Embed Size (px)
Citation preview

I
Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica
tesi di laurea
Realizzazione di uno strumento web-based per il supporto al design di Reti di Sensori W ireless Anno Accademico 2010/11 relatore Ch.mo prof. Marcello Cinque correlatore Ing. Catello Di Martino candidato Antonella Caniano matr. 885 000 389

II
Ai grandi amori della mia vita, i miei genitori, Carmine ed Elena , che hanno sempre creduto in me, anche quando io stessa avevo smesso di farlo, Francesco, che si è preso cura di me in tutti questi anni restandomi accanto in ogni avversità, e senza il cui supporto ora sarei di sicuro finita in un ospedale psichiatrico (Ciccio come avrei fatto senza di te...), Lilli, il mio piccolo angelo nero. Ragazzi, Marty, Gigio e ultimo acquisto della scuderia, Serena, naturalmente anche voi avete giocato un ruolo determinante, abbiamo riso e pianto insieme, ma soprattutto insieme ne siamo usciti vincenti!!!

III
Indice Introduzione 5 Capitolo 1. Wireless Sensor Network 9 1.1 Introduzione alle Wireless Sensor Network 9 1.2 Scenari Applicativi 13 1.3 Sfide Progettuali di un sistema WSN 14 1.4 Architettura di Rete 17 1.4.1 Physical Layer 18 1.4.2 Data Link layer 18 1.4.3 Network layer 20 1.4.4 Transport Layer 21 1.5 I Sistemi Operativi nelle WSN 22 1.5.1 TinyOs 23 1.5.2 Mantis 25 1.5.3 LiteOS 26 Capitolo 2. Tecniche e Strumenti per la valutazione di WSN 29 2.1 Dependability in un sistema WSN 30 2.1.1 Tecniche di Valutazione Sperimentali 31 2.1.2 Tecniche di Valutazione Modellistiche 31 2.2 Ambienti di simulazione 36 2.2.1 Simulazioni Discrete-Event e Trace-Driven 37 2.2.2 Simulatori e Emulatori 37 2.2.3 Analisi Qualitativa 39 2.3 Osservazioni finali 46 Capitolo 3. Sviluppo di nuove soluzioni per il design di WSN: un approccio Multi-formalismo 48 3.1 Descrizione dell’approccio 49 3.2 Il tool Failure Model WSN Generator 52 3.3 Il simulatore Möbius 53 3.3.1 Il Simulation Engine e il SimulationManager 57 3.4 Il tool WebFAMOGEN 61

IV
Capitolo 4. Progettazione ed implementazione dello Strumento di Simulazione 64 4.1 Analisi dei Requisiti 64 4.2 Use Case Diagram 67 4.3 Architettura della RIA 71 4.4 L’archivio dati remoto 74 4.4.1 La scelta del database 74 4.4.2 La struttura di db_ Möbius 78 4.5 Il componente Model: il tool desktop-based Failure Model WSN Generator 81 4.5.1 La classe MobiusProject del package project e il file scriptShell.sh 81 4.5.2 Le classi del package simulator 84 4.6 I componenti View e Controller: il tool web-based Web Model WSN Generator 105 4.6.1 La scelta del framework 105 4.6.2 Le classi controller e i file.zul 108 Capitolo 5. Un Caso di Studio 112 Conclusioni e Sviluppi futuri 118 Bibliografia 117

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
5
Introduzione
I continui progressi tecnologici hanno portato al recente sviluppo di sistemi di elaborazione
sempre più funzionali e performanti; economici e di dimensioni trascurabili, attrezzati con
sensori estremamente avanzati per la rilevazione di grandezze fisiche complesse, e dotati di
connessioni wireless per la comunicazione, questi dispositivi elettronici (più o meno
intelligenti) vengono impiegati in articolati ed efficienti sistemi di monitoraggio embedded,
attraverso la realizzazione di reti di sensore senza fili, meglio conosciute come Wireless
Sensor Network (WSN), che sono così in grado di offrire un'ottima soluzione a basso costo
per la raccolta e l’elaborazione affidabile dei dati, e soprattutto di gestire al meglio le risorse
disponibili.
Queste caratteristiche hanno determinato l’uso consolidato delle WSN nelle più svariate
aree applicative, alcune delle quali con stringenti requisiti di affidabilità: si pensi, ad
esempio, alla possibilità di gettare tali sensori da un elicottero in volo durante un incendio
per individuare i sopravvissuti ed identificare le aree di rischio per i soccorritori, o nel
monitorare strutture per diagnosticarne eventuali cedimenti strutturali, e ancora in ambito
militare nella rilevazione di attacchi chimici, biologici e nucleari. Si intuisce, pertanto,
l’estrema importanza di prevedere e garantire un certo livello di affidabilità per questi
sistemi, poiché un qualsiasi malfunzionamento potrebbe avere delle conseguenze disastrose
anche gravi, ed è necessario che il sistema reagisca nel modo migliore, tollerando gli
eventuali errori. Tuttavia, nonostante l’impiego di tecniche di sviluppo e verifica imposte da
rigorosi standard internazionali, il rischio di fallimenti aumenta rapidamente al crescere
della complessità del sistema; questo, assieme all’inadeguatezza degli approcci e degli

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
6
strumenti tradizionalmente utilizzati nella valutazione della dependability, ha suscitato da
parte del mondo scientifico una rinnovata attenzione verso di essa: è in questo scenario che
negli ultimi anni è andata muovendosi anche l'attività del laboratorio Mobilab del
Dipertimento di Informatica e Sistemistica, il quale ha apportato un notevole contributo sia
nell'approccio della modellazione e simulazione delle Wireless Sensor Networks, sia
nell'implementazione di framework e strumenti software.
L’obiettivo principale del laboratorio è stato quello di formalizzare e implementare un
approccio finalizzato alla valutazione dell’affidabilità delle reti wireless, tale da risultare
generale, ma soprattutto concepito in modo da considerarne tutti gli aspetti, dall’hardware
impiegato come piattaforma, al sistema operativo, e ancora alle caratteristiche ambientali
del particolare scenario considerato. Esso è basato sulla modellazione e dunque su tecniche
di fault forecasting relative ad un accurato modello dei fallimenti che necessita di una fase
preliminare di raccolta e analisi dei dati comportamentali della WSN da modellare. I
formalismi utilizzati fin’ora con successo per l’implementazione di modelli di fallimento e
per la stima degli attributi della dependability (Reti di Petri, catene di Markov e Reliability
Blocks) non si prestano a garantire una generalità del modello e soprattutto a modellare
aspetti intrinsechi di una rete, quali topologia, canale trasmissivo, o le caratteristiche
ambientali nelle quali essa si trova ad operare. A valle di quanto detto sembrerebbe che una
valida alternativa andrebbe ricercata nella simulazione, tuttavia molte ricerche hanno
concluso che non è possibile soddisfare tutti i requisiti necessari a compiere uno studio
esaustivo delle proprietà comportamentali di una WSN con un unico strumento.
E’ da queste premesse che nasce l’idea di un innovativo e potente approccio per la
composizione di un modello multi-formalismo che risulti flessibile, ma allo stesso tempo
rigoroso, e che fonda le diverse peculiarità di un modello comportamentale e di un modello
formale dei fallimenti, attraverso cui ottenere una valutazione olistica dei vari aspetti di una
WSN. In seguito tale approccio si è concretizzato nell'implementazione di un tool deskto-
based per la generazione automatica di modelli di fallimento, il Failure Model WSN
Generator, il cui utilizzo però, richiedeva notevoli risorse di calcolo, per questo si è pensato

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
7
di remotizzare il tool, realizzando uno strumento web-based che convogliasse in un
ambiente operativo caratterizzato da immediata disponibilità e da un minore carico
computazionale tutte le funzionalità del generatore automatico: questo è il tool web-based
WebFAMOGEN.
E’ in questo contesto che va ad inserirsi il seguente lavoro di tesi, mirato ad estendere le già
numerose possibilità di funzionamento della web application. Oltre a poter generare in
modo semplice il modello di fallimento della particolare rete da modellare, il sistema è in
grado di fornire tutti gli strumenti per:
• Caratterizzare uno o più scenari da simulare, inserendo attraverso una schermata
grafica, tutti i parametri del modello del caso di studio, come il protocollo di routing
o il sistema operativo adottato sui nodi;
• Simulare sul server remoto il modello generato ed esportarne i risultati, così che
l’utente possa analizzarli nell’ambiente di calcolo più appropriato; operazione,
questa, che ha richiesto un reverse-enginering del complesso software Möbius al
fine di utilizzarne le classi;
• Archiviare su un database remoto MySQL sia i risultati delle singole simulazioni
che le diverse topologie che l’utente impiega nella generazione dei propri modelli.
Il lavoro è stato strutturato in cinque capitoli:
- il Cap. 1 introduce gli aspetti peculiari delle Wireless Sensor Networks che ne hanno
sancito il notevole successo;
- il Cap. 2 fornisce la definizione di dependability per le reti WSN e approfondisce le
principali tecniche di valutazione dei suoi attributi, ed espone una trattazione
sintetica dei più accreditati strumenti di simulazione a supporto dello sviluppo delle
WSN ad oggi sul mercato;
- il Cap 3 presenta l’approccio multi-formalismo proposto in [9] finalizzato a fornire
le semantiche necessarie per l’implementazione di un modello di fallimento di una
WSN capace di una descrizione eterogenea della realtà; contiene inoltre
un’esposizione degli strumenti realizzati a supporto del suo sviluppo e della sua

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
8
risoluzione, frutto dell’attività di ricerca del laboratorio Mobilab della Facoltà di
Ingegneria Informatica dell’Università Federico II di Napoli;
- il Cap 4 è focalizzato sulle tecnologie e sulle tecniche usate per implementare il tool;
dopo una breve introduzione sul contesto nel quale si inserisce il lavoro di tesi
svolto, saranno illustrate le modifiche realizzate ai tool desktop-based e web-based
al fine di implementare le nuove funzionalità, e la struttura del database sul quale le
applicazioni si appoggiano.
- Il Cap 5, infine, mostra attraverso una serie di screeshot le nuove funzionalità
imlementate nel tool.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
9
Capitolo 1
Wireless Sensor Network
“The most profound technologies are those that disappear…”
È con questa frase che Mark Weiser apre il suo celebre articolo del settembre 1991
intitolato “The Computer for the 21st Century”. In questo lavoro Weiser immagina un
mondo sempre più ibrido, in cui le macchine saranno così presenti da inserirsi dappertutto,
diventare quasi indistinguibili dal resto e soprattutto in grado di influenzare e migliorare
tutti gli aspetti della nostra vita. In effetti il futuro immaginato da Weiser non è poi così
lontano e immaginifico: a Cambridge, l’università di Harward e la BBN Technologies
stanno sviluppando CitySense, un progetto che prevede nei prossimi anni di realizzare la
copertura dell’intera città con una serie di sensori wireless, montati su pali del telefono,
semafori e edifici. La rete, progettata secondo un’architettura Mesh, prevede un centinaio di
nodi, ognuno dei quali è grande all’incirca come un Mac Mini e comprende un PC con
Linux e una memoria flash di qualche gigabyte come disco rigido, una comunicazione
wireless 802.11 a/b/g e diversi tipi di sensori.
1.1 Introduzione alle Wireless Sensor Network
Le Wireless Sensor Network (WSN) rappresentano ormai una realtà consolidata,
caratterizzate da elevati livelli di funzionalità, esse sono impiegate nei più svariati campi di

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
10
applicazione grazie alla loro capacità di interagire con l’ambiente circostante in qualsiasi
situazione. Il loro successo è dovuto ai progressi compiuti negli ultimi anni dai sistemi
microelettromeccanici, dalle comunicazioni wireless e dall’elettronica digitale che hanno
permesso lo sviluppo di sensori di dimensioni sempre più ridotte, a basso consumo
energetico, con un costo infinitamente più basso delle tradizionali reti cablate in termini sia
di manodopera che di materiali per le operazioni di cablatura. Inoltre, se da un lato le
cosiddette reti wired non presentano limitazioni in termini di potenza (poiché laddove è
possibile realizzare una connessione, è anche possibile portare delle linee di alimentazione)
e presentano altissimi livelli di sicurezza e ottime prestazioni, dall’altro, invece, esse sono
di difficile impiego in quei contesti ambientali che presentano caratteristiche fisiche che ne
rendano impossibile non solo la manutenzione, ma la stessa realizzazione.
Una rete di sensori wireless è una rete senza fili formata da nodi distribuiti con una densità
spaziale molto elevata (decine o centinaia di sensori nello spazio di pochi metri), costituiti da
sensori e/o attuatori che cooperano allo scopo di monitorare, rilevare, elaborare e
condividere, comunicando a breve distanza, i dati acquisiti dall’ambiente fisico nel quale
sono immersi. I sensori sono di dimensioni trascurabili, mimetizzabili e poco costosi, ma
soprattutto, la rete risultante risulta semplice da progettare, utilizzare e mantenere.
Quest’ultima, per di più, deve essere in grado di auto-regolarsi e auto-ripararsi poiché
impiegata in ambienti fisicamente remoti, ostili o inaccessibili all’uomo.
Un nodo sensore è generalmente composto da:
• un micro-controller (CPU) che ha il compito di gestire la logica con cui ogni nodo
deve agire collaborando con gli altri nodi per portare a termine le attività di
rilevazione assegnategli;
• una memoria solitamente propria del microcontrollore, utilizzata per salvare le
variabili durante l’esecuzione e per memorizzare il programma da eseguire
all’accensione;
• un modulo radio costituito da un ricetrasmettitore ad onde radio;
• sensori ed attuatori per effettuare le misurazioni sull’ambiente circostante;

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
11
• una fonte di energia, per alimentare i componenti.
Queste dotazioni fanno sì che ogni singolo nodo abbia specifiche capacità sensoristiche e
sia in grado di rilevare differenti grandezze fisiche, come temperatura, umidità, vento,
pressione, e trasformarle in segnali elettrici che vengono in seguito inviati a un uno o più
Figura 1.1: Architettura comune Wireless Sensor Network
nodi principali, detti sink o gateway, preposti alla raccolta e all’aggregazione dei dati di
tutta la rete e alla loro trasmissione a un server o a un calcolatore.
Caratteristiche stringenti dei sensori risultano essere la potenza di calcolo relativamente
bassa, la memoria limitata e il ridotto raggio di copertura della radio. Inoltre essi sono
normalmente alimentati da sorgenti di potenza che non possono essere in generale
sostituite, o quantomeno non frequentemente, quindi essendo la riserva d'energia limitata e
non rinnovabile, una efficiente implementazione di wireless sensor networking deve
prevedere meccanismi per mantenere costantemente i consumi molto bassi, per garantire
alla rete un tempo di vita sufficientemente elevato da consentirne l’impiego in applicazioni
reali. A tal proposito l’elevata densità di posizionamento, se da un lato implica problemi di
mutua interferenza fra sensori distinti, dall’altro fornisce la possibilità di impiegare
algoritmi di rete multi-hop che consentono l’utilizzo di basse potenze di trasmissione e

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
12
quindi di migliorare le caratteristiche dei nodi in termini di requisiti di potenza. Non solo,
ma l’elevata densità di sensori che implementano una rete dà luogo a una struttura di controllo
che genera grandi quantità di informazioni le quali possono essere impiegate per migliorare la
qualità dell’elaborazione globale.
La struttura di una WSN non è rigida pertanto, a differenza delle reti cablate, non risulta
difficile aggiungere nuovi nodi alla rete o modificare la posizione di sensori preesistenti
senza dover necessariamente riconsiderare l’intera struttura della rete. Questa flessibilità
della topologia consente la formazione di reti facilmente installabili e non geograficamente
preconfigurate, ma che dipendono solo dalla distribuzione dei sensori sul territorio: la
posizione non è predeterminata, ma può essere casuale, e i nodi della rete sono dotati di
capacità di auto-organizzazione e di una conoscenza diffusa sullo stato della rete.
Una simile tecnologia sembrerebbe essere la soluzione ideale in qualsiasi applicazione,
tuttavia comporta anch’essa una serie di svantaggi che vanno sicuramente tenuti in
considerazione in fase di progettazione e che fanno sì che le reti cablate siano ancora oggi
non del tutto sostituibili:
• la limitazione della velocità di trasferimento, poiché la capacità del canale
trasmissivo deve essere suddivisa tra tutti coloro che ne stanno facendo uso;
• il rischio sicurezza in assenza di specifici controlli, risulta facile infatti per un
intruso intercettare le informazioni che viaggiano nell’etere;
• l’influenza della qualità delle comunicazioni da parte di fattori esterni, come
interferenze elettromagnetiche e ostacoli in movimento;
• il consumo energetico degli apparati di trasmissione radio più elevato di quelli per la
comunicazione via cavo.
In Figura 1.2 sono evidenziate le principali differenze tra le reti cablate e quelle wireless :

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
13
Figura 1.2: Confronto tra reti Wired e reti Wireless.
1.2 Scenari Applicativi
La nascita delle WSN è sicuramente da attribuire alle applicazioni di carattere militare, basti
pensare alla più recente Smart Dust o “polvere intelligente”, una tecnologia strategica in
fase di sviluppo, costituita da una nube artificiale di microsensori che integrano capacità di
calcolo, parti meccaniche, figlie della nano-robotica, più i sensori elettronici in grado di
captare movimenti o vibrazioni. Di dimensioni ridottissime, questi micro-computer si
mimetizzano nell’ambiente per recepire e inviare informazioni in tempo reale via onde
radio ai satelliti. In un futuro non troppo lontano il Pentagono ha previsto di dispiegare in
massa questi sensori remoti per scopi di ricognizione e sorveglianza degli scenari di
battaglia. Non solo, ma potrebbero anche essere incorporati nelle nuove tute da
combattimento dei marines, inibendo i veleni delle armi chimiche e monitorando la salute
dei militari esposti ad aggressioni batteriologiche. Inoltre poiché i sensori sono visibili ai
raggi infrarossi garantirebbero il riconoscimento tra i soldati nei combattimenti notturni,
evitando, così, le vittime del "fuoco amico".
In generale i campi d’impiego delle reti di sensori wireless sono molteplici e l’elenco delle
applicazioni interminabile, la stessa polvere intelligente non è stata pensata solo per la
guerra, ma verrà presto introdotta in altri settori che vanno dal monitoraggio ambientale (i
sensori, sparsi nelle foreste, hanno il compito di sentinelle anti-inquinamento e nella
prevenzione degli incendi), ai sistemi antisismici, dove sono stati usati all’interno di edifici

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
14
o ponti per verificarne lo stato di salute dopo essere stati sottoposti a scosse sismiche: la
precisione di queste micro-apparecchiature consente, infatti, di percepire lesioni che
sfuggono agli occhi più esperti ma che possono determinare dei cedimenti strutturali; o
ancora nel campo della home automation, in cui i micro-computer spalmati nelle vernici
delle pareti consentiranno di auto-regolare la temperatura e la luminosità dell'ambiente in
modo da eliminare ogni spreco di energia.
Figura 1.3: Smart Dust a grandezza naturale e ingrandito.
In conclusione il monitoraggio embedded comprende una’ampia gamma di aree applicative:
le WSN sono oggi impiegate nei campi più disparati che vanno dalla domotica, scienza che
si occupa di applicare l’informatica e l’elettronica alle abitazioni, all’ingegneria civile e
ancora, in quello sanitario dove è possibile utilizzare queste reti per monitorare pazienti ed
eseguire accurate valutazioni diagnostiche; tutto allo scopo di migliorare significativamente
a costi irrisori la qualità di vita di ogni individuo.
1.3 Sfide progettuali di un sistema WSN
Sulla base di quanto detto nel paragrafo 1.1, risulta quindi evidente che la fase di
progettazione di una rete di sensori wireless debba tenere in considerazione tutta una serie

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
15
di fattori che ne influenzano in modo decisivo la realizzazione. Gli aspetti più critici sono:
• la fault tolerance, ovvero la capacità di una rete di garantire le sue funzionalità
anche in presenza di malfunzionamenti da parte dei suoi nodi; ricordiamo che un
nodo può smettere di funzionare semplicemente perché ha esaurito la sua batteria,
anche il quel caso il corretto funzionamento della rete non deve essere pregiudicato.
E’ necessario definire una tolleranza che varierà in funzione della specifica
applicazione e rispettarla attraverso opportuni algoritmi;
• la scalabilità dovrà assicurare che all’aumentare del numero di nodi di una rete, i
diversi dispositivi saranno ugualmente in grado di interagire tra di loro,
scambiandosi informazioni senza tuttavia generare mutue interferenze; questo è uno
scenario più che plausibile dal momento che i nodi possono evolvere nel tempo sia
in termini di posizione che di funzionamento;
• i costi di produzione che risiedono nella tecnologia di comunicazione,
nell’elettronica di condizionamento del segnale e nelle unità di calcolo; come più
volte ripetuto l’impiego di sensori risulta essere piuttosto massiccio all’interno delle
reti, sia per migliorare la qualità delle informazioni ricevute, che per agevolare la
comunicazione dei vari device che avendo un ridotto raggio di comunicazione
vanno pertanto posizionati il più vicino possibile gli uni agli altri; Appare quindi
chiaro il motivo che spinge a cercare soluzioni dal costo sempre più contenuto;
• gli ambienti operativi all’interno dei quali i sensori sono “immersi” sono spesso
impraticabili e fortemente inospitali, pertanto il progetto di una rete non può
assolutamente prescindere dal contesto in cui andrà ad operare;
• la topologia di rete che durante il suo ciclo di vita subisce continue variazioni sia
per la libertà con la quale si possono aggiungere o rimuovere i nodi, sia a causa della
eventualità che un nodo possa spegnersi; trovare una strategia che che garantisca
l’affidabilità della rete anche in corrispondenza dei continui cambiamenti e sia in grado
di bilanciare il consumo di banda e di energia è compito dei protocolli di routing;
• i requisiti hardware legati alla struttura interna dei sensori i quali si differenziano

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
16
dal tipo di unità di elaborazione, di scheda radio, e soprattutto dall’unità energetica.
E’ quest’ultima che riveste il ruolo principale poiché determina la vita funzionale della
rete che deve essere il più duratura possibile;
• i consumi relativi fondamentalmente alle azioni svolte dai sensori wireless, ovvero
la misurazione di grandezze fisiche (temperatura, umidità..), l’elaborazione
dell’informazione rilevata ed infine la comunicazione di questa agli altri nodi della
rete. Di sicuro il fattore che impatta maggiormente risulta esserre l’attività di
comunicazione poiché ogni qualvolta uno sensore deve trasmettere i dati dovrà
mantenere attivo l’ascolto sul canale radio per verificare che l’informazione sia stata
effettivamente ricevuta dal destinatario; risulta pertanto necessario analizzare
consumi e tempistiche connessi alla trasmissione ed alla ricezione, ma anche ai
consumi dovuti alle fasi di accensione e spegnimento del dispositivo;
• i requisiti sull’affidabilità della WSN:
- sincronizazione affidabile delle misure;
- consegna affidabile di una quantità significativa di misure;
- garanzie sulla copertura dell’area da monitorare;
- minimizzazione dell’ intervento umano sulla rete.
(L’argomento verrà ulteriormente approfonditi nel capitolo 2).
Tutti questi aspetti concomitanti fanno della progettazione e caratterizzazione di una
WSN attività assai complesse. A queste difficoltà si aggiungono i vincoli dettati
dall’applicazione specifica che impediscono di effettuare scelte univoche, risulta
quindi indispensabile conoscere in dettaglio le caratteristiche del sistema reale per
individuare le modalità e la gravità dei sui possibili fallimenti. Da qui l’esigenza di
formalizzare e implementazione tecniche e strumenti che mettano in luce come
queste criticità, dall’hardware al software e al sistema operativo, e ancora le
caratteristiche ambientali di operatività, s’influenzino a vicenda, e che siano di
ausilio ai progettisti durante le fasi di sviluppo di una WSN, al fine di:
• Conferire fiducia nelle scelte progettuali effettuate, validando e confrontando

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
17
le diverse soluzioni individuate;
• Effettuare una valutazione preventiva che consenta di prevenire e tollerare
possibili guasti che degradino le performance e l’affidabilità della rete;
• Permettere di rilevare, durante la vita operativa del sistema, eventuali colli di
bottiglia e suggerire le soluzioni da adottare in future revisioni.
1.4 Architettura di Rete
Le sfide progettuali che abbiamo esposto nei paragrafi precedenti si riflettono soprattutto
sulla quella che è la scelta del software da installare, ciò ha indotto la realizzazione di vari
protocolli dedicati creati ex novo per le esigenze delle WSN. Tra i vari standard presenti nel
settore, quello più promettente risulta essere lo IEEE 802.15.4, approvato nel 2003, è stato
designato per reti flessibili, di basso costo, bassi consumi energetici e bassi bit-rate. Così
come nel campo delle reti informatiche viene utilizzato il modello di riferimento ISO/OSI
(International Organization for Standardization/Open Systems Interconnection) per
distinguere, in maniera orizzontale, le funzionalità di rete, anche per le reti wireless è
definito uno stack protocollare simile che ingloba tutti gli aspetti relativi alla comunicazione
tra nodi. E’ da sottolineare che la separazione dei layer in una WSN non è ugulmente netta;
al contrario, essi si sovrappongono tra loro e la motivazione è da ricercare nello sviluppo di
protocolli di comunicazione efficienti, leggeri e capaci di supportare avanzate funzionalità
di risparmio energetico e flessibili ai cambiamenti della rete stessa. Al primo livello
troviamo quello fisico che fa riferimento al canale di comunicazione e alla parte di
sensoristica e di elaborazione dei segnali; segue il cuore di una WSN ovvero i livelli Data
link e Network che ne definiscono il profilo, dal momento che hanno il compito vero e
proprio di risolvere le sfide più difficili; infine il livello di rete e quello di trasporto. I livelli
sovrastanti vengono presi in considerazione solo per il gateway o host su cui girano
particolari applicativi, ad eccezione delle proprietarie che implementano parte del layer
Applicativo nei nodi. Analizziamo nel dettaglio i primi quattro layer.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
18
Figura 1.4: stack protocollare nelle WSN
1.4.1 Physical Layer
Il physical layer fornisce i servizi per abilitare la ricezione e la trasmissione dei pacchetti
del trasduttore radio. Rileva l’energia sul canale radio (Energy Detection) attraverso una
stima della potenza del segnale ricevuto; alla ricezione di un pacchetto, effettua una stima
della qualità in termini di bit error rate così da poter caratterizzando il canale radio (Link
Quality Indication); seleziona il canale di comunicazione ottimale ed è inoltre in grado di
effettuare il riconoscimento di canale libero o occupato (Clear Channel Assesment):
essendo l’accesso al canale condiviso, ogni nodo deve poter “ascoltare” prima di trasmettere
e se il canale è già in uso, deve attendere. Il canale viene indicato come ‘impegnato’ se
l’analisi dell’energia in banda rileva che essa è al di sopra di una certa soglia, oppure se
vengono riconosciute particolari caratteristiche di modulazione del segnale. Seppur
importante, perché altimenti la rete nemmeno esisterebbe, in realtà non riveste un ruolo così
determinante poiché le reti di sensori senza fili a bassa potenza sfruttano tutte apparati radio
con caratteristiche simili, ovvero bassa potenza di trasmissione, basso consumo, basso bit-
rate.
1.4.2 Data Link layer
Questo livello si compone di due distinti sottolivelli: LLC e MAC. Il primo, detto Logical

