Embed Size (px)
DESCRIPTION
test 1
Citation preview

Zusammenfassung NumerischeMethoden erster Test
27. April 2015

Inhaltsverzeichnis
1 Vorlesung 1 41.1 Numerische Ableitungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.1.1 Gleitkommazahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.1.2 Methoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2 Nullstellenbestimmung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.2.1 Sekantenverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.2.2 Regular falsi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.2.3 Newton-Raphson-Verfahren . . . . . . . . . . . . . . . . . . . . . . 10
1.3 Integration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.3.1 Trapezregel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.3.2 Rhombergintegration . . . . . . . . . . . . . . . . . . . . . . . . . . 121.3.3 Simpson-Regel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.3.4 Offene Grenzen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.4 Zufallszahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.4.1 Berechnung nicht gleichverteilter Zufallszahlen . . . . . . . . . . . 14
2 Vorlesung 2 162.1 Lineare Algebra in der Physik . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.1.1 Näherung für den Zeitentwicklungsoperator . . . . . . . . . . . . . 162.1.2 explizites Eulerverfahren . . . . . . . . . . . . . . . . . . . . . . . . 172.1.3 implizites Eulerverfahren . . . . . . . . . . . . . . . . . . . . . . . . 182.1.4 Crank-Nicolson-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2 Tridiagnoale Gleichungssysteme . . . . . . . . . . . . . . . . . . . . . . . . 192.2.1 Thomas-Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . 192.2.2 LU (LR)-Faktorisierung . . . . . . . . . . . . . . . . . . . . . . . . . 19
3 Vorlesung 3 213.1 Polynom-Interpolation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.1 Vandermonde-Matrix . . . . . . . . . . . . . . . . . . . . . . . . . . 213.1.2 Lagrange-Interpolationspolynome . . . . . . . . . . . . . . . . . . . 213.1.3 Newton-Interpolation . . . . . . . . . . . . . . . . . . . . . . . . . . 223.1.4 Spline-Interpolation . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2 Anpassungsprobleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.3 Integration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3.1 Gauss-Integration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4 Vorlesung 4 264.1 Fouriertransformation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2

4.2 Lineare Gleichungssysteme . . . . . . . . . . . . . . . . . . . . . . . . . . . 274.2.1 Gauss-Elimination . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274.2.2 LU-Faktorisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5 Vorlesung 5: Eigenwertanalyse, Eigenvektoren 285.1 Eigenwerte einer Tridiagonalmatrix . . . . . . . . . . . . . . . . . . . . . . 285.2 Givens-Transformation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295.3 Jacobi-Methode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295.4 QR (QL) - Zerlegung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 305.5 Rayleigh-Ritz-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 305.6 Lanczos-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3

1 Vorlesung 1
1.1 Numerische Ableitungen
1.1.1 Gleitkommazahlen
Prinzipiell wird in einem Computer eine Gleitkommazahl dargestellt als:
x = (−1)s ·m · be (1.1)
Dabei ist s das Vorzeichenbit, m die Mantisse, b die Basis und e der Exponent. Die Basisist (normalerweise) immer 2, wird daher nicht abgespeichert. Um sich ein weiteres Bitzu sparen, wird immer die Mantisse darauf hin getrimmt, dass sie ungleich null ist. Beieinem Binären System muss sei also immer 1 sein (hidden bit).
Bei Addition und Subtraktion kommt es auf Grund von einer endlich verfügbaren Bit-Anzahl zu zwei Effekten, die die Genauigkeit beeinflussen. Absorption und Cancella-tion. Dazu muss man sich bewusst sein, dass bei einer Addition bzw. Subtraktion wiefolgt abläuft: Es werden die Exponenten angeglichen und dann die Mantissen addiertund das Ergebnis dann wieder auf die typische Fließkomma-Darstellung zurücktrans-formiert. Liegen die Summanden in sehr unterschiedlichen Größenordnungen, wird derkleinere Summand ’absorbiert’ (Subtraktion analog). Bsp: Man hat zwei Nachkommas-tellen zur Verfügung:
1.00 · 102 + 1.00 · 10−2 = 1.00 · 102 + 0.00|01 · 102 = 1.00 · 102 (1.2)
Die Cancellation tritt auf, wenn zwei ähnlich große Zahlen subtrahiert werden. Bsp:Man hat zwei Nachkommastellen zur Verfügung:
π − 3.14 = 3.14|159... · 100 − 3.14 · 100 = 0.00 · 100 (1.3)
Prinzipiell können Gleitkommazahlen umso genauer dargestellt werden, umso nähersie um die Stelle null liegen. Als Maschinengenauigkeit bezeichnet man die kleins-te Zahl εm bei der die Operation 1 + εm ein Ergebnis größer null liefert (siehe Abbil-dung1.1).
4
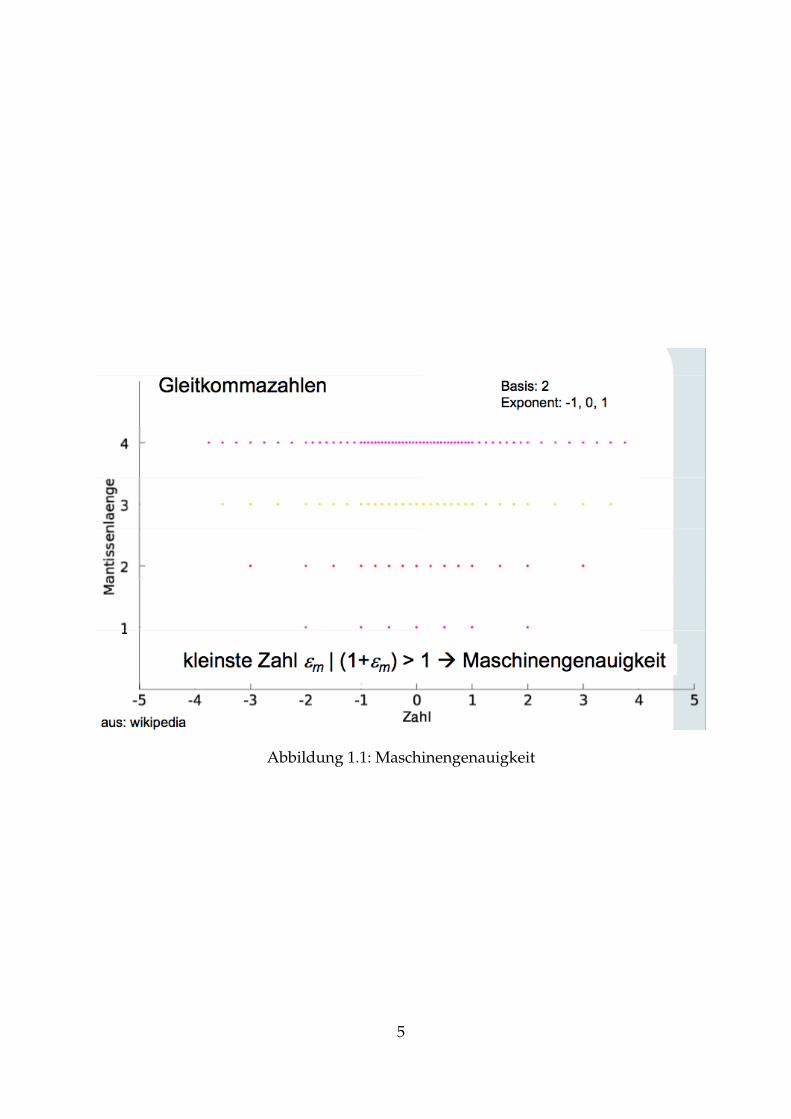
Abbildung 1.1: Maschinengenauigkeit
5

