Upload
duongliem
View
219
Download
0
Embed Size (px)
Citation preview

PostData Curso de Introduccioacuten a la Estadiacutestica
Tutorial 06Muestreo e intervalos de confianza
Atencioacuten
Este documento pdf lleva adjuntos algunos de los ficheros de datos necesarios Y estaacute pensadopara trabajar con eacutel directamente en tu ordenador Al usarlo en la pantalla si es necesariopuedes aumentar alguna de las figuras para ver los detalles Antes de imprimirlo piensa sies necesario Los aacuterboles y nosotros te lo agradeceremos
Fecha 19 de abril de 2017 Si este fichero tiene maacutes de un antildeo puede resultar obsoleto Buscasi existe una versioacuten maacutes reciente
Iacutendice
1 La distribucioacuten muestral de la media con R 1
2 Intervalos de confianza para la media con la distribucioacuten normal 10
3 Muestras pequentildeas La t de Student 20
4 Intervalos de confianza para la media usando t 27
5 La distribucioacuten χ2 32
6 Intervalos de confianza para la varianza con χ2 35
7 Las funciones de la libreriacutea asbio de R 39
8 Ejercicios adicionales y soluciones 42
1 La distribucioacuten muestral de la media con R
La Seccioacuten 61 del libro contiene el Ejemplo 611 en el que se discute la distribucioacuten muestral dela media para la variable aleatoria
X(a b) = a+ b
que representa la suma de puntos obtenidos al lanzar dos dados En ese ejemplo consideramosmuestras aleatorias (con reemplazamiento) de tamantildeo
n = 3
Nuestro primer paso en ese ejemplo es el caacutelculo del nuacutemero de esas muestras que resulta ser46656 En este tutorial vamos a empezar construyendo la lista completa de esas 46656 muestraspara estudiar la distribucioacuten de la media muestral a partir de ellas
Para hacer esto vamos a utilizar la misma estrategia que se usa en el libro en el que cada uno delos 36 resultados (equiprobables) distintos que se pueden obtener al lanzar dos dados se representacon un nuacutemero del 1 al 36 En la Seccioacuten 62 del Tutorial03 usamos la libreriacutea gtools de R paraobtener todas las tiradas posibles con este coacutedigo
1
library(gtools)(dosDados = permutations(6 2 repeatsallowed=TRUE))
[1] [2] [1] 1 1 [2] 1 2 [3] 1 3 [4] 1 4 [5] 1 5 [6] 1 6 [7] 2 1 [8] 2 2 [9] 2 3 [10] 2 4 [11] 2 5 [12] 2 6 [13] 3 1 [14] 3 2 [15] 3 3 [16] 3 4 [17] 3 5 [18] 3 6 [19] 4 1 [20] 4 2 [21] 4 3 [22] 4 4 [23] 4 5 [24] 4 6 [25] 5 1 [26] 5 2 [27] 5 3 [28] 5 4 [29] 5 5 [30] 5 6 [31] 6 1 [32] 6 2 [33] 6 3 [34] 6 4 [35] 6 5 [36] 6 6
El resultado es una matriz de 36 filas y tres columnas en la que cada fila representa un resultadoposible al lanzar los dos dados Una muestra de tamantildeo 3 se obtiene al elegir tres filas de estamatriz Por ejemplo si elegimos (como en el libro) las filas 2 15 y 23
muestraFilas = c(2 15 23)
entonces los resultados correspondientes de los dados son
(muestra = dosDados[muestraFilas ])
[1] [2] [1] 1 2 [2] 3 3 [3] 4 5
Para calcular el valor de X en cada una de las tres tiradas que forman la muestra hacemos
(XenMuestra = rowSums(muestra))
[1] 3 6 9
Y finalmente la media muestral de esa muestra es
2
(mediaMuestral = mean(XenMuestra))
[1] 6
Hemos calculado la media muestral en una muestra concreta Pero lo que queremos hacer es repetireste proceso para todas y cada una de las 46656 muestras posibles Lo primero que vamos a hacer esconstruir la lista completa de las muestras Eso significa saber cuaacuteles son las tres filas de la matrizdosDados que se han elegido en cada muestra concreta Podemos obtener la lista de muestrasusando de nuevo la libreriacutea gtools
n = 3Muestras = permutations(36 n repeatsallowed=TRUE)
El comienzo y final de la matriz Muestras son
head(Muestras)
[1] [2] [3] [1] 1 1 1 [2] 1 1 2 [3] 1 1 3 [4] 1 1 4 [5] 1 1 5 [6] 1 1 6
tail(Muestras)
[1] [2] [3] [46651] 36 36 31 [46652] 36 36 32 [46653] 36 36 33 [46654] 36 36 34 [46655] 36 36 35 [46656] 36 36 36
Fiacutejate en que como hemos dicho se trata de muestras con reemplazamiento Por ejemplo laprimera muestra de la lista es aquella en la que hemos elegido las tres veces la primera fila dedosDados Es decir volviendo a los dados originales que hemos elegido una muestra de tamantildeo 3pero las tres veces hemos elegido la tirada (1 1) de los dados
Vamos a comprobar que el nuacutemero de muestras que hemos construido coincide con el caacutelculo teoacutericoque aparece en el libro (es decir 46656)
dim(Muestras)
[1] 46656 3
(numMuestras = dim(Muestras)[1])
[1] 46656
Hemos guardado el nuacutemero de muestras en numMuestras para utilizarlo maacutes adelante Por otraparte hay que tener en cuenta que puesto que se trata de muestras con reemplazamiento podemoselegir la misma fila varias veces Por eso hemos incluido la opcioacuten repeatsallowed=TRUE Lafuncioacuten dim nos indica que como esperaacutebamos la matriz que contiene la lista de muestras tiene46656 filas y 3 columnas que contienen los nuacutemeros de fila de dosDados que se usan en cadamuestra Para seguir con el ejemplo del libro la muestra muestraFilas = c(2 15 23) quehemos usado antes aparece en la fila nuacutemero 1823
3
Muestras[1823 ]
[1] 2 15 23
Recuerda que 2 15 23 corresponde a las tiradas (1 2) (3 3) y (4 5) respectivamente de los dosdados
Ahora una vez que tenemos la lista completa de muestras tenemos que calcular la media muestralpara cada una de ellas El resultado seraacute un vector mediasMuestrales de R que contendraacute 46656medias muestrales Para construir ese vector
Usaremos un bucle for (ver Tutorial05) para recorrer una a una las filas de Muestras
Para cada fila (esto es para cada muestra) calcularemos tres valores de X y a partir de ellosla media muestral X como hemos hecho en el ejemplo maacutes arriba
Y almacenaremos esa media en el vector mediasMuestrales
El codigo correspondiente es este (lee los comentarios)
mediasMuestrales = numeric(numMuestras)for(i in 1numMuestras)
Identificamos las 3 filas que se han elegido en esta muestramuestraFilas = Muestras[i ]
Recuperamos los resultados de las 3 tiradas de los dos dadosmuestra = dosDados[muestraFilas ]
Aqui calculamos 3 valores de XXenMuestra = rowSums(muestra)
A partir de ellos calculamos una media muestralmediaMuestral = mean(XenMuestra)
Y la guardamos en el vector de medias muestralesmediasMuestrales[i] = mediaMuestral
iexclY ya estaacute Ya tenemos las 46656 medias muestrales El comienzo del vector es
head(mediasMuestrales)
[1] 20000 23333 26667 30000 33333 36667
Y para la muestra que hemos usado de ejemplo
mediasMuestrales[1823]
[1] 6
como ya sabiacuteamos
Ejercicio 1 Esfueacuterzate en entender de doacutende provienen los primeros valores de la media muestralEs importante que entiendas el mecanismo de construccioacuten de las muestras para que el conceptode media muestral quede claro
11 Distribucioacuten de la media muestral X y de la variable original X
Ahora que tenemos todas las medias muestrales podemos estudiar coacutemo se distribuyen Es decirtenemos 46656 valores de X pero desde luego no son todos distintos Hay muchas muestras
4
distintas de tamantildeo 3 que producen el mismo valor de X Asiacute que lo que tenemos que hacer esesencialmente obtener la tabla de frecuencias de los valores de X (Tabla 62 del libro ver paacuteg200) y representar graacuteficamente el resultado (Figura 63(b) del libro paacuteg 202)
Pero antes vamos a detenernos a estudiar la distribucioacuten de la variable original X para podercompararlas despueacutes La tabla de frecuencias de X es muy faacutecil de obtener (ya la obtuvimos porotro meacutetodo al principio del Tutorial04) Recuerda que el valor de X se obtiene sumando las filasde dosDados
X = rowSums(dosDados)(tablaX = table(X))
X 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 5 4 3 2 1
Y su representacioacuten graacutefica es
barplot(tablaX)
2 3 4 5 6 7 8 9 10 11 12
01
23
45
6
La forma de la distribucioacuten es claramente triangular sin curvatura alguna El valor medio deX (media teoacuterica) es microX = 7 Podemos confirmar esto y ademaacutes calcular la varianza (teoacuterica opoblacional)
(muX = mean(X))
[1] 7
(sigma2_X = sum((X - muX)^2)length(X))
[1] 58333
Ahora vamos a hacer lo mismo para estudiar la distribucioacuten (la forma en que se distribuyen losvalores) de X La Tabla 62 del libro se obtiene con
5
(tablaMediaMuestralX = asmatrix(table(mediasMuestrales)))
[1] 2 1 233333333333333 6 266666666666667 21 3 56 333333333333333 126 366666666666667 252 4 456 433333333333333 756 466666666666667 1161 5 1666 533333333333333 2247 566666666666667 2856 6 3431 633333333333333 3906 666666666666667 4221 7 4332 733333333333333 4221 766666666666667 3906 8 3431 833333333333333 2856 866666666666667 2247 9 1666 933333333333333 1161 966666666666667 756 10 456 103333333333333 252 106666666666667 126 11 56 113333333333333 21 116666666666667 6 12 1
Esta es la tabla (o funcioacuten) de densidad de X La hemos convertido en una matriz porque lapresentacioacuten por defecto de la tabla que se obtiene de R no es gran cosa (hay libreriacuteas que seencargan de esto) Pero en cualquier caso puedes comprobar que los valores son los que aparecenen el libro Fiacutejate en que los valores de X avanzan de 13 en 13 (porque la muestra es de tamantildeo3 claro)
A partir de aquiacute la representacioacuten graacutefica es inmediata
barplot(table(mediasMuestrales))
2 3 4 5 6 7 8 9 11
020
00
La forma curvada aproximadamente normal de esta distribucioacuten se hace ahora evidente
6
Ejercicio 2 En este ejemplo hemos trabajado con muestras realmente pequentildeas en las que n = 3iquestQueacute modificaciones habriacutea que hacer en el coacutedigo para estudiar las muestras de tamantildeo 4 dela misma variable X iquestCuaacutentas muestras de tamantildeo n = 20 hay iquestQueacute crees que sucederiacutea sitratases de ejecutar el coacutedigo muestras de tamantildeo n = 20 iexclNo lo intentes R se bloquearaacute El mejorordenador en el que hemos probado esto a duras penas podiacutea con las muestras de tamantildeo n = 5Solucioacuten en la paacutegina 44
Media y desviacioacuten tiacutepica de X
Ahora una vez que hemos comprobado que la distribucioacuten de X es aproximadamente normalvamos a comprobar los resultados sobre su media microX y su varianza σ2
X Se trata en primer lugar
de calcular el valor medio de X cuando consideramos todas las 46656 muestras de tamantildeo 3posibles El resultado es el que la figura anterior anunciaba
(mu_barX = mean(mediasMuestrales))
[1] 7
En cuanto a la varianza (iexclpoblacional) se tiene
(sigma2_barX = sum((mediasMuestrales - mu_barX)^2) length(mediasMuestrales) )
[1] 19444
Pero lo realmente interesante es el cociente entre esta varianza de X y la varianza de X (ambaspoblacionales)
sigma2_X sigma2_barX
[1] 3
El resultado es 3 No aproximadamente 3 sino un 3 exacto igual al tamantildeo n de las muestras queestamos considerando Asiacute hemos confirmado la relacioacuten
σX =σXradicn
que aparece en la paacutegina 204 del libro
12 Otro ejemplo
Este resultado nos parece tan importante que vamos a incluir aquiacute un ejemplo adicional tal vezincluso maacutes espectacular que el anterior Lo que vamos a hacer es estudiar la distribucioacuten muestralde la media de una variable aleatoria distinta a la que vamos a llamar W La variable W toma losvalores del 1 al 20 todos con la misma probabilidad Por lo tanto su tabla (o funcioacuten) de densidades
Valor 1 2 middot middot middot 19 20
Probabilidad 120
120 middot middot middot 1
20120
Puedes pensar que la variable aleatoriaX describe el resultado de un experimento en el que elegimosun nuacutemero al azar del 1 al 20 de forma que todos los nuacutemeros sean equiprobables Graacuteficamentela forma de la distribucioacuten es plana horizontal a una altura constante (igual a 120)
W = 120table(W)20
7
W 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 005 005 005 005 005 005 005 005 005 005 005 005 005 005 005 16 17 18 19 20 005 005 005 005 005
barplot(table(W)20)
1 3 5 7 9 11 13 15 17 19
000
003
Ahora vamos a considerar muestras con reemplazamiento de X de tamantildeo n = 4 Es decir unamuestra consiste en elegir (iexclcon reemplazamiento) cuatro nuacutemeros del 1 al 20 y queremos pensaren el conjunto de todas las muestras de tamantildeo 4 posibles Vamos a proponer al lector que exploreeste conjunto mediante ejercicios
Ejercicio 3
1 iquestCuaacutentas muestras distintas de tamantildeo 4 existen
2 Construacuteyelas todas Imita lo que hemos hecho en el ejemplo de los dados y usa gtools paraobtener una matriz MuestrasW que contenga en cada fila una de las muestras
Soluciones en la paacutegina 45
iexclNo sigas si no has hecho este ejercicioUna vez construidas las muestras podemos calcular las medias muestrales de X En este caso lascosas son maacutes sencillas porque las 160000 medias muestrales se obtienen directamente usando lafuncioacuten rowMeans aplicada a la matriz MuestrasW
mediasMuestralesW = rowMeans(MuestrasW)length(mediasMuestralesW)
[1] 160000
Y ahora podemos hacer una tabla de frecuencia de las medias muestrales
(tablaMediaMuestralW = asmatrix(table(mediasMuestralesW)))
[1] 1 1 125 4 15 10 175 20 2 35 225 56
8
25 84 275 120 3 165 325 220 35 286 375 364 4 455 425 560 45 680 475 816 5 969 525 1140 55 1330 575 1540 6 1767 625 2008 65 2260 675 2520 7 2785 725 3052 75 3318 775 3580 8 3835 825 4080 85 4312 875 4528 9 4725 925 4900 95 5050 975 5172 10 5263 1025 5320 105 5340 1075 5320 11 5263 1125 5172 115 5050 1175 4900 12 4725 1225 4528 125 4312 1275 4080 13 3835 1325 3580 135 3318 1375 3052 14 2785 1425 2520 145 2260 1475 2008 15 1767 1525 1540 155 1330 1575 1140 16 969 1625 816 165 680 1675 560 17 455 1725 364 175 286 1775 220 18 165 1825 120 185 84 1875 56
9
19 35 1925 20 195 10 1975 4 20 1
y representar graacuteficamente la forma de la distribucioacuten
barplot(table(mediasMuestralesW))
1 25 4 55 7 85 105 1275 15 17 19
010
0030
0050
00
Como se ve obtenemos de nuevo una curva con la forma de campana caracteriacutestica de las curasnormales muy similar a la del ejemplo con dos dados Es muy importante que observes quelas dos variables que hemos usado como punto de partida son bastante distintas entre siacute y que eltamantildeo de muestra tampoco era el mismo Y sin embargo la distribucioacuten de la media muestrales en ambos casos aproximadamente normal
Ejercicio 4
1 Calcula la media microW y la varianza σ2W
2 Comprueba que se cumple la relacioacuten
σW =σWradicn
Soluciones en la paacutegina 45
2 Intervalos de confianza para la media con la distribucioacutennormal
En el Tutorial05 hemos aprendido a usar el ordenador para resolver problemas directos e inversosde probabilidad asociados con la normal estaacutendar Para refrescar esos problemas vamos a empezarcon un par de ejercicios
Ejercicio 5
10
1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

library(gtools)(dosDados = permutations(6 2 repeatsallowed=TRUE))
[1] [2] [1] 1 1 [2] 1 2 [3] 1 3 [4] 1 4 [5] 1 5 [6] 1 6 [7] 2 1 [8] 2 2 [9] 2 3 [10] 2 4 [11] 2 5 [12] 2 6 [13] 3 1 [14] 3 2 [15] 3 3 [16] 3 4 [17] 3 5 [18] 3 6 [19] 4 1 [20] 4 2 [21] 4 3 [22] 4 4 [23] 4 5 [24] 4 6 [25] 5 1 [26] 5 2 [27] 5 3 [28] 5 4 [29] 5 5 [30] 5 6 [31] 6 1 [32] 6 2 [33] 6 3 [34] 6 4 [35] 6 5 [36] 6 6
El resultado es una matriz de 36 filas y tres columnas en la que cada fila representa un resultadoposible al lanzar los dos dados Una muestra de tamantildeo 3 se obtiene al elegir tres filas de estamatriz Por ejemplo si elegimos (como en el libro) las filas 2 15 y 23
muestraFilas = c(2 15 23)
entonces los resultados correspondientes de los dados son
(muestra = dosDados[muestraFilas ])
[1] [2] [1] 1 2 [2] 3 3 [3] 4 5
Para calcular el valor de X en cada una de las tres tiradas que forman la muestra hacemos
(XenMuestra = rowSums(muestra))
[1] 3 6 9
Y finalmente la media muestral de esa muestra es
2
(mediaMuestral = mean(XenMuestra))
[1] 6
Hemos calculado la media muestral en una muestra concreta Pero lo que queremos hacer es repetireste proceso para todas y cada una de las 46656 muestras posibles Lo primero que vamos a hacer esconstruir la lista completa de las muestras Eso significa saber cuaacuteles son las tres filas de la matrizdosDados que se han elegido en cada muestra concreta Podemos obtener la lista de muestrasusando de nuevo la libreriacutea gtools
n = 3Muestras = permutations(36 n repeatsallowed=TRUE)
El comienzo y final de la matriz Muestras son
head(Muestras)
[1] [2] [3] [1] 1 1 1 [2] 1 1 2 [3] 1 1 3 [4] 1 1 4 [5] 1 1 5 [6] 1 1 6
tail(Muestras)
[1] [2] [3] [46651] 36 36 31 [46652] 36 36 32 [46653] 36 36 33 [46654] 36 36 34 [46655] 36 36 35 [46656] 36 36 36
Fiacutejate en que como hemos dicho se trata de muestras con reemplazamiento Por ejemplo laprimera muestra de la lista es aquella en la que hemos elegido las tres veces la primera fila dedosDados Es decir volviendo a los dados originales que hemos elegido una muestra de tamantildeo 3pero las tres veces hemos elegido la tirada (1 1) de los dados
Vamos a comprobar que el nuacutemero de muestras que hemos construido coincide con el caacutelculo teoacutericoque aparece en el libro (es decir 46656)
dim(Muestras)
[1] 46656 3
(numMuestras = dim(Muestras)[1])
[1] 46656
Hemos guardado el nuacutemero de muestras en numMuestras para utilizarlo maacutes adelante Por otraparte hay que tener en cuenta que puesto que se trata de muestras con reemplazamiento podemoselegir la misma fila varias veces Por eso hemos incluido la opcioacuten repeatsallowed=TRUE Lafuncioacuten dim nos indica que como esperaacutebamos la matriz que contiene la lista de muestras tiene46656 filas y 3 columnas que contienen los nuacutemeros de fila de dosDados que se usan en cadamuestra Para seguir con el ejemplo del libro la muestra muestraFilas = c(2 15 23) quehemos usado antes aparece en la fila nuacutemero 1823
3
Muestras[1823 ]
[1] 2 15 23
Recuerda que 2 15 23 corresponde a las tiradas (1 2) (3 3) y (4 5) respectivamente de los dosdados
Ahora una vez que tenemos la lista completa de muestras tenemos que calcular la media muestralpara cada una de ellas El resultado seraacute un vector mediasMuestrales de R que contendraacute 46656medias muestrales Para construir ese vector
Usaremos un bucle for (ver Tutorial05) para recorrer una a una las filas de Muestras
Para cada fila (esto es para cada muestra) calcularemos tres valores de X y a partir de ellosla media muestral X como hemos hecho en el ejemplo maacutes arriba
Y almacenaremos esa media en el vector mediasMuestrales
El codigo correspondiente es este (lee los comentarios)
mediasMuestrales = numeric(numMuestras)for(i in 1numMuestras)
Identificamos las 3 filas que se han elegido en esta muestramuestraFilas = Muestras[i ]
Recuperamos los resultados de las 3 tiradas de los dos dadosmuestra = dosDados[muestraFilas ]
Aqui calculamos 3 valores de XXenMuestra = rowSums(muestra)
A partir de ellos calculamos una media muestralmediaMuestral = mean(XenMuestra)
Y la guardamos en el vector de medias muestralesmediasMuestrales[i] = mediaMuestral
iexclY ya estaacute Ya tenemos las 46656 medias muestrales El comienzo del vector es
head(mediasMuestrales)
[1] 20000 23333 26667 30000 33333 36667
Y para la muestra que hemos usado de ejemplo
mediasMuestrales[1823]
[1] 6
como ya sabiacuteamos
Ejercicio 1 Esfueacuterzate en entender de doacutende provienen los primeros valores de la media muestralEs importante que entiendas el mecanismo de construccioacuten de las muestras para que el conceptode media muestral quede claro
11 Distribucioacuten de la media muestral X y de la variable original X
Ahora que tenemos todas las medias muestrales podemos estudiar coacutemo se distribuyen Es decirtenemos 46656 valores de X pero desde luego no son todos distintos Hay muchas muestras
4
distintas de tamantildeo 3 que producen el mismo valor de X Asiacute que lo que tenemos que hacer esesencialmente obtener la tabla de frecuencias de los valores de X (Tabla 62 del libro ver paacuteg200) y representar graacuteficamente el resultado (Figura 63(b) del libro paacuteg 202)
Pero antes vamos a detenernos a estudiar la distribucioacuten de la variable original X para podercompararlas despueacutes La tabla de frecuencias de X es muy faacutecil de obtener (ya la obtuvimos porotro meacutetodo al principio del Tutorial04) Recuerda que el valor de X se obtiene sumando las filasde dosDados
X = rowSums(dosDados)(tablaX = table(X))
X 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 5 4 3 2 1
Y su representacioacuten graacutefica es
barplot(tablaX)
2 3 4 5 6 7 8 9 10 11 12
01
23
45
6
La forma de la distribucioacuten es claramente triangular sin curvatura alguna El valor medio deX (media teoacuterica) es microX = 7 Podemos confirmar esto y ademaacutes calcular la varianza (teoacuterica opoblacional)
(muX = mean(X))
[1] 7
(sigma2_X = sum((X - muX)^2)length(X))
[1] 58333
Ahora vamos a hacer lo mismo para estudiar la distribucioacuten (la forma en que se distribuyen losvalores) de X La Tabla 62 del libro se obtiene con
5
(tablaMediaMuestralX = asmatrix(table(mediasMuestrales)))
[1] 2 1 233333333333333 6 266666666666667 21 3 56 333333333333333 126 366666666666667 252 4 456 433333333333333 756 466666666666667 1161 5 1666 533333333333333 2247 566666666666667 2856 6 3431 633333333333333 3906 666666666666667 4221 7 4332 733333333333333 4221 766666666666667 3906 8 3431 833333333333333 2856 866666666666667 2247 9 1666 933333333333333 1161 966666666666667 756 10 456 103333333333333 252 106666666666667 126 11 56 113333333333333 21 116666666666667 6 12 1
Esta es la tabla (o funcioacuten) de densidad de X La hemos convertido en una matriz porque lapresentacioacuten por defecto de la tabla que se obtiene de R no es gran cosa (hay libreriacuteas que seencargan de esto) Pero en cualquier caso puedes comprobar que los valores son los que aparecenen el libro Fiacutejate en que los valores de X avanzan de 13 en 13 (porque la muestra es de tamantildeo3 claro)
A partir de aquiacute la representacioacuten graacutefica es inmediata
barplot(table(mediasMuestrales))
2 3 4 5 6 7 8 9 11
020
00
La forma curvada aproximadamente normal de esta distribucioacuten se hace ahora evidente
6
Ejercicio 2 En este ejemplo hemos trabajado con muestras realmente pequentildeas en las que n = 3iquestQueacute modificaciones habriacutea que hacer en el coacutedigo para estudiar las muestras de tamantildeo 4 dela misma variable X iquestCuaacutentas muestras de tamantildeo n = 20 hay iquestQueacute crees que sucederiacutea sitratases de ejecutar el coacutedigo muestras de tamantildeo n = 20 iexclNo lo intentes R se bloquearaacute El mejorordenador en el que hemos probado esto a duras penas podiacutea con las muestras de tamantildeo n = 5Solucioacuten en la paacutegina 44
Media y desviacioacuten tiacutepica de X
Ahora una vez que hemos comprobado que la distribucioacuten de X es aproximadamente normalvamos a comprobar los resultados sobre su media microX y su varianza σ2
X Se trata en primer lugar
de calcular el valor medio de X cuando consideramos todas las 46656 muestras de tamantildeo 3posibles El resultado es el que la figura anterior anunciaba
(mu_barX = mean(mediasMuestrales))
[1] 7
En cuanto a la varianza (iexclpoblacional) se tiene
(sigma2_barX = sum((mediasMuestrales - mu_barX)^2) length(mediasMuestrales) )
[1] 19444
Pero lo realmente interesante es el cociente entre esta varianza de X y la varianza de X (ambaspoblacionales)
sigma2_X sigma2_barX
[1] 3
El resultado es 3 No aproximadamente 3 sino un 3 exacto igual al tamantildeo n de las muestras queestamos considerando Asiacute hemos confirmado la relacioacuten
σX =σXradicn
que aparece en la paacutegina 204 del libro
12 Otro ejemplo
Este resultado nos parece tan importante que vamos a incluir aquiacute un ejemplo adicional tal vezincluso maacutes espectacular que el anterior Lo que vamos a hacer es estudiar la distribucioacuten muestralde la media de una variable aleatoria distinta a la que vamos a llamar W La variable W toma losvalores del 1 al 20 todos con la misma probabilidad Por lo tanto su tabla (o funcioacuten) de densidades
Valor 1 2 middot middot middot 19 20
Probabilidad 120
120 middot middot middot 1
20120
Puedes pensar que la variable aleatoriaX describe el resultado de un experimento en el que elegimosun nuacutemero al azar del 1 al 20 de forma que todos los nuacutemeros sean equiprobables Graacuteficamentela forma de la distribucioacuten es plana horizontal a una altura constante (igual a 120)
W = 120table(W)20
7
W 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 005 005 005 005 005 005 005 005 005 005 005 005 005 005 005 16 17 18 19 20 005 005 005 005 005
barplot(table(W)20)
1 3 5 7 9 11 13 15 17 19
000
003
Ahora vamos a considerar muestras con reemplazamiento de X de tamantildeo n = 4 Es decir unamuestra consiste en elegir (iexclcon reemplazamiento) cuatro nuacutemeros del 1 al 20 y queremos pensaren el conjunto de todas las muestras de tamantildeo 4 posibles Vamos a proponer al lector que exploreeste conjunto mediante ejercicios
Ejercicio 3
1 iquestCuaacutentas muestras distintas de tamantildeo 4 existen
2 Construacuteyelas todas Imita lo que hemos hecho en el ejemplo de los dados y usa gtools paraobtener una matriz MuestrasW que contenga en cada fila una de las muestras
Soluciones en la paacutegina 45
iexclNo sigas si no has hecho este ejercicioUna vez construidas las muestras podemos calcular las medias muestrales de X En este caso lascosas son maacutes sencillas porque las 160000 medias muestrales se obtienen directamente usando lafuncioacuten rowMeans aplicada a la matriz MuestrasW
mediasMuestralesW = rowMeans(MuestrasW)length(mediasMuestralesW)
[1] 160000
Y ahora podemos hacer una tabla de frecuencia de las medias muestrales
(tablaMediaMuestralW = asmatrix(table(mediasMuestralesW)))
[1] 1 1 125 4 15 10 175 20 2 35 225 56
8
25 84 275 120 3 165 325 220 35 286 375 364 4 455 425 560 45 680 475 816 5 969 525 1140 55 1330 575 1540 6 1767 625 2008 65 2260 675 2520 7 2785 725 3052 75 3318 775 3580 8 3835 825 4080 85 4312 875 4528 9 4725 925 4900 95 5050 975 5172 10 5263 1025 5320 105 5340 1075 5320 11 5263 1125 5172 115 5050 1175 4900 12 4725 1225 4528 125 4312 1275 4080 13 3835 1325 3580 135 3318 1375 3052 14 2785 1425 2520 145 2260 1475 2008 15 1767 1525 1540 155 1330 1575 1140 16 969 1625 816 165 680 1675 560 17 455 1725 364 175 286 1775 220 18 165 1825 120 185 84 1875 56
9
19 35 1925 20 195 10 1975 4 20 1
y representar graacuteficamente la forma de la distribucioacuten
barplot(table(mediasMuestralesW))
1 25 4 55 7 85 105 1275 15 17 19
010
0030
0050
00
Como se ve obtenemos de nuevo una curva con la forma de campana caracteriacutestica de las curasnormales muy similar a la del ejemplo con dos dados Es muy importante que observes quelas dos variables que hemos usado como punto de partida son bastante distintas entre siacute y que eltamantildeo de muestra tampoco era el mismo Y sin embargo la distribucioacuten de la media muestrales en ambos casos aproximadamente normal
Ejercicio 4
1 Calcula la media microW y la varianza σ2W
2 Comprueba que se cumple la relacioacuten
σW =σWradicn
Soluciones en la paacutegina 45
2 Intervalos de confianza para la media con la distribucioacutennormal
En el Tutorial05 hemos aprendido a usar el ordenador para resolver problemas directos e inversosde probabilidad asociados con la normal estaacutendar Para refrescar esos problemas vamos a empezarcon un par de ejercicios
Ejercicio 5
10
1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

