Embed Size (px)
Citation preview

Лекция 1. Базовые понятия стандарта MPI. Дифференцированные обмены
Пазников Алексей Александрович
Параллельные вычислительные технологии СибГУТИ (Новосибирск) Осенний семестр 2015
www: cpct.sibsutis.ru/~apaznikov/teaching q/a: piazza.com/sibsutis.ru/fall2015/pct2015fall

Особенности распределённых вычислительных систем

Вычислительные системы с распределённой памятью
3
CPU 1
Кэш
CPU 3
Кэш
CPU n
Кэш
CPU 1
Кэш
CPU 2
Кэш
CPU 3
Кэш
CPU n
Кэш
Общая память (shared memory) Общая память (shared memory)
Коммуникационная сеть (Interconnect, Communication network)
Распределённая вычислительная система (ВС) (distributed computer system) представляет собой совокупность вычислительных узлов, взаимодействующих через коммуникационную сеть (Gigabit Ethernet, InfiniBand, Cray Gemeni, Fujitsu Tofu, etc)
▪ Каждый узел включает в себя несколько процессоров (CPU 1, …, CPU n), взаимодействующих через общую память (shared memory).
CPU 2
Кэш

CPU 2CPU 1
Вычислительные системы с распределённой памятью
4
Ядро 1
Кэш L1
Ядро 2
Кэш L1
Ядро 1
Кэш L1
Ядро 2
Кэш L1
Общая память (shared memory)
Коммуникационная сеть (Interconnect, Communication network)
Распределённая вычислительная система (ВС) (distributed computer system) представляет собой совокупность вычислительных узлов, взаимодействующих через коммуникационную сеть (Gigabit Ethernet, InfiniBand, Cray Gemeni, Fujitsu Tofu, etc)
▪ Каждый узел включает в себя несколько процессоров (CPU1...CPUn), взаимодействующих через общую память (shared memory).
▪ Процессоры могут быть многоядерными (multicore) и ядра могут поддерживать одновременное выполнение нескольких потоков (SMT, Hyper-threading).
Кэш L2 Кэш L2
CPU 2CPU 1
Ядро 1
Кэш L1
Ядро 2
Кэш L1
Ядро 1
Кэш L1
Ядро 2
Кэш L1
Общая память (shared memory)
Кэш L2 Кэш L2
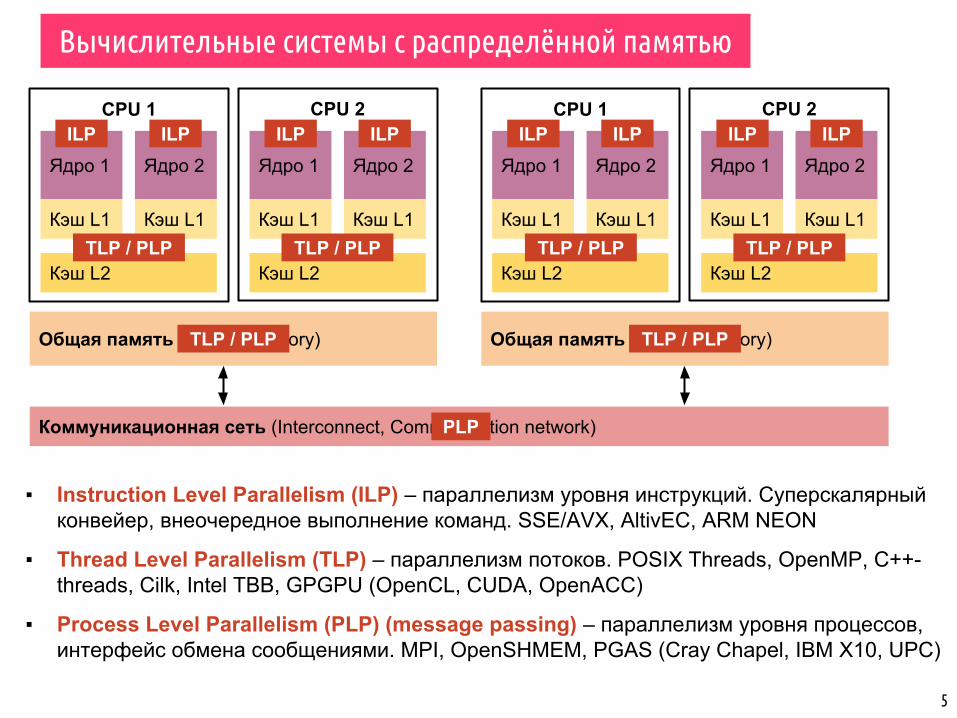
CPU 2CPU 1
Вычислительные системы с распределённой памятью
5
Ядро 1
Кэш L1
Ядро 2
Кэш L1
Ядро 1
Кэш L1
Ядро 2
Кэш L1
Общая память (shared memory)
Коммуникационная сеть (Interconnect, Communication network)
▪ Instruction Level Parallelism (ILP) – параллелизм уровня инструкций. Суперскалярный конвейер, внеочередное выполнение команд. SSE/AVX, AltivEC, ARM NEON
▪ Thread Level Parallelism (TLP) – параллелизм потоков. POSIX Threads, OpenMP, C++-threads, Cilk, Intel TBB, GPGPU (OpenCL, CUDA, OpenACC)
▪ Process Level Parallelism (PLP) (message passing) – параллелизм уровня процессов, интерфейс обмена сообщениями. MPI, OpenSHMEM, PGAS (Cray Chapel, IBM X10, UPC)
Кэш L2 Кэш L2
CPU 2CPU 1
Ядро 1
Кэш L1
Ядро 2
Кэш L1
Ядро 1
Кэш L1
Ядро 2
Кэш L1
Общая память (shared memory)
Кэш L2 Кэш L2
ILP ILP ILPILP ILP ILPILPILP
TLP / PLP TLP / PLP TLP / PLP TLP / PLP
TLP / PLP TLP / PLP
PLP
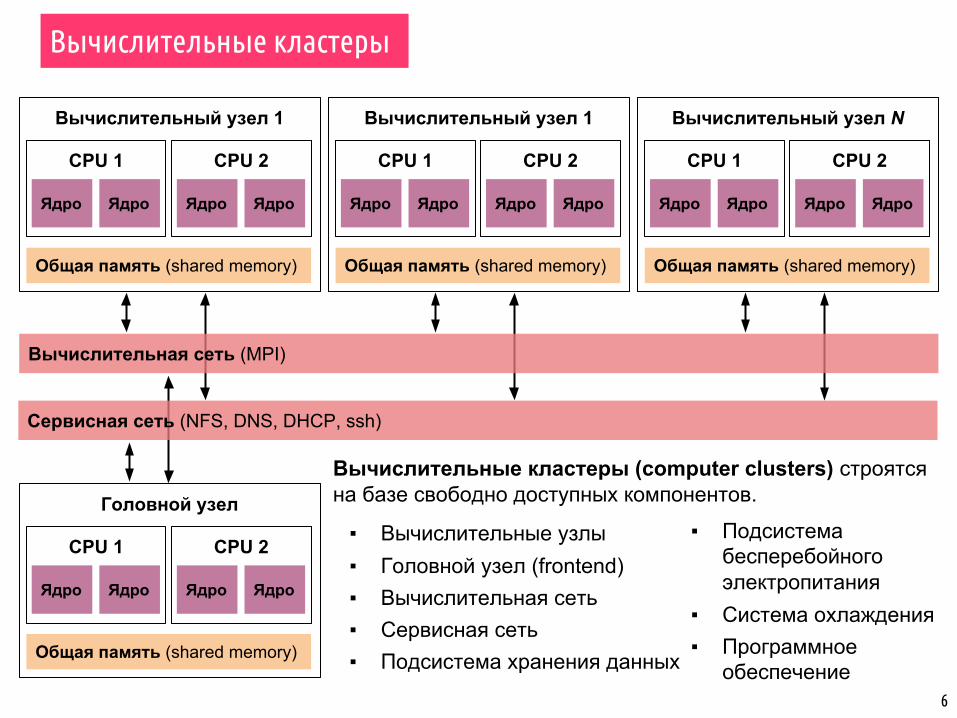
Вычислительный узел 1
CPU 1
Вычислительные кластеры
6
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 1
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Головной узел
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Сервисная сеть (NFS, DNS, DHCP, ssh)
Вычислительная сеть (MPI)
Вычислительные кластеры (computer clusters) строятся на базе свободно доступных компонентов.
▪ Вычислительные узлы▪ Головной узел (frontend)▪ Вычислительная сеть▪ Сервисная сеть▪ Подсистема хранения данных
▪ Подсистема бесперебойного электропитания
▪ Система охлаждения▪ Программное
обеспечение
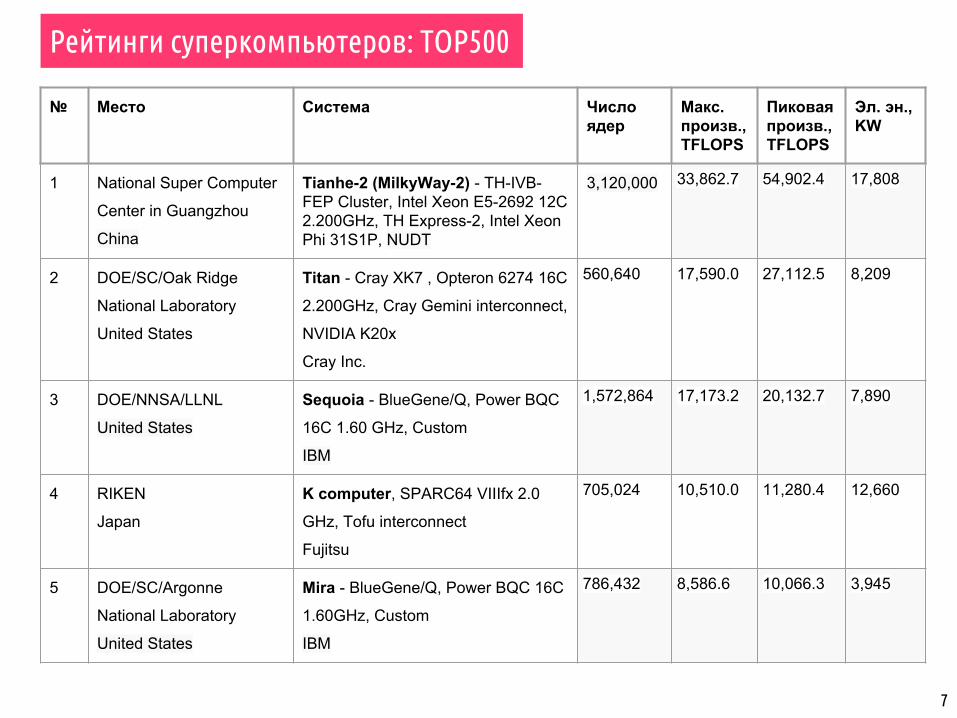
Рейтинги суперкомпьютеров: TOP500
7
№ Место Система Число ядер
Макс. произв., TFLOPS
Пиковая произв., TFLOPS
Эл. эн., KW
1 National Super Computer
Center in Guangzhou
China
Tianhe-2 (MilkyWay-2) - TH-IVB-FEP Cluster, Intel Xeon E5-2692 12C 2.200GHz, TH Express-2, Intel Xeon Phi 31S1P, NUDT
3,120,000 33,862.7 54,902.4 17,808
2 DOE/SC/Oak Ridge
National Laboratory
United States
Titan - Cray XK7 , Opteron 6274 16C
2.200GHz, Cray Gemini interconnect,
NVIDIA K20x
Cray Inc.
560,640 17,590.0 27,112.5 8,209
3 DOE/NNSA/LLNL
United States
Sequoia - BlueGene/Q, Power BQC
16C 1.60 GHz, Custom
IBM
1,572,864 17,173.2 20,132.7 7,890
4 RIKEN
Japan
K computer, SPARC64 VIIIfx 2.0
GHz, Tofu interconnect
Fujitsu
705,024 10,510.0 11,280.4 12,660
5 DOE/SC/Argonne
National Laboratory
United States
Mira - BlueGene/Q, Power BQC 16C
1.60GHz, Custom
IBM
786,432 8,586.6 10,066.3 3,945

Рейтинги суперкомпьютеров: TOP500
8
Архитектурные особенности современных суперкомпьютеров:
▪ Большемасштабность: более 1000000 процессорных ядер
▪ Многоядерные процессоры с количеством ядер более 10 на процессор
▪ Высокое энергопотребление: несколько MW
▪ Коммуникационная сеть: Infiniband, Gigabit Ethernet, 10 Gigabit Ethernet, Cray Gemini, TH Express, Tofu Interconnect
▪ Процессоры: Intel, IBM Power, AMD Opteron, …
▪ Гетерогенные системы: наличие ускорителей NVIDIA GPU, Intel Xeon Phi, Tilera Tile-GX, PLD-accelerators,
▪ Операционные системы GNU/Linux (преимущественно), IBM AIX и др.

Введение в MPI

Стандарт MPI
10
Message Passing Interface (MPI, интерфейс передачи сообщений) – стандарт программного интерфейса коммуникационных функций для создания переносимых параллельных программ в модели передачи сообщений (message passing).
▪ Стандарт реализован в MPI-библиотеках MPICH, Open MPI, Intel MPI и т.д.
▪ MPI появился в 1991 и был предложен группой учёных. С тех пор появился семинар по стандарту Workshop on Standards for Message passing in a Distributed Memory environment и сформирован комитет по стандартизации. Создан MPI-форум.
▪ MPI определяет синтаксис и семантику функций библиотек передачи сообщений для языков Fortran и C.
▪ Является стандартным средством для организации взаимодействия процессов в параллельных программах, выполняющихся на распределённых ВС.
▪ Обеспечивается переносимость программ между разными архитектурами процессоров (Cray, Intel, IBM, NEC, …)
▪ Последний стандарт MPI-3.1. вышел 4 июня 2015 г.
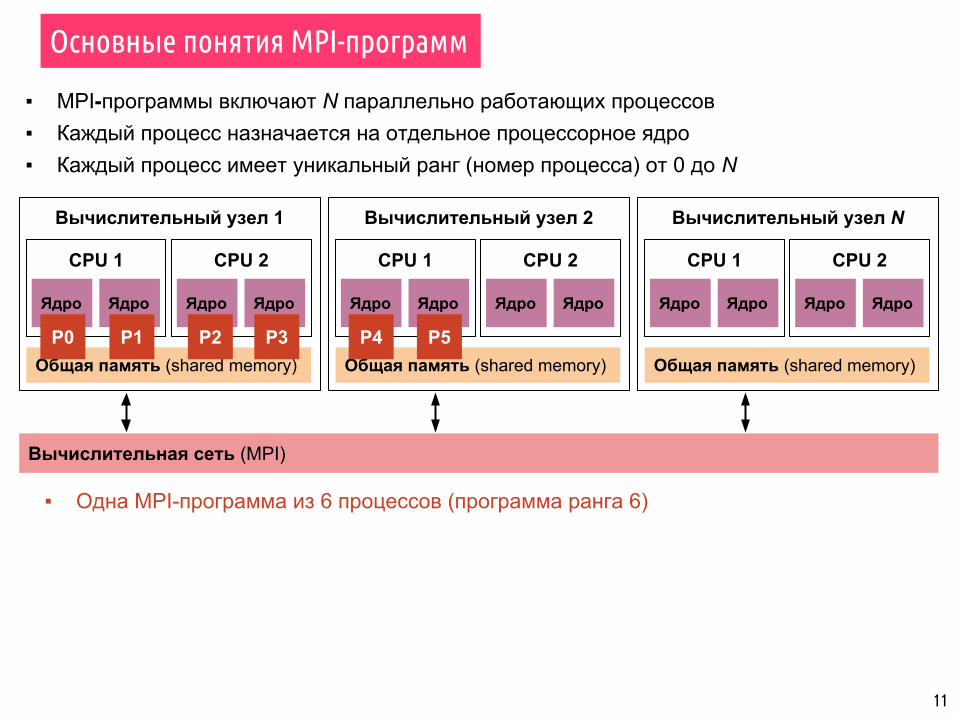
Вычислительный узел 1
CPU 1
Основные понятия MPI-программ
11
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительная сеть (MPI)
P0
▪ MPI-программы включают N параллельно работающих процессов▪ Каждый процесс назначается на отдельное процессорное ядро▪ Каждый процесс имеет уникальный ранг (номер процесса) от 0 до N
P1 P2 P3 P4 P5
▪ Одна MPI-программа из 6 процессов (программа ранга 6)

Вычислительный узел 1
CPU 1
Основные понятия MPI-программ
12
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительная сеть (MPI)
P0
▪ MPI-программы включают N параллельно работающих процессов▪ Каждый процесс назначается на отдельное процессорное ядро▪ Каждый процесс имеет уникальный ранг (номер процесса) от 0 до N
P1 P2 P3 P4 P5
▪ Четыре программы рангов 6, 1, 3, 2▪ Одна программа может быть запущена с разным количеством процессов
P0 P0 P1 P2 P0 P1
Вычислительный узел 1
CPU 1
Основные понятия MPI-программ
13
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
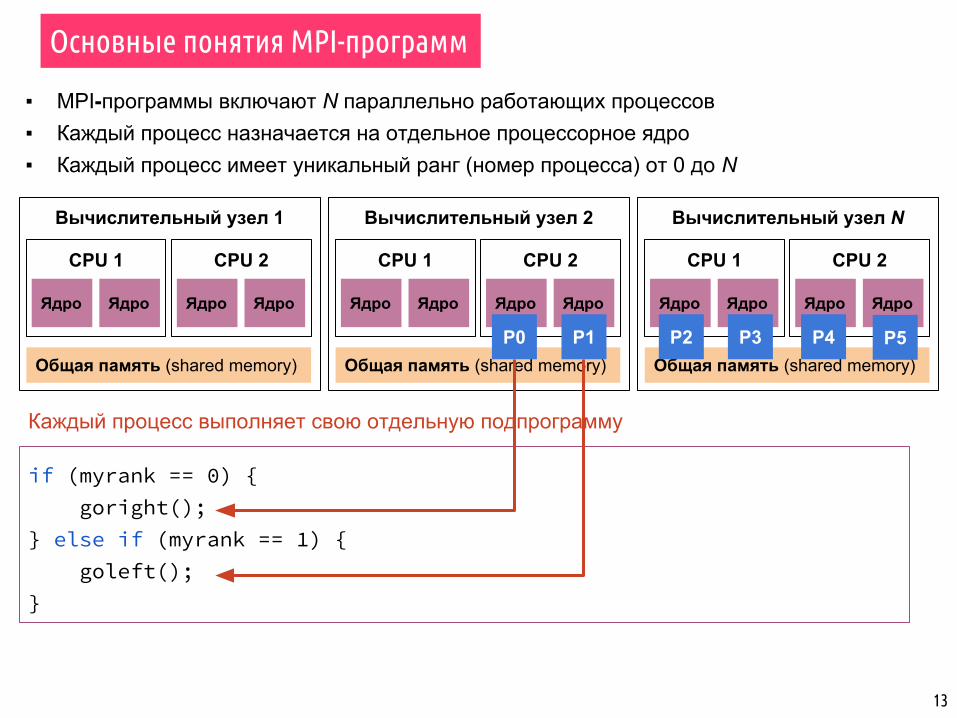
▪ MPI-программы включают N параллельно работающих процессов▪ Каждый процесс назначается на отдельное процессорное ядро▪ Каждый процесс имеет уникальный ранг (номер процесса) от 0 до N
P0 P1 P2 P3 P4 P5
if (myrank == 0) { goright();} else if (myrank == 1) { goleft();}
Каждый процесс выполняет свою отдельную подпрограмму