1.1.2 Methoden
Man geht von der mathematischen Definition der Ableitung aus:
f ′(x) = limh→0
f (x + h)− f (x)h
(1.4)
Man hat in der Numerik keine Möglichkeit, Limiten zu bilden. Daher eine erste Nähe-rung mit Taylorreihe:
f (x + h) = f (x) + h f ′(x) +h2
2f ′′(x) +
h3
6f ′′′(x) +O(h4) (1.5)
f (x− h) = f (x)− h f ′(x) +h2
2f ′′(x)− h3
6f ′′′(x) +O(h4) (1.6)
f (x + h)− f (x)h
≈ f ′(x) +12
h f ′′(x) + ... (1.7)
Dabei wird ab der zweiten Ableitung abgeschnitten und nur (1.5) verwendet. Prinzi-piell muss h möglichst klein gewählt werden, um mathematisch möglichst genau aufden Wert der Ableitung zu kommen. Allerdings ist es nicht möglich, h beliebig klein zuwählen, da die Maschinengenauigkeit und die Cancellation-Effekte dem Gewinn derGenauigkeit durch wählen eines kleineren h stark entgegenwirken (siehe Abbildung1.2. Eine genauere erste Ableitung bzw. ein Ausdruck für die zweite Ableitung kanndurch Addieren bzw. Subtrahieren von (1.5) und (1.6) gewonnen werden. Durch Sub-traktion ergibt sich:
f ′(x) =f (x + h)− f (x− h)
2h+O(h3) (1.8)
Analog ergibt sich durch Addition:
f ′′(x) =f (x + h)− 2 f (x) + f (x− h)
h2 +O(h4) (1.9)
Außerdem hängt das h nicht mehr von der Quadratwurzel, sondern von der kubischenWurzel von der Maschinengenauigkeit in etwa ab. Verbessert kann das Verfahren wer-den, indem man die Ableitung für mehrere Werte von h berechnet und die Ergebnisseüber Polynominterpolation nach h = 0 extrapoliert.
Eine weitere Möglichkeit der Extrapolation, die analog zur Rhombergintegration ist, istdie Richardson-Extrapolation.
Außerdem besteht auch die Möglichkeit, die Funktion in eine Reihe zu entwickeln.
f (x) = ∑ ciFi(x)⇒ f ′(x) = ∑ ciF′i (x) (1.10)
Dabei bieten sich für Fi die Tschebyscheff-Polynome an, da sie orthogonal sind (also eineBasis bilden) und die Ableitungen analytisch einfach zu bestimmen sind. Es werden oftnur wenige Koeffizienten cj benötigt. Allerdings ist die Methode nur dann numerischEffizient, wenn f (x) analytisch bekannt ist.
6

