Embed Size (px)
Citation preview

Text mining1. Введение в автоматическую обработку текстов
Дмитрий Ильвовский, Екатерина Черняк[email protected], [email protected]
Национальный Исследовательский Университет – Высшая Школа ЭкономикиНУЛ Интеллектуальных систем и структурного анализа
March 11, 2016

Краткая история АОТ (1)
7 января 1954. Джорджтаунский эксперимент по машинномупереводу с русского на английский;1957. Ноам Хомский ввел “универсальную грамматику”;1961. Начинается сбор Брауновского корпуса;конец 1960-х. ELIZA � программа, ведущая психотерапевтическиеразговоры;1975. Солтон ввел векторную модель (Vector Space Model, VSM);до 1980–х. Методы решения задач, основанные на правилах;после 1980–х. Методы решения задач, основанные на машинномобучении и корпусной лингвистике;1998. Понте и Крофт вводят языковую модель (Language Model,LM);
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 2 / 55

Краткая история АОТ (2)
конец 1990–х. Вероятностные тематические модели (LSI, pLSI,LDA, и т.д.) ;1999. Опубликован учебник Маннинга и Щютце “Основыстатистической автоматической обработки текстов” (“Foundationsof Statistical Natural Language Processing”) ;2009. Опубликован учебник Берда, Кляйна и Лопера“Автоматическая обработка текстов на Python” (“Natural LanguageProcessing with Python”) ;2014. Deep learning in NLP. Mikolov, Tomas и др. “Efficientestimation of word representations in vector space”.
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 3 / 55
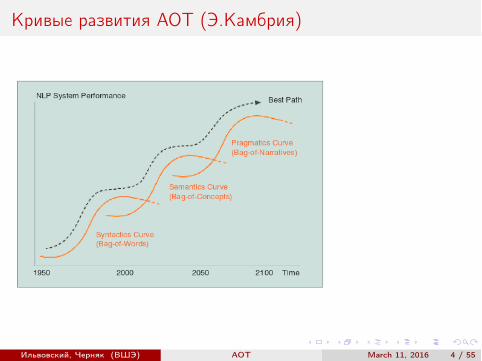
Кривые развития АОТ (Э.Камбрия)
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 4 / 55

Основные задачи АОТ
Машинный переводКлассификация текстов
IФильтрация спама
IПо тональности
IПо теме или жанру
Кластеризация текстовИзвлечение именованных сущностейВопросно-ответные системыСуммаризация текстовГенерация текстовРаспознавание речиПроверка правописанияОптическое распознавание символовПользовательские эксперименты и оценка точности и качестваметодов
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 5 / 55

Основные техники
Уровень символов:I
Токенизация: разбиение текста на слова
IРазбиение текста на предложения
Уровень слов – морфология:I
Разметка частей речи
IСнятие морфологической неоднозначности
Уровень предложений – синтаксис:I
Синтаксический разбор
Уровень смысла – семантика и дискурс:I
Разрешение кореферентных связей
IАнализ дискурсивных связей
IАнализ семантических ролей
IВыделение синонимов
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 6 / 55

Основные подходы
1 Методы, основанные на правилах2 Методы, основанные на статистическом анализе и машинном
обучении3 Комбинированные методы
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 7 / 55

Основные проблемы
НеоднозначностьI
Лексическая неоднозначность
F орган, парить, рожки, атласI
Морфологическая неоднозначность
F Хранение денег в банке.F Что делают белки в клетке?
IСинтаксическая неоднозначность
F Мужу изменять нельзя.F Его удивил простой солдат.
Неологизмы: печеньки, заинстаграммить, репостнуть, расшаритьРазные варианты написания: Россия, Российская Федерация, РФНестандартное написание: каг дила?
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 8 / 55

How many meanings can you get for the sentence “I saw theman on the hill with a telescope”?
I saw the man. The man was on the hill. I was using a telescope.
I saw the man. I was on the hill. I was using a telescope.
I saw the man. The man was on the hill. The hill had a telescope.
I saw the man. I was on the hill. The hill had a telescope.
I saw the man. The man was on the hill. I saw him using a telescope.
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 9 / 55

