Embed Size (px)
DESCRIPTION
计算机视觉介绍 Introduction to Computer Vision. ---- 系列讲座之 1 计算机视觉的背景及几何基础简介. 邹丰美 联系: [email protected], 13459246202 资料下载 : http://teach.xmu.edu.cn 2006-2-13. 5次讲座的题目 / 时间. 1.计算机视觉的背景及几何基础 ( 2/13 , 第 1 周 ) 2.摄像机的几何标定 ( 3/6 , 第 4 周 ) 3.刚体运动姿态估计问题 ( 3/27 , 第 7 周 ) - PowerPoint PPT Presentation
Citation preview

计算机视觉介绍Introduction to Computer Vision
邹丰美联系: [email protected], 13459246202
资料下载 : http://teach.xmu.edu.cn
2006-2-13
---- 系列讲座之 1计算机视觉的背景及几何基础简介

5次讲座的题目 / 时间1.计算机视觉的背景及几何基础 (2/13, 第 1 周 )
2.摄像机的几何标定 (3/6, 第 4 周 )
3.刚体运动姿态估计问题 (3/27, 第 7 周 )
4.姿态估计问题 (II)( 或对应问题 ) (4/17, 第 10
周 )
5.应用 (5/8, 第 13 周 )

要求• 听 5 次讲座并积极提问 , 共同讨论 ( 每次有约
15-20 分钟的提问及讨论时间 )• 至少完成 3 个实验中的一个 ( 程序 + 报告 )• ( 上机地点头两周内定,到时候我通知 )• 完成一篇 ( 与实验相关的 ) “ 学术”论文
• 最终成绩计算 :• 本科生 : 60%( 实验 ) + 40%( 文章 )• 研究生 : 40%( 实验 ) + 60%( 文章 )

纲要• 什么是 CV?
– 什么是 CV? 它是从什么时候发展起来的 ?– 它有哪些研究内容 ?– 它与哪些学科 / 领域相关 ?– CV 的若干问题及应用展望
• 几何基础/概率基础• 一些相关资源

Definitions of CV (1)
• “Today, the study of extracting 3-D information from video images and building a 3-D model of the scene, called computer vision or image understanding, is one of the research areas that attract the most attention all over the world.” – from K. Kanatani, “Statistical Optimization for Geometric Computation: Theory and Practics”, 1996.

CV 的定义 (2)
• “ 视觉,不仅指对光信号的感受,它还包括了对视觉信息的获取、传输、处理、存储与理解的全过程.信号处理理论与计算机出现以后,人们试图用摄像机获取环境图像并将其转换成数字信号,用计算机实现对视觉信息处理的全过程,这样,就形成了一门新兴的学科--计算机视觉”.“计算机视觉的研究目标是使计算机具有通过二维图像认知三维环境信息的能力.”
-“计算机视觉-计算理论与算法基础” , 马颂德 , 张正友 , 1998.
• “计算机视觉是当前计算机科学研究的一个非常活跃的领域,该学科旨在为计算机和机器人开发出具有与人类水平相当的视觉能力。各国学者对于计算机视觉的研究始于 20 世纪 60年代初,但相关基础研究的大部分重要进展则是在 80 年代以后取得的。” – “ http://research.microsoft.com/asia/news/displayArticle.aspx?id=1332”

研究的内容• 早期 : 低层 (low-level) 图像处理 , 如 image
transformation, image restoration, image enhancement, thresholding, region labelling, and shape characterization.
• “Tried to identify and classify objects in images by techniques of Pattern Recognition (模式识别 ), which had been developed for the purpose of recognizing 2-D characters and symbols by feature extraction and statistical decision making by learning”.

• “Many pattern recognition researchers believed that the
paradigm of pattern recognition would also lead to
intelligent vision systems that could understand 3-D
scenes”.
• “However, they soon realized the crucial fact that 3-D
objects look very different from viewpoint to viewpoint
beyond the capability of 2-D feature-based learning; 3-
D meanings of 2-D images cannot be understood unless
some a prior knowledge about the scene is given. Thus,
‘Knowledge’ came to play an essential role”.