Вычислительный узел 1
CPU 1
Основные понятия MPI-программ
14
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
▪ MPI-программы включают N параллельно работающих процессов▪ Каждый процесс назначается на отдельное процессорное ядро▪ Каждый процесс имеет уникальный ранг (номер процесса) от 0 до N
Каждый процесс выполняет свою отдельную подпрограмму
P0 P1 P2 P3 P4 P5
if (myrank == 0) { goright();} else if (myrank == 1) { goleft();} else { stand_and_wait();}

Вычислительный узел 1
CPU 1
Основные понятия MPI-программ
15
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительная сеть (MPI)
P0 P1 P2 P3 P4 P5
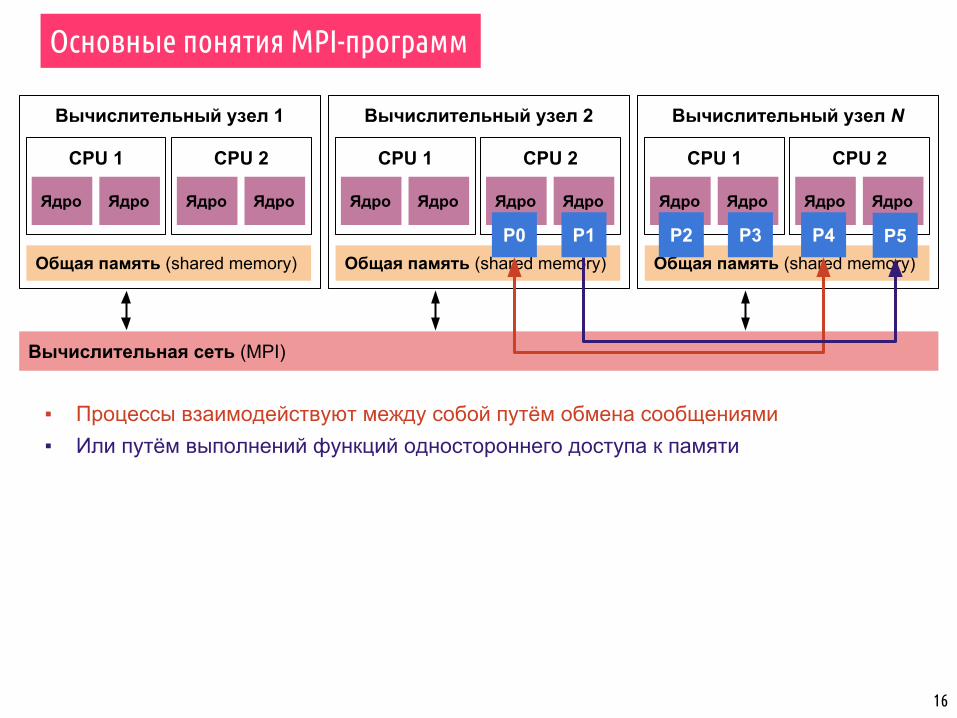
▪ Процессы взаимодействуют между собой путём обмена сообщениями
Вычислительный узел 1
CPU 1
Основные понятия MPI-программ
16
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительная сеть (MPI)
P0 P1 P2 P3 P4 P5
▪ Процессы взаимодействуют между собой путём обмена сообщениями▪ Или путём выполнений функций одностороннего доступа к памяти
Вычислительный узел 1
CPU 1
Основные понятия MPI-программ
17
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительная сеть (MPI)
P0 P1 P2 P3 P4 P5
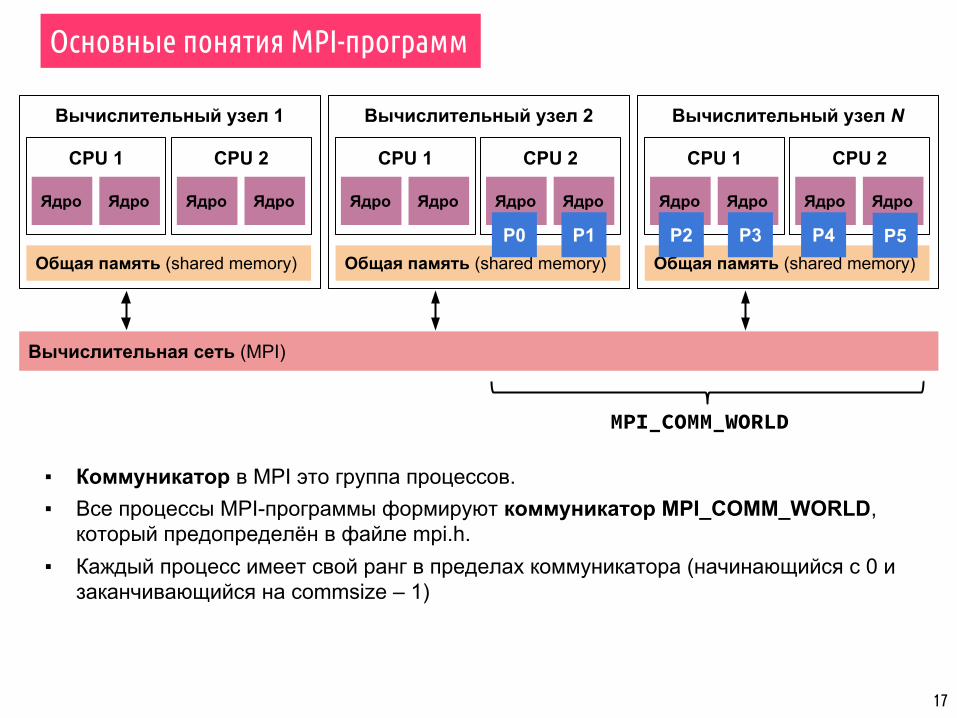
▪ Коммуникатор в MPI это группа процессов.▪ Все процессы MPI-программы формируют коммуникатор MPI_COMM_WORLD,
который предопределён в файле mpi.h.▪ Каждый процесс имеет свой ранг в пределах коммуникатора (начинающийся с 0 и
заканчивающийся на commsize – 1)
MPI_COMM_WORLD
Вычислительный узел 1
CPU 1
Основные понятия MPI-программ
18
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительная сеть (MPI)
P0 P1 P2 P3 P4 P5
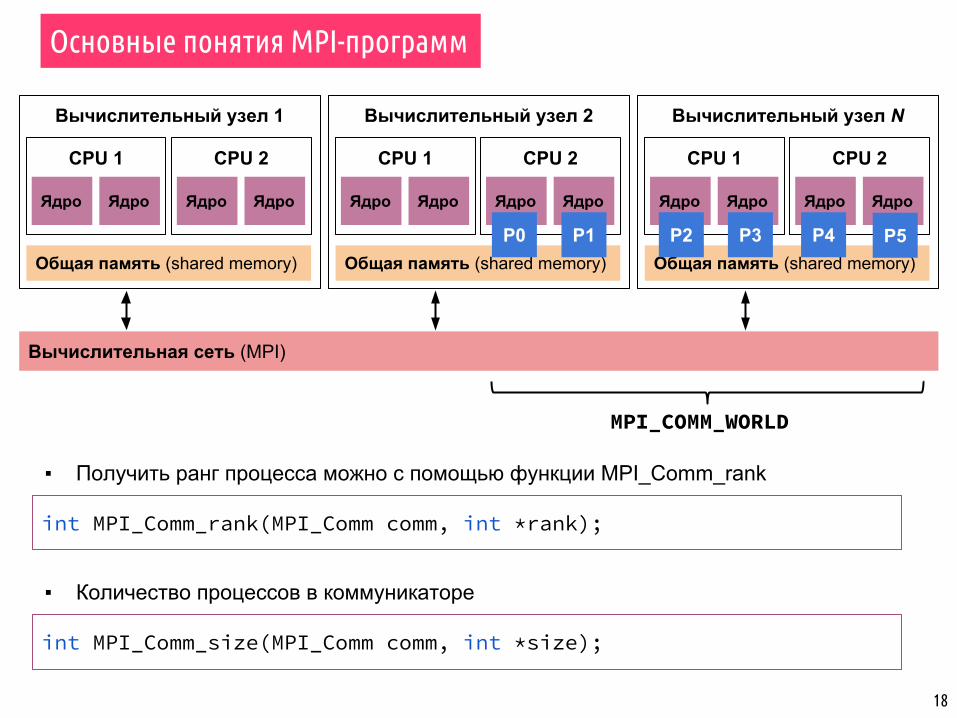
▪ Получить ранг процесса можно с помощью функции MPI_Comm_rank
MPI_COMM_WORLD
int MPI_Comm_rank(MPI_Comm comm, int *rank);
int MPI_Comm_size(MPI_Comm comm, int *size);
▪ Количество процессов в коммуникаторе
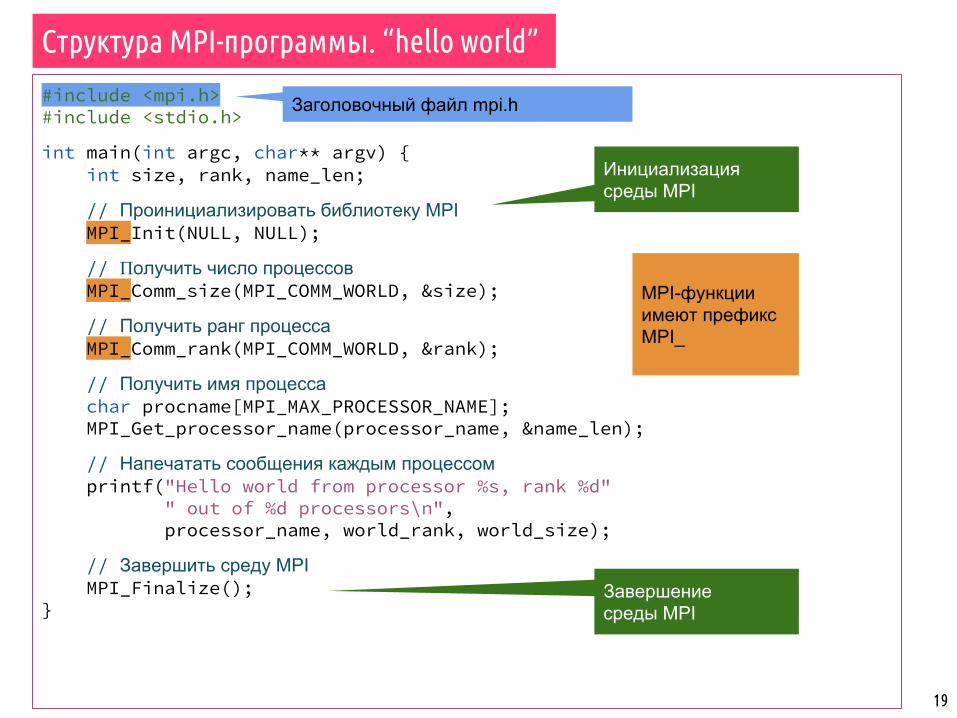
19
#include <mpi.h>#include <stdio.h>
int main(int argc, char** argv) { int size, rank, name_len;
// Проинициализировать библиотеку MPI MPI_Init(NULL, NULL);
// Получить число процессов MPI_Comm_size(MPI_COMM_WORLD, &size);
// Получить ранг процесса MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// Получить имя процесса char procname[MPI_MAX_PROCESSOR_NAME]; MPI_Get_processor_name(processor_name, &name_len);
// Напечатать сообщения каждым процессом printf("Hello world from processor %s, rank %d" " out of %d processors\n", processor_name, world_rank, world_size);
// Завершить среду MPI MPI_Finalize();}
Заголовочный файл mpi.h
MPI-функции имеют префикс MPI_
Инициализация среды MPI
Завершение среды MPI
Структура MPI-программы. “hello world”

Структура MPI-программы. “hello world”
20
#include <mpi.h>#include <stdio.h>
int main(int argc, char** argv) { int size, rank, name_len, rc;
// Проинициализировать библиотеку MPI rc = MPI_Init(NULL, NULL);
if (rc == MPI_SUCCESS) { // Получить число процессов MPI_Comm_size(MPI_COMM_WORLD, &size);
// Получить ранг процесса MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// Получить имя процесса char procname[MPI_MAX_PROCESSOR_NAME]; int name_len; MPI_Get_processor_name(processor_name, &name_len);
// Напечатать сообщения каждым процессом printf(...);
// Завершить среду MPI MPI_Finalize();
} else { fprintf(stderr, "Can't initialize MPI!\n"); }}
Заголовочный файл mpi.h
MPI-функции имеют префикс MPI_
MPI-функции возвращают MPI_SUCCESS в случае успеха и код ошибки в противном случае

Структура MPI-программы. “hello world”
21
#include <mpi.h>#include <stdio.h>
int main(int argc, char** argv) { int size, rank, name_len, rc;
// Проинициализировать библиотеку MPI rc = MPI_Init(NULL, NULL);
if (rc == MPI_SUCCESS) { // Получить число процессов MPI_Comm_size(MPI_COMM_WORLD, &size);
// Получить ранг процесса MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// Получить имя процесса char procname[MPI_MAX_PROCESSOR_NAME]; int name_len; MPI_Get_processor_name(processor_name, &name_len);
// Напечатать сообщения каждым процессом printf(...);
if (rank == 0) printf("hello world!\n");
// Завершить среду MPI MPI_Finalize();
}
Заголовочный файл mpi.h
Только нулевой процесс печатает сообщение “hello world”

Компиляция MPI-программ
22
$ mpicc -Wall -O2 -o prog prog.c
Программа на С
Программа на С++
$ mpicxx -Wall -O2 -o prog prog.c
Программа на Fortran
$ mpif90 -Wall -O2 -o prog prog.c
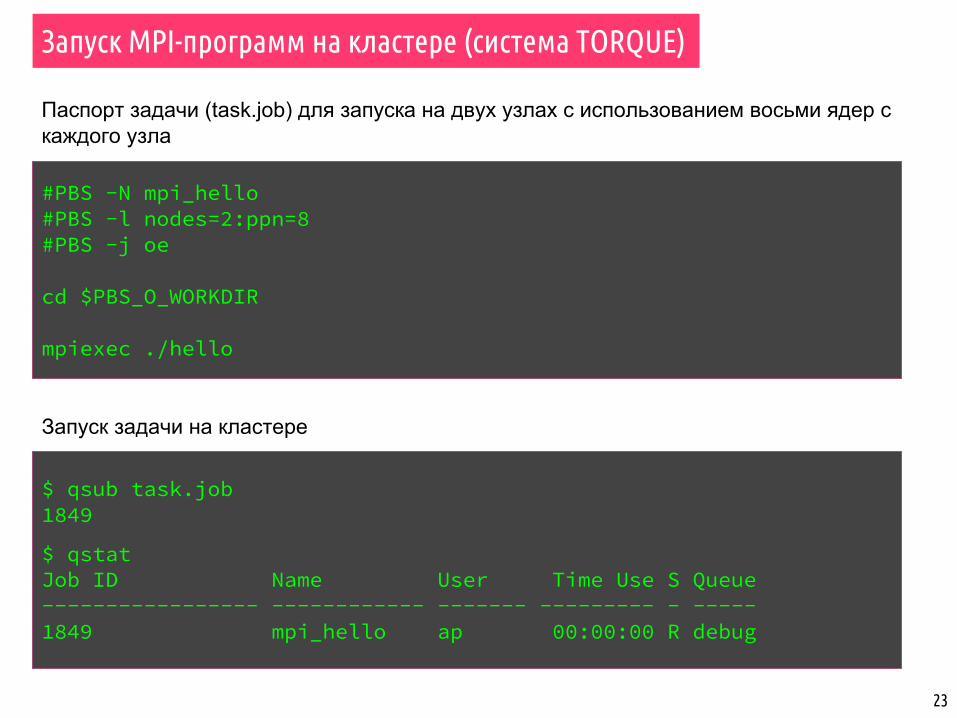
Запуск MPI-программ на кластере (система TORQUE)
23
#PBS -N mpi_hello#PBS -l nodes=2:ppn=8#PBS -j oe
cd $PBS_O_WORKDIR
mpiexec ./hello
Паспорт задачи (task.job) для запуска на двух узлах с использованием восьми ядер с каждого узла
$ qsub task.job 1849
$ qstatJob ID Name User Time Use S Queue----------------- ------------ ------- --------- - -----1849 mpi_hello ap 00:00:00 R debug
Запуск задачи на кластере
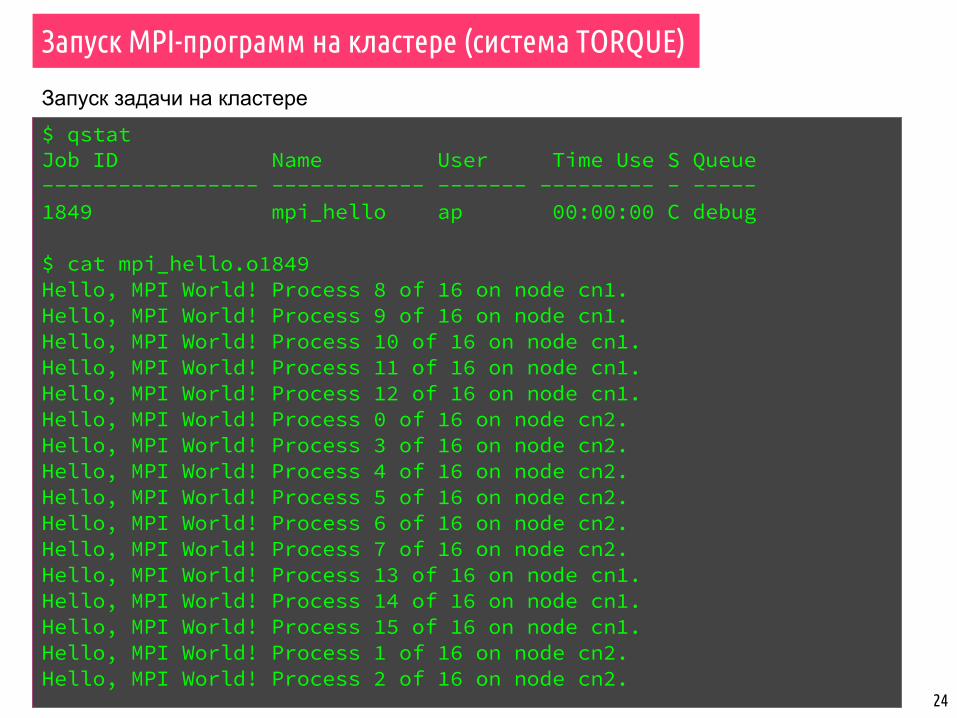
Запуск MPI-программ на кластере (система TORQUE)
24
$ qstatJob ID Name User Time Use S Queue----------------- ------------ ------- --------- - -----1849 mpi_hello ap 00:00:00 C debug
$ cat mpi_hello.o1849 Hello, MPI World! Process 8 of 16 on node cn1.Hello, MPI World! Process 9 of 16 on node cn1.Hello, MPI World! Process 10 of 16 on node cn1.Hello, MPI World! Process 11 of 16 on node cn1.Hello, MPI World! Process 12 of 16 on node cn1.Hello, MPI World! Process 0 of 16 on node cn2.Hello, MPI World! Process 3 of 16 on node cn2.Hello, MPI World! Process 4 of 16 on node cn2.Hello, MPI World! Process 5 of 16 on node cn2.Hello, MPI World! Process 6 of 16 on node cn2.Hello, MPI World! Process 7 of 16 on node cn2.Hello, MPI World! Process 13 of 16 on node cn1.Hello, MPI World! Process 14 of 16 on node cn1.Hello, MPI World! Process 15 of 16 on node cn1.Hello, MPI World! Process 1 of 16 on node cn2.Hello, MPI World! Process 2 of 16 on node cn2.
Запуск задачи на кластере
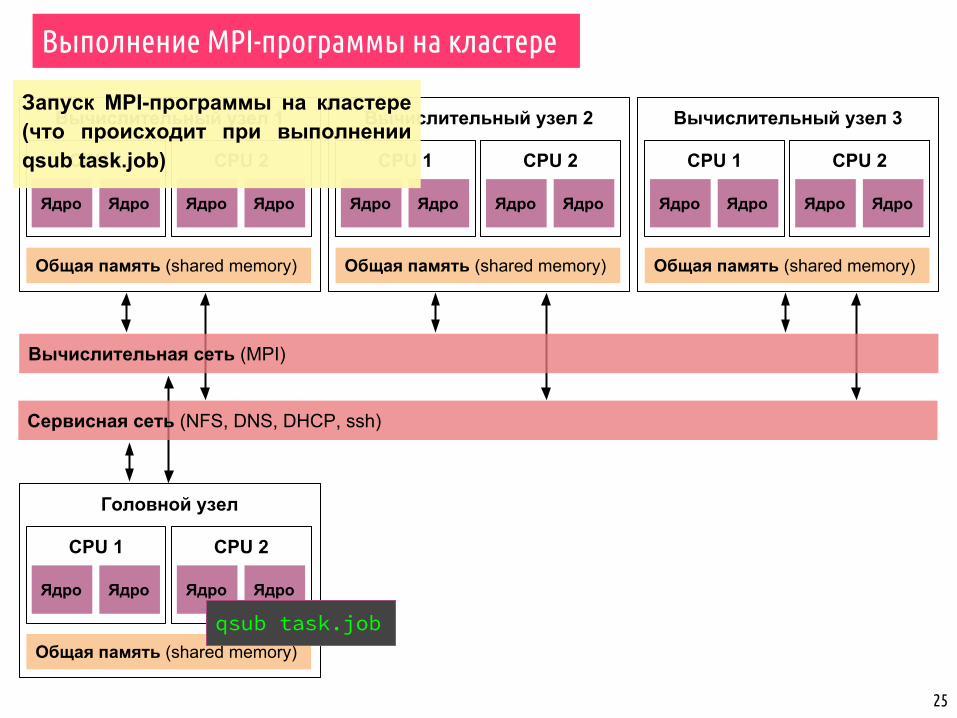
Вычислительный узел 1
CPU 1
25
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 3
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Головной узел
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Сервисная сеть (NFS, DNS, DHCP, ssh)
Вычислительная сеть (MPI)
Выполнение MPI-программы на кластере
qsub task.job
Запуск MPI-программы на кластере (что происходит при выполнении qsub task.job)

