Embed Size (px)
Citation preview

Volt: Interaktives Volumenrendering mit CUDA
Oliver Jato, André Hinkenjann
Labor für Computergra�k
Hochschule Bonn-Rhein-Sieg
Grantham-Allee 20
53757 Sankt Augustin
Tel.: +49 (0)2241 / 865 - 229
Fax: +49 (0)2241 / 865 - 8229
E-Mail: {[email protected]|[email protected]}
Zusammenfassung: In diesem Beitrag wird der interaktive Volumenrenderer Volt für die
NVIDIA CUDA Architektur vorgestellt. Die Beschleunigung wird durch das Ausnutzen der
technischen Eigenschaften des CUDA Device, durch die Partitionierung des Algorithmus
und durch die asynchrone Ausführung des CUDA Kernels erreicht. Parallelität wird auf dem
Host, auf dem Device und zwischen Host und Device genutzt. Es wird dargestellt, wie die
Berechnungen durch den gezielten Einsatz der Ressourcen e�zient durchgeführt werden. Die
Ergebnisse werden zurückkopiert, so dass der Kernel nicht auf dem zur Anzeige bestimmten
Device ausgeführt werden muss. Synchronisation der CUDA Threads ist nicht notwendig.
Stichworte: Volumenrendering, Ray Casting, 3D Visualisierung, CUDA, Echtzeit
1 Einleitung
Interaktivität, hohe Visualisierungsqualität und günstige Hardware waren für lange Zeit Zie-
le, die sich im Feld der Volumenvisualisierung nicht miteinander vereinbaren lieÿen. Dass
Volumendaten besonders zur Darstellung ober�ächenloser Phänomene geeignet sind spricht
für direkte Verfahren wie das Ray Casting, das in diesem Zusammenhang auch als direktes
Volumenrendering bezeichnet wird. Zusätzlich ist Ray Casting durch die erreichbare visuelle
Qualität anderen Verfahren überlegen. Der Rechenaufwand und die Anforderungen an den
Speicher sind allerdings hoch. Es handelt sich um ein Bildraumverfahren. Pro Bildpunkt
wird ein Sehstrahl abgetastet und für jeden einzelnen Abtastpunkt sind mehrere unregel-
mäÿige Speicherzugri�e nötig. Interpolationen und Beleuchtungsberechnungen müssen auf
Basis von Nachbarschaften durchgeführt werden. Dabei ist Ray Casting aber hervorragend
parallelisierbar. Die Berechnungen der einzelnen Sehstrahlen sind voneinander unabhängig
und es ist ein �exibler und unkomplizierter Algorithmus, der einfach zu erweitern ist.
Angetrieben durch den Entertainment Bereich steigt die Leistung und Flexibilität von
GPUs beständig an. Ursprünglich stellten sie eine Pipeline mit fester Funktionalität zur Ver-
fügung, heutzutage sind sie sehr frei programmierbar. Um seine GPUs gänzlich für gra�kferne
Programmierung zu ö�nen, hat der Hersteller NVIDIA die CUDA Architektur entworfen.

Hierdurch stehen kostengünstige massiv parallele Systeme zur Verfügung, die mehrere hun-
dert Rechenkerne mit Zugri� auf einen gemeinsamen Adressraum besitzen. Durch CUDA
ist es möglich, hochwertige interaktive Volumenvisualisierung auf aktueller und verbreiteter
Standardhardware zu betreiben. Dies kann aber nur erfolgreich sein, wenn die technischen
Eigenschaften der Hardware beachtet werden.
Nach einer Betrachtung bisheriger Entwicklungen im Volumenrendering (Abschnitt 2),
besonders im Bereich der GPUs, wird der Volumenrenderer Volt [Jat10] (Abb. 1) vorge-
stellt. An seinem Beispiel wird gezeigt, wie der grundlegende Algorithmus zum direkten
Volumenrendering e�zient mit CUDA umgesetzt werden kann, so dass gleichzeitig hohe
Visualisierungsqualität und Interaktivität erreicht werden. Dazu wird ein Überblick über
den angewendeten Visualisierungsalgorithmus und die Anwendungsarchitektur gegeben (Ab-
schnitt 3). Danach werden Eigenschaften des Kernels beschrieben und relevante Parameter
der CUDA Architektur betrachtet (Abschnitt 4). Abschlieÿend folgen Ergebnisse (Abschnitt
5) und das Fazit (Abschnitt 6).