• “This type of knowledge-based ‘high-level’ reasoning is called the
top-down (自上而下 ) (or goal-driven ( 目标驱动 )) approach.”
• “In a sense, this approach corresponds to the psychological view
toward human perception( 感知 ) that humans understand the
environment by unconsciously ‘matching’ the vast amount of
knowledge accumulated from experience in the process of
growth.”
• “This view can be compared to what is known as the Gestalt
psychology, which regards human perception as integration of the
environment and experience. ”

• Thus, the problem of how to represent and
organize such knowledge became a major concern,
and many symbolic schemes were derived.
Establishing such symbolic representations is one
of the central themes of artificial intelligence (人工智能 ), and machine vision was regarded as
problem solving by artificial intelligence.

• “However, the inherent difficulty of this approach was
soon realized: the amount of necessary knowledge,
most of which has the form of “if … then … else …”,
is limitless, heavily depending on the domain of each
application (“office scene”, “outdoor scene”, etc) and
constantly changing (e.g., today, many telephones are
no longer black and do not have dials). However large
the amount of knowledge is, exceptions are bound to
appear, and computation time blows up exponentially
as the amount of knowledge increases.”

• Many combinatorial techniques were
proposed so as to find plausible
interpretation efficiently without doing
exhaustive search. Such techniques include
various types of heuristic (启发式的 )
search as well as special techniques such as
constraint propagation ( 约束繁殖 ) and
probabilistic relaxation ( 概率松弛 ).

• “Realizing that such computational
problems are inevitable as long as
knowledge is directly matched with features
extracted from raw images, researchers
began to pay attention to “physical/optical
laws” governing 3-D scenes. In analyzing
2-D images, such laws can provide clues to
the 3-D shapes and positions of objects. ”

• “For example, the surface gradients of objects can be
estimated by analyzing shading intensities (shape
from shading). The orientation of a surface in the
scene can also be estimated by analyzing the
perspective distortion of a texture on it (shape from
texture). If objects are moving in the scene (or the
camera is moving relative to the objects), the 3-D
shapes of the objects and their 3-D motions (or the
camera motion) can be computed (shape from motion
or structure from motion).”

• “Although such analyses require appropriate assumptions
about surface reflectance, illumination, perspective
distortion, and rigid motion, they do not depend on
specific application domains; they are called constraints
in contrast to ‘knowledge’ for the top-down approach.
• This approach is in line with the psychological view
toward human vision that human perception occurs
automatically when visual signals trigger ‘computation’
in the brain and that this computational functionality is
innate, acquired in the process of evolution. ”

• This view was asserted by J. J. Gibson, who had a
great influence on not only psychologists but also
machine vision researchers.
• Thus, a new paradigm ( 范例 ) was established.
First, primitive features are extracted from raw
images by edge detection and image segmentation,
resulting in primal sketches; next, approximate
shapes and surface orientations are estimated by
applying available constraints (shading, texture,
motion, stereo, etc.), resulting in 2.5-D sketches;

• then, appropriate 3-D models (e.g., generalized cylinders) are fitted to such data, resulting in a numerical and symbolic representation of the scene; finally, high-level inference is made from such representations. This is called the bottom-up (自下向上 ) (or data-driven (数据驱动 )) approach, which is also known as the Marr paradigm after David Marr, who strongly endorsed this approach.

Marr 的计算视觉理论框架
• Marr 从信息处理系统的角度出发,认为视觉系统的研究应分为三个层次,即计算理论层次、表达(representation) 与算法层次、硬件实现层次.
• 计算理论层次要回答系统各部分的计算目的与计算策略,亦即各部分的输入输出是什么,之间的关系是什么变换或什么约束.
• 表达与算法层次应给出各部分的输入输出和内部的信息表达,以及实现计算理论所规定的目标的算法 .
• 硬件实现层次要回答“如何用硬件实现以上算法”.

• A major drawback of this approach is its
susceptibility to noise. Computation solely based on
physical/optical constraints is likely to produce
meaningless interpretations in the presence of noise.
This is because 3-D reconstruction from 2-D data is a
typical inverse problem (逆问题 ), for which
solutions are known to be generally unstable with
respect to noise.