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
19
Link Control layer, fa da tramite tra i livelli superiori e il livello fisico, consentendo
l’interoperabilità tra diversi tipi di rete. Il livello MAC (Medium Access Control ), è
fondamentale nel determinare le prestazioni di una rete WSN perchè ha l’importante
compito di assemblare i dati in frame tramite l’aggiunta di un header, contenente
informazioni sull’indirizzo, e un trailer, contenente informazioni per la correzione degli
errori; disassemblare i frame ricevuti per estrarre informazioni sull’indirizzo e la correzione
degli errori; ma soprattutto gestire l’accesso al mezzo di trasmissione condiviso. I requisiti
di cui bisogna si solito tener conto nella progetttazione di un protocollo MAC sono l’entità
dei ritardi, il throughput, la robustezza e la scalabilità, ma nel caso specifico delle delle reti
di sensori senza fili riveste un’importanza particolare l’efficienza energetica del protocollo.
I fattori che hanno un significativo impatto sulle prestazioni e sul consumo di energia sono:
• la frequenza delle collisioni che determina la perdita e la ritrasmissione dei
pacchetti;
• l’ascolto prolungato in attesa di pacchetti sul canale;
• la frequenza di overhearing ovvero la ricezione e la decodifica di pacchetti destinati
ad altri nodi;
• l’eccesso di pacchetti di controllo;
• la frequente commutazione fra le diverse modalità di funzionamento nello stato
dormiente e quello di veglia.
I protocolli vengono pertanto progettati in modo da impedire queste criticità, essi possono
essere suddivisi in due macro categorie: Schedule-Based e Content-Based.
Nei primi, l’accesso al canale di trasmissione radio è regolato da una schedulazione
preassegnata ad ogni nodo affinchè uno solo per volta possa occuparlo. Il risparmio
energetico legato a questa tecnica è dovuto principalmente al fatto che i nodi vengono posti
in uno stato di inattività definito “sleep mode” (questo avviene spegnendo la radio) quando
non devono né trasmettere né ricevere dati.
I protocolli Content-based, conosciuti anche come Random Access-Based Protocols, non
richiedono che i nodi si coordino perché l’accesso avviene mediante meccanismi di

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
20
sincronizzazione del tipo RTS (Request-To-Send) e CTS (Clear-To-Send); il protocollo
risulta più robusto, ma non riduce in maniera significativa il dispendio di energia: in caso di
accesso contemporaneo da parte di più nodi non è possibile eliminare del tutto la possibilità
di collisione, ma solo minimizzarne l’occorrenza.
1.4.3 Network layer
A questo livello viene determinato il percorso ottimale che i pacchetti dovranno attraversare
a partire dai vari nodi dislocati in tutta la rete, fino al sink (o i sink). Abbiamo più volte
ripetuto che i nodi sono caratterizzati da un raggio di comunicazione ridotto, per questo
motivo è necessario che le misurazioni effettuino numerosi hop prima di raggiungere la
destinazione prefissata: il compito di un algoritmo di routing è proprio quello di individuare
il set di nodi intermedi più efficiente in termini di costi energetici e consumo di banda. In
generale il routing ha inizio con la scansione di tutti i nodi attivi nelle vicinanze, così che
ogni nodo si possa creare una mappa locale della rete per effettuare la sceltta ottima. Ad
oggi diverse sono le tecniche di routing che tengono conto delle particolari esigenze delle
reti WSN, vediamone alcune:
• il flooding è una tecnica basata su un approccio di tipo reattivo, in pratica ogni nodo
che riceve un pacchetto di controllo lo rinvia a tutti i suoi vicini. Questa strategia
presenta lo svantaggio di generare un numero enorme (teoricamente infinito) di
pacchetti; esistono tuttavia delle sue varianti che limitano il traffico generato come il
‘selective flooding’ in cui i pacchetti sono duplicati solo sulle linee che vanno
all’incirca nella giusta direzione, o il ‘gossiping’ che anzicchè usare il broadcasting
per la trasmissione, prevede l’invio dei pacchetti ad un solo nodo selezionato in
modo random tra i vicini.
• SPIN (Sensor Protocol for Information via Negotiation) è un protocollo basato sulla
diffusione di metadati sul sensore che sono di dimensioni molto inferiori rispetto a
quelle dei dati, risulta quindi meno oneroso del flooding. I nodi interessati al dato ne
richiedono in seguito l’invio completo. Allo scopo vengono utilizzati dei messaggi

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
21
specifici: ADV per l’invio dei metadati; REQ, per richiedere il dato e DATA,
contenente il valore vero e proprio fornito dal sensore. I vantaggi risiedono oltre che
nella diminuzione di traffico sulla rete, anche nella significativa riduzione di
ridondanza nella trasmissione e di consumo energetico.
• LEACH (Low-Energy Adaptive Clustering Hierarchy) adotta una topologia in cui i
nodi si auto-organizzano in cluster ed eleggono un nodo capo-cluster. Questi ultimi
comunicano con i capo-cluster vicini costituendo così una struttura gerarchica fino
alla stazione base. Il protocollo minimizza la dissipazione di energia, in quanto il
capo-cluster riceve ed aggrega i dati dei nodi appartenenti al cluster prima di
inviarli alla stazione base. Dopo un certo periodo di tempo la rete entra nuovamente
in fase di setup e inizia nuovamente la fase di selezione dei capo-cluster.
• Geographical routing ha l’obiettivo principale di usare informazioni sulla locazione
dei nodi per formulare un’efficiente ricerca fino alla destinazione. Un algoritmo di
questo tipo è molto comodo nelle reti di sensori perché minimizza il numero di
trasmissioni attraverso la stazione base eliminando ridondanza di dati trasmessi.
1.4.4 Transport Layer
Il livello di trasporto fornisce servizi di trasporto messaggi e di segmentazione dei dati
provenienti dal livello immediatamente superiore: questi, organizzati alla sorgente in catene
di segmenti, vengono poi riassemblati nel messaggio originale una volta giunti a
destinazione. Alcuni fattori critici di progettazione sono :
• il controllo della della congestione e il trasporto dei dati in maniera affidabile;
• la semplificazione del processo di connessione iniziale per accelerare il processo,
aumentare il throughput e abbassare il ritardo di trasmissione; questa potrebbe
essere realizzata utilizzando una tecnica connectionless, come in UDP, in cui lo
scambio di dati tra la sorgente destinatario non richiede l’operazione preliminare di
creare tra di essi un circuito, fisico o virtuale, su cui instradare il flusso di
informazioni;

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
22
• evitare quanto più possibile le perdite di pacchetto poiché esse si traducono in
spreco di energia; sarebbe utile un controllo di congestione attiva (Active
Congestion Control) attraverso cui, per esempio, il nodo che invia oppure un nodo
intermedio può ridurre la velocità quando la dimensione del buffer raggiunge una
certa soglia; inoltre avvalendosi di criteri di ottimizzazione cross-layer potrebbe
essere possibile aumentare le prestazioni della rete: attraverso le informazioni
inviate dall’algoritmo di instradamento, il protocollo di trasporto sarebbe in grado di
dedurre se il problema è causato dal percorso o da una congestione così da limitare o
meno la velocità di trasferimento.
A valle di quanto descritto, risulta piuttosto evidente che i protocolli di trasporto oggi
esistenti non sono idonei per le WSN: l’assenza d’interazione con i protocolli dei livelli più
bassi, il controllo della congestione end-by-end e non hop-by-hop, la garanzia di affidabilità
al solo livello di pacchetto oppure di applicazione, questi e altri aspetti li rendono inadatti al
singolo impiego nelle reti di sensori wirelss, mentre sarebbe più utile fondere i servizi
offerti da ognuno, in un unico protocollo performante alla specifica applicazione.
1.5 I Sistemi Operativi nelle WSN
Un sistema operativo per reti di sensori, non gode della possibilità di poter usufruire di
abbondanti risorse: il generico nodo sensore dispone di unità di elaborazione molto
elementari (la frequenza di clock è di qualche centinaio di MHZ), di supporti di memoria di
al più un centinaio di KB, ma soprattutto di limitate fonti energetiche quali le comuni
batterie alcaline. Di conseguenza i requisiti funzionali che il sistema operativo deve
soddisfare sono estremamente stringenti e investono aspetti quali il supporto efficiente alla
concorrenza, per ottimizzare l’uso delle limitate risorse e vincoli real-time, la flessibilità e
modularità, per adeguarsi alle diverse piattaforme e scenari applicativi, e l’uso efficiente
delle risorse, per ottimizzare il consumo energetico. Inoltre, anche l'installazione di questi
sistemi deve essere molto semplice: generalmente non è richiesta nessuna formattazione del
disco rigido, ma bensì, essi vengono facilmente installati come un qualsiasi altro

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
23
programma su un sistema operativo host.
In letteratura, si distinguono principalmente due approcci allo sviluppo di sistemi operativi
per reti di sensori senza filo:
• sviluppare un sistema i cui componenti vengono compilati assieme ad una
particolare applicazione. In altri termini, una volta individuata un'applicazione, essa
viene compilata assieme all'intero sistema operativo, il quale può da quel momento
fornire soltanto le funzionalità di quella precisa applicazione all'utente. I vantaggi
risiedono ovviamente in ridotte dimensioni e bassi consumi, mentre gli svantaggi in
una scarsa versatilità e riconfigurabilità dell'applicazione (TinyOS).
• sviluppare un sistema che includa i tradizionali strati di software dei sistemi general
purpose in versione ridotta (come Mantis e LiteOS). In questo caso è difficile tenere
sotto controllo i consumi e le risorse impiegate, ma si guadagna in versatilità,
potendo eseguire più applicazioni contemporaneamente.
1.5.1 TinyOS
I requisiti funzionali che il Sistema Operativo adottato all’interno dei sensori di una WSN
deve soddisfare sono estremamente stringenti e investono aspetti quali il supporto efficiente
un sistema open-source specifico per Wireless Sensor Network sviluppato dall’Università di
Berkley e il centro ricerche Intel. I principali punti di forza risiedono soprattutto nelle
dimensioni fortemente ridotte (basti pensare che una tipica applicazione TinyOS-Based
occupa in media una decina di KB di cui solo 400B circa competono al sistema operativo),
e in una libreria di componenti legacy che include protocolli di rete, servizi distribuiti,
driver sensor e tool acquisizione progettati per svolgere i più consueti compiti per WSN:
grazie al suo ausilio, nei casi più semplici, lo sviluppo di un'applicazione si riduce al solo
collegamento (wiring) dei componenti di libreria necessari, mentre applicazioni più
complesse richiederanno la scrittura di componenti aggiuntivi ed il loro collegamento con il
kernel, i driver delle periferiche, ed eventualmente, altri componenti di libreria forniti con
TinyOS. Le applicazioni per TinyOS vengono scritte in nesC (network embedded systems
C), un dialetto del C, di cui implementa solo un sottoinsieme di costrutti per limitarne la

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
24
complessità e soprattutto la potenza espressiva alle sole parti che realmente interessano;
inoltre aggiunge vari nuovi comandi orientati a definire la struttura dell'applicazione stessa
sostituendo la necessita di usare un linker dinamico a tempo di esecuzione. Questo permette
al compilatore, il nescc (uno strumento che si basa sul compilatore gcc della Gnu) di
conoscere esattamente tutti i componenti in uso in una determinata applicazione, come
anche l'occupazione di memoria (dati e programma) e di produrre il relativo codice oggetto,
linkato staticamente con le sole parti richieste del kernel, il tutto quanto più possibile
ottimizzato in termini di dimensioni. La gestione di tutto avviene in maniera statica,
attraverso la Known Programming Interface, una serie di prototipi di funzioni ai quali
potersi appoggiare, linkandole (staticamente) all'atto della compilazione. La scelta di
rinunciare alla flessibilità di un modello di gestione dinamica è legata soprattutto alla
necessità di ridurre al minimo gli sprechi, infatti in questo modo il sistema operativo (e, di
conseguenza, il microcontrollore) non viene caricato dei vari task di gestione delle
operazioni dinamiche.
La sua architettura si basa su un modello a componenti riutilizzabili che comunicano
attraverso l’invocazione di comandi (solitamente da parte dei componenti più lontani a
quelli pù vicini) e sollevando eventi (nel verso opposto), la cui esecuzione avviene al livello
più alto di proprietà dello sheduler.
I componenti differiscono a seconda del ruolo che svolgono:
• Gli Hardware abstractions realizzano il mapping tra le funzionalità fornite via
software e quelle messe a disposizione dall’hardware, creando un’astrazione di
queste ultime che ne facilitano l’uso da parte dei moduli superiori;
• I Syntetic hardware simulano il comportamento di hardware specializzato, più
complesso di quesso realmente presente sul sensore;
• Gli High level software component sono quelli di livello superiore e hanno il
compito di eseguire gli algoritmi che prescindono dal particolare hardware.
Per richiedere un servizio ad un componente è necessario invocare un comando sul
componente stesso; per garantire un alto livello di concorrenza e una gestione più snella dei

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
25
task, ogni operazione non banale è eseguita come una split phase operation. Questo
significa che il componente chiamante riacquisisce il controllo immediatamente dopo che il
comando che esso ha lanciato ha avviato un task e invece di entrare in uno stato di attesa
bloccante, continua le sue operazioni. Al termine del task, che andrà in esecuzione in un
tempo successivo, verrà notificato un evento al componente che ha richiesto il comando. E’
perciò necessario che il componente utilizzatore del comando definisca determinati event-
handler su eventi del componente utilizzato. Il codice split-phase è sicuramente più lungo e
complesso di quello sequenziale ma ha l’indubbio vantaggio, oltre a quello di consentire
una parallelismo delle esecuzioni delle operazioni di un componente, di ridurre l’utilizzo
dello stack in quanto non è necessario tornare alla funzione chiamante e creare grosse
variabili sullo stack.
1.5.2 Mantis
Mantis OS è un sistema operativo progettato e sviluppato dalla Colorado University. Da un
punto di vista concettuale è corretto dire che esso è opposto a TinyOS, poichè, essendo un
SO general purpose, ha una classica architettura multithread stratificata, inoltre contiene
uno scheduler preemptive con time slicing. Queste caratteristiche rendono possibile in un
nodo sensore, intrecciare l’esecuzione di task complessi con quella di task che hanno dei
requisiti temporali stringenti. Inoltre utilizza meccanismi di sincronizzazione attraverso
sezioni in mutua esclusione, ed ha uno stack protocollare standard per la rete e device
driver. L’occupazione di memoria di Mantis è molto ridotta. infatti in un’immagine che non
supera i 500 byte è contenuto il kernel, lo scheduler e lo stack di rete. Il consumo energetico
in Mantis è molto basso in quanto viene utilizzato uno scheduler che quando tutti i thread
attivi chiamano la funzione sleep() di MOS, spegne il microcontrollore, riducendo
notevolmente i consumi. Le sue caratteristiche principali sono la flessibilità, che garantisce
il supporto per piattaforme diverse, e la gestione di sensori attraverso la ri-programmazione
dinamica da remoto. Quest’ultima risulta estremamente importante poiché studi condotti sul
campo, hanno dimostrato che i nodi sensori necessitano di riconfigurazioni o modifiche

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
26
periodiche ed essendo i contesti ambientali nei quali essi sono inseriti difficilmente
accessibili, la possibilità di poter effettuare tali riconfigurazioni da remoto semplifica
enormemente la gestione della rete. Mantis quindi consente:
• il reflash dell’intero OS;
• la riprogrammazione di un singolo thread;
• cambiamento delle variabili all'interno di un thread.
Inoltre le modalità attraverso le quali ciò avviene sono due: la programmazione semplice e
quella avanzata.
Nella modalità di programmazione semplice, è necessario un collegamento diretto del nodo
Mantis (ad esempio attraverso la porta seriale del sensore), ad un personal computer per
poter avviare la shell di Mantis. A questo punto (dopo un restart) MOS avvia un boot loader
che cerca eventuali comunicazioni dalla shell, in questo modo il nodo accetterà il nuovo
codice immagine che verrà scaricato dal personal computer attraverso la connessione
diretta. Il boot loader trasferisce il controllo al kernel di Mantis o in seguito ad un apposito
comando dalla shell oppure se durante lo startup non è individuata nessuna shell.
La modalità di programmazione avanzata è utilizzata quando il nodo è stato già messo in
esercizio, di conseguenza è richiesto un collegamento diretto al nodo sensore. La possibilità
di gestire i nodi da remoto è fornita attraverso il Mantis Command Server (MCS) che è in
ascolto sia sulla porta seriale che sull’interfaccia radio di comandi che possono essere
inviati sia dal kernel che dalle applicazioni. L’utente, attraverso un qualsiasi dispositivo
della rete dotato di terminale, può invocare il mantis command client ed effettuare il login
in un nodo sensore; può visualizzare la lista dei comandi supportati dall’MCS, può
ispezionare e modificare la memoria del nodo, cambiare le impostazioni di configurazione,
eseguire o terminare programmi, visualizzare la tabella dei thread e riavviare il nodo.
1.5.3 LiteOS
LiteOS è un sistema operativo open-souce per WSN, nato nel 2007 dalla sinergia dei
dipartimenti di scienze informatiche dell’Università dell'Illinois at Urbana-Champaign,

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
27
dell’Università del Minnesota e dell’Università della Virginia. Questo OS è stato progettato
per fornire un'astrazione di tipo Unix per una wireless sensor network. I nodi infatti (come
si vedrà in seguito) vengono considerati come delle semplici directory disposte all'interno di
un file system organizzato in una struttura gerarchica. Esso è stato scritto in C, ed adotta un
modello di programmazione più semplice di quello di altri sistemi operativi della stessa
categoria. Attraverso una serie di interfacce semplici, esso ha come obiettivo quello di
ridurre gli sforzi di apprendimento di un generico utente o di un programmatore, che voglia
cimentarsi nella gestione o nell'uso di una WSN. Infatti, già ad esempio TinyOS è un
sistema più difficile da apprendere, poiché, come visto sopra, è scritto in NesC e di
conseguenza adotta un modello di programmazione basato sugli eventi, molto più
complesso. LiteOS invece, offre anche ad utenti inesperti ambienti familiari, basati proprio
su grafiche e interfacce tipiche di sistemi operativi di tipo UNIX. Infatti, per avere un
approccio diretto con LiteOS, è necessario semplicemente:
• Conoscere il linguaggio C;
• Avere un po' di esperienza d'uso di sistemi operativi di tipo UNIX;
• Conoscere il concetto di thread.
Inoltre, poiché l'utente vede ciascun nodo della rete come una semplice cartella, può
interagire con essi in maniera molto semplice, per trasferire un file, o ancora, per ricevere
un pacchetto dati.
Come per i due OS analizzati nei paragrafi precedenti, anche LiteOS dispone di
un'architettura modulare. Tuttavia a differenza di TinyOS e Mantis, i tre moduli di cui essa
è costituita, la Liteshell, il FileSystem, e il Kernel, non si dispongono su diversi livelli
secondo una struttura top-down così da intravedere una netta stratificazione. Inoltre questi
non risiedono tutti sulla stessa apparecchiatura, ma si distribuiscono tra stazione base di
controllo e nodi. Quando un utente, attraverso la shell, realizza una certa operazione su un
nodo, questa in realtà si traduce in una azione sul file system del sistema operativo (questo
perché, come si è già detto, i nodi vengono visti come semplici cartelle), e per questo
motivo l'interazione tra File System e Liteshell, è solo di natura occasionale: cioè, solo se

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
28
un utente, seduto al terminale della stazione base, richiede di compiere una precisa azione
sui nodi, allora i due moduli interagiscono tra loro, altrimenti non vi è alcuna forma di
interazione.
Il secondo modulo dell'architettura, il file system, è chiamato LiteFS, ed è stato progettato
appositamente per garantire un efficiente meccanismo di montaggio dei nodi: l'allaccio di
un nuovo nodo alla rete è paragonabile all’inserimento di un dispositivo USB ad una porta
di un Personal Computer. Stesso discorso dicasi per quanto concerne il distacco di un
sensore dalla WSN.
Il terzo ed ultimo modulo dell'architettura è il Kernel, Ii vero fiore all'occhiello del sistema
operativo poiché la sua principale caratteristica è quella di realizzare il caricamento
dinamico della memoria, che consente a più threads di occupare aree di memoria in maniera
concorrente, senza generare dei conflitti. La tecnica adottata prevede di salvare gli indirizzi
di memoria riservati ai singoli processi, in un file in formato HEX sotto forma, cioè, di
stringhe di caratteri esadecimali in modo da ridurre al minimo l’occupazione di memoria.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
29
Capitolo 2
Tecniche e Strumenti per la valutazione di WSN
Le caratteristiche che sono state approfondite nel capitolo precedente, quali l’assenza o
quasi di robustezza, dovuta alle dimensioni ridotte dei sensori, la significativa limitazione in
termini di potenza di calcolo, memoria e durata energetica, e l’affidabilità, fanno delle WSN
una fonte inesauribile di problemi di ricerca interessanti e stimolanti per la comunità
scientifica. Se fino a qualche anno fa l’attività dei ricercatori era incentrata
prevalentemente su tematiche come lo sviluppo di strategie di routing, protocolli di livello
MAC o ancora algoritmi e protocolli energeticamente efficienti, negli ultimi tre anni
l’attenzione si è spostata verso la modellizzazione dei sistemi, gli studi sulla reliability, in
particolare sulla valutazione della dependability, e sulle soluzioni per la fault tolerant, con
un’attenzione maggiore alle problematiche legate alla security. Esiste infatti una particolare
classe di sistemi tali che se si dovesse verificare un fallimento durante l’esecuzione di una
delle loro funzionalità potrebbe comportare conseguenze di notevole entità, sia in termini di
perdite finanziarie, sia di danni a persone e/o ambiente. E’ evidente perché per tali sistemi,
definiti critici, i concetti di affidabilità e sicurezza assumano un’importanza fondamentale.
Inoltre è opportuno che ad una prima analisi teorica delle soluzioni proposte segua una
ulteriore fase di validazione basata sull’uso di simulatori o di emulatori, indispensabile per
realizzare soluzioni che siano non solo efficienti, ma soprattutto pratiche.
Nel seguito del capitolo verranno quindi approfondite dapprima le principali tecniche di

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
30
valutazione degli attributi di un sistema dependable; seguirà una esposizione delle
caratteristiche che distinguono i vari simulatori; infine verrà fornita una trattazione sintetica
dei più accreditati strumenti di simulazione a supporto dello sviluppo delle WSN ad oggi
sul mercato, elencando per ognuno di essi punti di forza e limitazioni.
2.1 Dependability nelle WSN
Un sistema può considerarsi dependable se “è possibile riporre fiducia nel suo
funzionamento in modo giustificato” [1], in realtà vari sono i livelli di affidabilità che si
possono raggiungere, i quali dipendono dalle finalità e dalle caratteristiche che devono
essere soddisfatte nella particolare applicazione in cui il sistema andrà ad operare. In
generale però è possibile affermare che un sistema affidabile sarà operativo quando
necessario(availability), terrà un funzionamento corretto durante il suo utilizzo (reliability),
non consentirà alcun accesso non autorizzato(confidentiality) o la modifica delle
informazioni che esso utilizza (integrity) e che il suo funzionamento sarà sicuro sia in
termini di incolumità a persone e/o ambienti, sia di protezione nei confronti di minacce
esterne, di natura naturale o intenzionale (safety). Le tecniche adottate oggi, sono basate su
rigorosi standard internazionali e mirano a prevedere, prevenire, tollerare e rimuovere
eventuali guasti, errori o fallimenti che possano minare l’integrità della rete (un esempio è il
DO-178B impiegato in campo aeronautico).
Esse possono essere classificate in due categorie principali, la prima include quelle basate
su una valutazione probabilistica o quantitativa, e hanno come obiettivo quello si stimare gli
attributi delle dependability del sistema (o delle sue componenti) sopra menzionati; l’altra,
comprende le tecniche impostate su un’analisi di carattere qualitativo, che puntano a
stabilire come eventuali guasti dei componenti possano riflettersi sulla perdita di
funzionalità, prestazioni e su malfunzionamenti di sistema. La valutazione quantitativa può
essere eseguita attraverso tecniche sperimentali oppure tecniche modellistiche [2][9].

