Embed Size (px)
Citation preview

Змiст
Передмова 5
1 Моделi сумiшей зi змiнними концентрацiями 61.1 Вступ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.2 Прикладнi задачi аналiзу сумiшей . . . . . . . . . . . . . . . . 81.3 Приклади модельованих даних . . . . . . . . . . . . . . . . . . 17
2 Оцiнювання функцiй розподiлу 222.1 Незмiщенi мiнiмакснi оцiнки . . . . . . . . . . . . . . . . . . . 222.2 Асимптотика емпiричних мiр . . . . . . . . . . . . . . . . . . . 292.3 Виправленi зваженi емпiричнi функцiї розподiлу . . . . . . . 422.4 Асимптотично ефективна оцiнка розподiлу . . . . . . . . . . . 52
3 Оцiнки числових характеристик розподiлiв компонент 603.1 Лiнiйнi оцiнки функцiональних моментiв . . . . . . . . . . . . 603.2 Адаптивнi оцiнки моментiв . . . . . . . . . . . . . . . . . . . . 663.3 Виправленi оцiнки для моментiв . . . . . . . . . . . . . . . . . 713.4 Оцiнювання квантилiв . . . . . . . . . . . . . . . . . . . . . . 783.5 Оцiнка екстремальних точок розподiлiв
компонент . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
4 Оцiнювання щiльностей розподiлiв компонент 894.1 Ядернi оцiнки щiльностi . . . . . . . . . . . . . . . . . . . . . 894.2 Асимпототична нормальнiсть ядерних оцiнок . . . . . . . . . 934.3 Вибiр параметра згладжування . . . . . . . . . . . . . . . . . 984.4 Неядернi оцiнки щiльностей розподiлiв . . . . . . . . . . . . 106
5 Аналiз спостережень з домiшкою 1165.1 Оцiнки щiльностi по спостереженнях з домiшкою . . . . . . . 116

4 Змiст
5.2 Адаптивнi оцiнки для параметрiв . . . . . . . . . . . . . . . . 126
6 Задачi класифiкацiї 1406.1 Баєсова класифiкацiя . . . . . . . . . . . . . . . . . . . . . . . 1406.2 Метод найближчого сусiда . . . . . . . . . . . . . . . . . . . . 1466.3 Асимптотика порогових класифiкаторiв . . . . . . . . . . . . 1506.4 Класифiкацiя на основi єдиного iндекса . . . . . . . . . . . . 1616.5 Швидкiсть збiжностi класифiкаторiв єдиного iндекса . . . . . 171
7 Допомiжнi вiдомостi 1897.1 Формули iнтегрування i пов’язанi з ними нерiвностi . . . . . 1897.2 Нерiвнiсть для визначникiв . . . . . . . . . . . . . . . . . . . . 1917.3 Ймовiрнiснi нерiвностi i граничнi теореми . . . . . . . . . . . 1967.4 Слабка збiжнiсть випадкових функцiй . . . . . . . . . . . . . 2007.5 Ефективнiсть. Мiнiмакснiсть. Iнформацiя. . . . . . . . . . . . 2037.6 Оцiнювання щiльностi за кратними вибiрками . . . . . . . . . 205
Лiтература 207
Список позначень 212*

Передмова
Моделi сумiшей природно виникають у задачах статистичного аналiзу да-них медико-бiологiчних, соцiологiчних, економiчних дослiджень. Матема-тична теорiя статистичного оцiнювання у рамках таких моделей успiшнорозвивається починаючи з кiнця ХIХ столiття. У класичнiй моделi скiн-ченної сумiшi вважається, що концентрацiї компонент є сталими, а данi єнезалежними, однаково розподiленими випадковими величинами.
Дана книга присвячена аналiзу сумiшей, у яких концентрацiї компо-нент змiнюються вiд спостереження до спостереження. Ми розглядаємозадачi оцiнювання розподiлiв компонент сумiшi та їх характеристик: мо-ментiв, квантилiв, щiльностей розподiлу. Отриманi оцiнки дають змогупобудувати алгоритми класифiкацiї на основi спостережень з сумiшi зiзмiнними концентрацiями.
Основна увага у книзi придiлена дослiдженню асимптотичних власти-востей побудованих алгоритмiв при необмеженому зростаннi обсягу вибiр-ки. Ми застосовуємо адаптивний пiдхiд для побудови асимптотично оп-тимальних оцiнок i порiвнюємо асимптотичнi властивостi класифiкаторiв,отриманих на основi рiзних технiк класифiкацiї.
Книга мiстить в основному результати, опублiкованi за останнi роки,пiсля виходу монографiї [15]. Для зручностi читачiв основнi твердження зцiєї роботи, що використовуються у данiй книзi, вмiщено у п. 2.1-2.2. Крiмвласних результатiв ми розглядаємо також результати О. Кубайчук, Ю.Iванька та А. Лодатко.
Автори вдячнi проф. В.В. Булдигiну, Ю.В. Козаченку, Ю.С. Мiшурiта М.П. Моклячуку за пiдтримку у роботi.
Книга пiдготовлена та опублiкована за пiдтримки програми Tempus урамках проекту TEMPUS PROJECT IB-JEP-25054-2004.

Роздiл 1
Моделi сумiшей зi змiннимиконцентрацiями
1.1 Вступ
У цiй книжцi розглядаються методи статистичного аналiзу даних, роз-подiл яких задається моделлю сумiшi зi змiнними концентрацiями. Ця мо-дель придатна для опису даних рiзних медико-бiологiчних, соцiологiчних,економiчних дослiджень. Деякi приклади застосування аналiзу сумiшейдо прикладних задач наведено у книжцi [15]. У п. 1.2 описано два такихприклади: бiологiчний та соцiально-психологiчний. Вони досить умовнi,оскiльки мають на метi дати загальне враження про можливостi аналi-зу сумiшей, без заглиблення у детальний опис реального статистичногодослiдження. Цi приклади вмiщенi у п. 1.2.
Для того, щоб читач отримав уявлення про те, як можуть вигляда-ти данi, що задаються моделлю сумiшi зi змiнними концентрацiями, мирозглянемо декiлька прикладiв модельованих даних у п. 1.3.
У наступних роздiлах книги описано методи оцiнки функцiй розподiлукомпонент сумiшi (роздiл 2) та таких характеристик розподiлiв, як функ-цiональнi моменти, квантилi (роздiл 3) та щiльностi розподiлу (роздiл 4).Всi цi оцiнки отриманi непараметричними методами, тобто жодних припу-щень про параметричну модель розподiлiв компонент ми не використовує-мо. Концентрацiї компонент, тобто ймовiрностi з якими певнi компонен-ти будуть спостерiгатись у даному спостереженнi, вважаються вiдомими.(Про оцiнювання концентрацiй див. у книжцi [15]).
Задачi аналiзу сумiшей двох компонент у випадку, коли розподiл однiєї

1.1. Вступ 7
компоненти повнiстю невiдомий, а для iншої задана параметрична модель,розгянуто у роздiлi 5. Тут побудованi семiпараметричнi оцiнки невiдомихпараметрiв та непараметричнi оцiнки для щiльностi компоненти, яка немає параметричної моделi.
Нарештi у роздiлi 6 розглядається задача побудови класифiкаторiв, якiдозволяють роздiлити сумiш на компоненти.
В останньому роздiлi вмiщено допомiжнi вiдомостi з теорiї ймовiрно-стей, теорiї випадкових процесiв та математичної статистики та iншi твер-дження, якi використовуються у основних роздiлах книги.
Моделi сумiшей кiлькох розподiлiв для опису статистичних даних з’яви-лися iще у ХIХ столiттi у роботах С. Ньюкомба [42] та К. Пiрсона [43]. Про-тягом ХХ столiття розвитку набули дослiдження у галузi класичної моделiскiнченних сумiшей, в якiй розподiл спостережуваних даних ξj один i тойже для всiх спостережень j = 1, . . . , N i описується у виглядi
P{ξj ∈ A} = w1H1(A) + w2H2(A) + · · ·+ wMHM(A),
де Hi — розподiли компонент сумiшi, wi — ймовiрностi змiшування (mixingprobabilities) якi можна трактувати як концентрацiї компонент у сумiшi,M — кiлькiсть компонент сумiшi.
Огляд результатiв у цiй областi можна знайти у книгах Дж. Макла-хлана та К. Басфорда [39], Дж. Маклахлана та Д. Пiла [40]. Як правило,у класичнiй моделi використовують параметричнi моделi розподiлiв ком-понент. Це пов’язано з тим, що у загальнiй непараметричнiй формi задачаоцiнювання розподiлiв компонент не є iдентифiковною. Тому для отри-мання консистентних оцiнок потрiбно накладати додатковi обмеження нарозподiли, що роблять задачу iдентифiковною. Зокрема умови iдентифi-ковностi багатьох параметричних задач оцiнювання у класичнiй моделiсумiшей встановлено у роботах Г. Тейчера [45], С. Яковiца та Ж. Спрагiн-са [55], Г. Гольцмана, А. Мунка, Т. Гнетiнга [36].
Останнiм часом з’явився ряд робiт, у яких на модель накладаютьсяумови iдентифiковностi непараметричного типу. У роботi П. Холла та К.Зоу [32] iдентифiковнiсть досягається внаслiдок незалежностi координатбагатовимiрних спостережень у кожнiй компонентi. Роботи Л. Борде, С.Моттле, П. Вандекерхове [25] та Д. Хантера, С. Ванга, Т. Хетмансрергера[37] присвяченi випадку, коли компоненти мають розподiл, симетричнийвiдносно медiани, причому вiдрiзняються одна вiд одної лише змiщенням.
Iнший пiдхiд до отримання консистентних оцiнок полягає в тому, щобвiдмовитись вiд припущення про однакову розподiленiсть даних. У робо-

8 Роздiл 1. Моделi сумiшей зi змiнними концентрацiями
тах П. Халла, Д. Тiттерiнгтона [33] та Д. Тiттерiнгтона, А. Смiта, У. Ма-кова [51] розглядається багатовибiркова задача, причому у кожнiй вибiрцiданi описуються класичною моделлю сумiшi, компоненти всiх сумiшей од-наковi, але концентрацiї компонент у рiзних вибiрках рiзнi. Очевиднимузагальненням цiєї моделi є сумiшi зi змiнними концентрацiями, у якихкожному спостереженню вiдповiдають свої значення концентрацiй. Самедослiдженню цiєї моделi присвячена дана книжка. Вона спирається на рядробiт авторiв а також О. Кубайчук, Ю. Iванька та А. Лодатко. Нажаль,через обмеження обсягу книги, ми не змогли включити до неї результатиД. Похилько з теорiї вейвлет-оцiнок щiльностей розподiлу та А. Рижоваз аналiзу сумiшей за цензурованими спостереженнями. Ми також не роз-глядаємо задачi оцiнки параметрiв функцiй концентрацiї, з якими можнаознайомитись в [15]. У цiй книжцi концентрацiї завжди вважаються по-внiстю вiдомими.
1.2 Прикладнi задачi аналiзу сумiшей
Аналiз даних генетичного дослiдження. Нехай спостерiгаються деякiживi органiзми — це можуть бути люди, тварини або рослини. Для визна-ченостi, будемо вважати, що мова йде про мишей. Нас цiкавить зв’язокмiж певною характеристикою фенотипу мишi, наприклад — довжиною тi-ла i наявнiстю або вiдсутнiстю певного варiанта (алеля) деякого гена у їїгенотипi. Зрозумiло, що такий зв’язок не може бути жорстко детермiно-ваним — той чи iнший алель не визначає однозначно довжину мишi. Моваможе йти лише про те, що рiзним генотипам вiдповiдають рiзнi розподiлидовжини тiла мишей з цими генотипами.
Позначимо дослiджуваний об’єкт — мишу через O, а номер алеля до-слiджуваного гена, котрий присутнiй у генотипi O — через ind(O).1 Дов-жину мишi O позначимо через ξ(O). З математичної точки зору, ξ(O) —випадкова величина, розподiл якої залежить вiд ind(O). Позначимо
Hk(x) = P{ξ(O) < x | ind(O) = k}
— функцiя розподiлу довжини мишi, яка має k-тий варiант генотипу.
1Строго кажучи, у кожної мишi повинно бути два, можливо рiзних, алеля одногогена — по одному у кожнiй з двох гомологiчних хромосом. Тому, якщо нас цiкавитьвзаємодiя цих алелiв, потрiбно перенумерувати всi можливi рiзнi пари i пiд ind(O) слiдрозумiти номер тiєї пари, яка присутня у O.

1.2. Прикладнi задачi аналiзу сумiшей 9
Нехай в результатi дослiдження були вимiрянi довжини N мишей — O1,O2, . . . , ON , якi дорiвнюють вiдповiдно ξ1 = ξ(O1),. . . , ξN = ξ(ON). Сукуп-нiсть всiх даних вимiрювання позначимо ΞN = (ξ1, . . . , ξN). Якщо бiологмає можливiсть однозначно розкласифiкувати мишей за їх генотипом, тооцiнка Hk за спостереженнями ξ(Oj), j = 1, . . . , N не викликає жоднихускладнень. Дiйсно, у цьому випадку можна просто сформувати вибiрку,що складається з мишей iз даним генотипом i на роль оцiнки Hk обратиемпiричну функцiю розподiлу, побудовану за цiєю вибiркою. В результатiотримуємо оцiнку
HkN(x) =
1
Nk
N∑j=1
1I{ξ(Oj) < x, ind(Oj) = k}.
(Тут 1I{A} — iндикатор подiї A, Nk =∑N
j=1 1I{ind(Oj) = k} — кiлькiстьдослiджених мишей, якi мали генотип k-того типу.)
Ця оцiнка є найкращою непараметричною оцiнкою для функцiї роз-подiлу з усiх загальноприйнятих точок зору — вона консистентна, незмi-щена, має найменшу дисперсiю в класi всiх незмiщених оцiнок, є оцiнкоюемпiричної найбiльшої вiрогiдностi i т.д.
Однак генетичнi тести, що використовуються для визначення генотипу,як правило, працюють не безпомилково. Крiм того, часто дослiдник вза-галi не має можливостi виявити безпосередньо той ген, який його цiкавитьi змушений судити про його наявнiсть або вiдсутнiсть опосередковано, занаявнiстю так званих маркерiв — генiв, що знаходяться поруч з дослiд-жуваним на тiй же хромосомi. Якщо у такому випадку не враховуватиможливi помилки класифiкацiї, то оцiнка на основi емпiричної функцiїрозподiлу стане змiщеною.
Для того, щоб врахувати ефекти помилок, доцiльно замiсть однознач-ної класифiкацiї задати ймовiрностi того, що генотип даної мишi належитьпевному класу:
wkj = P{ind(Oj) = k}.
Цi ймовiрностi для Oj визначаються за результатами генетичних тестiв (якправило, для таких тестiв вiдомi ймовiрностi помилкової класифiкацiї),наявнiстю або вiдсутнiстю певних генетичних маркерiв та за апрiорнимиймовiрностями того, що навмання обрана з популяцiї миша має генотипвiдповiдного типу. Зрозумiло, що за таких обставин wk
j будуть рiзнимидля рiзних мишей. Фактично, для кожної дослiджуваної тварини можна

10 Роздiл 1. Моделi сумiшей зi змiнними концентрацiями
визначити свої апрiорнi ймовiрностi наявностi заданого варiанту генотипу2Якщо wk
j та Hk заданi, то розподiл спостережуваної характеристики ξj =ξ(Oj) визначається за формулою3
P{ξj ∈ A} =M∑
m=1
wmj Hm(A). (1.1)
При цьому данi, що вiдповiдають рiзним мишам, природно вважати неза-лежними мiж собою.
Данi, якi складаються з незалежних випадкових величин (векторiв),розподiл яких описується (1.1), будемо називати вибiркою з сумiшi зi змiн-ними концентрацiями. Популяцiї об’єктiв O (мишей) якi вiдповiдають рiз-ним значенням ind(O) будемо називати компонентами сумiшi. Функцiя Hk
— це функцiя розподiлу спостережуваної характеристики (у нашому при-кладi — довжини тiла) об’єктiв, що належать k-тiй компонентi. Для про-стоти ми будемо скорочувати цю назву до “функцiя розподiлу k-тої ком-поненти”. wk
j — це ймовiрнiсть, з якою у j-тому спостереженнi спостерi-гається об’єкт з k-тої компоненти. Ми будемо називати wk
j концентрацiєюk-тої компоненти у сумiшi пiд час j-того спостереження. Iнша назва дляцих величин — ймовiрностi змiшування (mixing probabilities).
У класичнiй моделi скiнченної сумiшi концентрацiї компонент є од-ними i тими самими для всiх спостережень. Цю модель можна назватисумiшшю зi сталими концентрацiями. У цiй книжцi розглядається випа-док, коли концентрацiї змiнюються вiд спостереження до спостереження.Очевидно, що для розглянутого нами прикладу генетичних дослiдженьмодель зi змiнними концентрацiями є бiльш адекватною.
Якi статистичнi задачi виникають перед дослiдником при аналiзi та-ких сумiшей? Звичайно, бiолог цiкавиться розподiлами рiзних компонент,тобто оцiнками для Hk. Цi розподiли доцiльно оцiнювати параметричнимиметодами, якщо iснує априорна параметрична модель для Hk, наприклад,якщо можна вважати, що ξ для кожної окремої компоненти має гауссiврозподiл. Однак таке припущення часто є занадто обмежуючим. Тому ко-рисними є непараметричнi методи оцiнювання Hk. Таким методам присвя-чений роздiл 2. Вони спираються на використання зважених емпiричних
2Апрiорними цi ймовiрностi є в тому розумiннi, що вони визначаються до вимiрю-вання спостережуваної характеристики ξj лише за результатами генетичного аналiзу.
3Тут i далi розподiл (мiра) та вiдповiдна функцiя розподiлу, як правило, познача-ються однiєю i тiєю ж лiтерою: для випадкової величини ηk з функцiєю розподiлу Hk,Hk(A) = P{ηk ∈ A}.

1.2. Прикладнi задачi аналiзу сумiшей 11
функцiй розподiлу вигляду
Hk(x) =1
N
N∑j=1
akj1I{ξj < x}, (1.2)
де akj — деякi ваговi коефiцiєнти, покликанi компенсувати наявнiсть у ви-
бiрцi спостережень, що належать “непотрiбним” (у даний момент) компо-нентам сумiшi.
Ваговi коефiцiєнти можна обирати по рiзному, виходячи з рiзних вимогдо оцiнки. У роздiлi 2 розглянутi три можливих варiанти. Найпростiшийварiант — мiнiмакснi коефiцiєнти, якi дозволяють отримати незмiщенуоцiнку, мiнiмаксну по вiдношенню до квадратичного ризику у класi всiхнезмiщених оцiнок. Цi коефiцiєнти пiдраховуються за простими форму-лами (2.10) i визначаються лише за концентрацiями wm
j (не залежать вiдзначень спостережуваної характеристики ξj). Недолiком таких мiнiмакс-них коефiцiєнтiв є те, що вони породжують оцiнки Hk, якi не є монотоннозростаючими, тобто не можуть вважатися функцiями розподiлу.
Для усунення цього недолiку, можна запропонувати рiзнi алгоритмивиправлення Hk, якi перетворюють її на функцiю розподiлу. Ряд такихалгоритмiв розглянуто у п. 2.3. Виявляється, що виправленi оцiнки такожможна записати у формi, аналогiчнiй (1.2), однак їх ваговi коефiцiєнтибудуть залежати вiд ξj. Незважаючи на це, асимптотичнi властивостi ви-правлених оцiнок виявляються цiлком аналогiчними властивостям мiнi-максних — вони так само є консистентними та асимптотично нормальни-ми, а їх коефiцiєнт розсiювання (гранична дисперсiя) такий самий, як i умiнiмаксних оцiнок.
Мiнiмакснi оцiнки є найкращими у найгiршому випадку, але це не озна-чає, що не iснує оцiнок, якi могли б переважати мiнiмакснi у певних ситу-ацiях. Ми розглядаємо питання про побудову асимптотично ефективнихоцiнок функцiй розподiлу у п. 2.4 для випадку, коли розподiли компонент єдискретними. Отриманi оцiнки також можна записати у виглядi зваженоїсуми iндикаторiв, однак вираз є дещо бiльш складним, нiж (1.2). Асимпто-тично ефективнi оцiнки при великих обсягах вибiрки у багатьох випадкахє бiльш точними нiж мiнiмакснi, однак для малих обсягiв вибiрки бiльшнадiйними є мiнiмакснi оцiнки.
Хоча функцiї розподiлу несуть повну iнформацiю про розподiл да-них, у прикладнiй статистицi оцiнки для них використовуються не часто.Бiолога скорiше можуть зацiкавити середнi значення довжин тiла тва-

12 Роздiл 1. Моделi сумiшей зi змiнними концентрацiями
рин з рiзними генотипами, їх дисперсiї, медiани, квартилi, тощо. Анало-гiчнi характеристики рiзних компонент сумiшей цiкавлять i спецiалiстiву iнших предметних областях. Задачi оцiнки таких числових характери-стик розподiлiв розглядаються у роздiлi 3. Зрозумiло, що такi характе-ристики можна оцiнювати, виходячи з оцiнки для вiдповiдної функцiїрозподiлу. Наприклад, якщо потрiбно оцiнити функцiональний моментgk =
∫g(x)Hk(dx) = E g(ηk), то оцiнкою, що вiдповiдає Hk, буде зваже-
ний емпiричний момент
gk =
∫g(x)Hk(dx) =
1
N
N∑j=1
akj g(ξj). (1.3)
Однак виявляється, що дослiджувати такi оцiнки iнколи зручнiше не наосновi властивостей зважених емпiричних функцiй розподiлу, а виходячиз загальних теорем про асимптотику сум випадкових величин. Таке до-слiдження проведено у п. 3.1–3.2 для оцiнок функцiональних моментiв i врезультатi отриманi оцiнки з мiнiмальним коефiцiєнтом розкиданостi.
Якщо спецiалiсту у предметнiй областi потрiбно “подивитись” на роз-подiл даних, то для однорiдної вибiрки вiн, скорiше за все, побудує гiсто-граму або графiк iншої оцiнки щiльностi розподiлу. Аналогам таких оцiнокдля сумiшей зi змiнними концентрацiями присвячено роздiл 4. На вiдмiнувiд розглянутих ранiше характеристик розподiлу, задача оцiнки щiльностiє “нерегулярною”: якщо емпiричнi функцiї розподiлу, емпiричнi моментита квантилi збiгаються до оцiнюваних характеристик з швидкiстю поряд-ку 1/
√N , то для оцiнок щiльностi за однорiдною вибiркою характерна
швидкiсть збiжностi порядку 1/Nβ/(2β+1), де β — порядок гладкостi оцi-нюваної щiльностi (див. п. 7.6). Виявляється, що такий порядок гладкостiє характерним i для зважених ядерних оцiнок щiльностi, побудованих завибiркою з сумiшi зi змiнними концентрацiями. У п. 4.4 коротко описанiтакож проекцiйнi та гiстограмнi оцiнки i оцiнки щiльностi за методом най-ближчого сусiда.
Досi ми вважали, що для розподiлiв всiх компонент сумiшi використо-вується непараметрична модель. Iнколи додаткова iнформацiя для деякихкомпонент дозволяє побудувати параметричнi моделi розподiлу. Для та-ких випадкiв можуть стати у пригодi методи, описанi у роздiлi 5. Туту випадку двокомпонентної сумiшi розглядаються оцiнки методу вiдсiя-ної найбiльшої вiрогiдностi та методу моментiв для невiдомих параметрiвпараметрично заданої компоненти та для щiльностi розподiлу “непарамет-ричної компоненти”.

1.2. Прикладнi задачi аналiзу сумiшей 13
Нарештi, окрiм задач вивчення та опису розподiлiв компонент, до-слiдник може мати прикладну мету побудови класифiкацiйного алгорит-му, який дозволив би за спостережуваною характеристикою визначити,до якої компоненти належить об’єкт. У нашому прикладi задача вигля-дає так: у нової мишi O, для якої не проводився генетичний аналiз, ви-мiрюється довжина тiла — ξ(O). Потрiбно з’ясувати, який рiзновид гено-типу ind(O) вона має. Iнформацiя для прийняття рiшення мiститься у ви-бiрцi ΞN . Це задача статистичного навчання (розпiзнавання образiв). Длявипадку, коли у розпорядженнi дослiдника є повнiстю розкласифiковананавчаюча вибiрка, вона добре дослiджена. Ми у роздiлi 6 розглядаємовипадок, коли навчаюча вибiрка вибрана з сумiшi зi змiнними концен-трацiями. На основi баєсового пiдходу будуються рiзнi класифiкатори iвивчаються їх асимптотичнi властивостi.
Розглянемо тепер менш очевидний приклад застосування аналiзу су-мiшей зi змiнними концентрацiями.
Соцiологiя дражливих питань. При проведеннi соцiологiчних тапсихологiчних дослiджень часто виникають ускладнення, пов’язанi з тим,що питання, котрi цiкавлять дослiдника, є “болючими”, дражливими дляопитуваного внаслiдок певної культурної або соцiальної специфiки. Драж-ливими можуть бути питання про особливостi сексуального життя, вжи-вання наркотикiв та iн. Годi сподiватись вiдвертої вiдповiдi незнайомихлюдей на такi питання, особливо, якщо опитуваний є, скажiмо, пiдлiтком,а дослiдник є тим, хто уособлює для нього авторитет “дорослого свiту” —вчителем, лiкарем, психологом.
Зрозумiло, що при проведеннi соцiологiчних опитувань з дражливихпитань наявнiсть невизначеної кiлькостi хибних вiдповiдей ускладнює ста-тистичний аналiз результатiв i приводить до змiщення оцiнок. Тому подражливих питаннях намагаються або проводити анонiмнi опитування уяких шанси отримати правдивi вiдповiдi вищi, або оцiнювати ситуацiюза опосередкованими даними. При цьому виникає проблема узгодженнятаких анонiмних/опосередкованих даних з даними, отриманими за допо-могою iндивiдуалiзованих методик, скажiмо — за даними психологiчноготестування.
Як приклад розглянемо дослiдження учнiв-старшокласникiв середнiхшкiл з метою виявлення зв’язкiв мiж епiзодичним вживанням наркотич-них речовин та психологiчними характеристиками особистостi, такими якрiвень iнтелекту, тривожнiсть, iнтровертованiсть-екстравертованiсть, то-що. Питання “чи вживаєте ви наркотики?” вiдноситься до дражливих.

14 Роздiл 1. Моделi сумiшей зi змiнними концентрацiями
Задаючи його психолог ризикує викликати напруження i втратити кон-такт з опитуваним, причому достовiрнiсть отриманої вiдповiдi буде доситьсумнiвною. Об’єктивнi медичнi методики обстеження дозволяють вияви-ти лише осiб з цiлком сформованою наркотичною залежнiстю. Крiм тогопримусовi обстеження такого роду з дослiдницькою метою є етично непри-пустимими, а використання добровольцiв або даних, отриманих в зв’язкуз кримiнальними порушеннями, очевидно, веде до змiщення вибiрки.
В той же час можна оцiнити частку учнiв, якi у данiй школi мали до-свiд вживання наркотикiв на основi результатiв анонiмних опитувань, заекспертними оцiнками вчителiв та шкiльних психологiв, за даними прокiлькiсть зафiксованих випадкiв виявлення незаконного обороту наркоти-кiв у данiй школi.
Нехай дослiдження проводиться у рiзних школах мiста, причому коженопитуваний O проходить набiр стандартизованих тестiв, за результатамияких визначаються певнi значення його особистiсних характеристик, на-приклад, ξ1(O) — рiвень iнтелектуального розвитку (IQ), ξ2(O) — рiвеньтривожностi (нейротизм), ξ3(O) — рiвень iнтровертованостi-екстраверто-ваностi i т.д., всього d рiзних характеристик. Таким чином, з кожнимопитуваним пов’язаний вектор характеристик ξ(O) = (ξ1(O), . . . , ξd(O)) ∈Rd. В результатi обстеження N осiб O1,. . . ,ON отримано значення ξj =(ξ1
j , . . . , ξdj ) = ξ(Oj).
Дослiдника цiкавить, чи вiдрiзняється розподiл характеристик ξ(O) упопуляцiї осiб, якi мають досвiд вживання наркотикiв, вiд розподiлу ξ(O)у тих, хто наркотикiв не вживав.
Позначимо ind(O) — статус особи O по вiдношенню до наркотикiв:ind(O) = 1, якщо O не вживав наркотикiв, ind(O) = 2 — якщо O мавдосвiд вживання наркотикiв. (Можна розглянути i бiльш детальну кла-сифiкацiю, наприклад, роздiлити тих, хто обмежився однiєю спробою iпiсля того не вживав наркотикiв, тих, хто вживає їх не регулярно, i тих,хто знаходиться у станi сформованої наркотичної залежностi).
Оскiльки питання про вiдношення до наркотикiв є дражливим, статусOj невiдомий. Однак за опосередкованими даними вiдомо, що у школi, вякiй навчається Oj, частка тих, хто не має досвiду вживання наркотикiв,становить w1
j , а частка тих, хто має такий досвiд — w2j = 1 − w1
j . ЯкщоOj був обраний серед учнiв школи навмання, то P{ind(Oj) = m} = wm
j .Нехай Hm(·) — розподiл психологiчних характеристик особи, що має m-тий

1.2. Прикладнi задачi аналiзу сумiшей 15
статус. Тодi
P{ξj ∈ A} =2∑
m=1
wmj Hm(A),
тобто розподiл спостережень описується моделлю сумiшi зi змiнними кон-центрацiями. Для дослiдження даних можна тепер використати всю тутехнiку, яка була описана вище у контекстi аналiзу генетичних даних: оцi-нювання розподiлiв, моментiв, квантилiв, щiльностей розподiлу для пси-хологiчних характеристик осiб, що вживають або не вживають наркотики.Можна також будувати класифiкатори, якi за психологiчними характери-стиками особистостi намагатимуться визначити її статус по вiдношеннюдо наркотикiв.
При такому пiдходi виникають певнi сумнiви методологiчного характе-ру.
По-перше, якщо у обстеженнi приймає участь велика кiлькiсть учнiводнiєї школи, то вибiрку всерединi цiєї школи слiд вважати вибiркою безповернення. У такiй ситуацiї статуси обстежуваних не можна вважатинезалежними мiж собою, отже i спостереження ξj будуть залежними. Цезауваження, безумовно є важливим, i для таких ситуацiй потрiбно вико-ристовувати модифiкацiї вiдповiдних алгоритмiв, якi враховували б наяв-нiсть залежностi.
Друге зауваження стосується напрямку причинних зв’язкiв у розгля-дуванiй моделi. У нашому генетичному прикладi цей напрямок очевидний:той чи iнший рiзновид генотипу є причиною, що визначає довжину тiлата iншi фенотипiчнi ознаки тварини. Ситуацiї, коли змiни довжини тiлавпливають на генетичнi особливостi даної мишi, у сучаснiй генетицi вва-жаються неможливими.
Для психологiчного прикладу напрямок причинностi не можна визна-чити так однозначно, але скорiше вiн є оберненим: не вживання наркотикiвприводить до змiн рiвня екстравертованостi, а екстравертний пiдлiток маєiншi шанси стати споживачем наркотикiв, нiж iнтравертний4. Для рiвняiнтелекту можливий i “прямий” зв’язок: споживання наркотикiв знижуєiнтелект (точнiше, зменшує здатнiсть правильно виконувати тести, якi по-кликанi вимiряти рiвень iнтелекту).
При “оберненому” зв’язку, коли спостережувана характеристика є при-чиною, що визначає, до якої компоненти популяцiї потрапить об’єкт, мо-
4Бiльшi чи меншi? Це може залежати вiд культурних та соцiальних особливостейданого мiста, країни, народу.

16 Роздiл 1. Моделi сумiшей зi змiнними концентрацiями
дель сумiшi не виглядає адекватною. Природнiше було б описувати такiданi у термiнах регресiї з дискретним вiдгуком (бiнарним, якщо компо-нент лише двi). У простiшому випадку це може бути логiстична регресiя.Насправдi принципової протилежностi мiж моделями, що спираються нарегресiйний пiдхiд та моделями, якi використовують логiку класифiкацiїпо компонентах сумiшi, немає. Часто за статистичними даними взагалi неможна визначити напрямок причинного зв’язку, а можна лише стверджу-вати, що деякий зв’язок iснує.
У таких випадках використання моделi сумiшi зi змiнними концентра-цiями для опису даних можна вважати не менш виправданим, нiж за-стосування iнших технiк (наприклад, регресiйних). Однак при цьому неможна вкладати в iнтерпретацiю отриманих результатiв змiст, якого вонинасправдi не мають. Наприклад, не варто сподiватись, що класифiкатор,побудований за результатами дослiдження, дозволить виявляти прихова-них наркоманiв на основi їх психологiчних характеристик, так, як бiоло-гiчнi дiагностичнi процедури дозволяють визначати особливостi генотипуза його вiдображенням у фенотипi. У iншому мiстi, за iнших соцiальнихобставин зв’язок мiж психологiчними змiнними та ставленням до нарко-тикiв може бути зовсiм iншим, нiж у тих обставинах, у яких проводилосьдослiдження.
Нарештi третє зауваження, яке варто зробити щодо аналiзу наших“наркологiчних” даних, полягає в тому, що сам розподiл по компонентахтут виглядає досить штучно. Ми вже вiдмiтили, що, крiм розбиття надвi групи можна запропонувати i iншi класифiкацiї, побудованi на бiльшдетальному аналiзi вiдношення опитуваного до наркотикiв. В принципi,“статус” мiг би взагалi бути неперервною змiнною, що характеризувала ббiльший або менший рiвень використання наркотикiв даною особою. Чине є у такiй ситуацiї застосування моделi скiнченної сумiшi надмiрнимспрощенням ситуацiї?
Зрозумiло, що вiдповiдь на це питання можна дати лише у рамках ре-ального дослiдження, причому статистик i спецiалiст у предметнiй областiмають тiсно спiвпрацювати для того, щоб ця вiдповiдь була коректною.
Зробленi нами перестороги мають на метi показати можливi обмеженняу застосуваннi моделi сумiшi зi змiнними концентрацiями. Втiм, вони такабо iнакше стосуються i бiльшостi iнших статистичних методiв.

1.3. Приклади модельованих даних 17
0 100 200 300 400 500
-2
0
2
4
6
8
10
-2.5 0 2.5 5 7.5 10
10
20
30
40
50
(а) (б)
Рисунок 1.1: “Проста” двокомпонентна сумiш.
1.3 Приклади модельованих данихЯк, розглядаючи реальнi данi, помiтити, що їх природно описувати модел-лю сумiшi зi змiнними концентрацiями? Для того, щоб продемонструватице, ми використаємо три приклади модельних даних, згенерованих датчи-ками псевдовипадкових чисел. Данi перших двох прикладiв описуютьсямоделлю сумiшi зi змiнними концентрацiями, що мiстить двi компонен-ти з розподiлами H1 та H2. Концентрацiя першої компоненти у сумiшiзмiнюється лiнiйно вiд (майже) 0 до 1: w1
j = j/N , де N — кiлькiсть спосте-режень. Таким чином, функцiя розподiлу j-того спостереження — ξj маєвигляд
Fj(x) = P{ξj < x} =j
NH1(x) + (1− j
N)H2(x).
У першому прикладi розподiли обох компонент гауссовi: H1 ∼ N(0, 1),H2 ∼ N(7, 1). На дiаграмi розсiювання (рис. 1.1а) по горизонталi вiдкла-дено номер спостереження по порядку — j, а по вертикалi — значеннявiдповiдного ξj. Чудово помiтно, як поступово друга компонента у сумiшiзмiнюється першою. Зрозумiло, що спроба опису змiн розподiлу ξj в за-лежностi вiд j за допомогою, скажiмо, такої стандартної моделi як лiнiйнарегресiя є цiлком не адекватними. Лiнiя регресiї (зображена на дiаграмi)вiрно вiдображає змiну математичних сподiвань Fj, але сам феномен двохкомпонент iгнорує зовсiм.
Розбиття на двi компоненти чудово помiтне i на гiстограмi даних (рис.1.1б). У певному розумiннi, цей приклад є “нецiкавим”: дослiдник може

18 Роздiл 1. Моделi сумiшей зi змiнними концентрацiями
0 100 200 300 400 500-3
-2
-1
0
1
2
3
4
-2 0 2 4 6 8
10
20
30
40
50
60
(а) (б)
Рисунок 1.2: “Непомiтна” двокомпонентна сумiш.
практично безпомилково роздiлити сумiш на компоненти i далi дослiджу-вати кожну компоненту окремо.
Складнiша ситуацiя зображена на рис.1.2: тут розподiли компонентH1 ∼ N(0, 1), H2 ∼ N(2, 1).
Вони значно ближчi одни до одного, тому дiаграма розсiювання несприймається як складена з двох кластерiв. Скорiше це виглядає як лiнiй-на регресiя з сильно розкиданими похибками. Гiстограма також не даєможливостi помiтити сумiш.
Але i в цiй, складнiй для аналiзу ситуацiї, зваженi емпiричнi функ-цiї розподiлу адекватно оцiнюють розподiли компонент (див. рис.1.3). Тутпунктиром зображено графiки справжнiх функцiй розподiлу, а суцiльноюлiнiєю — їх оцiнки. (Оцiнка для другої компоненти виглядає помiтно гiр-шою нiж для першої, але це чисто випадковий ефект, на iнших данихмогло б бути навпаки).
Для порiвняння наведемо результат аналiзу даних, згенерованих за ре-гресiйною моделлю:
ξj = 3− 0.00317j + εj,
де εj — незалежнi, гауссовi, однаково розподiленi похибки з нульовим се-реднiм та дисперсiєю 2.89. Цi параметри обранi, щоб дiаграма розсiюваннявийшла подiбною до дiаграми для сумiшей. I дiйсно, на дiаграмi рис. 1.4aне можна помiтити принципових вiдмiнностей вiд дiаграми рис.1.3а.
Бiльше того, на рис. 1.4б наведено графiки емпiричних функцiй роз-подiлу, якi мали б бути оцiнками справжнiх функцiй розподiлу компонент

1.3. Приклади модельованих даних 19
-2 0 2 4 60
0.2
0.4
0.6
0.8
1
-2 0 2 4 60
0.2
0.4
0.6
0.8
1
(а) (б)
Рисунок 1.3: Функцiї розподiлу та їх оцiнки для “непомiтної” сумiшi.(а) перша компонента; (б) друга компонента
0 100 200 300 400 500
-2
0
2
4
6
8
-2 2 4 6
0.2
0.4
0.6
0.8
1
(а) (б)
Рисунок 1.4: Регресiя. (а) дiаграма розсiювання (б) оцiнки розподiлiв неiс-нуючих компонент

20 Роздiл 1. Моделi сумiшей зi змiнними концентрацiями
0 100 200 300 400 5000
1
2
3
4
5
6
0 100 200 300 400 5000
1
2
3
4
5
6
7
(а) (б)
Рисунок 1.5: Дiаграма квадратiв залишкiв зi згладжуванням полiномiаль-ною регресiєю. (а) сумiш зi змiнними коецентрацiями (б) регресiя
сумiшi. Зрозумiло, що для даних, отриманих у регресiйнiй моделi, компо-нент не iснує в принципi. Однак оцiнки виглядають цiлком природно, негiрше нiж тi, якi зображенi на рис. 1.3. Вони не є монотонними i їх значен-ня трохи виходять за межi iнтервалу [0, 1], але те ж саме можна помiтитиi для оцiнок з попереднього прикладу.
Чи є який-небудь простий спосiб вiдрiзнити такi “регресiйнi” данi вiдданих, що описуються моделлю сумiшей? Можна, наприклад, звернутиувагу на дисперсiї спостережень ξj. У розглядуванiй регресiйнiй моделiVar ξj = 2.89 є константою. У моделi двокомпонентної сумiшi
Var ξj = E ξ2j − (E ξj)
2
= w1j (σ
21 + m2
1) + w2j (σ
22 + m2
2)− (w1jm1 + w2
jm2)2,
де mi та σ2i позначають математичне сподiвання та дисперсiю i-тої компо-
ненти. Легко бачити, що для w1j = j/N Var ξj є квадратичною функцiєю
вiд j, вигнутою вгору.Щоб побачити це на рисунку, пiдрахуємо залишки лiнiйної регресiї для
Xj по j: ej = b0 + b1j, де bi — оцiнки методу найменших квадратiв длякоефiцiєнтiв лiнiйної регресiї. Розглянемо дiаграму квадратiв залишкiв —(ej)
2 (рис. 1.5).На рис. 1.5а зображенi квадрати залишкiв спостережень з сумiшi. По-
мiтно, що лiнiя регресiї5 яка описує залежнiсть середнього (ej)2 вiд j ви-
5Це полiномiальна регресiя третього порядку.

1.3. Приклади модельованих даних 21
гинається вгору. На рис. 1.5б зображено квадрати залишкiв справжньоїрегресiї — для них залежностi вiд номеру спостереження немає (як i слiдбуло сподiватись).
Якщо вiдкинути модель сумiшi i стояти на позицiях регресiйної моделi,рис. 1.5а можна iнтерпретувати як свiдчення гетероскедастичностi похи-бок. Звичайно, коли дослiдник має справу з реальними даними, механiзмутворення яких невiдомий, припущення про гетероскедастичну регресiйнумодель є цiлком допустимим. Але ця модель на змiстовному рiвнi вже не єтакою очевидною, як проста лiнiйна регресiя. В усякому випадку, залеж-нiсть дисперсiї вiд номера спостережень вимагатиме якогось пояснення.Для сумiшi зi змiнними концентрацiями цей ефект випливає безпосеред-ньо з самої моделi.
Змiна дисперсiї вiд спостереження до спостереження буде ознакою мо-делi сумiшi лише в тому випадку, коли математичнi сподiвання i/або дис-персiї компонент є рiзними. Якщо вони однаковi, звичайнi методи аналiзуможуть взагалi не помiчати неоднорiднiсть даних. Але спецiальнi технiкианалiзу сумiшей, описанi у цiй книзi, дозволяють видiлити i дослiдитиособливостi розподiлiв компонент таких даних.
Пiдсумовуючи, можна сказати, що питання про можливiсть застосу-вання моделi сумiшi до певних даних не простiше i не складнiше, нiждля бiльшостi класичних статистичних моделей. У простiших випадкахнаявнiсть сумiшi є очевидною. У складних — тiльки виходячи з певнихапрiорних мiркувань про природу даних доцiльно визначати, якою саме зможливих альтернативних моделей слiд їх описувати.

Роздiл 2
Оцiнювання функцiй розподiлу
2.1 Незмiщенi мiнiмакснi оцiнки
У цьому роздiлi розглядаються задачi оцiнювання розподiлiв компонентза спостереженнями з сумiшi зi змiнними концентрацiями. Вважаємо, щоспостерiгаються деякi об’єкти O1,. . . , ON , кожен з яких може належатиоднiй з M популяцiй (компонент). Номер популяцiї, якiй належить об’єктOj позначимо ind(Oj). Справжнє значення ind(Oj) вважається невiдомим,але вiдомi ймовiрностi wk
j:N = P{ind(Oj) = k}. Цi ймовiрностi називаютьконцентрацiями або ймовiрностями перемiшування (mixing probabilities).Концентрацiї компонент повиннi задовольняти наступнi умови: 0 ≤ wm
j:N ≤1,
∑Mm=1 wm
j:N = 1.У всiх об’єктiв спостерiгається один i той самий набiр характеристик ξ.
Для Oj цей набiр (вектор) позначимо ξj:N = ξ(Oj:N). Множину всiх мож-ливих значень характеристик ξ позначимо X . У цiй книжцi, як правило,X це або дiйсна пряма або дiйснозначний вектор. Взагалi кажучи, X можебути будь-яким вимiрним простором, тобто простором, на якому заданаσ-алгебра вимiрних пiдмножин A. Спостережуванi характеристики вва-жаємо випадковими елементами X , незалежними для рiзних Oj. Розподiлцих характеристик залежить вiд того, якiй компонентi належить об’єкт.Розподiл характеристик k-тої компоненти будемо позначати Hm, тобто
Hm(A) = P{ξ(O) ∈ A | ind(O) = m}
для всiх вимiрних множин з X . Надалi, у випадку, коли X = Rd — скiн-ченновимiрний векторний простiр, будемо також Hm позначати вiдповiдну

2.1. Незмiщенi мiнiмакснi оцiнки 23
функцiю розподiлу:
Hm(x) = P{ξ(O) < x | ind(O) = m}для всiх x ∈ Rd.(Нерiвностi для векторiв слiд розумiти покоординатно).
Таким чином, розподiл спостережуваних характеристик має вигляд
P{ξj:N ∈ A} = µj:N(A) =M∑
m=1
wmj:NHm(A). (2.1)
Надалi ми будемо використовувати схему серiй для опису асимптотич-ної поведiнки наших оцiнок при необмеженому зростаннi обсягу вибiрки,тобто коли N →∞. Тому спостережуванi данi ΞN = (ξ1, . . . , ξN) розгляда-ються як один рядок трикутного масиву Ξ = {ΞN : N = 1, 2, . . . }. (Зрозу-мiло, що реально статистик має справу лише з вибiркою фiксованого обся-гу — з одним рядочком Ξ). Вiдповiдно i концентрацiї кожної компонентиможна трактувати як трикутнi масиви: wm = {wm
j:N , j = 1, . . . , N, N ∈ N}.Крiм концентрацiй будуть використовуватись i iншi масиви аналогiчної
структури. Часто до таких масивiв буде застосовуватись оператор усеред-нення по рядочках. Ми будемо позначати його
〈wm〉N = 〈wm· 〉N =
1
N
N∑j=1
wmj:N .
Аналогiчно, якщо a = {aj:N , j = 1, . . . , N, N ∈ N}, b = {bj:N , j = 1, . . . , N,N ∈ N}, то
〈a· + b·〉N =1
N
N∑j=1
(aj:N + bj:N), 〈(a·)2〉N =
1
N
N∑j=1
(aj:N)2,
〈a·b·〉N =1
N
N∑j=1
(aj:Nbj:N) (2.2)
i т.д. Функцiонал 〈a·b·〉N , визначений (2.2), можна розглядати як скаляр-ний добуток N -тих рядочкiв наших масиiв. Якщо границя limN→∞〈a·〉Niснує, то ми будемо позначати її 〈a·〉 = 〈a〉.
Ми будемо використовувати зваженi емпiричнi мiри вигляду
µN(A, a) =1
N
N∑j=1
aj:N1I{ξj:N ∈ A}, A ∈ A, (2.3)

24 Роздiл 2. Оцiнювання функцiй розподiлу
як оцiнки для Hm за ΞN . Тут a є деяким невипадковим трикутним масивомвагових коефiцiєнтiв. (Пiд невипадковiстю ми маємо на увазi незалежнiстьвiд ΞN , але не вiд wm). Цi ваговi коефiцiєнти часто будуть залежати вiддеякого параметра (параметрiв), скажiмо, ϑ ∈ Θ. У таких випадках миiнколи будемо писати просто µN(A, a(ϑ)) = µN(A, ϑ).
Якщо X = Rd i A(x) = {y ∈ Rd : y < x} то
FN(x, a) := µN(A(x), a) =1
N
N∑j=1
aj:N1I{ξj:N < x} (2.4)
є оцiнкою для функцiї розподiлу Hk i зветься зваженою емпiричною функ-цiєю розподiлу (з.е.ф.р.).
Якщо вимагати незмiщеностi µN(A, a) як оцiнки Hk(A), то з (2.3) от-римуємо
Hk(A) = E µN(A, a) =1
N
N∑j=1
aj:N P{ξj:N ∈ A} =M∑
m=1
〈awm〉NHm(A)
для всiх можливих наборiв Hm, m = 1, . . . , M . При N > M ця умовавиконується тодi i тiльки тодi, коли
〈awm〉N = 1I{m = k} для всiх m = 1, . . . , M. (2.5)
Умову (2.5) ми будемо називати умовою незмiщеностi.Помiтимо, що коли (2.5) виконується, то
〈a〉N = 〈a1〉N = 〈aM∑
m=1
wm〉N =M∑
m=1
〈awm〉N = 1,
отже, якщо µN є незмiщеною оцiнкою для Hk, то µN(X ) = 1N
∑Mj=1 aj:N = 1.
Однак, оскiльки wm ≥ 0 для всiх m, то з умови незмiщеностi випли-ває, що aj:N повиннi приймати негативнi значення для деяких j. З (2.3)легко бачити, що у цьому випадку µN не може бути ймовiрнiсною (тобтоневiд’ємною) мiрою на X якщо всi ξj:N є рiзними. З iншого боку, для всiхA, |µN(A)| ≤ 〈|a·:N |〉N . Отже, якщо (2.5) виконано, то µN є знакозмiнноюмiрою (зарядом) зi скiнченною варiацiєю на σ-алгебрi A.
З класу всiх можливих незмiщених оцiнок вигляду (2.3) доцiльно обра-ти одну, в деякому розумiннi найкращу. Як мiру якостi у цьому параграфi

2.1. Незмiщенi мiнiмакснi оцiнки 25
будемо використовувати гарантований ризик при квадратичнiй функцiївитрат1. Нагадаємо, що це таке.
Нехай є деяка оцiнка Hk(A) для Hk(A) за спостереженнями ΞN . Мибудемо вважати, що витрати вiд використання неточної оцiнки Hk за-мiсть справжнього значення Hk задаються квадратичною функцiєю ризи-ку (Hk(A)−Hk(A))2. Вiдповiдно, середнi витрати при використаннi оцiнкиHk становлять E(Hk(A)−Hk(A))2. Тодi
R(Hk) = supHm, m=1,...,M, A∈A
E(Hk(A)−Hk(A))2
являє собою гарантований ризик оцiнки Hk, тобто максимальнi витрати,якi в середньому можна понести при використаннi оцiнки при найгiршихзначеннях характеристик моделi. Ми будемо брати sup по всiх можливихймовiрнiсних розподiлах на (X , A) оскiльки розглядається непараметрич-на задача оцiнювання. Розглянемо зважену емпiричну мiру µ(A, a) як оцiн-ку для Hk(A). Тодi гарантований ризик буде функцiєю вектора коефiцiєн-тiв a, J(a) = R(µ(·, a)). Знайдемо J(a) якщо виконанi умови незмiщеностi(2.5). Використовуючи цi умови, отримуємо
J(a) = supHm,A
E
(1
N
N∑j=1
aj:N(1I{ξj:N ∈ A} − P{ξj:N ∈ A}))2
= supHm,A
1
N2
N∑j=1
(aj:N)2 E(1I{ξj:N ∈ A} − P{ξj:N ∈ A})2
=1
4N〈(a)2〉N ,
оскiльки supHm,A(P{ξj:N ∈ A} − (P{ξj:N ∈ A})2) ≤ 14причому значення 1
4
досягається коли Hm(A) = 12для всiх m = 1, . . . , M .
Отже, ми повиннi знайти вектор a = (a1:N , . . . , aN :N), який мiнiмiзує
J(a) =1
4N〈a2〉N , (2.6)
при виконаннi умов незмiщеностi
〈wma〉N = 1I{m = k} ∀m = 1, . . . ,M. (2.7)1Про iнший пiдхiд, що спирається на поняття асимптотичної ефективностi, див. п.
2.4

26 Роздiл 2. Оцiнювання функцiй розподiлу
Використаємо метод множникiв Лагранжа для розв’язання цiєї задачi мiнi-мiзацiї. Як вiдомо, необхiдною умовою того, що a є точкою умовного екс-тремуму J при обмеженнях (2.7), є
∂
∂aj:N
(J(a) +M∑
m=1
λm〈wma〉N) = 0, (2.8)
де j = 1, . . . , N , λm — невизначенi множники Лагранжа. Умова (2.8) рiв-носильна
a =M∑
l=1
clwl·:N ,
де cl — довiльнi константи. Тобто вектор оптимальних вагових коефiцiєн-тiв є лiнiйною комбiнацiєю векторiв навантажень. Пiдставляючи цей роз-клад у (2.7), отримуємо систему лiнiйних рiвнянь для cl:
M∑
l=1
cl〈wlwm〉N = 1I{m = k}. (2.9)
Припустимо, що матриця ΓN = (〈wlwm〉N)Ml,m=1 є невиродженою. Тодi (2.9)
має єдиний розв’язок
cl =(−1)l+kγlk:N
det ΓN
,
де γlk:N — це lk-мiнор ΓN . Вiдповiдний оптимальний (мiнiмаксний) векторвагових коефiцiєнтiв визначається як
akj:N =
1
det ΓN
M∑m=1
(−1)m+kγkm:Nwmj:N . (2.10)
Умова det ΓN 6= 0 еквiвалентна лiнiйнiй незалежностi системи векторiвwm
·:N , m = 1, . . . , M , оскiльки ΓN є матрицею Грама цiєї системи у скаляр-ному добутку 〈wlwm〉N . Щоб пiдкреслити, що 〈wlwm〉N є скалярним добут-ком векторiв з RN , iнколи будемо записувати його у виглядi 〈wl, wm〉N =〈wlwm〉N .
Пiдставивши ak, визначенi (2.10), у (2.6), отримуємо найменше можли-ве значення гарантованого ризику
J(ak) =γkk:N
4N det ΓN
.