(mediaMuestral = mean(XenMuestra))
[1] 6
Hemos calculado la media muestral en una muestra concreta Pero lo que queremos hacer es repetireste proceso para todas y cada una de las 46656 muestras posibles Lo primero que vamos a hacer esconstruir la lista completa de las muestras Eso significa saber cuaacuteles son las tres filas de la matrizdosDados que se han elegido en cada muestra concreta Podemos obtener la lista de muestrasusando de nuevo la libreriacutea gtools
n = 3Muestras = permutations(36 n repeatsallowed=TRUE)
El comienzo y final de la matriz Muestras son
head(Muestras)
[1] [2] [3] [1] 1 1 1 [2] 1 1 2 [3] 1 1 3 [4] 1 1 4 [5] 1 1 5 [6] 1 1 6
tail(Muestras)
[1] [2] [3] [46651] 36 36 31 [46652] 36 36 32 [46653] 36 36 33 [46654] 36 36 34 [46655] 36 36 35 [46656] 36 36 36
Fiacutejate en que como hemos dicho se trata de muestras con reemplazamiento Por ejemplo laprimera muestra de la lista es aquella en la que hemos elegido las tres veces la primera fila dedosDados Es decir volviendo a los dados originales que hemos elegido una muestra de tamantildeo 3pero las tres veces hemos elegido la tirada (1 1) de los dados
Vamos a comprobar que el nuacutemero de muestras que hemos construido coincide con el caacutelculo teoacutericoque aparece en el libro (es decir 46656)
dim(Muestras)
[1] 46656 3
(numMuestras = dim(Muestras)[1])
[1] 46656
Hemos guardado el nuacutemero de muestras en numMuestras para utilizarlo maacutes adelante Por otraparte hay que tener en cuenta que puesto que se trata de muestras con reemplazamiento podemoselegir la misma fila varias veces Por eso hemos incluido la opcioacuten repeatsallowed=TRUE Lafuncioacuten dim nos indica que como esperaacutebamos la matriz que contiene la lista de muestras tiene46656 filas y 3 columnas que contienen los nuacutemeros de fila de dosDados que se usan en cadamuestra Para seguir con el ejemplo del libro la muestra muestraFilas = c(2 15 23) quehemos usado antes aparece en la fila nuacutemero 1823
3
Muestras[1823 ]
[1] 2 15 23
Recuerda que 2 15 23 corresponde a las tiradas (1 2) (3 3) y (4 5) respectivamente de los dosdados
Ahora una vez que tenemos la lista completa de muestras tenemos que calcular la media muestralpara cada una de ellas El resultado seraacute un vector mediasMuestrales de R que contendraacute 46656medias muestrales Para construir ese vector
Usaremos un bucle for (ver Tutorial05) para recorrer una a una las filas de Muestras
Para cada fila (esto es para cada muestra) calcularemos tres valores de X y a partir de ellosla media muestral X como hemos hecho en el ejemplo maacutes arriba
Y almacenaremos esa media en el vector mediasMuestrales
El codigo correspondiente es este (lee los comentarios)
mediasMuestrales = numeric(numMuestras)for(i in 1numMuestras)
Identificamos las 3 filas que se han elegido en esta muestramuestraFilas = Muestras[i ]
Recuperamos los resultados de las 3 tiradas de los dos dadosmuestra = dosDados[muestraFilas ]
Aqui calculamos 3 valores de XXenMuestra = rowSums(muestra)
A partir de ellos calculamos una media muestralmediaMuestral = mean(XenMuestra)
Y la guardamos en el vector de medias muestralesmediasMuestrales[i] = mediaMuestral
iexclY ya estaacute Ya tenemos las 46656 medias muestrales El comienzo del vector es
head(mediasMuestrales)
[1] 20000 23333 26667 30000 33333 36667
Y para la muestra que hemos usado de ejemplo
mediasMuestrales[1823]
[1] 6
como ya sabiacuteamos
Ejercicio 1 Esfueacuterzate en entender de doacutende provienen los primeros valores de la media muestralEs importante que entiendas el mecanismo de construccioacuten de las muestras para que el conceptode media muestral quede claro
11 Distribucioacuten de la media muestral X y de la variable original X
Ahora que tenemos todas las medias muestrales podemos estudiar coacutemo se distribuyen Es decirtenemos 46656 valores de X pero desde luego no son todos distintos Hay muchas muestras
4
distintas de tamantildeo 3 que producen el mismo valor de X Asiacute que lo que tenemos que hacer esesencialmente obtener la tabla de frecuencias de los valores de X (Tabla 62 del libro ver paacuteg200) y representar graacuteficamente el resultado (Figura 63(b) del libro paacuteg 202)
Pero antes vamos a detenernos a estudiar la distribucioacuten de la variable original X para podercompararlas despueacutes La tabla de frecuencias de X es muy faacutecil de obtener (ya la obtuvimos porotro meacutetodo al principio del Tutorial04) Recuerda que el valor de X se obtiene sumando las filasde dosDados
X = rowSums(dosDados)(tablaX = table(X))
X 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 5 4 3 2 1
Y su representacioacuten graacutefica es
barplot(tablaX)
2 3 4 5 6 7 8 9 10 11 12
01
23
45
6
La forma de la distribucioacuten es claramente triangular sin curvatura alguna El valor medio deX (media teoacuterica) es microX = 7 Podemos confirmar esto y ademaacutes calcular la varianza (teoacuterica opoblacional)
(muX = mean(X))
[1] 7
(sigma2_X = sum((X - muX)^2)length(X))
[1] 58333
Ahora vamos a hacer lo mismo para estudiar la distribucioacuten (la forma en que se distribuyen losvalores) de X La Tabla 62 del libro se obtiene con
5
(tablaMediaMuestralX = asmatrix(table(mediasMuestrales)))
[1] 2 1 233333333333333 6 266666666666667 21 3 56 333333333333333 126 366666666666667 252 4 456 433333333333333 756 466666666666667 1161 5 1666 533333333333333 2247 566666666666667 2856 6 3431 633333333333333 3906 666666666666667 4221 7 4332 733333333333333 4221 766666666666667 3906 8 3431 833333333333333 2856 866666666666667 2247 9 1666 933333333333333 1161 966666666666667 756 10 456 103333333333333 252 106666666666667 126 11 56 113333333333333 21 116666666666667 6 12 1
Esta es la tabla (o funcioacuten) de densidad de X La hemos convertido en una matriz porque lapresentacioacuten por defecto de la tabla que se obtiene de R no es gran cosa (hay libreriacuteas que seencargan de esto) Pero en cualquier caso puedes comprobar que los valores son los que aparecenen el libro Fiacutejate en que los valores de X avanzan de 13 en 13 (porque la muestra es de tamantildeo3 claro)
A partir de aquiacute la representacioacuten graacutefica es inmediata
barplot(table(mediasMuestrales))
2 3 4 5 6 7 8 9 11
020
00
La forma curvada aproximadamente normal de esta distribucioacuten se hace ahora evidente
6
Ejercicio 2 En este ejemplo hemos trabajado con muestras realmente pequentildeas en las que n = 3iquestQueacute modificaciones habriacutea que hacer en el coacutedigo para estudiar las muestras de tamantildeo 4 dela misma variable X iquestCuaacutentas muestras de tamantildeo n = 20 hay iquestQueacute crees que sucederiacutea sitratases de ejecutar el coacutedigo muestras de tamantildeo n = 20 iexclNo lo intentes R se bloquearaacute El mejorordenador en el que hemos probado esto a duras penas podiacutea con las muestras de tamantildeo n = 5Solucioacuten en la paacutegina 44
Media y desviacioacuten tiacutepica de X
Ahora una vez que hemos comprobado que la distribucioacuten de X es aproximadamente normalvamos a comprobar los resultados sobre su media microX y su varianza σ2
X Se trata en primer lugar
de calcular el valor medio de X cuando consideramos todas las 46656 muestras de tamantildeo 3posibles El resultado es el que la figura anterior anunciaba
(mu_barX = mean(mediasMuestrales))
[1] 7
En cuanto a la varianza (iexclpoblacional) se tiene
(sigma2_barX = sum((mediasMuestrales - mu_barX)^2) length(mediasMuestrales) )
[1] 19444
Pero lo realmente interesante es el cociente entre esta varianza de X y la varianza de X (ambaspoblacionales)
sigma2_X sigma2_barX
[1] 3
El resultado es 3 No aproximadamente 3 sino un 3 exacto igual al tamantildeo n de las muestras queestamos considerando Asiacute hemos confirmado la relacioacuten
σX =σXradicn
que aparece en la paacutegina 204 del libro
12 Otro ejemplo
Este resultado nos parece tan importante que vamos a incluir aquiacute un ejemplo adicional tal vezincluso maacutes espectacular que el anterior Lo que vamos a hacer es estudiar la distribucioacuten muestralde la media de una variable aleatoria distinta a la que vamos a llamar W La variable W toma losvalores del 1 al 20 todos con la misma probabilidad Por lo tanto su tabla (o funcioacuten) de densidades
Valor 1 2 middot middot middot 19 20
Probabilidad 120
120 middot middot middot 1
20120
Puedes pensar que la variable aleatoriaX describe el resultado de un experimento en el que elegimosun nuacutemero al azar del 1 al 20 de forma que todos los nuacutemeros sean equiprobables Graacuteficamentela forma de la distribucioacuten es plana horizontal a una altura constante (igual a 120)
W = 120table(W)20
7
W 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 005 005 005 005 005 005 005 005 005 005 005 005 005 005 005 16 17 18 19 20 005 005 005 005 005
barplot(table(W)20)
1 3 5 7 9 11 13 15 17 19
000
003
Ahora vamos a considerar muestras con reemplazamiento de X de tamantildeo n = 4 Es decir unamuestra consiste en elegir (iexclcon reemplazamiento) cuatro nuacutemeros del 1 al 20 y queremos pensaren el conjunto de todas las muestras de tamantildeo 4 posibles Vamos a proponer al lector que exploreeste conjunto mediante ejercicios
Ejercicio 3
1 iquestCuaacutentas muestras distintas de tamantildeo 4 existen
2 Construacuteyelas todas Imita lo que hemos hecho en el ejemplo de los dados y usa gtools paraobtener una matriz MuestrasW que contenga en cada fila una de las muestras
Soluciones en la paacutegina 45
iexclNo sigas si no has hecho este ejercicioUna vez construidas las muestras podemos calcular las medias muestrales de X En este caso lascosas son maacutes sencillas porque las 160000 medias muestrales se obtienen directamente usando lafuncioacuten rowMeans aplicada a la matriz MuestrasW
mediasMuestralesW = rowMeans(MuestrasW)length(mediasMuestralesW)
[1] 160000
Y ahora podemos hacer una tabla de frecuencia de las medias muestrales
(tablaMediaMuestralW = asmatrix(table(mediasMuestralesW)))
[1] 1 1 125 4 15 10 175 20 2 35 225 56
8
25 84 275 120 3 165 325 220 35 286 375 364 4 455 425 560 45 680 475 816 5 969 525 1140 55 1330 575 1540 6 1767 625 2008 65 2260 675 2520 7 2785 725 3052 75 3318 775 3580 8 3835 825 4080 85 4312 875 4528 9 4725 925 4900 95 5050 975 5172 10 5263 1025 5320 105 5340 1075 5320 11 5263 1125 5172 115 5050 1175 4900 12 4725 1225 4528 125 4312 1275 4080 13 3835 1325 3580 135 3318 1375 3052 14 2785 1425 2520 145 2260 1475 2008 15 1767 1525 1540 155 1330 1575 1140 16 969 1625 816 165 680 1675 560 17 455 1725 364 175 286 1775 220 18 165 1825 120 185 84 1875 56
9
19 35 1925 20 195 10 1975 4 20 1
y representar graacuteficamente la forma de la distribucioacuten
barplot(table(mediasMuestralesW))
1 25 4 55 7 85 105 1275 15 17 19
010
0030
0050
00
Como se ve obtenemos de nuevo una curva con la forma de campana caracteriacutestica de las curasnormales muy similar a la del ejemplo con dos dados Es muy importante que observes quelas dos variables que hemos usado como punto de partida son bastante distintas entre siacute y que eltamantildeo de muestra tampoco era el mismo Y sin embargo la distribucioacuten de la media muestrales en ambos casos aproximadamente normal
Ejercicio 4
1 Calcula la media microW y la varianza σ2W
2 Comprueba que se cumple la relacioacuten
σW =σWradicn
Soluciones en la paacutegina 45
2 Intervalos de confianza para la media con la distribucioacutennormal
En el Tutorial05 hemos aprendido a usar el ordenador para resolver problemas directos e inversosde probabilidad asociados con la normal estaacutendar Para refrescar esos problemas vamos a empezarcon un par de ejercicios
Ejercicio 5
10
1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