Abbildung 1.2: Fehler bei der Wahl von h
7

1.2 Nullstellenbestimmung
Die Suche von Nullstellen erfolgt zwischen zwei Punkten a und b. Prinzipiell suchtman diese Punkte a und b indem man annimmt, dass f (a) < 0 und f (b) > 0 ist. Eskann zu verschiedenen Problemen führen: Es kann keine (z.B. f (x) = x2 + 1), mehrere(z.B. f (x) = x2− 1) oder unendlich viele (z.B. f (x) = sin 1/x) Nullstellen zwischen denPunkten geben, bzw. eine Singularität.
1.2.1 Sekantenverfahren
Abbildung 1.3: Sekantenverfahren
Wie man in Abbildung 1.3 sieht, wird hier zwischen den Funktionswerten der erstenbeiden Punkte (x1 und x2 bzw. f (x1) und f (x2)) eine Sekante gezogen. Die Nullstelle derSekante dient als neuer Punkt x3. Es wird wieder eine Sekante gezogen und die Nullstel-le dieser bestimmt, allerdings wird der älteste Punkt x1 verworfen und durch x3 ersetzt.Dieses Prinzip wird bis zur Konvergenz durchiteriert.
8
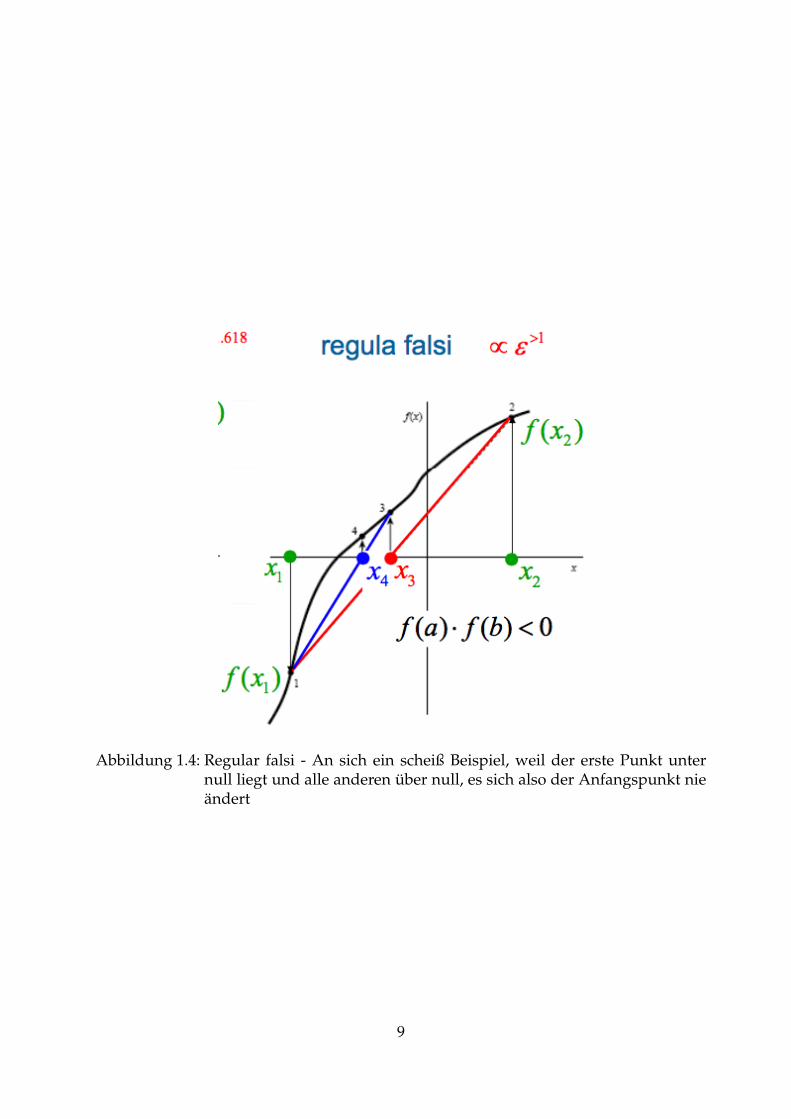
Abbildung 1.4: Regular falsi - An sich ein scheiß Beispiel, weil der erste Punkt unternull liegt und alle anderen über null, es sich also der Anfangspunkt nieändert
9
1.2.2 Regular falsi
Regular falsi (Abbildung 1.4) funktioniert wie das Sekantenverfahren, allerdings wirdder ältere Punkt nur verworfen, wenn sich das Vorzeichen des Funktionswerts vomneuen Punkt vom Vorzeichen des Funktionswerts des alten Punkts nicht mehr unter-scheidet.
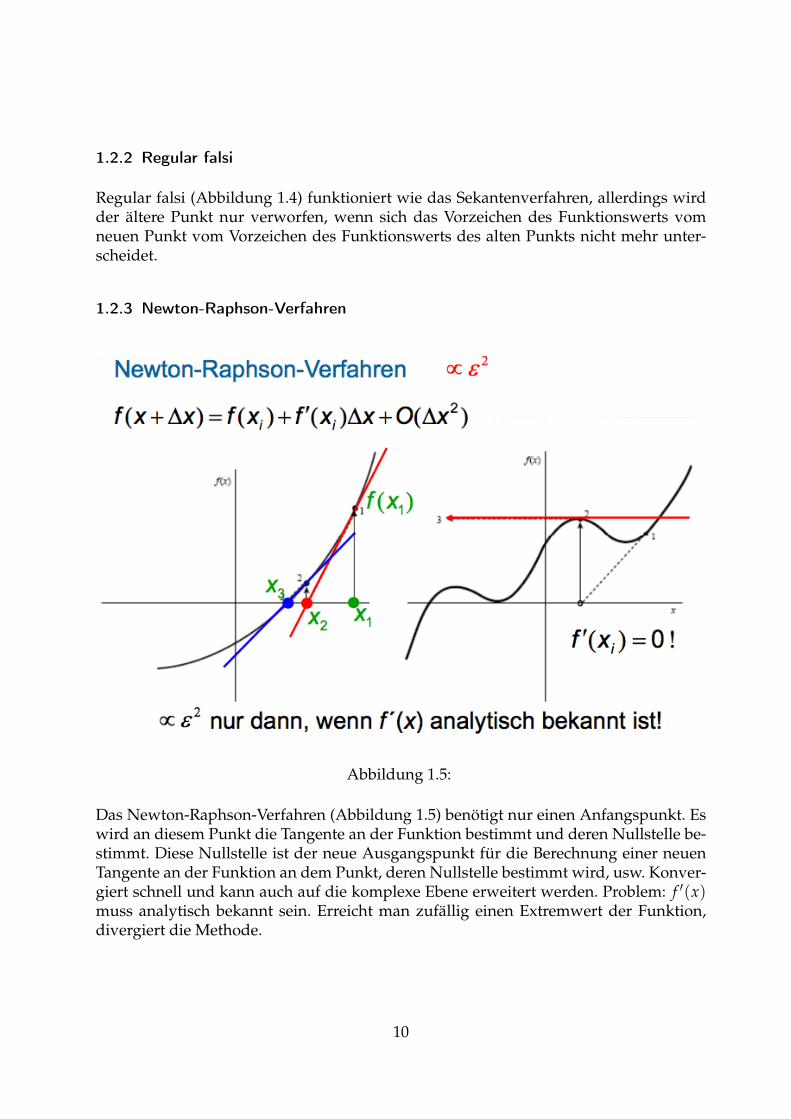
1.2.3 Newton-Raphson-Verfahren
Abbildung 1.5:
Das Newton-Raphson-Verfahren (Abbildung 1.5) benötigt nur einen Anfangspunkt. Eswird an diesem Punkt die Tangente an der Funktion bestimmt und deren Nullstelle be-stimmt. Diese Nullstelle ist der neue Ausgangspunkt für die Berechnung einer neuenTangente an der Funktion an dem Punkt, deren Nullstelle bestimmt wird, usw. Konver-giert schnell und kann auch auf die komplexe Ebene erweitert werden. Problem: f ′(x)muss analytisch bekannt sein. Erreicht man zufällig einen Extremwert der Funktion,divergiert die Methode.
10

1.3 Integration
Gesucht ist das bestimmte Integral einer Funktion. Bevor man eine Lösungsverfahrenauswählt, muss folgendes bedacht werden:
• Integral analytisch lösbar?
• Funktion integrabel?
• Funktion ’glatt’?
• Liegen die Grenzen im unendlichen?
• Gibt es Sinularitäten am Rand oder innerhalb vom Intervall?
• Ist es ein mehrdimensionales Integral?
• Kennt man die Funktion analytisch ( f (x)) oder handelt es sich um diskrete Messwertef (xi)?
Prinzipiell nähert man ein Integral numerisch durch:
I =∫ b
af (x)dx =
n
∑i=0
wi f (ai) + En(ν) (1.11)
Es stellt sich die Frage, ob die Funktion durch eine Transformation vereinfacht werdenkann. Für die Wahl der Stützstellen ai ist zu beachten:
• Minimierung der Anzahl der Stützstellen
• Sind sie durch ein Experiment vorgegeben?
• Positionen?
• wie sehen die daraus abgeleiteten Gewichte wi aus?
• Fehlerabschätzung?
11

Abbildung 1.6: Trapezregel
1.3.1 Trapezregel
Bei geschlossenen Integralen mit equidistanten Stützstellen ai ist es am einfachsten, dieTrapezregel (siehe Abbildung 1.6) zu verwenden.
Ein Teilschritt in erster Ordnung kann wie folgt beschrieben werden:∫ ai+1
ai
f (x)dx =h2( f (ai) + f (ai + h︸ ︷︷ ︸
ai+1
)) +O(h3 f ′′) (1.12)
Das ganze Integral ergibt sich zu:
∫ b
af (x)dx ≈
n−1
∑i=0
h2( f (ai) + f (ai+1)) (1.13)
1.3.2 Rhombergintegration
Es werden Trapeze mit verschiedenen Schrittweiten unter die Funktion gelegt. Manfängt mit sehr wenigen großen Trapezen an und verkleinert bzw. vermehrt die Trapeze.Mit einer Rekursion kann über eine Mittelung der Trapeze mit verschiedenen Schritt-weiten genauere Ergebnisse erhalten. Sobald sich die verschiedenen Stufen der Rekursi-on nicht mehr, als ε unterscheiden, kann man von Konvergenz sprechen.
1.3.3 Simpson-Regel
Die Simpson-Regel funktioniert ähnlich wie die Trapez-Regel, allerdings wird hier beijedem Schritt über drei statt zwei Stützstellen eine Fläche approximiert. Prinzipiell kön-nen mit der Simpson-Regel Polynome des Grades 2 exakt gelöst werden (per Definiti-on). Dies liegt daran, dass hier im Prinzip die Funktion mit einem Polynom zweiten Gra-des interpoliert wird. Es gibt auch eine Abwandlung, die Simpson-3/8-Regel.
12