2.1. Незмiщенi мiнiмакснi оцiнки 27
Дiйсно, J(ak) = 14N〈ak, ak〉N . Помiтимо, що ak
·:N = eTk Γ−1
N ~w·:N , де ~w·:N =(w1
·:N , . . . , wM·:N)T . Отже маємо
〈ak, ak〉N = 〈eTk Γ−1
N ~w·:N , eTk Γ−1
N ~w·:N〉N = eTk Γ−1
N ΓNΓ−1N ek = eT
k Γ−1N ek.
Ми показали, що ваговi коефiцiєнти ak, визначенi (2.10), забезпечу-ють найкращий (з точки зору гарантованого ризику) результат при оцi-нюваннi Hk зваженою емпiричною мiрою µN(A, a). Чи можна оцiнити Hk
якою-небудь iншою незмiщеною оцiнкою, що мала б менший гарантованийризик? Вiдповiдь негативна.
Теорема 2.1.1 Нехай ΞN має розподiл (2.1), wm m = 1, . . . , M вiдомi, Hm
— невiдомi. Якщо det ΓN 6= 0, то для будь-якої вимiрної функцiї Hk : A×XN → [0, 1], такої, що E Hk(A, ΞN) = Hk(A) для всiх можливих розподiлiвHm,
R(Hk(·, ΞN)) ≥ J(ak) =γkk:N
4N det ΓN
.
Доведення. Виберемо будь-якi x1, x2 ∈ X , x1 6= x2. Нехай розподiли Hm
мають вигляд
Hm(A) = pm1I{x1 ∈ A}+ (1− pm)1I{x2 ∈ A}. (2.11)
Якщо обмежитись розглядом лише таких розподiлiв, то задача оцiнки роз-подiлiв Hk зведется до оцiнки вектора p = (p1, . . . , pm). Це задача парамет-ричного оцiнювання i нижня межа ризику для неї визначається нерiвнiстюКрамера (див. 7.9).
Щоб використати цю нерiвнiсть, обчислимо iнформацiйну матрицю Фi-шера для стохастичного експерименту по оцiнюванню Hm({x1}) = pm,m = 1, . . . , M за одним спостереженням ξj:N у випадку, коли справжнiзначення параметрiв є pm = p0
m = 12. Для цього задамо мiру ν(A) = 1I{x1 ∈
A} + 1I{x2 ∈ A}. Мiри Hm є абсолютно неперервними вiдносно ν для всiхp та m i
hm(x, p) =dHm
dν= pm1I{x = x1}+ (1− pm)1I{x = x2}.
Елементи iнформацiйної матрицi Ij = (Ijkl)
Mk,l=1 для спостереження ξj:N
обчислюються за формулою
Ijkl =
∫
X
∂hj(x, p)
∂pk
∂hj(x, p)
∂pl
ν(dx)
h(x, p)
∣∣∣∣p=p0
,

28 Роздiл 2. Оцiнювання функцiй розподiлу
де
hj(x, p) =dµj:N
dν=
M∑m=1
wj:Nhm(x, p).
Легко бачити, що
Ijkl =
wkj:Nwl
j:N∑Mm=1 wj:Np0
m
+wk
j:Nwlj:N
1−∑Mm=1 wj:Np0
m
= 4wkj:Nwl
j:N
(оскiльки p0m = 1/2,
∑Mm=1 wm
j:N = 1). З незалежностi спостережень ξj:N от-римуємо, що iнформацiйна матриця ΞN є I =
∑Nj=1 Ij = 4NΓN . За нерiв-
нiстю Крамера, враховуючи незмiщенiсть оцiнки Hk, отримуємо
E(Hk({x1}, ΞN)−Hk({x1}))2 ≥ eTk I−1ek =
eTk Γ−1
N ek
4N=
γkk
4N det ΓN
,
де ek є одиничним вектором у RM , k-та координата якого дорiвнює 1 (аiншi є нулями). Символ AT позначає транспонування матрицi A.
Супремум в означеннi гарантованого ризику береться по класу, якийвключає всi можливi розподiли Hk вигляду (2.11) i всi можливi множиниA = {x1}. Тому
R(Hk(·, ΞN)) ≥ γkk
4N det ΓN
. (2.12)
Теорема доведена.Приклад 1. Нехай у сумiшi з двох компонент (M = 2) концентрацiї є
константами, w1j:N = w не залежить вiд j та N , w2
j:N = 1−w. Тодi з умовинезмiщеностi випливає
〈wa1〉N = w〈a1〉N = 1
〈(1− w)a1〉N = (1− w)〈a1〉N = 0.
Це можливо тiльки тодi, коли w = 1, тобто коли у нашiй “сумiшi” присут-ня лише одна компонента. Отже, зважена емпiрична мiра не може бутинезмiщеною оцiнкою розподiлу компонент у випадку, коли концентрацiї єконстантами.
Бiльше того, у цьому випадку однозначне оцiнювання неможливе. Дiйс-но, у нашiй моделi
P{ξj:N ∈ A} = wH1(A) + (1− w)H2(A), (2.13)

2.2. Асимптотика емпiричних мiр 29
де w — вiдоме число, а H1 i H2 повнiстю невiдомi. Припустимо, що справж-нiй розподiл ξj:N має вигляд
ξj:N =
{x1 з ймовiрнiстю α
x2 з ймовiрнiстю 1− α.
Нехай Hm(A) = pm1I{x1 ∈ A} + (1 − pm)1I{x2 ∈ A}, де pm ∈ [0, 1] — деякiчисла. Якщо
wp1 + (1− w)p2 = α, (2.14)
то легко перевiрити, що (2.13) виконується. Тому (2.13) не визначає H1
та H2 однозначно i їх неможливо оцiнити навiть знаючи розподiли ξj:N
абсолютно точно. Тим бiльше, їх не можна оцiнити маючи лише вибiркуΞN .
Приклад 2. Нехай сумiш складається з двох компонент, тобто M = 2.Тодi w2
j:N = 1 − w1j:N , отже, щоб задати концентрацiї досить визначити
w1j:N . Надалi у випадку сумiшi з двома компонентами ми будемо позначати
wj:N = w1j:N , пропускаючи iндекс 1 для спрощення позначень. Позначимо
sk = 〈(w)k〉N . За означенням,
ΓN =
( 〈w, w〉N 〈w, 1− w〉N〈1− w, w〉N 〈1− w, 1− w〉N
)=
(s2 s1 − s2
s1 − s2 1− 2s1 + s2
)
i det ΓN = ∆ = s2 − (s1)2 = 〈w,w〉N − (〈w〉N)2., Вiдмiтимо, що ∆ являєсобою вибiркову дисперсiю набору концентрацiй w1
j:N , j = 1, . . . , N роз-глядуваних як “вибiрка”(вибiркова дисперсiя w2
j:N така ж сама).Зрозумiло, що det ΓN = ∆ = 0 тодi i тiльки тодi, коли w1
j:N = const незалежить вiд j. У цьому випадку непараметричне оцiнювання Hk немож-ливе, як це показано у прикладi 1. Якщо концентрацiї не є константами,то γ11:N = 1− 2s1 + s2, γ22:N = s2,
a1j:N = ((1− s1)wj:N + (s2 − s1))/∆, a2
j:N = (s2 − s1wj:N)/∆. (2.15)
2.2 Асимптотика емпiричних мiр
У цьому параграфi ми розглянемо основнi результати про поведiнку ем-пiричних мiр i емпiричних функцiй розподiлу при зростаннi обсягу вибiркидо нескiнченностi. Вони будуть використовуватись далi у цiй книжцi для

30 Роздiл 2. Оцiнювання функцiй розподiлу
аналiзу асимптотичної поведiнки рiзних оцiнок та класифiкаторiв, при-значених для аналiзу сумiшей зi змiнними концентрацiями. Цi результа-ти можна роздiлити на три великих групи: (i) твердження про збiжнiстьмайже напевне або за ймовiрнiстю до граничного невипадкового значен-ня, (ii) оцiнки швидкостi цiєї збiжностi та (iii) твердження про гранич-ний розподiл певним способом нормованих вiдхилень емпiричних мiр вiдїх граничних значень (цi нормованi вiдхилення називають емпiричнимипроцесами). Якщо розглядати емпiричнi мiри як оцiнки для невiдомихрозподiлiв компонент, то твердження групи (i) описують умови конси-стентностi оцiнок, а (iii) — умови асимптотичної нормальностi (випадокнегауссових граничних розподiлiв для емпiричних мiр ми не розглядає-мо). Однак, оскiльки емпiричнi мiри можна використовувати не тiльки якоцiнки розподiлiв, ми наведемо тут дещо бiльш загальнi теореми про їхасимптотику, нiж це потрiбно для оцiнювання. Консистентнiсть та асимп-тотична нормальнiсть будуть наслiдками цих загальних теорем.
Асимптотику емпiричних мiр µN(a,A), визначених (2.3) коли N →∞,можна вивчати або при фiксованих вагових коефiцiєнтах a та множинiA, або рiвномiрно по деякому класу множин i/або деякому класу ваговихфункцiй, або, розглядаючи µN(a,A) як функцiї A та функцiонали a — увiдповiдних функцiональних просторах. Тут ми, в основному, зосередимо-ся на другому варiантi. Одразу вiдмiтимо, що годi сподiватись, наприклад,рiвномiрної збiжностi µN(a,A) на класi всiх можливих вимiрних множину R. Цей клас є занадто великим. Ми будемо обирати такi класи множин,на яких умови рiвномiрної збiжностi є не набагато важчими, нiж умовизбiжностi при фiксованiй множинi. Для збiжностi майже напевне це умоваскiнченної апроксимованостi, описана нижче. Скiнченна апроксимовнiстькласу множин вiдносно певної мiри на X = Rd — досить слабка умова, якпоказують леми 2.2.1, 2.2.2, поданi нижче.
При дослiдженнi збiжностi розподiлiв емпiричних процесiв ми обме-жуємось лише функцiями розподiлу, тобто на роль множин A вибираємолише напiвнескiнченнi iнтервали (прямокутники) у просторi X = Rd. Цедуже сильне обмеження, якого, в принципi, можна позбутись. Але для по-треб асмптотичного аналiзу алгоритмiв, якi розглядаються у цiй книж-цi, нам буде цiлком достатньо тверджень про рiвномiрну асмптотичнунормальнiсть емпiричних функцiй розподiлу. Пiд асимпотичною нормаль-нiстю звичайно розумiють слабку збiжнiсть розподiлiв. Вiдповiдно рiвно-мiрною асимптотичною нормальнiстю природно вважати слабку збiжнiстьрозподiлiв дослiджуваної послiдовностi випадкових процесiв (полiв) роз-

2.2. Асимптотика емпiричних мiр 31
глядуваних як елементи деякого простору функцiй з рiвномiрною метри-кою до певного гауссового розподiлу на цьому просторi. Чудовим прикла-дом застосування такого пiдходу є книжка П. Бiлiнгслi [1].
Однак використання функцiональних просторiв для опису рiвномiр-ної слабкої збiжностi зустрiчається з певними труднощами, коли вини-кає потреба дослiджувати розривнi функцiї на некомпактних множинах— це ускладнює опис вiдповiдних функцiональних просторiв, робить ре-зультати менш зрозумiлими iнтуїтивно. Тому ми, поруч з функцiональ-ним пiдходом, будемо використовувати технiку одного ймовiрнiсного про-стору, введену А.В. Скороходом [23]. Вона спирається на той фундамен-тальний факт, що у сепарабельних метричних просторах слабка збiжнiстьрозподiлiв випадкових елементiв ζn до розподiлу елемента ζ еквiвалентнаiснуванню послiдовностi ζ ′n та елемента ζ ′, таких, що розподiл ζ ′n той са-мий що у ζn, а у ζ ′ — той самий, що у ζ, причому ζ ′n → ζ ′ майже напевно(теорема Скорохода). Таким чином, слабка збiжнiсть виявляється, пара-доксальним чином еквiвалентною “сильнiй” збiжностi майже напевно, алене самої дослiджуваної послiдовностi, а послiдовностi “копiй” з тим же роз-подiлом. Часто застосування теореми Скорохода дозволяє зробити технiкуасимптотичного аналiзу прозорiшою i зрозумiлiшою.
Доведення тверджень (i) спирається на пiдсилений закон великих чи-сел, (iii) — на центральну граничну теорему (ЦГТ). Для отримання твер-джень групи (ii) ми використаємо варiант класичної нерiвностi Вапника-Червоненкiса [7], поширений на випадок сумiшей зi змiнними концентра-цiями. Нерiвнiсть Вапника-Червоненкiса дозволяє отримувати як оцiнкишвидкостi збiжностi майже напевне, так i оцiнки ймовiрностей вiдхилен-ня емпiричних мiр вiд граничних значень. Цi оцiнки уточнюють пiдси-лений закон великих чисел, але не досягають точностi ЦГТ — в той часяк ЦГТ забезпечує швидкiсть збiжностi порядку
√N , нерiвнiсть Вапника-
Червоненкiса — тiльки√
N/ log(N). Важливою перевагою цих оцiнок є те,що вони рiвномiрнi не тiльки по певному класу множин A, але i по обсягувибiрки N — вони виконуються для всiх N . Вони також не залежать вiдрозподiлiв компонент i концентрацiй компонент у сумiшi. Така унiверсаль-нiсть робить нерiвностi Вапника-Червоненкiса досить грубими — для ви-бiрок помiрного обсягу вони часто виявляються не набагато кращими нiжтривiальна нерiвнiсть P(A) < 1. Однак рiвномiрнiсть оцiнок буває дужекорисною для того, щоб доводити прямування до 0 залишкових доданкiву асимптотичних формулах.
Для набору вагових коефiцiєнтiв a ми будемо розглядати два варiанти

32 Роздiл 2. Оцiнювання функцiй розподiлу
умов: коли a є фiксованою функцiєю i коли a = a(v) є функцiєю деякогопараметру. Варiант з фiксованими ваговими коефiцiєнтами дозволяє по-мiтно спростити умови граничних теорем, а твердження про асимтотикуµN(a(v), A) рiвномiрно по v використовуються при дослiдженнi адаптив-них оцiнок, коли ваговi коефiцiєнти обираються залежними вiд вибiрки.
Перейдемо до перелiку основних результатiв (їх доведення можна знай-ти в [15], п.2.3–2.5).
(i) Збiжнiсть майже напевно. Нехай µN(A, a) — емпiрична мiра,визначена (2.3). Позначимо
µN(A, a) := E µN(A, a) =1
N
N∑j=1
aj:N P{ξj:N ∈ A} =M∑
m=1
〈awm〉NHm(A).
Ми розглянемо твердження про збiжнiсть µN(A, a) до µN(A, a) рiвномiрнопо A на деякому класi множин S ⊆ A, тобто
supA∈S
|µN(A, a)− µN(A, a)| → 0,
N → ∞. Для однорiдних вибiрок така збiжнiсть доводится у теоремiГлiвенка-Кантеллi. Сформулюємо аналогiчний результат для сумiшей зiзмiнними концентрацiями. Для цього нам буде потрiбне означення класумножин скiнченно-апроксимованого вiдносно деякої мiри.
Нехай (Y ,Y) є вимiрним простором з мiрою ν.
Означення 2.2.1 Клас множин S ⊂ Y зветься скiнченно-апроксимова-ним вiдносно мiри ν, якщо для будь-якого ε > 0 iснує такий скiнченнийклас множин S(ε), що для всiх A ∈ S знайдуться множини A− та A+
з S(ε) такi, що A− ⊆ A ⊆ A+, ν(A \ A−) ≤ ε,ν(A+ \ A) ≤ ε.Клас S(ε) назвемо ε-мережею для S, A− i A+ — вiдповiдно, нижньою
та верхньою апроксимацiями A.
Наступнi леми показують, що скiнченно-апроксимованi класи є достат-ньо великими для багатьох застосувань.
Лема 2.2.1 ([2], додаток 1.) Нехай Y = Rd , S є класом всiх прямокут-никiв вигляду S = {x ∈ Rd : y1 ≤ x ≤ y2}, де y1, y2 довiльнi вектори у Rd.Тодi клас S є скiнченно-апроксимованим вiдносно будь-якої ймовiрнiсноїмiри на Rd.

2.2. Асимптотика емпiричних мiр 33
Лема 2.2.2 ([2], додаток 1.) Нехай Y = Rd , S є класом всiх опуклихмножин на Y, H є мiрою на Y, абсолютно неперервною вiдносно мiриЛебега. Тодi S є скiнченно-апроксимованим класом вiдносно H.
Наступна теорема дає достатнi умови збiжностi емпiричних мiр м.н. увипадку фiксованого набору вагових коефiцiєнтiв a.
Теорема 2.2.1 Нехай(i)S є скiнченно-апроксимованим класом вiдносно всiх розподiлiв Hm,
m = 1,. . . ,M ;(ii) ваговi коефiцiєнти є рiвномiрно обмеженими: |aj:N | ≤ C для дея-
кого C < ∞ i всiх можливих j та N ;(iii) для всiх m = 1, . . . , M iснують 〈a·1I{a· > 0}wm〉 i 〈a·1I{a· < 0}wm〉.Тодi
supA∈S
|µN(a,A)− µN(A, a)| → 0
м.н. при N →∞.
Зауваження. Умова (i) успадкована вiд класичної теореми Глiвенка-Кантеллi для однорiдних вибiрок. Умова (ii), в принципi, не є непокра-щуваною. Використовуючи нерiвнiсть Вапника-Червоненкiса, можна от-римувати умови збiжностi емпiричних мiр з коефiцiєнтами, що прямуютьдо нескiнченностi при N → ∞. Але ця умова є iнтуiтивно зрозумiлою,легко перевiряється i виконується у багатьох застосуваннях. Тому ми їївикористовуємо.
Умова (iii) виглядає дещо дивно. Насправдi, для того, щоб можна буловизначити µN(A, a), потрiбне iснування границь
limN→∞
〈awm〉N = limN→∞
(1
N
N∑j=1
aj:N1I{aj:N > 0}+1
N
N∑j=1
aj:N1I{aj:N < 0})
= 〈a·1I{a· > 0}wm〉+ 〈a·1I{a· < 0}wm〉Таким чином, замiсть природної умови збiжностi 〈awm〉N ми вимагаємо,щоб збiгався кожен з двох доданкiв на якi ця величина розбивається.Неважко побудувати приклад, в якому б послiдовнiсть 〈awm〉N збiгалась,а послiдовностi 〈a·1I{a· > 0}wm〉N та 〈a·1I{a· < 0}wm〉N — нi. Однак у прак-тичних застосуваннях такi випадки нам не зустрiчались.
Нагадаємо, що у випадку X = Rd зважена емпiрична функцiя розподi-лу визначається як FN(x, a) = µ((−∞, x], a). Аналогiчно, функцiя розподi-лу m-тої компоненти сумiшi — це Hm(x) = Hm((−∞, x]).

34 Роздiл 2. Оцiнювання функцiй розподiлу
Наслiдок 2.2.1 Нехай |aj:N | < C. Якщо для всiх m = 1, . . . ,M iснують〈a·1I{a· > 0}wm〉 i 〈a·1I{a· < 0}wm〉, то
supx∈Rd
|FN(x, a)−M∑
m=1
〈awm〉Hm(x)| → 0(м.н.)
Доведення зводиться до застосування теореми 2.2.1 та леми 2.2.1.Нехай ak є мiнiмаксним вектором вагових коефiцiєнтiв, визначеним
(2.10). Позначимо HNk (A) = µ(ak, A), A ∈ A — емпiрична мiра, що є мiнi-
максною оцiнкою Hk, HNk (x), x ∈ Rd — вiдповiдна зважена емпiрична
функцiя розподiлу.
Наслiдок 2.2.2 Нехай для всiх m, l = 1, . . . M i для будь-якого C ∈ Riснують 〈wm
· 1I{wm· > C}〉, 〈wmwl〉, i матриця Γ = (〈wmwl〉)M
m,l=1 є неви-родженою. Тодi
supx∈Rd
|HNm (x)−Hm(x)| → 0(м.н.)
для всiх m.Якщо, крiм того, S є скiнченно-апроксимованим класом вiдносно всiх
Hm, m = 1, . . . , M , то
supA∈S
|HNm (A)−Hm(A)| → 0(м.н.).
Тепер розглянемо випадок, коли ваговi коефiцiєнти aj:N є функцiямидеякого параметра v ∈ V : aj:N = aj:N(v) i потрiбна рiвномiрна по v ∈ Vзбiжнiсть емпiричних мiр. Ми накладемо на ваговi вектори спецiальнi умо-ви, якi використовують поняття варiацiї. Варiацiю N -того рядочка масивуa визначимо як
|a|VAR:N=
N∑j=2
|aj:N − aj−1:N |,
а варiацiю всього масиву — як |a|VAR = supN |a|VAR:N.
Теорема 2.2.2 Нехай(i) виконуються умови (i) та (ii) теореми 2.2.1;(ii) для всiх t ∈ T = [0, 1] iснують границi
limN→∞
tN∑j=1
aj:Nwmj:N1I{aj:N > 0},

2.2. Асимптотика емпiричних мiр 35
limN→∞
tN∑j=1
aj:Nwmj:N1I{aj:N < 0};
(iii) supv∈V |a(v)|VAR < ∞.Тодi
supv∈V,A∈S
|µN(a(v), A)−M∑
m=1
〈a(v)wm〉NHm(A)| → 0 (2.16)
м.н. при N →∞.
Приклад 1. Стохастичнi концентрацiї. Нехай вектори кнцентрацiй(w1
j:N , . . . , wMj:N) генеруються деяким випадковим механiзмом, незалежно
при рiзних j. Пiсля того, як wmj:N були згенерованi, ймовiрностi P{ξj:N ∈ A}
визначаються (2.1). Тобто цi ймовiрностi розглядаються як умовнi прифiксованих wm
j:N , j = 1, . . . , N , m = 1, . . . , M . Якщо вектори (w1j:N , . . . , wM
j:N)незалежнi, однаково розподiленi при всiх j та N , то за законом великихчисел отримуємо
〈wmwk〉N → E wm1:1w
k1:1 = 〈wmwk〉 (2.17)
м.н. при N →∞ (адже |wmj:N | < 1).
Така модель зветься моделлю зi стохастичними концентрацiями. Якправило, розглядаючи такi моделi, фiксують одну реалiзацiю wm, яка на-справдi спостерiгається i розглядають її як дану, невипадкову. Iгноруючиподiї, що мають нульовi ймовiрностi, вважаємо, що для моделей зi стоха-стичними концентрацiями (2.17) виконується завжди.
Аналогiчно переконуємось у iснуваннi 〈wm· 1I{
∑m wm
· > C}〉. Таким чи-ном, для забезпечення збiжностi HN
k до Hk за наслiдком 2.2.2, досить до-сить вимагати, щоб матриця — (E wm
1:1wk1:1)
Mm,k=1 була невиродженою.
(ii) Оцiнки швидкостi збiжностi. Використаємо тепер пiдхiд Вап-ника-Червоненкiса для отримання деяких оцiнок швидкостi збiжностi неод-норiдних емпiричних мiр. Щоб зробити це, нам будуть потрiбнi додатковiобмеження на класи множин, на яких будуть отриманi рiвномiрнi оцiнкишвидкостi збiжностi за ймовiрнiстю. Цi обмеження будуть сформульованiу термiнах класiв Вапника-Червоненкiса.
Щоб з’ясувати це поняття, сформулюємо спочатку деякi допомiжнiозначення та твердження. Нехай (X , A) — вимiрний простiр спостережень,S ⊆ A — деякий клас вимiрних множин, X l = (x1, . . . , xl) — послiдовнiстьелементiв X . Кожна множина A ∈ S породжує пiдпослiдовнiсть XA послi-довностi X l, яка складається з усiх X l, що належать A. Послiдовнiсть XA

36 Роздiл 2. Оцiнювання функцiй розподiлу
назвемо породженою (множиною A) пiдпослiдовнiстю послiдовностi X l.Позначимо δS(X l) кiлькiсть всiх рiзних послiдовностей XA, породженихмножинами A ∈ S на X l i
gS(l) = maxXl
δS(X l),
де максимум береться по всiх можливих послiдовностях X l з X . ФункцiяgS зветься функцiєю зростання класу S. Наступне твердження доведеноу (Вапник, Червоненкiс, 1974) теорема 10.1.
Твердження 2.2.1 Для будь-якого класу множин S функцiя зростанняgS(l) або є тотожньо рiвною 2l для всiх l ∈ N, або задовольняє нерiвнiсть
gS(l) ≤ 3ln−1
2(n− 1)!, (2.18)
де n — це перше значення l, для якого gS 6= 2l.
Класи множин, для яких функцiя зростання не є тотожньо рiвною2l для всiх l, називають класами Вапника-Червоненкiса (VC-класами). Знерiвностi (2.18) випливає, що функцiя зростання VC-класу має не бiльше,нiж степеневий порядок зростання з показником n.
Найменше n, для якого iснує таке C < ∞, що для всiх l: gS(l) ≤ Cln,зветься ємнiстю VC-класу S.
Оцiнки швидкостi збiжностi, отриманi у цьому параграфi, мають нетри-вiальний змiст лише для VC-класiв. При цьому повинна виконуватись та-кож наступна умова емпiричної вимiрностi.
Ми будемо казати, що клас S задовольняє умовi емпiричної вимiрностi,якщо для всiх l ∈ N функцiя
ρ(x1, . . . , xl, y1, . . . , yl) = supA∈S
∣∣∣∣∣1
N
l∑i=1
(1I{xi ∈ A} − 1I{yi ∈ A})∣∣∣∣∣
є вимiрною функцiєю вiдносно A2l.Вiдомо багато VC-класiв на X = Rd, для яких умова емпiричної вимiр-
ностi виконується вiдносно борелевської σ-алгебри. Такими є, наприклад,клас усiх прямокутникiв у Rd, клас усiх куль в Rd (функцiя зростання цихкласiв gS(l) ≤ (l + 1)d), клас всiх багатогранникiв у Rd, кiлькiсть гранейяких не перевищує C (для цього класу gS(l) ≤ (3(l − 1)d/d!)C) (див. [7]).Сформулюємо тепер аналог теореми Вапника-Червоненкiса для випадкусумiшей зi змiнними концентрацiями.

2.2. Асимптотика емпiричних мiр 37
Наслiдок 2.2.3 Нехай A — клас всiх можливих трикутних масивiвaj:N . Тодi, для всiх λ > 2M/N ,
P
{supA∈S
supa∈A
|µN(A, a)− µN(A, a)|2 sup1≤j≤N |aj:N |+ |a|VAR:N
≥ λ
}
≤ M
(6NgS(2N) exp
(− λ2N
32M2
)+ 2 exp
(−λ2N
8M2
)).
У випадку, коли потрiбна оцiнка ймовiрностi вiдхилення емпiричноїмiри вiд граничного значення для фiксованого вагового масиву, можнаскористатись наступною теоремою.
Теорема 2.2.3 Нехай aj:N — довiльний масив вагових коефiцiєнтiв, S —VC-клас. Тодi, для всiх λ > 2M/N ,
P
{supA∈S
|µN(A, a)− µN(A, a)|2 sup1≤j≤N |aj:N |+ max1≤j≤N aj:N −min1≤j≤N aj:N
≥ λ
}
≤ M
(6NgS(2N) exp
(− λ2N
32M2
)+ 2 exp
(−λ2N
8M2
)).
Цi двi теореми дозволяють оцiнити швидкiсть збiжностi за ймовiр-нiстю. Використовуючи лему Бореля-Кантеллi, з них можна отриматиоцiнку швидкостi збiжностi майже напевне. Ця оцiнка подiбна до рiвномiр-ної версiї закону повторного логарифму (ЗПЛ) для емпiричних функцiйрозподiлу однорiдних вибiрок. Однак ми отримаємо швидкiсть збiжностi√
ln NN
, а не√
ln ln NN
, як у ЗПЛ. Це погiршення швидкостi збiжностi є на-слiдком того, що ми використовуємо для опису асимптотичної поведiнкинашої вибiрки схему серiй, а не послiдовнiсть незалежних, однаково роз-подiлених випадкових елементiв.
Теорема 2.2.4 Нехай S є VC-класом. Тодi1.Для будь-якого вагового масиву a iснує така випадкова величина Λ <
∞ м.н., що
supA∈S
|µN(A, a)− µN(A, a)| ≤ Λ
√ln N
Nsup
1≤j≤N|aj:N |, (2.19)
для всiх N ∈ N.

38 Роздiл 2. Оцiнювання функцiй розподiлу
2. Iснує така випадкова величина Λ < ∞ м.н., що для всiх N та всiхA ∈ S,
|µN(A, a)− µN(A, a)| ≤ Λ
√ln N
Nsup
1≤j≤N(|aj:N |+ |a|VAR:N
). (2.20)
Зауваження. З цiєї теореми, вочевидь, випливає збiжнiсть майже на-певно емпiричних мiр у випадку обмежених вагових коефiцiєнтiв. Однакклас множин S, на якому збiжнiсть є рiвномiрною, тут вужчий, нiж утеоремi 2.2.1, оскiльки не кожен скiнченно-апроксимований клас є класомВапника-Червоненкiса.
Наприклад, за лемою 2.2.2, клас S всiх опуклих множин в Rd є скiнчен-но-апроксимованим вiдносно будь-якої абсолютно неперервної на Rd ймо-вiрнiсної мiри. Отже, за теоремою 2.2.1, supA∈S |µN(a,A) − µN(a,A)| → 0якщо розподiли компонент є абсолютно неперервними, а ваговi коефiцiєн-ти задовольняють умовам (ii)-(iii) цiєї теореми. Але, як показано у [7], S
не є VC-класом, тому теорема 2.2.4 нiчого не дає для оцiнки швидкостiцiєї збiжностi.
У випадку X = Rd для зважених емпiричних функцiй розподiлу отри-муємо наступне твердження про оцiнку швидкостi рiвномiрної збiжностiдо оцiнюваної компоненти щiльностi Hk.
Наслiдок 2.2.4 Нехай для вагових коефiцiєнтiв a виконана умова незмi-щеностi (2.5). Тодi
1. Iснує така абсолютна константа C, що для всiх λ > 2M/N ,
P
{supx∈Rd |FN(x, a)−Hk(x)|
2 sup1≤j≤N |aj:N |+ max1≤j≤N aj:N −min1≤j≤N aj:N
≥ λ
}
≤ M
(C(2N + 2)d+1 exp
(− λ2N
32M2
)+ 2 exp
(−λ2N
8M2
)).
2.Для будь-якого вагового масиву a iснує така випадкова величина Λ <∞ м.н., що
supx∈Rd
|FN(x, a)−Hk(x)| ≤ Λ
√ln N
Nsup
1≤j≤N|aj:N |, (2.21)
для всiх N ∈ N.

2.2. Асимптотика емпiричних мiр 39
Зрозумiло, що з цього наслiдку випливає рiвномiрна консистентнiстьFN(x, a) за умови, що
√ln NN
sup1≤j≤N |aj:N | прямує до 0.(iii) Збiжнiсть розподiлiв. Ми будемо розглядати слабку збiжнiсть
розподiлiв випадкових полiв у просторах функцiй з рiвномiрною метри-кою а також еквiвалентну їй збiжнiсть за Скороходом, тобто збiжнiстьм.н. копiй розглядуваних випадкових полiв до копiї граничного процесу.Нагадаємо основнi означення.
Нехай S — будь-який метричний простiр, {ζn} — деяка послiдовнiстьйого випадкових елементiв (в.е.). Кажуть, що {ζn} слабко збiгається до ви-падкового елемента ζ, якщо для будь-якої неперервної, обмеженої функцiїg : S → R виконується
limn→∞
E g(ζn) = E g(ζ).
Слабку збiжнiсть будемо позначати ζn ⇒ ζ.Будемо казати, що послiдовнiсть {ζn} випадкових елементiв деякого
метричного простору S збiгається за Скороходом (позначення ζnSk→ζ), як-
що iснує такий ймовiрнiсний простiр, на якому можна побудувати послi-довнiсть в. е. ζ ′n та в.е. ζ ′ такi, що
1. ζ ′n, ζ ′ мають тi ж самi розподiли, що i ζn, ζ вiдповiдно.2. ζ ′n → ζ ′ у S м.н. при n →∞.
Твердження 2.2.2 теорема Скорохода (див. [23, 44]). Нехай S є се-парабельним метричним простором, ζn, ζ є в.е. з S такими, що ζn ⇒ ζ,n →∞. Тодi ζn
Sk→ζ у S.
(Оскiльки зi збiжностi м.н. випливає слабка збiжнiсть, то з ζnSk→ζ завжди
випливає ζn ⇒ ζ.)У наступних роздiлах нам будуть потрiбнi умови асимптотичної нор-
мальностi емпiричних функцiй розподiлу як оцiнок для функцiй розподiлукомпонент сумiшi. Розглянемо емпiричний процес
BN(x) =√
N(FN(x, a)−Hm(x)), (2.22)
де FN зважена емпiрична функцiя розподiлу, визначена (2.4), з ваговимикоефiцiєнтами a, що задовольняють умову незмiщеностi (2.5). Ми будемовивчати збiжнiсть емпiричних процесiв у просторi D(Rd) функцiй на Rd
без розривiв другого роду з рiвномiрною нормою
|z|∞ = supx∈Rd
|z(x)|.

40 Роздiл 2. Оцiнювання функцiй розподiлу
Вiдмiтимо, що цей простiр не є сепарабельним, тому твердження про збiж-нiсть за Скороходом у ньому є бiльш сильним, нiж твердження про слабкузбiжнiсть.
Теорема 2.2.5 Нехай1. Для деякого A < ∞: supj,N |aj:N | < A;2.Для всiх l, m = 1, . . . , M iснують границi 〈wlwm(a)2〉;3. Hm є неперервними функцiями на Rd при всiх m = 1, . . . , M ;4. Виконана умова незмiщеностi (2.5).Тодi на деякому випадковому просторi можна побудувати процеси
B′N(x) та B(x), такi, що:1. Процеси B′
N(x) мають такий самий розподiл, як i BN(x);2. B(x) є гаусовим випадковим процесом з неперервними траекторiя-
ми, нульовим середнiм i коварiацiйною функцiєю
E B(x)B(y) =M∑
m=1
〈wm(a)2〉Hm(min(x, y))
−M∑
i,m=1
〈wmwi(a)2〉Hm(x)Hi(y)
3. supx∈Rd |B′N(x)−B(x)| → 0 м.н. при N →∞.
( З∑M
m=1 wmj:N = 1 випливає 〈wm(a)2〉N =
∑Mi=1〈wmwi(a)2〉N , тому iснуван-
ня 〈wmwi(a)2〉 є наслiдком умови 2 теореми).Теорема, по сутi, стверджує, що BN
Sk→B у рiвномiрнiй нормi. Вона єтривiальним узагальненням наслiдку 2.5.1 з [15].
Тепер наведемо теорему про асимптотичну нормальнiсть емпiричнихфункцiй розподiлу, у яких ваговi коефiцiєнти залежать вiд деякого пара-метра v. Для цього нам будуть потрiбнi наступнi позначення.
Будемо вважати, що X = Rd. Позначимо bj:N(t) = 1I{j < tN}. При-пустимо, що границi 〈b(u)b(v)wmwl〉 iснують для всiх u, v ∈ [0, 1], m, l =1, . . . , M , t ∈ [0, 1] i введемо у розгляд випадковий процес U(x, t), x ∈ Rd,розподiл якого визначений наступними умовами:
1. U(x, t) — гауссiв процес на Rd × [0, 1];2. E U(x, t) = 0

2.2. Асимптотика емпiричних мiр 41
3. Коварiацiйна функцiя процесу U має вигляд
E U(x, u)U(y, v) =M∑
m=1
〈b(u)b(v)wm〉Hm(min(x, y))
−∑
m1,m2=1
〈b(u)b(v)wm1wm2〉Hm1(x)Hm2(y). (2.23)
(Можна показати, що для будь-яких функцiй розподiлу Hm та концентра-цiй wm ця функцiя є коварiацiйною функцiєю деякого гауссового процесу.Якщо Hm — неперервнi функцiї, то U(·, t) має м.н. неперервну реалiзацiюна Rd).
Будемо розглядати ваговi масиви спецiального вигляду, а саме, вважа-тимем, що ваговий масив aj:N можна зобразити у формi
aj:N(v) = a(j
N, v), (2.24)
де aN(t, v) є деякими неперервними функцiями aN : [0, 1] × V → R, v —деякий параметр, що належить множинi V .
Теорема 2.2.6 Нехай масив aj:N(v) визначається (2.24) i виконуютьсянаступнi умови
(i) iснує функцiя a : [0, 1]× V → R така, що supv VARta(t, v) < ∞ i
supv
VARt|aN(t, v)− a(t, v)| → 0
при N →∞;(ii) Для всiх u, v ∈ [0, 1], m, l = 1, . . . , M , iснують 〈b(u)b(v)wmwl〉;(iii) функцiї розподiлу Hm m = 1, . . . , M є неперервними на Rd.Тодi випадкове поле
YN(x, v) =√
N(FN(x, a(v))− E FN(x, a(v)))
збiгається за Скороходом у рiвномiрнiй метрицi до
Y (x, v) =
∫ 1
0
a(t, v)U(x, dt).

42 Роздiл 2. Оцiнювання функцiй розподiлу
Зрозумiло, що граничне випадкове поле Y (x, v) також буде гауссовимз нульовим середнiм, а його коварiацiйна функцiя буде мати вигляд
E Y (x1, v1)Y (x2, v2) =M∑
m=1
〈a(u)a(v)wm〉Hm(min(x, y))
−∑
m1,m2=1
〈a(u)a(v)wm1wm2〉Hm1(x)Hm2(y).
Приклад 2. Функцiональнi концентрацiї. При описi даних при-кладних дослiджень поруч зi стохастичною моделлю концентрацiй, опи-саною у прикладi 1, зустрiчаються моделi iншого типу, якi ми назвемомоделями функцiональних концентрацiй. У цих моделях вважається, щоwm
j:N = wm(tj:N), де wm : [0, 1] → [0, 1] деякi функцiї, t·:N - послiдовнi роз-биття t1:N < t2:N < · · · < tN :N iнтервалу [0, 1]. В принципi, цi розбиттяможуть бути досить рiзноманiтними, але ми, для простоти викладу, обме-жимось рiвномiрним розбиттям tj:N = j/N .
Якщо функцiї wm є iнтегровними за Рiманом, то
〈b(u)b(v)wmwl〉 =
∫ min(u,v)
0
wm(t)wl(t)dt
i аналогiчно визначаються всi iншi характеристики, пов’язанi з застосу-ванням оператора 〈·〉 до концентрацiй та вагових коефiцiєнтiв.
2.3 Виправленi зваженi емпiричнi функцiїрозподiлу
Нехай спостереження являють собою випадковi величини ξj:N (одновимiр-нi, тобто X = R) що описуються моделлю сумiшi зi змiнними концентра-цiями (2.1).
У п. 2.1 на роль оцiнки для розподiлу Hk k-тої компоненти сумiшiзi змiнними концентрацiями запропоновано використовувати зваженi ем-пiричнi функцiї розподiлу
FN(x, a) =1
N
N∑j=1
aj:N1I{ξj:N < x} (2.25)
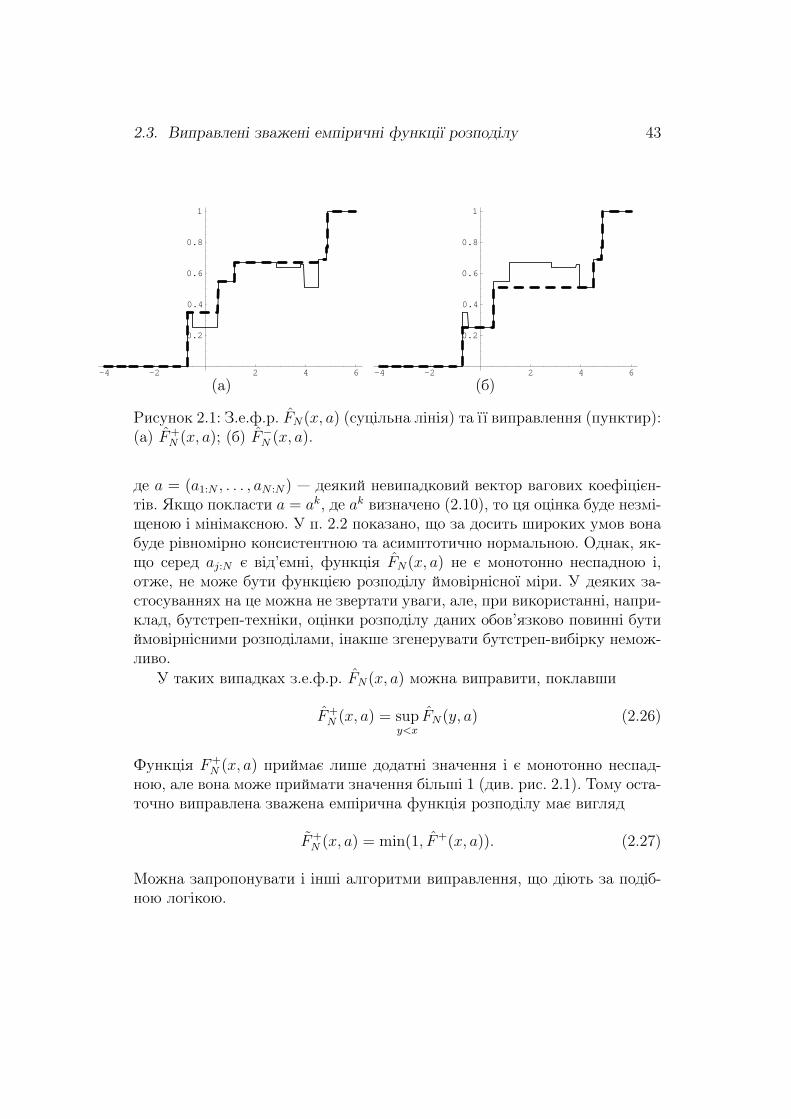
2.3. Виправленi зваженi емпiричнi функцiї розподiлу 43
-4 -2 2 4 6
0.2
0.4
0.6
0.8
1
-4 -2 2 4 6
0.2
0.4
0.6
0.8
1
(а) (б)
Рисунок 2.1: З.е.ф.р. FN(x, a) (суцiльна лiнiя) та її виправлення (пунктир):(а) F+
N (x, a); (б) F−N (x, a).
де a = (a1:N , . . . , aN :N) — деякий невипадковий вектор вагових коефiцiєн-тiв. Якщо покласти a = ak, де ak визначено (2.10), то ця оцiнка буде незмi-щеною i мiнiмаксною. У п. 2.2 показано, що за досить широких умов вонабуде рiвномiрно консистентною та асимптотично нормальною. Однак, як-що серед aj:N є вiд’ємнi, функцiя FN(x, a) не є монотонно неспадною i,отже, не може бути функцiєю розподiлу ймовiрнiсної мiри. У деяких за-стосуваннях на це можна не звертати уваги, але, при використаннi, напри-клад, бутстреп-технiки, оцiнки розподiлу даних обов’язково повиннi бутиймовiрнiсними розподiлами, iнакше згенерувати бутстреп-вибiрку немож-ливо.
У таких випадках з.е.ф.р. FN(x, a) можна виправити, поклавши
F+N (x, a) = sup
y<xFN(y, a) (2.26)
Функцiя F+N (x, a) приймає лише додатнi значення i є монотонно неспад-
ною, але вона може приймати значення бiльшi 1 (див. рис. 2.1). Тому оста-точно виправлена зважена емпiрична функцiя розподiлу має вигляд
F+N (x, a) = min(1, F+(x, a)). (2.27)
Можна запропонувати i iншi алгоритми виправлення, що дiють за подiб-ною логiкою.

44 Роздiл 2. Оцiнювання функцiй розподiлу
У цьому параграфi ми опишемо рiзнi варiанти виправлення з.е.ф.р.,наведемо ефективний алгоритм їх пiдрахунку та дослiдимо їх асимпто-тичну поведiнку. Буде показано, що за певних умов вони є асимптотичнонормальними з таким самим граничним розподiлом, як i у з.е.ф.р., визна-чених (2.25). Тобто, асимптотична поведiнка емпiричного процесу
B+N(x) =
√N(F+
N (x, a)−Hk(x)) (2.28)
у рiвномiрнiй нормi не вiдрiзняється вiд поведiнки емпiричного процесу
BN(x) =√
N(FN(x, a)−Hk(x)). (2.29)
Алгоритм обчислення виправленої з.е.ф.р. Припустимо спочат-ку, що всi значення у вибiрцi ΞN = (ξ1:N , . . . , ξN :N) є рiзними. Позначимоσ перестановку чисел 1, 2,. . . , N , яка забезпечує впорядкування вибiр-ки у порядку зростання: ξσ(1):N < ξσ(2):N < · · · < ξσ(N):N . (Числа σ(j),j = 1, . . . , N прийнято називати “антирангами”, оскiльки σ−1(j) це рангj-того спостереження у вибiрцi). Оскiльки функцiя FN(x, a) є сталою наiнтервалах (ξσ(j):N , ξσ(j+1):N), то такою ж є i F+
N (x, a), визначена (2.26). От-же,
F+N (x, a) =
1
N
N∑j=1
b+j 1I{ξj:N < x} =
1
N
N∑j=1
b+σ(j):N1I{ξσ(j):N < x}
де b+j — це деякi коефiцiєнти, що (на вiдмiну вiд aj:N) залежать вiд вибiрки
ΞN .Iдея алгоритму полягає в тому, щоб, рухаючись по варiацiйному ряду
злiва направо, послiдовно виправляти коефiцiєнти aσ(j):N , якi вiдповiдаютьза те, що сума
SNj = NFN(ξσ(j):N , a) =
∑
i:ξi:N≤ξσ(j):N
ai:N
“спускається нижче” своїх попереднiх значень.Алгоритм має наступний вигляд:1. Обчислити антиранги σ(j), j = 1, . . . , N вибiрки ΞN .2. Покласти b+
σ(1) = max(aσ(1):N , 0), S1 = aσ(1):N , S+1 = b+
σ(1).3. Для j вiд 2 до N виконати:Sj = Sj−1 + aσ(j):N ;

2.3. Виправленi зваженi емпiричнi функцiї розподiлу 45
b+σ(j) = max(Sj − S+
j−1, 0);S+
j = S+j−1 + b+
σ(j).Якщо потрiбно обчислити коефiцiєнти b∗j для функцiї F+
N , визначеної(2.27), то у п.3 алгоритму потрiбно ввести додаткову перевiрку: поки Sj <
N , b∗σ(j) = b+σ(j), а як тiльки при деякому j0 виконано Sj0 ≤ N , то b∗σ(j0) =
N − Sj0 i b∗σ(j) = 0 для всiх j > j0.Помiтимо, що знаходження антирангiв — це процедура, аналогiчна
сортуванню вибiрки. Швидкi алгоритми сортування вимагають порядкуCN ln N операцiй. Виконання п. 2-3 вимагає порядку CN операцiй. Отже,загальна кiлькiсть операцiй, потрiбних для розрахунку коефiцiєнтiв b+ таb∗ має порядок CN ln N . Такi алгоритми прийнято вважати швидкими.
Якщо у вибiрцi наявнi декiлька рiвних мiж собою значень, скажiмо,ξj1:N = ξj2:N = · · · = ξjl:N , то доцiльно замiнити їх одним значенням ξj1:N ,якому вiдповiдає ваговий коефiцiєнт a∗j1:N = aj1:N + · · ·+ajl:N . Коефiцiєнтивиправленої з.е.ф.р. можна пiсля цього розраховувати за наведеним вищеалгоритмом.
Коефiцiєнти b+ та b∗ залежать вiд спостережень, але не залежать вiдзначення x, при якому пiдраховується з.е.ф.р. F+
N або F+N . Зрозумiло, що
коли виправлену з.е.ф.р. F+N потрiбно обчислити при багатьох рiзних зна-
ченнях x, ї ї коефiцiєнти доцiльно пiдрахувати один раз i запам’ятати, звер-таючись до них кожного разу, коли виникне потреба обчислення виправ-леної з.е.ф.р.
Iншi варiанти виправлення з.е.ф.р.Крiм F+
N визначеної (2.27), ми розглянемо кiлька iнших варiантiв ви-правлення з.е.ф.р. Усi функцiї, отриманi в результатi виправлення, ми бу-демо вважати неперервними злiва, що вiдповiдає означенню ф.р. Fξ(x) =P{ξ < x}. У деяких випадках формули виправлення зручно будувати так,що отримана функцiя виходить неперервною зправа. Для того, щоб “дови-правити” такi функцiї введемо оператор L[f ](x) = limy↑x f(y), який замiняєзначення функцiї f у точцi стрибка на границю f у цiй точцi злiва. За-уважимо, що з практичної точки зору, це “довиправлення” нiякої ролi неграє, оскiльки всi розглядуванi нами виправленi з.е.ф.р. матимуть вигляд
1
N
N∑j=1
bj1I{ξj:N < x},
i для їх використання досить тiльки обчислити коефiцiєнти bj.

46 Роздiл 2. Оцiнювання функцiй розподiлу
Отже, введемоF+
N (x, a) := supy<x
FN(y, a), (2.30)
F−N (x, a) := L[inf
y>xFN(y, a)], (2.31)
F−N (x, a) := max(F−
N (x, a), 0), (2.32)
F±N (x, a) :=
1
2(F+
N (x, a) + F−N (x, a)), (2.33)
F±N (x, a) =
F+N (x, a), якщо F+
N (x, a) ≤ 1/2;F−
N (x, a), якщо F−N (x, a) ≥ 1/2;
1/2, в iнших випадках.(2.34)
Функцiю F+N (x, a) можна назвати “верхньою огинаючою” для функцiї
FN(x, a), оскiльки це найменша монотонно неспадна функцiя, графiк якоїлежить вище FN(x, a). Аналогiчно, F−
N (x, a) — нижня огинаюча FN(x, a)(див. рис. 2.1 на с. 43). Виправляючи зважену емпiричну функцiю роз-подiлу, природно вимагати, щоб отримана оцiнка лежала мiж нижньоюта верхньою огинаючими. Зрозумiло, що таких оцiнок iснує нескiнченнобагато.
Функцiї F+N (x, a) та F−
N (x, a) зрiзають оцiнки F+N (x, a) та F−
N (x, a) вiд-повiдно на правому та на лiвому кiнцях областi можливих значень спосте-режень, там, де цi оцiнки виходять за межi iнтервалу [0,1].
Для пiдрахунку F−N (x, a) та F−
N (x, a) можна скористатись тим же алго-ритмом, який був запропонований для верхньої огинаючої, але з рухом поварiацiйному ряду у протилежному напрямку — вiд найбiльших значеньдо найменших.
Оцiнка F±N (x, a) отримана склеюванням верхньої та нижньої огинаю-
чої FN(x, a): лiва нижня частина графiка F+N (x, a) утворюється верхньою
огинаючою, тобто F+N (x, a), а верхня права частина — нижньою огина-
ючою, тобто F−N (x, a). Склеювання проведено “по медiанi”. Такий спосiб
утворення оцiнки дозволяє вiдмовитись вiд зрiзання на кiнцях, оскiльки0 ≤ F±
N (x, a) ≤ 1 для всiх x ∈ R i для будь-яких вагових коефiцiєнтiв a.Асимптотика виправлених з.е.ф.р. Надалi iндексом ∗ позначати-
мем будь-яку комбiнацiю ˆ або ˜ з +, − або ±, тобто F ∗(x, a) може бутибудь-якою з функцiй, визначених (2.30-2.34). У цьому параграфi ми буде-мо розглядати лише з.е.ф.р., якi використовуються для оцiнки розподiлуk-тої компоненти сумiшi, тобто Hk.

2.3. Виправленi зваженi емпiричнi функцiї розподiлу 47
Враховуючи монотоннiсть Hk, легко бачити, що
supx∈R
|F+N (x, a)−Hk(x)| ≤ sup
x∈R|FN(x, a)−Hk(x)| (2.35)
isupx∈R
|F−N (x, a)−Hk(x)| ≤ sup
x∈R|FN(x, a)−Hk(x)|, (2.36)
тому нерiвнiсть Вапника-Червоненкiса без змiн переноситься на виправ-ленi з.е.ф.р. i з рiвномiрної консистентностi FN(·, a) як оцiнки Hk (напри-клад, при виконаннi умов наслiдку 2.2.4) випливає рiвномiрна консистент-нiсть F ∗
N(x, a).Перейдемо до дослiдження асимптотичної нормальностi.Емпiричним процесом для FN(x, a) як i ранiше будемо називати
BN(x) = BN(x, a) :=√
N(FN(x, a)−Hk(x)),
i, вiдповiдно, емпiричним процесом для виправленої з.е.ф.р. F ∗N(x, a) на-
звемоB∗
N(x) = BN(x, a) :=√
N(F ∗N(x, a)−Hk(x)).
Спочатку ми дослiдимо асимптотичну поведiнку B+N .
Помiтимо, що процес B+N , визначений (2.28), можна задати за допомо-
гою BN(x):
B+N(x) =
√N(sup
y<x(Hk(y) + BN(y)/
√N)−Hk(x)). (2.37)
Для доведення асимптотичної нормальностi B+N скористаємося технiкою
одного ймовiрнiсного простору з п. 2.2.Надалi ми будемо ототожнювати процес BN(x) з B′
N(x), побудованиму теоремi 2.2.5. (оскiльки їх розподiли однаковi, а нас по сутi цiкавитьслабка збiжнiсть). Пiд B+
N(x) будемо розумiти процес, визначений (2.37).Будемо називати x точкою росту функцiї розподiлу Hk, якщо ∀δ > 0,
Hk(x) −Hk(x − δ) > 0. Множину всiх точок росту функцiї Hk позначимоsupp Hk i назвемо носiєм розподiлу Hk.
Теорема 2.3.1 Нехай виконанi умови теореми 2.2.5 i для всiх m = 1,. . . ,M , supp Hm ⊆ supp Hk. Тодi
supx∈R
|B+N(x)−BN(x)| → 0 (2.38)
при N →∞ за ймовiрнiстю.

48 Роздiл 2. Оцiнювання функцiй розподiлу
Доведення теореми проведемо у два кроки. Спочатку доведемо, щомає мiсце поточкова збiжнiсть за ймовiрнiстю, тобто, для всiх x ∈ R,
P{|B+N(x)−BN(x)| > ε} → 0 при N →∞. (2.39)
На другому кроцi, використовуючи (2.39), доведемо (2.38).Покажемо, що при доведеннi досить розглянути випадок, коли носiї
розподiлiв усiх компонент є обмеженими. Зробимо перетворення ξj:N →ξj:N = 2
πarctan ξj:N . Нехай Hm — ф.р. випадкової величини 2
πarctan ηm,
де ηm — в.в. з розподiлом Hm. Тодi (ξj:N , j = 1, . . . , N) є вибiркою iз су-мiшi зi змiнними концентрацiями з розподiлами компонент Hm i концен-трацiями wm
j:N . При цьому, якщо BN i ˆB+
N — вiдповiднi емпiричнi про-цеси, побудованi по (ξj:N , j = 1, . . . , N), то BN( 2
πarctan(x)) = BN(x) i
supx |BN(x)− ˆB+
N(x)| = supx |BN(x)− B+N(x)|. Оскiльки supp Hm ⊆ [−1, 1],
то це означає, що ми можемо надалi обмежитись лише розглядом такихвибiрок, у яких supp Hm ⊆ [−1, 1].
Отже, доведемо (2.39). Оскiльки, за побудовою, завжди B+N(x) ≥ BN(x),
то нам досить переконатись, що ∀ε > 0, P{B+N ≥ BN(x) + ε} → 0 при
N →∞.Помiтимо, що коли для деяких δ > 0 та x ∈ R, (x− δ, x) ∩ supp Hk = ∅
(i, за умовою теореми, (x− δ, x) ∩ supp Hm = ∅ для всiх m = 1, . . . , M), тоP{ξj:N ∈ (x− δ, x)} = 0 i, отже, FN(x, a) = FN(x− δ, a), Hk(x) = Hk(x− δ),F+
N (x, a) = F+N (x−δ, a), BN(x) = BN(x−δ), B+
N(x) = BN(x−δ). Позначимоs(x) = sup{x′ ∈ supp Hk : x′ < x}. Тодi s(x) ∈ supp Hk i BN(x) = BN(s(x)),B+
N(x) = B+N(s(x)). Тому (2.39) досить довести для x ∈ supp Hk, що ми i
зробимо.Нехай δ — довiльне число, таке, що 0 < δ < ε, t0 ∈ R, r ∈ N. Позначимо
tj = t0 + δj, AN = {B+N(x) ≥ BN(x) + ε}, A−
N = {BN(x) < t0}, A+N = {B+
N ≥tr +ε}, Aj
N = {BN(x) ∈ [tj, tj +δ], B+N > tj +ε}. Тодi AN ⊆ A+
N ∪A−N ∪r−1
j=0 AjN .
Зафiксуємо довiльнi z > 0, ε > 0. Покладемо δ = ε/2. Оцiнимо ймо-вiрностi подiй A+
N , A−N , Aj
N . Оскiльки, для будь-якого фiксованого λ > 0,P{|BN(x) − B(x)| > λ} → 0 при N → ∞ i P{|B(x)| > λ} → 0 при λ → ∞,то можна обрати t0 так, щоб p−N = P(A−
N) < ε/3 для всiх досить великих N .Враховуючи, що, крiм того, B+
N(x) > BN(x), можна обрати досить великеr (i, отже, tr) так, щоб p+
N = P(A+N) < ε/3. Фiксуємо t0 та r.
Оцiнимо тепер pjN = P(Aj
N) ≤ P{BN(x) < tj+1, B+N(x) > tj+1+δ} (оскiль-

2.3. Виправленi зваженi емпiричнi функцiї розподiлу 49
ки tj+1 = tj + δ, ε = 2δ). Але
{B+N(x) > tj+1 + δ} = {sup
y<x(Hk(y) + BN(y)/
√N) > Hk(x) + (tj+1 + δ)/
√N}
= {∃y ≤ x : BN(y) > tj+1 + δ +√
N(Hk(x)−Hk(y)))}i
AjN ⊆ {BN(x) < tj+1 i ∃y ≤ x : BN(y) > tj+1 + δ +
√N(Hk(x)−Hk(y)))}.
Фiксуємо деяке l > 0. Помiтимо, що остання подiя виконується або тодi,коли процес BN(y) виходить за рiвень
√N(Hk(x) − Hk(y)) + tj+1 + δ при
деякому y < x− l, або за рiвень tj+1 + δ на iнтервалi [x− l, x]. Тому pjN ≤
P(CN) + P(DN), де CN = {supy BN(y) > tj+1 + δ +√
N(Hk(x)−Hk(x− l))},DN = {BN(x) < tj+1, ∃y ∈ [x− l, x], BN(y) > tj+1 + δ}
Оцiнимо P{DN} ≤ P{sup|y−x|<l |BN(x)− BN(y)| > δ}. Оскiльки B(x) —процес з неперервними траєкторiями, то можна обрати достатньо мале lтак, щоб
P{ sup|x−y|<l
|B(x)−B(y)| > δ
3} ≤ ε
18r, (2.40)
а за теоремою 2.2.5, при достатньо великих N ,
P{supx|BN(x)−B(x)| > δ
3} ≤ ε
18r(2.41)
Оскiльки |BN(x)−BN(y)| ≤ |BN(x)−B(x)|+ |B(x)−B(y)|+ |B(y)−BN(y)|,то з виконання (2.40) - (2.41) маємо
P{DN} ≤ ε
6r. (2.42)
Фiксуємо l i оцiнимо P(CN). Оскiльки при l > 0, Hk(x) > Hk(x − l), аsupy BN(y) → supy B(y) < ∞ (N → ∞) за теоремою 2.2.5, то P(CN) → 0при N →∞. Тому при великих N ,
P(CN) ≤ ε
6r. (2.43)
Об’єднуючи нерiвностi (2.42) i (2.43) отримуємо pjN ≤ ε
3r.
Остаточно маємо
P(AN) ≤ p+N + p−N +
r∑j=1
pjN ≤ ε
3+
ε
3+
r∑j=1
ε
3r≤ ε

50 Роздiл 2. Оцiнювання функцiй розподiлу
при достатньо великих N . Отже (2.39) доведено.Доведемо (2.38). Нехай [a, b] — довiльний iнтервал. Оскiльки B+
N(x) ≥BN(x), то infx∈[a,b] B
+N(x) ≥ infx∈[a,b] BN(x). Оцiнимо supx∈[a,b] B
+N(x) зверху.
Оскiльки B+N — монотонно спадна функцiя на iнтервалах мiж стрибками
F+N (x, a), то цей супремум може досягатись або у момент стрибка функ-
цiї F+N (x, a), або на лiвому кiнцi iнтервала [a, b]. У першому випадку вiн
спiвпадає з supx∈[a,b] BN(x). Отже
supx∈[a,b]
B+N(x) ≤ max(B+
N(a), supx∈[a,b]
BN(x)). (2.44)
Внаслiдок того, що траєкторiї B(x) неперервнi, для будь-яких λ, ε > 0,можна обрати таке δ, що для tj = −1 + δj буде виконуватись нерiвнiстьP{supj |B(tj)−B(tj−1)| > ε} < λ, а за (2.39), для достатньо великих N ,
P{supj|B+
N(tj)−BN(tj)| > ε} < λ. (2.45)
За теоремою 2.2.5, δ можна обрати так, що
P{ sup|x−y|<δ
|BN(x)−BN(y)| > ε} < λ
i, отже,P{max
j( supy∈[tj ,tj+1]
BN(x)− infy∈[tj ,tj+1]
BN(x)) > ε} < λ. (2.46)
Для будь-якого x ∈ [−1, 1] знайдеться j таке, що x ∈ [tj, tj+1] i
B+N(x) ≥ inf
y∈[tj ,tj+1]B+
N(y) ≥ infy∈[tj ,tj+1]
BN(y),
а за (2.44),
B+N(x) ≤ sup
y∈[tj ,tj+1]
B+N(y) ≤ max(B+
N(tj), supy∈[tj ,tj+1]
BN(y))
≤ max(BN(tj) + ε, supy∈[tj ,tj+1]
BN(y)) ≤ supy∈[tj ,tj+1]
BN(y) + ε,
якщо виконана подiя, що стоїть пiд знаком ймовiрностi у (2.45). Тому,враховуючи (2.45), маємо
P{∀j, ∀x ∈ [tj, tj+1] infy∈[tj ,tj+1]
BN(y) ≤ B+N(x) ≤ sup
y∈[tj ,tj+1]
BN(y) + ε} < λ.

2.3. Виправленi зваженi емпiричнi функцiї розподiлу 51
Звiдси, враховуючи (2.46), отримуємо
P{supx|B+
N(x)−BN(x)| > 2ε} < 2λ.
Внаслiдок довiльностi ε i λ отримуємо твердження теореми.Тепер переконаємось, що твердження теореми 2.3.1 вiрне i для iнших
методiв виправлення зважених емпiричних функцiй розподiлу.
Теорема 2.3.2 Нехай1. Для деякого A < ∞ supj,N |aj:N | < A;2.Для всiх l, m = 1, . . . , M iснують границi 〈wlwm(a)2〉;3. Hm є неперервними функцiями на R при всiх m = 1, . . . , M ;4. Виконана умова незмiщеностi (2.5):
〈awm〉N = 1I{m = k} для всiх m = 1, . . . , M ;
5.Для всiх m = 1,. . . , M , supp Hm ⊆ supp Hk.Тодi
supx∈R
|B∗N(x)−BN(x)| → 0 (2.47)
при N →∞ за ймовiрнiстю.
Зауваження. Якщо рiвномiрної збiжностi вимагати лише на деякомуiнтервалi I = [x0, x1], тобто (2.47) замiнити на
supx∈I
|B∗N(x)−BN(x)| → 0, (2.48)
то умову 5 теореми можна замiнити на5’.Для всiх m = 1,. . . , M , (supp Hm ∩ I) ⊆ (supp Hk ∩ I).Нагадаємо, що за теоремою 2.2.5, емпiричний процес BN слабко збi-
гається до гауссового процесу B з нульовим середнiм i коварiацiйною функ-цiєю
E B(x)B(y) =M∑
m=1
〈wm(a)2〉Hm(min(x, y))
−M∑
i,m=1
〈wmwi(a)2〉Hm(x)Hi(y)
Наслiдок 2.3.1 В умовах теореми 2.3.2 емпiричнi процеси B∗N слабко
збiгаються до B у просторi D(R) з рiвномiрною нормою.