Abbildung 1: Volt Volumenrenderer mit Transferfunktionseditor
2 Stand der Technik
Slicing In [CN94] wird Volumenvisualisierung durch Verwendung von Texturhardware als
Slicing beschrieben. Das verwendete Silicon Graphics RealityEngine-System unterstützt drei-
dimensionale Texturen. Das Volumen wird an äquidistant geschichteten Schnittebenen ab-
getastet, wodurch Proxygeometrie texturiert wird. Hier wird bereits die Texturhardware zur
schnellen trilinearen Interpolation genutzt. Die texturierten Polygone werden im Back-To-
Front Verfahren zusammengefügt. Bei perspektivischer Projektion sind die Abstände der
Abtastpunkte auf den verschiedenen Sehstrahlen unterschiedlich. Werden statt einer dreidi-
mensionalen Textur drei zweidimensionale Texturstapel verwendet, so variiert der Abstand
zusätzlich noch mit dem Betrachtungswinkel.

In [WE98] wird Slicing um di�use Schattierung für Isoober�ächen erweitert. Dazu werden
die Materialgradienten im Voraus berechnet, normalisiert und zusammen mit den Dichtewer-
ten in einer 3D-Textur gespeichert. Die Berechnung des Gradienten für einen Abtastpunkt
führt hier aber zu Artefakten in der Schattierung, da die Interpolation der umliegenden
Gradienten durch die GPU keinen normalisierten Vektor mehr zum Ergebnis hat.
Prä-Integration wird in [EKE01] für Slicing umgesetzt. Damit sind Volumen mit hoch-
frequenten Transferfunktionen ohne Erhöhen der Abtastrate darstellbar. Gleichzeitig kann
das Volumenrenderingintegral genauer approximiert werden, ohne dass sich dies auf die Ge-
schwindigkeit auswirkt. Dabei werden alle möglichen Strahlsegmente in einem Vorverarbei-
tungsschritt integriert und die Ergebnisse in einer Textur gespeichert. Da der Berechnungs-
aufwand für diese Textur hoch ist, gestalten sich Änderungen an Farbe und Opazität zur
Laufzeit schwierig. An den Abtastpunkten lässt sich zudem keine zuverlässige Schattierung
für das gesamte Strahlsegment berechnen.
Die Parallelisierung von Slicing wird in [MHE01] und [MWMS07] untersucht. Die Volu-
men werden für ein Sort-Last Verfahren in kleinere Blöcke unterteilt und auf einem Cluster
berechnet.
Ray Casting In [PBMH02] wird erstmals Ray Tracing auf programmierbarer Gra�khard-
ware implementiert. Darauf folgen [KW03] und [RGW+03] mit Volumenrenderern, die Early
Ray Termination (ERT) und Empty Space Leaping nutzen. Die Approximation von Licht-
streuung und volumetrischen Schatten wird in [KPH+03] beschrieben. In [SSKE05] wird
erstmals ein Single-Pass Algorithmus vorgestellt, da die Nutzung von Schleifen und Ver-
zweigungen in Shaderprogrammen möglich geworden ist.
Die Entwicklung des Prototypen eines Volumenrenderers für CUDA hat in [MHS08] zum
Ergebnis, dass die gewonnene Flexibilität keine Einbuÿen in der Performanz mit sich bringt.
In [ZCC09] wird ebenfalls von einer Implementierung für CUDA berichtet, die im Vergleich
zur eigenen, älteren Implementierung mit einer Shadersprache, schneller sein soll.
In [MRH10] wird eine Technik beschrieben, die Zugri�e auf den Texturspeicher verringert.
Die Sehstrahlen eines CUDA Thread Block erhalten denselben Startpunkt und schreiten
das Volumen als Strahlenfront ab. Der Shared Memory des Device wird als Cache für die
Samples verwendet. Ist der Cache gefüllt, werden die Strahlen von ihrer letzten Startposition
neu abgeschritten und alle Berechnungen werden auf Grundlage des Caches durchgeführt.
Bei Perspektivprojektion sind die Materialgradienten hierdurch weniger genau und zur ERT
müssen alle Strahlen eines Thread Blocks die maximale Sättigung erreicht haben. Dieses
Verfahren steigert die Performanz, wenn für Berechnungen oft auf dieselben Voxel zugegri�en
werden muss.

3 Anwendungsarchitektur
3.1 Visualisierungsalgorithmus
Zur Abtastung des Datenraumes wird direkte Volumenvisualisierung im Front-To-Back Ver-
fahren angewendet. Vom Volumen emittierte Strahlung wird an den Abtastpunkten durch
approximative Sehstrahlintegration akkumuliert. Dabei wird auch Absorption durch Über-
deckung berücksichtigt. Um hohe Frequenzen im Volumen mit möglichst geringem Fehler
darstellen zu können wird Postklassi�kation verwendet. Die Übersetzung der Funktionswerte
zu Farbe und Opazität wird an jedem einzelnen Abtastpunkt erst nach seiner Rekonstruk-
tion vorgenommen. An jedem Abtastpunkt, dessen Opazität einen geringen Schwellenwert
überschreitet, wird der Materialgradient berechnet. Dieser dient als Approximation einer
Ober�ächennormalen zur Schattierung nach dem Blinn-Phong Modell. Die Opazität homo-
gener Bereiche kann zur Betonung von Materialgrenzen abgesenkt werden.
