Embed Size (px)
Citation preview

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 1
ARQUITECTURA DE COMPUTADORAS
CAPITULO VII
COMPUTADORAS PARALELO
AÑO 2014

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 2
IX - INTRODUCCIÓN:
La tendencia actual para alcanzar grandes velocidades y capacidades de elaboración de datos, que son necesarias para el llamado procesamiento de inteligencia, es la disponer varios procesadores en paralelo, actuando simultáneamente.
Las ventajas de estos sistemas son notables, por cuanto hacen uso de procesadores estándar para alcanzar enormes velocidades de cálculo, del orden de un TIPS (Tera Instrucciones Por Segundo) o sea 1012 instrucciones por segundo, y ya se avizora el funcionamiento en el orden de los PIPS o sea Peta Instrucciones por Segundo que corresponde a 1018 IPS.
La evolución de las computadoras, desde el punto de vista de los sistemas operativos, nos muestra la siguiente secuencia de innovaciones:
1 - Procesamiento por lotes: En el cual cada programa es cargado y ejecutado, en forma separada.
2 - Multiprogramación: En el cual se carga una serie de programas en memoria, y se ejecutan de acuerdo a las necesidades de cada uno.
3 - Tiempo compartido: En este caso, todos los programas están cargados en la memoria, y se asigna un tiempo de ejecución para cada uno, en forma tal que parecen ejecutarse todos simultáneamente.
4 - Multiprocesamiento: En este caso se disponen varias unidades de procesamiento, en forma tal que operan simultáneamente sobre varios programas.
También, desde el punto de vista de la arquitectura, se han tenido niveles de sofisticación crecientes, que podemos sintetizar en:
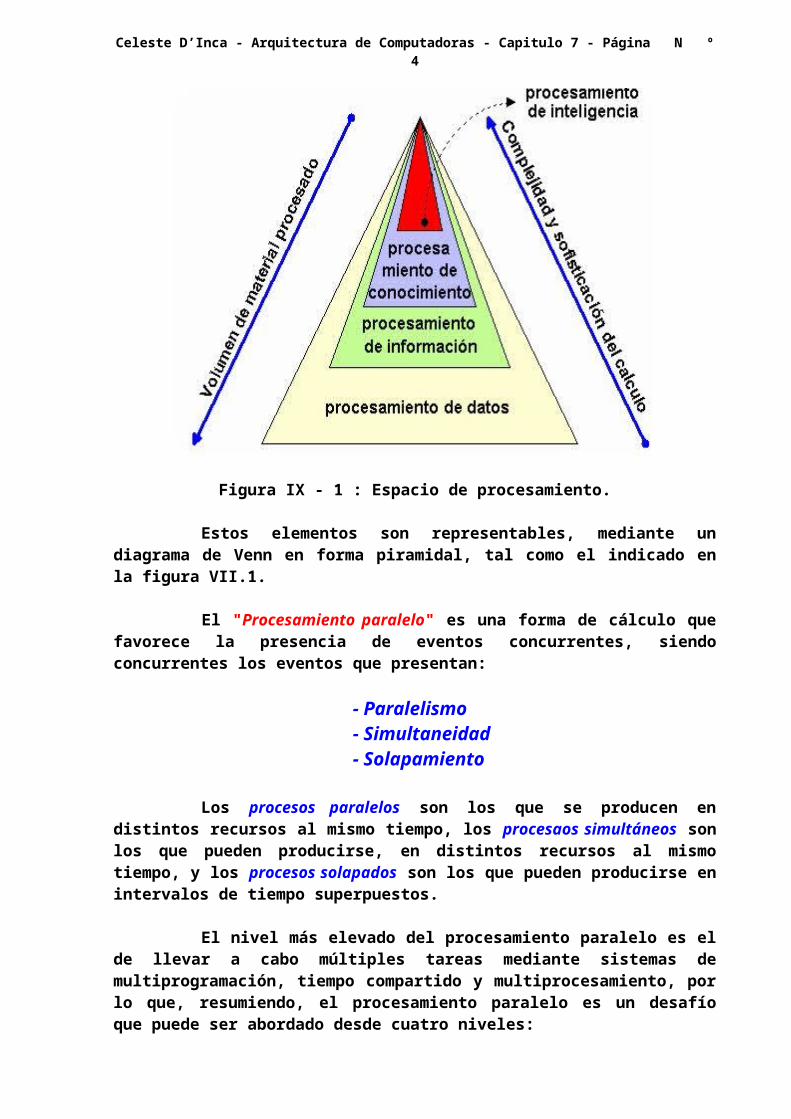
1 - Procesamiento de datos: es el tipo de procesamiento que mayormente se emplea aún actualmente, pues consiste en operar sobre datos alfanuméricos no relacionados
2 - Procesamiento de información: La información consiste en un cúmulo de datos, que están de alguna manera ligados mediante una estructura sintáctica o una relación espacial cualquiera.
3 - Procesamiento de conocimientos: El conocimiento, es una forma de información más algún significado semántico, o sea que forman un sub-espacio de la información.
4 - Procesamiento de inteligencia: La inteligencia, es derivada de una colección de ítems de conocimiento.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 3
Figura IX - 1 : Espacio de procesamiento.
Estos elementos son representables, mediante un diagrama de Venn en forma piramidal, tal como el indicado en la figura VII.1.
El "Procesamiento paralelo" es una forma de cálculo que favorece la presencia de eventos concurrentes, siendo concurrentes los eventos que presentan:
- Paralelismo- Simultaneidad- Solapamiento
Los procesos paralelos son los que se producen en distintos recursos al mismo tiempo, los procesaos simultáneos son los que pueden producirse, en distintos recursos al mismo tiempo, y los procesos solapados son los que pueden producirse en intervalos de tiempo superpuestos.
El nivel más elevado del procesamiento paralelo es el de llevar a cabo múltiples tareas mediante sistemas de multiprogramación, tiempo compartido y multiprocesamiento, por lo que, resumiendo, el procesamiento paralelo es un desafío que puede ser abordado desde cuatro niveles:
- de programación (Algoritmos)- de procedimientos (Interacción hard-soft)- de interisntrucciones (Interacción soft-hard)- de intrainstrucciones (Hardware)
O sea que la tarea primordial, es la de implementar algoritmos que permitan realizar tareas en paralelo, continuando con los procedimientos y los sistemas
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 4
operativos para tal objetivo, y terminando con la construcción de sistemas con organizaciones que permitan la realización de tareas simultáneas.
Lo dicho sugiere que el procesamiento paralelo es un campo de estudios combinado, en el cual debe hacerse un perfecto balance entre hardware y software.
Otro tipo de procesamiento muy relacionado con el procesamiento paralelo, es el procesamiento distribuido, en el cual se utilizan diversas máquinas, interconectadas de alguna manera, para la realización de una gran tarea.
VII.1 - PARALELISMO ES SISTEMAS MONOPROCESADORES:
Un monoprocesador, es un procesador tal como los que vimos hasta ahora, se trata de una unidad lógica y aritmética, una unidad de entrada y salida, una unidad de memoria y una unidad de control, de las cuales hemos citado múltiples ejemplos, que por lo tanto no repetiremos aquí.
VII.1.1 - MECANISMOS DE PROCESAMIENTO PARALELO:
Según vimos, se han desarrollado una gran cantidad de mecanismos para la realización de algunas tareas en paralelo, los que pueden ser catalogados en seis categorías:
- Multiplicidad de unidades funcionales- Paralelismo y encauzamiento en la CPU- Solapamiento de las operaciones de E/S y de la CPU.- Uso de sistemas jerárquicos de memoria- Balanceo de los anchos de banda de los subsistemas- Multiprogramación y tiempo compartido
Lo cual pasaremos a describir someramente en lo que sigue.
VII.1.1.1 - MULTIPLICIDAD DE UNIDADES FUNCIONALES:
Ya en varias oportunidades hemos citado los dos procesadores estándar más modernos, el Pentium y el Power PC, y en ellos hemos podido ver que emplean varias unidades funcionales. En el caso del Pentium, ver figura VIII.21, tenemos dos unidades de cálculo para enteros, y una para números en coma flotante. En el caso del Power PC 620, ver figura VIII.20, tenemos tres Unidades Lógicas y Aritméticas para enteros y una para coma flotante.
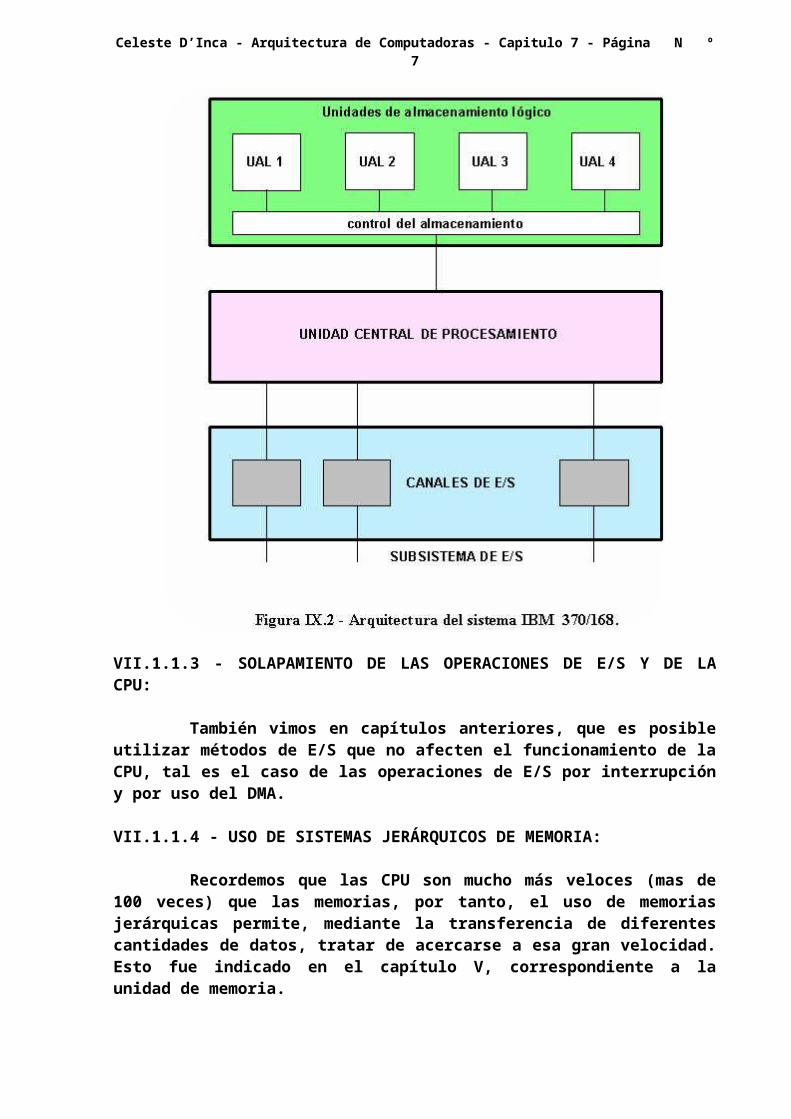
Existen otros ejemplos que hacen uso de múltiples módulos de E/S, como la IBM 370/168, cuya estructura simplificada se indica en la figura VII.2.
VII.1.1.2 - PARALELISMO Y ENCAUZAMIENTO EN LA CPU:
Prácticamente todas las ALU actuales poseen algún tipo de sumador paralelo con anticipo del arrastre, además de realizar varias operaciones en paralelo, por tener varias unidades de cálculo, tal como en el Pentium y en el Power PC.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 5
Por otra parte, también se utilizan sistemas encauzados, no solo para las instrucciones, sino también en la ALU, tal como veremos más adelante.
VII.1.1.3 - SOLAPAMIENTO DE LAS OPERACIONES DE E/S Y DE LA CPU:
También vimos en capítulos anteriores, que es posible utilizar métodos de E/S que no afecten el funcionamiento de la CPU, tal es el caso de las operaciones de E/S por interrupción y por uso del DMA.
VII.1.1.4 - USO DE SISTEMAS JERÁRQUICOS DE MEMORIA:
Recordemos que las CPU son mucho más veloces (mas de 100 veces) que las memorias, por tanto, el uso de memorias jerárquicas permite, mediante la transferencia de diferentes cantidades de datos, tratar de acercarse a esa gran velocidad. Esto fue indicado en el capítulo V, correspondiente a la unidad de memoria.

