Embed Size (px)
Citation preview

Documentacion del sistema de codigoabierto Opentrad Apertium de
traduccion automatica de transferenciasintactica superficial
AUTORES:Mikel L. Forcada
Boyan Ivanov BonevSergio Ortiz Rojas
Juan Antonio Perez OrtizGema Ramırez SanchezFelipe Sanchez Martınez
COORDINADORA:Mireia Ginestı Rosell
Departament de Llenguatges i Sistemes InformaticsUniversitat d’Alacant
29 de enero de 2008

Copyright c©2006 Grup Transducens, Universitat d’Alacant. Seotorga permiso para copiar, distribuir y/o modificar este docu-mento bajo los terminos de la Licencia de Documentacion Librede GNU, Version 1.2 o cualquier otra version posterior publica-da por la Free Software Foundation; sin Secciones Invariantesni Textos de Cubierta Delantera ni Textos de Cubierta Trasera.Una copia de la licencia se puede consultar en http://www.gnu.org/copyleft/fdl.html. En http://gugs.sindominio.net/licencias/gfdl-1.2-es.html puede leerse la traduc-cion no oficial de la licencia al espanol, en http://www.softcatala.org/llicencies/fdl-ca.html la traduccion no oficial alcatalan y en http://members.tripod.com.br/RamonFlores/GNU/gpl.html la traduccion no oficial al gallego.

Indice general
Introduccion 1
1. El ingenio de traduccion 5
2. Especificacion del formato de flujo 112.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2. Flujo de datos sin formato . . . . . . . . . . . . . . . . . . . . 13
2.2.1. Formato de flujo . . . . . . . . . . . . . . . . . . . . . 142.3. Flujo de datos segmentado . . . . . . . . . . . . . . . . . . . . 15
3. Especificacion de los modulos 173.1. Modulos de procesamiento lexico . . . . . . . . . . . . . . . . 17
3.1.1. Descripcion del funcionamiento . . . . . . . . . . . . 173.1.2. Formato de los datos: los diccionarios . . . . . . . . . 203.1.3. Generacion automatica de los modulos . . . . . . . . 55
3.2. Desambiguador lexico categorial . . . . . . . . . . . . . . . . 573.2.1. Descripcion del funcionamiento . . . . . . . . . . . . 573.2.2. Datos para el desambiguador lexico categorial . . . . 583.2.3. Consideraciones sobre el entrenamiento del desam-
biguador lexico categorial . . . . . . . . . . . . . . . . 623.3. Preproceso de la transferencia . . . . . . . . . . . . . . . . . . 67
3.3.1. Motivacion . . . . . . . . . . . . . . . . . . . . . . . . 673.3.2. Comportamiento y ejemplo . . . . . . . . . . . . . . . 67
3.4. Modulo de seleccion lexica . . . . . . . . . . . . . . . . . . . . 683.4.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . 683.4.2. Preprocesamiento de los diccionarios bilingues . . . . 713.4.3. Funcionamiento del modulo de seleccion lexica . . . 73
3.5. Modulo de transferencia estructural . . . . . . . . . . . . . . 763.5.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . 763.5.2. Transferencia sintactica superficial . . . . . . . . . . . 773.5.3. Transferencia sintactica avanzada . . . . . . . . . . . 80
III

IV INDICE GENERAL
3.5.4. Especificacion del formato de las reglas de transfe-rencia estructural . . . . . . . . . . . . . . . . . . . . . 83
3.5.5. Especificacion de los tres modulos del sistema detransferencia avanzada . . . . . . . . . . . . . . . . . . 110
3.5.6. Preproceso del modulo de transferencia estructural . 1183.6. Desformateador y reformateador . . . . . . . . . . . . . . . . 118
3.6.1. Funcionamiento . . . . . . . . . . . . . . . . . . . . . . 1183.6.2. Datos: reglas de especificacion de formato . . . . . . 1223.6.3. Generacion de formateadores y desformateadores . . 125
4. Instalacion y ejecucion del sistema 1294.1. Requisitos del sistema . . . . . . . . . . . . . . . . . . . . . . 1294.2. Instalacion de los paquetes de programas . . . . . . . . . . . 1294.3. Instalacion de los paquetes de datos . . . . . . . . . . . . . . 1314.4. Ejecucion del traductor . . . . . . . . . . . . . . . . . . . . . . 131
5. Mantenimiento de datos linguısticos 1355.1. Descripcion de los datos linguısticos . . . . . . . . . . . . . . 1355.2. Introducir palabras en los diccionarios . . . . . . . . . . . . . 137
5.2.1. Anadir restricciones de direccion . . . . . . . . . . . . 1435.2.2. Anadir multipalabras . . . . . . . . . . . . . . . . . . 1455.2.3. Colaborar en la mejora de datos lexicos . . . . . . . . 150
5.3. Introducir reglas de transferencia . . . . . . . . . . . . . . . . 1515.4. Anadir datos al desambiguador lexico . . . . . . . . . . . . . 1585.5. Deteccion de errores . . . . . . . . . . . . . . . . . . . . . . . 161
5.5.1. Control de las marcas de error . . . . . . . . . . . . . 1615.5.2. Salida de los diferentes modulos de Apertium . . . . 1625.5.3. Ejemplos de errores . . . . . . . . . . . . . . . . . . . . 1665.5.4. Comprobacion de la integridad de los diccionarios . 167
5.6. Generar un nuevo sistema con los nuevos datos . . . . . . . 168
6. Formularios web de insercion de datos 1696.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1696.2. Instalacion y administracion . . . . . . . . . . . . . . . . . . . 169
6.2.1. Instalacion de la herramienta . . . . . . . . . . . . . . 1696.2.2. Estructura de directorios . . . . . . . . . . . . . . . . . 1716.2.3. Ficheros php . . . . . . . . . . . . . . . . . . . . . . . . 1736.2.4. Ficheros de diccionario . . . . . . . . . . . . . . . . . . 1816.2.5. Ficheros de paradigmas . . . . . . . . . . . . . . . . . 181
6.3. Utilizacion de los formularios . . . . . . . . . . . . . . . . . . 1856.3.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . 185

INDICE GENERAL V
6.3.2. Insercion de entradas . . . . . . . . . . . . . . . . . . . 1866.3.3. Validacion de entradas pendientes de aprobacion . . 187
A. DTDs en XML 189A.1. DTD para el formato de los diccionarios . . . . . . . . . . . . 189
A.1.1. Modificacion en la DTD de diccionarios para selec-cion lexica . . . . . . . . . . . . . . . . . . . . . . . . . 190
A.2. DTD para el desambiguador . . . . . . . . . . . . . . . . . . . 191A.3. DTD del modulo chunker . . . . . . . . . . . . . . . . . . . . 192A.4. DTD del modulo interchunk . . . . . . . . . . . . . . . . . . . 197A.5. DTD del modulo postchunk . . . . . . . . . . . . . . . . . . . 201A.6. DTD para reglas de formato . . . . . . . . . . . . . . . . . . . 205A.7. DTD de los paradigmas del formulario . . . . . . . . . . . . . 207
B. Sımbolos gramaticales 209B.1. Sımbolos de los diccionarios . . . . . . . . . . . . . . . . . . . 210
B.1.1. Lista de sımbolos . . . . . . . . . . . . . . . . . . . . . 210B.1.2. Especificacion de formas lexicas . . . . . . . . . . . . 212
B.2. Categorıas del desambiguador . . . . . . . . . . . . . . . . . 214B.2.1. Desambiguador de espanol . . . . . . . . . . . . . . . 214B.2.2. Desambiguador de catalan . . . . . . . . . . . . . . . 216B.2.3. Desambiguador de gallego . . . . . . . . . . . . . . . 217
C. Abreviaturas usadas en el texto 219

VI INDICE GENERAL

Introduccion
La presente documentacion describe el sistema Opentrad Apertium1, unode los sistemas de traduccion automatica de codigo abierto creados en elmarco del proyecto ”Traduccion automatica de codigo abierto para las len-guas del estado espanol”
[Nota: Posem un resum de les dades del projecte en un apendix (co-di, durada, financament, participants, etc.) i hi fem referencia acı? -Mikel]
. Se trata de un sistema de traduccion automatica de transferencia sintacti-ca superficial y esta pensado inicialmente para la traduccion entre pa-res de lenguas relacionadas, aunque algunos de sus componentes se hanutilizado tambien en la arquitectura de transferencia sintactica profunda(Opentrad Matxin) que se ha desarrollado en el mismo proyecto para elpar espanol–euskera. Apertium traduce actualmente entre los pares espa-nol–gallego y espanol–catalan2, y puede utilizarse para la construccion detraductores entre otros pares de lenguas relacionadas como danes–sueco,checo–eslovaco, etc.
Los demas sistemas de traduccion automatica disponibles hasta el mo-mento para los pares es–ca y es–gl son mayoritariamente comercialeso utilizan tecnologıa de propiedad, con lo que es muy difıcil adaptarlosa nuevos usos; ademas, utilizan diferentes tecnologıas para los distintospares de lenguas, lo que hace muy difıcil integrarlos en un unico sistemade gestion de contenidos multilingues.
Una de las principales novedades de la arquitectura que presentamoses que se ha liberado bajo una licencia de codigo abierto (licencia GNUGPL para los programas y Creative Commons para los datos) y es de dis-tribucion gratuita. Esto significa que cualquier persona que tenga los cono-cimientos linguısticos e informaticos necesarios podra adaptar o ampliar
1En adelante, nos referiremos a el simplemente como Apertium2Con la denominacion catalan nos referimos tambien a la variante dialectal valenciana
de este idioma.
1

2 INDICE GENERAL
el producto para crear un nuevo sistema de traduccion automatica, inclu-so para nuevos pares de lenguas relacionadas. Esperamos, por ello, quela introduccion de esta arquitectura de traduccion automatica de codigoabierto solucione algunos de los problemas mencionados (existencia de di-ferentes tecnologıas para diferentes pares, dificultad de adaptacion de lasarquitecturas de codigo cerrado a nuevos usos, etc.) y favorezca el inter-cambio de datos linguısticos ya existentes utilizando los formatos basadosen XML que se definen en esta documentacion. Al mismo tiempo, creemosque ayudara a cambiar el modelo de negocio actual en este campo, basadoen licencias, por un modelo basado en la prestacion de servicios.
Cabe mencionar que es la primera vez que el Gobierno espanol ha sub-vencionado un proyecto de codigo abierto de esta envergadura, aunquela adopcion de software de codigo abierto por las administraciones es-panolas no es algo nuevo.
En los capıtulos de la presente documentacion se explican detallada-mente las caracterısticas del sistema Apertium, con la informacion organi-zada de la siguiente manera:
Capıtulo 1: descripcion general del sistema de traduccion automati-ca de transferencia superficial y de los modulos de los que se com-pone.
Capıtulo 2: descripcion del formato del flujo de los datos que circu-lan de un modulo a otro.
Capıtulo 3: especificacion de los modulos del sistema. Para cadamodulo se describe: el funcionamiento del modulo, el formato de los datossobre los que trabaja el modulo, y los compiladores correspondientes.Este capıtulo se divide en las siguientes secciones:
- seccion 3.1: Modulos de procesamiento lexico, en la que se descri-be el funcionamiento del analizador morfologico, del modulode transferencia lexica, del generador morfologico y del postge-nerador (apartado 3.1.1), el formato de los diccionarios con losque trabajan estos modulos (apartado 3.1.2) y los compiladoresde los mismos (apartado 3.1.3)
- seccion 3.2: Desambiguador lexico categorial, en la que se describeel funcionamiento del desambiguador (apartado 3.2.1), el for-mato de los datos linguısticos con los que trabaja (apartado 3.2.2.
[Nota: falta parlar del lextor, i afegir-ho a tot arreu on es parlidels moduls del sistema]

INDICE GENERAL 3
- seccion 3.3: Modulo de preproceso del transfer, en la que se des-cribe el modulo que se ejecuta antes del modulo de transfere-cia estructural para realizar ciertas operaciones en las unidadesmultipalabra
- seccion 3.5: Modulo de transferencia estructural, en la que se des-cribe el funcionamiento del modulo (apartado 3.5.2) y el forma-to de las reglas de transferencia estructural (apartado 3.5.4).
- seccion 3.6: Desformateador y reformateador, en la que se describeel funcionamiento de estos modulos (apartado 3.6.1), las reglasde especificacion de formato (apartado 3.6.2) y el proceso degeneracion de los modulos (apartado 3.6.3)
Capıtulo 4: describe como instalar el sistema y cuales son los requi-sitos para ello, ası como la manera de utilizar el traductor.
Capıtulo 5: describe como se pueden modificar los datos linguısti-cos del traductor, es decir, los diccionarios, los datos de desambigua-cion lexica categorial y las reglas de transferencia estructural que sehan creado para el espanol, el catalan, el gallego. Ademas, aquı sedescriben brevemente las caracterısticas de los datos existentes paralos tres pares de lenguas del proyecto.
[Nota: Es diuen a tot arreu els noms de programa i en quin pa-quet estan?]
Los ficheros a los que hace referencia este informe se pueden consul-tar y descargar desde la pagina web del proyecto en Sourceforge: http://apertium.sourceforge.net/. En esta pagina se pueden descargarlos paquetes para la instalacion, ası como consultar los archivos indivi-dualmente, en el repositorio de CVS (http://cvs.sourceforge.net/viewcvs.py/apertium/). Los sistemas de traduccion automatica tam-bien se pueden probar a traves de internet en http://xixona.dlsi.ua.es/prototype/.
Agradecimientos:
El presente trabajo se ha beneficiado de las aportaciones de muchaspersonas e instituciones:
El Ministerio de Industria, Comercio y Turismo ha financiado es-te trabajo a traves del proyecto “Traduccion automatica de codigoabierto para las lenguas del Estado espanol” del programa PROFIT,claves FIT-340101-2004-3 y su ampliacion FIT-340001-2005-2.

4 INDICE GENERAL
Trabajadores y becarios de otros proyectos de traduccion automati-ca de la Universidad de Alicante: Mıriam Antunes Scalco, CarmeArmentano i Oller, Raul Canals i Marote, Alicia Garrido Alenda,Patrıcia Gilabert i Zarco, Maribel Guardiola i Savall, Javier Herre-ro Vicente, Amaia Iturraspe Bellver, Sandra Montserrat i Buendia,Hermınia Pastor Pina, Antonio Pertusa Ibanez, Francisco Javier Ra-mos Salas, Marcial Samper Asensio y Miguel Sanchez Molina.
Las empresas e instituciones que han financiado estos otros proyec-tos de traduccion automatica: el Ministerio de Ciencia y Tecnologıa,la Caja de Ahorros del Mediterraneo, la Universitat d’Alacant y Por-tal Universia, S.A.
Inaki Alegria, del grup Ixa de la Euskal Herriko Unibertsitatea, porsu lectura atenta de versiones anteriores de este documento.
ADVERTENCIA: Algunas partes de esta documentacion estan provi-sionalmente en catalan, a la espera de su traduccion al espanol.

Capıtulo 1
El ingenio de traduccion detransferencia sintactica superficial
Este capıtulo describe brevemente la estructura del ingenio de traduc-cion automatica de transferencia superficial, basado en el de los sistemasespanol–catalan interNOSTRUM [2, 5, 4] y espanol–portugues TraductorUniversia [7, 17], ambos desarrollados por el grupo Transducens de la Uni-versitat d’Alacant. Se trata de un sistema clasico de traduccion automaticaindirecta que utiliza una estrategia de transferencia sintactica parcial simi-lar a la de algunos sistemas comerciales de TA para ordenadores persona-les.
El diseno del sistema permite obtener sistemas de TA rapidos (que tra-ducen decenas de miles de palabras por segundo en ordenadores de so-bremesa comunes) y cuyos resultados son, a pesar de los errores, razona-blemente inteligibles y faciles de corregir. En el caso de lenguas emparen-tadas como las que nos ocupan (espanol, gallego, catalan), una traduccionmecanica palabra por palabra (con un equivalente fijo) presentarıa erroresque, en su mayorıa, se pueden resolver con un analisis bastante somero(un analisis morfologico seguido de un analisis sintactico superficial, lo-cal y parcial) y con un tratamiento adecuado de las ambiguedades lexicas(principalmente de la homografıa). El diseno adoptado sigue estas direc-trices con resultados muy interesantes. La arquitectura de Apertium utili-za transductores de estados finitos para el procesamiento lexico, modelosocultos de Markov para la desambiguacion lexica y procesamiento de pa-trones basado en estados finitos para la transferencia estructural.
El ingenio de traduccion consiste en una cadena de montaje de ochomodulos, que puede verse representada en la figura 1.1. Para facilitar eldiagnostico y la comprobacion independiente, los modulos se comunicanentre sı en formato de texto. De esta manera, siempre que se quiera se
5

6 CAPITULO 1. EL INGENIO DE TRADUCCION
textoLO↓
desfor-mateador
→ anal.morf.
→ desamb.categ. → transf.
estruc.→ gen.
morf. →post-genera-dor
→ reforma-teador
l ↓transf.lexica
textoLM
Figura 1.1: Los ocho modulos que forman la cadena de montaje del sistema detraduccion automatica por transferencia sintactica superficial.
puede comprobar cual es la entrada y la salida de los mismos y, cuando seproduce algun error en la traduccion, examinar por separado la salida decada uno de ellos para detectar donde se localiza el error. Asimismo, la co-municacion vıa texto permite que los modulos se usen de manera aislada,independientemente del resto del sistema de traduccion automatica, paraotras tareas de procesamiento del lenguaje natural, y posibilita la construc-cion de prototipos con modulos modificados o anadidos.
Se ha elegido que el formato de los ficheros de datos linguısticos seaXML1 por su interoperabilidad, por su independencia del juego de carac-teres y por la existencia de numerosos utiles y librerıas que facilitan elanalisis de los datos codificados en este formato. Como bien se afirma en[8], XML es el estandar emergente para la representacion y el intercambiode datos en Internet. Las tecnologıas en torno a XML incluyen mecanis-mos muy potentes para el acceso y la manipulacion de documentos XMLque probablemente tendran un impacto significativo en el desarrollo deherramientas para el procesamiento del lenguaje de natural y de corpusanotados.
Los modulos de los que se compone Apertium son los siguientes:
El desformateador, que separa el texto a traducir de la informacionde formato (RTF, HTML, etc.); su especificacion se describe en elapartado 3.6.1. La informacion de formato es encapsulada de mane-ra que los modulos restantes la tratan como blancos entre palabras.Por ejemplo, ante el texto HTML en espanol:
es <em>una senal</em>
1http://www.w3.org/XML/

7
el desformatador encapsula las etiquetas HTML entre corchetes yproporciona como salida:
es [<em>]una senal[</em>]
Las secuencias de caracteres entre corchetes son tratadas por el restode modulos como simples espacios en blanco entre palabras.
El analizador morfologico, que segmenta el texto en formas superficia-les (FS) (las unidades lexicas tal como se presentan en los textos) yentrega para cada FS una o mas formas lexicas (FL) consistentes enun lema (la forma base comunmente usada para las entradas de losdiccionarios clasicos), la categorıa lexica (nombre, verbo, preposicion,etc.) y la informacion de flexion morfologica (numero, genero, per-sona, tiempo, etc.). La division de un texto en FS presenta aspectoscomplejos debido a la existencia, por un lado, de contracciones (del,teniendolo, vamonos) y, por otro, de unidades lexicas de mas de unapalabra (a pesar de, echo de menos). El analizador morfologico permiteanalizar estas FS complejas y tratarlas adecuadamente para que seanprocesadas por los modulos posteriores. En el caso de las contraccio-nes, el sistema lee una unica forma superficial y da como salida unasecuencia de dos o mas formas lexicas (por ejemplo, la contracciondel serıa analizada como dos formas lexicas, una para la preposicionde y otra para el artıculo el). Las unidades lexicas de mas de una pa-labra (multipalabras) son tratadas como formas lexicas individualesy, segun su naturaleza, reciben un tratamiento especıfico.2
Al recibir como entrada el texto de ejemplo proveniente del moduloanterior, el analizador morfologico proporcionarıa como salida:
ˆes/ser<vbser><pri><p3><sg>$[ <em>]ˆuna/un<det><ind><f><sg>/unir<vblex><prs><1><sg>/unir<vblex><prs><3><sg>$ˆsenal/senal<n><f><sg>$[</em>]
donde cada forma superficial es analizada como una o mas formaslexicas. Ası, es es analizada como una FS con lema ser, mientras queuna recibe tres analisis: lema un, determinante indefinido femeninosingular; lema unir, verbo en presente de subjuntivo, 1a persona del
2Para mas detalles sobre la el tratamiento de las unidades lexicas de mas de una pala-bra, vease la pagina 44.

8 CAPITULO 1. EL INGENIO DE TRADUCCION
singular, y lema unir, verbo en presente de subjuntivo, 3a persona delsingular.
Este modulo se genera a partir de un diccionario morfologico para lalengua origen (LO), cuyo formato se especifica en el apartado 3.1.2.
El desambiguador lexico categorial, elige, usando un modelo estadıstico(modelo oculto de Markov), uno de los analisis de una palabra am-bigua de acuerdo con su contexto; en el ejemplo utilizado, la palabraambigua serıa la forma superficial una, que puede analizarse de tresmaneras diferentes. Las formas superficiales ambiguas por tener masde un lema, mas de una categorıa o representar mas de una flexionson muy comunes (en las lenguas romanicas, en torno a una de cadatres palabras) y son una fuente muy importante de errores de traduc-cion en caso de elegir el equivalente incorrecto. El modelo estadısticose entrena sobre corpus suficientemente representativos de textos enLO.
El resultado de procesar mediante el desambiguador el texto de ejem-plo proporcionado por el analizador morfologico serıa:
ˆser<vbser><pri><p3><sg>$[ <em>]ˆun<det><ind><f><sg>$ˆsenal<n><f><sg>$[</em>]
en que se ha elegido la forma lexica correcta (el determinante) parala palabra una.
La especificacion del desambiguador lexico categorial se describe enla seccion 3.2.
El modulo de transferencia lexica, que gestiona un diccionario bilinguey es invocado por el modulo de transferencia estructural, lee cadaFL en LO y entrega la FL correspondiente en lengua meta (LM). Eldiccionario contiene un unico equivalente para cada forma lexica dela LO; esto significa que no se realiza ningun tipo de tratamiento dela polisemia. Las multipalabras son traducidas como una unidad. Enel ejemplo utilizado, cada una de las formas lexicas se traducirıa alcatalan de la siguiente manera:
ser<vbser> −→ ser<vbser>un<det> −→ un<det>senal<n><f> −→ senyal<n><m>

9
Este modulo se genera a partir de un diccionario bilingue, descritoen el apartado 3.1.2).
El modulo de transferencia estructural, que detecta y trata patrones depalabras (sintagmas) que exigen un tratamiento especial por cau-sa de las divergencias gramaticales entre las lenguas (cambios degenero y numero, reordenamientos, cambios preposicionales, etc.).Este modulo se genera a partir de un archivo de reglas que des-criben la accion que debe realizarse para cada patron. Ante la fra-se de ejemplo, el patron formado por ˆun<det><ind><f><sg>$ˆsenal<n><f><sg>$ serıa detectado por una regla determinante–nombre, que en este caso modificarıa el genero del determinante pa-ra que concuerde con el nombre; el resultado serıa:
ˆser<vbser><pri><p3><sg>$[ <em>]ˆun<det><ind><m><sg>$ˆsenyal<n><m><sg>$[</em>]
La especificacion del formato del archivo de reglas de transferenciaestructura, que se inspira en la descrita en [5], se encuentra en laseccion 3.5.
El generador morfologico, que genera a partir de la forma lexica en len-gua meta una forma superficial flexionada adecuadamente. El resul-tado para la frase de ejemplo serıa:
es[ <em>]un senyal[</em>]
Este modulo se genera a partir de un diccionario morfologico, cuyascaracterısticas estan descritas en el apartado 3.1.2.
El postgenerador, que realiza algunas operaciones ortograficas en LMtales como contracciones y apostrofaciones, y que es generado a par-tir de un archivo de reglas de transformacion con un formato similaral de los diccionarios anteriores. Su formato se especifica en la sec-cion 3.1.2. En la frase de ejemplo utilizada no hay que realizar nin-guna contraccion ni apostrofacion.
El reformateador, que reintegra la informacion de formato original altexto traducido; el resultado para la frase de ejemplo serıa la correctaconversion del texto a formato HTML:
es <em>un senyal</em>

10 CAPITULO 1. EL INGENIO DE TRADUCCION
La especificacion del reformateador se describe en la seccion 3.6.1.
Los cuatro modulos de procesamiento lexico (el analizador morfologi-co, el modulo de transferencia lexica, el generador morfologico y el postge-nerador) utilizan un unico compilador, basado en un tipo de transductoresde estados finitos [4], concretamente en transductores de letras [14, 11] cuyascaracterısticas se explican en 3.1.3.

Capıtulo 2
Especificacion del formato delflujo de datos entre modulos
[Nota: Material duplicat en ”formatadors i reformatadors”: declarar-ho, treure-ho? - Gema]
2.1. Introduccion
Para enteder y hacer mas efectivo el procesamiento de documentos esnecesario especificar el formato de la informacion que circula como textoentre los modulos del traductor. El diseno propuesto (vease seccion 1) im-pone la necesidad de utilizar tres tipos de flujo de datos distintos como seexpresa en la figura 2.1.
El formato de flujo esta basado en texto para facilitar, entre otras cosas,la tarea de diagnostico sobre posibles errores del sistema ya que resul-ta sencillo manipular el flujo para reproducir aquellos fenomenos que sedesee probar y modificarlos para comprobar el resultado. Otra ventaja des-tacable es la posibilidad de comprobar de manera independiente la salidade cada modulo del traductor y, junto a esto, la rapidez en la construccionde prototipos para comprobar su funcionamiento global, la validez de losdatos linguısticos, etc.
Estos flujos de datos son:
Flujo de datos con formato: Es el texto en su formato original, sin ningunotro tipo de marca: XML, texto ANSI, RTF, HTML, etc. Por ser el for-mato original de los documentos, de este flujo de datos no hay nadaque especificar salvo el tipo de formato de que se trata.
11

12 CAPITULO 2. ESPECIFICACION DEL FORMATO DE FLUJO
Re-formateador
Analizadormorfólogico Etiquetador
Transfer.estructural Generador
Post-generador
Transfer.léxica
Textoorigen
Textometa
Flujo de texto segmentado
Flujo de texto original
Flujo de texto sin formato
Des-formateador
Figura 2.1: Los diversos tipos de flujo de datos en el sistema de traduccion au-tomatica. Vease el texto para la definicion de los diferentes tipos de flujo.
Flujo de datos sin formato: Consiste en el texto con superblancos, mar-cas que encapsulan el formato (vease el apartado 3.6.1) y que sontratadas como si de blancos se tratase (con algunas salvedades) porlos modulos linguısticos del sistema. Este formato es el que generael desformateador, y el que utiliza el reformateador para generar eldocumento traducido final.
Flujo de datos segmentado: Ademas de superblancos, este formato tie-ne delimitadas mediante marcas las unidades lexicas que se debe tra-ducir. Estas marcas son establecidas por el analizador morfologico, yson eliminadas por el generador, que entrega las formas superficialesfinales.
A continuacion describiremos las caracaterısticas del flujo de datos em-pleado entre modulos del traductor. A grandes rasgos, se trata de un for-mato en texto llano con marcas de caracter que poseen un significado es-pecial. Dicho formato esta orientado al procesamiento en servidores quetraduzcan grandes volumenes de texto.
Algunos de los formatos que puede tratar el traductor pueden contenerbloques extensos de informacion en formato binario —como por ejemploRTF, que puede incluir imagenes de mapa de bits—. Para facilitar un pro-cesamiento eficiente de este tipo de documentos se especifica en el apar-tado 3.6.1 una forma de extraer esta informacion para restituirla tras latraduccion.

2.2. FLUJO DE DATOS SIN FORMATO 13
2.2. Flujo de datos sin formatoEl flujo de datos sin formato es producido como salida por el desfor-
mateador y por el generador
[Nota: no del tot: postgenerador]
, y es usado como entrada por el analizador morfologico, por el postgene-rador y por el reformateador.
En el subapartado de esta seccion se especifica la forma de delimitarsuperblancos y superblancos extensos. Para los ejemplos, tomaremos comoreferencia el documento HTML de la figura 2.2.
<html><head><title>Tıtulo</title>
</head><body><p>Frase
dividida</p></body>
</html>
Figura 2.2: Ejemplo de documento HTML
Los elementos estructurales que debe incluir este flujo de datos son lossiguientes:
Superblancos. Se trata de bloques que incluyen segmentos de infor-macion de formato incluida en los documentos, cuando estos soncortos.
Superblancos extensos. Son marcas que se usan para especificar aque-llos documentos externos que incluyan segmentos de informacionde formato del documento que se esta procesando, cuando estos sonlargos.
Texto. El texto de los documentos susceptible de ser traducido.
Finales de frase artificiales. Cuando el formato de los documento in-duzca una separacion de frases que no este marcada por ningunsigno de puntuacion (por ejemplo, los tıtulos que no acaban en puntoo el contenido de las celdillas de una tabla), el formato debe instru-mentar un mecanismo (invisible para el usuario) que permita marcarestos finales de frase.

14 CAPITULO 2. ESPECIFICACION DEL FORMATO DE FLUJO
Proteccion de caracteres especiales (para el caso del flujo no XML). Loscaracteres que se deben proteger para que no entren en conflicto conlos usados en el propio formato del flujo de datos.
2.2.1. Formato de flujo
Este formato se basa en el formato utilizado en los sistemas de traduc-cion interNOSTRUM [2, 5, 4] y Traductor Universia [7, 17].
En este tipo de flujo se usan los caracteres [ y ] para marcar los super-blancos tal y como se muestra a continuacion:
[contenido del superblanco]
Si se trata de superblancos extensos, el nombre del fichero se especificautilizando el caracter de arroba @:
[@nombre de fichero]
El texto se encuentra fuera de las marcas de superblanco.Los finales de frase artificialesse expresan mediante un punto y un super-
blanco vacıo inmediatamente a continuacion.
.[]
Los caracteres protegidos se muestran en la siguiente tabla:
Nombre Caracter Forma proteg. SignificadoArroba @ \@ Superblanco externoBarra / \/ Divisor de acepcionesBarra invertida \ \\ Caracter de proteccionCircunflejo ˆ \ˆ Inicio de FLCorchete de apertura [ \[ Inicio de blancoCorchete de cierre ] \] Fin de blancoDolar $ \$ Fin de FLMayor que > \> Inicio de sımbolo gram.Menor que < \< Fin de sımbolo gram.
En la figura 2.3 muestra como quedarıa encapsulado el documento dela figura 2.2.

2.3. FLUJO DE DATOS SEGMENTADO 15
[<html><head><title>]Tıtulo.[][</title>
</head><body><p>]Frase[
]dividida.[][</p></body>
<html>]
Figura 2.3: El documento de la figura 2.2 con el formato encapsulado usandocorchetes
2.3. Flujo de datos segmentado
El flujo de datos segmentado es el que circula entre los modulos quemanejan informacion linguıstica dentro del traductor. En este flujo las pa-labras se encuentran delimitadas y etiquetadas. Hay dos tipos de flujo seg-mentado:
Flujo segmentado ambiguo. Su caracterıstica principal es que las pala-bras tienen forma superficial y potencialmente varias formas lexicas(multiformas lexicas). Este flujo es el formato en el que el analiza-dor morfologico proporciona los datos de entrada al desambiguadorlexico categorial (consulte el esquema 3.2 de la pagina 59 para obte-ner una descripcion detallada del flujo segmentado ambiguo).
Flujo segmentado no ambiguo. Solo tiene una forma lexica para cadapalabra y no incluye la forma superficial. En este formato transitanlos datos desde el desambiguador al modulo de transferencia y des-de este al generador (consulte el esquema 3.3 de la pagina 62 paraver el formato del flujo segmentado no ambiguo).
Por otro lado, ademas de la informacion que ya marca el flujo de datossin formato, el nuevo flujo debera permitir marcar la siguiente informa-cion:
Unidades lexicas. Una unidad lexica consta de la forma superficial (pa-ra el caso del flujo segmentado ambiguo) mas una o mas formas lexi-cas (que corresponden a los posibles analisis de la FS) con sus sımbo-los gramaticales.

16 CAPITULO 2. ESPECIFICACION DEL FORMATO DE FLUJO
[<html><head><title>]ˆTıtulo/Tıtulo<n><m><sg>$ˆ./.<sent>$[][</title>
</head><body><p>]ˆFrase/Frase<n><f><sg>$[
]ˆdividida/dividir<vblex><pp><f><sg>$ˆ./.<sent>$[][</p></body>
<html>]
Figura 2.4: Ejemplo de flujo segmentado con el formato encapsulado en formatono XML, correspondiente al documento HTML de la figura 2.2.
Formas superficiales (flujo segmentado ambiguo). Se trata de la palabratal y como se encuentra en el texto original.
Formas lexicas. El lema de la palabra con los sımbolos gramaticalescorrespondientes.
Sımbolos gramaticales. Marcan los atributos gramaticales de la formasuperficial correspondiente.
Para delimitar palabras se usan los caracteres de comienzo de palabra’ˆ’ y de fin de palabra ’$’ como se muestra a continuacion:
ˆpalabra$
Para delimitar la forma superficial y las sucesivas formas lexicas se usael caracter de separacion /. Este separador solo tiene sentido en el flujosegmentado ambiguo ya que el no ambiguo solo tiene la forma lexica. Suforma es la siguiente:
ˆforma superficial/forma lexica 1/...$
Las formas lexicas pueden incluir sımbolos (generalmente situados alfinal), tal y como se muestra en el ejemplo de la figura 2.4.

Capıtulo 3
Especificacion de los modulos
3.1. Modulos de procesamiento lexico
3.1.1. Descripcion del funcionamiento
Una de las aproximaciones mas eficientes al procesamiento lexico usatransductores de estados finitos (TEF) [10, 15]. Los TEF son una clase deautomatas de estados finitos que se describen en el apartado siguiente. LosTEF pueden ser usados como analizadores morfologicos de una sola pa-sada y se pueden implementar de manera muy eficiente. En este proyectose usa una clase de TEF denominados transductores de letras [15, 6, 4]; dehecho, cualquier transductor de estados finitos se puede convertir siem-pre en un transductor de letras. Garrido y colaboradores [4, 6] dan unauna definicion formal de los transductores de letras usados en este traba-jo; informalmente, un transductor de letras es una maquina idealizada quese compone de:
1. Un conjunto (finito) de estados, es decir, de situaciones en las quese puede encontrar el transductor segun va leyendo, de izquierdaa derecha, las letras o sımbolos de la entrada. Entre los estados delconjunto se distinguen:
a) Un unico estado inicial: el estado en el que se encuentra el trans-ductor antes de procesar la primera letra o el primer sımbolo dela entrada.
b) Uno o mas estados de aceptacion, a los que solo se llega despuesde haber leıdo completamente una entrada valida y, por tanto,sirven para detectar las palabras validas.
17

18 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
2. Un conjunto (tambien finito) de transiciones de estado, cada una delas cuales se compone de:
a) el estado de partida
b) el estado de llegada
c) la letra o el sımbolo de entrada
d) la letra o el sımbolo de salida
Para permitir que la salida y la entrada tengan longitud diferente encualquier momento, se permite que el sımbolo de entrada este ausen-te, que el sımbolo de salida este ausente o que ambos esten ausentes.Esta circunstancia se indica normalmente usando un sımbolo espe-cial (el sımbolo vacıo).
El transductor construye, cada vez que lee un sımbolo de la entrada,una lista de estados vivos o activos, cada uno de los cuales tiene una salidaasociada (una secuencia de sımbolos). El funcionamiento del transductorde letras es distinto para cada tipo de operacion de procesamiento lexico.Por ejemplo, en el analisis morfologico se intenta leer la entrada mas lar-ga que reconoce el diccionario (modo “de izquierda a derecha, segmentoconcordante mas largo”).
1. Iniciacion: se hace que el conjunto de estados vivos contenga un uni-co estado vivo: el estado inicial, con la palabra vacıa () como salidaasociada al estado.
2. Si desde alguno de los estados del conjunto de estados vivos actualse llega a otros estados mediante transiciones que no tienen sımbolode entrada, se anaden estos estados al conjunto de estados vivos, yse les asocia la salida obtenida alargando las salidas asociadas conel sımbolo de salida que se haya encontrado en las correspondientestransiciones. Esta operacion de ampliacion del conjunto de estadosvivos se efectua hasta que no sea posible anadir mas.
3. Se lee un sımbolo de la palabra de entrada.
4. Se crea un nuevo conjunto de estados vivos con aquellos a los que sellega mediante transiciones que tienen ese sımbolo como entrada, yse asocia a estos estados las salidas alargadas con los correspondien-tes sımbolos de salida encontrados en las transiciones.
5. Si el conjunto actual tiene algun estado vivo se va al paso 2.

3.1. MODULOS DE PROCESAMIENTO LEXICO 19
6. Se recorren hacia atras los conjuntos de estados vivos hasta que en-contramos algun conjunto en el que aparecen estados de aceptacion.Los analisis morfologicos seran las salidas asociadas a dichos esta-dos, y la posicion de lectura se fija a la posicion inmediatamente pos-terior a la de ese conjunto (para que pueda volver a ser procesadapor el transductor en la siguiente pasada).
No todos los estados de aceptacion son de la misma clase, y esto anadealgunas condiciones mas al proceso de aceptacion, para permitir el trata-miento de palabras desconocidas o de palabras que van unidas a otras,como se explicara mas adelante.
Como puede verse, el transductor lee la palabra de entrada solo unavez como caso promedio, de izquierda a derecha y sımbolo a sımbolo, ymantiene una lista tentativa de posibles salidas parciales que va actuali-zando y podando segun lee la entrada. Cuando los transductores de letrasse usan como analizadores morfologicos o como lematizadores, leen unaforma superficial y escriben la(s) forma(s) lexica(s) correspondiente(s). Eneste caso, los sımbolos de entrada son las letras de la forma superficial ylos de salida las letras necesarias para formar los lemas y los sımbolos es-peciales que representan el analisis morfologico, como, por ejemplo, <n>,<f>, <2p>, etc.
El funcionamiento de los transductores en otras tareas de procesamien-to lexico es similar.
[Nota: La nocio de LRLM (left-to-right, longest-match) (o ODSCML,”izquierda a derecha, recortando el segmento concordante mas lar-go”) ha de quedar clara en el funcionamient del morfologic i del transferestructural. Afegir coses de l’article de EAMT 2005.]
3.1.1.1. Tratamiento de mayusculas y minusculas en los diccionarios
Una misma palabra a la entrada de un modulo de procesamiento lexicopuede presentar aspectos diferentes respecto al formato de mayusculas yminusculas. Los casos mas frecuentes son los siguientes:
Toda la palabra esta en minusculas.
Toda la palabra esta en mayusculas.
La primera letra de la palabra esta en mayusculas y el resto en minuscu-las (caso mas tıpico de los nombres propios).

20 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
Las transducciones en el diccionario tambien se pueden encontrar enlos tres estados. La forma en la que un termino se encuentre en el dicciona-rio se usa para tratar de descartar acepciones de la palabra de la siguientemanera:
Si la letra de la entrada es mayuscula y en el estado actual de analisistenemos transiciones concordantes en minusculas, estas transduccio-nes se realizan.
Si la letra de la entrada es minuscula y en el estado actual no tenemostransiciones concordantes en minusuculas, no se realizan.
Esta polıtica nos facilita que no figuren acepciones de nombres propiospara una forma superficial que no empieza por mayuscula.
La condicion de mayuscula o minuscula de una letra en una palabrasera respetada a la salida del traductor a menos que se decida cambiardicha condicion. Esta opcion esta disponible en el modulo de transferenciaestructural para casos como el de traduccion de una palabra en origen pordos palabras en la lengua meta: Cante –¿Vaig cantar.
3.1.2. Formato de los datos: los diccionarios
3.1.2.1. Criterios generales para el diseno de los diccionarios
La experiencia del grupo Transducens de la Universitat d’Alacant en laconstruccion de sistemas de traduccion automatica ya operativos y publi-camente accesibles entre lenguas romanicas (es, ca y pt) ha inspirado losaspectos fundamentales del diseno completo del sistema de traduccionautomatica de transferencia sintactica superficial que se describe en estedocumento y de su aplicacion a las lenguas romanicas de Espana (es, cay gl). En cierto sentido, se podrıa decir que en el presente proyecto solose ha tenido que adaptar (reescribir en un formato estandarizado e inter-operable) las especificaciones y los programas ya usados en proyectos yaoperativos.
En particular, el diseno de los diccionarios se ha seguido realizandoa partir de una arquitectura que pretende independizar al maximo la len-gua origen de la lengua meta, incluso sabiendo que se trata de diccionariosorientados a la traduccion y que no conviene elaborarlos completamentepor separado. El formato utilizado sirve para especificar tanto los diccio-narios morfologicos (monolingues) como los diccionarios bilingues.
El formato de los diccionarios, al igual que el de los demas datos linguısti-cos (fichero de definicion del desambiguador y reglas de transferencia

3.1. MODULOS DE PROCESAMIENTO LEXICO 21
estructural) es XML1, un estandar internacional utilizado en numerososproyectos de tratamiento del lenguaje natural que, gracias a la existenciade numerosos utiles y librerıas, se esta conviertiendo en una herramientamuy potente para la representacion y el intercambio de datos linguısticos(vease el artıculo [8]).
Los diccionarios estan disenados de manera que puedan compilarsepara elaborar transductores de letras con ellos, por cuestiones de eficiencia.Para mas informacion sobre transductores de letras como caso particularde transductores de estados finitos vease el artıculo [6].
Los transductores de letras que se elaboran a partir de los diccionarios(morfologicos, bilingues y de postgeneracion) procesan cadenas de carac-teres de entrada para ofrecer cadenas de salida. De este modo, los diccio-narios estan formados por entradas consistentes en parejas de cadenas queconstituyen las entradas y las salidas de los transductores.
La herramienta mas potente de estos diccionarios es la definicion y eluso de paradigmas. Como en las lenguas romances muchos lemas compar-ten una misma flexion (existen regularidades en la flexion), resulta util ydirecto agrupar estas regularidades en paradigmas de flexion para evitartener que escribir todas las formas de cada palabra. Los paradigmas per-miten representar las entradas del diccionario de manera compacta y op-timizar la velocidad de construccion del diccionario. Una vez establecidoslos paradigmas mas frecuentes en un diccionario, un linguista no tiene quepreocuparse en la mayorıa de ocasiones por toda la flexion de un nuevotermino, puesto que introducir una palabra que se flexiona se reduce gene-ralmente a indicar el lema e identificar la flexion entre los paradigmas pre-viamente definidos. Ademas, el uso de paradigmas reduce los requisitosde memoria, favorece la construccion de transductores de letras eficientesy aumenta la velocidad de compilacion [11]. En los diccionarios bilinguesno se han utilizado paradigmas (aunque se podrıan utilizar), puesto que lamayor parte de la informacion de flexion se procesa de manera implıcita,como se explica en la pagina 40.
3.1.2.2. Tipos de diccionarios
En el sistema tenemos tres tipos de diccionarios: diccionarios morfologi-cos (monolingues) de cada uno de los idiomas implicados (espanol, ca-talan y gallego); diccionarios bilingues para los distintos pares de traduc-cion (espanol–catalan y espanol–gallego), y diccionarios de postgenera-cion para cada uno de los idiomas (que mas que un diccionario con lemas
1http://www.w3.org/XML/

22 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
e informacion morfologica son un pequeno diccionario de las transforma-ciones ortograficas que pueden sufrir las palabras al entrar en contactoentre sı). La estructura de los tres tipos de diccionarios esta especificadamediante la misma DTD (definicion de tipo de documento), que puede con-sultarse en el apendice A.1.
Los diccionarios morfologicos se usan tanto para construir analizado-res morfologicos —el modulo del sistema de traduccion que se usa paraobtener todas las formas lexicas posibles para una forma superficial dadaen la lengua origen— como generadores morfologicos —el modulo quese ocupa de generar la forma superficial en la lengua meta a partir de laforma lexica de cada palabra—. Estos dos modulos se obtienen a partir deun mismo diccionario morfologico, segun el sentido en que el sistema lolea: leıdo de izquierda a derecha se obtiene el analizador, y de derecha aizquierda, el generador.
La estructura de bloques tıpica de estos diccionarios consta de:
Una definicion del alfabeto. Esta definicion se usa exclusivamente pa-ra la construccion del analizador morfologico; en concreto, para queeste pueda recortar las palabras desconocidas y las de las seccio-nes condicionales (ver la explicacion del elemento <section> en lapagina 25) de forma adecuada; el generador morfologico no necesitaesta definicion.
Una definicion de los sımbolos. Consiste en una declaracion de los sımbo-los gramaticales que se usaran en las entradas del diccionario (veaseen el Apendice B una lista con los sımbolos gramaticales utilizadosen este proyecto).
Una definicion de paradigmas. Para poder referirse a ellos en las seccio-nes del diccionario o en otros paradigmas.
Una o mas secciones de diccionario de recorte condicional, de tipo standard.Para incluir la mayorıa de las palabras del diccionario.
Una o mas secciones de diccionario de recorte incondicional. Para incluirciertas palabras que siguen algun patron regular o se recortan inde-pendientemente del texto que les sigue (ver discusion del elemento<section> en la pagina 25). En los diccionarios morfologicos de ca-talan, las palabras que requieren un recorte incondicional se repartenen dos secciones: una para las formas que necesitan que se coloqueun blanco a continuacion (por razones de procesamiento de las for-mas lexicas), como l’ o d’, y otra para signos de puntuacion, numerosy otros signos.

3.1. MODULOS DE PROCESAMIENTO LEXICO 23
Los diccionarios bilingues son los que representan en el sistema el pro-ceso de la transferencia lexica, esto es, la asignacion de la forma lexica dela LM que corresponde a cada forma lexica de la LO. De cada diccionariobilingue se obtienen dos productos segun el sentido en el que el sistema loslea: leıdos de izquierda a derecha se obtiene el modulo de transferencialexica en uno de los sentidos de traduccion, y leıdos de derecha a izquier-da, en el otro sentido. Para los diccionarios bilingues de este proyecto seha convenido que el espanol se situara siempre en la parte izquierda de lasentradas, y las demas lenguas (catalan y gallego), en la parte derecha. Ası,por ejemplo, el diccionario bilingue espanol–gallego se leera de izquier-da a derecha para la traduccion es–gl y de derecha a izquierda para latraduccion gl–es. En aplicaciones como las de este proyecto, estos diccio-narios no tienen paradigmas: se construyen mediante entradas genericasen las que casi nunca se especifica mas que su lema y categorıa gramaticaly no hay informacion de flexion.
El esquema de bloques usado en este proyecto para los diccionariosbilingues es el siguiente:
Una definicion de los sımbolos. Consiste en una declaracion de los sımbo-los gramaticales que se usaran en las entradas del diccionario.
Una seccion unica de diccionario. Para incluir las correspondencias bi-lingues del diccionario.
A partir de 2007, los diccionarios bilingues permiten la especificacionde mas de una traduccion en lengua meta para que un modulo de selec-cion lexica (vease el apartado 3.4) pueda elegir el equivalente mas adecua-do segun el contexto. Para tal fin se ha anadido un atributo a los dicciona-rios bilingues, que se describe en la seccion 3.1.2.4.
Los diccionarios de postgeneracion se usan para llevar a cabo las ope-raciones de transformacion ortografica, contraccion, apostrofacion, etc. quesean necesarias una vez generadas las formas superficiales de la lenguameta debido al contacto entre palabras. Como este tipo de operaciones sepueden expresar como traducciones de cadenas de caracteres se ha opta-do por usar el mismo tipo de diccionarios. Implıcitamente, se entiende quelas partes del texto cuyo procesamiento no se especifica se copian tal comollegan. En estos diccionarios es util la definicion de paradigmas para ex-presar cambios sistematicos en los fenomenos de contacto entre palabras.A diferencia de los demas tipos de diccionarios, estos no tienen sımbolosgramaticales, ya que procesan formas superficiales.
El esquema de bloques de los diccionarios de postgeneracion es el si-guiente:

24 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
Una seccion de definicion de paradigmas. Para componer las entradas.
Una seccion de diccionario. Para incluir los patrones para realizar lapostgeneracion.
En la siguiente tabla se presentan de forma resumida los sentidos delectura de los diccionarios y su utilidad para las lenguas romanicas delpresente proyecto:
Diccionario Sentido de lectura FuncionMorfologico izquierda–derecha analisis de es, ca y gl
derecha–izquierda generacion de es, ca y glBilingue izquierda–derecha traduccion es-ca y es-gl
derecha–izquierda traduccion ca-es y gl-esPostgeneracion izquierda–derecha postgeneracion para ca, es y gl
3.1.2.3. Descripcion del formato de los diccionarios
En esta seccion se presentan los principales elementos del formato enel que se construyen los diccionarios. La definicion formal (una DTD) seda en el apendice A.1. En la seccion 3.1.2.4 se describen las caracterısticasde un diccionario bilingue que funcione en un sistema Apertium que dis-ponga de modulo de seleccion lexica. Finalmente, en las paginas 40 a 43se describen las caracterısticas particulares de las entradas de los tres tiposde diccionarios (morfologicos, bilingues y de postgeneracion respectiva-mente).
Elemento diccionario <dictionary>
Es el elemento raız, que incluye todo el diccionario. Incluye una defi-nicion de caracteres alfabeticos, una definicion de sımbolos (que son lasetiquetas morfologicas de las palabras), una definicion de paradigmas deflexion y una o varias secciones de diccionario, en las que se encuentranlas entradas correspondientes a las formas lexicas (formadas por pares deforma superficial–forma lexica). En la figura 3.1 se muestra la estructurabasica de bloques de un diccionario generico.
Elemento alfabeto <alphabet>
Permite especificar una definicion de caracteres alfabeticos. El objeto deesta especificacion es que los modulos que procesan la entrada mediantetransductores de letras puedan recortarla en palabras individuales.

