Embed Size (px)
DESCRIPTION
Một số kỹ thuật phân tích đa biến trong thống kê
Citation preview

CHƯƠNG 7:
PHÂN TÍCH NHÂN TỐ, PHÂN TÍCH KẾT HỢP
PHÂN TÍCH PHÂN BIỆT VÀ PHÂN TÍCH
CROSS-TABULATION( FACTOR, CONJOINT, DISCRIMINANT AND CROSS-TAB ANALYSIS)
I. PHÂN TÍCH NHÂN TỐ 1. Khái niệm 2. Mô hình phân tích nhân tố 3. Tiến trình phân tích nhân tố
II. PHÂN TÍCH KẾT HỢP 1. Khái niệm 2. Mục đích 3. Tiến trình phân tích kết hợp 4. Giả thuyết và hạn chế của phân tích kết hợp
III. PHÂN TÍCH PHÂN BIỆT 1. Khái niệm 2. Mục tiêu phân tích phân biệt 3. Mối quan hệ giữa phân tích hồi qui, phân tích ANOVA và phân tích phân
biệt4. Phân loại phân tích phân biệt 5. Mô hình phân tích phân biệt 6. Tiến trình phân tích phân biệt 7. Phân tích đa nhóm
IV. CROSS - TABULATION 1. Định nghĩa 2. Phân tích Cross - Tabulation hai biến 3. Phân tích Cross - tabulation ba biến

BÀI TẬP
Ngoài các phân tích đã đề cập trong những chương trước như phân tích ANOVA, phân tích hồi qui tương quan, kiểm định giả thuyết..., còn một số phân tích khác nhằm đáp ứng những nhu cầu khác nhau trong quá trình xử lý thông tin và ra quyết định, chẳng hạn như phân tích nhân tố, phân tích cụm, phân tích kết hợp và phân tích phân biệt giữa các nhóm. Trong phạm vi chương này, ba phân tích được ứng dụng phổ biến là phân tích nhân tô,ú phân tích kết hợp và phân tích phân biệt giữa các nhóm được đề cập. Tùy theo đặc điểm dữ liệu và mục tiêu nghiên cứu, việc sữ dụng các mô hình phân tích này sẽ rất quan trọng, tránh việc chọn mô hình phân tích không phù hợp, điều này sẽ dẫn đến sai lầm trong việc ra quyết định.
I. PHÂN TÍCH NHÂN TỐ - FACTOR ANALYSIS 1. Khái niệm
Phân tích nhân tố được sử dụng để rút gọn và tóm tắt dữ liệu. Trong nghiên cứu Marketing, có thể có rất nhiều biến để nghiên cứu, hầu hết chúng có tương quan với nhau và thường được rút gọn để có thể dễ dàng quản lý. Mối quan hệ giữa những bộ khác nhau của nhiều biến được xác định và đại diện bởi một vài nhân tố (hay nói cách khác một nhân tố đại diện cho một số biến). Chẳng hạn như hình tượng của một cửa hàng có thể đo lường bằng cách hỏi khách hàng để đánh giá và xác định các nhân tố có liên quan đến hình tượng của cửa hàng. Trong phân tích ANOVA hay hồi qui, tất cả các biến nghiên cứu thì có một biến phụ thuộc còn các biến còn lại là các biến độc lập, nhưng đối với phân tích nhân tố thì không có sự phân biệt này. Hơn nữa, phân tích nhân tố có quan hệ phụ thuộc lẫn nhau giữa các biến trong đó mối quan hệ phụ thuộc này được xác định. Vì những lý do trên, phân tích nhân tố được sử dụng trong các trường hợp sau:
1. Nhận dạng các nhân tố để giải thích mối quan hệ giữa các biến. Ví dụ như các câu trả lời về lối sống có thể được sử dụng để đo lường tâm lý của khách hàng. Các câu trả lời này có thể là nhân tố được phân tích để nhận dạng các nhân tố tâm lý.
2. Nhận dạng các biến mới thay thế cho các biến gốc ban đầu trong phân tích đa biến (hồi qui). Chẳng hạn các nhân tố tâm lý được nhận dạng có thể sử dụng như là các biến độc lập để phân biệt số khách hàng trung thành và không trung thành.
3. Nhận dạng một bộ có số biến ít hơn cho việc sử dụng phân tích đa biến. Chẳng hạn có một ít câu trả lời về lối sống tương quan khá cao với các nhân tố đã nhận dạng được sử dụng như các biến độc lập để giải thích sự khác biệt giữa khách hàng trung thành và không trung thành.
- Phân tích nhân tố được sử dụng rộng rãi trong nghiên cứu Marketing. Ví dụ,
1. Phân tích nhân tố được sử dụng trong phân khúc thị trường để nhận dạng các biến phân nhóm khách hàng. Chẳng hạn những người mua xe mới có thể tập hợp thành các nhóm dựa vào các nhân tố như tính kinh tế, tiện nghi, vận hành tốt và tính sang trọng. Ðiều này có thể có bốn phân khúc thị trường theo bốn nhân tố trên.

2. Trong nghiên cứu sản phẩm, phân tích nhân tố được sử dụng để xác định phẩm chất của nhãn hiệu có ảnh hưởng đến sự chọn lựa của khách hàng. Những nhãn hiệu kem đánh răng có thể được đánh giá về các khía cạnh: bảo vệ răng, làm trắng răng, mùi vị, hơi thở thơm tho và giá.
3. Các nghiên cứu trong quảng cáo, phân tích nhân tố được dùng để hiểu thói quen sử dụng phương tiện thông tin của thị trường mục tiêu. Chẳng hạn, những người sử dụng thức ăn lạnh có thể thích xem tivi, xem phim và nghe nhạc...
4. Trong nghiên cứu giá, phân tích nhân tố được sử dụng để nhận dạng những đặc điểm của khách hàng nhạy cảm về giá. Những khách hàng này có thể là những người không có thu nhập cao, thường xuyên ở nhà.
2. Mô hình phân tích nhân tố
Về mặt tóan học, mô hình phân tích nhân tố giống như phương trình hồi qui nhiều chiều mà trong đó mỗi biến được đặc trưng cho mỗi nhân tố. Những nhân tố này thì không được quan sát một cách riêng lẻ trong mô hình. Nếu các biến được chuẩn hóa mô hình nhân tố có dạng như sau:
Xi = Ai1F1 + Ai2F2+... + AimFm +ViUi
Trong đó:
XI: Biến được chuẩn hóa thứ i
Aịj: Hệ số hồi qui bội của biến được chuẩn hóa i trên nhân tố chung j
F: Nhân tố chung
Vi: Hệ số hồi qui của biến chuẩn hóa i trên nhân tố duy nhất i
Ui: Nhân tố duy nhất của biến i
m: Số nhân tố chung.
Mỗi nhân tố duy nhất thì tương quan với mỗi nhân tố khác và với các nhân tố chung. Các nhân tố chung có sự kết hợp tuyến tính của các biến được quan sát.
Fi = wi1x1 + wi2x2 +...+ wikxk
Trong đó:
Fi: Ước lượng nhân tố thứ i
wi: Trọng số hay hệ số điểm nhân tố

k: Số biến
Trong phân tích này có thể chọn trọng số (hay hệ số điểm nhân tố) để nhân tố thứ nhất có tỷ trọng lớn nhất trong tổng phương sai. Các nhân tố có thể được ước lượng điểm nhân tố của nó. Theo ước lượng này, nhân tố thứ nhất có điểm nhân tố cao nhất, nhân tố thứ hai có điểm nhân tố cao thứ hai ... Dĩ nhiên, kỹ thuật ước lượng liên quan rất nhiều đến thống kê, điều này sẽ được giải thích chi tiết trong các phần sau.
3. Tiến trình phân tích nhân tố
Tiến trình thực hiện phân tích nhân tố được trình bày theo các bước trong sơ đồ dưới đây:
Tiến trình phân tích nhân tố trong phần mềm SPSS như sau:
¨ Nhập dữ liệu 7 biến theo ví dụ của bước 1 - chọn menu Analyze - chọn Data Reduction - chọn Factor ... - chọn các chi tiết của các menu trong hộp thoại Factor Analysis như Descriptives, Extraction, Rotation, Scores and options - chọn OK, sau đó ta có bảng kết quả (từ bảng 7.1 đến bảng 7.2c) được giải thích theo các bước dưới đây.
Bước 1: Xác định vấn đề
Có rất nhiều nhiệm vụ trong việc xác định vấn đề phân tích. Trước tiên, mục tiêu nghiên cứu phải được xác định. Các biến trong mô hình phân tích nhân tố phải cụ thể, điều này có thể

