Embed Size (px)
Citation preview

MCMCについて
遠洋水産研究所 外洋資源部
鯨類管理研究室
岡村 寛
水産資源学におけるベイズ統計の応用ワークショップ
2007年8月2-3日,中央水研

事後分布からサンプルする
Pr(θ1, θ2, θ3, …)θ1は重要.あとは必要だけど直接的じゃないというようなとき,
P(θ1|x)=∫⋯∫P(θ1, …, θn|x)dθ2 dθn を計算したい.
モンテカルロ近似
Eπ(f(X)) = ∫f(x)π(x)dxを計算したい
(1/N)Σf(x(i)) → Eπ(f(X)), x(1), …, x(N) ~ π(x)
π(x)からデータを取り出せれば良い.しかし,ある確率分布か
らランダムにデータを取り出すのは一般に難しい…

MCMCでない方法

逆関数法
まず分布関数F(x) = Pr(X≤x) の逆関数を求める.一様分布
U[0,1]から乱数uを発生.F-1(u)は分布関数F(x)の確率分布か
らとったランダムサンプルとなる.なぜなら,
Pr(F-1(U) ≤ x) = Pr(U ≤ F(x)) = F(x)だから,F-1(U)はXに対応している.
例:指数分布
密度関数 f(x) = 1/2 exp(-x/2)分布関数 F(x) = Pr(X≤x) = 1-exp(-x/2)
U = F(v) → v = - 2log(1-U)
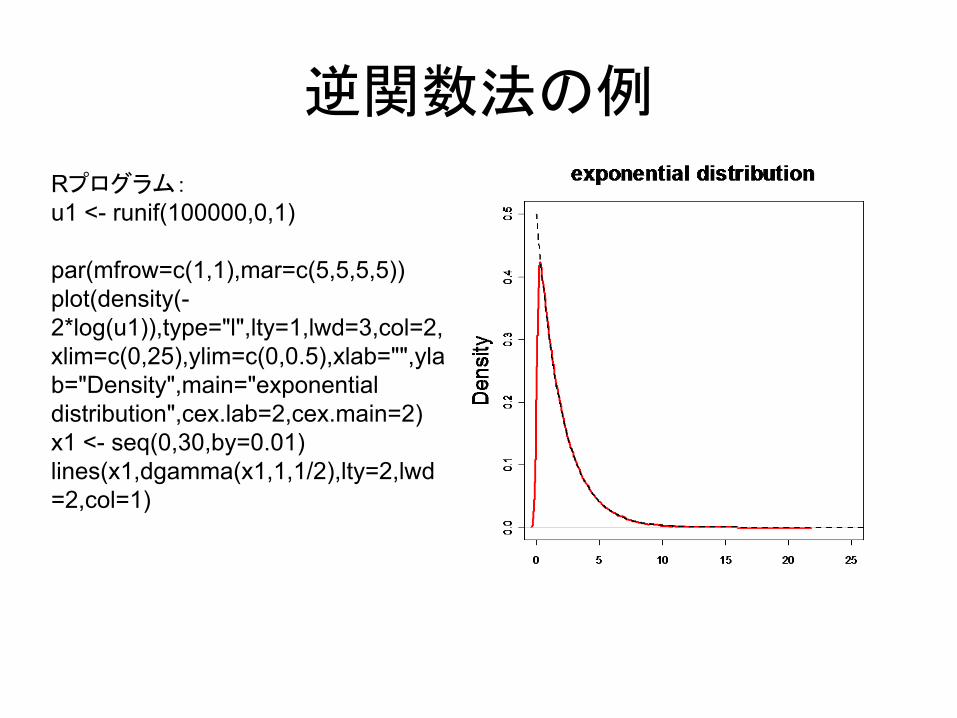
逆関数法の例
Rプログラム:u1 <- runif(100000,0,1)
par(mfrow=c(1,1),mar=c(5,5,5,5))plot(density(-2*log(u1)),type="l",lty=1,lwd=3,col=2,xlim=c(0,25),ylim=c(0,0.5),xlab="",ylab="Density",main="exponential distribution",cex.lab=2,cex.main=2)x1 <- seq(0,30,by=0.01)lines(x1,dgamma(x1,1,1/2),lty=2,lwd=2,col=1)

グリッド法(復習)
• 1つ2つのパラメータ,細かい分析をする必要がなければ有効(楽チン)
1. パラメータのグリッドを用意する
2. 各値に事前確率を割り当てる(一様分布なら必要なし)
3. 事後確率(∝ 尤度×事前確率)を計算.
4. 事後確率に従ってグリッドの値を抽出する→ 事後サンプル

2変数の場合
上の事後確率行列をMとする.
1. まずxの周辺事後分布からxをB個サンプルする
2. 次に上でサンプルしたxの条件付確率p(y|x)にしたがってyをB個サンプルする
3. 得られた(x, y)は上の事後確率を持つ分布からのサンプルである
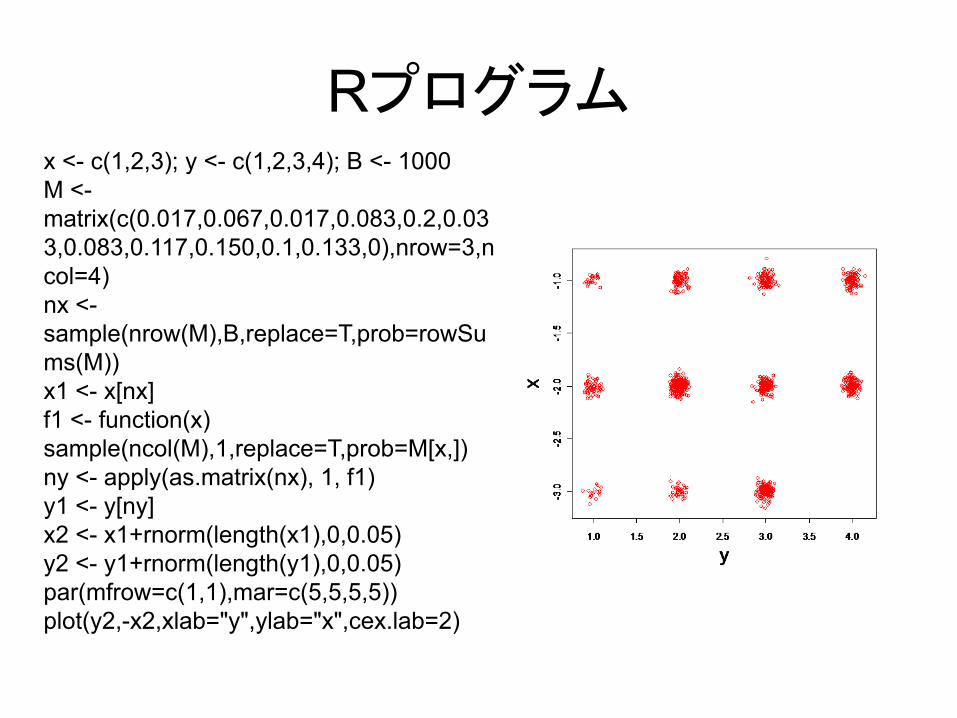
Rプログラムx <- c(1,2,3); y <- c(1,2,3,4); B <- 1000M <-matrix(c(0.017,0.067,0.017,0.083,0.2,0.033,0.083,0.117,0.150,0.1,0.133,0),nrow=3,ncol=4)nx <-sample(nrow(M),B,replace=T,prob=rowSums(M))x1 <- x[nx]f1 <- function(x) sample(ncol(M),1,replace=T,prob=M[x,])ny <- apply(as.matrix(nx), 1, f1)y1 <- y[ny]x2 <- x1+rnorm(length(x1),0,0.05)y2 <- y1+rnorm(length(y1),0,0.05)par(mfrow=c(1,1),mar=c(5,5,5,5))plot(y2,-x2,xlab="y",ylab="x",cex.lab=2)
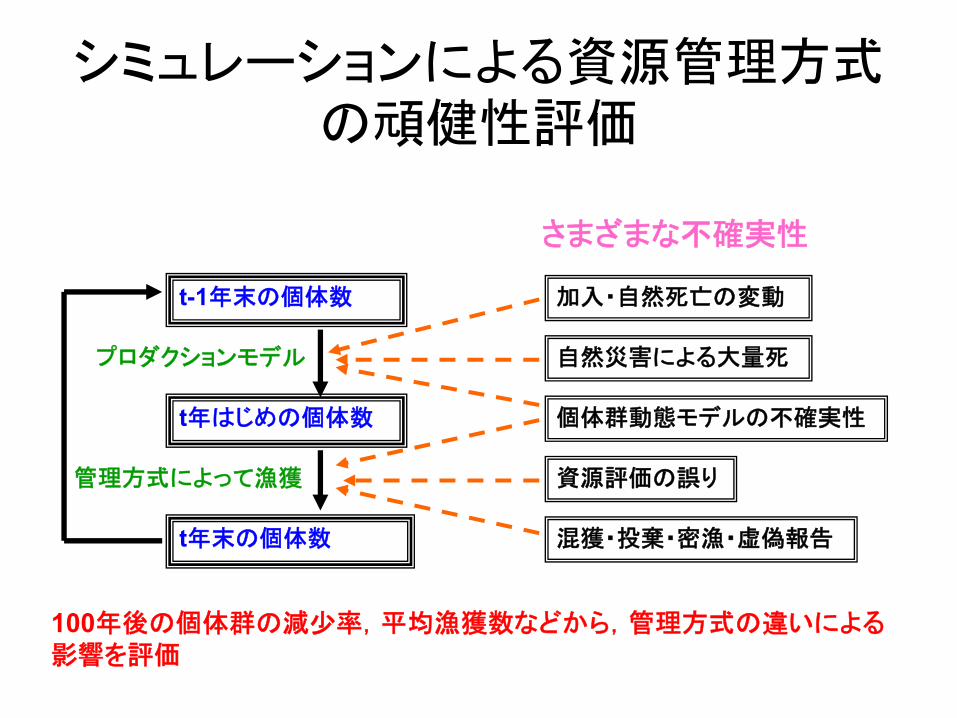
シミュレーションによる資源管理方式の頑健性評価
t-1年末の個体数
t年末の個体数
加入・自然死亡の変動
自然災害による大量死
個体群動態モデルの不確実性t年はじめの個体数
プロダクションモデル
管理方式によって漁獲
100年後の個体群の減少率,平均漁獲数などから,管理方式の違いによる影響を評価
さまざまな不確実性
混獲・投棄・密漁・虚偽報告
資源評価の誤り