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
31
2.1.1 Tecniche Sperimentali
Le Tecniche Sperimentali o basate su misure, operano direttamente sul sistema reale, quindi
non sono praticabili in assenza del sistema oppure di un suo prototipo. La verifica della
validità delle scelte eseguite in fase di progettazione avviene attraverso una stima delle
grandezze di interesse ottenuta dall’analisi diretta dei dati statistici. Presentano l’indubbio
vantaggio di raccogliere dati con un livello di accuratezza nettamente maggiore rispetto a
quelli ricavati da qualsiasi modello del sistema, tuttavia la loro attuazione può risultare
estremamente costosa a causa della strumentazione apposita necessaria e come spesso
accade in presenza di osservazioni sperimentali, per ottenere campioni statisticamente
significativi di dati, sono necessari lunghi periodi di osservazione, rendendo l’analisi dei
risultati di non facile valutazione; inoltre, in caso di sistema troppo complesso risulta
impraticabile sviluppare il prototipo.
2.1.2 Tecniche Modellistiche
Un modello è l’insieme delle assunzioni semplificative fatte sul funzionamento di un
sistema ed espresse sotto forma di relazioni logico-matematiche. Modellare un sistema
significa rimpiazzarlo con qualcosa che sia più semplice e/o facile da studiare, equivalente
al sistema originale in tutti i particolari aspetti importanti. Un buon modello deve riuscire a
combinare accuratezza e semplicità, fornendo informazioni dettagliate, ma a un costo, in
termini di tempi e risorse, accettabile. Infatti, la motivazione che spinge al loro impiego va
ricercata soprattutto nel fatto che la valutazione della risposta di un sistema in seguito alla
variazione in alcuni dei suoi parametri o caratteristiche strutturali è solitamente ottenuta in
maniera molto più conveniente tramite la soluzione di un modello che dal sistema reale.
Sono da annoverare tra le metodologie di analisi basate sui modelli le Tecniche Analitiche e
quelle Simulative.
Per quanto concerne le prime, i molteplici formalismi usati sono classificati in base alla
tipologia di analisi alla quale si prestano: di tipo combinatoriale o basata sullo spazio degli
stati. Le tecniche combinatoriali hanno il vantaggio di essere molto semplici da trattare, ma

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
32
non riescono a rappresentare certe dipendenze dei sistemi, poiché necessitano di assunzioni
troppo restrittive, come l’indipendenza delle probabilità di guasto dei singoli costituenti.
Esempi di tali formalismi sono i Fault Trees, caratterizzati da un approccio deduttivo
(procedendo dagli effetti verso le cause puntano a identificare le origini dei fallimenti del
sistema al livello dei componenti elementari), e i Reliability Block Diagram, che invece
adottano un approccio induttivo (procedendo nel verso opposto puntano a determinare come
si ripercuotono al livello del sistema i malfunzionamenti dei componenti). Per ovviare alle
limitazione imposte da questa tipologia di formalismi, possono essere impiegati quelli
basati sullo spazio degli stati, i quali sono, sì, più sofisticati, ma anche più difficili da
trattare, poiché soffrono del problema dell’esplosione degli stati: il fatto che eventi
concorrenti possano essere eseguiti in qualsiasi ordine e che ogni possibile esecuzione
generi sequenze di stati diversi, rende lo spazio degli stati, seppur finito, così ampio non
poter essere analizzato in modo effettivo. E’ in questa categoria che rientrano, ad esempio, i
processi Markoviani, le reti di Petri Stocastiche o le Stochastic Activity Networks (SAN). In
realtà non esiste un formalismo in assoluto migliore degli altri, la scelta varia in funzione
degli aspetti da modellare e degli obiettivi dell’analisi e quindi dalla potenza espressiva
richiesta al particolare linguaggio: sarebbe infatti impensabile modellare un sistema
complesso utilizzando formalismi di elevata potenza espressiva, come quelli basati sulle reti
di Petri, perché se anche si riuscisse a gestire la difficoltà modellistica, si otterrebbe un
modello impossibile da risolvere su qualsiasi elaboratore commerciale.
Quando anche i modelli analitici risultano essere inappropriati a causa dell’elevata richiesta
di risorse computazionali, le tecniche simulative si presentano ad essere l’unica strada
percorribile: una simulazione e’ un sistema che rappresenta o emula nel tempo, il
comportamento di un altro sistema [17], generando così una storia artificiale del sistema
fisico emulato che può essere usata per il suo studio. Come tutte le altre tecniche model-
based, anch’essa presuppone l'esistenza di un modello che sia adeguatamente aderente al
sistema reale oggetto di studio, ossia fornisca con sufficiente accuratezza una descrizione
del comportamento del sistema, e in aggiunta prevede l'esecuzione di un software dedicato,

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
33
detto simulatore, il cui compito è quello di rappresentare l'evoluzione temporale del sistema
e fornire una stima delle misure di interesse. Le tecniche simulative sono classificate in
statiche se riproducono un sistema in un determinato istante di tempo, e dinamiche se
invece almeno una delle variabili dipende da tempo. Quest’ultimi utilizzano un modello
formato da variabili che permettono di rappresentare lo stato del sistema, si distinguono a
seconda che la variazione rispetto al tempo avvenga in modo discreto, Discrete-Event, (le
variabili di stato cambiano istantaneamente ad istanti di tempo separati, in corrispondenza
di eventi discreti) oppure continuo, Continuous-Event, nel qual caso la simulazione
consisterà tipicamente nella soluzione analitica (esatta) o numerica (approssimata) di
equazioni differenziali.
Modelli Analitici
Da un’analisi approfondita realizzata in [9] sui vari modelli analitici proposti in letteratura
per stimare le caratteristiche prestazionali di WSN, è risultato come le ipotesi semplificative
di affidabilità comunemente adottate nella quasi totalità dei lavori non tengano bene nella
pratica, fornendo una conseguente valutazione errata di parametri critici come, esempio, il
tempo di vita della rete.
In [10] viene supposto che il consumo energetico e la sopravvivenza della rete dipendano
unicamente dall’attività di trasmissione dati; in [11] viene studiato l’effetto che avrebbe
sulla rete l’impiego di nodi sink mobili per la raccolta dei dati, per mitigare il consumo di
quelli fissi. In questi lavori il tempo di vita della WSN è considerato quindi solo funzione
del consumo energetico e del numero di pacchetti trasmessi, senza tenere in considerazione
altri fattori importanti come la probabilità di fallimento dei singoli nodi.
Un concetto più generico viene proposto in [12], che tiene conto dei vari requisiti che
un’applicazione deve soddisfare, come il numero di nodi attivi, la latenza dei tempi di
consegna, la connettività, la copertura etc. Quindi la durata una rete wireless viene a essere
definita dal tempo durante il quale tutti questi requisiti sono soddisfatti.
Il lavoro in [13], invece, focalizza l’attenzione sull’affidabilità e sulle misure di ritardo di

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
34
consegna dei pacchetti, relativi alla probabilità di operatività dei singoli nodi: si è assunto
che la frequenza con la quale i fallimenti occorrono avviene in modo uniforme su tutta la
rete ed è dovuta essenzialmente all’usura dei componenti, alle interruzioni di corrente e a
catastrofi ambientali, dimostrando che valutare l’affidabilità in una rete generica è in realtà
un problema estremamente complesso e articolato.
In [14] gli autori affrontano il fenomeno dell’invecchiamento dei nodi al quale concorrono
il tasso di consumo energetico e quello di fallimento: è presentata una funzione di
sopravvivenza per ogni componente, in termini di una distribuzione di Weibull. In pratica
viene analizzato il comportamento di una rete organizzata ad albero con e senza tecniche di
aggregazione dei nodi, il che ha messo in evidenza che l’uso di queste ultime ne rallenta in
modo significativo il consumo di energia, avallando la tesi che vede il numero di nodi
intermedi in una trasmissione di dati che adotti una strategia multi-hop, cruciale nel
consumo energetico.
Il lavoro presentato in [15] è uno dei primi ad adottare un modello analitico per
rappresentare i passaggi tra le modalità di funzionamento dormiente/attivo dei nodi, in
particolare in termini di contesa del canale radio e delle problematiche di routing. Tuttavia
l’assunzione che è possibile usare catene Markoviane [9] nella modellizzazione, potrebbe
dar luogo alla formulazione di metriche di performance spesso sopravvalutate.
Tutte le opere che abbiamo citato aiutano a comprendere come gli approcci analitici ben si
prestano alla valutazione di caratteristiche prestazionali di WSN, ma solo sotto particolari
ipotesi semplificative che il più delle volte sono molto lontane dalla realtà, mentre non
bastano a risolvere il problema, dimostrato essere NP-Hard [16], in una rete arbitraria.
Modello dei fallimenti
Per studiare l’affidabilità di una WSN durante la fase di progettazione è necessario essere in
possesso di un suo accurato modello dei fallimenti. Per poter definire delle assunzioni
valide, si è ricorso al prezioso ausilio di studi sperimentali che hanno contribuito a
modellare un comportamento delle reti il più possibile aderente alla realtà.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
35
Come descritto in [9], nel lavoro[18] allo scopo di analizzare l’impatto della connettività
sulla reliability della rete, viene analizzata una rete organizzata in clusters, i soli fallimenti
considerati sono quelli del gateway, relativi all’esaurimento delle batterie, e del modulo
radio, dovuti sia a guasti hardware che a fallimenti di nodi nel suo range operativo. Il lavoro
fornisce anche un’analisi teorica sulla soglia del range radio che garantisce la connettività
tra nodi di una rete dislocata casualmente, utilizzando un modello matematico.
In [19], invece analizzano come il fallimento di un singolo nodo si rifletta sullo stato di
funzionamento dell’intera WSN: è stato proposto un limite superiore alla probabilità che
tutti i nodi siano connessi e tutta l’area della rete sia coperta, per nodi uniformemente
distribuiti sul suolo e con probabilità di fallimento anch’essa uniforme in tutta la rete. Non
viene però fornita alcuna analisi sulla connettività in grado di fornire risultati circa i
fenomeni di invecchiamento di una WSN come la ‘morte’ di nodi faulty o con batterie
esauste, ipotesi in cui cadrebbe l’assunzione di densità uniforme della rete.
In [20] viene proposto un modello in cui la rete è organizzata in cluster con cluster-head
rotante. I nodi possono fallire in maniera arbitraria generando mancati o falsi rapporti. Ad
ogni nodo è inoltre associato un ‘indice di fiducia’ per indicarne la credibilità in funzione
dei suoi fallimenti passati: l’indice è poi usato dal cluster head per valutare se gli
eventi generati da un nodo siano o meno ‘credibili’.
In [6] gli autori considerano un modello dei fallimenti in cui le modalità di fallimento sono
crashing oppure Byzantine behavior quindi le cause di un fallimento di un nodo possono
essere sia relative a guasti che a manomissioni. Insieme al modello dei fallimenti viene
utilizzato anche un modello della rete in cui si adottano sia tecniche statistiche sulla
clusterizzazione che tecniche orientate al rispetto della security ricavate da stime sul tasso di
fallimento dei sensori. Viene definita la reliability di una WSN come la probabilità che
esista un cammino tra il sink e almeno un unico nodo funzionante del cluster: adottando
questa definizione viene dimostrato come per reti di topologia arbitraria, la soluzione del
modello di affidabilità considerato rappresenti un problema di complessità non polinomiale,
tranne che per un caso particolare analizzato, per cui vengono fornite anche delle misure

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
36
ottenute tramite simulazione [3].
2.2 Ambienti di Simulazione
Come più volte ripetuto nel corso di questa tesi, le Wireless Sensor Networks sono formate
da un grande numero di nodi di rete di rilevamento, risulta quindi piuttosto complesso, o
addirittura irrealizzabile, modellare analiticamente una WSN; se pure fosse fattibile, ne
conseguirebbe un’analisi spesso troppo semplificativa, poco aderente alla realtà. D’altro
canto, l’impiego di banchi di prova concreti prevede uno sforzo enorme in termini di costi
di attuazione e di tempi di esecuzione. Eseguire infatti esperimenti sul sistema reale per
effettuarne una valutazione delle prestazioni che sia di supporto in fase di progettazione, è
costoso e difficile, e richiede spesso tempi di analisi piuttosto lunghi. Inoltre la ripetibilità
degli stessi è in gran parte compromessa in quanto molti fattori ne influenzano i risultati
sperimentali, non solo, ma risulta anche difficile isolare i singoli aspetti. Queste sono le
ragioni del recente boom nel settore dei simulatori, strumenti universalmente utilizzati per
sviluppare WSN, soprattutto nella fase iniziale: consentono, infatti di emulare il
comportamento di migliaia di nodi ad un costo contenuto e in tempi di esecuzione molto
brevi, al fine di studiarne gli aspetti critici; impiegati nell’analisi di sistemi ‘ipotetici’,
permettono di determinare il valore ottimale di parametri o i punti critici (bottlenecks). Ci
sono tuttavia due aspetti importanti da non sottovalutare per ottenere conclusioni fondate da
uno studio di simulazione: per ricavare risultati di fiducia è richiesta, da un lato, la
correttezza dei modelli di simulazione, ovvero che siano basati su solide assunzioni,
dall’altro, l'idoneità del particolare strumento impiegato per attuare il modello. Poiché sul
mercato esistono vari software che offrono funzionalità per modellare e riprodurre il
comportamento dei sistemi reali, alcuni dei quali sono progettati per raggiungere buone
prestazioni, mentre altri per fornire un semplice ed amichevole interfaccia grafica o
funzionalità emulative, è necessario trovare un compromesso tra la precisione e la necessità
dei dettagli, e le prestazioni e la scalabilità della simulazione, in base a quelli che saranno i
fini della rete da sviluppare.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
37
2.2.1 Simulazioni Discrete-Event e Trace-Driven
Una prima classificazione delle simulazioni può essere effettuata in funzione del tipo di
approccio adottato per condurre la simulazione. La tipologia trace-driven è quella più
comunemente utilizzata dai sistemi reali poiché presenta risultati più credibili e fornisce
un’accuratezza maggiore relativa al carico di lavoro. Essa opera su una sequenza di eventi
ordinati per tempo e registrati dal sistema reale, e non essendo basata su semplici ipotesi
risulta essere sicuramente più affidabile.
La simulazione ad eventi discreti, invece, esamina lo stato del sistema solo in
corrispondenza degli istanti in cui avviene un evento significativo. Con questo approccio si
salta immediatamente da un evento al successivo, senza simulare gli intervalli di tempo che
intercorrono fra due eventi, e questo avvantaggia notevolmente tale tipo di simulatori
rispetto a quelli tempo-continui in termini di complessità computazionale. Un apposito
scheduler degli eventi gestisce la coda di eventi generati dalla simulazione, ed ha la
responsabilità di ordinarli correttamente, nello stesso modo in cui essi si succederebbero
nella realtà. La maggior parte dei simulatori che esamineremo sono ad eventi discreti,
poiché è tipico delle applicazioni per WSN lasciare il processore ed i componenti hardware
in uno stato di sleep per la maggior parte del tempo, allo scopo di risparmiare energia.
2.2.2 Simulatori o Emulatori
Un software d'emulazione è un programma che permette l'esecuzione di software
originariamente scritto per un ambiente (hardware o software) diverso da quello sul quale
l'emulatore viene eseguito. Esistono varie categorie di emulatori, così come esistono diversi
metodi per emulare una piattaforma. È possibile emulare completamente un ambiente sia
hardware che software oppure soltanto uno dei due. Emulare un ambiente software è
tecnicamente meno complicato poiché può essere sufficiente un semplice traduttore di
istruzioni che renda comprensibile all'ambiente sul quale l'emulatore gira le istruzioni del
programma emulato. Nel caso invece dell'emulazione hardware, sarà necessario simulare la

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
38
circuiteria e il comportamento fisico del sistema. Un emulatore necessita sempre del
software di quel sistema (ottenuto con un processo detto spesso dumping), limitandosi
quindi ad emulare l'hardware, in modo da poter interpretare correttamente i file contenenti i
dump del software (che rimane scritto in un linguaggio comprensibile soltanto al sistema
emulato e non al sistema emulante, o sistema host). Si prefigge lo scopo di replicare il
funzionamento di un sistema. Una categoria particolare di emulatori sono quelli che fanno
uso di emulazione ad alto livello (high-level emulation), che si pongono a metà strada tra un
emulatore e un simulatore, in quanto ricreano le funzionalità di un sistema emulato facendo
uso di funzioni simili o equivalenti nel sistema emulante, raggiungendo alte velocità di
esecuzione a scapito dell'accuratezza. A questa categoria appartengono ad esempio Tossim
e EmStar, che ricompilano il codice ad alto livello e scelgono di perdere un po’ di fedeltà
nell’emulazione, in cambio di una maggiore scalabilità ed attenzione al funzionamento
macroscopico della rete, e Avrora e Atemu che invece puntano ad un’emulazione del codice
in linguaggio macchina o assemblativo, fornendo i addirittura meccanismi per effettuare il
debugging delle applicazioni, dedicando meno attenzione verso quelli che sono gli aspetti
macroscopici della rete
Un simulatore, invece, si prefigge lo scopo di replicare il comportamento di un sistema,
riscrivendo però (in tutto o in parte) le routine del programma da simulare, in modo da
renderlo comprensibile alla macchina su cui gira. Non essendoci alcuna emulazione
dell'hardware (cosa che prende diversi cicli-macchina), un simulatore è per forza di cose più
veloce, tuttavia è spesso poco preciso nel riproporre fedelmente il software simulato ed
inoltre la maggioranza delle volte il suo codice sorgente non è disponibile. Per tali motivi,
se i simulatori hanno dalla loro una notevole velocità di esecuzione, gli emulatori hanno
l'accuratezza (che comprende, ovviamente, anche eventuali bug del software e/o della
macchina originale). Appartengono a questa categoria Omnet++ che riproduce gli aspetti
legati ai protocolli di livello rete, trasporto o MAC, e Ns-2 e J-Sim, che invece puntano solo ad
uno studio applicativo degli algoritmi di instradamento.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
39
2.2.3 Analisi Qualitativa
In questo paragrafo analizzeremo le principali caratteristiche dei più accreditati strumenti di
simulazione per WSN. Poiché non è scopo di questa tesi fornirne aspetti dettagliati, per un
approfondimento si rimanda a [6].
NS-2
Ns-2 è un simulatore Discrete-Event utilizzato nella simulazione di protocolli di routing, a
supporto protocolli di rete. Nato nel 1989, si è imposto nel corso di tutti questi anni come
uno dei simulatori di reti più usati, anche grazie alla sua estensibilità ed alla possibilità di
simulare scenari del tipo più disparato. E’ scritto C++ e fornisce un'interfaccia di
simulazione attraverso OTcl, un dialetto object-oriented di Tcl. L'utente descrive una
topologia di rete scrivendo script OTcl, e poi il programma principale si occupa di simulare
la topologia con i parametri specificati. E’ a oggi uno dei più popolari simulatori di rete
non-specifici e supporta una notevole gamma di protocolli a tutti i livelli; inoltre il modello
open source consente di risparmiare i costi di simulazione e la documentazione online
permette facilmente agli utenti di modificare e migliorare i codici.
Tuttavia a causa dell’assenza di una GUI, talvolta la simulazione risulta più complessa e
richiede tempi assai maggiori rispetto ad altri simulatori; l’assenza un supporto grafico pone
gli utenti direttamente a contatto con i comandi testuali dei dispositivi elettronici e devono
pertanto avere familiarità con la scrittura di linguaggi di scripting, le teorie delle code e le
tecniche di modellazione; inoltre a causa dei continui cambiamenti del codice di base e dei
numerosi bug contenuti in alcuni protocolli, i risultati ottenuti possono non essere
consistenti. Altre limitazioni sono invece dovute alle origini di NS-2, legate essenzialmente
alle reti IP, per le quali era stato inizialmente sviluppato. Ad esempio abbiamo detto che è
in grado di simulare i protocolli a vari livelli, ma non il comportamento delle applicazioni
con le quali essi interagiscono, e il fatto che in una WSN non esiste una netta separazione
tra i due, rende spesso NS-2 inadeguato; ancora, poiché è progettato come un simulatore di
rete generale, non prende in considerazione alcune caratteristiche uniche di WSN come i

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
40
problemi del consumo di banda, potenza o risparmio energetico; soffre di un problema di
scalabilità poiché all’aumentare del numero di nodi, la dimensione del file di traccia ne
renderà difficoltosa la gestione.
TOSSIM
TOSSIM è un emulatore Discret-Event bit-level (ogni volta che un bit è trasmesso o
ricevuto viene generato un evento) specificatamente progettato per WSN e in esecuzione su
TinyOS. La trasmissione a livello del bit lo rende però molto poco scalabile e soprattutto
non adatto alla simulazione di reti realmente complesse. Il modello open-source e la
documentazione online ne fanno un simulatore grandemente estensibile, con funzionalità
che possono essere ampliate notevolmente scrivendo plug-in. E’ caratterizzato da un uso
semplice e immediato grazie alla sua GUI, TinyViz, che permette all’utente di interagire
con i dispositivi elettronici attraverso immagini invece che con comandi testuali. Con
questa interfaccia TOSSIM condivide un event bus attraverso cui essa può essere sempre in
ascolto di tutti gli eventi generati durante la simulazione. Questa strategia fornisce a
TinyViz la capacità sia di visualizzare in tempo reale lo stato della simulazione che di
controllarne l’avanzamento. La sua semplicità non ne limita tuttavia potenza e accuratezza
in quanto, simulando il codice ad un livello molto basso, produce risultati precisi e fedeli
alla realtà. Come emulatore specifico di rete, è in grado di supportare la simulazione di
migliaia nodi e fornire molte informazioni sia sul funzionamento individuale dei sensori che
sul comportamento macroscopico della rete. Essendo progettato specificatamente per
simulare i comportamenti e le applicazioni di TinyOS, non fornisce misurazioni delle
prestazioni di altri nuovi protocolli. Inoltre il fatto che l’eseguibile viene ottenuto attraverso
la compilazione contestuale dei componenti hardware emulati e con quelli di TinyOS
(usando il compilatore nesC, un linguaggio di programmazione event-driven, basato su
componenti e implementata su TinyOS), limita alle sole applicazioni omogenee la
possibilità di essere emulate. Per simulare correttamente i problemi del consumo energetico
nelle WSN viene fornito PowerTOSSIM, un altro simulatore di TinyOS, che estende le

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
41
numerose potenzialità di TOSSIM. Infine, attraverso un tool chiamato ‘lossy builder’mette
a disposizione un ottimo modello di propagazione radio per topologie a griglia, basato su
dati empirici che forniscono una stima delle probabilità di perdita di un pacchetto.
EmStar
Emstar è un framework concepito per studiare due tipi di WSN: quelle costituite da sensori
Microservers con architettura a 32-bit, che fanno uso tipicamente di sistema operativo
Linux, e quelle composte da sensori Mica a 8-bit, che sfruttano il sistema operativo TinyOs,
fornendo, a seconda dei casi, sia funzionalità di emulazione che di simulazione. La sua
architettura modulare, ma non strettamente livelizzata, permette agli utenti di eseguire ogni
modulo separatamente, senza sacrificare la riusabilità del software; inoltre le sue
caratteristiche di robustezza mitigano i guasti tra i sensori. Il tool principale per eseguire
applicazioni nell’ambiente Emstar è Emrun, progettato per i) lanciare le applicazioni nel
giusto ordine, verificandone le eventuali dipendenze attraverso la consultazione di un file
di configurazione, e massimizzandone il parallelismo; ii)far ripartire le applicazioni
interrotte; iii)individuare le applicazioni che non rispondono per riattivarle. La simulazione
vera e propria avviene usando i tool EmSim, per la simulazione di microservers, e EmCee,
per l’emulazione di radio dispositivi a bassa potenza. Inoltre lo staff della UCLA ha
sviluppato EmTOS che è un’estensione per abilitare anche l’esecuzione di applicazioni
basate su nesC/TinyOS. L’ambiente di simulazione offre anche una serie di servizi utili per
creare applicazioni Linux, come vari algoritmi di routing (tra i quali il Direct Diffusion, che
si occupa di inviare messaggi solo a gruppi di nodi interessati, utile per effettuare query
mirate all’interno della rete di sensori), un servizio di localizzazione che i sensori possono
adoperare per costruire e mantenere aggiornata in maniera dinamica la topologia della rete
circostante, un servizio di sincronizzazione tempo virtuale/reale indispensabile nelle
simulazioni ibride, ed altri ancora. Non tutte le componenti hardware di un sensore vengono
simulate da Emtos: è possibile per le applicazioni usare i led, la radio, e l’orologio di
sistema per la gestione dei timer. Non viene simulato l’uso del sensore, né il consumo

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
42
energetico, e queste sono delle limitazioni importanti in un emulatore che si prefigge lo
scopo di studiare il funzionamento dei sensori a basso livello.
ATEMU
ATEMU è un emulatore costruito in C delle piattaforme Atmel e Mica, dotate di processore
AVR. Il comportamento dei sensori è emulato a livello istruzione, invece il modello della
radio viene simulato. La sua GUI, Xatdb, fornisce la possibilità di utilizzarlo in modo
semplice per eseguire il codice dei nodi di cui è possibile effettuare il debuging, e
monitorarne il processo di esecuzione.
Atemu fornisce una libreria di device hardware come temporizzatori e ricetrasmettitori,
quindi una delle possibilità più interessanti è quella di poter definire l’hardware dei sensori
su cui eseguire le applicazioni. L’architettura hardware di un sensore può essere definita
scrivendo un file in XML, nel quale si indica quali e quanti moduli utilizzare per comporre
il sensore. Il modello di un sensore è piuttosto semplice: l’unica parte che non si può
modificare è il processore AVR, e si possono usare moduli software per emulare il
comportamento di tutti i dispositivi quali radio, led, sensore, ed altri ancora che possono
essere aggiunti. L’utente ha la possibilità di caratterizzare e combinare questi moduli nella
maniera che preferisce; in questo modo può simulare non solo i sensori esistenti,
impostando la corretta configurazione, ma anche sensori che non esistono nella realtà, allo
scopo sperimentale di studiarne il comportamento I vantaggi che comportano dall’impiego
di questo simulatore sono soprattutto due: la capacità di testare applicazioni e sistemi
operativi diversi da TinyOS la possibilità di simulare reti eterogenee di sensori caratterizzati
da hardware differenti (diversamente da quanto accade per esempio in Tossim). Tuttavia
essi sono ottenuti al prezzo di alti requisiti di processazione e limitata scalabilità. La
simulazione avviene ricercando la massima sincronia possibile, eseguendo un colpo di
clock per volta ed attendendo che tutti i nodi della rete ne abbiano portato a termine
l’esecuzione prima di passare al prossimo; l’approccio tempo-continuo è il più semplice per
gestire il delicato problema della sincronia, ma non il più conveniente dal punto di vista

