Embed Size (px)
Citation preview

深度学习在机器翻译中的最新进展
熊德意
苏州大学
2017 年 11 月 9 日

目标
一. NMT基本知识
二. NMT固有问题及应对方法
三. NMT最新动态
四. NMT研究思路、角度与方法
五. NMT未来发展趋势

Part1
一. 神经机器翻译简介
二. 改进的注意力机制
三. 神经机器翻译固有问题应对方法
四. 神经机器翻译与统计机器翻译的融合
五. 字符级神经机器翻译
六. 短语级神经机器翻译

Part2
一. 句法驱动的神经机器翻译
二. 多语与多模态神经机器翻译
三. 面向资源稀缺语种的神经机器翻译
四. 神经机器翻译深度模型
五. 神经机器翻译新架构
六. 神经机器翻译未来发展方向

Part1
一. 神经机器翻译简介
二. 改进的注意力机制
三. 神经机器翻译固有问题应对方法
四. 神经机器翻译与统计机器翻译的融合
五. 字符级神经机器翻译
六. 短语级神经机器翻译
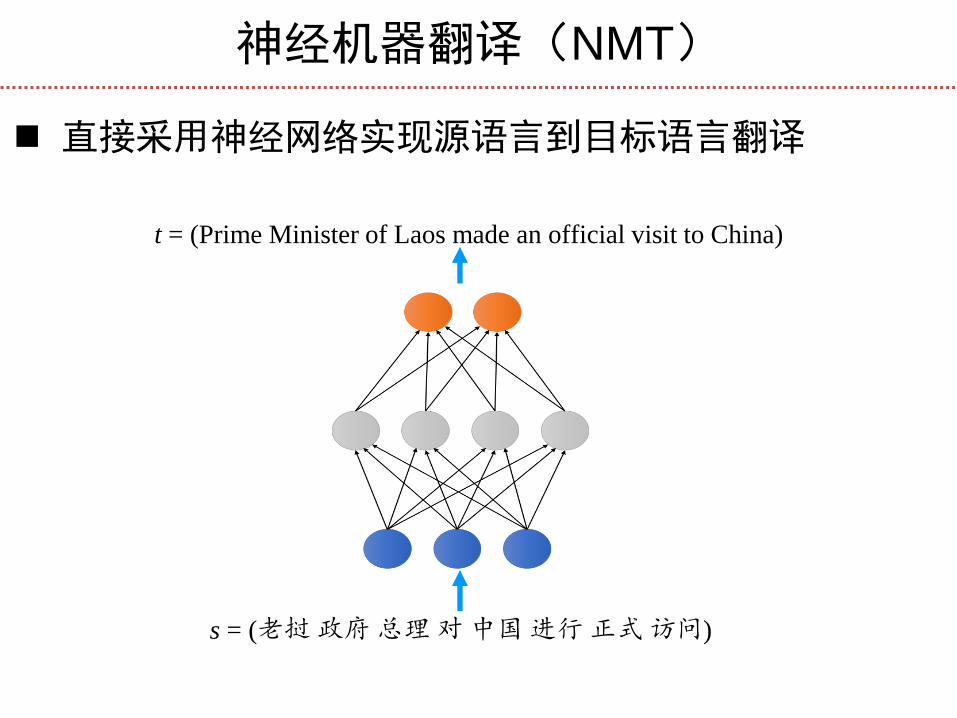
神经机器翻译(NMT)
直接采用神经网络实现源语言到目标语言翻译
s = (老挝 政府 总理 对 中国 进行 正式 访问)
t = (Prime Minister of Laos made an official visit to China)

早期方法(80-90年代)
Allen 1987 IEEE 1st ICNN
3310 En-Es pairs constructed on 31En, 40 Es words, max
10/11 word sentence; 33 used as test set
The grandfather offered the little girl a book ➔
El abuelo le ofrecio un libro a la nina pequena
Binary encoding of words – 50 inputs, 66 outputs; 1 or 3
hidden 150-unit layers. Ave WER: 1.3 words
Robert Allen. Several Studies on Natural Language and Back-Propagation. IEEE First
International Conference on Neural Networks, vol. 2, 1987.
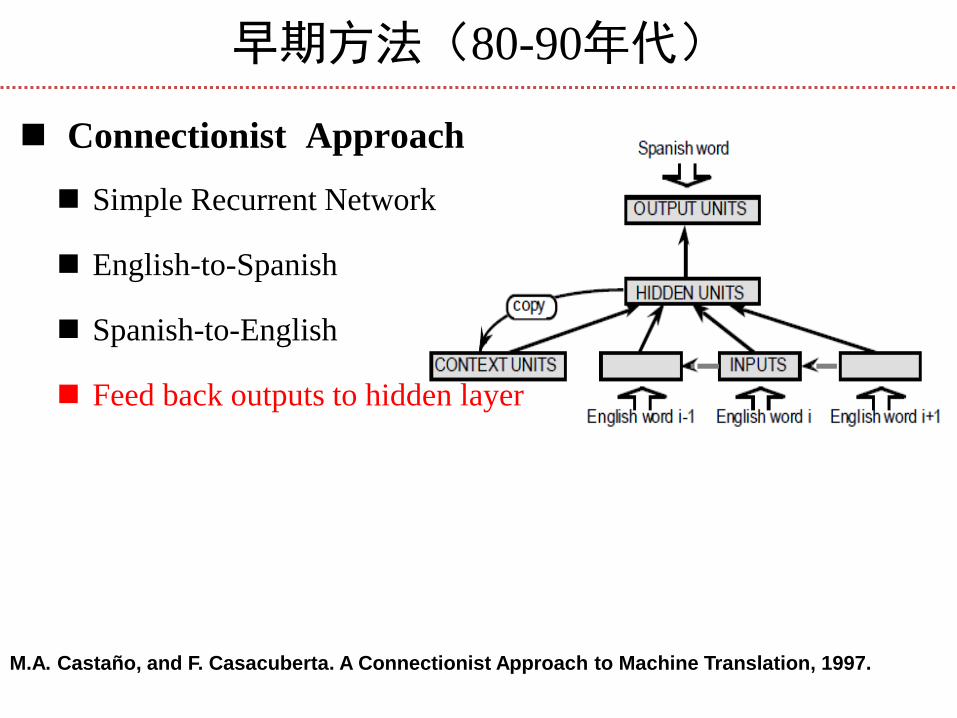
早期方法(80-90年代)
Connectionist Approach
Simple Recurrent Network
English-to-Spanish
Spanish-to-English
Feed back outputs to hidden layer
M.A. Castaño, and F. Casacuberta. A Connectionist Approach to Machine Translation, 1997.

发展前期
神经语言模型
采用神经网络对语言模型进行建模(Bengio et al, 2003; Mikolov
et al, 2010)
连续表示方法
用向量表示词、短语和句子(Grefenstette et al, 2011; Socher et al,
2011, 2012)
连续翻译模型
采用神经网络进行翻译建模 (Schwenk et al, 2006; Schwenk et al,
2012)

发展期
Recurrent Continuous Translation Models
Networks-based MT在2013年被重新提出来(Kalchbrenner et al,
2013)
Sequence to Sequence Model
Google提出的方法 (Sutskever et al, 2014)
Encoder-Decoder Model
蒙特利尔大学提出的方法 (Cho et al, 2014)
Attention-based NMT
Neural Machine Translation by Jointly Learning to Align and
Translate (Bahdanau, et al. 2015)
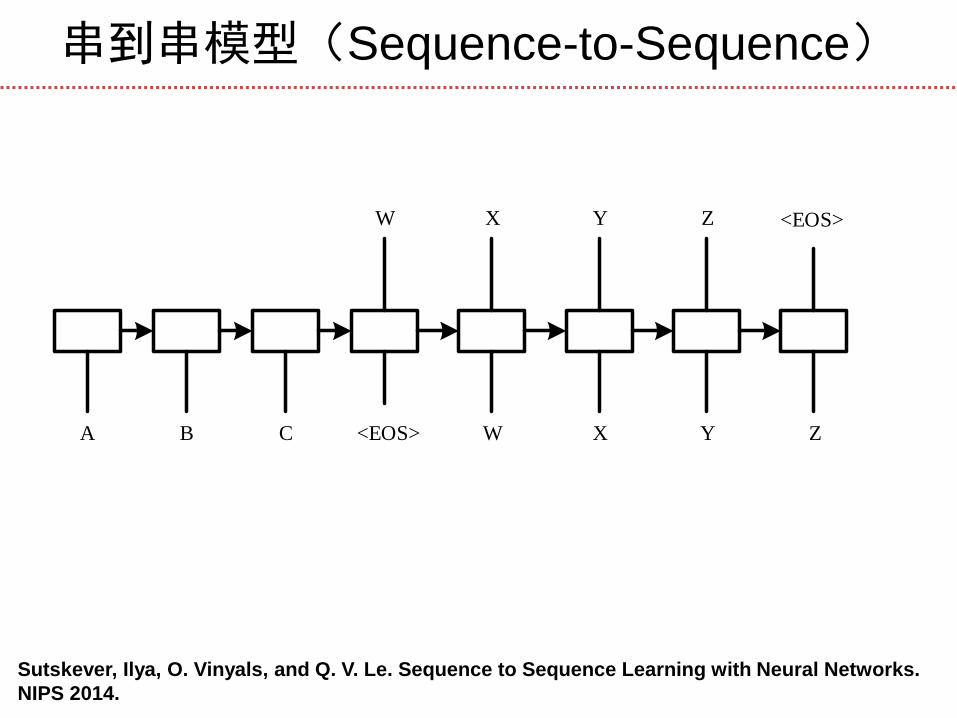
串到串模型(Sequence-to-Sequence)
Sutskever, Ilya, O. Vinyals, and Q. V. Le. Sequence to Sequence Learning with Neural Networks.
NIPS 2014.
A B C <EOS> W X Y Z
W X Y Z <EOS>
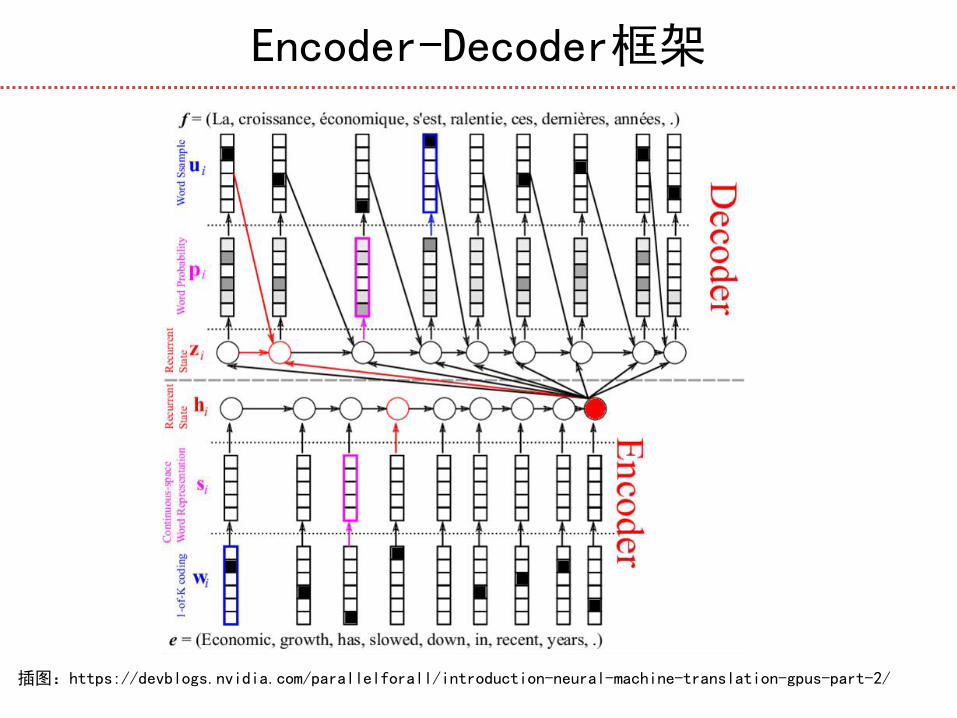
Encoder-Decoder框架
插图:https://devblogs.nvidia.com/parallelforall/introduction-neural-machine-translation-gpus-part-2/
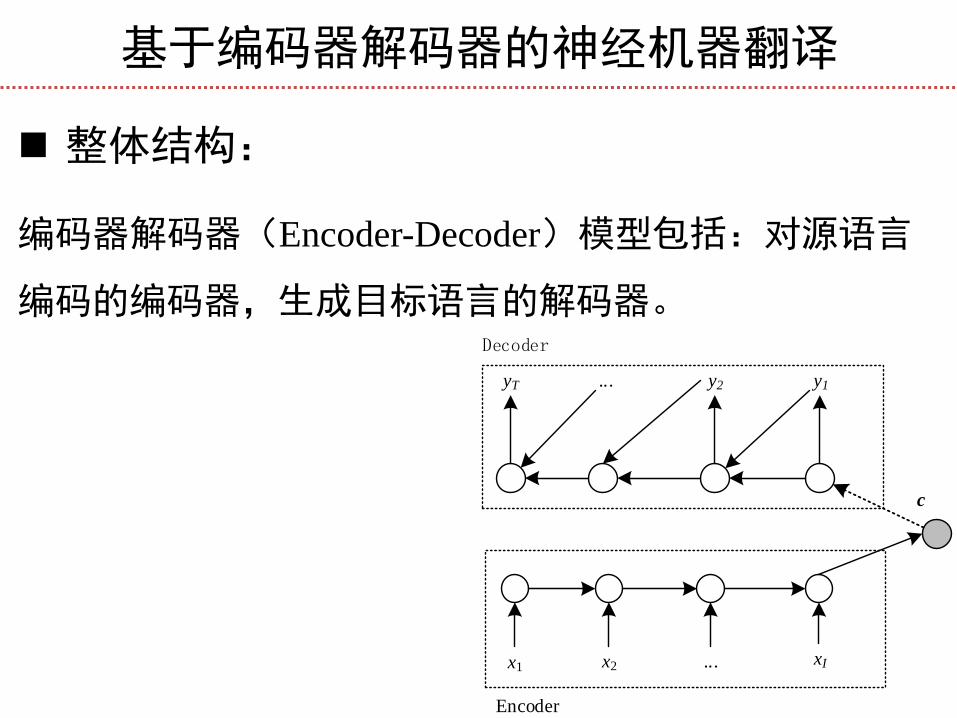
基于编码器解码器的神经机器翻译
整体结构:
编码器解码器(Encoder-Decoder)模型包括:对源语言
编码的编码器,生成目标语言的解码器。
x1 x2 ... xI
yT ... y2 y1
Encoder
Decoder
c
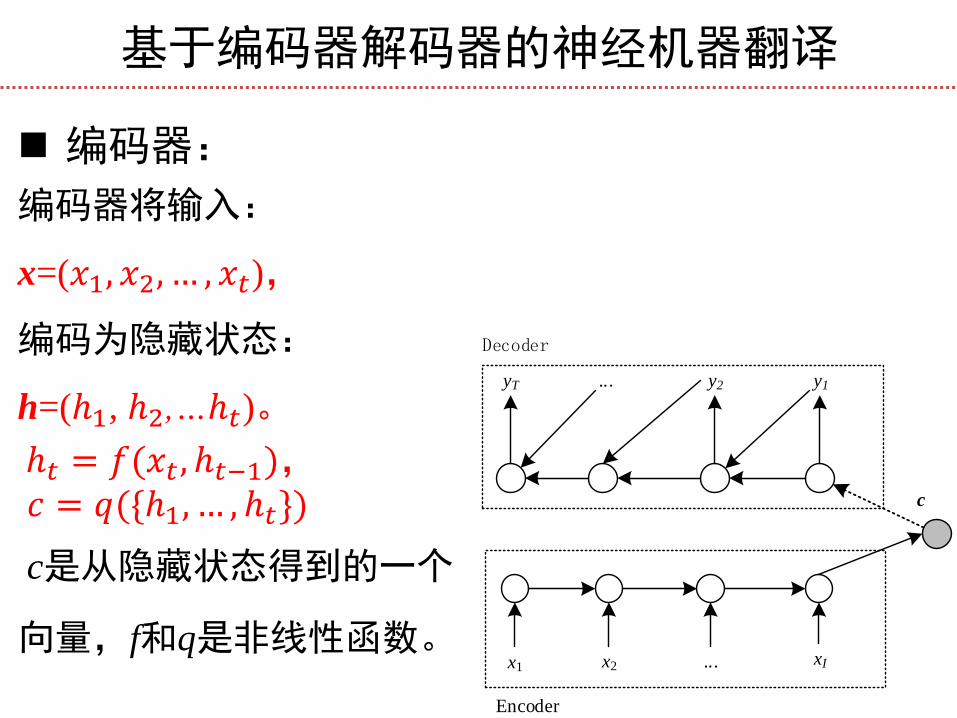
基于编码器解码器的神经机器翻译
编码器:
编码器将输入:
x=(𝑥1, 𝑥2, … , 𝑥𝑡),
编码为隐藏状态:
h=(ℎ1, ℎ2,…ℎ𝑡)。
ℎ𝑡 = 𝑓(𝑥𝑡 , ℎ𝑡−1),
𝑐 = 𝑞({ℎ1, … , ℎ𝑡})
c是从隐藏状态得到的一个
向量,f和q是非线性函数。 x1 x2 ... xI
yT ... y2 y1
Encoder
Decoder
c

基于编码器解码器的神经机器翻译
解码器:
𝑝 𝐲 = 𝑝 𝑦𝑡|{𝑦1, … , 𝑦𝑡−1 , 𝑐)
𝑇
𝑡=1
𝑝 𝑦𝑡 𝑦1, … , 𝑦𝑡−1, 𝑐
= 𝑔(𝑦𝑡−1, 𝑠𝑡 , 𝑐)
y = (y1, y2, …, 𝑦𝑇) x1 x2 ... xI
yT ... y2 y1
Encoder
Decoder
c
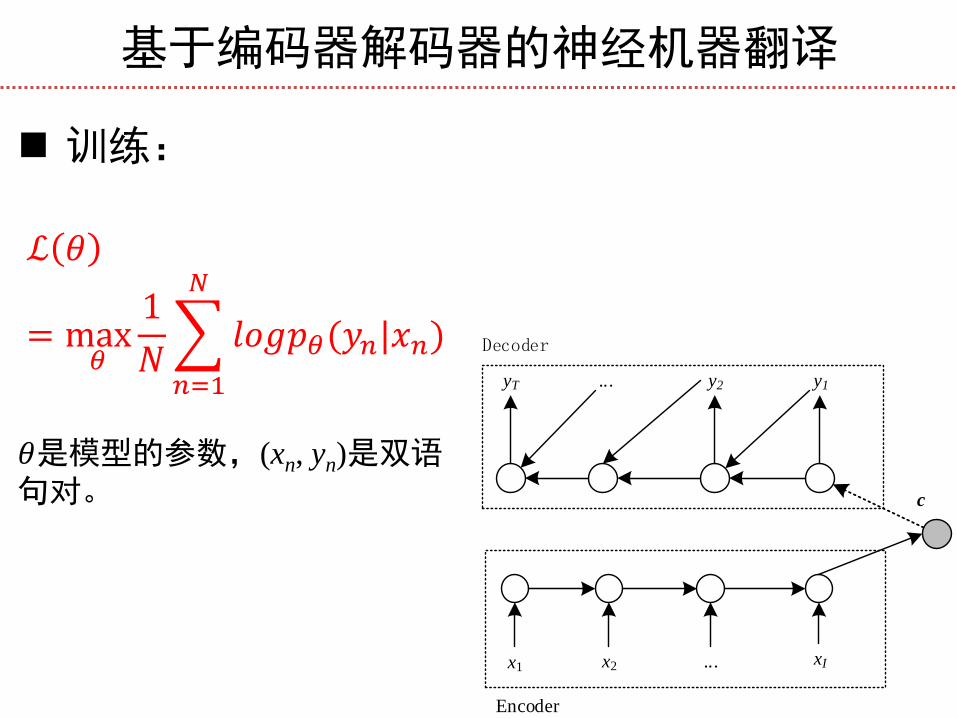
基于编码器解码器的神经机器翻译
训练:
ℒ 𝜃
= max𝜃
1
𝑁 𝑙𝑜𝑔𝑝𝜃(𝑦𝑛|𝑥𝑛)
𝑁
𝑛=1
𝜃是模型的参数,(xn, yn)是双语句对。
x1 x2 ... xI
yT ... y2 y1
Encoder
Decoder
c
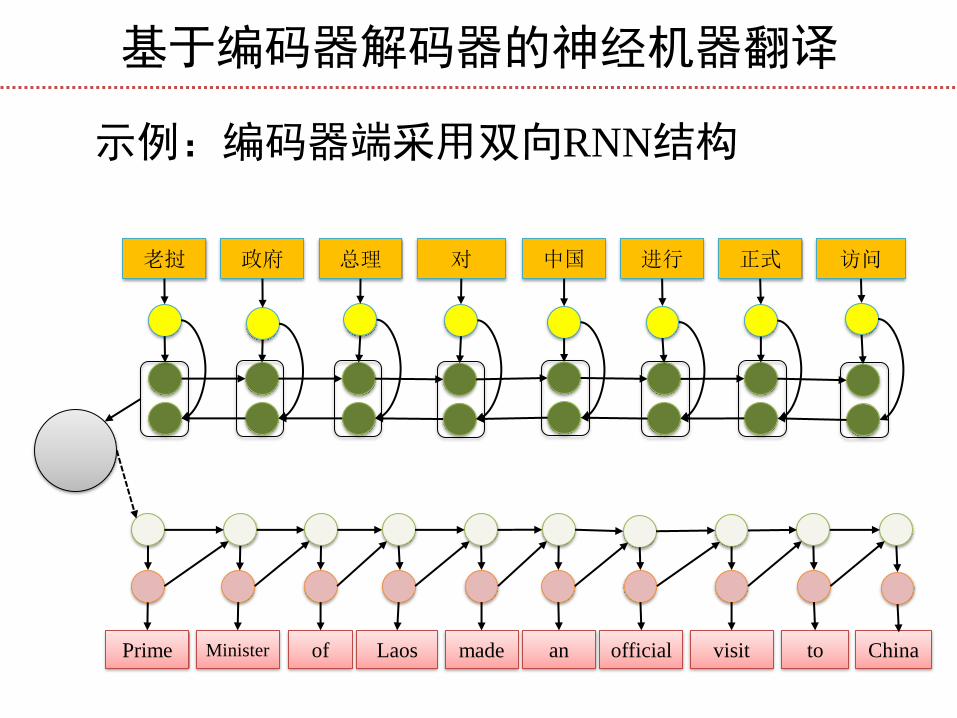
基于编码器解码器的神经机器翻译
老挝 政府 总理 对
Prime Minister of Laos
中国 进行 正式 访问
made an official visit to China
示例:编码器端采用双向RNN结构
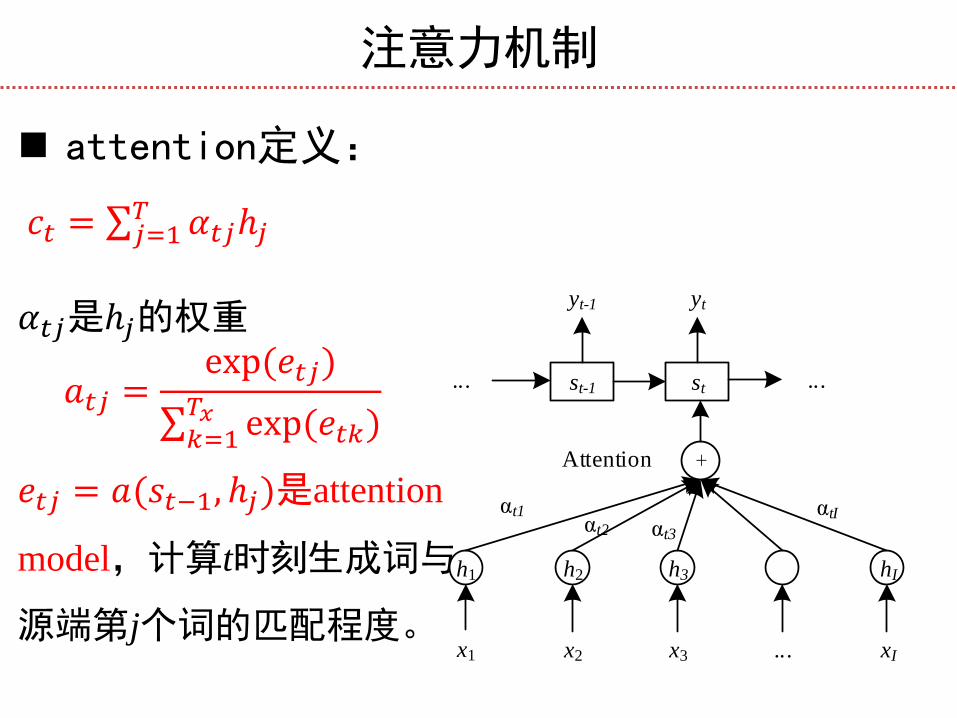
注意力机制
attention定义:
𝑐𝑡 = 𝛼𝑡𝑗ℎ𝑗𝑇𝑗=1
𝛼𝑡𝑗是ℎ𝑗的权重
𝑎𝑡𝑗 =exp(𝑒𝑡𝑗)
exp(𝑒𝑡𝑘)𝑇𝑥𝑘=1
𝑒𝑡𝑗 = 𝑎(𝑠𝑡−1, ℎ𝑗)是attention
model,计算t时刻生成词与
源端第j个词的匹配程度。
h1 h2 h3
x1 x2 x3 ...
hI
xI
+
αt1αt2 αt3
αtI
st-1 st
yt-1 yt
... ...
Attention
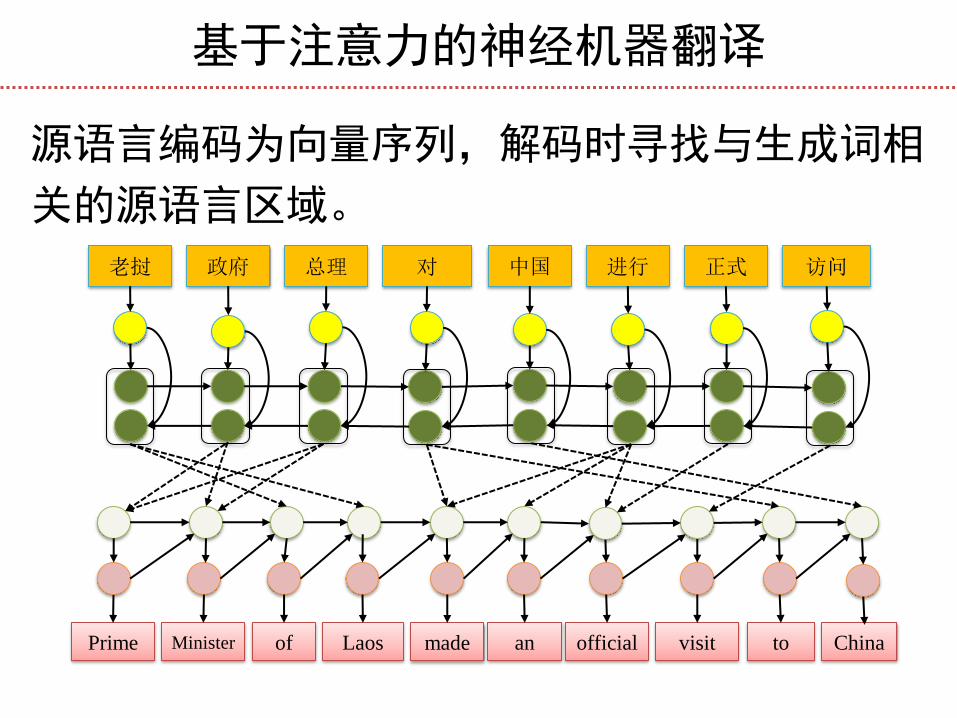
基于注意力的神经机器翻译
老挝 政府 总理 对
Prime Minister of Laos
中国 进行 正式 访问
made an official visit to China
源语言编码为向量序列,解码时寻找与生成词相
关的源语言区域。

开源工具与平台
开源NMT系统
GroundHog https://github.com/lisa-groundhog/GroundHog
dl4mt-tutorial https://github.com/nyu-dl/dl4mt-tutorial
OpenNMT https://github.com/OpenNMT/OpenNMT
Seq2Seq
https://github.com/google/seq2seq

深度学习平台
TensorFolw
Theano
Dynet
Caffe
Torch
PyTorch
开源工具与平台

Part1
一. 神经机器翻译简介
二. 改进的注意力机制
三. 神经机器翻译固有问题应对方法
四. 神经机器翻译与统计机器翻译的融合
五. 字符级神经机器翻译
六. 短语级神经机器翻译

注意力机制存在的问题
计算量较大
缺乏约束信息
目标单词之间的“attention”相互独立
不能记忆“已翻译”和“未翻译”部分
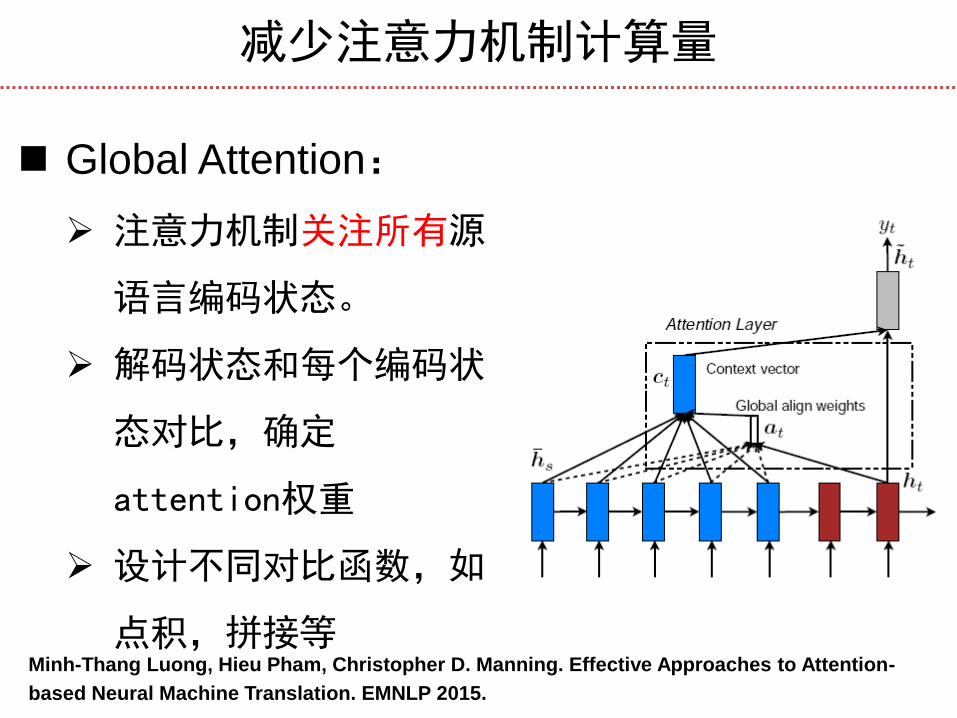
减少注意力机制计算量
Global Attention:
注意力机制关注所有源
语言编码状态。
解码状态和每个编码状
态对比,确定
attention权重
设计不同对比函数,如
点积,拼接等 Minh-Thang Luong, Hieu Pham, Christopher D. Manning. Effective Approaches to Attention-
based Neural Machine Translation. EMNLP 2015.
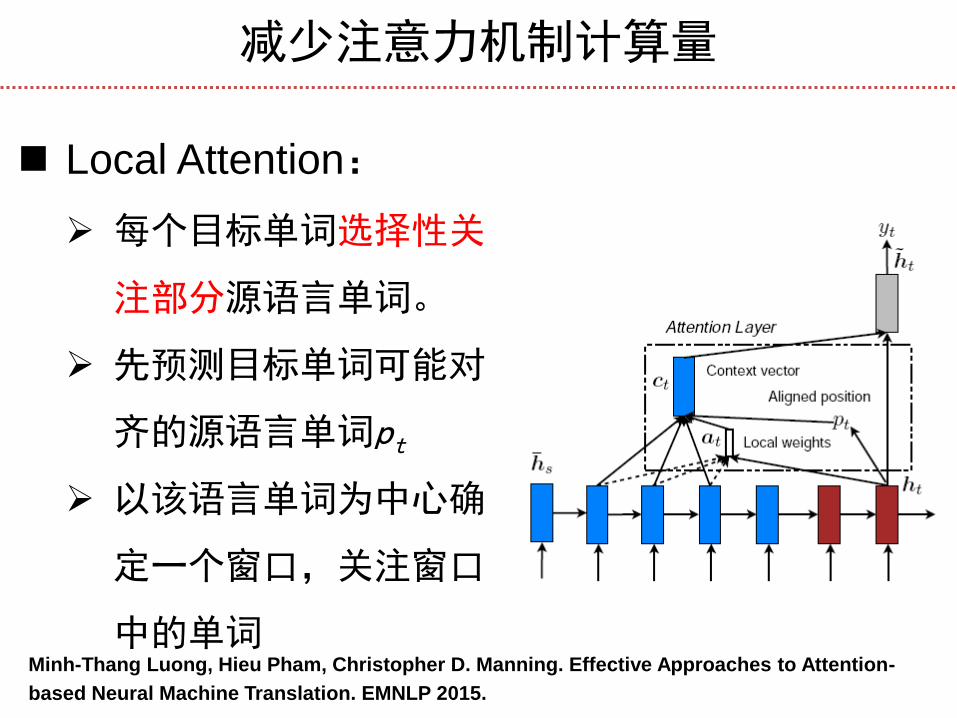
减少注意力机制计算量
Local Attention:
每个目标单词选择性关
注部分源语言单词。
先预测目标单词可能对
齐的源语言单词pt
以该语言单词为中心确
定一个窗口,关注窗口
中的单词 Minh-Thang Luong, Hieu Pham, Christopher D. Manning. Effective Approaches to Attention-
based Neural Machine Translation. EMNLP 2015.

融合约束信息
Absolute position bias(源目标语言单词顺序
相似)
Fertility(源语言单词规律性对应到某种数目
的目标语言单词上)
Markov condition(当前单词的attention与前
一单词attention之间的关系)
Bilingual Symmetry(两个方向的对齐矩阵尽可能相似)
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina Vymolova, et al. Incorporating Structural
Alignment Biases into an Attentional Neural Translation Model. NAACL 2016.

融合约束信息:How
修改解码状态与编码状态对比函数:
𝑒𝑡𝑗 = 𝑎(𝑠𝑡−1, ℎ𝑗)
修改objective function
Trevor Cohn, Cong Duy Vu Hoang, Ekaterina Vymolova, et al. Incorporating Structural
Alignment Biases into an Attentional Neural Translation Model. NAACL 2016.
ℒ 𝜃 = max𝜃
1
𝑁 𝑙𝑜𝑔𝑝𝜃(𝑦𝑛|𝑥𝑛)
𝑁
𝑛=1
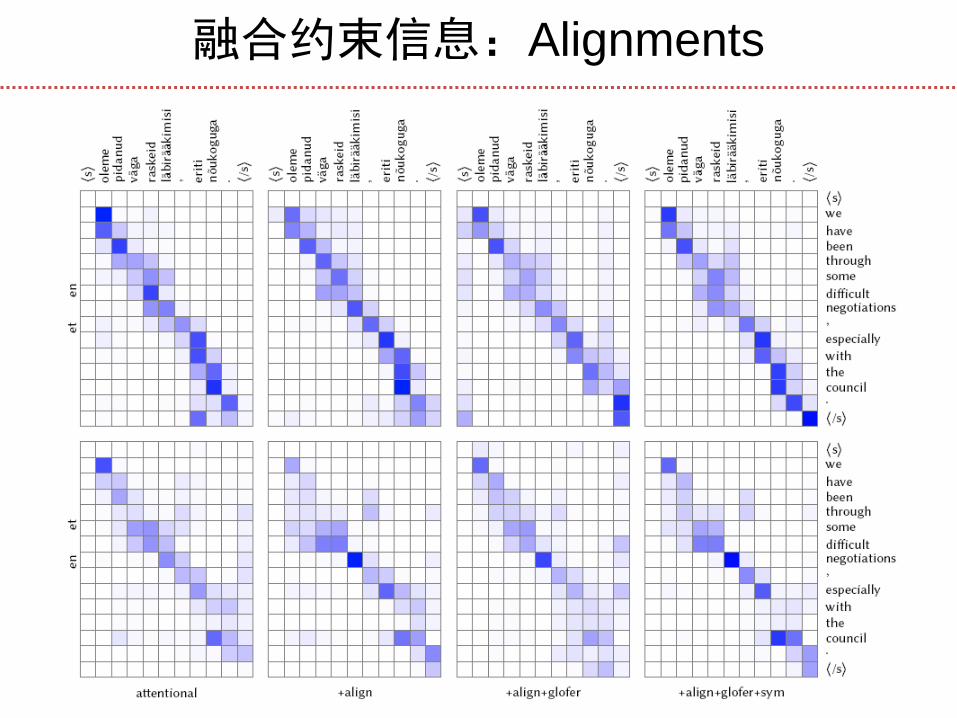
融合约束信息:Alignments
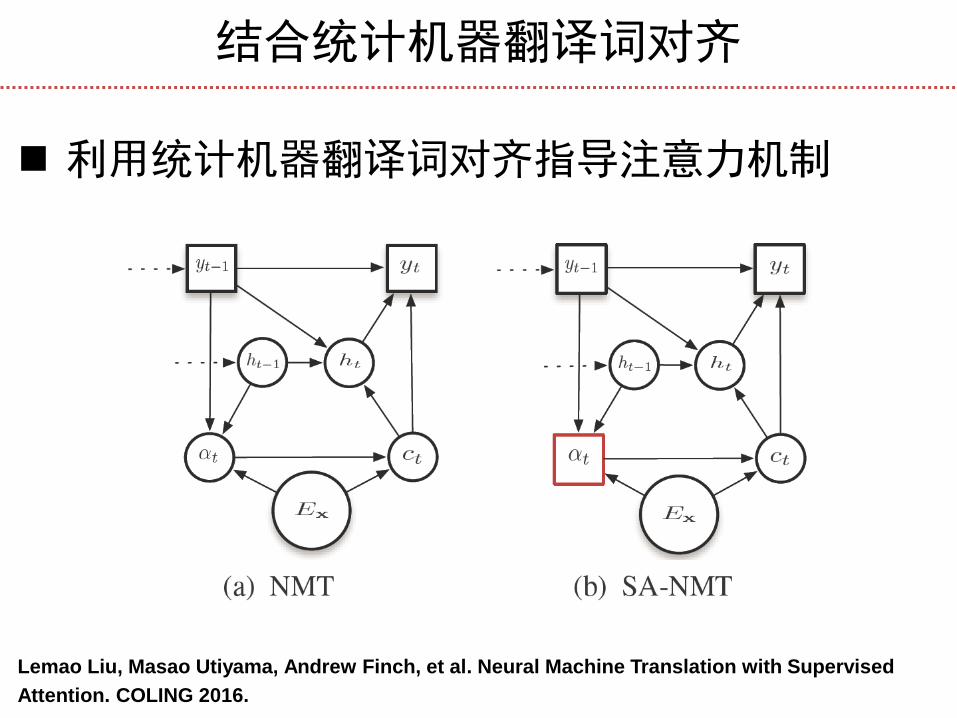
结合统计机器翻译词对齐
利用统计机器翻译词对齐指导注意力机制
Lemao Liu, Masao Utiyama, Andrew Finch, et al. Neural Machine Translation with Supervised
Attention. COLING 2016.

Jointly Supervising Translation and Attention
𝛼𝑖 注意力机制词对齐
𝛼 𝑖 统计机器翻译词对齐
结合统计机器翻译词对齐
Lemao Liu, Masao Utiyama, Andrew Finch, et al. Neural Machine Translation with Supervised
Attention. COLING 2016.

Part1
一. 神经机器翻译简介
二. 改进的注意力机制
三. 神经机器翻译固有问题应对方法
四. 神经机器翻译与统计机器翻译的融合
五. 字符级神经机器翻译
六. 短语级神经机器翻译

神经机器翻译固有问题
受限词汇表问题(集外词):
低频词统一映射成为UNK符号
覆盖度问题:
“过翻”或“漏翻”
翻译不准确问题:
翻译的忠实度
Xing Wang, Zhengdong Lu, Zhaopeng Tu, Hang Li, Deyi Xiong, Min Zhang. Neural Machine
Translation Advised by Statistical Machine Translation. AAAI-2017.