• “In order to cope with this inherent ill-posedness,
many optimization techniques were devised so as to
force the solution to have required properties. Such
techniques are generally called regularization. Other
types of optimization include a stochastic relaxation
technique called simulated annealing ( 模拟退火 ),
which was constructed by analogy with statistical
mechanics, and the use of neural networks, which
gave rise to a new view toward human cognition
called connectionism. ”

• “Today, many attempts are being made to enhance
the reliability of image data. One approach is to
actively control the motion of the camera so that
the resulting 3-D interpretation becomes stable
(active vision). Another approach is using multiple
sensors (stereo, range sensing, etc.) and fusing the
data (sensor fusion). ”

• “In order to fuse data, the reliability of individual data
must be evaluated in quantitative terms so that reliable
data contribute more than unreliable data.”
• “Some researchers are attempting to use only
minimum information that is enough to achieve a
specific goal such as object avoidance (qualitative
vision, purposive vision, etc.). ”
• --- for detailed information, read “intro_KKanatani.doc”

相关领域• 数学,物理学• 脑科学 ( 或神经生理学 )• 心理学,认知科学 , AI, …
– “ 计算机视觉发展得益于神经生理学、心理学与认知科学对动物视觉系统的研究,但计算机视觉已发展起一套独立的计算理论与算法,它并不刻意去‘仿真’生物视觉系统”.
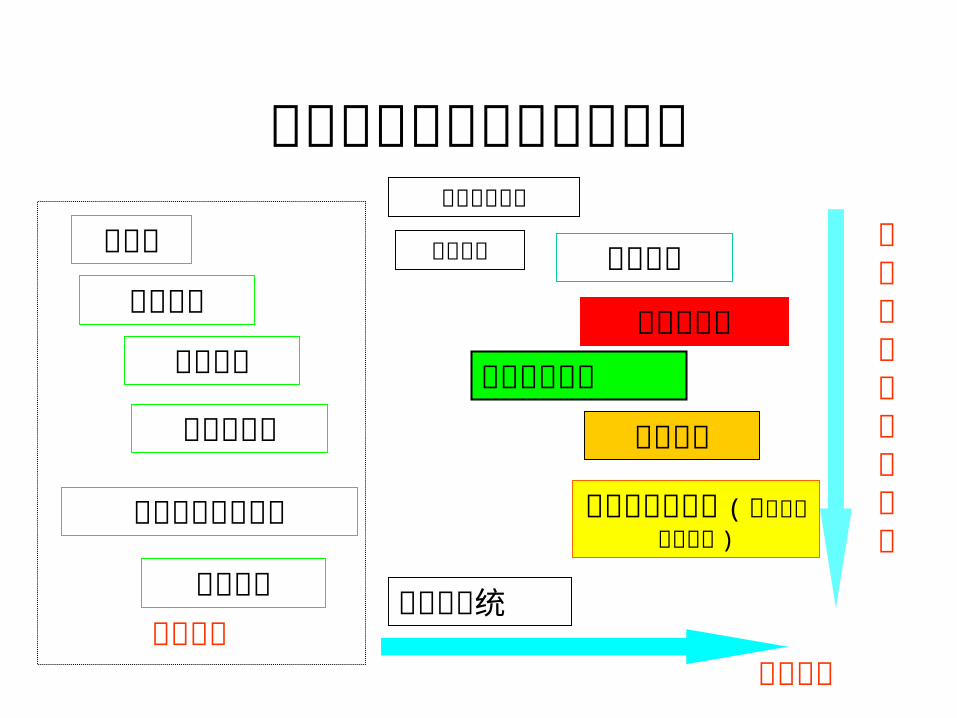
相关学科与相关课程的联系
数字图象处理计算机视觉
模式识别
机器视觉
计算机图形学
线性代数
集合论
高级语言程序设计
数据结构
先后顺序
重叠量反应相关程度
基础知识
计算机视觉专题( 如图象与视觉计算 )
高等代数
最优化方法。。。。。。。。。。。。
信号与系统
计算几何

Overview (1)
• 计算机视觉的几何学基础– 摄像机模型
• 单摄像机 (pinhole model/perspective transformation)• 双摄像机 (epipolar geometry: fundamental/essential matrix)• 三摄像机及更多 (multi-view geometry)
– 运动估计• 对应点问题( correspondence problem)• 光流计算方法• 刚体运动参数估计( minimal projective reconstruction)
– 2-view, 7 points in correspondence; (Faugeras)– 3-view, 6 points in correspondence; (Quan Long)– 3-view, 8 points with one missing in one of the three view. (Quan Long)
– 几何重构( Geometry reconstruction)• 立体视觉 (stereo vision)• Shape from X (shading/motion/texture/contour/focus/de-focus/….)

