Embed Size (px)
Citation preview

Einführung OpenMP

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Warum parallele Programmierung?
• Viele Bildverarbeitungsalgorithmen leicht parallelisierbar
• Oft wird mit zwei Schleifen über das gesamte Bild gelaufen
• Schleifeniterationen meist voneinander unabhängig
• Parallele Programmierung bietet sich somit an
• Im Praktikum: Grundlagen mit OpenMP

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Was ist OpenMP?
• Steht für „Open Multi-Processing“
• API für shared-memory multiprocessing
– C/C++, Fortran ...
• Multithreading auf abstrakter Ebene
• Beinhaltet:
– Compileranweisungen und Pragmas
– Spezifische Funktionen
– Spezifische Umgebungsvariablen
• Mehr Infos: www.openmp.org

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Überblick
• Prozesse und Threads
• Paralleles Programmieren mit OpenMP
– Parallelisieren von Schleifen
– Synchronisierung
– Scheduling

Prozesse und Threads

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
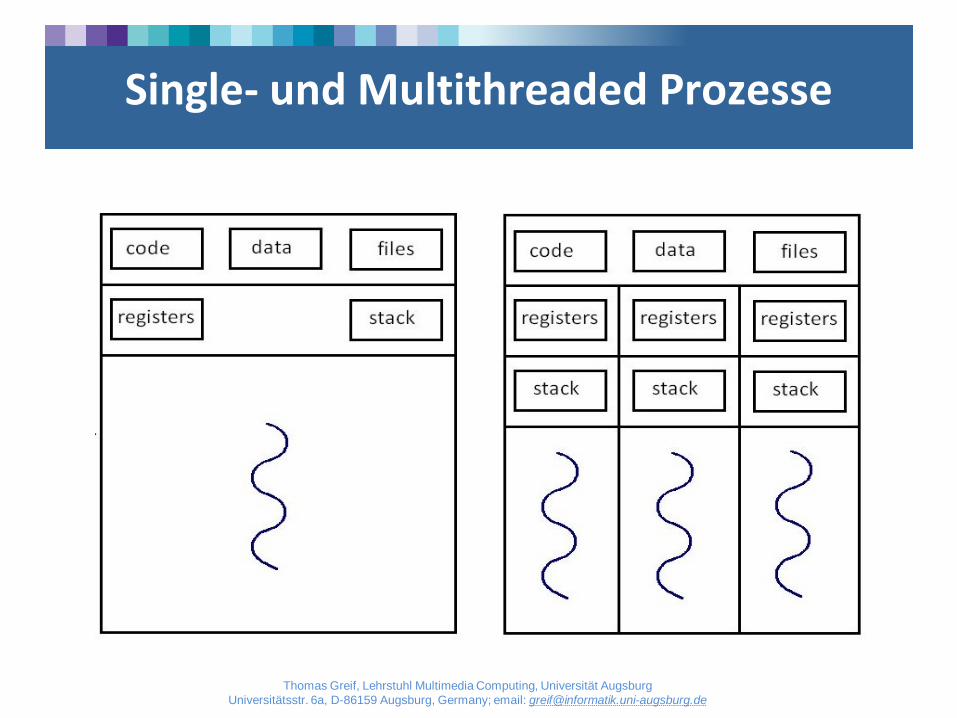
Prozess
• Ein momentan ausgeführtes Programm
• Sequentielle Abarbeitung
• Ein Prozess beinhaltet:
– Prozess-ID
– Programmcode
– Schrittzähler
– Registerwerte
– Stack
– Lokale Variablen, Rücksprungadressen, Funktionsparameter
– Datenbereich
– Globale Variablen
– Heap
– Speicherplatz für dynamisch allozierte Variablen

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Thread
• (Potentiell) parallel ausgeführte Programmflüsse mit gemeinsamem Adressraum
• Sequentielle Abarbeitung
• Ein Thread beinhaltet: – Thread-ID
– Schrittzähler
– Registerwerte
– Stack
– Lokale Variablen, Rücksprungadressen, Funktionsparameter
– Alles andere (Globale Variablen, Heap, dynamischer Speicher): Geteilt mit anderen Threads
Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Single- und Multithreaded Prozesse