Bm= Wtm
Bp Otp
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 6
VII.1.1.5 – BALANCE O EQUILIBRADO DE LOS ANCHOS DE BANDA:
En general, es conocido como ancho de banda a la cantidad de información que es posible transferir u operar en una unidad de tiempo. En nuestro caso serán bits, Bytes, o palabras por segundo.
Así es posible decir que:
B Wt
Donde: B es el ancho de banda W es la cantidad de información (palabras / bits / bytes)
t es la unidad de tiempo considerada (segundos)
Cuando hablamos de la memoria, el ancho de banda es la cantidad de Bytes o de bits que puede transferir en cada ciclo de memoria, así escribiremos:
(palabras/segundo)
Donde: Bm = ancho de banda de la memoria (palabras/segundo)W = cantidad de palabrastm = tiempo de un ciclo de memoria
Y si estamos considerando la CPU, diremos:
(Operaciones/segundo)
Donde: Bp = ancho de banda del procesadorO = cantidad de operacionestp = tiempo total para realizar la operación.
En realidad, la velocidad de cálculo de la CPU, se mide en:
- MEGAFLOPS (Mega Operaciones en coma flotante por segundo)- MIPS (Mega Instrucciones por segundo)
En general, podemos decir sobre los anchos de banda, que el mayor corresponde a la CPU, le sigue la memoria central (incluyendo cache, si la hay), y finalmente la memoria masiva, o externa), por lo que podemos escribir:
Bm Bp BdDonde el último término corresponde al ancho de banda de los dispositivos
externos de almacenamiento.
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 7
Es interesante considerar los efectos de las demoras existentes en las transferencias de datos, para lo cual definiremos el llamado ancho de banda útil, que siempre es menor al calculado anteriormente.
Para el equilibrado de los anchos de banda entre la CPU y la memoria, se utiliza el sistema jerárquico, donde se cambia tiempo por cantidad, o dicho de otra manera, entre la memoria central y la caché se transfieren bloques de datos, y entre la caché y la CPU se transfieren unidades de datos (palabras).
Para el equilibrado de los anchos de banda entre la memoria y los dispositivos de almacenamiento masivo, es posible utilizar una mayor cantidad de éstos.
Resumiendo, tenemos lo indicado en la figura VII.3, donde se observa lo antedicho.
Figura VII.3 – Equilibrado de los anchos de banda.
VII.1.1.6 - MULTIPROGRAMACIÓN Y TIEMPO COMPARTIDO:
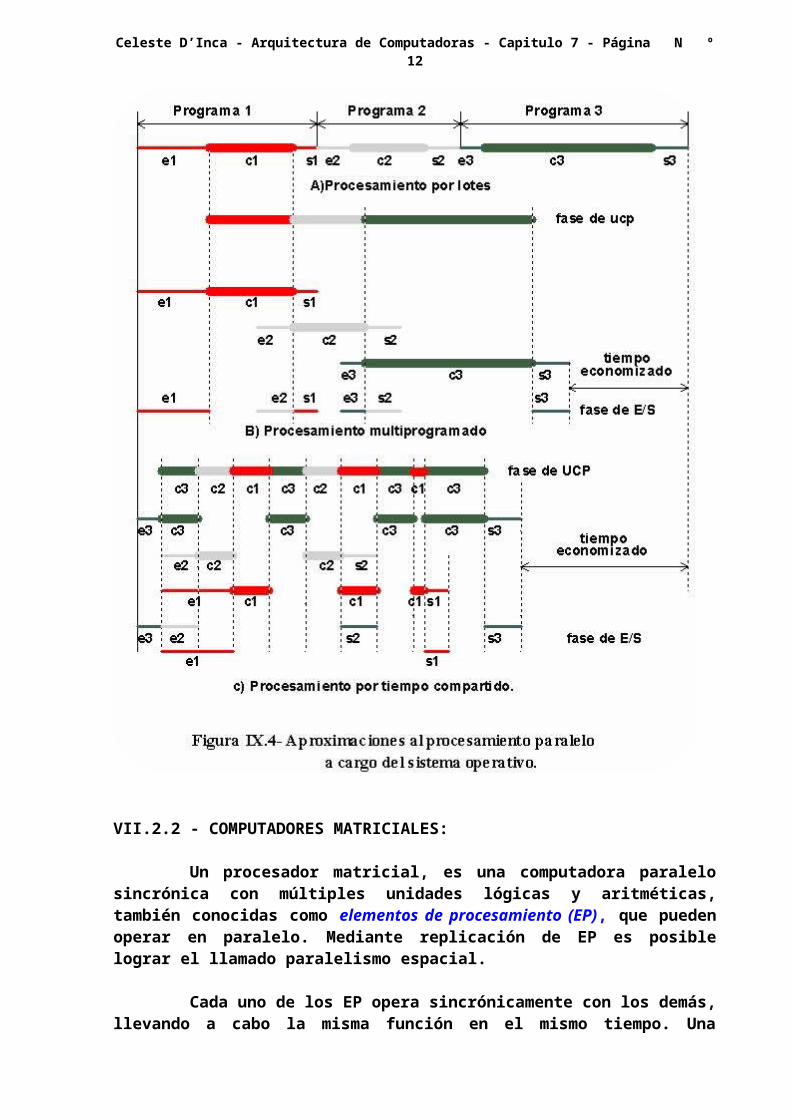
Estas son dos formas de procesamiento que permiten cierto paralelismo en la ejecución de programas en sistemas monoprocesadores. El procesamiento multiprogramado, permite la utilización de tiempos muertos en algunas de las unidades, por ejemplo, si hay dos programas cargados en memoria, y uno de ellos hace uso de la CPU, sin necesitar de la unidad de E/S, el segundo programa puede hacer uso de ésta, y esperar a que se desocupe la CPU, cuando ello ocurre, el primer programa puede dar sus salidas, mientras que el segundo es ejecutado.
En el tiempo compartido en cambio, el uso de las diferentes unidades es repartido entre los programas, en forma tal que cada uno de ellos hace uso de la CPU un cierto tiempo.
En la figura VII.4 se tiene un diagrama comparativo entre estas dos formas de operación, y la común, por lotes.
VII.2 - ESTRUCTURAS DE COMPUTADORAS PARALELO:
Los computadores paralelo son aquellos sistemas que enfatizan el procesamiento paralelo, y de acuerdo a los desarrollos realizados, podemos dividirlas en tres configuraciones arquitectónicas.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 8
- Computadores Encauzados: son los que llevan a cabo tareas solapadas, por lo que explota el paralelismo temporal.
- Procesadores Matriciales: son los que utilizan diversas ALU sincronizadas, por lo que usan un paralelismo espacial.
- Sistemas Multiprocesadores: es el que alcanza un paralelismo asincrónico, mediante un conjunto de procesadores interactivos, con recursos distribuidos.
Estos tres conceptos de paralelismo, no son excluyentes entre ellos, sino que casi todas las computadoras actuales tienen cauces, y además pueden tener estructuras matriciales o multiprocesadores. La diferencia fundamental entre ambos, el matricial o el multiprocesador, en que en el primero los elementos de proceso deben actuar sincrónicamente, mientras que en el segundo, pueden operar asincrónicamente.
También es posible introducir tres nuevos conceptos de la computación:
- Computadores de Flujo de Datos: operan en base a los datos, no a la secuencia de instrucciones.
- Procesadores algorítmicos VLSI: generan algoritmos mediante hardware.
- Procesadores multirruta: denominados “multithread” en inglés, los cuales operan en base a una cierta cantidad de procesadores conectados en cascada, y que su vez cada cascada está en paralelo con otra u otras.
VII.2.1 - COMPUTADORAS ENCAUZADAS:
Ya hemos visto en capítulos anteriores a los computadores que tienen cauces de instrucciones, aún varios en paralelo (superencauzadas y superescalares). Estos cauces son extensibles a la ULA, según veremos más adelante.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 9
VII.2.2 - COMPUTADORES MATRICIALES:
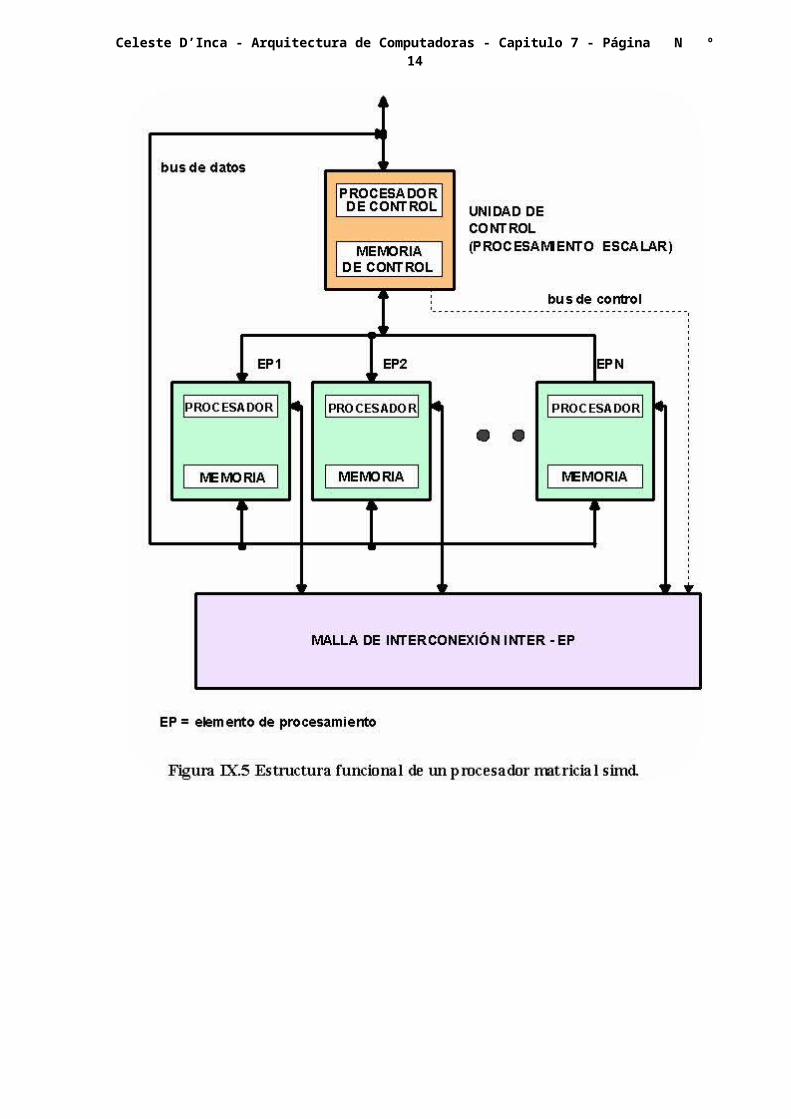
Un procesador matricial, es una computadora paralelo sincrónica con múltiples unidades lógicas y aritméticas, también conocidas como elementos de procesamiento (EP), que pueden operar en paralelo. Mediante replicación de EP es posible lograr el llamado paralelismo espacial.
Cada uno de los EP opera sincrónicamente con los demás, llevando a cabo la misma función en el mismo tiempo. Una estructura funcional típica de este tipo de computadores se indica en la figura VII.5.
La unidad de control se encarga de la elaboración de las instrucciones y del envío de las órdenes a todos los EP, para ello tiene un procesador de control CP y una

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 10
memoria de control CM. Los elementos de procesamiento a su vez, además del procesador poseen una memoria para los datos.
La malla de conexión inter-EP, es configurable por el control en forma tal de disponer espacialmente los EP a fin de resolver un dado problema, además se encarga del encaminamiento de los datos.
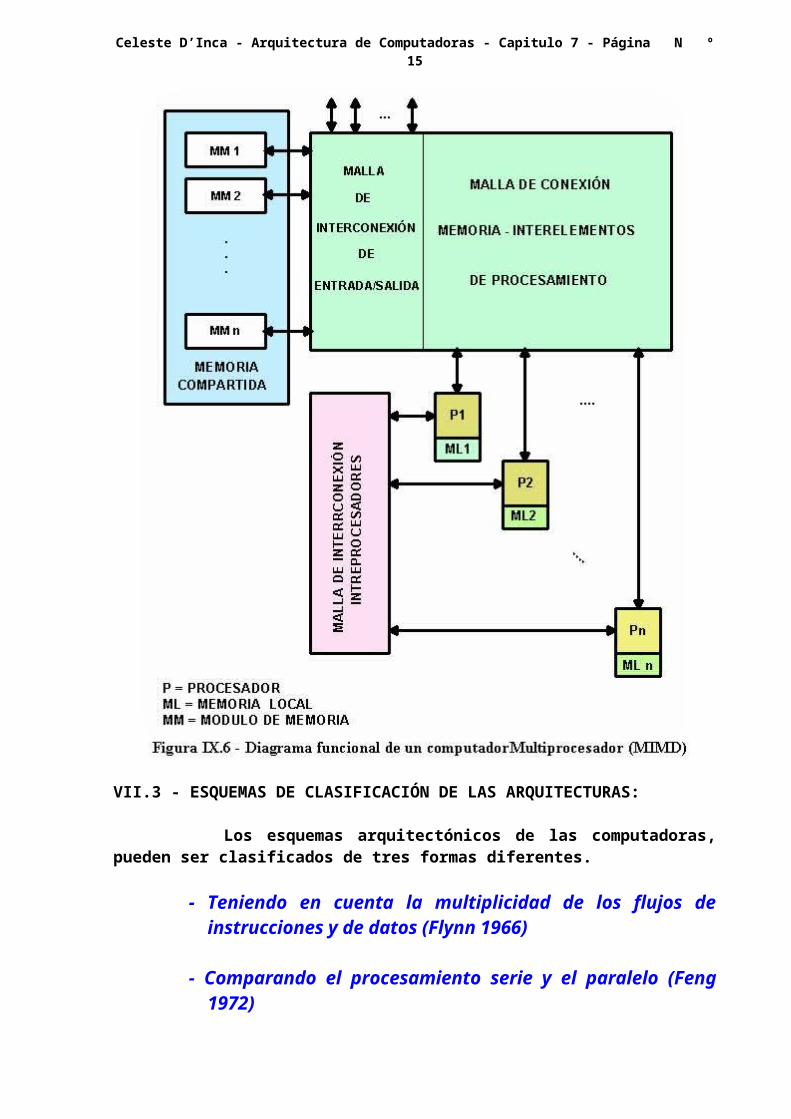
VII.2.3 - SISTEMAS MULTIPROCESADORES:
La organización básica de un multiprocesador es la indicada en la figura VII.6. El sistema contiene dos o más procesadores de capacidades semejantes.
Todos los procesadores comparten el acceso a varios módulos de memoria, varios canales de E/S, y dispositivos periféricos.
Lo más importante es que todo el conjunto puede ser controlado por un sistema operativo integrado, que provee interacción entre los procesadores y sus programas en varios niveles.
Cada procesador posee su propia memoria y puede tener sus dispositivos privados. La intercomunicación entre procesadores puede ser a través de las memorias compartidas o por medio de una malla conmutada.
La organización del hardware es determinada, primariamente, por la estructura de interconexión utilizada entre memorias y procesadores, de la cual se han utilizado al presente tres modelos:
- Bus común de tiempo compartido- Malla de conmutación tipo crossbar- Memorias multipuerto.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 11
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 12
VII.3 - ESQUEMAS DE CLASIFICACIÓN DE LAS ARQUITECTURAS:
Los esquemas arquitectónicos de las computadoras, pueden ser clasificados de tres formas diferentes.
- Teniendo en cuenta la multiplicidad de los flujos de instrucciones y de datos (Flynn 1966)
- Comparando el procesamiento serie y el paralelo (Feng 1972)
- Considerando el grado de paralelismo y de encauzamiento (Händler 1977)

