Embed Size (px)
Citation preview

МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ Федеральное государственное бюджетное образовательное
учреждение высшего образования «ТЮМЕНСКИЙ ГОСУДАРСТВЕННЫЙ НЕФТЕГАЗОВЫЙ УНИВЕРСИТЕТ»
С. В. Вершинина О. В. Руденок Н.С. Кулакова О.В. Тарасова
СТАТИСТИЧЕСКИЕ МЕТОДЫ ОБРАБОТКИ ДАННЫХ
Учебное пособие
Тюмень ТюмГНГУ
2015

УДК 311.2 (075.8) БКК 60.6я73
В37
Рецензенты: Доктор физико-математических наук, профессор, за-
ведующий кафедрой «Алгебры и математической ло-гики» ФГБОУ ВПО «Тюменский государственный уни-верситет» - В.Н. Кутрунов.
Доктор экономических наук, профессор ФГБОУ ВПО «Тюменский государственный университет» - Т.В. Авилова.
Вершинина С. В., Руденок О. В., Кулакова Н.С. Тарасова О.В. В37 Статистические методы обработки данных: учебное пособие /
С. В. Вершинина, О. В. Руденок, Н. С. Кулакова, О. В. Тарасова. – Тюмень: ТюмГНГУ, 2015. – 160 с.
ISBN 978-5-9961-1124-4
Учебное пособие состоит из двух разделов: теоретического и практического. В первом разделе излагаются методы математиче-ской статистики для обработки результатов измерений, рассматри-ваются основные понятия математической статистики, выбороч-ный метод, интервальные оценки параметров, проверка гипотез, корреляционный и регрессионный анализ. Второй раздел содер-жит образцы примеров выполнения лабораторных работ и вари-анты индивидуальных задания для самостоятельного решения.
Содержание учебного пособия соответствует требованиям ФГОС ВО и отражает содержание компетентностной модели ма-гистранта.
Пособие предназначено для магистров по направлению подго-товки «Нефтегазовое дело», а также аспирантов, преподавателей ву-зов, научных и практических работников, связанных с анализом дан-ных.
УДК 311.2 (075.8) БКК 60.6я73
ISBN 978-5-9961-1124-4 © Федеральное государственное бюджетное образовательное учреждение высшего обра-зования «Тюменский государственный нефтегазовый университет», 2015

3
СОДЕРЖАНИЕ
ВВЕДЕНИЕ 5
РАЗДЕЛ I. СТАТИСТИЧЕСКИЕ МЕТОДЫ ОБРАБОТКИ ДАННЫХ 8
ГЛАВА 1. ВАРИАЦИОННЫЕ РЯДЫ И ИХ ХАРАКТЕРИСТИКИ 8 1.1. Первичная обработка результатов наблюдений 8 1.2. Графическое изображение статистических данных 12 1.3. Расчет выборочных характеристик статистического распределения 15 1.4. Интервальные (доверительные) оценки параметров распределения 21 Контрольные вопросы 23
ГЛАВА 2. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ 24 2.1. Построение кривой нормального распределения 24 2.2. Классический метод проверки гипотез 26 2.3. Проверка гипотез о законе распределения 28 Контрольные вопросы 34
ГЛАВА 3. ПАРНАЯ РЕГРЕССИЯ И КОРРЕЛЯЦИЯ 35 3.1. Понятие функциональной, статистической и корреляционной зависимости 35 3.2. Линейная модель парной регрессии и корреляции 36 3.3. Нелинейные модели парной регрессии и корреляции 41 Контрольные вопросы 46
ГЛАВА 4. МНОЖЕСТВЕННАЯ РЕГРЕССИЯ И КОРРЕЛЯЦИЯ 48 4.1. Спецификация модели. Отбор факторов при построении уравнения множественной регрессии 48 4.2. Метод наименьших квадратов (МНК). Свойства оценок на основе МНК 50 4.3. Проверка существенности факторов и показатели качества регрессии 53 Контрольные вопросы 59
РАЗДЕЛ II. ЛАБОРАТОРНЫЙ ПРАКТИКУМ 60 Лабораторная работа № 1. Комплексная статистическая обработка экспериментальных данных и проверка гипотезы принадлежности выборки нормальному распределению 60 Лабораторная работа № 2. Построение модели линейной регрессии (случай несгруппированных данных) 71 Лабораторная работа № 3. Построение уравнения модели линейной регрессии (случай сгруппированных данных) 77

4
Лабораторная работа № 4. Изучение модели нелинейной регрессии 84 Лабораторная работа № 5. Построение модели множественной регрессии 89 Лабораторная работа № 6. Прогнозирование. Анализ аддитивной модели 95 Варианты индивидуальных заданий 99
К лабораторной работе № 1 99 К лабораторной работе № 2 105 К лабораторной работе № 3 110 К лабораторной работе № 4 120 К лабораторной работе № 5 125 К лабораторной работе № 6 139
Тестовые задания 140 Список литературы 149 Приложения 150

5
ВВЕДЕНИЕ
Современный этап научно-техническое развитие характеризуется ши-роким применением статистических методов во всех областях знаний. За-дача любой науки - выявление и исследование закономерностей, обладаю-щих не только теоретическойценностью, но и применяемых практически. Достижению поставленных целей помогает использование вероятностных и математико-статистических методов исследования.Применение указан-ных методов дает возможность изучать закономерности массовых случай-ных явлений, прогнозировать их характеристики, контролировать их, огра-ничивать область действия случайности.
Решение научных и инженерных задач в области геологии нефти и газа и нефтегазового дела является неотъемлемой частью профессиональ-ной деятельности инженера-исследователя. Для формирования научных выводов важным моментом было и остается не только умелое планирова-ние и постановка эксперимента, но и грамотное обработка его результатов. Современная математическая статистика разрабатывает способы опреде-ления числа необходимых испытаний до начала исследования, а также способы последовательного анализа в ходе эксперимента. Ни одна науч-ная работа не может являться законченной без статистической обработки данных, с использованием более сложных экспериментально-статистиче-ских методов, позволяющих получать математические модели, а также адекватной интерпретацией их количественных и качественных характе-ристик.
Цель курса «Статистические методы обработки данных» – изучение ос-новных положений теории вероятностей и математической статистики, изу-чение и выработка навыков использования статистического аппарата обра-ботки данных и особенностей его применения к анализу случайных явле-ний, наблюдаемых на практике.
Предметом изучения в курсе являются вероятностные закономерности возникающие при взаимодействии большого числа случайных факторов массовых однородных случайных явлений в науке, а также математические методы систематизации и использования статистических данных для науч-ных выводов.Изучение курса поможет в формировании логического мыш-ления, повышении уровня фундаментальной математической подготовки с усилением ее прикладной технологической направленности, а также в зна-комстве с методикойстатистической обработки данных в научных исследо-ваниях будущих магистров.
Учебное пособие представлено двумя разделами. В первом разделе, со-стоящем из четырех глав, последовательно освещаются базовые основные положения, начиная с методов обработки результатов наблюдений, про-верки гипотез и заканчивая методами, применяемыми для построения мате-матических многофакторных моделей.

6
В целях повышения эффективности восприятия изучаемого теоретиче-ского материала первого раздела, второй раздел учебного пособия содержит методические рекомендации по выполнению лабораторных работ и вари-анты индивидуальных заданийк шести лабораторным работам для самосто-ятельного решения.
Для самостоятельной проверки и контроля знаний в конце каждой главы приводится список вопросов, который используется в дальнейшем для формирования базы вопросов итогового тестирования, в заключение по-собия имеются тестовые задания.
Изучение настоящего учебного пособия позволит сформировать следу-ющие общекультурные и профессиональные компетенции в области научно-исследовательской и проектной деятельности:
− самостоятельно совершенствовать и развивать свой интеллекту-альный и общекультурный уровень;
− понимать роль философии в современных процессах развития науки, анализировать основные тенденции развития философии и науки;
− самостоятельно приобретать и использовать в практической дея-тельности новые знания и умения, в том числе в новых областях знаний, непосредственно не связанных со сферой деятельности;
− использовать программно-целевые методы решения научных проблем; − самостоятельно овладевать новыми методами исследований, мо-
дифицировать их и разрабатывать новые методы, исходя из задач конкрет-ного исследования;
− проявлять инициативу, в том числе в ситуациях риска, находить нестандартные решения, брать на себя всю полноту ответственности;
− формулировать и решать задачи, возникающие в ходе научно-ис-следовательской и практической деятельности;
− использовать на практике знания, умения и навыки в организации исследовательских, проектных и конструкторских работ, в управлении кол-лективом;
− изменять научный и научно-производственный профиль своей профессиональной деятельности;
− разрабатывать научно-техническую, проектную и служебную до-кументацию, оформлять научно-технические отчеты, обзоры, публикации по результатам выполненных исследований;
− использовать методологию научных исследований в профессио-нальной деятельности;
− планировать и проводить аналитические, имитационные и экспери-ментальные исследования, критически оценивать данные и делать выводы;
− использовать профессиональные программные комплексы в области математического моделирования технологических процессов и объектов;

7
- проводить анализ и систематизацию научно-технической информа-ции по теме исследования, осуществлять выбор методик и средств решения задачи, проводить патентные исследования с целью обеспечения патентной чистоты новых разработок;
- применять методологию проектирования. Особенностью данного пособия является то, что теоретические поло-
жения и разделы дополнены достаточным количеством подробно решенных задач в области геологии нефти и газа и нефтегазового дела.
Учебное пособие предназначено для магистров по направлению подго-товки «Нефтегазовое дело» в рамках изучения дисциплины «Статистиче-ские методы обработки данных», а также аспирантов, преподавателей вузов, научных и практических работников, связанных с анализом данных.

8
РАЗДЕЛ I. СТАТИСТИЧЕСКИЕ МЕТОДЫ ОБРАБОТКИ ДАННЫХ
ГЛАВА 1. ВАРИАЦИОННЫЕ РЯДЫ И ИХ ХАРАКТЕРИСТИКИ
1.1. Первичная обработка результатов наблюдений
В первичной обработке результатов наблюдений при анализе показате-
лей работы разных отраслей производственной сферы (добыча нефти и газа, ремонт скважин, машиностроение, строительная индустрия и т.д.) и их про-гнозировании используют методы математической статистики, которые позволяют установить закономерности производственных результатов с требуемой точностью, надежностью и минимальных материальных, трудо-вых затратах и оценить их основные свойства. Решение этих вопросов осу-ществляется методами математической статистики.
Основными понятиями математической статистики являются генераль-ная совокупность и выборка.
Генеральная совокупность – это некоторое множество А или совокуп-ность всех мысленно возможных объектов данного вида, над которыми про-водятся наблюдения с целью получения конкретных значений определен-ной случайной величины. Например, множество всех единиц продукции данного предприятия. Выборка (выборочная совокупность) – случайно вы-бранное подмножество B⊂Aиз генеральной совокупности. Например, мно-жество случайно выбранных единиц продукции, при этом некий наблюда-тель измерил у них вес в килограммах.
Одним из основных методов математической статистики является вы-борочный метод – метод исследования общих свойств множества А на ос-нове изучения статистических свойств только подмножества В.
Число N = | A | элементов множества А называется объемом генеральной совокупности, а число n = | B | -объемом выборки. При изучении некоторого признака Х (в данном примере – веса) выборки производят испытания или наблюдения (измерение веса).
Выборку образуют полученные разными способами отбора исходные данные, которые представляют собой множество чисел, расположенных в хаотичном порядке (беспорядке). По такой выборке невозможно выявить определенную закономерность их варьирования (изменчивости). Поэтому с целью обработки исходных данных применяют операцию ранжирования, которая заключается в том, что наблюдаемые значения случайной величины располагают в определенном порядке (возрастания или убывания).
После проведения операции ранжирования отдельные значения случайной величины группируют таким образом, чтобы в каждой отдельной группе значения случайной величины были одинаковыми. Каждое из таких значений называется вариантой ix .

9
Число, которое показывает, сколько раз встречаются соответствующие значение варианты ix в ряду наблюдений, называется частотой или
эмпирической частотой и обозначается как in , где i - номер варианты. Отношение wi = ni/n частоты ni к объему выборки n называют относи-
тельной частотой (частостью) варианты хi. Вариационным рядом (или статистическим распределением) назы-
вают последовательность вариантов, записанных в возрастающем порядке и соответствующих им частот или относительных частот.
Различают дискретные и непрерывные вариационные ряды. Дискретным статистическим рядом принято называть
ранжированную совокупность вариант ( )ix и соответствующих им частот ( )in или частостей ( )iω .
Принято записывать дискретный статистический ряд в виде табл.1.1.
Таблица 1.1
Варианты,xi x1 x2 . . . xk
Частоты,ni n1 n2 . . . nk
В случае, когда исследуемая случайная величина X является непре-рывной или число ее значений достаточно велико ( 30>n ), то принято со-ставлять интервальный вариационный ряд.
Интервальный вариационный ряд, формируется на основании следую-щего алгоритма:
1. Вычисляют размах R варьирования признака Х, как разность между наибольшим maxx и наименьшим minx значениями признака совокупности:
minmax xxR −= . (1.1)
2. Размах R варьирования признака Х делится на k равных частей и таким образом определяется число столбцов (интервалов) в таблице. Число kчастичных интервалов выбирают, пользуясь одним из следую-щих правил:
206)1 ≤≤k ,
nk ≈)2 ,(1.2)
nnk lg221,31log1)3 2 ⋅+≈+≈ .
При небольшом объеме n выборки число k интервалов принимают равным от 6 до 10.

10
3. По формуле (1.3) рассчитывают длину частичного интервала h :
kxxh minmax −= , (1.3)
где h – шаг; k– число интервалов.
Величину h обычно округляют до некоторого значения d. Так, если ре-зультаты ix признака Х– целые числа, то h округляют до целого значения, если ix содержат десятичные знаки, то h округляют до значения d, содержа-щего такое же число десятичных знаков.
4. Подсчитывается частотаni, с которой попадают значения ix признака Х в i-й интервал.
Изучая полученные результаты наблюдений, выявляют, сколько значений случайной величины отнесено в каждый конкретный интервал. В интервал включаются значения, большие или равные нижней границе, а меньшие - верхней границы интервала. В первую строку таблицы статистического ряда распределения вписываются частичные промежутки [ ) [ ) [ )kk xxxxxx ,,,,,, 12110 − . Во вторую строку – количество наблюдений
in (где ki ,1= ) попавших в каждый конкретный интервал, т. е. частоты соответствующих интервалов.
В качестве начала первого интервала рекомендуется брать начальную величину, определяемую по формуле:
2hxx minнач −= , (1.4)
Конец последнего интервала ряда должен полностью удовлетворять условию:
конmaxкон xxhx <≤− . (1.5)
Промежуточные интервалы обычно получают, прибавляя к верхней границе (концу) предыдущего интервала шаг.
Сформированный интервальный вариационный ряд записывают в виде табл. 1.2.
Таблица 1.2
Варианты-интервалы, ( ix ; 1+ix ) ( 0x ; 1x ) ( 1x ; 2x ) . . . ( 1−kx ; kx )
частоты, ni n1 n2 . . . nk

11
Для расчета статистик (выборочной средней, выборочной дисперсии, асимметрии и эксцесса) переходят от интервального к дискретному вариа-ционному ряду. В данном случае серединное значение i -го интервала при-нимается за варианту ix , а соответствующая интервальная частота in при-нимается за частоту данного варианта. При этом дискретный вариационный ряд записывается в виде табл. 1.3 или табл. 1.4.
Таблица 1.3
Варианты,xi x1 x2 . . . xk Частоты,ni n1 n2 . . . nk
Здесь ∑ = nni , где n - объем выборки.
Таблица 1.4 Варианты,xi x1 x2 . . . xk Частности, wi= ni/ n w1 w2 . . . wk
Здесь ∑=
=k
ii
11w .
Для характеристики свойств статистического распределения в матема-тической статистике вводится понятие эмпирической функции распределе-ния. Под эмпирической функцией или функцией распределения выборки по-нимается функция ( )xF* , которая определяет частость события { }xX < для каждого отдельного значения x :
( )nnxF x* = , (1.6)
где n - объем выборки,
xn – число наблюдений, меньших x ( )Rx∈ .
В случае увеличения объема статистической выборки частость события { }xX < приближается к вероятности данного события, поэтому эмпириче-
ская функция ( )xF* является оценкой интегральной функции ( )xF . Стоит отметить, что функции ( )xF * и ( )xF обладают одинаковыми свой-ствами. К числу этих свойств относятся:
1. ( ) 10 ≤≤ xF* ;

12
2. ( )xF* - неубывающая функция;
3. ( ) 0=∞−*F , ( ) 1=∞+*F .
В теории вероятностей аналогом этой функции является интеграль-ная функция распределения F(x), для которой достоверно приближенное равенство:
( ) ( ) ( ) xxfxFxF ∆⋅≈−∆+ , (1.7)
где ( )xf – дифференциальная функция распределения или функция плот-ности вероятности.
Выборочным тождеством функции ( )xf следует считать функцию:
( ) ( ) ( )x
xFxxFxf**
*
∆−∆+
= , (1.8)
где ( ) ( )xFxxF ** −∆+ – частость попадания наблюдаемых значений слу-чайной величины X в интервал [ )xx;x ∆+ . Следовательно, значение
( )xf * является характеристикой плотности частости на данном интервале. В случае, если наблюдаемые значения непрерывной случайной вели-
чины представлены в виде интервального вариационного ряда, и, предпола-гая, что wi – это частость попадания данных значений в интервал [ )ha;a ii + , где h – длина частичного интервала, то выборочная функция
плотности ( )xf * задается соотношением:
( )
>
=≤≤
<
=
+
+
,,0
,,2,1,,
,,0
1
1
1
*
k
iii
axпри
kiaxaприh
axпри
xf ω
(1.9)
где 1+ka – конец последнего k-го интервала ряда.
В виду того, что функция ( )xf * является тождеством распределения плотности случайной величины, то область под графиком данной функции всегда равна единице.
1.2. Графическое представление статистических данных
В статистике принято изображать статистическое распределение
графически с помощью полигона и гистограммы.
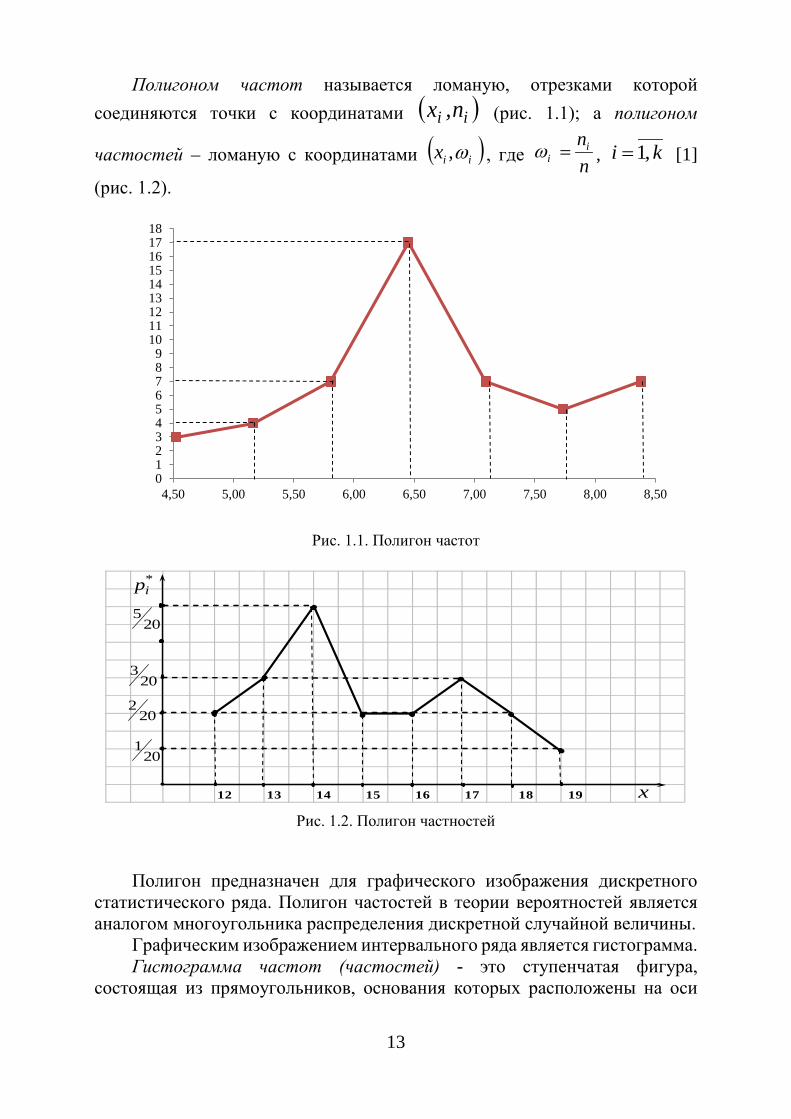
13
Полигоном частот называется ломаную, отрезками которой соединяются точки с координатами ( )ii n,x (рис. 1.1); а полигоном
частостей – ломаную с координатами ( )iix ω, , где nni
i =ω , ki ,1= [1]
(рис. 1.2).
Рис. 1.1. Полигон частот
Рис. 1.2. Полигон частностей
Полигон предназначен для графического изображения дискретного статистического ряда. Полигон частостей в теории вероятностей является аналогом многоугольника распределения дискретной случайной величины.
Графическим изображением интервального ряда является гистограмма. Гистограмма частот (частостей) - это ступенчатая фигура,
состоящая из прямоугольников, основания которых расположены на оси
0123456789
101112131415161718
4,50 5,00 5,50 6,00 6,50 7,00 7,50 8,00 8,50
12 13 14 15 16 17 18 19
*ip
202
203
205
201
x
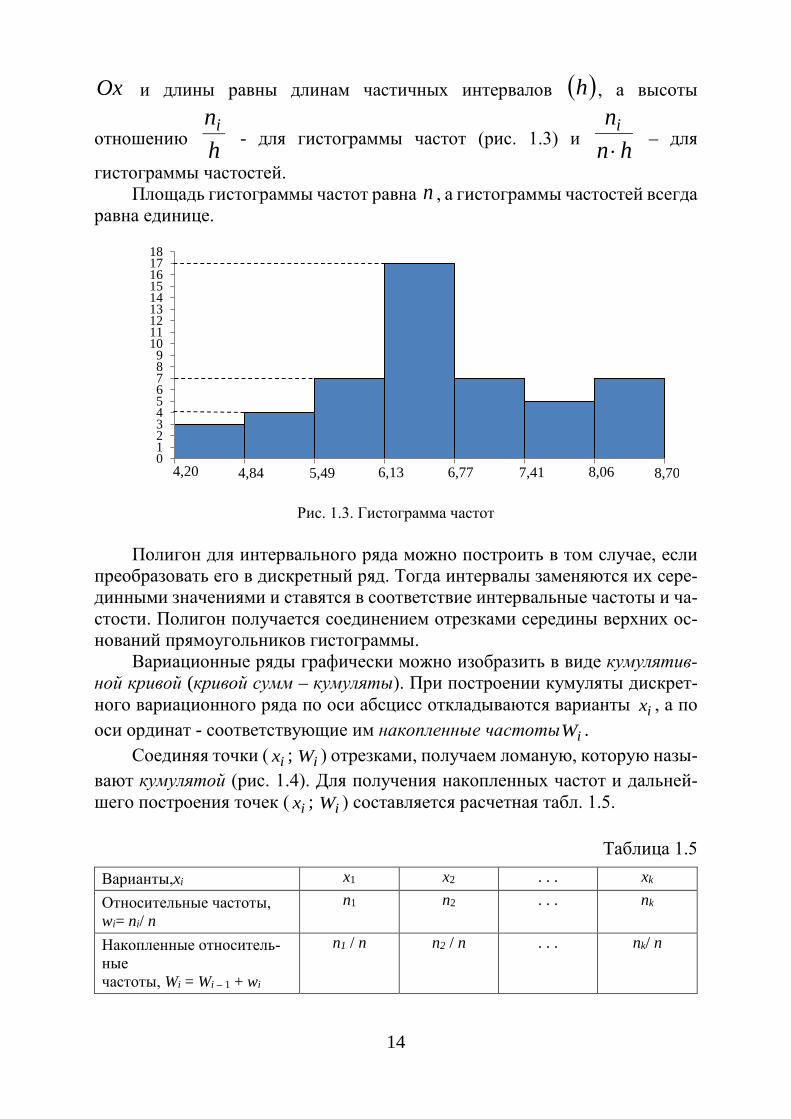
14
Ox и длины равны длинам частичных интервалов ( )h , а высоты
отношению hni
- для гистограммы частот (рис. 1.3) и hnni⋅ – для
гистограммы частостей. Площадь гистограммы частот равна n , а гистограммы частостей всегда
равна единице.
Рис. 1.3. Гистограмма частот
Полигон для интервального ряда можно построить в том случае, если
преобразовать его в дискретный ряд. Тогда интервалы заменяются их сере-динными значениями и ставятся в соответствие интервальные частоты и ча-стости. Полигон получается соединением отрезками середины верхних ос-нований прямоугольников гистограммы.
Вариационные ряды графически можно изобразить в виде кумулятив-ной кривой (кривой сумм – кумуляты). При построении кумуляты дискрет-ного вариационного ряда по оси абсцисс откладываются варианты ix , а по оси ординат - соответствующие им накопленные частоты iW .
Соединяя точки ( ix ; iW ) отрезками, получаем ломаную, которую назы-вают кумулятой (рис. 1.4). Для получения накопленных частот и дальней-шего построения точек ( ix ; iW ) составляется расчетная табл. 1.5.
Таблица 1.5
Варианты,xi x1 x2 . . . xk Относительные частоты, wi= ni/ n
n1 n2 . . . nk
Накопленные относитель-ные частоты, Wi = Wi – 1 + wi
n1 / n n2 / n . . . nk/ n
0123456789
101112131415161718
4,20 4,84 5,49 6,13 6,77 7,41 8,06 8,70
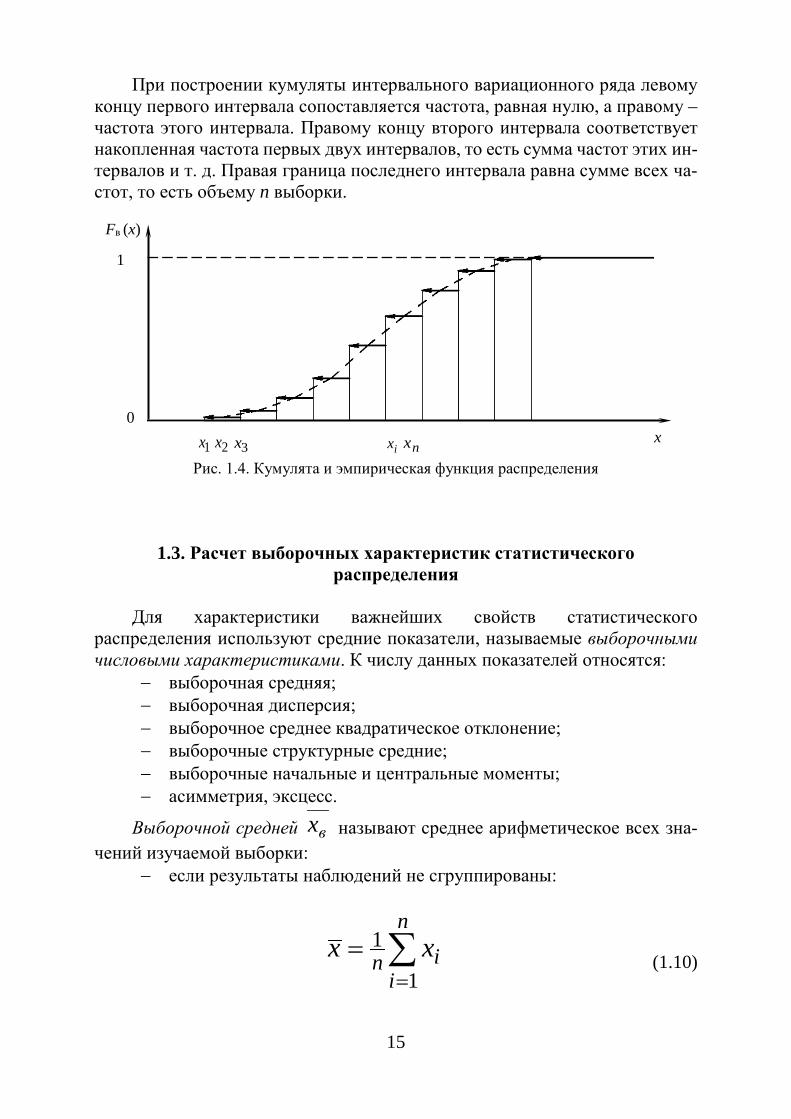
15
При построении кумуляты интервального вариационного ряда левому концу первого интервала сопоставляется частота, равная нулю, а правому – частота этого интервала. Правому концу второго интервала соответствует накопленная частота первых двух интервалов, то есть сумма частот этих ин-тервалов и т. д. Правая граница последнего интервала равна сумме всех ча-стот, то есть объему n выборки.
Рис. 1.4. Кумулята и эмпирическая функция распределения
1.3. Расчет выборочных характеристик статистического
распределения
Для характеристики важнейших свойств статистического распределения используют средние показатели, называемые выборочными числовыми характеристиками. К числу данных показателей относятся:
− выборочная средняя; − выборочная дисперсия; − выборочное среднее квадратическое отклонение; − выборочные структурные средние; − выборочные начальные и центральные моменты; − асимметрия, эксцесс.
Выборочной средней вx называют среднее арифметическое всех зна-чений изучаемой выборки:
− если результаты наблюдений не сгруппированы:
∑=
=n
iin xx
1
1 (1.10)
0
1x 2x 3x ix nx x
1
Fв (x)

16
− если результаты сгруппированы в дискретный вариационный ряд:
∑=
=m
iiiв nx
nx
1
1. (1.11)
Выборочную среднюю можно записать как:
∑=
=m
iiiâ x
nx
1
1 ω , (1.12)
где iω – частость.
В случае интервального статистического ряда в качестве ix следует
брать середины интервалов, а in – соответствующие им частоты.
Выборочной дисперсией вD принято называть среднее арифметиче-
ское квадратов отклонений значений выборки от выборочной средней вx : − если результаты наблюдений не сгруппированы: −
∑=
−=n
iân xxD
1
212 )( (1.13)
− если результаты наблюдений сгруппированы в дискретный вариа-ционный ряд:
( ) i
m
iвiв nxx
nD ⋅−= ∑
=
2
1
1 (1.14)
или
( ) i
m
iâiâ xx
nD ω*1 2
1∑=
−= . (1.15)
Выборочное среднее квадратическое отклонение выборки определя-ется на основании формулы:
вв D=σ . (1.16)
Особенность выборочного среднего квадратического отклонения заклю-чается в том, что оно измеряется в тех же единицах, что и данные выборки.
В случае, когда объем выборки достаточно невелик ( 30≤n ) пользу-ются исправленной выборочной дисперсией, которая определяется на осно-вании формулы:

17
вDn
nS1
2
−= . (1.17)
Соответственно, величину 2SS = называют исправленным сред-ним квадратическим отклонением.
Для анализа вариационных рядов вычисляют такие статистики, как моду и медиану.
Модой XM o называют варианту, которая имеет наибольшую частоту. Например, для вариационного ряда:
мода равна 14=XM o . Медианой XMe – значение случайной величины, приходящееся на сере-
дину ряда. Если kn 2= , где n – объем выборки, то есть ряд имеет четное число
членов, то медиана находится на основании формулы:
21++
= kke
xxXM . (1.18)
Например, для следующего вариационного ряда:
медиана равна 5,2122318 == +XM e .
Если ряд имеет нечетное число членов, то есть 12 += kn , то медиана равна серединному члену вариационного ряда:
1+= ke xXM . (1.19)
Например, для вариационного ряда
медиана равна 18=XM e .
xi 6 14 21 27 ni 12 29 21 9
xi 10 13 18 23 25 31 ni 4 8 3 5 4 2
xi 6 14 18 21 27 ni 12 29 25 21 9

18
Показатели средней выборочной и выборочной дисперсии являются частным случаем более общего понятия - момента статистического ряда.
Начальный выборочный момент порядка l - это среднее арифметиче-ское l- ых степеней всех значений исследуемой выборки:
i
m
i
li
*l nx
n⋅= ∑
=1
1ν (1.20)
или
i
m
i
lil x ων ⋅=∑
=1
*. (1.21)
Из представленного определения следует, что начальным выборочным моментом первого порядка является:
вi
m
ii
* xnxn
=⋅= ∑=1
11ν . (1.22)
Центральным выборочным моментом порядка l называют среднее арифметическое l- ыхстепеней отклонений наблюдаемых значений выборки
от выборочной средней вx :
( ) i
lm
iâil nxx
nm ⋅−= ∑
=1
* 1 (1.23)
или
( ) i
lm
iâil xxm ω⋅−=∑
=1
*. (1.24)
Таким образом, центральным выборочным моментом второго по-рядка является:
( ) 22
1
*2 *1
ââi
m
iâi Dnxx
nm σ==−= ∑
=. (1.25)
Выборочным коэффициентом асимметрииназывают число *sA , кото-
рое определяется на основании формулы:
3
*3*
âs
mAσ
=. (1.26)

19
Выборочный коэффициент асимметрии является характеристикой асимметрии полигона вариационного ряда – в случае если полигон асиммет-ричен, то одна из ветвей его, начиная с вершины, имеет более пологий «спуск», чем вторая.
Если 0<*sA , то более пологий «спуск» полигона наблюдается слева
от центра и асимметрию называют левосторонней; в противном случае 0>*
sA - справа от цента и асимметрию называют правосторонней. Выборочный коэффициент эксцесса (коэффициент крутости) позволяет
сравнить на «крутость» выборочное распределение с нормальным распределе-нием. Выборочным коэффициентом эксцесса или коэффициентом крутости
называется число *kE , которое определяется на основании формулы:
34
*4* −=â
kmEσ . (1.27)
Важно заметить, что коэффициент эксцесса для случайной величины, распределенной по нормальному закону, равен нулю. В связи с чем, за стан-дартное значение выборочного коэффициента эксцесса принимается
0=*kE . В случае, когда 0<*
kE полигон имеет более «пологую» вершину
в сравнении с нормальной кривой; когда 0>*kE - полигон более «крутой»
в сравнении с нормальной кривой. При больших количествах значений вариантов ( 30>n ) и соответству-
ющих им частот, расчет выборочной средней, дисперсии и выборочных мо-ментов по приведенным формулам приводит к громоздким вычислениям. Поэтому для их вычисления используются условные варианты iu , опреде-ляемые на основании формулы:
hCxu i
i−
= , (1.28)
где C = MoX, h — шаг (длина интервала). Для вычисления числовых характеристик выборки составляется рас-
четная табл. 1.6.
Таблица 1.6
ix in iu iiun 2iiun 3
iiun 4iiun
контрольный столбец
2)1( +ii un
1x 1u 1n

20
Продолжение Таблицы 1.6
mx mu mn
строка сумм: Σ = Σ = Σ = Σ = Σ = Σ = Σ =
Контроль вычислений осуществляется на основании выражения:
∑ ∑ ∑ ∑ +=++ 22 )1(2 iiiiiii unununn .
С помощью сумм, полученных в нижней строке таблицы 6.1, вычис-ляют условные моменты на основании формул:
∑=
=m
iii
* nun
М1
11
, (1.29)
∑=
=m
iii
* nun
M1
22
1, (1.30)
∑=
=m
iii
* nun
M1
33
1, (1.31)
∑=
=m
iii
* nun
M1
44
1. (1.32)
Числовые характеристики выборки вычисляют на основании ниже
представленных формул:
chMx *в += 1 ; (1.33)
( ) 2212 hMMD **
в ⋅
−= ; (1.34)
вв D=σ ; (1.35)
3
*3*
âs
mAσ
= ; (1.36)

21
34
*4* −=â
kmEσ , (1.37)
где *3µ и *
4µ находим по формулам: − условного центрального момента третьего порядка:
( )( ) 33*1
*2
*1
*3
*3 23 hMMMMm ⋅+−= , (1.38)
− условного центрального момента четвертого порядка:
( ) ( )( ) 44*1
*2
2*1
*3
*1
*4
*4 364 hMMMMMMm ⋅−⋅+−= . (1.39)
Для характеристики колеблемости признака Х используют отно-сительный показатель - коэффициент вариации V, который вычисляют по формуле:
%100⋅= xвV σ
. (1.40) Величина коэффициента вариации показывает степень сгруппирован-
ности значений около центра рассеяния – чем ближе значение показателя к нулевому значению, тем теснее сгруппированы значения признака около центра рассеяния.
1.4. Интервальные (доверительные) оценки параметров распределения
В случае, когда объем выборки небольшой ( 30≤n ) точечная оценка
может существенно отличаться от оцениваемого параметра и целесообразно использовать интервальные оценки. Интервальной называется оценка, определяемая двумя числами - концами интервала.
Допустим, найденная по данным изучаемой выборки величина θ слу-жит оценкой неизвестного параметра θ . Оценка θ определяет θ тем точ-нее, чем меньше θθ − , то есть чем меньше δ в неравенстве δθθ <−
( )0>δ . В виду того, что θ – случайная величина, то и разность θθ −
будет случайной величиной. Следовательно, неравенство δθθ <− , при
заданном δ может быть выполнена только с некоторой заданной вероятно-стью.

22
Доверительная вероятность (надежность) оценки θ параметра θ - это вероятность γ , с которой выполняется неравенство δθθ <− .
Обычно в практике статистики задается вероятность γ и определяется значение δ . Чаще всего надежность задается значениями от 0,95 и выше в зависимости от конкретно решаемой задачи. Тогда неравенство δθθ <−
можно быть записано δθθδθ +<<− .
Доверительным интервалом называется интервал ( )δθδθ +− ; , покрывающий неизвестный параметр с заданной вероятностью (надеж-ностью) γ .
Пусть случайная величина Х имеет нормальное распределение: ( )σ;aN , при этом значение σ неизвестно, а вероятностьγ задана.
В случае, когда ( )XD неизвестна, используют оценку 2S . Следует ввести случайную величину:
nS
aXT в −= , (1.41)
где S – исправленное среднее квадратическое отклонение случайной вели-чины X , определенное по выборке:
( )∑=
−−
=n
iвi XX
nS
1
2
11
. (1.42)
Случайная величина T имеет распределение Стьюдента со степенью свободы, равной ( )1−n . Тогда доверительный интервал для оценки
( )XMa = будет иметь следующий вид:
⋅+⋅−
nStX;
nStX jвjв , (1.43)
где вX – выборочная средняя; S – исправленное среднее квадратическое отклонение;
jt – находится по таблице квантилей распределения Стьюдента (приложе-ние 1) в зависимости от числа степеней свободы и доверительной надежно-сти γ .

23
Тогда вид доверительного интервала для оценки ( )Xσ нормального распределения будет иметь следующий вид:
( ) ( )qSqS +<<− 11 σ при 1<q ; (1.44)
( )qS +<< 10 σ при 1>q ; где S – исправленное среднее квадратическое отклонение;
( )n;qq γ= находится по таблице значений (приложение 2) по заданным значениям n и γ.
Контрольные вопросы
1. Что называется статистической совокупностью? 2. Что понимается под генеральной и выборочной совокупностью? 3. Что называется вариационным рядом? 4. Сформулировать алгоритм построения непрерывного вариационного
ряда. 5. Графическое изображение дискретного и непрерывного вариацион-
ных рядов, в чем отличия графиков? 6. Что называется эмпирической функцией распределения? Сформули-
ровать ее свойства и рассказать о ее назначении. 7. По каким формулам находятся выборочные средние статистического
распределения? 8. Дать определение выборочной дисперсии и формулы для вычисления
дисперсии для простой и взвешенной выборки. 9. Записать формулы для вычисления исправленной дисперсии и расска-
зать для чего она вводится. 10. Что называется модой и медианой вариационного ряда, особенности
нахождения медианы при различном объеме выборки? 11. Дать определения асимметрии и эксцесса статистического распреде-
ления и рассказать об их назначении. 12. Записать доверительные интервалы для оценки генеральных матема-
тического ожидания и среднего квадратического отклонения.

24
ГЛАВА 2. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Любое высказывание о генеральной совокупности (случайной вели-чине), которое проверяется по результатам наблюдений (по выборке), назы-вается статистической гипотезой.
Примерами статистических гипотез могут быть: − математическое ожидание случайной величины равно конкрет-
ному числовому значению; − генеральная совокупность распределена по нормальному закону.
Гипотезы бывают двух видов: параметрические (гипотезы о парамет-рах распределения известного вида) и непараметрические (гипотезы о виде неизвестного распределения).
При этом принято различать простые гипотезы, содержащие только одно предположение, и сложные, которые содержат два и более предполо-жения.
Например, гипотеза 7 :0 =σH является простой, а гипотеза 0H :
ib=λ , ( где Rbi ∈ ) – сложной, потому что данная гипотеза состоит из бесконечного множества простых гипотез.
Процедуру сопоставления гипотезы с выборочными данными назы-вают проверкой гипотезы. При этом используются аналитические и стати-стические методы.
2.1. Построение кривой нормального распределения
Проверку соответствия опытных данных предполагаемому закону рас-пределения в первом приближении можно осуществить графическим мето-дом. Опытные данные наносят на вероятностную бумагу и сравнивают с графиком принятой функции распределения, которая на вероятностной сетке изображается прямой линией. Если экспериментальные точки ложатся вблизи прямой со случайными отклонениями вправо или влево, то опытные данные соответствуют рассматриваемому закону распределения. Система-тическое и значительное отклонения экспериментальных точек от аппрок-симирующей прямой свидетельствует о несоответствии данной выборки предполагаемому закону распределения.
Возможен другой вариант применения графического метода для проверки соответствия опытных данных предполагаемому закону распределения.
Пусть требуется определить соответствие опытных данных нормаль-ному закону распределения. С этой целью за основу берут дискретный ва-риационный ряд и в системе координат строят эмпирическую кривую рас-пределения – полигон частот. Затем в этой же системе координат строят
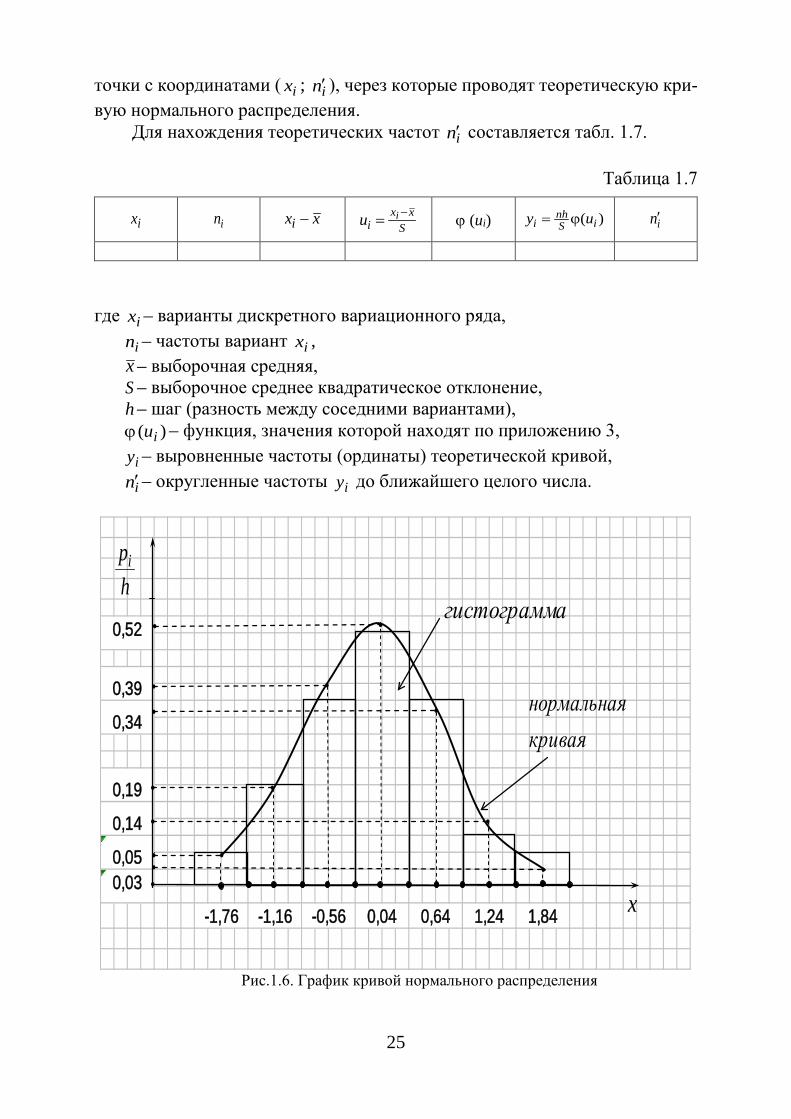
25
точки с координатами ( ix ; in′ ), через которые проводят теоретическую кри-вую нормального распределения.
Для нахождения теоретических частот in′ составляется табл. 1.7.
Таблица 1.7
ix in xxi − S
xxi
iu −= ϕ (ui) )( iSnh
i uy ϕ= in′
где ix – варианты дискретного вариационного ряда, in – частоты вариант ix ,
x – выборочная средняя, S – выборочное среднее квадратическое отклонение, h – шаг (разность между соседними вариантами),
)( iuϕ – функция, значения которой находят по приложению 3, iy – выровненные частоты (ординаты) теоретической кривой, in′– округленные частоты iy до ближайшего целого числа.
Рис.1.6. График кривой нормального распределения
0,39
0,52
0,04 1,24 1,840,64-1,76 -1,16
0,03
-0,56
0,34
0,05
0,19
0,14
агистограмм
x
криваянормальная
hpi

26
2.2. Классический метод проверки гипотез
При использовании классического метода проверки гипотез в соответ-ствии с поставленной задачей и на основании выборочных данных выдви-гается гипотеза 0H , называемая нулевой гипотезой. Одновременно с вы-двинутой гипотезой 0H , рассматривают противоположную ей гипотезу
1H , называемую альтернативной. Для проверки нулевой гипотезы необходимо ввести специально по-
добранную случайную величину K , распределение которой известно и называется ее критерием. Вследствие того, что для генеральной сово-купности гипотеза 0H принимается по выборочным данным, то она мо-жет быть ошибочной. При этом различают следующие ошибки.
Ошибка первого рода - заключается в том, что гипотезу 0H отвергают, когда она на самом деле верна. Для определения вероятности ошибки пер-вого рода вводят параметр ( )10
HPH=α , т.е. вероятностью того, что будет
принята альтернативная гипотеза 1H , при условии, что гипотеза 0H верна. Величину α называется уровнем значимости, который выбирается, как правило, в пределах от 0,001 до 0,1.
Ошибка второго рода заключается в том, что отвергают альтернатив-ную гипотезу 1H , когда она на самом деле верна.
Вероятность ошибки второго рода определяется параметром( )01HPH=β , т.е. вероятностью того, что будет принята гипотеза 0H ,
при условии, что альтернативная гипотеза 1H верна. Величину ( )β−1 , то есть недопустимость ошибки второго рода, принято называть мощно-стью критерия.
Множество всех значений критерия разбивают на два непересекаю-щихся подмножества: одно из них содержит значения критерия, при кото-рых нулевая гипотеза 0H отвергается; другое – при которых она принима-ется. При этом совокупность значений критерия, при которых нулевая ги-потеза отвергается, принято называть критической областью ω .
Совокупность значений критерия, при которых принимают нулевую гипотезу, называют областью принятия гипотезы или областью допу-стимых значений.
Гипотеза 0H отвергается и принимается альтернативная гипотеза 1H в том случае, когда вычисленное по выборке значение критерия K попа-дает в критическую область ω . В данном случае может быть совершена ошибка первого рода, вероятность которой равна α . Иначе, вероятность
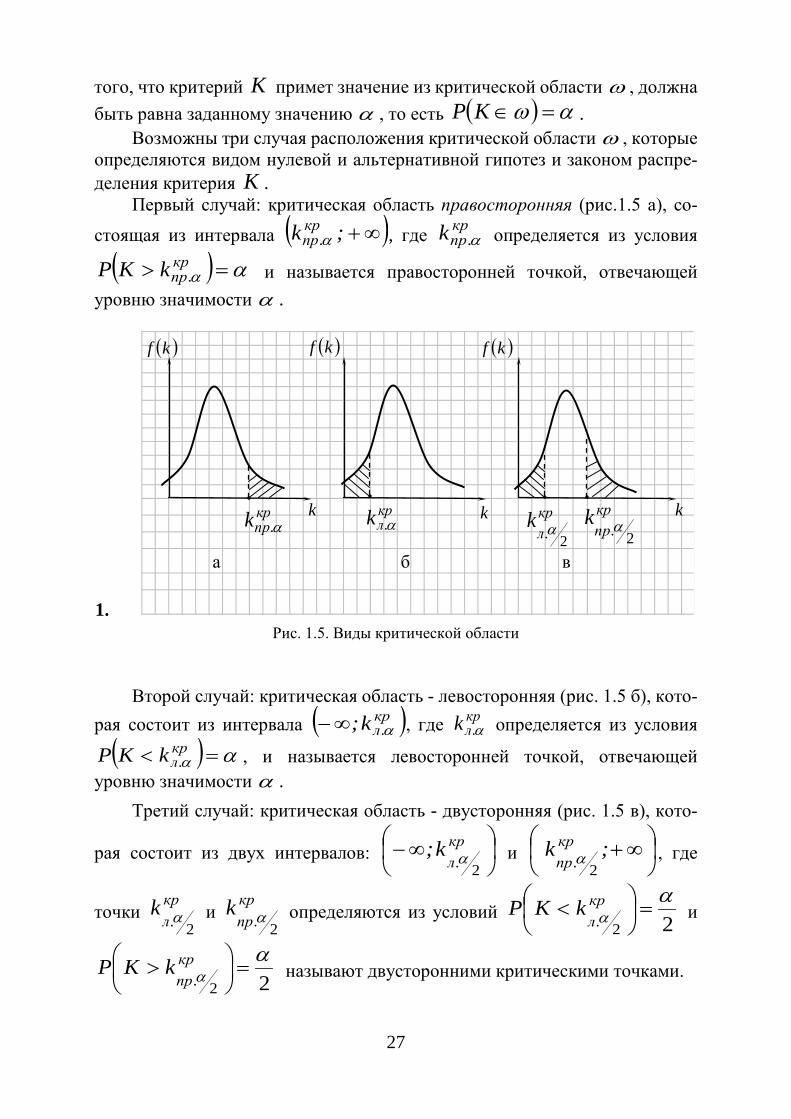
27
того, что критерий K примет значение из критической области ω , должна быть равна заданному значению α , то есть ( ) αω =∈KP .
Возможны три случая расположения критической области ω , которые определяются видом нулевой и альтернативной гипотез и законом распре-деления критерия K .
Первый случай: критическая область правосторонняя (рис.1.5 а), со-стоящая из интервала ( )∞+;k кр
.пр α , где кр.прk α определяется из условия
( ) αα => кр.прkKP и называется правосторонней точкой, отвечающей
уровню значимости α .
1. Рис. 1.5. Виды критической области
Второй случай: критическая область - левосторонняя (рис. 1.5 б), кото-рая состоит из интервала ( )кр
.лk; α∞− , где кр.лk α определяется из условия
( ) αα =< кр.лkKP , и называется левосторонней точкой, отвечающей
уровню значимости α . Третий случай: критическая область - двусторонняя (рис. 1.5 в), кото-
рая состоит из двух интервалов:
∞− кр
.лk;
2α и
∞+;k кр
.пр 2α , где
точки кр.л
k2
α и кр
.прk
2α определяются из условий 22
αα =
< кр
.лkKP и
22
αα =
> кр
.прkKP называют двусторонними критическими точками.
а б в
( )kf ( )kf ( )kf
k k kкр.прk α
кр.лk α
кр.пр
k2
αкр.л
k2
α

28
Проверка нулевой гипотезы осуществляется по следующему алгоритму: 1. Формулируется нулевая 0H и альтернативная 1H гипотезы по
располагаемой выборке. 2. Выбирается критерий проверки гипотезы 0H , которая зависит от
выборочных данных и условия рассматриваемой задачи. Наиболее часто ис-пользуются случайные величины, имеющие такие законы распределения как нормальный, Стъюдента, Фишера-Снедекора, хи-квадрат.
3. Задается уровень значимости выбранного критерия и определяется соответствующая ему критическая область. Для определения критической области находят критическую точку крt - ее границу. Для каждого критерия имеются таблицы, по которым и находят критическую точку.
4. Вычисляют значение критерия по результатам произведенных из-мерений и сравнивают с критической точкой.
5. Нулевая гипотеза отвергается в случае, когда вычисленное значе-ние критерия попадает в границы критической области, или ее считают справедливой в случае, когда значение критерия оказывается внутри области допустимых значений.
2.3. Проверка гипотез о законе распределения
В большинстве случаев закон распределения изучаемой случайной ве-личины Х неизвестен, но существуют основания предполагать, что он имеет вполне определенный вид: нормальный, экспоненциальный или какой-либо другой.
В качестве статистического критерия проверки гипотезы о предполага-емом законе неизвестного распределения используют критерий согласия, который используют для проверки согласия предполагаемого вида распре-деления с опытными данными на основе исследуемой выборки. В стати-стике используют различные критерии согласия: Пирсона, Колмогорова, Фишера и др.
Критерий Пирсона
Наиболее часто при проверке гипотезы о предполагаемом законе неиз-вестного распределения пользуются критерием Пирсона.
Пусть задана выборка из генеральной совокупности X в виде стати-стического интервального ряда.
Необходимо проверить нулевую гипотезу 0H о том, что генераль-ная совокупность X распределена по нормальному закону, пользуясь критерием Пирсона.

