Embed Size (px)
Citation preview

Интеллектуальные агенты и обучение с
подкреплением
Студент: Сапин А.С.Руководитель: Большакова Е.И.

Содержание● Интеллектуальные агенты
■ Термины и понятия■ Обучение и агенты: разновидности
● Обучение с подкреплением и MDP■ Марковская модель принятия решений (MDP)■ Алгоритмы решения MDP
● Обучение без модели и Q-обучение■ Пассивное обучение (по значениям)■ Активное обучение (по q-значениям)
2

ТерминыАгент - все, что может воспринимать среду и воздействовать на неё.
Среда - окружение, в котором агент находится и совершает действия.
Восприятие - полученные агентом сенсорные данные в некоторый момент времени.
Действие - влияние, которое агент оказывает на среду.
Автономность - свойство агента, выбирать действия на основании опыта, а не данных о среде, которые заложил разработчик.
3
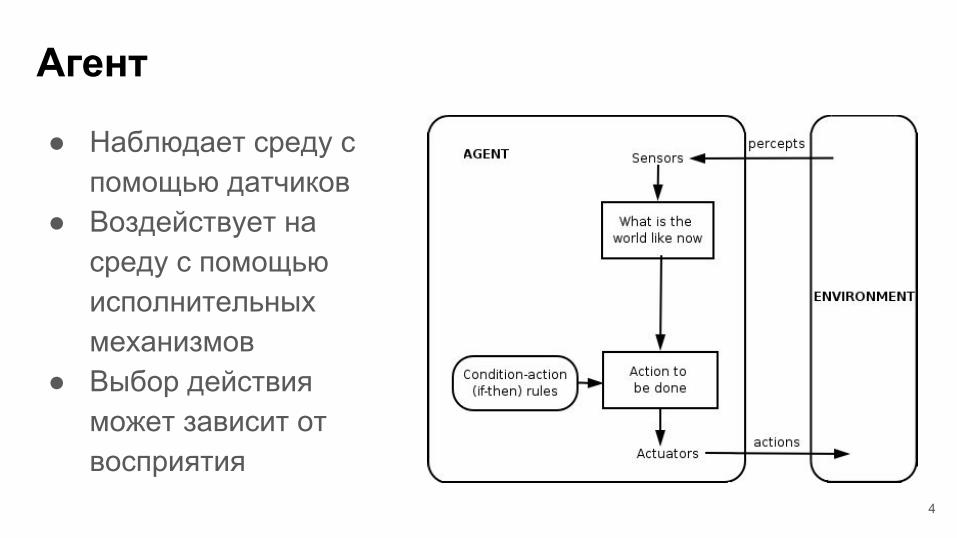
Агент
● Наблюдает среду с помощью датчиков
● Воздействует на среду с помощью исполнительных механизмов
● Выбор действия может зависит от восприятия
4

Проблемная среда Включает в себя задачу, которую должен решить агент.Свойства среды:
● Детерминированная● Стохастическая
● Статическая● Динамическая
● Дискретная● Непрерывная
● Полностью наблюдаемая● Частично наблюдаемая
● Эпизодическая● Не эпизодическая
5
● Одноагентная● Мультиагентная

Примеры сред
6
Проблемная среда
Наблюдаемость
Детерминированность
Эпизодичность
Динамичность
Дискретность
Кол-во агентов
Игра в шахматы
Полная Стохастическая
Поледовательная
Полудинамическая
Дискретная Мультиагентная
Игра в покер Частичная Стохастическая
Последовательная
Статическая Дискретная Мультиагнетная
Анализ изображения
Полная Детерминированная
Эпизодическая
Полудинамическая
Непрерывная
Одноагентная
Сортировка деталей
Частичная Стохастическая
Эпизодическая
Динамическая
Непрерывная
Одноагентная