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Warum OpenMP?
• Shared-memory –Systeme mittlerweile fast überall – z.B. Multiprozessor- und Multicore-Rechner
• Daher: Bedarf Aufgaben zu parallelisieren
• Bibliotheken zur Threaderzeugung (wie pthread) – sind “low-level”
– verlangen tiefe Kenntnis, sowie (schwierige) manuelle Synchronisierung/Zugriffsverwaltung
– sind schlecht portierbar
• OpenMP bietet Möglichkeit Aufgaben schnell und zuverlässig zu parallelisieren auf einer abstrakten Ebene

Paralleles Programmieren mit OpenMP

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
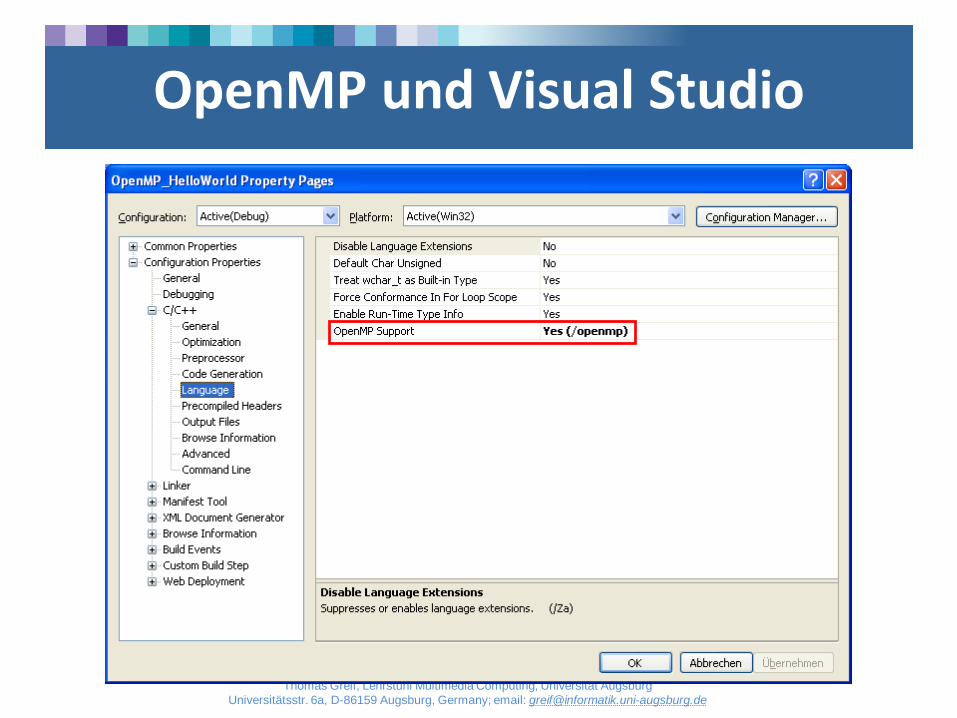
Unterstützte Compiler
• Visual Studio C/C++-Compiler ab 2005
• Allerdings nicht in der Express-Edition
• Intel C/C++-Compiler ab Version 8
• GCC ab Version 4.2
• Compiler, die OpenMP nicht unterstützen ignorieren OpenMP-Anweisungen
• Compiler erlauben meist An- und Abschalten von OpenMP
Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
OpenMP und Visual Studio

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Hello OpenMP world
#include <stdio.h>
#ifdef _OPENMP
#include <omp.h>
#endif
int main()
{
#ifdef _OPENMP
printf("Number of processors: %d\n", omp_get_num_procs());
#pragma omp parallel
{
printf("This is thread: %3d out of %3d\n", omp_get_thread_num(),
omp_get_num_threads());
}
printf("Back to serial. Done.");
#else
printf("OpenMP support is not available.");
#endif
return 0;
}
OpenMP pragma
OpenMP library routine
OpenMP preprocessor
macro

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Mögliche Ausgabe
• Reihenfolge der Ausführung nicht vorhersagbar, sofern die Threads nicht synchronisiert werden
Number of processors: 4
This is thread 0 out of 4
This is thread 2 out of 4
This is thread 1 out of 4
This is thread 3 out of 4
Back to serial. Done.