29
Правило проверки: 1. Вычисляют вx и вσ (формулы 1.10-1.12, 1.16). 2. Находят теоретические частоты 'ni .
Вычислить теоретические частоты 'ni можно по формуле:
( )iв
i thn'n ϕσ
⋅⋅
= , (1.45)
где n – объем выборки, h – шаг,
в
вii
xxtσ−
= ; (1.46)
( ) 2
2
21
x
ex−
⋅=π
ϕ (1.47)
− функция Гаусса, значение которой в точке it , находится по таб-лице (приложение 3).
( ) htPв
ii ⋅=
σϕ
(1.48)
− вероятность попадания значений случайной величины X в i -й интервал.
Для определения 'ni составляют вспомогательную таблицу (табл. 1.8). Таблица 1.8
i ix in вi xx − it ( )itϕ iP nP'n ii ⋅=
1 1x 1n вxx −1 1t ( )1tϕ 1P nP'n ⋅= 11 m mx mn вm xx − mt ( )mtϕ mP nP'n mm ⋅=
∑ n 1 n
3. Сравнивают эмпирические ( in ) и теоретические ( 'ni ) частоты с ис-пользованием критерия Пирсона по алгоритму:
1) составляется расчетная табл.1.9, из которой определяется наблю-даемое значение критерия 2
наблχ по формуле

30
( )∑=
−=
m
i i
iiнабл 'n
'nn1
22χ . (1.49)
Таблица 1.9
i in 'ni 'nn ii −
( )2'nn ii − ( )
'n'nn
i
ii2−
2in
'nn
i
i2
1 1n 'n1 'nn 11 −
( )211 'nn − ( )
'n'nn
1
211 − 2
1n 'n
n1
21
m mn 'nm nn mm −
( )2'nn mm −
( )'n
'nn
m
mm2−
2mn
'nn
m
m2
∑ n 2наблχ
2) Определяется число степеней свободы k на основании формулы:
1−−= rmk , (1.50)
где m – число интервалов; r – число параметров предполагаемого распределения.
Для нормального распределения число степеней свободы равно 3−= mk в виду того, что 2=r - нормальный закон распределения ха-
рактеризуется двумя параметрами a и σ . 4. По данным таблицы критических точек (квантилей) распределение
2χ (приложение 4) по заданному уровню значимости α и числу степеней
свободы определяют ( )k;кр αχ 2 правосторонней критической области.
Когда 22крнабл χχ < то отвергнуть гипотезу 0H о нормальном распре-
делении генеральной совокупности оснований не существует. В случае если 22
крнабл χχ > – гипотеза отвергается. Замечание: 1) Объем изучаемой выборки должен быть достаточно большой ( )50≥n . 2) Малочисленные частоты при 5<in следует объединять, в том
числе и соответствующие им теоретические частоты. В случае, когда производилось объединение частот при определении числа
степеней свободы по формуле 3−= mk в качестве m необходимо принимать число интервалов, оставшихся после объединения частот.
31
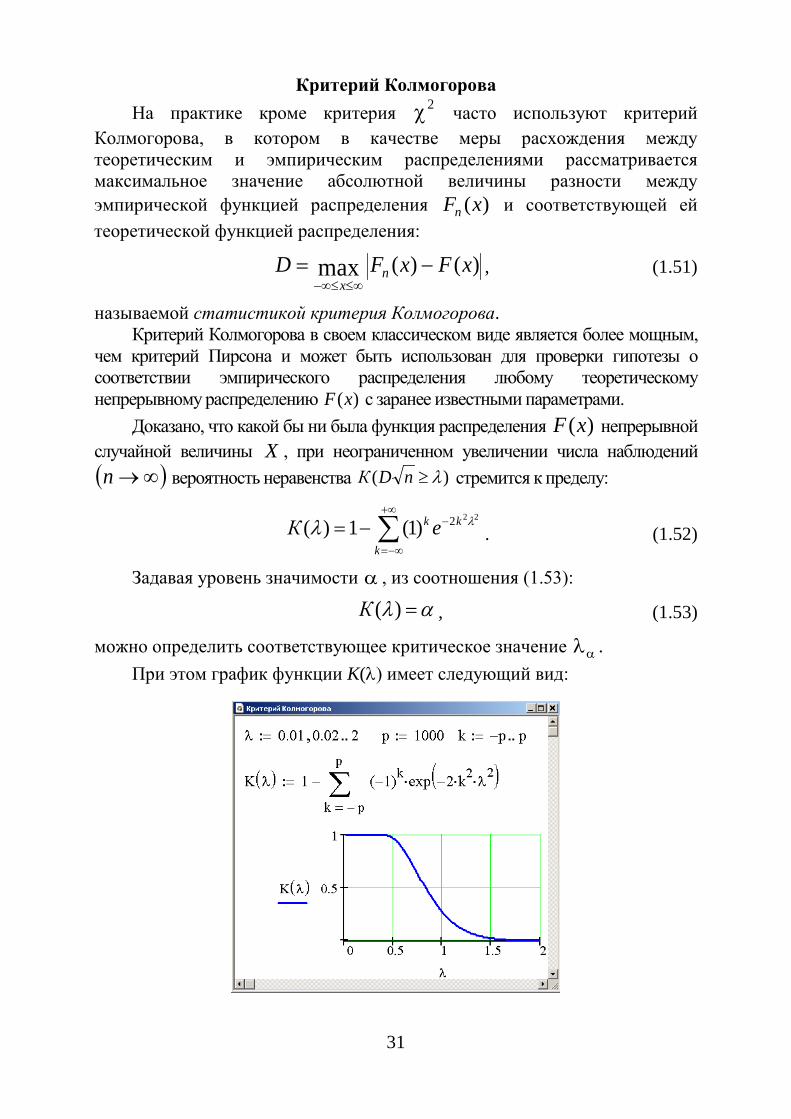
Критерий Колмогорова На практике кроме критерия 2χ часто используют критерий
Колмогорова, в котором в качестве меры расхождения между теоретическим и эмпирическим распределениями рассматривается максимальное значение абсолютной величины разности между эмпирической функцией распределения )(xFn и соответствующей ей теоретической функцией распределения:
)()(max xFxFD nx
−=∞≤≤∞−
, (1.51)
называемой статистикой критерия Колмогорова. Критерий Колмогорова в своем классическом виде является более мощным,
чем критерий Пирсона и может быть использован для проверки гипотезы о соответствии эмпирического распределения любому теоретическому непрерывному распределению )(xF с заранее известными параметрами.
Доказано, что какой бы ни была функция распределения )(xF непрерывной случайной величины X , при неограниченном увеличении числа наблюдений ( )∞→n вероятность неравенства )( λ≥nDК стремится к пределу:
∑+∞
−∞=
−−=k
kk eК222)1(1)( λλ . (1.52)
Задавая уровень значимости α , из соотношения (1.53):
αλ =)(К , (1.53)
можно определить соответствующее критическое значение αλ . При этом график функции K(λ) имеет следующий вид:

32
Значения K(λ) находят, пользуясь данными табл. 1.10. Таблица 1.10
λ K(λ) λ K (λ) 0,30 1,0000 1,10 0,1777 0,35 0,9997 1,20 0,1122 0,40 0,9972 1,30 0,681 0,45 0,9874 1,40 0,397 0,50 0,9639 1,50 0,222 0,55 0,9228 1,60 0,120 0,60 0,8643 1,70 0,052 0,70 0,7112 1,90 0,015 0,75 0,6272 2,00 0,007 0,80 0,5441 2,10 0,0003 0,85 0,4653 2,20 0,0001 0,90 0,3927 2,30 0,0001 0,95 0,3275 2,40 0,0000 1,00 0,2700 2,50 0,0000
Если найденному значению λ соответствует очень малая вероятность,
то есть 05,0)( <λK , то расхождение между эмпирическим и теоретическим распределениями нельзя считать случайным. Следовательно, рассматривае-мая выборка не подчиняется нормальному закону распределения.
Если вероятность 05,0)( >λK , то расхождение между частотами может быть случайным, и распределения хорошо соответствуют одно другому.
Схема применения критерия Колмогорова следующая: 1. Строят эмпирическую функцию распределения )(xFn и
предполагаемую теоретическую функцию распределения )(xF . 2. Определяют меру расхождения между теоретическим и
эмпирическим распределениями d с использованием формулы (1.54) и вычисляют величину λ :
nD=λ . (1.54)
где MMD ′−= max – максимум абсолютного значения разности между накопленными эмпирическими частотами М и накопленными теоретиче-скими частотами M ′ , n – объем выборки.
Если вычисленное значение λ больше критического αλ ,
определенного при уровне значимости α , то нулевая гипотеза 0H о том, что случайная величина X имеет заданный закон распределения, отвергается (односторонний критерий). Если же αλ≤λ , то считают, что гипотеза 0H не противоречит опытным данным и принимается.

33
Замечание: Можно отметить, что решение подобных задач можно было бы найти с
помощью критерия 2χ . Потенциальное преимущества критерия Колмогорова в том, что он не требует группирования данных (с неизбежной потерей информации), а дает возможность рассматривать индивидуальные наблюдаемые значения. Этот критерий можно успешно применять для малых выборок. Считается, что его мощность выше, чем у критерия 2χ .
Приближенные критерии нормальности распределения
Приближенный метод проверки нормальности распределения основан на вычислении по результатам измерения эмпирических оценок коэффици-ентов асимметрии, эксцесса и их дисперсий.
В этом случае названные статистики вычисляют по формулам (1.36) и (1.37). Затем вычисляют их средние квадратические отклонения по формулам:
( ) ( )( )( )31
26++
−=
nnnAD , (1.55)
( ) ( )( )( ) ( )( )531
32242 +++
−−=
nnnnnnED . (1.56)
Если выборочные асимметрия и эксцесс удовлетворяют неравенствам:
( )ADA
3≤ ( )EDE
5≤ , (1.57)
то гипотеза о нормальности наблюдаемого распределения принимается. Если sA и xE заметно больше своих средних квадратических
отклонений, то выборочная совокупность не будет распределена по нормальному закону.
Проверку выборочной совокупности на нормальное распределение можно производить, используя статистики 2χ , sA и xE . Сначала вычисляют статистику 2χ по формуле:
SE
E x
x
sA
s
S
A2
2
2
22 +=χ . (1.58)
Затем при заданном уровне значимости α и числе степеней свободы 2=k (используют в расчетах две статистики sA и xE ) по приложению 4
для распределения 2χ Пирсона находят 2крχ .
Если выполняется неравенство 2кр
2 χ<χ , то гипотезу о нормальном распределении выборочной совокупности принимают. В противном случае,

34
т.е. когда 2кр
2 χ>χ , гипотезу о нормальном распределении выборки отвер-гают.
Контрольные вопросы 1. Рассказать о возможных вариантах построения кривой нормального
распределения. 2. Дать определение статистической гипотезы. 3. Что называется статистическим критерием? 4. Сформулировать алгоритм применения любого статистического крите-
рия для обработки данных. 5. Сформулировать правило применения критерия согласия 2χ Пирсона
для проверки гипотезы согласованности эмпирического распределения с теоретическим нормальным.
6. Сформулировать алгоритм применения критерия Колмогорова для про-верки соответствия эмпирического распределения нормальному теоре-тическому распределению.
7. Рассказать о приближенных критериях, применяемых для проверки ги-потезы о нормальном распределении выборочной совокупности.

35
ГЛАВА 3. ПАРНАЯ РЕГРЕССИЯ И КОРРЕЛЯЦИЯ
3.1. Понятие функциональной, статистической и корреляционной зависимости
В статистическом анализе две случайные величины могут быть либо
связаны функциональной, статистической или корреляционной зависимостью, либо быть независимыми.
Функциональной называют зависимость величины Y от X в том случае, когда каждому значению величины X соответствует одно единственное значение Y .
Зависимость называют статистической, в случае, когда изменение одной величины влечет соответственно изменение распределения другой.
В том случае, кода изменение одной из переменных величин сопровождается изменениями условного среднего значения другой переменной, зависимость называется корреляционной.
При этом среднее арифметическое значений Y , соответствующих значению xX = называют условным средним xy . Если каждому значению X соответствует одно значение условной средней, то условная средняя есть функция от x . В данном случае случайная величина Y зависит от X корреляционно.
Корреляционной зависимостью Y от X называют функцию ( )xfyx = . Уравнение ( )xfyx = называют уравнением регрессии Y на
X , а его график - линией регрессии Y на X . Аналогичным образом определяют условную среднюю yx и
корреляционную зависимость X от Y . В данном случае условным средним yx называют среднее арифметическое значений X , соответствующих yY = . Корреляционной зависимостью X от Y
называется функция ( )yxy ϕ= . Уравнение ( )yfyx = называется уравнением регрессии X на Y , а его график, соответственно, линией регрессии X на Y .
В теории корреляции корреляционный анализ решает две задачи: 1 задача: установление формы корреляционной связи, т. е. определение
вид функции регрессии (линейная, квадратичная и так далее). 2 задача: оценка тесноты (силы) корреляционной зависимости. Теснота
корреляционной зависимости Y на X оценивается по величине рассеивания значений Y вокруг условного среднего. Большое рассеивание указывает на наличие слабой зависимости, малое рассеивание - сильной зависимости.

36
3.2. Линейная модель парной регрессии и корреляции
Ввиду четкой экономической интерпретации параметров линейной ре-грессии, она нашла широкое применение при статистических методах обра-ботки данных.
Построение линейной регрессии сводится к нахождению уравнения вида:
xy a b x= + ⋅ или y a b x ε= + ⋅ + .
Уравнение вида xy a b x= + ⋅ позволяет по заданным значениям фак-
тора x определять теоретические значения результативного признака xy , при подставлении в него фактических значений фактора x .
Построение линейной регрессии сводится к оценке двух параметров a и b .
Классическим подходом к оценке параметров линейной регрессии яв-ляется метод наименьших квадратов (МНК), позволяющий получать такие оценки параметров a и b , при которых сумма квадратов отклонений фак-тических значений результативного признака y от теоретических xy стано-вится минимальной
( )22
1 1min
i
n n
i ixi i
y y ε= =
− = →∑ ∑ .
Чтобы определить минимум функции, необходимо вначале вычислить частные производные по каждому из параметров a и b , а затем приравнять их к нулю. Если обозначить 2
iiε∑ через ( ), S a b , тогда получают:
( ) ( )2, S a b y a b x= − − ⋅∑ .
( )
( )
2 0;
2 0.
S y a b xaS x y a b xb
∂ = − − − ⋅ =∂∂ = − − − ⋅ =∂
∑
∑
После проведения несложных преобразований, получают нормальную
систему линейных уравнений для оценки параметров a и b :
2
;
.
a n b x y
a x b x x y
⋅ + ⋅ =
⋅ + ⋅ = ⋅
∑ ∑∑ ∑ ∑
(1.59)

37
При решении системы уравнений (1.59) определяют искомые оценки параметров a и b . Из решения системы (1.59) непосредственно получают следующие формулы:
a y b x= − ⋅ , 22 хxxyухb
−⋅−
= (1.60)
где 1x xn
= ∑ , 1y yn
= ∑ , ______ 1y x y x
n⋅ = ⋅∑ ,
____2 21x x
n= ∑ .
Параметр b - коэффициент регрессии, величина которого показывает среднее изменение признака-результата с изменением признака-фактора на одну единицу.
Параметр a - это значение y при 0x = . Если факторный признак x не может иметь нулевого значения, то параметр a не может иметь экономического содержания.
Нахождение уравнения регрессии всегда дополняют расчетом показателя тесноты связи. При использовании линейной регрессии в качестве такого показателя используют линейный коэффициент корреляции xyr , который рассчитывается на основании следующей формулы:
yxy
x xyyxbrσσσ
σ⋅⋅−
== , (1.61)
где 22 )(ххх −=σ , 22 )(ууу −=σ Значение линейного коэффициента корреляции может находиться в
пределах: 1 1xyr− ≤ ≤ . Чем ближе абсолютное значение линейного коэффициента
корреляции xyr к единице, тем сильнее линейная связь между двумя факторами
(при 1xyr = ± имеется строгая функциональная зависимость). Однако, следует учитывать, что близость абсолютной величины линейного коэффициента корреляции к нулю может не означать отсутствие связи между двумя признаками - при нелинейной спецификации модели связь между признаками может оказаться достаточно тесной.
Оценку тесноты линейной корреляционной связи принято определять, пользуясь данными табл. 1.11.
Таблица 1.11
Теснота связи Величина r
Прямая связь Обратная связь
Линейной связи нет 2,00÷ 2,00 −÷

38
Продолжение Таблицы 1.11 Слабая 5,02,0 ÷ 5,02,0 −÷−
Средняя 75,05,0 ÷ 75,05,0 −÷−
Сильная 95,075,0 ÷ 95,075,0 −÷−
Функциональная 195,0 ÷ 195,0 −÷−
Для оценки качества подбора линейной функции рассчитывают коэф-фициент детерминации, представляющий собой квадрат линейного коэф-фициента корреляции 2
xyr . Коэффициент детерминации характеризует долю дисперсии признака-
результата y , объясняемую регрессией, в общей дисперсии результатив-ного признака. Определяется на основании формулы:
2
2 ост21xyy
r σσ
= − , (1.62)
где ( )22ост
1xy y
nσ = −∑ , ( )22 2 21
y y y y yn
σ = − = −∑ .
Величина 21 xyr− дает характеристику доли дисперсии y , вызванной влиянием остальных, не учтенных в модели, факторов.
После того как найдено уравнение линейной регрессии, проводят оценку значимости уравнения и отдельных его параметров.
Проверка значимости уравнения регрессии означает установление со-ответствия математической модели, выражающей зависимость между пере-менными, экспериментальным данным и достаточность включенных в урав-нение объясняющих переменных (одной или нескольких) для описания за-висимой переменной.
Качество модели из относительных отклонений по каждому наблюде-нию определяют на основании средней ошибки аппроксимации, которая находится по формуле:
1 100%xy yAn y
−= ⋅∑ . (1.63)
Средняя ошибка аппроксимации не должна превышать 8,0 - 10,0%. Оценка значимости уравнения регрессии в целом проводится на осно-
вании -критерия Фишера.

39
Согласно принципам дисперсионного анализа, общая сумма квадратов отклонений переменной y от среднего значения y раскладывается на две части – «объясненную» и «необъясненную»:
( ) ( ) ( )2 22x xy y y y y y− = − + −∑ ∑ ∑ , (1.64)
где ( )2y y−∑ – общая сумма квадратов отклонений;
( )2
xy y−∑ – сумма квадратов отклонений, объясненная регрессией
(или факторная сумма квадратов отклонений); ( )2
xy y−∑ – остаточная сумма квадратов отклонений, характеризую-
щая влияние неучтенных в модели факторов. Схема проведения дисперсионного анализа представлена в табл. 1.12.
Таблица 1.12
Компоненты дисперсии Сумма квадратов Число степеней
свободы Дисперсия на одну степень свободы
Общая ( )2y y−∑ 1n − ( )2
2общ 1
y yS
n−
=−
∑
Факторная ( )2
xy y−∑ m ( )2
2факт
xy yS
m
−=∑
Остаточная ( )2
xy y−∑ 1n m− − ( )2
2ост 1
xy yS
n m
−=
− −
∑
Примечание: n – число наблюдений, m – число параметров при переменной x .
Величину F - критерия Фишера получают, сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы:
2факт2ост
SF
S= . (1.65)
Расчетное значение - критерия Фишера (1.65) сравнивают с табличным ( )табл 1 2; ;F k kα при уровне значимости α и степенях свободы 1k m= и
2 1k n m= − − (приложение 7). При этом, если фактическое значение - кри-терия больше табличного, то признается статистическая значимость уравне-ния в целом.
Для парной линейной регрессии 1m = , поэтому:

40
( )( )
( )2
2факт
22ост
2x
x
y ySF n
S y y
−= = ⋅ −
−
∑∑
. (1.66)
Величина F - критерия связана с коэффициентом детерминации 2xyr , и
ее можно рассчитать по следующей формуле:
( )2
2 21
xy
xy
rF n
r= ⋅ −
−. (1.67)
В парной линейной регрессии оценивается значимость также отдель-ных параметров уравнения.
Для оценки статистической значимости коэффициентов регрессии и корреляции определяют t-критерий Стьюдента и доверительные интервалы каждого из показателей. Оценку значимости коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента проводят путем сопоставле-ния их значений с величиной случайной ошибки:
;b
b mbt = ;
aa m
at = .r
r mrt = (1.68)
Случайные ошибки параметров линейной регрессии и коэффициента корреляции определяют на основании формул:
;)()(
)2/()(2
2
2
2^
nS
xxS
xxnyy
mx
остостxb σ
=−
=−
−−=
∑∑∑
.)()2(
)( 2
22
22
2
22^
xост
xост
xa n
xS
nx
Sxxnnxyy
mσσ∑∑
∑∑ ∑ ===
−⋅−
⋅−= (1.69)
;2
1 2
−
−=
nr
m xyrxy
Для проверки существенности коэффициента регрессии и для расчета его доверительного интервала совместно с - распределением Стьюдента при
2n − степенях свободы применяют величину стандартной ошибки. Для оценки существенности коэффициента регрессии определяют фак-
тическое значение t -критерия Стьюдента, которое затем сравнивают с таб-личным значением при определенном уровне значимости α и числе степе-ней свободы ( )2n − .

41
Если tтабл<tфак, то a, b и rxy не случайно отличаются от нуля и сформи-ровались под влиянием систематически действующего фактора x. Если tтабл>tфак, то признается случайная природа формирования a, b или rxy.
Между t -критерием Стьюдента и F -критерием Фишера существует связь, определяемая:
b rt t F= = . (1.70)
Для расчета доверительного интервала определяется предельная ошибка∆ для каждого из показателей: ,aт аблa mt=∆ .bт аблb mt=∆
Для расчета доверительных интервалов используют формулы:
;aa a ∆±=γ ;min aa a ∆−=γ ;
max aa a ∆+=γ (1.71)
;bb b ∆±=γ ;min bb b ∆−=γ .
max bb b ∆+=γ
В случае, если нижняя граница доверительного интервала отрица-тельна, а верхняя положительна, то оцениваемый параметр принимают рав-ным нулю, так как он не может одновременно принимать и положительные, и отрицательные значения.
3.3. Нелинейные модели парной регрессии и корреляции
Когда между экономическими явлениями существуют нелинейные со-отношения, то их выражают с помощью соответствующих нелинейных функций. Принято различать два класса нелинейных регрессий:
1. Регрессии, нелинейные относительно включенных в анализ объ-ясняющих переменных, но линейные по оцениваемым параметрам:
− полиномы различных степеней: 2xy a b x c x= + ⋅ + ⋅ ,
2 3xy a b x c x d x= + ⋅ + ⋅ + ⋅ ;
− равносторонняя гипербола: xy a b x= + ;
− полулогарифмическая функция: lnxy a b x= + ⋅ . 2. Регрессии, нелинейные по оцениваемым параметрам: – степенная: b
xy a x= ⋅ ;
– показательная: xxy a b= ⋅ ;
– экспоненциальная: ea b xxy + ⋅= .

42
Регрессии, нелинейные по включенным переменным, приводятся к линей-ному виду простой заменой переменных (метод выравнивания). Дальнейшую оценку параметров производят с помощью метода наименьших квадратов.
Следует рассмотреть некоторые из функций. Параболу второй степени 2
xy a b x c x= + ⋅ + ⋅ приводят к линейному
виду с помощью замены: 21 2,x x x x= = . В результате приходят к двухфактор-
ному уравнению вида 1 2xy a b x c x= + ⋅ + ⋅ , оценку параметров которого при-водят при помощи МНК к системе следующих нормальных уравнений:
1 2
21 1 1 2 1
22 1 2 2 2
;
;
.
a n b x c x y
a x b x c x x x y
a x b x x c x x y
⋅ + ⋅ + ⋅ = ⋅ + ⋅ + ⋅ ⋅ = ⋅
⋅ + ⋅ ⋅ + ⋅ = ⋅
∑ ∑ ∑∑ ∑ ∑ ∑∑ ∑ ∑ ∑
После обратной замены переменных получают: 2
2 3
2 3 4 2
;
;
.
a n b x c x y
a x b x c x x y
a x b x c x x y
⋅ + ⋅ + ⋅ = ⋅ + ⋅ + ⋅ = ⋅
⋅ + ⋅ + ⋅ = ⋅
∑ ∑ ∑∑ ∑ ∑ ∑∑ ∑ ∑ ∑
(1.72)
Параболу второй степени часто применяют в случаях, когда для определенного интервала значений фактора меняется характер связи рассматриваемых признаков: прямая связь меняется на обратную или наоборот.
Равностороннюю гиперболу xy a b x= + используют для характеристики связи удельных расходов ресурсов от объема выпускаемой продукции. Гипер-болу приводят к линейному уравнению простой заменой: 1z x= . Система ли-
нейных уравнений при применении МНК выглядит следующим образом:
2
1 ;
1 1 1 .
a n b yx
a b yx x x
⋅ + ⋅ = ⋅ + ⋅ = ⋅
∑ ∑
∑ ∑ ∑ (1.73)
Аналогичным образом приводят к линейному виду зависимости lnxy a b x= + ⋅ , xy a b x= + ⋅ и другие.
Несколько иначе обстоит дело с регрессиями нелинейными по оценивае-мым параметрам, которые делятся на два типа: нелинейные моделивнутренне ли-нейные (приводятся к линейному виду с помощью логарифмирования) и нели-нейные модели внутренне нелинейные (к линейному виду не приводятся).

43
К внутренне линейным моделям относятся, например, степенная функ-ция – b
xy a x= ⋅ , показательная – xxy a b= ⋅ , экспоненциальная –
ea b xxy + ⋅= , логистическая –
1 ex c x
ayb − ⋅=
+ ⋅, обратная – 1
xya b x
=+ ⋅
.
К внутренне нелинейным моделям можно отнести модели вида:
cxy a b x= + ⋅ ,
111x by a
x = ⋅ − −
.
Среди нелинейных моделей наиболее часто используют степенную функцию by a x ε= ⋅ ⋅ , которую приводят к линейному виду логарифмированием.
( )ln ln by a x ε= ⋅ ⋅ ;
ln ln ln lny a b x ε= + ⋅ + ; Y A b X= + ⋅ + Ε ,
где ln , ln , ln , lnY y X x A a ε= = = Ε = , т.е. МНК применяют для преобра-зованных данных:
2
,
,
A n b X Y
A X b X X Y
⋅ + ⋅ =
⋅ + ⋅ = ⋅
∑ ∑∑ ∑ ∑
а затем потенцированием находят искомое уравнение. Широкое применение степенной функции связано с тем, что параметр
b в ней имеет четкое экономическое истолкование – он является коэффи-циентом эластичности, показывающим, на сколько процентов изменится в среднем результат, если фактор изменится на 1%. Формула для расчета ко-эффициента эластичности имеет вид:
( ) xЭ f xy
′= ⋅ . (1.74)
Средний коэффициент эластичности:
( ) xЭ f xy
′= ⋅ . (1.75)
Формулы расчета средних коэффициентов эластичности для наиболее часто используемых типов уравнений регрессии представлены в табл. 1.13.
Таблица 1.13
Вид функции, y Первая производная, y′ Средний коэффициент
эластичности, Эy a b x ε= + ⋅ + b b x
a b x⋅
+ ⋅
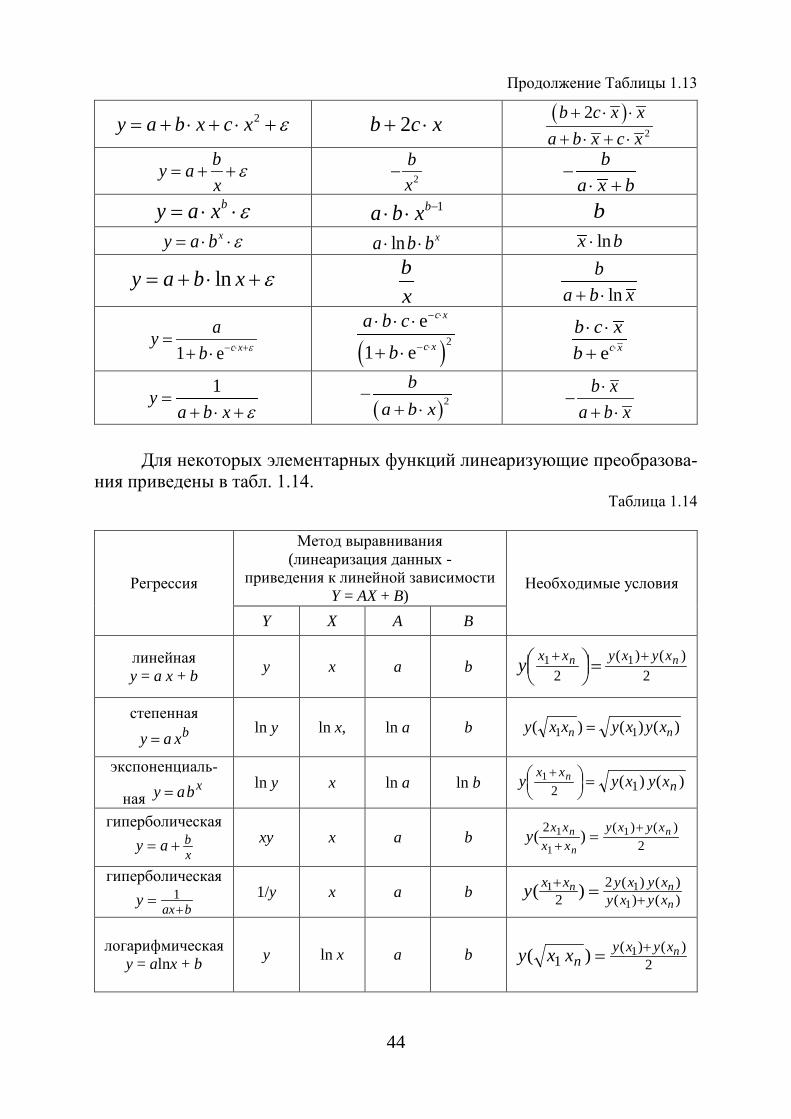
44
Продолжение Таблицы 1.13
2y a b x c x ε= + ⋅ + ⋅ + 2b c x+ ⋅ ( )
2
2b c x xa b x c x
+ ⋅ ⋅+ ⋅ + ⋅
by ax
ε= + + 2
bx
− ba x b
−⋅ +
by a x ε= ⋅ ⋅ 1ba b x −⋅ ⋅ b xy a b ε= ⋅ ⋅ ln xa b b⋅ ⋅ lnx b⋅
lny a b x ε= + ⋅ + bx
ln
ba b x+ ⋅
1 e c x
ayb ε− ⋅ +=
+ ⋅
( )2
e
1 e
c x
c x
a b c
b
− ⋅
− ⋅
⋅ ⋅ ⋅
+ ⋅
ec x
b c xb ⋅
⋅ ⋅+
1ya b x ε
=+ ⋅ +
( )2
ba b x
−+ ⋅
b xa b x
⋅−
+ ⋅
Для некоторых элементарных функций линеаризующие преобразова-ния приведены в табл. 1.14.
Таблица 1.14
Регрессия
Метод выравнивания (линеаризация данных -
приведения к линейной зависимости Y = AX + B)
Необходимые условия
Y X A B
линейная y = a x + b y x a b 2
)()(2
11 nn xyxyxxy ++ =
степенная bxay =
ln y ln x, ln a b )()()( 11 nn xyxyxxy =
экспоненциаль-
ная xbay =
ln y x ln a ln b )()( 121
nxx xyxyy n =
+
гиперболическая
xbay +=
xy x a b 2
)()(2 1
1
1 )( n
n
n xyxyxxxxy +
+=
гиперболическая
baxy+
= 1
1/y x a b )()()()(2
2 111 )(
nnn
xyxyxyxyxxy +
+ =
логарифмическая y = alnx + b y ln x a b
2)()(
11)( nxyxy
nxxy +=

45
Выбор эмпирической формулы сделан правильно, если выровненные точки ),( ii YX хорошо ложатся на прямую.
Если характер исследуемой зависимости неизвестен и в корреляционном поле около построенных точек предполагается проведение разных по типу ли-ний, при этом никаких теоретических соображений по этому поводу сделать нельзя. В таких случаях для выбора одной из них, характеризующей наилучшим образом зависимость между признаками X и Y , кроме описанного выше метода выравнивания (линеаризации данных) производят либо проверку необходимых условий, либо применяют метод конечных разностей.
Проверку необходимых условий для выбора одной из предполагаемых нелинейных зависимостей проводят, пользуясь табл. 1.14. Если выполня-ется одно из условий последнего столбца таблицы, то выбирают в качестве предполагаемой формулы соответствующую формулу, стоящую в первом столбце таблицы рассматриваемой строки.
Если в таблице опытных данных отсутствуют значения функции, вы-численные в последнем столбце таблицы при выбранных значениях аргу-мента, то их находят линейным интерполированием по формуле:
)()()( 1)()(
1 1212 xxxyxy xx
xyxy −+= −− , (1.76)
где 1x и 2x – два рядом стоящих значения признака X в таблице опытны данных, между которыми находится значение x , вычисленное по табл. 1.14 последнего столбца.
Для всех предполагаемых формул по результатам последнего столбца табл. 1.14 вычисляют отклонения ∆ правой части от левой необходимого условия. Вычисленные отклонения i∆ сравнивают и по наименьшему из них выбирают окончательно одну из формул.
Метод конечных разностей заключается в том, что для обоснования выбора зависимости, первоначально, предполагаемую формулу сводят к ли-нейной BAXY += по табл. 1.14, затем вычисляют конечные разности пер-вого порядка X∆ , Y∆ и отношения XY ∆∆ / . Аналитическим критерием вы-бора формулы по этому методу служит тот факт, что отношения XY ∆∆ / мало отличаются друг от друга для выбранной формулы.
Конечные разности находят, пользуясь табл. 1.15. Таблица 1.15
x x0 x1 x2 x3 … xn-1 xn
y y0 y1 y2 y3 … yn-1 yn
∆y ∆y0 ∆y1 ∆y2 ∆y3 … ∆yn-1
∆2y ∆2y0 ∆2y1 ∆2y2 ∆2y3 … ∆2yn-2

46
Уравнение нелинейной регрессии дополняют расчетом показателя тесноты связи - индекса корреляции:
2ост
21xyy
σρσ
= − , (1.77
где ( )22 1y y y
nσ = −∑ – общая дисперсия результативного признака y ;
( )22ост
1xy y
nσ = −∑ – остаточная дисперсия.
Величина данного показателя находится в пределах: 0 1xyρ≤ ≤ . Чем ближе значение индекса корреляции к единице, тем теснее связь между рас-сматриваемыми признаками, тем более надежно уравнение регрессии.
Квадрат индекса корреляции носит название индекса детерминации и характеризует долю дисперсии результативного признака y , объясняемую регрессией, в общей дисперсии результативного признака
2 22 ост объясн
2 21xyy y
σ σρσ σ
= − = .
Индекс детерминации используют для проверки существенности в це-лом уравнения регрессии по F -критерию Фишера:
2
2
11
xy
xy
n mFm
ρρ
− −= ⋅
−, (1.78)
где 2xyρ – индекс детерминации,
n – число наблюдений, m – число параметров при переменной x . Фактическое значение F -критерия (1.78) сравнивают с табличным при
уровне значимости α и числе степеней свободы 2 1k n m= − − (для оста-точной суммы квадратов) и 1k m= (для факторной суммы квадратов).
О качестве нелинейного уравнения регрессии можно также судить и по средней ошибке аппроксимации, которая, так же как и в линейном случае, вычисляется на основании формулы (1.63).
Контрольные вопросы
1. Дать определение корреляционной зависимости между двумя призна-ками X и Y . 2. Дать определение условной средней признака Y и записать формулу для ее нахождения.

47
3. Записать уравнения регрессий y на x и x на y, используя коэффициентлинейной корреляции r.
4. Дать определение коэффициента линейной корреляции, сформу-лировать его свойства. 5. Как определяется значимость коэффициента линейной корреляции?6. Записать доверительные интервалы для оценки коэффициента линей-ной корреляции. 7. Записать формулу для нахождения коэффициента детерминации вслучае парной линейной корреляции и рассказать о его назначении. 8. Как производится оценка коэффициентов a и b уравнения линейнойрегрессии bxayx +=ˆ ? 9. Записать систему нормальных уравнений для нахождения коэффици-ентов a , b , c уравнения регрессии 2ˆ cxbxayx ++= . 10. Рассказать о применении необходимых условий выбора одной изпредполагаемых нелинейных зависимостей. 11. Рассказать об установлении тесноты связи между признаками в случаенелинейной зависимости с помощью корреляционного отношения и ин-декса корреляции. 12. Как осуществляется проверка адекватности нелинейной регрессион-ной модели?

ГЛАВА 4. МНОЖЕСТВЕННАЯ РЕГРЕССИЯ И КОРРЕЛЯЦИЯ
4.1. Спецификация модели. Отбор факторов при построении уравнения множественной регрессии
Парная регрессия может дать хороший результат при моделировании, если влиянием других факторов, воздействующих на объект исследования, можно пренебречь. Однако, производственные взаимосвязи, как правило, определяются большим числом одновременно и совокупно действующих факторов. Например, себестоимость продукции зависит от стоимости материала, основной зарплаты рабочих, премиальных, расходов на содержание оборудования и др. В связи с этим возникает задача исследования зависимости между факторными признаками (называемыми также регрессорами или предикторами) 1х , 2х , . . ., nх и результативнымпризнаком у . Для этого используется множественный регрессионныйанализ, т.е. построение уравнений множественной регрессии:
( )mхххfy ,...,, 21=, (1.79)
где y - результативный признак (зависимая переменная),
ix – признаки-факторы (независимые, или объясняющие, переменные).
Основной целью множественной регрессии является построение модели с большим числом факторов и определение при этом влияния каждого из них в отдельности, а также совокупно на моделируемый показатель (результативный признак).
Построение уравнения множественной регрессии начинают с решения вопроса о спецификации модели, который включает в себя отбор признаков-факторов и выбор вида уравнения регрессии.
Включение в уравнение множественной регрессии определенного набора факторов связано, в первую очередь, с представлениями исследователя о природе взаимосвязи моделируемого показателя с другими социально-экономическими явлениями. Важно отметить, что факторы, которые включаются в уравнение множественной регрессии, должны объяснить вариацию зависимой переменной, т.е. результативного признака.
В случае, когда строится модель с набором m факторов в первую очередь необходимо определить показатель детерминации 2R , фиксирующий долю объясненной вариации результативного признака за счет рассматриваемых в регрессии m факторов. Влияние не учтенных в регрессионной модели факторов, оценивается как (1-R2) с соответствующей величиной остаточной дисперсии S2.
48

49
Отбор факторов осуществляется в два тапа: на первом подбираются факторы исходя из сущности изучаемой проблемы; на втором – на основании матрицы показателей корреляции определяют статистики для параметров регрессии.
Коэффициенты корреляции между объясняющими переменными позволяют исключать из модели дублирующие факторы. Считают, что две переменные явно коллинеарны, т.е. находятся между собой в линейной зависимости, если 0,7
i jx xr ≥ . Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключать из регрессионной модели.
Предпочтение при этом отдается тому факторному признаку, который при достаточно тесной связи с результативным признаком имеет наименьшую тесноту связи с другими признаками-факторами. В этом требовании проявляется специфика использования множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга.
Следует отметить, что наибольшие сложности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторных признаков, когда имеет место совокупное воздействие факторов друг на друга, т.е. более чем два признака-фактора связаны между собой линейной зависимостью. В результате вариация в исходных данных перестает быть полностью независимой и поэтому невозможно оценить воздействие каждого фактора в отдельности. Включение в модель мультиколлинеарных факторных признаков нежелательно в силу следующих последствий:
1. Затрудняется интерпретация параметров множественнойрегрессии как характеристик действия факторов в «чистом» виде – в виду того, что факторы коррелированы параметры линейной регрессии теряют экономический смысл.
2. Оценки параметров ненадежны, обнаруживают большиестандартные ошибки и меняются с изменением объема наблюдений не только по величине, но и по знаку - это делает модель непригодной для анализа и прогнозирования.
Отбор факторов, включаемых в регрессию, является одним из важнейших этапов практического использования методов регрессии. Подходы к отбору факторов на основе показателей корреляции могут быть разные. Наиболее широкое применение получили такие методы построения уравнения множественной регрессии как:
1. Метод исключения – отсев факторов из полного его набора.2. Метод включения – дополнительное введение фактора.3. Шаговый регрессионный анализ – исключение ранее введенного
фактора.

50
4.2. Метод наименьших квадратов (МНК). Свойства оценок на основе МНК
Существуют разные виды уравнений множественной регрессии:
линейные и нелинейные. Наиболее широкое применение получила линейная функция ввиду
четкой интерпретации ее параметров. В линейной множественной регрессии 1 1 2 2 ... m mxy a b x b x b x= + + + +
параметры при x называются коэффициентами «чистой» регрессии и характеризуют среднее изменение признака-результата с изменением соответствующего признака-фактора на единицу при неизмененном значении других факторов, закрепленных на среднем уровне.
Следует рассмотреть линейную модель множественной регрессии, выраженную уравнением:
1 1 2 2 ... m my a b x b x b x ε= + + + + + . (1.80)
Классический подход к оцениванию параметров линейной модели множественной регрессии основан на использовании метода наименьших квадратов (МНК), который позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака y от расчетных y минимальна
( )2 min
ii xi
y y− →∑ .
Для нахождения экстремума функции нескольких переменных необходимо вычислить частные производные первого порядка по каждому из параметров и приравнять их к нулю.
Имеется функция 1m + аргумента: ( ) ( )2
1 2 1 1 2 2, , , ..., ...m m mS a b b b y a b x b x b x= − − − − −∑ . После элементарных преобразований приходят к системе линейных
нормальных уравнений для нахождения параметров линейного уравнения множественной регрессии (1.80):
1 1 2 2
21 1 1 2 1 2 1 1
21 1 2 2
... ,
... ,................................................................
... .
m m
m m
m m m m m m
na b x b x b x y
a x b x b x x b x x yx
a x b x x b x x b x yx
+ + + + =
+ + + + = + + + + =
∑ ∑ ∑ ∑∑ ∑ ∑ ∑ ∑
∑ ∑ ∑ ∑ ∑
(1.81)

51
Для двухфакторной модели данная система имеет вид:
1 1 2 2
21 1 1 2 1 2 1
22 1 1 2 2 2 2
,
,
.
na b x b x y
a x b x b x x yx
a x b x x b x yx
+ + = + + =
+ + =
∑ ∑ ∑∑ ∑ ∑ ∑∑ ∑ ∑ ∑
Метод наименьших квадратов также применим к уравнению множественной регрессии в стандартизированном масштабе:
1 21 2 ... ,my x x m xt t t tβ β β ε= + + + + (1.82)
где 1
, , ..., my x xt t t - стандартизированные переменные: y
y
y ytσ−
= ,
i
i
i ix
x
x xtσ−
= , для которых среднее значение равно нулю: 0iy xt t= = ,
а среднее квадратическое отклонение равно единице: 1y xit tσ σ= = ;
iβ – стандартизированные коэффициенты регрессии.Стандартизованные коэффициенты регрессии показывают на
сколько единиц изменится в среднем результат, если соответствующий фактор ix изменится на одну единицу при неизменном среднем уровне других факторов. Стандартизованные коэффициенты регрессии iβ можно сравнивать между собой для ранжирования факторов по силе их воздействия на признак-результат. В этом состоит основное достоинство стандартизованных коэффициентов регрессии в отличие от коэффициентов «чистой» регрессии, которые несравнимы между собой.
Применяя МНК к уравнению множественной регрессии в стандартизированном масштабе, получают систему нормальных уравнений вида:
1 1 2 1 3 1
2 1 2 1 3 1
1 2 3
1 2 3
1 2 3
1 2 3
... ,
... ,
........................................................... ,
m
m
m m m m
yx x x x x m x x
yx x x x x m x x
yx x x x x x x m
r r r r
r r r r
r r r r
β β β β
β β β β
β β β β
= + + + +
= + + + + = + + + +
(1.83)
где iyxr и
i jx xr – коэффициенты парной и межфакторной корреляции.
Коэффициенты «чистой» регрессии ib связаны со стандартизованными коэффициентами регрессии iβ следующим образом:

52
i
yi i
x
bσ
βσ
= . (1.84)
Поэтому можно переходить от уравнения регрессии в стандартизованном масштабе (1.82) к уравнению регрессии в натуральном масштабе переменных (1.80), при этом параметр a определяется как
1 1 2 2 ... m ma y b x b x b x= − − − − . Рассмотренный смысл стандартизованных коэффициентов регрессии
позволяет их использовать при отсеве факторов – из модели исключаются факторы с наименьшим значением iβ .
На основе линейного уравнения множественной регрессии вида:
1 1 2 2 ... m my a b x b x b x ε= + + + + + (1.85)
могут быть найдены частные уравнения регрессии, которые связывают результативный признак с соответствующим фактором ix при закреплении остальных факторов на среднем уровне. В развернутом виде данную систему можно записать в виде:
1 2 3
2 1 3
1 2 1
, ,..., 1 1 2 2 3 3
, ,..., 1 1 2 2 3 3
, ,..., 1 1 2 2 3 3
... ,
... ,
..........................................................................
m
m
m m
x x x x m m
x x x x m m
x x x x
y a b x b x b x b x
y a b x b x b x b x
y a b x b x b x
ε
ε
−
⋅
⋅
⋅
= + + + + + +
= + + + + + +
= + + + + . .m mb x ε
+ +
(1.86)
При подстановке в данные уравнения средних значений соответствующих признаков-факторов они принимают вид парных уравнений линейной регрессии:
1 2 3
2 1 3
1 2 1
, ,..., 1 1 1
, ,..., 2 2 2
, ,...,
,
,
................................,
m
m
m m
x x x x
x x x x
x x x x m m m
y A b x
y A b x
y A b x−
⋅
⋅
⋅
= +
= + = +
(1.87)
где
1 2 2 3 3
2 1 1 3 3
1 1 2 2 3 3 1 1
... ,... ,
................................................. .
m m
m m
m m m
A a b x b x b xA a b x b x b x
A a b x b x b x b x− −
= + + + + = + + + + = + + + + +

53
Частные уравнения регрессии в отличие от парной регрессии характеризуют изолированное влияние фактора на результат, т.к. другие факторные признаки закреплены на неизменном уровне. Эффекты влияния других факторов присоединены в них к свободному члену уравнения множественной регрессии. Это позволяет на основе частных уравнений регрессии определять частные коэффициенты эластичности:
1 2 1 1, ,... , ,...,
xi
i i i m
iy i
x x x x x x
xЭ by
− +⋅
= ⋅ , (1.88)
где ib – коэффициент регрессии для фактора ix в уравнении множественной регрессии,
1 2 1 1, ,... , ,...,i i i mx x x x x xy− +⋅ – частное уравнение регрессии.
Наряду с частными коэффициентами эластичности могут быть найдены средние по совокупности показатели эластичности:
i
ii i
x
xЭ by
= ⋅ , (1.89)
которые показывают на сколько процентов в среднем изменится результат, при изменении соответствующего фактора на 1%. Средние показатели эластичности можно сравнивать друг с другом и соответственно ранжировать факторы по силе их воздействия на результат.
4.3. Проверка существенности факторов и показатели качества регрессии
Практическую значимость уравнения множественной регрессии оценивают при помощи показателя множественной корреляции и его квадрата – показателя детерминации.
Показатель множественной корреляции оценивает тесноту совместного влияния набора факторов на результат.
Показатель множественной корреляции может быть определен как индекс множественной корреляции:
1 2
2ост
... 21myx x x
y
R σσ
= − , (1.90)
где 2yσ – общая дисперсия результативного признака;
2остσ – остаточная дисперсия.

54
Изменение индекса множественной корреляции находится в границах от 0 до 1. Чем ближе его значение к 1, тем теснее связь результативного признака со всем набором исследуемых факторов. Величина индекса множественной корреляции должна быть больше или равна максимальному парному индексу корреляции: ( )1 2 ... (max) 1,
m iyx x x yxR r i m≥ = .
При правильном включении факторов в регрессионную модель величина индекса множественной корреляции будет существенно отличаться от индекса корреляции парной зависимости. Если же дополнительно включенные в уравнение множественной регрессии факторы третьестепенны, то индекс множественной корреляции может практически совпадать с индексом парной корреляции. Следовательно, сравнивая индексы множественной и парной корреляции, можно сделать вывод о целесообразности включения в уравнение регрессии того или иного признака-фактора.
Расчет индекса множественной корреляции предполагает определение уравнения множественной регрессии и на его основе остаточной дисперсии:
( )1 2
22ост ...
1mx x xy y
nσ = −∑ . (1.91)
Можно пользоваться следующей формулой индекса множественной детерминации:
( )( )
1 2
1 2
2
...2... 21 m
m
x x x
yx x x
y yR
y y
−= −
−
∑∑
. (1.92)
При линейной зависимости признаков формула индекса множественной корреляции может быть представлена следующим выражением:
1 2 ... m iyx x x i yxR rβ= ⋅∑ , (1.93)
где iβ – стандартизованные коэффициенты регрессии;
iyxr – парные коэффициенты корреляции результата с каждым фактором.
Формула индекса множественной корреляции для линейной регрессии называется линейным коэффициентом множественной корреляции или совокупным коэффициентом корреляции.
В рассмотренных показателях множественной корреляции используется остаточная дисперсия, которая имеет систематическую ошибку в сторону преуменьшения, тем более значительную, чем больше параметров определяется в уравнении регрессии при заданном объеме наблюдений n . Если число параметров при ix равно m и приближается

55
к объему наблюдений, то остаточная дисперсия будет близка к нулю и коэффициент (индекс) корреляции приблизятся к единице даже при слабой связи факторов с результатом. Для того чтобы не допустить возможного преувеличения тесноты связи, используется скорректированный индекс (коэффициент) множественной корреляции.
Скорректированный индекс множественной корреляции содержит поправку на число степеней свободы, а именно остаточная сумма квадратов
( )1 2
2
... mx x xy y−∑ делится на число степеней свободы остаточной вариации
( )1n m− − , а общая сумма квадратов отклонений ( )2y y−∑ на число
степеней свободы в целом по совокупности ( )1n − .Скорректированный индекс множественной детерминации
определяется на основании формулы:
( ) ( )( ) ( )
2
2 11
1
y y n m
R′
y y n
− − −= −
− −
∑∑
, (1.94)
где m – число параметров при переменных x ; n – число наблюдений.
Ввиду того, что ( )
( )1 2
2
... 22 1mx x xy y
Ry y
−= −
−
∑∑
, величину
скорректированного индекса детерминации можно представить в виде:
( )2 2 11 11
nRn m
−= − − ⋅
− −. (1.95)
Чем больше величина m, тем сильнее различия между R′2 и R2 .Ранжирование факторов, участвующих в моделях множественной
линейной регрессии, можно провести с помощью частных коэффициентов корреляции (для линейных связей). Частные показатели корреляции часто используют при решении вопросов отбора факторов - целесообразность включения того или иного фактора в модель можно доказать величиной показателя частной корреляции.
Частные коэффициенты корреляции характеризуют тесноту связи между результатом и соответствующим фактором при устранении влияния других факторов, включенных в уравнение регрессии.
В общем виде при наличии m факторов для уравнения регрессии:
1 1 2 2... m my a b x b x b x ε= + + + +
R

56
коэффициент частной корреляции, измеряющий влияние фактора ix на y , при неизменном уровне других факторов, можно определить при двух факторах по формулам:
1 2
1 2
2
2
2
11
1yx x
yx xyx
Rr
r⋅
−= −
−; 1 2
2 1
1
2
2
11
1yx x
yx xyx
Rr
r⋅
−= −
−. (1.96)
Порядок частного коэффициента корреляции определяется количеством факторов, влияние которых исключается. Так,
1 2yx xr ⋅ – коэффициент частной корреляции первого порядка. Коэффициенты частной корреляции более высоких порядков можно определить через коэффициенты частной корреляции более низких порядков по рекуррентной формуле. При двух факторах данная формула примет вид:
( ) ( )1 2 1 2
1 2
2 1 2
2 21 1yx yx x x
yx x
yx x x
r r rr
r r⋅
− ⋅=
− ⋅ −;
( ) ( )2 1 1 2
2 1
1 1 2
2 21 1yx yx x x
yx x
yx x x
r r rr
r r⋅
− ⋅=
− ⋅ −. (1.97)
Для уравнения регрессии с тремя факторами частные коэффициенты корреляции второго порядка определяются на основе частных коэффициентов корреляции первого порядка.
Частные коэффициенты корреляции, рассчитанные по рекуррентной формуле, изменяются в пределах от –1 до +1, а по формулам через множественные коэффициенты детерминации – от 0 до 1. Сравнение их друг с другом позволяет ранжировать факторы по тесноте их связи с результатом.
Частные коэффициенты корреляции показывают меру тесноты связи каждого фактора с результатом в чистом виде. Если из стандартизованного уравнения регрессии
1 2 31 2 3y x x xt t t tβ β β ε= + + + следует, что
1 2 3β β β> > , т.е. по силе влияния на результат порядок факторов таков: 1x, 2x , 3x , то этот же порядок факторов определяется и по соотношению частных коэффициентов корреляции, как
1 2 3 2 1 3 3 1 2yx x x yx x x yx x xr r r⋅ ⋅ ⋅> > .
Зная частные коэффициенты корреляции (последовательно первого, второго и более высокого порядка), можно определить совокупный коэффициент корреляции. Так, для двухфакторного уравнения формула совокупного коэффициента корреляции принимает вид:
( ) ( )1 2 1 2 1
2 2... 1 1 1
myx x x yx yx xR r r ⋅= − − ⋅ − . (1.98)
При полной зависимости результативного признака от исследуемых признаков-факторов коэффициент совокупного их влияния равен единице.

