Embed Size (px)
DESCRIPTION
Citation preview

Язык поисковых запросов
как естественный язык
Андрей ПлаховРуководитель группы функциональности поиска

Проблема усвоения языка

Проблема усвоения языка
Нативизм
«Язык и мышление»Хомского
Генеративная грамматика
Универсалии
Аргумент бедности стимула
Эмпиризм
Оперантное, статистическое научение
Когнитивная лингвистика
Критика универсалий
Аргумент отсутствия LAD

Алгоритмическая сложность
задачи усвоения языкаГрамматика: только положительные примеры, ок. 105-106 штук
Значение слов: 1-2 новых слова в день, по нескольким примерам употребления
Полиномиально ограниченный решатель
Рекурсия, сложные грамматики

Язык запросов

Язык запросов
[восточная музыка слушать онлайн]
[слушать онлайн восточную музыку]
* [восточную музыку слушать онлайн]

Язык запросов
[фото котят]
[котята фото]
* [котят фото]

Язык запросов
Язык запросов - не русский язык (хотя в основном состоит из тех же слов)
Возник и развивается естественным путём
в 1997 средняя длина запроса 1,2 слова
в 2013 >3,5 словобучение на примерах
(подсказки)тиражирование
«коммуникативного успеха»
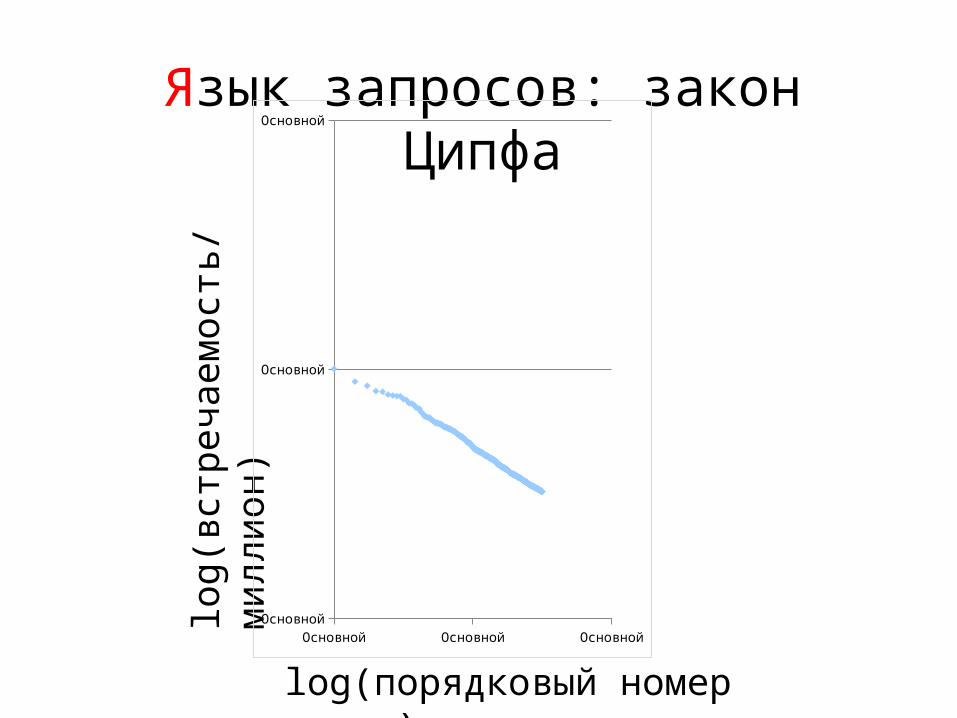
Язык запросов: закон Ципфа
log(в
стречаем
ост
ь/
ми
лл
ион
)
Основной Основной ОсновнойОсновной
Основной
Основной
log(порядковый номер слова)

Язык запросов
Словарная энтропия: около 13 бит(русский язык, тексты одного автора -11 бит)
Доля глаголов 5,4% (17,5%)10 самых частых – 46% (11,4%)
Средняя длина «фразы» - меньше 4 слов

Синтаксические структурыЗапрос – не предложение, а
высказывание. Запросы короткие (3 слова и менее).

Синтаксические структурыЗапрос – не предложение, а
высказывание. Запросы короткие (3 слова и менее).
Можно ли вообще говорить о синтаксисе применительно к языку запросов?

Синтаксические структурыNP
[фото котята] [котята фото]
[фото котят]*[котят фото]

Синтаксические структурыNP
[фото котята] - ? [котята фото]
[фото котят] - традиционная ИГ, падежная маркировка
*[котят фото]

Синтаксические структурыVP
[смотреть трейлер семейка крудс] [трейлер семейка крудс смотреть]

VP [смотреть [трейлер семейка крудс]] [[трейлер семейка крудс] смотреть]
Топикализация Zoo -wa hana -ga nagai Слон-TOP хобот-NOM длинный
[[Pos:семейка крудс] [трейлер Pos:0] смотреть][[Pos:семейка крудс] смотреть [трейлер Pos:0]]
Синтаксические структуры

Синтаксические структурыVP
[смотреть [трейлер семейка крудс]] [[трейлер семейка крудс] смотреть]
Запрет прочих конструкций*[трейлер смотреть семейка крудс]*[смотреть семейка крудс трейлер]

Синтаксические структурыNP
[фото котята] - ? [котята фото] - ?

