5 = 5
5 = 10 · 2 + 0 ⇒ q5 = 2, r6 = 0.

450 B Teoria dei numeri
Quindi t = 5 e gcd(a, b) = rt = 5. È banale verificare, inoltre, che x5 = 3 edy5 = 14. Pertanto:
gcd(185, 40) = rt = 5 = (−1)5 · 3 · 185 + (−1)6 · 14 · 40,
il che implica x = −3 ed y = 14. Non è complesso mostrare che anche laversione estesa ha complessità polinomiale.
B.2 L’aritmetica dell’orologio
In questo paragrafo studieremo i concetti di base dell’aritmetica modulare (det-ta anche aritmetica dell’orologio poiché su tale principi si basa il calcolo delleore in cicli di 12 o 24). Per fare ciò ci occorrono alcune nozioni basilari dialgebra, in particolare gruppi, anelli e campi.
Definizione B.2 (Gruppo). Un gruppo (G,+) è un insieme di elementi conun’operazione, per i quali sono verificati i seguenti assiomi:
• Chiusura. ∀g1, g2 ∈ G si ha g1 + g2 ∈ G.
• Associatività. ∀g1, g2, g3 ∈ G si ha g1 + (g2 + g3) = (g1 + g2) + g3.
• Commutatività. ∀g1, g2 ∈ G si ha g1 + g2 = g2 + g1.
• Elemento neutro. Esiste un elemento neutro e ∈ G, tale che ∀g ∈ G si hag + e = g.
• Elemento inverso. ∀g ∈ G esiste ed è unico un elemento inverso g′ ∈ G taleche g + g′ = e. �
Quando vale la proprietà commutativa, il gruppo91 si dice abeliano (in onoredel matematico norvegese Niels Henrik Abel). Si definisce ordine del gruppola sua cardinalità #G. Inoltre diremo che (H,+) è un sottogruppo di (G,+) seH è contenuto in G e se (H,+) è esso stesso un gruppo.
Definizione B.3 (Anello). Un anello (A,+, ·) è un insieme di elementi condue operazioni, per i quali sono verificati i seguenti assiomi:
• (A,+) è un gruppo abeliano con elemento neutro e.
91Solitamente quando l’operazione è + l’elemento neutro è indicato con 0, l’inverso di g con −ge si scrive ng per g + . . .+ g (n volte).

B.2 L’aritmetica dell’orologio 451
• Associatività del ·. ∀a1, a2, a3 ∈ A si ha a1 · (a2 · a3) = (a1 · a2) · a3.
• Distributività del · rispetto al +. ∀a1, a2, a3 ∈ A si ha a1 · (a2 + a3) =a1 · a2 + a1 · a3. �
Quando l’operazione · soddisfa anche la proprietà commutativa, si parla dianello commutativo, mentre diremo che A è unitario se esiste l’elemento 1 taleche ∀a ∈ A si abbia a · 1 = a. Se infine l’anello è commutativo e non esistonodivisori dello zero — ovvero se a · b = 0 implica che a = 0 oppure b = 0 — siparla di dominio d’integrità.
Definizione B.4 (Campo). Un campo (K,+, ·) è un insieme di elementi condue operazioni, per i quali sono verificati i seguenti assiomi:
• (K,+, ·) è un anello unitario commutativo, con elemento neutro 1.
• Inverso del ·. ∀x ∈ K esiste ed è unico x−1 ∈ K tale che x · x−1 = 1. �
Ad esempio l’insieme Z degli interi è un gruppo rispetto alla somma, manon lo è rispetto al prodotto (in quanto non sempre c’è un inverso). L’insiemeR \ {0} di numeri reali (escluso lo 0) è un gruppo rispetto al prodotto.
Il seguente risultato, fondamentale in algebra, è dovuto a Lagrange.
Teorema B.8 (Teorema di Lagrange). Sia H un sottogruppo di un gruppofinito G. Allora #H divide #G.
Si veda ad esempio [Lan02, Proposizione 2.2] per una dimostrazione.
Congruenze e classi di residui. Possiamo ora dare la nozione di congruen-za. Diremo che gli interi a e b sono congruenti modulo n — indicato con a ≡ b(mod n) — se n divide a − b. Ad esempio −2 ≡ 19 (mod 21), 6 ≡ 0 (mod 2)e 2340 ≡ 1 (mod 341).
Le congruenze modulo n definiscono una relazione d’equivalenza92 su Z. Inquesto modo Z è ripartito in classi d’equivalenza contenenti gli interi tra loro
92Una relazione � tra elementi di un insieme S è detta di equivalenza se è:• Riflessiva. Per ogni elemento s di S si ha s�s.
• Simmetrica. Per ogni coppia (s1, s2) di S si ha s1�s2 ⇒ s2�s1.
• Transitiva. Per ogni terna (s1, s2, s3) di S si ha s1�s2 e s2�s3 ⇒ s1�s3.Un sottoinsieme di S che contiene tutti e soli gli elementi equivalenti a un qualche elemento s diS prende il nome di classe di equivalenza di s. L’insieme delle classi di equivalenza su S si chiamainsieme quoziente di S per la relazione � e viene talvolta indicato con l’espressione S/�.

452 B Teoria dei numeri
congruenti modulo n, ovvero gli interi che hanno lo stesso resto quando sonodivisi per n. Ciò definisce l’insieme di residui modulo n, indicati con Zn =Z/nZ. Ad esempio per n = 2, abbiamo Z2 = {0, 1}, in quanto tutti gli interisono congrui a 0 (se sono pari) oppure ad 1 (se sono dispari) modulo 2. (In altritermini le due classi d’equivalenza sono qui i numeri pari e i numeri dispari.)Quando invece n = 3, abbiamo Z3 = {0, 1, 2} in quanto tutti gli interi n sonocongrui a 0 (se n/3 ha resto 0), oppure ad 1 (se n/3 ha resto 1) oppure a 2 (sen/3 ha resto 2), modulo 3.
È facile verificare che (Zn,+) è un gruppo rispetto all’operazione di sommamodulo n; inoltre (Zn,+, ·) è un anello commutativo. In generale invece Zn
non è un campo, in quanto non tutti gli elementi a ∈ Zn sono invertibili:
Lemma B.9 (Elementi invertibili in Zn). Se gcd(a, n) > 1 allora a ∈ Zn
non è invertibile modulo n.
Dimostrazione. Supponiamo per assurdo che a sia invertibile, ovvero esisteb ∈ Zn con ab ≡ 1 (mod n). Allora:
ab = 1 + nk ⇒ ab− nk = 1,
per qualche intero k. Evidentemente gcd(a, n) divide ab − nk e quindi deveanche dividere 1, da cui gcd(a, n) = 1 contro l’ipotesi.
Si definisce con Z∗n l’insieme dei residui invertibili modulo n. Applicando il
Lemma B.9, sappiamo che:
Z∗n = {a ∈ Zn : gcd(a, n) = 1} .
Notare che la cardinalità di Z∗n è data dal numero di elementi minori di n e
coprimi con esso.
Definizione B.5 (Funzione toziente di Eulero). Si definisce la funzionetoziente di Eulero ϕ(n) come il numero di elementi minori di n e coprimi conesso. �
Pertanto #Z∗n = ϕ(n). Osserviamo che se n = p è un primo, allora ϕ(p) =
p− 1; si può dimostrare invece che se n = p1 · p2, allora ϕ(n) = ϕ(p1) · ϕ(p2).È immediato verificare che (Zn,+, ·) è un campo se e solo se n è primo.
Infatti se n è primo, ogni elemento tranne lo zero è invertibile. D’altra partese Zn è un campo, ogni elemento < n è coprimo con n e quindi n deve essereprimo. L’inverso di a ∈ Z∗
n può essere calcolato come soluzione dell’equazioneaX + nY = 1 usando l’algoritmo di Euclide esteso (cf. Lemma B.7).

B.2 L’aritmetica dell’orologio 453
Fig. B.1. Il gruppo ciclico Z∗7 con il generatore g = 3
Sia ora p un primo e consideriamo il gruppo unitario:
Z∗p = {1, 2, . . . , p− 1} con #Z∗
p = ϕ(p) = p− 1,
ovvero il sottogruppo moltiplicativo di Zp contenente tutti gli elementi inver-tibili modulo p (cioè tutti tranne lo zero). A partire da g ∈ Z∗
p calcoliamole potenze successive di g: g0, g1, g2, . . .; siccome Z∗
p è finito esistono i, j (coni = j, diciamo j < i) tali che gi ≡ gj (mod p). Pertanto gi−j ≡ 1 (mod p),ovvero esiste q tale che gq ≡ 1 (mod p). Si definisce ordine di g il più piccolointero ord(g) tale che gord(g) ≡ 1 (mod p). Un elemento g ∈ Z∗
p di ordineord(g) = k genera un sottogruppo G =
{g0, g1, g2, . . . , gk−1
}di Z∗
p, quindipossiamo concludere ord(g) ≤ p − 1. L’elemento g è detto generatore delsottogruppo G.
Un elemento di ordine p−1 genera tutto Z∗p ed è detto primitivo. Osserviamo
che se g è un elemento primitivo allora Z∗p =
{g0, g1, . . . , gp−2
}; un gruppo
generato dalle potenze successive di un suo elemento è detto ciclico. Si puòdimostrare che Z∗
p è sempre ciclico, con ϕ(p−1) elementi primitivi. Ad esempiol’insieme Z∗
7 = {1, 2, 3, 4, 5, 6} è ciclico con ϕ(6) = ϕ(3) · ϕ(2) = 6 elementiprimitivi (cf. Fig. B.1).
A volte è utile calcolare l’ordine di un elemento g appartenente ad un gruppoG con #G = q elementi. Sia q = pe11 · · · · ·pekk la scomposizione in fattori primi di
q. Per ogni divisore primo pi di q, sia fi il massimo intero tale che gq/pfi
i = 1.Allora, l’ordine di g è:
ord(g) = pe1−f11 · · · · · pek−fk
k .

454 B Teoria dei numeri
Se ad esempio prendiamo Z∗101 e g = 2, si ha q = 100 = 22 ·52. Poiché 250 ≡ −1
(mod 101) e 220 ≡ −6 (mod 101) si ha f1 = 0 ed f2 = 0; quindi ord(2) = 100in Z∗
101 (ovvero Z∗p è ciclico e 2 è un elemento primitivo).
È anche facile verificare quando un certo intero k è l’ordine di un elementog ∈ G. Ciò si verifica quando gk ≡ 1 e gk/p = 1 in G, per ogni divisore primop di k. Ad esempio 25 è l’ordine di 5 in Z∗
101, poiché 525 ≡ 1 (mod 101), ma55 ≡ −6 (mod 101).
Alcuni teoremi fondamentali. Concludiamo il paragrafo con la dimostra-zione di alcuni teoremi fondamentali nelle applicazioni crittografiche della teoriadei numeri.
Teorema B.10 (Teorema di Eulero). Sia n un intero positivo. Allora perogni a ∈ Z∗
n si ha aϕ(n) ≡ 1 (mod n).
Dimostrazione. Consideriamo l’insieme Z∗n =
{x1, . . . , xϕ(n)
}. Definiamo gli
elementi yi = a · xi mod n; è facile mostrare che questi non sono altro chegli elementi di Z∗
n in ordine diverso (ovvero permutati). Sia inoltre M =y1 · · · · · yϕ(n); notare che M è coprimo con n, quindi è invertibile modulo n.Pertanto
M ≡ y1 · · · · · yϕ(n) = ax1 · · · · · axϕ(n) = aϕ(n)M (mod n)
⇒ aϕ(n) ≡ 1 (mod n).
Un corollario del teorema di Eulero è il piccolo teorema di Fermat, dimostratoindipendentemente da Fermat.
Teorema B.11 (Piccolo teorema di Fermat). Sia p un primo. Allora perogni a ∈ Z∗
p si ha ap−1 ≡ 1 (mod p).
Dimostrazione. Banale se sostituiamo n = p (per un primo p) nel Teorema diEulero.
Il teorema del resto cinese (Chinese Remainder Theorem, CRT) studia alcunisistemi di congruenze.