1.3.4 Offene Grenzen
Man spricht von offenen Grenzen, wenn das Integral am Rand unbekannte oder falschgemessene Funktionswerte aufweist. Man kann diese Integrale lösen, in dem man dieletzten unbekannten Punkte extrapoliert. Man kann auch über Variablentransformatio-nen Singularitäten an den Rändern beseitigen. Anwendung: Fourier-Analyse
1.4 Zufallszahlen
Die meisten Zufallszahlengeneratoren generieren üblicherweise nur Pseudozufallszah-len. Ein Zufallszahlengenerator sollte vorher statistische Tests bestanden haben. Manerkennt bei schlechten Generatoren wiederkehrende Muster. Beispiele für schlechte Ge-neratoren:
• Lineare Kongruenzmethode: ai+1 = (ai ∗ b + c) ·mod(m)
• Fibonacci-Generator: ai+1 = (ai + ai−1) ·mod(m)
• von-Neumann-Generator: ai+1 = ai · ai
Dabei muss man bei jedem dieser Generatoren mit einer Zahl a0 beginnen. a, b, c sindKonstanten, mod(m) der Divisonsrest einer sehr großen Zahl m ≈ 2 · 1031 und ai eineZahlenfolge aus der Mitte von ai.
Moderne Zufallszahlengeneratoren sind XOR-Shift-Generatoren, Mersenne twister undWELL (well equidistributed long-period linear). Diese liefern allerdings alle nur Pseu-dozufallszahlen.
Um wahre Zufallszahlen zu generieren, muss man physikalische Prozesse herbeiziehen.Z.B.
• radioaktiver Zerfall
• thermisches Rausche
• Radio/Mikrofon-Rauschen
• Rauschen eines CCD-Sensors
In der Natur kommen selten gleichverteilte Zufallszahlen vor. Man kann sich über dieErwartungswerte eines Datensatzes von gemessenen Zufallsgrößen berechnen, ob dieZufallszahlen gleichverteilt sind.
13
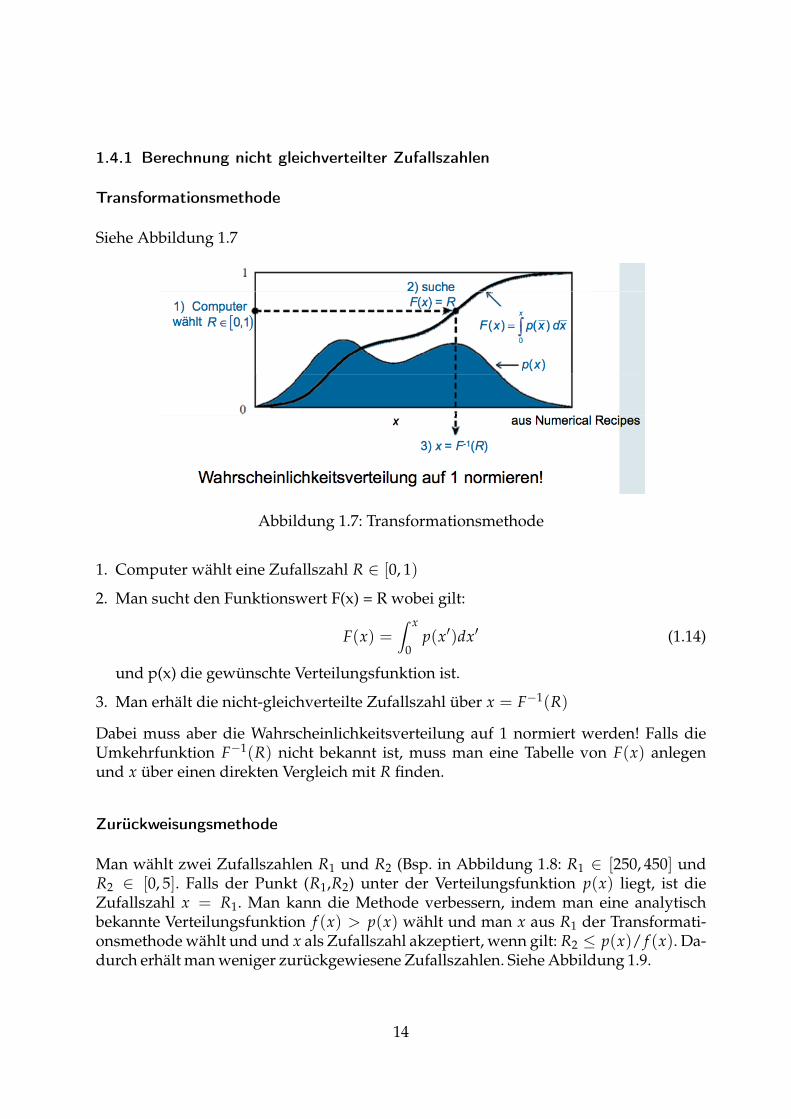
1.4.1 Berechnung nicht gleichverteilter Zufallszahlen
Transformationsmethode
Siehe Abbildung 1.7
Abbildung 1.7: Transformationsmethode
1. Computer wählt eine Zufallszahl R ∈ [0, 1)
2. Man sucht den Funktionswert F(x) = R wobei gilt:
F(x) =∫ x
0p(x′)dx′ (1.14)
und p(x) die gewünschte Verteilungsfunktion ist.
3. Man erhält die nicht-gleichverteilte Zufallszahl über x = F−1(R)
Dabei muss aber die Wahrscheinlichkeitsverteilung auf 1 normiert werden! Falls dieUmkehrfunktion F−1(R) nicht bekannt ist, muss man eine Tabelle von F(x) anlegenund x über einen direkten Vergleich mit R finden.
Zurückweisungsmethode
Man wählt zwei Zufallszahlen R1 und R2 (Bsp. in Abbildung 1.8: R1 ∈ [250, 450] undR2 ∈ [0, 5]. Falls der Punkt (R1,R2) unter der Verteilungsfunktion p(x) liegt, ist dieZufallszahl x = R1. Man kann die Methode verbessern, indem man eine analytischbekannte Verteilungsfunktion f (x) > p(x) wählt und man x aus R1 der Transformati-onsmethode wählt und und x als Zufallszahl akzeptiert, wenn gilt: R2 ≤ p(x)/ f (x). Da-durch erhält man weniger zurückgewiesene Zufallszahlen. Siehe Abbildung 1.9.
14

Abbildung 1.8: Zurückweisungsmethode
Abbildung 1.9: Verbesserung der Zurückweisungsmethode mit Hilfe derTransformationsmethode
15