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 13
VII.3.1 - MULTIPLICIDAD DE FLUJOS DE INSTRUCCIONES Y DE DATOS:
Dentro de este sistema de clasificación, solo se tiene en cuenta la secuencia de instrucciones realizada por la máquina, y las corrientes de datos servidas por las instrucciones en cualquiera de los niveles.
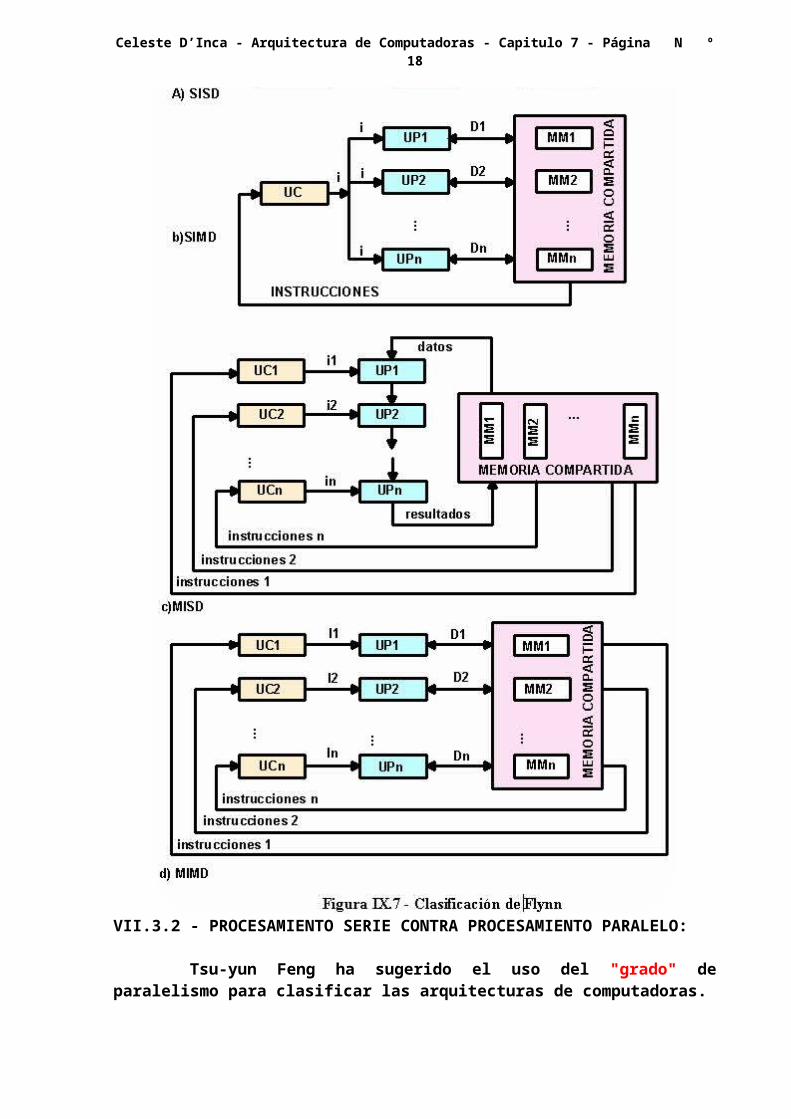
Esto permite determinar cuatro categorías:
- Simple flujo de instrucciones y simple corriente de datos (SISD)
- Simple flujo de instrucciones y multiples corrientes de datos (SIMD)
- Multiple Flujo de instrucciones y simnple corriente de datos (MISD)
- Multiple flujo de instrucciones y múltiple flujo de datos (MIMD)
En todos los casos las instrucciones son buscadas en los módulos de memoria, decodificadas por la unidad de control, la que remite una corriente de ordenes a las unidades de procesamiento para le ejecución.
Las corrientes de datos fluyen bidireccionalmente entre los módulos de memoria y los procesadores.
VII.3.1.1 - ORGANIZACIÓN SISD:
Esta que es la mostrada en la figura VII.7.a, representa todas las computadoras que operan actualmente en serie, aún cuando posean múltiples unidades funcionales en la CPU y utilicen canales tanto de instrucciones como de operaciones.
VII.3.1.2 - ORGANIZACIÓN SIMD:
Esta organización, mostrada en la figura VII.7.b, es la correspondiente a los sistemas matriciales, que consiste en una malla de procesadores controlados por una única unidad de control, por lo que todos ellos reciben las mismas órdenes, aunque operan sobre datos distintos. El subsistema de memoria compartida puede contener varios módulos.
VII.3.1.3 - ORGANIZACIÓN MISD:
El concepto es ilustrado en la figura VII.7.c, donde hay n procesadores, cada uno de ellos recibiendo diferente instrucciones para operar sobre los mismos datos. Esta organización no ha sido estudiada, y aun más algunos arquitectos de computadoras la consideran impracticable.
VII.3.1.4 - ORGANIZACIÓN MIMD:
La mayoría de los sistemas multiprocesadores, y aún varios sistemas de múltiples computadoras, pueden ser clasificados en éste grupo, el cual se ilustra en la figura VII.7.b.
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 14
En este caso, n corrientes de datos son derivadas a m procesadores, cada uno de los cuales recibiendo una de las múltiples corriente de instrucciones. Por tanto cada procesador ejecuta un programa distinto sobre un conjunto de datos diferentes.
Pi P 1
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 15
VII.3.2 - PROCESAMIENTO SERIE CONTRA PROCESAMIENTO PARALELO:
Tsu-yun Feng ha sugerido el uso del "grado" de paralelismo para clasificar las arquitecturas de computadoras.
El máximo número de dígitos binarios (bits) que pueden ser procesados en una unidad de tiempo, por un sistema de computación, es denominado "máximo grado de paralelismo" y es identificado con P. La unidad de tiempo considerada debe ser el intervalo de reloj, o el intervalo del ciclo de reloj.
Si consideramos T ciclos del procesador, y en cada uno de ellos la cantidad de bits operados en paralelo, el grado promedio de paralelismo es:
En general, es:
Por lo que podemos llamar relación de utilización, o factor de utilización de un sistema de computación, dentro de T ciclos, a la relación:
Si la capacidad de un procesador es utilizada a pleno, o sea que es explotado plenamente el paralelismo, tendremos que: para cualquier i, y entonces,
lo que significa en porcentaje el 100%.
Podemos intuir que la relación de utilización depende del programa que está siendo ejecutado.
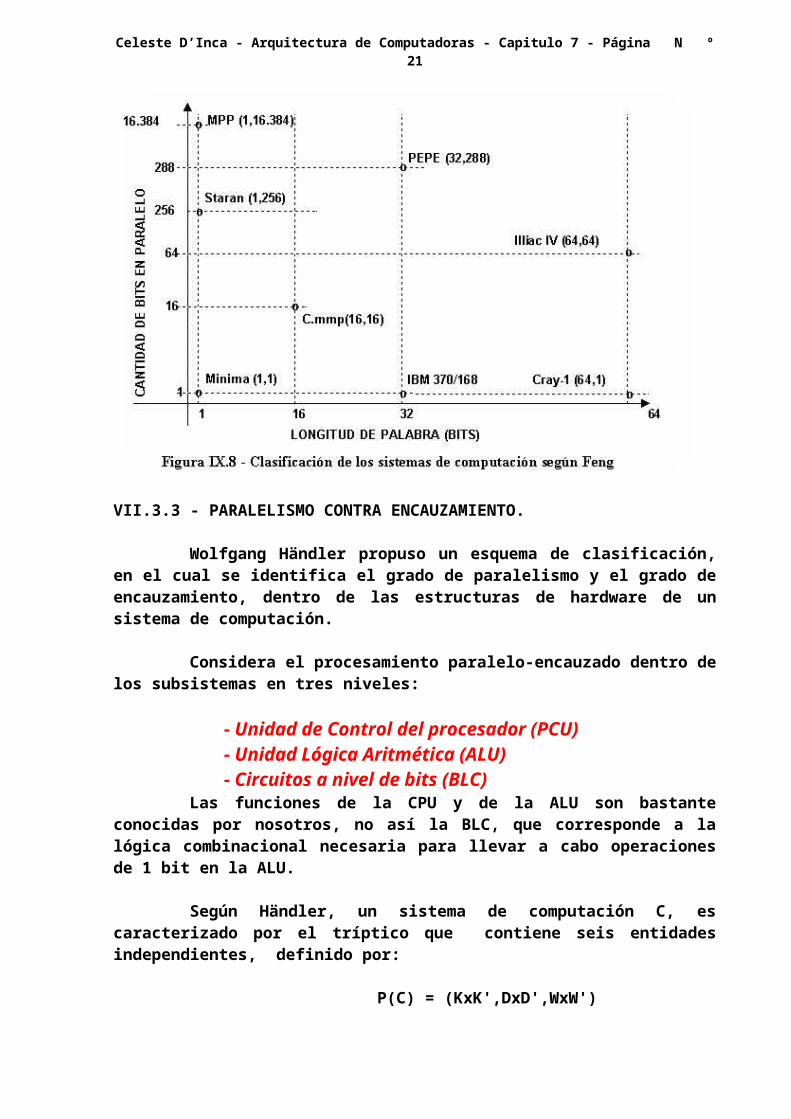
El máximo grado de paralelismo es representado por el producto de la longitud de palabra por la cantidad de bits operados en paralelo. [ P(n,m)]
Esta cantidad de bits operados en paralelo, tiene en cuenta el efecto de los canales, si una unidad tiene cuatro canales y cada uno de ellos puede operar ocho bits a la vez, la cantidad de bits operados en paralelo es de 4x8 = 32 bits. Si además esa máquina tiene palabras de 64 bits de longitud, decimos que su grado de paralelismo es: P (64,32).
En la figura VII.8 se indica la clasificación de Feng para varias máquinas, del gráfico se desprende que hay cuatro tipos de métodos de procesamiento:
- Palabra Serie y Bit Serie (PSBS)- Palabra Paralelo y Bit Serie (PPBS)