АОТ в индустрии
Популярные задачи: суммаризация большого колчиества документов,анализ историй болезни, анализ тональности, рекомендательныесистемы, веб-аналитика
Поисковые машины: Google, Baidu, Yahoo, YandexРаспознавание речи: Siri, Google Now, XboxАналитика: SAS Text Miner, IBM Watson, IBM Content Analytics,OntosMiner, Intersystems iKnow, SAP HANA, Oracle TextПроверка правописания: Word, Pages, iOS apps, Android apps
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 10 / 55

План
1 Введение в автоматическую обработку текстов2 Введение в информационный поиск3 Вероятностное тематическое моделирование4 Классификация текстов по теме и по тональности5 Кластеризация текстов6 Методы поиска синонимов7 Визуализация текстов
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 11 / 55

Сегодня
1 Введение
2 Токенизация и подсчет количества слов
3 Морфологический анализ
4 Извлечение ключевых слов и словосочетаний
5 Векторная модель коллекции текстов
6 Cинтаксический анализ
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 12 / 55

Сколько слов в этом предложении?
“На дворе трава, на траве дрова, не руби дрова на траве двора.”12 токенов: На, дворе, трава, на, траве, дрова, не, руби, дрова, на,траве, двора8 - 9 типов: Н/на, дворе, трава, траве, дрова, не, руби, двора.5 лексем: на, двор, трава, дрова, рубить
Токен и типТип – уникальное слово из текстаТокен – тип и его позиция в тексте
N = число токеновV – словарь (все типы)|V | = количество типов в словареКак связаны N и |V |?
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 13 / 55

Закон Ципфа
В любом достаточно большом тексте ранг типа обратнопропорционален его частоте:
f =a
r
f – частота типаr – ранг типаa – параметр, для славянских языков – около 0.07
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 14 / 55

Закон Ципфа: пример
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 15 / 55

Закон Хипса
С увеличением длины текста (количества токенов), количество типовувеличивается в соответствии с законом :
|V | = K ⇤ Nb
N = число токенов|V | = количество типов в словареK , b – параметры, обычно K 2 [10, 100], b 2 [0.4, 0.6]
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 16 / 55

Токенизация
Разбиение текста на отдельные словаСегментация предложений
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 17 / 55

Почему сложна токенизация?
Простой пример: “В Нью-Йорке хороший маффин стоит 3.88$”.I
“.” – это токен?
I3.88$ – это один токен или несколько?
IНью-Йорк – это один токен или несколько?
В реальных данных много шума: html-разметка, ссылки, лишниезнаки пунктуации.В реальных данных много опечаток: аптом она сказлаТочка не всегда означает конец предложения: р. Москва, к.т.н.,20-ые гг.
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 18 / 55

Токенизация с помощью регулярных выражений
Задаем шаблоны, описывающие токены.
Регулярные выражения на PythonIn[1]: import reIn[2]: prog = re.compile(’[A-Za-z]+’)In[3]: prog.findall("Words, words, words.")Out[1]: [’Words’, ’words’, ’words’]
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 19 / 55

Сегментация предложений (1)
Как определить границы предложения?“?”, “!” как правило, однозначныТочка “.” не всегда означает конец предложенияПрямая речь: � Кто там? � спросил дядя Фёдор. � Это я!
Бинарный классификатор для сегментации предложений: для каждойточки “.” определить, является ли она концом предложения или нет.
Бинарный классификаторБинарный классификатор f : X =) 0, 1 получает на вход таблицу X(каждая строчка – одна точка в тексте, столбцы – признаки) и решаетEndOfSentence (0) или NotEndOfSentence (1).
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 20 / 55

Сегментация предложений (2)
Какие признаки использовать для классификации?Количество пробелов после точкиЗаглавная или строчная буква после точкиПринадлежит ли точка к аббревиатуреи т.д.
Нужно много разметки!
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 21 / 55