dựa vào các nhân tố truớc, lý thuyết hoặc sự cân nhắc của nhà nghiên cứu. Việc những biến này sử dụng thang đo khoảng và thang đo tỷ lệ thì rất quan trọng và phải chọn cỡ mẫu phù hợp. Thường thường, cỡ mẫu phù hợp phải gấp từ bốn đến năm lần số biến nghiên cứu. Trong nhiều trường hợp nghiên cứu Marketing, vì một lý do nào đó, cỡ mẫu lấy thấp hơn tỷ lệ trên thì kết quả nghiên cứu nên được giải thích một cách thận trọng.
Ví dụ, giả sử nhà nghiên cứu muốn xác định những lợi ích cơ bản mà khách hàng cần tìm khi mua kem đánh răng. Một mẫu gồm 237 người được phỏng vấn theo thang đo 7 điểm (điểm 1 là hoàn toàn không đồng ý, điểm 7 là hoàn toàn đồng ý) với các nội dung khi sử dụng kem đánh răng như sau: (các biến từ V1 đến V7)
V1: Chống được sâu răng
V2: Tạo được hàm răng sáng
V3: Không làm nhiễm trùng nướu răng
V4: Tạo hơi thở thơm tho
V5: Chống được canxi hóa răng
V6: Có hàm răng hấp dẫn
V7: Có hàm răng khỏe mạnh
Bước 2: Lập ma trận tương quan
Sau khi thu thập thông tin, dựa vào dữ liệu của 7 biến trên ta lập ma trân tương quan giữa các biến. Nếu phân tích nhân tố thích hợp thì các biến này phải có tương quan với nhau. Trong thực tế, nếu sự tương quan giữa các biến tương đối nhỏ thì phân tích nhân tố có thể không phù hợp. Chúng ta mong đợi rằng các biến phải có tương quan ở mức độ cao trong từng biến và giữa các biến.
- Ðể nhận dạng điều này chúng ta sử dụng phần mềm SPSS hoặc Excel để tạo ma trận tương quan giữa các biến bằng câu lệnh Correlation. Chẳng hạn, kết quả ma trận tương quan của 7 biến trong ví dụ về kem đánh răng được trình bày như sau:
Bảng 7.1: Ma trận tương quan giữa các biến

Nhận xét:
Ma trận tương quan giữa 7 biến (V1(V7) biểu hiện những lợi ích của kem đánh răng thông qua sự liên hệ giữa các biến. Theo kết quả bảng 7.1, các biến V1,V3, V5 và V7 có tương quan rất cao. Chúng ta sẽ đặt một nhân tố chung đại diện cho 4 biến này là F1. Tương tự, các biến V2, V4 và V6 được đại diện bởi nhân tố chung F2.
Tiếp theo, để xác định tất cả 7 biến có tương quan như thế nào, ta sử dụng kiểm định Barletts để kiểm định giả thuyết:
Tuy nhiên, để xác định số nhân tố ta quan tâm đến tổng phương sai của 7 nhân tố (cột 2) và của từng nhân tố (cột 5). Kết quả xử lý theo kiểm định Bartlett như sau:
Giải thích:
* Communality: phương sai tối đa của mỗi biến
* Eigenvalue: phuơng sai tổng hợp của từng nhân tố
* Percent of variance: phương sai của từng nhân tố tính bằng %

[(cột (5) = cột (4)/tổng cột (2) x100)]
* Cumulative Percentage: phương sai tích lũy [cột (6) = cột (5) cộng dồn]
Bước 3: Xác định số nhân tố
Trong nghiên cứu thường số nhân tố sau khi xử lý ít hơn số biến ban đầu. Rất hiếm có trường hợp tất cả các biến ban đầu đều là các nhân tố ảnh hưởng hay tác động đến vấn đề nghiên cứu. Theo ví dụ trên, trong 7 biến ban đầu nhưng chỉ có hai nhân tố (V1) và (V2) là có trọng số cao về phương sai thể hiện kết quả trong cột 5 (48,3% và 28,0%) làm đại diện. Tuy nhiên, có rất nhiều cách để xác định số nhân tố trong mô hình phù hợp:
1. Quyết định trước số nhân tô:ú thỉnh thoảng nhà nghiên cứu biết trước có bao nhiêu nhân tố trước khi tiến hành phân tích. Số nhân tố có giảm đi hay không là do nhà nghiên cứu hoàn toàn quyết định.
2. Quyết định dựa vào phương sai tổng hợp của từng nhân tố (Eigenvalue): Trong cách tiếp cận này chỉ có những nhân tố có Eigenvalue lớn hơn 1 mới được đưa vào mô hình. Nếu số biến ban đầu ít hơn 20 thì cách tiếp cận này vẫn còn tác dụng.
3. Quyết định dựa vào phần trăm phương sai của từng nhân tố (cột 5): Số nhân tố được chọn vào mô hình phải có tổng phương sai tích lũy giữa hai nhân tố lớn hơn 60%. Tuy nhiên, tùy thuộc vào vấn đề nghiên cứu mức độ này có thể thấp hơn. Chẳng hạn tổng phương sai của nhân tố 1 và nhân tố 2 trong ví dụ về kem đánh răng là 76,3%.
Bước 4: Giải thích các nhân tố
Trở lại kết quả của kiểm định Bartlett ta có kết quả của ma trận nhân tố như sau:
Bảng 7.2a. Ma trận nhân tố đã chuẩn hóa các biến
Bảng ma trận 7.2a chứa đựng các biến đã được chuẩn hóa, ma trận này thể hiện mối tương quan giữa hai nhân tố (V1) và (V2) với 7 biến (V1(V7). Ta thấy rằng nhân tố 1 có tương quan với cả 7 biến nhưng chỉ có các biến V1 (chống sâu răng), V3(chống nhiễm trùng nướu), V5
(chống canxi hóa) và V7 (răng khỏe) là có hệ số tương quan cao, các biến này thể hiện lợi ích về sức khỏe. Như vậy, nhân tố 1 có thể đặt tên là nhân tố lợi ích về sức khỏe. Tương tự, nhân tố 2

