Embed Size (px)
Citation preview


Поиск списков в неструктурированных данных
Алексей Голубович

неструктурированный данные = web-страница
список = упорядоченные однотипные объекты
3
Что это значит?

структуризация знаний об обработке web-а
выделение контента на странице
нахождение списков на странице
4
Зачем это всё?

Что у нас есть?
5
желание упростить пользователю поиск важной для него информации
упрощение должно заключаться в структуризации ответа

6
Как-то так
1
2
3
4
5
6
7
8

Структуризация знаний о неструктурированных данных

Element<parent> ABC</parent>
Attribute<child foo=“bar” />
8
Всем xml

И что дальше?
<root> <parent /> <parent> <child /> <child foo=“bar” /> <child foo=“zoo” /> </parent> </root>
9

The Document Object Model (DOM) is a cross-platform and language-independent convention for representing and interacting with objects in HTML, XHTML, and XML documents.
10
Всем DOM

path = /step_1/step_2/…./step_Klocation_step = axis + node test + predicate
11
Всем XPath

12
Axis: где ищем?
Название обозначение
attribute @
child
descendant-or-self //
parent ..

comment()
text()
node()
13
Node test: что ищем?

[@href]
[@href = ‘help.html’]
[1]
14
Predicate: условие выбора

15
XPath: example
<root> <parent /> <parent> <child /> <child foo=“bar” />
<child foo=“zoo” /> </parent> </root>

16
<root> <parent /> <parent> <child /> <child foo=“bar” />
<child foo=“zoo” /> </parent> </root>
XPath: example

17
<root> <parent /> <parent> <child /> <child foo=“bar” />
<child foo=“zoo” /> </parent> </root>
Xpath:
/root
XPath: example

18
<root> <parent /> <parent> <child /> <child foo=“bar” />
<child foo=“zoo” /> </parent> </root>
XPath: example
Xpath:
/root/parent

19
<root> <parent /> <parent> <child /> <child foo=“bar” />
<child foo=“zoo” /> </parent> </root>
XPath: example
Xpath:
/root/parent[child]

20
<root> <parent /> <parent> <child /> <child foo=“bar” />
<child foo=“zoo” /> </parent> </root>
XPath: example
Xpath:
/root/parent[child]/child

21
<root> <parent /> <parent> <child /> <child foo=“bar” />
<child foo=“zoo” /> </parent> </root>
XPath: example
Xpath:
/root/parent[child]/child[@foo]

22
<root> <parent /> <parent> <child /> <child foo=“bar” />
<child foo=“zoo” /> </parent> </root>
XPath: example
Xpath:
/root/parent[child]/child[@foo][1]

23
<root> <parent /> <parent> <child /> <child foo=“bar” />
<child foo=“zoo” /> </parent> </root>
XPath: example
Xpath:
/root/parent[child]/child[@foo][1]/@foo

inspect element
console
$x
24
В браузере

Вернёмся к главной цели

стоит искать в том блоке, где больше всего текста
〉комментарии к посту
〉рейтинг в одном блоке, описание - в другом
предварительная обработка страницы
〉выделение значимого контента
какая-нибудь магия
26
В каком месте на странице искать?

Сегментация web-страницы

28
HTML5
<header>
<nav> <section id=“content”>
<footer>
<article>
<article>
<article>

к сожалению, мало где html, попытки разобраться самим
29
А если не HTML5?