3.1. MODULOS DE PROCESAMIENTO LEXICO 25
<?xml version="1.0" encoding="iso-8859-15"?><dictionary><alphabet>abcdefghijk ... ABCDEFGH ... cnaeıou</alphabet><sdefs><!-- ... -->
</sdefs><pardefs><!-- ... -->
</pardefs><section ...><!-- ... -->
</section><!-- ... -->
</dictionary>
Figura 3.1: Uso de los elementos <dictionary> y <alphabet>
[Nota: Parlar dels mots desconeguts. Cita 3.1.2.3 - Mikel?]
En la actual especificacion, solo tiene sentido la definicion de este ele-mento en los diccionarios morfologicos, por ser necesario para el analisis.La figura 3.1 muestra un ejemplo de uso de este elemento.
Elemento seccion de definicion de sımbolos <sdefs>
Agrupa todas las definiciones de sımbolos de un diccionario (<sdef>).Un ejemplo se muestra en la figura 3.2.
Elemento definicion de sımbolos <sdef>
Se trata de un elemento vacıo (no delimita ningun contenido): sirvepara especificar los nombres de los sımbolos gramaticales que se usan eneste diccionario mediante los valores del atributo n. Estos sımbolos son losque se utilizaran para etiquetar morfologicamente las formas lexicas. En lafigura 3.2 se ilustra un ejemplo del ambito en el que se usa este elemento.En el Apendice B puede verse una lista de todos los simbolos gramaticalesutilizados en los diccionarios de este proyecto.
Elemento de seccion del diccionario <section>
Define en su interior las palabras que seran reconocidas por el diccio-nario. La razon de dividir el diccionario en secciones es porque ciertos

26 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<sdefs><sdef n="n"/><sdef n="det"/><sdef n="sg"/><sdef n="pl"/><!-- ... -->
</sdefs>
Figura 3.2: Uso del elemento <sdefs>
grupos de formas —como por ejemplo, las que proceden de la identifi-cacion de ciertos patrones regulares, o las que pudieran depender de undialecto especıfico— necesitan en ocasiones un procesamiento diferente.
Uno de los procesamientos especıficos que se resuelven mediante ladefinicion de secciones en el diccionario es el problema del procedimientode recorte (division de palabras) en el analisis morfologico. La mayor par-te de formas se recortan mediante un criterio condicional, atendiendo a siviene un caracter no alfabetico —es decir, no definido en <alphabet>—despues del caracter que esta siendo procesado. Pero hay otras formas, co-mo las catalanas l’ o d’, que requieren un modo de recorte incondicional,sin esperar a leer lo que viene despues —ya que si viene un caracter al-fabetico despues, forma parte de la siguiente palabra—. Estas formas querequieren de un recorte incondicional se incluyen en una seccion especıficadel diccionario. Otros tipos de procesamiento tambien pueden resolversemediante estas divisiones.
Se usa el valor del atributo type para expresar el tipo de reconocimien-to de las cadenas que se usa en cada seccion del diccionario: los valoresdel atributo son standard para casi todos los propositos del diccionario(condicional), postblank para las formas que requieren un recorte incon-dicional y la colocacion de un blanco, e inconditional para las demasformas de recorte incondicional.
El atributo id se usa para otorgar un identificador (un nombre) a lassecciones del diccionario.
Elementos de las entradas <e>
La entrada es la unidad basica del diccionario o de la definicion de pa-radigma. Las entradas consisten en una concatenacion en cualquier ordende parejas de cadenas <p>, transducciones identidad <i>, referencias aparadigmas <par> o expresiones regulares <re>. La estructura y el signi-

3.1. MODULOS DE PROCESAMIENTO LEXICO 27
<section id="principal" type="standard"><!-- ... --></section><section id="patterns" type="inconditional"><!-- ... --></section>
Figura 3.3: Uso del elemento <section>
ficado de estos elementos se explica mas adelante (en las paginas 28, 29,33 y 34 respectivamente).
Se usan dos atributos opcionales con esta entrada. Uno es r (de res-triction) que define si esa entrada se tiene que tener en cuenta durante lalectura del diccionario solo de izquierda a derecha (LR) o solo de derechaa izquierda (RL). Si no se especifica nada se supone que la entrada se debetener en cuenta en ambas direcciones.
En los diccionarios morfologicos, la restriccion de direccion LR se uti-liza para que una FL sea analizada pero no generada (por ejemplo, portratarse de una FL en una variante dialectal que se desea reconocer perono generar) y la restriccion RL para que una palabra solo se genere pero nose analice (necesario, por ejemplo, para las formas con marca de activaciondel postgenerador, vease la pagina 36).
En los diccionarios bilingues, las restricciones LR y RL sirven para quela traduccion se haga solo en un sentido: por ejemplo, en un diccionariobilingue es–ca, LR indicarıa que la FL solo se traduce de espanol a ca-talan, y RL solo de catalan a espanol. Lo ilustraremos con un ejemplo: losadverbios espanoles aun y todavıa los traducimos al catalan por una mis-ma palabra, encara. El adverbio catalan encara solo podemos traducirlo alespanol por uno de las dos, y decidimos traducirlo por todavıa. En estecaso, debemos escribir dos entradas en el diccionario bilingue: la que em-pareja aun con encara debe tener la restriccion LR (traduccion solo de es aca) y la que empareja todavıa con encara no debe tener ninguna restriccion(traduccion en ambos sentidos).
Las restricciones de direccion en diccionarios bilingues son necesariastambien en el caso de palabras con genero por determinar (”GD”) o nume-ro por determinar (”ND”) (vease la pagina 40).
El otro atributo opcional de las entradas es el nombre del lema lm. De-bido a la utilizacion de paradigmas para representar las regularidades enla flexion de las unidades lexicas, las entradas de los diccionarios mor-fologicos contienen la parte del lema que es comun a todas las formas

28 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<p><l><!-- ... --></l><r><!-- ... --></r>
</p>
Figura 3.4: Uso del elemento <p>
flexionadas, es decir, contienen el lema cortado en el punto en que em-pieza la regularidad del paradigma (por ejemplo, los adjetivos espanolesdistinto, absoluto y marino aparecen en las entradas como distint, absolut ymarin, siendo el resto de sus formas flexionadas comun a todos ellos ydescrito en un paradigma). Este hecho puede provocar dificultades en lacomprension del diccionario. Por ello, en las entradas se ha anadido esteatributo, que contiene el lema completo de la forma lexica, de modo que eldiccionario gane en claridad y los linguistas puedan solucionar problemasrapidamente. En los diccionarios bilingues, que no suelen tener referenciasa paradigmas,2 no suele ser necesario usarlo.
Elemento pareja de cadenas <p>
Este elemento basico de los diccionarios se usa en cualquier tipo deentrada para indicar la correspondencia entre dos cadenas de sımbolos,correspondencia que especifica una transformacion lexica que sera reali-zada por un camino de estados en el transductor de estados finitos [4]resultante.
Estan definidas por un par de elementos internos. Uno es el izquierdo(elemento <l>, left) y el otro el derecho (elemento <r>, right). La estructurade esta etiqueta presenta el aspecto que se muestra en la figura 3.4.
Una pareja <p> debe incluir estas dos partes aunque una de ellas pue-de estar vacıa, lo que se corresponde con borrar (o insertar) una cadena.Los elementos <l> y <r> tienen la misma estructura interna y los mis-mos requisitos. Dentro de cada pareja puede haber texto y referencias asımbolos gramaticales (que en las lenguas del presente proyecto, con fle-xion sufijal, se suelen poner al final en cualquier cantidad). En el exteriorde las etiquetas <l> y <r> de las parejas de cadenas no hay nada.
2Podrıan tener referencias a paradigmas, pero no lo hemos considerado necesario paralas lenguas involucradas
[Nota: atencio: ex–, vice–?]
.

3.1. MODULOS DE PROCESAMIENTO LEXICO 29
Elemento referencia a sımbolo (o etiqueta) <s>
Las referencias a sımbolos sirven para especificar la informacion mor-fologica de una FL y se usan en cualquier punto dentro de una pareja decadenas, es decir, dentro de <l>, <r> o de ambos, como si se tratasen decaracteres individuales, aunque en las lenguas del presente proyecto sesuelen poner al final de las parejas y siempre en el mismo orden para elmismo tipo de palabra. Este orden lo decide el linguista segun como quie-ra caracterizar morfologicamente las FL de los diccionarios, y debe ser elmismo en todos los diccionarios del sistema para que las operaciones detransferencia lexica y estructural funcionen correctamente. Ası, por ejem-plo, en los diccionarios de este proyecto, un nombre comun lleva primeroel sımbolo de categorıa (n, nombre), luego el de genero (m, masculino, f,femenino, mf, masculino–femenino), y finalmente el de numero (sg, singu-lar, pl, plural, sp, singular–plural). En el Apendice B se ofrece una lista conlos sımbolos gramaticales utilizados en los diccionarios de este proyecto yel orden que se ha establecido para definir los distintos tipos de palabra.
En los diccionarios morfologicos las referencias a sımbolos se usan enlos paradigmas de flexion y en las entradas que no incluyen ninguna refe-rencia a paradigma. En los diccionarios bilingues suelen indicarse unica-mente los primeros sımbolos gramaticales (normalmente solo el primero)de cada FL, ya que el resto se copia automaticamente de la FL en lenguaorigen a la FL en lengua meta (si coincide en ambas lenguas).
Para especificar el sımbolo al que nos referimos se usa el atributo (obli-gatorio) n. Se requiere que el sımbolo este definido en la seccion de defini-cion de sımbolos (<sdefs>).
Elemento transduccion identidad <i>
Debe ser visto como una forma de escribir una pareja de cadenas enla que la parte izquierda y la parte derecha son identicas. Por ejemplo, atodos los efectos las dos entradas que se muestran en la figuras 3.5 sonequivalentes. La ventaja de escribir las entradas en esta notacion es queresultan mas compactas y tambien mas legibles.
Elemento seccion de definicion de paradigmas <pardefs>
Este elemento agrupa todas las definiciones de paradigmas del diccio-nario, contenidas cada una en un elemento <pardef>, como se muestraen la figura 3.6.

30 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
[1]
<e lm="perro"><p><l>perr</l><r>perr</r>
</p><par n="abuel_o__n"/>
</e>
[2]
<e lm="perro"><i>perr</i><par n="abuel_o__n"/>
</e>
Figura 3.5: Uso del elemento <i>: las entradas [1] y [2] son equivalentes
<pardefs><pardef n="abuel_o__n"><!-- ... -->
</pardef><!-- ... -->
</pardefs>
Figura 3.6: Uso del elemento <pardefs>

3.1. MODULOS DE PROCESAMIENTO LEXICO 31
Elemento de definicion de paradigmas <pardef>
Define un paradigma de flexion del diccionario. Un paradigma se pue-de entender como un pequeno diccionario de transformaciones alternati-vas que se pueden concatenar a partes de las palabras (o a entradas deotro paradigma) para especificar regularidades en el procesamiento lexicode las entradas del diccionario, como, por ejemplo, regularidades en la fle-xion. Para especificar estas regularidades, cada paradigma es una lista deentradas <e> como las del diccionario, es decir, tiene la misma estructuraque una seccion del diccionario <section>; por tanto, las entradas con-sisten en una pareja (<p>) con parte izquierda (<l>) y parte derecha (<r>).Dentro de estos elementos se puede incluir texto o sımbolos morfologicos<s>.
Como en el caso de las definiciones de sımbolos, las definiciones deparadigmas tienen un atributo n que especifica el nombre del paradigmapara poder utilizarlo posteriormente dentro de las entradas del dicciona-rio. Ası, en cada entrada del diccionario bastara con indicar el nombre delparadigma que le corresponde para que queden especificadas todas susposibles formas.
El ejemplo de definicion de paradigma que se apunta en la figura 3.6se desarrolla en la figura 3.7. Para ilustrar que informacion se expresa me-diante el paradigma se presenta la siguiente tabla:
Raız (FS y FL) Desinencia (FS) Analisis (FL)abuel o o<n><m><sg>abuel a o<n><f><sg>abuel os o<n><m><pl>abuel as o<n><f><pl>
Este paradigma se asigna a todos los sustantivos (n) que se flexionanigual que abuelo, como alumno, amigo o gato, y esta pensado para ser usa-do como sufijo en las entradas del diccionario. En general se pueden usarparadigmas en cualquier punto de las entradas del diccionario (siempreque tenga sentido, claro esta). Podemos pensar en los paradigmas comotransductores que se insertan en el punto en el que se haga referencia aellos. En la figura 3.8 se muestra un ejemplo de un paradigma definidopara ser usado como prefijo. Es el caso del paradigma que se usa paraanalizar y generar las palabras que empiezan por ex, ex-, etc., como ex-presidente, exministro, ex director, etc., con sus variaciones ortograficas (excon guion, sin guion unido y sin guion separado por un blanco <b/>,vease la pagina 3.1.2.3); el lema entregado simplemente anade ex sin guion

32 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<pardef n="abuel_o__n"><e><p><l>o</l><r>o<s n="n"/><s n="m"/><s n="sg"/></r>
</p></e><e><p><l>a</l><r>o<s n="n"/><s n="f"/><s n="sg"/></r>
</p></e><e><p><l>os</l><r>o<s n="n"/><s n="m"/><s n="pl"/></r>
</p></e><e><p><l>as</l><r>o<s n="n"/><s n="f"/><s n="pl"/></r>
</p></e>
</pardef>
Figura 3.7: Uso del elemento <pardef> para definir la morfologıa flexiva desubstantivos de cuatro terminaciones como abuelo, -a, -os, -as.

3.1. MODULOS DE PROCESAMIENTO LEXICO 33
<pardef n="ex"><e r="LR"><p><l>ex<b/></l><r>ex</r></p></e><e><i>ex</i></e><e r="LR"><p><l>ex-</l><r>ex</r></p></e><e><i/></e>
</pardef>
Figura 3.8: Uso del elemento <pardef> en el paradigma usado para el prefijo ex.
ni blanco al lema del resto. Las restricciones de direccion ("LR") que apa-recen en el ejemplo se usan para decidir que forma es la que va a generarel traductor. La transduccion identidad vacıa (<i/>) es necesaria en estecaso para analizar y generar la palabra sin el prefijo ex.
Las entradas de un paradigma pueden incluir referencias a otros para-digmas con la condicion de que hayan sido definidos previamente en elfichero. Por otro lado, por el momento, una definicion de paradigma nopuede incluirse a sı mismo ni directa ni indirectamente.
Los paradigmas se usan en los diccionarios morfologicos para el anali-sis y la generacion de formas lexicas. Para los pares de lenguas de esteproyecto, no es necesaria la definicion de paradigmas en los diccionariosbilingues (vease la pagina 40).
A partir de Apertium 2 existe un nuevo tipo de paradigma, llamadometaparadigma, que permite definir paradigmas con variaciones segunel valor de un atributo especificado en cada entrada que haga referenciaal metaparadigma. En el apartado 3.1.2.7 se explican sus caracterısticas yutilizacion.
Elemento referencia a paradigma de flexion <par>
Se utiliza dentro de las entradas para indicar que paradigma, de los quese han definido en <pardefs>, sigue la entrada en cuestion. Gracias a lasreferencias a paradigmas no es necesario escribir en cada entrada de undiccionario morfologico todas las formas flexionadas del lema. El atributon sirve para especificar a que paradigma se hace referencia.
El resultado de insertar una referencia a paradigma en una entrada esla creacion de tantas parejas de cadenas como casos especifique el paradig-ma. Por ejemplo, la entrada de la figura 3.9, con la referencia al paradigma”abuel o n”(que esta definido en la figura 3.7), equivale a realizar unaentrada con cada pareja de cadenas del paradigma concatenada al lema(es decir, con cada forma flexionada del lema), como se representa en la

34 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<e lm="perro"><i>perr</i><par n="abuel_o__n"/>
</e>
Figura 3.9: Uso del elemento <par>
figura 3.10. En ella puede verse como el paradigma ofrece siempre comocadena derecha (<r>) el lema (perro) junto con los sımbolos gramaticalescorrespondientes a la forma superficial, ya que es a partir del lema que serealizan las operaciones de transferencia.
El uso adecuado de paradigmas, ademas de permitir la creacion dediccionarios compactos, favorece la velocidad de compilacion y rebaja lanecesidad de memoria durante la misma, ya que durante el proceso decompilacion es posible crear una unica estructura de datos para cada unode la mayor parte de paradigmas [11].
Elemento expresion regular <re>
En los lenguajes naturales tambien hay patrones que se pueden reco-nocer como expresiones regulares: por ejemplo, los signos de puntuacion,los numeros (latinos o romanos), las direcciones de correo electronico o depaginas de internet o cualquier tipo de codigo identificable mediante estosmecanismos.
Para estos usos se utiliza la cadena que contiene la etiqueta <re>. Elcompilador lee la definicion de la expresion regular y la transforma en untransductor que se integra en el resto del diccionario y que traduce todaslas cadenas que concuerdan con la expresion por cadenas identicas.
La sintaxis de la implementacion actual de estas expresiones regularesprocesa un subconjunto de las expresiones regulares de Unix, que incluyelos operadores *, ?, | y +, ademas de agrupaciones mediante parentesisy rangos de caracteres opcionales como por ejemplo [a-zA-znu] o susversiones negadas, por ejemplo [ˆa-z].
Por analogıa, se pueden ver como si se tratase de elementos <i>, perocon la caracterıstica de que pueden identificar cadenas que en algun casopueden ser infinitas (como los numeros).
En la figura 3.11 se muestra como etiquetar cantidades expresadas co-mo numeros arabigos en el diccionario.

3.1. MODULOS DE PROCESAMIENTO LEXICO 35
<e><p><l>perro</l><r>perro<s n="n"/><s n="m"/><s n="sg"/></r>
</p></e><e><p><l>perra</l><r>perro<s n="n"/><s n="f"/><s n="sg"/></r>
</p></e><e><p><l>perros</l><r>perro<s n="n"/><s n="m"/><s n="pl"/></r>
</p></e><e><p><l>perras</l><r>perro<s n="n"/><s n="f"/><s n="pl"/></r>
</p></e>
Figura 3.10: Entrada equivalente a la de la figura 3.9 que muestra el resultado deinsertar la referencia a paradigma <par> con el paradigma definido en la figura3.7.
<e><re>[0-9]+([.,][0-9]+)?(%)?</re><p><l/><r><s n="num"/></r></p>
</e>
Figura 3.11: Uso del elemento <re> en una entrada que sirve para la identifica-cion de numeros arabigos.

36 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<e lm="hoy en dıa"><p><l>hoy<b/>en<b/>dıa</l><r>hoy<b/>en<b/>dıa<s n="adv"/></r>
</p></e>
Figura 3.12: Uso del elemento <b>
Elemento de bloque de blancos <b>
Se usa para expresar la presencia de blancos entre palabras de una uni-dad multipalabra (vea la explicacion de las multipalabras en la pagina 44).Se puede usar dentro de los elementos <i>, <l> y <r>. En la figura 3.12 sepuede ver la entrada correspondiente a la expresion hoy en dıa: los espaciosexistentes entre las palabras aparecen como elementos <b/> dentro de lascadenas izquierda y derecha.
Los blancos pueden ser caracteres de espaciado normales o bloques deinformacion sobre el formato del documento encapsulados por el desfor-matador (superblancos, ver seccion 3.6.1).
Elemento de activacion del postgenerador <a>
El elemento de activacion del postgenerador <a> se usa para indicarque algunas palabras en la lengua meta son susceptibles de sufrir trans-formaciones ortograficas por contacto con otras palabras; por ejemplo,ser apostrofadas, contraıdas, escritas sin espacios intermedios, etc. Estastransformaciones deben realizarse tras la generacion de las formas super-ficiales en la lengua meta, ya que antes, con las palabras aisladas, no es po-sible saber que palabras entraran en contacto. Ası, es el modulo siguienteal generador (llamado postgenerador) el que se encarga de tales operacio-nes. Para indicar que palabras debe procesar el postgenerador, se usa esteelemento en la parte de la forma superficial de las entradas correspondien-tes de los diccionarios morfologicos.
El ejemplo de la figura 3.13 muestra su uso en un diccionario mor-fologico de catalan para la preposicion de, la cual, si aparece delante delartıculo definido masculino singular o plural (el, els) forma una contrac-cion (del, dels). La etiqueta <a/> incluye informacion que provoca la ac-tivacion del postgenerador, el cual comprueba si la preposicion viene se-guida de las palabras que provocan su contraccion y, de ser ası, la realiza(vease la pagina 43 para mas detalles). La restriccion RL indica que es-

3.1. MODULOS DE PROCESAMIENTO LEXICO 37
<e r="RL" lm="de"><p>
<l><a/>de</l><r>de<s n="pr"/></r>
</p></e>
Figura 3.13: Uso del elemento <a> en un diccionario morfologico
ta entrada es solo de generacion, ya que no tiene ningun sentido para elanalisis.
Elemento de marcado de grupos <g>
Este elemento se usa para definir, dentro de los elementos <l> y <r>,grupos que requieren un tratamiento especial mas alla del tratamiento pa-labra por palabra. Se utiliza en las multipalabras con flexion para senalarel principio y el final de la forma o formas lexicas que van unidas a la pa-labra flexionada y que, junto a ella, forman una unidad inseparable. En lapagina 44 se explican con mas detalle los distintos tipos de multipalabra, yen la figura 3.22 del mismo puede verse un ejemplo de utilizacion de esteelemento.
Elemento de union de formas lexicas <j>
Este elemento se utiliza solo en la parte izquierda de las entradas (<r>)para indicar que las palabras que forman parte de una multipalabra sontratadas como formas lexicas individuales y, por lo tanto, tienen cada unaun sımbolo morfologico. Estas multipalabras seran tratadas como una uni-dad por el analizador y por el desambiguador hasta llegar al modulo au-xiliar pretransfer (vease el apartado 3.3), que se encarga de separar lasformas lexicas que las componen para que lleguen al modulo de transfe-rencia como formas independientes. Si se desea que estas formas lleguenal generador como formas unidas, formando una multipalabra otra vez,debe haber una regla de transferencia estructural que realice la accion deagruparlos (vease el apartado 3.5.4). Si, por el contrario, estas formas de-ben ser solo de analisis, la entrada debe tener la restriccion LR.
En la pagina 44 se ilustra mas detalladamente el uso de este elemento.Puede verse un ejemplo de uso en la figura 3.20 de la mencionada seccion.

38 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
3.1.2.4. Modificacion de los diccionarios bilingues para el nuevo modu-lo de seleccion lexica
En 2007 se ha anadido un nuevo modulo al sistema Apertium: el modu-lo de seleccion lexica, que se describe en el apartado 3.4.
Para funcionar en un sistema de seleccion lexica, los diccionarios bi-lingues deben ser modificados ligeramente para permitir la especificacionde mas de una traduccion en lengua meta. El unico cambio consiste en elanadido de dos nuevos atributos al elemento <e>. Estos nuevos atributospueden utilizarse en todos los diccionarios pero solo tienen sentido cuan-do se trata de una entrada del diccionario bilingue.
En el Apendice A.1.1 se muestra el fragmento de la DTD dix.dtd
[Nota: MG: no caldria ajuntar les dues DTDs en una de sola?]
donde se define el elemento e usado para codificar las entradas en losdiccionarios. Los nuevos atributos introducidos son:
slr (sense from left to right) se utiliza para especificar la marca de traduc-cion cuando hay mas de una traduccion de izquierda a derecha parael lema situado en la parte izquierda de la entrada. El atributo puederecibir cualquier valor; sin embargo, lo mas apropiado es que recibacomo valor el lema situado en la parte derecha <r> (la traducciondel lema).
srl (sense from right to left) se utiliza para especificar la marca de traduc-cion cuando hay mas de una traduccion de derecha a izquierda parael lema situado en la parte derecha de la entrada. Como antes, elatributo puede recibir cualquier valor, pero lo mas apropiado es quereciba el lema situado en la parte izquierda <l> (la traduccion dellema).
Ademas, en ambos casos el valor del atributo puede acabar con unespacio en blanco y la letra “D” para indicar que esta es la traduccion pre-determinada, es decir, la traduccion a emplear cuando no hay suficienteinformacion para elegir otra. Es obligatorio que las entradas con mas deun equivalente en lengua meta tengan una, y solo una, de estas equivalen-cias marcada con la letra “D” de predeterminado.
El siguiente ejemplo ilustra el funcionamiento de los nuevos atribu-tos. Consideramos el caso de un diccionario bilingue ingles–catalan y lassiguientes entradas con mas de una traduccion en lengua meta:
look: que se puede traducir al catalan por mirar (por defecto) o porsemblar (en espanol, mirar/parecer),

3.1. MODULOS DE PROCESAMIENTO LEXICO 39
floor: que se puede traducir al catalan por pis (por defecto) o por terra(en espanol, piso/suelo)
pis: que se puede traducir al ingles por flat (por defecto) o por floor.
Esta informacion se representa utilizando los dos atributos descritosantes:
<e srl="flat D"><p>
<l>flat<s n="n"/></l><r>pis<s n="n"/><s n="m"/></r>
</p></e>
<e slr="pis D" srl="floor"><p>
<l>floor<s n="n"/></l><r>pis<s n="n"/><s n="m"/></r>
</p></e>
<e slr="terra"><p>
<l>floor<s n="n"/></l><r>terra<s n="n"/><s n="m"/></r>
</p></e>
<e slr="mirar D"><p>
<l>look<s n="vblex"/></l><r>mirar<s n="vblex"/></r>
</p></e>
<e slr="semblar"><p>
<l>look<s n="vblex"/></l><r>semblar<s n="vblex"/></r>
</p></e>

40 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<e><p><l>pan<s n="n"/></l><r>pa<s n="n"/></r>
</p></e>
Figura 3.14: Entrada en el diccionario bilingue para la traduccion pan (es)–pa (ca)
3.1.2.5. Particularidades de los distintos tipos de diccionarios
Las entradas de los diccionarios tienen algunas caracterısticas diferen-ciadas segun el diccionario de que se trate. Aunque en la especificacionprecedente han quedado apuntadas algunas de estas particularidades, acontinuacion las presentamos de manera mas exhaustiva.
Diccionarios morfologicos
En estos diccionarios, que se usan para construir los analizadores ylos generadores morfologicos, se deben marcar mediante <a/> las formassuperficiales que una vez generadas pueden necesitar ciertas transforma-ciones ortograficas por contacto con otras palabras, operaciones de la quese encarga el postgenerador. Como se trata de marcas que solo se generan,las entradas que contengan estas marcas deben ser solo de generacion, esdecir, con la restriccion r="RL" (de derecha a izquierda). En la figura 3.13puede verse un ejemplo de entrada con este elemento.
Diccionarios bilingues
Como ya hemos explicado, en nuestro sistema no se utilizan paradig-mas en los diccionarios bilingues; estos se construyen mediante entradasgenericas en las que casi nunca se especifica mas que su categorıa gramati-cal y no hay informacion de flexion. Por ejemplo, en el diccionario es-cala entrada para la palabra espanola pan, panes, traducida al catalan por pa,pans, quedarıa como muestra la figura 3.14.
Como vemos, en la entrada unicamente se especifica el primero sımbo-lo gramatical <s n="..."/> de ambas palabras, ya que los sımbolos noespecificados que siguen a los especificados en el diccionario bilingue soncopiados de la forma lexica original a la forma lexica de la lengua meta;ası, esta entrada vale tanto para pan (singular) como para panes (plural),ya que el modulo analizador entrega el lema (pan) seguido de los sımbo-

3.1. MODULOS DE PROCESAMIENTO LEXICO 41
<e><p><l>cama<s n="n"/><s n="f"/></l><r>llit<s n="n"/><s n="m"/></r>
</p></e>
Figura 3.15: Entrada en el diccionario bilingue para la traduccion cama (es)–llit(ca)
los gramaticales correspondientes a la forma superficial analizada (n m sgo n m pl segun el caso); por lo tanto, los sımbolos no especificados en laentrada (m sg o m pl) se copian a la lengua meta. Lo mismo vale para losdos sentidos de traduccion. La idea es que se especifica la informacionimprescindible para diferenciar las entradas y el resto de informacion sesobreentiende (se copia). Es importante tener en cuenta este hecho ya que,si existen diferencias entre los sımbolos gramaticales de una forma lexi-ca entre la LO y la LM, estas diferencias deben quedar especificadas en eldiccionario bilingue. Ası, por ejemplo, cuando hay un cambio de generoo de numero entre la forma original y la forma traducida, hay que especi-ficar los sımbolos gramaticales por orden (el orden en que aparecen estossımbolos en los diccionarios morfologicos)3 hasta que lleguemos al sımbo-lo divergente entre LO y LM.
Por ejemplo, para traducir la palabra espanola cama, nombre femenino,por la palabra catalana llit, nombre masculino, la entrada en el diccionariobilingue debe ser como se muestra en la figura 3.15. Debe especificarse elgenero (f, m) ya que, de no hacerlo, se copiarıan los sımbolos de generoy numero de la forma lexica en LO a la forma lexica en LM. Por lo tanto,al traducir de es a ca se obtendrıa la forma lexica llit con los sımbolosn f sg o bien n f pl. En ambos casos, el generador se encontrarıa conuna palabra imposible de generar, ya que los diccionarios morfologicosdel catalan no contienen ninguna entrada con lema llit y genero femenino.
En este ejemplo el numero no se especifica y la entrada sirve tanto pa-ra la correspondencia cama–llit como para la correspondencia camas–llits.Sin embargo, si hay que especificar un cambio de numero, no hay mas re-medio que especificar tambien el genero si en todo el diccionario el ordenusado es genero, numero.
Mediante la restriccion de direccion r podemos indicar que traduccio-
3Para saber que sımbolos gramaticales se han utilizado en los diccionarios morfologi-cos y en que orden, consultese el Apendice B.

42 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
nes tienen lugar en un sentido y no en el otro (vease la descripcion de lasrestricciones LR y RL en la pagina 27). Esto es necesario cuando la corres-pondencia entre dos formas lexicas no es simetrica, en cuyo caso debenrealizarse varias entradas en el diccionario bilingue con alguna restriccionde direccion, como en el ejemplo de la figura 3.16. En este ejemplo, cuandotraducimos de espanol a catalan (LR), necesitamos que solo se generen for-mas en plural porque la palabra postres en catalan no tiene singular. Peroen cambio, solo traduciremos al espanol en plural porque no hay forma dedeterminar si el numero serıa singular o plural.
<e r="LR"><p><l>postre<s n="n"/><s n="m"/><s n="sg"/></l><r>postres<s n="n"/><s n="m"/><s n="pl"/></r>
</p></e>
<e><p><l>postre<s n="n"/><s n="m"/><s n="pl"/></l><r>postres<s n="n"/><s n="m"/><s n="pl"/></r>
</p></e>
Figura 3.16: Entradas en el diccionario bilingue espanol–catalan/valenciano parala correspondencia postre–postres
Existe otro problema debido a las diferencias gramaticales entre doslenguas determinadas que se soluciona con dos sımbolos especiales, GD(de genero por determinar) y ND (de numero por determinar), sımbolos que de-beran estar definidos en la seccion de sımbolos del diccionario bilingue.Este problema surge cuando la informacion gramatical de una forma lexi-ca en LO no es suficiente para determinar el genero (masculino o feme-nino) o el numero (singular o plural) de la forma lexica en LM. Por po-ner un ejemplo, el adjetivo comun en espanol es tanto masculino comofemenino (y por tanto masculino/femenino, mf), pero en catalan hay for-mas diferentes para el masculino, comu/comuns, y para el femenino, co-muna/comunes. En el diccionario bilingue la entrada quedarıa como se veen la figura 3.17: en la direccion LR (de espanol a catalan), la informacionde genero no es m, f ni mf sino GD; este genero por determinar lo deter-minara a continuacion el modulo de transferencia estructural mediante

3.1. MODULOS DE PROCESAMIENTO LEXICO 43
la aplicacion de las reglas de transferencia apropiadas (normalmente re-glas de concordancia entre formas lexicas de un patron; vease el apartado3.5 para obtener una descripcion detallada del funcionamiento de las re-glas de este modulo). Analogamente, se puede definir un mecanismo simi-lar, mediante el sımbolo ND, para el caso del numero singular–plural (porejemplo, en espanol analisis es singular y plural, mientras que en catalanel singular es analisi y el plural analisis).
<e r="LR"><p><l>comun<s n="adj"/><s n="mf"/></l><r>comu<s n="adj"/><s n="GD"/></r>
</p></e>
<e r="RL"><p><l>comun<s n="adj"/><s n="mf"/></l><r>comu<s n="adj"/><s n="m"/></r>
</p></e>
<e r="RL"><p><l>comun<s n="adj"/><s n="mf"/></l><r>comu<s n="adj"/><s n="f"/></r>
</p></e>
Figura 3.17: Entradas en el diccionario bilingue espanol–catalan para la corres-pondencia comun–comu, la primera para la traduccion del espanol al catalan y lasdos ultimas para la traduccion del catalan al espanol
Diccionarios de postgeneracion
En el diccionario morfologico, las formas lexicas que, una vez genera-das, pueden sufrir operaciones de contraccion, apostrofacion, etc., segunlas palabras que entren en contacto con ellas en el texto resultante, debenllevar la marca de activacion del postgenerador (<a/>, vease la pagina 36)en la entrada de generacion (direccion LR). Es fundamental que las for-mas superficiales marcadas con la marca de activacion del postgenerador

44 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
coincidan en los diccionarios morfologicos y de postgeneracion del mismotraductor. En el diccionario de postgeneracion, todas las entradas comien-zan por esta marca de activacion.
En la figura 3.18 se muestra un ejemplo de fragmento del postgene-rador para el espanol; en este ejemplo se puede ver como se realiza lacontraccion de de y el para formar del. En el ejemplo, el paradigma no defi-nido, puntuacion, es un paradigma que se limita a definir los caracteresno alfabeticos que pueden formar parte de un texto. Vemos en el ejem-plo que la entrada para la preposicion de lleva la marca <a/>. El paradig-ma asignado a esta entrada, ”el”, es el que encontramos definido arriba.De este modo, cuando el sistema se encuentra con la cadena izquierdade la entrada (la parte entre <l>) concatenada con la cadena izquierdadel paradigma (es decir, cuando se encuentra con las cadenas de entra-da "<a/>de<b/>el<b/>" o bien "<a/>de<b/>el[puntuacion]"), elmodulo ofrece como cadena de salida (la parte entre <r>) la cadena "del"seguida de los blancos representados por <b/> o de los sımbolos repre-sentados por [puntuacion]. Notese que a la salida del modulo todas lasmarcas <a/> han sido eliminadas.
[Nota: en l’exemple, .el”no ha de portar la marca d’activacio oi? - l’hetreta de l’exemple, treure-la dels diccionaris (Mikel?)]
3.1.2.6. Unidades lexicas multipalabra
Con el formato propuesto para los diccionarios es posible introducirunidades lexicas multipalabra —simplificando, multipalabras— de formas di-ferentes dependiendo del problema que haya que resolver.
En este proyecto se consideran tres tipos basicos de unidades multipa-labra:
1. El caso mas sencillo es el de las multipalabras sin flexion, que estanformadas por una sola forma lexica, ya que su lema consta de variaspalabras ortograficas invariables pero se etiqueta como una unidad.En la figura 3.19 se muestra un ejemplo de unidad multipalabra in-variable (la expresion hoy en dıa). Esta multipalabra consta de trespalabras separadas por un blanco (<b/>) y, aunque estrictamenteeste formada por un adverbio, una preposicion y un nombre, se eti-queta globalmente como adverbio, pues cumple una funcion equi-valente.
2. Un caso algo mas complejo es el de las multipalabras compuestas, queestan formadas por mas de una forma lexica, cada una con sus sımbo-

3.1. MODULOS DE PROCESAMIENTO LEXICO 45
<dictionary><pardefs>...<pardef n="el"><e><p><l>el<b/></l><r>l<b/></r>
</p></e><e><p><l>el</l><r>l</r>
</p><par n="puntuacion"/>
</e></pardef>...
</pardefs><section id="main" type="standard">...<e><p><l><a/>de<b/></l><r>de</r>
</p><par n="el"/>
</e>...
</section/></ditionary>
Figura 3.18: Diccionario de postgeneracion en el que se observa la informacionnecesaria para la contraccion espanola de + el = del .

46 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<e lm="hoy en dıa"><p><l>hoy<b/>en<b/>dıa</l><r>hoy<b/>en<b/>dıa<s n="adv"/></r>
</p></e>
Figura 3.19: Ejemplo de multipalabra sin flexion en el diccionario mor-fologico.
los gramaticales. Se considera que las palabras de las que se compo-nen no conforman una unidad semantica como en el caso anterior, yque solo aparecen juntas formando una unidad por razones de con-tacto entre sı (razones foneticas u ortograficas). En esta categorıa en-tran las contracciones y los pronombres enclıticos que acompananan alos verbos. Para marcar este fenomeno se usa la etiqueta <j> descri-ta en la pagina 37. Puede verse un ejemplo en la figura 3.20, en la queel analisis de del entrega una multiforma lexica compuesta por dosformas lexicas: de, preposicion, y el, determinante definido mascu-lino singular, enlazadas mediante el elemento <j/>. El analizador yel desambiguador lexico categorial tratan estas multipalabras comouna unidad; sin embargo, antes de entrar al modulo de transferen-cia son procesadas por un modulo auxiliar llamado pretransfer(vease el apartado 3.3) que se encarga de separar las formas lexicasde las que se componen. De este modo llegan al modulo de transfe-rencia como formas independientes; es el linguista quien debe deci-dir si hay que volver a unirlas (tarea que debe realizarse en el modulode transferencia estructural) o si deben continuar como formas inde-pendientes a traves de los modulos posteriores.
En nuestro sistema, los elementos que forman cada contraccion pro-siguen como formas independientes, y es tarea del postgeneradorrealizar la contraccion en la lengua meta en caso de que sea necesa-ria. En cambio, los pronombres enclıticos vuelven a unirse al verbomediante una regla de transferencia estructural (vease el apartado3.5), de modo que el verbo mas los enclıticos llegan como una so-la multiforma lexica al modulo de generacion, unidos entre sı me-diante el elemento <j/>. Por lo tanto, las entradas que contienenpronombres enclıticos no deberan tener ninguna restriccion de direc-cion, como puede verse en el ejemplo de la figura 3.21, que muestraun fragmento del paradigma del verbo ”dar”, concretamente la en-

3.1. MODULOS DE PROCESAMIENTO LEXICO 47
<e lm="del" r="LR"><p><l>del</l><r>de<s n="pr"/><j/>el<s n="det"/><s n="def"/><s n="m"/><s n="sg"/></r>
</p></e>
Figura 3.20: Ejemplo de entrada para analizar una contraccion (la contrac-cion espanola del) en el diccionario morfologico.
<e><p><l>ar</l><r>ar<s n="vblex"/><s n="inf"/><j/></r>
</p><par n="S__cantar"/>
</e>
Figura 3.21: Fragmento del paradigma de flexion del verbo dar, que mues-tra la entrada correspondiente a la forma de infinitivo seguida de un pro-nombre enclıtico. Los pronombres enclıticos estan contenidos en el para-digma S cantar. Observese que, a diferencia de la figura 3.20, la entradaes tanto de analisis como de generacion.
trada correspondiente a la forma de infinitivo unida a un pronombreenclıtico.
3. El caso mas complejo de los que se especifican en este documentoes el de las multipalabras con flexion intercalada en medio del lema (oformas de ”lema partido”), que se muestra en la figura 3.22. Este tipode multipalabras se caracterizan por tener lemas con una parte afec-tada por la flexion (a la que llamamos cabeza del lema) seguida de unaparte invariable (a la que llamamos cola del lema). La parte invariablese colocara entre elementos <g>, para poder moverla a la posicioninmediatamente posterior a la cabeza del lema con el objetivo de ob-tener el lema de la multipalabra. Es decir, conviene considerar queel lema de multipalabras como echo de menos, echandole de menos, etc.sea echar de menos, ya que sera esta forma la que se buscara en eldiccionario bilingue para encontrar su traduccion. Esto supondra un

48 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<e lm="echar de menos"><i>ech</i><par n="aspir/ar__vblex"/> <!-- incluye pronombres enclıticos --><p><l><b/>de<b/>menos</l><r><g><b/>de<b/>menos</g></r>
</p></e>
Figura 3.22: Ejemplo de entrada en el diccionario morfologico que contieneun grupo <g>.
adelantamiento de la cola del lema (de menos) detras de la forma noflexionada de la cabeza del lema (echar). Este adelantamiento se rea-lizara en el modulo auxiliar pretransfer (vease el apartado 3.3)que se ejecuta antes del modulo de transferencia estructural.
Para entender el ejemplo de la figura 3.22, hay que tener en cuentaque el paradigma que define el verbo echar incluye, ademas de laflexion del verbo, los pronombres enclıticos que van al final de lasformas flexionadas del verbo, los cuales aparecen enlazados, en lamultiforma lexica resultante, usando el elemento vacıo <j/>.
Cuando la traduccion es tambien un lema partido (por ejemplo, encatalan trobar a faltar, con formas como trobem a faltar, trobar-lo a fal-tar, etc.), es necesario recolocar la cola en su sitio, tras la forma fle-xionada mas los pronombres enclıticos, en caso de haberlos, e in-dicar la correspondencia de estos fragmentos invariables del lema(de menos, a faltar) a ambos lados de la traduccion. Ası, en el ejem-plo de la figura 3.22, el elemento <g> sirve para diferenciar el grupo‘<b/>de<b/>menos’ en el diccionario morfologico. En el dicciona-rio bilingue (vease la figura 3.23), el elemento <g> sirve para esta-blecer una correspondencia entre los grupos “<b/>de<b/>menos”y “<b/>a<b/>faltar”.
[Nota: I com sera el cas de “direccion general” - “direccionesgenerales”?]
Cuando la traduccion no es ningun lema partido, no hace falta intro-ducir ningun elemento <g> en la cadena correspondiente a la lenguameta.

3.1. MODULOS DE PROCESAMIENTO LEXICO 49
<e><p><l>echar<g><b/>de<b/>menos</g><s n="vblex"/></l><r>trobar<g><b/>a<b/>faltar</g><s n="vblex"/></r>
</p></e>
Figura 3.23: Ejemplo de entrada en el diccionario bilingue que contiene dos gru-pos <g> en correspondencia.
3.1.2.7. Metaparadigmas
[Nota: Marco diu: Especificar la DTD?]
Al desarrollar los diccionarios para el traductor de occitano surgio lanecesidad de crear una herramienta que permitiera la especificacion deparadigmas para verbos que tenıan una misma flexion pero cuya raız cam-biaba en las diferentes formas flexionadas. Con el sistema de especificacionde paradigmas existente, era necesario crear un paradigma diferente paracada verbo, puesto que los paradigmas solo permitıan especificar regulari-dades en la flexion de verbos con raız invariable. Con los metaparadigmas,se puede especificar la regularidad de flexion junto con variaciones en laraız del verbo.
Asimismo, los metaparadigmas permiten tambien especificar, en unmismo paradigma, variacion de sımbolos gramaticales para determinadoslemas. Es decir, varios lemas pueden hacer referencia a un mismo metapa-radigma aunque tengan algun sımbolo gramatical diferente. Ası como enel caso del occitano, los metaparadigmas han servido para tener un mismoparadigma para entradas con variaciones en la raız, para el ingles, estoshan servido para tener un mismo paradigma para entradas con variacio-nes en los sımbolos gramaticales.
A partir de ahı se ha creado el concepto de metadiccionario: un dic-cionari que contiene tanto metaparadigmas como paradigmas con el for-mato utilizado hasta ahora. El nombre de un diccionario de este tipo esapertium-L1-L2.L1.metadix (por ejemplo, para el diccionario mono-lingue ingles de Apertium-en-ca, apertium-en-ca.en.metadix). Es-tos diccionarios son preprocesados cuando se compilan los datos linguısti-cos de modo que tengan un formato apto para el compilador de dicciona-rios.

50 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
Especificacion de metaparadigmas
Los metaparadigmas se definen en la seccion <pardefs> del dicciona-rio monolingue, que es donde se definen tambien los demas paradigmasdel diccionario. Un metaparadigma, al igual que un paradigma, tiene unnombre especificado en el atributo n. Este nombre tendra las mismas ca-racterısticas que en los demas paradigmas, con la diferencia de que la par-te variable del lema estara entre corchetes y con las letras en mayusculas,como se ve en este ejemplo:
<pardef n="m/e[T]er vblex">
Esto define un paradigma para verbo, donde las terminaciones de fle-xion presentan una parte variable en la raız. La flexion que se especifiqueen este metaparadigma tiene que ser tal que flexione solo la parte que haya la derecha de los corchetes, por ejemplo la que se especifica en el para-digma:
<par n="met/er vblex"/>
De este modo, un ejemplo entero de elemento de definicion de meta-paradigma mediante <pardef> serıa:
<pardef n="m/e[T]er__vblex"><e>
<p><l>e</l><r>e</r>
</p><i><prm/></i><par n="sent/eria__vblex"/>
</e><e>
<i>e<prm/></i><par n="met/er__vblex"/>
</e></pardef>
La etiqueta <prm/> es el indicativo que sirve para situar la parte detexto variable (la terminacion variable de la raız) dentro de la definiciondel paradigma.

3.1. MODULOS DE PROCESAMIENTO LEXICO 51
Ası es como se define un metaparadigma. Si ahora queremos que unverbo lo utilice, en la entrada del verbo (dentro de un elemento <e>) debeindicarse el metaparadigma correspondiente y , mediante el atributo prm,especificar por que letras se debe sustituir la parte variable cerrada entrecorchetes. Por ejemplo:
<e lm="acuelher"><i>acu</i><par n="m/e[T]er__vblex" prm="lh"/>
</e>
Esta entrada define el verbo acuelher y especifica que el paradigma deflexion que debe seguir es el indicado por el metaparadigma m/e[T]er vblexpero sustituyendo T por lh; es decir, las letras que vienen despues de acuseran elher en lugar de eter.
Como se ha apuntado antes, los metaparadigmas pueden utilizarsetambien para entradas que presenten alguna variacion en los sımbolosmorfologicos. El modo de especificarlos es basicamente el mismo: la par-te variable debe especificarse en la entrada correspondiente, mediante unatributo sa, y en el paradigma debe colocarse la etiqueta <sa> en el lugaren el que debe situarse el sımbolo morfologico opcional.
Por ejemplo, tenemos el siguiente metaparadigma:
<pardef n="house__n"><e>
<p><l/><r><s n="n"/><sa/><s n="sg"/></r>
</p></e><e>
<p><l>s</l><r><s n="n"/><sa/><s n="pl"/></r>
</p></e></pardef>
y una entrada como la que sigue:

52 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<e lm="time"><i>time</i><par n="house__n" sa="unc"/>
</e>
en la que unc especifica que el nombre es incontable.En el metaparadigma, la etiqueta <sa> indica el lugar que debe ocupar
la etiqueta, en el caso de que una entrada contenga el atributo sa con unvalor, como es el caso de la entrada para time.
Un diccionario que presenta entradas como las descritas se denominametadiccionario y tiene que ser procesado para generar un diccionario quesiga la DTD de Apertium 2, puesto que el motor no permite el uso directode estos metaparadigmas. A continuacion se explica en que consiste esteprocesamiento.
Procesamiento del metadiccionario
El metadiccionario es un fichero escrito en XML al que, para procesarlos metaparadigmas, se aplican dos hojas de estilo XSLT para obtener eldiccionario con todos los paradigmas derivados de los metaparadigmas.Con una primera hoja de estilo, buscaPar.xsl, se obtienen los verbosque hacen uso de metaparadigmas y se eliminan posibles repeticiones demetaparadigmas a expandir. Esta hoja de estilo genera, en combinacio conla hoja principal.xsl, una segunda hoja de estilo llamada gen.xsl,que procesa el metadiccionario con la lista de paradigmas a expandir paragenerar un diccionario con formato de Apertium 2. Basicamente lo quehace esta hoja de estilo generada es:
1. En las entradas de verbos, si el verbo utiliza la flexion de un meta-paradigma, se sustituye el metaparadigma por su correspondienteparadigma expandido y desparametrizado. Ası, la entrada del ejem-plo anterior:
<e lm="acuelher"><i>acu</i><par n="m/e[T]er__vblex" prm="lh"/>
</e>
se desparametrizarıa y expandirıa a:

3.1. MODULOS DE PROCESAMIENTO LEXICO 53
<e lm="acuelher"><i>acu</i><par n="m/elher__vblex"/>
</e>
2. Por otro lado, como de la primera pasada ya se sabe que paradigmasse tienen que crear a partir de los metaparadigmas, estos se crean. Enel caso del ejemplo anterior, a partir del metaparadigma
<pardef n="m/e[T]er__vblex"><e>
<p><l>e</l><r>e</r>
</p><i><prm/></i><par n="sent/eria__vblex"/>
</e><e>
<i>e<prm/></i><par n="met/er__vblex"/>
</e></pardef>
se generarıa el paradigma <pardef n="m/elher vblex/> :
<pardef n="m/elher__vblex"><e>
<p><l>e</l><r>e</r>
</p><i>lh/></i><par n="sent/eria__vblex"/>
</e><e>
<i>elh</i><par n="met/er__vblex"/>
</e></pardef>

54 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
Despues de haber procesado el metadiccionario de esta forma se gene-ra un diccionario .dix que sigue la DTD de Apertium 2 y que ya se puedecompilar.
En el segundo ejemplo que hemos dado, en el que la parte variableera la secuencia de sımbolos morfologicos del paradigma, a partir de laespecificacion del atributo sa como unc y de la aplicacion de las hojas deestilo, se generarıa el paradigma:
<pardef n="house__n__unc"><e>
<p><l/><r><s n="n"/><s n="unc"/><s n="sg"/></r>
</p></e><e>
<p><l>s</l><r><s n="n"/><s n="unc"/><s n="pl"/></r>
</p></e></pardef>
para nombres cuyo analisis morfologico deba ser (en formato del flujode datos):
time<n><unc><sg>
La utilizacion de metaparadigmas permite, en este caso, aprovecharun mismo paradigma para entradas con misma flexion pero con analisismorfologico ligeramente diferente.
Es importante tener en cuenta que, cuando un diccionario utilice meta-paradigmas y, por lo tanto, tenga un nombre con extension .metadix,este sera el fichero en el que deben realizarse todos los cambios en eldiccionario (modificacion, adicion y borrado de entradas o paradigmas),puesto que el fichero .dix se genera automaticamente a partir del prime-ro cada vez que se compilan los datos linguısticos y, por lo tanto, cualquiercambio realizado directamente en este ultimo sera sobrescrito al realizarsela compilacion.