liên quan đến các biến có hệ số tương quan cao như V2 (răng sáng), V4 (hơi thở thơm tho) và V6 (hàm răng hấp dẫn), nhân tố nầy được đặt tên là nhân tố lợi ích về xã hội.
Như vậy, qua xử lý ta thấy có hai loại lợi ích từ việc sử dụng kem đánh răng là lợi ích sức khỏe và lợi ích xã hội được đại diện bởi nhân tố 1 (F1) và nhân tố 2 (F2).
Bước 5: Xác định điểm nhân tố và chọn nhân tố thay thế
- Ðiểm nhân tố (hay trọng số) để kết hợp các biến chuẩn hóa (F) được lấy từ ma trận hệ số điểm (bảng 7.2b: Factor score coefficient matrix). Theo ví dụ trên, trong mô hình có hai nhân tố chung F1 và F2, trong đó F1 có bốn biến liên quan là V1, V3, V5 và V7, và F2 có ba biến liên hệ là V2, V4, và V6.
Cụ thể ước lượng điểm nhân tố của hai nhân tố F1 và F2 như sau:
F1= 0,31x1 + 0,29 x3 + 0,3x5 +0,29x7
F2= 0,38x2 + 0,38x4 + 0,37x6
Các tham số của hai phương trình trên được rút ra từ bảng kết quả phân tích mục Factor score coefficient matrix. Trong hai phương trình trên, biến nào có hệ số điểm nhân tố cao nhất thì biến đó ảnh hưởng lớn nhất đến nhân tố chung. Tuy nhiên, trong thực tế nghiên cứu, có những trường hợp có thể có một số biến đã được nhà nghiên cứu quan tâm từ trước, mặc dù nó có hệ số điểm nhân tố thấp hơn nhưng vẫn được coi là quan trọng hơn. Chẳng hạn như chống canxi hóa răng (V5) được coi là quan trọng hơn chống sâu răng (V1) trong mô hình phân tích này. Thực hiện điều này có nghĩa là ta đã chọn nhân tố thay thế.
Bảng 7.2b: Factor score coefficient matrix
Variable Factor 1 Factor 2V1
V2
V3
V4
V5
V6
V7
.30931
-.05548
.29250
-.04918
.30199
-.04160
.29173
-.06814
.38315
-.03331
.38087
-.05191
.37478
.00697
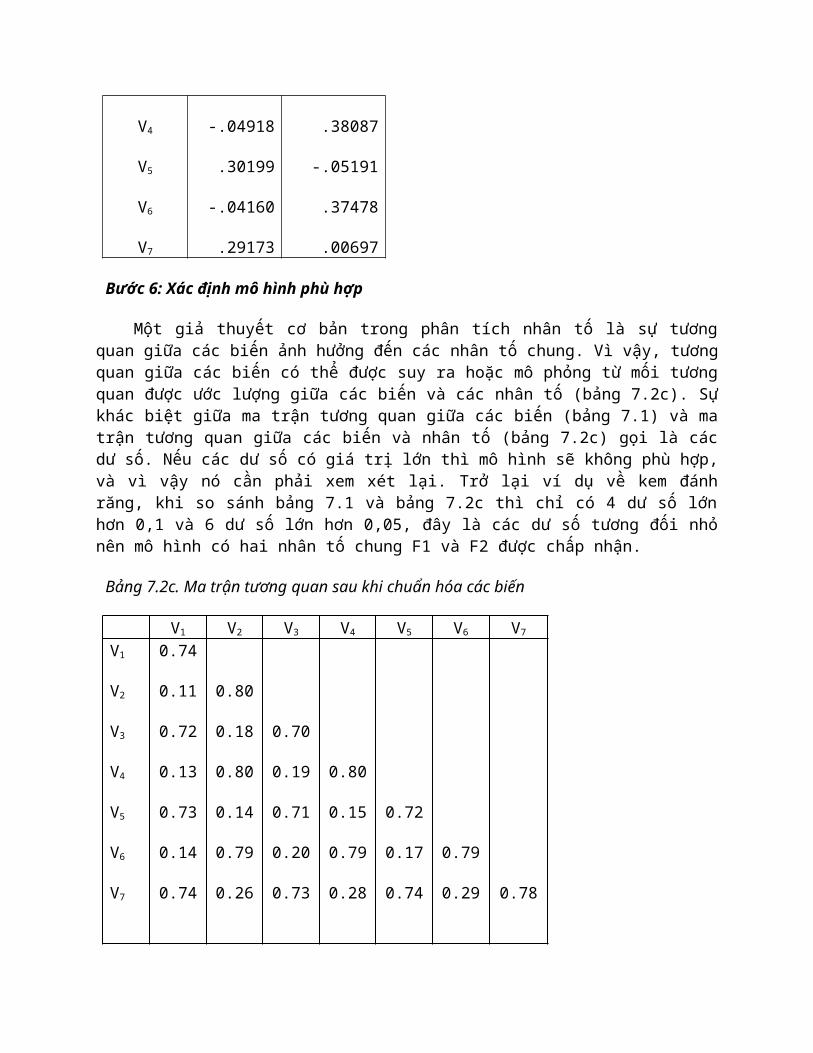
Bước 6: Xác định mô hình phù hợp

Một giả thuyết cơ bản trong phân tích nhân tố là sự tương quan giữa các biến ảnh hưởng đến các nhân tố chung. Vì vậy, tương quan giữa các biến có thể được suy ra hoặc mô phỏng từ mối tương quan được ước lượng giữa các biến và các nhân tố (bảng 7.2c). Sự khác biệt giữa ma trận tương quan giữa các biến (bảng 7.1) và ma trận tương quan giữa các biến và nhân tố (bảng 7.2c) gọi là các dư số. Nếu các dư số có giá trị lớn thì mô hình sẽ không phù hợp, và vì vậy nó cần phải xem xét lại. Trở lại ví dụ về kem đánh răng, khi so sánh bảng 7.1 và bảng 7.2c thì chỉ có 4 dư số lớn hơn 0,1 và 6 dư số lớn hơn 0,05, đây là các dư số tương đối nhỏ nên mô hình có hai nhân tố chung F1 và F2 được chấp nhận.
Bảng 7.2c. Ma trận tương quan sau khi chuẩn hóa các biến
V1 V2 V3 V4 V5 V6 V7
V1
V2
V3
V4
V5
V6
V7
0.74
0.11
0.72
0.13
0.73
0.14
0.74
0.80
0.18
0.80
0.14
0.79
0.26
0.70
0.19
0.71
0.20
0.73
0.80
0.15
0.79
0.28
0.72
0.17
0.74
0.79
0.29 0.78
II. PHÂN TÍCH KẾT HỢP - CONJOINT ANALYSIS 1. Khái niệm
Phân tích kết hợp là một kỹ thuật để xác định tầm quan trọng tương đối về các phẩm chất nổi bật của sản phẩm hay nhãn hiệu sản phẩm và lợi ích của mỗi phẩm chất đó qua đánh giá chủ quan của khách hàng. Phân tích kết hợp dùng để phát triển những hàm giá trị hoặc hàm lợi ích, nó mô tả lợi ích mà khách hàng đưa ra đối với mỗi phẩm chất của vấn đề nghiên cứu.
2. Mục đích
Phân tích kết hợp được sử dụng trong Marketing với nhiều mục đích khác nhau:
- Xác định tầm quan trọng tương đối về phẩm chất trong tiến trình chọn lựa của người tiêu dùng.
- Xác định thị phần của các nhãn hiệu (brands) ở các mức độ khác nhau về phẩm chất.

- Xác định sự cấu thành của nhãn hiệu được ưa thích nhất. Những đặc trưng của nhãn hiệu có thể khác nhau về chất lượng, những đặc trưng này nếu có lợi ích cao nhất thì nhãn hiệu sẽ được yêu thích nhất.
- Phân khúc thị trường dựa vào sự giống nhau của sở thích ở các mức độ khác nhau về phẩm chất.
Ứng dụng của phân tích kết hợp sử dụng trong các lĩnh vực hàng tiêu dùng, sản phẩm công nghiệp, các dịch vụ, tài chính và các dịch vụ khác. Hơn nữa, những ứng dụng này có thể mở rộng cho toàn bộ các lĩnh vực Marketing. Một vài nghiên cứu gần đây ứng dụng phân tích kết hợp trong các lĩnh vực như nhận dạng sản phẩm mới, phân tích cạnh tranh, giá, phân khúc thị trường, quảng cáo và phân phối sản phẩm.
3. Tiến trình phân tích kết hợp
Tiến trình phân tích kết hợp được trình bày như trong sơ đồ 7.2.
Bước 1: Xác định vấn đề
Vấn đề được xác định có liên quan đến việc nhận dạng các phẩm chất nổi bật ở các mức độ khác nhau. Khách hàng đánh giá hoặc xếp hạng trong các thang đo phù hợp. Trước tiên, nhà nghiên cứu phải nhận dạng các phẩm chất ở các mức độ khác nhau và sắp xếp, kết hợp chúng lại với nhau bằng các giá trị đại diện. Về lý thuyết, các phẩm chất được chọn thường thì nổi bật trong việc ảnh hưởng đến sự chọn lựa có liên quan đến thị hiếu của khách hàng. Chẳng hạn, trong việc chọn lựa nhãn hiệu của xe honda thì giá cả, mức độ tiêu tốn xăng/100km, màu xe, tính bền của xe.v.v... là các phẩm chất rất được người mua quan tâm.
Ðể giảm thiểu công việc đánh giá của người được phỏng vấn và để ước lượng các tham số (về phẩm chất) với tính chính xác hợp lý, nên hạn chế số lượng phẩm chất thông qua việc thảo luận với ban quản lý, chuyên gia, phân tích số liệu thứ cấp, nghiên cứu định tính, điều tra thử.v.v... để chọn các phẩm chất nổi bật. Các hàm lợi ích trong phân tích có thể không tuyến tính, lợi ích sẽ mất đi khi chuyển từ giá trung bình lên giá cao hơn. Các mức độ phẩm chất khác nhau (chẳng hạn giá thấp, giá trung bình và giá cao của honda) ảnh hưởng đến sự đánh giá của người tiêu dùng. Nếu ba mức giá của xe honda là 10 triệu đồng, 12 triệu đồng và 14 triệu đồng thì mức độ chênh lệch giá không quan trọng. Nhưng nếu ba mức giá thể hiện ba phẩm chất khác nhau như 10 triệu đồng, 20 triệu đồng và 30 triệu đồng thì giá sẽ là một nhân tố rất quan trọng. Vì vậy, nhà nghiên cứu nên tính toán các mức độ phẩm chất phổ biến trên thị trường và mục tiêu nghiên cứu. Thông thường, để chọn lựa cơ cấu phẩm chất lớn hơn cái nó có trong thị trường nhưng cũng đừng chọn mức độ phẩm chất quá lớn vì nó sẽ tác động đến khả năng tin tưởng của việc đánh giá.
Ví dụ, Vấn đề nhà nghiên cứu muốn biết khách hàng mong muốn sản phẩm giày như thế nào. Qua phỏng vấn thử, kết quả cho thấy có ba phẩm chất nổi bật là: đế giày, thân giày và giá bán. Mỗi phẩm chất được mô tả ở ba mức độ (1, 2 và 3). Số liệu thu thập như trong bảng sau:
Bảng 7.3: Phẩm chất và các mức độ của phẩm chất