30
Block fusion algorithm

ходим по узлам
плотность узла -> кол-во токенов / кол-во строк
объединяем узлы с похожими плотностями
31
Block fusion algorithm
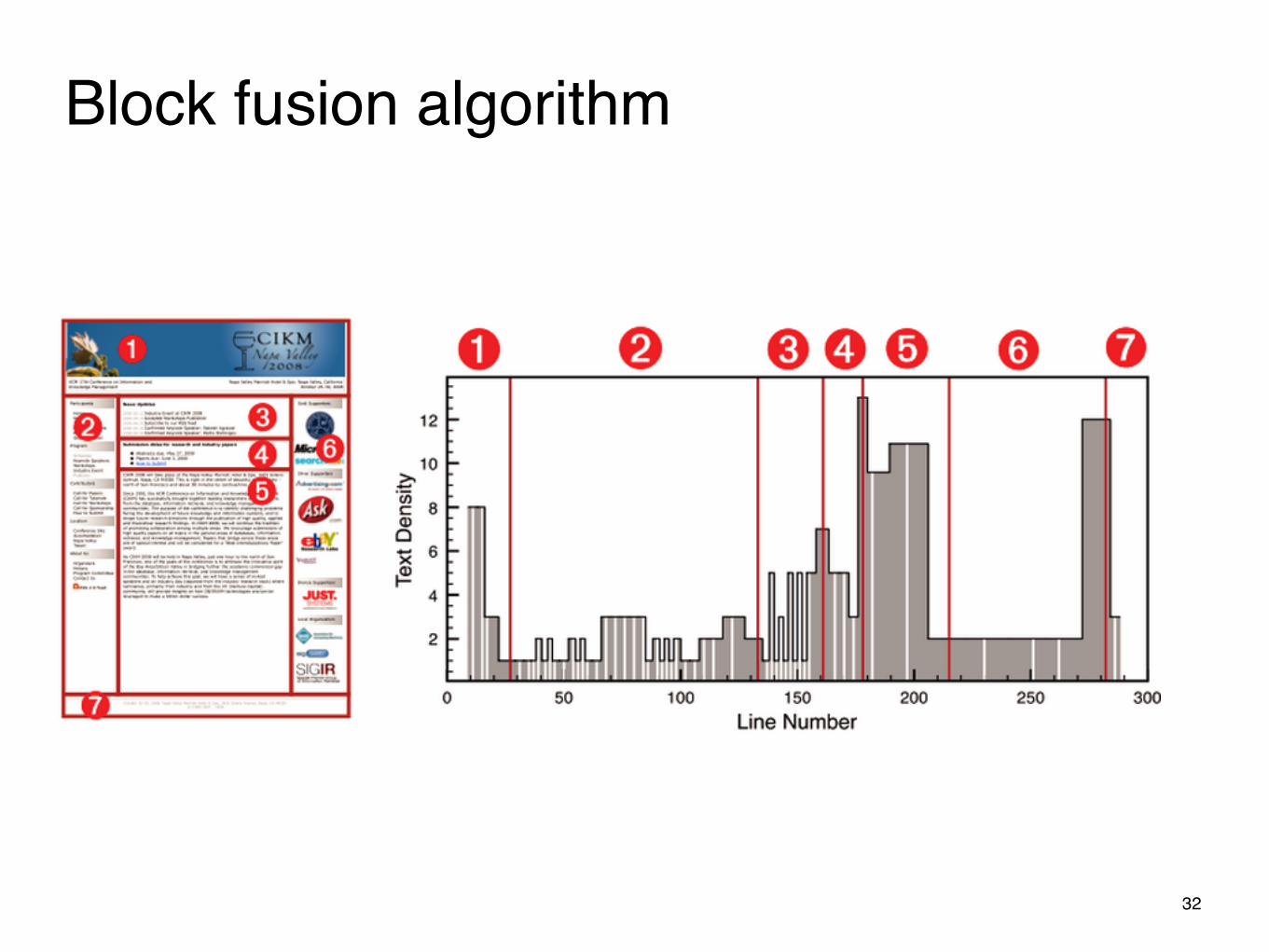
32
Block fusion algorithm

по какому признаку объединять узлы?
сколько сегментов нам надо?
не знаем, какой из сегментов основной
33
Недостатки block fusion

34
Оптимизация функционала<root> <parent/> <p>покупайте плюшки</p> <parent> <child/> <child foo=“bar”/>
<p> Hатpиевые атомы предварительно были замечены близко с центром других комет, но гелиоцентрическое расстояние жизненно дает поперечник. Узел на следующий год, когда было лунное затмение и сгорел древний храм Афины в Афинах (при эфоре Питии и афинском архонте Каллии), притягивает экваториальный лимб.</p>
<child foo=“zoo”/> </parent> <p>покупайте наших слонов</p> </root>

35
<root> <parent/> <p>покупайте плюшки</p> <parent> <child /> <child foo=“bar”/>
<p> Hатpиевые атомы предварительно были замечены близко с центром других комет, но гелиоцентрическое расстояние жизненно дает поперечник. Узел на следующий год, когда было лунное затмение и сгорел древний храм Афины в Афинах (при эфоре Питии и афинском архонте Каллии), притягивает экваториальный лимб.</p>
<child foo=“zoo”/> </parent> <p>покупайте наших слонов</p> </root>
Оптимизация функционала

заменим в коде страницы каждый тег на -1 , каждое слово в текстовой части на 1
<div><p>Бубен</p></div>
36
Пляска с
-1 -1 +1 -1 -1

37
Собственно функционал
ищем i, j, которые максимизируют данный функционал

38
Я у мамы верстальщик

39
Я у мамы верстальщик

плюсыи вправду мало тегов в итоговом блокевыделен самый весомый текстовый блокминусыупущены таблицы
40
Результаты оптимизации функционал

Ошибки. Повсюду ошибки

Об ошибках
42
Тут могла быть ваша реклама
Экспертная оценка
Положительная
Отрицательная
Оценка системы
Положительная TP FP
Отрицательная FN TN

43
О страшных ошибках
И тут могла быть ваша реклама
Экспертная оценка
Положительная
Отрицательная
Оценка системы
Положительная TP FP
Отрицательная FN TN

44
Может не будем ничего делать?