B.2 L’aritmetica dell’orologio 455
Teorema B.12 (Teorema del resto cinese). Siano m1, . . . ,mk interi a duea due coprimi (ovvero gcd(mi,mj) = 1 per ogni i = j). Allora, per ogni insiemedi valori (a1, . . . , ak), esiste un intero x soluzione del sistema di congruenze:
x ≡ ai (mod mi) per i = 1, . . . , k.
Tale soluzione è unica modulo∏k
i=1 mi.
Dimostrazione. Sia Mi =∏
j �=i mj . Siccome gli mi sono a due a due copri-mi, gcd(Mi,mi) = 1. Usando l’algoritmo di Euclide esteso possiamo quindicalcolare gli interi (xi, yi) tali che:
yiMi + ximi ≡ gcd(Mi,mi) = 1 (mod mi).
Per tali valori risulta ovviamente yiMi ≡ 1 (mod mi). Sia allora:
x ≡k∑
i=1
aiyiMi (mod m) con m =k∏
i=1
mi.
È facile verificare che tale x è il valore cercato. Infatti x ≡ ai (mod mi) inquanto aiyiMi ≡ ai (mod mi) ed ajyjMj ≡ 0 (mod mi) per ogni j = i. Talesoluzione è inoltre unica; siano infatti x ed x′ due soluzioni. Allora x ≡ x′
(mod mi), per ogni i = 1, 2, . . . k. Ma poiché gli mi sono coprimi, x− x′ deveessere multiplo di m =
∏ki=1 mi, ovvero x ≡ x′ (mod m).
Consideriamo ad esempio le seguenti congruenze:
x ≡ 2 (mod 4) x ≡ 1 (mod 3) x ≡ 0 (mod 5).
Abbiamo m1 = 4, m2 = 3, m3 = 5, a1 = 2, a2 = 1 ed a3 = 0. Quindim = 60, M1 = 15, M2 = 20, M3 = 12. È facile verificare che le soluzionidelle congruenze y1M1 ≡ 1 (mod m1), y2M2 ≡ 1 (mod m2) ed y3M3 ≡ 1(mod m3), sono (rispettivamente) y1 = 3, y2 = 2 ed y3 = 3. Pertanto
x ≡ (2 · 3 · 15 + 1 · 2 · 20 + 0 · 3 · 12) ≡ 130 ≡ 10 (mod 60).
Notare che il costo computazionale è O(log2 m
), l’occupazione di memoria
O (logm).Nella sua forma più generale il CRT caratterizza la struttura di alcuni anelli
commutativi attraverso isomorfismi. Ricordiamo che un isomorfismo è una

456 B Teoria dei numeri
mappa biettiva ψ, tale che sia ψ che ψ−1 sono omomorfismi. Consideriamo glianelli (A1,+, ·) ed (A2,�,�). La mappa
ψ : A1 −→ A2
x ∈ A1 %→ ψ(x) ∈ A2,
è un omomorfismo di anelli se preserva la struttura, ovvero se soddisfa
ψ(x1 + x2) = ψ(x1)� ψ(x2)
ψ(x1 · x2) = ψ(x1)� ψ(x2).
(Una definizione identica vale per i gruppi e si parla di omomorfismo di gruppi.)Quando A1 ed A2 sono isomorfi, si scrive A1 A2.
Teorema B.13 (CRT generalizzato). Siano p1, . . . , pn numeri primi taliche gcd(pi, pj) = 1 per ogni i = j. Sia inoltre n =
∏ni=1 pi. Allora la mappa
f : Zn −→ Zp1× · · · ×Zpn
x %→ (x mod p1, . . . , x mod pn) ,
e la mappa
g : Z∗n −→ Z∗
p1× · · · ×Z∗
pn
x %→ (x mod p1, . . . , x mod pn) ,
sono isomorfismi.
B.3 Residui quadratici
In questo paragrafo ci concentreremo sulle proprietà dei residui quadratici,definiti di seguito.
Residui quadratici modulo p. Diremo che a ∈ Z∗p è un residuo quadra-
tico (quadratic residue) modulo p, se esiste b ∈ Z∗p tale che a ≡ b2 (mod p).
L’insieme dei residui quadratici modulo p si indica con
QRp ={a ∈ Z∗
p : a ≡ b2 mod p, per qualche b ∈ Z∗p
}.
Quante radici quadrate ha un residuo quadratico modulo p?

B.3 Residui quadratici 457
Lemma B.14 (Radici quadrate in QRp). Ogni elemento a ∈ QRp haesattamente due radici quadrate modulo p.
Dimostrazione. Sia a ∈ QRp. Allora a ≡ b2 (mod p) per qualche b ∈ Z∗p.
Ovviamente (−b)2 = b2 ≡ a (mod p). Inoltre b ≡ −b (mod p) e quindi glielementi ±b sono due radici quadrate di a e possiamo concludere che a haalmeno due radici quadrate modulo p.
Per vedere che queste sono uniche, sia b′ un’altra radice di a. Allora b2 = a ≡(b′)2 (mod p), da cui b2−(b′)2 ≡ 0 (mod p). Fattorizzando il primo membro siottiene (b−b′)(b+b′) ≡ 0 (mod p), così che una delle due seguenti condizioni èverificata: (i) p | (b− b′), oppure (ii) p | (b+ b′). Nel primo caso b ≡ b′ (mod p)e nel secondo caso −b ≡ b′ (mod p); pertanto ±b sono le uniche radici di amodulo p.
Siccome l’elemento neutro del prodotto è 1 ∈ QRp, e siccome quando a, a′ ∈QRp anche a · a′ ∈ QRp, l’insieme dei residui quadratici modulo p è un sotto-gruppo di (Z∗
p, ·). L’insieme QNRp = Z∗p \QRp è detto insieme dei non-residui
quadratici di Z∗p.
Consideriamo, ad esempio, Z∗11 = {0, 1, 2, . . . , 10}. È facile verificare che
QR11 = {1 = 12 = 102, 4 = 22 = 92, 9 = 32 = 82, 5 = 42 = 72, 3 = 52 = 62} (cf.Fig. B.2).
Il seguente lemma determina la cardinalità di QRp.
Lemma B.15 (Cardinalità di QRp). Per ogni primo p, si ha #QRp =(p− 1)/2.
Fig. B.2. Il gruppo QR11

458 B Teoria dei numeri
Dimostrazione. Sia g un generatore di Z∗p; abbiamo QRp =
{g2, g4, . . . , gp−1
}.
Infatti, siccome ogni x ∈ Z∗p è uguale a gi per qualche i, possiamo concludere:
x2 ≡ g2i (mod p−1) ≡ gj (mod p),
per un qualche j pari.
Una conseguenza immediata è che #QNRp = p − (p − 1)/2 = (p − 1)/2.Quindi esattamente metà degli elementi di Z∗
p è un residuo quadratico e l’altrametà è un non-residuo quadratico.
Possiamo anche verificare velocemente se un dato elemento è un residuoquadratico modulo p o meno.
Lemma B.16 (Criterio di Eulero). Per ogni primo p, abbiamo che a ∈ QRp
se e solo se a(p−1)/2 ≡ 1 (mod p).
Dimostrazione. (⇒) Se a ∈ QRp allora a ≡ g2i (mod p) per qualche i. Pertan-to:
ap−12 ≡
(g2i) p−1
2 ≡ gi(p−1) ≡ 1 (mod p).
(⇐) Per assurdo. Supponiamo che a /∈ QRp con a(p−1)/2 ≡ 1 (mod p). Dunquea è della forma a ≡ g2i+1 (mod p) per qualche i. Pertanto:
ap−12 ≡
(g2i+1
) p−12 ≡ gi(p−1)g
p−12 ≡ g
p−12 ≡ 1 (mod p),
(essendo g un generatore) contro l’ipotesi.
Per distinguere i residui quadratici dai non-residui quadratici, si introduce ilsimbolo di Legendre.
Definizione B.6 (Simbolo di Legendre). Sia a ∈ Z∗p. Il simbolo di Legen-
dre Jp(a) è definito come:
Jp(a) =
{+1 se a ∈ QRp
−1 se a ∈ QNRp.
�
Il criterio di Eulero può essere quindi riformulato come Jp(a) ≡ a(p−1)/2
(mod p) per ogni a ∈ Z∗p.
Il simbolo di Legendre soddisfa la seguente proprietà moltiplicativa:

B.3 Residui quadratici 459
Lemma B.17 (Proprietà moltiplicativa del simbolo di Legendre). Siap > 2 un primo ed a, b ∈ Z∗
p. Allora:
Jp(a · b) = Jp(a) · Jp(b).
Dimostrazione. Usando il criterio di Eulero, possiamo scrivere:
Jp(a · b) = (a · b) p−12 ≡ a
p−12 · b p−1
2 = Jp(a) · Jp(b) (mod p).
Siccome Jp(a · b), Jp(a), Jp(b) ∈ {±1}, l’uguaglianza vale anche senza modulo.
Un semplice corollario del Lemma B.17 è che se a, a′ ∈ QRp e b, b′ ∈ QNRp,allora:
a · a′ mod p ∈ QRp b · b′ mod p ∈ QRp a · b mod p ∈ QNRp.
A volte non vogliamo solamente poter verificare se un dato elemento è unresiduo quadratico, ma (in caso affermativo) calcolarne esplicitamente una ra-dice quadrata. In QRp ciò è sempre possibile in modo efficiente. Ci limiteremocomunque a discutere il caso semplice in cui p ≡ 3 (mod 4). Sia dunque p dellaforma p = 4k + 3, ne segue che l’ordine di QRp è (p− 1)/2 = 2k + 1. È facileverificare allora che
√a ≡ ak+1 (mod p); infatti:(
ak+1)2 ≡ a2(k+1) ≡ a2k+1a ≡ a (mod p).
Residui quadratici modulo N = p · q. Passiamo ora a discutere il caso diQRN , quando N = p · q è il prodotto di due primi distinti; in questo caso, iresidui quadratici in Z∗
N sono tutti gli elementi a ∈ Z∗N della forma a ≡ b2
(mod N). Per caratterizzare la struttura di QRN useremo il teorema del restocinese (cf. Teorema B.13) ovvero il fatto che Z∗
N Z∗p × Z∗
q ; in virtù di ciòpossiamo rappresentare un elemento a ∈ Z∗
N come a = (ap, aq), dove ap =a mod p ed aq = a mod q. L’osservazione chiave è data dal seguente:
Lemma B.18 (Elementi di QRN). Sia N = p · q con p e q primi distinti eda = (ap, aq). Allora a ∈ QRN se e solo se ap ∈ QRp ed aq ∈ QRq.
Dimostrazione. (⇒) Se a è in QRN , allora esiste b ∈ Z∗N tale che a ≡ b2
(mod N). Sia b = (bp, bq); segue:
(ap, aq) = a = b2 = (b2p mod p, b2q mod q).

460 B Teoria dei numeri
Ma allora:ap ≡ b2p (mod p) aq ≡ b2q (mod q) (B.1)
ed ap, aq sono residui quadratici in QRp e QRq (rispettivamente).(⇐) D’altra parte, se a = (ap, aq) ed ap, aq sono residui quadratici (rispetto
agli opportuni moduli), allora esistono bp ∈ Z∗p e bq ∈ Z∗
q tali che l’Eq. (B.1)è verificata. Sia b = (bp, bq). Percorrendo l’altro verso della dimostrazione alcontrario, è immediato verificare che b è la radice quadrata di a modulo N .
Se esaminiamo con attenzione la dimostrazione precedente, possiamo conclu-dere che ogni residuo quadratico a ∈ QRN ha esattamente 4 radici quadrate.Scriviamo a = (ap, aq) e siano ±bp e ±bq le radici quadrate di ap ed aq modu-lo p e modulo q rispettivamente. (Queste sono le uniche radici quadrate di bmodulo p e modulo q, cf. Lemma B.14.) Ne segue che le radici di a sono datedagli elementi di Z∗
N corrispondenti alle coppie
(bp, bq) (−bp, bq) (bp,−bq) (−bp,−bq).
Tali elementi sono distinti, perché bp e −bp (risp. bq e −bq) sono unici modulop (risp. modulo q). Pertanto:
#QRN
Z∗N
=#QRp ·#QRq
#Z∗N
=p−12
q−12
(p− 1)(q − 1)=
1
4.
Possiamo anche estendere il simbolo di Legendre al caso N = p · q; in questocaso si parla di simbolo di Jacobi. Per ogni a coprimo con N , definiamo
JN (a) = Jp(a) · Jq(a).
Indicheremo con J+1N l’insieme degli elementi in Z∗
N con simbolo di Jacobi +1(una definizione simile vale per J−1
n ). Già sappiamo (dal Lemma B.18) che sea ∈ QRN , allora JN (a) = +1; ciò implica immediatamente che QRN ⊆ J+1
N .Osserviamo però che JN (a) = +1 anche quando Jp(a) = Jq(a) = −1. In altreparole, JN (a) = +1 anche quando entrambi a mod p ed a mod q non sonoresidui quadratici (e quindi anche se a è un non-residuo quadratico moduloN). Per tenere conto di ciò, si introduce l’insieme di elementi di Z∗
N che hannosimbolo di Jacobi +1 pur essendo non-residui quadratici modulo N :
QNR+1N = {a ∈ Z∗
N : a ∈ QNRN , ma JN (a) = +1} .
Lemma B.19 (Struttura di Z∗N). Sia N = p · q, con p e q primi distinti.
Allora: (i) esattamente metà degli elementi di Z∗N sono in J+1
N , (ii) esattamentemetà degli elementi di J+1
N sono in QRN (e l’altra metà sono in QNRN ).

