Embed Size (px)
Citation preview

Természetes nyelvek feldolgozása

Nyelvtanok szerepe
• A szoveg feldolgozása során tobb esetben is hasznos a nyelvtan ismerete
• Kapcsolodo problémakorok:– A vektormodell reprezentacio redukcioja:
a szavakat a szotovukkel reprezentaljuk (kanonikus alak) – A szovegek tisztitása:
a nyelvtanilag hibás szavak detektálása, kijavitása – A szoveg kivonatolás:
a szavak nyelvtani szerepének felhasználása – A szovegkeresés javitása: NLP lekérdezo felulet

Morphology
• Morpheme = "minimal meaning-bearing unit in a language"
• Morphology handles the formation of words by using morphemes– base form (stem), e.g., believe– affixes (suffixes, prefixes, infixes), e.g., un-, -able, -ly
• Morphological parsing = the task of recognizing the morphemes inside a word– e.g., hands, foxes, children
• Important for many tasks– machine translation– information retrieval – lexicography– any further processing (e.g., part-of-speech tagging)

4
Morphology• Morphology is the study of the internal structure of words, of
the way words are built up from smaller meaning units.• Two classes of morphemes
– Stems: “main” morpheme of the word, supplying the main meaning (i.e. establish in the example below)
– Affixes: add additional meaning• Prefixes: Antidisestablishmentarianism• Suffixes: Antidisestablishmentarianism• Infixes: hingi (borrow) – humingi (borrower) in Tagalog• Circumfixes: sagen (say) – gesagt (said) in German

5
Morphology: examples• Unladylike
– The word unladylike consists of three morphemes and four syllables. – Morpheme breaks:
• un- 'not' • lady '(well behaved) female adult human' • -like 'having the characteristics of'
– None of these morphemes can be broken up any more without losing all sense of meaning. Lady cannot be broken up into "la" and "dy," even though "la" and "dy" are separate syllables. Note that each syllable has no meaning on its own.
• Dogs– The word dogs consists of two morphemes and one syllable:
• dog, and • -s, a plural marker on nouns
– Note that a morpheme like "-s" can just be a single phoneme and does not have to be a whole syllable.
• Technique– The word technique consists of only one morpheme having two syllables. – Even though the word has two syllables, it is a single morpheme because it cannot be
broken down into smaller meaningful parts.
Adapted from http://www.sil.org/linguistics/GlossaryOfLinguisticTerms/WhatIsAMorpheme.htm

6
Types of morphological processes
• Inflection:– Systematic modification of a root form by means of
prefixes and suffixes to indicate grammatical distinctions like singular and plural.
– Stems: also called lemma, base form, root, lexeme– Doesn’t change the word class– New grammatical role– Usually produces a predictable, non idiosyncratic change
of meaning. • run runs | running | ran• hope+ing hoping hop hopping

Inflectional Morphology
• Inflectional Morphology• word stem + grammatical morpheme cat + s• only for nouns, verbs, and some adjectives
• Nouns– plural: – regular: +s, +es irregular: mouse - mice; ox - oxen– rules for exceptions: e.g. -y -> -ieslike: butterfly - butterflies– possessive: +'s, +'
• Verbs– main verbs (sleep, eat, walk)– modal verbs (can, will, should)– primary verbs (be, have, do)

Inflectional Morphology (verbs)
• Verb Inflections for:• main verbs (sleep, eat, walk); primary verbs (be, have, do)
• Morpholog. Form Regularly Inflected Form• stem walk merge try map• -s form walks merges tries maps• -ing participle walking merging trying mapping• past; -ed participlewalked merged tried mapped
• Morph. Form Irregularly Inflected Form• stem eat catch cut • -s form eats catches cuts • -ing participle eating catching cutting • -ed past ate caught cut• -ed participle eaten caught cut

• Noun Inflections for:• regular nouns (cat, hand); irregular nouns(child, ox)
• Morpholog. Form Regularly Inflected Form• stem cat hand• plural form cats hands
• Morph. Form Irregularly Inflected Form• stem child ox • plural form children oxen
Inflectional Morphology (nouns)

10
Types of morphological processes
• Derivation:– Ex: compute computer computerization– Less systematic that inflection– It can involve a change of meaning
• Wide Widely• Suffix en transforms adjective into verbs
– Weak weaken, soft soften• Suffix able transforms verbs into adjective
– Understand Understandable• Suffix er transforms verbs into nouns (nominalization)
– teach teacher
– Difficult cases:• building from which sense of “build”?