シミュレーションを用いる利点
様々な不確実性を取り込んだ上で影響評価が
可能
これまでの水産資源評価・管理は,不確実性の
大きさのため,意思決定が不可能であった.
“分からないから何もしない”から“分からない
中でどうするか”へ

シミュレーションモデル
Nt+1 = [Nt + r Nt {1-(Nt/K)z}]exp(ut), ut~N(0,s2)
・ 今後5年ごとに調査を行って新しい個体数推定値を得る
・ 翌年から最新の個体数推定値に従って捕獲枠を決定.5年ごとに見直しをする(前年に新しい個体数推定値が得られることを想定)
・ 捕獲の方法として,個体数推定値の2%をとる場合,PBRでとる場合を考える

PBR
• Potential Biological RemovalPBR = 1/2RmaxNminFR
Nmin: 最小個体数推定値(下限20%点)
Nmin = Nexp(-0.84CV)Rmax: 純増加率(鯨類0.04,鰭脚類0.12)FR: 回復係数(0.1 for endangered,
0.5 for depleted)
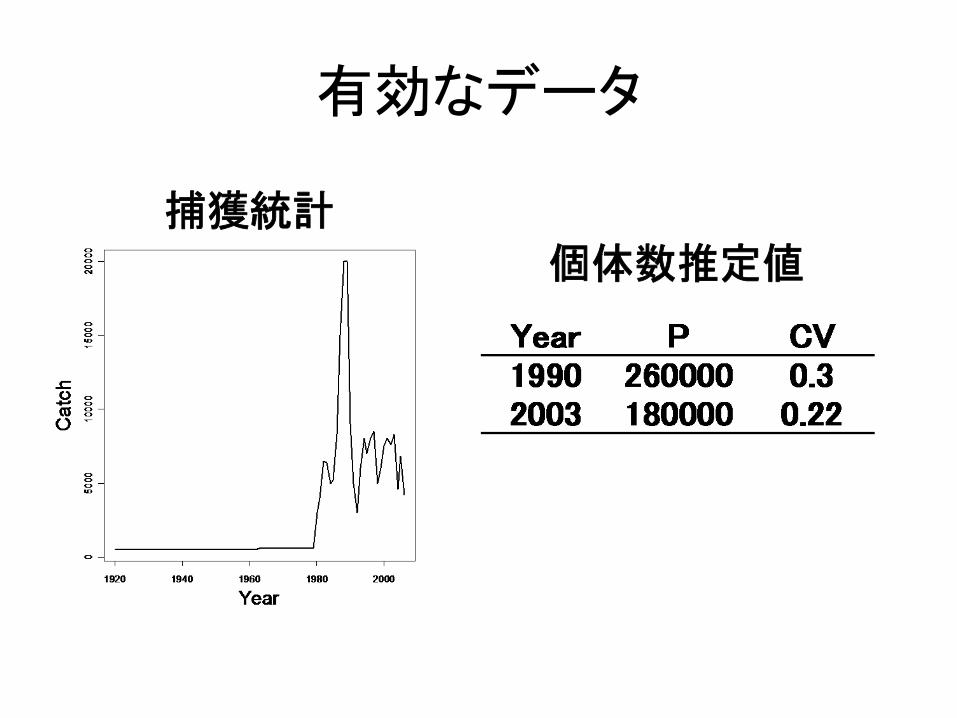
有効なデータ
捕獲統計個体数推定値