B.3 Residui quadratici 461
Dimostrazione. (i) Sappiamo che JN (a) = +1 se Jp(a) = Jq(a) = +1 oppurese Jp(a) = Jq(a) = −1. Inoltre metà degli elementi in Z∗
p (risp. Z∗q) ha simbolo
di Jacobi +1 e l’altra metà −1. Allora:
#J+1N = #(J+1
p × J+1q ) + #(J−1
p × J−1q ) = #J+1
p ·#J+1q +#J−1
p ·#J−1q
= 2(p− 1)(q − 1)
4=
ϕ(N)
2=
#Z∗N
2.
(ii) Siccome a ∈ QRN se e solo se Jp(a) = Jq(a) = +1, abbiamo:
#QRN = #(J+1p × J+1
q ) =(p− 1)
2
(q − 1)
2=
ϕ(N)
4,
da cui segue #QRN = #J+1N /2. Siccome QRN ⊆ J+1
N , metà degli elementi diJ+1N sono in QRN (e quindi l’altra metà in QNRN ).
Il simbolo di Jacobi eredita la proprietà moltiplicativa dal simbolo di Legen-dre:
Lemma B.20 (Proprietà moltiplicativa del simbolo di Jacobi). Sianoa, b ∈ Z∗
N . Allora JN (a · b) = JN (a) · JN (b).
Dimostrazione. Possiamo scrivere:
JN (a · b) = Jp(a · b) · Jq(a · b) Lemma B.17= Jp(a) · Jp(b) · Jq(a) · Jq(b)
= Jp(a) · Jq(a) · Jp(b) · Jq(b) = JN (a) · JN (b).
Una conseguenza delle proprietà elencate è il seguente:
Lemma B.21 (QRN e QNR+1). Siano a, a′ ∈ QRN e b, b′ ∈ QNR
+1N . Allora:
(i) a · a′ mod N ∈ QRN , (ii) b · b′ mod N ∈ QRN e (iii) a · b mod N ∈ QNR+1N .
Dimostrazione. Dimostriamo solo la (iii), la prova delle altre affermazioni èlasciata come esercizio. Siccome a ∈ QRN , abbiamo Jp(a) = Jq(a) = +1.D’altra parte, siccome b ∈ QNR
+1N , abbiamo Jp(b) = Jq(b) = −1. Usando il
Lemma B.17, possiamo scrivere:
Jp(a · b) = Jp(a) · Jp(b) = −1 e Jq(a · b) = Jq(a) · Jq(b) = −1,
quindi JN (a · b) = +1 per il Lemma B.20. Ora chiaramente a · b non è unresiduo quadratico modulo N , perché Jp(a · b) = −1 ovvero a · b mod p non èun residuo quadratico modulo p. Di conseguenza, a · b ∈ QNR
+1N .

462 B Teoria dei numeri
Abbiamo visto che, usando il criterio di Eulero (cf. Lemma B.16), è possibileverificare in modo efficiente se un dato elemento di Z∗
p è un residuo quadraticooppure no. Analogamente, è semplice verificare se a ∈ Z∗
N è un elemento diQRN : si calcolano Jp(a), Jq(a) e quindi si verifica che Jp(a) = Jq(a) = +1; sequesto è il caso a ∈ QRN , altrimenti a ∈ QNRN . La situazione è più complicataquando la fattorizzazione di N non è nota: in questo caso non si conosce nessunalgoritmo efficiente per decidere se a è un residuo quadratico modulo n oppureno. (Sorprendentemente, però, è noto un algoritmo per calcolare JN (a) senzaconoscere la fattorizzazione di N [ES98; BZ10].)
Interi di Blum. Un primo di Blum è un primo p della forma p ≡ 3 (mod 4).Un intero N è detto di Blum se N = p · q e se sia p che q sono primi di Blum.La principale proprietà degli interi di Blum è che ogni residuo quadratico a hauna radice b che è anch’essa un residuo quadratico. Tale radice quadrata, èanche detta radice quadrata principale di a.
Lemma B.22 (Radici in QRp quando p è un primo di Blum). Sia p unprimo di Blum ed a ∈ QRp. Allora b = a(p+1)/4 mod p è una radice quadrataprincipale di b modulo p.
Dimostrazione. Dobbiamo mostrare che la radice quadrata di b (modulo p), èanch’essa un residuo quadratico. Siccome a è un residuo quadratico per ipotesi,il criterio di Eulero (cf. Lemma B.16) implica a(p−1)/2 ≡ 1 (mod p). In effetti:
b2 ≡(a(p+1)/4
)2≡ a · a(p−1)/2 ≡ a (mod p),
e quindi b è una radice quadrata di a modulo p. Per verificare che b ∈ QRp
basta applicare nuovamente il criterio di Eulero
b(p−1)/2 ≡(a(p+1)/4
)(p−1)/2
≡(a(p−1)/2
)(p+1)/4
≡ 1(p+1)/4 ≡ 1 (mod p).
Segue b ∈ QRp e quindi b è principale.
Il caso di QRN , con N = p · q, è simile:
Lemma B.23 (Radici in QRN quando N è un intero di Blum). SiaN = p ·q un intero di Blum e sia a ∈ QRN . Allora a ha quattro radici quadratemodulo N , una sola delle quali è principali.

B.4 Curve ellittiche 463
Dimostrazione. Abbiamo già mostrato (cf. discussione dopo il Lemma B.18)che ogni a ∈ QRN per N = p · q ha quattro radici modulo N . È un sempliceesercizio verificare che di queste una sola è a sua volta un residuo quadratico.
B.4 Curve ellittiche
Le curve ellittiche sono uno strumento potente in teoria dei numeri con svariateapplicazioni in diversi campi della scienza. In crittografia hanno dato vitaad una vera e propria branca, detta appunto crittografia sulle curve ellittiche(Elliptic Curve Cryptography, ECC). In questo paragrafo introdurremo (perlo più informalmente) i concetti relativi alle curve ellittiche utili ad alcuneapplicazioni crittografiche. Una trattazione completa e rigorosa esula dagliscopi del testo. Si vedano ad esempio [Sil86; Was08] per approfondire. Unapanoramica si trova anche in [Ven09].
Curve ellittiche su campo K. Sia (K,+, ·) un campo (cf. Definizione B.4)con elemento neutro della somma 0 ed elemento neutro del prodotto 1. Sidefinisce caratteristica di K (indicata con char(K)), come il minimo numerodi volte che bisogna sommare l’elemento 1 per ottenere 0. Se tale valore nonesiste, si dice che il campo ha caratteristica nulla, char(K) = 0. (Ad esempioZ∗
p ha caratteristica p, mentre l’insieme dei reali R ha caratteristica 0.) Daremola definizione di curva ellittica per campi con caratteristica diversa da 2 e 3;anche in questi casi è possibile dare una definizione, ma vanno in un certo sensotrattati a parte [Was08, Capitolo 2].
Definizione B.7 (Curva ellittica su un campo K). Sia K un campo concaratteristica char(K) = 2, 3. Una curva ellittica su K, indicata con E(K), èdefinita dall’equazione
E : Y 2 = X3 +AX +B A,B ∈ K. (B.2)
�
La curva E è detta non-singolare se non ha zeri doppi, il che si verificaquando il discriminante ΔE = 4A3 + 27B2 è diverso da 0 in K. Se K = R
possiamo tracciare un grafico della curva, come mostra la Fig. B.3. La curvaE è simmetrica (rispetto all’asse delle ascisse) e può avere uno oppure tre zerireali.
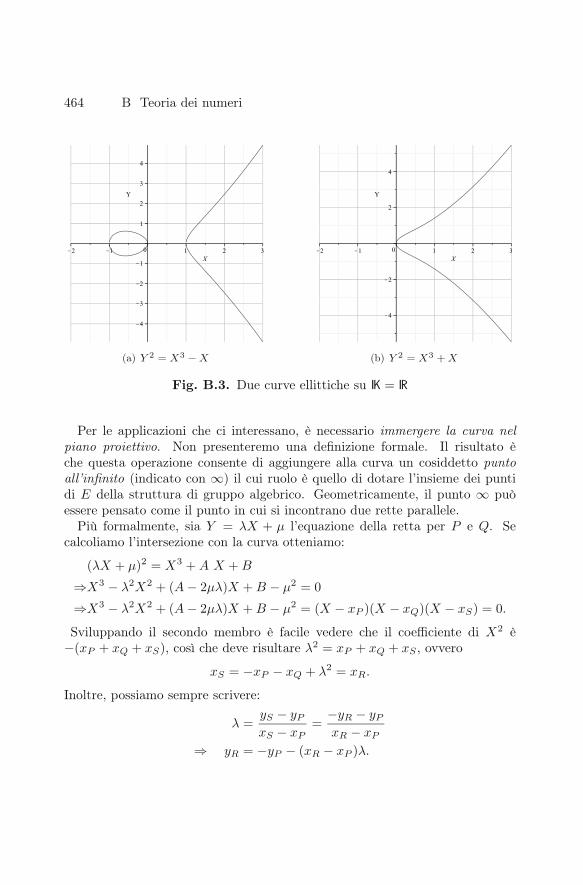
464 B Teoria dei numeri
(a) Y 2 = X3 −X (b) Y 2 = X3 +X
Fig. B.3. Due curve ellittiche su K = R
Per le applicazioni che ci interessano, è necessario immergere la curva nelpiano proiettivo. Non presenteremo una definizione formale. Il risultato èche questa operazione consente di aggiungere alla curva un cosiddetto puntoall’infinito (indicato con ∞) il cui ruolo è quello di dotare l’insieme dei puntidi E della struttura di gruppo algebrico. Geometricamente, il punto ∞ puòessere pensato come il punto in cui si incontrano due rette parallele.
Più formalmente, sia Y = λX + μ l’equazione della retta per P e Q. Secalcoliamo l’intersezione con la curva otteniamo:
(λX + μ)2 = X3 +A X +B
⇒X3 − λ2X2 + (A− 2μλ)X +B − μ2 = 0
⇒X3 − λ2X2 + (A− 2μλ)X +B − μ2 = (X − xP )(X − xQ)(X − xS) = 0.
Sviluppando il secondo membro è facile vedere che il coefficiente di X2 è−(xP + xQ + xS), così che deve risultare λ2 = xP + xQ + xS , ovvero
xS = −xP − xQ + λ2 = xR.
Inoltre, possiamo sempre scrivere:
λ =yS − yPxS − xP
=−yR − yPxR − xP
⇒ yR = −yP − (xR − xP )λ.

B.4 Curve ellittiche 465
�
��
�
Fig. B.4. Il punto R, somma dei punti P e Q su una curva ellittica
La legge di gruppo. Definiamo ora un’operazione su E(K) tale che dati duepunti di E(K), restituisce un altro punto di E(K). Iniziamo con i due puntiP = (xP , yP ) e Q = (xQ, yQ), e consideriamo la retta passante attraversoessi; come mostra la Fig. B.4, tale retta interseca la curva in un terzo puntoS = (xS , yS). Sia R = (xR, yR) = (xS ,−yS) il simmetrico del punto S rispettoall’asse delle ascisse. La somma dei punti P e Q è definita come P + Q = R.Restano da distinguere tre casi:
1. P = Q. Abbiamo semplicemente:
λ =yQ − yPxQ − xP
.
2. P = Q. In questo caso λ è il coefficiente angolare della retta tangentealla curva E in P = Q = (xP , yP ). Dunque:
Y =√X3 +Ax+B
⇒ dY
dX=
3X2 +A
2√X3 +AX +B
=3X2 +A
2Y
⇒ λ =3x2
P +A
2yP.
3. P = −Q. In questo caso poniamo P +Q = P − P =∞.

