Embed Size (px)
Citation preview

Politecnico di Milano
SCUOLA DI INGEGNERIA INDUSTRIALE E DELL’INFORMAZIONE
Corso di Laurea in Ingegneria Matematica
Tesi di laurea magistrale
Modelli statistici per la progressione del glaucoma
Candidato:
Valeria SpagnoloMatricola 813542
Relatore:
Prof.ssa Alessandra Guglielmi
Anno Accademico 2016-2017


Abstract
Open Angle Glaucoma (OAG) is an eye disease characterized by progressive retinalganglion cell death. In the eye affected by glaucoma, a gradual loss of the visualfield occurs, until it reaches a condition of complete blindness for the patients.Unfortunately, OAG is not curable and the vision loss cannot be recovered. Forthese reasons, it’s important to provide early diagnosis in order to slow down thecourse of the disease. In the last few years, a variety of OAG risk factors havebeen identified, however, it remains unclear which of these factors are causes orconsequences of the disease. The available data analyzed in this work, containinformation about a group of patients affected by OAG. Measurements in the da-ta are recorded every 6 months. From a statistical point of view, we are in theframework of longitudinal data.The aim of this thesis work is to develop appropriate statistical models for OAGlongitudinal data in order to describe the progression of the disease over time,taking into account the most important risk factors. Since the dataset containsthe large number of variables, firstly, we have reduced the size of the data in orderto select only the most significant factors to explain the progress of the diseaseover time.Starting from the selected variables, mixed effect model for longitudinal data havebeen applied to the dataset. Exploiting the fitted model, the variability amongdifferent subjects and within the single subject have been investigated.Finally, we have applied a multi-state Markov model to describe the time evo-lution of the disease. Since the states of the disease are not directly observable,we resorted to Hidden Markov Models (HMMs). Once we estimated the modelparameters, the HMM can be used to estimate the (hidden) state of the diseasefor a given patient at a given time instant.
i

ii

Sommario
Il Glaucoma ad Angolo Aperto, in inglese Open Angle Glaucoma (OAG) è unamalattia oculare caratterizzata dalla perdita di cellule ganglionari retiniche. Nel-l’occhio affetto da glaucoma avviene una perdita graduale del campo visivo, finoad arrivare ad una condizione di completa cecità per i pazienti. Sfortunatamentel’OAG non è curabile ed è quindi importante fornire una diagnosi precoce al fine dirallentare il decorso della malattia stessa. Negli ultimi anni sono stati individuatidiversi fattori di rischio dell’OAG, ma non è ancora ben chiaro quali di questi sia-no cause o conseguenze della malattia. I dati a utilizzati in questa tesi riportanoinformazioni riguardanti un insieme di pazienti affetti da OAG. Le misurazioniriguardanti le caratteristiche mediche dei pazienti avvengono ad intervalli di circa6 mesi; dal punto di vista statistico ci collochiamo quindi in un contesto di datilongitudinali.
Lo scopo di questo lavoro di tesi è quello di utilizzare opportuni modelli stati-stici per dati longitudinali per descrivere la progressione nel tempo della malattia,tenendo in considerazione i principali fattori di rischio. Dato il grande numero divariabili a disposizione, un primo passo è stato quello di ridurre le dimensioni deldataset al fine di individuare solo i fattori più significativi per spiegare l’avanza-mento della malattia nel tempo.
Successivamente, sulla base delle covariate selezionate al passo precedente, ab-biamo applicato i modelli lineari a effetti misti per dati longitudinali al nostrodataset. Attraverso la stima dei parametri di tali modelli, abbiamo studiato lavariabilità tra diversi soggetti e all’interno del singolo soggetto del campione didati. Infine un modello multi-stato markoviano è stato adottato per descrivere laprogressione nel tempo del glaucoma. Tuttavia, gli stati di progressione della ma-lattia non sono direttamente osservabili ma nascosti, si sono quindi considerati dei
iii

modelli di Markov nascosti. Una volta stimati i parametri del modello, questo puòessere utilizzato per stimare lo stato (nascosto) della malattia di un dato pazientead un dato istante temporale.
iv

Indice
Abstract i
Sommario iii
Elenco delle figure vii
Elenco delle tabelle ix
Introduzione 1
1 Glaucoma ad angolo aperto 51.1 Descrizione della malattia . . . . . . . . . . . . . . . . . . . . . . . 51.2 Presentazione del Dataset . . . . . . . . . . . . . . . . . . . . . . . 81.3 Analisi Preliminari . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3.1 Analisi di letteratura . . . . . . . . . . . . . . . . . . . . . . 121.3.2 Analisi alla Baseline . . . . . . . . . . . . . . . . . . . . . . 15
2 Modelli Lineari a Effetti Misti per dati longitudinali 252.1 Formulazione del Modello . . . . . . . . . . . . . . . . . . . . . . . 25
2.1.1 Passo 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.1.2 Passo 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.1.3 Modello Lineare a Effetti Misti . . . . . . . . . . . . . . . . 26
2.2 Stima dei parametri . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.2.1 Stima di massima verosimiglianza . . . . . . . . . . . . . . . 28
2.3 Selezione del Modello . . . . . . . . . . . . . . . . . . . . . . . . . . 332.4 Caso Studio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3 Hidden Markov Models 513.1 Catene di Markov . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
v

3.2 Hidden Markov Models . . . . . . . . . . . . . . . . . . . . . . . . . 533.2.1 Distribuzioni marginali . . . . . . . . . . . . . . . . . . . . . 54
3.3 Verosimiglianza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 563.3.1 Stime di massima verosimiglianza . . . . . . . . . . . . . . . 573.3.2 Alcuni problemi . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.4 Decoding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.5 HMMs per dati longitudinali . . . . . . . . . . . . . . . . . . . . . . 613.6 Selezione del Modello . . . . . . . . . . . . . . . . . . . . . . . . . . 633.7 HMMs con covariate . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.7.1 Covariate nella distribuzione di emissione . . . . . . . . . . . 643.8 Caso Studio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
Conclusioni 85
Bibliografia 89
vi

Elenco delle figure
1.1 Glaucoma ad angolo aperto . . . . . . . . . . . . . . . . . . . . . . 6(a) Perdita progressiva del campo visivo . . . . . . . . . . . . . . 6(b) Raprresentazione schematica dell’occhio . . . . . . . . . . . . 6
1.2 Boxplot per gruppi . . . . . . . . . . . . . . . . . . . . . . . . . . . 16(a) Sesso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16(b) Razza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16(c) Presenza di diabete . . . . . . . . . . . . . . . . . . . . . . . . 16
2.1 Istogramma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.2 Intervalli di confidenza effetti fissi: Modello 1 . . . . . . . . . . . . . 392.3 Intervalli di confidenza effetti casuali: Modello 1 . . . . . . . . . . . 402.4 Stime effetti casuali: Modello 1 . . . . . . . . . . . . . . . . . . . . 412.5 Intervalli di confidenza effetti fissi: Modello 2 . . . . . . . . . . . . . 442.6 Intervalli di confidenza effetti casuali: Modello 2 . . . . . . . . . . . 442.7 Stime effetti casuali: Modello 2 . . . . . . . . . . . . . . . . . . . . 452.8 Intervalli di confidenza effetti fissi: Modello 3 . . . . . . . . . . . . . 482.9 Intervalli di confidenza effetti casuali: Modello 3 . . . . . . . . . . . 482.10 Stime effetti casuali: Modello 3 . . . . . . . . . . . . . . . . . . . . 49
3.1 Rappresentazione di un HMM . . . . . . . . . . . . . . . . . . . . . 533.2 Predizione degli stati Modello 1 . . . . . . . . . . . . . . . . . . . . 723.3 Predizione degli stati Modello 2 . . . . . . . . . . . . . . . . . . . . 773.4 Predizione degli stati Modello 3 . . . . . . . . . . . . . . . . . . . . 82
vii

viii

Elenco delle tabelle
1.1 Caratteristiche dei pazienti . . . . . . . . . . . . . . . . . . . . . . . 131.2 Test di Wilcoxon . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
(a) CDI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14(b) OCT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.2 Test di Wilcoxon . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15(c) HRF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.3 Test di Wilcoxon sulla differenza nei gruppi . . . . . . . . . . . . . 17(a) Sesso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17(b) Razza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17(c) Diabete . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.4 Variance Inflation Factor . . . . . . . . . . . . . . . . . . . . . . . . 191.5 Variance Inflation Factor aggiornato . . . . . . . . . . . . . . . . . 191.6 Covariate selezionate dai Modelli alla Baseline . . . . . . . . . . . . 24
2.1 Principali funzioni utilizzate del pacchetto nlme . . . . . . . . . . . . 342.2 Test di Shapiro-Wilk . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.1 AIC HMMs Modello 1 . . . . . . . . . . . . . . . . . . . . . . . . . 673.2 Stime Modello 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 683.3 Decoding Modello 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . 693.4 Stime Modello 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 733.5 Decoding Modello 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . 743.6 Stime Modello 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 783.7 Decoding Modello 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
ix

x

Introduzione
Il glaucoma ad angolo aperto, in inglese Open Angle Glaucoma - OAG, è unamalattia oculare progressiva caratterizzata da modifiche morfologiche (escavazio-ne della papilla ottica) dovuta alla perdita di cellule ganglionari retiniche ed è unadelle prime cause di cecità nel mondo. Negli ultimi decenni, sono stati identificatisvariati fattori di rischio per l’OAG. Tuttavia il meccanismo con cui i vari fattoricontribuiscono allo sviluppo del Glaucoma è ancora sconosciuto. In particolarenon è ben chiaro se tali fattori siano delle cause o delle conseguenze dello sviluppodella malattia.
Il lavoro descritto in questa tesi ha come scopo lo studio di relazioni statistichetra alcune variabili che misurano la malattia OAG e potenziali variabili esplicativedella malattia stessa. I dati a nostra disposizione vengono dal dipartimento dioftalmologia della facoltà di medicina dell’Indiana University Purdue UniversityIndianapolis, USA, diretta dal Dottor Alon Harris.
I dati forniti riportano informazioni riguardantiM = 122 pazienti affetti da glauco-ma ad angolo aperto. Un primo dataset contiene informazioni generali riguardantii pazienti (come ad esempio età, sesso, presenza o meno diabete, razza). I restantidataset contengono misurazioni riguardanti le caratteristiche mediche dei pazientistessi; tali dataset possono essere classificati in due gruppi. Il primo gruppo didataset descrive variabili considerate "standard" per asserire la comparsa o menodella malattia. Tali variabili valutano, per esempio, l’acutezza visiva, i parame-tri del campo visivo, la pressione interoculare, la morfologia del nervo ottico, lospessore della cornea centrale e la lunghezza assiale del bulbo oculare per ogni pa-ziente. Un secondo gruppo di dataset descrive misurazioni ottenute tramite nuovetecniche di imaging avanzate, utili per valutare la struttura oculare e i parametrivascolari. Tali tecniche sono il Color Doppler Imaging, Optical Coherence Tomo-

Introduzione
graphy e Heidelberg Retinal Flowmeter.Nei dataset a disposizione, le caratteristiche mediche dei pazienti sono registratead intervalli di circa 6 mesi. Il numero massimo di visite effettuate è pari a 13.Per ogni paziente si avrà quindi un insieme di misurazioni ripetute nel tempo e ilnumero di visite effettuate è variabile: può avvenire il caso in cui il paziente saltauna o più visite, oppure il caso in cui il paziente smette di presentarsi ai controlliperiodici. Dal punto di vista statistico, ci collochiamo quindi in un contesto didati longitudinali.
L’obiettivo di questa tesi è utilizzare opportuni modelli statistici per dati lon-gitudinali per descrivere la progressione nel tempo della malattia, tenendo in con-siderazione i principali fattori di rischio. Diventa dunque interessante analizzarequali siano i fattori esplicativi delle misure longitudinali scelte per rappresentarela malattia e quali influenzano lo stato latente che "misura" la malattia stessa.Modellizzare la progressione della malattia può essere molto importante dal puntodi vista medico. L’OAG infatti è una malattia non curabile caratterizzata da unariduzione graduale del campo visivo. Tale malattia non presenta sintomi finchénon si avverte una perdita della vista che interessa dapprima la parte perifericadel campo visivo (il paziente continuerà a vedere nitidamente al centro del campovisivo). Con la progressione della malattia il campo visivo si riduce sempre di più,fino ad arrivare a una condizione di cecità completa per il paziente. Solitamente ilpaziente si accorge di presentare l’OAG quando la malattia è già in uno stato avan-zato e i danni irreversibili hanno raggiunto una notevole gravità. Sfortunatamentela perdita della vista non può essere recuperata, quindi non ci sono opportunità dimiglioramento per il paziente. Individuare i principali fattori di rischio dell’OAG estudiare la progressione della malattia nel tempo, può essere utile per fornire unadiagnosi precoce dell’OAG, al fine di prescrivere al paziente opportune cure perrallentarne il decorso.
Nel seguito dettagliamo i contributi del lavoro svolto, capitolo per capitolo.
Nel Capitolo 1, dopo aver introdotto le caratteristiche peculiari del glaucoma edescritto dettagliatamente i dati a disposizione, sono state effettuate delle analisistatistiche preliminari. In primo luogo, sono state applicate metodologie utilizzatein un articolo che abbiamo usato come riferimento controllando di aver ottenuto
2

Introduzione
le stesse informazioni; si noti che i dataset utilizzati sono diversi, benché simili.Successivamente è stata effettuata un’analisi considerando solo le misurazioni allaprima visita dei pazienti. Dato il grande numero di variabili a disposizione, taleanalisi è stata utile per ridurre le dimensioni del dataset considerando solo i fattoripiù significativi per spiegare l’avanzamento della malattia nei modelli longitudinalistudiati nel seguito.
Nel Capitolo 2, dopo aver introdotto i modelli lineari a effetti misti per dati longi-tudinali e rivisto le loro caratteristiche principali, abbiamo applicato tali modellial nostro dataset e stimato i parametri di tali modelli con i dati a disposizione.Tali modelli statistici permettono di descrivere la variabilità tra diversi soggetti eall’interno del singolo soggetto del campione di dati. Sono state quindi scelte alcu-ne variabili di interesse, indicate dagli esperti come utili per spiegare la comparsadel glaucoma, e sono state studiate in funzione di effetti fissi e casuali nel tempo.Per "effetto" si intende una variabile che presenta una qualche dipendenza con lavariabile risposta. Attraverso gli effetti casuali, non si è interessati a valutare ledifferenze fra gli specifici soggetti, ma la variabilità fra essi.
Nel Capitolo 3, abbiamo assunto che la progressione del glaucoma sia descrittaattraverso un modello multi stato markoviano con dipendenza a "lag" 1; modellimarkoviani con dipendenza a "lag" maggiore di 1 potranno essere oggetto di unlavoro futuro. Inoltre, poiché gli stati della malattia non sono direttamente os-servabili, abbiamo considerato dei Modelli di Markov Nascosti (Hidden MarkovModels - HMMs), secondo i quali si assume che lo stato della malattia di un pa-ziente possa essere stimato utilizzando alcune delle covariate osservate. Per questimodelli è necessario fissare il numero di stati della catena markoviana sottostante;per fissare tale numero abbiamo fittato dei modelli con numero di stati differentie abbiamo utilizzato l’indice Bayesian Information Criterion (BIC) per scegliere ilmodello più appropriato. Una volta fissato il numero di stati, abbiamo utilizzandole stime di massima verosimiglianza dei parametri del modello fissato, abbiamointerpretato le probabilità di transizione e quanto in media ci si aspetta che unpaziente soggiorni in un dato stato. Inoltre, per ogni paziente, per ogni osserva-zione (i.e., variabili osservate ad un dato istante temporale) è stato associato ilcorrispondente stato di progressione della malattia, selezionando quello che massi-mizza la probabilità di essere occupato; per ogni paziente, è stata pure stimata la
3

Introduzione
sequenza di stati più probabile durante il periodo in cui avvengono le osservazioniIn questo modo è stato possibile classificare il paziente in un determinato "livello"di avanzamento della malattia in ogni istante temporale.
Nella fase preliminare di riduzione del dataset abbiamo trovato che la variabi-le che spiega meglio la progressione della malattia è Horizontal Integrated RimWidth che misura l’area totale del bordo neuroretinico. Le covariate longitudina-li che spiegano tale variabile risposta sono risultate Vertical Integrated Rim Areache misura il volume totale dello strato di fibre nervose retiniche nel bordo neu-roretinico, Retinal Nerve Fiber Layer (RNFL) che misura lo spessore dello stratodelle fibre nervose retiniche e Temporal short Posterior Ciliary Arteries(TPCA)che misura la velocità del flusso sanguigno nell’arteria ciliare posteriore tempora-le. Non abbiamo trovato un’influenza sulla variabile di interesse da parte dei trefattori Sesso, Razza e Diabete, spesso indicati in letteratura come possibili fattoridi rischio sulla comparsa dell’OAG.L’analisi di modelli lineari a effetti misti ha confermato la presenza di variabilitàtra gli individui, ma non abbiamo riscontrato nessuna dipendenza con la covariatariferita al tempo.Anche per quanto riguarda l’analisi degli HMMs, la variabile che meglio descrive laprogressione della malattia è risultata Horizontal Integrated Rim Width (HIRW)con un numero di stati ottimale pari a 6. I fattori legati alla progressione dellamalattia descritta dalla variabile HIRW sono risultati Sesso, Razza e Diabete. In-fine, sfruttando le stime dei parametri del modello selezionato, è stato possibileassociare a un dato paziente ad un dato istante temporale il corrispondente statodi avanzamento della malattia.
Le analisi statistiche sono state svolte utilizzando il software R. Per i modelli linea-ri a effetti misti e gli Hidden Markov Models sono stati utilizzati, rispettivamente,i pacchetti nlme e msm.
4

Capitolo 1
Glaucoma ad angolo aperto
1.1 Descrizione della malattia
Il glaucoma ad angolo aperto, in inglese Open Angle Glaucoma - OAG, è unaneuropatia ottica cronica caratterizzata dalla perdita di cellule ganglionari retini-che, cambiamenti strutturali nella retina e nel nervo ottico, perdita irreversibiledel campo visivo. Tale malattia non presenta sintomi finché non si avverte unaperdita della vista. La perdita della vista interessa dapprima la parte perifericadel campo visivo (il paziente continuerà a vedere nitidamente al centro del campovisivo). Con la progressione della malattia il campo visivo si riduce sempre di più(Figura 1.1(a)), fino ad arrivare a una condizione di cecità completa per il pa-ziente. Solitamente il paziente si accorge di presentare l’OAG quando la malattiaè già in uno stato avanzato e i danni irreversibili hanno raggiunto una notevolegravità. Sfortunatamente, il glaucoma ad angolo aperto non è curabile e la perditadella vista non può essere recuperata, pertanto è opportuno fornire una diagnosiprecoce della mattia, al fine di rallentarne il decorso. Per comprendere la malattiae i fattori ad essa legati, si è fatto riferimento ad alcuni articoli come Guidoboniet al. (2013), Tobe, Harris, Trinidad et al. (2012) e Shoshani et al. (2012).
Uno dei principali fattori di rischio per lo sviluppo dell’OAG è la pressione in-traoculare (IOP). Infatti una IOP elevata può provocare danni sul nervo ottico,alterare la circolazione oculare o compromettere la funzionalità delle cellule gaglio-nari retiniche. Nonostante ciò, un individuo può presentare IOP elevata, ma nonsviluppare mai il glaucoma. Per questo motivo è utile individuare altri fattori di

1. Glaucoma ad angolo aperto
(a) Perdita progressiva del campo visivo (b) Raprresentazione schematica dell’oc-chio
Figura 1.1: Perdita progressiva del campo visivo in soggetti affetti da Glaucoma ad angoloaperto e rappresentazione schematica dell’occhio e delle sue componenti.Fonte: National Eye Institute (2017)
rischio che possono essere d’aiuto nel diagnosticare la malattia.Negli ultimi decenni, sono stati identificati fattori di rischio per l’OAG di diversanatura. Infatti, per diagnosticare la malattia, è possibile valutare alcune proprietàstrutturali dell’occhio come l’escavazione del disco ottico, la miopia e lo spessorecorneale centrale; valutare alcune proprietà riguardanti il flusso sanguigno ocularecome la pressione di perfusione oculare, la disregolazione vascolare ed emorragienel disco ottico; infine può essere utile tener conto di alcune condizioni del pazientecome la pressione arteriosa e il diabete.
Panoramica dell’occhio
Di seguito sono descritte alcune componenti oculari utili per comprendere la de-scrizione della malattia. La Figura 1.1(b) rappresenta una schematizzazione del-l’occhio e delle sue componenti principali.
• Arteria oftalmica: è la prima diramazione intradurale dell’arteria carotideinterna, responsabile dell’irrorazione sanguigna del globo oculare. Essa sidirama in diverse arterie come l’arteria centrale della retina, arterie ciliariposteriori nasali e arterie ciliari posteriori temporali.
6

1.1. Descrizione della malattia
• Bordo neuroretinico: tessuto tra i margini della papilla e dell’escavazione.Principalmente composto da assoni delle cellule ganglionari retiniche.
• Coroide: strato intermedio tra la sclera e la retina, che fornisce il sangue allaretina.
• Cornea: tessuto trasparente che riveste la superficie anteriore dell’occhio.Permette il passaggio dei raggi luminosi verso le strutture interne dell’occhioe concorre a mettere a fuoco le immagini sulla retina.
• Macula: area centrale della retina. Essa è preposta alla visione distinta ealla percezione dei dettagli.
• Nervo ottico: è uno dei dodici nervi cranici. Appartiene al sistema nervosocentrale e manda gli impulsi dalla retina al cervello
• Papilla ottica (chiamata anche disco ottico): è la testa del nervo ottico ed è illuogo in cui convergono gli assoni delle cellule gaglionari per formare il nervoottico. Essa ha una forma ellittica, con il massimo diametro verticale. Nelcentro presenta una depressione imbutiforme, detta escavazione fisiologicadella papilla.
• Retina: sottile membrana che riveste la superficie interna dell’occhio: essaha il compito di mandare impulsi al nervo ottico.
• Cellule ganglionari retiniche: neuroni situati vicino alla superficie inter-na della retina che trasmettono informazioni visive dalla retina al cervelloattraverso lunghi assoni.
• Strato delle fibre nervose retiniche:lo strato interno della retina che contieneassoni nervosi e cellule gangliari retiniche che si collegano al nervo ottico.
• Sclera: membrana fibrosa che costituisce la parte posteriore del bulbo ocu-lare.
In generale la valutazione clinica del Glaucoma ad angolo aperto (OAG) è eseguitaattraverso una valutazione standard dell’acutezza visiva, del campo visivo, dellapressione interoculare, della morfologia del nervo ottico, dello spessore della corneacentrale e della lunghezza dell’assiale del bulbo oculare. Oltre a queste valutazioni
7

1. Glaucoma ad angolo aperto
classiche, è possibile valutare la struttura oculare e parametri vascolari attraversotecnologie di imaging avanzate. Per questo lavoro di tesi, sono stati forniti i datiriguardanti tre delle principali tecniche non invasive utilizzate per la valutazionedel OAG. Di seguito è riportata una breve descrizione di tali tecniche.
• Color Doppler Imaging (CDI) è una tecnica utilizzata per valutare la velocitàdel flusso ematico nei vasi retrobulbari;
• Optical Coherence Tomography (OCT) è una tecnica che permette di otte-nere scansioni dettagliate delle fibre nervose retiniche;
• Heidelberg retinal flowmeter (HRF) è una tecnica utilizzata per misurare ilvolume e la velocità del flusso ematico nei vasi retinici peripapillari.
Tuttavia l’interpretazione dei diversi dati a disposizione è molto complessa, poichéil meccanismo con cui i vari fattori contribuiscono allo sviluppo del Glaucoma èancora sconosciuto. In particolare non è ben chiaro se tali fattori siano delle causeo delle conseguenze dello sviluppo della malattia.
1.2 Presentazione del Dataset
I dataset disponibili raccolgono misurazioni effettuate su M = 122 pazienti af-fetti da Open Angle Glaucoma (OAG). All’interno dei datasets sono presenti in-formazioni riguardanti i pazienti (come ad esempio sesso ed età) e informazioniriguardanti le caratteristiche mediche del paziente. In particolare è disponibile undataset che raccoglie alcune misurazioni utilizzate solitamente per la valutazionedella malattia (come ad esempio la Pressione Intraoculare) e altri tre dataset cheregistrano i risultati ottenuti attraverso le tecniche di immaging CDI, OCT, HRFdescritte, nel Paragrafo 1.1. Le misurazioni riguardanti le caratteristiche medichedei pazienti vengono effettuate ad intervalli di 6 mesi.Di seguito è riportata una lista delle covariate che racchiudono informazioni ri-guardanti i pazienti:
• Tempo: variabile tij, i = 1, . . . ,M, j = 1, . . . , ni, che indica quando vieneeffettuata la misurazione per il paziente. Ogni paziente effettua al massimo13 visite, quindi nimax = 13. La prima visita del paziente (tij = 0) è chiamataBaseline.
8

1.2. Presentazione del Dataset
• Sesso del paziente. In questo studio il 60% dei pazienti è di sesso femminilee il 40% di sesso maschile.
• Età del paziente. La media empirica dell’età alla prima visita è pari a 64.49.La media empirica per l’età suddivisa per genere è pari a 63.92 per le donnee 65.35 per gli uomini.
• Diabete: variabile categorica che indica la presenza o meno del diabete. Il20% dei pazienti presentano il diabete.
• Razza: variabile categorica nell’insieme {"Bianca", "Nera", "Asiatica", "Ispa-nica"}. I pazienti considerati appartengono per il 71.31% alla razza Bianca,26.23% alla razza Nera, 1.64% alla razza Asiatica e il restante 0.81% a quellaIspanica.
Le covariate Sesso, Diabete, Razza non variano nel tempo, pertanto sono conside-rate "fisse". L’Età alla fine di ogni intervallo temporale è considerata una variabiledipendente dal tempo e considerare tale covariata equivale a considerare la varia-bile Tempo nel modello.
Di seguito sono riportate le covariate utilizzate in generale per la valutazionestandard del Glaucoma ad angolo aperto. Utilizzeremo la loro denominazioneinglese poiché ci sono state fornite in questo modo, e inoltre molti termini vengonoutilizzati anche nella lingua italiana.
• Intraocular Pressure (IOP): pressione interoculare misurata attraverso il to-nometro ad applanazione di Goldmann. In genere una IOP elevata è conside-rata uno dei principali fattori di rischio del glaucoma, tuttavia una pressioneinteroculare elevata non sempre giustifica la diagnosi della malattia.
• Systolic Pressure (SYS): pressione sistolica, è la pressione arteriosa massima.
• Diastolic Pressure (DIA): pressione diastolica, è la pressione arteriosa mini-ma.
• Mean Arterial Pressure (MAP): Pressione Arteriosa Media, è un indice de-finito come combinazione convessa della pressione sistolica e diastolica, inparticolare MAP = (1/3)SY S + (2/3)DIA.
9

1. Glaucoma ad angolo aperto
• Ocular Perfusion Pressure (OPP): pressione di perfusione oculare, è un in-dice utilizzato per combinare gli effetti di un’elevata IOP e di una bassapressione arteriosa. Tale indice è definito come: OPP = (2/3)MAP − IOP .
• Heart Rate (HR): battito cardiaco.
Le covariate sovraelencate sono tutte dipendenti dal tempo, in quanto i valori ditali covariate sono registrati in ogni visita, cioè ad ogni tij.
Attraverso la tecnica CDI si registrano le seguenti misurazioni:
• Ophthalmic Artery (OA): misura la velocità del flusso sanguigno nell’arteriaoftalmica.
• Central Retinal Artery (CRA): misura la velocità del flusso sanguigno nel-l’arteria retinica centrale.
• Temporal short Posterior Ciliary Arteries(TPCA): misura la velocità delflusso sanguigno nell’arteria ciliare posteriore temporale.
• Nasal short Posterior Ciliary Arteries (NPCA): misura la velocità del flussosanguigno nell’arteria ciliare posteriore nasale.
In ogni vaso sanguigno, è calcolata la velocità di picco sistolico (PSV), la fi-ne della velocità diastolica (EDV) e l’indice resistivo di Pourcelot (RI) pari aRI = (PSV − ECV )/PSV .
Attraverso la tecnica OCT si registrano le seguenti misurazioni:
• Disc Area(DA): area del disco ottico.
• Cup Area(CA): area dell’escavazione del disco ottico ("Cupping" del discoottico).
• Cup Disc Vertical Ratio (CDVratio): rapporto tra diametro dell’escavazionee diametro del disco ottico verticale.
• Cup Disc Horizontal Ratio (CDHratio): rapporto tra diametro dell’escava-zione e diametro del disco orizzontale.
10