Inflectional and Derivational Morphology (adjectives)
• Adjective Inflections and Derivations:
• prefix un- unhappy adjective, negation• suffix -ly happily adverb, mode• -er happier adjective, comparative 1• -est happiest adjective, comparative 2• suffix -ness happiness noun
• plus combinations, like unhappiest, unhappiness.
• Distinguish different adjective classes, which can or cannot take certain inflectional or derivational forms, e.g. no negation for big.

12
Types of morphological processes
• Compounding:– Merging of two or more words into a new
word• Downmarket, (to) overtake

Word Stemming
• What is Word Stemming?– Word stemming is an important feature supported
by present day indexing and search systems. Idea is to improve recall by automatic handling of word affixes by reducing the words to their stems, at the time of indexing and searching.
• How Word Stemming works? – Stemming broadens our results to include both word
roots and word derivations. It is commonly accepted that removal of word-endings (sometimes called suffix stripping) is a good idea; removal of prefixes can be useful in some subject domains.

14
Stemming
• The removal of the inflectional ending from words (strip off any affixes)
• Laughing, laugh, laughs, laughed laugh
– Problems• Can conflate semantically different words
– Gallery and gall may both be stemmed to gall
– A further step is to make sure that the resulting form is a known word in a dictionary, a task known as lemmatization.

Algorithms for Word Stemming
• A stemming algorithm is an algorithm that converts a word to a related form. One of the simplest such transformations is conversion of plurals to singulars.– Affix removal algorithms – Successor Variety – Table Lookup – N-gram
• Pros & Cons– Word Stemmers are used to conflate terms to improve
retrieval effectiveness and/or to reduce the size of indexing files
– increase recall at the cost of decreased precision– Over stemming and Under Stemming also create a problem
for retrieving the documents

Brute Force Algorithms These stemmers employ a lookup table which contains relations between root forms and inflected forms. To
stem a word, the table is queried to find a matching inflection. If a matching inflection is found, the associated root form is returned.
Advantages.
• Stemming error less.• User friendly. Problems
• They lack elegance to converge to the result fast.• Time consuming.• Back end updating• Difficult to design.
.

Suffix Stripping Algorithms Suffix stripping algorithms do not rely on a lookup table that consists of inflected forms and
root form relations. Instead, a typically smaller list of "rules" are stored which provide a path for the algorithm, given an input word form, to find its root form. Some examples of the rules include:
• if the word ends in 'ed', remove the 'ed' • if the word ends in 'ing', remove the 'ing' • if the word ends in 'ly', remove the 'ly'
Benefits
• Simple

Matching Algorithms
These algorithms use a stem database (for example a set of documents that contain stem words). These stems, as mentioned above, are not necessarily valid words themselves (but rather common sub-strings, as the "brows" in "browse" and in "browsing"). In order to stem a word the algorithm tries to match it with stems from the database, applying various constraints, such as on the relative length of the candidate stem within the word (so that, for example, the short prefix "be", which is the stem of such words as "be", "been" and "being", would not be considered as the stem of the word "beside").

19
Regular Expressions for Stemming
• Note: the star operator is "greedy" and the .* part of the expression tries to consume as much of the input as possible. If we use the "non-greedy" version of the star operator, written *?, we get what we want:

20
Regular Expressions for Stemming
• Let’s define a function to perform stemming, and apply it to a whole text
• The RE removed the s from ponds but also from is and basis. It produced some non-words like distribut and deriv, but these are acceptable stems in some applications.