57
Из единицы вычитается доля остаточной вариации результативного признака ( )21 r− , обусловленная последовательно включенными в анализ факторами. В результате подкоренное выражение характеризует совокупное действие всех исследуемых признаков-факторов.
Значимость уравнения множественной регрессии в целом, так же как и в моделях парной регрессии, оценивается с помощью F -критерия Фишера:
2факт
2ост
11
S R n mFS R m
− −= = ⋅
−, (1.99)
где фактS – факторная сумма квадратов на одну степень свободы;
остS – остаточная сумма квадратов на одну степень свободы; 2R – коэффициент (индекс) множественной детерминации;
m – число параметров при переменных x (в линейной регрессии совпадает с числом включенных в модель факторов); n – число наблюдений. Оценивается значимость не только уравнения в целом, но также и
признака-фактора, дополнительно включенного в регрессионную модель. Необходимость такой оценки обусловлена тем, что не каждый фактор, вошедший в модель, может существенно увеличивать долю объясненной вариации результативного признака. Кроме того, при наличии в модели нескольких факторов они могут вводиться в модель в разной последовательности. Ввиду корреляции между факторами значимость одного и того же фактора может быть разной в зависимости от последовательности его введения в модель. Мерой для оценки включения фактора в модель служит частный F -критерий, т.е.
ixF . Частный F -критерий построен на сравнении прироста факторной
дисперсии, обусловленного влиянием дополнительно включенного фактора, с остаточной дисперсией на одну степень свободы по регрессионной модели в целом. Для двухфакторного уравнения частные F-критерии имеют вид:
( )1 2 2
1
1 2
2 2
2 31
yx x yxx
yx x
R rF n
R−
= ⋅ −−
, ( )1 2 1
2
1 2
2 2
2 31
yx x yxx
yx x
R rF n
R−
= ⋅ −−
. (1.100)
Фактическое значение частного F -критерия сравнивается с табличным при уровне значимости α и числе степеней свободы: 1 и 1n m− − . Если фактическое значение
ixF превышает ( )табл 1 2, , F k kα , то дополнительное
включение фактора ix в модель статистически оправданно и коэффициент чистой регрессии ib при факторе ix статистически значим. Если же

58
фактическое значение ixF меньше табличного, то дополнительное
включение в модель фактора ix не увеличивает существенно долю объясненной вариации признака y , следовательно, нецелесообразно его включение в модель. Коэффициент регрессии при данном факторе в этом случае статистически незначим.
С помощью частного F -критерия можно проверить значимость всех коэффициентов регрессии в предположении, что каждый соответствующий признак-фактор ix вводится в уравнение множественной регрессии последним. Частный F -критерий оценивает значимость коэффициентов чистой регрессии. Зная величину
ixF , можно определить и t -критерий для коэффициента регрессии
при i -м факторе, ibt , а именно:
i ib xt F= . (1.101)
Оценка значимости коэффициентов чистой регрессии по t -критерию Стьюдента может быть проведена и без расчета частных F -критериев. В данном случае, как и в парной регрессии, для каждого фактора используют формулу:
i
i
ib
b
btm
= , (1.102)
где ib – коэффициент чистой регрессии при факторе ix ,
ibm – средняя квадратическая ошибка коэффициента регрессии ib .
Для уравнения множественной регрессии 1 1 2 2 ... m my a b x b x b x= + + + + среднюю квадратическую ошибку коэффициента регрессии можно определить по следующей формуле:
1
1
2...
2...
1 111
m
i
i i m
y yx xb
x x x x
Rm
n mR
σ
σ
−= ⋅
− −−, (1.103)
где yσ – среднее квадратическое отклонение для признака y ,
ixσ – среднее квадратическое отклонение для признака ix ,
1
2... myx xR – коэффициент детерминации для уравнения множественной
регрессии,
1
2...i mx x xR – коэффициент детерминации для зависимости фактора ix со всеми
другими факторами уравнения множественной регрессии; 1n m− − – число степеней свободы для остаточной суммы квадратов
отклонений.

59
Чтобы воспользоваться данной формулой, необходимы матрица межфакторной корреляции и расчет по ней соответствующих коэффициентов детерминации
1
2...i mx x xR . Так, для уравнения
1 1 2 2 3 3y a b x b x b x= + + + оценка значимости коэффициентов регрессии 1b , 2b
, 3b предполагает расчет трех межфакторных коэффициентов
детерминации: 1 2 3
2x x xR ⋅ ,
2 1 3
2x x xR ⋅ ,
3 1 2
2x x xR ⋅ .
Взаимосвязь показателей частного коэффициента корреляции, частного F -критерия и t -критерия Стьюдента для коэффициентов чистой регрессии может быть использована в процедуре отбора факторов. Отсев факторов при построении уравнения регрессии методом исключения практически можно осуществлять не только по частным коэффициентам корреляции, исключая на каждом шаге фактор с наименьшим незначимым значением частного коэффициента корреляции, но и по величинам
ibt и ixF
. Частный F -критерий широко используется и при построении модели методом включения переменных и шаговым регрессионным методом.
Контрольные вопросы
1. Рассказать о механизме включения факторных признаков в модель множественной линейной регрессии.
2. Как найти коэффициенты 0a , 1a , 2a уравнения регрессии221102.1̂ XaXaaY ++= ?
5. Как определяется надежность коэффициентов уравнения множе-ственной линейной регрессии?
6. Как решается вопрос об измерении тесноты связи между фактор-ными и результативными признаками в случае множественной линейной ре-грессии?
7. Как осуществляется корректировка множественного коэффициента корреляции?
8. Как определить степень влияния каждого факторного признака в отдельности, включенного в модельное уравнение множественной линей-ной регрессии, на изменение результативного признака?
9. Рассказать, как осуществляется проверка адекватности модели мно-жественной линейной регрессии.

60
РАЗДЕЛ II. ЛАБОРАТОРНЫЙ ПРАКТИКУМ
Лабораторная работа № 1. КОМПЛЕКСНАЯ СТАТИСТИЧЕСКАЯ ОБРАБОТКА
ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ И ПРОВЕРКА ГИПОТЕЗЫ ПРИНАДЛЕЖНОСТИ ВЫБОРКИ НОРМАЛЬНОМУ
РАСПРЕДЕЛЕНИЮ
Цель работы: овладеть способами построения рядов распределения и ме-тодами расчета числовых характеристик, а также овладеть методами примене-ния выбранных критериев для проверки выдвинутой гипотезы.
З а д а ч а. Имеются данные о числе рабочих дней без простоя буровых бригад Тюменского региона.
Таблица 2.1
261 272 268 264 259 262 258 254 261 270 264 261 265
269 270 263 260 260 259 260 258 265 259 265 261 258
259 259 258 262 264 258 259 263 266 259 261 266 262
259 262 261 266 262 259 262 261 259 262 262 260 269
261 260 258 263 257 260 259 264 261 260 264 261 265
261 260 263 260 260 259 260 258 265 259 265 261 258
256 259 258 262 264 258 259 263 266 259 261 268 262
258 262 261 266 262 259 262 261 259 262 262 261 266
250 262 262 265 268 259 260 265 259 255 260 256 254
259 262 261 266 262 259 262 261 259 262 262 260 269
261 260 258 263 257 260 259 264 261 260 264 261 265
261 260 263 260 260 259 260 258 265 259 265 261 258
256 248 254 252 264 258 258 253 266 259 261 268 262
259 262 261 266 262 259 262 261 262 262 262 261 266
С о д е р ж а н и е р а б о т ы: на основе совокупности данных опыта выполнить следующее:
1. Построить и изобразить графически ряды распределения (интервальный и дискретный).

61
2. Изобразитьграфически кумуляту и эмпирическую функцию распределе-ния.
3. Найти значение моды, медианы, выборочной средней, выборочной дис-персии, выборочного среднего квадратического отклонения, коэффициент вари-ации, асимметрию, эксцесс.
4. Найти доверительные интервалы для среднего квадратического откло-нения и истинного значения измеряемой величины.
6. Проверить согласованность эмпирического распределения с теоретиче-ским нормальным, применяя следующие критерии: Пирсона, Колмогорова, Ро-мановского, Ястремского и Фишера.
7. Раскрыть смысловую сторону каждой характеристики. Сделать вывод.
Выполнение работы Обозначим через Х – число рабочих дней без простоя буровых бригад
Тюменского региона. 1. По данным выборки строим интервальный вариационный ряд. Для
этого найдем максимальное и минимальное значение данной выборки. По-скольку xmax = 272, xmin = 248, то размах варьирования признака Х (ф.1.1) равен R = xmax – xmin = 272 – 248 = 24.
Далее определим число k интервалов (число столбцов в таблице) вари-ационного ряда (ф.1.2), положим 9=k .
Длина h каждого частичного интервала равна 366,2924 ≈=== k
Rh . Так как исходные данные мало отличаются друг от друга и содержат целые числа, то величину h округляем до целого: 3=h . В других случаях округ-лять не рекомендуется.
Подсчитываем число вариант, попадающих в каждый интервал, по дан-ным выборки. Значение ix , попадающее на границу интервала, относим к левому концу. За начало 0x первого интервала берем величину
2465,24635,02485,0min0 ≈=⋅−=−= hxx . Конец kx последнего интервала нахо-дим по формуле 2735,2735,12725,0max ≈=+=+= hxxk . Сформированный ин-тервальный вариационный ряд записываем в виде табл. 2.2.
Таблица 2.2
Варианты- интервалы
246-
249
249-
252
252-
255
255-
258
258-
261
261-
264
264-
267
267-
270
270-
273
Частоты, ni 1 2 5 21 77 45 21 9 1
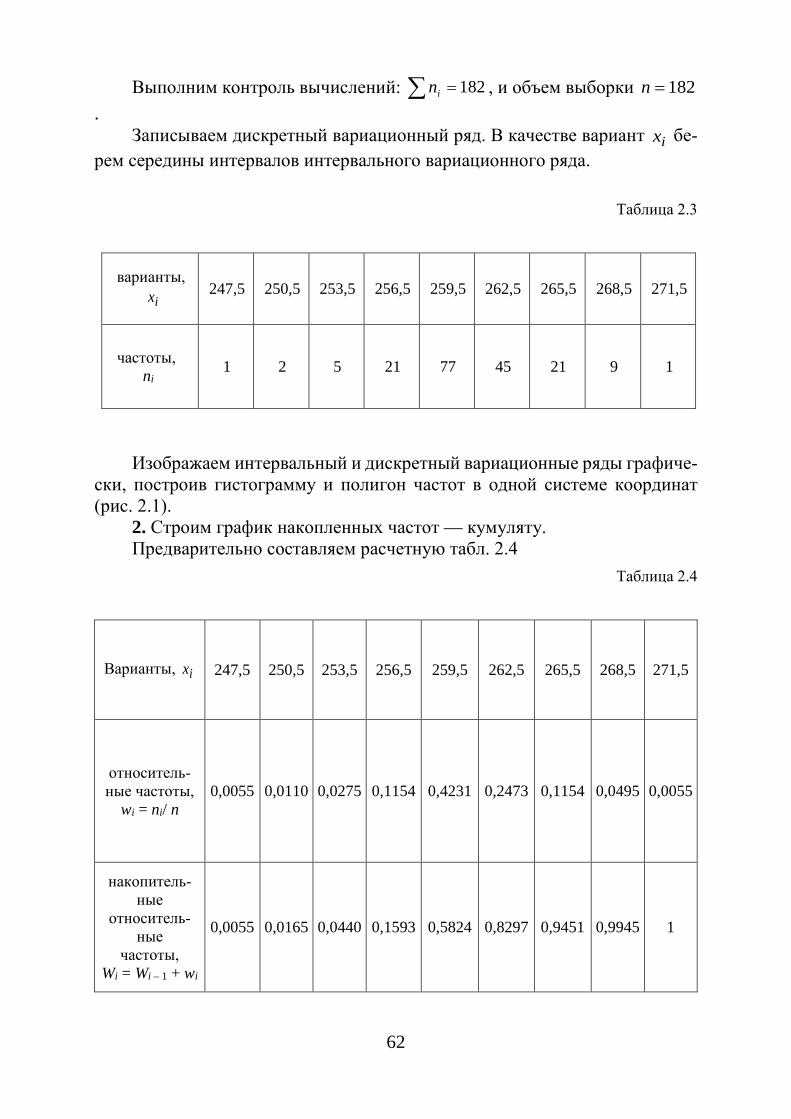
62
Выполним контроль вычислений: ∑ = 182in , и объем выборки 182=n.
Записываем дискретный вариационный ряд. В качестве вариант ix бе-рем середины интервалов интервального вариационного ряда.
Таблица 2.3
варианты, ix 247,5 250,5 253,5 256,5 259,5 262,5 265,5 268,5 271,5
частоты, ni
1 2 5 21 77 45 21 9 1
Изображаем интервальный и дискретный вариационные ряды графиче-ски, построив гистограмму и полигон частот в одной системе координат (рис. 2.1).
2. Строим график накопленных частот — кумуляту. Предварительно составляем расчетную табл. 2.4
Таблица 2.4
Варианты, ix 247,5 250,5 253,5 256,5 259,5 262,5 265,5 268,5 271,5
относитель-ные частоты,
wi = ni/ n 0,0055 0,0110 0,0275 0,1154 0,4231 0,2473 0,1154 0,0495 0,0055
накопитель-ные
относитель-ные
частоты, Wi = Wi – 1 + wi
0,0055 0,0165 0,0440 0,1593 0,5824 0,8297 0,9451 0,9945 1
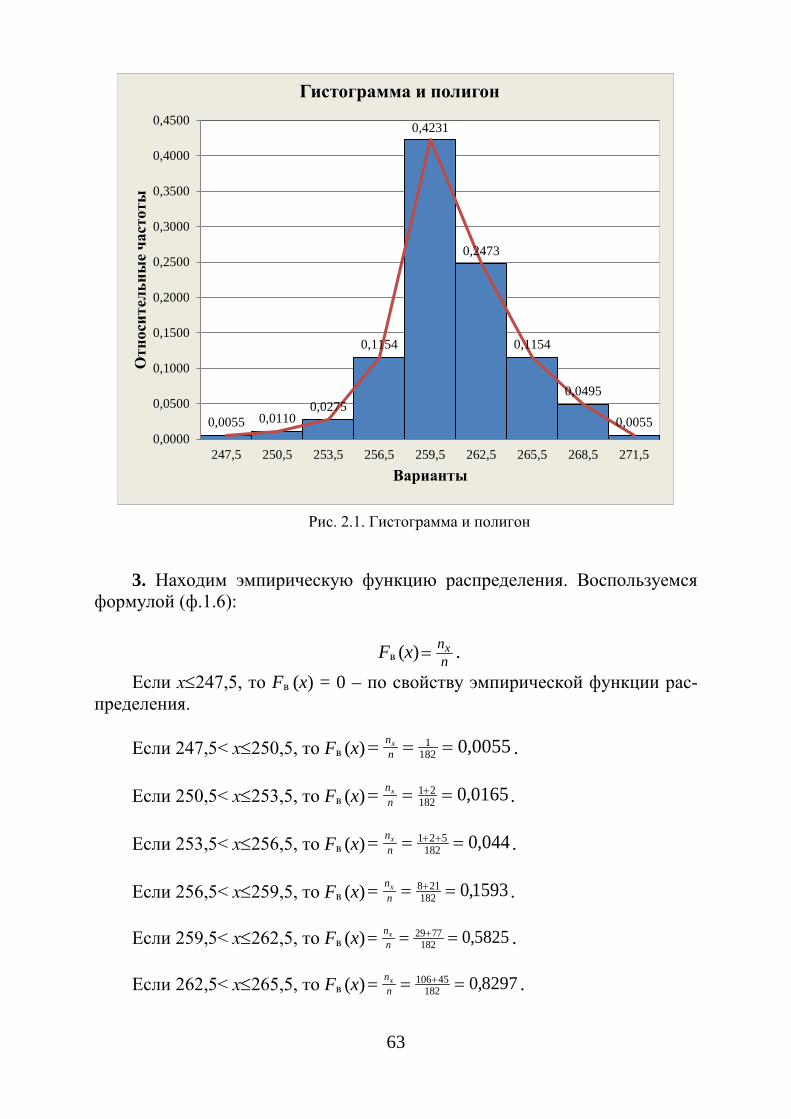
63
Рис. 2.1. Гистограмма и полигон
3. Находим эмпирическую функцию распределения. Воспользуемся формулой (ф.1.6):
Fв (x) nnx= .
Если х≤247,5, то Fв (x) = 0 – по свойству эмпирической функции рас-пределения.
Если 247,5< х≤250,5, то Fв (x) 0055,01821 === n
nx .
Если 250,5< х≤253,5, то Fв (x) 0165,018221 === +
nnx .
Если 253,5< х≤256,5, то Fв (x) 044,0182521 === ++
nnx .
Если 256,5< х≤259,5, то Fв (x) 1593,0182218 === +
nnx .
Если 259,5< х≤262,5, то Fв (x) 5825,01827729 === +
nnx .
Если 262,5< х≤265,5, то Fв (x) 8297,018245106 === +
nnx .
0,0055 0,01100,0275
0,1154
0,4231
0,2473
0,1154
0,0495
0,00550,0000
0,0500
0,1000
0,1500
0,2000
0,2500
0,3000
0,3500
0,4000
0,4500
247,5 250,5 253,5 256,5 259,5 262,5 265,5 268,5 271,5
Отн
осит
ельн
ые
част
оты
Варианты
Гистограмма и полигон

64
Если 265,5< х≤268,5, то Fв (x) 9451,018221151 === +
nnx .
Если 268,5< х≤271,5, то Fв (x) 9945,01829172 === +
nnx .
Если 271,5>x , то Fв (x) = 1 – по свойству эмпирической функции рас-пределения.
Записываем полученную эмпирическую функцию в виде:
Fв (x)
∞+∈∈∈∈∈∈∈∈∈−∞∈
=
);5,271(,1],5,271;5,268(,9945,0],5,268;5,265(,9451,0],5,265;5,262(,8297,0],5,262;5,259(,5824,0],5,259;5,256(,1593,0
],5,256;5,253(,044,0],5,253;5,250(,0165,0],5,250;5,247(,0055,0
],5,247,(0
xxxxxx
xxx
x
График функции Fв (x) представлен на рис. 2.3. Соединив середины вертикальных частей ступенчатой кусочно-посто-
янной кривой, являющейся графиком функции Fв (x), получаем плавную кривую (на рис. 2.3 это штриховая линия). Абсциссами точек этой кривой служат значения чисел рабочих дней без простоя, а ординатами – значения эмпирической функции распределения, характеризующей оценку вероятно-сти события X≤ ix , т.е. вероятности попадания возможных значений чисел рабочих дней без простоя для пятидесяти буровых бригад на промежуток
],( ix−∞ .
Для нахождения числовых характеристик признака Х – чисел рабочих дней без простоя (несмещенных оценок для aXM =)( , )(XD , а также XM e, XM o , sA , xE ) воспользуемся табл. 2.3.
Так как варианта 5,259=x в табл. 2.3 встречается с наибольшей ча-стотой 295 =n , то 5,259=XM o , т.е. это значение чисел рабочих дней без простоя, встречающееся в данной выборке с наибольшей частотой.
Находим XM e . Так как табл. 2.3 содержит нечетное число столбцов, то 5,259=XM e . Это значение чисел рабочих дней без простоя, которое делит данные выборки признака Х на равные части.
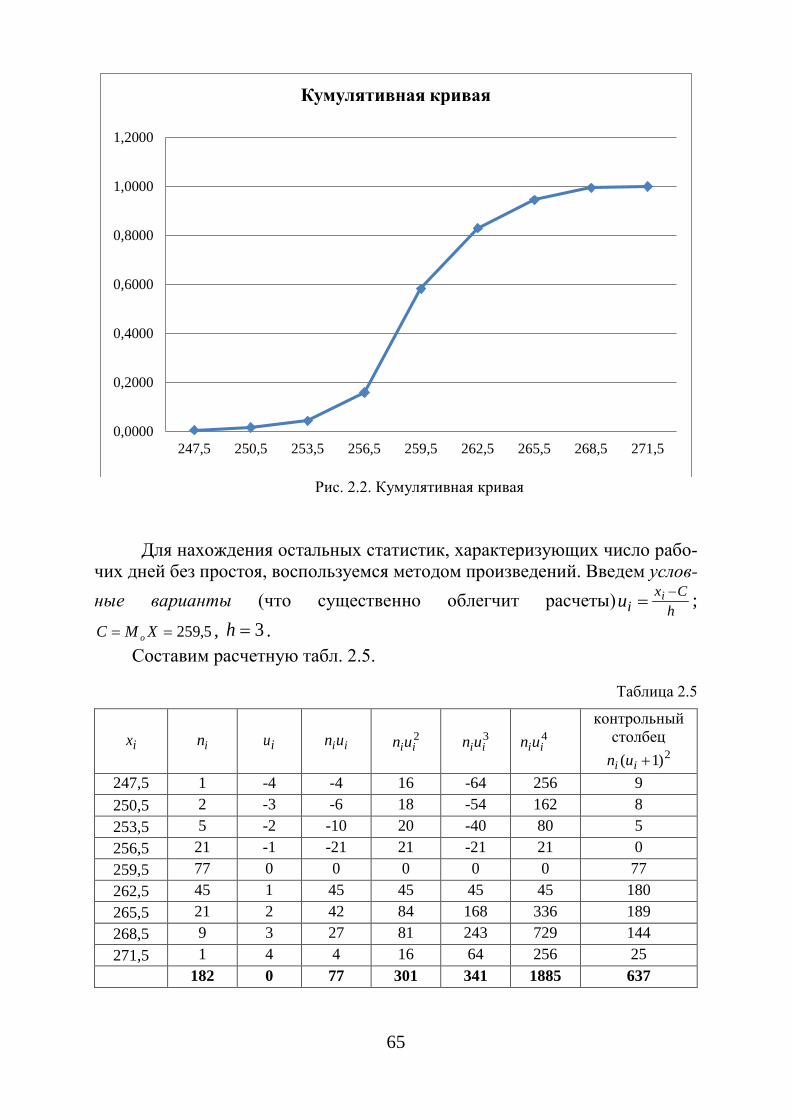
65
Рис. 2.2. Кумулятивная кривая
Для нахождения остальных статистик, характеризующих число рабо-
чих дней без простоя, воспользуемся методом произведений. Введем услов-ные варианты (что существенно облегчит расчеты) h
Cxi
iu −= ; 5,259== XMC o , 3=h .
Составим расчетную табл. 2.5.
Таблица 2.5
ix in iu iiun 2iiun 3
iiun 4iiun
контрольный столбец
2)1( +ii un
247,5 1 -4 -4 16 -64 256 9 250,5 2 -3 -6 18 -54 162 8 253,5 5 -2 -10 20 -40 80 5 256,5 21 -1 -21 21 -21 21 0 259,5 77 0 0 0 0 0 77 262,5 45 1 45 45 45 45 180 265,5 21 2 42 84 168 336 189 268,5 9 3 27 81 243 729 144 271,5 1 4 4 16 64 256 25
182 0 77 301 341 1885 637
0,0000
0,2000
0,4000
0,6000
0,8000
1,0000
1,2000
247,5 250,5 253,5 256,5 259,5 262,5 265,5 268,5 271,5
Кумулятивная кривая
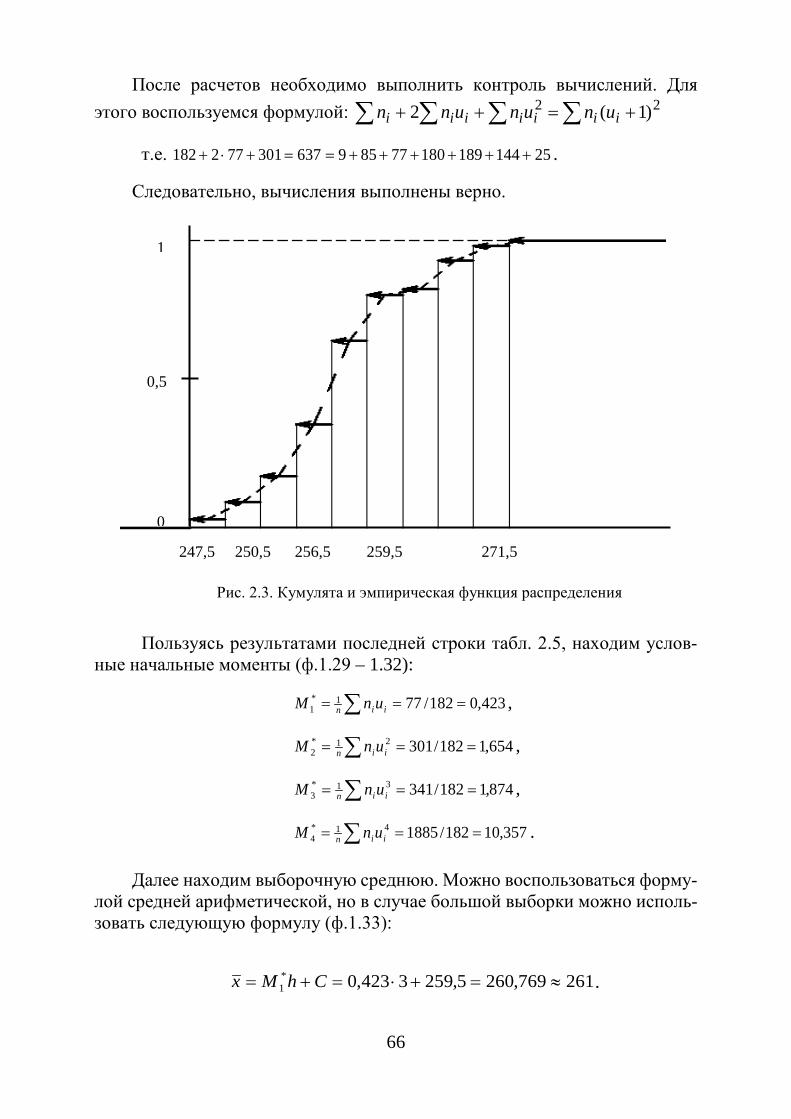
66
После расчетов необходимо выполнить контроль вычислений. Для этого воспользуемся формулой: ∑ ∑ ∑ ∑ +=++ 22 )1(2 iiiiiii unununn
т.е. 637301772182 =+⋅+ 2514418918077859 ++++++= .
Следовательно, вычисления выполнены верно.
Рис. 2.3. Кумулята и эмпирическая функция распределения
Пользуясь результатами последней строки табл. 2.5, находим услов-
ные начальные моменты (ф.1.29 – 1.32):
423,0182/771*1 === ∑ iin unM ,
∑ === 654,1182/30121*2 iin unM ,
874,1182/34131*3 === ∑ iin unM ,
357,10182/188541*4 === ∑ iin unM .
Далее находим выборочную среднюю. Можно воспользоваться форму-лой средней арифметической, но в случае большой выборки можно исполь-зовать следующую формулу (ф.1.33):
261769,2605,2593423,0*1 ≈=+⋅=+= ChMx .
1
0
247,5 250,5 256,5 259,5 271,5
0,5

67
Данная формула характеризует среднее число рабочих дней без про-стоя и составляет 261 рабочий день.
Находим выборочную дисперсию и выборочное среднее квадратичное отклонение (ф.1.34, 1.35):
276,139)423,0654,1()( 222*
1*2
2 =⋅−=−= hMMS
64357,3276,132 === SS .
Величина выборочного среднего квадратичного отклонения 644,3=S характеризует степень рассеяния значений числа рабочих дней без простоя относительно среднего числа рабочих дней.
Далее вычислим коэффициент вариации (ф.1.40):
%396,1%100%100 261644,3 =⋅=⋅= x
SV .
Величина коэффициента вариации мала (составляет 1%), что означает достаточно тесную сгруппированность значений числа рабочих дней без простоя около центра рассеяния, т.е. около средней.
Для предварительной оценки отклонения значений числа рабочих дней без простоя от нормального распределения вычисляем асимметрию и экс-цесс (ф.1.36, 1,37). Сначала находим центральные моменты третьего и чет-вертого порядков (ф.1.38, 1.39):
9988,13)423,02423,0654,13873,1()23( 3333*1
*1
*2
*33 −=⋅⋅+⋅⋅−=+−= hMMMMm .
=−+−= 44*1
2*1
*2
*1
*3
*44 )364( hMMMMMMm
1821,7183)423,03423,0654,16423,0873,14357,10( 442 =⋅⋅−⋅⋅+⋅⋅−= .
Тогда в соответствии с этими расчетами находим:
04133,0333
643,39988,1 −=== −
Sm
sA , 0761,133 444
643,31821,718 =−=−=
Sm
xE .
Таким образом, получили что, значения sA и xE мало отличаются от нуля. Поэтому можно предположить близость данной выборки, характери-зующей число рабочих дней без простоя, к нормальному распределению.
4. Произведем оценку генеральной средней aXM =)( и генерального среднеквадратического отклонения σ = S по выборочным статистикам x и S используя теорию доверительных интервалов для нормального распределения.
Доверительный интервал для истинного значения числа рабочих дней без простоя с надежностью 95,0=γ находим, согласно следующей формуле:

68
γγ ⋅+<<⋅− txatxn
Sn
S .
Согласно приложению 1, при 182=n и 95,0=γ находим 96,1=γt . За-писываем доверительный интервал:
96,126196,1261182643,3
182643,3 ⋅+<<⋅− a ,
или 261,29260,24 << a .
Но условия задачи таковы, что необходимо записать интервал с цело-
численными значениями, то есть )262;260( . Таким образом, среднее число рабочих дней без простоя (в количестве
дней) по данным выборки должна находиться в промежутке )262;260(
Запишем доверительный интервал для генерального среднеквадратиче-ского отклонения S=σ . При заданных 95,0=γ и 182=n по приложению 2 находим 099,0=q . Так как 1<q , то доверительный интервал записываем в виде:
)1()1( qSqS +<σ<− ,
или )099,01(643,3)099,01(643,3 +<<− σ ,
или 004,428,3 << σ ;
следовательно, отклонения истинных значений число рабочих дней без про-стоя не должны выходить за пределы промежутка )004,4;28,3( .
Этот интервал поможет нам правильно подобрать и построить график нормального распределения.
5. Продолжим вероятностно-статистическую обработку результатов эксперимента. Значения полученных характеристик дают нам возможность предположить, что данная выборка подчиняется нормальному распределе-нию. Для подтверждения (или опровержения) данной гипотезы выполним следующие действия.
Построим теоретическую кривую. За основу берем дискретный вариа-ционный ряд в табл. 2.3 и значения 261=x и 643,3=S .
Эмпирическая кривая распределения представляет собой полигон частот. Для построения теоретической (нормальной) кривой найдем координаты точек
),( ii nx ′ , для чего рассчитаем теоретические частоты in′ (табл. 2.6).
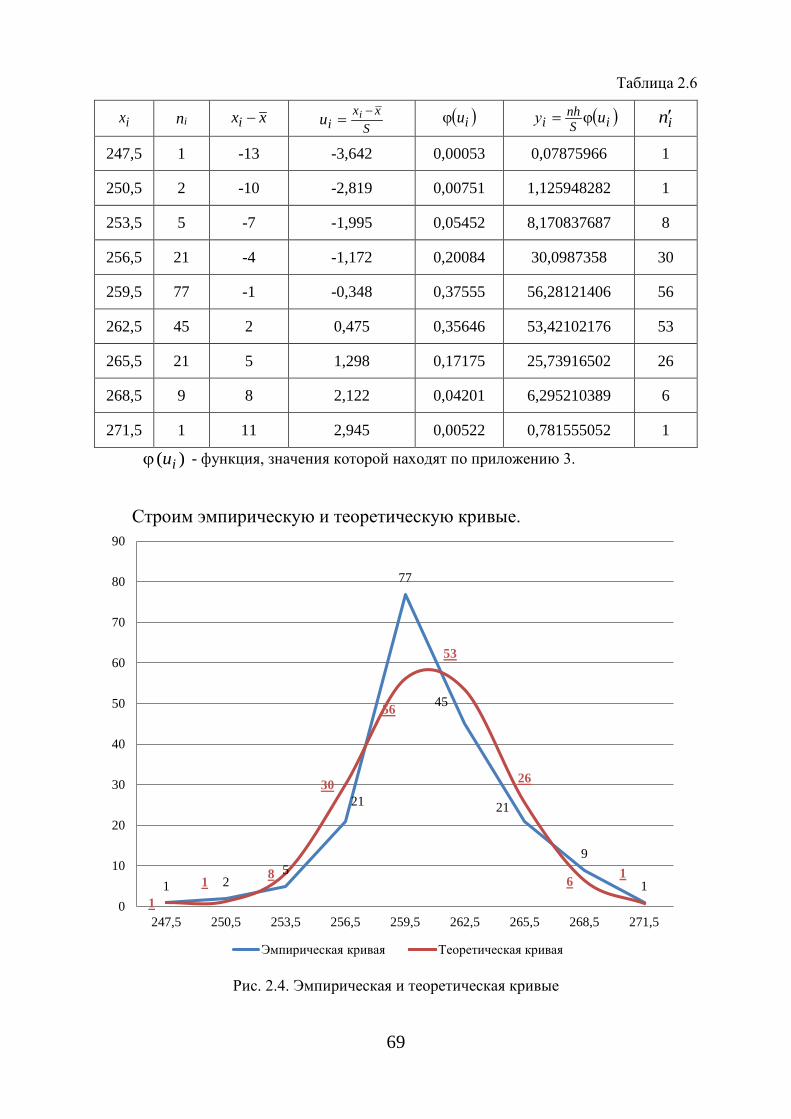
69
Таблица 2.6
ix ni xxi − S
xxi
iu −= ( )iuϕ ( )iS
nhi uу ϕ= in′
247,5 1 -13 -3,642 0,00053 0,07875966 1
250,5 2 -10 -2,819 0,00751 1,125948282 1
253,5 5 -7 -1,995 0,05452 8,170837687 8
256,5 21 -4 -1,172 0,20084 30,0987358 30
259,5 77 -1 -0,348 0,37555 56,28121406 56
262,5 45 2 0,475 0,35646 53,42102176 53
265,5 21 5 1,298 0,17175 25,73916502 26
268,5 9 8 2,122 0,04201 6,295210389 6
271,5 1 11 2,945 0,00522 0,781555052 1
)( iuϕ - функция, значения которой находят по приложению 3.
Строим эмпирическую и теоретическую кривые.
Рис. 2.4. Эмпирическая и теоретическая кривые
1 25
21
77
45
21
9
11
1 8
30
56
53
26
6 1
0
10
20
30
40
50
60
70
80
90
247,5 250,5 253,5 256,5 259,5 262,5 265,5 268,5 271,5
Эмпирическая кривая Теоретическая кривая

70
Проверим согласованность эмпирического распределения (число ра-бочих дней без простоя) с теоретическим нормальным по критерию Пир-
сона. Вычислим величину 2χ по формуле: ∑=
′′−=χ
l
innni
ii
1
)(2 2.
Для нахождения суммы составляем расчетную табл. 2.7. Таблица 2.7
in in′ ii nn ′− 2)( ii nn ′− i
iinnn′′− 2)(
1 1 0 0 0 2 1 1 1 1 5 8 -3 9 1,125 21 30 -9 81 2,7 77 56 21 441 7,875 45 53 -8 64 1,20754717 21 26 -5 25 0,961538462 9 6 3 9 1,5 1 1 0 0 0
36,1620 =χ
Находим число степеней свободы 6393 =−=−=−= srsk . Выбираем уровень значимости 95,0=α и по таблице критических точек распределе-ния 2χ (приложение 4) находим 64,12
кр =χ . Так как, 20
2кр χ<χ )36,1664,1( < , то
делаем вывод, что данные выборки, характеризующие число рабочих дней без простоя, не подчиняются нормальному закону распределения.
Проведём проверку близости эмпирического распределения к нормаль-
ному по критерию Романовского. Вычислим величину kk
2
2−χ . Так как,
36,1620
2 == χχ , 6=k , то 399,212
636,162
2
<== −−kkχ , т.е. расхождение между эмпи-
рическим и теоретическим распределением несущественно, что позволяет утверждать, что данные выборки, характеризующие число рабочих дней без простоя по критерию Романовского подчиняются нормальному закону рас-пределения.
Итак, для проверки согласованности эмпирического распределения с теоретическим нормальным мы применили два критерия, один из них под-твердил близость выборочной совокупности к нормальному распределе-нию. В данном случае необходимо применить еще один или несколько кри-териев, для того чтобы сделать окончательный вывод.
Магистрам предлагается сделать это самостоятельно.

71
Лабораторная работа № 2. ПОСТРОЕНИЕ МОДЕЛИ ЛИНЕЙНОЙ РЕГРЕССИИ
(СЛУЧАЙ НЕСГРУППИРОВАННЫХ ДАННЫХ)
Ц е л ь р а б о т ы: овладеть способами построения моделей линейной регрессии, и выработать умения и навыки оценки надежности коэффици-ента корреляции, уравнения регрессии и его коэффициентов.
З а д а ч а. Найти эмпирическую формулу, устанавливающую зависи-мость между коэффициентами сменности техники Y и её средним возрастом X по предприятию ПМК-7 объединения Сибкомплектмонтаж на основании следующих данных:
Таблица 2.8
Y 1,18 1,21 1,25 1,26 1,3 1,32 1,33 0,69 0,72 0,8 X 6,31 5,8 5,1 5,6 6,1 6,5 6,55 3,8 3,41 4
С о д е р ж а н и е р а б о т ы: на основании данных необходимо: 1. Построить корреляционное поле и по характеру расположения то-
чек в корреляционном поле определить общий вид регрессии. 2. Вычислить основные характеристики x , y , xS , yS , r , rσ , необ-
ходимые для построения модели регрессии. 3. Определить коэффициент корреляции r , найти уровень его значи-
мости и доверительный интервал (степень надежности определяется само-стоятельно).
4. Написать эмпирические уравнения линий регрессий y на x и x на y . 5. Вычислить коэффициент детерминации 2R и объяснить получен-
ное значение. 6. Проверить адекватность уравнения регрессии. 7. Провести оценку величины погрешности уравнения регрессии y
на x и его коэффициентов. 8. Построить уравнение регрессии y на x в первоначальной системе
координат.
Выполнение работы На основании, анализа взаимосвязи коэффициента сменности техники
от ее среднего возраста следует, что за факторный признак Х следует при-нять средний возраст техники, а коэффициент сменности за результативный признак Y.
1. Для определения формы связи между признаками X и Y строим на координатной плоскости точки (xi.yi), пользуясь табл. 2.8. Около построен-ных точек проводим так называемую линию тренда (рис. 2.5).
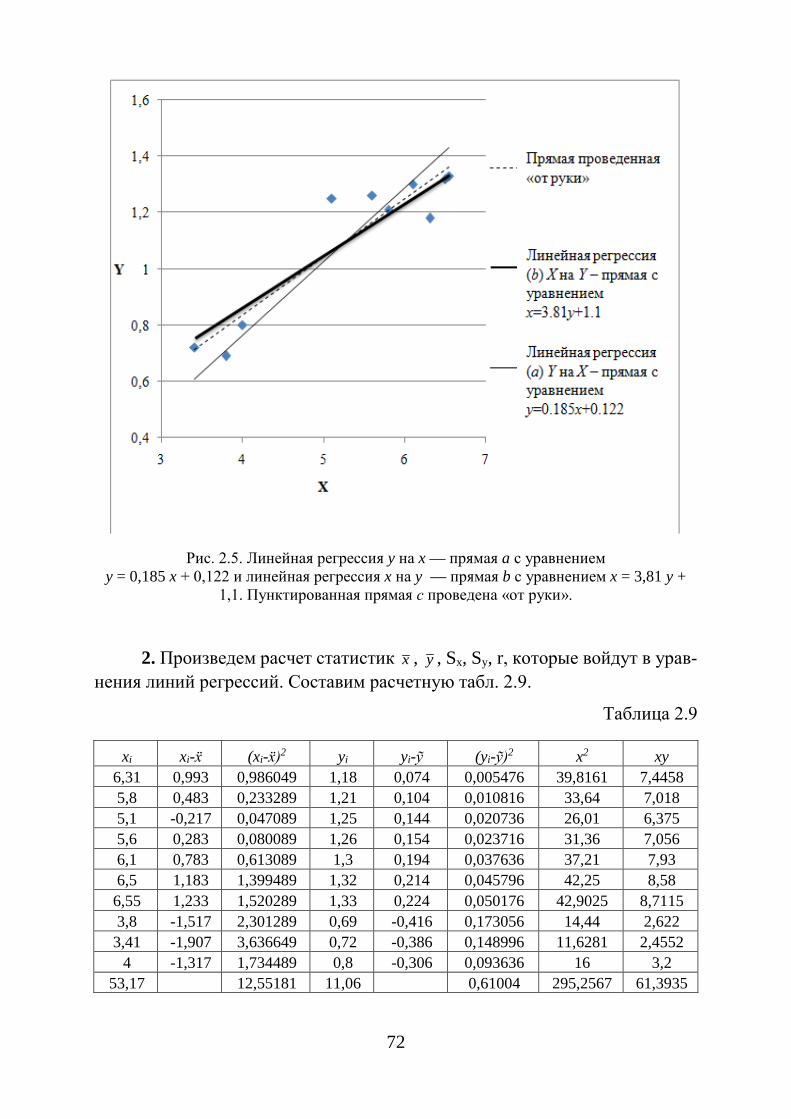
72
Рис. 2.5. Линейная регрессия y на x — прямая a с уравнением
y = 0,185 x + 0,122 и линейная регрессия x на y — прямая b с уравнением x = 3,81 y + 1,1. Пунктированная прямая с проведена «от руки».
2. Произведем расчет статистик x , y , Sx, Sy, r, которые войдут в урав-
нения линий регрессий. Составим расчетную табл. 2.9.
Таблица 2.9
xi xi-ẍ (xi-ẍ)2 yi yi-ỹ (yi-ỹ)2 x2 xy 6,31 0,993 0,986049 1,18 0,074 0,005476 39,8161 7,4458 5,8 0,483 0,233289 1,21 0,104 0,010816 33,64 7,018 5,1 -0,217 0,047089 1,25 0,144 0,020736 26,01 6,375 5,6 0,283 0,080089 1,26 0,154 0,023716 31,36 7,056 6,1 0,783 0,613089 1,3 0,194 0,037636 37,21 7,93 6,5 1,183 1,399489 1,32 0,214 0,045796 42,25 8,58 6,55 1,233 1,520289 1,33 0,224 0,050176 42,9025 8,7115 3,8 -1,517 2,301289 0,69 -0,416 0,173056 14,44 2,622 3,41 -1,907 3,636649 0,72 -0,386 0,148996 11,6281 2,4552
4 -1,317 1,734489 0,8 -0,306 0,093636 16 3,2 53,17 12,55181 11,06 0,61004 295,2567 61,3935

73
Теперь найдем средний возраст техники и средний коэффициент смен-ности.
1 110
153,17 5,317
n
ini
x x=
= = ⋅ =∑ — средний возраст техники
1 110
111,06 1,106
n
ini
y y=
= = ⋅ =∑ — средний коэффициент сменности.
Рассчитаем следующие числовые характеристики:
2 21 11 10
1
ˆ ( ) 12,55 1,3946n
x ini
S x x−=
= − = ⋅ =∑ ⇒ ˆ 1,1810xS = ,
2 21 11 10
1
ˆ ( ) 0,6104 0,0678n
y ini
S y y−=
= − = ⋅ =∑ ⇒ ˆ 0, 2604yS = ,
1 110
161,39 6,13935
n
i ini
xy x y=
= = ⋅ =∑ ,
Подставим найденные значения в формулу для нахождения коэффици-ента корреляции (1.61).
6,31 5,317 1,106ˆ ˆ 1,18*0,0678 0,8416x y
xy x yS S
r − ⋅ − ⋅⋅
= = = .
Коэффициент корреляции получился достаточно большим, его значе-ние близко к единице. Следовательно, между признаками существует доста-точно тесная связь.
3. Теперьпроверим значимость коэффициента корреляции. Вычислим статистику tp по формуле:
2 2
2 0,8416 10 2p 1 1 0,8416
4, 406684r n
rt − ⋅ −
− −= = = .
По таблице критических точек распределения Стьюдента (приложение 5) по уровню значимости 05,0=α и числу степеней свободы
2 10 2 8k n= − = − = находим т 2,306t = . Так как 𝑡𝑡𝑝𝑝 = 4,406684 > 𝑡𝑡𝑇𝑇, то выбо-рочный коэффициент корреляции значимо отличается от нуля. Следова-тельно, средний коэффициент сменности Y и средним возрастом X коррели-рованны.
Находим доверительный интервал для выборочного коэффициента корреляции r с надежностью 95,0=γ . Так как объем выборки 10 50n = < , то доверительный интервал находим по формуле: rr trrtr σσ γγ ⋅+≤≤⋅− ˆ .
Так как по условию надежность (доверительная вероятность) равна 95,0=γ , то по таблице функции Лапласа (приложение 6) находим 1,96tγ = .
Вычисляем среднюю квадратичную ошибку rσ по формуле:

74
22 1 0,841612 10 2
0,1032rr n
σ −−− −
= = = .
Записываем доверительный интервал:
0,8416− 1,96 ∗ 0.1032 < �̂�𝑟 < 0,8416 + 1,96 ∗ 0,1032
или r̂ ϵ [0,64;1].
Следовательно, с вероятностью 0,64 линейный коэффициент корреля-ции генеральной совокупности находится в пределах от 0,64 до 1. По имею-щейся выборке следует ожидать влияние среднего возраста техники на ко-эффициент сменности не менее чем на 64%.
4. Найдем эмпирические линейные уравнения регрессии y на x и x на y, которые являются приближенными уравнениями для истинных уравнений регрессий.
ẏx=0,185*x+0,122 ẋy=3,81*y+1,1 Контроль вычислений:
a1b1=0,185*3,81=0,705
r2=0,84*0,84=0,705
Получили, что a1b1= r2, а это значит, что вычисления выполнены верно. Из уравнения ẏx=0.185*x+0.122 следует, что при уменьшении коэффи-
циента сменности на 1 средний возраст техники вырастет на 0,185 5. Найдем коэффициент детерминации. Для линейной регрессии при
вычисленном коэффициенте r он равен r2= 0,705≈0,71. Это означает, что коэффициент сменности техники зависит от ее возраста на 71%, и только 29% рассеивания среднего показателя коэффициента сменности остались необъяснимыми.
6. Проверим адекватность уравнений линейной регрессии y на x по кри-терию Фишера-Снедекора. Для этого вычислим статистику Fн по формуле (ф.1.67):
𝐹𝐹𝐻𝐻 =𝑅𝑅2
1 − 𝑅𝑅2(𝑛𝑛 − 2), = 51,3 ,
где R2 определяем по формуле (ф.1.62) используя расчетную табл. 2.10:
865,01 2
2
)(
)ˆ(2 =∑∑−=
−
−
yy
yy
i
ixiR .
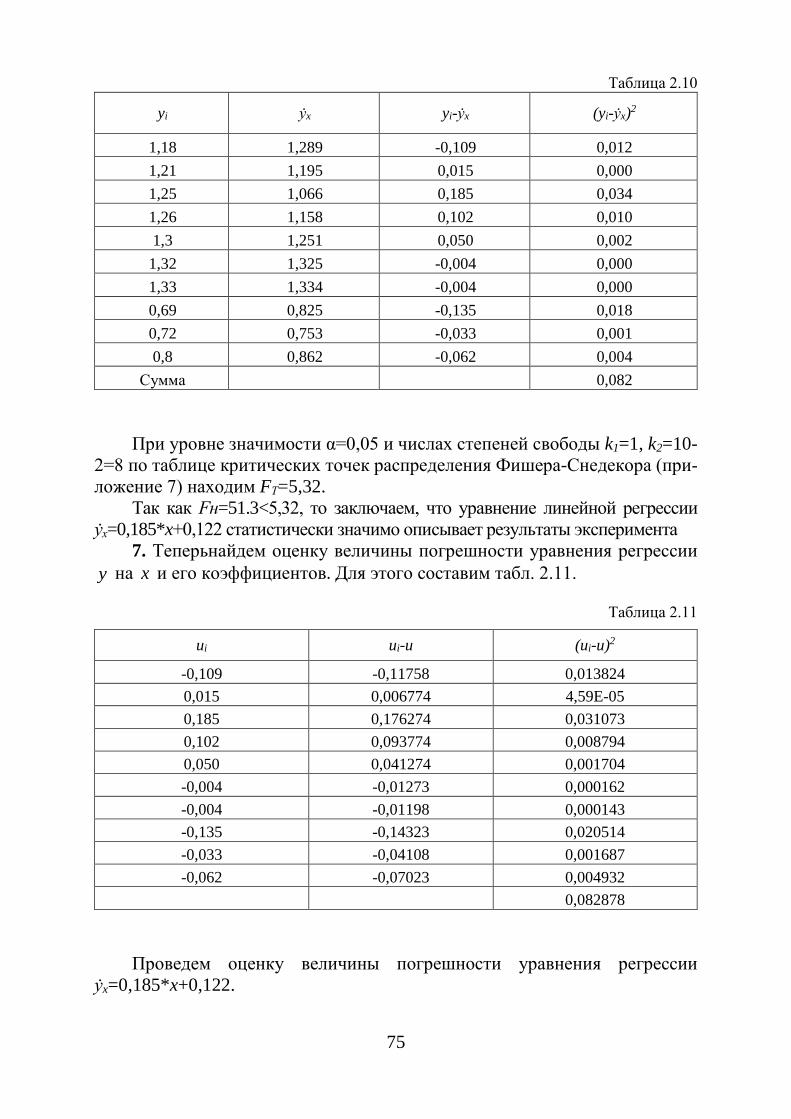
75
Таблица 2.10
yi ẏx yi-ẏx (yi-ẏx)2
1,18 1,289 -0,109 0,012 1,21 1,195 0,015 0,000 1,25 1,066 0,185 0,034 1,26 1,158 0,102 0,010 1,3 1,251 0,050 0,002 1,32 1,325 -0,004 0,000 1,33 1,334 -0,004 0,000 0,69 0,825 -0,135 0,018 0,72 0,753 -0,033 0,001 0,8 0,862 -0,062 0,004
Сумма 0,082
При уровне значимости α=0,05 и числах степеней свободы k1=1, k2=10-2=8 по таблице критических точек распределения Фишера-Снедекора (при-ложение 7) находим FТ=5,32.
Так как Fн=51.3<5,32, то заключаем, что уравнение линейной регрессии ẏх=0,185*x+0,122 статистически значимо описывает результаты эксперимента
7. Теперьнайдем оценку величины погрешности уравнения регрессии y на x и его коэффициентов. Для этого составим табл. 2.11.
Таблица 2.11
ui ui-u (ui-u)2
-0,109 -0,11758 0,013824 0,015 0,006774 4,59E-05 0,185 0,176274 0,031073 0,102 0,093774 0,008794 0,050 0,041274 0,001704 -0,004 -0,01273 0,000162 -0,004 -0,01198 0,000143 -0,135 -0,14323 0,020514 -0,033 -0,04108 0,001687 -0,062 -0,07023 0,004932
0,082878
Проведем оценку величины погрешности уравнения регрессии ẏx=0,185*x+0,122.

76
Найдем относительную погрешность δ уравнения по формуле:
%,100⋅= yuσδ
где 2)( 2
−−∑== n
uuu
iDuσ , xii yyu ˆ−= , ∑ −= 21 )ˆ( xin yyu Так как 2ˆ( ) 0,0823
ii xy y− =∑ , то 0,083u = . Для нахождения суммы ∑ − 2)( uui используем табл. 2.11.
Тогда 0,0838 0,10uσ = = , 0,10
1,106 100% 9,2%δ = ⋅ = . Так как величина δ до-статочно мала, то уравнение линейной регрессии ẏx= 0,185*x+0,122 описы-вает опытные данные.
Оценим коэффициенты уравнения регрессии. У нас 0 0,122a = , 1 0,185a =
. Для нахождения отношений 00 / aSa и 11 / aSa вычислим средние квадрати-ческие ошибки коэффициентов по формулам:
22
2
0 )(/ xxn
xxya SS
−∑∑⋅= , 221 )(/ xxn
nxya SS ∑∑=
− , 2/ 1ˆ rSS yxy −= .
По табл. 2.9 находим: 17,53=∑ ix , ( ) 257,2952∑ =ix . Учитывая, что 10=n
, 2 0.7089r = и ˆ 0, 2604yS = , находим:
/ 0, 2604 1 0,7089 0,14063y xS = ⋅ − =
𝑆𝑆𝑎𝑎0 = 0,14063 ∗ �295,26
10 ∗ 295,26 − 53,172= 0,2155
𝑆𝑆𝑎𝑎1 = 0,14063 ∗ �10
10 ∗ 295,26 − 53,172= 0,0397
Коэффициенты ia считаются значимыми, если выполняется условие: 2𝑆𝑆𝑎𝑎𝑖𝑖 < |𝑎𝑎𝑖𝑖|.
Проверяя это условие для коэффициентов 𝑎𝑎0и 𝑎𝑎1 получим, что коэффи-циент 1 0,185a = значим, а коэффициент 0 0,122a = не значим. Следует отме-тить, что это легко можно устранить увеличивая объем выборки. Графиками найденных регрессий являются прямые a, b, представленные на рис. 2.5. Та-ким образом, полученное уравнение может быть принято для практического руководства.

