Embed Size (px)
Citation preview

7 Key Recipesfor
Data Engineering
Scala Matsuri 2017
データ・エンジニアリング 7大レシピ

7 Key Recipes For Data Eng
Introduction
We will explore 7 key recipes on Data Engineering.
If you could only pick one, the 5th on joins/cogroups is essential.
2
文字数制限あり。折りたたみやエンコーディングは無し。データ・エンジニアリングの 7大レシピ

7 Key Recipes For Data Eng
About Me
Jonathan WINANDYScala user (6 years)
Lead Data Engineer: - Data Lake building, - Audit/Coaching, - Spark/Scala/Kafka Trainings.
Founder of Univalence (BI / Big Data)
Co-Founder of CYM (Predictive Maintenance), and Valwin (Health Care Data).
3
データエンジニアとしてデータ基盤構築やトレーニング等を実施
Univalence、CYM、Valwin などのデータ分析ビジネスを創業

7 Key Recipes For Data Eng
Bachir AIT MBAREK
4
Thank you

7 Key Recipes For Data Eng
Outline
1. Organisations
2. Work Optimization
3. Staging
4. RDD/Dataframe
5. Join/Cogroup
6. Data quality
7. Real Programs
5

1. It’s always about our organizations! (in Europe)
6
一に組織 (ヨーロッパはこればっかり)

7 Key Recipes For Data Eng 7
1. Organisations
In Data Engineering, we tend to think our problems come from or are solved by those tools :
データエンジニアリングではツールが問題の原因であるとか
あるいはツールによって問題を解くのだと思われがち

7 Key Recipes For Data Eng
1. Organisations
However our most difficult problems or durable
solutions come from organisational contexts.
It’s true for IT at large, but it’s much more
dominant in Data Engineering.
8
IT において、最も困難な課題や持続的な解決策は組織の文脈からやってくる
この点、データエンジニアリングではさらに支配的