Bước 2: Cấu trúc kết hợp
Có hai cách tiếp cận cho cấu trúc phân tích kết hợp: đánh giá hai nhân tố và đánh giá đa nhân tố.
- Ðánh giá hai nhân tố (two-factor evaluations): còn được gọi là đánh giá từng cặp. Người được phỏng vấn đánh giá hai phẩm chất cùng một lúc cho đến khi nào tất cả các cặp đều được đánh giá. Mỗi cặp được đánh giá trên tất cả sự kết hợp các mức độ của hai phẩm chất (hay hai nhân tố).
- Ðánh giá đa nhân tố (multiple evaluations): người được phỏng vấn đánh giá tất cả các phẩm chất trên tất cả các mặt của nhãn hiệu, mỗi mặt thì được mô tả bằng một chỉ số riêng. Trong thực tế, không cần thiết phải đánh giá tất cả sự kết hợp bởi vì nó không khả thi trong tất cả các trường hợp. Trong đánh giá hai nhân tố, có thể giảm các cặp kết hợp bằng cách sử dụng thiết kế chu kỳ (cyclical designs). Trong khi đó đánh giá đa nhân tố sử dụng thiết kế nhân tố phân đọan (fractional factorial designs) để giảm số lần đánh giá của phẩm chất. Nói chung, có hai bộ số liệu được thu thập. Thứ nhất là bộ dùng để đánh giá (evaluation set) được sử dụng để đánh giá hàm lợi ích cho các mức độ phẩm chất. Thứ hai là bộ được yêu cầu (holdout set) để đánh giá độ tin cậy và hiệu quả.
Thuận lợi của đánh giá từng cặp là dễ dàng cho người trả lời cung cấp những ý kiến đánh giá. Tuy nhiên, nó cũng đòi hỏi nhiều đánh giá hơn trong tiếp cận đa nhân tố, vì vậy đánh giá đa nhân tố được sử dụng phổ biến hơn trong thực tế. Trở lại ví dụ về giày, ta có ba phẩm chất (đế giày, thân giày và giá) để đánh giá, mỗi phẩm chất lại có ba mức độ. Do đó, tổng các mặt kết hợp phẩm chất cần phải đánh giá là 27 (3.3.3) được thể hiện như sau:

Sơ đồ 7.3: Ðánh giá từng cặp trong thu thập dữ liệu kết hợp
Trước khi tiến hành các kỹ thuật để giảm công việc đánh giá cho người trả lời, việc quyết định hình thức dữ liệu là hết sức cần thiết.
Bước 3: Quyết định hình thức dữ liệu
Dữ liệu trong phân tích kết hợp được người trả lời đánh giá bằng cách dùng tỷ lệ hay xếp hạng các mặt của các kết hợp phẩm chất. Ðối với dữ liệu sử dụng hệ thống thang đo thì người trả lời đánh giá bằng cách xếp hạng. Các hạng được xếp có liên quan đến việc đánh giá một cách tương đối các mức độ phẩm chất và nó cũng phản ánh một cách chính xác hành vi của người tiêu dùng trên thị trường.
Ðối với dữ liệu không sử dụng hệ thống thang đo thì người trả lời đánh giá theo hình thức tỷ lệ. Hình thức này được người trả lời đánh giá một cách độc lập, dữ liệu dưới hình thức tỷ lệ được phân tích dễ dàng hơn dữ liệu được xếp hạng. Trong thực tế, việc sử dụng hình thức tỷ lệ rất phổ biến. Cho dù đánh giá dưới hình thức nào thì người trả lời cũng dựa vào sở thích và sự quan tâm để mua hàng.
Bảng 7.4 trình bày việc đánh giá dưới hình thức tỷ lệ của người được phỏng vấn. Các tỷ lệ này sử dụng thang đo 9 điểm với mức độ tăng dần về sở thích mua hàng của 9 cách kết hợp trên 27 mặt (điểm 1: không thích, điểm 9: rất thích).

Bảng 7.4: Ðánh giá theo hình thức tỷ lệ
Theo đánh giá của khách hàng trong bảng 7.4, cách kết hợp thứ nhất với tỷ lệ 1.1.1 ở các mức độ phẩm chất tương ứng, điều này có nghĩa là khách hàng quan tâm đến một đôi giày có đế giày
bằng nhựa, thân giày bằng nilon với giá 450.000đ (kết hợp nội dung ở bảng 7.3 để giải thích các kết hợp còn lại).
Bước 4: Mô hình phân tích kết hợp
Mô hình phân tích kết hợp là mô hình toán học thể hiện mối quan hệ cơ bản giữa các phẩm chất và lợi ích trong phân tích kết hợp. Cụ thể mô hình được trình bày như sau:
Trong đó:
U(x) : Lợi ích chung của mỗi phương án
Ki : Số mức độ của phẩm chất
m : Số phẩm chất
Và: Ii : {Max ((ij) - Min ((ij)}
Trong đó: Ii : Tầm quan trọng của mỗi phẩm chất
((ij) : Hệ số lợi ích
Có nhiều cách để ước lượng mô hình cơ bản này, đơn giản nhất là sử dụng mô hình hồi qui với các biến độc lập là các biến giả (dummy) đại diện cho các mức độ của phẩm chất, biến phụ