3.1. MODULOS DE PROCESAMIENTO LEXICO 55
3.1.3. Generacion automatica de los modulos de procesa-miento lexico
Los cuatro modulos de procesamiento lexico (analizador morfologico,transferencia lexica, generador morfologico y postgenerador) se compi-lan a partir de los diccionarios mediante un unico compilador basado entransductores de letras [14]. Este compilador es mucho mas rapido que losutilizados en los sistemas interNOSTRUM [2, 5, 4] y Traductor Universia[7, 17], gracias a la utilizacion de nuevas estrategias de construccion detransductores y a la minimizacion de transductores parciales durante laconstruccion [11].
La division de entradas del diccionario en lema y paradigma permi-te construir eficazmente transductores de letras mınimos. El compiladoraprovecha completamente la factorizacion que permiten los paradigmaspara acelerar la construccion. Como en la mayorıa de lenguas europeaslas modificaciones de las palabras tienen lugar al final o al principio de lasmismas, hemos explotado este hecho para mejorar la velocidad de cons-truccion del transductor mınimo.
Los paradigmas se minimizan antes de ser insertados en el transductorpara reducir el tamano del transductor completo final antes de minimi-zar. Como antes de minimizar, los paradigmas de los diccionarios de laslenguas con las que hemos trabajado suelen tener unos pocos cientos deestados, la minimizacion de estos paradigmas es un proceso muy rapido.
Si suponemos que una entrada puede presentar una referencia a unparadigma en cualquier punto de la misma, podrıamos pensar en copiaren ese punto el transductor que se calcula en la definicion del paradig-ma. El procedimiento utilizado en Apertium se basa en que no siempre esnecesario copiar, sino que en determinadas ocasiones es posible reutilizarun paradigma que ya haya sido copiado. En particular, dos o mas entra-das que comparten un paradigma como sufijo pueden reutilizar la mismacopia de ese paradigma y lo mismo sucede cuando ocurre como prefijo.Sin embargo, en general, no es posible reutilizar paradigmas si se encuen-tran en posiciones intermedias de entradas diferentes, ya que se puedenintroducir nuevos sufijos (prefijos) a entradas existentes, lo que hace quela informacion que se introduce en el transductor no sea consistente conel diccionario, y el transductor generado serıa incorrecto (anadirıa paresde cadenas que no se encuentran en el lenguaje formal que definen losdiccionarios).
La construccion de transductores de letras mınimos se realiza como seexplica a continuacion. A partir de una transduccion de cadenas se puedeconstruir una secuencia de transducciones de letras S(s : t) de longitud N =

56 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
-es n m
z/-ces n m
p : p
v : v
a : a
e : e
e : e
n : n
θ : θ
θ : θ
θ : θ
Figura 3.24: Construccion del diccionario como aceptor de prefijos y enlace conparadigmas mediante transiciones (θ : θ).
θ : n
e : n
θ : m
θ : sg
s : m θ : pl
Figura 3.25: Paradigma ((-es n m)) minimizado que se usa en la figura 3.24.
max(|s|, |t|) que se define como sigue para cada elemento 1 ≤ i ≤ N :
Si(s : t) =
(si : θ) si i ≤ |s| ∧ i > |t|(θ : ti) si i ≤ |t| ∧ i > |s|(si : ti) en otro caso
(3.1)
Hay que destacar que, por construccion, se asegura que no puede exis-tir ningun (s : t) que sea igual a (ε : ε), lo que es crucial para la consistenciadel metodo de construccion.
El metodo de construccion usa dos procedimientos, el procedimientode montaje que se infiere de la ecuacion 3.1 y el de minimizacion, que serealiza por un algoritmo convencional de minimizacion [16] de automatasfinitos que consiste en invertir, determinizar, volver a invertir y volver adeterminizar, tomando como alfabeto del automata que hay que minimi-zar el producto cartesiano L y como transicion vacıa la (θ : θ).
En la figura 3.24 se observa un ejemplo simplificado de este montaje.Se introduce transduccion por transduccion compuesta como en la ecua-cion 3.1 en un transductor en forma de aceptor de prefijos o trie, es decir, demanera en la que haya solo un nodo para cada prefijo comun del conjunto

3.2. DESAMBIGUADOR LEXICO CATEGORIAL 57
z : n
c : n
θ : m
θ : sg
e : m s : pl
Figura 3.26: Paradigma ((z/-ces n m)) minimizado que se usa en la figura 3.24.
de transducciones que forman el diccionario. Con los sufijos de las trans-ducciones (que no se comparten) se crean estados nuevos. En el punto enel que se haga referencia a un paradigma, se crea una replica de ese para-digma y se enlaza a la entrada del diccionario que se esta insertando en eltransductor mediante una transduccion nula (θ : θ).
Cada uno de los paradigmas, en tanto que pueden ser vistos como pe-quenos diccionarios, se han construido por este mismo procedimiento asu vez y se han minimizado para reducir el tamano del problema en laconstruccion del diccionario grande. En las figuras 3.25 y 3.26 se muestrael estado de los dos paradigmas utilizados en la figura 3.24 despues de laminimizacion.
3.2. Desambiguador lexico categorial
3.2.1. Descripcion del funcionamiento
El desambiguador lexico categorial esta basado en modelos ocultos deMarkov [13] de primer orden, es decir, en informacion de naturaleza es-tadıstica. Los estados del modelo de Markov representan categorıas gra-maticales y los observables son clases de ambiguedad [3], esto es, conjun-tos de categorıas gramaticales.
A pesar de trabajar con informacion estadıstica, el entrenamiento y elcomportamiento actual del desambiguador mejoran si se introducen res-tricciones que impiden determinadas secuencias de categorıas (en los mo-delos de primer orden, estas secuencias solo pueden implicar a dos cate-gorıas); por ejemplo, en espanol o catalan una preposicion nunca puede irseguida de un verbo conjugado en forma personal, restriccion que es degran ayuda cuando la forma que sigue a la preposicion es ambigua y uno

58 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
de sus analisis morfologicos es verbo en forma personal (p.e., de trabajo,en libertad, etc.). En el fichero de definicion del desambiguador se declaranexplıcitamente estas restricciones, a veces en forma de prohibiciones y otrasen forma de obligaciones.
Las etiquetas gramaticales con las que trabaja el desambiguador no sonlas mismas que se utilizan en el analizador morfologico. Normalmente, lainformacion que entrega el analizador morfologico es demasiado detalla-da para la desambiguacion lexica categorial (por ejemplo, para la mayorıade los propositos, es suficiente agrupar en una misma categorıa todos lossubstantivos comunes, independientemente de su genero y su numero).El empleo de etiquetas mas finas no mejora los resultados, al tiempo queincrementa considerablemente el numero de parametros a estimar y hacemas acusado el problema de la escasez de recursos linguısticos tales comotextos desambiguados a mano. Por este motivo, en el fichero del desam-biguador se especifica como agrupar las etiquetas finas (o especıficas) pro-porcionadas por el analizador morfologico en etiquetas gruesas —que lla-maremos categorıas— mas generales que se emplearan en la desambigua-cion lexica categorial. Ademas de las categorıas gruesas, tambien puedendefinirse etiquetas lexicalizadas. En la bibliografıa se describen basicamen-te dos tipos de lexicalizaciones, las que anaden nuevos observables y lasque ademas anaden nuevos estados al modelo de Markov [12]; el desam-biguador lexico categorial de Apertium utiliza este ultimo tipo de lexicali-zacion.
Cabe recordar que, pese a trabajar con categorıas gruesas, el desambi-guador proporciona a su salida etiquetas finas como las del analizadormorfologico. De hecho, en ocasiones, puede suceder que el analizadormorfologico entregue, para una palabra dada, dos o mas etiquetas finasque pueden agruparse bajo una misma categorıa: p. e., en espanol cantepuede ser la 1a o la 3a persona del presente de subjuntivo del verbo cantar;las dos etiquetas finas, <vblex><prs><p1><sg> y <vblex><prs><p1><sg>,se agrupan bajo la categorıa VLEXSUBJ (verbo subjuntivo). En este caso,una de las dos etiquetas finas es descartada; en el fichero de definicion deldesambiguador se puede definir que etiqueta fina de las que componenuna etiqueta gruesa sera la entregada tras la desambiguacion.
3.2.2. Datos para el desambiguador lexico categorial
3.2.2.1. Introduccion
A continuacion se describe el formato de los ficheros en los que se es-pecifica como agrupar las etiquetas finas proporcionadas por el analiza-

3.2. DESAMBIGUADOR LEXICO CATEGORIAL 59
dor morfologico en etiquetas gruesas mas generales. En dichos ficheros,ademas, se pueden especificar restricciones que ayuden a la estimaciondel modelo estadıstico encargado del proceso de desambiguacion lexica,ası como reglas de preferencia para el caso de que a dos etiquetas finas lescorresponda la misma categorıa.
El desambiguador asume que a su entrada las palabras se encontraranconvenientemente delimitadas, tal como se especifica en el formato del flu-jo de datos entre modulos (capıtulo 2). El formato de los datos entregadospor el analizador morfologico, a grandes rasgos, es como sigue:
formaanalizada → multiformalexica [ multiformalexica ]∗
multiformalexica → formalexica [ formalexica ]∗ cola-lema?formalexica → lema etiquetafina
cola-lema → lemaetiquetafina → sımbologram [ sımbologram ]∗
(3.2)
donde:
formaanalizada es toda la informacion que se entrega para cada formasuperficial a la salida del analizador morfologico
multiformalexica es una secuencia de una o mas formas lexicas se-guida, opcionalmente, por una cola invariable como en el caso dealgunas multipalabras (cantale las cuarenta).
formaslexicas4 son unidades compuestas por un lema y una o masetiquetas con la informacion de la salida del analizador
cola-lema esta compuesta por uno o mas lemas5 que forman la parteinvariable de una multipalabra. La cola de una multipalabra esta for-mada por el lema o los lemas sin flexion que siguen a los lemas conflexion. Por ejemplo, la multipalabra cantar las cuarenta puede tomarlas formas cantale las cuarenta, (le) cantare las cuarenta, cantandole lascuarenta, etc. La cola serıa en este caso las cuarenta (vease la pagina 44para mas informacion).
etiquetafina corresponde a uno o mas sımbolos gramaticales (sımbolo-gram).
4Separadas entre ellas por un delimitador que se corresponde con el elemento <j/>(ver pagina 37).
5Separados entre ellos mediante el elemento <b/> (ver pagina 36).

60 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
Por ejemplo, la entrada correspondiente a la forma superficial ambiguaespanola correos tendrıa dos multiformas lexicas; la primera multiformalexica tendrıa una unica forma lexica, con lema correo y una etiqueta finacompuesta de los sımbolos gramaticales nombre comun, masculino, plural; lasegunda multiforma lexica serıa una secuencia de dos formas lexicas, unacon lema correr y etiqueta fina compuesta de los sımbolos gramaticalesverbo lexico, imperativo, segunda persona, plural y la otra con lema vosotros, yetiqueta fina compuesta por los sımbolos pronombre, enclıtico, segunda per-sona, masculino-femenino, plural.
3.2.2.2. Especificacion del formato
El formato del fichero (codificado en XML) se especifica mediante laDTD que se observa en el apendice A.2.
El significado de las etiquetas es como sigue:
tagger : es el elemento raız; su atributo obligatorio name sirve para es-pecificar el nombre del etiquetador generado a partir del fichero.
tagset : define el etiquetario grueso de las categorıas con el que trabajael desambiguador. Las categorıas se definen a partir de las etiquetasfinas que proporciona el analizador morfologico a su salida.
def-label : define una categorıa o etiqueta gruesa (cuyo nombre se indi-ca en el atributo obligatorio name) en terminos de listas de etiquetasfinas definidas mediante uno o mas elementos tags-item; un atri-buto opcional closed indica si la categorıa es cerrada; de ser cerradase entiende que una palabra desconocida nunca puede pertenecer aesta categorıa.6
Las categorıas mas especıficas deben definirse antes de las mas gene-rales. Cuando la definicion de una categorıa general incluye implıci-tamente la de una categorıa especıfica definida previamente, se en-tiende que se refiere a todos los casos excepto los definidos por lascategorıas mas especıficas.
tags-item : permite definir una etiqueta fina en terminos de una secuen-cia de sımbolos gramaticales. Mediante el atributo obligatorio tagsse define la secuencia de sımbolos gramaticales que conforman la eti-queta fina. En dicha secuencia los sımbolos gramaticales se separan
6Las categorıas cerradas son aquellas que no crecen cuando se crea nuevo lexico: pre-posiciones, determinantes, conjunciones, etc.

3.2. DESAMBIGUADOR LEXICO CATEGORIAL 61
por puntos y el asterisco “*” se utiliza para indicar que en deter-minada posicion puede aparecer cualquier secuencia de sımbolos.Tambien se pueden especificar categorıas lexicalizadas indicando enel atributo lemma el lema deseado.
def-mult : define categorıas especiales (multicategorıas) formadas por va-rias categorıas, para tratar el caso de que una entrada presente mul-tiformas lexicas como las definidas en la seccion anterior. Cada cate-gorıa se define como un conjunto de secuencias (sequence) validasde categorıas definidas previamente o de etiquetas finas. Su uso esapropiado para contracciones, verbos con enclıticos, etc.
sequence : define una secuencia de elementos que pueden ser categorıas(label-item) o etiquetas finas (tags-item). El utilizar directa-mente etiquetas finas es util si se desea utilizar una secuencia desımbolos gramaticales que no forma parte de una etiqueta fina yadefinida o que supone una especializacion mayor de una etiquetafina ya creada.
label-item : permite hacer referencia a una categorıa o etiqueta gruesaya definida con anterioridad y que se especifica en el atributo obli-gatorio label.
forbid : esta seccion (opcional) permite definir restricciones en forma desecuencias de categorıas label-sequence que no pueden darse enel idioma en cuestion. En la version actual, al estar el desambiguadorbasado en modelos ocultos de Markov de primer orden, las secuen-cias solo pueden estar formadas por dos label-items.
label-sequence : define una secuencia de categorıas (label-item).
enforce-rules : esta seccion (opcional) permite definir restricciones enforma de obligaciones.
enforce-after : define una restriccion que obliga a que a una determi-nada categorıa solo puedan seguirle categorıas pertenecientes al con-junto (label-set) de categorıas que se define. Notese que este tipode restricciones es equivalente a definir varias secuencias (label-sequence)prohibidas (forbid) con la categorıa definida mediante el atributoobligatorio label y el resto de categorıas no pertenecientes al con-junto definido en label-set. Por esta razon, este tipo de restricciondebe usarse con mucha cautela.
label-set : define un conjunto de categorıas (label-items).

62 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
preferences : permite definir prioridades en cuanto a que etiquetas fi-nas se deben producir a la salida del desambiguador cuando una omas etiquetas finas sean asignadas a la misma categorıa.
prefer : especifica que en caso de conflicto entre varias etiquetas finasasignadas a la misma categorıa, el desambiguador debe proporcio-nar a la salida la etiqueta definida mediante el atributo obligatoriotags. Si la categorıa contiene mas de una de las etiquetas finas de-finidas en estos elementos prefer, se entregara la que este definidaantes.
Las figuras 3.27 y 3.28 muestran con un ejemplo las partes mas impor-tantes de un fichero de especificacion de desambiguador definido por laDTD que acabamos de describir.
3.2.3. Consideraciones sobre el entrenamiento del desam-biguador lexico categorial
El entrenamiento del desambiguador lexico categorial podra hacersetanto de forma supervisada, utilizando textos desambiguados a mano, co-mo de forma no supervisada, con textos ambiguos.
Cuando el entrenamiento se realice a partir de textos ambiguos (de for-ma no supervisada) el formato de dicho texto se podra obtener de formaautomatica a partir de un corpus de texto llano de la lengua deseada utili-zando el analizador morfologico del sistema; en este caso el formato de lasformas del texto sera como el definido en el esquema 3.3 (puede leerse sudescripcion en la pagina 59). Como muestra el esquema, puede haber masde un analisis para cada forma superficial analizada (una formaanalizadapuede dar como resultado mas de una multiformalexica).
formaanalizada → multiformalexica [ multiformalexica ]∗
multiformalexica → formalexica [ formalexica ]∗ cola-lema?formalexica → lema etiquetafina
cola-lema → lemaetiquetafina → sımbologram [ sımbologram ]∗
(3.3)
Para el entrenamiento supervisado se necesita texto desambiguado amano. El formato de las formas de estos textos sera como el proporciona-do por el analizador morfologico (vease el capıtulo 2) con la salvedad de

3.2. DESAMBIGUADOR LEXICO CATEGORIAL 63
<?xml version="1.0" encoding="iso-8859-1"?><!DOCTYPE tagger SYSTEM "tagger.dtd"><tagger name="es-ca"><tagset>
<def-label name="adv"><tags-item tags="adv"/>
</def-label><def-label name="detnt" closed="true">
<tags-item tags="detnt"/></def-label><def-label name="detm" closed="true">
<tags-item tags="det.*.m"/></def-label><def-label name="vlexpfci">
<tags-item tags="vblex.pri"/><tags-item tags="vblex.fti"/><tags-item tags="vblex.cni"/>
</def-label><def-mult name="infserprnenc" closed="true">
<sequence><label-item label="vserinf"/><label-item label="prnenc"/>
</sequence><sequence>
<label-item label="vserinf"/><label-item label="prnenc"/><label-item label="prnenc"/>
</sequence></def-mult><def-mult name="prepdet" closed="true">
<sequence><label-item label="prep"/><tags-item tags="det.def.m.sg"/>
</sequence></def-mult>
</tagset><!-- ... -->
Figura 3.27: Ejemplo de fichero de definicion del desambiguador (continua en lafigura 3.28).

64 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<!-- ... --><forbid>
<label-sequence><label-item label=="prep"/><label-item label=="vlexpfci"/>
</label-sequence><!-- ... -->
</forbid><enforce-rules>
<enforce-after label=="prnpro"><label-set>
<label-item label=="prnpro"/><label-item label=="vlexpfci"/><!-- ... -->
</label-set></enforce-after><!-- ... -->
</enforce-rules><preferences>
<prefer tags="vblex.pii.3.sg"/><prefer tags="vbser.pii.3.sg"/><!-- ... -->
</preferences></tagger>
Figura 3.28: Ejemplo de fichero de definicion del desambiguador (viene de la fi-gura 3.27).

3.2. DESAMBIGUADOR LEXICO CATEGORIAL 65
que, al tratarse de texto ya desambiguado, nunca habra mas de una for-ma lexica asociada a cada forma superficial como se muestra en 3.4 (unaformadesambiguada consistira siempre en una unica multiformalexica).
formadesambiguada → multiformalexicamultiformalexica → formalexica [ formalexica ]∗ cola-lema?
formalexica → lema etiquetafinacola-lema → lema
etiquetafina → sımbologram [ sımbologram ]∗
(3.4)Por ultimo, para el entrenamiento tambien se precisa del diccionario de
la lengua implicada. Este diccionario se emplea para determinar conjun-tamente con la especificacion del etiquetario a emplear las distintas clasesde ambiguedad con las que trabaja el desambiguador.
La figura 3.29 muestra el esquema de dependencias para el entrena-miento y el uso del desambiguador.
[Nota: Aquest esquema canviara amb el nou tagger - Sergio]

66 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
lang.tsx
apertium-tagger { --train <n> | --supervised <n> } lang
lang.dic lang.crp
lang.prob
lang.tagged lang.untagged
input/output file
program
data file
dictionary training corpus tagged corpus analized corpus
used only if supervised training
apertium-tagger --tagger langinput text output text (tagged)
HMM definition and probabilities
tagset definition
optional
Figura 3.29: Esquema de dependencias del desambiguador lexico categorial.

3.3. PREPROCESO DE LA TRANSFERENCIA 67
3.3. Modulo auxiliar: modulo de preproceso dela transferencia
3.3.1. Motivacion
El modulo de preproceso de la transferencia pretransfer, se ocupade fragmentar las unidades multipalabra compuestas (ver la pagina 44) ymover ciertas partıculas de lugar en las multipalabras con flexion inter-calada o de lema partido. Este modulo procesa la salida del etiquetador ygenera una entrada apta para el modulo de transferencia. Este procesa-miento es necesario por varias razones:
Para que el modulo de transferencia pueda tratar estas unidades porseparado para tratar, por ejemplo, fenomenos de cambio de pronom-bres enclıticos por pronombres proclıticos o viceversa.
Para que en el diccionario bilingue solo haya que almacenar infor-macion de los lemas que se traducen. Si las partıculas que componenuna unidad multipalabra se presentan conjuntamente en el dicciona-rio bilingue, este diccionario tiene que tener una entrada para cadauna de estas composiciones. Mediante la separacion se consigue notener entradas para multipalabras que incluyan la flexion en el dic-cionario bilingue.
3.3.2. Comportamiento y ejemplo
El funcionamiento del programa consiste en sustituir cada <j/> en eldiccionario, es decir, cada + en el flujo de datos, por un caracter de finde palabra, un espacio en blanco y un caracter de comienzo de palabra.Ademas, si se trata de una multipalabra de lema partido, se mueve la colaa la posicion que queda entre el final de la primera palabra de la mul-tipalabra y la primera etiqueta morfologica que se corresponde con estapalabra.
La responsabilidad de generar una salida de este modulo que tenga elorden original que acepta el generador se deja a las reglas correspondien-tes del modulo de transferencia, ası como la de crear las multipalabrascompuestas que sean necesarias en la lengua meta. El generador trabaja,en general, con las mismas multipalabras que el analizador morfologico, ycon los elementos en el mismo orden, y es por eso que esta tarea hay querealizarla en el modulo de transferencia.

68 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
A continuacion se muestra el resultado de aplicar este proceso a la mul-tipalabra compuesta darlo:
$ pretransferˆdar<vblex><inf>+lo<prn><enc><p3><m><sg>$ ←− entradaˆdar<vblex><inf>$ ˆlo<prn><enc><p3><m><sg>$ ←− salida
Como se puede ver, sencillamente se trata de dividir las formas lexicasde una unidad multipalabra compuesta en formas lexicas individuales.
Cuando se trata de una multipalabra con lema partido, se opera comose ve en el siguiente ejemplo para la multipalabra echarte de menos:
$ pretransferˆechar<vblex><inf>+te<prn><enc><p2><m><sg># de menos$ˆechar# de menos<vblex><inf>$ ˆte<prn><enc><p2><m><sg>$
Aquı, ademas de dividir las formas lexicas, se produce un movimientode la cola invariable del lema a la posicion anunciada. Como vemos, con elmovimiento de esta cola invariable, las unidades semanticas se mantienen,ya que se puede considerar echar de menos como una unidad verbal consignificado propio.
3.4. Modulo de seleccion lexica
3.4.1. Introduccion
Cuando el sistema Apertium se utiliza para traducir automaticamenteentre lenguas menos emparentades que las que ha tratado hasta ahora, to-ma importancia la cuestion de la seleccion lexica, que debe llevarse a cabocuando una palabra de la lengua origen puede tener mas de una traduc-cion en lengua meta. Por este motivo se ha creado un nuevo modulo, elmodulo de seleccion lexica, que se ocupa de esta cuestion.
Antes de explicar sus caracterısticas, veremos como los problemas deequivalencia multiple (la existencia de mas de una traduccion posible en len-gua meta para un lema o una forma lexica en lengua origen) se tratan enApertium de dos maneras diferentes.
Por un lado, nos encontramos con la situacion en que entre los multi-ples equivalentes en lengua meta no hay una gran diferencia de significa-do, y el hecho de escoger entre uno u otro no comportarıa ningun errorde traduccion. Podrıamos decir que entre estos equivalentes hay una rela-cion de sinonımia o casi-sinonımia. En este caso, el linguista escoge como

3.4. MODULO DE SELECCION LEXICA 69
traduccion uno de los dos lemas (generalmente el mas frecuente o masusual), y pone una restriccion de direccion en los otros (con los atributosLR o RL) para que sean traducidos en la direccion contraria pero no en ladireccion en que hay multiples equivalentes.
Por otro lado, tenemos el caso en que entre los multiples equivalen-tes en lengua meta hay una evidente diferencia de significado que puedeconllevar errores de traduccion cuando se elige el lema inadecuado. Estoscasos son los que trata el nuevo modulo de seleccion lexica. El linguis-ta codifica las entradas con los atributos slr o srl que se explican en elapartado siguiente, identificando ası las diferentes posibilidades de tra-duccion, y el modulo de seleccion lexica se ocupa de escoger, medianteprocedimientos estadısticos, cual es la traduccion adecuada en un contex-to determinado.
Decidir cuando una situacion de equivalencia multiple debe solucio-narse de una manera o de la otra, a veces no es sencillo. Por ejemplo,cuando entre dos o mas lemas de la lengua meta existe diferencia de signi-ficado, pero consideramos que el modulo de seleccion lexica no sera capazde escoger la buena traduccion a partir del contexto, seguiremos el primermetodo: escoger la traduccion fija que queramos (la mas general, la queconsideramos adecuada en el maximo de situaciones posibles) y poneruna restriccion de direccion en el resto de equivalentes. En los demas ca-sos, codificaremos las entradas de forma que la decision quede en manosdel modulo de seleccion lexica.
Cuando se utilice un sistema Apertium sin modulo de seleccion lexi-ca, la unica manera de codificar entradas con varias traducciones posibleses la primera, es decir, escogiendo una unica traduccion y marcando elresto de equivalencias con una restriccion de direccion. En caso de queutilicemos diccionarios bilingues con multiples traducciones, codificadescon los atributos slr o srl, en un sistema que no dispone de modulo deseleccion lexica, una hoja de estilo se encarga de convertir estas entradaspensadas para el modulo de seleccion lexica en entradas con restriccionesde direccion LR o RL, de manera que uno de los multiples equivalentes(el que el linguista haya escogido como entrada predeterminada) quedacomo traduccion fija del lema en lengua origen.
Como ejemplos de equivalencias bilingues que deberıan llevar una res-triccion de direccion, podemos dar los pares de traduccion ca-es encara –aun/todavıa y sobtat – subito/repentino, el primero de los cuales podrıa que-dar ası:

70 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
textenllen-guaori-gen↓
desfor-matador
→ anal.morf.
→ desamb.categ. →
selec.lexic
→transf.es-truc.
→ gen.morf.→
post-generador→
refor-matador
l ↓
transf.lexica
textenllen-guameta
Figura 3.30: Los nuevo modulos que forman la cadena de montaje de la version 2del sistema de traduccion automatica Apertium.
<e r="LR"><p>
<l>aun<s n="adv"/></l><r>encara<s n="adv"/></r>
</p></e><e>
<p><l>todavıa<s n="adv"/></l><r>encara<s n="adv"/></r>
</p></e>
Como ejemplo del segundo caso (multiples equivalentes con gran di-ferencia de significado) tenemos los pares es-ca hoja – full/fulla o muneca– nina/canell, y los ejemplos en-ca que se muestran en la pagina 39, don-de se explica de que manera se indican en el diccionario bilingue estosmultiples equivalentes.
La figura 3.30 muestra como queda la cadena de montaje en la version2 de Apertium.7
7Esta figura reemplaza la figura 1.1 que se encuentra en la pagina 6 de la documenta-cion de la version 1 de Apertium.

3.4. MODULO DE SELECCION LEXICA 71
[Nota: MG: caldria canviar la figura de la pagina 6 per aquesta d’aquı?]
El modulo encargado de la seleccion lexica (selector lexico) se ejecuta des-pues del desambiguador lexico categorial y antes del modulo encargadode la transferencia estructural; por lo tanto, este nuevo modulo trabajaunicamente con informacion de la lengua origen.
A continuacion, en la seccion 3.4.2 se explica el preprocesamiento a quedebe someterse un diccionario bilingue que contiene mas de una traduc-cion por entrada, tanto si se usa un modulo de seleccion lexica como si no,y en la seccion 3.4.3 se explica como funciona y como se tiene que entrenarel modulo que realiza la seleccion lexica.
3.4.2. Preprocesamiento de los diccionarios bilingues
El hecho de que, con esta modificacion, se creen diccionarios bilinguesque permiten la especificacion de mas de una traduccion por entrada (veaseen la seccion 3.1.2.4 como se especifican estas entradas) hace necesario unpreprocesamiento de estos diccionarios, puesto que el motor de traduccionApertium trabaja con diccionarios compilados en los que cada palabra tie-ne solo una traduccion posible.
El preprocesamiento de los diccionarios se hace automaticamente du-rante la compilacion, por lo que el usuario final no tiene que ejecutar nin-guna accion especial.
3.4.2.1. Preprocesamiento sin modulo de seleccion lexica
Cuando los diccionarios bilingues con multiples equivalentes se utili-cen en un sistema que no dispone de modulo de seleccion lexica, el prepro-cesamiento se realiza con la aplicacion de la hoja de estilo translate-to--default-equivalent.xsl. Esta hoja de estilo convierte los dicciona-rios con mas de una posible traduccion por entrada en diccionarios conuna sola traduccion por entrada, escogiendo como traduccion la entradamarcada como equivalente predeterminado, y poniendo una restriccionde direccion (LR o RL segun el caso) en las demas entradas, de forma queestas solo se traducen en la direccion de traduccion en la que no hay mul-tiplicidad de equivalentes. Esta hoja de estilo se llama desde el Makefile.
Como ejemplo, las tres primeras entradas que se muestran en la pagina39 quedan ası despues de la aplicacion de la hoja de estilo mencionada:
<e><p>

72 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<l>flat<s n="n"/></l><r>pis<s n="n"/><s n="m"/></r>
</p></e>
<e r="LR"><p>
<l>floor<s n="n"/></l><r>pis<s n="n"/><s n="m"/></r>
</p></e>
<e r="RL"><p>
<l>floor<s n="n"/></l><r>terra<s n="n"/><s n="m"/></r>
</p></e>
3.4.2.2. Preprocesamiento con modulo de seleccion lexica
En el caso de que el sistema Apertium funcione con un modulo deseleccion lexica, el diccionario bilingue se tiene que preprocessar para ob-tener:
un diccionario monolingue que para cada palabra en lengua origen(por ejemplo look) devuelva todas las posibles marcas de traducciono equivalencias (look mirar D y look semblar), este dicciona-rio sera utilizado por el modulo que hace la seleccion lexica; y
un nuevo diccionario bilingue que dada una palabra con la seleccionlexica ya hecha (por ejemplo look semblar) devuelva la traduc-cion (pareixer); este sera el diccionario bilingue a emplear en la trans-ferencia lexica.
Este preprocesamiento se hace automaticamente con el siguiente soft-ware en compilar los diccionarios:
apertium-gen-lextormono, que recibe tres parametros:
• el sentido de traduccion para el cual se quiere obtener el diccio-nario monolingue usado en la seleccion lexica; lr (left to rigth)para la traduccion de izquierda a derecha, y rl (right to left) parala traduccion de derecha a izquierda;

3.4. MODULO DE SELECCION LEXICA 73
• el diccionario bilingue a preprocesar; y
• el fichero donde se tiene que escribir el diccionario monolingueresultante.
apertium-gen-lextorbil, que recibe tres parametros:
• el sentido de traduccion (lr o rl) para el que se quiere obtenerel diccionario bilingue a usar por el modulo de transferencialexica;
• el diccionario bilingue a preprocesar; y
• el fichero donde se tiene que escribir el diccionario bilingue re-sultante.
3.4.3. Funcionamiento del modulo de seleccion lexica
El modulo encargado de la seleccion lexica se ejecuta despues del desam-biguador lexico categorial y antes de la transferencia estructural (vease lafigura 3.30 de la pagina 70); por lo tanto hace uso unicamente de infor-macion de la lengua origen de la traduccion. Sin embargo, para el entre-namiento del modulo tambien se hace uso de informacion de la lenguameta.
3.4.3.1. Entrenamiento
Para el entrenamiento del modulo que realiza la seleccion lexica se ne-cesitan un corpus en lengua origen y otro en lengua meta; no es necesarioque esten relacionados. Los dos corpus tienen que ser preprocesados an-tes del entrenamiento. Este preprocesamiento, que consiste en analizar loscorpus y hacer la desambiguacion lexica categorial, se puede hacer conapertium-preprocess-corpus-lextor.
El entrenamiento del modulo encargado de la seleccion lexica consisteen hacer las siguientes tareas:8
1. obtener la lista de palabras que no tendran que ser tenidas en cuen-ta a la hora de hacer la seleccion lexica (stopwords). Esta lista puedehacerse a mano o mediante apertium-gen-stopwords-lextor;
8El entrenamiento de los modelos usados para la seleccion lexica se ha automatizadoen aquellos paquetes linguısticos que lo usan. Ademas todo el software mencionado tienesu pagina de manual UNIX

74 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
2. obtener la lista de palabras (en lengua origen) que tienen mas de unatraduccion en lengua meta con apertium-gen-wlist-lextor;
3. traducir a la lengua meta cada una de las palabras obtenidas en el pa-so anterior con apertium-gen-wlist-lextor-translation;
4. entrenar con apertium-lextor --trainwrd y usando el corpuspreprocesado de la lengua meta un modelo de coaparicion de pala-bras para las obtenidas en el paso anterior;
5. entrenar con apertium-lextor --trainlch y usando el corpuspreprocesado de la lengua origen, los diccionarios generados con losprogramas mencionados en la seccion 3.4.2 y los modelos de coapari-cion de palabras estimados en el paso anterior, un modelo de coapa-ricion para cada una de las marcas de traduccion de aquellas pala-bras que pueden tener mas de una traduccion en lengua meta.
3.4.3.2. Utilizacion
Los modelos de coaparicion de palabras estimados en la seccion ante-rior para cada una de las marcas de traduccion proporcionan la informa-cion necesaria para llevar a cabo la seleccion lexica con informacion delcontexto.
La seleccion lexica se hace con apertium-lextor --lextor; losformatos usados para la comunicacion con el resto de modulos del mo-tor de traduccion son:
Entrada: texto en el mismo formato que el de entrada al modulo de trans-ferencia estructural, es decir, texto analizado y desambiguado conlas colas invariantes de las multipalabras desplazadas antes de cual-quier etiqueta.
Salida: texto en el mismo formato pero con la marca de traduccion a em-plear cuando se haga la transferencia lexica.
El siguiente ejemplo ilustra los formatos de entrada/salida usados porel selector lexico (suponemos que unicamente el verbo ingles get tiene masde un equivalente de traduccion en los diccionarios):
Texto en lengua origen (ingles): To get to the city centre
Entrada al selector lexico: ˆTo<pr>$ ˆget<vblex><inf>$ ˆto<pr>$ˆthe<det><def><sp>$ ˆcity<n><sg>$ ˆcentre<n><sg>$

3.4. MODULO DE SELECCION LEXICA 75
Marcas de traduccion en el diccionario bilingue para el verbo get:rebre, agafar, arribar, aconseguir D
Salida del selector lexico: ˆTo<pr>$ ˆget__arribar<vblex><inf>$ˆto<pr>$ ˆthe<det><def><sp>$ ˆcity<n><sg>$ ˆcentre<n><sg>$

76 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
3.5. Modulo de transferencia estructural
[Nota: Faena per fer (mlf):
El document no diu encara res de metaparadigmes. En cal unadescripcio.
Caldria demanar comentaris a Marta Villegas com a usuaria deldocument perque ens indique parts fosques, possibles sugge-riments, etc.
Hi ha bastants vacil·lacions en la terminologia usada per a referir-se a conceptes i en els noms usats per als programes.
He intentat substituir en cada cas l’expressio per defecte peruna altra mes adequada; pero caldra distingir en quin cas enstrobem en cada cas.
]
3.5.1. Introduccion
A partir de 2007, Apertium dispone de un sistema de transferencia es-tructural mas avanzado que el que utilizaba anteriormente, cuya necesi-dad aparece con el desarrollo de traductores para pares de lenguas menosemparentadas entre sı que los que se habıan tratado hasta el momento,como por ejemplo el par ingles–catalan.
Este sistema de transferencia se compone de tres modulos, el prime-ro de los cuales puede utilitzarse aisladamente cuando se desee ejecutarun sistema de transferencia sintatica superficial, es decir, el sistema detransferencia utilizado ya para pares de lenguas emparentadas como es-panol–catalan o espanol–gallego. Cuando el sistema se utiliza para pares delenguas mas alejadas y se desee, por lo tanto, realizar una transferenciasintactica avanzada, se ejecutaran los tres modulos de transferencia.
Los dos sistemas de transferencia se diferencian por el numero de pa-sadas que se realizan sobre el texto de entrada. El sistema de transferenciasuperficial realiza las transformaciones estructurales en una unica pasadade las reglas, las cuales detectan secuencias o patrones de formas lexicasy realizan sobre ellas las comprobacions y cambios pertinentes. Por otrolado, el sistema de transferencia avanzado funciona con una nueva arqui-tectura de transferencia que permite detectar patrones de patrones de formaslexicas mediante tres pasadas, que realizan sus tres modulos.
A continuacion se describen sus caracterısticas. En el apartado 3.5.2 sedescribe el sistema de transferencia superficial y en el apartado 3.5.3, el

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 77
sistema de transferencia avanzada. La descripcion del sistema de trans-ferencia superficial es aplicable tambien al funcionamiento del primeromodulo del sistema de transferencia avanzada, con las diferencias que seexponen en el apartado correspondiente. En el apartado 3.5.4 se describeel formato utilizado para crear reglas en ambos sistemas. En el apartado3.5.5 se describe en detalle el funcionamiento de los tres modulos del siste-ma de transferencia avanzada y finalmente, en el apartado 3.5.6 se explicael preprocesamiento de los modulos para su ejecucion.
3.5.2. Transferencia sintactica superficial
Este sistema utiliza unicamente el primero de los tres modulos de losque se compone el sistema de transferencia avanzada. Este modulo lo he-mos denominado chunker.
El diseno del lenguaje y del compilador que se usan para generar elmodulo encargado de la transferencia estructural esta fuertemente inspi-rado en el lenguaje MorphTrans descrito en [5] y usado por los sistemasde TA espanol–catalan interNOSTRUM [2, 5, 4] y espanol–portugues Tra-ductor Universia [7, 17], desarrollados por el grupo Transducens de la Uni-versitat d’Alacant.
La tarea de transferencia se realiza a partir de patrones que represen-tan secuencias de longitud fija de formas lexicas (vease pagina 7) de lalengua origen (FLLO); una secuencia sigue un cierto patron cuando con-tiene la secuencia de categorıas lexicas correspondiente. Los patrones notienen por que ser constituyentes o sintagmas en un sentido sintactico es-tricto, sino que son meras concatenaciones de formas lexicas que puedennecesitar un procesamiento conjunto adicional a la simple traduccion pa-labra por palabra, debido a las divergencias gramaticales existentes entrela LO y la LM (cambios de genero y numero, reordenamientos, cambiospreposicionales, etc). Los patrones que forman el conjunto definido parauna lengua determinada se escogen de manera que definan las transfor-maciones estructurales mas comunes. Cuando las lenguas origen y metason sintacticamente similares, como es el caso del espanol, el catalan y elgallego, reglas simples basadas en secuencias de categorıas lexicas permi-ten obtener una calidad razonable en la traduccion.
El modulo de transferencia detecta en la LO secuencias de formas lexi-cas que concuerden con algun patron de los previamente definidos en uncatalogo de patrones y los procesa aplicando unas reglas de transferenciaestructural al mismo tiempo que realiza la transferencia lexica consultan-do el diccionario bilingue.

78 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
La deteccion de patrones funciona como sigue: si el modulo de transfe-rencia empieza a procesar la iesima FLLO del texto, li, este intenta compa-rar la secuencia de FLLO li, li+1, . . . con todos los patrones que hay en sucatalogo: escoge el patron mas largo que coincida, procesa la secuencia de-tectada (mirar mas abajo), y el proceso continua en la FLLO li+k, donde kes la longitud del patron que se acaba de procesar. Si ningun patron coinci-de con la secuencia que empieza con la FLLO li, esta se traduce como unapalabra aislada y el proceso comienza de nuevo con la FLLO li+1 (es decir,cuando ningun patron es aplicable, el sistema recurre a la traduccion pa-labra por palabra). Notese que cada FLLO es procesada una sola vez: lospatrones no se solapan; por tanto, el procesamiento se realiza de izquierdaa derecha y en fragmentos bien definidos.
Para el procesamiento de patrones, el sistema toma la secuencia de FLLOdetectada y construye (utilizando un programa para la consulta del diccio-nario bilingue) una secuencia de formas lexicas en la lengua meta (FLLM)obtenidas por aplicacion de las operaciones descritas en la regla que afec-ta al patron (reordenacion, adicion, sustitucion o eliminacion de palabras,cambios en la flexion, etc.). La informacion que no cambia se copia au-tomaticamente de la lengua origen a la lengua meta. Los datos resultantes,es decir, los lemas mas todas las etiquetas morfologicas correspondientes,se envıan al generador, el cual se encarga de crear las formas flexionadas.
Como ejemplo, la secuencia en espanol una senal inequıvoca, que lle-garıa desde el desambiguador al modulo de transferencia en el siguienteformato 9:
ˆuno<det><ind><f><sg>$ˆsenal<n><f><sg>$ˆinequıvoco<adj><f><sg>$
serıa detectado como patron por una regla para determinante–nombre–adjetivo. El modulo de transferencia consultarıa el diccionario bilingue pa-ra establecer las correspondencias en catalan y, como detectarıa un cambiode genero en la palabra senal (su equivalente catalan senal es masculino),propagarıa este cambio al determinante y al adjetivo para ofrecer la se-cuencia de salida:
9El ejemplo se ha elegido de manera que no tenga superblancos con informacion deformato, para que quede mas clara la parte linguıstica de la transformacion. Vease elcapıtulo 2

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 79
ˆun<det><ind><m><sg>$ˆsenyal<n><m><sg>$ˆinequıvoc<adj><m><sg>$
que el modulo de generacion convertirıa en la forma catalana flexionada:un senyal inequıvoc.
La mayorıa de reglas se encargan de garantizar la concordancia degenero y numero en varios sintagmas nominales (SN) sencillos (determi-nante–nombre, determinante–nombre–adjetivo, determinante–adjetivo–nombre, determinante–adjetivo, etc.), siempre que haya concordancia en-tre las FLLO del patron detectado. Estas reglas son necesarias bien porqueel nombre cambia de genero o numero entre la LO y la LM (como en elejemplo que acabamos de describir) o bien porque hay que determinar elgenero o el numero en la LM debido a que en la LO era ambiguo para al-guna de las palabras (por ejemplo, el determinante cap en catalan se puedetraducir al espanol por ningun (masc.) o ninguna (fem.) segun el nombre alque acompane: cap cotxe (ca)→ ningun coche (es) y cap casa (ca)→ ningunacasa (es)). Ademas, hay definidas otras reglas para solucionar problemasfrecuentes de transferencia entre el espanol, el catalan y el gallego, como,entre otras:
reglas para cambiar preposiciones en determinadas construcciones:en Barcelona (es)→ a Barcelona (ca); consiste en hacer (es)→ consisteixa fer (ca);
reglas para anadir/quitar la preposicion a en determinadas construc-ciones modales del gallego con ir y vir: vai comprar (gl)→ va a com-prar (es);
reglas para los artıculos delante de nombres propios: ve la Marta (ca)→ viene Marta (es);
reglas lexicas, por ejemplo, para decidir la traduccion correcta deladverbio molt (ca) al espanol (muy, mucho) o la del adjetivo primeiro(gl) o primer (ca) al espanol (primer, primero);
reglas para reposicionar los pronombres atonos o clıticos, cuya distri-bucion en gallego es diferente que en espanol (proclıtico en gallego yenclıtico en espanol o viceversa): envioume (gl)→ me envio (es); paranos dicir (gl)→ para decirnos (es).

80 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
Las multipalabras (sus diferentes tipos estan explicados en la pagina 44)son procesadas de una manera especial en este modulo:
Las multipalabras sin flexion, formadas por una sola forma lexica, nonecesitan ningun procesamiento especıfico, ya que son tratadas co-mo las demas FL.
Cuando se trata de multipalabras compuestas, es decir, multipalabrasformadas por varias formas lexicas, cada una con un sımbolo gramati-cal propio y unidas mediante el elemento <j> en la entrada del dic-cionario (que se corresponde con el sımbolo ’+’ en el flujo de datos),el modulo auxiliar pretransfer (vease 3.3), situado antes del pre-sente modulo, separa las distintas formas lexicas para que lleguenaquı como FL independientes. Si se desea volver a unirlas para quelleguen al generador como multipalabras (como es el caso de los pro-nombres enclıticos en nuestro sistema), hay que hacerlo medianteuna regla de transferencia, utilizando el elemento <mlu> (descritomas adelante, en el apartado 3.5.4.42). En la pagina 156 puede ver-se un ejemplo de regla para la union de los pronombres enclıticos alverbo.
En el caso de las multipalabras con flexion intercalada, el modulo pre-transfer adelanta la cola del lema (la parte invariable) y la colocadetras de la cabeza del lema (la forma que se flexiona), para que seaposible buscar la multipalabra en el diccionario bilingue. Este tipo demultipalabras deben procesarse mediante una regla de transferenciaestructural, que recoloque la cola del lema en la posicion adecuada.Esto se realiza utilizando los atributos lemh (lemma head o “cabe-za del lema” y lemq (lemma queue o “cola del lema”) del elemento<clip> a la salida de la regla. Vease la pagina 105 para obtener unaexplicacion mas detallada del uso de este elemento, y la pagina 156para ver dos reglas en que se utilizan estos atributos.
3.5.3. Transferencia sintactica avanzada
La arquitectura de transferencia superficial descrita en el apartado an-terior se basa, como hemos visto, en la manipulacion automatica de deter-minados patrones de aparicion de palabras mediante reglas definidas porel usuario. Este modelo considera dos niveles desde el punto de vista dela naturaleza de los datos: un nivel basico que denominamos nivel lexico,que se ocupa de las palabras y de las operaciones de consulta y modifica-cion de sus caracterısticas (lema y etiquetas), ademas de la traduccion de

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 81
lemas individuales mediante consultas al diccionario bilingue; y otro nivelque denominamos nivel de patrones de palabras, que se encarga de realizar,cuando conviene, reordenamientos con las palabras que constituyen estospatrones, ası como cambios en las caracterısticas de las palabras que de-pendan de cada patron concreto que haya sido detectado. Todo este proce-samiento de deteccion y manipulacion lexica y de patrones se lleva a caboen una unica pasada.
Como contraste, la nueva arquitectura de transferencia avanzada se de-fine como un sistema de transferencia en tres niveles y tres pasadas. Losdos primeros niveles, el nivel lexico y el de patrones, son homologos a losdel sistema de transferencia superficial. El nuevo nivel que aparece es unnivel de patrones de patrones de palabras. El objetivo de la existencia de es-te nuevo nivel de procesamiento es permitir la manipulacion y la relacionde patrones de patrones de palabras de manera similar a como se tratanlas palabras en los patrones de palabras del sistema superficial. Con es-ta nueva estructura de niveles se pretende que haya un tratamiento masadecuado de todas las transformaciones que se requieren para traducir deuna lengua a otra. Por esto se tiene que poner de manifiesto que la identi-ficacion de patrones de palabras en el sistema de transferencia superficialno tiene que coincidir con la identificacion de patrones de palabras en elsistema avanzado: se pretende que los patrones en este ultimo tengan unespıritu de sintagmas que no tienen en el sistema anterior. Por esta razonutilizaremos el termino segmento (en ingles chunk), para referirnos a lassecuencias de palabras del sistema de transferencia avanzada.
La arquitectura de transferencia avanzada se organiza en tres pasadas.Siguiendo el modelo de procesamiento de Apertium, estas tres pasadasson realizadas por tres modulos (programas) diferentes:
chunker: identifica los segmentos, realiza la traduccion palabra porpalabra, ası como ciertas operaciones de reordenamiento y propaga-cion de informacion morfosintactica dentro del segmento (por ejem-plo, para establecer la concordancia). Ademas, crea los segmentospara que sean tratados por el modulo siguiente. El chunker tienela opcion de funcionar como unico modulo en un sistema de trans-ferencia sintactica superficial. Ello se controla mediante un atributodel elemento <transfer>.
interchunk: este modulo recibe los segmentos construidos por elchunker y permite reordenarlos, modificar la “informacion sintacti-ca” asociada a cada segmento y, finalmente, imprimir los segmentosen el orden nuevo y con las caracterısticas nuevas en la salida, crean-do segmentos nuevos si es necesario.