77
Лабораторная работа № 3. ПОСТРОЕНИЕ УРАВНЕНИЯ МОДЕЛИ ЛИНЕЙНОЙ РЕГРЕССИИ
(СЛУЧАЙ СГРУППИРОВАННЫХ ДАННЫХ)
Ц е л ь р а б о т ы: овладеть способами построения моделей линейной регрессии, и выработать умения и навыки оценки надежности коэффици-ента корреляции, уравнения регрессии и его коэффициентов.
З а д а ч а. Фонтанную скважину исследовали на приток нефти. При различных режимах работы с замерами забойных давлений глубинным ма-нометром. Данные замеров приведены в корреляционной табл. 2.12.
Таблица 2.12
X Y 125 135 145 155 165 175 185 195 205 yn
11 3 4 7
12 5 4 9
13 3 5 8
14 5 6 11
15 2 18 20
16 4 14 18
17 7 2 9
18 4 6 10
19 2 6 8
xn 3 9 12 13 22 21 6 8 6 100
С о д е р ж а н и е р а б о т ы: по опытным данным, представленным в корреляционной таблице необходимо:
1) Построить корреляционное поле и выбрать общий вид регрессии; 2) Записать уравнение линейной регрессии y на x используя: а) метод наименьших квадратов б) коэффициент корреляции . Выбрать наиболее подходящее уравнение, и математически обосно-
вать данный выбор; 3) Найти выборочный коэффициент корреляции и оценить тесноту
связи между признаками X и Y ; 4) Проверить на адекватность уравнение регрессии; 5) Проверить надежность уравнения регрессии и его коэффициентов; 6) Изобразить графически уравнение регрессии.
r
r
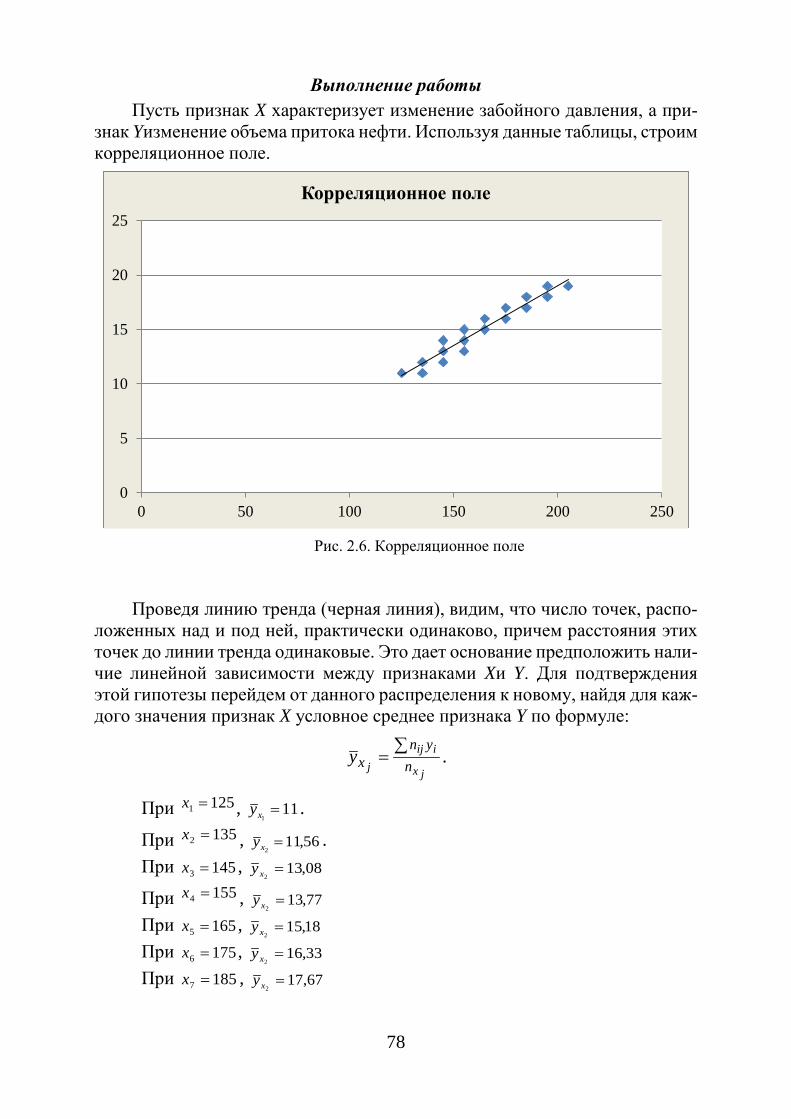
78
Выполнение работы Пусть признак X характеризует изменение забойного давления, а при-
знак Yизменение объема притока нефти. Используя данные таблицы, строим корреляционное поле.
Рис. 2.6. Корреляционное поле
Проведя линию тренда (черная линия), видим, что число точек, распо-ложенных над и под ней, практически одинаково, причем расстояния этих точек до линии тренда одинаковые. Это дает основание предположить нали-чие линейной зависимости между признаками Xи Y. Для подтверждения этой гипотезы перейдем от данного распределения к новому, найдя для каж-дого значения признак X условное среднее признака Y по формуле:
jx
iijj n
ynxy ∑= .
При 1251 =x , 111=xy .
При 1352 =x , 56,112=xy .
При 1453 =x , 08,132=xy
При 1554 =x , 77,132=xy
При 1655 =x , 18,152=xy
При 1756 =x , 33,162=xy
При 1857 =x , 67,172=xy
0
5
10
15
20
25
0 50 100 150 200 250
Корреляционное поле
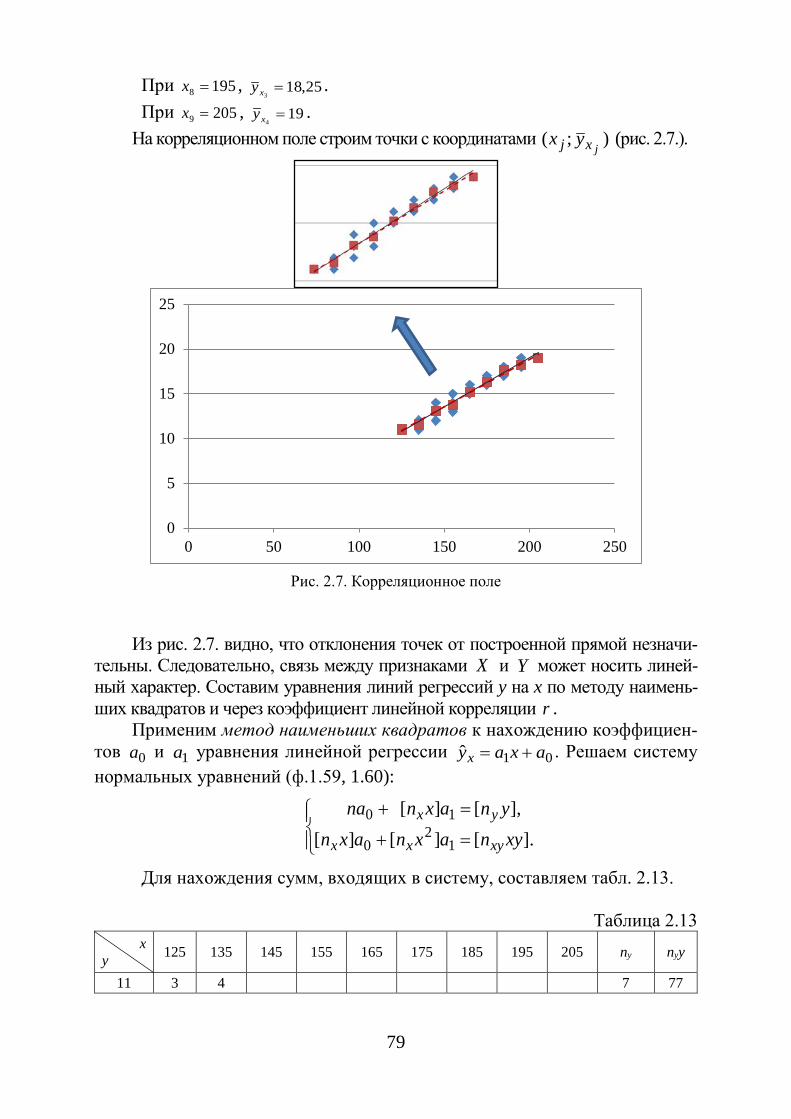
79
При 1958 =x , 25,183=xy .
При 2059 =x , 194=xy .
На корреляционном поле строим точки с координатами );(jxj yx (рис. 2.7.).
Рис. 2.7. Корреляционное поле
Из рис. 2.7. видно, что отклонения точек от построенной прямой незначи-тельны. Следовательно, связь между признаками X и может носить линей-ный характер. Составим уравнения линий регрессий y на x по методу наимень-ших квадратов и через коэффициент линейной корреляции r .
Применим метод наименьших квадратов к нахождению коэффициен-тов 0a и 1a уравнения линейной регрессии 01ˆ axayx += . Решаем систему нормальных уравнений (ф.1.59, 1.60):
=+
=+
].[][][],[][
12
0
10
xynaxnaxnynaxnna
xyxx
yx
Для нахождения сумм, входящих в систему, составляем табл. 2.13.
Таблица 2.13 x
y 125 135 145 155 165 175 185 195 205 ny nyy
11 3 4 7 77
0
5
10
15
20
25
0 50 100 150 200 250
Y

80
Продолжение Таблицы 2.13 12 5 4 9 108 13 3 5 8 104 14 5 6 11 154 15 2 18 20 300 16 4 14 18 288 17 7 2 9 153 18 4 6 10 180 19 2 6 8 152
nx 3 9 12 13 22 21 6 8 6 100 1516
nxx 375 1215 1740 2015 3630 3675 1110 1560 1230 16550 nxx2 46875 164025 252300 312325 598950 643125 205350 304200 252150 2779300 nxyx
y 4125 14040 22765 27745 55110 60025 19610 28470 23370 255260
Полученная из табл. 2.13 система
=+=+
255260277930016550,151616550100
10
10
aaaa
имеет решение (а0, а1) = (-2,7645; 0,108). Тогда уравнение линейной регрес-сии запишется в виде:
108,07645,2 +−= xyx
Найдем уравнение линейной регрессии y на x по формуле, используя коэффициент линейной корреляции:
)( xxryyx
y
SS
x −+= .
Так как данные выборки для признаков X и Y заданы в виде корреляци-онной таблицы и объем выборки 100=n , то для нахождения величин, вхо-дящих в уравнение регрессии, переходим к вспомогательному распределе-нию с условными вариантами iu и jv . По корреляционной табл. 2.12 нахо-дим наибольшую частоту совместного появления признаков X и Y: 18=n . Тогда 16501 == XMC , 1502 == YMC , 101 =h , 12 =h . Составляем корреляци-онную табл. 2.14 в условных вариантах.
Таблица 2.14
u v -4 -3 -2 -1 0 1 2 3 4 nv
-4 3 4 7 -3 5 4 9 -2 3 5 8 -1 5 6 11 0 2 18 20
81
Продолжение Таблицы 2.14 1 4 14 18 2 7 2 9 3 4 6 10 4 2 6 8 nu 3 9 12 13 22 21 6 8 6 100
По таблице находим: 05,0)463826121022)1(13)2(12)3(9)4(3(100
1 =⋅+⋅+⋅+⋅+⋅+−⋅+−⋅+−⋅+−⋅== ∑ iin uu un
1,
16,0)4831029118020)1(11)2(8)3(9)4(7(1001 =⋅+⋅+⋅+⋅+⋅+−⋅+−⋅+−⋅+−⋅== ∑ ii
n vv vn1
, 03,4212 == ∑ jun unu
j,
08,5212 == ∑ in in vv v .
Тогда 951,1223,003,4)( 22 =−=−= uuSu ,
163,24,008,5)( 22 =−=−= vvSv .
Для нахождения суммы ∑ ijvu vunij
составляем табл. 2.15.
Таблица 2.15
u v -4 -3 -2 -1 0 1 2 3 4 nv
-4 16 12 96 -3 9 6 69 -2 4 2 22 -1 2 1 16 0 0 0 1 1 14 2 2 4 22 3 6 9 78 4 12 16 120 nx 48 93 46 16 0 28 32 78 96 437
Тогда, согласно формулам вычисления коэффициента корреляции
находим:
v
v vvSnS
ununв u
ur ∑ −= 99,0163,2951,110016,005,0100437 == ⋅⋅
⋅⋅−,
5,1651651005,011 =+⋅=+= Chux ,

82
16,1515116,022 =+⋅=+= Chvy ,
51,1910951,11 =⋅=⋅= hSS ux ,
163,21163,22 =⋅== hSS vy .
Отсюда следуют уравнение линии регрессии y на х:
)5,165(99,016,15 51,19163,2 −+= xyx ,
или 707,3114,0 −= xyx ,
и уравнение линии регрессии x на y:
)16,15(99,05,165 163,251,19 −+= yxy ,
или 2461,243175,9 −= yxy .
Проверяем тесноту связи между признаками X и Y. Для этого, исполь-зуя критерий Стьюдента, вычисляем статистику:
5,6922 99,01210099,0
1
2н ===
−
−
−
−
в
в
r
nrt .
При уровне значимости 05,0=α и числе степеней свободы 9821002 =−=−= nk находим по таблице распределения Стьюдента
98,198;05,0; == tt kα . Так как 98,15,69н >=t , то выборочный коэффициент ли-
нейной корреляции вr значимо отличается от нуля. Следовательно, можно считать, что изменение притока нефти и изменение забойного давления связаны линейной корреляционной зависимостью. Дадим интерпрета-цию, например, уравнению регрессии y на x. Из уравнения регрессии видно, что при изменении забойного давления, например, на 10 атм на забое, изменение притока составит 14,110114,0 =⋅=xy . Это результат воз-действия отклонений при изменении забойного давления. Фактически из-менение притока может составить 567,2707,310114,0 −=−⋅=xy , что является результатом воздействия неучтенных в модели факторов, не зависящих от давления. Проверим полученное уравнение регрессии y на x на адекват-ность по критерию Фишера-Снедекора. Вычислим статистику:
)1()2(
н −−= kQ
nQeRF
.
83
где eQ – остаточная сумма квадратов, характеризующая влияние неучтен-ных в модели факторов, определяемая по формуле:
Re QQQ −= , где ∑ −= 2)( yyQ i – сумма квадратов отклонений значений iy от средней
y , 2)( yyQixR −=∑ – сумма квадратов отклонений условных средних
ixy
от средней y . Составим расчетные табл. 2.16 и 2.17. Находим
7,177823,60 −=−=−= Re QQQ . По условию 100=n , 9=k . Тогда 679,53)19(7,17
)2100(78н −== −⋅−
−⋅F . Таблица 2.16
iy yyi − 2)( yyi − 11 -4,16 17,3056 12 -3,16 9,9856 13 -2,16 4,6656 14 -1,16 1,3456 15 -0,16 0,0256 16 0,84 0,7056 17 1,84 3,3856 18 2,84 8,0656 19 3,84 14,7456 11 -4,16 17,3056 23,60=Q
Таблица 2.17
iy yyix − 2)( yy
ix − 10,543 -4,617 21,316689 11,683 -3,477 12,089529 12,823 -2,337 5,461569 13,963 -1,197 1,432809 15,103 -0,057 0,003249 16,243 1,083 1,172889 17,383 2,223 4,941729 18,523 3,363 11,309769 19,663 4,503 20,277009 78=RQ
При уровне значимости 05,0=α и числах степеней свободы 11 =k , 98210022 =−=−= nk по таблице критических точек распределения Фи-
шера-Снедекора находим 94,3т =F . Так как 94,3679,53н >=F , то модель ли-нейной регрессии 707,3114,0 −= xyx согласуется с опытными данными.
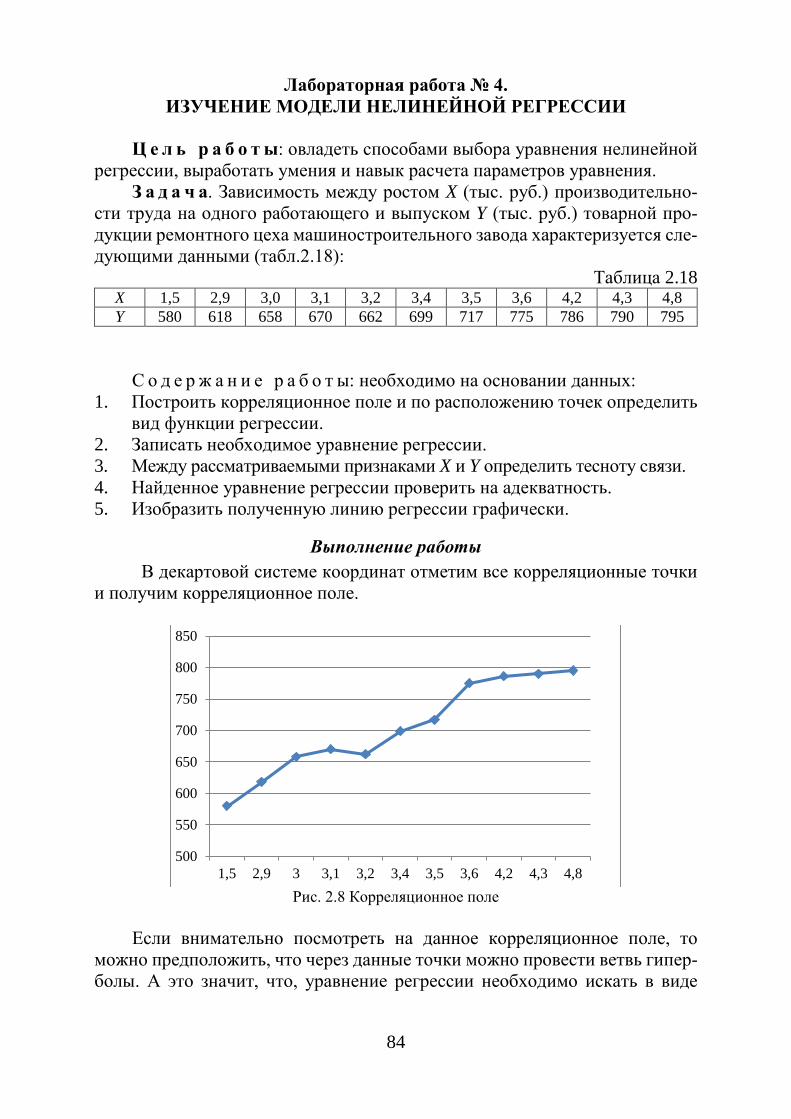
84
Лабораторная работа № 4. ИЗУЧЕНИЕ МОДЕЛИ НЕЛИНЕЙНОЙ РЕГРЕССИИ
Ц е л ь р а б о т ы: овладеть способами выбора уравнения нелинейной
регрессии, выработать умения и навык расчета параметров уравнения. З а д а ч а. Зависимость между ростом X (тыс. руб.) производительно-
сти труда на одного работающего и выпуском Y (тыс. руб.) товарной про-дукции ремонтного цеха машиностроительного завода характеризуется сле-дующими данными (табл.2.18):
Таблица 2.18 X 1,5 2,9 3,0 3,1 3,2 3,4 3,5 3,6 4,2 4,3 4,8 Y 580 618 658 670 662 699 717 775 786 790 795
С о д е р ж а н и е р а б о т ы: необходимо на основании данных: 1. Построить корреляционное поле и по расположению точек определить
вид функции регрессии. 2. Записать необходимое уравнение регрессии. 3. Между рассматриваемыми признаками X и Y определить тесноту связи. 4. Найденное уравнение регрессии проверить на адекватность. 5. Изобразить полученную линию регрессии графически.
Выполнение работы В декартовой системе координат отметим все корреляционные точки
и получим корреляционное поле.
Рис. 2.8 Корреляционное поле
Если внимательно посмотреть на данное корреляционное поле, то
можно предположить, что через данные точки можно провести ветвь гипер-болы. А это значит, что, уравнение регрессии необходимо искать в виде
500
550
600
650
700
750
800
850
1,5 2,9 3 3,1 3,2 3,4 3,5 3,6 4,2 4,3 4,8

85
baxy+
= 1 или xbay += . Что бы определиться с выбором вида данного урав-
нения, необходимо проверить следующие условия, представленные в таб-лице (табл. 1.14).
Рассмотрим формулу xbay += . Для нее необходимо проверить следу-
ющее равенство: 2)()(2 1
1
1 )( n
n
n xyxyxxxxy +
+= . После вычисления получим:
( ) ( ) ( ) )28,2(8,45,18,45,1222
111
111
1
1 yyyy xxxx
xxxx
n
n === +⋅⋅
++ .
Так как значения 2,28 в теоретических данных нет, то его необходимо найти. Применим для этого линейное интерполирование (ф.1.76):
1,65478,0580)5,128,2()5,1()28,2( 4,0580618
5,19,2)5,1()9,2( =⋅+=−+= −
−−yyyy .
5,6872795580
2)8,4()5,1(
2)()( 1 === +++ yyxyxy n .
Теперь необходимо вычислить отклонения 1∆ и 2∆ и проверить выпол-
нение равенства ( ) )()()()(2
2 111
nnn
xyxyxyxyxxy +
⋅+ =.
Отклонение 331,6545,6871 =−=∆ . Для формулы baxy+
= 1 находим:
( ) ( ) ( ) )15,3(28,45,1
221111 yyyy xxxx n === +++
.
Так же как и в предыдущем случае находим значение )15,3(y применяя линейное интерполирование (ф.1.76):
66605,0670)11,315,3()1,3()15,3( 1,0670662
1,0)11,3()2,3( =⋅+=−+= −−yyyy .
69,6707955807955802
)8,4()5,1()8,4()5,1(2
)()()()(2
1
1 === +⋅⋅
+⋅
+⋅
yyyy
xyxyxyxy
n
n
Перейдем к вычислению отклонения 2∆ : 69,466669,6702 =−=∆ . Срав-ним полученные значения. Так как 12 ∆<∆ , то по методу необходимых условий необходимо выбирать следующую формулу:
baxy+
= 1.
Используем теперь метод конечных разностей и произведем выбор од-ной из выше рассматриваемых формул. Пусть x
bay += . Необходимо свести эту зависимость к линейной BAXY += . Применим следующие преобразо-вания: xX = , xyY = (табл. 1.14). Вычисляем отношения XY ∆∆ / . Состав-ляем расчетную табл. 2.19.
86
Рассмотрим теперь зависимость baxy+
= 1 . Пользуясь теоретическим ма-териалом (табл. 1.14), сводим нелинейную зависимость к линейной
BAXY += , где xX = , yY 1= .Для нахождения отношений XY ∆∆ / составляем
расчетную табл. 2.20. Таблица 2.19
xX = 1,5 2,9 3 3,1 3,2 3,4 3,5 3,6 4,2 4,3 4,8 y 580 618 658 670 662 699 717 775 786 790 795
xyY = 870 1792,2 1974 2077 2118,4 2376,6 2509,5 2790 3301,2 3397 3816 Y∆ 922,2 181,8 103 41,4 258,2 132,9 280,5 511,2 95,8 419 X∆ 1,4 0,1 0,1 0,1 0,2 0,1 0,1 0,6 0,1 0,5
∆Y/∆X 658,7 1818 1030 414 1291 1329 2805 852 958 838
Таблица 2.20
X = x 1,5 2,9 3 3,1 3,2 3,4 3,5 3,6 4,2 4,3 4,8
y 580 618 658 670 662 699 717 775 786 790 795
Y = 1/y 0,0017 0,0016 0,0015 0,0015 0,0015 0,0014 0,0014 0,0013 0,0013 0,0013 0,0013
Y∆ -0,000106 -0,0001 0 0 -0,0001 0 -0,0001 0 0 0
X∆ 1,4 0,1 0,1 0,1 0,2 0,1 0,1 0,6 0,1 0,5
∆Y/∆X -0,00008 -0,00100 0 0 -0,0005 0,00000 -0,00100 0 0 0
Отношения XY
∆∆ , полученные для формулы baxy
+= 1 , мало отлича-
ются друг от друга, чем для формулы xbay += . Поэтому по методу ко-
нечных разностей в качестве лучшей выбираем формулу baxy+
= 1 . К та-кому же выводу мы пришли, применяя метод необходимых условий. Итак, зависимость между ростом X (тыс. руб.) производительности труда на одного работающего и выпуском Y (тыс. руб.) товарной продукции ремонтного цеха машиностроительного завода выражается формулой
baxxy += 1 . Оценки a и b неизвестных параметров истинного уравнения регрессии находим, решая систему нормальных уравнений:
=+=+
]./[][][],/1[][
12
0
10yxaxax
yaxna
Для вычисления сумм, входящих в систему, составляем расчетную
табл. 2.21.

87
Таблица 2.21
х y y/1 yx / 2x
1,5 580 0,0017 0,0026 2,25
2,9 618 0,0016 0,0047 8,41
3 658 0,0015 0,0046 9
3,1 670 0,0015 0,0046 9,61
3,2 662 0,0015 0,0048 10,24
3,4 699 0,0014 0,0049 11,56
3,5 717 0,0014 0,0049 12,25
3,6 775 0,0013 0,0046 12,96
4,2 786 0,0013 0,0053 17,64
4,3 790 0,0013 0,0054 18,49
4,8 795 0,0013 0,0060 23,04
37,5 0,0158 0,0525 135,45
Составляем и решаем систему
=+=+
0525,045,1355,37,0158,05,3711
10
10
aaaa
Решением является точка (а0, а1) = (0,00204; -0,00018). Поэтому урав-нение регрессии примет вид:
0,002040,00018-1+= xxy
. Оценим силу корреляционной связи между ростом X (тыс. руб.) произ-
водительности труда на одного работающего и выпуском Y (тыс. руб.) то-варной продукции. Вычислим индекс корреляции по формуле (ф.1.77):
2
2
1y
yx
S
Si −= ,
где ∑ −= −
21
12 )( xiinyx yyS , ∑ −= −2
112 )( yyS iny
(так как n=11>50). Для нахождения 2yxS и 2
yS составляем расчетную табл. 2.20.

88
Тогда 999,0=i . Связь между ростом производительности труда на од-ного работающего и выпуском товарной продукции сильная.
Таблица 2.20
ix iy xy 2)( xii yy − 2)( yyi −
1,1 25 19 36 91,2025 1,4 22,7 18 22,09 52,5625 1,7 22,1 17,2 24,01 44,2225 2,1 19,8 16,2 12,96 18,9225 2,6 17 15,1 3,61 2,4025 4,7 12,3 11,7 0,36 9,9225 6,1 10,7 10,2 0,25 22,5625 7,0 10 9,4 0,36 29,7025 10 8,2 7,5 0,49 52,5625
12,8 6,7 6,3 0,16 76,5625 100,29 400,0625
Проверяем адекватность полученного уравнения регрессии по крите-рию Фишера — Снедекора (ф.1.78). Находим статистику:
72,52972
2
1)2(
н ==−−i
niF .
При уровне значимости 05,0=α и числах степеней свободы 11 =k , 921122 =−=−= nk по таблице критических точек распределения Фишера —
Снедекора (приложение 7) находим
12,59;1;05,0;;т 21=== FFF kkα .
Так как
12,572,5297н >=F ,
то модель адекватна. Следовательно, зависимость роста производительно-сти труда на одного работающего и выпуском товарной продукции описы-
вается уравнением 0,002040,00018-1+= xxy .
Построение данной кривой в корреляционном поле предлагается вы-полнить самостоятельно.
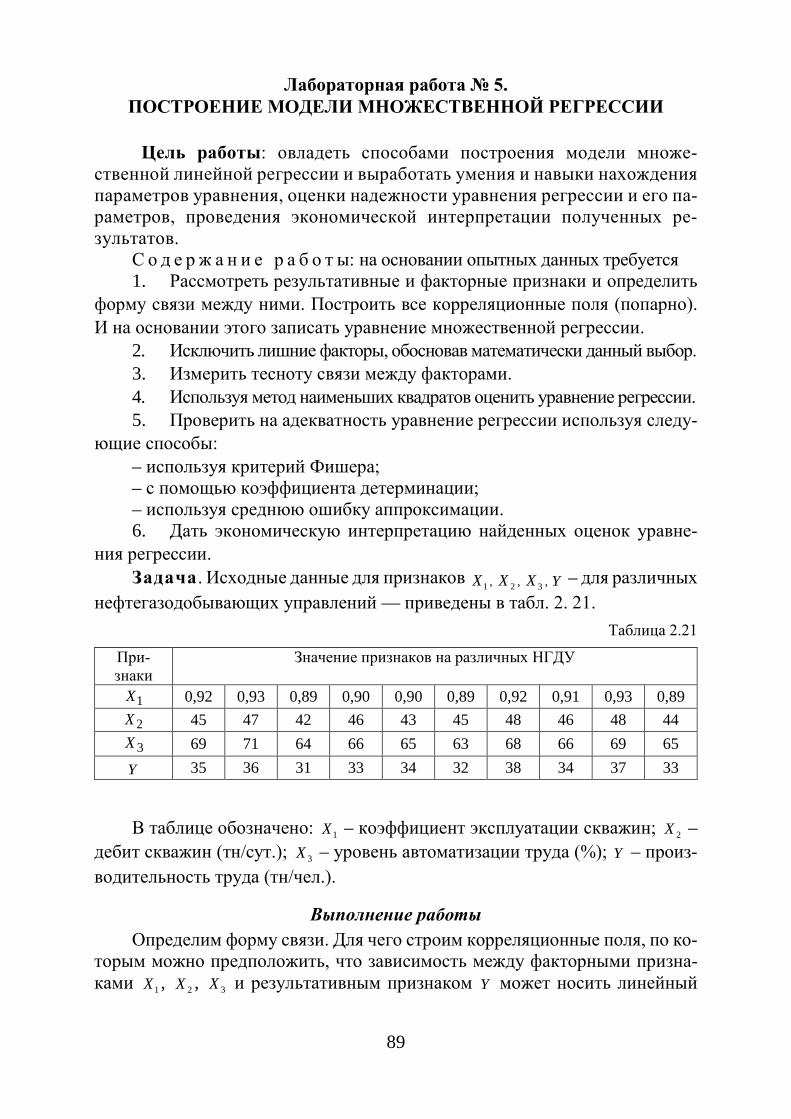
89
Лабораторная работа № 5. ПОСТРОЕНИЕ МОДЕЛИ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
Цель работы: овладеть способами построения модели множе-
ственной линейной регрессии и выработать умения и навыки нахождения параметров уравнения, оценки надежности уравнения регрессии и его па-раметров, проведения экономической интерпретации полученных ре-зультатов.
С о д е р ж а н и е р а б о т ы: на основании опытных данных требуется 1. Рассмотреть результативные и факторные признаки и определить
форму связи между ними. Построить все корреляционные поля (попарно). И на основании этого записать уравнение множественной регрессии.
2. Исключить лишние факторы, обосновав математически данный выбор. 3. Измерить тесноту связи между факторами. 4. Используя метод наименьших квадратов оценить уравнение регрессии. 5. Проверить на адекватность уравнение регрессии используя следу-
ющие способы: – используя критерий Фишера; – с помощью коэффициента детерминации; – используя среднюю ошибку аппроксимации. 6. Дать экономическую интерпретацию найденных оценок уравне-
ния регрессии. Задача. Исходные данные для признаков
1X , 2X , 3X , Y – для различных нефтегазодобывающих управлений — приведены в табл. 2. 21.
Таблица 2.21
При-знаки
Значение признаков на различных НГДУ
1X 0,92 0,93 0,89 0,90 0,90 0,89 0,92 0,91 0,93 0,89
2X 45 47 42 46 43 45 48 46 48 44
3X 69 71 64 66 65 63 68 66 69 65 Y 35 36 31 33 34 32 38 34 37 33
В таблице обозначено: 1X – коэффициент эксплуатации скважин; 2X – дебит скважин (тн/сут.); 3X – уровень автоматизации труда (%); Y – произ-водительность труда (тн/чел.).
Выполнение работы Определим форму связи. Для чего строим корреляционные поля, по ко-
торым можно предположить, что зависимость между факторными призна-ками 1X , 2X , 3X и результативным признаком Y может носить линейный
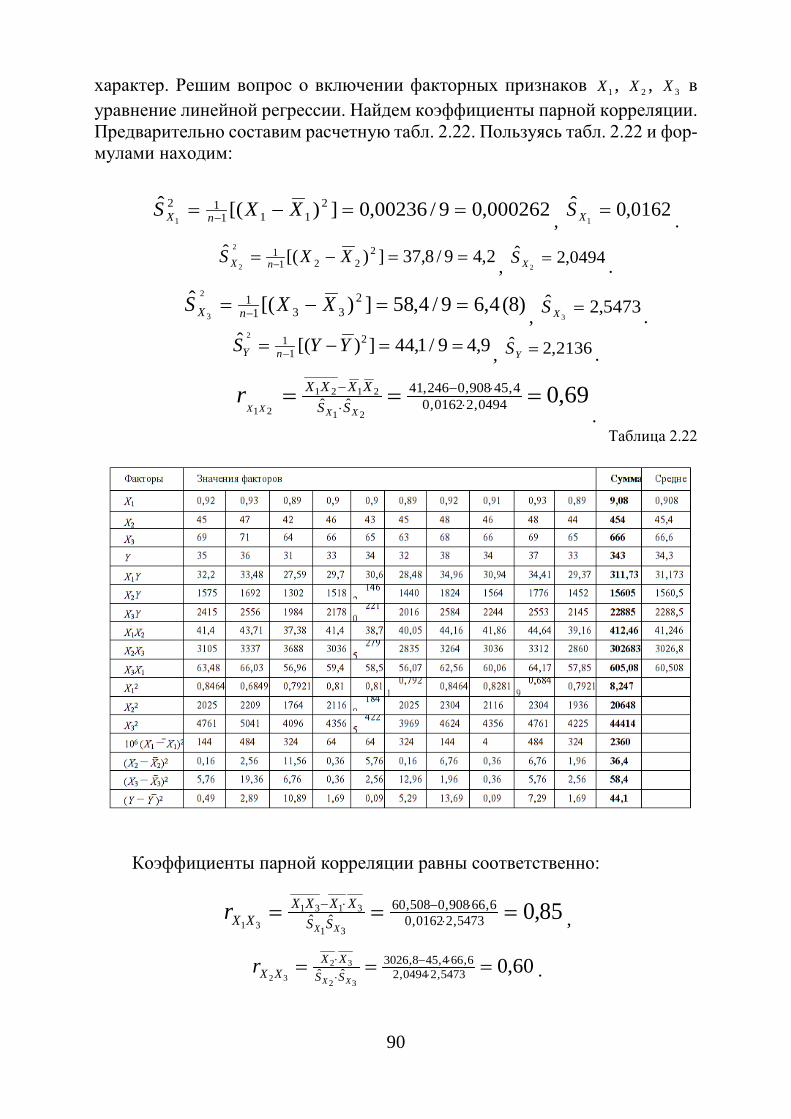
90
характер. Решим вопрос о включении факторных признаков 1X , 2X , 3X в уравнение линейной регрессии. Найдем коэффициенты парной корреляции. Предварительно составим расчетную табл. 2.22. Пользуясь табл. 2.22 и фор-мулами находим:
000262,09/00236,0])[(ˆ 2111
121
==−= − XXS nX , 0162,0ˆ1=XS .
2,49/8,37])[(ˆ 2221
12
2==−= − XXS nX , 0494,2ˆ
2=XS .
)8(4,69/4,58])[(ˆ 2331
12
3==−= − XXS nX , 5473,2ˆ
3=XS .
9,49/1,44])[(ˆ 21
12
==−= − YYS nY , 2136,2ˆ =YS .
69,00494,20162,04,45908,0246,41
ˆˆ21
2121
21=== ⋅
⋅−⋅−
XXXX SSXXXXr
. Таблица 2.22
Коэффициенты парной корреляции равны соответственно:
85,05473,20162,06,66908,0508,60
ˆˆ31
3131
31=== ⋅
⋅−⋅−
XX SSXXXX
XXr ,
60,05473,20494,26,664,458,3026
ˆˆ32
32
32=== ⋅
⋅−⋅⋅
XX SSXX
XXr .
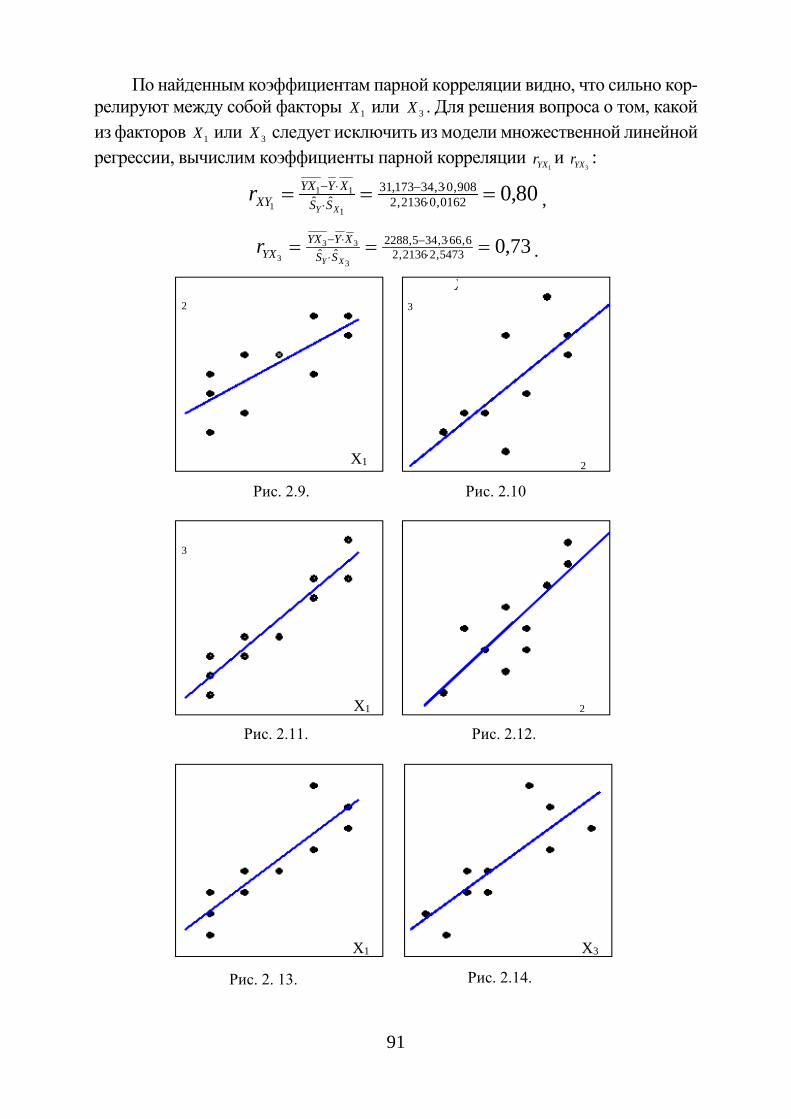
91
По найденным коэффициентам парной корреляции видно, что сильно кор-релируют между собой факторы 1X или 3X . Для решения вопроса о том, какой из факторов 1X или 3X следует исключить из модели множественной линейной регрессии, вычислим коэффициенты парной корреляции
1YXr и 3YXr :
80,00162,02136,2908,03,34173,31
ˆˆ1
11
1=== ⋅
⋅−⋅⋅−
XY SSXYYX
XYr ,
73,05473,22136,26,663,345,2288
ˆˆ3
33
3=== ⋅
⋅−⋅
⋅−
XY SSXYYX
YXr .
Рис. 2.9.
Рис. 2.11.
Рис. 2. 13.
Рис. 2.10
Рис. 2.12.
Рис. 2.14.
X1
X1
X1
2
X2
X3
2
X3
3

92
Так как 31 YXYX rr > ,то между признаками 1X и Y связь сильнее, чем между
3X и Y . Этот факт подтверждается путем вычисления коэффициентов част-ной корреляции )( 31 XYXr и )( 13 XYXr :
50,0)73,01)(85,01(
73,085,080,0)1)(1()( 222
32
31
3211
31===
−−
⋅−
−−
⋅−
YXXX
YXXXYX
rr
rrrXYXr ,
16,0)80,01)(85,01(
80,085,073,0)1)(1()( 222
12
31
1313
13===
−−
⋅−
−−
⋅−
YXXX
YXXXYX
rr
rrrXYXr .
Поэтому из модели множественной линейной регрессии исключаем
фактор 3X . Тогда в модель будут включены факторы 1X и 2X и уравнение регрессии запишется в виде:
221102.1̂ XaXaaY ++= .
Включение фактора 2X в модель обосновано значимостью коэффици-ента парной корреляции
2YXr :
72,00494,22136,24,453,345,1560
ˆˆ2
22
2=== ⋅
⋅−⋅−
XY SSXYYX
YXr .
Для выяснения вопроса о силе линейной связи между факторами, вклю-ченными в модель, вычисляем множественный коэффициент корреляции R:
83,02
22
221
21212
22
1
69,0172,080,069,0272,080,0
1
2 ===−
⋅⋅⋅−+−
⋅⋅−+
XX
YXYXXXYXYX
rrrrrrR .
Так как в нашем примере объем выборки небольшой ( 10=n ), то произ-ведем корректировку R:
81,0)83,01(1)1(1ˆ89212 =−−=−−= −
−kn
nRR .
Проверяем значимость RR ˆ= по критерию Стьюдента. Вычисляем среднеквадратическую ошибку RS :
3,031
11 ===−nRS ,
Вычисляем статистику (ф.1.102):
7,23,081,0ˆ
н ===RS
Rt

93
По таблице критических точек распределения Стьюдента при уровне значимости 05,0=α с числом степеней свободы 82102 =−=−= nk находим
86,1т =t (приложение 5). Так как тн 7,2 tt >= , то делаем вывод, что RR ˆ= зна-чим.
Для нахождения оценок 0a , 1a , 2a уравнения регрессии 221103,2̂ XaXaaY ++= решаем систему нормальных уравнений:
=++=++=++
.156052064846,412454,73,31146,412247,808,9
,34345408,910
210210210
aaaaaaaaa
Решив эту систему, получаем 360611,02 =a , 3271,861 =a , 45674,600 −=a . То-
гда уравнение регрессии, устанавливающее зависимость производительно-сти труда Y от коэффициента эксплуатации 1X и дебита скважин 2X запи-шется в виде 212.1 360611,03271,8645674,60ˆ XXY ++−= .
Проверяем адекватность уравнения регрессии. Используем коэффици-ент детерминации 2R , полагая RR ˆ= . Для полученной модели
66,081,0ˆ 22 ==R . Это означает, что полученная модель приблизительно на 66% объясняет изменение производительности труда в зависимости от из-менения включенных в модель факторов 1X и 2X , что является не плохим показателем.
Проведем проверку модели на адекватность по критерию Фишера – Сне-декора. Найдем статистику нF по формуле (ф.1.78), полагая в ней RR
= :
5,32)81,01(
)1210(81,0)ˆ1(
)1(ˆн 2
2
2
2
===⋅−−−⋅
⋅−−−⋅pR
pnRF .
По таблице критических точек распределения Фишера — Снедекора при уровне значимости 05,0=α и числах степеней свободы 21 == pk ,
7121012 =−−=−−= pnk (p — число факторов iX , включенных в модель, n — объем выборки) находим 26,37;2;05,0;;т 21
=== FFF kkα . Так как тн FF > , то найденное уравнение регрессии, устанавливающее зависимость произво-дительности труда на десяти нефтегазодобывающих управлениях (НГДУ) от коэффициента эксплуатации скважин 1X и дебита скважин 2X, значимо описывает опытные данные и может быть принято для руко-водства.
Оценим адекватность уравнения регрессии по средней ошибке аппрок-симации ε , которую вычислим по формуле (ф.1.63):
%1002.1̂1 ⋅= ∑−
Y
YY
pε .
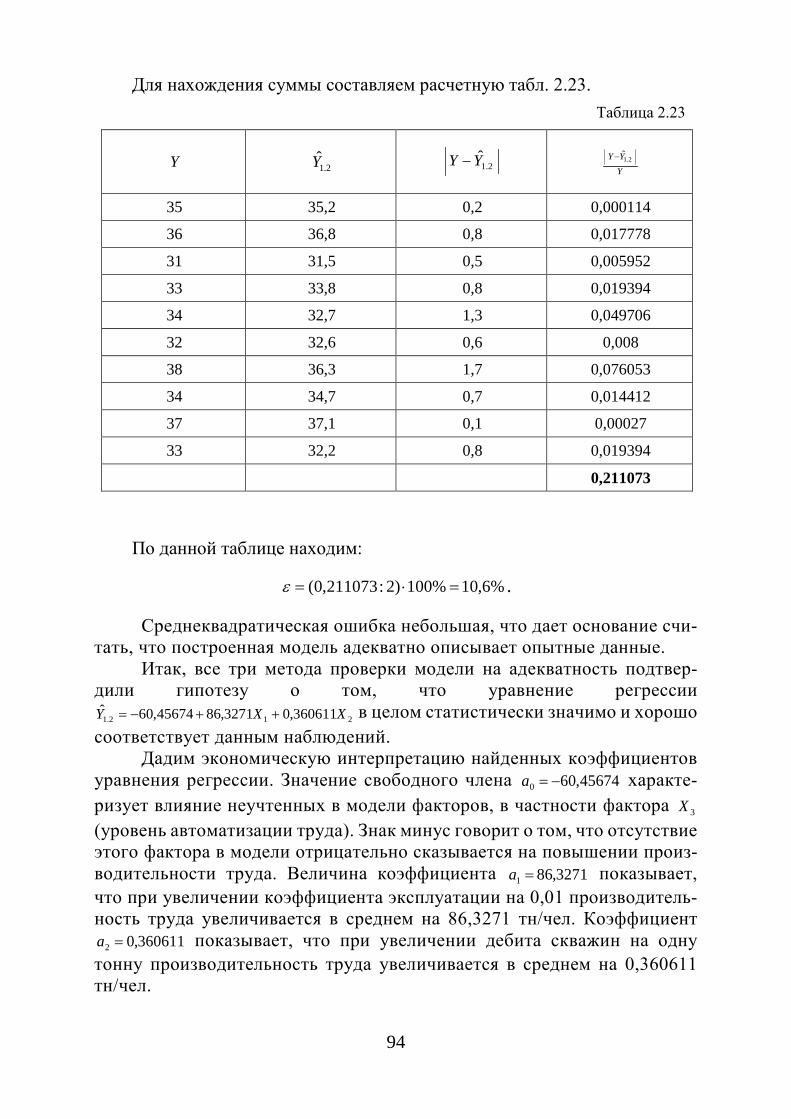
94
Для нахождения суммы составляем расчетную табл. 2.23. Таблица 2.23
Y 2.1̂Y 2.1̂YY − Y
YY 2.1̂−
35 35,2 0,2 0,000114
36 36,8 0,8 0,017778
31 31,5 0,5 0,005952
33 33,8 0,8 0,019394
34 32,7 1,3 0,049706
32 32,6 0,6 0,008
38 36,3 1,7 0,076053
34 34,7 0,7 0,014412
37 37,1 0,1 0,00027
33 32,2 0,8 0,019394
0,211073
По данной таблице находим:
%6,10%100)2:211073,0( =⋅=ε .
Среднеквадратическая ошибка небольшая, что дает основание счи-тать, что построенная модель адекватно описывает опытные данные.
Итак, все три метода проверки модели на адекватность подтвер-дили гипотезу о том, что уравнение регрессии
212.1 360611,03271,8645674,60ˆ XXY ++−= в целом статистически значимо и хорошо соответствует данным наблюдений.
Дадим экономическую интерпретацию найденных коэффициентов уравнения регрессии. Значение свободного члена 45674,600 −=a характе-ризует влияние неучтенных в модели факторов, в частности фактора 3X (уровень автоматизации труда). Знак минус говорит о том, что отсутствие этого фактора в модели отрицательно сказывается на повышении произ-водительности труда. Величина коэффициента 3271,861 =a показывает, что при увеличении коэффициента эксплуатации на 0,01 производитель-ность труда увеличивается в среднем на 86,3271 тн/чел. Коэффициент
360611,02 =a показывает, что при увеличении дебита скважин на одну тонну производительность труда увеличивается в среднем на 0,360611 тн/чел.

95
Лабораторная работа № 6. ПРОГНОЗИРОВАНИЕ.
АНАЛИЗ АДДИТИВНОЙ МОДЕЛИ
Цель работы:овладеть навыками прогнозирования. Задача. В таблице указан объем экспорта нефти* (млн. т) за 12 месяцев
2014 года. Дать прогноз экспорта нефти на январь-февраль 2015 года.
Таблица 2. 24
Месяц 1 2 3 4 5 6 7 8 9 10 11 12
Нефть, млн.т 18,1 15,5 19 21,1 19,1 16,9 21,4 18 17,2 20,6 17,7 16,2
*Данные за 10 месяцев взяты с сайта Федеральной службы государственной ста-
тистики. За ноябрь и декабрь данные взяты по данным газеты РБК.
Выполнение работы
Аддитивной моделью называется модель, для которой фактическое значение А будет равно сумме трендового значения, сезонной вариации (S) и ошибки (Е), то есть А = Т + S + Е.
Напомним, что временным рядом называется множество данных, где время является независимой переменной.
В свою очередь, общее изменение со временем значений результатив-ного признака будет называться трендом. Графически тренд изображается так называемой линией тренда.
Сезонная вариация будем называть повторение определенных данных через небольшой промежуток времени. Это может быть связано с различ-ными факторами, но в любом случае для хорошего адекватного прогноза влияние сезонной вариации мы будем исключать.
Это и будет первым шагом в нашей работе. Воспользуемся методом скользящей средней. Для удобства расчеты
представим в таблице 2.25 Так как один квартал равен трем месяцам, поэтому найдем среднее
значение объема экспорта нефти за три последовательных месяца. Общее количество сезонов в данной работе нечетное, а это значит, что при заполнении третьего столбца скользящую среднюю нужно центри-ровать.
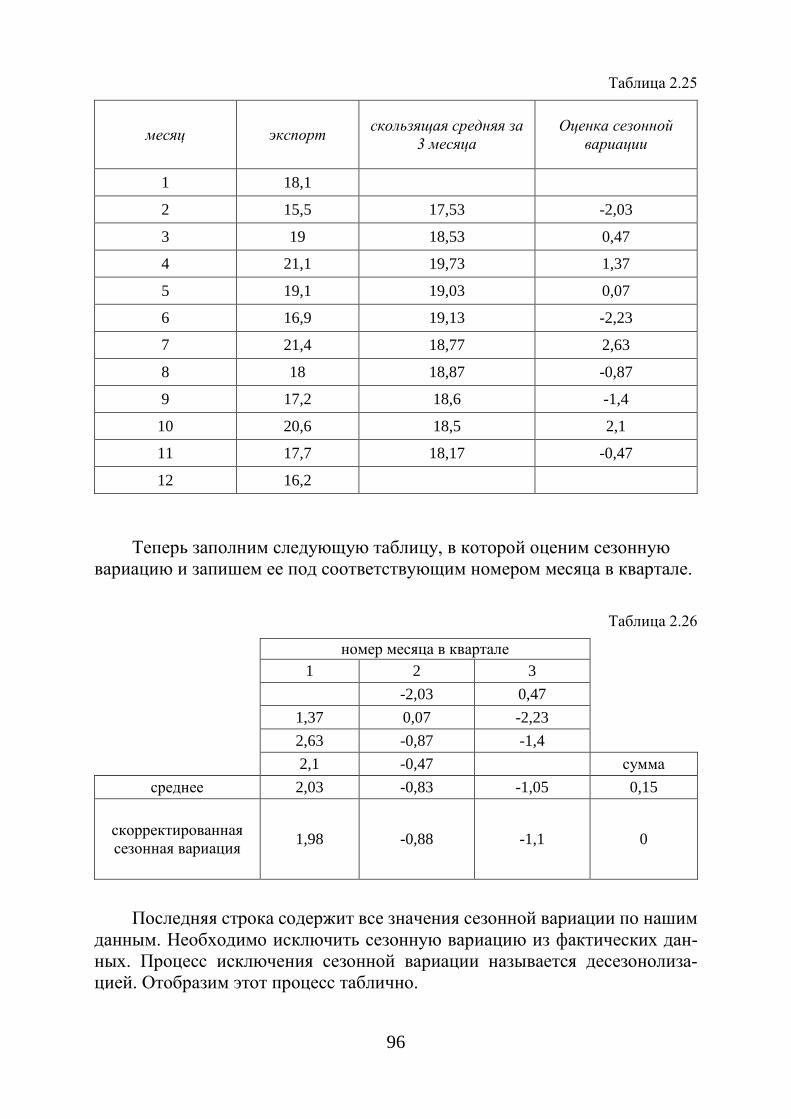
96
Таблица 2.25
месяц экспорт скользящая средняя за 3 месяца
Оценка сезонной вариации
1 18,1
2 15,5 17,53 -2,03
3 19 18,53 0,47
4 21,1 19,73 1,37
5 19,1 19,03 0,07
6 16,9 19,13 -2,23
7 21,4 18,77 2,63
8 18 18,87 -0,87
9 17,2 18,6 -1,4
10 20,6 18,5 2,1
11 17,7 18,17 -0,47
12 16,2
Теперь заполним следующую таблицу, в которой оценим сезонную вариацию и запишем ее под соответствующим номером месяца в квартале.
Таблица 2.26
номер месяца в квартале 1 2 3 -2,03 0,47 1,37 0,07 -2,23 2,63 -0,87 -1,4 2,1 -0,47 сумма среднее 2,03 -0,83 -1,05 0,15
скорректированная сезонная вариация 1,98 -0,88 -1,1 0
Последняя строка содержит все значения сезонной вариации по нашим
данным. Необходимо исключить сезонную вариацию из фактических дан-ных. Процесс исключения сезонной вариации называется десезонолиза-цией. Отобразим этот процесс таблично.