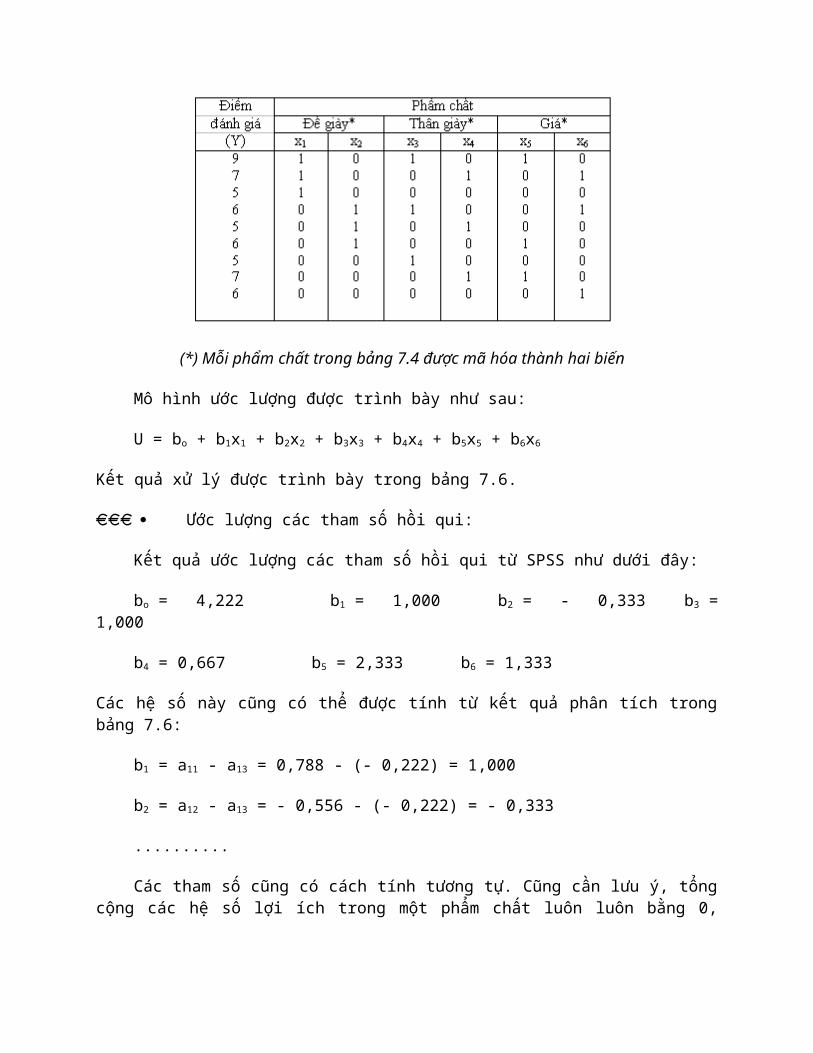
thuộc là tỷ lệ đánh giá của người trả lời. Từ số liệu bảng 11.4, ta sử dụng hai biến giả cho mỗi phẩm chất, như vậy sẽ có 6 biến giả được sử dụng cho ba phẩm chất: đế giày (x1 và x2), thân giày (x3 và x4) và giá (x5 và x6). Ba mức độ 1, 2 và 3 trong mỗi phẩm chất được mã hóa như sau:
- Trong các biến x1, x3 và x5 thì mức độ 1 được mã hóa là 1, các mức độ 2 và 3 được mã hóa là 0.
- Trong các biến x2, x4 và x6 thì mức độ 2 được mã hóa là 1, mức độ 1 và 3 được mã hóa là 0.
Số liệu trong bảng 7.4 được mã hóa trong bảng 7.5 như sau:
Bảng 7.5: Mã hóa dữ liệu biến giả trong mô hình hồi qui
(*) Mỗi phẩm chất trong bảng 7.4 được mã hóa thành hai biến
Mô hình ước lượng được trình bày như sau:
U = bo + b1x1 + b2x2 + b3x3 + b4x4 + b5x5 + b6x6
Kết quả xử lý được trình bày trong bảng 7.6.
Ước lượng các tham số hồi qui:
Kết quả ước lượng các tham số hồi qui từ SPSS như dưới đây:
bo = 4,222 b1 = 1,000 b2 = - 0,333 b3 = 1,000
b4 = 0,667 b5 = 2,333 b6 = 1,333
Các hệ số này cũng có thể được tính từ kết quả phân tích trong bảng 7.6:
b1 = a11 - a13 = 0,788 - (- 0,222) = 1,000
b2 = a12 - a13 = - 0,556 - (- 0,222) = - 0,333
..........
Các tham số cũng có cách tính tương tự. Cũng cần lưu ý, tổng cộng các hệ số lợi ích trong một phẩm chất luôn luôn bằng 0, chẳng hạn các giá trị của (11 + (12 + (13 trong bảng 7.6 thì bằng 0.
Bảng 7.6: Kết qủa phân tích kết hợp
Tính mức độ quan trọng của mỗi phẩm chất:
- Tổng các mức độ quan trọng của ba phẩm chất:
I = {Max ((ij) - Min ((ij)}= I đế giày + I thân giày + I giá
= [0,778 - (- 0,556)] + [ 0,445 - (- 0,556)] + [1,111 - (- 1,222)]
= 1,334 + 1,001 + 2,333 = 4,668
- Hệ số quan trọng của đế giày (DG) =Ġā
- Hệ số quan trọng của thân giày (TG) =Ġ
- Hệ số quan trọng của giá (G) =Ġ
Bước 5: Giải thích kết quả

Kết quả phân tích trong bảng 7.6 cho ta hai kết luận cơ bản sau:
Trong mỗi phẩm chất, hệ số quan trọng của mức độ nào có giá trị cao nhất chứng tỏ khách quan tâm nhiều nhất đến phẩm chất đó. Như vậy, qua kết quả tính toán khách hàng rất nhạy cảm về giá (I = 0,500), sau đó đến đế giày (I = 0,286) và sau cùng là thân giày (I = 0, 214).
Trong các mức độ của mỗi phẩm chất, nếu hệ số lợi ích của mức độ nào cao nhất thì được khách hàng ưa chuộng nhất. Theo ví dụ trên, kết quả nhận xét như sau:
Khách hàng thích một đôi giày được sản xuất với đế giày làm bằng cao su ((11= 0,778), thân giày làm bằng da ((21= 0,445) và giá khoảng 150.000 đồng ((31=1,111). Vấn đề tiếp theo ta cần xem xét độ tin cậy của tài liệu phân tích để chứng minh rằng kết luận trên có độ tin cậy cao.
Bước 6: Ðánh giá độ tin cậy và hiệu quả phân tích
Có nhiều cách để đánh giá độ tin cậy và hiệu quả của phân tích kết hợp:
1. Dùng phân tích sự phù hợp (Goodness of Fit) hay mô hình hồi qui. Nếu dùng mô hình hồi qui thì hệ số xác định (R2) sẽ là chỉ tiêu để đánh giá sự phù hợp của mô hình. Giá trị của R2 càng lớn chứng tỏ sự phù hợp của mô hình càng cao.
2. Kiểm tra lại dữ liệu để đánh giá lại độ tin cậy. Trong trường hợp này người trả lời được phỏng vấn lại để đánh giá một lần nữa các phẩm chất, sau đó so sánh ma trận tương quan để đánh giá độ tin cậy của kết quả phân tích.
3. Ðánh giá hiệu quả phân tích còn có thể sử dụng các hàm lợi ích để ước lượng tầm quan trọng của các phẩm chất. Ðánh giá ước lượng này có thể kết hợp với đánh giá của người được phỏng vấn để xác định hiệu quả phân tích.
4. Nếu một phân tích tổng hợp đã được tiến hành, mẫu ước lượng có thể chia làm nhiều hướng và phân tích kết hợp có thể tiến hành cho từng mẫu nhỏ được tách ra. Sau đó kết quả có thể so sánh với nhau để đánh giá sự ổn định của các giải pháp được sử dụng trong phân tích kết hợp.
4. Giả thuyết và hạn chế của phân tích kết hợp
Mặc dù phân tích kết hợp là một kỹ thuật được sử dụng khá phổ biến nhưng nó cũng chứa đựng nhiều giả thuyết và hạn chế. Giả thuyết trong phân tích kết hợp là các phẩm chất quan trọng của một sản phẩm có thể được nhận dạng. Hơn nữa, khách hàng có thể đánh giá những phương án chọn lựa trong các phẩm chất này. Có một số trường hợp hình tượng và nhãn hiệu thì quan trọng. Tuy nhiên, khách hàng không thể đánh giá nhãn hiệu trong các phương án khác nhau về phẩm chất ngay cả nếu khách hàng rất quan tâm đến các phẩm chất của sản phẩm, mô hình đánh đổi (trade off) không thể đại diện tốt cho tiến trình chọn lựa. Một hạn chế khác của phân tích kết hợp là dữ liệu thu thập quá phức tạp nếu số lượng phẩm chất khá lớn.