Natural Language Toolkit
Natural Language Toolkit умеет все
NLTK tokenizersIn[1]: from nltk.tokenize import RegexpTokenizer,wordpunct_tokenizeIn[2]: s = ”Good muffins cost $3.88 in New York. \n Pleasebuy me two of them. \n Thanks.”In[3]: tokenizer = RegexpTokenizer(’\w+| \$ [\d \.]+ | S\+’)In[4]: tokenizer.tokenize(s)Out[1]:[’Good’, ’muffins’, ’cost’, ’$3.88’, ’in’, ’New’,’York’, ’.’, ’Please’, ’buy’, ’me’, ’two’, ’of’, ’them’,’.’, ’Thanks’, ’.’]In[5]: wordpunct_tokenize(s)Out[2]: [’Good’, ’muffins’, ’cost’, ’$’, ’3’, ’.’, ’88’,’in’, ’New’, ’York’, ’.’, ’Please’, ’buy’, ’me’, ’two’,’of’, ’them’, ’.’, ’Thanks’, ’.’]
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 22 / 55

Обучение токенизации
nltk.tokenize.punkt – это инструмент для обучения токенизации поразмеченным данным. Содержит обученный токенизаторPunkt_tokenizer для текстов на английском языке.
Punkt_tokenizerIn[1]: import nltk.dataIn[2]: sent_detector =nltk.data.load(’tokenizers/punkt/english.pickle’)In[3]: sent_detector.tokenize(s)Out[1]: [’Good muffins cost $3.88 in New York.’, ’Pleasebuy me two of them.’, ’Thanks.’]
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 23 / 55
1 Введение
2 Токенизация и подсчет количества слов
3 Морфологический анализ
4 Извлечение ключевых слов и словосочетаний
5 Векторная модель коллекции текстов
6 Cинтаксический анализ
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 24 / 55

Морфологический анализ
Задачи морфологического анализа:Разбор слова � определение нормальной формы (леммы) играмматических характеристик словаСинтез слова � генерация слова по заданным грамматическимхарактеристикам
Морфологический процессор – инструмент морфологическогоанализа:
Морфологический словарьМорфологический анализатор
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 25 / 55
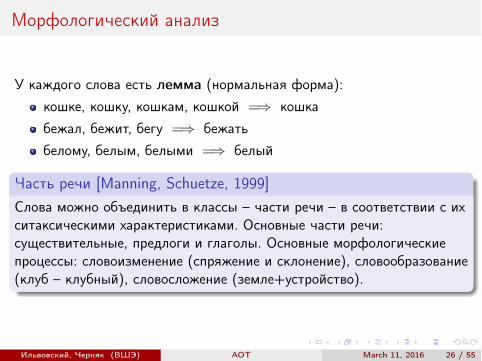
Морфологический анализ
У каждого слова есть лемма (нормальная форма):кошке, кошку, кошкам, кошкой =) кошкабежал, бежит, бегу =) бежатьбелому, белым, белыми =) белый
Часть речи [Manning, Schuetze, 1999]Слова можно объединить в классы – части речи – в соответствии с ихситаксическими характеристиками. Основные части речи:существительные, предлоги и глаголы. Основные морфологическиепроцессы: словоизменение (спряжение и склонение), словообразование(клуб – клубный), словосложение (земле+устройство).
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 26 / 55

Парадигма
Словоизменительная парадигма � список словоформ, принадлежащиходной лексеме и имеющих разные грамматические значения.
пальто- плакать рук-аплач-у рук-иплач-ешь рук-еплач-ет рук-уплач-ем рук-ойплач-ете о рук-еплач-ут
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 27 / 55