コンディショニング
• 実際のデータに合うような環境収容力のサンプルを取り出す(ここでグリッド法を使う)
• それから将来に対するシミュレーションを行う
環境収容力Kのサンプルの取り出し方Kにある範囲のグリッドデータを割り当てるそれぞれのKに対して,既存の個体数推定値に基づく尤度を計算尤度の大きさに従ってKをサンプルプログラムを配布するので詳細はそれを見てください
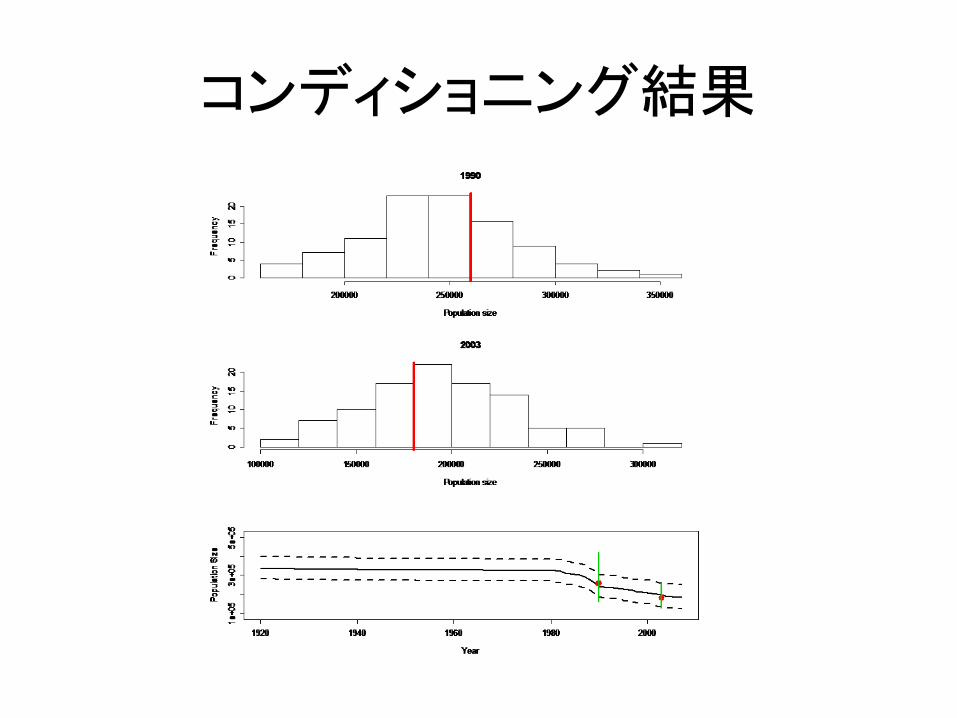
コンディショニング結果
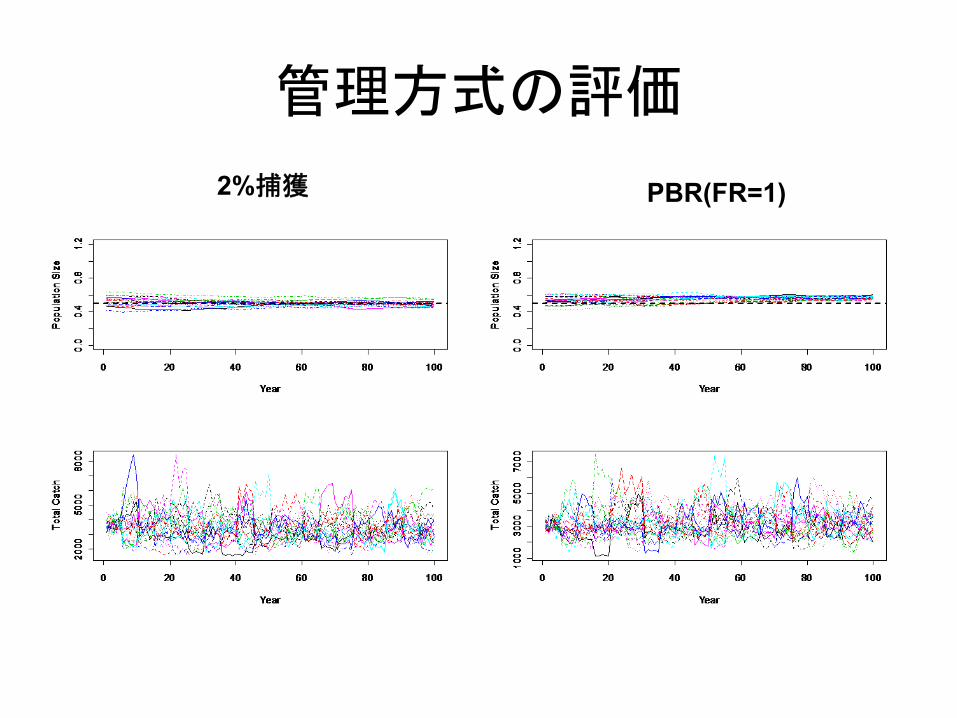
管理方式の評価
2%捕獲 PBR(FR=1)
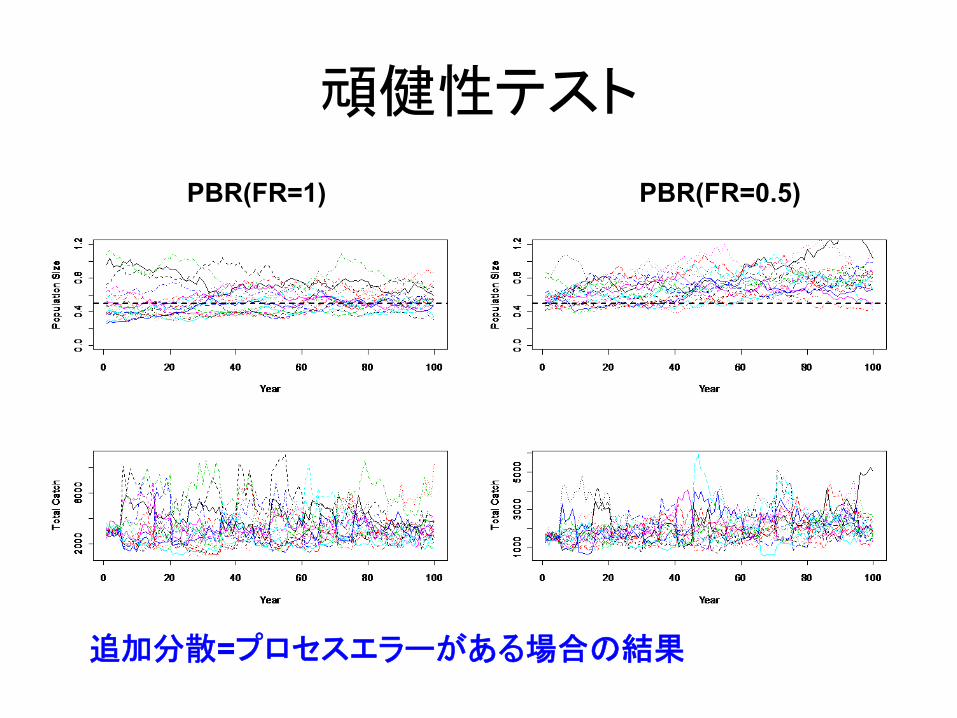
頑健性テスト
PBR(FR=1) PBR(FR=0.5)
追加分散=プロセスエラーがある場合の結果