IV. CROSS- TABULATION
1. Ðịnh nghĩa
Cross- tabulation là một kỹ thuật thống kê mô tả hai hay ba biến cùng lúc và bảng kết quả phản ánh sự kết hợp hai hay nhiều biến có số lượng hạn chế trong phân loại hoặc trong giá trị phân biệt. Ví dụ, tiếp cận một sản phẩm mới có liên quan đến tuổi và trình độ học vấn hay không? Giả sử một nhà nghiên cứu quan tâm đến mức độ trung thành cuả khách hàng đối với các cửa hàng công ty ở các thị trường khác nhau. Khách hàng chia làm 2 loại: khách hàng trung thành và không trung thành. Có thể chọn 3 cửa hàng ở 3 thị trường khác nhau (hoặc nhiều cửa hàng cho mỗi thị trường), sau đó xử lý bằng Cross- tabulation để so sánh mức độ trung thành và không trung thành của khách hàng giữa các thị trường, từ đó có biện pháp giữ khách hàng,
Mô tả dữ liệu bằng Cross- tabulation đoọc sử dụng rất rộng rãi trong nghiên cứu Marketing thương mại bởi vì (1) phân tích Cross- tabulation và kết quả của nó có thể giải thích và hiểu một cách dễ dàng đối với những nhà quản lý không có chuyên môn thống kê, (2) sự rõ ràng trong việc giải thích cung cấp 1 sự kết hợp chặt chẽ giữa kết quả nghiên cứu và quyêt định trong quản lý; (3) chuỗi phân tích Cross- tabulation cung cấp những kết luận sâu hơn trong các trường hợp phức tạp; (4) Cross- tabulation có thể làm giảm bớt các vấn đề của các ô (cells) và (5) phân tích Cross- tabulation tiến hành đơn giản. Trong phần này, chúng ta sẽ thảo luận phân tích Cross- tabulation hai và ba biến.
2. Phân tích Cross- tabulation hai biến
Bảng phân tích Cross- tabulation 2 biến còn được gọi là bảng tiếp liên (Contigency table), mỗi ô trong bảng chứa đựng sự kết hợp phân loại của hai biến. Chẳng hạn như xem xét mức độ gần gũi hay không gần gũi của khách hàng đối với cửa hàng của công ty dựa vào độ tuổi. Tuổi của khách được phân loại làm 3 trường hợp: nhỏ hơn 15 tuổi, từ 15 đến 30 tuổi và trên 30 tuổi. Ðiều tra ngẫu nhiên 266 khách hàng được sắp xếp như trong bảng sau:
Bảng 7.10: số lượng khách hàng theo tuổi và mức độ gần gũi với cửa hàng
Kết qủa xử lý bằng phần mềm SPSS như sau:
Bảng 7.11: Phần trăm mức độ gần gũi của khách hàng đối với cửa hàng theo cột
Bảng 7.12. Phần trăm mức độ gần gũi của khách hàng đối với cửa hàng theo hàng
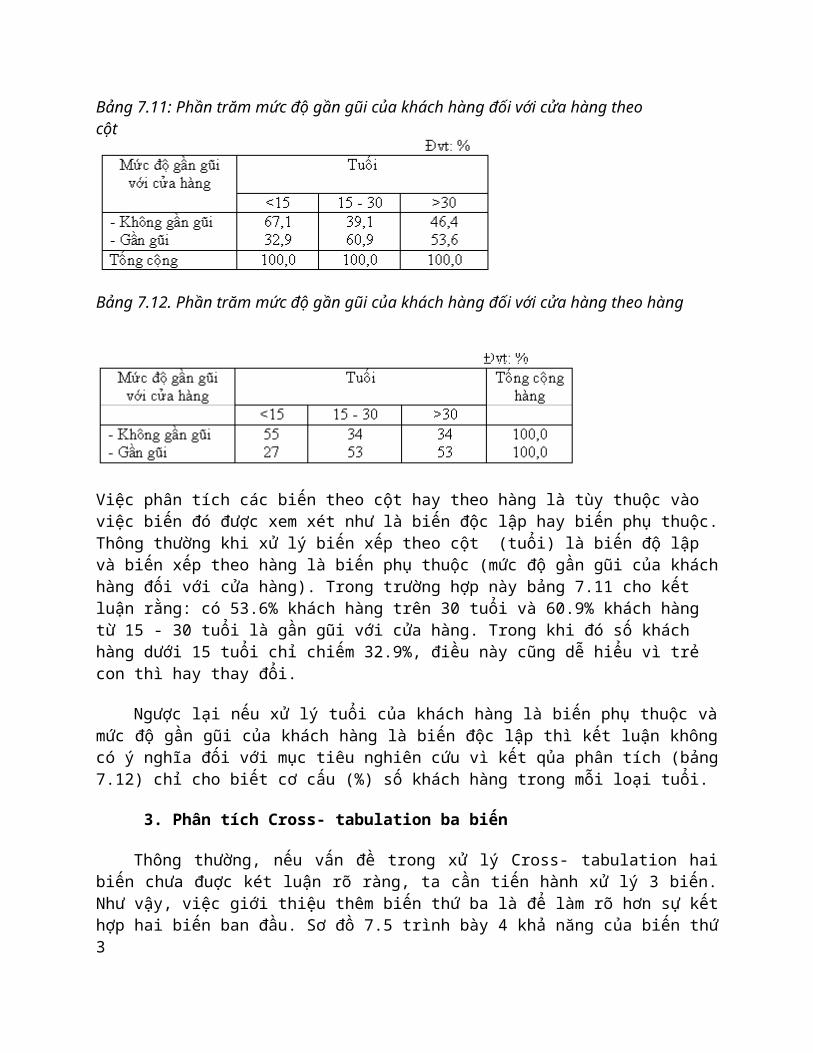
Việc phân tích các biến theo cột hay theo hàng là tùy thuộc vào việc biến đó được xem xét như là biến độc lập hay biến phụ thuộc. Thông thường khi xử lý biến xếp theo cột (tuổi) là biến độ lập và biến xếp theo hàng là biến phụ thuộc (mức độ gần gũi của khách hàng đối với cửa hàng). Trong trường hợp này bảng 7.11 cho kết luận rằng: có 53.6% khách hàng trên 30 tuổi và 60.9% khách hàng từ 15 - 30 tuổi là gần gũi với cửa hàng. Trong khi đó số khách hàng dưới 15 tuổi chỉ chiếm 32.9%, điều này cũng dễ hiểu vì trẻ con thì hay thay đổi.
Ngược lại nếu xử lý tuổi của khách hàng là biến phụ thuộc và mức độ gần gũi của khách hàng là biến độc lập thì kết luận không có ý nghĩa đối với mục tiêu nghiên cứu vì kết qủa phân tích (bảng 7.12) chỉ cho biết cơ cấu (%) số khách hàng trong mỗi loại tuổi.
3. Phân tích Cross- tabulation ba biến
Thông thường, nếu vấn đề trong xử lý Cross- tabulation hai biến chưa đuợc két luận rõ ràng, ta cần tiến hành xử lý 3 biến. Như vậy, việc giới thiệu thêm biến thứ ba là để làm rõ hơn sự kết hợp hai biến ban đầu. Sơ đồ 7.5 trình bày 4 khả năng của biến thứ 3
1. Nó có thể làm rõ sự kết hợp của hai biến ban đầu..
2. Nó có thể chỉ ra không có sự kết hợp giữa hai biến ban đầu, hay là sự kết hợp giữa hai biến ban đầu là giả mạo.
3. Nó có thể làm nổi bật 1 sự kết hợp nào đó giữa hai biến đầu tiên.
4. Nó cũng có thể chỉ ra không có sự thay đổi trong sự kết hợp ban đầu.
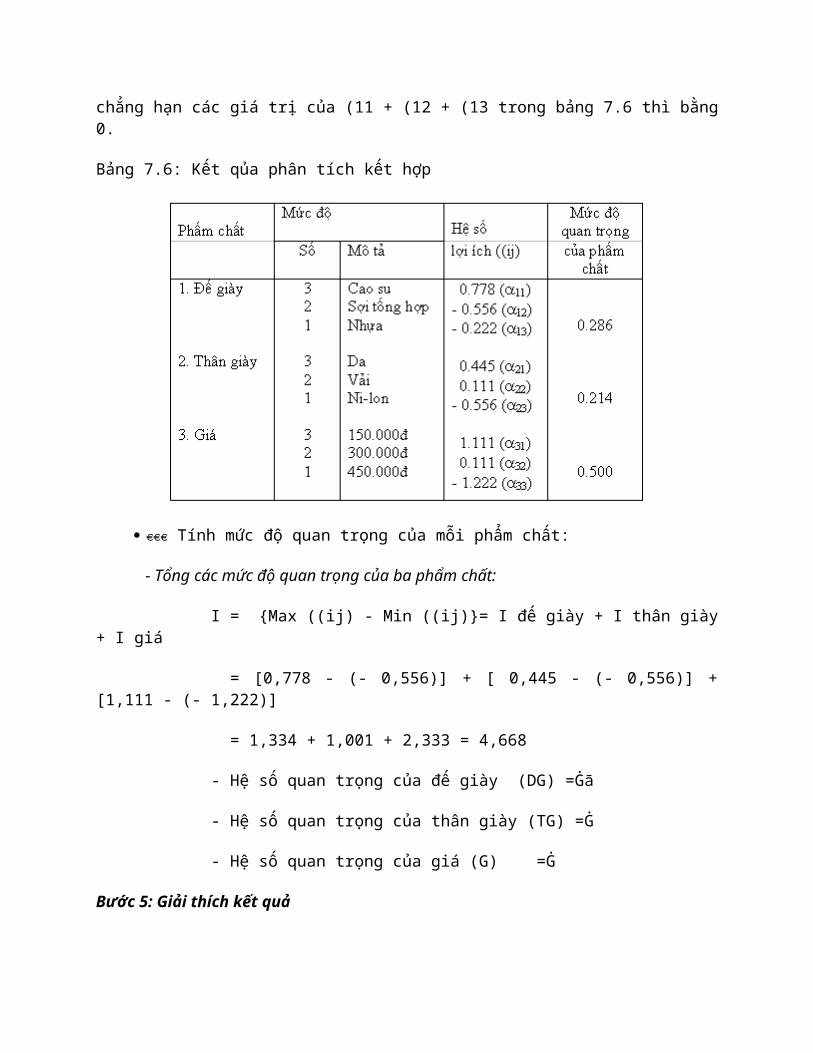
Những trường hợp trên được giải thích dựa vào một mẫu 1000 khách hàng. Mặc dù các ví dụ sau đây có thể làm sáng tỏ các trường hợp trên, những ví dụ khá phổ biến trong nghiên cứu Marketing thương mại.
3.1. Làm rõ mối quan hệ ban đầu
Một nghiên cứu về mối liên hệ giữa việc mua quần áo thời trang và tình trạng hôn nhân. Khách hàng được chia làm hai loại cao và thấp dựa vào việc mau quần áo thời trang. Kết quả phân tích được trình bày trong bảng sau:
Bảng 7.13: Khả năng mua quần áo thời trang theo tình trạng hôn nhân
Mức độ Tình trạng hôn nhânmua hàng Có gia đình Chưa có gia đìnhCao (%)
Thấp (%)
Tổng cộng (%)
Số khách hàng (người)
31
69
100
700
52
48
100
300
Số liệu bảng 7.13 chỉ ra số người chưa có gia đình mua quần áo thời trang cao hơn (52%), trong khi đó, chỉ tiêu này đối với người có gia đình chỉ chiếm 31%. Ðể hiểu rõ hơn, ta xem xét chỉ tiêu giới tính ảnh hưởng đến việc mau quần áo thời trang - kết quả được mô tả trong bảng 7.14.
Sơ đồ 7.5: Giới thiệu biến thứ ba trong phân tích Cross- tabulation.