Overview (2)
• 计算机视觉的物理学基础– 摄像机及其成像过程
• 视点、光源、空间中光线、表面处的光线… .• 明暗 (shading)、阴影 (shadow)
– 光学 /色彩 (light/color)• 辐射学 (radiometry) ,辐照率 , …,
– 物体表面特性• 漫反射表面(各向同性) Lambertian surface• BDRF (bi-directional reflectance distribution
function)

Overview (3)
• 计算机视觉的图像模型基础– 摄像机模型及其校准
• 内参数、外参数– 图像特征
• 边缘、角点、轮廓、纹理、形状…
– 图像序列特征 ( 运动 )• 对应点、光流

Overview (4)计算机视觉的信号处理层次• 低层视觉处理
– 单图像:滤波 /边缘检测 /纹理– 多图像:几何 /立体 / 从运动恢复仿射或透视结构 (affine/perspective
structure from motion)• 中层视觉处理
– 聚类分割 /拟合线条、曲线、轮廓 clustering for segmentation, fitting line…
– 基于概率方法的聚类分割 /拟合– 跟踪 tracking
• 高层视觉处理– 匹配– 模式分类 / 关联模型识别 pattern classification/aspect graph recognition
• 应用– 距离数据( range data ) / 图像数据检索 / 基于图像的绘制

Overview (5)计算机视觉的数学基础• 射影/仿射几何、微分几何• 概率统计与随机过程• 数值计算与优化方法• 机器学习
计算机视觉的基本的分析工具和数学模型• Signal processing approach: FFT, filtering, wavelets, …
• Subspace approach: PCA, LDA, ICA, …• Bayesian inference approach: EM, Condensation/sequential importance
sampling (SIS) …, Markov chain Monte Carlo (MCMC) , ….
• Machine learning approach: SVM/Kernel machine, Boosting/Adaboost, k-NN/Regression, …
• HMM, BN/DBN (Dynamic Bayesian Network), …
• Gibbs, MRF, …
• …

Overview (6)
计算机视觉问题的特点• 高维数据的本质维数很低,使得模型化成为可能。High dimensional image/video data lie in a very low
dimensional manifold.
• 解的不唯一性 缺少约束的逆问题• 优化问题

CV 的若干问题及应用展望• 基本视觉系统如下:
特征检测 Shape from X 识别图像 低层特征 位置与形状 物体
描述• 涉及模块与系统的研究存在的问题与出现的一些新 思路,如“视觉信息处理系统的‘任务’”, “关于模块化 问题” , “局部特征与全局特征” , “物体建模” ,等等.• 三维计算机视觉将会有极广泛的应用前景 , 如 : 计算机人-机交互;多媒体技术,数据库与图像通信; 生产自动化;医学;自动导航;三维场景建模与可视化.

纲要• 什么是 CV?
– 什么是 CV? 它是从什么时候发展起来的 ?– 它有哪些研究内容 ?– 它与哪些学科 / 领域相关 ?– CV 的若干问题及应用展望
• 几何基础/概率基础• 一些相关资源