Um den Anwender bei der Exploration von Volumen zu unterstützen, können die Far-
ben und Opazitäten der rekonstruierten Werte über einen Transferfunktionseditor interaktiv
verändert werden. Abweichungen in der Transparenz des Volumens durch Ändern der Ab-
tastrate werden dabei mit Opazitätskorrektur auf Basis der Integrationsschrittweite vermie-
den. Durch die Gewichtung der Farbwerte mit den Opazitäten (assoziierte Farben) in der
Look-Up-Table (LUT) der Transferfunktion wird Color Bleeding zwischen transparenten und
opaken Bereichen verhindert.
Zur Bestimmung der Start- und Endpunkte auf den Sehstrahlen kommen ein Bounding
Box Schnitttest nach der Kay & Kajiya Slab-Method und ERT zum Einsatz.
3.2 Aufgabenpartitionierung
Ziel der Architektur und Aufgabenpartitionierung ist es, die optimale Auslastung des Device
zu gewährleisten und ein Blockieren der gra�schen Ober�äche zu verhindern, da die Transfer-
funktion zur Manipulation der optischen Eigenschaften der Volumendaten zur Laufzeit bear-
beitbar sein soll. Die Anwendung ist horizontal und vertikal partitioniert (Abb. 2). Sie stellt
eine mehrstu�ge Pipeline dar, deren Abschnitte durch unterschiedliche Host Threads bear-
beitet werden. An den Synchronisationspunkten werden über Pu�erobjekte Speicheradressen
getauscht. Der CUDA Kernel führt nur Berechnungen durch, die von einem Sehstrahl ab-
hängig sind und die Farbe eines Bildpunktes zum Ergebnis haben. Alle Berechnungen, die für
jeden CUDA Thread dieselbe Eingabe und dasselbe Ergebnis hätten, werden zuvor auf dem
Host durchgeführt. Aus diesem Grund wird auch die Opazitätskorrektur mit einer Potenz-
funktion schon auf dem Host durchgeführt. Zusätzlich wird jede arithmetische Operation,
die auf dem Device kostspielig ist, nach Möglichkeit auf dem Host in eine günstigere Form
gebracht. Muss zum Beispiel jeder CUDA Thread mit demselben Wert eine Division durch-
führen, dann wird auf dem Host das Reziprok berechnet und dieses dem CUDA Kernel als
Teil seiner Kon�guration übergeben. Hierdurch wird das Device deutlich entlastet.

Abbildung 2: Partitionierung der Anwendung auf Host und Device
Benutzerober�äche Im Thread der Benutzerober�äche werden Interaktionen registriert
und fertig berechnete Einzelbilder in das Anwendungsfenster gezeichnet. Werden durch Edi-
toren Änderungen an der Transferfunktion oder an Kon�gurationsparametern vorgenommen,
werden diese ebenfalls registriert und signalisiert.
Szenenkon�guration Die Szenenkon�guration verarbeitet die, im letzten Durchlauf ak-
kumulierten, Benutzereingaben und erzeugt hieraus das Szenenkon�gurationspaket. Hier sind
alle für Interaktivität notwendigen Parameter für den Kernel enthalten. Dies sind der Ort
und die Richtung des ersten Sehstrahls (Firstray), zwei Vektoren zur Bestimmung der Lage
und Kantenlänge der Pixel, die transformierte Bounding Box in Ebenendarstellung für den
Schnitttest und die inverse Transformationsmatrix. Zur Optimierung werden die Daten im
Structure of Arrays Layout organisiert.
Einzelbildberechnung Im Thread zur Einzelbildberechnung muss anfangs die statische
Kon�guration der Szene in einen Kon�gurationsblock geschrieben werden. Er enthält un-
veränderliche Werte, die nur einmal zum Device übertragen werden müssen. Dies sind die
Adresse des Ergebnispu�ers auf dem Device und die Abmessungen der Zeichen�äche. Über
die Ober�äche veränderbare Laufzeitparameter werden, getrennt von der Szenenkon�gurati-
on, in einem Paket zur Laufzeitkon�guration abgelegt. Diese Kon�gurationen werden in der
Regel nicht gleichzeitig durch den Benutzer verändert. Im Laufzeitkon�gurationsblock be�n-
den sich unter anderem die maximale Strahlsättigung für ERT, die normalisierte Schrittweite,
ihr Reziprok und Beleuchtungsparameter. Werden Änderungen an der Transferfunktion oder
an Laufzeitparametern signalisiert, wird durch diesen Thread auch die Aktualisierung durch-
geführt. Er ist auch für die Initialisierung des Device, den Datenaustausch mit ihm und den
Start des Kernels verantwortlich. Vor jedem Aufruf des Kernels wird geprüft, ob erst geän-
derte Daten zum Device übertragen werden müssen. Der Kernel wird asynchron gestartet, so
dass der Host Thread nicht blockiert. Dadurch können schon alle notwendigen Berechnungen

durchgeführt werden, die vor dem nächsten Start des Kernels abgeschlossen sein müssen. Vor
dem nächsten Kernelaufruf muss der Ergebnispu�er vom Device kopiert werden. Da Kernel
und Kopieroperation im Default Stream gestartet werden, blockiert der Host Thread an die-
ser Stelle solange, bis der vorhergehende Kernelaufruf beendet ist. Der Kernel startet sofort
neu, nachdem der Ergebnispu�er und veränderte Kon�gurationen übertragen sind.