集外词翻译
集外词产生:
词典大小通常限制在3-5万
超出词典的词映射为UNK
集外词影响:
训练语料词语覆盖率
测试语料中的集外词
Sébastien Jean, Orhan Firat, Kyunghyun Cho, et al. Montreal Neural Machine Translation
Systems for WMT’15. Proceedings of WMT

集外词翻译:unk replacement
unk替换技术:
追踪每个目标端unk对应的源端单词
构建一个翻译词典
在后处理步骤中,根据对应的源端单词利用词典对
应的译文替换unk

unk replacement技术:追踪源端单词
语料标注(视NMT系统为黑盒):
Copyable model
Position all model
Position unknown model
Minh-Thang Luong, Ilya Sutskever, Quoc V. Le, et al. Addressing the Rare Word Problem in
Neural Machine Translation, 2014.

unk replacement技术:追踪源端单词
Attention model获得unk对应的源端单词:
Sébastien Jean, Kyunghyun Cho, Roland Memisevic, and Yoshua Bengio. 2015. On using very
large target vocabulary for neural machine translation. In ACL.
寻找最大的𝛼𝑡对应的源端单词
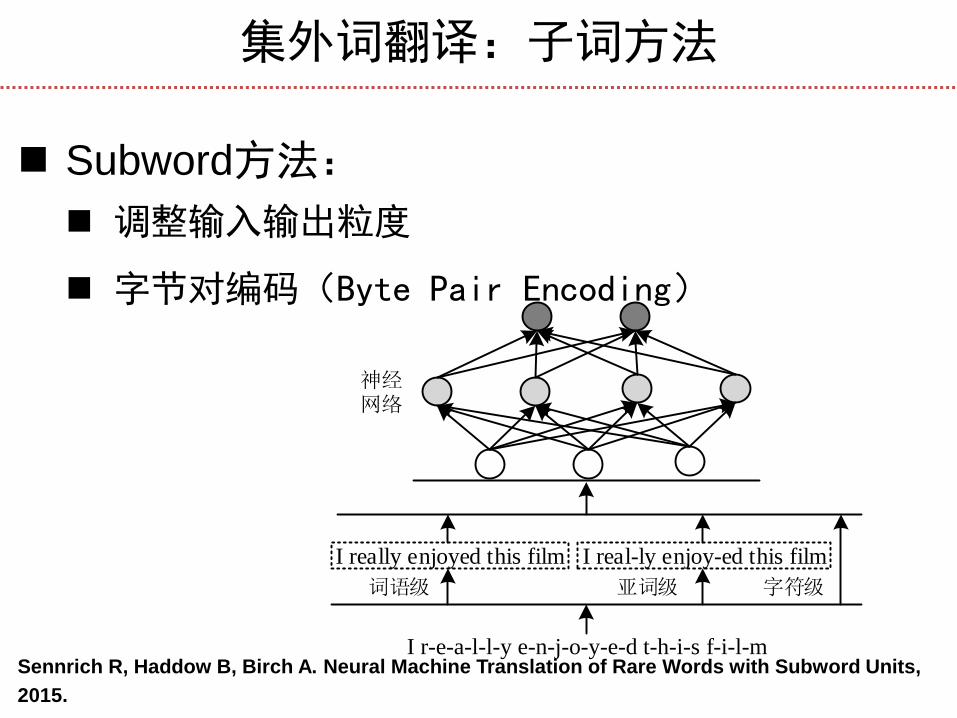
集外词翻译:子词方法
Subword方法:
调整输入输出粒度
字节对编码(Byte Pair Encoding)
Sennrich R, Haddow B, Birch A. Neural Machine Translation of Rare Words with Subword Units,
2015.
I r-e-a-l-l-y e-n-j-o-y-e-d t-h-i-s f-i-l-m
I really enjoyed this film I real-ly enjoy-ed this film
词语级 亚词级 字符级
神经网络
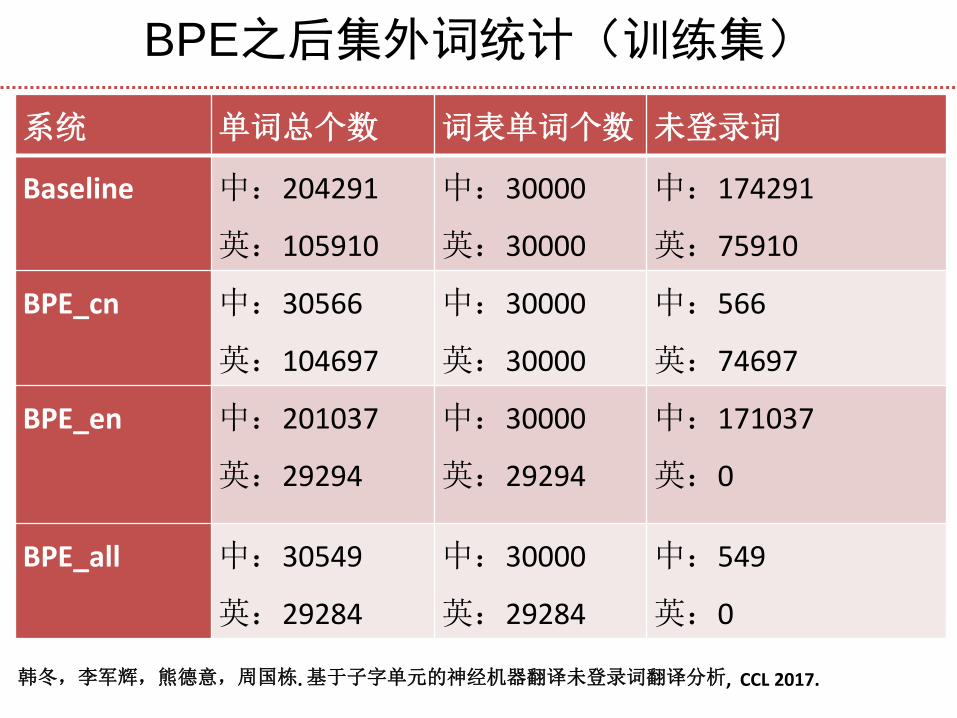
BPE之后集外词统计(训练集)
韩冬,李军辉,熊德意,周国栋. 基于子字单元的神经机器翻译未登录词翻译分析, CCL 2017.
系统 单词总个数 词表单词个数 未登录词
Baseline 中:204291
英:105910
中:30000
英:30000
中:174291
英:75910
BPE_cn 中:30566
英:104697
中:30000
英:30000
中:566
英:74697
BPE_en 中:201037
英:29294
中:30000
英:29294
中:171037
英:0
BPE_all 中:30549
英:29284
中:30000
英:29284
中:549
英:0
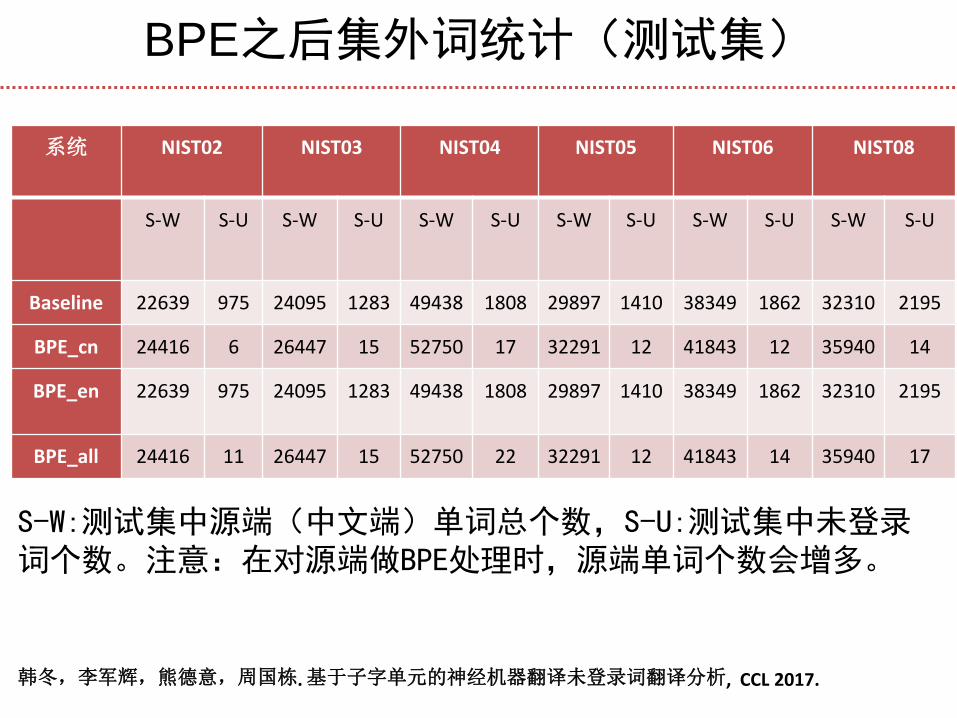
BPE之后集外词统计(测试集)
系统 NIST02 NIST03 NIST04 NIST05 NIST06 NIST08
S-W S-U S-W S-U S-W S-U S-W S-U S-W S-U S-W S-U
Baseline 22639 975 24095 1283 49438 1808 29897 1410 38349 1862 32310 2195
BPE_cn 24416 6 26447 15 52750 17 32291 12 41843 12 35940 14
BPE_en 22639 975 24095 1283 49438 1808 29897 1410 38349 1862 32310 2195
BPE_all 24416 11 26447 15 52750 22 32291 12 41843 14 35940 17
S-W:测试集中源端(中文端)单词总个数,S-U:测试集中未登录词个数。注意:在对源端做BPE处理时,源端单词个数会增多。
韩冬,李军辉,熊德意,周国栋. 基于子字单元的神经机器翻译未登录词翻译分析, CCL 2017.
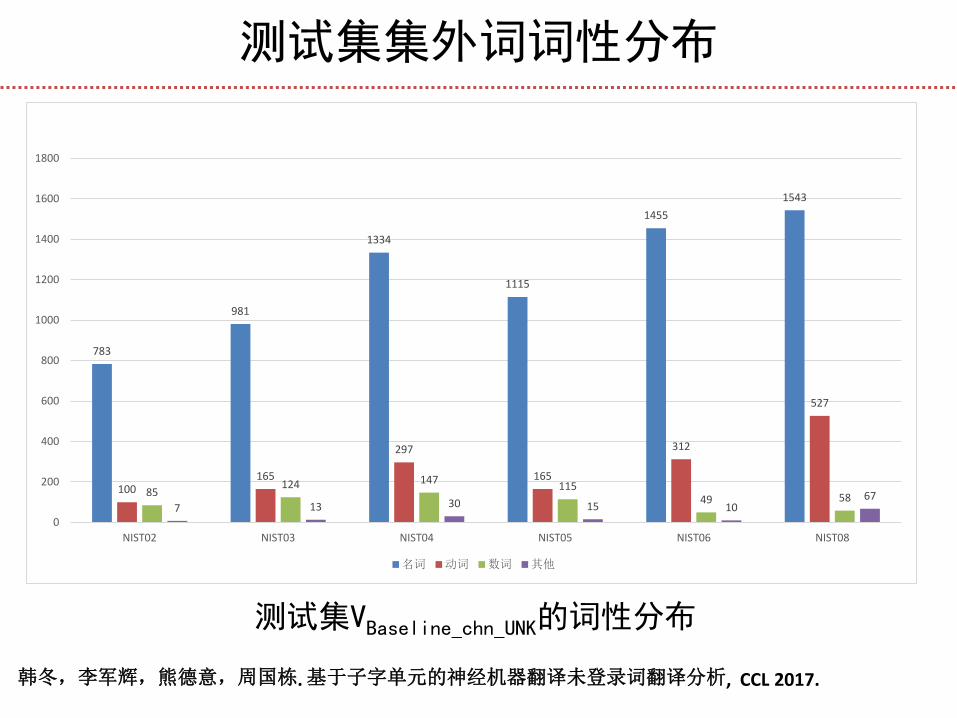
测试集集外词词性分布
测试集VBaseline_chn_UNK的词性分布
783
981
1334
1115
1455
1543
100 165
297
165
312
527
85 124 147
115 49 58
7 13 30 15 10 67
0
200
400
600
800
1000
1200
1400
1600
1800
NIST02 NIST03 NIST04 NIST05 NIST06 NIST08
名词 动词 数词 其他
韩冬,李军辉,熊德意,周国栋. 基于子字单元的神经机器翻译未登录词翻译分析, CCL 2017.
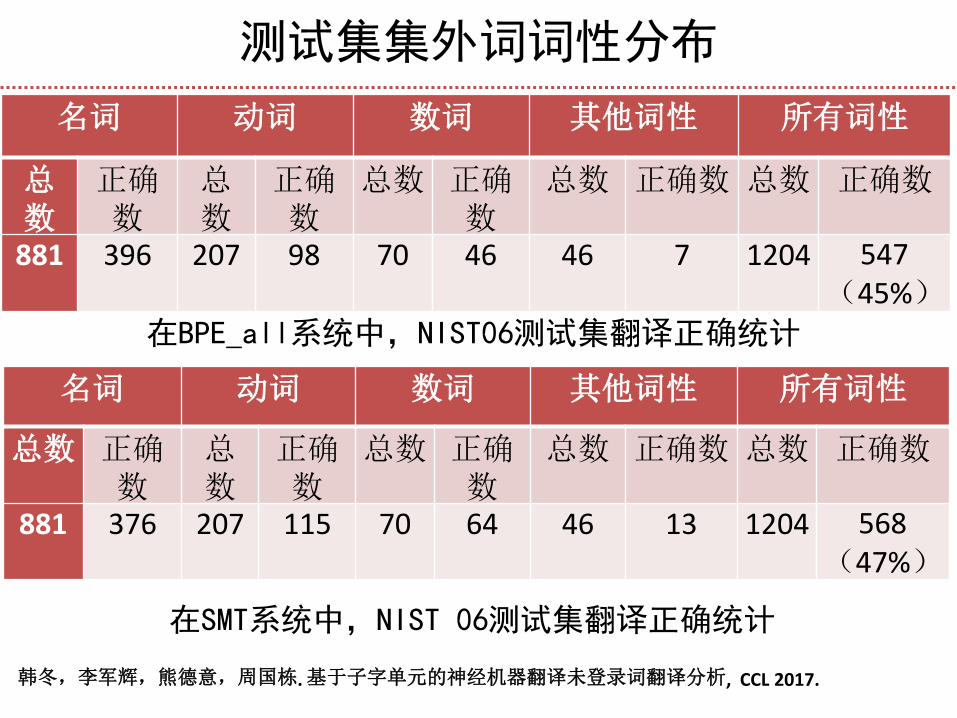
测试集集外词词性分布
在BPE_all系统中,NIST06测试集翻译正确统计
名词 动词 数词 其他词性 所有词性
总数
正确数
总数
正确数
总数 正确数
总数 正确数 总数 正确数
881 396 207 98 70 46 46 7 1204 547(45%)
名词 动词 数词 其他词性 所有词性
总数 正确数
总数
正确数
总数 正确数
总数 正确数 总数 正确数
881 376 207 115 70 64 46 13 1204 568(47%)
在SMT系统中,NIST 06测试集翻译正确统计
韩冬,李军辉,熊德意,周国栋. 基于子字单元的神经机器翻译未登录词翻译分析, CCL 2017.

覆盖度问题
神经机器翻译主要问题:
Over-translation: some words are unnecessarily
translated for multiple times;
Under-translation: some words are mistakenly
untranslated.
Zhaopeng Tu, Zhengdong Lu, Yang Liu, et al. Modeling Coverage for Neural Machine
Translation. ACL 2016.
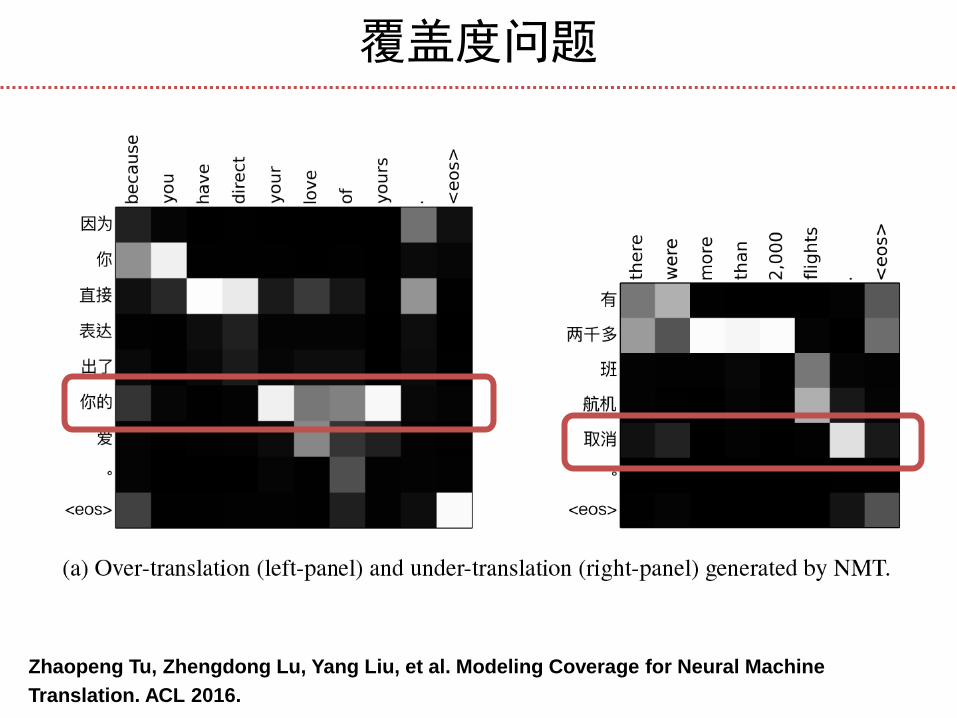
覆盖度问题
Zhaopeng Tu, Zhengdong Lu, Yang Liu, et al. Modeling Coverage for Neural Machine
Translation. ACL 2016.
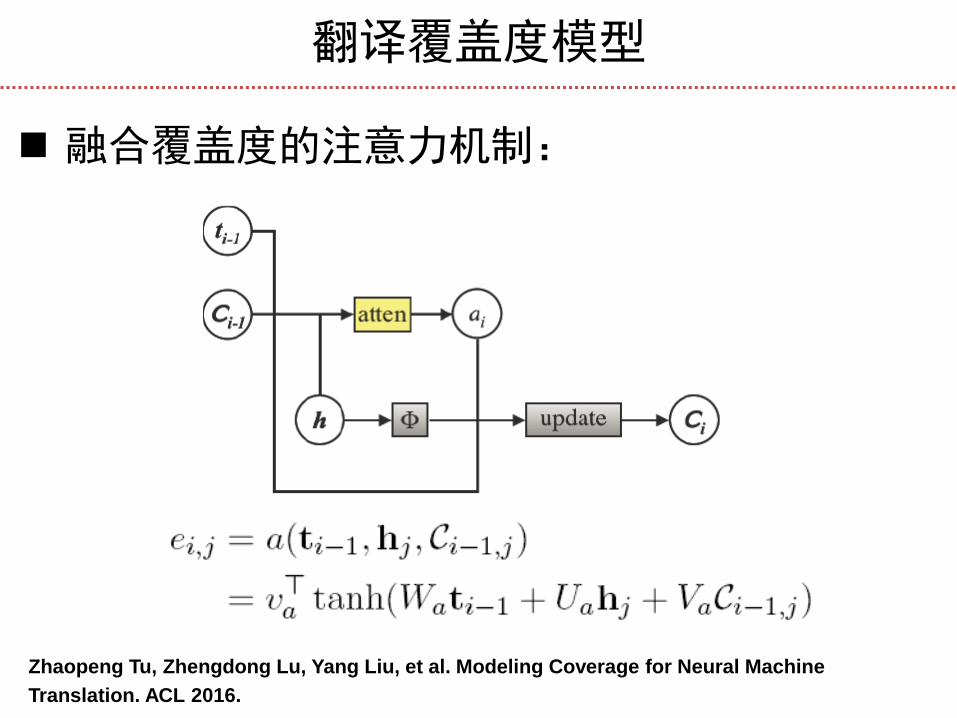
翻译覆盖度模型
融合覆盖度的注意力机制:
Zhaopeng Tu, Zhengdong Lu, Yang Liu, et al. Modeling Coverage for Neural Machine
Translation. ACL 2016.
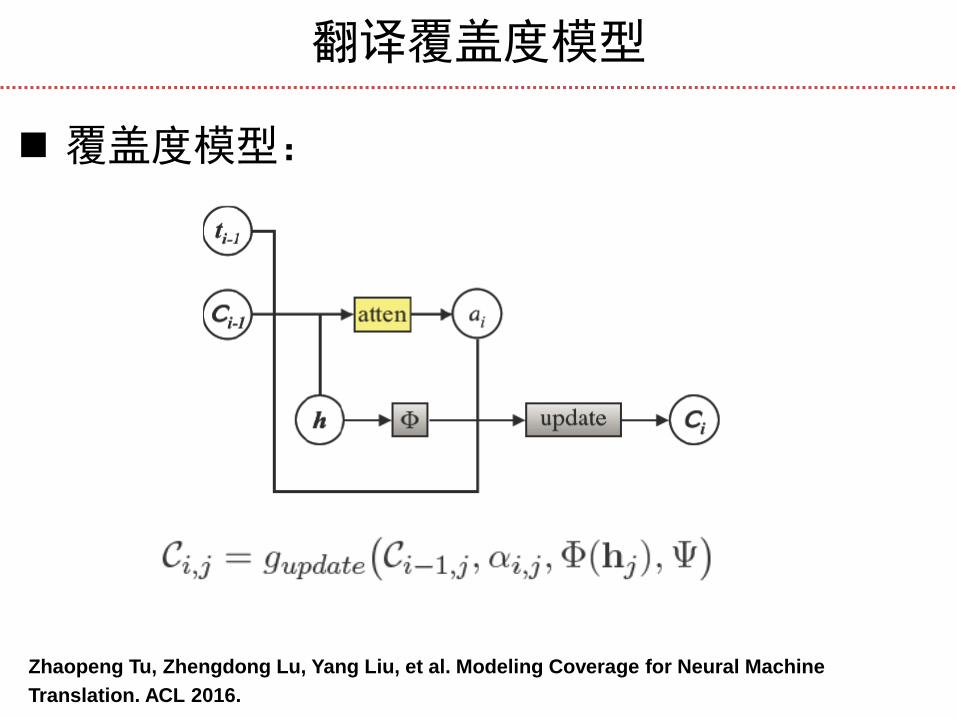
翻译覆盖度模型
覆盖度模型:
Zhaopeng Tu, Zhengdong Lu, Yang Liu, et al. Modeling Coverage for Neural Machine
Translation. ACL 2016.
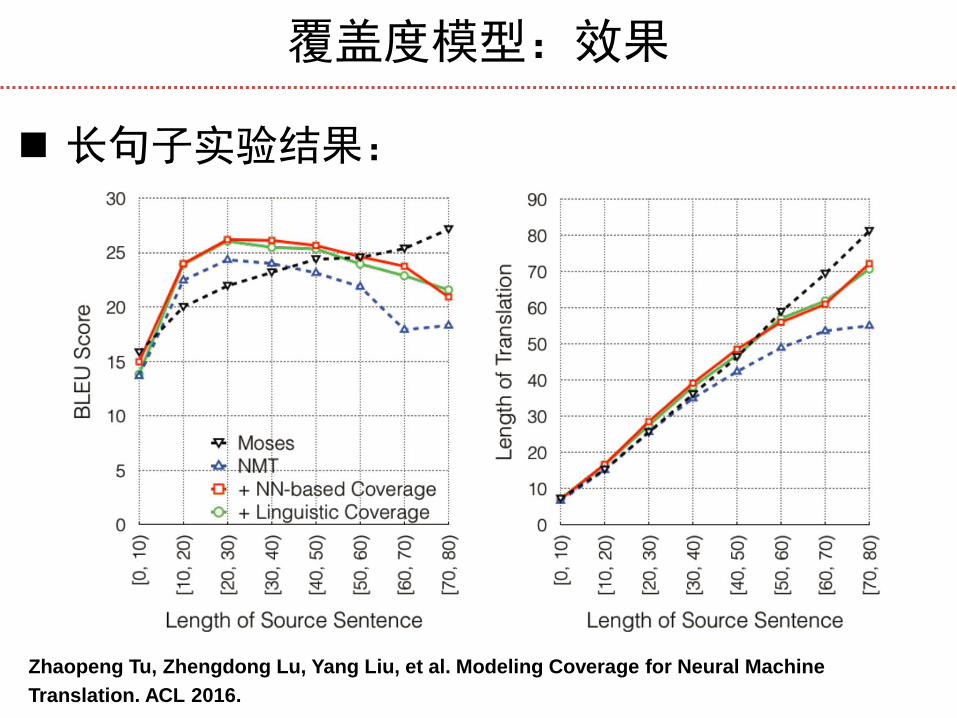
覆盖度模型:效果
长句子实验结果:
Zhaopeng Tu, Zhengdong Lu, Yang Liu, et al. Modeling Coverage for Neural Machine
Translation. ACL 2016.
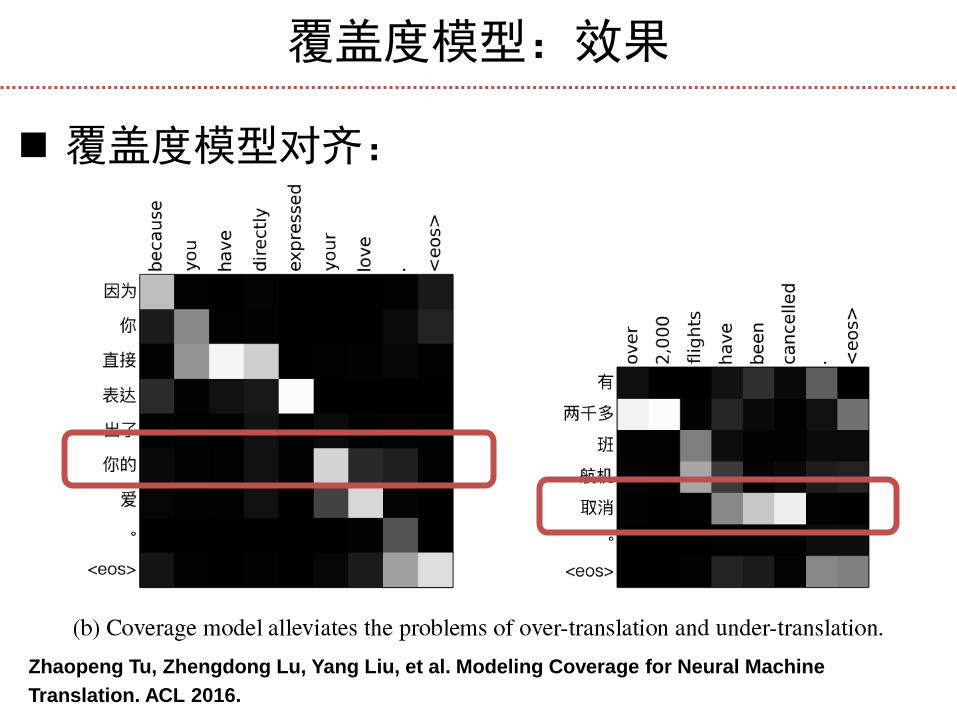
覆盖度模型对齐:
覆盖度模型:效果
Zhaopeng Tu, Zhengdong Lu, Yang Liu, et al. Modeling Coverage for Neural Machine
Translation. ACL 2016.

Part1
一. 神经机器翻译简介
二. 改进的注意力机制
三. 神经机器翻译固有问题应对方法
四. 神经机器翻译与统计机器翻译的融合
五. 字符级神经机器翻译
六. 短语级神经机器翻译
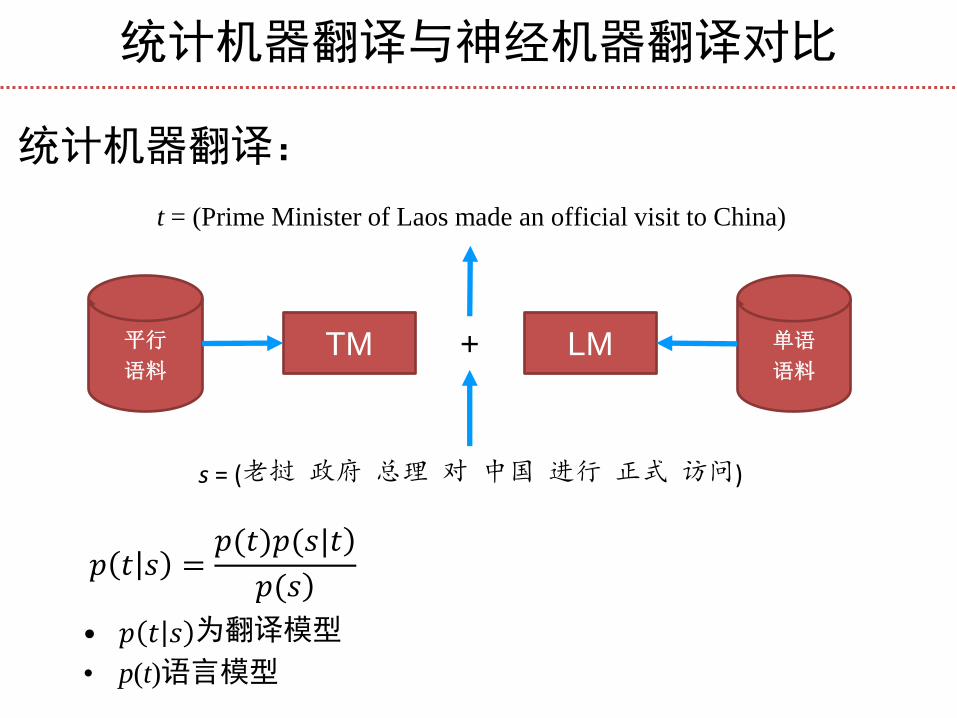
统计机器翻译与神经机器翻译对比
统计机器翻译:
平行
语料 TM LM 单语
语料
𝑝 𝑡 𝑠 =𝑝(𝑡)𝑝(𝑠|𝑡)
𝑝(𝑠)
• 𝑝 𝑡 𝑠 为翻译模型
• p(t)语言模型
s = (老挝 政府 总理 对 中国 进行 正式 访问)
t = (Prime Minister of Laos made an official visit to China)
+
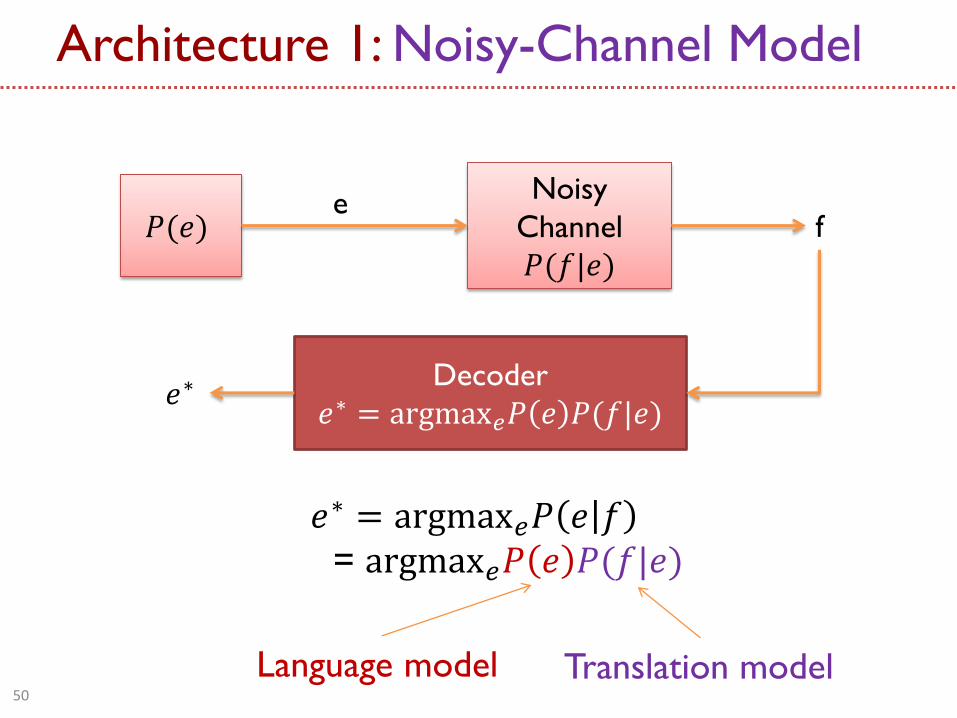
Architecture 1: Noisy-Channel Model
𝑃(𝑒) Noisy
Channel
𝑃(𝑓|𝑒)
e f
Decoder
𝑒∗ = argmax𝑒𝑃 𝑒 𝑃(𝑓|𝑒) 𝑒∗
𝑒∗ = argmax𝑒𝑃 𝑒 𝑓
= argmax𝑒𝑃 𝑒 𝑃(𝑓|𝑒)
Language model Translation model 50
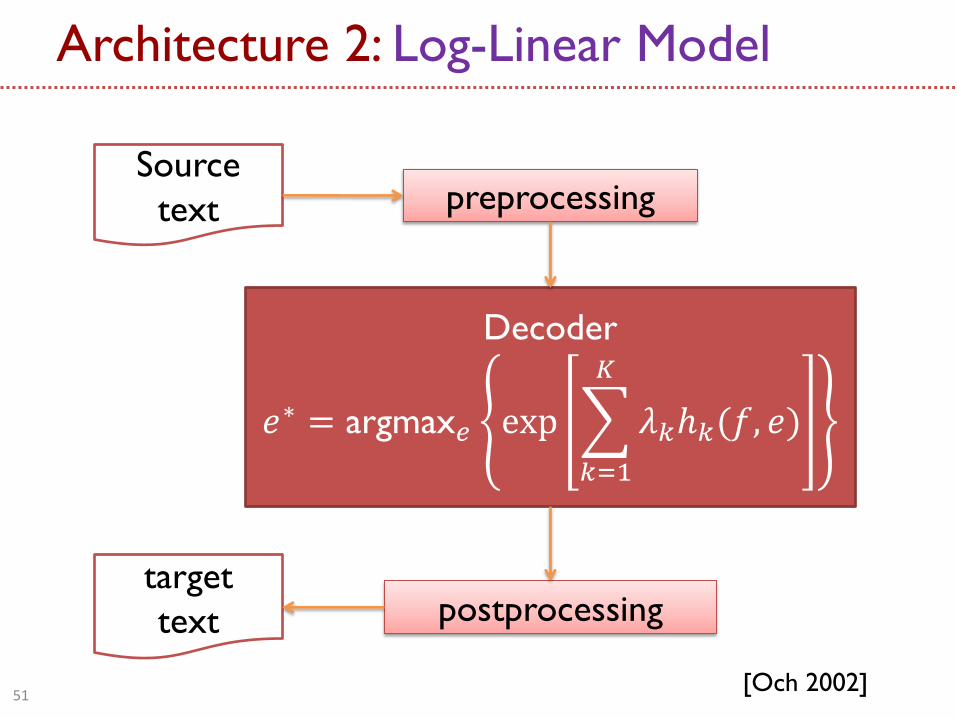
Source
text preprocessing
postprocessing target
text
Decoder
𝑒∗ = argmax𝑒 exp 𝜆𝑘ℎ𝑘(𝑓, 𝑒)
𝐾
𝑘=1
[Och 2002] 51
Architecture 2: Log-Linear Model
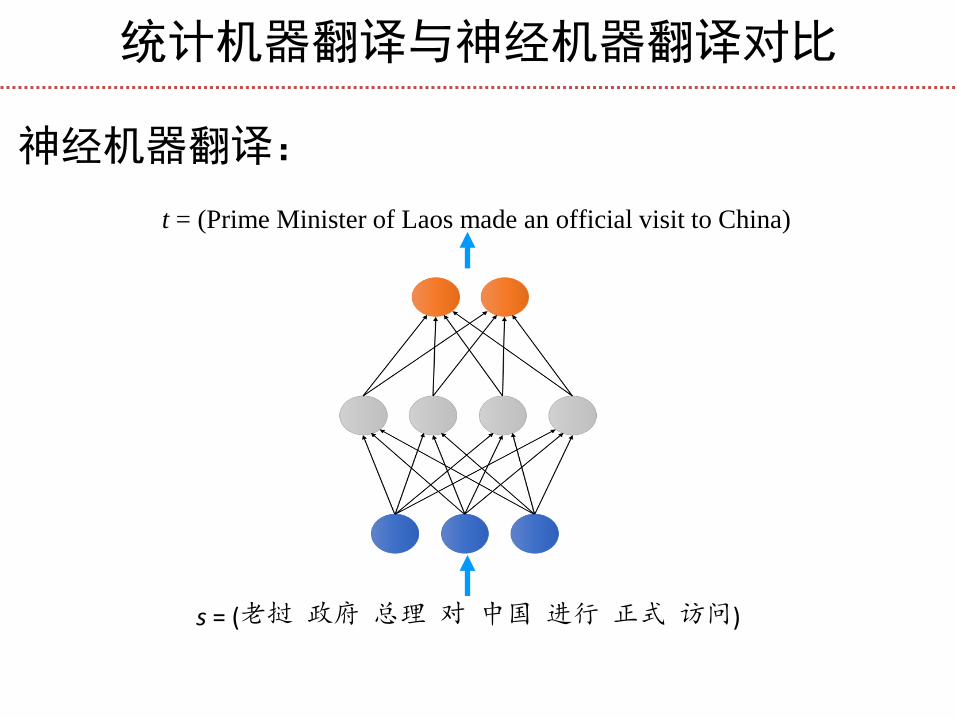
统计机器翻译与神经机器翻译对比
神经机器翻译:
s = (老挝 政府 总理 对 中国 进行 正式 访问)
t = (Prime Minister of Laos made an official visit to China)
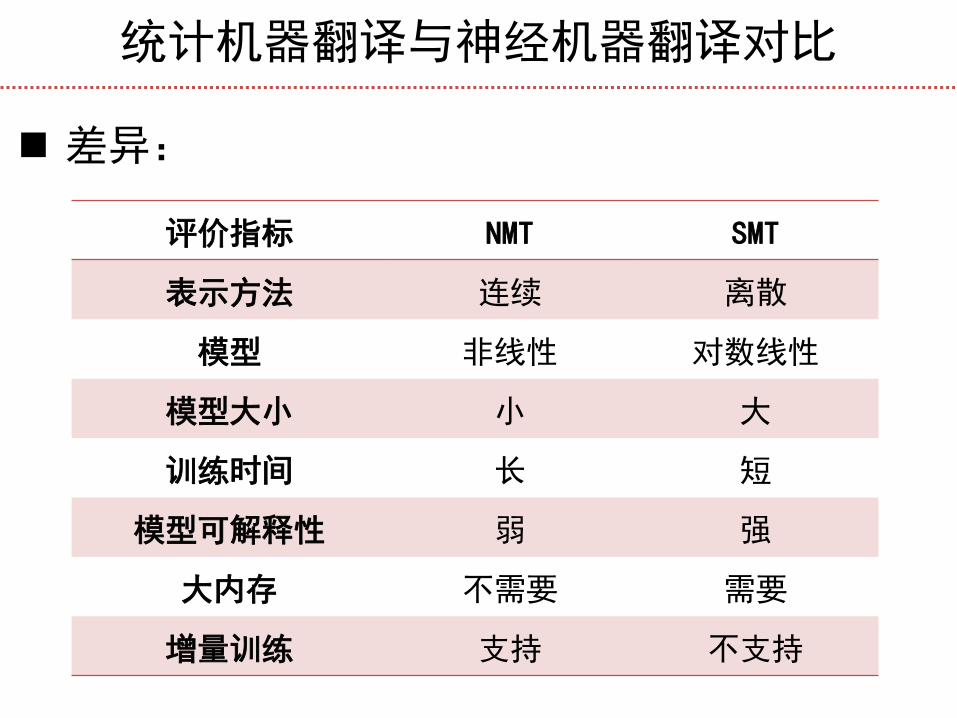
统计机器翻译与神经机器翻译对比
差异:
评价指标 NMT SMT
表示方法 连续 离散
模型 非线性 对数线性
模型大小 小 大
训练时间 长 短
模型可解释性 弱 强
大内存 不需要 需要
增量训练 支持 不支持
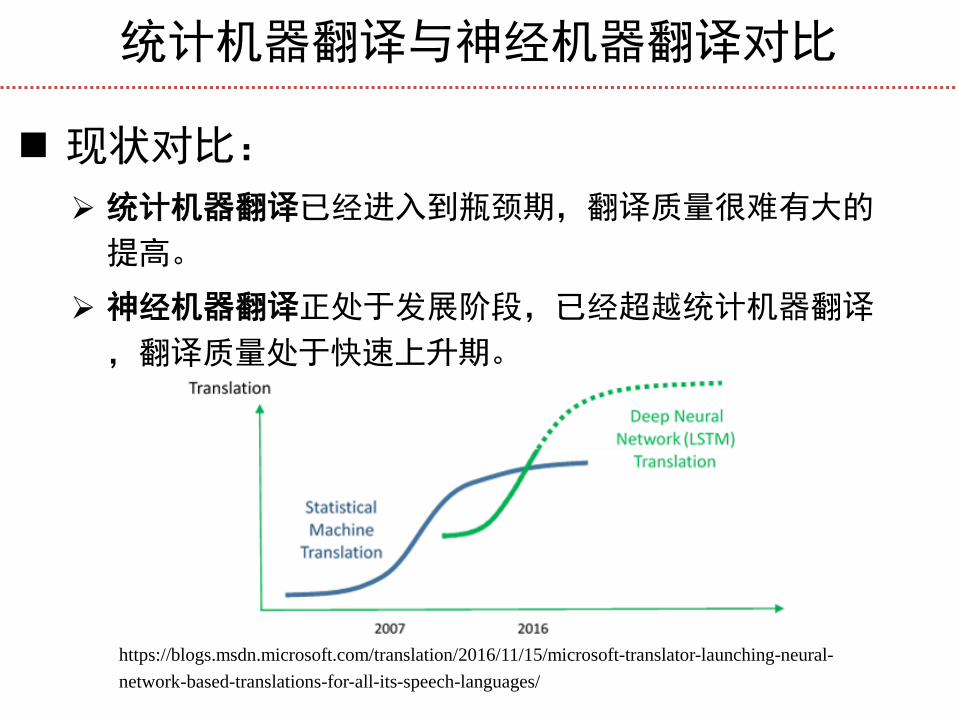
统计机器翻译与神经机器翻译对比
现状对比: 统计机器翻译已经进入到瓶颈期,翻译质量很难有大的
提高。
神经机器翻译正处于发展阶段,已经超越统计机器翻译
,翻译质量处于快速上升期。
https://blogs.msdn.microsoft.com/translation/2016/11/15/microsoft-translator-launching-neural-
network-based-translations-for-all-its-speech-languages/
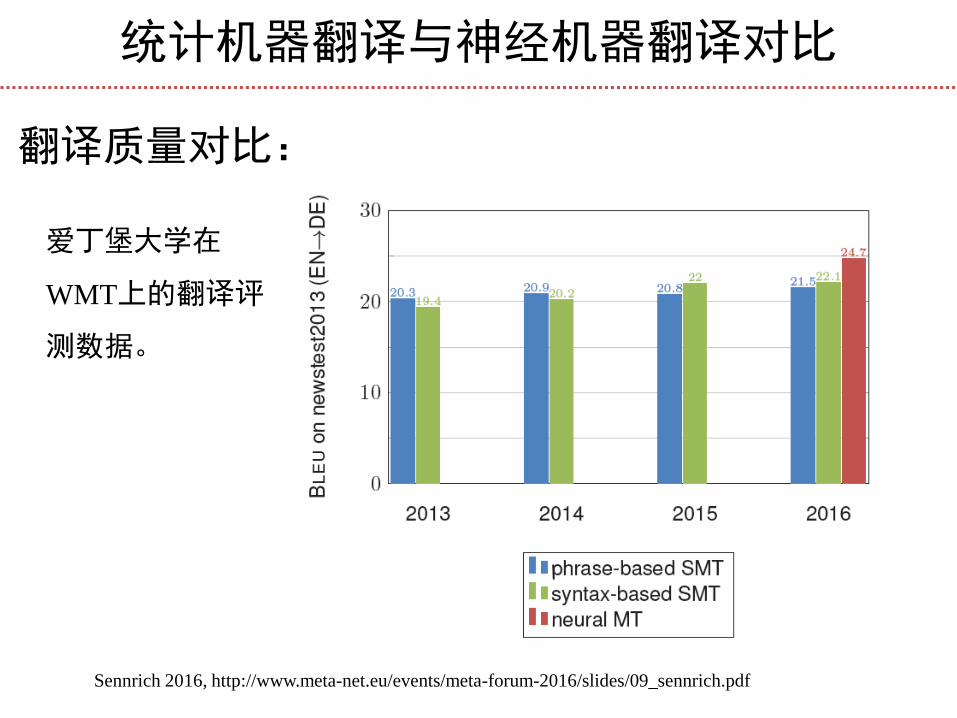
统计机器翻译与神经机器翻译对比
翻译质量对比:
爱丁堡大学在
WMT上的翻译评
测数据。
Sennrich 2016, http://www.meta-net.eu/events/meta-forum-2016/slides/09_sennrich.pdf

统计机器翻译与神经机器翻译融合
神经机器翻译面临的三个问题:
1. 词汇表受限问题
2. 源语言翻译覆盖问题
3. 翻译不忠实问题
统计机器翻译在上述三个方面可以对神经机器翻译形成有益的补充。

浅层融合方法
Log-linear NMT:
对数线性模型融合SMT、NMT
集成词汇翻译模型
集成语言模型
集成单词数奖赏模型
Wei He, Zhongjun He, Hua Wu, et al.Improved Neural Machine Translation with SMT Features.
AAAI 2016.
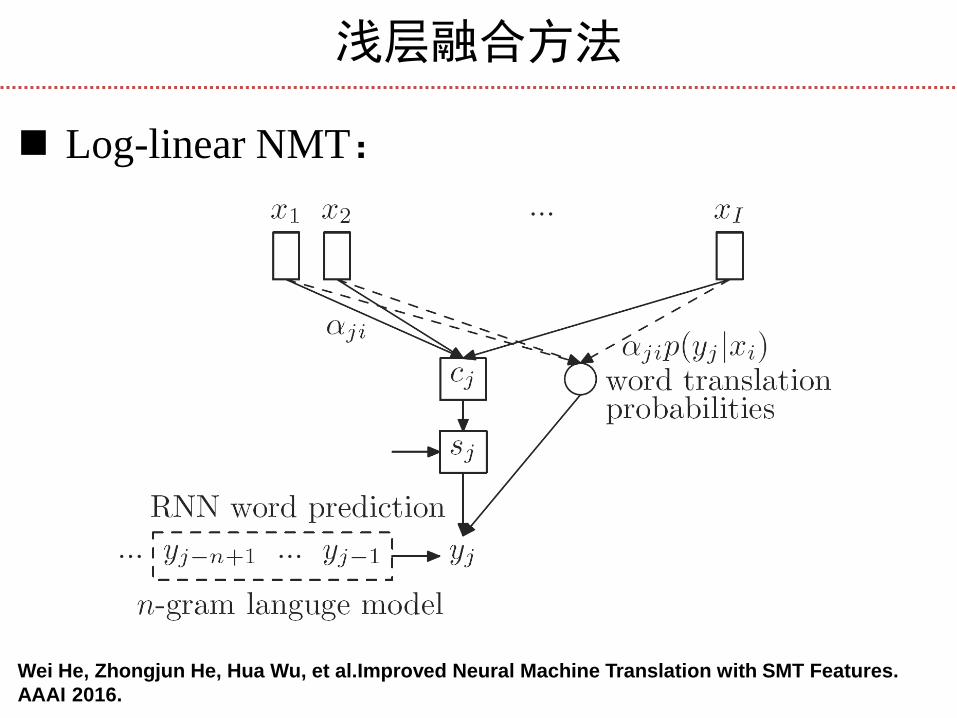
浅层融合方法
Log-linear NMT:
Wei He, Zhongjun He, Hua Wu, et al.Improved Neural Machine Translation with SMT Features.
AAAI 2016.