7 Key Recipes For Data Eng
1. Organisations
9
Because Data Engineering
enables access to Data!
理由はデータ・エンジニアリングはデータへのアクセスを活性化させるから
7 Key Recipes For Data Eng 10
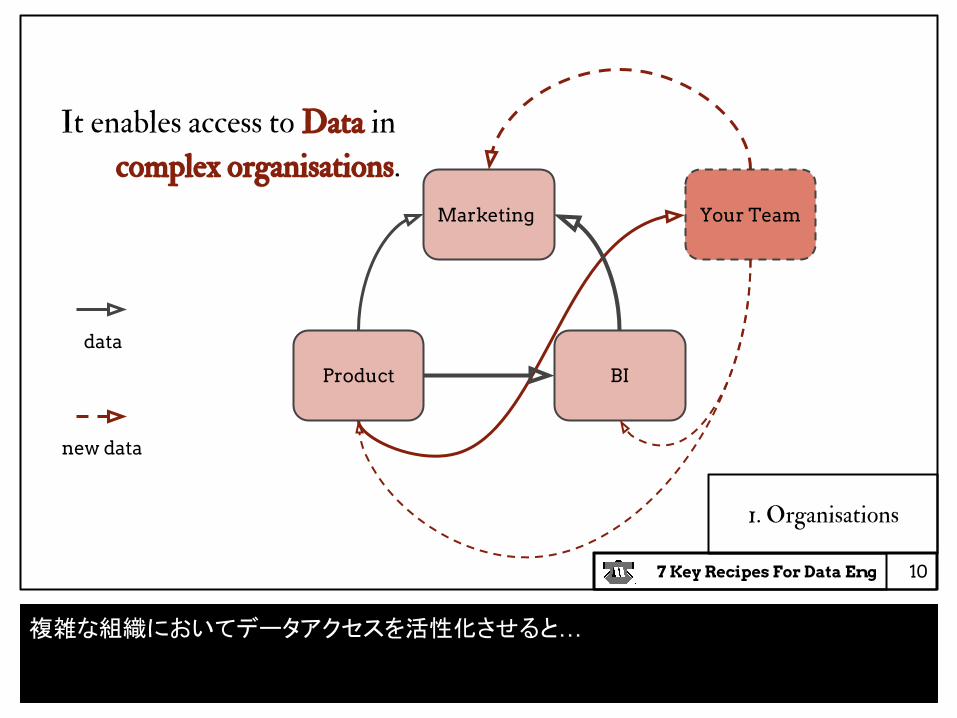
It enables access to Data in
very complex organisations.
1. Organisations
Product BI
Your TeamMarketing
data
new data
複雑な組織においてデータアクセスを活性化させると…
7 Key Recipes For Data Eng
data
11
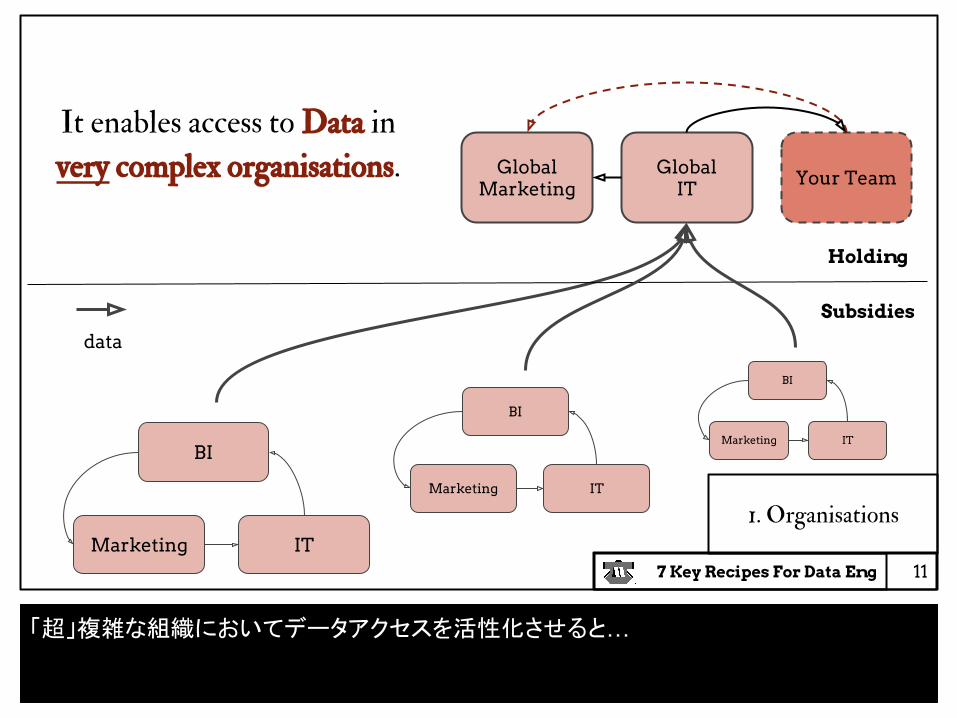
Your TeamGlobalMarketing
1. Organisations
It enables access to Data in
very complex organisations. GlobalIT
Marketing IT
BI
Holding
Subsidies
Marketing IT
BI
Marketing IT
BI
「超」複雑な組織においてデータアクセスを活性化させると…

7 Key Recipes For Data Eng
It happens to be very frustrating!
12
1. Organisations
By being a Data Eng, you take part in some of the most
technically diverse teams that are:
● Running cutting edge technologies,
● Solving some of the hardest problems,
while being constantly dependent on other teams that
often don’t share your vision.
先端技術を駆使して難題に取り組みつつ、ビジョンを共有しない他のチームに依存して仕
事を進めざるをえない。とてもフラストレーションが溜まる状況だ

7 Key Recipes For Data Eng
1. Organisations
Small tips:
● One hadoop cluster (no Test or QA clusters).
● Document your vision, so it can be shared.
● What happens between teams matters a lot.
13
コツ: Hadoopクラスタは1つに、ビジョンは文書化して事前に根回し
チーム間の関係は大切

2. Optimizing our work
14
業務の最適化

7 Key Recipes For Data Eng
2. Work Optimization
To optimize our work, there are 3 key concerns
governing our decisions :
● Lead time,
● Impact,
● Failure management.
15
業務最適化における意思決定で大切なこと:
リードタイム、インパクト、失敗の管理

7 Key Recipes For Data Eng
2. Work Optimization
Lead time:
The period of time between the initial phase and the completion.
Impact:
Positive effects beyond the current context.
Failure management:
Failure is the nominal case.Unprepared failures will pile up.
16
リードタイム→企画から完成までの期間、インパクト→今の文脈を超えた良い効果失敗の
管理→想定外の失敗は積み上がる

7 Key Recipes For Data Eng
2. Work Optimization
Being Proactive!
To avoid the “MapReduce then Wait”, two methods :
● Proactive Task Simulation,● “What will fail?”
17
先を見越して動こう!
「MapReduce を動かして待機」を回避するには?