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
43
della complessità computazionale. Inoltre a suo sfavore c’è da dire anche che esso supporta
un numero limitato di funzioni per la simulazione di problemi di routing e clustering.
AVRORA
Avrora è un emulatore Discrete-Event specificatamente progettato per WSN e sviluppato
interamente in Java, pertanto può solo simulare il comportamento hardware dei sensori
delle famiglie Atmel e Mica, dotati di processore AVR, eseguendo il codice del programma
in linguaggio assemblativo.
La principale differenza con Atemu consiste nel fatto che Avrora è un simulatore ad eventi,
e non tempo continuo. Non viene simulato il funzionamento dei sensori quando essi sono in
sleep, saltando direttamente al prossimo evento nella coda d’attesa di quel sensore che ne
provoca il risveglio ed il funzionamento. A questo si accompagna il fatto che ogni nodo
viene simulato in un thread a parte dal simulatore, il che consente di velocizzare
ulteriormente la simulazione, anche se ciò pone il delicato problema della sincronizzazione
degli eventi che riguardano nodi diversi. Avrora possiede due meccanismi per garantire la
sincronizzazione degli eventi, che è un aspetto cruciale della simulazione. Il primo metodo è
quello degli intervalli di sincronizzazione: ad intervalli temporali regolari, i nodi devono
fermarsi ed attendere gli altri prima di ripartire; questo dà modo a tutti gli eventi di essere
generati, prima di continuare con la simulazione, rendendo impossibile che qualche evento
venga “saltato” da qualche nodo. Questo metodo è efficace quando la simulazione è densa
di eventi. Il secondo metodo è quello di registrare in una struttura dati comune l’istante
virtuale al quale ciascun nodo è arrivato, e fare in modo che un nodo si blocchi quando la
differenza temporale con gli altri nodi diviene eccessiva; tale differenza non deve mai
superare il tempo necessario ad un evento, generato dai nodi vicini, per raggiungere il nodo
in questione. Questo metodo è efficace quando la simulazione è povera di eventi, e i sensori
trascorrono la quasi totalità del tempo in modalità sleep. A causa dell’assenza di
un’interfaccia grafica, per visualizzare i risultati della simulazione bisogna ricorrere
all’utilizzo dei monitor, ossia oggetti che “ascoltano” eventi di vario genere che accadono

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
44
durante la simulazione, ed elaborano dei parametri sintetici che vengono stampati alla fine
della stessa. Sono dei plug-in che l’utente può scrivere, sfruttando il fatto che il codice del
simulatore è aperto. Ad esempio il monitor interrupt gestisce una struttura dati,
aggiornandola di volta in volta che avviene un’interruzione nella simulazione, elaborando
statistiche su invocazioni, tempo di latenza, tipo, durata di tutte le interruzioni.
J-Sim
J-Sim è un simulatore Discrete-Event basato su componenti, sviluppato completamente in
Java. I principali vantaggi derivano dal notevole numero di protocolli supportati, inclusi i
framework per la simulazione di WSN, forniti di dettagliati modelli e algoritmi di
localizzazione, routing e di diffusione dati. I modelli sono riusabili e intercambiabili,
garantendo la massima flessibilità. Supporta una interfaccia grafica, Jacl, per le operazioni
di tracing e debugging e per la generazione degli script Tcl più semplice, anche se comunque il
lavoro richiede una certa complessità. All’interno di ogni nodo c’è un componente che simula
l’applicazione, ed interagisce con due pile protocollari sottostanti: una rappresenta il
software di rete (con livello di trasporto, rete, MAC, fisico) l’altra invece il sensore (con
uno strato agente ed uno che si occupa della ricezione degli stimoli). Il funzionamento dei
sensori è passivo, effettuano rilevazioni solo quando giungono degli opportuni stimoli
dall’ambiente esterno. Una possibilità offerta da J-Sim, ed assente in altri simulatori, è
quella di piazzare i cosiddetti Target node, ovverosia le sorgenti degli stimoli che verranno
captati dai nodi, e di impostare la politica con cui generano segnali. Anche il modello
energetico è simile a quello di Sensorsim: ci sono moduli che rappresentano la CPU e la
Radio, che possono operare in differenti stati di consumo energetico, ed un modello per
rappresentare la Batteria e la sua legge di scarica. I nodi wireless possono spostarsi
all’interno della topologia tridimensionale, come accade in Ns-2, secondo varie politiche
(spostamento casuale o movimento su di una rotta predefinita), questo vale anche per i
Target Node. Esistono inoltre dei sink, nodi che ricevono i messaggi della rete WSN e che
non sono sensori. C’è la possibilità di creare reti eterogenee, costituite da elementi wireless

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
45
e wired al tempo stesso.
Un’altra caratteristica in comune con Ns-2, è la presenza di un supporto a livello di libreria
(quindi sotto forma di componenti) per costruire applicazioni basate sul concetto di direct
diffusion, ossia che prevedono un modello di comunicazione publisher/subscriber in cui i
messaggi vengono inviati a gruppi di nodi interessati; utile per sviluppare alcune
applicazioni per WSN, che prevedono l’invio di query, o la ricezione di dati, coinvolgendo
l’insieme di nodi che soddisfano una certa condizione.
OMNeT++
Omnet++ è un simulatore Discret-Event scritto in C++ secondo il paradigma della
programmazione basata sui componenti, che usa il linguaggio Ned per la configurazione
della simulazione. Anche se non supporta in modo nativo librerie specificatamente
progettate per le WSN, grazie al contributo dei team progetto, ora esso è in grado di
supportare protocolli MAC e di localizzazione di WSN seppur in numero molto limitato;
inoltre è possibile realizzare la simulazione dei controlli del canale radio e dei problemi del
consumo energetico delle reti, e estrarre alcuni dati sul traffico di rete. Tuttavia, poiché i
vari moduli aggiunti per consentire di estenderne le funzionalità anche nel settore delle reti
wireless sono sviluppati separatamente dai vari gruppi di ricerca, si prevede un aumento
delle problematiche di compatibilità tra essi: la combinazione di modelli risulterà sempre
più difficile, e i programmi potrebbero avere elevate probabilità di riportare bug.
Omnet++ è fornito di una potente GUI che permette all’utente di effettuare in modo agevole
le operazioni di tracing e debugging, più che in tutti gli altri simulatori visti fin’ora. Il
simulatore è concepito per una rappresentazione astratta dei nodi della rete, che nella
maggior parte dei casi avviene tramite un unico componente, o un insieme di pochi
componenti interni, che si occupano unicamente di descrivere come il nodo in questione
gestisce la ricetrasmissione di messaggi. I messaggi sono semplici strutture dati con poche
informazioni, come ad esempio mittente, destinatario finale, dimensione in bit del pacchetto
per calcolare il tempo di trasmissione su di un link.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
46
2.3 Osservazioni finali
Da quanto osservato fin’ora è emerso che sugli approcci tradizionalmente impiegati nella
valutazione delle proprietà non funzionali delle Wsn, come il consumo energetico e
l’affidabilità, pesano in maniera determinante la forte eterogeneità delle applicazioni
all’interno delle quali esse sono impiegate, e la complessità delle dinamiche della rete
stessa, come routing, propagazione radio dei segnali, protocolli di livello Mac, etc... Le
tecniche più comunemente utilizzate sono per lo più basate su simulatori comportamentali e
modelli analitici: un modello simulativo, spesso chiamato behavioral è un modello
operativo che mima il comportamento di un sistema reale e che contiene le sue relazioni
funzionali; un modello analitico è un insieme di equazioni attraverso cui è possibile
caratterizzare un sistema. I primi sono estremamente potenti nel fornire dati statistici ad un
alto livello di dettaglio, ma sono indispensabili modelli minuziosi e un numero significativo
di esperimenti per ottenere risultati realistici, e questo a sua volta aumenta il tempo
necessario per la simulazione. D’altro canto anche i modelli analitici, che sono stati
utilizzati con successo da decenni per la valutazione delle caratteristiche non funzionali dei
sistemi informatici, presentano elevate limitazioni a causa delle forti ipotesi semplificative
sulle quali si fondano e che rendono i risultati dell’analisi poco attendibili; infatti la natura
altamente dinamica della WSN richiede la definizione di modelli complessi che sono
difficili da realizzare, ma soprattutto difficili da riutilizzare in contesti differenti da quelli
per i quali sono stati pensati, richiedendo così un elevato costo di sviluppo.
Per superare i limiti sopra esposti, in [9] è stato concepito un approccio ibrido per la stima
degli attributi della dependability che combina la flessibilità di un modello simulativo e il
rigore di un modello analitico, così da ottenere un modello multi-formalismo e attraverso
cui fornire le semantiche necessarie per l’implementazione di un modello dettagliato e
generale, capace di una descrizione eterogenea della realtà.
Il seguente lavoro di tesi è finalizzato, appunto, a concretizzare tale approccio in uno
strumento web-based di supporto alla progettazione di WSN, attraverso il quale il

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
47
modellista possa porsi ad un livello di astrazione più alto, lavorando nel proprio dominio
applicativo, e che renda la modellazione stessa più flessibile ed i modelli prodotti generali e
facilmente particolarizzabili. L’idea si fonda sulla costruzione di un modello versatile e
rappresentativo di un’ampia gamma di sistemi da un lato, e sulla possibilità di specializzarlo
attraverso l’uso di un tool di generazione automatica [15], così da ottenere un modello
finale per la simulazione del particolare sistema, senza snaturare la generalità del modello
iniziale e senza apportarne modifiche dirette. Il tutto in un ambiente di sviluppo che
garantisca:
• immediatezza di accesso;
• estensibilità;
• manutenibilità;
• carico di lavoro server-side.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
48
Capitolo 3
Sviluppo di nuove soluzioni per il design di WSN: un approccio Multi-Formalismo
Come sempre più spesso accade, l’unica soluzione accettabile per poter modellare i sistemi
reali caratterizzati dalle complesse proprietà strutturali e dinamiche relazionali va ricercata
in tecniche modulari o composizionali in cui modelli eterogenei sono integrati allo scopo di
fornire una visione olistica dell’intero sistema. Una possibile strada per affrontare il
problema consiste nell’adottare tecniche di modellazione multi-formalismo, il cui obiettivo
è di supportare la rappresentazione di sistemi complessi combinando diversi linguaggi e
tecniche di analisi.
Un modello multi-formalismo è un modello costituito da parti, ciascuna delle quali modella
un particolare componente o aspetto del sistema che si intende modellare, utilizzando il
formalismo più adatto allo scopo. I diversi sotto-modelli contribuiscono alla composizione
del modello complessivo che viene pertanto risolto coinvolgendo diverse tecniche e
strumenti di analisi. Un siffatto modello consente una valutazione olistica di attributi di
dependability (per esempio, disponibilità o sicurezza), relativi a modi di guasto definiti a
livello di sistema complessivo, che altrimenti andrebbero valutati attraverso l’analisi di
modelli isolati, con la conseguenza di dover effettuare ipotesi poco realistiche. Questo tipo
di definizione gerarchica dei modelli consente di affrontare l’analisi di un sistema
complesso secondo opportune metodologie. Per esempio è possibile modellare un sistema
definendo un livello che descriva il comportamento dei diversi sotto-sistemi, uno che

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
49
descriva l’interazione tra i sotto-sistemi mediante una rete e un livello che modelli la rete di
comunicazione. Ancora, è possibile sviluppare dei modelli che consentano di considerare
l’impatto della manutenzione sull’affidabilità e sicurezza del sistema, sviluppando
separatamente e poi componendo un modello di guasto ed uno di riparazione.
Evidentemente, l’analisi di modelli complessi implica la disponibilità di opportune tecniche
di soluzione e di strumenti automatici che supportino anche lo sviluppo del modello. Se è
pensabile, infatti, di sviluppare e risolvere separatamente, utilizzando i tool disponibili,
modelli molto semplici, realizzando “a mano” l’operatore di composizione, ovvero
prelevando il risultato ottenuto dall’analisi del primo modello e immettendolo
opportunamente nel secondo, non è possibile procedere in questo modo nei casi in cui gli
operatori realizzino funzioni complesse, ad esempio nel caso in cui forniscano informazioni
circa l'evoluzione di simulazioni in corso.
In questo capitolo verrà presentato un approccio per la composizione di un particolare
modello multi-formalismo per WSN basato sull’interoperabilità di due classi di modelli,
simulativi e analitici, proposto in [9]; seguirà un’esposizione degli strumenti realizzati a
supporto del suo sviluppo e della sua risoluzione, frutto dell’attività di ricerca del
laboratorio Mobilab della Facoltà di Ingegneria Informatica dell’Università Federico II di
Napoli.
3.1 Descrizione dell’Approccio
Come già anticipato, la potenza di questo nuovo approccio risiede nell’uso combinato di
modelli comportamentali e modelli analitici parametrici di fallimento per effettuare una
valutazione olistica e realistica delle proprietà non-funzionali di una rete di sensori wireless,
quali consumo energetico, sopravvivenza della rete e affidabilità.
Il diagramma in figura 3.1 mostra le cinque fasi salienti dell’approccio:
1. Inizialmente è indispensabile configurare la rete in termini di quelle che sono le
caratteristiche strutturali della particolare rete da analizzare, ovvero il numero e il
tipo di nodi, la topologia della rete, il carico di lavoro, il tipo di chip radio installato

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
50
sui nodi, l’algoritmo di routing adottato, la tecnologia delle batterie e del sensing
hardware adottati su ogni nodo; inoltre l’utente fornisce anche un set di metriche da
valutare, come per esempio disponibilità, performance, etc. Tutto ciò allo scopo di
performare i diversi esperimenti che serviranno poi a raccogliere le informazioni
necessarie a discriminare i parametri dei modelli di fallimento.
2. Durante questa fase viene mandato in esecuzione il particolare tool di simulazione
adottato (uno dei tanti analizzati nel capitolo precedente) il quale fornisce le stime
necessarie alla specializzazione dei parametri del modello analitico.
3. Alcuni dei parametri che vanno specializzati sono dinamici e variano al mutare delle
condizioni di funzionamento della rete, come il numero dei nodi guasti/isolati o il
rate di trasmissione di ogni nodo: se ad esempio un nodo X smette di funzionare
perché ha esaurito la sua energia, questo si ripercuote sull’albero di routing che va
conseguentemente aggiornato; ma ciò si riflette indirettamente anche su una diversa
velocità con cui si carica la batteria degli altri nodi, e quindi, sul di vita tempo e
dell’intera rete. Poiché questi parametri andrebbero ricalcolati coerentemente con le
nuove condizioni di lavoro, per supervisionare l’evoluzione del modello analitico
l’approccio prevede l’ausilio di un componente aggiuntivo, un motore esterno, che
ha il compito di disaccoppiare la generazione dei modelli analitici dal problema
della gestione dei cambiamenti della rete. Non solo, ma è essenziale per mantenere
la semplicità, la generabilità e riusabilità dei modelli. Durante questa fase quindi il
Model Generator produce modelli analitici partendo da una predefinita libreria di
template modello, e il numero e il tipo di modelli da generare dipendono dagli input
dell’utente. Un altro aspetto legato a queste operazioni è l’altro punto importante
che l’approccio vuole concretare e cioè ridurre lo sforzo di modellazione a carico dei
progettisti attraverso l’automatizzazione della creazione dei modelli analitici.
4. Questo passo riguarda la simulazione del modello analitico generato. Risulta chiaro
come il funzionamento di un singolo nodo modifichi il comportamento dell’intera
rete in modi inimmaginabili, e viceversa differenti scelte da parte dell’utente (come

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
51
ad esempio l’algoritmo di routing) influenzino il comportamento di ogni singolo
nodo. Per cercare di dominare questa complessità, utilizziamo modelli parametrici e
riusabili, i quali sono autonomi e capaci di adattarsi ai cambiamenti indotti da altri
modelli. Infine, durante la simulazione, vengono valutate le metriche scelte e i
risultati vengono proposti all’utente.
5. A questo punto, in dipendenza dai risultati ottenuti, l’utente può decidere se
necessario di rivedere le proprie scelte e di riprogettare il sistema.
Figura 3.1: Diagramma del nuovo approccio per la modellazione e la simulazione di Wsn
L’approccio appena descritto consente di anticipare le scelte progettuali, valutando
caratteristiche proprietà di una rete di sensori wireless in condizioni di guasto e in diversi
scenari di funzionamento, inoltre adottato in reti già distribuite, è di supporto nella
programmazione di interventi di manutenzione in seguito all’azione previsionale di un
potenziale degradamento delle stesse.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
52
3.2 Il tool Failure Model WSN Generator
Il tool Failure Model WSN Generator descritto in [15] non è altro che la concretizzazione
del nuovo approccio alla modellazione esposto nel paragrafo precedente: esso consiste in
un’applicazione desktop scritta in Java con GUI Swing, progettata a partire da un reverse-
engineering del tool di simulazione Möbius, e in grado di generare automaticamente i
modelli a partire da direttive di generazione e librerie fornite dal modellista. Queste ultime
devono fornire i modelli di base per una descrizione generale e vanno poi performati sul
particolare sistema oggetto di studio.
Figura 3.2: Il nuovo approccio alla modellazione e simulazione utilizzato da Failure Model WSN Generator
Attraverso l’interfaccia grafica, l’utente inserisce il path in cui si trovano i file contenenti le
informazioni riguardanti la particolare topologia da usare, seleziona il numero di nodi che
formano la rete di cui si vuole valutare il comportamento, specifica il tempo di simulazione,
infine immette il percorso in cui verranno generati i file del modello di fallimento. A questo
punto cliccando il tasto Generate, il tool è in grado di ricavare dalla topologia, le
descrizioni xml dei modelli SAN (Stochastic Activity Networks), che verranno date in
ingresso al simulatore Möbius per la compilazione dei file. Il codice C++ ottenuto dai
modelli viene linkato alle librerie Möbius che incapsulano comportamenti della simulazione

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
53
che prescindono dai particolari modelli su cui si vuole effettuare la simulazione stessa, e,
eventualmente, librerie definite dal modellista, producendo l’eseguibile per la simulazione
del modello generato. L’avanzamento dell’elaborazione viene infine comunicato all’utente
attraverso una serie di messaggi inviati ad una JTextArea della GUI.
3.3 Möbius
Nel tempo l’uso di modelli nel settore dell’analisi di sistemi critici per imitarne il
comportamento ed esaminarne prestazioni e affidabilità prima della produzione finale è
divenuto sempre più frequente. Numerosi sono gli esempi di strumenti realizzati ad hoc per
definire e risolvere i modelli analitici, come, ad esempio, i tool UltraSAN, HiQPN,
DEPEND, i quali, attraverso una semplice interfaccia, ne facilitano la costruzione. Questa
semplicità però limita il numero di formalismi supportati da ogni tool che risulta per questo
inefficace nella modellazione di sistemi complessi che avrebbero invece bisogno di
modellare ogni componente con il formalismo più appropriato. E’ in questo scenario che
viene sviluppato il software Möbius, concepito per creare un ambiente di modellazione
estensibile che permette di specificare il modello utilizzando una varietà di formalismi di
modellazione. Möbius è uno dei maggiori progetti di ricerca del Performability Engineering
Research Group (PERFORM) presso il Center for Reliable and High-performance
Computing dell'Università dell'Illinois ad Urbana-Champaign (Il-USA). Il progetto è
supportato da vari enti governativi americani e dal Motorola Center for High-Availability
System Validation. Nasce da un precedente tool del medesimo gruppo di ricerca, Ultra-
SAN, con l'obiettivo di sviluppare un framework di modellazione object-oriented e
formalism-independent per la performance-dependability evaluation.
Il tool è costituito da due componenti principali (Figura 3.3):
1. l’interfaccia grafica e il simulation manager, entrambi implementati in Java;
2. il core del simulatore, il simulation engine, realizzato in C++.
Questa divisione è spiegata dal fatto che mentre da un lato Java permette una buona
gestione degli ambienti visuali ed un'ottima portabilità degli stessi, dall’altro invece, il C++

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
54
risulta essere molto più performante ma meno portabile e meno adatto alla grafica.
Figura 3.3: architettura del simulatore Möbius.
Lo strumento lavora a step e durante ogni fase l'interfaccia grafica fornisce all'utente una
modalità user-friendly per la definizione dei modelli, dei vari parametri e la presentazione
dei risultati. Segue una breve descrizione delle varie fasi:
• Dapprima occorre definire uno o più modelli atomici attraverso un editor grafico, si
tratta delle unità fondamentali che possono essere caratterizzate anche da
formalismi differenti. Al termine, per ognuno di essi, viene generata e compilata una
classe C++, estensione della classe contenuta nella libreria del formalismo adottato;
l'oggetto risultante contiene due liste, una di state variables (rappresentano parti
dello stato del modello di cui sono componenti basilari), l'altra di actions (innescano
i cambiamenti dei valori delle variabili di stato con conseguenti transizioni di stato
del sistema complessivo modellato).
• La creazione di un modello composto è invece opzionale e avviene con un
approccio gerarchico, utilizzando i submodel definiti precedentemente. Il suo
salvataggio porta alla generazione e compilazione di un'ulteriore classe C++, erede
della superclasse propria del formalismo di composizione, contenente due o più

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
55
istanze di modelli atomici e le informazioni sullo sharing tra le loro variabili di
stato.
• Indispensabile per la valutazione delle misure di performance del sistema è la
definizione delle performance variables, attraverso il preposto editor, all’interno del
modello di reward. Il salvataggio di tale modello comporta la generazione e la
compilazione di una classe C++ con referenze al modello composto e/o ai submodel
e informazioni circa le variabili.
• Affinché il modello sia risolvibile è necessario infine fissare per ognuna delle global
variables (che vengono usate per parametrizzare le caratteristiche del modello e solo
dopo che è stato assegnato loro uno specifico valore, è possibile applicare una delle
tecniche risolutive) precedentemente definite sui modelli atomico e/o composto, uno
specifico valore. Tale assegnazione determina la creazione di un set di experiments
che insieme vanno a formare lo study, una struttura che consente di esaminare
l’effetto della variazione di queste variabili sulle performance del sistema oggetto di
analisi. Alla fine di questa fase viene generata e compilata un'altra classe che
incapsula i modelli di cui sopra.
• Una volta definita la tecnica di risoluzione analitica/simulazione più adatta alla
classe del problema trattato, il tool provvede alla fase di linking dei file oggetto con
le librerie dei formalismi, dell’interfaccia funzionale (AFI), che consente
l’interazione tra i vari formalismi utilizzati nella composizione del modello e il
solver, e del simulatore/risolutore analitico selezionato. Solo a questo punto il
simulation engine simula il modello, colleziona le osservazioni e le invia al Java
manager che si occupa di calcolare le statistiche sulle variabili di reward definite
nell’omonimo modello (tale argomento verrà approfondito nella sezione
successiva).
Ogni formalismo supportato da Möbius per la costruzione di un modello è caratterizzato da
una precisa tipologia di file xml prodotti [15]:
• nella cartella principale del progetto è presente la subdirectory Atomic che contiene

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
56
a sua volta tante sottocartelle quanti sono i modelli atomici definiti per il progetto,
ogni sottocartella ha il nome del modello atomico così come definito nel project file.
Per la costruzione del modello, Möbius, mette a disposizione vari tipi di formalismi
come buckets and balls, PEPA, fault trees, SAN ed è data la possibilità di definire
nuovi formalismi di modellazione attraverso estensioni del tool. In ogni cartella col
nome del modello atomico, è presente il file xml NOMEMODELLOSAN.san,
insieme a un file cpp, un headerfile e un makefile ottenuti dalla traduzione del
modello in codice C++ e alla sua compilazione effettuata da Möbius per la
generazione dell’eseguibile per la risoluzione del modello stesso.
• I file xml dei modelli composti sono ubicati nella subdirectory Composed, nella
cartella principale del progetto. Ogni modello composed ha la propria cartella, col
medesimo nome del modello, contenente il file NOMEMODELLO.cmp, oltre ai file
ottenuti dalla traduzione del modello in codice C++ e il makefile per la
compilazione. Il file NOMEMODELLO.cmp contiene informazioni sui sottomodelli
di cui il modello composto è costituito, sulle variabili condivise ossia i place che i
modelli mettono in comune, e sugli archi che congiungono i modelli (edge).
Esistono essenzialmente due formalismi per i modelli composed, corrispondenti alle
due operazioni per la composizione di modelli previste da Möbius: all’operazione
di join corrisponde il formalismo ‘graph’ mentre all’operazione di ‘replicate’ il
formalismo rep\join.
• I file dei modelli di reward sono ubicati ognuno in una cartella col medesimo nome
del modello a sua volta posizionata nella cartella Reward, nella directory principale
del modello. E’ presente un file xml NOMEMODELLO.pvm e i file ottenuti da
quest’ultimo traducendo il modello in codice C++ e il makefile per la compilazione
del codice.
• I file dei modeli di study sono salvati nella cartella Study, situata nella main
directory del progetto.Ogni singolo modello di study ha la propria cartella chiamata
col nome del modello stesso. Ripetiamo che uno study dà la possibilità al modellista