52 Роздiл 2. Оцiнювання функцiй розподiлу
Доведення теореми 2.3.2. Для B+N твердження теореми доведено у
теоремi 2.3.1. Оскiльки
F−N (x, a) = L[1− F+
−ΞN(−x)],
(тут через F+−ΞN
(x) позначено виправлену з.е.ф.р. (2.26), обчислену за ви-бiркою −ΞN = (−ξ1:N , . . . ,−ξN :N)) то справедливiсть твердження теоремидля B−
N випливає з його справедливостi для B+N . Далi маємо
F−N (x, a) ≤ F−
N (x, a) ≤ F±N (x, a) ≤ F+
N (x, a) ≤ F+N (x, a)
i аналогiчнi нерiвностi є вiрними для вiдповiдних B∗N . Звiдси робимо вис-
новок, що твердження теореми є вiрним для B−N , B+
N , B±N . Вiрнiсть твер-
дження теореми для B±N також випливає з того, що
F−N (x, a) ≤ F±
N (x, a) ≤ F+N (x, a).
2.4 Асимптотично ефективна оцiнкарозподiлу
Емпiричнi мiри µ(ak, ·) з мiнiмаксними ваговими коефiцiєнтами (2.10) єоцiнками розподiлiв компонент Hk(·), найкращими у найгiршому випад-ку: як показано у теоремi 2.1.1, iснує такий (найгiрший) набiр розподiлiвкомпонент, для якого жодна незмiщена оцiнка не може мати середньоквад-ратичний ризик, менший нiж µ(ak, ·), а для всiх iнших розподiлiв ризикµ(ak, ·) кращий, нiж для найгiршого.
В той же час ця теорема не заперечує iснування оцiнок, якi могли б бутикращими нiж µ(ak, ·) на розподiлах, вiдмiнних вiд найгiршого. Хотiлося бзнайти таку оцiнку, яка оцiнювала б будь-який розподiл краще, нiж будь-яка iнша оцiнка. Зрозумiло, що в такiй формi це бажання нездiйсненне— для будь-якого розподiлу H0
k найкращою можливою буде оцiнка Hk,яка незалежно вiд даних тотожно дорiвнює H0
k . Однак для всiх розподiлiвHk 6= H0
k ця оцiнка буде чи не найгiршою.Тому у класичнiй теорiї оцiнювання по вибiрках великого обсягу (див.
короткий огляд у п. 7.5, а бiлш докладно — наприклад, у книзi [10]), най-кращими вважаються оцiнки, якi можна назвати асимптотично локальномiнiмаксними. У [10] саме такi оцiнки називають асимптотично ефектив-ними (АЕ). Для будь-якого значення невiдомого параметра2, якщо роз-глядати задачу оцiнювання у як завгодно малому вiдкритому околi цього
2у нас параметром є набiр розподiлiв компонент

2.4. Асимптотично ефективна оцiнка розподiлу 53
значення, мiнiмаксний по цьому околу ризик АЕ оцiнки стає меншим нiжмiнiмаксний ризик будь-якої iншої оцiнки.
Нажаль, емпiричнi мiри µ(ak, ·) не є асимптотично ефективними оцiн-ками. У цьому параграфi ми розглянемо побудову АЕ оцiнок для випадку,коли простiр спостережень X є скiнченним. Без обмеження загальностiможна вважати, що X = {1, . . . , L}, де L — фiксоване число. РозподiлиHk у цьому випадку визначаються набором ймовiрностей Hm({l}) = H(l,m),l = 1, . . . , L, m = 1, . . . , M . Вибiрка з сумiшi зi змiнними концентрацiямискладається з незалежних спостережень ξj з розподiлом
P{ξj = l} =M∑
m=1
wmj H(l,m). (2.49)
Тут wmj вiдомi (як звичайно у цiй книзi), а H(l,m) потрiбно оцiнити за
вибiркою ΞN = (ξ1, . . . , ξN). (Щоб зменшити i без того велику кiлькiстьiндексiв, ми у цьому парагарфi дещо вiдступимо вiд загальної схеми по-значень, прийнятої у книзi, зокрема, не будемо писати у нижньому iндексiспостережень, концентрацiй i вагових коефiцiєнтiв :N , вважаючи, що всю-ди йдеться про вибiрку обсягу N .)
У такiй постановцi задача стає параметричною, а при мiнiмальних об-меженнях — регулярною. Це дозволяє використовувати асимптотичну тео-рiю параметричного оцiнювання. Зокрема, виявляється, що оцiнки най-бiльшої вiрогiдностi (ОНВ) для H(l,m) будуть асимптотично ефективними.(Вiдмiтимо, що у загальнiй непараметричнiй постановцi задачi оцiнюваннярозподiлiв компонент оцiнки емпiричного методу найбiльшої вiрогiдностiне є навiть консистентними.) Однак у цiй задачi ОНВ не записуються у яв-ному виглядi, а знаходження їх чисельними методами може бути пов’язанез труднощами навiть при не дуже великих значеннях L.
Ми розглянемо iнший пiдхiд до оцiнювання, який також забезпечуєпобудову асимптотично ефективних оцiнок. Цей пiдхiд спирається на за-гальну технiку адаптивного оцiнювання: спочатку невiдомий параметроцiнюється грубо, за допомогою пiлотної оцiнки, а потiм пiлотна оцiн-ка використовується для бiльш акуратного налаштування характеристикоцiнюючого алгоритму на локальнi особливостi задачi.
Спочатку введемо у розгяд клас оцiнок, якi ми будемо використовуватидля побудови адаптивного алгоритму.
Ми побудуємо асимптотично ефективну оцiнку набору невiдомих па-раметрiв (H(l,m))l=1,...,L;m=1,...,M . Оскiльки
∑Ll=1 H(l,m) = 1, досить оцiнити
H(l,m) при l = 1, . . . , L − 1. Надалi ми будемо розглядати пару (l,m) як

54 Роздiл 2. Оцiнювання функцiй розподiлу
один блочний iндекс, еквiвалентний iндексу j(l, m) = (L − 1)(m − 1) + l.Набiр ~H = (H(l,m))l=1,...,L−1;m=1,...,M у цьому випадку являє собою векторвимiрностi (L− 1)M . Розглянемо спочатку статистики вигляду
H(a··) =1
N
N∑j=1
L−1∑
l1=1
al1j χl1
j , (2.50)
де χlj = 1I{ξj = l} — iндикатор подiї ξj = l, al1
j — невипадковi ваговiкоефiцiєнти3. Цi статистики назвемо лiнiйними оцiнками.
Зважена емпiрична мiра з мiнiмаксними коефiцiєнтами є частковимвипадком лiнiйної оцiнки. Щоб задати її введемо
gm1m2 =1
N
N∑j=1
wm1j wm2
j = 〈wm1wm2〉N . (2.51)
Як i ранiше позначатимем
ΓN = (gm1m2)Mm1,m2=1.
Нехай det ΓN 6= 0. Тодi iснує обернена матриця Γ−1N , елементи якої будемо
позначати gm1m2 , тобто (gm1m2)Mm1,m2=1 := Γ−1
N .Тепер мiнiмаксну оцiнку для H(l1,m1) можна зобразити у виглядi (2.50)
з ваговими коефiцiєнтами
alj(m1) =
{∑Mm=1 gm1mwm
j якщо l = l1,
0 якщо l 6= l1.
Цю оцiнку позначимо HLS(l1,m1) (Iндекс LS є скороченням для “least squares”
— найменшi квадрати. Вiн вказує на те, що оцiнка мiнiмiзує середньоквад-ратичний ризик.)
Як вже було вiдмiчено, HLS(l1,m1) не є ефективною оцiнкою — можливi
незмiщенi оцiнки, якi для певного значення параметру ~H мають диспер-сiю, меншу нiж HLS
(l1,m1). Фiксуємо ~H i знайдемо ваговi коефiцiєнти, з якимилiнiйна оцiнка (2.51) буде мати найменшу дисперсiю в класi всiх незмiще-них лiнiйних оцiнок для ~H.
3Звернiть увагу на те, що у цьому позначеннi верхнiй iндекс вагових коефiцiєнтiвпов’язаний не з номером оцiнюваної компоненти, а зi значенням, яке можуть прийматиданi.

2.4. Асимптотично ефективна оцiнка розподiлу 55
Позначимо Pj(l) = Pj(l, ~H) = P{ξj = l} =∑M
m=1 wmj H(l,m),
pl1l2j ( ~H) = Pj(l1, ~H)1I{l1 = l2} − Pj(l1, ~H)Pj(l2, ~H),
Πj = Πj( ~H) = (pl1l2j ( ~H))L−1
l1,l2=1,
pl1l2j = pl1l2
j ( ~H) =
Pj(L, ~H)+Pj(l1, ~H)
Pj(L, ~H)Pj(l1, ~H)якщоl1 = l2,
1
Pj(L, ~H)якщоl1 6= l2.
Вiдмiтимо, що матриця Πj = (pl1l2j )L−1
l1,l2=1 є оберненою до Πj (це перевiряєть-ся безпосереднiм множенням цих матриць).
Тепер позначимо
γN(l1,m1)(l2,m2)( ~H) =
1
N
N∑j=1
pl1l2j wm1
j wm2j ,
ΓN( ~H) = (γN(l1,m1)(l2,m2)( ~H))li=1,...,L−1;mi=1,...,M .
Набiр ΓN( ~H) можна розглядати як квадратну матрицю вимiрностi ((L −1) ·M)× ((L− 1) ·M). Позначимо ΛN( ~H) = (λN
(l1,m1)(l2,m2)(~H))) — матрицю,
обернену до ΓN( ~H), якщо вона iснує. (Тобто∑
l,m λ(l1,m1)(l,m)γ(l,m)(l2,m2) =1I{l1 = l2,m1 = m2}). Покладемо
al2j ( ~H, l1,m1) = al2
j (l1,m1) =L−1∑
l=1
M∑m=1
pl2l1j λN
(l1,m1)(l,m)( ~H)wmj (2.52)
Теорема 2.4.1 Нехай(i) N > L ·M ,(ii) матриця ΓN , визначена (2.51), є невиродженою,(iii) для всiх j = 1, . . . , N , l = 1, . . . , L, 0 < Pj(l) < 1.Тодi матриця ΓN( ~H) невироджена i статистика H(a··( ~H, l1,m1)) є
незмiщеною оцiнкою H(l1,m1) з дисперсiєю, мiнiмальною в класi всiх незмi-щених оцiнок вигляду (2.50). Ця дисперсiя дорiвнює
σN(l1,m1)( ~H) = E(H(a··(l1,m1))−H(l1,m1))
2 =1
NλN
(l1,m1)(l1,m1)( ~H).

56 Роздiл 2. Оцiнювання функцiй розподiлу
Зауваження. Оскiльки ΓN є матрицею Грама системи векторiв wm =(wm
1 , . . . , wmN ), m = 1, . . . , M , то її невиродженiсть еквiвалентна лiнiйнiй
незалежностi цих векторiв.Доведення. Легко бачити, що оцiнки вигляду (2.50) є незмiщеними
для H(l1,m1) тодi i тiльки тодi, коли
1
N
N∑j=1
aljw
m2j = 1I{m1 = m2, l = l1}. (2.53)
Позначимо J(a··, ~H) = J(a··) = E(H(a··)−H(l1,m1))2. Якщо H(a··) — незмiщена
оцiнка, то
J(a··, ~H) =1
N2
N∑j=1
~aTj Πj~aj, (2.54)
де ~aj = (a1j , . . . , a
L−1j )T . Розв’язуючи задачу мiнiмiзацiї функцiоналу J ,
заданого (2.54) при обмеженнi (2.53), отримуємо (2.52), якщо ΓN( ~H) iвсi Πj — невиродженi матрицi. Безпосереднiм обчисленням отримуємоJ(a··(l1,m1), ~H) = 1
NλN
(l1,m1)(l1,m1)(~H). Невиродженiсть Πj випливає з того,
шо при 0 < Pj(l) < 1, iснує Πj = Π−1j . Невиродженiсть ΓN( ~H) випливає з
наступної леми.
Лема 2.4.1 Нехай Zj = (zj(l1,l2))
L−1l1,l2=1, j = 1, . . . , N — довiльнi симетрич-
нi, додатньовизначенi матрицi, wmj , j = 1, . . . , N , m = 1, . . . , M — довiль-
нi числа, ΓN визначено (2.51), emin(Z) — найменше власне число матрицiZ,
g(l1,m1)(l2,m2) =1
N
N∑j=1
zj(l1,l2)w
m1j wm2
j , G = (g(l1,m1)(l2,m2))(l1,m1)(l2,m2).
Тодidet G ≥ ( min
1≤j≤Nemin(Zj))
M(L−1) det Γ.
Твердження леми випливає з теореми 7.2.1, якщо у цiй теоремi покла-сти T = {1, . . . , N}, wm(j) = wm
j , µl1,l2(A) = N−1∑
j∈A zjl1,l2
.Застосовуючи лему 2.4.1 до матрицi ΓN( ~H) з урахуванням додатньо-
визначеностi Πj, отримуємо det ΓN( ~H) 6= 0.Теорема доведена.

2.4. Асимптотично ефективна оцiнка розподiлу 57
Скористатись теоремою 2.4.1 безпосередньо для побудови оцiнки неможна, оскiльки оптимальнi ваговi коефiцiєнти у (2.52) залежать вiд невi-домого параметра ~H. Пiдставляючи в (2.52) замiсть ~H його оцiнку ~HLS =(HLS
(l,m)), отримуємо адаптивну оцiнку
HN(l1,m1) = H(a··( ~HLS, l1,m1)), HN = (HN
(l,m)).
Оскiльки у цьому випадку ваговi коефiцiєнти є випадковими i залежатьвiд спостережень, теорему 2.4.1 до адаптивної оцiнки застосувати немож-на. Однак, як свiдчить наступна теорема, граничний розподiл адаптивноїоцiнки такий самий, як i у найкращої лiнiйної оцiнки.
Теорема 2.4.2 Нехай виконанi наступнi умови(i) Iснують δ1, δ2 > 0, такi, що для всiх j ∈ N i всiх ~H1, таких, що
| ~H1 − ~H| < δ1,δ2 < Pj( ~H1) < 1− δ2. (2.55)
(ii) Iснує limN→∞ ΓN = Γ, det Γ 6= 0.(iii) Iснує δ3, таке, що для всiх ~H1, ~H2 | ~Hi − ~H| < δ3 i всiх m1,m2 =
1, . . . , M , l1, l2 = 1, . . . , L− 1, iснують границi
limN→∞
γN(l1,m1)(l2,m2)( ~H1, ~H2) = γ(l1,m1)(l2,m2)( ~H1, ~H2), (2.56)
де
γN(l1,m1)(l2,m2)( ~H1, ~H2) =
1
N
N∑j=1
L−1∑i1,i2=1
pi1l1j ( ~H1)p
i2l2j ( ~H2)w
m1j wm2
j pi1i2j ( ~H).
Тодi при N →∞ розподiл√
N(HN − ~H) слабко збiгається до нормаль-ного з нульовим середнiм та коварiацiйною матрицею Λ( ~H).
Зауваження. Умова (i) виконана, якщо δ < H(l,m) < 1 − δ для всiхl, m, або якщо δ < wk
j < 1− δ для всiх j, k.Дещо громiздка умова (iii) виконана для звичайних моделей wm
j — длястохастичних i для функцiональних концентрацiй (див. приклади 1 i 2 уп. 2.2).
Доведення теореми. Нехай D — деякий окiл ~H, такй, що для будь-яких ~H1, ~H2 ∈ D виконано (2.55) та (2.56). Позначимо
F(l1,m1)( ~H1) =1
N
N∑j=1
L−1∑
l=1
pll1j ( ~H1)w
m1j χl
j,

58 Роздiл 2. Оцiнювання функцiй розподiлу
Y N(l1,m1)( ~H1) =
√N(F(l1,m1)( ~H1)− E F(l1,m1)( ~H1)).
Покажемо, що ~Y N(·) слабко збiгається у C(D) до гауссового випадково-го поля ~Y з середнiм 0 та E ~Y ( ~H1)(~Y ( ~H2))
T = Γ(H1, H2), де Γ(H1, H2) =
(γ(l1,m1)(l2,m2)( ~H1, ~H2)). Легко бачити, що E ~Y N(H1) = 0 i
E Y N(l1,m1)( ~H1)Y
N(l2,m2)( ~H2) = γN
(l1,m1)(l2,m2)( ~H1, ~H2).
Оскiльки в.в. χlj незалежнi i |χl
j| ≤ 1, а pl1l2j (H1) рiвномiрно обмеженi на
D, з цього випливає збiжнiсть скiнченновимiрних розподiлiв ~Y N до ~Y .Доведемо компактнiсть розподiлiв ~Y N у C(D). Для цього помiтимо, що
на D,
Y(l1,m1)( ~H1)− Y(l2,m2)( ~H2) =1√N
N∑j=1
L−1∑
l=1
zjl( ~H1, ~H2)(χlj − Pj(l, ~H)),
де |zjl( ~H1, ~H2)| ≤ C| ~H1 − ~H2|, C — деяка константа. Тому
E |Y(l1,m1)( ~H1)− Y(l2,m2)( ~H2)|2k ≤ C| ~H1 − ~H2|2k
для будь-якого цiлого k ≥ 1. Тому, внаслiдок критерiю компактностi вC(D) (теорема 7.4.4), отримуємо компактнiсть розподiлiв ~Y N i, отже, слаб-ку збiжнiсть у C(D).
За законом великих чисел з умови (ii) випливає, що HLS(l,m) збiгаєть-
ся м.н. при N → ∞ до H(l,m). Отже, ~ZN = ~Y N( ~HLS) слабко збiгаєть-ся до ~Y ( ~H). Вiдмiтимо, що згiдно з (2.52),
√N(HN − ~H) = ΛN( ~HLS)~ZN .
Оскiльки E ~Y ( ~H)(~Y ( ~H))T = Γ( ~H, ~H) = Λ−1( ~H), то залишилось довести, щоΛN( ~HLS) → Λ( ~H) м.н. Помiтимо, що для ~H1, ~H2 ∈ D, |ΓN( ~H1)−ΓN( ~H2)| ≤C| ~H1 − ~H2|. Тому
|ΓN( ~HLS)− Γ( ~H)| ≤ |ΓN( ~HLS)− ΓN( ~H)|+ |ΓN( ~H)− Γ( ~H)|≤ C| ~HLS − ~H|+ |ΓN( ~H)− Γ( ~H)| → 0
м.н. за умовою (iii) теореми i внаслiдок збiжностi ~HLS до ~H. Враховуючиумову (ii) та лему 2.4.1, отримуємо det ΓN( ~H) ≥ C > 0. Тому det Γ( ~H) > 0.Отже, iснує Λ( ~H) = Γ−1( ~H) i ΛN( ~HLS) → Λ( ~H) м.н.
Теорема доведена.Покажемо тепер, що гранична поведiнка локально-мiнiмаксного серед-
ньоквадратичного ризику HN є найкращою можливою для всiх можливихоцiнок.

2.4. Асимптотично ефективна оцiнка розподiлу 59
Теорема 2.4.3 Нехай ~TN — довiльна оцiнка ~H за ΞN . Якщо(i) для ~H0 = (H0
(l,m)) виконано 0 < H0(l,m) < 1 для всiх 1 ≤ l ≤ L,
1 ≤ m ≤ M ,(ii) виконана умова (ii) теореми 2.4.2,(iii) для будь-якого ~H1 з деякого околу ~H0 iснує
limN→∞
ΓN( ~H1) = Γ( ~H1)
(iv) виконано (2.55),то для будь-якого δ > 0 и будь-якого вектора ~h,
limN→∞
N sup| ~H− ~H0|<δ
E((~TN − ~H)T~h)2 ≥ ~hT Λ( ~H0)~h,
зокрема,
limN→∞
N sup| ~H− ~H0|<δ
E(TN(l,m) −H(l,m))
2 ≥ λ(l,m)(l,m)( ~H0).
Доведення. Скористаємось теоремою Гаека (теорема 7.5.2). Для цьо-го необхiдно перевiрити, що стохастичний експеримент по оцiнюванню ~Hза ΞN є локально асимптотично нормальним (ЛАН) i його iнформацiйнаматриця Фiшера IN асимптотично еквiвалентна N(Λ( ~H))−1 = NΓ( ~H).
Обчислимо IN =∑N
j=1 Ij, де Ij — iнформацiйна матриця одного спо-стереження ξj. За означенням (див. п. 7.5),
Ij(l1,m1)(l2,m2) =
L∑x=1
∂Pj(x, ~H)
∂H(l1,m1)
∂Pj(x, ~H)
∂H(l2,m2)
1
Pj(x, ~H)
= wm1j wm2
j
(1I{l1 = l2}Pj( ~H, l1)
+1
Pj( ~H,L)
)= wm1
j wm2j pl1l2
j .
Отже, IN = NΓN( ~H) i, внаслiдок умови (ii), отримуємо IN ∼ NΓ( ~H) =
N(Λ( ~H))−1. Матриця, обернена до Λ( ~H) iснує, оскiльки det G 6= 0 i, отже,за лемою 2.4.1, det Γ( ~H) 6= 0.
Доведення ЛАН стохастичного експерименту зводиться до перевiркиумов 1 та 2 у теоремi 7.5.1. Вони виконанi, оскiльки ∂
∂ ~Hln Pj(χ
lj,
~H) та∂2
∂ ~H2Pj(χ
lj, ~H) є рiвномiрно обмеженими функцiями в околi ~H0.
Теорема доведена.

Роздiл 3
Оцiнки числових характеристикрозподiлiв компонент
У цьому роздiлi ми розглянемо методи оцiнювання таких ймовiрнiсних ха-рактеристик, як функцiональнi моменти та квантилi розподiлiв компонентсумiшей зi змiнними концентрацiями. Цi характеристики можна тракту-вати як функцiонали вiд розподiлiв (функцiй розподiлу) i застосувати дляпобудови та дослiдження оцiнок загальнi методи, якi використовують пiд-становку емпiричних оцiнок функцiй розподiлу у вiдповiднi функцiонали(метод пiдстановки). Технiка пiдстановки загальновiдома (див, наприклад,[2], [46]). Умови консистентностi та асимптотичної нормальностi оцiнок ме-тоду пiдстановки у моделях сумiшей зi змiнними концентрацiями наведенiу п. 4.1. [15]. Однак тут ми вiддамо перевагу прямим методам дослiджен-ня, орiєнтованим на конкретний вигляд оцiнюваних функцiоналiв. Зав-дяки цьому вдається побудувати бiльш точну теорiю та iнколи отриматиоцiнки, якi мають кращi властивостi, нiж оцiнки методу пiдстановки.
3.1 Лiнiйнi оцiнки функцiональних моментiв
У цьому параграфi ми почнемо розгляд задачi оцiнювання функцiональ-них моментiв розподiлiв компонент сумiшi зi змiнними концентрацiями.Як i ранiше, ми вважаємо, що спостережуванi данi (ξj:N , j = 1, . . . , N)являють собою вибiрку з незалежних спостережень з сумiшi зi змiнними

3.1. Лiнiйнi оцiнки функцiональних моментiв 61
концентрацiями, тобто
P{ξj ≤ x} =M∑
k=1
wkj:NHk(x) (3.1)
де M — кiлькiсть компонент у сумiшi, Hk — невiдомi розподiли компонент,wk
j:N — вiдомi концентрацiї компонент. Задача полягає в тому, щоб оцiнитизаданий функцiональний момент k-тої компоненти у сумiшi, тобто
gk =
∫g(x)Hk(dx) (3.2)
де g — деяка фiксована вiдома вимiрна функцiя, g : X → R. (У цьомупараграфi X може бути довiльним вимiрним простором).
Функцiональнi моменти з рiзними функцiями g грають велику роль яку теорiї ймовiрностей та математичнiй статистицi, так i у статистичномуаналiзi реальних даних. Такi основнi характеристики розподiлу випадко-вої величини, як математичне сподiвання, дисперсiя, асиметрiя та ексцесвиражаються через першi чотири полiномiальних моменти
∫xkHm(dx),
k = 1, 2, 3, 4. На використаннi рiзних функцiональних моментiв побудованiметод оцiнюючих рiвнянь та метод моментiв для оцiнювання невiдомихпараметрiв.
У випадку незалежних, однаково розподiлених випадкових елементiвζ1,. . . ,ζN з розподiлом Hk, “теоретичному” моменту gk вiдповiдає емпiрич-ний момент
1
N
N∑j=1
g(ζj),
котрий можна розглядати як результат пiдстановки звичайної (не зваже-ної) емпiричної мiри, побудованої по ζj, у формулу (3.2) замiсть Hk. Такимчином, емпiричний момент однорiдної вибiрки можна розглядати як оцiн-ку методу пiдстановки для теоретичного моменту.
По аналогiї з цiєю класичною оцiнкою, у випадку спостережень з су-мiшi зi змiнними концентрацiями можна для оцiнки gk пiдставити у (3.2)замiсть Hk зважену емпiричну мiру
µN(A, a) =1
N
N∑j=1
aj:N1I{ξj:N ∈ A},

62 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
вибравши ваговi коефiцiєнти a так, щоб ця мiра була хорошою оцiнкою Hk.В результатi такої пiдстановки отримуємо зважений емпiричний момент
gN(a) =
∫g(x)µN(a, dx) =
1
N
N∑j=1
aj:Ng(ξj), (3.3)
котрий ми будемо розглядати як оцiнку gk. Оцiнки вигляду (3.3) з невипад-ковими (незалежними вiд ξj:N) ваговими коефiцiєнтами будемо називатилiнiйними оцiнками.
Якщо det ΓN 6= 0, на роль a можна обрати вектор мiнiмаскних ваговихкоефiцiєнтiв ak, визначений (2.10). Однак чи буде цей вибiр найкращим?Вiдповiдь на це питання, взагалi кажучи, негативна: важко знайти такуточку зору, з якої мiнiмакснi ваговi коефiцiєнти слiд було б вважати най-кращими можливими.
Але i занадто поганим такий вибiр теж не є. Оцiнка
gk,0N = gN(ak) (3.4)
за досить широких умов буде консистентною та асимптотично нормаль-ною. В той же час, можна пiдiбрати ваговi коефiцiєнти a, при яких коефi-цiєнт розсiювання (асимптотична дисперсiя) gN(a) буде кращим (меншим)нiж у gk,0
N . Нажаль коефiцiєнт розсiювання лiнiйної оцiнки залежить вiдневiдомих характеристик розподiлу компонент сумiшi, зокрема, i вiд самихоцiнюваних функцiональних моментiв. При рiзних розподiлах компонентрiзнi ваговi набори забезпечують мiнiмiзацiю коефiцiєнта розсiювання.
Тому ми розглянемо технiку адаптивного оцiнювання, подiбну до вико-ристаної у п. 2.4: спочатку невiдомi характеристики розподiлу оцiнюютьсяза допомогою не найкращих лiнiйних оцiнок (наприклад, з мiнiмаксни-ми ваговими коефiцiєнтами), потiм за допомогою таких “пiлотних” оцiнокрозраховуються оцiнки для оптимальних коефiцiєнтiв i остаточна оцiн-ка використовує цi оцiненi коефiцiєнти. Отримана адаптивна оцiнка будемати коефiцiєнт розсiювання, рiвний найменшому можливому коефiцiєн-ту розсiювання лiнiйної оцiнки. (Зауважимо, що сама адаптивна оцiнкау нашому розумiннi не є лiнiйною — її ваговi коефiцiєнти залежать вiдвипадкових даних).
Слiд вiдмiтити, що ця схема має i принципову вiдмiннiсть вiд схемиадаптацiї емпiричних розподiлiв з п. 2.4. Задача, розглянута у п. 2.4 булапараметичною: задавши розподiли всiх компонент, ми повнiстю визнача-ли розподiл спостережуваних даних. Задання функцiональних моментiв

3.1. Лiнiйнi оцiнки функцiональних моментiв 63
gk не визначає однозначно розподiл ξj:N . З цiєї вiдмiнностi випливаютьдва наслiдки: (i) для побудови адаптивної оцiнки ми змушенi на першомукроцi оцiнювати бiльше параметрiв (функцiональних моментiв) нiж зби-раємось оцiнити остаточною оцiнкою; (ii) отримана адаптивна оцiнка будеасимптотично кращою (не гiршою), нiж будь-яка лiнiйна оцiнка, але невиключено, що iснують оцiнки зовсiм iншого типу, кращi нiж адаптивнi.Тобто у данiй ситуацiї ми не можемо гаратнувати асимптотичну ефектив-нiсть адаптивної оцiнки в класi всiх можливих оцiнок, як це було у п.2.4.
Цей параграф присвячено виконанню першої половини описаної про-грами: тут ми отримаємо умови консистентностi та асимптотичної нор-мальностi лiнiйних оцiнок, знайдемо їх коефiцiєнти розсiювання, отримає-мо точну нижню межу для цих коефiцiєнтiв i визначимо ваговi вектори, наяких ця межа досягається. Побудова адаптивих оцiнок та їх асимптотичнiвластивостi розглянутi у наступному параграфi.
Точнiше, ми дещо узагальнимо свою задачу при вивченнi асимптотич-ної нормальностi. Замiсть того, щоб використовувати для нормування вiд-хилення оцiнок вiд справжнього значення оцiнюваної величини
√N , ми
будемо дiлити їх на їх дисперсiї i отримувати умови збiжностi розподiлiвтаких нормованих вiдхилень до стандартного нормального. Такий пiдхiддозволяє вивчати асимптотику оцiнок у випадку, коли границi 〈wkwm〉Nне iснують або гранична матриця det Γ є виродженою. (Матрицi det ΓN ,звичайно, мають бути невиродженими, iнакше консистентне оцiнюванняу нашiй непараметричнiй моделi буде неможливе). Результати для нор-мування
√N ми, таким чином, отримаємо як наслiдки бiльш загальних
теорем. Для формулювання та доведення результатiв ми будемо викори-стовувати матрично-векторнi позначення, якi дещо видозмiнюють позна-чення, прийнятi у iнших частинах книги. Набiр концентрацiй всiх компо-нент для фiксованого N WN = (wk
j:N , j = 1, . . . , N, k = 1, . . . , N) будеморозглядати як матрицю з k стовпчикiв та N рядкiв. Вектори-стовпчикицiєї матрицi будемо позначати ~wk
N . Вiдповiдно ваговi вектори у (3.3) такожє векторами-стовпчиками довжини N : ~aN = (aj:N , j = 1, . . . , N)T Iндекс Nдля спрощення позначень iнколи писати не будемо.
Статистика gN(~a), визначена (3.3), є незмiщеною оцiнкою gk (тобтоE gN(~a) = gk для всiх Hm, m = 1, . . . ,M) тодi i тiльки тодi, коли
1
N~aT WN = eT
k , (3.5)
де ek = (0, . . . , 0, 1, 0, . . . , 0)T k-тий базисний вектор стандартного базису у

64 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
RM .Це, по сутi, матричний запис звичної для нас умови незмiщеностi (2.5)Нехай вектори ~w1
N ,. . . ,~wMN лiнiйно незалежнi. Тодi мiнiмакснi ваговi ко-
ефiцiєнти у матричнiй формi записуються у виглядi
~a = ~ak,0 = WNΓ−1N ek, (3.6)
де ΓN = 1N
W TNWN — звична для нас матриця Грама системи векторiв
{~wmN}M
m=1 у скалярному добутку 〈~wkN , ~wm
M〉N = 1N
(~wkN)T ~wm
N . (Ми використо-вуємо тут у позначеннi ~ak,0 додатковий верхнiй iндекс 0, щоб пiдкреслити,що мова йде саме про мiнiмакснi ваговi коефiцiєнти на вiдмiну вiд iншихможливих коефiцiєнтiв лiнiйних оцiнок для gk). Як ми вже домовились,будемо позначати gk,0
N = gN(~ak,0).Тепер розглянемо лiнiйнi оцiнки gN(~a) визначенi (3.3) з ваговим век-
тором ~a для якого виконується умова незмiщеностi (3.5). Клас всiх такихоцiнок позначимо L0. Пiдрахуємо дисперсiю gN(~a).
Позначимо γ = (γ1, . . . , γ2M) = (g1, . . . , gM , g21, . . . , g2
M), де
g2m
=∫
g2(x)Hm(dx),
dj:N(γ) = Var g(ξj:N) = E(g(ξj:N))2−(E g(ξj:N))2 =M∑
m=1
g2m
wmj:N−
(M∑
m=1
gmwmj:N
)2
Далi ми як правило будемо вважати, що (gm)2 < g2m
< ∞ для всiхm = 1, . . . , M . Тодi
Var gN(~a) =1
N2
N∑j=1
(aj:N)2dj:N(γ).
Мiнiмум цього виразу по ~a при виконаннi умови (3.5) дорiвнює
σ2(k, N) =1
Nd(k,N),
деd(k, N) = eT
k Γ−1N (γ)ek, (3.7)
i досягається на ваговому векторi
~a = ~ak(γ) = D−1(γ)WNΓ−1N (γ)ek, (3.8)

3.1. Лiнiйнi оцiнки функцiональних моментiв 65
де D(γ) = diag(d1(γ), . . . , dN(γ)), ΓN(γ) = 1N
W TND−1(γ)WN є матрицею
Грама системи векторiв {~wmN}M
m=1 у скалярному добутку
〈~wmN , ~wk
N〉D =1
N
N∑j=1
d−1j:N(γ)wm
j:Nwkj:N .
(Це можна довести, використовуючи метод множникiв Лагранжа так само,як у п. 2.1).
Отже, ефективний ваговий вектор для оцiнки gk визначається (3.8),якщо справжнє значення вектора (g1, . . . , gM , g2
1, . . . , g2
M) дорiвнює γ.
Асимптотична поведiнка оцiнок. Позначимо через ηk деякi випад-ковi елементи з розподiлами Hk. Надалi лiтерою C позначаються деякiконстанти, можливо рiзнi.
Теорема 3.1.1 Нехай1. Для всiх m = 1, . . . , M , E |g(ηm)| < ∞.2.Для деякого C > 0, det ΓN > C для всiх N .Тодi оцiнка gk
N є консистентною, тобто gkN → gk за ймовiрнiстю.
Доведення. З умови 1 випливає, що |E g(ξj:N)| < ∞. Позначимо gj:N =
g(ξj:N)− E g(ξj:N), ζj:N =ak,0
j:N
Ngj:N . Застосуємо до gk
N − gk = SN =∑N
j=1 ζj:N
закон великих чисел у схемi серiй (теорема 7.3.7). За цiєю теоремою, якщо(a) M1 :=
∑Nj=1 E |ζj:N | ≤ C < ∞ ∀N ,
(b) M2(τ) :=∑N
j=1 E |ζj:N |1I{|ζj:N | > τ} → 0 при N →∞ для будь-якогоτ > 0,
то SN → 0 за ймовiрнiстю.Вiдмiтимо, що з умови 2 теореми випливає supN,j |ak,0
j:N | < ∞. Отжевиконання (a) є наслiдком умови 1 теореми.
Щоб перевiрити (b), оцiнимо
E |ζj:N |1I{|ζj:N | > τ} ≤ C
NE ζ1I{ζ >
Nτ
C},
де ζ =∑M
m=1 |g(ηm)|.Отже, M2(τ) ≤ C E ζ1I{ζ > Nτ
C} → 0 при N →∞, оскiльки E ζ < ∞, за
умовою 1.
Теорема 3.1.2 Нехай1. Для всiх m = 1, . . . , M , 0 < Var g(ηm) < ∞.

66 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
2. Для деякого C > 0, det ΓN > C для всiх N .Тодi розподiли випадкових величин
YN :=
√N√
d(k,N)(gN(~ak(γ))− gk)
слабко збiгаються при N →∞ до стандартного нормального розподiлу.
Доведення. Вiдмiтимо, що при виконаннi умови 1 iснують такi 0 <C1, C2 < ∞ що C1 ≤ dj:N ≤ C2 для всiх j та N . Тому
C1〈~wm, ~wk〉 ≤ 〈~wm, ~wk〉D ≤ C2〈~wm, ~wk〉.
Оскiльки ΓN та ΓN(γ) є матрицями Грама однiєї i тiєї ж системи век-торiв у скалярних добутках 〈·, ·〉 та 〈·, ·〉D вiдповiдно, то з теореми 7.2.1отримуємо, що для деяких 0 < c′1, c
′2 < ∞ (незалежних вiд N та γ)
c′1 det ΓN ≤ det ΓN(γ) ≤ c′2 det ΓN .
Отже, з виконання умови 2 випливає det ΓN(γ) > c > 0. Тому матри-ця Γ−1
N (γ) iснує i всi її елементи є рiвномiрно обмеженими по N . Отже,supj,N |ak
j:N(γ)| < ∞.Позначимо
ζj:N =aj:N(γ)√Nd(k, N)
(g(ξj:N)− gk).
Тодi YN =∑N
j=1 ζj:N . Твердження теореми випливає тепер з центральноїграничної теореми для ζj:N з умовою Лiндеберга (теорема 5 у п. 4 роздiлу8, [3]). Умова Лiндеберга перевiряється аналогiчно умовi (b) теореми 3.1.1.
Теорема доведена.
3.2 Адаптивнi оцiнки моментiв
У цьому параграфi ми розглянемо адаптивнi оцiнки моментiв, побудованiза схемою, описаною у п. 3.1. Тут зберiгаються позначення, введенi у п.3.1.
З точки зору мiнiмiзацiї асимптотичної дисперсiї, найкращою лiнiйноюоцiнкою для функцiонального моменту g, визначеного (3.2), є оцiнка зваговими коефiцiєнтами ak(γ), визначеними (3.8), де γ = (γ1, . . . , γ2M) =

3.2. Адаптивнi оцiнки моментiв 67
(g1, . . . , gM , g21, . . . , g2
M) — вектор, який складається з функцiональних мо-
ментiв з функцiями g та g2 для всiх компонент сумiшi. Елементи цього век-тора нам невiдомi, тому реалiзувати “найкращу лiнiйну оцiнку” практичнонеможливо.
Оцiнимо γ за допомогою очевидної (але не оптимальної) оцiнки, γN =
(g1,0N , . . . , gM,0
N , g21,0
, . . . , g2M,0
). Пiдставивши цю оцiнку замiсть справжньо-го γ у формулу для оптимальної лiнiйної оцiнки отримуємо адаптивнуоцiнку
gkN = gN(~ak(γN)). (3.9)
Покажемо, що при виконаннi умов теореми 3.1.2 асимптотична поведiнкаадаптивної оцiнки така ж сама, як асимптотична поведiнка найкращоїлiнiйної оцiнки.
Теорема 3.2.1 Нехай1. Для всiх m = 1, . . . , M , 0 < Var g(ηm) < ∞.2. Для деякого C > 0, det ΓN > C для всiх N .Тодi розподiли випадкових величин
ZN :=
√N√
d(k, N)(gk
N − gk)
слабко збiгаються при N →∞ до стандартного нормального розподiлу.
Для доведення теореми нам буде потрiбна лема, яка описує граничнуповедiнку випадкової величини
τε(N) := supα:|α−γ|<ε
√N |gN(~ak(α))− gN(~ak(γ))|.
Лема 3.2.1 В умовах теореми 3.2.1
supN
P{τε(N) > δ} → 0
при ε → 0 для всiх δ > 0.
Спочатку ми покажемо, як з цiєї леми випливає твердження теореми,а потiм доведемо саму лему.
Доведення теореми 3.2.1. Розглянемо випадковi величини YN , визна-ченi у теоремi 3.1.2. Для будь-якого δ > 0
JN := P{|ZN − YN | > δ} ≤ P{τε(N) > δ}+ P{|γN − γ| > ε}

68 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
Зафiксуємо довiльне λ > 0. За лемою 3.2.1 можна обрати ε > 0 так, щоP{τε(N) > δ} < λ для всiх N . За теоремою 3.1.1, в умовах теореми 3.2.1γN → γ за ймовiрнiстю при N → ∞. Отже, при достатньо великому N ,P{|γN − γ| > ε} < λ. Тому, для таких N , JN < 2λ. Внаслiдок довiльностiλ > 0 звiдси випливає, що JN → 0, тобто |ZN − YN | → 0 за ймовiрнiстю.
За теоремою 3.1.2, розподiл YN слабко збiгається до стандартного нор-мального розподiлу. Отже, i розподiл ZN також збiгається до стандартногонормального.
Теорема доведена.Для доведення леми 3.2.1 нам буде потрiбна iще одна допомiжна лема.
Для будь-якого α ∈ {0, 1}d i будь-якої гладенької функцiї f : K → Rпозначимо Dαf(u) частинну похiдну функцiї f по всiх координатах uj дляяких αj = 1, тобто
Dα =∏αj=1
∂
∂uj.
Лема 3.2.2 Нехай fN(u) = 1√N
∑Nj=1 bj(u)ζj u ∈ Rd, де
1. ζj — незалежнi випадковi величини з нульовим математичнимсподiванням i Var ζj ≤ S для деякого S < ∞,
2. bj(u) є d + 1-кратно диференцiйовними функцiями u i для деякогоL < ∞
supu∈K,j,l,α
|Dα ∂
∂ulbj(u)| < L,
де K деякий паралелепiпед у Rd, sup береться по j = 1, . . . , N , l = 1, . . . , d,α ∈ {0, 1}d.
ТодiP{ sup
|u−v|<ε,u,v∈K
|fN(u)− fN(v)| > δ} ≤ CKSL2ε2
δ2
де CK — константа, що залежить лише вiд K.
Доведення леми 3.2.2. Помiтимо, що
τ := sup|u−v|<ε,u,v∈K
|fN(u)− fN(v)| ≤ supu∈K
d∑
l=1
∣∣∣∣∂
∂ulfN(u)
∣∣∣∣ ε =: µε
Отже, за нерiвнiстю Чебишова
P{τ ≥ δ} ≤ P{µε ≥ δ} ≤ ε2 E µ2
δ2. (3.10)

3.2. Адаптивнi оцiнки моментiв 69
Зафiксуємо довiльне l та оцiнимо f ′N(u) := ∂∂ul fN(u). Застосовуючи лему
7.1.1 отримуємо, що
E
(supu∈K
|f ′N(u)|)2
≤ C E
∑
α∈{0,1}d
∫
Kα
(Dαf ′N(uα))2(du1)α
≤ C∑
α∈{0,1}d
∫
Kα
1
N
N∑i,j=1
Dαb′j(u)Dαb′i(u) E ζiζj(du1)α
≤ CS∑
α∈{0,1}d
∫
Kα
1
N
N∑j=1
(Dαb′i(u))2(du1)α < CKSL2.
Отже E µ2 ≤ CKSL2, i за (3.10) отримуємо твердження леми.Лема доведена.Доведення леми 3.2.1 Позначимо ζj = g(ξj:N) − E g(ξj:N), bj(u) =
akj:N(u)− ak
j:N(γ) (u ∈ R2M). Тодi
√N(gN(~ak(u))− gN(~ak(γ))) =
1√N
N∑j=1
bj(u)ζj. (3.11)
Так само, як у теоремi 3.1.2 отримуємо, що infu,N det ΓN(u) > c′ > 0. От-же функцiї bj(u) є диференцiйовними по u у деякому околi справжньогозначення γ. Тому Dαb′j(u) є рiвномiрно обмеженими по u у цьому околi γ.Застосування леми 3.2.2 до суми у правiй частинi (3.11)закiнчує доведен-ня.
Лема доведена.Приклад. Поведiнка лiнiйних та адаптивних оцiнок дослiджувалась
на модельованих вибiрках. Вибiрки були побудованi з сумiшi двох ком-понент (M = 2), причому їх концентрацiї змiнювались за лiнiйним за-коном: w1
j:N = jN, w2
j:N = 1 − jN. Розподiли обох компонент були нор-
мальними: H1 була N(0, 1), H2 була N(1, 2). Для вибiрок обсягу вiд 50до 1000 двi оцiнки для середнiх (тобто мiнiмаксна gk,0
N та адаптивна gkN з
g(x) = x) пiдраховано для K = 500 модельованих вибiрок. Пiдрахованiсередньоквадратичнi похибки оцiнок (MSE) та їх вiдносна ефективнiстьREk = MSE(gk,0
N )/MSE(gkN).
Результати зображенi на рисунку 3.1.

70 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
Рисунок 3.1: Вiдносна ефективнiсть оцiнок REk = MSE(gk,0N )/MSE(gk
N)для рiзних об’ємiв вибiрки N. • - для першої компоненти (k = 1); ◦ - длядругої компоненти (k = 2).
Цi результати показують, що лiнiйнi оцiнки з мiнiмаксними ваговимикоефiцiєнтами мають меншi середньоквадратичнi похибки при обсягах ви-бiрки до 500 спостережень. Для вибiрок бiльшого обсягу бiльш ефективни-ми виявляються адаптивнi оцiнки. Зрозумiло, що для iнших розподiлiв таiнших концентрацiй порiг, пiсля якого адаптивнi оцiнки починають пере-важати мiнiмакснi, може бути iншим. Але загальна картина залишаєтьсянезмiнною: при малих обсягах вибiрок простi мiнiмакснi лiнiйнi оцiнкидають кращi результати, на великих вибiрках вони поступаються адап-тивним.
При використаннi gkN на роль пiлотних оцiнок, можуть виникати про-
блеми, пов’язанi з тим, що цi оцiнки самi не є моментами деякого ймовiр-нiсного розподiлу: наприклад, оцiнка g2
k,0може бути вiд’ємною, хоча g2
k,0
завжди додатнiй. В результатi матриця Γ−1N (γN) може не бути додатньо-
визначеною i навiть бути виродженою. Це, звичайно погiршує поведiнкуадаптивних оцiнок на вибiрках скiнченного обсягу, хоча i не впливає на їхасимптотичнi властивостi.
Для того, щоб пом’якшити цей недолiк, можна запропонувати на рольпiлотних оцiнки, аналогiчнi лiнiйним оцiнкам 3.3, у яких зважена емпiрич-на функцiя замiняється виправленню емпiричною функцiєю розподiлу, за-

3.3. Виправленi оцiнки для моментiв 71
пропонованою у п. 2.3. Такi оцiнки ми розглянемо у наступному параграфi.
3.3 Виправленi оцiнки для моментiв
У цьому параграфi ми обмежуємось розглядом одновимiрних спостере-жень, тобто X = R i ξj:N є випадковими величинами. У цьому випадкулiнiйна оцiнка для функцiонального момента gk набуває вигляду
gk:N :=
∫g(x)FN(dx, a) =
1
N
N∑j=1
aj:Ng(ξj:N) (3.12)
де, як i ранiше
FN(x, a) :=1
N
N∑j=1
aj:N1I{ξj:N < x} (3.13)
— зважена емпiрична функцiя розподiлу, побудована по спостереженняхξj:N .
У п. 2.3 ми ввели виправленi емпiричнi функцiї розподiлу F+N (x, a) та
подiбнi до них. На вiдмiну вiд FN(x, a), F+N (x, a) самi є функцiями розподi-
лу деяких ймовiрнiсних мiр, тому можна очiкувати, що оцiнки моментiв,побудованi на основi цих функцiй, будуть мати кращi властивостi при фiк-сованому обсязi вибiрки, нiж оцiнки (3.12). Найпростiшим варiантом такоїоцiнки є
g+k:N :=
∫g(x)F+
N (dx, a). (3.14)
У даному параграфi нашою метою буде дослiдити асимптотичну поведiнкуцих та подiбних оцiнок i показати, що за певних умов вправлення емпiрич-ної функцiї розподiлу не змiнює асимптотику оцiнок. При цьому ми будемоспиратись на результати про асимптотику емпiричних процесiв (нормова-них вiдхилень емпiричних ф.р. вiд оцiнюваних).
На роль виправленої з.е.ф.р. ми будемо використовувати функцiї визна-ченi (2.30-2.34), тобто F+
N (x, a), F+N (x, a), F−
N (x, a), F±N (x, a), F±
N . Як i ранi-ше, F ∗
N(x, a) може бути будь-якою з цих функцiй.У п. 2.3 показано, що функцiї F ∗
N(x, a) можна зобразити у виглядi
F ∗N(x, a) =
1
N
N∑j=1
b∗j:N1I{ξj:N < x},

72 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
де b∗j:N — деякi коефiцiєнти, що залежать вiд вибiрки ΞN . Вiдповiдно, оцiн-ки для моментiв, побудованi на основi F ∗(x, a), можна записати як
g∗k;N :=
∫g(x)F ∗
N(dx, a) =1
N
N∑j=1
b∗j:Ng(ξj:N).
Нас буде цiкавити асимптотична нормальнiсть таких оцiнок, тобто слаб-ка збiжнiсть Y ∗
k;N :=√
N(g∗k;N − g) до нормального розподiлу з нульовимматематичним сподiванням.
Як показано у теоремi 3.1.2, якщо для всiх Hm, m = 1, . . . , M є скiнчен-ними функцiональнi моменти g2
m =∫
g2(x)Hm(dx), то Yk;N :=√
N(gk;N −g) ⇒ Y , де Y має нормальний розподiл з нульовим середнiм i дисперсiєюσ2 = 〈(a)2d〉, dj:N =
∑Mm=1 g2
mwmj:N − (
∑Mm=1 gmwm
j:N)2.
Теорема 3.3.1 Нехай1. supj,N |aj:N | < A < ∞.2.Для всiх m = 1, . . . , M , ∃ 〈wkwm(a)2〉.3. Для всiх m = 1, . . . , M , Hm є неперервними функцiями на R.4. Для всiх m = 1, . . . , M , supp Hm ⊆ supp Hk.5. Виконанi умови незмiщеностi FN(x, a) як оцiнки для Hk, тобто
〈awm〉N = 1I{k = m} для всiх m = 1, . . . , M .6. g — функцiя обмеженої варiацiї на R.Тодi Y ∗
k;N ⇒ Y для всiх розглядуваних g∗k;N .
Зауваження. Насправдi досить вимагати, щоб g була функцiєю обме-женої варiацiї на supp Hm, m = 1, . . . , M .
Доведення. Помiтимо, що
Y ∗k;N =
√N
(∫g(x)F ∗
N(dx, a)−∫
g(x)H(dx)
)
=
∫g(x)B∗
N(dx, a).
За теоремою 2.3.2, iснують процеси B∗N(x) та BN(x), такi, що розподiл
Y ∗N :=
∫g(x)B∗
N(x) той же самий, що i у Y ∗k;N , а розподiл YN :=
∫g(x)BN(x)
той же, що у YN , причому supx |B∗N(x)− BN(x)| → 0 за ймовiрнiстю.
Отже|Y ∗
N − YN | =∣∣∣∣∫
g(x)(B∗N(dx)− BN(dx))
∣∣∣∣

3.3. Виправленi оцiнки для моментiв 73
=
∣∣∣∣∫
(B∗N(x)− BN(x))g(dx)
∣∣∣∣ ≤ VARxg(x) · supx|B∗
N(x)− BN(x)| → 0
за ймовiрнiстю. Звiдси випливає, що розподiл Y ∗N (а отже i Y ∗
k;N) збiгаєтьсяслабко до тiєї ж границi, до якої збiгається Yk;N , тобто до Y .
Теорема доведена.
Теорема 3.3.2 Нехай1. supj,N |aj:N | < A < ∞.2.Для всiх m = 1, . . . , M , ∃ 〈wkwm(a)2〉.3. Для всiх m = 1, . . . , M , Hm є неперервними функцiями на R.4. Для всiх m = 1, . . . , M , supp Hm ⊆ supp Hk.5. Виконанi умови незмiщеностi FN(x, a) як оцiнки для Hk, тобто
〈awm〉N = 1I{k = m} для всiх m = 1, . . . , M .6. g : R→ R — неперервна монотонна функцiя i для всiх m = 1, . . . ,M
та деяких 0 < D, C < ∞, γ > 0
Hm(x) ≤ D
|g(x)|2+γ, ∀x < −C, (3.15)
1−Hm(x) ≤ D
|g(x)|2+γ, ∀x > C. (3.16)
Тодi Y ±k;N ⇒ Y при N → +∞.
Зауваження. Оскiльки будь-яку функцiю g, що має обмежену варiа-цiю на всiх скiнченних iнтервалах, можна зобразити у виглядi g(x) =g+(x)−g−(x), де g+ та g− — монотоннi функцiї, то насправдi теорему 3.3.2можна переформулювати для функцiй з обмеженою варiацiєю на скiн-ченних iнтервалах, але тодi умови (3.15-3.16) потрiбно перевiряти окремодля g+ та g−. Наприклад, для g(x) = x2, цi умови перетворюються наHm(x) = O(|x|−4−γ) при x → −∞, 1−Hm(x) = O(x−4−γ) при x →∞.
Крiм теореми 2.3.2 про близькiсть емпiричних процесiв для виправле-них та невиправлених з.е.ф.р. у рiвномiрнiй нормi для доведення теореми3.3.2 нам буде потрiбна характеризацiя поведiнки BN(x), B+
N(x) та B−N(x)
при x →∞ та x → −∞.Позначимо
H(x) =M∑
m=1
Hm(x). (3.17)

74 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
Теорема 3.3.3 Нехай1. supj,N |aj:N | < A < ∞.2.Для всiх m = 1, . . . , M , ∃ 〈wkwm(a)2〉.3. Для всiх m = 1, . . . , M , Hm є неперервними функцiями на R.4. Для всiх m = 1, . . . , M , supp Hm ⊆ supp Hk.5. Виконанi умови незмiщеностi FN(x, a) як оцiнки для Hk, тобто
〈awm〉N = 1I{k = m} для всiх m = 1, . . . , M .Тодi, для довiльних b i δ, 0 < δ < 1/2,
supN
P
{supx<b
|BN(x)|H(x)1/2−δ
> λ
}→ 0 при λ →∞,
supN
P
{supx<b
|B+N(x)|
H(x)1/2−δ> λ
}→ 0 при λ →∞,
supN
P
{supx>b
|BN(x)|(M − H(x))1/2−δ
> λ
}→ 0 при λ →∞,
supN
P
{supx>b
|B−N(x)|
(M − H(x))1/2−δ> λ
}→ 0 при λ →∞.
Доведення цiєї теореми спирається на наступну лему.
Лема 3.3.1 В умовах теореми 3.3.3 iснує таке C < ∞, не залежне вiдN , що для всiх ε > 0, x ∈ R,
P{supt<x
|B+N(t)| ≥ ε} ≤ P{sup
t<x|BN(t)| ≥ ε} ≤ C(H2(x)ε−4 + H(x)ε−2), (3.18)
P{supt>x
|B−N(t)| ≥ ε} ≤ P{sup
t>x|BN(t)| ≥ ε}
≤ C((M − H(x))2ε−4 + (M − H(x))ε−2),
Доведення. Щоб довести другу нерiвнiсть у (3.18), застосуємо лему 7.4.2на iнтервалi (−∞, x] з γ = 2, α = 1. Для цього оцiнимо
J := E(BN(t)−BN(t1))2(BN(t2)−BN(t))2.
Позначимо
ηj(x, y) := aj:N(1I{ξj:N ∈ [y, x)} − P{ξj:N ∈ [y, x)}).

3.3. Виправленi оцiнки для моментiв 75
Тодi
BN(t)−BN(s) =1√N
N∑j=1
ηj(s, t)
i
J =1
N2E
N∑
j,k,l,m=1
ηj(t, t1)ηk(t, t1)ηl(t2, t)ηm(t2, t)
≤ C
N2
∑
j 6=k
{E(ηj(t, t1))
2(ηk(t2, t))2 + E ηj(t, t1)ηj(t2, t)ηk(t, t1)ηk(t2, t)
}
+1
N2
N∑j=1
E(ηj(t, t1)ηj(t2, t))2
(ми скористались тим, що E ηj = 0 i ηk та ηm незалежнi при k 6= m).Оскiльки
E η2j (t, t1) ≤ E(aj:N)21I{ξj:N ∈ [t1, t)} ≤ A2H([t1, t]) ≤ A2H([t1, t2]),
E ηj(t, t1)ηj(t2, t) = −(aj:N)2 P{ξj:N ∈ [t1, t]}P{ξj:N ∈ [t, t2]} ≤ A2H2([t1, t2]),
E(aj:N)4(1I{ξj:N ∈ [t1, t]}−P{ξj:N ∈ [t1, t]})2(1I{ξj:N ∈ [t, t2]}−P{ξj:N ∈ [t, t2]})2
≤ CA4H3([t1, t2])
i H(R) ≤ M , отримуємо J ≤ C(H([t1, t2]))2. Отже, за лемою 7.4.2,
P{supt<x
|BN(t)| > ε} ≤ P{|BN(x)| > ε
2}+
C
ε4(H(x))2 (3.19)
(оскiльки BN(−∞) = H(−∞) = 0). Оцiнимо
P{|BN(x)| < ε/2} ≤ Var BN(x)
ε2≤ A2H(x)
ε, (3.20)
оскiльки Var BN(x) ≤ 1N
∑Nj=1(aj:N)2 P{ξj:N < x}. З (3.19) та (3.20) отри-
муємо другу нерiвнiсть (3.18).Перша нерiвнiсть у (3.18) випливає з того, що B+
N(x) ≥ BN(x) для всiхx, i, в той же час, при t < x,
B+N(t) =
√N sup
y<t(FN(y, a)−Hk(t))

76 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
=√
N supy<t
(BN(y)/√
N + Hk(y)−Hk(t)) ≤ supy<x
BN(y),
оскiльки Hk(y)−Hk(t) ≤ 0 при y ≤ t. Друга пара нерiвностей леми дово-диться аналогiчно.
Доведення теореми 3.3.3. Доведемо перше твердження теореми.Твердження 2-4 доводяться аналогiчно. Позначимо
pλ := P
{supx<b
|BN(x)|H(x)1/2−δ
> λ
},
xj — число, для якого H(xj) = 2−j. Тодi
P
{sup
xj+1≤x≤xj
|BN(x)|H(x)1/2−δ
> λ
}⊆ Aj
деAj := {∀x < xj, BN(x) ≤ λH1/2−δ(xj+1)}
Застосовуючи лему 3.3.1 до подiї Aj з εj = λH1/2−δ(xj+1), отримуємо
pλ ≤∞∑
j=1
P{Aj} ≤∞∑
j=1
C(H2(xj)ε−4 + H(xj)ε
−2)
= C
∞∑j=1
(22j
λ42(−2+4δ)j+
2j
λ22(−1+2δ)j
)≤ C(λ−4 + λ−2) → 0 при λ → +∞.
Лема 3.3.2 В умовах теореми 3.3.3, якщо Hk(b) < 1/2, Hk(c) > 1/2, то
P{∃x < b : F±N (x, a) 6= F+
N (x, a)} → 0, N →∞,
P{∃x > c : F±N (x, a) 6= F−
N (x, a)} → 0, N →∞,
Доведення. З теореми 2.3.2 випливає, що supx |F+N (x, a)−Hk(x)| → 0
i supx |F−N (x, a)−Hk(x)| → 0 при N → ∞ за ймовiрнiстю. Отже, врахову-
ючи монотоннiсть Hk i умову леми, маємо P{supx<b F+N (x, a) > 1/2} → 0,
P{infx>c F−N (x, a) < 1/2} → 0, при N →∞.
Враховуючи (2.34), отримуємо твердження леми.Доведення теореми 3.3.2. Доведемо теорему для випадку, коли g
— монотонно зростаюча функцiя. Згiдно з теоремою 2.3.2, iснують такiвипадковi процеси B±
N та BN , що B±N має той самий розподiл, що i B±
N , а

3.3. Виправленi оцiнки для моментiв 77
BN — той же, що i BN , причому supx |B±N(x)− BN(x)| → 0 при N →∞ за
ймовiрнiстю. Помiтимо, що Y ±k,N =
∫g(x)B±
N(dx) має той же розподiл, що iY ±
k,N , а Yk,N =∫
g(x)BN(dx) — той же, що i Yk,N . Тому для доведення тео-реми досить переконатись, що Y ±
k,N − Yk,N → 0 за ймовiрнiстю. Помiтимо,що для довiльного b > 0,
J := |Y ±k,N − Yk,N | =
∣∣∣∣∫ +∞
−∞(B±
N(x)− BN(x))g(dx)
∣∣∣∣ ≤ J1 + J2 + J3
де
J1 =
∫ b
−b
|B±N(x)− BN(x)|g(dx),
J2 =
∫ −b
−∞|B±
N(x)− BN(x)|g(dx),
J3 =
∫ ∞
b
|B±N(x)− BN(x)|g(dx).
Ми доведемо, що для довiльних фiксованих α > 0, ε > 0 можна обратичисла b та N0 так, що
supN>N0
P{JN2 > α} < ε, (3.21)
supN>N0
P{JN3 > α} < ε. (3.22)
Звiдси, враховуючи, що для будь-якого фiксованого b,
JN1 ≤ (g(b)− g(−b) sup
|x|<b
)|B±N(x)− BN(x)| → 0
при N →∞ за ймовiрнiстю, отримуємо твердження теореми.Отже, доведемо (3.21). (Доведення (3.22) аналогiчне). Оберемо b так,
щоб Hk(b) < 1/2. Тодi, враховуючи лему 3.3.2, досить довести, що придостатньо великих b, supN P{JN
2 > α} < ε, де JN2 := JN
21 + JN22, JN
21 :=∫ −b
−∞ |BN(x)|g(dx), JN21 :=
∫ −b
−∞ |B+N(x)|g(dx).
Оцiнимо JN21. Фiксуємо довiльне число r та 0 < δ < 1/2 таке, що γ′ :=
(2 + γ)(1/2− δ) > 1. За теоремою 3.3.3 iснує таке λ, що для подiй
AN :=
{supt<r
|BN(t)|H1/2−δ(t)
> λ
}

78 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
виконано supN{AN} < ε. Якщо виконано AN , то ∀t < r,
|BN(t)| < λH1/2−δ(t) ≤ C
|g(t)|γ′
i, вiдповiдно, при b < r, JN21 ≤
∫ −b
−∞C
(g(t))γ′ g(dt) < ∞. Тому можна обрати b
достатньо великим, щоб JN21 < α/2 при виконаннi AN . Отже supN P{JN
21 >α/2} ≤ supN P{AN} ≤ ε.
Аналогiчно оцiнюється JN22. Таким чином, (3.21) доведено, що i завер-
шує доведення теореми.
3.4 Оцiнювання квантилiвКвантилi розподiлiв випадкових величин грають у статистицi роль не мен-шу, нiж моменти. Задача оцiнки квантилiв природно виникає при побудовiдовiрчих iнтервалiв. Оцiнки, що використовують емпiричнi квантилi, ви-являються найбiльш стiйкими по вiдношенню до забруднень вибiрки. Ви-користання квантилiв лежить в основi так званої VaR-технологiї (Value AtRisk technology) у фiнансовiй математицi.
У цьому роздiлi ми розглянемо задачу оцiнки квантиля розподiлу од-нiєї компоненти сумiшi зi змiнними концентрацiями. Кажуть, що x є кван-тилем рiвня α функцiї розподiлу H деякої випадкової величини η, якщоP{η < x} = α. Це позначають x = Qη(α) = Qη(α)
Якщо H — неперервна функцiя розподiлу, строго зростаюча в околiточки Qη(α), то
QH(α) = Qη(α) = H−1(α),
де H−1 — функцiя, обернена до H.Якщо H(x) є константою: H(x) = α на деякому iнтервалi x ∈ (x0, x1],
то будь-яке число з цього iнтервалу можна вважати квантилем рiвня αдля H. Якщо H є розривною у деяких точках, то квантилi вiдповiдно-го рiвня у нашому розумiннi не iснуватимуть1. Надалi ми вважаємо, щофункцiї розподiлу всiх компонент сумiшi, яка розглядається є неперерв-ними i оцiнюваний квантиль є точкою росту для них усiх. Таким чином,у цьому випадку наше означення квантиля є однозначним.
1Звичайно, можна усунути цi неприємнi особливостi, визначивши функцiю, що задаєквантилi, як узагальнену (у якому-небудь розумiннi) обернену для функцiї розподiлу.Однак варто вiдмiтити, що практична користь вiд таких “узагальнених” квантилiв мiнi-мальна.