7 Key Recipes For Data Eng
2. Work Optimization
Proactive Task Simulation.
The idea is to solve a task:
● map all the possible ways,● on each way estimate:
○ Lead time and cost,○ Decidability, ○ Success rate,○ Generated opportunities,○ and other By-Products.
● then choose which way to start with.
18
解決したいタスクについて、ありうる可能性を全て挙げてリードタイムやコストなどを見積
もった上で、どの方法から始めるかを選ぶ

7 Key Recipes For Data Eng
2. Work Optimization
What will fail ?
The idea is to guess what may fail on a given component.
Then you can engage in a discussion on:
● Knowing how likely it will fail, ● Preventing that failure, ● Planning the recovery ahead.
19
あるコンポーネントで何が失敗しそうか考え、
その頻度や予防策、復旧プランを議論する

3. Staging DataBack to technical recipes!
20
技術的なレシピに戻ろう

7 Key Recipes For Data Eng
3. Staging
Data is moving around, freeze it!
Staging changed with Big Data. We moved from
transient staging (FTP, NFS, etc.) to persistent
staging thank to distributed solutions:
● in Kafka, we can retain logs for months,
● in HDFS, we can retain sources for years.
21
まずは、動いているデータを凍結する
Kafka や HDFS のおかげでビッグデータを長期間ステージングできるように

7 Key Recipes For Data Eng
3. Staging
But there are a lot of staging
anti-patterns out there:
● Updating directories,● Incomplete datasets,● Short retention.
Staging should be seen as a persistent data structure.
If you liked immutability in Scala, go for it with your Data!
22
ステージングは永続データ構造として見えるようにすべき
データは Scala のイミュータブルと同じように扱おう

7 Key Recipes For Data Eng
3. Staging
Example, with HDFS:
Writing in unique directories: /staging|-- $tablename |-- dtint=$dtint |-- dsparam.name=$dsparam.value |-- ... |-- ... |-- uuid=$uuid
23
UUID を使ったディレクトリに書き込む

4. Using RDDs or Dataframes
24
RDD と Dataframe について

7 Key Recipes For Data Eng
4. RDD/Dataframe
Dataframes have great performance,
but are “untyped” and foreign.
RDDs have a robust Scala API,
but are a difficult to map from data sources.
SQL is the current lingua franca of Data.
25
データ操作にはなんだかんだ言っても SQL
7 Key Recipes For Data Eng
4. RDD/Dataframe
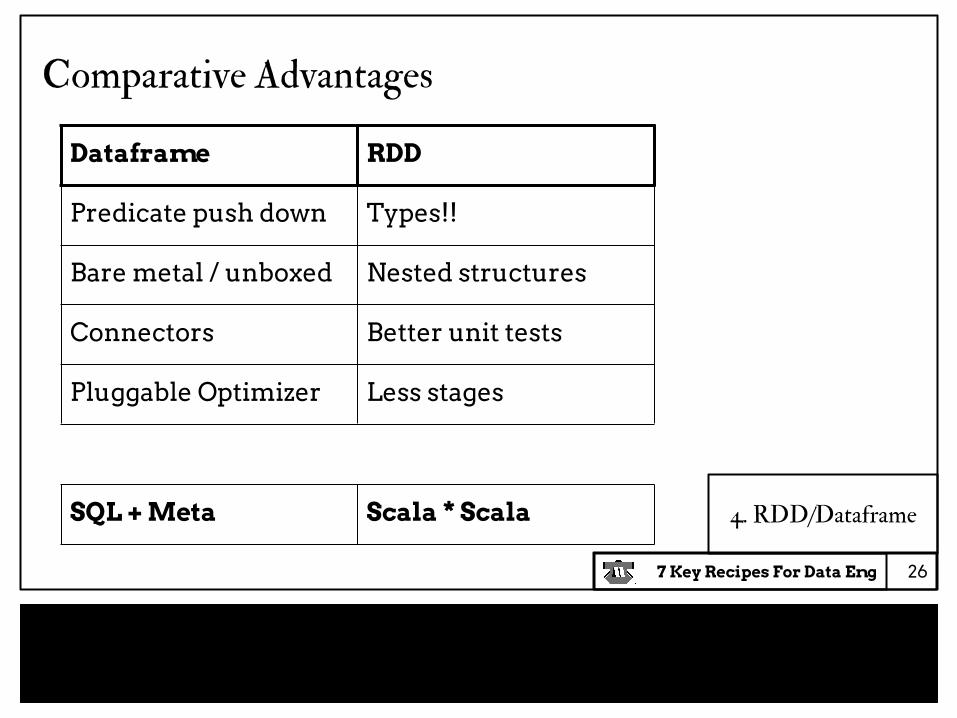
Dataframe RDD
Predicate push down Types!!
Bare metal / unboxed Nested structures
Connectors Better unit tests
Pluggable Optimizer Less stages
SQL + Meta Scala * Scala
26
Comparative Advantages