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 16
- Palabra Serie y Bit Paralelo (PSBP)- Palabra Paralelo y Bit Paralelo (PPBP)
La primera también es conocida como procesamiento bit serie, por cuanto se opera el bit de una palabra por vez, respondiendo a un sistema mínimo (n=m=1).
Las computadoras PPBS, han sido denominadas procesamiento por tajada de bit (Bit Slice), y en ellas es n = 1, m > 1.
Las PSBP, o sea n > 1,m = 1, son la mayoría de las existentes, y son denominadas de procesamiento de tajada de palabra (Word Slice), Finalmente las PPBP, son las de procesamiento totalmente paralelo, en las que tanto n como m son mayores que la unidad. (n > 1; m > 1)
VII.3.3 - PARALELISMO CONTRA ENCAUZAMIENTO.
Wolfgang Händler propuso un esquema de clasificación, en el cual se identifica el grado de paralelismo y el grado de encauzamiento, dentro de las estructuras de hardware de un sistema de computación.
Considera el procesamiento paralelo-encauzado dentro de los subsistemas en tres niveles:
- Unidad de Control del procesador (PCU)- Unidad Lógica Aritmética (ALU)- Circuitos a nivel de bits (BLC)
Las funciones de la CPU y de la ALU son bastante conocidas por nosotros, no así la BLC, que corresponde a la lógica combinacional necesaria para llevar a cabo operaciones de 1 bit en la ALU.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 17
Según Händler, un sistema de computación C, es caracterizado por el tríptico que contiene seis entidades independientes, definido por:
P(C) = (KxK',DxD',WxW')
Donde: K es la cantidad de procesadores de la computadora (PCU).K' es la cantidad de procesadores que pueden ser encauzados.D es la cantidad de ALU’s bajo control de una CPU.D' es la cantidad de ALU’s que pueden ser encauzadas.W es la longitud de palabra de una ALU .W' es el número de etapas de los cauces de todas las ALU’s.
Como ejemplo, consideremos la computadora TI-ASC (Texas Instruments - Advanced Scientific Computer), que tiene un controlador, que controla cuatro cauces aritméticos de ocho etapas, y cada uno con 64 bits de longitud de palabra. Esto nos entrega:
P(ASC) = (1x1,4x1,64x8) = (1,4,64x8)
Cuando tenemos una segunda entidad, la que lleva " ' ", o sea, K’, D’ y W’, y vale uno, el mismo no es escrito.
VII.4 - SISTEMAS ENCAUZADOS:
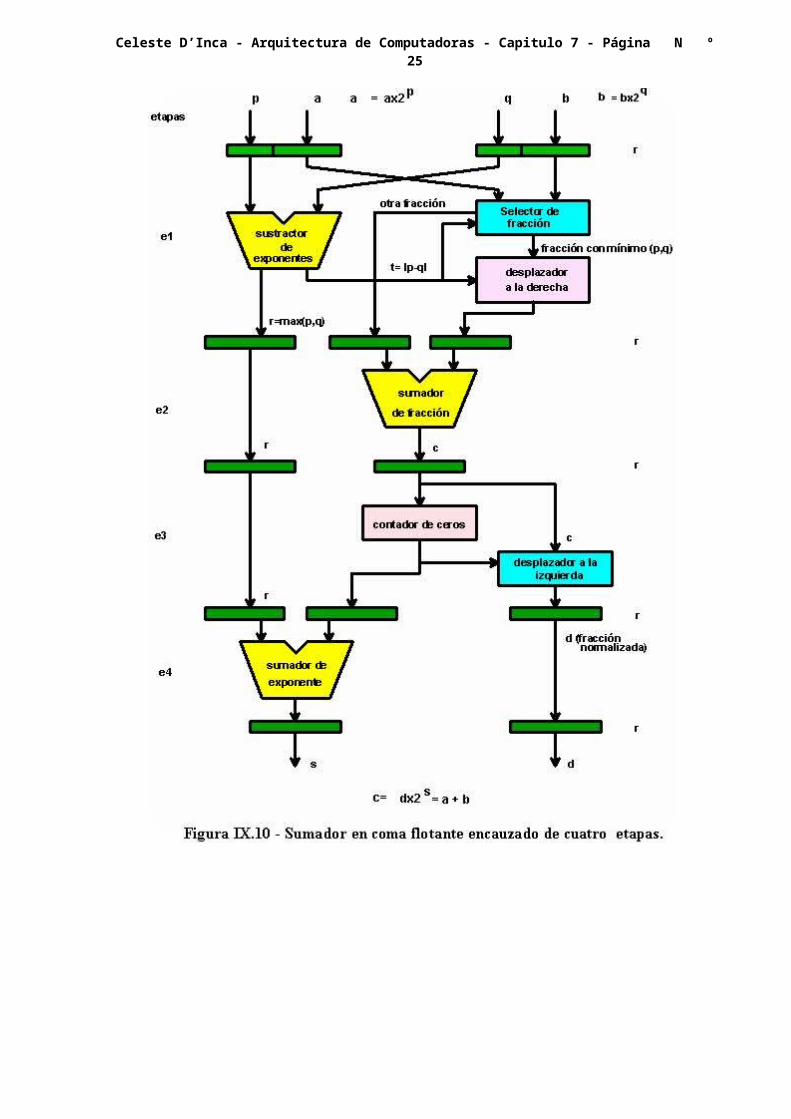
Ya vimos en el capítulo anterior los principios del encauzamiento, en especial para las instrucciones, ahora podemos ampliar el concepto a las unidades lógicas y aritméticas, en las cuales se utiliza para la realización de aquellas operaciones complejas, tales como suma y resta de cantidades en coma flotante y producto de cantidades binarias o binarias codificadas.
En la figura VII.9, se tiene la forma genérica de un cauce lineal. Como puede observarse, consta de un nivel de registros seguido de una etapa de cálculo, más otro nivel de registros, y así sucesivamente.
Como ejemplo, podemos implementar el sumador de dos cantidades expresadas en coma flotante, realizado según el diagrama de flujo mostrado en la figura IV.33, el que se tiene en la figura VII.10.
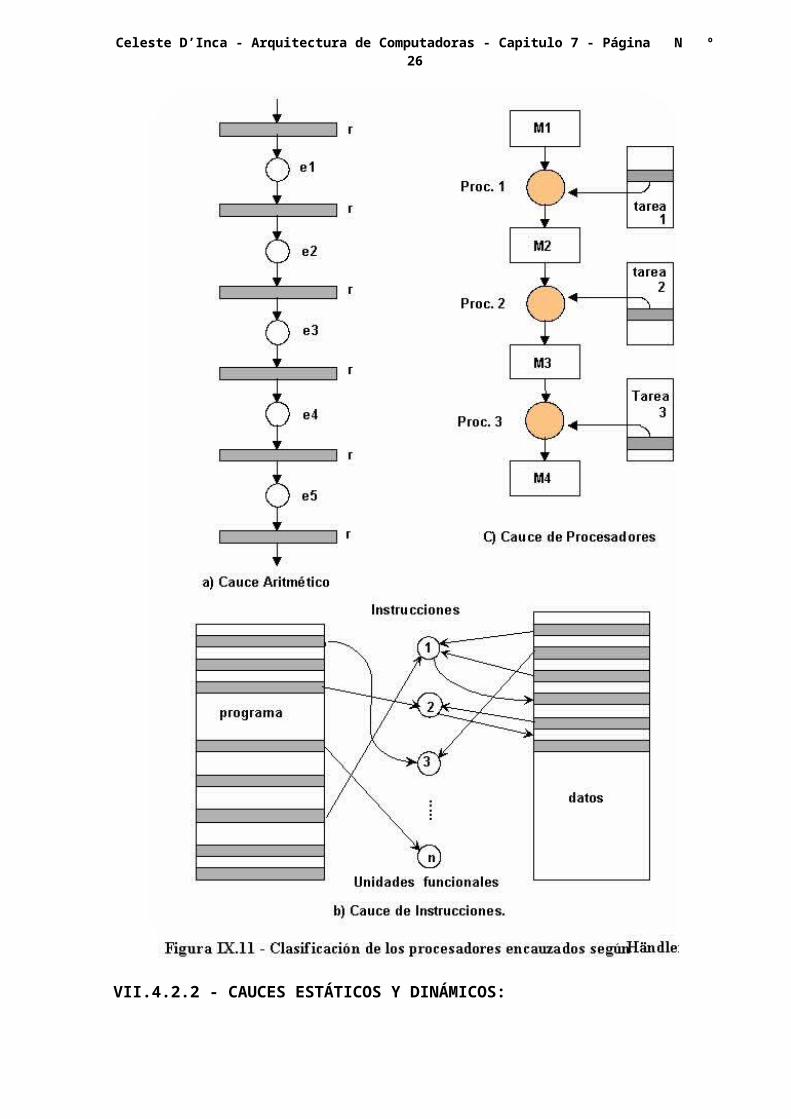
VII.4.1 - CLASIFICACIÓN DE LOS PROCESADORES ENCAUZADOS:
De acuerdo con los niveles de procesamiento, el ya citado Händler propuso un esquema de clasificación de los procesadores encauzados, en la forma que se ilustra en la figura VII.11.
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 18
VII.4.1.1 - CAUCES ARITMÉTICOS:
La unidad lógica y aritmética puede ser segmentada para realizar operaciones encauzadas con varios formatos de datos. En la figura VII.11.a, se tiene un cauce lineal del tipo correspondiente al de 8 etapas de la ASC, o al de hasta 14 etapas del Cray-1, y hasta 16 del Cyber-205.
VII.4.1.2 - CAUCES DE INSTRUCCIONES:
La ejecución de una corriente de instrucciones puede ser encauzada, solapando la ejecución de una con la búsqueda de la siguiente, etc., según lo expuesto en el capítulo anterior.
En la figura VII.11.b, se muestra como actúa el cauce, buscando primero una instrucción, luego un dato, o más, y devolviendo los resultados.
VII.4.1.3 - ENCAUZAMIENTO DE PROCESADORES:
Esto se refiere a un sistema multiprocesadores, en el cual cada uno de los procesadores conforma una etapa del cauce, tal como se indica en la figura VII.11.c.
El primer procesador recibe los datos de la memoria, realiza su operación y devuelve el resultado a un módulo de memoria, que es accesible por el segundo procesador, el cual realiza una operación semejante.
VII.4.2 - CLASIFICACIÓN SEGÚN RAMAMOORTHY Y LI:
Estos estudiosos de los sistemas encauzados, propusieron otro tipo de clasificación basado en la configuración del cauce y sus estrategias de control.
VII.4.2.1 - CAUCES UNIFUNCIÓN Y MULTIFUNCIÓN:
Un cauce que tiene una función fija y determinada, tal como un sumador de coma flotante, es denominado cauce unifuncional. La Cray-1 tiene 12 cauces unifuncionales, cada uno para una función diversa.
Un cauce multifunción, puede llevar a cabo diferentes funciones, al mismo tiempo o en tiempos diferentes, mediante la interconexión de diferentes subconjuntos de

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 19
etapas. El ASC tiene cuatro cauces multifuncionales, los que son reconfigurables para realizar una amplia variedad de funciones lógicas y aritméticas en distintos tiempos.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 20
VII.4.2.2 - CAUCES ESTÁTICOS Y DINÁMICOS:
Un cauce estático, solo puede asumir una configuración funcional por vez, además pueden ser unifuncionales o multifuncionales. El encauzamiento puede ser
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 21
realizado en estos cauces solamente cuando se ejecutan instrucciones del mismo tipo en forma continuada.
En un cauce dinámico, se permiten varias configuraciones funcionales simultáneas, en consecuencia el cauce debe ser obligadamente multifuncional. Al tiempo que un cauce estático es preferentemente unifuncional.
La configuración dinámica necesita disponer de un control, y mecanismos de secuenciamiento mucho más sofisticados que los de un cauce estático.
VII.4.2.3 - CAUCES ESCALARES Y VECTORIALES:
En forma dependiente de los tipos de instrucciones o de datos, los cauces de procesamiento pueden ser clasificados como escalares o como vectoriales.
Un cauce escalar, procesa una secuencia de operandos escalares, bajo el control de un bucle DO.
Un cauce vectorial, es aquel diseñado especialmente para operar con instrucciones vectoriales sobre operandos vectoriales.
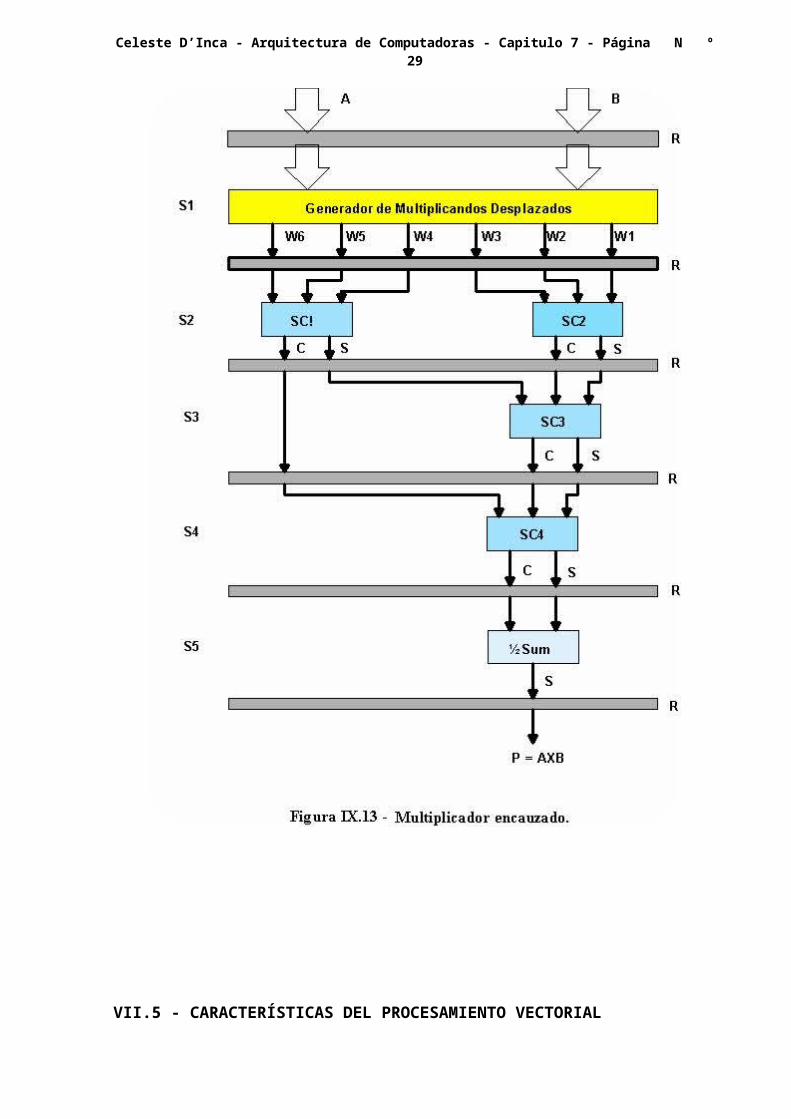
VII.4.3 - EJEMPLO DE CAUCE ARITMÉTICO:
Según vimos en los capítulos II y IV, la multiplicación de dos cantidades binarias en coma fija, es realizada por la ALU mediante operaciones reiteradas de suma y desplazamiento, siendo su cantidad acorde con la cantidad de dígitos de los operandos. Esto hace que la operación sea muy lenta.
Examinando la forma de realizar la operación en forma manual, vemos que el proceso es equivalente a la adición de pares múltiples de multiplicandos desplazados, lo que se observa en la figura VII.12.
La suma de varios números, puede ser llevada a cabo por un árbol de suma multinivel. El sumador propagador del arrastre, es de tipo convencional, que suma dos cifras binarias y da una salida. Mientras que el sumador salvador del arrastre es el que suma tres entradas, dando dos salidas, la correspondiente a la suma y la del arrastre que eventualmente puede producirse.
a5 a4 a3 a2 a1 a0 =Ax b5 b4 b3 b2 b1 b0 =B
a5b0 a4b0 a3b0 a2b0 a1b0 a0bo =W1
a5b1 a4b1 a3b1 a2b1 a1b1 a0b1 =W2
a5b2 a4b2 a3b2 a2b2 a1b2 a0b2 =W3
a5b3 a4b3 a3b3 a2b3 a1b3 a0b3 =W4
a5b4 a4b4 a3b a2b4 a1b4 a0b4 =W5
+ a5b5 a4b5 a3b5 a2b5 a1b5 a0b5 =W6
P11 P10 P9 P8 P7 P6 P5 P4 P3 P2 P1 P0 =AXB =P
Figura VII.12 - Ejemplo de multiplicación de dos cantidades binarias