Muestras[1823 ]
[1] 2 15 23
Recuerda que 2 15 23 corresponde a las tiradas (1 2) (3 3) y (4 5) respectivamente de los dosdados
Ahora una vez que tenemos la lista completa de muestras tenemos que calcular la media muestralpara cada una de ellas El resultado seraacute un vector mediasMuestrales de R que contendraacute 46656medias muestrales Para construir ese vector
Usaremos un bucle for (ver Tutorial05) para recorrer una a una las filas de Muestras
Para cada fila (esto es para cada muestra) calcularemos tres valores de X y a partir de ellosla media muestral X como hemos hecho en el ejemplo maacutes arriba
Y almacenaremos esa media en el vector mediasMuestrales
El codigo correspondiente es este (lee los comentarios)
mediasMuestrales = numeric(numMuestras)for(i in 1numMuestras)
Identificamos las 3 filas que se han elegido en esta muestramuestraFilas = Muestras[i ]
Recuperamos los resultados de las 3 tiradas de los dos dadosmuestra = dosDados[muestraFilas ]
Aqui calculamos 3 valores de XXenMuestra = rowSums(muestra)
A partir de ellos calculamos una media muestralmediaMuestral = mean(XenMuestra)
Y la guardamos en el vector de medias muestralesmediasMuestrales[i] = mediaMuestral
iexclY ya estaacute Ya tenemos las 46656 medias muestrales El comienzo del vector es
head(mediasMuestrales)
[1] 20000 23333 26667 30000 33333 36667
Y para la muestra que hemos usado de ejemplo
mediasMuestrales[1823]
[1] 6
como ya sabiacuteamos
Ejercicio 1 Esfueacuterzate en entender de doacutende provienen los primeros valores de la media muestralEs importante que entiendas el mecanismo de construccioacuten de las muestras para que el conceptode media muestral quede claro
11 Distribucioacuten de la media muestral X y de la variable original X
Ahora que tenemos todas las medias muestrales podemos estudiar coacutemo se distribuyen Es decirtenemos 46656 valores de X pero desde luego no son todos distintos Hay muchas muestras
4
distintas de tamantildeo 3 que producen el mismo valor de X Asiacute que lo que tenemos que hacer esesencialmente obtener la tabla de frecuencias de los valores de X (Tabla 62 del libro ver paacuteg200) y representar graacuteficamente el resultado (Figura 63(b) del libro paacuteg 202)
Pero antes vamos a detenernos a estudiar la distribucioacuten de la variable original X para podercompararlas despueacutes La tabla de frecuencias de X es muy faacutecil de obtener (ya la obtuvimos porotro meacutetodo al principio del Tutorial04) Recuerda que el valor de X se obtiene sumando las filasde dosDados
X = rowSums(dosDados)(tablaX = table(X))
X 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 5 4 3 2 1
Y su representacioacuten graacutefica es
barplot(tablaX)
2 3 4 5 6 7 8 9 10 11 12
01
23
45
6
La forma de la distribucioacuten es claramente triangular sin curvatura alguna El valor medio deX (media teoacuterica) es microX = 7 Podemos confirmar esto y ademaacutes calcular la varianza (teoacuterica opoblacional)
(muX = mean(X))
[1] 7
(sigma2_X = sum((X - muX)^2)length(X))
[1] 58333
Ahora vamos a hacer lo mismo para estudiar la distribucioacuten (la forma en que se distribuyen losvalores) de X La Tabla 62 del libro se obtiene con
5
(tablaMediaMuestralX = asmatrix(table(mediasMuestrales)))
[1] 2 1 233333333333333 6 266666666666667 21 3 56 333333333333333 126 366666666666667 252 4 456 433333333333333 756 466666666666667 1161 5 1666 533333333333333 2247 566666666666667 2856 6 3431 633333333333333 3906 666666666666667 4221 7 4332 733333333333333 4221 766666666666667 3906 8 3431 833333333333333 2856 866666666666667 2247 9 1666 933333333333333 1161 966666666666667 756 10 456 103333333333333 252 106666666666667 126 11 56 113333333333333 21 116666666666667 6 12 1
Esta es la tabla (o funcioacuten) de densidad de X La hemos convertido en una matriz porque lapresentacioacuten por defecto de la tabla que se obtiene de R no es gran cosa (hay libreriacuteas que seencargan de esto) Pero en cualquier caso puedes comprobar que los valores son los que aparecenen el libro Fiacutejate en que los valores de X avanzan de 13 en 13 (porque la muestra es de tamantildeo3 claro)
A partir de aquiacute la representacioacuten graacutefica es inmediata
barplot(table(mediasMuestrales))
2 3 4 5 6 7 8 9 11
020
00
La forma curvada aproximadamente normal de esta distribucioacuten se hace ahora evidente
6
Ejercicio 2 En este ejemplo hemos trabajado con muestras realmente pequentildeas en las que n = 3iquestQueacute modificaciones habriacutea que hacer en el coacutedigo para estudiar las muestras de tamantildeo 4 dela misma variable X iquestCuaacutentas muestras de tamantildeo n = 20 hay iquestQueacute crees que sucederiacutea sitratases de ejecutar el coacutedigo muestras de tamantildeo n = 20 iexclNo lo intentes R se bloquearaacute El mejorordenador en el que hemos probado esto a duras penas podiacutea con las muestras de tamantildeo n = 5Solucioacuten en la paacutegina 44
Media y desviacioacuten tiacutepica de X
Ahora una vez que hemos comprobado que la distribucioacuten de X es aproximadamente normalvamos a comprobar los resultados sobre su media microX y su varianza σ2
X Se trata en primer lugar
de calcular el valor medio de X cuando consideramos todas las 46656 muestras de tamantildeo 3posibles El resultado es el que la figura anterior anunciaba
(mu_barX = mean(mediasMuestrales))
[1] 7
En cuanto a la varianza (iexclpoblacional) se tiene
(sigma2_barX = sum((mediasMuestrales - mu_barX)^2) length(mediasMuestrales) )
[1] 19444
Pero lo realmente interesante es el cociente entre esta varianza de X y la varianza de X (ambaspoblacionales)
sigma2_X sigma2_barX
[1] 3
El resultado es 3 No aproximadamente 3 sino un 3 exacto igual al tamantildeo n de las muestras queestamos considerando Asiacute hemos confirmado la relacioacuten
σX =σXradicn
que aparece en la paacutegina 204 del libro
12 Otro ejemplo
Este resultado nos parece tan importante que vamos a incluir aquiacute un ejemplo adicional tal vezincluso maacutes espectacular que el anterior Lo que vamos a hacer es estudiar la distribucioacuten muestralde la media de una variable aleatoria distinta a la que vamos a llamar W La variable W toma losvalores del 1 al 20 todos con la misma probabilidad Por lo tanto su tabla (o funcioacuten) de densidades
Valor 1 2 middot middot middot 19 20
Probabilidad 120
120 middot middot middot 1
20120
Puedes pensar que la variable aleatoriaX describe el resultado de un experimento en el que elegimosun nuacutemero al azar del 1 al 20 de forma que todos los nuacutemeros sean equiprobables Graacuteficamentela forma de la distribucioacuten es plana horizontal a una altura constante (igual a 120)
W = 120table(W)20
7
W 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 005 005 005 005 005 005 005 005 005 005 005 005 005 005 005 16 17 18 19 20 005 005 005 005 005
barplot(table(W)20)
1 3 5 7 9 11 13 15 17 19
000
003
Ahora vamos a considerar muestras con reemplazamiento de X de tamantildeo n = 4 Es decir unamuestra consiste en elegir (iexclcon reemplazamiento) cuatro nuacutemeros del 1 al 20 y queremos pensaren el conjunto de todas las muestras de tamantildeo 4 posibles Vamos a proponer al lector que exploreeste conjunto mediante ejercicios
Ejercicio 3
1 iquestCuaacutentas muestras distintas de tamantildeo 4 existen
2 Construacuteyelas todas Imita lo que hemos hecho en el ejemplo de los dados y usa gtools paraobtener una matriz MuestrasW que contenga en cada fila una de las muestras
Soluciones en la paacutegina 45
iexclNo sigas si no has hecho este ejercicioUna vez construidas las muestras podemos calcular las medias muestrales de X En este caso lascosas son maacutes sencillas porque las 160000 medias muestrales se obtienen directamente usando lafuncioacuten rowMeans aplicada a la matriz MuestrasW
mediasMuestralesW = rowMeans(MuestrasW)length(mediasMuestralesW)
[1] 160000
Y ahora podemos hacer una tabla de frecuencia de las medias muestrales
(tablaMediaMuestralW = asmatrix(table(mediasMuestralesW)))
[1] 1 1 125 4 15 10 175 20 2 35 225 56
8
25 84 275 120 3 165 325 220 35 286 375 364 4 455 425 560 45 680 475 816 5 969 525 1140 55 1330 575 1540 6 1767 625 2008 65 2260 675 2520 7 2785 725 3052 75 3318 775 3580 8 3835 825 4080 85 4312 875 4528 9 4725 925 4900 95 5050 975 5172 10 5263 1025 5320 105 5340 1075 5320 11 5263 1125 5172 115 5050 1175 4900 12 4725 1225 4528 125 4312 1275 4080 13 3835 1325 3580 135 3318 1375 3052 14 2785 1425 2520 145 2260 1475 2008 15 1767 1525 1540 155 1330 1575 1140 16 969 1625 816 165 680 1675 560 17 455 1725 364 175 286 1775 220 18 165 1825 120 185 84 1875 56
9
19 35 1925 20 195 10 1975 4 20 1
y representar graacuteficamente la forma de la distribucioacuten
barplot(table(mediasMuestralesW))
1 25 4 55 7 85 105 1275 15 17 19
010
0030
0050
00
Como se ve obtenemos de nuevo una curva con la forma de campana caracteriacutestica de las curasnormales muy similar a la del ejemplo con dos dados Es muy importante que observes quelas dos variables que hemos usado como punto de partida son bastante distintas entre siacute y que eltamantildeo de muestra tampoco era el mismo Y sin embargo la distribucioacuten de la media muestrales en ambos casos aproximadamente normal
Ejercicio 4
1 Calcula la media microW y la varianza σ2W
2 Comprueba que se cumple la relacioacuten
σW =σWradicn
Soluciones en la paacutegina 45
2 Intervalos de confianza para la media con la distribucioacutennormal
En el Tutorial05 hemos aprendido a usar el ordenador para resolver problemas directos e inversosde probabilidad asociados con la normal estaacutendar Para refrescar esos problemas vamos a empezarcon un par de ejercicios
Ejercicio 5
10
1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

distintas de tamantildeo 3 que producen el mismo valor de X Asiacute que lo que tenemos que hacer esesencialmente obtener la tabla de frecuencias de los valores de X (Tabla 62 del libro ver paacuteg200) y representar graacuteficamente el resultado (Figura 63(b) del libro paacuteg 202)
Pero antes vamos a detenernos a estudiar la distribucioacuten de la variable original X para podercompararlas despueacutes La tabla de frecuencias de X es muy faacutecil de obtener (ya la obtuvimos porotro meacutetodo al principio del Tutorial04) Recuerda que el valor de X se obtiene sumando las filasde dosDados
X = rowSums(dosDados)(tablaX = table(X))
X 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 5 4 3 2 1
Y su representacioacuten graacutefica es
barplot(tablaX)
2 3 4 5 6 7 8 9 10 11 12
01
23
45
6
La forma de la distribucioacuten es claramente triangular sin curvatura alguna El valor medio deX (media teoacuterica) es microX = 7 Podemos confirmar esto y ademaacutes calcular la varianza (teoacuterica opoblacional)
(muX = mean(X))
[1] 7
(sigma2_X = sum((X - muX)^2)length(X))
[1] 58333
Ahora vamos a hacer lo mismo para estudiar la distribucioacuten (la forma en que se distribuyen losvalores) de X La Tabla 62 del libro se obtiene con
5
(tablaMediaMuestralX = asmatrix(table(mediasMuestrales)))
[1] 2 1 233333333333333 6 266666666666667 21 3 56 333333333333333 126 366666666666667 252 4 456 433333333333333 756 466666666666667 1161 5 1666 533333333333333 2247 566666666666667 2856 6 3431 633333333333333 3906 666666666666667 4221 7 4332 733333333333333 4221 766666666666667 3906 8 3431 833333333333333 2856 866666666666667 2247 9 1666 933333333333333 1161 966666666666667 756 10 456 103333333333333 252 106666666666667 126 11 56 113333333333333 21 116666666666667 6 12 1
Esta es la tabla (o funcioacuten) de densidad de X La hemos convertido en una matriz porque lapresentacioacuten por defecto de la tabla que se obtiene de R no es gran cosa (hay libreriacuteas que seencargan de esto) Pero en cualquier caso puedes comprobar que los valores son los que aparecenen el libro Fiacutejate en que los valores de X avanzan de 13 en 13 (porque la muestra es de tamantildeo3 claro)
A partir de aquiacute la representacioacuten graacutefica es inmediata
barplot(table(mediasMuestrales))
2 3 4 5 6 7 8 9 11
020
00
La forma curvada aproximadamente normal de esta distribucioacuten se hace ahora evidente
6
Ejercicio 2 En este ejemplo hemos trabajado con muestras realmente pequentildeas en las que n = 3iquestQueacute modificaciones habriacutea que hacer en el coacutedigo para estudiar las muestras de tamantildeo 4 dela misma variable X iquestCuaacutentas muestras de tamantildeo n = 20 hay iquestQueacute crees que sucederiacutea sitratases de ejecutar el coacutedigo muestras de tamantildeo n = 20 iexclNo lo intentes R se bloquearaacute El mejorordenador en el que hemos probado esto a duras penas podiacutea con las muestras de tamantildeo n = 5Solucioacuten en la paacutegina 44
Media y desviacioacuten tiacutepica de X
Ahora una vez que hemos comprobado que la distribucioacuten de X es aproximadamente normalvamos a comprobar los resultados sobre su media microX y su varianza σ2
X Se trata en primer lugar
de calcular el valor medio de X cuando consideramos todas las 46656 muestras de tamantildeo 3posibles El resultado es el que la figura anterior anunciaba
(mu_barX = mean(mediasMuestrales))
[1] 7
En cuanto a la varianza (iexclpoblacional) se tiene
(sigma2_barX = sum((mediasMuestrales - mu_barX)^2) length(mediasMuestrales) )
[1] 19444
Pero lo realmente interesante es el cociente entre esta varianza de X y la varianza de X (ambaspoblacionales)
sigma2_X sigma2_barX
[1] 3
El resultado es 3 No aproximadamente 3 sino un 3 exacto igual al tamantildeo n de las muestras queestamos considerando Asiacute hemos confirmado la relacioacuten
σX =σXradicn
que aparece en la paacutegina 204 del libro
12 Otro ejemplo
Este resultado nos parece tan importante que vamos a incluir aquiacute un ejemplo adicional tal vezincluso maacutes espectacular que el anterior Lo que vamos a hacer es estudiar la distribucioacuten muestralde la media de una variable aleatoria distinta a la que vamos a llamar W La variable W toma losvalores del 1 al 20 todos con la misma probabilidad Por lo tanto su tabla (o funcioacuten) de densidades
Valor 1 2 middot middot middot 19 20
Probabilidad 120
120 middot middot middot 1
20120
Puedes pensar que la variable aleatoriaX describe el resultado de un experimento en el que elegimosun nuacutemero al azar del 1 al 20 de forma que todos los nuacutemeros sean equiprobables Graacuteficamentela forma de la distribucioacuten es plana horizontal a una altura constante (igual a 120)
W = 120table(W)20
7
W 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 005 005 005 005 005 005 005 005 005 005 005 005 005 005 005 16 17 18 19 20 005 005 005 005 005
barplot(table(W)20)
1 3 5 7 9 11 13 15 17 19
000
003
Ahora vamos a considerar muestras con reemplazamiento de X de tamantildeo n = 4 Es decir unamuestra consiste en elegir (iexclcon reemplazamiento) cuatro nuacutemeros del 1 al 20 y queremos pensaren el conjunto de todas las muestras de tamantildeo 4 posibles Vamos a proponer al lector que exploreeste conjunto mediante ejercicios
Ejercicio 3
1 iquestCuaacutentas muestras distintas de tamantildeo 4 existen
2 Construacuteyelas todas Imita lo que hemos hecho en el ejemplo de los dados y usa gtools paraobtener una matriz MuestrasW que contenga en cada fila una de las muestras
Soluciones en la paacutegina 45
iexclNo sigas si no has hecho este ejercicioUna vez construidas las muestras podemos calcular las medias muestrales de X En este caso lascosas son maacutes sencillas porque las 160000 medias muestrales se obtienen directamente usando lafuncioacuten rowMeans aplicada a la matriz MuestrasW
mediasMuestralesW = rowMeans(MuestrasW)length(mediasMuestralesW)
[1] 160000
Y ahora podemos hacer una tabla de frecuencia de las medias muestrales
(tablaMediaMuestralW = asmatrix(table(mediasMuestralesW)))
[1] 1 1 125 4 15 10 175 20 2 35 225 56
8
25 84 275 120 3 165 325 220 35 286 375 364 4 455 425 560 45 680 475 816 5 969 525 1140 55 1330 575 1540 6 1767 625 2008 65 2260 675 2520 7 2785 725 3052 75 3318 775 3580 8 3835 825 4080 85 4312 875 4528 9 4725 925 4900 95 5050 975 5172 10 5263 1025 5320 105 5340 1075 5320 11 5263 1125 5172 115 5050 1175 4900 12 4725 1225 4528 125 4312 1275 4080 13 3835 1325 3580 135 3318 1375 3052 14 2785 1425 2520 145 2260 1475 2008 15 1767 1525 1540 155 1330 1575 1140 16 969 1625 816 165 680 1675 560 17 455 1725 364 175 286 1775 220 18 165 1825 120 185 84 1875 56
9
19 35 1925 20 195 10 1975 4 20 1
y representar graacuteficamente la forma de la distribucioacuten
barplot(table(mediasMuestralesW))
1 25 4 55 7 85 105 1275 15 17 19
010
0030
0050
00
Como se ve obtenemos de nuevo una curva con la forma de campana caracteriacutestica de las curasnormales muy similar a la del ejemplo con dos dados Es muy importante que observes quelas dos variables que hemos usado como punto de partida son bastante distintas entre siacute y que eltamantildeo de muestra tampoco era el mismo Y sin embargo la distribucioacuten de la media muestrales en ambos casos aproximadamente normal
Ejercicio 4
1 Calcula la media microW y la varianza σ2W
2 Comprueba que se cumple la relacioacuten
σW =σWradicn
Soluciones en la paacutegina 45
2 Intervalos de confianza para la media con la distribucioacutennormal
En el Tutorial05 hemos aprendido a usar el ordenador para resolver problemas directos e inversosde probabilidad asociados con la normal estaacutendar Para refrescar esos problemas vamos a empezarcon un par de ejercicios
Ejercicio 5
10
1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

(tablaMediaMuestralX = asmatrix(table(mediasMuestrales)))
[1] 2 1 233333333333333 6 266666666666667 21 3 56 333333333333333 126 366666666666667 252 4 456 433333333333333 756 466666666666667 1161 5 1666 533333333333333 2247 566666666666667 2856 6 3431 633333333333333 3906 666666666666667 4221 7 4332 733333333333333 4221 766666666666667 3906 8 3431 833333333333333 2856 866666666666667 2247 9 1666 933333333333333 1161 966666666666667 756 10 456 103333333333333 252 106666666666667 126 11 56 113333333333333 21 116666666666667 6 12 1
Esta es la tabla (o funcioacuten) de densidad de X La hemos convertido en una matriz porque lapresentacioacuten por defecto de la tabla que se obtiene de R no es gran cosa (hay libreriacuteas que seencargan de esto) Pero en cualquier caso puedes comprobar que los valores son los que aparecenen el libro Fiacutejate en que los valores de X avanzan de 13 en 13 (porque la muestra es de tamantildeo3 claro)
A partir de aquiacute la representacioacuten graacutefica es inmediata
barplot(table(mediasMuestrales))
2 3 4 5 6 7 8 9 11
020
00
La forma curvada aproximadamente normal de esta distribucioacuten se hace ahora evidente
6
Ejercicio 2 En este ejemplo hemos trabajado con muestras realmente pequentildeas en las que n = 3iquestQueacute modificaciones habriacutea que hacer en el coacutedigo para estudiar las muestras de tamantildeo 4 dela misma variable X iquestCuaacutentas muestras de tamantildeo n = 20 hay iquestQueacute crees que sucederiacutea sitratases de ejecutar el coacutedigo muestras de tamantildeo n = 20 iexclNo lo intentes R se bloquearaacute El mejorordenador en el que hemos probado esto a duras penas podiacutea con las muestras de tamantildeo n = 5Solucioacuten en la paacutegina 44
Media y desviacioacuten tiacutepica de X
Ahora una vez que hemos comprobado que la distribucioacuten de X es aproximadamente normalvamos a comprobar los resultados sobre su media microX y su varianza σ2
X Se trata en primer lugar
de calcular el valor medio de X cuando consideramos todas las 46656 muestras de tamantildeo 3posibles El resultado es el que la figura anterior anunciaba
(mu_barX = mean(mediasMuestrales))
[1] 7
En cuanto a la varianza (iexclpoblacional) se tiene
(sigma2_barX = sum((mediasMuestrales - mu_barX)^2) length(mediasMuestrales) )
[1] 19444
Pero lo realmente interesante es el cociente entre esta varianza de X y la varianza de X (ambaspoblacionales)
sigma2_X sigma2_barX
[1] 3
El resultado es 3 No aproximadamente 3 sino un 3 exacto igual al tamantildeo n de las muestras queestamos considerando Asiacute hemos confirmado la relacioacuten
σX =σXradicn
que aparece en la paacutegina 204 del libro
12 Otro ejemplo
Este resultado nos parece tan importante que vamos a incluir aquiacute un ejemplo adicional tal vezincluso maacutes espectacular que el anterior Lo que vamos a hacer es estudiar la distribucioacuten muestralde la media de una variable aleatoria distinta a la que vamos a llamar W La variable W toma losvalores del 1 al 20 todos con la misma probabilidad Por lo tanto su tabla (o funcioacuten) de densidades
Valor 1 2 middot middot middot 19 20
Probabilidad 120
120 middot middot middot 1
20120
Puedes pensar que la variable aleatoriaX describe el resultado de un experimento en el que elegimosun nuacutemero al azar del 1 al 20 de forma que todos los nuacutemeros sean equiprobables Graacuteficamentela forma de la distribucioacuten es plana horizontal a una altura constante (igual a 120)
W = 120table(W)20
7
W 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 005 005 005 005 005 005 005 005 005 005 005 005 005 005 005 16 17 18 19 20 005 005 005 005 005
barplot(table(W)20)
1 3 5 7 9 11 13 15 17 19
000
003
Ahora vamos a considerar muestras con reemplazamiento de X de tamantildeo n = 4 Es decir unamuestra consiste en elegir (iexclcon reemplazamiento) cuatro nuacutemeros del 1 al 20 y queremos pensaren el conjunto de todas las muestras de tamantildeo 4 posibles Vamos a proponer al lector que exploreeste conjunto mediante ejercicios
Ejercicio 3
1 iquestCuaacutentas muestras distintas de tamantildeo 4 existen
2 Construacuteyelas todas Imita lo que hemos hecho en el ejemplo de los dados y usa gtools paraobtener una matriz MuestrasW que contenga en cada fila una de las muestras
Soluciones en la paacutegina 45
iexclNo sigas si no has hecho este ejercicioUna vez construidas las muestras podemos calcular las medias muestrales de X En este caso lascosas son maacutes sencillas porque las 160000 medias muestrales se obtienen directamente usando lafuncioacuten rowMeans aplicada a la matriz MuestrasW
mediasMuestralesW = rowMeans(MuestrasW)length(mediasMuestralesW)
[1] 160000
Y ahora podemos hacer una tabla de frecuencia de las medias muestrales
(tablaMediaMuestralW = asmatrix(table(mediasMuestralesW)))
[1] 1 1 125 4 15 10 175 20 2 35 225 56
8
25 84 275 120 3 165 325 220 35 286 375 364 4 455 425 560 45 680 475 816 5 969 525 1140 55 1330 575 1540 6 1767 625 2008 65 2260 675 2520 7 2785 725 3052 75 3318 775 3580 8 3835 825 4080 85 4312 875 4528 9 4725 925 4900 95 5050 975 5172 10 5263 1025 5320 105 5340 1075 5320 11 5263 1125 5172 115 5050 1175 4900 12 4725 1225 4528 125 4312 1275 4080 13 3835 1325 3580 135 3318 1375 3052 14 2785 1425 2520 145 2260 1475 2008 15 1767 1525 1540 155 1330 1575 1140 16 969 1625 816 165 680 1675 560 17 455 1725 364 175 286 1775 220 18 165 1825 120 185 84 1875 56
9
19 35 1925 20 195 10 1975 4 20 1
y representar graacuteficamente la forma de la distribucioacuten
barplot(table(mediasMuestralesW))
1 25 4 55 7 85 105 1275 15 17 19
010
0030
0050
00
Como se ve obtenemos de nuevo una curva con la forma de campana caracteriacutestica de las curasnormales muy similar a la del ejemplo con dos dados Es muy importante que observes quelas dos variables que hemos usado como punto de partida son bastante distintas entre siacute y que eltamantildeo de muestra tampoco era el mismo Y sin embargo la distribucioacuten de la media muestrales en ambos casos aproximadamente normal
Ejercicio 4
1 Calcula la media microW y la varianza σ2W
2 Comprueba que se cumple la relacioacuten
σW =σWradicn
Soluciones en la paacutegina 45
2 Intervalos de confianza para la media con la distribucioacutennormal
En el Tutorial05 hemos aprendido a usar el ordenador para resolver problemas directos e inversosde probabilidad asociados con la normal estaacutendar Para refrescar esos problemas vamos a empezarcon un par de ejercicios
Ejercicio 5
10
1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

Ejercicio 2 En este ejemplo hemos trabajado con muestras realmente pequentildeas en las que n = 3iquestQueacute modificaciones habriacutea que hacer en el coacutedigo para estudiar las muestras de tamantildeo 4 dela misma variable X iquestCuaacutentas muestras de tamantildeo n = 20 hay iquestQueacute crees que sucederiacutea sitratases de ejecutar el coacutedigo muestras de tamantildeo n = 20 iexclNo lo intentes R se bloquearaacute El mejorordenador en el que hemos probado esto a duras penas podiacutea con las muestras de tamantildeo n = 5Solucioacuten en la paacutegina 44
Media y desviacioacuten tiacutepica de X
Ahora una vez que hemos comprobado que la distribucioacuten de X es aproximadamente normalvamos a comprobar los resultados sobre su media microX y su varianza σ2
X Se trata en primer lugar
de calcular el valor medio de X cuando consideramos todas las 46656 muestras de tamantildeo 3posibles El resultado es el que la figura anterior anunciaba
(mu_barX = mean(mediasMuestrales))
[1] 7
En cuanto a la varianza (iexclpoblacional) se tiene
(sigma2_barX = sum((mediasMuestrales - mu_barX)^2) length(mediasMuestrales) )
[1] 19444
Pero lo realmente interesante es el cociente entre esta varianza de X y la varianza de X (ambaspoblacionales)
sigma2_X sigma2_barX
[1] 3
El resultado es 3 No aproximadamente 3 sino un 3 exacto igual al tamantildeo n de las muestras queestamos considerando Asiacute hemos confirmado la relacioacuten
σX =σXradicn
que aparece en la paacutegina 204 del libro
12 Otro ejemplo
Este resultado nos parece tan importante que vamos a incluir aquiacute un ejemplo adicional tal vezincluso maacutes espectacular que el anterior Lo que vamos a hacer es estudiar la distribucioacuten muestralde la media de una variable aleatoria distinta a la que vamos a llamar W La variable W toma losvalores del 1 al 20 todos con la misma probabilidad Por lo tanto su tabla (o funcioacuten) de densidades
Valor 1 2 middot middot middot 19 20
Probabilidad 120
120 middot middot middot 1
20120
Puedes pensar que la variable aleatoriaX describe el resultado de un experimento en el que elegimosun nuacutemero al azar del 1 al 20 de forma que todos los nuacutemeros sean equiprobables Graacuteficamentela forma de la distribucioacuten es plana horizontal a una altura constante (igual a 120)
W = 120table(W)20
7
W 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 005 005 005 005 005 005 005 005 005 005 005 005 005 005 005 16 17 18 19 20 005 005 005 005 005
barplot(table(W)20)
1 3 5 7 9 11 13 15 17 19
000
003
Ahora vamos a considerar muestras con reemplazamiento de X de tamantildeo n = 4 Es decir unamuestra consiste en elegir (iexclcon reemplazamiento) cuatro nuacutemeros del 1 al 20 y queremos pensaren el conjunto de todas las muestras de tamantildeo 4 posibles Vamos a proponer al lector que exploreeste conjunto mediante ejercicios
Ejercicio 3
1 iquestCuaacutentas muestras distintas de tamantildeo 4 existen
2 Construacuteyelas todas Imita lo que hemos hecho en el ejemplo de los dados y usa gtools paraobtener una matriz MuestrasW que contenga en cada fila una de las muestras
Soluciones en la paacutegina 45
iexclNo sigas si no has hecho este ejercicioUna vez construidas las muestras podemos calcular las medias muestrales de X En este caso lascosas son maacutes sencillas porque las 160000 medias muestrales se obtienen directamente usando lafuncioacuten rowMeans aplicada a la matriz MuestrasW
mediasMuestralesW = rowMeans(MuestrasW)length(mediasMuestralesW)
[1] 160000
Y ahora podemos hacer una tabla de frecuencia de las medias muestrales
(tablaMediaMuestralW = asmatrix(table(mediasMuestralesW)))
[1] 1 1 125 4 15 10 175 20 2 35 225 56
8
25 84 275 120 3 165 325 220 35 286 375 364 4 455 425 560 45 680 475 816 5 969 525 1140 55 1330 575 1540 6 1767 625 2008 65 2260 675 2520 7 2785 725 3052 75 3318 775 3580 8 3835 825 4080 85 4312 875 4528 9 4725 925 4900 95 5050 975 5172 10 5263 1025 5320 105 5340 1075 5320 11 5263 1125 5172 115 5050 1175 4900 12 4725 1225 4528 125 4312 1275 4080 13 3835 1325 3580 135 3318 1375 3052 14 2785 1425 2520 145 2260 1475 2008 15 1767 1525 1540 155 1330 1575 1140 16 969 1625 816 165 680 1675 560 17 455 1725 364 175 286 1775 220 18 165 1825 120 185 84 1875 56
9
19 35 1925 20 195 10 1975 4 20 1
y representar graacuteficamente la forma de la distribucioacuten
barplot(table(mediasMuestralesW))
1 25 4 55 7 85 105 1275 15 17 19
010
0030
0050
00
Como se ve obtenemos de nuevo una curva con la forma de campana caracteriacutestica de las curasnormales muy similar a la del ejemplo con dos dados Es muy importante que observes quelas dos variables que hemos usado como punto de partida son bastante distintas entre siacute y que eltamantildeo de muestra tampoco era el mismo Y sin embargo la distribucioacuten de la media muestrales en ambos casos aproximadamente normal
Ejercicio 4
1 Calcula la media microW y la varianza σ2W
2 Comprueba que se cumple la relacioacuten
σW =σWradicn
Soluciones en la paacutegina 45
2 Intervalos de confianza para la media con la distribucioacutennormal
En el Tutorial05 hemos aprendido a usar el ordenador para resolver problemas directos e inversosde probabilidad asociados con la normal estaacutendar Para refrescar esos problemas vamos a empezarcon un par de ejercicios
Ejercicio 5
10
1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