466 B Teoria dei numeri
Abbiamo così trovato la legge di gruppo (group law):
Definizione B.8 (Legge di gruppo). Sia E(K) una curva ellittica E : Y 2 =X3 +AX +B su un campo K, e siano P = (xP , yP ) e Q = (xQ, yQ) due puntidi E diversi dal punto all’infinito. Definiamo P + Q = R = (xR, yR) comesegue:
λ =
⎧⎪⎨⎪⎩yQ − yPxQ − xP
se P = Q
3x2P +A
2yPse P = Q
xR = −xP − xQ + λ2
yR = −yP − (xR − xP )λ.
Quando P = −Q poniamo P +Q =∞. �
Consideriamo ad esempio la curva E : Y 2 = X3 + X + 1, con K = R eP = (0, 1). Notare che ΔE = 4A3+27B2 = 31 = 0 e quindi E è non-singolare.In effetti è semplice verificare che P è un punto di E. Calcoliamo R = P + P :
λ =3x2
P +A
2yP=
0 + 1
2=
1
2
xR = −xP − xP + λ2 =1
4
yR = −yP − (xR − xP )λ = −9
8
⇒ P + P = R =
(1
4,−9
8
).
È immediato verificare che R è un punto di E(R).Il punto chiave, a prima vista sorprendente, è che l’insieme
E(K) ={(x, y) ∈ K×K : y2 = x3 +A x+B
}∪ {∞}
dei punti di E(K) più il punto all’infinito, è un gruppo algebrico (E(K),+) (cf.Definizione B.2) rispetto all’operazione di somma della Definizione B.8.
Curve ellittiche su Zp. Le principali applicazioni delle curve ellittiche incrittografia hanno a che fare con curve ellittiche definite su un campo finito,ad esempio K = Zp. Possiamo adattare facilmente la Definizione B.8 a questocaso particolare.

B.4 Curve ellittiche 467
Definizione B.9 (Curva ellittica su Zp). Sia p = 2, 3. Una curva ellitticasu Zp, indicata con E(Zp), è definita da un’equazione della forma:
E : Y 2 ≡ X3 +AX +B (mod p) A,B ∈ Zp.
�
La curva E è detta non-singolare se non ha zeri doppi, ovvero se il discri-minante ΔE = 4A3 + 27B2 ≡ 0 (mod p). Possiamo anche adattare la legge digruppo di Definizione B.8:
Definizione B.10 (Legge di gruppo per E(Zp)). Sia E(Zp) una curvaellittica E : Y 2 ≡ X3+AX+B (mod p) sul campo Zp, e siano P = (xP , yP ) eQ = (xQ, yQ) due punti di E diversi dal punto all’infinito. Definiamo P +Q =R = (xR, yR) come segue:
λ ≡
⎧⎪⎨⎪⎩yQ − yPxQ − xP
(mod p) se P = Q
3x2P +A
2yP(mod p) se P = Q
(B.3)
xR ≡ −xP − xQ + λ2 (mod p)
yR ≡ −yP − (xR − xP )λ (mod p).
Nel caso in cui P = −Q poniamo P +Q =∞. �
Anche nel caso K = Zp, infine, l’insieme
E(Zp) ={(x, y) ∈ Zp ×Zp : y2 ≡ x3 +A x+B (mod p)
}∪ {∞},
è un gruppo algebrico rispetto all’operazione di somma della Definizione B.10.Inoltre tale gruppo è finito, come mostrato dal seguente:
Teorema B.24 (Teorema di Hasse). Sia E : Y 2 = X3+AX+B una curvaellittica su Zp, con p un primo. Allora:
#E(Zp) = p+ 1− t,
per |t| < 2√p.
Il primo algoritmo efficiente per calcolare #E(Zp) è dovuto a Schoof [Sch85].Concludiamo discutendo brevemente della complessità computazionale asso-
ciata alla manipolazione e alla rappresentazione di una curva ellittica su un

468 B Teoria dei numeri
campo finito. Definire una curva ellittica su Zp equivale a scegliere A e B inZp, quindi l’occupazione di memoria è 2 log p = O(log p). Un discorso identicovale per lo spazio necessario a memorizzare un punto P (due coordinate). Ilcosto dell’addizione è dominato dalla divisione nel calcolo di λ, quindi O(log3 p)se ci riferiamo all’algoritmo euclideo (cf. Corollario B.5). Per calcolare un pun-to P di E(Zp) si deve scegliere un valore x ∈ Zp, calcolare α ≡ x3 + Ax + B(mod p) e sperare che α sia un residuo quadratico modulo p (il che è facilmenteverificabile attraverso il criterio di Eulero, cf. Lemma B.16). Infine, è necessa-rio estrarre la radice, il che può sempre essere fatto efficientemente in Zp (cf.Appendice B.3).

Esercizi
Esercizio B.1. Determinare la complessità degli algoritmi elementari di som-ma, moltiplicazione e divisione in funzione della dimensione degli input.
Esercizio B.2. Usare l’algoritmo di Euclide per calcolare gcd(841, 294). Quin-di, esprimere il risultato come combinazione lineare dei due numeri usandol’algoritmo di Euclide esteso.
Esercizio B.3. Calcolare gcd(X4 − 4X3 + 6X2 − 4X + 1, X3 −X2 +X − 1).
Esercizio B.4. Risolvere la congruenza 3X ≡ 4 (mod 7).
Esercizio B.5. Usando il teorema del resto cinese, risolvere il seguente sistemadi congruenze: ⎧⎪⎪⎨⎪⎪⎩
X ≡ 2 (mod 3)X ≡ 3 (mod 5)X ≡ 4 (mod 11)X ≡ 5 (mod 16).
Esercizio B.6. Dimostrare che Z56 non è un gruppo rispetto all’operazionedi moltiplicazione.
Esercizio B.7. Quanti e quali sono gli elementi di Z∗19? Il gruppo è ciclico? In
caso affermativo dire quanti generatori ci sono, altrimenti trovare il sottogruppodi Z∗
19 con ordine più grande.
Esercizio B.8. Calcolare 7120007 mod 143 a mano.
Esercizio B.9. Calcolare J167(91).
Esercizio B.10. Risolvere X2 ≡ 100 (mod 231).
Esercizio B.11. Considerare il gruppo Z∗35.
1. Quanti elementi ci sono? Elencarli.
2. Per ogni elemento del gruppo, decidere se ha simbolo di Jacobi +1 oppure−1. Quanti sono gli elementi con simbolo di Jacobi +1.
3. Per ogni elemento con simbolo di Jacobi +1, determinare se l’elemento èun residuo quadratico oppure no. Quanti elementi con simbolo di Jacobi+1 sono residui quadratici?
4. Per ogni residuo quadratico, trovare le corrispondenti radici quadrate.
5. Supponiamo di utilizzare RSA in Z35 con e = 7. Qual è il valore di d?

470 B Teoria dei numeri
Esercizio B.12. Sia E : Y 2 = X3 + 1 su Z5. Verificare che si tratta di unacurva ellittica. Determinare l’ordine del punto (2, 2) nel gruppo E(Z5).
Esercizio B.13. Consideriamo la curva E : Y 2 ≡ X3 + X + 2 (mod p) perp = 5. Elencare i punti di E(Z5). Sia P = (1, 2); calcoliamo P + P = 2P .Infine, mostrare che E(Z5) è ciclico e che P è un generatore.

Letture consigliate
[BZ10] Richard P. Brent e Paul Zimmermann. “An O(M(n) log n) Algorithm forthe Jacobi Symbol”. In: ANTS. 2010, pp. 83–95.
[ES98] Shawna Meyer Eikenberry e Jonathan Sorenson. “Efficient Algorithmsfor Computing the Jacobi Symbol”. In: J. Symb. Comput. 26.4 (1998),pp. 509–523.
[JJ05] Gareth A. Jones e Josephine M. Jones. Elementary Number Theory. Springer-Verlang, 2005.
[Lan02] Serge Lang. Algebra. Springer-Verlang Berlin, 2002.
[Sch85] René Schoof. “Elliptic Curves over Finite Fields and the Computation ofSquare Roots modp”. In: Math. Comp. 44(170) (1985), pp. 483–494.
[Sil86] Joseph H. Silverman. Arithmetic of Elliptic Curves. Springer-Verlang,1986.
[Sin97] Simon Singh. Fermat’s Last Theorem: The Story of a Riddle that Con-founded the World’s Greatest Minds. Fourth Estate, 1997.
[Ven09] Daniele Venturi. Introduction to Algorithmic Number Theory. Rapp. tecn.ECCC TR09-62. SAPIENZA University of Rome, 2009. url: http://eccc.hpi-web.de/report/2009/062/.
[Was08] Lawrence C. Washington. Elliptic Curves: Number Theory and Crypto-graphy. Seconda edizione. Chapman & Hall (CRC Press), 2008.
[Wil95] Andrew Wiles. “Modular elliptic curves and Fermat’s Last Theorem”. In:Annals of Mathematics 142 (1995), pp. 443–551.

Ap
pe
nd
ice
CProblemi computazionali
«Quanto fa uno più uno più uno più uno più uno più uno più uno piùuno più uno più uno?». «Non saprei», disse Alice. «Ho perso il conto».«Non è in grado di fare l’addizione», disse la Regina Rossa.
Lewis Carroll, Attraverso lo Specchio e quel che Alice vi trovò [Car71]
Come abbiamo avuto modo di vedere in diverse occasioni, l’ipotesi di base sucui si regge tutta la teoria della crittografia moderna è l’esistenza di alcuniproblemi computazionali ritenuti in qualche modo “difficili” da risolvere (indeterminate condizioni). Questa appendice offre una panoramica su alcuni diquesti problemi, discutendo la loro origine e studiando alcuni degli algoritmipiù efficienti conosciuti per attaccarli.
Guida per il lettore. Il primo problema computazionale di cui ci occupe-remo (nel Paragrafo C.1) è quello di determinare se un dato numero è primooppure no. Ciò è molto importante nel contesto di alcuni crittosistemi a chia-ve pubblica, ad esempio il cifrario RSA (cf. Paragrafo 6.2). Come vedremo,in realtà, questo problema non è un problema difficile, in quanto è semprerisolvibile in tempo polinomiale.
Nel Paragrafo C.2 passeremo a studiare alcuni algoritmi per fattorizzareinteri della forma p · q, dove p e q sono primi di grande dimensione (diciamo ≈50 cifre decimali).
Nel Paragrafo C.3, infine, studieremo il problema del logaritmo discreto, cherichiede, dato un elemento gx in un gruppo finito G, di calcolare l’esponente x.
Per una trattazione esaustiva si rimanda a [CP01]. Una panoramica si trovaanche in [Sch08; Ste08; Ven09].
Venturi D.: Crittografia nel Paese delle MeraviglieDOI 10.1007/978-88-470-2481-6 17, c© Springer-Verlag Italia 2012

474 C Problemi computazionali
C.1 Test di primalità
Un numero intero p > 1 è detto primo se p ha come divisori solamente 1 e séstesso. Lo studio della differenza tra numeri primi e numeri composti (ovveronumeri che sono esprimibili come prodotto di primi) sembra avere origini moltoantiche. Euclide è stato il primo a mostrare che ogni numeri intero positivo èesprimibile come prodotto di primi, oppure è primo esso stesso.
Teorema C.1 (Euclide, Libro VII Proposizioni 31 e 32). Ogni numerointero maggiore di 1 è esprimibile come prodotto di primi oppure è esso stessoun primo.
Dimostrazione. Per induzione. Supponiamo che l’asserto sia vero per tutti gliinteri inferiori ad n. Se n è primo non c’è niente da dimostrare. Se n non èprimo, esistono due interi n1, n2 tali che n = n1 · n2, con n1, n2 < n. Ma perl’ipotesi induttiva n1 e n2 devono essere esprimibili come prodotto di primi(oppure essere loro stessi primi); sostituendo tali espressioni, otteniamo cheanche n è esprimibile come prodotto di primi.
Quanti sono i numeri primi? La risposta a questa domanda è stata dataancora da Euclide.
Teorema C.2 (Euclide, Libro IX Proposizione 20). Ci sono infinitinumeri primi.
Dimostrazione. Per assurdo supponiamo che l’insieme dei primi sia finito e paria {p1, . . . , pk}. Consideriamo il numero:
n =k∏
i=1
pi + 1.
Tale numero non è divisibile per nessuno dei numeri p1, . . . , pk. D’altro canton deve essere divisibile per qualche primo oppure essere primo a sua volta (peril Teorema C.1). Dunque esiste un primo pk+1 diverso da p1, . . . , pk e ci sonoinfiniti primi.
Gauss è stato il primo a mostrare che la scomposizione in fattori primi di unnumero intero è unica.
Teorema C.3 (Teorema fondamentale dell’aritmetica). Ciascun numeronaturale è esprimibile in uno ed un sol modo come prodotto di primi.