射影几何知识简介• 欧氏几何:旋转和平移都是欧氏变换.研究在欧氏变换下保持不变的性质(欧氏性质)的几何是欧氏几何.如平行性,长度,角度等都是欧氏性质.
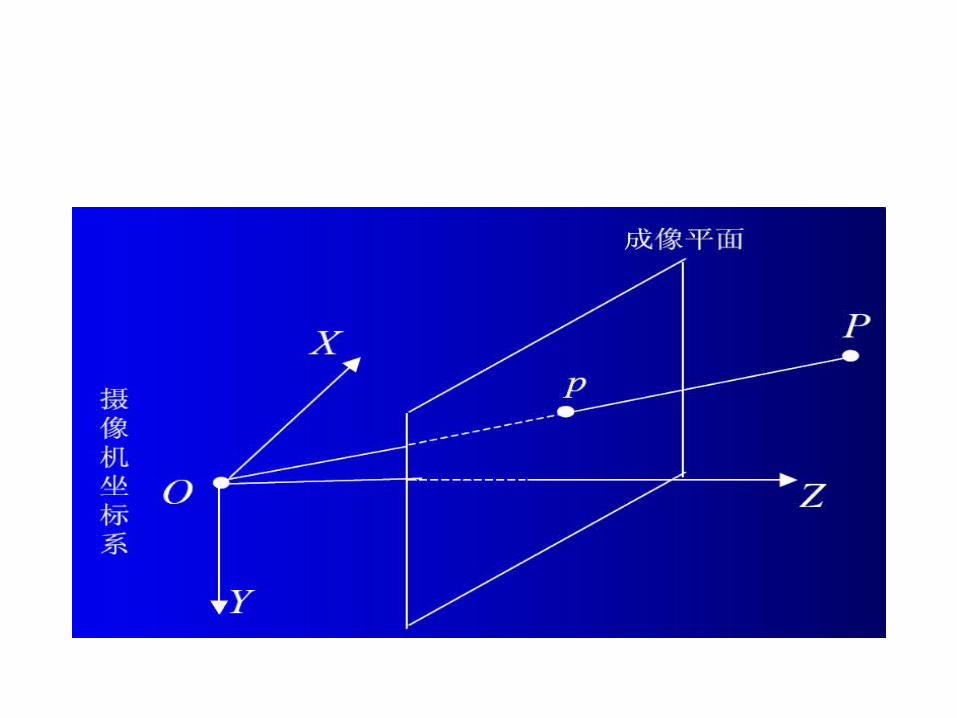
• 射影几何:照相机的成像过程是一个射影(透视或中心射影)的过程.它不保持欧氏性质,如平行线不再平行.研究射影空间中在射影变换下保持不变的性质(射影性质)的几何学是射影几何.