浅层融合方法
Log-linear NMT:
NMT prediction probability作为一个特征
特征权重由MERT训练得到
最终的单词分数由log-linear融合NMT与SMT特征后
给出
Wei He, Zhongjun He, Hua Wu, et al.Improved Neural Machine Translation with SMT Features.
AAAI 2016.
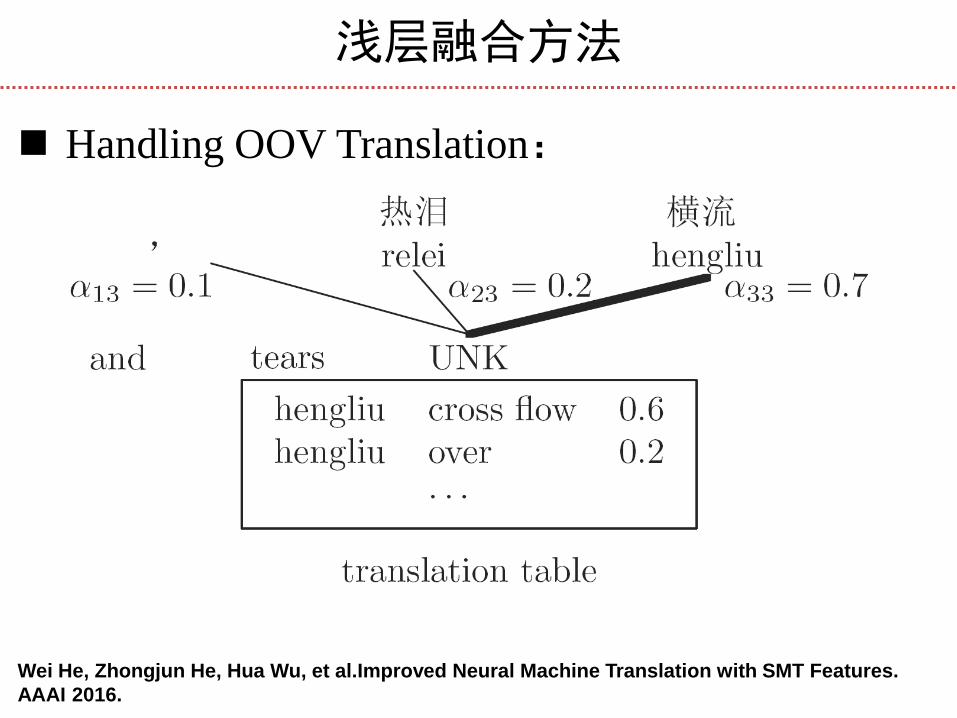
浅层融合方法
Handling OOV Translation:
Wei He, Zhongjun He, Hua Wu, et al.Improved Neural Machine Translation with SMT Features.
AAAI 2016.
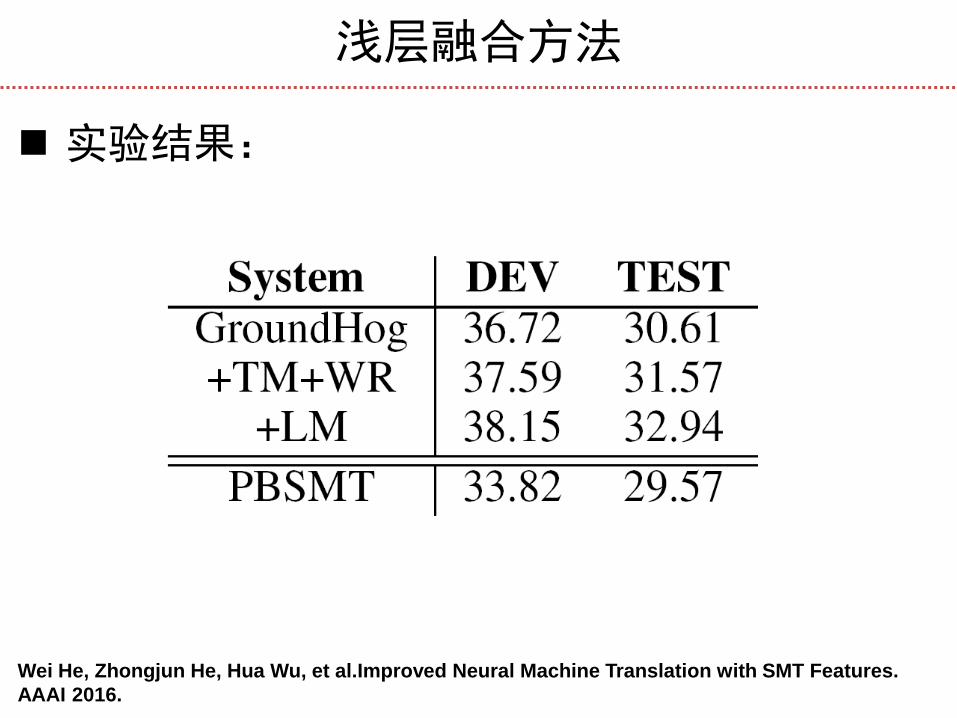
浅层融合方法
实验结果:
Wei He, Zhongjun He, Hua Wu, et al.Improved Neural Machine Translation with SMT Features.
AAAI 2016.

深度融合方法
深度融合:
将SMT融合到NMT中,SMT获取NMT提供的信息
Gate机制
联合训练
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
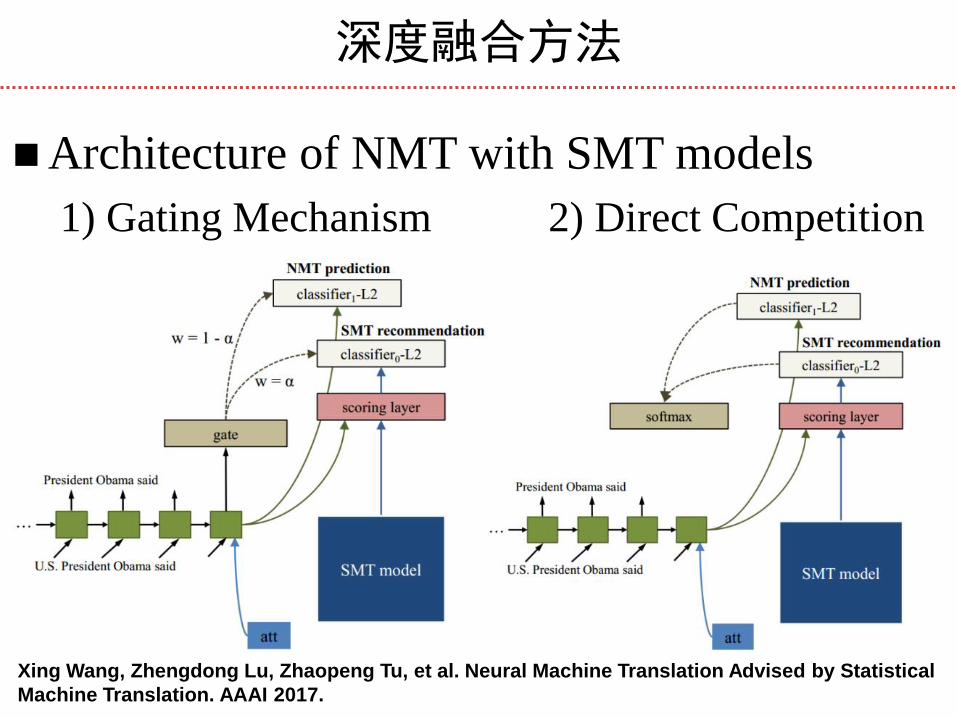
深度融合方法
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
Architecture of NMT with SMT models
1) Gating Mechanism 2) Direct Competition
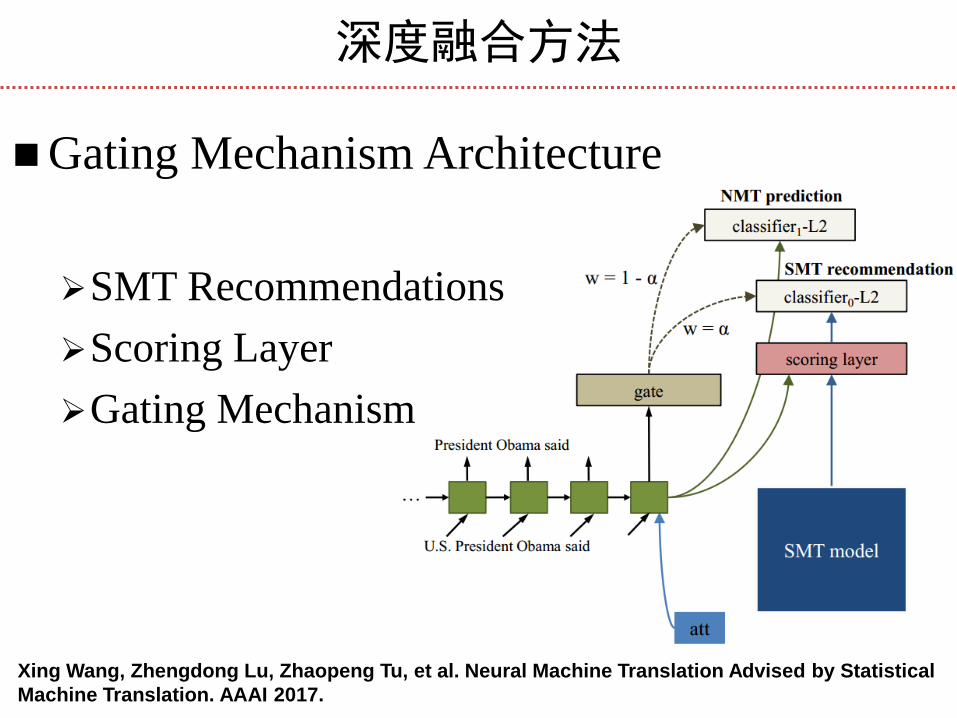
深度融合方法
Gating Mechanism Architecture
SMT Recommendations
Scoring Layer
Gating Mechanism
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
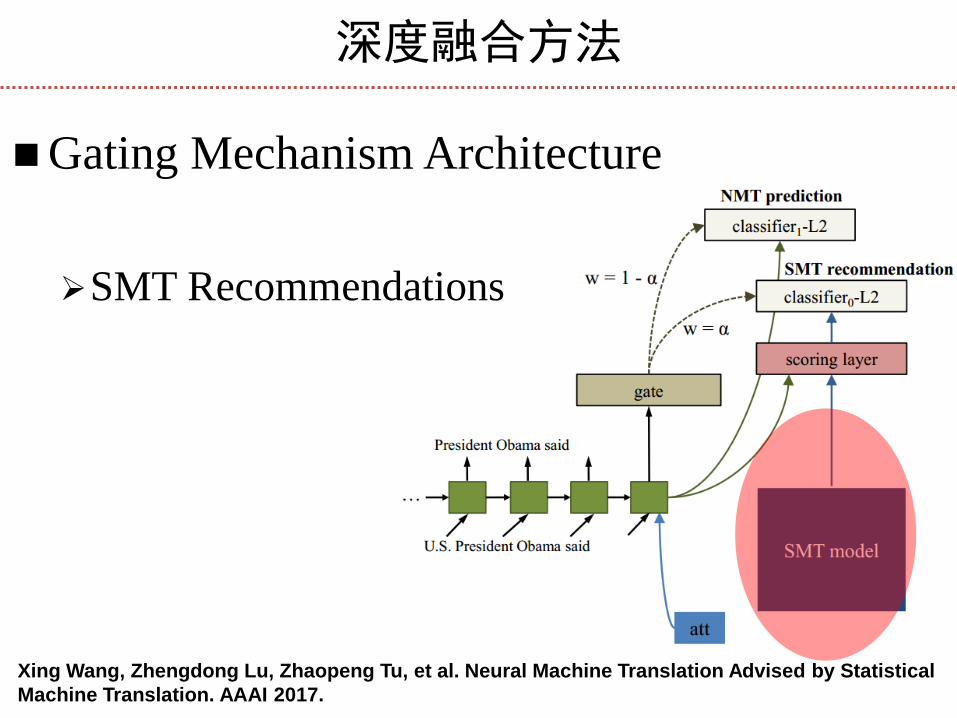
Gating Mechanism Architecture
SMT Recommendations
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
深度融合方法

SMT Recommendations
Two problems are encountered with SMT
recommendations due to the different word
generation mechanisms between SMT and
NMT
SMT lacks of coverage information
SMT reordering model lacks of alignment
information
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.

SMT lacks of coverage information
Introducing a SMT coverage vector
SMT reordering model lacks of alignment
information
Reordering cost is computed using the alignments
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
SMT Recommendations
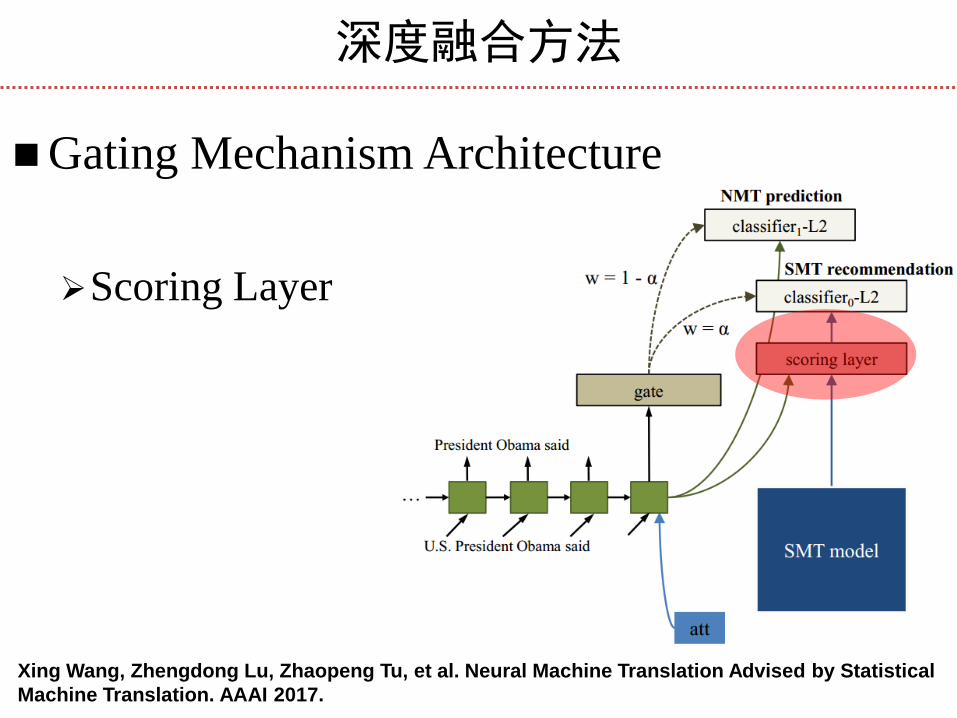
Gating Mechanism Architecture
Scoring Layer
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
深度融合方法

Scoring Layer
Scores the recommendations
Generates probability estimates
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
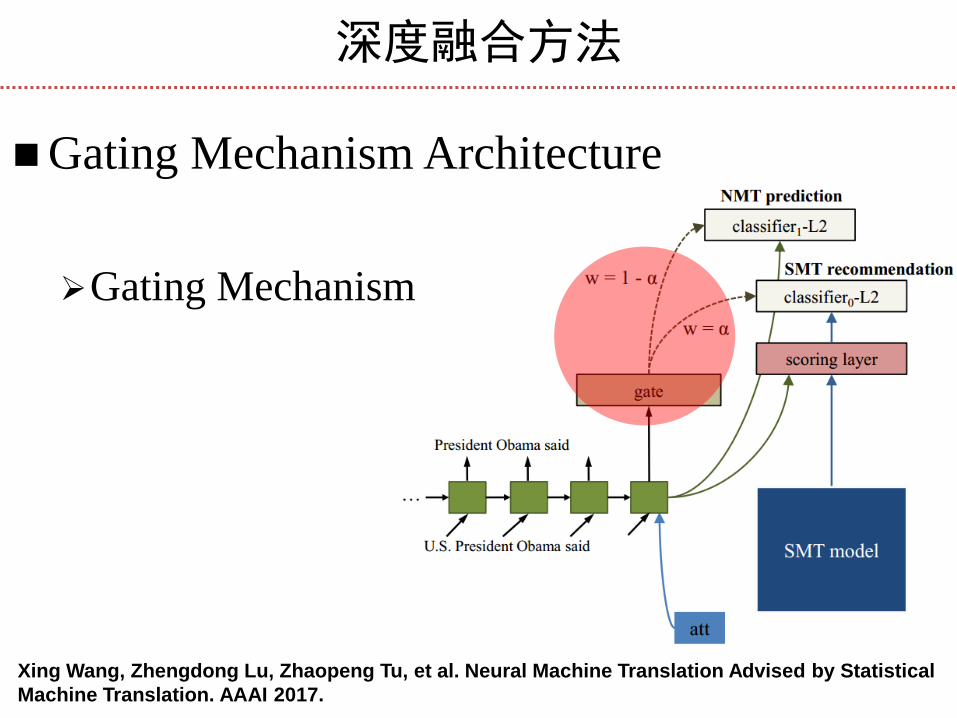
深度融合方法
Gating Mechanism Architecture
Gating Mechanism
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.

Gating Mechanism
Computes the gate
Updates word prediction probabilities
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
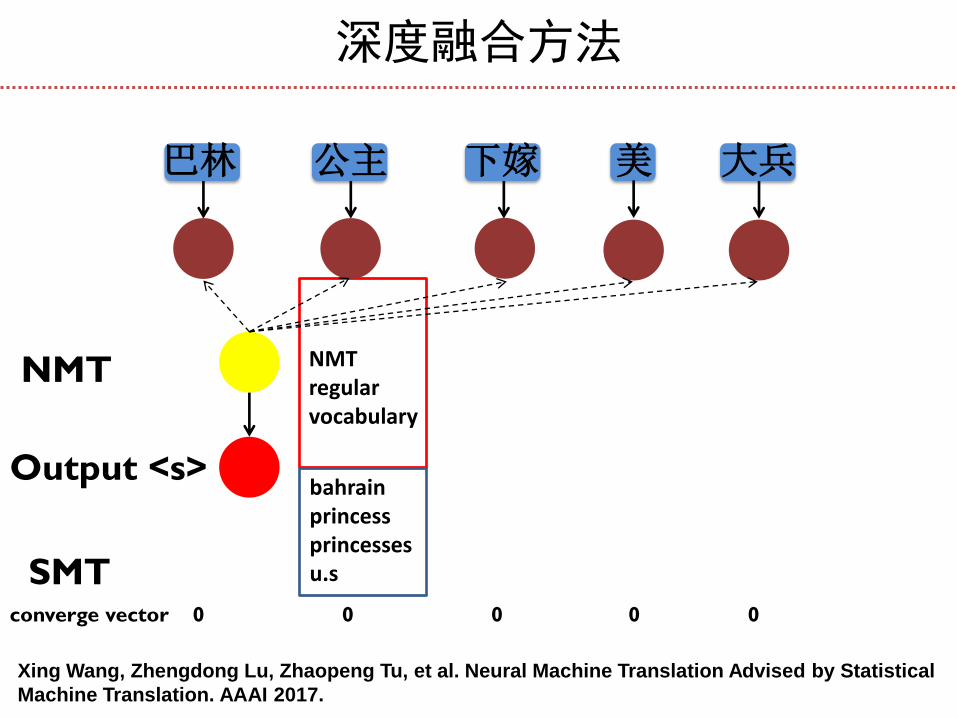
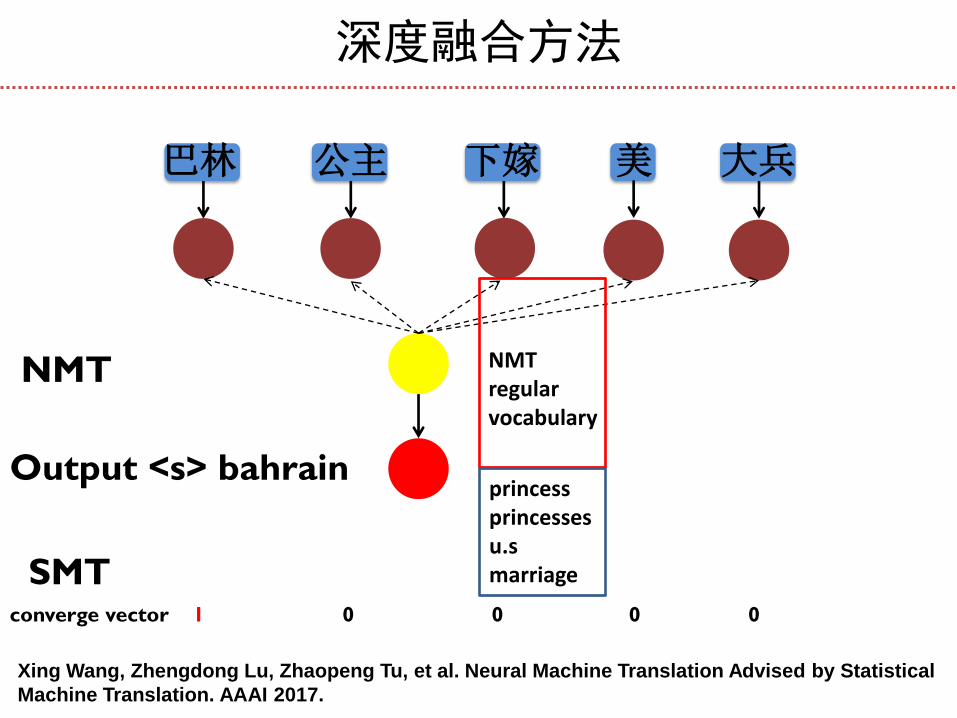
深度融合方法
巴林 公主 下嫁 美 大兵
Output <s>
converge vector 0 0 0 0 0
bahrain princess princesses u.s
NMT regular vocabulary
NMT
SMT
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
巴林 公主 下嫁 美 大兵
Output <s> bahrain
converge vector 1 0 0 0 0
NMT
SMT
princess princesses u.s marriage
NMT regular vocabulary
深度融合方法
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
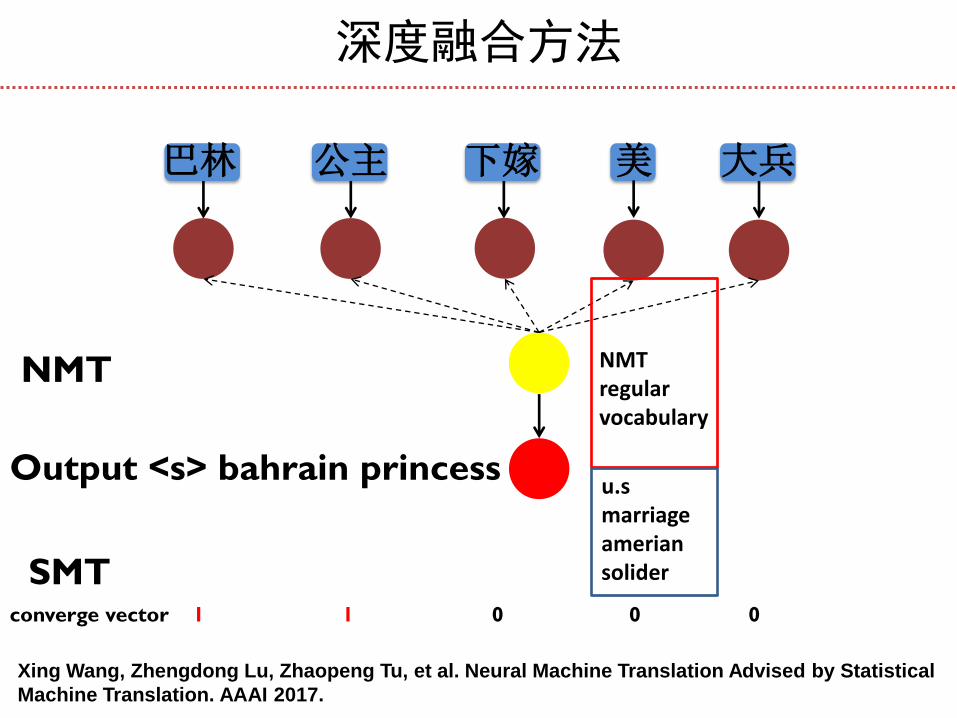
巴林 公主 下嫁 美 大兵
Output <s> bahrain princess
converge vector 1 1 0 0 0
NMT
SMT
u.s marriage amerian solider
NMT regular vocabulary
深度融合方法
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
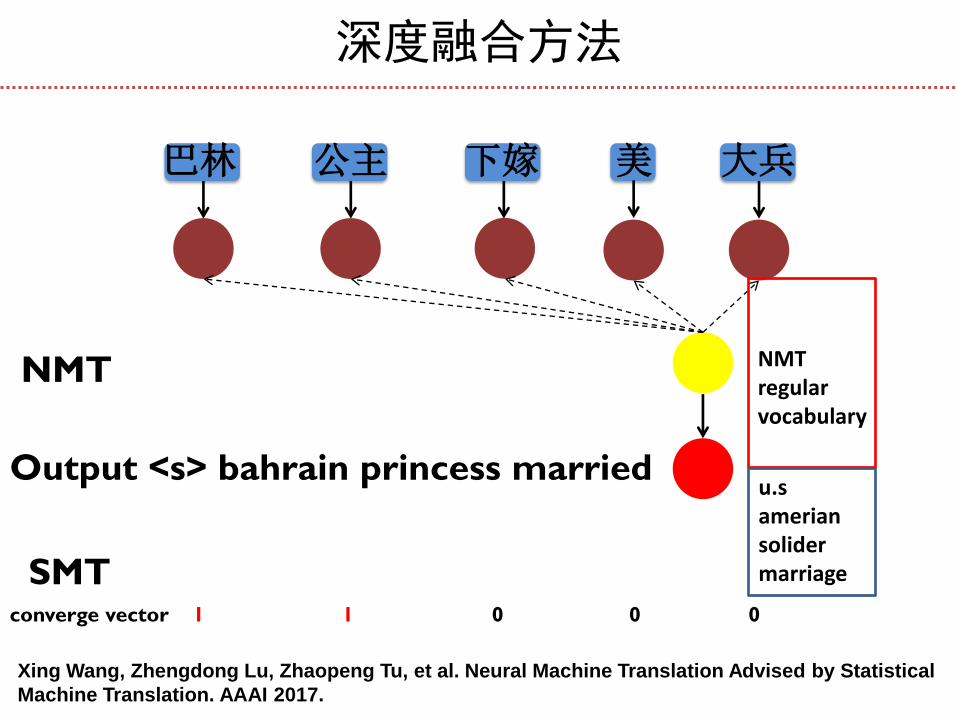
巴林 公主 下嫁 美 大兵
Output <s> bahrain princess married
converge vector 1 1 0 0 0
NMT
SMT
u.s amerian solider marriage
NMT regular vocabulary
深度融合方法
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
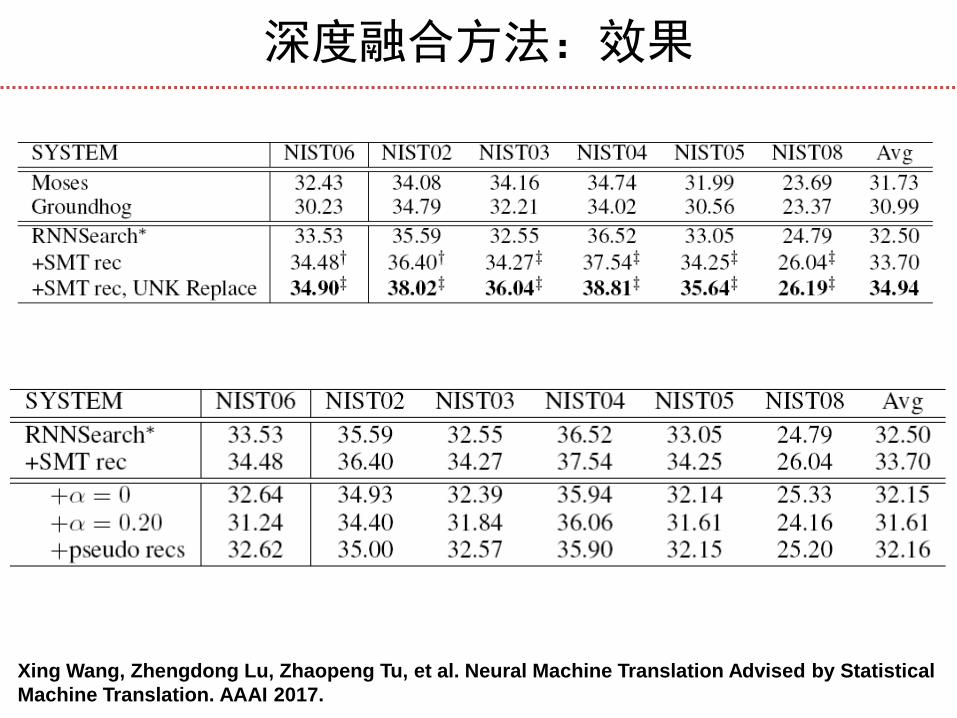
深度融合方法:效果
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.

Part1
一. 神经机器翻译简介
二. 改进的注意力机制
三. 神经机器翻译固有问题应对方法
四. 神经机器翻译与统计机器翻译的融合
五. 字符级神经机器翻译
六. 短语级神经机器翻译

字符级神经机器翻译:Why&Challenges
Why character-level translation?
1. do not suffer from out-of-vocabulary issues.
2. are able to model different, rare morphological
variants of a word.
3. do not require segmentation.
Challenges
1. needs to summarize what has been translated.
2. must be able to generate a long, coherent sequence
of characters.

从基本单位来看:
字符/character
subword
word
从是否保留单词边界来看: 保留单词边界 不保留单词边界
字符级神经机器翻译
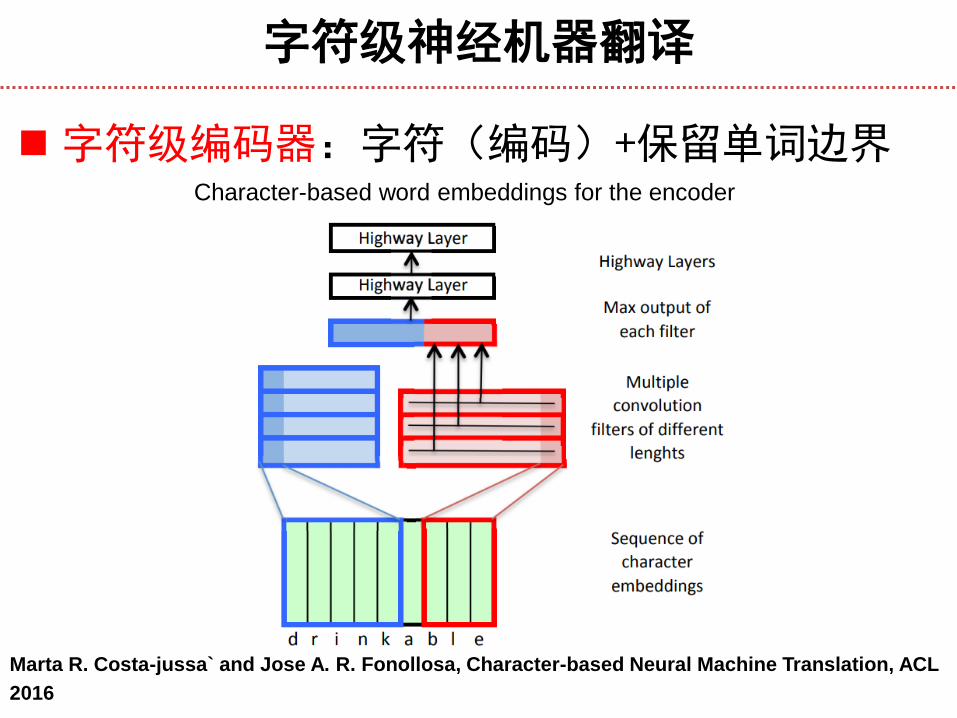
字符级神经机器翻译
字符级编码器:字符(编码)+保留单词边界
Marta R. Costa-jussa` and Jose A. R. Fonollosa, Character-based Neural Machine Translation, ACL
2016
Character-based word embeddings for the encoder
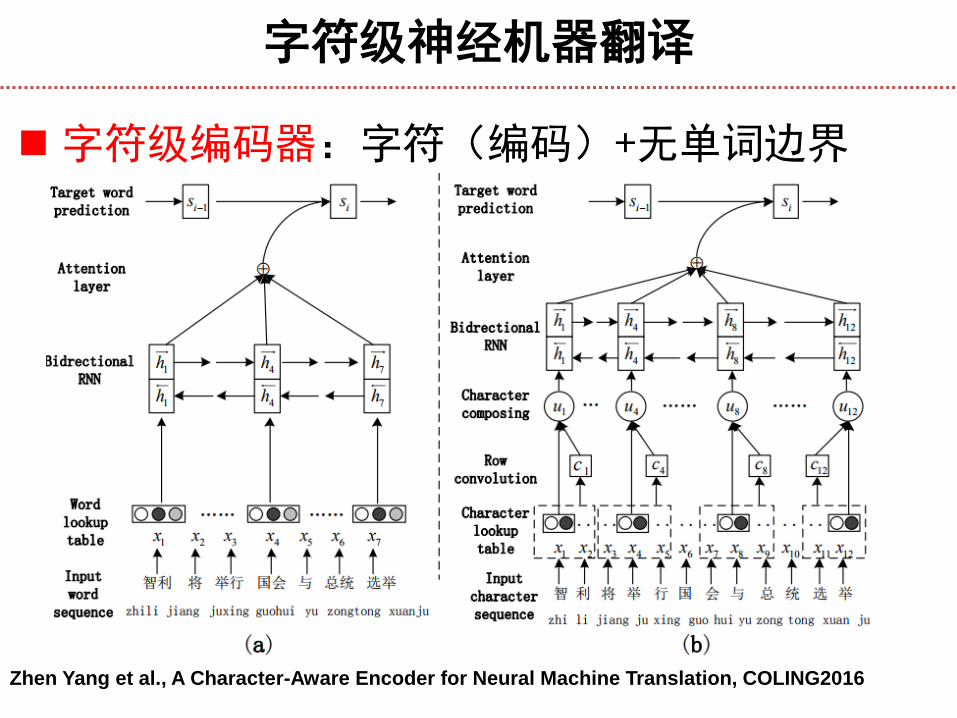
字符级神经机器翻译
Zhen Yang et al., A Character-Aware Encoder for Neural Machine Translation, COLING2016
字符级编码器:字符(编码)+无单词边界
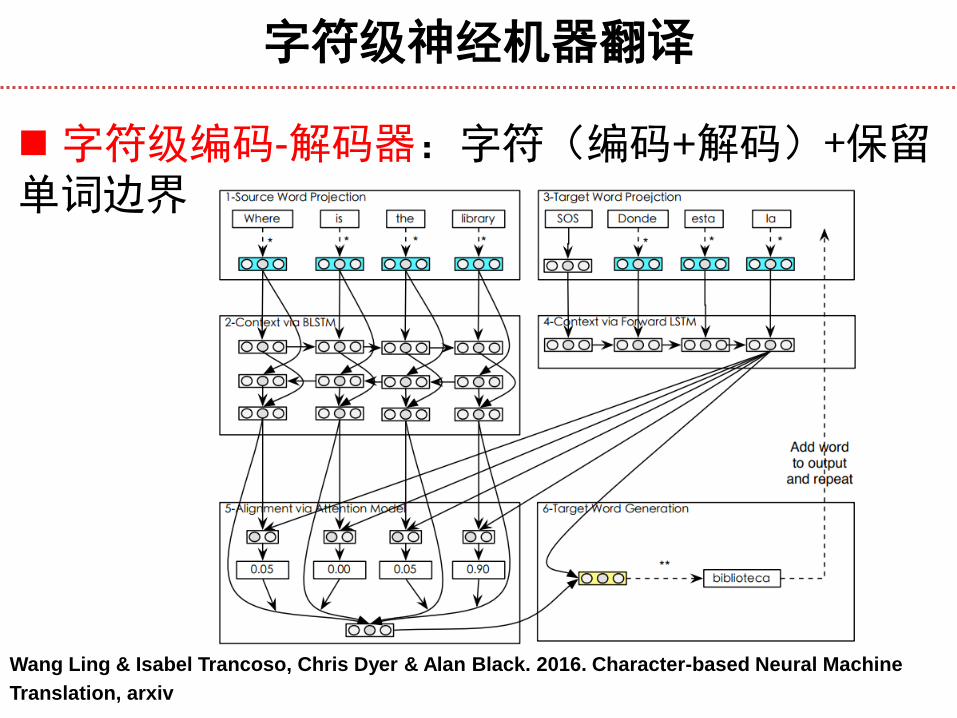
字符级神经机器翻译
Wang Ling & Isabel Trancoso, Chris Dyer & Alan Black. 2016. Character-based Neural Machine
Translation, arxiv
字符级编码-解码器:字符(编码+解码)+保留单词边界
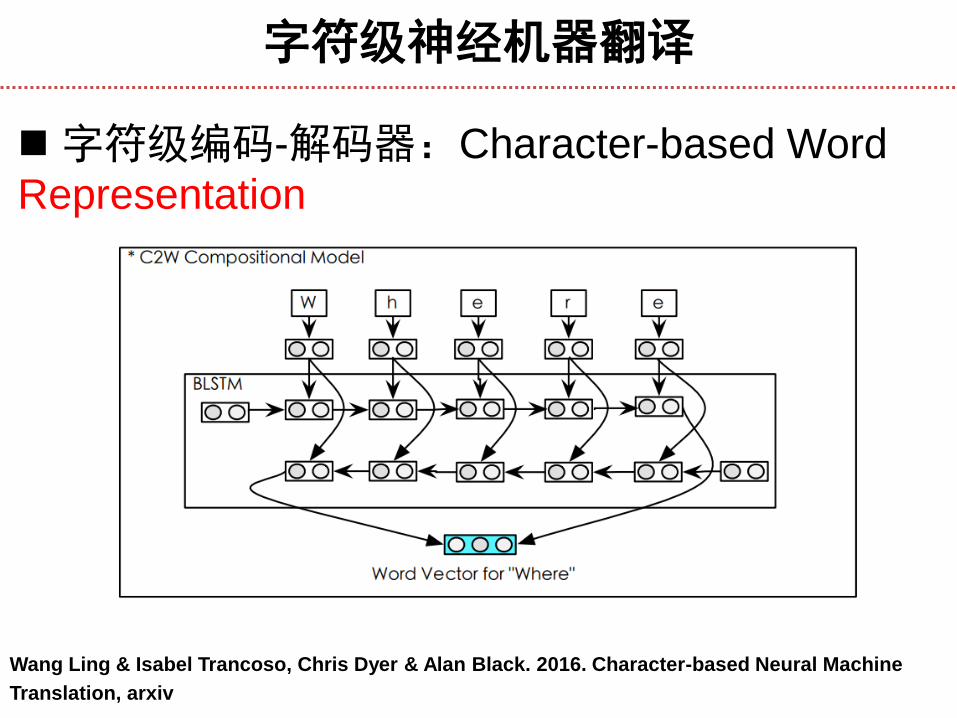
字符级神经机器翻译
Wang Ling & Isabel Trancoso, Chris Dyer & Alan Black. 2016. Character-based Neural Machine
Translation, arxiv
字符级编码-解码器:Character-based Word
Representation
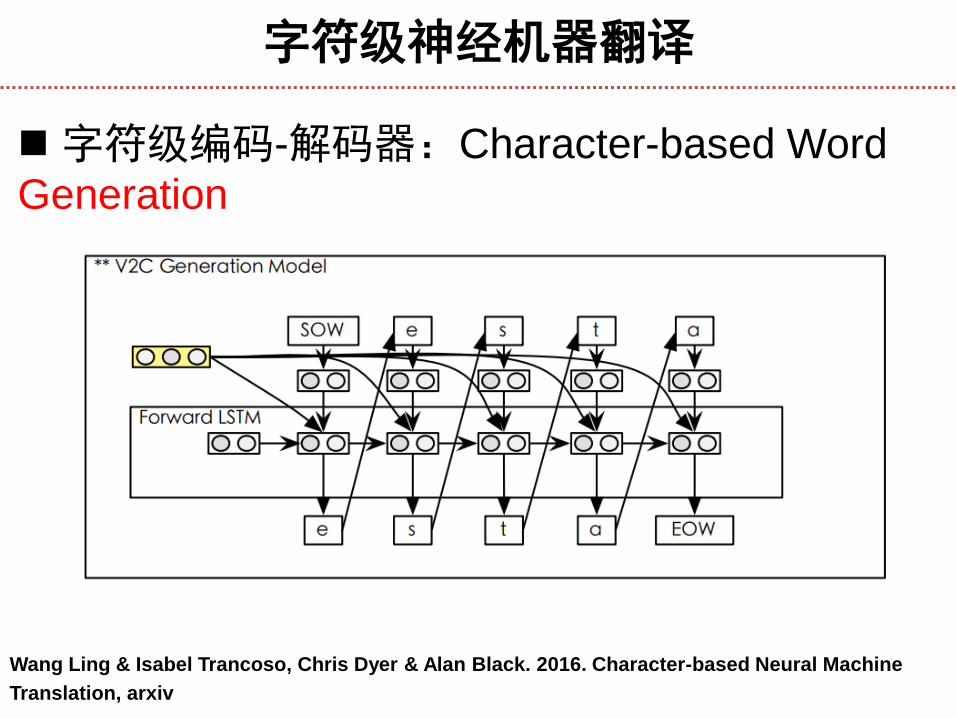
字符级神经机器翻译
Wang Ling & Isabel Trancoso, Chris Dyer & Alan Black. 2016. Character-based Neural Machine
Translation, arxiv
字符级编码-解码器:Character-based Word
Generation
字符级神经机器翻译
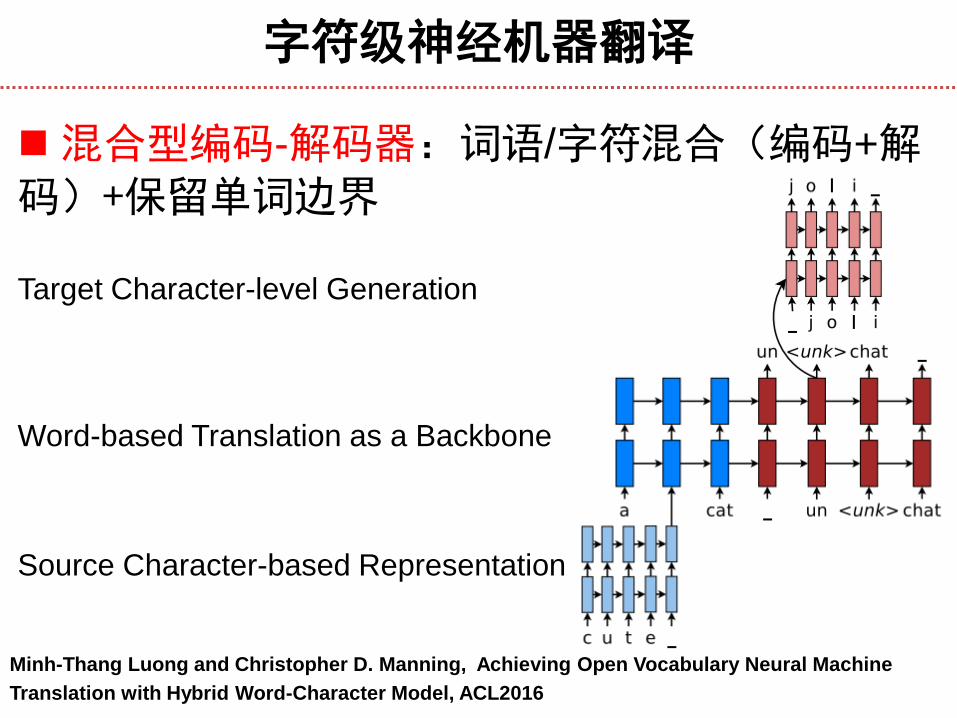
混合型编码-解码器:词语/字符混合(编码+解码)+保留单词边界
Target Character-level Generation
Word-based Translation as a Backbone
Source Character-based Representation
Minh-Thang Luong and Christopher D. Manning, Achieving Open Vocabulary Neural Machine
Translation with Hybrid Word-Character Model, ACL2016
字符级神经机器翻译
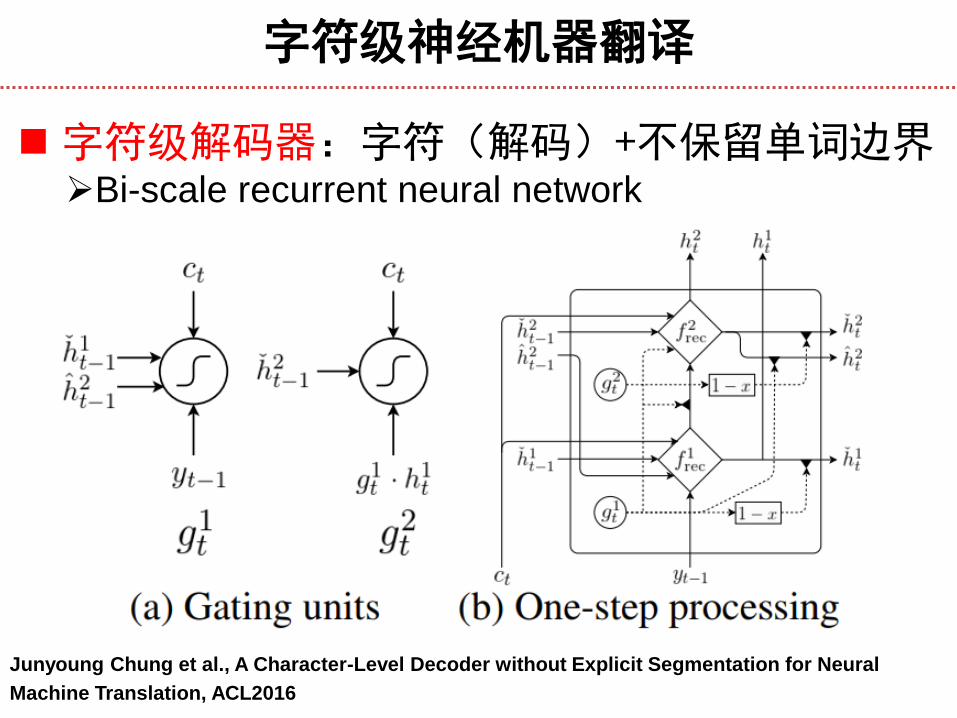
字符级解码器:字符(解码)+不保留单词边界 Bi-scale recurrent neural network
Junyoung Chung et al., A Character-Level Decoder without Explicit Segmentation for Neural
Machine Translation, ACL2016

字符级神经机器翻译:小结
字符级编码器(保留单词边界)
字符级编码器(无单词边界)
字符级解码器(保留单词边界)
字符级解码器(无单词边界)
字符级编码-解码器(保留单词边界)
字符-单词混合型编码-解码器(保留单词边界)
字符级编码-解码器(无单词边界):character
sequence to character sequence?
Or unicode-based nmt?

