Embed Size (px)
Citation preview

1
Introduction toMachine Learning with Python
3. Unsupervised Learning
Honedae Machine Learning Study Epoch #2

ContactsHaesun Park
Email : [email protected]
Meetup: https://www.meetup.com/Hongdae-Machine-Learning-Study/
Facebook : https://facebook.com/haesunrpark
Blog : https://tensorflow.blog
2

Book파이썬라이브러리를활용한머신러닝, 박해선.
(Introduction to Machine Learning with Python, Andreas Muller & Sarah Guido의번역서입니다.)
번역서의 1장과 2장은블로그에서무료로읽을수있습니다.
원서에대한프리뷰를온라인에서볼수있습니다.
Github: https://github.com/rickiepark/introduction_to_ml_with_python/
3

머신러닝구분
지도학습(Supervised) – KNN, Linear models, SVM, Random Forest, Boosting, Nueral Networks
비지도학습(Unsupervised) – 변환(Scaler, PCA, NMF, tSNE), 군집(K-means, 병합군집, DBSCAN)
준지도학습(Semisupervised) – Label propagation, Label spreading (sklearn.semi_supervised)
강화학습(Reinforcement Learning)
4

비지도학습
5

종류
비지도변환unsupervised transformation
사람이나머신러닝알고리즘을위해새로운데이터표현을만듦니다차원축소: PCA, NMF, t-SNE, 오토인코더autoencoder
토픽모델링: LDA (e.g. 소셜미디어토론그룹핑, 텍스트문서의주제추출)
군집clustering
비슷한데이터샘플을모으는것 (e.g. 사진어플리케이션: 비슷한얼굴그룹핑)k-평균, 병합, DBSCAN
데이터스케일링scaling
이상치탐지anomaly detection, GANgenerative adversarial networks
6

비지도학습의어려움
레이블이없기때문에올바르게학습되었는지알고리즘을평가하기가어렵습니다
사진애플리케이션에서옆모습, 앞모습으로군집되었다해도직접눈으로확인하기전에는결과를평가하기가어렵습니다.
비지도학습은데이터를잘이해하기위해서(탐색적분석) 사용되거나,
지도학습알고리즘의정확도향상과메모리/시간절약을위해새로운데이터표현을만드는전처리단계로활용
7

데이터스케일조정
8
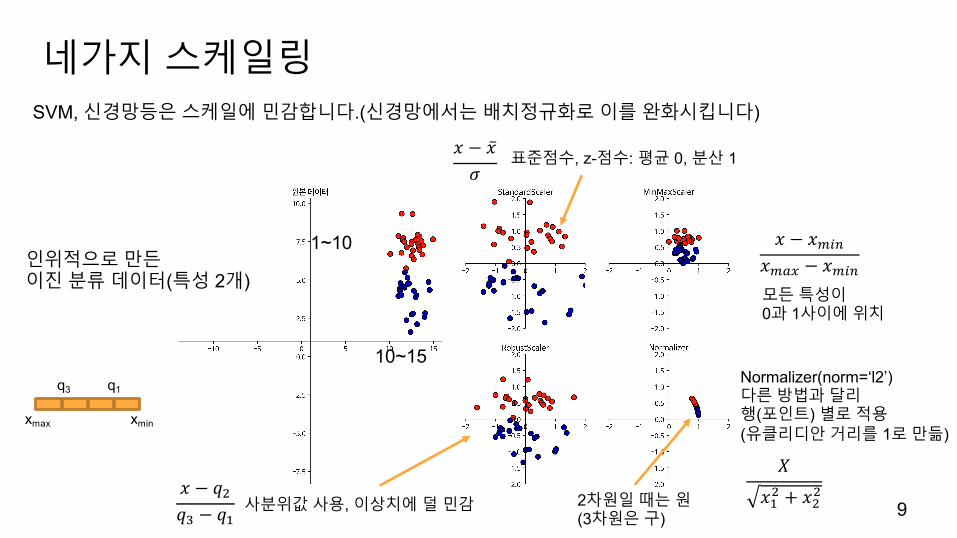
네가지스케일링
9
인위적으로만든이진분류데이터(특성 2개)
10~15
1~10
표준점수, z-점수: 평균 0, 분산 1𝑥 − �̅�𝜎
사분위값사용, 이상치에덜민감𝑥 − 𝑞&𝑞' − 𝑞(
𝑥 − 𝑥)*+𝑥),- − 𝑥)*+모든특성이0과 1사이에위치
Normalizer(norm=‘l2’)다른방법과달리행(포인트) 별로적용(유클리디안거리를 1로만듦)
SVM, 신경망등은스케일에민감합니다.(신경망에서는배치정규화로이를완화시킵니다)
q1q3
xminxmax
𝑋
𝑥(& + 𝑥&&�
2차원일때는원(3차원은구)
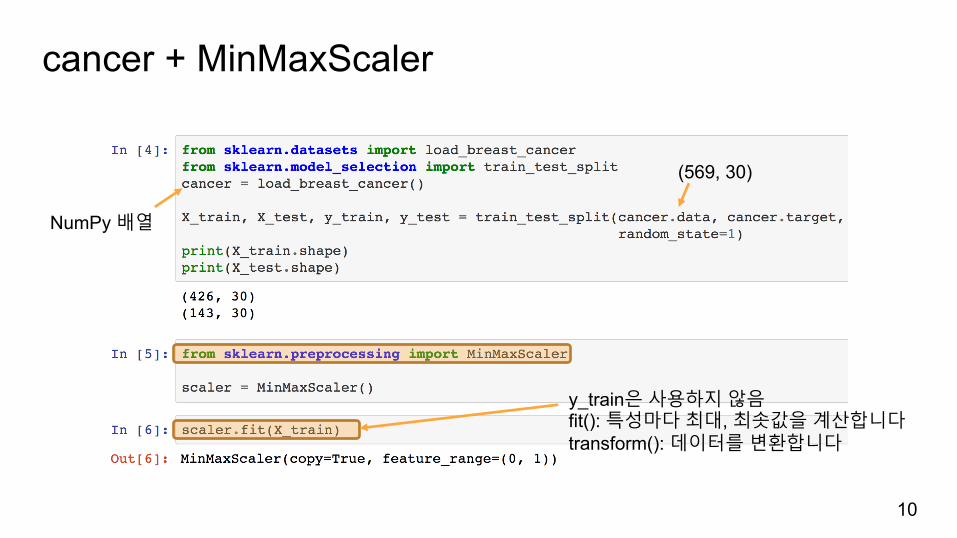
cancer + MinMaxScaler
10
y_train은사용하지않음fit(): 특성마다최대, 최솟값을계산합니다transform(): 데이터를변환합니다
NumPy 배열
(569, 30)

MinMaxScaler.transform
11
fit à transform
numpy 배열의min, max 메서드
MinMaxScaler이므로최소와최댓값이0, 1로바뀜
학습한변환내용을훈련데이터에적용
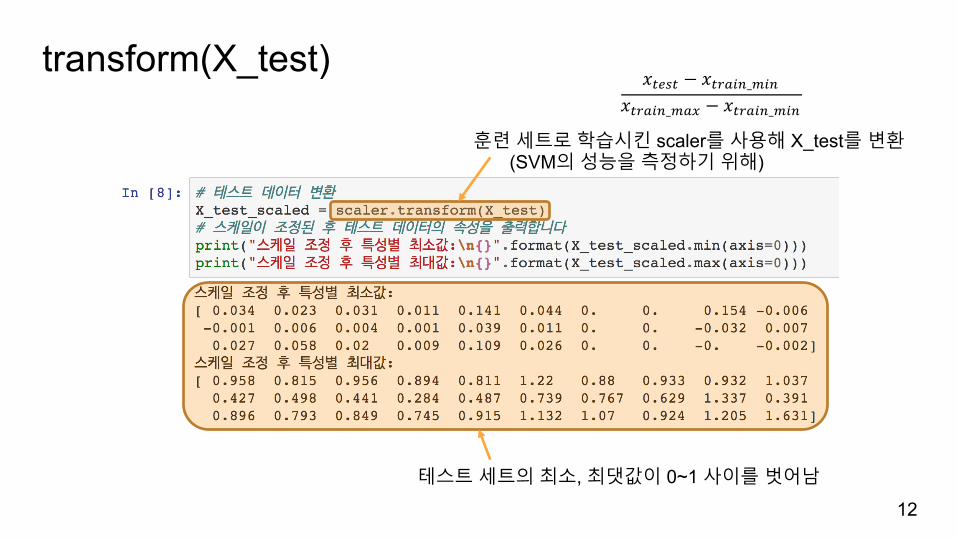
transform(X_test)
12
훈련세트로학습시킨 scaler를사용해 X_test를변환(SVM의성능을측정하기위해)
테스트세트의최소, 최댓값이 0~1 사이를벗어남
𝑥1231 − 𝑥14,*+_)*+𝑥14,*+_),- − 𝑥14,*+_)*+
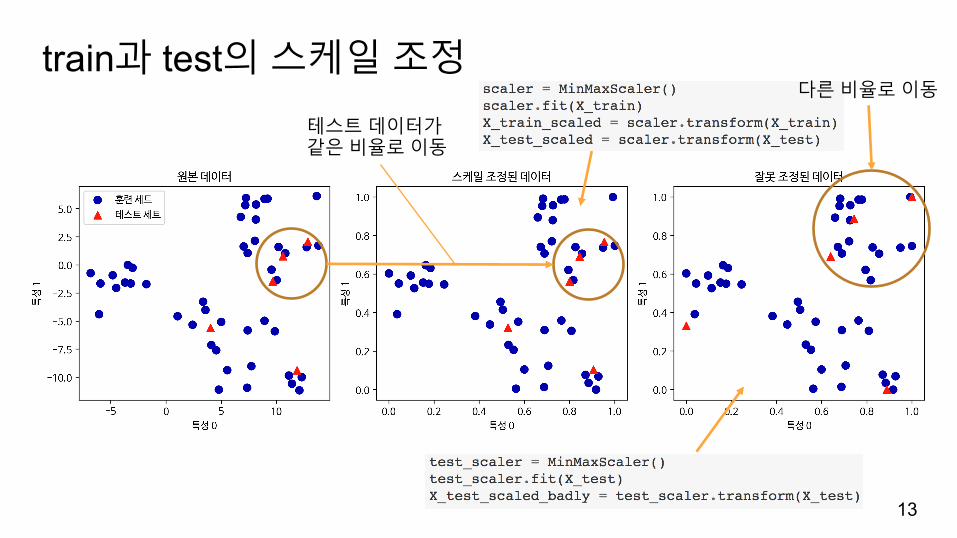
train과 test의스케일조정
13
테스트데이터가같은비율로이동
다른비율로이동