W 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 005 005 005 005 005 005 005 005 005 005 005 005 005 005 005 16 17 18 19 20 005 005 005 005 005
barplot(table(W)20)
1 3 5 7 9 11 13 15 17 19
000
003
Ahora vamos a considerar muestras con reemplazamiento de X de tamantildeo n = 4 Es decir unamuestra consiste en elegir (iexclcon reemplazamiento) cuatro nuacutemeros del 1 al 20 y queremos pensaren el conjunto de todas las muestras de tamantildeo 4 posibles Vamos a proponer al lector que exploreeste conjunto mediante ejercicios
Ejercicio 3
1 iquestCuaacutentas muestras distintas de tamantildeo 4 existen
2 Construacuteyelas todas Imita lo que hemos hecho en el ejemplo de los dados y usa gtools paraobtener una matriz MuestrasW que contenga en cada fila una de las muestras
Soluciones en la paacutegina 45
iexclNo sigas si no has hecho este ejercicioUna vez construidas las muestras podemos calcular las medias muestrales de X En este caso lascosas son maacutes sencillas porque las 160000 medias muestrales se obtienen directamente usando lafuncioacuten rowMeans aplicada a la matriz MuestrasW
mediasMuestralesW = rowMeans(MuestrasW)length(mediasMuestralesW)
[1] 160000
Y ahora podemos hacer una tabla de frecuencia de las medias muestrales
(tablaMediaMuestralW = asmatrix(table(mediasMuestralesW)))
[1] 1 1 125 4 15 10 175 20 2 35 225 56
8
25 84 275 120 3 165 325 220 35 286 375 364 4 455 425 560 45 680 475 816 5 969 525 1140 55 1330 575 1540 6 1767 625 2008 65 2260 675 2520 7 2785 725 3052 75 3318 775 3580 8 3835 825 4080 85 4312 875 4528 9 4725 925 4900 95 5050 975 5172 10 5263 1025 5320 105 5340 1075 5320 11 5263 1125 5172 115 5050 1175 4900 12 4725 1225 4528 125 4312 1275 4080 13 3835 1325 3580 135 3318 1375 3052 14 2785 1425 2520 145 2260 1475 2008 15 1767 1525 1540 155 1330 1575 1140 16 969 1625 816 165 680 1675 560 17 455 1725 364 175 286 1775 220 18 165 1825 120 185 84 1875 56
9
19 35 1925 20 195 10 1975 4 20 1
y representar graacuteficamente la forma de la distribucioacuten
barplot(table(mediasMuestralesW))
1 25 4 55 7 85 105 1275 15 17 19
010
0030
0050
00
Como se ve obtenemos de nuevo una curva con la forma de campana caracteriacutestica de las curasnormales muy similar a la del ejemplo con dos dados Es muy importante que observes quelas dos variables que hemos usado como punto de partida son bastante distintas entre siacute y que eltamantildeo de muestra tampoco era el mismo Y sin embargo la distribucioacuten de la media muestrales en ambos casos aproximadamente normal
Ejercicio 4
1 Calcula la media microW y la varianza σ2W
2 Comprueba que se cumple la relacioacuten
σW =σWradicn
Soluciones en la paacutegina 45
2 Intervalos de confianza para la media con la distribucioacutennormal
En el Tutorial05 hemos aprendido a usar el ordenador para resolver problemas directos e inversosde probabilidad asociados con la normal estaacutendar Para refrescar esos problemas vamos a empezarcon un par de ejercicios
Ejercicio 5
10
1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

25 84 275 120 3 165 325 220 35 286 375 364 4 455 425 560 45 680 475 816 5 969 525 1140 55 1330 575 1540 6 1767 625 2008 65 2260 675 2520 7 2785 725 3052 75 3318 775 3580 8 3835 825 4080 85 4312 875 4528 9 4725 925 4900 95 5050 975 5172 10 5263 1025 5320 105 5340 1075 5320 11 5263 1125 5172 115 5050 1175 4900 12 4725 1225 4528 125 4312 1275 4080 13 3835 1325 3580 135 3318 1375 3052 14 2785 1425 2520 145 2260 1475 2008 15 1767 1525 1540 155 1330 1575 1140 16 969 1625 816 165 680 1675 560 17 455 1725 364 175 286 1775 220 18 165 1825 120 185 84 1875 56
9
19 35 1925 20 195 10 1975 4 20 1
y representar graacuteficamente la forma de la distribucioacuten
barplot(table(mediasMuestralesW))
1 25 4 55 7 85 105 1275 15 17 19
010
0030
0050
00
Como se ve obtenemos de nuevo una curva con la forma de campana caracteriacutestica de las curasnormales muy similar a la del ejemplo con dos dados Es muy importante que observes quelas dos variables que hemos usado como punto de partida son bastante distintas entre siacute y que eltamantildeo de muestra tampoco era el mismo Y sin embargo la distribucioacuten de la media muestrales en ambos casos aproximadamente normal
Ejercicio 4
1 Calcula la media microW y la varianza σ2W
2 Comprueba que se cumple la relacioacuten
σW =σWradicn
Soluciones en la paacutegina 45
2 Intervalos de confianza para la media con la distribucioacutennormal
En el Tutorial05 hemos aprendido a usar el ordenador para resolver problemas directos e inversosde probabilidad asociados con la normal estaacutendar Para refrescar esos problemas vamos a empezarcon un par de ejercicios
Ejercicio 5
10
1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

19 35 1925 20 195 10 1975 4 20 1
y representar graacuteficamente la forma de la distribucioacuten
barplot(table(mediasMuestralesW))
1 25 4 55 7 85 105 1275 15 17 19
010
0030
0050
00
Como se ve obtenemos de nuevo una curva con la forma de campana caracteriacutestica de las curasnormales muy similar a la del ejemplo con dos dados Es muy importante que observes quelas dos variables que hemos usado como punto de partida son bastante distintas entre siacute y que eltamantildeo de muestra tampoco era el mismo Y sin embargo la distribucioacuten de la media muestrales en ambos casos aproximadamente normal
Ejercicio 4
1 Calcula la media microW y la varianza σ2W
2 Comprueba que se cumple la relacioacuten
σW =σWradicn
Soluciones en la paacutegina 45
2 Intervalos de confianza para la media con la distribucioacutennormal
En el Tutorial05 hemos aprendido a usar el ordenador para resolver problemas directos e inversosde probabilidad asociados con la normal estaacutendar Para refrescar esos problemas vamos a empezarcon un par de ejercicios
Ejercicio 5
10
1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

1 Usa R para calcular la probabilidad (recuerda que Z sim N(0 1))
P (minus2 lt Z lt 15)
que aparece en el Ejemplo 621 del libro (paacuteg 209)
2 Localiza el valor a para el que se cumple P (Z gt a) = 025 como en el Ejemplo 622 del libro(paacuteg 210)
Soluciones en la paacutegina 46
Volviendo al tema que nos ocupa en la Seccioacuten 62 del libro (paacuteg 206) hemos visto que con-cretamente los problemas inversos (de caacutelculo de cuantiles) son la clave para obtener los valorescriacuteticos necesarios para construir un intervalo de confianza Es decir que tenemos que ser capacesde encontrar el valor criacutetico zα2 que satisface (ver paacutegina 213 del libro)
F(zα2
)= P
(Z le zα2
)= 1minus α
2
Por tanto zα2 es el valor que deja una probabilidad α2 en la cola derecha de Z y una probabilidad1minus α2 en la cola izquierda
Concretando supongamos que queremos calcular un intervalo de confianza al (nivel de confianza)95 Entonces α = 1minus 095 = 005 O sea α2 = 0025 y por tanto 1minusα2 = 0975 La siguientefigura ilustra los pasos que hemos dado
Esta cuenta el hecho de que empezamos con 095 pero terminamos preguntando por el valor 0975es de las que inicialmente maacutes dificultades causan Con la praacutectica y dibujando siempre lo quequeremos las cosas iraacuten quedando maacutes y maacutes claras
Vamos a continuacioacuten a ver coacutemo calcular ese valor zα2 = z0025 y los correspondientes intervalosde confianza usando R y algunos otros programas Nuestra recomendacioacuten es que te acostumbresa usar R
21 Usando la funcioacuten qnorm de R
Para calcular el valor zα2 = z0025 en R basta con ejecutar el comando
qnorm(0975)
[1] 196
Pero esta forma de proceder tiene el inconveniente de que nos obliga a hacer nosotros mismos lacuenta desde el nivel de confianza nc = 095 hasta ese valor 1minusα2 = 0975 Si cambiamos el nivel
11
de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

de confianza a nc = 090 tenemos que repetir las cuentas y corremos el riesgo de equivocarnos enalguacuten paso Es mejor automatizar asiacute que haremos que R haga toda la cuenta por nosotros
nc=095(alfa=1-nc)
[1] 005
(alfa2=alfa2)
[1] 0025
(z_alfa2=qnorm(1-alfa2) )
[1] 196
Tambieacuten podriacuteas usar qnorm con la opcioacuten lowertail = FALSE Es en el fondo una cuestioacuten degustos
Usando este tipo de coacutedigo es muy faacutecil elaborar un fichero con todas las instrucciones necesariaspara automatizar casi por completo la tarea de calcular el intervalo de confianza Hay dos casosposibles que hemos visto en las Secciones 62 y 63 del libro
Cuando podemos suponer que X es normal y la varianza de la poblacioacuten es conocida lafoacutermula del intervalo es (Ecuacioacuten 610 paacuteg 216 del libro)
X minus zα2σXradicnle microX le X + zα2
σXradicn
Si la varianza de la poblacioacuten es desconocida pero el tamantildeo de la muestra es grande (eneste curso estamos usando n gt 30) entonces la foacutermula del intervalo es (Ecuacioacuten 614 paacuteg223 del libro)
X minus zα2sradicnle microX le X + zα2
sradicn
Las expresiones de ambos intervalos son muy parecidas simplemente hay que cambiar σ por s Asiacuteque teniendo siempre en cuenta las condiciones teoacutericas podemos usar el mismo coacutedigo Rpara ambos casos el coacutedigo es muy simple porque no hay que tomar decisiones introducimos losdatos del problema y calculamos por orden todos los ingredientes del intervalo
Pero todaviacutea debemos tener en cuenta otro detalle coacutemo recibimos los datos de la muestra Pode-mos haber recibido la muestra en bruto como un vector de datos (por ejemplo en un fichero detipo csv) o podemos tener directamente los valores X n s etc Esta uacuteltima situacioacuten es tiacutepicade los problemas de libro de texto mientras que la primera es una situacioacuten maacutes frecuente en losque llamaremos problemas del mundo real en los que los datos no vienen preparados
En consecuencia vamos a presentar dos ficheros ldquoplantillardquo uno para cada una de estas situacionesEl coacutedigo estaacute en los ficheros
y
que aparecen en las Tablas 1 y 2 respectivamente Eacutechales un vistazo antes de seguir leyendo
Cuando vayas a utilizar estos ficheros especialmente las primeras veces lee atentamente las ins-trucciones que aparecen en los comentarios En particular
Los ficheros no funcionaraacuten si no introduces toda la informacioacuten en las liacuteneas adecuadasde la primera parte del coacutedigo Para ayudarte a identificar donde termina la parte del ficheroen la que tienes que introducir esa informacioacuten hemos incluido un bloque comentado en elcoacutedigo con este aspecto
12
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

NO CAMBIES NADA DE AQUI PARA ABAJO
En el segundo de estos ficheros el que trabaja con datos en bruto existen a su vez dosposibilidades
bull Usar como punto de partida un vector de datos de R
bull Usar como punto de partida un fichero de datos por ejemplo de tipo csv
Para indicarle a R cuaacutel de esas dos posibilidades queremos utilizar es necesario comentar(usando ) la(s) liacutenea(s) que no vamos a usar e introducir la informacioacuten necesaria en lasliacuteneas de la opcioacuten que siacute usamos
En cualquier caso es esencial tener en cuenta las condiciones teoacutericas de aplicabilidadde estos ficheros Para empezar se supone que la poblacioacuten es normal Pero incluso asiacute sila muestra es pequentildea (pongamos n lt 30) y no conoces σ entonces no debes usar estosficheros
Para usar estos ficheros no utilices copiar y pegar a partir de este pdf Descarga los ficherosadjuntos en tu ordenador y aacutebrelos directamente con RStudio
Para que puedas practicar el funcionamiento de estos ficheros aquiacute tienes un ejercicio con unoscuantos apartados que cubren esencialmente todas las situaciones en las que te puedes encontrar
Ejercicio 6
1 Una muestra de n = 10 elementos de una poblacioacuten normal con desviacioacuten tiacutepica conocidaσ = 23 tiene media muestral X = 1325 Calcula intervalos de confianza al 90 95 y99 para la media micro iquestCoacutemo son las anchuras de esos intervalos
2 Una muestra de 10 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23y media muestral X = 1325 Calcula un intervalo de confianza al 95 para la media micro
3 Una muestra de n = 450 elementos de una poblacioacuten normal tiene cuasidesviacioacuten tiacutepicas = 23 y media muestral X = 1325 Calcula un intervalo de confianza al 99 para lamedia micro
4 Dado este vector de datos
datos = c(309306279244254352307267299282294357238324316345324297339297268291284315315)
del que sabemos que procede de una poblacioacuten normal con σ = 05 calcula un intervalo deconfianza al 95 para la media micro de esa poblacioacuten
5 El fichero adjunto contiene una muestra de ciertapoblacioacuten Utiliza esos datos para calcular un intervalos de confianza al 95 para la mediamicro de esa poblacioacuten
6 Usa R para comprobar los resultados del Ejemplo 623 del libro (paacuteg 216)
Soluciones en la paacutegina 46
13
71684863934956339833777103516749514639579862711354519438546646926971460680562972790485176553266880571765692441849543467718885692776107716815664887774713887836815066066054949811027314996446816387235497355472459594535828732799035982475464271476580256456251172802707618741528891982972482843774832776777745552646769874896439117434835785748226867217389836098216076378048648696135496477187367261933705689646632814728725627487777906822764505604617931927788955507654853706717817992705956105795637762519102914656628633438758763565882575448792848597764687449689283275559272981494142546196588979484610236652829837642564697685631016825221078774665537764598774719693831382444594624385828747045829148068098362944858380652465572762165788866737476567283610256469746896595607763777087031185808675839651616844691829719859731689684604738517626583739048946344137196446101983529677601506655685767864547757857898318386825483978482575910656748638103838871724691795684937169104763722851159892982572282271858859910844491666854751560960297681564857965964438983754629827954765674435101464787572654942807655691502695111481675615639776752968778493747708608533915129984039174978078617516656066215397748638746086148626772147581955849281689388710272915741559591616711807845568845734741834476828817595635747695579751562559929922706572817577694745721752831681867616827736651535974109776856715733549677648935688779841595931721808108842108796697817838138181857689963767865180779868897647427
wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

wwwpostdata -statisticscom POSTDATA Introduccion a la Estadistica Tutorial -06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(mu sigma) a partir de una muestra con n datos Este fichero usa los resumenes de una muestra previamente calculados (numero de datos media muestral etc)
rm(list=ls()) limpieza inicial
Introduce el numero de datos de la muestra n =
Introduce aqui el valor de xbar la media muestralxbar =
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos introduce el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes usarla en lugar de s aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
s = O sigma lee las instrucciones
y el nivel de confianza deseadonc =
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
Calculamos el valor critico
(z_alfa2 = qnorm( 1 - alfa 2 ) )
y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) )
El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
Tabla 1 Coacutedigo R del fichero
14
13 wwwpostdata-statisticscom13 POSTDATA Introduccion a la Estadistica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la media de una13 poblacion normal N(musigma) a partir de una13 muestra con n datos1313 Este fichero usa los resumenes de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 Si la muestra tiene mas de 30 elementos13 introduce el valor de s la cuasidesviacion tipica de la poblacion13 Si la poblacion es normal y conoces sigma la desviacion tipica de13 la poblacion puedes usarla en lugar de s aunque sea nlt30 13 13 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA 13 NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313s = O sigma lee las instrucciones1313 y el nivel de confianza deseado13nc = 131313 NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(z_alfa2 = qnorm( 1 - alfa 2 ) )1313y la semianchura del intervalo13(semianchura=z_alfa2 s sqrt(n) )1313 El intervalo de confianza (ab) para mu es este13(intervalo = xbar + c(-1 1) semianchura )1313
www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

www postdataminuss t a t i s t i c s com POSTDATA Int roducc ion a l a E s t ad i s t i c a Tutor ia l minus06 Fichero de i n s t r u c c i o n e s R para c a l c u l a r un i n t e r v a l o de con f i anza (1minus a l f a ) para l a media de una poblac ion normal N(mu sigma ) a p a r t i r de una muestra con n datos Este f i c h e r o usa l o s datos de l a muestra en bruto en forma de vec to r o en un f i c h e r o csv Lee l a s i n s t r u c c i o n e s mas abajo
rm( l i s t=l s ( ) ) l imp i e za i n i c i a l
EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA
Una po s i b i l i d a d es que tengas l a muestra como un vecto r muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si l e e s l a muestra de un f i c h e r o csv 1 s e l e c c i o n a e l d i r e c t o r i o de t raba jo Para eso e s c r i b e e l nombre ent re l a s c om i l l a s En RStudio puedes usar e l
tabulador como ayuda ( setwd ( d i r= ) ) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora int roduce ent re l a s c om i l l a s e l nombre de l f i c h e r o y e l t i po deseparador e t c
muestra = read t ab l e ( f i l e= header = sep= dec= ) [ 1 ] SI NO SEUSA ESCRIBE AL PRINCIPIO DE ESTA LINEA
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si l a muestra t i e n e mas de 30 elementos calcu lamos e l va l o r de s l a cua s i d e s v i a c i on t i p i c a de l a pob lac ion Si l a pob lac ion es normal y conoces sigma l a de sv i a c i on t i p i c a de la poblac ion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
( s = sd ( muestra ) ) O sigma l e e l a s i n s t r u c c i o n e s
y e l n i v e l de con f i anza deseado nc =
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos l a l ong i tud de l a muestra
(n = length ( muestra ) )
Calculamos l a media muestra l( xbar = mean( muestra ) )
Calculamos a l f a( a l f a = 1 minus nc )
Calculamos e l va l o r c r i t i c o
( z_a l f a 2 = qnorm( 1 minus a l f a 2 ) )
y l a semianchura de l i n t e r v a l o( semianchura=z_a l f a 2 lowast s sq r t (n) )
El i n t e r v a l o de con f i anza (a b ) para mu es e s t e ( i n t e r v a l o = xbar + c (minus1 1) lowast semianchura )
Tabla 2 Coacutedigo R del fichero
15
wwwpostdata-statisticscom POSTDATA Introduccion a la Estadistica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la media de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES(s = sd(muestra) ) O sigma lee las instrucciones y el nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos la longitud de la muestra(n = length( muestra )) Calculamos la media muestral (xbar = mean( muestra ) ) Calculamos alfa(alfa = 1 - nc ) Calculamos el valor critico(z_alfa2 = qnorm( 1 - alfa 2 ) )y la semianchura del intervalo(semianchura=z_alfa2 s sqrt(n) ) El intervalo de confianza (ab) para mu es este(intervalo = xbar + c(-1 1) semianchura )
22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

22 Otros programas
Vamos a ver brevemente las herramientas que nos ofrecen otros programas pra calcular intevalosde confianza para micro usando Z
GeoGebra
En GeoGebra disponemos en primer lugar de la funcioacuten
IntervaloMediaZ[ ltMedia (muestra)gt ltσgt ltTamantildeo (muestra)gt ltNivelgt ]
donde los nombres de los argumentos entre los siacutembolos lt y gt indican en que orden debemosintroducir los datos del problema Por ejemplo para obtener el intervalo de confianza del apartado3 del Ejercicio 6 usariacuteamos la funcioacuten de esta manera (en la Liacutenea de entrada)
IntervaloMediaZ[1325 23 450 099]
y GeoGebra contesta con una lista que contiene los dos extremos del intervalo
Si lo que tenemos es un vector de datos con un nuacutemero no demasiado grande de elementos podemosusar esta misma funcioacuten de otra manera siguiendo esta sintaxis
IntervaloMediaZ[ ltLista de datos (muestra)gt ltσgt ltNivelgt ]
Para ver como funciona usaremos como ejemplo el apartado 4 del Ejercicio 6 En primer lugarcreamos una lista en GeoGebra con los datos del problema ejecutando este comando (tendraacutes quecopiar cada liacutenea por separado para pegarlas formando una uacutenica liacutenea de entrada en GeoGebra)
datos = 309 306 279 244 254 352 307 267 299 282 294 357238 324 316 345 324 297 339 297 268 291 284 315 315
Una vez hecho esto calculamos el intervalo mediante
IntervaloMediaZ[datos 05 095]
Como puedes ver es difiacutecil utilizar de forma praacutectica esta funcioacuten cuando partimos de los datos enbruto de una muestra grande
Ejercicio 7 Usa GeoGebra para hacer el apartado 1 del Ejercicio 6 Solucioacuten en la paacutegina 49
Interpretacioacuten probabiliacutestica del intervalo de confianza usando GeoGebra
Antes de pasar a otros programas queremos sentildealar que la Figura 69 del libro (paacuteg 218) queilustra la interpretacioacuten probabiliacutestica de los intervalos de confianza se ha obtenido con este ficherode GeoGebra
Al abrirlo veraacutes una ventana de GeoGebra similar a la de esta figura
16
function ggbOnInit()
La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