7 Key Recipes For Data Eng
RDD based jobs are like marine mammals, fit for their environnement starting from a certain size.
RDDs are building blocks for large jobs.
27
RDD は海獣みたいなもので、その環境に特化している
RDD は大きい仕事のビルディング・ブロック
4. RDD/Dataframe

7 Key Recipes For Data Eng
4. RDD/Dataframe
RDDs are very good for ETL workloads:
● Control over shuffles,● Unit tests are easier to write.
They can leverage Dataframe API for job boundaries:
● Loading, storing data with Dataframe APIs,● Map Dataframe in case classes,● Perform type safe transformations.
28
RDD は ETL に向いている
データ順の制御や単体テストの書き易さ

7 Key Recipes For Data Eng
4. RDD/Dataframe
Dataframes are perfect for:
● Data Exploration (notebook),● Light Jobs (SQL + DF) ,● Dynamic jobs (xlsx specs =>
spark job).
User Defined Functions improve code reuse,
User Defined Aggregate Functions improve performance over Standard SQL. 29
Dataframe は Notebook を使ったデータ探索や SQL と組み合わせた軽量なジョブ、
動的なジョブに向いている

5. Cogroup all the things
30
Cogroup を使ってみる

7 Key Recipes For Data Eng
5. Cogroup
The cogroup is the best operation
to link data together.
31
データの連結に使える

7 Key Recipes For Data Eng