<단축메서드>
14
transform 메서드를가진변환기는모두 fit_transform 메서드를가지고있습니다.
TransformerMixIn 클래스를상속하는대부분의경우 fit_transform은단순히scaler.fit().transform()처럼연이어호출합니다.
테스트데이터를변환하려면반드시 transform()을사용합니다.
일부의경우 fit_transform 메서드가효율적인경우가있습니다(PCA)
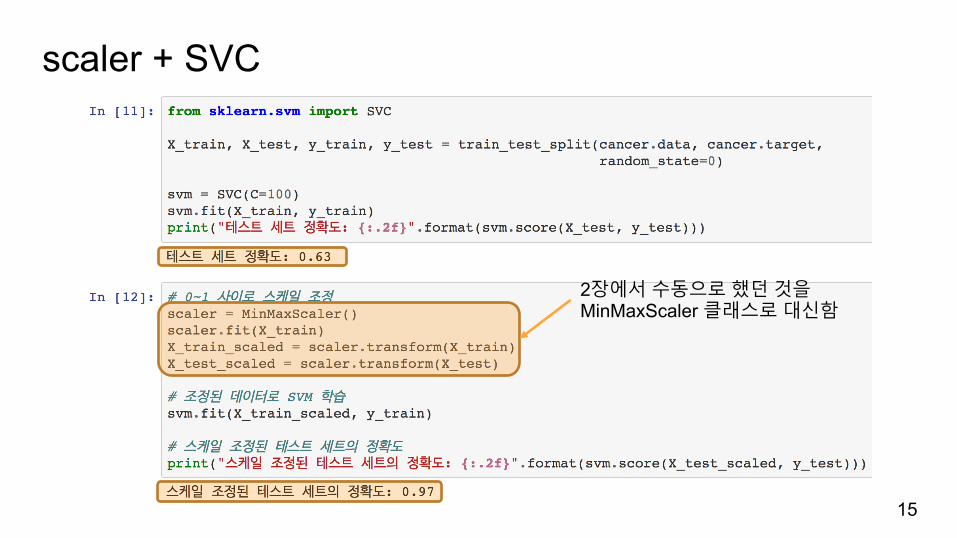
scaler + SVC
15
2장에서수동으로했던것을MinMaxScaler 클래스로대신함

PCA
16
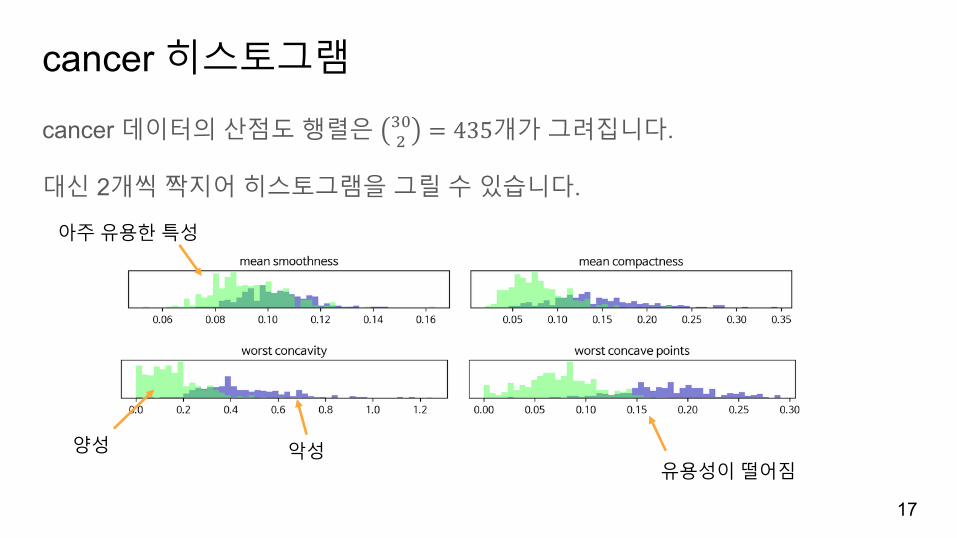
cancer 히스토그램
cancer 데이터의산점도행렬은 '6& = 435개가그려집니다.
대신 2개씩짝지어히스토그램을그릴수있습니다.
17
양성 악성유용성이떨어짐
아주유용한특성
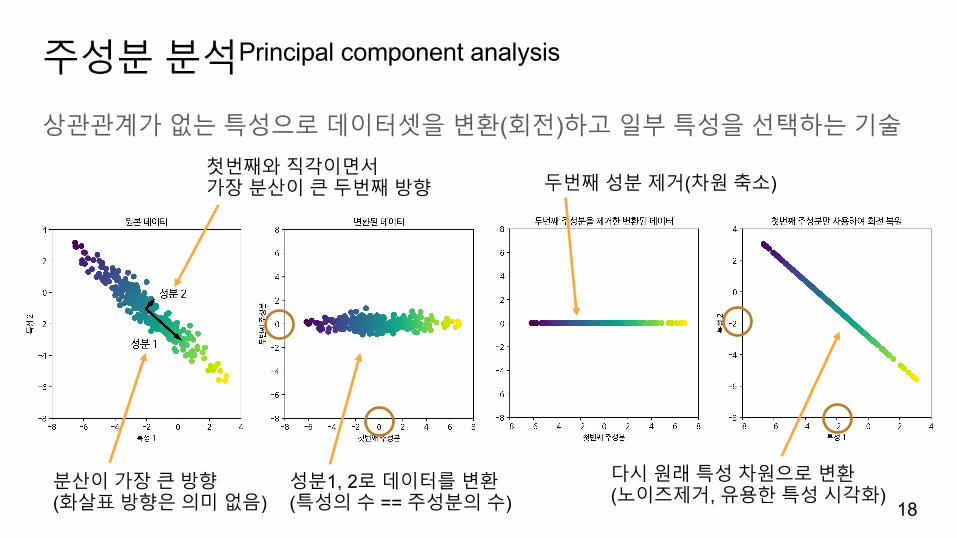
주성분분석Principal component analysis
상관관계가없는특성으로데이터셋을변환(회전)하고일부특성을선택하는기술
18분산이가장큰방향(화살표방향은의미없음)
첫번째와직각이면서가장분산이큰두번째방향
성분1, 2로데이터를변환(특성의수 == 주성분의수)
두번째성분제거(차원축소)
다시원래특성차원으로변환(노이즈제거, 유용한특성시각화)

PCA와특이값분해
19
C𝑜𝑣 𝑋*, 𝑋? =1
𝑛 − 1[(𝑋* − 𝑋D*)(𝑋? − 𝑋D?)]
행렬 X의공분산
평균을뺀행렬로표현하면(평균이 0이되도록변환)
C𝑜𝑣 𝑋, 𝑋 =1
𝑛 − 1𝑋H𝑋
특이값분해(SVD) 𝑋 = 𝑈𝑆𝑉H로부터
C𝑜𝑣 𝑋, 𝑋 =1
𝑛 − 1𝑋H𝑋 =
1𝑛 − 1
𝑉𝑆𝑈H 𝑈𝑆𝑉H = 𝑉𝑆&
𝑛 − 1VM
𝑉( 𝐶(,& 𝐶(,'𝐶(,& 𝑉& 𝐶&,'𝐶(,' 𝐶&,' 𝑉'
C𝑜𝑣 𝑋, 𝑋 행렬의고유벡터(V) à분산의주방향
𝑋OP, = 𝑋𝑉 = 𝑈𝑆𝑉H𝑉 = 𝑈𝑆
행렬의고유벡터à크기만바뀌고방향은바뀌지않음
𝑦 = 𝐴𝑥 = 𝜆𝑥𝐴 = 𝑉𝑑 𝜆 𝑉U(

PCA 변환차원
𝑋OP, = 𝑋𝑉 = 𝑈𝑆𝑉H𝑉 = 𝑈𝑆
X = [mxn] 행렬, m: 샘플수, n: 특성수, p: 주성분수
U = [mxm] 행렬, s = [mxn] 행렬, V = [nxn] 행렬
XnewV = [mxn]・[nxp]=[mxp] : Xnew가주어지면 V의몇개열만사용, fit() àtransform()
US = [mxm]・[mxp]=[mxp] : 학습한데이터를변환할때는 S의몇개열만사용,fit_transform()
20
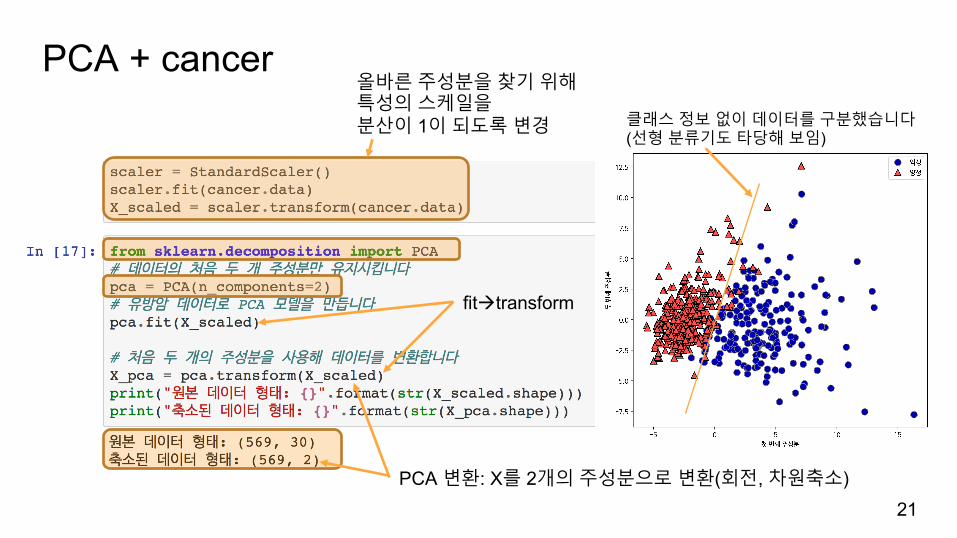
PCA + cancer
21
올바른주성분을찾기위해특성의스케일을분산이 1이되도록변경
fitàtransform
클래스정보없이데이터를구분했습니다(선형분류기도타당해보임)
PCA 변환: X를 2개의주성분으로변환(회전, 차원축소)