2 Vorlesung 2
2.1 Lineare Algebra in der Physik
Meistens beschäftigt man sich mit der Lösung der Schördingergleichung
ih∂
∂tΨ(x, t) = HΨ(x, t) =
− h2
2me︸ ︷︷ ︸T
+V(x)
Ψ(x, t) (2.1)
Meist wählt man atomare Einheiten, also me = e = h = 1.
Da in der Numerik nur diskrete Orts- und Zeitschritte gewählt werden können, werdenWellenfunktionen als Vektoren geschrieben und Operatoren als Matritzen.
Ψ(x, t) =
Ψ(x0, tj)Ψ(x1, tj)
...Ψ(xi, tj)
...Ψ(xN, tj)
(2.2)
2.1.1 Näherung für den Zeitentwicklungsoperator
Die zeitliche Fortpflanzung der Wellenfunktion um einen numerischen Schritt ∆t be-rechnet man über den Zeitentwicklungsoperator:
U(t→ t + ∆t) = e−iH∆t = e−i∆t
(− ∂2
x2 +V(x)
)(2.3)
Die Propagation ergibt sich über
Ψ(x, tj + ∆t) = Ψ(x, tj+1) = e−iH∆tΨ(x, tj) (2.4)
Für den Zeitentwicklungsoperator gibt es verschiedene Möglichkeiten der Näherung.
U(t→ t + ∆t) = e−iH∆t = e−i(T+V)∆t = e−iT∆te−iV∆t +O(∆t2) (2.5)
16

Der Fehler ergibt sich durch eAeB = eA+Be[A,B]/2. Man kann (2.6) besser nähern durch:
e−iH∆t = e−iT∆t/2e−iV∆te−iT∆t/2 +O(∆t3) (2.6)
Dabei ist die e-Funktion mit der kinetischen Energie im Impulsraum diagonal und diee-Funktion mit dem potentiellen Term im Ortstraum diagonal. Man kann das Problemdann durch Fast Fourier Transformationen zwischen Matrix-Vektor-Multiplikationenlösen.
Alternativ kann man auch die e-Funktion in eine Reihe entwickeln.
e−iH∆t ≈ 1− iH∆t− (H∆t)2
2+
i(H∆t)3
6+ ... (2.7)
2.1.2 explizites Eulerverfahren
Für die Lösung der Schrödingergleichung verwendet man (1.7) und (1.9) und den Fakt,dass man die e-Funktion wie in (2.7) entwickeln kann.
∂2xΨ(i, j) ≈
Ψ(xi−1, tj)− 2Ψ(xi, tj) + Ψ(xi+1, tj)
∆x2 =
1∆x2
−2 1 01 −2 1
. . . . . . . . .1 −2 1
0 1 −2
Ψ(1, j)...
Ψ(i− 1, j)Ψ(i, j)
Ψ(i + 1, j)...
Ψ(n, j)
(2.8)
∂tΨ(i, j) ≈Ψ(xi, tj+1)−Ψ(xi, tj)
∆x2 =
1∆t
Ψ(1, j + 1)...
Ψ(i− 1, j + 1)Ψ(i, j)
Ψ(i + 1, j + 1)...
Ψ(n, j + 1)
−
Ψ(1, j)...
Ψ(i− 1, j)Ψ(i, j)
Ψ(i + 1, j)...
Ψ(n, j)
(2.9)
Man kann nun in die Schrödingergleichung einsetzen und erhält:
17

Ψ(1, j + 1)...
Ψ(i− 1, j + 1)Ψ(i, j)
Ψ(i + 1, j + 1)...
Ψ(n, j + 1)
=
δik +i∆t
2∆x2
−2 1 01 −2 1
. . . . . . . . .1 −2 1
0 1 −2
− i∆tδikV(xk)
Ψ(1, j)...
Ψ(i− 1, j)Ψ(i, j)
Ψ(i + 1, j)...
Ψ(n, j)
(2.10)
Das Problem beim expliziten Eulerverfahren liegt darin, dass es nummerisch nur stabilist, wenn man ∆t ≤ ∆x2/2 wählt. Da die Propergationsmatrix nicht unitär ist, muss dieWellenfunktion nach jedem Schritt neu normiert werden.
2.1.3 implizites Eulerverfahren
Hier geht man in den Zeitschritten rückwärts (U†Ψ(x, tj+1) = Ψ(x, tj). Man erhält einlineares Gleichungssystem.
Ψ(1, j)...
Ψ(i− 1, j)Ψ(i, j)
Ψ(i + 1, j)...
Ψ(n, j)
=
δik −i∆t
2∆x2
−2 1 01 −2 1
. . . . . . . . .1 −2 1
0 1 −2
+ i∆tδikV(xk)
Ψ(1, j + 1)...
Ψ(i− 1, j + 1)Ψ(i, j)
Ψ(i + 1, j + 1)...
Ψ(n, j + 1)
(2.11)
Im Gegensatz zum expliziten Eulerverfahren, bei dem Matrix-Vektor-Multiplikationenbei jedem Schritt durchgeführt werden, muss hier in jedem Schritt ein Gleichungssys-tem gelöst werden. Allerdings ist das Verfahren numerisch stabil, jedoch nicht Norm-erhaltend, da die Matrix wieder nicht unitär ist.
2.1.4 Crank-Nicolson-Verfahren
Beim Crank-Nicolson-Verfahren wird ausgenützt, dass es eine Funktion gibt, die eineähnliche Reihenentwicklung, wie die e-Funktion hat.
18

e−iH∆t ≈ 1− iH∆t1 + iH∆t
≈ 1− iH∆t− (H∆t)2
2+
i(H∆t)3
4+ ... (2.12)
Die Funktion 1−iH∆t1+iH∆t ist bis zum dritten Glied mit der Reihenentwicklung der e-Funktion
identisch, also genauer, als die Verwendung der ersten zwei Glieder, wie bei den Euler-verfahren. Das Verfahren ist unitär, konsistent und stabil.
2.2 Tridiagnoale Gleichungssysteme
2.2.1 Thomas-Algorithmus
Es soll ein Gleichungsystem der Form
A~x =
b1 c1 0a2 b2 c2
. . . . . . . . .an−1 bn−1 cn−1
0 an bn
x1...
xi...
xn
=
f1...fi...fn
(2.13)
gelöst werden. Dafür wird eine Vorwärts- und Rückwärtsrekursion benötigt. Vorwärts:
c′i =ci
bi − c′i−1aimit c′1 =
c1
b1(2.14)
f ′i =fi − f ′i−1ai
bi − c′i−1aimit c′1 =
f1
b1(2.15)
Rückwärts:
xi = f ′i − c′1xi+1 mit xn = f ′n (2.16)
2.2.2 LU (LR)-Faktorisierung
Analog zum Thomas-Algorithmus gibt es ein Verfahren, das bei mehreren Ergebnisvek-toren effizienter ist. Das Gleichungssystem wird aufgeteilt in:
A~x = L(U~x) = L~y = ~f (2.17)
19