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 22
El circuito resultante para el cauce de cinco etapas resultante, es el indicado en la figura VII.13, donde se aplican los dos tipos de sumadores, y un generador de multiplicandos desplazados.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 23
VII.5 - CARACTERÍSTICAS DEL PROCESAMIENTO VECTORIAL
Un operando vectorial contiene un conjunto ordenado de de n elementos, donde n es la longitud del vector. Cada elemento del vector es una cantidad escalar, que puede ser un número en coma flotante, un entero, un valor lógico, o un caracter.
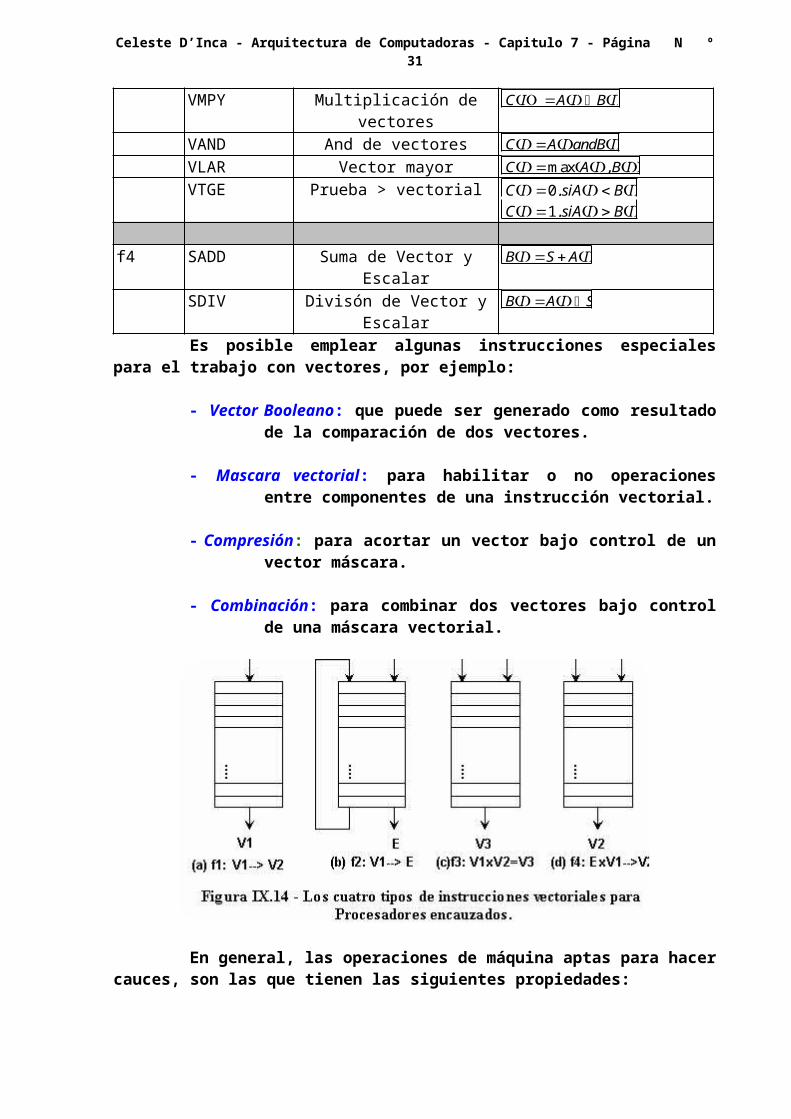
Las instrucciones vectoriales pueden clasificarse en cuatro tipos principales:
f1 : V V
f2 : V E
f3 : V V V
f4 : V E V
Donde los términos V y E denotan respectivamente, Vector y Escalar.
Además, f1 y f2 denotan operaciones unitarias, o sea sobre un solo elemento, mientras que las restantes son binarias. Las cuatro pueden realizarse en un procesador encauzado, de acuerdo a lo indicado en la figura VII.14, mientras que en la tabla siguiente se se detallan algunas operaciones vectoriales representativas.Tipo Nemotecnica Descripción Expresiónf1 VSQR Raíz Cuadrada Vectorial B(I) A(I)
VSIN Vector Seno B(I) sinA(I)VCOM Complemento Vectorial A(I) A(I)
f2 VSUM Sumatoria VectorialS
I1
n
A(I)
VMAX Vector Máximo S max I1;n AI
f3 VADD Suma de vectores CI AIBIVMPY Multiplicación de vectores CI AI BIVAND And de vectores CI AIandBIVLAR Vector mayor CI maxAI,BIVTGE Prueba > vectorial CI 0, siAI BI
CI 1, siAI BI
f4 SADD Suma de Vector y Escalar BI S AISDIV Divisón de Vector y Escalar BI AI SEs posible emplear algunas instrucciones especiales para el trabajo con
vectores, por ejemplo:
- Vector Booleano: que puede ser generado como resultado de la comparación de dos vectores.
- Mascara vectorial: para habilitar o no operaciones entre componentes de una instrucción vectorial.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 24
- Compresión: para acortar un vector bajo control de un vector máscara.
- Combinación: para combinar dos vectores bajo control de una máscara vectorial.
En general, las operaciones de máquina aptas para hacer cauces, son las que tienen las siguientes propiedades:
- Procesos o funciones idénticas son invocados repetidamente y además reiteradamente, cada una de las cuales puede ser descompuesta en una serie de sub-procesos, o sub-funciones.
- Los operandos son sucesivamente alimentados a segmentos de cauce,
requiriendo tan pocos buffers y controles locales como sea posible.
- Las operaciones ejecutadas por cauces diferentes deben ser capaces de compartir recursos caros, tales como memorias y buses del sistema.
Estas características explican porque la mayoría de los procesadores vectoriales tienen estructuras encauzadas. Las instrucciones vectoriales necesitan de la realización reiterada de la misma operación sobre diferentes conjuntos de datos.
Lo dicho no es cierto para el procesamiento escalar, que generalmente opera sobre un par de datos únicamente.
Las instrucciones vectoriales son especificadas usualmente por los siguientes campos:
1 - El código de operación debe contener especificaciones para que permita la selección de la unidad funcional o para que configure una unidad multifuncional, a fin de que conforme la operación especificada.
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 25
Normalmente se utilizan microordenes de control para disponer los recursos necesarios.
2 - Para instrucciones con referencia a memoria, la dirección base es necesaria tanto para los opeandos fuente como para los vectores resultado. Si los operandos y los resultados son colocados en un archivo de registros vectoriales, se deben especificar dichos registros.
3 - El incremento de la dirección entre los elementos también debe ser especificado.
4 - El desplazamiento relativo de las direcciones con referencia a la dirección base, también debe ser especificado.
5 - La longitud del vector también debe ser indicada en la instrucción, para determinar la finalización del proceso.
Es posible clasificar las computadoras vectoriales encauzadas en dos configuraciones arquitectónicas, según donde son buscados los operandos.
l - Arquitectura memoria a memoria, en la cual tanto los operandos como los resultados son dispuestos en la memoria central.
2 - Arquitectura registro a registro, en la cual los operandos y los resultados son buscados indirectamente en la memoria central mediante la utilización de una gran cantidad de registros vectoriales o escalares.
Para finalizar, en la figura VII.15, tenemos la arquitectura típica de un procesador vectorial con múltiples cauces funcionales.
VII.5 - PROCESADORES MATRICIALES SIMD:
Una matriz sincrónica de procesadores paralelo conforman un procesador matricial. Este computador consiste en un conjunto de elementos de procesamiento (EP), bajo supervisión de una unidad de control (UC), y puede manejar un flujo secuencial único de instrucciones y múltiples datos flujos de datos, de alli la denominación SIMD (Single Instruction Multiple Data), construidos con el objeto de efectuar cálculos vectoriales sobre matrices (o conjuntos ordenados) de datos.
Las computadoras SIMD aparecen en dos formas arquitectónicas, procesadores matriciales o procesadores asociativos, según como utilicen la memoria. En el primer caso, utilizan una memoria común de acceso aleatorio, en el segundo, utilizan memoria asociativa, o direccionable por el contenido.
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 26
VII.5.1 - ORGANIZACIÓN DE LAS COMPUTADORAS SIMD:
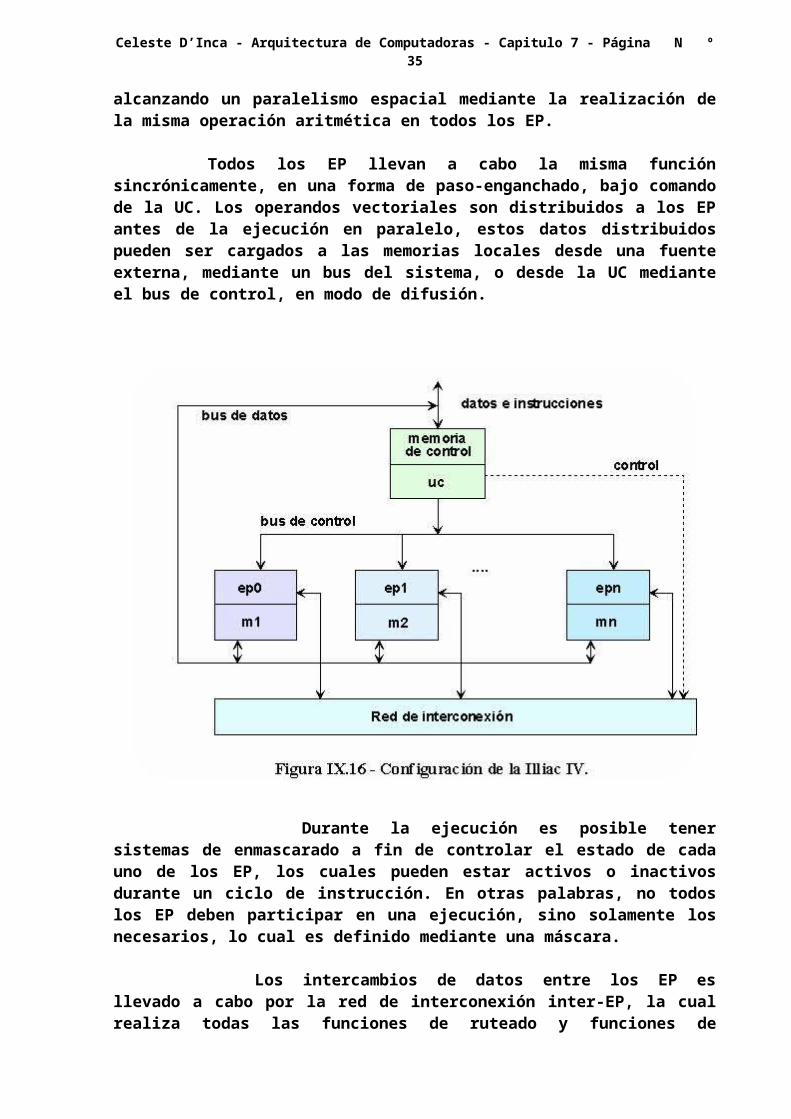
Los computadores matriciales pueden asumir dos configuraciones levemente diferentes, la que se ilustra en la figura VII.16, y corresponde a la Illiac IV (Illinois Automatic Computer, modelo 4), que ha sido estructurada con 64 elementos de procesamiento, todos bajo el control de una única unidad de control.
Esencialmente cada EP es una unidad lógica y aritmética, con varios registros de trabajo y el agregado de una memoria local MEP, para el almacenamiento de datos distribuidos. La UC también posee una memoria para almacenar programas.
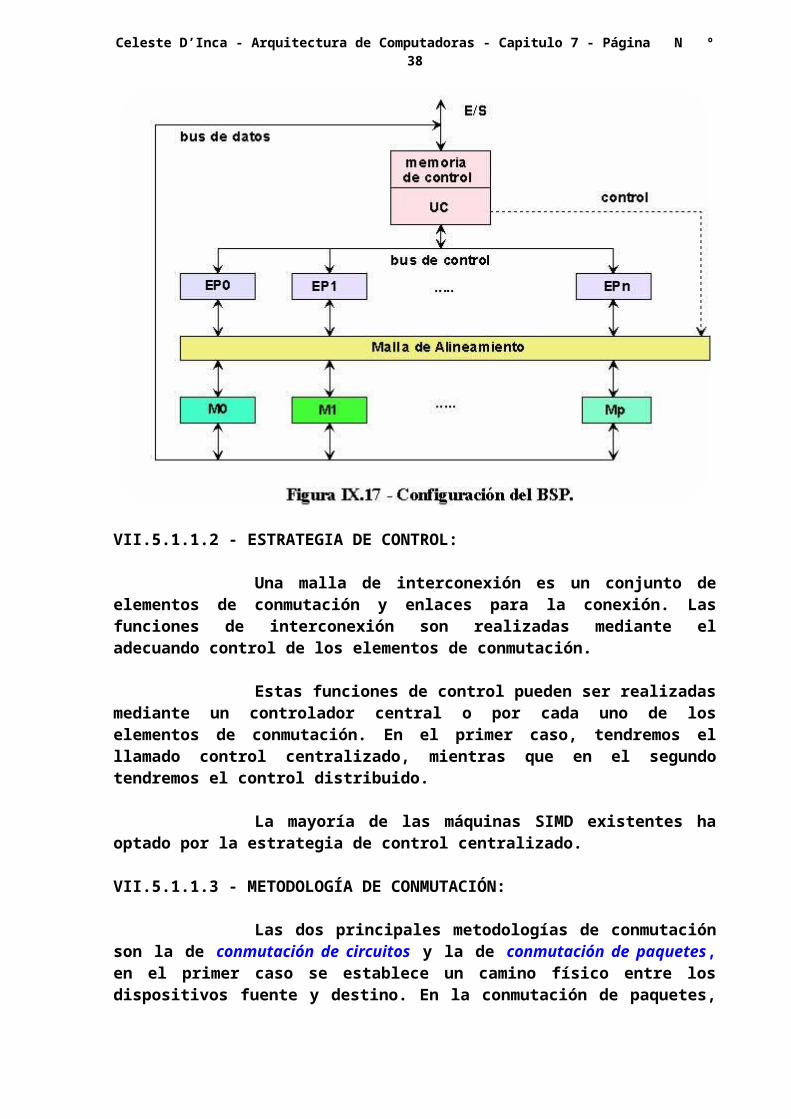
El sistema operativo y los programas de usuario se cargan en la memoria de la UC, cuya función es la decodificar las instrucciones y determinar donde deberá ser ejecutada. Las instrucciones escalares o de control son directamente ejecutadas dentro de la UC, mientras que las vectoriales son difundidas a todos los EP para su ejecución distribuida, alcanzando un paralelismo espacial mediante la realización de la misma operación aritmética en todos los EP.
Todos los EP llevan a cabo la misma función sincrónicamente, en una forma de paso-enganchado, bajo comando de la UC. Los operandos vectoriales son distribuidos a los EP antes de la ejecución en paralelo, estos datos distribuidos pueden ser cargados a las memorias locales desde una fuente externa, mediante un bus del sistema, o desde la UC mediante el bus de control, en modo de difusión.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 27
Durante la ejecución es posible tener sistemas de enmascarado a fin de controlar el estado de cada uno de los EP, los cuales pueden estar activos o inactivos durante un ciclo de instrucción. En otras palabras, no todos los EP deben participar en una ejecución, sino solamente los necesarios, lo cual es definido mediante una máscara.
Los intercambios de datos entre los EP es llevado a cabo por la red de interconexión inter-EP, la cual realiza todas las funciones de ruteado y funciones de manipulación de datos, para lo cual está bajo control de la UC.
Un procesador matricial normalmente está conectado a una máquina huésped, a través de la UC. Esta computadora huésped normalmente es de propósitos generales, y tiene la función del "gerenciamiento de operaciones" de todo el sistema, consistente de ella y el procesador matricial.
Las funciones de éste computador huésped, incluyen el manejo de recursos y la supervisión de los periféricos y los sistemas de E/S, por lo que a la UC del procesador matricial le queda la supervisión de la ejecución de los programas, por lo que puede ser considerado como un computador adjunto, o coprocesador.
La segunda configuración posible, es la indicada en la figura VII.17, donde vemos que difiere de la anterior en dos aspectos:

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 28
1 - Las memorias locales adjuntas a los EP, ahora son reemplazados por módulos de memoria compartidos por todos ellos, mediante una malla de alineamiento.
2 - La malla de conmutación inter-EP es reemplazada por la malla de alineamiento entre módulos de memoria, la que es controlada siempre por la UC.
Un buen ejemplo de esta configuración es el BSP (Burroughs Scientific Processor), que posee 16 elementos de procesamiento.
Formalmente, un computador SIMD es caracterizado por el siguiente conjunto de parámetros:
C = < N,F,I,M >
Donde: N = cantidad de EP del sistema.
F = Conjunto de funciones de interconexión realizadas por la malla de interconexión o
por la malla de alineamiento.I = Conjunto de instrucciones de la máquina para operaciones escalares,
vectoriales, encaminado de datos y de manipulación de la malla.M = Conjunto de esquemas de enmascarado.
VII.5.1.1 - COMUNICACIONES INTER-EP:
A continuación, veremos cuales son las decisiones a tomar para el diseño de mallas de conexión inter-EP, enlas cuales intervienen los modos de operación, las estrategias de control, las metodologías de conmutación y las topologías de las mallas.
VII.5.1.1.1 - MODO DE OPERACION:
Es posible identificar dos tipos de comunicaciones: la sincrónica y la asincrónica. La primera es necesaria para establecer caminos sincrónicos tanto para la manipulación de datos como para difusión de instrucciones.
La comunicación asincrónica es necesaria para el multiprocesamiento en el cual los requerimientos de interconexión son dinámicos. Es posible diseñar un sistema en el cual se tengan ambos tipos de funcionamiento.
Por otra parte, los modos típicos de operación de las mallas de interconexión, puede ser clasificados en tres categorías:
1 - Sincrónico2 - Asincrónico3 - Combinado
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 29
De cualquier manera, todas las máquinas SIMD existentes han elegido el sistema sincrónico, en el cual se fuerza la operación paso-enganchado en todos los EP.
VII.5.1.1.2 - ESTRATEGIA DE CONTROL:
Una malla de interconexión es un conjunto de elementos de conmutación y enlaces para la conexión. Las funciones de interconexión son realizadas mediante el adecuando control de los elementos de conmutación.
Estas funciones de control pueden ser realizadas mediante un controlador central o por cada uno de los elementos de conmutación. En el primer caso, tendremos el llamado control centralizado, mientras que en el segundo tendremos el control distribuido.
La mayoría de las máquinas SIMD existentes ha optado por la estrategia de control centralizado.
VII.5.1.1.3 - METODOLOGÍA DE CONMUTACIÓN:
Las dos principales metodologías de conmutación son la de conmutación de circuitos y la de conmutación de paquetes, en el primer caso se establece un camino físico entre los dispositivos fuente y destino. En la conmutación de paquetes, los datos son contenidos en un paquete, y encaminados en la malla de interconexión sin formar un camino físico.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 30
Generalmente, la conmutación de circuitos es mucho más práctica para la transmisión de grandes cantidades de datos, mientras que la conmutación de paquetes es mucho más eficiente para mensajes relativamente cortos.
Una tercera opción, sería la de integrar las cualidades de cado uno de los dos métodos anteriores, por lo que podríamos tener una tercera categoría, la de la conmutación integrada.
La mayoría de las implementaciones de máquinas SIMD utilizan la conmutación de circuitos, mientras que la conmutación de paquetes se utiliza principalmente para transmisión de datos a gran distancia, y para las máquinas MIMD.
VII.5.1.1.4 - TOPOLOGÍA DE LA RED:
Una red puede ser imaginada como un grafo, en el cual los nodos representan puntos de conmutación, y las líneas representan enlaces de comunicación.
Las topologías tienden a ser regulares, y pueden ser agrupadas en dos categorías:
1 - Estáticas2 - Dinámicas
Las estáticas, el enlace entre dos EP es pasivo y dedicado, y no puede ser reconfigurado para conectar otros EP. En cambio los enlaces dinámicos, pueden ser reconfigurados mediante elementos de conmutación activos.
El espacio de las mallas de interconexión es representable mediante cuatro conjuntos de características de diseño:
[modo de operación]x[estrategia de control]x[metodología de conmutación]x[topología de la red]
No todas las combinaciones son de interés, y la selección de una malla particular, depende de las demandas de la aplicación, los soportes tecnológicos, y el costo.
VII.5.1.2 - MALLAS DE INTERCONEXIÓN SIMD:
Estas mallas de interconexión, pueden ser:
1 - de una etapa2 - recirculantes3 - multietapa
Además, nos concentraremos en el primer modelo visto de comunicaciones inter-EP.
VII.5.1.2.1 - MALLAS ESTÁTICAS Y MALLAS DINÁMICAS.
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 31
Topológicamente hablando, la estructura de un procesador matricial SIMD está caracterizada por la malla de enrutamiento de datos utilizada para la interconexión de los EP.
Formalmente, tales redes de interconexión pueden ser caracterizadas por un conjunto de funciones de enrutamiento de datos. Si identificamos las direcciones de los EP por un conjunto:
S = {0,1,2,3,.....N-1}
Cada función de enrutamiento f es una biyección (conexión uno a uno) de S a S.
Cuando se ejecuta una función de enrutamiento f, por la malla de interconexión, el EP i copia el contenido de su registro Ri en el registro Rf(i) del EPf(i).
Esta operación de ruteo de datos, ocurre simultáneamente en todos los EP activos. Un EP inactivo puede recibir datos de otros EP si se ejecuta la función de enrutamiento, pero el no puede transmitir datos.
Para pasar datos entre EPs que no están directamente conectados a la malla, deben pasar por un EP intermediario, ejecutando una secuencia de funciones de enrutamiento en la malla de interconexión.
VII.5.1.2.1.1 - REDES ESTÁTICAS:
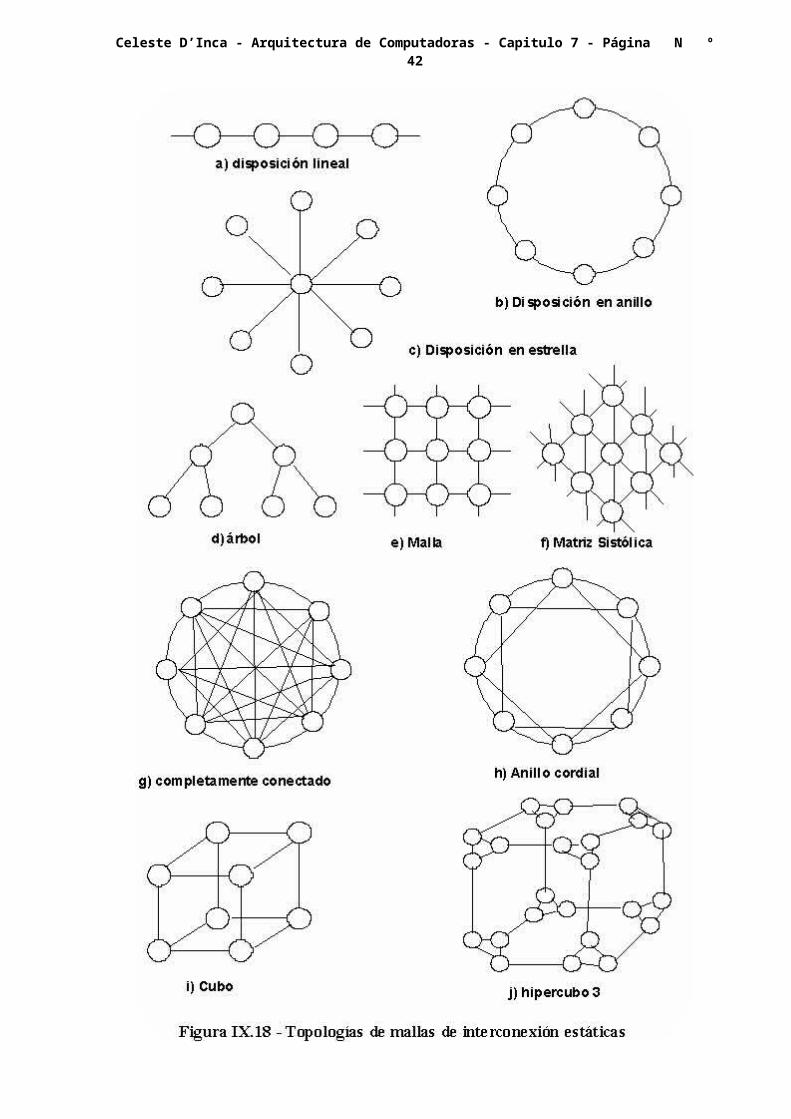
Las topologías de las mallas estáticas pueden ser clasificadas en acuerdo a las dimensiones requeridas para el trazado. En la figura VII.18, se tienen ilustradas las de una dimensión o unidimensionales, las de dos dimensiones o bidimensionales, las de tres dimensiones o tridimensionales y las hipercúbicas que son las de más de tres dimensiones.
Entre las unidimensionales tenemos a la disposición lineal, utilizada en algunos sistemas encauzados. Entre las de dos dimensiones, tenemos la disposición en anillo, en estrella, en árbol, en matriz y en matriz sistólica.
Las tridimensionales incluyen la de conexión completa, el anillo cordial, y la cúbica.
Las redes hipercúbicas, tienen una cierta cantidad de nodos de cada dimensión, así una forma de indicarlos es diciendo cuantos nodos hay en cada esquina de un cubo, tal como el cubo de ciclo triple, de la figura VII.18.j.
VII.5.1.2.1.2 - REDES DINÁMICAS:
Consideraremos dos clases de mallas dinámicas, las monoetapa y las multietapa, que describiremos separadamente.
VII.5.1.2.1.2.1 - REDES MONOETAPA:
Una red monoetapa es una malla de conmutación con N selectores de entrada (SE) y N selectores de salida (SS), tal como se muestra en la figura VII.19.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 32