pca.components_components_ 속성에주성분방향principal axis VT([nxn])가부분저장되어있습니다.
components_ 크기 (n_components, n_features)
22
주성분방향을직관적으로설명하기어렵습니다.
30개의특성
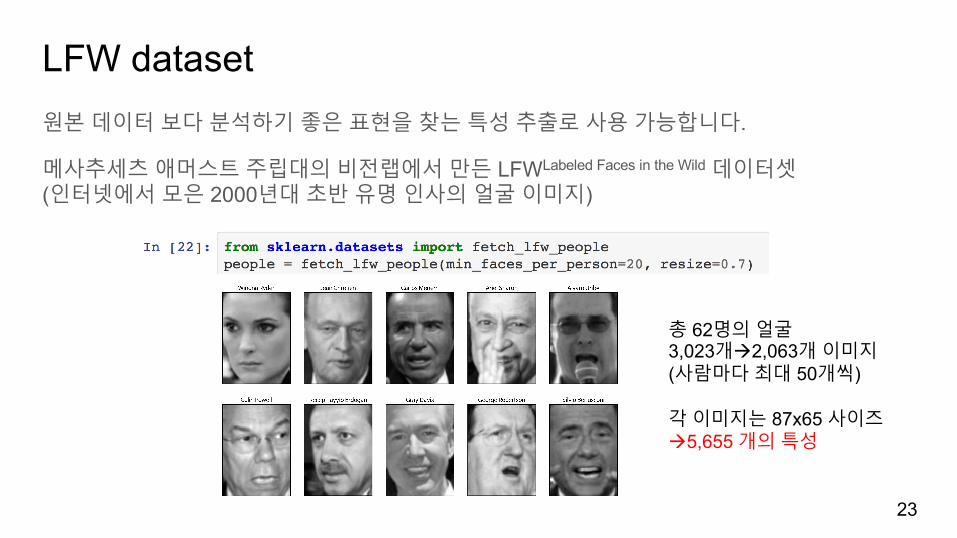
LFW dataset원본데이터보다분석하기좋은표현을찾는특성추출로사용가능합니다.
메사추세츠애머스트주립대의비전랩에서만든 LFWLabeled Faces in the Wild 데이터셋(인터넷에서모은 2000년대초반유명인사의얼굴이미지)
23
총 62명의얼굴3,023개à2,063개이미지(사람마다최대 50개씩)
각이미지는 87x65 사이즈à5,655 개의특성

k-NN + lfw얼굴인식: DB에있는얼굴중하나를찾는작업(사람마다사진수가적음)
얼굴인식을위해 (지도학습) 1-최근접이웃을적용합니다.
87x65 픽셀값의거리를계산하므로위치에매우민감합니다.
24무작위로분류할경우 1/62=0.016
1547개
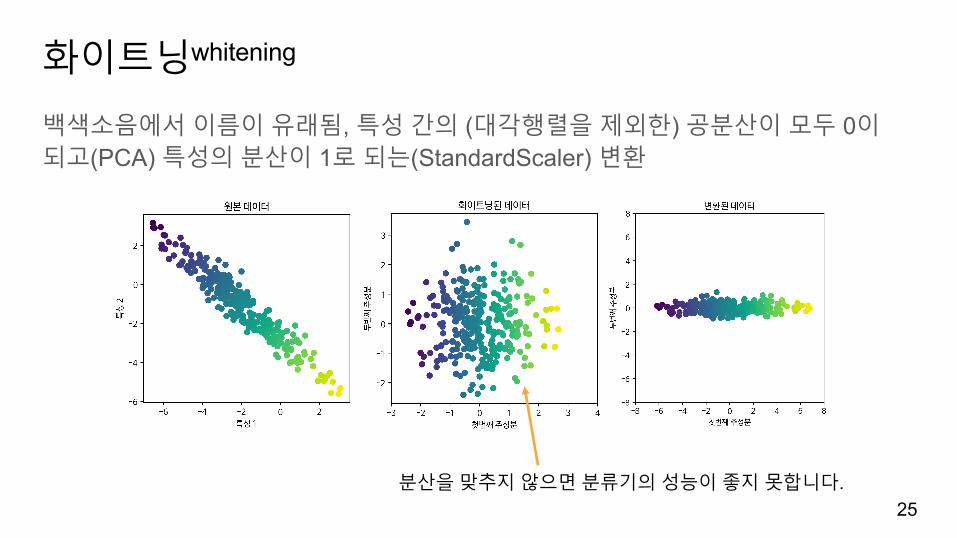
화이트닝whitening
백색소음에서이름이유래됨, 특성간의 (대각행렬을제외한) 공분산이모두 0이되고(PCA) 특성의분산이 1로되는(StandardScaler) 변환
25분산을맞추지않으면분류기의성능이좋지못합니다.
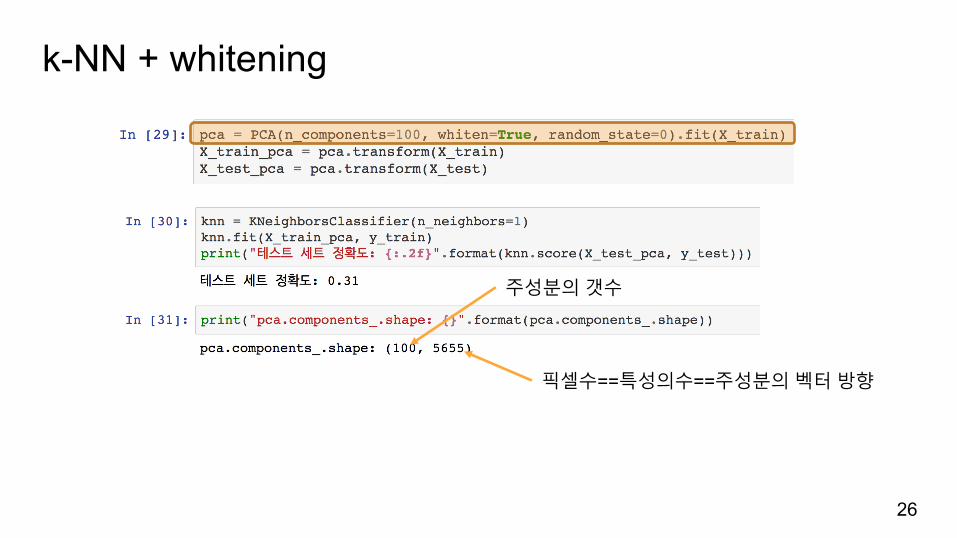
k-NN + whitening
26
주성분의갯수
픽셀수==특성의수==주성분의벡터방향

lfw 주성분
배경, 명앙 ,조명의차이를구분하고있습니다. 하지만사람이이미지를판단할때는정성적인속성(나이, 표정, 인상등)을사용합니다.
신경망: 입력이미지에서유용한특성을찾음(representative learning, end-to-end learning)
27
VT = components_= [n_component, features]
5655=87x65

PCA as weighted sum
주성분방향으로변환한데이터(X_trained_pca)에주성분방향을곱하여원본을복원할수있습니다.
[1 x 5655] = [1 x 100] ∙ [100 x 5655]
원본샘플을주성분의가중치합으로표현할수있습니다.
5655개의주성분을사용하면완전히복원됩니다.
28
10개 50개 100개 500개
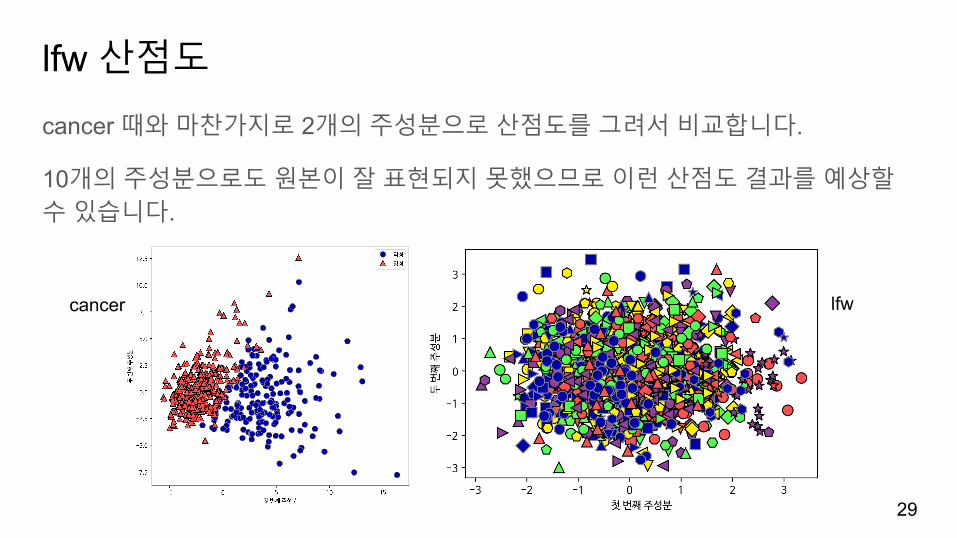
lfw 산점도
cancer 때와마찬가지로 2개의주성분으로산점도를그려서비교합니다.
10개의주성분으로도원본이잘표현되지못했으므로이런산점도결과를예상할수있습니다.
29
cancer lfw