1.3. Analisi Preliminari
• Cup Disc Area Ratio (CDratio): rapporto tra area dell’escavazione e areadel disco ottico.
• Rim Area (RA): area del bordo neuroretinico, ottenuta sottraendo l’areadell’escavazione all’area del disco ottico
• Retinal Nerve Fiber Layer (RNFL): misura lo spessore dello strato delle fibrenervose retiniche. Per tale misura sono forniti i valori dello spessore mediodella retina e il valore dello spessore dell’area superiore, inferiore, nasale etemporale.
• Vertical Integrated Rim Area (Volume) (VIRA): volume totale dello stratodi fibre nervose retiniche nel bordo neuroretinico.
• Horizontal Integrated Rim Width (Area) (HIRW): area totale del bordo neu-roretinico, ottenuta moltiplicando la media delle singole larghezze del nervoper la circonferenza del disco ottico.
• Macular Volume (MV): volume della macula
La tecnica HRF misura il flusso ematico neuro-retinico su campi d’indagine neltessuto peripapillare di 100µm × 100µm × 100µm, equivalenti a 10 × 10 pixels.Tramite questa tecnica si genera un istogramma per descrivere il flusso nell’areaconsiderata. In particolare si registrano le seguenti quantità:
• Mean Flow : flusso medio.
• 25th, 50th, 75th, 90th, 95th, 99th, 100th percentile: flusso nell’area conside-rata.
• Zero Pixel : Percentuale di pixel senza flusso.
Infine, per valutare il campo visivo, è fornita la variabile Mean Deviation(MD).Tale variabile è un indice di sensitività che misura le differenze fra i valori di sogliadel paziente con quelli ritenuti normali per quell’età.
1.3 Analisi Preliminari
Dato il grande numero di variabili a disposizione, prima di passare ad un’analisilongitudinale dei dati, sono stati utilizzati alcuni metodi per indagare sulla corre-
11

1. Glaucoma ad angolo aperto
lazione tra le varie covariate, al fine di eliminare quelle ridondanti e di ridurre ladimensione del dataset a disposizione.
1.3.1 Analisi di letteratura
Come prima attività è stata applicata ai dati la metodologia descritta nell’articoloTobe, Harris, Hussai et al. (2014). Lo scopo dell’analisi è quello di indagare suicambiamenti nel tempo del flusso ematico nei vasi retrobulbari e retinici in pazienticon OAG ed esaminare le relazioni con la progressione della malattia.Le metodologia utilizzata nell’articolo si basa su:
• Confronto tra la media alla Baseline (prima visita) e la media dopo 36 mesidalla prima visita, per le variabili relative alla pressione oculare e per levariabili nei datasets CDI, OCT, HRF;
• Test di Wilcoxon, per le variabili relative alla pressione oculare e per levariabili nei datasets CDI, OCT, HRF.
Il test di Wilcoxon è un test statistico non parametrico utilizzato per verificare sedue campioni provengono dalla stessa distribuzione o meno. In particolare:
H0 : F = G H1 : F 6= G.
Dove F e G sono due campioni statistici contenenti rispettivamente nF e nG os-servazioni. In questo caso è stato utilizzato per capire se c’è evidenza statisticaper affermare che ci sia una differenza tra i dati registrati alla Baseline e quelliregistrati dopo 36 mesi.
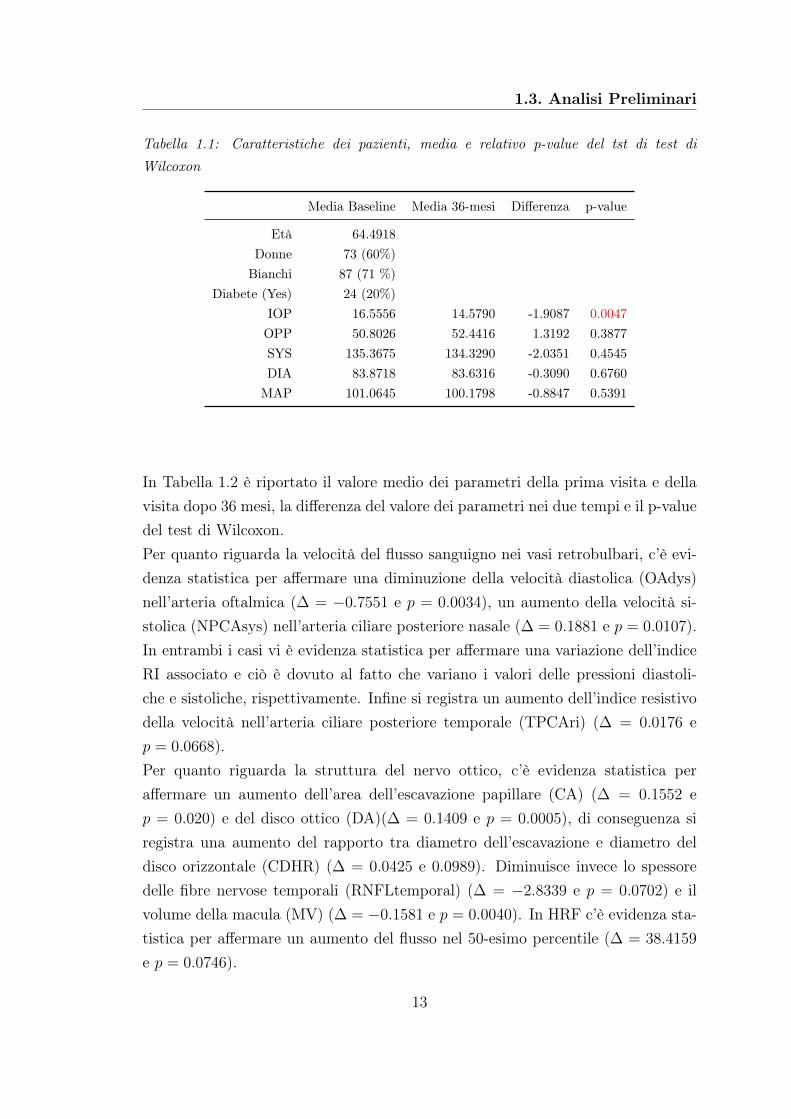
In Tabella 1.1 sono riportate alcune caratteristiche dei pazienti alla Baseline edopo 36 mesi. Inoltre è riportato il valore medio dei parametri della prima visitae della visita dopo 36 mesi, la differenza del valore dei parametri nei due tempi eil p-value del test di Wilcoxon per le variabili relative alla pressione. Diciamo chevi è evidenza statistica per affermare che ci sia differenza tra i dati registrati neidue periodi, quando il p-value del test è minore o uguale al 10%. Si osserva cheIOP e MAP diminuiscono dopo 36 mesi, mentre OPP aumenta. Secondo il test diWilcoxon c’è evidenza statistica per affermare un aumento di IOP (∆ = −1.9087
e p = 0.0047).
12
1.3. Analisi Preliminari
Tabella 1.1: Caratteristiche dei pazienti, media e relativo p-value del tst di test diWilcoxon
Media Baseline Media 36-mesi Differenza p-value
Età 64.4918Donne 73 (60%)Bianchi 87 (71 %)
Diabete (Yes) 24 (20%)IOP 16.5556 14.5790 -1.9087 0.0047OPP 50.8026 52.4416 1.3192 0.3877SYS 135.3675 134.3290 -2.0351 0.4545DIA 83.8718 83.6316 -0.3090 0.6760MAP 101.0645 100.1798 -0.8847 0.5391
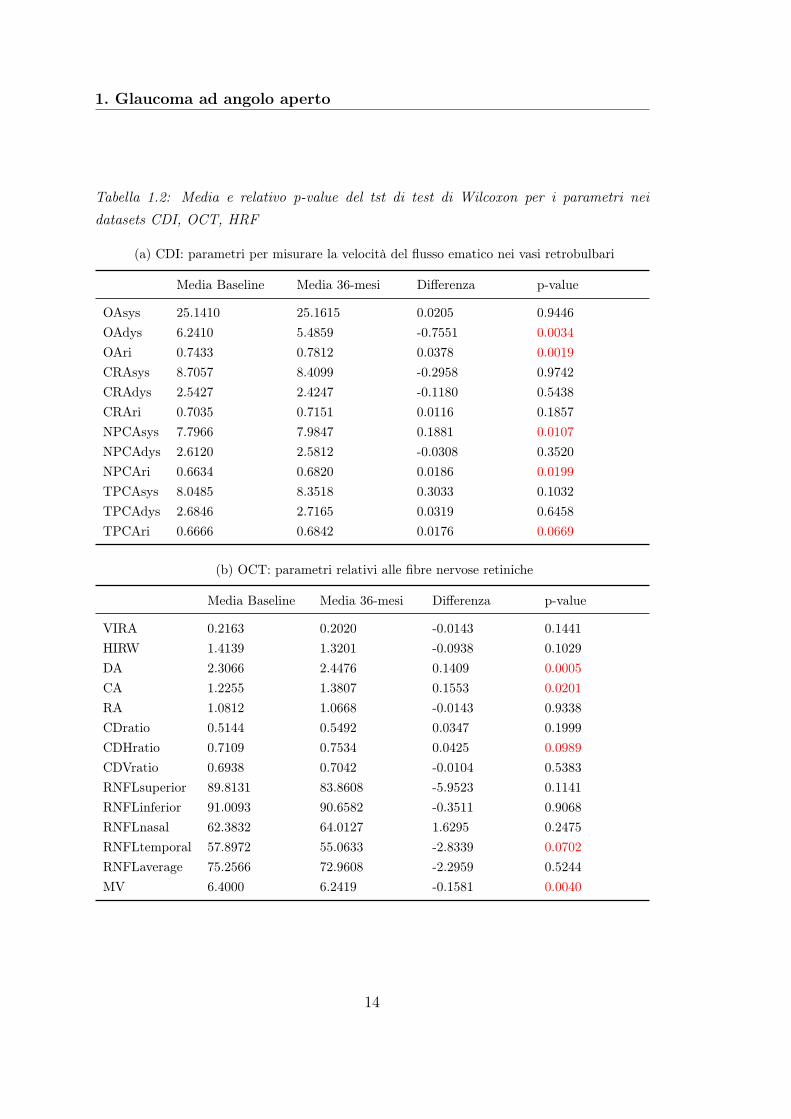
In Tabella 1.2 è riportato il valore medio dei parametri della prima visita e dellavisita dopo 36 mesi, la differenza del valore dei parametri nei due tempi e il p-valuedel test di Wilcoxon.Per quanto riguarda la velocità del flusso sanguigno nei vasi retrobulbari, c’è evi-denza statistica per affermare una diminuzione della velocità diastolica (OAdys)nell’arteria oftalmica (∆ = −0.7551 e p = 0.0034), un aumento della velocità si-stolica (NPCAsys) nell’arteria ciliare posteriore nasale (∆ = 0.1881 e p = 0.0107).In entrambi i casi vi è evidenza statistica per affermare una variazione dell’indiceRI associato e ciò è dovuto al fatto che variano i valori delle pressioni diastoli-che e sistoliche, rispettivamente. Infine si registra un aumento dell’indice resistivodella velocità nell’arteria ciliare posteriore temporale (TPCAri) (∆ = 0.0176 ep = 0.0668).Per quanto riguarda la struttura del nervo ottico, c’è evidenza statistica peraffermare un aumento dell’area dell’escavazione papillare (CA) (∆ = 0.1552 ep = 0.020) e del disco ottico (DA)(∆ = 0.1409 e p = 0.0005), di conseguenza siregistra una aumento del rapporto tra diametro dell’escavazione e diametro deldisco orizzontale (CDHR) (∆ = 0.0425 e 0.0989). Diminuisce invece lo spessoredelle fibre nervose temporali (RNFLtemporal) (∆ = −2.8339 e p = 0.0702) e ilvolume della macula (MV) (∆ = −0.1581 e p = 0.0040). In HRF c’è evidenza sta-tistica per affermare un aumento del flusso nel 50-esimo percentile (∆ = 38.4159
e p = 0.0746).
13
1. Glaucoma ad angolo aperto
Tabella 1.2: Media e relativo p-value del tst di test di Wilcoxon per i parametri neidatasets CDI, OCT, HRF
(a) CDI: parametri per misurare la velocità del flusso ematico nei vasi retrobulbari
Media Baseline Media 36-mesi Differenza p-value
OAsys 25.1410 25.1615 0.0205 0.9446OAdys 6.2410 5.4859 -0.7551 0.0034OAri 0.7433 0.7812 0.0378 0.0019CRAsys 8.7057 8.4099 -0.2958 0.9742CRAdys 2.5427 2.4247 -0.1180 0.5438CRAri 0.7035 0.7151 0.0116 0.1857NPCAsys 7.7966 7.9847 0.1881 0.0107NPCAdys 2.6120 2.5812 -0.0308 0.3520NPCAri 0.6634 0.6820 0.0186 0.0199TPCAsys 8.0485 8.3518 0.3033 0.1032TPCAdys 2.6846 2.7165 0.0319 0.6458TPCAri 0.6666 0.6842 0.0176 0.0669
(b) OCT: parametri relativi alle fibre nervose retiniche
Media Baseline Media 36-mesi Differenza p-value
VIRA 0.2163 0.2020 -0.0143 0.1441HIRW 1.4139 1.3201 -0.0938 0.1029DA 2.3066 2.4476 0.1409 0.0005CA 1.2255 1.3807 0.1553 0.0201RA 1.0812 1.0668 -0.0143 0.9338CDratio 0.5144 0.5492 0.0347 0.1999CDHratio 0.7109 0.7534 0.0425 0.0989CDVratio 0.6938 0.7042 -0.0104 0.5383RNFLsuperior 89.8131 83.8608 -5.9523 0.1141RNFLinferior 91.0093 90.6582 -0.3511 0.9068RNFLnasal 62.3832 64.0127 1.6295 0.2475RNFLtemporal 57.8972 55.0633 -2.8339 0.0702RNFLaverage 75.2566 72.9608 -2.2959 0.5244MV 6.4000 6.2419 -0.1581 0.0040
14

1.3. Analisi Preliminari
Tabella 1.2: Media e relativo p-value del tst di test di Wilcoxon per i parametri neidatasets CDI, OCT, HRF
(c) HRF: parametri per misurare il volume e la velocità di flusso ematico nei vasi retinici
Media Baseline Media 36-mesi Differenza p-value
10thpercentile 79.7282 86.6620 6.9338 0.3175X25thpercentile 182.0683 199.7767 17.7084 0.1322X50thpercentile 346.8266 385.2425 38.4160 0.0746X75thpercentile 563.5446 614.8565 51.3120 0.1666X90thpercentile 827.0440 862.2868 35.2428 0.3629meanflow 415.0272 442.8483 27.8211 0.2981
1.3.2 Analisi alla Baseline
Prima di proseguire con l’analisi longitudinale, si è voluto studiare il comportamen-to delle variabili alla Baseline. Le variabili di interesse considerate per descriverela progressione della malattia sono le variabili risposta utilizzate nei modelli linea-ri dell’articolo Tobe, Harris, Hussai et al. (2014), i.e., Horizontal Integrated RimWidth, Cup Disc Vertical Ratio e Cup Area. Tali variabili sono state indicate dagliesperti come variabili utili per descrivere l’OAG. Le altre variabili di interesse sono:Età, Sesso, Razza, Diabete, Interocular Pressure (IOP), Ocular Perfusion Pression(OPP), Mean Arterial Pressure (MAP), Systolic Blood Pressure (SYS), Diasto-lic Blood Pressure (DIA), Heart Rate (HR), hrf-meanflow, Opthalmic Artery(OA)sys/dys, Central Retinal Artery (CRA) sys/dys, Nasal and Temporal PosteriorCiliary Arteries (NPCA e TPCA) sys/dys, Vertical Integrated Rim Area Volume,Macular Volume, Retinal Nerve Fiber Layer (RNFL).
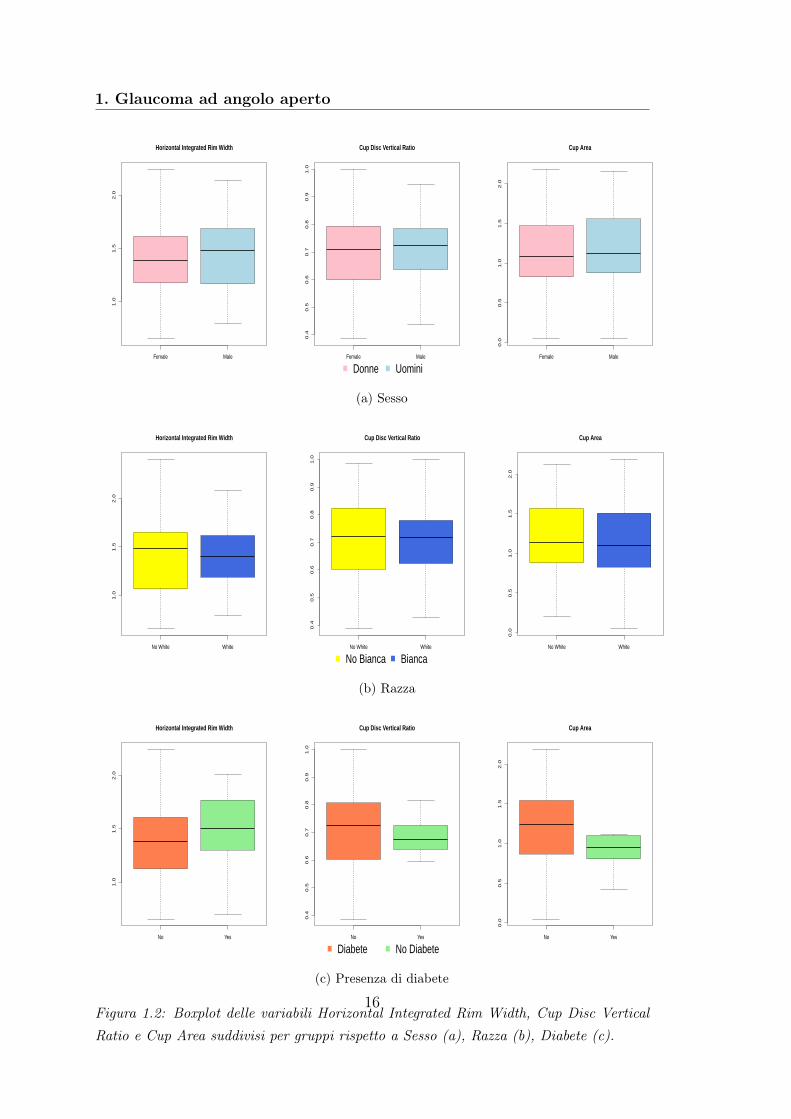
Differenza nei gruppi
Attraverso un’analisi grafica, si è cercato di individuare una prima differenza do-vuta a Sesso, Razza e presenza o meno di Diabete.In Figura 1.2 sono rappresentati i Boxplot suddivisi nei tre gruppi per le variabiliHorizontal Integrated Rim Width, Cup Disc Vertical Ratio e Cup Area.Si osserva che il sesso del paziente sembra influenzare le variabili Horizontal In-tegrated Rim Width e Cup Disc Vertical Ratio, in particolare la variabilità delledonne è molto più ampia per entrambe le variabili e il valor medio delle variabili
15
1. Glaucoma ad angolo aperto
Female Male
1.0
1.5
2.0
Horizontal Integrated Rim Width
Female Male
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Cup Disc Vertical Ratio
Donne UominiFemale Male
0.0
0.5
1.0
1.5
2.0
Cup Area
(a) Sesso
No White White
1.0
1.5
2.0
Horizontal Integrated Rim Width
No White White
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Cup Disc Vertical Ratio
No Bianca BiancaNo White White
0.0
0.5
1.0
1.5
2.0
Cup Area
(b) Razza
No Yes
1.0
1.5
2.0
Horizontal Integrated Rim Width
No Yes
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Cup Disc Vertical Ratio
Diabete No DiabeteNo Yes
0.0
0.5
1.0
1.5
2.0
Cup Area
(c) Presenza di diabete
Figura 1.2: Boxplot delle variabili Horizontal Integrated Rim Width, Cup Disc VerticalRatio e Cup Area suddivisi per gruppi rispetto a Sesso (a), Razza (b), Diabete (c).
16

1.3. Analisi Preliminari
Tabella 1.3: Test di Wilcoxon per le variabili Horizontal Integrated Rim Width, Cup DiscVertical Ratio e Cup Area per indagare la differenza nei gruppi.
(a) Sesso
p-value
Horizontal Integrated Rim Width 0.5205Cup Disc Vertical Ratio 0.6877Cup Area 0.3945
(b) Razza
p-value
Horizontal Integrated Rim Width 0.9350Cup Disc Vertical Ratio 0.7367Cup Area 0.4758
(c) Diabete
p-value
Horizontal Integrated Rim Width 0.1155Cup Disc Vertical Ratio 0.2339Cup Area 0.1500
è maggiore nel caso degli uomini.La Razza specifica soprattutto la variabile Horizontal Integrated Rim Width conmaggiore variabilità per i pazienti di razza non bianca. Il diabete sembra essereun fattore determinante per tutte e tre le variabili considerate, in particolare levariabili hanno molta più variabilità nel caso di pazienti affetti da diabete.Per confermare tali ipotesi è stato effettuato il test di Wilcoxon descritto nel pa-ragrafo 1.3.1, per capire se c’è evidenza statistica per affermare che ci sia unadifferenza tra i dati nelle due categorie considerate per le variabili Sesso, Razzae Diabete. In Tabella 1.3 sono riportati i p-value del test di Wilcoxon. Il p-valuedel test di Wilcoxon risulta ≥ 10% per tutte le variabili considerate, quindi, nonc’è evidenza statistica per affermare che le variabili differiscano nei gruppi per letre categorie considerate.
17

1. Glaucoma ad angolo aperto
Analisi delle Componenti Principali
L’analisi delle componenti principali (PCA) è una tecnica di feature extraction(Guyon e Elisseeff, 2003) che permette di ottenere una riduzione dimensionale deldataset tramite la generazione di nuove variabili (Principal Components) ottenutecome combinazione lineare delle variabili originarie. I coefficienti delle combina-zioni lineari che definiscono le componenti principali sono detti loadings.È stata applicata tale tecnica alle variabili alla Baseline per cercare di ridurre ladimensione del dataset. Tuttavia i risultati dell’analisi non sono stati soddisfacen-ti in quanto, la combinazioni lineari ottenute erano difficili da interpretare da unpunto di vista medico.
Modelli Lineari Alla Baseline
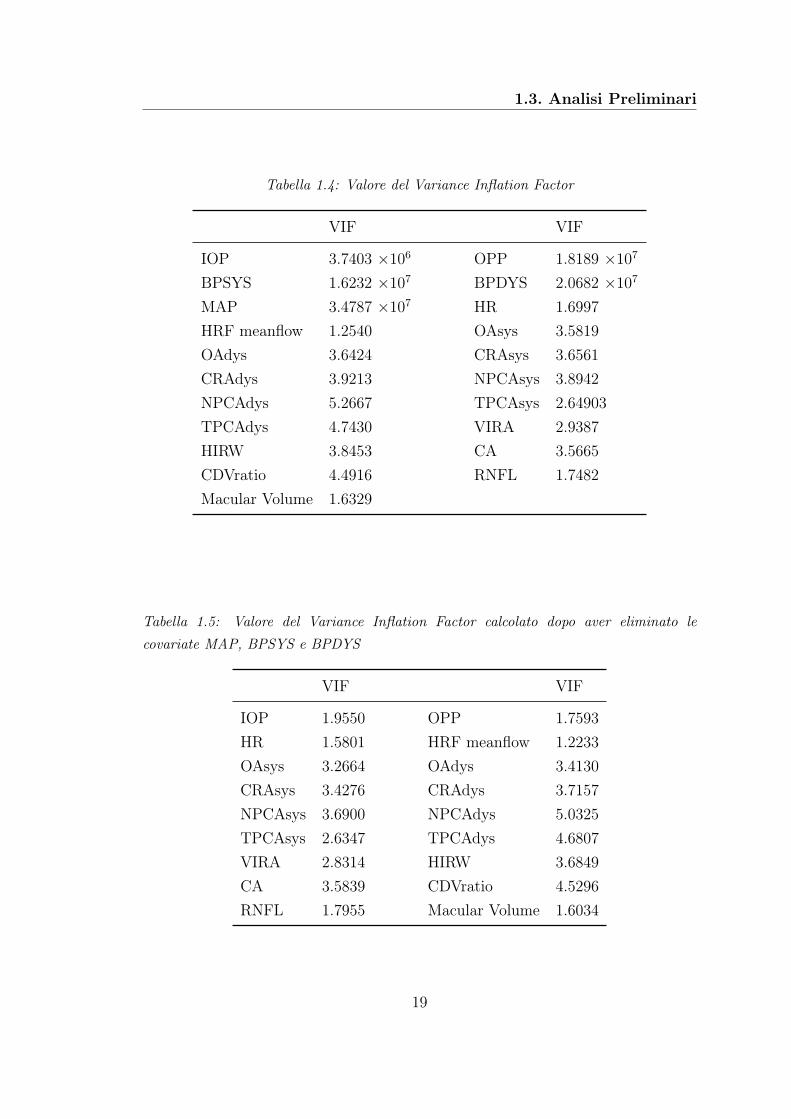
Un primo passo è stato quello di studiare la correlazione tra le variabili, in mododa eliminare quelle ridondanti. L’indice utilizzato per quantificare la correlazionetra le variabili è il Variance Inflation Factor (VIF). Si avrà multicollinearità quan-do il VIF è ≥ 10. Il comando utilizzato in R per il calcolo dell’indice è VIF nelpacchetto faraway. In Tabella 1.4 sono riportati i valori dei VIF per tutte le varia-bili. I risultati ottenuti danno evidenza di correlazione molto elevata (VIF ≥ 10)tra le variabili che descrivono la pressione oculare: IOP, OPP, BPSYS, BPDYS,MAP. Si è provato dapprima ad eliminare le variabili BPDYS e MAP, in quanto,per definizione, formano una combinazione lineare e sono linearmente dipendenticon la covariata OPP; si è ottenuta una diminuzione del VIF per le variabili chedescrivono la pressione ( IOP = 4.2034, OPP = 4.2034, BPSY S = 13.1039),ma il risultato non è stato soddisfacente in quanto OPP e BPSYS presentavanoancora VIF ≥ 10. È stata quindi eliminata anche la variabili BPSYS. In Tabella1.5 è riportato il VIF per le variabili presenti all’interno del dataset, dopo avereliminato BPSYS, BPDYS e MAP. Si osserva che tutti i valori sono accettabili;tali variabili sono state utilizzate per studiare i modelli di regressione lineare cheverranno descritti in seguito.
Successivamente sono stati implementati tre modelli di regressione lineare con-siderando inizialmente tutte le covariate e come variabili risposta: Horizontal In-tegrated Rim Width, Cup Disc Vertical Ratio, Cup Area. Il comando utilizzatoin R è lm.
18
1.3. Analisi Preliminari
Tabella 1.4: Valore del Variance Inflation Factor
VIF VIF
IOP 3.7403 ×106 OPP 1.8189 ×107
BPSYS 1.6232 ×107 BPDYS 2.0682 ×107
MAP 3.4787 ×107 HR 1.6997HRF meanflow 1.2540 OAsys 3.5819OAdys 3.6424 CRAsys 3.6561CRAdys 3.9213 NPCAsys 3.8942NPCAdys 5.2667 TPCAsys 2.64903TPCAdys 4.7430 VIRA 2.9387HIRW 3.8453 CA 3.5665CDVratio 4.4916 RNFL 1.7482Macular Volume 1.6329
Tabella 1.5: Valore del Variance Inflation Factor calcolato dopo aver eliminato lecovariate MAP, BPSYS e BPDYS
VIF VIF
IOP 1.9550 OPP 1.7593HR 1.5801 HRF meanflow 1.2233OAsys 3.2664 OAdys 3.4130CRAsys 3.4276 CRAdys 3.7157NPCAsys 3.6900 NPCAdys 5.0325TPCAsys 2.6347 TPCAdys 4.6807VIRA 2.8314 HIRW 3.6849CA 3.5839 CDVratio 4.5296RNFL 1.7955 Macular Volume 1.6034
19