Porter féle szotovezo
• Szabály alapu szotovezo • Angol nyelvre illesztett
A szabályokat adatbázisban, listában tárolja • A helyettesitési szabályok alakja:
– (feltétel) S1 → S2 • Az S1 szovégzodést S2-re cseréli, ha az S1 elotti részre a megadott
feltétel teljesul.• A leghosszabb illeszkedo szabály helyettesitése valosul meg. • Az algoritmus 5 szabálycsoportot definiál.• Egy csoport sikeres végrehajtása után a kovetkezo csoportra ugrik a
vezérlés . Az 5. szabálycsoport után terminál az algoritmus.

Porter's Algorithm
• The Porter Stemmer is a conflation Stemmer developed by Martin Porter at the University of Cambridge in 1980.
• Porter stemming algorithm (or 'Porter stemmer') is a process for removing the commoner morphological and inflexional endings from words in English.
• Most effective and widely used.• Porter's Algorithm works based on number of vowel
characters, which are followed be a consonant character in the stem (Measure), must be greater than one for the rule to be applied.
• A word can have any one of the forms: C……C, C…..V, V…..V, V…..C.
• These can be represented as [C](VC){m}[V].

Porter's Algorithm contd..
• The rules in the Porter algorithm are separated into five distinct steps numbered from 1 to 5. They are applied to the words in the text starting from step 1 and moving on to step 5.
• Step 1 deals with plurals and past participles. The subsequent steps are much more straightforward.
Ex. plastered->plaster, motoring-> motor • Step 2 deals with pattern matching on some common
suffixes.Ex. happy -> happi, relational -> relate, callousness -> callous
• Step 3 deals with special word endings.Ex. triplicate-> triplic, hopeful-> hope

Porter's Algorithm contd..
• Step 4 checks the stripped word against more suffixes in case the word is compounded.Ex. revival -> reviv, allowance-> allow, inference-> infer
etc.,
• Step 5 checks if the stripped word ends in a vowel and fixes it appropriatelyEx. probate -> probat, cease -> ceas, controll -> control
The algorithm is careful not to remove a suffix when the stem is too short, the length of the stem being given by its measure, m. There is no linguistic basis for this approach.

25
Porter Stemmer
• Lexicon free stemmer• Rewrite rules
• ATIONAL ATE (e.g. relational, relate)• FUL ε (e.g. hopeful, hope)• SSES SS (e.g. caresses, caress)
• Errors of Commission• Organization organ• Policy police
• Errors of Omission• Urgency (not stemmed to urgent)• European (not stemmed to Europe)

Porter féle szotovezo• Segédfogalmak:
– consonant (mássalhangzok) (minden, ami nem A,E,I,O,U,és mássalhangzot koveto Y), jele: c; C = c*
• pl. TOY → T,Y SYZYGY → S,Z,G
– vowel (magánhangzo), jele: v; V = v* • Egy szo általános alakja: [C](VC)m[V]
– ahol m is ismétlési tényezo (méret) • trouble → ccvvccv → CVCV → C (VC)1 V, m = 1• oaten → vvcvc → VCVC → (VC)2 , m = 2
• A szabályban ezen elemekre hivatkozhatunk: – A : egy a betu– m : méret– v,c : szovegrészek– * : tetszoleges szovegrész– d : cc– o:cvc (de a záro c nem V,W,Y) – and, or, not : logikai muveletek

Porter féle szotovezo példák
• (m > 1) EMENT → ε (ε: ures elem)– A szabály jelenése: ha a méret nagyobb mint 1, és
a szo végén az EMENT áll, akkor az elhagyhato– replacement → replac
• (m>1 and *v* )) SSES -> SS– A szabály jelenése: ha a méret nagyobb mint 1, és
a szo belsejében van magánhangzo, akkor a szovégi sses-bol ss lesz

Szotovezok tipikus hibái
• tultovezés: kulonbség elvesztése– házas → ház – házak → ház
• alultovezés: azonosság elvesztése– szabványosságot → szabványos – szabványt → szabvány
• félreértelmezés– német → ném