비음수행렬분해(NMF)
30

NMFPCA와비슷하고차원축소에사용할수있습니다.
원본 = 뽑아낸성분의가중치의합
음수가아닌성분과계수를만드므로양수로이루어진데이터에적용가능합니다.
여러악기나목소리가섞인오디오트랙처럼독립된소스가덧붙여진데이터를분해하는데유용합니다.
성분과계수가음수를가진 PCA 보다 NMF를이해하기가쉽습니다.
31
𝑋 = 𝑊𝐻를만족하는𝑊와𝐻를구함𝑊:변환된데이터, 𝐻:성분(𝑐𝑜𝑚𝑝𝑜𝑛𝑒𝑛𝑡𝑠_에저장)
손실함수 L2노름의제곱 : 12∑ 𝑋*? −𝑊𝐻*?
&
좌표하강법
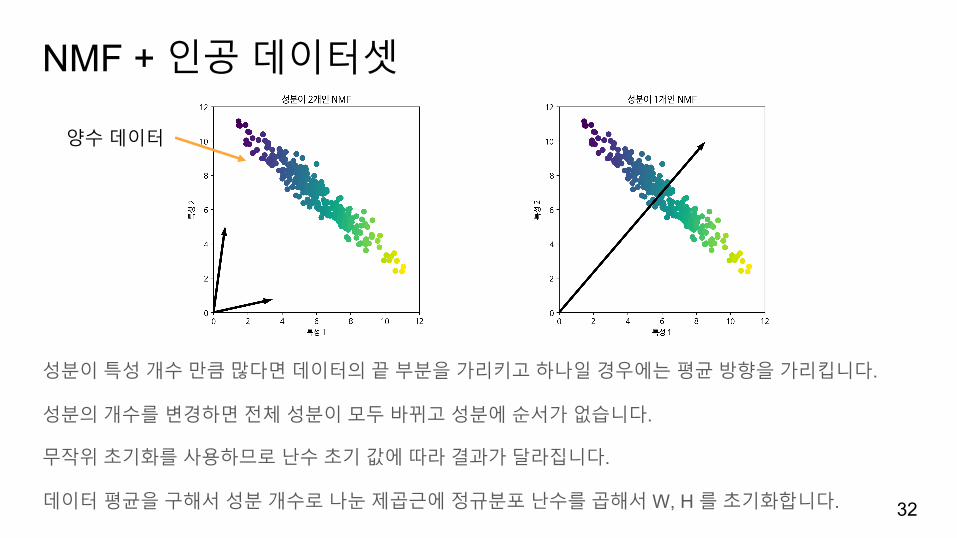
NMF + 인공데이터셋
32
성분이특성개수만큼많다면데이터의끝부분을가리키고하나일경우에는평균방향을가리킵니다.
성분의개수를변경하면전체성분이모두바뀌고성분에순서가없습니다.
무작위초기화를사용하므로난수초기값에따라결과가달라집니다.
데이터평균을구해서성분개수로나눈제곱근에정규분포난수를곱해서 W, H 를초기화합니다.
양수데이터

NMF < PCANMF는재구성보다는주로데이터에있는패턴을분할하는데주로사용합니다.
NMF + lfw
33
PCA가재구성에유리한성분(분산)을찾습니다.

NMF - lfw의성분
NMF PCA성분이모두양수이므로얼굴이미지와가까운형태를띱니다.
34
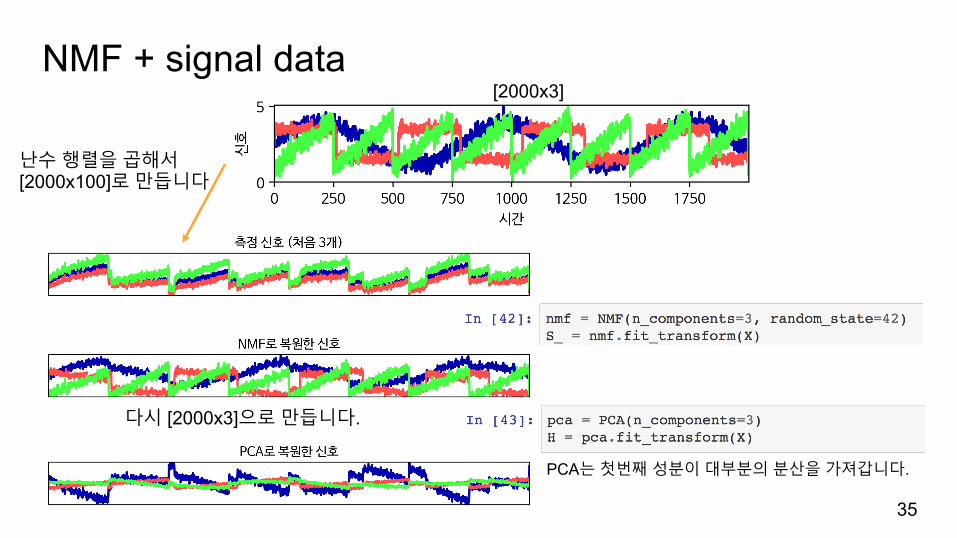
NMF + signal data
35
[2000x3]
난수행렬을곱해서[2000x100]로만듭니다
다시 [2000x3]으로만듭니다.
PCA는첫번째성분이대부분의분산을가져갑니다.

t-SNE
36
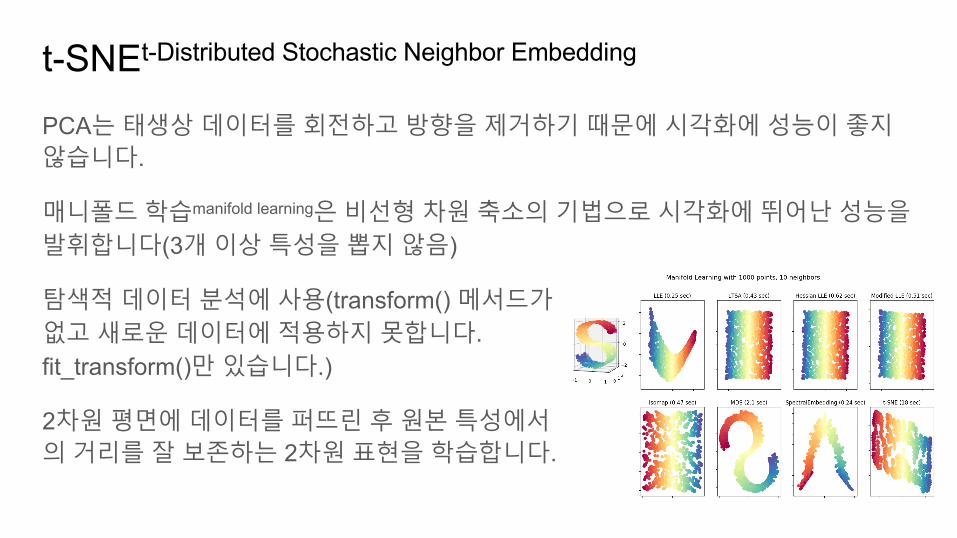
t-SNEt-Distributed Stochastic Neighbor Embedding
PCA는태생상데이터를회전하고방향을제거하기때문에시각화에성능이좋지않습니다.
매니폴드학습manifold learning은비선형차원축소의기법으로시각화에뛰어난성능을발휘합니다(3개이상특성을뽑지않음)
탐색적데이터분석에사용(transform() 메서드가없고새로운데이터에적용하지못합니다.fit_transform()만있습니다.)
2차원평면에데이터를퍼뜨린후원본특성에서의거리를잘보존하는 2차원표현을학습합니다.
37

load_digits8x8 흑백이미지의손글씨숫자데이터셋(MNIST 데이터셋아님. UC 얼바인머신러닝저장소:http://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits)
38
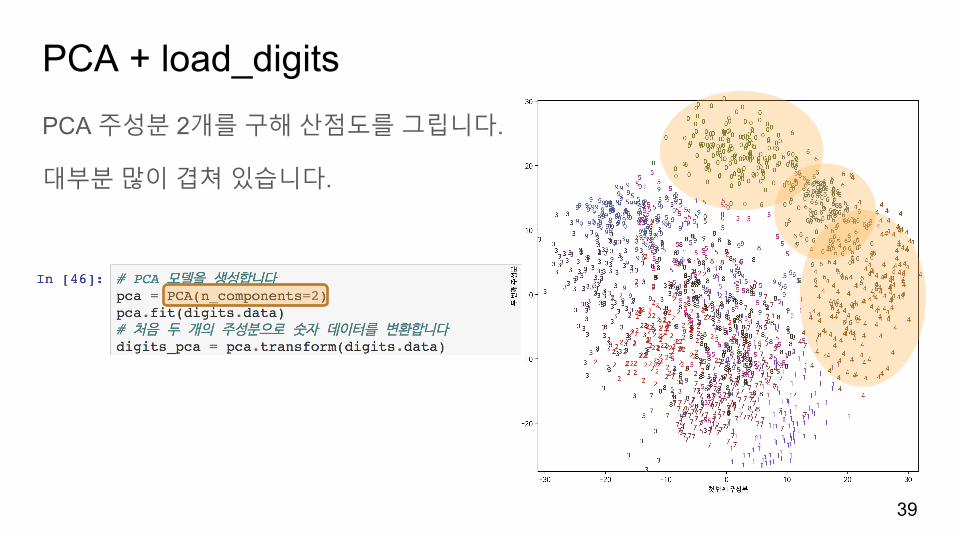
PCA + load_digitsPCA 주성분 2개를구해산점도를그립니다.
대부분많이겹쳐있습니다.
39
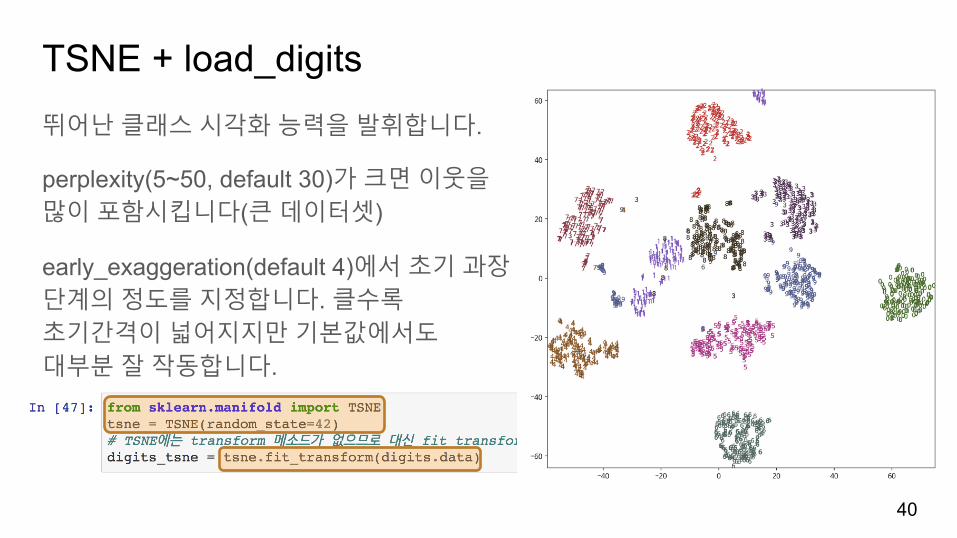
TSNE + load_digits뛰어난클래스시각화능력을발휘합니다.
perplexity(5~50, default 30)가크면이웃을많이포함시킵니다(큰데이터셋)
early_exaggeration(default 4)에서초기과장단계의정도를지정합니다. 클수록초기간격이넓어지지만기본값에서도대부분잘작동합니다.
40