1. Glaucoma ad angolo aperto
I modelli di regressione lineare (si veda, per esempio, Johnson e Wichern, 2007)sono modelli del tipo:
Y = Zβ + ε
dove Y è il vettore M -dimensionale che rappresenta la variabile risposta, Z è lamatrice (M × q) di covariate, β è il vettore q-dimensionale dei coefficienti di re-gressione, e ε è il vettore M -dimensionale dei residui. Si assume che le variabilialeatorie ε siano indipendenti e identicamente distribuiti come una Normale M -dimensionale con media pari al vettore nullo e matrice di varianza-covarianza paria σ2I, con I matrice identità di dimensione (M ×M). Il comando di R calcola lestime di massima verosimiglianza dei parametri di regressione.
Infine, con il comando step è stato applicato il metodo di Stepwise BackwardElimination (SBE) per selezionare le covariate che spiegano meglio la variabile ri-sposta.
Alcune covariate sono state log-trasformate.
Di seguito è riportato l’output di R per il primo modello con variabile rispostaHorizontal Integrated Rim Width.
> mod1 <- lm(log(Horz.integrated.rim.width) ~
+ Age + Race + Sex + Diabetes + IOP + OPP + HR
+ + hrf.meanflow
+ + OAsys + I(log(OAdys)) + I(log(CRAsys)) + I(log(CRAdys))
+ + NPCAsys + I(log(NPCAdys)) + I(log(TPCAsys)) + TPCAdys
+ + I(log(Vert.integrated.rim.area)) + RNFL.average+macular.volume)
> summary(mod1)
Call:
lm(formula = log(Horz.integrated.rim.width) ~ Age +
Race + Sex + Diabetes + IOP + OPP + HR + hrf.meanflow + OAsys +
I(log(OAdys)) + I(log(CRAsys)) + I(log(CRAdys)) + NPCAsys +
I(log(NPCAdys)) + I(log(TPCAsys)) + TPCAdys + I(log(Vert.integrated.rim.area)) +
RNFL.average + macular.volume)
Residuals:
Min 1Q Median 3Q Max
-0.227690 -0.061154 -0.000816 0.068955 0.205400
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.709e-01 2.404e-01 1.127 0.26300
Age 1.189e-03 1.061e-03 1.120 0.26590
20

1.3. Analisi Preliminari
Race -4.224e-02 2.373e-02 -1.780 0.07876 .
Sex 1.758e-02 2.332e-02 0.754 0.45306
Diabetes -1.601e-02 2.733e-02 -0.586 0.55961
IOP -3.819e-03 2.861e-03 -1.335 0.18553
OPP -4.828e-04 1.248e-03 -0.387 0.69982
HR -1.119e-03 8.976e-04 -1.246 0.21608
hrf.meanflow 1.462e-05 7.822e-05 0.187 0.85221
OAsys -2.583e-03 2.100e-03 -1.230 0.22205
I(log(OAdys)) 1.363e-01 5.209e-02 2.617 0.01051 *I(log(CRAsys)) -4.839e-02 6.553e-02 -0.739 0.46226
I(log(CRAdys)) -3.990e-02 5.922e-02 -0.674 0.50236
NPCAsys -1.361e-02 9.043e-03 -1.505 0.13606
I(log(NPCAdys)) 1.543e-01 7.527e-02 2.050 0.04344 *I(log(TPCAsys)) 1.920e-01 7.237e-02 2.653 0.00954 **TPCAdys -4.994e-02 2.926e-02 -1.707 0.09158 .
I(log(Vert.integrated.rim.area)) 2.422e-01 1.341e-02 18.062 < 2e-16 ***RNFL.average 1.877e-03 7.499e-04 2.503 0.01426 *macular.volume 2.077e-02 2.958e-02 0.702 0.48442
---
Signif. codes: 0 ’***’ 0.001 ’**’ 0.01 ’*’ 0.05 ’.’ 0.1 ’ ’ 1
Residual standard error: 0.1001 on 84 degrees of freedom
Multiple R-squared: 0.879, Adjusted R-squared: 0.8516
F-statistic: 32.11 on 19 and 84 DF, p-value: < 2.2e-16
Per capire se un predittore è significativo o meno, si può confrontare il pvalue econsiderare predittori significativi quelli con p-value inferiori al 5%. In questo casola variabile risposta Horizontal Integrated Rim Width sembra dipendere da diversecovariate (OA, NPCA, TPCA, Vertical integrated rim area, RNFL).Un indice per valutare la bontà del modello è R2
adj che misura la proporzione divariabilità della variabile risposta spiegata dalle variabili esplicative considerate.In genere si considera un buon modello quando l’indice R2
adj è maggiore dell’ 80%.In questo caso la variabile risposta Horizontal Integrated Rim Width risulta essereben spiegata dalle covariate in quanto R2
adj è pari a 0.8516.Di seguito è riportato l’output per il modello selezionato dopo la procedura diStepwise Backward Elimination.
Call:
lm(formula = log(Horz.integrated.rim.width)~ Race +
HR + I(log(OAdys)) + I(log(CRAdys)) + NPCAsys + I(log(NPCAdys)) +
I(log(TPCAsys)) + I(log(Vert.integrated.rim.area)) +
RNFL.average)
Residuals:
Min 1Q Median 3Q Max
-0.235700 -0.060613 -0.001828 0.060032 0.203167
Coefficients:
21

1. Glaucoma ad angolo aperto
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.5210702 0.1240137 4.202 6.03e-05 ***Race -0.0358836 0.0223101 -1.608 0.1111
HR -0.0017029 0.0007613 -2.237 0.0277 *I(log(OAdys)) 0.0640557 0.0302832 2.115 0.0371 *I(log(CRAdys)) -0.0546832 0.0374672 -1.459 0.1478
NPCAsys -0.0143714 0.0078325 -1.835 0.0697 .
I(log(NPCAdys)) 0.1172936 0.0619721 1.893 0.0615 .
I(log(TPCAsys)) 0.1133805 0.0508378 2.230 0.0281 *I(log(Vert.integrated.rim.area)) 0.2495779 0.0119531 20.880 < 2e-16 ***RNFL.average 0.0015464 0.0006439 2.402 0.0183 *---
Signif. codes: 0 ’***’ 0.001 ’**’ 0.01 ’*’ 0.05 ’.’ 0.1 ’ ’ 1
Residual standard error: 0.09812 on 94 degrees of freedom
Multiple R-squared: 0.8699, Adjusted R-squared: 0.8574
F-statistic: 69.83 on 9 and 94 DF, p-value: < 2.2e-16
Il modello selezionato dalla procedura SBE sembra essere un buon modello (R2adj =
0.8574). Si osserva che le covariate più significative (p ≤ 5%) sono HR, OAdys,TPCAsys, RNFL e Vertical ntegrated rim area.
Il modello con variabile risposta Cup Disc Vertical Ratio selezionato dopo laprocedura SBE è il seguente:Call:
lm(formula = cup.disk.vert.ratio ~ I(log(Vert.integrated.rim.area)) +
macular.volume)
Residuals:
Min 1Q Median 3Q Max
-0.36369 -0.04265 0.01308 0.05314 0.58359
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.72345 0.17853 4.052 9.98e-05 ***I(log(Vert.integrated.rim.area)) -0.12026 0.01221 -9.851 < 2e-16 ***macular.volume -0.04011 0.02640 -1.519 0.132
---
Signif. codes: 0 ’***’ 0.001 ’**’ 0.01 ’*’ 0.05 ’.’ 0.1 ’ ’ 1
Residual standard error: 0.1059 on 101 degrees of freedom
Multiple R-squared: 0.5502, Adjusted R-squared: 0.5413
F-statistic: 61.78 on 2 and 101 DF, p-value: < 2.2e-16
In questo caso le covariate selezionate sono solo Macular Volume e Vertical Inte-grated Rim Area. Le performance di questo modello sono peggiori in quanto l’R2
adj
è pari a 0.5413.
22

1.3. Analisi Preliminari
Il modello con variabile risposta Cup Area selezionato dopo la procedura SBEè il seguente:Call:
lm(formula = Cup.area ~ I(log(NPCAsys)) + I(log(NPCAdys)) + I(log(Vert.integrated.rim.
area)))
Residuals:
Min 1Q Median 3Q Max
-0.71038 -0.26635 -0.08418 0.19130 2.02093
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.19503 0.43513 2.746 0.00715 **I(log(NPCAsys)) -0.71535 0.28785 -2.485 0.01461 *I(log(NPCAdys)) 0.54459 0.25116 2.168 0.03251 *I(log(Vert.integrated.rim.area)) -0.52211 0.05289 -9.872 < 2e-16 ***---
Signif. codes: 0 ’***’ 0.001 ’**’ 0.01 ’*’ 0.05 ’.’ 0.1 ’ ’ 1
Residual standard error: 0.4758 on 100 degrees of freedom
Multiple R-squared: 0.4995, Adjusted R-squared: 0.4845
F-statistic: 33.27 on 3 and 100 DF, p-value: 5.36e-15
Anche nel caso del modello con variabile risposta Cup Area, la covariata più si-gnificativa risulta Vertical integrated rim area. Inoltre Cup Area è ben spiegatada NPCA sistolica e diastolica. Anche in questo caso le performance di questomodello sono peggiori rispetto al primo modello, avendo R2
adj = 0.4845.
I modelli selezionati per le tre variabili risposta alla Baseline faranno da guidaper selezionare modelli per risposte longitudinali nel capitolo successivo. Sarannoconsiderate soltanto le covariate più significative ottenute nei modelli precedenti.Inoltre, in questo paragrafo alcune variabili sono state log-trasformate; nell’analisilongitudinale, tali variabili verranno trattate inizialmente senza considerare alcunatrasformazione. In Tabella 1.6 sono riportate le covariate che verranno utilizzatein seguito per ciascuna delle tre variabili risposta.
23

1. Glaucoma ad angolo aperto
Tabella 1.6: Covariate selezionate dai modelli alla Baseline per le variabili rispostaHorizontal Integrated Rim Width, Cup Disc Vertical Ratio e Cup Area.
Variabile Risposta Covariate Selezionate
Horizontal Integrated Rim Width TPCAsysVertical Integrated Rim AreaRNFL
Cup Disc Vertical Ratio Vertical Integrated Rim AreaMacular Volume
Cup Area NPCAsysNPCAdysVertical Integrated Rim Area
24

Capitolo 2
Modelli Lineari a Effetti Misti perdati longitudinali
I Modelli Lineari a Effetti Misti per dati longitudinali sono modelli statistici chepermettono di descrivere la variabilità tra diversi soggetti e all’interno del singolosoggetto del campione di dati.Questo tipo di modelli può essere formulato come un modello a due passi dovenello passo 1 si assume che la distribuzione di probabilità per le osservazioni è lastessa per ogni individuo, tenedo così conto della variabilità all’interno del singoloindividuo, mentre nel passo 2 si assume che i parametri di tale distribuzione varianotra gli individui.
2.1 Formulazione del Modello
Secondo la notazione di Verbeke e Molenberghs (2001), sia Yij la variabile rispostadi interesse per il soggetto i-esimo, misurata al tempo tij, con i = 1, . . . ,M ej = 1, . . . , ni e sia Yi il vettore ni-dimensionale delle misurazioni effettuate sulsoggetto i-esimo, cioè Yi = (Yi1, Yi2, . . . , Yini
). Dunque la variabile risposta perogni soggetto i viene misurata ni volte.
2.1.1 Passo 1
Nel primo passo dell’analisi si assume che Yi soddisfi un modello di regressionelineare
Yi = Ziβi + εi (2.1)

2. Modelli Lineari a Effetti Misti per dati longitudinali
dove Zi è la matrice (ni × q) di covariate, βi è il vettore q-dimensionale dei coef-ficienti di regressione, e εi è il vettore ni-dimensionale dei residui. Si assumeche le v.a. εi siano indipendenti e identicamente distribuiti da una Normale ni-dimensionale con media pari al vettore nullo e matrice di varianza-covarianza paria σ2I, con I matrice identità di dimensione (ni × ni).Il modello (2.1) descrive l’evoluzione nel tempo della variabile risposta per ilsoggetto i-esimo.
2.1.2 Passo 2
Nel secondo passo, si assume un modello di regressione multivariate della forma
βi = Kiβ + bi (2.2)
dove Ki è la matrice (q× p) di covariate, β vettore p-dimensionale dei coefficientidi regressione, e bi vettore q-dimensionale dei residui. Si assumono bi indipendentie distribuiti come una normale q-dimensionale con media pari al vettore nulla ematrice di varianza-covarianza generica Ψ di dimensione (q × q). Tale matrice èsimmetrica e definita positiva.Il modello (2.2) è usato per spiegare la variabilità tra i soggetti, rispetto ai coeffi-cienti di regressione βi.
2.1.3 Modello Lineare a Effetti Misti
Combinando i modelli dell’analisi a due passi, sostituendo βi nel modello (2.1) conl’espressione (2.2), si ottiene il Modello Lineare a Effetti Misti (MLEM)
Yi =Xiβ +Zibi + εi, i = 1, . . . ,M
biiid∼ Nq(0,Ψ )
εiiid∼ Nni
(0, σ2I)
(2.3)
dove β è il vettore p-dimensionale degli effetti fissi, bi è il vettore q-dimensionaledegli effetti casuali,Xi = ZiKi (di dimesione (ni×p)) e Zi ( di dimensione (ni×q))sono le matrici delle covariate relative agli effetti fissi e casuali, e εi è il vettore ni-dimensionale dei residui; i vettori bi e εi si ipotizza che siano indipendenti tra diloro (i.e. βi ⊥⊥ εi) e indipendenti dai vettori relativi ad altri gruppi (i.e. βi ⊥⊥ βje εi ⊥⊥ εj per i 6= j).
26

2.2. Stima dei parametri
2.2 Stima dei parametri
Uno dei principali metodi utilizzati per stimare i parametri dei modelli lineari aeffetti misti è la stima di massima verosimiglianza. Quindi riportiamo un minimodi teoria, per rendere chiara la lettura. Si veda J. C. Pinheiro e Bates (2000, Cap.2), per ogni ulteriore riferimento.
I parametri da stimare del modello (2.3) sono β, σ2 e la matrice di varianza-covarianza Ψ , come indicato in J. C. Pinheiro e Bates (2000). È convenienteesprimere Ψ in termini del fattore di precisione relativo ∆, ovvero come
Ψ−1
1/σ2= ∆T∆ (2.4)
Al posto della matrice Ψ , si è interessati a stimare un vettore di parametri θ chedescriva il fattore di precisione relativo ∆ (o equivalentemente Ψ/σ2).Poichè Ψ/σ2 è simmetrica e definita positiva, ∆ esiste, ma non è definito in modounivoco. Si può parametrizzare Ψ/σ2 attraverso la matrice logaritmo.
Per definire tale parametrizzazione, si noti che ogni matrice A simmetrica e de-finita positiva, può essere espressa come matrice esponenziale di un’altra matriceB simmetrica, cioè
A = eB = I +B +B2
2!+B3
3!+ . . .
Se A è la matrice esponenziale di B, allora B è la matrice logaritmo di A.Assumedo A matrice (q× q) simmetrica e definita positiva. Un modo per valutarela sua matrice logaritmo B è considerare la sua decomposizione
A = UΛUT
dove Λ è una matrice diagonale (q × q) e U matrice (q × q) ortogonale. Si haquindi
B = logA = U logΛUT
dove logΛ è una matrice diagonale i cui elementi sono il logaritmo degli elementidi Λ.
Il vettore di parametri θ può essere definito come il vettore contenente gli elementidella parte triangolare superiore della matrice log(Ψ/σ2).
27

2. Modelli Lineari a Effetti Misti per dati longitudinali
2.2.1 Stima di massima verosimiglianza
La funzione di verosimiglianza per il modello (2.3) è definita come
L(β,θ, σ2|y) = p(y|β,θ, σ2) =M∏i=1
p(yi|β,θ, σ2) (2.5)
dove L indica la verosimiglianza, p è una densità di probabilità, e y è il vettoreN -dimensionale di osservazioni, N =
∑Mi=1 ni.
L’equazione (2.5) si riscrive come
L(β,θ, σ2|y) =M∏i=1
∫p(yi|bi,β, σ2)p(bi|θ,σ2)dbi (2.6)
Le distribuzioni marginali di yi e bi nel modello (2.3) sono normali multivariate,quindi
p(yi|bi,β, σ2) =1
(2πσ2)ni/2exp
(−‖yi −Xiβ −Zibi‖2
2σ2
)(2.7)
p(bi|θ,σ2) =1
(2π)q/2√|Ψ |
exp
(−bTi Ψ−1bi
)=
1
(2πσ2)q/2abs|∆|−1exp
(−‖∆bi‖
2
2σ2
) (2.8)
Sostituendo le equazioni (2.7) e (2.8) in (3.12) si ottiene
L(β,θ, σ2|y) =M∏i=1
abs|∆|(2πσ2)ni/2
∫1
(2πσ2)q/2exp
(−‖yi −Xiβ −Zibi‖2 + ‖∆bi‖2
2σ2
)dbi
=M∏i=1
abs|∆|(2πσ2)ni/2
∫1
(2πσ2)q/2exp
(−‖yi − Xiβ − Zibi‖2
2σ2
)dbi
(2.9)
dove
yi =
[yi
0
], Xi =
[Xi
0
], Zi =
[Zi
∆
]|.| indica il determinante della matrice e ‖.‖ indica la norma del vettore.
Sia ora bi lo stimatore di massima verosimiglianza di bi
bi = (ZiTZi)
−1ZiT
(yi − Xiβ)
28

2.2. Stima dei parametri
L’integrale all’interno della verosimiglianza può essere calcolato riscrivendo lanorma come
‖yi − Xiβ − Zibi‖2 = ‖yi − Xiβ − Zibi‖2 + ‖Zi(bi − bi)‖2
=‖yi − Xiβ − Zibi‖2 + (bi − bi)T ZiTZi(bi − bi)
(2.10)
Il primo termine in (2.10) non dipende da bi e quindi il suo esponenziale può essereportato fuori dall’integrale in (2.9). Integrare l’esponenziale del secondo terminein (2.10) equivale a integrare la densità di una normale multivariata a meno di unacostante moltiplicativa. Si noti che√
|ZiTZi|√
|ZiTZi|
∫1
(2πσ2)q/2exp
(−(bi − bi)T Zi
TZi(bi − bi)
2σ2
)dbi
=1√|Zi
TZi|
∫1
(2πσ2)q/2/
√|Zi
TZi|
exp
(−(bi − bi)T Zi
TZi(bi − bi)
2σ2
)dbi
=1√|Zi
TZi|
=1√
|ZTi Zi +∆T∆|
(2.11)
Combinando (2.10) e (2.11) possiamo esprimere l’integrale in (2.9) come
∫1
(2πσ2)q/2exp
(−‖yi − Xiβ − Zibi‖2
2σ2
)dbi
= exp
(−‖yi − Xiβ − Zibi‖2
2σ2
)1√|Zi
TZi|
(2.12)
La verosimiglianza è quindi pari a
L(β,θ, σ2|y)
=1
(2πσ2)N/2exp
(−∑M
i=1‖yi − Xiβ − Zibi‖2
2σ2
) M∏i=1
abs|∆|√|Zi
TZi|
(2.13)
Per stimare i parametri, si considera θ fissato e si calcolano le stime β(θ) e σ2(θ)
massimizzando la verosimiglianza rispetto a β e σ2. Si osserva che le parti di (2.13)che coinvolgono β e σ2, hanno la stessa forma della verosimiglianza di un modellodi regressione lineare standard, quindi β(θ) e σ2(θ) possono essere calcolate se-guendo la teoria dei modelli di tali modelli Johnson e Wichern (2007); bisogna
29

2. Modelli Lineari a Effetti Misti per dati longitudinali
però considerare che la stima di β dipenderà dalla stima di bi, e viceversa.Per stimare β e bi consideriamo
(bT1 , . . . , bTM , β
T )T = arg minb1,...,bM ,β
‖ye −Xe(b1, . . . , bM ,β)‖2
dove
Xe =
Z1 0 . . . 0 X1
∆ 0 . . . 0 0
0 Z2 . . . 0 X2
0 ∆ . . . 0 0...
......
......
0 0 . . . ZM XM
0 0 . . . ∆ 0
e ye =
y0
0
y2
0...yM
0
(2.14)
Concettualmente si può riscrivere
(bT1 , . . . , bTM , β
T )T = (XTe Xe)
−1XTe ye (2.15)
La stima di massima verosimiglianza σ2 è data da
σ2(θ) =‖ye −Xe(b
T1 , . . . , b
TM , β
T )T‖2
N(2.16)
Sostituendo queste stime nell’equazione della massima verosimiglianza (2.13) siottiene
L(θ) = L(β(θ),θ, σ2(θ)) =exp(−N/2)
(2πσ2(θ))N/2
M∏i=1
abs|∆|√|Zi
TZi|
(2.17)
Si può notare che il profilo di verosimiglianza in (2.17) non dipende dalle stime dibi o β, ma solo dalla stima di σ2. Si può quindi calcolare σ2 attraverso il metododei minimi quadrati. A tal fine è conveniente usare la decomposizione QR dellamatice Zi.
La decomposizione QR di una matrice è una scomposizione del tipo
X = Q
[R
0
]= QtR
dove X è una matrice (n × p) di rango p, con (n ≥ p), Q è una matrice (n × n)
ortogonale, R è una matrice (p × p) triangolare superiore, e Qt è una matrice
30

2.2. Stima dei parametri
costituita dalle prime p colonne di Q.
Nel caso dei modelli lineari a effetti misti, si effettua una decomposizione QRdella matrice Zi nel seguente modo
Zi = Q(i)
[R11(i)
0
]
dove Q(i) e R11(i) sono di dimensione (ni + q)× (ni + q) e q × q, rispettivamente.Si definiscono le seguenti quantità[
R10(i)
R00(i)
]= QT
(i)Xi e
[c1(i)
c0(i)
]= QT
(i)yi
dove R10(i) matrice (q × p), R00(i) matrice (ni × p), c1(i) vettore q-dimensionale ec0(i) vettore ni- dimensionale.Si ottiene quindi
‖yi − Xiβ − Zibi‖2 =‖QT(i)(yi − Xiβ − Zibi)‖2
=‖c1(i) −R10(i)β −R11(i)bi‖2 + ‖c0(i) −R00(i)β‖2(2.18)
dove si è usata la proprietà
‖QTy‖2 = yTQQTy = ‖y‖2
con Q matrice ortogonale.
La verosimiglianza in (2.9) si riscrive come
L(β,θ, σ2|y) =M∏i=1
abs|∆|(2πσ2)ni/2
∫1
(2πσ2)q/2exp
(−‖yi − Xiβ − Zibi‖2
2σ2
)dbi
=M∏i=1
abs|∆|(2πσ2)ni/2
exp
(−‖c0(i) −R00(i)β‖2
2σ2
)1
abs|R11(i)|
=1
(2πσ2)N/2exp
(−∑M
i=1‖c0(i) −R00(i)β‖2
2σ2
) M∏i=1
abs
(|∆||R11(i)|
)(2.19)
in quanto ∫1
(2πσ2)q/2exp
(‖c1(i) −R10(i)β −R11(i)bi‖2
)dbi
31

2. Modelli Lineari a Effetti Misti per dati longitudinali
a meno di una costante moltiplicativa, è l’integrale di una densità multivariata dimedia c1(i) −R10(i)β e matrice di varianza-covarianza σ2(RT
11(i)R11(i))−1.
Effettuando un’ulteriore fattorizzazione QRR00(1) c0(1)
......
R00(M) c0(M)
= Q0
[R00 c0
0 c−1
]
Si riscrive la verosimiglianza nella forma
L(β,θ, σ2|y) =1
(2πσ2)N/2exp
(−‖c−1‖
2 + ‖c0 −R00β‖2
2σ2
) M∏i=1
abs
(|∆||R11(i)|
)(2.20)
Per θ, i valori di β e σ2 che massimizzano (2.20) sono pertanto
β(θ) = R−100 c0
σ2(θ) =‖c−1‖2
N
(2.21)
Tali valori forniscono il profilo di verosimiglianza
L(θ|y) =L(β(θ),θ, σ2(θ)|y)
=
(N
2π‖c−1‖2
)N/2exp
(−N
2
) M∏i=1
abs
(|∆||R11(i)|
) (2.22)
Massimizzando (2.22) rispetto a θ, si ottiene la stima θ. Le stime β e σ2 si otten-gono ponendo θ = θ nelle equazioni (2.21).
Si osserva che l’equazione (2.22) è analoga all’equazione (2.17), infatti
√|Zi
TZi| =
√√√√[RT11(i) 0
]QTi Qi
[R11(i)
0
]=√|RT
11(i)R11(i)| = abs|R11(i)|
e c−1 si pùò definire come
‖c−1‖ = ‖ye −Xe(b1, . . . , bM ,β)‖ (2.23)
con ye e Xe definite nelle equazioni (2.14).
Anche se tecnicamente gli effetti casuali bi non sono considerati parametri del
32

2.3. Selezione del Modello
modello, a volte risulta utile stimare tali valori. Una stima può essere ottenutasfruttando la decomposizione QR. Si ottiene quindi
bi = R−111(i)(c1(i) −R10(i)βi(θ)).
bi sono detti Best Linear Unbiased Predictors (BLUP) di bi e rappresentano lamoda condizionata degli effetti casuali.
Per il calcolo degli stimatori di massimaverosimiglianza nell’applicazione consi-derata, sarà utilizzato il pacchetto di R nlme.
2.3 Selezione del Modello
Diversi sottoinsiemi di covariate danno luogo a modelli differenti. Per scegliere ilmodello più opportuno possono essere considerati due indici. Il primo è chiamatoAkaike Information Criterion (AIC) (Sakamoto et al., 1986), il secondo BayesianInformation Criterion (BIC)(Schwarz, 1978). Sono definiti come segue:
AIC = −2logL+ 2npar
BIC = −2logL+ npar log(N)
dove logL è il logaritmo della verosimiglianza, npar indica il numero di parametridel modello e N il numero totale di osservazioni usate per fittare il modello. Inbase a queste definizioni, si preferiscono modelli con AIC o BIC minori.
2.4 Caso Studio
Per studiare la progressione della malattia attraverso i modelli lineari a effetti mi-sti, si è continuato a studiare le variabili risposta Horizontal Integrated Rim Width,Cup Disk Vertical Ratio e Cup Area.I modelli lineari per il Passo 1 descritto nel paragrafo 2.1.1, sono i modelli ri-sultanti dall’ analisi alla Baseline del paragrafo 1.3.2 a cui è stata aggiunta lavariabile Tempo (tij).Il modello considerato per il Passo 2 tiene conto della variabile categorica Sesso,indipendente dal tempo. Combinando i modelli del Passo 1 e Stage 2 si ottengonoi Modelli Lineari a Effetti Misti per dati longitudinali descritti in seguito.
33

2. Modelli Lineari a Effetti Misti per dati longitudinali
Tabella 2.1: Principali funzioni utilizzate del pacchetto nlme
intervals calcola gli intervalli di confidenza per i parametri del modellolme stima i parametri di un modello lineare a effetti mistiplot.lme permette di rappresentare alcuni risultati per i modelli fittatiranef stima i coefficienti degli effetti casuali per ogni singolo gruppo isummary fornisce informazioni sul modello fittato
I diversi modelli a effetti misti sono stati fittati in R, utilizzando il pacchettonlme (J. Pinheiro et al., 2017). Le funzioni utilizzate e i rispettivi significati sonoriportati in Tabella 2.1.
Le variabili continue sono state standardizzate nel seguente modo
xstdij =xij −mini,j xij
maxi,j xij −mini,j xij
.
Modello 1
Nel primo modello sarà studiata la variabile risposta Horizontal Integrated RimWidth (HIRW) in funzione delle covariate Temporal short Posterior Ciliary Arte-ries(TPCA), Vertical Integrated Rim Area (Volume) (VIRA), Retinal Nerve FiberLayer (RNFL). Tali covariate sono dipendenti dal tempo e quindi faranno partedel Passo 1 dell’analisi. L’effetto della covariata categorica riguardante il sessodel paziente sarà considerato nel Passo 2 dell’analisi. Il modello risultante saràquindi:
HIRWij = β0 + β1tij + β2TPCAsysij
+ β3V IRAij + β4RNFLij + β5Sessoi + β6tij × Sessoi+ β7TPCAsysij × Sessoi + β8V IRAij × Sessoi + β9RNFLij × Sessoi+ b0i + b1itij + b2iTPCAsysij + b3iV IRAij + b4iRNFLij
+ εij
i = 1, . . . , ni, j = 1, . . . ,M
εijiid∼ N(0, σ2)
34