97
Таблица 2.27
месяц экспорт A Cезонная вариация S
Десезонализированный экспорт A-S=T+E
1 18,1 1,98 16,12 2 15,5 -0,88 16,38 3 19 -1,1 20,1 4 21,1 1,98 19,12 5 19,1 -0,88 19,98 6 16,9 -1,1 18 7 21,4 1,98 19,42 8 18 -0,88 18,88 9 17,2 -1,1 18,3 10 20,6 1,98 18,62 11 17,7 -0,88 18,58 12 16,2 -1,1 17,3
Уравнение линии тренда Т=a+bx. Для нахождения коэффициентов a
и b составим табл. 2.28. Таблица 2.28
Номер х у Х2 xy 1 1 16,12 1 16,12 2 2 16,38 4 32,76 3 3 20,1 9 60,3 4 4 19,12 16 76,48 5 5 19,98 25 99,9 6 6 18 36 108 7 7 19,42 49 135,94 8 8 18,88 64 151,04 9 9 18,3 81 164,7 10 10 18,62 100 186,2 11 11 18,58 121 204,38 12 12 17,3 144 207,6
Сумма 78 220,8 650 1443,42
𝑏𝑏 =𝑛𝑛∑ 𝑥𝑥𝑖𝑖𝑦𝑦𝑖𝑖 − ∑ 𝑥𝑥𝑖𝑖𝑛𝑛
𝑖𝑖=1 ∑ 𝑦𝑦𝑖𝑖𝑛𝑛𝑖𝑖=1
𝑛𝑛𝑖𝑖=1
𝑛𝑛∑ 𝑥𝑥𝑖𝑖2𝑛𝑛𝑖𝑖=1 − (∑ 𝑥𝑥𝑖𝑖𝑛𝑛
𝑖𝑖=1 )2,
𝑎𝑎 =∑ 𝑦𝑦𝑖𝑖𝑛𝑛𝑖𝑖=1 − 𝑏𝑏∑ 𝑥𝑥𝑖𝑖𝑛𝑛
𝑖𝑖=1𝑛𝑛 .
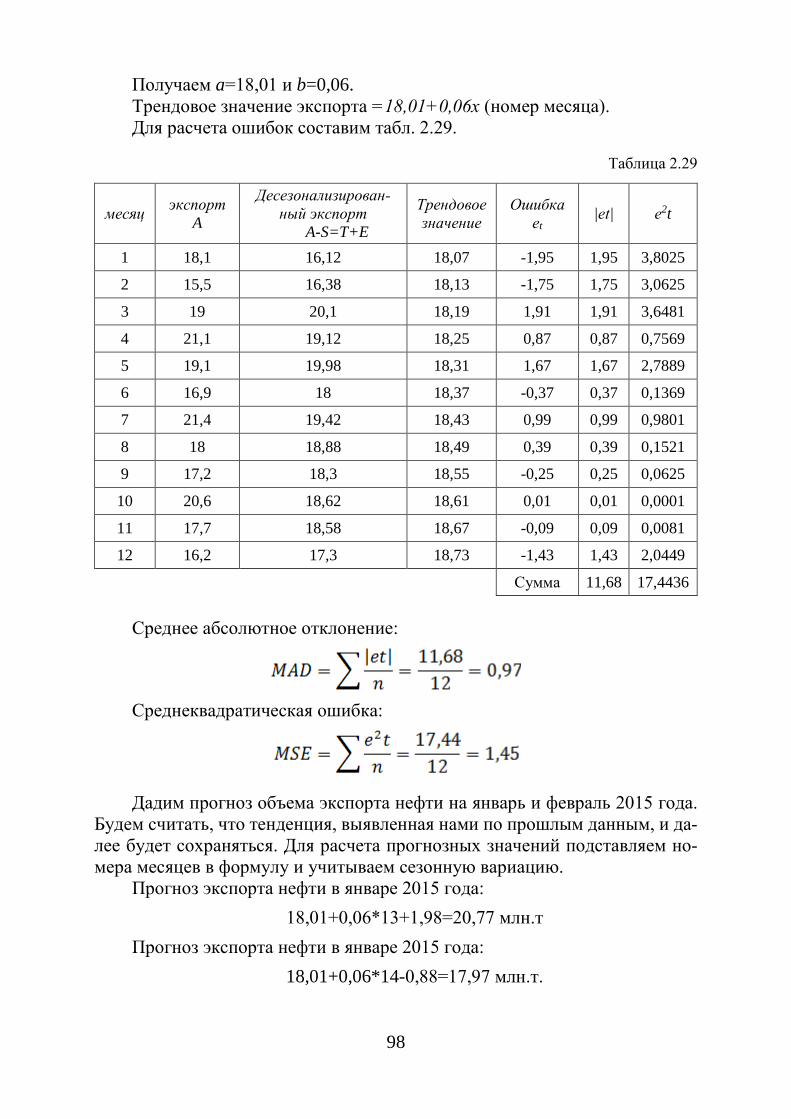
98
Получаем a=18,01 и b=0,06. Трендовое значение экспорта =18,01+0,06х (номер месяца). Для расчета ошибок составим табл. 2.29.
Таблица 2.29
месяц экспорт A
Десезонализирован-ный экспорт A-S=T+E
Трендовое значение
Ошибка еt |еt| е2t
1 18,1 16,12 18,07 -1,95 1,95 3,8025
2 15,5 16,38 18,13 -1,75 1,75 3,0625
3 19 20,1 18,19 1,91 1,91 3,6481
4 21,1 19,12 18,25 0,87 0,87 0,7569
5 19,1 19,98 18,31 1,67 1,67 2,7889
6 16,9 18 18,37 -0,37 0,37 0,1369
7 21,4 19,42 18,43 0,99 0,99 0,9801
8 18 18,88 18,49 0,39 0,39 0,1521
9 17,2 18,3 18,55 -0,25 0,25 0,0625
10 20,6 18,62 18,61 0,01 0,01 0,0001
11 17,7 18,58 18,67 -0,09 0,09 0,0081
12 16,2 17,3 18,73 -1,43 1,43 2,0449
Сумма 11,68 17,4436
Среднее абсолютное отклонение:
Среднеквадратическая ошибка:
Дадим прогноз объема экспорта нефти на январь и февраль 2015 года. Будем считать, что тенденция, выявленная нами по прошлым данным, и да-лее будет сохраняться. Для расчета прогнозных значений подставляем но-мера месяцев в формулу и учитываем сезонную вариацию.
Прогноз экспорта нефти в январе 2015 года: 18,01+0,06*13+1,98=20,77 млн.т
Прогноз экспорта нефти в январе 2015 года: 18,01+0,06*14-0,88=17,97 млн.т.
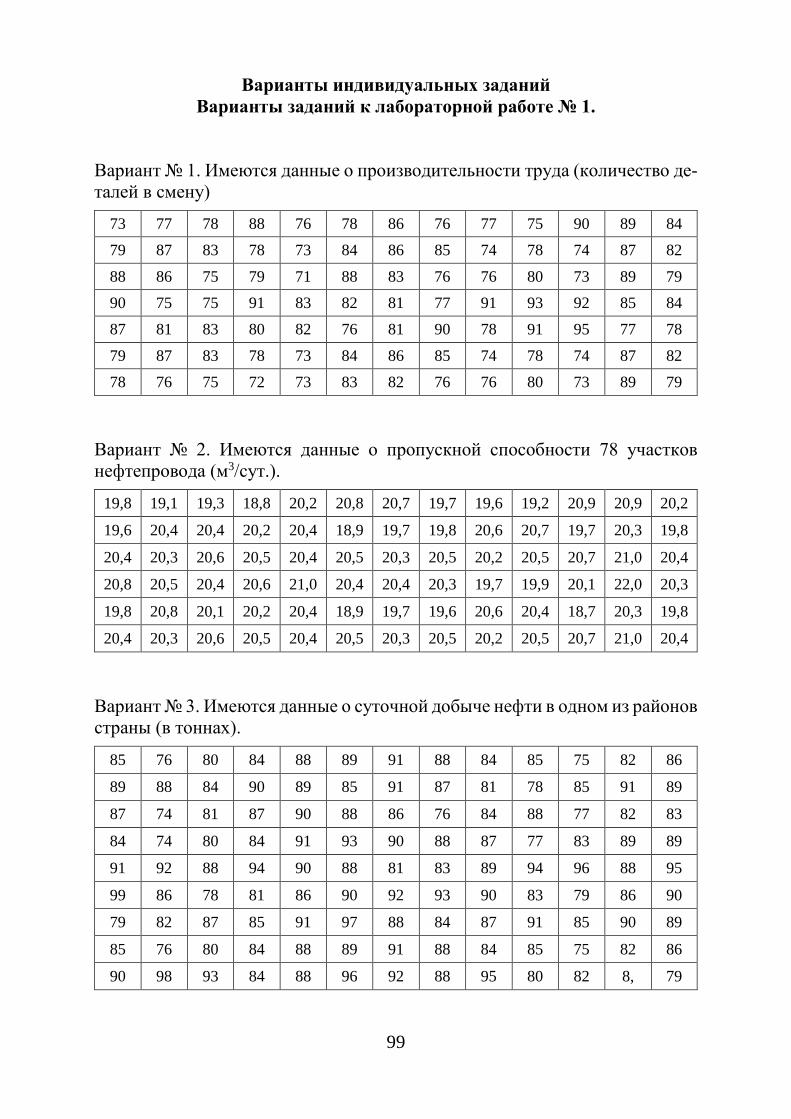
99
Варианты индивидуальных заданий Варианты заданий к лабораторной работе № 1.
Вариант № 1. Имеются данные о производительности труда (количество де-талей в смену)
73 77 78 88 76 78 86 76 77 75 90 89 84
79 87 83 78 73 84 86 85 74 78 74 87 82
88 86 75 79 71 88 83 76 76 80 73 89 79
90 75 75 91 83 82 81 77 91 93 92 85 84
87 81 83 80 82 76 81 90 78 91 95 77 78
79 87 83 78 73 84 86 85 74 78 74 87 82
78 76 75 72 73 83 82 76 76 80 73 89 79 Вариант № 2. Имеются данные о пропускной способности 78 участков нефтепровода (м3/сут.).
19,8 19,1 19,3 18,8 20,2 20,8 20,7 19,7 19,6 19,2 20,9 20,9 20,2
19,6 20,4 20,4 20,2 20,4 18,9 19,7 19,8 20,6 20,7 19,7 20,3 19,8
20,4 20,3 20,6 20,5 20,4 20,5 20,3 20,5 20,2 20,5 20,7 21,0 20,4
20,8 20,5 20,4 20,6 21,0 20,4 20,4 20,3 19,7 19,9 20,1 22,0 20,3
19,8 20,8 20,1 20,2 20,4 18,9 19,7 19,6 20,6 20,4 18,7 20,3 19,8
20,4 20,3 20,6 20,5 20,4 20,5 20,3 20,5 20,2 20,5 20,7 21,0 20,4
Вариант № 3. Имеются данные о суточной добыче нефти в одном из районов страны (в тоннах).
85 76 80 84 88 89 91 88 84 85 75 82 86
89 88 84 90 89 85 91 87 81 78 85 91 89
87 74 81 87 90 88 86 76 84 88 77 82 83
84 74 80 84 91 93 90 88 87 77 83 89 89
91 92 88 94 90 88 81 83 89 94 96 88 95
99 86 78 81 86 90 92 93 90 83 79 86 90
79 82 87 85 91 97 88 84 87 91 85 90 89
85 76 80 84 88 89 91 88 84 85 75 82 86
90 98 93 84 88 96 92 88 95 80 82 8, 79

100
Вариант № 4. Имеются данные о вводе в эксплуатацию новых газовых сква-жин за год по различным газодобывающим районам страны.
52 33 10 22 28 34 39 29 21 27 31 12 28 40 46 51 44 32 16 11 29 31 38 44 31 24 18 17 32 41 47 31 42 18 21 29 50 55 37 19 57 32 7 28 23 20 45 18 29 25 54 50 39 17 45 41 47 31 52 30 41 29 50 58 40 19 17 30 40 42 35 42 15 20 27 50 55 37 19 57 32 7 28 23 20 45 18 29 25 54 50
Вариант № 5. Имеются энергетические затраты на 1 метр проходки при экс-плуатационном бурении нефтяных скважин в различных нефтеносных рай-онах страны (руб.).
14 13 18 15 12 13 14 12 13 16 16 15 12 13 13 14 16 18 13 15 14 15 14 13 15 12 13 12 14 16 12 13 15 15 15 13 14 15 18 15 12 15 13 13 15 15 15 17 17 19 17 18 18 16 18 17 18 15 16 18 15 16 18 17 19 14 13 18 15 12 13 14 12 13 16 18 15 12 13 13 14 15 18 14 15 14 17 14 13 14 14
Вариант № 6. Имеются данные о суточном дебите газа в наблюдаемой сква-жине (м3/сут.).
30 19 21 28 27 29 31 24 25 28 28 32 34 26 24 19 23 27 30 29 25 18 18 24 28 31 33 18 21 26 30 32 34 29 26 23 25 27 32 21 22 21 26 22 20 27 28 29 31 28 27 29 23 20 29 25 28 25 28 28 20 31 28 31 29 20 19 21 20 27 29 21 21 25 28 25 22 24
Вариант № 7. Имеются данные о себестоимости 1 тонны нефти и нефтяного попутного газа (тыс. руб.).
0,3 0,4 0,8 1,2 1,4 1,9 0,7 1,3 1,0 0,5 0,9 1,2 1,0 1,3 0,6 1,0 1,0 1,1 0,5 1,2 1,0 1,4 1,6 0,5 1,1 1,1 1,8 0,3 0,6 1,1 0,8 1,2 0,9 1,4 1,3 1,6 2,7 1,5 0,8 0,7 0,9 1,5 1,3 1,1 1,2 1,8 1,1 1,0 1,2 0,9 1,5 1,3 1,1 1,2 1,3 1,4 0,8 0,7 1,8 1,6 1,5 1,6 0,9 1,5 1,6 1,5 0,8 0,9 1,6 0,8 1,2 19 1,6 1,5 1,6 2,7 1,5 0,8
101
Вариант № 8. Имеются данные о числе рабочих дней без простоя для пяти-десяти буровых бригад одного из районов страны.
261 260 258 263 257 260 259 264 261 260 264 261 265 260 263 263 261 260 259 260 258 265 259 265 261 258 259 259 258 262 264 258 259 263 266 259 261 266 262 256 262 261 266 262 259 262 261 259 262 262 261 266 257 261 264 265 258 259 260 265 259 255 260 256 254 259 262 261 266 264 262 268 264 261 262 262 261 266 259 264 266 267 262 260 268 264 261 263 260 260 264
Вариант № 9. Приведено количество деталей, выработанных за смену раз-личными рабочими.
75 90 76 81 77 83 85 75 81 73 75 83 73 84 85 83 88 76 79 85 81 89 83 76 77 84 83 88 87 77 82 85 74 79 82 87 71 78 85 84 81 83 88 82 83 88 80 79 82 86 74 75 78 76 84 81 76 74 81 93 84 92 75 82 77 87 85 87 79 80 85 74 78 82 89 71 77 85 78 73 83 82 79 76 84 90 84 92 75 80 78
Вариант № 10. Имеются данные о рабочих дебитах газовой скважины (тыс. м3/сут.). 552 553 556 550 561 562 550 563 560 550 540 545 546 539 537 543 540 556 546 556 556 534 548 533 558 560 558 548 540 541 551 549 551 550 552 568 538 551 547 552 559 557 546 552 550 557 547 552 554 547 554 567 558 563 562 569 552 554 549 545 560 539 549 539 560 550 550 551 550 551 562 550 562 561 530 542 535 542 554 544 547 551 550 547 558 550 550 558 541 551 540
Вариант № 11. Имеются данные о коэффициенте эксплуатации насосных скважин в различных нефтеносных районах страны.
0,90 0,79 0,84 0,86 0,88 0,90 0,89 0,85 0,91 0,98 0,91 0,80 0,87 0,89 0,88 0,78 0,81 0,85 0,88 0,94 0,86 0,80 0,86 0,91 0,78 0,86 0,91 0,95 0,97 0,88 0,79 0,82 0,84 0,90 0,81 0,87 0,91 0,90 0,82 0,85 0,90 0,82 0,85 0,90 0,96 0,98 0,89 0,87 0,99 0,85 0,95 0,85 0,89 0,88 0,88 0,82 0,85 0,88 0,93 0,86 0,82 0,86 0,91 0,88 0,86 0,87 0,89 0,91 0,88 0,85 0,89 0,94 0,89 0,84 0,80 0,95 0,88 0,86 0,80 0,81 0,82 0,85 0,84 0,80 0,83 0,96 0,86 0,86 0,81 0,78 0,81

102
Вариант № 12. 104 сверла были подвергнуты испытанию на твердость. При этом фиксировалась твердость лапки. Результаты испытания представлены в таблице.
14,5 14,6 15,1 15,5 16,3 16,8 17,9 16,3 14,5 14,9 13,6 15,4 16,9
15,4 14,3 15,5 11,3 15,5 17,1 16,8 12,2 15,2 15,7 11,6 16,9 15,7
17,7 16,6 16,2 15,5 12,8 14,2 15,5 16,1 14,3 16,5 14,5 17,9 17,8
16,9 11,7 13,2 14,9 19,8 16,6 17,9 14,9 15,2 17,3 16,9 17,6 17,8
17,7 16,6 16,9 19,5 12,8 16,2 15,6 16,1 16,3 17,5 18,5 17,9 16,8
16,5 11,6 13,0 14,7 17,8 16,8 17,4 16,9 16,2 14,9 16,9 17,5 17,8
17,0 16,5 14,9 18,5 12,9 15,2 15,8 16,4 16,3 18,5 16,5 17,9 16,8
17,1 16,1 15,9 19,0 13,8 16,9 16,6 16,5 16,9 17,5 18,4 17,7 169
Вариант № 13. Даны значения обследуемого признака Х — себестоимости единицы продукции (в руб.).
73 77 78 88 76 78 86 77 75 90 88 84 79 87 83 79 73 84 86 85 74 77 74 88 81 87 85 76 79 71 88 83 76 76 82 73 89 79 90 76 75 91 83 82 84 85 78 85 85 79 92 86 84 77 92 93 91 85 84 87 81 83 80 82 76 81 90 78 81 95 77 91 84 96 84 79 79 83 88 84 83 93 73 79 92 89 75 83 87 89 71 75 83 87 92 80 88 91 95 82 80 75 76 71 78 75 90 84 86 85 85 80 84 85 79 92 86
Вариант № 14. Имеются данные о суточном дебите газа в наблюдаемой скважине.
39 19 21 28 26 27 29 28 28 27 23 26 32 34 26 24 22 19 23 27 30,2 29 25 18 18,5 20 22 24 28 31,5 33 25 18 21 26 30 32 34 29 26 21 20 23 25 27 30 32,4 29 27 23 30,5 31,5 34 29 28 20 29 23,5 27 32 28 25 28 18,5 20 26 28 23 31,1 30 25,4 18,6 21 26 30 32 34 29 26 21 20 23 25 27,5 31 32,4 28 26 27 30 31,8 29 27 23 31,2 30 25,4 18,9 21 26 30 32 38 29

103
Вариант № 15. Имеются данные о расходах, связанных с подготовитель-ными работами, на 1 м проходки при разведочном бурении нефтяных сква-жин в различных нефтеносных районах страны (в тыс. руб.).
11 15 20 25 29 34 19 25 16 21 29 20 21 13 16 22 27 31 34 22 28 22 21 32 27 29 22 23 26 28 30 18 13 17 22 29 26 39 14 16 24 27 25 31 32 23 37 23 27 37 36 42 32 34 39 38 44 28 33 23 35 36 34 25 30 31 36 28 29 45 29 30 28 32 35 33 29 38 16 19 29 26 27 39 21 26 17 22 28 30 21
Вариант № 16. Имеются данные о расходах, связанных с монтажом и демон-тажом оборудования на предприятии (в тыс. руб.).
4,7 7,2 6,2 6,7 7,2 5,7 7,7 8,2 6,2 5,2 7,2 5,7 6,2 5,7 8,2 5,7 6,7 6,2 5,7 6,2 6,7 5,2 7,7 6,2 7,2 7,7 6,7 7,2 8,2 6,2 5,7 6,2 7,7 6,6 7,0 5,7 6,7 8,2 7,7 8,2 4,7 8,7 4,2 8,7 6,2 6,7 6,2 7,5 4,9 5,5 7,7 8,1 8,1 5,7 6,7 6,2 7,7 6,2 7,2 6,3 7,2 4,2 5,4 7,3 8,0 5,7 8,2 5,9 6,7 6,4 5,7 6,2 6,6 8,2 6,7 6,9 7,4 7,5
Вариант № 17. Даны значения обследуемого признака Х — себестоимости одной детали (в руб.).
82 83 73 76 79 89 95 92 93 84 88 76 88 81 78 86 84 84 86 85 87 84 74 83 87 73 76 73 78 76 76 74 88 82 73 85 79 77 79 97 84 80 75 81 73 78 83 75 90 83 77 84 85 90 92 91 85 71 85 87 82 94 92 76 93 90 73 92 84 93 88 84 81 93 81 91 78 85 84 95 79 79 83 96 89 82 79 77 83 88 81 88 82 77 92 76 84 83 87 89 75 77 78 80
Вариант № 18. Даны значения диаметров шестерен, обрабатываемых на станке.
21 29 27 29 27 29 31 29 31 29 29 23 39 31 29 31 29 31 29 31 33 31 31 31 27 23 27 33 29 25 29 19 29 31 23 31 29 27 33 29 31 29 31 23 35 27 29 29 27 29 29 21 29 27 29 29 29 33 29 25 25 27 31 29 29 27 33 29 31 29 29 29 35 27 29 35 29 33 29 27 31 31 27 29 35 27 33 29 27 29 25 27 31 37 25 31 27 27 29 25 30 26 25 28 25 30 31 29 25 24 26 30 24 25 29 31 25

104
Вариант № 19. Даны значения израсходованных долот на 104 скважинах при механической скорости проходки 18 м/сек.
28 30 28 27 28 29 29 29 31 28 26 25 33 35 27 31 31 30 28 33 23 30 31 33 31 27 30 28 30 29 30 26 25 31 33 26 27 33 29 30 30 36 26 25 28 30 29 27 32 29 31 30 31 26 25 29 31 33 27 32 30 31 34 28 26 38 29 31 29 27 31 30 28 34 30 26 30 32 30 29 30 28 32 30 29 34 32 35 29 27 28 30 30 29 32 29 34 30 32 24 31 32 30 29
Вариант № 20. Даны значения внутреннего диаметра гайки (в мм).
4,25 4,38 4,48 4,53 4,54 4,41 4,52 4,39 4,16 4,27 4,59 4,48 4,56 4,13 4,51 4,31 4,27 4,87 4,32 4,49 4,74 4,17 4,66 4,92 4,48 4,68 4,45 4,12 4,69 4,28 4,74 4,55 4,28 4,54 4,51 4,77 4,71 4,78 4,13 4,51 4,42 4,36 4,45 4,32 4,17 4,79 4,13 4,52 4,73 4,95 4,93 4,32 4,35 4,48 4,46 4,56 4,55 4,81 4,92 4,99 4,15 4,37 4,68 4,58 4,56 4,51 4,42 4,36 4,45 4,32 4,17 4,79 4,13 4,52 4,73 4,95 4,93 4,32 4,46 4,5 4,36 4,49 4,5 4,62 4,65 4,7 4,36 4,60 4,55 4,62 4,4
Вариант № 21. Даны значения ширины пера круглой плашки (в мм).
3,59 3,47 3,50 3,66 3,59 3,53 3,49 3,52 3,31 3,68 3,86 3,57 3,69 3,77 3,13 3,59 3,52 3,43 3,46 3,61 3,33 3,66 3,52 3,96 3,92 3,49 3,60 3,65 3,47 3,75 3,74 3,52 3,49 3,78 3,65 3,48 3,49 3,32 3,27 3,63 3,43 3,78 3,45 3,64 3,43 3,62 3,55 3,42 3,73 3,48 3,63 3,65 3,87 3,43 3,58 3,32 3,93 3,66 3,51 3,35 3,68 3,53 3,90 3,99 3,79 3,77 3,13 3,59 3,50 3,48 3,43 3,63 3,33 3,66 3,54 3,96 3,92 3,49 3,62 3,62 3,55 3,65 3,64 3,62 3,69 3,78 3,65 3,49 3,59 3,36 3,29
Вариант № 22. Имеются данные об энергетических затратах на 1 м проходки при разведочном бурении нефтяных скважин в различных нефтяных райо-нах страны (в тыс. руб.).
48 29 16 18 24 30 35 25 17 24 36 42 47 40 28 12 17 25 23 33 28 19 14 18 40 27 20 27 15 22 16 25 34 17 25 46 16 51 13 32 37 43 29 38 52 34 43 21 28 26 39 37 40 28 12 15 25 23 33 28 19 14 18 40 27 25 29 15 27 16 25 34 17 25 46 16 51 13 32 37 43 29 38 52 34 43 30 38 42 29 30

105
Вариант № 23. Имеются данные о пластовом давлении (в атм.) при насосном способе эксплуатации 104 скважин.
95 57 15 26 35 46 52 55 59 47 42 48 58 55 102 96 45 54 56 60 10 16 20 49 48 43 12 19 51 103 62 61 38 29 10 39 40 18 14 41 58 63 59 60 63 68 70 71 75 82 87 92 99 65 68 78 91 94 77 65 79 67 74 80 89 69 81 83 100 90 36 64 97 50 76 72 31 55 28 57 85 69 13 53 11 61 90 76 17 37 48 52 59 51 65 68 69 78 55 52 53 50 52 62
Вариант № 24. Имеются данные о продолжительности (в мес.) 65 фонтани-рующих скважин.
19,2 18,1 18,4 18,2 18,6 18,9 19,0 18,4 18,5 19,3 18,3 18,7 18,8 19,1 18,9 19,3 18,4 19,2 18,2 18,7 19,5 18,7 19,1 18,7 19,1 19,6 18,6 18,8 19,3 18,8 19,0 19,5 18,9 19,0 19,8 19,7 19,4 19,3 19,1 19,8 18,9 19,7 18,5 19,0 19,9 19,2 19,1 18,6 19,5 19,6 19,8 19,3 19,6 18,9 18,8 18,3 18,5 18,8 19,2 18,8 18,6 19,1 18,3 18,7 18,8
Вариант № 25. Результаты измерения температуры раздела фракции бензин-авиакеросин на установке первичной переработке нефти (в °С):
133 133 142 135 145 144 145 147 146 134 130 134 138 144 141 141 134 141 136 140 143 139 141 137 140 145 145 141 144 138 139 143 141 141 146 143 140 139 143 143 139 140 139 138 138 135 141 141 140 138 145 135 148 136 139 142 143 143 137 138 138 139 138 144 143 138 142 138 140 140 137 139 140 139 137 136 136 135 135 141 142 136 140 136 137 138 138 137 139 139 140 139 140 140 139 139 139 140 140 146 138 136 130 141
Варианты заданий к лабораторной работе № 2.
Вариант № 1. В таблице представлены данные, характеризующие зависи-мость между стоимостью X основных производственных фондов и объемом Y валовой продукции по десяти однотипным предприятиям. Найти фор-мулу, устанавливающую зависимость между Х и Y.
X 1 2 3 4 5 6 7 8 9 10 11 13 14 15 17 Y 20 25 31 31 40 56 52 60 67 72 76 81 90 99 104

106
Вариант № 2. Зависимость между стоимостью X (тыс. млн. руб.) основных средств предприятий и месячным выпуском Y (тыс. руб.) продукции харак-теризуется данными, представленными в таблице. Найти формулу, устанав-ливающую эту зависимость.
X 1 2 3 4 5 6 7 8 9 10 11
Y 10 12 28 40 42 52 54 55 59 65 67 Вариант № 3. Имеются данные наблюдений изменения средней заработ-ной платы Y (руб.) в зависимости от изменения производительности труда X (шт.) за 4 месяца 2014 года по девяти токарям цеха № 23 электромеха-нического завода. Найти формулу, устанавливающую зависимость между Х и Y.
X 406 660 914 1168 1422 1676 1930 2184 2438 2565
Y 518,5 813,5 1108,5 1403,5 1698,5 1993,5 2288,5 2583,5 2878,5 3012.2
Вариант № 4. Дано распределение заводов по производственным средствам X (млн. руб.) и по суточной выработке Y (тыс. руб.). Найти формулу, уста-навливающую зависимость между Х и Y.
X 50 49 48 51 52 53 54 57 59 60 61 55 60 62 63 64 65
Y 10 8 10 9 10 12 13 15 16 18 20 17 21 25 24 27 29 Вариант № 5. Данные нормы расхода моторного масла на угар и замену Y (л/100 л.т.) от максимальной мощности двигателя X (л.с.) приведены в таблице. Найти формулу, устанавливающую зависимость между Х и Y.
X 39 42 53 70 73,5 75 90 98 110 115 121 126
Y 1,3 1,3 0,8 2,2 1,8 2 2,2 1,8 2,8 2,6 3.3 3.6
Вариант № 6. Результаты наблюдений изменения диаметра Y (мм) вала и износа X (мм) резца приведены в следующей таблице. Найти формулу, уста-навливающую зависимость между Х и Y.
X 0,01 0,02 0,024 0,03 0,032 0,035 0,037 0,042 0,048 0,057 0.061 0.067
Y 20 20,01
20,014
20,022
20,024
20,027
20,029
20,034
20,04
20,049
20.120
20.231

107
Вариант № 7. Компанию по прокату автомобилей интересует зависимость между пробегом X автомобилей и стоимостью Y ежемесячного техниче-ского обслуживания. Для выяснения характера этой связи было отобрано 19 автомобилей. Данные приведены в таблице. Найти формулу, устанавливаю-щую зависимость между Х и Y.
X 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Y 13 16 15 20 19 21 26 24 30 32 30 35 34 40 39 42 46 48 52
Вариант № 8. При исследовании зависимости между выпуском готовой продук-ции Y (тыс. руб.) и энерговооруженностью труда X (кВт-час) получены следую-щие данные. Найти формулу, устанавливающую эту зависимость.
X 1201 1300 1375 1412 1443 1500 1526 1516 1718 1783 1819 1877 1899
Y 14 21 27 29 30 31,5 35 34 41 38 39 46 51
Вариант № 9. В таблице приведены данные, характеризующие зависимость израсходованных долот Y (шт.) при бурении 8 скважин в зависимости от ме-ханической скорости X (м/с) проходки. Найти формулу, устанавливающую эту зависимость.
X 10 15 12 11 10 8 7 6 5 4 3 2
Y 55 40 60 50 40 30 25 20 18 16 15 10
Вариант № 10. Скорость Y (м/час) бурения в твердых породах от нагрузки X (атм.) на долото характеризуется следующими данными. Найти формулу, устанавливающую зависимость между Х и Y.
X 10 10,5 11 11,5 12 12,5 13 13,5 14 14,5
Y 6,5 5,5 4,5 3,5 3 2,5 2 1,5 1 0,5
Вариант № 11. Зависимость между выработкой продукции X (тыс. руб.) и затратами топлива Y в условных единицах характеризуется следую-щими данными. Найти формулу, устанавливающую зависимость между Х и Y.
X 3 4 5 6 7 8 9 10 11 12 13 14
Y 2 2,3 2,2 2,3 2,5 2,6 2,8 2,9 3 3,2 3,35 3,7

108
Вариант № 12. Имеются данные распределения заводов по производствен-ным средствам X (млн. руб.) и по суточной выработке Y (млн. руб.). Найти формулу, устанавливающую зависимость между Х и Y.
X 48 49 50 52 53 54 57 60 63 65 68 80 85 90
Y 11 8 10,6 10 12 13 15 18 24 26 25 38 41 44
Вариант № 13. Найти формулу, устанавливающую зависимость между коэффициентом Y сменности техники и ее средним возрастом Х по предприятию ПМК-7 объединения Сибкомплект на основании следую-щих данных.
Y 1,18 1,21 1,25 1,26 1,3 1,42 1,58 1,69 1,73 1,8 2,2
X 6,31 5,8 5,1 5,6 5,1 4,5 4,7 4,02 3,6 3,2 2,3
Вариант № 14. Имеются данные о реализации продукции X (млн. руб.) и накладных расходах Y (тыс. руб.) на реализацию. Найти формулу, устанав-ливающую зависимость между Х и Y.
X 9 13 17 22 29 36 44 51 60 65 67 69 Y 27 36 29 41 54 71 65 81 90 95 99 100
Вариант № 15. Зависимость линейной нормы расхода топлива Y (л) от мак-симальной мощности двигателя автомобиля X (л.с.) характеризуется следу-ющими данными. Найти формулу, устанавливающую эту зависимость.
X 39 53 70 75 90 98 110 115 120 150 165 188 Y 12 11 21,5 22,8 18 21 31 25 30 36 40 46
Вариант № 16. Имеются данные нормы расхода моторных масел на угар и замену Y (л/100 л.т.) в зависимости от максимального крутящего момента Х. Найти формулу, устанавливающую зависимость между Х и Y.
X 7,4 7,6 8,2 10,8 17 21 35 41 42 44 48 51 Y 1,3 1,35 1,5 1,8 2,2 2,1 2,8 2,6 2,3 2,4 2,6 2,8
Вариант № 17. Фазовая проницаемость нефти Y и насыщенность породы нефтью X характеризуются следующими данными. Найти формулу, уста-навливающую зависимость между Х и Y.
X 0,05 0,15 0,25 0,35 0,45 0,55 0,65 0,75 0,85 0,95 1 Y 0,35 0,45 0,55 0,65 0,75 0,8 0,85 0,95 1 1,25 1,45

109
Вариант № 18. Имеются данные нормы расхода моторных масел на угар и замену Y (л/100 л.т.) в зависимости от максимальной мощности двигателя автомобиля X (л.с.). Найти формулу, устанавливающую зависимость между Х и Y.
X 39 42 53 70 75 90 110 115 150 170 185 199
Y 1,3 1,33 0,9 2,2 2,2 2,2 2,8 2,4 2,5 2,6 2,76 2,98
Вариант № 19. Зависимость между среднегодовой стоимостью основных производственных фондов X (млн. руб.) и стоимостью товарной продукции Y (млн. руб.) характеризуется следующими данными. Найти формулу, уста-навливающую зависимость между Х и Y.
X 1,94 2,68 3,47 4,12 4,77 5,34 5,85 6,65 7,8 9, 5
Y 0,82 0,97 1,06 1,08 1,1 1,14 1,21 1,25 1,28 1,32
Вариант № 20. Найти формулу, устанавливающую зависимость себестоимо-сти одной тонны нефти Y (в руб.) от затрат X (в тыс. руб.) на одну тонну по следующим данным.
X 1,44 1,6 1,85 2,1 2,25 2,42 2,55 2,65 2,74 2,85 2,95
Y 161,5 165 170 175 178 182 186 190 193 197 201
Вариант № 21. Ниже приводятся данные о производительности труда Y (м) на одного чел/час и стаже рабочих X (в годах). Найти формулу, устанавли-вающую зависимость между Х и Y.
X 1 2 3 4 5 6 7 8 9 10 11
Y 9,8 15 16 19 20 22 23 27 27,1 27,3 27,5
Вариант № 22. Найти формулу зависимости электрического сопротивления R (Ом) проводника от температуры Θ˚С по следующим данным.
Θ 19,1 25,0 30,1 36,0 40,0 45,1 50,0 51,0
R 76,30 77,80 79,75 80,80 82,35 83,90 85,10 85,77

110
Вариант № 23. Найти зависимость израсходованных долот Y при бурении 10 скважин в зависимости от механической скорости X проходки на основа-нии следующих данных.
X 8 10 12 14 15 16 18 19 20 21 22 23 Y 60 55 50 48 45 40 30 31 29 32 36 39
Вариант № 24. Имеются данные о реализованной продукции X (млн. руб.) и накладных расходах Y (тыс. руб.) на реализацию. Найти формулу, устанав-ливающую зависимость между Х и Y.
X 9 13 17 22 29 36 44 51 60 65 Y 27 36 29 41 54 71 65 81 90 95
Вариант № 25. В таблице приведены данные, характеризующие зависимость растворимости азотно-натриевой соли S в зависимости от температуры T. Найти формулу, устанавливающую зависимость между Х и Y.
T 0 4 10 15 21 29 36 51 68 S 66,7 71 76,3 80,6 85,7 92,9 99,4 113,6 125,1
Варианты заданий по лабораторной работе № 3
Вариант № 1. В корреляционной таблице представлена зависимость объема Y (см3) разрушенной породы от глубины X (мм) внедрения зуба при посто-янном давлении.
X Y 0,5 1,5 2,5 3,5 4,5 5,5 yn
0,05 4 3 7
0,15 5 3 8
0,25 8 1 9
0,35 4 6 10
0,45 5 1 6
0,55 6 6
0,65 1 3 9 13
0,75 1 1
xn 4 8 15 19 4 10 60
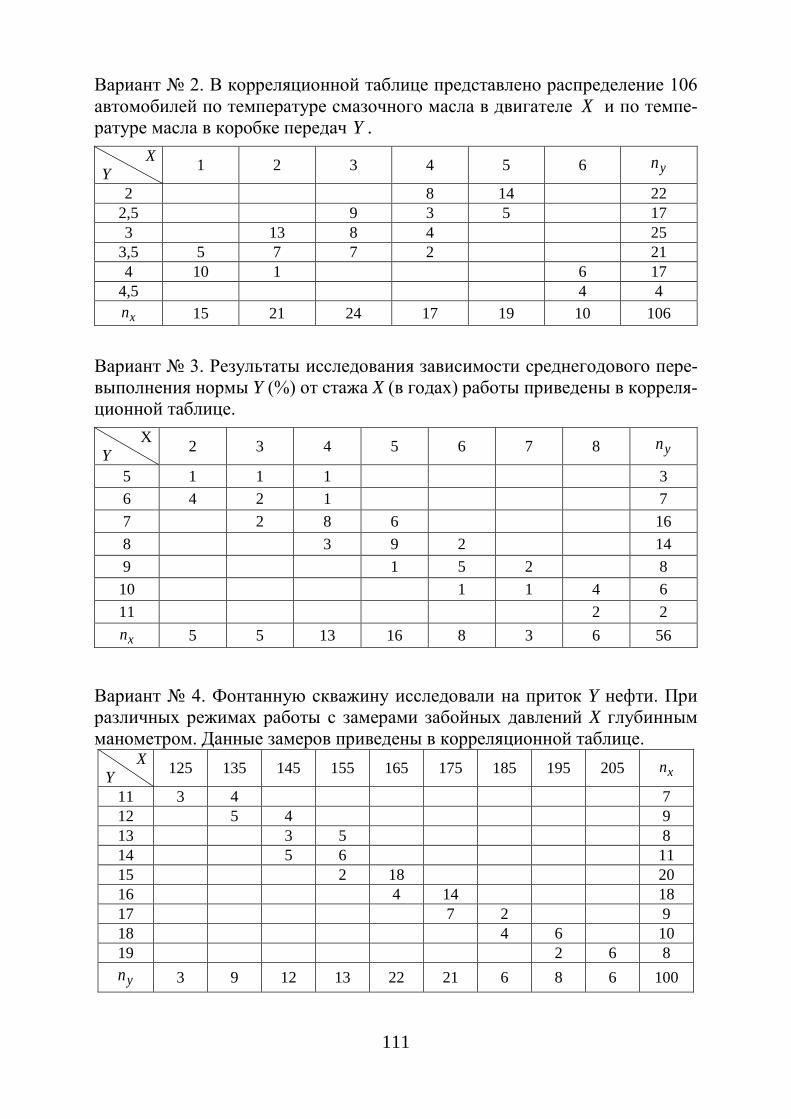
111
Вариант № 2. В корреляционной таблице представлено распределение 106 автомобилей по температуре смазочного масла в двигателе X и по темпе-ратуре масла в коробке передач Y .
X Y 1 2 3 4 5 6 yn
2 8 14 22 2,5 9 3 5 17 3 13 8 4 25
3,5 5 7 7 2 21 4 10 1 6 17
4,5 4 4 xn 15 21 24 17 19 10 106
Вариант № 3. Результаты исследования зависимости среднегодового пере-выполнения нормы Y (%) от стажа X (в годах) работы приведены в корреля-ционной таблице.
X Y 2 3 4 5 6 7 8 yn
5 1 1 1 3 6 4 2 1 7 7 2 8 6 16 8 3 9 2 14 9 1 5 2 8 10 1 1 4 6 11 2 2
xn 5 5 13 16 8 3 6 56 Вариант № 4. Фонтанную скважину исследовали на приток Y нефти. При различных режимах работы с замерами забойных давлений X глубинным манометром. Данные замеров приведены в корреляционной таблице.
X Y 125 135 145 155 165 175 185 195 205 xn
11 3 4 7 12 5 4 9 13 3 5 8 14 5 6 11 15 2 18 20 16 4 14 18 17 7 2 9 18 4 6 10 19 2 6 8
yn 3 9 12 13 22 21 6 8 6 100
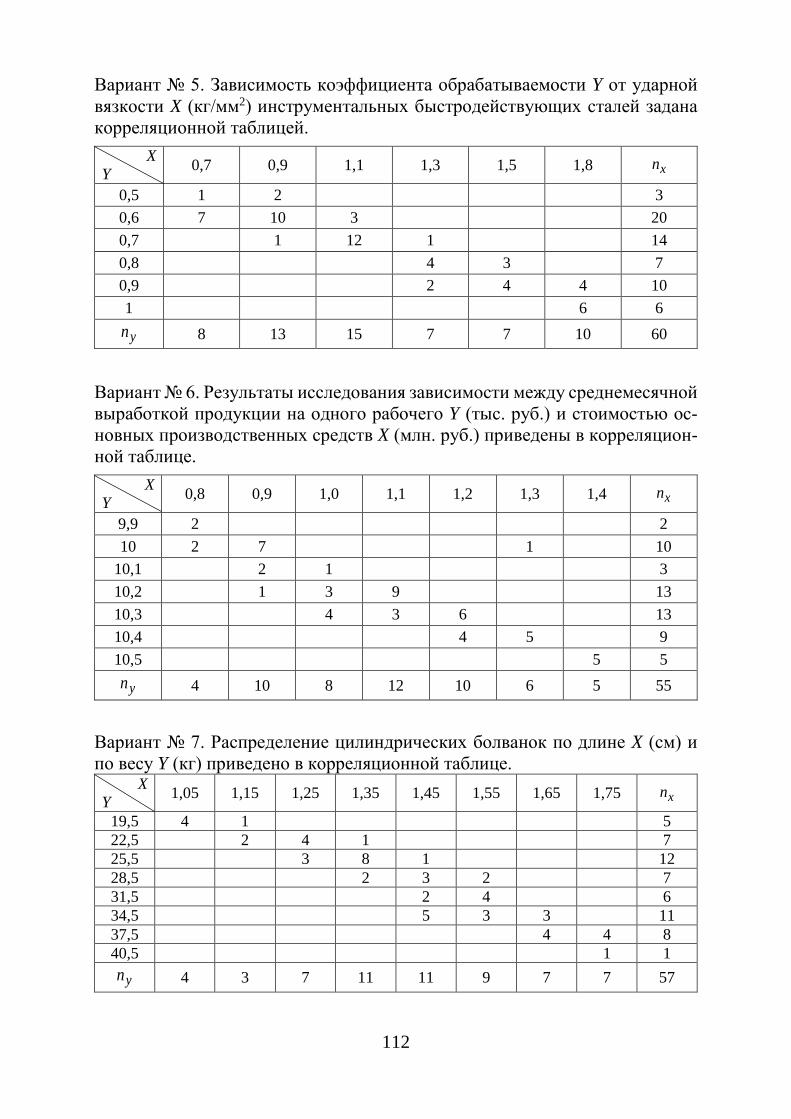
112
Вариант № 5. Зависимость коэффициента обрабатываемости Y от ударной вязкости X (кг/мм2) инструментальных быстродействующих сталей задана корреляционной таблицей.
X Y 0,7 0,9 1,1 1,3 1,5 1,8 xn
0,5 1 2 3 0,6 7 10 3 20 0,7 1 12 1 14 0,8 4 3 7 0,9 2 4 4 10 1 6 6
yn 8 13 15 7 7 10 60
Вариант № 6. Результаты исследования зависимости между среднемесячной выработкой продукции на одного рабочего Y (тыс. руб.) и стоимостью ос-новных производственных средств X (млн. руб.) приведены в корреляцион-ной таблице.
X Y 0,8 0,9 1,0 1,1 1,2 1,3 1,4 xn
9,9 2 2 10 2 7 1 10
10,1 2 1 3 10,2 1 3 9 13 10,3 4 3 6 13 10,4 4 5 9 10,5 5 5
yn 4 10 8 12 10 6 5 55
Вариант № 7. Распределение цилиндрических болванок по длине X (см) и по весу Y (кг) приведено в корреляционной таблице.
X Y 1,05 1,15 1,25 1,35 1,45 1,55 1,65 1,75 xn
19,5 4 1 5 22,5 2 4 1 7 25,5 3 8 1 12 28,5 2 3 2 7 31,5 2 4 6 34,5 5 3 3 11 37,5 4 4 8 40,5 1 1
yn 4 3 7 11 11 9 7 7 57