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 33
Cada SE es esencialmente un demultiplexor de 1 a D, y cada SS es un multiplexor M a 1, donde 1 < D < N; y 1 < M < N. Para establecer diferentes caminos, se deberán dar diferentes datos de entrada a los selectores.
Este tipo de malla, también es conocido como recirculante, dado que los datos deben recircular a través de etapas de un solo nivel varias veces antes de alcanzar su terminal de destino. El número de recirculaciones necesarias depende de la conectividad de cada malla. En general, cuanto mayor es la conectividad del hardware, menor es el número de recirculaciones. La malla tipo crossbar es el caso límite, donde hay una sola circulación.
VII.5.1.2.1.2.2 - REDES MULTIETAPA:
Las redes multietapa están formadas por varias etapas conectadas mediante conmutadores. Estas son descriptas por tres elementos que las caracterizan:
1 - la caja de llaves2 - la topología de la red3 - la estructura de control
Cada caja de llaves, es un dispositivo de intercambio con dos entradas y dos salidas, tal como se indica en la figura VII.20, donde además se indican los cuatro estados que puede asumir dicha caja de conexiones:
1 - lineal2 - intercambio3 - difusión superior4 - difusión inferior

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 34
Cada una de las figuras correspondientes es suficientemente indicativa del significado de cada uno de los estados, al que podemos agregar el de no conexión.
Figura VII.20 – Cajas de llaves.Una malla multietapa es capaz de conectar un cantidad arbitraria
de terminales de entrada con una arbitraria cantidad de terminales de salida, además pueden ser unilaterales o bilaterales.
Las redes unilaterales, tienen sus puertos de E/S del mismo lado. Las bilaterales en cambio, tienen un lado de entrada y otro de salida y además pueden ser divididas en tres clases:
1 - de bloqueo2 - reconfigurable3 - de no bloqueo
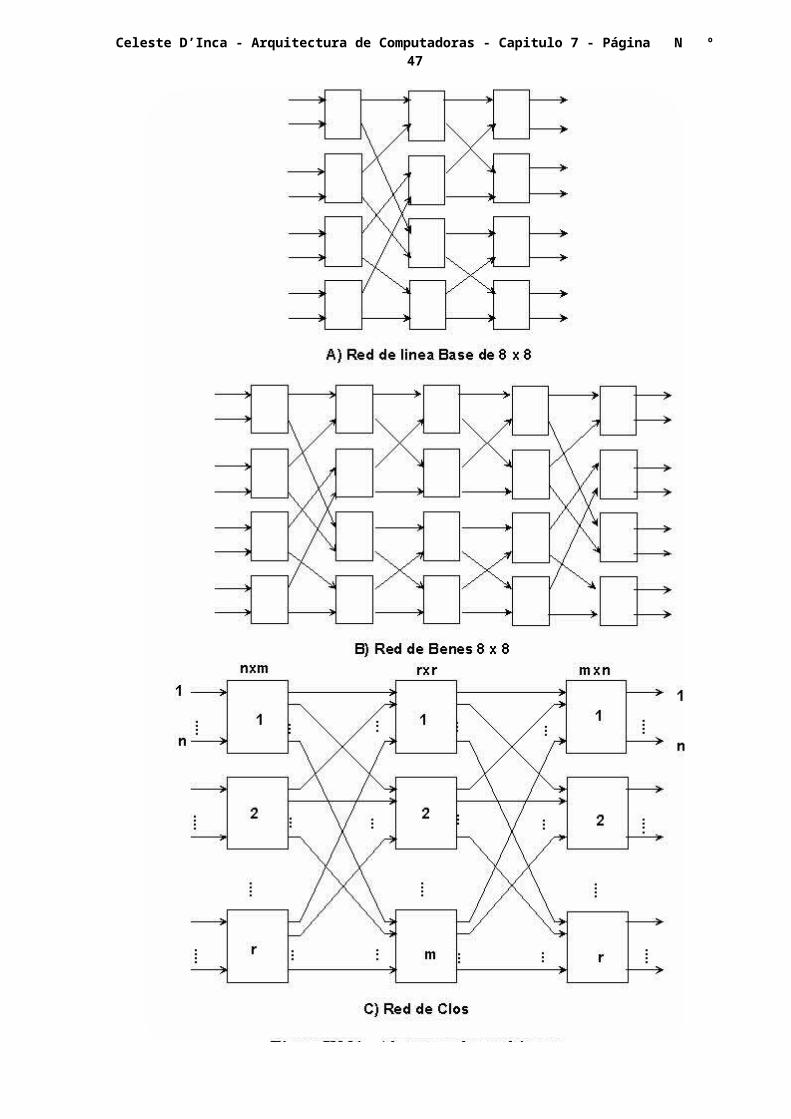
Las primeras se caracterizan por cuanto la conexión simultánea de más de un par de terminales puede dar lugar a conflictos en el uso de los lazos de conexión. Ejemplos de este tipo de redes de bloqueo son: el manipulador de datos, el Omega, el flip, cubo-n, y la línea base. Algunas de éstas se incluyen en la figura VII.21.a.
Se dice que una red es reconfigurable cuando puede llevar a cabo todas las conexiones posibles entre entradas y salidas, mediante la reconfiguración de sus conexiones. En la figura VII.21.b, se muestra la red de Benes, que es perteneciente a ésta clase.
Una malla que puede manejar todas las conexiones posibles sin bloquearse, es denominada red no bloqueante o de no bloqueo, de las cuales se han
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 35
estudiado dos tipos, la red de Clos y la red Crossbar. La primera se muestra en la figura VII.21.c.
VII.5.2 - PROCESAMIENTO MATRICIAL ASOCIATIVO:
En este caso, en vez de utilizar memorias convencionales de acceso aleatorio, se construye la máquina teniendo como base un sistema de "memoria asociativa". La principal diferencia entre una RAM y una MA (memoria asociativa), es que su contenido es direccionable mediante el acceso paralelo a cierta cantidad de palabras a la vez, en vez que necesitar una secuencia de direcciones para acceder a cada una de las palabras.
De esta forma se logra un gran impacto sobre la arquitectura de los procesadores asociativos, que son una clase especial de procesadores SIMD matriciales.
VII.5.2.1 - ORGANIZACIONES DE MEMORIA ASOCIATIVA:
Los datos almacenados en una memoria asociativa, son direccionados por su contenido, dicho de otra manera, los datos son buscados por su significado.
Estas memorias también han sido denominadas: direccionables por su contenido, de búsqueda paralela, o multiacceso.
Su principal ventaja frente a las RAM convencionales, es la capacidad de realizar búsquedas y comparaciones en paralelo, lo cual es muy útil en sistemas de bases de datos de rápida variación, tales como procesamiento de imágenes, seguimiento de señales de radar, visión de computadora e inteligencia artificial.
Lógicamente, ello se consigue con el agregado de una gran cantidad de hardware, y por ende un costo mucho más elevado que el de una RAM convencional.
La estructura básica de una MA es indicada en la figura VII.22, donde vemos que la matriz de memoria asociativa consta de n palabras de m bits cada una. Cada celda de bit en la matriz nxm, es un multivibrador asociado a una lógica de comparación, que permite la comparación del contenido con alguna configuración de bits de búsqueda, y un control de lectura/escritura.
Una tajada de bit (bit slice) es una columna de celdas de bit, correspondientes a la misma posición de todas las palabras. Cada celda de bit puede ser accedida para escritura o lectura, o comparada con una señal externa de interrogación.
La operación de búsqueda en paralelo incluye comparación y enmascarado, siendo ejecutada de acuerdo a la organización de la MA. Existe además una cierta cantidad de registros y contadores.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 36

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 37
El registro comparando, es utilizado para contener el operando clave, que está siendo comparado con el contenido de todas las palabras de la memoria, para buscar la/s palabra/s indicada/s.
El registro de enmascaramiento, es utilizado para inhabilitar o habilitar los bits involucrados en la búsqueda paralela en todas las palabras de la memoria.
El registro indicador (I), y uno o mas de los registros temporarios (T), se utilizan para contener los esquemas de comparación actual y previo, respectivamente.
Cada uno de estos registros puede ser seteado, reseteado o cargado desde una fuente externa, con cualquier patrón binario. Los contadores son utilizados para el rastreo de los valores de índice de la matriz.
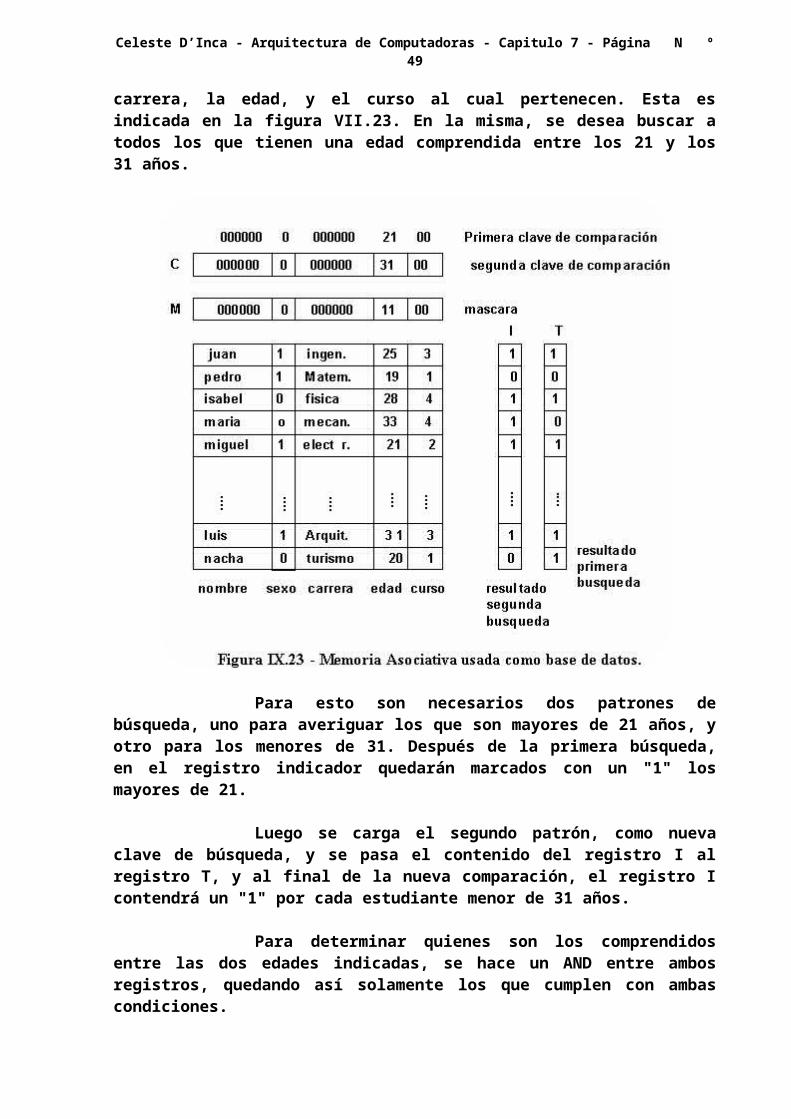
Como ejemplo, consideremos una base de datos para alumnos, en la cual se indican el nombre, el sexo, la carrera, la edad, y el curso al cual pertenecen. Esta es indicada en la figura VII.23. En la misma, se desea buscar a todos los que tienen una edad comprendida entre los 21 y los 31 años.
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 38
Para esto son necesarios dos patrones de búsqueda, uno para averiguar los que son mayores de 21 años, y otro para los menores de 31. Después de la primera búsqueda, en el registro indicador quedarán marcados con un "1" los mayores de 21.
Luego se carga el segundo patrón, como nueva clave de búsqueda, y se pasa el contenido del registro I al registro T, y al final de la nueva comparación, el registro I contendrá un "1" por cada estudiante menor de 31 años.
Para determinar quienes son los comprendidos entre las dos edades indicadas, se hace un AND entre ambos registros, quedando así solamente los que cumplen con ambas condiciones.
Es obvio que el registro de enmascaramiento solo permitirá el acceso a la información de edad.
VII.6 - ARQUITECTURAS MULTIPROCESADORES:
Los multiprocesadores pueden ser groseramente caracterizados por dos atributos:
1 - Un multiprocesador es una computadora formada por muchos procesadores.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 39
2 - Los procesadores pueden comunicarse y cooperar entre ellos a diferentes niveles, para resolver un dado problema. Esta comunicación puede hacerse mediante mensajes entre ellos o mediante una memoria compartida.
Hay algunas similitudes entre los sistemas multiprocesadores y los multicomputadores, dado que ambos han sido motivados por el mismo objetivo, la realización de operaciones concurrentes.
Sin embargo, hay una diferencia importante entre ellos, fundada en la cantidad de recursos compartidos y la cooperación en la resolución de un problema.
Un sistema multicomputadora, consiste en varias computadoras autónomas que pueden o no comunicarse entre ellas. Un sistema multiprocesador es controlado por un sistema operativo que provee interacción entre los procesadores y sus programas, en los niveles de procesos, conjunto de datos y datos.
Existen dos modelos arquitecturales de los sistemas multiprocesador:
1 - El levemente acoplado.2 - El fuertemente acoplado.
VII.6.1 - MULTIPROCESADORES LEVEMENTE ACOPLADOS:
En estos sistemas, cada procesador tiene un conjunto de dispositivos de entrada/salida y una gran memoria local, donde obtienen la mayoría de sus instrucciones y datos.
Nos referiremos al procesador, a su memoria y a sus dispositivos de E/S como un "módulo computador". Los procesos que se ejecutan en diferentes módulos computadores, se comunican mediante el intercambio de mensajes a través de un sistema de transferencia de mensajes (STM).
El grado de acoplamiento, o sea la interacción procesador-procesador, en estos sistemas es muy pobre, tanto que a veces se los conoce como "sistemas de procesamiento distribuido", aunque en realidad, el término procesamiento distribuido se aplica al procesamiento de un problema y sus partes en diferentes computadores, interconectados de alguna manera.
En la figura VII.24, se indica la conformación de un módulo computador y del sistema de conexión entre ellos. En la interfase de cada módulo, hay un conmutador de arbitraje y un canal. El canal es un dispositivo particular de E/S, mientras que la llave de arbitraje es la que permite la conexión con el STM de acuerdo con los requerimientos que se establezcan para evitar colisiones.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 40
Figura VII – 24 – Sistema levemente acoplado.
VII.6.2 - MODELO FUERTEMENTE ACOPLADO.
En el modelo fuertemente acoplado, los procesadores se comunican por medio de una memoria compartida, con lo cual la velocidad a la que se transfieren datos es del orden del ancho de banda de la memoria.
Cada procesador puede tener asimismo una pequeña caché o memoria local de alta velocidad, existiendo una total conectividad entre procesadores y memoria, la que puede ser implementada por una malla de interconexión o por una memoria multipuerto.
La limitación más importante de este tipo de computadores, es la degradación que sufre el rendimiento por los múltiples accesos a memoria necesarios para la comunicación.
Los multiprocesadores fuertemente acoplados, tienen un modelo tal como el expuesto en la figura VII.25, donde se tiene un conjunto de N procesadores, L módulos de memoria y varios canales de E/S, conectados mediante un conjunto de tres mallas de interconexión:

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 41
1 - La red de conexión procesador-memoria2 - La red de conexión procesador-E/S3 - La red de conexión para interrupción entre
procesadores.
La primera es un sistema de conmutación que conecta a cualquier procesador con cualquier módulo de memoria, normalmente es un conmutador crossbar.
La red de conexión procesador-E/S permite a un procesador cualquiera conectarse con uno de los dispositivos periféricos. Esta también es normalmente una red crossbar.
Finalmente, la red interprocesadores, permite que cualquiera de ellos interrumpa a cualquier otro a fin de o bien transferirle datos, o información de estado. En este último caso, la información puede ser la de mal funcionamiento, solicitando así su reemplazo.
VII.6.3 - REDES DE INTERCONEXIÓN:
La característica principal de un sistema multiprocesador, es la habilidad, que cada procesador posee para compartir un conjunto de módulos de memoria y de dispositivos de E/S. Esta capacidad es dada por la malla de interconexión que liga a cada uno de ellos.
VII.6.3.1 - BUSES COMUNES EN TIEMPO COMPARTIDO:
Es la forma de interconexión más simple, cuyo esquema se indica en la figura VII.26. Esta organización es la mas simple y la más fácil de reconfigurar. Además, casi siempre es una malla totalmente pasiva, lo cual la hace al mismo tiempo la más económica.
De cualquier manera, se deben complicar los distintos módulos para que ellos puedan realizar transferencias sin interferencias y sin conflictos.
El sistema de arbitraje centralizado, si bien simplifica la resolución de conflictos, puede tener efectos negativos sobre la confiabilidad y flexibilidad del sistema.
De cualquier modo, este sistema no es utilizado en aquellos multiprocesadores de alto rendimiento, por cuanto su desempeño es generalmente muy pobre, al permitir la conexión de solo dos módulos por vez.
Si bien es posible utilizar algún medio para difundir valores de datos o instrucciones, el mismo no es práctico cuando la cantidad de procesadores es relativamente elevada.
Una extensión del sistema, que mejora en algo su rendimiento, es la ubicar dos buses unidireccionales, lo cual se indica en la figura VII.27, que si bien alivia algunos problemas, no los evita completamente, dado que hay transferencias simples que requieren el uso simultáneo de ambos buses.
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 42
El próximo paso, es la utilización de un sistema multibuses, en el cual estos se convierten en sistemas activos, con un conmutador en cada conexión. Si bien el método es un poco más complejo que los anterior, su costo es mucho mayor. Además, dado que siempre un bus sirve solo para la interconexión de dos elementos, su aplicación se reduce a pequeños sistemas, con pocos módulos conectados.
En esta disposición es donde se deben aplicar aquellos métodos de arbitraje vistos en el capítulo III.
Figura VII.25 – Configuración multiprocesador fuertemente acoplado.
Figura VII.26 – Configuración multiprocesadores a bus único.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 43
VII.6.3.2 - CONMUTADOR CROSSBAR Y MEMORIAS MULTIPUERTO:
Si se aumenta la cantidad de buses, es posible llegar al extremo de tener uno por cada módulo, tal como se indica en la figura VII.29, si además se instala un conmutador en cada cruce, con la estructura mostrada en la figura VII.30, tendremos un conmutador Crossbar del tipo que hace al sistema no bloqueable.
Figura VII.27 – Sistema multiprocesador con buses ndireccionale.
Figura VII.28 – Sistema multiprocesador con red Crossbar.
El sistema crossbar (que significa barras cruzadas) provee una conectividad completa, dado que cada módulo de memoria puede comunicarse con cada procesador, sin que pueda haber interferencia, si la comunicación es uno a uno.
Además de la forma indicada es posible tener múltiples comunicaciones simultáneas, siempre por pares.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 44
El conmutador indicado en la figura VII.29, va directamente conectado a los módulos de memoria, por lo que el mismo trata los pedidos, y fija las opciones de acceso, que pueden estar dispuestas según prioridades.
De forma similar se puede actuar con las restantes mallas de conmutación, en especial las que conectan los procesadores con los módulos de E/S, en una disposición tal como la mostrada en la figura VII.30.
Figura VII.29 – Estructura funcional de un punto de cruce en una red crossbar.
Figura VII.30 - Mallas de interconexión crossbar para procesadores – memoria yprocesadores - entrada salida y periféricos.
De cualquier manera, si bien el sistema crossbar, es el más flexible y el que ofrece el mayor ancho de banda, es también muy caro, por lo que puede no ser

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 45
adecuado para grandes sistemas. Tengamos en cuenta que el costo depende de la cantidad de nodos, o sea de conmutadores.
En estos casos, a veces es preferible sacrificar algo de flexibilidad, por lo que pueden disponerse memorias multipuerto, tal como se indica en la figura VII.31. Este sistema que es apto tanto para sistemas monoprocesadores como multiprocesadores, tiene la cualidad de resolver muchos de los conflictos que se presentan en los accesos a memoria, para lo cual se dispone de un sistema de prioridades permanente asignadas a cada puerto.
Figura VII.31 – Organización de memora multipunto sin prioridades.
El sistema puede ser configurado según las necesidades de cada instalación, para que provea las adecuadas prioridades de acceso a cada unidad funcional, tal como se muestra en la figura VII.32. Excepto por esa prioridad asociada a cada puerto, los dos son idénticos.
P0 P1
M0 M1 M2 M3
E/S0 E/S1
P0 P1
M0 M1 M2 M3
E/S0 E/S1
0 1 0 1 1 0 1 0
2 3 3 2 2 3 3 2

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 46
Figura VII.32 – Organización con memorias multipunto, con prioridades.
Otra de las posibilidades que ofrece este sistema, es la asignación de porciones de los módulos para que sean exclusivas de ciertos procesadores, unidades de E/S o cualquier combinación.
Así es que, según se observa, en la figura VII.33, donde los módulos de memoria M0 y M3 son de uso privado de los procesadores P0 y P1 respectivamente.
Este tipo de organización puede tener muchas ventajas mejorando la protección contra accesos no autorizados, y puede permitir el almacenamiento de rutinas de recuperación, en áreas de memoria no susceptibles de modificación por el acceso de otros procesadores, sien embargo, esto también tiene serias desventajas para la recuperación del sistema, si el otro procesador no es capaz de acceder a la información de estados y al control, en un bloque de memoria perteneciente a un procesador en falla.
Figura VII.33 – Organización con módulos de memoria privados.
VII.7 - COMPUTADORES DE FLUJO DE DATOS:
Las computadoras de flujo de datos están basadas en el concepto de la computación "conducida por datos", la cual difiere drásticamente del modelo de Von Neumann.
Jack Dennis, investigador del MIT, en le año 1979 identificó las tres propiedades que permitirían el desarrollo de una arquitectura ideal para las computadoras:
1 - Alcanzar elevadas performances con mínimo costo.
P0 P1
M0 M1 M2 M3
E/S0 E/S1
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 47
2 - Igualar la relación con el avance tecnológico
3 - Ofrecer la mejor programabilidad en las áreas de aplicación.
El modelo de flujo de datos, parece satisfacer estas demandas, mientras que la microelectrónica VHSI y SHSI parecen estar proveyendo las bases tecnológicas para el desarrollo de estas máquinas.
VII.8 - LA ARQUITECTURA MATRICIAL SISTÓLICA:
Este tipo de arquitecturas son el prototipo de lo establecido en los incisos anteriores, utilizando estructuras paralelo donde cada EP solo se conecta con sus vecinos. El concepto de matriz sistólica, ha sido desarrollado por Kung y asociados en la Universidad Carnegie Mellon, mientras que se han realizado luego varias implementaciones tanto en otras universidades, como en organizaciones industriales.
Un sistema sistólico consiste de una cierta cantidad de celdas interconectadas, cada una de las cuales es capaz de llevar a cabo una operación sencilla. En la figura VII.34, se ilustra un sencillo ejemplo, en el cual se reemplaza un elemento de procesamiento por un conjunto de ellos dispuestos en cascada como en un cauce.
La parte fundamental, es la de asegurar que en cada pulso de reloj, los resultados de un EP sean llevados al siguiente, y que ellos sean todo lo necesario para efectuar su cálculo.
Figura VII.34 – Concepto de procesador sistólico.
Existe una cierta cantidad de algoritmos que son pasibles de implementación en sistemas parecidos, casi todos ellos de tipo aritmético. Consideremos el caso de la multiplicación de dos matrices banda tales como las indicadas en la figura VII.36.a.
Sabemos que el producto es una tercera matriz cuyos elementos son calculados mediante la expresión:
cij k1
n
a ik.bkj
donde n es dimensión común de ambas matrices A y B.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 48
Cada EP tiene tres entradas y tres salidas, siendo las primeras a, b y c, donde a y b son los elementos de las matrices A y B, correspondientes, mientras que c es parte del cálculo anteriormente hecho, según la relación:
cijsalida cijentrada a ik.bkj
Al comienzo se hace: Cij = 0 , y allí se tiene el primer elemento de la matriz resultado.
Las salidas serán nuevamente a, b y c indicado como de salida, los que son utilizados en EP próximos, según se indica en la figura VII.36.b.
En cada pulso de reloj, se alimenta un nuevo nivel de datos en la malla, y se tiene una salida en el lado c, todo opera como en el caso de la sístole del corazón, que empuja la sangre en cada latido.
Otras formas de matrices sistólicas pueden verse en la figura VII.35.
Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 49
Figura VII.35 – Diversas configuraciones de matrices sistólicas.

Celeste D’Inca - Arquitectura de Computadoras - Capitulo 7 - Página N º 50
Figura VII.36 - Matriz sistólica para calcular el producto de dos matrices banda.





