Грамматические характеристики [Попов, 1982]
Существительное: род (м.р., ж.р., с.р.), число (ед., мн.), падеж (им., род., дат., вин., твор., пред.),
одушевленность (од., неод.)
Полное прилагательное и причастие: пассивность (пасс., акт.), время (прош., наст.), род (м.р., ж.р.,
с.р.), число (ед., мн.), падеж (им., род., дат., вин., твор., пред.), одушевленность (од., неод.), вид
(сов., несов.)
Краткое прилагательное и причастие: пассивность (пасс., акт.), время (прош., наст.), род (м.р., ж.р.,
с.р.), число (ед., мн.)
Глагол: пассивность (пасс., акт.), время (прош., наст.) род (м.р., ж.р., с.р.), число (ед., мн.)
Деепричастие: пассивность (пасс., акт.), время (прош., наст.), число (ед., мн.)
Наречие: обстоятельственное (обст.), определительное (опред.)
Количественное числительное: тип “1”, “2”, “5”, дробное (дроб.), неопределенное (неопр.),
именнованное (именнов.),
Местоимение: класс: притяжательное (прит.), указательное (указ.), возвратное (возвр.,),
возвратно-аттрибутивное (возвр.-атр.), третьего лица (3 л.); род (м.р., ж.р., с.р.), число (ед., мн.),
падеж (им., род., дат., вин., твор., пред.)
Союз: сочинительный (соч.), подчинительный (подч.)
Предлог: падеж (род., дат., вин., твор., пред.)
Частица: вопросительная (вопр.), отрицательная (отр.)
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 28 / 55

Типы существительных [Попов, 1982]
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 29 / 55

Стемминг
Слова состоят из морфем: word = stem + a�xes. Стемминг позволяетотбросить аффиксы. Чаще всего используется алгоритм Портера.1-ый вид ошибки: белый, белка, белье =) бел2-ой вид ошибки: трудность, трудный =) трудност, труд, кротость=) кротост, крот3-ий вид ошибки: быстрый, быстрее =) быст, побыстрее =)побыстАлгоритм Портера состоит из 5 циклов комманд, на каждом цикле –операция удаления / замены суффикса. Возможны вероятностныерасширения алгоритма.
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 30 / 55

Разрешение морфологической неоднозначности
Существительное или глагол: стали, стекло, течь, белила, падалиПрилагательное или существительное: мороженое, простойСуществительное или существительное: черепах
N-граммные морфологические анализаторы:unigram tagging: выбирает самый частый / вероятный разборngram tagging: анализирует контекст текущего слова – nпредыдущих слов (HMM, CRF, нужно много данных для обучения)Временные затраты VS точность разбора VS количествонеоднозначных слов =) ансамбли морфологическиханализаторов
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 31 / 55

1 Введение
2 Токенизация и подсчет количества слов
3 Морфологический анализ
4 Извлечение ключевых слов и словосочетаний
5 Векторная модель коллекции текстов
6 Cинтаксический анализ
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 32 / 55

Классификация методов извлечения ключевых слов исловосочетаний
Ключевые слова и словосочетания сложно определить формально.Поскольку определений ключевых слов и словосочетаний множество,существует масса методов их извлечения:
с учителем VS без учителячастотные VS по-сложнееиз одного текста VS из коллекции текстовслова (униграммы) VS биграммы VS N-граммытермины VS именованные сущности VS коллокациипоследовательные слова VS с использованием окна
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 33 / 55

Методы извлечения ключевых слов и словосочетании сучителем
Построим бинарный классификатор с целевым признаком KeyWord (1)NotKeyWord (0). Возможные признаки для классификации:
Слово употребляется в начале предложенияСлово написано с заглавной буквыЧастота словаСлово используется в качестве названия статьи или категории вВикипедииСлово – именованная сущностьСлово – терминИ т.д.
Но нужны размеченные коллекции текстов.
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 34 / 55

Методы извлечения ключевых слов и словосочетаниибез учителя
Морфологические шаблоныМеры ассоциации биграмм: PMI, T-Score, LLRГрафовые методы: TextRank [Mihalcea, Tarau, 2004]Синтаксические шаблоны
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 35 / 55

Меры ассоциации биграмм (1)
w1,w2 – два словаf (w1), f (w2) – их частотыf (w1,w2) – частота биграммы w1w2
PMI (w1,w2) = log f (w1
,w2
)f (w
1
)f (w2
)
Pointwise Mutual Information [Manning, Shuetze, 1999]PMI (w1,w2) показывает сколько информации о появлении одногослова содержится в появлении другого слова.
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 36 / 55