La parte izquierda contiene la Vista Graacutefica con una coleccioacuten de 100 intervalos de confianzacorrespondientes a 100 muestras distintas extraiacutedas todas de la misma poblacioacuten normal La partederecha es la Vista de hoja de caacutelculo Esta parte de GeoGebra tiene un comportamiento similaral de una hoja de caacutelculo como Calc La diferencia fundamental es que las celdas de esta hoja decaacutelculo pueden guardar objetos geomeacutetricos funciones etc Por ejemplo puedes tener una columnallena de paraacutebolas por decir algo En nuestro caso la columna A contiene las 100 muestras lascolumnas B y C contienen respectivamente las medias y cuasidesviaciones tiacutepicas de esas muestrasy la columna D contiene los intervalos de confianza El resto de columnas contienen operacionesauxiliares para dibujar el graacutefico y aquiacute no nos detendremos en comentarlas
Prueba a pulsar Ctrl + R varias veces seguidas Cada vez que lo haces GeoGebra genera 100nuevos intervalos de confianza Veraacutes destacados en color rojo aquellos intervalos de confianza queno contienen a la media real de la poblacioacuten micro cuyo valor es 0 y cuya posicioacuten se indica medianteel segmento vertical Si el nivel de confianza es del 95 es previsible que aparezcan alrededor de5 intervalos rojos Tal vez alguno maacutes o alguno menos Pero lo que significa ese nivel de confianzaes que si tomamos muchas muestras el 95 de los intervalos de confianza correspondientes a esasmuestras seraacuten intervalos azules de los que contienen a la media real de la poblacioacuten Si lo deseaspuedes hacer clic con el botoacuten derecho del ratoacuten sobre cualquiera de los intervalos de la figura yGeoGebra te indicaraacute el nuacutemero de fila que corresponde a ese intervalo concreto Con ese nuacutemerode fila puedes localizar el intervalo en la columna D de la Hoja de Caacutelculo Si el intervalo es rojopodraacutes comprobar que micro = 0 no pertenece al intervalo y a la reciacuteproca en el caso de intervalosazules
Wolfram Alpha
Para calcular intervalos de confianza como estos con Wolfram Alpha prueba a introducir esta fraseen el campo de entrada del programa
confidence interval for population mean
Al hacerlo Wolfram Alpha abre una paacutegina con una serie de campos en los que podemos introducirlos valores necesarios para la construccioacuten del intervalo La siguiente figura muestra esa paacuteginaen la que hemos introducido los valores correspondientes al apartado 1 del Ejercicio6 Tambieacuten semuestra el resultado que ha producido Wolfram Alpha
17
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||
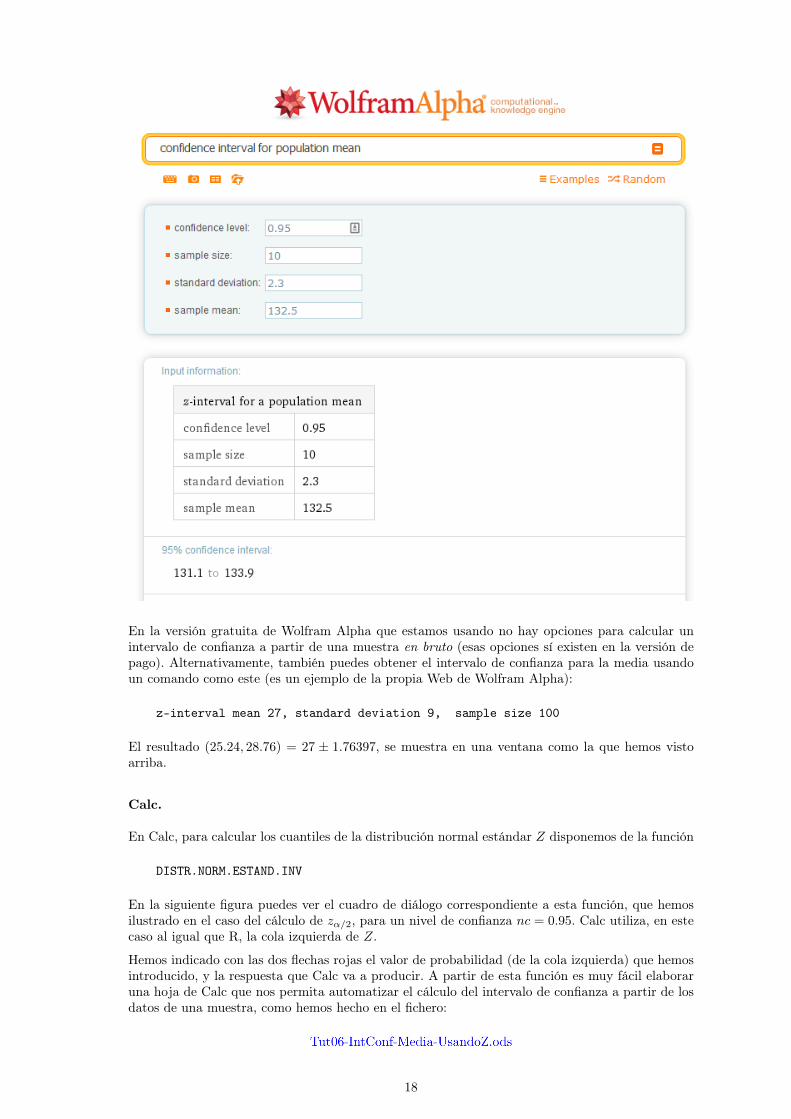
En la versioacuten gratuita de Wolfram Alpha que estamos usando no hay opciones para calcular unintervalo de confianza a partir de una muestra en bruto (esas opciones siacute existen en la versioacuten depago) Alternativamente tambieacuten puedes obtener el intervalo de confianza para la media usandoun comando como este (es un ejemplo de la propia Web de Wolfram Alpha)
z-interval mean 27 standard deviation 9 sample size 100
El resultado (2524 2876) = 27 plusmn 176397 se muestra en una ventana como la que hemos vistoarriba
Calc
En Calc para calcular los cuantiles de la distribucioacuten normal estaacutendar Z disponemos de la funcioacuten
DISTRNORMESTANDINV
En la siguiente figura puedes ver el cuadro de diaacutelogo correspondiente a esta funcioacuten que hemosilustrado en el caso del caacutelculo de zα2 para un nivel de confianza nc = 095 Calc utiliza en estecaso al igual que R la cola izquierda de Z
Hemos indicado con las dos flechas rojas el valor de probabilidad (de la cola izquierda) que hemosintroducido y la respuesta que Calc va a producir A partir de esta funcioacuten es muy faacutecil elaboraruna hoja de Calc que nos permita automatizar el caacutelculo del intervalo de confianza a partir de losdatos de una muestra como hemos hecho en el fichero
18
Paacutegina
()
08112013 103833
Paacutegina
Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 36 | |||||||||||||||
| Desviacioacuten tiacutepica | 06 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 30 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 099 | rarr | 001 | rarr | 0005 | rarr | 25758293035 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 332 | lt μ lt | 388 | 02821679628 | |||||||||||||

Ejercicio 8 Usa este fichero para tratar de calcular los intervalos de confianza de los apartados1 y 3 del Ejercicio 6 (paacuteg 13) iquestQueacute dificultades encuentras Solucioacuten en la paacutegina 49
Antes de seguir adelante vamos a aprovechar nuestro paso por aquiacute para comentar los recursosque Calc ofrece para trabajar con distribuciones normales tanto para problemas directos comoinversos Ya hemos comentado la funcioacuten DISTRNORMESTANDINV Pero ademaacutes de esta en Calcdisponemos de las siguientes funciones
DISTRNORMINV Sirve para problemas inversos en distribuciones normales no necesariamen-te iguales a Z En la siguiente figura puedes ver el cuadro de diaacutelogo en el que estamos usandoesta funcioacuten para resolver el problema inverso
P (X lt K) = 08
en una normal X de tipo N(micro = 63 σ = 023) Usamos DISTRNORMINV(08063023)para obtener 64935728837
19
DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |

DISTRNORM Sirve para problemas directos en distribuciones normales no necesariamenteiguales a Z La siguiente figura muestra el cuadro de diaacutelogo en el que estamos usando estafuncioacuten para resolver el problema directo
P (X lt 42) =
en una normal X de tipo N(micro = 32 σ = 115) Usamos DISTRNORM(42321151) paraobtener 0 8077309735
En el caso de esta funcioacuten debemos introducir un paraacutemetro adicional que Calc llama C quepuede ser C = 1 o C = 0 El valor C = 1 sirve para calcular la funcioacuten de distribucioacuten de lanormal (como pnorm en R y tambieacuten con la cola izquierda) El valor C = 0 devuelve valoresde la funcioacuten de densidad de la normal (como dnorm en R) y apenas lo vamos a utilizar eneste curso
DISTRNORMESTAND Finalmente esta funcioacuten se usa para problemas directos en la distribu-cioacuten normal estaacutendar Z En este caso siempre se calcula la funcioacuten de distribucioacuten (pnormcola izquierda) y el uacutenico argumento es el valor del que sea calcular la probabilidad de sucola izquierda Por ejemplo para resolver
P (Z lt 21)
usariacuteamos DISTRNORM(21) para obtener 0 9821355794
3 Muestras pequentildeas La t de Student
En esta seccioacuten vamos a ver coacutemo utilizar los programas que conocemos para trabajar en problemasen los que interviene la distribucioacuten t de Student
31 Relacioacuten entre la t de Student y la normal Z usando GeoGebra
Al principio de la Seccioacuten 64 del libro hemos explicado que si Tk es una distribucioacuten tipo t deStudent con k grados de libertad entonces a medida que k aumenta la distribucioacuten se parece cadavez maacutes a la normal estaacutendar Z de manera que a partir de k = 30 las graacuteficas de las densidades deambas distribuciones son praacutecticamente ideacutenticas Para ilustrar esto te hemos preparado un ficheroGeoGebra muy sencillo
20
function ggbOnInit()
Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |

Al abrirlo veraacutes algo como esto
El fichero muestra las dos funciones de densidad Z en rojo y Tk en azul y un deslizador quepermite ir variando el valor de k entre 1 y 100 para que puedas ver lo que sucede Para dibujarlas dos curvas hemos usado estos comandos de GeoGebra
DistribucioacutenT[k x ]Normal[0 1 x ]
32 Caacutelculos de probabilidad para la t de Student en R
Una ventaja de trabajar con R como ya hemos comentado anteriormente es la homogeneidaden la sintaxis para todas las distribuciones de probabilidad Concretamente el trabajo con la tde Student es praacutecticamente igual al que hemos visto con la normal estaacutendar Z salvo por eldetalle de los grados de libertad Si en el caso de Z teniacuteamos las funciones dnorm pnorm qnorm yrnorm ahora tenemos sus anaacutelogas dt pt qt y rt con los significados evidentes La primera deellas dt sirve para calcular la funcioacuten de densidad y apenas la usaremos La uacuteltima rt permitecalcular valores aleatorios distribuidos seguacuten la t de Student La usaremos sobre todo para hacersimulaciones Las dos restantes pt y qt llevaraacuten el peso de nuestro trabajo con esta distribucioacutenVamos a presentarlas brevemente antes de ponerlas a trabajar
Las funciones pt y qt
La funcioacuten pt calcula la probabilidad de la cola izquierda (como siempre) de una distribucioacuten tde Student Por ejemplo si T18 es una distribucioacuten t de Student con k = 18 grados de libertad elproblema directo de probabilidad
P (T18 lt 23)
se resuelve mediante este comando en R
pt(23 df = 18)
[1] 098319
Los grados de libertad se indican como ves con el argumento df (del ingleacutes degrees of freedom) Sideseas usar la cola derecha dispones como siempre de la opcioacuten lowertail=FALSE Para calcularen una T12 (es decir una distribucioacuten t de Student con 12 grados de libertad) la probabilidad
P (T12 gt 31)
21
podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |

podemos usar indistintamente estos dos comandos
1 - pt(31 df = 12)
[1] 0004595
pt(31 df = 12 lowertail=FALSE)
[1] 0004595
La funcioacuten qt por su parte permite calcular los cuantiles y por tanto resolver problemas inversosde probabilidad asociados con la t de Student Como siempre por defecto se usa la cola izquierdade la distribucioacuten salvo que usemos lowertail=FALSE Es decir que para resolver un problemacomo el de encontrar el valor K tal que
P (T24 lt K) = 087
usariacuteamos este comando de R
qt(087 df = 24)
[1] 11537
Vamos a practicar el uso de ambas funciones con unos cuantos ejercicios
Ejercicio 9 Sea T15 una variable aleatoria de tipo t de Student con k = 15 grados de liber-tad Calcular los siguientes valores Es muy recomendable hacer un dibujo esquemaacutetico de lasituacioacuten en cada uno de los apartados
1 P (T15 le minus1341)
2 P (T15 ge 2602)
3 P (minus1753 le T15 le 1753)
4 Valor de t tal que P (T15 le t) = 095
5 Valor de t tal que P (T15 ge t) = 0025
6 Valor de t tal que P (T15 le t) = 005
7 Valor de t tal que P (T15 ge t) = 0975
8 Valor de t tal que P (minust le T15 le t) = 095
9 Valor de t tal que P (minust le T15 le t) = 093
Soluciones en la paacutegina 49
Los dos uacuteltimos apartados de este ejercicio son ejemplos del tipo de caacutelculo que necesitamos paraobtener los valores criacuteticos que se usan en un intervalo de confianza como los que vamos a construira continuacioacuten
33 La t de Student en GeoGebra Wolfram Alpha y Calc
331 GeoGebra
La Calculadora de Probabilidades de GeoGebra permite trabajar con la distribucioacuten t de Studentde forma muy parecida a lo que vimos en el caso de la distribucioacuten normal Basta con seleccionarStudent en el menuacute desplegable que se situacutea bajo la graacutefica
Aparte de esto puedes usar directamente algunas funciones en la Liacutenea de Entrada de GeoGebraPor ejemplo
22
DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |

DistribucioacutenT[k x]
produce como resultado la probabilidad de la cola izquierda de x en la distribucioacuten Tk
P (Tk le x)
Es decir el mismo efecto que si en R utilizaras pt(x df = k) Recuerda que los resultados seobtienen en el panel de Vista Algebraica a la izquierda (si no es visible usa el menuacute Vista parahacerlo aparecer)
En la versioacuten actual de GeoGebra para conseguir la probabilidad de una cola derecha hay queusar el truco de 1minus p Es decir
1 - DistribucioacutenT[k x]
produce como cabe esperar el valorP (Tk gt x)
Para los problemas inversos de probabilidad disponemos de la funcioacuten
DistribucioacutenTInversa[k p]
cuyo resultado es el valor x tal queP (Tk le x) = p
Es decir el cuantil p de Tk que en R calculariacuteamos con qt(p df=k) De nuevo si deseas localizarel valor cuya cola derecha representa una probabilidad p usa un truco como
DistribucioacutenTInversa[k 1- p]
Ejercicio 10 Usa estas funciones o la Calculadora de Probabilidades de GeoGebra para repetirel Ejercicio 9
332 Wolfram Alpha
La sintaxis de Wolfram Alpha es como siempre algo maacutes peculiar Seguramente existen otrasformas de calcular estas cantidades pero las que incluimos aquiacute son las maacutes sencillas que conocemos
Vamos a resolver en primer lugar un problema directo de probabilidad Concretamente dada unadistribucioacuten T21 vamos a calcular la probabilidad
P (T21 gt 27)
Para ello en Wolfram Alpha ejecutamos el comando
P[X gt 23] for X student t with 21 dof
y obtenemos como resultado aproximado 00159011 Si lo que deseas es la probabilidad de unintervalo como en este ejemplo (procede de la propia paacutegina de Wolfram Alpha)
P (minus12 lt T12 lt 23)
puedes usar una sintaxis como esta
P[-12 lt X lt 23] for X student t with 12 dof
y obtendraacutes el valor aproximado 0853254
Ejercicio 11 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar estos resultados Solucioacutenen la paacutegina 52
23
Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |

Los problemas inversos se pueden resolver reducieacutendolos manualmente a problemas sobre la colaizquierda de la distribucioacuten Tk Por ejemplo para encontrar el valor x tal que (es una cola derecha)
P (T12 gt x) = 007
hacemos un pequentildeo esquema graacutefico que nos ayude a entender que esto es lo mismo que buscarel valor x tal que
P (T12 lt x) = 093
Y ahora podemos pedirle a Wolfram Alpha que nos diga cuaacutel es ese valor usando esta sintaxis
93th percentile for student t with 12 dof
El resultado aproximado es 15804
Ejercicio 12 Usa R o GeoGebra (o auacuten mejor ambos) para comprobar este resultado Solucioacutenen la paacutegina 53
333 Calc
En Calc las funciones DISTRT y DISTRTINV permiten resolver problemas directos e inversosde probabilidad para la distribucioacuten t de Student de modo parecido a lo que hemos visto para ladistribucioacuten normal Pero es importante entender las diferencias Empecemos en este caso por losproblemas directos El cuadro de diaacutelogo que aparece al utilizar la funcioacuten DISTRT para resolverusando la distribucioacuten T3 (con k = 3 grados de libertad) un problema directo es este
La funcioacuten tiene un paraacutemetro modo que puede tomar los valores 1 o 2 Ese valor indica el nuacutemero decolas de la distribucioacuten que se utilizan Si modo = 2 entonces Calc obtiene el resultado repartiendola probabilidad entre las dos colas de la distribucioacuten t (que es justo lo que se utiliza para construirel intervalo de confianza) Pero si modo = 1 entonces Calc soacutelo utiliza una de las dos colas
Ejercicio 13
1 Observa los datos del ejemplo que aparecen en ese cuadro de diaacutelogo Es decir
24
Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |

Nuacutemero = 05grados_libertad = 3modo = 1
Y el resultado que es aproximadamente 03257 Teniendo en cuenta este ejemplo iquestqueacute colade la distribucioacuten t usa Calc cuando modo = 1 Una representacioacuten graacutefica puede ayudartecon esta pregunta
2 Para confirmar que lo has entendido usa R para calcular este mismo valor
Solucioacuten en la paacutegina 53
iexclNo sigas si no has hecho este ejercicio
25
Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |

Puesto que la distribucioacuten T tiene (como la normal estaacutendar Z) una forma de campana simeacutetricacentrada en el 0 si tomamos un valor situado a la derecha del cero (como el 0 5 del ejercicio) sucola derecha tiene que valer menos de 1
2 y su cola izquierda maacutes de 12 Viendo el resultado de Calc
en este ejemplo concluimos que (lamentablemente desde nuestro punto de vista)
La funcioacuten DISTRT de Calc con modo = 1 usa la cola derecha de ladistribucioacuten t de Student
Es decir que el resultado de un comando como
DISTRT(a k 1)
esP (Tk gt a)
Si se usa modo = 2 se obtiene el aacuterea de ambas colas Es decir se calcula
P (Tk lt minusa) + P (Tk gt a)
o lo que es lo mismo P (|Tk| gt a))
El ejemplo que hemos visto antes con
DISTRT(05 3 1) = 03257239824
corresponde al caacutelculo de
P
(T3 gt
1
2
)
que se ilustra en esta figura
Si lo que queremos es calcular una cola izquierda como en P (T3 lt12 ) debemos utilizar el truco
de 1minus p1 - DISTRT(0531) = 06742760176
Para los problemas inversos de probabilidad y por lo tanto para obtener los valores criacuteticos nece-sarios para los intervalos de confianza la hoja de caacutelculo incluye la funcioacuten DISTRTINV Y aquiacutede nuevo hay que ir con cuidado porque el resultado de
DISTRTINV(p k)
es el valor x tal queP (Tk lt minusx) + P (Tk gt x) = p
Es decir
La funcioacuten DISTRTINV siempre usa el aacuterea de las dos colas derecha e izquierda
26
Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |

Por ejemplo para calcular el x tal que
P (T3 lt minusx)︸ ︷︷ ︸cola izda
+P (T3 gt x)︸ ︷︷ ︸cola dcha
=1
2
usamosDISTRTINV(05 3) = 07648923284
El problema se ilustra en esta figura
A pesar de la confusioacuten que probablemente genera la ventaja de esto es que si lo que quiero esencontrar el valor criacutetico para construir un intervalo de confianza entonces a partir del nivel deconfianza 1minus α precisamente lo que necesitamos saber es cuaacutel es el valor de K tal que
P (X gt K) + P (X lt minusK) = α
y eso directamente es lo que nos da DISTRTINV Por ejemplo con 3 grados de libertad elvalor criacutetico para un intervalo de confianza para la media al 95 (es decir α = 005) que estkα2 = t30025 se obtiene con
DISTRTINV(0053)=31824463053
Como resumen final nuestra opinioacuten es que la falta de coherencia entre las distintas funcionesde Calc (a veces cola izquierda a veces derecha a veces las dos) aconseja ser muy prudentes ala hora de usar el programa Afortunadamente creemos haber presentado suficientes alternativascomo para hacer esencialmente innecesario el uso de Calc en estos problemas
4 Intervalos de confianza para la media usando t
Empecemos recordando que la t de Student se usa para calcular intervalos de confianza cuando secumplen estas condiciones
(1) La poblacioacuten original es normal (o al menos aproximadamente normal)
(2) Desconocemos la varianza de la poblacioacuten σ2X
(3) El tamantildeo de la muestra es pequentildeo (n lt 30 sirve de referencia)
La foacutermula del intervalo (Ecuacioacuten 619 del libro paacuteg 229) es
X minus tkα2sradicnle microX le X + tkα2
sradicn
Es decir es praacutecticamente igual a la del caso en que usaacutebamos Z pero sustituyendo zα2 por tkα2
(donde k = n minus 1 recueacuterdalo) En esta seccioacuten vamos a ver como usar distintos programas paracalcular los intervalos de confianza en esos casos
27
41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |

41 Usando R primera versioacuten ficheros plantilla
Para construir intervalos de confianza usando t en R disponemos de dos ficheros ldquoplantillardquo casiideacutenticos a los que vimos para la normal
Datos resumidos
Datos en bruto
El primero de estos ficheros se usa para los ejercicios ldquo de libro de textordquo en los que en lugar de usarcomo punto de partida los datos de la muestra disponemos de los valores de n X y s calculadospreviamente El segundo en cambio es el adecuado cuando partimos de la muestra completa enun vector de R o en un fichero csv en la paacutegina 30 veremos que esa diferencia no es tan relevante)
El uso de estos ficheros es praacutecticamente ideacutentico al que vimos en el caso en el que se usaba Z Lauacutenica diferencia resentildeable es que aquiacute siempre se va a usar s la cuasidesviacioacuten tiacutepica muestralporque se supone que desconocemos σ (iexclde otro modo usariacuteamos Z) Lo mejor es simplementepracticar haciendo algunos ejercicios
Ejercicio 14
1 El ldquoejercicio trampardquo del apartado 2 del Ejercicio 6 (paacuteg 13) Una muestra de 10 elementosde una poblacioacuten normal tiene cuasidesviacioacuten tiacutepica s = 23 y una media muestral X =1325 Calcula un intervalo de confianza al 95 para la media micro
2 Los siguientes 15 valores proceden de una poblacioacuten normal Calcula un intervalo de confianzaal 95 para la media de esa poblacioacuten
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
3 La t de Student se usa (principalmente) con muestras pequentildeas Por esa razoacuten puede quepienses que aprender a trabajar a partir de ficheros csv no es en este caso tan necesarioPara intentar persuadirte de que puede merecer la pena aquiacute tienes un fichero csv con 20valores procedentes de una distribucioacuten normal
Usa R para calcular un intervalo de confianza al 95 para estos datos
Yo desde luego prefiero leer este fichero usando readtable (y la opcioacuten dec= paragestionar la coma como separador de decimales) De esa forma los datos se leen en una solaliacutenea de coacutedigo en R en lugar de hacer operaciones de copiapega reemplazar comas porpuntos etc
4 IMPORTANTE la distribucioacuten t de Student es muy uacutetil para trabajar con muestras peque-ntildeas Pero eso no significa que no pueda usarse con muestras grandes Para ver lo que sucederepite el apartado 3 del Ejercicio 6 (en el que n = 450)
5 Comprueba con R la solucioacuten del Ejemplo 641 del libro (paacuteg 230)
Solucioacuten en la paacutegina 53
42 Usando R segunda versioacuten la funcioacuten ttest y similares
Aparte de las plantillas que hemos descrito en la seccioacuten precedente R incluye una funcioacuten propiala funcioacuten ttest que puede usarse para calcular intervalos de confianza con la t de Student Enrealidad el objetivo principal de esta funcioacuten es realizar un Contraste de Hipoacutetesis una teacutecnicaque se explica en el Capiacutetulo 7 del libro Cuando estudiemos ese tema volveremos a visitar estafuncioacuten ttest para conocerla con maacutes detalle (y todaviacutea tendremos ocasioacuten de volver sobre ellamaacutes adelante en el curso) Pero como aperitivo aquiacute vamos a ver coacutemo se puede usar esta funcioacutenpara obtener el intervalo de confianza
La funcioacuten ttest como muchas otras funciones de R estaacute pensada para trabajar directamentesobre un vector de datos El motivo por el que esto es asiacute es que R se disentildeoacute para un uso profesional
28
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 MEDIA de una poblacion normal N(musigma)1313 a partir de una muestra con n datos13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 13131313rm(list=ls()) limpieza inicial1313 LEE ESTAS INSTRUCCIONES ATENTAMENTE13 La distribucion t de Student se usa cuando13 (1) La poblacioacuten es (al menos aprox) normal13 (2) Se desconoce sigma la desviacion tipica de la poblacion13 (3) La muestra es pequentildea (lt30 elementos) 13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 EL FICHERO NO FUNCIONARAacute BIEN HASTA13 QUE HAYAS COMPLETADO CORRECTAMENTE TODA 13 LA INFORMACIOacuteN NECESARIA13131313 Introduce el numero de datos de la muestra13n = 1313 Introduce aqui el valor de xbar la media muestral 13xbar = 1313 Cuasidesviacion tipica muestral13s = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313(alfa = 1 - nc )1313 Calculamos el valor critico1313(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )1313y la semianchura del intervalo13(semianchura=t_alfa2 s sqrt(n) )1313 Y el intervalo de confianza (ab) para mu es este13xbar + c(-1 1) semianchura1313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza nc=(1-alfa) para la MEDIA de una poblacion normal N(musigma) a partir de una muestra con n datos Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial LEE ESTAS INSTRUCCIONES ATENTAMENTE La distribucion t de Student se usa cuando (1) La poblacioacuten es (al menos aprox) normal (2) Se desconoce sigma la desviacion tipica de la poblacion (3) La muestra es pequentildea (lt30 elementos) EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE TODA LA INFORMACIOacuteN NECESARIA Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda(setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Nivel de confianza deseadonc = NO CAMBIES NADA DE AQUI PARA ABAJO Numero de datos de la muestra(n = length(muestra)) Calculamos el valor de xbar la media muestral (xbar = mean(muestra)) Cuasidesviacion tipica muestrals = sd(muestra) alfa(alfa = 1 - nc ) Calculamos el valor critico(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )y la semianchura del intervalo(semianchura = t_alfa2 s sqrt(n) ) Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
| 2 | 119 | ||
| 3 | 415 | ||
| 3 | 129 | ||
| 4 | 924 | ||
| 1 | 063 | ||
| 3 | 417 | ||
| 3 | 336 | ||
| 3 | 53 | ||
| 3 | 616 | ||
| 6 | 089 | ||
| 4 | 533 | ||
| 2 | 999 | ||
| 3 | 513 | ||
| 2 | 734 | ||
| 1 | 892 | ||
| 4 | 289 | ||
| 2 | 704 | ||
| 5 | 633 | ||
| 3 | 151 | ||
| 3 | 917 |

para tratar los que antes hemos llamado problemas del mundo real para marcar la diferencia conlos problemas de libro de texto Recuerda que en un problema de libro de texto partimos de losvalores estadiacutesticos ya calculados de la muestra (n X s) Pero en un problema del mundo real elpunto de partida es un conjunto de datos sin procesar en bruto
En la Seccioacuten previa hemos visto dos ficheros de coacutedigo R para calcular intervalos de confianzapara la media usando la t de Student Pues bien lo que estamos diciendo es que ttest se pareceal que usa la muestra en bruto Veamos por ejemplo coacutemo usar ttest para obtener el intervalode confianza del apartado 2 del Ejercicio 14
datos=c(314371277408418151365341451227328226280254377)ttest(datos conflevel=095)
One Sample t-test data datos t = 149 df = 14 p-value = 57e-10 alternative hypothesis true mean is not equal to 0 95 percent confidence interval 27316 36524 sample estimates mean of x 3192
De la salida del comando soacutelo nos interesa por el momento la parte en la que aparece el intervaloque resulta ser (2731598 3652402) Puedes comprobar que este resultado es el mismo que apareceen la solucioacuten del Ejercicio 14 con el fichero Tut06-IntConf-Media-UsandoT-MuestraEnBrutoR
Si lo uacutenico que queremos es ver cuaacutel es el intervalo no hay ninguacuten problema en usar la funcioacutenttest de esta manera Pero si queremos usar los extremos del intervalo para hacer alguna otraoperacioacuten con ellos (por ejemplo iquestcuaacutento vale la semianchura de ese intervalo) entonces tenemosque aprender a separar el intervalo del resto de resultados de ttest (en el Tutorial05 nos sucedioacutealgo parecido con el comando para calcular integrales) Afortunadamente esto es faacutecil Basta conguardar el resultado de ttest en una variable (la hemos llamado TtestDatos)
datos=c(314371277408418151365341451227328226280254377)TtestDatos = ttest(datos conflevel=095)
y ahora usar la notacioacuten $ para extraer las piezas que componen la respuesta de R (en RStudiopuedes escribir TtestDatos$ y pulsar el tabulador para ver la lista de piezas) En particular elintervalo se extrae usando
TtestDatos$confint
[1] 27316 36524 attr(conflevel) [1] 095
(confint es la abreviatura de confidence interval) El resultdo es un vector No te preocupes porla parte que empieza por attr R a veces antildeade atributos (en ingleacutes attributes) a los vectores paraconservar alguna informacioacuten relevante sobre ellos En este caso el atributo del intervalo es el nivelde confianza que se ha usado para calcularlo Pero como deciacuteamos el resultado es un vector de Rque contiene los extremos del intervalo y con el que podemos trabajar sin problemas Por ejemplopara calcular la semianchura hacemos
(intervalo = TtestDatos$confint)
[1] 27316 36524 attr(conflevel) [1] 095
29
(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

(extremoInf = intervalo[1])
[1] 27316
(extremoSup = intervalo[2])
[1] 36524
(semianchura = (extremoSup - extremoInf) 2)
[1] 04604
Ejercicio 15 Usa ttest para repetir el apartado3 del Ejercicio 14 Solucioacuten en la paacutegina 54
iquestPlantillas o ttest cuaacutel debo usar
La funcioacuten ttest es muy aacutegil y permite obtener respuestas tecleando muy poco De hecho unavez definido el vector datos podemos realizar el caacutelculo del intervalo de confianza en una solaliacutenea
ttest(datos conflevel=095)$confint
[1] 27316 36524 attr(conflevel) [1] 095
Los usarios experimentados de R trabajan asiacute porque les permite obtener los resultados muyraacutepido Los usuarios muy experimentados de R en cambio tienden a ser maacutes cuidadosos y atrabajar aplicando ese sabio refraacuten que dice ldquoviacutesteme despacio que tengo prisardquo Pero la sabiduriacuteasoacutelo llega con la experiencia y cada uno de nosotros va descubriendo con el tiempo y la praacutectica cuaacuteles la forma de trabajo que maacutes conviene a cada tarea Te aconsejamos en tanto que principianteque incialmente uses las plantillas que te hemos proporcionado Tienen la virtud de mostrar pasoa paso todos los ingredientes de la construccioacuten del intervalo de confianza De esa forma si teequivocas en algo (y al principio te equivocaraacutes a menudo) es maacutes faacutecil que puedas localizarel fallo y corregirlo Cuando ganes en experiencia y seguridad empezaraacutes a usar ttest maacutes amenudo
iquestY si no tengo el vector de datos Cocinando muestras
La funcioacuten ttest como decimos permite trabajar de una forma muy aacutegil en los casos en losque partimos de datos en bruto iquestPero queacute podemos hacer si el punto de partida no es el vectorde datos sino (como sucede a menudo en los ejercicios de libro de texto) la media muestral X lacuasidesviacioacuten s etc
Afortunadamente hay un remedio que consiste en pedirle a R que a partir de los valores nX s ldquococinerdquo para nosotros una muestra de una poblacioacuten normal que tenga precisamente esascaracteriacutesticas Esto se hace usando la funcioacuten mvrnorm de la libreriacutea MASS Por ejemplo en elapartado 1 del Ejercicio 14 hemos hablado de una muestra de una poblacioacuten normal con estascaracteriacutesticas
n = 10 X = 1325 s = 23
El coacutedigo necesario para fabricar la muestra que queremos con mvrnorm a partir de esos valoreses este
library(MASS)n = 10media_muestral = 1325s = 23(muestra = asvector(mvrnorm(n mu=media_muestral Sigma=s^2 empirical=T)))
30
[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

[1] 13072 13465 12901 13559 13377 13380 13173 12896 13362 13315
Usamos asvector para convertir el resultado en un vector porque mvrnorm devuelve como resul-tado una matriz Fiacutejate en que tenemos que utilizar Sigma=s^2 porque la funcioacuten espera la cuasi-varianza muestral (la notacioacuten Sigma es desafortunada) Ademaacutes el argumento empirical=TRUEsirve para garantizar que la muestra tendraacute las caracteriacutesticas deseadas Comprobeacutemoslo
length(muestra)
[1] 10
mean(muestra)
[1] 1325
sd(muestra)
[1] 23
Como ves R ha cocinado la muestra a la medida de lo que queriacuteamos Una vez hecho esto podemosusar la funcioacuten ttest sobre el vector muestra para obtener el intervalo de confianza como en elcaso anterior
Hay un detalle que nos parece importante aclarar El lector puede estar preguntaacutendose iquestno puedousar rnorm para esto Por ejemplo haciendo
n = 10media_muestral = 1325s = 23setseed(2014)(muestra2 = rnorm(n mean=media_muestral sd=s))
[1] 13120 13324 13279 13561 12954 13324 13311 13342 13356 13745
Pero esto no sirve porque si tomas una muestra aleatoria de una poblacioacuten con media micro la mediamuestral X de esa muestra se pareceraacute a micro pero no seraacute exactamente micro iexclAl fin y al cabo por esohemos tenido que empezar el Capiacutetulo 6 del libro estudiando la distribucioacuten de la media muestralY lo mismo sucede con s claro Para verlo en este ejemplo
length(muestra2)
[1] 10
mean(muestra2)
[1] 13332
sd(muestra2)
[1] 21468
Como ves al usar rnorm la media muestral y la cuasidesviacioacuten tiacutepica de la muestra no coincidencon los valores 1325 y 23 respectivamente que deseaacutebamos Eso es lo que hace necesario el usode mvrnorm para ldquococinarrdquo las muestras
31
43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

43 Intervalos de confianza para la media usando GeoGebra y WolframAlpha
GeoGebra
En GeoGebra disponemos de la funcioacuten IntervaloMediaT que se puede usar de esta forma
IntervaloMediaT[ Media Muestral Cuasidesviacioacuten Tamantildeo muestra Nivel de confianza ]
o de esta otra
IntervaloMediaT[ Lista de datos Nivel de confianza ]
que se corresponden aproximadamente como ves con los dos ficheros ldquoplantillardquo de R que hemosvisto antes El uso de ambas versiones de la funcioacuten no tiene ninguna complicacioacuten Es aconsejableen el segundo caso definir previamente una lista que contenga los valores de la muestra y usar elnombre de esa lista al ejecutar IntervaloMediaT
Ejercicio 16 Usa estas funciones para repetir los apartados 1 y 2 del Ejercicio 14 Solucioacuten enla paacutegina 54
Wolfram Alpha
En Wolfram Alpha para calcular el intervalo de confianza del primer apartado del Ejercicio 14puedes usar sintaxis como esta (es un ejemplo de la propia paacutegina de Wolfram Alpha)
t-interval xbar=1325 s=23 n=10 confidence level=095
Pero tambieacuten puedes usar algo parecido introduciendo entre llaves los valores de la muestra
t-interval 314 371 277 408 418 151 365 341 451 227 328 226 280 254 377
Lo que sucede es que en este caso no resulta tan faacutecil indicar el nivel de confianza y Wolfram Alphausa 95 por defecto Naturalmente siempre podriacuteamos pedirle a Wolfram Alpha que calcule lamedia y cuasidesviacioacuten tiacutepica de esa muestra y entonces usar el primer meacutetodo aunque esasolucioacuten no resulte muy coacutemoda (la versioacuten de pago de Wolfram Alpha no tiene estos inconvenientesdicho sea de paso)
5 La distribucioacuten χ2
51 χ2 en GeoGebra
La familia de distribuciones χ2k depende de un paraacutemetro k los grados de libertad al igual que
sucediacutea con la distribucioacuten t de Student Hemos preparado un fichero GeoGebra para que puedasexplorar de forma dinaacutemica coacutemo son las funciones de densidad de las distribuciones χ2
k paradistintos valores de k
Cuando abras este fichero veraacutes una imagen similar a la de la siguiente figura
32
function ggbOnInit()
Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

Usa el deslizador para cambiar los valores de k y explorar asiacute esta familia de distribuciones Nodejes de observar el comportamiento cuando k = 1 que es excepcional dentro de la familia Ademaacutesde esto observa el aspecto y posicioacuten de la funcioacuten de densidad cuando k crece (tal vez tengas quehacer zoom para verlo) En particular comprobaraacutes que la media de la distribucioacuten χ2
k aumenta amedida que k aumenta Esta primera exploracioacuten debe servir para recordar dos aspectos baacutesicosque nunca debemos olvidar al trabajar con χ2
La distribucioacuten soacutelo es distinta de cero en los valores positivos (una variable χ2 no tomavalores negativos al fin y al cabo es un cuadrado)
En consecuencia la distribucioacuten no es simeacutetrica en ninguacuten sentido
Estas caracteriacutesticas de la distribucioacuten condicionan y complican ligeramente el trabajo que tenemosque hacer La Calculadora de Probabilidades de GeoGebra es un buen punto de partida paraempezar a trabajar con esta distribucioacuten La siguiente figura muestra la situacioacuten que por defectonos encontramos al abrir la Calculadora y seleccionar χ2 en el menuacute desplegable
33
La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

La mejor manera de adentrarnos en este terreno es con una lista de problemas directos e inversosde probabilidad
Ejercicio 17 Sea Y una variable aleatoria de tipo χ29 (con k = 9 grados de libertad) Usa la
Calculadora de Probabilidades de GeoGebra para calcular estos valores
1 P (Y le 209)
2 P (Y ge 114)
3 P (147 le Y le 169)
4 Valor de y tal que P (Y ge y) = 005
5 Valor de y tal que P (Y le y) = 001
6 Valores y1 y2 tales que P (y1 le Y le y2) = 090 y ademaacutes P (Y le y1) = P (Y ge y2)
Soluciones en la paacutegina 55
Aparte de la Calculadora de Probabilidades en GeoGebra disponemos de la funcioacuten ChiCuadradopara efectuar caacutelculos de probabilidad usando como en R la cola izquierda de la distribucioacuten Porejemplo la respuesta del apartado 1 del Ejercicio 17 se puede obtener con
ChiCuadrado[9 209]
Recuerda que las soluciones se obtienen en la Vista Algebraica de GeoGebra Como ves los gradosde libertad se colocan en el primer argumento de la funcioacuten Para resolver problemas inversosdispones de la funcioacuten ChiCuadradoInversa Con esa funcioacuten el apartado 5 del Ejercicio 17 seresuelve asiacute
ChiCuadradoInversa[9 001]
Ejercicio 18 Usa estas funciones para comprobar las soluciones de los restantes apartados delEjercicio 17 Soluciones en la paacutegina 58
52 χ2 en R
En R disponemos como era previsible de cuatro funciones llamadas dchisq rchisq pchisq yqchisq El papel de cada una de estas cuatro funciones a estas alturas empieza a ser evidente apartir de sus nombres dchisq es es la funcioacuten de densidad (y apenas vamos a usarla en este curso)pchisq es la funcioacuten de distribucioacuten (probabilidad de la cola izquierda) qchisq proporciona loscuantiles (de nuevo usando la cola izquierda) y finalmente rchisq sirve para generar valoresaleatorios de una variable de tipo χ2
k Los grados de libertad (el valor de k) se indican en todasestas funciones con el argumento df como sucediacutea en la t de Student
Como ejemplo vamos a usar pchisq para resolver un par de problemas directos de probabilidadasociados con χ2
k Por ejemplo para calcular la probabilidad de esta cola derecha
P (χ214 gt 7)
usamos uno de estos dos comandos indistintamente
1 - pchisq(7 df=14)
[1] 093471
pchisq(7 df=14 lowertail=FALSE)
[1] 093471
34
mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

mientras que para encontrar el valor y tal que
P (χ23 gt y) = 01
usariacuteamos uno de estos comandos
qchisq(1 -01 df=3)
[1] 62514
qchisq(01 df=3 lowertail=FALSE)
[1] 62514
Para que practiques el uso de estas funciones haremos un ejercicio
Ejercicio 19
1 Repite con R el Ejercicio 17
2 Usa R para comprobar los resultados del Ejemplo 651 del libro (paacuteg 233)
Soluciones en la paacutegina 58
53 χ2 en Wolfram Alpha
El trabajo con χ2k en Wolfram Alpha es muy parecido al que hicimos con la t de Student Por
ejemplo este problema directo de probabilidad
P (10 lt χ212 lt 15)
se resuelve con este comando
P[10 lt Y lt 15] for Y chi-square with 12 dof
Y el resultado aproximado es 03745 Los problemas directos son muy faacuteciles de resolver pero losinversos nos daraacuten algo maacutes de trabajo Para encontrar por ejemplo el valor y tal que
P (χ27 gt y) =
7
13
tenemos que comprender primero que esto es lo mismo que buscar el valor de y tal que
P (χ27 le y) = 1minus 7
13=
6
13asymp 046154
y ahora usar este comando en Wolfram Alpha
46154th percentile for chi-square with 7 dof
El resultado aproximado es 601105
Ejercicio 20 Comprueba estos dos ejemplos con R y GeoGebra Soluciones en la paacutegina 60
6 Intervalos de confianza para la varianza con χ2
A la hora de construir un intervalo de confianza la asimetriacutea de la distribucioacuten χ2k marca una
diferencia importante con las otras distribuciones que hemos visto antes En el trabajo con la Zy la t de Student podiacuteamos aprovechar la simetriacutea para calcular un uacutenico valor criacutetico con laseguridad de que si por ejemplo zα2 deja una probabilidad igual a α2 a su derecha entoncesel simeacutetrico minuszα2 deja una probabilidad α2 a su izquierda Con χ2 esto no es asiacute y tendremosque calcular dos valores criacuteticos χ2
kα2 pero tambieacuten χ2k1minusα2 Esos son los valores necesarios
35
para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

para construir el intervalo de confianza para σ2 (en poblaciones normales) que hemos visto en laEcuacioacuten 624 (paacuteg 237) del libroradic
(nminus 1)s2
χ2kα2
le σ leradic
(nminus 1)s2
χ2k1minusα2
Vamos a ver como construir estos intervalos en varios de los programas que venimos utilizando
61 Intervalo de confianza para σ con R
Para fijar ideas supongamos que tenemos una muestra procedente de una poblacioacuten normal detamantildeo n = 18 (de manera que los grados de libertad son k = n minus 1 = 17) en la que s = 21 yqueremos construir un intervalo de confianza para σ a un nivel de confianza del 99 Para seguirla discusioacuten es bueno que tengas presente la Figura 615 del libro (paacuteg 236) que reproducimosaquiacute por comodidad iexclPero atencioacuten Esa figura se corresponde a otro valor de k asiacute que no esperesque los valores criacuteticos esteacuten donde indica la figura
Por lo tanto para comenzar la buacutesqueda de los valores criacuteticos hacemos en R
n = 17k = n - 1s = 21
nc = 099(alfa = 1 - nc)
[1] 001
(alfa2 = alfa 2)
[1] 0005
Para construir el intervalo necesitamos calcular el valor criacutetico situado maacutes a la derecha que dejauna probabilidad α
2 = 0005 en su cola derecha (y α2 = 0995 en la cola izquierda que usa R) alque hemos llamado
χ2kα2 = χ2
160005
36
Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