3.4. Оцiнювання квантилiв 79
На роль оцiнки для квантиля Qη(α) за спостереженнями незалежнихкопiй η, як правило, використовують QFN (α), де FN — вiдповiдним чиномзгладжена емпiрична функцiя розподiлу, побудована по спостереженнях.У випадку спостережень з сумiшi зi змiнними концентрацiями природнозамiсть FN використати зважену емпiричну функцiю розподiлу, теж вiдпо-вiдним чином пiдправлену. По-перше, оскiльки зважена емпiрична функ-цiя розподiлу FN(x, a), як правило, є немонотонною, її варто виправитиодним iз способiв, розглянутих у п. 2.3. По-друге, пiсля цього доцiльнозгладити стрибки виправленої з.е.ф.р. так, щоб вiдповiдний квантиль длянеї завжди iснував. Процедуру згладжування доцiльно обрати так, щоб їїрезультат не надто сильно вiдрiзнявся вiд початкової функцiї.
Опишемо тепер бiльш детально запропоновану оцiнку. Нехай X = R,спостереження являють собою вибiрку ΞN = {ξi:N , j = 1, . . . , N} з сумiшiзi змiнними концентрацiями, розподiл якої задано 3.1. Ми будуємо оцiнкудля квантиля рiвня α (0 < α < 1) функцiї розподiлу k-тої компоненти,тобто для QHk
(α). Для цього розглянемо довiльну виправлену зваженуфункцiю розподiлу, отриману за однiєю з формул (2.30-2.34). Знову черезF ∗
N(x, a) будемо позначати яку-небудь з цих функцiй. (Як стане зрозумiлодалi, дослiджувана нами асимптотика отриманих оцiнок не залежить вiдспособу виправлення з.е.ф.р.).
Використовуючи алгоритм, описаний у п. 2.3, функцiю F ∗N(x, a) можна
зобразити у виглядi
F ∗N(x, a) =
1
N
N∑j=1
b∗j:N1I{ξj:N < x},
де b∗j:N — деякi коефiцiєнти, що залежать вiд вибiрки ΞN . Перенумерує-мо точки стрибкiв F ∗
N(x, a) у порядку зростання x1,. . . , xn. (Зрозумiло,що xj дорiвнюють вибiрковим значенням, розташованим у порядку зрос-тання, тобто порядковим статистикам. Однак деякi порядковi статистикивиявляться пропущеними, оскiльки, за способом побудови F ∗
N(x, a), деякib∗j:N = 0 i у цих точках стрибкiв F ∗
N(x, a) немає. Тому n < N .) Значеннякоефiцiєнта b∗j:N , який вiдповiдає xi, позначимо bi. Тодi
F ∗N(x, a) =
1
N
n∑i=1
bi1I{xi < x}, (3.23)
Стрибок функцiї F ∗N(x, a) у точцi xi дорiвнює bi/N .

80 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
Згладимо функцiю F ∗N(x, a) функцiєю F (x), графiк якої є ламаною, яка
має злами у точках xi i проходить у цих точках через середину стрибкаF ∗
N(x, a). Точнiше, позначимо yi = F ∗N(xi, a) 1
N
(∑j<i bj + 1
2bi
), тодi
F (x) = FN(x) =yi+1 − yi
xi+1 − xi
(x− xi) + yi, (3.24)
якщо x ∈ [xi, xi+1]. (За межами [x1, xn] функцiя F ′ не визначена).Оцiнку Qk
N(α) для квантиля QHk(α) визначимо як
QkN(α) = F−1(α). (3.25)
Зрозумiло, що при такому означеннi можуть виникнути проблеми при зна-ходженнi квантилiв дуже високого α ' 1 або дуже низького α ' 0 рiвнiв,коли вiдповiдна обернена функцiя виявляється невизначеною. В принципi,щоб усунути цей недолiк, можна довизначнти F (x) за межами iнтервалу[x1, xn] будь-яким способом, так, щоб вона стала неперервною строго мо-нотонною функцiєю розподiлу. Тодi (3.25) визначатиме оцiнку для будь-якого рiвня α. Спосiб довизначення F (x) не вплине на асимптотику Qk
N(α)при фiксованому α та N → ∞, якщо у початкової зваженої емпiричноїфункцiї розподiлу ваговi коефiцiєнти рiвномiрно обмеженi, тобто
supj,N
|aj,N | < C < ∞. (3.26)
Однак слiд вiдмiтити, що для екстремальних квантилiв (тобто для кван-тилiв з рiвнями α ' 0 або α ' 0) оцiнювання доцiльно проводити метода-ми, що використовують технiку аналiзу хвостiв розподiлу. У граничномувипадку α = 1 це питання розглядається у наступному параграфi. Запро-понований метод призначений для квантилiв, що знаходяться посерединiрозподiлу — таких, як медiана, квартилi або децилi.
Неважко визначити оцiнку QkN(α) у явному виглядi. Для цього потрiб-
но знайти таке i, при якому yi < α < yi+1 i покласти
QkN(α) =
α− yi
yi+1 − yi
(xi+1 − xi) + xi.
По сутi, це формула для лiнiйної iнтерполяцiї (так само, як i (3.24)). Од-нак для дослiдження асимптотичної поведiнки оцiнок ми скористаємосьозначенням (3.25). При цьому нам буде корисною наступна лема.

3.4. Оцiнювання квантилiв 81
Лема 3.4.1 Нехай F — неперервна функцiя розподiлу на R, F ∗N — по-
слiдовнiсть функцiй розподiлу вигляду (3.23), така, що supx∈R |F ∗N(x) −
F (x)| → ∞. Тодi supx∈R |FN(x)− F (x)| → ∞,(Функцiї FN(x) довизначаються за межами iнтервалiв їх визначення
довiльним чином, так, щоб бути функцiями розподiлу на R).
Доведення. Застосовуючи перетворення аргументу x → 2 tan(x)/π мож-на перевести всi розглядуванi функцiї у функцiї розподiлу, зосередженiна [−1, 1], причому рiвномiрна норма не змiнюється. Тому будемо одразувважати, що всi розглядуванi функцiї зосередженi на [−1, 1] i sup беретьсяпо x ∈ [−1, 1].
Зафiксуємо довiльне ε > 0. Оскiльки F є неперервною на [−1, 1], томожна побудувати скiнченний набiр вiдкритих iнтервалiв U1,. . . ,UK , якийпокриває [−1, 1] i для всiх k = 1, . . . , K, supx,y∈Uk
|F (x) − F (y)| < ε/3.Враховуючи рiвномiрну збiжнiсть F ∗
N до F отримуємо, що, при достатньовеликих N , для всiх k = 1, . . . , K, supx,y∈Uk
|F ∗N(x)− F ∗
N(y)| < 2ε/3. Отже,для таких N величини стрибкiв bi/N функцiй F ∗
N не можуть бути бiльши-ми, нiж 2ε/3. Але supx∈[−1,1] |F ∗
N(x)− FN(x)| ≤ maxi bi/N за побудовою FN .Тому supx∈R |FN(x)−F (x)| ≤ supx∈[−1,1] |F ∗
N(x)−FN(x)|+supx∈[−1,1] |FN(x)−F (x)| ≤ 2ε/3 + ε/3 = ε для достатньо великих N .
Внаслiдок довiльностi ε отримуємо твердження леми.
Теорема 3.4.1 Нехай Hk — неперервна ф.р., для вагових коефiцiєнтiв aвиконана умова незмiщеностi (2.5):
〈awm〉N = 1I{m = k} для всiх m = 1, . . . , M ;
i supj,N |aj:N | < ∞.Тодi supx∈R |FN(x)−Hk(x)| → 0 м.н. при N →∞.
Доведення. Враховуючи (2.21) отримуємо, що в умовах теореми
supx∈R
|FN(x, a)−Hk(x)| → 0
м.н. З урахуванням (2.36-2.35) звiдси випливає, що supx∈R |F ∗N(x, a)−Hk(x)|
прямує до 0, а, отже, за лемою 3.4.1, supx∈R |FN(x)−Hk(x)| → 0.Теорема доведена.З цiєї теореми одразу отримуємо консистентнiсть Qk
N(α) як оцiнкиQHk(α) у випадку, коли Hk — неперервна функцiя.

82 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
Теорема 3.4.2 Нехай Hk — неперервна ф.р., для вагових коефiцiєнтiвa виконана умова незмiщеностi (2.5) i supj,N |aj:N | < ∞. Тодi Qk
N(α) →QHk(α) м.н. при N →∞.
Доведення випливає з теореми 3.4.1, оскiльки вiдображення F → QF (α)є неперервним у просторi неперервних функцiй розподiлу з рiвномiрноюметрикою.
Тепер доведемо асимптотичну нормальнiсть QkN(α).
Теорема 3.4.3 Нехай1. Для деякого A < ∞ supj,N |aj:N | < A.2.Для всiх l, m = 1, . . . , M iснують границi
〈wlwm(a)2〉 = limN→∞
1
N
N∑j=1
wlj:Nwm
j:N(aj:N)2.
3. Hm є неперервними функцiями на R при всiх m = 1, . . . , M .4. Виконана умова незмiщеностi (2.5).5.Iснує такий окiл I точки QHk(α), що для всiх m = 1,. . . , M , всi
точки I є точками росту Hm.6.На I у Hk(x) iснує неперервна похiдна hk(x) i hk(Q
Hk(α)) 6= 0.Тодi розподiл
√N(Qk
N(α) − QHk(α)) слабко збiгається при N → ∞ догауссового розподiлу з нульовим середнiм i дисперсiєю, рiвною
s2 =1
(hk(QHk(α)))2
(M∑
m=1
〈wm(a)2〉Hm(QHk(α))
−M∑
i,m=1
〈wmwi(a)2〉Hm(QHk(α))Hi(QHk(α))
)
Доведення. Позначимо
B∗N(x) = BN(x, a) :=
√N(F ∗
N(x, a)−Hk(x)).
За теоремою 2.3.2, BNSk→B де B — неперервний м.н. гауссiв процес, описа-
ний у цiй теоремi. Покажемо, що процес
BN(x) = BN(x, a) :=√
N(FN(x, a)−Hk(x))

3.4. Оцiнювання квантилiв 83
також збiгається за Скороходом до B(x) на I.Для цього помiтимо, що за побудовою F ∗
N(x, a)
0 < b∗j ≤ supj,N
|aj:N | < A,
а за побудовою FN(x, a)
supx∈[xi,xi+1]
|FN(x, a)− F ∗N(x, a)| ≤ 1
2Nmax(b∗i , b
∗i+1).
Отжеsupx∈R
|FN(x, a)− F ∗N(x, a)| ≤ A
2N.
Тому |BN(x)−B∗N(x)| ≤ A
2√
Ni BN
Sk→B. Оскiльки нас цiкавить лише слабказбiжнiсть розподiлiв, можна ототожнити BN з їх копiями, побудованимина одному ймовiрнiсному просторi i вважати, що
supx∈I
|BN(x)−B(x)| → 0, при N →∞. (3.27)
Для довiльного x ∈ R позначимо
AN = {√
N(QkN(α)−QHk(α)) < x}.
Покажемо, що P(AN) → P{η < x}, де η ∼ N(0, s2). Це i є твердженнятеореми.
ОтжеAN = {
√N(F−1
N (α)−H−1k (α)) < x}
= {F−1N (α) < H−1
k (α) + x/√
N}= {α < FN(H−1
k (α) + x/√
N)}
=
{α < Hk(H
−1k (α) + x/
√N) +
BN(H−1k (α) + x/
√N)√
N
}
= {−BN(H−1k (α) + x/
√N) <
√N(Hk(H
−1k (α) + x/
√N)− α)}
Звiдси, враховуючи збiжнiсть BN до B, неперервнiсть B, i той факт, що
∆(Hk(H−1k (α) + x∆)− α)/∆ → hk(H
−1k (α))x,

84 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
отримуємо, що
P(AN) → P{B(H−1k (α)) < hk(H
−1k (α))x}.
Оскiльки B(H−1k (α))/hk(H
−1k (α)) ∼ N(0, s2), отримуємо твердження
теореми.Теорема доведена.
3.5 Оцiнка екстремальних точок розподiлiвкомпонент
Нехай ξ — деяка дiйснозначна випадкова величина з неперервною функ-цiєю розподiлу H. Позначимо mξ = mH = essinf(ξ) = sup{x : P{ξ < x} =H(x) = 0}, Mξ = MH = ess sup(ξ) = inf{x : P{ξ ≥ x} = 1−H(x) = 0}. Зна-чення mξ та Mξ називають вiдповiдно нижньою та верхньою екстремаль-ними точками розподiлу в.в. ξ. У даному параграфi ми розглянемо задачуоцiнювання нижньої екстремальної точки (верхня оцiнюється аналогiчно)по спостереженнях, що являють собою вибiрку з сумiшi зi змiнними кон-центрацiями.
Задача оцiнювання екстремальних точок у випадку вибiрок з незалеж-них, однаково розподiлених (з ф.р. H) випадкових величин ξ1, . . . , ξN добредослiджена [2], c.203–207. Нехай, скажiмо, mξ > −∞ i для деяких c > 0,δ > 0,
P{ξ ∈ [mξ, x)} ≥ c(x−mξ) для всiх x ∈ (mξ,mξ + δ). (3.28)
Розглянемо оцiнкуmN = min{ξ1, . . . , ξN}. (3.29)
Легко бачити, що для будь-якого εN , такого, що εN → 0 при N →∞,
P{mN −mξ > εN} =N∏
j=1
(1− P{ξj ∈ [mξ,mξ + εN)}) ≤ (1− cεN)N ∼ e−cNεN ,
отже, для довiльної числової послiдовностi AN →∞, N →∞, поклавши
εN =AN ln N
N, (3.30)

3.5. Оцiнка екстремальних точок розподiлiв компонент 85
отримуємо
|mN −mξ| ≤ εN м.н. при достатньо великих N. (3.31)
Збiжнiсть зi швидкiстю εN свiдчить про нерегулярнiсть задачi оцiнюванняmξ, оскiльки для регулярних задач, з якими ми мали справу досi, харак-терною є швидкiсть 1/
√N (точнiше ln ln N/
√N , якщо йдеться про збiж-
нiсть майже напевне). I справдi, умова (3.28) виконується, якщо, напри-клад, iснує щiльнiсть розподiлу h(x) = dH(x)/dx, вiддiлена вiд 0 на iнтер-валi [mξ,mξ + δ]. Оскiльки при x < mξ, h(x) = 0, то в точцi mξ щiльнiстьмає стрибок. Як вiдомо ([10], роздiл 5), у задачах оцiнювання по однорiд-них вибiрках параметрiв, пов’язаних з стрибками щiльностi, справедливiнерiвностi, аналогiчнi (3.30-3.31), а слабка збiжнiсть нормованих оцiнокмає мiсце при нормуваннi порядку 1/N . Ми отримаємо для сумiшей зiзмiнними концентрацiями оцiнки, якi матимуть швидкiсть збiжностi, ана-логiчну (3.30-3.31).
Наша мета полягає в тому, щоб по спостереженням ξ1:N , . . . , ξN :N оцi-нити нижню екстремальну точку першої (скажiмо) компоненти сумiшi —mH1 . Якщо для всiх k = 2, . . . ,M mH1 ≤ mHk
, то оцiнка mN буде конси-стентною для mH1 i збiжнiсть зi швидкiстю (3.30) буде мати мiсце. Але,якщо, при деякому k, mH1 > mHk
, то спостереження, що вiдповiдаютьk-тiй компонентi, будуть заважати оцiнцi. Як у такому випадку оцiнитинижню екстремальну точку першої компоненти?
Використовуючи означення mH1 , можна запропонувати для нього оцiн-ку m∗
N = sup{x : HN1 (x) < CN}, де HN
1 (x) — зважена емпiрична функцiярозподiлу з мiнiмаксними коефiцiєнтами для оцiнки ф.р. першої компо-ненти, CN — деяке число, близьке до 0. (Точнiше, слiд покласти CN → 0при N →∞.) Але така оцiнка не може мати швидкостi збiжностi порядку(3.30). Дiйсно, згiдно з теоремою 2.2.5, процес
√N(HN
l (x)−Hl(x)) слабкозбiгається до невиродженого гаусiвського процесу у рiвномiрнiй метрицiпри N → ∞. Тому, щоб забезпечити виконання HN
1 < CN при x < mH1
м.н., слiд обрати рiвень CN > 1/√
N . Але в цьому випадку, щоб забезпе-чити H1(x) > CN за умови, що щiльнiсть розподiлу першої компонентиобмежена, значення x має бути бiльшим, нiж mH1 + α/
√N для деякого
додатного α. Тобто швидкiсть збiжностi оцiнки m∗N не може бути кращою
нiж 1/√
N . Чи можна побудувати оцiнку, яка для сумiшей зi змiннимиконцентрацiями мала б швидкiсть збiжностi порядку (3.30)?
Вiдповiдь на це запитання позитивна, в усякому випадку, для достатньогладеньких розподiлiв компонент сумiшi. Спочатку ми побудуємо оцiнку, а

86 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
потiм доведемо, що вона має гарну швидкiсть збiжностi при правильномувиборi параметрiв.
Iдея оцiнки полягає в тому, щоб шукати стрибок щiльностi, який маєрозподiл H1 у точцi mH1 , за допомогою непараметричної оцiнки щiльностi.Ми застосуємо гiстограмну оцiнку щiльностi, що використовує HN
1 як ба-зову оцiнку функцiї розподiлу. Зауважимо, що швидкiсть збiжностi оцiнокщiльностi, як правило, гiрша, нiж у оцiнок функцiй розподiлу, на яких во-ни грунтуються. (В нашому випадку це теж так, див. п. 4.4). Але стрибокщiльностi є настiльки помiтним явищем, що гiстограма реагує на ньогошвидше, нiж регулярна оцiнка HN
1 .Отже, нехай нам вiдомо, що оцiнювана екстремальна точка mH1 на-
лежить деякому iнтервалу (xL, xR), −∞ < xL < xR < ∞. Розiб’ємо цейiнтервал на K = KN пiдiнтервалiв однакової довжини ∆N = (xR−xL)/KN
точками tk = xL + ∆Nk, k = 0, 1, . . . , K. Обчислимо
ZNk = N(HN
1 (tk+1)− HN1 (tk)) =
N∑j=1
a1j:N1I{ξj:N ∈ [tk, tk+1)}.
Нехай TN — деякий “порiг", тобто додатне число. Як оцiнку для mH1 ви-беремо
mN = inf{tk : ZNk > TN}. (3.32)
Iнакше кажучи, ZNk — це висота стовпчика гiстограми2, побудованого над
iнтервалом (tk, tk+1]. Ми знаходимо крайнiй стовпчик лiворуч, який пере-вищує порiг, i лiвий його кiнець приймаємо як оцiнку для нижньої екс-тремальної точки. При правильному виборi порогу та кiлькостi iнтервалiврозбиття така оцiнка має потрiбну нам швидкiсть збiжностi (3.30).
Зауважимо, що вимога апрiорного задання iнтервалу (xL, xR), якомуналежить оцiнювана екстремальна точка, не є суттєвою. Дiйсно, викори-стовуючи “негарну"оцiнку m∗
N , можна спочатку знайти iнтервал, якомуmH1 належить з великою ймовiрнiстю, а потiм застосувати оцiнку mN нацьому iнтервалi.
Теорема 3.5.1 Нехай виконуються наступнi умови1. Для деяких вiдомих −∞ < xL, xR < ∞, mH1 ∈ (xL, xR)2. Для деяких α > 0, δ > 0 при всiх x1, x2 ∈ (mH1 ,mH1 +δ) виконується
нерiвнiсть|H1(x1)−H1(x2)| ≥ α|x1 − x2|.
2Тут ми маємо на увазi гiстограму абсолютних частот, про гiстограму вiдноснихчастот, як оцiнку щiльностi, див. 4.4.

3.5. Оцiнка екстремальних точок розподiлiв компонент 87
3. Для всiх k = 1, . . . ,M при деякому L < ∞, для всiх x1, x2 ∈ Rвиконується нерiвнiсть
|Hk(x1)−Hk(x2)| ≤ L|x1 − x2|.4. Ваговi коефiцiєнти a1
j:N задовольняють умову незмiщеностi (2.5) iдля деякого D < ∞, |a1
j:N | < D при всiх j = 1, . . . , N , N ∈ N.5. Оцiнка mN визначена (3.32) з TN = RN ln N , KN =
[N
SN ln N
], де [x]
— цiла частина числа x; SN , RN — числовi послiдовностi, такi, що приN →∞, SN →∞, RN →∞, KN →∞, RN/SN → 0, R2
N/SN →∞.Тодi нерiвнiсть
|mN −mH1| ≤2(xR − xL)
KN
виконується м.н. при достатньо великих N .
Зауваження.1. Умова 2) виконується, якщо розподiл першої компо-ненти має щiльнiсть, вiддiлену вiд 0 на iнтервалi (mH1 ,mH1 + δ).
2. Умова 4) виконується, якщо lim infN→∞ ΓN > 0 i a1j:N — мiнiмакснi
ваговi коефiцiєнти, визначенi визначенi за (2.10).3. Для довiльного SN →∞ обравши RN = S
3/4N , отримуємо RN/SN → 0,
R2N/SN → ∞, отже в умовi 5) SN може прямувати до ∞ як завгодно
повiльно.Доведення. Позначимо
χkjN = a1
j:N(1I{ξj:N ∈ [tk, tk+1)} − P{ξj:N ∈ [tk, tk+1)}),
Y Nk =
∑Nj=1 χk
jN . Якщо KN та TN задовольняють умовi 5) теореми, то
sup1≤k≤KN
|Y Nk | ≤ TN (3.33)
м.н. при достатньо великих N .Дiйсно,
P{supk
Y Nk > TN} ≤
KN∑
k=1
P{Y Nk > TN}. (3.34)
Внаслiдок умови 4), |χkjN | < D i χk
jN є незалежними випадковими величи-нами. Отже виконується нерiвнiсть Прохорова (див. теорему 7.3.1):
P{Y Nk > TN} ≤ exp
(−TN
2Darcsh
(DTN
2BN
)),

88 Роздiл 3. Оцiнки числових характеристик розподiлiв компонент
де
BN =N∑
j=1
E(χkjN)2 =
N∑j=1
(a1j:N)2(P{ξj:N ∈ [tk, tk+1)} − (P{ξj:N ∈ [tk, tk+1)})2)
≤ D2
N∑j=1
P{ξj:N ∈ [tk, tk+1)} ≤ D2LN∆N ≤ D2SN ln N.
Таким чином, для деякої константи C < ∞,
P{Y Nk > TN} ≤ exp
(−RN ln N
2Darcsh
(RN
DSN
))
≤ C exp
(− R2
N
2D2SN
ln N
)
при достатньо великих N (оскiльки RN/SN → 0 i arcsh(z) ∼ z при z → 0).Отже, продовжуючи (3.34), маємо, для деякого C < ∞,
P{supk
Y Nk > TN} ≤ CN ·N−R2
N/(2D2SN ).
Звiдси, враховуючи R2N/SN →∞, маємо
∞∑N=1
P{supk
Y Nk > TN} < ∞.
Отже, за лемою Бореля-Кантеллi, supk Y Nk < TN м.н. при достатньо вели-
ких N . Аналогiчно supk(−Y Nk ) < TN м.н. Нерiвнiсть (3.33) доведено.
Легко бачити, що ZNk = Y N
k + ZNk , де
ZNk = E ZN
k = N E(HN1 (tk+1)− HN
1 (tk)).
Оскiльки HN1 є незмiщеною оцiнкою H1, то при tk+1 < mH1 , ZN
k = 0. Длязначення k∗, такого, що tk∗−1 ≤ mH1 ≤ tk, внаслiдок умови 2) отримуємо,при достатньо великих N ,
Zk∗ ≥ Nα|tk∗+1 − tk∗| ≥ αSN ln N. (3.35)
Оскiльки RN/SN → 0, то з (3.33) та (3.35) отримуємо при достатньо вели-ких N ,
ZNk∗ ≥ ZN
k∗ − |Y Nk∗ | ≥ αSN ln N −RN ln N ≥ RN ln N = TN .
Отже, при достатньо великих N , mN дорiвнює або tk∗ , або tk∗−1. Такимчином, |mN −mH1| ≤ 2∆N .
Теорему доведено.

Роздiл 4
Оцiнювання щiльностейрозподiлiв компонент
4.1 Ядернi оцiнки щiльностi
Мабуть найбiльш популярними непараметричними оцiнками щiльностi роз-подiлу по вибiрках з незалежних, однаково розподiлених одновимiрнихспостережень є гiстограми. Друге (а може i перше) мiсце належить ядер-ним оцiнкам щiльностi. У випадку, коли простiр спостережень X = Rd,причому його вимiрнiсть d > 1, але не дуже велика (d = 2, 3), ядернiоцiнки безумовно займають перше мiсце по популярностi. Це пояснюєтьсяяк порiвняною простотою їх обчислення, так i хорошими асимптотичнимивластивостями: можна показати, що при виконаннi деяких, досить ши-роких умов на оцiнювану щiльнiсть та на параметри ядерних оцiнок, цiоцiнки є, у певному розумiннi, асимптотично ефективними, точнiше наних досягається локально-мiнiмаксна межа середньоквадратичного ризи-ку (див. п. 5, роздiлу 4 у [10]).
У цьому параграфi ми введемо ядернi оцiнки щiльностi для спосте-режень з сумiшi зi змiнними концентрацiями у випадку, коли спостере-ження належать X = Rd та доведемо теорему про консистентнiсть цихоцiнок у просторi L1(Rd). Вибiр саме цього простору не є випадковим —на збiжностi оцiнок щiльностi у L1(Rd) базується доведення консистент-ностi емпiрично-баєсових класифiкаторiв, що використовують цi оцiнки(див. роздiл 6).
Як i ранiше, будемо вважати, що незалежнi спостереження ξj:N опису-

90 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
ються моделлю
P{ξj ≤ x} =M∑
k=1
wkj:NHk(x), (4.1)
де Hm — розподiл m-тої компоненти, wmj:N — її концентрацiя у сумiшi.
Будемо вважати, що розподiли усiх компонент сумiшi мають щiльностiвiдносно λ – мiри Лебега на Rd. Позначимо цi щiльностi hi(x) = ∂Hi
∂λ(x).
Iнакаше кажучи, для будь-якої вимiрної множини A ⊆ Rd,
Hi(A) =
∫
A
hi(x)dx
(тут dx = λ(dx) позначає iнтегрування по мiрi Лебега у Rd, тобто, фак-тично, цей iнтеграл є d-кратним iнтегралом).
Функцiю K : Rd → [0, +∞] будемо називати ядром, якщо∫Rd K(x)dx =
1. Можна сказати, що ядро — це щiльнiсть деякої ймовiрнiсної мiри на Rd.Отже, нехай K – ядро на Rd, а s = sN → 0, N →∞ деяка послiдовнiсть
додатних чисел. Ядерною оцiнкою з ядром K називають
hNi (x) = s−d 1
N
N∑j=1
aij:NK
(x− ξj
s
)
= s−d
∫K
(x− y
s
)HN
i (dy), (4.2)
де ai – мiнiмакснi ваговi коефiцiєнти, визначенi (2.10), а HNi — зважена
емпiрична мiра з цими коефiцiєнтами, тобто мiнiмаксна оцiнка Hi.Число sN називають “параметром згладжування” (smoothing parameter)
оцiнки hNi (x). Для вибору параметра згладжування iснують двi проти-
лежнi вимоги. По-перше, вiн повинен бути достатньо малим, оскiльки чимбiльше sN , тим бiльш гладенькою виходить оцiнка, i при занадто вели-ких sN вона перетворюється на “майже константу”. По-друге, вiн повиненбути достатньо великим, оскiльки при малих значеннях параметру зглад-жування оцiнка має велику статистичну розкиданiсть.
Наступна теорема задає умови на параметр згладжування, при якихядерна оцiнка буде консистентною у L1(Rd).
Теорема 4.1.1 Нехай1. Для деякої константи C > 0, det ΓN > C.2. sN → 0,
√ln NN
s−dN → 0 при N →∞.

4.1. Ядернi оцiнки щiльностi 91
Тодi ∫
Rd
|hNi (x)− hi(x)|dx → 0м.н.
Для доведення теореми нам буде потрiбна одна лема.Для x ∈ Rd, A,B ⊆ Rd, s ∈ R будемо позначати
x + A = {x + a : a ∈ A},A + B = {a + b : a ∈ A, b ∈ B},
sA = {sa : a ∈ A}.Лема 4.1.1 Для довiльної скiнченної мiри ν
∫
x∈B
ν(x + A)dx =
∫
z∈A
ν(z + B)dz.
Доведення. Якщо ν має щiльнiсть h вiдносно λ, то∫
x∈B
ν(x + A)dx =
∫ ∫1I{x ∈ B}1I{y − x ∈ A}ν(dy)dx =
=
∫ ∫1I{x ∈ B}1I{z ∈ A}h(x + z)dzdx =
∫1I{z ∈ A}ν(z + B)dx.
Перехiд до ν загального вигляду можна здiйснити, апроксимуючи ν абсо-лютно неперервними мiрами.
Доведення теореми. Позначимо εN =√
ln NN
. З умови 1 випливає, щоsupj,N |ai
j,N | < C ′ < ∞. Тому, враховуючи, що клас всiх прямокутникiв уRd є класом Вапника-Червоненкiса, за теоремою 2.2.4 маємо, що, для всiхпрямокутникiв1 B ⊆ Rd,
|HNi (B)−Hi(B)| ≤ ΛεN м.н.
i |HNi | = VARHN
i ≤ C < ∞ м.н.2Фiксуємо деяке δ > 0. Виберемо нове ядро вигляду
K∗(x) =n∑
k=1
dk1I{x ∈ Di},
1Тут i далi ми маємо на увазi прямокутники (паралелограми, бруски) з ребрами,паралельними осям координат.
2VARµ позначає повну варiацiю заряда µ

92 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
де Di – обмеженi прямокутники, 0 ≤ di ≤ H < ∞, так, щоб∫ |K(x) −
K∗(x)|dx < δ. Позначимо gs(x) = s−d∫
K(x−ys
)Hi(dy), g∗s та h∗N визнача-ються аналогiчно gs i hN
i вiдповiдно, з замiною K на K∗. Згiдно [9],∫|hi(x)− gs(x)|dx → 0 при s → 0.
Оцiнимо
J =
∫|hN
i (x)− gs(x)|dx ≤ J1 + J2 + J3,
де
J1 =
∫s−d
∫|K∗((x− y)/s)−K((x− y)/s)| × |HN
i |(dy)dx ≤ Cδ,
J2 =
∫s−d
∫|K∗((x− y)/s)−K((x− y)/s)|hi(y)dydx ≤ δ,
J3 =
∫|h∗N(x)− g∗s(x)|dx ≤ Hs−d
n∑
k=1
∫|Hi(x + sDk)− HN
i (x + sDk)|dx.
Залишилось тiльки довести, що
J ′ = s−d
∫|Hi(x + sDk)− HN
i (x + sDk)|dx → 0 м.н. при N →∞.
Позначимо B ⊂ Rd обмежений прямокутник, такий, що Hi(Dk +Rd \B) ≤δ′. Тодi J ′ ≤ J ′1 + J ′2 + J ′3, де
J ′1 = s−d
∫
B
|Hi(x + sDk)− HNi (x + sDk)|dx = s−d
∫
B
CεNdx ≤ Λ′εNs−d,
J ′2 = s−d
∫
Rd\BHi(x + sDk)dx = s−d
∫
sAi
Hi(Rd \B + sDk)dx ≤ δ′λ(Dk)
якщо s < 1 (за леммою 4.1.1),
J ′3 = s−d
∫
Rd\B|HN
i (x + sDk)|dx ≤ δ′λ(Dk) + Λ′εNλ(Dk).
Об’єднуючи всi цi оцiнки, маємо J ′ ≤ C(δ+δ′)+Λ′εNs−d та Λ′εNs−d → 0при N →∞ за умовою теореми. Внаслiдок довiльностi δ та δ′ отримуємоJ → 0 м.н.

4.2. Асимпототична нормальнiсть ядерних оцiнок 93
Теорему доведено.Доведення теореми не дає жодних натякiв на те, якою може бути швид-
кiсть збiжностi ядерних оцiнок до оцiнюваної щiльностi. У [9] показано,що навiть для незалежних, однаково розподiлених спостережень, ядернiоцiнки щiльностi можуть збiгатись як завгодно повiльно, якщо оцiнюванащiльнiсть не є гладенькою. Накладаючи рiзнi умови на гладкiсть оцiню-ваних щiльностей та на збiжнiсть до 0 параметра згладжування можнаотримувати вiдповiднi швидкостi збiжностi ядерних оцiнок. Приклади до-слiдження збiжностi ядерних оцiнок ми розглянемо далi у цьому роздiлi.
4.2 Асимпототична нормальнiсть ядерних оцi-нок
У цьому параграфi ми розглянемо одновимiрнi спостереження X = R iпокажемо, що ядерна оцiнка щiльностi, розглянута у попередньому па-раграфi, є асимптотично нормальною, але змiст цього твердження будедещо вiдмiнним вiд того, як ми розумiли асимптотичну нормальнiсть дляемпiричних функцiй розподiлу або зважених емпiричних моментiв.
По-перше, ми будемо дослiджувати вiдхилення оцiнки (ядерної) не вiдоцiнюваної величини (щiльностi розподiлу), а вiд математичного сподiван-ня самої оцiнки. У випадку зважених емпiричних функцiй розподiлу аболiнiйних оцiнок моментiв така вiдмiннiсть була б несуттєвою: оскiльки мирозглядали лише незмiщенi оцiнки, їх математичне сподiвання дорiвню-вало оцiнюваним характеристикам. Для виправлених з.е.ф.р., адаптивнихоцiнок розподiлiв та моментiв це вже не так — вони не є незмiщеними.Однак вiдповiднi теореми про асимптотичну нормальнiсть цих оцiнок по-казують, що асимптотично це змiщення є несуттєвим, порiвняно зi стати-стичним розкидом оцiнки навколо свого середнього значення.
У випадку оцiнок щiльностi це не так. Виявляється, що для того, щобдосягти оптимальної швидкостi збiжностi цих оцiнок, потрiбно обиратипараметр згладжування так, щоб забезпечити приблизно однаковий вне-сок у загальне вiдхилення оцiнки статистичних вiдхилень вiд середньогоз одного боку та змiщення середнього вiд оцiнюваної щiльностi з iншо-го боку. Теорема про асимптотичну нормальнiсть дозволяє досить точнооцiнити розмiр статистичного вiдхилення.
По-друге, нормування вiдхилення оцiнки вiд її математичного сподi-вання буде нормуватись не
√N , а
√NsN , де sN — параметр згладжуван-

94 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
ня ядерної оцiнки. Оскiльки для розумних оцiнок sN → 0, це означає,що отримана швидкiсть збiжностi буде повiльнiшою, нiж
√N — традицiй-
на швидкiсть збiжностi оцiнок у параметричнiй статистцi. Вiдомо, що увипадку оцiнювання по незалежних однаково розподiлених випадкових ве-личинах, нормування ядерних оцiнок для отримання асимптотичної нор-мальностi повинно бути саме
√NsN . Це характеризує “нерегулярнiсть”
задачi оцiнювання щiльностi порiвняно з параметричними задачами та ззадачами непараметричного оцiнювання моментiв або функцiй розподiлу.Таким чином, у цьому розумiннi задача оцiнки щiльностей компонент су-мiшi зi змiнними концентрацiями є так само нерегулярною (не бiльше i неменше) як i ця задача у випадку однаково розподiлених спостережень.
Теорема 4.2.1 Нехай виконуються наступнi умовиа) щiльнiсть hi(x) неперервна i обмежена: hi(x) < c для усiх i = 1÷M
i деякої константи с;б)
d2 =
∫ ∞
−∞K2(t)dt < ∞;
в)
σ2i (x) = lim
N→∞
M∑
k=1
〈(ai)2(wk)2〉Nhk(x) < ∞;
г) det ΓN > g для деякого g > 0 i всiх N ∈ N;д) sN → 0, NsN →∞ при N →∞.Тодi
hNi (x) = hN
i (x) +1√
NsN
ζ iN , (4.3)
де hNi (x) = E hN
i (x) є невипадковою функцiєю, hNi (x) → hi(x) при sN → 0,
а випадковi величини ζ iN є асимптотично нормальними з параметрами
N(0, d2σ2i (x)).
Доведення. Спочатку розглянемо функцiю hNi (x).
hNi (x) = E hN
i (x) =1
NsN
N∑j=1
aij:N E K
(x− ξj:N
sN
)=
=1
NsN
N∑j=1
aij:N
M∑
k=1
wkj:N
∫ +∞
−∞K
(x− y
sN
)hk(y)dy.

4.2. Асимпототична нормальнiсть ядерних оцiнок 95
Використавши умову незмiщеностi (2.5) i зробивши замiну змiнної в iнте-гралi, одержуємо
hNi (x) =
∫ +∞
−∞K(z)hi(x− sNz)dz → hi(x)
при sN → 0. Введемо у розгляд послiдовнiсть
X ij,N =
1√NsN
aij:N
(K
(x− ξj:N
sN
)− E K
(x− ξj:N
sN
)).
Тодi
hNi (x)− hN
i (x) =1√
NsN
N∑j=1
X ij,N ; E X i
j,N = 0.
Оскiльки спостереження ξj:N незалежнi, {X ij,N}N
j=1 являють собою по-слiдовнiсть незалежних випадкових величин. Для доведення теореми 4.2.1застосуємо центральну граничну теорему з умовою Лiндеберга (теорема7.3.8) до послiдовностi {X i
j,N}Nj=1. Спершу перевiримо виконання умови
(7.6).
Var ζ iN =
N∑j=1
Var X ij,N
=N∑
j=1
(aij:N)2
NsN
(E K2
(x− ξj:N
sN
)−
(E K
(x− ξj:N
sN
))2)
= SN1 − SN
2 (4.4)
де
SN1 =
N∑j=1
(aij:N)2
NsN
E K2
(x− ξj:N
sN
)
i
SN2 = −
N∑j=1
(aij:N)2
NsN
(E K
(x− ξj:N
sN
))2
Розглянемо кожний доданок правої частини (4.4) окремо.
1
sN
(E K
(x− ξj:N
sN
))2
=1
sN
(M∑
k=1
wkj:N
∫ ∞
−∞K
(x− y
sN
)hk(y)dy
)2
=

96 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
= sN
(M∑
k=1
wkj:N
∫ ∞
−∞K(z)hk(x− sNz)dz
)2
. (4.5)
Величини wkj:N , ai
j:N , hk(x) є обмеженими; K(z) — щiльнiсть на R, томуочевидно, що
SN2 < sNC1,
де C1 — деяка константа. Отже,
limN→∞
SN2 = 0.
Оцiнимо SN1 .
1
sN
E K2
(x− ξj:N
sN
)=
1
sN
M∑
k=1
wkj:N
∫ ∞
−∞K2
(x− y
sN
)hk(y)dy =
=M∑
k=1
wkj:N
∫ ∞
−∞K2(z)hk(x− sNz)dz.
Отже,
SN1 =
N∑j=1
(aij:N)2
N
M∑
k=1
wkj:N
∫ ∞
−∞K2(z) (hk(x− zsN)− hk(x) + hk(x)) dz =
= d2〈(ai)2wk〉hk(x) + εN ,
де
εN ≤ c2
∫ ∞
−∞K2(z) sup
1≤k≤M| hk(x− zsN)− hk(x) | dz;
c2 - деяка константа. εN → 0 при N →∞, отже,
limN→∞
SN1 = d2σi(x).
Умова (7.6) теореми 7.3.8 перевiрена. Розглянемо виконання умови Лiн-деберга (7.7). З нерiвностi
(x− y)2 ≤ 2(x2 + y2)
випливає
(X i
j,N
)2 ≤ 2(aij:N)2
NsN
(K2
(x− ξj:N
sN
)+
(E K
(x− ξj:N
sN
))2)
.

4.2. Асимпототична нормальнiсть ядерних оцiнок 97
Тому
B =N∑
j=1
E(X ij,N)21I
(| X ij,N |> τ
) ≤
≤ 2
NsN
N∑j=1
(aij:N)2 E K2
(x− ξj:N
sN
)1I{| X i
j,N |> τ}+
+2
NsN
N∑j=1
(aij:N)2
(E K2
(x− ξj:N
sN
))2
P{| X ij,N |> τ} =
= S3 + S4.
З того, що aij:N обмеженi i виконується спiввiдношення (4.5), випливає,
що S4 → 0 при N →∞. Розглянемо доданок S3.
S3 =2
NsN
N∑j=1
(aij:N)2 E K2
(x− ξj:N
sN
)
×1I{| K(
x− ξj:N
sN
)− E K
(x− ξj:N
sN
)|> τ
√NsN
aij:N
} =
=2
N
N∑j=1
(aij:N)2
M∑
k=1
wkj:N
∫
BN,τ
K2(z)hk(x− zsN)dz, (4.6)
де
BN,τ = {z :
∣∣∣∣K(z)− E K
(x− ξj:N
sN
)∣∣∣∣ >τ√
NsN
aij:N
}.
Щiльностi hk(x) < c для усiх k = 1÷M , отже,∫
BN,τ
K2(z)hk(x− zsN)dz ≤ c
∫
BN,τ
K2(z)dz. (4.7)
Враховуючи, що
E K
(x− ξN
j
sN
)= O(sN)
при N →∞, i завдяки умовi (б) теореми, можемо записати∫
AN,τ
K2(z)dz → 0,
де AN,τ = {z : K(z) > CN}, а CN → ±∞. Отже, S3 → 0 при N → ∞, длядовiльної сталої τ , умова Лiндеберга виконується.
Теорема 4.2.1 доведена.

98 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
4.3 Вибiр параметра згладжуванняВиникає питання про оптимальний вибiр sN i K(z). Для того, щоб оцiни-ти якiсть оцiнки hN
i (x) “в середньому” i вибрати найкраще значення sN ,традицiйно використаємо L2-пiдхiд. Ми будемо мiнiмiзувати по sN проiн-тегровану середньоквадратичну похибку (mean integrated squared error,MISE)
JN =
∫ ∞
−∞E
(hN
i (x)− hi(x))2
dx. (11)
Припустимо, що виконуються умовиа)hi(x) > 0 лише на скiнченному iнтервалi;б)iснує (hi(x))′′ = hi(x) друга похiдна щiльностi i-тої компоненти сумiшi
та φi =∫∞−∞
(hi(x)
)2dx < ∞;
в)∫∞−∞ zK(z)dz = 0;
г)D2 =∫∞−∞ z2K(z)dz < ∞;
д)AN = 1N
∑Nj=1(a
ij:N)2 → A при N →∞, де A - деяка константа.
Теорема 4.3.1 В умовах (а) - (д) виконується спiввiдношення
limN→∞
inf N45 JN ≥ 5
4
(DAd2
) 45 ,
причому рiвнiсть досягається при
sN =
(Ad2
ND4φi
) 15
. (4.8)
Доведення. Перетворимо JN таким чином
JN =
∫ ∞
−∞E
(hN
i (x)− hNi (x)
)2
dx +
∫ ∞
−∞
(hN
i (x)− hi(x))2
dx = BN1 + BN
2 .
Вiдомо, що
BN2 =
∫ ∞
−∞
(∫ ∞
−∞K(z)hi(x− zsN)dz − hi(x)
)2
dx =
(D2s2
N
2
)2
φi + o(s4N).
(4.9)(Доведення цього факту є, наприклад, у [16],c. 132.) Оцiнимо BN
1 .
E(hN
i (x)− hNi (x)
)2
=

4.3. Вибiр параметра згладжування 99
=N∑
j=1
(aij:N)2
NsN
(E K2
(x− ξj:N
sN
)−
(E K
(x− ξj:N
sN
))2)
(4.10)
Знайдемо iнтеграл вiд кожного доданку (4.10) окремо.
1
sN
∫ ∞
−∞E K2
(x− ξj:N
sN
)dx
=M∑
k=1
wkj:N
∫ ∞
−∞K2(z)
[∫ ∞
−∞hk(x− zsN)dx
]dz = d2. (4.11)
Розглянемо другий доданок у (4.10).
1
sN
(E K
(x− ξj:N
sN
))2
= sN
(M∑
k=1
wkj:N
∫ ∞
−∞K(z)hk(x− zsN)dz
)2
.
Оскiльки hk(x) обмежена для усiх k, hk(x) > 0 лише на скiнченному iн-тервалi, то
1
sN
∫ ∞
−∞
(E K
(x− ξj:N
sN
))2
dx = O(sN) (4.12)
Враховуючи (4.10-4.12), отримуємо
BN1 =
1
NsN
1
N
N∑j=1
(aij:N)2
(d2 + O(sN)
) ' Ad2
NsN
+ O
(A
N
)(4.13)
Пiдставимо (4.9) i (4.13) у вираз JN .
JN =D4φi
4s4
N +Ad2
NsN
+ o((sN)4) (4.14)
Мiнiмум головної частини (4.14) досягається, коли sN задається формулою(4.8). Пiдставляючи (4.8) у (4.8), одержуємо твердження теореми 4.3.1.
Ми одержали вираз для JN , що характеризує збiжнiсть у середньоквад-ратичному ядерної оцiнки щiльностi компоненти сумiшi до щiльностi цiєїкомпоненти. Але JN мiстить параметр φi, який залежить вiд щiльностihi(x). Його потрiбно оцiнити за данними спостережень {ξj:N}N
j=1. Нехай{κN} - послiдовнiсть додатних чисел, таких, що κN → 0 при N → ∞,причому κN = O(N−β), де 0 < β < 1
10. За оцiнку φi приймемо
φNi =
∫ ∞
−∞
((hN
i (x, κN))′′)2
dx,

100 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
де
hNi (x, κ) = hN
i (x) =1
Nκ
N∑j=1
aij:NK
(x− ξj
κ
)
— ядерна оцiнка щiльностi з параметром згладжування κ. Легко бачити,що
φNi =
1
N2κ6N
∫ ∞
−∞
(N∑
j=1
aij:NK
(x− ξj:N
κN
))2
dx, (4.15)
тут K(z) = K ′′(z) - друга похiдна K(z). Припустимо, що виконуютьсянаступнi умови
а)hi(x) є неперервною обмеженою функцiєю, що належить L2;б)K(x) - симетричне ядро на R; K ′(x) → 0 при x → ±∞;в) ∫ ∞
−∞xK(x)dx = 0;
∫ ∞
−∞x2 | K(x) | dx < ∞.
Теорема 4.3.2 В умовах (а) - (в) для довiльного цiлого m > 0 оцiнка(4.15) задовольняє спiввiдношення
E(φi − φi
)2m
= O((
N−(1−10β))m
)(4.16)
Доведення. Позначимо
µiN(x) =
∫ ∞
−∞K(z)hi(x− zκN)dz
Скористаємося наступною лемою [6, c. 133].
Лема 4.3.1 У припущеннях (а) - (в) виконується
limN→∞
∫ ∞
−∞
(µi
N(x))2
dx =
∫ ∞
−∞
(hi(x)
)2dx = φi.
Отже, нам залишається довести замiсть (4.16) твердження
α = E
(φi −
∫ ∞
−∞
(µi
N(x))2
dx
)2m
= O(N−(1−10β)m
). (4.17)

4.3. Вибiр параметра згладжування 101
Введемо позначення
K∗(u) =
∫ ∞
−∞K(v)K(u− v)dv; TN(u) =
1
κN
∫ ∞
−∞K∗
(u− v
κN
)hi(v)dv
Неважко пересвiдчитися, що∫ ∞
−∞
(µi
N(x))2
dx =1
κ4N
∫ ∞
−∞hi(u)TN(u)du =
=1
Nκ4N
EN∑
j=1
aij:NTN(ξj:N). (4.18)
Окрiм того,
φi =1
N2κ6N
∫ ∞
−∞
(N∑
j=1
aij:NK
(x− ξj:N
κN
))2
dx =
=1
N2κ5N
N∑j=1
N∑
l=1
aij:Nai
l:NK∗(
ξl:N − ξj:N
κN
). (4.19)
Пiдставимо (4.18), (4.19) у лiву частину (4.17):
α = E
(1
N2κ5N
N∑j=1
N∑
l=1
aij:Nai
l:NK∗(
ξl:N − ξj:N
κN
)
− 1
Nκ4N
EN∑
j=1
aij:NTN(ξj:N)
)2m
=
=1
κ8mN
E
(1
N2
N∑j=1
N∑
l=1
aij:Nai
l:N
1
κN
K∗(
ξl:N − ξj:N
κN
)−
− 1
N
N∑j=1
aij:NTN(ξj:N) +
1
N
N∑j=1
aij:NTN(ξj:N)− 1
N
N∑j=1
aij:N E TN(ξj:N)
)2m
Звiдси, вiдповiдно нерiвностi
|m∑
k=1
zk |p≤ mp−1
m∑
k=1
| zk |p,

102 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
де p > 0 — цiле число, знаходимо
α ≤ 22m−1κ−8mN
(EN
1 + EN2
), (4.20)
де
EN1 = E
(1
N2
N∑j=1
N∑
l=1
aij:Nai
l:N
1
κN
K∗(
ξl:N − ξj:N
κN
)− 1
N
N∑j=1
aij:NTN(ξj:N)
)2m
;
EN2 =
1
N2mE
(N∑
j=1
aij:N (TN(ξj:N)− E TN(ξj:N))
)2m
.
Для оцiнки EN2 скористаємося наступним твердженням.
Теорема 4.3.3 [17], c. 89. Нехай x1, x2, . . . , xN — незалежнi випадковi ве-личини; Exk = 0 для усiх k = 1÷ n. Тодi
E | SN |p≤ C(p)np2−1
n∑
k=1
E | xk |p;
тут Sn =∑n
i=1 xk; p ≥ 2; C(p) - константа, що залежить лише вiд p.
Отже,
EN2 ≤ c
N2m
N∑j=1
(aij:N)2m E (TN(ξj:N)− E TN(ξj:N))2m Nm−1.
(Тут i далi через c, c1, c2, . . . позначаємо рiзнi константи.) З того, що
TN(x) ≤ c1
κN
, (4.21)
випливає
EN2 =
cc2
Nm+1(κN)2m
N∑j=1
(aij:N)2m ≤ c3
(Nκ2N)
m ;
EN2 = O
(1
(Nκ2N)
m
). (4.22)

4.3. Вибiр параметра згладжування 103
Тепер розглянемо EN1 . Функцiя K∗(u) обмежена i виконується (4.21), тому
можна окремо оцiнити доданок з EN1 , для якого l = j.
EN1 ≤ c4
(NκN)2m
+ E
(1
N
N∑j=1
aij:N
(1
N
N∑
l=1;l 6=j
ail:N
1
κN
K∗(
ξl:N − ξj:N
κN
)− TN(ξj:N)
))2m
.
Скористаємося нерiвнiстю Єнсена:
EN1 ≤ c4
(NκN)2m
+1
N
N∑j=1
(aij:N)2m E
(1
N
N∑
l=1;l 6=j
ail:N
1
κN
K∗(
ξl:N − ξj:N
κN
)− TN(ξj:N)
)2m
=c4
(NκN)2m+ EN
3 (4.23)
де
EN3 =
1
N
N∑j=1
(aij:N)2m E (γ(ξj:N)) ,
γ(y) = E
[(1
N
N∑
l=1;l 6=j
ail:N
1
κN
K∗(
ξl:N − ξj:N
κN
)− TN(ξj:N)
)2m∣∣∣∣∣ ξj:N = y
]
= E
(1
N
N∑
l=1;l 6=j
ail:N
1
κN
K∗(
ξl:N − y
κN
)− TN(y)
)2m
.
Таким чином, нам необхiдно оцiнити EN3 . Представимо
TN(y) =1
N
N∑
l=1
ail:N
1
κN
M∑
k=1
wkl:N
∫ ∞
−∞K∗
(u− y
κN
)hk(u)du
i позначимо
VN(ξl:N) = ail:N
1
κN
(K∗
(ξl:N − y
κN
)−
M∑
k=1
wkl:N
∫ ∞
−∞K∗
(u− y
κN
)hk(u)du
)

104 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
Тодi
γ(y) ≤ c5
(E
(1
N
∑
l=1;l 6=j
ail:N
1
κN
(K∗(
ξl:N − y
κN
))
−M∑
k=1
wkl:N
∫ ∞
−∞K∗
(u− y
κN
)hk(u)du
)2m
+
(1
Nai
j:N
1
κN
M∑
k=1
wkj:N
∫ ∞
−∞K∗
(u− y
κN
)hk(u)du
)2m
(4.24)
Другий доданок у (4.24) не перевищує (c6/(NκN)2m. Таким чином,
γ(y) ≤ c5 E
(1
N
N∑
l=1;l 6=j
VN(ξl:N)
)2m
+c6
(NκN)2m.
VN(ξl:N) являє собою послiдовнiсть незалежних випадкових величин, при-чому E VN(ξl:N) = 0 для усiх l. Застосуємо до цiєї послiдовностi теорему4.3.3:
E
(N∑
l=1;l 6=j
VN(ξl:N)
)2m
≤ c7Nm−1
N∑
l=1;l 6=j
(E VN(ξl:N))2m
≤ c8Nm−1N − 1
κ2mN
< c8Nm
κ2mN
Отже, для довiльного y
γ(y) ≤ c6
(NκN)2m+
c8
(Nκ2N)m
Пiдсумовуючи оцiнки (4.23) i (4.24), одержуємо
EN1 ≤ c4
(NκN)2m+
c6
(NκN)2m+
c8
(Nκ2N)m
= O
((1
Nκ2N
)m)(4.25)
Пiдставляючи (4.22) i (4.25) у (4.20), отримуємо (4.17).Теорема доведена.Вiдмiтимо, що асимптотика вектора ядерних оцiнок щiльностей ком-
понент сумiшi зi змiнними концентрацiями, а також асимптотичнi власти-востi похiдних вiд цих щiльностей дослiдженi в роботi [12]. Зокрема, в

4.3. Вибiр параметра згладжування 105
подальшому розглядi з цього джерела нам будуть потрiбнi наступнi ре-зультати, якi ми наводимо без доведення.
Позначимо похiдну вiд ядерної оцiнки щiльностi
h′k,N(x) =1
NsN2
N∑j=1
akj:NK ′
(x− ξj:N
sN
), 1 ≤ k ≤ M.
Теорема 4.3.4 Нехай виконуються наступнi умови.(i) щiльностi hk(x) є неперервними та обмеженими деякою сталою:
∃ c > 0 : hk(x) < c, 1 ≤ k ≤ M ;(ii) iснують границi
σ2k(x) = lim
N→∞
M∑r=1
⟨(ak)2wr
⟩N
hr(x) < ∞; 1 ≤ k ≤ M ;
(iii) iснують h′k(x), якi є обмеженими деякою сталою ∃ c1 > 0 :hk′(x) < c1, 1 ≤ k ≤ M ;(iv) d2
2 =∫∞−∞ (K ′(z))2 dz < ∞.
Тодih′k,N(x) = h′k,N(x) +
1√NsN
2ζN
k, (4.26)
де h′k,N(x) = E h′k,N(x) є невипадковими функцiями, h′k,N(x) → f ′k(x) приsN → 0, а випадковi величини ζN
k є асимптотично нормальними з пара-метрами N(0, d2
2σ2k(x)).
Позначимо ~ζN = N2/5(hNi (x)− hi(x))d
i=1.
Теорема 4.3.5 Нехай виконуються наступнi умови(i) Функцiї hk(x) та їх другi похiднi h′′k(x) є неперервними та обме-
женими для x ∈ R.(ii) Iснують границi σ2
km(x) = limN→∞∑M
r=1〈akamwr〉Nhr(x).(iii) d2 =
∫∞−∞ K2(z)dz < ∞,
∫∞−∞ zK(z)dz = 0, D2 =
∫∞−∞ zK(z)dz < ∞.
(iv) sN = cN−1/5 де 0 < c < ∞ — деяка константа.Тодi ζN ⇒ ζ при N →∞, де ζ — гауссiв випадковий вектор з матема-
тичним сподiванням D2c2/5~h′′(x)/2 i коварiацiйною матрицею d2
c1/5 G(x),~h′′(x) = (h′′1(x), . . . , h′′M(x))T , G(x) = (σ2
km(x))Mk,m=1.