Part1
一. 神经机器翻译简介
二. 改进的注意力机制
三. 神经机器翻译固有问题应对方法
四. 神经机器翻译与统计机器翻译的融合
五. 字符级神经机器翻译
六. 短语级神经机器翻译

Motivation
Phrases play an important role in natural language
understanding and machine translation.
– Neural machine translation is an approach to machine
translation that uses a large neural network.
However, the word-by-word generation
philosophy in NMT makes it difficult to translate
multi-word phrases.
Can we translate phrases in NMT?
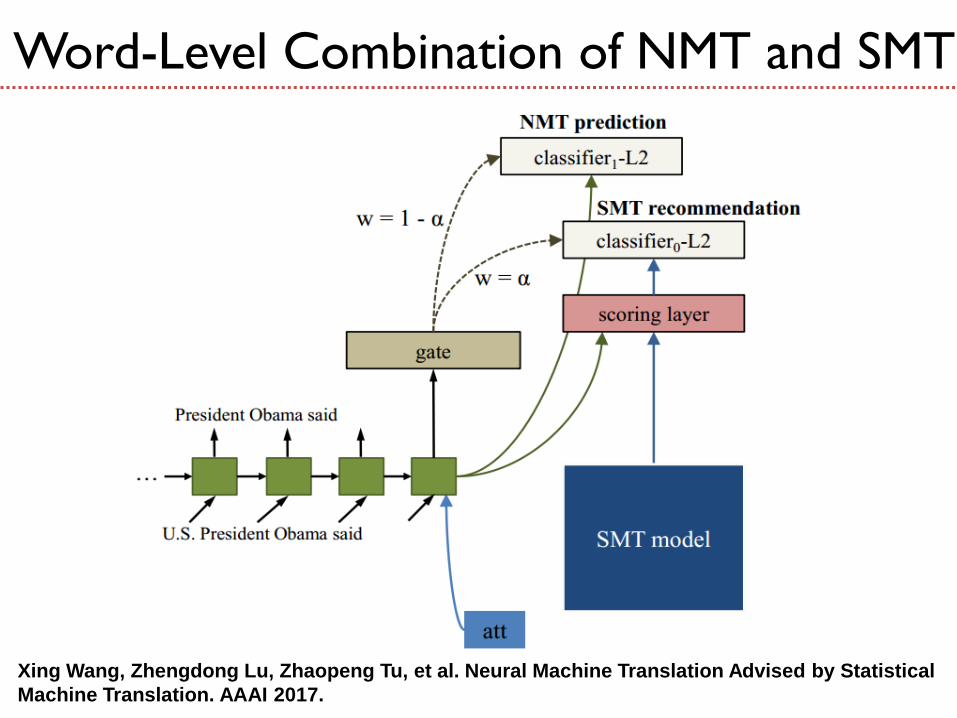
Word-Level Combination of NMT and SMT
Xing Wang, Zhengdong Lu, Zhaopeng Tu, et al. Neural Machine Translation Advised by Statistical
Machine Translation. AAAI 2017.
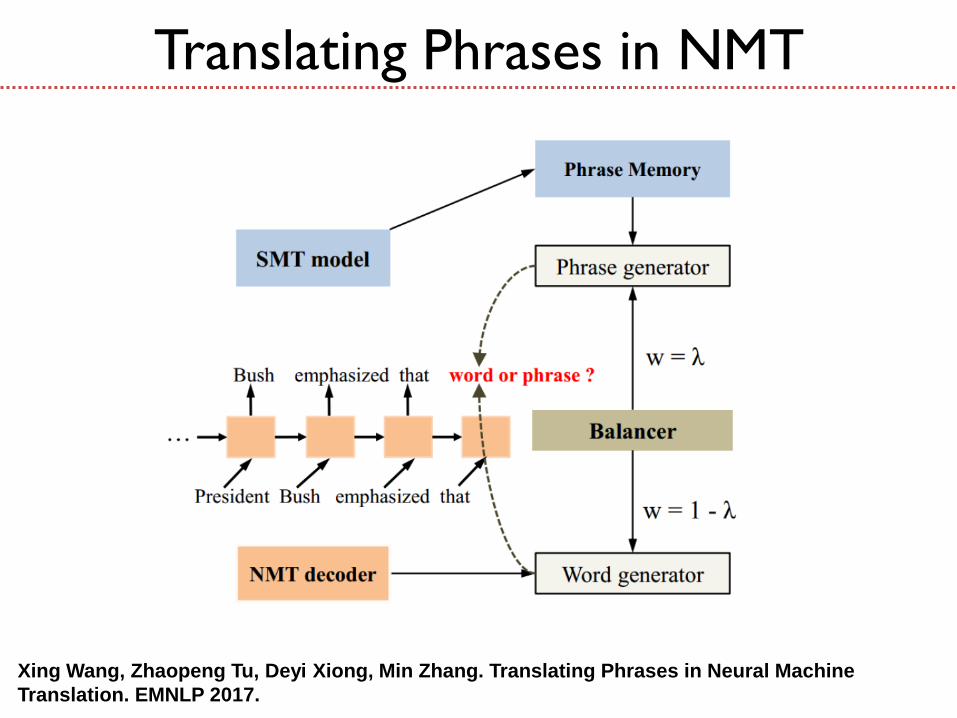
Translating Phrases in NMT
Xing Wang, Zhaopeng Tu, Deyi Xiong, Min Zhang. Translating Phrases in Neural Machine
Translation. EMNLP 2017.

Phrase Memory
Writes to Phrase Memory
SMT model writes relevant target phrases to the
phrase memory, based on the decoding
information from NMT at each decoding step.
Reads Phrase Memory
NMT model reads and scores the target phrases
in the phrase memory.

Balancer
The balancing weight λ is produced by the
balancer – a multi-layer network.
Intuitively, the weight λ can be treated as the
estimated importance of the phrase to be
generated.
We expect λ to be high if the phrase is
appropriate at the current decoding step.

Training
The translation y = {y1; y2; …; yTy} consists of
two sets of fragments: words w = {w1; w2; …;
wK} and phrases p = {p1; p2; …; pL} . The
probability of generating y is calculated by
The cost:

Challenges: Phrase Segmentation
Problem: the target sentence can be split into
different segmentations (word and phrase
fragments) .
Solution: use a source-side chunker to chunk
the source sentence, and only phrases that
corresponds to a source chunk is used in our
model.

Chunking
Generate the well-formed chunk phrases
based on the following considerations:
dynamic programming, to generate non-
overlap phrases.
the boundary information, to better guide
the model to generate a target phrase at an
appropriate decoding step.

Testing
During testing, the NMT decoder generates a
target sentence which consists of a mixture of
words and phrases.
–E.g. Neural machine translation is an
approach to machine translation that uses
a large neural network.

Testing
At decoding step i:
computes Pphrase for all phrases in the phrase
memory and Pword for all words in NMT
vocabulary.
uses a balancing weight λi to scale the
phrase and word probabilities : λi ×Pphrase
and (1-λi)×Pword.
the NMT decoder generates a proper
phrase or word of the highest probability.

If a target phrase in the phrase memory has
the highest probability, the decoder generates
the target phrase to complete the multi-word
phrase generation process, and updates its
decoding state by consuming the words in the
selected phrase.
Phrase Generation Mode

Experiments
Chinese-to-English translation
Training corpus: 1.25M sentence pairs (27.9M,
34.5M words)
Vocabulary size: 30K
Max sentence length: 50
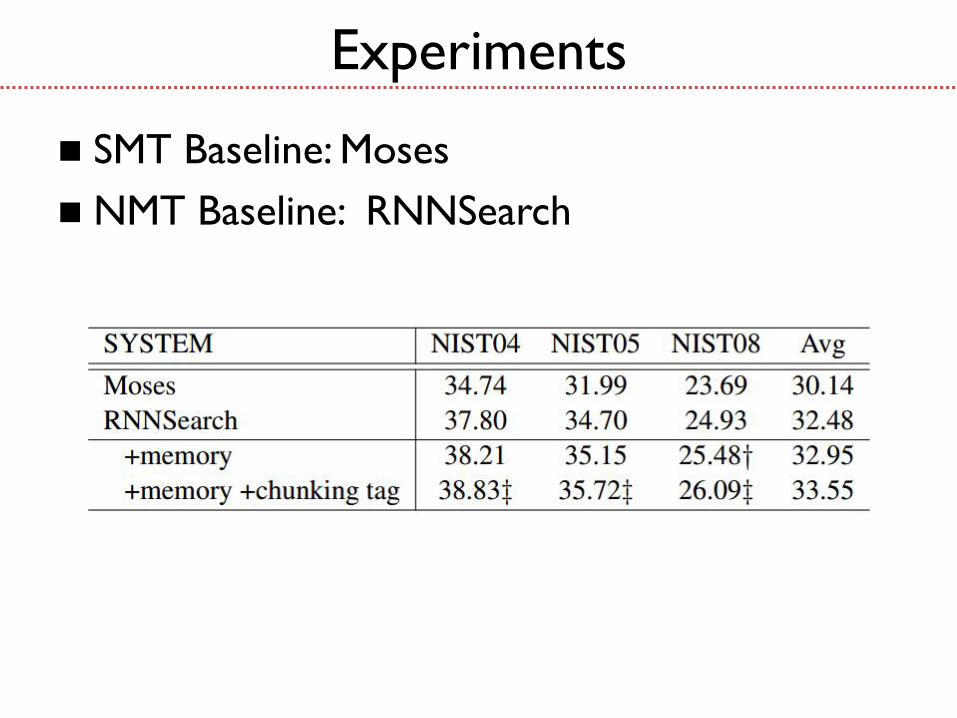
Experiments
SMT Baseline: Moses
NMT Baseline: RNNSearch
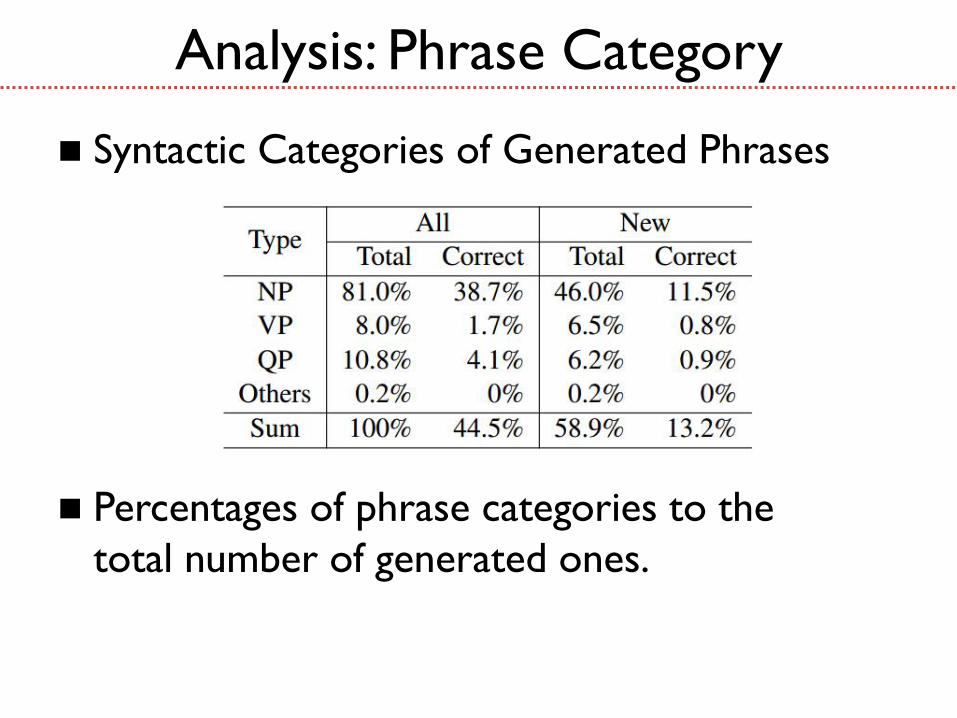
Syntactic Categories of Generated Phrases
Percentages of phrase categories to the
total number of generated ones.
Analysis: Phrase Category

Number of Words in Generated Phrases
Percentages of phrases with different word
counts to the total number of generated ones.
Analysis: Phrase Length

中场休息

Part2
一. 句法驱动的神经机器翻译
二. 多语与多模态神经机器翻译
三. 面向资源稀缺语种的神经机器翻译
四. 神经机器翻译深度模型
五. 神经机器翻译新架构
六. 神经机器翻译未来发展方向
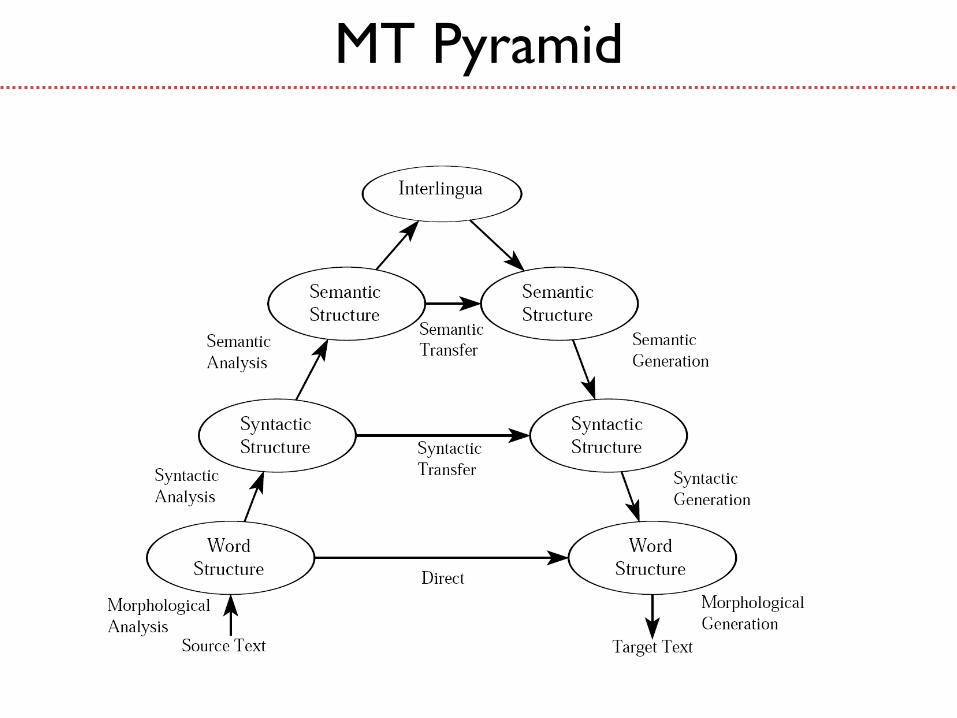
MT Pyramid
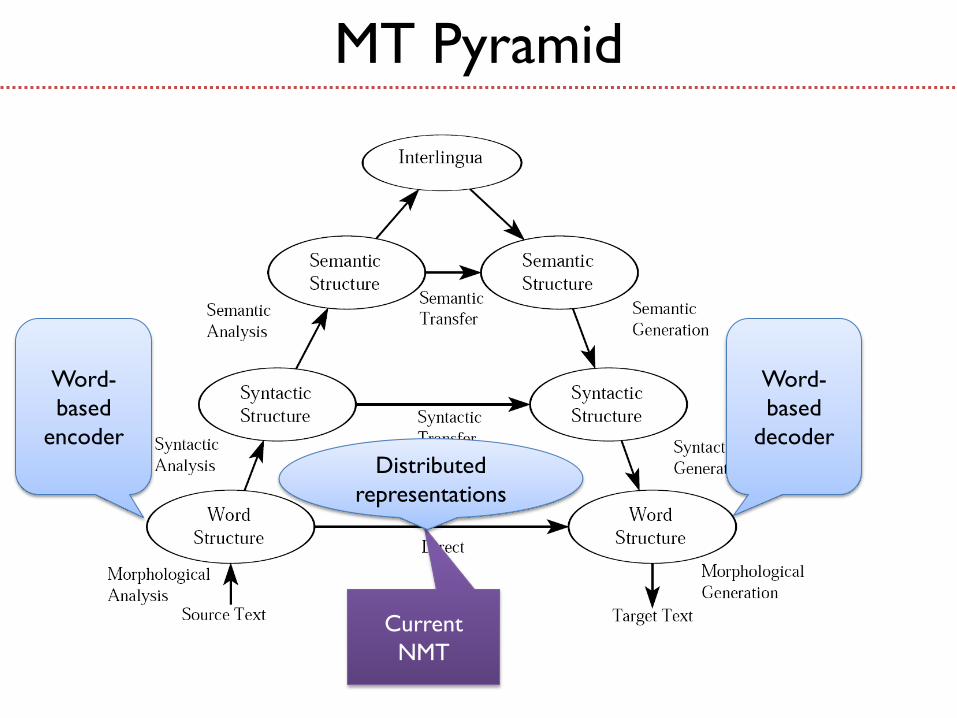
Current
NMT
Word-
based
encoder
Word-
based
decoder
Distributed
representations
MT Pyramid

Modeling Syntax or Semantics
Given the property of LSTM RNN in
modeling variable-length structures, do we
need explicit parse trees? (Graves et al., 2014)
Or do we need to explicitly model syntax and
semantics in NMT?
Or do we need to go further to syntactic and
semantic NMT?

Why do we need syntax?
Related studies on NMT show that we need
syntax.
NMT translation error analysis shows that we
need syntax.
Previous studies on SMT show that we need
syntax.

Why do we need syntax?
Related study (Shi et al. 2016) shows that ...
the seq2seq model still fails to capture a lot of deep structural details, even though it is capable of learning certain implicit source syntax from sentence-aligned parallel corpus.
it requires an additional parsing-task-specific training mechanism to recover the hidden syntax in NMT.
Xing Shi, Inkit Padhi, and Kevin Knight. 2016. Does string-based neural MT learn source syntax? In Proceedings of EMNLP 2016.

句法的引入
从句法的组织形式看:
图/graph
树/tree
线性化树/linearized tree
向量/vector
从工作的开展方式看: 丰富NMT的输入/输出 多任务学习/ Multi-task learning
树到序列转换或序列到树转换

句法的引入
Sequence to linearized tree
训练语料目标端做句法分析
句法分析树以括号形式表示( linearized
tree )
仍然基于seq2seq model,将源语言序列翻
译为目标语言linearized tree
Roee Aharoni and Yoav Goldberg, Towards String-to-Tree Neural Machine Translation, ACL 2017
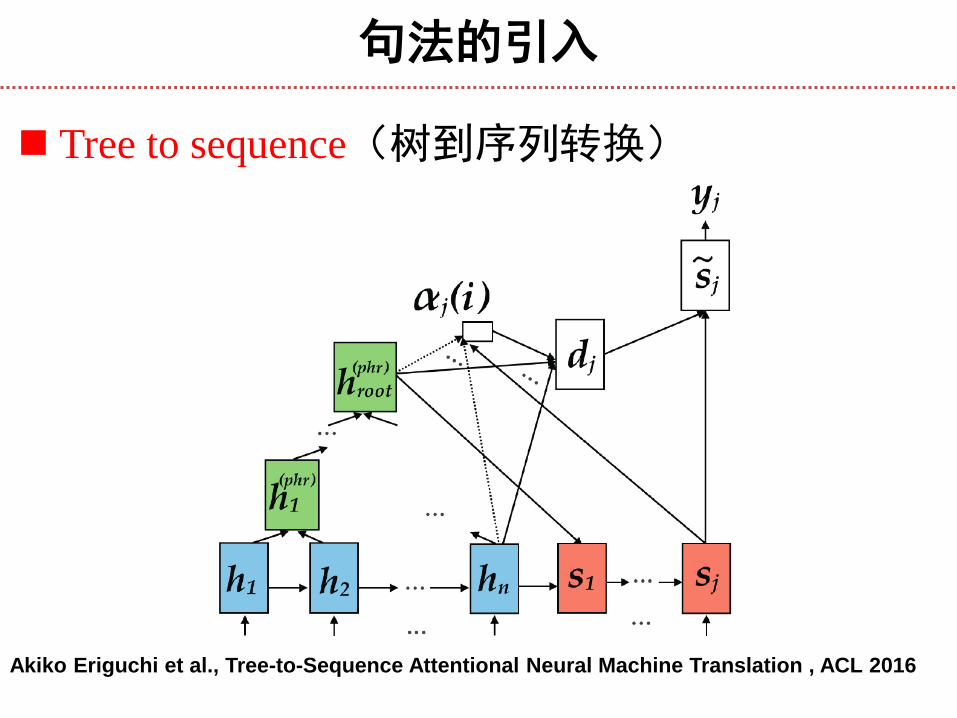
句法的引入
Tree to sequence(树到序列转换)
Akiko Eriguchi et al., Tree-to-Sequence Attentional Neural Machine Translation , ACL 2016
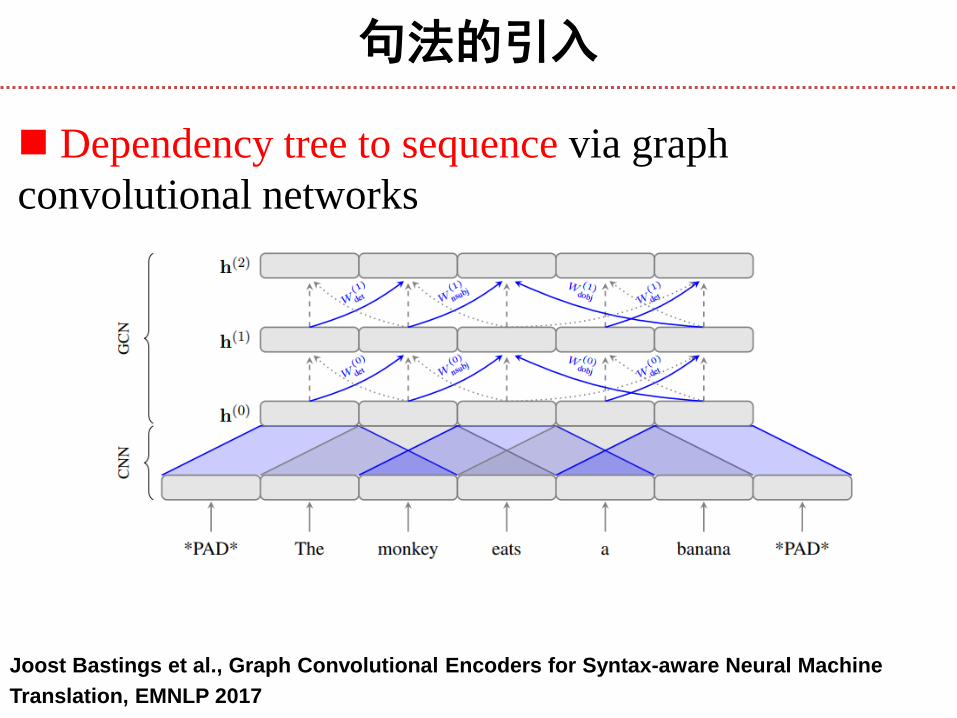
句法的引入
Dependency tree to sequence via graph
convolutional networks
Joost Bastings et al., Graph Convolutional Encoders for Syntax-aware Neural Machine
Translation, EMNLP 2017
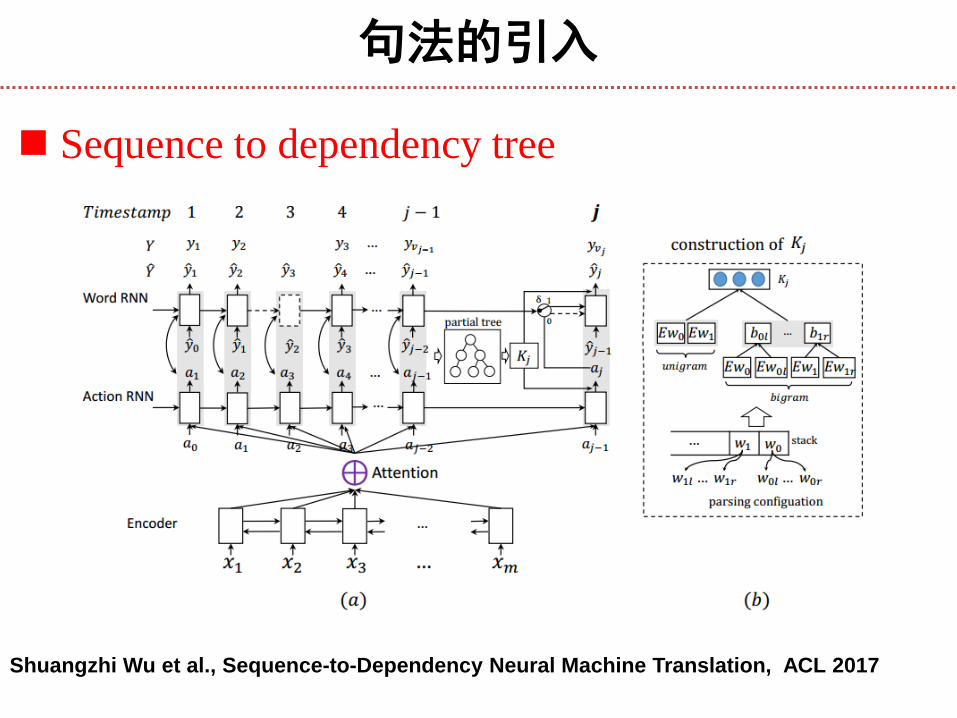
句法的引入
Shuangzhi Wu et al., Sequence-to-Dependency Neural Machine Translation, ACL 2017
Sequence to dependency tree
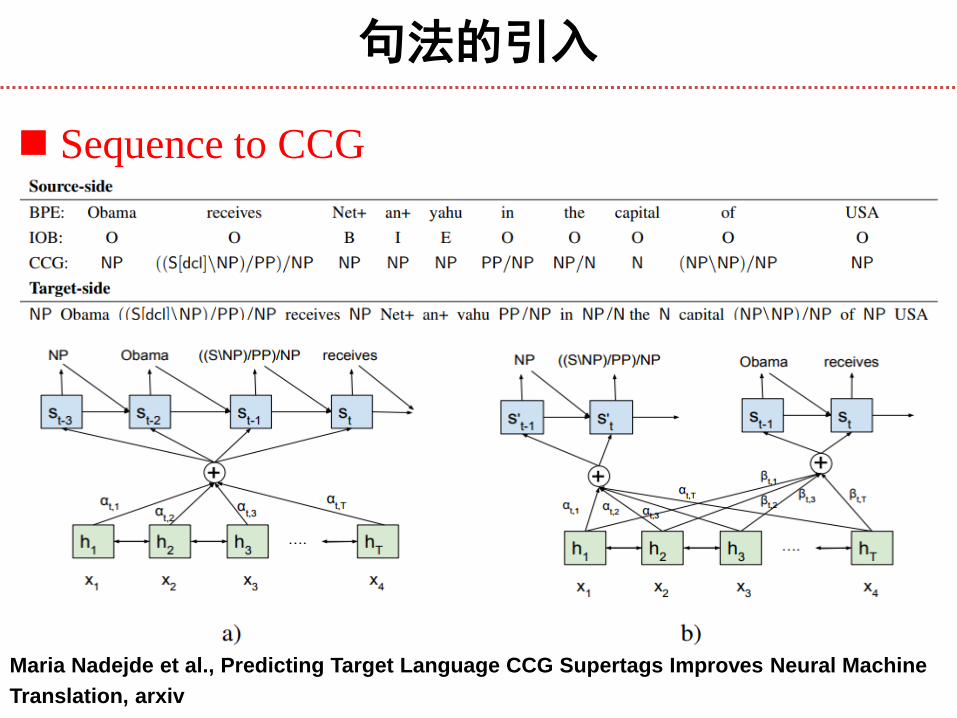
句法的引入
Maria Nadejde et al., Predicting Target Language CCG Supertags Improves Neural Machine
Translation, arxiv
Sequence to CCG
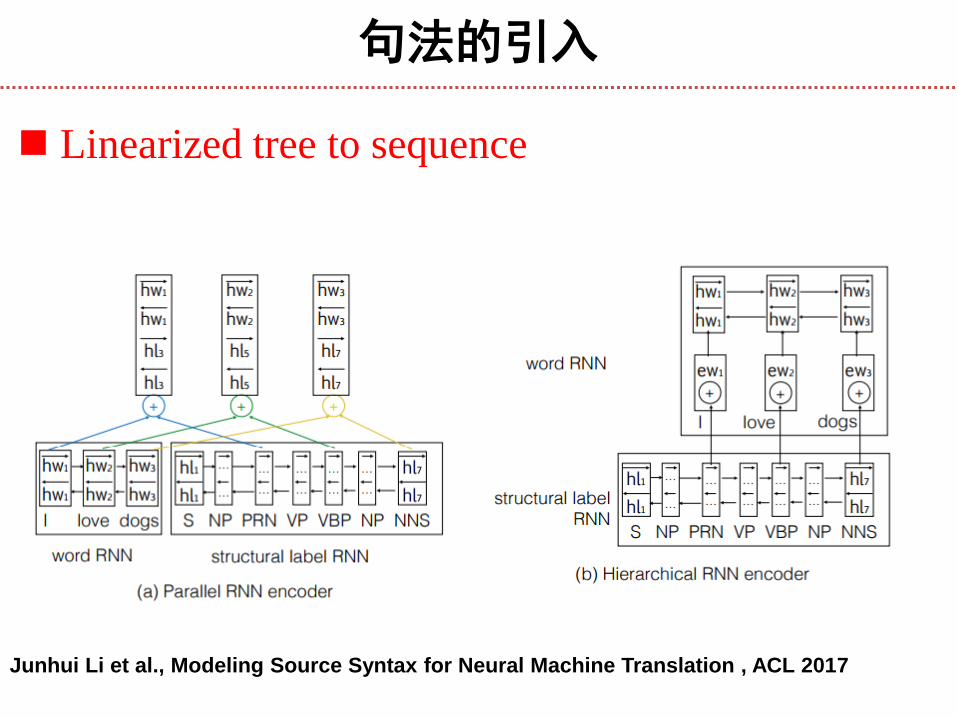
句法的引入
Junhui Li et al., Modeling Source Syntax for Neural Machine Translation , ACL 2017
Linearized tree to sequence
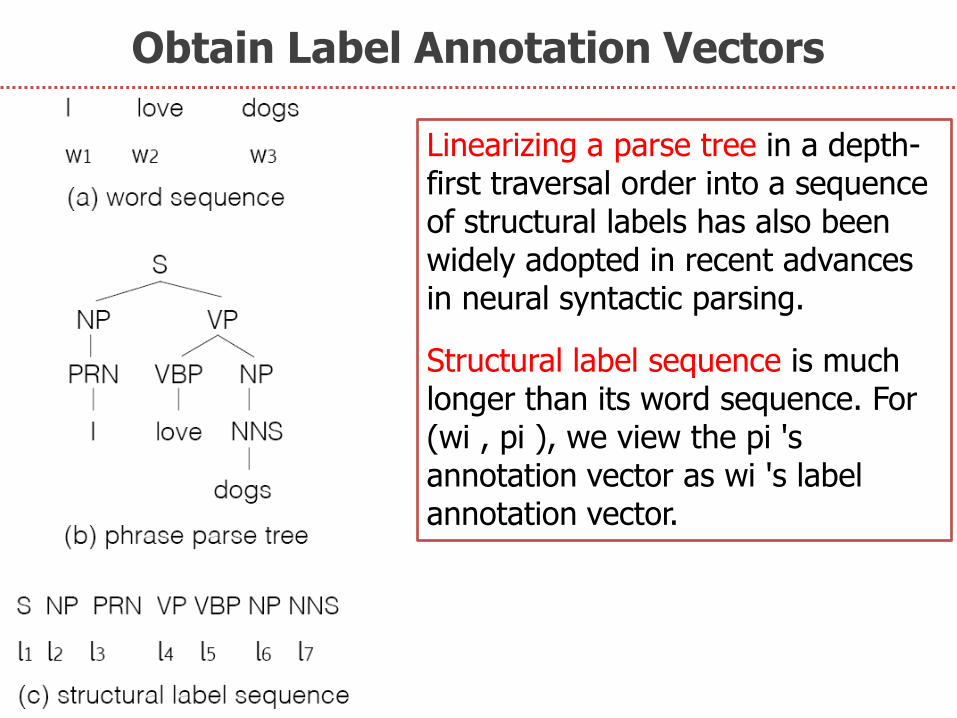
Obtain Label Annotation Vectors
Linearizing a parse tree in a depth-first traversal order into a sequence of structural labels has also been widely adopted in recent advances in neural syntactic parsing.
Structural label sequence is much longer than its word sequence. For (wi , pi ), we view the pi 's annotation vector as wi 's label annotation vector.
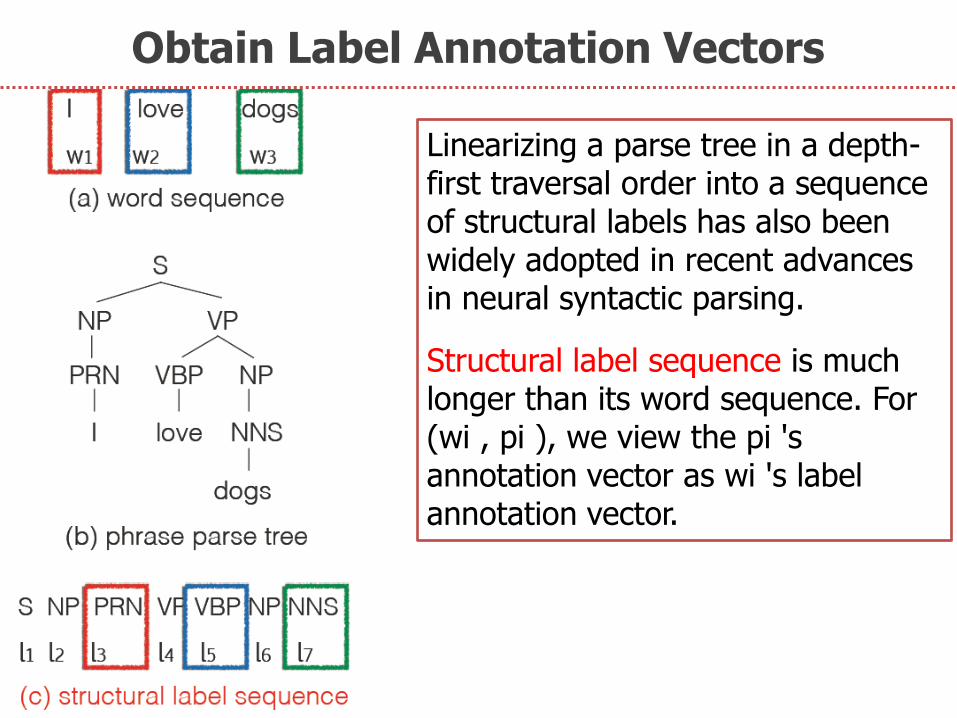
Obtain Label Annotation Vectors
Linearizing a parse tree in a depth-first traversal order into a sequence of structural labels has also been widely adopted in recent advances in neural syntactic parsing.
Structural label sequence is much longer than its word sequence. For (wi , pi ), we view the pi 's annotation vector as wi 's label annotation vector.