C.1 Test di primalità 475
Dimostrazione. Per induzione. Supponiamo che l’asserto sia valido per ogninumero naturale strettamente minore di n. Se n è esso stesso primo non c’èniente da dimostrare. Sia allora n composto e supponiamo che esso ammettadue scomposizioni distinte in fattori primi, vale a dire:
n = p · q · r · · · = p′ · q′ · r′ · · · ,
dove p, q, r, . . . e p′, q′, r′, . . . sono tutti primi. Osserviamo che nessun primopuò comparire in entrambe le scomposizioni in quanto, se così fosse, potrebbeessere cancellato generando due scomposizioni distinte di un numero minore din, contro l’ipotesi induttiva.
Senza perdita di generalità supponiamo che p e p′ siano i primi più piccolidelle due scomposizioni. Siccome n è composto, abbiamo n ≥ p2 ed n ≥ (p′)2;ma p e p′ sono distinti e quindi una delle due uguaglianze deve essere vera insenso stretto, ovvero p · p′ < n. Consideriamo ora il numero n− p · p′; siccometale numero è minore di n, deve ammettere un’unica scomposizione in fattoriprimi. È evidente d’altra parte che sia p che p′ dividono n − p · p′, in quantoentrambi dividono n e p · p′. Di conseguenza:
n− p · p′ = p · p′ · q′′ · r′′ · · · ,
dove q′′, r′′, . . . sono tutti primi. Segue che p · p′ deve essere un fattore di n,il che è impossibile, in quanto abbiamo già osservato che i primi p, q, r, . . . ep′, q′, r′, . . . devono essere distinti. Concludiamo che la fattorizzazione di n èunica.
Fissiamo un intero n e chiediamoci quanti sono i primi minori o uguali ad n.Il teorema dei numeri primi (Prime Number Theorem, PNT) afferma che pern abbastanza grande ci sono circa n/ lnn primi in [1, n].
Teorema C.4 (Teorema dei numeri primi). Sia π(n) il numero di primistrettamente minori di n. Abbiamo:
limn→∞
π(n) lnn
n= 1.
La prova di questo fatto è complessa ed esula dagli scopi del testo. In generaledomande di questo tipo vengono studiate in teoria analitica dei numeri. Siveda [Apo76] per un’introduzione.
Il compito di stabilire se un dato intero è un primo oppure no, è moltoimportante in crittografia. Nel seguito discuteremo due algoritmi: il test di

476 C Problemi computazionali
Miller-Rabin ed il test di Agrawal, Kayal e Saxena. Il primo algoritmo è pro-babilistico; in particolare non è escluso che un numero composto passi il testvenendo identificato come primo (tuttavia ciò avviene solo con bassa probabi-lità). Il secondo algoritmo è stato il primo test di primalità ad essere contem-poraneamente deterministico e polinomiale (mostrando così che il problema distabilire la primalità di un numero è in P). Un altro algoritmo molto impor-tante (basato sulle curve ellittiche) è dovuto a Goldwasser e Killian [GK86]ed è stato poi migliorato da Atkin e Morain [AM93]; seppure il test sia deter-ministico, l’analisi della complessità è probabilistica (ma si congettura che siapolinomiale). Distingueremo test probabilistici (in cui la risposta è correttacon alta probabilità) e test deterministici (in cui la risposta è sempre corretta).
Il test di Miller e Rabin. L’algoritmo di Miller-Rabin è probabilistico: es-so è in grado di stabilire con elevata probabilità (ed in tempo polinomiale) seun dato numero n non è primo. D’altro canto, se n passa il test, non possiamoessere certi che esso sia primo. È necessario quindi ripetere l’algoritmo di-verse volte, rendendo così trascurabile la probabilità che un numero compostonon sia riconosciuto come tale. L’idea originale è dovuta ad Artjuhov[Art67].Rabin[Rab80] ha proposto la versione probabilistica dell’algoritmo; indipen-dentemente Miller [Mil76] ha mostrato che, sotto alcune ipotesi, il test puòessere trasformato in deterministico.
In un certo senso il test di Miller-Rabin può essere visto come una genera-lizzazione del seguente test di Fermat . Per il piccolo teorema di Fermat (cf.Teorema B.11), se p è un primo, allora per ogni x ∈ Z∗
p, abbiamo xp−1 ≡ 1(mod p). Pertanto, dato un numero n da testare, potremmo pensare di sce-gliere x ∈ Z∗
n e controllare se per caso xn−1 ≡ 1 (mod n). Il problema diquesta strategia è che il piccolo teorema di Fermat fornisce solo una condizionenecessaria per la primalità di n; esistono infatti numeri — detti pseudo-primidi Fermat in base x — tali che xn−1 ≡ 1 (mod n), anche quando n è composto(cf. Esercizio C.1). In realtà c’è di peggio: esistono numeri — detti numeridi Carmichael — che soddisfano la relazione di cui sopra per qualsiasi valo-re di x ∈ Z∗
n, indipendentemente dal fatto che n sia primo o composto (cf.Esercizio C.2). L’idea di Miller-Rabin è quella di aumentare la probabilità disuccesso del test di Fermat.
Lemma C.5 (Radici dell’unità modulo p). Sia p > 2 un primo. Nonesistono radici non-banali di 1 modulo p.

C.1 Test di primalità 477
Dimostrazione. Osserviamo che sia 1 che −1 restituiscono sempre 1 quandosono elevati al quadrato modulo p; queste sono le radici banali dell’unità.Supponiamo che x ∈ Zp sia una radice non-banale dell’unità modulo p. Allora
x2 ≡ 1 (mod p) ⇒ (x+ 1)(x− 1) ≡ 0 (mod p).
Siccome x è non-banale, abbiamo x ≡ ±1 (mod p), vale a dire x+ 1 ed x− 1sono coprimi con p, ovvero né x+ 1 né x− 1 sono divisibili per p. Ma allora pnon può neanche dividere il prodotto tra x+1 ed x− 1 e possiamo concludere:
(x+ 1)(x− 1) ≡ 0 (mod p),
che è una contraddizione. Concludiamo che le uniche radici dell’unità modulop sono quelle banali.
Lemma C.6 (Algoritmo di Miller-Rabin). Sia n un primo dispari. Scri-viamo n − 1 = 2sd, con d un intero dispari ed s ≥ 1. Per ogni x ∈ Z∗
n si hache xd ≡ 1 (mod n) oppure x2rd ≡ −1 (mod n) per qualche 0 ≤ r < s.
Dimostrazione. Siccome n è primo, il piccolo teorema di Fermat ci dice chexn−1 ≡ 1 (mod n), ovvero n è congruo all’unità in Z∗
n. Se ora calcoliamoripetutamente la radice quadrata di xn−1, il Lemma C.5 ci dice che otterremosempre +1 oppure −1. Quando il risultato è −1, la seconda uguaglianza èverificata.
Supponiamo d’altra parte di aver continuato ad estrarre le radici quadrate dixn−1 senza che la seconda uguaglianza sia mai verificata; ciò equivale a dire chex2rd ≡ −1 (mod p) per ogni r = 0, 1, · · · , s−1. Notare che siccome anche xd èuna radice quadrata dell’unità, deve aversi xd ≡ ±1 (mod n). Comunque perr = 0 abbiamo ottenuto xd ≡ −1 (mod n), quindi se la seconda uguaglianzanon vale deve valere la prima.
Analogamente al caso dei numeri pseudo-primi in base x, possiamo definirei numeri pseudo-primi forti in base x come gli interi dispari n > 3 per cuila condizione del Lemma C.6 è soddisfatta. Se scegliamo a caso x ∈ Z∗
n e lacondizione del Lemma C.6 non è verificata, possiamo concludere subito che n ècomposto. D’altro canto, se tale condizione vale per un dato x, non possiamoconcludere che n è primo, in quanto n potrebbe essere uno pseudo-primo fortein base x. La speranza è che stavolta la frazione di numeri composti che passinoil test sia più bassa. In effetti posto
B ={x ∈ Z∗
n : xd = 1 oppure x2rd = −1 per qualche 0 ≤ r < s}
,

478 C Problemi computazionali
si può dimostrare che (per ogni intero dispari composto n > 9) si ha (#B)/ϕ(n) ≤1/4.
Questo fatto può essere usato per costruire il seguente test di primalità pro-babilistico. Si sceglie un valore a caso x ∈ Z∗
n e si verifica se x ∈ B. Quandociò accade si conclude che n è composto, altrimenti n è probabilmente primo.In una singola istanza la probabilità che x ∈ B per n composto è al più 1/4;ripetendo il test k volte tale valore può essere ridotto a 4−k e quindi reso piccoloa piacere.
Notare che per verificare che x sia un elemento di B, bisogna elevare x ∈ Z∗n
ad un esponente non più grande di n. Ciò richiede O(log(n)(log(n))μ), conμ = 2 se si fa riferimento agli algoritmi di moltiplicazione ordinaria in Zn eμ = 1 + ε usando le tecniche di moltiplicazione veloce [Ber08].
Il test di Agrawal, Kayal e Saxena. L’algoritmo AKS [AKS04] (dalleiniziali dei suoi inventori) ha dimostrato per la prima volta che il compito distabilire la primalità di un dato intero è in P. L’ingrediente chiave è contenutonel seguente teorema, la cui dimostrazione esula dagli scopi del testo.
Teorema C.7 (Algoritmo AKS). Sia n > 0 un intero dispari ed r un primo.Supponiamo che sia verificato quanto segue:
(i) n non è divisibile per nessuno dei primi ≤ r;
(ii) l’ordine di n in Z∗r è:
ord(n) ≥(log(n)
log(2)
)2
;
(iii) per ogni 0 ≤ a ≤ r, possiamo scrivere:
(X + a)n = Xn + a in Zn[X]/
(Xr − 1
X − 1
).
Allora n è potenza di un primo.
Per un primo r, si definisce l’r-simo polinomio ciclotomico93:
Φr(X) =Xr − 1
X − 1= Xr−1 + · · ·+X2 +X + 1.
93Tali polinomi sono connessi al problema di dividere un cerchio unitario in segmenti uguali,ovvero il problema di iscrivere poligoni regolari in un cerchio di raggio 1.

C.1 Test di primalità 479
In questo modo, l’anello
Zn[X]/ (Φr(X)) ={ar−2X
r−2 + · · ·+ a1X + a0 : ai ∈ Zn
}contiene tutti i polinomi di grado al più r − 2 con coefficienti in Zn. Pertantorappresentare un singolo elemento di tale anello richiede O(r log n) bit.
Osserviamo che quando n è primo i coefficienti del polinomio (X + a)n
sono tutti nulli modulo n, quindi, usando il piccolo teorema di Fermat (cf.Teorema B.11), possiamo concludere:
(X + a)n =n∑
i=0
(n
i
)Xn−iai = Xn + an = Xn + a in Zn[X].
Purtroppo valutare (X + a)n per ogni a è troppo costoso quando n è grande:l’idea di Agrawal, Kayal e Saxena è quella di calcolare (X+a)n modulo l’r-simopolinomio ciclotomico Φr(X).
Si può trasformare il Teorema C.7 in un test di primalità, come segue:
1. Controlla94 che n non sia potenza di qualche intero.
2. Provando i valori r = 2, 3, . . . trova il più piccolo primo r che non divide n
e che non divide nessuno degli elementi ni−1 (con i = 0, 1, . . . ,(
log(n)log(2)
)2).
In simboli:
r � n ·( log(n)
log(2) )2∏
i=1
(ni − 1).
3. Controlla che la condizione (iii) del Teorema C.7 sia verificata.
4. Se n passa il Test, concludi che n è primo, altrimenti concludi che n ècomposto.
Dimostriamo che il test funziona. Banalmente se n è primo, passerà il testper il piccolo teorema di Fermat. Supponiamo d’altra parte che n passi il test.
94Tale controllo può essere effettuato alla seguente maniera. Sia n della forma n = md con d > 1ed m ≥ 2, ovvero
n = md ≥ 2d ⇒ d ≤ log(n)
log(2).
Per d = 2, 3, . . . ,log(n)log(2)
approssimiamo, con una certa precisione, il valore n1/d in R e poniamo
m = round(n1/d) ∈ Z. Verifichiamo quindi che md �= n. Il costo è O(log4(n)).