113
Вариант № 8. Результаты замера температуры X (°С) смазочного масла в двигателе и температуры Y (°С) масла в коробке передач автомобиля приве-дены в корреляционной таблице.
X
Y 6 10 14 18 22 26 30 xn
15 4 3 7 21 1 5 1 7 27 2 5 7 33 6 3 9 39 5 4 9 45 2 9 6 17 51 3 1 4
yn 5 10 12 8 6 12 7 60
Вариант № 9. Результаты измерений сверл по твердости Y (HRC) и по стой-кости X (час) приведены в корреляционной таблице.
X Y 20,5 25,5 30,5 35,5 40,5 45,5 50,5 xn
25 2 3 5 35 1 7 8 43 2 4 6 51 1 9 4 14 59 4 3 1 8 67 3 8 5 16 76 4 4
yn 3 10 3 17 10 9 9 61
Вариант № 10. Результаты измерений времени X (час) непрерывной работы и количества Y (шт.) полностью обработанных деталей приведены в корре-ляционной таблице.
X Y 6 10 14 18 22 26 30 xn
0,95 5 5 10 1,85 4 2 6 2,75 6 8 14 3,65 1 6 7 4,55 5 3 8 7 23 5,45 4 1 5
yn 5 9 8 14 9 12 8 65
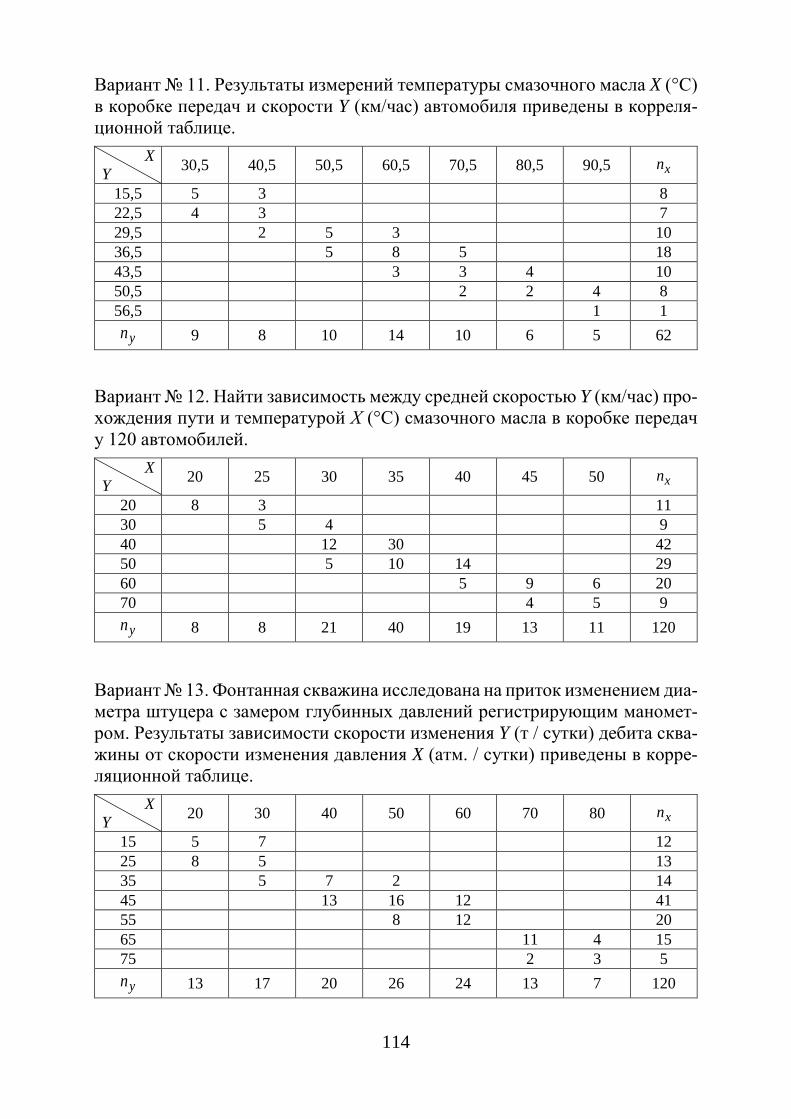
114
Вариант № 11. Результаты измерений температуры смазочного масла X (°С) в коробке передач и скорости Y (км/час) автомобиля приведены в корреля-ционной таблице.
X Y 30,5 40,5 50,5 60,5 70,5 80,5 90,5 xn
15,5 5 3 8 22,5 4 3 7 29,5 2 5 3 10 36,5 5 8 5 18 43,5 3 3 4 10 50,5 2 2 4 8 56,5 1 1
yn 9 8 10 14 10 6 5 62 Вариант № 12. Найти зависимость между средней скоростью Y (км/час) про-хождения пути и температурой Х (°С) смазочного масла в коробке передач у 120 автомобилей.
X Y 20 25 30 35 40 45 50 xn
20 8 3 11 30 5 4 9 40 12 30 42 50 5 10 14 29 60 5 9 6 20 70 4 5 9
yn 8 8 21 40 19 13 11 120 Вариант № 13. Фонтанная скважина исследована на приток изменением диа-метра штуцера с замером глубинных давлений регистрирующим маномет-ром. Результаты зависимости скорости изменения Y (т / сутки) дебита сква-жины от скорости изменения давления X (атм. / сутки) приведены в корре-ляционной таблице.
X Y 20 30 40 50 60 70 80 xn
15 5 7 12 25 8 5 13 35 5 7 2 14 45 13 16 12 41 55 8 12 20 65 11 4 15 75 2 3 5
yn 13 17 20 26 24 13 7 120
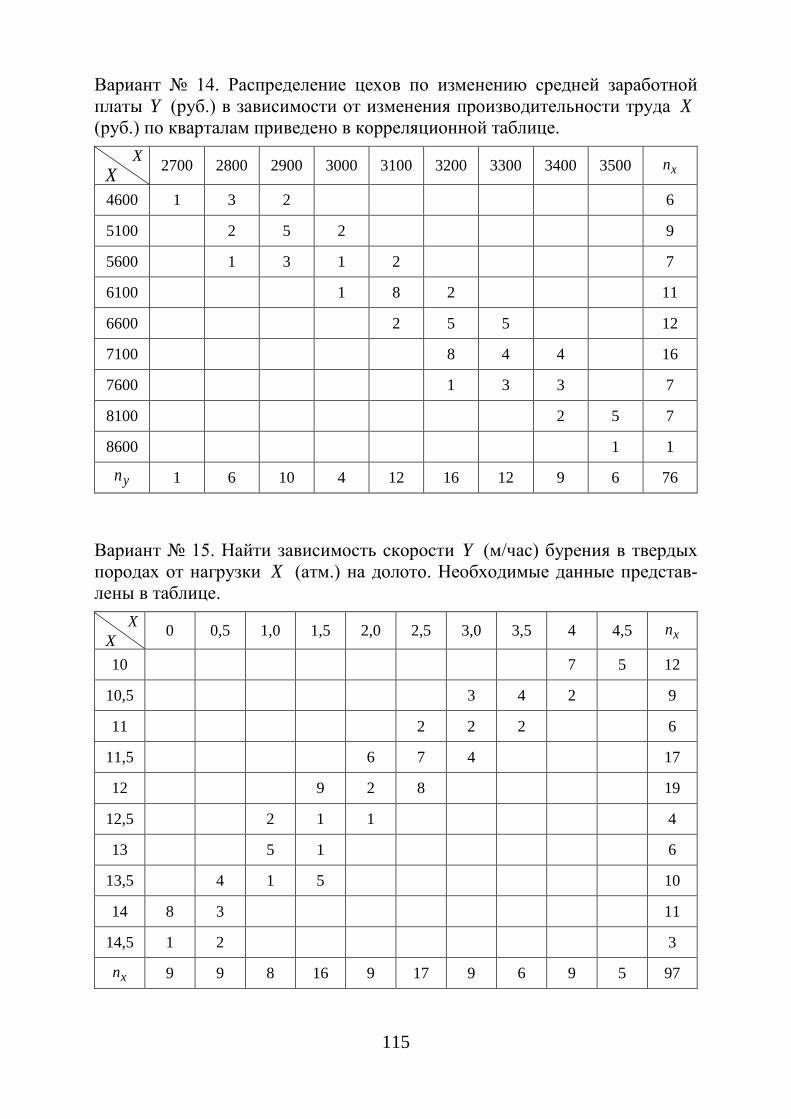
115
Вариант № 14. Распределение цехов по изменению средней заработной платы Y (руб.) в зависимости от изменения производительности труда X (руб.) по кварталам приведено в корреляционной таблице.
X X
2700 2800 2900 3000 3100 3200 3300 3400 3500 xn
4600 1 3 2 6
5100 2 5 2 9
5600 1 3 1 2 7
6100 1 8 2 11
6600 2 5 5 12
7100 8 4 4 16
7600 1 3 3 7
8100 2 5 7
8600 1 1
yn 1 6 10 4 12 16 12 9 6 76
Вариант № 15. Найти зависимость скорости Y (м/час) бурения в твердых породах от нагрузки X (атм.) на долото. Необходимые данные представ-лены в таблице.
X X 0 0,5 1,0 1,5 2,0 2,5 3,0 3,5 4 4,5 xn
10 7 5 12
10,5 3 4 2 9
11 2 2 2 6
11,5 6 7 4 17
12 9 2 8 19
12,5 2 1 1 4
13 5 1 6
13,5 4 1 5 10
14 8 3 11
14,5 1 2 3
xn 9 9 8 16 9 17 9 6 9 5 97
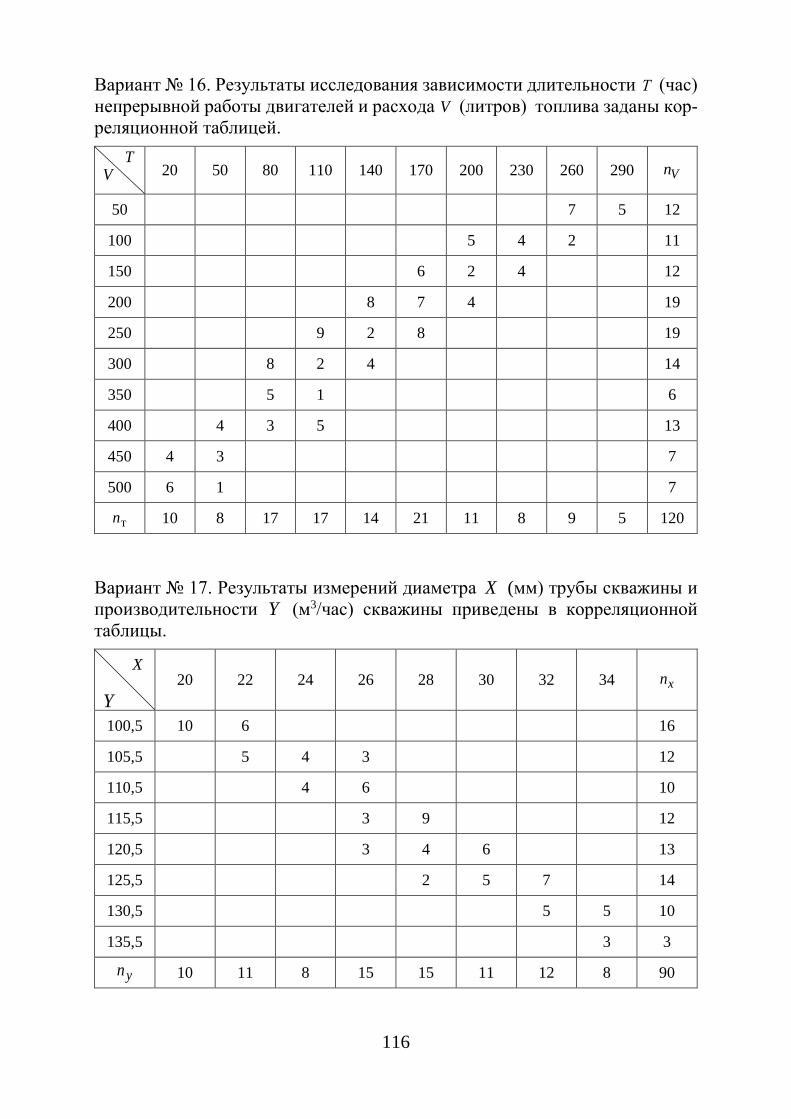
116
Вариант № 16. Результаты исследования зависимости длительности Т (час) непрерывной работы двигателей и расхода V (литров) топлива заданы кор-реляционной таблицей.
T V 20 50 80 110 140 170 200 230 260 290 Vn
50 7 5 12
100 5 4 2 11
150 6 2 4 12
200 8 7 4 19
250 9 2 8 19
300 8 2 4 14
350 5 1 6
400 4 3 5 13
450 4 3 7
500 6 1 7
тn 10 8 17 17 14 21 11 8 9 5 120
Вариант № 17. Результаты измерений диаметра X (мм) трубы скважины и производительности Y (м3/час) скважины приведены в корреляционной таблицы.
X Y
20 22 24 26 28 30 32 34 xn
100,5 10 6 16
105,5 5 4 3 12
110,5 4 6 10
115,5 3 9 12
120,5 3 4 6 13
125,5 2 5 7 14
130,5 5 5 10
135,5 3 3
yn 10 11 8 15 15 11 12 8 90
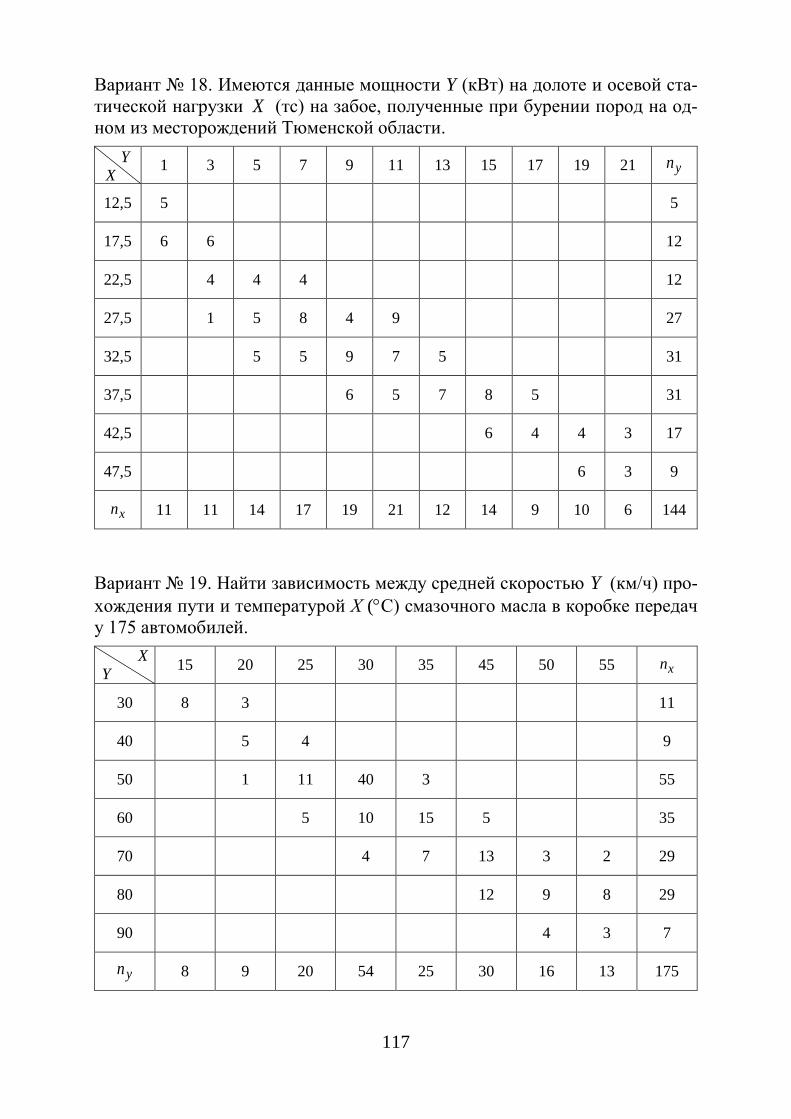
117
Вариант № 18. Имеются данные мощности Y (кВт) на долоте и осевой ста-тической нагрузки X (тс) на забое, полученные при бурении пород на од-ном из месторождений Тюменской области.
Y X 1 3 5 7 9 11 13 15 17 19 21 yn
12,5 5 5
17,5 6 6 12
22,5 4 4 4 12
27,5 1 5 8 4 9 27
32,5 5 5 9 7 5 31
37,5 6 5 7 8 5 31
42,5 6 4 4 3 17
47,5 6 3 9
xn 11 11 14 17 19 21 12 14 9 10 6 144
Вариант № 19. Найти зависимость между средней скоростью Y (км/ч) про-хождения пути и температурой Х (°С) смазочного масла в коробке передач у 175 автомобилей.
X Y 15 20 25 30 35 45 50 55 xn
30 8 3 11
40 5 4 9
50 1 11 40 3 55
60 5 10 15 5 35
70 4 7 13 3 2 29
80 12 9 8 29
90 4 3 7
yn 8 9 20 54 25 30 16 13 175
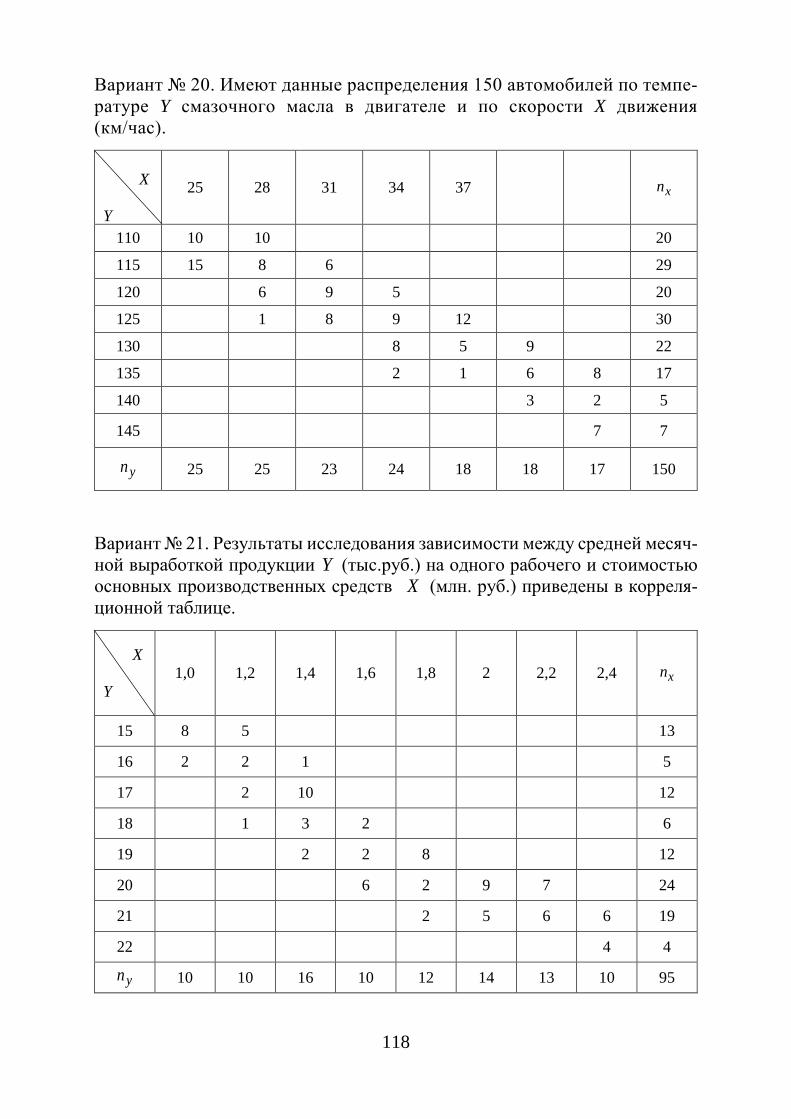
118
Вариант № 20. Имеют данные распределения 150 автомобилей по темпе-ратуре Y смазочного масла в двигателе и по скорости X движения (км/час).
X
Y
25 28 31 34 37 xn
110 10 10 20
115 15 8 6 29
120 6 9 5 20
125 1 8 9 12 30
130 8 5 9 22
135 2 1 6 8 17
140 3 2 5
145 7 7
yn 25 25 23 24 18 18 17 150
Вариант № 21. Результаты исследования зависимости между средней месяч-ной выработкой продукции Y (тыс.руб.) на одного рабочего и стоимостью основных производственных средств X (млн. руб.) приведены в корреля-ционной таблице.
X
Y
1,0 1,2 1,4 1,6 1,8 2 2,2 2,4 xn
15 8 5 13
16 2 2 1 5
17 2 10 12
18 1 3 2 6
19 2 2 8 12
20 6 2 9 7 24
21 2 5 6 6 19
22 4 4
yn 10 10 16 10 12 14 13 10 95
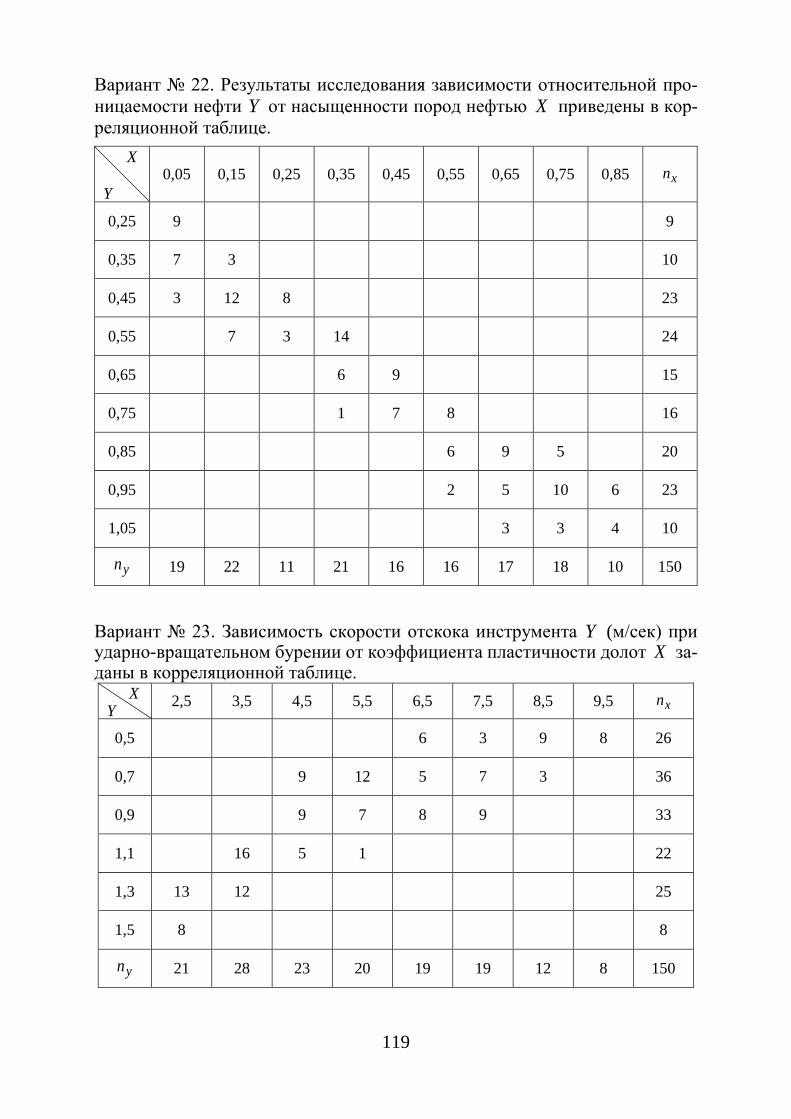
119
Вариант № 22. Результаты исследования зависимости относительной про-ницаемости нефти Y от насыщенности пород нефтью X приведены в кор-реляционной таблице.
X Y
0,05 0,15 0,25 0,35 0,45 0,55 0,65 0,75 0,85 xn
0,25 9 9
0,35 7 3 10
0,45 3 12 8 23
0,55 7 3 14 24
0,65 6 9 15
0,75 1 7 8 16
0,85 6 9 5 20
0,95 2 5 10 6 23
1,05 3 3 4 10
yn 19 22 11 21 16 16 17 18 10 150
Вариант № 23. Зависимость скорости отскока инструмента Y (м/сек) при ударно-вращательном бурении от коэффициента пластичности долот X за-даны в корреляционной таблице.
X Y 2,5 3,5 4,5 5,5 6,5 7,5 8,5 9,5 xn
0,5 6 3 9 8 26
0,7 9 12 5 7 3 36
0,9 9 7 8 9 33
1,1 16 5 1 22
1,3 13 12 25
1,5 8 8
yn 21 28 23 20 19 19 12 8 150
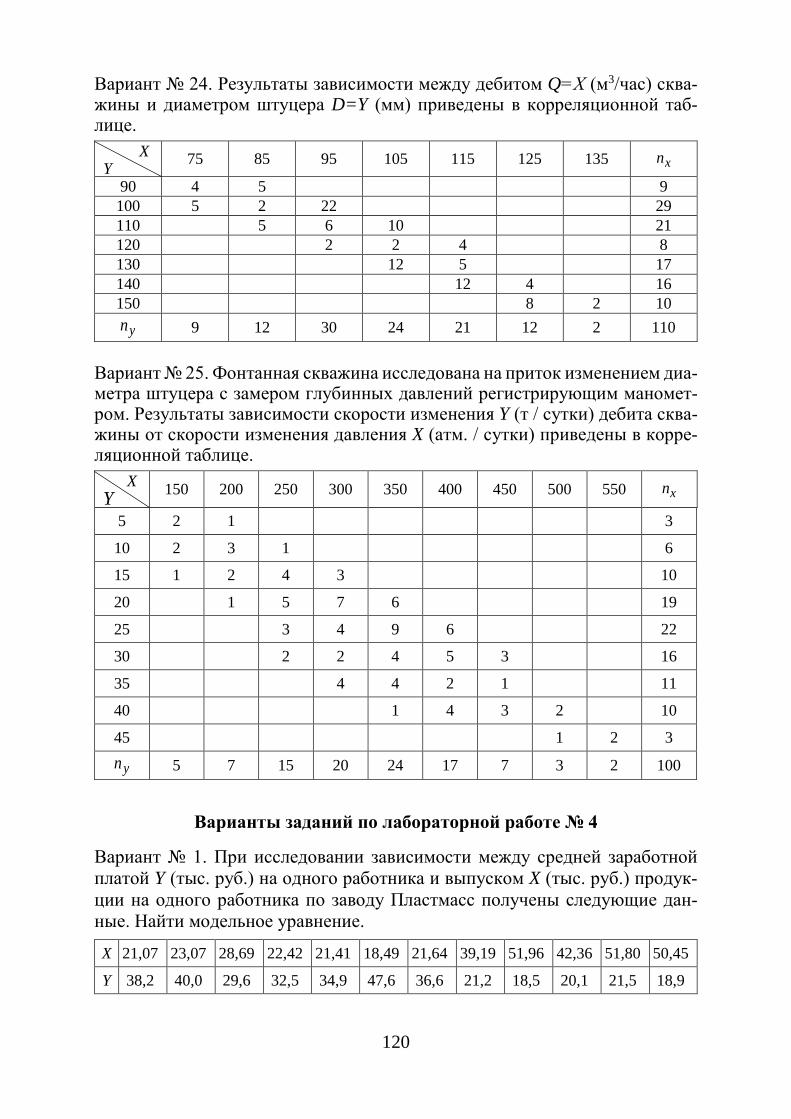
120
Вариант № 24. Результаты зависимости между дебитом Q=Х (м3/час) сква-жины и диаметром штуцера D=Y (мм) приведены в корреляционной таб-лице.
X Y 75 85 95 105 115 125 135 xn
90 4 5 9 100 5 2 22 29 110 5 6 10 21 120 2 2 4 8 130 12 5 17 140 12 4 16 150 8 2 10
yn 9 12 30 24 21 12 2 110
Вариант № 25. Фонтанная скважина исследована на приток изменением диа-метра штуцера с замером глубинных давлений регистрирующим маномет-ром. Результаты зависимости скорости изменения Y (т / сутки) дебита сква-жины от скорости изменения давления X (атм. / сутки) приведены в корре-ляционной таблице.
X Y 150 200 250 300 350 400 450 500 550 xn
5 2 1 3
10 2 3 1 6
15 1 2 4 3 10
20 1 5 7 6 19
25 3 4 9 6 22
30 2 2 4 5 3 16
35 4 4 2 1 11
40 1 4 3 2 10
45 1 2 3
yn 5 7 15 20 24 17 7 3 2 100
Варианты заданий по лабораторной работе № 4
Вариант № 1. При исследовании зависимости между средней заработной платой Y (тыс. руб.) на одного работника и выпуском X (тыс. руб.) продук-ции на одного работника по заводу Пластмасс получены следующие дан-ные. Найти модельное уравнение.
X 21,07 23,07 28,69 22,42 21,41 18,49 21,64 39,19 51,96 42,36 51,80 50,45
Y 38,2 40,0 29,6 32,5 34,9 47,6 36,6 21,2 18,5 20,1 21,5 18,9

121
Вариант № 2. Данные о производстве Х (тыс. руб.) дизтоплива и себестои-мости Y (тыс. руб.) приведены в таблице. Найти модельное уравнение
X 5 6 8 13 34 72 95 113 127 90
Y 143 125 87 45 33 27 16 25 24 27
Вариант № 3. Зависимость скорости v (м/мин) резания от площади S (мм2) поперечного сечения стружки при обработке стали задана таблицей. Найти модельное уравнение.
v 1 1,2 1,7 2,4 3,6 4,7 6 8 11 14
S 26 22 22,6 19,1 15,2 12,8 11,3 9,5 7,8 6,5
Вариант № 4. Данные зависимости на долота N (кВт) от осевой статической нагрузки на забой Pc (тс) при бурении пород приведены в таблице. Найти модельное уравнение.
Pc 1 3 5 7 9 11 13 15 17
S 12,5 17,8 37 41,9 45 47 39 32 28
Вариант № 5. Зависимость скорости отскока инструмента v0 (м/с) при ударно-вращательном бурении от коэффициента K пластичности долот за-дана таблицей. Найти модельное уравнение.
K 1,5 2,5 3,5 4,5 5,5 6,5
v0 1,2 0,6 0,21 0,9 0,8 0,75
Вариант № 6. Данные о количестве X (тыс. шт.) выпускаемых деталей и пол-ных затратах Y (сотни руб.) на их изготовление на однотипных предприя-тиях приведены в таблице. Найти модельное уравнение.
X 1 2 4 9 13 18 20
Y 26 22 19 12 9 8 6

122
Вариант № 7. При исследовании зависимости времени Y (мин.) на обра-ботку одной детали от стажа X (в годах) работы на Тюменском моторостро-ительном объединении в цехе резиново-технических и пластмассовых изде-лий на слесарном участке получены следующие данные. Найти модельное уравнение.
X 1 2 3 4 5 6 7
Y 5 3,33 2,9 2,2 2,1 2 2
Вариант № 8. Зависимость удельного момента My (кгс·м/тс) на долоте от осевой статической нагрузки Pc (тс) на забой при бурении пород задана таб-лицей. Найти модельное уравнение.
Pc 1 3 5 7 9 11 13 15
My 22,5 11,5 6 5,5 2,6 2,4 2,1 2
Вариант № 9. Результаты измерений зависимости фазовой проницаемости KВ воды от нефтенасыщенности SН породы приведены в таблице. Найти мо-дельное уравнение.
KВ 0,25 0,35 0,45 0,55 0,65 0,75 0,85
SН 0,65 0,45 0,25 0,15 0,10 0,05 0,07
Вариант № 10. В результате исследований установлено, что между овальностью X колец после их обработки и овальностью Y термической обработки, суще-ствует связь, которая задана таблицей. Найти модельное уравнение.
X 5 10 15 20 25 30
Y 21 29,3 36 38 39,2 40,3
Вариант № 11. При исследовании зависимости между выпуском Y(тыс. руб.) готовой продукции и коэффициентом X (%) использования техники полу-чены следующие данные. Найти модельное уравнение.
X 73 75 79 82 83 86 80 85 95 93 97 77
Y 14 21 29 30 315 35 34 41 38 39 46 27

123
Вариант № 12. Давление P (кг) воздуха на парашют возрастает при увели-чении скорости v (м / сек) падения следующим образом. Найти модельное уравнение.
P 2,23 3,28 4,65 6,5 8,1
v 0,3 0,6 1,2 2,4 4,2
Вариант № 13. Прочность Y (кг/см2) бетона при испытании цилиндрических образцов в зависимости от отношения X = h / α высоты h к диаметру α ока-залась равной. Найти модельное уравнение.
X 0,5 1,0 2,0 3,0 4,0 5,0 6,0
Y 290 250 216 206 200 195 190
Вариант № 14. Зависимость между размером предприятия по стоимости X (млн. руб.) основных средств и себестоимостью Y (руб.) единицы продукции характеризуется следующими данными. Найти модельное уравнение.
X 0,5 1,5 2,5 3,5 4,5 5,5 7,5
Y 15 11 12 10,8 10 9 8
Вариант № 15. Зависимость между ростом X (тыс. руб.) производительности труда на одного работающего и выпуском Y (тыс. руб.) товарной продукции ремонтного цеха машиностроительного завода характеризуется следую-щими данными. Найти модельное уравнение.
X 1,5 2,9 3,0 3,1 3,2 3,4 3,5 3,6 4,2
Y 580 618 658 670 662 699 717 775 786
Вариант № 16. Зависимость себестоимости Y (тыс. руб.) продукции от затрат X (тыс. руб.) на единицу продукции по объединению «Сибкомплектмонтаж» ха-рактеризуется следующими данными. Найти модельное уравнение.
X 0,1 0,4 1 4 6 10 20 26
Y 2248 1950 1500 1020 906 290 175 121

124
Вариант № 17. Компрессорную скважину исследовали на приток Q (т/сут.) нефти при различных режимах работы с величиной ∆P (атм) забойных дав-лений глубинным манометром. Результаты исследований приведены в таб-лице. Найти модельное уравнение.
Q 5 15 25 35 45 55
∆P 1,25 1,3 5,25 11,25 17,25 21,25
Вариант № 18. Зависимость между стоимостью X (млн. руб.) основных средств предприятия и выработкой Y (тыс. руб.) продукции на одного работника ха-рактеризуется следующими данными. Найти модельное уравнение.
X 1 1,5 2,5 3,5 4,5 5,5 6,5
Y 4 6 6,8 7,9 8,7 9 9,5
Вариант № 19. Ниже приводятся данные удельного момента Y (кг·м/тс) на до-лото и осевой статической нагрузки X (тс) на забой при бурении пород на одном из месторождений Тюменской области. Найти модельное уравнение.
X 1 3 5 7 9 11 13 15 17
Y 25 15 12 8 10 5 4,5 3 2,8
Вариант № 20. Зависимость между мощностью X (млн. ед. продукции в год) предприятия и фактическими капитальными вложениями Y (млн. руб.) ха-рактеризуется следующими данными. Найти модельное уравнение.
X 1 2 3 4 5 6
Y 1,2 2,6 3,8 4,6 4,9 5,4
Вариант № 21. Результаты изучения зависимости между среднемесячной производительностью X (руб.) труда рабочего и себестоимостью Y (руб.) од-ной тонны продукции приведены в следующей таблице. Найти модельное уравнение.
X 21 24 30 34 35 36 39 40
Y 20 13 12 13 11 10 11 10

125
Вариант № 22. Энерговооруженность X (тыс. кВт-час) труда на одного ра-бочего и производительность Y (тыс. штук изделий) труда одного рабочего на ряде предприятий характеризуется следующими данными. Найти мо-дельное уравнение.
X 3 3,05 3,6 4,25 4,45 4,55
Y 1 1,5 1,8 2,5 3 4
Вариант № 23. Зависимость между стоимостью X (млн. руб.) основных средств предприятий и месячным выпуском Y (тыс. руб.) продукции харак-теризуется следующими данными. Найти модельное уравнение.
X 1 2 3 4 5 6 7
Y 10 12 28 40 42 52 54
Вариант № 24. Зависимость между капитальными вложениями Y (млн. руб.) и мощностью X (млн. тонн продукции) предприятий данного типа задана таблицей. Найти модельное уравнение.
X 1 2 3 4 5 6
Y 0,9 2,59 3,67 4,45 4,95 5,20 Вариант № 25. Распределение однотипных предприятий по объему X произ-веденной за день продукции и себестоимости Y единицы продукции в услов-ных единицах приведено в таблице. Найти модельное уравнение.
X 50 100 150 200 250 300
Y 140 120 118 110 115 100
Варианты заданий к лабораторной работе № 5.
Вариант № 1. Прогнозные показатели разработки по нефти на одном из ме-сторождений Тюменской области, — характеризующие зависимость сред-него дебита Y действующих скважин по нефти, от фонда 1X действующих нагнетательных скважин на конец года, средней приемистости 2X нагнета-тельных скважин и фонда 3X механизированных скважин на конец года,— приведены в таблице.
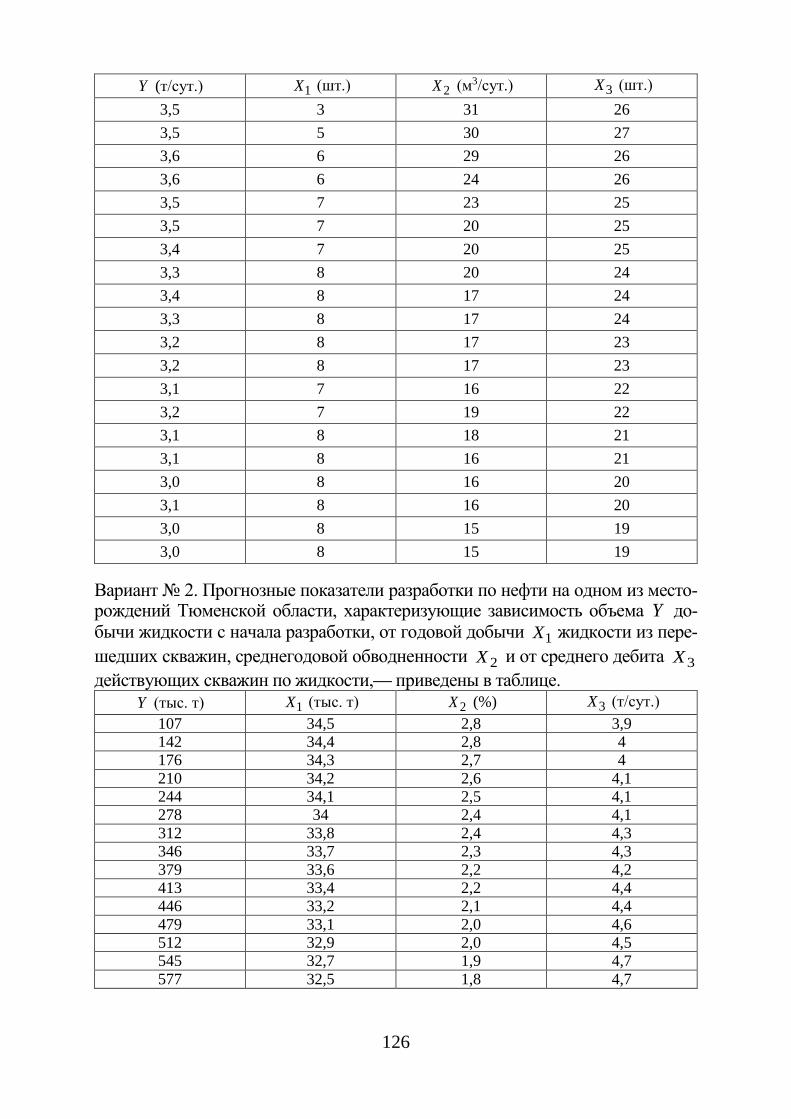
126
Y (т/сут.) 1X (шт.) 2X (м3/сут.) 3X (шт.) 3,5 3 31 26 3,5 5 30 27 3,6 6 29 26 3,6 6 24 26 3,5 7 23 25 3,5 7 20 25 3,4 7 20 25 3,3 8 20 24 3,4 8 17 24 3,3 8 17 24 3,2 8 17 23 3,2 8 17 23 3,1 7 16 22 3,2 7 19 22 3,1 8 18 21 3,1 8 16 21 3,0 8 16 20 3,1 8 16 20 3,0 8 15 19 3,0 8 15 19
Вариант № 2. Прогнозные показатели разработки по нефти на одном из место-рождений Тюменской области, характеризующие зависимость объема Y до-бычи жидкости с начала разработки, от годовой добычи 1X жидкости из пере-шедших скважин, среднегодовой обводненности 2X и от среднего дебита 3X действующих скважин по жидкости,— приведены в таблице.
Y (тыс. т) 1X (тыс. т) 2X (%) 3X (т/сут.) 107 34,5 2,8 3,9 142 34,4 2,8 4 176 34,3 2,7 4 210 34,2 2,6 4,1 244 34,1 2,5 4,1 278 34 2,4 4,1 312 33,8 2,4 4,3 346 33,7 2,3 4,3 379 33,6 2,2 4,2 413 33,4 2,2 4,4 446 33,2 2,1 4,4 479 33,1 2,0 4,6 512 32,9 2,0 4,5 545 32,7 1,9 4,7 577 32,5 1,8 4,7

127
Вариант № 3. Прогнозные показатели разработки по нефти на одном из ме-сторождений Тюменской области, характеризующие зависимость добычи Y нефти с начала разработки от суммарной добычи нефти из скважин предыдущего года, падения 2X добычи нефти и фонда 3X добывающих скважин на конец года,— приведены в таблице.
(тыс.т) (тыс.т) (тыс.т) (шт.) 100,5 30,4 -0,5 27 102 33 -0,9 26
133,1 32,1 -1 26 163,1 31,1 -0,9 25 192,6 30,2 -0,9 25 220,9 29,3 -0,9 25 248,5 28,4 -0,9 24 275,1 27,5 -0,8 24 301 26,7 -0,8 23
326,1 25,9 -0,8 23 350,4 25,1 -0,7 22 374 24,3 -0,7 21
379,5 23,6 -0,6 20
Вариант № 4. Прогнозные показатели разработки по нефти на одном из ме-сторождений Тюменской области, характеризующие зависимость добычи
нефти с начала разработки от суммарной добычи нефти из скважин предыдущего года, падение добычи нефти и коэффициента нефте-извлечения,— приведены в таблице.
(тыс.т) (тыс. т) (тыс.т) (%) 286 22 -0,7 0,9 360 22,7 -0,9 1,2 86,9 31,7 -0,9 1,9 117,3 31,2 -0,8 2,5 147,1 30,5 -0,8 3,2 176,1 29,7 -0,8 3,8 204,5 29 -0,7 4,4 232,2 28,4 -0,7 5,0 259,2 27,7 -0,6 5,6 285,6 26,4 -0,6 6,2 311,4 25,8 -0,6 6,7 336,6 25,2 -0,5 7,3 361,2 24,6 -0,5 7,8 385,3 24 -0,5 8,3 408,7 23,5 -0,5 8,8
1X
Y 1X 2X 3X
Y 1X2X 3X
Y 1X 2X 3X
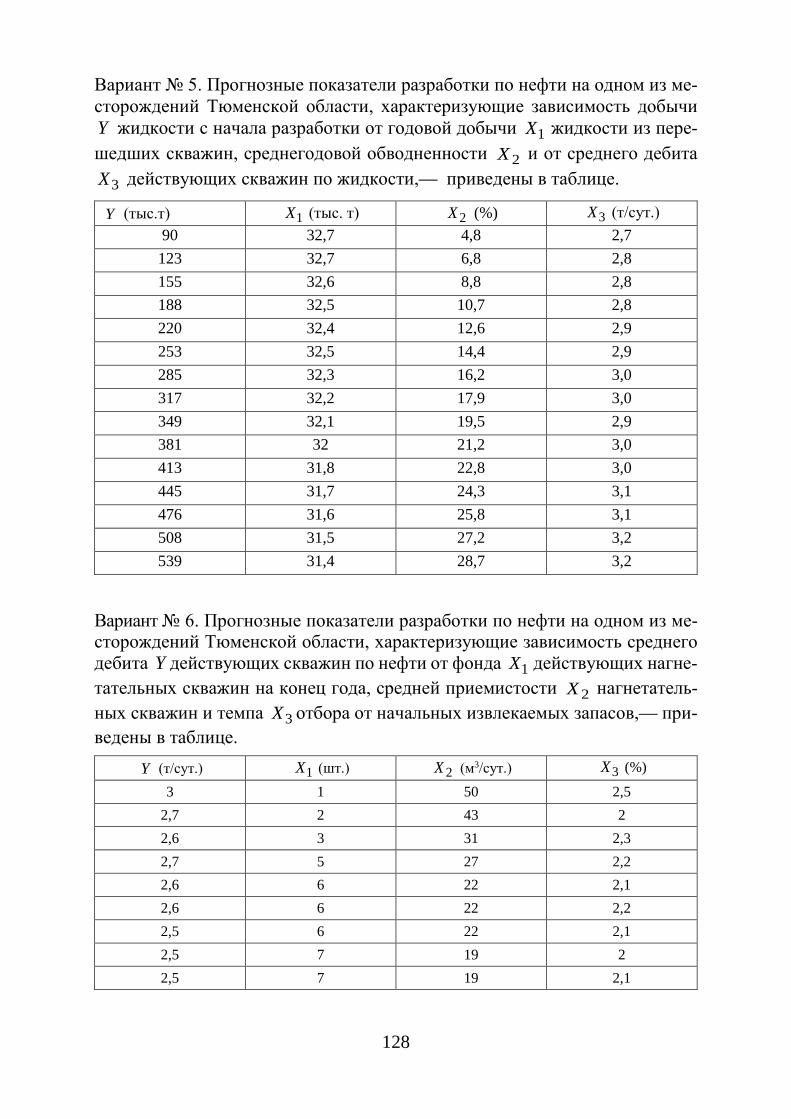
128
Вариант № 5. Прогнозные показатели разработки по нефти на одном из ме-сторождений Тюменской области, характеризующие зависимость добычи
жидкости с начала разработки от годовой добычи жидкости из пере-шедших скважин, среднегодовой обводненности 2X и от среднего дебита
действующих скважин по жидкости,— приведены в таблице.
(тыс.т) (тыс. т) (%) (т/сут.) 90 32,7 4,8 2,7 123 32,7 6,8 2,8 155 32,6 8,8 2,8 188 32,5 10,7 2,8 220 32,4 12,6 2,9 253 32,5 14,4 2,9 285 32,3 16,2 3,0 317 32,2 17,9 3,0 349 32,1 19,5 2,9 381 32 21,2 3,0 413 31,8 22,8 3,0 445 31,7 24,3 3,1 476 31,6 25,8 3,1 508 31,5 27,2 3,2 539 31,4 28,7 3,2
Вариант № 6. Прогнозные показатели разработки по нефти на одном из ме-сторождений Тюменской области, характеризующие зависимость среднего дебита действующих скважин по нефти от фонда действующих нагне-тательных скважин на конец года, средней приемистости 2X нагнетатель-ных скважин и темпа отбора от начальных извлекаемых запасов,— при-ведены в таблице.
(т/сут.) (шт.) (м3/сут.) (%)
3 1 50 2,5 2,7 2 43 2 2,6 3 31 2,3 2,7 5 27 2,2 2,6 6 22 2,1 2,6 6 22 2,2 2,5 6 22 2,1 2,5 7 19 2 2,5 7 19 2,1
Y 1X
3X
Y 1X 2X 3X
Y 1X
3X
Y 1X 2X 3X
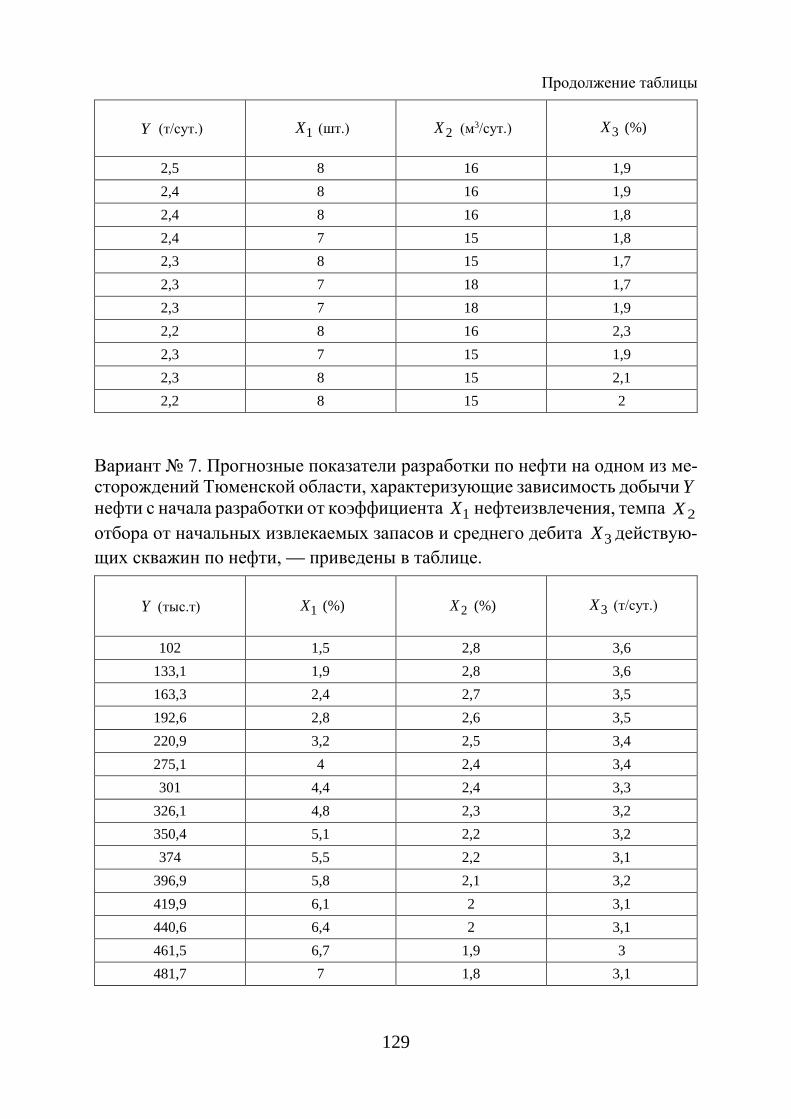
129
Продолжение таблицы
(т/сут.) (шт.) (м3/сут.) (%)
2,5 8 16 1,9 2,4 8 16 1,9 2,4 8 16 1,8 2,4 7 15 1,8 2,3 8 15 1,7 2,3 7 18 1,7 2,3 7 18 1,9 2,2 8 16 2,3 2,3 7 15 1,9 2,3 8 15 2,1 2,2 8 15 2
Вариант № 7. Прогнозные показатели разработки по нефти на одном из ме-сторождений Тюменской области, характеризующие зависимость добычинефти с начала разработки от коэффициента нефтеизвлечения, темпа 2X отбора от начальных извлекаемых запасов и среднего дебита действую-щих скважин по нефти, — приведены в таблице.
Y (тыс.т) 1X (%) 2X (%) 3X (т/сут.)
102 1,5 2,8 3,6 133,1 1,9 2,8 3,6 163,3 2,4 2,7 3,5 192,6 2,8 2,6 3,5 220,9 3,2 2,5 3,4 275,1 4 2,4 3,4 301 4,4 2,4 3,3
326,1 4,8 2,3 3,2 350,4 5,1 2,2 3,2 374 5,5 2,2 3,1
396,9 5,8 2,1 3,2 419,9 6,1 2 3,1 440,6 6,4 2 3,1 461,5 6,7 1,9 3 481,7 7 1,8 3,1
Y 1X 2X 3X
Y1X
3X
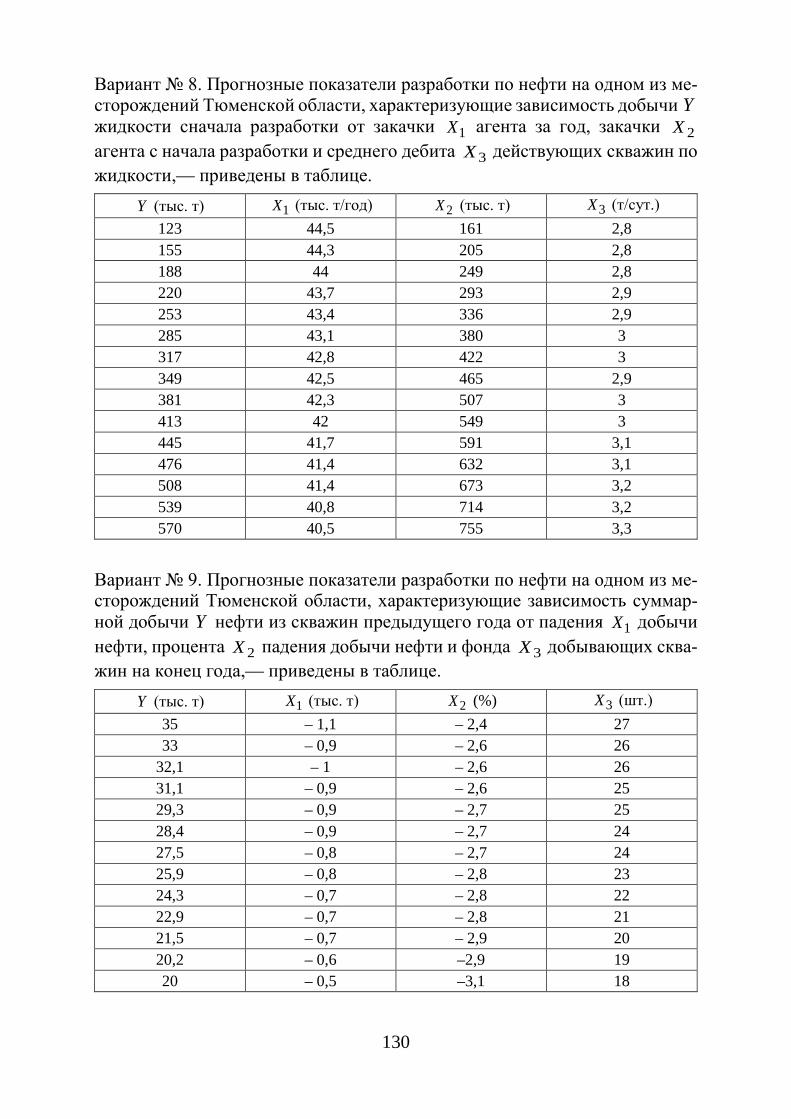
130
Вариант № 8. Прогнозные показатели разработки по нефти на одном из ме-сторождений Тюменской области, характеризующие зависимость добычи Y жидкости сначала разработки от закачки 1X агента за год, закачки 2X агента с начала разработки и среднего дебита 3X действующих скважин по жидкости,— приведены в таблице.
Y (тыс. т) 1X (тыс. т/год) 2X (тыс. т) 3X (т/сут.) 123 44,5 161 2,8 155 44,3 205 2,8 188 44 249 2,8 220 43,7 293 2,9 253 43,4 336 2,9 285 43,1 380 3 317 42,8 422 3 349 42,5 465 2,9 381 42,3 507 3 413 42 549 3 445 41,7 591 3,1 476 41,4 632 3,1 508 41,4 673 3,2 539 40,8 714 3,2 570 40,5 755 3,3
Вариант № 9. Прогнозные показатели разработки по нефти на одном из ме-сторождений Тюменской области, характеризующие зависимость суммар-ной добычи Y нефти из скважин предыдущего года от падения 1X добычи нефти, процента 2X падения добычи нефти и фонда 3X добывающих сква-жин на конец года,— приведены в таблице.
Y (тыс. т) 1X (тыс. т) 2X (%) 3X (шт.) 35 – 1,1 – 2,4 27 33 – 0,9 – 2,6 26
32,1 – 1 – 2,6 26 31,1 – 0,9 – 2,6 25 29,3 – 0,9 – 2,7 25 28,4 – 0,9 – 2,7 24 27,5 – 0,8 – 2,7 24 25,9 – 0,8 – 2,8 23 24,3 – 0,7 – 2,8 22 22,9 – 0,7 – 2,8 21 21,5 – 0,7 – 2,9 20 20,2 – 0,6 –2,9 19 20 – 0,5 –3,1 18
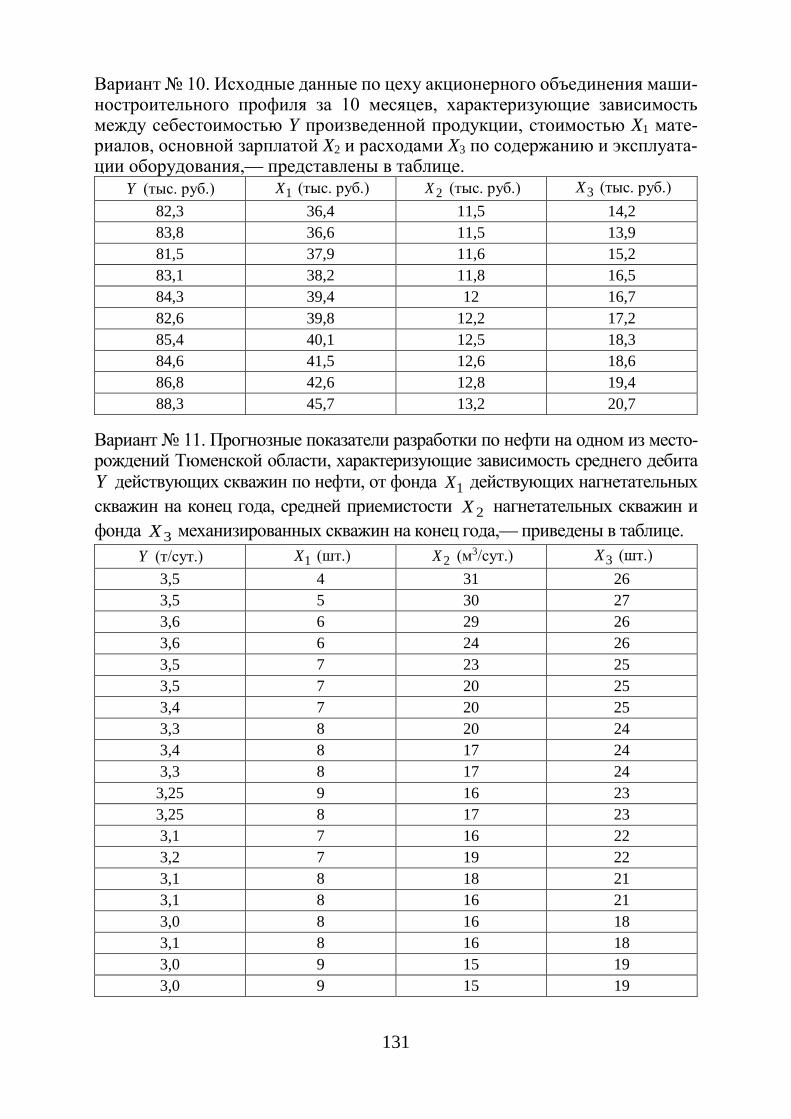
131
Вариант № 10. Исходные данные по цеху акционерного объединения маши-ностроительного профиля за 10 месяцев, характеризующие зависимость между себестоимостью Y произведенной продукции, стоимостью X1 мате-риалов, основной зарплатой X2 и расходами X3 по содержанию и эксплуата-ции оборудования,— представлены в таблице.
Y (тыс. руб.) 1X (тыс. руб.) 2X (тыс. руб.) 3X (тыс. руб.) 82,3 36,4 11,5 14,2 83,8 36,6 11,5 13,9 81,5 37,9 11,6 15,2 83,1 38,2 11,8 16,5 84,3 39,4 12 16,7 82,6 39,8 12,2 17,2 85,4 40,1 12,5 18,3 84,6 41,5 12,6 18,6 86,8 42,6 12,8 19,4 88,3 45,7 13,2 20,7
Вариант № 11. Прогнозные показатели разработки по нефти на одном из место-рождений Тюменской области, характеризующие зависимость среднего дебита Y действующих скважин по нефти, от фонда 1X действующих нагнетательных скважин на конец года, средней приемистости 2X нагнетательных скважин и фонда 3X механизированных скважин на конец года,— приведены в таблице.
Y (т/сут.) 1X (шт.) 2X (м3/сут.) 3X (шт.) 3,5 4 31 26 3,5 5 30 27 3,6 6 29 26 3,6 6 24 26 3,5 7 23 25 3,5 7 20 25 3,4 7 20 25 3,3 8 20 24 3,4 8 17 24 3,3 8 17 24 3,25 9 16 23 3,25 8 17 23 3,1 7 16 22 3,2 7 19 22 3,1 8 18 21 3,1 8 16 21 3,0 8 16 18 3,1 8 16 18 3,0 9 15 19 3,0 9 15 19
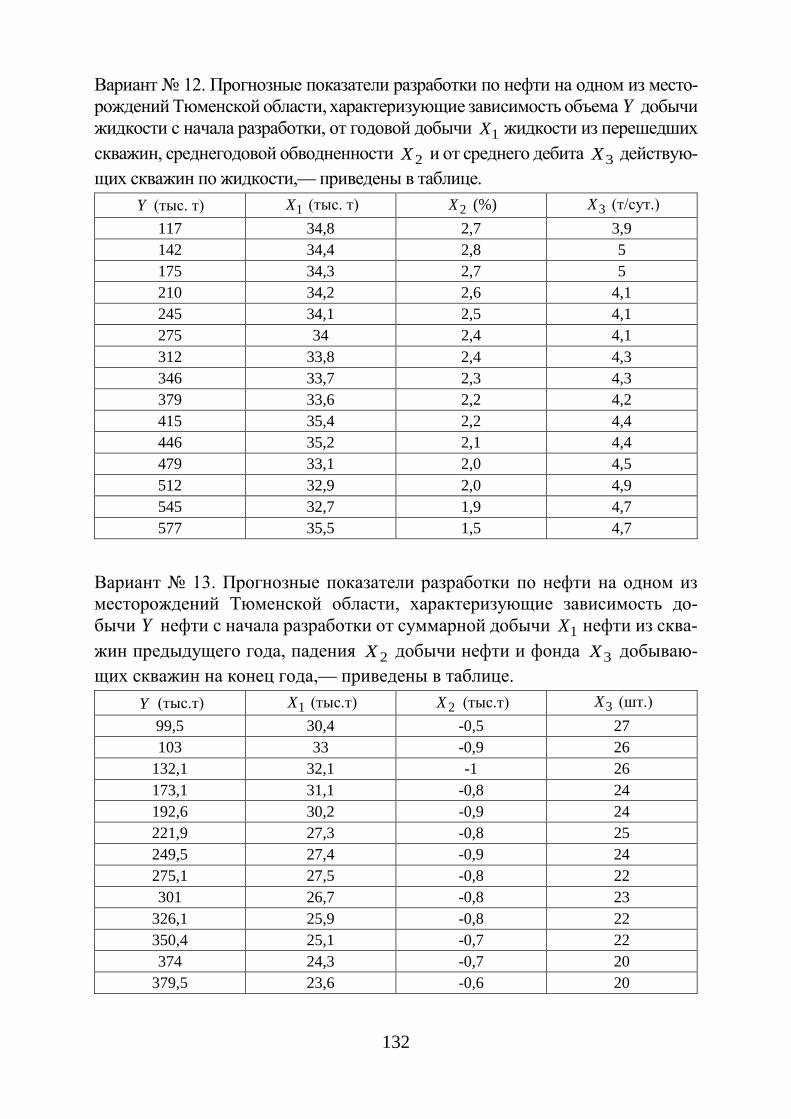
132
Вариант № 12. Прогнозные показатели разработки по нефти на одном из место-рождений Тюменской области, характеризующие зависимость объема Y добычи жидкости с начала разработки, от годовой добычи 1X жидкости из перешедших скважин, среднегодовой обводненности 2X и от среднего дебита 3X действую-щих скважин по жидкости,— приведены в таблице.
Y (тыс. т) 1X (тыс. т) 2X (%) 3X (т/сут.) 117 34,8 2,7 3,9 142 34,4 2,8 5 175 34,3 2,7 5 210 34,2 2,6 4,1 245 34,1 2,5 4,1 275 34 2,4 4,1 312 33,8 2,4 4,3 346 33,7 2,3 4,3 379 33,6 2,2 4,2 415 35,4 2,2 4,4 446 35,2 2,1 4,4 479 33,1 2,0 4,5 512 32,9 2,0 4,9 545 32,7 1,9 4,7 577 35,5 1,5 4,7
Вариант № 13. Прогнозные показатели разработки по нефти на одном из месторождений Тюменской области, характеризующие зависимость до-бычи Y нефти с начала разработки от суммарной добычи нефти из сква-жин предыдущего года, падения 2X добычи нефти и фонда 3X добываю-щих скважин на конец года,— приведены в таблице.
(тыс.т) (тыс.т) (тыс.т) (шт.) 99,5 30,4 -0,5 27 103 33 -0,9 26
132,1 32,1 -1 26 173,1 31,1 -0,8 24 192,6 30,2 -0,9 24 221,9 27,3 -0,8 25 249,5 27,4 -0,9 24 275,1 27,5 -0,8 22 301 26,7 -0,8 23
326,1 25,9 -0,8 22 350,4 25,1 -0,7 22 374 24,3 -0,7 20
379,5 23,6 -0,6 20
1X
Y 1X 2X 3X
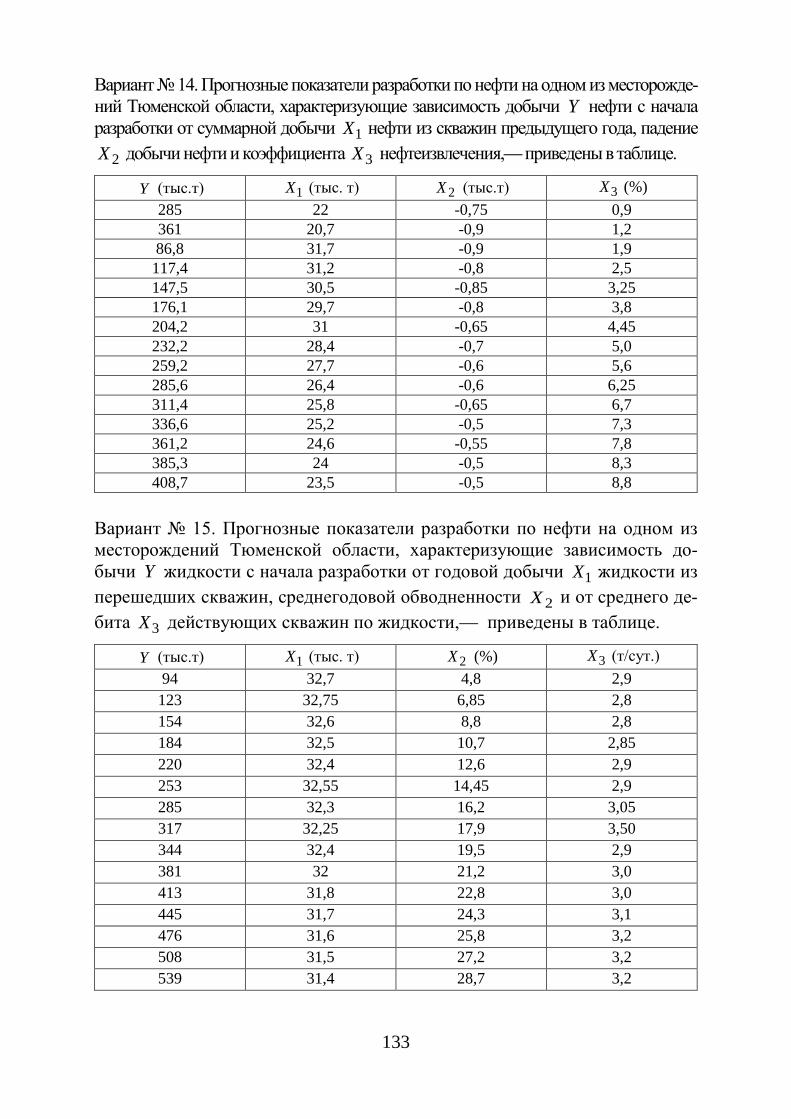
133
Вариант № 14. Прогнозные показатели разработки по нефти на одном из месторожде-ний Тюменской области, характеризующие зависимость добычи нефти с начала разработки от суммарной добычи нефти из скважин предыдущего года, падение
добычи нефти и коэффициента нефтеизвлечения,— приведены в таблице.
(тыс.т) (тыс. т) (тыс.т) (%) 285 22 -0,75 0,9 361 20,7 -0,9 1,2 86,8 31,7 -0,9 1,9 117,4 31,2 -0,8 2,5 147,5 30,5 -0,85 3,25 176,1 29,7 -0,8 3,8 204,2 31 -0,65 4,45 232,2 28,4 -0,7 5,0 259,2 27,7 -0,6 5,6 285,6 26,4 -0,6 6,25 311,4 25,8 -0,65 6,7 336,6 25,2 -0,5 7,3 361,2 24,6 -0,55 7,8 385,3 24 -0,5 8,3 408,7 23,5 -0,5 8,8
Вариант № 15. Прогнозные показатели разработки по нефти на одном из месторождений Тюменской области, характеризующие зависимость до-бычи жидкости с начала разработки от годовой добычи жидкости из перешедших скважин, среднегодовой обводненности 2X и от среднего де-бита действующих скважин по жидкости,— приведены в таблице.
(тыс.т) (тыс. т) (%) (т/сут.) 94 32,7 4,8 2,9 123 32,75 6,85 2,8 154 32,6 8,8 2,8 184 32,5 10,7 2,85 220 32,4 12,6 2,9 253 32,55 14,45 2,9 285 32,3 16,2 3,05 317 32,25 17,9 3,50 344 32,4 19,5 2,9 381 32 21,2 3,0 413 31,8 22,8 3,0 445 31,7 24,3 3,1 476 31,6 25,8 3,2 508 31,5 27,2 3,2 539 31,4 28,7 3,2
Y1X
2X 3X
Y 1X 2X 3X
Y 1X
3X
Y 1X 2X 3X