How to Use Label Annotation Vectors
Now, the input includes:
1. word sequence
2. structural label sequence
Next, we propose:
1. Parallel RNN Encoder
2. Hierarchical RNN Encoder
3. Mixed RNN Encoder
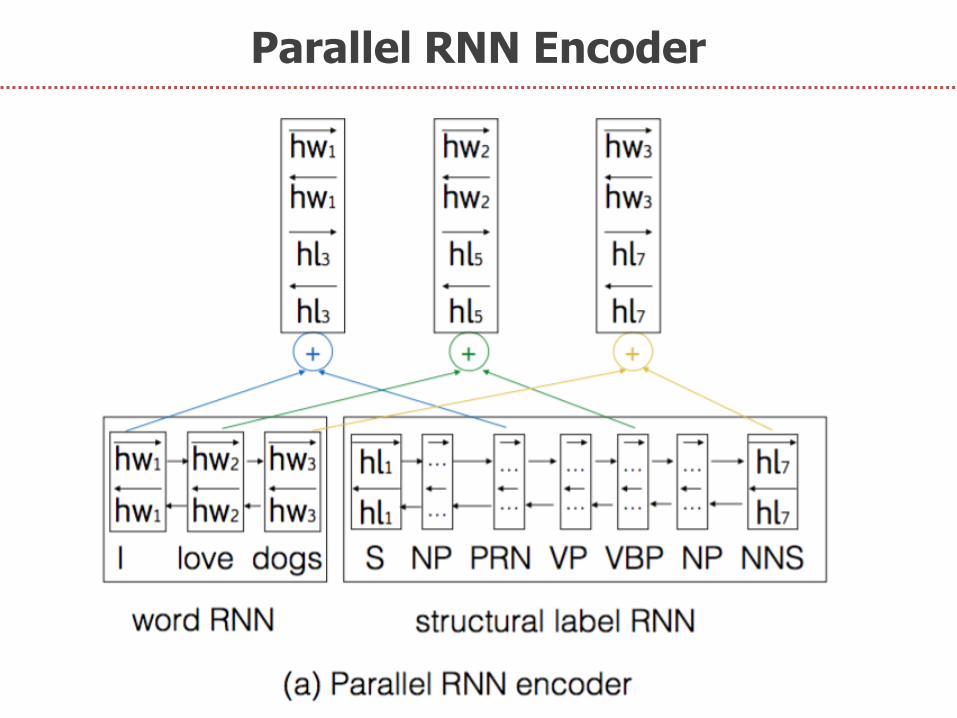
Parallel RNN Encoder
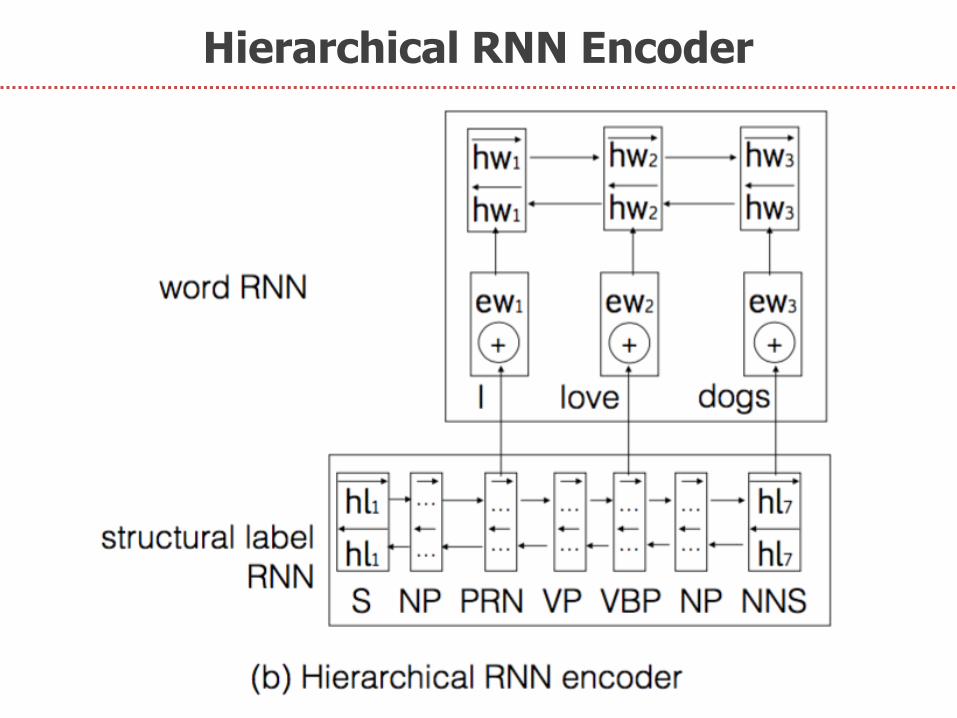
Hierarchical RNN Encoder
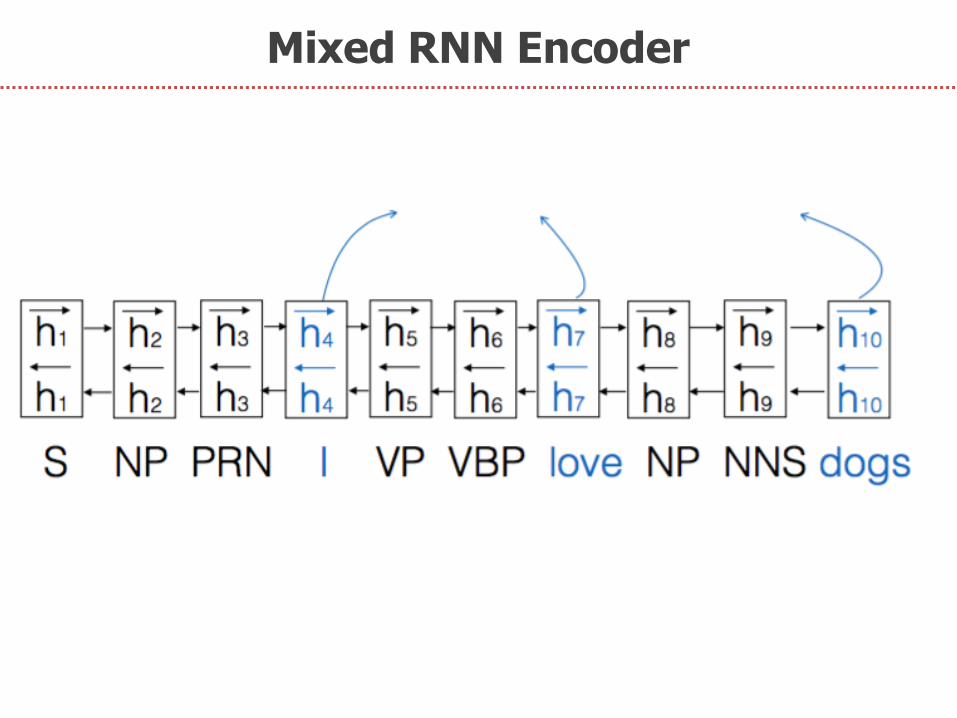
Mixed RNN Encoder
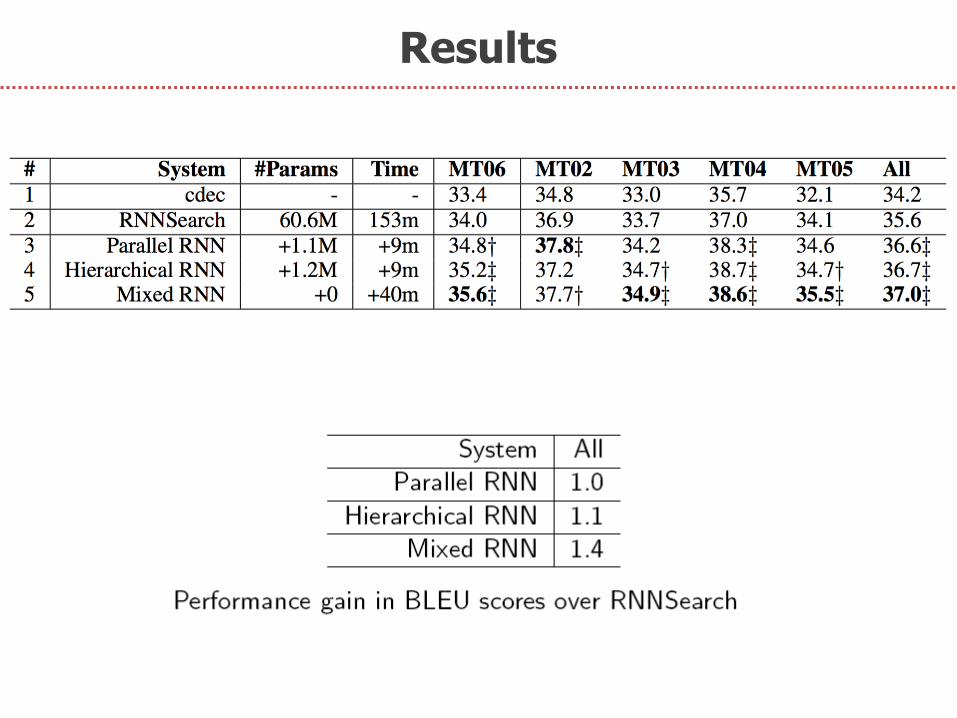
Results

Analysis
1. Effects on Long Sentences
2. Analysis on Word Alignment
3. Analysis on Phrase Alignment
4. Analysis on Over Translation
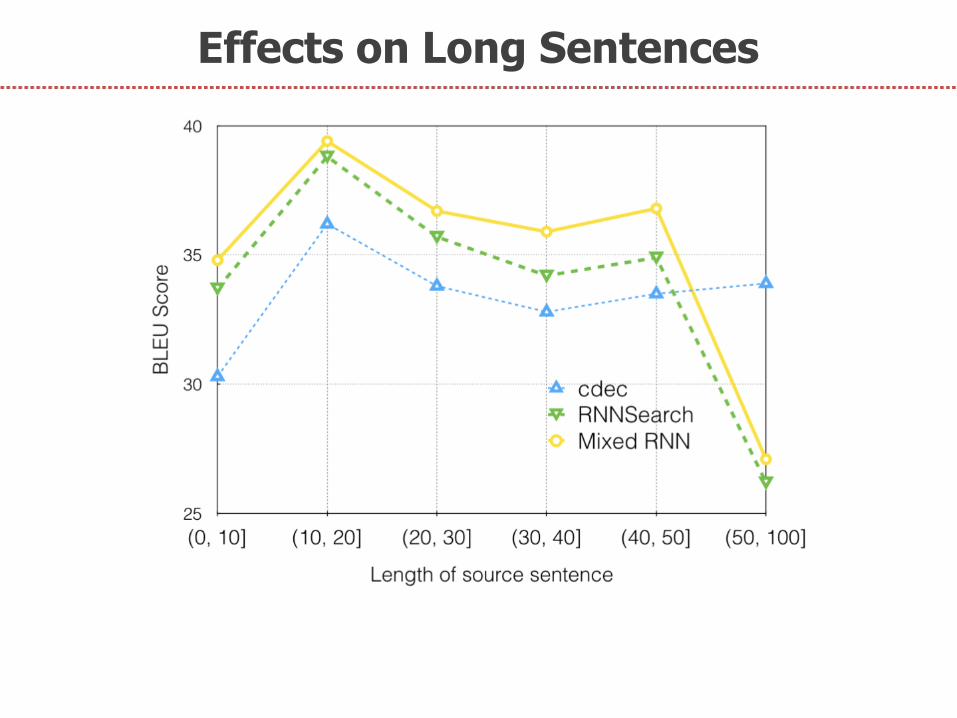
Effects on Long Sentences

Analysis on Word Alignment
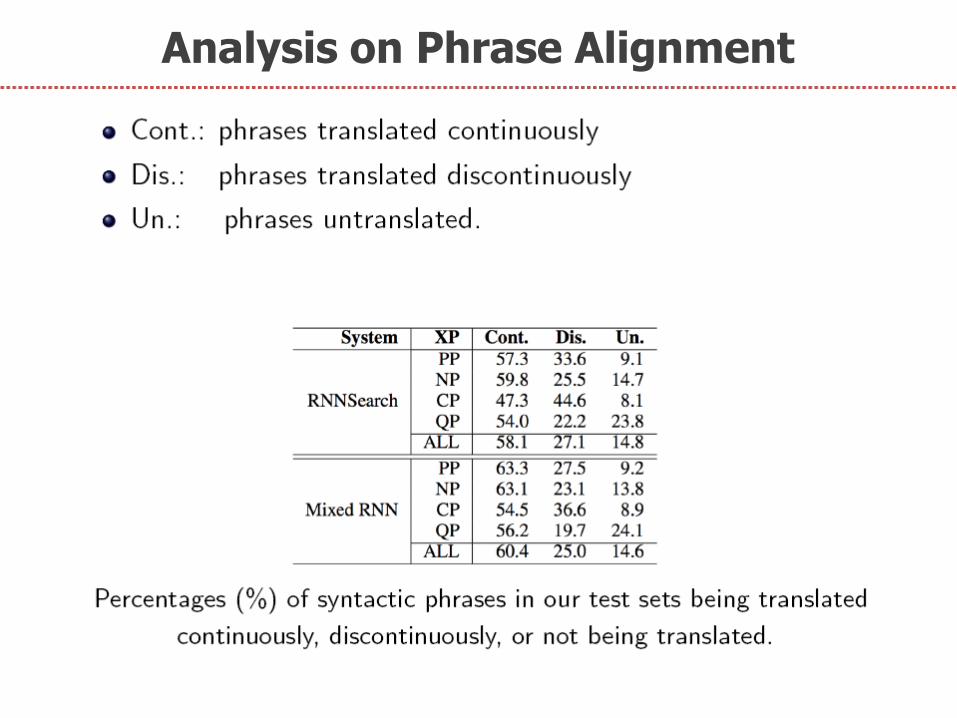
Analysis on Phrase Alignment

Analysis on Over Translation
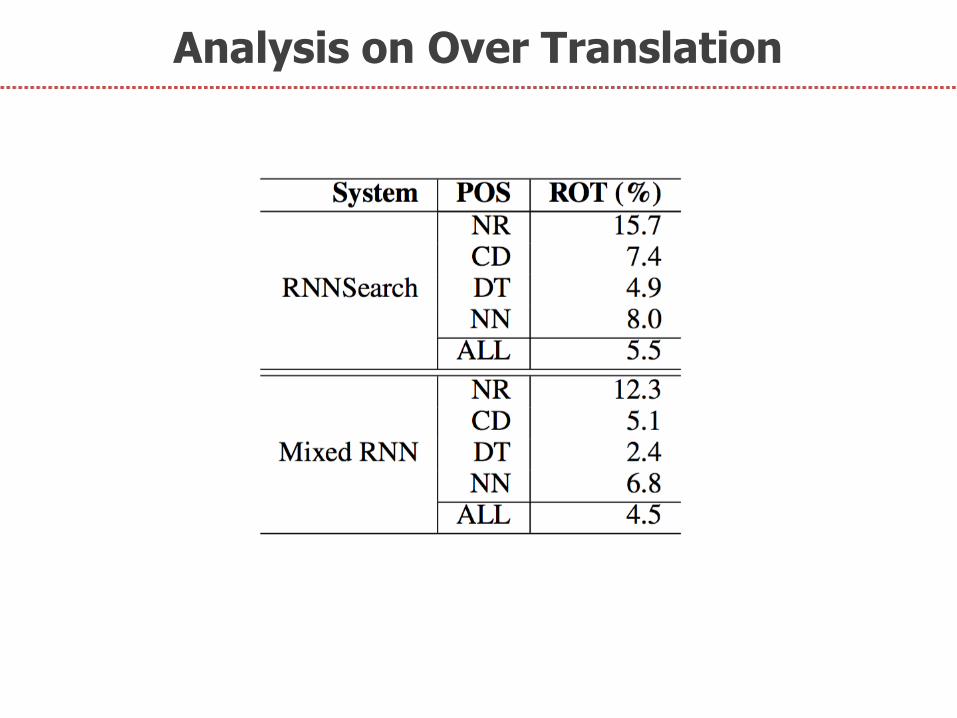
Analysis on Over Translation
source
semantics
target
semantics
interlingual
source
words
target
words
target
syntax
source
syntax
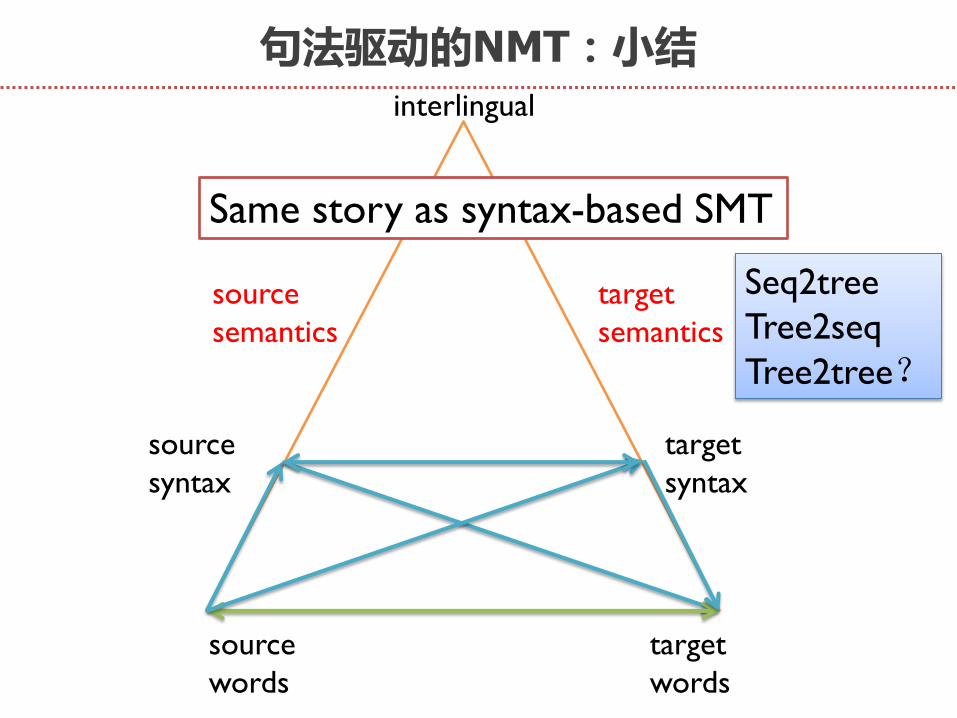
句法驱动的NMT:小结
Same story as syntax-based SMT
Seq2tree
Tree2seq
Tree2tree?

Part2
一. 句法驱动的神经机器翻译
二. 多语与多模态神经机器翻译
三. 面向资源稀缺语种的神经机器翻译
四. 神经机器翻译深度模型
五. 神经机器翻译新架构
六. 神经机器翻译未来发展方向

多语神经机器翻译:Why?
同一个网络模型用于多种语言翻译,更有利于实际翻译系统部署
多语的“多”巧用于:
不同语种间“信息”的复用,互相增强
实现Zero-Resource Translation
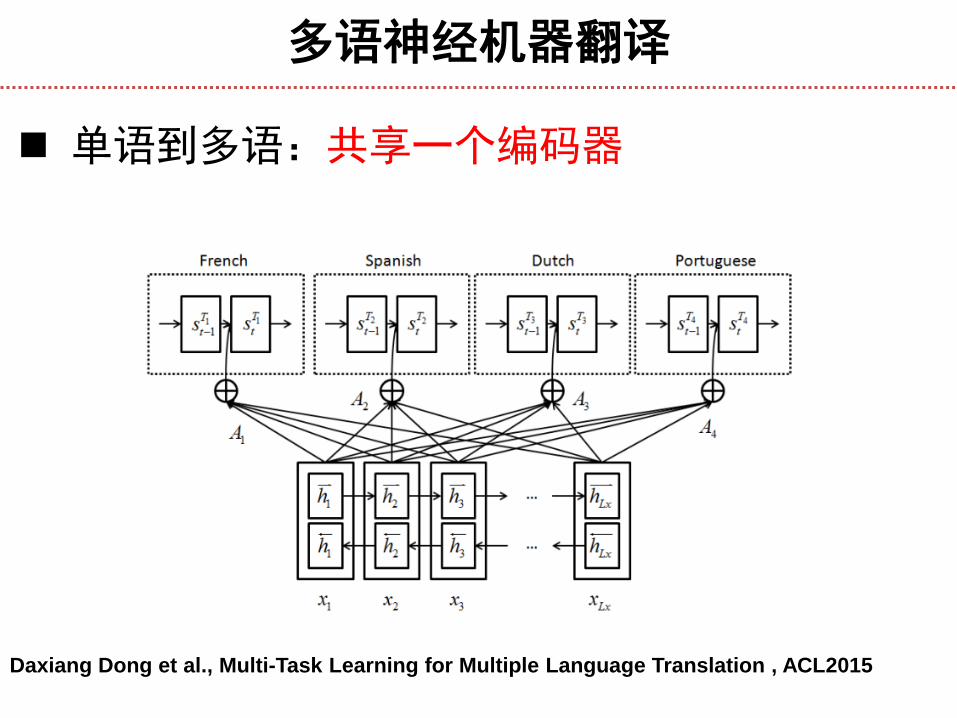
多语神经机器翻译
单语到多语:共享一个编码器
Daxiang Dong et al., Multi-Task Learning for Multiple Language Translation , ACL2015
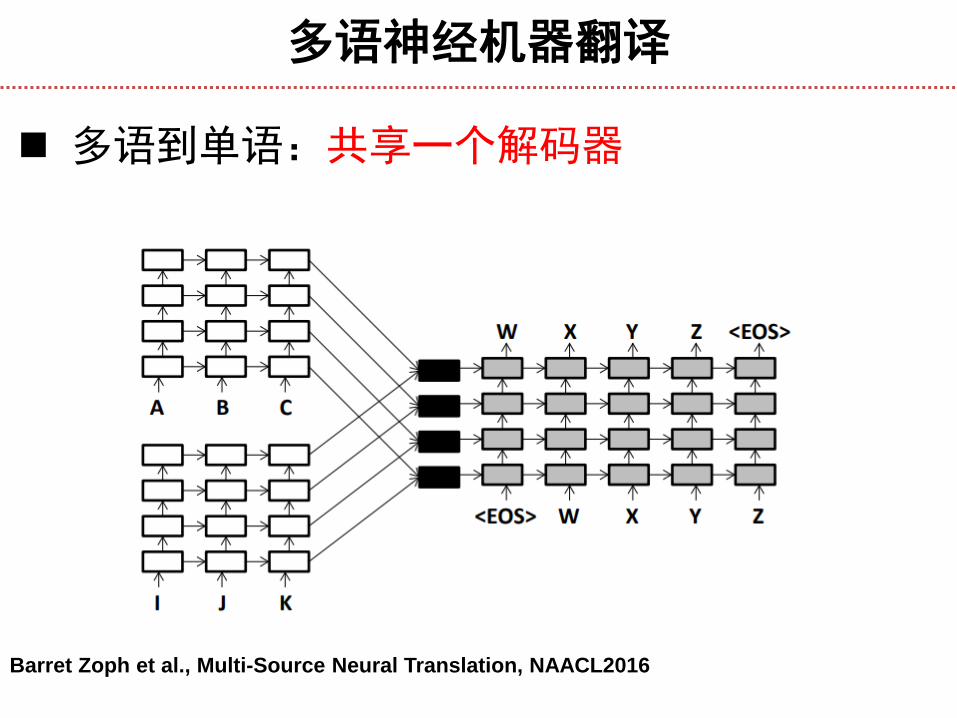
多语神经机器翻译
多语到单语:共享一个解码器
Barret Zoph et al., Multi-Source Neural Translation, NAACL2016
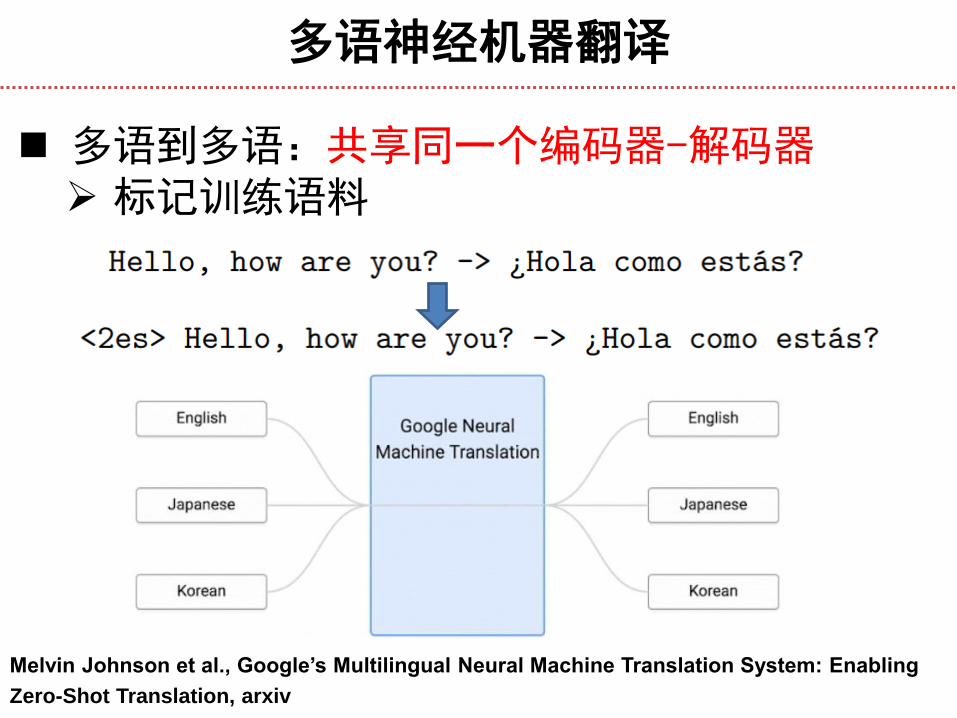
多语神经机器翻译
多语到多语:共享同一个编码器-解码器 标记训练语料
Melvin Johnson et al., Google’s Multilingual Neural Machine Translation System: Enabling
Zero-Shot Translation, arxiv
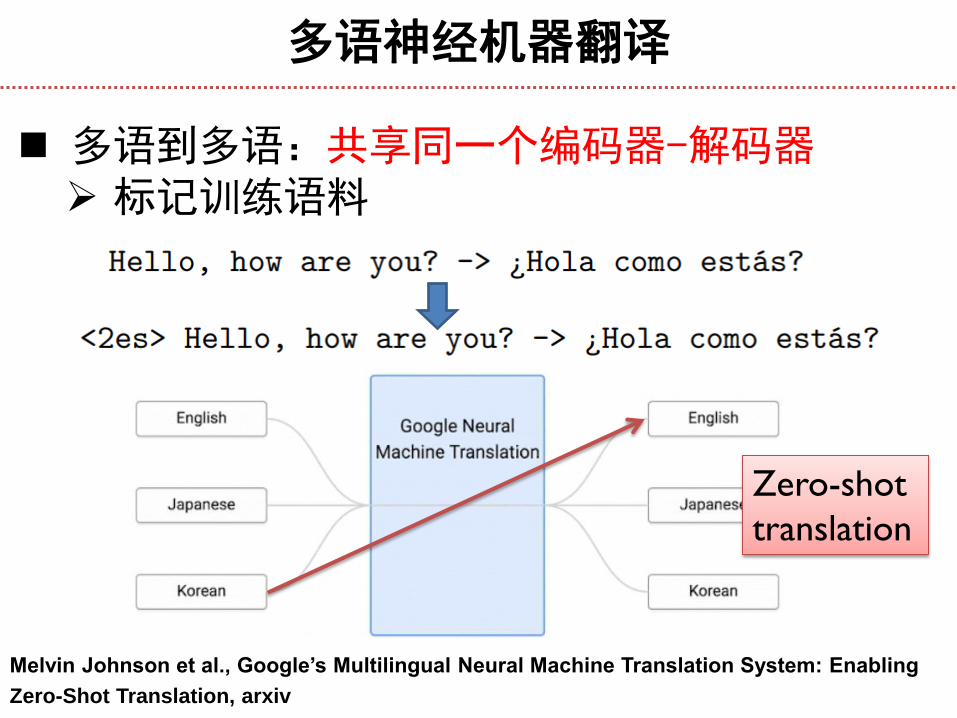
多语神经机器翻译
多语到多语:共享同一个编码器-解码器 标记训练语料
Melvin Johnson et al., Google’s Multilingual Neural Machine Translation System: Enabling
Zero-Shot Translation, arxiv
Zero-shot
translation

多模态神经机器翻译
多语神经机器翻译中
多源语言句子:一条语义信息由不同语种的文字信息展示
能否扩展为一条语义信息由不同模态(文字、图像、语音)形式进行展示?
多模态神经机器翻译
关键:如何引入图像/语音信息?
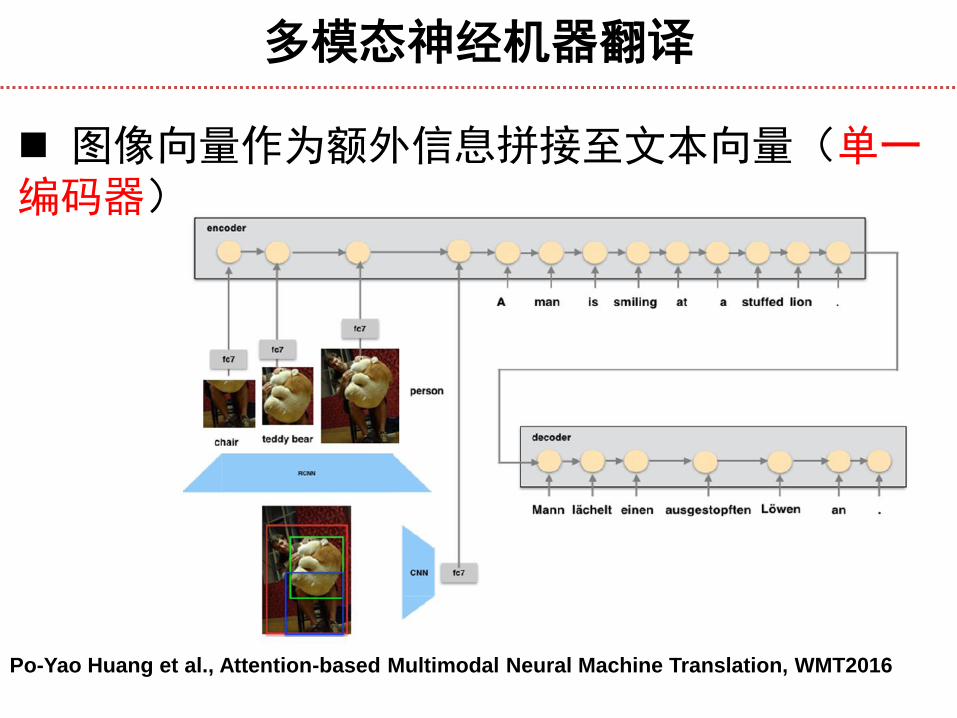
多模态神经机器翻译
图像向量作为额外信息拼接至文本向量(单一编码器)
Po-Yao Huang et al., Attention-based Multimodal Neural Machine Translation, WMT2016
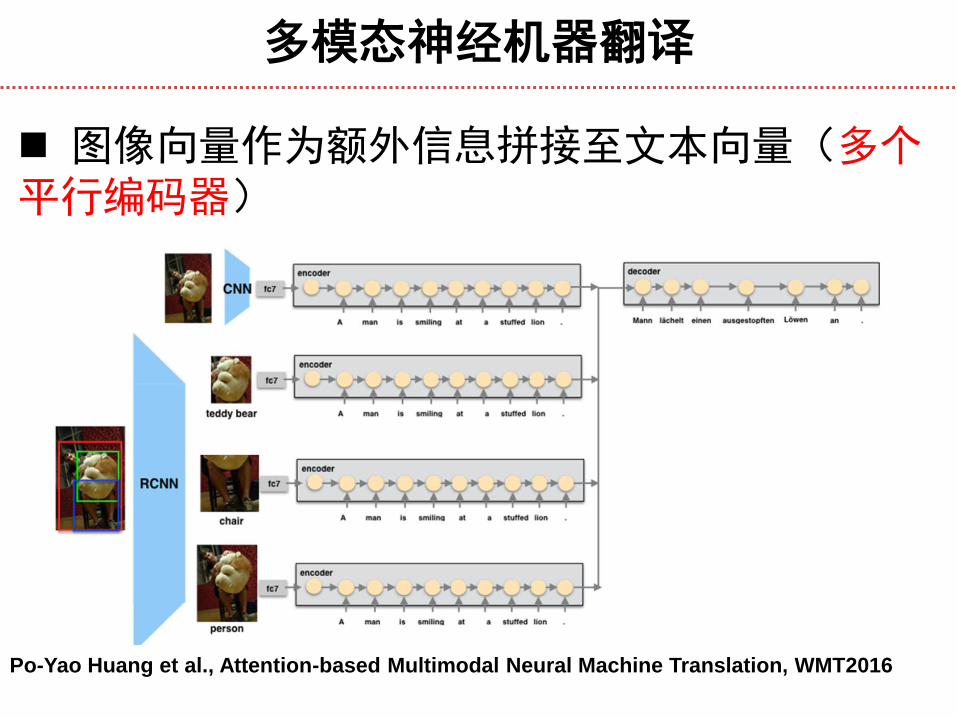
多模态神经机器翻译
图像向量作为额外信息拼接至文本向量(多个平行编码器)
Po-Yao Huang et al., Attention-based Multimodal Neural Machine Translation, WMT2016
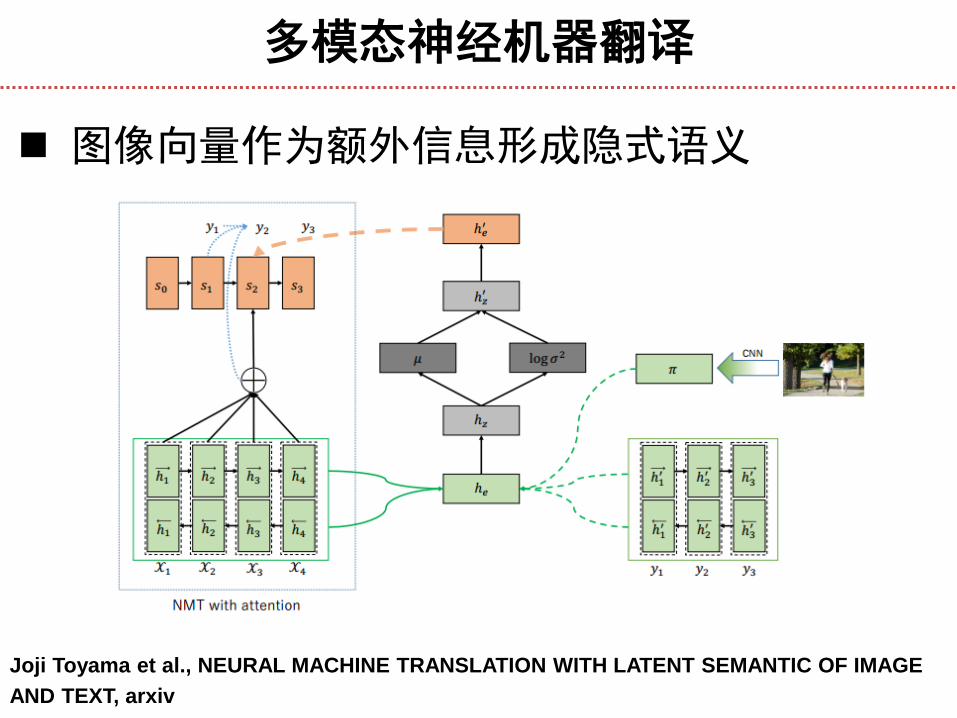
多模态神经机器翻译
图像向量作为额外信息形成隐式语义
Joji Toyama et al., NEURAL MACHINE TRANSLATION WITH LATENT SEMANTIC OF IMAGE
AND TEXT, arxiv
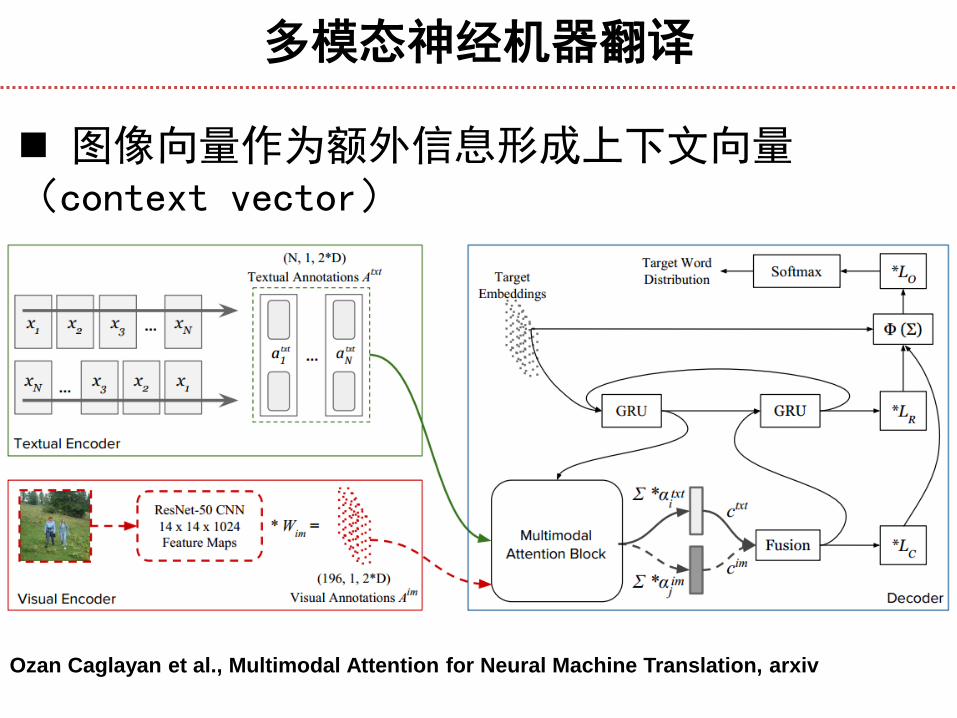
多模态神经机器翻译
图像向量作为额外信息形成上下文向量(context vector)
Ozan Caglayan et al., Multimodal Attention for Neural Machine Translation, arxiv
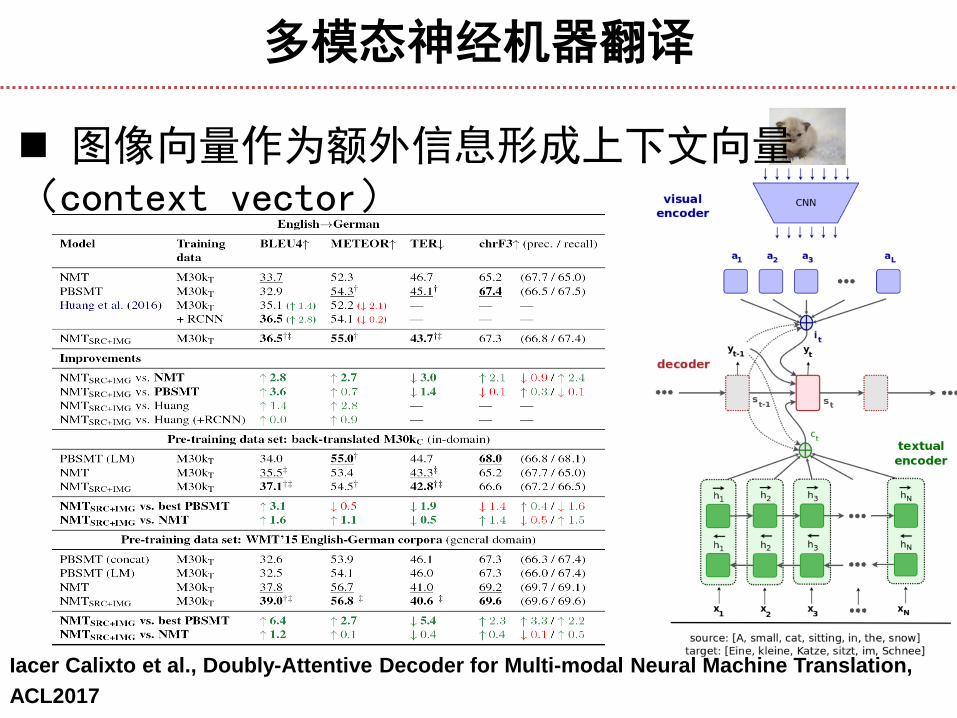
多模态神经机器翻译
Iacer Calixto et al., Doubly-Attentive Decoder for Multi-modal Neural Machine Translation,
ACL2017
图像向量作为额外信息形成上下文向量(context vector)

多语与多模态神经机器翻译:小结
多语NMT
1-to-m
m-to-1
m-to-m
多模态:图像
多语+多模态?
多模态:语音?
多语/多模态:迁移学习

Part2
一. 句法驱动的神经机器翻译
二. 多语与多模态神经机器翻译
三. 面向资源稀缺语种的神经机器翻译
四. 神经机器翻译深度模型
五. 神经机器翻译新架构
六. 神经机器翻译未来发展方向

资源稀缺语种翻译问题
目前的机器翻译都是基于数据驱动的
针对相同的解码算法,翻译结果好坏取决于平行语料的规模
对于常见的语言对(中文-英文),通过互联网可以获取大规模双语平行语料
对于大多数语言对(中文-泰文),仅存在少量双语平行语料,并不足以构建高质量翻译模型

中轴语:存在一种语言P,使得源语言-语言P、语言P-目的语之间均存在大量双语平行语料,则称该语言P为中轴语。
短语级中轴语翻译方法 在短语层面上先将源语言(Ls)短语翻译成中轴语(Lp),然后再把相应的中轴语短语翻译到目标语言(Lt),这样就得到了一个短语对在源语言和目标语言之间的翻译映射路径。
句子级中轴语翻译方法 给定一个输入句子,通过源语言-中轴语翻译系统翻译成n个中轴语句子,对于生成的每一个中轴语句子,通过中轴语-目标语翻译系统可以翻译成m个目标语句子,这样可以得到m*n个目标语翻译候选。
传统SMT中轴语方法

基于短语的中轴语翻译方法中的概率空间不统一的问题 将源语言-目标语的概率空间分割为源语言-中轴语与中轴语-目标语两个独立的概率空间,不符合机器翻译的实际情况的。
中轴语衔接能力问题 不存在能将所有互为翻译的源语言-中轴语-目标语短语对链接起来的中轴语,选择不同的中轴语对翻译结果有很大的差异。
噪声放大问题 由于源语言-中轴语及中轴语-目的语短语表中均存在噪声,因此通过合并两个噪声短语表所得到的源语言-目的语必然会存在更为严重的噪声问题。 针对这个问题主要处理方法是基于概率过滤,即删除短语表中概率值较低的短语对。
传统SMT中轴语方法的问题
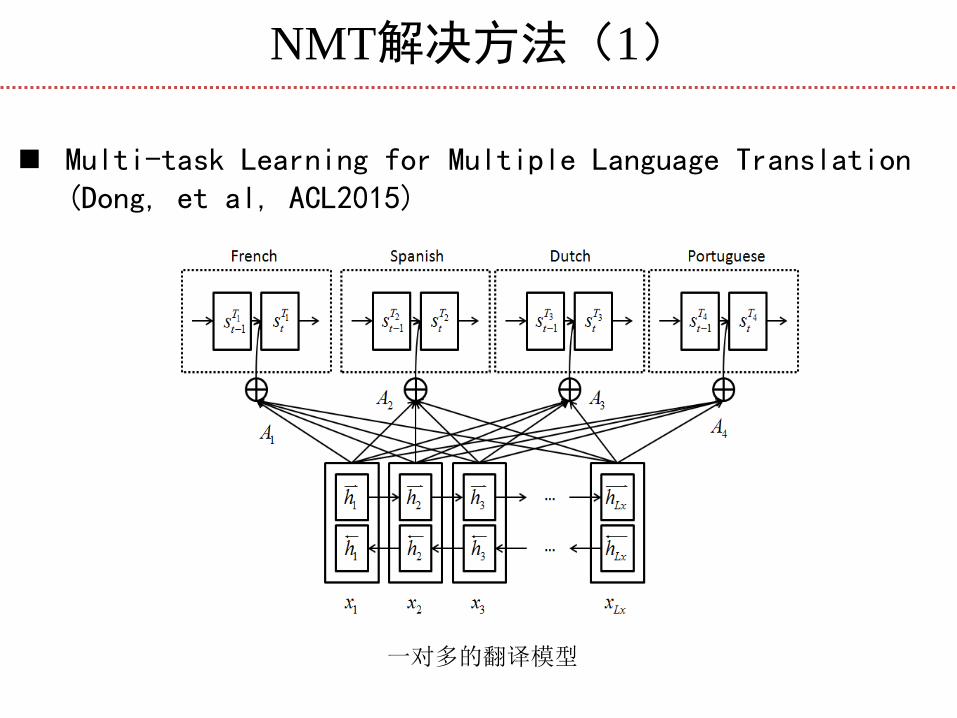
NMT解决方法(1)
Multi-task Learning for Multiple Language Translation (Dong, et al, ACL2015)
一对多的翻译模型
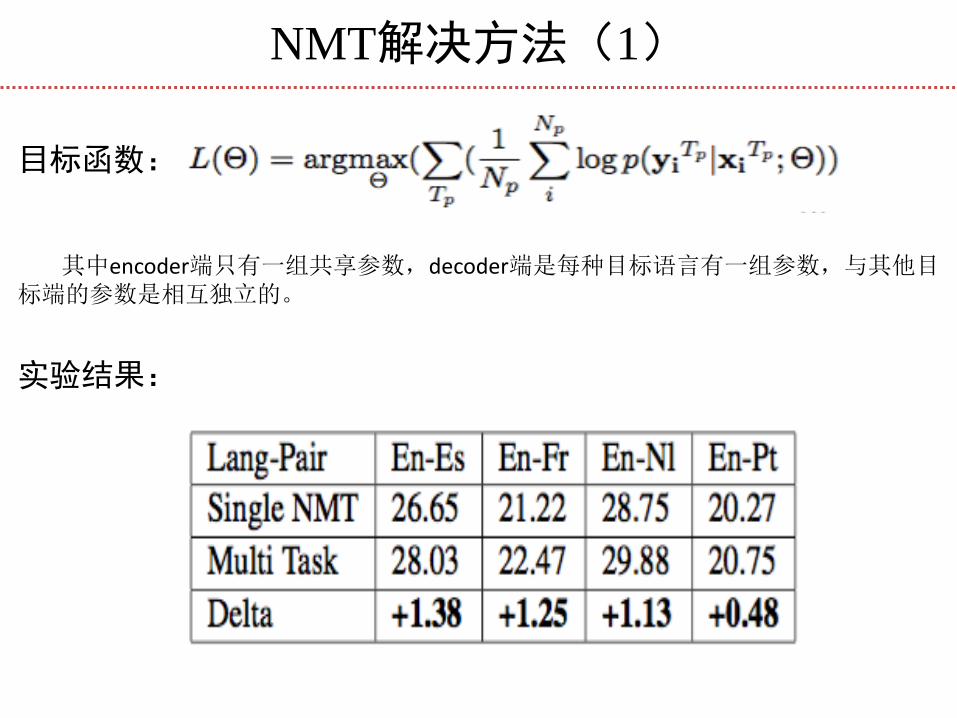
NMT解决方法(1)
目标函数:
其中encoder端只有一组共享参数,decoder端是每种目标语言有一组参数,与其他目标端的参数是相互独立的。
实验结果:
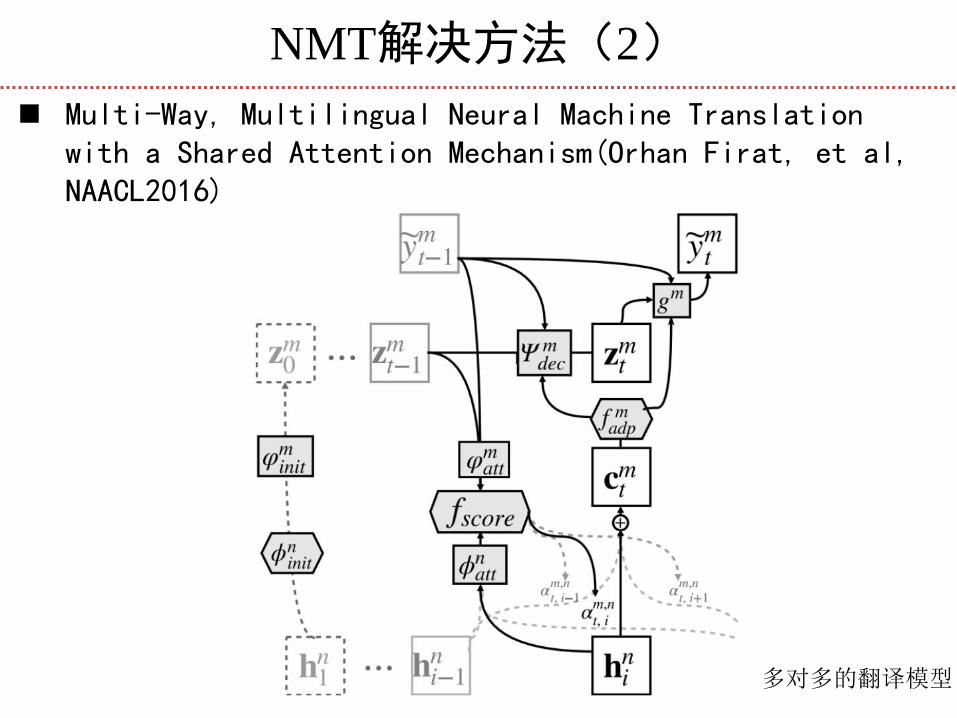
NMT解决方法(2)
Multi-Way, Multilingual Neural Machine Translation with a Shared Attention Mechanism(Orhan Firat, et al, NAACL2016)
多对多的翻译模型
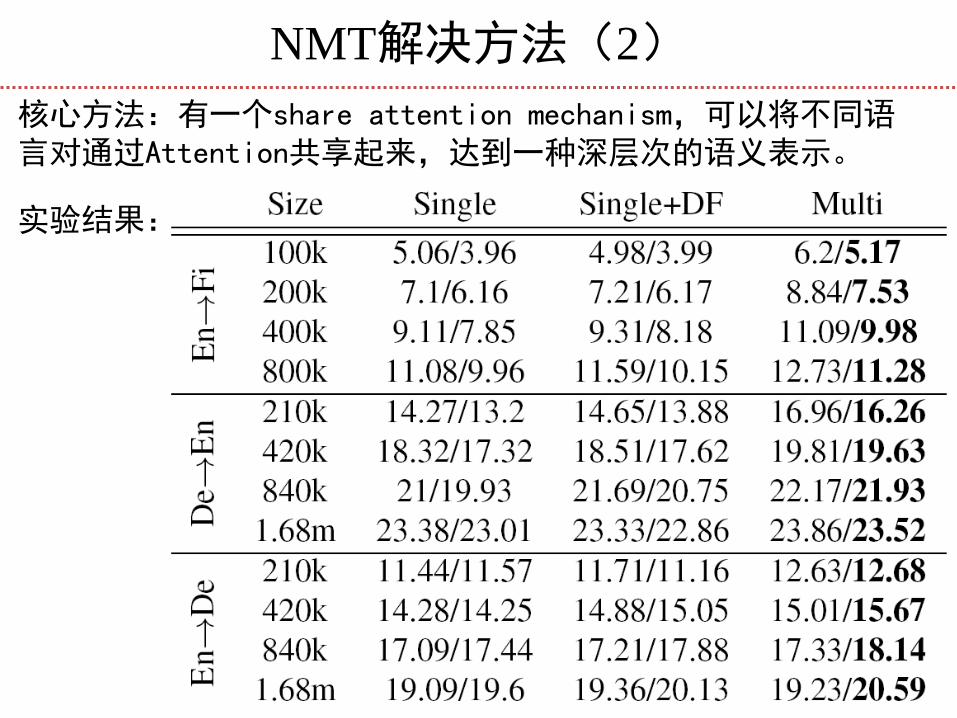
NMT解决方法(2)
核心方法:有一个share attention mechanism,可以将不同语言对通过Attention共享起来,达到一种深层次的语义表示。
实验结果:

NMT解决方法(3)
Zero-Resource Translation with with Multi-Lingual Neural Machine Translation(Orhan Firat, et al, EMNLP2016)
核心方法:基于上一篇文章的结构修改两个地方,分别为 early average和late average
Early Average:在两种翻译同时进行的情况下,上下文向量c则为:
相应得decoder端得隐层向量为:
NMT解决方法(3)
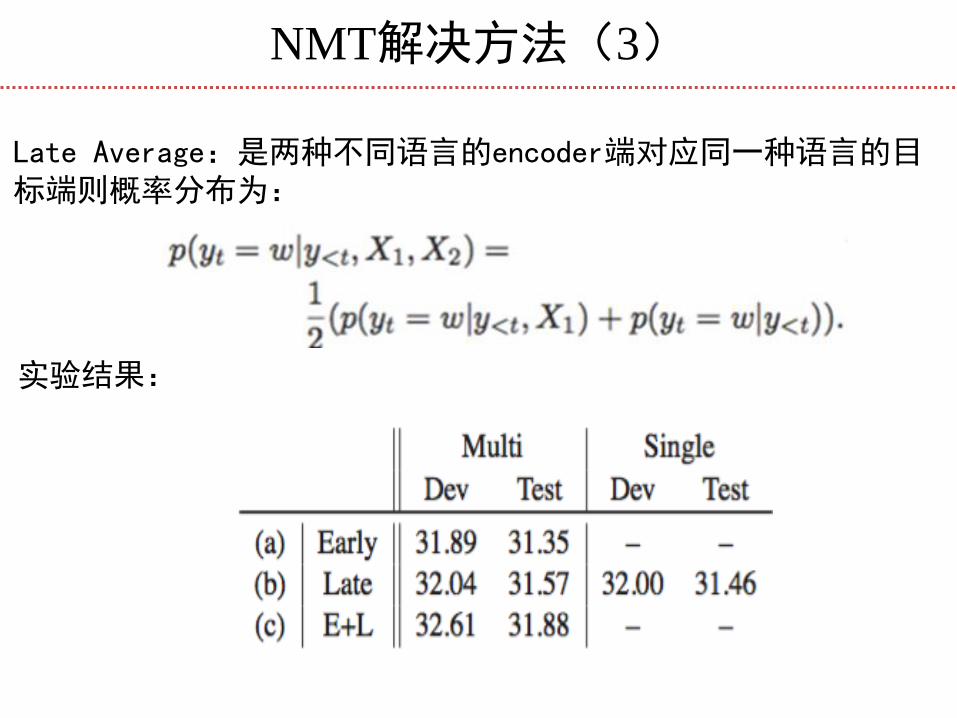
实验结果:
Late Average:是两种不同语言的encoder端对应同一种语言的目标端则概率分布为:
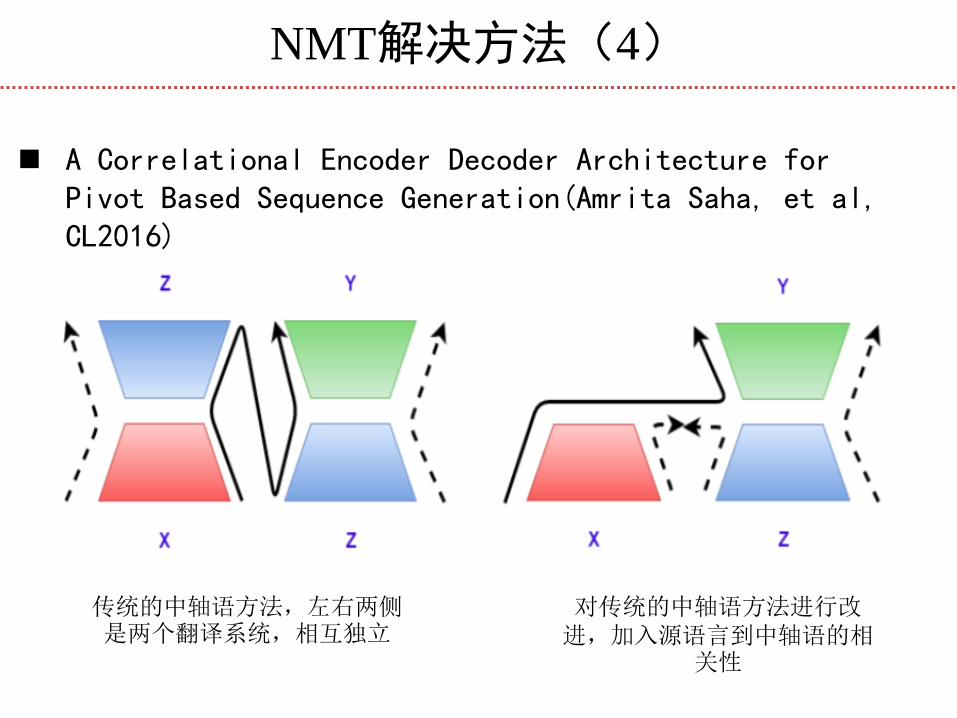
NMT解决方法(4)
A Correlational Encoder Decoder Architecture for Pivot Based Sequence Generation(Amrita Saha, et al, CL2016)
对传统的中轴语方法进行改进,加入源语言到中轴语的相
关性
传统的中轴语方法,左右两侧是两个翻译系统,相互独立
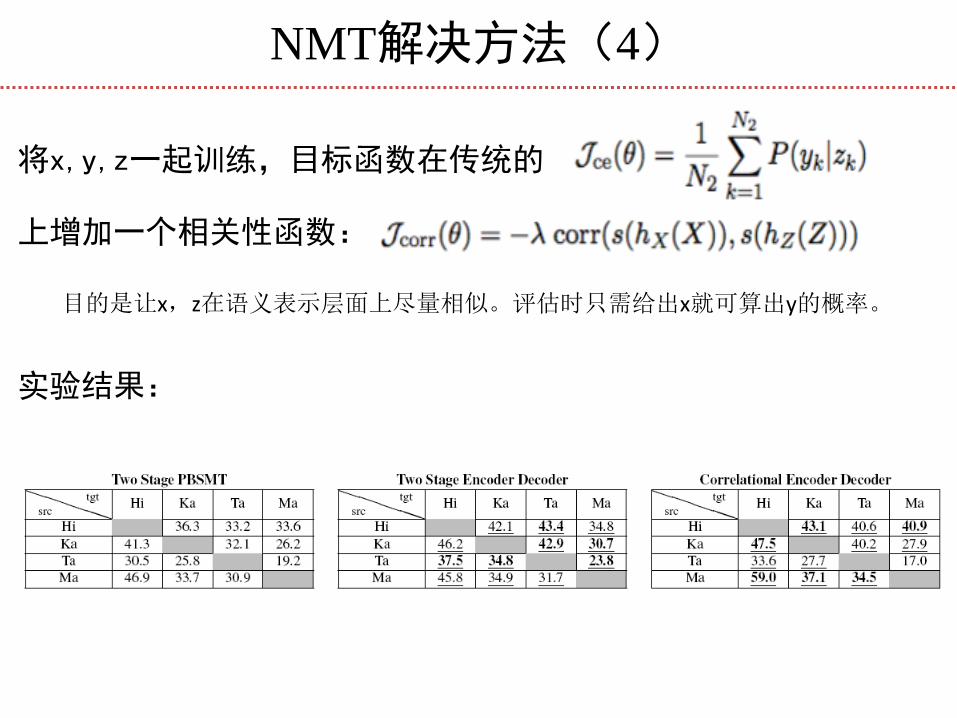
NMT解决方法(4)
将x,y,z一起训练,目标函数在传统的
目的是让x,z在语义表示层面上尽量相似。评估时只需给出x就可算出y的概率。
实验结果:
上增加一个相关性函数:
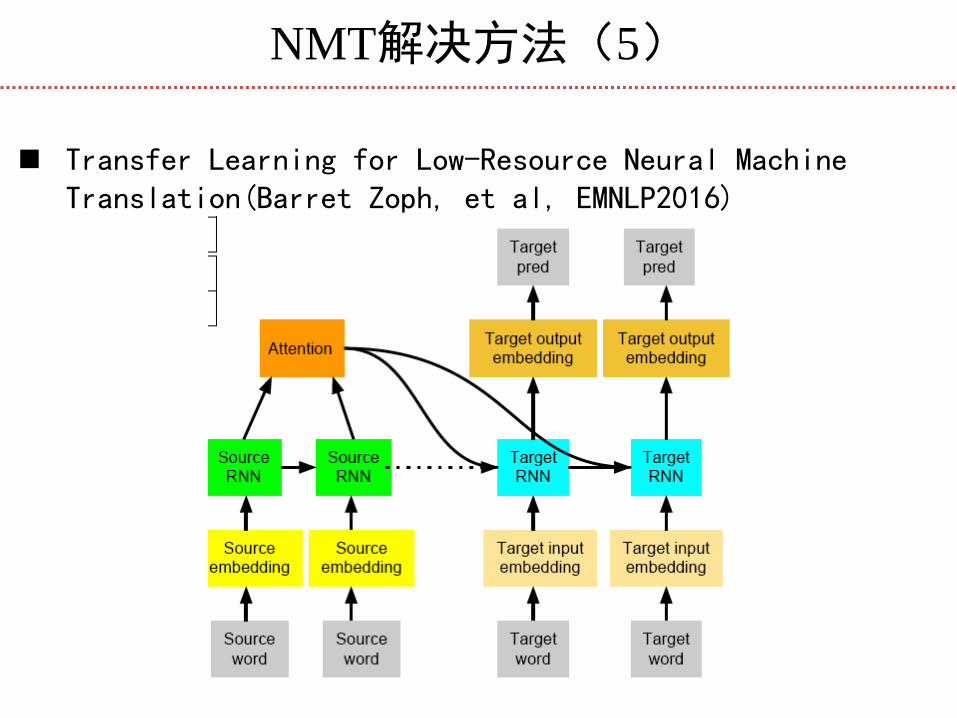
NMT解决方法(5)
Transfer Learning for Low-Resource Neural Machine Translation(Barret Zoph, et al, EMNLP2016)
Attention NMT Model
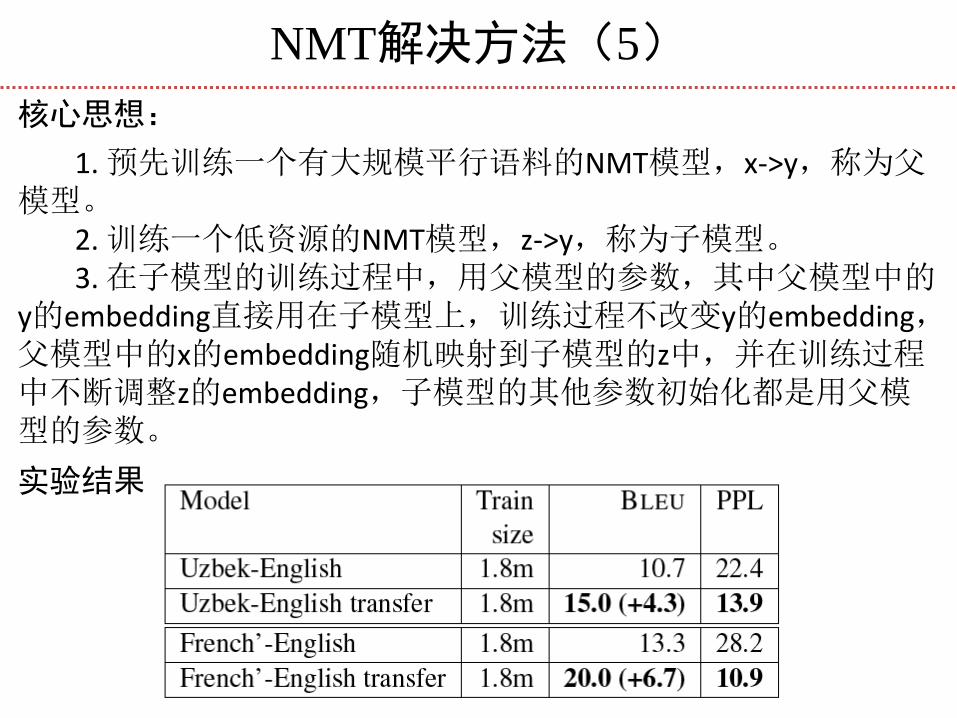
NMT解决方法(5)
核心思想:
1. 预先训练一个有大规模平行语料的NMT模型,x->y,称为父模型。 2. 训练一个低资源的NMT模型,z->y,称为子模型。 3. 在子模型的训练过程中,用父模型的参数,其中父模型中的y的embedding直接用在子模型上,训练过程不改变y的embedding,父模型中的x的embedding随机映射到子模型的z中,并在训练过程中不断调整z的embedding,子模型的其他参数初始化都是用父模型的参数。
实验结果:
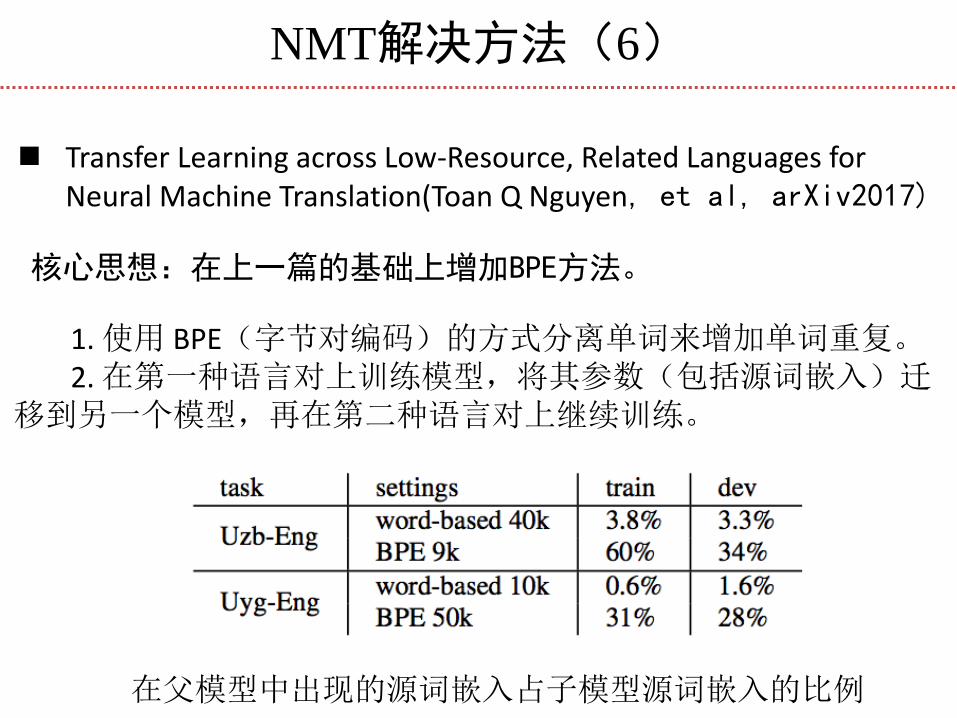
NMT解决方法(6)
Transfer Learning across Low-Resource, Related Languages for Neural Machine Translation(Toan Q Nguyen, et al, arXiv2017)
核心思想:在上一篇的基础上增加BPE方法。
1. 使用 BPE(字节对编码)的方式分离单词来增加单词重复。 2. 在第一种语言对上训练模型,将其参数(包括源词嵌入)迁移到另一个模型,再在第二种语言对上继续训练。
在父模型中出现的源词嵌入占子模型源词嵌入的比例
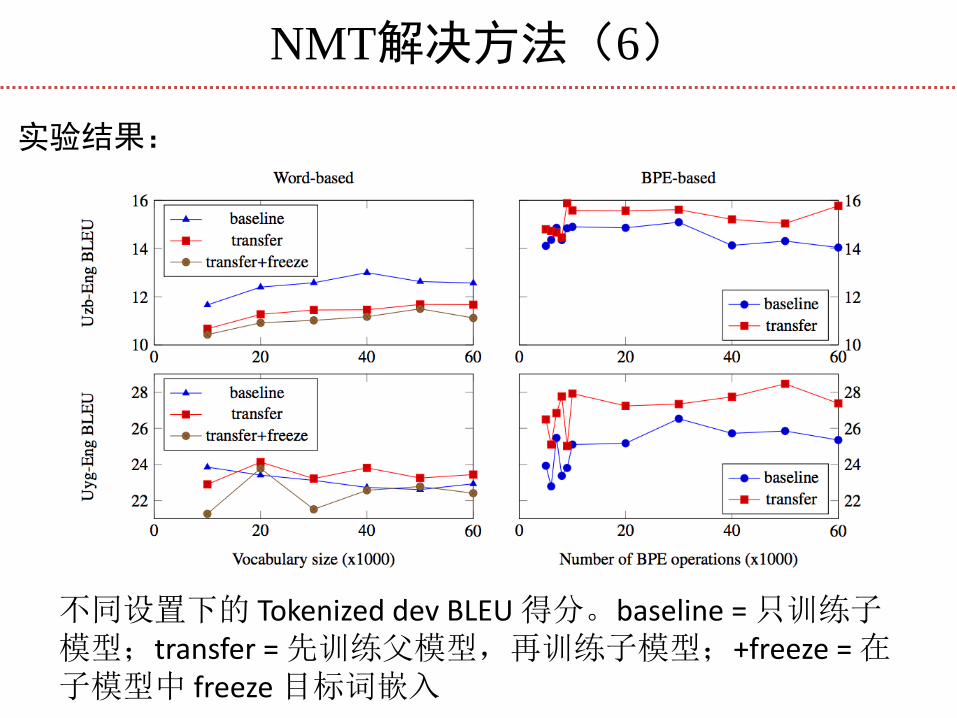
NMT解决方法(6)
实验结果:
不同设置下的 Tokenized dev BLEU 得分。baseline = 只训练子模型;transfer = 先训练父模型,再训练子模型;+freeze = 在子模型中 freeze 目标词嵌入

Part2
一. 句法驱动的神经机器翻译
二. 多语与多模态神经机器翻译
三. 面向资源稀缺语种的神经机器翻译
四. 神经机器翻译深度模型
五. 神经机器翻译新架构
六. 神经机器翻译未来发展方向
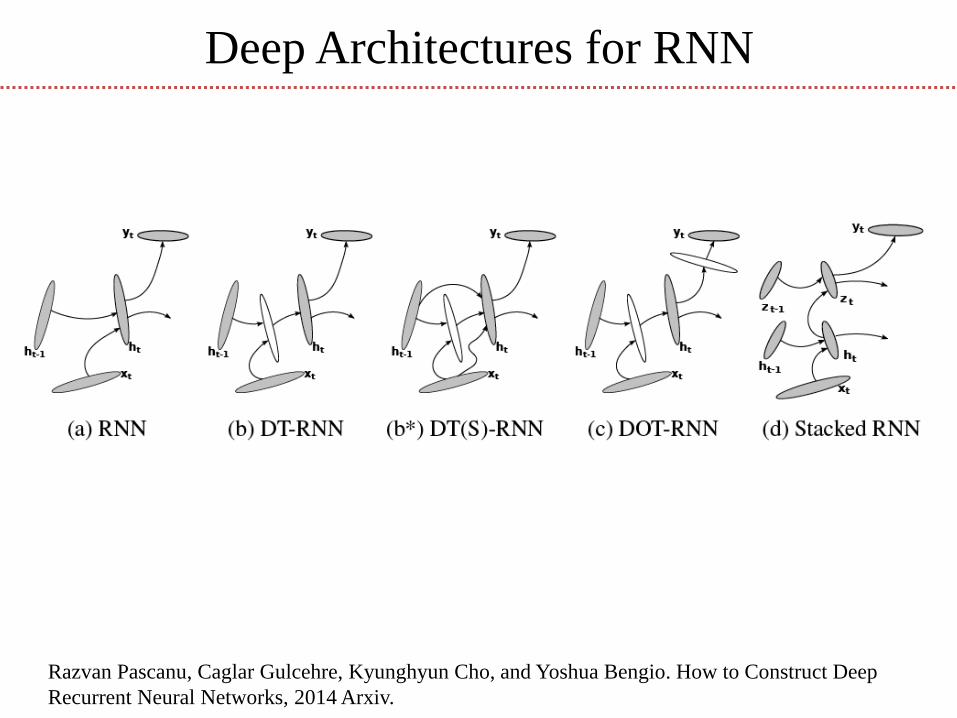
Deep Architectures for RNN
Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, and Yoshua Bengio. How to Construct Deep
Recurrent Neural Networks, 2014 Arxiv.

Deep Transition Architectures
Deep Transition Encoder:
Antonio, Jindˇrich Helcl, Rico Sennrich. Deep Architectures for Neural Machine Translation, 2017.
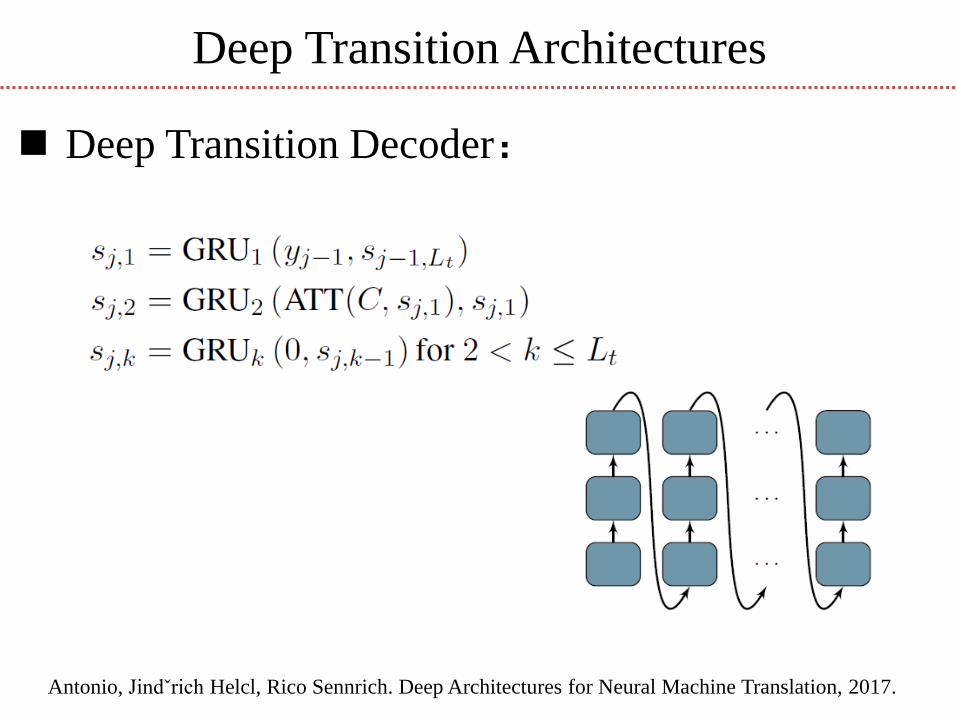
Deep Transition Architectures
Deep Transition Decoder:
Antonio, Jindˇrich Helcl, Rico Sennrich. Deep Architectures for Neural Machine Translation, 2017.
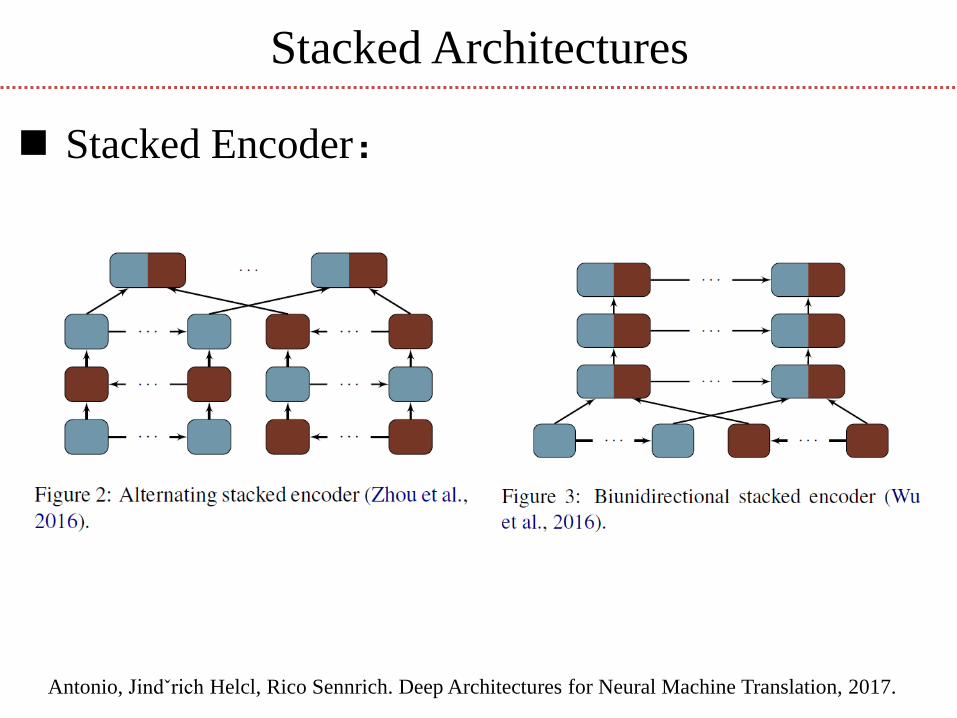
Stacked Architectures
Stacked Encoder:
Antonio, Jindˇrich Helcl, Rico Sennrich. Deep Architectures for Neural Machine Translation, 2017.
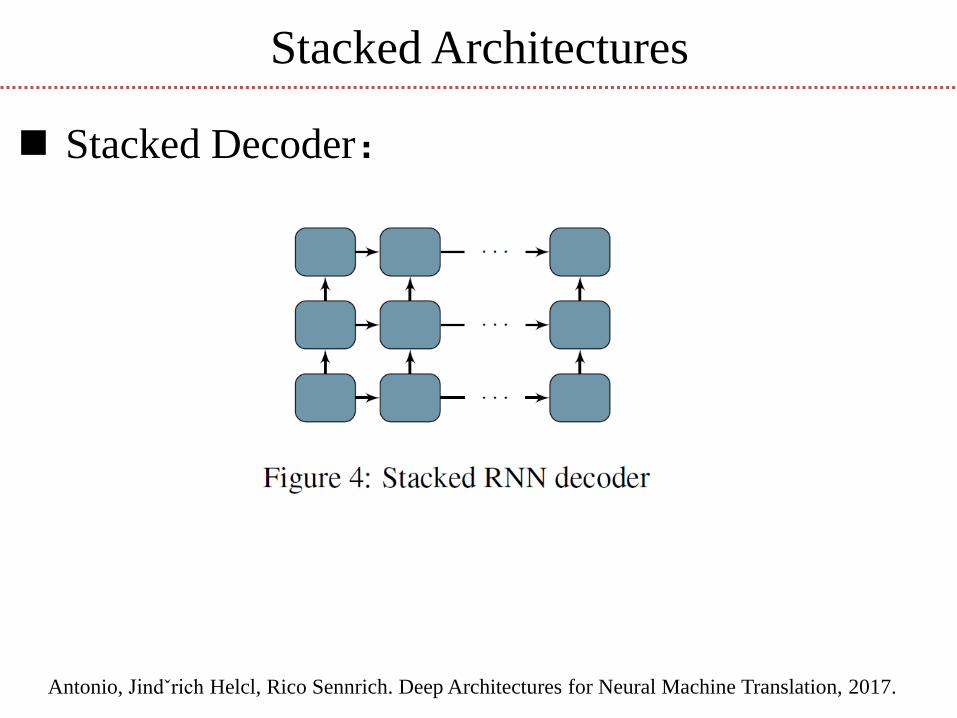
Stacked Architectures
Stacked Decoder:
Antonio, Jindˇrich Helcl, Rico Sennrich. Deep Architectures for Neural Machine Translation, 2017.
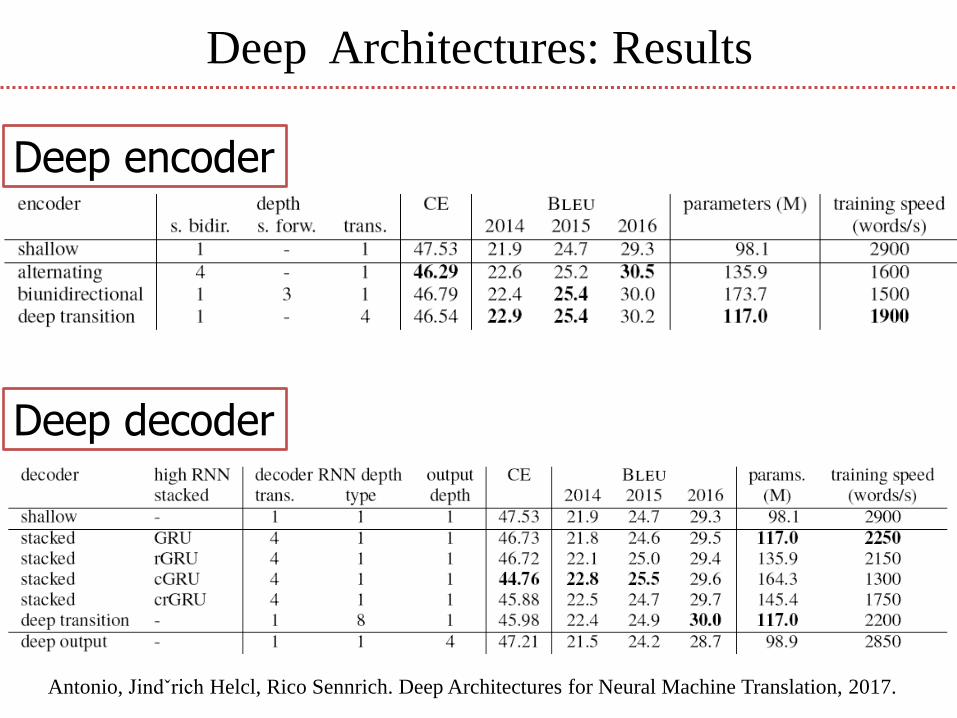
Deep Architectures: Results
Antonio, Jindˇrich Helcl, Rico Sennrich. Deep Architectures for Neural Machine Translation, 2017.
Deep encoder
Deep decoder
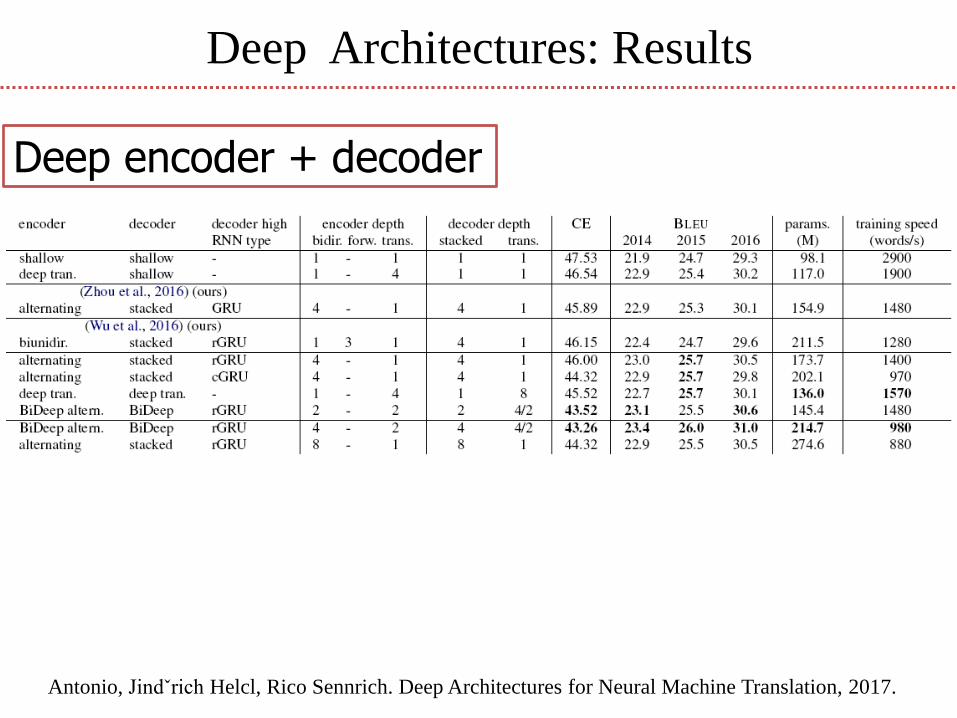
Deep Architectures: Results
Antonio, Jindˇrich Helcl, Rico Sennrich. Deep Architectures for Neural Machine Translation, 2017.
Deep encoder + decoder

Recurrent Units for Deep NMT
Recurrent Layers
Gated Recurrent Unit
Linear Associative Unit
MingxuanWang. Deep Neural Machine Translation with Linear Associative Unit, 2017.
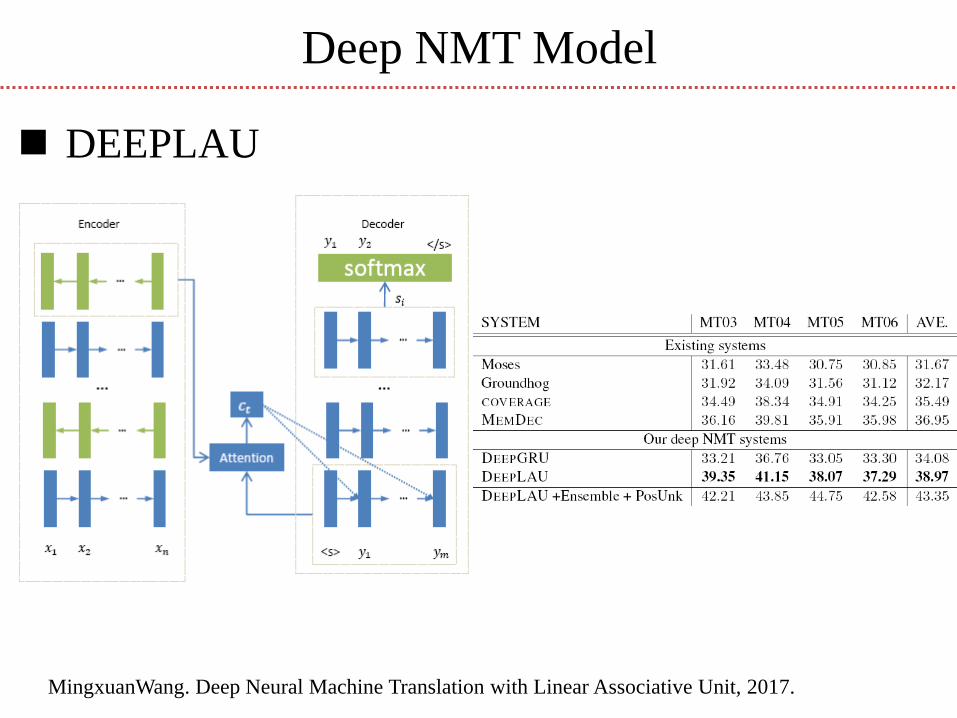
Deep NMT Model
DEEPLAU
MingxuanWang. Deep Neural Machine Translation with Linear Associative Unit, 2017.
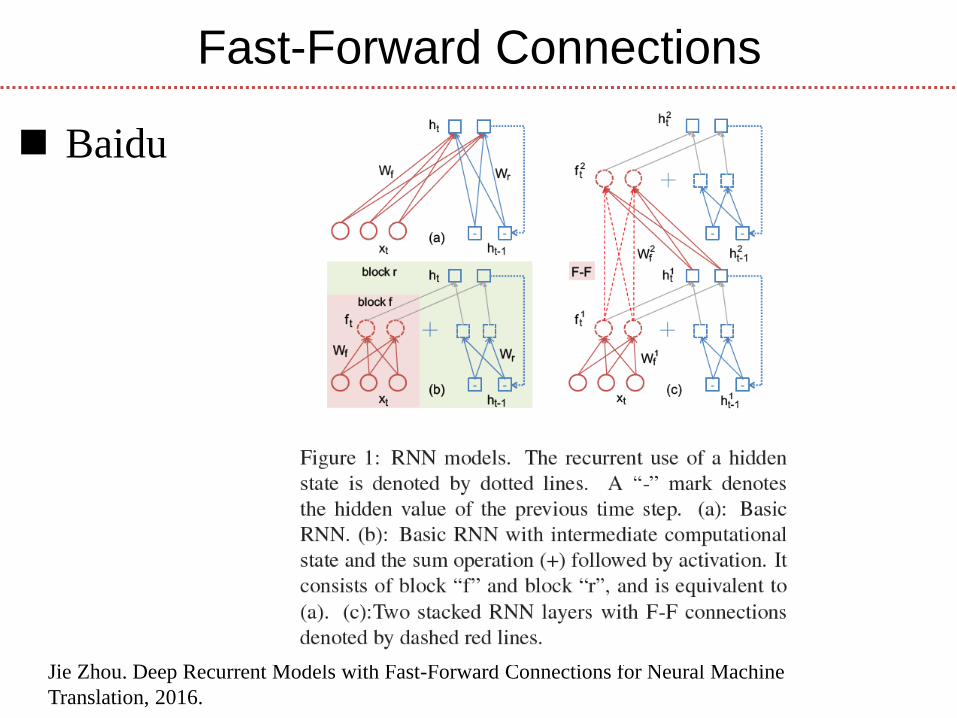
Fast-Forward Connections
Jie Zhou. Deep Recurrent Models with Fast-Forward Connections for Neural Machine
Translation, 2016.
Baidu
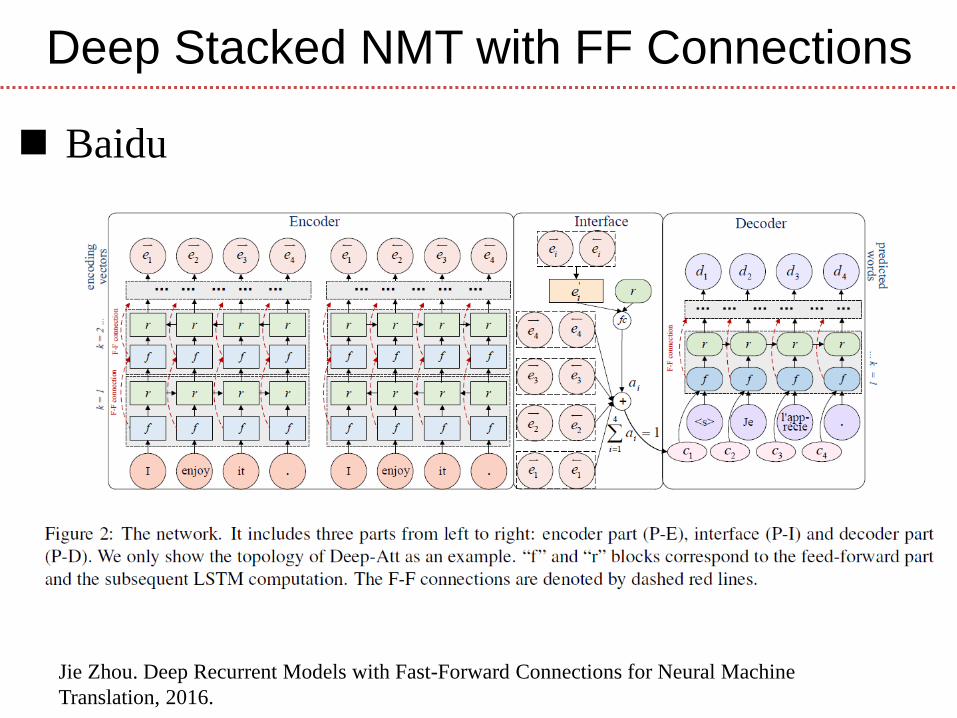
Deep Stacked NMT with FF Connections
Jie Zhou. Deep Recurrent Models with Fast-Forward Connections for Neural Machine
Translation, 2016.
Baidu
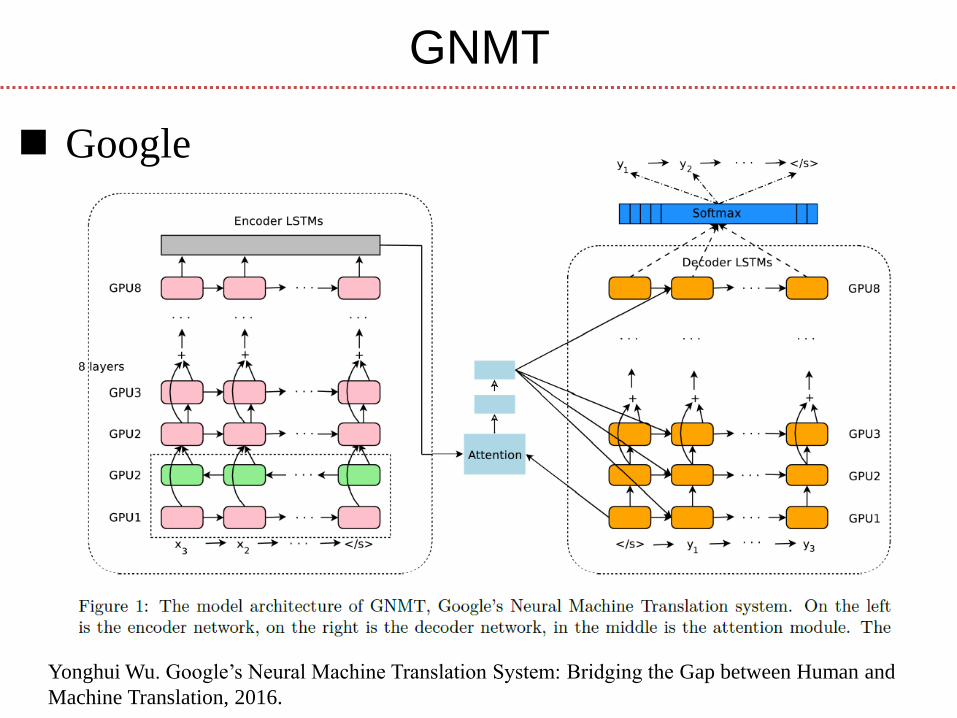
GNMT
Yonghui Wu. Google’s Neural Machine Translation System: Bridging the Gap between Human and
Machine Translation, 2016.
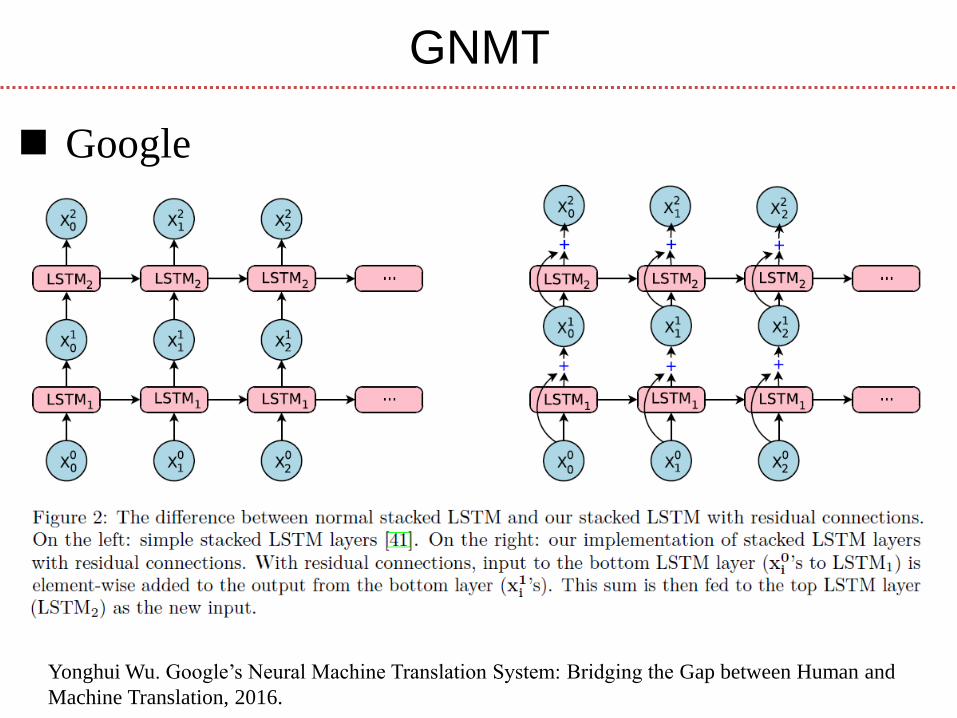
GNMT
Yonghui Wu. Google’s Neural Machine Translation System: Bridging the Gap between Human and
Machine Translation, 2016.