Szotovezés Paice-féle minosége
• alultovezési index:
– n1: Sikeresen kozos tore hozott szopárok
– n2: Kozos tovel rendelkezo szopárok
• tultovezési index:
– m1: Sikeresen eltéro tore hozott szopárok
– m2: Eltéro tovel rendelkezo szopárok
• eros szotovezo: ha sok alakot von kozos tore• gyenge szotovezo: ha kevés alakot hoz kozos tore

30
Is stemming useful?• For IR performance, some improvement (especially for
smaller documents)• May help a lot for some queries, but on average (across all
queries) it doesn’t help much (i.e. for some queries the results are worse)– Word sense disambiguation on query terms: business may be
stemmed to busy, saw (the tool) to see– A truncated stem can be intelligible to users– Most studies for stemming for IR done for English (may help more for
other languages)– The possibility of letting people interactively influence the stemming
has not been studied much• Since improvement is small, often IR engine usually don’t use
stemming• More on this when we’ll talk about IR

31
Text Normalization• Stemming• Convert to lower case• Identifying non-standard words including numbers,
abbreviations, and dates, and mapping any such tokens to a special vocabulary. – For example, every decimal number could be mapped to a single
token 0.0, and every acronym could be mapped to AAA. This keeps the vocabulary small and improves the accuracy of many language modeling tasks.
• Lemmatization– Make sure that the resulting form is a known word in a dictionary – WordNet lemmatizer only removes affixes if the resulting word is in its
dictionary

Lemmatization
• Reduce inflectional/derivational forms to base form• Direct impact on vocabulary size• E.g.,
– am, are, is be– car, cars, car's, cars' car
• the boy's cars are different colors the boy car be different color
• How to do this?– Need a list of grammatical rules + a list of irregular words– Children child, spoken speak …– Practical implementation: use WordNet’s morphstr function
• Perl: WordNet::QueryData (first returned value from validForms function)

33
Lemmatization
• WordNet lemmatizer only removes affixes if the resulting word is in its dictionary
• The WordNet lemmatizer is a good choice if you want to compile the vocabulary of some texts and want a list of valid
lemmas
Notice that if doesn't handle lying, but it converts women to woman.

Morphological Processing
• Knowledge– lexical entry: stem plus possible prefixes, suffixes plus word classes,
e.g. endings for verb forms (see tables above)– rules: how to combine stem and affixes, e.g. add s to form plural of
noun as in dogs– orthographic rules: spelling, e.g. double consonant as in mapping
• Processing: Finite State Transducers– take information above and analyze word token / generate word form
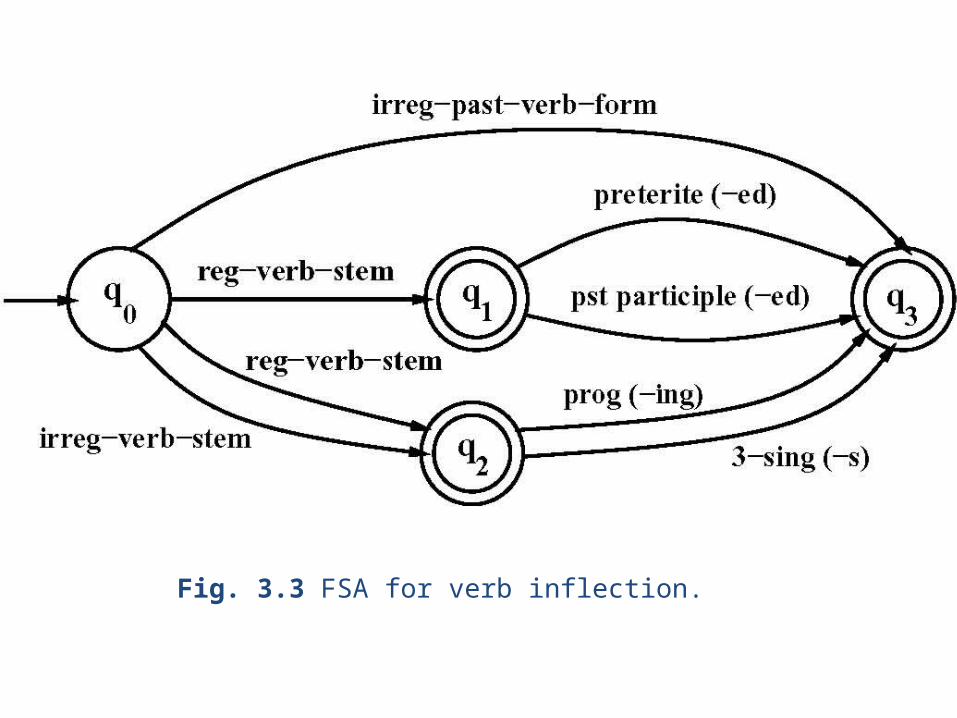
Fig. 3.3 FSA for verb inflection.