Dabei gilt für die Matrizen:
L =
1 0 0
λ2 1 0. . . . . . . . .
λn−1 1 00 λn 1
(2.18)
U =
d1 c1 00 d2 c2
. . . . . . . . .0 dn−1 cn−1
0 0 dn
(2.19)
20

3 Vorlesung 3
3.1 Polynom-Interpolation
Es existiert nur ein Polynom vom Grad n oder kleiner, das n+1 reele Funktionswertef (ai) and den Stützstellen a0 bis an interpoliert. Man kann dies leicht Beweisen, indemman annimmt, dass zwei Polynome p(n1) und p(n2) existieren. Subtrahiert man sie, er-hält man wieder ein Polynom vom Grad n, das aber an allen Stellen ai eine Nullstellebesitzen müsste (da ja f (ai), die Stützstellen für beide Polynome den gleichen Funk-tionswert haben müssen). Das Polynom müsste also n+1 Nullstellen haben, da es n+1Stützstellen/Funktionswerte gibt. Dies ist für kein Polynom vom Grad n erfüllt, da einPolynom vom Grad n immer n Nullstellen besitzt.
3.1.1 Vandermonde-Matrix
Das einfachste Verfahren besteht darin, das Polynom direkt über ein Gleichungssystemzu finden. Als Basissystem wählt man die Polynome Pi(x) = xi
pn(x) =n
∑i=0
ciPi(x) = c0 + c1x + c2x2 + ... + cnxn (3.1)
Man setzt voraus, dass pn(ai) = f (ai) ist. Man erhält n Gleichungssysteme, die man ineine Matrix schreiben kann:
1 a0 a20 . . . an
01 a1 a2
1 . . . an1
1 a2 a22
......
... . . .1 an a2
n . . . ann
c0...ci...
cn
=
f (a0)
...f (ai)
...f (an)
(3.2)
3.1.2 Lagrange-Interpolationspolynome
Mit Hilfe der Lagrange-Interpolationspolynome kann man auch das Interpolationspo-lynom finden:
pn(x) =n
∑k=0
f (ak)lk(x) (3.3)
21

wobei
lk(x) =n
∏i=0 i 6=k
x− ai
ak − ai(3.4)
Wegen lk(aj) = δjk ist pn(aj) = f (aj) erfüllt. Das Verfahren benötigt im besten FallO(n2)
Additionen,O(n2) Multiplikationen undO(n) Divisionen.
3.1.3 Newton-Interpolation
Als Basisfunktionen wählt man
Ni(x) =i−1
∏j=0
(x− aj) (3.5)
mit N0(x) = 1. Wegen der Forderung pn(ai) = f (ai) erhält man1 01 N1(a1)
1 N1(a2) N2(a2)...
...... . . .
1 N1(an) . . . Nn(an)
c0...ci...
cn
=
f (a0)
...f (ai)
...f (an)
(3.6)
Die Koeffizienten werden über die dividierenden Differenzen berechnet. Der Aufwandzur EINMALIGEN Berechnung von den Koeffizienten ist O(n2). Die Berechnung vonp−n(x) kann über das Hornerschema mitO(n) durchgeführt werden.
pi(x) = pi−1(x)x + cn−i (3.7)
Wenn die dividierenden Differenzen gespeichert sind, ist es sehr einfach (O(n)) einenzusätzlichen Stützpunkt zu berechnen. Die dividierenden Differenzen können als Ana-logie zur Taylorreihe gesehen werden.
3.1.4 Spline-Interpolation
Da Polynome hohen Grades sehr stark oszillieren können und bei vielen Stützstellendadurch schlecht interpolieren, gibt es die Spline-Methode, wo immer nur zwischenzwei Stützstellen interpoliert wird (meist mit einem Polynom vom Grad 3, kubischerSpline). Die Funktion, mit der interpoliert wird, muss zwei mal stetig an den Stützstel-len differenzierbar sein, um die Daten auf dem Intervall [ai, ai+1] zu interpolieren. Fürden kubischen Spline kann man schreiben:
p(i)3 (x) = c(i)3 (x− ai)3 + c(i)2 (x− ai)
2 + c(i)1 (x− ai) + c0 (3.8)
22

Abbildung 3.1: Problem der Polynominterpolation: Oszillationen hochgradigerPolynome
Es müssen nun die ersten und zweiten Ableitungen der verschiedenen Spline-Polynomean den Stützstellen stetig sein. Diese Bedingungen kann man in in eine tridiagonalesGleichungssystem umschreiben.
∆0∆0+∆1
2 ∆1∆0+∆1
0. . . . . .∆0
∆0+∆12 ∆1
∆0+∆1. . . . . .
0 ∆n−2∆n−2+∆n−1
2 ∆n−1∆n−2+∆n−1
S0...
Si...
Sn
=
y1...
yi...
yn−1
(3.9)
Dabei ist Si = 2c(i)2 und ∆i = ai+1 − ai. Die übrigen Koeffizienten können leicht ausdiesen Ergebnissen hergeleitet werden. S0 und Sn müssen vorgegeben werden, da dasGleichungssystem sonst unterbestimmt ist:
• natürlicher Spline: beide werden null gesetzt
• Extrapolation aus den vorherigen Koeffizienten S
• Vorgabe oder Schätzwert
• Vollständiger Spline: Definition zusätzlicher y
23

• Periodischer Spline: erste und zweite Ableitungen am Rand gleich (Achtung: Verlustder tridiagonalität)
3.2 Anpassungsprobleme
Man unterscheidet zwischen linearen und nicht-linearen Anpassungsproblemen. Line-ar:
f (x) =M
∑k=1
akXk(x) (3.10)
Nicht-Linear:
f (x) =M
∑k=1
akXk(bkx) (3.11)
Die Anpassung sollte die Fitparameter, eine Abschätzung des Fehlers für jeden Param-ter und eine Abschätzung für die Qualität des Fits liefern. Man will NICHT die Punktedurch eine möglichst glatte Kurve ersetzen (Interpolation) oder eine optisch anspre-chende Kurve durch die Datenpunkte legen, denn dies erlaubt keine Aussage über denphysikalischen Prozess.
Als Maß für die Abweichung wird
χ2 =N
∑j=1
(yj − f (xj; a1...an)
σj
)2
(3.12)
definiert. Dabei sind yj die Messwerte, f die Fitfunktion und sigmaj der Messfehler. Manerhält den Fit durch Ableiten nach den Fitparametern und Nullsetzen von χ. Man erhältein lineares Gleichungssystem. Wenn σj nicht bekannt ist, wird er 1 gesetzt und kannnach dem Lösen des Anpassungsproblems bestimmt werden.
3.3 Integration
Bereits besprochene Ansätze, die zur Integration verwendet werden können: Integrati-on von
• Fitfunktionen
• Interpolationspolynom
• (kubischen) Splines
24