Este valor criacutetico se obtiene en R con
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 34267
Tambieacuten necesitamos el otro valor criacutetico situado maacutes a la izquierda el que deja una probabilidadα2 = 0005 en su cola izquierda
χ2k1minusα2 = χ2
k0995
que en R se obtiene con
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 51422
Lee varias veces esto si te pierdes Sabemos que la notacioacuten χ2kp es un poco complicada porque p se
refiere a la probabilidad en la cola derecha y R usa la cola izquierda Pero es mejor que lo piensesdetenidamente para evitar que este pequentildeo embrollo notacional te juegue una mala pasada
Una vez construidos los dos valores criacuteticos el intervalo es muy faacutecil de construir Soacutelo una uacuteltimaadvertencia el valor criacutetico situado a la derecha se usa en realidad para calcular el extremo izquierdodel intervalo y viceversa En cualquier caso si alguna vez te equivocas los extremos del intervalo seintercambiariacutean y eso te serviriacutea de advertencia de que debes revisar tus cuentas para comprobarque no se debe a ninguacuten otro error
La construccioacuten del intervalo se realiza mediante una operacioacuten vectorial de R en la que obtenemosa la vez los dos extremos
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 14350 37043
Asiacute que el intervalo de confianza para σ al 99 es
1435 lt σ lt 3704
Si lo que deseamos es un intervalo de confianza para la varianza σ2 basta con elevar al cuadradola desigualdad
2059 lt σ2 lt 1372
Ejercicio 21 Usa R para comprobar los resultados del Ejemplo 652 del libro (paacuteg 238) Solucioacutenen la paacutegina 60
Ficheros ldquoplantillardquo de R para intervalos de confianza para σ
Hemos hecho el caacutelculo anterior paso a paso para que puedas entender coacutemo se calculan estosintervalos de confianza en R Pero como sucede siempre una vez que se ha entendido esto lomejor es tratar de automatizar el proceso de construccioacuten de los intervalos y para conseguirloincluimos dos ficheros ldquoplantillardquo de coacutedigo R que apenas necesitan presentacioacuten El primero deellos es para problemas de libro de texto y el segundo para trabajar a partir de datos en bruto
Abre los dos ficheros y estudia su coacutedigo Veraacutes entre otras cosas que se obtienen dos intervalosuno para σ2 y otro para σ Vamos a practicar el uso de estos ficheros con algunos ejercicios
Ejercicio 22
1 Usa estos ficheros para repetir la construccioacuten del intervalo que hemos usado como ejemploal principio de la Seccioacuten 61
37
13 wwwpostdata-statisticscom13 POSTDATA Introduccioacuten a la Estadiacutesitica13 Tutorial-06 1313 Fichero de instrucciones R para calcular13 un intervalo de confianza (1-alfa) para la 1313 DESVIACION TIPICA de una poblacion normal N(musigma) 1313 a partir de una muestra de tamantildeo n13 Este fichero usa los estadisticos de una muestra13 previamente calculados (numero de datos media muestral etc) 131313rm(list=ls()) limpieza inicial1313 ATENCIOacuteN13 Para usar este fichero 13 la poblacioacuten debe ser (al menos aprox) normal13 EN OTROS CASOS NO USES ESTE FICHERO13 ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES1313 Introducimos el valor de la desviacion tipica muestral13s = 1313 el tamantildeo de la muestra13n = 1313 y el nivel de confianza deseado13nc = 131313NO CAMBIES NADA DE AQUI PARA ABAJO1313 Calculamos alfa13alfa = 1 - nc1313 y los grados de libertad1313(k= n - 1)1313 Calculamos los valores criticos necesarios1313(chiAlfa2 = qchisq(1 - (alfa2) df=k))1313(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))131313Para la varianza el intervalo de confianza sera13 extremo inferior13(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))1313 Y para la desviacion tipica el intervalo de confianza es este13(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))131313131313
wwwpostdata-statisticscom POSTDATA Introduccioacuten a la Estadiacutesitica Tutorial-06 Fichero de instrucciones R para calcular un intervalo de confianza (1-alfa) para la DESVIACION TIPICA de una poblacion normal N(musigma) a partir de una muestra de tamantildeo n Este fichero usa los datos de la muestra en bruto en forma de vector o en un fichero csv Lee las instrucciones mas abajorm(list=ls()) limpieza inicial ATENCIOacuteN Para usar este fichero la poblacioacuten debe ser (al menos aprox) normal EN OTROS CASOS NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES EL FICHERO NO FUNCIONARAacute BIEN HASTA QUE HAYAS COMPLETADO CORRECTAMENTE LA INFORMACIOacuteN DE LAS LINEAS 32 43 Y 47 Una posibilidad es que tengas la muestra como un vector muestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayudasetwd(dir=) SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA 2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etcmuestra = readtable(file= header = sep= dec=)[ 1] SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA Introducimos el nivel de confianza deseadonc=NO CAMBIES NADA DE AQUI PARA ABAJO alfa(alfa = 1 - nc ) Numero de datos de la muestra grados de libertad(n = length(muestra))k = n - 1 Cuasidesviacion tipica muestral(s = sd(muestra)) Calculamos los valores criticos necesarios(chiAlfa2 = qchisq(1 - (alfa2) df=k))(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2)) Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||
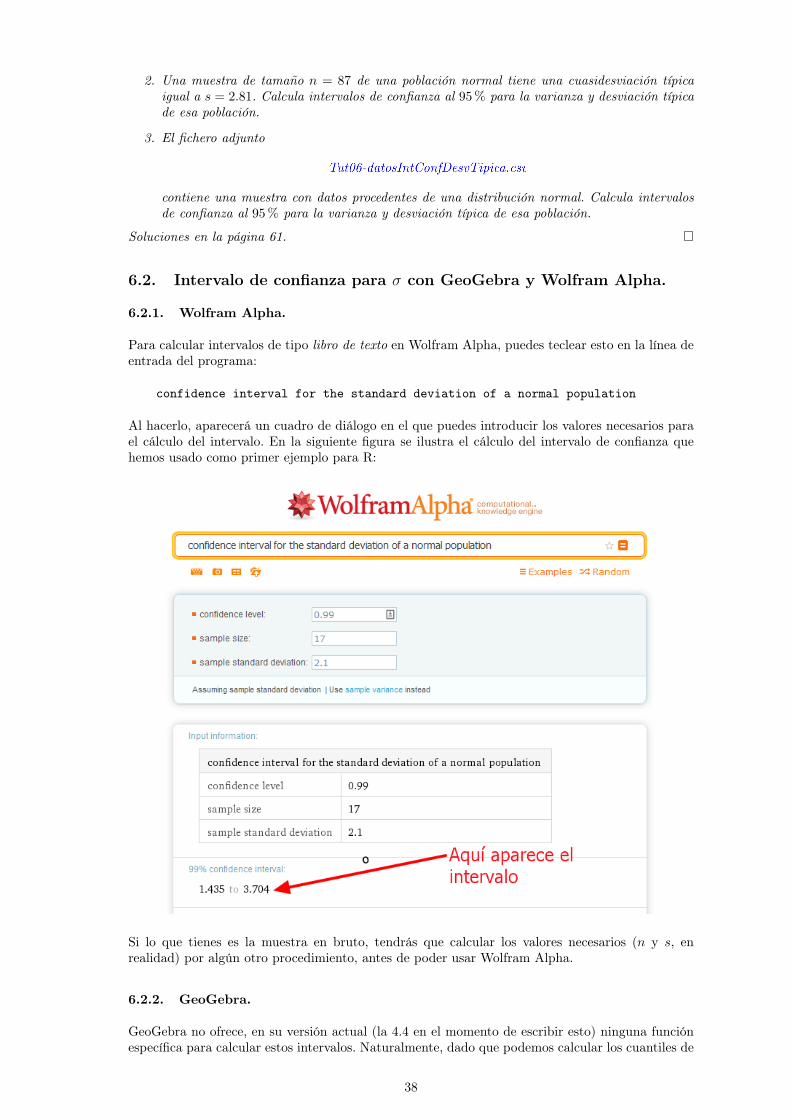
2 Una muestra de tamantildeo n = 87 de una poblacioacuten normal tiene una cuasidesviacioacuten tiacutepicaigual a s = 281 Calcula intervalos de confianza al 95 para la varianza y desviacioacuten tiacutepicade esa poblacioacuten
3 El fichero adjunto
contiene una muestra con datos procedentes de una distribucioacuten normal Calcula intervalosde confianza al 95 para la varianza y desviacioacuten tiacutepica de esa poblacioacuten
Soluciones en la paacutegina 61
62 Intervalo de confianza para σ con GeoGebra y Wolfram Alpha
621 Wolfram Alpha
Para calcular intervalos de tipo libro de texto en Wolfram Alpha puedes teclear esto en la liacutenea deentrada del programa
confidence interval for the standard deviation of a normal population
Al hacerlo apareceraacute un cuadro de diaacutelogo en el que puedes introducir los valores necesarios parael caacutelculo del intervalo En la siguiente figura se ilustra el caacutelculo del intervalo de confianza quehemos usado como primer ejemplo para R
Si lo que tienes es la muestra en bruto tendraacutes que calcular los valores necesarios (n y s enrealidad) por alguacuten otro procedimiento antes de poder usar Wolfram Alpha
622 GeoGebra
GeoGebra no ofrece en su versioacuten actual (la 44 en el momento de escribir esto) ninguna funcioacutenespeciacutefica para calcular estos intervalos Naturalmente dado que podemos calcular los cuantiles de
38
3691343451342135107133157134346134305134403134447135695134911341351343941340011335751347871339861354651342121345981341871349041351641338811341661359441356413435213318313509513469613427513447713303913399813423413474113447913390113330113332134831134046133889133559134267132785134131134044133471134448134355133469134981339651347171346891341431341871341991343121334531330691342241342721359781333871334411352371331661328711342131341651327111342191360561342151352391345921343371323951348771335661324141335851347031344991347611339313170113357613462613480613489313468713334813450113574213501133779135246134151133679133662132331342761352791343291335021344341323061348811343631330331349751339541338671341541342571348651343591333831346861353661331631342113434613518713353813374313438213384913603713307713360213274135006135461134007134347134567134262134087134153134092134839133646135059134477134101134067134643134851341931343021348321323231345531340351344371333431326213349213483613436613445713418313418313407113394313402213471336061330711339651337641330291350561332441348751326311328361336051340113439813433313418313435134461354161336413340213360613559713559135164134171339071335331338591342811323651335741342931348891343351344491335211328791342241343431337413409613380413395113356313400113393413391313369213371134449135442134501133981334241330791352951333831340341342331354831334521336651338031346751339361345231348851351211346461343371343221342561339161349913386313527913445813433113490113491135102134777134668134742134928135121344011340991332211336371332981348361347541333911354251343581338213447613423134315133926135694134891339761333511331381325941342661335671343891332881338135403133938135253134204133344135131135018134342133726135406133704133432133731333061330581342151333111346541344841348731359221352591354241340961347251336713371913517813545413294613397513291413438513435213335813437613490413509313342413391313274613401813566613524813495713445913526313361813374213484113398613411134302132821133304134797134981337781338451342781340851344551340481344771337841336931340691345511350971330831346361338113369813442213438133617135285133547134314133575134604133696134533133519133021333761339691340161333881336811337411348621347121340291328341337513494413588213461613471713518413388213432913322813424613364613418413489713469113303613529913454513427313317513416213415134132134748133974134013134885133885134242133063134496133518132976135213403813400513358213445713466213376513332713456213464113462213329813490213313413387134155135279133836133981350134569133524133241351781353611339711337213298213384413326413423513431313455813493913439113363113351313358813546813447134766134109134971337911334671337171341311347161337713441613373313270713482313395613315513419133245134171132322134465133701134405133477134193134154135002134774133481339631343021338461345471344441335951344731342161341161340813415713411513389413364413231133912134223134042134051344021340121347071346491338021333841338313430513483213432113407213477133771134739134189132773133828133823132811134913361513455613386513553713407613383513517413410713446713321913433613431413240913397313448213386213455613392313519113393813367213371113417513329513440813351313357913418913326313302413490413430113442213361113352213562413381213409713441813365413502213409913315113481713534213486913287413416132822133921342631332681341471343251347941339881343671331461327791338071334561340751337971332311353011341021341931345981341271345791343861334161340171346511342251341231347521343491335613295133017134087132942135087132919134263134731134612134684133162133284133736134359135328134001135082133805134943133023133541132931134571347371345213425713441350161343531338171334111330021334713425213438913445513390213448413308913516913471213379613451336351334441340621353311351671349731335491342761330461336471337921337321333461334211339331363581346481341291348831346951346021333151342831346211355411328531323781337811350221336541326121334161341191329911343281334661346134091134146133306132985134184135906134427134147134215134045133104133668134177135238133541351821335121345571343321346171344691344111337921344081352981351641331891345481334391337271335041332441341151323931341741338311343711334221333751345791331611345611338151339651347441343081345231341811323481344213264134439134333134813134767135152134595134198133772134896135273133358134297134181133661346171338361344491339811346221333134339134508134246132753134267133521339371331121332961341571340134372134061341861343851349171338213280713407913381113431713393313283613358613358613308134445135438134811338913519613343313217413459713433213371213497413345713484413456134777133751334091344541352561331051339481347951351041353231348713281213
χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

χ2k siempre es posible hacer la construccioacuten paso a paso como hicimos al empezar la discusioacuten con
R
Ejercicio 23 Repite esa construccioacuten paso a paso usando GeoGebra Es decir suponiendo quehemos tomado una muestra procedente de una poblacioacuten normal de tamantildeo n = 18 y en la ques = 21 usa las funciones de GeoGebra para construir un intervalo de confianza para σ a un nivelde confianza del 99 Solucioacuten en la paacutegina 62
7 Las funciones de la libreriacutea asbio de R
En la Seccioacuten 42 (paacuteg 28) hemos visto que la funcioacuten ttest de R se puede usar para obtenerintervalos de confianza en el caso de muestras pequentildeas Pero a diferencia de lo que sucede conla t de Student R no incluye en la instalacioacuten baacutesica funciones que permitan calcular intervalosde confianza para la media usando Z o para σ2 usando χ2 Hay sin embargo varias libreriacuteas queofrecen ese tipo de foacutermulas Nosotros vamos a utilizar una bastante completa llamada asbiocreada por Ken Aho Puedes encontrar informacioacuten sobre esta libreriacutea en el enlace
httpcranr-projectorgwebpackagesasbioindexhtml
en el que encontraraacutes entre otras cosas el manual en formato pdf
Recuerda que antes de usar la libreriacutea asbio debes instalarla (en la Seccioacuten 8 del Tutorial03 seexplica como instalar libreriacuteas adicionales en R) Despueacutes de instalarla para usarla debes cargarlaen la memoria del ordenador utilizando el comando
library(asbio)
Loading required package tcltk
La libreriacutea asbio incluye muchas funciones pero las tres que maacutes nos interesan en este momento soncimuz cimut y cisigma Todas ellas permiten calcular intervalos de confianza (ci provienedel ingleacutes confidence interval) Concretamente
cimuz calcula intervalos de confianza para la media usando Z
cimut calcula intervalos de confianza para la media usando t de Student Es decir lo mismoque antes hemos visto con ttest
cisigma calcula intervalos de confianza para la varianza σ2 (iexcly no para σ a pesar delnombre) usando χ2
Y en todos los casos podemos partir de un vector (datos en bruto) o de los estadiacutesticos que resumenla muestra (los que hemos llamado problemas de libro de texto) Para distinguir en queacute caso estamosbasta con utilizar el argumento booleano summarized si es summarized=TRUE usamos los valoresresumidos (n X s o σ) mientras que si es summarized=FALSE usamos la muestra en bruto
Vamos a ver como usar estas funciones mediante algunos ejemplos basados en ejercicios que hemospropuesto anteriormente en este tutorial
Ejemplos con cimuz
En el apartado 3 del Ejercicio 6 (paacuteg 13) teniacuteamos una muestra de 450 elementos de una poblacioacutennormal con cuasidesviacioacuten tiacutepica s = 23 y una media muestral X = 1325 Para calcular unintervalo de confianza al 99 para la media micro teniendo en cuenta el tamantildeo de la muestra podemosusar la distribucioacuten normal Z Podemos por tanto utilizar la funcioacuten cimuz con la opcioacutensummarized=TRUE de esta manera
(intAsBio = cimuz(n=450 sigma=23 xbar=1325 conf=099 summarized=TRUE))
39
99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

99 z Confidence interval for population mean Estimate 05 995 13250 13222 13278
Compara esto con lo que obtuvimos en el Ejercicio 6 La respuesta de la funcioacuten cimuz es enrealidad una lista de R (puedes usar class para comprobarlo) Ya nos hemos encontrado antes coneste tipo de situaciones en las que para acceder a los resultados tenemos que utilizar el operador$ Para saber cuales son los elementos de una lista (o de cualquier otro objero de R) disponemosde la funcioacuten str que en este caso produce
str(intAsBio)
List of 4 $ margin num 0279 $ ci num [13] 132 132 133 $ head chr 99 z Confidence interval for population mean $ ends chr [13] Estimate 05 995 - attr( class)= chr ci
Nos interesa el elemento ci de esta lista Y podemos acceder a ese elemento con este comando
intAsBio$ci
[1] 13250 13222 13278
Asiacute se obtiene un vector con tres componentes La primera es X y las dos uacuteltimas son los extremosdel intervalo de confianza Podemos usarlos por tanto
para por ejemplo calcular la semianchura del intervalo de esta manera
(semianchura = (intAsBio$ci[3] - intAsBio$ci[2]) 2)
[1] 027928
Ahora puedes comprobar que la semianchura es el elemento margin de la lista intAsBio que hemosobtenido como salida de cimuz
intAsBio$margin
[1] 027928
El resto de los elementos de intAsBio son simplemente roacutetulos
Vamos ahora a usar a calcular un intervalo de confianza a partir de datos en bruto usando el ficheroTut06-IntConf-Media-UsandoZ-datoscsv del apartado 5 del Ejercicio 6 Esto nos va a servirpara descubrir una peculiaridad muy importante de esta funcioacuten Para ello nos aseguramos deque el fichero csv estaacute en el directorio de trabajo de R y usamos de nuevo cimuz pero ahoracon summarized=FALSE
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[ 1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE sigma = sd(muestra)))
95 z Confidence interval for population mean Estimate 25 975 72313 70932 73694
Como ves en el caso de datos en bruto hemos tenido que pedirle expliacutecitamente a cimuz queuse la cuasidesviacioacuten tiacutepica de la muestra calculada con sd Si no haces esto comprobaraacutes que elresultado no es correcto
40
Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

Ejercicio 24 Comprueacutebalo Solucioacuten en la paacutegina 63
Ejemplos con cimut
Vamos a usar la funcioacuten cimut para hacer el apartado 2 del Ejercicio 6 Tenemos una muestrade 10 elementos de una poblacioacuten normal con media muestral X = 1325 y cuasidesviacioacuten tiacutepicas = 23 Dado que la muestra es pequentildea y desconocemos σ debemos usar la t de Student paracalcular un intervalo de confianza al 95 para la media micro Lo hacemos asiacute
cimut(n=10 xbar=1325 sd=23 conf=095 summarized=TRUE)
95 t Confidence interval for population mean Estimate 25 975 13250 13085 13415
Puedes comprobar que el resultado coincide con lo que obtuvimos en la solucioacuten del Ejercicio 14(paacuteg 53) usando ttest
Si partes de una muestra en bruto como la muestra
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
del apartado 2 del Ejercicio 14 entonces para calcular un intervalo de confianza al 95 para microharemos
muestra = c(314 371 277 408 418 151 365 341 451 227 328226 280 254 377)
(intAsBio = cimut(data=muestra conf=095 summarized=FALSE))
95 t Confidence interval for population mean Estimate 25 975 31920 27316 36524
Fiacutejate en que en este caso no ha sido necesario usar la opcioacuten sigma = sd(muestra) para ob-tener el resultado correcto a diferencia de lo que sucede con cimuz Ademaacutes si la incluyesdesafortunadamente la funcioacuten devuelve el error unused argument
Ejemplos con cimusigma
Vamos a empezar usando la funcioacuten cimusigma para repetir el apartado 2 del Ejercicio 22 (paacuteg37 y solucioacuten en la paacutegina 61) En ese ejercicio teniacuteamos una muestra de tamantildeo n = 87 de unapoblacioacuten normal con cuasidesviacioacuten tiacutepica igual a s = 281 y queriacuteamos calcular un intervalo deconfianza al 95 para la varianza de esa poblacioacuten Lo podemos hacer asiacute
cisigma(n=87 Ssq = 281^2 conf=095 summarized=TRUE)
95 Confidence interval for population variance Estimate 25 975 78961 59807 109107
Atencioacuten El argumento Ssq es la cuasivarianza no la cuasidesviacioacuten tiacutepica Por eso hemostenido que elevar 281 al cuadrado Y el intervalo que se obtiene es para σ2 no para σ (a pesardel nombre de la funcioacuten)
41
Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

Ejercicio 25 Usa cisigma para calcular el intervalo de confianza a partir de una muestra enbruto (fichero csv) que aparece en el apartado 3 del Ejercicio 22 (paacuteg 37) Solucioacuten en la paacutegina63
Con esto hemos concluido nuestra primera visita a la libreriacutea asbio Volveremos sobre ella maacutesadelante en futuros tutoriales y aprenderemos a usar otras funciones de esta libreriacutea
8 Ejercicios adicionales y soluciones
Ejercicios adicionales
Ejercicio 26 Simulaciones sobre la interpretacioacuten probabilista de los intervalos deconfianzaEn este ejercicio vamos a usar R para volver sobre la interpretacioacuten probabiliacutestica de los intervalosde confianza que vimos usando GeoGebra en la Seccioacuten 22 de este tutorial (paacuteg 16) Para hacerlovamos a construir algunas simulaciones
1 Empieza por usar rnorm para generar un nuacutemero grande (por ejemplo N = 1000) de muestrasde una poblacioacuten norma cada una de tamantildeo por ejemplo n = 100 Puedes usar la normalestaacutendar Z = N(0 1) para esto el resultado no dependeraacute de la media o desviacioacuten tiacutepica de lapoblacioacuten Para cada una de esas muestras calcula el correspondiente intervalo de confianza(a b) para la media micro de la poblacioacuten En este paso te puede resultar muy conveniente usarla libreriacutea asbio como se explica en la Seccioacuten 7 (paacuteg 39) Comprueba para cada intervalosi la media real de la poblacioacuten (que es 0 si usas Z) pertenece al intervalo Y finalmenteresponde a la pregunta iquestqueacute porcentaje de los intervalos que has construido contiene a micro
2 Repite la anterior simulacioacuten con muestras de tamantildeo n mucho menor (por ejemplo de menosde 10 elementos) todaviacutea usando Z para el caacutelculo del intervalo
3 Ahora repite la cuenta para las muestras pequentildeas usando la t de Student iquestCambia el por-centaje Aseguacuterate de que las muestras sean las mismas por ejemplo usando setseed (oguardaacutendolas en una matriz antes de construir los intervalos con Z o t)
4 Finalmente en todos los casos anteriores hemos trabajado con poblaciones normales (genera-das con rnorm) Usa ahora runif para generar muestras pequentildeas de una variable aleatoriauniforme (puedes usar el intervalo (minus1 1) para que la media sea de nuevo 0) y repite elproceso de los anteriores apartados
Ejercicio 27 Bootstrap La teacutecnica que vamos a investigar en este ejercicio se denomina boots-trap En la forma que vamos a ver aquiacute esta teacutecnica nos proporciona un meacutetodo alternativo paraconstruir un intervalo de confianza para la media de una poblacioacuten a partir de una muestra
Originalmente la palabra inglesa bootstrap denominaba a las correas de cuero que se colocabanen la parte alta de unas botas y que serviacutean para como ayuda para calzarse las botas tirando dedichas correas De ahiacute derivoacute la expresioacuten popular pull yourself up by your bootstraps que podemostratar de traducir como elevarte tirando de tus botas y que representa la idea de conseguir algomediante el esfuerzo propio a menudo de forma inesperada Es ese caraacutecter de conseguir algo deforma inesperada lo que seguramente hizo que se eligiera ese nombre para esta teacutecnica que podemosdescribir como una teacutecnica de remuestreo
Vamos a utilizar los mismos 15 valores que apareciacutean en el apartado 2 del Ejercicio 14 Esos valoreseran
314 371 277 408 418 151 365 341 451 227 328226 280 254 377
En aquel ejercicio calculamos un intervalo de confianza para la media usando la foacutermula 610 (paacuteg216) del libro El resultado era el intervalo
2732 lt micro lt 3652
42
Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