Rejectionサンプリング
ある確率分布f(x)から乱数を発生させるのが難しいとき,まず発生させやすい確率分布g(x)から乱数x*を発生させて,さらに一様分布U[0,1]から値uをとり,
u < f(x*)/{cg(x*)}ならば,x*をとっておき,
u ≥ f(x*)/{cg(x*)}ならばx*を捨てる.結果,残ったx*はf(x)からのランダムサンプル.
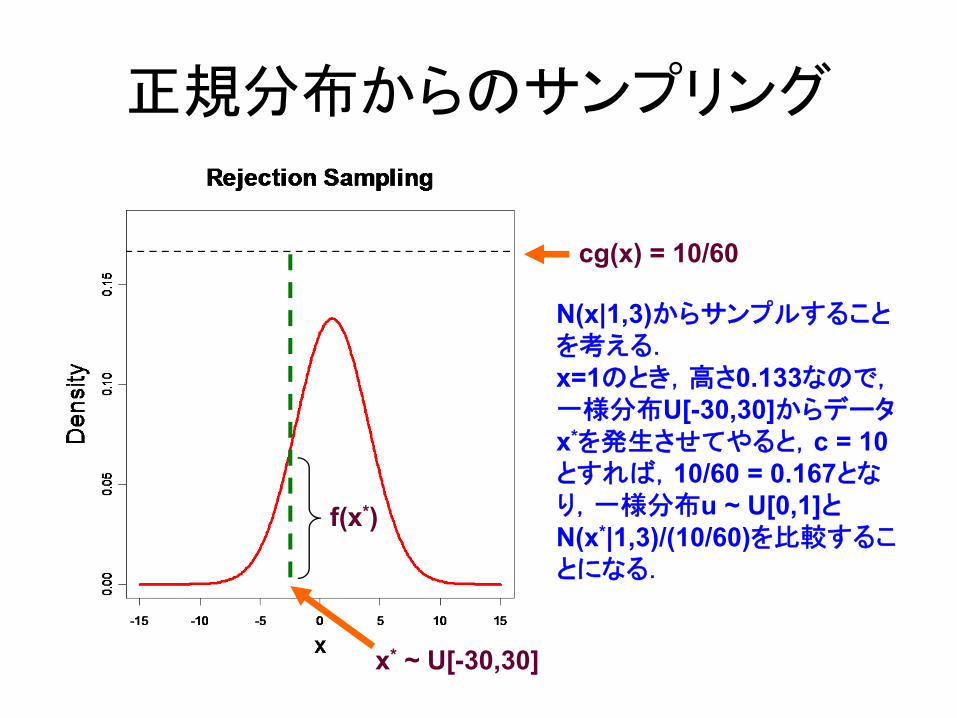
正規分布からのサンプリング
x* ~ U[-30,30]
cg(x) = 10/60
f(x*)
N(x|1,3)からサンプルすることを考える.x=1のとき,高さ0.133なので,一様分布U[-30,30]からデータx*を発生させてやると,c = 10とすれば,10/60 = 0.167となり,一様分布u ~ U[0,1]とN(x*|1,3)/(10/60)を比較することになる.
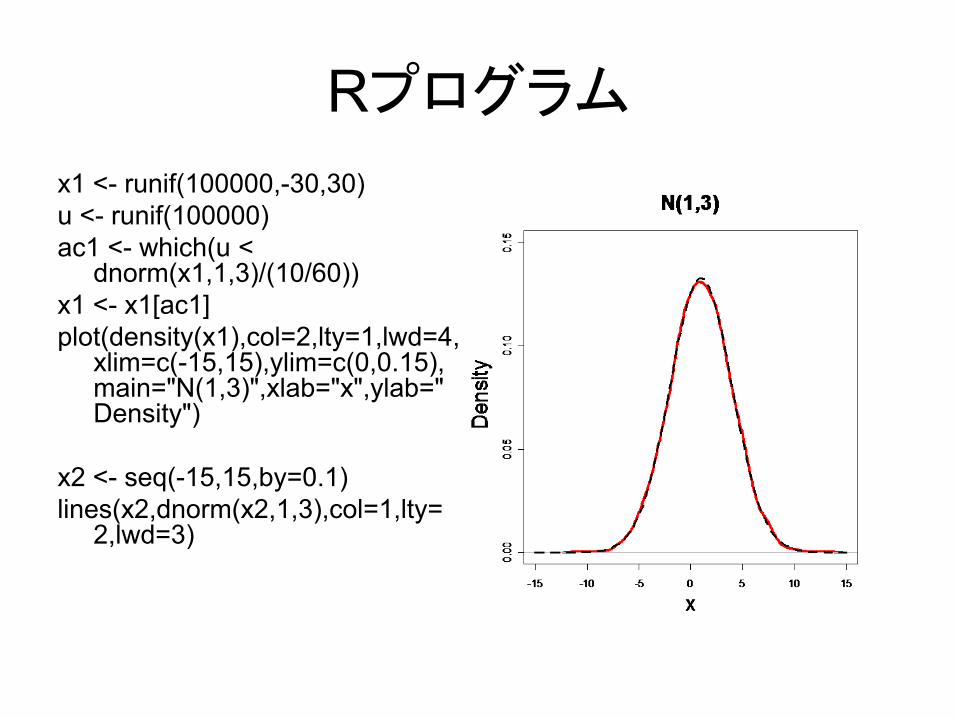
Rプログラム
x1 <- runif(100000,-30,30)u <- runif(100000)ac1 <- which(u <
dnorm(x1,1,3)/(10/60))x1 <- x1[ac1]plot(density(x1),col=2,lty=1,lwd=4,
xlim=c(-15,15),ylim=c(0,0.15), main="N(1,3)",xlab="x",ylab=" Density")
x2 <- seq(-15,15,by=0.1)lines(x2,dnorm(x2,1,3),col=1,lty=
2,lwd=3)

インポータンスサンプリング
Q. 対数正規分布LN(1.1, 0.6)の平均を求めよ.
f(x)からのサンプルが難しいとき,サンプルしやすい
g(x)からサンプルして,
E(x) = (1/n)Σ{f(x*)/g(x*)}x* と計算する.
アルゴリズム:
x1 <- runif(100000,0,60)mean(dlnorm(x1,1.1,0.6)*x1*60) = 3.587真の平均 exp(1.1+0.62/2) = 3.597
この重みをインポータンス比と呼ぶ

SIR法
• Sampling-Importance Resampling法f(x)からのサンプルは困難,g(x)からは容易
1. g(x)からM個のサンプルx1*, …, xM
*を発生
2. w* = f(x*)/g(x*)を計算
3. x1*, …, xM
*からw1*, …, wM
*に比例する確率でサン
プルをm個とってくる
4. 得られたm個のサンプルはf(x)からの事後サンプル
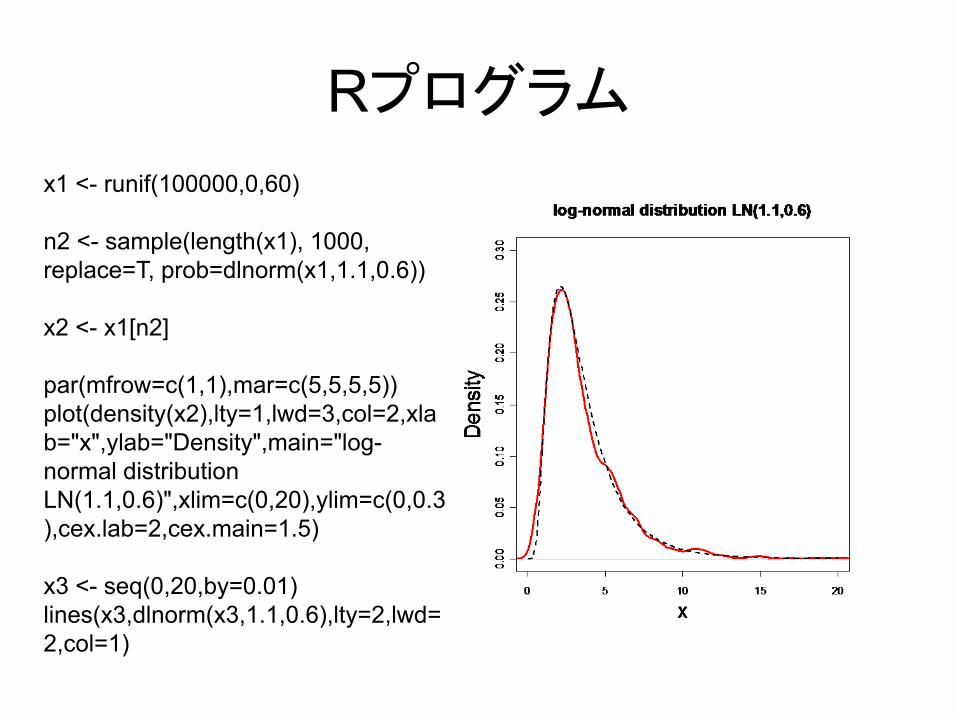
Rプログラム
x1 <- runif(100000,0,60)
n2 <- sample(length(x1), 1000, replace=T, prob=dlnorm(x1,1.1,0.6))
x2 <- x1[n2]
par(mfrow=c(1,1),mar=c(5,5,5,5))plot(density(x2),lty=1,lwd=3,col=2,xlab="x",ylab="Density",main="log-normal distribution LN(1.1,0.6)",xlim=c(0,20),ylim=c(0,0.3),cex.lab=2,cex.main=1.5)
x3 <- seq(0,20,by=0.01)lines(x3,dlnorm(x3,1.1,0.6),lty=2,lwd=2,col=1)

MCMC

マルコフ連鎖とは
• Pr(xt+1|xt,xt-1,xt-2,…) = Pr(xt+1|xt)良い性質を持つマルコフ連鎖は定常分布に収束する
(生態学の例では,Leslie行列モデルが安定齢分布を
持つ,というのを想像せよ).この性質を使って,定常
分布が(サンプルしたいけどしにくい)f(x)になるように
データを生成するのがマルコフ連鎖モンテカルロ法
(MCMC)である.マルコフ性により得られるサンプル
は独立でないことに注意(これまでと違うとこ).