Вычислительный узел 1
CPU 1
26
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 3
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Головной узел
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Сервисная сеть (NFS, DNS, DHCP, ssh)
Вычислительная сеть (MPI)
Выполнение MPI-программы на кластере
qsub task.job
Запуск MPI-программы на кластере (что происходит при выполнении qsub task.job)
1. TORQUE выделят подсистему процессорных ядер по паспорту задачи.

Вычислительный узел 1
CPU 1
27
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 2
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 3
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Головной узел
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Сервисная сеть (NFS, DNS, DHCP, ssh)
Вычислительная сеть (MPI)
Выполнение MPI-программы на кластере
mpiexec ./prog
P0 P1 P2 P3 P4 P5
prog
prog
prog
prog
prog
prog
ssh cn2 ssh cn3
Запуск MPI-программы на кластере (что происходит при выполнении qsub task.job)
1. TORQUE выделят подсистему процессорных ядер по паспорту задачи.
2. mpiexec (скрипт) заходит по ssh на узлы, на которых выделена подсистема и запускает одинаковые экземпляры MPI-программы.

Подсчет количества простых чисел (последовательная версия)
28
int is_prime_number(int n) { int limit = sqrt(n) + 1; for (int i = 2; i <= limit; i++) { if (n % i == 0) return 0; } return (n > 1) ? 1 : 0;}
int count_prime_numbers(int a, int b) { int nprimes = 0; if (a <= 2) { nprimes = 1; // Посчитать '2' как простое a = 2; }
if (a % 2 == 0) a++; // Сместить 'a' до нечётного числа
// Цикл по нечётным числам: a, a + 2, a + 4, ... , b for (int i = a; i <= b; i += 2) if (is_prime_number(i)) nprimes++;
return nprimes;}
Определяет, является ли число n простым
Подсчитывает количество простых чисел в интервале [a, b]

Подсчет количества простых чисел (MPI версия)
29
int main(int argc, char **argv){ MPI_Init(&argc, &argv);
// Запустить последовательную версию double tserial = 0; if (get_comm_rank() == 0) tserial = run_serial();
// Дождаться завершения выполнения последовательной версиии // нулевым процессом MPI_Barrier(MPI_COMM_WORLD);
// Запустить параллельную версию double tparallel = run_parallel(); if (get_comm_rank() == 0) { printf("Count prime numbers on [%d, %d]\n", a, b); printf("Execution time (serial): %.6f\n", tserial); printf("Execution time (parallel): %.6f\n", tparallel); printf("Speedup (processes %d): %.2f\n", get_comm_size(), tserial / tparallel); }
MPI_Finalize(); return 0;}

Подсчет количества простых чисел (MPI версия)
30
double run_serial() { double t = MPI_Wtime(); int n = count_prime_numbers(a, b); t = MPI_Wtime() - t; printf("Result (serial): %d\n", n); return t;}
double run_parallel() { double t = MPI_Wtime(); int n = count_prime_numbers_par(a, b); t = MPI_Wtime() - t; printf("Process %d/%d execution time: %.6f\n", get_comm_rank(), get_comm_size(), t);
if (get_comm_rank() == 0) printf("Result (parallel): %d\n", n);
return t;}
MPI-функция измерения временных интервалов
Получение ранга процесса и количества процессов

Подсчет количества простых чисел (MPI версия)
31
int get_comm_rank() { int rank; MPI_Comm_rank(MPI_COMM_WORLD, &rank); return rank;}
int get_comm_size() { int size; MPI_Comm_size(MPI_COMM_WORLD, &size); return size;}

Подсчет количества простых чисел (MPI версия)
32
void get_chunk(int a, int b, int commsize, int rank, int *lb, int *ub) { int n = b - a + 1; int q = n / commsize; if (n % commsize) q++; int r = commsize * q - n;
// Расчитать размер порции данных для процесса int chunk = q; if (rank >= commsize - r) chunk = q - 1;
// Определить начало порции для процесса *lb = a; if (rank > 0) { // Подсчитать сумму предыдущих порций if (rank <= commsize - r) *lb += q * rank; else *lb += q * (commsize - r) + (q - 1) * (rank - (commsize - r)); } *ub = *lb + chunk - 1;}

Подсчет количества простых чисел (MPI версия)
33
int count_prime_numbers_par(int a, int b) { int nprimes = 0; int lb, ub; get_chunk(a, b, get_comm_size(), get_comm_rank(), &lb, &ub);
if (lb <= 2) { nprimes = 1; // Посчитать '2' как простое lb = 2; }
if (lb % 2 == 0) lb++; // Сместить 'lb' до нечётного числа
// Цикл по нечётным числам: a, a + 2, a + 4, ... , b for (int i = lb; i <= ub; i += 2) { if (is_prime_number(i)) nprimes++;
int nprimes_global; MPI_Reduce(&nprimes, &nprimes_global, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
return nprimes_global;}
Подсчитать сумму простых чисен, найденных всеми процессами

Определение ускорения параллельной программы
34
Process 1/8 execution time: 0.641697Process 3/8 execution time: 0.915595Process 2/8 execution time: 0.915649Process 5/8 execution time: 1.104982Process 7/8 execution time: 1.267695Process 6/8 execution time: 1.267713Process 4/8 execution time: 1.267691Result (serial): 664579Process 0/8 execution time: 0.390985Result (parallel): 664579Count prime numbers on [1, 10000000]Execution time (serial): 7.310900Execution time (parallel): 0.390985Speedup (processes 8): 18.70
Проблема 1Дисбаланс загрузки процессов
Проблема 2Неверно подсчитанное ускорение

Подсчет количества простых чисел (MPI версия)
35
int count_prime_numbers_par(int a, int b) { int nprimes = 0; int lb, ub; get_chunk(a, b, get_comm_size(), get_comm_rank(), &lb, &ub);
if (lb <= 2) { nprimes = 1; // Посчитать '2' как простое lb = 2; }
if (lb % 2 == 0) lb++; // Сместить 'lb' до нечётного числа
// Цикл по нечётным числам: a, a + 2, a + 4, ... , b for (int i = lb; i <= ub; i += 2) { if (is_prime_number(i)) nprimes++;
int nprimes_global; MPI_Reduce(&nprimes, &nprimes_global, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
return nprimes_global;}
Проблема 1Неравномерно загрузка процессов
Процесс 0: 0, 1, 2, 3Процесс 1: 4, 5, 6, 7Процесс 3: 8, 9, 10, 11

Подсчет количества простых чисел (MPI версия)
36
int main(int argc, char **argv){ MPI_Init(&argc, &argv);
// Запустить последовательную версию double tserial = 0; if (get_comm_rank() == 0) tserial = run_serial();
// Запустить параллельную версию double tparallel = run_parallel(); if (get_comm_rank() == 0) { printf("Count prime numbers on [%d, %d]\n", a, b); printf("Execution time (serial): %.6f\n", tserial); printf("Execution time (parallel): %.6f\n", tparallel); printf("Speedup (processes %d): %.2f\n", get_comm_size(), tserial / tparallel); }
MPI_Finalize(); return 0;}
Проблема 2Неверно подсчитанное ускорение
s = t1 / tptp – время процесса 0
За tp необходимо принять наибольшее время выполнения процессов

Подсчет количества простых чисел (MPI версия)
37
double run_parallel() { double t = MPI_Wtime(); int n = count_prime_numbers_par(a, b); t = MPI_Wtime() - t; printf("Process %d/%d execution time: %.6f\n", get_comm_rank(), get_comm_size(), t);
if (get_comm_rank() == 0) printf("Result (parallel): %d\n", n);
// Собираем в процессе 0 максимальное из времён выполнения double tmax; MPI_Reduce(&t, &tmax, 1, MPI_DOUBLE, MPI_MAX, 0, MPI_COMM_WORLD); return tmax;}
Решение проблемы 2
s = t1 / (max(t0, t1, …, tn))
Определить максимальное среди всех времён выполнения процессов.

Подсчет количества простых чисел (MPI версия)
38
int count_prime_numbers_par(int a, int b) { int nprimes = 0;
// Посчитать '2' как простое int commsize = get_comm_size(); int rank = get_comm_rank(); if (a <= 2) { a = 2; if (rank == 0) nprimes = 1; }
for (int i = a + rank; i <= b; i += commsize) { if (i % 2 > 0 && is_prime_number(i)) nprimes++; }
int nprimes_global = 0; MPI_Reduce(&nprimes, &nprimes_global, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
return nprimes_global;}
Решение проблемы 1
Циклическое распределение итераций (round-robin)

Вычислительный узел 1
CPU 1
39
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 1
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительная сеть (MPI)
P0 P1 P2 P3
Подсчет количества простых чисел (MPI версия)
1 2 43 5 7 87 9 11 1211 13 15 1615 17 18 20192 6 10 14
commsize
Решение проблемы 1
Циклическое распределение итераций (round-robin)

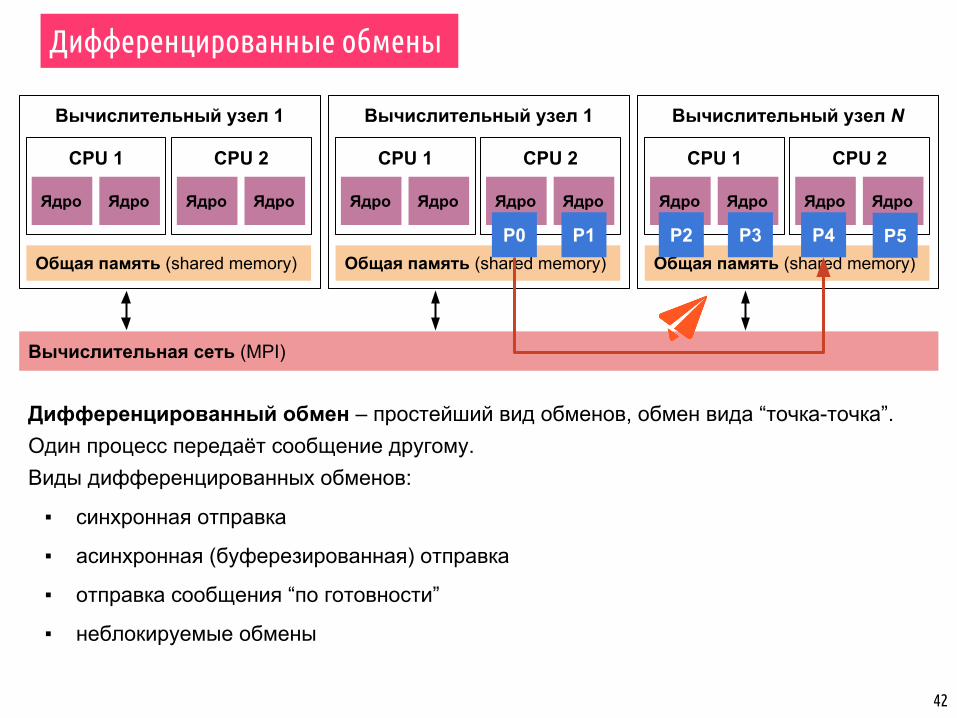
Дифференцированные обмены

Дифференцированные обмены
41
Вычислительный узел 1
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 1
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительная сеть (MPI)
P0 P1 P2 P3 P4 P5
Сообщения представляют собой пакеты данных, которые “перемещаются” между процессами.Сообщение имеет следующие параметры:
▪ процесс-отправитель
▪ адрес отправляемых данных
▪ тип отправляемых данных
▪ размер данных
▪ процесс-получатель
▪ адрес данных для получения
▪ тип данных назначения
▪ размер буфера для получения
Дифференцированные обмены
42
Вычислительный узел 1
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел 1
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительный узел N
CPU 1
Ядро Ядро
Общая память (shared memory)
CPU 2
Ядро Ядро
Вычислительная сеть (MPI)
P0 P1 P2 P3 P4 P5
Дифференцированный обмен – простейший вид обменов, обмен вида “точка-точка”.Один процесс передаёт сообщение другому.Виды дифференцированных обменов:
▪ синхронная отправка
▪ асинхронная (буферезированная) отправка
▪ отправка сообщения “по готовности”
▪ неблокируемые обмены

43
Отправка и получение дифференцированных сообщений
int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
▪ buf – адрес для начала отправляемого сообщения с количеством count элементов типа datatype
▪ tag – тэг, дополнительное неотрицательное целое число, передаваемое вместе с сообщением; тэг может быть использован программой для разделения разных типов сообщений.
▪ comm – коммуникатор, в котором находятся процессы.
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
▪ buf, count, datatype – описывают буфер для получения.
▪ source – ранг процесса в коммуникаторе comm, который отправляет сообщение.
▪ status – результат выполнения операции.
▪ Только сообщение с тэгом tag будет получено.

44
Отправка и получение дифференцированных сообщений
int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
▪ buf – адрес для начала отправляемого сообщения с количеством count элементов типа datatype
▪ tag – тэг, дополнительное неотрицательное целое число, передаваемое вместе с сообщением; тэг может быть использован программой для разделения разных типов сообщений.
▪ comm – коммуникатор, в котором находятся процессы.
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
▪ buf, count, datatype – описывают буфер для получения.
▪ source – ранг процесса в коммуникаторе comm, который отправляет сообщение (возможно значение source = MPI_ANY_SOURCE для получения сообщения от любого источника).
▪ status – результат выполнения операции (возможно значение status = MPI_STATUS_IGNORE).
▪ Только сообщение с тэгом tag будет получено. (возможно значение tag = MPI_ANY_TAG для получения сообщения с любым тегом).

45
Требования для выполнения дифференцированного обмена
▪ Отправитель должен указать необходимый ранг получателя.▪ Получатель должен указать корректный ранг отправителя (или получатель
использует MPI_ANY_SOURCE).▪ Коммуникатор должен быть одним и тем же.▪ Тэги должны совпадать (или получатель использует MPI_ANY_TAG)▪ Типы данных должны при отправке и получении должны совпадать.▪ Буфер получателя должен быть достаточно большим.