Part2
一. 句法驱动的神经机器翻译
二. 多语与多模态神经机器翻译
三. 面向资源稀缺语种的神经机器翻译
四. 神经机器翻译深度模型
五. 神经机器翻译新架构
六. 神经机器翻译未来发展方向

神经机器翻译新架构: Why?
现有的RNN编码-解码器+注意力机制(成功之处)
大量的工作试图解决vanillla NMT的缺陷(受限词汇表,attention机制)
大量的工作试图将encoder-decoder adapt到新的问题(e.g.,多语翻译,多模态翻译),新的任务(翻译短语,翻译句法树)
大量的工作试图在encoder-decoder框架上添加新的组件(e.g.,字符编码)

神经机器翻译新架构: Why?
现有的RNN编码-解码器+注意力机制(硬性约束之处)
难以在GPU上实现高度并行化
不够灵活,难以调整修改
不透明:内部运行机制仍然没有得到深入理解
相比于smt模型,现有nmt模型简单,许多有用信息没有涵盖

神经机器翻译新架构: Why?
能否跳出现有的框架(RNN encoder-decoder+attention),设计出新的架构
易于并行
易于调整
易于理解内部机制
易于集成更多信息和知识(语言学、世界知识)
体现一种新的翻译建模思路,有别于“编码-注意-解码”框架
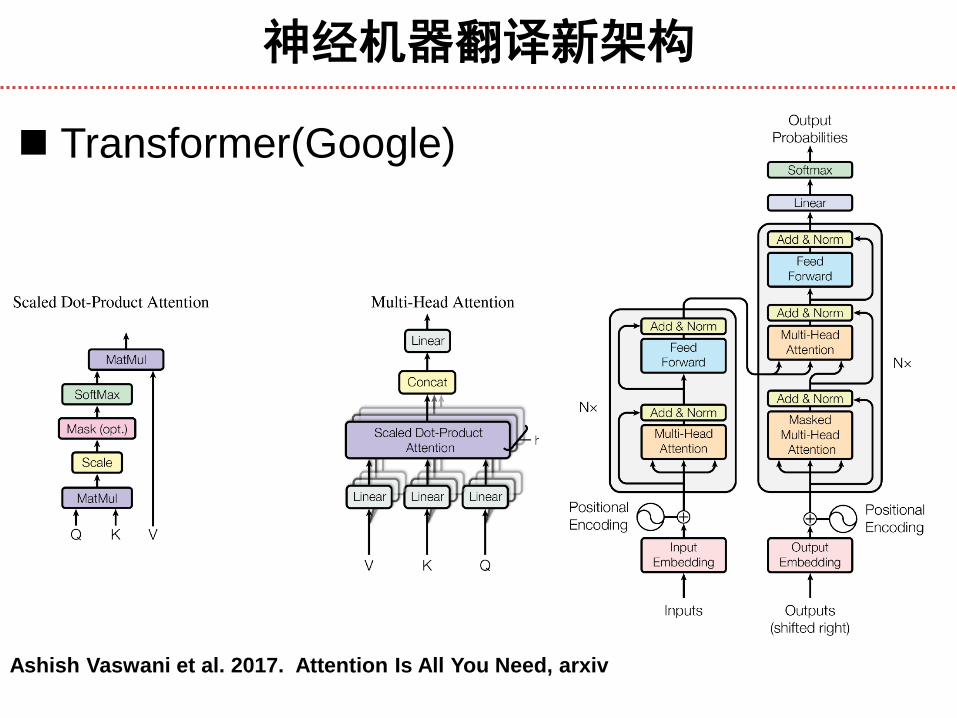
神经机器翻译新架构
Transformer(Google)
Ashish Vaswani et al. 2017. Attention Is All You Need, arxiv
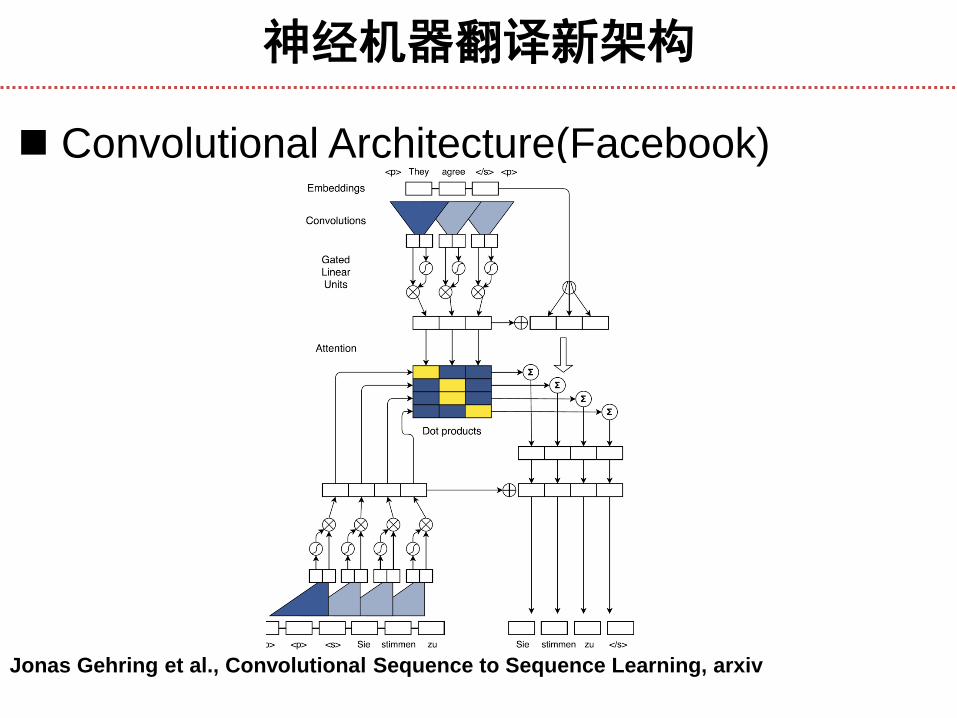
神经机器翻译新架构
Convolutional Architecture(Facebook)
Jonas Gehring et al., Convolutional Sequence to Sequence Learning, arxiv
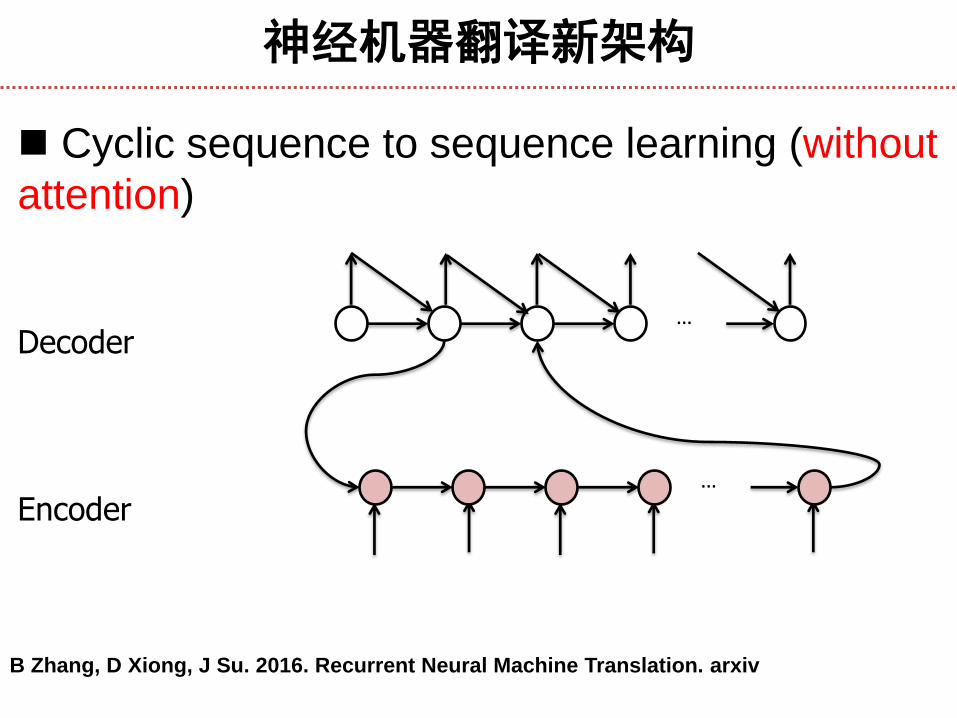
神经机器翻译新架构
Cyclic sequence to sequence learning (without
attention)
…
… Decoder
Encoder
B Zhang, D Xiong, J Su. 2016. Recurrent Neural Machine Translation. arxiv
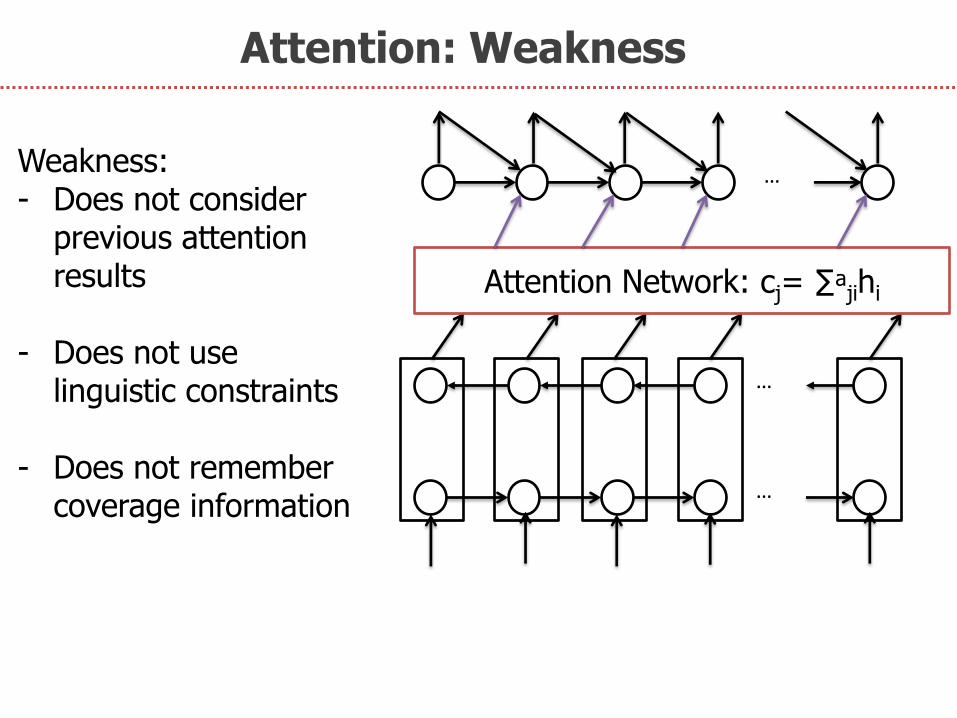
Attention: Weakness
Weakness: - Does not consider
previous attention results
- Does not use
linguistic constraints - Does not remember
coverage information …
…
Attention Network: cj= ∑ᵃjihi
…
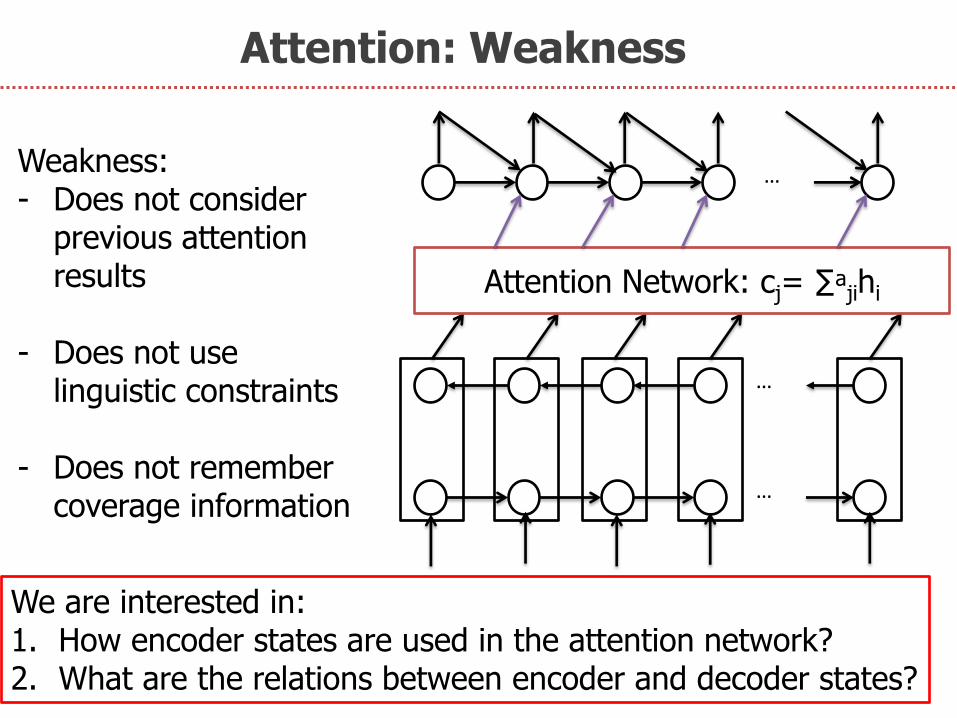
Attention: Weakness
…
…
Attention Network: cj= ∑ᵃjihi
…
We are interested in: 1. How encoder states are used in the attention network? 2. What are the relations between encoder and decoder states?
Weakness: - Does not consider
previous attention results
- Does not use
linguistic constraints - Does not remember
coverage information
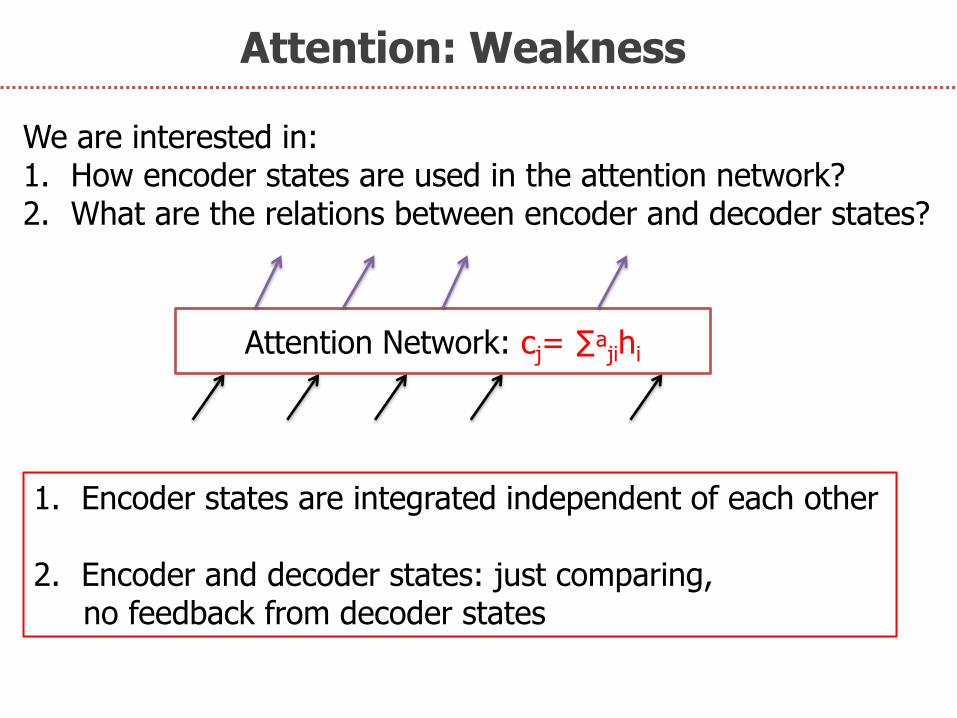
Attention: Weakness
Attention Network: cj= ∑ᵃjihi
1. Encoder states are integrated independent of each other
2. Encoder and decoder states: just comparing, no feedback from decoder states
We are interested in: 1. How encoder states are used in the attention network? 2. What are the relations between encoder and decoder states?
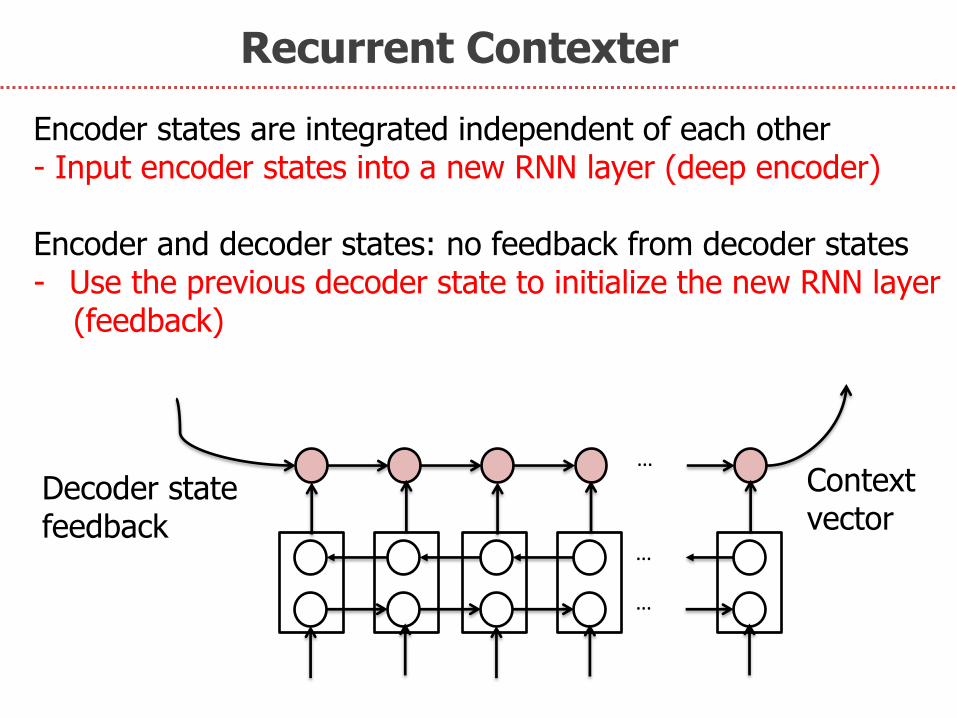
Recurrent Contexter
Encoder states are integrated independent of each other - Input encoder states into a new RNN layer (deep encoder)
Encoder and decoder states: no feedback from decoder states - Use the previous decoder state to initialize the new RNN layer (feedback)
…
…
…
Decoder state feedback
Context vector
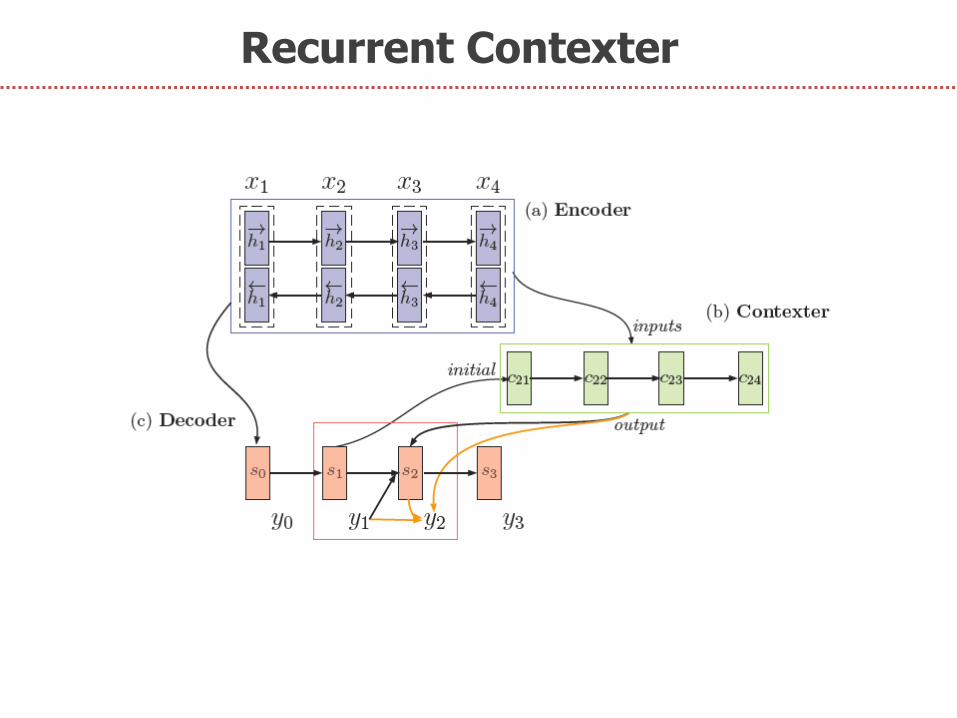
Recurrent Contexter
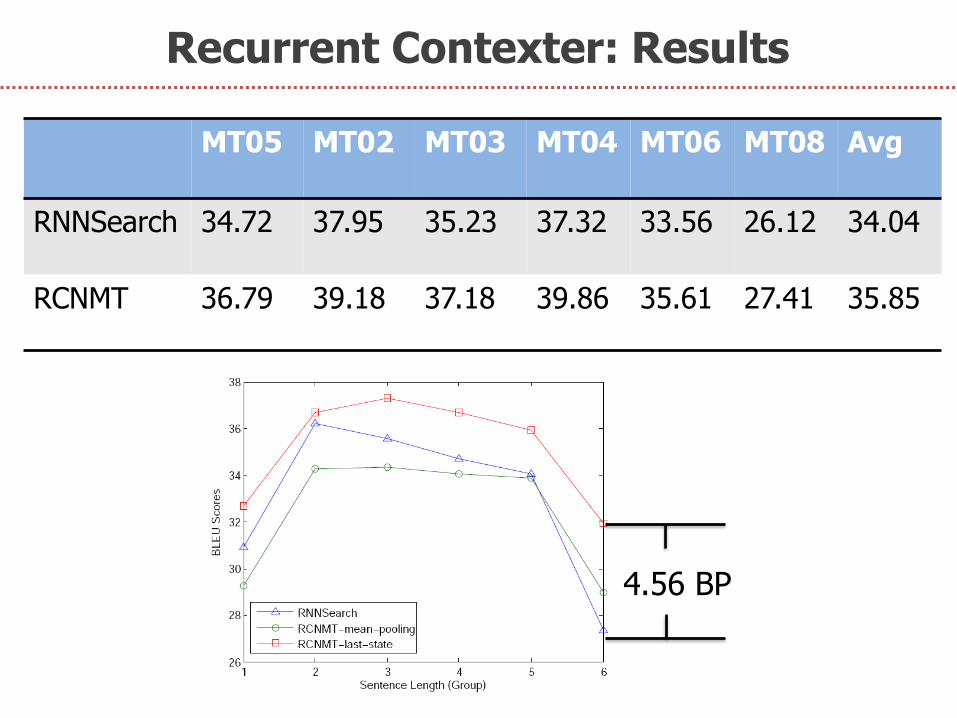
Recurrent Contexter: Results
MT05 MT02 MT03
MT04
MT06
MT08
Avg
RNNSearch 34.72 37.95 35.23 37.32 33.56 26.12 34.04
RCNMT 36.79 39.18 37.18 39.86 35.61 27.41 35.85
4.56 BP