Fig. 3.5 More detailed FSA for adjective inflection.
Fig. 3.4 Simple FSA for adjective inflection.
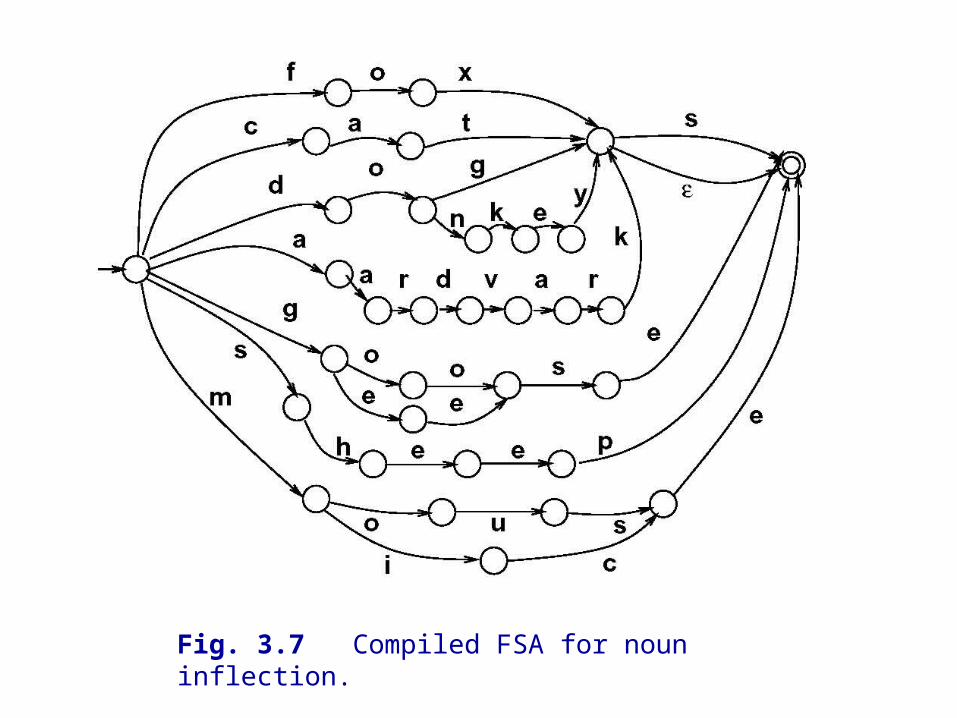
Fig. 3.7 Compiled FSA for noun inflection.
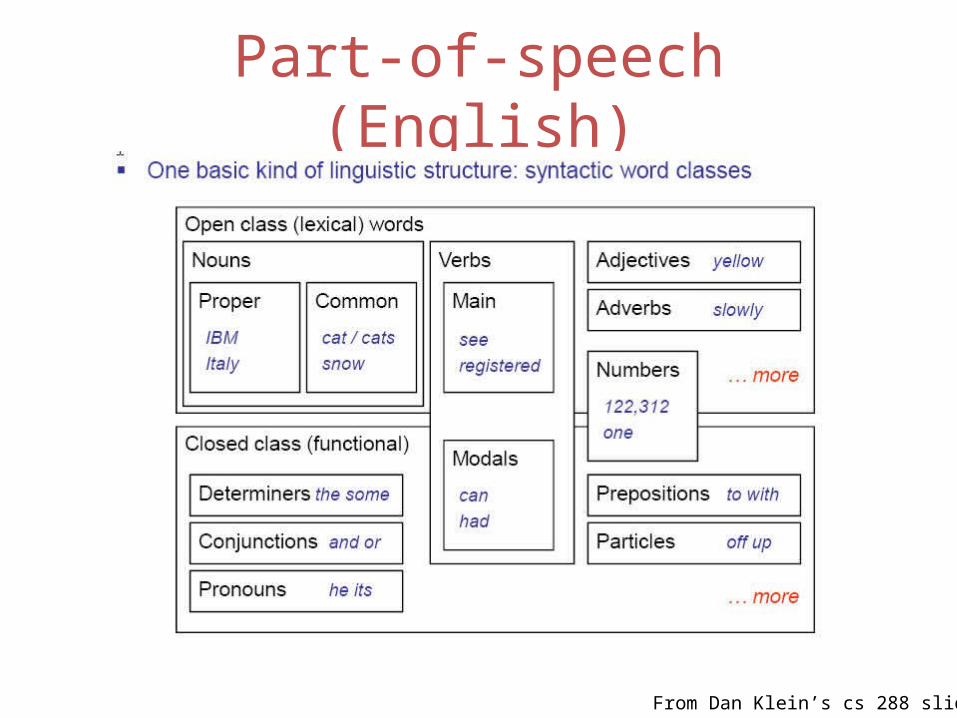
Part-of-speech (English)
From Dan Klein’s cs 288 slides