46
Требования для выполнения дифференцированного обмена
▪ Отправитель должен указать необходимый ранг получателя.▪ Получатель должен указать корректный ранг отправителя (или получатель
использует MPI_ANY_SOURCE).▪ Коммуникатор должен быть одним и тем же.▪ Тэги должны совпадать (или получатель использует MPI_ANY_TAG)▪ Типы данных должны при отправке и получении должны совпадать.▪ Буфер получателя должен быть достаточно большим.
Параметр status получателя содержит актуальную информацию о полученном сообщении:
▪ отправитель: status.MPI_SOURCE▪ тэг: status.MPI_TAG▪ количество полученных сообщений:
int MPI_Get_count(MPI_Status *status, MPI_Datatype datatype, int *count)

47
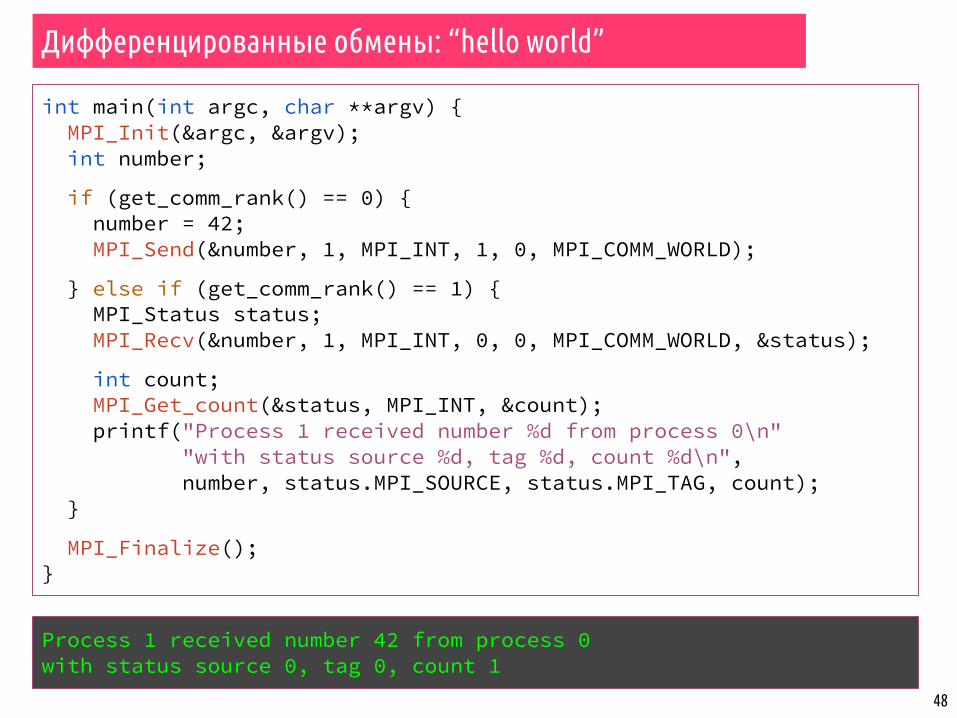
Дифференцированные обмены: “hello world”
int main(int argc, char **argv){ MPI_Init(&argc, &argv); int number;
if (get_comm_rank() == 0) { number = 42; MPI_Send(&number, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); } else if (get_comm_rank() == 1) { MPI_Recv(&number, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf("Process 1 received number %d from process 0\n", number); }
MPI_Finalize(); return 0;}
Process 1 received number 42 from process 0
48
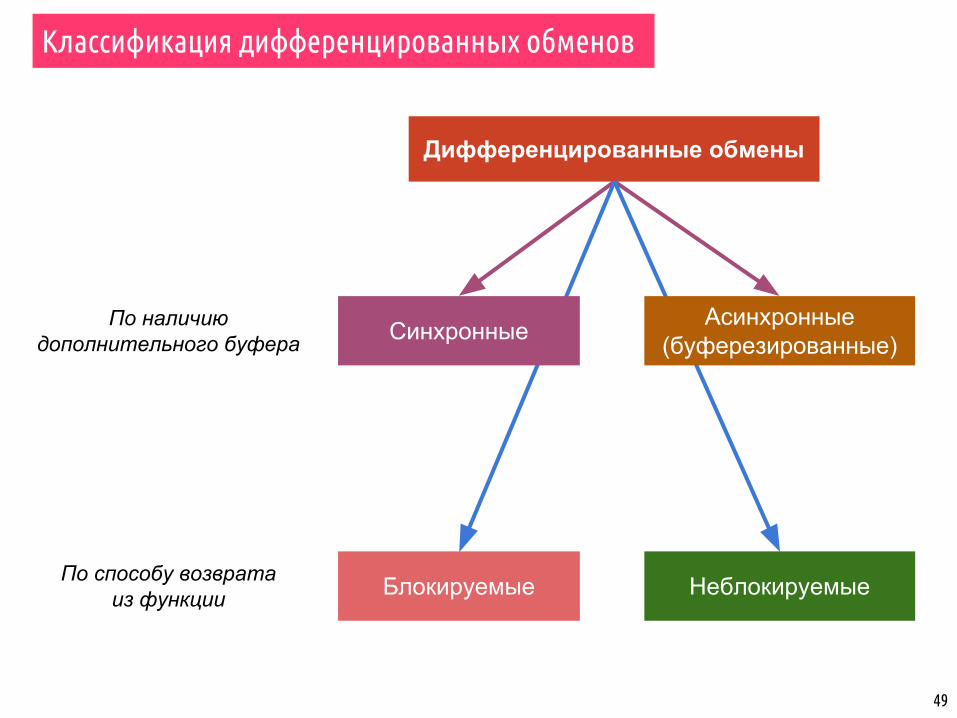
Дифференцированные обмены: “hello world”
int main(int argc, char **argv) { MPI_Init(&argc, &argv); int number;
if (get_comm_rank() == 0) { number = 42; MPI_Send(&number, 1, MPI_INT, 1, 0, MPI_COMM_WORLD);
} else if (get_comm_rank() == 1) { MPI_Status status; MPI_Recv(&number, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);
int count; MPI_Get_count(&status, MPI_INT, &count); printf("Process 1 received number %d from process 0\n" "with status source %d, tag %d, count %d\n", number, status.MPI_SOURCE, status.MPI_TAG, count); }
MPI_Finalize();}
Process 1 received number 42 from process 0with status source 0, tag 0, count 1
49
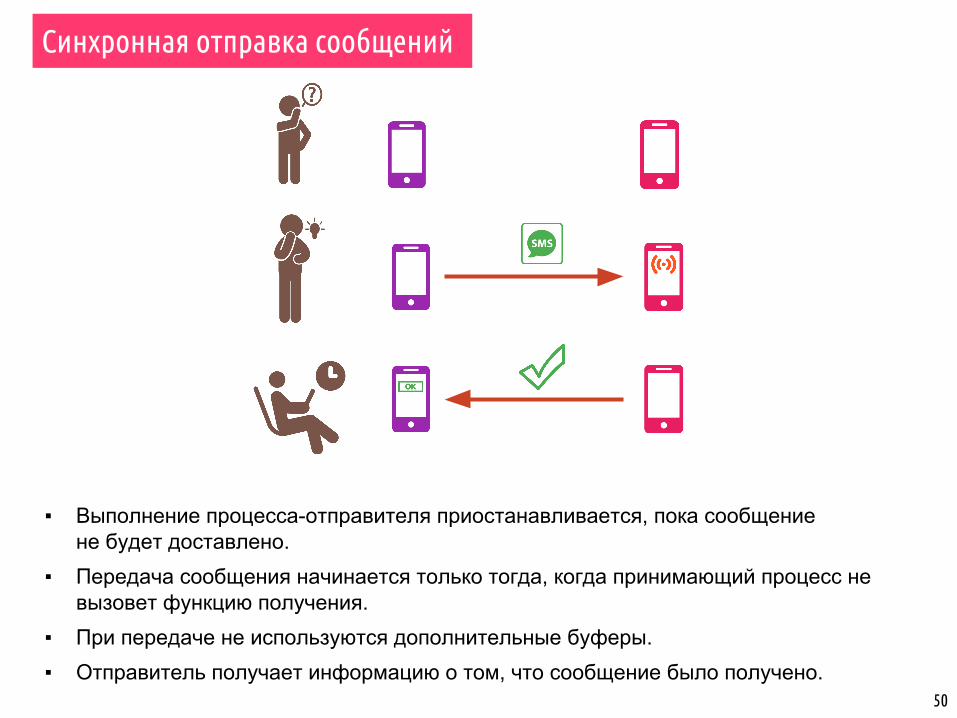
Классификация дифференцированных обменов
Дифференцированные обмены
Блокируемые Неблокируемые
По наличию дополнительного буфера
По способу возврата из функции
Синхронные Асинхронные (буферезированные)
50
▪ Выполнение процесса-отправителя приостанавливается, пока сообщение не будет доставлено.
▪ Передача сообщения начинается только тогда, когда принимающий процесс не вызовет функцию получения.
▪ При передаче не используются дополнительные буферы.▪ Отправитель получает информацию о том, что сообщение было получено.
Синхронная отправка сообщений
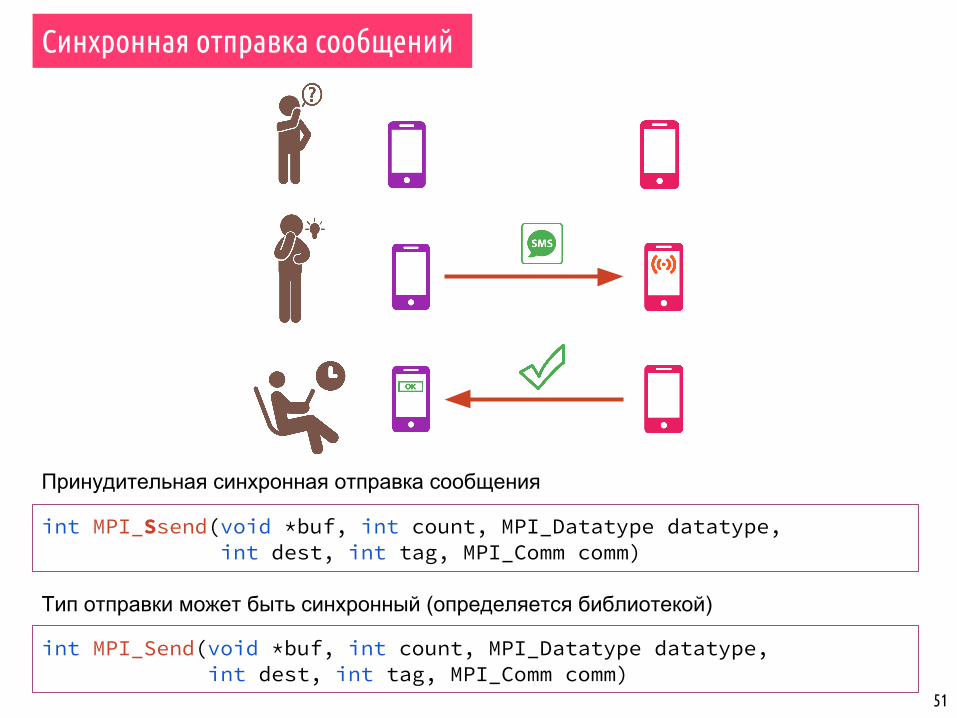
51
Синхронная отправка сообщений
int MPI_Ssend(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
Принудительная синхронная отправка сообщения
Тип отправки может быть синхронный (определяется библиотекой)
52
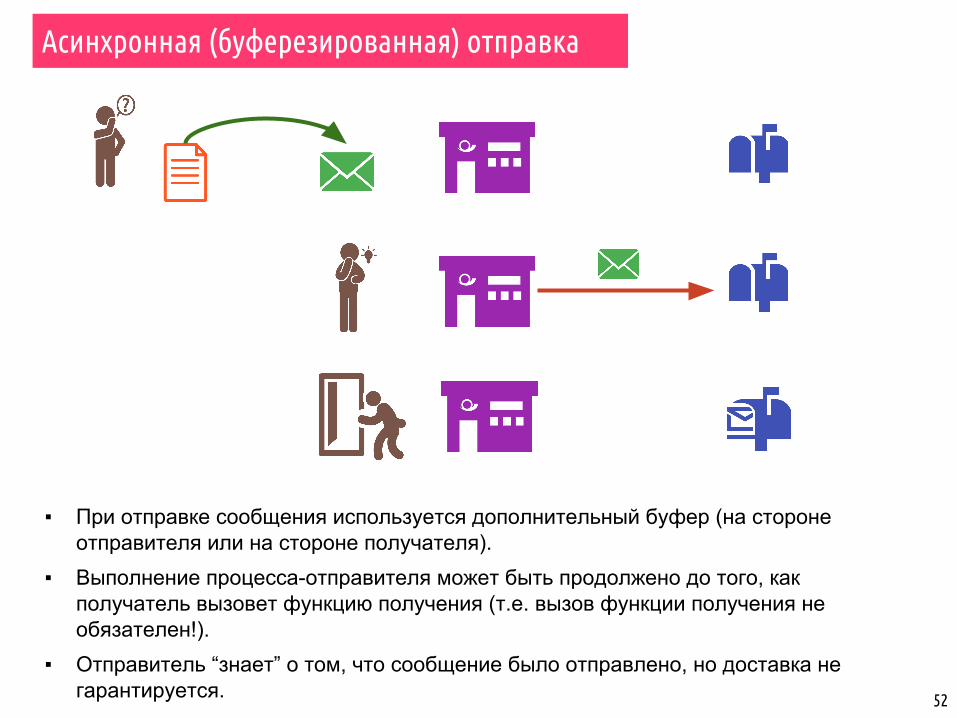
▪ При отправке сообщения используется дополнительный буфер (на стороне отправителя или на стороне получателя).
▪ Выполнение процесса-отправителя может быть продолжено до того, как получатель вызовет функцию получения (т.е. вызов функции получения не обязателен!).
▪ Отправитель “знает” о том, что сообщение было отправлено, но доставка не гарантируется.
Асинхронная (буферезированная) отправка
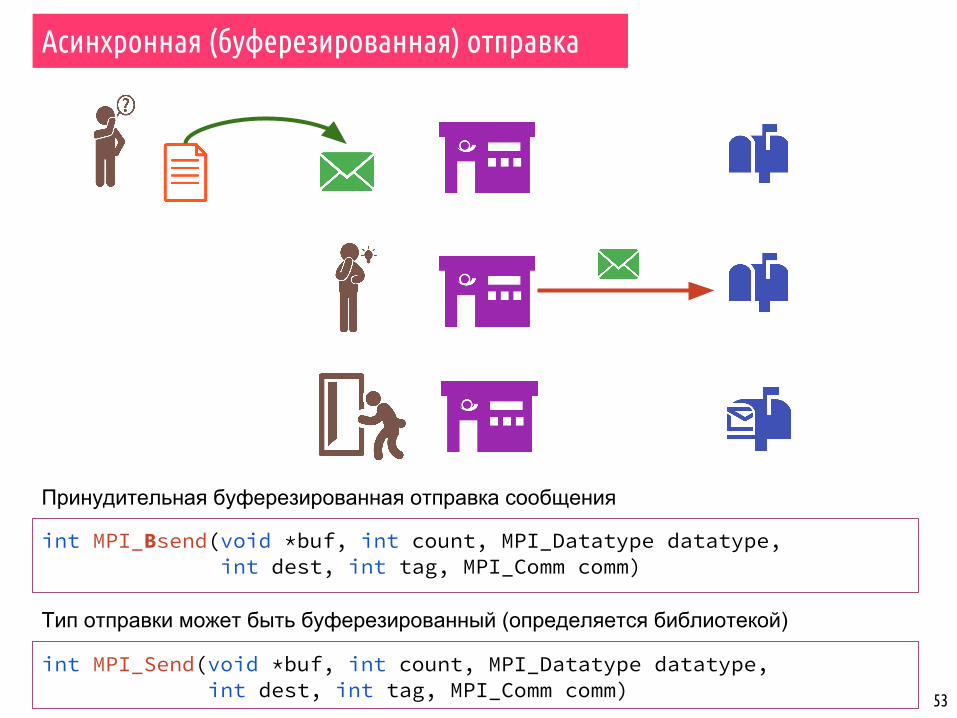
53
Асинхронная (буферезированная) отправка
int MPI_Bsend(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
Тип отправки может быть буферезированный (определяется библиотекой)
Принудительная буферезированная отправка сообщения
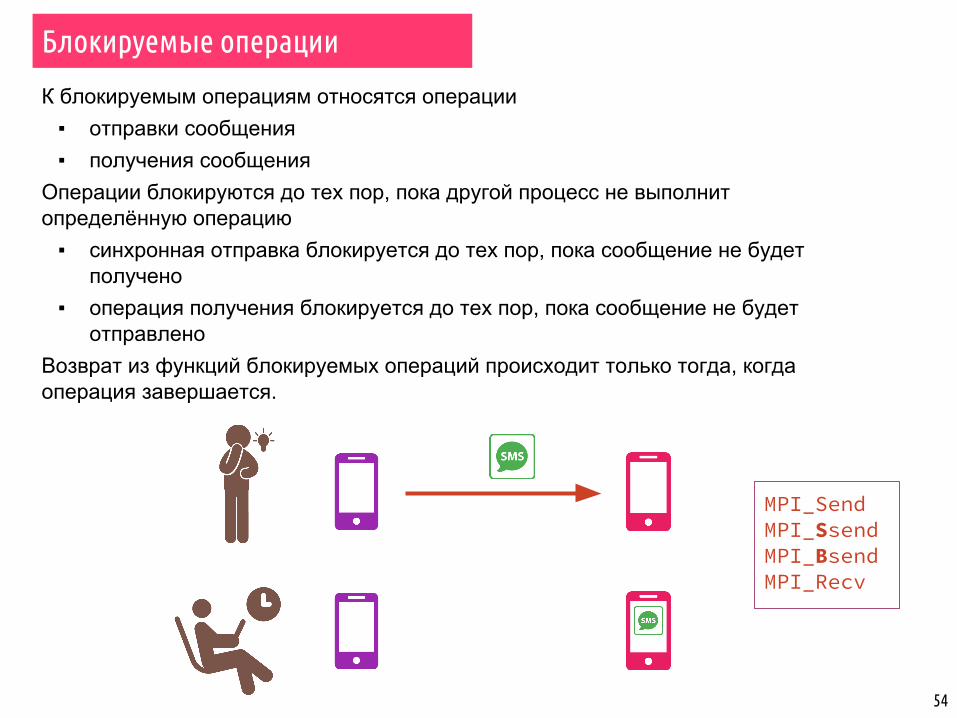
54
К блокируемым операциям относятся операции▪ отправки сообщения▪ получения сообщения
Операции блокируются до тех пор, пока другой процесс не выполнит определённую операцию
▪ синхронная отправка блокируется до тех пор, пока сообщение не будет получено
▪ операция получения блокируется до тех пор, пока сообщение не будет отправлено
Возврат из функций блокируемых операций происходит только тогда, когда операция завершается.
Блокируемые операции
MPI_SendMPI_SsendMPI_BsendMPI_Recv
55
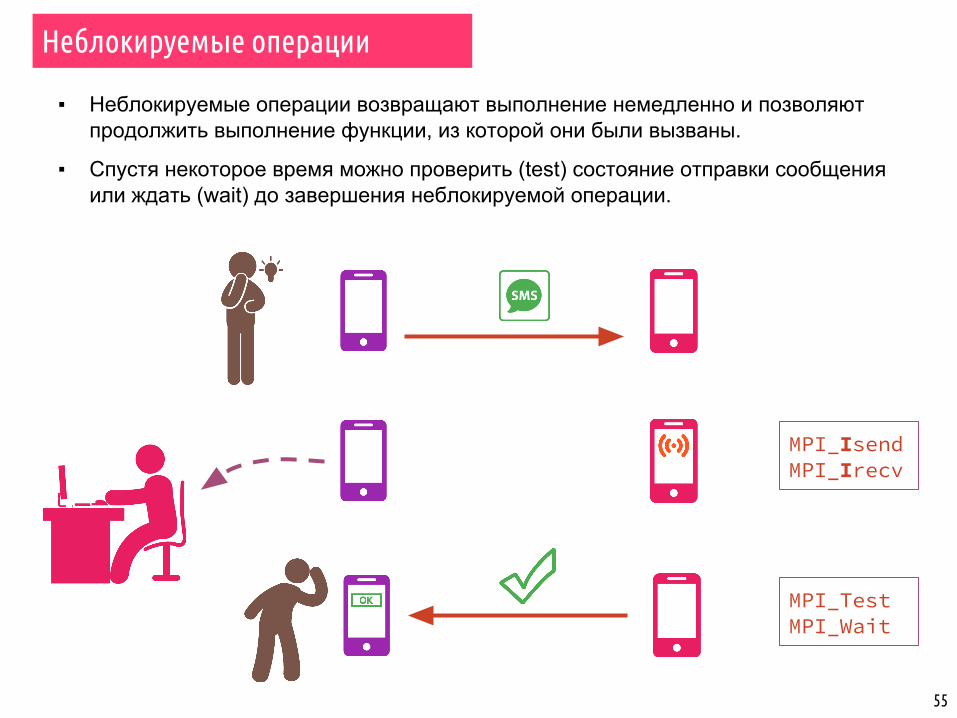
▪ Неблокируемые операции возвращают выполнение немедленно и позволяют продолжить выполнение функции, из которой они были вызваны.
▪ Спустя некоторое время можно проверить (test) состояние отправки сообщения или ждать (wait) до завершения неблокируемой операции.
Неблокируемые операции
MPI_IsendMPI_Irecv
MPI_TestMPI_Wait
56
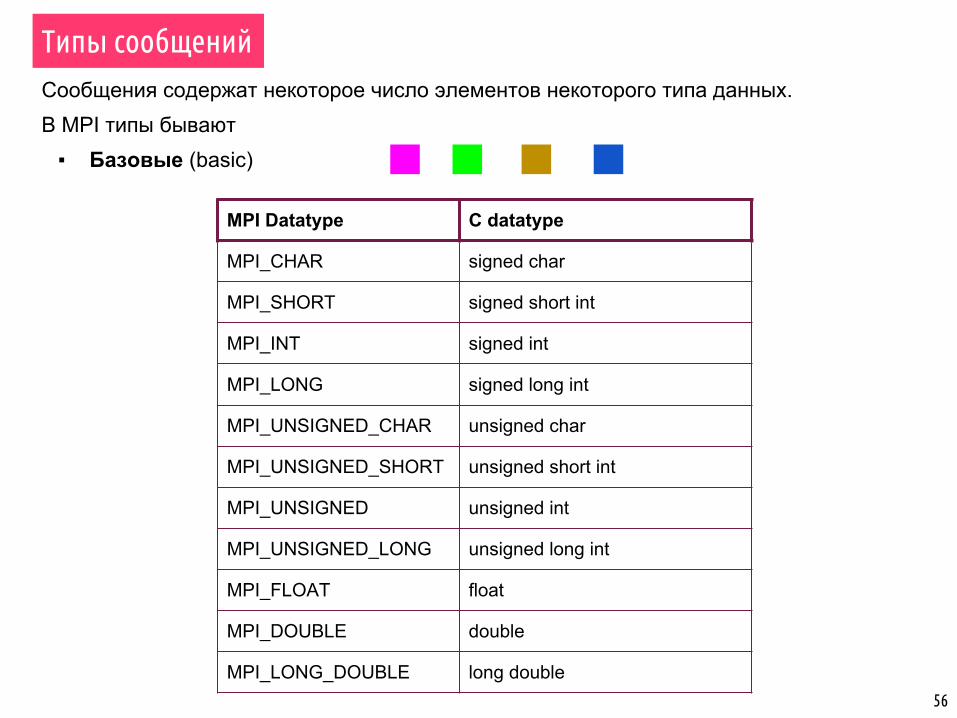
Сообщения содержат некоторое число элементов некоторого типа данных.В MPI типы бывают
▪ Базовые (basic)
Типы сообщений
MPI Datatype C datatype
MPI_CHAR signed char
MPI_SHORT signed short int
MPI_INT signed int
MPI_LONG signed long int
MPI_UNSIGNED_CHAR unsigned char
MPI_UNSIGNED_SHORT unsigned short int
MPI_UNSIGNED unsigned int
MPI_UNSIGNED_LONG unsigned long int
MPI_FLOAT float
MPI_DOUBLE double
MPI_LONG_DOUBLE long double