106 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
4.4 Неядернi оцiнки щiльностей розподiлiв
Розглянутi у попереднiх параграфах ядернi оцiнки щiльностей компонентсумiшi мають ряд хороших властивостей: вони порiвняно просто обчислю-ються при помiрних обсягах вибiрки, забезпечують оптимальну швидкiстьзбiжностi до оцiнюваної щiльностi, їх легко використовувати для багато-вимiрних даних. Однак у деяких задачах виявляються бiльш зручнимиiншi пiдходи до оцiнювання щiльностей. У цьому параграфi представле-но короткий огляд таких пiдходiв. Оскiльки навiть для непараметричногооцiнювання щiльностей за однаково розподiленими спостереженнями iснуєвелетенський обсяг лiтератури, що включає у себе чимало монографiй,наш огляд нiяк не може претендувати на вичерпнiсть.
Гiстограмнi оцiнки. Гiстограми абсолютних та вiдносних частот єнастiльки поширеним i загальновизнаним засобом вiзуального аналiзу да-них, що багато дослiдникiв, якi використовують статистичнi методи напрактицi, сприймають щiльнiсть розподiлу як “граничний” або “теоретич-ний” аналог гiстограми. Тому розробка версiй гiстограмних оцiнок для ви-бiрки з сумiшi зi змiнними концентрацiями потрiбна хоча б для того, щобдати таким дослiдникам можливiсть порiвнювати гiстограми, отриманi заоднорiдними даними, з результатами аналiзу сумiшей.
Нагадаємо спочатку технiку побудови гiстограм для однорiдної вибiр-ки. Нехай вибiрка складається з ζ1,. . . ,ζN — одновимiрних спостережень зодним i тим самим розподiлом. Для побудови гiстограми потрiбно обратискiнченний iнтервал, на якому зосереджений цей розподiл — A = [b, c] такiлькiсть K маленьких “пiдiнтервалiв”, на якi буде розбито цей iнтервал. Укласичному варiантi для побудови гiстограми використовують рiвномiрнерозбиття A на пiдiнтервали Ak = [tk−1, tk), k = 1,. . . ,K− 1, AK = [tK−1, tK ]де tk = b + kδ, δ = (c− b)/K — ширина пiдiнтервалiв.
Пiсля цього пiдраховують “абсолютнi частоти” nk iнтервалiв Ak у ви-бiрцi: nk =
∑Nj=1 1I{ζj ∈ Ak}. Iнакше кажучи, nk — це кiлькiсть елементiв
вибiрки, якi потрапили у k-тий пiдiнтервал. Гiстограма абсолютних частотскладається зi стовпчикiв, основами яких є Ak, а висоти дорiвнюють nk. Угiстограмi абсолютних частот висоту k-того стовпчика обирають рiвноюfk = nk/(Nδ). Оскiльки вiдноснi частоти (або просто “частоти”) iнтервалiввизначаються як νk = nk/N , то fk = νk/δ.
Очевидно, що за формою гiстограми абсолютних та вiдносних частотцiлком однаковi i вiдрiзняються лише масштабом вертикальної осi. Оцiн-кою для щiльностi розподiлу є гiстограма вiдносних частот, але гiстогра-

4.4. Неядернi оцiнки щiльностей розподiлiв 107
ми абсолютних частот бувають зручнiшими при використаннi, наприклад,для аналiзу викидiв. Надалi пiд гiстограмою ми будемо розумiти саме гi-стограму вiдносних частот.
Точнiше, формально гiстограму вiдносних частот можна визначити якграфiк функцiї
f(x) =
{fk якщо x ∈ Ak
0 у iншому випадку=
K∑
k=1
fk1I{x ∈ Ak}.
Саму цю функцiю також iнколи називають гiстограмою або гiстограм-ною оцiнкою щiльностi розподiлу [9]. При правильному виборi параметрiв(iнтервалу-носiя гiстограми A та кiлькостi пiдiнтервалiв K) в залежностiвiд обсягу вибiрки, гiстограма є консистентною оцiнкою щiльностi розподi-лу f за вибiркою з незалежних однаково розподiлених випадкових вели-чин.
Щоб створити аналог гiстограми для оцiнювання щiльностi m-тої ком-поненти по спостереженнях ξj:N , j = 1,. . . ,N з сумiшi зi змiнними кон-центрацiями, досить задати аналоги вiдносних частот νk. Оскiльки νk єнасправдi оцiнками для ймовiрностей P{ζj ∈ Ak) =
∫Ak
f(x)dx, то у випад-ку сумiшi їх можна замiнити на HN
m (Ak) = HNm (tk) − HN
m (tk−1), де HNm —
оцiнка для функцiї розподiлу m-тої компоненти Hm по спостереженнях зсумiшi. На роль HN
m можна обрати(i) мiнiмаксну оцiнку HN
m з п. 2.1;(ii) яку-небуть версiю виправленої зваженої емпiричної функцiї роз-
подiлу F ∗(x, am) з розглянутих у п. 2.3;(iii) оцiнку, отриману за допомогою групування (дискретизацiї) даних
i застосування асимптотично ефективної технiки оцiнювання з п. 2.4.У варiантi (i) отримуємо наступну оцiнку щiльностi hm:
hNm =
K∑
k=1
(HN
m (Ak)1I{x ∈ Ak})
=K∑
k=1
N∑j=1
amj:N1I{x ∈ Ak, ξj:N ∈ Ak}, (4.27)
де amj:N — мiнiмакснi ваговi коефiцiєнти з (2.10).Варiант (ii) вiдрiзняється вiд (i) лише тим, що замiсть вагових коефi-
цiєнтiв мiнiмаксної оцiнки у (4.27) використовуються коефiцiєнти b∗j вiд-повiдної виправленої зваженої емпiричної ф.р. описанi у п. 2.3.
Нарештi, при використаннi пiдходу (iii), ми “групуємо” спостережен-ня, тобто замiняємо кожне ξj:N величиною ζj:N , яка дорiвнює номеру того

108 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
пiдiнтервалу, на який потрапляє ξj:N : ζj:N =∑K
k=1 k1I{ξj:N ∈ Ak}. Якщоiнтервали Ak — не випадковi (тобто вибранi незалежно вiд спостережень),то розподiл ζj:N описується формулою (2.49):
P{ζj:N = k} =M∑
m=1
wmj H(k,m), (4.28)
де3 H(k,m) = Hm(Ak) = Hm(tk)−Hm(tk−1). Оцiнки HN(k,m) для H(k,m), отри-
манi у п. 2.4, пiдставляються у формулу для гiстограми замiсть вiдноснихчастот. Оскiльки цi оцiнки також мають вигляд сум вагових коефiцiєнтiв,помножених на iндикатори, загальний вигляд оцiнки залишається подiб-ним до (4.27), однак є i суттєва вiдмiннiсть: при розрахунку HN
m (Ak) пiд-сумовуються лише ваговi коефiцiєнти am
j:N , що вiдповiдають спостережен-ням, якi потрапили на пiдiнтервал Ak. У формулi для HN
(k,m) використову-ються коефiцiєнти, пов’язанi з усiма спостереженнями i усiма пiдiнтерва-лами, на якi розбивається носiй гiстограми A. Врахування цiєї iнформацiїнеобхiдне для отримання ефективної оцiнки.
Нажаль, як показують дослiдження на модельованих даних, перевагиадаптивних оцiнок стають помiтними лише при достатньо великих обся-гах вибiрки (потрiбнi сотнi спостережень на один пiдiнтервал розбиття),що робить їх незручними для використання у гiстограмних оцiнках, деми, як правило, намагаємось зробити пiдiнтервали якомога вужчими, щобпомiтити особливостi оцiнюваної щiльностi.
Точнiше, для вибору ширини пiдiнтервалiв δ (або, вiдповiдно, їх кiль-костi K) ми маємо двi протилежнi рекомендацiї: з одного боку, δ має бутивеликим, щоб на кожен пiдiнтервал Ak потрапляла достатня кiлькiсть спо-стережень для оцiнки P{Ak}, з iншого — δ повинно бути досить малим,щоб оцiнювана щiльнiсть не дуже сильно змiнювалась всерединi пiдiнтер-валiв. Фактично, у гiстограмних оцiнках δ (точнiше (c − b)/K, оскiлькивибирають саме K) вiдiграє роль параметра згладжування аналогiчногопараметру s для ядерних оцiнок.
Ми не будемо розглядати тут загальнi теореми про вибiр кiлькостiпiдiнтервалiв в залежностi вiд обсягу вибiрки та швидкiсть збiжностi оцiн-ки. Прикладом тверджень такого роду є лема 5.2.3 у наступному роздiлi.
Значення K можна намагатись обирати адаптивно, виходячи з деякогофункцiонала якостi оцiнки, методами, подiбними розглянутому у п. 4.3.
3Оскiльки ми оцiнюємо щiльнiсть розподiлу Hm, то його слiд вважати неперервним,тому Hm([tk−1, tk]) = Hm([tk−1, tk)), тобто з вiдкритими/замкненими кiнцями iнтер-валiв проблем не виникає.

4.4. Неядернi оцiнки щiльностей розподiлiв 109
Однак можливий i iнший пiдхiд, при якому ширина кожного iнтервалурозбиття регулюється окремо, щоб забезпечити адаптацiю до локальнихособливостей оцiнюваної щiльностi.
Простiший приклад такої адаптацiї полягає в тому, щоб розбиватидослiджуваний iнтервал (емпiричними) квантилями розподiлу оцiнюва-ної компоненти. На роль таких емпiричних квантилiв можна використатиоцiнки Qm
N(α), визначенi (3.25). Таким чином, алгоритм побудови оцiнкинаступний:
1. Вибираємо кiлькiсть iнтервалiв K та носiй оцiнки [b, c].2. Задаємо точки розбиття iнтервалу [b, c]: t0 = b, tK = c, tk = QN
m(k/K)для k = 1,. . . ,K − 1 та iнтервали розбиття Ak = [tk−1, tk), k = 1,. . . ,K − 1,AK = [tK−1, tK ].
3. Визначаємоfk =
1
K(tk − tk−1)
4. Задаємо оцiнку для hm формулою
hNm(x) =
K∑
k=1
fk1I{x ∈ Ak}.
Тут коментарiв вимагає лише пункт 3: насправдi величина fk повиннабути оцiнкою вiдношення ймовiрностi того, що випадкова величина по-трапить на iнтервал Ak, до довжини цього iнтервалу. Але якщо iнтервалутворений квантилями рiвнiв (k− 1)/K та k/K, то ймовiрнiсть потрапитина нього дорiвнює 1/K.
Для випадку незалежних однаково розподiлених спостережень анало-гiчна оцiнка зветься полiграмою [50]. Вона не набула великого поширеннячерез те, що оцiнки квантилiв є, як правило, менш точними, нiж оцiнкиймовiрностей i, отже, полiграма часто поступається у точностi оцiнюваннязвичайнiй гiстограмi.
Iнший варiант локальної адаптацiї полягає в тому, щоб проводити роз-биття носiя на пiдiнтервали послiдовно. На першому кроцi розбиття скла-дається з одного елемента — самого носiя. На кожному наступному кроцiперебирають всi елементи i намагаються розбити їх навпiл. На кожнiйполовинцi оцiнюють дослiджувану щiльнiсть, вважаючи її (майже) кон-стантою, тобто для н.о.р. спостережень використовують вiдношення ча-стоти до довжини iнтервалу, а для сумiшi — один з пiдходiв (i)-(iii). По-тiм порiвнюють отриманi оцiнки по двох половинах. Якщо вони не дуже

110 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
вiдрiзняються одна вiд одної, елемент залишають цiлим i бiльше не змiню-ють. Якщо оцiнки сильно вiдрiзняються — обидвi половинки включаютьу розбиття i вони можуть бути розбитi далi на наступних кроках.
Процедура зупиняється коли всi елементи виявляються “стiйкими” дорозбиття або настiльки вузькими, що їх немає рацiї розбивати.
Така процедура забезпечує локальну адаптацiю, але її доцiльно засто-совувати (як i iншi адаптивнi процедури) лише при наявностi великогообсягу даних. Неважко розробити аналогiчну процедуру послiдовного роз-биття i для полiграмних оцiнок.
При використаннi всiх варiантiв як полiграми, так i гiстограми важли-вим є питання про вибiр носiя [b, c]. Для незалежних, однаково розподiле-них спостережень, як правило, b обирають рiвним найменшому значеннюу вибiрцi (або трошки менше), а c — найбiльшому (або трошки бiльше).Це робить стандартну гiстограму дуже чутливою до викидiв. У випад-ку спостережень з сумiшi такий вибiр носiя створює додаткову проблему,оскiльки найменше та найбiльше значення у вибiрцi зовсiм не обов’язковоналежать тiй компонентi вибiрки, для якої оцiнюється щiльнiсть. Тому до-цiльно бiльш-менш точно оцiнити межi справжнього носiя щiльностi аналi-зованої компоненти, наприклад, використовуючи технiку, описану у п. 3.5.Отриманi оцiнки можна використовувати як межi носiя гiстограми.
А що робити, коли оцiнювана щiльнiсть має необмежений носiй? Гi-стограмнi оцiнки не призначенi для таких випадкiв. Втiм, i ядернi оцiнкине дають цiлком адекватних результатiв при застосуваннi до щiльностей знеобмеженим розподiлом, особливо, якщо це щiльностi розподiлiв, що по-роджують викиди (тобто до розподiлiв з важкими хвостами). Можливийобхiдний маневр у цьому випадку полягає в тому, щоб використати попе-редню трансформацiю вибiрки за допомогою монотонного перетворення,яке вiдображає R на iнтервал [0, 1], оцiнити щiльнiсть на цьому iнтервалi,а потiм “розгорнути” оцiнку назад оберненим перетворенням. Для н.о.р.спостережень така процедура описана у [9]. При цьому слiд мати на увазi,що неакуратне використання таких перетворень без урахування “хвосто-вої” поведiнки оцiнюваної щiльностi може привести до того, що щiльнiстьвiдображених на [0, 1] стане необмеженою — прямуватиме до +∞ в околi0 або 1. Звичайнi оцiнки щiльностей зовсiм не пристосованi до таких си-туацiй.
Нажаль, технiка аналiзу хвостiв розподiлу по спостереженнях з сумiшiiще зовсiм не розроблена. Невiдомо навiть, чи iснують методи, якi доз-воляли б оцiнювати екстремальнi iндекси окремо для кожної компоненти

4.4. Неядернi оцiнки щiльностей розподiлiв 111
сумiшi.Проекцiйнi оцiнки. Iнший пiдхiд до оцiнювання невiдомих щiльно-
стей полягає в тому, щоб розглядати їх як елементи гiльбертового просто-ру L2 i оцiнювати коефiцiєнти у розкладi аналiзованої функцiї за деякимбазисом у L2. Оцiнки такого роду мають назву проекцiйних, оскiльки, посутi, оцiнюється не сама щiльнiсть, а її проекцiя на деякий пiдпростiр уL2.
Отже, нехай потрiбно оцiнити щiльнiсть hm = ∂∂x
Hm m-тої компонентисумiшi за спостереженнями ξj:N , що описуються стандартною моделлю 4.1.Припустимо, що розподiл Hm зосереджений на деякому iнтервалi S ⊆ R(скiнченному або нескiнченному) i hm ∈ L2(S), де L2(S) — простiр функ-цiй, iнтегрованих з квадратом вiдносно мiри Лебега на S зi скалярнимдобутком
〈a, b〉L2 =
∫
S
a(x)b(x)dx.
Як вiдомо, L2(S) є сепарабельним гiльбертовим простором. Виберемо iзафiксуємо ортонормований базис у цьому просторi: p1, p2,. . .Функцiя hm
розкладається у ряд за цим базисом, який збiгається у нормi L2:
hm(x) =∞∑i=1
cipi(x),
де ci — узагальненi коефiцiєнти Фур’є функцiї hm, якi можна обчислитиза формулою
ci =
∫
S
pi(x)hm(x)dx =
∫pi(x)Hm(dx) = E pi(ηm),
ηm — випадкова величина з розподiлом Hm.Таким чином, ci є функцiональними моментами розподiлу Hm, що вiд-
повiдають функцiям pi. Для їх оцiнки можна використовувати методи,розробленi у роздiлi 3. Наприклад, використовуючи лiнiйну оцiнку 3.3,отримуємо
cNi =
1
N
N∑j=1
amj:Npi(ξj:N), (4.29)
де, як i ранiше, amj:N — мiнiмакснi ваговi коефiцiєнти для оцiнки Hm. Про-
екцiйна оцiнка для hm має вигляд
hNm(x) =
L∑i=1
cipi(x) (4.30)

112 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
=1
N
N∑j=1
L∑i=1
pi(ξj:N)pi(x) =1
N
N∑j=1
KL(ξj:N , x),
де L — деяке цiле число, що є параметром алгориму,
KL(x, y) =L∑
i=1
pi(x)pi(y).
Функцiю KL називають ядром проекцiйної оцiнки. Вона вiдiграє при-близно таку ж роль, яку “масштабоване” ядро
Kh(x, y) =1
hK
(x− y
h
)
грає для ядерної оцiнки.Вiдповiдно, задача вибору базису pi, i = 1, 2, . . . для проекцiйної оцiнки
виявляється подiбною до вибору ядра для ядерної оцiнки, а “ядерному”параметру згладжування h вiдповiдає “проекцiйний” параметр L.
Оцiнка hNm оцiнює скорiше не hm(x), а
∑Li=1 cipi(x), тобто проекцiю
hm(x) на простiр, натягнутий на першi L базисних функцiй. Тому пара-метр L називають вимiрнiстю простору проекцiї. Вибiр скiнченного L обу-мовлений мiркуваннями як практичного, так i теоретичного характеру.
З практичної точки зору, нескiнченну суму∑∞
i=1 cipi(x) просто немож-ливо обчислити i тому її замiняють скiнченною. Крiм того, якщо обрати Lне дуже великим (помiтно меншим, нiж N), то проекцiйнi оцiнки виявля-ються зручнiшими для користування, нiж ядернi. Дiйсно, якщо потрiбнообчислювати одну i ту ж саму оцiнку hN
m(x) для багатьох рiзних значень x(наприклад, при побудовi її графiку або при використаннi у задачах кла-сифiкацiї), то досить один раз обчислити L коефiцiєнтiв ci, виконавши дляцього ∼ LN операцiй, а потiм пiдставляти цi коефiцiєнти у формулу (4.30)стiльки разiв, скiльки це потрiбно для рiзних x. При пiдрахунку ядерноїоцiнки за (4.2) для нових x оцiнку потрiбно переобчислювати за даниминаново, кожного разу виконуючи ∼ N операцiй.
З точки зору точностi оцiнювання на L накладаються такi ж супереч-ливi вимоги, як на параметр згладжування h ядерної оцiнки та кiлькiстьпiдiнтервалiв K гiстограми або полiграми. З одного боку, чим бiльшим єL, тим ближчою є оцiнювана проекцiя до справжньої щiльностi i, отже,тим точнiшою буде оцiнка. З iншого боку, при зростаннi L ми змушенiоцiнювати бiльше коефiцiєнтiв ci. Оскiльки кожен коефiцiєнт оцiнюєтьсяз похибкою, то i сумарна похибка оцiнки зростає iз зростанням L.

4.4. Неядернi оцiнки щiльностей розподiлiв 113
Таким чином, при зростаннi обсягу вибiрки N →∞, L також повиннозростати, але помiтно повiльнiше, нiж N . Можливий адаптивний вибiр Lна основi попереднього оцiнювання ступеня гладкостi щiльностi hm. Цiка-вий варiант адаптивного проекцiйного оцiнювання полягає в тому, щоб Lобрати порiвняно великим, але значення ci, якi виявляються малими за аб-солютною величиною, покласти рiвними 0. Формально, задається деякийпорiг MN i оцiнка визначається як
hNm(x) =
L∑i=1
ci1I{|ci| < MN}pi(x). (4.31)
Можна показати, що такi оцiнки при правильному виборi порогу MN тавимiрностi простору проекцiї L = LN мають швидкiсть збiжностi, близькудо оптимальної.
На вiдмiну вiд ядерних оцiнок, у яких асимптотичну теорiю можна по-будувати для широкого класу ядер одразу, поведiнка проекцiйних оцiнокдуже сильно залежить вiд властивостей обраного базису проекцiї.
Останнiм часом у статистицi великого поширення набули алгоритми,якi спираються на використання вейвлет-базисiв (див., наприклад, [13]).Вейвлети зручнi для апроксимацiї функцiй (у статистицi звичайно — функ-цiй регресiї або щiльностей розподiлу) тим, що вони дозволяють вико-ристовувати локальнi особливостi функцiї у рiзних частинах областi їївизначення. Там, де функцiя є гладенькою, для її апроксимацiї викори-стовується менше елементiв вейвлет-базису, там, де вона має особливостi— бiльше.
Оцiнкам щiльностей розподiлiв компонент сумiшi зi змiнними концен-трацiями присвяченi роботи Д.I.Похилька [18]-[20].
Оцiнки методу найближчого сусiда. Розглянутi вище оцiнки при-значенi для використання, як правило, у одновимiрному просторi даних X .Хоча, в принципi, iснують версiї “багатовимiрних” гiстограм та проекцiй-них оцiнок, але на практицi їх використовують рiдко. Для багатовимiрнихданих, або навiть для даних з довiльних метричних просторiв, найбiльшпоширеною є оцiнка методу k найближчих сусiдiв. Такi оцiнки зручнi, зо-крема тим, що дозволяють оцiнювати щiльнiсть не тiльки вiдносно мiриЛебега, а вiдносно довiльної мiри на X . Це, наприклад, дозволяє викори-стовувати такi оцiнки для побудови емпiрично-баєсових класифiкаторiв удуже загальних ситуацiях (див. п. 6.2).
Ми опишемо версiю оцiнки методу k найближчих сусiдiв, призначенудля аналiзу сумiшей зi змiнними концентрацiями. Нехай спостереження

114 Роздiл 4. Оцiнювання щiльностей розподiлiв компонент
ξj:N є елементами сепарабельного метричного простору X з метрикою ρ.Розподiл ξj:N описується моделлю сумiшi зi змiнними концентрацiями:
P{ξj:N ∈ A} =M∑
m=1
wmj:NHm(A)
для будь-якої множини A з борелевої σ-алгебри на просторi (X , ρ). Нехайна цьому просторi задана деяка мiра ν i ми хочемо побудувати оцiнкудля щiльностi розподiлу m-тої компоненти вiдносно цiєї мiри, тобто дляпохiдної Радона hm = ∂Hm
∂ν.
Для довiльного x ∈ X розглянемо набiр вiдстаней вiд x до всiх елемен-тiв вибiрки: zj = ρ(x, ξj:N), j = 1, . . . , N . Впорядкуємо цей набiр у порядкузростання: z[1] ≤ z[2] ≤ z[3] ≤ . . . ,≤ z[N ]. Зрозумiло, що z[1] — це вiдстаньвiд x до його найближчого сусiда серед елементiв вибiрки, z[2] — вiдстаньдо наступного (другого) сусiда i так далi. (Якщо серед zj є однаковi, тобтовiдстанi вiд x до деяких елементiв вибiрки є рiвними мiж собою, то поря-док нумерацiї таких сусiдiв по ступеню близькостi є для нас несуттєвим).Позначимо r(x, k) = z[k] — вiдстань до k-того найближчого сусiда.
Позначимо B(x, r) = {y ∈ X : ρ(x, y) ≤ r} — замкнена куля в X радiусаr з центром у x. Як оцiнку для hm(x) використаємо
hNm(x) =
HNm (B(x, r(x, k)))
ν(B(x, r(x, k))), (4.32)
де HNm (A) — деяка оцiнка для Hm за спостереженнями. Наприклад, це
може бути зважена емпiрична функцiя розподiлу з мiнiмаксними ваговимикоефiцiєнтами. Параметр k = kN (кiлькiсть найближчих сусiдiв) вiдiграєроль, аналогiчну параметру згладжування у ядерних оцiнках (з точнiстюдо навпаки): обираючи kN → ∞ так, щоб послiдовнiсть kN зростала недуже швидко, можна отримати консистентну оцiнку.
Iдею оцiнки (4.32) особливо легко зрозумiти якщо X = Rd, а ν є мiроюЛебега. У цьому випадку, якщо hm iснує, то при N →∞, kN/N → 0 будемати мiсце збiжнiсть r(x, kN) → 0. Отже, куля B(x, r(x, kN) буде стягува-тися до x i Hm(B(x,r(x,kN )))
ν(B(x,r(x,kN )))→ hm(x). Якщо kN → ∞ при N → ∞, то кiль-
кiсть елементiв вибiрки, якi попадають до B(x, r(x, k)), прямує до нескiн-ченностi, тому можна сподiватись, що HN
m (B(x, r(x, k)) ∼ Hm(B(x, r(x, k))(обидвi цi величини за даних умов прямують до 0). Звiдси i отримуємоконсистентнiсть оцiнки.

4.4. Неядернi оцiнки щiльностей розподiлiв 115
Але оцiнка (4.32) виявляється консистентною i у значно бiльш широ-ких умовах, наприклад, якщо Hm та ν — дискретнi мiри. Ми не будемотут формулювати загальнi результати для оцiнок методу k найближчихсусiдiв. У роздiлi 6 цi оцiнки використовуються для побудови емпiрично-баєсових класифiкаторiв. Там наведенi i результати щодо цих оцiнок, якiдозволяють довести консистентнiсть вiдповiдних класифiкаторiв.
Iще один напрямок розробки оцiнок щiльностi — застосування певнихмодифiкацiй методу найбiльшої вiрогiдностi. Як вiдомо, оцiнки най-бiльшої вiрогiдностi для щiльностей розподiлу в загальному випадку неiснують. Тому застосовують рiзнi технiки виправлення цього методу, якiдозволяють будувати консистентнi оцiнки — або з використанням штраф-них функцiй, або з обмеженням класу, по якому шукають точку максиму-му функцiї вiрогiдностi. Застосування останнього пiдходу (метод максиму-ма вiдсiяної вiрогiдностi) ми розглянемо у наступному роздiлi в контекстiаналiзу даних з домiшкою.

Роздiл 5
Аналiз спостережень з домiшкою
5.1 Оцiнки щiльностi по спостереженнях з до-мiшкою
У медико-бiологiчнiй статистицi часто виникає задача аналiзу даних з до-мiшками. Опишемо модельний приклад таких даних.
Нехай дослiджуються N пацiєнтiв, яким поставлено попереднiй дiаг-ноз, скажiмо “атипiчна пневмонiя”(АП). У кожного з дослiджуваних ви-мiрюється певна фiзiологiчна характеристика ξ (наприклад — кiлькiстьеритроцитiв у кровi). В результатi отримано набiр ΞN = (ξ1, . . . , ξN), деξj — значення ξ у j-того пацiєнта. Припускається, що розподiл ξ у хво-рих на АП не такий, як у пацiєнтiв, що не є хворими на АП. Позначимощiльнiсть розподiлу ξ у хворих на АП через h1, у не хворих — h2. Якбибуло точно вiдомо, що всi пацiєнти з дослiджуваної вибiрки хворi на АП,то можна було б вважати, що ΞN — проста вибiрка з щiльнiстю спостере-жень h1. Нажаль, АП важко вiдрiзнити вiд iнших захворювань (звичайнапневмонiя, грип, застуда) тому, скорiше за все, в ΞN є домiшка ξj з щiль-нiстю h2. Часто за симптомами можна вказати (оцiнити) ймовiрнiсть wj
того, що j-тий пацiєнт є хворим саме АП. У такому випадку щiльнiсть ξj
являє собою сумiш щiльностей hi:
wjh1(x) + (1− wj)h2(x).
Як за такими даними оцiнити h1?Цей параграф присвячено задачi оцiнювання щiльностей за даними
з домiшкою у випадку, коли щiльнiсть основної компоненти h1 повнiстю

5.1. Оцiнки щiльностi по спостереженнях з домiшкою 117
невiдома, тобто її потрiбно оцiнювати непараметрично. Щодо щiльностiдомiшки, h2, можливi рiзнi припущення:
(1) h2 може бути так само невiдома, як i h1 (непараметричний випадок);(2) h2 може бути повнiстю вiдома, наприклад, оцiнена з достатньою
точнiстю за спостереженнями ξ у осiб, якi напевне не є хворими на АП(детермiнований випадок);
(3) h2 може бути вiдома з точнiстю до параметру (параметрична модельдомiшки).
Третiй варiант виникає, коли ми припускаємо, що пацiєнти “не хворi наАП” у нашiй вибiрцi мають розподiл ξ такого ж типу, як i здоровi (скажiмо— гауссiв) але, можливо, з iншими параметрами (наприклад, з iншим се-реднiм) оскiльки цi особи все ж є хворими якимось (неiдентифiкованими)хворобами.
Ми розглянемо оцiнки гiстограмного типу для щiльностей розподiлу увсiх трьох випадках, побудованi методом вiдсiяної найбiльшої вiрогiдностi(sieve maximum likelihood)1. Для третього випадку побудуємо також оцiнкиневiдомих параметрiв розподiлу домiшки. Доведемо консистентнiсть цихоцiнок i оцiнимо швидкiсть їх збiжностi.
Як i ранiше, вибiрку ΞN будемо вважати елементом схеми серiй: ΞN =(ξ1:N , . . . , ξN :N) де ξj:N — незалежнi при фiксованому N випадковi величиниi
Pr{ξj:N < x} = wj:NH1(x) + (1− wj:N)H2(x),
де H1 — функцiя розподiлу (ф.р.) основної компоненти, H2 — ф.р. домiш-ки, wj:N — концентрацiя основної компоненти у сумiшi в момент j-тогоспостереження, тобто ймовiрнiсть того, що j-те спостереження вибрано зосновної компоненти.
Надалi припускаємо, що розподiли Hi зосередженi на скiнченному iн-тервалi, який (без обмеження загальностi) вважаємо рiвним [0, 1]. Вважає-мо, що iснують щiльностi hi розподiлiв Hi вiдносно мiри Лебега, причомувиконана умова
(А) iснують числа 0 < u < U < ∞, такi, що u ≤ hi(x) ≤ U для всiхx ∈ [0, 1].
Для побудови оцiнок скористаємося методом максимума вiдсiяної вiро-гiдностi. Будемо шукати оцiнку hN
i (x) для hi(x) лише серед схiдчастих
1Про метод вiдсiяної найбiльшої вiрогiдностi див., наприклад, [47].

118 Роздiл 5. Аналiз спостережень з домiшкою
функцiй вигляду
gk(x) =
KN∑
k=1
gk1I{x ∈ Ak}, (5.1)
де KN — кiлькiсть пiдiнтервалiв розбиття Ak, Ak = [tk−1, tk) для k =1,. . . ,KN − 1, AKN
= [tKN−1, tKN], tk = k/KN , gi — довiльнi додатнi числа,
такi, що 1KN
∑KN
k=1 gk = 1. Нехай 0 < uN < UN < ∞ деякi дiйснi числа. Мно-жину всiх функцiй вигляду (5.1), для яких uN ≤ gk ≤ UN , k = 1,. . .KN ,позначимо HN . Нехай χkj = 1I{ξj:N ∈ Ak} Якщо припустити, що справжнiщiльностi компонент hi = gi(x) де gi(x) =
∑KN
k=1 gki1I{x ∈ Ak}, то логариф-мiчна функцiя вiрогiдностi, пiдрахована за вибiркою, ΞN має вигляд:
l(g1, g2) =N∑
j=1
ln
(wj:N
KN∑
k=1
gk1χkj + (1− wj:N)
KN∑
k=1
gk2χkj
)
=N∑
j=1
KN∑
k=1
χkj ln(wj:Ngk1 + (1− wj:N)gk2).
Якщо i h1 i h2 повнiстю невiдомi, на роль оцiнки для пари (h1, h2) оберемопару (hN
1 , hN2 ) ∈ HN ×HN = H2
N , яка максимiзує функцiю l на H2N :
(hN1 , hN
2 ) = argmax(g1,g2)∈H2
N
l(g1, g2). (5.2)
(Якщо argmax досягається на кiлькох парах функцiй, оцiнкою може бутибудь-яка з них.)
Для випадку однорiдних даних (без домiшок) метод вiдсiяної вiрогiд-ностi приводить до гiстограмних оцiнок щiльностi. По аналогiї будемо на-зивати гiстограмами всi оцiнки щiльностей, якi мають вигляд (5.1).
Якщо щiльнiсть другої компоненти, h2 вiдома з точнiстю до параметруϑ, тобто h2(x) = h2(x; ϑ), де ϑ ∈ Θ — невiдомий параметр, позначимо
h2(x, ϑ) =
KN∑
k=1
hk2(ϑ)1I{x ∈ Ak},
де
hk2 = hk2(ϑ) =1
sN
∫ tk
tk−1
h2(x, ϑ)dx.

5.1. Оцiнки щiльностi по спостереженнях з домiшкою 119
Позначимо ΘN = {ϑ ∈ Θ : h2(·, ϑ) ∈ HN}. На роль оцiнки для париневiдомих параметрiв розподiлу даних (h1, ϑ) використаємо
(hN1 , ϑN) = argmax
g1∈HN ,τ∈ΘN
l(g1, h2(·, τ)), (5.3)
тобто максимум шукається лише по тих “гiстограмах”, якi для другої ком-поненти можна отримати усередненням щiльностi, що вiдповiдає обранiйпараметричнiй моделi.
Якщо h2 повнiстю вiдома, можна скористатись (5.3) з множиною мож-ливих значень параметра Θ, що складається з одного елемента. Тобто вцьому випадку
h1 = argmaxg1∈HN
l(g1, h2(·)).
Основнi теореми. Позначимо sN = 1/KN — довжина пiдiнтервалiврозбиття Ak, wN = 1
N
∑Nj=1 wj:N — “середня концентрацiя” основної компо-
ненти у сумiшi.Наступна теорема дає умови консистентностi гiстограмних оцiнок у
непараметричному випадку в просторi L2[0, 1], тобто у просторi функцiйна [0,1] з нормою
‖a‖2 =
(∫ 1
0
a2(x)dx
)1/2
.
Теорема 5.1.1 Нехай виконана умова (А) i1) Iснує c > 0, таке, що 1
N
∑Nj=1(wj:N − wN)2 > c для всiх N ;
2) sN → 0, sNN →∞ при N →∞;3) UN →∞, uN → 0,
U5N
NsNu4N
→ 0,UN ln2 uN
sNN→ 0 при N →∞.
Тодi для оцiнок hNi , i = 1, 2, визначених (5.2),
‖hNi − hi‖2 → 0
за ймовiрнiстю при N →∞.
Зауваження. Умова 1 теореми еквiвалентна умовi det ΓN > c > 0.У випадку параметричної моделi домiшки позначимо
ω(s) = sup|x−y|≤s
supτ∈Θ
|h2(x, τ)− h2(y, τ)|

120 Роздiл 5. Аналiз спостережень з домiшкою
— рiвномiрний модуль неперервностi h2 при всiх можливих значеннях невi-домого параметру.
Умови консистентностi в цьому випадку дає наступна теорема
Теорема 5.1.2 Припустимо, що виконанi умова (А) i умови 1)-3) тео-реми 5.1.1. Нехай крiм того виконано:
1) ω(s) → 0 при s → 0;2) Θ є компактом у напiвметрицi ρ(α, τ) = ‖h2(·, α)− h2(·, τ)‖2;3) При τ 6= ϑ, ρ(τ, ϑ) > 0.Тодi для оцiнок hN
1 та ϑN , визначених (5.3), має мiсце збiжнiсть‖hN
1 − h1‖2 → 0 i ρ(ϑN , ϑ) → 0 за ймовiрнiстю при N →∞.
Накладаючи додатковi умови на щiльностi hi, можна отримати швид-костi збiжностi оцiнок. Наприклад, нехай
ωi(s) = sup|x−y|≤s
|hi(x)− hi(y)|.
Розглянемо непараметричний випадок. Лiтерою C будемо позначати до-вiльнi скiнченнi додатнi константи, можливо, рiзнi.
Теорема 5.1.3 Нехай виконанi умова (А) i умова 1) теореми (5.1.1). До-датково припустимо, що:
1) для деякого β > 0, ωi(s) ≤ Csβ;2) для деякого α > 0, sN = CN−α;3) UN = C ln N , uN = C/ ln N .Тодi для оцiнок, визначених (5.2), для будь-якого γ, такого, що 0 <
γ < αβ, γ < (1 − α)/4, знайдуться константи C1, C2 > 0, такi, що длявсiх λ > 0, при достатньо великих N ,
P{‖hNi − hi‖2 > λN−γ} ≤ C1 ln N
N1−α(λN−γ − C2N−αβ)4
Доведення теорем. Для gk1, gk2 > 0 позначимо
Jk(gk1, gk2) =1
N
N∑j=1
χkj ln(wj:Ngk1 + (1− wj:N)gk2).
Тодi1
Nl(g1, g2) = J(g1, g2) :=
KN∑
k=1
Jk(gk1, gk2).

5.1. Оцiнки щiльностi по спостереженнях з домiшкою 121
(Надалi ми схiдчасту функцiю∑KN
k=1 gki1I{x ∈ Ak} i набiр чисел (gki, k =1, . . . , KN) позначаємо одним символом gi.)
Нехай ηi — випадковi величини з розподiлом Hi. Позначимо
hki =1
sN
P{ηi ∈ Ak} =1
sN
∫ tk
tk−1
hi(x)dx,
hi(x) =
KN∑
k=1
hki1I{x ∈ Ak},
Jk(gk1, gk2) = E Jk(gk1, gk2)
=1
N
N∑j=1
sN(wj:N hk1 + (1− wj:N)hk2) · ln(wj:Ngk1 + (1− wj:N)gk2),
J(g1, g2) =
KN∑
k=1
Jk(gk1, gk2).
Лема 5.1.1 При виконаннi умови (А) для всiх ε > 0
P
{sup
g1,g2∈HN
|J(g1, g2)− J(g1, g2)| > ε
}
≤ 4U
sNNε2
(U4
N
u4N
+ 2U2
N
u2N
+ max(ln2(uN), ln2(UN))
).
Доведення. Позначимо f(gk1, gk2) = Jk(gk1, gk2) − Jk(gk1, gk2). Скори-стаємося рiвнiстю (7.2):
f(x1, x2) =
∫ x2
uN
∫ x1
uN
∂2
∂t1∂t2f(t1, t2)dt1dt2
+
∫ x2
uN
∂
∂t2f(uN , t2)dt2 +
∫ x1
uN
∂
∂t1f(t1, uN)dt1 + f(uN , uN)
(5.4)
Застосовуючи нерiвнiсть Кошi-Бунякiвського до перших трьох доданкiв(5.4), отримуємо:
supx1,x2∈[uN ,UN ]
|f(x1, x2)| ≤(∫ UN
uN
∫ UN
uN
(∂2
∂t1∂t2f(t1, t2)
)2
dt1dt2(UN − un)2
)1/2

122 Роздiл 5. Аналiз спостережень з домiшкою
+
(∫ UN
uN
(∂
∂t2f(uN , t2)
)2
dt2(UN − un)
)1/2
+
(∫ UN
uN
(∂
∂t1f(t1, uN)
)2
dt1(UN − un)
)1/2
+ f(uN , uN).
Оцiнимо
E supx1,x2∈[uN ,UN ]
(f(x1, x2))2 ≤ 4(R1(UN−un)2+R2(UN−uN)+R3(UN−uN)+R4),
де
R1 =
∫ UN
uN
∫ UN
uN
(∂2
∂t1∂t2f(t1, t2)
)2
dt1dt2, R2 =
∫ UN
uN
(∂
∂t2f(uN , t2)
)2
dt2,
R3 =
∫ UN
uN
(∂
∂t1f(t1, uN)
)2
dt1, R4 = f 2(uN , uN).
Розглянемо кожен доданок окремо. Маємо
R1 =1
N2
∫ UN
uN
∫ UN
uN
N∑
j,l=1
wj:N(1− wj:N)wl:N(1− wl:N)
(wj:N t1 + (1− wj:N)t2)2(wl:N t1 + (1− wl:N)t2)2×
×E(χjk − E χjk)(χlk − E χlk)dt1dt2.
При l 6= j, E(χjk − E χjk)(χlk − E χlk) = 0, а при l = j, E(χjk − E χjk)(χlk −E χlk) ≤ E χj,k. Тому
R1 ≤ 1
N2
N∑j=1
∫ UN
uN
∫ UN
uN
1
u4N
sN(wj:N hk1 + (1− wj:N)hk2)dt1dt2
≤ sN(UN − un)2UN
Nu4N
.
Аналогiчно для R2 та R3 маємо
R2 ≤∫ UN
uN
N∑j=1
w2j:N
(wj:N t1 + (1− wj:N)uN)2E(χjk − E χjk)
2dt1
≤ sN(UN − uN)U
Nu2N
,

5.1. Оцiнки щiльностi по спостереженнях з домiшкою 123
i, так само,
R3 ≤ sN(UN − uN)U
Nu2N
.
Для R4 маємо
R4 ≤ 1
N2
N∑j=1
ln2(uN) E(χj:N − E χj:N)2
≤ 1
Nln2(uN)sNU.
ОтжеE sup
t1,t2∈[uN ,UN ]
|Jk(t1, t2)− Jk(t1, t2)|2 ≤ sND
N,
де
D = 4U
((UN − uN)4
u4N
+ 2(UN − uN)2
u2N
+ ln2(uN)
).
Тому (E sup
g1,g2∈HN
|J(t1, t2)− J(t1, t2)|2)1/2
≤E
(KN∑
k=1
supg1k,g2k∈[uN ,UN ]
|Jk(g1k, g2k)− Jk(g1k, g2k)|)2
1/2
≤(
KN
KN∑
k=1
E supg1k,g2k∈[uN ,UN ]
(Jk(g1k, g2k)− Jk(g1k, g2k))2
)1/2
≤√
K2N
sND
N=
√D
sNN.
Звiдси, використовуючи нерiвнiсть Чебишова, отримуємо
P
{sup
g1,g2∈HN
|J(t1, t2)− J(t1, t2)| ≥ ε
}≤ D
sNNε2.
Лема доведена.Доведення теореми 5.1.1. Позначимо
BN(ε) =
{sup
g1,g2∈HN
|J(g1, g2)− J(g1, g2)| > ε
}.

124 Роздiл 5. Аналiз спостережень з домiшкою
Згiдно з лемою 5.1.1, P{BN(ε)} → 0 при N → ∞ для всiх ε > 0. Нехайвиконана подiя BN(ε), протилежна до BN(ε). Тодi |J(hN
1 , hN2 )−J(hN
1 , hN2 )| <
ε i |J(h1, h2)− J(h1, h2)| < ε. Отже
J(hN1 , hN
2 ) ≥ J(hN1 , hN
2 )− ε ≥ J(h1, h2)− ε ≥ J(h1, h2)− 2ε.
Тому0 ≥ J(hN
1 , hN2 )− J(h1, h2) ≥ −2ε.
Позначимо
ρj1N :=
∫ 1
0
ln
(wj:N hN
1 (x) + (1− wj:N)hN2 (x)
wj:N h1(x) + (1− wj:N)h2(x)
)(wj:N h1(x)+(1−wj:N)h2(x))dx
Використовуючи означення J(h1, h2), отримуємо
ρ1N :=
∣∣∣∣∣1
N
N∑j=1
ρj1N
∣∣∣∣∣ ≤ 2ε.
Кожен доданок ρj1N у цiй сумi являє собою дивергенцiю Кульбака-Ляйблера
мiж щiльностями fj(x) := wj:N hN1 (x)+(1−wj:N)hN
2 (x) та fj(x) := wj:N h1(x)+(1 − wj:N)h2(x). Використовуючи нерiвнiсть мiж дивергенцiєю Кульбака-Ляйблера та вiдстанню Хелiнгера з [2] с. 195, для
ρj2N :=
∫ 1
0
(√fj(x)−
√fj(x)
)2
dx
отримуємо ρj2N ≤ ρj
1N i
ρ2N :=1
N
N∑j=1
ρj2N ≤ ρ1N ≤ 2ε.
Нехай
ρj3N :=
∫ 1
0
(fj(x)− fj(x)
)2
dx.
Оскiльки для всiх додатних a, b,
|√a−√
b| = |a− b|/(√a +√
b) ≥ |a− b|/2 max(√
a,√
b),

5.1. Оцiнки щiльностi по спостереженнях з домiшкою 125
то
ρ3N :=1
N
N∑j=1
ρj3N ≤ 2 max(
√UN
√U)ρ2N ≤ 4
√UNε
при достатньо великих N .Позначимо b11 = N−1
∑Nj=1 w2
j:N , b12 = b21 = N−1∑N
j=1 wj:N(1 − wj:N),b22 = N−1
∑Nj=1(1− wj:N)2, B = (bik)
2i,k=1. Маємо
ρ3N = b11‖hN1 − h1‖2
2 + 2b12‖hN1 − h1‖2·‖hN
2 − h2‖2 + b22‖hN2 − h2‖2
2.
Томуρ3N ≥ λmin(‖h1 − h1‖2
2 + ‖h2 − h2‖22),
де λmin — найменше, λmax — найбiльше власне число матрицi B. Оскiлькивсi елементи матрицi B не перевищують 1, то λmax ≤ 2. За умовою 1)теореми λminλmax = det B ≥ c, тому λmin > c/2. Отже,
‖hi − hNi ‖2
2 ≤8√
UNε
c.
Покладемо ε = cz/(8√
UN), де z — довiльне додатне число. Використову-ючи лему 5.1.1, отримуємо
P{‖hi − hNi ‖2
2 ≥ z} ≤ 36UUN
csNNz2
(U4
N
u4N
+ 2U2
N
u2N
+ ln2(uN)
)(5.5)
За другою i третьою умовами теореми, права частина прямує до 0 приN → ∞. За теоремою 6 з [9],
∫ 1
0|hi(x) − hi(x)|dx → 0 при sN → 0. За
умовою (А), |hi(x)| ≤ U , тому |hi(x)| ≤ U . Отже
‖hi − hi‖22 ≤ 2U
∫ 1
0
|hi(x)− hi(x)|dx → 0,
при N →∞. Враховуючи (5.5), отримуємо твердження теореми.Доведення теореми 5.1.2. Так само, як у теоремi 5.1.1, використо-
вуючи лему 5.1.1, отримуємо ‖hN1 − h1‖2 → 0 i ‖h2(·, ϑN) − h2(·, ϑ)‖2 → 0
при N →∞. Для довiльного x ∈ [0, 1] виберемо Ai, для якого x ∈ Ai. Тодiдля будь-якого τ ∈ Θ,
|h2(x, τ)− h2(x, τ)| ≤ 1
sN
∫
Ai
|h2(y, τ)− h2(x, τ)|dy ≤ ω(sN).

126 Роздiл 5. Аналiз спостережень з домiшкою
Отже, ‖h2(·, τ) − h2(·, τ)‖2 ≤ ω(sN) → 0 при N → ∞. Тому ‖h2(·, ϑN) −h2(·, ϑ)‖2 → 0 за ймовiрнiстю. Враховуючи умови 2) i 3) теореми, отримує-мо ϑN → ϑ за ймовiрнiстю при N →∞.
Теорема доведена.Доведення теореми 5.1.3. Так само, як у доведеннi теореми 5.1.2,
отримуємо ‖hi − hi‖2 ≤ ω(sN). Отже
P{‖hNi − hi‖2 ≥ λN−γ} ≤ P{‖hN
i − hi‖2 + ‖hi − hi‖2 ≥ λN−γ}
≤ P{‖hNi − hi‖2 + ω(sN) ≥ λN−γ} ≤ P{‖hN
i − hi‖2 ≥ λN−γ − CN−αβ}.Використовуючи (5.5), отримуємо твердження теореми.
5.2 Адаптивнi оцiнки для параметрiвУ цьому параграфi продовжується розгляд задач оцiнювання по спосте-реженнях з домiшкою, розпочатий у п. 5.1. Тепер ми дослiдимо випадок,коли розподiл основної компоненти сумiшi заданий параметрично, а роз-подiл домiшки — повнiстю невiдомий. Задача полягає в оцiнцi невiдомогопараметру основної компоненти. Концентрацiї компонент у сумiшi змiню-ються вiд спостереження до спостереження i вважаються вiдомими.
Для оцiнювання ми використаємо узагальнений метод моментiв, в яко-му замiсть звичайних емпiричних моментiв використано зваженi функ-цiональнi моменти, якi вивчались у 3.1. Будуть доведенi консистентнiстьта асимптотична нормальнiсть таких оцiнок. Оскiльки при побудовi мо-ментної оцiнки пробну функцiю можна задавати значною мiрою довiльно,виникає питання про оптимальний вибiр цiєї функцiї. Ми знайдемо проб-ну функцiю, що забезпечує найменший коефiцiєнт розсiювання оцiнки.Нажаль, вона залежить вiд невiдомого параметру та щiльностi розподiлудомiшки (теж невiдомої).
Тому можна використати адаптивний пiдхiд, подiбний до розглянутогоу п. 3.2 для оцiнок моментiв, а у п. — 2.4 — для оцiнок розподiлу. На пер-шому кроцi оцiнюються параметр — за допомогою грубої пiлотної оцiнки(скажiмо, неоптимальної моментної оцiнки) i щiльнiсть розподiлу домiш-ки. На другому — цi оцiнки пiдставляються у формулу для оптимальноїпробної функцiї i отримана (випадкова) функцiя використовується у адап-тивнiй моментнiй оцiнцi. Оскiльки моментне рiвняння для такої пробноїфункцiї, як правило, не розв’язується аналiтично, справжнiй теоретичниймомент у ньому замiняється диференцiалом в околi пiлотної оцiнки.

5.2. Адаптивнi оцiнки для параметрiв 127
Вiдомо, що у випадку однорiдних спостережень без домiшки, ця адап-тивна схема приводить до наближених оцiнок методу найбiльшої вiрогiд-ностi (оцiнок Вальда), якi у регулярних задачах є асимптотично ефектив-ними (див. [2], п.2.26). Загальна теорiя адаптивного оцiнювання [24, 49] даєумови, за яких можна сподiватись асимптотичної ефективностi адаптив-них оцiнок незалежно вiд того, наскiльки ефективними є оцiнки “першогокроку”. Нажаль, цi умови не виконуються у моделi спостережень з домiш-кою. Однак ми покажемо (у теоремi 5.2.3) що, за певних умов, адаптивнаоцiнка має той же коефiцiєнт розсiювання, що i моментна оцiнка з опти-мальною пробною функцiєю. Умови теореми 5.2.3 дещо схожi на умовиефективностi оцiнок методу штрафних функцiй з [47]. Вони виконуються,наприклад, при оцiнюваннi параметру зрiзаного експоненцiйного розподi-лу при достатньо гладенькiй щiльностi розподiлу домiшки.
Постановка задачi. Ми будемо розглядати спостереження з домiш-кою, тобто данi вигляду ΞN = {ξj:N , j = 1, . . . , N}, де, при фiксованомуN , ξj:N — незалежнi мiж собою випадковi величини з функцiєю розподiлу
P{ξj:N < x} = wj:NH1(x, ϑ) + (1− wj:N)H2(x),
де wj:N — концентрацiя основної компоненти у сумiшi пiд час j-того спо-стереження, H1(x, ϑ) —функцiя розподiлу основної компоненти, ϑ ∈ Θ ∈ R— невiдомий параметр, H2 — функцiя розподiлу домiшки (вважається по-внiстю невiдомою). Задача полягає в тому, щоб оцiнити ϑ за спостережен-нями ΞN .
Для зручностi позначень введемо випадковi величини η1 з ф.р. H1(·, ϑ)i η2 з ф.р. H2.
Ми будемо припускати, що
∆N = 〈(w)2〉N − (〈w〉N)2 > c > 0 (5.6)
для деякого c i всiх N . Для двокомпонентних сумiшей ∆N = det ΓN , то-му ця умова еквiвалентна тому, що концентрацiї wj:N не вироджуються уконстанту при N →∞.
Для оцiнювання ϑ можна застосувати вiдповiдним чином модифiко-ваний метод моментiв. Для цього задамо "пробну функцiю"g : R → R iрозглянемо
Gg(t) := G(t) := Et g(η1) =
∫g(x)H1(dx, t)
— функцiональний момент основної компоненти, що вiдповiдає значеннюневiдомого параметру ϑ = t. Згiдно з п. 3.1, хорошею оцiнкою для G(ϑ) є

128 Роздiл 5. Аналiз спостережень з домiшкою
зважений вибiрковий функцiональний момент
gN =1
N
N∑j=1
aj:Ng(ξj:N),
де
aj:N = a1j:N =
1
∆N
[(1− 〈w〉N)wj:N + 〈(w)2〉N − 〈w〉N ] (5.7)
— мiнiмаксний набiр вагових коефiцiєнтiв для оцiнювання розподiлу ос-новної компоненти (див. (2.10)).
Прирiвнюючи теоретичний момент з невiдомим значенням параметруt до емпiричного, отримуємо оцiнку методу моментiв:
ϑN(g) := ϑN := G−1(gN), (5.8)
де G−1 — функцiя, обернена до G. (Зрозумiло, що iснування G−1 необхiднедля того, щоб можна було визначити оцiнку методу моментiв з даноюпробною функцiєю g).
Приклади. 1. Нехай H1 — експоненцiйний розподiл з щiльнiстю роз-подiлу h1(x, ϑ) = ϑe−ϑx1I{x > 0}, ϑ ∈ Θ = (0, +∞). Тодi Etη1 = 1
t, на роль
пробної функцiї можна взяти g(x) = x, а вiдповiдною оцiнкою буде
ϑN =
(1
N
N∑j=1
aj:Nξj:N
)−1
.
2.Нехай H1 — “зрiзаний експоненцiйний” розподiл з щiльнiстю
h1(x, ϑ) =ϑe−ϑx
1− e−ϑT1I{x ∈ (0, T )}, (5.9)
ϑ ∈ Θ = (0, +∞) — невiдомий параметр, T вважаємо вiдомим. Вочевидь,при такому розподiлi основної компоненти можна вважати, що розподiлдомiшки теж зосереджений на [0, T ] (оскiльки всi спостереження за межа-ми цього iнтервалу запевне не належать основнiй компонентi i їх можнапросто вiдкинути).
Виберемо пробну функцiю g(x) = x. Тодi
G(ϑ) =1− eϑT + ϑT
ϑ(1− eϑT ).

5.2. Адаптивнi оцiнки для параметрiв 129
Ця функцiя є монотонно спадною i неперервною, тому у неї iснує оберненаi оцiнку можна задавати (5.8).
Асимптотика моментних оцiнок. Дослiдимо поведiнку моментнихоцiнок при зростаннi обсягу вибiрки.
Теорема 5.2.1 (консистентнiсть) Нехай(i) iснують E |g(ηi)| < ∞ для i = 1, 2.(ii) Виконана умова (5.6).(iii) Функцiя G−1 iснує i є неперервною в точцi G(ϑ).Тодi ϑN → ϑ за ймовiрнiстю.
Доведення. За теоремою 3.1.1, з умов (i)-(ii) випливає, що gN →E g(η1) = G(ϑ). Звiдси, враховуючи неперервнiсть G−1, отримуємо твер-дження теореми.
Теорема 5.2.2 Нехай виконанi наступнi умови.(i) Iснують E(g(ηi))
2 < ∞ для i = 1, 2.(ii) Виконана умова (5.6).(iii) Iснує неперервна похiдна G′(t) = dG(t)
dt, рiвномiрно вiдокремлена вiд
0 для всiх t ∈ Θ (тобто або G′(t) > c > 0 для всiх t ∈ Θ, або G′(t) < c < 0для всiх t ∈ Θ).
Тодi розподiл√
N(ϑN−ϑ)/sϑ,N слабко збiгається до стандартного нор-мального розподiлу.
Тут s2ϑ,N := σ2
ϑ,N/(G′(ϑ))2,
σ2ϑ,N := σ2
ϑ,N(g) := 〈(a)2w〉N E(g(η1))2 + 〈(a)2(1− w)〉N E(g(η2))
2 (5.10)
−[〈(a)2(w)2〉N(E g(η1))2 + 2〈(a)2w(1− w)〉N E g(η1) E g(η2)
+〈(a)2(1− w)2〉N(E g(η2))2].
Наслiдок 5.2.1 Якщо виконанi умови (i) та (iii) теореми 5.2.2, i умова(ii’) Iснують границi 〈(w)k〉 для k = 1, 2, 3, 4, i
∆ = 〈(w)2〉 − (〈w〉)2 6= 0,
то√
N(ϑN − ϑ) слабко збiгається до нормального розподiлу з нульовимсереднiм i дисперсiєю s2
ϑ(g) := s2ϑ := σ2
ϑ/(G′(ϑ))2, де σ2
ϑ визначається заформулою (5.10) з замiною 〈·〉N на 〈·〉.