82 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
postchunk: este modulo recibe los segmentos modificados por elinterchunk y realiza tareas finales de modificacion de las palabrascontenidas en cada segmento y de impresion del texto contenido enlos segmentos en el formato que acepta el generador.
A continuacion se especifica el formato de los segmentos que circulanentre los tres modulos del sistema de transferencia (seccion 3.5.3.1) y el tra-tamiento de mayusculas y minusculas en los segmentos (seccion 3.5.3.2),que difiere del que se da para las formas lexicas individuales en el caso deun sistema de transferencia superficial.
El siguiente apartado, 3.5.4, esta dedicado a la descripcion del formatode las reglas de transferencia, que es comun para los tres modulos y paralos dos modos de transferencia, con algunas diferencias. Finalmente, trasesta descripcion, en 3.5.5 se describen en mas detalle los tres modulos delos que se compone un sistema de transferencia sintactiva avanzada.
3.5.3.1. Formato de los segmentos
La comunicacion entre los modulos chunker e interchunk, al igualque la comunicacion entre interchunk y postchunk, se lleva a cabomediante secuencias de segmentos. Definimos C como una secuenca de seg-mentos, que tiene la forma:
C = b0c1b1c2b2 . . . bk−1ckbk
Donde cada bi es un superblanco, y cada c es un segmento. Un segmentoc se define como a una cadena ˆF{W}$ que contiene la siguiente infor-macion:
F es el pseudolema del segmento, y es una cadena que tiene la formafE, donde f es el pseudolema del segmento, y E = e1e2 . . . es una se-cuencia de etiquetas morfologicas denominadas etiquetas del segmen-to. La modificacion de estas etiquetas provocara la modificacion dela informacion morfologica de las palabras del segmento que este en-lazada a estos parametros.
W = b0w1b1w2b2 . . . wkbk es la secuencia de palabras wi enviada porel chunker con los superblancos bi intercalados. Estas palabras se en-cuentran en el mismo formato an ambos sistemas de transferencia, esdecir, una palabra individual wi =ˆliEi$ contiene lema li y etiquetasEi, algunas de las cuales pueden ser referencias o enlaces a las etiquetasdel segmento y se designan con numeros naturales <1>, <2>, <3>,

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 83
etc. Estas referencias a etiquetas se corresponden, en el orden especi-ficado, con las etiquetas de E.
Un ejemplo de uso de este formato es el siguiente:
ˆdet_nom<SN><m><pl>{ˆel<det><def><2><3>$[<a href="http://www.ua.es">]ˆgat<n><2><3>$}$[</a>]
Los caracteres { y }, cuando esten presentes en el texto original, de-beran protegerse colocando una barra invertida \ delante.
3.5.3.2. Tratamiento de mayusculas y minusculas
Para cada segmento, la informacion de mayusculas y minusculas de laspalabras viene determinada por la informacion de mayusculas y minuscu-las del pseudolema del segmento, teniendo en cuenta estas condiciones:
Si todas las letras del pseudolema estan en minusculas: el estado demayusculas y minusculas no se modifica.
Si la primera letra del pseudolema esta en mayusculas y el resto enminusculas: en la generacion en el modulo postchunk, se hara quela primera letra que resulto de todos los posibles cambios de ordende las palabras del segmento este en mayusculas.
Si todas las letras del pseudolema estan en mayusculas: todas laspalabras permaneceran en mayusculas.
Un requisito es que las palabras del interior del segmento no empie-cen por mayusculas si no se trata de nombres propios, con tal de evitarque el ultimo modulo busque cual es la palabra que tiene que perder lamayuscula, si la hay. Esta tarea corresponde al modulo chunker y se hacemediante una macro o algun mecanismo similar.
3.5.4. Especificacion del formato de las reglas de transfe-rencia estructural
En esta seccion se explica el formato en el que se escriben las reglas detransferencia estructural. En el apendice, en las secciones A.3, A.4 i A.5 seofrece la descripcion formal (DTD).
Los archivos de reglas de transferencia estructural tienen dos partesbien diferenciadas: una de declaracion de los elementos que se utilizaran

84 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
en las reglas y otra de reglas propiamente dichas.
En la parte de declaracion encontramos:
Una serie de declaraciones de categorıas lexicas que especifican aque-llas formas lexicas que seran tratadas como una categorıa particulary que seran detectadas en los patrones. Hemos de destacar que ellinguista puede incluir cualquier informacion de la forma lexica paradefinir una categorıa; las categorıas pueden ser muy genericas (p.e.todos los nombres) o muy especıficas (p.e. solo aquellos determinan-tes que son demostrativos femeninos plurales).
Una serie de declaraciones de los atributos que queremos detectar enlas formas lexicas (como el genero, el numero, la persona o el tiempo),para realizar con ellos las operaciones de transformacion pertinen-tes y enviar la informacion resultante a la salida de las reglas. En ladeclaracion de los atributos se incluye el nombre del atributo y losposibles valores que puede tomar este atributo en una forma lexica(por lo general se corresponden con los sımbolos morfologicos quela caracterizan): por ejemplo, el atributo de numero puede tomar losvalores de singular, plural, singular-plural (para formas lexicas inva-riables, como crisis en espanol) y numero por determinar (para formaslexicas de la LM con distincion singular–plural cuyo numero no sepuede determinar en la traduccion al ser la forma lexica de la LOinvariable en numero, vease la explicacion de la pagina 42). Si den-tro de la regla, fuera del patron, debe hacerse referencia a alguna delas categorıas lexicas definidas en el punto anterior (para someterlasa acciones o comprobaciones), deberan definirse tambien atributospara las mismas.
Una serie de declaraciones de variables globales, que se usan paratransferir valores de atributos activos dentro de cada regla o de unaregla a las que se apliquen posteriormente.
Una seccion de definicion de listas de cadenas, generalmente listas delemas, que seran utilizados para buscar en ellas un valor que corres-ponda para realizar una transformacion determinada.
Una serie de declaraciones de macroinstrucciones; las macroinstruc-ciones contienen secuencias de instrucciones de operaciones frecuen-tes y pueden incluirse en varias reglas (por ejemplo, una macroins-truccion para asegurar la concordancia de genero y numero entre dosformas lexicas de un mismo patron).

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 85
En las reglas de transferencia estructural encontramos:
La definicion del patron que sera detectado, especificado como unasecuencia de categorıas lexicas tal como se han definido en la partede declaracion. Cabe resaltar que, si la secuencia de formas lexicasconcuerda con dos reglas diferentes, primero, prevalece la mas lar-ga y, segundo, para reglas de la misma longitud, prevalece la regladefinida en primer lugar.
La parte de proceso de las reglas, en la que especifican las acciones arealizar sobre las FLLO y se construye el patron en la LM.
[Nota: Assegurem-nos que totes les sigles estan definides]
A continuacion se explican detalladamente las caracterısticas de cadauno de los elementos utilizados.
3.5.4.1. Elemento <transfer>
(Solo en el modulo chunker)Es el elemento raız del modulo chunker y contiene todos los demas
elementos del archivo de reglas de transferencia estructural de este modu-lo.
Su atributo default puede tomar dos valores:
lu: indica que funcionara en modo superficial, es decir, como uni-co modulo de transferencia en un sistema de transferencia sintacticasuperficial y que, por lo tanto, las palabras implıcitas deben dejarseintactas
chunk: indica que funcionara en modo avanzado y, por lo tanto,cuando una palabra no es reconocida por ninguna regla, se creara deoficio un segmento que encapsule esta palabra para que pueda sertratada por los siguientes modulos de transferencia de un sisema detransferencia sintactica avanzada.
El valor por defecto es lu.
3.5.4.2. Elemento <interchunk>
(Solo en interchunk)Es el elemento raız del modulo interchunk y contiene todos los demas
elementos del archivo de reglas de transferencia estructural de este modu-lo.

86 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
3.5.4.3. Elemento <postchunk>
(Solo en postchunk)Es el elemento raız del modulo postchunk y contiene todos los demas
elementos del archivo de reglas de transferencia estructural de este modu-lo.
3.5.4.4. Elemento de seccion de definicion de categorıas<section-def-cats>
[Nota: Atencio a l’us polisemic del mot categoria en el document]
En esta seccion se definen las categorıas lexicas que se usaran paracrear los patrones utilizados en las reglas. Cada definicion se realiza conun <def-cat>.
3.5.4.5. Elemento de definicion de categorıas <def-cat>
Cada definicion de categorıa tiene un nombre n obligatorio como porejemplo det, adv, prep, etc. y una lista de categorıas (<cat-item>) quela definen. El nombre de la categorıa no puede contener acentos.
3.5.4.6. Elemento de categorıa <cat-item>
Este elemento tiene dos usos marcadamente diferenciados segun elmodulo en el que se utilice.
Uso en el modulo chunker (transferencia superficial y transferencia avan-zada)
Mediante este elemento se definen las categorıas lexicas que se utili-zaran en los patrones, es decir, que se desea detectar en el texto origen.Estas categorıas se definen a partir de una subsecuencia de las etiquetasfinas (ver definicion en la pagina 58) que entregan tanto el analizador mor-fologico como el desambiguador10.
10Hay que tener en cuenta que a lo largo de los distintos modulos de procesamientolinguıstico se utilizan distintas categorizaciones lexicas: en los diccionarios morfologicos,los lemas se acompanan de una etiqueta fina (por ejemplo, <n><m><pl> para los nom-bres masculinos en plural); el desambiguador categorial agrupa estas etiquetas finas enetiquetas mas generales (por ejemplo, la categorıa NOM para todos los nombres), aunque asu salida vuelve a entregar la etiqueta fina completa de cada FL; finalmente, en el modulode transferencia, las etiquetas finas de las FL se agrupan otra vez en categorıas mas ge-

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 87
Cada elemento <cat-item> tiene un atributo obligatorio tags cu-yo valor es una secuencia de sımbolos gramaticales separados por pun-tos; esta secuencia es una subsecuencia de la etiqueta fina, es decir, de lasecuencia de sımbolos gramaticales que define cada posible forma lexicaentregada por el desambiguador lexico categorial. De este modo, una cate-gorıa representa un determinado conjunto de formas lexicas. Tenemos quedefinir tantas categorıas distintas como tipos de formas lexicas queramosdetectar en los patrones. Ası, si nos interesa detectar todos los nombres pa-ra realizar operaciones con ellos, crearemos una categorıa definida a partirdel sımbolo gramatical n. Por otro lado, si nos interesa detectar todos losnombres femeninos en plural, deberemos definir una categorıa mediantelos sımbolos n f y pl.
Cuando un sımbolo gramatical utilizado para definir una categorıa vie-ne seguido por otros sımbolos gramaticales en el grupo de lemas que sequiere incluir, se utiliza el caracter "*". Por ejemplo, tags="n.*" abarcatodas las formas lexicas que contengan este sımbolo, como casa<n><f><pl>o coche<n><m><sg>. En cambio, cuando detras del sımbolo utilizado nopuede venir ningun otro sımbolo, no se incluye el asterisco: por ejemplo,tags="adv" abarcara todos los adverbios, pues en nuestro sistema soncaracterizados por una unica etiqueta. Tambien puede utilizarse el asteris-co para indicar la existencia de sımbolos precedentes: tags="*.f.*" in-cluye a todas las formas lexicas femeninas, sean de la categorıa que sean.Ademas, puede utilizarse un atributo opcional, lemma, para definir for-mas lexicas a partir de su lema (ver figura 3.31).
Uso en el modulo interchunk
Se utiliza igual que en el modulo chunker, pero aquı, en lugar de de-finirse a partir de los sımbolos gramaticales de las formas lexicas, se de-fine a partir de los sımbolos de los segmentos entregados por el modulochunker. Si, por ejemplo, queremos definir una categorıa para detectartodos los sintagmas nominales determinados, la definiremos mediante lossımbolos SN y DET si ası hemos caracterizado el segmento o chunk me-diante las instrucciones <tag> contenidas en el elemento <chunk> (vease3.5.5.1). Tambien se puede utilizar el atributo opcional lemma para hacerreferencia al pseudolema del segmento. Ası pues, sus caracterısticas forma-les son las mismas en los modulos chunker e interchunk, con la unicadiferencia que en el primero se utilizan para detectar formas lexicas y en
nerales (aunque pueden definirse tambien categorıas detalladas) segun el tipo de formaslexicas que se quiera detectar en los patrones.

88 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<def-cat n="nom"/><cat-item tags="n.*"/>
</def-cat>
<def-cat n="que"/><cat-item lemma="que" tags="cnjsub"/><cat-item lemma="que" tags="rel.an.mf.sp"/>
</def-cat>
Figura 3.31: Uso del elemento <cat-item> para definir dos categorıas, una paranombres sin especificar ningun lema (nom) en la que se incluyen todas las formaslexicas cuyo primer sımbolo morfologico sea n, y otra con lema asociado (que),que tiene mas de un sımbolo gramatical asociado, para incluir el que conjunciony el que relativo.
<def-cat n="det-nom"/><cat-item name="det-nom"/>
</def-cat>
Figura 3.32: Uso del elemento <cat-item> en el modulo postchunk para detec-tar chunks de determinante-nombre.
el segundo, para detectar segmentos o chunks.
Uso en el modulo postchunk
En este modulo, este elemento solo preve el atributo obligatorio name,que hace referencia al nombre del segmento o chunk,
[Nota: MG: abans deia ’al nom de la regla’, comentari mlf: De la reglao del patro?]
sin etiquetas, ya que en el modulo postchunk solo se usa el pseudolema(nombre del segmento) para la deteccion. En la deteccion no se distingueentre mayusculas y minusculas, porque el pseudolema se usa para trans-mitir la informacion sobre las mayusculas y las minusculas del segmento.(Vease la figura 3.32).

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 89
3.5.4.7. Elemento de seccion de definicion de atributos de categorıa<section-def-attrs>
En esta seccion se definen los atributos que se extraeran de las cate-gorıas detectadas por el patron y que se utilizaran en la parte de accion delas reglas. Cada atributo se define mediante una etiqueta <def-attr>.
[Nota: De vegades les etiquetes aprareixen en el text en negretes ide vegades sense negretes. Decidim-nos per una tipografia i usem-laen tot el document.]
3.5.4.8. Elemento de definicion de atributos de categorıa<def-attr>
Cada <def-attr> define un atributo con informacion morfologica(tanto informacion flexiva –genero, numero, persona, etc.–, como catego-rial –verbo, adjetivo, etc–) mediante una lista de elementos de atributode categorıa (<attr-item>) y tiene un nombre unico obligatorio n. Unatributo se define, por lo tanto, a partir de los sımbolos morfologicos quepueden encontrarse en una forma lexica dada. Cada atributo extrae, de lasformas lexicas del patron, los sımbolos que estas contienen de entre losposibles valores dados.
3.5.4.9. Elemento de atributo de categorıa <attr-item>
Cada elemento de atributo de categorıa representa uno de los valoresposibles que puede tomar el atributo. Por ejemplo, el atributo de numeronbr puede tomar los valores singular sg, plural pl, singular–plural spy numero por determinar ND. Estos valores son una subsecuencia de lasetiquetas morfologicas que caracterizan a las formas lexicas y se indicanen el atributo tags del elemento, separadas por punto si hay mas de una.En la figura 3.33 puede verse un ejemplo de utilizacion de este elementopara el atributo de numero y el atributo de nombre.
[Nota: Potser s’hauria d’explicar per que s’ha triat el nom a nom enla figura]
Comparese la definicion del atributo de nombre en esta figura (con to-dos los valores posibles y sin asteriscos) con la definicion de la categorıade nombre de la figura 3.31.

90 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<def-attr n="nbr"/><attr-item tags="sg"/><attr-item tags="pl"/><attr-item tags="sp"/><attr-item tags="ND"/>
</def-attr>
<def-attr n="a_nom"/><attr-item tags="n"/><attr-item tags="n.acr"/>
</def-attr>
Figura 3.33: Definicion del atributo de categorıa numero nbr, que puede tomarlos valores singular, plural, singular-plural o numero por determinar, ası como delatributo de categorıa nombre a nom, que puede tomar los valores de los sımbolosn o n acr.
3.5.4.10. Elemento de seccion de definicion de variables<section-def-vars>
En esta seccion se definen (mediante etiquetas <def-var>) las varia-bles globales de tipo cadena que se utilizaran para transferir informaciondentro de una regla y de una regla a otra (por ejemplo, para poder trans-mitir informacion de genero o numero entre dos patrones).
[Nota: Que quede clar que aquesta transferencia d’una regla a altraes fa nomes d’una aplicacio d’una regla a l’aplicacio d’altra regla enun moment posterior, o d’esquerra a dreta]
3.5.4.11. Elemento de definicion de variables <def-var>
La definicion de una variable global de tipo cadena tiene un nombreunico obligatorio n que se utilizara para referirse a la misma dentro de lasreglas. Las variables contienen cadenas que describen informacion de es-tado, como la existencia de concordancia entre dos elementos, la deteccionde un signo de interrogacion en la LO que haya que eliminar en LM, etc.

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 91
<def-list n="verbos_est"><list-item v="actuar"/><list-item v="buscar"/><list-item v="estudiar"/><list-item v="existir"/><list-item v="ingressar"/><list-item v="introduir"/><list-item v="penetrar"/><list-item v="publicar"/><list-item v="treballar"/><list-item v="viure"/>
</def-list>
Figura 3.34: Definicion de una lista de lemas en catalan. Estos lemas se utilizanen una regla que puede verse en la figura 3.39.
3.5.4.12. Elemento de seccion de definicion de listas de cadenas<section-def-lists>
En esta seccion se definen (mediante etiquetas <def-list>) las lis-tas que se utilizaran para realizar busquedas de cadenas. Estas listas sepueden utilizar para agrupar lemas de palabras que tengan alguna carac-terıstica comun (por ejemplo, verbos que expresen movimiento, adjetivosque expresen estados de animo, etc.). Esta seccion es opcional.
3.5.4.13. Elemento de definicion de listas de cadenas <def-list>
Este elemento sirve para ponerle nombre a la lista de cadenas medianteel atributo n y para encapsular la lista que se define mediante uno o maselementos <list-item>. Puede verse un ejemplo de uso en la figura 3.34.
3.5.4.14. Elemento de miembro de lista de cadenas <list-item>
Este elemento define, mediante el valor del atributo v, la cadena con-creta que se incluye en la definicion de la lista que engloba a este elemento.Puede verse un ejemplo de uso en la figura 3.34.
3.5.4.15. Elemento de seccion de definicion de macroinstrucciones<section-def-macros>
En esta seccion se definen las macroinstrucciones que contienen frag-mentos de codigo utilizado con frecuencia en la parte de accion de las

92 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
reglas.
3.5.4.16. Elemento de definicion de macroinstrucciones<def-macro>
Cada definicion de una macroinstruccion tiene un nombre obligatorio(el valor del atributo n), el numero de argumentos que se le pasan comoreferencia (atributo npar) y un cuerpo con instrucciones.
3.5.4.17. Elemento de seccion de reglas <section-rules>
Esta seccion contiene las reglas de transferencia estructural, cada unaen un elemento <rule>.
3.5.4.18. Elemento de regla <rule>
Cada regla tiene un patron (<pattern>) y la accion (<action>) aso-ciada que se ejecuta cuando es detectado.
La regla puede especificar en un atributo opcional comment un comen-tario que explique cual es la funcion de la regla.
3.5.4.19. Elemento de patron <pattern>
Un patron se especifica utilizando componentes de patron (<pattern-item>), cada uno de los cuales corresponde a una forma lexica en el patrondetectado, en orden de aparicion.
3.5.4.20. Elemento de componente de patron <pattern-item>
En cada componente de un patron se indica, mediante un atributo denombre obligatorio n, que tipo de forma lexica se quiere detectar. Paraello se utiliza una de las categorıas definidas en <section-def-cats>(vease un ejemplo de como se detecta el patron determinante–nombre enla figura 3.41).
3.5.4.21. Elemento de accion <action>
En este elemento se incluyen las “instrucciones” que se tienen que eje-cutar para llevar a cabo el procesamiento que se desee para cada deteccionde patrones.
La parte de procesamiento del patron detectado es un bloque de cero omas instrucciones de tipo: <choose> (procesamiento condicional), <let>

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 93
(asignacion de valores), <out> (escritura de formas lexicas de la LM),<modify-case> (modificacion del estado de las mayusculas y minuscu-las de una forma lexica), <call-macro> (llamadas a macroinstrucciones)y <append> (concatenacion de cadenas).
Durante el procesamiento, segun se cumplan o no una serie de opcio-nes condicionales, se realizan distintas operaciones, como por ejemplo laconcordancia de los elementos de un patron, ya que estos estan sujetos aposibles cambios de genero o numero durante el proceso de transferencialexica. Para ello, a pesar de trabajar con FL en LM tambien se tiene en cuen-ta la informacion de la LO ya que si, por ejemplo, en LO los elementos deun patron no concuerdan, tal vez tampoco deben hacerlo en LM. Durantela aplicacion de las distintas operaciones realizadas dentro un patron, seasignan valores a atributos del patron y, en su caso, a variables globaleso de estado y se envıa la informacion del patron en LM resultante al si-guiente modulo (el generador morfologico en un sistema de transferenciasintactica superficial, o bien un modulo posterior de transferencia en unsistema de transferencia sintactica avanzada).
3.5.4.22. Elemento de llamada a macroinstruccion<call-macro>
Dentro de una regla puede invocarse cualquiera de las macroinstruc-ciones definidas en <section-def-macros>. Para ello, hay que especi-ficar el nombre de la macroinstruccion en el atributo n y uno o mas ar-gumentos en el elemento de parametros <with-param> (ver a continua-cion).
3.5.4.23. Elemento de parametros <with-param>
Este elemento se utiliza dentro de las llamadas a macroinstrucciones<call-macro>. El atributo pos de cada argumento se utiliza para refe-rirse a una forma lexica de la regla que invoca la macroinstruccion. Porejemplo, si se ha definido una macroinstruccion de 2 parametros que reali-za operaciones de concordancia nombre–adjetivo, puede utilizarse con losargumentos 1 y 2 en una regla de nombre–adjetivo, con los argumentos 2y 3 en una regla de determinante–nombre–adjetivo, con los argumentos 1y 3 en una regla de nombre–adverbio–adjetivo y con los argumentos 2 y 1en una regla de adjetivo–nombre. Vease un ejemplo de llamada a macro-instruccion en la figura 3.35.

94 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<call-macro n="f_concord2"><with-param pos="3"/><with-param pos="1"/>
</call-macro>
Figura 3.35: Llamada a la macroinstrucion f-concord2 para hacer concordarlos elementos de un patron como por ejemplo determinante–adverbio–nombre.La propagacion de genero y numero se hace a partir de uno de los elementos,en este caso el nombre que aparece como tercer elemento del patron (3). Por eso,la posicion del nombre se pasa como primer parametro y despues se pasan elresto de elementos. Como el adverbio (en posicion 2) no necesita informacion deconcordancia, solo se pasa la posicion del determinante (1).
3.5.4.24. Elemento de seleccion <choose>
La instruccion de seleccion se compone de una o mas opciones condi-cionales (<when>) y una opcion alternativa <otherwise>, de inclusionopcional.
3.5.4.25. Elemento de condicion <when>
Con este elemento se describe una opcion condicional (vease la pagina94). Se compone de la condicion a verificar <test> y de un bloque de ceroo mas instrucciones de tipo <choose>, <let>, <out>, <modify-case>,<call-macro> o <append>,
[Nota: OK append?]
que se ejecutaran si se cumple la citada condicion.
3.5.4.26. Elemento de opcion alternativa <otherwise>
El elemento <otherwise> contiene un bloque de una o mas instruc-ciones (de tipo <choose>, <let>, <out>, <modify-case>, <call-macro>y <append>) que deben realizarse si no se cumple la condicion descrita enninguno de los <when> de un <choose>.
3.5.4.27. Elemento de evaluacion <test>
El elemento de evaluacion <test> dentro de un elemento de condi-cion <when> puede estar compuesto por una conjuncion (<and>), una dis-yuncion (<or>) o una negacion (<not>) de condiciones a evaluar, ası co-mo por una simple condicion de igualdad de cadenas (<equal>), de prin-

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 95
cipio de cadena (<begins-with>), de final de cadena (<ends-with>),de subcadena (<contains-substring>) o de inclusion en conjunto (<in>).
[Nota: Segur que es pot millorar la redaccio de l’ultim paragraf, can-viat per mlf perque hi estiguen totes les condicions booleanes sim-ples.]
3.5.4.28. Elementos de operadores condicionales o booleanos: <equal>,<and>, <or>, <not>, <in>
[Nota: Cal completar-ho: falten contains-substring, ends-with,begins-with, etc.]
El elemento de conjuncion <and> representa una condicion, com-puesta de dos o mas condiciones, que se cumple cuando todas lascondiciones en el incluidas son ciertas. Se puede ver un ejemplo desu uso en la figura 3.41
El elemento de disyuncion <or> representa una condicion, compues-ta de dos o mas condiciones, que se cumple cuando al menos una deellas es cierta. En la figura 3.38 hay un ejemplo de este tipo de condi-cion para evaluar la concordancia de genero de un patron en LO.
El elemento de negacion <not> representa una condicion que secumple cuando la condicion incluida no se cumple y viceversa. Sepuede ver un ejemplo de negacion de una igualdad en la figura 3.38.
El operador condicional de igualdad <equal> es una instruccionque comprueba si dos argumentos (dos cadenas) son o no identi-cos. Vease un ejemplo del uso de este elemento en las figuras 3.36y 3.37. En este operador, ademas, se puede especificar el atributocaseless, el cual, si tiene el valor yes, hace que la comparacion en-tre cadenas se realice sin tener en cuenta las diferencias de mayuscu-las y minusculas.
[Nota: Totes les comprovacions condicionals de cadenes tenenl’atribut caseless; in tambe; mes avall]
El operador de busqueda en listas, <in> sirve para buscar cualquiervalor (que corresponde al primer parametro de la condicion) en unalista a la que se hace referencia mediante el atributo n del elemen-to <list> y que debe estar definida en la seccion correspondiente(<section-

96 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
def-lists). El resultado de la busqueda es cierto si el valor se en-cuentra en la lista. En esta comparacion se puede utilizar tambien elatributo caseless: si se le asigna el valor yes, se realiza la busque-da en la lista sin tener en cuenta las diferencias de mayusculas yminusculas. En la figura 3.39 puede verse un ejemplo de su uso.
[Nota: Cal unificar tota la discussio anterior, traient factor comu.]
[Nota: Cal descriure la resta d’elements condicionals que no hi son.]
3.5.4.29. Elemento <clip>
El elemento <clip> representa una subcadena de una forma lexicade la LO o de la LM, definida por el valor de varios atributos (vease unejemplo de uso en la figura 3.36):
pos es un ındice (1, 2, 3, etc.) utilizado para seleccionar una formalexica dentro de la regla: se corresponde con el lugar que ocupa laforma lexica en el patron. En el modulo postchunk, tambe existe elındice “0”, que hace referencia al pseudolema del chunk, el cual estratado como una palabra mas para poder acceder a su informaciony tomar decisiones a partir de ella.
side (solo en modulo chunker) especifica si se selecciona un clip dela lengua de origen (sl, por source language) o de la lengua de destino(tl, por target language).
part indica que parte de la forma lexica se procesa; generalmentesu valor es uno de los atributos definidos en <section-def-attrs> (gen, nbr, etc.), aunque tambien puede tomar cuatro valo-res predefinidos que son: lem (para hacer referencia al lema de laforma lexica), lemh (para hacer referencia a la primera parte de unlema partido), lemq (la cola del lema partido), y whole (la formalexica completa, con el lema y todos los sımbolos gramaticales, quepueden haber sido modificados en la parte precedente de la regla).
link-to (solo en chunker en modo avanzado) sustituye el valor quese derivarıa de la consulta del resto de atributos del clip por el valorespecificado en este atributo, que ha de ser un numero natural (> 0).Este numero indica con que etiqueta <tag> del <chunk> se enlaza elcontenido del clip, siendo el numero el orden que ocupa esta etiquetadentro de <tags>. El resto de atributos del clip quedan unicamentecomo informacion, pues son sobrescritos por el valor de la etiquetaenlazada. Puede verse un ejemplo de su uso en la figura 3.45.

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 97
<test><not><equal><clip pos="2" side="tl" part="gen"/><clip pos="2" side="sl" part="gen"/>
</equal></not>
</test>
Figura 3.36: Fragmento de una regla en la que se comprueba si el genero (gen)en LM (tl) de la segunda unidad lexica identificada en un patron es distinto delgenero de la misma unidad lexica en LO (sl)
<equal><clip pos="2" side="tl" part="nbr"/><lit-tag v="ND"/>
</equal>
Figura 3.37: Uso del elemento <lit-tag>: se comprueba si la etiqueta (o sımbo-lo) de numero (nbr) de la segunda unidad lexica de la LM (tl) es ND (numeropor determinar)
3.5.4.30. Elemento de cadena literal <lit>
Este elemento sirve para especificar el valor de una cadena literal me-diante el atributo v. Por ejemplo, <lit v="andar"/> representa la ca-dena andar.
3.5.4.31. Elemento de valor de etiqueta <lit-tag>
Es similar al elemento <lit> pero no especifica el valor de una cadenaliteral sino el de una etiqueta morfologica, mediante el atributo v. Veaseun ejemplo de su uso en la figura 3.37.
3.5.4.32. Elemento de variable <var>
Cada <var> es un identificador de variable: el atributo obligatorion indica su nombre tal como se ha definido en <section-def-vars>.Cuando se encuentra en un <out>, un <test>, o la parte derecha de un<let>, representa el valor de la variable; cuando se encuentra en la parteizquierda de un <let>, dentro de un <append> o en un <modify-case>,

98 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<test><or><not><equal><clip pos="1" side="sl" part="gen"/><clip pos="3" side="sl" part="gen"/>
</equal></not><not><equal><clip pos="2" side="sl" part="gen"/><clip pos="3" side="sl" part="gen"/>
</equal></not>
</or></test>
Figura 3.38: Fragmento de una regla en la que se comprueba si el genero en LOde la primera o de la segunda unidad lexica identificada en un patron (podrıa serdeterminante–adjetivo–nombre) es distinto del genero de la tercera unidad lexicatambien en LO.
representa la referencia de la variable y se puede cambiar su valor.
3.5.4.33. Elemento de referencia a lista de cadenas <list>
Este elemento solo se usa como segundo parametro de una busqueda<in>. El atributo n hace referencia a la lista concreta definida en la sec-cion de definicion de listas de cadenas <section-def-lists>. Veaseun ejemplo de uso en la figura 3.39.
3.5.4.34. Elemento de informacion de mayusculas/minusculas<get-case-from>
El elemento <get-case-from> representa la cadena resultante deaplicar el esquema de mayusculas que presenta el lema de una unidadlexica en LO a una cadena (clip, lit o var). Para hacer referencia a la uni-dad lexica de la que se tomara la informacion, se utiliza el atributo posque indica la posicion de dicha unidad lexica en LO. Se utiliza cuando sereordenan las unidades lexicas de un patron o cuando se anade o se su-prime una unidad lexica. Puede verse un ejemplo de uso en la figura 3.40,

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 99
<rule><pattern><pattern-item n="verb"/><pattern-item n="a"/>
</pattern><action><choose><when><test><in caseless="yes"/><clip pos="1" side="sl" part="lem"/><list n="verbos_est"/>
</in></test><let><clip pos="2" side="tl" part="lem"/><lit v="en"/>
</let></when><!-- ... -->
Figura 3.39: Fragmento de una regla que detecta un patron formado por un verbomas la preposicion a y a continuacion comprueba si el verbo (el lema indicado enlem) de la lengua origen (sl) es uno de los que se han incluido en la lista deverbos de estado (definida en la figura 3.34). En caso afirmativo, el lema de lasegunda palabra de la lengua meta (tl) se cambia por en.

100 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
que contiene una regla para transformar el preterito perfecto simple es-panol (dije) por el preterito perfecto perifrastico catalan (vaig dir). En estaregla se anade una FL con lema anar y sımbolo morfologico vaux (”verboauxiliar”), el cual debe tomar la informacion de mayusculas del verbo enespanol (que tiene la posicion ”1.en el patron), para que se traduzca Dijepor Vaig dir, dije por vaig dir y DIJE por VAIG DIR.
3.5.4.35. Elemento de obtencion del patron de mayusculas/minusculas<case-of>
Sirve para obtener el patron de mayusculas/minusculas, es decir, unode los valores ”aa”, ”Aa" o ”AA”, de una cadena, que se obtiene comoen el caso de la etiqueta <clip>, pues tiene los mismos atributos: pos,la posicion que ocupa la palabra en el patron detectado; part, el atributoconcreto al que se hace referencia (normalmente el lema), con los atribu-tos predefinidos que ya se mencionan en la pagina 96, y, solo en el casodel modulo chunker, el atributo side, el lado de la traduccion, sl pa-ra la LO y tl para la LM. En la figura 3.40 puede verse un ejemplo deutilizacion de este elemento, y en el apartado siguiente (la explicacion de<modify-case>) se encuentra una explicacion mas detallada del ejem-plo.
3.5.4.36. Elemento de modificacion de estado demayusculas/minusculas <modify-case>
Esta instruccion sirve para modificar las mayusculas o minusculas dela primera expresion (el primer parametro, tıpicamente un lema) median-te un literal o una variable (el segundo parametro). El primer parametropuede ser una <var>, un <clip> o un <case-of>, mientras que el se-gundo puede ser cualquier cosa que devuelva un valor, pero en princi-pio sera <var> o <lit>. Los valores que puede tomar este valor suelenser “Aa” para expresar que la “parte izquierda” de esta modificacion delas mayusculas debe tener la primera letra en mayusculas y el resto enminusculas, “aa” para poner todo en minusculas y “AA” para poner todoen mayusculas.
En la figura 3.40 puede verse un ejemplo de su utilizacion. En esta reglase modifica el estado de mayusculas del lema en LM en posicion ”1”, quecorresponde a dir, puesto que, aunque a la salida de la regla sea la segundaforma lexica (vaig dir), es la traduccion de la FL que tiene la posicion 1 en laLO, y por lo tanto sigue teniendo asignada esta posicion en la LM. A estelema se le asigna el valor “aa” en caso de que el lema en LO tenga el estado

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 101
“Aa”. En los demas casos no hay que especificar nada, pues el estado demayusculas/minusculas en la FL con posicion 1 coincidira en la LO y enla LM y, por lo tanto, se transfiere automaticamente (vease la pagina 19para mas informacion sobre la gestion de mayusculas y minusculas en losdiccionarios).
3.5.4.37. Elemento de asignacion <let>
La instruccion de asignacion <let> asigna el valor de la parte derechade la asignacion (una cadena literal, un clip, una variable, etc.) a la parteizquierda (un clip, una variable, etc.). Vease un ejemplo de uso en lafigura 3.41.
3.5.4.38. Elemento de concatenacion de cadenas <concat>
Este elemento se usa para concatenar cadenas para asignarlas a unavariable. Se usa de manera combinada con <let>, y el valor anterior de lavariable que se modifica con la asignacion de <concat>, se pierde.
No tienen ningun atributo. Puede contener qualquier instruccion quedevuelva una cadena, como <lit>, <lit-tag> o <clip>.
En la figura 3.42 puede verse un ejemplo de uso.
3.5.4.39. Elemento de concatenacion de cadenas<append>
La instruccion <append> puede utilizarse para almacenar la salida deuna accion antes de imprimirla en el <out> correspondiente, por conve-niencia del disenador de las reglas de transferencia.
El atributo obligatorio n especifica el nombre de variable que tiene laexpresion. Al final de la instruccion, el contenido antiguo de la variablereferenciada sera prefijo del nuevo contenido, es decir, el nuevo contenidoindicado dentro de <append> se concatenara al contenido preexistente enla variable indicada en n.
El contenido de esta instruccion puede ser una o mas de las siguientesetiquetas: <b>, <clip>, <lit>, <lit-tag>, <var>, <get-case-from>,<case-of> o <concat>. Se puede ver un ejemplo en la figura 3.43.
3.5.4.40. Elemento de salida <out>
En la instruccion de salida se especifican las formas lexicas que se envıana la salida del modulo tras haber sido sometidas a las operaciones de

102 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<rule><pattern><pattern-item n="pretind"/>
</pattern><action><out><lu>
<get-case-from pos ="1"><lit v="anar"/>
</get-case-from><lit-tag v="vaux"/><clip pos="1" side="sl" part="persona"/><clip pos="1" side="sl" part="nbr"/>
</lu><b/>
</out><choose><when><test><equal>
<case-of pos="1" side="sl" part="lemh"/><lit v="Aa"/>
</equal></test><modify-case>
<case-of pos="1" side="tl" part="lemh"/><lit v="aa"/>
</modify-case></when>
</choose><out><lu>
<clip pos="1" side="tl" part="lemh"/><clip pos="1" side="tl" part="a_verb"/><lit-tag v="inf"/><clip pos="1" side="tl" part="lemq"/>
</lu></out>
</action></rule>
Figura 3.40: Regla para traducir de espanol a catalan que transforma los verbos enpreterito perfecto simple o indefinido (dije) en la forma de preterito perfecto pe-rifrastico usual en catalan (vaig dir), al mismo tiempo que se asigna la informacioncorrecta de mayusculas/minusculas a las dos palabras resultantes.

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 103
<rule><pattern><pattern-item n="det"/><pattern-item n="nom"/>
</pattern><action>
<choose><when><test><and><not><equal><clip pos="2" side="tl" part="gen"/><clip pos="2" side="sl" part="gen"/>
</equal></not><not><equal><clip pos="2" side="tl" part="gen"/><lit-tag v="mf"/>
</equal></not><not><equal><clip pos="2" side="tl" part="gen"/><lit-tag v="GD"/>
</equal></not>
</and></test><let><clip pos="1" side="tl" part="gen"/><clip pos="2" side="tl" part="gen"/>
</let></when>
</choose><!-- Otras operaciones de concordancia de genero y numero -->
Figura 3.41: Fragmento de una regla en la que el patron detectado esdeterminante–nombre (continua en la fig. 3.44): en esta parte de la regla, se asignael genero del nombre al determinante en caso de que el nombre cambie de gene-ro entre la LO (sl) y la LM (tl) durante el proceso de transferencia lexica entreambas lenguas.

104 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<let><var n="palabra"/><concat>
<clip pos="3" side="tl" part="lem"/><lit-tag v="adj"/>
</concat></let>
Figura 3.42: En este ejemplo se atribuye a la variable palabra el valor de la con-catenacion de un clip (el lema de la posicion 3) y una etiqueta adj.
<append n="temporal"><clip pos="3" part="gen" side="tl"/>
</append>
Figura 3.43: En este ejemplo se concatena a la variable temporal el valor degenero de la parte de LM de la tercera palabra detectada por la regla.
transferencia estructural pertinentes. El uso de este elemento varıa segunel modulo. Por un lado, el uso en el modulo chunker cuando funcionacomo unico modulo (transferencia sintactica superficial) y en el modulopostchunk son similares, pues la salida que hay que imprimirse en losdos casos sera la entrada del generador. El modulo chunker en Apertium2 y el modulo interchunk tienen modos de uso diferentes: el primeropara crear los segmentos y el segundo para modificar los segmentos sinmodificar su parte interna.
1. Uso en chunker en modo superficial y en postchunk
La instruccion envıa cada forma lexica dentro de un conjunto <lu>,que a su vez puede estar contenido dentro de un elemento <mlu>si lo que se envıa es una multipalabra compuesta de dos o mas FL.Ademas, se envıan tambien los espacios en blanco o superblancos(<b>) que haya que colocar entre FL y FL. En las figuras 3.40 y 3.44puede verse un ejemplo de uso.
2. Uso en chunker en modo avanzado
La salida de este modulo se espera que sea una secuencia de unoo mas chunks (enviados con el elemento <chunk>) separados porblancos <b>. Las formas lexicas y multiformas lexicas, ası como losblancos entre las mismas, se envıan dentro de los chunks. En la figura3.45 se puede ver su uso.

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 105
<!-- ... --><out><lu>
<clip pos="1" side="tl" part="whole"/></lu><lu>
<clip pos="2" side="tl" part="whole"/></lu>
</out></process></action>
</rule>
Figura 3.44: Fragmento de una regla (viene de la fig. 3.41). Al final de laregla, y tras varias operaciones, se da salida a la informacion resultante me-diante el atributo whole, que contiene el lema y los sımbolos morfologicosde cada FL (posiciones 1 y 2 del patron).
3. Uso en interchunk
En este modulo, las formas lexicas de las palabras son inaccesibles,pues solo son posibles las operaciones con los chunks y, por lo tanto,dentro de un elemento <out> solo puede haber elementos <chunk>o blancos <b>. La informacion de lema y de etiquetas que hay dentrodel elemento <chunk> corresponde al lema del chunk y a las etique-tas del chunk exclusivamente.
Se puede ver un ejemplo de uso en la figura 3.46.
3.5.4.41. Elemento de unidad lexica <lu>
Su nombre proviene de lexical unit o “unidad lexica” y es el elementomediante el que se envıa cada forma lexica del patron en lengua meta ala salida de la regla, dentro del elemento <out>. Mediante este elemen-to puede enviarse la forma lexica completa, con el atributo whole de un<clip>, o bien, en caso necesario, indicar explıcitamente cada una de suspartes (lema mas etiquetas, especificadas mediante cadenas <clip>, cade-nas literales <lit>, etiquetas <lit-tag>, variables <var>, ası como in-formacion de mayusculas y minusculas [<get-case-from>, <case-of>]).
Hay que tener en cuenta que, como se ha explicado antes, en el caso delas multipalabras con lema partido hay que resituar la cola de un lema mul-tipalabra detras de los sımbolos gramaticales de la palabra flexionada (o

106 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<out><chunk name="pr" case="caseFirstWord"><tags><tag><lit-tag v="PREP"/></tag>
</tags><lu><clip pos="1" side="tl" part="whole"/>
</lu></chunk><b pos="1"/><chunk name="probj" case="caseOtherWord"><tags><tag><lit-tag v="SN"/></tag><tag><lit-tag v="tn"/></tag><tag><clip pos="2" side="tl" part="pers"/></tag><tag><clip pos="2" side="tl" part="gen"/></tag><tag><clip pos="2" side="tl" part="nbr"/></tag>
</tags><lu><clip pos="2" side="tl" part="lem"/><lit-tag v="prn"/><lit-tag v="2"/><clip pos="2" side="tl" part="pers"/><clip pos="2" side="tl" part="gen" link-to="4"/><clip pos="2" side="tl" part="nbr" link-to="5"/>
</lu></chunk>
</out>
Figura 3.45: Instruccion de salida que imprime dos segmentos separadospor un blanco. La secuencia que se imprime es la de preposicion seguidade sintagma nominal. Las etiquetas que se enlazan a fuera como referenciason la persona, el genero y el numero del sintagma nominal. Usa las eti-quetas <tag> para especificar las etiquetas del segmento, y el valor de losatributos name y case para especificar la forma lexica del chunk.

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 107
<out><b pos="1"><chunk><clip pos="2" part="lem"/><clip pos="2" part="tags"/><clip pos="2" part="chcontent"/>
</chunk></out>
Figura 3.46: Esta salida se ha hecho para descartar el primer chunk de unaregla (caıda de pronombre). El uso de los tres elementos <clip> se ha he-cho aquı con fines ilustrativos, puesto que se habrıan podido sustituir porla part="whole" que los agruparıa en un unico <clip> .
cabeza del lema), ya que el modulo pretransfer ha adelantado la colay la ha colocado antes de los sımbolos gramaticales de la cabeza. Esta re-colocacion se realiza aquı, dentro del elemento <lu>, mediante los valoreslemh y lemq del atributo part de un <clip>. El atributo lemh corres-ponde a la cabeza de lema, y el atributo lemq, a la cola del lema. Comose ve en el ejemplo 3.40, la parte lemq del <clip> se coloca detras de lacabeza del lema y de los sımbolos gramaticales que la acompanan. Esta re-gla servirıa, por ejemplo, para la forma en espanol eche de menos, que debetraducirse al catalan por vaig trobar a faltar. El atributo a verb que aparecedetras de lemh contiene el sımbolo gramatical que describe la categorıadel verbo (vblex, vbser, vbhaver o vbmod segun el caso). Ası, la ultima formalexica enviada por esta regla, para el caso de vaig trobar a faltar, serıa en elflujo de datos:
ˆtrobar<vblex><inf># a faltar$
El sımbolo almohadilla del flujo de datos se corresponde con el elemento<g> de los diccionarios, utilizado para indicar la posicion de las partesinvariables de una unidad multipalabra con lema partido.
Es importante tener en cuenta que los atributos que se incluyen dentrode <lu> pueden estar vacıos. Ası, un verbo que entre por la regla de lafigura 3.40 y que no sea una multipalabra con lema partido, sera enviadocon el atributo lemq vacıo, puesto que no tiene cola de lema. De este mo-do no hay que definir reglas diferentes para formas lexicas con cola y sincola. Puede verse tambien otro ejemplo en la pagina 156, en que la reglapara verbo envıa con <lu> los atributos gen (genero) y nbr (numero). Deeste modo se incluyen los participios (con genero y numero) y las demasformas verbales (que llevaran estos atributos vacıos).

108 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
En la misma pagina puede verse una regla para verbo seguido de pro-nombre enclıtico. Aquı, la cola del lema se coloca detras del pronombreenclıtico; ası, las formas lexicas enviadas en el caso de una multipalabraunida a un pronombre enclıtico, como echandote de menos, serıan, en el flu-jo de datos y traduciendo al catalan:
ˆtrobar<vblex><ger>+et<prn><enc><p2><mf><sg># a faltar$
Por supuesto, esta regla sirve tambien para verbos que no sigan estepatron de multipalabra, de modo que la forma explicandote serıa ası envia-da por la regla en la traduccion de espanol a catalan:
ˆexplicar<vblex><ger>+et<prn><enc><p2><mf><sg>$
En cuanto al atributo whole de un <clip>, es importante tener encuenta que solo puede utilizarse para enviar la forma lexica completa encaso de que la palabra enviada no pueda ser una multipalabra, es decir,no pueda contener un lema partido. Comparense las figuras 3.40 y 3.44. Elatributo whole puede utilizarse en el segundo ejemplo porque contieneel lema lem mas todas las etiquetas morfologicas de las formas lexicas enposicion 1 y 2 (determinante y nombre). En cambio, en el primer ejemplo,la forma lexica enviada dentro de <lu> se envıa por partes, con un lemh(cabeza del lema) y un lemq (cola del lema), puesto que puede ser que elverbo detectado en el patron sea una multipalabra con lema partido. Enla practica, esto significa que, en nuestro sistema, el atributo whole puedeutilizarse para enviar cualquier tipo de forma lexica excepto los verbos ylos nombres, puesto que solo hemos definido multipalabras con flexionpara formas verbales y nombres.
3.5.4.42. Elemento de unidad lexica <mlu>
Su nombre proviene de multilexical unit o “multiforma lexica” y se utili-za dentro del elemento <out> para enviar multipalabras compuestas pormas de una forma lexica. Cada forma lexica de una <mlu> se envıa dentrode un elemento <lu>. A la salida del modulo, las formas lexicas conteni-das dentro de este elemento apareceran unidas entre sı mediante el sımbo-lo ’+’ del flujo de datos. Esto significa que se convertiran en una multipa-labra compuesta por varias formas lexicas y que seran tratadas como unaunidad por los modulos subsiguientes; por lo tanto, en el diccionario degeneracion debera existir una entrada para esta multipalabra para que seaposible generarla.
En nuestro sistema, este elemento se utiliza para unir los pronombresenclıticos a los verbos conjugados.

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 109
3.5.4.43. Elemento de encapsulamiento de segmento <chunk>
Es el elemento con el que se envıan los chunks a la salida del modulodentro de un elemento <out>. Este elemento solo se utiliza en el modulochunker en modo avanzado y en el modulo interchunk. En el modulopostchunk no se usa porque no es necesario crear ningu chunk a la salida.En el modulo chunker en modo superficial tampoco seusa porque a lasalida no se envıan chunks sino unidades lexicas individuales y blancos.
1. Uso en el modulo chunker en modo avanzado
En este modo, el elemento <chunk> debe tener un atributo nameque es el lema del segmento, o bien un atributo namefrom que hacereferencia a una variable previamente definida, el valor de la cual seusara como lema del segmento. Ademas, puede incorporar un atri-buto case para especificar de que variable se toma la polıtica demayusculas (con un valor obtenido con la instruccion <case-from>,por ejemplo).
Se puede ver un ejemplo de uso del elemento en la figura 3.45.
2. Uso en el modulo interchunkEn este modulo, el elemento <chunk> no especifica ningun atributo,solo se usa del modo en que se usa <lu> en el transfer superficialo en el postchunk para deliminar la forma lexica. Dentro de el seenvıan (generalmente con una instruccion de <clip>)
[Nota: MG: generalmente o sempre]
, el lema del chunk (lem), las etiquetas (tags) y el contenido delchunk (chcontent, contiene las FL mas los blancos), que es unaparte invariable pues en el modulo interchunk no se puede acce-der a el. La parte invariable del segmento se envıa al final. Tambienpuede utilizarse el atributo whole para enviar el chunk entero (lema,etiquetas y contenido invariable).
Se puede ver un ejemplo de uso del elemento en la figura 3.46.
3.5.4.44. Elemento de seccion de enlace de etiquetas <tags>
Solo en chunker en modo avanzado.Este elemento sirve para especificar una lista de etiquetas o elementos
<tag> que seran las pseudoetiquetas del chunk. No tiene atributos, y debeespecificarse como primer elemento dentro del elemento <chunk>. Veasela figura 3.45.

110 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
3.5.4.45. Elemento de enlace de etiquetas <tag>
Solo en chunker en modo avanzado.El elemento <tag> tiene que contener una una etiqueta morfologica,
que se puede especificar mediante una instruccion <clip> o bien una eti-queta literal <lit-tag>. No tiene atributos.
La etiqueta o las etiquetas especificadas de esta manera dentro de unchunk pasaran a ser las etiquetas morfologicas del segmento, que el modu-lo siguiente, interchunk, podra utilizar para realizar comprobaciones ymodificaciones en las caracterısticas de los segmentos.
3.5.4.46. Elemento de blanco <b>
El elemento <b> hace referencia a los [super]blancos, y se indexa me-diante el atributo pos; por ejemplo, un <b> con pos="2" se refiere a los[super]blancos (incluidos los datos de formato encapsulados por el des-formatador) entre la 2a FLLO y la 3a FLLO. La gestion explıcita de [su-per]blancos permite la colocacion correcta del formato cuando el resultadode la transferencia estructural tiene mas o menos elementos lexicos que eloriginal o bien ha sido sometido a algun tipo de reordenacion.
3.5.5. Especificacion de los tres modulos del sistema de trans-ferencia avanzada
A continuacion se describen las caracterısticas diferenciadas del forma-to de los reglas en los tres modulos de un sistema de transferencia sintacti-ca avanzada. Cuando Apertium funcione con un sistema de transferen-cia sintactica superficial, solo entra en accion el primero modulo, llamadochunker, que se comunica directamente con el modulo de generacion.
3.5.5.1. Programa chunker
Este modulo puede utilizarse individualmente como sistema de trans-ferencia sintactica superficial, o en combinacion con los otros dos modu-los de transferencia para construir un sistema de transferencia sintacticaavanzada. Un atributo del elemento <transfer> controla su modo defuncionamiento.