Modified from Diane Litman's version of Steve Bird's notes
39
Terminology
• Tagging– The process of associating labels with each token in
a text• Tags
– The labels– Syntactic word classes
• Tag Set– The collection of tags used

Part-of-Speech Ambiguity
Words that are highly ambiguous as to their part of speech tag

Sources of information
• Syntagmatic: tags of the other words– AT JJ NN is common– AT JJ VBP impossible (or unlikely)
• Lexical: look at the words– The AT– Flour more likely to be a noun than a verb– A tagger that always chooses the most common tag is 90%
correct (often used as baseline)
• Most taggers use both

Modified from Diane Litman's version of Steve Bird's notes
42
What does Tagging do?
1. Collapses Distinctions• Lexical identity may be discarded• e.g., all personal pronouns tagged with PRP
2. Introduces Distinctions• Ambiguities may be resolved• e.g. deal tagged with NN or VB
3. Helps in classification and prediction

Modified from Diane Litman's version of Steve Bird's notes
43
Why POS?• A word’s POS tells us a lot about the word
and its neighbors:– Limits the range of meanings (deal), pronunciation (text
to speech) (object vs object, record) or both (wind)– Helps in stemming: saw[v] → see, saw[n] → saw– Limits the range of following words – Can help select nouns from a document for
summarization– Basis for partial parsing (chunked parsing)

Slide modified from Massimo Poesio's
44
Choosing a tagset
• The choice of tagset greatly affects the difficulty of the problem
• Size of tag sets depends on language, objectives and purpose– Some tagging approaches (e.g., constraint grammar based) make
fewer distinctions e.g., conflating prepositions, conjunctions, particles– Simple morphology = more ambiguity = fewer tags
• Need to strike a balance between– Getting better information about context – Make it possible for classifiers to do their job

Tagging methods
• Hand-coded• Statistical taggers
– N-Gram Tagging– HMM– (Maximum Entropy)
• Brill (transformation-based) tagger

Hand-coded Tagger
• The Regular Expression Tagger

Unigram Tagger
• Unigram taggers are based on a simple statistical algorithm: for each token, assign the tag that is most likely for that particular token. – For example, it will assign the tag JJ to any occurrence of the word frequent,
since frequent is used as an adjective (e.g. a frequent word) more often than
it is used as a verb (e.g. I frequent this cafe).
)wP(t nn |