130 Роздiл 5. Аналiз спостережень з домiшкою
Зауваження. Всi коефiцiєнти у формулi (5.10), якi залежать вiд a,виражаються через 〈(w)k〉, k = 1, 2, 3, 4, за допомогою (5.7).
Доведення теореми 5.2.2. Зауважимо, що з умови (iii) випливає ви-конання умови (iii) теореми 5.2.1. Тому оцiнка ϑN є консистентною. Привиконаннi умов (i) та (ii) за теоремою 3.1.2 розподiли випадкових вели-чин
√N(gN −G(ϑ))/σϑ,N слабко збiгаються до стандартного нормального
розподiлу. Використовуючи теорему 7.3.9, з урахуванням(iii), отримуємотвердження теореми.
Доведення наслiдку 5.2.1. З (ii’) випливає виконання умови (5.6)а також збiжнiсть σ2
ϑ,N → σ2ϑ. Використовуючи теорему Слуцького 7.3.10,
отримуємо твердження наслiдку.Оптимальна пробна функцiя. Згiдно з наслiдком 5.2.1, найкра-
щою серед всiх пробних функцiй g буде та, для якої коефiцiєнт розсiю-вання (гранична дисперсiя) оцiнки s2
ϑ(g) буде найменшою. Позначимо цюфункцiю g∗. Визначимо, який вигляд матиме g∗, в припущеннi, що ϑ таH2 — вiдомi. Будемо також припускати, що iснують щiльностi розподiлiвhϑ
1(x) = ∂H1(x,ϑ)x
, h2(x) = ∂H2(x)x
. Додатковi умови на цi функцiї ми будемонакладати далi в ходi побудови g∗.
Помiтимо, що при переходi вiд пробної функцiї g0(x) до
g(x) = αg0(x) + β, (5.11)
(де α та β — довiльнi дiйснi числа) моментна оцiнка, по сутi, не змiнюється,оскiльки змiни gN компенсуються вiдповiдними змiнами G−1. Тому s2
ϑ(g) =s2
ϑ(g0) (це легко перевiрити i безпосередньо за формулою (5.10)).Отже, можна шукати оптимальну пробну функцiю лише в класi певним
чином нормованих та центрованих функцiй g. Виберемо α та β так, щобвиконувались рiвностi:
G(ϑ) =
∫g(x)hϑ
1(x)dx = 0 (тобто E g(η1) = 0) (5.12)
таG′(ϑ) =
∂
∂ϑ
∫g(x)hϑ
1(x)dx =
∫g(x)hϑ
1(x)dx = 1. (5.13)
(Тут ми позначили hϑ1(x) = ∂
∂ϑhϑ
1(x). Iснування цiєї похiдної та можливiстьперестановки iнтегрування i диференцiювання долучимо до умов на роз-подiли компонент).
Точнiше кажучи, для того, щоб лiнiйним перетворенням (5.11) з будь-якої функцiї g0 (не рiвної константi) можна було отримати g, що задоволь-няє (5.12)-(5.13), потрiбно, щоб функцiї 1, hϑ
1 , hϑ1 не були компланарними:

5.2. Адаптивнi оцiнки для параметрiв 131
нi при яких α, β ∈ R не повинно виконуватись hϑ1 − αhϑ
1 − β = 0 майжевсюди.
При такому обмеженнi на функцiї g наша задача зводиться до мiнiмi-зацiї функцiоналу
σ2ϑ(g) = 〈(a)2w〉
∫(g(x))2hϑ
1(x)dx + 〈(a)2(1− w)〉∫
(g(x))2h2(x)dx
−〈(a)2(1− w)2〉(∫
g(x)h2(x)dx
)2
(5.14)
за умов
∫g(x)hϑ
1(x)dx = 0∫
g(x)hϑ1(x)dx = 1
(5.15)
Помiтимо, що σ2ϑ(g) являє собою невiд’ємно визначену квадратичну
форму в лiнiйному просторi вiдповiдних функцiй g (невiд’ємна визна-ченiсть випливає з того, що σ2
ϑ(g) є граничною дисперсiєю gN). Умови(5.15) видiляють афiнний пiдпростiр цього простору. Отже, мiнiмум σ2
ϑ(g)завжди досягається, хоча може бути не єдиним. Цей мiнiмум можна шу-кати методом множникiв Лагранжа.
ПозначимоI =
∫g(x)h2(x)dx, (5.16)
z(x) = 〈(a)2w〉hϑ1(x) + 〈(a)2(1− w)〉h2(x),
γ = 〈(a)2(1− w)2〉.Функцiя Лагранжа має виглядL(g) =
∫(g(x))2z(x)dx−γ
(∫g(x)h2(x)
)2+λ1
∫g(x)hϑ
1(x)dx+λ2
∫g(x)hϑ
1(x)dx,де λ1, λ2 — множники Лагранжа. Диференцiал L:
δL(g) =
∫(2g(x)z(x) + λ1h
ϑ1(x) + λ2h
ϑ1(x)− 2γIh2(x))δ(x)dx.
У стацiонарнiй точцi δL(g) = 0 для всiх можливих приростiв аргументуδ(x). Отже, екстремум досягається у точцi
g∗(x; ϑ, h2) := g∗(x) :=λ1h
ϑ1(x) + λ2h
ϑ1(x) + γIh2(x)
〈(a)2w〉hϑ1(x) + 〈(a)2(1− w)〉h2(x)
, (5.17)

132 Роздiл 5. Аналiз спостережень з домiшкою
де λ1, λ2 та I знаходяться з системи рiвнянь, якi вiдповiдають умовам(5.15)-(5.16):
λ1
∫(hϑ
1(x))2
z(x)dx + λ2
∫hϑ
1(x)hϑ1(x)
z(x)dx + Iγ
∫h2(x)hϑ
1(x)
z(x)dx = 0
λ1
∫hϑ
1(x)hϑ1(x)
z(x)dx + λ2
∫(hϑ
1(x))2
z(x)dx + Iγ
∫h2(x)hϑ
1(x)
z(x)dx = 1
λ1
∫hϑ
1(x)h2(x)
z(x)dx + λ2
∫hϑ
1(x)h2(x)
z(x)dx + Iγ
∫(h2(x))2
z(x)dx = I
(5.18)
Функцiя g∗, якщо вона задовольняє умови теореми 5.2.2, є оптимальноюпробною функцiєю для оцiнки ϑ методом моментiв.
Адаптивна оцiнка. Зрозумiло, що не знаючи справжнiх ϑ та h2,неможливо безпосередньо використати оптимальну пробну функцiю (5.17)для оцiнювання. Вихiд може полягати у застосуваннi адаптивного пiдходу.
Для побудови адаптивної оцiнки ми на першому кроцi оцiнюємо ϑ таh2 за допомогою грубих “пiлотних” оцiнок ϑN та h2,N i пiдставляємо зна-чення цих оцiнок в (5.17). Отримана функцiя g∗N(x) := g∗(x; ϑN , h2,N) ви-користовується як пробна функцiя для моментної оцiнки: ϑ∗N = G−1
g∗N(g∗N),
де g∗N = 1N
∑Nj=1 aj:Ng∗N(ξj:N).
При цьому виникають два ускладнення.По-перше, зовсiм не очевидно, чи буде iснувати функцiя G−1
g∗Nдля обра-
ної нами пробної функцiї g∗N , а коли так, то як її обчислювати.По-друге, оскiльки g∗N є випадковою функцiєю, залежною вiд даних,
теорему 5.2.2 не можна застосовувати до вiдповiдної оцiнки. Тому асимп-тотична поведiнка оцiнки вимагає додаткового аналiзу.
Перше ускладнення можна обiйти, розв’язуючи рiвняння
Gg∗N (t) = g∗N (5.19)
наближено методом Ньютона з початковим наближенням ϑN . Дiйсно, роз-кладаючи Gg∗N (t) у ряд в околi ϑN , отримуємо, що рiвняння (5.19) при-близно еквiвалентне
Gg∗N (ϑN) + G′g∗N
(ϑN)(t− ϑN) = g∗N . (5.20)
Оскiльки функцiя g∗N задовольняє умови (5.12)-(5.13) з ϑ = ϑN , тоGg∗N (ϑN) = 0 i G′
g∗N(ϑN) = 1. Отже розв’язок (5.20) має вигляд
ϑN = ϑN + g∗N . (5.21)

5.2. Адаптивнi оцiнки для параметрiв 133
Цю оцiнку ми i будемо назвати адаптивною оцiнкою методу моментiв дляϑ.
Визначимо тепер умови, за яких ϑN буде асимптотично нормальною зоптимальним коефiцiєнтом розсiювання s2
ϑ(g∗). Вiдповiдне твердження мисформулюємо для трохи бiльш загальної ситуацiї адаптивного оцiнювання,нiж розглянута вище.
Нехай A — деякий вимiрний простiр, g : R × A → R — фiксовананевипадкова вимiрна функцiя. Визначимо g(α) = 1
N
∑Nj=1 aj:Ng(ξj:N , α),
G(ϑ, α) = Eϑ g(η1, α) =∫
g(x, α)hϑ1(x)dx.
Припустимо, що у нас є пiлотна оцiнка ϑN для ϑ i послiдовнiсть ви-падкових елементiв A (оцiнок) αN , яка наближається до невипадковогоелемента α∞. При цьому αN ∈ AN , де AN — послiдовнiсть невипадковихпiдмножин A. Розглянемо оцiнку
ϑN = ϑN +gN(αN)−G(ϑN , αN)
G′(ϑN , αN)(5.22)
де G′(t, α) = ∂∂t
G(t, α).(Якщо αN = (ϑN , h2,N), де h2,N — оцiнка для h2, g(x, α) = g∗(x, ϑN , h2,N),
то (5.22) перетворюється на (5.21)).Позначимо через FN клас усiх множин вигляду {x ∈ R : g(x, α) −
g(x, α∞) < C} для всiх можливих α ∈ AN , C ∈ R. Позначимо νN(l) =ν(l,FN) функцiю зростання класу FN . (Означення функцiй зростання див.у п. 2.2).
Нехай
σ2∞ := lim
N→∞Var
(1√N
N∑j=1
aj:Ng(ξj, α∞)
)
= 〈(a)2w〉E(g(η1, α∞))2 + 〈(a)2(1− w)〉E(g(η2, α∞))2
− [〈(a)2(w)2〉(E g(η1, α∞))2 + 2〈(a)2w(1− w)〉E g(η1, α∞) E g(η2, α∞)
+〈(a)2(1− w)2〉(E g(η2, α∞))2].
Теорема 5.2.3 Нехай виконанi наступнi умови.(i) Iснують E(g(ηi, α∞))2 < ∞ для i = 1, 2.(ii)Iснують границi 〈(w)k〉 для k = 1, 2, 3, 4, i
∆ = 〈(w)2〉 − (〈w〉)2 6= 0,
(iii) supN P{√N(ϑN − ϑ) > c} → 0 при c →∞

134 Роздiл 5. Аналiз спостережень з домiшкою
(iv) G′(ϑ, α∞) 6= 0, G′(t, α) є неперервною по t в деякому околi ϑ длявсiх α ∈ A i G′(tN , αN) → G′(ϑ, α∞) при N →∞ за ймовiрнiстю, для всiхвипадкових послiдовностей tN , таких, що tN → ϑ за ймовiрнiстю.
(v) Для деякої невипадкової послiдовностi δN → 0,
1
δN
supx∈R
|g(x, αN)− g(x, α∞)| → 0
при N →∞ за ймовiрнiстю.(vi) ln νN(2N) = o(δ−2
N ).Тодi
√N(ϑN − ϑ) слабко збiгається до нормального розподiлу з нульо-
вим середнiм i дисперсiєю σ2∞/(G′(ϑ, α∞)).
Теорема фактично стверджує, що коефiцiєнт розсiювання адаптивноїоцiнки ϑN , визначеної (5.22), буде таким самим, як у моментної оцiнкиg(·, α∞). Доведення теореми див. далi, наприкiнцi параграфу.
Розглянемо застосування цiєї теореми для аналiзу даних з прикладу 2(зi зрiзаним експоненцiйним розподiлом H1). На роль пiлотної оцiнки ϑN
для ϑ можна використати моментну оцiнку з пробною функцiєю g(x) = x.Як оцiнку для h2 використаємо зважену гiстограму. Точнiше, задамо KN —кiлькiсть пiдiнтервалiв розбиття iнтервалу [0, T ), покладемо tk = kT/KN ,k = 0,. . . ,KN , Ak = [tk−1, tk) — k-тий пiдiнтервал розбиття. Тодi зваженагiстограма h2,N визначається як
h2,N(x) =KN
NT
N∑j=1
KN∑
k=1
a2j:N1I{ξj:N ∈ Ak}, (5.23)
де a2j:N — мiнiмакснi ваговi коефiцiєнти для оцiнювання другої компоненти
(домiшки):a2
j:N = (〈(w)2〉N − 〈w〉Nwj:N)/∆N . (5.24)
Наслiдок 5.2.2 Нехай виконуються наступнi умови.(i) Основна компонента має зрiзаний експоненцiйний розподiл (5.9).(ii) Виконана умова (ii) теореми 5.2.3.(iii) У розподiлу домiшки iснує щiльнiсть h2, яка є неперервно дифе-
ренцiйовною функцiєю на [0, T ].(iv) KN = CNβ для деяких C > 0, 0 < β < 1/4.(v) Пiлотна оцiнка ϑN є моментною оцiнкою з пробною функцiєю
g(x) = x.Тодi виконано твердження теореми 5.2.3.

5.2. Адаптивнi оцiнки для параметрiв 135
У випадку необмеженого носiя розподiлу H1, як от — експоненцiйного,у прикладi 1, можна використовувати гiстограму на iнтервалi, що розши-рюється зi збiльшенням обсягу вибiрки, скажiмо, на [0, TN). Якщо TN пря-мує до нескiнченностi досить повiльно, щоб забезпечити виконання умов(v) та (vi) теореми 5.2.3, i, в той же час, досить швидко, щоб забезпечитиP{supj ξj:N > TN} → 0 при N → ∞, то твердження теореми буде викону-ватись. Зокрема, у схемi прикладу 1, якщо хвiст розподiлу H2 субекспо-ненцiйний, (тобто H2([x, +∞)) < Ce−αx для деяких C, α > 0) то можнапокласти TN = C(ln N)ln N
Доведення теорем.Для доведення теореми 5.2.3 нам будуть потрiбнi допомiжнi леми.
Лема 5.2.1 Нехай F — деякий клас множин на R з функцiєю зростанняνF(l), виконана умова (5.6), ai задано (5.7) або (5.24). Тодi для деяких λ0,C i α при λ > λ0/N ,
P{supA∈F
|HNi (A)−Hi(A)| > λ} ≤ CνF(2N) exp(−αλ2N),
причому константи λ0 > 0, C < ∞ i α > 0 залежать лише вiд концен-трацiй wj:N i не залежать вiд Hi, F i λ.
Ця лема є тривiальним наслiдком нерiвностi Вапника-Червоненкiса —теореми 2.2.4.
Нехай G — клас функцiй g : R→ R. Позначимо FG = {{x ∈ R : g(x) <c}, ∀c ∈ R, ∀g ∈ G}.Лема 5.2.2 Нехай G — деякий клас вимiрних обмежених функцiйf : R→ R, K = supx∈R,f∈G |f(x)|. Тодi
supf∈G
∣∣∣∣∣1
N
N∑j=1
f(ξj:N)aij:N −
∫f(x)Hi(dx)
∣∣∣∣∣ ≤ 2K supA∈FG
|HNi (A)−Hi(A)|.
Доведення. Зафiксуємо f ∈ G. Для n ∈ N i j = ±1,±2, · · · ±n позначимо
Anj =
{x ∈ R : f(x) ≤ Kj
n
}.
Враховуючи, що |f(x)| ≤ K, за означенням iнтегралу Лебега маємо∫
f(x)Hi(dx) = limn→∞
n∑j=−n
Kj
nHi(A
nj \ An
j−1)

136 Роздiл 5. Аналiз спостережень з домiшкою
i, аналогiчно,
1
N
N∑j=1
f(ξj:N)aij:N = lim
n→∞
n∑j=−n
Kj
nHN
i (Anj \ An
j−1).
Тому
supf∈G
∣∣∣∣∣1
N
N∑j=1
f(ξj:N)aij:N −
∫f(x)Hi(dx)
∣∣∣∣∣
≤ limn→∞
n∑j=−n
Kj
n|Hi(A
nj \ An
j−1)− HNi (An
j \ Anj−1)|
≤ limn→∞
n∑j=−n
Kj
n(|Hi(A
nj )− HN
i (Anj )|+ |Hi(A
nj−1)− HN
i (Anj−1)|)
≤ 2K supA∈FG
|HNi (A)−Hi(A)|.
Внаслiдок довiльностi f отримуємо твердження леми.Лема доведена.Доведення теореми 5.2.3. Помiтимо, що
√N(ϑN − ϑ) =
√N(ϑN − ϑ) +
√N(gN(αN)−G(ϑ, αN))
G′(ϑN , αN)
+
√N(G(ϑ, αN)−G(ϑN , αN))
G′(ϑN , αN).
Враховуючи, що G(ϑ, αN)−G(ϑN , αN) = G′(ζN , αN)(ϑ− ϑN), де ζN — про-мiжна точка мiж ϑ i ϑN , отримуємо
√N(ϑN − ϑ) = J1 + J2/G
′(ϑN , αN) + J3,
де
J1 =√
N(ϑN − ϑ)
(1− G′(ζN , αN)
G′(ϑN , αN)
),
J2 =√
N(gN(αN)−G(ϑ, αN)− gN(α∞) + G(ϑ, α∞)),
J3 = (gN(α∞)−G(ϑ, α∞))/G′(ϑN , αN)).

5.2. Адаптивнi оцiнки для параметрiв 137
За умовами (iii) та (iv) J1 → 0 за ймовiрнiстю. Враховуючи (i) та (ii), затеоремою 3.1.2 отримуємо, що J3 збiгається слабко до нормального роз-подiлу з нульовим середнiм та дисперсiєю σ2
∞/(G′(ϑ, α∞)).Залишилось показати, що J2 → 0 за ймовiрнiстю. Зробимо це. По-
значимо f(x; α) = g(x, α∞) − g(x, α) i розглянемо клас функцiй GN :={f(·; α), α ∈ AN}.
Тодi
gN(α∞)− gN(α) =1
N
N∑j=1
aj:N(g(ξ:N , α∞)− g(ξj:N , α)) =1
N
N∑j=1
aj:Nf(ξj:N),
G(ϑ, α∞)−G(ϑ, α) =
∫f(x, α)H1(dx, α).
Тому, за лемою 5.2.2, для будь-яких λ,
pN := P{|J2| > λ} ≤ P
{sup
x|g(x, αN)− g(x, α∞)| > δN
}
+ P
{sup
A∈FG|H1,N(A)−H1(A)| > λδ−1
2√
N
}.
За умовою (v), перший доданок праворуч прямує до 0, а за лемою 5.2.1та умовою (vi) другий не перевищує
CνN(2N) exp(−αλ2δ−2N /4) ≤ C exp(−αλ2δ−2
N /4 + ln νN(2N)) → 0.
Теорема доведена.Для доведення наслiдку 5.2.2, нам буде потрiбна наступна оцiнка швид-
костi збiжностi зваженої гiстограми h2,N , визначеної (5.23), до оцiнюваноїщiльностi.
Лема 5.2.3 Нехай розподiли компонент зосередженi на [0, T ] i(i) h2 є неперервно диференцiйовною на [0, T ];(ii) Виконана умова (ii) теореми 5.2.3;(iii) Для деяких 0 < Ci, β, γ < ∞, δN = C1N
−β, KN = C2Nγ.
Тодi, якщо β < γ, β + γ < 1/2, то
1
δN
supx∈[0,T ]
|h2,N(x)− h2(x)| → 0
за ймовiрнiстю.

138 Роздiл 5. Аналiз спостережень з домiшкою
Доведення. Позначимо hk = KNH2(Ak)/T ,
h2,N(x) = E h2,N =
KN∑
k=1
hk1I{x ∈ Ak},
h′ = supx∈[0,T ]ddx
h2(x).Фiксуємо довiльне λ > 0. Твердження леми еквiвалентне тому, що
JN := P{ supx∈[0,T ]
|h2,N(x)− h2(x)| > λδN} → 0
при N →∞. Легко бачити, що JN ≤ J1N + J2
N , де
J1N = P{ sup
x∈[0,T ]
|h2,N(x)− h2,N(x)| > λδN/2},
J2N = 1I{ sup
x∈[0,T ]
|h2,N(x)− h2(x)| > λδN/2}.
Нехай x ∈ Ak. Оцiнимо
|h2,N(x)− h2(x)| ≤ KN
T
∫ tk
tk−1
|h2(x)− h2(t)|dt ≤ KN
Th′
∫ tk
tk−1
|x− t|dt
≤ h′T2KN
=Th′
2C2
N−γ < C1N−β
при достатньо великих N . Отже, при великих N , JN2 = 0.
За лемою 5.2.1,
JN1 ≤
KN∑
k=1
P
{KN
T|H2,N(Ak)−H2(Ak)| ≥ λδN/2
}
≤ CKN exp
(−α
(TλδN
2KN
)2
N
)= CNγ exp
(−α
(Tλ
2
)2
N1−2β−2γ
)→ 0
при N →∞. Отже i J1 → 0.Лема доведена.Доведення наслiдку 5.2.2. перевiримо виконання умов теореми 5.2.3.
Позначимо t ∈ T := [ϑ− ε, ϑ + ε], де ϑ — справжнє значення параметру, ε— будь-яке додатне число, таке, що ϑ−ε > 0. При N → 0, P{ϑN ∈ T } → 1,тому можна вважати, що множина можливих значень параметру Θ = T .

5.2. Адаптивнi оцiнки для параметрiв 139
Тодi в.в. g∗(ηi, h2(ηi), t) є обмеженими для всiх t ∈ T , тому (i) — вико-нано. Умова (iii) виконана внаслiдок теореми 5.2.2. Умова (ii) — внаслiдокнеперервностi G′ i збiжностi ϑN → ϑ, h2,N → h2.
Покладемо δN = N−γ, де γ = 3β/2 при β < 1/6 i γ = 1/4 при 1/6 ≤ β ≤1/4. Виконання умови (iv) випливає з леми 5.2.3, теореми 5.2.2 i гладкостig∗(x, h, t) по h i t при h > 0, t ∈ T .
Оцiнимо νN(2N). Легко бачити, що коли t = const, h = const, g∗(x, h, t)як функцiя x ∈ (0, +∞) може мати не бiльше нiж C iнтервалiв монотон-ностi, де C — деяке фiксоване число, що не залежить вiд h та t. Томуg∗(x, h2,N , t) має не бiльше нiж CKN iнтервалiв монотонностi i νN(2N) ≤(2N)CKN . Тому
ln νN(2N) ≤ CNγ ln(2N) ≤ δ−2N = (C1)
−2N2β,
оскiльки γ < 2β.Наслiдок доведено.

Роздiл 6
Задачi класифiкацiї
6.1 Баєсова класифiкацiя
Загальна задача класифiкацiї має наступний вигляд. Об’єкт O може на-лежати однiй з M рiзних популяцiй P1,. . . , PM . Номер популяцiї, якiйналежить O (як i ранiше, ми позначаємо його ind(O)) невiдомий. Спо-стерiгається набiр характеристик O — ξ(O). Потрiбно за спостережувани-ми характеристиками ξ(O) визначити (вгадати, оцiнити) до якої популяцiїналежить O.
Розв’язком задачi класифiкацiї є функцiя g : X → {1, . . . , M}, якакожному можливому значенню спостережуваних характеристик x ∈ Xставить у вiдповiднiсть номер популяцiї g(x), до якої слiд вiднести об’єктз такими характеристиками. Функцiю g називають класифiкатором.
Прикладом задачi класифiкацiї є задача медичної дiагностики. У цiйзадачi O — пацiєнт, якому потрiбно встановити дiагноз, Pi, i = 1,. . . ,M— хвороби, якими вiн в принципi може бути хворий (точнiше, Pi — по-пуляцiя всiх людей, хворих i-тою хворобою), ind(O) — номер справжньоїхвороби, якою хворiє O, ξ(O) — сукупнiсть даних обстеження, за якимиможна встановлювати дiагноз (температура, артерiальний тиск, формулакровi, кардiограма, рентгенiвський знiмок — ξ(O) зовсiм не обов’язковомає бути набором виключно числових даних). Класифiкатор g у даномувипадку — це сукупнiсть правил дiагностики, якi за даними ξ(O) дозво-ляють встановити дiагноз, тобто вказати номер хвороби g(ξ(O)), якою надумку дiагноста хворiє O.
На роль класифiкатора можна, взагалi кажучи, використати будь-якувимiрну функцiю. Для вибору найкращого класифiкатора можна скори-

6.1. Баєсова класифiкацiя 141
статись яким-небудь критерiєм якостi. Найбiльш поширеним серед цихкритерiїв є ймовiрнiсть помилкової класифiкацiї. Щоб ввести це поняттяпотрiбно припустити, що ξ(O) є випадковими елементами X , а ind(O) —випадковою величиною зi значеннями на множинi {1, . . . , M}.
Отже, нехайpi = P{ind(O) = i} — “апрiорна” ймовiрнiсть того, що об’єкт, який
спостерiгається, належить i-тiй популяцiї,Hi(A) = P{ξ(O) ∈ A | ind(O) = i} — розподiл спостережуваних харак-
теристик об’єкта, що належить i-тiй популяцiї (тут A — будь-яка вимiрнапiдмножина X ).
Тодi, для будь-якого класифiкатора g визначена ймовiрнiсть помилки:
L(g) = P{g(ξ(O) 6= ind(O)} = 1− P{g(ξ(O) = ind(O)}
=1−M∑i=1
pi P{g(ξ(O)) = i | ind(O) = i} = 1−M∑i=1
piHi(Ai),(6.1)
де Ai = {x ∈ X : g(x) = i} — множина значень характеристик, при якихкласифiкатор g вiдносить об’єкт до i-тої популяцiї1. L(g) називають такожбаєсовим ризиком класифiкатора g.
Зрозумiло, що чим меншою є ймовiрнiсть помилки, тим кращим є кла-сифiкатор. Нехай фiксована деяка множина допустимих класифiкаторiвG. Класифiкатор g0 називають баєсовим в класi G, якщо g0 ∈ G i длябудь-якого g ∈ G, L(g0) ≤ L(g). Будемо позначати баєсiв класифiкаторgB
G .Класифiкатор, баєсiв у класi всiх можливих класифiкаторiв, називають
просто “баєсовим” i позначають gB.Надалi всюди у цьому роздiлi нас буде цiкавити можливiсть побудови
класифiкаторiв, баєсових у деяких класах, або наближених до баєсових.У випадку, коли апрiорнi ймовiрностi pi та розподiли характеристик Hi
вiдомi, побудова баєсового класифiкатора не викликає утруднень. Дiйсно,нехай ν — мiра, вiдносно якої всi розподiли Hi є абсолютно неперервними2.Позначимо hi(x) = ∂Hi
∂ν(x) — щiльнiсть hi вiдносно ν, тобто
Hi(A) =
∫
A
hi(x)ν(dx).
1Класифiкатор можна навiть формально ввести як розбиття простору X на областiAi. Таке означення буде еквiвалентним характеризацiї класифiкатора функцiєю g
2Така мiра завжди iснує, наприклад, можна покласти ν =∑M
i=1 Hi.

142 Роздiл 6. Задачi класифiкацiї
ТодigB(x) = argmax
ipihi(x). (6.2)
Доведення цього факту дуже просте. За (6.1), для будь-якого класифiка-тора g,
L(g) = 1−M∑i=1
pi
∫
Ai
hi(x)ν(dx) =
∫
Xpg(x)hg(x)ν(dx). (6.3)
Зрозумiло, що
1−∫
Xpg(x)hg(x)ν(dx) ≥ 1−
∫
Xmax
i(pihi(x))ν(dx) = L(gB).
Отже, класифiкатор gB, визначений (6.2), дiйсно є баєсовим.Вiдмiтимо, що апостерiорнi ймовiрностi p∗i (x) = P{ind(O) = i | ξ(O) =
x} можна обчислювати за формулою Баєса:
p∗i (x) =pihi(x)∑M
m=1 pmhm(x),
i, оскiльки у цiй формулi знаменник не залежить вiд i,
gB(x) = argmaxi
p∗i (x),
тобто баєсiв класифiкатор — це класифiкатор, що обирає популяцiю, якамає найбiльшу апостерiорну ймовiрнiсть. Iнколи цю властивiсть вибира-ють як означення баєсового класифiкатора, але ми будемо дотримуватисьпочаткового означення.
На практицi, як правило, апрiорнi ймовiрностi та/або розподiли харак-теристик є невiдомими. У такiй ситуацiї для побудови класифiкаторiв ви-користовують навчаючi вибiрки, тобто вибiрки, що складаються з об’єктiв,подiбних до тих, якi потрiбно буде класифiкувати.
У розглянутому нами прикладi медичної дiагностики такою вибiркоюможе бути набiр даних про пацiєнтiв, якi ранiше звертались до даної ме-дичної установи, та про дiагнози, якi їм були поставленi. В такiй вибiрцiбудуть мiститись значення ξj = ξ(Oj) — спостережуваних характеристикj-того пацiєнта, j = 1,. . . ,N та, наприклад, встановленi пацiєнтам дiагнозиij. Якщо вважати, що ij = ind(Oj) — безпомилковий остаточний дiагноз, тоотримана навчаюча вибiрка (ξj, ij, j = 1, . . . , N) буде повнiстю розкласи-фiкованою, тобто розпадеться на M вибiрок, кожна з яких вiдповiдатиме

6.1. Баєсова класифiкацiя 143
однiй популяцiї (одному дiагнозу). По цих вибiрках звичайними метода-ми можна оцiнити hi, а за частотою появи рiзних дiагнозiв у навчаючiйвибiрцi оцiнити апрiорнi ймовiрностi pi. Отриманi оцiнки, скажiмо, pi таhi, можна пiдставити замiсть справжнiх значень у формулу для баєсовогокласифiкатора gB i отримати класифiкатор g, який зветься емпiрично-баєсовим:
g(x) = argmaxi
pihi(x). (6.4)
Такий пiдхiд називають емпiрично-баєсовою класифiкацiєю.Однак для реальних даних часто немає впевненостi в тому, що кла-
сифiкацiя навчаючої вибiрки проведена абсолютно вiрно. (Наприклад, якправило, ми маємо данi не про остаточнi, а про попереднi дiагнози пацiєн-тiв3). Замiсть точних ij у цьому випадку природно розглядати деякi ймо-вiрностi того, що об’єкт Oj належить m-тiй популяцiї, тобто P{ind(Oj) =m} = wm
j:N . Скажiмо, якщо попереднiй дiагноз розглядати як результатпевної класифiкацiї на основi обмеженої iнформацiї, то на роль wi
j:N мож-на взяти апостерiорнi ймовiрностi цiєї попередньої класифiкацiї.
При такiй iнтерпретацiї навчаюча вибiрка виявляється вибiркою з су-мiшi зi змiнними концентрацiями. Для побудови емпiрично-баєсового кла-сифiкатора можна тепер використовувати оцiнки щiльностей розподiлiвкомпонент, описанi у роздiлi 4. Оцiнку апрiорних ймовiрностей можна ви-конувати по-рiзному — або з використанням додаткової iнформацiї проконкретного пацiєнта (об’єкта), або на основi статистичних даних про по-ширенiсть тої чи iншої хвороби (появи об’єктiв з рiзних популяцiй). У цьо-му роздiлi ми, як правило, будемо вважати апрiорнi ймовiрностi вiдомими(тобто iгноруватимем помилку, що виникає при їх оцiнюваннi). Пiдстав-ляючи отриманi оцiнки у (6.4), отримуємо емпiрично-баєсiв класифiкатор,побудований по вибiрцi з сумiшi зi змiнними концентрацiями.
Процес побудови класифiкатора на основi навчаючої вибiрки назива-ють статистичним навчанням (statistical learning). У цьому роздiлi ми роз-глядаємо рiзнi алгоритми статистичного навчання на основi неповнiстюрозкласифiкованих навчаючих вибiрок та вивчаємо асимптотичнi власти-востi отриманих класифiкаторiв при зростаннi обсягу вибiрки.
Якiсть емпiрично-баєсового класифiкатора g (або iншого класифiка-тора, побудованого за вибiркою) прийнято також оцiнювати у термiнахбаєсового ризику L(g), який тепер є випадковою величиною, залежною
3Остаточнi дiагнози ставлять паталогоанатоми.

144 Роздiл 6. Задачi класифiкацiї
вiд вибiрки:
L(g) =
∫pg(x)hg(x)ν(dx) = P{g(ξ(O)) 6= ind(O) | ΞN}, (6.5)
тут у другiй рiвностi ймовiрнiсть трактуємо як умовну при фiксованiй нав-чаючiй вибiрцi ΞN , а об’єкт, що класифiкується — O вважаємо незалежнимвiд ΞN .
Безумовна ймовiрнiсть помилки P{g(ξ(O)) 6= ind(O)} = E L(g) харак-теризує не конкретний класифiкатор, отриманий за даною вибiркою, асередню якiсть класифiкаторiв, побудованих певним методом за данимипевного вигляду.
Класифiкатор gN , побудований за вибiркою ΞN , будемо називати кон-систентним у класi G, якщо gN ∈ G м.н. i L(gN) → L(gB
G) (за ймовiрнiстю)при N →∞. Якщо має мiсце збiжнiсть майже напевне, класифiкатор бу-демо називати сильно консистентним.
Зв’язок мiж консистентнiстю емпiрично-баєсового класифiкатора таконсистентнiстю оцiнок щiльностi, за якими вiн побудований, встановлюєнаступна теорема.
Теорема 6.1.1 (Межа Джорфi) Нехай gB(x) — баєсiв класифiкатор,визначений (6.2), а g(x) — емпiрично баєсiв класифiкатор, визначений(6.4). Тодi
0 ≤ L(g)− L(gB) ≤ 2M∑i=1
∫
X|pihi(x)− pihi(x)|ν(dx).
Доведення. Нерiвнiсть 0 ≤ L(g)− L(gB) випливає з означення баєсовогокласифiкатора. Для доведення правої нерiвностi використаємо (6.3):
L(g)− L(gB) ≤∫
X|pg(x)hg(x) −max
i(pihi(x))|ν(dx) ≤ J1 + J2,
де
J1 =
∫
X|max
i(pihi(x))−max
i(pihi(x))|ν(dx),
J2 =
∫
X|max
i(pihi(x))− pg(x)hg(x)|ν(dx).

6.1. Баєсова класифiкацiя 145
Оцiнимо
J1 ≤∫
Xmax
i|pihi(x)− pihi(x))|ν(dx) ≤
M∑i=1
∫
X|pihi(x)− pihi(x)|ν(dx).
Враховуючи, що за означенням g, maxi(pihi(x)) = pg(x)hg(x),
J2 ≤∫
X|pg(x)hg(x) − pg(x)hg(x)|ν(dx) ≤
M∑i=1
∫
X|pihi(x)− pihi(x)|ν(dx).
Об’єднуючи цi двi оцiнки, отримуємо твердження теореми.Теорема доведена.
Наслiдок 6.1.1 В умовах теореми 6.1.1, якщо |pi| < 1, для всiх i =1, . . . , M , то
|L(g)− L(gB)| ≤ 2M∑i=1
∫
X|hi(x)− hi(x)|ν(dx) + 2
M∑i=1
|pi − pi|
Доведення. Враховуючи, що∫
pi(x)ν(dx) = 1, за теоремою 6.1.1 отри-муємо
|L(g)− L(gB)| ≤ 2M∑i=1
(∫
X|pihi(x)− pihi(x)|ν(dx)
+
∫
X|pihi(x)− pihi(x)|ν(dx)
)
≤ 2M∑i=1
|pi − pi|+ 2M∑i=1
∫
X|hi(x)− hi(x)|ν(dx).
Наслiдок доведено.Як приклад застосування нерiвностi Джорфi розглянемо емпiрично-
баєсiв класифiкатор, побудований за вибiркою з сумiшi зi змiнними кон-центрацiями (ξj:N , j = 1, . . . , N) у випадку, коли X = Rd i розподiли ком-понент мають неперервнi обмеженi щiльностi вiдносно мiри Лебега hi. Уцьому випадку для оцiнювання hi можна використати ядернi оцiнки щiль-ностi hN
i (x), визначенi (4.2). Емпiрично-баєсiв класифiкатор gN задамо якзвичайно
gN(x) = pNi hN
i (x),

146 Роздiл 6. Задачi класифiкацiї
де pNi деякi оцiнки апрiорних ймовiрностей pi.Використовуючи наслiдок 6.1.1 та теорему 4.1.1, отримуємо наступну
теорему.
Теорема 6.1.2 Нехай1. Для деякої константи C > 0, det ΓN > C.2. Параметр згладжування sN ядерних оцiнок hN
i (x) обрано так, що
sN → 0,√
ln NN
s−dN → 0 при N →∞.
3. Оцiнки pNi для апрiорних ймовiрностей є консистентними.
Тодi емпiрично баєсiв класифiкатор gN є консистентим.
6.2 Класифiкацiя за методом найближчогосусiда
Для багатовимiрних спостережень та спостережень з бiльш загальних мет-ричних просторiв одним з найбiльш популярних методiв класифiкацiї є ме-тод k найближчих сусiдiв [30, 31]. У випадку повнiстю розкласифiкованоївибiрки ця процедура виглядає зовсiм просто: для об’єкта, який хочутьрозкласифiкувати, знаходять k найближчих (у метрицi простору спосте-режень) сусiдiв серед елементiв навчаючої вибiрки. Класифiкацiя прово-диться голосуванням цих сусiдiв — об’єкт вiдносять до того класу, до якогоналежить найбiльше його сусiдiв. Коротко кажучи: “скажи, хто твої сусi-ди, i я скажу хто ти”.
При такому описi процедури класифiкацiї непомiтно, що насправдi кла-сифiкатор k найближчих сусiдiв — це емпiрично-баєсiв класифiкатор. Аленасправдi це так: якщо на роль оцiнок апрiорних ймовiрностей взяти вiд-повiднi частоти у навчаючiй вибiрцi, а щiльностi розподiлу оцiнювати оцiн-ками методу k найближчих сусiдiв, то емпiрично-баєсiв класифiкатор, по-будований за цими оцiнками як раз i буде класифiкатором k найближчихсусiдiв.
У випадку, коли спостереження для побудови класифiкатора обира-ються з сумiшi зi змiнними концентрацiями, можна використати оцiнкиk найближчих сусiдiв для щiльностей компонент сумiшi, описанi у п. 4.4.Ми покажемо, що отриманий в результатi класифiкатор є консистентнимза дуже слабких умов.
Отже, нехай простiр спостережень X є сепарабельним метричним про-стором з метрикою ρ, а данi ΞN = (ξj:N j = 1, . . . , N) описуються моделлю

6.2. Метод найближчого сусiда 147
сумiшi зi змiнними концентрацiями (2.1), тобто
P{ξj:N ∈ A} = µj:N(A) =M∑
m=1
wmj:NHm(A). (6.6)
Будемо вважати, що det ΓN 6= 0 i оцiнювати розподiли компонент сумiшiмiнiмксними оцiнками
HNm (A) =
1
N
N∑j=1
amj:N1I{ξj:N ∈ A},
де amj:N — мiнiмакснi ваговi коефiцiєнти, визначенi (2.10). Використаємо
HNm для побудови оцiнок k найближчих сусiдiв для щiльностi Hm вiдносно
мiри ν(A) = H0(A) =∑M
i=1〈wi〉Hi(A).Для довiльного x ∈ X позначимо r(x, k) вiдстань вiд x до його k-того
найближчого сусiда у вибiрцi ΞN (бiльш детальне пояснення див. у п. 4.4).Нехай B(x, r) — замкнена куля радiуса r з центром x у просторi (X , ρ). Якоцiнку для hi(x) = ∂Hi
∂H0використаємо
hNi (x) =
HNi (B(x, r(x, kN))
H0(B(x, r(x, kN)), (6.7)
де kN — деяка невипадкова числова послiдовнiсть, H0 — зважена емпiрич-на мiра з ваговими коефiцiєнтами a0
j:N ≡ 1. (Вiдмiтимо, що hi iснує, якщо〈wi〉 6= 0, тобто якщо частка спостережень з i-тої компоненти у вибiрцi непрямує до 0 при N →∞).
Припустимо, що апрiорнi ймовiрностi pi, i = 1,. . . ,M для класифiкацiїоб’єкта O вiдомi. Як класифiкатор для O за спостереженням x = ξ(O)використаємо
gN(x) = argmaxi
pihNi (x)
Теорема 6.2.1 Нехай(i) (X , ρ) є сепарабельним метричним простором.(ii) |〈wiwm〉N −〈wiwm〉| = O(1/
√N) для всiх i,m = 1,. . . ,M i det Γ 6= 0.
(iii) kN/N → 0, kN/√
N log N →∞ при N →∞.Тодi hN
i є консистентною оцiнкою hi у просторi L1(H0), а класифiка-тор gN є консистентним класифiкатором.

148 Роздiл 6. Задачi класифiкацiї
Зауваження. 1. Теорема не накладає жодних умов на розподiли спо-стережуваних характеристик для рiзних популяцiй. Вони можуть бутибудь-якими — неперервними, дискретними, сингулярними.
2. З умови (ii) випливає iснування 〈wi〉 6= 0, оскiльки 〈wi〉 = 〈wi × 1〉 =∑Mm=1〈wiwm〉.Для доведення теореми нам будуть потрiбнi три леми.
Лема 6.2.1 (див. [28]). Позначимо
D1 = supp H0 = {z ∈ X : H0(B(z, r)) > 0 ∀r > 0}.Тодi H0(D1) = H0(X ).
Лема 6.2.2 (див. теорему 2.9.8 у [29]). Позначимо
Di2 =
{z ∈ X : lim
r→0
Hi(B(z, r))
H0(B(z, r))→ ∂Hi
∂H0
(z)
}.
Тодi H0(Di2) = H0(X ).
Позначимо
βN =
√log N
N
Лема 6.2.3 Якщо kN/N → 0 то для всiх z ∈ X (mod H0)
r(z, kN) → 0 м.н. (6.8)
iH0(B(z, r(z, kN))) ≥ kN/N − ΛβN , (6.9)
де Λ — деяка випадкова величина, Λ < ∞ м.н.
Доведення леми.Нехай z ∈ D1 = supp H0. Тодi, за лемою 6.2.1, H0(D1) =H0(X ). Враховуючи означення HN
0 та r(z, kN) отримуємо, що
HN0 (B(z, r(z, kN))) ≥ kN/N. (6.10)
Розглянемо набiр ζj:N = ρ(z, ξj:N), j = 1,. . . ,N . Зрозумiло, що цей набiрутворює вибiрку з сумiшi зi змiнними концентрацiями. Застосовуючи доцiєї вибiрки п. 2 наслiдку 2.2.4, отримуємо, що
supr|HN
0 (B(z, r))−H0(B(z, r))| ≥ ΛβN .

6.2. Метод найближчого сусiда 149
Ця нерiвнiсть разом з (6.10) забезпечує (6.9). Щоб довести (6.8) помiтимо,що
∀ε > 0 {r(z, kN) > ε} ⊆ {HN0 (B(z, ε/2)) ≤ kN
N}
i, отже,P{r(z, kN) > ε} ≤
P{H0(B(z, ε/2))− HN0 (B(Z, ε/2)) ≥ H0(B(z, ε/2))− kN/N}
≤ exp(−C(H0(B(z, ε/2))− kN/N)2N).
Остання нерiвнiсть випливає з того, що |I{ξj ∈ B(z, ε/2)}| ≤ 1 внаслiдокнерiвностi Хьофдiнга (теорема 7.3.2). Але H0(B(z, ε/2)) > 0 для всiх ε > 0оскiльки z ∈ supp H0. Отже,
∑P{r(z, kN) > ε} < ∞ i r(z, kN) → 0 м.н.
Доведення теореми. Доведемо, що для майже всiх z ∈ X (mod H0),hi
N(z) → hi(z) м.н. Позначимо B(z, r(z, kN)) = BN , D = supp H0∩(∩Mi=1D
i2).
Тодi за лемами 6.2.1 та 6.2.2 H0(D) = H0(X ). Будемо вважати, що z ∈ D.Використовуючи наслiдок 2.2.4, отримуємо
|HNi (BN)−Hi(BN)| ≤ ΛβN (6.11)
Тодi за (6.7)
|hiN(z)− hi(z)| ≤ |H
Ni (BN)H0(BN)−Hi(BN)HN
0 (BN)
HN0 (BN)H0(BN)
|+
+|Hi(BN)
H0(BN)− hi(z)|
Другий доданок прямує до 0 внаслiдок (6.8) та z ∈ Di2. Згiдно з (6.11),
перший доданок менший, нiж
CΛβN(kN/N + βN)/(kN/N · (kN/N − βN)) → 0
за умовою теореми.Отже, hi
N(z) → hi(z)м.н. для всiх z (mod H0). За теоремою Фубiнiмаємо P{hi
N → hi, (mod H0)} = 1, а за теоремою про мажоровану збiж-нiсть,
∫ |hNi (z) − hi(z)|H0(dz) → 0 м.н., оскiльки hi ≤ 1/wi (mod H0) i
hiN ≤ supj,N |ai
j:N |.Отже, hN
i є консистентними у L1(H0) оцiнками щiльностей hi. Конси-стентнiсть емпiрично-баєсового класифiкатора випливає з наслiдку 6.1.1.

150 Роздiл 6. Задачi класифiкацiї
6.3 Асимптотика порогових класифiкаторiвУ цьому параграфi ми розглянемо задачу класифiкацiї об’єкта O за спо-стереженням його числової характеристики ξ = ξ(O) ∈ R. Будемо вважа-ти, що об’єкт може належати лише одному з двох класiв, i обмежимосярозглядом порогових класифiкаторiв вигляду
gt(ξ) =
{1, при ξ ≤ t,
2, при ξ > t,(6.12)
тобто об’єкт вiдносять до першого класу, якщо його характеристика неперевищує порiг t, i до другого класу — в iншому випадку. Елементарнийприклад такої класифiкацiї - визначення людини (об’єкт) як хворої (дру-гий клас), якщо її температура (характеристика ξ) перевищує 37◦ (порiгt).
Найкращим (баєсовим) будемо вважати такий порiг t = tB, при яко-му gt має найменшу ймовiрнiсть помилки. При цьому виникає пробле-ма вибору (оцiнки) порогу на основi навчаючої вибiрки. Найбiльш поши-реними методами оцiнювання tB за повнiстю класифiкованою вибiкою єемпiрично-баєсова класифiкацiя (ЕБК) описана у п. 6.1 та метод мiнiмi-зацiї емпiричного ризику (МЕР) [6, 53]. У цьому параграфi розглядаєтьсяузагальнення МЕР на випадок, коли навчаюча вибiрка отримана з сумiшiзi змiнними концентрацiями i порiвнюється асимптотична поведiнка кла-сифiкаторiв, отриманих за допомогою цих двох методiв.
МЕР - порiвняно проста технiка, яка спирається на емпiричнi функцiїрозподiлу як оцiнки вiдповiдних справжнiх розподiлiв. Цi оцiнки мають“гарну” швидкiсть збiжностi порядку N−1/2 (див. роздiл 2). ЕБК викори-стовує оцiнки щiльностей розподiлу, якi мають значно гiршу швидкiстьзбiжностi: у гладенькому випадку, який ми розглядаємо, — порядку N−2/5
(пор. п. 4.3). Тому на перший погляд здається, що оцiнки методу МЕР дляtB повиннi бути асимптотично кращими, нiж ЕБК-оцiнки. Але ми покаже-мо, що для оцiнок методу МЕР характерна швидкiсть збiжностi порядкуN−1/3, в той час як оцiнки ЕБК забезпечують порядок збiжностi N−2/5.
Для випадку повнiстю розкласифiкованої навчаючої вибiрки збiжнiстьпорядку N−1/3 для МЕР-оцiнок отримана у [41]. Асимптотика порядкукубiчного кореня характерна для максимiзацiї негладеньких функцiоналiввiд емпiричних функцiй розподiлу [27, 38]. Метод ЕБК дозволяє врахову-вати гладкiсть функцiй розподiлу i вiдповiдно згладжувати оцiнки щiль-ностей, тому вiн i забезпечує бiльшу точнiсть класифiкатора.

6.3. Асимптотика порогових класифiкаторiв 151
Отже, нехай у об’єкта O спостерiгається деяка числова характеристи-ка ξ = ξ(O). Цей об’єкт може належати одному з двох класiв. Невiдо-мий нам номер класу, якому належить O, позначаємо ind(O). Вважа-ються вiдомими апрiорнi ймовiрностi pi = P(ind(O) = i), i = 1, 2. Ха-рактеристика ξ вважається випадковою, її розподiл залежить вiд ind(O):P(ξ(O) < x | ind(O) = i) = Hi(x). Розподiли Hi невiдомi, але ми вважаємо,що вони мають неперервнi щiльностi hi вiдносно мiри Лебега.
Як ми вже вiдмiтили, в принципi, класифiкатором g : R→ {1, 2} можебути будь-яка вимiрна функцiя, але у даному параграфi розглядаютьсялише пороговi класифiкатори вигляду (6.12). Множину всiх таких кла-сифiкаторiв позначимо G = {gt : t ∈ R}. Ймовiрнiсть помилки такогокласифiкатора
L(gt) = L(t) = P{gt(ξ(O)) 6= ind(O)}
=2∑
i=1
P{ind(O) = i}P{gt(ξ(O)) = 3− i | ind(O) = i}
= p1(1−H1(t)) + p2H2(t).
Баєсовим класифiкатором у класi G є класифiкатор gB ∈ G, для якогодосягається мiнiмум L(g):
gB = argming∈G
L(g).
Порiг tB баєсового класифiкатора будемо називати баєсовим порогом: gB =gtB ,
tB = argmint∈R
L(t). (6.13)
(Надалi argminx∈U f(x) позначає будь-яке значення x∗ ∈ U , для якогоf(x∗) = infx∈U f(x). Якщо функцiя f є випадковою, то додатково вима-гається, щоб x∗ було випадковою величиною, тобто вимiрною функцiєюна основному ймовiрнiстному просторi). Оскiльки d
dtHi(t) = H ′
i(t) = hi(t),отримуємо, що tB є розв’язком рiвняння
L′(t) = −p1h1(t) + p2h2(t) = 0. (6.14)
Функцiї Hi (та, вiдповiдно, hi) вважаються невiдомими. Їх можна оцi-нити за даними, що являють собою вибiрку з сумiшi зi змiнними концен-трацiями: ΞN = {ξj:N}N
j=1, де ξj:N незалежнi мiж собою при фiксованомуN i
P{ξj:N < x} = wj:NH1(x) + (1− wj:N)H2(x),

152 Роздiл 6. Задачi класифiкацiї
де wj:N — вiдома концентрацiя об’єктiв першого класу у сумiшi в моментj-того спостереження.
Для оцiнки ф.р. Hi скористаємося зваженими емпiричними функцiямирозподiлу
HNi (x) =
1
N
N∑j=1
aij:N1I{ξj < x},
з мiнiмаксними ваговими коефiцiєнтами aij:N .
Для оцiнки щiльностей розподiлiв hi можна скористатись ядернимиоцiнками
hNi (x) =
1
NsN
N∑j=1
aij:NK
(x− ξj:N
sN
)
де K — ядро (щiльнiсть деякого ймовiрнiсного розподiлу), sN > 0 — пара-метр згладжування (див. п. 4.1).
Виходячи з формул (6.13) та (6.14), можна запропонувати два пiдходидо оцiнювання tB. Оцiнка МЕР визначається як
tMER = argmint∈R
LN(t), (6.15)
де LN(t) = p1(1− HN1 (t))+p2H
N2 (t) — емпiричний ризик класифiкатора gt.
ЕБК-оцiнка будується наступним чином: знаходиться множина TN усiхрозв’язкiв рiвняння
−p1hN1 (t) + p2h
N2 (t) = 0
i як оцiнка використовується
tEBCN = argmin
t∈TN
LN(t). (6.16)
Зауваження. Оцiнки, визначенi (6.15) та (6.16) можуть не iснуватиабо бути не єдиними. В умовах, що накладаються далi, ймовiрнiсть того,що цi оцiнки не iснують, прямує до 0 при N → ∞. Тому для вивченняасимптотичної поведiнки оцiнок у розумiннi слабкої збiжностi несуттєво,як вони довизначаються, коли мiнiмуми не iснують.
Аналогiчно, в цих умовах, ймовiрнiсть того, що оцiнка tEBCN визначе-
на не однозначно, прямує до 0. Мiнiмум у (6.15) завжди досягається нанескiннченiй множинi точок (як правило, на iнтервалi). Але при виконан-нi умов теореми 6.3.3 всi точки мiнiмуму мають однакову асимптотичнуповедiнку, тобто на роль оцiнки можна вибрати будь-яку з них.

6.3. Асимптотика порогових класифiкаторiв 153
Основнi теореми.Будемо вважати, що виконуються наступнi умови:(А) tB, визначене (6.13), iснує i є єдиною точкою глобального мiнiмуму
L(t), L(tB) < min(p1, p2).(Остання нерiвнiсть вилучає випадок, коли баєсовим є класифiкатор,
який вiдносить всi спостереження до одного класу, незалежно вiд значеньξ).
(Bk) Iснують границi 〈w〉, 〈(w)2〉,. . . , 〈(w)k〉 i ∆ = 〈(w)2〉 − 〈w〉2 > 0.
Теорема 6.3.1 Нехай виконанi умови (А) та (В2), Hi — неперервнi функ-цiї на R. Тодi tMER
N → tB за ймовiрнiстю при N →∞.
Теорема 6.3.2 Нехай виконано (А), (В2), iснують i є неперервними щiль-ностi hi, sN → 0, NsN →∞, K — неперервна функцiя,
d2 :=
∫ ∞
−∞K2(t)dt < ∞.
Тодi tEBC → tB за ймовiрнiстю.
Нехай щiльностi hi iснують i є s разiв неперервно диференцiйовними удеякому околi tB. Позначимо
fs(t) = (−1)s
(p1
dsh1(t)
dts− p2
dsh2(t)
dts
)
Зокрема, f1(t) = f(x) = p2h′2(x)− p1h
′1(x),
rN =
[1
N
N∑j=1
(p2a2j:N + p1a
1j:N)2(wj:Nh1(t
B) + (1− wj:N)h2(tB))
]1/2
,
r = limN→∞
rN .
Зауваження. Для того, щоб ця границя iснувала, достатньо виконанняумови (B3).
Знаком ⇒ будемо позначати слабку збiжнiсть.
Теорема 6.3.3 Якщо виконанi умови (A) та (B3), hi iснують, є непере-рвно диференцiйовними у деякому околi tB i f(tB) 6= 0, то
N1/3(tMERN − tB) ⇒
(2r
f(tB)
)2/3
Z,

154 Роздiл 6. Задачi класифiкацiї
де Z = argmint∈R(W (t) + t2), W (t) — двостороннiй стандартний вiнерiвпроцес.
Зауваження. Те, що mint∈R(W (t) + t2) м.н. досягається в єдинiй (ви-падковiй) точцi Z ∈ R, випливає з леми 2.6 у [38]
Теорема 6.3.4 Нехай виконанi умови (А), (В3) i(i) у деякому околi tB iснують i є обмеженими h′′i (t) = d2hi(t)/dt2,
f(tB) 6= 0,(ii)
∫∞−∞ zK(z)dz = 0, D2 :=
∫∞−∞ z2K(z)dz < ∞, d2 < ∞,
(iii) sn = c/N1/5 для деякого невипадкового c > 0.Тодi
N2/5(tEBC − tB) ⇒ A + Bη,
де A = D2c2/5f2(tB)/(2f(tB)), B = dr/(c1/10f(tB)),
η — стандартна нормальна випадкова величина.
Доведення теореми 6.3.1. Помiтимо, що умова (В2) еквiвалентнаневиродженостi матрицi Γ. Тому за наслiдком 2.2.2,
supx|HN
i (x)−Hi(x)| → 0
за ймовiрнiстю при N →∞. Звiдси випливає, що i supx |LN(x)−L(x)| → 0за ймовiрнiстю. Фiксуємо довiльнi λ > 0, ε > 0. Нехай AN = {supx |LN(x)−L(x)| < ε/2}. При достатньо великих N , P(AN) > 1− λ.
Оскiльки L — неперервна функцiя на R, L(−∞) = p1, L(+∞) = p2 iвиконана умова (А), то ∀δ > 0 ∃ε, таке, що для всiх t, для яких |t−tB| > δ,має мiсце нерiвнiсть L(t) > L(tB) + ε. Нехай подiя AN виконана. Тодi
L(tMERN )− ε
2≤ LN(tMER
N ) ≤ LN(tB) ≤ L(tB) +ε
2,
отже L(tMERN ) ≤ L(tB) + ε i |tMER
N − tB| ≤ δ. Внаслiдок довiльностi δ та λтеорема доведена.
Доведення теореми 6.3.2. Згiдно з теоремою 4.2.1 в наших умовахhN
i (x) → hi(x) за ймовiрнiстю в кожнiй точцi x ∈ R. Отже,
uN(x) := p2hN2 (x)− p1h
N2 (x) → u(x) := p2h2(x)− p1h1(x)

6.3. Асимптотика порогових класифiкаторiв 155
за ймовiрнiстю. Для будь-якого δ > 0 розглянемо подiю AN(δ) = {∃t :|t− tB| ≤ δ, uN(t) = 0}. Покажемо, що
P(AN(δ)) → 1 (6.17)
при N →∞.Оскiльки tB — точка мiнiмуму L(t), а L′(t) = u(t) — неперервна функ-
цiя, то u повинна змiнювати знак в околi точки tB, тобто iснують такit−, t+, що tB − δ < t− < tB < t+ < tB + δ i u(t−)u(t+) < 0. Отже,P{uN(t−)uN(t+) < 0} → 1. Але оскiльки uN — неперервна функцiя, то{uN(t−)uN(t+) < 0} ⊆ AN(δ). Отже, (6.17) доведено.
Фiксуємо δ. Так само, як у доведеннi теореми 6.3.1, маємо, що ∃ε > 0,L(t) > L(tB) + ε для всiх t 6∈ [tB − δ, tB + δ]. Виберемо 0 < δ′ < δ так, щобдля всiх t ∈ [tB − δ′, tB + δ′] виконувалось L(t) < L(tB) + ε/4. Розглянемовипадкову подiю
BN = { inft 6∈[tB−δ,tB+δ]
LN(t) > L(tB) + ε/2 > supt∈[tB−δ′,tB+δ′]
LN(t)}.
Фiксуємо довiльне λ > 0. Використовуючи рiвномiрну збiжнiсть LN доL, отримуємо, що, при достатньо великих N , P(BN) > 1 − λ
2. Згiдно з
(6.17), при великих N , P(AN(δ′)) > 1− λ2. Якщо виконано AN(δ′), то iснує
t∗ ∈ TN ∩ [tB − δ′, tB + δ′] i, при виконаннi BN , LN(t∗) < LN(t) для всiхt 6∈ [tB − δ, tB + δ]. Отже, в цьому випадку tEBC ∈ [tB − δ, tB + δ]. Тому
P{|tEBC − tB| < δ} ≥ P(AN(δ′)) ∩BN) ≥ 1− λ
при великих N .Враховуючи довiльнiсть λ, отримуємо твердження теореми.Доведення теореми 6.3.3. Позначимо
WN(τ) = N2/3(LN(tB + N−1/3τ)− LN(tB)− L(tB + N−1/3τ) + L(tB)).
Для доведення теореми нам будуть потрiбнi твердження про асимпто-тичну поведiнку процесу WN , якi ми сформулюємо у виглядi двох лем.
Лема 6.3.1 На будь-якому скiнченному iнтервалi U = [τ−, τ+] випадковiпроцеси WN слабко збiгаються при N → ∞ до процесу rW у просторiVar(U) функцiй без розривiв другого роду з рiвномiрною метрикою.