2.4. Caso Studio
Tabella 2.2: P-value del test di Shapiro-Wilk per la variabile Horizontal Integrated RimWidth
p-value
(totale) 1.639e-09
Tempo 0 0.76319713Tempo 1 0.01625483Tempo 2 0.01028885Tempo 3 0.00315492Tempo 4 0.15262329Tempo 5 0.29111877Tempo 6 0.16425010Tempo 7 0.10932522Tempo 8 0.06568374Tempo 9 0.39114034Tempo 10 0.30082350Tempo 11 0.00000000
Per giustificare tale modello, è stato effettuato il test di Shapiro-Wilk che prevedecome ipotesi nulla che il campione sia distribuito come una normale multivariata.Il comando per effettuare il test in questione in R è shapiro.test. In Tabella 2.2 sonoriportati i valori del p-value del test di Shapiro per la variabile risposta HorizontalIntegrated Rim Width complessiva e per la variabile risposta suddivisa per tempidifferenti. Complessivamente il p-value del test è molto basso (p = 1.639e − 09),quindi non si può assumere che il campione complessivo sia distribuito come unanormale multivariata. Tuttavia il p-value risulta essere ≥ 5% per il campionepreso in diversi istanti temporali (Tempo = 0, 4, 5, 6, 7, 8, 9, 10). Come ulterioreconferma di normalità, in Figura 2.1 è rappresentato l’istogramma della variabilerisposta Horizontal Integrated Rim Width suddivisa per tempi differenti.L’output di R per il primo modello è il seguente:
> mod1 <- lme(Horz.integrated.rim.width..area. ~
+ Time*Sex + TPCAsys*Sex + Vert.integrated.rim.area..vol.*Sex + RNFL.average*Sex,
+ random =~ Time + TPCAsys + Vert.integrated.rim.area..vol. + RNFL.average|Id,
+ control= lmeControl(msMaxIter = 200),
+ method = "ML")
35
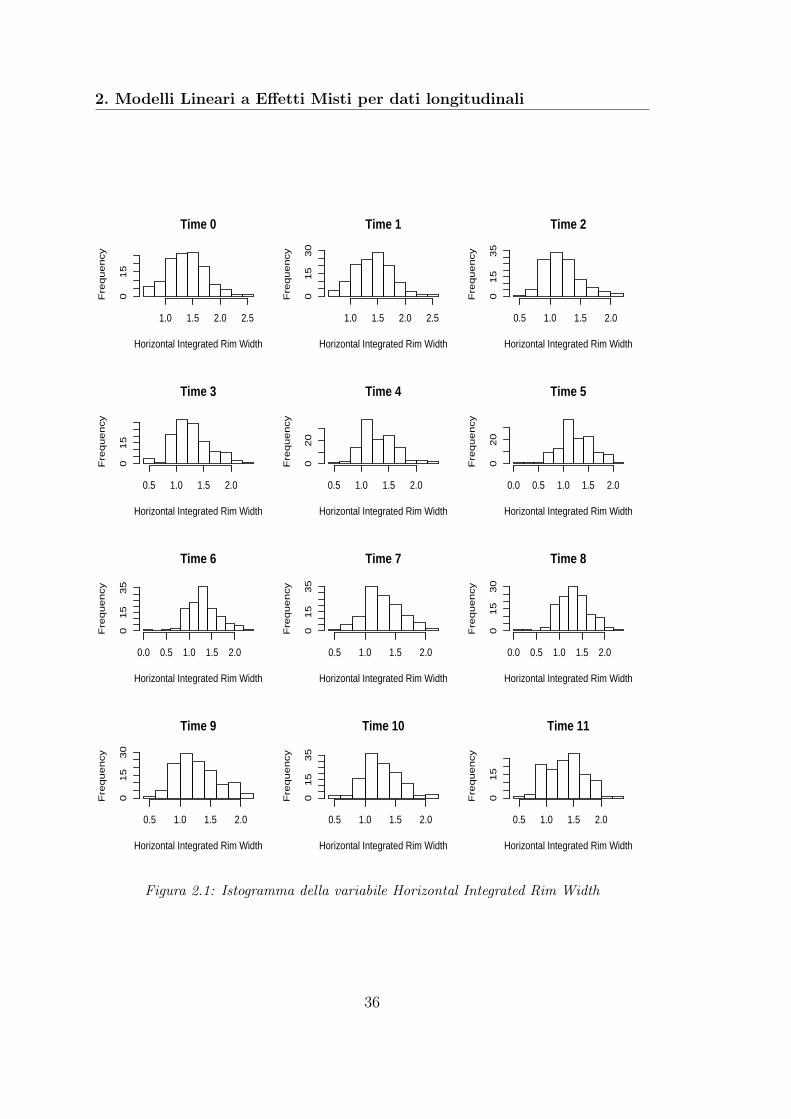
2. Modelli Lineari a Effetti Misti per dati longitudinali
Time 0
Horizontal Integrated Rim Width
Fre
qu
en
cy
1.0 1.5 2.0 2.5
01
5
Time 1
Horizontal Integrated Rim Width
Fre
qu
en
cy
1.0 1.5 2.0 2.50
15
30
Time 2
Horizontal Integrated Rim Width
Fre
qu
en
cy
0.5 1.0 1.5 2.0
01
53
5
Time 3
Horizontal Integrated Rim Width
Fre
qu
en
cy
0.5 1.0 1.5 2.0
01
5
Time 4
Horizontal Integrated Rim Width
Fre
qu
en
cy
0.5 1.0 1.5 2.0
02
0
Time 5
Horizontal Integrated Rim Width
Fre
qu
en
cy
0.0 0.5 1.0 1.5 2.00
20
Time 6
Horizontal Integrated Rim Width
Fre
qu
en
cy
0.0 0.5 1.0 1.5 2.0
01
53
5
Time 7
Horizontal Integrated Rim Width
Fre
qu
en
cy
0.5 1.0 1.5 2.0
01
53
5
Time 8
Horizontal Integrated Rim Width
Fre
qu
en
cy
0.0 0.5 1.0 1.5 2.0
01
53
0
Time 9
Horizontal Integrated Rim Width
Fre
qu
en
cy
0.5 1.0 1.5 2.0
01
53
0
Time 10
Horizontal Integrated Rim Width
Fre
qu
en
cy
0.5 1.0 1.5 2.0
01
53
5
Time 11
Horizontal Integrated Rim Width
Fre
qu
en
cy
0.5 1.0 1.5 2.0
01
5
Figura 2.1: Istogramma della variabile Horizontal Integrated Rim Width
36

2.4. Caso Studio
> summary(mod1)
Linear mixed-effects model fit by maximum likelihood
Data: data.tot
AIC BIC logLik
-3608.787 -3469.194 1830.393
Random effects:
Formula: ~Time + TPCAsys + Vert.integrated.rim.area..vol. + RNFL.average | Id
Structure: General positive-definite, Log-Cholesky parametrization
StdDev Corr
(Intercept) 0.151356381 (Intr) Time TPCAsy V.....
Time 0.001247351 -0.648
TPCAsys 0.110854468 -0.829 0.274
Vert.integrated.rim.area..vol. 0.467355944 0.088 -0.480 -0.197
RNFL.average 0.199059195 -0.935 0.862 0.680 -0.273
Residual 0.065753057
Fixed effects:
Horz.integrated.rim.width..area. ~ Time * Sex + TPCAsys * Sex + Vert.integrated.rim.
area..vol. * Sex + RNFL.average * Sex
Value Std.Error DF t-value p-value
(Intercept) 0.2151212 0.02423284 1456 8.877260 0.0000
Time 0.0005172 0.00065026 1456 0.795428 0.4265
Sex1 0.0442592 0.03771820 120 1.173418 0.2430
TPCAsys 0.0295847 0.02599684 1456 1.138011 0.2553
Vert.integrated.rim.area..vol. 0.8913050 0.06718432 1456 13.266563 0.0000
RNFL.average 0.2992618 0.03179038 1456 9.413597 0.0000
Time:Sex1 -0.0011568 0.00101890 1456 -1.135313 0.2564
Sex1:TPCAsys -0.0396629 0.04061448 1456 -0.976571 0.3289
Sex1:Vert.integrated.rim.area..vol. 0.1700139 0.10718163 1456 1.586222 0.1129
Sex1:RNFL.average -0.0365747 0.05098249 1456 -0.717398 0.4732
Correlation:
(Intr) Time Sex1 TPCAsy V..... RNFL.v Tm:Sx1 S1:TPC S1:V..
Time -0.305
Sex1 -0.642 0.196
TPCAsys -0.663 0.013 0.426
Vert.inte..vol. 0.088 -0.080 -0.057 -0.077
RNFL.average -0.793 0.197 0.509 0.179 -0.318
Time:Sex1 0.194 -0.638 -0.269 -0.008 0.051 -0.126
Sex1:TPCAsys 0.424 -0.008 -0.654 -0.640 0.049 -0.114 0.011
Sex1:Vert.inte..vol. -0.055 0.050 0.095 0.048 -0.627 0.199 -0.065 -0.080
Sex1:RNFL.average 0.494 -0.123 -0.796 -0.111 0.198 -0.624 0.142 0.173 -0.322
Standardized Within-Group Residuals:
Min Q1 Med Q3 Max
-6.916792355 -0.484072804 -0.001784554 0.526517161 4.618571152
Number of Observations: 1586
Number of Groups: 122
Il primo blocco dell’output fornisce alcuni indici per valutare la bontà del modello.
37

2. Modelli Lineari a Effetti Misti per dati longitudinali
Il secondo blocco fornisce le stime relative agli effetti casuali, come la deviazionestandard dei residui, deviazione standard e correlazione degli effetti casuali (σ2 eΨ dell’equazione (2.3)).Si osserva in questo caso una correlazione elevata e positiva tra RNFL con Timee TPCA.
Il terzo blocco fornisce informazioni relative agli effetti fissi. Oltre alle stime deicoefficienti di regressione, sono presenti t-value e p-value per valutare la significa-tività del parametro. In questo caso si ottiene p-value pari a 0 per l’intercetta eper le variabili Vertical Integrated Rim Area Volume e RNFL. Per queste variabiliquindi si ha evidenza statistica per ritenere che siano significative. Al contrarioTempo, la variabile categorica Sesso e la sua interazione con le altre variabili consi-derate, presentano un p-value elevato, quindi si ha evidenza statistica per accettarel’ipotesi nulla β = 0, e quindi tali variabili non sono significative.La parte relativa alla correlazione tra gli effetti fissi di solito non è di interesse perla stima dei modelli.
L’ultimo blocco dell’output presenta informazioni relative ai residui standardiz-zati, il numero di osservazioni e il numero di gruppi del modello.
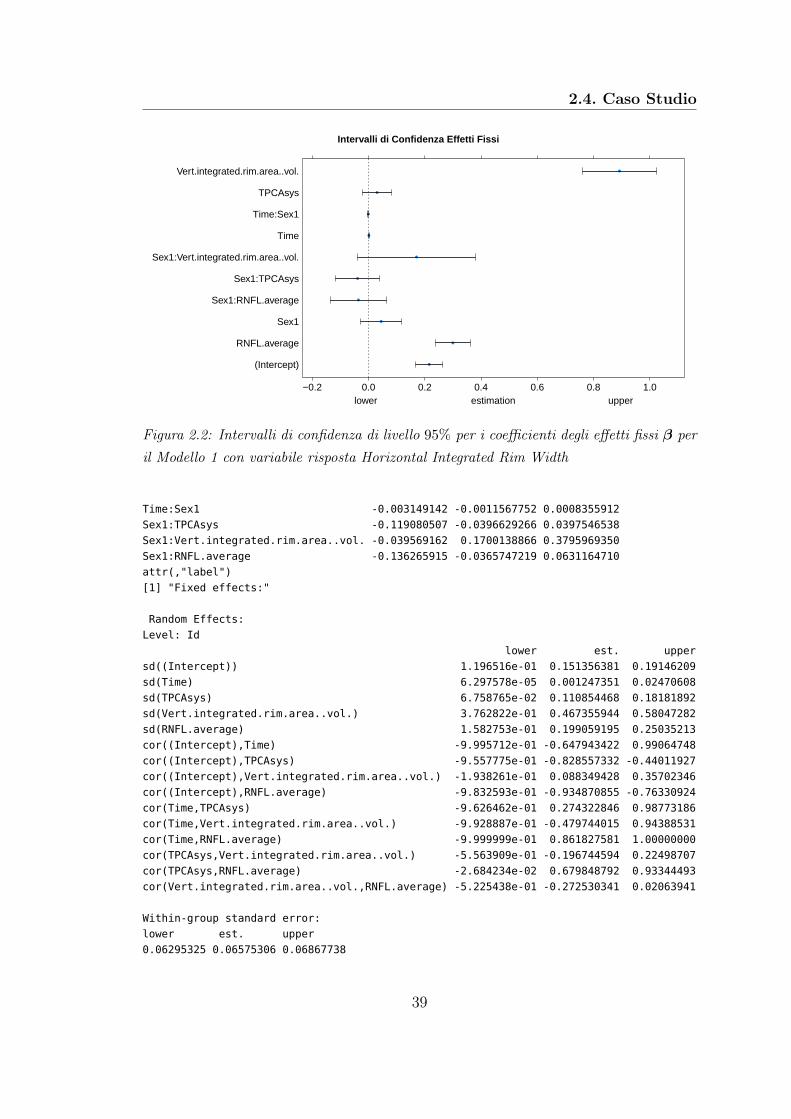
Secondo J. C. Pinheiro e Bates (2000), un metodo per verificare se la stima deiparametri è accurata o meno, è quello di valutare gli intervalli di confidenza di talistime. Se l’intervallo di confidenza è molto ampio, la stima del parametro risulteràimprecisa.Sono stati quindi calcolati gli intervalli di confidenza a livello 95% per i parametristimati>intervals(mod1)
Approximate 95% confidence intervals
Fixed effects:
lower est. upper
(Intercept) 0.167736309 0.2151212208 0.2625061323
Time -0.000754288 0.0005172383 0.0017887647
Sex1 -0.030184370 0.0442592283 0.1187028264
TPCAsys -0.021249550 0.0295846966 0.0804189436
Vert.integrated.rim.area..vol. 0.759932760 0.8913050288 1.0226772978
RNFL.average 0.237098911 0.2992618500 0.3614247885
38
2.4. Caso Studio
Intervalli di Confidenza Effetti Fissi
lower estimation upper
(Intercept)
RNFL.average
Sex1
Sex1:RNFL.average
Sex1:TPCAsys
Sex1:Vert.integrated.rim.area..vol.
Time
Time:Sex1
TPCAsys
Vert.integrated.rim.area..vol.
−0.2 0.0 0.2 0.4 0.6 0.8 1.0
●
●
●
●
●
●
●
●
●
●
Figura 2.2: Intervalli di confidenza di livello 95% per i coefficienti degli effetti fissi β peril Modello 1 con variabile risposta Horizontal Integrated Rim Width
Time:Sex1 -0.003149142 -0.0011567752 0.0008355912
Sex1:TPCAsys -0.119080507 -0.0396629266 0.0397546538
Sex1:Vert.integrated.rim.area..vol. -0.039569162 0.1700138866 0.3795969350
Sex1:RNFL.average -0.136265915 -0.0365747219 0.0631164710
attr(,"label")
[1] "Fixed effects:"
Random Effects:
Level: Id
lower est. upper
sd((Intercept)) 1.196516e-01 0.151356381 0.19146209
sd(Time) 6.297578e-05 0.001247351 0.02470608
sd(TPCAsys) 6.758765e-02 0.110854468 0.18181892
sd(Vert.integrated.rim.area..vol.) 3.762822e-01 0.467355944 0.58047282
sd(RNFL.average) 1.582753e-01 0.199059195 0.25035213
cor((Intercept),Time) -9.995712e-01 -0.647943422 0.99064748
cor((Intercept),TPCAsys) -9.557775e-01 -0.828557332 -0.44011927
cor((Intercept),Vert.integrated.rim.area..vol.) -1.938261e-01 0.088349428 0.35702346
cor((Intercept),RNFL.average) -9.832593e-01 -0.934870855 -0.76330924
cor(Time,TPCAsys) -9.626462e-01 0.274322846 0.98773186
cor(Time,Vert.integrated.rim.area..vol.) -9.928887e-01 -0.479744015 0.94388531
cor(Time,RNFL.average) -9.999999e-01 0.861827581 1.00000000
cor(TPCAsys,Vert.integrated.rim.area..vol.) -5.563909e-01 -0.196744594 0.22498707
cor(TPCAsys,RNFL.average) -2.684234e-02 0.679848792 0.93344493
cor(Vert.integrated.rim.area..vol.,RNFL.average) -5.225438e-01 -0.272530341 0.02063941
Within-group standard error:
lower est. upper
0.06295325 0.06575306 0.06867738
39

2. Modelli Lineari a Effetti Misti per dati longitudinali
Intervalli di Confidenza per i parametri degli Effetti Casuali
lower estimation upper
cor((Intercept),RNFL.average)
cor((Intercept),Time)
cor((Intercept),TPCAsys)
cor((Intercept),Vert.integrated.rim.area..vol.)
cor(Time,RNFL.average)
cor(Time,TPCAsys)
cor(Time,Vert.integrated.rim.area..vol.)
cor(TPCAsys,RNFL.average)
cor(TPCAsys,Vert.integrated.rim.area..vol.)
cor(Vert.integrated.rim.area..vol.,RNFL.average)
sd((Intercept))
sd(RNFL.average)
sd(Time)
sd(TPCAsys)
sd(Vert.integrated.rim.area..vol.)
−1.0 −0.5 0.0 0.5 1.0
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
Figura 2.3: Intervalli di confidenza di livello 95% per i parametri Ψ degli effetti casualiper il Modello 1 con variabile risposta Horizontal Integrated Rim Width
Gli intervalli di confidenza di livello 95% relativi agli effetti fissi sono rappresentatiin Figura 2.2. Anche graficamente si osserva che il tempo non risulta significativoper spiegare la variabile risposta. Al contrario la stima per la variabile VerticalIntegrated Rim Area si discosta notevolmente dal valore nullo.In Figura 2.3 sono rappresentati gli intervalli di confidenza per i parametri relativiagli effetti casuali. Per la maggior parte dei parametri la stima si discosta da 0.Gli intervalli relativi alla correlazione tra le covariate risultano ampi, in particolarenel caso della correlazione tra il tempo e le variabili Vertical Integrated Rim Area,TPCA e RNFL. Tali stime potrebbero quindi essere imprecise.
Infine in Figura 2.4 sono rappresentati i valori stimati per coefficienti degli ef-fetti casuali bi per ogni paziente i. Si osserva che le stime di bi presentano unavariabilità per tutte le covariate incluse nel modello come effetti casuali; pertan-to è giustificato l’utilizzo di un modello ad effetti misti per spiegare la variabilerisposta.
Modello 2
Il secondo modello analizzerà la variabile risposta Cup Disc Vertical Ratio (CD-VR) in funzione delle covariate dipendenti dal tempo Vertical Integrated Rim Area
40

2.4. Caso Studio
Random effects
Pat
ient
501502503504505506507508509511512513514515516517518519520521522523524525526527528529530531532533534535536537538539540541542543544545546547548549550551552553554555556557558559560561562563564565566567568569570571572573574575576577578579580581582583584585586587588589590591592593594595596597598599600601602603604605606607608609610611612613614615616617618619620621622623
−0.2 0.0 0.2 0.4 0.6
●● ●●●● ● ●●● ●●● ●●●●● ●● ●●●●●● ●●●●● ●●● ● ●● ●●●●●● ●● ● ●●● ●● ●● ●● ●● ● ●●●● ●● ●● ●● ●● ●● ●●● ●● ●● ●●● ●● ●● ●●● ● ●● ●●● ● ●●●●●● ●●● ● ●● ●● ●● ●●● ●● ●● ●● ●(Intercept)
−0.002 0.000 0.001 0.002
● ●● ● ● ●●● ● ●● ●●● ●● ● ●● ●● ●●● ● ●● ●●● ●● ●●●● ●● ● ● ● ●●● ●●● ●●● ●● ●●●● ●●●● ● ●●●● ●●●●●●●● ● ●●●● ●● ● ●● ●●● ●● ●●●●● ● ●●● ●●● ●●● ● ●●● ●● ●● ●●● ●●● ●●● ● ●Time
−0.3 −0.2 −0.1 0.0 0.1
● ●●● ● ●● ● ●●● ●●● ● ●● ●● ●● ●●● ● ●●●● ● ●●● ●●● ●●●●●●●● ● ●● ● ●● ●● ●●●● ●●● ● ● ●●●● ●●●● ●● ●● ● ●● ●●●● ● ●● ●●●● ● ●●● ●● ● ●●● ●●● ●●●● ●●● ●● ●● ●●●●● ●●●● ●●
TPCAsys
501502503504505506507508509511512513514515516517518519520521522523524525526527528529530531532533534535536537538539540541542543544545546547548549550551552553554555556557558559560561562563564565566567568569570571572573574575576577578579580581582583584585586587588589590591592593594595596597598599600601602603604605606607608609610611612613614615616617618619620621622623
−1.0 −0.5 0.0 0.5 1.0
●● ●● ● ● ●●● ●●● ●●● ●●● ●● ●● ●●●● ●● ●●●●●● ●● ● ●●●●● ●●●● ●● ●●● ●● ● ●●●●● ●●●● ●●●● ●● ●●● ●● ●●● ● ● ●● ● ● ●●●● ●● ●● ●● ●●●●● ●●● ● ● ●● ● ●● ●● ●● ●●● ●●● ●● ●●Vert.integrated.rim.area..vol.
−0.6 −0.4 −0.2 0.0 0.2
● ●● ● ● ●●● ● ●● ●●● ●●● ●● ●● ●●● ● ●●●●● ●● ● ●●● ●●●● ●●●● ●●● ● ●● ●● ●●●● ●●●● ● ●●●● ●●●●●●●● ● ●●●● ●● ● ●● ●●●● ● ●●● ●● ● ●●● ● ●● ● ●●● ●●● ●● ●● ●●●●●●●●● ●●RNFL.average
Figura 2.4: Valore stimato dei coefficienti bi per ogni soggetto i per il Modello 1 convariabile risposta Horizontal Integrated Rim Width
41

2. Modelli Lineari a Effetti Misti per dati longitudinali
(Volume) (VIRA) e Macular Volume (MD). Inoltre sarà considerata la variabilecategorica Sesso. Il modello risultante è il seguente:
CDV ratioij = β0 + β1tij + β2V IRAij
+ β3MVij + β4Sessoi + β5tij × Sessoi+ β6V IRAij × Sessoi + β7MVij × Sessoi+ b0i + b1itij + b2iV IRAij + b3iMVij
+ εij
i = 1, . . . , ni, j = 1, . . . ,M
εijiid∼ N(0, σ2)
Sono state effettuate delle analisi per studiare la natura della variabile rispostaCDVR; tale variabile non soddisfa le ipotesi di gaussianità. Essa assume valorinell’intervallo [0, 1) ed assume valore pari a 1 per un numero molto ridotto diosservazioni. Si è provato a effettuare delle trasformazioni su questa variabile (e.g.trasformazione logaritmica, trasformazione di tipo logit), ma anche in questo caso irisultati non sono stati soddisfacenti. Si è deciso comunque di riportare il risultatodell’analisi per la variabile non trasformata. Di seguito è riportato quindi l’outputR per il secondo modello:> mod2 <- lme(Cup.disk.vert.ratio ~
+ Time*Sex + Vert.integrated.rim.area..vol.*Sex + Macular.volume*Sex,
+ random =~ Time + Vert.integrated.rim.area..vol. + Macular.volume|Id,
+ control= lmeControl(msMaxIter = 200),
+ method = "ML")
> summary(mod2)
Linear mixed-effects model fit by maximum likelihood
Data: data.tot
AIC BIC logLik
-2182.425 -2080.414 1110.212
Random effects:
Formula: ~Time + Vert.integrated.rim.area..vol. + Macular.volume | Id
Structure: General positive-definite, Log-Cholesky parametrization
StdDev Corr
(Intercept) 0.373753910 (Intr) Time V.....
Time 0.006266329 -0.267
Vert.integrated.rim.area..vol. 0.702144293 -0.285 0.531
Macular.volume 0.668817319 -0.963 0.012 0.120
Residual 0.103901428
Fixed effects:
42