k-평균군집
41

군집
데이터셋을클러스터cluster라는그룹으로나누는작업입니다.
한클러스터안의데이터는매우비슷하고다른클러스터와는구분되도록만듭니다.
분류알고리즘처럼테스트데이터에대해서어느클러스터에속할지예측을만들수있습니다.
• k-평균군집
• 병합군집
• DBSCAN
42

k-평균means 군집
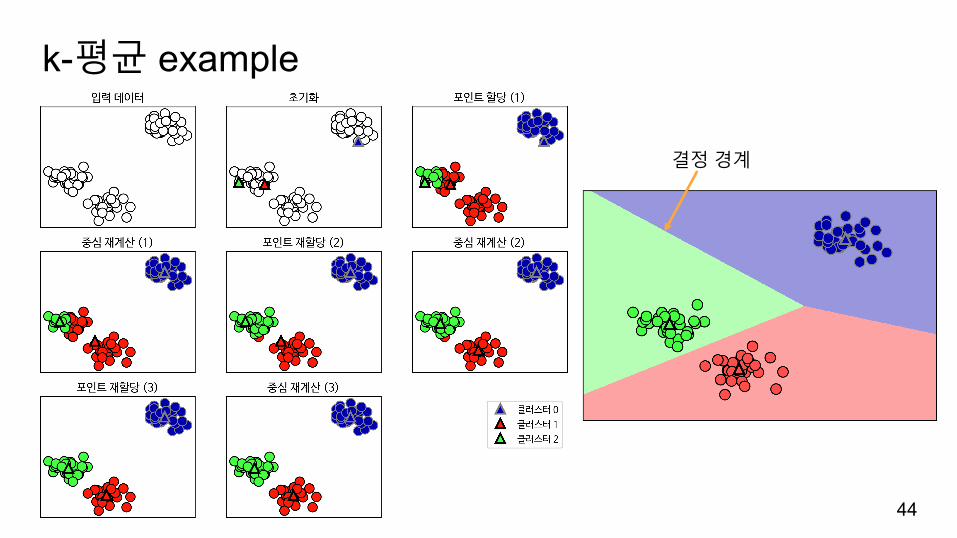
가장간단하고널리사용되는군집알고리즘입니다.
임의의클러스터중심에데이터포인트를할당합니다.
그다음클러스터안의데이터포인트를평균을내어다시클러스터중심을계산하고이전과정을반복합니다.
클러스터에할당되는데이터포인트의변화가없으면알고리즘종료됩니다.
43
k-평균 example
44
결정경계
KMeans
45
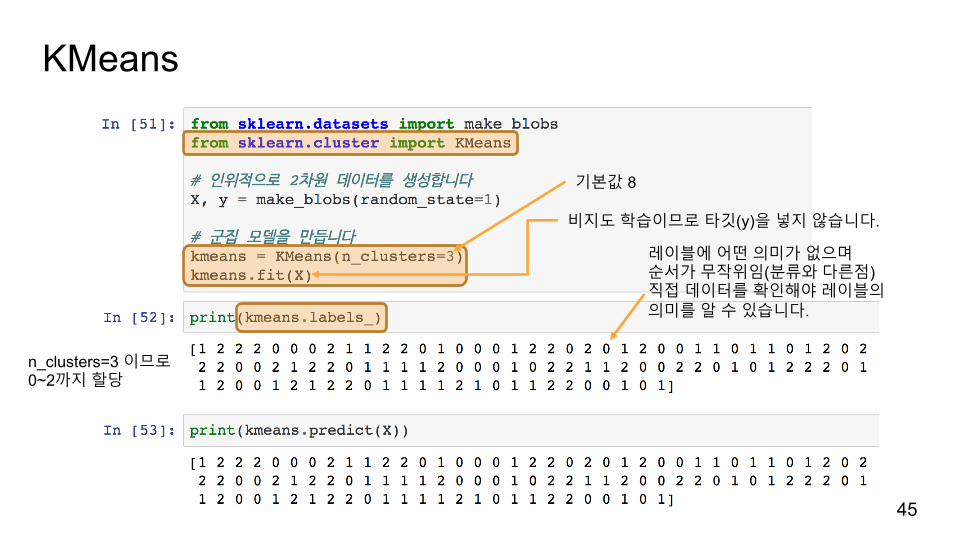
레이블에어떤의미가없으며순서가무작위임(분류와다른점)직접데이터를확인해야레이블의의미를알수있습니다.
기본값 8
비지도학습이므로타깃(y)을넣지않습니다.
n_clusters=3 이므로0~2까지할당
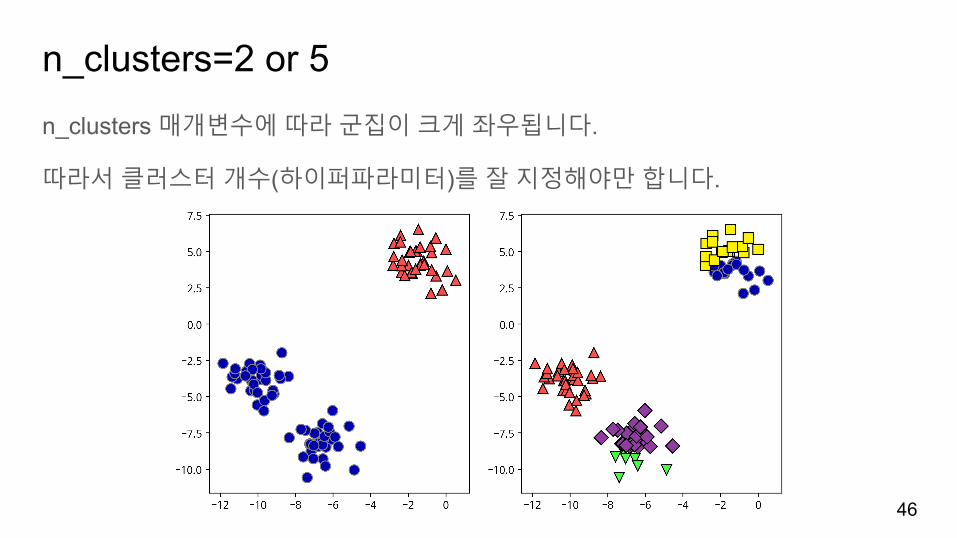
n_clusters=2 or 5n_clusters 매개변수에따라군집이크게좌우됩니다.
따라서클러스터개수(하이퍼파라미터)를잘지정해야만합니다.
46
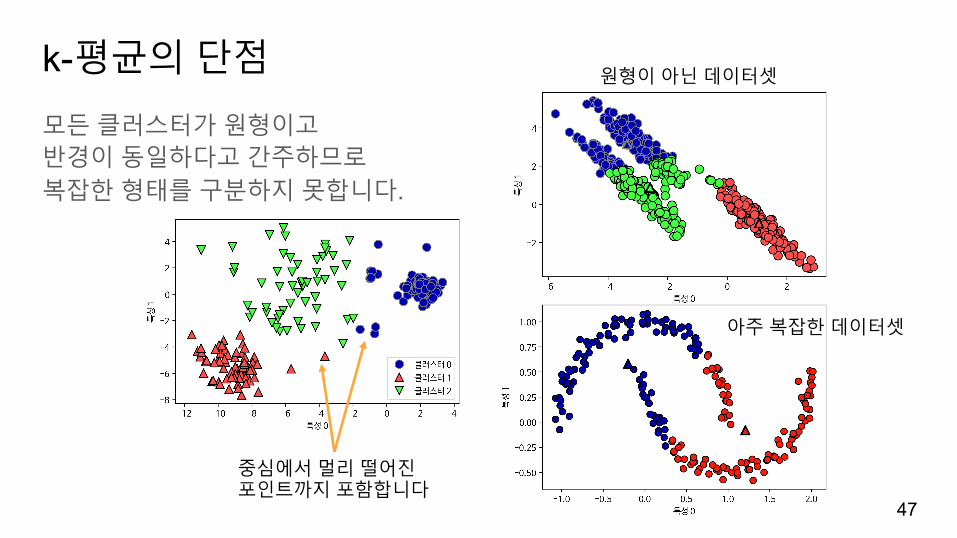
k-평균의단점
모든클러스터가원형이고반경이동일하다고간주하므로복잡한형태를구분하지못합니다.
47
중심에서멀리떨어진포인트까지포함합니다
원형이아닌데이터셋
아주복잡한데이터셋