156 Роздiл 6. Задачi класифiкацiї
Доведення Згiдно з [1], враховуючи неперервнiсть траєкторiй W , до-сить довести асимптотичну нормальнiсть скiнченновимiрних розподiлiвWN , збiжнiсть других моментiв приростiв i щiльнiсть розподiлiв WN уD(U) (пор. п.7.4).
Спочатку пiдрахуємо E(WN(τ2) −WN(τ1))2. Нехай τ1 < τ2. Позначимо
bj:N = p2a2j:N − p1a
1j:N , тодi
WN(τ2)−WN(τ1) = N−1/3
N∑j=1
bj:N(1I{ξj:N ∈ AN} − P{ξj:N ∈ AN}), (6.18)
де AN = AN(τ1, τ2) = [N−1/3τ1, N−1/3τ2). Отже,
E(WN(τ2)−WN(τ1))2 =
= N−2/3
N∑j=1
(bj:N)2 [(wj:NH1(AN) + (1− wj:N)H2(AN))
−(wj:NH1(AN) + (1− wj:N)H2(AN))2]
Враховуючи, що Hi(AN) ∼ hi(tB)N−1/3(τ2 − τ1), отримуємо при N →∞,
E(WN(τ2)−WN(τ1))2 → r2(τ2 − τ1) = E(rW (τ2)− rW (τ1))
2.
Асимптотичну нормальнiсть скiнченновимiрних розподiлiв WN можна до-вести, використовуючи центральну граничну теорему з умовою Лiндебергаз урахуванням рiвномiрної обмеженостi всiх доданкiв у сумi (6.18).
Залишилось перевiрити щiльнiсть сiм’ї розподiлiв WN . Щоб використа-ти вiдповiдний критерiй (лема 7.4.1), покажемо, що для всiх τ1 < τ < τ2,
J := E(WN(τ)−WN(τ1))2(WN(τ2)−WN(τ))2 ≤ C1(τ2 − τ1)
2, (6.19)
де C1 не залежить вiд N , τ1, τ , τ2.Покладемо
ηj(τ1, τ2) = bj:N(1I{ξj:N ∈ AN(τ1, τ2)} − P{ξj:N ∈ AN(τ1, τ2)}).
Тодi
J ≤ C2
N4/3
(∑
j 6=k
{E(ηj(τ, τ2))
2(ηk(τ1, τ))2

6.3. Асимптотика порогових класифiкаторiв 157
+|E ηj(τ, τ2)ηj(τ1, τ)ηk(τ, τ2)ηk(τ1, τ)|}
+N∑
j=1
E(ηj(τ, τ2))2(ηj(τ1, τ))2
)
≤ C2
N4/3(N2C3(h
∗)2N−1/3(τ−τ1)N−1/3(τ2−τ)+NC4(h
∗)4N−1/3(τ−τ1)(τ2−τ))
≤ C1(τ2 − τ1)2.
(Тут C2 — абсолютна константа, C3, C4 залежать лише вiд supj,N |bj:N | <∞, h∗ = supt∈U(h1(t) + h2(t))).
Тепер, використовуючи теореми 15.4 та 15.6 з [1],отримуємо тверджен-ня леми.
Лема 6.3.2 Для будь-якого ε > 0 iснує D > 0 таке, що для всiх N
P{∃τ ∈ R : |WN(τ)| > D(1 + |τ |)} < ε.
Доведення. За нерiвнiстю 15.30 [1], з (6.19) випливає, що
J1 := P{ supτ∈[τ−,τ+]
min(|WN(τ)−WN(τ1)|, |WN(τ2)−WN(τ)|) > ε/2}
≤ 16C1
ε4(τ+ − τ−)2.
Так само, як при доведеннi (6.19), отримуємо, що
E W 4N(τ) ≤ C5τ
2,
тому, за нерiвнiстю Чебишова,
J2(τ) := P{|WN(τ)| > ε/2} ≤ 16C5τ2
ε4.
Отже
P{ supτ∈[τ−,τ+]
|WN(τ)| > ε} ≤ J1 + J2(τ−) + J2(τ+) ≤ C6
ε4((τ+ − τ−)2 + τ 2
− + τ 2+).
Таким чином,P{∃τ ∈ R : |WN(τ)| > D(1 + |τ |)}

158 Роздiл 6. Задачi класифiкацiї
≤∞∑
j=0
[P{∃τ ∈ [i, i + 1] : |WN(τ)| > D(1 + i)}
+ P{∃τ ∈ [−i− 1,−i] : |WN(τ)| > D(1 + i)}]
≤ C7
∞∑i=0
((i + 1− i)2
D4(i + 1)4+
i2
D4(1 + i)4+
(i + 1)2
D4(1 + i)4
)≤ C8
D4,
звiдки i випливає твердження леми.Тепер, для того, щоб вiд збiжностi випадкових процесiв перейти до
збiжностi їх точок мiнiмуму, нам будуть потрiбнi наступнi позначення.Фiксуємо довiльне S > 0. Нехай f — функцiя на U = [−S, S]. Позначи-
моAm−(f, ε) = inf{x ∈ U : f(x) ≤ inf
y∈Uf(y) + ε},
Am+(f, ε) = sup{x ∈ U : f(x) ≤ infy∈U
f(y) + ε},
Am−(f) = limε↓0
Am−(f, ε), Am+(f) = limε↓0
Am+(f, ε).
(Оскiльки Am−(f, ε) та Am+(f, ε) є монотонно незростаючими по ε, цi гра-ницi завжди iснують.)
Легко бачити, що коли iснує x∗ = argminx∈U f(x), то
Am−(f) ≤ x∗ ≤ Am+(f).
Позначимо |f |∞ = supx∈U |f(x)| — рiвномiрна метрика. У наступнiй лемiвсi iнфiнуми беруться по x ∈ U , тобто inf g = infx∈U g(x) i т.д.
Лема 6.3.3 Функцiонали Am− та Am+ є неперервними у просторi D(U)з метрикою | · |∞.
Доведення. Покажемо, що для fn, g ∈ D(U) з |fn − g|∞ → 0 приn →∞ випливає Am−(fn) → Am−(g). (Для Am+ доведення аналогiчне.)
За означенням Am−(g, ε), для будь-якого λ > 0 знайдеться таке xg, щоg(xg) ≤ inf g + ε i xg ≤ Am−(g, ε)+λ. Нехай f , g ∈ D(U), |f − g|∞ ≤ δ. Тодiinf g − δ ≤ inf f ≤ inf g + δ. Отже,
f(xg) ≤ g(xg) + δ ≤ inf g + δ + ε ≤ inf f + ε + 2δ.
ТомуAm−(f, ε + 2δ) ≤ Am−(g, ε) (6.20)

6.3. Асимптотика порогових класифiкаторiв 159
i, аналогiчно,Am−(g, ε + 2δ) ≤ Am−(f, ε). (6.21)
Нехай |fn − g|∞ → 0. Для будь-якого γ > 0, знайдеться ε0 > 0, таке, щодля всiх 0 ≤ ε ≤ ε0,
Am−(g, ε)− γ ≤ Am−(g) ≤ Am−(g, ε) + γ.
Виберемо довiльне 0 < ε′ < ε0, δ = ε = ε′/3. При достатньо великих n,|fn − g|∞ ≤ δ i за (6.20),
Am−(fn, ε′) = Am−(fn, ε + 2δ) ≤ Am−(g, ε) ≤ Am−(g) + γ.
Тому Am−(fn) ≤ Am−(g) + γ при достатньо великих n. Використовуючи(6.21), маємо (при великих n)
Am−(g)− γ ≤ Am−(g, ε + 2δ) ≤ Am−(f, ε)
iAm−(g)− γ ≤ Am−(fn) + γ.
Внаслiдок довiльностi γ отримуємо Am−(fn) → Am−(g).Лема доведена.Продовження доведення теореми 6.3.3. Нехай U — окiл точки tB,
на якому hi є неперервно диференцiйовними. За теоремою 6.3.1, tMER → tB
за ймовiрнiстю, отже, для будь-якого ε > 0 i достатньо великих N , дляAN = {tMER ∈ U} виконано P(AN) > 1−ε/2. Позначимо τN = N1/3(tMER
N −tB). Покажемо, що знайдеться таке S = Sε, що для достатньо великих N ,
P{|τN | < S} > 1− ε. (6.22)
Оскiльки
LN(tB + N−1/3τ)− LN(tB) = N−2/3WN(τ) + L(tB + N−1/3τ)− L(tB),
тоτN = argmin
τv(τ),
деv(τ) = WN(τ) + N2/3(L(tB + N−1/3τ)− L(tB)).
Будемо вважати, що подiя {tMER ∈ U} виконана. Оскiльки Hi — двiчiдиференцiйовнi на U i tB — точка мiнiмуму L, то
L(tB + N−1/3τ)− L(tB) =1
2L′′(ζ)N−2/3τ 2,

160 Роздiл 6. Задачi класифiкацiї
де ζ ∈ U — промiжна точка, L′′(ζ) = f(ζ). Оскiльки f(tB) > 0, можнаобрати таке U , щоб f(ζ) > c > 0 на U . Тодi v(τ) ≥ WN(τ) + c
2τ 2 при
N−1/3τ + tB ∈ U .Позначимо BN = {|WN(τ) < D(1 + |τ |),∀τ ∈ R}. За лемою 6.3.2, для
достатньо великих D, P(BN) > 1 − ε/2. Але, якщо виконано BN , то приcτ 2/2 > D(1 + |τ |), v(τ) > 0 = v(0), тому у таких точках мiнiмум v(τ)досягатись не може. Отже, при виконаннi AN ∩ BN , cτ 2
N < D(1 + |τN |),тобто |τN | ≤ max(1, 2D/c) = S. Оскiльки P(AN ∩ BN) > 1 − ε, то (6.22)доведено.
Аналогiчно або з використанням закону повторного логарифму для Wдоводиться, що, для достатньо великих S,
P{| argminτ∈R
W (τ)| < S} > 1− ε, (6.23)
де W (τ) = rW (τ) + f(0)2
τ 2. За лемою 6.3.2, на iнтервалi [−S, S] процес WN
слабко збiгається до rW , а внаслiдок неперервної диференцiйовностi hi,N2/3(L(tB + N−1/3τ) − L(tB)) рiвномiрно збiгається до f(0)τ 2/2. Тому vслабко збiгається до W у Var[−S, S] з рiвномiрною метрикою.
Оскiльки функцiя v(τ) є сталою на iнтервалах мiж стрибками, то мiнi-мум v(τ) завжди досягається, тобто argminτ v(τ) iснує, хоча i не є єди-ним. При цьому Am−(v) ≤ argminτ∈[−S,S] v(τ) ≤ Am+(v). Враховуючи ле-му 6.3.3, отримуємо Am−(v) ⇒ Am−(W ), Am+(v)−Am−(v) ⇒ Am+(W )−Am−(W ). За лемою 2.6 з [38], мiнiмум W м.н. досягається рiвно в однiйточцi, тому Am−(W ) = argminτ∈[−S,S] W (τ) i Am+(W )− Am−(W ) = 0.
Звiдси випливає, що, для всiх x ∈ R,
P{argminτ∈[−S,S]
v(τ) < x} → P{argminτ∈[−S,S]
W (τ) < x}.
Це, разом з (6.22-6.23) забезпечує збiжнiсть τN до argminτ∈R W (τ) =argminτ∈R(W (τ) + ατ 2), де α = f(tB)/(2r). Враховуючи, що W (ατ)
.=√
αW (τ) ( .= позначає рiвнiсть за розподiлом) отримуємо
argminτ∈R
(W (τ) + ατ 2).= argmin
τ∈R(α−1/3W (α2/3τ) + α−1/3(α2/3τ)2) = α−2/3Z
Теорема доведена.Доведення теореми 6.3.4.Нехай, як i ранiше, uN(t) = p2h
N2 (t) − p1h
N1 (t). За означенням tEBC
N ,uN(tEBC
N ) = 0. Покладемо δN = tEBCN − tB. За теоремою 6.3.2, δN → 0 за

6.4. Класифiкацiя на основi єдиного iндекса 161
ймовiрнiстю. Тому
0 = uN(tB + δN) ≈ uN(tB) + δNu′N(tB).
Отже
δN ≈ −uN(tB)
u′N(tB)=
p2hN2 (tB)− p1h
N1 (tB)
(p2hN2 (tB)− p1hN
1 (tB))′
≈ p2(hN2 (tB)− h2(t
B))− p1(hN1 (tB)− h1(t
B))
f1(tB).
В останнiй рiвностi використано, що p1h1(tB)− p2h2(t
B) = 0.З теореми 4.3.5 випливає, що при sN = c/N1/5,
N2/5(p1(hN1 (tB)−h1(t
B))−p2(hN2 (tB)−h2(t
B))) ⇒ D2c2/5f2(tB)/2+dr/c1/10η,
де η — стандартна нормальна величина.Звiдси отримуємо твердження теореми.
6.4 Класифiкацiя на основi єдиного iндексаУ цьому параграфi ми розглянемо класифiкацiю об’єктiв за багатовимiр-ними спостереженнями X = Rd, розподiли яких для всiх популяцiй є аб-солютно неперервними вiдносно мiри Лебега. До таких даних застосов-на технiка емпiрично-баєсової класифiкацiї з ядерними оцiнками (конси-стентна за теоремою 6.1.2) або за методом найближчого сусiда (див. п.6.2) Але для багатовимiрних спостережень емпiрично-байєсовi класифi-катори мають дуже складну, непрозору форму, їх важко iнтерпретувати.Тому на практицi часто використовують наступний пiдхiд. Багатовимiрнiхарактеристики аналiзованих об’єктiв проектують на деякий напрямок,тобто обирають певну лiнiйну комбiнацiю всiх спостережуваних змiнних,що характеризують об’єкт. У економетрицi та соцiальнiй статистицi та-кi комбiнацiї звуть "сумарними iндексами", у психометрицi - "шкалами".Класифiкацiя об’єктiв проводиться на основi подiбного загального iндекса.
Ми розглянемо задачу побудови такого "лiнiйного"iндекса, який за-безпечував би асимптотично мiнiмальну помилку класифiкацiї. Для цьо-го вектори спостережуваних даних проектуються на рiзнi напрямки, закожною проекцiєю будується емпiрично-байєсiв класифiкатор, оцiнюєть-ся ймовiрнiсть його помилки, i на роль "найкращого" iндекса беруть той,для якого ця оцiнка є найменшою. Виявляється, що ймовiрнiсть помилки

162 Роздiл 6. Задачi класифiкацiї
емпiрично-байєсової класифiкацiї на основi iндексiв, вибраних таким спо-собом, прямує до найменшої можливої ймовiрностi помилки класифiкацiїза лiнiйними iндексами.
Отже, нехай спостережувана характеристика ξ = ξ(O) є d-вимiрнимвектором ξ = (ξ1, . . . , ξd)T , а навчаюча вибiрка є вибiркою зi змiннимиконцентрацiями, причому ξj:N = (ξ1
j:N , . . . , ξdj:N)T .
Ми будемо розглядати "лiнiйнi iндекси" вигляду
S(b) =d∑
i=1
biξi, (6.24)
та, вiдповiдно, для елементiв навчаючої вибiрки:
SNj (b) =
d∑i=1
biξij:N , (6.25)
де b = (b1, b2, . . . , bd)T ∈ Rd; довжина невипадкового вектора b дорiвнює
одиницi:b21 + b2
2 + · · ·+ b2d = 1. (6.26)
Iндекс S(b) є, по сутi, проекцiєю ξ на напрямок b. Ми будемо мати спра-ву лише з класифiкаторами вигляду gb(ξ) = g(S(b)), де g : R → {1, . . . , M}— довiльна вимiрна функцiя. Ймовiрнiсть помилки класифiкатора gb
Lgb= P{gb(ξ) 6= ind(O)}.
Мiнiмум Lgbпо всiх g при фiксованому b досягається на байєсовому
класифiкаторig∗(x) = arg max
i(piui(x)) ,
де pi = P{ind(O) = i} — апрiорнi ймовiрностi (концентрацiї компонентсумiшi пiд час спостереження O); uk(x) = uk(x, b) — щiльностi в.в. ηk(b) =∑d
i=1 ηikbi, де ηk = (η1
k, η2k, . . . η
dk) має щiльнiсть hk. Ймовiрнiсть помилки
цього класифiкатора має вигляд
L∗g = L∗(b) = 1−∫ ∞
−∞max
1≤k≤M(pkuk(x))dx.
Найкращим для побудови класифiкатора є iндекс, отриманий проекцiєю ξна напрямок
b∗ = argminb
L∗(b) = argmax
∫ ∞
−∞max
1≤k≤M(pkuk(x))dx.

6.4. Класифiкацiя на основi єдиного iндекса 163
Оскiльки справжнi значення uk невiдомi, замiнимо їх ядерними оцiнками,побудованими за вибiркою (Sj(b))
Nj=1. Цi оцiнки мають вигляд:
uNi (b, x) =
1
NσN
N∑j=1
aij:NK
(x− Sj(b)
sN
), (6.27)
де aij:N — мiнмакснi ваговi коефiцiєнти, визначенi (2.10). На параметр згла-
джування sN накладаються звичайнi умови: sN → 0, NsN →∞.За оцiнку ймовiрностi помилкової класифiкацiї L∗(b) беремо
LN(b) = 1−∫ ∞
−∞max
1≤k≤M(pku
Nk (b, x))dx, (5)
а за оцiнку b∗ —b = arg min LN(b)
Емпiрично-баєсiв класифiкатор для спостереження ξ будуємо за форму-лою
g(b, x) = arg max1≤i≤M
(piuNi (b, x))
Для оцiнки якостi класифiкатора служить умовна ймовiрнiсть помилкипри фiксованiй навчаючiй вибiрцi (пор. (6.5)):
Lg(b) = 1−∫ ∞
−∞pg(b,x)ug(b,x)dx.
Припустимо, що виконуються наступнi умови:
(i) K(x) ≤ a,
∫ ∞
−∞|x|K(x)dx < ∞;
де a < ∞ — деяка стала.Сукупнiсть множин S = {A}, де
(ii) A =
{y : K
(x−∑d
i=1 biyi
sN
)≥ c
}
(c—деяка стала), утворює VC-клас (див. п. 2.2).Для усiх i = 1÷M iснують i обмеженi усi частиннi похiднi щiльностей
hi(x1, . . . , xd):
(iii)
∣∣∣∣∂hi
∂xs
(x1, . . . , xd)
∣∣∣∣ ≤ cis; s = 1÷ d.

164 Роздiл 6. Задачi класифiкацiї
Ваговi коефiцiєнти aij,N задовольняють умовi
(iv)∣∣ai
j,N
∣∣ ≤ a,
де a < ∞ — деяка стала.
(v)1
sN
= o(N14 ), N →∞.
Теорема 6.4.1 При виконаннi умов (i) - (v)
E Lg(b) → L∗g(b∗) при N →∞.
Наслiдок 6.4.1 В умовах теореми 6.4.1,
Lg(b) → L∗g(b∗) при N →∞
за ймовiрнiстю.
Спочатку доведемо наступну лему.
Лема 6.4.1 За умов (i) — (v) для усiх k = 1÷M
E supb,x
∣∣uNk (b, x)− uk(b, x)
∣∣ → 0 при N →∞.
Доведення леми 6.4.1. Зробимо наступнi оцiнки
supb,x
∣∣uNk (b, x)− uk(b, x)
∣∣ ≤
≤ supb,x
∣∣∣∣∣1
NsN
N∑j=1
akj,NK
(x− SN
j (b)
sN
)− 1
NsN
EN∑
j=1
akj,NK
(x− SN
j (b)
sN
)∣∣∣∣∣ +
+ supb,x
∣∣∣∣∣1
NsN
EN∑
j=1
akj,NK
(x− SN
j (b)
sN
)− uk(b, x)
∣∣∣∣∣ = SN1 + SN
2 . (6.28)
Розглянемо SN1 . Використаємо зважену емпiричну мiру спiввiдношенням
µN(A) =1
N
N∑j=1
akj,N1I{ξN
j ∈ A}; µN(A) = E µN(A). (6.29)

6.4. Класифiкацiя на основi єдиного iндекса 165
Нехай P(dy) — ймовiрнiсна мiра. Тодi, використовуючи лему 5.2.2, можемонаписати
SN1 = sup
b,x
∣∣∣∣∣1
sN
∫
Rd
K
(x−∑d
i=1 biyi
sN
)P(dy)−
− 1
sN
∫
Rd
K
(x−∑d
i=1 biyi
sN
)µN(dy)
∣∣∣∣∣ ≤a
sN
supA∈S
|P(A)− µN(A)| , (6.30)
де S — система множин з умови (ii).Тут ми скористалися умовою (i). Далi,вiдзначимо, що
supA∈S
|P(A)− µN(A)| ≤ sup1≤j≤N
∣∣aij,N
∣∣ + 1 ≤ a + 1,
а також введемо позначення
CkN = sup
1≤j≤N
∣∣aij,N
∣∣ + sup1≤j≤N
aij,N − inf
1≤j≤Nai
j,N .
де gG — функцiя росту класу G.Зробимо наступну оцiнку:
E supA∈S
∣∣∣∣∣P(A)− µN(A)
CkN
∣∣∣∣∣ ≤∫ a+1
˜Ck
N
0
P
{supA∈S
∣∣∣∣∣P(A)− µN(A)
CkN
∣∣∣∣∣ ≥ λ
}dλ
Оскiльки CkN — обмежена знизу величина, то, не обмежуючи загальностi
можемо вважати, що2M4√
N<
a + 1
CkN
.
Розiб’ємо iнтеграл на двi частини, i до оцiнки другої застосуємо наслiдок2.2.4:
E supA∈S
∣∣∣∣∣P(A)− µN(A)
CkN
∣∣∣∣∣ ≤∫ 2M
4√N
0
dλ +
∫ a+1˜
CkN
2M4√
N
(6MNgS(2N) exp
(− λ2N
32M2
)+
+2 exp
(−λ2N
8M2
))dλ ≤ 2MN− 1
4 +
(6MNgS(2N) exp
(−1
8
√N
)+
+2 exp
(−1
2
√N
)) (a + 1
CkN
− 2M4√
N
). (6.31)

166 Роздiл 6. Задачi класифiкацiї
(тут gS — функцiя росту класу S). З оцiнок (6.30), (6.31) випливає, що
E SN1 ≤ O
(s−1
N N− 14
)+ O
(s−1
N NgS(2N) exp
(−1
8
√N
))+
+O
(s−1
N exp
(−1
2
√N
)). (6.32)
При N →∞ права частина (6.32) прямує до нуля: перший доданок черезумову (v); другий i третiй завдяки тому, що gS(N), як функцiя росту VCкласу S, зростає як степенева функцiя, s−1
N теж, а експоненцiйнi множникипрямують до нуля швидше, нiж степеневi. Отже,
E SN1 = o(1) при N →∞. (6.33)
Тепер оцiнимо SN2 .
1
NsN
EN∑
j=1
akj,NK
(x− SN
j (b)
sN
)=
1
NsN
N∑j=1
akj,N E K
(x− SN
j (b)
sN
)=
=1
NsN
N∑j=1
akj,N
M∑
k=1
wkj,N
∫ ∞
−∞K
(x− y
sN
)uk(b, y)dy =
=
∫ ∞
−∞K(z)uk(b, x− sNz)dz.
Тут ми скористалися незмiщенiстю оцiнок з мiнiмiксними коефiцiєнтами.Отже, SN
2 можна представити наступним чином
SN2 = |E uk(b, x− sNη)− uk(b,X)| ,
де η — в.в. зi щiльнiстю K(x) . Оскiльки ‖b‖ = 0, у вектора b =(b1, b2, . . . , bd) хоча б одна компонента ненульова, не обмежуючи загаль-ностi, вважаємо bd 6= 0. Тодi щiльнiсть випадкової величини µk можнапредставити так:
uk(b, x) =1
bd
∫ ∞
−∞dx1 . . .
∫ ∞
−∞hk
(x1, . . . , xd−1,
1
bd
(x−
d−1∑i=1
bixi
))dxd−1.
Для спрощення далi будемо писати hk(xd) замiсть hk(x1, . . . , xd−1, xd). Ви-беремо послiдовнiсть t = tN →∞, N →∞. Зробимо наступнi оцiнки
SN2 =
1
|bd| E∫ ∞
−∞dx1 . . .
∫ ∞
−∞
∣∣∣∣∣hk
(1
bd
(x−
d−1∑i=1
bixi − sNη
))−

6.4. Класифiкацiя на основi єдиного iндекса 167
−hk
(1
bd
(x−
d−1∑i=1
bixi
))∣∣∣∣∣ dxd−1 ≤
≤ 1
|bd| E∫
x21+···+x2
d−1≤t2dx1 . . . dxd−1
∣∣∣∣∣hk
(1
bd
(x−
d−1∑i=1
bixi − sNη
))−
−hk
(1
bd
(x−
d−1∑i=1
bixi
))∣∣∣∣∣ +
+1
|bd| E∫
x21+···+x2
d−1>t2dx1 . . . dxd−1hk
(1
bd
(x−
d−1∑i=1
bixi − sNη
))+
+1
|bd|∫
x21+···+x2
d−1>t2dx1 . . . dxd−1hk
(1
bd
(x−
d−1∑i=1
bixi
))= A+B+C. (6.34)
Для оцiнки A застосуємо теорему Лагранжа:
A ≤ EsN |η|
b2d
∫
x21+···+x2
d−1≤t2dx1 . . . dxd−1
∣∣∣∣∣∂hk
∂xd
(x1, . . . , xd−1,
s−∑d−1i=1 bixi
bd
)∣∣∣∣∣(6.35)
Тут s — деяка в.в., що знаходиться мiж величинами
1
bd
(x−
d−1∑i=1
bixi −−sNη
)
та1
bd
(x−
d−1∑i=1
bixi
).
У iнтегралi правої частини (6.35) робимо замiну x1 = vb2d, а потiм викори-
стовуємо умову обмеженностi частинних похiдних (iii). Маємо
A ≤ sN E |η|×
×∫
v2
b2d
+···+x2d−1≤t2
dv . . . dxd−1
∣∣∣∣∣∂hk
∂xd
(vb2
d, . . . , xd−1,1
bd
(s−
d−1∑i=1
bixi
))∣∣∣∣∣ ≤
≤ sNckd E |η|λ{
(v, x2, . . . , xd−1) ∈ Rd−1 :v2
b2d
+ x22 + · · ·+ x2
d−1 ≤ t2}≤

168 Роздiл 6. Задачi класифiкацiї
≤ sNckd E |η|λ {(v, x2, . . . , xd−1) ∈ Rd−1 : v2 + x2
2 + · · ·+ x2d−1 ≤ t2
} ≤≤ sNckd E |η|(2t)d−1. (6.36)
(Тут λ(A) — мiра Лебега множини A). Тепер оцiнимо B.
B =1
|bd| E∫
x21+···+x2
d−1>t2;xd=x−∑d−1i=1 bixi−sNη
dx1 . . . dxd−1hk
(x1, . . . , xd−1,
xd
bd
).
Оскiльки пiдiнтегральна функцiя невiд’ємна, то, збiльшуючи область iн-тегрування, ми не зменшимо величину iнтеграла.
B ≤ 1
|bd|∫
x21+···+x2
d−1>t2;−∞<xd<∞dx1 . . . dxdhk
(x1, . . . , xd−1,
xd
bd
).
Зробимо замiну змiнної vd = xd
bdв iнтегралi.
B ≤∫
x21+···+x2
d−1>t2;−∞<vd<∞dx1 . . . dvdhk (x1, . . . , vd) . (6.37)
Доданок C оцiнюється аналогiчно B.
C ≤∫
x21+···+x2
d−1>t2;−∞<vd<∞dx1 . . . dvdhk (x1, . . . , vd) . (6.38)
Отже, враховуючи (6.34)—(6.38), можемо написати
SN2 ≤ ckd E |η|sN(2t)d−1+
+2
∫
x21+···+x2
d−1>t2;−∞<vd<∞dx1 . . . dvdhk (x1, . . . , vd) . (6.39)
Зрозумiло, що можна вибрати t = tN таким чином, щоб sN(2t)d−1 → 0 приN → ∞. При такому виборi права частина (16) буде прямувати до 0 приN →∞ i отже,
SN2 → 0 при N →∞ (6.40)
рiвномiрно по x та b. Збираючи докупи твердження (6.28), (6.33) та (6.40),завершуємо доведення леми.
Зауваження. Якщо K(x) — кусково-монотонна функцiя зi скiнченноюкiлькiстю iнтервалiв монотонностi, то система подiй S, визначена в (ii),являє собою VC-клас.

6.4. Класифiкацiя на основi єдиного iндекса 169
Дiйсно, в цьому випадку iснує скiнченна кiлькiсть G вiдрiзкiв [dl, dl+1]таких, що{
y : K
(x−∑d
i=1 biyi
sN
)≥ c
}= ∪G
l=1
{x− sNdl+1 ≤
d∑i=1
biyi ≤ x− sNdl
}.
Кожна така множина — прошарок мiж двома гiперплощинами; об’єднанняскiнченної кiлькостi таких множин є VC-класом [7], с.232.
Теорема 6.4.2 В умовах (i)—(iv)
E supb
∣∣∣LNg (b)− L∗g(b)
∣∣∣ → 0 при N →∞.
Доведення. За нерiвнiстю Джорфi (наслiдок 6.1.1),
LNg − L∗g ≤ 2
M∑
k=1
∫ ∞
−∞|uk(x)− uN
k (x)|dx. (6.41)
Виберемо послiдовнiсть DN →∞, N →∞ та зробимо наступнi оцiнки
E
∫ ∞
−∞|uN
k (b, x)− uk(b, x)|dx ≤ E
∫ DN
−DN
|uNk (b, x)− uk(b, x)|dx+
+ E
(∫ ∞
DN
uNk (b, x)dx +
∫ −DN
−∞uN
k (b, x)dx
)+
+
(∫ ∞
DN
uk(b, x)dx +
∫ −DN
−∞uk(b, x)dx
)= A + B + C. (6.42)
Оцiнимо кожний доданок у правiй частинi (6.42).
A ≤ 2DN E supb,x
∣∣uNk (b, x)− uk(b, x)
∣∣ . (6.43)
За лемою 6.4.1, E supb,x
∣∣uNk (b, x)− uk(b, x)
∣∣ → 0, N → ∞ i отже, можнавибрати таку послiдовнiсть DN →∞, щоб права частина (6.43) прямуваладо нуля.
Тепер оцiнимо доданок C. За нерiвнiстю Кошi-Буняковського4
−
√√√√d∑
i=1
(ηik)
2 ≤d∑
i=1
biηik ≤
√√√√d∑
i=1
(ηik)
2 (6.44)
4Нагадаємо, що ηk = (η1k, . . . , ηd
k)T це випадковi вектори з розподiлом Hk, а uk(b, x)— щiльнiсть розподiлу випадкової величини
∑di=1 biη
ik.

170 Роздiл 6. Задачi класифiкацiї
Позначимо F (x) функцiю розподiлу, що вiдповiдає щiльностi uk(b, ·) тапри оцiнюваннi скористаємося нерiвнiстю (6.44).
∫ ∞
DN
uk(b, x)dx = 1− F (DN) ≤ P
√√√√d∑
i=1
(ηik)
2 ≥ DN
;
∫ −DN
−∞uk(b, x)dx = F (−DN) ≤
≤ P
−
√√√√d∑
i=1
(ηik)
2 ≤ −DN
= P
√√√√d∑
i=1
(ηik)
2> DN
.
З цих оцiнок випливає, що
C ≤ 2 P
{d∑
i=1
(ηi
k
)2 ≥ D2N
}→ 0 при N →∞. (6.45)
Аналогiчно оцiнимо доданок B. Не обмежуючи загальностi, вважаємо, щоsN ≤ 1. За нерiвнiстю Кошi-Буняковського
(d∑
i=1
biηik + sNη
)2
≤ (1 + s2N)
(d∑
i=1
(ηi
k
)2+ η2
)
Отже,
−
√√√√d∑
i=1
(ηik)
2+ η2 ≤
d∑i=1
biηik + sNη ≤
√√√√d∑
i=1
(ηik)
2+ η2.
E
∫ ∞
DN
uNk (b, x)dx =
1
NsN
E
∫ ∞
DN
N∑j=1
akj,NK
(x− SN
j (b)
sN
)dx =
=
∫ ∞
DN
E uk(b, x− sNη)dx = E(1− F (DN − sNη)) =
= P
{d∑
i=1
biηik + sNη ≥ DN
}≤ P
2
√√√√d∑
i=1
(ηik)
2+ η2 ≥ DN
;
E
∫ −DN
−∞uN
k (b, x)dx = E F (−DN − sNη) ≤

6.5. Швидкiсть збiжностi класифiкаторiв єдиного iндекса 171
≤ P
−2
√√√√d∑
i=1
(ηik)
2+ η2 < −DN
= P
2
√√√√d∑
i=1
(ηik)
2+ η2 > DN
.
(6.46)З оцiнок (6.46) випливає
B ≤ 2 P
{d∑
i=1
(ηi
k
)2+ η2 ≥ D2
N
4
}→ 0 при N →∞. (6.47)
Збираючи докупи граничнi твердження (6.43), (6.45), (6.47) та оцiнку(6.42), за нерiвнiстю Джорфi отримуємо твердження теореми 6.4.2.
Доведення теореми 6.4.1. Зробимо такi перетворення
Lg(b)−L∗g(b∗) = (Lg(b)− LN
g (b))+(LNg (b)− LN
g (b∗))+ LNg (b∗)−L∗g(b
∗). (6.48)
Оскiлькиb = argmin
bLN
g (b),
а класифiкатор побудований так, що
Lg(b) ≤ LNg (b),
то першi два доданки у (6.48) є вiд’ємними.З (6.48) випливає
0 ≤ Lg(b)− L∗g(b∗) ≤
∣∣∣LNg (b∗)− L∗g(b
∗)∣∣∣ ≤
≤ supb
∣∣∣LNg (b)− L∗g(b)
∣∣∣ . (6.49)
За теоремою 6.4.2 математичне сподiвання правої частини (26) прямує до0 при N →∞. Теорема 6.4.1 доведена.
Твердження наслiдку 6.4.1 випливає з теореми 6.4.1 та нерiвностi Че-бишова.
6.5 Швидкiсть збiжностi класифiкаторiв єди-ного iндекса
В п. 6.3 ми розглядали асимптотику порогових емпiрично-байєсових кла-сифiкаторiв для випадку, коли спостерiгається одновимiрна характеристи-ка об’єкту. В цьому параграфi ми дослiдимо асимптотику порогового ЕБК-класифiкатора, побудованого на основi "сумарного iндексу", введеного вп. 6.4.

172 Роздiл 6. Задачi класифiкацiї
Для спрощення викладу ми обмежимось випадком двовимiрного векто-ра спостережуваних характеристик ξ = (ξ1, ξ2)T , хоча отриманi асимпто-тичнi результати без принципових труднощiв можна перенести на випадокбiльших вимiрностей.
Постановка задачi має наступний вигляд. Нехай в нашому розпоряд-женнi є вибiрка з N об’єктiв, кожен з яких може належати одному з двохкласiв. Спостерiгається векторна характеристика ξj:N = (ξ1
j:N , ξ2j:N) ∈ R2 j-
го об’єкту; ξj:N незалежнi мiж собою. Концентрацiї k-ї компоненти сумiшiпiд час j-го спостереження, тобто безумовнi ймовiрностi того, що j-й об’єктвiдноситься до класу k, вважаються вiдомими i рiвними wk
j:N ; k = 1, 2.Щiльностi розподiлу елементiв з одного класу позначаємо hk (x1, x2) ; k =1, 2 i вважаємо їх невiдомими.
Наша мета — маючи в розпорядженнi навчаючу вибiрку{ξj:N , j = 1, N
},
побудувати класифiкатор g : R2 → {1, 2}, який за спостережуваними ха-рактеристиками об’єкту оцiнював би номер класу, якому цей об’єкт нале-жить.
Отже, проектуємо вектор спостережуваних характеристик (ξ1, ξ2) надеякий невипадковий напрямок b = (cos α, sin α), отримуємо "сумарнийiндекс"
SN(α) = ξ1 cos α + ξ2 sin α,
i на його основi будуємо пороговий класифiкатор типу (6.12):
gBt,α
(ξ1, ξ2
)=
{1, SN(α) ≤ t;
2, SN(α) > t.(6.50)
Як було вiдмiчено в п. 6.3, при баєсовому пiдходi найкращим вважаєть-ся класифiкатор, який мiнiмiзує ймовiрнiсть помилки
L∗(t) = p1 (1−H1(t)) + p2H2(t),
де p1, p2 - апрiорно вiдомi концентрацiї компонентiв сумiшi, Hi(t); i = 1, 2 -функцiя розподiлу спостережуваних характеристик об’єкту, що належитьi-му класу. Оскiльки розподiли H1(t), H2(t) невiдомi, то за навчаючою ви-бiркою будуємо H1(t), H2(t) - оцiнки для них, i, пiдставивши в формулудля баєсiвського класифiкатора (6.50), отримують емпiрично-баєсiв кла-сифiкатор. За оцiнку ймовiрностi помилкової класифiкацiї беруть
LN(t) = p1
(1− H1(t)
)+ p2H2(t).

6.5. Швидкiсть збiжностi класифiкаторiв єдиного iндекса 173
Оптимальний напрямок α∗ i порiг баєсiвського класифiкатора tB оби-раються з умови (
α∗, tB)
= argmin(α,t)
L∗(α, t).
Оцiнка напрямку та порогу визначається як їх вибiрковий аналог:(α, t
)= argmin
(α,t)
L(α, t).
За оцiнку Hi(t) беремо iнтеграл вiд ядерної оцiнки щiльностi, що задаєтьсяформулою (4.2), при цьому мiнiмакснi ваговi коефiцiєнти a1
j:N , a2j:N зада-
ються (2.15).Чому ми використовуємо iнтеграли вiд uN
i замiсть того, щоб одразупiдставити у вираз для ймовiрностi похибки емпiричнi мiри? Як ми пере-конались у п. 6.3, таке згладжування за допомогою ядерного оцiнюваннящiльностi дозволяє полiпшити точнiсть наближення справжнього баєсово-го класифiкатора його емпiричним аналогом.
Таким чином,
uNi (α, t) =
1
NsN
N∑j=1
aij:NK
(t− SN
j (α)
sN
); i = 1, 2; (6.51)
Hαi (t) =
1
N
N∑j=1
aij:NF
(t− SN
j (α)
sN
),
де F (t) =∫ t
−∞ K(x)dx. При цьому ваговi коефiцiєнти aij:N задовольняють
умову незмiщеностi 2.7
⟨wkai
⟩=
1
N
N∑j=1
wkj:Nai
j:N = 1I {k = i} . (6.52)
Щiльностi компонент сумiшi сумарного iндексу SNj (α) позначимо як ui(α, t)
i помiтимо, що
ui(α, t) =
(∫ ∞
−∞dx2
∫ ∞
−∞1I {x1 cos α + x2sinα < t}hi(x1, x2)dx1
)′
t
=
=
∫ ∞
−∞hi(t cos α− u sin α, t sin α + u cos α)du; i = 1, 2.

174 Роздiл 6. Задачi класифiкацiї
Припустимо, що виконуються наступнi умови:(а1) для всiх δ > 0 виконується:
infα,t:(α−α∗)2+(t−tB)2>δ2
L∗(α, t) > L∗(α∗, tB);
(а2) ваговi коефiцiєнти aij:N обмеженi: a = supi,j,N |ai
j:N | < ∞;(а3) щiльностi компонент сумарного iндексу SN
j (α) є обмеженими по ti α : maxi=1,2 sup(t,α) |ui(α, t)| < ∞;
(а4)∫∞−∞ |x|K(x)dx < ∞.
Лема 6.5.1 За умов (a1)-(a4) t → tB, α → α∗ за ймовiрнiстю при N →∞.
Доведення леми 6.5.1. Спершу доведемо, що L∗(α, t) → L∗(α∗, tB) займовiрнiстю. Оскiльки
0 ≤ L∗(α, t)− L∗(α∗, tB) = L∗(α, t)− L(α, t) + L(α, t)− L(α∗, tB)+
+L(α∗, tB)− L∗(α∗, tB) ≤ 2 sup(α,t)
∣∣∣L(α, t)− L∗(α, t)∣∣∣ ,
то для цього достатньо довести, що sup(α,t)
∣∣∣L(α, t)− L∗(α, t)∣∣∣ → 0 при N →
∞ за ймовiрнiстю. Зробимо наступнi оцiнки.
L(α, t)− L∗(α, t) = p1
(Hα
1 (t)− Hα1 (t)
)+ p2
(Hα
2 (t)− Hα2 (t)
).
sup(α,t)
∣∣∣Hαi (α, t)−Hα
i (α, t)∣∣∣ ≤
≤ sup(α,t)
∣∣∣∣∣1
N
N∑j=1
aij:NF
(t− SN
j (α)
sN
)− 1
N
N∑j=1
aij:N E F
(t− SN
j (α)
sN
)∣∣∣∣∣
+ sup(α,t)
∣∣∣∣∣1
N
N∑j=1
aij:N E F
(t− SN
j (α)
sN
)−Hα
i (t)
∣∣∣∣∣ = V N1 + V N
2
(6.53)
Розглянемо V N1 . Визначимо зважену емпiричну мiру спiввiдношенням,
як ми це робили у (2.3):
µN(A) =1
N
N∑j=1
aij:N1I {ξj:N ∈ A} ; µN(A) = E µN(A) = P(A) = Hi(A);

6.5. Швидкiсть збiжностi класифiкаторiв єдиного iндекса 175
Pr(dy) - ймовiрнiсна мiра. Тодi, згiдно з лемою 5.2.2,
V N1 = sup
(α,t)
∣∣∣∣∫
R2
F
(t− cos αy1 − sin αy2
sN
)Hi(dy)
−∫
R2
F
(t− cos αy1 − sin αy2
sN
)µN(dy)
∣∣∣∣ ≤ supA∈S
|Hi(A)− µN(A)| .(6.54)
Тут S — сукупнiсть множин:
S =
{(y1, y2) : F
(t− cos αy1 − sin αy2
sN
)≥ C
}
для всiх α, t, C. Позначимо
CiN = sup
1≤j≤N|ai
j:N |+ sup1≤j≤N
aij:N − inf
1≤j≤Nai
j:N
i вiдмiтимо, що sup C iN < 2a.
Тепер застосуємо теорему 2.2.3. Оскiльки функцiя F є монотонною, тоS являє собою VC-клас (див. c. 36), тобто функцiя росту класу задовольняєgG(N) ≤ 3 (N−1)2
2. Згiдно з теоремою 2.2.3 маємо для довiльної сталої
λ > 4/N :
P{supA∈S
|µN(A)− P(A)| ≥ λ} ≤ P
{supA∈S
|µN(A)− P(A)|Ci
N
≥ λ
sup CiN
}
≤ 4
(3NgG(2N) exp
(− λ2N
(2a)2128
)+ exp
(− λ2N
(2a)232
)).
(6.55)
Права частина (6.55) при N → 0 прямує до 0, бо gG(2N) зростає якстепенева функцiя, а експоненцiальний множник прямує до нуля швидше.Отже, з (6.54), (6.55) маємо: за ймовiрнiстю
V N1 → 0, N →∞. (6.56)
Тепер оцiнимо V N2 , застосувавши спiввiдношення (6.52).
1
N
N∑j=1
aij:N E F
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
)=
=1
N
N∑j=1
aij:N
2∑
k=1
wkj:N
∫ ∞
−∞dx1
∫ ∞
−∞F
(t− x1 cos α− x2 sin α
sN
)hk(x1, x2)dx2

176 Роздiл 6. Задачi класифiкацiї
=
∫ ∞
−∞dx1
∫ ∞
−∞F
(t− x1 cos α− x2 sin α
sN
)hi(x1, x2)dx2.
Отже, позначивши (ηi1, η
i2) в.в. зi щiльнiстю hi(x1, x2) , маємо:
V N2 = sup
(α,t)
∣∣∣∣E F
(t− ηi
1 cos α− ηi2 sin α
sN
)−
∫ t
−∞ui(α, x)dx
∣∣∣∣ =
= sup(α,t)
∣∣∣∣sN
∫ ∞
−∞F (v)ui(α, t− vsN)dv −
∫ t
−∞ui(α, x)dx
∣∣∣∣ =
= sup(α,t)
∣∣∣∣∫ ∞
−∞
∫ t−vsN
t
ui(α, x)dxK(v)dv
∣∣∣∣ ≤ sN sup(α,t)
|ui(α, t)|∫ ∞
−∞|v|K(v)dv.
(6.57)
Зi спiввiдношень (6.53), (6.56), (6.57) робимо висновок, що
sup(α,t)
∣∣∣Hαi (t)−Hα
i (t)∣∣∣ → 0
за ймовiрнiстю при N → ∞, а, отже, i sup(α,t)
∣∣∣L(α, t)− L∗(α, t)∣∣∣ → 0.
Звiдси випливає, що L∗(α, t) → L∗(α∗, tB) за ймовiрнiстю.Згiдно з умовою (а1) для довiльного δ > 0 iснує таке c > 0, що
L∗(α∗, tB) < −c + inf(α,t):(α−α∗)2+(t−tB)2>δ2
L∗(α, t).
Задамо довiльне δ > 0 i припустимо, що виконується нерiвнiсть(α−α∗)2 +(t − tB)2 > δ2 . Тодi iснує таке c > 0, що L∗(α∗, tB) < −c + L∗(α, t). Ймо-вiрнiсть такої подiї за доведеним вище збiгається до 0 при N →∞. Звiдсивипливає, що P{(α− α∗)2 + (t− tB)2 > δ2} →N→∞ 0. Отже, для довiльнихсталих c1, c2 > 0
P{|α− α∗| > c1; |t− t∗| > c2} ≤ P{(α− α∗)2 + (t− tB)2 > c21 + c2
2} →N→∞ 0
Лема 6.5.1 доведена.Тепер оцiнимо швидкiсть цiєї збiжностi.
Теорема 6.5.1 Нехай на додачу до умов (а1)-(а4) виконуються наступнiумови (k=1,2):
(а5) функцiї L(α, t); L∗(α, t) двiчi неперервно диференцiйовнi;
uk(t) < c < ∞;

6.5. Швидкiсть збiжностi класифiкаторiв єдиного iндекса 177
∫ ∞
−∞dx1
∫ ∞
−∞dx2
(x4
1 + x42
)hk(x1, x2) < ∞; hk(x1, x2) → 0, x1, x2 → ±∞;
функцiї hk(x1, x2) тричi неперервно-диференцiйовнi i мають обмеженi по-хiднi до третього порядку включно;∫ ∞
−∞vs ∂
2hi
∂x2i
(t cos α− v sin α, t sin α + v cos α)dv < ∞; i = 1, 2 для всiх α, t;
∫ ∞
−∞vs ∂2hi
∂x1∂x2
(t cos α− v sin α, t sin α + v cos α)dv < ∞; s = 1, 2 для всiх α, t.
(а6)
σ2k(α, t) = lim
N→∞
2∑r=1
⟨(ak)2wr
⟩N
ur(α, t) < ∞;
σ2(α, t) = limN→∞
2∑r=1
⟨(−p1a
1 + p2a2)2wr
⟩N
ur(α, t) < ∞;
∆2(α, t) = limN→∞
2∑r=1
⟨(−p1a
1 + p2a2)2wr
⟩N×
×∫ ∞
−∞v2hr(t cos α− v sin α, t sin α + v cos α)dv < ∞;
ω2(α, t) = limN→∞
2∑r=1
⟨(−p1a
1 + p2a2)2wr
⟩N
ar(α, t) < ∞;
σ2(α∗, tB)∆2(α∗, tB)− ω4(α∗, tB) > 0.
(а7)
∃∂uk(t)
∂t< c < ∞;
iснують i обмеженi рiвномiрно по p, q iнтеграли∫ ∞
−∞
∂hk
∂xi
(p− v sin α, q − v cos α)dv, i = 1, 2;
∫ ∞
−∞(1 + v2)hk(p− v sin α, q − v cos α)dv, k = 1, 2;
∫ ∞
−∞vshk(t cos α− v sin α, t sin α + v cos α)dv < ∞; k = 1, 2; s = 1, 2.

178 Роздiл 6. Задачi класифiкацiї
(а8) умови, що накладаються на ядро:
d21 =
∫ ∞
−∞(K ′(z))2dz < ∞; |K ′(z)| < ∞; K(z) → 0, z → ±∞;
∫ ∞
−∞zK(z)dz = 0; D2 =
∫ ∞
−∞z2K(z)dz < ∞;
d2 =
∫ ∞
−∞K2(z)dz < ∞;
∫ ∞
−∞|z|3K(z)dz < ∞;
∫ ∞
−∞z2K2(z)dz < ∞.
(а9)sN = cN−1/5; де c− деяка стала.
Тодi при N →∞:
N2/5
(α− α∗
t− tB
)⇒
(η1
η2
)
де (η1, η2)T гауссiв випадковий вектор з математичним сподiванням A
та коварiацiйною матрицею S, причому
A = D2B
∂S∂t
(−p1T1 + p2T2) + 12
∂r∂t
(p1
∂2u1
∂t2− p2
∂2u2
∂t2
)
12
∂r∂α
(−p1
∂2u1
∂t2+ p2
∂2u2
∂t2
)− ∂r
∂t(p1T1 − p2T2)
|(α∗,tB)
B =1(
∂r∂t
)2 − ∂S∂t
∂r∂α
|(α∗,tB);
Ti(α, t) задаються в формулюваннi леми 6.5.2;
S = d2B2
(β2σ2 − 2βγω2 + γ2∆2 βµσ2 + γ2∆2 − γ(µ + β)ω2
βµσ2 + γ2∆2 − γ(µ + β)ω2 µ2σ2 − 2µγω2 + γ2∆2
)|(α∗,tB);
β =∂S
∂t|(α∗,tB); γ =
∂r
∂t|(α∗,tB); µ =
∂r
∂α|(α∗,tB);
S(α, t), r(α, t) задаються формулами (6.60), (6.61).
Доведення теореми 6.5.1. Запишемо необхiднi умови екстремуму дляL∗ та L вiдповiдно. {
∂L∗∂t
(α∗, tB) = 0;∂L∗∂α
(α∗, tB) = 0(6.58)

6.5. Швидкiсть збiжностi класифiкаторiв єдиного iндекса 179
{∂L∂t
(α, t) = 0;∂L∂α
(α, t) = 0(6.59)
Беручи похiднi, об’єднуючи першi i другi рiвностi формул (6.58), (6.59)вiдповiдно i вводячи новi позначення, маємо
{S(α∗, tB) = −p1u1(α
∗, tB) + p2u2(α∗, tB) = 0;
SN(α, t) = −p1u1(α, t) + p2u2(α, t) = 0.(6.60)
{r(α∗, tB) = −p1a1(α
∗, tB) + p2a2(α∗, tB) = 0;
rN(α, t) = −p1a1(α, t) + p2a2(α, t) = 0.(6.61)
Тут ui(α, t) задається формулою (6.51);
ai(α, t) =∂Hα
i (t)
∂α=
∫ t
−∞dt
∫ ∞
−∞
∂hi
∂x2
(s cos α− v sin α, s sin α + v cos α)×
× (s cos α− v sin α)dv −∫ t
−∞dt
∫ ∞
−∞
∂hi
∂x1
(s cos α− v sin α, s sin α + v cos α)×
× (s sin α + v cos α)dv =
= −∫ ∞
−∞vhi(t cos α− v sin α, t sin α + v cos α)dv.
(6.62)
(Тут ми врахували, що∫∞−∞
(cos α ∂hi
∂x2− sin α ∂hi
∂x1
)dv = 0;
∫ t
−∞
(cos α
∂hi
∂x1
− sin α∂hi
∂x2
)ds = hi(t cos α− v sin α, t sin α + v cos α).)
ai(α, t) =∂Hα
i (t)
∂α=
1
NSN
N∑j=1
aij:NK
(t− ξi
j:N cos α− ξ2j:N sin α
sN
)×
× (ξ1j:N sin α− ξ2
j:N cos α).
(6.63)
Далi, позначимо δN = α − α∗; ∆N = t − tB i розкладемо за формулоюТейлора лiву частину другої рiвностi (6.60):
0 = SN(α, t) = SN(α∗ + δN , tB + ∆N) ≈
≈ SN(α∗, tB) + δN∂SN
∂α(α∗, tB) + ∆N
∂SN
∂t(α∗, tB).

180 Роздiл 6. Задачi класифiкацiї
Лiву частину другої рiвностi (6.61) розкладаємо аналогiчно, отримуємосистему наближених рiвностей
{δN
∂SN
∂α(α∗, tB) + ∆N
∂SN
∂t(α∗, tB) ≈ S(α∗, tB)− SN(α∗, tB);
δN∂rN
∂α(α∗, tB) + ∆N
∂rN
∂t(α∗, tB) ≈ r(α∗, tB)− rN(α∗, tB).
(6.64)
(Праворуч до першої рiвностi ми додали S(α∗, tB) , до другої r(α∗, tB) , бовони рiвнi 0.) Розв’язуємо лiнiйну систему (6.64), спрощуємо позначення iпомiчаємо, що ∂SN
∂α= ∂rN
∂t. Отже,
{δN =
(S−S) ∂r∂t−(r−r) ∂S
∂t
( ∂r∂t )
2− ∂S∂t
∂r∂α
; ∆N =(r−r) ∂r
∂t−(S−S) ∂S
∂α
( ∂r∂t )
2− ∂S∂t
∂r∂α
(6.65)
Тепер треба знайти порядок спадання правих частин (6.65). Завдяки вико-нанню умов (а5)-(а8) можна застосувати теорему 4.3.4. Отже, справедливезображення
∂uk
∂t(t) = u
(1)k (t) +
1√NsN
3ςkN , k = 1, 2,
де u(1)k (t) = E ∂uk
∂t(t) → ∂uk
∂t(t), sN → ∞; — є невипадковою функцiєю,
а в.в. ςkN асимптотично нормальнi з параметрами N(0, d2
1σk2(t)) . Згiдно з
цим зображенням
∂SN
∂t− ∂S
∂t= −p1
(u
(1)1 (t)− ∂u1
∂t
)+ p2
(u
(1)2 (t)− ∂u2
∂t
)+
+1√
NsN3(p2ς
2N − p1ς
1N) = o(1); N →∞.
Отже,∂SN
∂t(α∗, tB) → ∂S
∂t(α∗, tB), N →∞ (6.66)
за ймовiрнiстю. Тепер впевнимося, що
∂rN
∂t(α∗, tB) → ∂r
∂t(α∗, tB), N →∞ (6.67)
за ймовiрнiстю. Для цього достатньо довести, що
∂ai
∂t(α∗, tB) → ∂ai
∂t(α∗, tB), N →∞; i = 1, 2

6.5. Швидкiсть збiжностi класифiкаторiв єдиного iндекса 181
за ймовiрнiстю. Зробимо такi перетворення
∂ai
∂t− ∂ai
∂t= B1
N + B2N , (6.68)
де
B1N =
1
NsN2
N∑j=1
aij:NK ′
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
)(ξ1
j:N sin α− ξ2j:N cos α)−
− 1
NsN2
N∑j=1
aij:N E K ′
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
)(ξ1
j:N sin α− ξ2j:N cos α);
B2N =
1
NsN2
N∑j=1
aij:N E K ′
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
)×
×(ξ1j:N sin α− ξ2
j:N cos α)− ∂ai
∂t.
Скористаємось законом великих чисел (теорема 7.3.6) для аналiзу B1N .
XN =ai
j:N
sN2K ′
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
)(ξ1
j:N sin α− ξ2j:N cos α);
E X2N =
(aij:N)2
sN4
2∑
l=1
wlj:N×
×∫ ∞
−∞dx1
∫ ∞
−∞dx2K
′(
t− x1 cos α− x2 sin α
sN
)(x1 sin α− x2 cos α)hi(x1, x2).
Цей iнтеграл iснує завдяки умовам (а5), (а8) i, як ми бачимо, E X2N =
O(
1sN
4
). Згiдно з умовою (а9) Var XN
N→ 0, N →∞. Отже, за ймовiрнiстю
BN → 0; N →∞. (6.69)
Тепер розглянемо B2N = E ∂ai
∂t− ∂ai
∂t. Пiсля замiни змiнної i iнтегрування
частинами (завдяки (а8)) маємо:
E∂ai
∂t=
1
sN2
∫ ∞
−∞dx1
∫ ∞
−∞dx2K
′(
t− x1 cos α− x2 sin α
sN
)(x1 sin α−
− x2 cos α)hi(x1, x2) = −∫ ∞
−∞K(z)
∫ ∞
−∞v
(cos α
∂hi
∂x1
+ sin α∂hi
∂x2
)dvdz,
(6.70)

182 Роздiл 6. Задачi класифiкацiї
де частиннi похiднi беруться в точцi (t cos α − v sin α − zsN cos α, t sin α +v cos α− zsN sin α). Вiдповiдно
∂ai
∂t=
∫ ∞
−∞
((t cos α− v sin α)
∂hi
∂x2
− (t sin α + v cos α)∂hi
∂x1
)dv =
= −∫ ∞
−∞v
(cos α
∂hi
∂x1
+ sin α∂hi
∂x2
)dv,
(6.71)
де похiднi беруться в точцi (t cos α−v sin α, t sin α+v cos α) . Згiдно з умовою(а7) пiдiнтегральна функцiя в iнтегралi (6.70) має iнтегровнi мажорантиi, очевидно, прямує до пiдiнтегральної функцiї (6.71) при sN → ∞. Затеоремою Лебега про мажоровану збiжнiсть B2
N → 0 при N → ∞, i всукупностi з (6.68), (6.69) це дає твердження (6.67). Збiжнiсть
∂rN
∂α(α∗, tB) → ∂r
∂α(α∗, tB), N →∞ (6.72)
за ймовiрнiстю можна довести за тiєю ж схемою.З (6.66), (6.67) та (6.72) випливає, що знаменник формул (6.65) задо-
вольняє:(
∂rN
∂t
)2
− ∂SN
∂t
∂rN
∂α|(α∗,tB) →
(∂r
∂t
)2
− ∂S
∂t
∂r
∂α|(α∗,tB), N →∞. (6.73)
Тепер розглянемо чисельники формул (6.65).
Лема 6.5.2 В умовах (а1)-(а8) справедливе граничне твердження
N2/5
(SN − SrN − r
)|(α∗,tB) ⇒
(D2
2
(−p1
∂2u1
∂t2+ p2
∂2u2
∂t2
)+ ζ1
D2
2(−p1T1 + p2T2) + ζ2
)|(α∗,tB),
деTi(α
∗, tB) =
∫ ∞
−∞(−v)
(∂2hi
∂x12
+ 2∂2hi
∂x1∂x2
+∂2hi
∂x22
)|x(α∗,tB)dv;
x(α, t) = (t cos α− v sin α, t sin α + v cos α); i = 1, 2.
При цьому випадковий вектор(
ζ1
ζ2
)розподiлений нормально N(0, B2) , де
B2 = d2
(σ2(α∗, tB) ω2(α∗, tB)ω2(α∗, tB) ∆2(α∗, tB)
).

6.5. Швидкiсть збiжностi класифiкаторiв єдиного iндекса 183
Доведення леми 6.5.2. Спершу доведемо, що
ai(α, t) = aNi (α, t) +
1√NsN
νiN , i = 1, 2,
де aNi (α, t) = E ai(α, t) - невипадкова функцiя; aN
i (α, t) → ai(α, t), N →∞;E νi
N = 0.Пiсля застосування (6.52) i замiни змiнної маємо
aNi (α, t) = E ai(α, t) =
1
sN
∫ ∞
−∞dx1
∫ ∞
−∞K
(t− x1 cos α− x2 sin α
sN
)(x1 sin α−
−x2 cos α)h1(x1, x2)dx2 = −∫ ∞
−∞dz
∫ ∞
−∞K(z)v×
×hi(t cos α− v sin α− zsN cos α, t sin α + v cos α− zsN sin α)dv.
Розкладемо за формулою Тейлора функцiю hi в точцi x = x(v)= (t cos α− v sin α, t sin α + v cos α) , також врахуємо (а8).
aNi (α, t) =
∫ ∞
−∞dz
∫ ∞
−∞K(z)
((−v)
(hi − zsN
∂hi
∂x1
− zsN∂hi
∂x2
)|x(v)+
+1
2z2sN
2(−v)
(∂2hi
∂x12
+ 2∂2hi
∂x1∂x2
+∂2hi
∂x22
)|x(v)−zsN (θ,η)
)dv,
де θ, η ∈ (0, 1).Отже,
aNi (α, t)− ai(α, t) =
sN2
2
∫ ∞
−∞dz
∫ ∞
−∞K(z)z2(−v)×
×(
∂2hi
∂x12
+ 2∂2hi
∂x1∂x2
+∂2hi
∂x22
)|x(v)−zsN (θ,η)dv.
(6.74)
Оскiльки ми припускаємо iснування цих iнтегралiв, то нескладно пе-реконатися, що права частина (6.74) являє собою вираз
sN2D2
2
∫ ∞
−∞(−v)
(∂2hi
∂x12
+ 2∂2hi
∂x1∂x2
+∂2hi
∂x22
)|x(v)dv + o(sN
2).

184 Роздiл 6. Задачi класифiкацiї
Справдi, позначимо R(x1, x2) = ∂2hi
∂x12 + 2 ∂2hi
∂x1∂x2+ ∂2hi
∂x22 i оберемо таку послi-
довнiсть CN : при N →∞ CN →∞, але CN2sN → 0. Тодi
∫ ∞
−∞K(z)z2dz
∫ ∞
−∞(−v)
(R|x(v)−zsN (θ,η) −R|x(v)
)dv =
=
∫ ∞
−∞K(z)z2dz
∫
|v|<CN
(−v)(R|x(v)−zsN (θ,η) −R|x(v)
)dv+
+
∫ ∞
−∞K(z)z2dz
(∫
|v|>CN
(−v)R|x(v)−zsN (θ,η)dv −∫
|v|>CN
(−v)R|x(v)dv
).
(6.75)
Другий i третiй iнтеграли як хвости збiжних iнтегралiв прямують до 0 приN →∞, перший iнтеграл не перевищує 2CN
2sNL∫∞−∞ |z|3K(z)dz → 0. (Тут
L = 3 max{
supx1,x2
∣∣∣ ∂R∂x1
∣∣∣ , supx1,x2
∣∣∣ ∂R∂x2
∣∣∣}- стала величина внаслiдок (а5)).
Далi, з доведеного вище випливає, що
r− r = −p1(a1− a1)+ p2(a2− a2) =D2sN
2
2(−p1T1 + p2T2)+
ζ2N
√NsN
+ o(sN2),
де
ζ2N = −p1ν
1N + p2ν
2N =
1√NsN
N∑j=1
(−p1a1j:N + p2a
2j:N)×
×(
K
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
)(ξ1
j:N sin α− ξ2j:N cos α)−
−E K
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
)(ξ1
j:N sin α− ξ2j:N cos α)
)=
1√NsN
N∑j=1
Y Nj .
Скористаємося лемою, доведеною в роботi [12]:
Лема 6.5.3 [12],c.31. Нехай PN(x) = λ1(uN1 (t)−u1(t))+λ2(u
N2 (t)−u2(t)), де
uN1 (t) - оцiнки виду (6.51), λ1, λ2 - сталi. За припущеннями, що iснують
d2 < ∞ та σ2(t) < ∞ з умов (а8) та (а6) вiдповiдно, а також умов(a3),(а9), при sN = c/N1/5
N2/5PN ⇒(
D2c2/5
2φ2(t) +
d
c1/10σ(t)ζ
),
де ζ є нормальною N(0, 1), φ2(t) = λ1u′′1(t) + λ2u
′′2(t).