2.4. Caso Studio
Cup.disk.vert.ratio ~ Time * Sex + Vert.integrated.rim.area..vol. * Sex + Macular.
volume * Sex
Value Std.Error DF t-value p-value
(Intercept) 1.0534439 0.07412581 1458 14.211567 0.0000
Time 0.0010949 0.00122408 1458 0.894483 0.3712
Sex1 -0.0697633 0.12258060 120 -0.569122 0.5703
Vert.integrated.rim.area..vol. -1.1759378 0.10025122 1458 -11.729910 0.0000
Macular.volume -0.4600729 0.13286967 1458 -3.462588 0.0006
Time:Sex1 -0.0038112 0.00191981 1458 -1.985207 0.0473
Sex1:Vert.integrated.rim.area..vol. -0.1275607 0.16051593 1458 -0.794692 0.4269
Sex1:Macular.volume 0.1909777 0.22103889 1458 0.864001 0.3877
Correlation:
(Intr) Time Sex1 V.... Mclr.v Tm:Sx1 S1:V..
Time -0.251
Sex1 -0.605 0.152
Vert.inte..vol. -0.096 0.275 0.058
Macular.volume -0.979 0.092 0.592 -0.028
Time:Sex1 0.160 -0.638 -0.217 -0.175 -0.059
Sex1:Vert.inte..vol. 0.060 -0.172 -0.069 -0.625 0.017 0.277
Sex1:Macular.volume 0.588 -0.055 -0.981 0.017 -0.601 0.066 -0.047
Standardized Within-Group Residuals:
Min Q1 Med Q3 Max
-6.95208624 -0.35915731 0.02422104 0.41732325 6.44819023
Number of Observations: 1586
Number of Groups: 122
In questo caso per quanto riguarda gli effetti fissi si ha un p-value pari a 0 perl’intercetta, per Vertical Integrated Rim Area e per Macular Volume. Inoltre ilp-value relativo a l’interazione tra il tempo e la variabile categorica Sex risultaessere minore del 5%, tale interazione è quindi significativa.
In Figura 2.5 sono rappresentati gli intervalli di confidenza di livello 95% per glieffetti fissi del Modello 2. Anche per questo modello il tempo non sembra esseresignificativo per spiegare la variabile risposta.
In Figura 2.6 sono rappresentati gli intervalli di confidenza di livello 95% per iparametri relativi agli effetti casuali del Modello 2. La stima si discosta dal valorenullo per tutti i parametri, tranne per la deviazione standard del tempo e la corre-lazione tra Time e Macular Volume. Anche in questo caso però la maggior partedegli intervalli relativi alla correlazione tra le covariate risultano ampi, la stima ditali valori potrebbe essere quindi imprecisa.
43
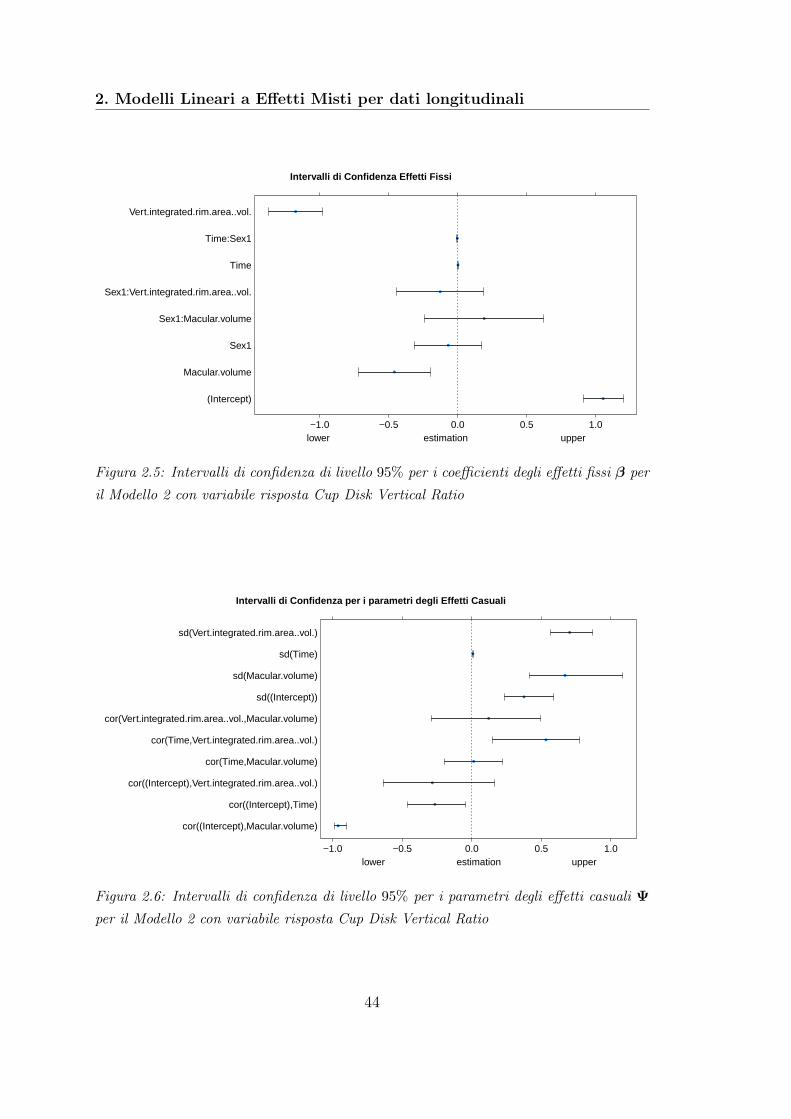
2. Modelli Lineari a Effetti Misti per dati longitudinali
Intervalli di Confidenza Effetti Fissi
lower estimation upper
(Intercept)
Macular.volume
Sex1
Sex1:Macular.volume
Sex1:Vert.integrated.rim.area..vol.
Time
Time:Sex1
Vert.integrated.rim.area..vol.
−1.0 −0.5 0.0 0.5 1.0
●
●
●
●
●
●
●
●
Figura 2.5: Intervalli di confidenza di livello 95% per i coefficienti degli effetti fissi β peril Modello 2 con variabile risposta Cup Disk Vertical Ratio
Intervalli di Confidenza per i parametri degli Effetti Casuali
lower estimation upper
cor((Intercept),Macular.volume)
cor((Intercept),Time)
cor((Intercept),Vert.integrated.rim.area..vol.)
cor(Time,Macular.volume)
cor(Time,Vert.integrated.rim.area..vol.)
cor(Vert.integrated.rim.area..vol.,Macular.volume)
sd((Intercept))
sd(Macular.volume)
sd(Time)
sd(Vert.integrated.rim.area..vol.)
−1.0 −0.5 0.0 0.5 1.0
●
●
●
●
●
●
●
●
●
●
Figura 2.6: Intervalli di confidenza di livello 95% per i parametri degli effetti casuali Ψper il Modello 2 con variabile risposta Cup Disk Vertical Ratio
44
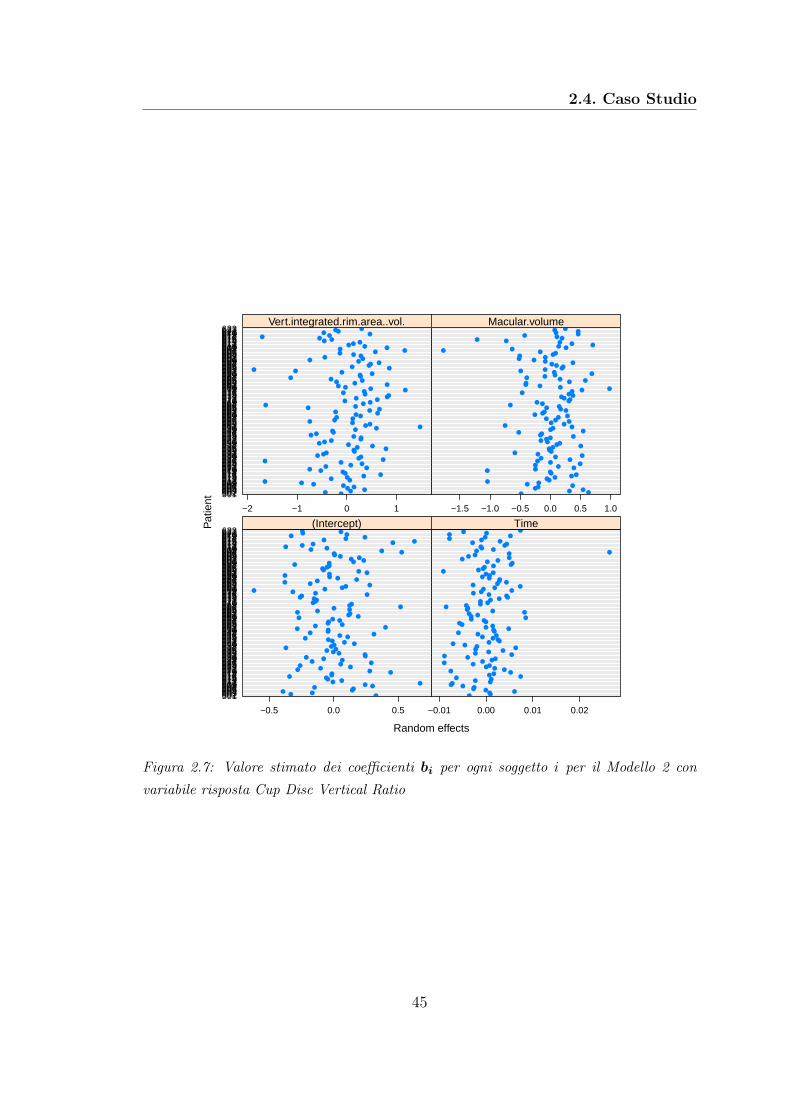
2.4. Caso Studio
Random effects
Pat
ient
501502503504505506507508509511512513514515516517518519520521522523524525526527528529530531532533534535536537538539540541542543544545546547548549550551552553554555556557558559560561562563564565566567568569570571572573574575576577578579580581582583584585586587588589590591592593594595596597598599600601602603604605606607608609610611612613614615616617618619620621622623
−0.5 0.0 0.5
●● ●● ●●● ●● ●● ●●●● ●● ●●● ● ●● ● ●● ●●● ●●●●● ●● ●● ●●●●● ●● ●● ●●● ●● ●●● ●●● ●●●● ● ●● ●●●●●●●●● ●●●● ● ●● ●●● ● ●●●● ● ●●●●●●● ● ● ●● ●●●● ●●● ●● ● ● ● ●● ● ●● ●● ●●(Intercept)
−0.01 0.00 0.01 0.02
● ●● ●●●●●●● ●● ●● ●●● ●● ●●●●●● ● ●●●● ●● ● ●● ●●●● ● ●●●● ●●● ●● ●● ●●● ●●● ●● ●● ●●●●● ● ● ●● ● ● ●●●● ● ●● ● ●● ● ●●●●● ●● ●● ●●● ● ●●● ●● ●● ● ● ●● ●●● ●●● ●●● ● ●● ●● ●Time
501502503504505506507508509511512513514515516517518519520521522523524525526527528529530531532533534535536537538539540541542543544545546547548549550551552553554555556557558559560561562563564565566567568569570571572573574575576577578579580581582583584585586587588589590591592593594595596597598599600601602603604605606607608609610611612613614615616617618619620621622623
−2 −1 0 1
●● ● ●● ●●●●● ●● ● ● ●●●●● ●● ● ●●● ●●●● ●● ●● ●● ●●●● ● ●●●●● ●● ● ● ●●●●● ● ●● ●● ●● ● ●● ●● ● ●● ●● ●●●● ● ●●●● ●●● ●●● ●● ●●●● ●● ●● ●●● ●● ●●● ● ●● ●●●● ●● ●●● ● ●● ●● ●Vert.integrated.rim.area..vol.
−1.5 −1.0 −0.5 0.0 0.5 1.0
● ●● ●●● ●● ●● ●● ● ●●●●● ● ●●● ●●● ●● ● ●●● ●●●● ●●●●●●● ●●●● ●●● ●● ●● ●●● ● ●● ●● ●●● ●● ●● ●●●● ●●● ● ● ●●●●● ● ●●● ● ● ●●● ● ●●●● ●●●● ●● ●●●● ● ●● ●●●●● ●●● ●● ●● ●
Macular.volume
Figura 2.7: Valore stimato dei coefficienti bi per ogni soggetto i per il Modello 2 convariabile risposta Cup Disc Vertical Ratio
45

2. Modelli Lineari a Effetti Misti per dati longitudinali
Infine in Figura 2.7, sono rappresentati i valori stimati per coefficienti degli ef-fetti casuali bi per ogni paziente i. In questo modello si osserva una notevolevariabilità nelle stime di bi presentano per tutte le covariate considerate come ef-fetti casuali; pertanto ha senso l’utilizzo di un modello ad effetti misti per spiegarela variabile risposta.
Modello 3
Il terzo modello studierà la variabile risposta Cup Area (CA) in funzione dellecovariate Vertical Integrated Rim Area (Volume) (VIRA) e Nasal short PosteriorCiliary Arteries(NPCA). Anche in questo caso è inclusa nel modello la variabilecategorica riguardante il sesso del Paziente. Il modello finale è il seguente:
CAij = β0 + β1tij + β2V IRAij + β3NPCAdysij
+ β4NPCAsysij + β5Sessoi + β6tij × Sessoiβ7V IRAij × Sessoi + β8NPCAdysij × Sessoi+ β9NPCAsysij × Sessoib0i1 + b1itij + b2iV IRAij + b3iNPCAdysij + b4iNPCAsysij
+ εij
i = 1, . . . , ni, j = 1, . . . ,M
εijiid∼ N(0, σ2)
In seguito è riportato l’output per il terzo modello:> mod3 <- lme(Cup.area ~
+ Time*Sex + Vert.integrated.rim.area..vol.*Sex + NPCAdys*Sex + NPCAsys*Sex,
+ random =~ Time + Vert.integrated.rim.area..vol. + NPCAdys + NPCAsys|Id,
+ control= lmeControl(msMaxIter = 200),
+ method = "ML")
> summary(mod3)
Linear mixed-effects model fit by maximum likelihood
Data: data.tot
AIC BIC logLik
-2930.401 -2790.808 1491.201
Random effects:
Formula: ~Time + Vert.integrated.rim.area..vol. + NPCAdys + NPCAsys | Id
Structure: General positive-definite, Log-Cholesky parametrization
StdDev Corr
(Intercept) 0.143371717 (Intr) Time V..... NPCAdy
Time 0.006733914 -0.705
46

2.4. Caso Studio
Vert.integrated.rim.area..vol. 0.410713771 -0.822 0.507
NPCAdys 0.132785142 -0.096 0.588 -0.153
NPCAsys 0.170591961 -0.279 -0.390 0.485 -0.897
Residual 0.081185668
Fixed effects:
Cup.area ~ Time * Sex + Vert.integrated.rim.area..vol. * Sex + NPCAdys * Sex + NPCAsys
* Sex
Value Std.Error DF t-value p-value
(Intercept) 0.3291928 0.02510681 1456 13.111691 0.0000
Time 0.0041749 0.00110328 1456 3.784130 0.0002
Sex1 0.0275207 0.03861537 120 0.712687 0.4774
Vert.integrated.rim.area..vol. -0.7036608 0.06207853 1456 -11.335011 0.0000
NPCAdys -0.0640673 0.03499473 1456 -1.830770 0.0673
NPCAsys 0.0460689 0.04961251 1456 0.928575 0.3533
Time:Sex1 -0.0026294 0.00175700 1456 -1.496504 0.1347
Sex1:Vert.integrated.rim.area..vol. 0.0291597 0.09959338 1456 0.292787 0.7697
Sex1:NPCAdys 0.0313421 0.05631800 1456 0.556521 0.5779
Sex1:NPCAsys -0.0476042 0.07990075 1456 -0.595791 0.5514
Correlation:
(Intr) Time Sex1 V.... NPCAdy NPCAsy Tm:Sx1 S1:V.. Sx1:NPCAd
Time -0.486
Sex1 -0.650 0.316
Vert.inte..vol. -0.535 0.312 0.348
NPCAdys 0.198 0.282 -0.129 -0.047
NPCAsys -0.632 -0.154 0.411 0.149 -0.779
Time:Sex1 0.305 -0.628 -0.410 -0.196 -0.177 0.097
Sex1:Vert.inte..vol. 0.334 -0.194 -0.541 -0.623 0.029 -0.093 0.293
Sex1:NPCAdys -0.123 -0.175 0.182 0.029 -0.621 0.484 0.329 -0.076
Sex1:NPCAsys 0.392 0.096 -0.619 -0.093 0.484 -0.621 -0.258 0.162 -0.768
Standardized Within-Group Residuals:
Min Q1 Med Q3 Max
-3.67187440 -0.46720369 -0.03611526 0.38232370 5.96111328
Number of Observations: 1586
Number of Groups: 122
Anche per il terzo modello, l’intercetta e la variabile Vertical Integrated Rim Arearisultano significative. In questo caso la variabile Tempo sembrerebbe significativain quanto il p-value risulta essere pari a 0.02%.
In Figura 2.8 e 2.9 sono rappresentati gli intervalli di confidenza di livello 95%
per gli effetti fissi e casuali del Modello 3. Anche per questo modello molti inter-valli risultano molto ampi, si ipotizza quindi una stima imprecisa per i parametriassociati a tali intervalli.
In Figura 2.10 sono rappresentati i valori stimati per coefficienti degli effetti ca-
47
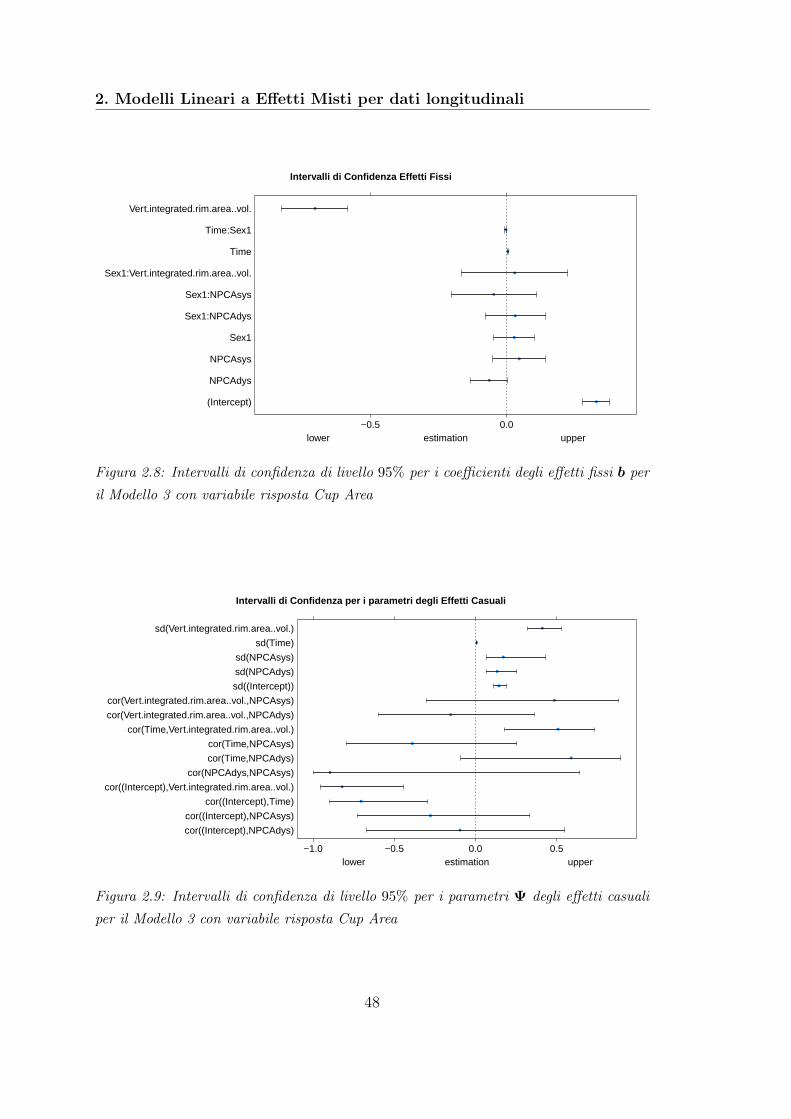
2. Modelli Lineari a Effetti Misti per dati longitudinali
Intervalli di Confidenza Effetti Fissi
lower estimation upper
(Intercept)
NPCAdys
NPCAsys
Sex1
Sex1:NPCAdys
Sex1:NPCAsys
Sex1:Vert.integrated.rim.area..vol.
Time
Time:Sex1
Vert.integrated.rim.area..vol.
−0.5 0.0
●
●
●
●
●
●
●
●
●
●
Figura 2.8: Intervalli di confidenza di livello 95% per i coefficienti degli effetti fissi b peril Modello 3 con variabile risposta Cup Area
Intervalli di Confidenza per i parametri degli Effetti Casuali
lower estimation upper
cor((Intercept),NPCAdys)
cor((Intercept),NPCAsys)
cor((Intercept),Time)
cor((Intercept),Vert.integrated.rim.area..vol.)
cor(NPCAdys,NPCAsys)
cor(Time,NPCAdys)
cor(Time,NPCAsys)
cor(Time,Vert.integrated.rim.area..vol.)
cor(Vert.integrated.rim.area..vol.,NPCAdys)
cor(Vert.integrated.rim.area..vol.,NPCAsys)
sd((Intercept))
sd(NPCAdys)
sd(NPCAsys)
sd(Time)
sd(Vert.integrated.rim.area..vol.)
−1.0 −0.5 0.0 0.5
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
Figura 2.9: Intervalli di confidenza di livello 95% per i parametri Ψ degli effetti casualiper il Modello 3 con variabile risposta Cup Area
48
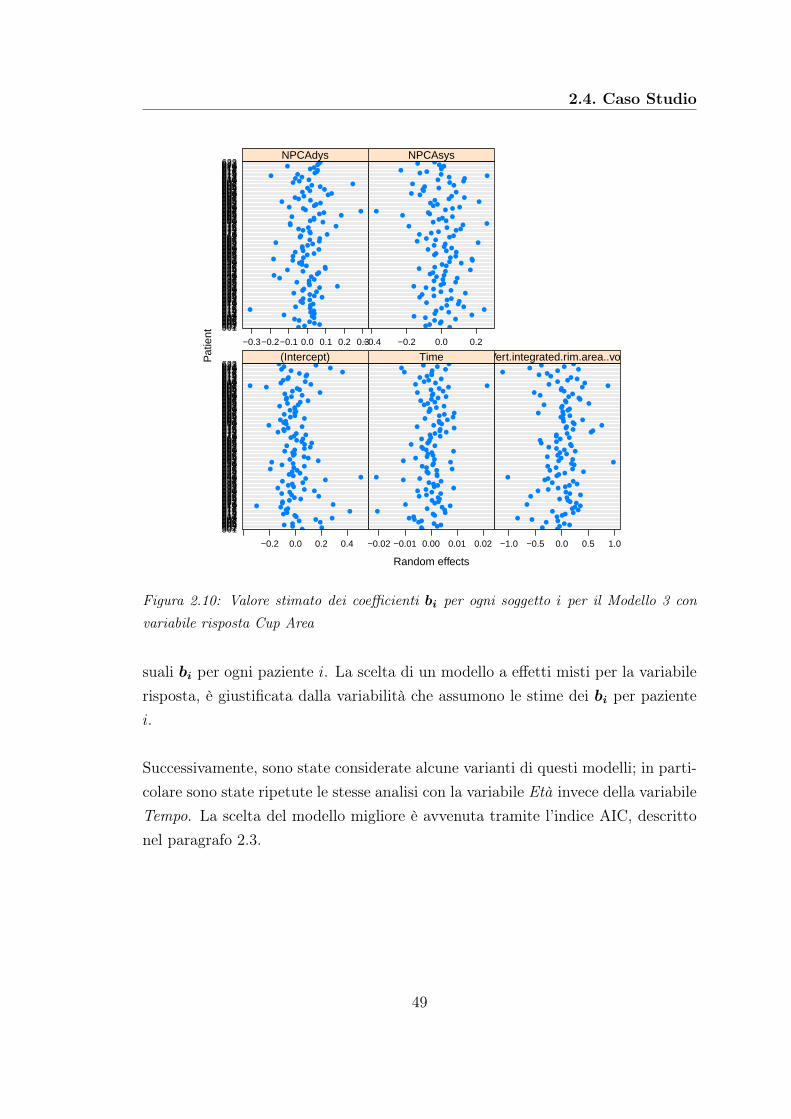
2.4. Caso Studio
Random effects
Pat
ient
501502503504505506507508509511512513514515516517518519520521522523524525526527528529530531532533534535536537538539540541542543544545546547548549550551552553554555556557558559560561562563564565566567568569570571572573574575576577578579580581582583584585586587588589590591592593594595596597598599600601602603604605606607608609610611612613614615616617618619620621622623
−0.2 0.0 0.2 0.4
● ●●● ● ●● ● ●●●●● ●●●●● ●●● ● ●● ●●● ● ●●● ●●● ●● ●● ●●● ●●●● ● ●● ●● ●● ●●●●●● ● ● ●● ● ●●● ●●● ●●● ●●● ●● ●●●
● ●●●● ●●●●●● ●● ● ●●●● ●● ●● ●●●● ●● ●●●● ●●● ●●● ●● ●●(Intercept)
−0.02 −0.01 0.00 0.01 0.02
●● ●●●●●●●● ●● ●● ●● ● ●● ●●● ●●● ● ●●● ● ●●●●● ●● ●● ●●●● ● ●●● ●● ●● ●● ● ●●● ●●●● ●● ●●●● ● ●●● ●●● ●● ● ●●●
●● ●●● ●●●●● ●●● ●● ● ● ●●●● ●● ● ● ●● ●●● ●● ●●●● ● ●● ●● ●
Time
−1.0 −0.5 0.0 0.5 1.0
●● ● ●●● ●●● ●●● ●● ●●●●● ●●●● ●● ●●●● ● ● ●● ●● ●●●● ●● ● ●● ●●● ●● ●● ●●● ● ●● ●●●● ●●● ●● ● ●●● ● ●●●●● ●●●● ●●● ●●● ●●●●●● ●●● ●●●● ●● ●●● ● ●● ●● ● ●●●● ●● ● ●● ●● ●Vert.integrated.rim.area..vol.
501502503504505506507508509511512513514515516517518519520521522523524525526527528529530531532533534535536537538539540541542543544545546547548549550551552553554555556557558559560561562563564565566567568569570571572573574575576577578579580581582583584585586587588589590591592593594595596597598599600601602603604605606607608609610611612613614615616617618619620621622623
−0.3−0.2−0.1 0.0 0.1 0.2 0.3
● ● ●●●●● ●●● ●●●● ●● ●●●● ●● ●●●● ●●● ● ●●●● ●●● ●● ●●●● ●●●●●●●● ●● ● ●● ● ●●●●●● ●● ●●● ●●●●● ● ●●● ●●●●● ●●● ●●●● ●●●● ●●● ● ●●● ● ●● ●● ●● ● ●● ●● ● ●●●●●● ●●●
NPCAdys
−0.4 −0.2 0.0 0.2
●●● ●●● ●●● ●● ●● ●● ●● ●● ●●●● ●● ●● ●●●● ●● ●● ● ●● ●●● ● ●● ● ●● ●● ●●●●●● ●●● ●●● ● ●● ●● ●●● ● ● ●●●● ● ●● ●●● ●● ●●● ● ● ●●●● ●● ● ●●●● ●●● ●● ●● ● ●● ●● ●●● ●● ●●●●● ●
NPCAsys
Figura 2.10: Valore stimato dei coefficienti bi per ogni soggetto i per il Modello 3 convariabile risposta Cup Area
suali bi per ogni paziente i. La scelta di un modello a effetti misti per la variabilerisposta, è giustificata dalla variabilità che assumono le stime dei bi per pazientei.
Successivamente, sono state considerate alcune varianti di questi modelli; in parti-colare sono state ripetute le stesse analisi con la variabile Età invece della variabileTempo. La scelta del modello migliore è avvenuta tramite l’indice AIC, descrittonel paragrafo 2.3.
49


Capitolo 3
Hidden Markov Models
La progressione di una malattia può essere descritta attraverso un modello multi-stato dove i diversi stati rappresentano diversi livelli della malattia. Tipicamen-te vengono utilizzati modelli di Markov musti-stato per descrivere l’avanzamentodella malattia. In alcuni casi, tuttavia lo stato della malattia non è direttamenteosservabile per questo motivo in letteratura è stato proposto l’utilizzo di Modellidi Markov nascosti (Hidden Markov Model- HMM). Un HMM è un modello stati-stico in cui l’evoluzione temporale del processo fisico segue un modello Markovianocon stati nascosti dalle osservazioni che sono governate da una certa distribuzionedi probabilità (detta distribuzione di emissione) condizionatamente agli stati nonosservati.In questo lavoro ci riferiremo alla teoria degli HMMs come descritta in Zucchiniet al. (2016); in primis gli autori descrivono i modelli di Markov nascosti per serietemporali e successivamente generalizzano al caso di dati longitudinali, infatti undataset longitudinale può essere visto come l’insieme di M serie temporali in cuiogni serie corrisponde ad un individuo.
3.1 Catene di Markov
Una sequenza di variabili aleatorie discrete {Ct : t ∈ N} a valori inM = {1, . . . ,m}è detta Catena di Markov (CdM) a tempo discreto se, per ogni t ∈ N, soddisfa laproprietà di Markov
Pr(Ct+1|Ct, . . . , C1) = Pr(Ct+1|Ct).

3. Hidden Markov Models
ovvero la variabile aleatoria Ct+1 dipende solo dal valore più recente Ct e non datutta la storia passata. M è detto spazio degli stati.Per le catene di Markov si definiscono le probabilità di transizione
P(Cs+t = k|Cs = h), h, k = 1, . . . ,m
Se tale probabilità non dipende da s, ma solo dal lag temporale t = (t + s) − sla CdM è detta omogenea, altrimenti non omogenea. In caso di catena di Markovomogena, le probabilità di transizione sono indicate come
γhk(t) = Pr(Cs+t = k|Cs = h) = Pr(Ct+1 = k|C1 = h), h, k = 1, . . . ,m
Si definisce matrice di transizione a t passi, Γ(t), come la matrice il cui elementohk è dato dalla probabilità di transizione γhk(t).Le CdM omogenee soddisfano l’equazione di Chapman-Kologorov
Γ(t+ u) = Γ(t)Γ(u)
; l’equazione di Chapman-Kologorov implica che
Γ(t) = Γ(1)t t ∈ N
ovvero la matrice di transizione dopo t passi, è pari alla potenza di ordine t diΓ(1). La matrice Γ(1), che si può indicare con Γ, è detta matrice di transizioneed è pari a
γ11 . . . γ1m... . . . ...γm1 . . . γmm
dove γhk ≥ 0 per hk, j = 1, . . . ,m e
∑mk=1 γhk = 1 per h = 1, . . . ,m.
Di interesse è la legge marginale delle variabili Ct, ovvero le probabilità Pr(Ct = k)
che la CdM sia in un dato stato k al tempo t. Tali probabilità sono indicate conil vettore riga
u(t) = (Pr(Ct = 1), . . . ,Pr(Ct = m)), t ∈ N
con la proprietàu(t+ 1) = u(t)Γ (3.1)
Il vettore u(1) è detto distribuzione iniziale della CdM.
Una Catena di Markov con matrice di transizione Γ, ha una distribuzione sta-zionaria δ = {δ1, . . . , δm} se
∑mk=1 δk = 1 e δ = δΓ.
52

3.2. Hidden Markov Models
Y1 Y2 Y3 Y4 · · ·
C1 C2 C3 C4 · · ·
Figura 3.1: Rappresentazione di un HMM. Le osservazioni sono generate condizionata-mente a un processo di Markov nascosto.
3.2 Hidden Markov Models
In un Hidden Markov Model (HMM) gli stati della Catena di Markov non sonoosservabili direttamente. Le osservazioni sono governate da una distribuzione diprobabilità (distribuzione di emissione) condizionatamente agli stati non osservati.Per ulteriori dettagli si veda Zucchini et al. (2016).
Sia {Ct : t = 1, 2, . . . } un insieme di variabili aleatorie che indica gli stati na-scosti del processo e {Yt : t = 1, 2, . . . } un insieme di osservazioni.Un processo di Markov nascosto (Hidden Markov Model - HMM) {Yt : t ∈ N} èun modello del tipo:
Pr(Ct|C(t−1)) = Pr(Ct|Ct−1), t = 2, 3, . . . (3.2)
Pr(Yt|Y (t−1),C(t)) = Pr(Yt|Ct), t ∈ N (3.3)
dove C(t) e Y (t) rappresentano la storia del processo dal tempo 1 al tempo t, econ Pr(·) si intende genericamente la legge di probabilità.Il modello è formato da due parti: la prima, rappresentata dall’equazione (3.2),indica che gli stati nascosti del processo soddisfano la proprietà di Markov; la se-conda, rappresentata dall’equazione (3.3), indica che le osservazioni sono tali chela distribuzione di Yt dipenda solo dallo stato corrente Ct e non dagli stati o dalleosservazioni precedenti. Tale struttura è mostrata in Figura 3.1.SeM = {1, 2, . . . ,m} è l’insieme di stati della CdM {Ct} (i.e. l’insieme di valoriche può assumere Ct), il processo {Yt} è chiamato HMM a m stati.Ora, secondo Zucchini et al. (2016), verranno introdotte alcune notazioni che val-gono per osservazioni che assumono valori sia discreti che continui. Nel caso di
53

3. Hidden Markov Models
osservazioni discrete, si definisce
ph(y) = Pr(Yt = y|Ct = h), h = 1, 2, . . . ,m (3.4)
dove ph è la densità discreta di Yt condizionata all’evento che la catena di Markovsia nello stato h al tempo t. Si avranno quindi m distribuzioni ph (una per ognistato) dette distribuzioni di emissione.Analogamente nel caso di osservazioni continue si definisce fh come
fh(y) = f(y|Ct = h) (3.5)
dove f(·|Ct = h) rappresenta la densità condizionale di Yt dato l’evento Ct = h.Si noti che in equazione (3.4) e (3.5) implicitamente si assume l’indipendenza daltempo t.
Riportiamo alcuni risultati per il caso di in cui le osservazioni sono variabili alea-torie discrete, ma possono essere facilmente estesi al caso continuo, sostituendo ladistribuzione di emissione dell’equazione (3.4), con la densità in equazione (3.5).Si veda Zucchini et al. (2016) per i dettagli.
3.2.1 Distribuzioni marginali
Distribuzioni univariate
Per osservazioni discrete Yt, dati uh(t) = Pr(Ct = h) per t = 1, 2, . . . , T e ph(y)
distribuzione di emissione, si avrà
Pr(Yt = y) =m∑h=1
Pr(Ct = h)Pr(Yt = y|Ct = h)
=m∑h=1
uh(t)ph(y)
Tale equazione può essere espressa in forma matriciale come
Pr(Yt = y) =(u1(t), . . . , um(t))
p1(y) 0
. . .
0 pm(y)
1...1
=u(t)P (y)1′.
54