Меры ассоциации биграмм (2)
w1,w2 – два словаf (w1), f (w2) – их частотыf (w1,w2) – частота биграммы w1w2N – число словT � score(w1,w2) =
f (w1
,w2
)�f (w1
)⇤f (w2
)f (w
1
,w2
)/N
T-Score [Manning, Shuetze, 1999]T � score(w1,w2) – это статистический t � test, используемый дляизвлечения ключевых словосочетаний. t � test измеряет разницумежду ожидаемым и наблюдаемым средним значением,нормированную стандартным отклонением. Считается лучшей меройассоциацией биграмм. Уровень значимости при анализе, как правило,не используется.
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 37 / 55

Меры ассоциации биграмм (3)
w1,w2 – два словаO11 = f (w1,w2) – наблюдаемая частота биграммы w1w2E11 = O
11
+O12
N ⇥ O11
+O21
N ⇥ N – ожидаемая частота биграммы w1w2
w2 not w2w1 O11 O12
not w1 O21 O22
chi2 =X
i ,j
(Oij � Eij)2
Eij= |i 2 1, 2, j 2 1, 2| =
=N(O11O22 � O12O21)2
(O11 + O12)(O11 + O21)(O12 + O22)(O21 + O22)
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 38 / 55

Меры ассоциации биграмм в NLTK
NLTK BigramCollocationFinderIn[1]: from nltk.collocations import *In[2]: bigram_measures =nltk.collocations.BigramAssocMeasures()In[3]: finder = BigramCollocationFinder.from_words(tokens)In[4]: finder.apply_freq_filter(3)In[5]: for i in finder.nbest(bigram_measures.pmi, 20): ...
Меры ассоциации биграмм в NLTK:bigram_measures.pmi
bigram_measures.student_t
bigram_measures.chi_sq
bigram_measures.likelihood_ratio
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 39 / 55

TextRank: использование мер центральности графов дляизлвечения ключевых слов и словосочетаний (1)[Mihalcea, Tarau, 2004]
1 Вершины графа: слова2 Ребра графа могут определяться по следующим правилам:
IПоследовательные слова
IСлова внутри левого или правого окна в ± 2-5 слов;
Ребра могут быть взвешенные или невзвегенные, направленныеили ненправленные.
3 Любая мера центральности графа использутся для определенияважности вершин в графе. Слова, соответствующие наиболееважным вершинам, считаются ключевыми.
4 Если две соседние вершины оказываются важными,соответствующие им слова формируют ключевое словосочетание.
http://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 40 / 55

TextRank (2)
Compatibility of systems of linear constraints over the set of natural numbers. Criteria of compatibility of a system of linear
Diophantine equations, strict inequations, and nonstrict inequations are considered. Upper bounds for components of a minimal
set of solutions and algorithms of construction of minimal generating sets of solutions for all types of systems are given. These
criteria and the corresponding algorithms for constructing a minimal supporting set of solutions can be used in solving all the
considered types systems and systems of mixed types.
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 41 / 55

TextRank (3)
G = (V ,E ) – граф, V – вершины, E – ребраIn(Vi ) – множество исходящих реберOut(Vi ) – множество входящих реберМеры центральности
PageRank [Brin, Page, 1998]
PR(Vi ) = (1 � d) + d ⇥P
Vj2In(Vi )PR(Vj )|Out(Vj )|
HITS [Kleinberg, 1999]HITSA(Vi ) =
PVj2In(Vi )
HITSH(Vj)
HITSH(Vi ) =P
Vj2Out(Vi )HITSA(Vj)
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 42 / 55

TextRank (4)
Найденные ключевые слова и словосочетанияlinear constraints; linear diophantine equations; natural numbers; nonstrictinequations; strict inequations; upper bounds
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 43 / 55

Меры контрастности для извлечения ключевых слов исловосочетаний
Рассмотрим некую коллекцию текстов. Требуется для данного текстаопределить слова и словосочетания, которые встречаются в немсущественно чаще, чем в других текстах.
Частота терма [Luhn, 1957]Важность терма в тексте пропорциональная его частоте.
Обратная документная частота [Spaerck Jones, 1972]Специфичность терма в тексте обратнопропорциональна числутекстов, в которых терм встречается.
tfidf (term, text, collection) = tf (term, document)⇥ idf (term, collection)
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 44 / 55