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 111
Entrada/salida
Entrada: datos con el formato de salida del pretransfer, es de-cir, con las colas invariantes de las multipalabras desplazadas a unaposicion anterior a cualquier etiqueta.
Salida:
- en modo avanzado (en un sistema de transferencia avanzada):segmentos (chunks), para que el modulo siguiente los detecte yrealice operaciones con ellos
- en modo superficial (en un sistema de transferencia superficial):formas lexicas que constituyen la entrada del modulo de gene-racion.
Ficheros de datos
[Nota: Explicar millor aixo de l’unic fitxer de configuracio]
Este programa usa un unico fichero de configuracion y un fichero pre-compilado de deteccion de patrones calculado a partir del primero. Elnombre del fichero de patrones (el fichero de configuracion) tendra la ex-tension .t1x. Como el chunker es quien hace la consulta del diccionariobilingue, este (en forma compilada) tambien se tiene que aportar al pro-grama.
[Nota: Potser seria bona idea esmentar en quina seccio s’explica elcompilador a que es fa referencia]
La DTD de este fichero de datos se especifica en el apendice A.3, y enel apartado 3.5.4 se describen los elementos utilizados para crear las reglasdel fichero.
Deteccion de patrones
El sistema de deteccion de reglas de este modulo sera el que se ha ex-plicado en 3.5.2 pues es el mismo en modo de transferencia avanzada y enmodo de transferencia superficial. El programa apertium-pretrans-fer
[Nota: Vacil·lacio terminologica pretransfer.]

112 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
es necesario para adaptar el formato de salida del etiquetador a la entra-da que reconoce el modulo de transferencia. En posteriores versiones deApertium no se descarta que se modifique el desambiguador categorial paraque haga el trabajo del apertium-pretransfer.
[Nota: Tambe hem d’unificar la terminologia d’altres moduls: desam-biguador categorial, etiquetador ; tal com esta redactat el paragraf espodria pensar que son dues coses diferents.]
Funcionamiento
El funcionamiento es basicamente similar en el modo superificial y enel modo avanzado, con estas diferencias:
Para que el modulo funcione como primer modulo de un sistema detransferencia sintactica avanzada, en el atributo opcional defaultdel elemento raız <transfer> debe especificarse el valor chunk.El valor por defecto es lu, que implica que el chunker funcione enmodo de transferencia sintactica superficial (como unico modulo).
Generacion de segmentos (chunks) a la salida: la etiqueta <chunk>es una etiqueta de un nivel mas alto que <lu> (lexical unit) que per-mite generar segmentos con las caracterısticas que han sido especifi-cadas en 3.5.3.1; tiene los siguientes atributos:
• name (opcional): pseudolema del segmento. Una cadena quepermita identificar el pseudolema del segmento.
• namefrom (opcional): pseudolema del segmento, obtenido deuna variable. Es obligatorio especificar o name o namefrom.
• case (opcional): variable que sirve para obtener la informacionde mayusculas o minusculas de una variable y aplicarla al lemaespecificado bien por name, bien por namefrom.
Cada chunk empieza por una instruccion <tags>, que no permiteespecificar ningun atributo, la cual, por su parte, contiene una o masinstrucciones individuales <tag>.
Las instrucciones <tag> no tienen atributos. Dentro de ellas se pue-de poner cualquier instruccion que devuelva como valor una cadena:<lit>, <var>.
Las instrucciones <clip> tienen un nuevo atributo opcional: link-to,que sirve para especificar una etiqueta <valor de link-to> en lugar de

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 113
[Nota: Es “en lugar de” o “adicionalmente a”?]
la informacion que contenga el <clip> en los demas atributos.
[Nota: No s’enten gaire be]
Esta informacion es prescindible pero puede servir como documen-tacion del origen de la decision linguıstica.
Veamos con un ejemplo el uso del elemento <chunk>:
<out><chunk name="adj-nom" case="variableCase">
<tags><tag><lit-tag v="SN"/></tag><tag><clip pos="2" side="tl" part="gen"/></tag><tag><clip pos="2" side="tl" part="nbr"/></tag>
</tags><lu>
<clip pos="2" side="tl" part="lemh"/><clip pos="2" side="tl" part="a_nom"/><clip pos="2" side="tl" part="gen" link-to="2"/><clip pos="2" side="tl" part="nbr" link-to="3"/>
</lu><b pos="1"/><lu>
<var n="adjectiu"/><clip pos="1" side="tl" part="lem"/><clip pos="1" side="tl" part="a_adj"/><clip pos="2" side="tl" part="gen" link-to="2"/><clip pos="2" side="tl" part="nbr" link-to="3"/>
</lu></chunk>
</out>
Accion implıcita
Los superblancos aislados, que no son detectados por ningun patron deeste modulo, se escriben en el mismo orden en el que llegan.
El elemento raız del fichero .t1x de reglas del chunker, <transfer>,tiene un atributo opcional default que puede tomar los valores

114 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
chunk: cuando el modulo funcione en modo avanzado (transferen-cia sintactiva avanzada), para que se generen segmentos triviales conlas palabras que no son detectadas por ninguna regla, para que ala salida no haya ninguna palabra no integrada en un segmento. Elnuevo segmento se creara mediante la traduccion de la palabra porel diccionario bilingue. El lema fijo de los chunks creados implıcita-mente es default.
lu (valor implıcito): cuando el modulo funcione como unico modulode transferencia en modo superficial (transferencia sintactica superfi-cial), para que no se creen segmentos para las palabras no detectadaspor reglas, y simplemente se traduzcan con el diccionario bilingue.
A continuacion se muestra el segmento generado automaticamente conuna forma lexica no detectada por ninguna regla del chunker cuando elatributo default tiene el valor chunk:
ˆdefault{ˆthat<cnjsub>$}$
[Nota: Va sense etiquetes entre default i {? No caldria dir-ho explıci-tament?]
3.5.5.2. Programa interchunk
[Nota: Es apertium-interchunk o interchunk nomes?]
El programa interchunk trata los segmentos, los reordena y hace loscambios pertinentes en la informacion morfosintactica. Esto se hace me-diante la deteccion de patrones de segmentos (secuencias de segmentos).Las instrucciones que se usan para controlar su funcionamiento son, conpocas diferencias, las mismas que usa el programa chunker, pero tieneque quedar claro que se utiliza un archivo diferente. Los segmentos sontratados de forma similar a como se tratan las palabras en el transfer ochunker de Apertium.
[Nota: Comprovar la denominacio dels programes]
Entrada/salida
Entrada: segmentos procedentes de chunker.
Salida: segmentos posiblemente reordenados y con la informaciondel pseudolema del segmento posiblemente modificada.

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 115
Ficheros de datos
Este modulo usa dos ficheros de datos. Un fichero de especificaciondel comportamiento del programa interchunk, con extension .t2x poranalogıa con el modulo anterior, y un fichero de patrones precalculadospara acelerar el analisis de la entrada. No se incluye el fichero binario deldiccionario bilingue porque no se usa.
[Nota: Citar el compilador?]
La sintaxi del fichero de especificacion es muy similar a la del modulochunker. Su DTD se especifica en el Apendice A.4, y en el apartado 3.5.4se describen los elementos utilizados para crear las reglas del fichero.
Deteccion de reglas
Las reglas detectan patrones que estan definidos mediante secuenciasde pseudopalabras. Estas pseudopalabras tienen un formato basado en elformato de la forma lexica de las palabras. Desde el punto de vista practi-co, este pseudolema es visto de manera equivalente a como se
[Nota: La alternanca pseudolema i pseudoparaula s’ha de resoldre]
ve la forma lexica de una palabra en el modulo chunker para realizar ladeteccion. De esta forma, se usara una deteccion de patrones con atribu-tos definidos sobre las pseudopalabras y no sobre las palabras del patronoriginal.
Funcionamiento
Las modificaciones en el juego de instrucciones de este modulo —respectodel juego de instrucciones utilizado en chunker— son las siguientes:
El elemento raız se llama <interchunk> y no especifica ningunatributo.
Desaparicion del atributo side: este modulo no usa diccionarios bi-lingues; por lo tanto el atributo que indica si la parte que se consultaes la lengua origen o la meta no tiene sentido. Este atributo era usadofundamentalmente en las instrucciones <out>.
La etiqueta <chunk> ahora se usa sin atributos, sencillamente dentrode <out> para delimitar la salida de segmentos.

116 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
El atributo predefinido lem hace referencia al pseudolema del seg-mento. De la misma manera, el atributo predefinido tags hace refe-rencia a las etiquetas del segmento. El contenido del segmento quedacomo una cola que se puede imprimir mediante el atributo implıcitochcontent.
[Nota: Nomes imprimir o s’hi pot fer referencia tambe?]
[Nota: Dir de quin element son aquests atributs]
Todos los valores de part, excepto chname, acceden a la informa-cion del lema y las etiquetas del pseudolema de cada segmento.
A diferencia de lo que sucede en el modulo chunker, no se permiteimprimir otra cosa que <chunk>s en las instrucciones <out> en elfichero de especificacion del comportamiento de este modulo, y enningun caso palabras sueltas.
Accion implıcita
Al igual que en el modulo anterior, se ha establecido una accion implıci-ta que escribe sin modificar los segmentos no reconocidos por ningunpatron del fichero de especificacion de este modulo. Esta accion implıcitaescribe exactamente lo que lee, tanto si se trata de chunks como de blan-cos.
[Nota: Atencio a la vacil·lacio regla/accio en la resta del document.Sempre havia cregut que era regla=patro+accio.]
3.5.5.3. Programa postchunk
El programa postchunk detecta segmentos individuales, y para cadauno de ellos, ejecuta unas acciones especificadas. La deteccion se basa en ellema del segmento, y no en patrones (no en las etiquetas); esto hara que ladeteccion en este modulo sea especıfica para cada “nombre” de segmento.
[Nota: Quan fixem be la terminologia hem d’assegurar-nos que laredaccio d’aquesta part es l’adequada.]
Por otro lado, el funcionamiento de la deteccion y del procesamientode las reglas se basa en que las referencias a parametros se resuelven inme-diatamente despues de la deteccion, es decir, las etiquetas <1>, <2>, etc.son sustituidas automaticamente por el valor de los parametros antes deempezar el procesamiento. Las posiciones (atributo pos) a las que se hace

3.5. MODULO DE TRANSFERENCIA ESTRUCTURAL 117
referencia con las instrucciones <clip>, etc. corresponden a la posicionde las palabras en el interior del segmento.
Tambien aplica automaticamente la polıtica de mayusculas (ver seccion3.5.3.2) de los lemas de las pseudopalabras hacia las palabras que estandentro del segmento.
Entrada/salida
Entrada: segmentos procedentes de interchunk.
Salida: entrada valida para el modulo de generacion morfologica deApertium.
Ficheros de datos
Este programa tiene su propio archivo de especificacion, que tendra ex-tension .t3x. La sintaxis esta basada igualmente en el chunker i en elinterchunk.
[Nota: Explicar que no ha de llegir cap fitxer compilat de patrons per-que usa noms i no patrons?]
Deteccion de reglas
La deteccion de los segmentos se basa en el nombre de los segmentos.Los segmentos no detectados reciben el procesamiento implıcito.
Funcionamiento
Las diferencias en las acciones en comparacion con interchunk sonlas siguientes:
Prohibicion de la escritura de segmentos (<chunk>s) a la salida: solose pueden escribir unidades lexicas (<lu> o <mlu>) y blancos.
[Nota: Comprovar aquest ıtem perque era incomplet i l’ha com-pletat mlf]
Nuevo atributo de deteccion name de <cat-item>, que se usa en laparte de <pattern> de las reglas de manera aislada, para forzar ladeteccion de los patrones por su nombre.
[Nota: Que vol dir “de manera aıllada”? Sembla que vulga dir “detant en tant”]

118 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
Tampoco existe el atributo side en los elementos a los que es apli-cable en el modulo interchunk, por la misma razon por que eninterchunk no se accede al diccionario bilingue.
[Nota: MG: pero llavors aixo no es una diferencia respecte deinterchunk no?]
Accion implıcita
En este modulo la accion implıcita es la de escribir las palabras de den-tro del segmento, sustituyendo las referencias por los parametros del seg-mento. Sera usada para la mayor parte de segmentos, ya que se preve queeste modulo se utilice para casos muy especıficos en los que sea necesariohacer algun procesamiento concreto.
Tambien se aplica implıcitamente la polıtica de mayusculas (seccion3.5.3.2).
En cualquier caso, los blancos externos a los segmentos son copiados enel mismo orden en que son leıdos, puesto que la deteccion de segmentoses unitaria (este modulo no los agrupa).
3.5.6. Preproceso del modulo de transferencia estructural
Los ficheros de especificacion de los modulos de transferencia estruc-tural, tambien llamados ficheros de reglas de transferencia, son preprocesadospor el programa apertium-preprocess-transfer que calcula los patrones paracasar precondiciones de las reglas y ademas indexa las reglas para acelerarsu procesamiento en tiempo de ejecucion. Esta informacion se almacena enun archivo en formato binario que se lee junto con el diccionario bilinguecorrespondiente y el propio fichero de reglas de transferencia para la eje-cucion conjunta de los modulos de transferencia lexica y estructural.
3.6. Desformateador y reformateador
3.6.1. Tratamiento del formato de los documentos
En esta seccion se describe como tratan el formato de los documentoslos desformateadores y reformateadores de este sistema, creados a partirde las reglas de especificacion de formato en XML que se describen masadelante, en la seccion 3.6.2.
Los requisitos del proyecto indican que el traductor debe ser capaz deprocesar documentos en formato XML, HTML, RTF y texto llano. En todos

3.6. DESFORMATEADOR Y REFORMATEADOR 119
estos tipos de documento es posible realizar una encapsulacion del formato,tal como se describe a continuacion.
El procedimiento consiste en encapsular las cadenas de texto —en ade-lante bloques de formato o superblancos— que se identifiquen como parte delformato entre delimitadores que dependeran de la especificacion del flujode datos entre modulos (que se discute en detalle en el capıtulo 2); ası, enel formato de flujo (secciones 2.2.1 y 2.3), los superblancos van entre corche-tes ’[’ y ’]’. Cada una de estas cadenas encapsuladas sera tratada como side un blanco <b/> (pagina 36) se tratara —de ahı lo de superblancos— yseran restituidas en el orden correcto a la salida del traductor.
Como ya se ha indicado en el capıtulo 2, cuando los bloques de forma-to sean grandes (como ocurre a veces en HTML con segmentos de codigoen Javascript, o en RTF con imagenes en formato de mapa de bits), se uti-lizara un mecanismo de almacenamiento en ficheros temporales de estosbloques de formato grandes para eliminarlos del flujo de datos de la tra-duccion.
Un requisito adicional que aparece es que muchas veces el formato deuna parte del documento marca implıcitamente la division del texto enoraciones (vease la pagina 13 del capıtulo 2). Por ejemplo, los tıtulos desecciones o de documentos pueden estar en frases que no acaben en pun-to. Si sabemos que una marca de formato nos esta indicando esta divisiondebemos aprovechar esta informacion para poder traducir mejor estos ca-sos. Ejemplos de este fenomeno pueden ser: dos saltos de lınea seguidosen el formato de texto llano, una etiqueta </h1> en HTML, etcetera. Elmodulo desformateador debe generar en estos casos una marca de finalde oracion equivalente a un punto.
3.6.1.1. Sistema de encapsulacion del formato y ejemplo
Los tipos de bloques de formato o superblancos que se generan comoresultado del procesamiento del formato se presentan a continuacion:
Bloques de formato o superblancos no vacıos. Son los que contienen ex-clusivamente marcas de formato del documento original. En el flujode datos descrito en el capıtulo 2 se abren con un corchete izquierdo’[’ y se cierran con el derecho ’]’.
Bloques de formato con referencia a archivo externo o superblancos exten-sos. Sirven para encapsular segmentos de formato largos y ası mejo-rar el rendimiento del traductor. En el flujo de datos descrito en elcapıtulo 2 comienzan por la cadena ’[@’, siguen con el nombre del

120 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
archivo en el que se almacena el segmento de formato extraıdo deldocumento original, y finalmente acaban en un corchete derecho ’]’.
Bloques de formato vacıos. Sirven para incorporar informacion artificialde segmentacion del texto obtenida a partir del formato. Antes delbloque de formato vacıo se coloca el signo de puntuacion artificialque se tenga que incluir. Cuando sea necesario restituir el formatooriginal al documento, la presencia de un bloque de formato de estascaracterısticas obligara a la supresion del caracter inmediatamenteanterior que se encuentre en el flujo de datos.
El criterio que se aplica para crear estos bloques de formato se basa enlos siguientes criterios generales:
Se debe encapsular todo lo que no se considere parte del texto quehay que traducir para formar bloques de formato.
No debe haber dos o mas bloques de formato no vacıos estrictamenteconsecutivos. Dos bloques de formato consecutivos siempre debenunirse en un solo bloque.
Los bloques de formato vacıos deben preceder a un bloque de for-mato no vacıo o al fin de fichero.
En la figura 3.47 se muestra un documento de ejemplo cuyo formatodebe ser tratado previamente a la traduccion; en el ejemplo, el encapsu-lamiento se corresponde con el formato de flujo no basado en XML. Lafigura 3.48 muestra el resultado de procesar el anterior documento.
De este ejemplo conviene resaltar los siguientes fenomenos:
No se generan bloques de formato con contenido (no vacıos) conse-cutivos.
Las etiquetas como </title> y </p> inducen la introduccion designos de puntuacion artificiales, y esta introduccion se realiza demanera sistematica (incluso cuando no hace falta, porque no molestay es eficiente).
Los superblancos extensos salen literalmente del proceso de la tra-duccion. En este caso, el fichero temporal temp35345 contiene lasetiquetas desde </title> hasta <p>
Los blancos sencillos entre palabras no se encapsulan. No ocurre lomismo con los blancos multiples (dos o mas blancos consecutivos),tabuladores, etc. que son encapsulados. Los saltos de lınea tambiense encapsulan.

3.6. DESFORMATEADOR Y REFORMATEADOR 121
<html><head><title>Esto es el tıtulo</title><script><!-- ... (un bloque de codigo extenso) --></script></head><body><p>Estoes un parrafo escrito en dos lıneas</p></body></html>
Figura 3.47: Ejemplo de documento HTML
[<html><head><title>]Esto es el tıtulo.[][@/tmp/temp35345]Esto[]es un parrafo escrito en dos lıneas.[][</p></body></html>]
Figura 3.48: Ejemplo de documento HTML con los bloques de formato encapsu-lados por el desformateador
[Nota: repeteix coses capıtol format -revisar -Gema]

122 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
3.6.2. Datos: reglas de especificacion de formato
En esta seccion se describe el proceso de generacion de formateadoresy desformateadores a partir de una especificacion de formato en XML.
Las reglas para los formatos se especifican, como los datos linguısticos,en XML, y dentro de ellas se declaran expresiones regulares con sintaxisde flex. La especificacion se estructura en tres partes (ver DTD de la de-finicion formal en el apendice A.6):
Opciones de configuracion. En este apartado se especifica el valorde la longitud maxima de un superblanco no extenso, las codifica-ciones de entrada y de salida, la necesidad de la distincion o no entremayusculas y minusculas y las expresiones regulares para los carac-teres de escape y para los caracteres de espaciado.
Reglas de formato. Se describe el conjunto de etiquetas propias deun formato determinado que han de ser encerradas en un bloque deformato por el desformateador. Dichas etiquetas de formato podran,opcionalmente, indicar el fin de frase para que el desformateadorinserte el signo de puntuacion artificial (seguido de un bloque deformato vacıo, como se especifica en la seccion anterior). Tambien seha de especificar la prioridad de aplicacion de las reglas aunque, encaso de no ser necesario, se puede dar a todas reglas la misma prio-ridad mediante la asignacion del mismo valor (cualquier numero) atodas ellas.
Se entiende que todo lo que no sea especificado como formato que-dara sin encapsular y sera texto para traducir.
Reglas de sustitucion. Permiten sustituir caracteres especiales deltexto. Una expresion regular recogera un conjunto de caracteres es-peciales, y los sustituira por los caracteres que se especifique. Porejemplo, en HTML los caracteres especificados en hexadecimal de-ben ser sustituidos por su correspondiente entidad o caracter ASCII.Por ejemplo, camión se corresponde con camion.
A continuacion se describen las reglas con mas detalle.
Raiz del documento de especificacion. En el atributo name esta elnombre del formato.
<?xml version="1.0" encoding="ISO-8859-1"?><format name="html">

3.6. DESFORMATEADOR Y REFORMATEADOR 123
<options>...</options>
<rules>...</rules>
</format>
Dentro deben estar las opciones y las reglas de las que se presenta unejemplo a continuacion:
Opciones.
<options><largeblocks size="8192"/><input encoding="ISO-8859-1"/><output encoding="ISO-8859-1"/><escape-chars regexp=’[\[\]ˆ$\\]’/><space-chars regexp=’[ \n\t\r]’/><case-sensitive value="no"/>
</options>
El elemento <largeblocks> sirve para especificar la longitud maxi-ma de un superblanco no extenso, mediante el valor del atributo size.Los elementos <input> y <output> sirven para especificar la codifica-cion de entrada y de salida del texto mediante el atributo encoding.
El elemento escape-chars permite especificar, mediante una expre-sion regular que se da en el valor del atributo regexp, que caracteres de-ben protegerse mediante una barra invertida. El elemento <space-chars>especifica el conjunto de caracteres que tienen que ser tomados como sifueran espacios en blanco.
Finalmente, el elemento case-sensitive sirve para especificar si, entodas las especificaciones de atributos del formato en las que intervenganexpresiones regulares es relevante si se especifican mayusculas o minuscu-las.
Reglas. Hay reglas de formato y de sustitucion.
<rules><format-rule ... >...

124 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
</format-rule>...
<replacement-rule>...
</replacement-rule>...
</rules>
Se detallan en los dos puntos siguientes.
Reglas de formato. El desformateador encerrara en bloques de for-mato las etiquetas que estas reglas indiquen en su campo regexp. Sise trata de etiquetas de inicio y fin, y todo lo que encierran es forma-to, se especifica una regexp tanto para begin como para end:
<format-rule eos="no" priority="1"><begin regexp=’"\<!--"’/><end regexp=’"--\>"’/>
</format-rule>
De lo contrario se utiliza solo un elemento begin-end:
<format-rule eos="yes" priority="3"><begin-end regexp=’"<"[/]?"li"[ˆ>]*">"’/>
</format-rule>
Ademas, en priority se especifica una prioridad que sirve parasaber en que orden se aplican las reglas de formato (el valor absolutono es relevante, solo se utiliza el orden que se establece entre losvalores usados en las reglas). En “eos” se indica mediante yes ono si el bloque de formato del que forme parte el patron detectadodebera ir precedido de un signo de puntuacion artificial o no.11
Reglas de sustitucion. Sirve para sustituir caracteres especiales deltexto. La expresion regular del atributo regexp recogera un conjun-to de caracteres especiales y los sustituira en el texto a traducir porlos caracteres que se especifiquen. La correspondencia entre carac-teres originales y sustituidos se establece en los atributos source ytarget de los elementos replace, que pueden ser multiples:
11En todos estos casos, se usan las tıpicas entidades < y > para representar loscaracteres < y > respectivamente.

3.6. DESFORMATEADOR Y REFORMATEADOR 125
<replacement-rule regexp=’"&"[ˆ;]+;’><replace source="&Agrave;" target="A"/><replace source="&#192;" target="A"/><replace source="&#xC0;" target="A"/><replace source="&#xc0;" target="A"/><replace source="&Aacute;" target="A"/><replace source="&#193;" target="A"/><replace source="&#xC1;" target="A"/><replace source="&#xc1;" target="A"/>...
</replacement-rule>
Expresiones regulares de los atributos regexp. Tienen la sintaxis uti-lizada en flex [9].
Como ejemplo de especificacion de formato vamos a utilizar el de HTML,del que se puede seguir la explicacion que ofrecemos a continuacion mi-rando la figura 3.49.
Encontramos, en primer lugar, la regla de formato que especifica deforma general todas las etiquetas de HTML, es decir, considera etiquetaHTML todo aquello que empiece por el signo < y termine por el signo >.Esta regla tiene la prioridad mas baja (4) para permitir que las reglas masespecıficas se apliquen preferentemente. Pero antes de considerar una eti-queta como general, es decir, antes de aplicar esta regla, se aplicara algunade las reglas de mayor prioridad. En el caso de HTML, la mayor priori-dad la tienen los comentarios <!-- ... -->. Las marcas de inicio y fin<script></script> y <style></style>, donde se considera forma-to todo que lo estas encierren, tienen prioridad 2. Prioridad 3 tienen lasetiquetas que implican fin de frase (puntuacion artificial), que son </br>,</hr>, </p>, etc.
Finalmente se especifican las reglas de sustitucion, para sustituir todoslos codigos que empiecen por &, y ası se especifica en la expresion regular.Despues se define cada una de las sustituciones: tanto À, comoÀ, À y À se sustituyen por A. De igual manera se declaranlos demas caracteres especiales.
3.6.3. Generacion de formateadores y desformateadores
Para generar el formateador y el desformateador de un formato dado,se aplica a las reglas en XML que declaran este formato (que se describena continuacion) una hoja de estilo generadora de formateadores y desfor-mateadores Esta transformacion XSLT da como resultado un fichero lex

126 CAPITULO 3. ESPECIFICACION DE LOS MODULOS
<?xml version="1.0" encoding="ISO-8859-1"?><format name="html"><options><largeblocks size="8192"/><input encoding="ISO-8859-1"/><output encoding="ISO-8859-1"/><escape-chars regexp=’[\[\]ˆ$\\]’/><space-chars regexp=’[ \ n\ t\ r]’/><case-sensitive value="no"/>
</options>
<rules><format-rule eos="no" priority="1">
<begin regexp=’"<!--"’/><end regexp=’"-->"’/>
</format-rule>
<format-rule eos="no" priority="2"><begin regexp=’"<script"[ˆ>]*">"’/><end regexp=’"</script"[ˆ>]*">"’/>
</format-rule><format-rule eos="no" priority="2"><begin regexp=’"<style"[ˆ>]*">"’/><end regexp=’"</style"[ˆ>]*">"’/>
</format-rule>
<format-rule eos="yes" priority="3"><begin-end regexp=’"<"[/]?"br"[ˆ>]*">"’/>
</format-rule><!-- Aquı faltan mas declaraciones format-rule eos="yes"--><!-- ... -->
<format-rule eos="no" priority="4"><begin-end regexp=’"<"[a-zA-Z][ˆ>]*">"’/>
</format-rule>
<replacement-rule regexp=’"&"[ˆ;]+;’><replace source="&Agrave;" target="A"/><replace source="&#192;" target="A"/><replace source="&#xC0;" target="A"/><replace source="&#xc0;" target="A"/><!-- Aquı faltan mas elementos replace --><!-- ... -->
</replacement-rule></rules>
</format>
Figura 3.49: Parte de la definicion de reglas del formato HTML

3.6. DESFORMATEADOR Y REFORMATEADOR 127
[9] que, una vez compilado, es el ejecutable del formateador o desforma-teador para el formato especificado.
Gracias a la especificacion general de formatos descrita en este capıtu-lo, se han podido definir las especificaciones para los formatos HTML, RTFy texto llano. Estas especificaciones se hallan en el paquete apertium, enlos ficheros respectivos html-format.xml, rtf-format.xml, txt-format.xml.En particular, es relativamente sencillo definir desformateadores y refor-mateadores de cualquier formato XML.

128 CAPITULO 3. ESPECIFICACION DE LOS MODULOS

Capıtulo 4
Instalacion y ejecucion delsistema
4.1. Requisitos del sistema
El sistema en el que se desee instalar y ejecutar Apertium debe tenerlos siguientes programas instalados:
libxml2 version 2.6.17 o superior
programa xmllint (generalmente viene incluido en libxml2, peropuede ser un paquete independiente en el sistema, por ejemplo enDebian GNU-Linux)
programa xsltproc (para no usuarios de PowerPC); tambien vienecon libxml2 pero puede ser igualmente un paquete independienteen el sistema, como en el caso de xmllint
programa sabcmd (usuarios de PowerPC), suministrado con el pa-quete sablotron
GNU make, gcc (g++), interprete de comandos bash
4.2. Instalacion de los paquetes de programas
Para instalar los programas y librerıas del sistema de traduccion au-tomatica Apertium, debera descargarse (de http://sourceforge.net/projects/apertium), compilar e instalar la ultima version de los si-guientes paquetes, en el orden especificado:
129

130 CAPITULO 4. INSTALACION Y EJECUCION DEL SISTEMA
1. lttoolbox
2. apertium
La manera mas sencilla de compilar los paquetes es la siguiente:
1. Vaya al directorio que contiene el codigo fuente del paquete y escriba./configure; se configurara el paquete en su sistema. Si utiliza cshen una version antigua de System V, probablemente debera escribirsh ./configure para evitar que csh (el interprete de comandospor defecto en el antiguo System V) intente ejecutar configure porsı solo. La ejecucion de configure tarda un tiempo; mientras seejecuta, muestra en pantalla algunos mensajes que indican que com-probaciones esta realizando.
2. Escriba make para compilar el paquete
3. Escriba make install (probablemente necesitara privilegios de ad-ministrador) para instalar los programas, los ficheros de datos y ladocumentacion.
4. Si desea eliminar del directorio de codigo fuente los archivos bina-rios y los archivos de objetos del programa, escriba make clean.Para eliminar tambien los ficheros que configure ha creado (demodo que pueda compilar el paquete para un ordenador de diferen-te tipo), escriba make distclean. Tambien hay una opcionmaintainer-clean en el Makefile, pero esta prevista principal-mente para los desarrolladores del paquete. Si lo utiliza, es probableque despues tenga que buscar varios programas que necesitara paravolver a generar los archivos que estaban incluidos en la distribu-cion.
Si no dispone de privilegios de administrador para instalar los pro-gramas en su sistema, puede utilizar la opcion -prefix con el script deconfiguracion para que se instalen en su cuenta de usuario. Por ejemplo:
$ pwd/home/me/lttoolbox-0.9.1$ ./configure --prefix=/home/me/myinstall
Las librerıas se instalaran en el directorio LIBDIR=$prefix/lib. Sino se especifica ninguna opcion -prefix con el script de configuracion,el directorio LIBDIR sera /usr/local/lib.

4.3. INSTALACION DE LOS PAQUETES DE DATOS 131
Si encuentra algun error de enlace con las librerıas instaladas en el di-rectorio LIBDIR, debera usar libtool y especificar la ruta de acceso com-pleta de la librerıa, o bien utilizar la opcion LIBDIR durante el enlace yrealizar al menos una de las siguientes acciones:
anadir LIBDIR a la variable de entorno LD_LIBRARY_PATH durantela ejecucion
anadir LIBDIR a la variable de entorno LD_RUN_PATH durante elenlace
utilizar -Wl, --rpath -Wl, opcion de enlazado LIBDIR
pedir al administrador del sistema que anada LIBDIR a /etc/ld.so.confy ejecute ldconfig
Consulte la documentacion del sistema operativo relativa a las librerıascompartidas para obtener mas informacion; por ejemplo, las paginas demanual ld(1) y ld.so(8).
4.3. Instalacion de los paquetes de datos
Para instalar los paquetes de datos linguısticos, siga los pasos siguien-tes:
1. Descargue un paquete de datos (apertium-L1-L2-VERSION.tar.gz)de la pagina web de Apertium en Sourceforge (http://apertium.sourceforge.net/). Por ejemplo, para obtener la version 0.9 delos datos linguısticos del traductor espanol–catalan, debera descar-garse el paquete apertium-es-ca-0.9.tar.gz.
2. Descomprima el archivo en cualquier directorio, vaya al directorioen cuestion y escriba make en el terminal. Espere mientras se compi-lan los datos linguısticos.
4.4. Ejecucion del traductor
Hay versiones del traductor Apertium que funcionan tanto en siste-mas operativos Linux (siempre mas actualizadas) como en Windows. Lainformacion de este capıtulo esta basicamente dirigida a los usuarios deLinux.

132 CAPITULO 4. INSTALACION Y EJECUCION DEL SISTEMA
Para utilizar el traductor, debe ejecutarse la herramienta apertium-translatorhaciendo referencia al directorio en el que se encuentran los datos linguısti-cos, indicando ademas la direccion de traduccion (es-ca, ca-es, es-gl,etc.), el formato del fichero (txt, html, rtf), el nombre del fichero a tra-ducir y el nombre del fichero resultante. La estructura del comando es portanto la siguiente:
$ apertium-translator <directorio> <traduccion> <formato>
< fichero_original > fichero_traducido
Por ejemplo, si el directorio es /home/maria/apertium-es-ca, hayque escribir lo siguiente para traducir un fichero en formato txt de es-panol a catalan:
$ apertium-translator /home/maria/apertium-es-ca es-catxt <fichero_esp >fichero_cat
Es aconsejable situarse en el directorio en el que estan almacenados losdatos linguısticos, porque de este modo es suficiente con escribir un puntopara hacer referencia al directorio presente:
$ apertium-translator . es-ca txt <fichero_esp >fichero_cat
Si no se indica ningun formato, el formato por defecto es txt. Con losformatos txt, html y rtf, las palabras desconocidas se marcan con unasterisco (*) y los errores con un sımbolo (@, # o /); si se desea que no semarquen las desconocidas ni los errores, se anade una u al nombre delformato. Ası, las opciones de formato son las siguientes:
txt : Opcion predeterminada, texto con marca de desconocidas y deerrores
txtu : texto sin marca de desconocidas ni de errores
html : HTML con marca de desconocidas y de errores
htmlu : HTML sin marca de desconocidas ni de errores
rtf : RTF con marca de desconocidas y de errores
rtfu : RTF sin marca de desconocidas ni de errores

4.4. EJECUCION DEL TRADUCTOR 133
Si no se desea traducir un fichero sino traducir directamente una fraseen pantalla, puede ejecutarse la herramienta apertium-translator sinindicar ningun nombre de archivo. El comando, si estamos situados en eldirectorio de datos linguısticos, serıa como sigue:
$ apertium-translator . es-ca
A continuacion, debe escribirse el texto que se desea traducir (puedenincluirse saltos de lınea). Para obtener la version traducida, debe pulsarseCtrl + D, con lo que la traduccion aparecera en pantalla.
Una tercera manera de traducir con Apertium es utilizando el comandoecho para pasar texto a traves del traductor:
$ echo "texto que quiero traducir" | apertium-translator . es-ca

134 CAPITULO 4. INSTALACION Y EJECUCION DEL SISTEMA

Capıtulo 5
Mantenimiento de los datoslinguısticos del traductor
5.1. Descripcion de los datos linguısticos existen-tes
Actualmente, Apertium posee datos linguısticos para dos pares de len-guas: espanol–catalan y espanol–gallego. Los archivos que contienen losdatos linguısticos estan contenidos en un solo directorio: apertium-es-capara el par espanol–catalan y apertium-es-gl para el par espanol–gallego.Los nombres de los ficheros contenidos en este directorio siguen la si-guiente estructura:
apertium-L1-L2.L1.dix : diccionario monolingue del idioma L1.apertium-L1-L2.L2.dix : diccionario monolingue del idioma L2.apertium-L1-L2.L1-L2.dix : diccionario bilingue del par de idio-mas L1-L2 (en ambas direcciones).apertium-L1-L2.trules-L1-L2.dix : reglas de transferencia es-tructural para la traduccion de L1 a L2.apertium-L1-L2.trules-L2-L2.dix : reglas de transferencia es-tructural para la traduccion de L2 a L1.apertium-L1-L2.L1.tsx : fichero de definicion del desambigua-dor para L1.apertium-L1-L2.L2.tsx : fichero de definicion del desambigua-dor para L2.apertium-L1-L2.post-L1.dix : diccionario de postgeneracion pa-ra L1 (se aplica al traducir hacia la lengua L1).
135
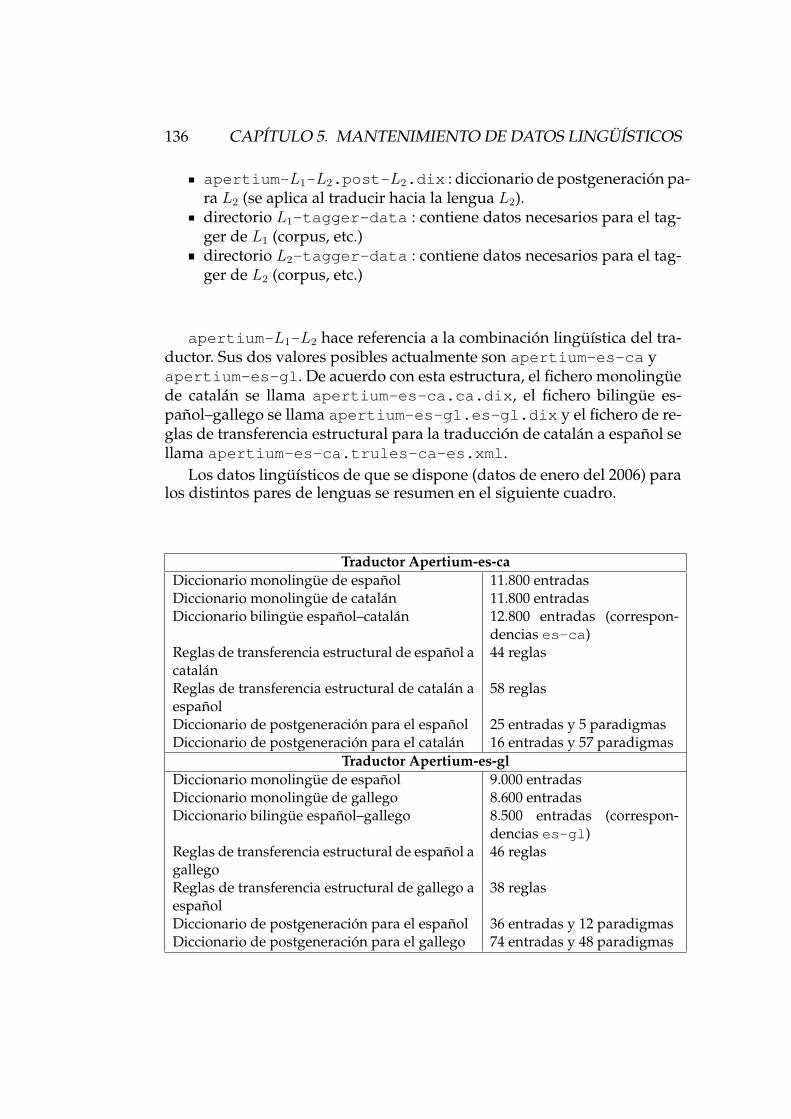
136 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
apertium-L1-L2.post-L2.dix : diccionario de postgeneracion pa-ra L2 (se aplica al traducir hacia la lengua L2).directorio L1-tagger-data : contiene datos necesarios para el tag-ger de L1 (corpus, etc.)directorio L2-tagger-data : contiene datos necesarios para el tag-ger de L2 (corpus, etc.)
apertium-L1-L2 hace referencia a la combinacion linguıstica del tra-ductor. Sus dos valores posibles actualmente son apertium-es-ca yapertium-es-gl. De acuerdo con esta estructura, el fichero monolinguede catalan se llama apertium-es-ca.ca.dix, el fichero bilingue es-panol–gallego se llama apertium-es-gl.es-gl.dix y el fichero de re-glas de transferencia estructural para la traduccion de catalan a espanol sellama apertium-es-ca.trules-ca-es.xml.
Los datos linguısticos de que se dispone (datos de enero del 2006) paralos distintos pares de lenguas se resumen en el siguiente cuadro.
Traductor Apertium-es-caDiccionario monolingue de espanol 11.800 entradasDiccionario monolingue de catalan 11.800 entradasDiccionario bilingue espanol–catalan 12.800 entradas (correspon-
dencias es-ca)Reglas de transferencia estructural de espanol acatalan
44 reglas
Reglas de transferencia estructural de catalan aespanol
58 reglas
Diccionario de postgeneracion para el espanol 25 entradas y 5 paradigmasDiccionario de postgeneracion para el catalan 16 entradas y 57 paradigmas
Traductor Apertium-es-glDiccionario monolingue de espanol 9.000 entradasDiccionario monolingue de gallego 8.600 entradasDiccionario bilingue espanol–gallego 8.500 entradas (correspon-
dencias es-gl)Reglas de transferencia estructural de espanol agallego
46 reglas
Reglas de transferencia estructural de gallego aespanol
38 reglas
Diccionario de postgeneracion para el espanol 36 entradas y 12 paradigmasDiccionario de postgeneracion para el gallego 74 entradas y 48 paradigmas

5.2. INTRODUCIR PALABRAS EN LOS DICCIONARIOS 137
5.2. Introducir palabras en los diccionarios mo-nolingues y bilingues
La adicion de lexico a los diccionarios es seguramente la operacion quecon mas probabilidad realizaran quienes quieran ampliar o adaptar Aper-tium, mas que anadir reglas de transferencia o de postgeneracion.
A continuacion se explican los aspectos mas importantes que hay quetener en cuenta a la hora de introducir palabras. Esta informacion es masgeneral que la ofrecida en el apartado de descripcion de los diccionarios(punto 3.1.2), aunque contiene informacion practica que puede ser de granutilidad para quienes decidan llevar a cabo esta tarea.
Para anadir una palabra a Apertium hay que realizar tres entradasen los diccionarios. Supongamos que esta trabajando con el par espanol–catalan. En este caso, debera anadir:
1. una entrada en el diccionario monolingue espanol: para que el tra-ductor pueda analizar (”entender”) la palabra cuando la encuentreen un texto, y la pueda generar al traducir esta palabra al espanol.
2. una entrada en el diccionario bilingue: para que Apertium puedatraducir esta palabra de una lengua a la otra.
3. una entrada en el diccionario monolingue de catalan: para que el tra-ductor pueda analizar (”entender”) la palabra cuando lo encuentreen un texto, y la pueda generar al traducir esta palabra al catalan.
Debera ir al directorio que contiene los diccionarios en XML (para elpar espanol–catalan, por ejemplo, es apertium-es-ca) y abrir con uneditor de texto o un editor de XML especializado los tres diccionarios men-cionados: apertium-es-ca.es.dix, apertium-es-ca.es-ca.dix yapertium-es-ca.ca.dix. Las entradas que debera anadir en estos tresdiccionarios tienen una estructura similar.
Diccionario monolingue (espanol)Supongamos que desea anadir el adjetivo espanol cosmico, cuyo equi-
valente en catalan es cosmic. El primer paso es anadir esta palabra al dic-cionario monolingue espanol.
Vera que un diccionario monolingue tiene principalmente dos tipos dedatos: paradigmas (en la seccion ”<pardefs>”del diccionario, cada unoen un elemento <pardef>) y entradas lexicas (en la seccion principal del

138 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
diccionario (<section>), cada una dentro de un elemento <e>. Las en-tradas lexicas se componen de un lema (es decir, la palabra que encon-trarıamos como entrada en un diccionario en papel) y de informacion gra-matical; los paradigmas contienen los datos de flexion de todos los lemasdel diccionario. Para buscar una palabra concreta, puede buscar la cadenalm="palabra" (lm de lema). Tenga en cuenta, sin embargo, que el ele-mento lm es opcional en los diccionarios y que es posible que algunos noincluyan esta informacion.
Observe como son las entradas lexicas del diccionario monolingue es-panol, por ejemplo la entrada para el adjetivo bonito. Puede encontrarlabuscando la cadena lm="bonito":
<e lm="bonito"><i>bonit</i>
<par n="absolut/o__n"/></e>
Para anadir una palabra, debera crear una entrada con la misma estruc-tura. La parte entre <i> e </i> contiene la parte inicial de la palabra quees comun a todas las formas flexionadas, y el elemento <par> indica cuales su paradigma de flexion. Por lo tanto, esta entrada significa que el ad-jetivo bonito se flexiona igual que el adjetivo absoluto con el mismo analisismorfologico: las formas bonito, bonita, bonitos, bonitas son equivalentes alas formas absoluto, absoluta, absolutos, absolutas y tienen el mismo analisismorfologico: adj m sg, adj f sg, adj m pl y adj f pl respectiva-mente.
Primero debe decidir cual es la categoria lexica de la palabra que deseaanadir: la palabra cosmico es un adjetivo, como bonito. A continuacion, debeencontrar el paradigma apropiado para este adjetivo. ¿Es el mismo queel de bonito o absoluto? ¿Puede decir cosmico, cosmica, cosmicos, cosmicas?Como la respuesta es afirmativa, ya tiene la informacion necesaria paracrear la entrada:
<e lm="cosmico"><i>cosmic</i>
<par n="absolut/o__adj"/></e>
Si la palabra que desea anadir tiene un paradigma diferente, debera bus-carlo en el diccionario y asignarlo a la entrada. Hay dos maneras de buscarun paradigma: mirando en la seccion <pardefs> del diccionario, dondeestan definidos todos los paradigmas, cada uno dentro de un elemento

5.2. INTRODUCIR PALABRAS EN LOS DICCIONARIOS 139
<pardef>, o bien buscando una palabra que pensemos que pueda exis-tir en el diccionario y que tenga el mismo paradigma de inflexion que laque queremos anadir. Por ejemplo, si desea anadir la palabra genoma, de-bera encontrar un paradigma para un nombre de genero masculino queforme el plural anadiendo una -s. En los diccionarios actuales, se trata delparadigma ”abismo n”. Por lo tanto, la entrada para esta nueva palabraserıa:
<e lm="genoma"><i>genoma</i>
<par n="abismo__n"/></e>
En casos excepcionales sera necesario crear un nuevo paradigma parauna palabra determinada. Para ello, observe la estructura de los demas pa-radigma y cree uno nuevo a partir de alguno que sea similar. Para obteneruna descripcion mas detallada de los paradigmas y de las entradas lexicasde los diccionarios, consulte la seccion 3.1.2.
Diccionario monolingue (catalan)Una vez anadida la palabra a un diccionario monolingue, hay que ha-
cer lo mismo en el otro diccionario monolingue del par de traduccion (enel ejemplo actual, el diccionario monolingue de catalan) aplicando la mis-ma estructura. El resultado serıa:
<e lm="cosmic"><i>cosmi</i>
<par n="academi/c__adj"/></e>
Diccionario monolingue (gallego)Si lo que quiere es mejorar los diccionarios XML para el par espanol–
gallego, debera ir al directorio apertium-es-gl y abrir, con un editorde texto o un editor XML especializado, los tres ficheros de diccionariosapertium-es-gl.es.dix, apertium-es-gl.es-gl.dix y apertium-es-gl.gl.dix.En este caso, una vez ha anadido la nueva palabra genoma al diccionariomonolingue espanol (apertium-es-gl.es.dix), debera anadir la pala-bra gallega equivalente xenoma al diccionario monolingue gallego (apertium-es-gl.gl.dix),es decir:
<e lm="xenoma"><i>xenoma</i>
<par n="Xulio__n"/></e>

140 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
Diccionario bilingueEl ultimo paso es anadir la traduccion al diccionario bilingue.Generalmente, un diccionario bilingue no tiene paradigmas, sino solo
lemas. Una entrada contiene unicamente el lema en ambos idiomas y elprimer sımbolo gramatical (la categorıa lexica) de cada uno. Las entradastienen una parte izquierda (<l>) y una parte derecha (<r>), y un idiomatiene que ocupar siempre la misma posicion: en nuestro sistema, se haconvenido que el espanol ocupe la parte izquierda, y el catalan y el gallegola parte derecha.
Anadiendo el lema de ambas palabras, el sistema traducira todas susformas flexionadas (puesto que los sımbolos gramaticales se copian desdela palabra original a la palabra en lengua meta). Esto solo dara resultadosi la palabra de origen y la palabra de destino son gramaticalmente equi-valentes, es decir, si comparten exactamente los mismos sımbolos grama-ticales para todas sus formas flexionadas. Como este es el caso del ejemploque nos ocupa, la entrada que hay que anadir al diccionario bilingue es:
<e><p><l>cosmico<s n="adj"/></l><r>cosmic<s n="adj"/></r>
</p></e>
Esta entrada servira para traducir todas las formas flexionadas, es de-cir, adj m sg, adj f sg, adj m pl y adj f pl. Sirve para ambas di-recciones: de espanol a catalan y de catalan a espanol.
En el caso del par espanol–gallego, la siguiente entrada en el diccio-nario bilingue espanol–gallego (apertium-es-gl.es-gl.dix) tradu-cira todas las formas flexionadas de las palabras equivalentes genoma/xenomaen ambas direcciones:
<e><p><l>genoma<s n="n"/></l><r>xenoma<s n="n"/></r>
</p></e>
En caso de que el par de traduccion no sea gramaticalmente equivalen-te (sus sımbolos gramaticales no sean exactamente los mismos), es necesa-rio especificar todos los sımbolos gramaticales (en el mismo orden en que

5.2. INTRODUCIR PALABRAS EN LOS DICCIONARIOS 141
estan especificados en los diccionarios monolingues) hasta llegar al sımbo-lo que cambia entre la forma lexica origen y la forma lexica destino. Porejemplo, el nombre espanol limon, de genero masculino, se traduce al ca-talan por un nombre de genero femenino, llimona. Por lo tanto, la entradaen el diccionario bilingue debe ser:
<e><p><l>limon<s n="n"/><s n="m"/></l><r>llimona<s n="n"/><s n="f"/></r>
</p></e>
Un caso mas complicado es el que surge cuando, teniendo dos formaslexicas con sımbolos gramaticales diferentes, la informacion gramatical dela forma de la lengua origen no es suficiente para determinar el genero(masculino o femenino) o el numero (singular o plural) de la forma de lalengua destino. Ası sucede, por ejemplo, con el adjetivo espanol canadiense.Su genero es masculino–femenino puesto que es de invariable en genero,es decir, puede acompanar a nombres tanto masculinos como femeninos(hombre canadiense, mujer canadiense. En catalan, en cambio, el adjetivo seflexiona de manera diferente para el masculino y para el femenino (homecanadenc, dona canadenca). Ası, al traducir de espanol a catalan no es posi-ble saber, sin mirar el nombre al que acompana, si el adjetivo espanol (mf )tiene que traducirse como un adjetivo femenino o masculino en catalan.En este caso se utiliza el sımbolo GD (de ”genero por determinar”) en lu-gar del sımbolo de genero. Sera en el modulo de transferencia estructuraldonde se determinara el genero de la palabra mediante una regla de trans-ferencia (en este caso concreto, una regla que detecte el genero del nombreprecedente). El sımbolo GD debe utilizarse solo para la traduccion de es-panol a catalan, y no viceversa, ya que en espanol el genero sera siempremf independientemente del genero de la palabra original. En el dicciona-rio bilingue, habra que anadir mas de una entrada con restricciones dedireccion, puesto que es necesario indicar en que direccion de traduccionel genero queda sin determinar. Las entradas para este adjetivo deben sercomo sigue:
<e r="LR"><p><l>canadiense<s n="adj"/><s n="mf"/></l><r>canadenc<s n="adj"/><s n="GD"/></r>
</p>

142 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
</e><e r="RL"><p><l>canadiense<s n="adj"/><s n="mf"/></l><r>canadenc<s n="adj"/><s n="f"/></r>
</p></e><e r="RL"><p><l>canadiense<s n="adj"/><s n="mf"/></l><r>canadenc<s n="adj"/><s n="m"/></r>
</p></e>
”LR”significa left to right (”de izquierda a derecha”) y ”RL”, right to left(”de derecha a izquierda”). Puesto que el espanol esta situado a la izquier-da y el catalan a la derecha, el adjetivo sera GD solo en la traduccion deespanol a catalan (LR). Para la traduccion RL hay que crear dos entradas,una para el adjetivo en femenino y otra para el adjetivo en masculino.1
Este mismo principio se aplica cuando no es posible determinar elnumero de la palabra destino por los mismos motivos que se acaban deexponer. Por ejemplo, el nombre espanol rascacielos es invariable en nume-ro, es decir, tiene la misma forma para el singular y para el plural (un ras-cacielos, dos rascacielos). En catalan, el nombre tiene diferente flexion para elsingular y para el plurar (un gratacel, dos gratacels). En este caso, el sımboloutilizado es ”ND”(de ”numero por determinar”) y las entradas para estoslemas deben ser como sigue:
<e r="LR"><p><l>rascacielos<s n="n"/><s n="m"/><s n="sp"/></l><r>gratacel<s n="n"/><s n="m"/><s n="ND"/></r>
</p></e><e r="RL"><p><l>rascacielos<s n="n"/><s n="m"/><s n="sp"/></l><r>gratacel<s n="n"/><s n="m"/><s n="pl"/></r>
</p></e><e r="RL">
1Tambien se podrıan agrupar usando un pequeno paradigma

5.2. INTRODUCIR PALABRAS EN LOS DICCIONARIOS 143
<p><l>rascacielos<s n="n"/><s n="m"/><s n="sp"/></l><r>gratacel<s n="n"/><s n="m"/><s n="sg"/></r>
</p></e>
Para obtener una descripcion mas detallada de este tipo de entradas,consulte lapagina 40.
5.2.1. Anadir restricciones de direccion
En el ejemplo anterior hemos visto el uso de restricciones de direccionen las entradas con genero o numero por determinar (GD o ND). Estas res-tricciones tambien pueden utilizarse en otros casos.
Hay que tener en cuenta que la version actual de Apertium solo puedeproporcionar un unico equivalente para cada forma lexica de la lengua ori-gen, es decir, no realiza ningun tipo de desambiguacion semantica.2 Cuan-do una forma lexica puede traducirse a la lengua meta de dos o mas ma-neras diferentes, hay que escoger una (las mas general, la mas frecuente,etc.). Puede indicarse al sistema que una forma sea analizada (.entendida”)pero no generada, puesto que no es la traduccion de ningun lema de laotra lengua.
Veamoslo con un ejemplo. El nombre espanol muneca puede traducir-se al catalan por dos palabras diferentes dependiendo de su significado:canell o nina. El contexto es el que decide cual es la traduccion correcta,pero el sistema Apertium actual no puede tomar este tipo de decisiones.3
Por lo tanto, debe decidirse que palabra sera el equivalente para la tra-duccion de espanol a catalan. Para la traduccion catalan–espanol, amboslemas pueden traducirse como muneca y no surge ningun problema. To-das estas circunstancias deben quedar reflejadas en las entradas bilinguesutilizando las restricciones de direccion (LR, ”de izquierda a derecha”, esdecir, es–ca, y RL, ”de derecha a izquierda”, es decir, ca–es). Si se deci-de traducir muneca como canell en todos los casos, las entradas que debencrearse en el diccionario bilingue son:
2El sistema realiza unicamente desambiguacion categorial para las palabras homogra-fas, es decir, para formas que pueden tener como analisis mas de una forma lexica, comoocurre con la forma vino en espanol, la cual puede ser tanto un sustantivo masculino co-mo la forma preterita del verbo venir. El desambiguador lexico categorial es el encargadode deshacer este tipo de ambiguedad.
3En el apartado 5.2.2 dedicado a la adicion de multipalabras se explican maneras desortear este problema.