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
57
di esaminare il comportamento del sistema al variare di parametri definiti come
variabili globali nei modelli atomici e composti. Tali parametri assumono uno
specifico valore solo quando, attraverso uno study, si definiscono uno o più
esperimenti. Un esperimento rappresenta così una tupla di valori dei parametri, per i
quali il modello può essere risolto. Möbius supporta due tipi di formalismi per la
definizione di study: range study, che viene salvato in un file
NOMEMODELLO.rsd, e set study salvato in NOMEMODELLO.ssd, oltre questa
tipologia di file saranno ovviamente presenti i file prodotti dalla traduzione del
modello in codice C++ e il makefile per la compilazione. La differenza tra i due
formalismi di study sta nel fatto che il primo permette al modellista di specificare
per i parametri valori fissi o un range di valori, dopodiché Möbius genererà
automaticamente gli esperimenti come il prodotto cartesiano di tutti i valori che
possono assumere le variabili, nel secondo il modellista specifica esplicitamente
tutti i valori dei parametri per ogni singolo esperimento.
• I solver sono situati nella directory $PROJECTROOT\NOMEPROGETTO\Study\
\NOMEMODELLO\ dove NOMEMODELLO sta a indicare il nome del singolo
solver. Möbius fornisce due tipi di solvers per ottenere soluzioni sulle misure di
interesse: simulazione e risoluzione numerica. Concentrandoci sulla simulazione,
questa permette, dopo la scelta dello study da simulare, di settare diverse
impostazione come il generatore di numeri pseudocasuali usato, il seme per la
generazione casuale, le macchine da usare per una simulazione distribuita, il numero
di processori impegnati etc…
3.3.1 Il Simulation Engine ed il Simulation Manager
Il simulation engine e il Java manager usano le standard BSD (Berkley Software
Distribution) sockets per scambiarsi le osservazioni elaborate, i dati relativi alla
registrazione di un processo manager e gli stessi comandi inviati da questo per gestire il
termine della simulazione. In realtà la comunicazione è mediata da un processo child del

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
58
simulation engine process il quale ha il compito di intercettare i comandi mandati dal
manager e di tradurli in segnali POSIX (Portable Operating System Interface) da inviare al
parent process. In particolare interpreta i comandi di ‘finish’ e ‘quit’ inviati dal manager e li
traduce rispettivamente nei segnali SIGINT , per indicare che la simulazione deve riportare
il set corrente dei risultati al manager e poi terminare, e SIGQUIT, per terminarla
immediatamente. Questa mediazione serve a facilitare la comunicazione di tipo asincrona
tra i due componenti, ma soprattutto ad evitare che il parent process impieghi, a discapito
della esecuzione delle osservazioni, cicli di cpu per monitorare la rete in attesa di ricevere
segnali dal manager.
Al simulation client viene passato come argomento dalla linea di comando, il port su cui si
pone in ascolto il simulation manager; dopo l’istanziazione del modello il child process
inizia una transazione con quest’ultimo allo scopo di effettuarne la registrazione presso il
parent: in questo modo il manager potrà identificare il port che il client usa per ricevere i
comandi visti sopra e verificare che la comunicazione sia possibile. Se si verificano degli
intoppi durante questa fase, allora il client termina e la transazione fallisce.
In aggiunta ai due comandi sopra menzionati, il child process accetta anche un ulteriore
comando di ‘ping’ al quale risponde direttamente, che può essere inviato dall’utente per
assicurarsi che il client stia eseguendo la simulazione; inoltre, sempre allo scopo di evitare
di sottrarre inutilmente cicli del processore all’elaborazione delle osservazioni, esso usa la
funzione ‘select’ di POSIX per entrare in uno stato ‘sleep’ mentre aspetta le istruzioni dal
manager.
Il reporting dei batch osservati al manager, viene fatto direttamente dal parent simulation
engine, eliminando il significativo numero di messaggi che sarebbe necessario scambiare
per la comunicazione tra i due processi padre-figlio. Questo onere aggiuntivo a carico del
parent process sembrerebbe apportare un ulteriore ritardo alla creazione delle osservazioni,
ma così non è poichè, per fortuna, molti sistemi operativi forniscono funzioni di rete per la
consegna quasi istantanea dei piccoli pacchetti di dati usati dal simulatore; questo grazie al
meccanismo di buffering del lower layers del protocollo di livello trasporto adottato, che

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
59
consente così di utilizzare solo una bassissima percentuale del tempo del processore ai fini
delle comunicazioni su rete.
L’intera gestione della simulazione è condotta dalle classi del Java manager: la sua
architettura può essere organizzata in tre componenti principali, il management simulation
clients, il data collection, e lo user interface.
• Il management simulation clients: la gestione del simulation clients avviene
attraverso una serie di thread che possono essere eseguiti in modo indipendente;
questo è importante dato essi impiegano gran parte del tempo ad attendere che si
verifichino determinate condizioni, come la terminazione di un particolare processo
oppure la ricezione dei dati per calcolare le statistiche sulle variabili di reward.
Evitare anche in questo caso di sprecare cicli del processore è motivato dal fatto che
il simulation manager è progettato per girare in parallelo sullo stesso sistema del
simulation client, del quale non si vogliono compromettere le performance. Per ogni
processore presente sulla macchina, che sia stato selezionato in caso di simulazione
distribuita (ma anche in caso di singolo processore è lo sttesso), viene creato il
relativo thread incaricato di gestirne le operazioni: esso ha il compito di individuare
un esperimento tra quelli attivati, e avviare la sua esecuzione sul simulation client.
Quando l’esecuzione termina, il thread è pronto a selezionare un nuovo esperimento
e a ripetere tutte le operazioni necessarie. La classe responsabile per questo thread è
la ProcessorManager, la quale interagisce quasi esclusivamente con gli oggetti della
classe ExperimentObject, che rappresentano ognuno, uno degli esperimenti definiti
sul modello, e che forniscono tutti i metodi necessari per calcolare, invocando una
particolare classe di oggetti, i risultati statistici sulle variabili di reward. Il
ProcessorManager, inoltre, gestisce un task per l’invio dei comandi di controllo da
inviare al client simulation engine, attraverso una serie di metodi per creare socket e
connettersi al child process del client.
• Il data collection: anche la raccolta dei dati trasmessi dal simulation engine è gestita
attraverso un gruppo di thread, i quali sono controllati da un NetworkThread (in

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
60
realtà ad esso corrisponde la classe Simulator del Möbius Project, ma in questa sede
viene così chiamato, perchè inteso nel termine generale di gestore della
comunicazione di rete) che ha il compito di istanziarli. Viene creato un
NetworkReader (un oggetto della classe StreamReader) per ogni ProcessorManager
istanziato, ed è questo che gli passa la socket creata in fase di connessione con il
client, indispensabile per leggere i dati dalla rete che verranno in seguito trasferiti in
un buffer locale. Una volta terminata questa operazione, la connessione è chiusa e i
dati vengono formattati e posizionati in una matrice di double che verrà usata dagli
esperimenti. La politica del simulation manager è orientata al riuso degli oggetti
istanziati, così da prevenire un uso non necessario del processore per istanziarne di
nuovi. Allo scopo vengono usate delle liste per tenere traccia degli oggetti che
hanno espletato i propri compiti e sono pertanto inattivi: un esempio sono gli stessi
network reader che, terminato un ciclo di lettura, se necessario, vengono
nuovamente riutilizzati, passando loro dei nuovi stream. Anche per gli oggetti
contenenti i dati formattati vale la stessa cosa: viene istanziato un nuovo oggetto
solo se nel frattempo che un esperimento sta ancora utilizzando i dati
precedentemente trasmessi, arrriva un nuovo pacchetto dal simulation client che
deve essere trasferito.
Per il calcolo delle variabili di reward viene usato un thread separato, il
CalculationThread, che è associato al particolare ExperimentObject e che coordina
un gruppo di oggetti (derivati da una classe base) che hanno il compito di gestire i
diversi calcoli da fare sulle variabili, quali media, varianza, e stime di intervallo e di
distribuzione.
• Lo user interface: l’interfaccia grafica del simulatore di Möbius fornisce varie
opzioni di debugging, e la possibilità di visualizzare in tempo reale lo stato della
della simulazione e di controllarne l’avanzamento. Questo è possibile poiché i valori
mostrati relativi ai singoli esperimenti, vengono aggiornati contestualmente al
calcolo statistico effettuato dal relativo Calculation Object.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
61
Figura 3.4: Data Flow del Simulation Manager
3.4 WebFAMOGEN
E’ uno strumento web-based per la simulazione di reti di sensori senza filo, nato dalla
neccessità di remotizzare il tool Failure Model WSN Generator, di cui mette a disposizione
gli strumenti in maniera semplice, rapida e con un carico computazionale esiguo da parte
dell'utente. Attraverso questo tool l’utente è in grado con un thin client di inserire o
disegnare lo scenario topologico da modellare, ottenere automaticamente un modello
analitico atto ad incentrarsi sulla dependability del sistema, scegliere le metriche da valutare
e scaricare il risultato ottenuto. Inoltre è in grado di ricavare dalla topologia come viene
propagata la comunicazione tra i vari nodi sensore attraverso un modello manuale, un
modello di tipo fixed radius e di altri modelli implementabili successivamente.
Le motivazioni del remoting vanno ricercate nei numerosi vantaggi che può offrire una
applicazione web-based rispetto a una desktop-based:
• L’aggiunta di nuovi modelli analitici si propaga in tempo reale ed è subito a
disposizione di ogni utente che accede alla web application;
• L’utente non ha bisogno di installare e configurare particolari software di modellazione
e di simulazione in ogni macchina che utilizza per lo sviluppo di WSN, e può accedere
all’applicazione ovunque e da ogni sistema dotato di un web browser;
• Tutto il codice gestito dalla web application non è ne visibile ne accessibile da parte
Network Thread
Network Reader
Vector-List dei Network Readers
Vector-List degli old Data Objects
Data Object
Vector-List dei nuovi Data Object
Calculation Thread
instaurazione connessione con il Simulation Client
Dati dal Simulation Client

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
62
dell’utente: tutto ciò a cui il modellista può accedere sono i dati di modellazione e
simulazione;
• Il calcolo computazionale delle simulazioni e della generazione di modelli analitici in
base alla topologia della rete, avviene sul server o potrebbe addirittura avvenire su un
sistema distribuito di server, in modo tale che il modellista possa utilizzare un normale
thin client con notevoli risparmi in ambito economico.
La natura web-based dell’applicazione, intrinsecamente multi-utente, ha reso necessaria la
gestione contemporanea di più utenti che si collegano al servizio, attraverso l’uso di un
accesso protetto con validazione delle credenziali per ogni sessione, ma soprattutto di un
ambiente personalizzato che viene creato eseguendo correttamente il primo accesso al web
server. Ogni modellista, progettista e sviluppatore di WSN, infatti, una volta autenticatosi è
in grado di accedere ai propri file contenenti le topologie, i modelli, e i risultati delle proprie
simulazioni archiviati in un database sul server. Tutto ciò grazie ad una semplice interfaccia
grafica che consente di navigare tra le principali funzionalità messe a disposizione
dell’utente, tra le quali, appunto, quella di fornire gli input necessari per caratterizzare il
sistema in esame e per configurare lo scenario da sperimentare.
Per il corretto funzionamento dell'applicazione è necessario specificare il numero di nodi da
modellare, il tempo di simulazione da valutare, una serie di parametri che andranno a
discriminare il particolare sistema da simulare e la topologia della rete. Quest’ultima può
essere fornita attraverso un upload del file compresso, oppure selezionata dal database
remoto nel quale sia stata precedentemente salvata dall’utente. Suddetta operazione può
essere effettuata in seguito a un upload oppure dopo essere stata disegnata on-line attraverso
le funzionalità offerte dall’applicazione stessa. Essa infatti mette a disposizione una
schermata simile ad un software di disegno, dove è possibile disporre i nodi con un drag
and drop su un piano bidimensionale e modificare, per ogni nodo, le coordinate, il tipo di
radio, il tipo di tecnologia della batteria e l'applicazione installata. Nel tracciare lo scenario
topologico, infine, l'utente può selezionare per la rete di nodi il modello di propagazione del
segnale, il quale differisce dall'ambiente scelto.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
63
La schermata principale si presenta sia graficamente sia in termini di funzionalità simile al
tool Failure Model WSN Generator descritto nel paragrafo 3.2, ovvero con delle aree
testuali che rappresentano i log dell'applicazione e dei messaggi inviati alla console di
sistema del server, e con i pulsanti che rendono possibile la generazione, la compilazione o
la simulazione del modello.
Una volta generato ed eventualmente compilato il modello, l'utente può scegliere se
scaricare i file da sottoporre al simulatore Möbius, così da valutare sul proprio computer i
risultati dell’elaborazione, oppure decidere di avviare la simulazione direttamente sul
server. In quest’ultimo caso è possibile attenderne la fine e visualizzarne i risultati
direttamente nella web-application, altrimenti sarà l’applicazione ad avvisare
opportunamente l’utente attraverso una mail. In ogni caso i dati saranno archiviati nel
database remoto e resi fruibili per le successive consultazioni. Il simulatore prende in input
il modello e i parametri specificati nel file dello study, linka le librerie del modello con
quelle del simulatore stesso, e fa partire l’eseguibile. Al termine della simulazione viene
offerta poi la possibilità di esportare i dati ottenuti in un foglio di calcolo .csv oppure .xsl.
In effetti, seppur previste in fase di progettazione, alcune delle modalità di funzionamento
elencate non sono state ancora implementate. L’utente allo stato attuale non è ancora in
grado di:
• gestire in alcun modo gli scenari topologici creati durante la fase di generazione del
modello: può solo disegnare la topologia ed eventualmente esportarla o effettuarne
l’upload sul sistema per fornirlo all’applicazione;
• caratterizzare più di uno scenario di simulazione per volta: il numero di esperimenti
da specializzare è vincolato dal numero limitato (1 soltanto) di valori che è possibile
specificare per il sottoinsieme di parametri descritti nel file dello study, che è
possibile modificare attraverso l’interfaccia grafica dell’applicazione;
• avviare la simulazione del modello generato e gestirne attraverso la visualizzazione
e l’esportazione, i risultati.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
64
Capitolo 4
Progettazione ed implementazione dello Strumento di Simulazione
Questo capitolo si pone l’obiettivo di mostrare le tecnologie e le tecniche usate per
implementare il tool. Seguirà una breve introduzione sul contesto nel quale si inserisce il
lavoro di tesi svolto, nella quale verranno analizzati i requisiti funzionali e non che
l’applicazione deve soddisfare; saranno esposti i principali scenari d’uso allo scopo di
osservare il comportamento del tool in base alle richieste dell’utente. Infine sarà esposta
l’architettura della web-application così da individuare e illustrate le principali modifiche
che l’hanno investita, e la struttura del database sul quale essa si appoggia.
4.1 Analisi dei Requisiti
Come descritto in 3.4 questa applicazione nasce con lo scopo di progettare, modellare e
simulare reti di sensori senza filo. Oggetto del presente lavoro di tesi è stato quello di
estenderne le già numerose possibilità di funzionamento.
Avendo ora una visione d’insieme del progetto è possibile fissare quelli che sono stati i
punti focali del seguente lavoro di tesi ovvero i requisiti non ancora implementati nel tool.
E’ stato innanzitutto necessario creare un database remoto che tenesse traccia degli utenti
connessi all’applicazione e rendesse possibile da parte di ognuno di essi, ove richiesto,
l’archiviazione dei file delle topologie disegnate. Infatti se in origine era possibile solo
esportare e salvare sulla propria periferica il file della topologia della rete, ora l’utente ha a

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
65
disposizione un vero e proprio strumento di gestione degli scenari topologici: una schermata
grafica consente di effettuarne il salvataggio, l’upload, il download e la cancellazione.
Il database ha inoltre il compito di memorizzare, contestualmente all’esecuzione di una
simulazione, i suoi risultati così da renderli fruibili anche durante i successivi accessi.
Notevoli cambiamenti relativi alla generazione del modello sono stati poi apportati
all’applicazione al fine di consentire all’utente di performare anche più esperimenti per ogni
simulazione, così da poter valutare la risposta del sistema in diversi contesti di
funzionamento. E’ ora possibile specificare oltre al numero di nodi e al tempo di
simulazione:
• Il/i tipo/i di sistema/i operativo/i a scelta tra TinyOS e/o Mantis.
• Il/i protocollo/i di routing a scelta tra “MultiHop”, “ReliableMultiHop”,
“Gossiping”, “Floody”, “Random” (in parte descritti in 1.5.3).
• I parametri della batteria quali capacità e voltaggio.
• Il Radio Platform adottato (allo stato attuale è possibile selezionare solo il tipo
CC2420, ma l’implementazione del codice è stata realizzata considerando la
possibilità di aggiungere nuove tipologie).
• Il/i Sensor Board utilizzato/i (per il momento è presente solo il tipo XBOW, ma
come per il radio platform, è stata prevista la possibilità di aggiungerne di nuovi).
• E’ possibile inoltre: abilitare o meno l’occorrenza di guasti software e/o hardware;
usare tecniche di Data Aggregation, specificando nel qual caso, il tempo di
aggregazione desiderato; indicare il Duty Cycle e la dimensione dei pacchetti
trasmessi dai sensori; fare l’upload dei file .txt contenenti le informazioni relative
latency e faults injection; e infine selezionare il file contenete la topologia di rete dal
db remoto o effettuarne l’upload.
Come detto, tutti i dati inseriti serviranno per discriminare i vari scenari di simulazione, allo
scopo di tenere traccia delle diverse condizioni di funzionamento della rete, il nome di ogni
esperimento viene generato come composizione dei vari parametri specificati, ad esempio:
“Tiny_AggrTime:30sec_DutyCycles:1sec_PacketSize:12Bytes_RoutingType:MultiHop_SW

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
66
_HW”, indica un esperimento per il quale sia indicato TinyOS come sistema operativo
adottato sui sensori, MultiHop come tipologia di routing utilizzata, un DutyCycles di 1
secondo, un PacketSize di 12 byte, in cui sia utilizzata una tecnica di data aggregation con
un AggrTime di 30 secondi; e per il quale siano stati abilitati sia i guasti hardware che quelli
software.
A questo punto sono stati forniti gli tutti gli input necessari affinché il modello possa essere
generato (e/o compilato) e/o compilato e simulato. In quest’ultimo caso una volta terminata
l’elaborazione una finestra visualizzerà un output creato dall’applicazione comprensibile
per l’utente. Esso include, per ognuno degli esperimenti, il tempo di simulazione, il suo
risultato finale (se converge o meno) e il numero di osservazioni effettuate (che può essere
anche inferiore a quello specificato nel file di configurazione della simulazione nel caso la
convergenza dell’esperimento sia stata raggiunta prima di esaminare tutti i batch). Inoltre
cliccando sullo specifico esperimento sarà possibile visualizzare i valori delle variabili di
reward del modello, relativi a tutte le varie osservazioni eseguite. Questi dati vengono
anche forniti in un file formattato come un comma-separated-value file (.csv) contenente,
tra l’altro, tutti i parametri di configurazione della simulazione (come il massimo numero di
osservazioni da eseguire oppure il valore delle variabili globali del modello), e progettato
per essere esportato in modo semplice e usato all’interno di tool di analisi come
Microsoft’s Excel oppure OpenOffice.org’s Calc..
Ad ogni modo, sia che il modello venga solo generato, sia che esso sia anche simulato,
viene offerta la possibilità all’utente di esportare un in un formato zip tutti i file prodotti.
Nell’ultima fase dello sviluppo sono state affrontate le problematiche legate
all’implementazione della simulazione del modello analitico generato e della
visualizzazione e valutazione dei risultati ottenuti. Queste operazioni hanno richiesto
maggiori sforzi e attenzione poiché per la loro realizzazione si è reso necessario un
approccio di reverse engineering sul complesso software Möbius (circa 182K di linee di
codice) per utilizzarne le classi, riadattandole al fine di ottenere nuove funzionalità non
previste dal famoso tool. Infatti, diversamente da quanto accade con il simulatore Möbius

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
67
(che fornisce i risultati statistici finali di un esperimento solo al termine della sua
esecuzione), la nostra applicazione è in grado di produrre i risultati parziali relativi alle
singole osservazioni così da fornire la possibilità, in future ulteriori estensioni, di plottarli al
fine di tracciarne un andamento nel tempo. In un primo momento è stato necessario
individuare le classi del software Möbius incaricate di comunicare con il simulatore e
interpretare i risultati inviati da esso su un bus ad eventi discreti (si veda 3.4). In seguito
queste sono state importate in un package all’interno del tool Failure Model WSN
Generator (usato dall’applicazione web per la generazione, la compilazione e la simulazione
del modello) denominato simulator. Infine, le modifiche apportate direttamente a queste
classi, sono state finalizzate alla realizzazione di quanto descritto sopra, ovvero intercettare
interpretare ed elaborare i dati inviati dal simulation engine di Möbius, e archiviare per ogni
esperimento e per ogni variabile di reward, tutte le statistiche calcolate.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
68
4.2 Use Case Diagram
Dai requisiti sopra analizzati viene proposto il caso d’uso generale in Figura 4.1, di cui
verranno approfonditi solo i casi d’uso principali.
Figura 4.1: Use Case Diagram dell’applicazione

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
69
CASO D’USO: GENERAZIONE MODELLO
Attori: User.
Pre-condizioni:
1. Lo user effettua con successo la verifica delle sue credenziali.
Sequenza degli eventi:
1. Lo user sceglie di generare il modello.
2. Il sistema visualizza all’utente la schermata relativa alla generazione del
modello.
3. Lo user caratterizza lo scenario di simulazione immettendo i dati
necessari.
4. Lo user seleziona la topologia della rete WSN dal db remoto.
5. IF lo user non seleziona la topologia dal db remoto, l’utente carica sul
server il file .zip della topologia WSN.
6. Il sistema importa la topologia in una cartella personale dell'utente
7. Lo user non seleziona la compilazione del modello.
8. IF lo user sceglie anche la compilazione, il sistema genererà un modello
compilato.
9. Lo user chiede la generazione del modello.
10. Il sistema genera il modello e invia come download il file compresso del
modello all'utente.
CASO D’USO: SIMULAZIONE MODELLO
Attori: User.
Pre-condizioni:
1. Il sistema ha generato e compilato correttamente il modello.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
70
Sequenza degli eventi:
1. Lo user richiede la simulazione del modello.
2. Il sistema inizia la simulazione.
3. Durante la simulazione il sistema archivia i risultati parziali relativi alle
osservazioni di ogni esperimento in un database sul server.
4.Terminata la simulazione, il sistema ne visualizza i risultati in una
schermata.
5. Lo user chiede di scaricare i risultati delle osservazioni.
6. Il sistema esporta i dati in un foglio di calcolo .csv e lo invia come
download all’utente.
7. IF lo user non chiede di scaricare i risultati delle osservazioni, lo user
chiede di scaricare il modello generato e compilato, e i risultati della
simulazione.
8. Il sistema invia come download il file compresso del modello compilato
contenente anche i risultati all'utente.
CASO D'USO: DISEGNA TOPOLOGIA
Attori: User.
Pre-condizioni:
1. Lo user effettua con successo la verifica delle sue credenziali.
Sequenza degli eventi:
1. Lo user sceglie di disegnare una topologia WSN.
2. Il sistema visualizza all'utente soltanto la parte di disegno topologia
3. Lo user chiede l'archiviazione della topologia, neldatabase sul server.
4. IF lo user non chiede l’archiviazione della topologia, lo user chiede di
esportare ifile contenenti la topologia creata.
5. Il sistema genera un file compresso contenente la topologia WSN e lo

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
71
invia all'utente.
4.3 Architettura della RIA
Per rendere il tool il più scalabile e modificabile possibile, si è deciso di strutturare il
software secondo il pattern MVC, meglio conosciuto come Model-View-Controller, esso si
basa sull’idea di separare i dati dalla rappresentazione poichè un forte accoppiamento tra
essi comporta che la modifica dell’uno, si rifletta automaticamente in un aggiornamento
dell’altro. Esso quindi prevede che il sistema software sia realizzato secondo un’architettura
“a livelli”, stabilendo il disaccopiamento fra dati e rappresentazione attraverso la
definizione dei tre elementi noti, appunto, come Model, View e Controlleri:
• Il Model è responsabile della gestione dei dati e del comportamento
dell’applicazione; esso coordina la “business logic” dell’applicazione, l’accesso ai
DBMS e tutte le parti critiche “nascoste” del sistema: si è scelto di racchiudere in
questo componente tutte le classi del progetto desktop-based
FailureModelGenerator, compreso il nuovo package “simulator” che incapsula la
logica della simulazione, e il simulatore Möbius.
• La View ha il compito di visualizzare i dati e presentarli all’utente: è l’insieme di
componenti grafici che compongono la pagina web, senza la logica di elaborazione
degli eventi: esso è costituito dai file dell’interfaccia grafica dell’applicazione web,
scritti utilizzando sia il linguaggio ZUML sia HTML;
• il Controller definisce il meccanismo mediante cui Model e View comunicano.
Realizza la connessione logica tra l’interazione dell’utente con l’interfaccia
applicativa e i servizi della business-logic nel back-end del sistema. Una qualsiasi
request verso quest’ultimo, viene acquisita dal controller che individua il gestore
della richiesta (request handler), poi una volta ottenuto il risultato dell’elaborazione,
passa alla view i dati per la presentazzione all’utente. Esso comprende le classi Java
che dialogano con i componenti della view e con le classi del model.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
72
Figura 4.1: Architettura della Web Application
Il Flusso di esecuzione della RIA può essere descritto più chiaramente in questo modo:
quando un utente digita l’indirizzo nel proprio web browser, viene fatta una richiesta al web
server, se l’indirizzo è corretto, i tre componenti sopra descritti operano sinergicamente allo
scopo di interpretare e creare correttamente i contenuti della pagina che in seguito sarà
inviata al browser dell’utente. Questi, interagendo con i componenti della pagina, con click
sui componenti grafici o modificando il valore di alcuni campi di input, scatena degli
‘event’ che vengono opportunamente gestiti da ‘handler’ definiti nelle classi Java del
controller. Essi hanno il compito di implementare la logica di controllo dell’intera
applicazione, traducendo in azioni eseguite dal model, gli input utente nella view.
Vediamo alcuni esempi nel dettaglio:
1. Nel caso in cui il client chieda di effettuare una registrazione o un’autenticazione
presso il web server, oppure necessiti di gestire i propri file archiviati sul server, le
classi del model incaricate di gestire l’elaborazione, aprono una connessione con il
Logica della simulazione