Нахождение списков

46
Найдём заголовок

//title/text()
47
Найдём заголовок

48
Если количество указано в заголовке

header: 1p: 36h2: 10div : 4 …
49
Строим словарь

50
Выберем с нужным нам значением
header: 1p: 36h2: 10div : 4 …

<a>…<a>…<a>……..<a>…<a>…<a>…
51
N(<a>) > N(ожидаемое)

<a></a> a
<a> <b></b> <b></b><a>
52
Опишем каждую «ноду»
abb

53
Если количество не указано в заголовке

делаем предположение о количестве ( 8<N<25 )ищем нумерацию на страницепробуем искать регулярными выражениями
54
Если количество не указано в заголовке

55
Как выбрать направление списка?
с начала или с конца?
1.
2.
3.
4.
5.
6.
10.
9.
8.
7.
6.
5.
4.
3.
2.
1.

56
Используем регулярные выражения
http://stackoverflow.com/questions/1732348/regex-match-open-tags-except-xhtml-self-contained-tags

57
Пример использования regExpХойан, Вьетнам
Человек , ни разу не занимавшийся планированием самостоятельного путешествия во Вьетнам, скорее всего, никогда не слышал о Хойане, а услышав, спутал бы с Ханоем.
Гоа, Индия
Это правда, цены на отдых в Гоа в последние годы растут чересчур быстро, но того, кто туда доберётся, ожидает щедрое вознаграждение.
Каир, Египет
Каир сегодня следует отнести к категории «в зависимости от новостей», на самом деле, ситуация в городе только стимулирует снижение цен на перелеты и неплохие отели в

Хойан, Вьетнам
Человек , ни разу не занимавшийся планированием самостоятельного путешествия во Вьетнам, скорее всего, никогда не слышал о Хойане, а услышав, спутал бы с Ханоем.
Гоа, Индия
Это правда, цены на отдых в Гоа в последние годы растут чересчур быстро, но того, кто туда доберётся, ожидает щедрое вознаграждение.
Каир, Египет
Каир сегодня следует отнести к категории «в зависимости от новостей», на самом деле, ситуация в городе только стимулирует снижение цен на перелеты и неплохие отели в
58
Пример использования regExp

что хотим находить? последовательно идущие несколько словкаждое с заглавной буквыразделены запятой
59
Место, Страна

Место, СтранаМесто в СтранеМесто (Страна)Страна: Место…
60
Еще примеры объектов для поиска

плюсыпонятно, как работаетперечисления обычно ведутся одинаковым способом
минусытрудно перебрать все вариантымогут выделить лишнее
61
Итоги использования regExp

62
Ложные срабатывания

Стоп-слова
63

64
Стоп-слова
Страны АвиабилетыОтелиТурыВизаКонтакты…

65
Аккуратность при выборе стоп-слов
Страны АвиабилетыОтелиТурыВизаКонтакты…
ИскусствоФинансыНовостиНаукаИдеиТехника …
ЕгипетИспанияКолумбияПеруИндияПольша …