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Anweisungen
• Eingeschlossener Codeblock der Form
#pragma omp directiveName [clause ..] newline
• Halten sich an C/C++-Konventionen
• Groß-/Kleinschreibung beachten
• Jede Anweisung gilt für den nächsten strukturierten Codeblock

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Die parallel-Anweisung
• Erzeugt eine Menge von Threads, die den Codeblock parallel ausführen
• Syntax:
#pragma omp parallel [clause[ [, ]clause]
...] newline
structured-block
• clauses werden später besprochen
• Können mit section-Anweisung und for-Anweisung kombiniert werden

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Fork/Join-Modell
Master thread
Master thread
Team of threads …
#pragma omp parallel
{
// …
}
The number of threads in a team is determined by the environment variable OMP_NUM_THREADS, the omp_set_num_threads() library function, or the num_threads clause.
Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
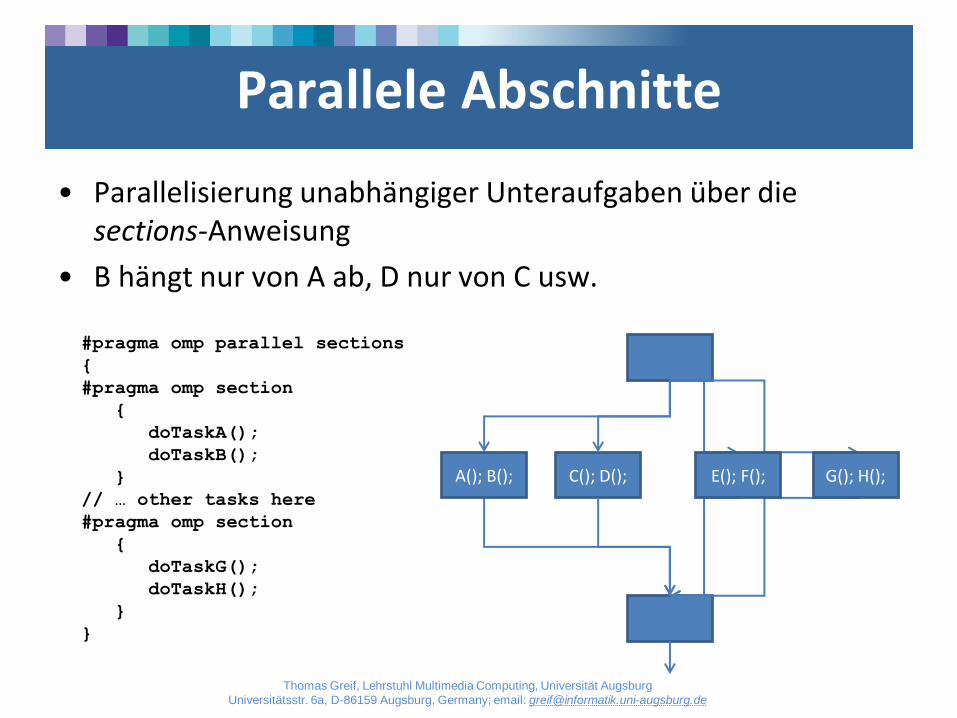
Parallele Abschnitte
• Parallelisierung unabhängiger Unteraufgaben über die sections-Anweisung
• B hängt nur von A ab, D nur von C usw.
#pragma omp parallel sections
{
#pragma omp section
{
doTaskA();
doTaskB();
}
// … other tasks here
#pragma omp section
{
doTaskG();
doTaskH();
}
}
C(); D(); A(); B(); G(); H(); E(); F();