57
Сообщения содержат некоторое число элементов некоторого типа данных.В MPI типы бывают
▪ Базовые (basic)
▪ Производные (derived), которые могут быт получены из базовых и производных типов.
Примеры сообщений в MPI
Соответствия между базовыми типами MPI и типами С:
Типы сообщений
58
Сохранение порядка отправки сообщений
Правило для сообщений, имеющих одинаковый коммуникатор, источник, приёмник и тэг:
▪ Сообщения не “обгоняют” друг друга: они доставляются в том же порядке, в котором они были отправлены.
▪ Правило верно также для несинхронных сообщений.
P1 P2

59
Пример: пинг-понг
▪ Процесс 0 передаёт сообщение процессу 1 (ping). В качестве сообщения используется счетчик переданных сообщений.
▪ Процесс 0 инкрементирует счетчик сообщений.▪ После получения, процесс 1 передаёт сообщение обратно процессу 0 (pong).▪ Процедура повторяется PING_PONG_LIMIT раз.
P1 P2
0
1
ping
pong
pingpong_count
2
3
4
5
6
7

60
Пример: пинг-понг – вариант 1
// Программа работает только для двух процессахif (get_comm_size() != 2) { fprintf(stderr, "World size must be two for %s\n", argv[0]); MPI_Abort(MPI_COMM_WORLD, 1);}int pingpong_count = 0;while (pingpong_count < PING_PONG_LIMIT) if (get_comm_rank() == 0) { pingpong_count++; // Увеличиваем счетчик перед отправкой MPI_Send(&pingpong_count, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); printf("0 sent and incremented pingpong_count %d\n", pingpong_count); MPI_Recv(&pingpong_count, 1, MPI_INT, 1, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf("0 received pingpong_count %d from 1\n", pingpong_count); } else { MPI_Recv(&pingpong_count, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf("1 received pingpong_count %d from 0\n", pingpong_count); pingpong_count++; // Увеличиваем счетчик перед отправкой MPI_Send(&pingpong_count, 1, MPI_INT, 0, 0, MPI_COMM_WORLD); printf("1 sent and incremented pingpong_count %d to 1\n", pingpong_count); }

61
// Программа работает только для двух процессахif (get_comm_size() != 2) { fprintf(stderr, "World size must be two for %s\n", argv[0]); MPI_Abort(MPI_COMM_WORLD, 1);}
int pingpong_count = 0;int partner_rank = (get_comm_rank() + 1) % 2;while (pingpong_count < PING_PONG_LIMIT) { if (get_comm_rank() == pingpong_count % 2) { // Увеличиваем счетчик перед отправкой pingpong_count++; MPI_Send(&pingpong_count, 1, MPI_INT, partner_rank, 0, MPI_COMM_WORLD); printf("%d sent and incremented ping_pong_count %d to %d\n", get_comm_rank(), pingpong_count, partner_rank); } else { MPI_Recv(&pingpong_count, 1, MPI_INT, partner_rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf("%d received pingpong_count %d from %d\n", get_comm_rank(), pingpong_count, partner_rank); } }}
Пример: пинг-понг – вариант 2
62
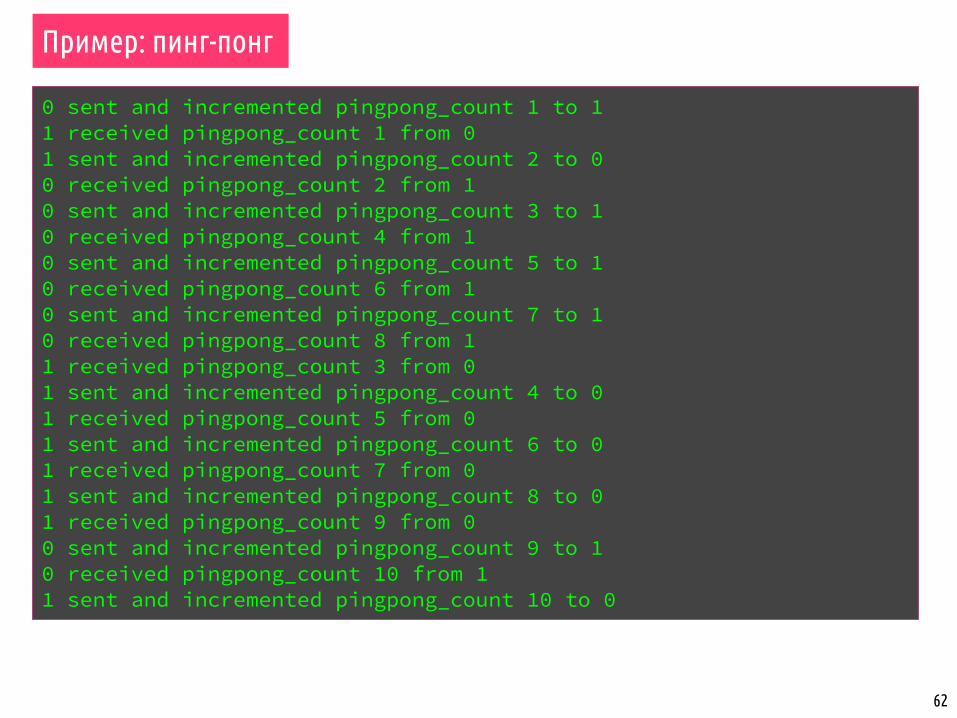
Пример: пинг-понг
0 sent and incremented pingpong_count 1 to 11 received pingpong_count 1 from 01 sent and incremented pingpong_count 2 to 00 received pingpong_count 2 from 10 sent and incremented pingpong_count 3 to 10 received pingpong_count 4 from 10 sent and incremented pingpong_count 5 to 10 received pingpong_count 6 from 10 sent and incremented pingpong_count 7 to 10 received pingpong_count 8 from 11 received pingpong_count 3 from 01 sent and incremented pingpong_count 4 to 01 received pingpong_count 5 from 01 sent and incremented pingpong_count 6 to 01 received pingpong_count 7 from 01 sent and incremented pingpong_count 8 to 01 received pingpong_count 9 from 00 sent and incremented pingpong_count 9 to 10 received pingpong_count 10 from 11 sent and incremented pingpong_count 10 to 0

63
double t = MPI_Wtime();
int pingpong_count = 0;int partner_rank = (get_comm_rank() + 1) % 2;while (pingpong_count < PING_PONG_LIMIT) { if (get_comm_rank() == pingpong_count % 2) { // Увеличиваем счетчик перед отправкой pingpong_count++; MPI_Send(&pingpong_count, 1, MPI_INT, partner_rank, 0, MPI_COMM_WORLD); printf("%d sent and incremented ping_pong_count %d to %d\n", get_comm_rank(), pingpong_count, partner_rank); } else { MPI_Recv(&pingpong_count, 1, MPI_INT, partner_rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf("%d received pingpong_count %d from %d\n", get_comm_rank(), pingpong_count, partner_rank); } }}
t = MPI_Wtime() - t;if (get_comm_rank() == 1) printf("Ping pong execution time: %f\n", t);
Пример: пинг-понг – вариант 2, с измерением времени
64
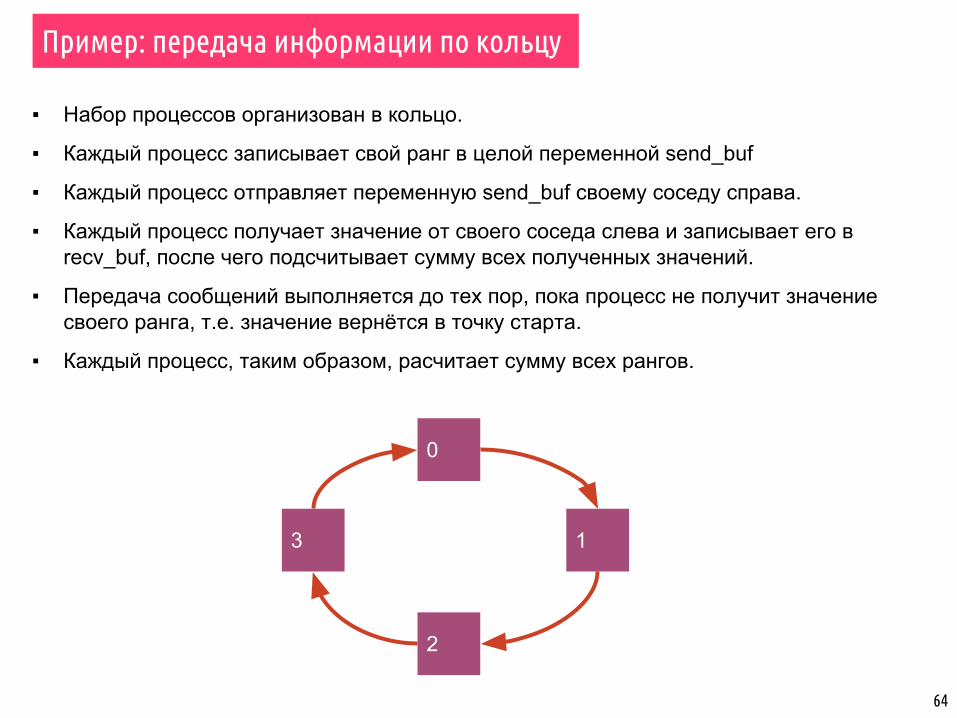
▪ Набор процессов организован в кольцо.
▪ Каждый процесс записывает свой ранг в целой переменной send_buf
▪ Каждый процесс отправляет переменную send_buf своему соседу справа.
▪ Каждый процесс получает значение от своего соседа слева и записывает его в recv_buf, после чего подсчитывает сумму всех полученных значений.
▪ Передача сообщений выполняется до тех пор, пока процесс не получит значение своего ранга, т.е. значение вернётся в точку старта.
▪ Каждый процесс, таким образом, расчитает сумму всех рангов.
Пример: передача информации по кольцу
0
3 1
2
65
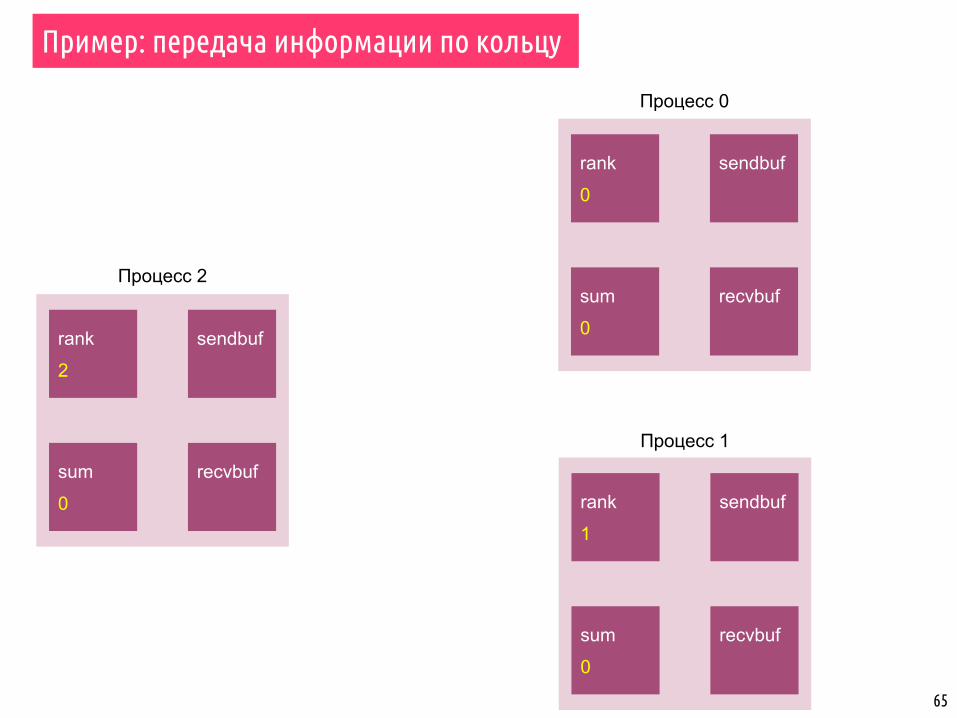
Пример: передача информации по кольцу
rank
0
sendbuf
recvbufsum
0
rank
1
sendbuf
recvbufsum
0
rank
2
sendbuf
recvbufsum
0
Процесс 0
Процесс 1
Процесс 2
66
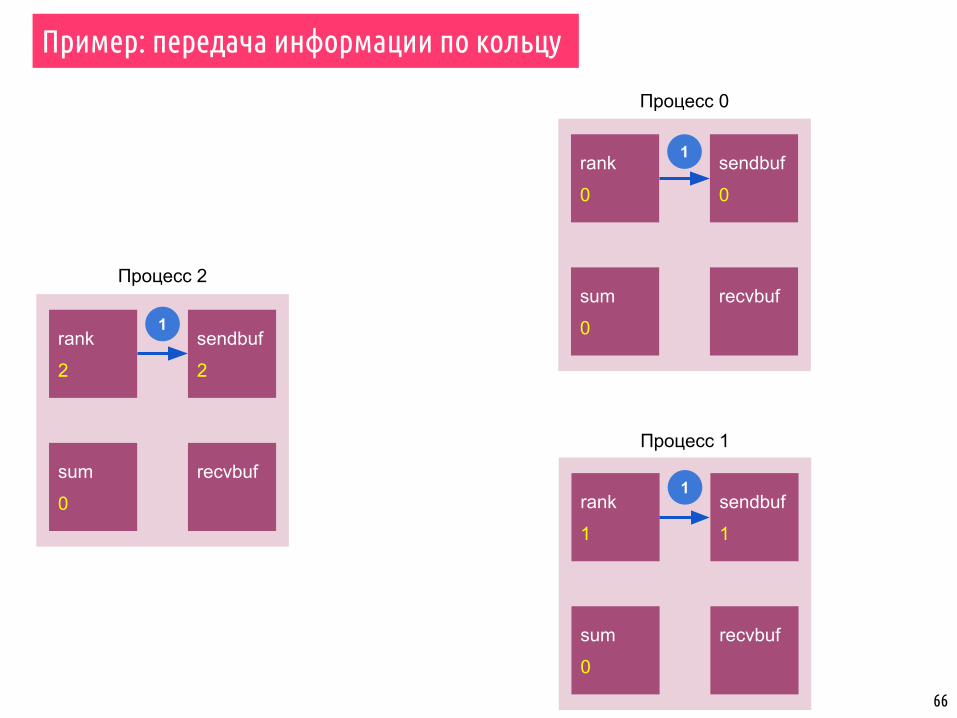
Пример: передача информации по кольцу
rank
0
sendbuf
0
recvbufsum
0
rank
1
sendbuf
1
recvbufsum
0
rank
2
sendbuf
2
recvbufsum
0
Процесс 0
Процесс 1
Процесс 2
1
1
1