Recurrent Contexter: Attention?
RCNMT does not use the attention network!
Without “attention”, how does the decoder know which parts of the source sentence correspond to the next target word?
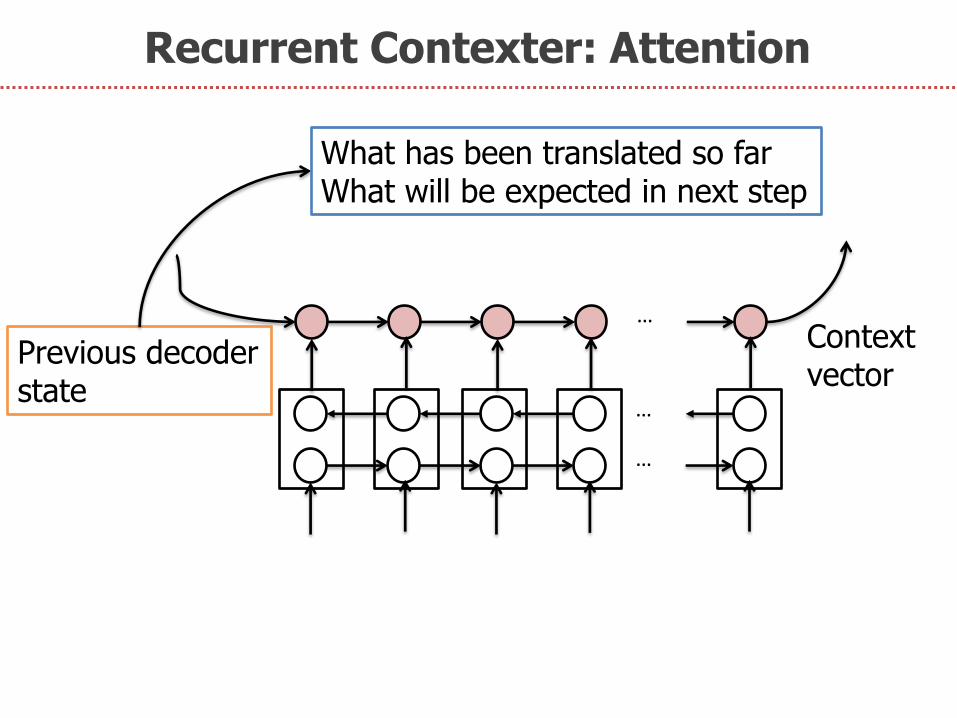
Recurrent Contexter: Attention
…
…
…
Previous decoder state
Context vector
What has been translated so far What will be expected in next step
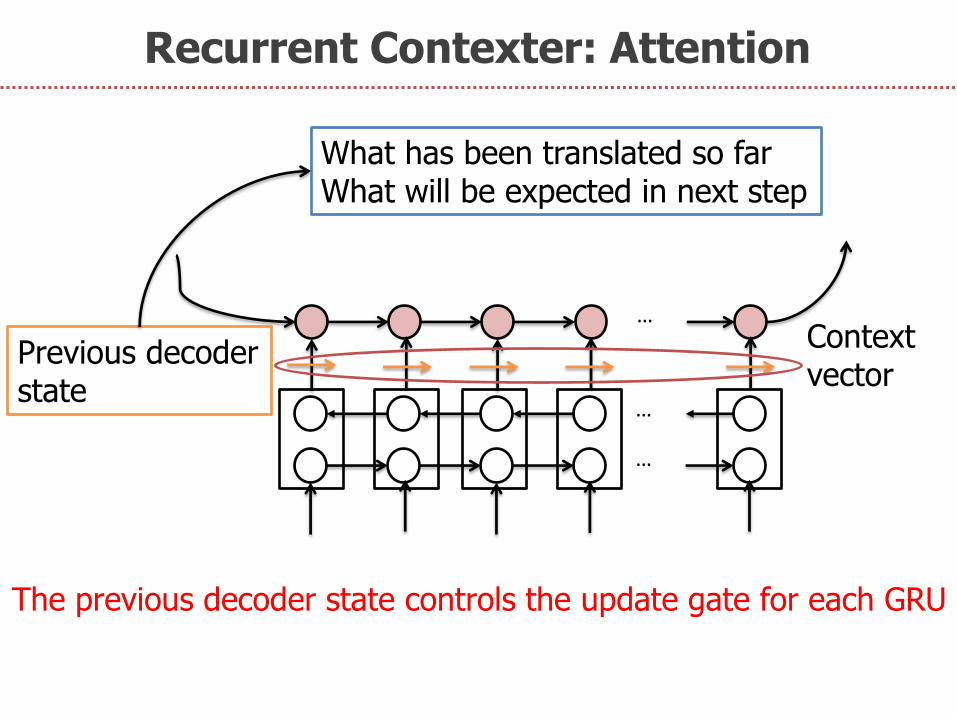
Recurrent Contexter: Attention
…
…
…
Previous decoder state
Context vector
What has been translated so far What will be expected in next step
The previous decoder state controls the update gate for each GRU
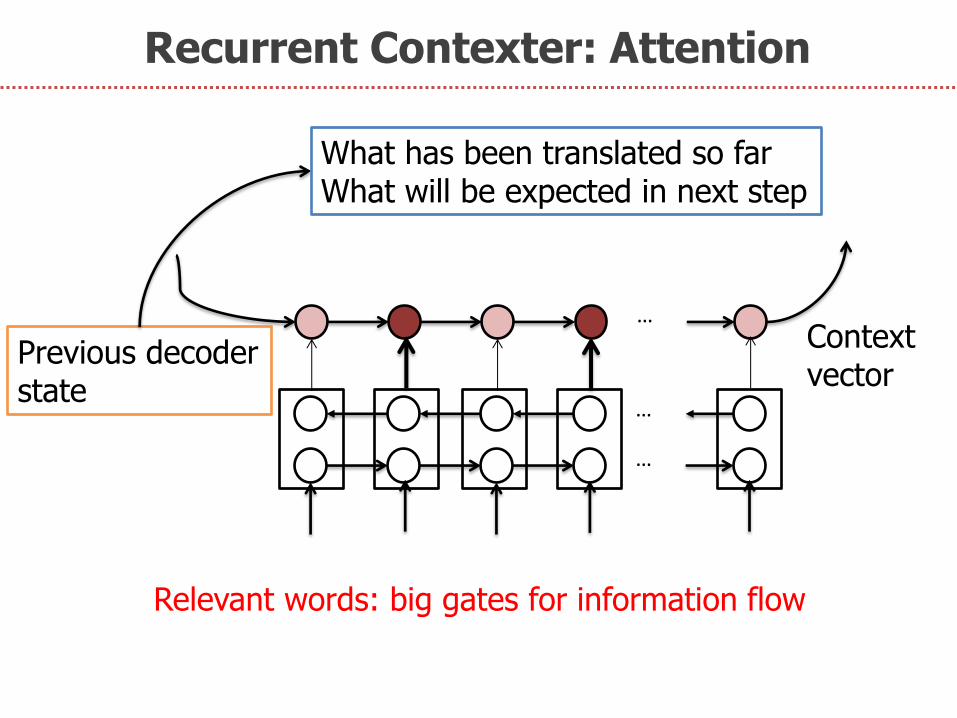
Recurrent Contexter: Attention
…
…
…
Previous decoder state
Context vector
What has been translated so far What will be expected in next step
Relevant words: big gates for information flow
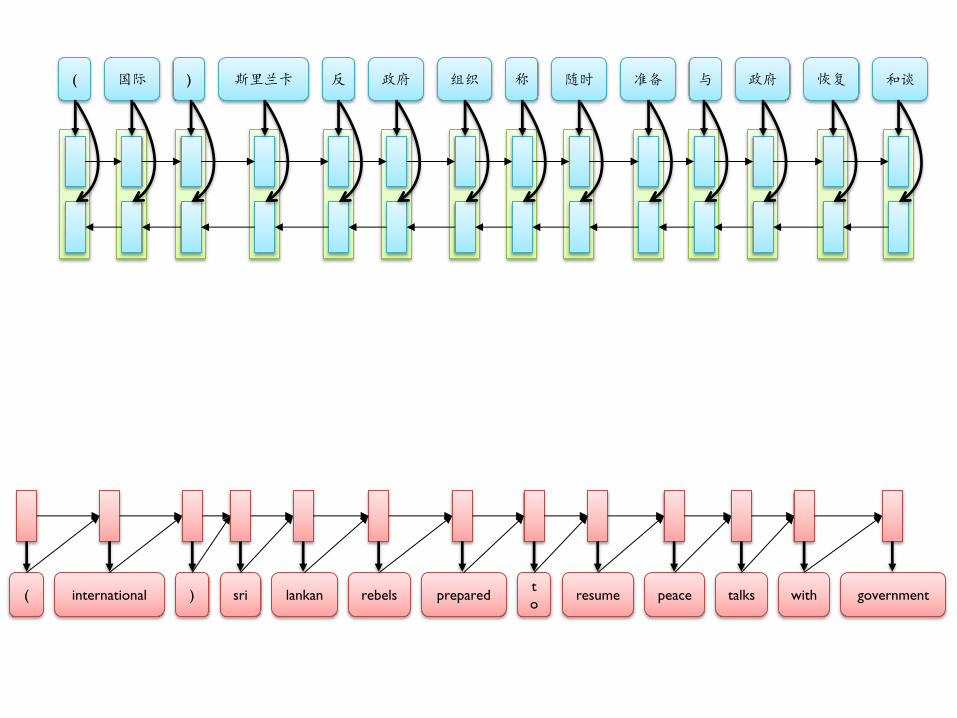
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri lankan rebels prepared t
o resume peace talks with government
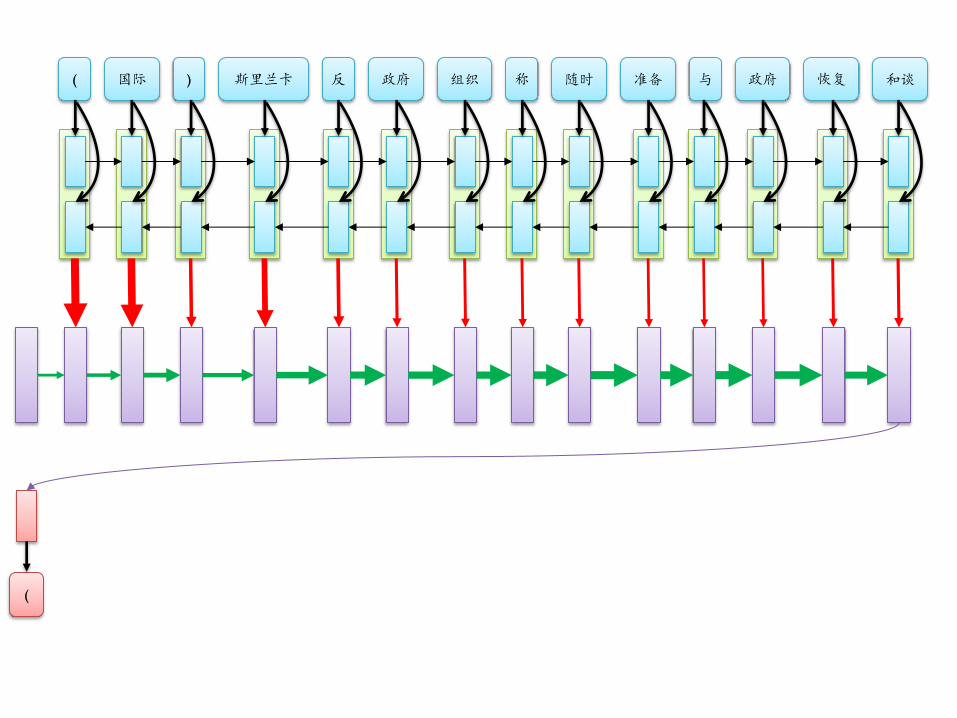
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
(
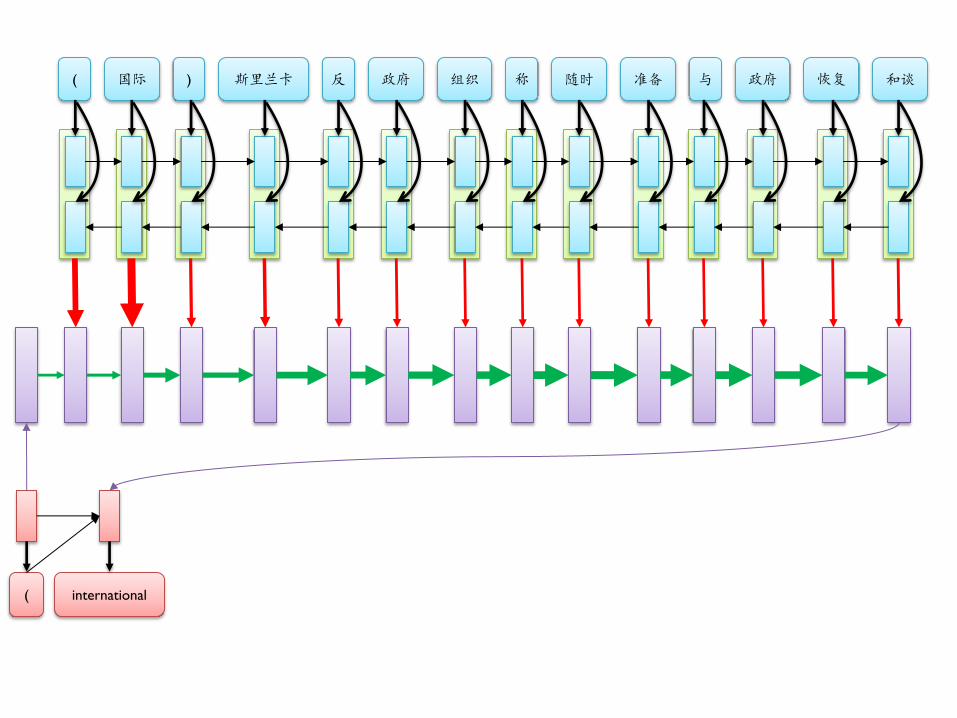
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international
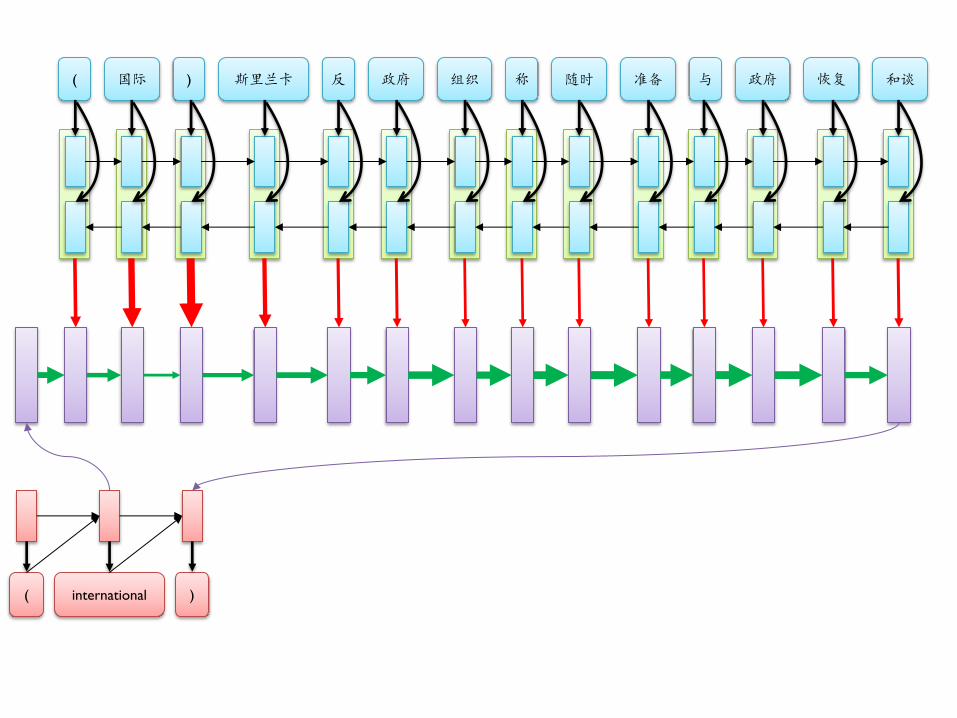
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international )
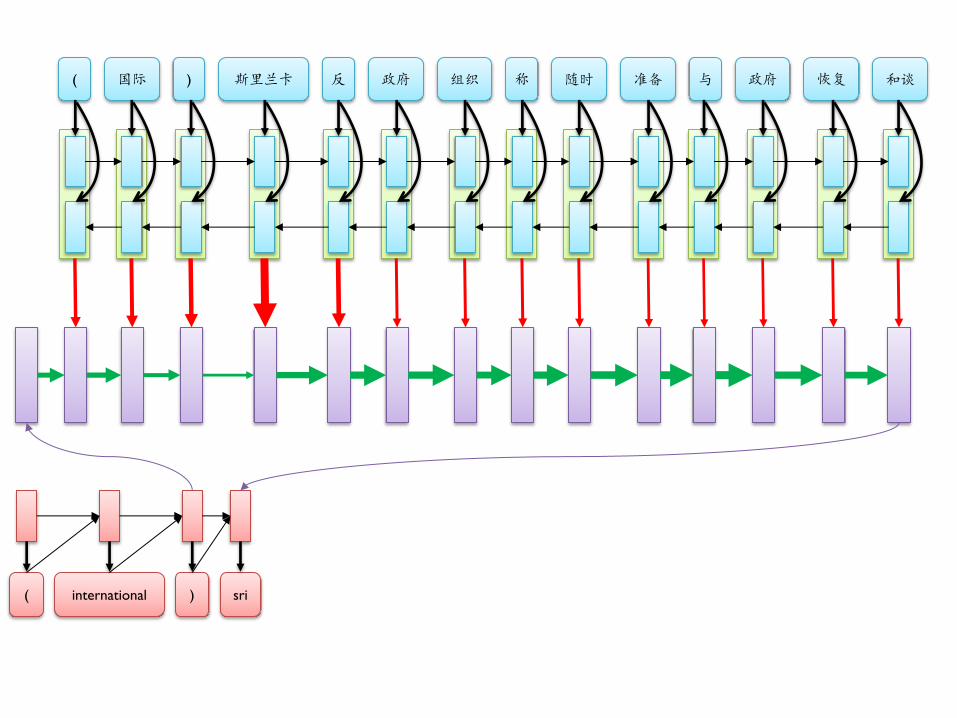
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri
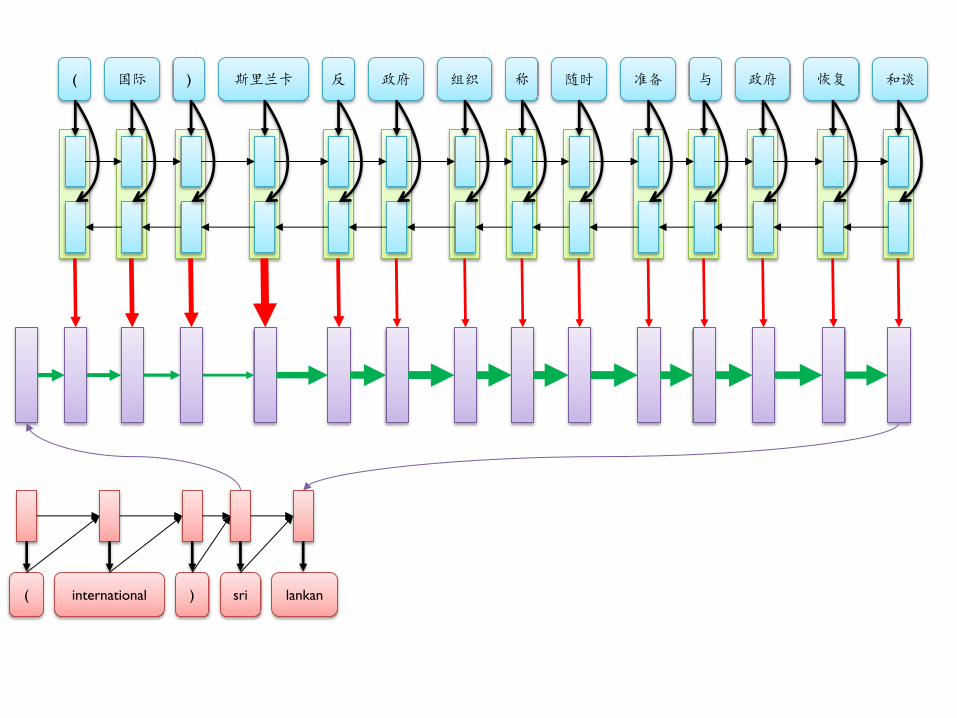
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri lankan
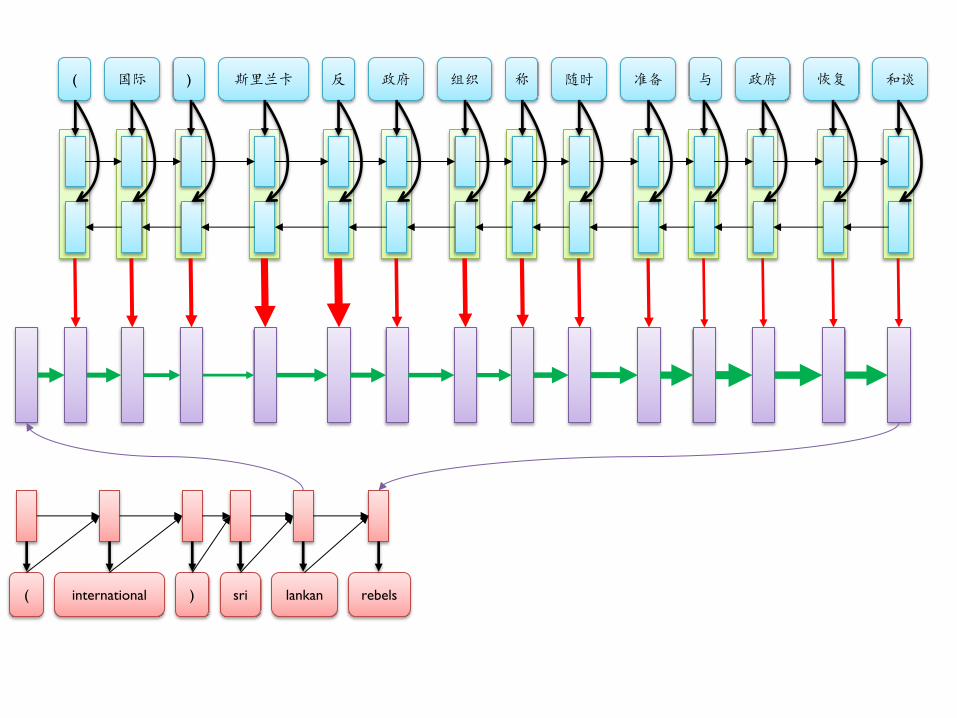
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri lankan rebels
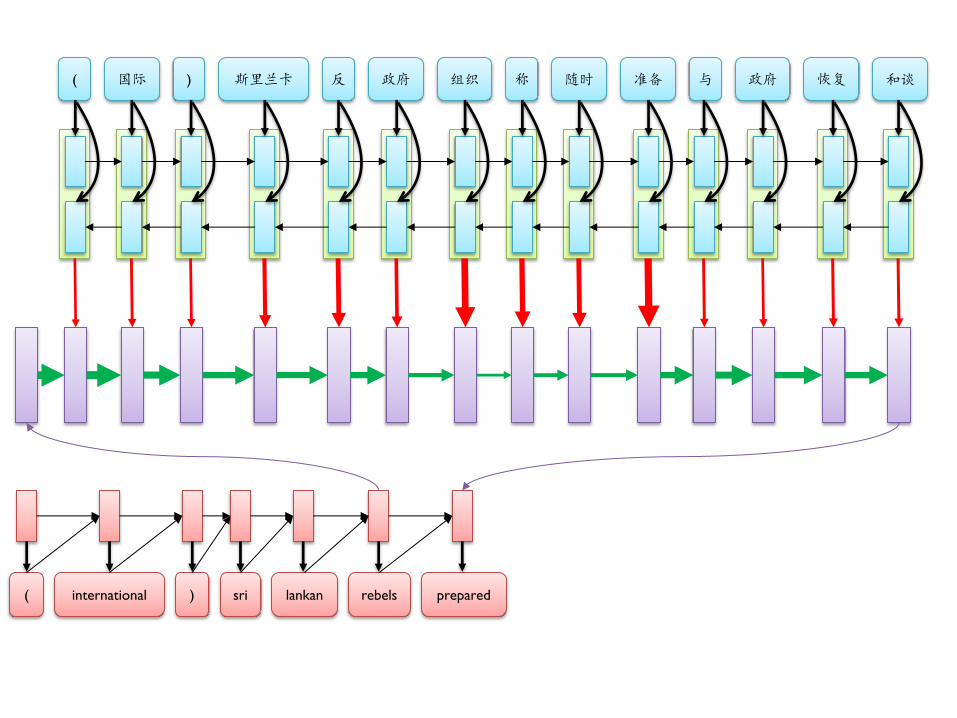
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri lankan rebels prepared
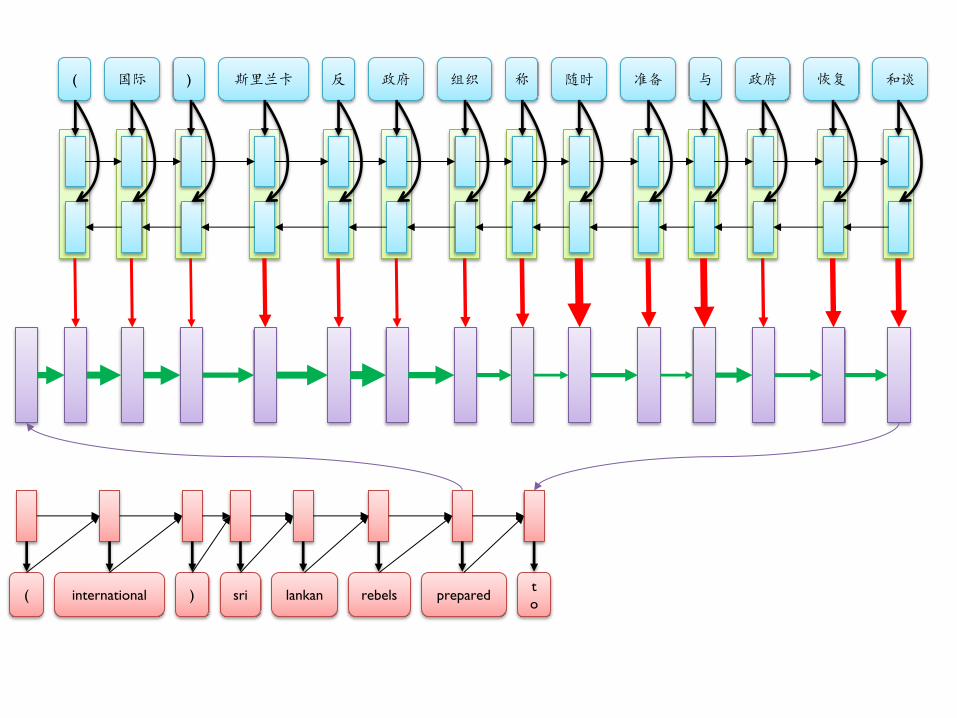
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri lankan rebels prepared t
o
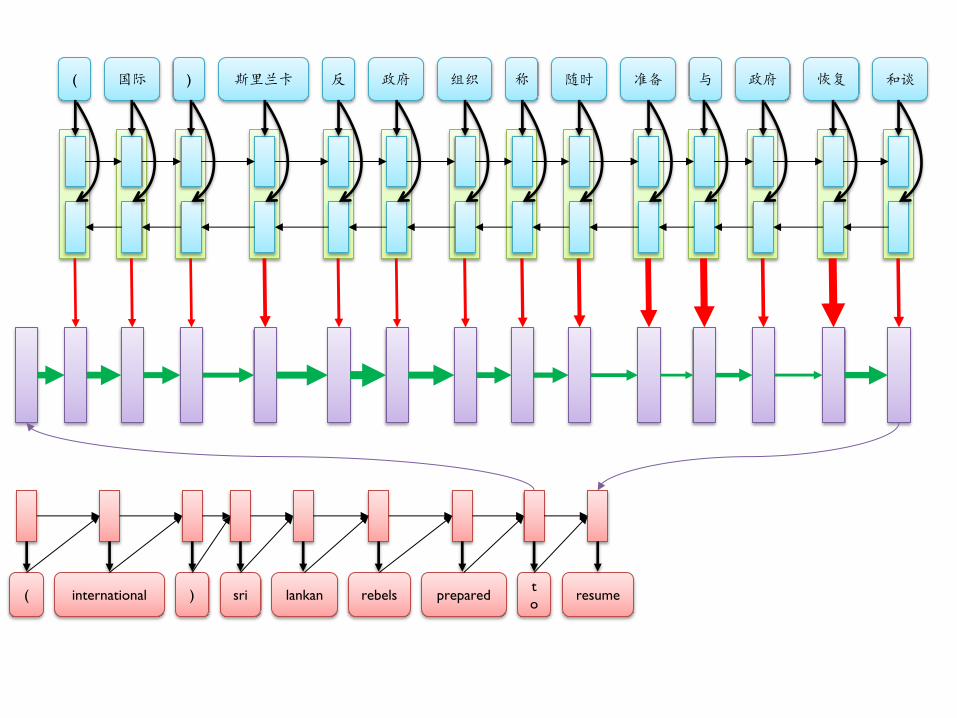
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri lankan rebels prepared t
o resume
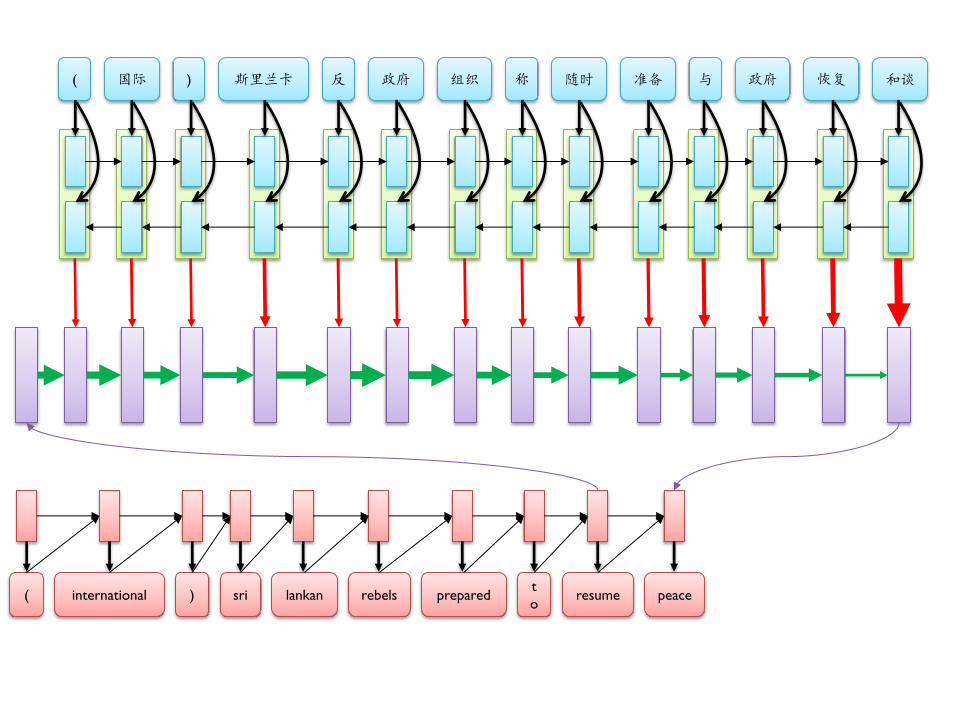
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri lankan rebels prepared t
o resume peace
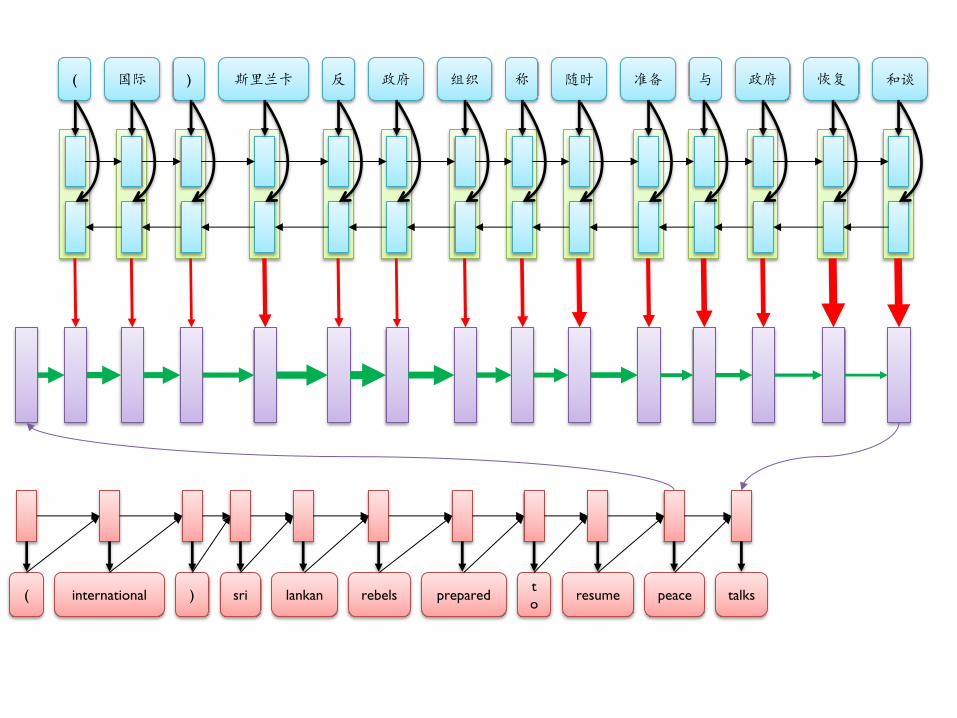
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri lankan rebels prepared t
o resume peace talks
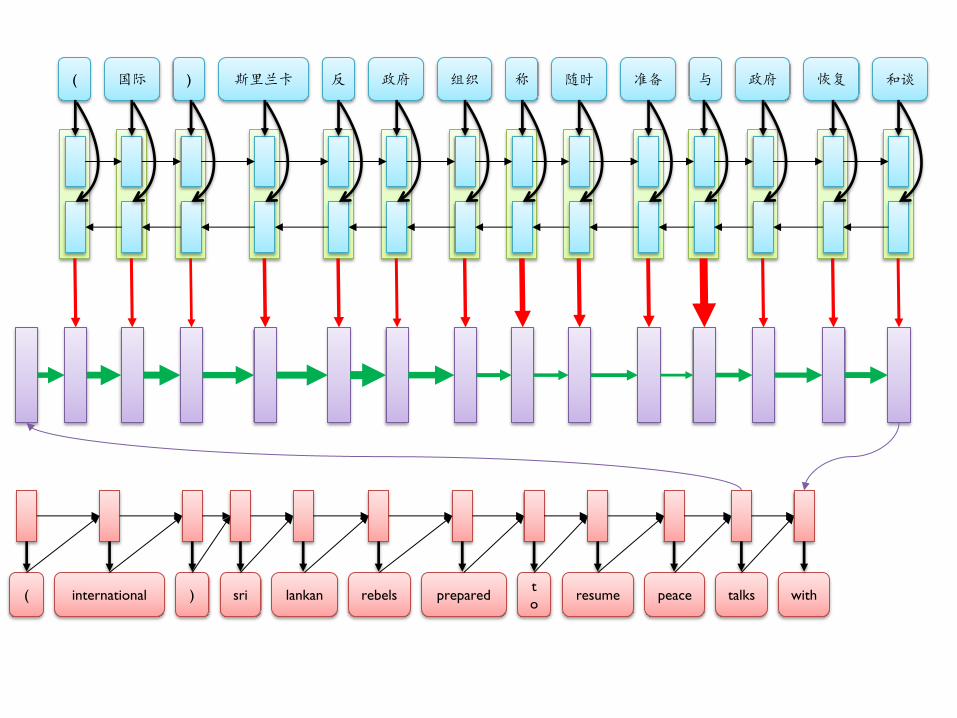
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri lankan rebels prepared t
o resume peace talks with
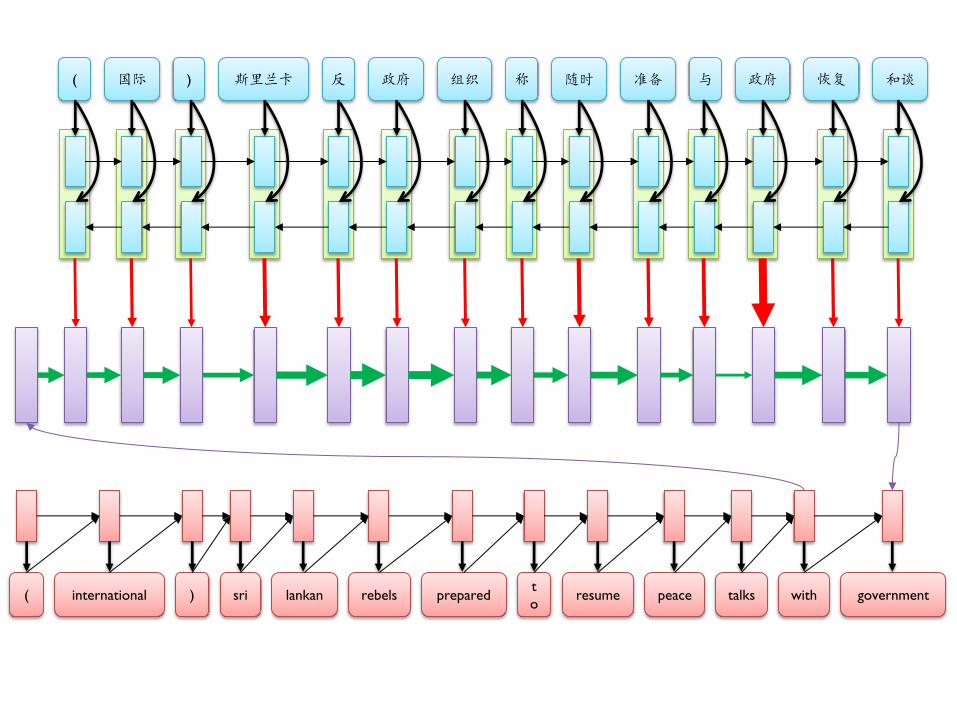
( 国际 ) 斯里兰卡 反 政府 组织 称 随时 准备 与 政府 恢复 和谈
( international ) sri lankan rebels prepared t
o resume peace talks with government
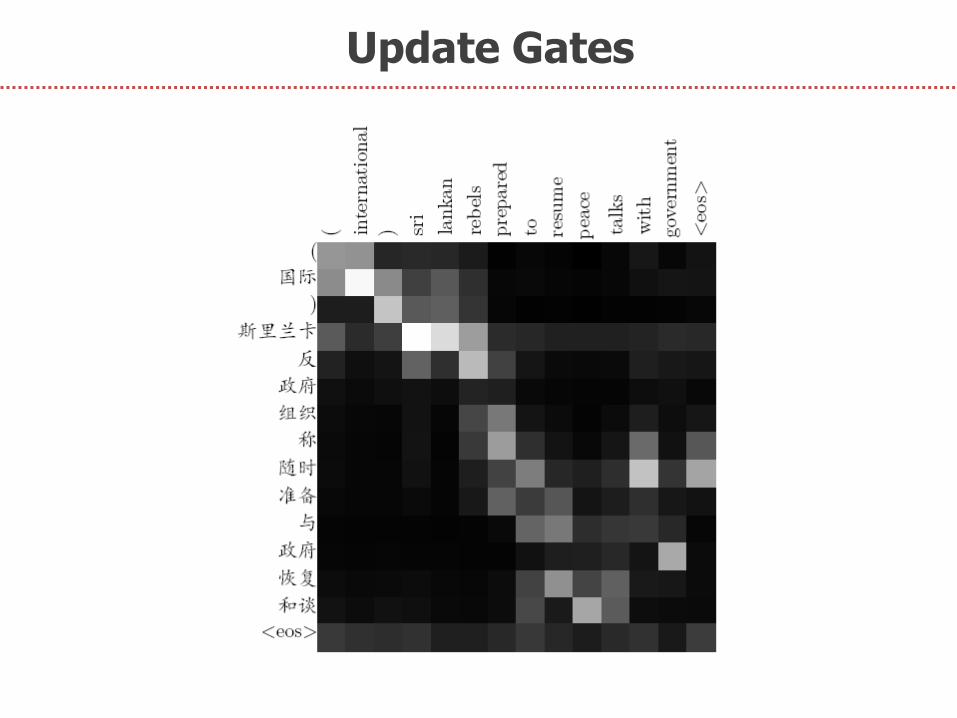
Update Gates
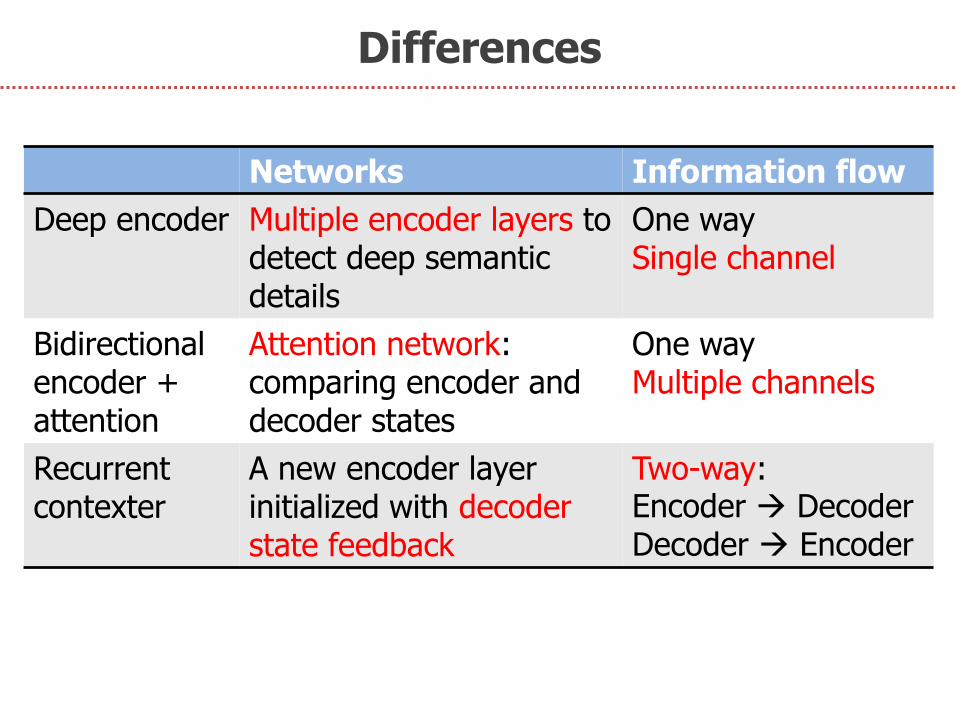
Differences
Networks Information flow
Deep encoder Multiple encoder layers to detect deep semantic details
One way Single channel
Bidirectional encoder + attention
Attention network: comparing encoder and decoder states
One way Multiple channels
Recurrent contexter
A new encoder layer initialized with decoder state feedback
Two-way: Encoder Decoder Decoder Encoder
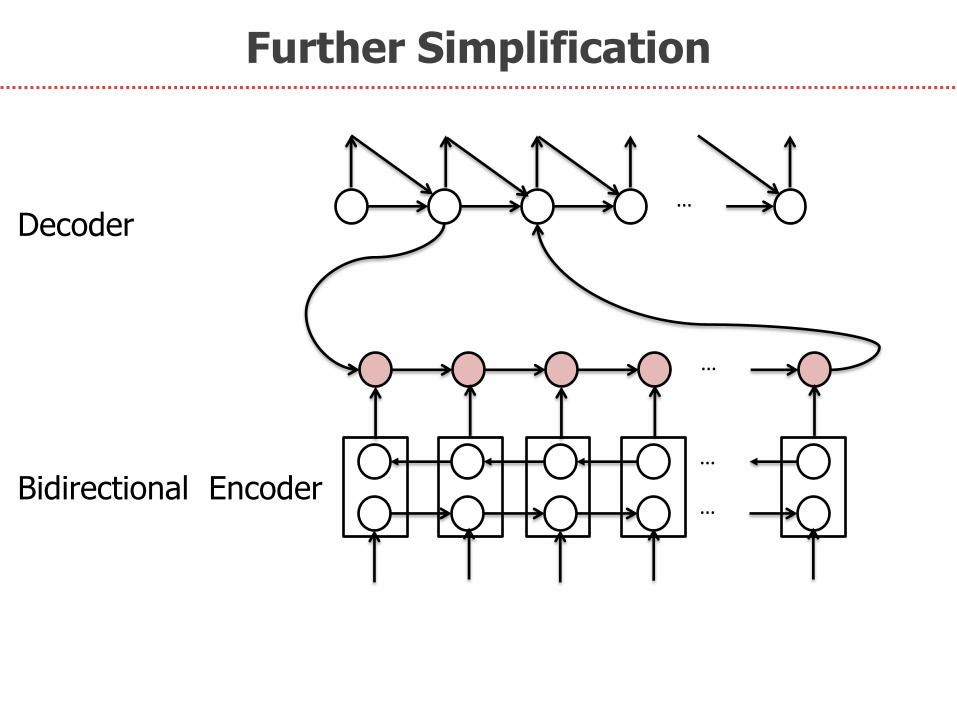
Further Simplification
…
…
…
…
Bidirectional Encoder
Decoder
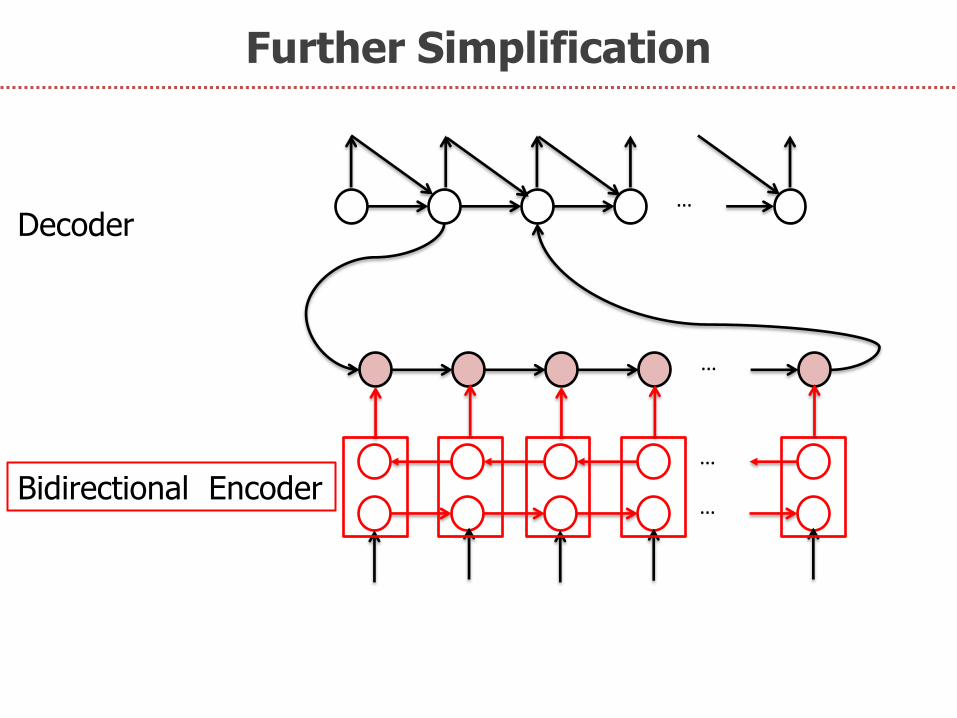
Further Simplification
…
…
…
…
Bidirectional Encoder
Decoder
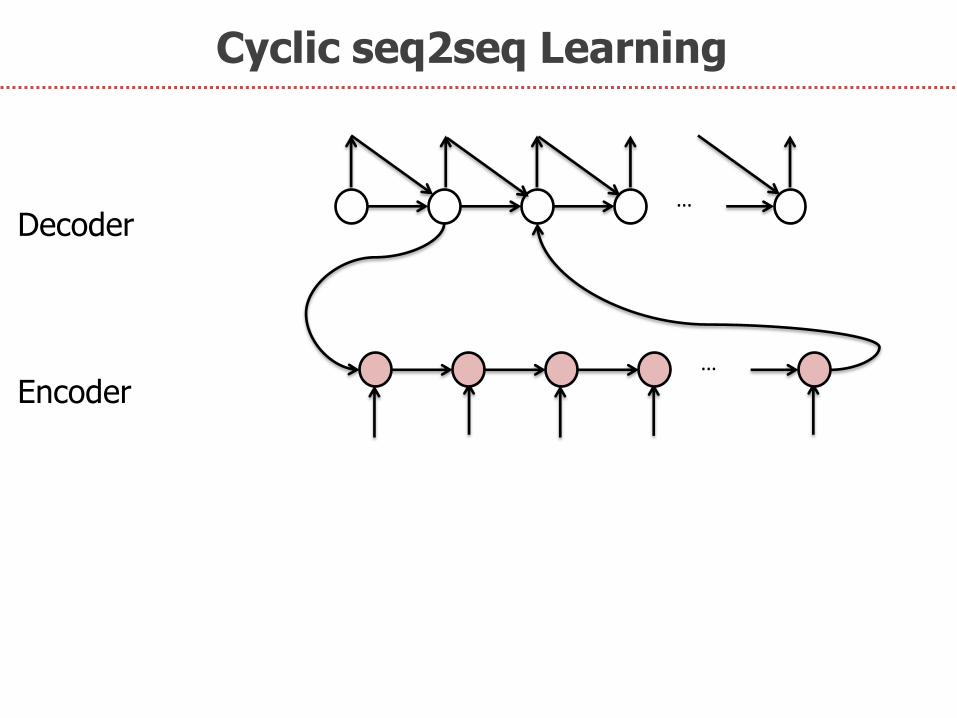
Cyclic seq2seq Learning
…
… Decoder
Encoder
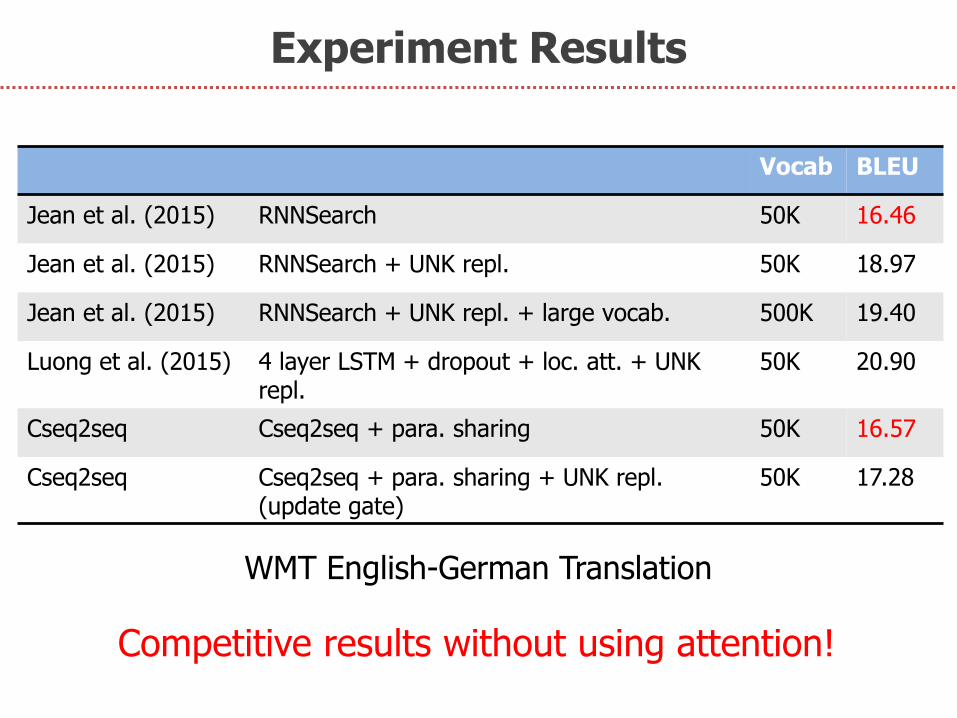
Experiment Results
Vocab BLEU
Jean et al. (2015) RNNSearch 50K 16.46
Jean et al. (2015) RNNSearch + UNK repl. 50K 18.97
Jean et al. (2015) RNNSearch + UNK repl. + large vocab. 500K 19.40
Luong et al. (2015) 4 layer LSTM + dropout + loc. att. + UNK repl.
50K 20.90
Cseq2seq Cseq2seq + para. sharing 50K 16.57
Cseq2seq Cseq2seq + para. sharing + UNK repl. (update gate)
50K 17.28
WMT English-German Translation
Competitive results without using attention!
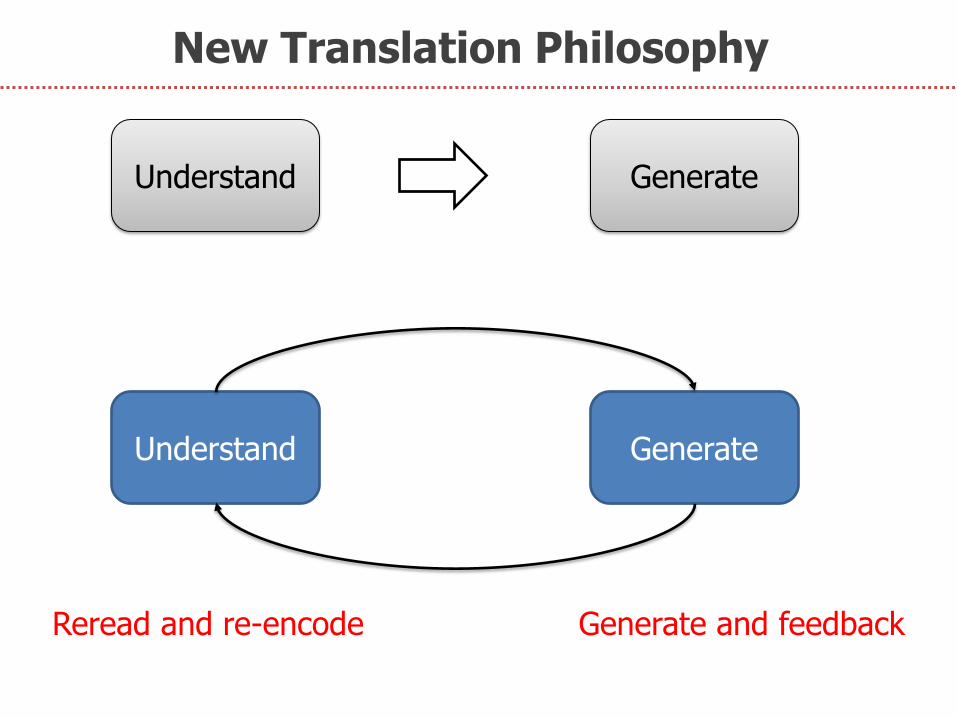
New Translation Philosophy
Understand Generate
Understand Generate
Reread and re-encode Generate and feedback
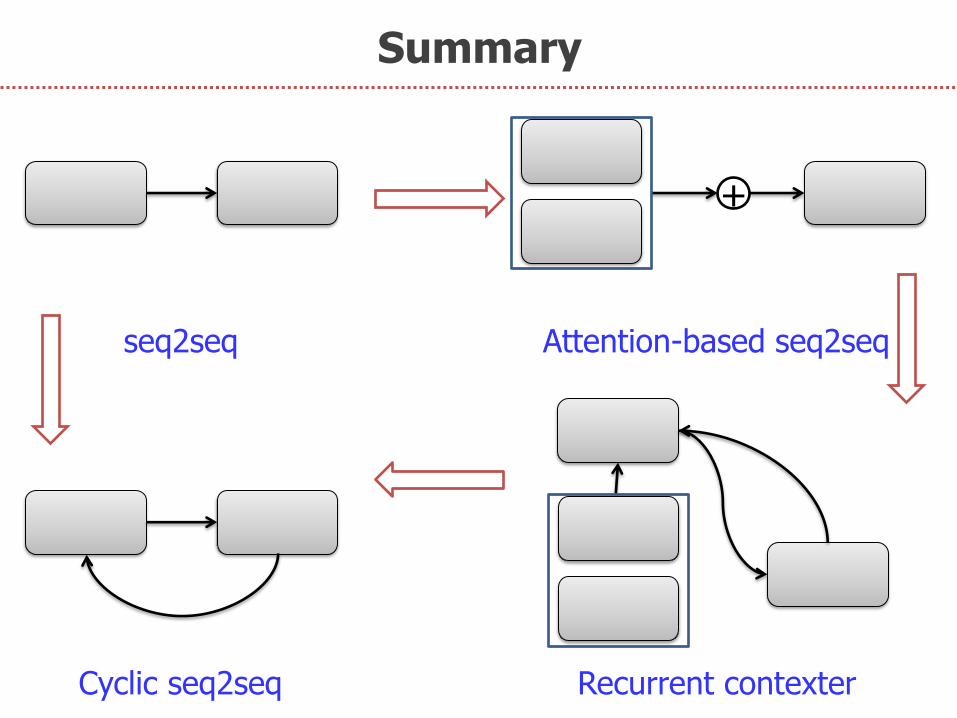
Summary
+
seq2seq Attention-based seq2seq
Recurrent contexter Cyclic seq2seq

1. Decoder states can be fed back to the encoder
2. Parameters of the encoder and decoder can be shared (at least in cseq2seq)
3. Attention can be implicitly obtained.
Summary

Part2
一. 句法驱动的神经机器翻译
二. 多语与多模态神经机器翻译
三. 面向资源稀缺语种的神经机器翻译
四. 神经机器翻译深度模型
五. 神经机器翻译新架构
六. 神经机器翻译未来发展方向

神经机器翻译未来发展方向
内部机制理解(比如:过翻欠翻的深层次原
因)
网络结构的创新与扩展
多模态信息融合(听觉、视觉)
集成语言学知识、世界知识
语言学句法
语言学语义
非语言学知识(常识、世界知识)

神经机器翻译未来发展方向
资源匮乏语言翻译
篇章级神经机器翻译
大一统网络结构
多语言神经机器翻译
机器翻译与NLP其他任务
机器翻译与其他非NLP任务

神经机器翻译未来发展方向
交互协同式神经机器翻译
人在回路
神经机器翻译中的迁移学习
领域迁移
语言迁移
模态迁移
神经机器翻译中的强化学习

神经机器翻译未来发展方向
更难翻译任务挑战
文学类翻译
诗歌类翻译
创意翻译
隐喻翻译
NMT技术在NLP其他任务中的应用

谢谢!
Gracias!
Thanks!
Danke!
감사합니다!
Obrigado!
شكرا لك !
Kiitos!
Merci! Grazie!
Dziękuję!





