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Mögliche Ausgabe
• Reihenfolge der Ausführung nicht vorhersagbar, sofern die Threads nicht synchronisiert werden
• Es gilt jedoch: – A vor B
– C vor D
– E vor F und
– G vor H
This is thread 0 of 4 doing task A
This is thread 2 of 4 doing task C
This is thread 1 of 4 doing task E
This is thread 3 of 4 doing task G
This is thread 1 of 4 doing task F
This is thread 0 of 4 doing task B
This is thread 2 of 4 doing task D
This is thread 3 of 4 doing task H

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Parallelisierung von Schleifen
void multiplyAdd(float* src, float* dst, float scale, float shift, int n)
{
for(int i = 0; i < n; i++)
{
dst[i] = scale * src[i] + shift;
}
}
void multiplyAdd(float* src, float* dst, float scale, float shift, int n)
{
#pragma omp parallel
{
#pragma omp for
for(int i = 0; i < n; i++)
{
dst[i] = scale * src[i] + shift;
}
}
}
Pragma genügt

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Bedingungen
• Voneinander unabhängige Iterationen – Abhängigkeiten oft im Vorhinein lösbar
• Indexvariable vorzeichenbehaftete Ganzzahl (int)
• Erlaubte Kontrollanweisungen: <, >, <=, >= für Abbruchkriterien und +, - für Zählweise
• Indexvariable muss sich pro Iteration um die gleiche Menge verändern
• Anzahl der maximalen Iterationen muss im Vorhinein bekannt sein
• Indexvariable darf sich innerhalb der Schleife nicht verändern
• Keine break-Anweisungen (continue ist in Ordnung)

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Beachten
• Wird eine Exception innerhalb der Schleife geworfen, muss diese auch in der Schleife abgefangen werden
• Implizite Barriere: Alle Threads müssen auf den langsamsten warten bevor sie ihre Ausführung beenden
– Falls nicht gewünscht:
#pragma omp for nowait
int i;
#pragma omp parallel
{
#pragma omp for nowait
for (i = 0; i < size; i++)
b[i] = a[i] * a[i];
#pragma omp for nowait
for (i = 0; i < size; i++)
c[i] = a[i]/2;
}

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
clauses: Überblick
• Syntax:
<clause> ([var [, var ] … ])
• clauses für den Gültigkeitsbereich von Variablen: – private
– shared
– firstprivate
– lastprivate
– default
– reduction
• Beispiel: #pragma omp parallel for private(x, f_x) shared(delta_x, sum)

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
clauses: Überblick
• schedule clause
– Steuert Verteilung der Aufgaben auf die Threads
• if clause
– Führt Block parallel aus, wenn Ausdruck wahr
• ordered clause
– Wenn die Reihenfolge der Iterationen eine Rolle spielt
• copyin clause
– Zum Initialisieren privater Variablen mit Werten des Vater-Threads

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Datenzugriff und Gültigkeit
• Threads haben einen gemeinsamen Adressraum
• Threads kommunizieren durch Lesen/Schreiben von/in gemeinsame Variablen
• Zugriff muss möglicherweise synchronisiert werden
• Standardmäßig: – Threads haben auf alle Variablen Zugriff (lesend und schreibend)
– Ausnahme: Indexvariable bei Schleifen

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
private clause
• Eine als privat markierte Variable exisitiert für jeden Thread separat in seinem Adressraum
• D.h. jeder Thread bestitzt eine eigene Kopie der Variable
• Initialisierungswert undefiniert: Muss vom Thread initialisiert werden
• Ausnahme: – Kontrollvariablen bei Schleifen (sind schon initialisiert)
– C++-Objekte (werden mit Copy- oder Standardkonstruktor initialisiert)

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Standard-Gültigkeitsbereich
void function(int a[], int n)
{
int i, j, m = 3;
#pragma omp parallel for
for(i = 0; i < n; i++)
{
int k = m;
for(j = 1; j <= 5; j++)
{
call(&a[i], &k, j);
}
}
}
Variable Scope Reason Safe?
a, n,
m
shared Declared outside parallel region
Yes
i private Parallel loop index variable
Yes
j shared Declared outside parallel region
No
k private Automatic variable declared inside parallel region
Yes
Achtung