なぜMCMC?
• Rejectionサンプリング,SIR法では,効率良いサンプリングのために,サンプラーg(x)を上手に選んでやる必要がある
• 非常に複雑な分布(非線形モデル),たくさんのパラメータがあるとき,適当なg(x)を見つけるのは難しい(ときに不可能)
• マルコフ連鎖を使うのは,暗闇でいきなり動くとタンスに頭をぶつけるが,手探りで(危ない時にはそろそろ,行ける時には大胆に)動けばより安全というイメージ(手探りで動くという部分がマルコフ連鎖)
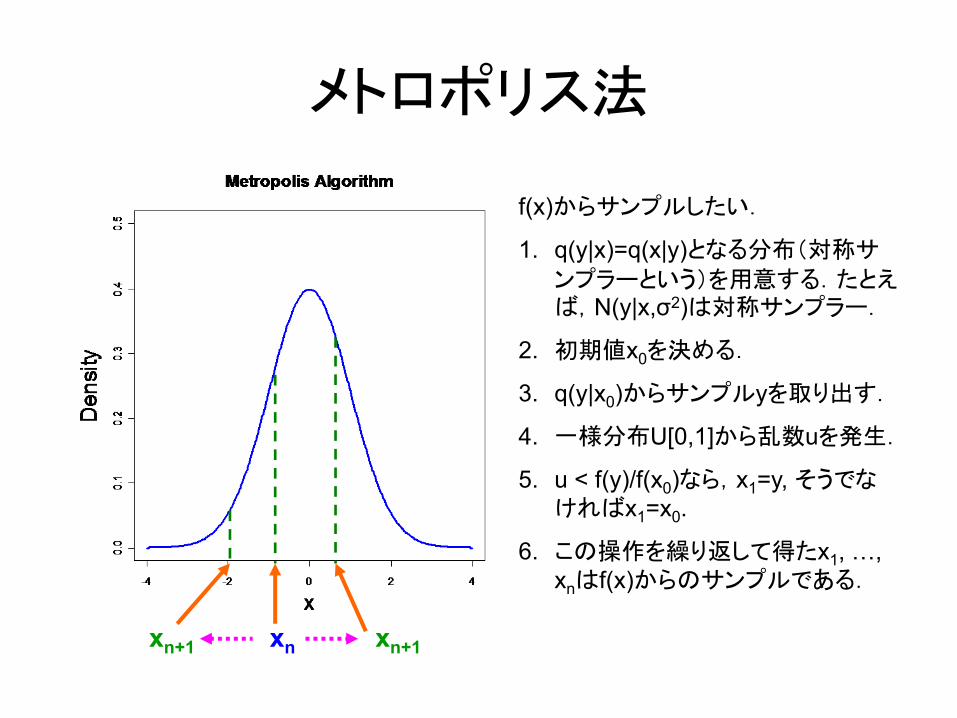
メトロポリス法
xn xn+1xn+1
f(x)からサンプルしたい.
1. q(y|x)=q(x|y)となる分布(対称サ
ンプラーという)を用意する.たとえば,N(y|x,σ2)は対称サンプラー.
2. 初期値x0を決める.
3. q(y|x0)からサンプルyを取り出す.
4. 一様分布U[0,1]から乱数uを発生.
5. u < f(y)/f(x0)なら,x1=y, そうでなければx1=x0.
6. この操作を繰り返して得たx1, …, xnはf(x)からのサンプルである.
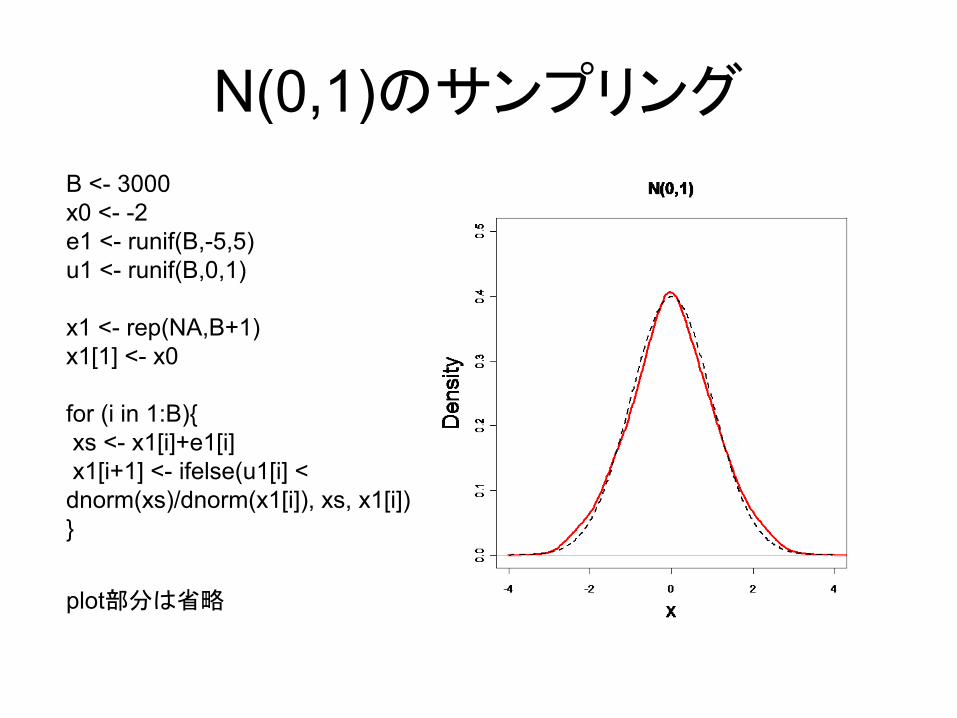
N(0,1)のサンプリング
B <- 3000x0 <- -2e1 <- runif(B,-5,5)u1 <- runif(B,0,1)
x1 <- rep(NA,B+1)x1[1] <- x0
for (i in 1:B){xs <- x1[i]+e1[i]x1[i+1] <- ifelse(u1[i] < dnorm(xs)/dnorm(x1[i]), xs, x1[i])}
plot部分は省略
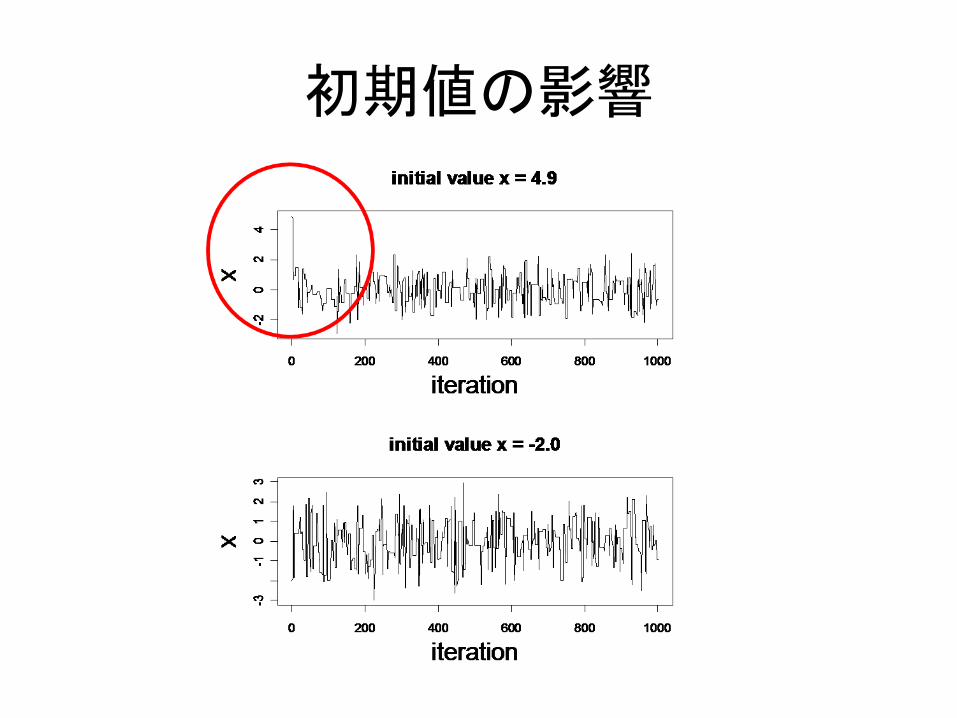
初期値の影響
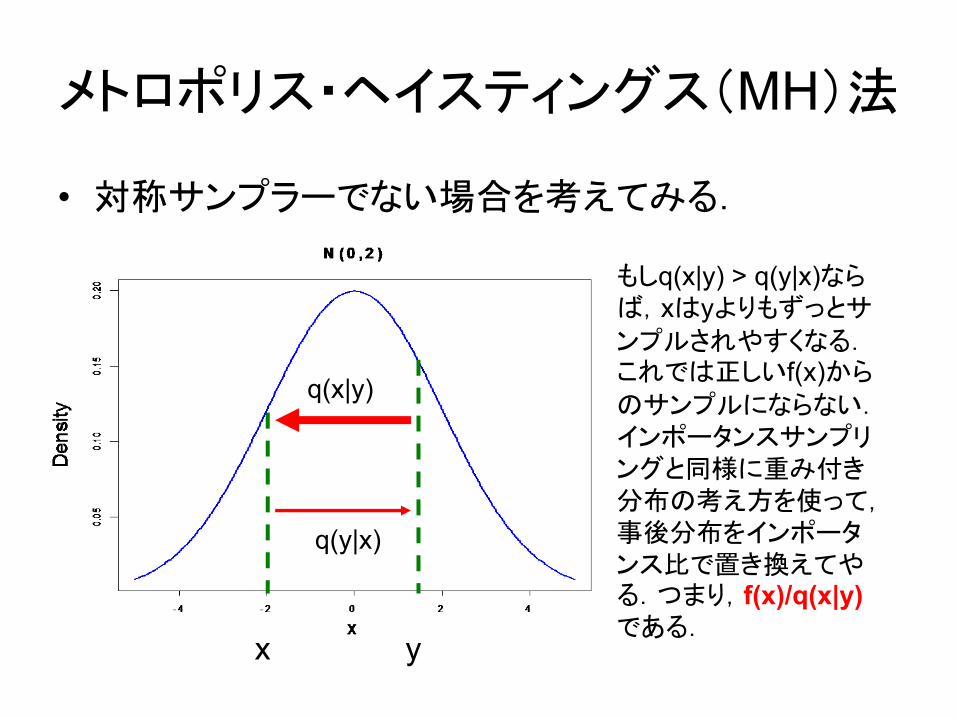
メトロポリス・ヘイスティングス(MH)法
• 対称サンプラーでない場合を考えてみる.
x y
q(y|x)
q(x|y)
もしq(x|y) > q(y|x)ならば,xはyよりもずっとサ
ンプルされやすくなる.これでは正しいf(x)から
のサンプルにならない.インポータンスサンプリングと同様に重み付き分布の考え方を使って,事後分布をインポータンス比で置き換えてやる.つまり,f(x)/q(x|y)である.