480 C Problemi computazionali
È sufficiente controllare che tutte le condizioni del Teorema C.7 siano rispettateper poter concludere che n sia primo (perché abbiamo già controllato nel punto(1) dell’algoritmo che esso non è potenza di un primo). La condizione (iii) èsicuramente verificata, in quanto essa coincide con il punto (3) del test; anche lacondizione (i) è verificata, per come abbiamo definito r al punto (2). Sia infineo l’ordine di n modulo r, ovvero no ≡ 1 (mod r) (il che ha senso in quantor � n); allora r|(no − 1). Nel punto (2) dell’algoritmo abbiamo verificato che
r non divide gli elementi ni − 1 per i = 0, 1, . . . ,(
log(n)log(2)
)2, così che possiamo
concludere:
o >
(log(n)
log(2)
)2
,
che è esattamente la condizione (ii) del Teorema C.7.Si può dimostrare che r ≤ O(log5 n). La parte più costosa del punto di vista
computazionale è quella in cui dobbiamo calcolare (X+a)n in Zn[X]/(Φr(X))per ogni a = 0, . . . , r − 1. Siccome un elemento nell’anello è rappresenta-bile con O(r log n) bit, valutare l’n-sima potenza costa O(log n(r2 log2 n)) seci si riferisce alle tecniche standard di moltiplicazione. Poiché dobbiamo ri-petere per ogni possibile a = 0, . . . , r − 1 la complessità nel caso peggioresarà O(r3 log3 n) = O(log18 n). Tale valore si abbassa a O(log12+ε n) se si fariferimento alle tecniche di moltiplicazione veloce [Ber08].
C.2 Fattorizzazione di interi
Come abbiamo visto, il teorema fondamentale dell’aritmetica assicura che ogninumero intero sia scomponibile in fattori primi in modo univoco. È possibilein qualche modo trovare tale scomposizione? Quando il numero da fattorizzareè molto grande, non esiste (ad oggi) alcun algoritmo efficiente per risolvereil problema. Questo è il motivo per cui alcuni crittosistemi come RSA (cf.Paragrafo 6.2) sono basati sull’ipotesi che fattorizzare alcuni interi sia difficile.
Per testare la robustezza del cifrario RSA, vengono pubblicate periodicamen-te delle “sfide” in cui si richiede di fattorizzare un intero di certe dimensioni.L’ultimo numero fattorizzato [Kle+10] — della forma p · q con 232 cifre — harichiesto circa due anni usando alcune tra le reti di super-computer più potential mondo (distribuite tra la Svizzera, il Giappone ed i Paesi Bassi).
Sia p|n il più piccolo primo divisore di n (il numero che vogliamo fattorizzare).È ovvio che p ≤ √n. L’idea più semplice è quella di scegliere un valore casualed < n e sperare che gcd(d, n) > 1. Siccome la probabilità che il numero scelto

C.2 Fattorizzazione di interi 481
sia divisibile per p è 1/p, e siccome il costo associato al calcolo del massimocomun divisore è O(log3 p) (cf. Corollario B.5), possiamo concludere che lacomplessità è O(p log3 n) che nel caso peggiore (ovvero quando p ≈ √n) è giàesponenziale in n.
Un’altra idea semplice è quella di cercare p semplicemente dividendo n pertutti i primi minori uguali della
√n. Siccome dobbiamo eseguire tante divisioni
quanti sono i primi minori o uguali a p — ovvero ≈ p/ log p per il teorema deinumeri primi (cf. Teorema C.4) — abbiamo una complessità O(log2 n ·p/ log p)che è ancora esponenziale quando p ≈ √n.
Nel resto di questo paragrafo discutiamo qualche algoritmo più sofisticato:l’algoritmo di Pollard p−1 e la sua estensione sulle curve ellittiche (detta ECM)dovuta a Lenstra.
Pollard p − 1. L’idea alla base dell’algoritmo di Pollard è abbastanza sem-plice. Purtroppo come vedremo, esso consente di trovare un fattore non banaledi n solo in casi molto “fortunati”. Nonostante ciò la sua versione sulle curveellittiche ha dato vita ad uno degli algoritmi più efficienti noti.
Sia n l’intero da fattorizzare. Fissiamo una costante B che rappresenti unlimite per il numero di passi che siamo disposti a compiere. Calcoliamo
M =∏
pi≤Bpi primopeii ≤B
peii , (C.1)
avendo indicato con ei l’esponente del fattore primo pi nella scomposizione diB. Ad esempio se B = 20, abbiamo M = 24 · 32 · 5 · 7 · 11 · 13 · 17 · 19.
Una conseguenza del teorema dei numeri primi (cf. Teorema C.4) è che M ≈eB . Fissiamo un valore casuale x ∈ Z∗
n e calcoliamo y = xM mod n e gcd(y −1, n) = d. La speranza è che 1 < d < n, così che abbiamo trovato un divisorenon banale d di n.
Sia ad esempio n = 10001 e B = 10, così che M = 23 · 32 · 5 · 7 = 2520. Perx = 2 ∈ Z∗
10001, abbiamo:
y = xM = 22520 ≡ 3579 (mod 10001)
gcd(3579− 1, 10001) = 73.
In effetti 10001 = 73 · 137.Indichiamo con p il divisore primo minimale di n; l’algoritmo riesce a cal-
colare p se p| gcd(y − 1, n), ovvero se p|(y − 1) poiché p è per definizione un

482 C Problemi computazionali
divisore di n. Quando ciò avviene
p|(y − 1) ⇒ y ≡ 1 (mod p) ⇒ xM ≡ 1 (mod p).
Per il piccolo teorema di Fermat (cf. Teorema B.11), quindi, è sufficiente cheM sia un multiplo di p− 1, ovvero p− 1 deve dividere M . Ciò è possibile solose tutti i divisori primi di p − 1 sono più piccoli di B (per costruzione di M),ovvero se p− 1 è B-liscio (B-smooth).
Definizione C.1 (Numeri B-lisci). Sia B > 0 un numero reale e n > 0 unintero. Diremo che n è B-liscio, se tutti i divisori primi di n sono più piccoli diB. �
Ad esempio 100 è 10-liscio, poiché 100 = 52 · 22 e 2, 5 < 10.Possiamo pertanto concludere che l’algoritmo p−1 di Pollard ha successo solo
se p−1 è B-liscio. Il costo computazionale è dato dal calcolo di y = xM mod ne del massimo comun divisore, ovvero:
O(log(M) log2(n) + log3(n)
)= O
(B log2(n)
).
In pratica, se B ≈ n1/10, si può vedere che la probabilità che n abbia un divisoreprimo p tale che p− 1 è B-liscio, è molto bassa; pertanto l’algoritmo funzionabene solo in casi fortunati. Ovviamente, più i valori di B sono grandi, maggioreè la probabilità che un numero sia B-liscio; d’altro canto la complessità è peròesponenziale in log(B).
Più in generale, l’algoritmo funziona se xM ≡ 1 (mod p), mentre xM ≡ 1(mod q) per ogni altro divisore primo q di n.
Il metodo delle curve ellittiche. Sebbene l’algoritmo Pollard p−1 sia pocoefficiente, esso costituisce il cuore dell’idea di Lenstra [Len87], che può esserevista come una traduzione nel linguaggio delle curve ellittiche dell’algoritmodi Pollard. L’algoritmo è detto metedo delle curve ellittiche (Elliptic CurveMethod, ECM).
Come abbiamo visto, l’algoritmo di Pollard funziona quando p−1 è B-liscio,dove p−1 = #Z∗
p. Nell’algoritmo ECM sostituiremo Zp con E(Zp), essendo Euna curva ellittica non-singolare (cf. Definizione B.9). Analogamente a quantoaccade nell’algoritmo di Pollard, il valore di p non è noto e tutti i calcoli sarannoquindi eseguiti in E(Zn) (al posto di Z∗
n).

C.2 Fattorizzazione di interi 483
Supponiamo per semplicità che n = pq, dove p e q sono primi distinti maggioridi 3. Il teorema del resto cinese (cf. Teorema B.13) implica che
Zn Zp ×Zq (come anelli)Z∗
n Z∗p ×Z∗
q (come gruppi)
E(Zn) E(Zp)× E(Zq) (come gruppi).
Pertanto l’insieme E(Zn) eredita la struttura di gruppo abeliano: la maggiorparte dei punti in E(Zn) può essere addizionata usando le formule di Defini-zione B.10. Infatti la formula fallisce solo quando alcune quantità calcolate inE(Zn) sono zero modulo p e diverse da zero modulo q (o viceversa). Quandociò accade n, sarà fattorizzato.
Traduciamo l’algoritmo di Pollard usando il linguaggio delle curve ellittiche.Consideriamo la curva ellittica di equazione
E : Y 2 = X3 +AX +B gcd(n, 6) = 1 e gcd(ΔE , n) = 1,
con ΔE = 4A3 + 27B2 = 0. Notare che abbiamo richiesto che il discriminanteΔE della curva non sia divisibile per nessuno dei divisori primi di n, ovvero chela curva E sia non-singolare95 su Zq, per ogni divisore primo q di n. (Osser-viamo che questo test preliminare è polinomiale, in quanto richiede solamenteil calcolo di un massimo comun divisore. Inoltre se per caso gcd(ΔE , n) = 1abbiamo già trovato un fattore non banale di n.)
Scegliamo una costante B e calcoliamo il valore M in Eq. (C.1). Fissiamoquindi un punto a caso su E(Zn) e proviamo a calcolare [M ]P = P + · · ·+ P(M volte) in E(Zn), il che corrisponde a calcolare y = xM nell’algoritmo diPollard. Se ad un certo punto la formula per calcolare il coefficiente angolareλ in Eq. (B.3) fallisce (vale a dire se troviamo un valore non invertibile), alloraabbiamo trovato un fattore di n. Ciò accade solo se
[M ]P =∞ in E(Zp)
[M ]P =∞ in E(Zq) ∀ divisore primo q = p di n⇔ #E(Zp)|M i. e. #E(Zp) è B-liscio.
95Siccome si può dimostrare che estrarre radici quadrate modulo n (quando n è composto) èequivalente a fattorizzare n (cf. Teorema 6.4), è necessario scegliere il punto P prima della curvaE. Quindi, si sceglie prima P = (xP , yP ) ed un valore casuale per A; poi si calcola:
B = y2P − x3P −AxP .
Infine, si verifica che gcd(ΔE , n) = 1.

484 C Problemi computazionali
Un esempio chiarisce immediatamente le idee. Sia n = 35 e supponiamo diusare E : Y 2 = X3 − X − 2. È facile verificare che gcd(ΔE , 35) = 1. SiaM = 3 e P ∈ E(Zn), diciamo P = (2, 2). Dobbiamo calcolare [M ]P in E(Zn)e sperare che [M ]P =∞ in E(Zp), ma [M ]P =∞ in E(Zq) per ogni divisoreprimo q = p di n. Ovviamente non conosciamo p, ma, se la condizione di cuisopra si verifica, è sufficiente calcolare [M ]P = [3]P = P + P + P in E(Zn)per trovare un fattore di n. Cominciamo calcolando [2]P , usando le equazionidella Definizione B.10; abbiamo:
λ =3x2
P +A
2yP=
11
4=
11 · 94 · 9 ≡ 99 ≡ −6 (mod 35).
Quindi,
x2P = −xP − xP + λ2 ≡ −3 (mod 35)
y2P = −yP − λ(x2P − xP ) ≡ 3 (mod 35).
Pertanto [2]P = (−3, 3). Se ora tentiamo di calcolare [3]P = 2P + P =(−3, 3) + (2, 2), otteniamo:
λ =3− 2
−3− 2= −1
5,
e 5 non è invertibile in Z35. Abbiamo così trovato un fattore di n = 5 · 7. Èfacile verificare che in effetti
[3]P = (2,−2) + (2, 2) =∞ in E(Z5)
[3]P = (−3, 3) + (2, 2) =∞ in E(Z7),
e che E(Z35) E(Z7)× E(Z5).Finora abbiamo solamente tradotto l’algoritmo di Pollard usando le curve
ellittiche. Il punto di forza dell’algoritmo ECM sta nel fatto che ora peròabbiamo un grado di libertà in più: se l’algoritmo fallisce per una data curva,possiamo semplicemente cambiare curva (senza incrementare B) e riprovare!(Ciò non è possibile in Pollard p − 1, in quanto Z∗
p è unico; se p − 1 non èB-liscio non resta altro da fare che aumentare B.)
Per stimare la complessità computazionale dell’algoritmo, bisogna stimareil numero di curve E che è necessario provare prima di avere successo. Ciò èpossibile conoscendo: (i) la distribuzione del numero di curve ellittiche su Zp
in funzione del loro numero di punti e (ii) quanti sono i numeri B-lisci per undato B. Si può dimostrare che questa analisi, nel caso in cui p ≈ √n fornisceuna complessità O(e
√log(n) log log(n)).