3.2. Hidden Markov Models
dove P (y) è una matrice diagonale con elementi pari a ph(y). Dall’equazione (3.1)segue che u(t) = u(1)Γt−1 e quindi
Pr(Yt = y) = u(1)Γt−1P (y)1′ (3.6)
l’equazione (3.6) vale per Catene di Markov omogenee, ma non necessariamentestazionarie. Se si assume che la CdM sia anche stazionaria con distribuzione δl’equazione (3.6) diventa
Pr(Yt = y) = δP (y)1′ (3.7)
Distribuzioni bivariate
Segue che
Pr(Yt, Yt+k, Ct, Ct+k) = Pr(Ct)Pr(Yt|Ct)Pr(Ct+k|Ct)Pr(Yt+k|Ct+k)
e quindi
Pr(Yt = v,Yt+s = w)
=m∑h=1
m∑k=1
Pr(Yt = v, Yt+s = w,Ct = h,Ct+s = k)
=m∑h=1
m∑k=1
Pr(Ct = h)︸ ︷︷ ︸uh(t)
Pr(Yt = v|Ct = h))︸ ︷︷ ︸ph(v)
Pr(Ct+s = k|Ct = h)︸ ︷︷ ︸γhk(s)
Pr(Yt+s = w|Ct+s = k)︸ ︷︷ ︸pk(w)
=m∑h=1
m∑k=1
uh(t)ph(v)γhk(s)pk(w).
Scrivendo le somme come prodotto tra matrici si ottiene
Pr(Yt = v, Yt+s = w) = u(t)P (v)ΓsP (w)1′. (3.8)
Inoltre se la CdM è stazionaria, con distribuzione δ, l’equazione (3.8) diventa
Pr(Yt = v, Yt+s = w) = δP (v)ΓsP (w)1′. (3.9)
In maniera analoga si ricavano la distribuzioni marginali multivariate; ad esempio,nel caso stazionario, l’espressione della distribuzione trivariata, per p e q interipositivi, è data da
Pr(Yt = v, Yt+p = w, Yt+p+q = z) = δP (v)ΓpP (w)ΓqP (z)1′. (3.10)
55

3. Hidden Markov Models
3.3 Verosimiglianza
Si consideri un HMM am stati con δ distribuzione iniziale, Γ matrice di transizionee ph distribuzione di emissione. Sia y1, y2, . . . , yT una sequenza di osservazionigenerate dal modello. La verosimiglianza è data da:
LT = Pr(Y (T ) = y(T )) =m∑
c1,c2,...,cT=1
Pr(Y (T ) = y(T ),C(T ) = c(T )).
Poichè
Pr(Y (T ),C(T )) = Pr(C1)T∏k=2
Pr(Ck|Ck−1)T∏k=1
Pr(Yk|Ck), (3.11)
si ottiene:
LT =m∑
c1,...,cT=1
(δc1γc1,c2γc2,c3 . . . γcT−1,cT )(pc1(y1)pc2(y2) . . . pcT (yT ))
=m∑
c1,...,cT=1
δc1pc1(y1)γc1,c2pc2(y2)γc2,c3 . . . γcT−1,cT pcT (yT )
Scritta in forma matriciale, l’espressione della verosimiglianza diventa
LT = δP (y1)ΓP (y2)ΓP (y3) . . .ΓP (yT )1′
(3.12)
Inoltre se la catena di Markov è stazionaria, con distribuzione δ si ha
δP (y1) = δΓP (y1)
e quindi l’equazione (3.12) diventa
LT = δΓP (y1)ΓP (y2)ΓP (y3) . . .ΓP (yT )1′
(3.13)
Le espressioni in forma matriciale sono particolarmente vantaggiose perché permet-tono di sfruttare l’algoritmo ricorsivo ‘forward–backward’. Tale algoritmo spessoè utilizzato per il calcolo della verosimiglianza degli HMMs e quindi per la stimadei parametri. Inoltre, l’algoritmo di forward–backward gioca un ruolo importanteper problemi di previsione, decoding e selezione dei modelli.Per utilizzare l’algoritmo forward–backward si definisce il vettore αt, per t =
1, 2, . . . , T come
αt =δP (y1)ΓP (y2)ΓP (y3) . . .ΓP (yt)
=δP (y1)t∏
s=2
ΓP (ys)(3.14)
56

3.3. Verosimiglianza
Gli elementi del vettore αt sono chiamati probabilità in avanti (forward probabi-lity).Utilizzando la definizione di αt, e tenedo conto dell’equazione della verosimiglianzain (3.12), si ottiene
α1 = δP (y1)
αt = αt−1ΓP (yt), t = 2, 3, . . . , T
LT = αT1′
mentre se la catena di Markov è stazionaria, tenendo conto dell’equazione (3.13),si ottiene
α0 = δ
αt = αt−1ΓP (yt), t = 1, 2, . . . , T
LT = αT1′
3.3.1 Stime di massima verosimiglianza
Il pacchetto di R che sarà utilizzato per fittare gli HMMs, utilizza un metododiretto per calcolare la verosimiglianza. In molte applicazioni è conveniente massi-mizzare il logaritmo della verosimiglianza; in questo caso però la verosimiglianza èformata da un prodotto di matrici, non di scalari, non è possibile quindi calcolareil logaritmo della verosimiglianza come somma dei logaritmi dei suoi fattori. Comesuggerito in Zucchini et al. (2016), si può calcolare LT effettuando una trasforma-zione lineare del vettore delle probabilità in avanti αt.Si consideri il caso di una catena di Markov stazionaria, con distribuzione stazio-naria δ.Si definisca, per t = 0, 1, . . . , T , il vettore
φt =αtwt
57

3. Hidden Markov Models
dove wt =∑
h αt(h) = αt1′.
Alcune conseguenze immediate della definizione di φt e wt sono:
w0 = α01′ = δ1′ = 1;
φ0 = δ;
wtφt = wt−1φt−1ΓP (yt);
Lt = αT1′ = wT (φT1′) = wT =T∏t=1
(wt/wt−1).
(3.15)
dall’equazione (3.15) segue
wt = wt−1(φt−1ΓP (yt)1′)
e quindi si conclude che
logLT =T∑t=1
log(wt/wt−1) =T∑t=1
log(φt−1ΓP (yt)1′)
Di seguito è riportato il pseudo-codice per il calcolo della log-verosimiglianza.
φ0 ← δ
l ← 0
for t = 1, 2, . . . , T
v ← φt−1ΓP (yt)
u ← v1′
l ← l + log u
φt ← v/u
return l
dove Γ e P (yt) sono matrici di dimensione m×m, v e φt sono vettori m- dimen-sionali, u e l sono scalari. Il valore finale di LT è dato da l.
I parametri da stimare sono la matrice di transizione Γ e i parametri della distri-buzione di emissione P . Tali parametri sono soggetti ad alcuni vincoli. Quindi permassimizzare la verosimiglianza si risolve un problema di ottimizzazione vincolata.In generale ci saranno quindi due gruppi di vincoli: quelli relativi alle distribuzionidi emissione e quelli relativi alla matrice di transizione della catena di Markov.
58

3.4. Decoding
Il primo gruppo di vincoli dipende dalla distribuzione scelta per le distribuzionidi emissione; ad esempio per una distribuzione Gaussiana, la deviazione standardσ dovrà essere strettamente positiva. Il secondo gruppo di vincoli è relativo allamatrice di transizione Γ, quindi i suoi elementi dovranno essere non negativi (i.e.γhk ≥ 0) e la somma su ogni riga sarà pari a 1 (i.e
∑mk=1 γhk = 1, ∀i = 1, 2 . . . ,m).
3.3.2 Alcuni problemi
La verosimiglianza di un HMM è una funzione complicata di diversi parametri efrequentemente ha diversi massimi locali. Uno dei problemi principali è quindicome scegliere i valori iniziali dei parametri in modo da evitare che l’algoritmo dimassimizzazione converga ad un ottimo locale.Per quanto riguarda la distribuzione di emissione, una strategia efficace è quelladi basarsi sui quantili delle osservazioni. Ad esempio, per un modello a tre stati,si utilizzano come valori iniziali per le medie della densità di emissione il quartileinferiore, la mediana e il quartile superiore delle osservazioni. Per quanto riguardala matrice di transizione, una strategia è quella di assegnare valori inziali comuniin tutti gli elementi al di fuori dalla diagonale (i.e., 0.01 o 0.05); Se una transizionetra due specifici stati non è permessa, l’elemento assumerà valore 0 (i.e. γ14 = 0
se non è possibile andare dallo stato 1 allo stato 4) .
3.4 Decoding
Come accennato nella Sezione 3.3, l’utilizzo dell’algoritmo di forward–backwardè utile per problemi di previsione e decoding. Per tali problemi si utilizzano ledefinizioni e alcune proprietà delle probabilità in avanti e indietro.
Il vettore delle probabilità in avanti è stato definito, per t = 1, 2, . . . , T , come
αt =δP (y1)ΓP (y2)ΓP (y3) . . .ΓP (yt)
=δP (y1)t∏
s=2
ΓP (ys)(3.16)
59

3. Hidden Markov Models
mentre si definisce il vettore di probabilità all’indietro, per t = 1, 2, . . . , T , come
β′t =ΓP (yt+1)ΓP (yt+2) . . .ΓP (yT )1′
=
(T∏
s=t+1
ΓP (ys)
)1′
(3.17)
Si osservi che se t = T , β′t = 1.
I vettori αt e βt rappresentano due vettori di probabilità. Si dimostrano infatti iseguenti risultati
Proposizione 1. Per t = 1, 2, . . . , T, e k = 1, 2, . . . ,m,
αt(k) = Pr(Y (t) = y(t), Ct = k), (3.18)
Proposizione 2. Per t = 1, 2, . . . , T − 1, e h = 1, 2, . . . ,m
βt(h) = Pr(Y Tt+1 = yTt+1|Ct = h) (3.19)
dove Y ba indica il vettore (Ya, Ya+1, . . . , Yb).
Di seguito sono elencate due proprietà relative a αt e βt.
Proposizione 3. Per t = 1, 2, . . . , T e h = 1, 2, . . . ,m,
αt(h)βt(h) = Pr(Y (T ) = y(T ), Ct = h) (3.20)
e di conseguenza αtβ′t = Pr(Y (T ) = y(T )) = LT , ∀t.
Proposizione 4. Per t = 1, 2, . . . , T ,
Pr(Ct = k|Y (T ) = y(T )) =αt(k)βt(k)
Lt(3.21)
mentre, per t = 2, . . . , T ,
Pr(Ct−1 = k, Ct = l|Y (T ) = y(T )) =αt−1(k)γklpl(yt)βt(l)
Lt(3.22)
Per le dimostrazioni delle proposizioni 1, 2, 3 e 4 si veda Zucchini et al. (2016,Cap. 4).
Partendo da un HMM e da un insieme di osservazioni, è possibile ricavare in-formazioni sugli stati occupati da una catena di Markov nascosta, tale inferenza èchiamata ‘decoding’.
60

3.5. HMMs per dati longitudinali
Local decoding Per ogni t ∈ {1, . . . , T} lo stato più probabile h∗t , data unasequenza di osservazioni, è definito come
h∗t = arg maxh=1,...,m
Pr(Ct|Y (T ) = y(T ))) (3.23)
Tale apprroccio determina lo stato più probabile per ogni t massimizzando laprobabilità condizionata Pr(Ct = h|Y (T ) = y(T )); per questo motivo è chiamato‘local decoding’.La distribuzione condizionata di Ct date le osservazioni, si ricava partendo dallaProposizione 3. Per t = 1, 2 . . . ,m, si ha
Pr(Ct = h|Y (T ) = y(T )) =Pr(Ct = h,Y (T ) = y(T ))
Pr(Y (T ) = y(T ))
=αt(h)βt(h)
LT
(3.24)
Global decoding Molto spesso può essere interessante calcolare la sequenza distati(nascosti) più probabile, data una sequenza di osservazioni. In questo caso sicerca la sequenza di stati {c1, . . . , cT} che massimizza la probabilità condizionata
Pr(C(T ) = c(T )|Y (T ) = y(T )) (3.25)
o equivalemtemente la probabilità congiunta
Pr(C(T ),Y (T )) = δc1
T∏t=2
γct−1ct
T∏t=1
pct(yt).
3.5 HMMs per dati longitudinali
I dati longitudinali possono essere visti come un insieme di M serie temporaliformate dallo stesso tipo di osservazioni, in cui ogni serie temporale corrispondead un soggetto i, con i = 1, . . . ,M .Sia {Ct : t = 1, . . . , ni}i l’insieme di variabili aleatorie che indica gli stati nascostidel processo per ogni soggetto i, i = 1, . . .M , e sia {Yit : i = 1 . . .M ; t = 1, . . . , ni}l’insieme di tutte le osservazioni. Sia M = {1, 2, . . . ,m} l’insieme di stati dellaCdM {Ct}i, ∀i = 1, . . . ,M . Il contributo alla verosimiglianza del soggetto i-esimoè dato da:
Lini= δ(i)P (i)(yi1)Γ
(i)P (i)(yi2)Γ(i)P (i)(yi3) . . .Γ
(i)P (i)(yini)1′. (3.26)
61

3. Hidden Markov Models
dove P (i)(y) è una matrice diagonale di dimensione m × m, il cui l’elemento k-esimo rappresenta la distribuzione di emissione per lo stato k, con k = 1, . . . ,m.Il vettore δ(i) è la distribuzione iniziale per la catena di Markov per il soggetto i eΓ(i) la matrice di transizione. Si assume che i soggetti siano indipendenti, quindila verosimiglianza totale sarà data dal prodotto delleM verosimiglianze dei singolisoggetti.I parametri da stimare sono quindi la matrice di transizione Γ(i) e i parametri dellamatrice di emissione P i per ogni soggetto i = 1, . . . ,M . Il numero di parametrida stimare per un HMM nel caso longitudinale è quindi molto elevato. SecondoZucchini et al. (2016) un metodo per ovviare a questo problema è quello di con-siderare alcuni parametri in comune tra i soggetti. In particolare si distinguono 4casi:
• Nessun parametro in comune: in questo si modellizza un HMMs per ognisoggetto i. I parametri da stimare sono quindi Γ(i) e P (i) per i = 1, . . . ,M ;
• Matrice di transizione in comune: in questo caso si ipotizza che la matricedi transizione abbia valori uguali per ogni soggetto. I parametri da stimaresono quindi P (i) per i = 1, . . . ,M e Γ(1) = Γ(2) = · · · = Γ(M) = Γ ;
• Parametri della distribuzione di emissione in comune: in questo caso si ipo-tizza che i parametri della distribuzione di emissione siano uguali per tut-ti i soggetti. I parametri da stimare sono quindi Γ(i) per i = 1, . . . ,M eP (1) = P (2) = · · · = P (M) = P ;
• Tutti i parametri in comune: in questo caso tutti i parametri hanno gli stessivalori. I parametri da stimare sono quindi: P (1) = P (2) = · · · = P (M) = P
e Γ(1) = Γ(2) = · · · = Γ(M) = Γ.
Il pacchetto di R che verrà utilizzato per fittare l’HMM per dati longitudinale èmsm (Jackson, 2011); tale pacchetto considera parametri uguali per ogni soggetto i.
62

3.6. Selezione del Modello
3.6 Selezione del Modello
Per selezionare il modello più appropriato si possono utilizzare i due indici AIC eBIC descritti nel Paragrafo 2.3, ovvero
AIC = −2logL+ 2npar,
BIC = −2logL+ npar log(N).(3.27)
dove logL è il logaritmo della verosimiglianza, npar indica il numero di parametridel modello e N il numero totale di osservazioni usate per fittare il modello.
Nel caso di HMM la scelta del modello è particolarmente importante sia per sce-gliere il numero di stati m necessari per descrivere il modello, che per scegliere laforma parametrica della distribuzione di emissione più appropriata.
Dopo aver selezionato il modello che ottimizza gli indici in equazione (3.27), èutile stabilire se il modello selezionato è appropriato per descrivere i dati. Per fareciò si introducono delle quantità chiamate ‘pseudo- residui’.Ricordiamo che, se Y è una variabile aleatoria con funzione di ripartizione F , alloraU := F (Y ) è uniformente distribuita su un intervallo unitario (i.e. U ∼ U(0, 1)).Si definisce ora la probabilità
ut = Pr(Yt ≤ yt) = FYt(yt)
tale probabilità è detta pseudo-residuo uniforme dell’osservazione yt e indica laprobabilità, sotto il modello fittato, di ottenere un’osservazione minore o ugualea yt. Se il modello fittato è corretto, lo pseudo-residuo uniforme è distribuito co-me U(0, 1); per verificare ciò si può osservare l’istogramma o il qq-plot (graficoche rappresenta i quantili di una distribuzione) di ut. Spesso però è più sempli-ce visualizzare i risultati relativi allo pseudo-residuo normale, definito nel modoseguente
zt = φ−1(ut) = φ−1(FYt(yt))
dove φ indica la distribuzione di una normale standard. Se il modello fittato èvalido, lo pseudo-residuo normale è distribuito come una normale standard, convalore del residuo pari a 0 quando l’osservazione coincide con la mediana. Anche inquesto caso, si può osservare l’istogramma o il qq-plot di zt per verificarne l’ipotesisulla distribuzione.
63

3. Hidden Markov Models
Se Y è una variabile aleatoria con distribuzione discreta F , si definisce il residuopseudo-uniforme come
[u−t ;u+t ] = [FYt(y−t );FYt(yt)]
dove y−t rappresenta la più grande realizzazzione possibile minore o uguale a yt.Mentre lo pseudo-residuo normale è definito come:
[z−t ; z+t ] = [Φ−1(u−t ); Φ−1(u+t )] = [Φ−1(FYt(y−t )); Φ−1(FYt(y
+t ))]
3.7 HMMs con covariate
All’interno del modello di Markov nascosto possono essere incorporate alcune co-variate di interesse, introducendone una dipendenza dai parametri del modello. Lecovariate possono essere quindi legate o ai parametri delle distribuzione di emis-sione ph(y) o agli elementi della matrice di transizione γhk.
3.7.1 Covariate nella distribuzione di emissione
Sia Cit la catena di Markov che rappresenta gli stati nascosti del modello perl’individuo i. Si può ipotizzare che il valore atteso condizionato dell’osservazionedato lo stato h , dipenda da un insieme di q covariate xt. Ad esempio:
E(Yit|Cit = h) = µh + β0h + β1
hx1it + · · ·+ βqhx
qit
Di conseguenza la verosimiglianza del modello cambierà tenendo conto delle cova-riate considerate.
3.8 Caso Studio
In questo lavoro di tesi, gli Hidden Markov Models sono stati utilizzati per studia-re la progressione dell’OAG per i pazienti nel nostro campione. In particolare èpossibile identificare un livello di avanzamento della malattia per i pazienti inclusinell’analisi. Saranno quindi stimati gli stati nascosti del processo e, grazie alla sti-ma della matrice di transizione sarà possibile calcolare la probabilità di andare dauno stato all’altro. Sono stati risolti i problemi di decoding, descritti nel paragrafo
64

3.8. Caso Studio
3.4, per identificare lo stato di avanzamento della malattia per ogni paziente.
Sono stati analizzati tre HMMs per le variabili Horizontal Integrated Rim Width,Cup Disk Vertical Ratio e Cup Area rispettivamente, già analizzate in precedenzacon altri metodi.I modelli sono stati implementati in R utilizzando il pacchetto msm (Jackson,2011). Il pacchetto fitta catene di Markov a tempo continuo e HMMs. In unacatena di Markov a tempo continuo con spazio degli stati finito, la matrice ditransizione Γt dopo t unità temporali è data da è data da Γt = exp(tQ), doveQ è detta matrice dei tassi di transizione ed è tale che la somma sulle righe siapari a 0. La matrice di transizione Γ dopo un istante temporale è data quindi daΓ = exp(Q). Il pacchetto quindi stimerà la matrice Q, ma sarà possibile ricavareΓ tramite un comando specifico.Altra caratteristica del pacchetto è la possibilità di utilizzare svariate distribuzionidi emissione. Nel nostro caso si è scelto di utilizzare una distribuzione normaleper la variabile Horizontal Integrated Rim Width, una distribuzione Beta per lavariabile Cup Disk Vertical Ratio, mentre per la variabile Cup Area è stato fittatoun HMM con distribuzione di emissione Log-normale e un HMM con distribuzionedi emissione Gamma; il modello migliore è stato scelto tramite gli indici AIC eBIC descritti nel Paragrafo 3.6.
Modello 1
Il primo modello analizza la variabile Horizontal Integrated Rim Width. Si è tenutoconto delle covariate Età, Sesso, Razza, Diabete e Mean Deviation(MD); MD è unamisura che descrive la differenza tra il campo visivo del paziente e il campo visivodi un individuo sano. Si è ipotizzata una distribuzione di emissione Normale.Dato Yi = (Yiti1 , . . . , Yitini
) il vettore di osservazioni per il paziente i, con i =
1, . . . ,M , e M = {1, 2, . . . ,m} l’insieme di stati nascosti della CdM {Ct : t =
ti1, . . . , tini}i, con {ti1, . . . , tini
} l’insieme dei tempi in cui vengono effettuate le misu-razioni per il paziente i, il modello risultante sarà:
HIRWit|{Cit = h} ind∼ N (µh, σ2h)
µh = bh + β1hEtait + β2hSessoi + β3hDiabetei + β4hRazzai + β5hMDit
h ∈M, t = ti1, . . . , tini, i = 1, . . . ,M
65

3. Hidden Markov Models
Come descritto nel Paragrafo 3.3.2, un primo passo necessario per fittare i modelliè quello di scegliere i valori iniziali dei parametri da stimare. Per quanto riguardala distribuzione di emissione Normale, per la scelta del valore atteso si è utilizzatala strategia di basarsi sui quantili empirici delle osservazioni, mentre la deviazionestandard è stata inizializzata con la deviazione standard campionaria. Per quantoriguarda la matrice di transizione iniziale, poichè l’OAG può solo peggiorare neltempo, si è ipotizzato che è possibile effettuare una transizione soltanto da unostato ad un altro più avanzato. La matrice di transizione sarà quindi triangolaresuperiore. Quest’ultima ipotesi implica che l’ultimo stato sarà necessariamenteuno stato assorbente, in quanto una volta arrivati non è possibile uscirne.Successivamente occorre decidere il numero di stati necessari per descrivere il fe-nomeno considerato. Per fare ciò sono stati fittati dei modelli a 2, 3, 4, 5, 6, 7,8, 9 e 10 stati. Successivamente, tramite gli indici AIC e BIC (Paragrafo 3.6) èstato scelto il modello migliore e quindi il numero di stati più appropriato permodellizzare le osservazioni secondo un HMM.
Di seguito è riportata l’analisi del primo modello riferita alla variabile HorizontalIntegrated Rim Width.Attraverso il comando msm si fitta il modello desiderato. Tale comando permettequindi di stimare la matrice dei tassi di transizione Q e i parametri delle distribu-zioni di emissione P, in questo caso media e deviazione standard in ogni stato.A titolo di esempio, si riporta il codice utilizzato per fittare un HMM a 3 stati.
Q3 <- rbind(c(0,0.05,0),c(0,0,0.05),c(0,0,0))
hmodel3 <- list(hmmNorm(mean =lower_quartile, sd = s),
hmmNorm(mean = median, sd = s),
hmmNorm(mean = upper_quartile, sd = s))
mod3 <- msm(Horz.integrated.rim.width. ~ Time, subject = Patient, qmatrix = q3,
hmodel = hmodel3, hcovariates = list(~MD,~MD,~MD))
Di seguito è riportata la stima della matrice dei tassi di transizione Q e dellamatrice di transizione Γ. La matrice Q si ricava tramite il comando qmatrix.msm(
mod3).
Q =
−0.1649 0.1250 0.0399
0.0000 −0.0003 0.0003
0.0000 0.0000 0.0000
66

3.8. Caso Studio
Tabella 3.1: Valore dell’indice AIC e BIC per i modelli multistato relativi alla variabileHorizontal Integrated Rim Width
Numero di stati AIC BIC
2 142.0778 217.97213 -71.3704 50.06044 -173.5026 -1.47565 -291.9395 -64.25676 -389.7990 -101.40087 -407.3909 -53.21778 -385.5179 39.49009 -403.3167 97.585410 -429.6330 152.2230
La matrice Γ si ricava tramite il comando pmatrix.msm(mod3).
Γ =
0.848 0.1152 0.0368
0.000 0.9997 0.0003
0.000 0.0000 1.0000
Si osserva che c’è maggiore probabilità di rimanere nello stato corrente, piuttostoche spostarsi in stati successivi.
La stessa procedura è stata ripetuta per fittare HMMs a 2, 3, 4, 5, 6, 7, 8, 9
e 10 stati. In Tabella 3.1 è riportato il valore dell’AIC e del BIC per i modelliconsiderati. Si osserva che il valore dell’AIC decresce all’aumentare del numerodegli stati; si è quindi deciso di utilizzare l’indice BIC come criterio di selezionedel modello. L’indice BIC infatti tiene conto anche del numero di osservazioni nelmodello, oltre al numero di parametri stimati. Tale indice assume minimo perm = 6. Il modello migliore risulta quindi quello a 6 stati.Le stime dei parametri relativi alla distribuzione di emissione (per il modello a
6 stati) sono riportate in Tabella 3.2. Si osserva che con il passare dell’età, lavariabile HIRW diminuisce condizionatamente a tutti gli stati, ad eccezione deglistati 3 e 5. All’aumentare diMD, la variabile HIRW aumenta condizionatamentea tutti gli stati ad eccezione dello stato 3 e dello stato 6. La media di HIRW perun individuo di sesso maschile aumenta condizionatamente agli stati 1,2 e 6. La
67
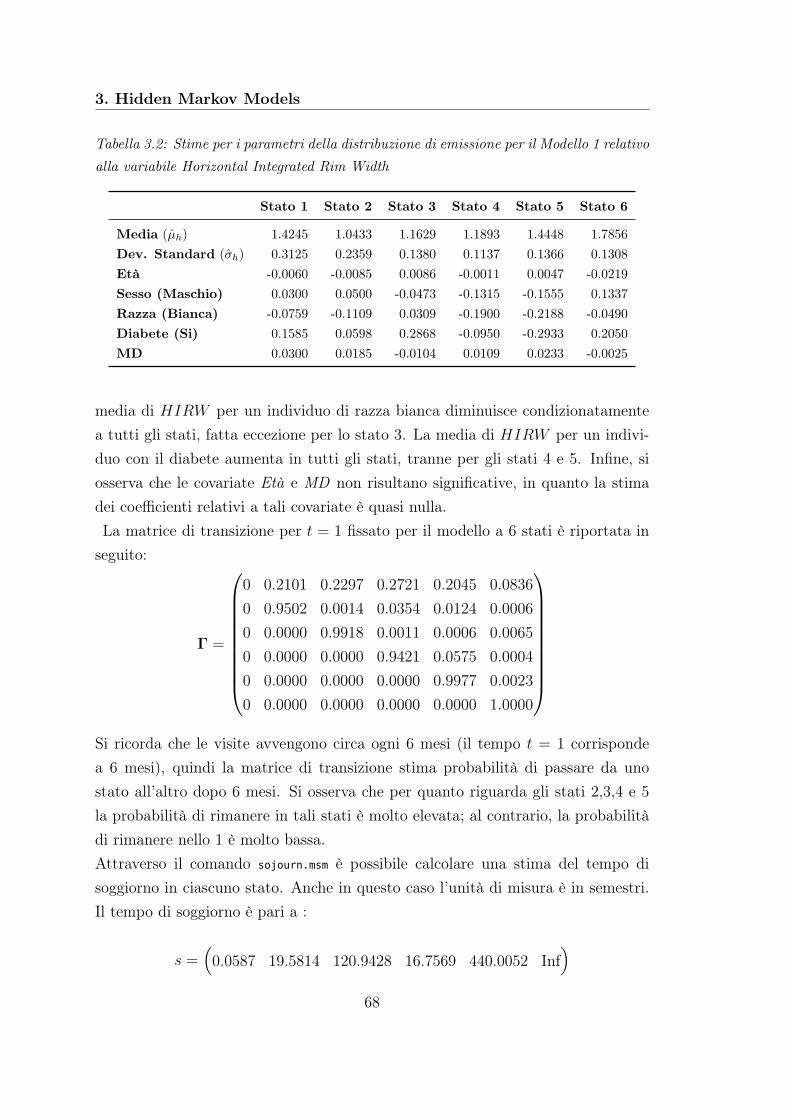
3. Hidden Markov Models
Tabella 3.2: Stime per i parametri della distribuzione di emissione per il Modello 1 relativoalla variabile Horizontal Integrated Rim Width
Stato 1 Stato 2 Stato 3 Stato 4 Stato 5 Stato 6
Media (µh) 1.4245 1.0433 1.1629 1.1893 1.4448 1.7856Dev. Standard (σh) 0.3125 0.2359 0.1380 0.1137 0.1366 0.1308Età -0.0060 -0.0085 0.0086 -0.0011 0.0047 -0.0219Sesso (Maschio) 0.0300 0.0500 -0.0473 -0.1315 -0.1555 0.1337Razza (Bianca) -0.0759 -0.1109 0.0309 -0.1900 -0.2188 -0.0490Diabete (Si) 0.1585 0.0598 0.2868 -0.0950 -0.2933 0.2050MD 0.0300 0.0185 -0.0104 0.0109 0.0233 -0.0025
media di HIRW per un individuo di razza bianca diminuisce condizionatamentea tutti gli stati, fatta eccezione per lo stato 3. La media di HIRW per un indivi-duo con il diabete aumenta in tutti gli stati, tranne per gli stati 4 e 5. Infine, siosserva che le covariate Età e MD non risultano significative, in quanto la stimadei coefficienti relativi a tali covariate è quasi nulla.La matrice di transizione per t = 1 fissato per il modello a 6 stati è riportata inseguito:
Γ =
0 0.2101 0.2297 0.2721 0.2045 0.0836
0 0.9502 0.0014 0.0354 0.0124 0.0006
0 0.0000 0.9918 0.0011 0.0006 0.0065
0 0.0000 0.0000 0.9421 0.0575 0.0004
0 0.0000 0.0000 0.0000 0.9977 0.0023
0 0.0000 0.0000 0.0000 0.0000 1.0000
Si ricorda che le visite avvengono circa ogni 6 mesi (il tempo t = 1 corrispondea 6 mesi), quindi la matrice di transizione stima probabilità di passare da unostato all’altro dopo 6 mesi. Si osserva che per quanto riguarda gli stati 2,3,4 e 5
la probabilità di rimanere in tali stati è molto elevata; al contrario, la probabilitàdi rimanere nello 1 è molto bassa.Attraverso il comando sojourn.msm è possibile calcolare una stima del tempo disoggiorno in ciascuno stato. Anche in questo caso l’unità di misura è in semestri.Il tempo di soggiorno è pari a :
s =(
0.0587 19.5814 120.9428 16.7569 440.0052 Inf)
68