3.3.1 Gauss-Integration
Wird verwendet, wenn es kompliziert ist, die Funktionswerte an den Stützstellen zu be-rechnen oder zu messen. Bisher wurden n+1 äquidistante Stützstellen verwendet, umn+1 Gewichtsfaktoren zu bestimmen und über ein Polynom des Grades n an die Funk-tion zu approximieren und zu integrieren. Mit der Gaußintegration kann ein Polynomvom Grad 2n-1 an die Funktion approximiert werden, wenn n Stützstellen bekannt sind.Der Ansatz lautet ähnlich wie bisher:∫ b
af (x)dx =
n
∑i=1
f (ai)wi (3.13)
Dabei sind wi wieder Gewichtungsfaktoren und f(x) ein Polynom von Grad 2n-1. Fürai setzt man die Nullstellen der des jeweiligen Basisvektors (z.B. bestimmes Legendre-polynoms) ein, dem der Gewichtungsfaktor zugeordnet ist. Man verwendet nun or-thogonale Polynome, in die man die zu integrierende Funktion entwickelt. Die Legen-drepolynome zum Beispiel entsprechen auf einem Intervall von -1 bis 1 dieser Forde-rung.
f (x) =n
∑i=0
ciPi(x) (3.14)
ci =2i + 1
2
∫ 1
−1f (x)Pi(x) dx (3.15)
Es können auch Integrale der Form∫ b
a W(x)pn(x) dx für beliebige Gewichtungsfunk-tionen W(x) mit den zugehörigen orthogonalen Polynomen ausgewertet werden. Da-durch kann auch das Intervall zwischen a und b angepasst werden. Aus den Gewich-tungsfunktionen können die Gewichtungsfaktoren ausgerechnet werden. Allgemein giltdann: ∫ b
aW(x) f (x) dx = ∑
j=1n f (aj)wj (3.16)
wj =∫ b
aW(x)lj(x) dx (3.17)
Dabei sind aj wieder die Nullstellen des geweiligen Polynoms lj(x) der gewählten Po-lynombasis.
25
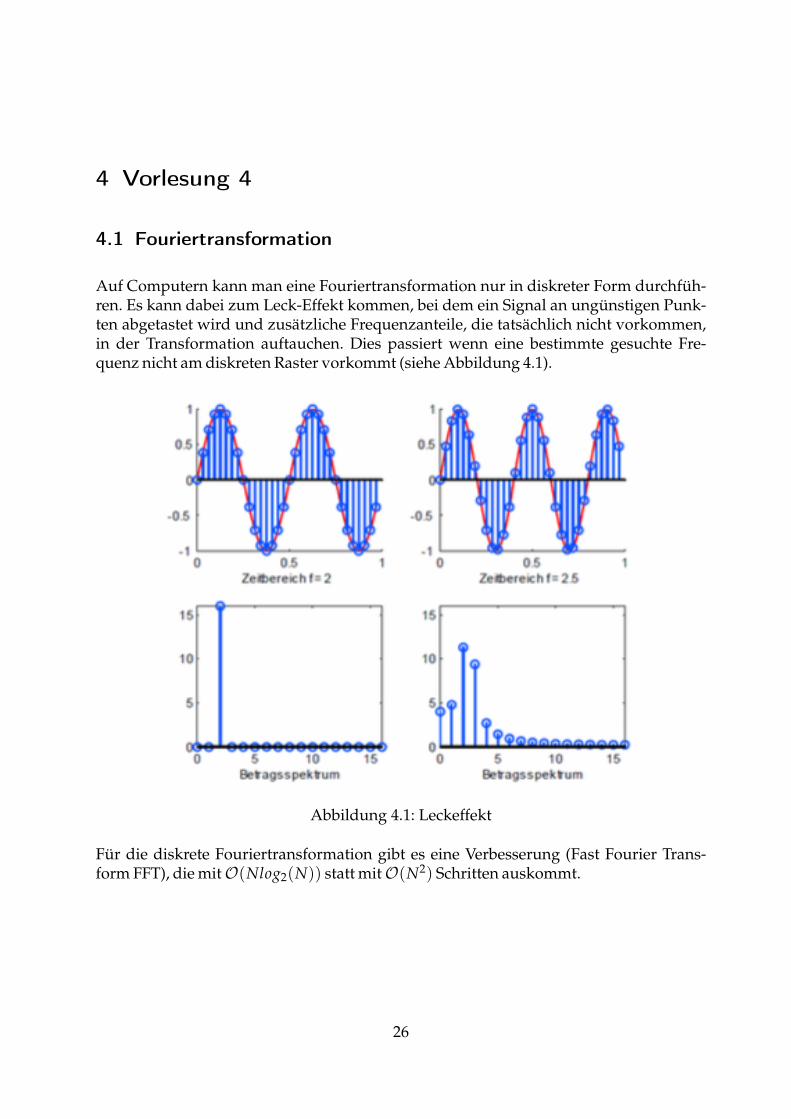
4 Vorlesung 4
4.1 Fouriertransformation
Auf Computern kann man eine Fouriertransformation nur in diskreter Form durchfüh-ren. Es kann dabei zum Leck-Effekt kommen, bei dem ein Signal an ungünstigen Punk-ten abgetastet wird und zusätzliche Frequenzanteile, die tatsächlich nicht vorkommen,in der Transformation auftauchen. Dies passiert wenn eine bestimmte gesuchte Fre-quenz nicht am diskreten Raster vorkommt (siehe Abbildung 4.1).
Abbildung 4.1: Leckeffekt
Für die diskrete Fouriertransformation gibt es eine Verbesserung (Fast Fourier Trans-form FFT), die mitO(Nlog2(N)) statt mitO(N2) Schritten auskommt.
26

4.2 Lineare Gleichungssysteme
Es gibt direkte Verfahren, bei denen ein exaktes Ergebnis in endlich vielen Schrittenerzielt wird und indirekte Verfahren, bei denen ein exaktes Ergebnis erst theoretischnach unendlich vielen Schritten gefunden werden kann.
4.2.1 Gauss-Elimination
Die Gauss-Elimination ist ein direktes Verfahren, bei dem die Matrix des Gleichungssys-tems zuerst auf eine Dreiecksform gebracht wird und dann durch eine Rückwärtssub-stitution gelöst wird. Der Prozess, die Matrix auf eine Dreiecksform zu bringen, kannzu Problemen führen, wenn ein Diagonalelement 0 ist. Dann werden Zeilen vertauscht,man wählt normalerweise das größte Element der verbleibenden Submatrix.
4.2.2 LU-Faktorisierung
Wenn man mehrere Ergebnisvektoren hat, ist es ratsam, ein Problem mit einer LU-Faktorisierung zu lösen. Wie bereits in der zweiten Vorlesung erwähnt, kann man dasProblem in mehrere Probleme unterteilen:
A~x = L(U~x) = L~y = ~f (4.1)
Aus der Gauss-Elimination erhält man die untere Dreiecksmatrix L, die in der Diago-nale immer 1 stehen hat und die obere Dreiecksmatrix U. Man löst zuerst das Pro-blem L~y = ~f (vorwärts einsetzten) und dann das Problem U~x = ~y (rückwärts ein-setzen). Anwendung: Berechnung der Inversen: Spaltenweise lösen von n Gleichungs-systemen.
An×n~xn = ~bn (4.2)
Dabei ist
b0 =
1...00
b1 =
01...0
... bn =
0...01
(4.3)
27