67
Пример: передача информации по кольцу
rank
0
sendbuf
0
recvbufsum
0
rank
1
sendbuf
1
recvbufsum
0
rank
2
sendbuf
2
recvbufsum
0
Процесс 0
Процесс 1
Процесс 2
1
1
1
2
2
2
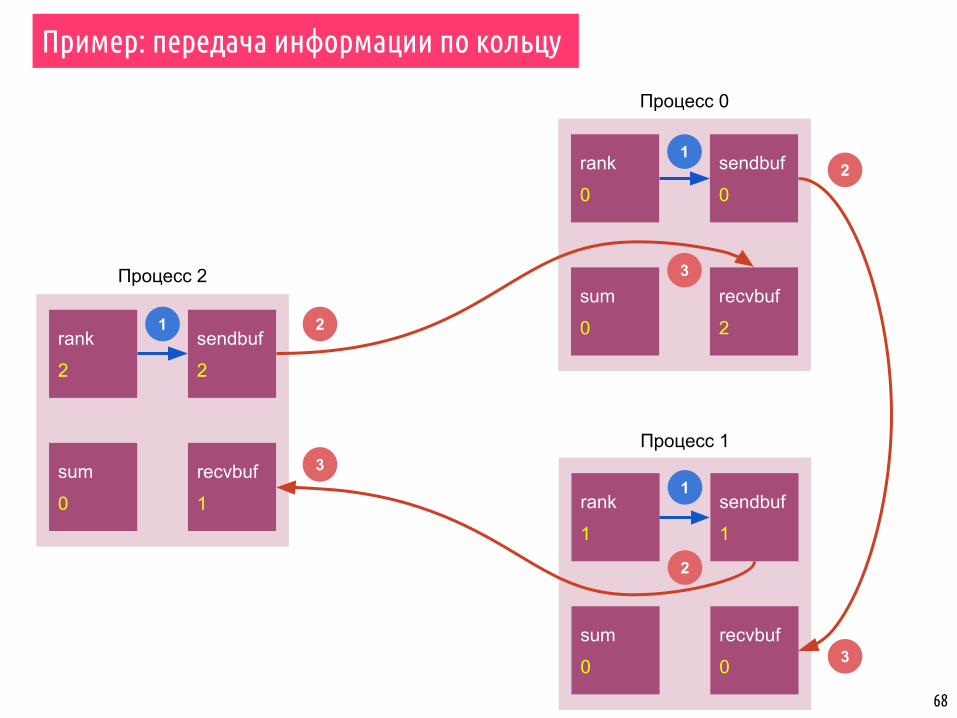
68
Пример: передача информации по кольцу
rank
0
sendbuf
0
recvbuf
2
sum
0
rank
1
sendbuf
1
recvbuf
0
sum
0
rank
2
sendbuf
2
recvbuf
1
sum
0
Процесс 0
Процесс 1
Процесс 2
1
1
1
2
2
2
3
3
3
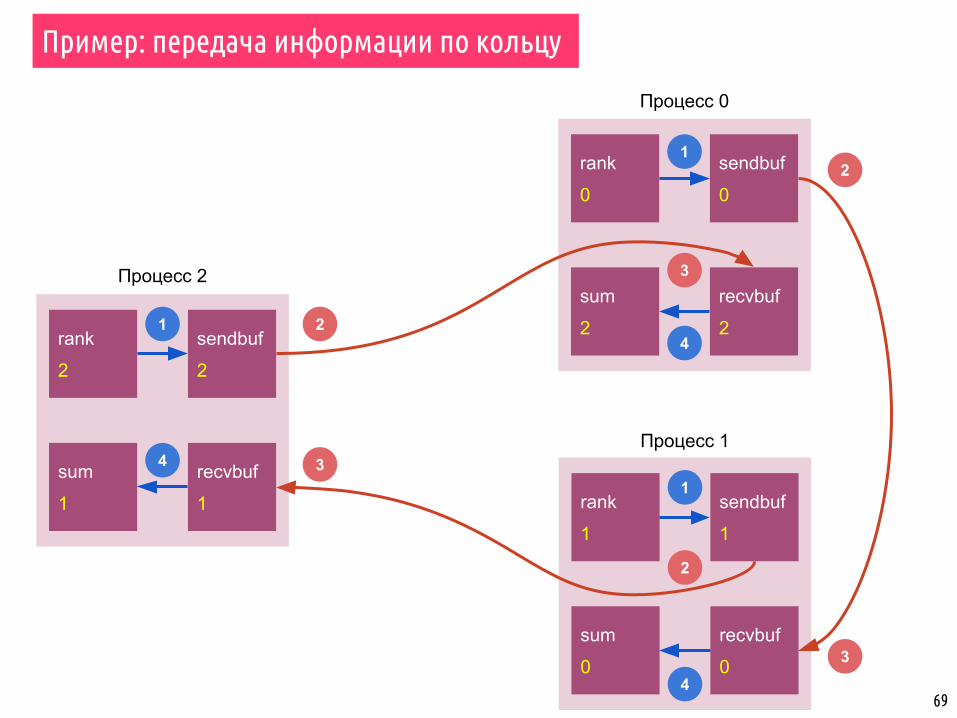
69
Пример: передача информации по кольцу
rank
0
sendbuf
0
recvbuf
2
sum
2
rank
1
sendbuf
1
recvbuf
0
sum
0
rank
2
sendbuf
2
recvbuf
1
sum
1
Процесс 0
Процесс 1
Процесс 2
1
1
1
2
2
2
3
3
3
4
4
4

70
Пример: передача информации по кольцу
rank
0
sendbuf
2
recvbuf
2
sum
2
rank
1
sendbuf
0
recvbuf
0
sum
0
rank
2
sendbuf
1
recvbuf
1
sum
1
Процесс 0
Процесс 1
Процесс 2
1
1
1
2
2
2
3
3
3
4
4
4
5
5
5
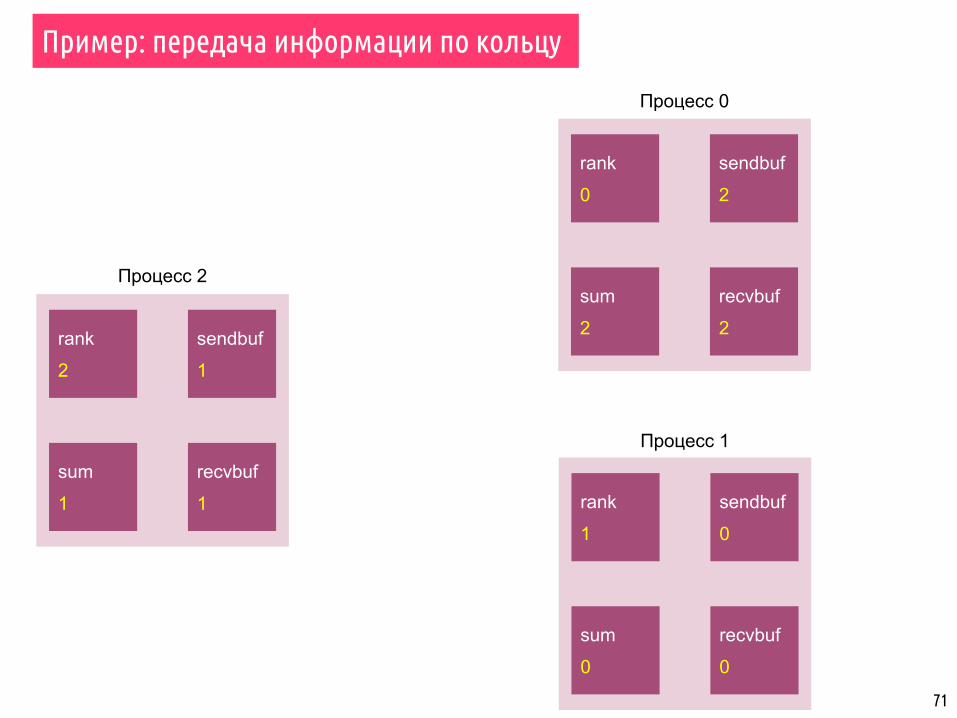
71
Пример: передача информации по кольцу
rank
0
sendbuf
2
recvbuf
2
sum
2
rank
1
sendbuf
0
recvbuf
0
sum
0
rank
2
sendbuf
1
recvbuf
1
sum
1
Процесс 0
Процесс 1
Процесс 2
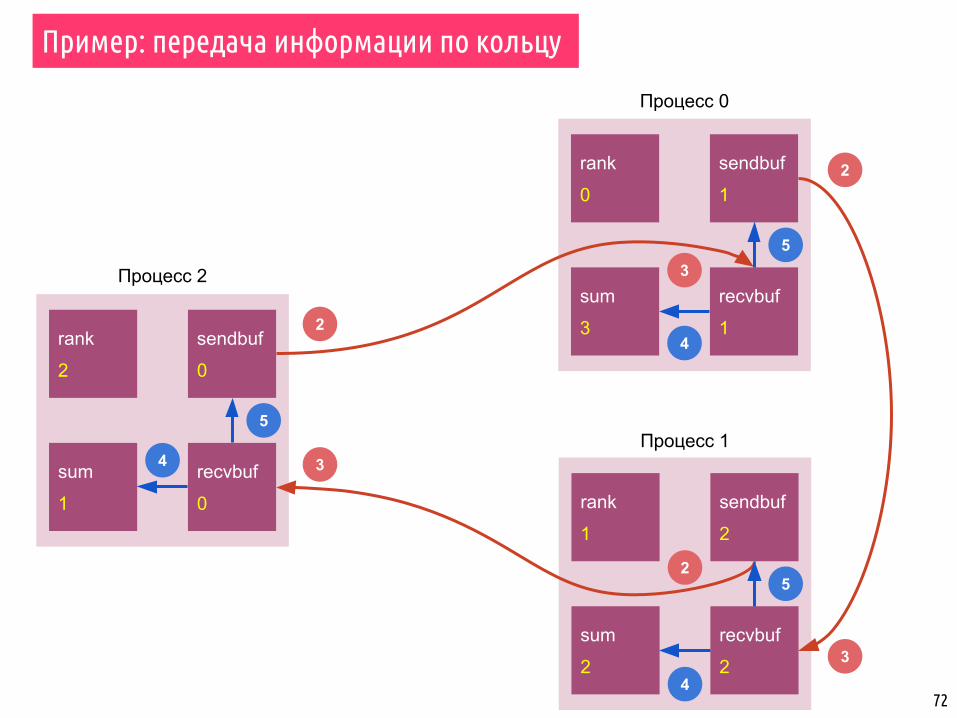
72
Пример: передача информации по кольцу
rank
0
sendbuf
1
recvbuf
1
sum
3
rank
1
sendbuf
2
recvbuf
2
sum
2
rank
2
sendbuf
0
recvbuf
0
sum
1
Процесс 0
Процесс 1
Процесс 2
2
2
2
3
3
3
4
4
4
5
5
5
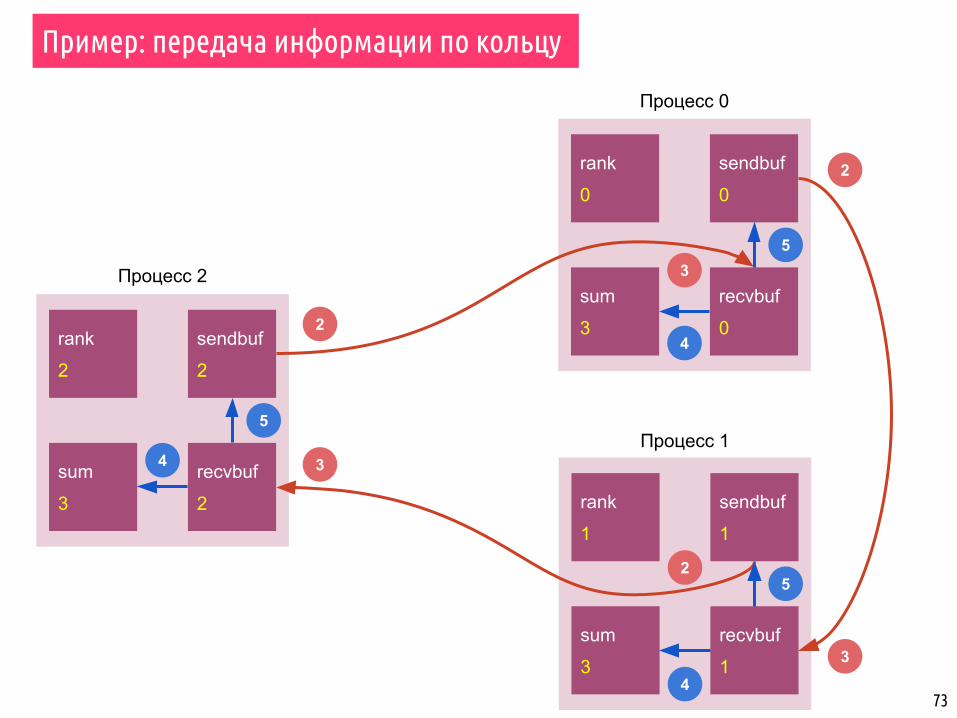
73
Пример: передача информации по кольцу
rank
0
sendbuf
0
recvbuf
0
sum
3
rank
1
sendbuf
1
recvbuf
1
sum
3
rank
2
sendbuf
2
recvbuf
2
sum
3
Процесс 0
Процесс 1
Процесс 2
2
2
2
3
3
3
4
4
4
5
5
5

74
Пример: передача информации по кольцу
int rank, size;MPI_Comm_rank(MPI_COMM_WORLD, &rank);MPI_Comm_size(MPI_COMM_WORLD, &size); int dest = (rank + 1) % size;int source = (rank - 1 + size) % size; int send_buf = rank;int recv_buf = 0;int sum = 0; do { MPI_Send(&send_buf, 1, MPI_INT, dest, 0, MPI_COMM_WORLD); printf("%d send %d to process %d\n", rank, send_buf, dest); MPI_Recv(&recv_buf, 1, MPI_INT, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); sum += recv_buf; send_buf = recv_buf; printf("%d received %d from process %d, sum %d\n", rank, recv_buf, source, sum);} while (recv_buf != rank);

75
Пример: передача информации по кольцу
Process 2 send 2 to process 0Process 1 send 1 to process 2Process 2 received 1 from process 1, sum 1Process 2 send 1 to process 0Process 0 send 0 to process 1Process 1 received 0 from process 0, sum 0Process 1 send 0 to process 2Process 2 received 0 from process 1, sum 1Process 2 send 0 to process 0Process 0 received 2 from process 2, sum 2Process 0 send 2 to process 1Process 0 received 1 from process 2, sum 3Process 0 send 1 to process 1Process 0 received 0 from process 2, sum 3Process 1 received 2 from process 0, sum 2Process 1 send 2 to process 2Process 1 received 1 from process 0, sum 3Process 2 received 2 from process 1, sum 3

76
Синхронная и асинхронная передача сообщений
1 Синхронная передача сообщений
Асинхронная передача сообщений2
MPI_Ssend
MPI_Bsend
MPI_SendMPI_Recv
3 Тип отправки определяется библиотекой

77
Взаимная блокировка (дедлок)
int rank, size;MPI_Comm_rank(MPI_COMM_WORLD, &rank);MPI_Comm_size(MPI_COMM_WORLD, &size); int dest = (rank + 1) % size;int source = (rank - 1 + size) % size; int send_buf = rank;int recv_buf = 0;int sum = 0; do { MPI_Send(...); printf("%d send %d to process %d\n", rank, send_buf, dest); MPI_Recv(&recv_buf, 1, MPI_INT, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); sum += recv_buf; send_buf = recv_buf; printf("%d received %d from process %d, sum %d\n", rank, recv_buf, source, sum);} while (recv_buf != rank);
MPI_Ssend
MPI_Bsend
Дедлок!
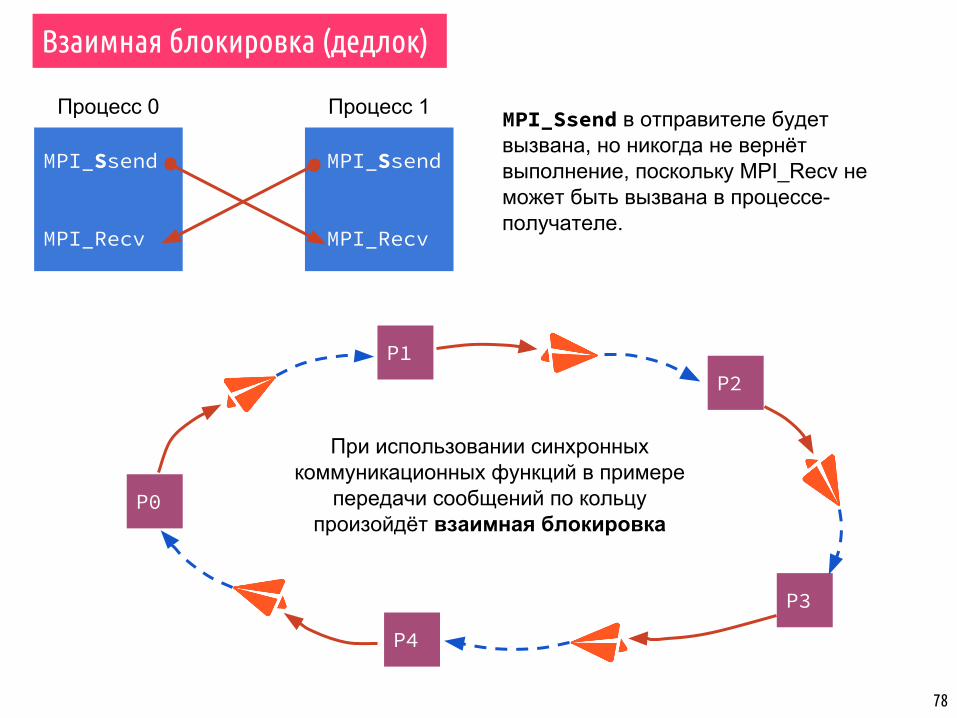
78
Взаимная блокировка (дедлок)
MPI_Ssend
MPI_Recv
Процесс 0
MPI_Ssend
MPI_Recv
Процесс 1
P0
MPI_Ssend в отправителе будет вызвана, но никогда не вернёт выполнение, поскольку MPI_Recv не может быть вызвана в процессе-получателе.
P1P2
P3
P4
При использовании синхронных коммуникационных функций в примере
передачи сообщений по кольцу произойдёт взаимная блокировка

79
Передача информации по кольцу: буферезированная отправка
int MPI_Bsend(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
▪ buf – адрес для начала отправляемого сообщения с количеством count элементов типа datatype;
▪ tag – тэг, дополнительное неотрицательное целое число, передаваемое вместе с сообщением; тэг может быть использован программой для разделения разных типов сообщений;
▪ comm – коммуникатор, в котором находятся процессы;
▪ Пользователь должен подключить буфер достаточного размера с помощью функции MPI_Buffer_attach.
int MPI_Buffer_attach(void *buffer, int size)
▪ присоединяет буфер размера size в памяти, начиная с адреса buffer, для отправления сообщений в буферезированном режиме;
▪ только один буфер может быть присоединён к процессу;
▪ отсоединяет присоединённый буфер, возвращает адрес и размер буфера;
▪ операция блокируется до тех пор, пока все сообщения не будут переданы.
int MPI_buffer_detach(void *buffer, int *size)

80
Размер буфера при буферизированной отправке
▪ размер буфера должен быть равен суммарному размеру всех передаваемых сообщений плюс MPI_BSEND_OVERHEAD для каждой функции Bsend;
▪ для расчета размера можно использовать MPI_Pack_size:
// Пример расчета размера буфераMPI_Pack_size(20, MPI_INT, comm, &s1 );MPI_Pack_size(40, MPI_FLOAT, comm, &s2 );size = s1 + s2 + 2 * MPI_BSEND_OVERHEAD;
// Размер буфера должен быть не меньше, чем расчитанный size:MPI_Buffer_attach(buffer, size);MPI_Bsend(..., count = 20, datatype = MPI_INT, ...);...MPI_Bsend(..., count = 40, datatype = MPI_FLOAT, ...);
int size;char *buf;MPI_Buffer_attach(malloc(BUFSIZE), BUFSIZE);// ...MPI_Buffer_detach(&buf, &size);// ...MPI_Buffer_attach(buf, size);
▪ Пример присоединения буфера размера BUFSIZE:

81
Пример: передача информации по кольцу
// ...
int dest = (rank + 1) % size;int source = (rank - 1 + size) % size;int send_buf = rank, recv_buf = 0int sum = 0;
int bufsize = 0;char *buf = NULL;
MPI_Pack_size(1, MPI_INT, MPI_COMM_WORLD, &bufsize);bufsize += MPI_BSEND_OVERHEAD;MPI_Buffer_attach(malloc(bufsize), bufsize);
do { MPI_Bsend(&send_buf, 1, MPI_INT, dest, 0, MPI_COMM_WORLD); printf("%d send %d to process %d\n", rank, send_buf, dest);
MPI_Recv(&recv_buf, 1, MPI_INT, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); sum += recv_buf; send_buf = recv_buf; printf("%d received %d from process %d, sum %d\n", rank, recv_buf, source, sum);} while (recv_buf != rank);
82
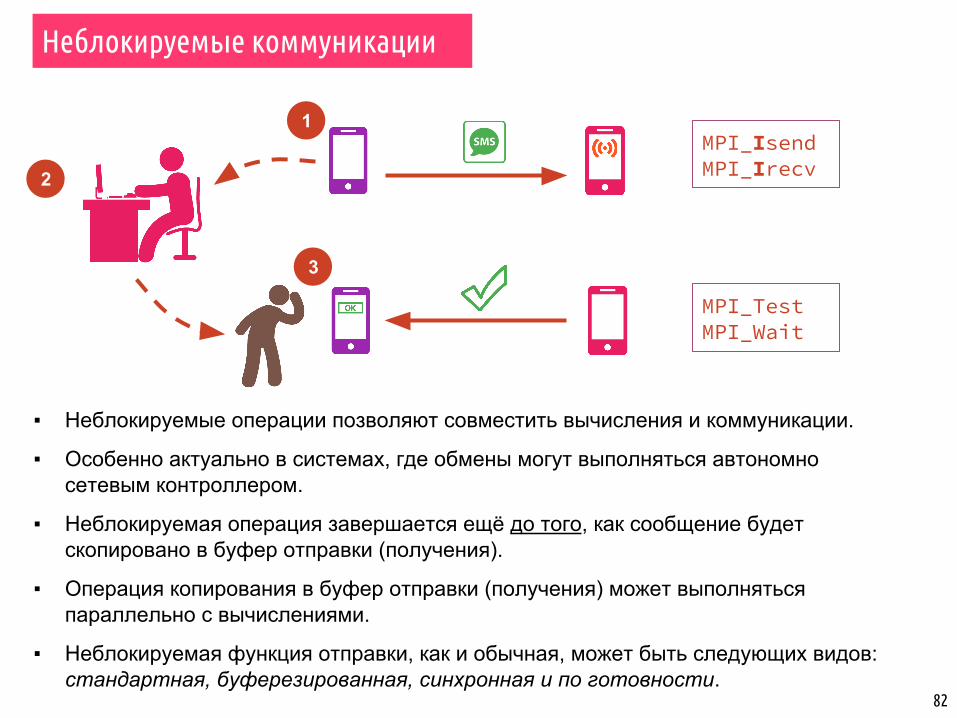
Неблокируемые коммуникации
MPI_IsendMPI_Irecv
MPI_TestMPI_Wait
1
2
3
▪ Неблокируемые операции позволяют совместить вычисления и коммуникации.
▪ Особенно актуально в системах, где обмены могут выполняться автономно сетевым контроллером.
▪ Неблокируемая операция завершается ещё до того, как сообщение будет скопировано в буфер отправки (получения).
▪ Операция копирования в буфер отправки (получения) может выполняться параллельно с вычислениями.
▪ Неблокируемая функция отправки, как и обычная, может быть следующих видов: стандартная, буферезированная, синхронная и по готовности.