3.8. Caso Studio
Si osserva inanzitutto che il tempo di soggiorno nell’ultimo stato è necessariamenteinfinito poichè si è fatta l’ipotesi di stato assorbente. Il risultato è coerente conla stima della matrice di transizione, infatti il tempo di soggiorno nello stato 1 èmolto piccolo e la probabilità di rimanere nello stato 1 è quasi pari zero (γ11 =
4× 10−8). Al contrario si osserva un tempo di soggiorno nello stato 3 e nello stato5 molto grande, infatti la probabilità di rimanere in questi stati è molto elevata(γ33 = 0.9918 e γ55 = 0.9977); questo vuol dire che, una volta che il pazienteentra negli stati 3 e 5, la probabilità di uscire da tali stati è molto bassa. Ciò èsupportato anche dal fatto che andando a vedere le stime della probabilità γ33 eγ55 per valori molto alti di t, queste continuano a rimanere elevate mentre le altreγhh, con h 6= 3, 5, 6 (stato assorbente) tendono a 0 al crescere di t. Ad esempio diseguito sono riportate le diagonali delle matrici di transizione per t = 50, 100, 150:
γhh(50) =(
0 0.0778 0.6614 0.0506 0.8926 1.0000)
γhh(100) =(
0 0.0061 0.4374 0.0026 0.7967 1.0000)
γhh(150) =(
0 0.0005 0.2893 0.0001 0.7111 1.0000)
Infine tramite il comando totlos.msm è possibile calcolare una stima del tempo totalespeso in ciascuno stato tra due istanti temporali. Ad esempio il tempo speso trat = 0 e t = 40 (20 anni) è pari a:
L0,40 =(
0.0587 3.7558 7.9856 6.0968 16.9610 5.1421)
Il problema di deconding è stato implementato tramite il comando viterbi.msm.Tale comando permette di calcolare la probabilità di essere in un determinato sta-to in ogni istante temporale e la sequenza di stati più probabili per ogni individuo.Per esempio in Tabella 3.3 sono riportati i risultati per 5 pazienti nel nostro cam-pione. In Figura 3.2 è rappresentata la predizione degli stati per tali pazienti.
Tabella 3.3: Local deconding e Global decoding su 5 pazienti per il Modello 1 con variabileHorizontal Integrated Rim Width
Id Tempo Stato P1 P2 P3 P4 P5 P6
69
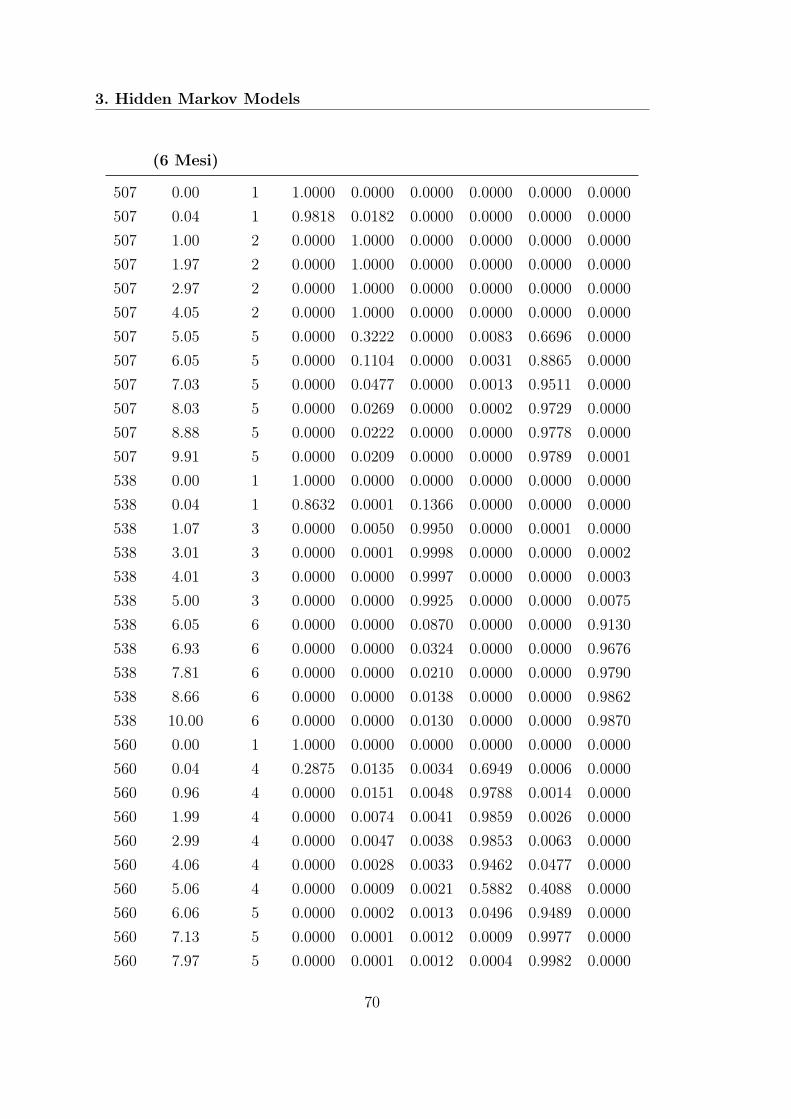
3. Hidden Markov Models
(6 Mesi)
507 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000507 0.04 1 0.9818 0.0182 0.0000 0.0000 0.0000 0.0000507 1.00 2 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000507 1.97 2 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000507 2.97 2 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000507 4.05 2 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000507 5.05 5 0.0000 0.3222 0.0000 0.0083 0.6696 0.0000507 6.05 5 0.0000 0.1104 0.0000 0.0031 0.8865 0.0000507 7.03 5 0.0000 0.0477 0.0000 0.0013 0.9511 0.0000507 8.03 5 0.0000 0.0269 0.0000 0.0002 0.9729 0.0000507 8.88 5 0.0000 0.0222 0.0000 0.0000 0.9778 0.0000507 9.91 5 0.0000 0.0209 0.0000 0.0000 0.9789 0.0001538 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000538 0.04 1 0.8632 0.0001 0.1366 0.0000 0.0000 0.0000538 1.07 3 0.0000 0.0050 0.9950 0.0000 0.0001 0.0000538 3.01 3 0.0000 0.0001 0.9998 0.0000 0.0000 0.0002538 4.01 3 0.0000 0.0000 0.9997 0.0000 0.0000 0.0003538 5.00 3 0.0000 0.0000 0.9925 0.0000 0.0000 0.0075538 6.05 6 0.0000 0.0000 0.0870 0.0000 0.0000 0.9130538 6.93 6 0.0000 0.0000 0.0324 0.0000 0.0000 0.9676538 7.81 6 0.0000 0.0000 0.0210 0.0000 0.0000 0.9790538 8.66 6 0.0000 0.0000 0.0138 0.0000 0.0000 0.9862538 10.00 6 0.0000 0.0000 0.0130 0.0000 0.0000 0.9870560 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000560 0.04 4 0.2875 0.0135 0.0034 0.6949 0.0006 0.0000560 0.96 4 0.0000 0.0151 0.0048 0.9788 0.0014 0.0000560 1.99 4 0.0000 0.0074 0.0041 0.9859 0.0026 0.0000560 2.99 4 0.0000 0.0047 0.0038 0.9853 0.0063 0.0000560 4.06 4 0.0000 0.0028 0.0033 0.9462 0.0477 0.0000560 5.06 4 0.0000 0.0009 0.0021 0.5882 0.4088 0.0000560 6.06 5 0.0000 0.0002 0.0013 0.0496 0.9489 0.0000560 7.13 5 0.0000 0.0001 0.0012 0.0009 0.9977 0.0000560 7.97 5 0.0000 0.0001 0.0012 0.0004 0.9982 0.0000
70

3.8. Caso Studio
560 8.93 5 0.0000 0.0001 0.0012 0.0004 0.9982 0.0000560 9.85 5 0.0000 0.0001 0.0012 0.0004 0.9983 0.0000578 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000578 0.08 1 0.6346 0.0014 0.0033 0.0003 0.0552 0.3051578 1.03 6 0.0000 0.0002 0.0000 0.0000 0.0410 0.9587578 2.03 6 0.0000 0.0000 0.0000 0.0000 0.0090 0.9910578 3.03 6 0.0000 0.0000 0.0000 0.0000 0.0076 0.9924578 4.06 6 0.0000 0.0000 0.0000 0.0000 0.0072 0.9928578 4.94 6 0.0000 0.0000 0.0000 0.0000 0.0070 0.9930578 5.94 6 0.0000 0.0000 0.0000 0.0000 0.0068 0.9932578 7.18 6 0.0000 0.0000 0.0000 0.0000 0.0066 0.9934578 7.95 6 0.0000 0.0000 0.0000 0.0000 0.0065 0.9935578 8.98 6 0.0000 0.0000 0.0000 0.0000 0.0064 0.9936578 10.04 6 0.0000 0.0000 0.0000 0.0000 0.0064 0.9936582 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000582 0.04 3 0.4509 0.0001 0.5490 0.0000 0.0000 0.0000582 1.05 3 0.0000 0.0004 0.9996 0.0000 0.0000 0.0000582 2.03 3 0.0000 0.0003 0.9997 0.0000 0.0000 0.0000582 3.03 3 0.0000 0.0001 0.9999 0.0000 0.0000 0.0000582 4.02 3 0.0000 0.0001 0.9999 0.0000 0.0000 0.0000582 5.25 3 0.0000 0.0001 0.9999 0.0000 0.0000 0.0000582 6.28 3 0.0000 0.0000 0.9989 0.0000 0.0000 0.0010
Modello 2
Dopo aver fissato un numero di stati pari a 6 per il modello con la variabile Ho-rizontal Integrated Rim Width, si è deciso anche in questo caso di analizzare ilmodello a 6 stati in modo da avere un confronto omogeneo sulla progressione dellamalattia. Il secondo modello analizza la variabile Cup Disk Vertical Ratio. Poichétale variabile assume valori nell’intervallo [0, 1], si è ipotizzata una distribuzionedi emissione di tipo Beta. Per tale distribuzione, il pacchetto msm non prevedel’inclusione di covariate all’interno del modello.Dato Yi = (Yiti1 , . . . , Yitini
) il vettore di osservazioni per il paziente i, con i =
71
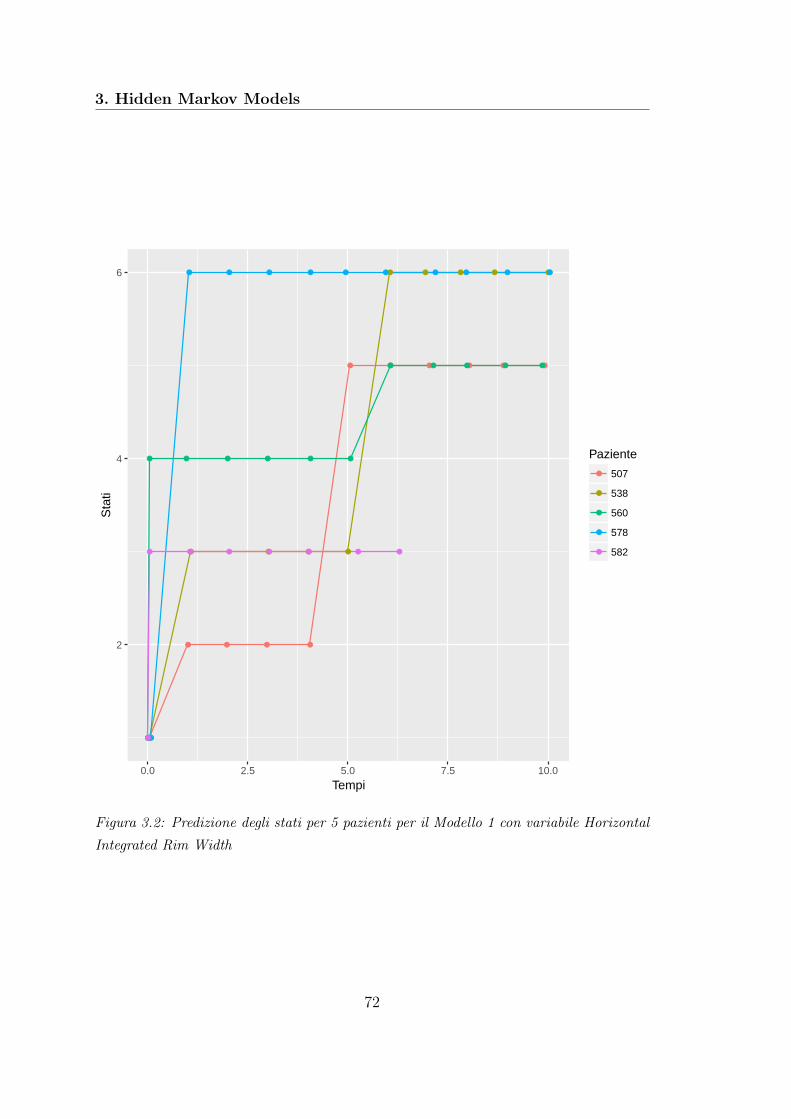
3. Hidden Markov Models
●●
● ● ● ●
● ● ● ● ● ●
●●
● ● ● ●
● ● ● ● ●
●
● ● ● ● ● ●
● ● ● ● ●
●●
● ● ● ● ● ● ● ● ● ●
●
● ● ● ● ● ● ●
2
4
6
0.0 2.5 5.0 7.5 10.0
Tempi
Sta
ti
Paziente●
●
●
●
●
507
538
560
578
582
Figura 3.2: Predizione degli stati per 5 pazienti per il Modello 1 con variabile HorizontalIntegrated Rim Width
72

3.8. Caso Studio
Tabella 3.4: Stime per i parametri della distribuzione di emissione per il Modello 2 relativoalla variabile Cup Disc Vertical Ratio
Stato 1 Stato 2 Stato 3 Stato 4 Stato 5 Stato 6
α 3.0194 12.6153 44.2060 44.2080 31.8443 0.4780β 1.2945 14.6950 25.3876 15.0310 5.3484 0.1164
1, . . . ,M , e M = {1, 2, . . . , 6} l’insieme di stati nascosti della CdM {Ct : t =
ti1, . . . , tini}i, con {ti1, . . . , tini
} l’insieme dei tempi in cui vengono effettuate le misu-razioni per il paziente i, il modello risultante sarà:
CDV Rit|{Cit = h} ind∼ Beta(αh, βh)
h ∈M, t = ti1, . . . , tini, i = 1, . . . ,M
Le stime dei parametri relativi alla distribuzione di emissione sono riportate inTabella 3.4. La matrice di transizione per t = 1 fissato per il modello a 6 stati èla seguente:
Γ =
0 0.1478 0.2109 0.3349 0.2778 0.0285
0 0.9749 0.0172 0.0003 0.0001 0.0074
0 0.0000 0.9756 0.0240 0.0003 0.0001
0 0.0000 0.0000 0.9844 0.0155 0.0001
0 0.0000 0.0000 0.0000 0.9960 0.0040
0 0.0000 0.0000 0.0000 0.0000 1.0000
Si osserva anche in questo caso che per quanto riguarda gli stati 2, 3, 4 e 5, laprobabilità di rimanere in tali stati è molto elevata; al contrario, la probabilità dirimanere nello stato 1 è nulla.La stima del tempo di soggiorno, considerando come unità di misura i semestri èla seguente:
s =(
0.0134 39.4043 40.5617 63.7658 251.6377 Inf)
Come per il Modello 1, anche in questo caso, il tempo di soggiorno nello stato 5
risulta essere molto elevato. Infatti andando a vedere le stime della probabilitàγ55 per valori molto alti di t, queste continuano a rimanere elevate mentre le altreγhh, con h 6= 5, 6 (stato assorbente) tendono a 0 al crescere di t. Di seguito sono
73
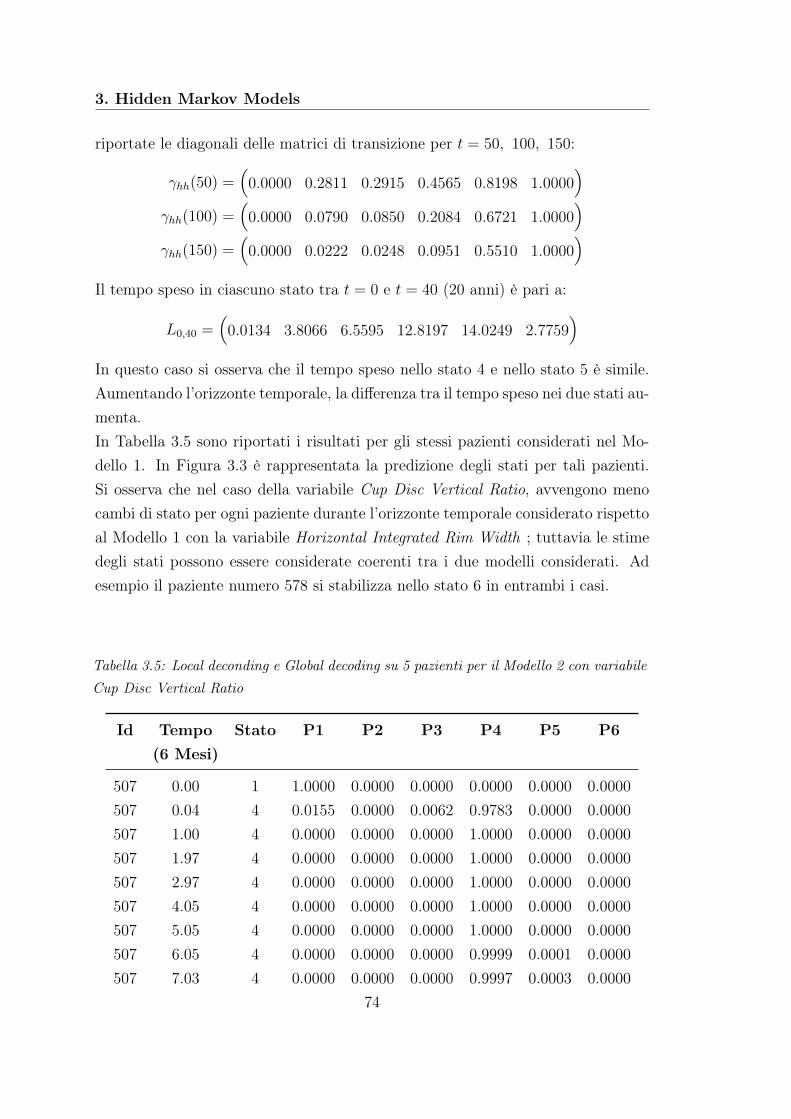
3. Hidden Markov Models
riportate le diagonali delle matrici di transizione per t = 50, 100, 150:
γhh(50) =(
0.0000 0.2811 0.2915 0.4565 0.8198 1.0000)
γhh(100) =(
0.0000 0.0790 0.0850 0.2084 0.6721 1.0000)
γhh(150) =(
0.0000 0.0222 0.0248 0.0951 0.5510 1.0000)
Il tempo speso in ciascuno stato tra t = 0 e t = 40 (20 anni) è pari a:
L0,40 =(
0.0134 3.8066 6.5595 12.8197 14.0249 2.7759)
In questo caso si osserva che il tempo speso nello stato 4 e nello stato 5 è simile.Aumentando l’orizzonte temporale, la differenza tra il tempo speso nei due stati au-menta.In Tabella 3.5 sono riportati i risultati per gli stessi pazienti considerati nel Mo-dello 1. In Figura 3.3 è rappresentata la predizione degli stati per tali pazienti.Si osserva che nel caso della variabile Cup Disc Vertical Ratio, avvengono menocambi di stato per ogni paziente durante l’orizzonte temporale considerato rispettoal Modello 1 con la variabile Horizontal Integrated Rim Width ; tuttavia le stimedegli stati possono essere considerate coerenti tra i due modelli considerati. Adesempio il paziente numero 578 si stabilizza nello stato 6 in entrambi i casi.
Tabella 3.5: Local deconding e Global decoding su 5 pazienti per il Modello 2 con variabileCup Disc Vertical Ratio
Id Tempo Stato P1 P2 P3 P4 P5 P6(6 Mesi)
507 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000507 0.04 4 0.0155 0.0000 0.0062 0.9783 0.0000 0.0000507 1.00 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000507 1.97 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000507 2.97 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000507 4.05 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000507 5.05 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000507 6.05 4 0.0000 0.0000 0.0000 0.9999 0.0001 0.0000507 7.03 4 0.0000 0.0000 0.0000 0.9997 0.0003 0.0000
74

3.8. Caso Studio
507 8.03 4 0.0000 0.0000 0.0000 0.9990 0.0010 0.0000507 8.88 4 0.0000 0.0000 0.0000 0.9974 0.0026 0.0000507 9.91 4 0.0000 0.0000 0.0000 0.9927 0.0073 0.0000538 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000538 0.04 4 0.0137 0.0000 0.0018 0.9845 0.0000 0.0000538 1.07 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000538 3.01 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000538 4.01 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000538 5.00 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000538 6.05 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000538 6.93 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000538 7.81 4 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000538 8.66 4 0.0000 0.0000 0.0000 0.9999 0.0001 0.0000538 10.00 4 0.0000 0.0000 0.0000 0.9981 0.0019 0.0000560 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000560 0.04 5 0.0271 0.0000 0.0000 0.1998 0.7731 0.0000560 0.96 5 0.0000 0.0000 0.0000 0.2101 0.7899 0.0000560 1.99 5 0.0000 0.0000 0.0000 0.2101 0.7899 0.0000560 2.99 5 0.0000 0.0000 0.0000 0.2101 0.7899 0.0000560 4.06 5 0.0000 0.0000 0.0000 0.2101 0.7899 0.0000560 5.06 5 0.0000 0.0000 0.0000 0.2101 0.7899 0.0000560 6.06 5 0.0000 0.0000 0.0000 0.2101 0.7897 0.0002560 7.13 5 0.0000 0.0000 0.0000 0.2101 0.7892 0.0007560 7.97 5 0.0000 0.0000 0.0000 0.2101 0.7887 0.0012560 8.93 5 0.0000 0.0000 0.0000 0.2100 0.7884 0.0016560 9.85 5 0.0000 0.0000 0.0000 0.2096 0.7876 0.0028578 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000578 0.08 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000578 1.03 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000578 2.03 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000578 3.03 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000578 4.06 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000578 4.94 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000578 5.94 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000
75

3. Hidden Markov Models
578 7.18 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000578 7.95 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000578 8.98 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000578 10.04 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000582 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000582 0.04 3 0.0112 0.0017 0.9871 0.0000 0.0000 0.0000582 1.05 3 0.0000 0.0001 0.9999 0.0000 0.0000 0.0000582 2.03 3 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000582 3.03 3 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000582 4.02 3 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000582 5.25 3 0.0000 0.0000 0.9999 0.0001 0.0000 0.0000582 6.28 3 0.0000 0.0000 0.9992 0.0008 0.0000 0.0000
Modello 3
L’ultimo modello analizza la variabile Cup Area. Anche in questo caso è statofittato un modello a 6 stati. Si è scelto di fittare un HMM con distribuzione diemissione Log-normale e un HMM con distribuzione di emissione Gamma; il mo-dello migliore è stato scelto tramite gli indici AIC e BIC descritti nel Paragrafo 3.6.In entrambi i casi vengono incluse le covariate Età, Sesso, Razza, Diabete e MeanDeviation(MD).Dato Yi = (Yiti1 , . . . , Yitini
) il vettore di osservazioni per il paziente i, con i =
1, . . . ,M , e M = {1, 2, . . . , 6} l’insieme di stati nascosti della CdM {Ct : t =
ti1, . . . , tini}i, con {ti1, . . . , tini
} l’insieme dei tempi in cui vengono effettuate le misu-razioni per il paziente i, i modelli risultanti sono quindi:
Caso A:
CAit|{Cit = h} ind∼ LN (µh, σ2h)
µh = bh + β1hEtait + β2hSessoi + β3hDiabetei + β4hRazzai + β5hMDit
h ∈M, t = ti1, . . . , tini, i = 1, . . . ,M
Caso B:
76
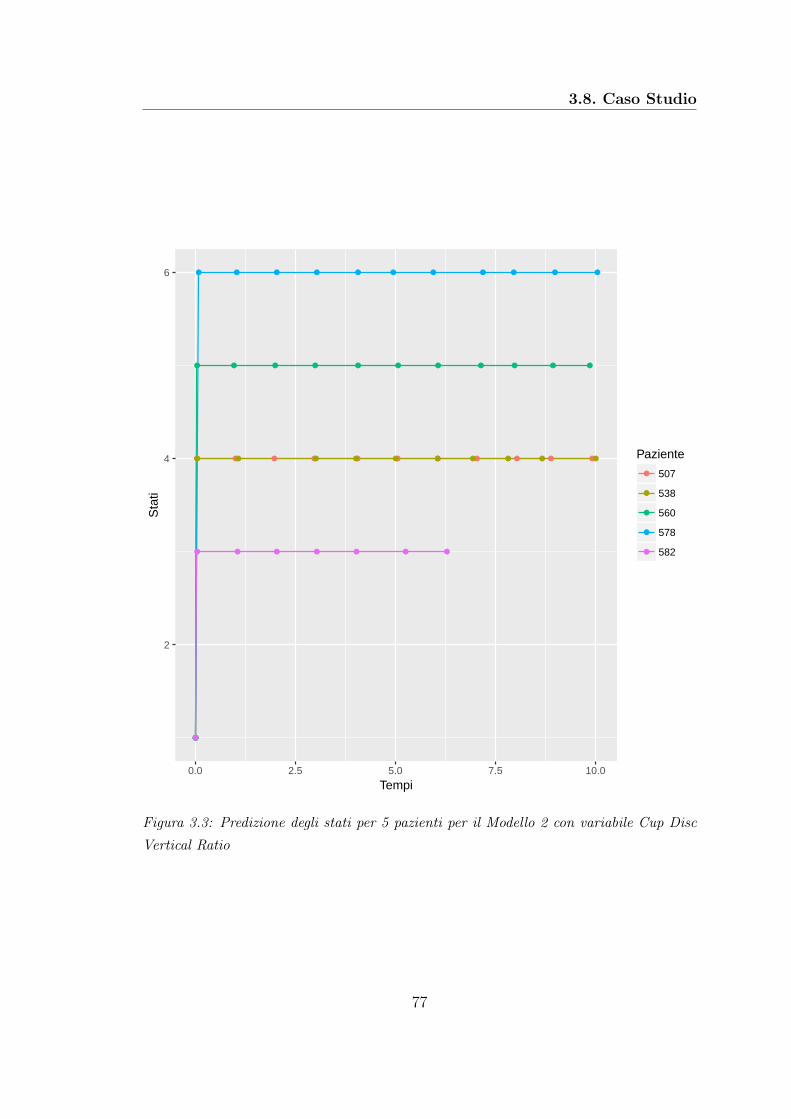
3.8. Caso Studio
●
● ● ● ● ● ● ● ● ● ● ●
●
● ● ● ● ● ● ● ● ● ●
●
● ● ● ● ● ● ● ● ● ● ●
●
● ● ● ● ● ● ● ● ● ● ●
●
● ● ● ● ● ● ●
2
4
6
0.0 2.5 5.0 7.5 10.0
Tempi
Sta
ti
Paziente●
●
●
●
●
507
538
560
578
582
Figura 3.3: Predizione degli stati per 5 pazienti per il Modello 2 con variabile Cup DiscVertical Ratio
77