Cogroup API
from (left:RDD[(K,A)],right:RDD[(K,B)])○ join : RDD[(K,( A , B ))]○ outerJoin : RDD[(K,(Option[A],Option[B]))]○ cogroup : RDD[(K,( Seq[A], Seq[B]))]
from (rdd:RDD[(K,A)])○ groupBy : RDD[(K,Seq[A])]
On cogroup and groupBy, for a given key:K, there is only one unique row with that key in the output dataset.
5. Cogroup
32
cogroup と groupBy は任意のキーに対して単一の行を返す
7 Key Recipes For Data Eng
5. Cogroup
33
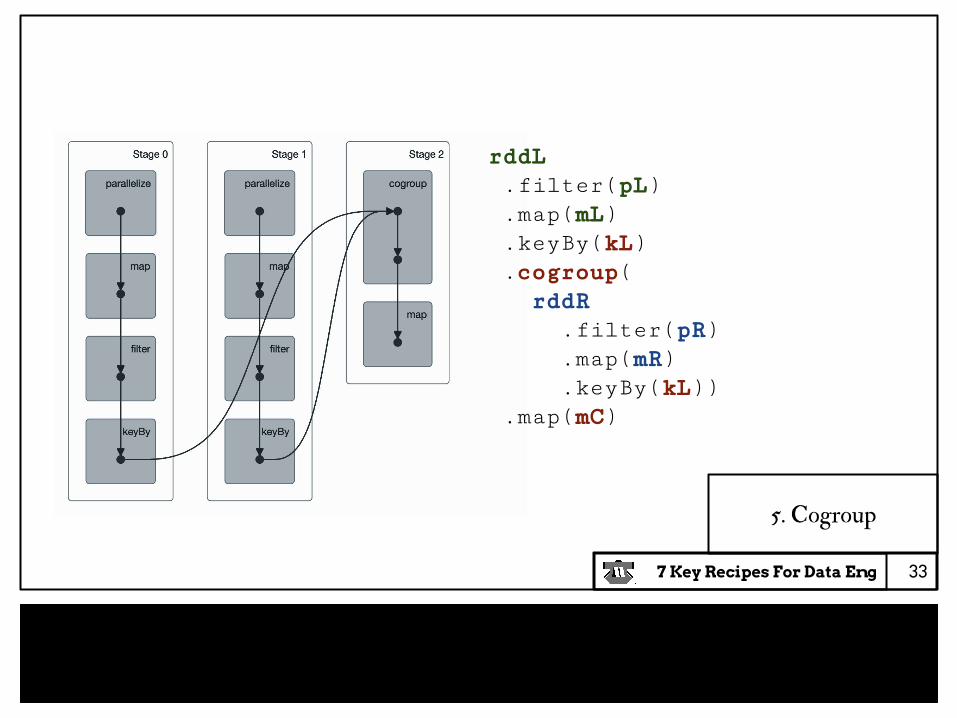
rddL .filter(pL) .map(mL) .keyBy(kL) .cogroup( rddR .filter(pR) .map(mR) .keyBy(kL)) .map(mC)
7 Key Recipes For Data Eng
5. Cogroup
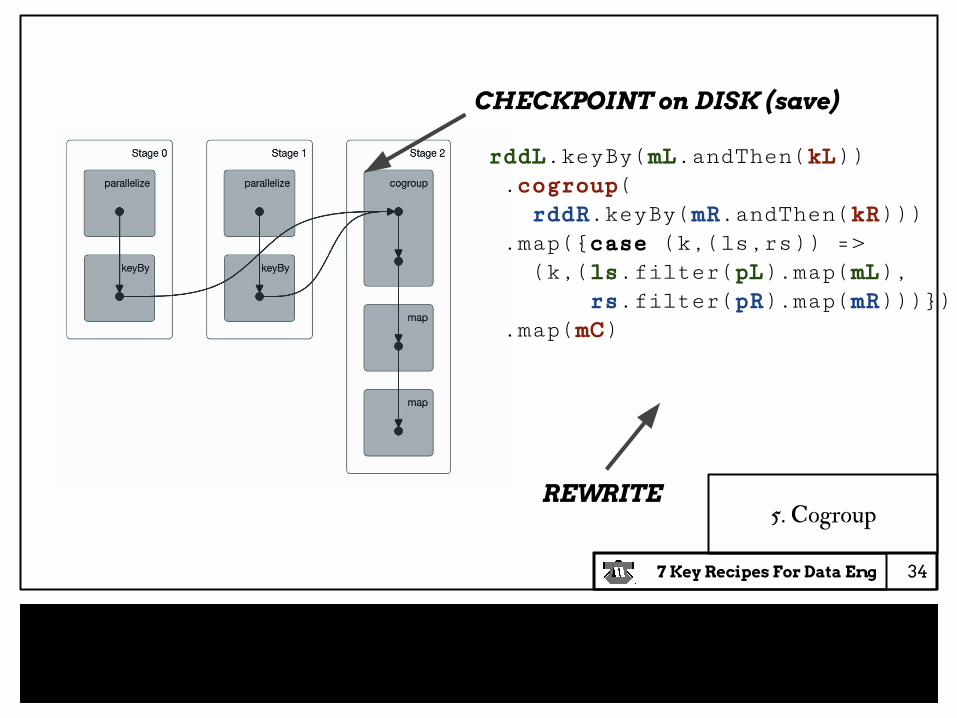
CHECKPOINT on DISK (save)
34
rddL.keyBy(mL.andThen(kL)) .cogroup( rddR.keyBy(mR.andThen(kR))) .map({case (k,(ls,rs)) => (k,(ls.filter(pL).map(mL), rs.filter(pR).map(mR)))}) .map(mC)
REWRITE
7 Key Recipes For Data Eng
5. Cogroup
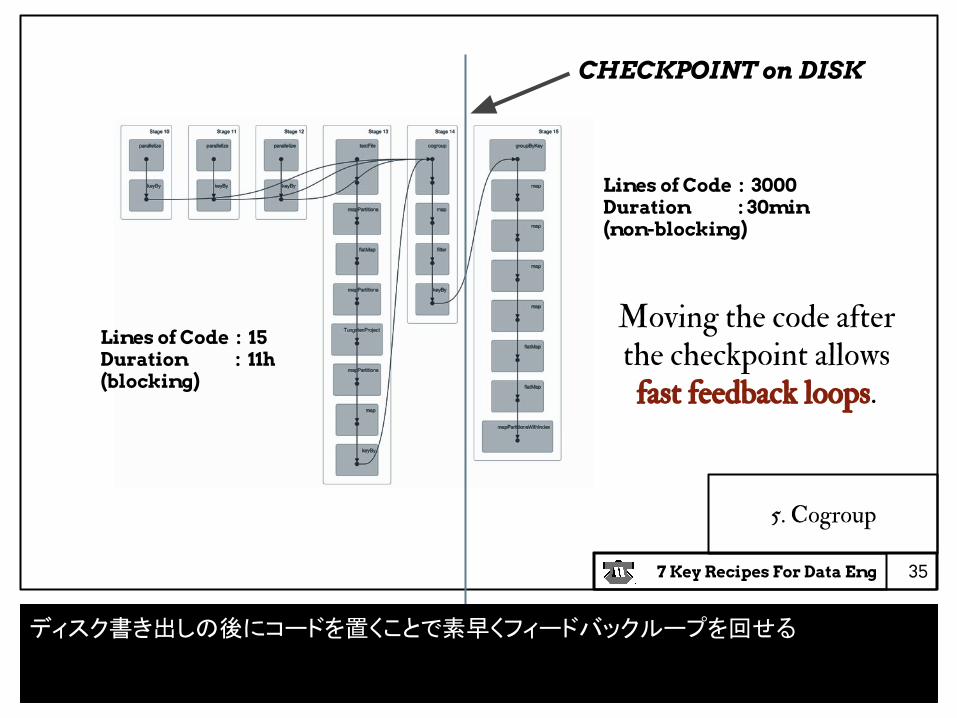
Lines of Code : 3000 Duration : 30min(non-blocking)
Lines of Code : 15Duration : 11h (blocking)
35
CHECKPOINT on DISK
Moving the code after the checkpoint allows
fast feedback loops.
ディスク書き出しの後にコードを置くことで素早くフィードバックループを回せる