Unigram Tagger• We train a UnigramTagger by specifying tagged sentence data as a parameter
when we initialize the tagger. The training process involves inspecting the tag of each word and storing the most likely tag for any word in a dictionary, stored inside the tagger.
• We must be careful not to test it on the same data. A tagger that simply memorized its training data and made no attempt to construct a general model would get a perfect score, but would also be useless for tagging new text.
• Instead, we should split the data, training on 90% and testing on the remaining 10% (or 75% and 25%)
• Calculate performance on previously unseen text. – Note: this is general procedure for learning systems
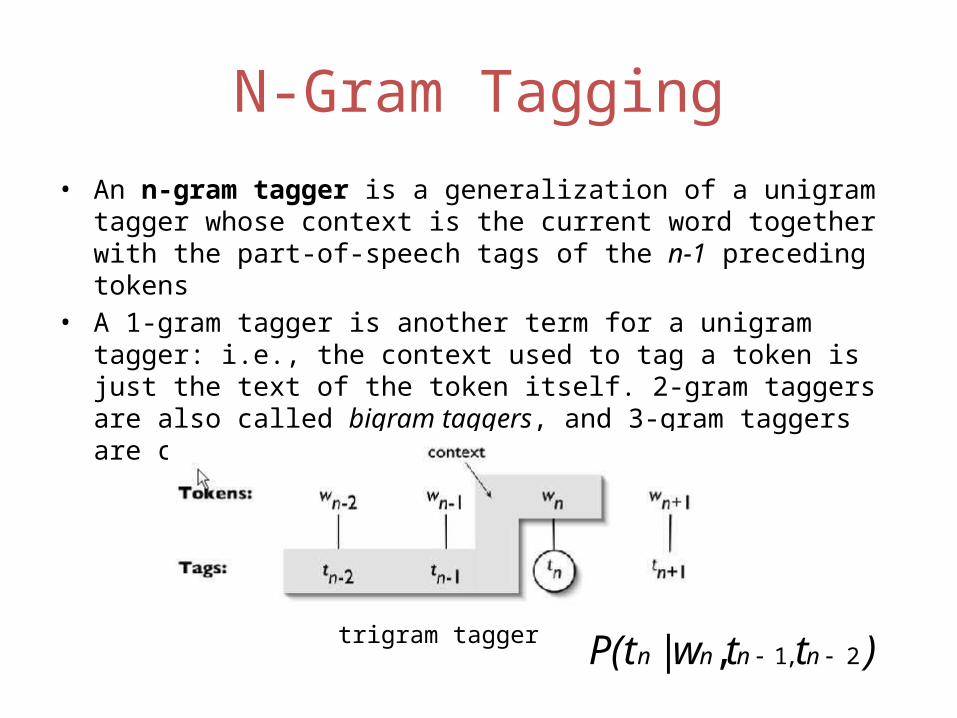
N-Gram Tagging• An n-gram tagger is a generalization of a unigram tagger whose context
is the current word together with the part-of-speech tags of the n-1 preceding tokens
• A 1-gram tagger is another term for a unigram tagger: i.e., the context used to tag a token is just the text of the token itself. 2-gram taggers are also called bigram taggers, and 3-gram taggers are called trigram taggers.
trigram tagger)ttwP(t nnnn 2,1,|

N-Gram Tagging• Why not 10-gram taggers?• As n gets larger, the specificity of the contexts
increases, as does the chance that the data we wish to tag contains contexts that were not present in the training data.
• This is known as the sparse data problem, and is quite pervasive in NLP. As a consequence, there is a trade-off between the accuracy and the coverage of our results (and this is related to the precision/recall trade-off)
• Next week: sparsity

Modified from Diane Litman's version of Steve Bird's notes
51
Rule-Based Tagger
• The Linguistic Complaint– Where is the linguistic knowledge of a tagger?– Just massive tables of numbers– Aren’t there any linguistic insights that could emerge
from the data?– Could thus use handcrafted sets of rules to tag input
sentences, for example, if input follows a determiner tag it as a noun.
)ttwP(t nnnn 2,1,|