C.3 Il logaritmo discreto 485
Tab. C.1. Algoritmi di fattorizzazione a confronto
Algoritmo Complessità Numero massimo di cifreDivisione O
(e
12 log(n)
)1-15
ECM O(e√
log(n) log log(n))
10-70
QS O(e√
log(n) log log(n))
60-120
NFS O(elog
13 (n)(log log(n))
23
)120-200
Metodi di crivello. Gli algoritmi più sofisticati sono basati sui cosiddettimetodi di crivello che si basano su una vecchia idea già nota ai tempi di Fermat:si può sperare di calcolare un fattore di n se si riesce a scrivere n come differenzadi due quadrati:
n = u2 − v2 = (u+ v)(u− v).
Il crivello quadratico (Quadratic Sieve, QS) ed il crivello dei campi di numeri(Number Field Sieve, NFS) sono basati esattamente su questa osservazione. LaTab. C.1 mette a confronto gli algoritmi di fattorizzazione più importanti.
C.3 Il logaritmo discreto
Un altro problema centrale in crittografia è quello del logaritmo discreto. Inquesto paragrafo daremo una definizione formale del problema. Quindi studie-remo un algoritmo semplice (ma non molto efficiente) per il calcolo di logaritmidiscreti in Z∗
p.
Logaritmi in Z∗p. Sia p un primo. Come abbiamo visto nell’Appendice B.2
il gruppo Z∗p è ciclico e si chiama generatore un elemento g che ha ordine p− 1
in Z∗p. Dato un tale generatore, ogni elemento y ∈ Z∗
p può essere espresso comey = gx per un qualche intero x.
Definizione C.2 (Logaritmo discreto in Z∗p). Con la notazione sopra intro-
dotta, diremo che x è il logaritmo discreto di y rispetto alla base g e scriveremox = logg y. �

486 C Problemi computazionali
Osserviamo che per il piccolo teorema di Fermat (cf. Teorema B.11) possiamosempre aggiungere multipli di p− 1 all’esponente, ovvero:
y = gx ≡ gx+k(p−1) (mod p) ∀ k ∈ Z.
Segue che l’esponente x = logg(y) è sempre un elemento di Zp−1.È facile convincersi che il logaritmo discreto soddisfa le stesse proprietà del
logaritmo canonico sui reali. In particolare se y1 = gx1 ed y2 = gx2 , abbiamoy1 · y2 = gx1+x2 e quindi
logg(y1 · y2) = x1 + x2 = logg(y1) + logg(y2).
D’altra parte, sia h = g un altro generatore di Z∗p. Possiamo sempre scrivere
g = hc per qualche c ∈ Zp−1. Dato allora un elemento y = gx = hcx, si ha:
logh(y) = cx = c logg(y) ⇒ logh(y)
logg(y)= c ∈ Z∗
p−1,
ovvero è possibile cambiare la base del logaritmo da g ad h moltiplicandoper una costante c che dipende solo da g ed h. Osserviamo infine che se g èun generatore di Z∗
p, allora necessariamente logg(−1) = p−12 , poiché g è un
non-residuo quadratico modulo p.
Passi-nani e passi-giganti. Sia p un primo e g un generatore di Z∗p; dato
un elemento y = gx ∈ Z∗p vogliamo calcolare x ∈ Zp−1. Il modo banale di
fare ciò è l’attacco a forza bruta: calcoliamo le potenze successive di g — valea dire g2, g3, . . . — fino a che non ritroviamo y e quindi x. La complessità èovviamente O(elog p), esponenziale nella dimensione di p.
Il seguente algoritmo — detto algoritmo passi-nani passi-giganti (Baby-StepGiant-Step, BSGS) e dovuto a Shanks — consente di migliorare le prestazioni.(Lo stesso algoritmo può essere utilizzato per calcolare il numero di punti diuna curva ellittica su Z∗
p.) Si sceglie una costante B =⌊√
p⌋+ 1 e si scrive
l’espansione in base B di x, ovvero x = c0 + c1B. Siccome x < B2 per costru-zione, deve aversi 0 ≤ c0, c1 ≤ B. Si eseguono quindi i passi-nani, calcolando ivalori
y, yg−1, . . . , yg−B ,
e memorizzando il risultato in una lista. Si eseguono poi i passi-giganti, calco-lando i valori
gB , (gB)2, . . . , (gB)B ,

C.3 Il logaritmo discreto 487
e memorizzando il risultato in una seconda lista.Siccome y = gx = gc0 · gc1B , basta cercare l’elemento c0 nella prima lista e
l’elemento c1 nella seconda lista. In altre parole, siccome
yg−c0 = (gB)c1 0 ≤ c0, c1 ≤ B,
dobbiamo semplicemente cercare un elemento che sia uguale nelle due liste.Il modo migliore per eseguire questa ricerca è quello di organizzare le liste in
modo efficiente, ad esempio usando una tabella hash (hash table in inglese).96
In questo modo la ricerca nelle due liste richiede tempo costante O(1) e lacomplessità è dominata dalla dimensione della costante B:
O(√
p log2(p))= O
(e
12 log(p) log2(p)
).
La complessità è ancora esponenziale (ma comunque più bassa che nell’attaccoa forza bruta).
Il metodo del calcolo dell’indice. Il calcolo dell’indice (Index Calculus) èil miglior algoritmo conosciuto per risolvere il problema del logaritmo discreto.Non daremo una descrizione di questo algoritmo. La complessità comunque èO(e
√3 log(p) log log(p)). È un problema aperto [SS98] quello di tradurre l’algorit-
mo usando il linguaggio delle curve ellittiche (il che potenzialmente potrebbeportare un notevole vantaggio in termini di complessità).
96Una tabella hash, è una struttura dati che usa una funzione hash (cf. Capitolo 4) per organizzarei dati in modo efficiente. Questa metodologia consente di ottenere tempo di accesso alla listacostante ed indipendente dalla dimensione della lista stessa [Knu98].

Esercizi
Esercizio C.1. Mostrare che 341 è uno pseudo-primo di Fermat in base 2, manon in base 3. Mostrare che 91 è uno pseudo-primo di Fermat in base 3, manon in base 2.
Esercizio C.2. Il seguente esercizio spiega il criterio di Korselt, che carat-terizza completamente i numeri di Carmichael: un intero n è un numero diCarmichael se e solo se n è positivo, composto, privo di quadrati (i.e., per ogniprimo p divisore di n si ha che p2 non divide n) e per ogni primo p divisore din si ha che p− 1|n− 1. Rispondere alle seguenti domande:
1. Usare il criterio di Korselt per dimostrare che non esiste un numero diCarmichael con solamente due fattori primi p1, p2.
2. Applicando il criterio di Korselt costruire un numero di Carmichael cheabbia tre fattori primi p1, p2, p3.
3. Dimostrare il criterio di Korselt.
Esercizio C.3. Verificare se il numero 341 è primo usando il test di Fermated il test di Miller-Rabin.
Esercizio C.4. Fattorizzare il numero 1001, usando il metodo p − 1 ed ilmetodo delle curve ellittiche.
Esercizio C.5. Calcolare log11 5 in Z31 e log5 27 in Z103, usando l’algoritmodi Shanks.
Esercizio C.6. Alice e Bob usano un sistema di scambio chiavi di Diffie-Hellman basato sulla curva ellittica E : Y 2 ≡ X3 + 3X + 12 (mod 23) che ha21 punti. Pubblicano anche il punto P = (2, 7). Successivamente Alice invia ilmessaggio A = aP = (7, 10) e Bob invia il messaggio B = bP = (9, 3).
1. Elencare i punti della curva.
2. Calcolare l’ordine del gruppo generato dal punto P .
3. Calcolare il numero segreto b usando l’algoritmo di Shanks.
4. Calcolare la chiave di sessione.

Letture consigliate
[AKS04] Manindra Agrawal, Neeraj Kayal e Nitin Saxena. “Primes is in P”. In:Annals of Mathematics 160 (2004), pp. 781–793.
[AM93] Arthur O. L. Atkin e Francois Morain. “Elliptic Curves and PrimalityProving”. In: Math. Comp. 61 (1993), pp. 29–68.
[Apo76] Tom M. Apostol. Introduction to Analytic Number Theory. Springer, 1976.
[Art67] M. M. Artjuhov. “Certain Criteria for Primality of Numbers Connectedwith the Little Fermat Theorem”. In: Acta Arith. 12 (1967), pp. 355–364.
[Ber08] Daniel J. Bernstein. Fast Multiplication and its Applications, pp. 325–384in Surveys in Algorithmic Number Theory. J. P. Buhler and P. Steven-hagen, Math. Sci. Res. Inst. Publ. 44. Cambridge University Press, NewYork, 2008.
[Car71] Lewis Carroll. Through the Looking-Glass, and What Alice Found There.Edizione Italiana Einaudi. Traduzione di Alessandro Ceni. Mac Millan &Co., 1871.
[CP01] Richard Crandall e Carl Pomerance. Prime Numbers: A ComputationalPerspective. Springer, 2001.
[GK86] Shafi Goldwasser e Joe Kilian. “Almost All Primes Can Be Quickly Cer-tified”. In: STOC. 1986, pp. 316–329.
[Kle+10] Thorsten Kleinjung, Kazumaro Aoki, Jens Franke, Arjen K. Lenstra, Em-manuel Thomé, Joppe W. Bos, Pierrick Gaudry, Alexander Kruppa, PeterL. Montgomery, Dag Arne Osvik, Herman J. J. te Riele, Andrey Timo-feev e Paul Zimmermann. “Factorization of a 768-Bit RSA Modulus”. In:CRYPTO. 2010, pp. 333–350.
[Knu98] Donald Knuth. The Art of Computer Programming 3: Sorting and Sear-ching. Addison-Wesley, 1998.
[Len87] Hendrik W. Lenstra. “Factoring Integers with Elliptic Curves”. In: Annalsof Mathematics 126 (1987), pp. 649–673.
[Mil76] Gary L. Miller. “Riemann’s Hypothesis and Tests for Primality”. In: JCSS13.3 (1976), pp. 300–317.
[Rab80] Michael O. Rabin. “Probabilistic Algorithms for Testing Primality”. In: J.Number Theory 12 (1980), pp. 128–138.
[Sch08] René Schoof. Four Primality Testing Algorithms, pp. 101–126 in Surveysin Algorithmic Number Theory. J. P. Buhler and P. Stevenhagen, Math.Sci. Res. Inst. Publ. 44. Cambridge University Press, New York, 2008.
[SS98] Joseph H. Silverman e Joe Suzuki. “Elliptic Curve Discrete Logarithmsand the Index Calculus”. In: ASIACRYPT. 1998, pp. 110–125.

490 C Problemi computazionali
[Ste08] Peter Stevenhagen. The Number Field Sieve, pp. 83–100 in Surveys inAlgorithmic Number Theory. J. P. Buhler and P. Stevenhagen, Math. Sci.Res. Inst. Publ. 44. Cambridge University Press, New York, 2008.
[Ven09] Daniele Venturi. Introduction to Algorithmic Number Theory. Rapp. tecn.ECCC TR09-62. SAPIENZA University of Rome, 2009. url: http://eccc.hpi-web.de/report/2009/062/.