벡터양자화
PCA, NMF가데이터포인트를성분의합으로표현할수있는것처럼 k-평균은데이터포인트를하나의성분으로나타내는것으로볼수있음(벡터양자화)
48
클러스터평균
Kmeans
PCA
NMF
Kmeans
PCA
NMF
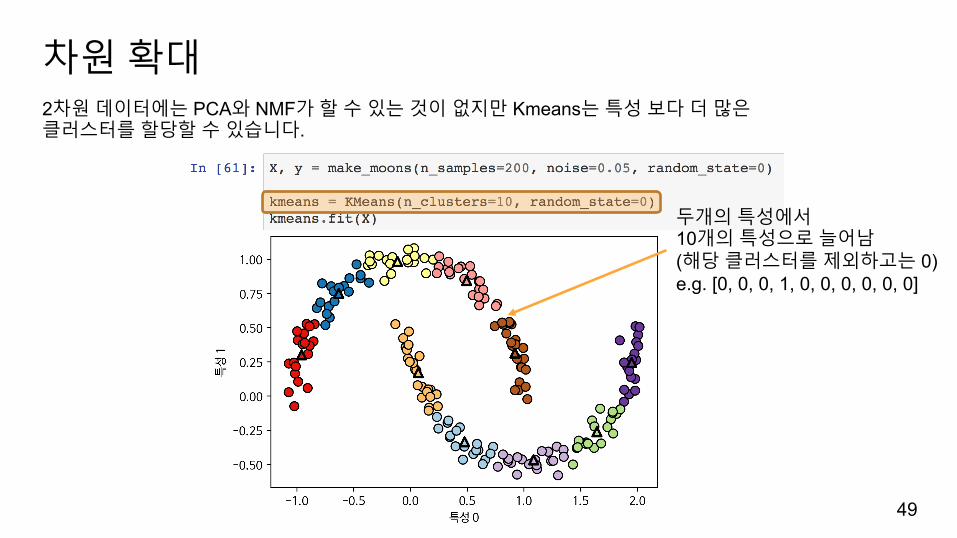
차원확대
49
두개의특성에서10개의특성으로늘어남(해당클러스터를제외하고는 0)e.g. [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
2차원데이터에는 PCA와 NMF가할수있는것이없지만 Kmeans는특성보다더많은클러스터를할당할수있습니다.
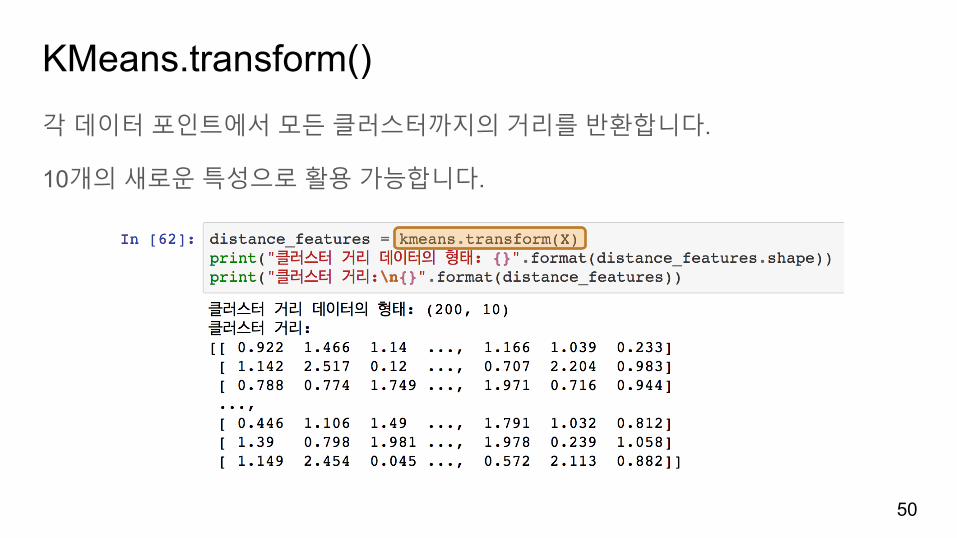
KMeans.transform()각데이터포인트에서모든클러스터까지의거리를반환합니다.
10개의새로운특성으로활용가능합니다.
50

장단점
장점
이해와구현이쉽고비교적빨라서인기가높습니다.대규모데이터셋에적용가능합니다(MiniBatchKMeans)
단점
무작위로초기화하므로난수에따라결과가달라집니다.n_init(default 10) 매개변수만큼반복하여클러스터분산이작은결과를선택합니다클러스터모양을원형으로가정하고있어제한적입니다.실제로는알수없는클러스터개수를지정해야합니다.
51
batch_size=100 기본값

병합군집
52

병합군집agglomerative clustering
시작할때데이터포인트를하나의클러스터로지정해지정된클러스터개수에도달할때까지두클러스터를합쳐나갑니다.
비슷한클러스터를선택하는방법을 linkage 매개변수에지정합니다.
• ward: 기본값, 클러스터내의분산을가장작게만드는두클러스터를병합(클러스터의크기가비슷해짐)
• average: 클러스터포인트사이의평균거리가가장작은두클러스터를병합
• complete: 클러스터포인트사이의최대거리가가장짧은두클러스터를병합
클러스터크기가매우다를때 average나 complete가나을수있습니다.
53
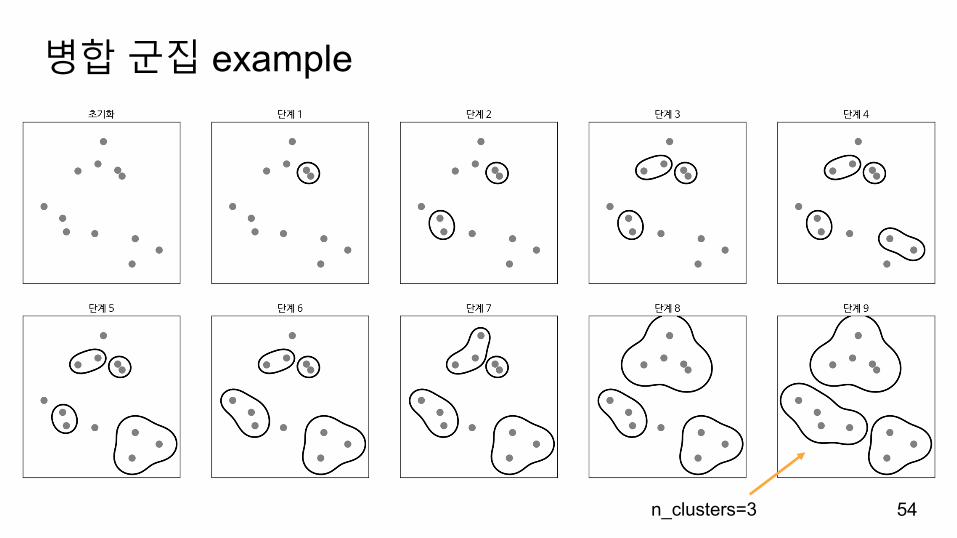
병합군집 example
54n_clusters=3
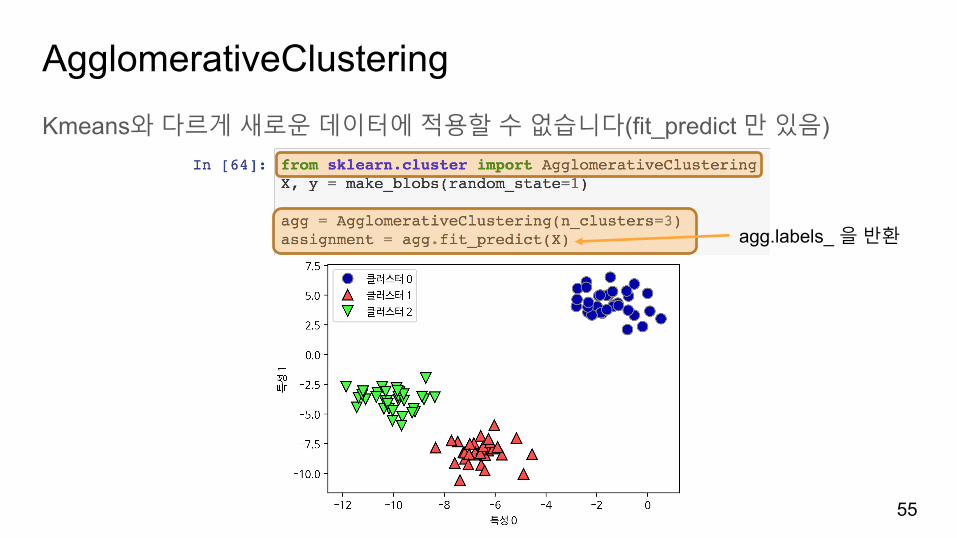
AgglomerativeClusteringKmeans와다르게새로운데이터에적용할수없습니다(fit_predict 만있음)
55
agg.labels_ 을반환
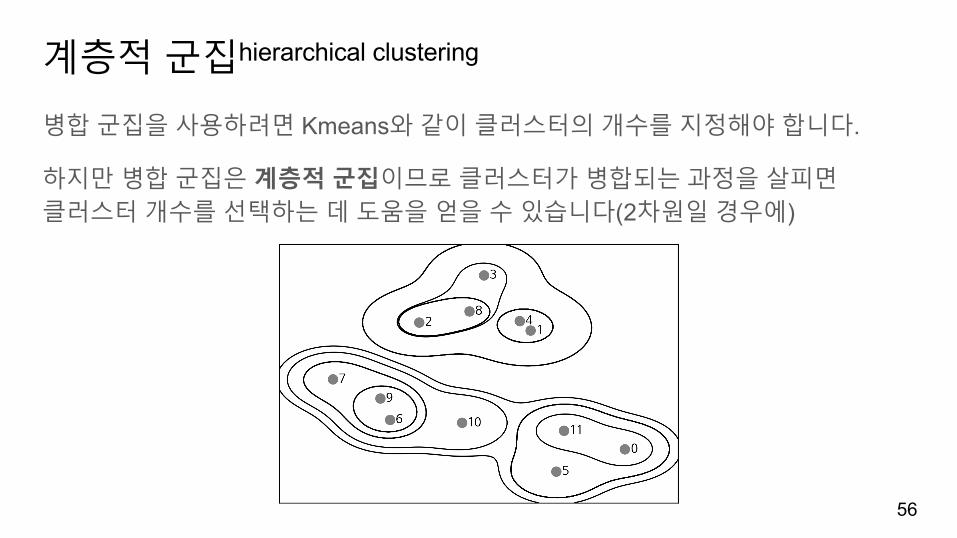
계층적군집hierarchical clustering
병합군집을사용하려면 Kmeans와같이클러스터의개수를지정해야합니다.
하지만병합군집은계층적군집이므로클러스터가병합되는과정을살피면클러스터개수를선택하는데도움을얻을수있습니다(2차원일경우에)
56
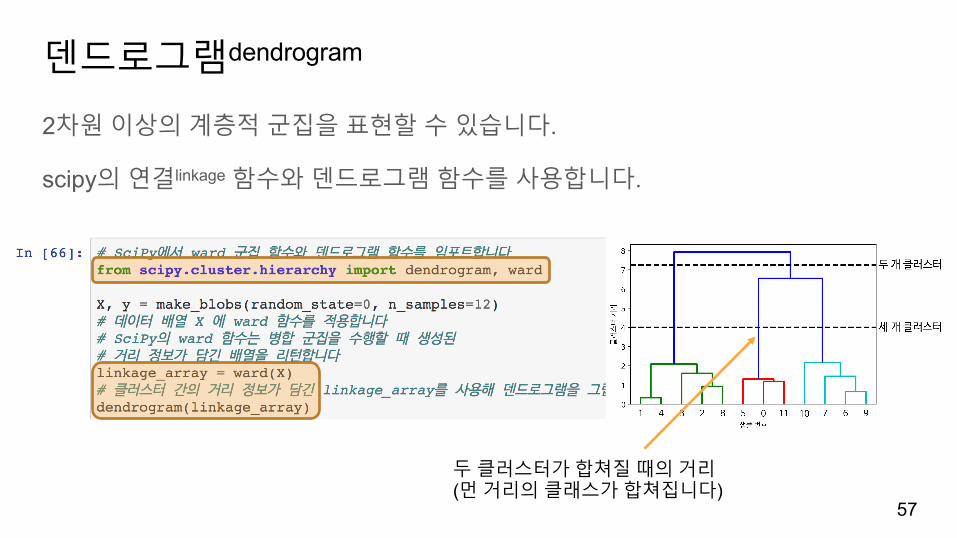
덴드로그램dendrogram
2차원이상의계층적군집을표현할수있습니다.
scipy의연결linkage 함수와덴드로그램함수를사용합니다.
57
두클러스터가합쳐질때의거리(먼거리의클래스가합쳐집니다)