Vamos a usar el meacutetodo bootstrap para calcular un intervalo de confianza alternativo para micro Elmeacutetodo consiste simplemente en
1 Tomar un nuacutemero muy grande (miles) de remuestras es decir de muestras aleatorias de lamuestra original obtenidas (y esto es muy importante) con reemplazamiento El tamantildeode las remuestras es un paraacutemetro del meacutetodo Se suelen emplear valores como 20 o 30
2 Para cada una de esas remuestras calculamos la media obteniendo un vector con miles demedias de remuestras
3 Si queremos un intervalo de confianza bootstrap al 95 nos quedamos con el intervalo defini-do por los percentiles 0025 y 0975 de ese vector de medias de remuestras (la generalizacioacutenpara otros niveles de confianza deberiacutea ser evidente)
En R el coacutedigo seriacutea este
setseed(2014)muestra = c(314 371 277 408 418 151 365 341 451 227328 226 280 254 377)
mean(muestra)
[1] 3192
tamannoRemuestra = 50
numRemuestras = 50000
mediasRemuestras = numeric(10000) este vector almacenara las medias de las remuestras
for(i in 1numRemuestras) muestras de tamantildeo tamannoRemuestra y con reemplazamientoremuestra = sample(muestra size = tamannoRemuestra replace = TRUE)mediasRemuestras[i] = mean(remuestra)
El intervalo bootstrap para nc=095 esquantile(mediasRemuestras probs = c(0025 0975))
25 975 29698 34148
Para entender el meacutetodo puede ayudar la visualizacioacuten de la distribucioacuten de las medias de lasremuestras
hist(mediasRemuestras breaks = 10 main=)
43
mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

mediasRemuestras
Fre
quen
cy
26 28 30 32 34 36
050
0015
000
Como puede verse las medias de las remuestras se concentran alrededor de la media de la muestraoriginal con una distribucioacuten que sin ser normal recuerda bastante a la distribucioacuten de la mediamuestral que aparece en el Teorema Central del Liacutemite
Ahora es tu turno
1 Modifica el coacutedigo en R para calcular intervalos bootstrap al 90 al 99 o maacutes en generalpara cualquier nivel de confianza dado
2 Modifica el valor de tamannoRemuestra hacieacutendolo maacutes grande Prueba con tamantildeos 30 40 50iquestQueacute sucede con la anchura del intervalo bootstrap
3 Usa rbinom para fabricar una muestra de 100 valores de una variable binomial X sim B(35 17)A continuacioacuten construye un intervalo de confianza para la media microX usando el meacutetodo boots-trap Fiacutejate en que en este caso conocemos la media de la poblacioacuten Construye tambieacuten unintervalo de confianza usando Z como hemos visto en el libro Compara los dos intervalosiquestCuaacutel es maacutes ancho Ya sabemos que el intervalo que usa Z estaacute centrado en X El inter-valo bootstrap en cambio no es simeacutetrico con respecto a X iquestHacia que lado estaacute sesgada ladistribucioacuten de valores de las medias de remuestras en este caso Compara la respuesta conel sesgo de la propia variable binomial
Soluciones de algunos ejercicios
bull Ejercicio 2 paacuteg 6
La uacutenica modificacioacuten necesaria es la liacutenea de coacutedigo
n = 4
Todo lo demaacutes funciona exactamente igual Es importante que te esfuerces en escribir coacutedigo lomaacutes reutilizable posible En cuanto al nuacutemero de muestras de tamantildeo n = 20 son
3620 = 13367494538843734067838845976576
del orden de 1031 Otro ejemplo de la Explosioacuten Combinatoria de la que ya hemos hablado
44
bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

bull Ejercicio 3 paacuteg 8
1 El nuacutemero de 4-muestras (con reemplazamiento) es simplemente
204 = 160000
Si lo quieres pensar usando Combinatoria son las variaciones con repeticioacuten de 20 elementostomados de 4 en 4
2 Para construir las muestras ver el tamantildeo del espacio muestral y el aspecto de las primerasy uacuteltimas muestras hacemos
n = 4MuestrasW = permutations(20 n repeatsallowed=T)dim(MuestrasW)
[1] 160000 4
head(MuestrasW)
[1] [2] [3] [4] [1] 1 1 1 1 [2] 1 1 1 2 [3] 1 1 1 3 [4] 1 1 1 4 [5] 1 1 1 5 [6] 1 1 1 6
tail(MuestrasW)
[1] [2] [3] [4] [159995] 20 20 20 15 [159996] 20 20 20 16 [159997] 20 20 20 17 [159998] 20 20 20 18 [159999] 20 20 20 19 [160000] 20 20 20 20
bull Ejercicio 4 paacuteg 10
1 Para calcular microW y σ2W
hacemos
(mu_barW = mean(mediasMuestralesW))
[1] 105
(sigma2_barW = sum((mediasMuestralesW - mu_barW)^2) length(mediasMuestralesW))
[1] 83125
2 Primero calculamos la media y varianza deW hacemos (para entender el vector probabilidadesrecuerda que los valores son equiprobables)
45
probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

probabilidades = 1 length(W)(muW = sum(W probabilidades))
[1] 105
(sigma2_W = sum((W - muW)^2 probabilidades ))
[1] 3325
Ahora se tiene
sigma2_W sigma2_barW
[1] 4
bull Ejercicio 5 paacuteg 10
1 La solucioacuten es
pnorm(15) - pnorm(-2)
[1] 091044
2 La solucioacuten es
qnorm(1 - 025)
[1] 067449
bull Ejercicio 6 paacuteg 13
1 Las condiciones se cumplen porque aunque la muestra es pequentildea se supone que conocemosel valor poblacional de σ Vamos a mostrar como calcular el intervalo al 90 Usa el ficheroTut06-IntConf-Media-UsandoZ-EstadisticosR e introduce estos valores en las liacuteneas delcoacutedigo que se indican
a) n = 10 en la liacutenea 19 del coacutedigob) xbar = 1325 en la liacutenea 22c) s = 23 en la liacutenea 34 Este valor corresponde al valor poblacional de σ aunque usemos
s para representarlo en el coacutedigod) nc = 095 en la liacutenea 37
El resultado que produce el coacutedigo es (soacutelo mostramos las liacuteneas finales)
gt gt NO CAMBIES NADA DE AQUI PARA ABAJOgt gt (alfa = 1 - nc )[1] 01gtgt Calculamos el valor criticogtgt (z_alfa2 = qnorm( 1 - alfa 2 ) )[1] 1645
46
gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

gtgt y la semianchura del intervalogt (semianchura=z_alfa2 s sqrt(n) )[1] 1196gtgt El intervalo de confianza (ab) para mu es estegt (intervalo = xbar + c(-1 1) semianchura )[1] 1313 1337
Asiacute que el intervalo de confianza al 90 es micro = 1325plusmn 1196 o de otro modo
1313 lt micro lt 1337
Te dejamos que compruebes que el intervalo al 95 es
1311 lt micro lt 1339 es decir micro = 1325plusmn 1426
mientras que al 99 es
1306 lt micro lt 1344 es decir micro = 1325plusmn 1873
Fiacutejate en que con los mismos datos a medida que queremos un nivel de confianza maacutes altoel intervalo tiene que ser maacutes ancho para intentar atrapar el valor de micro
2 Este es un ldquoejercicio trampardquo Las condiciones no se cumplen porque la muestra es demasiadopequentildea y desconocemos la desviacioacuten tiacutepica poblacional iexclNo debe hacerse usando Z Esnecesario usar en su lugar la t de Student como se explica en la Seccioacuten 64 del libro (paacuteg224)
3 A diferencia del anterior este ejercicio se puede hacer con Z porque la muestra es sufi-cientemente grande Usando el fichero Tut06-IntConf-Media-UsandoZ-EstadisticosR seobtiene sin dificultad este intervalo
1322 lt micro lt 1328 es decir micro = 1325plusmn 02793
Compaacuteralo con el primer apartado Fiacutejate en que los datos son iguales salvo por el tamantildeode la muestra Y al disponer de una muestra mucho maacutes grande la anchura del intervalose ha reducido mucho (la precisioacuten ha aumentado) de manera que este intervalo al 99 resulta maacutes estrecho que el intervalo al 90 que obtuvimos cuando la muestra era pequentildeaLa leccioacuten que hay que aprender aquiacute es que como nos dice la intuicioacuten a mayor tamantildeo demuestra maacutes precisioacuten en los resultados
4 Para hacer este ejercicio debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRcopiar el vector de datos introducir el nivel de confianza y comentar las liacuteneas que no se usa-raacuten Ademaacutes puesto que conocemos σ es muy importante que introduzcas ese valor amano en la variable s En caso contrario R calcularaacute y usaraacute la cuasidesviacioacuten tiacutepica conlo que el resultado no seriacutea correcto (la muestra es demasiado pequentildea) Las liacuteneas afectadasdel principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vectormuestra = c(309306279244254352307267299282294357
238324316345324297339297268291284315315) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo Para eso escribe el nombre entre las comillas En RStudio puedes usar el tabulador como ayuda (setwd(dir=)) SI NO SE USA ESCRIBE AL PRINCIPIO DE ESTA LINEA
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra = readtable(file= header = sep= dec=)
47
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = 05 ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
Fiacutejate en que el vector de datos ocupa dos filas de coacutedigo pero eso no afecta al correctofuncionamiento del fichero El resultado tras ejecutar el coacutedigo del fichero es el intervalo
2805 lt micro lt 3197 es decir micro = 3001plusmn 0196
Observa que el valor X asymp 3001 en este caso no es un dato Hay que calcularlo pero tambieacutenforma parte de la salida del programa
5 En este apartado tambieacuten debes usar el fichero Tut06-IntConf-Media-UsandoZ-MuestraEnBrutoRpero previamente tienes que guardar el fichero de datos en alguna carpeta de tu ordenadorLuego introduce en la liacutenea correspondiente del fichero la ubicacioacuten de esa carpeta (en micaso veraacutes que he usado como carpeta mi Escritorio en una maacutequina con Windows 7) Ade-maacutes introduce el nombre del fichero de datos y el nivel de confianza deseado Las liacuteneasafectadas del principio del fichero quedaraacuten asiacute
Una posibilidad es que tengas la muestra como un vector SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEA muestra =
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv header=FALSE
sep= dec=)[ 1]
LEE ESTAS INSTRUCCIONES ATENTAMENTE Si la muestra tiene mas de 30 elementos calculamos el valor de s la cuasidesviacion tipica de la poblacion Si la poblacion es normal y conoces sigma la desviacion tipica de la poblacion puedes CAMBIAR A MANO s por sigma aunque sea nlt30 SI LA MUESTRA TIENE lt 30 ELEMENTOS Y DESCONOCES SIGMA NO USES ESTE FICHERO ASEGURATE DE HABER ENTENDIDO ESTAS INSTRUCCIONES
(s = sd(muestra) ) O sigma lee las instrucciones
y el nivel de confianza deseadonc = 095
El resultado tras ejecutar el coacutedigo del fichero es el intervalo
7093 lt micro lt 7369 es decir micro = 7231plusmn 01381
De nuevo el valor X asymp 7231 se obtiene como parte de la salida del programa
48
bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

bull Ejercicio 7 paacuteg 16
Ejecuta este comando
IntervaloMediaZ[1325 23 10 099]
bull Ejercicio 8 paacuteg 19
El fichero adjunto
muestra como se obtiene la solucioacuten
bull Ejercicio 9 paacuteg 22
Vamos a guardar en k los grados de libertad para todos los apartados
k = 15
Y ahora vamos con cada uno de los apartados Por si te has despistado recuerda que en lasdistribuciones continuas a diferencia de lo que sucede por ejemplo en la binomial no hay ningunadiferencia entre lt y le o entre gt y ge Los tres primeros ejercicios piden una Probabilidad y poreso usamos pt Los siguientes piden un cuantil Quantile en ingleacutes y por eso usamos qt
1 pt(-1341 df=k)
[1] 0099937
2 Se puede hacer de dos formas
1 - pt(2602 df=k)
[1] 001001
pt(2602 df=k lowertail=FALSE)
[1] 001001
49
Paacutegina
()
29072014 212012
Paacutegina
3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63
| Intervalo de confianza para la media (nc=1-alfa) | ||||||||||||||||
| Poblacioacuten normal varianza conocida | ||||||||||||||||
| Media | 1325 | |||||||||||||||
| Desviacioacuten tiacutepica | 23 | larr | Puedes usar la cuasidesviacioacuten tiacutepica si la muestra es grande (ngt30 al menos) | |||||||||||||
| Tamantildeo de la muestra | 10 | |||||||||||||||
| alfa | alfa2 | valor criacutetico | ||||||||||||||
| Nivel de confianza (1-α) | 095 | rarr | 005 | rarr | 0025 | rarr | 19599639845 | |||||||||
| Intervalo de confianza | Semi-anchura | |||||||||||||||
| 13107 | lt μ lt | 13393 | 14255285743 | |||||||||||||

3 pt(1753 df=k) - pt(-1753 df=k)
[1] 089999
4 qt(095 df=k)
[1] 17531
iquestVes la relacioacuten con el apartado anterior En el apartado anterior las dos colas suman 01Asiacute que iquestcuaacutel es el aacuterea de cada una de las colas iquestY cuaacutel es el aacuterea de la cola derecha en lafigura de este apartado
5 De dos formas
qt(0025 df=k lowertail=FALSE)
[1] 21314
qt(1 - 0025 df=k)
[1] 21314
50
En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

En el segundo meacutetodo fiacutejate en que siempre que usamos el truco de restar de 1 lo querestamos tiene que ser una probabilidad p de forma que hacemos 1minus p Cuando usamos qtla probabilidad estaacute dentro de la funcioacuten y por eso expresiones como qt(1-p ) tienensentido En cambio una expresioacuten como 1 - qt() es casi siempre el resultado de unerror de interpretacioacuten
6 qt(005 df=k)
[1] -17531
El resultado es el opuesto del que obtuvimos en el apartado 4 y la figura deberiacutea dejar claropor queacute es asiacute iquestCuaacutento vale la cola derecha en la figura del apartado 4
7 De dos formas
qt(0975 df=k lowertail=FALSE)
[1] -21314
qt(1- 0975 df=k)
[1] -21314
51
La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

La relacioacuten con el apartados 5 debe estar clara a estas alturas
8 Este apartado es el maacutes directamente se relaciona con la construccioacuten de los intervalos deconfianza Y en este caso es mejor empezar por la figura
Como muestra la figura el aacuterea conjunta de las dos colas debe ser igual a 1 minus 095 = 005Asiacute que el aacuterea de la cola derecha no sombreada es 0025 Y eso demuestra que el valor quebuscamos es por tanto el que mismo que hemos calculado en el anterior apartado
9 Dejamos la figura de este apartado al lector es muy parecida a la del anterior cambiandosoacutelo los valores numeacutericos En cualquier caso la suma conjunta de las dos colas es en esteapartado 1 minus 093 = 007 Por lo tanto la cola derecha vale 0035 Y entonces el valor seobtiene con
qt(0035 df=k lowertail=FALSE)
[1] 19509
qt(1- 0035 df=k)
[1] 19509
bull Ejercicio 11 paacuteg 23
En R el primer valor se obtiene de una de estas dos maneras
pt(23 df=21 lowertail=FALSE)
[1] 0015901
1 - pt(23 df=21)
[1] 0015901
Y el segundo mediante
pt(23 df=12) - pt(-12 df=12)
[1] 085325
En GeoGebra para el primer valor puedes usar la Calculadora de Probabilidades o maacutes directa-mente el comando
1 - DistribucioacutenT[21 23]
Para el segundo valor usariacuteamos
DistribucioacutenT[12 23] - DistribucioacutenT[12 -12]
52
bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

bull Ejercicio 12 paacuteg 24
En R de cualquiera de estas maneras
qt(093 df=12)
[1] 15804
qt(007 df=12 lowertail=FALSE)
[1] 15804
En GeoGebra con
DistribucioacutenTInversa[12 093]
bull Ejercicio 13 paacuteg 24
1 Como se explica en la paacutegina que sigue al enunciado de este ejercicio la funcioacuten DISTRT deCalc con modo = 1 usa la cola derecha de la distribucioacuten t de Student
2 En R puedes calcular ese valor con
pt(05 df=3 lowertail=FALSE)
[1] 032572
bull Ejercicio 14 paacuteg 28
1 El intervalo es micro = 1325plusmn 1645 o de otro modo
1309 lt micro lt 1341
2 El intervalo es micro = 3192plusmn 04604 o de otro modo
2732 lt micro lt 3652
El valor X = 3192 se obtiene como parte de la salida del programa
3 Despueacutes de elegir el directorio de trabajo (el que contiene el fichero) en el paso 2 hemosusado la funcioacuten readtable asiacute
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsvheader=FALSE sep= dec=)[1]
El intervalo es micro = 35plusmn 05616 o de otro modo
2939 lt micro lt 4062
De nuevo el valor X = 35 se obtiene como parte de la salida del programa
4 Al usar la t de Student con n = 450 (y por tanto 449 grados de libertad) se obtiene un intervalode confianza con semianchura 02805 frente a la semianchura 02793 que se obtuvo en elEjercicio usando Z La diferencia entre los dos intervalos es del orden de mileacutesimas asiacute queson praacutecticamente iguales Este ejercicio indica que si usamos la t de Student en lugar de Zcuando las muestras son grandes los resultados seraacuten muy parecidos
53
5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

5 Mostramos aquiacute el coacutedigo correspondiente al intervalo al 95 Es simplemente el ficheroplantilla Tut06-IntConf-Media-UsandoT-EstadisticosR del que hemos eliminado los co-mentarios introductorios y las instrucciones Para hallar el intervalo al 99 soacutelo hay quecambiar una liacutenea del coacutedigo
Introduce el numero de datos de la muestran = 10
Introduce aqui el valor de xbar la media muestralxbar = 235
Cuasidesviacion tipica muestrals = 061
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO(alfa = 1 - nc )
[1] 005
Calculamos el valor critico
(t_alfa2 = qt( 1 - alfa 2 df=n-1 ) )
[1] 22622
y la semianchura del intervalo(semianchura=t_alfa2 s sqrt(n) )
[1] 043637
Y el intervalo de confianza (ab) para mu es estexbar + c(-1 1) semianchura
[1] 19136 27864
bull Ejercicio 15 paacuteg 30
Aseguacuterate usando por ejemplo setwd de que el directorio de trabajo (en mi caso es el Escritorio)es el que contiene el fichero de datos Tut06-DatosIntConfConStudentcsv Entonces leemos losdatos en un vector muestra como hicimos en el Ejercicio 14 y aplicamos ttest
muestra = readtable(file=datosTut06-DatosIntConfConStudentcsv sep= dec=)[1]TtestMuestra = ttest(muestra conflevel=095)(intervalo = TtestMuestra$confint)
[1] 29385 40618 attr(conflevel) [1] 095
La respuesta es la misma que en el apartado 3 del Ejercicio 14
bull Ejercicio 16 paacuteg 32
54
1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

1 Para el primer apartado ejecutamos
IntervaloMediaT[ 1325 23 10 095 ]
2 Para el segundo ejecutamos consecutivamente
datos = 314 371 277 408 418 151 365 341 451 227 328226 280 254 377IntervaloMediaT[datos 095 ]
bull Ejercicio 17 paacuteg 34
1 La probabilidad es aproximadamente 001
2 La probabilidad es aproximadamente 02493
3 La probabilidad es aproximadamente 00492
55
4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

4 El valor es aproximadamente 16919
56
5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

5 El valor es aproximadamente 20879
6 El uacuteltimo apartado es el maacutes difiacutecil a causa de la falta de simetriacutea Como ilustra la siguientefigura nuestro objetivo es conseguir que la zona central sombreada que corresponde a laprobabilidad P (y1 lt Y lt y2) tenga un aacuterea igual a 090 Eso significa que las dos colassuman 010 Pero como ademaacutes son iguales (es esencial saber esto porque no hay simetriacutea)eso significa que cada una de ellas vale 005
En particular eso implica que
P (Y lt y2) = 090 + 005 = 095
57
y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

y queP (Y lt y1) = 005
Ahora es faacutecil proceder como en el apartado 1 para obtener y1 = 33251 e y2 = 16919 iquestVesla relacioacuten entre y2 y el apartado 4 de este ejercicio iquestY ves tambieacuten que no hay ninguacuten tipode simetriacutea entre y1 e y2
bull Ejercicio 18 paacuteg 34Usa el menuacute Opciones de GeoGebra para ver maacutes cifras decimales si es necesario
Apartado 2
1- ChiCuadrado[9 114]
Apartado 3
ChiCuadrado[9 169] - ChiCuadrado[9 147]
Apartado 4 (Atencioacuten a la posicioacuten del 1minus p)
ChiCuadradoInversa[9 1- 005]
Apartado 6 El valor y1 se obtiene con
ChiCuadradoInversa[9 005]
mientras que el valor y2 se obtiene con
ChiCuadradoInversa[9 095]
bull Ejercicio 19 paacuteg 35
1 Coacutedigo del apartado 1
Fijamos los grados de libertad
k = 9
Apartado 1
pchisq(209 df=k)
[1] 0010037
Apartado 2
1 - pchisq(114 df=k)
[1] 024928
pchisq(114 df=k lowertail=FALSE)
[1] 024928
58
Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

Apartado 3
pchisq(169 df=k) - pchisq(147 df=k)
[1] 0049208
Apartado 4
qchisq(1 - 005 df=k)
[1] 16919
qchisq(005 df=k lowertail=FALSE)
[1] 16919
Apartado 5
qchisq(001 df=k)
[1] 20879
Apartado 6
y1 se obtiene con
qchisq(005 df=k)
[1] 33251
mientras que y2 se obtiene con
qchisq(095 df=k)
[1] 16919
2 Coacutedigo del apartado 2 El valor a que cumple
P (χ24 lt a) = 005
es
qchisq(005 df=4)
[1] 071072
y el valor b que cumpleP (χ2
4 gt b) = 005
se calcula de una de estas dos formas
qchisq(1 - 005 df=4)
[1] 94877
qchisq(005 df=4 lowertail=FALSE)
[1] 94877
59
bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

bull Ejercicio 20 paacuteg 35
En R para el primer ejemplo hacemos
pchisq(15 df=12) - pchisq(10 df=12)
[1] 037452
y para el segundo uno de estos comandos
qchisq(713 df=7 lowertail=FALSE)
[1] 6011
qchisq(1 - (713) df=7)
[1] 6011
En GeoGebra para el primero ejecuta en la Liacutenea de Entrada
ChiCuadrado[12 15] - ChiCuadrado[12 10]
y para el segundo
ChiCuadradoInversa[7 1 - (713)]
bull Ejercicio 21 paacuteg 37
El coacutedigo es este
n = 30k = n - 1s = 26
nc = 095(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
(chiAlfa2 = qchisq(1 - alfa2 df=k))
[1] 45722
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 16047
(intervalo = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 20707 34952
60
bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

bull Ejercicio 22 paacuteg 37
Para el segundo apartado el coacutedigo del fichero con los datos de ese apartado es este
Introducimos el valor de la desviacion tipica muestrals = 281
el tamantildeo de la muestran = 87
y el nivel de confianza deseadonc = 095
NO CAMBIES NADA DE AQUI PARA ABAJO Calculamos alfa(alfa = 1 - nc)
[1] 005
(alfa2 = alfa 2)
[1] 0025
y los grados de libertad
(k= n - 1)
[1] 86
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 11354
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 62239
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 59807 109107
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 24455 33031
Para el tercer apartado fijamos el directorio de trabajo (en mi caso el Escritorio de una maacutequinaWindows 7) para que sea el que contiene el fichero de datos y usamos este coacutedigo
Una posibilidad es que tengas la muestra como un vectormuestra = SI NO SE USA ESCRIBE AL PRINCIPIO DE LA LINEA
61
Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

Si lees la muestra de un fichero csv 1 selecciona el directorio de trabajo
2 Ahora introduce entre las comillas el nombre del fichero y el tipo de separador etc
SI NO SE USA ESCRIBE AL PRINCIPIO DE LA SIGUIENTE LINEAmuestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv dec=)[ 1]
Introducimos el nivel de confianza deseadonc=095
NO CAMBIES NADA DE AQUI PARA ABAJO
alfa(alfa = 1 - nc )
[1] 005
Numero de datos de la muestra grados de libertad(n = length(muestra))
[1] 800
k = n - 1
Cuasidesviacion tipica muestral(s = sd(muestra))
[1] 71999
Calculamos los valores criticos necesarios
(chiAlfa2 = qchisq(1 - (alfa2) df=k))
[1] 87923
(chiUnoMenosAlfa2 = qchisq(alfa2 df=k))
[1] 72256
Para la varianza el intervalo de confianza sera extremo inferior(intervaloVar = s^2 k c(chiAlfa2 chiUnoMenosAlfa2))
[1] 47108 57322
Y para la desviacion tipica el intervalo de confianza es este(intervaloS = s sqrt(k c(chiAlfa2 chiUnoMenosAlfa2)))
[1] 68635 75711
bull Ejercicio 23 paacuteg 39
Ejecuta uno tras otro estos comandos en la Liacutenea de Entrada de GeoGebra Veraacutes que la estructura
62
de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63

de la construccioacuten es praacutecticamente la misma que hemos usado en R salvo detalles sintaacutecticos decada programa El objeto entre llaves en el uacuteltimo comando es una lista de GeoGebra y como vesse puede multiplicar listas por nuacutemeros (una especie de ldquooperacioacuten vectorialrdquo como las de R peroa la GeoGebra)
n = 17k = n - 1s = 21nc = 099alfa = 1 - ncalfa2 = alfa 2chiAlfa2 = ChiCuadradoInversa[k 1 - alfa2]chiUnoMenosAlfa2 = ChiCuadradoInversa[k alfa2]intervalo = s sqrt(k chiAlfa2) sqrt(k chiUnoMenosAlfa2)
bull Ejercicio 24 paacuteg 41Ejecutamos el coacutedigo sin fijar el valor de sigma (recuerda fijar el directorio de trabajo) y elresultado es erroacuteneo
muestra = readtable(file=datosTut06-IntConf-Media-UsandoZ-datoscsv sep= dec=)[1](intAsBio = cimuz(data=muestra conf=095 summarized=FALSE))
95 z Confidence interval for population mean Estimate 25 975 72313 71436 73190
bull Ejercicio 25 paacuteg 42
muestra = readtable(file=datosTut06-datosIntConfDesvTipicacsv sep= dec=)[1](intAsBio = cisigma(data=muestra conf=095 summarized=FALSE))
95 Confidence interval for population variance Estimate 25 975 51838 47108 57322
El intervalo que hemos obtenido es para la varianza σ2 Para obtener un intervalo para σ hacemos
sqrt(intAsBio$ci[23])
[1] 68635 75711
Puedes compararlo con la solucioacuten del Ejercicio 22 que estaacute en la paacutegina 61
Fin del Tutorial06 iexclGracias por la atencioacuten
63





