5 Vorlesung 5: Eigenwertanalyse, Eigenvektoren
Ähnlichkeitstransformationen ändern die Eigenwerte einer Matrix nicht. Durch Trans-formation einer Matrix auf eine ähnliche Form kann die Suche nach Eigenwerten undEigenvektoren erleichtert werden. Oft wird nur ein bestimmter Eigenwert/Eigenvektorgesucht. Die Eigenwerte einer Matrix können leicht über die Gershgorin-Kreise abge-schätzt werden: Alle Eigenwerte einer Matrix befinden sich in Kreisen in der komplexenEbene um die Diagonalelemente. Es gilt zeilenweise:
|λi − cii ≤∑i 6=j|cij| (5.1)
analog spaltenweise:|λi − cii ≤∑
i 6=j|cji| (5.2)
Siehe Abbildung 5.1
Abbildung 5.1: Gershgorin-Kreise
5.1 Eigenwerte einer Tridiagonalmatrix
Die Eigenwerte einer Tridiagonalmatrix kann, wie immer, über das charakteristischePolynom bestimmt werden:
P(λ) = det
∣∣∣∣∣∣∣∣∣∣∣
a11 − λ a12 0
a21 a22 − λ a23. . . . . . . . .
. . . . . .0 ann−1 ann − λ
∣∣∣∣∣∣∣∣∣∣∣(5.3)
28

Das charakteristische Polynom kann einfach rekursiv bestimmt werden indem man dieMatrix in Submatrizen (Unterräume) aufteilt. Beginnend oben links mit einer 1× 1 Ma-trix, 2× 2 Matrix usw. bis man alle Eigenwerte sukzessiv bestimmt hat. Die Nullstellenkönnen mit der Newton-Raphson-Methode bestimmt werden, da die Ableitungen vomcharaktistschen Polynom einfach implementiert werden können. Die Eigenwerte liegenaußerdem innerhalb der Gershgorin-Kreise.
5.2 Givens-Transformation
Um eine Tridiagonalform zu erhalten, kann die Givens-Transformation verwendet wer-den, wenn nur wenige Elemente der Matrix nicht null sind. Dabei wird die folgendeMatrix eingeführt:
G(i, k, θ) =
1 . . . 0 . . . 0 . . . 0... . . . ...
......
0 . . . cos θ . . . sin θ . . . 0...
... . . . ......
0 . . . − sin θ . . . cos θ . . . 0...
...... . . . ...
0 . . . 0 . . . 0 . . . 1
(5.4)
Dabei beschreibt GT(i, k, θ)~x eine Drehung um θ in der i,k-Ebene. Es wird nun dieseTransformation angewendet um die neue Matrix A′ = GT(i, k, θ)AG(i, k, θ) zu erhal-ten. Dabei sollen möglichst die Elemente aik udn aki null gesetzt werden. Über diese Be-dingung kann man sich auch den Drehwinkel ausrechnen. Das transformierte Elementwird nicht verändert und es werden insgesamt n2/2 Rotationen benötigt.
5.3 Jacobi-Methode
Bei der Jacobi-Methode wird eine Matrix auf eine Diagonalform transformiert (D =QT AQ). Dabei ist Q eine Mehrfachanwendung der Givens-Matrix. Mit A′ = GT
i,k AGi,kwird immer wieder das betragsmäßig größte Element aki null gesetzt und durch dieseRotation alle unteren Nebendiagonalelemente behandelt. Nach und nach nähert sich A′
einer Diagonalmatrix an.
29

5.4 QR (QL) - Zerlegung
Mit Hilfe von mehreren Givens-Rotationen wird die Ausgangsmatrix auf eine obere(R) oder untere (L) Dreiecksform gebracht. Dabei werden, falls das Eigenwertspektrumnicht entartet ist, die Eigenwerte aufsteigend nach ihrem Betrag in der diagonale derneuen Dreiecksmatrix angeordnet. Es gilt A = QR. Weiters gilt:
Gnn−1Gnn−2Gn−1n−2...G31G21A = R (5.5)
Also ist Q = Gnn−1TGnn−2
TGn−1n−2T...G31
TG21T. Bei Bei entarteten Eigenwerten kann
der p-fach entartete block diagonalisiert werden.
5.5 Rayleigh-Ritz-Verfahren
Man geht vom Rayleigh-Quotienten aus:
ρ(~z, A) =~zT A~z~zT~z
(5.6)
Für die reele, symmetrische n× n-Matrix A gilt, dass λ1 = minρ(~z, A) = minρ(~x1, A)ist, wobei λ1 der kleinste Eigenwert und ~x1 der zugehörige Eigenvektor ist. Analogesgilt für den maximalen Eigenwert und zugehörigen Eigenvektor (maximum, statt mini-mum). Dabei ist z eine Linearkombination von Testfunktionen.
Beim Rayleigh-Ritz-Verfahren geht man wie folgt vor:
1. Wähle m beliebige Vektoren ~s1 bis ~sm ∈ Rn
2. Orthonomiere diese Vektoren. ~si → ~qi
3. Bilde H = QT AQ (H ∈ Rm×m) und bestimme die Eigenwerte und Eigenvektoren zuH.
4. Der kleinste Eigenwert von H entspricht näherungsweise dem kleinsten Eigenwertvon A, gilt analog für die größten Eigenwerte der Matrizen. Der Eigenvektor zumkleinsten Eigenwert von A kann näherungsweise berechnet werden, indem man Qauf den kleinsten Eigenwert von H anwendet. Für den Eigenvektor zum größtenEigenwert gilt analoges.
Die Matrix Q wird aus den Vektoren ~qi zusammengesetzt.
30

5.6 Lanczos-Verfahren
Es basiert auf dem Rayleigh-Ritz-Verfahren. Als Basisvektoren wird allerdings die Krylow-Basis S gewählt.
S = [~s1, ..., ~sm] = [~s1, A~s1, A2~s1, ..., Am−1~s1] (5.7)
s1 ist ein beliebiger normierter Startvektor. Der Vorteil liegt hier, dass die Matrix H tri-diagonal wird. Für sehr kleine m im Verhältnis zu n, konvergiert diese Methode sehrschnell zu extremalen Eigenwerten und ist sehr memory-effizient. Nachteile sind dieRechenungenauigkeit auf Grund des Verlusts der Orthognonalität.
Varianten:
• Verwende m = 2: Bestimmen der beiden Eigenvektoren, Eigenvektor zu kleineremEigenwert ist neuer Startvektor. Iteration, bis der Eigenwert von A konvergiert.
• Suche nach k kleinsten Eigenwerten, bei Wahl von m > k. Man bestimmt nun dieEigenwerte und Eigenwerte der m×m Matrix und verwendet als neuen Startvektoreine Linearkombination der gefunden Eigenvektoren und iteriert bis zur Konvergenz.
31





