Используемые TF и IDF веса
tf (term, document) =
бинарный вес: 1, если терм встречается в тексте, 0, иначечастота: ft,d
нормированная частота: log(1 + ft,d)
idf (term, collection) =
унарный вес: 1обратная частота: log N
nt, где N – число текстов в коллекции, nt –
число текстов, в которых встречается терм t
сглаженная обратная частота: log Nnt+1
Самая популярная комбинация весов: ft,d ⇥ log Nnt+1
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 45 / 55

1 Введение
2 Токенизация и подсчет количества слов
3 Морфологический анализ
4 Извлечение ключевых слов и словосочетаний
5 Векторная модель коллекции текстов
6 Cинтаксический анализ
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 46 / 55

Использование меры tf � idf для измерения сходстватекстов
Пусть каждый текст di из коллекции текстов D представлен векторомdi = (w i
1,wi2, ...,w
i|V |) , где V – это словарь, |V | – общее число термов
(типов) в словаре. Получается векторное пространство размерности|V |, где каждое измерение задано одним термом. w i
k – это вес терма kв тексте i – чаше всего, вычисленный по мере tf � idf . Сходствомежду двумя текстами может быть определено как косинус междусоответствующими векторами.
Косинусная мера близости в векторной моделиCosine similarity in Vector Space Model (VSM) [Salton et. al, 1975]
cos(di , dj) =di ⇥ dj
||di ||||dj ||=
Pk w
ik ⇥ w j
kq(P
k wik)
2q(P
k wjk)
2
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 47 / 55

Векторная модель коллекции текстов
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 48 / 55

1 Введение
2 Токенизация и подсчет количества слов
3 Морфологический анализ
4 Извлечение ключевых слов и словосочетаний
5 Векторная модель коллекции текстов
6 Cинтаксический анализ
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 49 / 55

Синтаксический анализ
Выделение синтаксических связей между словамиКаждое предложение представляется в виде дереваВыделяют деревья двух видов:
IДеревья составляющих (constituency tree)
IДеревья зависимостей (dependency tree)
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 50 / 55

Генеративная модель языка
Язык – множество цепочек словПравила порождения цепочек описываются формальнымиграмматиками ХомскогоГрамматика: правила вида [aAbB] ! [aBc], слева и справацепочки терминальных и нетерминальных символов4 вида грамматик:
IНеограниченные грамматики
IКонтекстно-зависимые и неукорачивающие грамматики
IКонтекстно-свободные грамматики
IРегулярные грамматики
Для естественных языков используются контекстно-свободныеграмматики вида A ! aBa
IСлева – ровно один нетерминальный символ
IСправа – произвольная цепочка
Дерево вывода цепочки-предложения – дерево составляющих
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 51 / 55

Пример дерева составляющих
S, NP, VP – нетерминальные символыV, N, Det – терминальные символы
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 52 / 55

Пример дерева зависимостей
Все слова в предложении связаны отношением типа“хозяин-слуга”, имеющим различные подтипыУзел дерева – слово в предложенииДуга дерева – отношение подчинения
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 53 / 55

Деревья зависимостей
1 Правила (rule-based)I
Набор шаблонов, схем, правил вывода, использующих
лингвистические сведения
IЗависит от языка
IЭТАП-3
2 Машинное обучениеI
Корпуса с морфологической и синтаксической разметкой
IНе требуется знание специфики языка
IMaltParser
3 Предложение с проективными связями может быть преобразованов дерево составляющих
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 54 / 55

Демо
Berkley Tomcat constituency parser http://tomato.banatao.berkeley.edu:8080/parser/parser.html
Stanford CoreNLP dependency parserhttp://nlp.stanford.edu:8080/corenlp/
ARK dependency parser (Carnegie Melon)http://demo.ark.cs.cmu.edu/parse
Ильвовский, Черняк (ВШЭ) АОТ March 11, 2016 55 / 55





