134
Вариант № 16. Прогнозные показатели разработки по нефти на одном из месторождений Тюменской области, характеризующие зависимость сред-него дебита действующих скважин по нефти от фонда действующих нагнетательных скважин на конец года, средней приемистости 2X нагнета-тельных скважин и темпа отбора от начальных извлекаемых запасов,— приведены в таблице.
(т/сут.) (шт.) (м3/сут.) (%) 3,1 1,5 51 2,52 2,7 2,5 47 2,3 2,6 3,5 31 2,3 2,7 5 27 2,2 2,65 6,5 22,5 2,1 2,6 6 22 2,2 2,5 6 22 2,1 2,5 7 19 2 2,5 7 19 2,1 2,5 8 16 1,9 2,4 8 16 1,9 2,4 8 16 1,8 2,4 7 15 1,8 2,3 8 15 1,7 2,3 7 18,5 1,8 2,3 7 18 1,9 2,2 8 16 2,3 2,3 7 15 1,9 2,3 8 15 2,1 2,2 8 15 2
Вариант № 17. Прогнозные показатели разработки по нефти на одном из месторождений Тюменской области, характеризующие зависимость до-бычи нефти с начала разработки от коэффициента нефтеизвлечения, темпа 2X отбора от начальных извлекаемых запасов и среднего дебита действующих скважин по нефти, — приведены в таблице.
Y (тыс.т) 1X (%) 2X (%) 3X (т/сут.) 106 1,56 2,84 3,66
133,1 1,9 2,8 3,6 163 2,4 2,7 3,5
192,8 2,8 2,6 3,5 220,9 3,2 2,5 3,45 278,1 4 2,45 3,1 305 4,4 2,4 3,32
326,1 4,8 2,3 3,2 350,4 5,1 2,25 3,2 374 5,5 2,2 3,1
396,8 5,85 2,1 3,2 419,9 6,1 2 3,1 440,8 6,45 2 3,1 461,5 6,78 1,9 3 481,7 7 1,8 3,1
Y 1X
3X
Y 1X 2X 3X
Y 1X3X
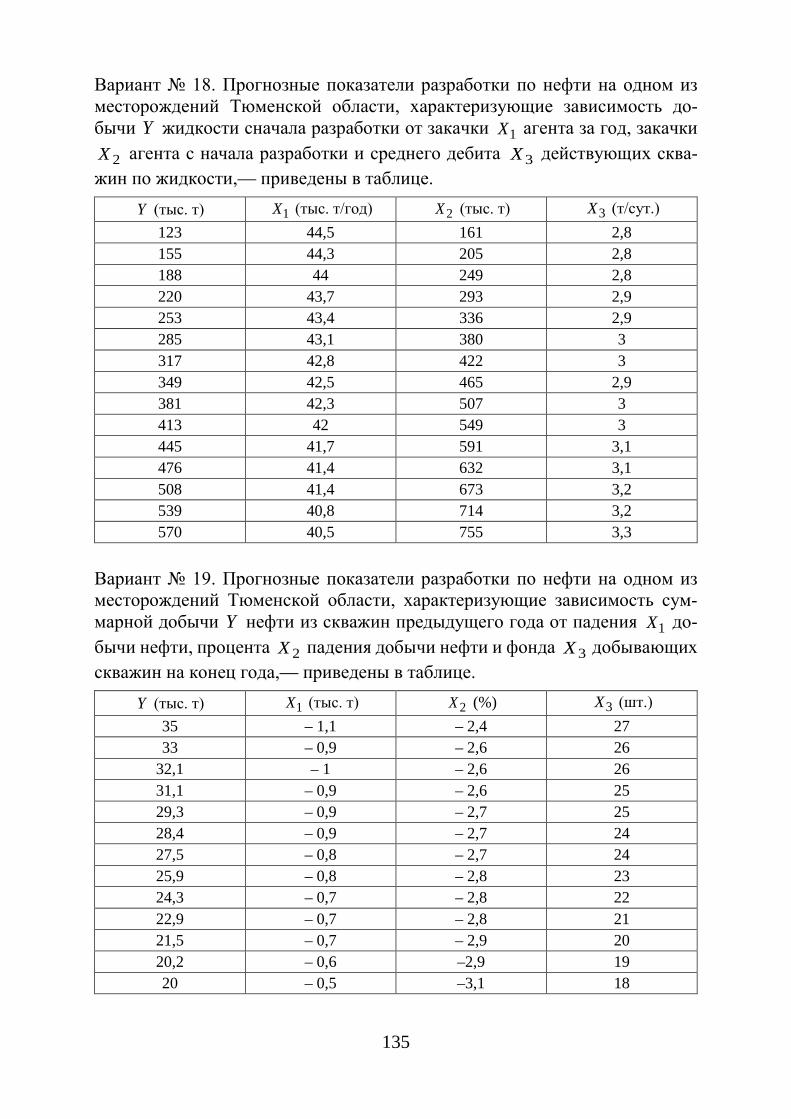
135
Вариант № 18. Прогнозные показатели разработки по нефти на одном из месторождений Тюменской области, характеризующие зависимость до-бычи Y жидкости сначала разработки от закачки 1X агента за год, закачки
2X агента с начала разработки и среднего дебита 3X действующих сква-жин по жидкости,— приведены в таблице.
Y (тыс. т) 1X (тыс. т/год) 2X (тыс. т) 3X (т/сут.) 123 44,5 161 2,8 155 44,3 205 2,8 188 44 249 2,8 220 43,7 293 2,9 253 43,4 336 2,9 285 43,1 380 3 317 42,8 422 3 349 42,5 465 2,9 381 42,3 507 3 413 42 549 3 445 41,7 591 3,1 476 41,4 632 3,1 508 41,4 673 3,2 539 40,8 714 3,2 570 40,5 755 3,3
Вариант № 19. Прогнозные показатели разработки по нефти на одном из месторождений Тюменской области, характеризующие зависимость сум-марной добычи Y нефти из скважин предыдущего года от падения 1X до-бычи нефти, процента 2X падения добычи нефти и фонда 3X добывающих скважин на конец года,— приведены в таблице.
Y (тыс. т) 1X (тыс. т) 2X (%) 3X (шт.) 35 – 1,1 – 2,4 27 33 – 0,9 – 2,6 26
32,1 – 1 – 2,6 26 31,1 – 0,9 – 2,6 25 29,3 – 0,9 – 2,7 25 28,4 – 0,9 – 2,7 24 27,5 – 0,8 – 2,7 24 25,9 – 0,8 – 2,8 23 24,3 – 0,7 – 2,8 22 22,9 – 0,7 – 2,8 21 21,5 – 0,7 – 2,9 20 20,2 – 0,6 –2,9 19 20 – 0,5 –3,1 18
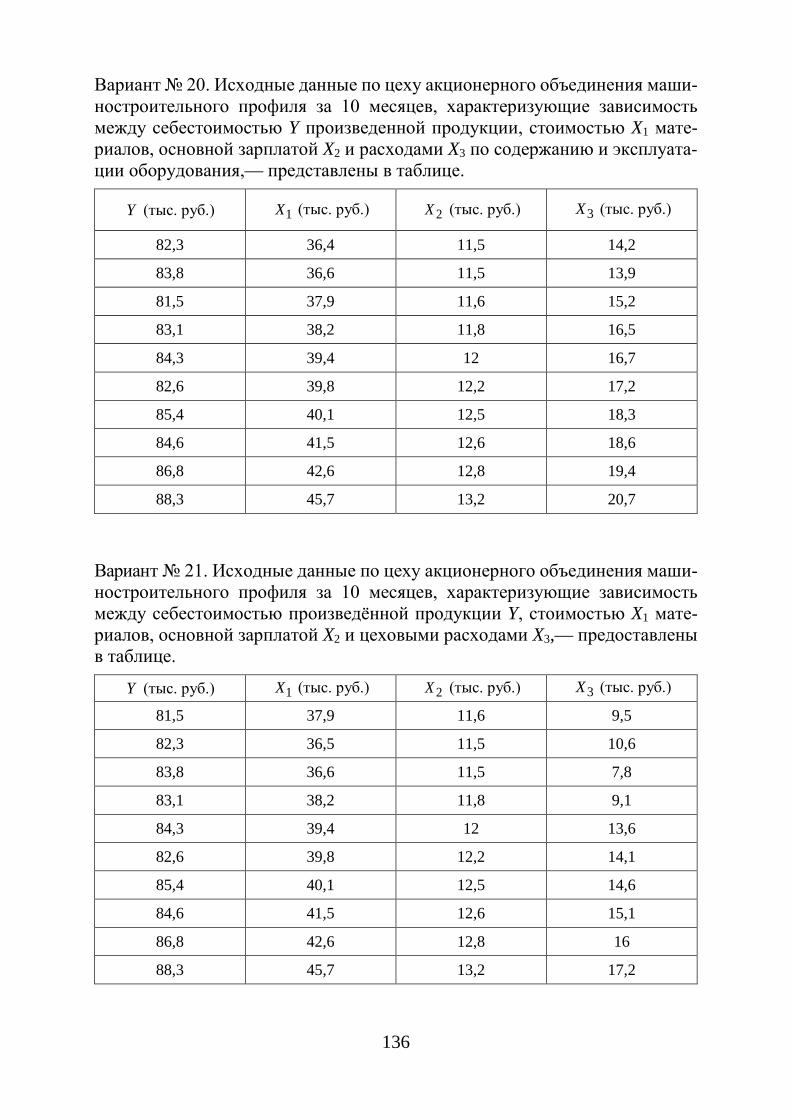
136
Вариант № 20. Исходные данные по цеху акционерного объединения маши-ностроительного профиля за 10 месяцев, характеризующие зависимость между себестоимостью Y произведенной продукции, стоимостью X1 мате-риалов, основной зарплатой X2 и расходами X3 по содержанию и эксплуата-ции оборудования,— представлены в таблице.
Y (тыс. руб.) 1X (тыс. руб.) 2X (тыс. руб.) 3X (тыс. руб.)
82,3 36,4 11,5 14,2
83,8 36,6 11,5 13,9
81,5 37,9 11,6 15,2
83,1 38,2 11,8 16,5
84,3 39,4 12 16,7
82,6 39,8 12,2 17,2
85,4 40,1 12,5 18,3
84,6 41,5 12,6 18,6
86,8 42,6 12,8 19,4
88,3 45,7 13,2 20,7 Вариант № 21. Исходные данные по цеху акционерного объединения маши-ностроительного профиля за 10 месяцев, характеризующие зависимость между себестоимостью произведённой продукции Y, стоимостью X1 мате-риалов, основной зарплатой X2 и цеховыми расходами X3,— предоставлены в таблице.
Y (тыс. руб.) 1X (тыс. руб.) 2X (тыс. руб.) 3X (тыс. руб.)
81,5 37,9 11,6 9,5
82,3 36,5 11,5 10,6
83,8 36,6 11,5 7,8
83,1 38,2 11,8 9,1
84,3 39,4 12 13,6
82,6 39,8 12,2 14,1
85,4 40,1 12,5 14,6
84,6 41,5 12,6 15,1
86,8 42,6 12,8 16
88,3 45,7 13,2 17,2
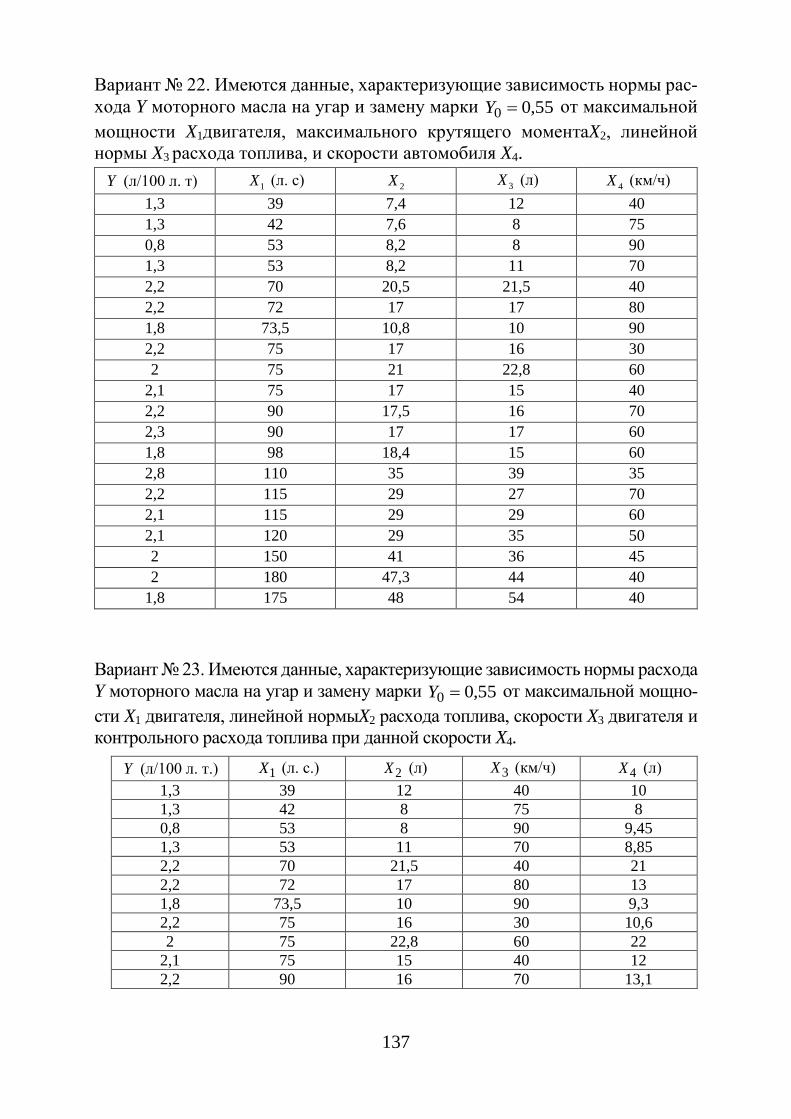
137
Вариант № 22. Имеются данные, характеризующие зависимость нормы рас-хода Y моторного масла на угар и замену марки 55,00 =Y от максимальной мощности X1двигателя, максимального крутящего моментаX2, линейной нормы X3 расхода топлива, и скорости автомобиля X4.
Y (л/100 л. т) 1X (л. с) 2X 3X (л) 4X (км/ч) 1,3 39 7,4 12 40 1,3 42 7,6 8 75 0,8 53 8,2 8 90 1,3 53 8,2 11 70 2,2 70 20,5 21,5 40 2,2 72 17 17 80 1,8 73,5 10,8 10 90 2,2 75 17 16 30 2 75 21 22,8 60
2,1 75 17 15 40 2,2 90 17,5 16 70 2,3 90 17 17 60 1,8 98 18,4 15 60 2,8 110 35 39 35 2,2 115 29 27 70 2,1 115 29 29 60 2,1 120 29 35 50 2 150 41 36 45 2 180 47,3 44 40
1,8 175 48 54 40
Вариант № 23. Имеются данные, характеризующие зависимость нормы расхода Y моторного масла на угар и замену марки 55,00 =Y от максимальной мощно-сти X1 двигателя, линейной нормыX2 расхода топлива, скорости X3 двигателя и контрольного расхода топлива при данной скорости X4.
Y (л/100 л. т.) 1X (л. с.) 2X (л) 3X (км/ч) 4X (л) 1,3 39 12 40 10 1,3 42 8 75 8 0,8 53 8 90 9,45 1,3 53 11 70 8,85 2,2 70 21,5 40 21 2,2 72 17 80 13 1,8 73,5 10 90 9,3 2,2 75 16 30 10,6 2 75 22,8 60 22
2,1 75 15 40 12 2,2 90 16 70 13,1
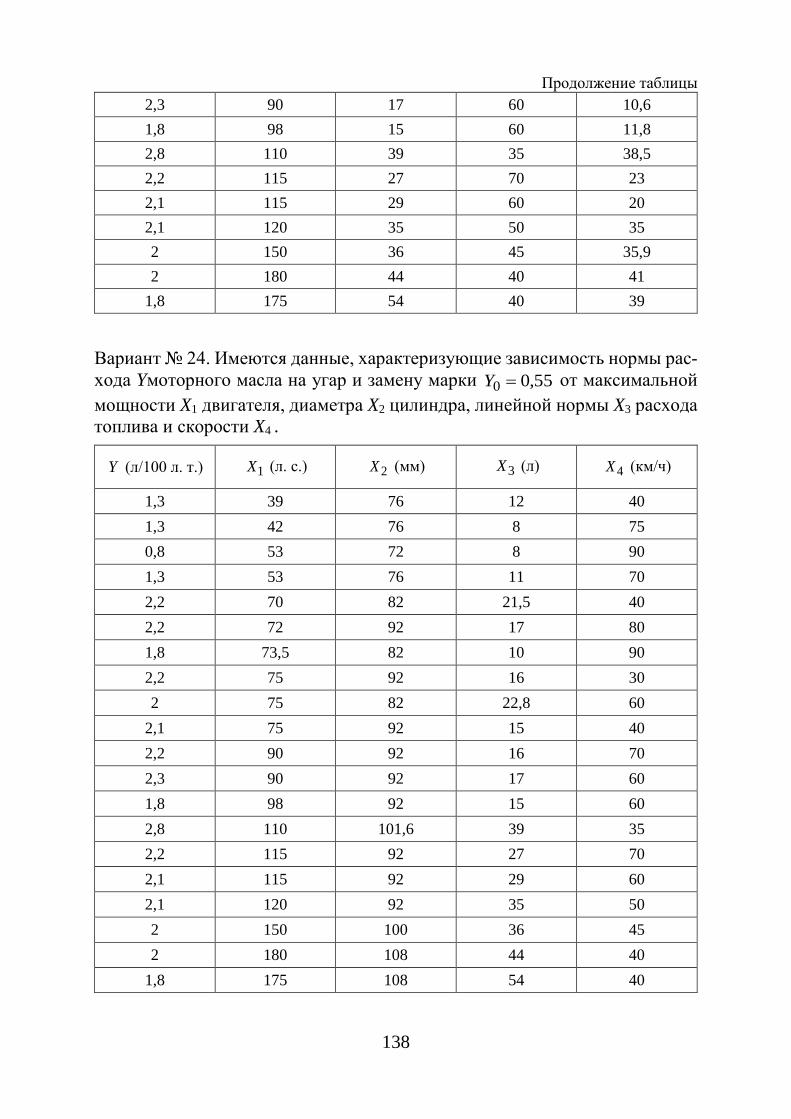
138
Продолжение таблицы 2,3 90 17 60 10,6 1,8 98 15 60 11,8 2,8 110 39 35 38,5 2,2 115 27 70 23 2,1 115 29 60 20 2,1 120 35 50 35 2 150 36 45 35,9 2 180 44 40 41
1,8 175 54 40 39 Вариант № 24. Имеются данные, характеризующие зависимость нормы рас-хода Yмоторного масла на угар и замену марки 55,00 =Y от максимальной мощности X1 двигателя, диаметра X2 цилиндра, линейной нормы X3 расхода топлива и скорости X4 .
Y (л/100 л. т.) 1X (л. с.) 2X (мм) 3X (л) 4X (км/ч)
1,3 39 76 12 40 1,3 42 76 8 75 0,8 53 72 8 90 1,3 53 76 11 70 2,2 70 82 21,5 40 2,2 72 92 17 80 1,8 73,5 82 10 90 2,2 75 92 16 30 2 75 82 22,8 60
2,1 75 92 15 40 2,2 90 92 16 70 2,3 90 92 17 60 1,8 98 92 15 60 2,8 110 101,6 39 35 2,2 115 92 27 70 2,1 115 92 29 60 2,1 120 92 35 50 2 150 100 36 45 2 180 108 44 40
1,8 175 108 54 40
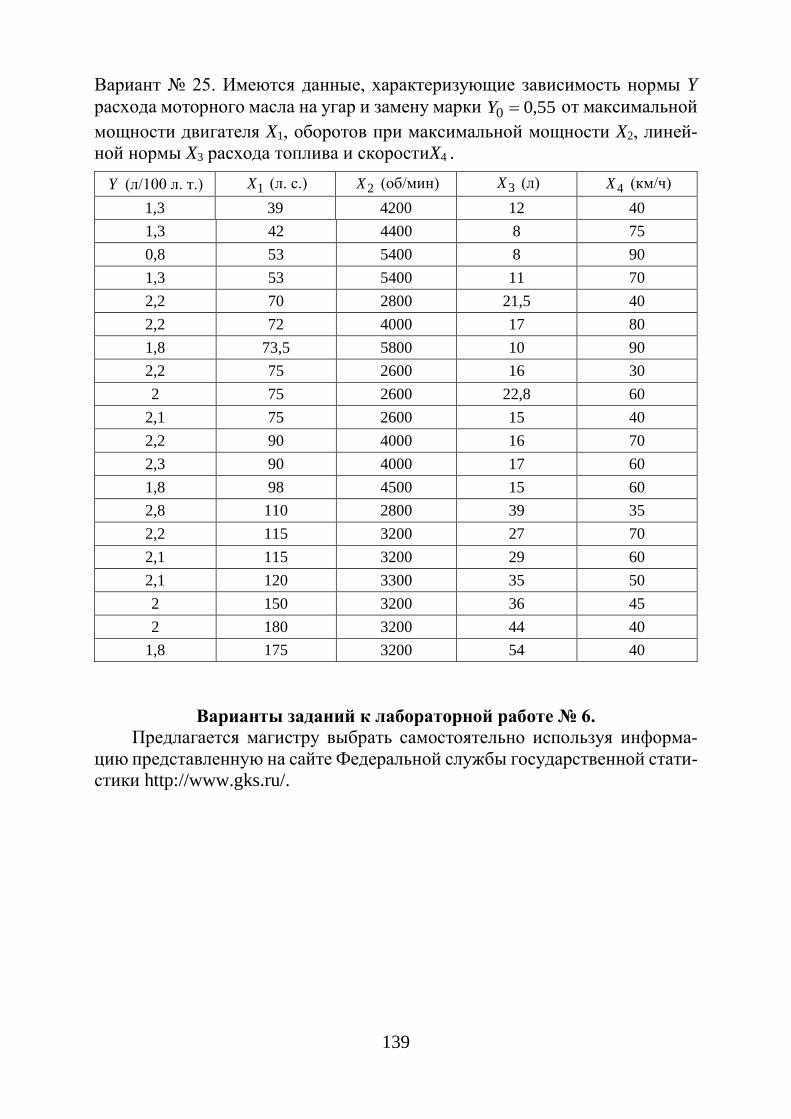
139
Вариант № 25. Имеются данные, характеризующие зависимость нормы Y расхода моторного масла на угар и замену марки 55,00 =Y от максимальной мощности двигателя X1, оборотов при максимальной мощности X2, линей-ной нормы X3 расхода топлива и скоростиX4 .
Y (л/100 л. т.) 1X (л. с.) 2X (об/мин) 3X (л) 4X (км/ч) 1,3 39 4200 12 40 1,3 42 4400 8 75 0,8 53 5400 8 90 1,3 53 5400 11 70 2,2 70 2800 21,5 40 2,2 72 4000 17 80 1,8 73,5 5800 10 90 2,2 75 2600 16 30 2 75 2600 22,8 60
2,1 75 2600 15 40 2,2 90 4000 16 70 2,3 90 4000 17 60 1,8 98 4500 15 60 2,8 110 2800 39 35 2,2 115 3200 27 70 2,1 115 3200 29 60 2,1 120 3300 35 50 2 150 3200 36 45 2 180 3200 44 40
1,8 175 3200 54 40
Варианты заданий к лабораторной работе № 6. Предлагается магистру выбрать самостоятельно используя информа-
цию представленную на сайте Федеральной службы государственной стати-стики http://www.gks.ru/.

140
ТЕСТОВЫЕ ЗАДАНИЯ
1. Статистическая совокупность – это … . a) первичные статистические данные и значения статистических показателей; b) множество любых изучаемых массовых явлений; c) множество однородных хотя бы по одному какому-либо признаку явле-
ний, существование которых ограничено в пространстве и времени; d) система статистических показателей.
2. Статистическое исследование включает: a) группировку и сводку статистических данных; b) статистическое наблюдение, группировку и сводку, построение
таблиц и графиков; c) статистическое наблюдение и отчетность; d) наблюдение, группировку и сводку, обработку и анализ данных.
3. Процесс образования однородных групп на основе разделения статисти-ческой совокупности на части или объединения единиц в частные совокуп-ности по определенным, существенным для них признаками – это:
a) построение вариационного ряда; b) частная закономерность; c) частная совокупность; d) статистическая группировка.
4. Выборочная совокупность отличается от генеральной ... . a) разными единицами измерения наблюдаемых объектов; b) структурой наблюдаемых объектов; c) разным объемом единиц непосредственного наблюдения; d) разным числом зарегистрированных наблюдений.
5. Необходимая численность выборочной совокупности определяется ... . a) колеблемостью признака; b) самостоятельно исследователем; c) программой статистического наблюдения; d) условиями формирования выборочной совокупности.
6. Множество единиц изучаемого явления, объединенных единой качественной основой – это … .
a) дискретный вариационный ряд; b) статистическая совокупность; c) частная совокупность; d) количественная оценка признака.
7. Ряд распределения – это ... . a) совокупность признаков, расположенных в определенном порядке; b) определенное расположение числовых значений отдельно взятой
выборки; c) единицы совокупности, расположенные в порядке возрастания или
убывания значений признака; d) распределение единиц совокупности по одному из признаков.

141
8. Ряды распределения называются вариационными, когда они … . a) построены в порядке возрастания (убывания); b) описывают вариационный признак; c) построены по количественному признаку; d) построены по качественному признаку.
9. Дискретным рядом распределения является ряд, в котором признак, по-ложенный в основание группировки … .
a) атрибутивный; b) дискретный, и число его разновидностей невелико; c) непрерывный или дискретный, но варьирует в широких пределах.
10. Интервальным рядом распределения является ряд, в котором признак, положенный в основание группировки – … .
a) непрерывный или дискретный, но варьирует в широких пределах; b) атрибутивный; c) дискретный, и число его разновидностей невелико.
11. Статистическое распределение можно задать в виде последовательно-сти интервалов и соответствующих им частот. В таком случае статисти-ческий ряд будет называться … .
a) нормальным; b) интервальным; c) дискретным; d) вариативным.
12. Вид наблюдения, при котором из всей изучаемой совокупности слу-чайно, наудачу отбирается определенное число единиц (выборочная сово-купность), для них регистрируются интересующие исследователя при-знаки, на основании которых исчисляются искомые выборочные показа-тели (средние величины, относительные и пр.), распространяемые затем на исходную генеральную совокупность называется … выборочное наблюдение.
a) массовое; b) периодическое; c) несплошное; d) сплошное.
13. Интервал в статистическом анализе – это… . a) разность между верхней и нижней границами значений признака
по одной группе; b) разность между максимальным и минимальным значениями при-
знака по совокупности; c) значение медианы; d) разность между числом частотами соседних групп.
14. Малая выборка - это выборка объемом до ... единиц изучаемой совокуп-ности.

142
a) 50; b) 100; c) 30; d) 4-5.
15. Разница между максимальным и минимальным значением признака – это … . 16. Средняя себестоимость выпускаемой продукции в двух группах пред-приятий одинаковая. В первой группе предприятий индивидуальные уровни себестоимости составляют: 23; 52; 30; 28; 37. Во второй группе: 30; 55; 20; 46; 19. Вариация себестоимости … .
a) одинакова; b) больше в первой группе предприятий; c) сравнить характер вариации себестоимости невозможно; d) больше во второй группе предприятий.
17. Среднее значение признака в двух совокупностях одинаково. Вариация признака в этих совокупностях может быть различной.
A. Верно; B. Неверно.
18. Верно ли следующее утверждение: «Размах вариации не отражает от-клонений всех значений признака».
A. Да, только если данные подчиняются нормальному закону распре-деления;
B. Да, только в случае дискретных данных; C. Нет, не верно; D. Да, всегда верно.
19. Ранжирование – это ... . a) расположение всех значений в возрастающем порядке; b) определение интервала изменений значений варьирующего при-
знака; c) распределение значений признака в определенном интервале; d) количественная оценка степени вариации изучаемого признака.
20.Ломаная линия, отрезки, которой соединяют точки (x1;n1), (x2;n2), …, (xk;nk) называется ... .
A. Функция распределения; B. Гистограмма; C. Кумулята; D. Полигон.
21. Гистограмма – это … . a) график зависимости одного признака от другого; b) графический рисунок процесса измерения; c) график дискретного ряда распределения; d) график интервального ряда распределения.
22. Кумулята – это … .

143
a) графическое изображение вариационного ряда в виде кривой сумм;
b) графический рисунок процесса измерения; c) график дискретного ряда распределения; d) графическое изображение интервального ряда распределения.
23. Средние значения признака в двух совокупностях неодинаковы. Вариа-ция признака в этих совокупностях может быть одинаковой.
A. Верно; B. Неверно.
24. Наиболее часто встречающийся вариант ряда – это... . a) мода; b) ассиметрия; c) медиана; d) вариация.
25. Изменение значения признака у отдельных единиц совокупности – это... .
a) ассиметрия; b) мода; c) медиана; d) вариация.
26. О достоверном отличии эмпирических распределений от нормального сви-детельствуют показатели асимметрии и эксцесса в том случае, если они ... .
a) сопоставимы с показателями вариации и выборочного среднего; b) не превышают свою ошибку репрезентативности в 2 раза; c) не превышают по абсолютной величине свою ошибку репрезента-
тивности в 3 и более раза; d) превышают свою ошибку репрезентативности в 3 и более раза.
27. Верно ли, что коэффициент вариации позволяет судить об однородности совокупности:
A. Да, всегда верно; B. Да, только в случае дискретных данных; C. Нет, не верно; D. Да, только если данные подчиняются нормальному закону распре-
деления. 28. Медиана в ряду распределения – это… .
a) значение признака, делящее ряд распределения на две равные ча-сти;
b) наибольшая частота; c) значение признака, встречающееся чаще всего; d) наименьшее значение признака.
29. Для измерения вариации значения признака применяются следующие показатели ... .
a) мода и медиана;

144
b) размах вариации, среднее линейное отклонение и дисперсия; c) темп роста, темп прироста, абсолютный прирост; d) любые средние величины.
30. Медиана в ряду распределения с четным числом вариант ряда равна... . a) полусумме двух вариант, находящихся в центре ряда; b) значению варианты, наиболее часто встречающейся в ряду распределения; c) полусумме двух крайних вариант; d) среднему значению из всех вариант.
31. Показатель дисперсии – это... . a) квадрат среднего отклонения; b) средний квадрат отклонений; c) отклонение среднего квадрата; d) корень из среднего значения показателя.
32. Среднеквадратическое отклонение характеризует ... . a) взаимосвязь данных; b) динамику данных; c) вариацию данных; d) разброс данных.
33. Среднее квадратическое отклонение исчисляется как ... . a) корень квадратный из медианы; b) корень квадратный из коэффициента вариации; c) квадратом среднего значения; d) корень квадратный из дисперсии.
34. Отношение, устанавливающее связь между возможными значениями случайной величины и вероятностями, с которыми принимаются эти значения – это ... .
a) ряд распределения; b) критерий согласованности; c) статистическая гипотеза; d) закон распределения.
35. Уровень значимости определяет: a) значение Kкр; b) тип критической области; c) формулировку конкурирующей гипотезы; d) формулировку нулевой гипотезы.
36. … распределение вероятностей может быть как дискретным, так и не-прерывным.
A. Равномерное; B. Нормальное; C. Пуассона; D. Бернулли.
37. Когда ставится вопрос: сколько раз происходит некоторое событие в се-рии из определенного числа независимых наблюдений, выполняемых в оди-наковых условиях, то говорят о распределении … .

145
A. Пуассона; B. Равномерном; C. Нормальном; D. Бернулли.
38. Уровнем значимости α при статистической проверке гипотез, называ-ется вероятность допустить ошибку … .
a) 1 - ого рода, т.е. принять правильную нулевую гипотезу; b) 1 - ого рода, т.е. отвергнуть правильную нулевую гипотезу; c) 2 - ого рода, т.е. отвергнуть правильную нулевую гипотезу; d) 2 - ого рода, т.е. принять неправильную нулевую гипотезу.
39. Проверяемая гипотеза обозначается: A. H0; B. H2; C. H1; D. H3.
40.Если наблюдаемое значение критерия лежит … гипотеза H0 принима-ется.
a) на границе критической области и области принятия гипотезы; b) в области принятия гипотезы; c) в области существования; d) в критической области.
41. Тип (вид) критической области определяется: a) знаком Kнаб b) знаком неравенства в альтернативной гипотезе; c) уровнем значимости α; d) знаком в нулевой гипотезе.
42. Альтернативная (конкурирующая) гипотеза обозначается: A. H0; B. H2; C. H3; D. H1.
43. В каком критерии для проверки статистической гипотезы необходимо вычислить максимум абсолютного значения разности между накопленными частотами и накопленными теоретическими частотами.
A. Хи-квадрат: B. Колмогорова: C. Ястремского: D. Романовского.
44. Статистическая зависимость, при которой каждому значению случайной величины Х ставится в соответствие … , называется корреляционной зави-симостью.
a) числовая характеристика соответствующего распределения случай-ной величины Y;

146
b) корреляционное отношение; c) распределение случайной величины Y; d) определенное значение случайной величины Y.
45. Корреляция характеризующая зависимость результативного и двух или более факторных признаков, включенных в исследование, является … .
a) множественной; b) парной; c) частной.
46. Корреляция характеризующая зависимость между результативным и од-ним факторным признаками при фиксированном значении других фактор-ных признаков, является … .
a) множественной; b) парной; c) частной.
47. … корреляция характеризует связь между результативным и факторным или двумя факторными признаками.
A. Множественная; B. Парная; C. Частная.
48. Парный коэффициент корреляции изменяется в пределах ... . a) от 0 до 1; b) от 0 до + ∞; c) от - ∞ до + ∞; d) от -1 до 1.
49. Если парный коэффициент корреляции между признаками х и у равен 1, это указывает на ... между признаками х и у.
a) наличие нелинейной функциональной связи; b) прямую линейную функциональную связь; c) отрицательную линейную связь; d) отсутствие связи.
50. Если парный коэффициент корреляции между признаками х и у равен 0, это указывает на ... между признаками х и у.
a) прямую линейную функциональную связь; b) отсутствие связи; c) обратную линейную функциональную связь; d) наличие нелинейной функциональной связи.
51. Если парный коэффициент корреляции между признаками х и у равен «-1», это указывает на ... между признаками х и у.
a) прямую линейную функциональную связь; b) наличие нелинейной функциональной связи; c) обратную линейную функциональную связь; d) отсутствие связи.
52. В уравнении регрессии коэффициент а показывает:

147
a) на сколько единиц изменится значение результативного признака при изменении факторного признака на 1 единицу;
b) тесноту связи между факторным и результативным признаками; c) изменение факторного признака; d) на сколько процентов изменится значение результативного признака.
53. Если при равномерном возрастании значений факторного признака сред-ние значения результативного признака неравномерно убывают, то уравне-ние регрессии следует выбирать в виде уравнения … .
a) линейного; b) гиперболы; c) параболы; d) третьей степени.
54. Уравнение регрессии имеет вид: у = 3,8 + 2,5 х. При увеличении х на единицу своего измерения у в среднем (в единицах своего измерения) ... .
a) увеличится на 2,5; b) увеличится на 3,8; c) не изменится; d) увеличится на 0,7.
55. Уравнение регрессии имеет вид: у = 1,7 - 5,1х. При увеличении х на еди-ницу своего измерения у в среднем (в единицах своего измерения) ... .
a) уменьшится на 3,4; b) увеличится на 1,7; c) уменьшится на 5,1; d) не изменится.
56. Коэффициент детерминации показывает ... . 57. При значении коэффициента корреляции равном… связь можно считать умеренной. 58. Показатель дисперсии – это … .
a) средний квадрат отклонений; b) отклонение среднего квадрата; c) корень из математического ожидания; d) квадрат из дисперсии; e) размах вариации в квадрате; f) квадрат среднего отклонения.
59. Коэффициент детерминации используется для ... . 60. Закон больших чисел утверждает, что ... .
a) для проявления общей закономерности достаточно не менее 100 еди-ниц выборки;
b) чем больше единиц охвачено статистическим наблюдением, тем хуже проявляется общая закономерность;
c) чем больше единиц охвачено статистическим наблюдением, тем лучше проявляется общая закономерность;

148
d) чем меньше единиц охвачено статистическим наблюдением, тем лучше проявляется общая закономерность.
61. … называется корреляционном полем переменных (х,у). A. Таблица, в которой даны значения (Xi+Yi). B. Совокупность точек (Xi,Yi) на координатной плоскости. C. Изображение линий, на которой обозначены точки (Xi,Yi). D. Совокупность точек (Xi/Yi,Yi).
62. … называется множественной корреляцией. A. Совокупность пар (хi ,уi); B. Зависимость результативного признака от двух и более факторных
признаков; C. Зависимость когда одному значению Yiсоответствует множество зна-
чений Xi; D. Криволинейная зависимость между X и Y.
63. Универсальным показателем отражающим тесноту связи между фактор-ным и результативным признаками является … .
a) корреляционное отношение; b) уравнение регрессии; c) остаточная дисперсия результативного признака; d) факторная дисперсия результативного признака.