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
73
database remoto e interagiscono con esso al fine di portare a termine le operazioni di
inserimento o di prelievo, richieste; a questo punto la connessione viene chiusa, i
contenuti della pagina aggiornati, e trasmessi nuovamete al web client.
2. Se l’utente avvia operazioni legate alla generazione, alla compilazione e alla
simulazione del modello, viene dapprima individuato l’handler relativo al
componente attraverso cui è stata richiesta l’elaborazione, il quale istanzia gli
oggetti e richiama e i metodi del tool FailureModelGenerator (del model) che
interagendo con il simulatore Möbius, espleta la funzionalità richiesta. In particolare
nel caso in cui l’evento rappresenti la richiesta di una simulazione, sarà necessario
da parte del desktop-based tool, instanziare gli oggetti delle classi del nuovo
package simulator che si occuperanno di avviarla, gestirne l’avanzamento
connettendosi con l’archivio dati remoto e aggiornandone i risultati, e terminarla.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
74
4.4 L’archivio dati remoto
4.4.1 La scelta del database
MySQL è un Database management system (DBMS) composto da un client con interfaccia
a caratteri e da un server. Ambedue i componenti sono disponibili sia per sistemi operativi
UNIX che per il sistema operativo Windows. Dal 1996 supporta la maggior parte della
sintassi SQL (Structured Query Language) e si prevede che in futuro supporti
completamente lo standard ANSI. Possiede delle interfacce, dette driver, per diversi
linguaggi i programmazione quali ad esempio Java e per gli ambienti di sviluppo quali
Mono, che opera sotto UNIX, e .NET, che opera sotto Windows. Il codice di MySQL viene
sviluppato fin dal 1979 dalla ditta TcX ataconsult, che ora ha il nome di MySQL AB, ma
solo dal 1996 viene distribuita una versione che supporta il linguaggio SQL , sfruttando del
codice proveniente da un’altra applicazione: mSQL. Il codice di MySQL viene distribuito
dall’omonima società sia sotto licenza GNU-GPL, quindi è codice open source e quindi
free, sia sotto licenza commerciale. Una buona parte del codice che compone il client è
licenziato sotto GNU-GPL e quindi può essere usato per applicazioni commerciali. MySQL
svolge il lavoro di DBMS sulla piattaforma LAMP, una della più usate e installate in
internet per lo sviluppo di siti e di applicazioni web dinamiche.
La scelta è ricaduta su questa tecnologia grazie a tutta una serie di vantaggi che essa
offre[16]:
1. Scalabilità e flessibilità: MySQL è la soluzione più avanzata a livello di scalabilità,
grazie alla sua capacità di integrarsi con applicazioni le cui dimensioni non devono
superare pochi MB, fino ad enormi data warehouse contenenti terabyte di
informazioni. La flessibilità di piattaforma è una funzionalità chiave di MySQL, che
è in grado di supportare Linux, UNIX e Windows. Ovviamente, la natura open
source di MySQL consente inoltre una personalizzazione totale per chi desidera
aggiungere requisiti unici al server database.
2. Prestazioni elevate: l’eccezionale architettura storage-engine consente di configurare
il server di MySQL per applicazioni specifiche, ottenendo prestazioni finali

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
75
incredibili. Sia che l’applicazione sia un sistema di elaborazione transazionale ad
alta velocità o un sito web che gestisce miliardi di interrogazioni al giorno, MySQL
è in grado di soddisfare le aspettative di qualsiasi sistema a livello di prestazioni.
Grazie alle utility di caricamento dati ad alta velocità, le cache specializzate, gli
indici full text ed altri meccanismi di aumento delle prestazioni, MySQL offre gli
strumenti giusti per i moderni sistemi aziendali di importanza critica.
3. Alta disponibilità: l’assoluta affidabilità e la costante disponibilità sono i punti di
forza di MySQL e i clienti si affidano a MySQL per garantire l’operatività 24 ore su
24. MySQL offre una varietà di opzioni ad alta disponibilità, dalle configurazioni di
replicazione master/slave ad alta velocità, ai server cluster specializzati con failover
istantaneo, alle soluzioni ad alta disponibilità di terze parti per il server di database
MySQL.
4. Solido supporto delle transazioni: MySQL offre uno dei motori database
transazionali più potenti disponibili sul mercato. Le funzionalità includono il
supporto completo per transazioni ACID (Atomic, Consistent, Isolated, Durable),
lock a livello di riga, gestione delle transazioni distribuite e supporto per transazioni
multiversione in cui chi legge non blocca mai chi scrive e viceversa. La completa
integrità dei dati è garantita anche dall’integrità referenziale controllata dal server,
dai livelli di isolamento delle transazioni specializzati e dall’individuazione
istantanea dei deadlock.
5. Punti di forza per Web e data warehouse: MySQL è lo standard di fatto per i siti
web con volumi di traffico elevati, grazie al suo query engine ad alte prestazioni,
alla capacità di inserimento dei dati estremamente veloce e al supporto delle
funzioni web specializzate, come ad esempio le ricerche full text rapide. Questi
stessi punti di forza valgono anche per gli ambienti di data warehousing in cui
MySQL deve gestire terabyte di dati per singoli server o per architetture di scale-
out. Altre caratteristiche, come le tabelle in memoria principale, gli indici B-tree, gli
indici hash e le tabelle di archivio compresse, che riducono le necessità di

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
76
memorizzazione fino all’80%, rendono MySQL una soluzione unica, sia per le
applicazioni web, sia per le applicazioni di business intelligence.
6. Elevata protezione dei dati: la protezione dei dati aziendali rappresenta la priorità
numero uno dei responsabili dei database, quindi MySQL offre eccezionali
caratteristiche per la sicurezza, che garantiscono la totale protezione dei dati. Per ciò
che riguarda l’autenticazione del database, MySQL offre potenti meccanismi per
assicurare che soltanto gli utenti autorizzati possano accedere al server di database,
con la possibilità di bloccare gli utenti fino al livello della macchina client. Oltre a
ciò, il supporto SSH e SSL garantisce che le connessioni siano sicure. Un sistema
granulare di gestione dei privilegi permette agli utenti di vedere solo i dati per i
quali sono autorizzati, mentre le potenti funzioni di crittografia e decifratura dei dati
garantisce che i dati sensibili siano protetti e non possano essere visualizzati da
coloro che non sono autorizzati. Per finire, le utility di backup e ripristino fornite da
MySQL e da software di terze parti consentono di eseguire il backup fisico e logico
completo, così come il ripristino completo e point-in-time.
7. Sviluppo completo di applicazioni: uno dei motivi per cui MySQL è il database
open source più diffuso al mondo è che fornisce supporto completo per le esigenze
di sviluppo di tutte le applicazioni. All’interno del database è possibile trovare
supporto per stored procedure, trigger, funzioni, viste, cursori, standard SQL ANSI e
altro ancora. Per le applicazioni integrate sono disponibili librerie plug-in per
espandere l'utilizzo del database MySQL a pressoché tutte le applicazioni. MySQL
fornisce inoltre connettori e driver (ODBC, JDBC, ecc.) che consentono a tutti i tipi
di applicazioni di utilizzare MySQL quale server di gestione dei dati. Non importa
che si tratti di PHP, Perl, Java, Visual Basic o .NET: MySQL offre agli sviluppatori
di applicazioni tutto ciò di cui hanno bisogno per realizzare sistemi informativi
basati su database.
8. Facilità di gestione: i tempi necessari per iniziare a usare MySQL sono
incredibilmente ridotti; il tempo medio che trascorre dal download del software al

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
77
completamento dell’installazione è inferiore ai 15 minuti. Ciò vale per qualsiasi
piattaforma, sia essa Microsoft Windows, Linux, Macintosh o UNIX. Una volta
installato, funzionalità indipendenti come l’espansione automatica dello spazio, il
riavvio automatico e le modifiche di configurazione dinamiche facilitano il lavoro
degli amministratori di database. MySQL offre inoltre una suite completa di
strumenti di migrazione e gestione grafici, che consente ai DBA di gestire, risolvere
e controllare le operazioni di più server MySQL da una singola stazione di lavoro.
Sono inoltre disponibili molti strumenti software di terze parti per MySQL, per
gestire attività che vanno dalla progettazione dei dati e l’ETL, alla completa
amministrazione del database, alla gestione dei job, al monitoraggio delle
prestazioni.
9. La libertà dell'open source: molte aziende esitano ad adottare solo software open
source perché credono di non poter ricevere il tipo di supporto o di servizi
professionali offerti dal software di tipo proprietario, per garantire il successo delle
loro applicazioni di importanza chiave. Un altro aspetto riguarda la questione degli
indennizzi. Queste preoccupazioni possono essere ignorate grazie a MySQL, che
attraverso MySQL Enterprise offre indennizzi e supporto completo 24 ore su 24.
MySQL non è un progetto open source tipico, poiché tutto il software è di proprietà
di Oracle ed è supportato da Oracle; è quindi disponibile un modello di costi e
supporto in grado di offrire una combinazione unica di libertà open source e
software supportato.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
78
4.4.2 Struttura di db_ Möbius
Figura 4.2: diagramma ER del database db_ Möbius
Il database MySQL db_Möbius viene creato al triplice scopo di tenere traccia degli utenti
che si collegano all’applicazione, archiviare tutte le topologie che essi utilizzano durante le
simulazioni dei modelli del caso di studio sulle WSN, rendendo più agevole l’operazione di
fornirle al generatore automatico, infine memorizzare i risultati ottenuti, così da potervi
accedere in qualunque momento.
Ora passiamo a dare una breve descrizione di ognuna delle tabelle che costituiscono il
database remoto.
La tabella users
Questa tabella viene utilizzata per memorizzare tutti gli utenti che si registrano per poter
usufruire delle funzionalità dell’applicazione. Ha una chiave primaria che è ‘username’

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
79
(questo perchè per scelte di progetto non è possibile che due utenti si logghino con lo stesso
username) e i due campi, ‘pwd’ ed ‘email’ per registrare, rispettivamente, la password e la
e-mail dell’utente.
La tabella topology
Questa tabella tiene traccia di tutte le topologie disegnate e in seguito archiviate da un
particolare utente oppure delle quali, questi, ha effettuato l’upload. Ha come chiave
primaria i campi ‘TopologyName’, che contiene il nome della topologia usata, e ‘Author’
che conterrà il riferimento alla chiave della tabella ‘user’, attraverso la quale risalire
all’utente che l’ha archiviata. La scelta è motivata dal fatto che non è possibile che due
diverse topologie di un utente presentino lo stesso nome; infatti esso deve fornire un’idea
immediata della tipologia di scenario che si andrà ad utilizzare. Il campo ‘File’ contiene
l’oggetto di tipo BLOB che rappresenta il file in formato zip della topologia; ‘date’, invece,
è di tipo TIMESTAMP e conterrà la data di archiviazione del file.
La tabella run
Questa tabella memorizza tutte le informazioni relative alle simulazioni effettuate da uno
specifico utente. Ha come chiave primaria il campo ‘ id_run’, di tipo INTEGER
AUTOINCREMENT, per identificare in modo univoco ogni simulazione. I campi ‘users’ e
‘ topology’, contengono i riferimenti relativi alla chiave della tabella topology, così da poter
risalire alla topologia utilizzata e all’utente che l’ha generata, che poi è lo stesso che ha
lanciato la simulazione . Il fatto che possano esistere più simulazioni che utilizzano la stessa
topologia è dovuto alla possibilità da parte dell’utente di poter modificare in qualsiasi
momento le caratteristiche del particolare scenario topologico: quindi può accadere che
venga eseguita una simulazione con una particolare topologia, che in seguito l’utente decida
di apportare dei cambiamenti al file e che riesegua la simulazione con i nuovi dati. I campi
‘start_time’ e ‘ProjectName’ contengono, rispettivamente la data di inizio della simulazione
e il nome del progetto mandato in esecuzione.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
80
La tabella experiments
Questa tabella contiene tutte le informazioni relative agli esperimenti di una simulazione.
Ha come chiave primaria i campi ‘id_run’, che contiene il riferimento alla chiave della
tabella run e attraverso cui è possibile risalire alla particolare simulazione, e ‘id_exp’ che
invece contiene l’identificativo con cui il simulation engine di Möbius discrimina i vari
esperimenti. Altri campi sono:
- ‘batch’, per sapere quante osservazioni sono state eseguite alla fine di ogni esperimento;
- ‘node’, per risalire al numero di nodi della rete;
- ‘simulation_time’, per avere un’idea del tempo servito al simulatore per fornire i risultati
di un esperimento;
- ‘experiment_name’, contiene il nome dell’esperimento;
- ‘converged’, per conoscere l’esito dell’esperimento, ovvero se tutte le variabili di reward
sono rientrate nello specifico intervallo di confidenza.
La tabella reward
Questa tabella contiene le informazioni relative a tutte le variabili di reward definite nel
modello del caso di studio. Ha come chiave primaria ‘id_rew’ per identificare
univocamente la singola variabile e come campo aggiuntivo ‘reward_name’, contenente il
suo nome.
Le tabelle mean e variance
Queste tabelle contengono le statistiche delle variabili di reward calcolate sui dati forniti dal
simulatore. Hanno come chiave primaria i campi contenenti il numero di batch osservati
correntemente, gli identificativi della simulazione, dell’esperimento e della particolare
variabile di reward cui fanno riferiento. Alla fine di ogni osservazione le statistiche appena
calcolate, quali media e varianza, saranno inserite rispettivamente nei campi ‘mean’ e
‘variance’. In entrambe le tabelle, i campi ‘confidence_interval’ e ‘converged’ conterranno,

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
81
al termine di ogni batch osservato, l’intervallo di confidenza e un valore booleano che
indicherà l’avvenuta convergenza della variabile.
4.5 Il componente Model:
il tool desktop-based Failure Model WSN Generator
Come anticipato nel primo paragrafo di questo capitolo, profonde e consistenti modifiche
hanno rivoluzionato la struttura interna del generatore automatico sviluppato in [15]. I
cambiamenti hanno investito tutte le classi adibite alla generazione delle descrizioni xml dei
modelli che caratterizzano il caso di studio sulle reti WSN e, conseguentemente, del Möbius
project file. Questa trasformazione è stata necessaria al fine di garantire la coerenza tra i
risultati prodotti dal generatore e il nuovo modello proposto in [9] per l’analisi delle reti
wireless. Tuttavia, nonostante il notevole impatto che queste modifiche hanno avuto sul
tool, si è preferito in questa tesi tralasciare la loro descrizione (rimandando l’utente che
voglia approfondire, alla lettura del codice allegato), per lasciare più ampio spazio alle
operazioni di reverse-engineering realizzate sul codice di Möbius, che hanno permesso
l’aggiunta della funzionalità di simulazione del modello generato, prima assente. Se in
origine, infatti, era unicamente possibile generare, a partire dai file prodotti, un eseguibile
che andava poi esportato dall’utente perchè lo eseguisse sulla propria macchina (e ciò
presupponeva quindi la presenza del tool di simulazione Möbius sul pc dell’utente), ora
finalmente è realizzabile anche la simulazione, così che il ruolo del possibile fruitore del
tool si limiti alla sola analisi dei risultati ottenuti.
Una particolare attenzione sarà inoltre data alla classe MobiusProject del package project,
del generatore automatico, alla quale sono state aggiunte, tra le varie modifiche, anche le
linee di codice per eseguire lo script avente il fondamentale compito di compilare le librerie
esterne necessarie alla generazione dell’eseguibile.
4.5.1 La classe MobiusProject del package project e il file scriptShell.sh
Dopo la generazione delle descrizioni xml, se richiesto dall’utente, i modelli possono essere

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
82
compilati richiamando il metodo compileAllModels() di questa classe; esso produce
come output un file di codice C++ con estensione cpp, un headerfile di estensione .h e un
makefile per ognuno di essi; tutti i file oggetto prodotti, vengono linkati alle librerie di
Möbius, e a librerie esterne definite in [9]: il risultato di questa operazione darà luogo
all’eseguibile per il solver, che viene poi lanciato per generare i risultati. Risulta quindi
necessario innanzitutto compilare le librerie esterne; questa operazione viene effettuata
eseguendo lo script contenente i comandi di shell adibiti allo scopo. Riportiamo di seguito
la porzione di codice che implementa quanto detto:
… String makefileName = new String(); String scriptShell = this.getFilePath() + File.sepa rator + "Scripts"+File.separator+"scriptShell.sh"; if(System.getProperty("os.name").equalsIgnoreCase(" Linux")) makefileName = "makefile_LINUX"; else if(System.getProperty("os.name").equalsIgnoreCase ("Win")) makefileName = "makefile_WIN"; else makefileName = "makefile_MAC"; String cmd1 = "chmod +x "+scriptShell; String cmd2 = scriptShell+""+this.getProjectPath()+ ""+ makefileName+""+getZipModelsPath()+"" + this.getDataFilesDirectory(); Process p = null; try { p = Runtime.getRuntime().exec(cmd1); try { sleep(1000); } catch (InterruptedException e) {e.printStackTrace();} p = Runtime.getRuntime().exec(cmd2); BufferedReader in = new BufferedReader(new InputStreamReader(p.getInputStream())); String line; while ((line = in.readLine()) != null) System.out.println(line); } catch (IOException e) {e.printStackTrace();}
Lo shell script è un file di comandi del sistema operativo, scritto nel linguaggio di shell,

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
83
così da risultare un vero e proprio programma. Per poterlo eseguire da un’applicazione Java
è necessario servirsi della classe Runtime che deriva da Object e che appartiene al
package java.lang . Una sua istanza rappresenta l’esecuzione dell’interprete Java, non è
possibile creare un suo oggetto in quanto ha un solo costruttore che è privato, ma si può
ottenere una referenza all’oggetto correntemente in esecuzione mediante il metodo statico
getRuntime() . Richiamando su tale riferimento il metodo exec(), viene restituito un
oggetto di tipo Process che si occupa di eseguire il comando specificato come argomento
del metodo. Viene eseguito prima il comando cmd1 contenente le direttive per cambiare i
permessi al file sriptShell.sh così che sia reso effettivamente eseguibile, e solo in
seguito è possibile inviare il comando cmd2 con i parametri che verranno passati allo script.
La shell infatti utilizza un tipo particolare di variabili, dette parametri posizionali, per
memorizzare ed identificare i parametri passati allo script sulla linea di comando. Il primo
parametro è memorizzato in una variabile chiamata 1, il secondo parametro è memorizzato
in una variabile chiamata 2 , e così via per tutti gli altri parametri posizionali. Questi nomi
di variabile sono riservati esclusivamente all'ambiente di shell, perciò non possono essere
utilizzati dagli utenti per nominare le proprie variabili. Per accedere al loro contenuto si
deve far precedere il nome della variabile scelta dall'operatore $ (ad esempio per ricavare il
contenuto del parametro posizionale 1 occorrerà scrivere nello script $1). Il parametro
relativo alla compilazione delle librerie (difatti lo script esegue anche altre operazioni che
necessitano di propri parametri, come ripulire le directory che andranno a ospitare i modelli
o decomprimere la cartella contenente le librerie da compilare) è il terzo, ovvero quello
contenuto nell’oggetto makefileName : il suo valore serve a individuare il tipo di sistema
operativo sul quale avverrà la compilazione. Allo scopo è stata utilizzata la classe System ,
anch’essa del package java.lang , che interfaccia il programma Java con il sistema sul
quale è eseguito. Su di essa è stato invocato il metodo getProperty("os.name") che
restituisce il valore della proprietà specificata come argomento, in questo caso il nome del
sistema operativo sul quale gira la Java Virtual Machine, appunto. E’ stato necessario
individuare il tipo di sistema operativo perchè è in relazione a questo che viene richiamato,

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
84
tra quelli presenti nella cartella delle librerie, il makefile opportuno.
Una volta indicati tutti i parametri, è possibile lanciare anche il secondo comando in modo
da avviare la compilazione delle librerie che verranno successivamente linkate da Möbius
con tutti gli altri file per produrre l’eseguibile che ‘sarà dato in pasto’ al simulatore.
4.5.2 Le classi del package simulator
Di seguito vengono illustrati i package del generatore automatico, così da avere un’idea del
contesto d’inserimento delle nuove classi che consentiranno la simulazione del modello del
caso di studio.
Figura 4.3: package del generatore automatico FailureModelGenerator
Le classi incaricate di generare le descrizioni xml dei vari modelli sono contenute nei
package atomicModels, composedModels, rewardModels, studyModels, solverModels,
mentre quelle contenute in basicelements, sanelements, composedelements hanno il compito
di produrre stringhe xml delle singole entità che concorreranno alla generazione
complessiva. Infine, i package failureModelWSNGenerator e project gestiscono il
salvataggio dei modelli e tutte le loro informazioni, utilizzandole per scrivere i file finali da
sottoporre alla compilazione.
Le classi che appartengono al package simulator sono tutte e sole quelle incaricate di gestire
l’avvio della simulazione, il trattamento dei dati inviati dal simulatore di Möbius per il

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
85
calcolo dei valori delle variabili definite nel modello di reward (vedi 3.3.2), l’archiviazione
di questi ultimi nel database remoto db_ Möbius, e la terminazione della simulazione. Come
anticipato, tali classi sono state estrapolate dal codice sorgente di Möbius e, solo dopo un
attento studio, sono state oggetto delle modifiche necessarie a conseguire quanto richiesto
dal seguente lavoro di tesi: riuscire ad intercettare e interpretare, allo scopo di calcolare e
memorizzare il valore statistico delle reward variables, i risultati trasmessi dal simulator
engine di Möbius sul bus a eventi condiviso con la nostra applicazione; il tutto alla fine di
ogni singola osservazione (o batch, il cui numero è specificato in uno dei file del solver)
relativa ai vari esperimenti performati nella fase di configurazione dello scenario da
simulare.
Di seguito riportiamo l’elenco delle classi importate dal Möbius Project nel package
simulator , e il collaboration diagram che ne mostra le relazioni esistenti.
Figura 4.4: classi del package simulator
Sono state omesse dal diagramma le classi adibite al calcolo effettivo dei valori statistici
(quali media e varianza) delle quali sarà riportato un class diagram che verrà analizzato
separatamente. Ci soffermeremo sulle classi che si occupano di avviare le operazioni
preliminari all’avvio della simulazione (la classe Simulator); gestire la comunicazione con
il simulation engine (la classe ProjectManager); intercettare, prelevare e interpretare i

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
86
risultati trasmessi sul bus di eventi (la classe StreamReader); infine calcolare e archiviare
nel database remoto le statistiche relative a ogni variabile (le classi ExperimentObject e
BaseCalculationObject). Per ognuna di esse verrà data una spiegazione dei metodi e delle
variabili membro principali che aiuterà a comprendere la complessa logica delle operazioni
che realizzano la simulazione nella sua totalità.
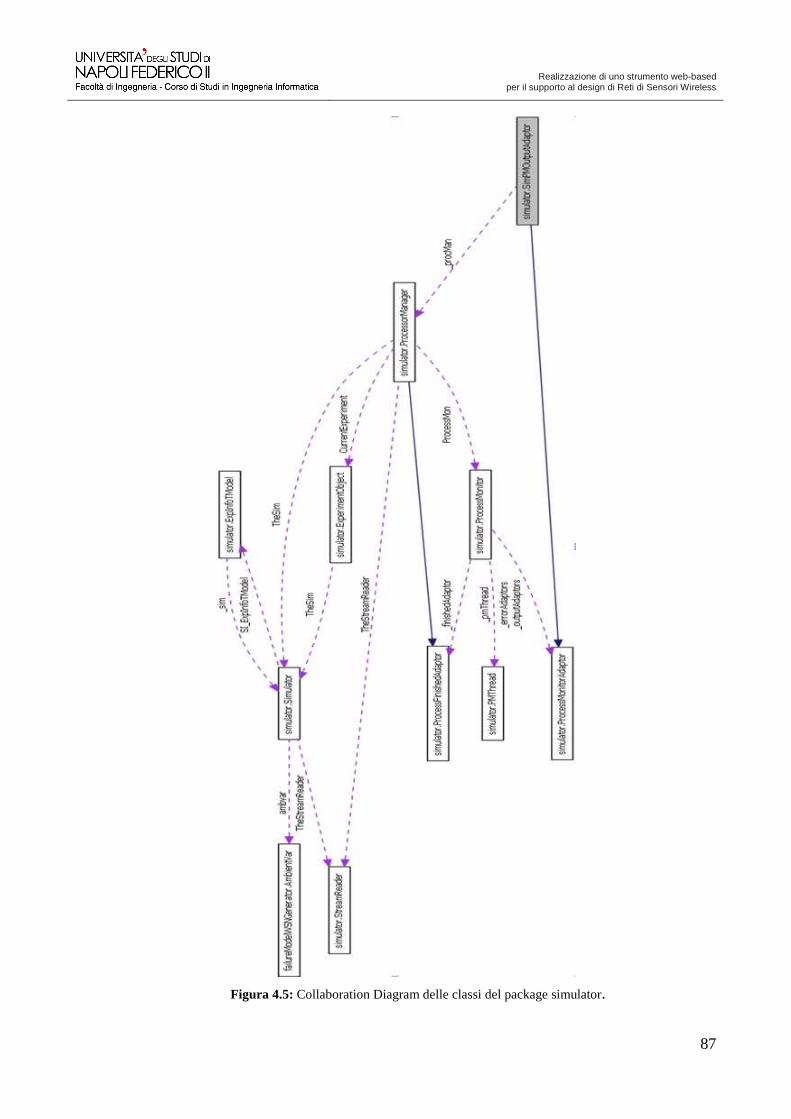
Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
87
Figura 4.5: Collaboration Diagram delle classi del package simulator.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
88
La classe Simulator
Questa è la classe più importante del package poiché crea le strutture dati indispensabili per
la gestione della simulazione. Le prime modifiche hanno riguardato il costruttore, cui è
risultato necessario passare come argomenti: i) un oggetto di tipo BaseInterfaceclass
attraverso cui gestire l’apertura e il salvataggio dei modelli e mantenere un riferimento alla
classe BaseInfoClass per avere accesso diretto alle principali informazioni su di essi (come
il numero e il nome dei vari esperimenti o lo tipologia di dati statistici da calcolare per le
variabili di reward); ii) il riferimento della connessione al database remoto db_ Möbius, in
cui archiviare i risultati degli esperimenti; iii) l’oggetto della classe Ambvar per accedere
alle informazioni riguardanti l’utente correntemente connesso. Diseguito sono riportate le
porzioni di codice che realizzano i punti i) e ii).
Simulator
+Mobius.BaseClasses.BaseInterfaceClass _baseinterfaceclass+int id_run+Connection conn-Mobius.Solvers.Simulators.SimInfoClass TheInfo-Vector ProcessorManager-StreamReader TheStreamReader-Vector Experiments-FailureModelWSNGenerator.failureModelWSNGenerator.AmbientVar ambvar+...
+Simulator()+void initDb()+void createRewardTable()+void StartSimulation()+void close_db()+void update_Experiment_Table()+void BuildProcessorManager()+void CreateExperiments()+void buildSimulator()+void writeMakefile()-void assignNextExperiments()+void StopSimulation()+...()