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
firstprivate/lastprivate clause
• firstprivate([Var [, Var]..])
– Jede private (also lokale) Kopie der Variable Var wird in der ersten Iteration mit dem Wert des Vater-Threads dieser Variable initialisiert
• lastprivate([Var [, Var]..])
– Der Wert der Variablen Var des Vater-Threads wird auf den Wert der privaten (also lokalen) Kopie des Threads gesetzt, der sich als letztes beendet

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Datenabhängigkeiten
• Bewahre Richtigkeit bei der Parallelisierung
• Datenabhängigkeit: Zwei Anweisungen greifen auf den gleichen Speicherbereich zu, mindestens eine schreibend
• Beispiel: for (int i=1; i<n; ++i) {
array[i] = array[i] + array[i-1];
}
• Während ein Thread liest, kann ein zweiter Thread bereits einen anderen Wert an entsprechende Stelle geschrieben haben
• Ergebnisse können nicht übereinstimmen

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Datenabhängigkeiten entdecken
• Benötigt eine Iteration Ergebnisse einer vorhergegangenen?
• Vorgehen:
– Jede Variable der Schleife überprüfen
– Wird daraus lediglich gelesen, liegt keine Abhängigkeit vor
– Wird nur an eine Stelle geschrieben, die lediglich von der aktuellen Iteration abhängt, liegt keine Abhängigkeit vor
– Ansonsten gilt: Abhängigkeit

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Datenabhängigkeitstypen
• Echte Abhängigkeit:
– Thread 1 schreibt an eine Stelle
– Thread 2 benötigt genau den von Thread 1 geschriebenen Wert
– Beispiel: • 1. A = 3
• 2. B = A
• 3. C = B
• 3. abhängig von 2., 2. abhängig von 1.
• Eliminierung: Keine allgemein gültige

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Datenabhängigkeitstypen
• Gegenabhängigkeit:
– Thread 1 benötigt Wert, der später von Thread 2 aktualisiert wird
– Beispiel:
• 1. B = 3
• 2. A = B + 1
• 3. B = 7
• Parallele Ausführung würde evtl. Wert A beeinflussen
• Eliminierung: Jede Iteration schreibt in private Kopie einer Variable (Registerumbenennung)
– 1. B1 = 3
– 2. A = B1 + 1
– 3. B2 = 7
– Gelöst: Antiabhängigkeit zwischen 2. und 3.
– Nicht gelöst: Echte Abhängigkeit

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Datenabhängigkeitstypen
• Ausgabeabhängigkeit: – Thread 1 schreibt an eine Stelle
– Thread 2 schreibt an dieselbe Stelle
– Beispiel:
• 1. A = 2 * X
• 2. B = A / 3
• 3. A = 9 * Y
• 3. ausgabeabhängig von 1.
• Eliminierung: Jede Iteration schreibt in private Kopie einer Variable (Registerumbenennung) – 1. A1 = 2 * X
– 2. B = A1 / 3
– 3. A2 = 9 * Y

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Synchronisierung
• Gleichzeitiger Schreibzugriff auf gemeinsame Variablen führt zu Wettlaufsituationen (engl. race conditions)
– Der letzte schreibende Thread “gewinnt”
– Bezeichnet auch als critical section problem
• Lösung: Gegenseitiger Ausschluss (engl. mutual exclusion)
– Immer nur ein Thread kann gleichzeitig auf eine Variable zugreifen
– Gewährleistet durch kritische Abschnitte (engl. critical sections)
• In OpenMP
– critical-Anweisung: • Gesamter Block kann nur von genau einem Thread betreten werden. Alle anderen warten bis
der Block verlassen wird
– atomic-Anweisung: • Anweisung wird als kanonische Operation gesehen, die immer nur von einem Thread
gleichzeitig ausgeführt werden kann
• Nur für eine Zuweisung an skalare Variablen erlaubt (z.B. x+=c oder x++)