Glossario
B-smooth: B-liscio. 482
Auxiliary Input Zero Knowledge: conoscenza nulla con input asiliario. 356
Baby-Step Giant-Step: passi-nani passi-giganti. 486
Bilinear Decisional Diffie-Hellman problem: problema decisionale bilinea-re di Diffie-Hellman. 267
blind signature: firma cieca. 411
Bounded Decoding Distance: decodifica a distanza limitata. 240
Bounded-Retrieval Model: modello della capacità limitata. 35
Bounded-Storage Model: modello dello spazio di memoria limitato. 35
broadcast: radiodiffusione circolare. 35, 408
Certificate Revocation List: lista di certificati revocati. 261
Certification Authority: autorità di certificazione. 258
chain rule: regola della catena. 437
Chinese Remainder Theorem: teorema del resto cinese. 454
Chosen Chipertext Attack: attacco a crittotesto scelto. 106
Chosen Plaintext Attack: attacco a messaggio scelto. 105
client: cliente. 336
Closest Vector Problem: problema del vettore più vicino. 238
commitment: impegno. 398
Common Reference String: stringa comune di riferimento. 370
Computational Diffie-Hellman problem: problema computazionale di Diffie-Hellman. 161
Decisional Diffie-Hellman problem: problema decisionale di Diffie-Hellman.161

492 Glossario
denial of service: interruzione del servizio. 283
e-cash: denaro digitale. 9
eavesdropping: spionaggio. 282
electronic voting: voto elettronico. 410
Elliptic Curve Cryptography: crittografia sulle curve ellittiche. 463
Elliptic Curve Method: metodo delle curve ellittiche. 482
Full Domain Hash: hash a dominio pieno. 211
fuzzy: sfocato. 272
greatest common divisor: massimo comun divisore. 444
group law: legge di gruppo. 466
hard-core: estremo. 57
hash table: tabella hash. 487
hash: polpettina fatta di avanzi di carne e verdure. 68
Hierarchical Identity-Based Encryption: cifrario su base identità di tipogerarchico. 272
honest but curious: onesti ma curiosi. 403
Honest Verifier Zero Knowledge: conoscenza nulla con verificatore one-sto. 355
Index Calculus: calcolo dell’indice. 487
Information Theory: teoria dell’informazione. 425
Initialization Vector: vettore di inizializzazione. 87
interleaving: interallacciamento. 283
Key Distribution Center: centro di distribuzione delle chiavi. 313

Glossario 493
Key Encapsulation Mechanism: meccanismo di incapsulamento della chia-ve. 151
Key Generation Center: centro di generazione delle chiavi. 262
knapsack: sacco. 246
leakage: perdita. 9
Learning Parity with Noise: imparare la parità in presenza di rumore. 243
Learning With Errors: imparare in presenza di errori. 239
Linear Feedback Shift Register: Registro a scorrimento a retroazione li-neare. 138
login: accesso. 293
malware: codice maligno. 35
man-in-the-middle: uomo-nel-mezzo. 283
meet-in-the-middle: incontro nel mezzo. 126
Message Authentication Code: codice autenticatore di messaggio. 184
min-entropy: entropia minima. 439
modification: modifica. 283
MultiParty Computation: computazione a parti multiple. 389
negligible: trascurabile. 12
Non-Interactive Zero Knowledge: conoscenza nulla non-interattiva. 371
Number Field Sieve: crivello dei campi di numeri. 485
Oblivious Transfer: trasferimento immemore. 395
One-Time Pad: blocco monouso. 33
One-Way Function: funzione unidirezionale. 54

494 Glossario
One-Way Permutation: permutazione unidirezionale. 63
One-Way Trapdoor Function: funzione unidirezionale con botola. 148
Optimal Asymmetric Encryption Padding: cifrario asimmetrico ottimocon riempimento. 158
padding: riempimento. 86, 132
Password-based Chosen-basis CDH: problema CDH su base password abasi scelte. 338
perfect forward secrecy: sicurezza perfetta in avanti. 292
perfectly binding: pefettamente vincolante. 399
perfectly hiding: pefettamente celante. 399
Permutation boxes: scatole di permutazione. 122
Prime Number Theorem: teorema dei numeri primi. 475
Probabilistic Polynomial Time: probabilistico a tempo polinomiale. 12
Proof of Knowledge: prova di conoscenza. 362
prover: dimostratore. 294
PseudoRandom Function: funzione pseudocasuale. 110
Pseudorandom Generator: generatore pseudocasuale. 49
PseudoRandom Permutation: permutazione pseudocasuale. 116
Public Key Infrastructure: infrastruttura a chiave pubblica. 258
quadratic residue: residuo quadratico. 456
Quadratic Sieve: crivello quadratico. 485
Radio-Frequency IDentification: identificazione a radio-frequenza. 304
random variable: variabile aleatoria. 426
re-play: ri-uso. 283

Glossario 495
receipt-freeness: assenza di ricevuta. 411
reflection: riflessione. 283
Registration Authority: autorità di registrazione. 264
round: turno. 119
salt and stretching: sale e stiramento. 329
Secure Hash Algorithm: algoritmo hash sicuro. 90
server: servente. 336
session hijacking: scambio della sessione. 282
Shortest Independent Vectors Problem: problema dei vettori più cortiindipendenti. 238
Shortest Vector Problem: problema del vettore più corto. 238
Simulation Soundness: Validità di simulazione. 378
Smallest Integer Solution: soluzione agli interi più piccoli. 245
Special Honest Verifier Zero Knowledge: conoscenza nulla speciale converificatore onesto. 362
Special Soundness: validità speciale. 362
Strong PseudoRandom Permutation: permutazione pseudocasuale forte.117
Strong Special Honest Verifier Zero Knowledge: conoscenza nulla spe-ciale in senso forte con verificatore onesto. 362
Subset Sum: somma di sottoinsiemi. 246
Substitution boxes: scatole di sostituzione. 122
threshold secret sharing: condivisione di segreti a soglia. 391
timestamp: francobollo temporale. 186
Trusted Third Party: terza parte fidata. 407

496 Glossario
uncoercibility: incoercibilità. 411
Universal Composability: componibilità universale. 409
Weak PseudoRandom Function: funzione pseudocasuale debole. 138
Witness Indistinguishability: indistinguibilità di indizi. 356
Zero Knowledge: conoscenza nulla. 349

Indice analitico
accoppiamenti bilineari, 265AES, 127algoritmo
di Euclide, 448LLL, 238di Euclide, 444
anelli, 450argomento ibrido, 46aste digitali, 390attacco
collisione parziale, 192della pre-immagine secondaria,
83della pre-immagine, 83estensione della lunghezza, 192ri-uso, 186uomo-nel-mezzo, 295
autenticazione, 292mediata, 313mutua, 300
bit estremi, vedi predicati estremiblocco monouso, 33bonsai crittografici, 272
campi, 451certificati digitali, 258
gestione, 260cifrari
a blocco, 25a flusso, 137di Cesare, 26di Hill, 27di Vigenère, 27ibridi, 151monoalfabetici, 25polialfabetici, 27su base attributi, 272su base identità, 262
vettore-affine, 27antichi, 24simmetrici, 24
cifrariodi Boneh e Franklin, 268di Cramer-Shoup, 171di ElGamal, 159di Goldwasser-Micali, 167di Naor-Yung, 371di Regev, 243
cifratura di messaggi multipli, 109componibilità universale, 409computazione a parti multiple, 389
panoramica, 405condivisione di segreti, 390
verificabile, 393di Shamir, 392
congruenze, 451costruzione di Merkle-Damgård, 86criterio di Eulero, 458crittografia su base identità, 257curve ellittiche
legge di gruppo, 464su K, 463su Zp, 467
DES, 123Triplo DES (3-DES), 127
difficoltànel caso medio, 235nel caso peggiore, 235
distanza di Hamming, 430disuguaglianza
di Markov, 432di Chebyshev, 432
disuguaglianza triangolare, 430DSS, 223
ECIES, 165

498 Indice analitico
estrattoriDL, 73ad � sorgenti, 72con seme, 68definizione, 67di Hadamard, 72di von Neumann, 67
euristica di Fiat-Shamirfirme, 379
famiglia di funzioni hash, 82fattorizzazione
ECM, 482Pollard p− 1, 481QS e NFS, 485
filtri di Bloom, 327firme digitali, 208
Hash & Firma, 215ad albero, 218basate su RSA, 210hash a dominio pieno, 211innegabili, 227monouso, 215
formula di Binet, 446funzione toziente di Eulero, 452funzioni di compressione, 86, 88funzioni indipendenti a coppie, 68funzioni pseudocasuali, 110
deboli, 138funzioni unidirezionali, 54
con botola, 148
generatore Blum-Blum-Shab, 66generatore pseudocasuale, 49gruppi, 450gruppo
ciclico, 453unitario, 453
identità di Bézout, 448
impredicibilità, 50indistinguibilità, 45, 47inforgiabilità universale, 185, 209infrastruttura a chiave pubblica, 258insiemi ignoranti, 394insiemi qualificati, 394interi di Blum, 462interpolazione di Lagrange, 391ipotesi
del logaritmo discreto, 161della residuosità quadratica, 166di Diffie-Hellman, 161RSA, 156
isomorfismo di grafi, 352
lancio di moneta al telefono, 397lemma dell’hash residuo, 69limite di Chernoff, 433linguaggio, 351logaritmi discreti
BSGS, 486calcolo dell’indice, 487
MAC, 184CBC-MAC, 190HMAC, 193Hash & MAC, 193XOR-MAC, 189su base PRF, 187
MD5, 91metodo Kasiski, 28modello
dell’oracolo casuale, 93della capacità limitata, 35dello spazio di memoria limita-
to, 34del cifrario ideale, 89
modi operativi, 132
numeri

Indice analitico 499
di Fibonacci, 446di Carmichael, 476primi, 474
OAEP, 158
paradigma sfida e risposta, 295paradosso del compleanno, 85password
entropia, 325gestione, 327memorizzazione, 329sale e stiramento, 329
permutazione di Feistel, 119permutazioni unidirezionali, 63peso di Hamming, 431PGP, 260PKCS # 1, 157PKI, vedi infrastruttura a chiave pub-
blicapolinomi ciclotomici, 478predicati estremi, 57primi di Blum, 462principio di Horton, 187problema
LPN, 304dello scambio delle chiavi, 284BDDH, 267BDD, 240CVP, 238LPN, 243LWE, 239PCCDH, 338S-PCCDH, 339SIS, 245SIVP, 238SS, 246SVP, 238
problema dei milionari, 389
protocolli-Σ, 361Guillou-Quisquater, 367Okamoto, 368Schnorr, 365WI, 365
protocolli-Σprove di conoscenza, 362
protocolloDiffie-Hellman, 286EKE, 334HB+, 308HB, 305Needham-Schröeder, 302, 314Otway-Rees, 316SRP, 335di Abdalla e Pointcheval, 335di Lamport, 330Needham-Schröeder-Lowe, 303
pseudo-primidi Fermat, 476forti, 477
randomicità, 43randomizzatore, 35RC4, 138relazione, 350residui quadratici
modulo N , 459modulo p, 456
resistenza alle collisioni, 83reticoli geometrici, 236
proprietà, 237dominio fondamentale, 237
RSAversione base, 152versione randomizzata, 157
scatole di permutazione, 122scatole di sostituzione, 122

500 Indice analitico
schemi di impegno, 398SHA-1, 90sicurezza
CCA, 106CPA, 105incondizionata, 23semantica, 105IND, 103
simbolodi Jacobi, 460di Legendre, 458
simulazioni crittografiche, 350sistemi di prova interattivi, 351
AIZK, 356HVZK, 355WI, 356ZK, 352
sistemi di prova non-interattivi, 370NIZK, 371
spazio metrico, 430stringa comune di riferimento, 370struttura d’accesso, 394
teoremadi Eulero, 454di Fermat (piccolo teorema), 454di Hasse, 467di Lagrange, 451fondamentale dell’aritmetica, 474dei numeri primi, 475del resto cinese, 454di Bayes, 427
test di primalitàAKS, 478Fermat, 476Miller-Rabin, 476
trasferimento immemore, 395(21
)-OT, 396
12 -OT, 395
trasformazione GGM, 111
variabili aleatorie, 426entropia minima, 438distanza statistica, 431distribuzione, 426entropia, 436indipendenti, 427informazione mutua, 437valore atteso, 428varianza, 428
voto elettronico, 390, 410

������������ � ���������� ��� ������� ���������������� ���������������������������������������������������������� �������������������� �� ������������������������������������������������������������� ���!����������������� ������ � �� � ����������� ���!���������"��������#���������$%�#��������&�������#�������� '�����())*#�+#�*,)� �#�-��.�/012112*0)2)(3*2)�����������"� ��������������������� ��� ��4�%���5���#�6������������())1#�++--#�,7,� �#�-��.�/012112*0)2)80/2(��#� ���$�����% ��"��������&�'��������������(���������������#�������������� ����())1#�++--#�(1)� �#�-��.�/012112*0)2)03321��)�*���� ���*���"������������������� ��� ��������.���9:��������������������'�������������#�;����������())1#�+&-#�(0(� �#�-��.�/012112*0)2)3182/��)����� �+��� ��� � �������������())/#�+&-#�83,� �#�-��.�/012112*0)2)1*821��������� �� �����, ����������'�� �������4�����&��'���()7(#�+-&#�8))� �#�-��.�/012112*0)2(*1)2/�������





