● Разновидность интеллектуального агента● Агент, который для каждой возможной
последовательности актов восприятия выбирает “правильное” действие
● “Правильное” действие - действие, которое позволяет агенту действовать максимально успешно
Рациональность Всезнание
Рациональный агент
7
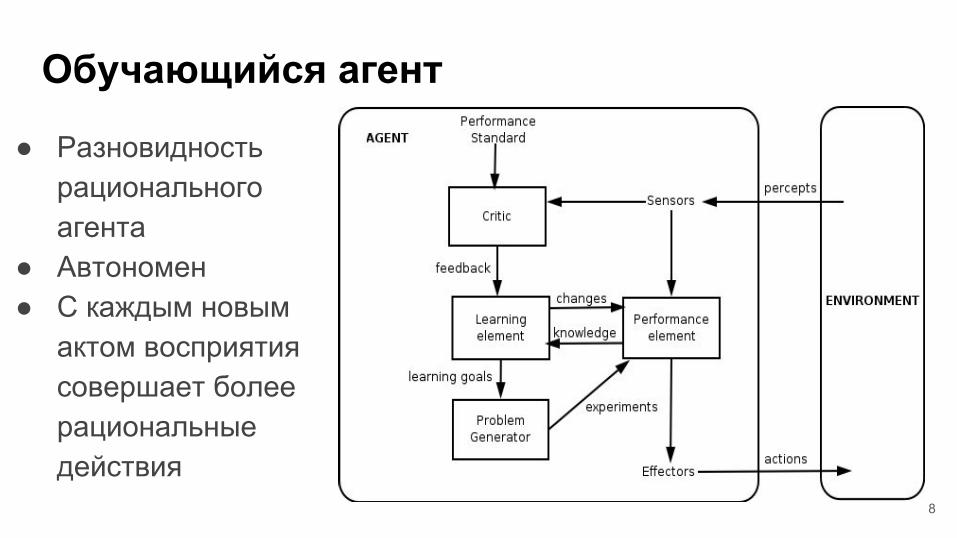
Обучающийся агент
● Разновидность рационального агента
● Автономен● С каждым новым
актом восприятия совершает более рациональные действия
8

Обучение агентаОбучение - это процесс, в результате которого агент может принимать решения на основе накопленного опыта и текущего восприятия.
Обучение бывает:
9
● контролируемым ● неконтролируемым● с подкреплением
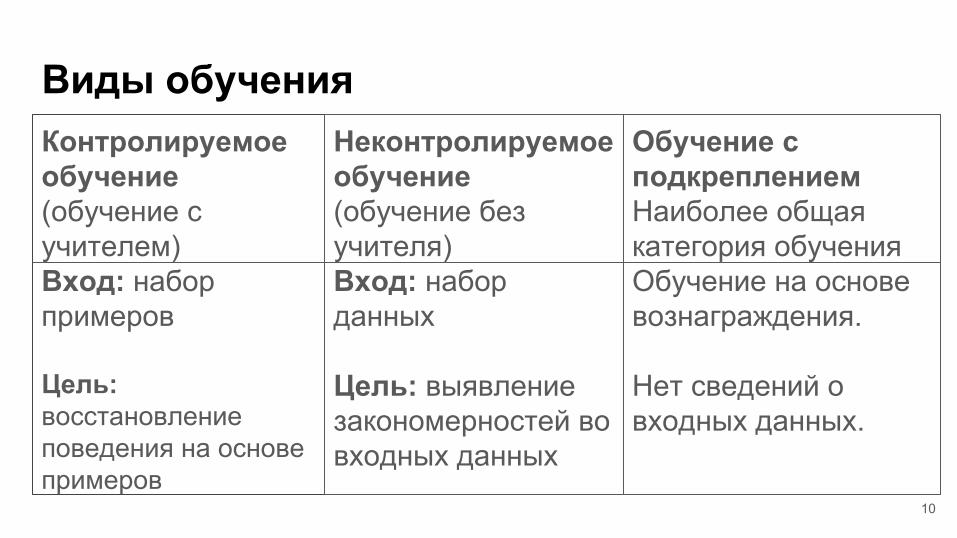
Виды обученияКонтролируемое обучение (обучение с учителем) Вход: набор примеров
Цель: восстановление поведения на основе примеров
Неконтролируемое обучение (обучение без учителя) Вход: набор данных
Цель: выявление закономерностей во входных данных
Обучение с подкреплениемНаиболее общая категория обучения Обучение на основе вознаграждения.
Нет сведений о входных данных.
10