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Beispiel Synchronisierung
max = a[0];
#pragma omp parallel for num_threads(4)
for (i = 1; i < SIZE; i++) {
if (a[i] > max) {
#pragma omp critical {
// compare a[i] and max again because max
// could have been changed by another thread after
// the comparison outside the critical section
if (a[i] > max)
max = a[i];
}
}
}
Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
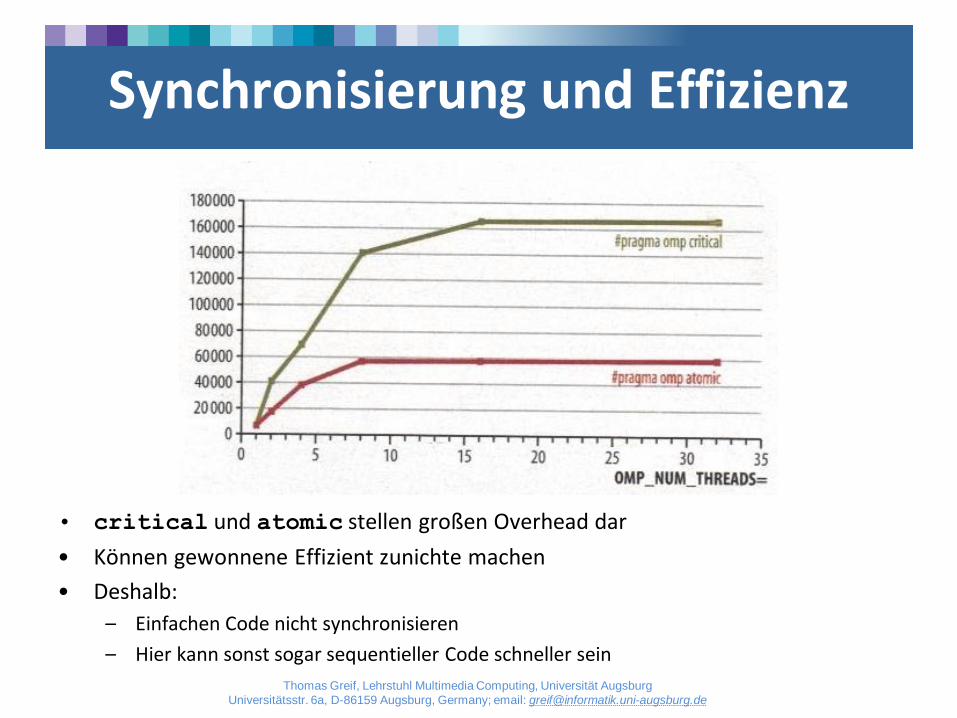
Synchronisierung und Effizienz
• critical und atomic stellen großen Overhead dar
• Können gewonnene Effizient zunichte machen
• Deshalb:
– Einfachen Code nicht synchronisieren
– Hier kann sonst sogar sequentieller Code schneller sein

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Sperren
• OpenMP bietet auch die Möglichkeit Sperren (engl. locks) auf einzelne Variablen zu setzen
• Sperrt ein Thread eine Variable, darf nur er darauf zugreifen bis die Sperre freigegeben wird
• Allokation der Sperre für eine Variable var: – omp_init_lock(var)
– omp_destroy_lock(var)
• Setzen/Freigeben einer Sperre: – omp_set_lock(var)
– omp_test_lock(var)
– omp_unset_lock(var)
• Flexibler als critical und atomic, da nicht auf Codeabschnitte beschränkt

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Deadlocks
• Entsteht wenn mehrere Threads auf ein Ereignis (z.B. Freigabe einer Sperre) warten, das nur durch einen ebenfalls wartenden Thread erzeugt werden kann
• Beispiel 1: – Ein Thread befindet sich in einer unbenannten critical section
– Er möchte in eine weitere unbenannte critical section eintreten
– Da immer nur ein Thread in eine unbenannten critical section eintreten kann, führt dies zu einem Deadlock
• Beispiel 2: – Ein Thread versucht eine Sperre auf eine Ressource zu setzen, die er
bereits gesperrt hat
– Führt ebenfalls zu einem Deadlock
– Lösung: Verwende omp_*_nest_lock(var)-Funktionen