Синтаксические структурыNP
[фото котята] - исходная структура [котята фото] - топикализация посессора

Вычислительные модели
Идея: «усвоение» языка можно оценить статистически, выполнением простых тестов
Пример подобной задачи: восстановить пропущенное слово
[в лесу * ёлочка в лесу она росла]
[mp3 * бесплатно и без регистрации]

Вычислительные модели
Шаблоны без обобщения:[ …скачать без *… ]
=> регистрации[...* принцессу карандашом] =>
нарисовать[ …проклятые * дрюон] =>
короли
Шаблоны с обобщением:[сокол и * {fb2, txt , автор, аудиокнига, читать}][ …сокол и * (книжный контекст) ] => ласточка

Вычислительные модели
Изучаем уровень «знания» языка в зависимости от количества обучающих примеров:
3100 фраз6200 фраз
12400 фраз24800 фраз41000 фраз
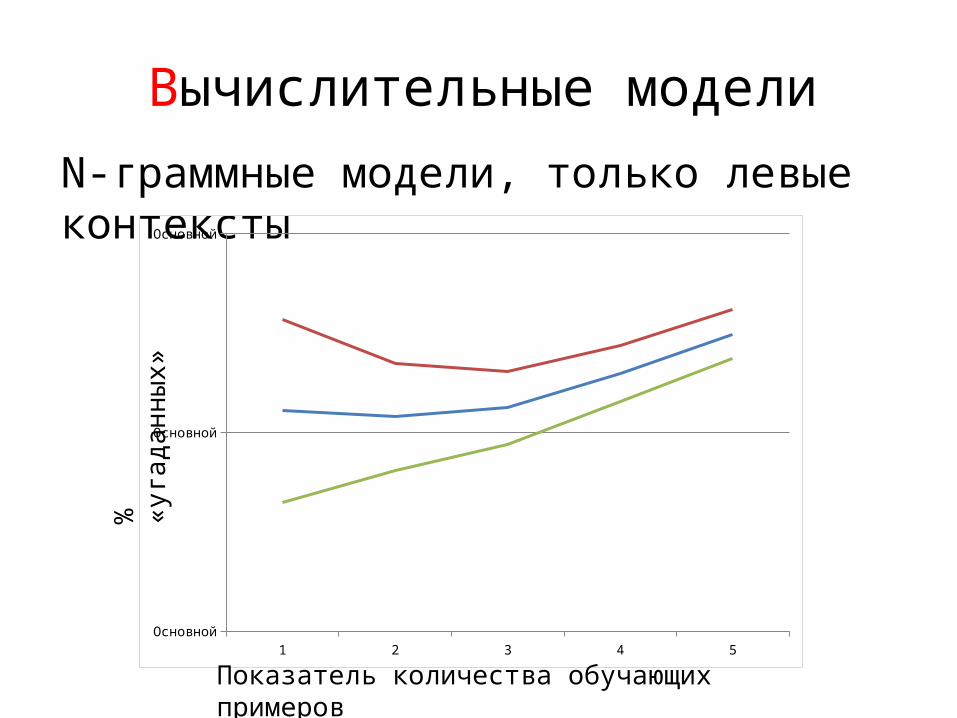
Вычислительные модели
N-граммные модели, только левые контексты
1 2 3 4 5Основной
Основной
Основной
%
«уга
дан
ны
х»
Показатель количества обучающих примеров
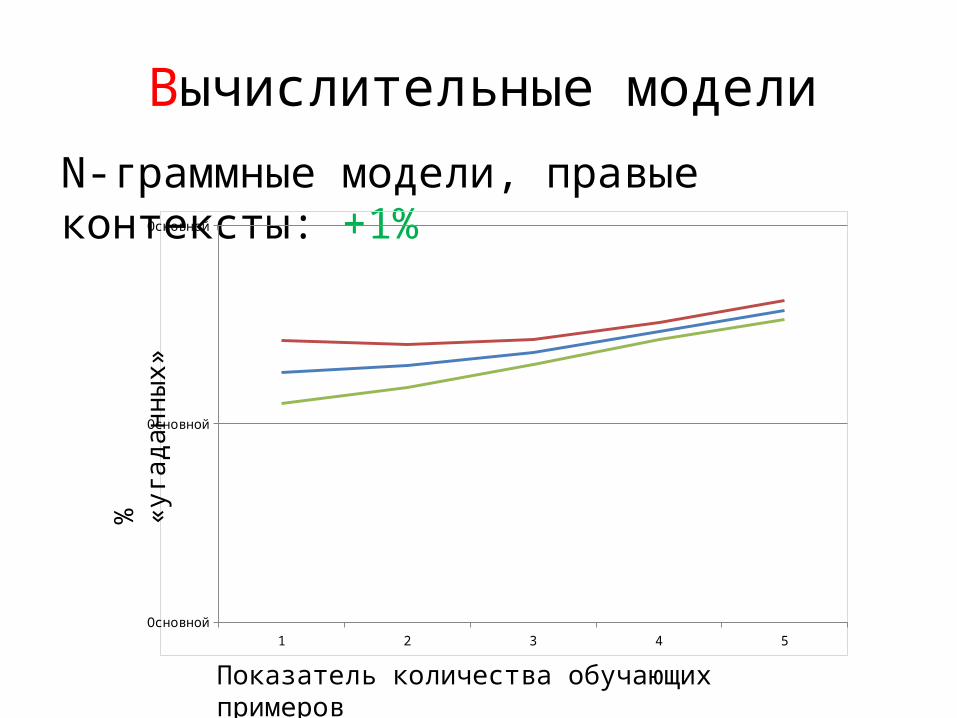
Вычислительные модели
N-граммные модели, правые контексты: +1%
1 2 3 4 5Основной
Основной
Основной
%
«уга
дан
ны
х»
Показатель количества обучающих примеров
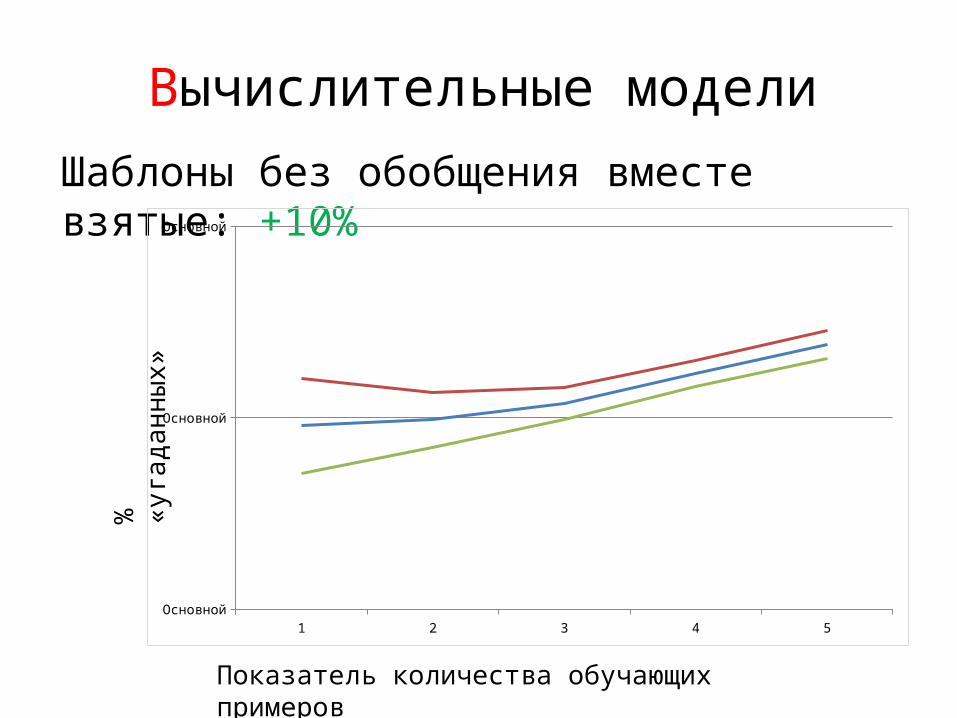
Вычислительные модели
Шаблоны без обобщения вместе взятые: +10%
1 2 3 4 5Основной
Основной
Основной
%
«уга
дан
ны
х»
Показатель количества обучающих примеров