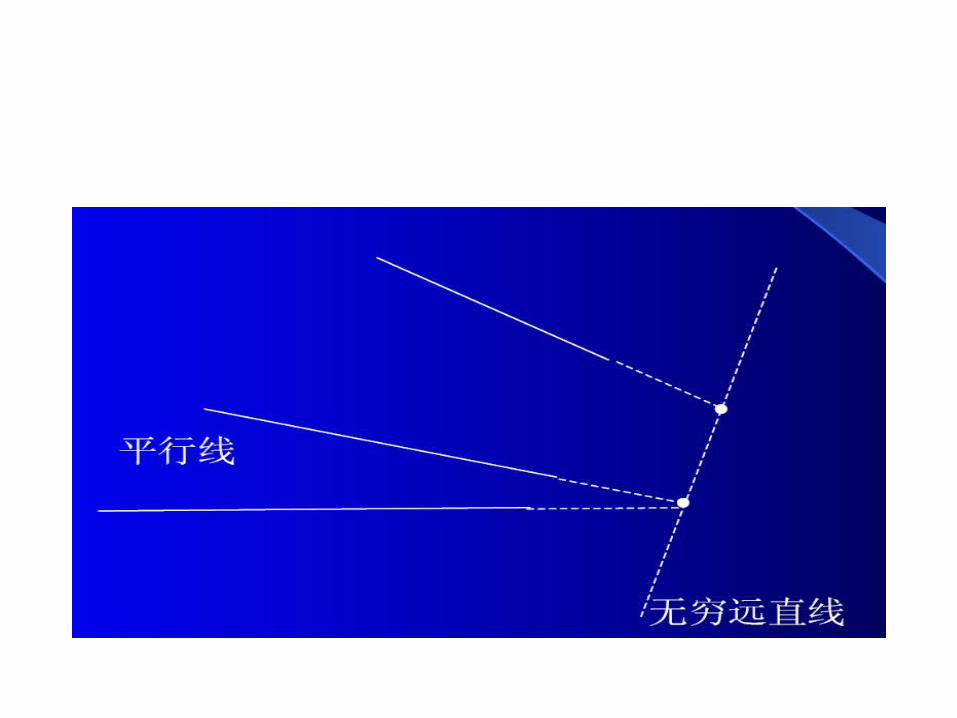
无穷远元素
• 平行线交于一个无穷远点;• 平行平面交于一条无穷远直线;• 在一条直线上只有唯一一个无穷远点;• 所有的一组平行线共有一个无穷远点.• 在一个平面上,所有的无穷远点组成一条直线,称为这个平面的无穷远直线.
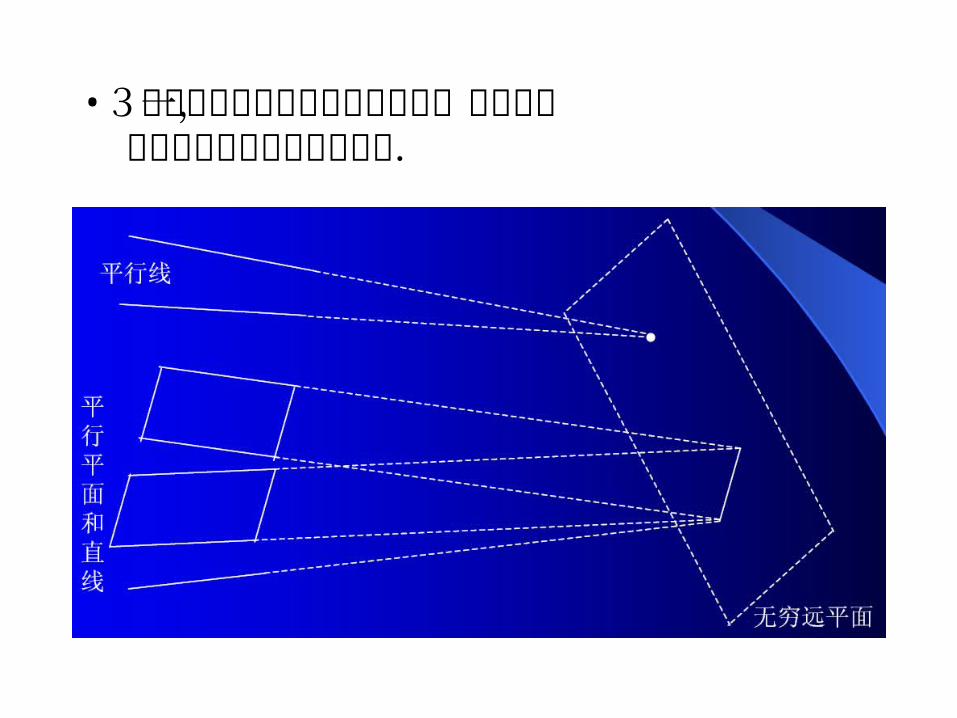
•3维空间中所有的无穷远点组成一个平面, 称为这个空间的无穷远平面.

射影空间• 对 n 维欧氏空间加入无穷远元素,并对
有限元素和无穷远元素不加区分,则它们共同构成了 n 维射影空间 .
• 1 维射影空间是一条射影直线,它由欧氏直线和它的无穷远点组成;
• 2 维射影空间是一个射影平面,它由欧氏平面和它的无穷远直线组成;
• 3 维射影空间是由 3 维欧氏空间加上无穷远平面组成.

齐次坐标• 在欧氏空间中建立坐标系以后,点与坐标有了一一
对应,但当引入无穷远点以后,无穷远点没有坐标,为了刻划无穷远点的坐标,可以引入齐次坐标.
• 在 n 维欧氏空间中,建立直角坐标以后,每个点的坐标为 (m1, …, mn) ,对任意 n+1 个数 x1, …, xn, x0 ,如果满足x00, xi/x0 = mi, (i = 1…n)
则称 (x1, …, xn, x0) 为该点的齐次坐标.而 (m1, …,
mn)被称为非齐次坐标.

• 不全为 0 的数 x1, …, xn组成的坐标 (x1, …, xn, 0)
被称为无穷远点的齐次坐标.• 例 设在欧氏直线上的普通点的坐标为 x ,
则适合 x1/ x0 = x
的任意两个数组成的坐标 (x1, x0) 为该点的齐次坐标,而 x 为该点的非齐次坐标.对任意x1 0 ,则 (x1, 0) 是无穷远点的齐次坐标.