149
СПИСОК ЛИТЕРАТУРЫ
1. Веричев С. Н. Специальные главы высшей математики : руководство к решению задач по теории вероятностей : учебное пособие / С. Н. Вери-чев, В. И. Икрянников, В. И. Бутырин ; Новосиб. гос. техн. ун-т. - Но-восибирск, 2009. - 98, [1] с. : табл., ил.. – Режим доступа: http://www.ciu.nstu.ru/fulltext/textbooks/2009/verichev.pdf
2. Володин И.Н. Лекции по теории вероятностей и математической стати-стике. - Казань: (Издательство), 2006. - 271с.
3. Геворкян П.С., Потемкин А.В., Эйсымонт И.М. Теория вероятностей и математическая статистика, М.: «Экономика». 2012.
4. Гмурман В. Е. Теория вероятностей и математическая статистика : учебное пособие для вузов / В. Е. Гмурман. - М., 2006. - 478 с. : ил.
5. Губин В. И., Осташков В. Н. Статистические методы обработки экспе-риментальных данных: Учеб. пособие для студентов технических ву-зов. - Тюмень: Изд-во «ТюмГНГУ», 2007. - 202 с.
6. Ефимова М. Р., Петрова Е. В., Румянцев В. Н. Общая теория стати-стики: Учебник. - 2-е изд., доп. и перераб. - М.: Инфра-М, 2010. - 416 с.
7. Калинина В.Н., Панкин В.Ф. Математическая статистика// Учебник, 4-е изд., испр. - М.: Дрофа, 2002. - 336 с
8. Прикладная статистика. Основы эконометрики: Учебник для вузов: В 2-х т. – Т. 1. Айвазян С.А., Мхитарян В.С. Теория вероятностей и при-кладная статистика. – М: ЮНИТИ-ДАНА, 2001. – 656 с.
9. Прикладная статистика. Основы эконометрики: Учебник для вузов: В 2-х т. – Т. 2. Айвазян С.А. Основы эконометрики. – М: ЮНИТИ-ДАНА, 2001. – 432 с
10. Статистика: учебник / И. И. Елисеева [и др.]; под ред. И. И. Елисеевой. — Москва: Проспект, 2011. — 448 с
11. Статистика. Учеб. пособие. Под ред. В.Г. Ионина. 2-е изд., доп. и пере-раб.- М.: Инфра-М, 2011, 384 с.
12. Теория статистики. Учебник. Под ред. Г. Л. Громыко. — 2-е изд., доп. и перераб. — М.: Инфра-М., 2010. — 476 с.
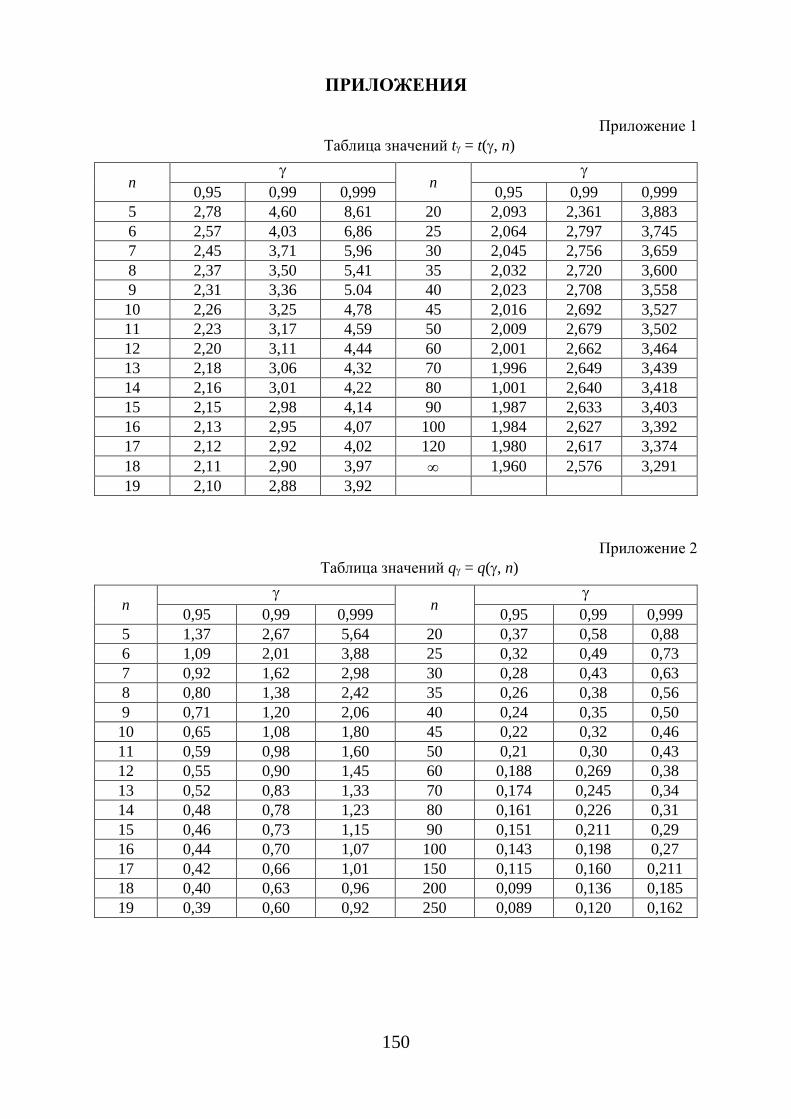
150
ПРИЛОЖЕНИЯ
Приложение 1 Таблица значений tγ = t(γ, n)
n γ
n γ
0,95 0,99 0,999 0,95 0,99 0,999 5 2,78 4,60 8,61 20 2,093 2,361 3,883 6 2,57 4,03 6,86 25 2,064 2,797 3,745 7 2,45 3,71 5,96 30 2,045 2,756 3,659 8 2,37 3,50 5,41 35 2,032 2,720 3,600 9 2,31 3,36 5.04 40 2,023 2,708 3,558 10 2,26 3,25 4,78 45 2,016 2,692 3,527 11 2,23 3,17 4,59 50 2,009 2,679 3,502 12 2,20 3,11 4,44 60 2,001 2,662 3,464 13 2,18 3,06 4,32 70 1,996 2,649 3,439 14 2,16 3,01 4,22 80 1,001 2,640 3,418 15 2,15 2,98 4,14 90 1,987 2,633 3,403 16 2,13 2,95 4,07 100 1,984 2,627 3,392 17 2,12 2,92 4,02 120 1,980 2,617 3,374 18 2,11 2,90 3,97 ∞ 1,960 2,576 3,291 19 2,10 2,88 3,92
Приложение 2 Таблица значений qγ = q(γ, n)
n γ
n γ
0,95 0,99 0,999 0,95 0,99 0,999 5 1,37 2,67 5,64 20 0,37 0,58 0,88 6 1,09 2,01 3,88 25 0,32 0,49 0,73 7 0,92 1,62 2,98 30 0,28 0,43 0,63 8 0,80 1,38 2,42 35 0,26 0,38 0,56 9 0,71 1,20 2,06 40 0,24 0,35 0,50 10 0,65 1,08 1,80 45 0,22 0,32 0,46 11 0,59 0,98 1,60 50 0,21 0,30 0,43 12 0,55 0,90 1,45 60 0,188 0,269 0,38 13 0,52 0,83 1,33 70 0,174 0,245 0,34 14 0,48 0,78 1,23 80 0,161 0,226 0,31 15 0,46 0,73 1,15 90 0,151 0,211 0,29 16 0,44 0,70 1,07 100 0,143 0,198 0,27 17 0,42 0,66 1,01 150 0,115 0,160 0,211 18 0,40 0,63 0,96 200 0,099 0,136 0,185 19 0,39 0,60 0,92 250 0,089 0,120 0,162
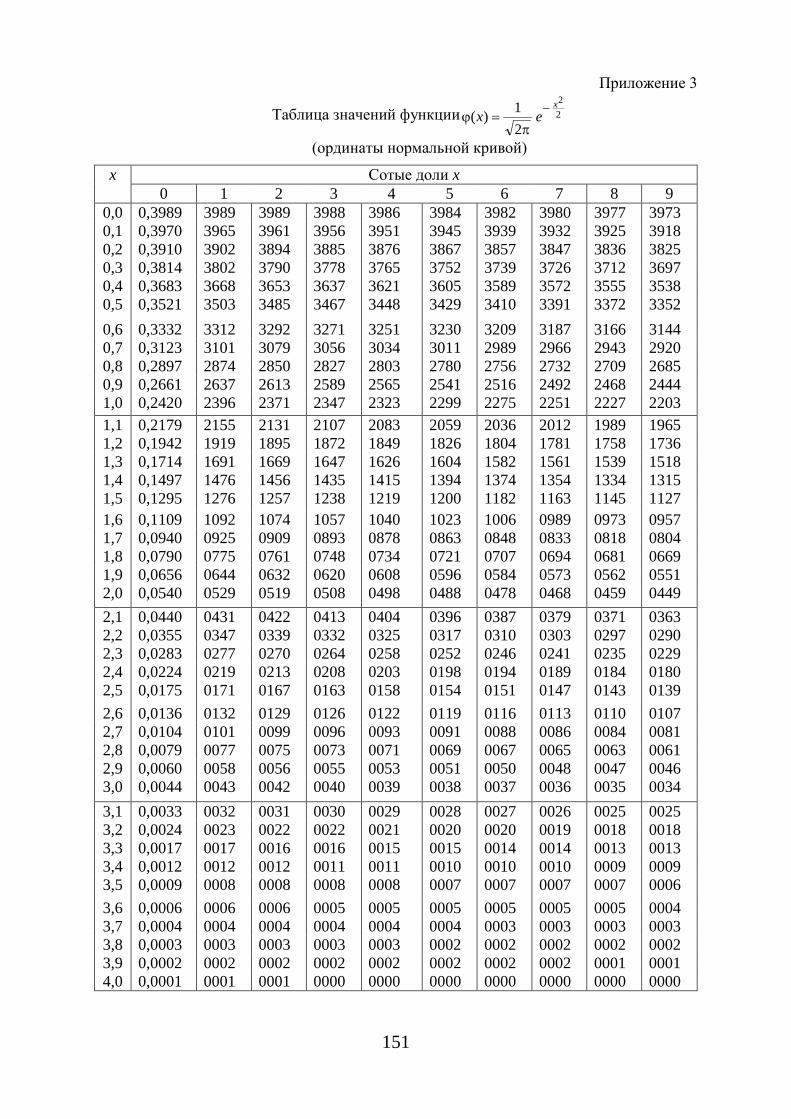
151
Приложение 3
Таблица значений функции 22
21)(
xex −
π=ϕ
(ординаты нормальной кривой)
x Сотые доли x 0 1 2 3 4 5 6 7 8 9
0,0 0,3989 3989 3989 3988 3986 3984 3982 3980 3977 3973 0,1 0,3970 3965 3961 3956 3951 3945 3939 3932 3925 3918 0,2 0,3910 3902 3894 3885 3876 3867 3857 3847 3836 3825 0,3 0,3814 3802 3790 3778 3765 3752 3739 3726 3712 3697 0,4 0,3683 3668 3653 3637 3621 3605 3589 3572 3555 3538 0,5 0,3521 3503 3485 3467 3448 3429 3410 3391 3372 3352 0,6 0,3332 3312 3292 3271 3251 3230 3209 3187 3166 3144 0,7 0,3123 3101 3079 3056 3034 3011 2989 2966 2943 2920 0,8 0,2897 2874 2850 2827 2803 2780 2756 2732 2709 2685 0,9 0,2661 2637 2613 2589 2565 2541 2516 2492 2468 2444 1,0 0,2420 2396 2371 2347 2323 2299 2275 2251 2227 2203 1,1 0,2179 2155 2131 2107 2083 2059 2036 2012 1989 1965 1,2 0,1942 1919 1895 1872 1849 1826 1804 1781 1758 1736 1,3 0,1714 1691 1669 1647 1626 1604 1582 1561 1539 1518 1,4 0,1497 1476 1456 1435 1415 1394 1374 1354 1334 1315 1,5 0,1295 1276 1257 1238 1219 1200 1182 1163 1145 1127 1,6 0,1109 1092 1074 1057 1040 1023 1006 0989 0973 0957 1,7 0,0940 0925 0909 0893 0878 0863 0848 0833 0818 0804 1,8 0,0790 0775 0761 0748 0734 0721 0707 0694 0681 0669 1,9 0,0656 0644 0632 0620 0608 0596 0584 0573 0562 0551 2,0 0,0540 0529 0519 0508 0498 0488 0478 0468 0459 0449 2,1 0,0440 0431 0422 0413 0404 0396 0387 0379 0371 0363 2,2 0,0355 0347 0339 0332 0325 0317 0310 0303 0297 0290 2,3 0,0283 0277 0270 0264 0258 0252 0246 0241 0235 0229 2,4 0,0224 0219 0213 0208 0203 0198 0194 0189 0184 0180 2,5 0,0175 0171 0167 0163 0158 0154 0151 0147 0143 0139 2,6 0,0136 0132 0129 0126 0122 0119 0116 0113 0110 0107 2,7 0,0104 0101 0099 0096 0093 0091 0088 0086 0084 0081 2,8 0,0079 0077 0075 0073 0071 0069 0067 0065 0063 0061 2,9 0,0060 0058 0056 0055 0053 0051 0050 0048 0047 0046 3,0 0,0044 0043 0042 0040 0039 0038 0037 0036 0035 0034 3,1 0,0033 0032 0031 0030 0029 0028 0027 0026 0025 0025 3,2 0,0024 0023 0022 0022 0021 0020 0020 0019 0018 0018 3,3 0,0017 0017 0016 0016 0015 0015 0014 0014 0013 0013 3,4 0,0012 0012 0012 0011 0011 0010 0010 0010 0009 0009 3,5 0,0009 0008 0008 0008 0008 0007 0007 0007 0007 0006 3,6 0,0006 0006 0006 0005 0005 0005 0005 0005 0005 0004 3,7 0,0004 0004 0004 0004 0004 0004 0003 0003 0003 0003 3,8 0,0003 0003 0003 0003 0003 0002 0002 0002 0002 0002 3,9 0,0002 0002 0002 0002 0002 0002 0002 0002 0001 0001 4,0 0,0001 0001 0001 0000 0000 0000 0000 0000 0000 0000
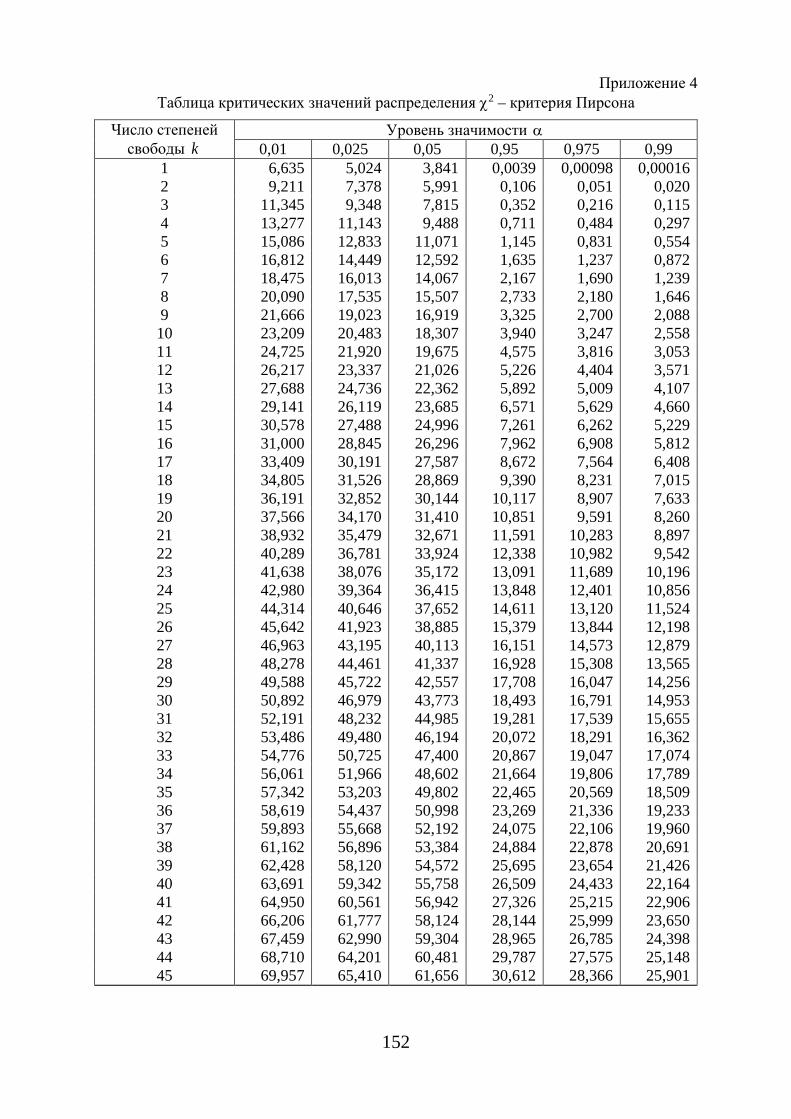
152
Приложение 4 Таблица критических значений распределения χ2 – критерия Пирсона
Число степеней свободы k
Уровень значимости α 0,01 0,025 0,05 0,95 0,975 0,99
1 6,635 5,024 3,841 0,0039 0,00098 0,00016 2 9,211 7,378 5,991 0,106 0,051 0,020 3 11,345 9,348 7,815 0,352 0,216 0,115 4 13,277 11,143 9,488 0,711 0,484 0,297 5 15,086 12,833 11,071 1,145 0,831 0,554 6 16,812 14,449 12,592 1,635 1,237 0,872 7 18,475 16,013 14,067 2,167 1,690 1,239 8 20,090 17,535 15,507 2,733 2,180 1,646 9 21,666 19,023 16,919 3,325 2,700 2,088 10 23,209 20,483 18,307 3,940 3,247 2,558 11 24,725 21,920 19,675 4,575 3,816 3,053 12 26,217 23,337 21,026 5,226 4,404 3,571 13 27,688 24,736 22,362 5,892 5,009 4,107 14 29,141 26,119 23,685 6,571 5,629 4,660 15 30,578 27,488 24,996 7,261 6,262 5,229 16 31,000 28,845 26,296 7,962 6,908 5,812 17 33,409 30,191 27,587 8,672 7,564 6,408 18 34,805 31,526 28,869 9,390 8,231 7,015 19 36,191 32,852 30,144 10,117 8,907 7,633 20 37,566 34,170 31,410 10,851 9,591 8,260 21 38,932 35,479 32,671 11,591 10,283 8,897 22 40,289 36,781 33,924 12,338 10,982 9,542 23 41,638 38,076 35,172 13,091 11,689 10,196 24 42,980 39,364 36,415 13,848 12,401 10,856 25 44,314 40,646 37,652 14,611 13,120 11,524 26 45,642 41,923 38,885 15,379 13,844 12,198 27 46,963 43,195 40,113 16,151 14,573 12,879 28 48,278 44,461 41,337 16,928 15,308 13,565 29 49,588 45,722 42,557 17,708 16,047 14,256 30 50,892 46,979 43,773 18,493 16,791 14,953 31 52,191 48,232 44,985 19,281 17,539 15,655 32 53,486 49,480 46,194 20,072 18,291 16,362 33 54,776 50,725 47,400 20,867 19,047 17,074 34 56,061 51,966 48,602 21,664 19,806 17,789 35 57,342 53,203 49,802 22,465 20,569 18,509 36 58,619 54,437 50,998 23,269 21,336 19,233 37 59,893 55,668 52,192 24,075 22,106 19,960 38 61,162 56,896 53,384 24,884 22,878 20,691 39 62,428 58,120 54,572 25,695 23,654 21,426 40 63,691 59,342 55,758 26,509 24,433 22,164 41 64,950 60,561 56,942 27,326 25,215 22,906 42 66,206 61,777 58,124 28,144 25,999 23,650 43 67,459 62,990 59,304 28,965 26,785 24,398 44 68,710 64,201 60,481 29,787 27,575 25,148 45 69,957 65,410 61,656 30,612 28,366 25,901
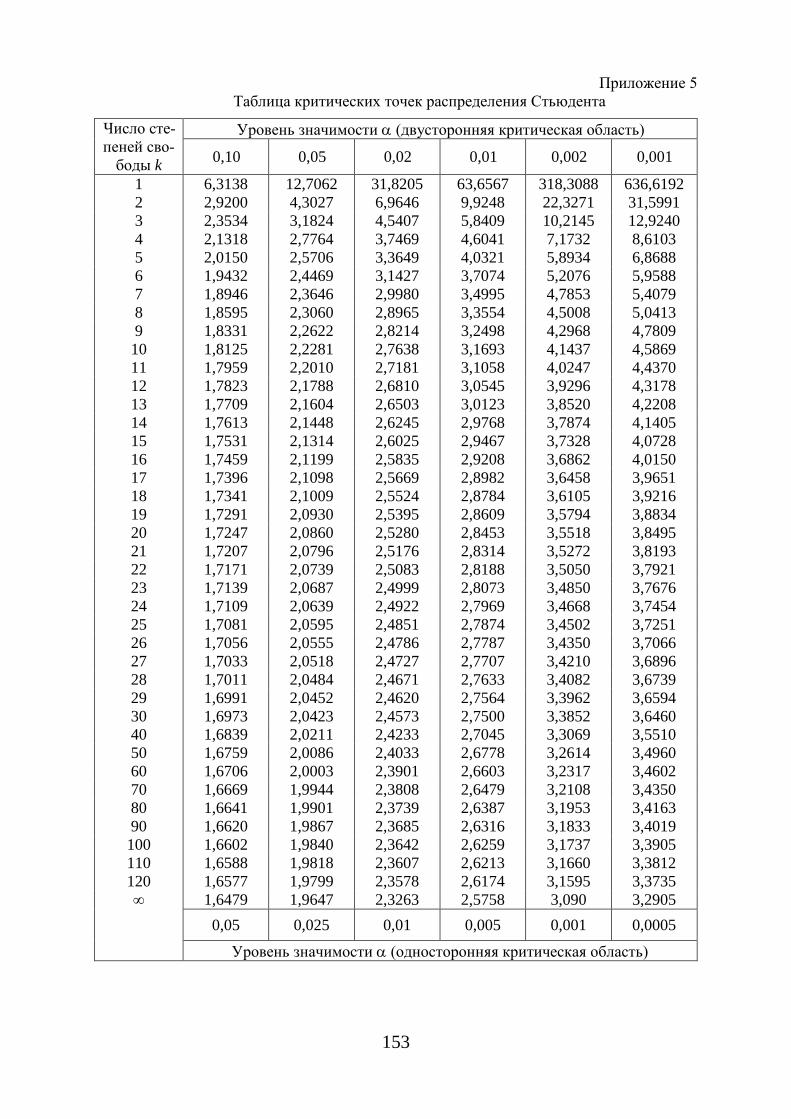
153
Приложение 5 Таблица критических точек распределения Стьюдента
Число сте-пеней сво-
боды k
Уровень значимости α (двусторонняя критическая область)
0,10 0,05 0,02 0,01 0,002 0,001
1 6,3138 12,7062 31,8205 63,6567 318,3088 636,6192 2 2,9200 4,3027 6,9646 9,9248 22,3271 31,5991 3 2,3534 3,1824 4,5407 5,8409 10,2145 12,9240 4 2,1318 2,7764 3,7469 4,6041 7,1732 8,6103 5 2,0150 2,5706 3,3649 4,0321 5,8934 6,8688 6 1,9432 2,4469 3,1427 3,7074 5,2076 5,9588 7 1,8946 2,3646 2,9980 3,4995 4,7853 5,4079 8 1,8595 2,3060 2,8965 3,3554 4,5008 5,0413 9 1,8331 2,2622 2,8214 3,2498 4,2968 4,7809 10 1,8125 2,2281 2,7638 3,1693 4,1437 4,5869 11 1,7959 2,2010 2,7181 3,1058 4,0247 4,4370 12 1,7823 2,1788 2,6810 3,0545 3,9296 4,3178 13 1,7709 2,1604 2,6503 3,0123 3,8520 4,2208 14 1,7613 2,1448 2,6245 2,9768 3,7874 4,1405 15 1,7531 2,1314 2,6025 2,9467 3,7328 4,0728 16 1,7459 2,1199 2,5835 2,9208 3,6862 4,0150 17 1,7396 2,1098 2,5669 2,8982 3,6458 3,9651 18 1,7341 2,1009 2,5524 2,8784 3,6105 3,9216 19 1,7291 2,0930 2,5395 2,8609 3,5794 3,8834 20 1,7247 2,0860 2,5280 2,8453 3,5518 3,8495 21 1,7207 2,0796 2,5176 2,8314 3,5272 3,8193 22 1,7171 2,0739 2,5083 2,8188 3,5050 3,7921 23 1,7139 2,0687 2,4999 2,8073 3,4850 3,7676 24 1,7109 2,0639 2,4922 2,7969 3,4668 3,7454 25 1,7081 2,0595 2,4851 2,7874 3,4502 3,7251 26 1,7056 2,0555 2,4786 2,7787 3,4350 3,7066 27 1,7033 2,0518 2,4727 2,7707 3,4210 3,6896 28 1,7011 2,0484 2,4671 2,7633 3,4082 3,6739 29 1,6991 2,0452 2,4620 2,7564 3,3962 3,6594 30 1,6973 2,0423 2,4573 2,7500 3,3852 3,6460 40 1,6839 2,0211 2,4233 2,7045 3,3069 3,5510 50 1,6759 2,0086 2,4033 2,6778 3,2614 3,4960 60 1,6706 2,0003 2,3901 2,6603 3,2317 3,4602 70 1,6669 1,9944 2,3808 2,6479 3,2108 3,4350 80 1,6641 1,9901 2,3739 2,6387 3,1953 3,4163 90 1,6620 1,9867 2,3685 2,6316 3,1833 3,4019 100 1,6602 1,9840 2,3642 2,6259 3,1737 3,3905 110 1,6588 1,9818 2,3607 2,6213 3,1660 3,3812 120 1,6577 1,9799 2,3578 2,6174 3,1595 3,3735 ∞ 1,6479 1,9647 2,3263 2,5758 3,090 3,2905
0,05 0,025 0,01 0,005 0,001 0,0005 Уровень значимости α (односторонняя критическая область)
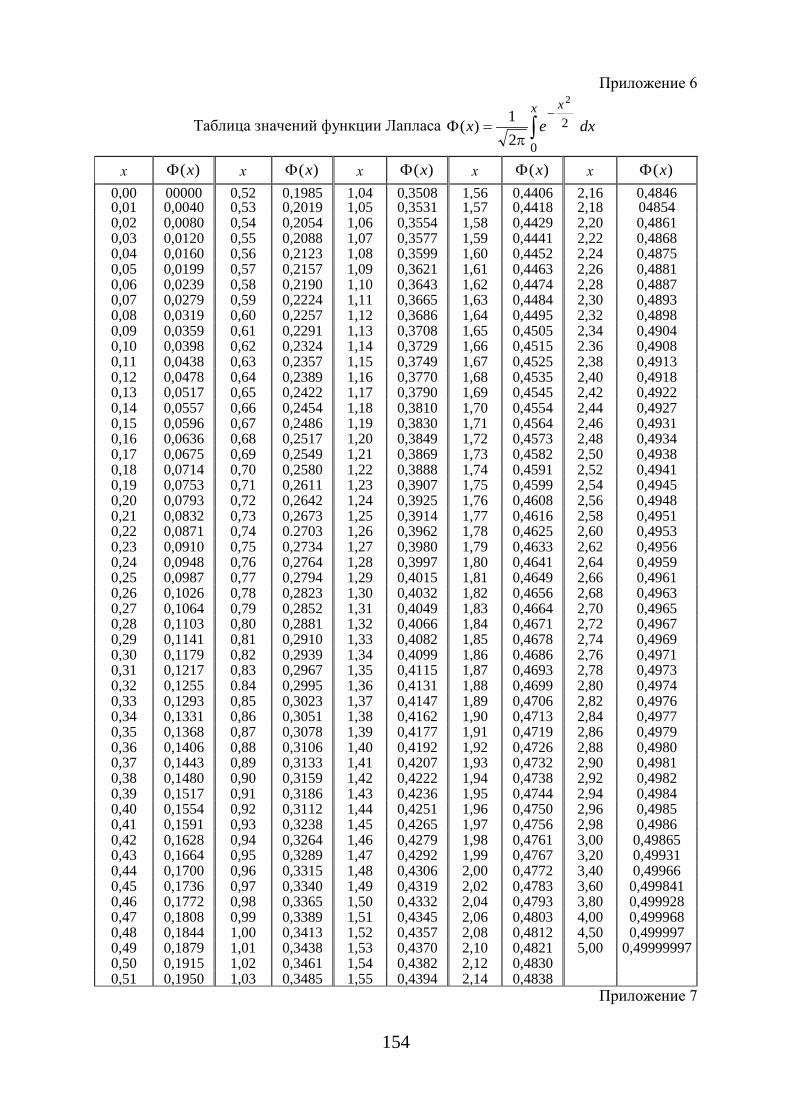
154
Приложение 6
Таблица значений функции Лапласа ∫−
π=Φ
x x
dxex0
2
2
21)(
х )(xΦ х )(xΦ х )(xΦ х )(xΦ х )(xΦ 0,00 00000 0,52 0,1985 1,04 0,3508 1,56 0,4406 2,16 0,4846 0,01 0,0040 0,53 0,2019 1,05 0,3531 1,57 0,4418 2,18 04854 0,02 0,0080 0,54 0,2054 1,06 0,3554 1,58 0,4429 2,20 0,4861 0,03 0,0120 0,55 0,2088 1,07 0,3577 1,59 0,4441 2,22 0,4868 0,04 0,0160 0,56 0,2123 1,08 0,3599 1,60 0,4452 2,24 0,4875 0,05 0,0199 0,57 0,2157 1,09 0,3621 1,61 0,4463 2,26 0,4881 0,06 0,0239 0,58 0,2190 1,10 0,3643 1,62 0,4474 2,28 0,4887 0,07 0,0279 0,59 0,2224 1,11 0,3665 1,63 0,4484 2,30 0,4893 0,08 0,0319 0,60 0,2257 1,12 0,3686 1,64 0,4495 2,32 0,4898 0,09 0,0359 0,61 0,2291 1,13 0,3708 1,65 0,4505 2,34 0,4904 0,10 0,0398 0,62 0,2324 1,14 0,3729 1,66 0,4515 2.36 0,4908 0,11 0,0438 0,63 0,2357 1,15 0,3749 1,67 0,4525 2,38 0,4913 0,12 0,0478 0,64 0,2389 1,16 0,3770 1,68 0,4535 2,40 0,4918 0,13 0,0517 0,65 0,2422 1,17 0,3790 1,69 0,4545 2,42 0,4922 0,14 0,0557 0,66 0,2454 1,18 0,3810 1,70 0,4554 2,44 0,4927 0,15 0,0596 0,67 0,2486 1,19 0,3830 1,71 0,4564 2,46 0,4931 0,16 0,0636 0,68 0,2517 1,20 0,3849 1,72 0,4573 2,48 0,4934 0,17 0,0675 0,69 0,2549 1,21 0,3869 1,73 0,4582 2,50 0,4938 0,18 0,0714 0,70 0,2580 1,22 0,3888 1,74 0,4591 2,52 0,4941 0,19 0,0753 0,71 0,2611 1,23 0,3907 1,75 0,4599 2,54 0,4945 0,20 0,0793 0,72 0,2642 1,24 0,3925 1,76 0,4608 2,56 0,4948 0,21 0,0832 0,73 0,2673 1,25 0,3914 1,77 0,4616 2,58 0,4951 0,22 0,0871 0,74 0.2703 1,26 0,3962 1,78 0,4625 2,60 0,4953 0,23 0,0910 0,75 0,2734 1,27 0,3980 1,79 0,4633 2,62 0,4956 0,24 0,0948 0,76 0,2764 1,28 0,3997 1,80 0,4641 2,64 0,4959 0,25 0,0987 0,77 0,2794 1,29 0,4015 1,81 0,4649 2,66 0,4961 0,26 0,1026 0,78 0,2823 1,30 0,4032 1,82 0,4656 2,68 0,4963 0,27 0,1064 0,79 0,2852 1,31 0,4049 1,83 0,4664 2,70 0,4965 0,28 0,1103 0,80 0,2881 1,32 0,4066 1,84 0,4671 2,72 0,4967 0,29 0,1141 0,81 0,2910 1,33 0,4082 1,85 0,4678 2,74 0,4969 0,30 0,1179 0,82 0,2939 1,34 0,4099 1,86 0,4686 2,76 0,4971 0,31 0,1217 0,83 0,2967 1,35 0,4115 1,87 0,4693 2,78 0,4973 0,32 0,1255 0.84 0,2995 1,36 0,4131 1,88 0,4699 2,80 0,4974 0,33 0,1293 0,85 0,3023 1,37 0,4147 1,89 0,4706 2,82 0,4976 0,34 0,1331 0,86 0,3051 1,38 0,4162 1,90 0,4713 2,84 0,4977 0,35 0,1368 0,87 0,3078 1,39 0,4177 1,91 0,4719 2,86 0,4979 0,36 0,1406 0,88 0,3106 1,40 0,4192 1,92 0,4726 2,88 0,4980 0,37 0,1443 0,89 0,3133 1,41 0,4207 1,93 0,4732 2,90 0,4981 0,38 0,1480 0,90 0,3159 1,42 0,4222 1,94 0,4738 2,92 0,4982 0,39 0,1517 0,91 0,3186 1,43 0,4236 1,95 0,4744 2,94 0,4984 0,40 0,1554 0,92 0,3112 1,44 0,4251 1,96 0,4750 2,96 0,4985 0,41 0,1591 0,93 0,3238 1,45 0,4265 1,97 0,4756 2,98 0,4986 0,42 0,1628 0,94 0,3264 1,46 0,4279 1,98 0,4761 3,00 0,49865 0,43 0,1664 0,95 0,3289 1,47 0,4292 1,99 0,4767 3,20 0,49931 0,44 0,1700 0,96 0,3315 1,48 0,4306 2,00 0,4772 3,40 0,49966 0,45 0,1736 0,97 0,3340 1,49 0,4319 2,02 0,4783 3,60 0,499841 0,46 0,1772 0,98 0,3365 1,50 0,4332 2,04 0,4793 3,80 0,499928 0,47 0,1808 0,99 0,3389 1,51 0,4345 2,06 0,4803 4,00 0,499968 0,48 0,1844 1,00 0,3413 1,52 0,4357 2,08 0,4812 4,50 0,499997 0,49 0,1879 1,01 0,3438 1,53 0,4370 2,10 0,4821 5,00 0,49999997 0,50 0,1915 1,02 0,3461 1,54 0,4382 2,12 0,4830 0,51 0,1950 1,03 0,3485 1,55 0,4394 2,14 0,4838
Приложение 7
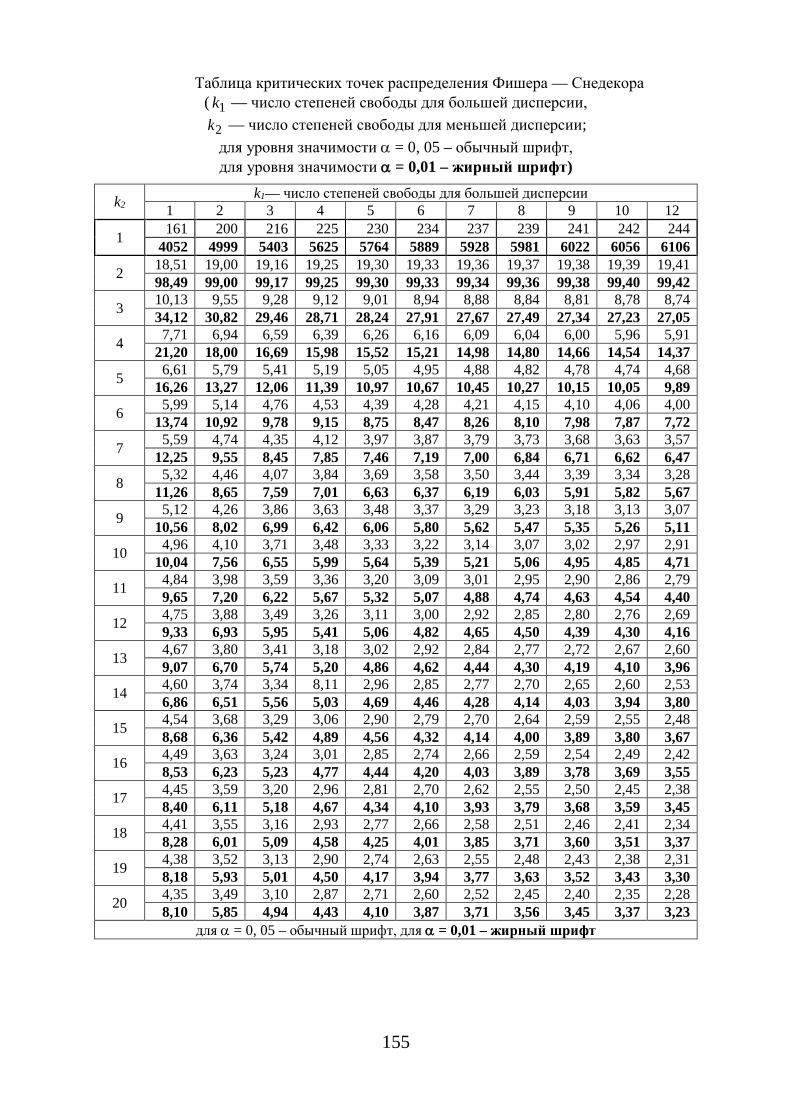
155
Таблица критических точек распределения Фишера — Снедекора ( 1k — число степеней свободы для большей дисперсии,
2k — число степеней свободы для меньшей дисперсии; для уровня значимости α = 0, 05 – обычный шрифт, для уровня значимости α = 0,01 – жирный шрифт)
k2 k1— число степеней свободы для большей дисперсии
1 2 3 4 5 6 7 8 9 10 12
1 161 200 216 225 230 234 237 239 241 242 244 4052 4999 5403 5625 5764 5889 5928 5981 6022 6056 6106
2 18,51 19,00 19,16 19,25 19,30 19,33 19,36 19,37 19,38 19,39 19,41 98,49 99,00 99,17 99,25 99,30 99,33 99,34 99,36 99,38 99,40 99,42
3 10,13 9,55 9,28 9,12 9,01 8,94 8,88 8,84 8,81 8,78 8,74 34,12 30,82 29,46 28,71 28,24 27,91 27,67 27,49 27,34 27,23 27,05
4 7,71 6,94 6,59 6,39 6,26 6,16 6,09 6,04 6,00 5,96 5,91 21,20 18,00 16,69 15,98 15,52 15,21 14,98 14,80 14,66 14,54 14,37
5 6,61 5,79 5,41 5,19 5,05 4,95 4,88 4,82 4,78 4,74 4,68 16,26 13,27 12,06 11,39 10,97 10,67 10,45 10,27 10,15 10,05 9,89
6 5,99 5,14 4,76 4,53 4,39 4,28 4,21 4,15 4,10 4,06 4,00 13,74 10,92 9,78 9,15 8,75 8,47 8,26 8,10 7,98 7,87 7,72
7 5,59 4,74 4,35 4,12 3,97 3,87 3,79 3,73 3,68 3,63 3,57 12,25 9,55 8,45 7,85 7,46 7,19 7,00 6,84 6,71 6,62 6,47
8 5,32 4,46 4,07 3,84 3,69 3,58 3,50 3,44 3,39 3,34 3,28 11,26 8,65 7,59 7,01 6,63 6,37 6,19 6,03 5,91 5,82 5,67
9 5,12 4,26 3,86 3,63 3,48 3,37 3,29 3,23 3,18 3,13 3,07 10,56 8,02 6,99 6,42 6,06 5,80 5,62 5,47 5,35 5,26 5,11
10 4,96 4,10 3,71 3,48 3,33 3,22 3,14 3,07 3,02 2,97 2,91 10,04 7,56 6,55 5,99 5,64 5,39 5,21 5,06 4,95 4,85 4,71
11 4,84 3,98 3,59 3,36 3,20 3,09 3,01 2,95 2,90 2,86 2,79 9,65 7,20 6,22 5,67 5,32 5,07 4,88 4,74 4,63 4,54 4,40
12 4,75 3,88 3,49 3,26 3,11 3,00 2,92 2,85 2,80 2,76 2,69 9,33 6,93 5,95 5,41 5,06 4,82 4,65 4,50 4,39 4,30 4,16
13 4,67 3,80 3,41 3,18 3,02 2,92 2,84 2,77 2,72 2,67 2,60 9,07 6,70 5,74 5,20 4,86 4,62 4,44 4,30 4,19 4,10 3,96
14 4,60 3,74 3,34 8,11 2,96 2,85 2,77 2,70 2,65 2,60 2,53 6,86 6,51 5,56 5,03 4,69 4,46 4,28 4,14 4,03 3,94 3,80
15 4,54 3,68 3,29 3,06 2,90 2,79 2,70 2,64 2,59 2,55 2,48 8,68 6,36 5,42 4,89 4,56 4,32 4,14 4,00 3,89 3,80 3,67
16 4,49 3,63 3,24 3,01 2,85 2,74 2,66 2,59 2,54 2,49 2,42 8,53 6,23 5,23 4,77 4,44 4,20 4,03 3,89 3,78 3,69 3,55
17 4,45 3,59 3,20 2,96 2,81 2,70 2,62 2,55 2,50 2,45 2,38 8,40 6,11 5,18 4,67 4,34 4,10 3,93 3,79 3,68 3,59 3,45
18 4,41 3,55 3,16 2,93 2,77 2,66 2,58 2,51 2,46 2,41 2,34 8,28 6,01 5,09 4,58 4,25 4,01 3,85 3,71 3,60 3,51 3,37
19 4,38 3,52 3,13 2,90 2,74 2,63 2,55 2,48 2,43 2,38 2,31 8,18 5,93 5,01 4,50 4,17 3,94 3,77 3,63 3,52 3,43 3,30
20 4,35 3,49 3,10 2,87 2,71 2,60 2,52 2,45 2,40 2,35 2,28 8,10 5,85 4,94 4,43 4,10 3,87 3,71 3,56 3,45 3,37 3,23
для α = 0, 05 – обычный шрифт, для α = 0,01 – жирный шрифт
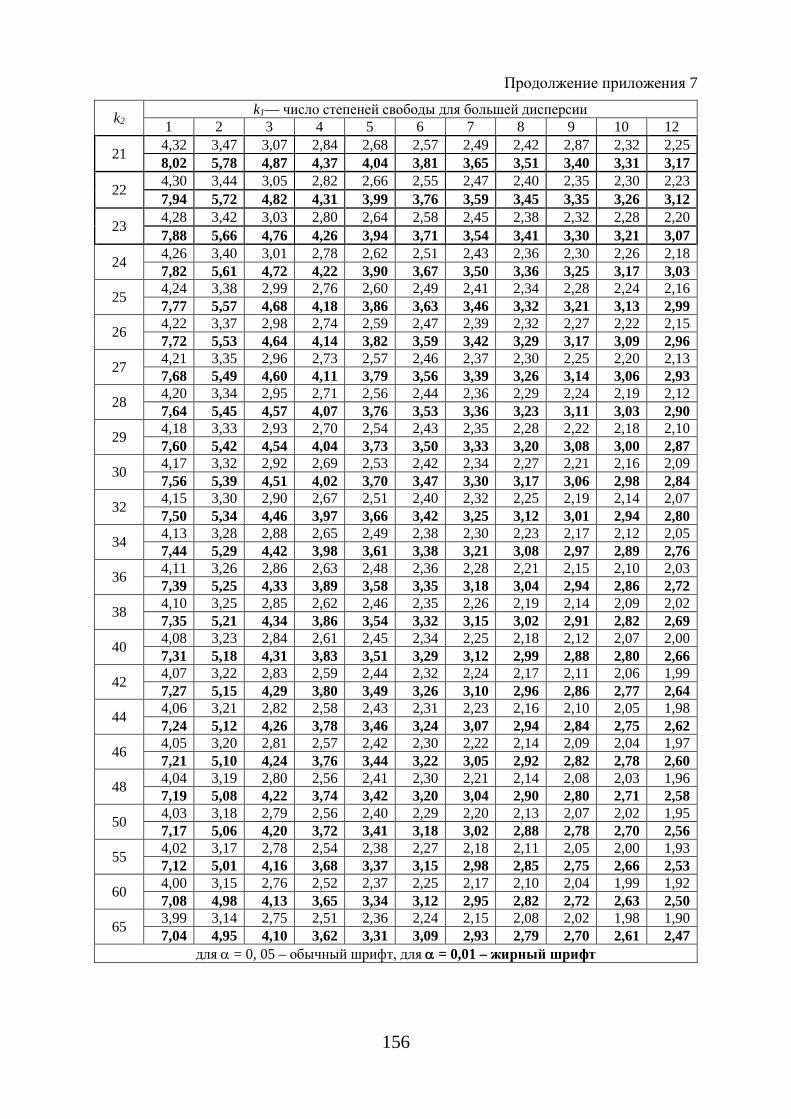
156
Продолжение приложения 7
k2 k1— число степеней свободы для большей дисперсии
1 2 3 4 5 6 7 8 9 10 12
21 4,32 3,47 3,07 2,84 2,68 2,57 2,49 2,42 2,87 2,32 2,25 8,02 5,78 4,87 4,37 4,04 3,81 3,65 3,51 3,40 3,31 3,17
22 4,30 3,44 3,05 2,82 2,66 2,55 2,47 2,40 2,35 2,30 2,23 7,94 5,72 4,82 4,31 3,99 3,76 3,59 3,45 3,35 3,26 3,12
23 4,28 3,42 3,03 2,80 2,64 2,58 2,45 2,38 2,32 2,28 2,20 7,88 5,66 4,76 4,26 3,94 3,71 3,54 3,41 3,30 3,21 3,07
24 4,26 3,40 3,01 2,78 2,62 2,51 2,43 2,36 2,30 2,26 2,18 7,82 5,61 4,72 4,22 3,90 3,67 3,50 3,36 3,25 3,17 3,03
25 4,24 3,38 2,99 2,76 2,60 2,49 2,41 2,34 2,28 2,24 2,16 7,77 5,57 4,68 4,18 3,86 3,63 3,46 3,32 3,21 3,13 2,99
26 4,22 3,37 2,98 2,74 2,59 2,47 2,39 2,32 2,27 2,22 2,15 7,72 5,53 4,64 4,14 3,82 3,59 3,42 3,29 3,17 3,09 2,96
27 4,21 3,35 2,96 2,73 2,57 2,46 2,37 2,30 2,25 2,20 2,13 7,68 5,49 4,60 4,11 3,79 3,56 3,39 3,26 3,14 3,06 2,93
28 4,20 3,34 2,95 2,71 2,56 2,44 2,36 2,29 2,24 2,19 2,12 7,64 5,45 4,57 4,07 3,76 3,53 3,36 3,23 3,11 3,03 2,90
29 4,18 3,33 2,93 2,70 2,54 2,43 2,35 2,28 2,22 2,18 2,10 7,60 5,42 4,54 4,04 3,73 3,50 3,33 3,20 3,08 3,00 2,87
30 4,17 3,32 2,92 2,69 2,53 2,42 2,34 2,27 2,21 2,16 2,09 7,56 5,39 4,51 4,02 3,70 3,47 3,30 3,17 3,06 2,98 2,84
32 4,15 3,30 2,90 2,67 2,51 2,40 2,32 2,25 2,19 2,14 2,07 7,50 5,34 4,46 3,97 3,66 3,42 3,25 3,12 3,01 2,94 2,80
34 4,13 3,28 2,88 2,65 2,49 2,38 2,30 2,23 2,17 2,12 2,05 7,44 5,29 4,42 3,98 3,61 3,38 3,21 3,08 2,97 2,89 2,76
36 4,11 3,26 2,86 2,63 2,48 2,36 2,28 2,21 2,15 2,10 2,03 7,39 5,25 4,33 3,89 3,58 3,35 3,18 3,04 2,94 2,86 2,72
38 4,10 3,25 2,85 2,62 2,46 2,35 2,26 2,19 2,14 2,09 2,02 7,35 5,21 4,34 3,86 3,54 3,32 3,15 3,02 2,91 2,82 2,69
40 4,08 3,23 2,84 2,61 2,45 2,34 2,25 2,18 2,12 2,07 2,00 7,31 5,18 4,31 3,83 3,51 3,29 3,12 2,99 2,88 2,80 2,66
42 4,07 3,22 2,83 2,59 2,44 2,32 2,24 2,17 2,11 2,06 1,99 7,27 5,15 4,29 3,80 3,49 3,26 3,10 2,96 2,86 2,77 2,64
44 4,06 3,21 2,82 2,58 2,43 2,31 2,23 2,16 2,10 2,05 1,98 7,24 5,12 4,26 3,78 3,46 3,24 3,07 2,94 2,84 2,75 2,62
46 4,05 3,20 2,81 2,57 2,42 2,30 2,22 2,14 2,09 2,04 1,97 7,21 5,10 4,24 3,76 3,44 3,22 3,05 2,92 2,82 2,78 2,60
48 4,04 3,19 2,80 2,56 2,41 2,30 2,21 2,14 2,08 2,03 1,96 7,19 5,08 4,22 3,74 3,42 3,20 3,04 2,90 2,80 2,71 2,58
50 4,03 3,18 2,79 2,56 2,40 2,29 2,20 2,13 2,07 2,02 1,95 7,17 5,06 4,20 3,72 3,41 3,18 3,02 2,88 2,78 2,70 2,56
55 4,02 3,17 2,78 2,54 2,38 2,27 2,18 2,11 2,05 2,00 1,93 7,12 5,01 4,16 3,68 3,37 3,15 2,98 2,85 2,75 2,66 2,53
60 4,00 3,15 2,76 2,52 2,37 2,25 2,17 2,10 2,04 1,99 1,92 7,08 4,98 4,13 3,65 3,34 3,12 2,95 2,82 2,72 2,63 2,50
65 3,99 3,14 2,75 2,51 2,36 2,24 2,15 2,08 2,02 1,98 1,90 7,04 4,95 4,10 3,62 3,31 3,09 2,93 2,79 2,70 2,61 2,47
для α = 0, 05 – обычный шрифт, для α = 0,01 – жирный шрифт
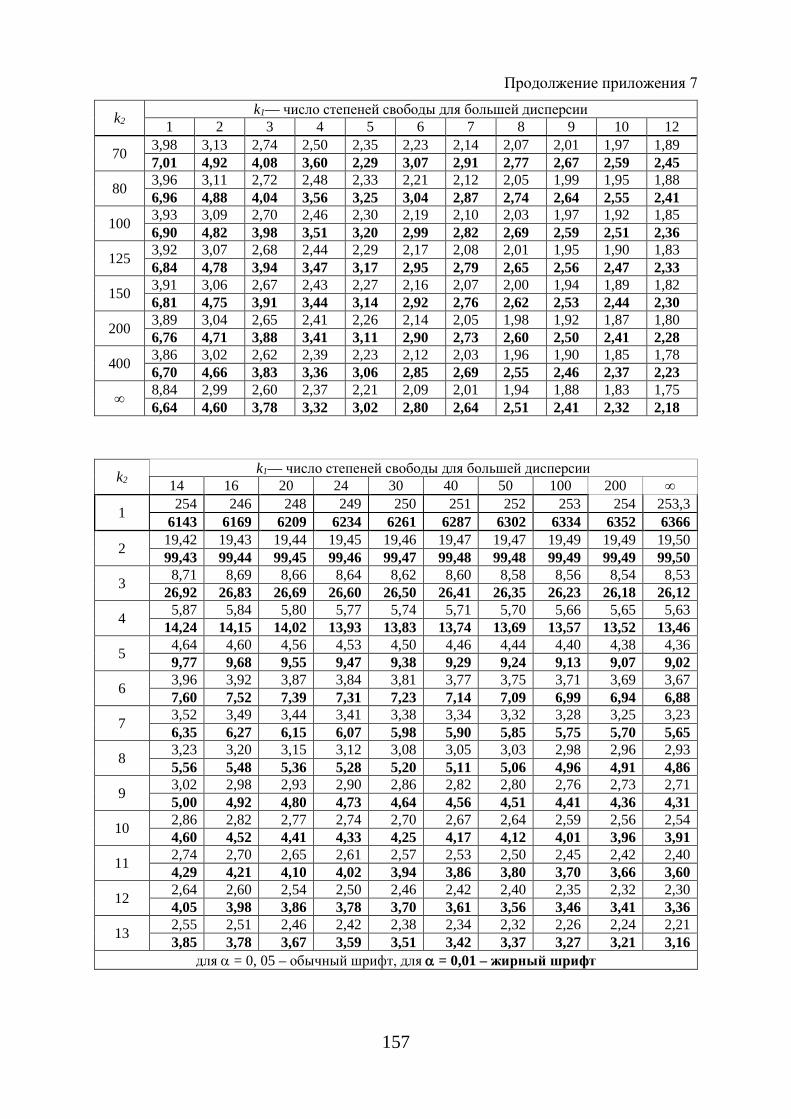
157
Продолжение приложения 7
k2 k1— число степеней свободы для большей дисперсии
1 2 3 4 5 6 7 8 9 10 12
70 3,98 3,13 2,74 2,50 2,35 2,23 2,14 2,07 2,01 1,97 1,89 7,01 4,92 4,08 3,60 2,29 3,07 2,91 2,77 2,67 2,59 2,45
80 3,96 3,11 2,72 2,48 2,33 2,21 2,12 2,05 1,99 1,95 1,88 6,96 4,88 4,04 3,56 3,25 3,04 2,87 2,74 2,64 2,55 2,41
100 3,93 3,09 2,70 2,46 2,30 2,19 2,10 2,03 1,97 1,92 1,85 6,90 4,82 3,98 3,51 3,20 2,99 2,82 2,69 2,59 2,51 2,36
125 3,92 3,07 2,68 2,44 2,29 2,17 2,08 2,01 1,95 1,90 1,83 6,84 4,78 3,94 3,47 3,17 2,95 2,79 2,65 2,56 2,47 2,33
150 3,91 3,06 2,67 2,43 2,27 2,16 2,07 2,00 1,94 1,89 1,82 6,81 4,75 3,91 3,44 3,14 2,92 2,76 2,62 2,53 2,44 2,30
200 3,89 3,04 2,65 2,41 2,26 2,14 2,05 1,98 1,92 1,87 1,80 6,76 4,71 3,88 3,41 3,11 2,90 2,73 2,60 2,50 2,41 2,28
400 3,86 3,02 2,62 2,39 2,23 2,12 2,03 1,96 1,90 1,85 1,78 6,70 4,66 3,83 3,36 3,06 2,85 2,69 2,55 2,46 2,37 2,23
∞ 8,84 2,99 2,60 2,37 2,21 2,09 2,01 1,94 1,88 1,83 1,75 6,64 4,60 3,78 3,32 3,02 2,80 2,64 2,51 2,41 2,32 2,18
k2 k1— число степеней свободы для большей дисперсии
14 16 20 24 30 40 50 100 200 ∞
1 254 246 248 249 250 251 252 253 254 253,3 6143 6169 6209 6234 6261 6287 6302 6334 6352 6366
2 19,42 19,43 19,44 19,45 19,46 19,47 19,47 19,49 19,49 19,50 99,43 99,44 99,45 99,46 99,47 99,48 99,48 99,49 99,49 99,50
3 8,71 8,69 8,66 8,64 8,62 8,60 8,58 8,56 8,54 8,53 26,92 26,83 26,69 26,60 26,50 26,41 26,35 26,23 26,18 26,12
4 5,87 5,84 5,80 5,77 5,74 5,71 5,70 5,66 5,65 5,63 14,24 14,15 14,02 13,93 13,83 13,74 13,69 13,57 13,52 13,46
5 4,64 4,60 4,56 4,53 4,50 4,46 4,44 4,40 4,38 4,36 9,77 9,68 9,55 9,47 9,38 9,29 9,24 9,13 9,07 9,02
6 3,96 3,92 3,87 3,84 3,81 3,77 3,75 3,71 3,69 3,67 7,60 7,52 7,39 7,31 7,23 7,14 7,09 6,99 6,94 6,88
7 3,52 3,49 3,44 3,41 3,38 3,34 3,32 3,28 3,25 3,23 6,35 6,27 6,15 6,07 5,98 5,90 5,85 5,75 5,70 5,65
8 3,23 3,20 3,15 3,12 3,08 3,05 3,03 2,98 2,96 2,93 5,56 5,48 5,36 5,28 5,20 5,11 5,06 4,96 4,91 4,86
9 3,02 2,98 2,93 2,90 2,86 2,82 2,80 2,76 2,73 2,71 5,00 4,92 4,80 4,73 4,64 4,56 4,51 4,41 4,36 4,31
10 2,86 2,82 2,77 2,74 2,70 2,67 2,64 2,59 2,56 2,54 4,60 4,52 4,41 4,33 4,25 4,17 4,12 4,01 3,96 3,91
11 2,74 2,70 2,65 2,61 2,57 2,53 2,50 2,45 2,42 2,40 4,29 4,21 4,10 4,02 3,94 3,86 3,80 3,70 3,66 3,60
12 2,64 2,60 2,54 2,50 2,46 2,42 2,40 2,35 2,32 2,30 4,05 3,98 3,86 3,78 3,70 3,61 3,56 3,46 3,41 3,36
13 2,55 2,51 2,46 2,42 2,38 2,34 2,32 2,26 2,24 2,21 3,85 3,78 3,67 3,59 3,51 3,42 3,37 3,27 3,21 3,16
для α = 0, 05 – обычный шрифт, для α = 0,01 – жирный шрифт

158
Продолжение приложения 7
k2 k1— число степеней свободы для большей дисперсии
14 16 20 24 30 40 50 100 200 ∞
14 2,48 2,44 2,39 2,35 2,31 2,27 2,24 2,19 2,16 2,13 3,70 3,62 3,51 3,43 3,34 3,26 3,21 3,11 3,06 3,00
15 2,43 2,39 2,33 2,29 2,25 2,21 2,18 2,12 2,10 2,07 3,56 3,48 3,36 3,29 3,20 3,12 3,07 2,97 2,92 2,87
16 2,37 2,33 2,28 2,24 2,20 2,16 2,13 2,07 2,04 2,01 3,45 3,37 3,25 3,18 3,10 3,01 2,96 2,86 2,80 2,75
17 2,33 2,29 2,23 2,19 2,15 2,11 2,08 2,02 1,99 1,96 3,35 3,27 3,16 3,08 3,00 2,92 2,86 2,76 2,70 2,65
18 2,29 2,25 2,19 2,15 2,11 2,07 2,04 1,98 1,95 1,92 3,27 3,19 3,07 3,00 2,91 2,83 2,78 2,68 2,62 2,57
19 2,26 2,21 2,15 2,11 2,07 2,02 2,00 1,94 1,91 1,88 3,19 3,12 3,00 2,92 2,84 2,76 2,70 2,60 2,54 2,49
20 2,23 2,18 2,12 2,08 2,04 1,99 1,96 1,90 1,87 1,84 3,13 3,05 2,94 2,86 2,77 2,69 2,63 2,53 2,47 2,42
21 2,20 2,15 2,09 2,05 2,00 1,96 1,93 1,87 1,84 1,81 3,07 2,99 2,88 2,80 2,72 2,63 2,58 2,47 2,42 2,36
22 2,18 2,13 2,07 2,03 1,98 1,93 1,91 1,84 1,81 1,78 3,02 2,94 2,83 2,75 2,67 2,58 2,53 2,42 2,37 2,31
23 2,14 2,10 2,04 2,00 1,96 1,91 1,88 1,82 1,79 1,76 2,97 2,89 2,78 2,70 2,62 2,53 2,48 2,37 2,32 2,26
24 2,13 2,09 2,02 1,98 1,94 1,89 1,86 1,80 1,76 1,73 2,93 2,85 2,74 2,66 2,58 2,49 2,44 2,33 2,27 2,21
25 2,11 2,06 2,00 1,96 1,92 1,87 1,84 1,77 1,74 1,71 2,89 2,81 2,70 2,62 2,54 2,45 2,40 2,29 2,23 2,17
26 2,10 2,05 1,99 1,95 1,90 1,85 1,82 1,76 1,72 1,69 2,86 2,77 2,66 2,58 2,50 2,41 2,36 2,25 2,19 2,13
27 2,08 2,03 1,97 1,93 1,88 1,84 1,80 1,74 1,71 1,67 2,83 2,74 2,63 2,55 2,47 2,38 2,33 2,21 2,16 2,10
28 2,06 2,02 1,96 1,91 1,87 1,81 1,78 1,72 1,69 1,65 2,80 2,71 2,60 2,52 2,44 2,35 2,30 2,18 2,13 2,06
29 2,05 2,00 1,94 1,90 1,85 1,80 1,77 1,71 1,68 1,64 2,77 2,68 2,57 2,49 2,41 2,32 2,27 2,15 2,10 2,03
30 2,04 1,99 1,93 1,89 1,84 1,79 1,76 1,69 1,66 1,62 2,74 2,66 2,55 2,47 2,38 2,29 2,24 2,13 2,07 2,01
32 2,02 1,97 1,91 1,86 1,82 1,76 1,74 1,67 1,64 1,59 2,70 2,62 2,51 2,42 2,34 2,25 2,20 2,08 2,02 1,96
34 2,00 1,95 1,89 1,84 1,80 1,74 1,71 1,64 1,61 1,57 2,66 2,58 2,47 2,38 2,30 2,21 2,15 2,04 1,98 1,91
36 1,98 1,93 1,87 1,82 1,78 1,72 1,69 1,62 1,59 1,55 2,62 2,54 2,43 2,35 2,26 2,17 2,12 2,00 1,94 1,87
38 1,96 1,92 1,85 1,80 1,76 1,71 1,67 1,60 1,57 1,53 2,59 2,51 2,40 2,32 2,22 2,14 2,08 1,97 1,90 1,84
40 1,95 1,90 1,84 1,79 1,74 1,69 1,66 1,59 1,55 1,51 2,56 2,49 2,34 2,29 2,20 2,11 2,05 1,94 1,88 1,81
42 1,94 1,89 1,82 1,78 1,73 1,68 1,64 1,57 1,54 1,49 2,54 2,46 2,35 2,26 2,17 2,08 2,02 1,91 1,85 1,78
для α = 0, 05 – обычный шрифт, для α = 0,01 – жирный шрифт
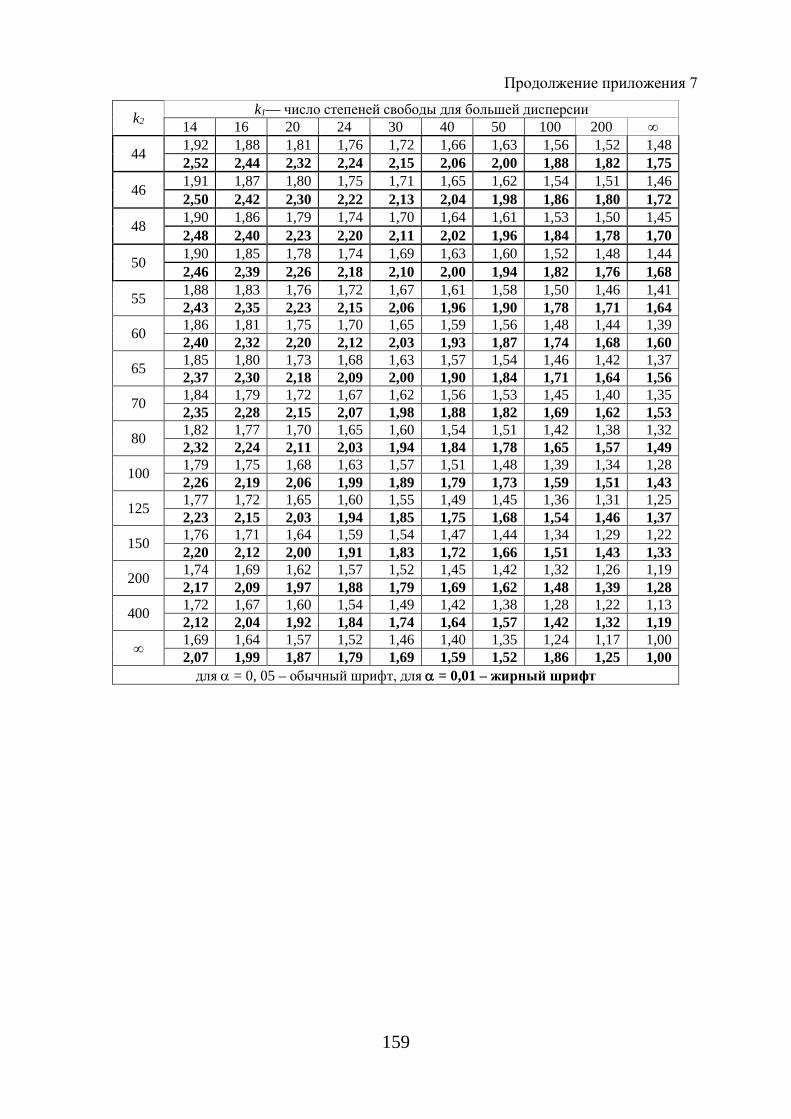
159
Продолжение приложения 7
k2 k1— число степеней свободы для большей дисперсии
14 16 20 24 30 40 50 100 200 ∞
44 1,92 1,88 1,81 1,76 1,72 1,66 1,63 1,56 1,52 1,48 2,52 2,44 2,32 2,24 2,15 2,06 2,00 1,88 1,82 1,75
46 1,91 1,87 1,80 1,75 1,71 1,65 1,62 1,54 1,51 1,46 2,50 2,42 2,30 2,22 2,13 2,04 1,98 1,86 1,80 1,72
48 1,90 1,86 1,79 1,74 1,70 1,64 1,61 1,53 1,50 1,45 2,48 2,40 2,23 2,20 2,11 2,02 1,96 1,84 1,78 1,70
50 1,90 1,85 1,78 1,74 1,69 1,63 1,60 1,52 1,48 1,44 2,46 2,39 2,26 2,18 2,10 2,00 1,94 1,82 1,76 1,68
55 1,88 1,83 1,76 1,72 1,67 1,61 1,58 1,50 1,46 1,41 2,43 2,35 2,23 2,15 2,06 1,96 1,90 1,78 1,71 1,64
60 1,86 1,81 1,75 1,70 1,65 1,59 1,56 1,48 1,44 1,39 2,40 2,32 2,20 2,12 2,03 1,93 1,87 1,74 1,68 1,60
65 1,85 1,80 1,73 1,68 1,63 1,57 1,54 1,46 1,42 1,37 2,37 2,30 2,18 2,09 2,00 1,90 1,84 1,71 1,64 1,56
70 1,84 1,79 1,72 1,67 1,62 1,56 1,53 1,45 1,40 1,35 2,35 2,28 2,15 2,07 1,98 1,88 1,82 1,69 1,62 1,53
80 1,82 1,77 1,70 1,65 1,60 1,54 1,51 1,42 1,38 1,32 2,32 2,24 2,11 2,03 1,94 1,84 1,78 1,65 1,57 1,49
100 1,79 1,75 1,68 1,63 1,57 1,51 1,48 1,39 1,34 1,28 2,26 2,19 2,06 1,99 1,89 1,79 1,73 1,59 1,51 1,43
125 1,77 1,72 1,65 1,60 1,55 1,49 1,45 1,36 1,31 1,25 2,23 2,15 2,03 1,94 1,85 1,75 1,68 1,54 1,46 1,37
150 1,76 1,71 1,64 1,59 1,54 1,47 1,44 1,34 1,29 1,22 2,20 2,12 2,00 1,91 1,83 1,72 1,66 1,51 1,43 1,33
200 1,74 1,69 1,62 1,57 1,52 1,45 1,42 1,32 1,26 1,19 2,17 2,09 1,97 1,88 1,79 1,69 1,62 1,48 1,39 1,28
400 1,72 1,67 1,60 1,54 1,49 1,42 1,38 1,28 1,22 1,13 2,12 2,04 1,92 1,84 1,74 1,64 1,57 1,42 1,32 1,19
∞ 1,69 1,64 1,57 1,52 1,46 1,40 1,35 1,24 1,17 1,00 2,07 1,99 1,87 1,79 1,69 1,59 1,52 1,86 1,25 1,00
для α = 0, 05 – обычный шрифт, для α = 0,01 – жирный шрифт

Учебное издание
СТАТИСТИЧЕСКИЕ МЕТОДЫ ОБРАБОТКИ ДАННЫХ
Вершинина Светлана Валерьевна Руденок Ольга Владимировна Кулакова Надежда Сергеевна Тарасова Оксана Валериевна
В авторской редакции
Подписано в печать 16.11.2015. Формат 60х90 1/16. Печ. л. 10 Тираж 500 экз. Заказ № 310.
Библиотечно-издательский комплекс федерального государственного бюджетного образовательного
учреждения высшего образования «Тюменский государственный нефтегазовый университет».
625000, Тюмень, ул. Володарского, 38.
Типография библиотечно-издательского комплекса. 625039, Тюмень, ул. Киевская, 52.





