3. Hidden Markov Models
Tabella 3.6: Stime per i parametri della distribuzione di emissione per il Modello 3 relativoalla variabile Cup Area
Stato 1 Stato 2 Stato 3 Stato 4 Stato 5 Stato 6
Shape (nh) 6.0072 0.9782 42.1472 23.7978 74.1668 62.7315Rate (λh) 4.8513 1.3251 29.4910 32.4831 53.3674 27.3822Età 0.0019 -0.0391 -0.0600 0.0195 -0.0078 0.0388Sesso(Maschio) -0.0953 -0.6020 1.4049 0.0661 0.1103 -0.3363Razza(Bianca) 0.0257 -1.6439 1.2921 -0.1088 -0.2942 0.1461Diabete(Si) 0.1258 -1.2610 0.6925 -0.5210 0.4317 -0.0830MD 0.0423 0.0704 0.0293 0.0675 0.0129 0.0023
CAit|{Cit = h} ind∼ Gamma(nh, λh)
log(λh) = bh + β1hEtait + β2hSessoi + β3hDiabetei + β4hRazzai + β5hMDit
h ∈M, t = ti1, . . . , tini, i = 1, . . . ,M
Gli indici AIC e BIC nei due casi considerati sono i seguenti:
• Caso A (Log-Normale): AIC = 927.2823 e BIC = 1215.681,
• Caso B (Gamma): AIC = 779.32320 e BIC = 1067.7210.
Entrambi gli indici sono minimi per il modello che considera distribuzione di emis-sione di tipo Gamma; verrà quindi analizzato questo modello.Le stime dei parametri relativi alla distribuzione di emissione sono riportate inTabella 3.6. Si osserva che, condizionatamente ad ogni stato, all’aumentare di MDla variabile Cup Area (CA) aumenta. La variabile CA aumenta con l’aumentaredell’età condizionatamente agli stati 1, 4 e 6. Per un individuo di sesso maschile,CA aumenta condizionatamente agli stati 3, 4 e 5. Per un individuo di razza bian-ca, CA diminuisce condizionatamente agli stati 2, 4 e 5. Per un individuo con ildiabete, CA aumenta condizionatamente agli stati 1, 3 e 5. Infine, si osserva che lecovariate Età e MD non risultano significative, in quanto la stima dei coefficientirelativi a tali covariate è quasi nulla.La matrice di transizione per t = 1 fissato per il modello a 6 stati è la seguente:
78

3.8. Caso Studio
Γ =
0.6878 0.0206 0.0560 0.0586 0.1219 0.0551
0.0000 0.9417 0.0004 0.0005 0.0297 0.0277
0.0000 0.0000 0.9996 0.0001 0.0002 0.0002
0.0000 0.0000 0.0000 0.9995 0.0003 0.0001
0.0000 0.0000 0.0000 0.0000 0.9998 0.0002
0.0000 0.0000 0.0000 0.0000 0.0000 1.0000
Si osserva anche in questo caso che per quanto riguarda gli stati 2, 3, 4 e 5 laprobabilità di rimanere in tali stati è molto elevata; tuttavia al contrario dei duemodelli precedenti, la probabilità di rimanere nello stato 1 è maggiore di 0.La stima del tempo di soggiorno, considerando come unità di misura i semestri, èla seguente:
s =(
2.6717 16.6384 2367.8717 2086.8302 4961.4345 Inf)
In questo caso si osserva un tempo di soggiorno elevato negli stati 3, 4, 5. Infattiandando a vedere le stime della probabilità γhh per h = 4, 5, 6 per valori molto altidi t, queste continuano a rimanere elevate mentre le altre γ11 e γ22 tendono a 0 alcrescere di t. Di seguito sono riportate le diagonali delle matrici di transizione pert = 50, 100, 150:
γhh(50) =(
0.0000 0.0495 0.9791 0.9763 0.9900 1.0000)
γhh(100) =(
0.0000 0.0025 0.9586 0.9532 0.9800 1.0000)
γhh(150) =(
0.0000 0.0001 0.9386 0.9306 0.9702 1.0000)
Tuttavia il tempo speso in ciascuno stato tra t = 0 e t = 40 (20 anni) è pari a:
L0,40 =(
2.6717 1.0960 10.1741 10.6748 23.7612 11.6223)
Quindi il tempo speso nello stato 5, in un intervallo temporale di 20 anni, è pari apiù del doppio di quello speso negli stati 3 e 4.
In Tabella 3.7 sono riportati i risultati per gli stessi pazienti considerati nel Mo-dello 1 e nel Modello 2. In Figura 3.4 è rappresentata la predizione degli stati pertali pazienti.
79
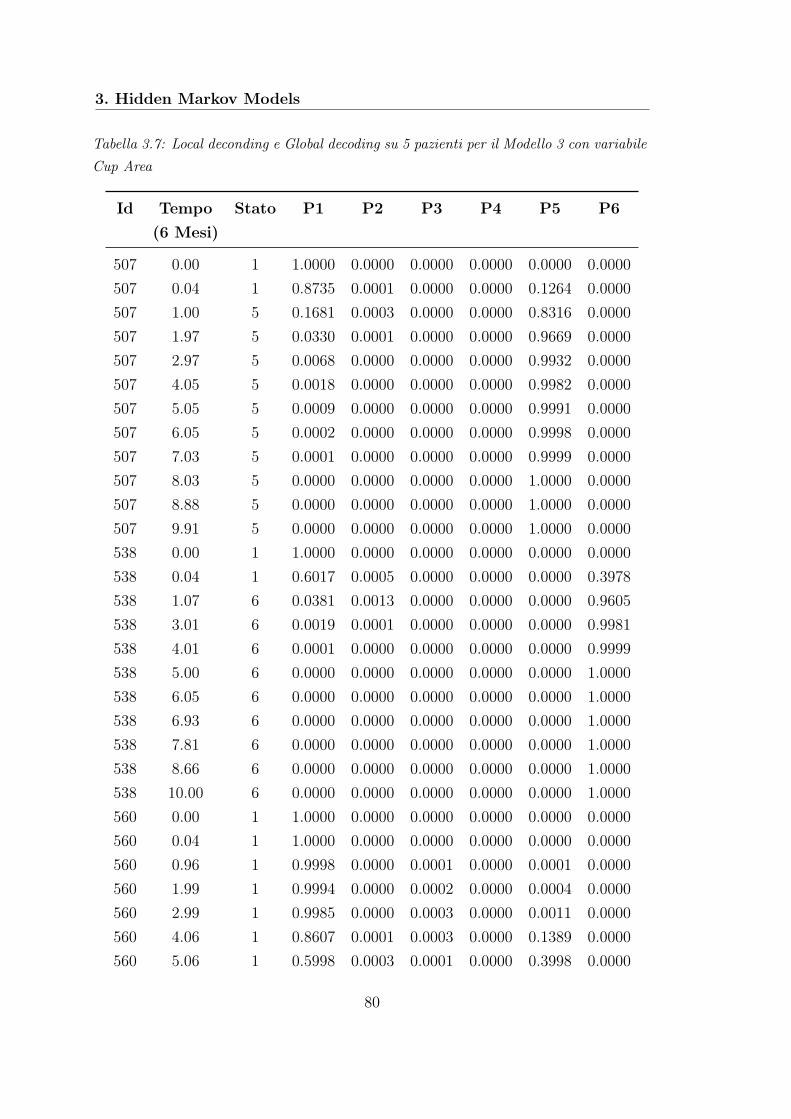
3. Hidden Markov Models
Tabella 3.7: Local deconding e Global decoding su 5 pazienti per il Modello 3 con variabileCup Area
Id Tempo Stato P1 P2 P3 P4 P5 P6(6 Mesi)
507 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000507 0.04 1 0.8735 0.0001 0.0000 0.0000 0.1264 0.0000507 1.00 5 0.1681 0.0003 0.0000 0.0000 0.8316 0.0000507 1.97 5 0.0330 0.0001 0.0000 0.0000 0.9669 0.0000507 2.97 5 0.0068 0.0000 0.0000 0.0000 0.9932 0.0000507 4.05 5 0.0018 0.0000 0.0000 0.0000 0.9982 0.0000507 5.05 5 0.0009 0.0000 0.0000 0.0000 0.9991 0.0000507 6.05 5 0.0002 0.0000 0.0000 0.0000 0.9998 0.0000507 7.03 5 0.0001 0.0000 0.0000 0.0000 0.9999 0.0000507 8.03 5 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000507 8.88 5 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000507 9.91 5 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000538 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000538 0.04 1 0.6017 0.0005 0.0000 0.0000 0.0000 0.3978538 1.07 6 0.0381 0.0013 0.0000 0.0000 0.0000 0.9605538 3.01 6 0.0019 0.0001 0.0000 0.0000 0.0000 0.9981538 4.01 6 0.0001 0.0000 0.0000 0.0000 0.0000 0.9999538 5.00 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000538 6.05 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000538 6.93 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000538 7.81 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000538 8.66 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000538 10.00 6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000560 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000560 0.04 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000560 0.96 1 0.9998 0.0000 0.0001 0.0000 0.0001 0.0000560 1.99 1 0.9994 0.0000 0.0002 0.0000 0.0004 0.0000560 2.99 1 0.9985 0.0000 0.0003 0.0000 0.0011 0.0000560 4.06 1 0.8607 0.0001 0.0003 0.0000 0.1389 0.0000560 5.06 1 0.5998 0.0003 0.0001 0.0000 0.3998 0.0000
80

3.8. Caso Studio
560 6.06 5 0.1301 0.0001 0.0000 0.0001 0.8697 0.0000560 7.13 5 0.0141 0.0000 0.0000 0.0004 0.9855 0.0000560 7.97 5 0.0024 0.0000 0.0000 0.0005 0.9971 0.0000560 8.93 5 0.0007 0.0000 0.0000 0.0005 0.9988 0.0000560 9.85 5 0.0004 0.0000 0.0000 0.0005 0.9991 0.0000578 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000578 0.08 1 0.9896 0.0104 0.0000 0.0000 0.0000 0.0000578 1.03 1 0.7771 0.2229 0.0000 0.0000 0.0000 0.0000578 2.03 1 0.5471 0.4529 0.0000 0.0000 0.0000 0.0000578 3.03 2 0.2983 0.7017 0.0000 0.0000 0.0000 0.0000578 4.06 2 0.0934 0.9066 0.0000 0.0000 0.0000 0.0000578 4.94 2 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000578 5.94 2 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000578 7.18 2 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000578 7.95 2 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000578 8.98 2 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000578 10.04 2 0.0000 0.8554 0.0000 0.0000 0.0023 0.1423582 0.00 1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000582 0.04 1 0.8877 0.0000 0.0000 0.0004 0.1119 0.0000582 1.05 5 0.2420 0.0003 0.0000 0.0048 0.7530 0.0000582 2.03 5 0.0572 0.0001 0.0000 0.0060 0.9368 0.0000582 3.03 5 0.0140 0.0000 0.0000 0.0067 0.9793 0.0000582 4.02 5 0.0052 0.0000 0.0000 0.0069 0.9879 0.0000582 5.25 5 0.0015 0.0000 0.0000 0.0069 0.9915 0.0000582 6.28 5 0.0009 0.0000 0.0000 0.0070 0.9921 0.0000
Nel caso della variabile Cup Area, la predizione degli stati per diversi pazienti noncoincide con quella dei due modelli precedenti. Si osservi ad esempio il paziente578 che viene classificato nello stato 6 in tempi brevi nei due modelli precedenti,mentre nel caso del terzo modello, tale paziente dallo stato 1 si stabilizza nellostato 2.Sarebbe quindi opportuno considerare un modello multivariato, oppure scegliereuna delle tre variabili come variabile di interesse. I risultati ottenuti con il Mo-
81
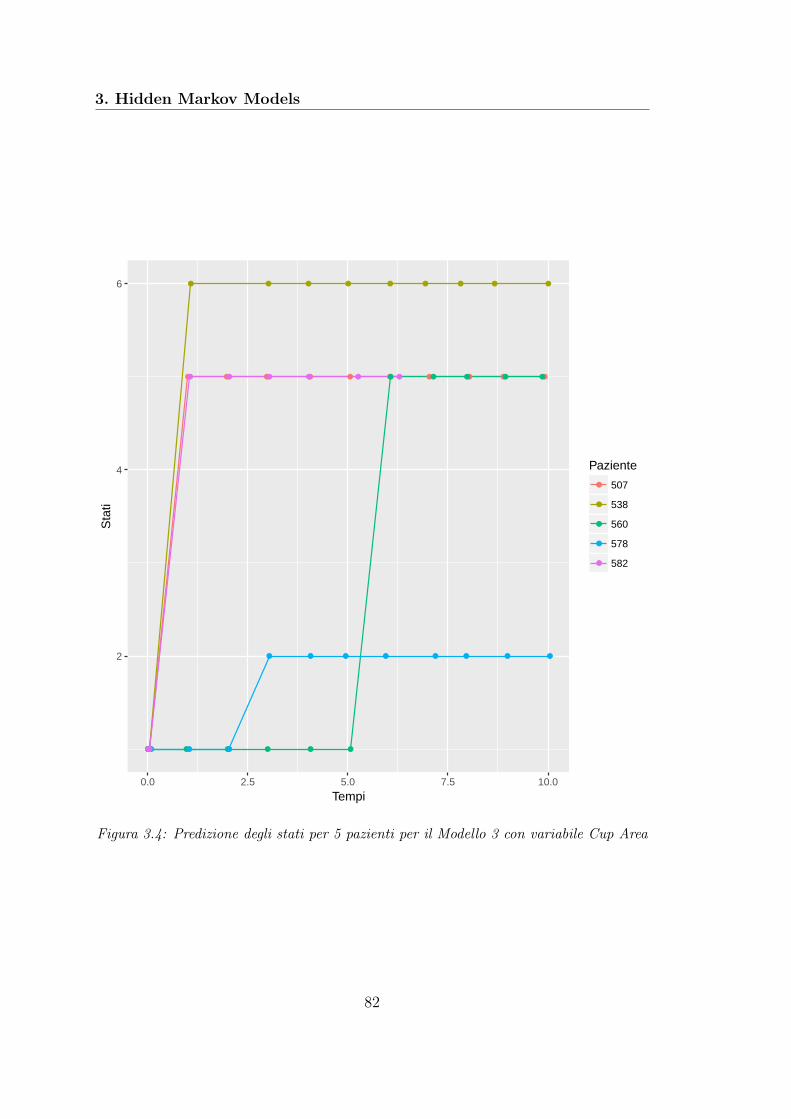
3. Hidden Markov Models
●●
● ● ● ● ● ● ● ● ● ●
●●
● ● ● ● ● ● ● ● ●
●● ● ● ● ● ●
● ● ● ● ●
●● ● ●
● ● ● ● ● ● ● ●
●●
● ● ● ● ● ●
2
4
6
0.0 2.5 5.0 7.5 10.0
Tempi
Sta
ti
Paziente●
●
●
●
●
507
538
560
578
582
Figura 3.4: Predizione degli stati per 5 pazienti per il Modello 3 con variabile Cup Area
82

3.8. Caso Studio
dello 1 e Modello 2 sono abbastanza concordi. La scelta del Modello più adattoricadrebbe comunque sul Modello 1 con variabile di interesse Horizontal IntegratedRim Width in quanto, rispetto al Modello 2 con variabile di interesse Cup Di-sc Vertical Ratio, include anche covariate che possono influenzare la progressionedella malattia.
83


Conclusioni
Il glaucoma ad angolo aperto, in inglese Open Angle Glaucoma (OAG), è una ma-lattia oculare caratterizzata dalla perdita di cellule ganglionari retiniche ed è unadelle prime cause di cecità nel mondo. Negli ultimi decenni, sono stati identificatisvariati fattori di rischio per l’OAG. Tuttavia il meccanismo con cui i vari fattoricontribuiscono allo sviluppo del Glaucoma è ancora sconosciuto. In particolarenon è ben chiaro se tali fattori siano delle cause o delle conseguenze dello sviluppodella malattia.
I dati disponibili riguardano M = 122 pazienti affetti da OAG. Nei dataset eranopresenti informazioni generali riguardanti i pazienti (come ad esempio età, sesso)e misurazioni riguardanti le caratteristiche mediche dei pazienti. Le misurazioniriguardanti le caratteristiche mediche dei pazienti sono state registrate ad intervallidi circa 6 mesi, collocandosi quindi in un contesto di dati longitudianli.Si sono quindi sviluppati modelli statistici per dati longitudinali per descrivere laprogressione nel tempo del glaucoma ad angolo aperto, tenendo in considerazionei principali fattori di rischio della malattia.Dato l’elevato numero di covariate che ci sono state fornite per analizzare il pro-blema, ci siamo posti fin da subito la questione di scegliere quali di queste fosseromaggiormente esplicative per descrivere la malattia. In particolare, sono state in-dividuate tre variabili di interesse utili per descrivere la malattia, che descrivonole fibre nervose retiniche e sono Horizontal Integrated Rim Width che misura l’areatotale del bordo neuroretinico, Cup Disc Vertical Ratio che misura il rapporto tradiametro dell’escavazione e diametro del disco ottico verticale e Cup Area che mi-sura l’area dell’escavazione del disco ottico ("Cupping" del disco ottico). Il discoottico è il luogo in cui convergono gli assoni delle cellule gaglionari per formareil nervo ottico, ha una forma ellittica con massimo diametro verticale; nel centropresenta una depressione imbutiforme, chiamata escavazione fisiologica del disco

Conclusioni
ottico. Il bordo neuroretinico è il tessuto tra i margini del disco ottico e dell’e-scavazione. Tali variabili di interesse sono state misurate attraverso una nuovatecnica di imaging avanzata chiamata Optical Coherence Tomography (OCT). Perciascuna delle variabili scelte per descrivere il glaucoma, sono state applicate di-verse tecniche statistiche per dati longitudinali.
Un primo passo è stato quello di capire quali fossero le covariate che spiegasse-ro maggiormente l’avanzamento della malattia attraverso le tre variabili rispostaelencate precedentemente. Per fare ciò, sono state analizzate le misurazioni effet-tuate durante la prima visita del paziente. Sono state esaminate le caratteristichedei pazienti come Sesso, Razza, Diabete. Tali caratteristiche sono infatti spessoindicate in letteratura come fattori che influenzano l’insorgere del glaucoma. Nelnostro caso però non abbiamo trovato particolari differenze in gruppi diversi di pa-zienti. Successivamente sono stati sviluppati dei modelli lineari sulle tre variabiliHorizontal Integrated Rim Width, Cup Disc Vertical Ratio e Cup Area. Il modellomigliore è risultato quello relativo alla variabile Horizontal Integrated Rim Width ele covariate longitudinali che spiegano tale variabile risposta sono risultate VerticalIntegrated Rim Area che misura il volume totale dello strato di fibre nervose re-tiniche nel bordo neuroretinico, Retinal Nerve Fiber Layer (RNFL) che misura lospessore dello strato delle fibre nervose retiniche e Temporal short Posterior Cilia-ry Arteries(TPCA) che misura la velocità del flusso sanguigno nell’arteria ciliareposteriore temporale.Successivamente, sono stati implementati dei modelli lineari a effetti misti per datilongitudinali per le tre variabili risposta di interesse per indagare la variabilità tragli individui e all’interno del singolo individuo. In questo caso, il modello relati-vo alla variabile Cup Disc Vertical Ratio non è stato soddisfacente per spiegarela progressione della malattia a causa della natura di tale variabile che assumevalori nell’intervallo [0,1]. Anche in questo caso il modello migliore per spiegarel’avanzamento della malattia è risultato quello relativo alla variabile Horizontal In-tegrated Rim Width. Il modello fittato ha confermato la presenza di variabilità tragli individui poichè la stima dei parametri di regressione relativi agli effetti casualiconsiderati, è risultata differente per ciascun individuo. Le covariate significativesono risultate Vertical Integrated Rim Area e Retinal Nerve Fiber Layer (RNFL).Tuttavia, ci aspettavamo che la covariata riferita al tempo fosse significativa perspiegare l’avanzamento della malattia, cosa che invece non è avvenuta.
86

Conclusioni
Infine, sono stati adottati dei modelli di Markov multi-stato per studiare la pro-gressione della malattia. Poichè gli stati della malattia non sono direttamenteosservabili, sono stati considerati dei Modelli di Markov Nascosti (Hidden MarkovModel - HMM); per stimare i parametri del modello si sono utilizzate le tre varia-bili di interesse Horizontal Integrated Rim Width, Cup Disc Vertical Ratio e CupArea insieme ad alcuni fattori che sono Età, Sesso, Razza, presenza o meno di Dia-bete e infine una variabile che misura la differenza tra il campo visivo del pazientee il campo visivo di un individuo sano. Abbiamo trovato che le tre covariate Sesso,Razza e Diabete influenzano la progressione della malattia per i modelli fittati conle variabili Horizontal Integrated Rim Width e Cup Area. Un primo passo è statoquello di decidere il numero di stati più opportuni per descrivere l’avanzamentodella malattia. Per fare ciò sono stati fittati degli HMMs con numero di stati diffe-renti per la variabile Horizontal Integrated Rim Width ed è stato utilizzato l’indiceBayesian Information Criterion (BIC) per scegliere il modello più appropriato; èstato individuato un numero di stati ottimale pari a 6. Quindi sono stati fittatitre HMMs a 6 stati per le tre variabili di interesse e successivamente sono staticonfrontati i risultati. Per quanto riguarda le variabili Horizontal Integrated RimWidth e Cup Disc Vertical Ratio i risultati sono stati abbastanza concordanti inquanto si è trovata una probabilità di uscita dal primo stato (primo stadio dellamalattia) molto elevata e ciò è coerente con il fatto che i pazienti presenti all’in-terno del dataset sono tutti malati; al contrario la probabilità di rimanere nellostato 5 una volta esserne entrati, è molto elevata: ciò vuol dire che tale stato èconsiderato già uno stadio molto avanzato della malattia ed è difficile uscirne. In-fine, per ogni paziente è stato stimato in ogni istante temporale lo stato in cui ilpaziente è classificato e, quindi, il livello di avanzamento della malattia per ognisingolo paziente in ogni istante temporale. Nel caso della variabile Cup Area, lapredizione degli stati per diversi pazienti non coincide con quella degli altri duemodelli, che sono abbastanza concordi tra di loro. Dovendo scegliere un modelloquindi, anche in questo caso si sceglierebbe quello relativo alla variabile HorizontalIntegrated Rim Width in quanto, a differenza di Cup Disc Vertical Ratio, è statoimplementato tendendo conto di più fattori di rischio per lo sviluppo della malat-tia, risultando quindi più preciso.Un interessante sviluppo futuro sarebbe quello di verificare come varia la descri-zione della progressione della malattia considerando HMMs multivariati. Inoltrel’HMM stimato, potrebbe servire per fare previsione sugli stati di nuove osserva-
87

Conclusioni
zioni. Infine sarebbe utile includere nell’analisi anche le caratteristiche relativea pazienti sani, in modo da confrontare, attraverso le stime di un nuovo modellomulti-stato a stati nascosti, la differenza tra la stima degli stati per le due categorieconsiderate.
88

Bibliografia
Diggle, P., Liang, K. e Zeger., S. (2002). Analysis of Longitudinal Data. Secondedition. New York: Oxford University Press.
Guidoboni, G., Harris, A., Arciero, J. C., Siesky, B. A., Amireskandari, A., Gerber,A. L., Huck, A. H., Kim, N. J., Cassani, S. e Carichino, L. (2013). «Mathema-tical modeling approaches in the study of glaucoma disparities among peopleof African and European descents». Journal of Coupled Systems and MultiscaleDynamics.
Guyon, I. e Elisseeff, A. (2003). «An Introduction to Variable and Feature Se-lection». J. Mach. Learn. Res. 3, 1157–1182. issn: 1532-4435. url: http://dl.acm.org/citation.cfm?id=944919.944968.
Jackson, C. H. (2011). «Multi-State Models for Panel Data: The msm Packa-ge for R». Journal of Statistical Software, 38,8, 1–29. url: http://www.jstatsoft.org/v38/i08/.
Johnson, R. A. e Wichern, D. W. (2007). Applied Multivariate Statistical Analysis.6th. Prentice Hall.
Laird, N. e Ware, J. (1989). «Random-effects Models for Longitudinal Data».Biometrics, 38,4, 963–974.
Marshall, G. e Jones, R. H. (1995). «Multi-state Markov models and diabeticretinopathy». Statistics in Medicine, 14, 1975–1983.
National Eye Institute (2017). url: https://nei.nih.gov/.Pinheiro, J. C. e Bates, D. M. (2000). Mixed Effects Models in S and S-Plus.
Springer.Pinheiro, J., Bates, D., DebRoy, S., Sarkar, D. e R Core Team (2017). nlme: Linear
and Nonlinear Mixed Effects Models. R package version 3.1-131. url: https://CRAN.R-project.org/package=nlme.
Rabiner, L. R. (1989). «A tutorial on hidden Markov models and selected appli-cations in speech recognition», 257–286.
89

Bibliografia
Sakamoto, Y., Ishiguro, M. e Kitagawa, G. (1986). Akaike Information CriterionStatistics. Springer Netherlands.
Schwarz, G. (1978). «Estimating the dimension of a model». The Annals of Stati-stics, 6, 461–464.
Shoshani, Y., Harris, A., Shoja, M. M., Arieli, Y., Ehrlich, R., BSc, S. P., Ciulla,T., BSc, A. C., Wirostko, B. e Siesky, B. A. (2012). «Impaired ocular bloodflow regulation in patients with open-angle glaucoma and diabetes». Clinicaland Experimental Ophthalmology, 697–705.
Tobe, L. A., Harris, A., Hussai, R. M., Eckert, G., Huck, A., Park, J., Egan, P.,Kim, N. J. e Siesky, B. (2014). «The role of retrobulbar and retinal circulationon optic nerve head and retinal nerve fibre layer structure in patients with open-angle glaucoma over an 18-month period». British Journal of Ophthalmology.
Tobe, L. A., Harris, A., Trinidad, J., Chandrasekhar, K., Cantor, A., Abrams, J.,Amireskandari, A. e Siesky, B. (2012). «Should Men and Women be ManagedDifferently in Glaucoma?» Ophthalmol Therapy, 1, (1), 1.
Verbeke, G. e Molenberghs, G. (2001). Linear Mixed Models for Longitudinal Data.Second edition. Springer.
Zucchini, W., MacDonald, I. e Langrock, R. (2016). Hidden Markov models fortime series: an introduction using R. Second edition. CRC Press.
90

Ringraziamenti
Ringrazio innanzitutto la Professoressa Guglielmi per avermi guidato durante que-sto periodo di tesi, dandomi l’opportunità di lavorare su un tema stimolante, di-mostrandomi costantemente disponibilità, sostegno e fiducia.Ringrazio anche la Professoressa Guidoboni per avermi dato la possibilità di potertrattare un argomento molto interessante e attuale in ambito medico e per avermidato il supporto per affrontarlo al meglio.Il ringraziamento più grande va a mia madre e mio padre per avermi sempre so-stenuto in ogni mia scelta, incoraggiandomi nei momenti difficili e gioendo con meper ogni traguardo raggiunto. Grazie per avermi dato l’opportunità di svolgerequesto importante percorso di studi, non facendomi mai mancare nulla.Grazie a Michela, sorella, coinquilina e amica. Siamo cresciute aiutandoci semprea vicenda con affetto e allegria e insieme siamo riuscite a raggiungere uno degliobiettivi più grandi della nostra vita.Ringrazio Francesco, per avermi pazientemente sopportata in questo periodo ditesi (e non solo). Grazie perché credi in me e mi sproni a fare sempre meglio.Grazie per tutto.Ringrazio Maria Giulia per esserci sempre stata e per la consapevolezza che ci saràsempre, che sia a uno, cento o mille chilometri di distanza.Ringrazio tutti gli amici e i compagni che ho incontrato durante il periodo univer-sitario. Ringrazio Debora e Stefania per aver reso più leggeri questi anni passati astudiare e grazie perché continuiamo ancora a brindare insieme.
91