Slide modified from Massimo Poesio's
52
The Brill tagger(transformation-based tagger)
• An example of Transformation-Based Learning – Basic idea: do a quick job first (using frequency), then
revise it using contextual rules.
• Very popular (freely available, works fairly well)– Probably the most widely used tagger (esp. outside NLP)– …. but not the most accurate: 96.6% / 82.0 %
• A supervised method: requires a tagged corpus

Brill Tagging: In more detail
• Start with simple (less accurate) rules…learn better ones from tagged corpus– Tag each word initially with most likely POS– Examine set of transformations to see which improves
tagging decisions compared to tagged corpus – Re-tag corpus using best transformation– Repeat until, e.g., performance doesn’t improve– Result: tagging procedure (ordered list of transformations)
which can be applied to new, untagged text

Slide modified from Massimo Poesio's
54
An example• Examples:
– They are expected to race tomorrow.– The race for outer space.
• Tagging algorithm:1. Tag all uses of “race” as NN (most likely tag in the
Brown corpus)• They are expected to race/NN tomorrow• the race/NN for outer space
2. Use a transformation rule to replace the tag NN with VB for all uses of “race” preceded by the tag TO:• They are expected to race/VB tomorrow• the race/NN for outer space
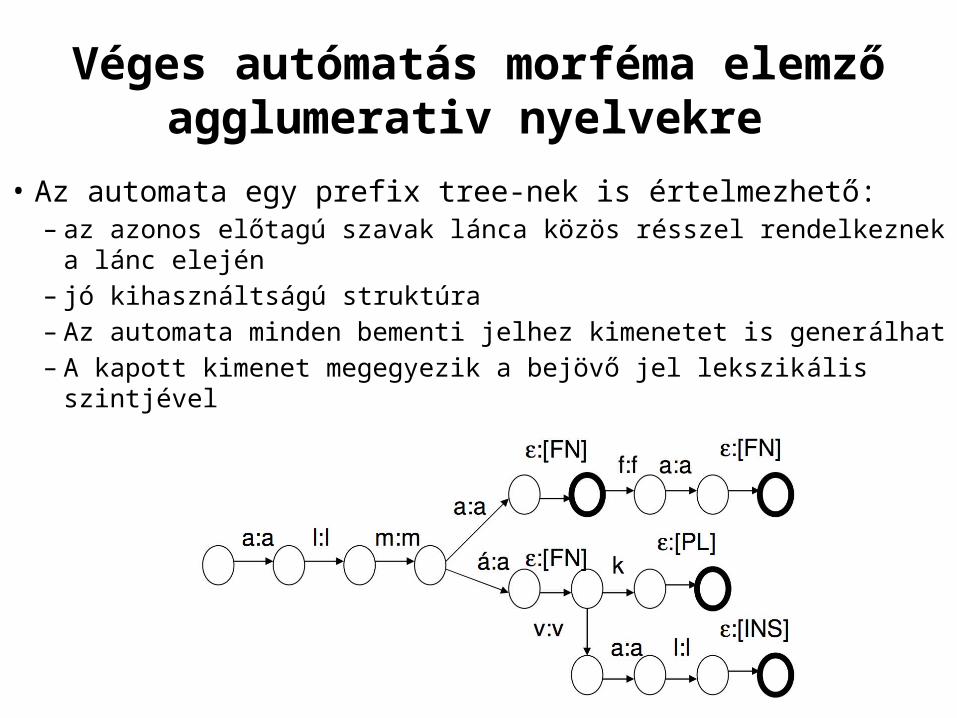
Véges automatas morféma elemzo agglumerativ nyelvekre
• Az automata egy prefix tree-nek is értelmezheto:– az azonos elotagu szavak lánca kozos résszel rendelkeznek a lánc
elején– jo kihasználtságu struktura– Az automata minden bementi jelhez kimenetet is generálhat – A kapott kimenet megegyezik a bejovo jel lekszikális szintjével





