Pixelpu�ererzeugung Dieser Thread holt den Ergebnispu�er von der Einzelbildberech-
nung ab. Da die Zeichen�äche nur durch den Thread der Benutzerober�äche manipuliert
werden darf, erhält er über den mit der Zeichen�äche gemeinsamen Pu�er ein durch die
Ober�äche darstellbares Objekt. Dieses befüllt er mit den Daten des Ergebnispu�ers und
signalisiert dann die Notwendigkeit einer Aktualisierung der Zeichen�äche.
4 Volumenrendering mit CUDA
4.1 Kon�guration
Während der Sehstrahlintegration wird unregelmäÿig auf Speicher zugegri�en und der Wert
eines Abtastpunktes muss anhand seiner Nachbarschaft rekonstruiert werden. Daher wird der
Volumenspeicher als CUDA Array alloziert und an eine dreidimensionale Textur für float
Werte gebunden. So werden die auf Lokalität optimierten Texturcaches der Multiprozessoren
(MP) genutzt und beim Auslesen des Volumens wird der Wert am Abtastpunkt von der
Special Function Unit (SFU) des Device durch trilineare Interpolation ermittelt. Für die
LUT der Transferfunktion wird ebenfalls Speicher als CUDA Array alloziert und an eine
eindimensionale Textur gebunden. Da die LUT bei Änderungen neu übertragen werden muss,
liegt sie auf dem Host als Struktur mit einem CUDA float4 Array vor. Dies garantiert
zum einen korrektes Speicheralignment, wodurch die Übertragungsgeschwindigkeit gesteigert
wird, zum anderen wird so die Verwendung der SFU zur Interpolation in den vier RGBA
Kanälen möglich.
Die bereits in Abschnitt 3.2 erwähnten Kon�gurationsblöcke enthalten Variablen, die
von den CUDA Threads nur gelesen werden. Da es allgemeingültige Parameter sind und alle
aktiven Threads eines CUDA Warps sich immer an derselben Programmadresse be�nden,
greifen sie auch simultan auf dieselben Kon�gurationsvariablen zu. Daher wird für die drei
Kon�gurationsblöcke der Constant Memory des Device verwendet, der nur vom Host ver-
ändert werden kann. Für diesen existiert auf jedem MP ein Cache. Wenn alle Threads eines
Warps gleichzeitig dieselbe Adresse im Constant Memory lesen, ist ein Broadcast Speicher-
zugri� möglich. Sobald sich der Wert im Cache be�ndet, ist eine Leseoperation so schnell wie
auf einem Register. Durch die Partitionierung der gesamten Kon�guration in drei Blöcke,
unterschieden nach Aktualisierungscharakteristiken, werden redundante Übertragungen ver-
mieden und die verfügbare Bandbreite besser genutzt.
Für den Ergebnispu�er wird ein Speicherbereich im Global Memory des Device reserviert.
Auf dem Host wird über die CUDA API Page-Locked Host Memory alloziert, was Paging

durch das Betriebssystem verhindert und damit den Kopiervorgang des Pu�ers optimiert.
Die Projektions�äche wird im Sort-First Ansatz uniform unterteilt. Um die Texturcaches
besser zu nutzen, werden den Threads einesWarps benachbarte Sehstrahlen zugewiesen. Die
optimale Vorgehensweise hängt hier von der Hardwarerevision ab. Bei Devices mit Compute
Capability (CC) 1.0 sind Zugri�e auf denGlobal Memory nur in einem Verbund durchführbar,
wenn jeder Thread eines Half-Warps auf das Wort zugreift, dass seinem Index entspricht und
wenn das gesamte Speichersegment am 16-fachen der Gröÿe des Datentyps ausgerichtet ist.