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Ereignissynchronisierung mit Barrieren
• Vor einer Barriere wartet jeder Thread bis alle an diesem Punkt angekommen sind
• Erst dann überschreiten sie die Barriere
• Setzen einer Barriere:
#pragma omp barrier
• Das Verhalten kann aber durch die nowait-Anweisung geändert werden

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
reduction clause
• Möglichkeit wiederholte Operationen auf Variablen zu synchronisieren ohne atomic oder critical
• Viel effizienter als atomic oder critical
• Erlaubt für: +, *, -, &, |, ^, &&, ||
• Kommutativ und assoziativ
• Variable wird mit dem Identitätselement initalisiert
• Identitätselement: – I, sodass gilt A op I = A
– wobei op eine erlaubte Operation ist
int i;
double sum;
#pragma omp for reduction(+ : sum)
for (i = 1; i <= 1000; i++)
{
sum += 0.5 * ((double)i + 42.);
}

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Scheduling
• Unter Scheduling versteht man die Art und Weise der Aufteilung der Arbeit auf die verschiedenen Threads
schedule(type[, chunk])
• Die schedule clause gibt an, wie der kommende parallele Abschnitt in Stücke (engl. chunks) aufgeteilt wird
• Typen: – static
– dynamic
– guided
– runtime

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Scheduling
•static –Aufgabe wird vor der Schleife in chunk Stücke zerlegt. Thread hört auf zu Arbeiten nachdem er seine zugewiesenen Iterationen abgearbeitet hat.
–Wenn chunk nicht angegeben wird, versucht der Compiler in etwa gleich große Stücke zu generieren
•dynamic –Threads holen sich dynamisch neue Iterationen nachdem sie chunk Iterationen abgearbeitet haben
–Wenn chunk nicht angegeben wird, wird 1 verwendet

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Scheduling
• guided (wenn chunk nicht angegeben, 1)
– Stückgröße nimmt exponentiell ab, startend von einer implentierungsabhängigen Größe, bis hin zu chunk
– Stücke werden dynamisch zur Laufzeit den Threads zugewiesen
• runtime (chunk darf nicht angegeben werden)
– Scheduling wird zur Laufzeit anhand der Umgebungsvariable OMP_SCHEDULE festgelegt
– Z.B. OMP_SCHEDULE=„guided, 10“

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Leistungssteigerung
• Speedup:
– Verhältnis von Ausführungszeit des sequentiellen Algorithmus zur Ausführungszeit des parallelen Algorithmus mit p Threads
– Formal:
• Effizienz:
– Verhältnis von Speedup zur Anzahl an Threads
– Formal:
p
sp
t
ts
p
se
p
p

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Leistungssteigerung messen
• Mithilfe der OpenMP Wanduhr
double start = omp_get_wtime();
// ...
printf("Time elapsed: %.2lf ms",
1000*(omp_get_wtime() - start));
• Auflösung/Genauigkeit ca. 2-3 Mikrosekunden (plattformabhängig)
• Daher: Keine zu kurzen Zeiten messen

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Zusammenfassung
• OpenMP ermöglicht es, aktuelle Prozessoren optimal auszunutzen
• Leichtester Ansatz zur parallelen, multithreaded Programmierung
• Löst jedoch nicht die grundsätzlichen Probleme der Parallelisierung
– Korrektheit beibehalten
– Synchronisierung
– Leistungssteigerung

Thomas Greif, Lehrstuhl Multimedia Computing, Universität Augsburg
Universitätsstr. 6a, D-86159 Augsburg, Germany; email: [email protected]
Zusammenfassung
• Verwende OpenMP
– wenn die Zielplattform ein Mehrkern/Mehrprozessor ist
– wenn die meiste Arbeit in Schleifen geschieht
– für Leistungssteigerung am Ende
• Beachte
– Kosten für Thread-Erzeugung und Synchronisation
– Es gibt keine Fehlerbehandlung
– Verhalten unter bestimmten Umständen nicht definiert
– Nicht jedes multithreading-Problem lässt sich damit schneller lösen





