144 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
<e><p><l>muneca<s n="n"/><s n="f"/></l><r>canell<s n="n"/><s n="m"/></r>
</p></e>
<e r="RL"><p><l>muneca<s n="n"/></l><r>nina<s n="n"/></r>
</p></e>
Con estas entradas, las direcciones de traduccion seran las siguientes:
muneca --> canellmuneca <-- canellmuneca <-- nina
(Observe tambien que hay un cambio de genero entre muneca y canell).Es muy importante que una forma lexica no tenga dos traducciones en
la lengua meta, puesto que, de lo contrario, se producirıa un error en elproceso de traduccion (vease la seccion 5.5 sobre como pueden detectarsey corregirse este y otros tipos de errores). Cuando una palabra puede tra-ducirse a la lengua meta de dos maneras diferentes en todos los contextos,hay que elegir una como equivalente de traduccion y dejar la otra comoforma lexica analizable pero no generable, valiendose de restricciones dedireccion como en el ejemplo anterior. Por ejemplo, como los lemas cata-lanes mot y paraula pueden traducirse ambos al espanol como palabra, lasentradas del diccionario bilingue deberıan ser como las siguientes:
<e><p><l>palabra<s n="n"/></l><r>paraula<s n="n"/></r>
</p></e>
<e r="RL"><p><l>palabra<s n="n"/><s n="f"/></l><r>mot<s n="n"/><s n="m"/></r>
</p></e>

5.2. INTRODUCIR PALABRAS EN LOS DICCIONARIOS 145
de las que resultan las siguientes direcciones de traduccion:
palabra --> paraulapalabra <-- paraulapalabra <-- mot
En algunos casos puede ser necesario especificar restricciones de direc-cion tambien en los diccionarios monolingues. Por ejemplo, las dos formasverbales espanolas cantaran y cantasen deben ser analizadas como lemacantar, verbo, preterito imperfecto de subjuntivo, 3a persona plural, peroal traducir al espanol, debe decidirse e indicarse que forma sera la que segenerara. Los diccionarios monolingues se leen en dos direcciones segunsu finalidad: para el analisis, la direccion de lectura es de izquierda a de-recha; para la generacion, de derecha a izquierda. Por lo tanto, una pala-bra que debe analizarse pero no generarse debe contener la restriccion LR,mientras que una que deba generarse pero no analizarse debe contener larestriccion RL.
El caso de cantaran o cantasen debe haberse tratado en los paradigmasde flexion verbal y es poco probable que constituya un problema para al-guien que este ampliando un diccionario. En algunos otros casos puede sernecesario introducir una restriccion en las entradas lexicas del diccionariomonolingue.
5.2.2. Anadir multipalabras
Es posible crear entradas formadas por dos o mas palabras si se con-sidera que estas forman una sola unidad de traduccion”. Las unidadesmultipalabra pueden ser utiles tambien cuando se trata de seleccionar elequivalente correcto de una palabra dentro de una expresion fija. Por ejem-plo, la palabra espanola direccion puede traducirse al catalan de dos ma-neras: direccio (el sentido mas general) y adreca (en el sentido de “direccionpostal”); si se anaden, por ejemplo, unidades multipalabra frecuentes co-mo direccion general → direccio general y direccion postal → adreca postal sepueden conseguir mejores traducciones en determinadas situaciones.
Las unidades multipalabra pueden clasificarse basicamente en dos ca-tegorıas: multipalabras con flexion intercada y multipalabras sin flexionintercalada.
5.2.2.1. Multipalabras sin flexion intercalada
Son iguales a las entradas lexicas de una sola palabra, con la unica di-ferencia de que debe inserirse el elemento <b> (que representa un espa-

146 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
cio en blanco) entre las palabras que forman la unidad. Ası, si se quiereanadir, por ejemplo, la multipalabra espanola hoy en dıa, cuyo equivalenteen catalan es avui dia, las entradas que habra que crear en los diferentesdiccionarios son:
Diccionario monolingue de espanol:
<e lm="hoy en dıa"><i>hoy<b/>en<b/>dıa</i>
<par n="ahora__adv"/></e>
Diccionario monolingue de catalan:
<e lm="avui dia"><i>avui<b/>dia</i>
<par n="ahir__adv"/></e>
Diccionario bilingue espanol–catalan:
<e><p><l>hoy<b/>en<b/>dıa<s n="adv"/></l><r>avui<b/>dia<s n="adv"/></r>
</p></e>
Para el par espanol–gallego, si desea anadir, por ejemplo, la multipala-bra espanola manga por hombro, cuyo equivalente en gallego es sen xeito ninmodo, las entradas que hay que crear son las siguientes:
Diccionario monolingue de espanol:
<e lm="manga por hombro"><i>manga<b/>por<b/>hombro</i>
<par n="ahora__adv"/></e>
Diccionario monolingue de gallego:
<e lm="sen xeito nin modo"><i>sen<b/>xeito<b/>nin<b/>modo</i>
<par n="Deo_gratias__adv"/></e>

5.2. INTRODUCIR PALABRAS EN LOS DICCIONARIOS 147
Diccionario bilingue espanol–gallego:
<e><p><l>manga<b/>por<b/>hombro<s n="adv"/></l><r>sen<b/>xeito<b/>nin<b/>modo<s n="adv"/></r>
</p></e>
5.2.2.2. Breve introduccion a los paradigmas
Los paradigmas de los ejemplos anteriores, como los adverbios, no tie-nen flexion, contienen solo el sımbolo gramatical de la forma lexica, comose puede ver a continuacion:
<pardef n="ahora__adv"><e><p><l/><r><s n="adv"/></r>
</p></e>
</pardef>
Los paradigmas se construyen del mismo modo que una entrada lexi-ca. Hasta ahora, hemos visto entradas lexicas en que la parte invariabledel lema se coloca entre <i> </i>:
<e lm="cosmico"><i>cosmic</i>
<par n="absolut/o__adj"/></e>
Ahora bien, es posible expresar lo mismo mediante un par de cade-nas: una cadena izquierda <l> y una cadena derecha <r> dentro de unelemento <p>:
<e lm="cosmico"><p><l>cosmic</l><r>cosmic</r>
</p><par n="absolut/o__adj"/>
</e>

148 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
Las dos entradas son equivalentes. El elemento <i> se utiliza porquepermite obtener entradas mas simples y compactas, y puede emplearsecuando la parte izquierda y la parte derecha del par de cadenas son identi-cas. Como ya se ha indicado, los diccionarios monolingues se leen LR parael analisis de un texto y RL para la generacion. Por ello, cuando hay algunadiferencia entre la cadena analizada y la cadena generada (cosa que no su-cede normalmente) la entrada no puede escribirse utilizando la <i>. Estoes lo que sucede con los paradigmas, en los cuales las cadenas izquierda yderecha no son nunca identicas, puesto que la parte derecha debe contenerlos sımbolos gramaticales que circularan a traves de todos los modulos delsistema.
5.2.2.3. Multipalabras con flexion intercalada
Consisten en una palabra con flexion (en general un verbo) seguidade una o mas palabras invariables. En las entradas correspondientes de-be especificarse el paradigma de flexion justo detras de la palabra que seflexiona, mientras que la parte invariable debe quedar incluida en un ele-mento <g> (de grupo) en la cadena derecha. Los blancos entre palabrasse indican, como en el caso anterior, mediante la colocacion del elemento<b>. Su estructura puede observarse en el siguiente ejemplo, correspon-diente a la multipalabra espanola echar de menos, que se traduce al catalanpor trobar a faltar:
Diccionario monolingue de espanol:
<e lm="echar de menos"><i>ech</i><par n="aspir/ar__vblex"/><p><l><b/>de<b/>menos</l><r><g><b/>de<b/>menos</g></r>
</p></e>
Diccionario monolingue de catalan:
<e lm="trobar a faltar"><i>trob</i><par n="abander/ar__vblex"/><p><l><b/>a<b/>faltar</l>

5.2. INTRODUCIR PALABRAS EN LOS DICCIONARIOS 149
<r><g><b/>a<b/>faltar</g></r></p>
</e>
Diccionario bilingue espanol–catalan:
<e><p><l>echar<g><b/>de<b/>menos</g><s n="vblex"/></l><r>trobar<g><b/>a<b/>faltar</g><s n="vblex"/></r>
</p></e>
Observese como el sımbolo gramatical se agrega al final, tras el grupomarcado con <g>.
Puede suceder tambien que un lema sea una multipalabra de este ti-po en un idioma, mientras que en el otro idioma sea una unica palabra.En este caso, en el diccionario bilingue, la multipalabra contendra el ele-mento <g> y la palabra simple no. En los diccionarios monolingues, secreara cada entrada de acuerdo con el tipo de lema. Esto se ilustra con elsiguiente ejemplo, correspondiente a la multipalabra espanola darse cuen-ta, cuya equivalencia en catalan es el verbo adonar-se:4
Diccionario monolingue de espanol:
<e lm="darse cuenta"><i>d</i><par n="d/ar__vblex"/><p><l><b/>cuenta</l><r><g><b/>cuenta</g></r>
</p></e>
Diccionario monolingue de catalan:
4El verbo adonar-se es considerado una palabra simple, pues la colocacion de los pro-nombres enclıticos es tratada dentro del paradigma de flexion de los verbos (para todoslos idiomas de Apertium); ası, no es necesario especificarlos en las entradas lexicas. Lacorrecta colocacion de los pronombres clıticos es una de las principales razones de lautilizacion de las etiquetas <g>... </g> alrededor de la parte invariable de los verbosmultipalabra.

150 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
<e lm="adonar-se"><i>adon</i><par n="abander/ar__vblex"/>
</e>
Diccionario bilingue espanol–catalan:
<e><p><l>dar<g><b/>cuenta</g><s n="vblex"/></l><r>adonar<s n="vblex"/></r>
</p></e>
Los mismos principios y acciones descritos para las entradas basicas(cambio de genero y numero, restricciones de direccion, etc.) se aplicantambien a todos los tipos de multipalabras. Para obtener una descripcionmas detallada de las unidades multipalabra, consulte la pagina 44.
5.2.3. Colaborar en la mejora de datos lexicos
Si ha anadido satisfactoriamente datos lexicos de proposito general pa-ra cualquiera de los pares linguısticos de Apertium, considere la opcion defacilitarlos a los desarrolladores del proyecto para que podamos ofreceruna mejor herramienta a los usuarios. Puede enviar los datos lexicos porcorreo electronico (en tres ficheros XML, uno para cada diccionario mono-lingue y uno para el diccionario bilingue) a las direcciones siguientes:
Datos espanol–catalan Mireia Ginestı: [email protected] espanol–portugues Carme Armentano: [email protected]
Datos espanol–gallego Xavier Gomez-Guinovart: [email protected]
Si cree que va a contribuir de manera mas decisiva al proyecto, pue-de unirse al grupo de desarrollo a traves de www.sourceforge.net. Si nodispone de cuenta en Sourceforge, primero debera crearse una; a continua-cion, escriba a Mikel L. Forcada ([email protected]) o a Sergio Ortiz ([email protected]),o bien a Xavier Gomez Guinovart si esta interesado en el par espanol–gallego, explicando brevemente sus motivaciones y experiencia para unir-se al proyecto. La forma usual de aportar datos es mediante CVS; comomiembro del proyecto, podra hacer commit para subir los cambios a losdiccionarios directamente.

5.3. INTRODUCIR REGLAS DE TRANSFERENCIA 151
La adicion de contribuciones lexicas se ha simplificado recientemente atraves de formularios web en http://xixona.dlsi.ua.es/prototype/webform/, de manera que los colaboradores ocasionales no tienen quemanejar ficheros XML.
Tenga en cuenta que los datos que aporte al proyecto seran distribuidosgratuitamente bajo la licencia que corresponda al producto (licencia GNUGPL o Creative Commons 2.5 Atribucion-NoComercial-LicenciarIgual, segunse indique). Asegurese de que los datos que entregue no esten afectadospor ningun tipo de licencia que pueda ser incompatible con las licenciasutilizadas en este proyecto. No se creara ningun tipo de acuerdo o contratoentre usted y los desarrolladores. Si tiene alguna duda, o si tiene previs-to hacer una contribucion de gran envergadura, pongase en contacto conMikel L. Forcada.
5.3. Introducir reglas de transferencia estructu-ral
El contenido de este capıtulo repite parcialmente informacion ya ex-puesta en el apartado de descripcion del modulo de transferencia estruc-tural (punto 3.5), aunque aquı se describen las reglas de una manera masgeneral y practica, orientada a quienes deseen una primera aproximaciona su funcionamiento.
Las reglas de transferencia estructural llevan a cabo transformacionesen el texto analizado y desambiguado, que son necesarias debido a diver-gencias gramaticales, sintacticas y lexicas entre los dos idiomas implica-dos (cambios de genero y de numero para garantizar la concordancia enla lengua meta, reordenamientos de palabras, cambios de preposiciones,etc.). Las reglas detectan patrones (secuencias) de formas lexicas de la len-gua origen y les aplican las transformaciones correspondientes. El modulodetecta los patrones de izquerda a derecha y recortando el segmento con-cordante mas largo (left-to-right, longest-match): Por ejemplo, el sintagmael gato verde sera detectado y procesado por la regla para determinante–nombre–adjetivo y no por la regla para determinante–nombre, puesto que elprimer patron es mas largo. Si dos patrones tienen la misma longitud, laregla que se aplica es la definida en primer lugar.
El modulo de transferencia estructural (generado a partir del ficherode reglas de transferencia estructural) llama, durante el procesamiento, almodulo de transferencia lexica (generado a partir del diccionario bilingue)para determinar los equivalentes en lengua de meta de las formas lexicas

152 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
en lengua origen.Las reglas de transferencia estructural estan guardadas en un fichero
XML, uno para cada direccion de traduccion (por ejemplo, para la traduc-cion de espanol a catalan, el fichero se llama apertium-es-ca.trules-es-ca.xml).Debera editar este fichero para anadir o modificar las reglas de transferen-cia.
Las reglas tienen un patron y una accion. El patron indica que se-cuencias de formas lexicas tienen que ser detectadas y procesadas. La ac-cion describe las verificaciones y transformaciones que deben realizarseen ellas. Algunas operaciones de transformacion usuales (como las ope-raciones de concordancia de genero y numero) estan definidas dentro deuna macroinstruccion que se llama dentro de la regla. Al final de la partede accion de cada regla, se envıan las formas lexicas resultantes en la len-gua meta para que puedan ser procesadas por los modulos posteriores delsistema de traduccion.
Un fichero de reglas de transferencia contiene cuatro secciones con de-finiciones de elementos utilizados en las reglas, y una quinta seccion enla que se definen las reglas propiamente dichas. Las secciones son las si-guientes:
<section-def-cats>: Esta seccion contiene la definicion de lascategorıas que se utilizaran en los patrones de las reglas (es decir,los tipos de formas lexicas que seran detectados por una regla deter-minada). Para la regla que se presenta mas abajo, es necesario haberdefinido aquı las categorıas det y nom (determinante y nombre). Lascategorıas se definen especificando los sımbolos gramaticales quetienen las formas lexicas que se quiere incluir. Un asterisco indica quelos sımbolos gramaticales especificados van seguidos de uno o massımbolos en las formas lexicas correspondientes. A continuacion sepresenta la definicion de la categorıa det, que agrupa determinantesy predeterminantes6 en una misma categorıa pues para el modulo detransferencia desempenan un papel similar:
<def-cat n="det"><cat-item tags="det.*"/><cat-item tags="predet.*"/>
</def-cat>
Tambien es posible definir definir una categorıa para un lema deter-minado, como la siguiente para la preposicion en:
6como el espanol todo, toda, todos, todas

5.3. INTRODUCIR REGLAS DE TRANSFERENCIA 153
<def-cat n="en"><cat-item lemma="en" tags="pr"/>
</def-cat>
<section-def-attrs>: Esta seccion contiene la definicion de losatributos que se utilizaran dentro de las reglas, en la parte de accion.Se necesitan atributos para las categorıas definidas en la seccion ante-rior si van a utilizarse en la parte de accion de una regla (para realizarverificaciones en ellas o para enviarlas al final de la regla), ası comopara otros atributos necesarios en la regla (como el genero o el nume-ro). Los atributos se definen especificando los sımbolos gramaticalescorrespondientes y no pueden llevar asteriscos; su nombre tiene queser unıvoco. A continuacion se muestran las definiciones para losatributos a det (para determinantes) y gen (para el genero):
<def-attr n="a_det"><attr-item tags="det.def"/><attr-item tags="det.ind"/><attr-item tags="det.dem"/><attr-item tags="det.pos"/><attr-item tags="predet"/>
</def-attr>
<def-attr n="gen"><attr-item tags="m"/><attr-item tags="f"/><attr-item tags="mf"/><attr-item tags="nt"/><attr-item tags="GD"/>
</def-attr>
<section-def-vars>: Esta seccion contiene la definicion de lasvariables utilizadas en las reglas.
<def-var n="interrogativa"/>
<section-def-macros>: Aquı se definen las macroinstrucciones,que contienen secuencias de codigo utilizado con frecuencia dentrode las reglas; esto evita tener que escribir repetidamente las mismasacciones al crear las reglas. Hay macroinstrucciones, por ejemplo, pa-ra operaciones de concordancia de genero y numero.

154 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
<section-def-rules>: Esta es la seccion en la que se escriben lasreglas de transferencia estructural.
A continuacion se presenta como ejemplo una regla que detecta la se-cuencia determinante–nombre:
<rule><pattern><pattern-item n="det"/><pattern-item n="nom"/>
</pattern><action><call-macro n="f_concord2"><with-param pos="2"/><with-param pos="1"/>
</call-macro><out><lu><clip pos="1" side="tl" part="whole"/>
</lu><b pos="1"/><lu><clip pos="2" side="tl" part="whole"/>
</lu></out>
</action></rule>
Una parte de la accion ejecutada en este patron esta especificada den-tro de la macroinstruccion f concord2, que esta definida en la seccion<section-def-macros>. Esta macroinstruccion realiza operaciones deconcordancia de genero y de numero: si se produce un cambio de generoo numero entre la lengua origen y la lengua meta (en el nombre), se cam-bia el genero o el numero del determinante de acuerdo con ello; ademas,si el genero o el numero son indeterminados (GD o ND7), el nombre re-cibe el valor correcto de genero o numero aportado por el determinanteque le precede. En Apertium es–ca, es–gl y es–pt, se han definido macro-instrucciones de concordancia para una, dos, tres o cuatro formas lexicas(f concord1, f concord2, f concord3, f concord4). Cuando se lla-ma una macroinstruccion en una regla, debe indicarse cual es la formalexica principal (la que tiene mas peso en la determinacion de genero o
7Veanse las paginas 42 o 141

5.3. INTRODUCIR REGLAS DE TRANSFERENCIA 155
numero de las demas formas lexicas) y que otras formas lexicas del patrontienen que incluirse en las operaciones de concordancia, en orden de im-portancia. Esto se realiza con el elemento <with-param pos=/>. En laregla precedente, la forma lexica principal es el nombre (posicion ”2.en elpatron) y la segunda es el determinante (posicion ”1.en el patron).
Tras las acciones pertinentes, se envıan las formas lexicas resultantes,dentro del elemento <out>. Cada forma lexica se define mediante un<clip>, cuyos atributos significan lo siguiente:
- pos: hace referencia a la posicion de la forma lexica en el patron; 1representa la primera forma lexica (el determinante) y 2 la seguna (elnombre).
- side: indica si la forma lexica esta en lengua origen (sl) o en lenguameta (tl). Naturalmente, al final de la regla las palabras se envıansiempre en la lengua meta; las formas lexicas en lengua origen pue-den necesitarse dentro de una regla para evaluar sus atributos o ca-racterısticas.
- part: indica que parte de la forma lexica incluye el clip. Puedenutilizarse algunos valores predefinidos:
- whole: la forma lexica completa (lema mas sımbolos grama-ticales). Se utiliza solo al enviar la forma lexica (dentro de unelemento <out>).
- lem: el lema de la forma lexica
- lemh: la cabeza del lema de una multipalabra con flexion inter-calada (vease el apartado 5.2.2 de este capıtulo, o bien la pagi-na 44 si desea una explicacion mas detallada)
- lemq: la cola del lema de una multipalabra con flexion interca-lada
A parte de estos valores predefinidos, puede utilizarse cualquiera delos atributos definidos en la seccion <section-def-attrs> (comogen o a det).
Los valores lemh y lemq se utilizan al enviar multipalabras con fle-xion intercalada para poder colocar la cabeza y la cola del lema en laposicion correcta, puesto que el modulo previo desplazo la cola justodespues de la cabeza del lema por varios motivos. En la practica, ennuestro sistema, esto significa que para enviar verbos hay que utili-zar estos valores en lugar de whole. Esto se debe a que, en nuestros

156 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
diccionarios, las multipalabras con flexion intercalada son siempreverbos y, si se utiliza el valor whole al enviarlos al final de una re-gla, la multipalabra quedarıa mal formada (la cabeza y la cola dellema no tendrıan la posicion correcta y la multipalabra no podrıagenerarse en el generador).
Segun lo dicho, pues, una regla que contenga un verbo en el patrondebe enviar las formas lexicas como en estos dos ejemplos:
<rule><pattern><pattern-item n="verb"/>
</pattern><action><out><lu><clip pos="1" side="tl" part="lemh"/><clip pos="1" side="tl" part="a_verb"/><clip pos="1" side="tl" part="temps"/><clip pos="1" side="tl" part="persona"/><clip pos="1" side="tl" part="gen"/><clip pos="1" side="tl" part="nbr"/><clip pos="1" side="tl" part="lemq"/>
</lu></out>
</action></rule>
<rule><pattern><pattern-item n="verb"/><pattern-item n="prnenc"/>
</pattern><action><out><mlu><lu><clip pos="1" side="tl" part="lemh"/><clip pos="1" side="tl" part="a_verb"/><clip pos="1" side="tl" part="temps"/><clip pos="1" side="tl" part="persona"/><clip pos="1" side="tl" part="nbr"/>
</lu>

5.3. INTRODUCIR REGLAS DE TRANSFERENCIA 157
<lu><clip pos="2" side="tl" part="lem"/><clip pos="2" side="tl" part="a_prnenc"/><clip pos="2" side="tl" part="persona"/><clip pos="2" side="tl" part="gen"/><clip pos="2" side="tl" part="nbr"/><clip pos="1" side="tl" part="lemq"/>
</lu></mlu>
</out></action>
</rule>
La primera regla detecta un verbo y coloca la cola en la posicion correc-ta, despues de todos los sımbolos gramaticales. La unidad lexica se envıaespecificando sus atributos por separado: cabeza del lema, categorıa lexica(verbo), tiempo, persona, genero (para los participios), numero y cola dellema.
La segunda regla detecta un verbo seguido de un pronombre enclıticoy envıa dos formas lexicas especificando tambien sus atributos por sepa-rado; la primera unidad lexica se compone de: cabeza del lema, categorıalexica (verbo), tiempo, persona y numero; la segunda unidad lexica secompone de: lema, categorıa lexica (pronombre enclıtico) , persona, gene-ro, numero y cola del lema (de la primera unidad lexica). De este modo, lacola se coloca despues del pronombre enclıtico. Las dos unidades lexicas(verbo y pronombre enclıtico) se envıan dentro de un elemento <mlu>,puesto que tienen que llegar al generador morfologico como unidad mul-tilexica.
Teniendo en cuenta todo lo que se ha explicado, para anadir una reglade transferencia deben seguirse los pasos siguientes:
1. Especificar el patron que se quiere detectar. Tengase presente que laspalabras solo son procesadas una vez por las reglas, y que las reglasse aplican de izquierda a derecha y escogiendo el segmento concor-dante mas largo. Por ejemplo, supongamos que tenemos un ficherode reglas de transferencia con solo dos reglas, una para el patrondeterminante–nombre y otra para el patron nombre–adjetivo. El sintag-ma espanol el valle verde serıa detectado y procesado por la primeraregla, no por la segunda. Si queremos que las tres palabras sean pro-cesadas por una misma regla, deberemos anadir una regla para elpatron determinante - nombre - adjetivo

158 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
2. Describir las operaciones que deben realizarse sobre el patron. En lossistemas Apertium es-ca, es-gl y es-pt, las operaciones norma-les de concordancia (de genero y numero) son faciles de especificarutilizando una macroinstruccion. Para realizar otras operaciones hayque utilizar elementos del lenguaje mas complicados, que estan ex-plicados con detalle en la seccion 3.5.4.
3. Enviar las unidades lexicas del patron en la lengua meta dentro deun elemento <out>. Cada unidad lexica debe estar dentro de un ele-mento <lu>. Si dos o mas unidades lexicas deben ser generadas co-mo una unidad multilexica (solo para pronombres enclıticos en lospares de lenguas actuales), deben estar agrupadas dentro de un ele-mento <mlu>.
Todas las palabras que sean detectadas por la regla (que son partedel patron) deben enviarse al final de la regla para que el modulosiguiente (el generador) las reciba. Si una unidad lexica es detecta-da por un patron y no se incluye dentro del elemento <out>, no segenerara.
5.4. Anadir datos para el desambiguador lexicocategorial
La informacion linguıstica que necesita el desambiguador lexico ca-tegorial para desambiguar un texto proviene basicamente de dos fuen-tes: del fichero de definicion del desambiguador y de corpus. Los ficherosde definicion del desambiguador se encuentran en el directorio de datoslinguısticos y su nombre tiene la estructura apertium-L1-L2.L1.tsx yapertium-L1-L2.L2.tsx, mientras que los corpus se encuentran en losdirectorios L1-tagger-data y L2-tagger-data que estan contenidosen el directorio anterior.
Los ficheros de definicion del desambiguador contienen la definicion de lasetiquetas gruesas (o categorıas) que utiliza el desambiguador durante suentrenamiento y al desambiguar un texto, ası como restricciones de ocu-rrencia de etiquetas que ayudan a obtener mejores probabilidades para ladesambiguacion. En el apartado 3.2 se describen en detalle sus caracterısti-cas.
Los corpus que deben encontrarse en el directorio LANG-tagger-datason diferentes segun si el entrenamiento del desambiguador se realiza deforma supervisada (con texto desambiguado a mano) o no supervisada

5.4. ANADIR DATOS AL DESAMBIGUADOR LEXICO 159
(sin texto desambiguado a mano):
para el entrenamiento de forma supervisada se necesitan los fiche-ros (para espanol): es.tagged.txt, es.untagged, es.tagged,es.dic.
para el entrenamiento de forma no supervisada se necesitan los fi-cheros (para espanol): es.crp.txt, es.crp, es.dic
Las caracterısticas de estos ficheros son las siguientes:
es.tagged.txt: Un corpus espanol en formato de texto llano.
es.untagged: El corpus es.tagged.txt analizado morfologica-mente, es decir, procesado por el desformateador de texto y el anali-zador morfologico (corpus creado automaticamente).
es.tagged: El corpus anterior desambiguado manualmente.
es.crp.txt: Un corpus grande (cientos de miles de palabras) utili-zado cuando se entrena el desambiguador de forma no supervisadamediante el algoritmo de maximizacion de la esperanza matematica.
es.crp: El corpus anterior procesado consecutivamente por el des-formateador de texto y el analizador morfologico (corpus creado au-tomaticamente).
es.dic: Fichero creado a partir del diccionario monolingue de es-panol *.es.dix, mediante las herramientas lt-expand y aper-tium-filter-ambiguity, que expanden el diccionario y filtranlas clases de ambiguedad, de modo que el fichero contenga todaslas formas distintas que el etiquetador definido mediante el archi-vo *.es.tsx identifica como clases de ambiguedad diferentes, esdecir, que categorıas lexicas pueden ser homografas (fichero creadoautomaticamente).
Al bajarse el traductor Apertium de Sourceforge (http://apertium.sourceforge.net/), si el desambiguador ha sido entrenado de formasupervisada es probable que se bajen los ficheros necesarios para este ti-po de entrenamiento, es.tagged y es.tagged.txt (para espanol). Losdemas ficheros requeridos son generados automaticamente al ejecutarseel entrenamiento. Si el desambiguador ha sido entrenado de forma no su-pervisada, no se bajara ningun corpus pues los ficheros necesarios para

160 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
entrenar de esta forma son de enorme tamano. En caso de que el usuariodesee reentrenar el traductor de este modo, debera recolectar un corpusde gran tamano para ello y ponerle el nombre es.crp.txt. Los demasficheros requeridos son generados automaticamente al ejecutarse el entre-namiento.
De todos modos, el traductor Apertium vienen con todos los datos ne-cesarios para que el desambiguador funcione correctamente. No es nece-sario entrenar el desambiguador para utilizar Apertium. Puede ser necesa-rio realizar un reentrenamiento en caso de que se hayan realizado grandescambios en los diccionarios o se haya modificado el fichero de definiciondel desambiguador.
Ası pues, los datos del desambiguador se pueden modificar de dosmaneras:
1. Modificar el fichero de definicion del desambiguador. Se pueden anadir,modificar o suprimir etiquetas gruesas si se considera que una nue-va categorıa serıa util para la desambiguacion o que la modificacionde una categorıa comportarıa mejoras. Tambien pueden anadirse res-tricciones (por ejemplo, se puede prohibir la secuencia determinante–determinante en un idioma si se trata de una combinacion imposibleo poco probable y con ello puede mejorarse la desambiguacion deciertas palabras homografas).
2. Modificar los corpus utilizados para entrenar el desambiguador. Pue-de modificarse el texto desambiguado a mano (es.tagged para es-panol) para corregir algunas etiquetas mal elegidas. Tambien puedenanadirse frases a este texto (ası como el corpus es.tagged.txt,usado para generar automaticamente el corpus es.untagged) paradar mas informacion al desambiguador, puesto que es posible quela mala desambiguacion de ciertas categorias de palabras se deba apoca presencia o inexistencia en los corpus de entrenamiento.
Para llevar a cabo el reentrenamiento, existen dos comandos:
para entrenar de forma supervisada, debe escribirse, en el directorioen el que se encuentren los datos linguısticos (ejemplo para es–ca):make -f es-ca-supervised.make
para entrenar de forma no supervisada, debe escribirse, en el directo-rio en el que se encuentren los datos linguısticos (ejemplo para es–ca):make -f es-ca-unsupervised.make
En ambos casos se generaran automaticamente los ficheros previstos.

5.5. DETECCION DE ERRORES 161
5.5. Deteccion de errores
Es facil cometer errores al anadir nuevas palabras o reglas de transfe-rencia al sistema Apertium.
Por un lado, es posible que, al compilar los ficheros nuevos, el sistemamuestre un mensaje de error. En este caso se tratara muy probablementede un error formal (una etiqueta XML que falta, una etiqueta no permiti-da en un determinado contexto, etc.). Solo hay que ir al numero de lıneaindicado en el mensaje de error, corregirlo y compilar de nuevo. Por otrolado, hay otros tipos de errores que no se detectan al compilar pero quepueden provocar una mala traduccion o la traduccion de una palabra poruna cadena de texto incomprensible. Estos son errores linguısticos, quepueden detectarse y corregirse con la ayuda de la informacion ofrecida eneste capıtulo. La siguiente informacion esta dirigida a los usuarios de Li-nux, puesto que por el momento Apertium funciona unicamente con estesistema operativo.8
5.5.1. Control de las marcas de error
Cuando el sistema tiene algun problema para traducir una o mas pala-bras del texto en lengua origen, en el modo de funcionamiento por defectose muestra la palabra problematica acompanada de un sımbolo que indicaque se ha producido algun error. El significado de los diferentes sımboloses el siguiente:
’@’: El problema se ha producido en el modulo de transferencia lexi-ca, que no puede traducir la forma lexica (el diccionario bilingue nola contiene)
’#’: El problema se ha producido en el generador, que no puede ge-nerar una forma superficial a partir de la forma lexica (el diccionariomorfologico no la contiene en la direccion de generacion)
’/’: Este sımbolo separa dos o mas formas superficiales ofrecidas porel generador. El problema, por lo tanto, esta en el diccionario mono-lingue de la lengua meta, que contiene, en la direccion de generacion,dos formas superficiales para una forma lexica, cuando deberıa con-tener solo una.
8Existen en http://apertium.org paquetes experimentales para Windows con losdatos linguısticos fijos (binarios no modificables).

162 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
El modulo de generacion tiene tres modos de funcionamiento, con loscuales podemos elegir la forma en que se mostraran los errores en el resul-tado final. Los tres parametros que pueden utilizarse son los siguientes:
-n : no se visualizan ni los sımbolos de error ni el sımbolo de palabradesconocida, ası como ninguna etiqueta morfologica
-g : se visualizan los sımbolos de error y el sımbolo de palabra des-conocida (funcionamiento por defecto)
-d : se visualizan los sımbolos de error y el de palabra desconocida,ademas de las etiquetas morfologicas de las formas lexicas en las quese ha producido el error.
Segun el tipo de usuario y la finalidad de la traduccion, es mas conve-niente utilizar una u otra opcion. La primera opcion es la mas adecuadacuando no se desea que signos ajenos al texto interfieran en la lectura de latraduccion. La segunda opcion es util cuando el usuario quiere que el sis-tema le muestre cuando ha habido algun problema en la traduccion (erro-res o palabras desconocidas) para poder posteditarla con mas facilidad. Latercera opcion es ideal para los desarrolladores linguısticos de Apertium,puesto que muestra toda la informacion linguıstica de las formas que hansufrido errores.
Utilizando los sımbolos de error visualizados por el sistema, se pue-de hacer una comprobacion exhaustiva de los diccionarios de un par delenguas determinado, para detectar y corregir todos los errores que con-tienen; la forma de hacerlo se explica en el apartado 5.5.4.
5.5.2. Salida de los diferentes modulos de Apertium
A veces es difıcil localizar el origen de un error determinado. En estecaso es util poder ver la salida de cada uno de los modulos. Como todos losdatos procesados por el sistema, desde el texto original al texto traducido,circulan entre los modulos del sistema en formato de texto, es posible de-tener el flujo de texto en cualquier punto y examinar la entrada o la salidade un modulo determinado.
Utilizando una estructura de tuberıa y los comandos echo o cat, sepuede enviar texto a traves de uno o varios modulos para detectar el mo-tivo del error. A continuacion se explica como hacerlo. El usuario debesituarse en el directorio en que se guardan los datos linguısticos y escribirlos comandos mostrados.

5.5. DETECCION DE ERRORES 163
5.5.2.1. La salida del analizador morfologico
Para saber como el traductor analiza una palabra, escriba lo siguienteen el terminal (ejemplo para la palabra catalana sabates):
echo "sabates" | apertium-destxt | lt-proc ca-es.automorf.bin
Puede sustituirse ca-es por la direccion de traduccion que se deseacomprobar.
La salida de Apertium deberıa ser:
ˆsabates/sabata<n><f><pl>$ˆ./.<sent>$[][]
La estructura de la cadena es ˆpalabra/lema<analisis morfologico>$.La etiqueta <sent> corresponde al analisis del punto, ya que el sistemarepresenta cada fin de frase como un punto, tanto si aparece explıcitamen-te en el texto como si no.
El analisis de una palabra desconocida es (prescindiendo de la infor-macion del final de frase):
ˆgenoma/*genoma$
y el analisis de una palabra ambigua:
ˆcasa/casa<n><f><sg>/casar<vblex><pri><p3><sg>/casar<vblex><imp><p2><sg>$
Cada forma lexica (lema mas analisis morfologico) es presentada comoanalisis posible de la palabra casa.
5.5.2.2. La salida del desambiguador
Para saber cual es la salida que da el desambiguador de un texto, escri-ba lo siguiente en el terminal (ejemplo para la direccion catalan – espanol):
echo "sabates" | apertium-destxt | lt-proc ca-es.automorf.bin|apertium-tagger -g ca-es.prob
La salida sera:
ˆsabata<n><f><pl>$ˆ./.<sent>$[][]
La salida de una palabra ambigua sera igual que esta, puesto que eldesambiguador elige una forma lexica de entre todas las posibles. Por lotanto, la salida para la palabra casa en catalan sera, por ejemplo (segun elcontexto):
ˆcasa<n><f><sg>$ˆ.<sent>$[][]

164 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
5.5.2.3. La salida del modulo pretransfer
Este modulo aplica algunos cambios a las multipalabras (desplaza lacola del lema de una multipalabra con flexion intercalada justo detras dela cabeza del lema). Para conocer su salida, escriba:
echo "sabates" | apertium-destxt | lt-proc ca-es.automorf.bin|apertium-tagger -g ca-es.prob | apertium-pretransfer
Como sabates no es una multipalabra este modulo no altera la entrada.
5.5.2.4. La salida del modulo de transferencia estructural
Para saber como se traduce a la lengua meta una palabra o un grupo depalabras y como lo procesan las reglas de transferencia estructural, escribalo siguiente en el terminal:
echo "sabates" | apertium-destxt | lt-proc ca-es.automorf.bin|apertium-tagger -g ca-es.prob | apertium-pretransfer| ./ca-es.transfer ca-es.autobil.bin
La salida para esta palabra serıa:
ˆzapato<n><m><pl>$ˆ.<sent>$[][]
Analizar como una palabra o frase sale de este modulo puede ayudara detectar errores en el diccionario bilingue o en las reglas de transferenciaestructural. Los errores mas comunes debidos al diccionario bilingue son:la existencia de dos equivalentes para una misma forma lexica de la lenguaorigen, o una asignacion incorrecta de sımbolos morfologicos. Los erroresdebidos a las reglas de transferencia estructural pueden ser muy variadosya que dependen de las acciones realizadas por las reglas.
5.5.2.5. La salida del generador morfologico
Para saber como el sistema genera una palabra, escriba lo siguiente enel terminal:
echo "sabates" | apertium-destxt | lt-proc ca-es.automorf.bin|apertium-tagger -g ca-es.prob | apertium-pretransfer| ./ca-es.transfer ca-es.autobil.bin | ltproc -g ca-es.autogen.bin

5.5. DETECCION DE ERRORES 165
Con este comando se pueden detectar errores de generacion causadospor una entrada incorrecta en el diccionario monolingue de la lengua metao por divergencias entre la salida del diccionario bilingue (la salida delmodulo anterior) y la entrada en el diccionario monolingue.
La salida correcta para la entrada sabates serıa:
zapatos.[][]
Aquı ya no aparecen los sımbolos morfologicos y la palabra apareceflexionada.
5.5.2.6. La salida del postgenerador
No es muy usual que se produzcan errores debido al postgenerador, yaque generalmente el diccionario de postgeneracion es de pequeno tamanoy raras veces se modifica una vez anadidas las combinaciones mas usuales,pero tambien puede comprobar como un texto en lengua origen sale deeste modulo, escribiendo:
echo "sabates" | apertium-destxt | lt-proc ca-es.automorf.bin|apertium-tagger -g ca-es.prob | apertium-pretransfer| ./ca-es.transfer ca-es.autobil.bin | ltproc -g ca-es.autogen.bin| ltproc -p es-ca.autopgen.bin
5.5.2.7. La salida de Apertium
Se pueden poner todos los modulos del sistema en la estructura de tu-berıa para ver como un texto en lengua origen pasa a traves de los modulosy es traducido a la lengua meta. Solo hace falta anadir el reformateador alcomando anterior:
echo "sabates" | apertium-destxt | lt-proc ca-es.automorf.bin|apertium-tagger -g ca-es.prob | apertium-pretransfer| ./ca-es.transfer ca-es.autobil.bin | ltproc -g ca-es.autogen.bin| ltproc -p es-ca.autopgen.bin | apertium-retxt
Esto es lo mismo que utilizar el script (guion del interprete de coman-dos de Linux) apertium-translator proporcionado por el paqueteApertium:
echo "sabates" | apertium-translator . ca-es

166 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
(El punto indica el directorio en el que se guardan los datos linguısticos,en este caso el directorio actual).
Naturalmente, en lugar de escribir todos los comandos presentados ca-da vez que necesite probar una traduccion, puede crear scripts para cadaaccion y utilizarlos para probar la salida de cada modulo.
5.5.3. Ejemplos de errores
1) Podemos encontrarnos con el siguiente resultado en la traduccion:
$ echo "nord" | apertium-translator . ca-es$ #norte<n><m><sg>
Esto significa que la palabra ha sido traducida correctamente por el dic-cionario bilingue pero que el sistema no la ha encontrado en el diccionariomorfologico de espanol para generarla. El problema puede encontrarseen el diccionario morfologico, pero puede deberse tambien a una entradabilingue incorrecta, en la que los sımbolos morfologicos que recibe la pala-bra traducida no se corresponden con los sımbolos morfologicos que estapalabra tiene en el diccionario morfologico.
2) La siguiente entrada bilingue es-ca no tiene en cuenta el cambio degenero entre adhesiu (masculino) y pegatina (femenino), con lo cual provocaun error del traductor:
<e><p><l>pegatina<s n="n"/></l><r>adhesiu<s n="n"/></r>
</p></e>
$ echo "adhesiu" | apertium-translator . ca-es$ #pegatina<n><m><sg>
La entrada correcta es:
<e><p><l>pegatina<s n="n"/><s n="f"/></l><r>adhesiu<s n="n"/><s n="m"/></r>
</p></e>

5.5. DETECCION DE ERRORES 167
3) El siguiente error se produce cuando la forma lexica de la lengua ori-gen no se ha podido encontrar en el diccionario bilingue, ya sea porque nohay ninguna entrada para este lema o porque la entrada no se correspondecon los sımbolos morfologicos recibidos del analizador:
$ echo "illot" | apertium-translator . ca-es$ @illot<n><m><sg>
4) Cuando una forma lexica de la lengua origen tiene dos equivalentesen el diccionario bilingue, la salida del traductor sera como la que sigue:
$ echo "llavor" | apertium-translator . ca-es$ #pepita<n>/semilla<n><m><sg>
La solucion es poner una restriccion de direccion en una de las entradasbilingues.
Algunos errores pueden ser debidos a reglas de transferencia estructu-ral. La manera de solucionar un error cuya causa no conocemos es com-probar la salida de cada uno de los modulos para detectar en que puntosurge el problema.
5.5.4. Comprobacion de la integridad de los diccionarios
Es muy recomendable comprobar la integridad de los diccionarios devez en cuando, especialmente si se ha hecho cambios significativos en ellos(o bien si se ha modificado las reglas de transferencia, ya que algunos erro-res pueden deberse a su aplicacion).
La comprobacion se realiza en una direccion de traduccion, por lo que,para un par de lenguas determinado, hay que realizar dos comprobacio-nes, una en cada direccion.
Para ello, los pasos a seguir son los siguientes:
expandir el diccionario monolingue de la lengua origen, mediante laherramienta lt-expand, para obtener todas las formas lexicas (queson las formas que aparecen a la derecha de los dos puntos en elfichero resultante);
pasar estas formas lexicas (exceptuando las que sean solo de genera-cion, que lt-expand habra marcado con el signo ’<’ ) por todos losmodulos del sistema desde el pretransfer hasta el generador;
Buscar en el resultado las formas lexicas marcadas con los signos ’#’, ’@’ o ’/’, que seran las formas con error (vease el apartado 5.5.1).

168 CAPITULO 5. MANTENIMIENTO DE DATOS LINGUISTICOS
5.6. Generar un nuevo sistema con los nuevosdatos
Si se realiza algun cambio a cualquiera de los ficheros de datos deApertium (diccionarios, reglas de transferencia o fichero de definicion deldesambiguador), es necesario volver a compilar los modulos para que elsistema incorpore estos cambios. Para ello, hay que escribir make en eldirectorio en el que se guardan los datos linguısticos, y el sistema genere-rara los nuevos ficheros binarios.
Si se ha hecho algun cambio en el fichero de definicion del desambigua-dor o en el corpus utilizado para entrenar el mismo, sera necesario ademasreentrenar el desambiguador: en el mismo directorio de datos linguısticos,debe escribirse (ejemplo para el desambiguador de espanol en el traduc-tor es-ca) make -f es-ca-unsupervised.make para el entrenamien-to no supervisado o make -f es-ca-supervised.make para el entre-namiento supervisado.
Tras las operaciones de compilacion, apertium-translator ya uti-lizara los nuevos datos.