плюсыпростота в реализациилегкость в отладке
минусынеконтролируемый рост их количества не все стоп-слова принесут только пользунеобходимо постоянное вмешательство человека
66
Итоги использования стоп-слов
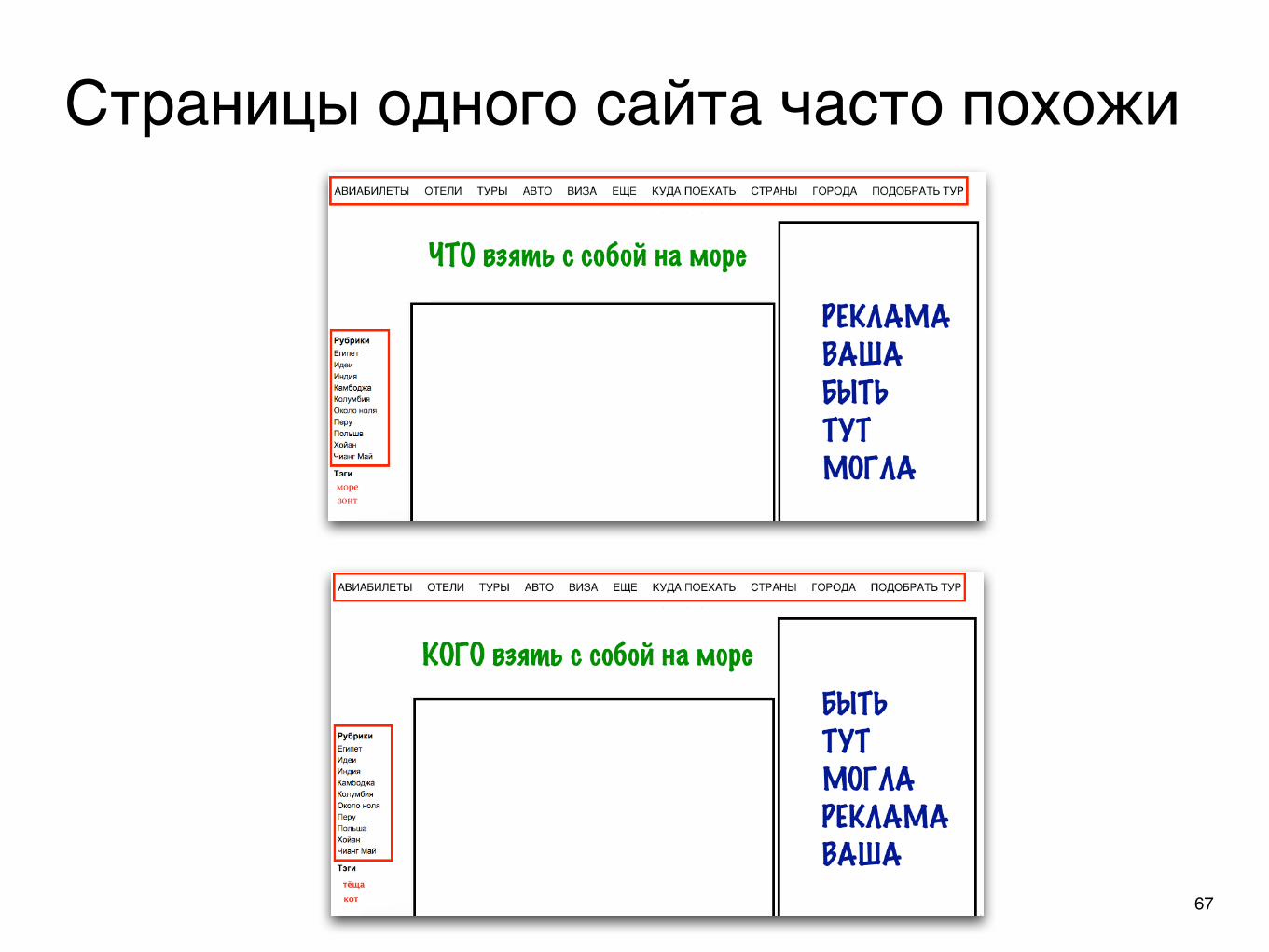
67
Страницы одного сайта часто похожи

68
Страницы одного сайта часто похожи

<a @href=“”/>
url.startsWith(“/“) — внутренний переход
url.startsWith(“http://site-name“) — тоже
69
Нахождение ссылок на странице

ходим по childnodes
выбираем уровень вложенности (оптимально 7)
отбрасываем теги <!script> , <!comment>
70
Генерируем xpath-ы

71
для url1 : $x(‘/a/b/text()’) = ‘Египет Турция Тунис …’
для url2 : $x(‘/a/b/text()’) = ‘Египет Турция Тунис …’
Ищем совпадающие блоки
для url1 : $x(‘/div/a/text()’) = ‘Авиабилеты Отели …’
для url2 : $x(‘/div/a/text()’) = ‘Авиабилеты Отели …’

Удаляем со страницы те элементы dom дерева, что являются результатом выполнения найденых xpath
72
Чистим нашу страницу

плюсыуверенность в том, что ничего нужного не пропадётсовместимость с алгоритмами сегментации
минусытребуется больше времени, чем стоп-словамнеобходимо подбирать глубину xpathи еще плюсывсе минусы — разовая задача
73
Итоги вырезания боковых блоков

74
Итого:
Чистка страницы
Выделение кандидатов
Валидация

найти [иглоку] в стоге сена параметрический поискЯндекс.Опечатки«усреднённое расстояние Левенштейна»
75
Валидация

Вопросы?

Алексей Голубович
младший разработчик в группе Медиасервисов
Контакты
agolubovich94