83
Неблокируемые коммуникации
MPI_IsendMPI_Irecv
MPI_TestMPI_Wait
Выполнение неблокируемых операций разделяются на три фазы:
1. Инициализация неблокируемого обмена данными. Немедленный (Immediate) возврат из функции (MPI_Isend, MPI_Irecv, MPI_Ibcast, MPI_Ireduce, …).
2. Процесс, вызвавший функцию, выполняет какую-то полезную работу (вычисления или другие коммуникации).
3. Ожидание завершения коммуникации (MPI_Wait) или периодическая проверка завершения (MPI_Test).
1
2
3
84
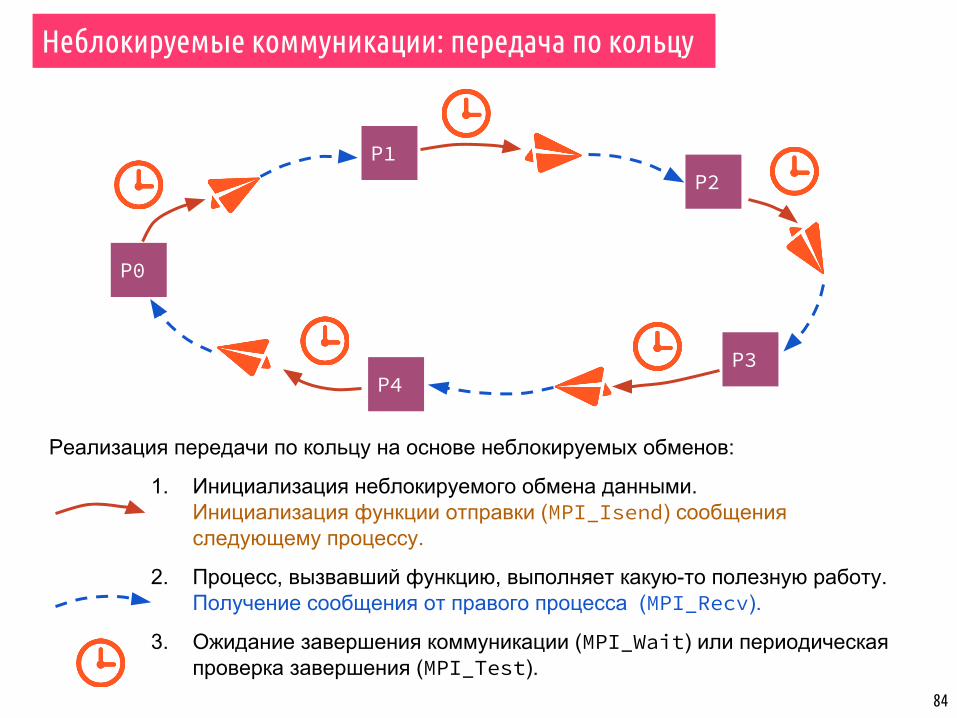
Неблокируемые коммуникации: передача по кольцу
Реализация передачи по кольцу на основе неблокируемых обменов:
1. Инициализация неблокируемого обмена данными. Инициализация функции отправки (MPI_Isend) сообщения следующему процессу.
2. Процесс, вызвавший функцию, выполняет какую-то полезную работу.Получение сообщения от правого процесса (MPI_Recv).
3. Ожидание завершения коммуникации (MPI_Wait) или периодическая проверка завершения (MPI_Test).
P0
P1P2
P3P4
85
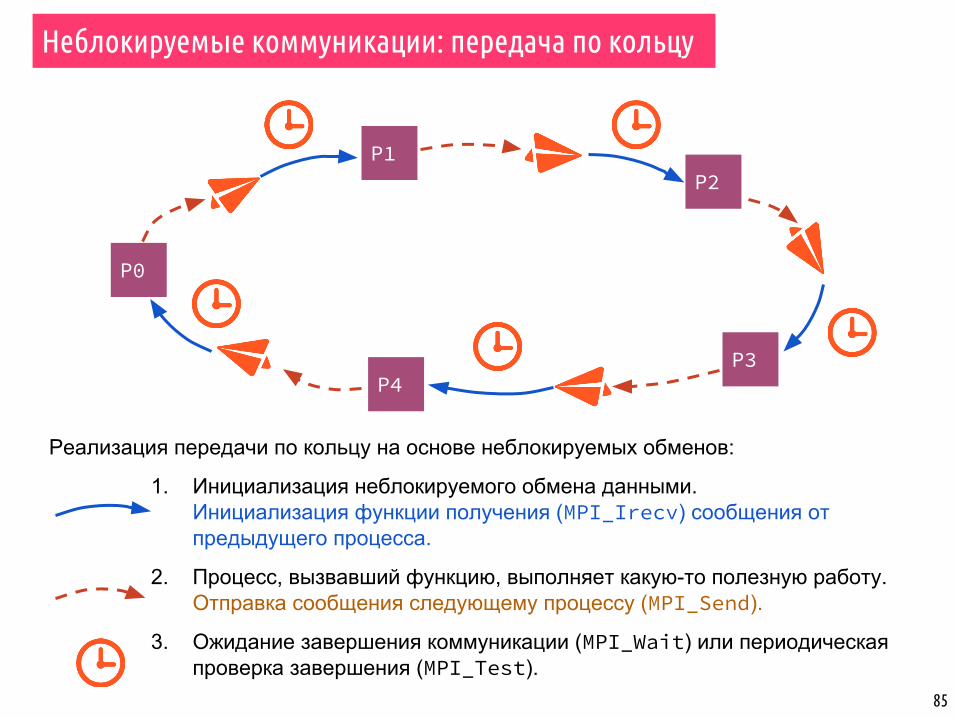
Реализация передачи по кольцу на основе неблокируемых обменов:
1. Инициализация неблокируемого обмена данными. Инициализация функции получения (MPI_Irecv) сообщения от предыдущего процесса.
2. Процесс, вызвавший функцию, выполняет какую-то полезную работу.Отправка сообщения следующему процессу (MPI_Send).
3. Ожидание завершения коммуникации (MPI_Wait) или периодическая проверка завершения (MPI_Test).
P0
P1P2
P3P4
Неблокируемые коммуникации: передача по кольцу

86
Неблокируемые дифференцированные обмены
int MPI_Isend(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request)
▪ request – идентификатор, по которому можно обратиться и получить статус операции или дождаться завершения её выполнения;
int MPI_Issend(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Ibsend(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Irecv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request)

87
Неблокируемые дифференцированные обмены
int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status)
▪ request – идентификатор, по которому можно обратиться и получить статус операции или дождаться завершения её выполнения;
▪ flag – равен true, если операция завершена;
▪ status – статус завершения операции (м.б. MPI_STATUS_IGNORE).
Проверка статуса выполнения неблокируемой операции:
int MPI_Wait(MPI_Request *request, MPI_Status *status)
Ожидание завершения неблокируемой операции:

88
Пеередача по кольцу на основе неблокируемых обменов
int rank, size;MPI_Comm_rank(MPI_COMM_WORLD, &rank);MPI_Comm_size(MPI_COMM_WORLD, &size);
int dest = (rank + 1) % size;int source = (rank - 1 + size) % size;
int send_buf = rank, recv_buf = 0;int sum = 0;
MPI_Request request;
do { MPI_Isend(&send_buf, 1, MPI_INT, dest, 0, MPI_COMM_WORLD, &request); printf("%d send %d to process %d\n", rank, send_buf, dest);
MPI_Recv(&recv_buf, 1, MPI_INT, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); sum += recv_buf; send_buf = recv_buf; printf("%d received %d from process %d, sum %d\n", rank, recv_buf, source, sum);
MPI_Wait(&request, MPI_STATUS_IGNORE);} while (recv_buf != rank);

89
Пеередача по кольцу на основе неблокируемых обменов
int rank, size;MPI_Comm_rank(MPI_COMM_WORLD, &rank);MPI_Comm_size(MPI_COMM_WORLD, &size);
int dest = (rank + 1) % size;int source = (rank - 1 + size) % size;
int send_buf = rank, recv_buf = 0;int sum = 0;
MPI_Request request;
do { MPI_Issend(&send_buf, 1, MPI_INT, dest, 0, MPI_COMM_WORLD, &request); printf("%d send %d to process %d\n", rank, send_buf, dest);
MPI_Recv(&recv_buf, 1, MPI_INT, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); sum += recv_buf; send_buf = recv_buf; printf("%d received %d from process %d, sum %d\n", rank, recv_buf, source, sum);
MPI_Wait(&request, MPI_STATUS_IGNORE);} while (recv_buf != rank);

90
Пример: обмен сообщениями динамического размера
MPI_Send
Процесс 0
MPI_Recv
Процесс 1
msgsize = X
Размер сообщения определяется в процессе выполнения программы и заранее известен только отправителю.

const int MAX_NUMBERS = 100;int numbers[MAX_NUMBERS];int number_amount;if (world_rank == 0) { // Выбираем случайный размер сообщения srand(time(NULL)); number_acount = ((rand() / (float) RAND_MAX) * MAX_NUMBERS;
// Отправляет сообщение случайного размера первому процессу MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD); printf("0 sent %d numbers to 1\n", number_amount);} else if (world_rank == 1) { MPI_Status status; // Получаем сообщение размера до MAX_NUMBERS от нулевого процесса MPI_Recv(numbers, MAX_NUMBERS, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);
// Определяем размер полученного сообщения и печатаем сообщение MPI_Get_count(&status, MPI_INT, &number_amount); printf("1 received %d numbers from 0. Message source = %d, " "tag = %d\n", number_amount, status.MPI_SOURCE, status.MPI_TAG);}
91
Пример: обмен сообщениями динамического размера
MPI_Send
Процесс 0 Процесс 1
msgsize = X MPI_Recv

const int MAX_NUMBERS = 100;int numbers[MAX_NUMBERS];int number_amount;if (world_rank == 0) { // Выбираем случайный размер сообщения srand(time(NULL)); number_acount = ((rand() / (float) RAND_MAX) * MAX_NUMBERS;
// Отправляет сообщение случайного размера первому процессу MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD); printf("0 sent %d numbers to 1\n", number_amount);} else if (world_rank == 1) { MPI_Status status; // Получаем сообщение размера до MAX_NUMBERS от нулевого процесса MPI_Recv(numbers, MAX_NUMBERS, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);
// Определяем размер полученного сообщения и печатаем сообщение MPI_Get_count(&status, MPI_INT, &number_amount); printf("1 received %d numbers from 0. Message source = %d, " "tag = %d\n", number_amount, status.MPI_SOURCE, status.MPI_TAG);}
92
Пример: обмен сообщениями динамического размера
MPI_Send
Процесс 0 Процесс 1
msgsize = X
0 sent 56 numbers to 11 received 56 numbers from 0. Message source = 0, tag = 0
MPI_Recv

const int MAX_NUMBERS = 100;int numbers[MAX_NUMBERS];int number_amount;if (world_rank == 0) { // Выбираем случайный размер сообщения srand(time(NULL)); number_acount = ((rand() / (float) RAND_MAX) * MAX_NUMBERS;
// Отправляет сообщение случайного размера первому процессу MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD); printf("0 sent %d numbers to 1\n", number_amount);} else if (world_rank == 1) { MPI_Status status; // Получаем сообщение размера до MAX_NUMBERS от нулевого процесса MPI_Recv(numbers, MAX_NUMBERS, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);
// Определяем размер полученного сообщения и печатаем сообщение MPI_Get_count(&status, MPI_INT, &number_amount); printf("1 received %d numbers from 0. Message source = %d, " "tag = %d\n", number_amount, status.MPI_SOURCE, status.MPI_TAG);}
93
Пример: обмен сообщениями динамического размера
MPI_Send
Процесс 0 Процесс 1
msgsize = X
Перед получением необходимо выделить буфер максимального размера.
0 sent 56 numbers to 11 received 56 numbers from 0. Message source = 0, tag = 0
MPI_Recv
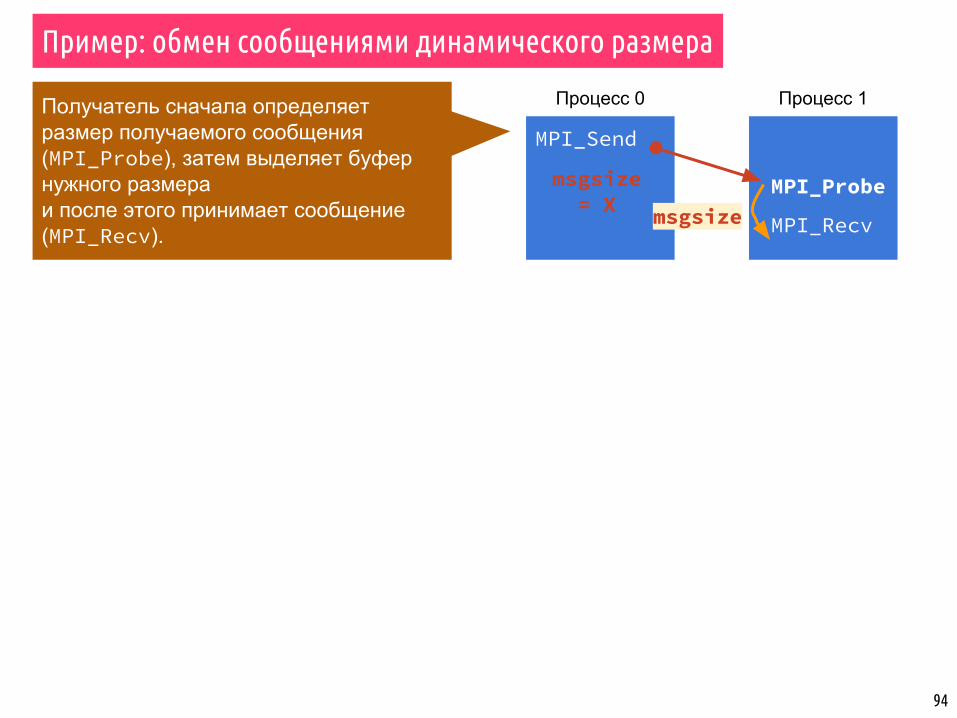
94
Пример: обмен сообщениями динамического размера
MPI_Send
Процесс 0
MPI_Probe
MPI_Recv
Процесс 1
msgsize = X msgsize
Получатель сначала определяет размер получаемого сообщения (MPI_Probe), затем выделяет буфер нужного размера и после этого принимает сообщение (MPI_Recv).

int numbers[MAX_NUMBERS];int number_amount;if (world_rank == 0) { const int MAX_NUMBERS = 100; // Выбираем случайный размер сообщения // и отправляем 1 процессу number_acount = ((rand() / (float) RAND_MAX) * MAX_NUMBERS; MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD); printf("0 sent %d numbers to 1\n", number_amount);} else if (world_rank == 1) { MPI_Status status; // Проверяем входящее сообщение и получаем его размер MPI_Probe(0, 0, MPI_COMM_WORLD, &status); MPI_Get_count(&status, MPI_INT, &number_amount);
// Выделяем буфер необходимого размера и используем его для получения int* number_buf = (int*) malloc(sizeof(int) * number_amount); // Получаем сообщение размера number_buf от нулевого процесса MPI_Recv(numbers, MAX_NUMBERS, MPI_INT, 0, 0, MPI_COMM_WORLD, &status); printf("1 received %d numbers from 0", number_amount); free(number_buf);}
95
Пример: обмен сообщениями динамического размера
MPI_Send
Процесс 0
MPI_Probe
MPI_Recv
Процесс 1
msgsize = X msgsize