Capıtulo 6
Formularios web de insercion dedatos
Este capıtulo presenta el sistema de mantenimiento de diccionarios deApertium 2. Esta estructurado en dos secciones. En la seccion 6.2 se da lainformacion necesaria para instalar la herramienta y realizar adaptaciones.En la seccion 6.3 se expone el modo de uso de la aplicacion web para llevara cabo la mejora de los datos linguısticos.
6.1. Introduccion
La tarea de introducir nuevos terminos a los diccionarios de las dife-rentes lenguas del traductor es lenta si se hace editando manualmente losdiccionarios en XML; para ello se han creado estos formularios, que facili-tan considerablemente la tarea de insercion de palabras y ademas permi-ten hacerlo de forma remota desde cualquier ordenador que tenga accesoa Internet.
Ası se plantean como unos formularios escritos en php que son uti-litzables con cualquier navegador de Internet, ya sea de forma local enel mismo ordenador donde se almacenan los diccionarios, ya sea remota-mente.
6.2. Instalacion y administracion
6.2.1. Instalacion de la herramienta
La instalacion debe realizarse en un maquina Unix que tenga instaladoun servidor web Apache con php. Ası, primero debe hacerse la instala-
169

170 CAPITULO 6. FORMULARIOS WEB DE INSERCION DE DATOS
cion del servidor php en caso de que no estuviera hecha, y a continuacionpuede ya instalarse la herramienta de formularios.
Para ello, debe descargarse el paquete ‘apertium-lexical-webform-0.9’ dela pagina web de Apertium en Sourceforge (http://apertium.sourceforge.net/) y descomprimirlo dentro del directorio donde vaya a dejarse la he-rramienta.
# cd /ruta/de los/formularios# tar -xvzf /ruta/apertium-lexical-webform-0.9.tar.gz
Hay que tener en cuenta que Apache solo sirve las paginas que estandentro del directorio raız con el que lo hemos configurado. Por lo tanto,el directorio donde dejemos los formularios tiene que ser un subdirectorioque este dentro de la raız del servidor Apache.
A continuacion debe editarse el fichero de configuracion que esta enprivate/config.php y dar valores adecuados a las variables de configuracion:
$anmor: ruta entera donde se encuentra el analizador morfologicolt-proc.
$dicos path: ruta donde se encuentran los diccionarios finales ylos binarios compilados de cada diccionario. Este directorio tiene quecontener un subdirectorio para cada diccionario con el que puedetrabajar el formulario. El nombre del subdirectorio tiene que seguirla siguiente sintaxis: paradigmes-ll-rr , donde ll y rr son las ini-ciales del par de lenguas del traductor en concreto. En cada directo-rio se dejan los diccionarios finales con los que trabaja el traductor ylos correspondientes binarios compilados. Estos directorios se pue-den sustituir por enlaces simbolicos en caso de que se encuentren endiferentes lugares.
$usuaris professionals: un listado de los usuarios profesiona-les del sistema que tienen permiso para inserir en los diccionariosdel formulario y validar entradas (equivalencias) pendientes de con-firmacion.
$mail: Direccion electronica del administrador encargado de los for-mularios. Cuando alguien solicite darse de alta como usuario se en-viara un correo electronico a esta direccion.
Una vez configurados los parametros de este fichero, el servidor deformularios ya se encuentra en funcionamiento.

6.2. INSTALACION Y ADMINISTRACION 171
6.2.2. Estructura de directorios
Todos los ficheros necesarios para el correcto funcionamiento se estruc-turan de la siguiente forma:
/index.php: presenta el formulario inicial de insercion. Tiene unapartado para cada par de lenguas donde se introduce el lema en len-gua origen y en lengua meta y se elige el tipo de categorıa gramaticalapropiado. Al pulsar el boton ’Go on’ se pasa a la pagina siguiente,donde deben seleccionarse los paradigmas de flexion correspondien-tes a cada uno de los lemas en lengua origen y lengua meta.
/dics: directorio con los diccionarios de las entradas que van in-seriendose desde los formularios. Estan los ficheros con las entradasde los usuarios no profesionales (pendientes de ser validades) y losdiccionarios con las entradas en formato XML de los usuarios profe-sionales.
/private: aquı esta la mayor parte de los modulos utilizados enlos formularios. Tambien contiene los directorios con la definicionde paradigmas para todas las lenguas con las que podemos trabajar;estos directorios tienen la forma paradigmes-ll-rr siendo ll y rrlas iniciales del par de lenguas del traductor en concreto. El ordenescogido para las dos lenguas, primero ll y despues rr, depende delorden en que se hayan construido las entradas para el diccionariobilingue. Tambien estan en este directorio los ficheros encargados dehacer todo el procesamiento de las palabras a inserir. Estos son:
• resultado.php: Este php es llamado cuando se insieren dospalabras de cualquier par de lenguas desde el modulo index.php.Basicamente lo que hace es establecer el par de lenguas con quese trabajara ($LR y $RL) y la categorıa gramatical de la palabraque se inserira ($tipus). Se incluye en el modulo selec.php quesera el siguiente que se llama en el proceso de insercion. En elsupuesto de que el tipus (tipo) de la palabra a inserir fuera unaunidad multipalabra (Multi Word Verb) entonces es el modulomultip.php el que se incluye y se llama en vez de selec.php. Loselementos Multi Word Verb o unidades multipalabra estan for-mados por un verbo que puede flexionar seguido de una colainvariable de una o mas palabras (vease una descripcion masdetallada en la seccion 3.1.2.6.

172 CAPITULO 6. FORMULARIOS WEB DE INSERCION DE DATOS
• selecc.php: Es el modulo encargado de proporcionar la se-leccion del paradigma escogido para cada una de las dos pa-labras, la palabra en lengua origen y la palabra en lengua me-ta. Proporciona una lista de paradigmas para escoger que de-penden del tipo gramatical de la entrada que estamos creando.Cuando se selecciona un nuevo paradigma para uno de los doslemas, proporciona unos ejemplos de la flexion del lema a in-serir segun el paradigma que hemos escogido. Si aceptamos losparadigmas escogidos, el modulo llama a insertarPro.php o inser-tar.php dependiendo de si el usuario que esta haciendo la nuevainsercion esta considerado como profesional o no profesionalrespectivamente.
• multip.php: Tiene la misma funcion que el modulo selecc.phppero para las unidades multipalabra. Utiliza las mismas varia-bles y realiza las mismas operaciones, pero cuando muestra losejemplos lo hace flexionando el verbo y anadiendo todas las pa-labras que forman la cola. La manera de funcionar del moduloes analoga a la del modulo selecc.php y su descripcion detalladala encontraremos en el apartado 6.2.3.2.
• valida.php: Este modulo se llama cuando un usuario pro-fesional decide validar palabras que estan en la cola de entradaspendientes de validacion. Lee el fichero con la cola de palabraspor validar y lo recorre de una en una, coge los datos de la entra-da correspondiente (LRlem, RLlem, paradigmaLR, paradigmaRL,LR, RL, etc...) y llama a selecc.php para continuar con el procesode insercion de esa entrada particular.
• insertarPro.php: Este modulo se llama cuando ya hemosseleccionado el paradigma adecuado para la palabra en len-gua origen y en lengua meta (operacion realizada en selecc.php)y queremos visualizar como quedara la entrada en el forma-to XML de los tres diccionarios, monolingue origen, bilingue ymonolingue meta. Desde esta pantalla se podra modificar di-rectamente el codigo y finalmente aceptar la nueva entrada ocancelar la operacion.
• ins multip.php: Tiene la misma funcion que insertarPro.phppero esta pensado para las unidades multipalabra, de forma quetiene un tratamiento especial con la entrada para que el codigoXML que se insiere en los diccionarios sea correcto.
• insertar.php: Es el modulo equivalente a insertarPro.php

6.2. INSTALACION Y ADMINISTRACION 173
pero cuando la operacion esta realizandola un usuario no pro-fesional. Las acciones que se realizan en este caso son muchomas sencillas puesto que la unica cosa que se hace es inseriren el fichero de terminos pendientes de validar los lemas y losparadigmas escogidos por el usuario no profesional, y quedanallı hasta que un usuario profesional los valida.
• verSemi.php: Este modulo tiene la funcion de mostrar elfichero con las entradas inseridas por usuarios no profesiona-les y que estan pendientes de ser validadas. Puede servir comoayuda para los usuarios profesionales que antes de empezar avalidar palabras quieran comprobar cuales estan en la cola paravalidar. Para llamarlo aparece un enlace en el formulario gene-rado por selec.php desde donde se puede llamar esta funcionali-dad.
• paradigmas.xsl: Hoja de estilos que se utiliza para generarlos ficheros de paradigmas con que trabajan los modulos delformulario. Se utiliza con la especificacion de los paradigmas decada lengua escrita en formato XML. Este punto se tratara masextensamente en el apartado Ficheros de Paradigmas.
• creaparadigma.awk: Fichero awk que tambien se utiliza pa-ra generar los ficheros de paradigmas de trabajo.
• gen paradig.sh: Script que se puede usar si queremos queautomaticamente se generan los ficheros de paradigmas de to-dos los pares de lenguas que tenemos instalados.
La especificacion detallada de las tareas de cada modulo se encuentraen las secciones correspondientes.
6.2.3. Ficheros php
6.2.3.1. resultado.php
Dependiendo del valor de la variable $nomtrad actualizada por in-dex.php el modulo asigna los valor adecuados a $LR y $RL (la lengua ori-gen y la lengua meta respectivamente). Seguidamente, dependiendo de lacategorıa gramatical de la palabra que se inserira, asignamos el valor ade-cuado a la variable $tipo y llamamos a selec.php o multip.php dependiendode si se trata de una palabra simple o de una unidad multipalabra.
[Nota: MG: “asignamos” i “llamamos” no seria mes aviat “se asigna”y “se llama”?]

174 CAPITULO 6. FORMULARIOS WEB DE INSERCION DE DATOS
6.2.3.2. selecc.php
Este modulo tiene la funcion de elegir el paradigma correspondiente alas palabras que queremos introducir. Se elige el paradigma de la palabraen lengua origen y en lengua meta.
En funcion de la categorıa gramatical de la palabra que estamos in-troduciendo, se asignan unos determinados valores a unas variables quedarrerament se utilizaran
[Nota: MG: vol dir “que se utilizaran mas adelante”?]
, estas son
cadFich: categorıa gramatical del lema.
show: cadena que se muestra en el formulario indicando la cate-gorıa gramatical de la palabra que esta inseriendose.
tag: cadena con la etiqueta XML de salida del analizador morfologi-co para esta categorıa gramatical.
tagout: cadena con el codigo XML que indica la categorıa grama-tical de la palabra. Esta cadena se utilizara cuando se componga laentrada final XML que se inserira en el diccionario.
nota: cadena con posibles comentarios a inserir en el codigo XMLde la entrada.
Los formularios trabajan con 4 tipos de diccionarios:
Semiprofesionales: Estos contienen las palabras inseridas desde el for-mulario por usuarios no profesionales y que estan pendientes de va-lidacion. Acaban con la extension ”semi.dic”
Diccionarios del formulario: Contienen las palabras que han sido inseri-das desde el formulario por usuarios profesionales y tambien las quehan sido validades desde los diccionarios semiprofesionales. Acabancon la extension ”webform”.
Finales: Son los ficheros con todas las entradas escritas en codigo XML. Estos ficheros son los que utiliza definitivamente el traductor des-pues de recibir un tratamiento adecuado de compilacion. Acabancon la extension ”dix”.
Finales compilados: Despues de haber compilado los diccionarios fi-nales ya pueden ser utilizados por los binarios del traductor. Acabancon la extension ”bin”

6.2. INSTALACION Y ADMINISTRACION 175
Estos diccionarios son utilizados por los formularios y hay variablesque contienen las rutas donde se pueden encontrar. Tambien se dan valo-res a las variables que mantienen las rutas donde se tienen que buscar losficheros auxiliares y de configuracion:
path: ruta para los diccionarios temporales.
fich LR: diccionario de la lengua origen de las palabras inseridasmediante el formulario y que todavıa no estan en el diccionario finalni en el diccionario compilado.
fich RL: diccionario de la lengua meta de las palabras inseridasmediante el formulario y que todavıa no estan en el diccionario finalni en el diccionario compilado.
fich LRRL: diccionario bilingue de las palabras inseridas medianteel formulario y que todavıa no estan en el diccionario final ni en eldiccionario compilado.
fich-semi: entradas inseridas mediante el formulario por usua-rios no profesionales y que estan pendientes de validacion.
path paradigmasLR: ruta de los ficheros con los paradigmas deflexion para la lengua origen.
path paradigmasRL: ruta de los ficheros con los paradigmas deflexion para la lengua meta.
anmor: ruta del analizador morfologico.
aut LRRL: ruta del binario morfologico de lengua origen a lenguameta.
[Nota: MG: no sera “binario bilingue”?]
aut RLLR: ruta del binario morfologico de lengua meta a lenguaorigen.
[Nota: MG: ıdem]
A continuacion se insiere el codigo html de lo que hay que hacer segunla accion seleccionada. Las acciones que se producen por orden secuencialson las siguientes:

176 CAPITULO 6. FORMULARIOS WEB DE INSERCION DE DATOS
Comprueba que el lema en lengua origen a inserir no este ya en losdiccionarios de palabras inseridas por el formulario. Si se ha lla-mado a selecc.php desde la pantalla de validacion de palabras(valida.php), entonces comprueba que el lema no este ya en el fi-chero de palabras inseridas por usuarios no profesionales. Tambienlo comprueba en el diccionario completo final.
Hace la misma comprobacion correspondiente para la lengua meta.
Seguidamente se escribe codigo para seleccionar restricciones delsentido de la traduccion.
Se definen una serie de funciones que se utilizaran en la generacionde ejemplos para los lemas cuando elegimos el correspondiente pa-radigma. Estas son:
• esVocalFuerte• esVocalDebil• esVocal• PosicioVocalTall
Estas funciones se describen mas adelante en el apartado correspon-diente a insertarPro.php.
Se abre el fichero de paradigmas para mostrar una ventana de selec-cion desplegable con los paradigmas que podemos elegir para el le-ma en lengua origen que estamos tratando. Para hacer esto se tienenque comprobar secuencialmente los paradigmas correspondientes ala categorıa gramatical del lema y comprobar que el paradigma sepuede aplicar al lema correspondiente.
A continuacion se hace lo mismo pero para los paradigmas del lemaen lengua meta.
Con los lemas y con los paradigmas correspondientes selecciona-dos, se tienen que generar los ejemplos de como quedarıa la flexionde esos lemas segun los paradigmas escogidos. Para conseguir es-to necesitamos, por un lado, la raız del lema (raiz LR y raiz RL)y, por otro, las terminacions de ejemplo para el paradigma escogi-do (paradigma LR y paradigma RL), terminaciones que se obtie-nen del fichero de paradigmas. Finalmente se compone una cadenacon los ejemplos generados (ejemplos LR y ejemplos RL) y semuestran.

6.2. INSTALACION Y ADMINISTRACION 177
Si estamos en esta pantalla porque venimos de validar palabras (va-lida=1) entonces se anade al formulario un boton para eliminar laentrada actual en caso de que no queramos validarla e inserirla.
Si el usuario que ha entrado en esta pantalla es un usuario reconoci-do como profesional, entonces se anade al formulario un boton paraque ese usuario pueda elegir la opcion de validar palabras inseridaspor usuarios no profesionales
Finalmente tenemos el tratamiento de la accion correspondiente ac-tivada al pulsar uno de los botones de confirmacion que se muestranen la parte inferior del formulario. Si la accion es ”Delete” , lo cualsolo puede ocurrir cuando se estan validando entradas, se eliminala entrada correspondiente del fichero con las entradas de usuariosno profesionales. Si la accion es la de confirmar (boton ”Go on”), sellama al modulo insertarPro.php o insertar.php dependien-do de si el usuario es profesional o no profesional respectivamente.Estos modulos se encargan de hacer la insercion en los diccionarios.
Cuando se ha inserido la palabra, se vuelve a mostrar la pagina de vali-dar.php o de selecc.php segun si habıamos entrado desde un procedi-miento de validacion (y entonces valida=1) o desde una insercion normal.
6.2.3.3. multip.php
El codigo y el comportamiento de este modulo es el mismo que el deselecc.php. La unica diferencia es que este esta pensado para tratar las uni-dades multipalabra, mientras que selec.php trata el resto de unidades. Ası,la diferencia mas evidente es que tenemos las variables $LRcua y $RLcuaque contienen la cola invariable que va despues de la parte variable de lamultipalabra. Cuando se muestran los ejemplos, aparte de mostrar la par-te variable flexionada segun el paradigma escogido, tambien se muestraun cuadro de texto modificable con la cola invariable.
Cuando se pulse el boton de seguir con la insercion de la entrada en losdiccionarios, se llama al modulo ins multip.php en vez de insertarPro.php..
6.2.3.4. valida.php
Este modulo es llamado cuando un usuario profesional pulsa el boton”validate pairs”. El control pasa a este modulo que lee el diccionario deentradas pendientes de ser validadas ($fichSemi) del par de lenguas co-rrespondiente. Entonces se entra en un bucle que recorre este fichero y va

178 CAPITULO 6. FORMULARIOS WEB DE INSERCION DE DATOS
leyendo las entradas una a una. Con la informacion de la entrada particu-lar da valor a una serie de variables que seran utilizadas en los modulosque haran el tratamiento posterior, como por ejemplo:
$LRlem $RLlem$paradigmaLR $paradigmaRL$direccions $tipo$comentarios $user$geneLR $geneRL$numLR $numRL$LR $RL
Una vez establecidos los valores adecuados para estas variables se ce-de el control a selec.php que trata la entrada como si de una insercion deusuario profesional se tratara. Despues de inserir las entradas en los dic-cionarios mediante insertarPro.php, el flujo vuelve a valida.php que continuacon la siguiente entrada por validar.
6.2.3.5. insertarPro.php
Una vez introducidos los lemas y seleccionados los paradigmas corres-pondientes en selec.php, este modulo es el encargado de generar las corres-pondientes entradas en codigo XML e inserirlas en los diccionarios mono-lingues y en el bilingue.
Realiza muchas operaciones parecidas a las realizadas en selec.php, co-mo por ejemplo generar los ejemplos de la palabra flexionada. Ası pri-meramente da valor a cadFich, show, tag, tagout, nota depen-diendo de la categorıa gramatical ($tipus) de la palabra a inserir. Asignarutas a las variables de ubicacion de ficheros y define unas funciones ne-cesarias de igual manera a como ocurrıa en selec.php.
esVocalFuerte: Devuelve true si la vocal es fuerte, es decir a, e, o.
esVocalDebil: Devuelve true si la vocal es debil, es decir a, e, o.
[Nota: MG: vol dir “i, u”?]
esVocal: Devuelve true si el caracter que le pasamos como argu-mento es una vocal.
diptongo: Devuelve true si las dos letras que se le pasan como argu-mentos forman diptongo. Esto ocurrira siempre que las dos vocalesno sean fuertes.

6.2. INSTALACION Y ADMINISTRACION 179
acentuar: Se le pasa una cadena de texto y lo acentua siguiendo lasreglas del castellano en funcion del parametro $siguienteletra.
esMayuscula: Devuelve true si el caracter esta en mayuscula.
TieneAcento: Devuelve true si la cadena tiene acento.
acentua: Acentua la ultima vocal accentuable de una palabra conun acento cerrado o abierto dependiendo del sentido indicado en elparametro $sentit.
PonQuitaAcento: Pone o quita el acento de la primera cadena pa-sada como argumento en funcion de si la segunda cadena argumentotiene o no tiene acento.
PosicioVocalTall: Devuelve la posicion dentro del lema ($lema)donde se encuentra la vocal ($vocal) que separa la raız de la desinen-cia. Se busca la vocal del final hacia el principio y se devuelve la pri-mera ocurrencia de $vocal.
Ahora se realizan las mismas operaciones que en selec.php. Primero,comprueba que la entrada no este ya en los diccionarios y genera los ejem-plos de la palabra flexionada con el paradigma previamente escogido. Acontinuacion se construye la cadena con el codigo XML que va a inserirseen el diccionario monolingue de lengua origen. Con la informacion que te-nemos de los lemas proveniente de selec.php, se genera una cadena de texto($cad LR) que contiene el codigo XML para el diccionario monolingue. Es-ta cadena se muestra en una ventana de texto que puede ser modificadamanualment. El mismo proceso se repite para generar la cadena corres-pondiente al diccionario monolingue de lengua meta ($cad RL) y parael diccionario bilingue ($cad bil). Luego, se concatena a estas variablesde cadena los comentarios y el nombre del usuario que insiere la entrada,si procede. Finalmente se acaba de componer la pantalla de formulario,con botones de aceptar, eliminar y volver atras. El codigo que hace el tra-tamiento de cada una de las posibles acciones se encuentra al final delfichero:
Inserir: En este caso, hace unas sustituciones de caracteres pa-ra que la entrada tenga el formato adecuado para los diccionarios,e insiere las cadenas $cad LR, $cad bil, $cad RL en los diccio-narios monolingue origen, bilingue y monolingue meta respectiva-mente ($fich LR, $fich LRRL, $fich RL). Si se produce alguntipo de error al inserir la entrada, informa de este hecho con una

180 CAPITULO 6. FORMULARIOS WEB DE INSERCION DE DATOS
notificacion por pantalla. Si insertarPro.php habıa sido llamado des-de un procedimiento de validacion de palabras ($valida=1), entoncesinsiere un boton ”Continue”para seguir validando palabras. En casocontrario insiere un boton de cerrar la ventana que nos permitira aca-bar.
Eliminar: En este caso, elimina la entrada del fichero de entradaspendientes de validar.
6.2.3.6. ins multip.php
Realiza las mismas operaciones que insertarPro.php pero cuando la en-trada a inserir es una unidad multipalabra. La diferencia principal es queahora disponemos de dos variables adicionales $LRcua y $RLcua quecontienen la parte invariable de la multipalabra. Cuando se insiere la en-trada en los diccionarios se tiene que anadir esta cola en el lugar conve-niente y convertir los espacios en blanco por la etiqueta de blanco <b/>.
6.2.3.7. insertar.php
La funcion de este modulo es muy sencilla. Compone una cadena detexto con la informacion proveniente de selec.php separada por tabulado-res. Esta cadena contiene toda la informacion necesaria para generar unaentrada de diccionario:
$LRlem.$RLlem.$paradigmaLR.$direccion.$paradigmaRL.$tipo.$comentarios.$user.$geneLR.$geneRL.Esta entrada se guarda en un fichero ($fichSemi) que contiene la cola
con las entradas pendientes de validar inseridas por usuarios no profesio-nales. Cuando un usuario considerado profesional quiera validar entradaspendientes, el modulo valida.php leera este mismo fichero.
6.2.3.8. verSemi.php
Se encarga de mostrar por pantalla el fichero de entradas pendientes devalidacion, y lo hace ası: lee el fichero con las entradas ($fichSemi) y entraen un bucle que recorre todas las entradas que se encuentran en el fichero.Para cada una de ellas muestra una lınea con la siguiente informacion:
$LRlem $paradigmaLR $direccion $RLlem$paradigmaRL $tipo $comentarios

6.2. INSTALACION Y ADMINISTRACION 181
6.2.4. Ficheros de diccionario
Los ficheros con las entradas inseridas desde el formulario se encuen-tran en /dics. Aquı se encuentran dos tipos de ficheros:
apertium-ll-rr.xx.webform: El fichero que contiene entradasen codigo XML preparadas para ser copiadas en los diccionarios fina-les. El nombre del fichero tiene el formato mostrado, siendo ll-rrlas iniciales correspondientes al traductor al que hace referencia elfichero y xx las iniciales de la lengua del monolingue al que ha-ce referencia o las iniciales del bilingue. Por ejemplo, las inicialesdel traductor espanol-catalan son es-ca. Para este traductor tene-mos el monolingue de espanol (es), el de catalan (can) y el bilingue(es-ca) Ası, en este directorio tendremos los siguientes ficheros pa-ra el traductor espanol-catalan:
apertium-es-ca.es.webformapertium-es-ca.ca.webform
apertium-es-ca.es-ca.webform
oo-mm.semi.dic: El fichero que contiene las entradas pendientesde ser validadas de un determinado par de lenguas. oo-mm son lasiniciales correspondientes al par concreto. Por ejemplo, el traductorespanol-catalan tendra este fichero para el semi-profesional: es-ca.semi.dic
6.2.5. Ficheros de paradigmas
Los paradigmas utilizados para cada par de lenguas se especifican endos archivos de formato XML denominados paradig.ll-rr.xx.xml don-de xx son las iniciales correspondientes a una lengua y ll-rr las inicialescorrespondientes a un par de lenguas. Estos archivos estan formados porun conjunto de entradas correspondientes a paradigmas o modelos de fle-xion de las palabras de una lengua en concreto. El fichero XML se componede las siguientes partes:
Cabecera/Raız del documento de especificacion.
<?xml version="1.0" encoding="ISO-8859-1"?><?xml-stylesheet type="text/xsl" href="paradigmas.xsl"?><!DOCTYPE form SYSTEM "form.dtd"><form lang="oc" langpair="oc-ca">

182 CAPITULO 6. FORMULARIOS WEB DE INSERCION DE DATOS
El atributo lang indica las iniciales de la lengua para la cual estanespecificandose paradigmas y el atributo langpair indica las inicialescorrespondientes al par de lenguas del traductor al que correspondeel fichero. Es necesario que en el mismo directorio donde estan losficheros de paradigmas este form.dtd, donde se especifica la DTDque siguen estos ficheros. Esta DTD esta detallada en el anexo A.7.
Un conjunto de elementos que definen los paradigmas. Para explicarel formato de los elementos reproducimos este ejemplo:
<entry PoS="adj" nbr="sg_pl" gen="mf"><endings>
<stem>amable</stem><ending/><ending>s</ending>
</endings><paradigms howmany="1">
<par n="amable adj"/></paradigms>
</entry>
Cada paradigma esta especificado en un elemento <entry>. Esteelemento puede tener tres atributos:
• PoS: la categorıa gramatical del paradigma. Puede tomar los va-lores: acr, adj, adv, noun, pname, pr, verbo.
[Nota: faltaria cnjadv?]
Es obligatorio para cualquier categorıa gramatical.
• nbr: los numeros admitidos por el paradigma. Puede tener losvalores: sg, pl, sg pl, sp.
• gen: los generos admitidos por el paradigma. Puede tener losvalores: m, f, m f, mf.
Ademas, esta formado por dos elementos:
• endings: la raız y las terminacions utilizadas para seleccionarel paradigma en el formulario y mostrar los ejemplos de flexion.
• paradigms: especificacion del paradigma o paradigmas quedefinen la flexion seguida por una entrada en concreto. Nece-sita del atributo howmany que indica el numero de paradigmas

6.2. INSTALACION Y ADMINISTRACION 183
que utiliza la entrada. Para cada uno de los paradigmas utiliza-dos hay una lınea que especifica el nombre del paradigma deldiccionario, y que tiene el siguiente formato:
<par n="long adj"/>
A partir del fichero de paradigmas escrito en XML, se tienen que ge-nerar los ficheros con los que directamente trabajan los modulos de losformularios. Si se ejecuta el script /private/gen paradig.sh el pro-ceso se realiza automaticamente para todos los pares de lenguas de quedisponemos:
# cd private# ./gen paradig.sh
Para anadir un nuevo paradigma a los formularios, debe prepararse laentrada correspondiente en el fichero de paradigmas en formato XML ydespues actualizar los archivos de trabajo con la orden anterior.
El proceso automatizado tambien se puede realizar de forma manualsi no queremos actualizar los ficheros de todos los pares de lenguas quetenemos instalados. La generacion manual de los archivos de trabajo sehace con una hoja de estilo XSL mediante esta orden:
# xsltproc paradigmas.xsl fichero de paradigmas.xml| ./creaparadig.awk
Esta accion genera un fichero de trabajo para cada categorıa gramatical.Los ficheros generados se encuentran en los directorios /private/paradigmas.ll-rr.Cada directorio contiene ficheros con los paradigmas que se pueden utili-zar para cada par de lenguas ll-rr y para cada componente gramatical.Cada uno de estos directorio contiene los ficheros siguientes:
paradigacr xx: paradigmas para acronimos de la lengua xx.
paradigadj xx: paradigmas para adjetivos de la lengua xx.
paradigadv xx: paradigmas para adverbios de la lengua xx.
paradigcnjadv xx: paradigmas para conjunciones adverbiales dela lengua xx.
paradigcnjcoo xx: paradigmas para conjunciones copulativas dela lengua xx.
[Nota: MG: aquesta no esta en la pagina web del formulari]

184 CAPITULO 6. FORMULARIOS WEB DE INSERCION DE DATOS
paradigcnjsub xx: paradigmas para conjunciones subordinadasde la lengua xx.
[Nota: ıdem]
paradignoun xx: paradigmas para nombres de la lengua xx.
paradigpname xx: paradigmas para nombres propios de la lenguaxx.
paradigpr xx: paradigmas para preposiciones de la lengua xx.
paradigverb xx: paradigmas para verbos de la lengua xx.
Los ficheros estan compuestos por una entrada por lınea. Cada entradacontiene la informacion siguiente:
ejemplos numero de paradigmas paradigmas modelo (numeros) (generos)
El separador utilizado para las diferentes partes de la entrada es el ta-bulador.
Ejemplos: son las terminacions que se utilizaran para generar los ejem-plos cuando escogemos este paradigma como prototipo para una de-terminada palabra a inserir.
Numero de paradigmas: es el numero de paradigmas del diccionarioque se utilizaran para flexionar adecuadamente este modelo de fle-xion en particular.
Paradigmas modelo: es el nombre del paradigma o paradigmas queestan en el diccionario y que son los que se utilizaran para flexionarla nueva entrada.
(Numeros): Solo se pone en el caso de nombres, adjetivos y acronimos.Hace referencia al numero del paradigma.
(Generos): Solo se pone en el caso de nombres, adjetivos y acronimos.Hace referencia al genero del paradigma.
Ası por ejemplo, en el traductor espanol-catalan tendrıamos el directo-rio /private/paradigmas.es-ca donde encontrarıamos dos ficherosXML: paradig.es-ca.es.xml y paradig.es-ca.ca.xml con la espe-cificacion de los paradigmas utilizados en cada lengua. A partir de estosficheros se pueden generar todos los ficheros de paradigmas para un parde lenguas concreto con la orden:

6.3. UTILIZACION DE LOS FORMULARIOS 185
# cd private/paradigmas.es-ca# xsltproc ../paradigmas.xsl paradig.es-ca.es.xml
| ../creaparadig.awk# xsltproc ../paradigmas.xsl paradig.es-ca.ca.xml
| ../creaparadig.awk
O bien, se pueden generar automaticamente para todos los pares delenguas con:
# ./private/gen paradig.sh
Entre los ficheros de trabajo generados, habrıa uno, por ejemplo, de-nominado paradigverb ca que contendrıa los posibles paradigmas deverbos para el catalan, donde una posible lınea serıa la siguiente:
abra/car /co /ci 1 abalan/car vblex
que deriva de la entrada en XML:
<entry PoS="verb"><endings>
<stem>abra</stem><ending>car</ending><ending>co</ending><ending>ci</ending>
</endings><paradigms howmany="1">
<par n="abalan/car vblex"/></paradigms>
</entry>
6.3. Utilizacion de los formularios
6.3.1. Introduccion[Intentar evitar el llenguatge sexista en tot el document: usuari, etc.]
Cuando la persona usuaria quiera inserir nuevas entradas a un diccionariotiene que conectarse mediante un cliente navegador a la direccion dondese haya instalado el servidor de formularios, por ejemplo:
http://xixona.dlsi.ua.se/forms

186 CAPITULO 6. FORMULARIOS WEB DE INSERCION DE DATOS
Se abrira una pagina web con el portal de entrada a Opentrad Apertium-Insertion Form. En el marco de la izquierda hay enlaces para obtenermas informacion , descargar los programas y contacto para solicitar inscribir-se como usuario del sistema. Para inscribirse como usuario hay que enviarun correo electronico al webmaster encargado de los formularios.
[Canviar a tot arreu registrar per inscribir.]
Para inserir nuevas palabras, se llenara el formulario con los datos corres-pondientes y se pulsara el boton ’Go On’; en este momento habra que iden-tificarse como usuario inscrito o no se podra continuar con el procedimien-to de inserir palabras. Cuando una persona se inscribe se puede registrarde dos maneras: como profesional o como no profesional. Cada modalidadtiene unas habilitacions diferentes, que se explicaran en los apartados si-guientes.
6.3.2. Insercion de entradas
6.3.2.1. Perfil profesional
Cuando se quiere inserir una nueva entrada a los diccionarios hay quedirigirse al apartado correspondiente al par de lenguas que se quiera am-pliar. Entonces se especifica el lema en lengua origen y en lengua meta yse elige la categorıa gramatical de las entradas que se inseriran. A conti-nuacion, se pulsa el boton Go on para seguir con el proceso de insercion.
En este punto aparece una nueva ventana que muestra los lemas y unosparametros que caracterizan la nueva entrada de diccionario. Si la entradaya esta en alguno de los diccionarios, se avisara a la persona usuaria y elsistema automaticamente escogera sentido unidireccional (de izquierda aderecha o al inreves). Si no esta en ninguno, se elegira doble sentido detraduccion.
En esta nueva ventana se pueden hacer estas tres acciones:
[Cal repassar la primera oracio del paragraf seguent; sembla que hiha algun material que hauria de ser esborrat; Una altra cosa, elsformularis en l’actualitat no tenen suport per a traduccions multiples,segons sembla. Caldria fer constar aquesta circumstancia en algunlloc.]
Escoger el paradigma para el lema en lengua origen y para el lemaen lengua meta (esta accion es obligatoria, el resto no).1
1Escoger el paradigma es un proceso que debe realizarse con mucho cuidado. Hay

6.3. UTILIZACION DE LOS FORMULARIOS 187
Escoger la direccion de traduccion de la entrada si es diferente de lapropuesta automaticamente.
Anadir comentarios en la entrada que quedaran en el diccionariofinal.
Una vez se han hecho las operaciones correspondientes, debe pulsarse’Go on’ si queremos confirmar la entrada o ’Close’ si queremos cancelar laoperacion de insercion.
La siguiente y ultima pantalla que se nos muestra contiene las tres en-tradas en formato XML generadas para los diccionarios monolingue lenguaorigen, bilingue y monolingue lengua meta. Estas entradas se muestranen tres ventanas de texto y se pueden editar si se desea hacer alguna mo-dificacion. Una vez revisadas las entradas, se pulsa el boton ’Insert’ parainserirlas definitivamente en los diccionarios correspondientes. Tambientenemos la posibilidad de pulsar el boton ’Go back’ si queremos volver alpaso anterior.
6.3.2.2. Usuario no profesional
Cuando un usuario entra al sistema de insercion como usuario no pro-fesional, el procedimiento de insercion de palabras es el mismo que para elusuario profesional, pero las entradas inseridas no se guardan en los dic-cionarios generados por los formularios sino que quedan en una cola deentradas pendientes de validacion. Para inserir las palabras de esta cola alos diccionarios hace falta que un usuario profesional las valide.
6.3.3. Validacion de entradas pendientes de aprobacion
Los usuarios profesionales, en la pantalla donde se escoge el paradig-ma de los lemas inseridos, tienen dos enlaces adicionales:
See pairs to be validated: Aquı se abre una ventana donde se muestra elcontenido del fichero con las palabras que estan pendientes de vali-
que elegir el paradigma exacto que describe el comportamiento del lema que estamosinseriendo. En el caso de adjetivos, nombres y acronimos, hay que escoger el paradigmaque se ajuste a la flexion deseada y tambien a los generos admitidos. En el caso de acroni-mos, por ejemplo, hay que fijarse en el genero y numero que admite cada paradigma delos que podemos escoger; por ejemplo BBC sirve para acronimos femeninos singulares ySA para acronimos femeninos que admiten plural). En el caso de nombres propios, debeescogerse el paradigma en funcion de si se trata de un nombre propio de cosa (p. ej. unperiodico), de persona o de lugar.

188 CAPITULO 6. FORMULARIOS WEB DE INSERCION DE DATOS
dacion; son palabras que han sido inseridas por usuarios no profesio-nales. Esta ventana es meramente informativa y se cierra pulsandoel boton ’Close’.
Validate pairs: Esta opcion permite a un usuario profesional validaruna a una las entradas pendientes. Al pulsar este boton se abre laventana de seleccion de paradigmas que se ha visto en el aparta-do de insercion de nuevas palabras. Esta ventana muestra los datosque ha escogido el usuario para la entrada que ha anadido. Ahora,el usuario profesional puede modificar los lemas, borrar la entrada(boton ’Delete’) o seguir con el proceso de insercion. Si sigue con lainsercion de la entrada, el proceso es el mismo que en una insercionnormal, solo que cuando la entrada queda definitivamente anadida alos diccionarios de formulario el control vuelve a mostrar la siguien-te entrada a validar de la cola.
Este proceso es repite hasta que se validen todas las palabras de lacola o se finalice el proceso pulsando el boton ’Close’.

Apendice A
Definiciones de tipos dedocumento (DTD) en XML
A.1. DTD para el formato de los diccionarios
Definicion de tipo de documento para el formato de los diccionariosmorfologicos, bilingues y de postgeneracion en XML; esta definicion vie-ne con el paquete apertium (ultima version) que se puede descargar dehttp://www.sourceforge.net.
La explicacion de los distintos elementos se encuentra en la pagina 24y siguientes.
<!ELEMENT dictionary (alphabet?, sdefs?,pardefs?, section+)>
<!ELEMENT alphabet (#PCDATA)>
<!ELEMENT sdefs (sdef+)>
<!ELEMENT sdef EMPTY><!ATTLIST sdef n ID #REQUIRED>
<!ELEMENT pardefs (pardef+)>
<!ELEMENT pardef (e+)><!ATTLIST pardef n CDATA #REQUIRED>
<!ELEMENT section (e+)>
<!ATTLIST section id ID #REQUIRED
189

190 APENDICE A. DTDS EN XML
type (standard|inconditional|postblank) #REQUIRED>
<!ELEMENT e (i | p | par | re)+><!ATTLIST e r (LR|RL) #IMPLIED
lm CDATA #IMPLIEDa CDATA #IMPLIEDc CDATA #IMPLIED
<!ELEMENT par EMPTY><!ATTLIST par n CDATA #REQUIRED>
<!ELEMENT i (#PCDATA | b | s | g | j | a)*>
<!ELEMENT re (#PCDATA)>
<!ELEMENT p (l, r)>
<!ELEMENT l (#PCDATA | a | b | g | j | s)*>
<!ELEMENT r (#PCDATA | a | b | g | j | s)*>
<!ELEMENT a EMPTY>
<!ELEMENT b EMPTY>
<!ELEMENT g (#PCDATA | a | b | j | s)*><!ATTLIST g i CDATA #IMPLIED>
<!ELEMENT j EMPTY>
<!ELEMENT s EMPTY>
<!ATTLIST s n IDREF #REQUIRED>
A.1.1. Modificacion en la DTD de diccionarios para selec-cion lexica
La DTD para el formato de los diccionarios se ha modificado ligera-mente para que estos pueden funcionar en un sistema con modulo de se-leccion lexica. A continuacion se muestra el cambio realizado, que afectasolo al elemento <e>

A.2. DTD PARA EL DESAMBIGUADOR 191
...<!ATTLIST e
r (LR|RL) #IMPLIEDlm CDATA #IMPLIEDa CDATA #IMPLIEDc CDATA #IMPLIED>i CDATA #IMPLIEDslr CDATA #IMPLIEDsrl CDATA #IMPLIED>
<!-- r: restriction LR: left-to-right,RL: right-to-left -->
<!-- lm: lemma --><!-- a: author --><!-- c: comment --><!-- i: ignore (’yes’) means ignore, otherwise it is not ignored) --><!-- slr: translation sense when translating from left to right --><!-- srl: translation sense when translating from right to left -->
...
A.2. DTD para el formato de los ficheros del desam-biguador
DTD que define el formato del fichero de especificacion del desambi-guador. Esta definicion viene con el paquete apertium (ultima version)que se puede descargar de http://www.sourceforge.net.
La descripcion de los distintos elementos se encuentra en la pagina 60.
<!ELEMENT tagger (tagset,forbid?,enforce-rules?,preferences?)><!ATTLIST tagger name CDATA #REQUIRED>
<!ELEMENT tagset (def-label+,def-mult*)>
<!ELEMENT def-label (tags-item+)><!ATTLIST def-label name CDATA #REQUIRED
closed CDATA #IMPLIED>
<!ELEMENT tags-item #EMPTY><!ATTLIST tags-item tags CDATA #REQUIRED
lemma CDATA #IMPLIED>

192 APENDICE A. DTDS EN XML
<!ELEMENT def-mult (sequence+)><!ATTLIST def-mult name CDATA #REQUIRED
closed CDATA #IMPLIED>
<!ELEMENT sequence ((tags-item|label-item)+)>
<!ELEMENT label-item #EMPTY><!ATTLIST label-item label CDATA #REQUIRED>
<!ELEMENT forbid (label-sequence+)>
<!ELEMENT label-sequence (label-item+)>
<!ELEMENT enforce-rules (enforce-after+)>
<!ELEMENT enforce-after (label-set)><!ATTLIST enforce-after label CDATA #REQUIRED>
<!ELEMENT label-set (label-item+)>
<!ELEMENT preferences (prefer+)>
<!ELEMENT prefer EMPTY><!ATTLIST prefer tags CDATA #REQUIRED>
A.3. DTD del modulo de transferencia estructu-ral (chunker)
DTD para el formato de las reglas de transferencia estructural del modu-lo chunker. Esta definicion viene con el paquete apertium (version 2.0)que se puede descargar de http://www.sourceforge.net.
La descripcion de los distintos elementos se encuentra en el apartado3.5.4.
<!ENTITY % condition "(and|or|not|equal|begins-with|ends-with|contains-substring|in)">
<!ENTITY % container "(var|clip)"><!ENTITY % sentence "(let|out|choose|modify-case|
call-macro|append)"><!ENTITY % value "(b|clip|lit|lit-tag|var|get-case-from|

A.3. DTD DEL MODULO CHUNKER 193
case-of|concat)"><!ENTITY % stringvalue "(clip|lit|var|get-case-from|
case-of)">
<!ELEMENT transfer (section-def-cats,section-def-attrs,section-def-vars,section-def-lists?,section-def-macros?,section-rules)>
<!ATTLIST transfer default (lu|chunk) #IMPLIED>
<!ELEMENT section-def-cats (def-cat+)>
<!ELEMENT def-cat (cat-item+)><!ATTLIST def-cat n ID #REQUIRED>
<!ELEMENT cat-item EMPTY><!ATTLIST cat-item lemma CDATA #IMPLIED
tags CDATA #REQUIRED >
<!ELEMENT section-def-attrs (def-attr+)>
<!ELEMENT def-attr (attr-item+)><!ATTLIST def-attr n ID #REQUIRED>
<!ELEMENT attr-item EMPTY><!ATTLIST attr-item tags CDATA #IMPLIED>
<!ELEMENT section-def-vars (def-var+)>
<!ELEMENT def-var EMPTY><!ATTLIST def-var n ID #REQUIRED>
<!ELEMENT section-def-lists (def-list)+>
<!ELEMENT def-list (list-item+)><!ATTLIST def-list n ID #REQUIRED>
<!ELEMENT list-item EMPTY><!ATTLIST list-item v CDATA #REQUIRED>

194 APENDICE A. DTDS EN XML
<!ELEMENT section-def-macros (def-macro)+>
<!ELEMENT def-macro (%sentence;)+><!ATTLIST def-macro n ID #REQUIRED><!ATTLIST def-macro npar CDATA #REQUIRED>
<!ELEMENT section-rules (rule+)>
<!ELEMENT rule (pattern, action)><!ATTLIST rule comment CDATA #IMPLIED>
<!ELEMENT pattern (pattern-item+)>
<!ELEMENT pattern-item EMPTY><!ATTLIST pattern-item n IDREF #REQUIRED>
<!ELEMENT action (%sentence;)*>
<!ELEMENT choose (when+,otherwise?)>
<!ELEMENT when (test,(%sentence;)*)>
<!ELEMENT otherwise (%sentence;)+>
<!ELEMENT test (%condition;)+>
<!ELEMENT and ((%condition;),(%condition;)+)>
<!ELEMENT or ((%condition;),(%condition;)+)>
<!ELEMENT not (%condition;)>
<!ELEMENT equal (%value;,%value;)><!ATTLIST equal caseless (no|yes) #IMPLIED>
<!ELEMENT begins-with (%value;,%value;)><!ATTLIST begins-with caseless (no|yes) #IMPLIED>
<!ELEMENT ends-with (%value;,%value;)><!ATTLIST ends-with caseless (no|yes) #IMPLIED>
<!ELEMENT contains-substring (%value;,%value;)><!ATTLIST contains-substring caseless (no|yes) #IMPLIED>

A.3. DTD DEL MODULO CHUNKER 195
<!ELEMENT in (%value;, list)><!ATTLIST in caseless (no|yes) #IMPLIED>
<!ELEMENT list EMPTY><!ATTLIST list n IDREF #REQUIRED>
<!ELEMENT let (%container;,%value;)>
<!ELEMENT append (%value;)+><!ATTLIST append n IDREF #REQUIRED>
<!ELEMENT out (mlu|lu|b|chunk)+>
<!ELEMENT modify-case (%container;,%stringvalue;)>
<!ELEMENT call-macro (with-param)*><!ATTLIST call-macro n IDREF #REQUIRED>
<!ELEMENT with-param EMPTY><!ATTLIST with-param pos CDATA #REQUIRED>
<!ELEMENT clip EMPTY><!ATTLIST clip pos CDATA #REQUIRED
side (sl|tl) #REQUIREDpart CDATA #REQUIREDqueue CDATA #IMPLIEDlink-to CDATA #IMPLIED>
<!ELEMENT lit EMPTY><!ATTLIST lit v CDATA #REQUIRED>
<!ELEMENT lit-tag EMPTY><!ATTLIST lit-tag v CDATA #REQUIRED>
<!ELEMENT var EMPTY><!ATTLIST var n IDREF #REQUIRED>
<!ELEMENT get-case-from (clip|lit|var)><!ATTLIST get-case-from pos CDATA #REQUIRED>
<!ELEMENT case-of EMPTY><!ATTLIST case-of pos CDATA #REQUIRED

196 APENDICE A. DTDS EN XML
side (sl|tl) #REQUIREDpart CDATA #REQUIRED>
<!ELEMENT concat (%value;)+>
<!ELEMENT mlu (lu+)>
<!ELEMENT lu (%value;)+>
<!ELEMENT chunk (tags,(mlu|lu|b)+)><!ATTLIST chunk name CDATA #IMPLIED
namefrom CDATA #IMPLIEDcase CDATA #IMPLIED>
<!ELEMENT tags (tag+)><!ELEMENT tag (%value;)>
<!ELEMENT b EMPTY><!ATTLIST b pos CDATA #IMPLIED>

A.4. DTD DEL MODULO INTERCHUNK 197
A.4. DTD del modulo interchunk
DTD para el formato de las reglas de transferencia estructural del modu-lo interchunk. Esta definicion viene con el paquete apertium (version2.0) que se puede descargar de http://www.sourceforge.net.
La descripcion de los distintos elementos se encuentra en el apartado3.5.4.
<!ENTITY % condition "(and|or|not|equal|begins-with|ends-with|contains-substring|in)">
<!ENTITY % container "(var|clip)"><!ENTITY % sentence "(let|out|choose|modify-case|
call-macro|append)"><!ENTITY % value "(b|clip|lit|lit-tag|var|get-case-from|
case-of|concat)"><!ENTITY % stringvalue "(clip|lit|var|get-case-from|
case-of)">
<!ELEMENT interchunk (section-def-cats,section-def-attrs,section-def-vars,section-def-lists?,section-def-macros?,section-rules)>
<!ELEMENT section-def-cats (def-cat+)>
<!ELEMENT def-cat (cat-item+)><!ATTLIST def-cat n ID #REQUIRED>
<!ELEMENT cat-item EMPTY><!ATTLIST cat-item lemma CDATA #IMPLIED
tags CDATA #REQUIRED >
<!ELEMENT section-def-attrs (def-attr+)>
<!ELEMENT def-attr (attr-item+)><!ATTLIST def-attr n ID #REQUIRED>
<!ELEMENT attr-item EMPTY><!ATTLIST attr-item tags CDATA #IMPLIED>

198 APENDICE A. DTDS EN XML
<!ELEMENT section-def-vars (def-var+)>
<!ELEMENT def-var EMPTY><!ATTLIST def-var n ID #REQUIRED>
<!ELEMENT section-def-lists (def-list)+>
<!ELEMENT def-list (list-item+)><!ATTLIST def-list n ID #REQUIRED>
<!ELEMENT list-item EMPTY><!ATTLIST list-item v CDATA #REQUIRED>
<!ELEMENT section-def-macros (def-macro)+>
<!ELEMENT def-macro (%sentence;)+><!ATTLIST def-macro n ID #REQUIRED><!ATTLIST def-macro npar CDATA #REQUIRED>
<!ELEMENT section-rules (rule+)>
<!ELEMENT rule (pattern, action)><!ATTLIST rule comment CDATA #IMPLIED>
<!ELEMENT pattern (pattern-item+)>
<!ELEMENT pattern-item EMPTY><!ATTLIST pattern-item n IDREF #REQUIRED>
<!ELEMENT action (%sentence;)*>
<!ELEMENT choose (when+,otherwise?)>
<!ELEMENT when (test,(%sentence;)*)>
<!ELEMENT otherwise (%sentence;)+>
<!ELEMENT test (%condition;)+>
<!ELEMENT and ((%condition;),(%condition;)+)>
<!ELEMENT or ((%condition;),(%condition;)+)>