Wird dies nicht beachtet, werden die Operationen auf dem Ergebnispu�er serialisiert. Für die
Anordnung der Sehstrahlen eines Half-Warps bedeutet dies aber, dass Lokalität und somit
die Texturcaches nicht optimal genutzt werden können. Bei neueren Hardwarerevisionen sind
die Bedingungen für verbundene Speicherzugri�e geändert worden. Ab CC 2.0 werden Global
Memory Zugri�e eines gesamten Warp in so viele Einzeloperationen unterteilt, wie unter-
schiedliche L1 Cache Lines (128 Byte) des MP betro�en sind. Sinnvolle Anordnungen der
Threads einesWarps liegen zwischen zwei übereinanderliegenden Reihen zu je 16 Sehstrahlen
und zwei mal vier übereinanderliegenden Reihen zu je vier Sehstrahlen. Die Letzte Kon�gu-
ration erzeugtWarps mit maximaler Ortskohärenz. Wie viele Warps zu einem CUDA Thread
Block zusammengefasst werden können, hängt von der Anzahl verfügbarer Register und der
Belegung des Shared Memory ab. Diese Werte unterscheiden sich ebenfalls zwischen älte-
ren und neueren Devices. Durch mehr Warps pro Block können Read-After-Write Kon�ikte
auf Registern besser verdeckt werden. Weniger Warps pro Thread Block ermöglichen jedoch
mehr aktive Thread Blocks pro MP, wodurch Latenzen von O�-Chip Speicherzugri�en besser
verdeckt werden. Eine optimale Kon�guration wird also durch die verwendete Hardware und
die Charakteristik des ausgeführten Programms bestimmt (siehe auch Abb. 5 und 6). Ein
weiterer Faktor, der durch gesteigerte Ortskohärenz minimiert wird, ist das Divergieren von
CUDA Threads. Führt ein Teil der Threads nur wenige zusätzliche Instruktionen aus, dann
bleiben durch Branch Predication die anderen Threads aktiv, ihrer Berechnungsergebnisse
werden lediglich verworfen. Sind die unterschiedlichen Ausführungspfade zu lang, werden die
Threads in Gruppen parallel verarbeitet, bis sich alle wieder an derselben Programmadres-
se be�nden. Da Threads mit benachbarten Sehstrahlen häu�g dieselben Ausführungspfade
nehmen, wird der parallele Anteil gesteigert.
4.2 Kernel
Im Kernel wird zuerst der Ergebnispu�erindex des Bildpunkts zwischengespeichert und ein
Pu�er für jeden Kanal der akkumulierten RGBA Werte initialisiert. Hierfür wird Shared
Memory verwendet, wodurch die Anzahl der benötigten Prozessorregister verringert wird.
Mit Ausnahme des Alphakanals werden diese Bereiche während der Sehstrahlintegration nur
geschrieben und erst zum Schreiben der Ergebnisfarbe wieder gelesen. Da im Shared Memory
16 (CC 1.0) bzw. 32 (CC 2.0) aufeinanderfolgende 32 Bit Worte in aufeinanderfolgenden
Speicherbänken liegen, müssen Operationen nicht serialisiert werden, da die Threads in Reihe
auf die ihrem Index entsprechenden Worte zugreifen. Solche Shared Memory Operationen

sind in einem Taktzyklus durchführbar.
Im Constant Memory be�nden sich der Firstray und zwei Pixelvektoren. Anhand dieser
berechnet jeder CUDA Thread seinen eigenen Sehstrahl. So ist es nicht nötig, für jeden
Frame alle Sehstrahlen zum Device zu übertragen, obwohl sich die Kamera auf dem Host
be�ndet. Bei der hier und auch an anderen Stellen notwendigen Normalisierung eines Vektors
wird eine reziproke Quadratwurzelfunktion der CUDA API verwendet, wodurch Divisionen
vermieden werden.
Der darau�olgende Bounding Box Schnitttest kann durch den Compiler wegen bedingter
Ausführungen nicht automatisch entrollt werden. Er ist manuell entrollt, wodurch auf die
Angaben zu den Seiten�ächen der Bounding Box im Constant Memory auch nicht dyna-
misch zugegri�en werden muss. Im Schnitttest sind Divisionen nötig, deren Divisor von der
Richtung des Sehstrahls abhängt. Daher kann auf dem Host nicht das Reziprok im Vor-
aus berechnet werden. An dieser Stelle wird eine intrinsische Divisionsfunktion des Device
verwendet. Diese benötigt weniger Prozessorzyklen und die geringere Präzision für Diviso-
ren im Bereich von y−126 bis y126 beeinträchtigt das Ergebnis nicht. Der Dividend besteht
aus dem Punktprodukt der Ebenennormalen mit dem Kameraort und dessen Summe mit
dem Abstand der Ebene zum Ursprung. Diese Berechnung ist unabhängig von Sehstrahlen
durchführbar. Sie wird für jede Ebene schon auf dem Host vorgenommen und ist Teil der
Ebenendarstellung in der Szenenkon�guration.
Im Loop zur iterativen Strahlintegration wird erst der aktuelle Abtastpunkt bestimmt.