6.5. Швидкiсть збiжностi класифiкаторiв єдиного iндекса 185
Отже, за цiєю лемою N2/5(SN − S)|(α,t) = φN(α, t) + ζN1 , де
φN(α, t) → D2
2
(−p1
∂2u1
∂t2+ p2
∂2u2
∂t2
),
ζN1 =
1√NsN
N∑j=1
(−p1a1j:N + p2a
2j:N)
(K
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
)−
−E K
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
))=
1√NsN
N∑j=1
XNj .
Для завершення доведення леми 6.5.2 достатньо довести асимптотичну
нормальнiсть випадкового вектора(
ζN1
ζN2
). Для цього скористаємося ЦГТ
в схемi серiй (теорема 7.3.8).Отже, з леми 6.5.3 випливає, що limN→∞ Var ζN
1 = d2σ2(α, t). Побачимо,що
Var ζN2 =
1
NsN
N∑j=1
(−p1a1j:N + p2a
2j:N)2
(E K2
(t− Sj(α)
sN
) (S ′j(α)α
)2−
−(
E K
(t− Sj(α)
sN
) (S ′j(α)α
))2)
= A1N + A2
N .
Розглянемо спершу A2N .
1
sN
(E K
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
)(ξ1
j:N sin α− ξ2j:N cos α)
)2
=
= sN
(2∑
k=1
wkj:N
∫ ∞
−∞dz
∫ ∞
−∞K(z)vhk(t cos α− v sin α− zsN cos α,
t sin α + v cos α− zsN sin α)dv)2 .
Як ми це вже показали, iнтеграл пiд квадратом прямує до ak(α, t) < ∞ , iоскiльки wk
j:N , akj:N обмеженi, то A2
N → 0, N →∞. Тепер розглянемо A1N .
1
sN
E K2
(t− ξ1
j:N cos α− ξ2j:N sin α
sN
)(ξ1
j:N sin α− ξ2j:N cos α)2 =

186 Роздiл 6. Задачi класифiкацiї
=2∑
k=1
wkj:N
∫ ∞
−∞dz
∫ ∞
−∞K2(z)v2hk(t cos α− v sin α− zsN cos α,
t sin α + v cos α− zsN sin α)dv.
Завдяки умовам (а5)-(а8) можна скористатися методом доведення форму-ли (6.74) i нескладно отримати, що
limN→∞
A1N = d2 lim
N→∞
2∑r=1
⟨(−p1a
1 + p2a2)2wr
⟩ ∫ ∞
−∞v2×
×hr(t cos α− v sin α, t sin α + v cos α)dv = d2∆2(α, t).
Отже, limN→∞ Var ζN2 = d2∆2(α, t).
Знайдемо граничне значення Cov(ζN1 , ζN
2 ).
Cov(ζN1 , ζN
2 ) = Cov
(1√
NsN
N∑j=1
XNj ,
1√NsN
N∑j=1
Y Nj
)=
1
NsN
N∑j=1
Cov(XN
j , Y Nj
)=
1
NsN
N∑j=1
(−p1a1j:N + p2a
2j:N)2×
×(
E K2
(t− Sj(α)
sN
) (S ′j(α)α
)−
−E K
(t− Sj(α)
sN
) (S ′j(α)α
)E K
(t− Sj(α)
sN
))= CN
1 + CN2 .
При цьому
CN2 =
sN
N
N∑j=1
(−p1a1j:N + p2a
2j:N)2
(2∑
k=1
wkj:N
∫ ∞
−∞dz
∫ ∞
−∞K(z)(−v)
hk(t cos α−−v sin α− zsN cos α, t sin α + v cos α− zsN sin α)dv
)
×(
2∑
k=1
wkj:N
∫ ∞
−∞dz×
∫ ∞
−∞K(z)(−v)
×hk(t cos α− v sin α− zsN cos α, t sin α + v cos α− zsN sin α)dv
)

6.5. Швидкiсть збiжностi класифiкаторiв єдиного iндекса 187
(Через те, що перший повторний iнтеграл пiд знаком суми збiжний доak(α, t), другий до uk(α, t) , отже, множник при sN — обмежений по Nвираз.) Далi, аналогiчно формулi (6.74) доводиться, що
CN1 =
1
N
N∑j=1
(−p1a1j:N + p2a
2j:N)2
2∑
k=1
wkj:N
∫ ∞
−∞dz
∫ ∞
−∞K2(z)(−v)
hk(t cos α−v sin α−zsN cos α, t sin α+v cos α−zsN sin α)dv →N→∞ d2ω2(α, t).
Тепер залишається перевiрити виконання умови Лiндеберга. Використову-ючи нерiвнiсть (x− y)2 ≤ 2(x2 + y2) i позначаючи lNj = (−p1a
1j:N + p2a
2j:N)2
бачимо, що
1
NsN
N∑j=1
E((XN
j )2 + (Y Nj )2
)1I
{(XN
j )2 + (Y Nj )2 > τ 2
}=
=1
NsN
N∑j=1
lNj E
((K
(t− Sj(α)
sN
)− E K
(t− Sj(α)
sN
))2
+
+
(K
(t− Sj(α)
sN
)(Sj(α)′α)− E K
(t− Sj(α)
sN
)(Sj(α)′α)
)2)×
× 1I{(XN
j )2 + (Y Nj )2 > τ 2
} ≤ 2
NsN
N∑j=1
lNj E
(K2
(t− Sj(α)
sN
)+
+K2
(t− Sj(α)
sN
)(Sj(α)′α)
2+
(E K
(t− Sj(α)
sN
))2
+
+
(E K
(t− Sj(α)
sN
)(Sj(α)′α)
)2)1I
{(XN
j )2 + (Y Nj )2 > τ 2
}
(6.76)
Як було встановлено вище,(
E K
(t− Sj(α)
sN
))2
= O(s2N);
(E K
(t− Sj(α)
sN
)(Sj(α)′α)
)2
= O(s2N).
Отже, двома вiдповiдними доданками в правiй частинi (6.76) можна знех-тувати - вiдповiднi суми прямують до нуля при N →∞ . Нам залишаєтьсярозглянути
E K2
(t− Sj(α)
sN
) (1 + (Sj(α)′α)
2)1I
{(K
(t− Sj(α)
sN
)−

188 Роздiл 6. Задачi класифiкацiї
−E K
(t− Sj(α)
sN
))2
+
(K
(t− Sj(α)
sN
)(Sj(α)′α)−
−E K
(t− Sj(α)
sN
)(Sj(α)′α)
)2
> τ 2NsN
}
≤ E K2
(t− Sj(α)
sN
) (1 + (Sj(α)′α)
2)×
×1I{
K2
(t− Sj(α)
sN
) (1 + (Sj(α)′α)
2)
>τ 2NsN
2−
−(
E K
(t− Sj(α)
sN
))2
−(
E K
(t− Sj(α)
sN
)(Sj(α)′α)
)2}
=
=2∑
k=1
wkj:N
∫
BN
K2(z)(1 + v2)×
×hk(t cos α− v sin α− zsN cos α, t sin α + v cos α− zsN sin α)dv,
де
BN =
{(z, v) : K2(z)(1 + v2) >
τ 2NsN
2−
−(
E K
(t− Sj(α)
sN
))2
−(
E K
(t− Sj(α)
sN
)(Sj(α)′α)
)2}
.
Завдяки виконанню умови (а7) цей вираз не перевищує
2∑
k=1
wkj:N
∫ ∞
−∞K2(z)dz sup
p,q
∫
BN
(1 + v2)hk(p− v sin α, q + v cos α)dv, (6.77)
де
BN =
{(z, v) : (1 + v2) >
τ 2NsN
2 supz K2(z)+ O(s2
N)
}.
Другий iнтеграл в правiй частинi (6.77) прямує до нуля при N → ∞ якзалишок збiжного iнтегралу. Отже, права частина (6.76) теж прямує донуля, i умова Лiндеберга виконується.
Лема 6.5.2 доведена. Отже, пiдставляючи формулу (6.73) i результатилеми 6.5.2 у правi частини (6.65) i пiдсумовуючи всi результати, завершує-мо доведення теореми 6.5.1.

Роздiл 7
Допомiжнi вiдомостi
7.1 Формули iнтегрування i пов’язанi з ниминерiвностi
Нехай вектори ui = (u1i , . . . , u
di ) ∈ Rd i = 0, 1, 2 задовольняють нерiвнiсть
u0 ≤ u1 ≤ u2. Позначимо K = [u0, u2] = {x ∈ Rd : u0 ≤ x ≤ u2}.Для будь-якого α ∈ {0, 1}d i будь-якої гладенької функцiї f : K → Rпозначимо Dαf(u) частинну похiдну функцiї f по всiх координатах uj дляяких αj = 1, тобто
Dα =∏αj=1
∂
∂uj,
Kα =⊗
αj=1[uj0, u
j2] паралелепiпед у Rd з “найменшою” вершиною u0 i “най-
бiльшою” — u2, uα = (u1α1
, . . . , udαd
), (du1)α =
∏αj=1 duj
1 — диференцiал потих змiнних, для яких αj = 1, V (Kα) — об’єм паралелепiпеда Kα, тобтоV (Kα) =
∏αj=1(u
j2 − uj
0)
Лема 7.1.1 Якщо f : K → R є d разiв диференцiйовною функцiєю то
supu∈K
|f(u)| ≤ ‖f‖H
∑
α∈{0,1}d
V (Kα)
1/2
де
‖f‖H =
f 2(u0) +
∑
α∈{0,1}d,α6=0
∫
Kα
(Dαf(uα))2(du1)α
1/2
.

190 Роздiл 7. Допомiжнi вiдомостi
Доведення. Спочатку отримаємо наступну рiвнiсть, яка є узагальнен-ням формули Ньютона-Лейбниця на багатовимiрний випадок:
f(u2) =∑
α∈{0,1}d
∫
Kα
Dαf(u1)(du1)α. (7.1)
Тут у випадку, коли Kα = ∅, вважаємо iнтеграл рiвним пiдiнтегральномувиразу.
Наприклад, у випадку d = 2 маємо наступну формулу (для спрощеннятут прийнятi позначення t1 = u1
1, t2 = u21):
f(u12, u
22) =
∫ u22
u20
∫ u12
u10
∂2
∂t1∂t2f(t1, t2)dt1dt2
+
∫ u22
u20
∂
∂t2f(uN , t2)dt2 +
∫ u12
u10
∂
∂t1f(t1, uN)dt1 + f(u1
0, u20).
(7.2)
Доведемо (7.1). Для γ ∈ {0, 1, 2}d позначимо γ = (γ1, . . . , γd), де γj = 1,якщо γ = 1 i γj = 0 в усiх iнших випадках. Позначимо
pkj γ = (γ1, . . . , γk−1, j, γk+1, . . . , γd),
J(γ) =
∫
Sγ
Dγf(uγ)(du1)γ.
Якщо γk = 2, тоJ(γ) = J(pk
0γ) + J(pk1γ). (7.3)
Дiйсно,
f(uγ) = f(upk0γ) +
∫ uj1
uj0
f(upk1γ)duk
1
∂
∂uk1
(це звичайна формула Ньютона-Лейбниця, застосована до k-того аргумен-та функцiї f). Диференцiюючи її за iншими змiнними, а потiм iнтегруючи,отримуємо (7.3).
Тепер, починаючи з f(u12, . . . , u
d2) = J(2, . . . , 2), застосуємо (7.3) послi-
довно при k рiвних d, d− 1,. . . , 1. Отримуємо:
f(u2) = J(2, . . . , 2, 2, 2)
= J(2, . . . , 2, 2, 0) + J(2, . . . , 2, 2, 1)

7.2. Нерiвнiсть для визначникiв 191
= J(2, . . . , 2, 0, 0) + J(2, . . . , 2, 1, 0) + J(2, . . . , 2, 0, 1) + J(2, . . . , 2, 1, 1) = . . .
На кроцi d отримаємо (7.1).Тепер, розширюючи у (7.1) там де потрiбно, межi iнтегрування i вико-
ристовуючи нерiвнiсть Кошi-Бунякiвського, оцiнимо
supu∈K
|f(u)| ≤∑
α∈{0,1}d
∫
Kα
|Dαf(uα)|
≤∑
α∈{0,1}d
(∫
Kα
(Dαf(uα))2
)1/2 ∑
α∈{0,1}d
V (Kα)
1/2
.
Лема доведена.
7.2 Нерiвнiсть для визначникiвУ цьому параграфi ми доведемо теорему про нерiвнiсть для визначникiвдвох матриць. Одна з цих матриць — матриця Грама скiнченного набо-ру функцiй у просторi L2(ν) вiдносно деякої мiри ν. Другу також можнатрактувати як матрицю Грама того ж набору функцiй, однак мiра, по якiйпiдраховується скалярний добуток є матричнозначною. Тому i матриця бу-дується з блокiв, кожен з яких вiдповiдає одному елементу першої матри-цi. Виявляється, що з невиродженостi першої матрицi випливає невирод-женiсть другої. Iнтуїтивно це легко зрозумiти, оскiльки невиродженiстьматрицi Грама рiвносильна лiнiйнiй незалежностi набору функцiй, а цявластивiсть практично не залежить вiд вибору мiри для простору L2(ν),в якому цi функцiї розглядаються. Хiба що, поклавши ν рiвною 0 на мно-жинi, на якiй розрiзняються функцiї, можна зробити їх лiнiйно залежнимиу L2(ν). Але такi виродженi випадки вiдсiкаються умовою теореми.
Введемо позначення.Нехай T ⊆ R, w1,. . . ,wM — вимiрнi дiйснозначнi функцiї на T . Розгля-
немо набiр зарядiв (знакозмiнних мiр) на T , — µl1,l2 , l1, l2 = 1,. . . ,r, де r —фiксоване цiле число. Символом µ(A), A ⊆ T , будемо позначати матрицю(µl1,l2(A))r
l1,l2=1. Iнакше кажучи, µ можна розглядати як матричнозначнумiру, визначену на T .
Позначимо
〈wm1 , wm2〉l1,l2 =
∫wm1(t)wm2(t)µl1,l2(dt)

192 Роздiл 7. Допомiжнi вiдомостi
— “скалярний добуток” функцiй wm1 та wm2 вiдносно заряду µl1,l2 . Покла-демо
〈wm1 , wm2〉µ = (〈wm1 , wm2〉l1,l2)rl1,l2=1.
Матрицю 〈wm1 , wm2〉µ можна iнтерпретувати як “матричнозначний скаляр-ний добуток” вiдносно матричнозначної мiри µ. (Надалi ми припускаємо,що всi розглядуванi функцiї та мiри такi, що введенi нами скалярнi добут-ки iснують i є скiнченними).
Нехай ν — деяка (додатнозначна) мiра на T i
〈wm1 , wm2〉ν =
∫wm1(t)wm2(t)ν(dt).
Позначимо через Γν = (〈wm1 , wm2〉ν)Mm1,m2=1 матрицю Грама для систе-
ми функцiй w1,. . . ,wM у просторi L2(ν), а через
Γµ =
〈w1, w1〉µ 〈w1, w2〉µ · · · 〈w1, wM〉µ〈w2, w1〉µ 〈w2, w2〉µ · · · 〈w2, wM〉µ
...... . . . ...
〈wM , w1〉µ 〈wM , w2〉µ · · · 〈wM , wM〉µ
— блочна матриця Грама для w1,. . . ,wM у матричнозначному скалярно-му добутку 〈·, ·〉µ. Матрицю Γµ будемо розглядати як звичайну квадратнуматрицю вимiрностi (Mr)× (Mr) з дiйснозначними елементами. Вiдповiд-но, визначник цiєї матрицi det Γµ є дiйсним числом.
Теорема 7.2.1 Нехай det Γν > 0 i iснує число Q > 0 таке, що
λmin(µ(A)) > Qν(A)
для всiх вимiрних множин A.Тодi det Γµ ≥ QMr det Γν.
(Нагадаємо, що λmin(Z) — найменше власне число матрицi Z).Доведення теореми. Ми будемо називати елементами формальнi су-
ми U =∑M
m=1 Amwm, де Am — довiльнi дiйснозначнi матрицi розмiру r×r,wm — елементи заданого в умовах теореми набору функцiй. Для елементiвочевидним способом визначенi операцiї додавання та множення на дiйсно-значнi r × r матрицi.

7.2. Нерiвнiсть для визначникiв 193
Нехай U та V =∑M
m=1 Bmwm — деякi елементи. Покладемо
〈U, V 〉 =M∑
m1,m2=1
Am1〈wm1wm2〉µBm2
i для довiльних елементiв U1,. . . ,UM ,
Γµ(U1, . . . , UM) = (〈Um1 , Um2〉)Mm1,m2=1.
Якщо U = Ewm, де E — одинична матриця, позначатимем U = wm. У цихпозначеннях Γµ = Γµ(w1, . . . , wm).
Для доведення теореми ми скористаємось процедурою ортогоналiзацiїелементiв w1,. . . ,wM вiдносно матричнозначного скалярного добутку 〈·, ·〉.Ця процедура подiбна до класичної процедури ортогоналiзацiї Грама-Шмi-дта для звичайних скалярних добуткiв. При цьому нам будуть потрiбнi тридопомiжнi леми.
Лема 7.2.1 Нехай для деякої дiйснозначної матрицi A, U ′m1
= AUm1 i,при m 6= m1, U ′
m = Um. Тодi
Γµ(U ′1, . . . , U
′M) = ST Γµ(U1, . . . , UM)S, (7.4)
де S є блочною матрицею складеною з блокiв Sm1,m2 розмiру r×r, причомуSm1,m1 = A, Sm,m = E для m 6= m1 i Sm,m2 = 0 для всiх пар m, m2, таких,що m 6= m2.
Лема 7.2.2 Нехай для деякої дiйснозначної матрицi A i деяких m1 6= m2,U ′
m1= Um1 + AUm2i, при m 6= m1, U ′
m = Um. Тодi (7.4) виконано для Sщо є блочною матрицею, складеною з блокiв Sij розмiру r × r, причомуSm1,m2 = A, Si,i = E для всiх i = 1, . . . , M i Sij = 0 для всiх пар i, j,таких, що i 6= j, (i, j) 6= (m1,m2).
Цi двi леми доводяться безпосереднiм пiдрахунком вiдповiдних матриць.
Лема 7.2.3 Нехай в умовах теореми для деякого m1 i деякого наборуiндексiв J , такого, що m1 6∈ J ,
U = wm1 +∑m∈J
Bmwm,
де Bm — дiйснозначнi r × r матрицi. Тодi
〈U,U〉 ≥ Q‖z‖2νE, (7.5)
де z є ортогональним доповненням wm1 до лiнiйного простору, натягну-того на вектори {wm,m ∈ J} у L2(ν), ‖z‖ν — норма z у L2(ν).

194 Роздiл 7. Допомiжнi вiдомостi
(Iнакше кажучи, ‖z‖ν — довжина перпендикуляра, опущеного з кiнця век-тора wm1 на простiр лiнiйних комбiнацiй векторiв {wm, m ∈ J}, причомувсi вектори розглядаються у L2(ν). Нерiвнiсть 7.5 слiд трактувати у мат-ричному розумiннi — рiзниця мiж лiвою i правою частинами є додатньо-визначеною матрицею.)
Доведення. Нехай c = (c1, . . . , cr)T — довiльний r-вимiрний вектор
стовпчик одиничної довжини (у звичайнiй евклiдовiй нормi ‖c‖ = 1). По-кладемо Bmc = bm = (bm
1 , . . . , bmr )T . Тодi
cT 〈U,U〉c = cT
⟨wm1 +
∑m∈J
Bmwm , wm1 +∑m∈J
Bmwm
⟩c
= cT 〈wm1 , wm1〉µc +∑m∈J
bTm〈wm, wm1〉µc
+∑m∈J
cT 〈wm, wm1〉µbm +∑
m2,m3∈J
bTm2〈wm, wm1〉µbm3
=
∫ (cT wm1(t) +
∑m∈J
bTmwm(t)
)µ(dt)
(cT wm1(t) +
∑m∈J
bTmwm(t)
)T
≥ Q
∫ ∥∥∥∥∥cT wm1(t) +∑m∈J
bTmwm(t)
∥∥∥∥∥
2
Rr
ν(dt)
= Q
r∑i=1
∫ (ciwm1(t) +
∑m∈J
bmi wm(t)
)2
ν(dt)
≥ Q∑
i:ci 6=0
(ci)2
∫ (wm1(t) +
∑m∈J
bmi
ci
wm(t)
)2
ν(dt)
≥ Q
r∑i=1
(ci)2‖z‖2
ν = Q‖z‖2ν
Щоб отримати останню нерiвнiсть, ми скористались тим фактом, що дов-жина перпендикуляра — найкоротша вiдстань вiд кiнця вектора до лiнiй-ного простору.
Лема доведена.Закiнчення доведення теореми. Побудуємо набiр елементiв U1,. . . ,
UM , таких, що

7.2. Нерiвнiсть для визначникiв 195
1. Um = Am(wm−∑m−1
m1=1 Bm1,mwm1), де Am та Bm1,m2 деякi дiйснозначнiматрицi.
2. 〈Um1 , Um2〉 = E якщо m1 = m2 i 〈Um1 , Um2〉 = 0 для m1 6= m2.Iнакше кажучи, U1,. . . ,UM це результат ортогоналiзацiї набору w1,. . . ,
wM . Ортогоналiзацiю проведемо узагальненим алгоритмом Грама-Шмiдта,послiдовно визначаючи U1,U2,. . . ,UM .
Спочатку покладемо A1 = (〈w1, w1〉µ)−1/2, U1 = A1w1. За лемою 7.2.3
〈w1, w1〉µ ≥ Q‖w1‖2νE,
томуA1 ≤ Q−1/2‖w1‖−1
ν E.
Нехай U1,. . . ,Um, що задовольняють умови 1-2, вже побудованi. Покладемо
Um+1 = wm+1 −m∑
m1=1
〈wm+1, Um1〉Um1 .
Тодi для всiх m1 < m отримуємо
〈Um+1, Um1〉 = 〈wm+1, Um1〉 − 〈wm+1, Um1〉 = 0
внаслiдок “ортонормованостi” U1,. . . ,Um. Покладемо Um+1 = Am+1Um+1, деAm+1 = (〈Um+1, Um+1〉)−1/2. Знову за лемою 7.2.3 маємо
Am+1 ≤ Q−1/2‖zm+1‖−1ν E,
де ‖zm+1‖ — довжина перпендикуляра, опущеного з кiнця вектора wm+1
на лiнiйний простiр, натягнутий на вектори w1,. . . ,wm у L2(ν).Таким чином, набiр U1,. . . ,UM побудовано. Згiдно з лемами 7.2.1 та
7.2.2,Γµ(U1, . . . , UM) = SΓµ(w1, . . . , wM)ST
де
S =
A1 B21 B31 · · · BM1
0 A2 B32 · · · BM2...
...... . . . ...
0 0 0 · · · AM
Зрозумiло, що Γµ(U1, . . . , UM) є одиничною матрицею, отже
1 = det Γµ(U1, . . . , UM) = det Γµ(det S)2,

196 Роздiл 7. Допомiжнi вiдомостi
звiдки отримуємо
det Γµ = (det S)−2 =M∏
m=1
(det Am)2 ≥ QMr
M∏m=2
‖zm‖2ν〈w1, w1〉ν = QMr det Γν .
Останню рiвнiсть легко отримати використовуючи звичайну процедуруортогоналiзацiї до набору функцiй w1,. . . ,wM у L2(ν).
Теорема доведена.
7.3 Ймовiрнiснi нерiвностi i граничнi теореми
У цьому параграфi зiбранi теореми про поведiнку сум незалежних випад-кових величин i векторiв. Вони розподiляються на три групи: нерiвностiдля ймовiрностей вiдхилення вiд математичного сподiвання, теореми прозбiжнiсть середнiх до математичних сподiвань (закони великих чисел) татеореми про слабку збiжнiсть нормованих вiдхилень вiд середнього (цен-тральна гранична теорема, ЦГТ). Крiм того, тут розглянутi теореми прослабку збiжнiсть, якi дозволяють застосовувати ЦГТ для асимптотично-го аналiзу статистичних оцiнок — такi як теорема Слуцького та теореминеперервностi.
Нерiвностi для сум випадкових величин. У цьому пунктi ξ1,. . . ,ξn,. . . , позначають незалежнi випадковi величини, Sn =
∑ni=1 ξi.
Теорема 7.3.1 Нерiвнiсть Прохорова. Нехай для деякого c > 0, |ξi| <c, E ξi = 0. Покладемо Bn =
∑ni=1 Var ξi. Тодi для всiх x ∈ R
P{Sn ≥ x} ≤ exp
{−x
carcsh
cx
2Bn
}.
Тут arcsh(x) = log(x +√
x2 + 1) — гiперболiчний арксинус (ареасинус).Доведення див. у [22] (пор. також [17], с.93).
Теорема 7.3.2 Нерiвнiсть Хьофдiнга. Нехай для деяких ai, bi ∈ R,ai < ξi < bi. Тодi для всiх x > 0,
P{Sn − E Sn ≥ nx} ≤ exp
{− 2n2x2
∑ni=1(bi − ai)2
}.

7.3. Ймовiрнiснi нерiвностi i граничнi теореми 197
Доведення див. [35] (пор. також [17], с.93).Трохи iнший варiант цiєї нерiвностi можна отримати використовуючи
теорiю субгауссових випадкових величин (див. леми 2.3.2-2.3.4 у [15], пор.[5]).
Теорема 7.3.3 Нехай для деякого c > 0, |ξi| < c, E ξi = 0. Тодi для всiхx > 0,
P
{1
n
n∑i=1
ξi ≥ x
}≤ exp
{−x2n
2c2
}.
Види збiжностi випадкових величин. Нехай ξ, ξn, n = 1, 2, . . . —випадковi вектори у Rd, |·| — евклiдова норма у Rd.
Кажуть, що ξn → ξ при n →∞ майже напевно (скорочення м.н.), якщо
P{ limn→∞
ξn = ξ} = 1.
Кажуть, що ξn → ξ при n →∞ за ймовiрнiстю, якщо для всiх ε > 0,
P{|ξn − ξ| > ε} → 0 при n →∞.
Кажуть, що ξn збiгається слабко до ξ (або розподiл ξn збiгається слабкодо ξ, запис: ξn ⇒ ξ) якщо для всiх неперервних, обмежених функцiйg : Rd → R
E g(ξn) → E g(ξ) при n →∞.
Зi збiжностi м.н. випливає збiжнiсть за ймовiрнiстю, а зi збiжностi за ймо-вiрнiстю — слабка збiжнiсть.
Для будь-якої множини A ⊆ Rd позначимо ∂A — границю A. Кажуть,що вимiрна множина A є множиною неперервностi розподiлу випадковоговектора ξ, якщо P{ξ ∈ A} = 0.
Теорема 7.3.4 Наступнi твердження еквiвалентнi:1. ξn ⇒ ξ при n →∞;2.P{ξn ∈ A} → P{ξ ∈ A} при n → ∞ для всiх A, що є множинами
неперервностi ξ;3. Функцiї розподiлу Fn випадкових векторiв ξn збiгаються до функцiї
розподiлу F вектора ξ в усiх точках неперервностi F .
Доведення див. у [8], теорема 4 п.4 роздiл 6.Закони великих чисел. Найпростiшу форму має пiдсилений закон
великих чисел для незалежних, однаково розподiлених випадкових вели-чин.

198 Роздiл 7. Допомiжнi вiдомостi
Теорема 7.3.5 Нехай ξi, i = 1, 2, . . . — послiдовнiсть незалежних одна-ково розподiлених векторiв у Rd зi скiнченним математичним сподiван-ням E ξi = a. Тодi
1
n
n∑i=1
ξi → a м.н. при n →∞.
Доведення див. у [8], c. 148.Для послiдовностей неоднаково розподiлених випадкових величин спра-
ведливий наступний закон великих чисел
Теорема 7.3.6 Якщо послiдовнiсть незалежних в.в. {XN , N ≥ 1} така,що Var XN iснує i Var XN
N→ 0, N →∞, то
1
N
N∑
k=1
Xk − 1
N
N∑
k=1
E Xk → 0; N →∞
за ймовiрнiстю.
(див. [14],с.47).Розглянемо тепер схему серiй випадкових величин ζi,n, i = 1, . . . , n, n =
1, 2, . . . Будемо вважати ζi,n незалежними всерединi кожної серiї (тобтопри фiксованому n). Позначимо Sn =
∑ni=1 ζi,n.
Умови виконання закону великих чисел у схемi серiй дає
Теорема 7.3.7 Нехай E ζi,n = 0,
M1 =N∑
i=1
E |ζi,n| ≤ c < ∞,
i для всiх τ > 0, при n →∞,
M2(τ) =n∑
i=1
E |ζi,n|1I{|ζi,n| > τ} → 0.
Тодi Sn → 0 за ймовiрнiстю при n →∞.
(див. [2], п.3 роздiлу 8).Центральна гранична теорема. Нехай ξi,n i = 1, . . . , n, n = 1, 2, . . .
— схема серiй випадкових векторiв1, незалежних всерединi кожної серiї,ζn =
∑nk=1 ξk,n. Позначимо |ξi,n| =
√ξTi,nξi,n евклiдову норму ξi,n.
1Всi вектори, як правило, вважаємо векторами-стовпчиками.

7.3. Ймовiрнiснi нерiвностi i граничнi теореми 199
Припустимо, що E ξi,n = 0, E |ξi,n|2 < ∞. Позначимо sk,n = E ξk,nξTk,n
коварiацiйну матрицю ξk,n, sn =∑n
k=1 sk,n коварiацiйну матрицю ζn.
Теорема 7.3.8 (див. [2], с.201) Нехай крiм вказаних вище обмежень ви-конуються умови
1. При n →∞,Sn → S, (7.6)
де S — невироджена матриця;2. Для всiх τ > 0 при n →∞
B =n∑
k=1
E | ξk,n |2 1I{| ξk,n |> τ} → 0 (7.7)
(умова Лiндеберга).Тодi має мiсце слабка збiжнiсть ζn до розподiлу N(0, S).
(Зрозумiло, що у випадку одновимiрних ξk,n, Sn є дисперсiєю ζn).Теореми неперервностi. Наступнi теореми разом з центральною гра-
ничною теоремою дозволяють аналiзувати швидкiсть збiжностi оцiнок, якiможна представити як функцiї вiд сум незалежних випадкових величин.
Теорема 7.3.9 (Теорема 3В у [2], п.5, роздiл 1). Нехай ηn — послiдов-нiсть випадкових векторiв у Rs, a ∈ Rs — фiксований вектор, bn ∈ R —числова послiдовнiсть, bn → 0, H : Rs → Rk — не випадкова функцiя.
Припустимо, що1. ηn ⇒ η при N →∞.2. Для j = 1, . . . , k iснують похiднi
H ′j = (
∂
∂x1
Hj(x1, . . . , xs), . . . ,∂
∂xs
Hj(x1, . . . , xs))T ,
неперервнi в точцi a.Тодi
(H(a + bnηn)−H(a))/bn ⇒ H ′(a)η,
де H ′(x) = ( ∂∂xi
Hj(x1, . . . , xs), i = 1, . . . , s; j = 1, . . . , k) — матриця з sстовпчикiв i k рядочкiв.

200 Роздiл 7. Допомiжнi вiдомостi
Теорема 7.3.10 (Слуцького) Нехай X, X1,X2,. . . ,Y1,Y2,. . .— випадковiвеличини, причому Xn ⇒ X i Yn → c, при n → ∞, де c — невипадковечисло. Тодi
(i) Xn + Yn ⇒ X + c;(ii) YnXn ⇒ cX;(iii) Xn/Yn ⇒ X/c якщо c 6= 0.
Доведення див. теорему 1.11 у [46].
7.4 Слабка збiжнiсть випадкових функцiй
У цьому параграфi розглядається теорiя слабкої збiжностi випадковихфункцiй, як випадкових елементiв певних функцiональних просторiв. Вiд-мiтимо, що можливi i iншi трактування поняття слабкої збiжностi. На-приклад, її можна визначати для функцiй, якi не задовольняють умовамвимiрностi, тобто не є випадковими елементами. Для таких функцiй слаб-ка збiжнiсть визначається у термiнах зовнiшньої ймовiрностi та зовнiшнiхматематичних сподiвань. Цей пiдхiд виявляється особливо плiдним дляаналiзу емпiричних мiр у випадку незалежних однаково розподiлених спо-стережень (див., наприклад [52]). Iнший можливий пiдхiд — використаннядля визначення слабкої збiжностi методу одного ймовiрнiсного просторуна основi теореми Скорохода (див. с.39). Однак у цьому параграфi ми бу-демо дотримуватись класичного пiдходу до визначення слабкої збiжностi,слiдуючи в основному книжкам [1, 4] та роботi [24].
В основному ми будемо розглядати функцiї f : Z → R де Z ⊆ Rd якелементи просторiв C(Z) та D(Z).
Простiр C(Z) — це простiр функцiй, неперервних на множинi Z з рiв-номiрною нормою ‖f‖∞ = supx∈Z |f(x)|. Якщо Z — компакт у Rd, то C(Z)— сепарабельний банахiв простiр.
Нехай Z = [a, b] ⊆ R. Простiр D(Z) = D[a, b] складається з обмеженихфункцiй f , неперервних злiва на [a, b]. На цьому просторi можна задатирiзнi топологiї. Перша задається рiвномiрною нормою. У цiй нормi простiр(D[a, b], ‖ · ‖) не є сепарабельним.
Iнший варiант визначення топологiї у D[a, b] — використання метрикиСкорохода — див. [1]. Використовуючи певний варiант цiєї метрики, про-стiр D[a, b] можна зробити сепарабельним. Цей метричний простiр будемопозначати D. (Означення простору D(Z) для Z ⊆ Rd див. [24]).

7.4. Слабка збiжнiсть випадкових функцiй 201
Простiр D(R) утворюється з простору D[0, 1] “розтягуванням” вiдрiзка[0,1] на R, наприклад, за допомогою логiстичної функцiї z(t) = 1/(1+e−t).Тобто D(R) = {y(z−1(·)) : y ∈ D[0, 1]}.
Нехай S — будь-який метричний простiр, {ζn} — деяка послiдовнiстьйого випадкових елементiв. Кажуть, що {ζn} слабко збiгається до випад-кового елемента ζ, якщо для будь-якої неперервної, обмеженої функцiїg : S → R виконується
limn→∞
E g(ζn) = E g(ζ).
Слабку збiжнiсть позначають ζn ⇒ ζ.Множина {ζn} випадкових елементiв S зветься компактною, якщо будь-
яка послiдовнiсть випадкових елементiв з цiєї множини має слабко збiжнупiдпослiдовнiсть.
Множина {ζn} випадкових елементiв S зветься щiльною, якщо длябудь-якого ε > 0 знайдеться компактна множина Kε ⊂ S, така, що
supn
P{ζn ∈ S \Kε} ≤ ε.
Теорема 7.4.1 (Теорема Прохорова) У будь-якому метричному просторiS для будь-якої множини випадкових елементiв з щiльностi випливаєкомпактнiсть.
Доведення див. [4] с. 33 або [21].Нехай ζ(t) — випадкова функцiя. Скiнченновимiрними розподiлами ζ
називають розподiли випадкових векторiв (ζ(t1), . . . , ζ(tk)), де t1,. . . ,tk —довiльнi точки з областi визначення ζ.
Функцiю ζ називають вибiрково неперервною на Z, якщо вона майженапевне є неперервною у всiх точках, тобто P{ζ ∈ C(Z)} = 1.
Теорема 7.4.2 Нехай {ζn} є послiдовнiстю випадкових елементiв D(Z)(вiдповiдно C(Z)) i ζ є випадковим елементом D(Z) (вiдповiдно C(Z)).Якщо всi скiнченновимiрнi розподiли ζn слабко збiгаються до вiдповiднихскiнченновимiрних розподiлiв ζ i набiр {ζn} є компактним у D(Z) (вiдпо-вiдно C(Z)), то ζn ⇒ ζ у D(Z) (вiдповiдно C(Z)).
Теорема 7.4.3 (див. Bikel, Wichura, 1971) Якщо {ζn} — набiр елементiвз D(Z) i
(i) ζn ⇒ ζ у D(Z),(ii) ζ є вибiрково неперервною на Z,то ζn ⇒ ζ у D(Z) у рiвномiрнiй нормi.

202 Роздiл 7. Допомiжнi вiдомостi
Теорема 7.4.4 Нехай ζn — послiдовнiсть випадкових елементiв у C(Z),де Z — компакт у Rd i виконуються наступнi умови.
1. Для деяких C > 0, α > 0, β > 0 i всiх n = 1, 2, . . . , всiх t, s ∈ Z,
E |ζn(t)− ζn(s)|α ≤ C|t− s|d+β.
2. Сiм’я випадкових величин ζn(t0) є щiльною при деякому t0 ∈ Z.Тодi набiр{ζn} є щiльним у C(Z).
Доведення див. наслiдок 2.7.1 у [4].
Лема 7.4.1 Нехай Xn — послiдовнiсть випадкових процесiв з D[a, b], та-ких, що для деяких γ > 0, α > 1/2 i всiх a ≤ t1 < t < t2 ≤ b,
E |Xn(t)−Xn(t1)|γ|X(t2)−X(t)|γ ≤ (t2 − t1)2α.
Тодi сiм’я розподiлiв Xn є щiльною в D[a, b].
Доведення див. теорему 15.6 у [1].
Лема 7.4.2 Нехай X — випадковий процес на iнтервалi [a, b] i для деякихγ > 0, α > 1/2 та неспадної неперервної функцiї F на [a, b], ∀ a ≤ t1 < t <t2 ≤ b
E |X(t)−X(t1)|γ|X(t2)−X(t)|γ ≤ (F (t2)− F (t1))2α.
Тодi iснує така константа C, яка залежить лише вiд α i γ, що для всiхε > 0
P{ supt∈[a,b]
|X(t)| ≥ ε} ≤ P{|X(a)| > ε/2}+P{|X(b)| > ε/2}+ C
ε2γ|F (b)−F (a)|2α.
Доведення. Згiдно з нерiвнiстю (15.30) з [1], в умовах леми iснує такаконстанта K < ∞, що
P
{sup
t∈[a,b]
min{|X(t)−X(t1)|, |X(t2)−X(t)|} ≥ ε
}
≤ 2K
ε2γ|F (b)− F (a)| sup
t,s∈[a,b]
|F (t)− F (s)|2α−1
=2K
ε2γ|F (b)− F (a)|2α. (7.8)
Для того, щоб у деякiй точцi t ∈ [a, b] мало мiсце |X(t)| > ε, необхiднощоб або |X(a)| > ε/2, або |X(t)−X(a)| > ε/2, або |X(b)−X(t)| > ε/2, або|X(b)| > ε/2. Тому, враховуючи (7.8), отримуємо твердження леми.

7.5. Ефективнiсть. Мiнiмакснiсть. Iнформацiя. 203
7.5 Ефективнiсть. Мiнiмакснiсть. Iнформацiя.Iнформацiйна матриця Фiшера. Нехай спостережуванi данi X є ви-падковим елементом деякого вимiрного простору X з розподiлом P{X ∈A} = Pϑ(A) визначеним з точнiстю до невiдомого параметра
ϑ = (ϑ1, . . . , ϑd)T ∈ Θ ⊆ Rd.
Будемо припускати, що для деякої мiри µ та для всiх ϑ ∈ Θ iснує щiльнiстьfϑ(·) розподiлу Pϑ вiдносно µ, тобто
Pϑ(A) =
∫
A
f(x)µ(dx).
Позначимо f ′ϑ(x) =(
∂∂ϑ1
fϑ(x), . . . , ∂∂ϑd
fϑ(x))T
— градiєнт fϑ(x) як функ-цiї вiд ϑ (припускаючи, звичайно, що цей градiєнт iснує). Iнформацiйноюматрицею Фiшера (або просто iнформацiєю) що мiститься у даних X пропараметр ϑ називають
IXϑ =
∫f ′ϑ(x)(f ′ϑ(x))T µ(dx)
fϑ(x)= E(log fϑ(X))′((log fϑ(X))′)T .
Iнакше кажучи, IXϑ = (iik)
dj,k=1, де
ijk =
∫∂fϑ(x)
∂ϑj
∂fϑ(x)
∂ϑk
µ(dx)
fϑ(x)= E
∂ log fϑ(X)
∂ϑj
∂ log fϑ(X)
∂ϑk
.
Iнформацiя не залежить вiд вибору мажоруючої мiри µ.Якщо данi X складаються з незалежних спостережень: X = (ξ1, . . . , ξN),
тоIXϑ = Iξ1
ϑ + Iξ2ϑ + · · ·+ IξN
ϑ
(властивiсть адитивностi iнформацiї, див. теорему 7.1 роздiлу 1 [10]).Набiр (X,Pϑ, Θ) називають статистичним експериментом. Експеримент
називають регулярним, якщо1.fϑ(x) є неперервною функцiєю ϑ для майже всiх x вiдносно мiри µ.2. Iснує скiнченна iнформацiя Фiшера IX
ϑ для всiх ϑ ∈ Θ.3. Iснує неперервна як елемент L2(µ) похiдна функцiї f
1/2ϑ (·) у серед-
ньому квадратичному (вiдносно мiри µ).(Бiльш докладно див. у п. 7 роздiлу 1 [10]).

204 Роздiл 7. Допомiжнi вiдомостi
Нерiвнiсть Крамера для незмiщених оцiнок. Нехай (X,Pϑ, Θ)— регулярний статистичний експеримент, ϑ — незмiщена оцiнка ϑ (тоб-то E ϑ = ϑ). Тодi
Covϑ(ϑ) ≥ (IXϑ )−1, (7.9)
де Covϑ(ϑ) — коварiацiйна матриця ϑ у випадку, коли справжнє значенняневiдомого параметра дорiвнює ϑ. (Див. теорему 7.3, п. 7 роздiлу 1 [10]).
Локальна асимптотична нормальнiсть i мiнiмакснiсть. Сiм’ю(послiдовнiсть) статистичних експериментiв (XN , PN
ϑ , Θ), N = 1, 2,. . . на-зивають асимптотично локально нормальною (ЛАН) у точцi t ∈ Θ приN → ∞ якщо для деякої невиродженої матрицi ϕN = ϕN(t) i будь-якогоu ∈ Rd справедливе зображення
∂PNt+ϕNu
∂PNt
(XN) = exp
(uT ∆N,t − 1
2|u|2 + ψN(u, t)
),
де ∆N,t ⇒ ζ при N →∞, ζ — гауссiв вектор з нульовим середнiм та одинич-ною коварiацiйною матрицею, ψN(u, t) → 0 за ймовiрнiстю при N →∞.
При цьому ϕN називають нормуючою матрицею послiдовностi експе-риментiв (XN , PN
ϑ , Θ).Нехай XN = (ξ1, . . . , ξN), де ξj — незалежнi випадковi елементи з щiль-
ностями fj(x) = fj(x, ϑ) вiдносно мiр µj. Позначимо
Ψ2(ϑ,N) =N∑
j=1
Iξj
ϑ
Теорема 7.5.1 Нехай Θ ⊆ Rd, матриця Ψ2(ϑ,N) строго додатньовизна-чена, i виконанi наступнi умови:
1. Для всiх k > 0,
limn→∞
sup|u|<k
n∑j=1
∫ ((∂f
1/2j (x, t + Ψ−1(n, t)u)
∂t
− ∂f1/2j (x, t)
∂t
)T
Ψ−1(n, t)u
2
µj(dx) = 0.
2. Умова Лiндеберга: для всiх ε > 0, u ∈ Rd,
limn→∞
N∑j=1
Et
[(uT Ψ−1(n, t)
∂fj(ξj, t)
∂t
)2

7.6. Оцiнювання щiльностi за кратними вибiрками 205
×1I(∣∣∣∣uT Ψ−1(n, t)
∂fj(ξj, t)
∂t
∣∣∣∣ > ε
)]= 0,
Тодi сiм’я XN є ЛАН з нормуючою матрицею ϕ(n, t) = Ψ−1(n, t).
(Див. теорему 6.1 роздiлу 2 [10]).
Теорема 7.5.2 (Гаека) Нехай сiм’я XN задовольняє ЛАН у точцi ϑ = tз нормуючою матрицею ϕN → 0 при N → ∞. Тодi для будь-якої послi-довностi оцiнок TN = TN(XN), будь-якого δ > 0 i будь-якого h ∈ Rd,
lim infN→∞
sup|ϑ−t|<δ
Eϑ(hT ϕN(TN − ϑ))2 ≥ E(hT ζ)2, (7.10)
де ζ — гауссiв вектор з нульовим середнiм та одиничною коварiацiйноюматрицею.
(Див. теорема 12.1 роздiлу 2 у [10]).Послiдовнiсть оцiнок TN для яких у (7.10) має мiсце рiвнiсть назива-
ють локально асимптотично мiнiмаксними (асимптотично ефективними урозумiннi Гаека).
7.6 Оцiнювання щiльностi за кратнимивибiрками
Використовуючи теорiю, описану у попередньому параграфi, можна знахо-дити нижню межу для швидкостi збiжностi параметричних оцiнок у регу-лярних випадках. Виявляється, що ця теорiя дозволяє також отримуватиподiбнi результати у задачах параметричного оцiнювання. Ми зупинимосьтут на оцiнках щiльностi розподiлу.
Нехай данi X = (ξ1, . . . , ξN) являють собою вибiрку з незалежних, одна-ково розподiлених випадкових величин, причому iснує щiльнiсть розподi-лу ξj (вiдносно мiри Лебега). Позначимо цю щiльнiсть через f . Функцiя fневiдома, але вважається, що вона належить класу Гьольдера Σ(β, L) длядеяких 0 < β < ∞, 0 < L < ∞.
Нагадаємо означення Σ(β, L). Нехай β = k + α де k — невiд’ємне цiлечисло, α ∈ (0, 1]. Функцiя f : R → R належить Σ(β, L) тодi i тiлькитодi, коли у неї iснує неперевна k-та похiдна f (k)(x) i для всiх x1, x2 ∈ Rвиконана нерiвнiсть
|f (k)(x1)− f (k)(x2)| ≤ L|x1 − xk|α.

206 Роздiл 7. Допомiжнi вiдомостi
По сутi, β є показником гладкостi функцiї f . Наприклад, при β = 1 класГьольдера Σ(1, L) являє собою клас функцiй, для яких виконується умоваЛiпшиця з константою L:
|f(x1)− f(x2)| ≤ L|x1 − xk|.
При β = 2, Σ(2, L) це клас функцiй, таких, що їх першi похiднi задоволь-няють умову Лiпшиця. (Тобто умова f ∈ Σ(2, L) є трохи слабшою, нiжумова обмеженостi другої похiдної f).
Нехай FN — клас всiх можливих оцiнок щiльностi, побудованих по спо-стереженнях X.
Теорема 7.6.1 Для будь-яких L > 0, β > 0, x ∈ R,
lim infN→∞
inffN∈FN
supf∈Σ(β,L)
Ef
[(fN(x0)− f(x0))N
β/(2β+1)]2
> 0.
(Див. теорему 5.1 роздiлу 4 у [10]).Iнакше кажучи, швидкiсть збiжностi оцiнок щiльностi не може бути
кращою нiж N−β/(2β+1) де β — показник гладкостi оцiнюваної щiльностi.Точнiше, для будь-якої оцiнки fn знайдеться така f ∈ Σ(β, L), для якої[Ef (fN(x0)− f(x0))
2]1/2
> cN−β/(2β+1) для деякого c > 0 i всiх N . Такушвидкiсть збiжностi забезпечують ядернi оцiнки щiльностi при правиль-ному виборi параметра згладжування (hN = N−1/(2β+1)).
У випадку багатовимiрних однаково розподiлених спостережень X =(ξ1, . . . , ξN), ξj ∈ Rd, для двiчи диференцiйовних щiльностей ядернi оцiнкизабезпечують оптимальну швидкiсть збiжностi N−2/(4+d) (див. [34, 54]).

Лiтература
[1] Биллингсли П. Сходимость вероятностных мер.- М.: Наука, 1977.—357с.
[2] Боровков А.А. Математична статистика.- М.: Наука, 1984.— 472с.
[3] Боровков А.А. Теория вероятностей.- М.: Наука, 1986.
[4] Булдыгин В.В. Сходимость случайных элементов в топологическихпространствах. — Киев.: Наукова думка, 1980. — 240с.
[5] Булдыгин В.В., Козаченко Ю.В. Метрические характеристики слу-чайных величин и процессов.- Киев: TViMS, 1998.— 289с.
[6] В.Н.Вапник Индуктивные принципы поиска эмпирических законо-мерностей., в кн. -Распознавание -Классификация -Прогноз, Вып. 1.“Наука”, Москва, 1989, 17–81.
[7] Вапник В.Н., Червоненкис А.Я. Теория распознавания образов.- М:Наука, 1974.— 416с.
[8] Гихман, И.И., Скороход А.В., Ядренко М.И. Теория вероятностей иматематическая статистика.- Киев: Вища школа, 1979.— 408с.
[9] Л.Деврой, Л.Дьерфи Непараметрическое оценивание плотности.Мир, Москва,1988.—408 с.
[10] Ибрагимов И.А., Хасьминский Р.З. Асимптотическая теория оцени-вания. — М. : Наука, 1979. — 528с.
[11] Ю.О.Iванько, Р.Є.Майборода Експоненцiальнi оцiнки емпiрично-баєсового ризику при класифiкацiї сумiшi зi змiнними концентрацiя-ми, Український математичний журнал.— т. 54 (2002), №10.— 1421–1428.

208 Лiтература
[12] Ю.О.Iванько Асимптотика ядерних оцiнок щiльностей та їх похiд-них, побудованих за спостереженнями iз сумiшi зi змiнними концен-трацiями, Вiсник КНУ, сер. Математика. Механiка 2003.— вип. 9-10,29-35.
[13] Козаченко Ю.В. Лекцiї з теорiї вейвлетiв.— К.: ТВiМС, 2004.— 147с.
[14] Королюк В.С., Портенко Н.И., Скороход А.В., Турбин А.Ф. Спра-вочник по теории вероятностей и математической статистике. —М.:Наука, 1985. — 640 с.
[15] Майборода Р.Є. Статистичний аналiз сумiшей.— К.: ВПЦ “Київськийунiверситет”, 2003.— 176с.
[16] Э.А.Надарая (). Об интегральной среднеквадратической ошиб-ке некоторых непараметрических оценок плотности вероятно-сти.//Теория вероятностей и ее применения.— 1974 т. 19.— c.131-139.
[17] Петров В.В. Предельные теоремы для сумм независимых случайныхвеличин.— М., Наука, 1987.— 320с.
[18] Похилько Д.I. Вейвлет-оцiнки щiльностi по спостереженням з сумi-шi// Теорiя ймовiрн. та математ. статист.— 2004.— Т. 70.— с. 121-130.
[19] Похилько Д.I. Адаптивна оцiнка щiльностi компоненти сумiшi.— Тео-рiя ймовiрн. та математ. статист.— 2006.— Т. 74.— с. 129-142.
[20] Похилько Д.I. Експоненцiйнi нерiвностi для швидкостi збiжностi врiвномiрнiй нормi вейвлет-оцiнки щiльностi компоненти сумiшi.—Вiсник КНУ. Серiя: фiзико-математичнi науки.— 2006.— N 1.— c/40–47.
[21] Прохоров Ю.В. Сходимость случайных процессов и предельные тео-ремы теории вероятностей.— Теория вероятностей и ее применения,1956, т.1.— с. 177-238.
[22] Прохоров Ю.В. Одна екстремальная задача теории вероятностей.—Теория вероятностей и ее применения, 1959, т.4, N.2, c.211-214.
[23] Скороход А.В. Исследования по теории случайных процессов.— Ки-ев, Изд-во КГУ, 1961.— 216с.

Лiтература 209
[24] Bickel P.J. The 1980 Wald memorial lectures on adaptive estimation.—Ann. Statist., 1982, v. 10, N.3.— p.647–671.
[25] Bordes L., Mottelet S., Vandekerkhove P. Semiparametric estimationof a two-component mixture model.- Ann. Statist.- 2006.- v.34, No 3.-p.1204-1232.
[26] Bordes L., Delmas C., Vandekerkhove P. Semiparametric Estimation of atwo-component Mixture model where one component is known.- Scand.J. Statist.- 2006.- v. 33.- p. 733-752.
[27] H.Chernoff Estimation of the mode.— Ann. Inst. Statist. Math.— 1964,16.— 31-41р.
[28] Cover T.M., Hart P.E. Nearest neighbor pattern classification.— IEEETrans. on Information Theory, 1967.— V.IT-13, p.21-27.
[29] Federer H. Geometric Measure Teory.— Springer Verlag: 1969.
[30] Gyorfi L. On the rate of convergence of nearest neighbor rules.— IEEETrans. on Information Theory, 1978.— V.IT-24, p.509-512.
[31] Gyorfi L. Recent results on nonparametric regression estimate andmultiple classification.— Problems of Control and Information Theory,1981.— V.10, N1, p.43-52.
[32] Hall P., Zhou X.-H. Nonparametric estimation of componentdistributions in a multivariate mixture.— Ann.Statist. 2003, V. 31, No1, 201-224.
[33] Hall P., Titterington D. M. The use of uncategorized data to improvethe performance of a nonparametric estimator of a mixture density.— J.Roy. Statist. Soc. Ser. B. 1985, v. 47.— p. 155–161.
[34] Hardle W., Muller M., Sperlich S., Werwatz A. Nonparametric andSemiparametric Models.— Berlin, Springer, 2004.— 300p.
[35] Hoeffding W. Probability inequalities for sums of bounded randomvariables.— J. Amer. Math. Assoc.— 1963, V. 58, N. 301.— p. 13-30.
[36] Holzmann H., Munk A., Gneiting T. Identfiability of Finite Mixtures ofElliptical Distributions.— Scand. J. Statist., 2006, v. 33.— p. 753–763.

210 Лiтература
[37] Hunter D.R., Wang S., Hettmansperger T.R. Inference for mixtures ofsymmetric distributions.- Technical Report 04-01, Penn State University,Philadelphia, 2004.- 39p.
[38] J.Kim, D.Pollard Cube root asymptotics.— Annals of statistics 1990V.18,№1.— 191-219.
[39] McLachlan G. J., Basford K.E. Mixture models: Inference andApplications to Clustering.— New York: Dekker, 1988.— 312p.
[40] McLachlan G. J., Peel D. Finite Mixture Models.— NY, Wiley.— 2000.
[41] L. Mohammadi, S van de Geer, On threshold-based classification rules.—Institute of Mathematical Statistics, Lecture Notes Monograph Series,Mathematical Statistics and Applications: Festschrift for Constance vanEeden. 42 (2003).— p.261–280.
[42] Newcomb S. A generalized theory of combination of observations so asto obtain the best result.— Amer. J. Math.— 1894.— V.8.— p. 343-366.
[43] Pearson K. Contribution to the mathematical theory of evolution.— Phil.Trans. Roy. Soc. A.— 1894.— v. 185.— p. 71–110.
[44] Pollard D. Convergence of Stochastic Processes.— New-York: Springer-Verlag, 1984.— 456p.
[45] Teicher H. Identifiability of mixtures.— Ann. Statist.— 1961.— v. 32,N1.— p. 244-248.
[46] Shao J. Mathematical statistics.- NY Berlin Heidelberg: Springer-Verlag,1999.— 530p.
[47] H. Shen On methods of sieves and penalization.— Ann. Statist. 1997V.25, No 6.— p.2555-2591.
[48] Stone C.J. Consistent nonparametric regression.- Ann. Statist., 1977,V.5.— p.595-645.
[49] Stone C. Adaptive maximum likelihood estimation of a locationparameter.— Ann. Statist., 1975, v.3.— p. 267–284.

Лiтература 211
[50] Tarasenko F.P. On the evaluation of an unknown probability densityfunction, the direct estimation of the entropy from independentobservations of a continuous random variable and the distribution-freetest of goodness-of-fit.— Proceedings IEEE, 1968, v. 56, N 1, p.2052-2053.
[51] Titterington D.M., Smith A.F. and Makov U.E. Analysis of FiniteMixture Distributions.- New York: Wiley, 1985.— 364p.
[52] Vaart A. W. van der, Welner J.A. Weak convergence and empiricalprocesses.— Springer-Verlag, NY, 1996, 512p.
[53] V.N.Vapnik The nature of Statistical Learning Theory. New York,Springer, 1996.
[54] Wand, M.P., Jones, M.C. Kernel Smoothing, Vol 60 of Monographson Statistics and Applied Probabaility.— London, Chapman and Hall,1995.— 212 p.
[55] Yakovitz S.A., Spragins J. On the identifiability of finite mixtures.— Ann.Math. Statist., 1968, V. 39, N1.— p.209-214.

СПИСОК ПОЗНАЧЕНЬ⇒ — слабка збiжнiстьSk→ — збiжнiсть за Скороходом1I{A} — iндикатор подiї A (1I{A} =
1 якщо A виконано, 1I{A} = 0якщо A не виконано)
〈a〉N = 1N
∑Nj=1 aj:N — оператор усе-
реднення N -того рядка три-кутного масиву a
〈a〉 = limN→∞〈a〉Nak — масив мiнiмаксних вагових
коефiцiєнтiв для оцiнки роз-подiлу k-тої компоненти
D — простiр функцiй, неперервнихзлiва
FN(x, a) — зважена емпiричнафункцiя розподiлу з вагови-ми коефiцiєнтами a
Hk(A) — розподiл спостережува-них характеристик k-тої ком-поненти сумiшi (A ∈ A)
Hk(x) — функцiя розподiлу спосте-режуваних характеристик k-тої компоненти сумiшi (x ∈Rd)
hk(x) — щiльнiсть розподiлу спо-стережуваних характеристикk-тої компоненти сумiшi
M — кiлькiсть компонент сумiшiE ξ — математичне сподiвання ви-
падкової величини ξ
E(ξ | η) — умовне математичнесподiвання випадкової вели-чини ξ при фiксованому η
P{A} — ймовiрнiсть подiї AP{A | B} — умовна ймовiрнiсть
подiї A за умови BR — множина дiйсних чиселP{A | η}— умовна ймовiрнiсть подiї
A при фiксованому ηX — простiр можливих значень да-
нихA — σ-алгебра вимiрних множин з
Xwk
j:N — концентрацiя k-тої компо-ненти сумiшi пiд час j-тогоспостереження
ΓN = (〈wkwm〉N)Mk,m=1 — матриця
Грама концентрацiй для ви-бiрки з N спостережень
Γ = (〈wkwm〉)Mk,m=1 — гранична мат-
риця Грама при N →∞µ(A, a) — зважена емпiрична мiра з
ваговими коефiцiєнтами aΞN = (ξj:1, . . . , ξj:N) — вибiрка з су-
мiшi зi змiнними концентра-цiями
Ξ = (ΞN , N = 1, 2, . . . ) — трикут-ний масив вибiрок
з.е.ф.р. — зважена емпiричнафункцiя розподiлу
м.н. — майже напевне


![83інформації можна почерпнути з літератури, при-свяченої загальній історії графічного дизайну [2]. Зокрема,](https://img.pdfslide.tips/doc/110x75/5e52adcd51a0ad78ac40fd52/83-f-f.jpg)


