MH法のアルゴリズム
f(x)からサンプルしたい.1. ある条件付分布q(y|x)を用意する.2. 初期値x0を決める.3. q(y|x0)からサンプルyを取り出す.4. 一様分布U[0,1]から乱数uを発生.5. u < {f(y)/q(y|x0)}/{f(x0)/q(x0|y)} =
{f(y)q(x0|y)}/{f(x0)q(y|x0)}なら,x1 = y,そうでなければ x1=x0.
6. この操作を繰り返して得たx1, …, xnはf(x)からのサンプルである.
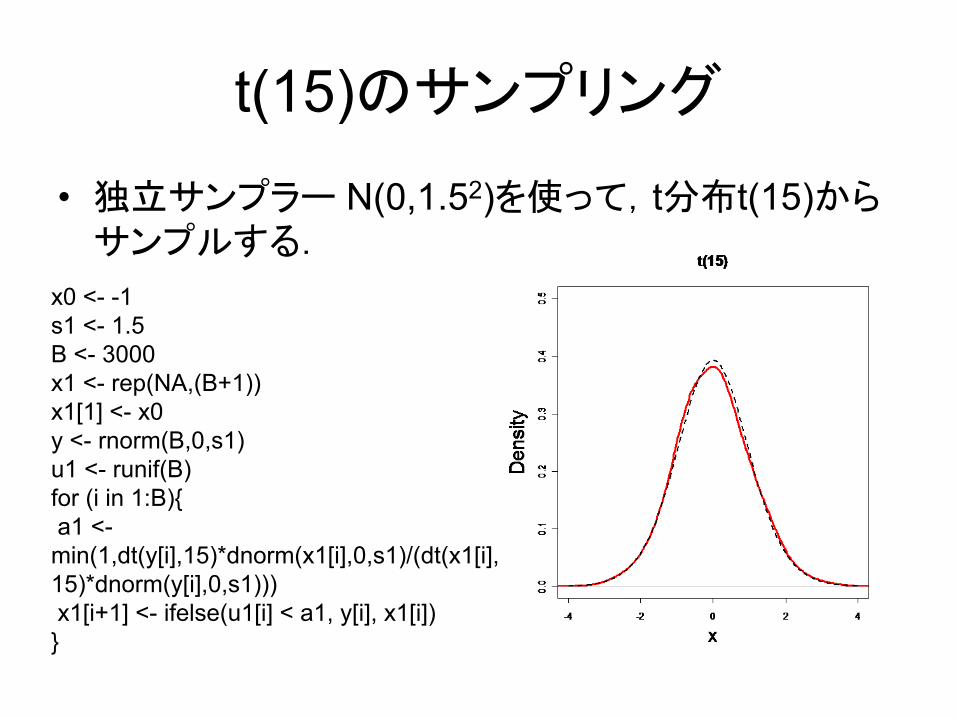
t(15)のサンプリング
• 独立サンプラー N(0,1.52)を使って,t分布t(15)からサンプルする.
x0 <- -1s1 <- 1.5B <- 3000x1 <- rep(NA,(B+1))x1[1] <- x0y <- rnorm(B,0,s1)u1 <- runif(B)for (i in 1:B){a1 <-min(1,dt(y[i],15)*dnorm(x1[i],0,s1)/(dt(x1[i],15)*dnorm(y[i],0,s1)))x1[i+1] <- ifelse(u1[i] < a1, y[i], x1[i])}

Single-component MH法
• 多変量f(x1,x2,…)の場合
ひとつの変数に対して順番にMH法を繰り返す
1. x(0), y(0)を決定
2. f(x|y(0))からのサンプルをMH法で,x(1)=x* or x(0)
3. f(y|x(1))からのサンプルをMH法で,y(1)=y* or y(0)
4. この操作を繰り返す
ここで,f(x|y) = f(x,y)/∫f(x,y)dx (フル条件付分布)

なぜうまくいくか(直感的に)
禁ななめ移動x|y1 x|y6
y|x7
y|x4
x|y2

例題
データ x = (1,2,3)を得たとき,正規分布
N(m,s2)の事後分布は,
事前分布をP(m,s)∝1/sとして,
P(m,s|x) ∝ (1/s4)exp{-{S2+3(m-mx)2}/(2s2)}となる(ここで,mx = (1+2+3)/3,S2=Σ(xi-mx)2).
このP(m,s|(1,2,3))からサンプリングせよ