Вычислительные модели
Генерализованные шаблоны: +???%
1) Грамматические: [(S,им, ед) * торрент] => скачать[инструкция * (S,дат,ед)] => по
2) Контекстно-концептные:[стучит * Х], допустимы [X тюнинг] и [X цена]
=> двигатель

Вычислительные модели
Можно ли вывести столько же информации, сколько её содержится в граммемах, только из контекстов?

Вычислительные модели
Генерализованные шаблоны:
1) Грамматические: + 0,2%[(S,им, ед) * торрент] => скачать[инструкция * (S,дат,ед)] => по

Вычислительные модели
Генерализованные шаблоны:
1) Грамматические: + 0,2%[(S,им, ед) * торрент] => скачать[инструкция * (S,дат,ед)] => по
2) Контекстно-концептные: +0,04%[стучит * Х], где [X тюнинг] и [X цена] => двигатель

Вычислительные модели
Можно ли вывести столько же информации, сколько её содержится в граммемах, только из контекстов?
Нельзя.

Вычислительные модели
Можно ли вывести столько же информации, сколько её содержится в граммемах, только из контекстов?
Нельзя.
Открытый вопрос: можно ли её вывести с помощью каких-то более сильных обобщений?

Что дальше?
Возник новый язык. Давайте его изучим!

Что дальше?
Возник новый язык. Давайте его изучим!
Насколько сложная и жёсткая грамматика? Какие в нём «части речи»? Можно ли построить для него полный парсер? На какие естественные языки он похож? Как развивается?






