7 Key Recipes For Data Eng
5. Cogroup
Cogroups allow writing tests on a
minimised case.
Test workflow:
● Isolate potential cases,● Get the smallest cogrouped row
○ output the row in test resources,
● Reproduce the bug,● Write tests and fix code.
36
cogroup を使うと問題を最小化してテストを書けるのでバグを再現しやすい

6. Inline data quality
37
データ品質のインライン化

7 Key Recipes For Data Eng
6. Inline data quality
Data quality improves resilience to bad data.
However, data quality concerns often come second.
38
データ品質を高めることでバッドデータへのレジリエンスが向上するが
データ品質は二の次にされがち

7 Key Recipes For Data Eng
6. Inline data quality
Our solution: Integrate Data Quality deep inside jobs, by
unifying Data quality with Data transformation.
We defined a structure Result similar to ValidationNeL (Applicatives).
39
データ品質はジョブの奥まで統合させる
ValidationNeL的な Result というものを定義した
7 Key Recipes For Data Eng
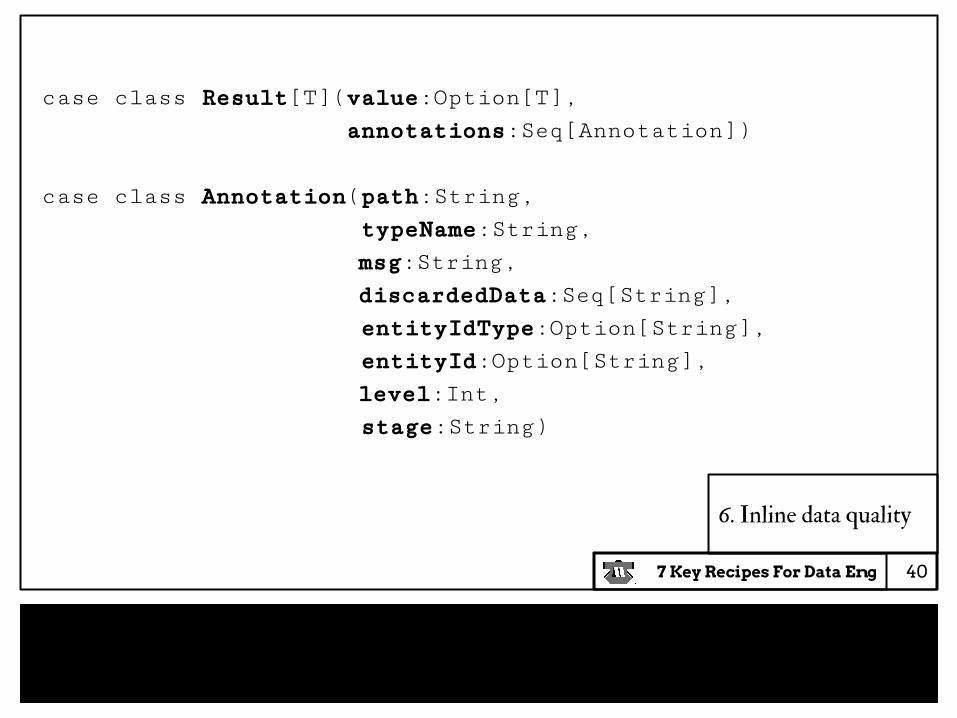
case class Result[T](value:Option[T], annotations:Seq[Annotation])
case class Annotation(path:String, typeName:String,
msg:String, discardedData:Seq[String],
entityIdType:Option[String], entityId:Option[String],
level:Int, stage:String)
6. Inline data quality
40

7 Key Recipes For Data Eng
case class Result[T](value:Option[T], annotations:Seq[Annotation])
Result is either:● Containing a value, with a list of warnings,● Empty, with a list containing the error and
warnings.
(Serialization and Big Data don’t like Sum types, so it’s pre-projected onto a product type)
6. Inline data quality
41
値を持つか、Empty の二値
それぞれ警告やエラーを表す注釈も持つ
7 Key Recipes For Data Eng
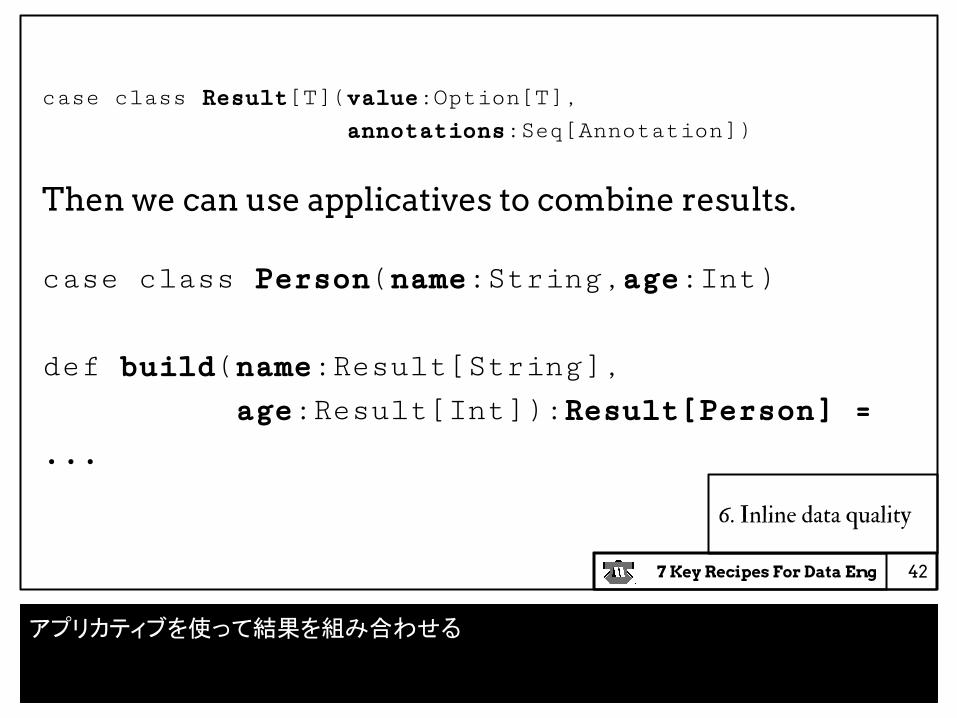
case class Result[T](value:Option[T], annotations:Seq[Annotation])
Then we can use applicatives to combine results.
case class Person(name:String,age:Int)
def build(name:Result[String], age:Result[Int]):Result[Person] = ...
6. Inline data quality
42
アプリカティブを使って結果を組み合わせる