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
89
… ProjectManager theProjectManager = ProjectManager. getProjectManager(); theProjectManager.setRootProjectPath(“pathModelloda Simulare”); Project project = theProjectManager.openProject("no meProgetto", true, false); BaseSolverInterface baseSolverInterface = (BaseSolverInterface)project.getInterface("nomeSol verFile"); …
Nell’ordine:
1. Il primo passo è quello di creare un’istanza del ProjectManager e salvarne il
riferimento; ricordando che questa classe utilizza il pattern singleton, basta chiamare
il metodo getProjectManager() che provocherà anche l’avvio della schermata
grafica principale di Möbius;
2. il secondo passo è quello di settare la directory dove verrà cercato il progetto da
aprire, ed è fatto invocando sul ProjectManager il seguente metodo
setRootProjectPath() ;
3. il terzo passo è aprire il progetto e ottenerne un riferimento. Ciò è fatto invocando il
metodo openProject() sul ProjectManager ottenuto al passo 1;
4. Il quarto passo è quello di ottenere un riferimento ad un oggetto della classe
BaseInterfaceClass, (in realtà si tratta di una classe astratta pertanto verrà passato un
oggetto della classe BaseSolverInterface che viene eredita da essa); Ciò è fatto
invocando il metodo getInterface() sull’istanza del progetto appena aperto.
Per quanto concerne la connessione con il database, occorre innanzitutto caricare il driver
JDBC specifico del db MySQL, chiamato Connector-J, e in seguito si utilizza la classe
DriverManager messa a disposizione da Jave per instaurare la connessione attraverso il
metodo getConnection() , a cui vengono passati il nome del database, quello del suo
amministratore e una password di controllo:

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
90
… try { Class.forName("com.mysql.jdbc.Driver").newInstance (); Connection conn = DriverManager.getConnection("jdbc:mysql://loca lhost/ db_Mobius?user=amministratore&password=admi n"); }catch (SQLException e) {e.printStackTrace();} …
Ora analizziamo nel dettaglio le variabili membro e i metodi più significativi.
VARIABILI PUBBLICHE E PRIVATE
Accanto a ognuna ci sarà un segnale di spunta a indicare se è stata aggiunta in fase di
sviluppo.
� BaseInterfaceClass _baseinterfaceclass e SimInfoClass TheInfo
Come sopra anticipato questa variabile viene impiegata per accedere alle
informazioni del modello, il suo ausilio è di notevole importanza, non solo perché
ha consentito di automatizzare la simulazione, sollevando lo sviluppatore dall’onere
di fornire tutti i dati necessari alla sua esecuzione, ma soprattutto nell’ottica che il
modello possa essere oggetto di ulteriori cambiamenti, magari con l’aggiunta di
nuove variabili di reward, in seguito alla quale non sarà necessario modificare il
codice esistente per riadattarlo. Questa variabile, infatti, mantiene nel suo attributo
pubblico Information un riferimento alla classe BaseInfoClass che consente in
modo semplice e automatico di ottenere, ad esempio, tutti i dati necessari al
popolamento della tabella delle reward variables nel database db_ Möbius, di
individuare il numero di esperimenti attivi da svolgere o, ancora, di reperire i
parametri di configurazione della simulazione come massimo e minimo numero di
batch da eseguire. Prima di essere utilizzata, ne viene effettuato il cast verso un
oggetto di tipo SimInfoClass per essere in seguito assegnata alla variabile
TheInfo che verrà passata alle altre classi del package.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
91
� Connection conn
Contiene il riferimento all’oggetto di tipo Connection che consente di interagire con
il db per le operazioni di inserimento dei risultati delle osservazioni e degli
esperimenti che avvengono durante la simulazione.
� int id_run
Questa variabile è stata aggiunta per individuare in modo univoco attraverso un ‘id’
di tipo intero che si incrementa in modo automatico, le singole simulazioni eseguite
dall’applicazione. Esso serve per inserire in modo corretto nel db i dati relativi a una
specifica simulazione.
• Vector ProcessorManager
E’ un vettore che tiene traccia di tutti i ProcessorManager istanziati per gestire le
esecuzioni concorrenti dei vari esperimenti.
• Vector Experiments
E’ un vettore contenente i riferimenti dei vari ExperimentObject istanziati uno per
ogni esperimento attivo.
• StreamReader TheStreamReader
Il suo compito è quello intercettare i risultati trasmessi dal simulation engine di
Möbius e riconvertirli nel corretto formato in base alle indicazioni fornite da
metadati anch’essi inviati sull’event bus, in modo che possano essere elaborati dalle
classi incaricate di fornire le stime statistiche richieste.
� FailureModelWSNGenerator.failureModelWSNGenerator.AmbientVar
ambvar
Contiene l’oggetto per risalire alle informazioni su utente correntemente connesso e
topologia da lui usata per la simulazione, necessarie per effettuare gli inserimenti nel
db.
METODI PUBBLICI E PRIVATI
Accanto ad ognuno ci sarà un segnale di spunta a indicare se è stato oggetto di modifica

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
92
(allora saranno illustrati i cambiamenti subiti dal codice) o è stato aggiunto in fase di
sviluppo.
� Simulator()
E’ il costruttore della classe e realizza tutte le operazioni preliminari all’esecuzione
della simulazione. Per farlo riceve come argomenti, nell’ordine: un oggetto di tipo
BaseInterfaceclass, uno di tipo Connection e l’ultimo della classe Ambvar. Quindi le
modifiche hanno riguardato i parametri passati per argomento e l’aggiunta delle
chiamate ai metodi initDb() e createRewardTable().
� void initDb()
Prepara il database per la simulazione inserendo i dati relativi all’utente, il nome
della topologia usata e quello del progetto. Inoltre archivia nella variabile pubblica
id_run il valore assegnato alla simulazione corrente.
Questo metodo non era presente in origine ed è stato implementato ex-novo.
� void createRewardTable()
In realtà il corpo di questo metodo viene eseguito una sola volta, e cioè quando
l’applicazione è resa fruibile e il database db_ Möbius viene acceduto per la prima
volta. Questo perché la tabella delle rewards variables viene lasciata vuota così da
poter essere popolata in funzione del particolare modello oggetto del generatore.
Con questa scelta di sviluppo, se il modello in futuro dovesse essere modificato,
basterebbe ripulire semplicemente questa tabella per continuare a garantire un
comportamento corretto dell’applicazione. Non solo, ma dal momento che allo stato
in cui si sta scrivendo questa tesi, il numero di variabili di reward si aggira intorno
alla sassantina, s’intuisce l’utilità di non doverle trascrivere manualmente nella
tabella.
Il metodo non era presente in origine ed è stato implementato ex-novo. Riportiamo
di seguito parte del codice:

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
93
… BaseStudyInfoClass basestudyinfoclass = getStud yInfo(); PVInfo pvinfo = basestudyinfoclass.getPVInfo(); Statement stm = null; ResultSet requery = null; PreparedStatement ps = null; final String SQL3 = "SELECT * FROM reward"; final String SQL4 = "INSERT INTO reward( id_rew,reward_name)VALUES(?,?)"; try { if(!conn.isClosed()){ conn.setAutoCommit(false); stm = conn.createStatement(); requery = stm.executeQuery(SQL3); if(!requery.next()) for(int k = 0; k < pvinfo.getNumPVCountingTimeArrays(); k++){ VariableInfoClass variableinfoclass = pvinfo.getVariableInfoCountingTimeArrays(k); ps = conn.prepareStatement(SQL4); ps.setInt(1, k); ps.setString(2,variableinfoclass.getName()); ps.executeUpdate(); } } }catch (SQLException e) {e.printStackTrace();} finally{ try { if(requery!=null && !requery.isClosed()) requery.close(); if(stm!=null && !stm.isClosed()) stm.close(); if(ps!=null && !ps.isClosed()) ps.close(); } catch (SQLException e) {e.printStackTrace();} }
Per avere le informazioni sulle variabili di reward che occorre inserire, viene
ottenuto un riferimento all’oggetto BaseStudyInfoClass sul quale viene invocato

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
94
il metodo getPVInfo() che restituisce un oggetto PVInfo . A questo punto viene
eseguita una query sul database per verificare se la tabella di reward era già stata
popolata; in caso negativo si accede ai dati, invocando i metodi
getNumPVCountingTimeArrays() , per risalire al numero di variabili, e
getVariableInfoCountingTimeArrays(), per ottenere l’oggetto
VariableInfoClass relativo alla singola variabile (identificata dall’id passatogli
come argomento) e per la quale essa fornisce i metodi get di accesso.
� void StartSimulation()
Questo metodo crea tutte le strutture dati necessarie durante la simulazione e ne
richiama le operazioni preliminari; vengono invocati nell’ordine i metodi
CreateExperiments(), BuildProcessorManager(), buildSimulator(), writeMakefile().
• void CreateExperiments()
Per ognuno degli esperimenti attivi presenti nel file dello study, istanzia un oggetto
di tipo ExperimentObject e lo aggiunge al vettore degli esperimenti visto sopra.
• void BuildProcessorManager()
Istanzia un numero di ProcessorManager pari al numero di processori presenti sulla
macchina che ospita l’applicazione, selezionati per la simulazione. Lo scopo è che
essi gestiscano in modo concorrente l’esecuzione degli esperimenti rappresentati
dagli oggetti contenuti nel vettore degli esperimenti, così da ridurre i tempi necessari
a terminare la simulazione.
• void buildSimulator()
Scrive il makefile del solver e lo compila con il resto dei modelli.
� void StopSimulation()
Questo metodo semplicemente ferma la simulazione: a ogni ProcessorManager
istanziato, viene dato l’ordine di inviare il comando di “QUIT” al simulation engine
e di chiudere la socket sulla quale avveniva la trasmissione dei dati. Inoltre anche lo
StreamReader che era adibito all’ascolto di nuovi flussi di trasmissione viene
chiuso. Infine, viene aggiornata la tabella degli esperimenti, invocando il metodo

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
95
update_Experiment_Table(), e viene chiuso il database attraverso la
chiamata di closeDb().
� void update_Experiment_Table()
Per ogni esperimento vengono accedute le tabelle nelle quali sono stati archiviati
durante la simulazione tutti i valori delle variabili di reward (vale a dire le tabelle
mean e variance); da esse viene prelevata l’informazione relativa al raggiungimento
dell’intervallo di confidenza che viene inserita, insieme all’id della simulazione,
all’identificativo dell’esperimento (che è lo stesso contenuto nel file dello study), al
numero di osservazioni effettuate, al numero di nodi della rete simulata, al tempo di
simulazione, e al nome dell’esperimento, nella tabella experiments del database. Il
metodo non era presente in origine ed è stato implementato ex-novo.
� void close_db()
Chiude la connessione con il database. Il metodo non era presente in origine ed è
stato implementato ex-novo. Riportiamo di seguito parte del codice:
… try { if(conn!=null && !(conn.isClosed())) conn.close(); } catch (SQLException e) {e.printStackTrace();}
Nonostante le classi che seguiranno non abbiano subito alcun cambiamento, è opportuno
comunque dare una spiegazione di alcuni dei loro metodi al fine di rendere più
comprensibile l’esecuzione della simulazione di un modello.
La classe ProcessorManager
Questa classe ha un ruolo fondamentale sia nella gestione della comunicazione con il
simulation engine, poiché si occupa di avviare e terminare la trasmissione dati, inviando su
una socket aperta allo scopo i relativi comandi, sia nel controllo dell’esecuzione dei diversi
esperimenti. Essa implementa l’interfaccia ProcessFinishedAdaptor di cui definisce

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
96
l’unico metodo processFinished() che coordina le operazioni per terminare la
simulazione. Alcuni attributi sono gli stessi della classe Simulator quindi ci concentreremo
su quelli non ancora analizzati.
VARIABILI PUBBLICHE E PRIVATE
• ProcessMonitor ProcessMon
Questo oggetto viene istanziato per comunicare con la Shell allo scopo di inviare il
comando al simulation engine affinchè si avvii e si metta in attesa di una richiesta di
connessione da parte della nostra applicazione.
• Int DefaultPort
Il port di default è fissato a 10000, ma viene incrementato automaticamente a ogni
tentativo fallimentare di usarlo per la comunicazione.
• Socket MySocket
E’ la socket aperta sul primo port libero trovato a partire da quello di default;
attraverso di essa l’applicazione riceverà i dati formattati da elaborare.
• InputStream MyStream
Questo stream, una volta creato, viene aggiunto alla lista di stream utilizzati
dall’oggetto StreamReader contenuto nella variabile TheStreamReader (istanziato
nella classe Simuletor e passato al costruttore del ProcessorManager), per
intercettare i dati relativi alle singole osservazioni.
METODI PUBBLICI E PRIVATI
• ProcessorManager()
E’ il costruttore della classe e tra i parametri che gli vengono passati occorre
menzionare l’oggetto StreamReader, per il motivo sopra citato, il SimInterfaceClass
che servirà ad ottenere le informazioni necessarie a comporre il comando da inviare
per dare inizio alla simulazione, e infine il Simulator al quale sarà indicato il
termine della simulazione per poter avviare la scrittura dei risultati in un file di

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
97
output.
• void runExperiment()
A questo metodo viene passato come argomento un oggetto di tipo
ExperimentObject che servirà per risalire all’id dell’esperimento che va specificato
durante la composizione del comando da inviare al simulatore ad opera del metodo
buildCommandArgs(). Fatto questo la stringa risultante viene passata a un’istanza
della classe ProcessorMonitor sul quale è invocato il metodo execCommand(), che
avrà il compito di eseguirla da linea di comando.
• String[] buildCommandArgs()
Viene invocato per comporre il comando da inviare al simulation engine. Attraverso
la variabile TheInfo è possibile risalire a tutti parametri che andranno specificati nel
comando, tra i quali citiamo:
- l’id dell’esperimento da eseguire;
- il numero di osservazioni che il simulatore deve inviare a ogni update;
- il port per la trasmissione dati;
- il Random Number Generator e il Random Number Seed sulla base dei quali
effettare le sperimentazioni;
• void createSocket()
Stabilisce una connessione con il simulatore e crea uno stream che viene aggiunto
alla lista degli stream della variabile TheStreamReader, invocando su di essa il
metodo add().
• void quitProcess()
Una volta terminati tutti gli esperimenti, al suo interno viene richiamato il metodo
boolean sendCommand(), per inviare al simulatore la stringa “QUIT” per indicargli
di terminare la simulazione. Viene eliminato lo stream relativo al particolare
ProcessorManager dalla lista della variabile TheStreamReader e infine viene chiusa
la socket instaurata per la comunicazione.
• void processFinished()

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
98
Questo metodo viene dichiarato nell’interfaccia implementata dalla classe
ProcessorManager e vuole come argomento un oggetto di tipo ProcessMonitor.
Attraverso quest’ultimo, infatti, viene ottenuta la stringa inviata dal simulation
engine in seguito alla richiesta di terminare la connessione. Il metodo analizza la
stringa per verificare la presenza delle parole "GOOD EXIT" e "SOCKET::Quit"
che indicano la disconnessione avvenuta con successo da parte del simulatore. Nel
caso non venga rilevato alcun riscontro viene stampato a video una stringa di errore
per segnalare all’utente che un qualche problema si è verificato durante la
simulazione.
La classe ExperimentObject
Il compito di questa classe è gestire e fornire tutte le informazioni circa i singoli esperimenti
e l’avanzamento della loro esecuzione, come il tempo di simulazione trascorso (contenuto
nella variabile ElapsedTime) o il numero di batch analizzati fino a un dato istante
(DoneBatches).
VARIABILI PUBBLICHE E PRIVATE
I nomi delle variabili sono abbastanza esplicativi dei valori da esse contenute, pertanto ci
soffermeremo solo sulla spiegazione di alcune di esse.
• Vector calculationElements
E’ un vettore creato per ospitare, per ognuna delle variabili di reward definite, i tipi
di misura statistica da calcolare. Ogni tipologia, come vedremo più avanti, è
rappresentata da una diversa classe ereditata dalla classe astratta
BaseCalculationObject.
• PVInfo ThePVInfo
Attraverso questa variabile è possibile accedere a tutte le informazioni relative alle
variabili di reward definite nel reward model, come il numero complessivo o il tipo
di analisi statistica di cui devono essere oggetto.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
99
• Vector Processors
Tiene traccia di tutti i ProcessorManager ai quali un dato esperimento è stato
assegnato al fine di ottimizzare le operazioni necessarie.
METODI PUBBLICI E PRIVATI
� ExperimentObject()
Dato che la classe ExperimentObject è incaricata di creare gli oggetti che da un lato,
effettueranno i calcoli necessari per determinare i valori delle variabili di reward, e
dall’altro aggiorneranno contestualmente a questa operazione la tabella affine, è
stato necessario modificare il costruttore della classe in modo che gli venissero
passati come argomenti anche il riferimento all’oggetto Connection e l’id
dell’esperimento, che a sua volta passerà agli oggetti durante la loro istanziazione.
• void addDataobject()
A questo metodo viene passato come argomento l’oggetto di tipo DataObject che
conterrà i dati utili al calcolo delle statistiche. In base alla frequenza con la quale
devono essere aggiornati i valori delle variabili di reward, esso richiama il metodo
updateData() che comunica con gli oggetti incaricati di effettuare i calcoli.
• void updateData()
In pratica questo metodo invoca, su ognuno degli oggetti
BaseCalculationObject contenuti nel vettore CalculationElements, il
metodo Update() per ricalcolare, tenendo conto dei nuovi dati ricevuti e contenuti
in nella variabile NewData, i valori statistici di ogni variabile. Di seguito è riportata
la porzione di codice che richiede il calcolo dei parametri statistici.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
100
... for(int j = 0; j < CalculationElements.size(); j++) { BaseCalculationObject basecalculationobject = (BaseCalculationObject)CalculationElements.elemen tAt(j); flag &= basecalculationobject.Update(NewData, i, MinBatches, MaxBatches); DoneBatches = Math.max(DoneBatches, basecalculationobject.getBatches()) ; } ...
Nella variabile booleana flag viene restituito il valore true se tutti i valori calcolati
relativi a tutte le variabili di reward rientrano nell’intervallo di confidenza
specificato, invece DoneBatches contiene il numero di osservazioni effettuate fino
a quell’istante.
Come vedremo più avanti, è proprio all’interno del corpo del metodo Update() ,
ridefinito in ognuna delle classi ereditate da BaseCalculationObject , che è
contenuto il codice necessario a svolgere le operazioni di aggiornamento dei valori
di media e varianza, e il loro inserimento all’interno del database db_ Möbius.
La classe StreamReader
Questa classe costituisce il fulcro dell’elaborazione dei dati inviati dal simulatore. Infatti
sul bus event vengono inviati, oltre ai dati utili formattati come double, anche metadati
riguardanti l’esperimento e la particolare variabile di reward cui essi fanno riferimento,
come pure il tempo impiegato dal processore per eseguire la simulazione. Questo è il
motivo per cui prelevare i dati direttamente dallo stream così come giungono non è
possibile e occorre, invece, conoscere l’ordine in cui essi sono trasmessi e la loro natura.
La classe StreamReader implementa la struttura necessaria a intercettare i dati sul bus, e
individuare il tipo di informazione che essi trasportano per poterli trattare in modo
appropriato. Dall’istante in cui l’oggetto Simulator avvia un suo thread, questo si mette in
attesa di poter prelevare dati dagli input stream che i vari ProcessorManager hanno creato.
Ogni thread, infatti mantiene nel vettore _addStream una lista di tutti gli stream utilizzati
dal simulatore per la trasmissione.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
101
Il metodo utilizzato per leggere il flusso di informazioni è readStream(), che ha come
argomenti il riferimento allo stream e al relativo ProcessorManager.
Vediamone una porzione di codice:
… if(datainputstream.available() > 0){ int i = datainputstream.readInt(); if(i > 0){ j++; byte byte0 = datainputstream.re adByte(); switch(byte0) { case -1: readReplyPacket(datainputst ream); break; case -2: readTimePacket(datainputstr eam); break; default: readDataPacket(datainputstr eam, process ormanager); break; } } }
Ogni pacchetto inviato (inteso in senso generale e non di datagramma UDP) contiene una
sorta di header che consente di individuarne il contenuto informativo, così da richiamare tra
i metodi per la lettura evidenziati in grigio, quello più congeniale. Quindi a seconda del
valore della variabile byte0 , seguirà la lettura di un ReplyPacket (inviato solo una volta
all’inizio della connessione), di un TimePacket o di un DataPacket. Questo perchè la natura
del pacchetto stabilisce intrinsecamente una sorta di protocollo da rispettare durante il ciclo
di lettura dei dati dallo stream affinchè essi abbiano senso. Concentriamoci sul metodo
readDataPacket() e analizziamone parte del codice:
…
short word0 = datainputstream.readShort(); short word1 = datainputstream.readShort();
…

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
102
for(int k = 0; dataobject != null && k < word1;){ short word2 = datainputstream.readShort(); byte byte0 = datainputstream.readByte(); int i = datainputstream.readInt(); try{ for(j = 0; j < i; j++){ double d = datainputstream.readDouble(); dataobject.addValue(word2, byte0, d); } k++; }catch(EOFException eofexception){continue;}
La prima lettura dello stream riguarda l’identificativo dell’esperimento cui fa riferimento il
pacchetto inviato, che verrà messo nella variabile word0 ; word1 conterrà il numero
complessivo di dati utili da leggere; lo short word2 conterrà l’identificativo della
particolare variabile di reward di cui calcolare le statistiche; byte0 il tipo di struttura dati
all’interno della quale memorizzare i dati contenuti nella variabile d (si tratta dei risultati
veri e propri delle osservazioni effettuate), infine i indicherà il numero di dati double che
occorre leggere successivamente (quest’ultimo parametro dipende dal numero di
osservazioni inviate per ogni variabile dal simulatore, specificato nel solver file). A questo
punto, terminata la lettura del pacchetto, i dati e tutte le informazioni necessarie a risalire a
quale variabile di reward essi fanno riferimento, sono archiviate nella matrice di double
dell’oggetto della classe DataObject.
Invocando il metodo retrieveExperiment() , è possibile recuperare l’esperimento di
cui calcolare le variabili dal vettore che tiene traccia di tutti gli esperimenti correntemente
in esecuzione sul simulatore. Solo a questo punto si possono avviare le operazioni
finalizzate al calcolo delle statistiche, attraverso la chiamata del metodo
addDataObject() sul riferimeto dell’ExperimentObject sopra ottenuto, e iniziare così un
nuovo ciclo di lettura.
… ExperimentObject experimentobject = retrieveExperim ent(word0); if(experimentobject != null){ experimentobject.addDataObject(dataobject); }

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
103
La classe astratta BaseCalculationObject
Figura4.6: class diagram delle classi adibite all’elaborazione statistica dei dati
In figura è stato riportato il diagramma delle classi che vengono utilizzate dall’oggetto
ExperimentObject per determinare i valori delle variabili di reward definite nel reward
model. Le classi incaricate di calcolare i valori statistici di ognuna sono quattro, ma di esse
solo due, MeanCalculatinoObject e VarianceCalculationObject, vengono usate durante la
simulazione del modelli del caso di studio. Tuttavia per completezza e in vista di eventuali

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
104
modifiche sul modello abbiamo preferito importarle comunque tutte nel package simulator.
La classe ‘genitore’ dalla quale esse ereditano è la BaseCalculatinObject, in cui viene
dichiarato il metodo astratto Update() che riceve come argomenti: un vettore di oggetti
DataObject, per risalire ai dati inviati dal simulation engine relativi a una data osservazione,
la dimensione del vettore, infine minimo e massimo numero di batch da eseguire. Il metodo
viene poi implementato in ognuna delle classi derivate specializzandone il comportamento a
seconda della tipologia di statistiche che esse devono restituire ovvero, media o varianza. E’
nel corpo di questo metodo, infatti, che risiede il codice che implementa tutte le operazioni
sui dati.
Sono stati modificati i costruttori delle due classi sopra citate poiché era necessario che
venissero passati loro il riferimento all’oggetto Connection indispensabile per le
comunicazioni con il database, e l’identificativo della simulazione e dell’esperimento, così
da poter effettuare correttamente l’inserimento dei valori nella tabella opportuna. Allo
scopo sono state aggiunte le variabili Connection conn_db , int id_run e int
id_exp ed è stato implementato il metodo update_run_reward_Table() che viene
richiamato in coda al codice contenuto nel metodo descritto sopra.
Poichè l’implementazione è simile in entrambe le classi (differisce infatti solo nella natura
dei dati inseriti e nella particolare tabella utilizzata), verrà analizzato il codice relativo
all’inserimento, nella tabella ‘mean’ del database db_Möbius, dei valori di media e di
intervallo di confidenza, calcolati nel metodo Update() della classe
MeanCalculatinoObject :