DBSCAN
58

DBSCAN 특징
클러스터개수를미리지정할필요없습니다.
복잡한형상에적용가능하고, 어느클러스터에도속하지않는노이즈포인트를구분합니다.
k-평균이나병합군집보다는다소느리지만큰데이터셋에적용가능합니다.
데이터가많은밀집지역을찾아다른지역과구분하는클러스터를구성합니다.
밀집지역의포인트를핵심샘플이라고부릅니다.
한데이터포인트에서 eps 안의거리에 min_samples 개수만큼데이터가있으면이포인트를핵심샘플로분류함. à클러스터가됨
59

DBSCAN 알고리즘
처음무작위로포인트를선택하고 eps 거리안의포인트를찾습니다.
eps 거리안의포인트 < min_samples 이면잡음포인트(-1)로분류합니다.
eps 거리안의포인트 > min_samples 이면핵심포인트로분류, 새클러스터할당
핵심포인트에서 eps 안의포인트를확인하여클러스터할당이없으면핵심샘플의클러스터를할당합니다(경계포인트)
eps 안의포인트가이미핵심샘플이면그포인트의이웃을또차례로방문하여클러스터가자라납니다. 그리고아직방문하지못한포인트를다시선택해동일한과정을반복합니다.
여러번실행해도같은핵심포인트, 잡음포인트를찾지만경계포인트는바뀔수있습니다.보통경계포인트는많지않아크게영향을미치지않습니다.
60
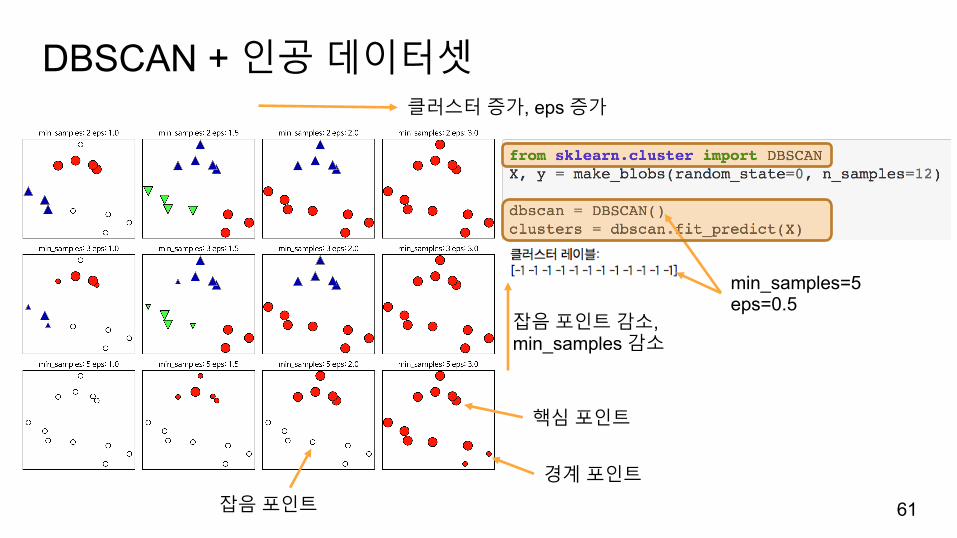
DBSCAN + 인공데이터셋
61
min_samples=5eps=0.5
잡음포인트
핵심포인트
경계포인트
클러스터증가, eps 증가
잡음포인트감소,min_samples 감소

eps, min_sampleseps가가까운포인트의범위를정하기때문에더중요합니다.
eps가아주작으면핵심포인트가생성되지않고모두잡음으로분류됩니다. eps를아주크게하면모든포인트가하나의클러스터가됩니다.
eps로클러스터의개수를간접적으로조정할수있습니다.
min_samples는덜조밀한지역이잡음포인트가될지를결정합니다.
min_samples 보다작은개수가모여있는지역은 잡음포인트가됩니다.(클러스터최소크기)
StandardScaler나 MinMaxScaler로특성의스케일을조정할필요있습니다.
잡음포인트의레이블이 -1이므로군집의결과를다른배열의인덱스로사용할때는주의해야합니다.
62
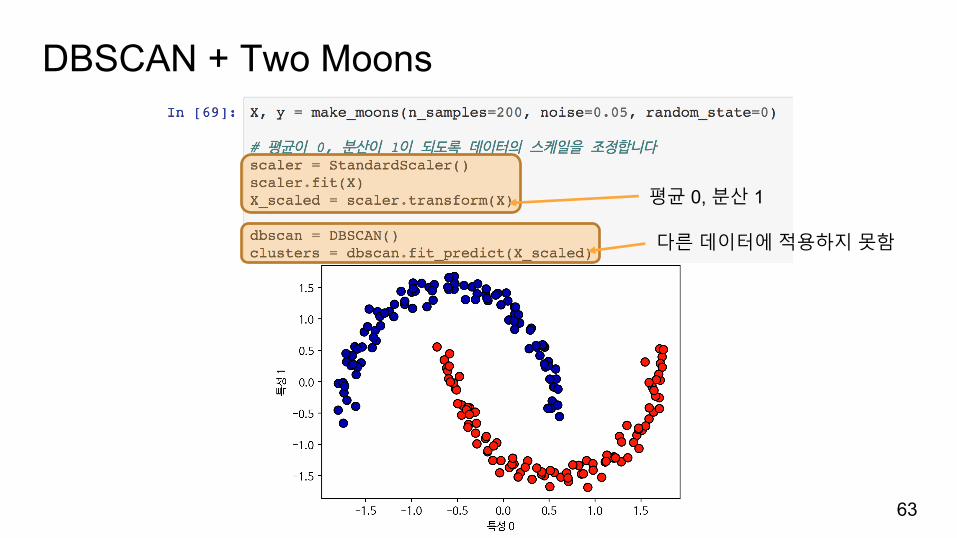
DBSCAN + Two Moons
63
평균 0, 분산 1
다른데이터에적용하지못함

군집알고리즘비교, 평가
64

ARI, NMI실제정답클래스(타깃)과비교해야합니다.
0(무작위)~1(최적) 사이의값, ARI의최저값은 -0.5 혹은 -1 임
65
NMI: normalized_mutual_info_score()
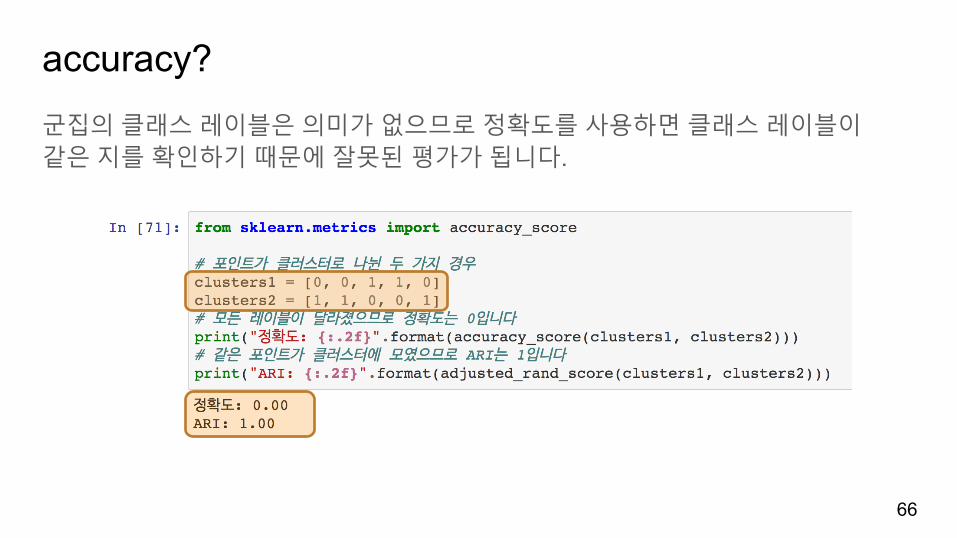
accuracy?군집의클래스레이블은의미가없으므로정확도를사용하면클래스레이블이같은지를확인하기때문에잘못된평가가됩니다.
66