射影参数

交比

射影变换



射影平面中的对偶• “ 点”与“直线”叫做射影平面上的对偶元素.
• “ 过一点作一直线”与“在直线上取一点”叫做对偶作图.
• 在射影平面设有点,直线及其相互结合和顺序关系所组成的一个命题,将此命题中的各元素改为它的对偶元,各作图改为它的对偶作图,其结果形成另一个命题,这两个命题称为平面对偶命题.
• 对偶原则:在射影平面中,若一个命题成立,则其对偶命题也成立.

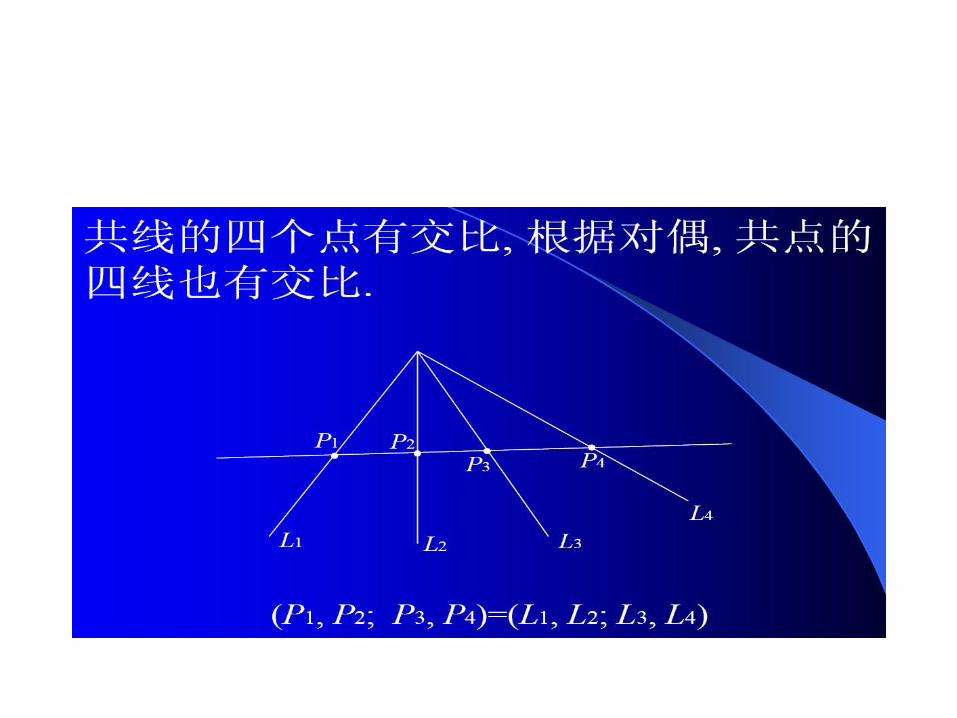

调和关系
• 若点对 (P1, P2) 和 (P3, P4) 的交比是 -1 ,即 (P1, P2;P3, P4) = -1,
则称 (P1, P2) 与 (P3, P4) 是调和的.• 点对 (P1, P2) 与 (P3, P4) 是调和的当且仅当
(1+2)(3+4) = 2(12 +34)
其中 i 分别是 Pi (i = 1, …, 4) 的射影参数.