Обучение с подкреплением● Во многих задачах является единственным возможным способом
обучения.● Обучение происходит автономно, на основании проб и ошибок.● Для моделирования среды используется марковский процесс принятия
решения - Markov’s Decision Process (MDP).
Обучение бывает:
11
● Активное● Пассивное
● На основе модели● Безмодельное
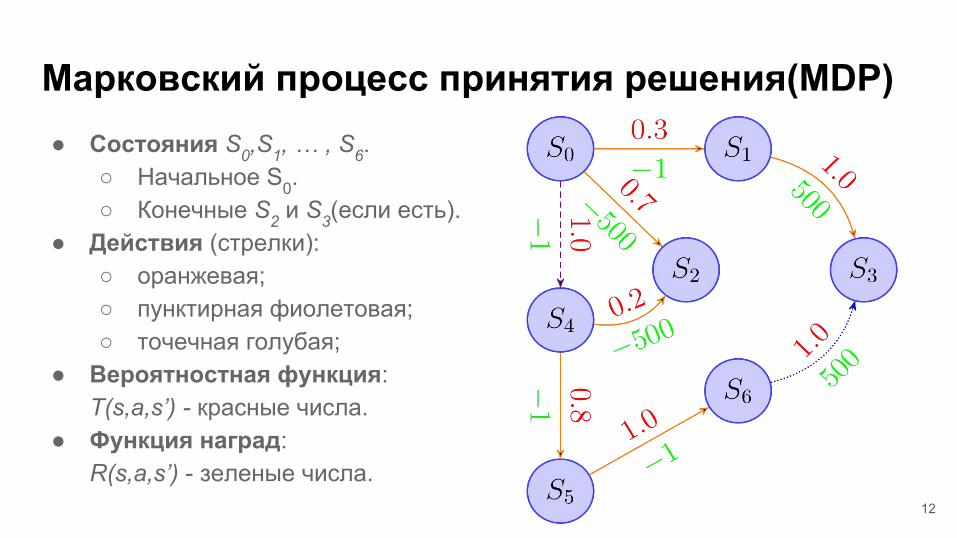
Марковский процесс принятия решения(MDP)● Состояния S0,S1, … , S6.
○ Начальное S0.○ Конечные S2 и S3(если есть).
● Действия (стрелки):○ оранжевая;○ пунктирная фиолетовая;○ точечная голубая;
● Вероятностная функция: T(s,a,s’) - красные числа.
● Функция наград: R(s,a,s’) - зеленые числа.