Dessen Koordinaten werden aber nicht in einem CUDA float3 Typen abgelegt. Der Compil-
er ist bemüht die Zahl belegter Register zu minimieren um mehr aktive Warps bzw. Thread
Blocks zu ermöglichen. Dynamisch indexierte Arrays und auch Strukturtypen wie die CUDA
Vektortypen können zur Optimierung in den Local Memory ausgelagert werden, was sich ne-
gativ auf die Performanz auswirken kann. Werden statt eines Vektortypen einfache Typen
verwendet, kann der Compiler die Registerbelegung besser optimieren. Aus diesem Grund
wird die Verwendung von CUDA Vektortypen nach Möglichkeit vermieden.
Die Transformationsmatrix wird auf dem Host so berechnet, dass der Abtastpunkt durch
ihre Inverse direkt in das lokale Koordinatensystem der Volumentextur übersetzt wird. Das
Ergebnis kann damit als dreidimensionaler Index zum Auslesen der Textur verwendet werden.
Dieser Wert dient wiederum als Index zum Auslesen des RGBAWertes aus der Transferfunk-
tionstextur. Dass die Opazitätskorrektur schon auf dem Host vorgenommen wird erspart hier
eine teure Potenzfunktion. Liegt die Opazität des Abtastpunktes über einem Schwellenwert,
so wird der Materialgradient an dieser Stelle berechnet, ansonsten werden für Punkte mit
geringem optischen Ein�uss hierdurch sechs Texturzugri�e gespart. An dieser Stelle kann
die Opazität homogener Bereiche abgesenkt werden. Ist die Opazität noch hoch genug, wird
schlieÿlich Blinn-Phong Shading berechnet. Der resultierende RGBA Wert wird im Shared
Memory Pu�er akkumuliert. Es folgen weitere Iterationen, bis die für ERT nötige Sättigung
des Sehstrahls erreicht ist oder das Volumen verlassen wird.
Weiterhin werden Register durch das Verbot von Inlining für die Funktionen zur Gradien-

tenberechnung und zum Shading eingespart, der Compiler nimmt dies sonst standardmäÿig
vor. Mehrfach verwendete Werte werden nicht zwischengespeichert, wenn die erneute Be-
rechnung schneller ist. double Typen werden nicht verwendet, auch auf int wird möglichst
verzichtet. float Werte sind bei vielen Operationen performanter und nie schlechter.
5 Ergebnisse
Wird der Kernel für eine CC unter 2.0 kompiliert, belegt er 38 Register. Wird das Inlining,
wie im vorigen Abschnitt berichtet, untersagt, ist der Compiler in der Lage, die Register-
belegung weiter zu optimieren. Unter Verwendung von 44 Byte Local Memory sinkt die
Anzahl benötigter Register so auf 32. Dadurch sind mehr Warps pro Thread Block bzw.
mehr aktive Thread Blocks auf einem MP möglich. Read-After-Write Kon�ikte von Regi-
stern und die Latenz von O�-Chip Speicherzugri�en können besser verdeckt werden. Wird
auf Shading verzichtet und bei der Sehstrahlintegration nur noch Emission und Absorption
berücksichtigt, werden pro Thread nur 14 Prozessorregister belegt.
Im weiteren Verlauf dieses Abschnitts werden Ergebnisse des Renderers dargestellt. Zur
Steigerung der Vergleichbarkeit werden Kon�gurationsparameter mit besonderem Ein�uss
angegeben. Abb. 3 zeigt mit Volt angefertigte Renderings. Alle in diesem Beitrag verwendeten
Datensätze sind bei [Röt06] erhältlich.
Abbildung 3: Renderings der Datensätze Bonsai1-HI, Engine und Porsche
Die Messungen werden mit zwei unterschiedlichen GPUs unter denselben Bedingungen
durchgeführt: einer GTX 280 (30 · 8 Kerne) (Abb. 5) und einer GTX 480 (15 · 32 Kerne)
(Abb. 6). In beiden Fällen wird dasselbe Kompilat für CC 1.2 verwendet. Die Performanz des
Kernels ist auf der GTX 480 mit einem CC 2.0 Kompilat schlechter, obwohl es sich um eine
Fermi GPU handelt. In den Messergebnissen werden die Frameraten für Kombinationen von
Ausgabegröÿen mit Thread Block Dimensionen angegeben. Die Gröÿen der Thread Blocks
sind paarweise so gewählt, dass 64 bzw. 256 Threads einen Block bilden. Im ersten Fall
können acht Thread Blocks auf einem MP mit 16384 Registern aktiv sein, im Letzten zwei,
wobei diese Gröÿe Read-After-Write Kon�ikte für CC unter 2.0 schon vollständig verdeckt.