96
Пример: случайное блуждание
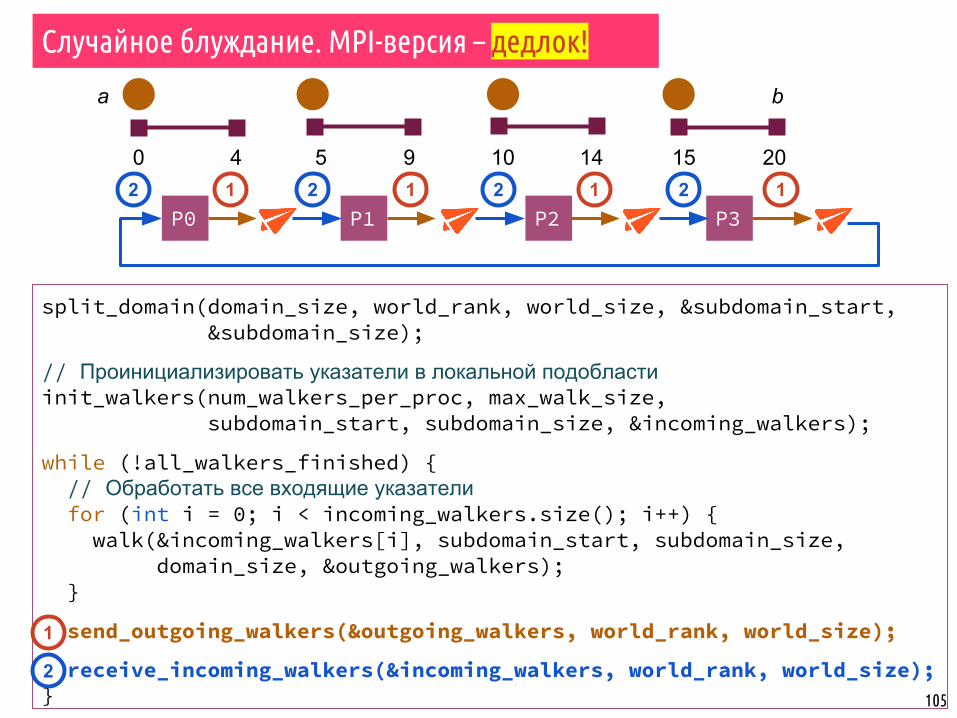
W
a b
S
▪ Даны границы области a, b и указатель W.▪ Указатель W делает S случайных шагов произвольной длины вправо.▪ Когда блуждатель доходит до конца области, он начинает с начала.
typedef struct { // Тип данных указателя int loc; // текущая позиция int steps; // оставшееся число шагов} walker_t;
walker.loc = 0;walker.steps = (rand() / (float) RAND_MAX) * max_walk_size
while (walker->steps > 0) { if (walker->loc == domain_size) // Если вышли за пределы области walker->loc = 0; // то вернулись в начало области } else { walker->steps--; walker->loc++; }}
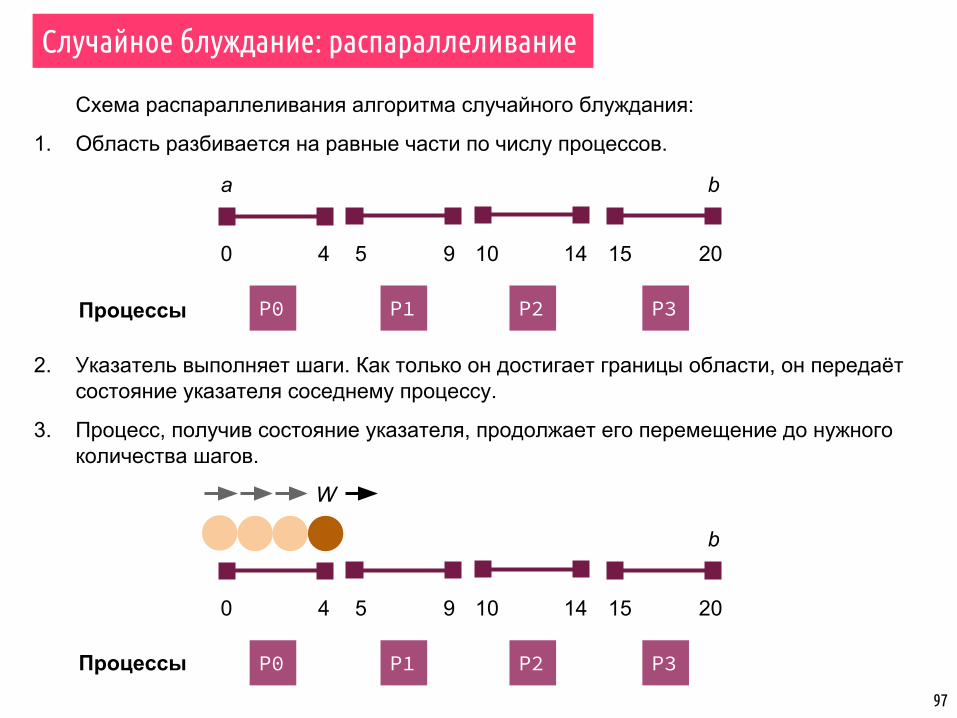
Схема распараллеливания алгоритма случайного блуждания:
1. Область разбивается на равные части по числу процессов.
2. Указатель выполняет шаги. Как только он достигает границы области, он передаёт состояние указателя соседнему процессу.
3. Процесс, получив состояние указателя, продолжает его перемещение до нужного количества шагов.
97
Случайное блуждание: распараллеливание
a b
P0 P1 P2 P3
0 4 5 9 10 14 15 20
Процессы
b
0 4 5 9 10 14 15 20
Процессы
W
P0 P1 P2 P3
98
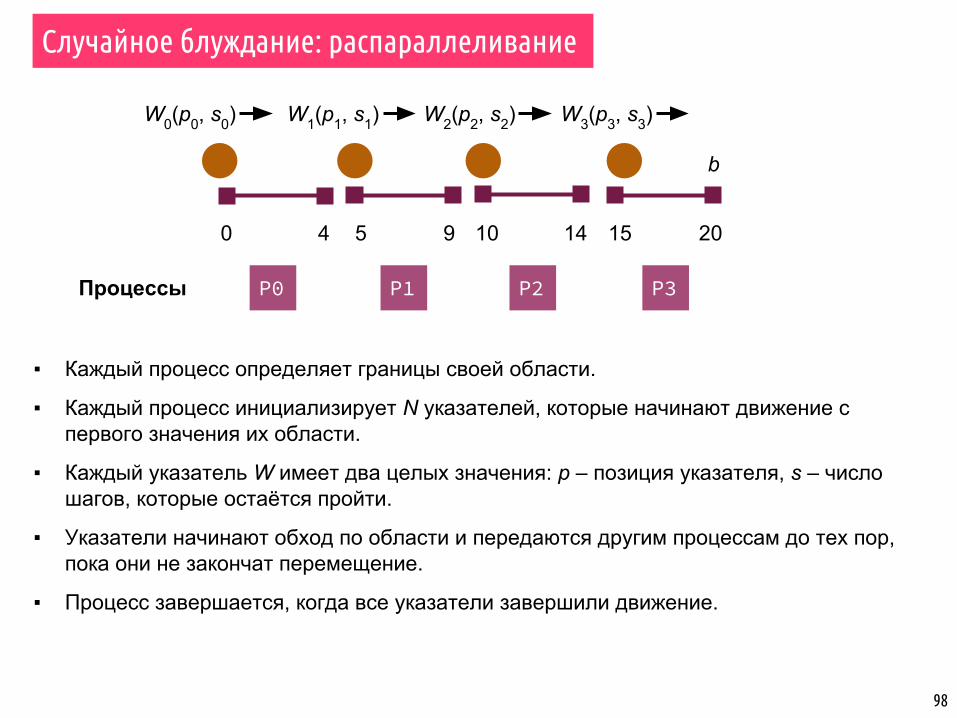
Случайное блуждание: распараллеливание
▪ Каждый процесс определяет границы своей области.
▪ Каждый процесс инициализирует N указателей, которые начинают движение с первого значения их области.
▪ Каждый указатель W имеет два целых значения: p – позиция указателя, s – число шагов, которые остаётся пройти.
▪ Указатели начинают обход по области и передаются другим процессам до тех пор, пока они не закончат перемещение.
▪ Процесс завершается, когда все указатели завершили движение.
b
0 4 5 9 10 14 15 20
Процессы
W0(p0, s0)
P0 P1 P2 P3
W1(p1, s1) W2(p2, s2) W3(p3, s3)

99
Случайное блуждание: декомпозиция области
void split_domain(int domain_size, int world_rank, int world_size, int* subdomain_start, int* subdomain_size) { if (world_size > domain_size) { // Размер области должен быть больше числа процессов MPI_Abort(MPI_COMM_WORLD, 1); }
*subdomain_start = domain_size / world_size * world_rank; *subdomain_size = domain_size / world_size; if (world_rank == world_size - 1) { // Оставшуюся часть области передать последнему процессу *subdomain_size += domain_size % world_size; }}

100
Случайное блуждание: указатели (walkers)
// Тип данных указателяtypedef struct { int loc; // текущая позиция int steps; // оставшееся число шагов} walker_t;
// Инициализация вектора указателей по заданной подобластиvoid init_walkers(int nwalkers_per_proc, int max_walk_size, int subdomain_start, int subdomain_size, vector<walker_t>* incoming_walkers) { walker_t walker; for (int i = 0; i < nwalkers_per_proc; i++) { // Начальное положение на подобласти walker.loc = subdomain_start; // Инициализация случайного количества шагов walker.steps = (rand() / (float) RAND_MAX) * max_walk_size;
incoming_walkers->push_back(walker); }}

101
Случайное блуждание: функция блуждания
// Функция блуждания, которая реализует перемещение указателя // до завершения всех шагов. Если указатель упёрся в границу подобласти,// он добавляется в вектор outgoing_walkersvoid walk(walker_t* walker, int subdomain_start, int subdomain_size, int domain_size, vector<walker_t>* outgoing_walkers) { while (walker->num_steps_left_in_walk > 0) { if (walker->location == subdomain_start + subdomain_size) { if (walker->location == domain_size) { // Если указатель достиг границы глобальной области, // он переходит на начало walker->location = 0; } // Если указатель достиг границы локальной области, // он добавляется в массив outgoing_walker outgoing_walkers->push_back(*walker); break; } else { walker->num_steps_left_in_walk--; walker->location++; } }}
102
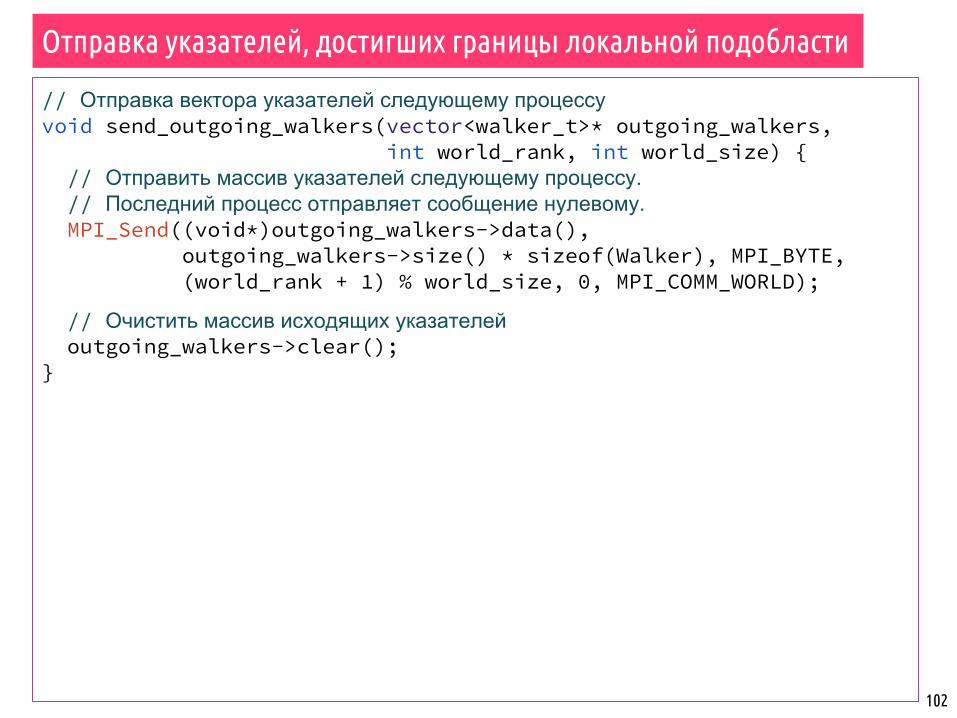
Отправка указателей, достигших границы локальной подобласти
// Отправка вектора указателей следующему процессуvoid send_outgoing_walkers(vector<walker_t>* outgoing_walkers, int world_rank, int world_size) { // Отправить массив указателей следующему процессу. // Последний процесс отправляет сообщение нулевому. MPI_Send((void*)outgoing_walkers->data(), outgoing_walkers->size() * sizeof(Walker), MPI_BYTE, (world_rank + 1) % world_size, 0, MPI_COMM_WORLD);
// Очистить массив исходящих указателей outgoing_walkers->clear();}

103
Получение указателей, достигших границы локальной подобласти
void receive_incoming_walkers(vector<walker_t>* incoming_walkers, int world_rank, int world_size) { MPI_Status status; // Получение сообщения неизвестного размера от предыдущего процесса. // Процесс 0 полчает от последнего процесса. int incoming_rank = (world_rank == 0) ? world_size - 1 : world_rank - 1; MPI_Probe(incoming_rank, 0, MPI_COMM_WORLD, &status);
// Подготовить буфер для получения: изменить его размер на размер // принимаемого сообщения. int incoming_walkers_size; MPI_Get_count(&status, MPI_BYTE, &incoming_walkers_size); incoming_walkers->resize( incoming_walkers_size / sizeof(Walker)); MPI_Recv((void*)incoming_walkers->data(), incoming_walkers_size, MPI_BYTE, incoming_rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); }

104
Случайное блуждание. MPI-версия
1. Инициализация указателей.2. Выполнение функции walk указателями.3. Все процессы отправляют вектор outgoing_walkers.4. Все процессы принимают новые указатели в вектор incoming_walkers.5. Повторять шаги до тех пор, пока все указатели не закончат перемещение.
split_domain(domain_size, world_rank, world_size, &subdomain_start, &subdomain_size);
// Проинициализировать указатели в локальной подобластиinit_walkers(num_walkers_per_proc, max_walk_size, subdomain_start, subdomain_size, &incoming_walkers);
while (!all_walkers_finished) { // Обработать все входящие указатели for (int i = 0; i < incoming_walkers.size(); i++) { walk(&incoming_walkers[i], subdomain_start, subdomain_size, domain_size, &outgoing_walkers); }
send_outgoing_walkers(&outgoing_walkers, world_rank, world_size);
receive_incoming_walkers(&incoming_walkers, world_rank, world_size);}
2
105
Случайное блуждание. MPI-версия – дедлок!
split_domain(domain_size, world_rank, world_size, &subdomain_start, &subdomain_size);
// Проинициализировать указатели в локальной подобластиinit_walkers(num_walkers_per_proc, max_walk_size, subdomain_start, subdomain_size, &incoming_walkers);
while (!all_walkers_finished) { // Обработать все входящие указатели for (int i = 0; i < incoming_walkers.size(); i++) { walk(&incoming_walkers[i], subdomain_start, subdomain_size, domain_size, &outgoing_walkers); }
send_outgoing_walkers(&outgoing_walkers, world_rank, world_size);
receive_incoming_walkers(&incoming_walkers, world_rank, world_size);}
b
0 4 5 9 10 14 15 20
P0 P1 P2 P3
a
1 1 1 1
1
2 22
2

106
Случайное блуждание. Способы решения проблемы дедлока
b
0 4 5 9 10 14 15 20
P0 P1 P2 P3
a
1. Использование всегда буферезированной функции отправки MPI_Bsend.2. Неблокируемые коммуникации MPI_Isend, MPI_Irecv.3. Изменить порядок отправки / получения сообщений так, чтобы каждому
send соответствовал recv. Для этого можно a. для чётных процессов указать порядок сначала send, потом recvb. для нечётных процессов сначала recv, потом send
212 1 212 1

2
107
Случайное блуждание. Решение проблемы дедлока
b
0 4 5 9 10 14 15 20
P0 P1 P2 P3
a
12 1
split_domain(...);init_walkers(...);
while (!all_walkers_finished) { for (int i = 0; i < incoming_walkers.size(); i++) walk(&incoming_walkers[i], subdomain_start, subdomain_size, domain_size, &outgoing_walkers);
if (rank % 2 == 0) send_outgoing_walkers(&outgoing_walkers, world_rank, world_size); receive_incoming_walkers(&incoming_walkers, world_rank, world_size);
} else {
receive_incoming_walkers(&incoming_walkers, world_rank, world_size); send_outgoing_walkers(&outgoing_walkers, world_rank, world_size); }
1
1
2
2
212 1

108
Случайное блуждание. Определение завершения
split_domain(...);init_walkers(...);
// Определяем максимальное количество обменов, необходимых для завершения// блужданий всех указателей. int maximum_sends_recvs = max_walk_size / (domain_size / world_size) + 1;
for (int m = 0; m < maximum_sends_recvs; m++) { for (int i = 0; i < incoming_walkers.size(); i++) { walk(&incoming_walkers[i], subdomain_start, subdomain_size, domain_size, &outgoing_walkers); }
if (rank % 2 == 0) send_outgoing_walkers(&outgoing_walkers, world_rank, world_size); receive_incoming_walkers(&incoming_walkers, world_rank, world_size);
} else { receive_incoming_walkers(&incoming_walkers, world_rank, world_size); send_outgoing_walkers(&outgoing_walkers, world_rank, world_size); }
109
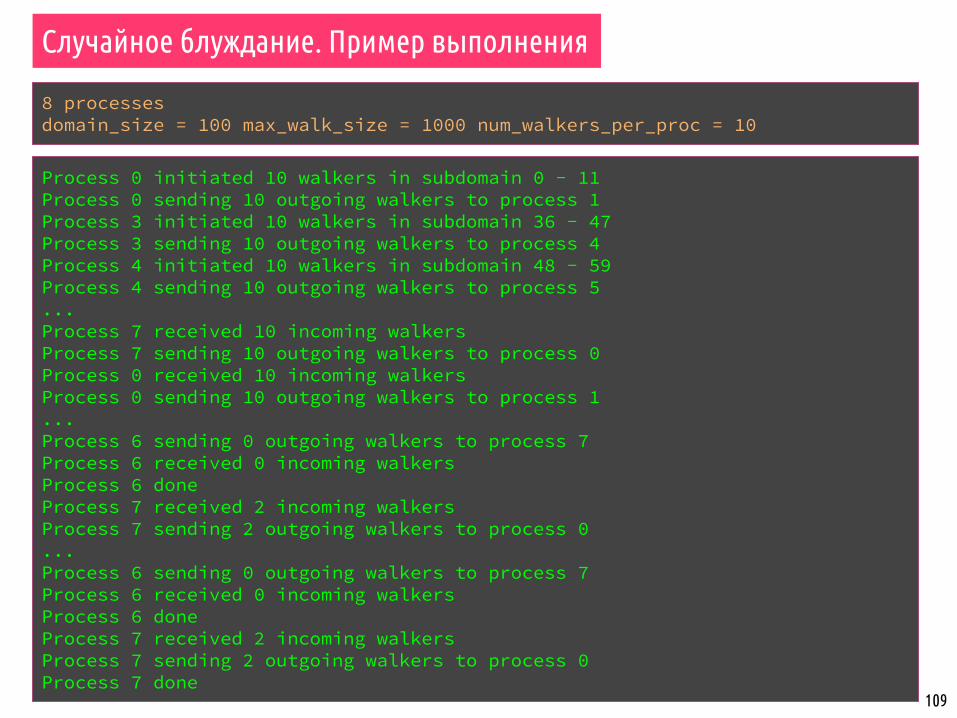
Случайное блуждание. Пример выполнения
8 processesdomain_size = 100 max_walk_size = 1000 num_walkers_per_proc = 10
Process 0 initiated 10 walkers in subdomain 0 - 11Process 0 sending 10 outgoing walkers to process 1Process 3 initiated 10 walkers in subdomain 36 - 47Process 3 sending 10 outgoing walkers to process 4Process 4 initiated 10 walkers in subdomain 48 - 59Process 4 sending 10 outgoing walkers to process 5...Process 7 received 10 incoming walkersProcess 7 sending 10 outgoing walkers to process 0Process 0 received 10 incoming walkersProcess 0 sending 10 outgoing walkers to process 1...Process 6 sending 0 outgoing walkers to process 7Process 6 received 0 incoming walkersProcess 6 doneProcess 7 received 2 incoming walkersProcess 7 sending 2 outgoing walkers to process 0...Process 6 sending 0 outgoing walkers to process 7Process 6 received 0 incoming walkersProcess 6 doneProcess 7 received 2 incoming walkersProcess 7 sending 2 outgoing walkers to process 0Process 7 done





