12
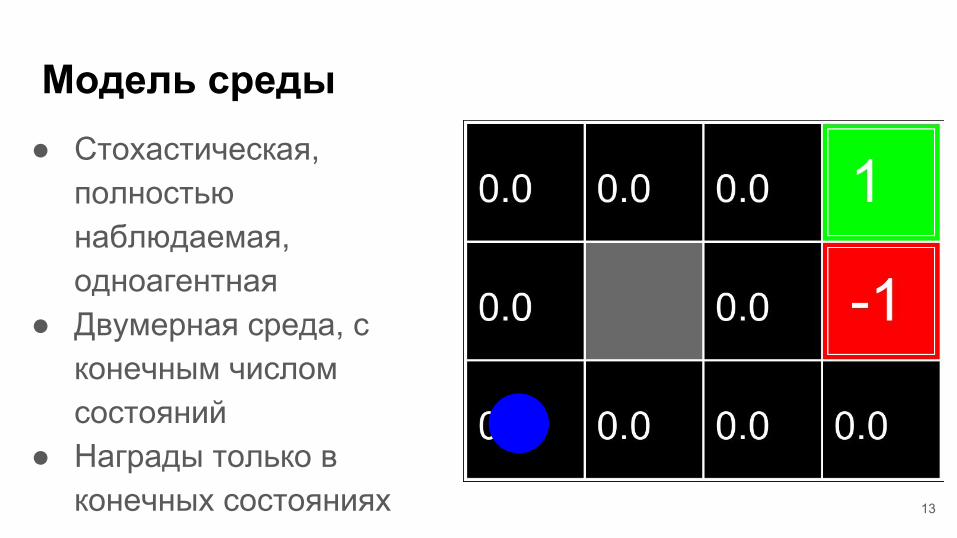
Модель среды● Стохастическая,
полностью наблюдаемая, одноагентная
● Двумерная среда, с конечным числом состояний
● Награды только в конечных состояниях 13
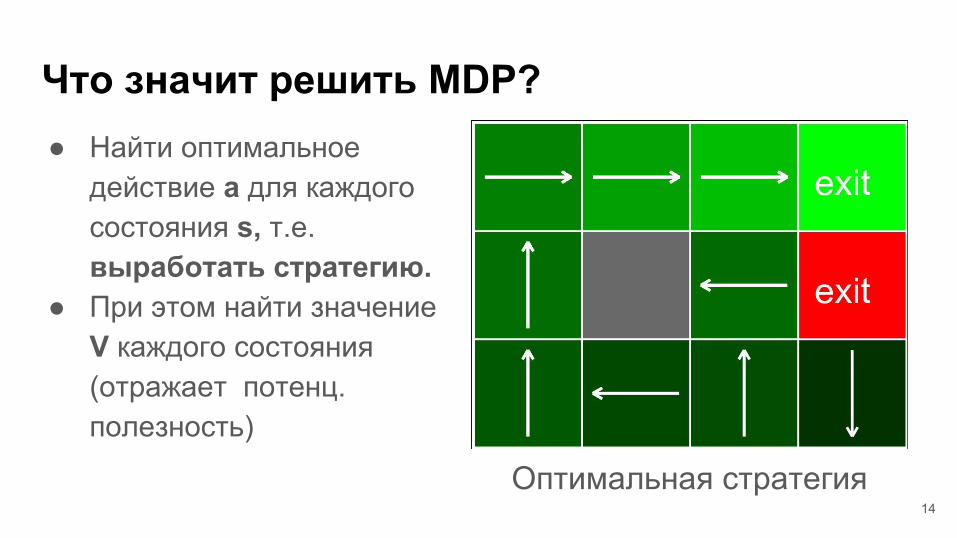
Что значит решить MDP?
14
● Найти оптимальное действие a для каждого состояния s, т.е. выработать стратегию.
● При этом найти значение V каждого состояния (отражает потенц. полезность)
Оптимальная стратегия
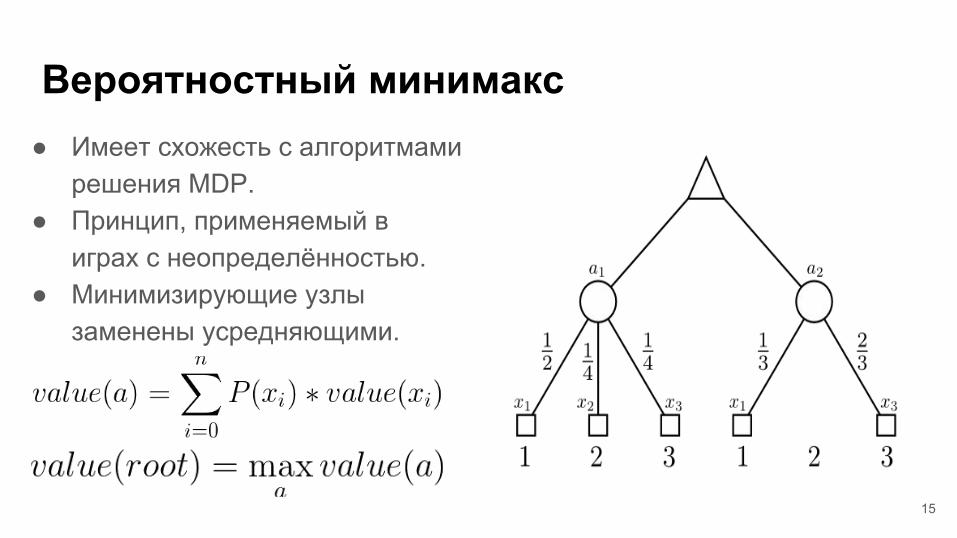
Вероятностный минимакс● Имеет схожесть с алгоритмами
решения MDP.● Принцип, применяемый в
играх с неопределённостью. ● Минимизирующие узлы
заменены усредняющими.
15