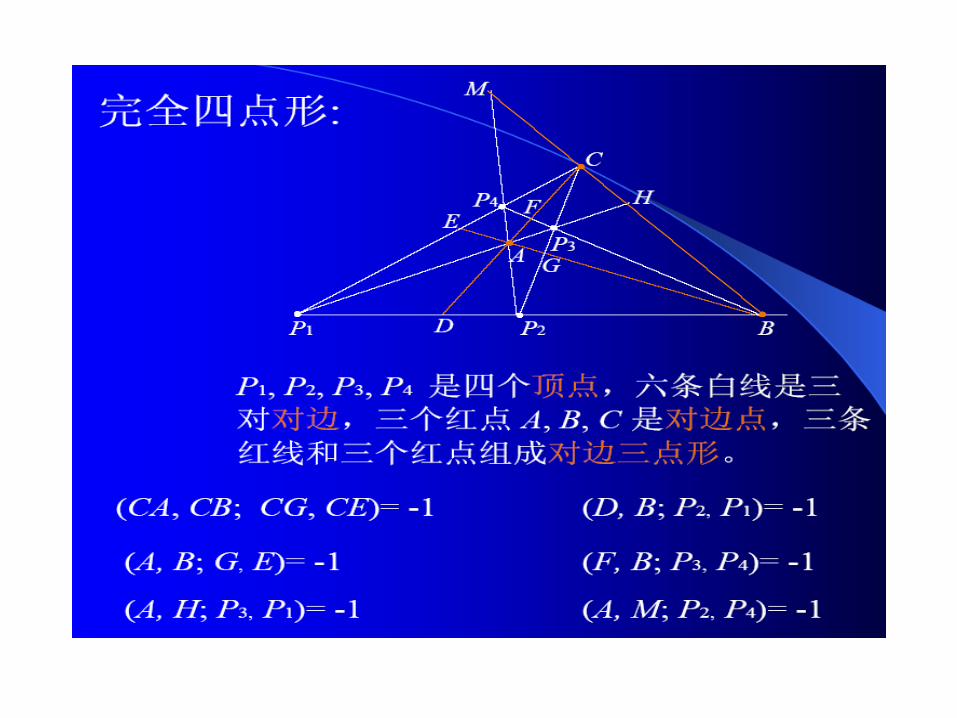
完全四点 ( 线 ) 形中的调和关系

二次曲线





绝对二次曲线 (Absolute Conic)



极点与极线• 对于一个二次曲线 C 和某个点 A(向量 ) ,由 L=CA确定的直线 (线坐标 )称为点 A 关于二次曲线 C 的极线.
• 当 A 在二次曲线 C 上时,点 A 的极线是过它的切线.
• 对于一个二次曲线 C 和某条直线 L (向量 ) ,由A=C*L确定的点称为线 L 关于二次曲线 C 的极点.
• 当 L 是二次曲线 C 的切线时,线 L 的极点是它上的切点.
• 对极关系是射影不变的关系,利用这个关系可以对照像机进行标定.


三维射影几何
• 点、直线、平面• 二次曲面• 扭三次曲线:与三维重建中的退化情况紧密联系.

几何基础的参考书
另外 , 马颂德等的书中有章节简略介绍相关几何知识 .“HZintroduction.pdf” 有些介绍.
概率论简介
• 有关概率论的知识,自学.

一些 internet 资源• http://www.cs.cmu.edu/~cil/v-source.html• Google search computer vision
– Computer vision homepage– Computer vision Research Groups– CVonline– Computer vision test Image
• Paper search– http://www.researchindex.com

文章来源
• 主要资源 : IEEE TPAMI; ICCV; CVPR; ECCV;
ACCV; IEEE Trans. on Robotics and Automation;
IEEE TIP; Computer Vision, Graphics and Image
Processing (CVGIP); Visual Image Computing;
International J. of PRAI; PR…
• 其它资源 : SIGGRAPH, ICIP, ….
• “每年的研究论文不下数千篇 , 发表的不下数百篇 .”

Tips
• “Computer Vision’s great trick is extracting descriptions of the
world from pictures or sequences of pictures.”
• “… 但是,这绝不意味着这些方法就是最优的方法了,也不意味着这些问题已完全解决了.相反,目前的方法一般都没有完美地解决视觉信息处理中的问题,它们都或多或少地有些问题,需要进一步的研究,因此,读者只能将这些方法看作是解决一问题的思路或目前已有的较好的方法.”
• “It is a great time to be studying this subject.”
• JUST DO IT!

Homework
• 安装并熟悉 Intel OpenCV (可先看一下其 FAQ
http://www.intel.com/technology/computing/opencv/faq.htm) 或其它开发包 /工具箱 ( 如 Matlab).
• 认真阅读课本的前言及 handout;
• 预习第三章及与几何标定相关内容 : sturm99.pdf;
TR98-71.pdf; calib_eccv.pdf; ZhangPAMI05.pdf;
HammarstedtSturmHeyden-iccv05.pdf.
• First project is ‘hw1.pdf’.





