Rプログラム
x0 <- -1; y0 <- 1; B <- 3000e1 <- runif(B,-7,7); u1 <- runif(B,0,1)ys <- rgamma(B,1,1); u2 <- runif(B,0,1)x1 <- y1 <- rep(NA,B+1); x1[1] <- x0; y1[1] <- y0xobs <- c(1,2,3)mx <- mean(xobs); S2 <- sum((xobs-mx)^2)n <- length(xobs); nu <- n-1post1 <- function(m,s1) (1/s1^(n+1))*exp(-(S2+n*(m-mx)^2)/(2*s1^2)) for (i in 1:B){xs <- x1[i]+e1[i]x1[i+1] <- ifelse(u1[i] < post1(xs,y1[i])/post1(x1[i],y1[i]), xs, x1[i])y1[i+1] <- ifelse(u2[i] <
post1(x1[i+1],ys[i])*dgamma(y1[i],2,0.5)/(post1(x1[i+1],y1[i])*dgamma(ys[i],2,0.5)), ys[i], y1[i])
}
MH法の場合,分母の
積分値がいらないのに注意
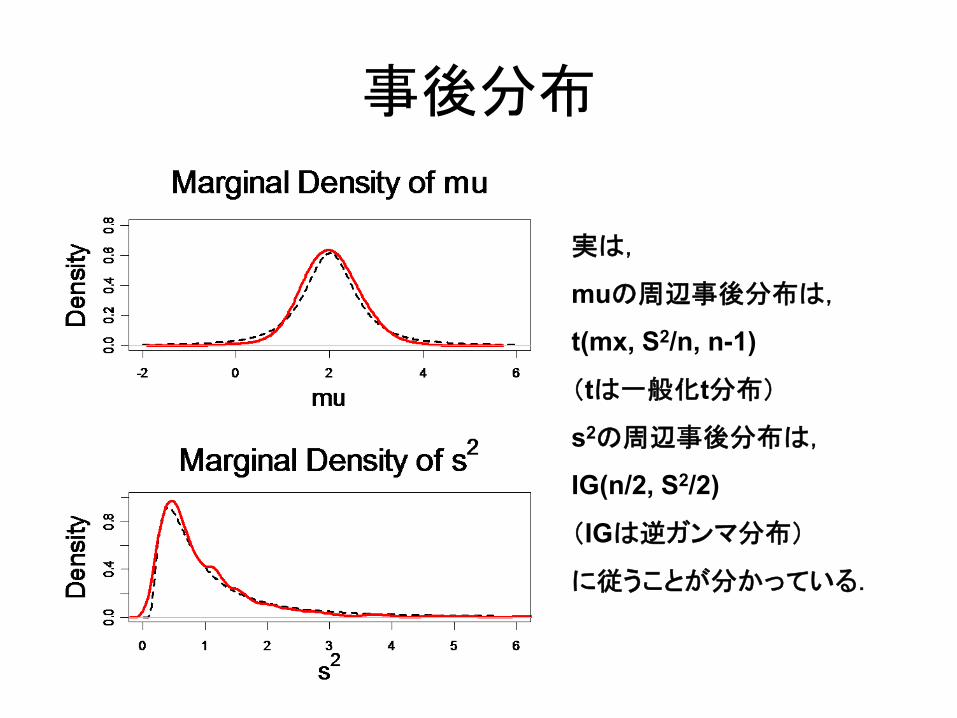
事後分布
実は,
muの周辺事後分布は,
t(mx, S2/n, n-1)
(tは一般化t分布)
s2の周辺事後分布は,
IG(n/2, S2/2)
(IGは逆ガンマ分布)
に従うことが分かっている.

ギブスサンプリング
Single-component MH法でサンプラーをフル
条件付分布にする.
MH法の採択確率は,f(x)q(y|x)/f(y)q(x|y)であ
るから,サンプルしたい目的の関数f(x)とサンプ
ルしやすい関数q(x|y)をどちらも同じフル条件
付分布にすることになる.
よって,採択確率=1 → 効率が良い

ギブスサンプリング
多変量関数f(x1,x2,x3,…)からサンプル
ひとつの変数に対して順番にフル条件付分布
からサンプルする
1. x1(0), x2
(0),x3(0),…を決定
2. f(x1|x2(0),x3
(0),…)からサンプルx1(1)を得る.
3. f(x2|x1(1),x3
(0), …)からサンプルx2(1)を得る.
4. この操作を繰り返す

ギブスサンプリング
• フル条件付分布からのサンプリングが簡単な場合とても魅力的
• フル条件付分布からのサンプリングが簡単ではない場合,RejectionサンプリングやMH法と組み合わせる(MH法と組み合わせたとき,MH within Gibbsと呼んだりする)
• 明日使うWinBUGSは基本的にGibbs Samplerを用いて事後分布からサンプルするソフトである

例題
• 2変量正規分布
からデータをサンプルする.この場合,
x1|x2 ~ N(1+0.7(x2-2), 1-0.72)x2|x1 ~ N(2+0.7(x1-1), 1-0.72)となることが分かっている.
⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛17.07.01
, 21
N~xx
2
1
フル条件付分布からのサンプルは通常の正規分布からのサンプル
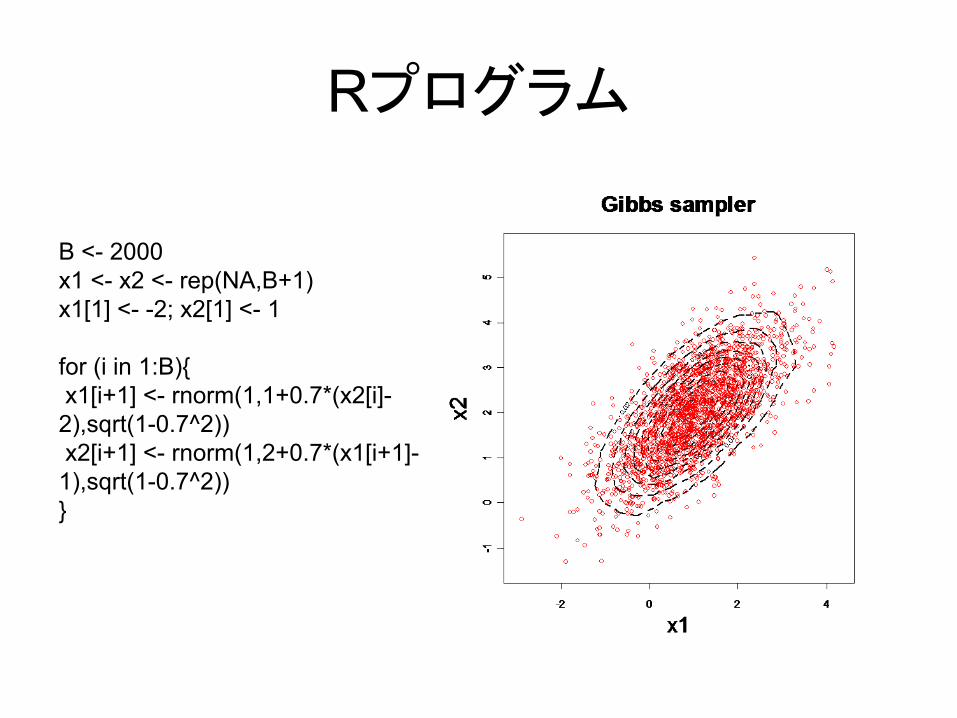
Rプログラム
B <- 2000x1 <- x2 <- rep(NA,B+1)x1[1] <- -2; x2[1] <- 1
for (i in 1:B){x1[i+1] <- rnorm(1,1+0.7*(x2[i]-2),sqrt(1-0.7^2))x2[i+1] <- rnorm(1,2+0.7*(x1[i+1]-1),sqrt(1-0.7^2))}