Решение MDP: Обозначения
● (s) - оптимальное действие в состоянии s.● V(s) - ожидаемое значение состояния, если
действовать оптимально из s.● Q(s,a) - значение, которое будет получено, если
действовать оптимально, после действия a в s.● γ - коэффициент обесценивания наград.
16

Уравнение Беллмана для решения MDP
17

Коэффициент обесценивания γ
● Описывает предпочтение агентом текущих вознаграждений перед будущими вознаграждениями.
● γ ∊ [0;1].
● γ ≈ 0 : будущие вознаграждения малозначащие
● γ ≈ 1 : будущие вознаграждения равноценны текущим
18

Решение MDP: Итерация по значениям 0 1 2 3 n
V(s): ... 00 0 00
● Сложность O(n2*len(A)). ● Итерационный процесс сходится из-за постоянного
влияния фактора γ.19
Алгоритм

Решение MDP: Итерация по действиям 0 1 2 3 n
V(s): ... 00 0 00
0 1 2 3 n
(s): ... →→ → →→
● Сходится быстрее, чем итерация по значениям. ● Сразу получаем оптимальную стратегию.
20
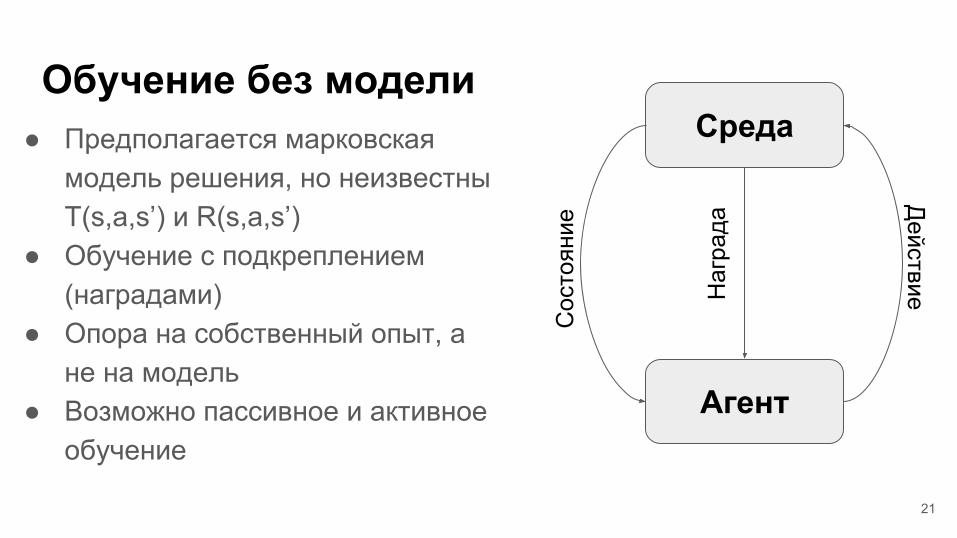
Обучение без модели● Предполагается марковская
модель решения, но неизвестны T(s,a,s’) и R(s,a,s’)
● Обучение с подкреплением (наградами)
● Опора на собственный опыт, а не на модель
● Возможно пассивное и активное обучение
21
Среда
Агент
ДействиеН
агра
да
Сос
тоян
ие

Пассивное обучение● Задана некоторая стратегия действий
● Вместо T и R используем накопленный опыт
● sample - полученный опыт● - коэффициент учета предыдущего опыта
22

Пассивное обучение: расчёт стратегии
● Для вычисления стратегии из значений состояний, необходимо знать T(s,a,s’), но её нет!
● Фактически, можно проверить только предложенную стратегию.
Выход: искать Q-значения сразу.23
Активное обучение: Q - обучение● Итерация не по V-значениям ,
а по Q-значениям.● Нет необходимости хранить
V-значения и стратегию.● Как и для пассивного
обучения, нет необходимости строить модель - безмодельное обучение.
0 1 2 3 n
V(s): ... 0
00 0
0
0 1
2 3
n
(s):
...
→
→
→→
→
24

Q-обучение: алгоритм
25
Уравнение для Q-значений:
Вместо T и R используем опыт:
Q-обучение: особенности
0
50 0 0 0
0 10 00 0 0 0
0 0.1 0 0 00
-20
0
...
←
→
↑
↖
0 1 2 3 ... n
Состояния...
...Дей
стви
я26
● Хранятся только Q-значения.
● Не требуется знать T(s,a,s’)
● Не требуется знать R(s,a,s’)
● Принцип выбора действия: исследование или применение опыта

Q-обучение: рандомизация
● Выгодные пути находятся достаточно быстро. ● Но что если существует нечто лучшее?● Для полного изучения среды вводится фактор
рандомизации ε.● В зависимости от ε, вместо более выгодного действия,
может выбираться новое.
27

Обучение с подкреплением: современное состояние● With deep learning● Temporal Difference Learning (TD - learning)● Double Q-learning● Google Deep Mind
○ Mnih V. et al. Human-level control through deep reinforcement learning //Nature. – 2015. – Т. 518. – №. 7540. – С. 529-533.
28

Спасибо за внимание!
29