Die drei Messreihen verwenden den Visible Male Datensatz mit unterschiedlichen 8 Bit
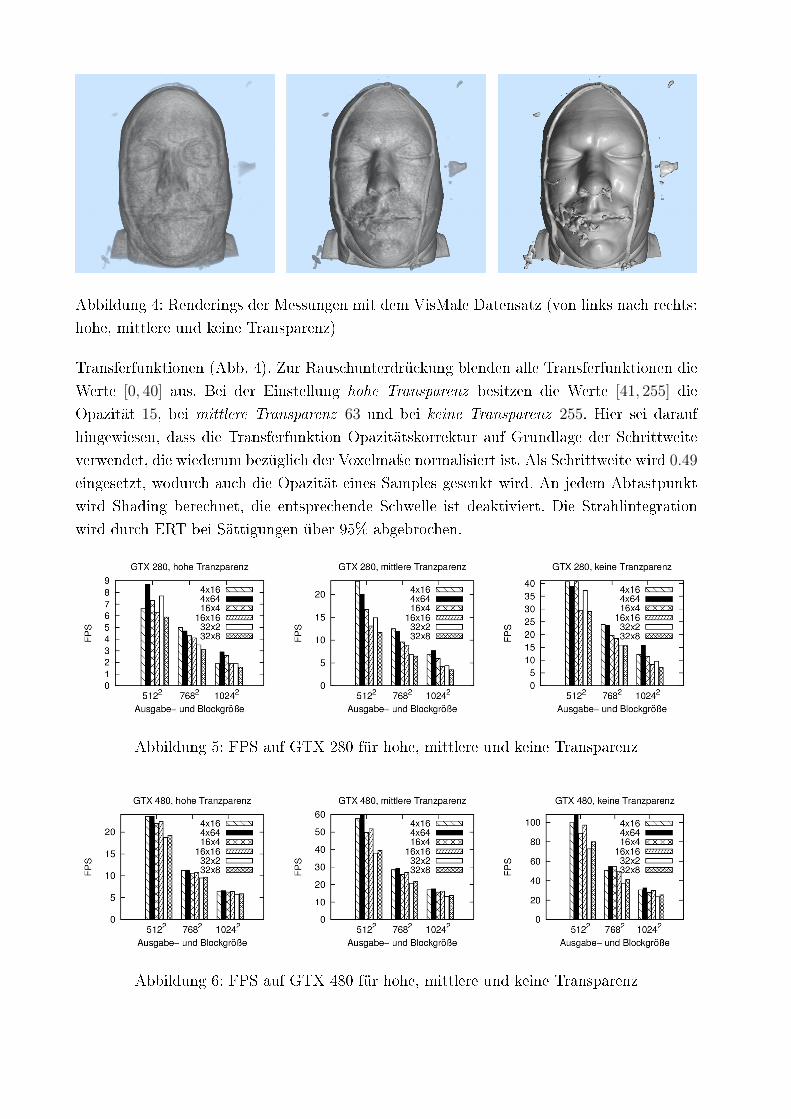
Abbildung 4: Renderings der Messungen mit dem VisMale Datensatz (von links nach rechts:
hohe, mittlere und keine Transparenz)
Transferfunktionen (Abb. 4). Zur Rauschunterdrückung blenden alle Transferfunktionen die
Werte [0, 40] aus. Bei der Einstellung hohe Transparenz besitzen die Werte [41, 255] die
Opazität 15, bei mittlere Transparenz 63 und bei keine Transparenz 255. Hier sei darauf
hingewiesen, dass die Transferfunktion Opazitätskorrektur auf Grundlage der Schrittweite
verwendet, die wiederum bezüglich der Voxelmaÿe normalisiert ist. Als Schrittweite wird 0.49
eingesetzt, wodurch auch die Opazität eines Samples gesenkt wird. An jedem Abtastpunkt
wird Shading berechnet, die entsprechende Schwelle ist deaktiviert. Die Strahlintegration
wird durch ERT bei Sättigungen über 95% abgebrochen.
Abbildung 5: FPS auf GTX 280 für hohe, mittlere und keine Transparenz
Abbildung 6: FPS auf GTX 480 für hohe, mittlere und keine Transparenz

6 Fazit
Die e�ziente Verwendung der GPU ermöglicht interaktives Volumenrendering durch klas-
sische Sehstrahlintegration. Dazu sind Details der CUDA Architektur und des Algorithmus
zu beachten. Für Berechnungen muss geprüft werden, ob sie auf dem Host oder dem De-
vice durchgeführt werden sollen. Die Betrachtung von Teilaufgaben ist dabei sinnvoll. Der
verwendete Bereich des Device Memory muss für die Aufgabe geeignet gewählt sein. Lässt
die Genauigkeit es zu, sollten auf dem Device intrinsische Funktionen verwendet werden.