スライスサンプリング
X~f(x) ⇔ (X,V)~U[(x,v):0 ≤ v ≤ f(x)]
これを使って,
1. u(0), x(0)を決めてやる
2. u(1) ~ U[0, f(x(0))]3. x(1) ~ U[x: f(x) ≥ u(1)]4. この操作を繰り返す
(f(x)の代わりにf1(x)=Cf(x)を用いてもOK)
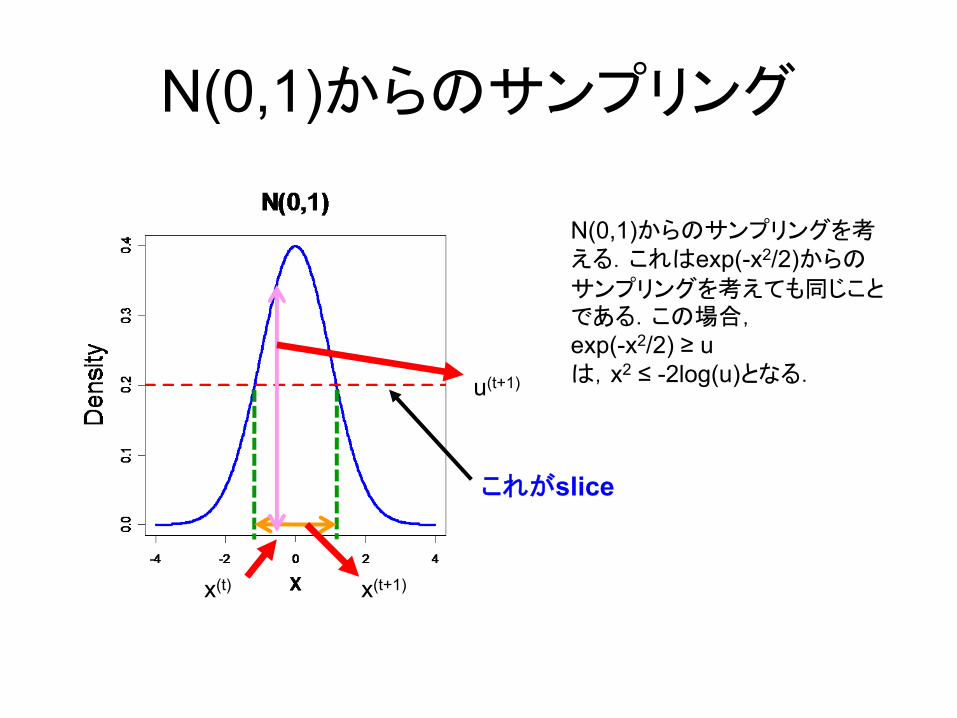
N(0,1)からのサンプリング
u(t+1)
x(t+1)x(t)
これがslice
N(0,1)からのサンプリングを考える.これはexp(-x2/2)からの
サンプリングを考えても同じことである.この場合,exp(-x2/2) ≥ uは,x2 ≤ -2log(u)となる.
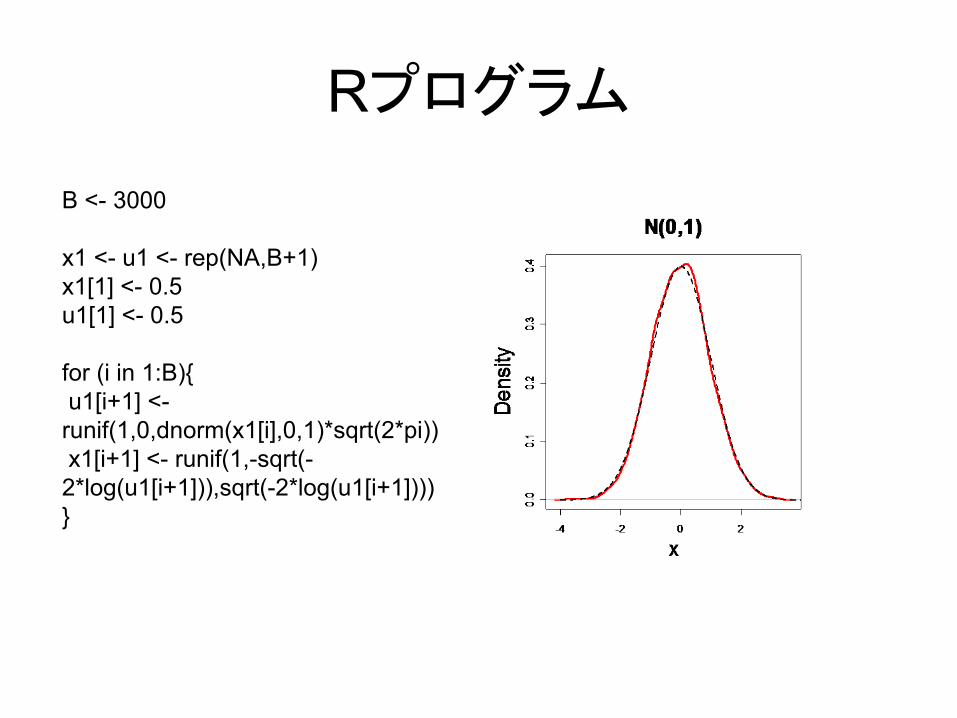
Rプログラム
B <- 3000
x1 <- u1 <- rep(NA,B+1)x1[1] <- 0.5u1[1] <- 0.5
for (i in 1:B){u1[i+1] <-runif(1,0,dnorm(x1[i],0,1)*sqrt(2*pi))x1[i+1] <- runif(1,-sqrt(-2*log(u1[i+1])),sqrt(-2*log(u1[i+1])))}

Burn-inとThinning
• Burn-in: 初期値が目的とする分布のはじっこの方にあるとき,最初の方のサンプルはまだ定常分布に収束していないので捨ててやる必要がある
• Thinning: MCMCの結果得られたサンプルは互いに相関しており,独立なサンプルとなっていない.独立サンプルを得るためのひとつの(ad hoc)方法として,ある間隔ごとにデータをとる.コンピュータメモリの節約にも.
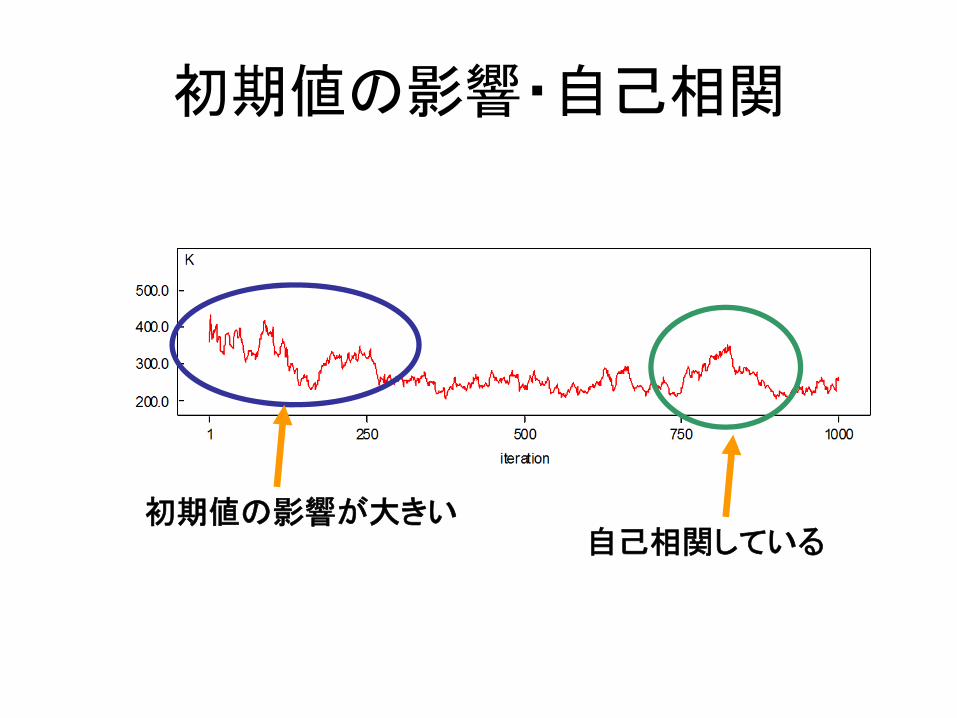
初期値の影響・自己相関
初期値の影響が大きい自己相関している

収束診断
MCMC時系列が目的とする分布に収束してい
る必要がある.収束したかどうかの判定にはい
くつかの方法が考えられている.よく使われる
のは,数本のMCMCを走らせて,それらがどれ
も同じようなところに分布するかどうかを見る方
法である(詳細は明日のWinBUGSの話で見
る).MCMCではとにかく色々とプロットしてみ
ることが重要である(そんなときRが便利).

MCMC注意
• 何でもOKな万能薬ではない
• パラメータが多いと計算時間がかかる
• パラメータ間の相関が大きいと計算時間がかかる
• logをとったりすると計算時間がかかる
• 初期値を変えて同じ結果になるか確かめろ,計算時間がかかるけど
• うまくプログラムしないと計算時間がやたらとかかる

参考文献
• 平松一彦 2004. MCMC入門. 水産資源管理談話会報 34: 72-76.
• 大森裕浩 2001. マルコフ連鎖モンテカルロ法の最近の展開.日本統計学会誌 31: 305-344.
• 伊庭幸人 2005. マルコフ連鎖モンテカルロ法の基礎.「統計科学のフロンティア 計算統計II」: 1-106.





