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
105
… PreparedStatement ps = null; final String SQL = "INSERT INTO mean(id_run, id_exp , id_rew, batch,mean,converged,confidence_interval)VALUES(?,? ,?,?,?,?,?)"; try { if(!conn_db.isClosed()){ conn_db.setAutoCommit(false); ps = conn_db.prepareStatement(SQL); p s.setInt(1, id_run); ps.setInt(2, id_exp); ps.setInt(3, getPVNumber()); ps.setInt(4, (int)getBatches()); ps.setDouble(5, getMean()); ps.setBoolean(6, getConverged()); ps.setDouble(7, getConfidenceInterval()); ps.executeUpdate(); }…
Quindi, una volta calcolate le statistiche sui nuovi valori pervenuti, vengono inseriti nel
database :
1. l’id della simulazione e quello dell’esperimento, passati al costruttore;
2. l’identificativo della variabile di reward di cui si sono effettuati i calcoli; questo è
ottenuto invocando il metodo getPVNumber() ;
3. il valore della media, ottenuta invocando il metodo getMean() ;
4. il numero di batch osservati, ottenuti invocando il metodo getBatches() ;
5. una variabile booleana che indica l’avvenuta convergenza relativa alla particolare
variabile, ottenuta invocando il metodo getConverged() ;
6. l’intervallo di confidenza, ottenuto invocando il metodo
getConfidenceInterval() .
Tutti i metodi invocati sono implementati nella particolare classe in oggetto.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
106
4.6 I componenti View e Controller :
il tool web-based Web Model WSN Generator
In questo paragrafo verranno descritte le modifiche che sono state applicate al tool web
based allo scopo di implementare le nuove funzionalità, esposte in 4.2, che esso deve essere
in grado di fornire. Poichè in [14] sono state ampliamente discusse le fasi di progettazione
dell’applicativo, si rimanda ad esso per eventuali approfondimenti.
Si ricorda che il componente software controller racchiude le classi realizzate per il
controllo che dialogano sia con i componenti ZK dell’interfaccia web, sia con le classi del
model; inoltre, questo componente, include anche il file .jar del progetto zkDiagram, un
porting opensource della libreria JavaScript draw2d necessaria per implementare la
funzionalità disegno topologia WSN. La View, invece, è composta di soli file .zul
dell’interfaccia grafica dell’applicazione web, scritti utilizzando sia il linguaggio ZUML sia
HTML.
4.6.1 La scelta del Framework
Zk è un web framework basato su componenti Ajax, scritto interamente in Java e che
permette di creare ricche intefacce grafiche per applicazioni web senza alcun bisogno di
utilizzare il linguaggio JavaScript nè Ajax. ZK è open source, ed ha di recente adottato la
licenza LGPL che permette di usarlo liberamente anche in ambito commerciale. La parte
centrale di ZK consiste in un meccanismo event-driven basato su oltre duecento componenti
Ajax, e un linguaggio di mark-up (XUL/XHTML) usato per disegnare interfacce grafiche.
A differenza di altri framework basati su Ajax, ZK non richiede al programmatore alcuna
conoscenza di Javascript per sviluppare applicazioni, perchè il framework si occupa
autonomamente di generare il codice Javascript necessario al corretto funzionamento
dell’applicazione. Per sviluppare correttamente una applicazione è necessario dunque, oltre
alla conoscenza di un linguaggio di programmazione ad oggetti tra quelli supportati, come
Java o Python, una minima conoscenza di HTML.
Il punto di forza di questo framework, quindi, è la possibilità di sviluppare una applicazione
web come se fosse una applicazione desktop, secondo un principio che viene definito dagli

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
107
stessi sviluppatori come Direct RIA, in cui la parte grafica ed il controllo associato vengono
sviluppati come in una normale applicazione Swing o SWT. E’ possibile ad esempio
l’utilizzo di componenti grafici (predefiniti dagli sviluppatori di ZK) comuni ad altre
tecnologie, come TextBox, Label e Button da aggiungere liberamente nell’interfaccia
grafica (pagina web) che si vuole sviluppare. Automaticamente verranno creati listener di
eventi comuni da monitorare (onClick, onChange etc.) e si potranno definire delle funzioni
da eseguire quando questi eventi si verificano.
Il linguaggio ZUML consente di aggiungere e posizionare questi componenti all’interno
della pagina web. Si tratta di un linguaggio di mark-up con una sintassi XML style che
permette lo sviluppo veloce di RIA. E’ inoltre disponibile un plugin per Eclipse che
permette, alla stregua dei tool RAD per applicazioni desktop, la progettazione visuale delle
interfacce.
Il framework ZK si è rivelato inoltre uno strumento facile da apprendere, e che ben si presta
allo sviluppo veloce di RIA, nonostante non sia particolarmente adatto ad applicazioni web
spiccatamente client side, per cui si consiglia l’uso di Flash o JavaFX.
Il pattern architetturale Model-View-Controller (MVC, talvolta tradotto in italiano con
Modello-Vista-Controllore) adottato nell’applicazione, è basato sulla separazione dei
compiti fra i componenti software che interpretano tre ruoli principali. Secondo tale
modello possiamo articolare un software secondo tre ruoli. Il primo, il model, fornisce i
metodi per accedere ai dati utili all’applicazione. Il secondo, il view, visualizza i dati
contenuti nel modem e si occupa dell’interazione con utenti ed agenti. Il terzo, il controller,
riceve i comandi dell’utente (in genere attraverso la view) e li attua modificando lo stato
degli altri due componenti. Si tratta di un modello molto diffuso nello sviluppo di interfacce
grafiche di sistemi software object oriented e che implica anche la tradizionale separazione
tra logica applicativa (logica di business) a carico del controller e del model, e l’interfaccia
utente a carico della view.
Il pattern MVC non è obbligatorio in ZK, ma ne è fortemente consigliato l’utilizzo da parte
degli sviluppatori. Per utilizzare il pattern MVC in ZK è sufficiente suddividere

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
108
l’applicazione in due file : nel primo, con estensione .zul andrà definita la parte grafica
dell’applicazione, mediante il linguaggio ZUML già presentato; nel secondo, con estensione
.java, andrà l’implementazione dei listener degli eventi, e quindi la parte Model e Controller
dell’applicazione.
4.6.2 Le classi controller e i file.zul
All’interno del componente Controller è stato implementato ex-novo il package ‘database’
contenente tutte le classi che, richiamate dai file .zul attraverso l’attributo “apply”,
dialogano con il database db_Möbius al fine di gestire i file archiviati nella tabella
‘topology’. In particolare di questo package fanno parte le classi:
• DatabaseManagement_ctrl: crea dinamicamente e visualizza la lista di tutti i file
delle topologie salvati dall’utente nel database; per ognuno di questi, di cui sono
specificati nome e data di inserimento, sono consentite le operazioni di esportazione
e di cancellazione innescate attraverso i pulsanti ‘Download Topolgy’ e ‘Delete
Topolgy’ definiti nel file DataBase.zul. Inoltre è possibile effettuare l’upload di un
nuovo file in formato .zip o, ancora, ripulire l’intera tabella delle topologie mediante
i pulsanti ‘Upload Topology’ e ‘Clean DataBase’.
• DbTopology_ctrl: permette all’utente di selezionare dal database il file della
particolare topologia che verrà poi esportata nella cartella dell’utente (creata all’atto
della sua registrazione) per essere utilizzata durante la generazione del modello. Il
file che essa controlla è WinDbTopology.zul.
• SaveTopology_ctrl: questa classe viene invocata dal file SaveTopology.zul e ha il
compito di implementare le operazioni per l’archiviazione del file compresso di una
topologia dopo che questa sia stata disegnata dall’utente attraverso la schermata
grafica messa a disposizione dall’applicazione; nel caso in cui il nome specificato
per la memorizzazione corrisponda a un file già presente nel db, è necessario
indicare un nome diverso, poichè questo deve intrinsecamente fornire un’idea
immediata della natura della topologia.
Fanno, invece, parte del package ‘webfamogen.controller’ tutte le classi che controllano il

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
109
funzionamento della GUI web e che dialogano con i software desktop installati nel server.
Di esso alcune classi sono state create ex-novo, altre, invece, sono solo state oggetto di
modifiche. In particolare di questo package fanno parte le nuove classi:
• RegisterBoxController: si occupa della registrazione dell’utente attraverso
l’interfaccia del file WinRegister.zul. E’ necessario indicare un nome utente, una
password alfanumerica e un’e-mail, i dati sono poi inseriti nella tabella ‘users’ del
database db_Möbius. Vengono utilizzati i metodi delle classi di utilità per creare i
file e le cartelle necessarie al funzionamento della simulazione remota alle quali
viene in seguito collegata la sessione corrente.
• LoginBoxController: è responsabile della sessione e dell’autenticazione dell’utente
attraverso l’interfaccia del file WinLogin.zul. L’autenticazione viene eseguita
inserendo username e password con i quali l’utente si è registrato, e si conclude
collegando la sessione corrente con i file e le cartelle necessarie al funzionamento
della simulazione remota create in fase di registrazione.
• ShowResults_ctrl: viene richiamata all’interno del file ShowResults.zul al termine di
una simulazione, al fine di crearne dinamicamente e visualizzarne la lista di tutti gli
esperimenti. Mostra per ognuno di essi: il nome, il tempo di simulazione, i batch
osservati e se esso ha raggiunto o meno la convergenza.
• ShowAllResults_ctrl: crea e visualizza dinamicamente tutte le informazioni relative
a un singolo esperimento, riporta per ogni osservazione eseguita: il nome della
variabile, il numero di batch correnti, il valore della media e il suo intervallo di
confidenza, infine il valore della varianza e il suo intervallo di confidenza. Questa
classe controlla il file ShowAllResults.zul.
• Download_ctrl: consente all’utente di effettuare il download del modello appena
compilato e simulato oppure di esportarne solamente i risultati. Queste operazioni
vengono innescate rispettivamente dai pulsanti “Download Model” e “Download
Results” definiti nel file ShowResults.zul. In particolare l’esportazione dei risultati
prevede la creazione di un file .csv direttamente a partire dal database db_Möbius

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
110
che conterrà il nome del progetto, il numero di nodi che costituiscono la rete, la
topologia utilizzata, il nome di tutti gli esperimenti e per ognuno di essi la durata
della simulazione, il numero di batch osservati e se esso ha raggiunto o meno la
convergenza; sono inoltre riportati per ogni variabile di reward: il nome, i valori di
media e varianza e i rispettivi intervalli di confidenza relativi a tutti i batch
osservati durante la simulazione.
Le classi del package oggetto di modifiche sono state invece:
• DesignerController: fa parte del package topology.designer ed è la classe controller
responsabile del disegno della topologia WSN (inclusi il posizionamento dei nodi, il
disegno dei link a seconda del metodo di propagazione selezionato, e il controllo
degli input dell’utente. Essa dialoga sia con l’interfaccia grafica implementata in
TopologyDesigner.zul, sia con la libreria ZKDiagram.jar. Le è stato aggiunto il
codice necessario a creare il componente definito dal file SaveTopology.zul per
l’archiviazione all’interno del database db_Möbius, del file compresso contenente la
topologia disegnata.
• WebTopologyController: è la classe che controlla l’interfaccia principale del tool
web-based, responsabile di due compiti: emulare il comportamento del tool desktop-
based (sia nell’interfaccia che nelle funzionalità) e gestire le scelte utente nella
modellazione e simulazione delle WSN. Le modifiche hanno riguardato la necessità
di gestire i nuovi eventi definiti nel componente Generator.zul e innescati
dall’immissione dei parametri discussi in 4.2, con i quali è possibile caratterizzare il
particolare modello di studio.
• ModelGeneratedUtil: è la classe che gestisce il modello generato o compilato con la
sinergia del tool desktop-based e di Möbius. Essa fornisce all’utente la possibilità di
salvare i modelli generati nel proprio sistema piuttosto che conservarli sul server,
sfruttando il metodo org.zkoss.zul.Filedownload.save, messo a disposizione dallo
ZK Framework.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
111
Inoltre, nel caso si sia scelta, in fase di generazione, la compilazione del modello,
sarà possibile avviarne la simulazione digitando il pulsante ‘simulate’
dell’interfaccia definita dal file Model_Generated.zul controllato dalla classe, e
aspettare la visualizzazione dei rirultati.
• WebUtil: tutte le classi fin’ora analizzate, per espletare le loro funzioni, devono
dialogare con questa classe, la quale ha subito i maggiori cambiamenti poichè
contenente i metodi di ausilio a tutte le altre. Essa contiene i metodi per:
a. la creazione e il controllo (attraverso l’utilizzo del packages java.io.File), e
la restituzione dei rispettivi path, delle directory e dei file creati all’atto della
registrazione al sistema da parte dell’utente;
b. la decompressione dei file .zip delle topologie caricati dall’utente, e la
compressione del modelli generati, compilati, e simulati; in particolare allo
scopo vengono utilizzati i packages java.io.File per la manipolazione dei file
e directory, java.util.zip per la compressione/decompressione,
org.zkoss.util.media e org.zkoss.zul.Fileupload per l’upload della topologia.
Inoltre sono stati implementati ex-novo i metodi per realizzare la comunicazione
con il database db_Möbius al fine di:
• gestire le topologie di uno specifico utente attraverso le operazioni prima
descritte;
• prelevare dal database i risultati delle simulazioni così da presentarli in
formato grafico, o, se richiesto, esportarli in un file .csv che possa essere
scaricato sulla propria macchina dall’utente.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
112
Capitolo 5
Un Caso di Studio
Il capitolo racchiude gli screenshot delle nuove funzionalità implementate, esse riflettono il
funzionamento descritto nel paragrafo 4.2 dedicato ai casi d’uso.
Inizialmente l’utente accede all’applicazione digitando correttamente l’indirizzo all’interno
del suo web browser. Attraverso la schermata che viene visualizzata egli può inserire e
validare le sue credenziali (il nome utente e la password con cui si sia precedentemente
registrato) così da poter accedere alle funzionalità del tool.
Fig. 5.1 – Login Page del tool

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
113
Dal menu principale è possibile selezionare i sottomenu sulla sinistra:
• “Topology Designer”: l’applicazione apre una schermata simile ad un software di
disegno nella quale è possibile disporre i nodi su un piano bidimensionale; nel
tracciare lo scenario topologico, l'utente può selezionare per la rete di nodi, il
modello di propagazione del segnale, il quale differisce dall'ambiente scelto, e
settare manualmente la probabilità di errore sui vari link, indicando per ognuno la
coppia di nodi che lo identifica. Terminata la configurazione della rete, mediante le
funzionalità offerte dal sottomenu sulla destra “Settings”, l’utente può decidere se
esportare la topologia appena creata oppure memorizzare i file all’interno dell’archivio
remoto. In quest’ultimo caso si aprirà una finestra che riporterà le topologie presenti nel
database con le rispettive date di immissione, e attraverso la quale sarà necessario
inserire il nome del nuovo scenario creato.
Fig. 5.2 – Disegno della topologia WSN – archivio della topologia nel database remoto

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
114
• “Database Management”: l’applicazione visualizza una schermata contenente la
lista dei file relativi a tutte le topologie inserite da un utente fino a un dato istante;
selezionando una particolare topologia è possibile cancellarla dall’archivio oppure
esportarla sul proprio computer, cliccando rispettivamente i pulsanti “Delete
Topology” e “Download Topology”. Inoltre l’utente può decdere di caricare un
nuovo scenario topologico, o ancora, ripulire il database da tutti i file (pulsanti
“Upload Topology” e “Clean Database”).
Fig. 5.3 – Pagina della Gestione delle Topologie – upload, download, delete, clean
• “Model Generator”: si apre una schermata che consente la caratterizzazione degli
scenari simulativi mediante l’immissione dei valori dei vari parametri del particolare
modello di fallimento. Il numero di esperimenti finale sarà determinato dalla
combinazione di tutti i valori inseriti: ad esempio indicando come algoritmi di
routing i protocolli “Multihop” e “Gossiping” e “Random” e come OS entrambi i

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
115
sistemi, “TinyOS” e “Mantis”, verranno generati sei esperimenti, relativo ognuno a
una delle combinazioni possibili: Multihop-TinyOS /Multihop-Mantis, etc…
Fig. 5.4 – Pagina del Failure Model WSN Generator per la generazione del modello: caratterizzazione degli scenari di simulazione
Una volta inseriti tutti gli input necessari alla generazione del modello compilato, si aprirà
una finestra che consentirà di esportare il modello così prodotto, oppure avviare la
simulazione sul server; in quest’ultimo caso una schermata visualizzerà lo stato della
simulazione.
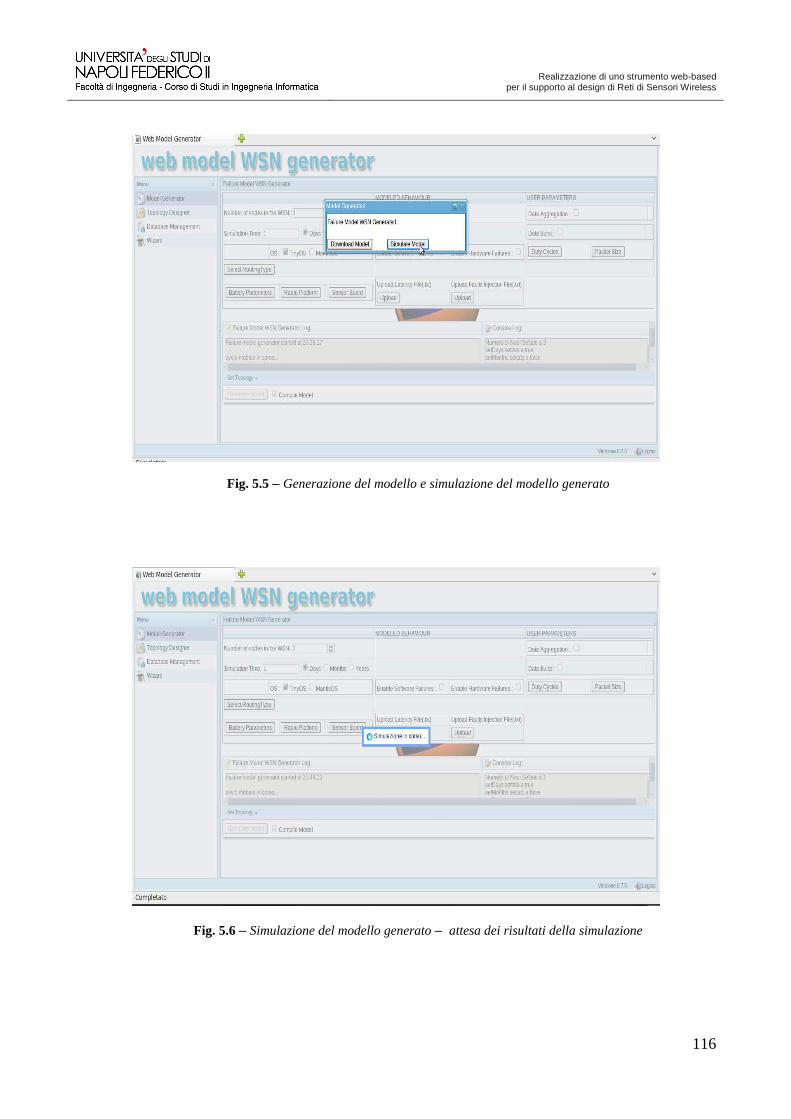
Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
116
Fig. 5.5 – Generazione del modello e simulazione del modello generato
Fig. 5.6 – Simulazione del modello generato – attesa dei risultati della simulazione

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
117
Terminata la simulazione, i risultati degli esperimenti saranno presentati all’utente
all’interno di una finestra, specificando per ognuno il nome del progetto all’interno del
quale sono stati definiti, il nome, i batch osservati, il tempo di simulazione e l’eventuale
convergenza: cliccando sul singolo esperimento è inoltre possibile visualizzare nel dettaglio
i valori delle variabili di reward del modello. Per ogni variabile vengono riportati il nome
della variabile, il numero di batch a cui si riferiscono i successivi valori di media e varianza
e i rispettivi intervalli di confidenza.
Infine l’applicazione mette a disposizione un sottomenu sulla sinistra, attraverso il quale
l’utente può decidere di esportare in un file .csv i soli risultati delle simulazioni (pulsante
“Downloads Results”), oppure l’intero modello generato, compilato e simulato.
Fig. 5.7 – Presentazione dei risultati della simulazionedel modellogenerato

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
118
Conclusioni e sviluppi futuri
Il presente lavoro di tesi è stato finalizzato allo sviluppo di uno strumento di supporto alla
progettazione di Wireless Sensor Network che guidi le scelte dei progettisti per prevedere,
prevenire, tollerare, e rimuovere eventuali guasti, errori o fallimenti che possano minare
l’integrità della rete o che possano deteriorarne performance e affidabilità. Il punto di
partenza è stato il tool “Web Model WSN Generator” ( basato sul generatore automatico di
modelli di fallimento [15] e sul simulatore Möbius), una Rich Internet Application (RIA)
attraverso la quale l’utente è in grado, in maniera semplice, rapida e con un esiguo carico
computazionale, di inserire o disegnare lo scenario topologico da modellare, ottenere
automaticamente un modello analitico atto ad incentrarsi sulla dependability del sistema,
scegliere le metriche da valutare e scaricare il risultato ottenuto.
Ci si è quindi concentrati su quelle che erano le funzionalità assenti nel tool:
• Consentire la gestione delle topologie disegnate o caricate dal singolo utente;
• Caratterizzare contestualmente più scenari simulativi, al fine di valutare la risposta
del sistema in diversi contesti di funzionamento;
• Simulare da remoto il modello generato ed esportarne i risultati, così da sollevare
l’utente dall’onere di dover configurare, installare e manutenere il software
necessario alla simulazione, ma soprattutto in modo che egli possa concentrarsi
sull’analisi dei risultati ottenuti, lavorando nel suo dominio di competenza;
• Mantenere i risultati delle simulazioni al fine di renderli sempre fruibili.
Allo scopo è stato aggiunto un database MySQL per il Topology Management, lo User
Management e il Simulation Management; inoltre sono state apportate modifiche che hanno

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
119
riguardato da una lato lo sviluppo di nuove interfacce grafiche all’interno del tool web-
based, e dall’altro lo sviluppo di nuove classi nel tool desktop-based, a partire da un reverse
engineering del tool Möbius, al fine di implementare la simulazione remota dei modelli
generati.
Le scelte di progetto nella realizzazione dell'applicazione web e delle sue nuove funzionalità
sono state mirate a rendere il risultato ottenuto quanto più estensibile possibile.
Successivamente, infatti, è possibile l’aggiunta di altri modelli di propagazione, di altri
modelli analitici e di ulteriori metriche di valutazione che possono essere aggiunti in
maniera semplice anche se si tratta di sfruttare librerie esterne o software di terze parti. Si
potrebbe inoltre pensare di sviluppare ulteriore software per consentire all’utente di
interagire direttamente con il simulatore adottato, modificandone i parametri di elaborazione
come il numero di batch osservati che è necessario garantire per poter terminare la
simulazione o ancora la frequenza di update delle stime effettuate.
Ancora, occorrerebbe integrare l’applicazione di ulteriori strumenti finalizzati alla gestione
remota dei risultati degli esperimenti delle simulazioni lanciate dall’utente, e al reporting
grafico degli stessi al fine di consentire un’analisi visiva dell’evoluzione statistica delle
metriche di valutazione adottate in funzione del numero di campioni osservati.

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
120
Bibliografia
[1] A. Avizienis, J. Laprie, B. Randell. “Fundamental Concepts of Computer System
Dependability”, 2001.
[2] F. Flammini, N. Mazzocca, V. Vittorini. “Modelli per l’analisi di sistemi critici”,
2009.
[3] A. M. Law, W. D. Kelton. “Simulation Modelling Analysis – Third Edition, Book,
McGraw-Hill”, 2000.
[4] J. Banks. “Introduction to Simulation”, Proceedings of the 1999 Winter Simulation
Conference.
[5] E. Egea-López, J. Vales-Alonso, A. S. Martínez-Sala, P. Pavón-Mariño, J. García-
Haro. “Simulation Tools for Wireless Sensor Networks”.
[6] R. Aquilone. “Analisi comparativa di simulatori di reti di sensori wireless”, 2006.
[7] Thomas J. Schriber, Daniel T. Brunner. “Inside discrete-event simulation software:
how it works and why it matters”, 1997.
[8] http://it.wikipedia.org/wiki/Emulatore
[9] Catello Di Martino. “Resilency Assessment of Wireless Sensor Networks: a
Holistic Approach”, 2009
[10] Isabel Dietrich and Falko Dressler. “On the lifetime of wireless sensor networks.
ACM Trans. Sen. Netw., 5(1):1–39”, 2009.
[11] M. Achir and L. Ouvry. “probabilistic model for energy estimation in wireless
sensor networks. In Proc. of first International Workshop on Algorithmic
Aspects of Wireless Sensor Networks”, 2002.
[12] F. Chiasserini and M. Garetto. “Modeling the performance of wireless sensor

Realizzazione di uno strumento web-based
per il supporto al design di Reti di Sensori Wireless
121
networks. In Proc. of the IEEE Conference on Computer Communications
(Infocom ’04), page 310”, 2004.
[13] Jeffrey Stanford and Sutep Tongngam. “Approximation algorithm for maximum
lifetime in wireless sensor networks with data aggregation”, 2006.
[14] Luigi Rossi. “Realizzazione di uno strumento web-based per la simulazione remota
di reti di sensori senza filo”, 2009.
[15] Umberto Sannolo. “Generazione automatica di modelli di fallimento per la
simulazione di reti WSN”, 2008.
[16] http://www.mysql.it/why-mysql.
[17] R.Fujimoto, “Parallel and distributed simulation systems”.
[18] G. Gupta and M. Younis. “Fault-tolerant clustering of wireless sensor
networks. IEEE”, 2003
[19] S. Shakkottai, R. Srikant, and N. Shroff. “Unreliable sensor grids: Coverage,
connectivity and diameter”, 2003.
[20] Mark D. Krasniewski, Padma Varadharajan, Bryan Rabeler, Saurabh Bagchi, and Y.
Charlie Hu. Tibfit. “Trust index based fault tolerance for arbitrary data faults in
sensor networks”, 2005.





