실루엣silhouette 계수
ARI, NMI는타깃값이있어야가능하므로애플리케이션보다알고리즘을개발할때도움이됩니다.
타깃값필요없이클러스터의밀집정도를평가합니다.
-1: 잘못된군집, 0: 중첩된군집, 1: 가장좋은군집
모양이복잡할때는밀집정도를평가하는것이잘맞지않습니다.
원형클러스터의실루엣점수가높게나옵니다.
67
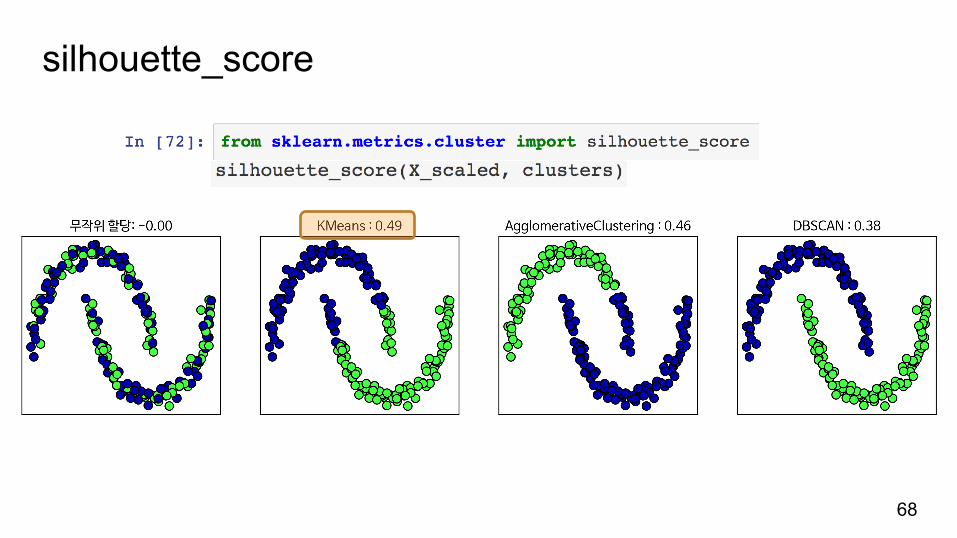
silhouette_score
68

군집평가의어려움
실루엣점수가높다하더라도찾아낸군집이흥미로운것인지는여전히알수없습니다.
사진애플리케이션이두개의클러스터를만들었다면
앞모습 vs 옆모습
밤사진 vs 낯사진
아이폰 vs 안드로이드
클러스터가기대한대로인지는직접확인해야만알수있습니다.
69
어떻게만들었을지알수없습니다.

군집 + LFW
70
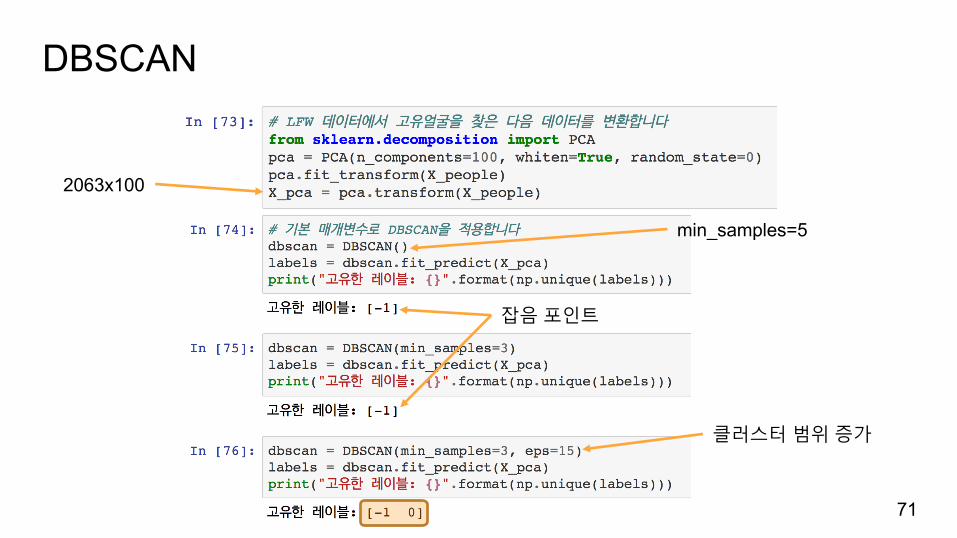
DBSCAN
71
2063x100
min_samples=5
잡음포인트
클러스터범위증가

DBSCAN 잡음포인트
72이상치검출용도로활용할수있습니다.
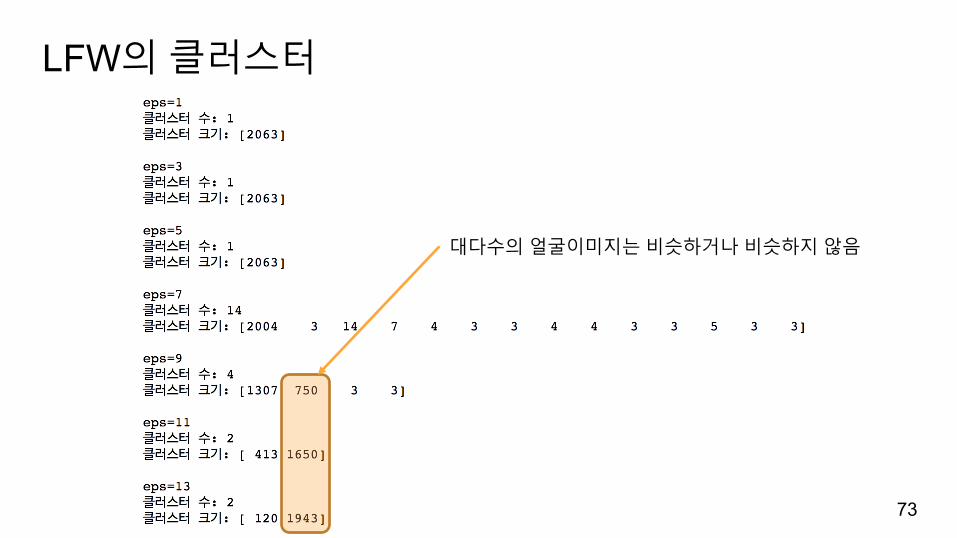
LFW의클러스터
73
대다수의얼굴이미지는비슷하거나비슷하지않음

k-평균 + LFW
74
2063x100
pca.inverse_transfom(km.cluster_centers_)
클러스터중심:10x100원본차원으로복원:
100x5655
클러스터에있는얼굴의평균이므로매우부드럽습니다

k-평균의중심에서가깝고먼이미지
75
중심에서먼이미지들은많이달라보임
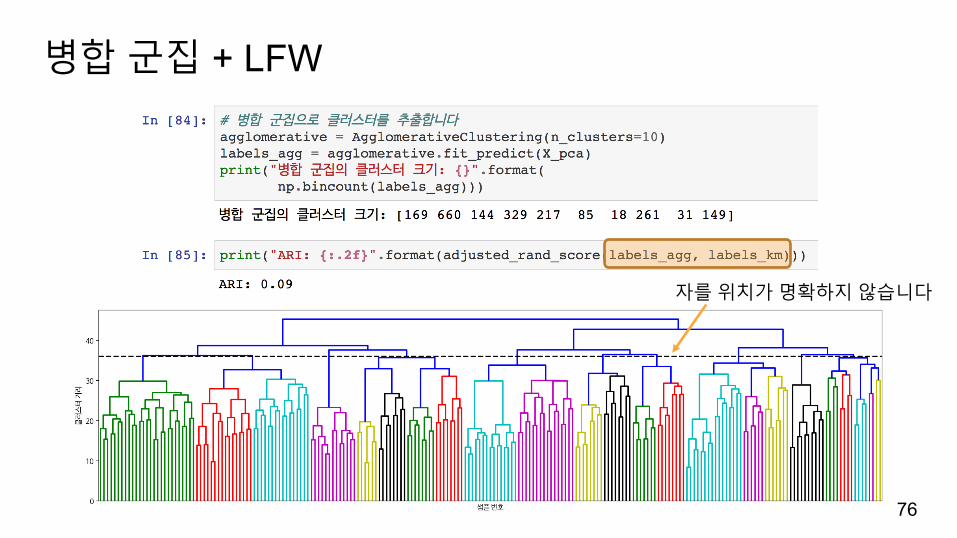
병합군집 + LFW
76
자를위치가명확하지않습니다

장단점
군집알고리즘은정성적분석과정이나탐색적분석단계에유용합니다.
k-평균, 병합군집: 클러스터개수지정
k-평균: 클러스터의중심을데이터포인트의분해방법으로볼수있음
DBSCAN: eps 매개변수로간접적으로클러스터크기를조정, 잡음포인트인식,클러스터개수자동인식, 복잡한형상파악가능
병합군집: 계층적군집으로덴드로그램을사용해표현할수있음
77



![KUN Ok U SYARfJ1 [kJh]kR313B 533 .31 (EPOCH 10.1 4LDK ... · [kJh]kR313B 533 .31 (EPOCH 10.1 4LDK (EPOCH 151.14nflE45.72 3LDK (EPOCH 300±-FV LDK16.08Ÿ 4LDK M. 1 4LDK 94.42m' (28.56ž-gi)](https://img.pdfslide.tips/doc/110x75/5f3b8a3ea9e6b339d3366509/kun-ok-u-syarfj1-kjhkr313b-533-31-epoch-101-4ldk-kjhkr313b-533-31-epoch.jpg)

