Bảng 7.14: Khả năng mua quần áo thời trang theo tình trạng hôn nhân và giới
tính Nhận xét kết quả phân tích:
- Có 60% số phụ nữ chưa có gia đình và 25% số phụ nữ có gia đình mua quần áo thời trang ở mức độ cao. Tương tự, chỉ tiêu này ở nam chỉ có 40% và 30%. Như vậy, biến thứ ba (giới tính) đã làm rõ hơn cơ cấu của giới tính trong việc mua quần áo thời trang ở mức độ cao của hai biến ban đầu: Mức độ mua hàng và tình trạng hôn nhân.
3.2. Không có liên hệ giữa hai biến ban đầu
Một nhà nghiên cứu làm việc trong 1 công ty quảng cáo khuyến mãi xe gắn máy. Với giá cao hơn 30 triệu đồng. Ông ta muốn xem xét mối quan hệ giữa việc sở hữu xe gắn máy và trình độ học vấn bậc đại học. Kết quả phân tích được trình bày trong bảng sau:
Bảng 7.15: Sở hữu xe máy theo trình độ học vấn
Sở hữu xe máy Trình độ học vấnCó bằng đại học Chưa có bằng đại
họcCó (%)
Không (%)
Tổng cộng (%)
Số người phỏng vấn
32
68
100
250
21
79
100
750
Nhận xét: - Chỉ có 32% số người được phỏng vấn có bằng đại học và 21% chưa có bằng đại học là có loại xe máy đắt tiền (lớn hơn 30 triệu/chiếc). Như vậy, trong phjam vi kết quả này nhà nghiên cứu kết luận, trình độ học vấn cũng có ảnh huwỏng đến việc sỉw hữu xe gắn máy. Tuy nhiên, nhân tố thứ ba có liên hệ đến việc sở hữu xe máy đó là thu nhập, vì vậy nhà nghiên cứu quyết định kiểm tra lại mối liên hệ giưa trình độ học vấn và sở hữu xe máy. Kết quả phân
tích như sau:

Bảng 7.16: Mối liên hệ giữa sở hữu xe máy với trình độ học vấn và thu nhập
Thu nhậpSở hữu Thấp Cao
Có bằng
đại học
Chưa có bằng đại học
Có bằng
đại học
Chưa có bằng đại học
Có (%)
Không (%)
Tổng cộng (%)
Số người được phỏng vấn
20
80
100
100
20
80
100
70
40
60
100
150
40
60
100
50
Nhận xét:
- Trong nhóm thu nhập thấp không có sự phân biệt giữa số người có bằng đại học và chưa có bằng đại học đối với việc sở hữu xe gắn máy (đều có tỷ trọng 20% và 80%)
- Trong nhóm thu nhập cao cũng có kết luận tương tự nhưng ở cơ cấu 40% và 60%.
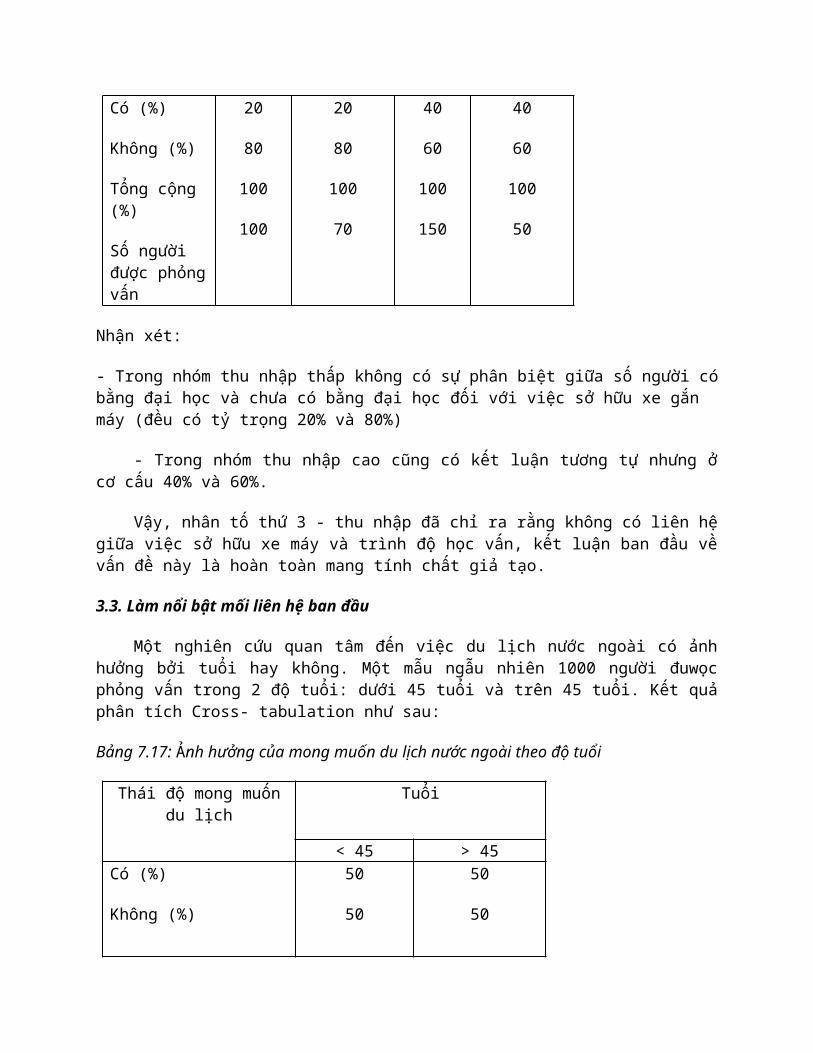
Vậy, nhân tố thứ 3 - thu nhập đã chỉ ra rằng không có liên hệ giữa việc sở hữu xe máy và trình độ học vấn, kết luận ban đầu về vấn đề này là hoàn toàn mang tính chất giả tạo.
3.3. Làm nổi bật mối liên hệ ban đầu
Một nghiên cứu quan tâm đến việc du lịch nước ngoài có ảnh hưởng bởi tuổi hay không. Một mẫu ngẫu nhiên 1000 người đuwọc phỏng vấn trong 2 độ tuổi: dưới 45 tuổi và trên 45 tuổi. Kết quả phân tích Cross- tabulation như sau:
Bảng 7.17: Ảnh hưởng của mong muốn du lịch nước ngoài theo độ tuổi
Thái độ mong muốn du lịch Tuổi
< 45 > 45