7 Key Recipes For Data Eng
case class Result[T](value:Option[T], annotations:Seq[Annotation])
The annotations are accumulated at the top of the hierarchy, and saved with the data:
6. Inline data quality
43
注釈は蓄積されて、データと一緒に保存される

7 Key Recipes For Data Eng
Annotations can be aggregated on dimensions:
6. Inline data quality
Message:
● EMPTY_STRING
● MULTIPLE_VALUES
● NOT_IN_ENUM
● PARSE_ERROR
● ______________
Levels:
● WARNING
● ERROR
● CRITICAL
44
注釈は次元ごとに集約できる

7 Key Recipes For Data Eng
6. Inline data quality
If you are interested by the approach, you can take a look at
this repository:
Macros based on Shapeless to build Result[T] from case classes.
https://github.com/ahoy-jon/autoBuild (~october 2015)
45
気になった人はレポジトリをみてください

7. Designing real programs
46
業務で使うプログラムの設計

7 Key Recipes For Data Eng
7. Real programs
Most pipelines parts are designed as
Stateless computations.
They either require no external state (great) or infer their state based on filesystem state (meh).
47
ステートレスな計算が基本

7 Key Recipes For Data Eng
7. Real programs
Spark allows us to program inside the Driver.We can create actual programs.
In Scala, we can use:
● Scopt to parse common args and feature flips,● TypesafeConfig to load/overload program settings,● EventSourcing to read/write app events,● Sbt-Pack Coursier to package and create launchers.
48
Spark なら Scala を使ってちゃんとしたプログラムが書ける

7 Key Recipes For Data Eng
Deterministic effects
We then make sure that our program are as deterministic as possible, and are idempotent (if possible).
Example: Storing past execution so as to not recompute something already computed, unless forced.
49
7. Real programs
できるかぎり決定論的なプログラムを目指す

7 Key Recipes For Data Eng
Level 0 Event Sourcing
Level 1 Name resolving
Level 2 Triggered exec (schema capture, deltaQA, …)
Level 3 Scheduling (replay, coherence, ...)
Level 4 “code as data” (=> continuous delivery)
7. Real programs
In progress: project Kerguelen, API for data jobs.
Enable the creation of coherent jobs, integrating different abstraction levels:
50
プロジェクト Kerguelen というものを作っている

7 Key Recipes For Data Eng
8. More
More recipes:
● Automatic QA,● Structural Sharing for Datasets, ● Jsonoids mapping generation,● Advanced UDAF,● ...
But that’s it for today!
51
他にもあるけど、今日はここまで

Conclusion
52

Thank youfor listening!
@ahoy_jon
53
ありがとうございました

7 Key Recipes For Data Eng
PSUG Note
54
If you happen to visit Paris, don’t hesitate to submit a talk at our Paris Scala User Group.
パリに来たら是非 Paris 勉強会でトークしてください

![Systems Engineering: Roles and Responsibilities - NASA · PDF file3 Systems Engineering Key Lessons •Truth of DeLuca’s Law (from Political Savvy) –[Space System development is]](https://img.pdfslide.tips/doc/110x75/5a72c0017f8b9ab6538dcd27/systems-engineering-roles-and-responsibilities-nasa-3-systems-engineering.jpg)



