A.4. DTD DEL MODULO INTERCHUNK 199
<!ELEMENT not (%condition;)>
<!ELEMENT equal (%value;,%value;)><!ATTLIST equal caseless (no|yes) #IMPLIED>
<!ELEMENT begins-with (%value;,%value;)><!ATTLIST begins-with caseless (no|yes) #IMPLIED>
<!ELEMENT ends-with (%value;,%value;)><!ATTLIST ends-with caseless (no|yes) #IMPLIED>
<!ELEMENT contains-substring (%value;,%value;)><!ATTLIST contains-substring caseless (no|yes) #IMPLIED>
<!ELEMENT in (%value;, list)><!ATTLIST in caseless (no|yes) #IMPLIED>
<!ELEMENT list EMPTY><!ATTLIST list n IDREF #REQUIRED>
<!ELEMENT let (%container;,%value;)>
<!ELEMENT append (%value;)+><!ATTLIST append n IDREF #REQUIRED>
<!ELEMENT out (b|chunk)+>
<!ELEMENT modify-case (%container;,%stringvalue;)>
<!ELEMENT call-macro (with-param)*><!ATTLIST call-macro n IDREF #REQUIRED>
<!ELEMENT with-param EMPTY><!ATTLIST with-param pos CDATA #REQUIRED>
<!ELEMENT clip EMPTY><!ATTLIST clip pos CDATA #REQUIRED
part CDATA #REQUIRED>
<!ELEMENT lit EMPTY><!ATTLIST lit v CDATA #REQUIRED>
<!ELEMENT lit-tag EMPTY>

200 APENDICE A. DTDS EN XML
<!ATTLIST lit-tag v CDATA #REQUIRED>
<!ELEMENT var EMPTY><!ATTLIST var n IDREF #REQUIRED>
<!ELEMENT get-case-from (clip|lit|var)><!ATTLIST get-case-from pos CDATA #REQUIRED>
<!ELEMENT case-of EMPTY><!ATTLIST case-of pos CDATA #REQUIRED
part CDATA #REQUIRED>
<!ELEMENT concat (%value;)+>
<!ELEMENT chunk (%value;)+>
<!ELEMENT pseudolemma (%value;)>
<!ELEMENT b EMPTY><!ATTLIST b pos CDATA #IMPLIED>

A.5. DTD DEL MODULO POSTCHUNK 201
A.5. DTD del modulo postchunk
DTD para el formato de las reglas de transferencia estructural del modu-lo postchunk. Esta definicion viene con el paquete apertium (version2.0) que se puede descargar de http://www.sourceforge.net.
La descripcion de los distintos elementos se encuentra en el apartado3.5.4.
<!ENTITY % condition "(and|or|not|equal|begins-with|ends-with|contains-substring|in)">
<!ENTITY % container "(var|clip)"><!ENTITY % sentence "(let|out|choose|modify-case|
call-macro|append)"><!ENTITY % value "(b|clip|lit|lit-tag|var|get-case-from|
case-of|concat)"><!ENTITY % stringvalue "(clip|lit|var|get-case-from|
case-of)">
<!ELEMENT postchunk (section-def-cats,section-def-attrs,section-def-vars,section-def-lists?,section-def-macros?,section-rules)>
<!ELEMENT section-def-cats (def-cat+)>
<!ELEMENT def-cat (cat-item+)><!ATTLIST def-cat n ID #REQUIRED>
<!ELEMENT cat-item EMPTY><!ATTLIST cat-item name CDATA #REQUIRED>
<!ELEMENT section-def-attrs (def-attr+)>
<!ELEMENT def-attr (attr-item+)><!ATTLIST def-attr n ID #REQUIRED>
<!ELEMENT attr-item EMPTY><!ATTLIST attr-item tags CDATA #IMPLIED>
<!ELEMENT section-def-vars (def-var+)>

202 APENDICE A. DTDS EN XML
<!ELEMENT def-var EMPTY><!ATTLIST def-var n ID #REQUIRED>
<!ELEMENT section-def-lists (def-list)+>
<!ELEMENT def-list (list-item+)><!ATTLIST def-list n ID #REQUIRED>
<!ELEMENT list-item EMPTY><!ATTLIST list-item v CDATA #REQUIRED>
<!ELEMENT section-def-macros (def-macro)+>
<!ELEMENT def-macro (%sentence;)+><!ATTLIST def-macro n ID #REQUIRED><!ATTLIST def-macro npar CDATA #REQUIRED>
<!ELEMENT section-rules (rule+)>
<!ELEMENT rule (pattern, action)><!ATTLIST rule comment CDATA #IMPLIED>
<!ELEMENT pattern (pattern-item+)>
<!ELEMENT pattern-item EMPTY><!ATTLIST pattern-item n IDREF #REQUIRED>
<!ELEMENT action (%sentence;)*>
<!ELEMENT choose (when+,otherwise?)>
<!ELEMENT when (test,(%sentence;)*)>
<!ELEMENT otherwise (%sentence;)+>
<!ELEMENT test (%condition;)+>
<!ELEMENT and ((%condition;),(%condition;)+)>
<!ELEMENT or ((%condition;),(%condition;)+)>
<!ELEMENT not (%condition;)>

A.5. DTD DEL MODULO POSTCHUNK 203
<!ELEMENT equal (%value;,%value;)><!ATTLIST equal caseless (no|yes) #IMPLIED>
<!ELEMENT begins-with (%value;,%value;)><!ATTLIST begins-with caseless (no|yes) #IMPLIED>
<!ELEMENT ends-with (%value;,%value;)><!ATTLIST ends-with caseless (no|yes) #IMPLIED>
<!ELEMENT contains-substring (%value;,%value;)><!ATTLIST contains-substring caseless (no|yes) #IMPLIED>
<!ELEMENT in (%value;, list)><!ATTLIST in caseless (no|yes) #IMPLIED>
<!ELEMENT list EMPTY><!ATTLIST list n IDREF #REQUIRED>
<!ELEMENT let (%container;,%value;)>
<!ELEMENT append (%value;)+><!ATTLIST append n IDREF #REQUIRED>
<!ELEMENT out (b|lu|mlu)+>
<!ELEMENT modify-case (%container;,%stringvalue;)>
<!ELEMENT call-macro (with-param)*><!ATTLIST call-macro n IDREF #REQUIRED>
<!ELEMENT with-param EMPTY><!ATTLIST with-param pos CDATA #REQUIRED>
<!ELEMENT clip EMPTY><!ATTLIST clip pos CDATA #REQUIRED
part CDATA #REQUIRED>
<!ELEMENT lit EMPTY><!ATTLIST lit v CDATA #REQUIRED>
<!ELEMENT lit-tag EMPTY><!ATTLIST lit-tag v CDATA #REQUIRED>

204 APENDICE A. DTDS EN XML
<!ELEMENT var EMPTY><!ATTLIST var n IDREF #REQUIRED>
<!ELEMENT get-case-from (clip|lit|var)><!ATTLIST get-case-from pos CDATA #REQUIRED>
<!ELEMENT case-of EMPTY><!ATTLIST case-of pos CDATA #REQUIRED
part CDATA #REQUIRED>
<!ELEMENT concat (%value;)+>
<!ELEMENT mlu (lu+)>
<!ELEMENT lu (%value;)+>
<!ELEMENT b EMPTY><!ATTLIST b pos CDATA #IMPLIED>

A.6. DTD PARA REGLAS DE FORMATO 205
A.6. DTD para las reglas de especificacion de for-mato
DTD para las reglas de especificacion de formato, que puede descargar-se de la pagina web http://cvs.sourceforge.net/viewcvs.py/apertium/apertium/apertium/format.dtd.
La descripcion de los distintos elementos se encuentra en el apartado3.6.2.
<!ELEMENT format (options,rules)><!ATTLIST format name CDATA #REQUIRED>
<!ELEMENT options (largeblocks, input, output,escape-chars, space-chars, case-sensitive)>
<!ELEMENT largeblocks EMPTY><!ATTLIST largeblocks size CDATA #REQUIRED>
<!ELEMENT input EMPTY><!ATTLIST input zip-path CDATA #IMPLIED
encoding CDATA #REQUIRED>
<!ELEMENT output EMPTY><!ATTLIST output zip-path CDATA #IMPLIED
encoding CDATA #REQUIRED>
<!ELEMENT escape-chars EMPTY><!ATTLIST escape-chars regexp CDATA #REQUIRED>
<!ELEMENT space-chars EMPTY><!ATTLIST space-chars regexp CDATA #REQUIRED>
<!ELEMENT case-sensitive EMPTY><!ATTLIST case-sensitive value (yes|no) #REQUIRED>
<!ELEMENT rules (format-rule|replacement-rule)+>
<!ELEMENT format-rule (begin-end|(begin,end))><!ATTLIST format-rule eos (yes|no) #IMPLIED
priority CDATA #REQUIRED>
<!ELEMENT begin-end EMPTY><!ATTLIST begin-end regexp CDATA #REQUIRED>

206 APENDICE A. DTDS EN XML
<!ELEMENT begin EMPTY><!ATTLIST begin regexp CDATA #REQUIRED>
<!ELEMENT end EMPTY><!ATTLIST end regexp CDATA #REQUIRED>
<!ELEMENT replacement-rule (replace+)><!ATTLIST replacement-rule regexp CDATA #REQUIRED>
<!ELEMENT replace EMPTY><!ATTLIST replace source CDATA #REQUIRED
target CDATA #REQUIREDprefer (yes|no) #IMPLIED>

A.7. DTD DE LOS PARADIGMAS DEL FORMULARIO 207
A.7. DTD de los paradigmas del formulario
DTD para el formato de los ficheros de paradigmas que utiliza la herra-mienta de formularios. Esta definicion viene con el paquete apertium-lexical-webform.
<!ELEMENT form (entry)+>
<!ATTLIST formlang CDATA #REQUIREDlangpair CDATA #REQUIRED>
<!ELEMENT entry (endings, paradigms)+>
<!ATTLIST entryPoS CDATA #REQUIREDnbr CDATA #IMPLIEDgen CDATA #IMPLIED>
<!ELEMENT endings (stem, ending+)>
<!ELEMENT stem (#PCDATA)>
<!ELEMENT ending (#PCDATA)>
<!ELEMENT paradigms (par+)>
<!ATTLIST paradigms howmany CDATA #REQUIRED>
<!ELEMENT par EMPTY>
<!ATTLIST par n CDATA #REQUIRED>

208 APENDICE A. DTDS EN XML

209

210 APENDICE B. SIMBOLOS GRAMATICALES
Apendice B
Sımbolos gramaticales utilizadosen los modulos
B.1. Sımbolos gramaticales utilizados en los dic-cionarios
B.1.1. Lista de sımbolosaa adjetivo-adjetivo (funcion antecedente relativo)acr acronimoal otrosan adjetivo-nombre (funcion antecedente relativo)ant antroponimocni condicionalcnjadv conjuncion adverbialcnjcoo conjuncion coordinativacnjsub conjuncion subordinativadef definidodem demostrativodet determinantedetnt determinante neutroenc enclıticof femeninofti futuro de indicativofts futuro de subjuntivoger gerundioifi preterito perfecto o indefinidoij interjeccionimp imperativoind indeterminadoinf infinitivo

B.1. SIMBOLOS DE LOS DICCIONARIOS 211
itg interrogativoloc locativolpar ([lquest ¿m masculinomf masculino-femeninon nombrenn nombre-nombre (funcion antecedente relativo)np nombre propiont neutronum numeralp1 primera personap2 segunda personap3 tercera personapii preterito imperfecto de indicativopis preterito imperfecto de subjuntivopl pluralpos posesivopp participiopr preposicionpreadv preadverbiopredet predeterminantepri presente de indicativoprn pronombrepro proclıticoprs presente de subjuntivoref reflexivorel relativorpar )]sent . ? ; : !sg singularsp singular-pluralsup superlativotn tonicovaux verbo auxiliarvbhaver verbo havervblex verbo lexicovbmod verbo modalvbser verbo ser
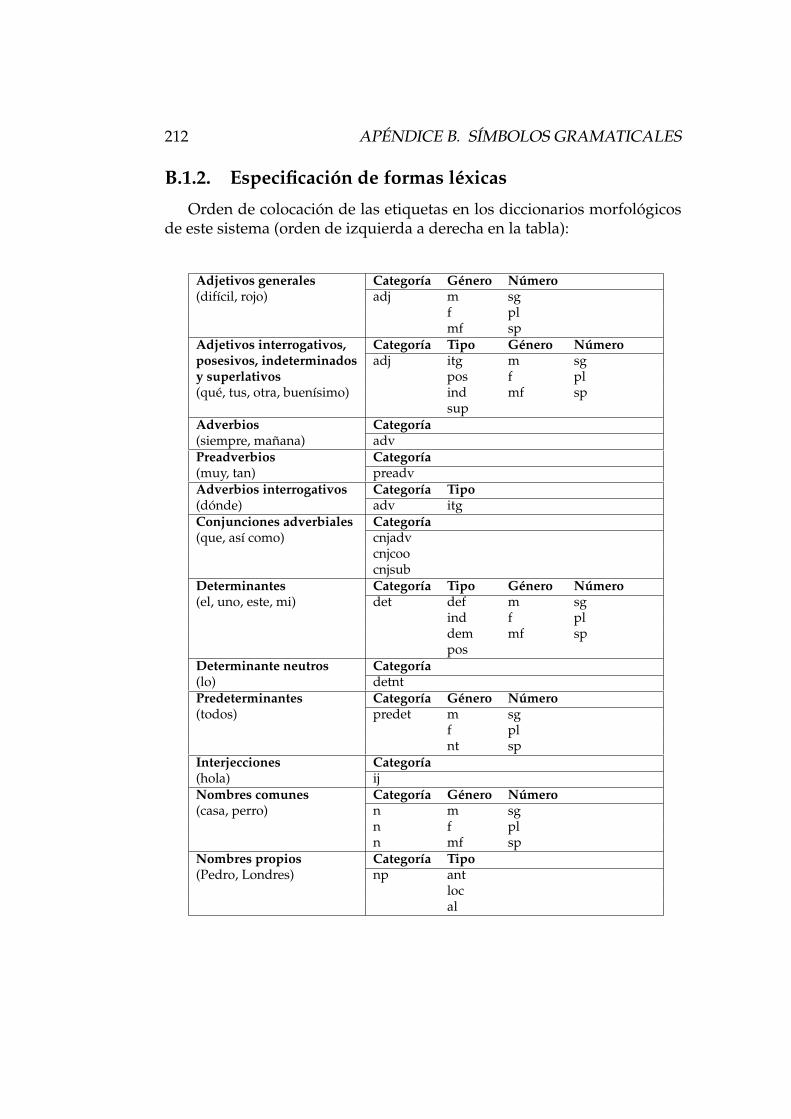
212 APENDICE B. SIMBOLOS GRAMATICALES
B.1.2. Especificacion de formas lexicas
Orden de colocacion de las etiquetas en los diccionarios morfologicosde este sistema (orden de izquierda a derecha en la tabla):
Adjetivos generales Categorıa Genero Numero(difıcil, rojo) adj m sg
f plmf sp
Adjetivos interrogativos, Categorıa Tipo Genero Numeroposesivos, indeterminados adj itg m sgy superlativos pos f pl(que, tus, otra, buenısimo) ind mf sp
supAdverbios Categorıa(siempre, manana) advPreadverbios Categorıa(muy, tan) preadvAdverbios interrogativos Categorıa Tipo(donde) adv itgConjunciones adverbiales Categorıa(que, ası como) cnjadv
cnjcoocnjsub
Determinantes Categorıa Tipo Genero Numero(el, uno, este, mi) det def m sg
ind f pldem mf sppos
Determinante neutros Categorıa(lo) detntPredeterminantes Categorıa Genero Numero(todos) predet m sg
f plnt sp
Interjecciones Categorıa(hola) ijNombres comunes Categorıa Genero Numero(casa, perro) n m sg
n f pln mf sp
Nombres propios Categorıa Tipo(Pedro, Londres) np ant
local
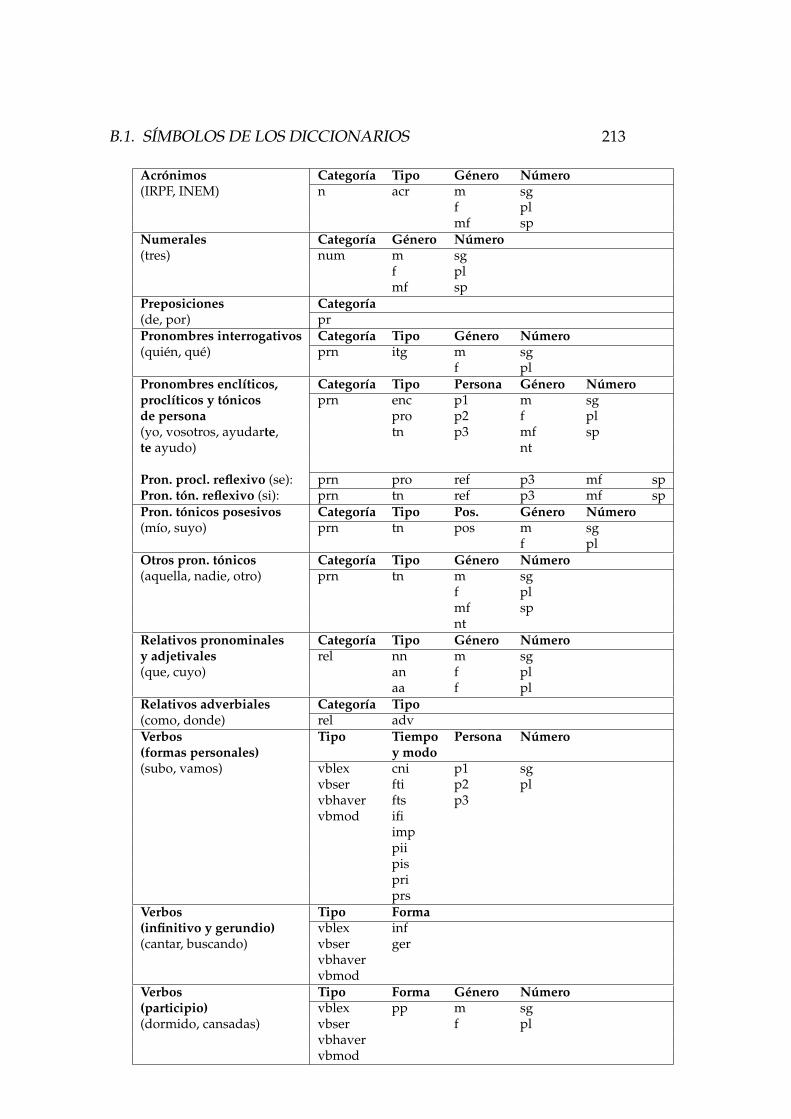
B.1. SIMBOLOS DE LOS DICCIONARIOS 213
Acronimos Categorıa Tipo Genero Numero(IRPF, INEM) n acr m sg
f plmf sp
Numerales Categorıa Genero Numero(tres) num m sg
f plmf sp
Preposiciones Categorıa(de, por) prPronombres interrogativos Categorıa Tipo Genero Numero(quien, que) prn itg m sg
f plPronombres enclıticos, Categorıa Tipo Persona Genero Numeroproclıticos y tonicos prn enc p1 m sgde persona pro p2 f pl(yo, vosotros, ayudarte, tn p3 mf spte ayudo) nt
Pron. procl. reflexivo (se): prn pro ref p3 mf spPron. ton. reflexivo (si): prn tn ref p3 mf spPron. tonicos posesivos Categorıa Tipo Pos. Genero Numero(mıo, suyo) prn tn pos m sg
f plOtros pron. tonicos Categorıa Tipo Genero Numero(aquella, nadie, otro) prn tn m sg
f plmf spnt
Relativos pronominales Categorıa Tipo Genero Numeroy adjetivales rel nn m sg(que, cuyo) an f pl
aa f plRelativos adverbiales Categorıa Tipo(como, donde) rel advVerbos Tipo Tiempo Persona Numero(formas personales) y modo(subo, vamos) vblex cni p1 sg
vbser fti p2 plvbhaver fts p3vbmod ifi
imppiipispriprs
Verbos Tipo Forma(infinitivo y gerundio) vblex inf(cantar, buscando) vbser ger
vbhavervbmod
Verbos Tipo Forma Genero Numero(participio) vblex pp m sg(dormido, cansadas) vbser f pl
vbhavervbmod
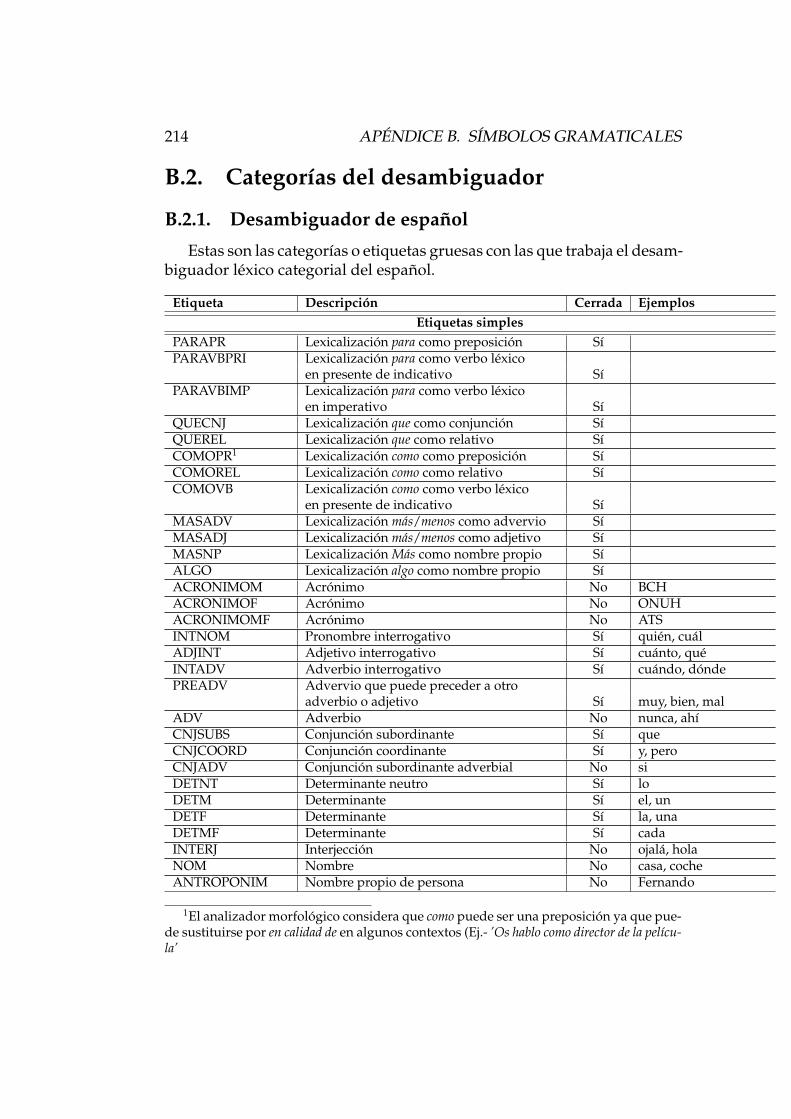
214 APENDICE B. SIMBOLOS GRAMATICALES
B.2. Categorıas del desambiguador
B.2.1. Desambiguador de espanol
Estas son las categorıas o etiquetas gruesas con las que trabaja el desam-biguador lexico categorial del espanol.
Etiqueta Descripcion Cerrada EjemplosEtiquetas simples
PARAPR Lexicalizacion para como preposicion SıPARAVBPRI Lexicalizacion para como verbo lexico
en presente de indicativo SıPARAVBIMP Lexicalizacion para como verbo lexico
en imperativo SıQUECNJ Lexicalizacion que como conjuncion SıQUEREL Lexicalizacion que como relativo SıCOMOPR1 Lexicalizacion como como preposicion SıCOMOREL Lexicalizacion como como relativo SıCOMOVB Lexicalizacion como como verbo lexico
en presente de indicativo SıMASADV Lexicalizacion mas/menos como advervio SıMASADJ Lexicalizacion mas/menos como adjetivo SıMASNP Lexicalizacion Mas como nombre propio SıALGO Lexicalizacion algo como nombre propio SıACRONIMOM Acronimo No BCHACRONIMOF Acronimo No ONUHACRONIMOMF Acronimo No ATSINTNOM Pronombre interrogativo Sı quien, cualADJINT Adjetivo interrogativo Sı cuanto, queINTADV Adverbio interrogativo Sı cuando, dondePREADV Advervio que puede preceder a otro
adverbio o adjetivo Sı muy, bien, malADV Adverbio No nunca, ahıCNJSUBS Conjuncion subordinante Sı queCNJCOORD Conjuncion coordinante Sı y, peroCNJADV Conjuncion subordinante adverbial No siDETNT Determinante neutro Sı loDETM Determinante Sı el, unDETF Determinante Sı la, unaDETMF Determinante Sı cadaINTERJ Interjeccion No ojala, holaNOM Nombre No casa, cocheANTROPONIM Nombre propio de persona No Fernando
1El analizador morfologico considera que como puede ser una preposicion ya que pue-de sustituirse por en calidad de en algunos contextos (Ej.- ’Os hablo como director de la pelıcu-la’
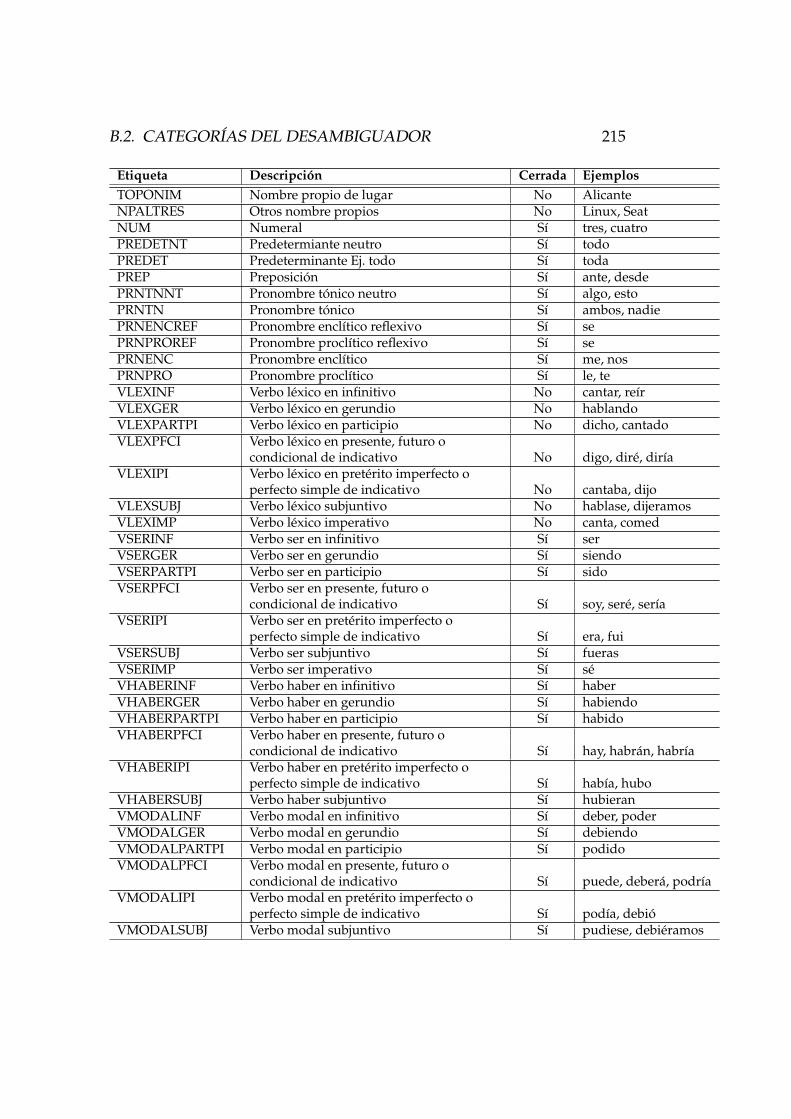
B.2. CATEGORIAS DEL DESAMBIGUADOR 215
Etiqueta Descripcion Cerrada EjemplosTOPONIM Nombre propio de lugar No AlicanteNPALTRES Otros nombre propios No Linux, SeatNUM Numeral Sı tres, cuatroPREDETNT Predetermiante neutro Sı todoPREDET Predeterminante Ej. todo Sı todaPREP Preposicion Sı ante, desdePRNTNNT Pronombre tonico neutro Sı algo, estoPRNTN Pronombre tonico Sı ambos, nadiePRNENCREF Pronombre enclıtico reflexivo Sı sePRNPROREF Pronombre proclıtico reflexivo Sı sePRNENC Pronombre enclıtico Sı me, nosPRNPRO Pronombre proclıtico Sı le, teVLEXINF Verbo lexico en infinitivo No cantar, reırVLEXGER Verbo lexico en gerundio No hablandoVLEXPARTPI Verbo lexico en participio No dicho, cantadoVLEXPFCI Verbo lexico en presente, futuro o
condicional de indicativo No digo, dire, dirıaVLEXIPI Verbo lexico en preterito imperfecto o
perfecto simple de indicativo No cantaba, dijoVLEXSUBJ Verbo lexico subjuntivo No hablase, dijeramosVLEXIMP Verbo lexico imperativo No canta, comedVSERINF Verbo ser en infinitivo Sı serVSERGER Verbo ser en gerundio Sı siendoVSERPARTPI Verbo ser en participio Sı sidoVSERPFCI Verbo ser en presente, futuro o
condicional de indicativo Sı soy, sere, serıaVSERIPI Verbo ser en preterito imperfecto o
perfecto simple de indicativo Sı era, fuiVSERSUBJ Verbo ser subjuntivo Sı fuerasVSERIMP Verbo ser imperativo Sı seVHABERINF Verbo haber en infinitivo Sı haberVHABERGER Verbo haber en gerundio Sı habiendoVHABERPARTPI Verbo haber en participio Sı habidoVHABERPFCI Verbo haber en presente, futuro o
condicional de indicativo Sı hay, habran, habrıaVHABERIPI Verbo haber en preterito imperfecto o
perfecto simple de indicativo Sı habıa, huboVHABERSUBJ Verbo haber subjuntivo Sı hubieranVMODALINF Verbo modal en infinitivo Sı deber, poderVMODALGER Verbo modal en gerundio Sı debiendoVMODALPARTPI Verbo modal en participio Sı podidoVMODALPFCI Verbo modal en presente, futuro o
condicional de indicativo Sı puede, debera, podrıaVMODALIPI Verbo modal en preterito imperfecto o
perfecto simple de indicativo Sı podıa, debioVMODALSUBJ Verbo modal subjuntivo Sı pudiese, debieramos
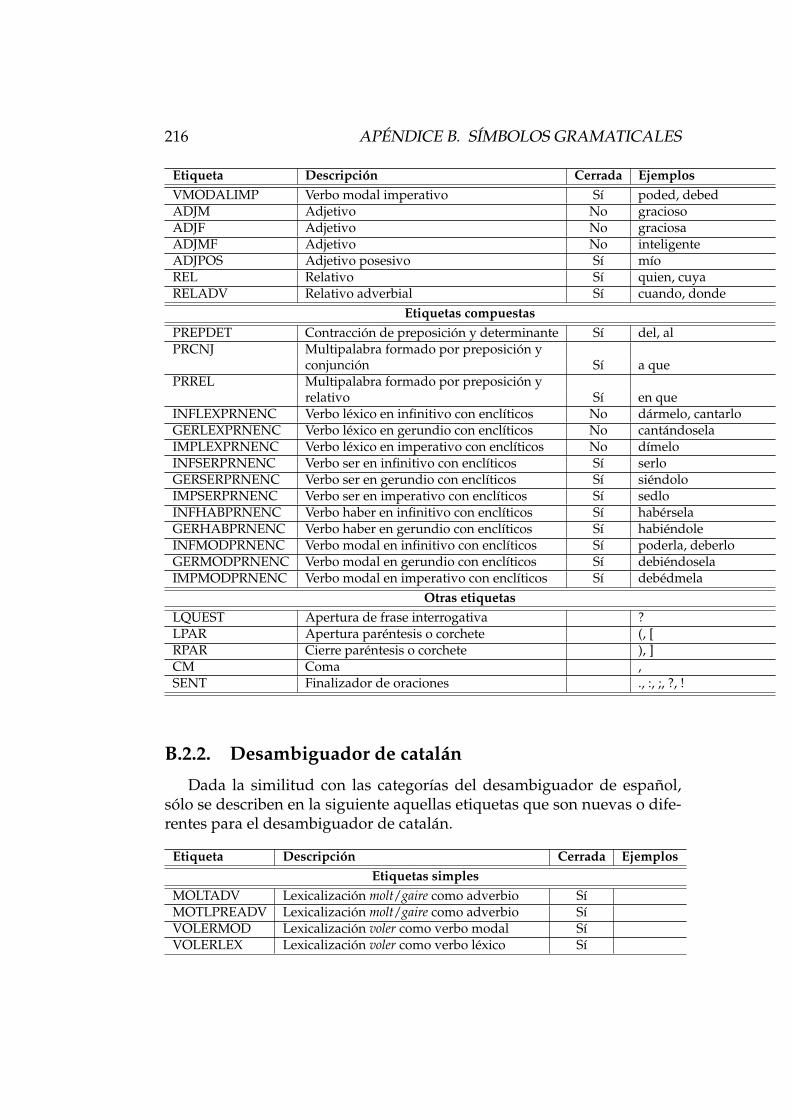
216 APENDICE B. SIMBOLOS GRAMATICALES
Etiqueta Descripcion Cerrada EjemplosVMODALIMP Verbo modal imperativo Sı poded, debedADJM Adjetivo No graciosoADJF Adjetivo No graciosaADJMF Adjetivo No inteligenteADJPOS Adjetivo posesivo Sı mıoREL Relativo Sı quien, cuyaRELADV Relativo adverbial Sı cuando, donde
Etiquetas compuestasPREPDET Contraccion de preposicion y determinante Sı del, alPRCNJ Multipalabra formado por preposicion y
conjuncion Sı a quePRREL Multipalabra formado por preposicion y
relativo Sı en queINFLEXPRNENC Verbo lexico en infinitivo con enclıticos No darmelo, cantarloGERLEXPRNENC Verbo lexico en gerundio con enclıticos No cantandoselaIMPLEXPRNENC Verbo lexico en imperativo con enclıticos No dımeloINFSERPRNENC Verbo ser en infinitivo con enclıticos Sı serloGERSERPRNENC Verbo ser en gerundio con enclıticos Sı siendoloIMPSERPRNENC Verbo ser en imperativo con enclıticos Sı sedloINFHABPRNENC Verbo haber en infinitivo con enclıticos Sı haberselaGERHABPRNENC Verbo haber en gerundio con enclıticos Sı habiendoleINFMODPRNENC Verbo modal en infinitivo con enclıticos Sı poderla, deberloGERMODPRNENC Verbo modal en gerundio con enclıticos Sı debiendoselaIMPMODPRNENC Verbo modal en imperativo con enclıticos Sı debedmela
Otras etiquetasLQUEST Apertura de frase interrogativa ?LPAR Apertura parentesis o corchete (, [RPAR Cierre parentesis o corchete ), ]CM Coma ,SENT Finalizador de oraciones ., :, ;, ?, !
B.2.2. Desambiguador de catalan
Dada la similitud con las categorıas del desambiguador de espanol,solo se describen en la siguiente aquellas etiquetas que son nuevas o dife-rentes para el desambiguador de catalan.
Etiqueta Descripcion Cerrada EjemplosEtiquetas simples
MOLTADV Lexicalizacion molt/gaire como adverbio SıMOTLPREADV Lexicalizacion molt/gaire como adverbio SıVOLERMOD Lexicalizacion voler como verbo modal SıVOLERLEX Lexicalizacion voler como verbo lexico Sı
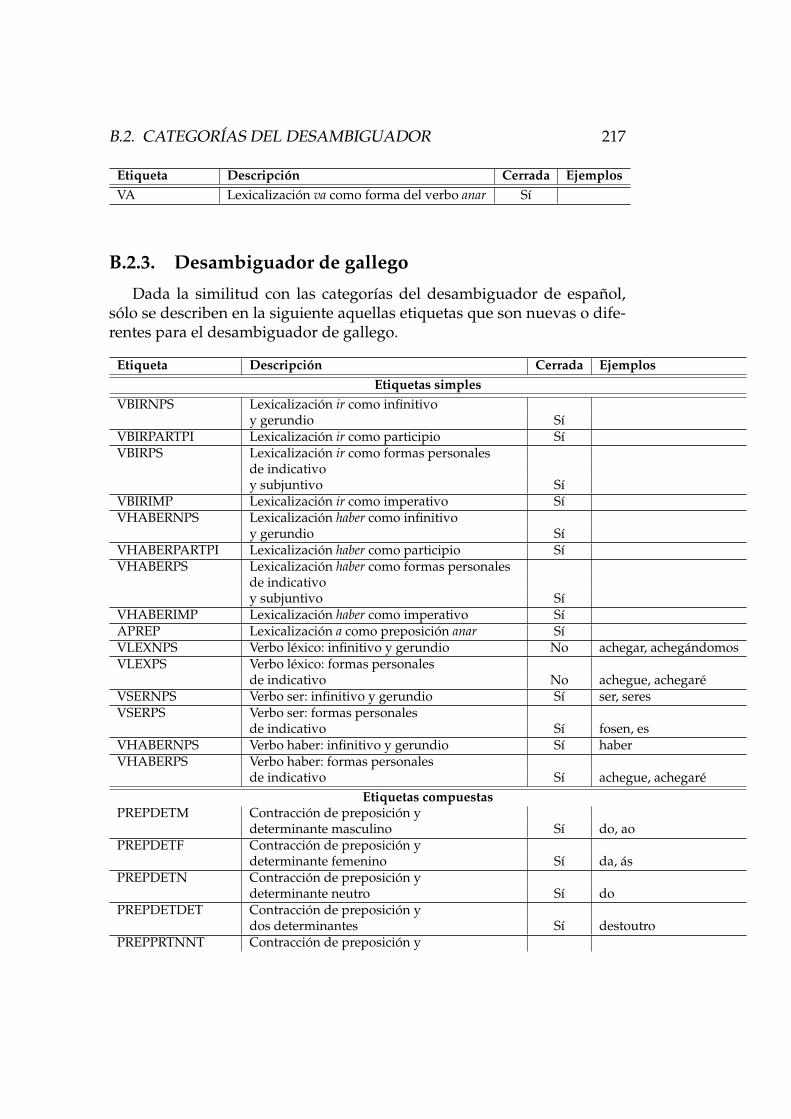
B.2. CATEGORIAS DEL DESAMBIGUADOR 217
Etiqueta Descripcion Cerrada EjemplosVA Lexicalizacion va como forma del verbo anar Sı
B.2.3. Desambiguador de gallego
Dada la similitud con las categorıas del desambiguador de espanol,solo se describen en la siguiente aquellas etiquetas que son nuevas o dife-rentes para el desambiguador de gallego.
Etiqueta Descripcion Cerrada EjemplosEtiquetas simples
VBIRNPS Lexicalizacion ir como infinitivoy gerundio Sı
VBIRPARTPI Lexicalizacion ir como participio SıVBIRPS Lexicalizacion ir como formas personales
de indicativoy subjuntivo Sı
VBIRIMP Lexicalizacion ir como imperativo SıVHABERNPS Lexicalizacion haber como infinitivo
y gerundio SıVHABERPARTPI Lexicalizacion haber como participio SıVHABERPS Lexicalizacion haber como formas personales
de indicativoy subjuntivo Sı
VHABERIMP Lexicalizacion haber como imperativo SıAPREP Lexicalizacion a como preposicion anar SıVLEXNPS Verbo lexico: infinitivo y gerundio No achegar, achegandomosVLEXPS Verbo lexico: formas personales
de indicativo No achegue, achegareVSERNPS Verbo ser: infinitivo y gerundio Sı ser, seresVSERPS Verbo ser: formas personales
de indicativo Sı fosen, esVHABERNPS Verbo haber: infinitivo y gerundio Sı haberVHABERPS Verbo haber: formas personales
de indicativo Sı achegue, achegareEtiquetas compuestas
PREPDETM Contraccion de preposicion ydeterminante masculino Sı do, ao
PREPDETF Contraccion de preposicion ydeterminante femenino Sı da, as
PREPDETN Contraccion de preposicion ydeterminante neutro Sı do
PREPDETDET Contraccion de preposicion ydos determinantes Sı destoutro
PREPPRTNNT Contraccion de preposicion y
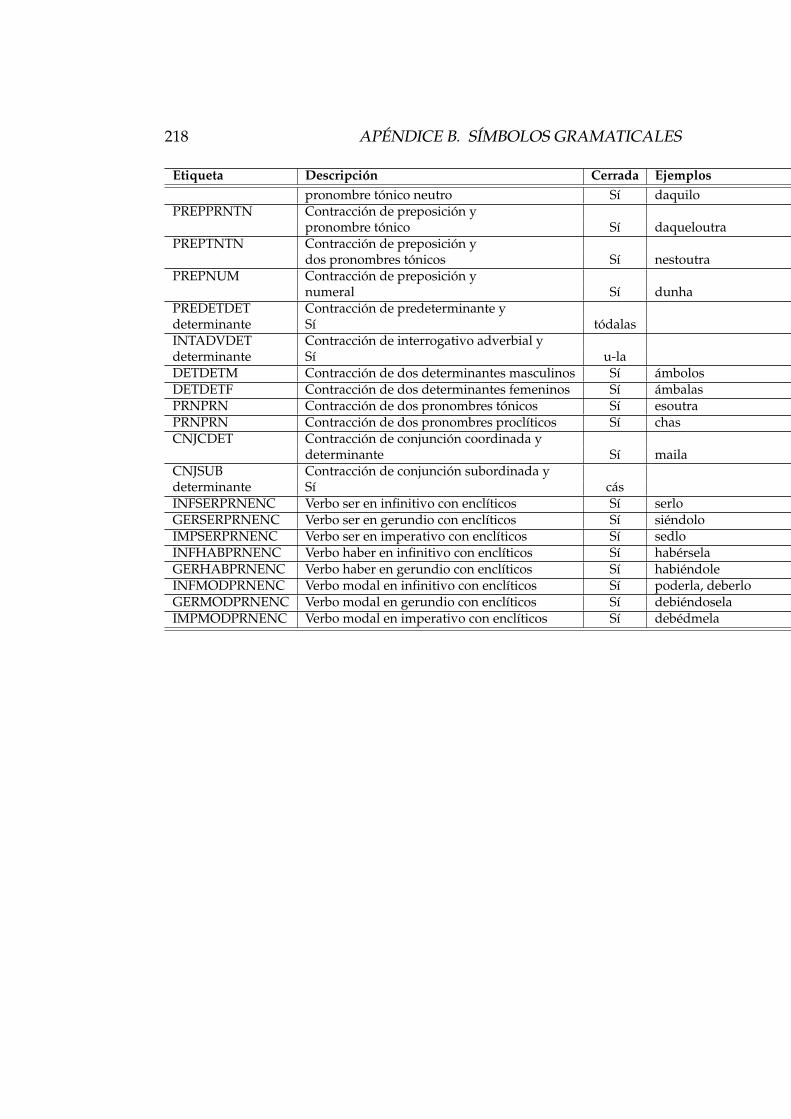
218 APENDICE B. SIMBOLOS GRAMATICALES
Etiqueta Descripcion Cerrada Ejemplospronombre tonico neutro Sı daquilo
PREPPRNTN Contraccion de preposicion ypronombre tonico Sı daqueloutra
PREPTNTN Contraccion de preposicion ydos pronombres tonicos Sı nestoutra
PREPNUM Contraccion de preposicion ynumeral Sı dunha
PREDETDET Contraccion de predeterminante ydeterminante Sı todalasINTADVDET Contraccion de interrogativo adverbial ydeterminante Sı u-laDETDETM Contraccion de dos determinantes masculinos Sı ambolosDETDETF Contraccion de dos determinantes femeninos Sı ambalasPRNPRN Contraccion de dos pronombres tonicos Sı esoutraPRNPRN Contraccion de dos pronombres proclıticos Sı chasCNJCDET Contraccion de conjuncion coordinada y
determinante Sı mailaCNJSUB Contraccion de conjuncion subordinada ydeterminante Sı casINFSERPRNENC Verbo ser en infinitivo con enclıticos Sı serloGERSERPRNENC Verbo ser en gerundio con enclıticos Sı siendoloIMPSERPRNENC Verbo ser en imperativo con enclıticos Sı sedloINFHABPRNENC Verbo haber en infinitivo con enclıticos Sı haberselaGERHABPRNENC Verbo haber en gerundio con enclıticos Sı habiendoleINFMODPRNENC Verbo modal en infinitivo con enclıticos Sı poderla, deberloGERMODPRNENC Verbo modal en gerundio con enclıticos Sı debiendoselaIMPMODPRNENC Verbo modal en imperativo con enclıticos Sı debedmela

Apendice C
Abreviaturas usadas en el texto
ANSI American National Standards Institute, instituto nacional norteame-ricano de estandares; cuando se usa informalmente en la expresiontexto ANSI, se refiere a un texto codificado en alguna de las codifi-caciones de un byte por caracter definidas en el estandar ISO-8859[1].
ca Codigo ISO 639 de dos letras1 del catalan
DTD Definicion del tipo de documento en XML
es Codigo ISO 639 de dos letras del espanol
eu Codigo ISO 639 de dos letras del euskera
FL Forma lexica (vease la pagina 7)
FLLM Forma lexica de la lengua meta
FLLO Forma lexica de la lengua origen
FS Forma superficial (vease la pagina 7)
gl Codigo ISO 639 de dos letras del gallego
HTML Hypertext markup language, lenguaje de marcas para hipertextos.
LM Lengua meta (lengua de llegada)
LO Lengua origen (lengua de partida)
RTF Rich text format, formato de texto enriquecido.
1Vease http://www.w3.org/WAI/ER/IG/ert/iso639.htm
219

220 APENDICE C. ABREVIATURAS USADAS EN EL TEXTO
TA Traduccion automatica
XML Extensible markup language, lenguaje de marcas extensible.

221
[Nota: Afegir article de l’EAMT 2005 i citar-lo]

222 APENDICE C. ABREVIATURAS USADAS EN EL TEXTO

Bibliografıa
[1] Unicode. http://www.unicode.org.
[2] R. Canals-Marote, A. Esteve-Guillen, A. Garrido-Alenda,M. Guardiola-Savall, A. Iturraspe-Bellver, S. Monserrat-Buendia,S. Ortiz-Rojas, H. Pastor-Pina, P.M. Perez-Anton, and M.L. Forcada.El sistema de traduccion automatica castellano-catalan interNOS-TRUM. Procesamiento del Lenguaje Natural, 27:151–156, 2001. XVIICongreso de la Sociedad Espanola de Procesamiento del LenguajeNatural, Jaen, Spain, 12-14.09.2001.
[3] D. Cutting, J. Kupiec, J. Pedersen, and P. Sibun. A practical part-of-speech tagger. In Third Conference on Applied Natural Language Proces-sing. Association for Computational Linguistics. Proceedings of the Confe-rence., pages 133–140, Trento, Italia, 31 marzo–3 abril 1992.
[4] A. Garrido, A. Iturraspe, S. Montserrat, H. Pastor, and M. L. Forca-da. A compiler for morphological analysers and generators based onfinite-state transducers. Procesamiento del Lenguaje Natural, (25):93–98,1999.
[5] Alicia Garrido-Alenda and Mikel L. Forcada. Morphtrans: un lengua-je y un compilador para especificar y generar modulos de transferen-cia morfologica para sistemas de traduccion automatica. Procesamien-to del Lenguaje Natural, 27:157–164, 2001.
[6] Alicia Garrido-Alenda, Mikel L. Forcada, and Rafael C. Carrasco. In-cremental construction and maintenance of morphological analysersbased on augmented letter transducers. In Proceedings of TMI 2002(Theoretical and Methodological Issues in Machine Translation, Keihan-na/Kyoto, Japan, March 2002), pages 53–62, 2002.
[7] Alicia Garrido-Alenda, Patrıcia Gilabert Zarco, Juan Antonio Perez-Ortiz, Antonio Pertusa-Ibanez, Gema Ramırez-Sanchez, Felipe
223

224 BIBLIOGRAFIA
Sanchez-Martınez, Miriam A. Scalco, and Mikel L. Forcada. Shallowparsing for portuguese-spanish machine translation. In A. Branco,A. Mendes, and R. Ribeiro, editors, TASHA 2003: Workshop on Taggingand Shallow Processing of Portuguese, pages 21–24, October 2003.
[8] N. Ide. The XML Framework and Its Implications for the Development ofNatural Language Processing Tools. Luxembourg, 2000.
[9] M.E. Lesk. Lex — a lexical analyzer generator. Technical Report Te-chnical Report 39, AT&T Bell Laboratories, Murray Hill, N.J., 1975.
[10] Mehryar Mohri. Finite-state transducers in language and speech pro-cessing. Computational Linguistics, 23(2):269–311, 1997.
[11] Sergio Ortiz-Rojas, Mikel L. Forcada, and Gema Ramırez-Sanchez.Construccion y minimizacion eficiente de transductores de letras apartir de diccionarios con paradigmas. Procesamiento del Lenguaje Na-tural, (25):51–57, 2005.
[12] Ferran Pla and Antonio Molina. Improving part-of-speech taggingusing lexicalized HMMs. Journal of Natural Language Engineering,10(2):167–189, June 2004.
[13] L. R. Rabiner. A tutorial on hidden Markov models and selected ap-plications in speech recognition. Proceedings of the IEEE, 77(2):257–286, 1989.
[14] E. Roche and Y. Schabes. Introduction. MIT Press, Cambridge, Massa-chusetts, 1997.
[15] E. Roche and Y. Schabes. Introduction. In E. Roche and Y. Schabes,editors, Finite-State Language Processing, pages 1–65. MIT Press, Cam-bridge, Mass., 1997.
[16] J. L. A. van de Snepscheut. What computing is all about. Springer-Verlag, New York, 1993.
[17] Patrıcia Gilabert Zarco, Javier Herrero-Vicente, Sergio Ortiz-Rojas,Antonio Pertusa-Ibanez, Gema Ramırez-Sanchez, Felipe Sanchez-Martınez, Marcial Samper-Asensio, Mıriam A. Scalco, and Mikel L.Forcada. Construccion rapida de un sistema de traduccion automati-ca espanol-portugues partiendo de un sistema espanol–catalan. Pro-cesamiento del Lenguaje Natural, (32):279–285, 2003. (Actas del XIX con-greso de la Sociedad Espanola de Procesamiento del Lenguaje Natu-ral).