Có (%)
Không (%)
Tổng cộng (%)
Số người được phỏng vấn
50
50
100
500
50
50
100
500
Nhận xét:
- Không có mối liên hệ giữa việc mong muón du lịch ở nước ngoài và độ tuổi vì kết quả cho thấy ở độ tuổi nào mong muốn cũng ở mức độ 50%.
Tuy nhiên, để làm rõ hơn mối quan hệ trên ta đưa vào phân tích Cross- tabulation với biến thứ 3 là giới tính. Kết quả phân tích 3 biến như dưới đây:
Bảng 7.18: Mối liên hệ giữa việc du lịch với độ tuổi và giới tính
Thái độ du lịch
Giới tính
Nam Nữ Nam Nữ<45 tuổi >45 tuổi <45 tuổi >45 tuổi
Có (%)
Không (%)
Tổng cộng
Số người được phỏng vấn
60
40
100
300
40
60
100
300
35
65
100
200
65
35
100
200
Nhận xét:
- Việc mong muốn đi du lịch hoàn toàn có liên quan đến độ tuổi, điều này đoọc làm rõ khi xét trong nhân tố giới tính.
- Nam dưới 45 tuổi có mong muốn đi du lịch nước ngoài hơn là nữ có cùng độ tuổi (60% so với 35%)
Ngược lại, nữ trên 45 tuổi thì có nhu cầu này cao hơn nam (65% so với 40%)
3.4. Không có sự thay đổi trong mối liên hệ ban đầu
Trong một số trường hợp việc thêm biến thứ 3 trong phân tích Cross- tabulation cũng không thay đổi mối quan hệ quan sát ban đầu, nói cách khác nếu hai biến ban đầu có liên hệ thì biến thứ 3 không ảnh hưởng đến mối quan hệ này. Chẳng hạn như mối quan hệ giữa số nhân khẩu trong 1 gia đình và xu hướng đi ăn nhà hàng 1 tuần. Kết quả xử lý không hề thay đổi khi thêm biến thu nhập vào mô hình phân tích. Ngoài việc mô tả mối liên hệ các biến qua kết quả phan tích Cross- tabulation, 1 số phân phối mẫu trong thống kê cũng cho phép ta xét mối quan hệ giữa các biến. Riêng trong phân tích Cross- tabulation, phân phối chi bình phương cho phép ta kiểm định mối quan hệ giữa các biến.
- Giả thuyết Ho trong kiểm định có nội dung như sau:
H0: không có mối quan hệ giữa các biến
H1: có mối quan hệ giữa các biến
- Giá trị kiểm định (2 trong kết quả phân tích sẽ cung cấp mức ý nghĩa của kiểm định (P-value). Nếu mức ý nghĩa này nhỏ hơn hoặc bằng ( (mức ý nghĩa phân tích ban đầu) thì kiểm định hoàn tòan có ý nghĩa, hay nói cách khác bác bỏ giả thuyết H0, nghĩa là các biến có liên hệ nhau. Ngược lại thì giả thuyết H0 đoọc chấp nhận hay giữa các biến không có liên hệ.
BÀI TẬP
I. Phân tích nhân tố
1. Bảng kết quả của một nghiên cứu được sử dụng kỹ thuật phân tích nhân tố như sau:
Variable Communality Factor Eigenvalue % of VarianceV1
V2
V3
V4
V5
V6
V7
V8
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1
2
3
4
5
6
7
8
3.25
1.78
1.23
0.78
0.35
0.30
0.19
0.12

a. Hãy hoàn chỉnh bảng kết quả trên?
b. Có bao nhiêu nhân tố cần rút ra từ bảng kết quả trên? Tại sao?
2. Trong một nghiên cứu nói về mối quan hệ giữa hành vi của khách hàng khi ở nhà và khi đi mua sắm, dữ liệu thu thập về cách sống dựa vào thang đo 7 điểm (điểm 1 là không đồng ý và điểm 7 là đồng ý) cho 7 biến thể hiện 7 nội dung như sau:
V1: Tôi thích có một buổi tối yên tỉnh ở nhà hơn là đi dự tiệc
V2: Tôi luôn luôn kiểm tra giá cả ngay cả đó là món hàng nhỏ nhất
V3: Tạp chí thì được thích thú hơn phim
V4: Tôi sẽ mua những sản phẩm được quảng cáo trên những áp-phích lớn
V5: Tôi chỉ là người thích ở nhà
V6: Tôi tiết kiệm chi tiêu
V7: Các công ty đã lãng phí nhiều tiền cho quảng cáo
Số liệu thu thập qua phỏng vấn một mẫu 25 người tiêu dùng như sau:
STT V1 V2 V3 V4 V5 V6 V7
1
2
3
4
5
6
7
8
9
6
5
5
3
4
2
1
3
7
2
7
3
2
2
6
3
5
3
7
5
4
2
3
2
3
1
6
6
6
5
5
2
4
6
4
3
5
6
6
1
2
3
2
2
5
3
6
6
3
1
7
5
5
2
5
4
7
2
3
5
7
6
4

10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
6
6
3
5
6
3
2
3
6
7
5
2
3
2
6
7
3
6
2
7
3
2
7
2
4
2
6
3
4
6
5
6
3
2
2
6
5
4
5
2
5
6
6
3
2
3
7
5
4
6
7
2
5
3
1
7
4
2
3
2
1
2
4
4
4
4
6
2
7
2
4
2
7
5
4
1
4
1
5
6
6
4
1
6
2
6
5
4
3
2
5
2
3
5
7
5
5
7
6
1
3
5
2
6
3
1
3
6
6
3
2
3
Hãy xử lý và nhận xét bảng dữ liệu trên đáp ứng mục tiêu phân tích nhân tố?
(Dùng menu Factor Analysis trong SPSS).
II. Phân tích kết hợp
1. Nhận dạng hai vấn đề nghiên cứu Marketing có thể vận dụng phân tích kết hợp? Giải thích bạn sẽ sử dụng phân tích kết hợp trong những trường hợp này như thế nào?

2. Phân tích kết hợp sử dụng để xác định khách hàng đánh đổi như thế nào giữa các phẩm chất khác nhau khi chọn mua máy vi tính. Bốn phẩm chất quan trọng chọn ra được trình bày trong bảng sau:
- Hệ số quan trọng:
Tiêu chuẩn đánh giá Hệ số quan trọng (%)1. Cách nhập dữ liệu
2. Màn hình
3. Cỡ màn hình
4. Giá
45,0
05,0
25,0
25,0
Hãy giải thích bảng kết quả phân tích trên?
III. Phân tích phân biệt
1. Trong một nghiên cứu sự khác biệt giữa hai nhóm người hút thuốc lá và không hút thuốc lá thấy rằng có hai hệ số hàm phân biệt chuẩn hóa lớn nhất là 0,97 cho biến thu nhập và 0,61 cho biến thái độ thích hút thuốc. Kết luận sau đây là đúng hay sai: Biến thu nhập thì quan trọng hơn thái độ thích hút thuốc nếu xem sét một cách độc lập?
2. Hãy cho một ví dụ để có thể sử dụng phân tích phân biệt?