Auf CUDA Vektortypen und dynamisch indexierte Arrays ist möglichst zu verzichten. Asyn-
chrone Kopieroperationen aktueller GPUs sind noch zu implementieren. Bei der Fermi Ar-
chitektur werden unregelmäÿige Zugri�e auf Global Memory durch L1 und L2 Caches unter-
stützt. Dies ist für räumliche Datenstrukturen nutzbar. Auf einer älteren Revision führte die
Implementierung eines Min/Max Octree mit Hilfe von Texturspeicher aufgrund zu häu�ger
abhängiger Leseoperationen und deutlich gestiegener Divergenz nicht zum Erfolg. Die Ver-
wendung eines Importance Volume zum adaptiven Sampling ist möglich. Zur Reduktion der
Banding Artefakte kann der O�set der Sehstrahlen gestreut werden. Mit mehrdimensionalen
Transferfunktionen und einem entsprechenden Editor können Benutzer mehr Informationen
aus einem Volumen extrahieren. Letztendlich ist die gewonnene Geschwindigkeit Ausgangs-
punkt zur Erprobung aufwändigerer Rekonstruktion, Beleuchtung und Schattierung.
Literatur
[CN94] Cullip, Timothy J. und Ulrich Neumann: Accelerating Volume Recon-
struction With 3D Texture Hardware. Technischer Bericht, Chapel Hill, NC,
USA, 1994.
[EKE01] Engel, Klaus, Martin Kraus und Thomas Ertl: High-quality pre-
integrated volume rendering using hardware-accelerated pixel shading. In:
HWWS '01: Proceedings of the ACM SIGGRAPH/EUROGRAPHICS workshop
on Graphics hardware, Seiten 9�16, New York, NY, USA, 2001. ACM.
[Jat10] Jato, Oliver: Fortgeschrittene Beschleunigung direkter Volumenvisualisierung
mit NVIDIA CUDA. Bachelor Thesis, Hochschule Bonn-Rhein-Sieg, Sankt Au-
gustin, 2010.
[KPH+03] Kniss, Joe, Simon Premoze, Charles Hansen, Peter Shirley und
Allen McPherson: A Model for Volume Lighting and Modeling. IEEE Trans-
actions on Visualization and Computer Graphics, 9(2):150�162, 2003.
[KW03] Krüger, Jens und Rüdiger Westermann: Acceleration Techniques for
GPU-based Volume Rendering. In: VIS '03: Proceedings of the 14th IEEE Vi-
sualization 2003 (VIS'03), Seiten 287�292, Washington, DC, USA, 2003. IEEE
Computer Society.

[MHE01] Magallón, Marcelo, Matthias Hopf und Thomas Ertl: Parallel Vol-
ume Rendering Using PC Graphics Hardware. In: Paci�c Conference on
Computer Graphics and Applications, Seiten 384�389, 2001.
[MHS08] Mar²álek, Luká², Armin Hauber und Philipp Slusallek: High-speed
volume ray casting with CUDA. In: Interactive Ray Tracing, 2008. RT 2008.
IEEE Symposium on, Seiten 185�185, Aug. 2008.
[MRH10] Mensmann, Jörg, Timo Ropinski und Klaus H. Hinrichs: An Advanced
Volume Raycasting Technique using GPU Stream Processing. In: GRAPP: In-
ternational Conference on Computer Graphics Theory and Applications, Seiten
190�198, Angers, 2010. INSTICC Press.
[MWMS07] Moloney, Brendan, Daniel Weiskopf, Torsten Möller und Magnus
Strengert: Scalable Sort-First Parallel Direct Volume Rendering with Dy-
namic Load Balancing. In: Eurographics Symposium on Parallel Graphics and
Visualization (EGPGV07), Seiten 45�52. Eurographics Association, 2007.
[PBMH02] Purcell, Timothy J., Ian Buck,William R. Mark und Pat Hanrahan:
Ray tracing on programmable graphics hardware. ACM Trans. Graph.,
21(3):703�712, 2002.
[RGW+03] Roettger, Stefan, Stefan Guthe, Daniel Weiskopf, Thomas Ertl
und Wolfgang Strasser: Smart hardware-accelerated volume rendering. In:
VISSYM '03: Proceedings of the symposium on Data visualisation 2003, Seiten
231�238, Aire-la-Ville, Switzerland, Switzerland, 2003. Eurographics Associa-
tion.
[Röt06] Röttger, Stefan: The Volume Library. Online, http://www9.informatik.uni-
erlangen.de/External/vollib, Abruf 14.6.2011, 2006.
[SSKE05] Stegmaier, Simon, Magnus Strengert, Thomas Klein und Thomas
Ertl: A Simple and Flexible Volume Rendering Framework for Graphics-
Hardware�based Raycasting. In: Proceedings of the International Workshop on
Volume Graphics '05, Seiten 187�195, 2005.
[WE98] Westermann, Rüdiger und Thomas Ertl: E�ciently using graphics hard-
ware in volume rendering applications. In: SIGGRAPH '98: Proceedings of the
25th annual conference on Computer graphics and interactive techniques, Seiten
169�177, New York, NY, USA, 1998. ACM.
[ZCC09] Zhao, Yue, Xiaoyu Cui und Ying Cheng: High-Performance and Real-Time
Volume Rendering in CUDA. In: Biomedical Engineering and Informatics, 2009.
BMEI '09. 2nd International Conference on, Seiten 1�4, Oct. 2009.