Embed Size (px)
Citation preview

NAVER Privacy White Paper


인공지능, 빅데이터, 사물인터넷 등의 융합으로 우리 사회에 큰 변화를 가져올 거
라고 기대하는 4차 산업혁명에 대한 관심이 뜨겁습니다. 초연결 사회에서 쏟아져 나
오는 빅데이터를 인공지능 등의 기술 발전에 활용하여 4차 산업혁명 시대를 활짝 열
기 위해서는 ‘개인정보’에 대한 논의가 선결되어야 합니다.
‘개인정보’와 관련있는 논의의 경우 한편에선 인간의 기본권으로서의 개인정보 보
호에 대해서만 강조하고, 다른 한편에서는 규제 완화를 통한 기술과 산업의 발전만을
강조합니다. 그런데 개인정보의 ‘보호’와 ‘활용’은 동전의 양면과 같아서 둘을 분리하여
생각할 수 없습니다. 정부와 기업이 시민(정보주체)의 개인정보를 잘 보호해 줄 거라
는 믿음이 있을 때에만 이용자는 기술 진보와 사회적 효용의 증대를 위해 자신의 개
인정보가 사용되는 것에 동의할 것이기 때문입니다. 그럼에도 개인정보의 ‘보호’와 ‘활
용’에 대한 논의는 함께 이루어지지 못 하고 있는 것이 현실입니다.
개인정보의 강력하고 실질적인 보호, 기술 혁신을 저해하지 않는 데이터의 자유로
운 활용과 유통이라는 두 마리 토끼를 모두 잡을 수 있는 방안을 고민하는 일련의 과
정에서 「NAVER Privacy White Paper」를 발행하였습니다. 올해는 경희대학교 박훤일
교수님께서 ‘개인정보의 로컬라이제이션(Localization)’을, 서울대학교 김용대 교수님께
서 ‘인공지능과 개인정보’를, 법무법인 민후의 김경환 변호사님이 ‘규제 측면에서의 한국 ․EU ․일본의 개인정보보호 법령’에 대해 연구해 주셨습니다.
부디 세 분의 연구가 효과적이며 실질적인 개인정보 보호 강화, 그리고 기술 혁신
과 발전을 위한 불필요한 규제 완화라는 두 마리 토끼를 동시에 모두 잡을 수 있는
논의의 실마리가 되길 기대합니다.
2017년 12월
한성숙
발간사

개인정보의 로컬라이제이션에 관한 연구_ 박훤일 (경희대학교 법학전문대학원 교수)
요약문 ································································································································ 11
1. 머리말 ··························································································································· 17
2. 개인정보 로컬라이제이션의 동기 ············································································· 20
가. 국가안보와 질서유지 ··························································································· 20
나. IT 거대기업에 대한 종속 탈피 ·········································································· 21
다. 공정 과세의 실현 ································································································ 22
라. 국내 기업의 역차별 방지 ··················································································· 24
마. 클라우딩 서비스의 이용 추세에서 U턴 ··························································· 24
3. 주요국의 사례 ············································································································· 25
가. 중국 ······················································································································· 26
나. 베트남 ··················································································································· 32
다. 인도네시아 ············································································································ 34
라. 인도 ······················································································································· 36
마. 유럽연합(EU) ······································································································· 36
바. 러시아 ··················································································································· 39
사. 그 밖의 나라들 ·································································································· 40
4. 개인정보 현지화 규제에 대한 평가 ········································································· 42
5. 결 론 ·························································································································· 43
참고문헌 ···························································································································· 45
목차

인공지능과 개인정보에 관한 연구_ 김용대 (서울대학교 통계학과 교수)
요약문 ································································································································ 51
1. 서론 ······························································································································ 55
2. 인공지능의 역사 ·········································································································· 58
가. 개척기(1952~1956) ·························································································· 58
나. 황금기(1956~1974) ·························································································· 58
다. 암흑기(1974~1980) ·························································································· 60
라. 개화기(1980년대) ······························································································· 60
마. 1990년대부터 현재까지의 인공지능 ································································ 61
3. 인공지능 기술들 ·········································································································· 62
가. 지도학습(Supervised learning) ········································································ 63
나. 비지도학습(Unsupervised learning) ······························································· 71
다. 강화학습(Reinforcement learning) ································································ 73
4. 인공지능 응용사례 ······································································································ 76
가. 의료 분야 ············································································································· 76
나. 금융 분야 ············································································································· 77
다. 교육 분야 ············································································································· 78
라. 쇼핑 분야 ············································································································· 78
마. 지능형 개인비서 ·································································································· 79
바. 기계번역 ··············································································································· 80
사. 자율주행 ··············································································································· 80
아. 기타 ······················································································································· 81
5. 프라이버시 침해와 인공지능 윤리 ··········································································· 81
가. 비식별화된 연구용 진료기록의 재식별화 ························································· 82
나. 스마트폰 어플리케이션을 통한 개인정보 유출 ··············································· 84
다. 광고 전달 시스템에 의한 인종차별 ·································································· 87
라. 얼굴 인식을 이용한 개인의 성적 지향 판별 ··················································· 89

6. 프라이버시 보호 관련 법률체계 고찰 ····································································· 90
가. 개인정보의 개념 ·································································································· 91
나. 주요 국가의 개인정보 보호를 위한 법률체계 ················································· 92
다. 주요 국가의 개인정보 비식별처리에 관한 접근 ············································· 95
라. 빅데이터 산업발전을 위한 법률체계 정비 ······················································· 96
7. 프라이버시 보호를 위한 기술들 ··············································································· 98
가. 데이터 변환을 통한 프라이버시 보호 ······························································ 98
나. 차등 정보 보호 ·································································································· 104
8. 맺음말 ························································································································· 107
가. 프라이버시 보호를 위한 법률적 · 기술적 측면 ·············································· 107
나. 윤리적 측면 ········································································································ 107
다. 결어 ····················································································································· 108
참고문헌 ·························································································································· 109
규제 측면에서의 한국 ․ EU ․일본의 개인정보보호 법령의 비교
_ 김경환 (법무법인 민후 대표 변호사)
요약문 ·························································································································· 121
1. 서설 ························································································································ 123
가. 규제의 개념 ······································································································ 123
나. 개인정보 규제의 특징 ····················································································· 124
다. 본 연구에서의 규제 비교의 방법 ·································································· 126
2. 수집 · 이용 관련 실체적 규제의 비교 ································································ 128
가. 일반 개인정보 수집 · 이용의 ‘허용 사유’의 비교 ········································ 128
나. 민감정보 수집 · 이용의 ‘허용 사유’의 비교 ·················································· 131
다. 목적 외 이용의 ‘허용 사유’의 비교 ···························································· 136

3. 제공 · 위탁 관련 실체적 규제의 비교 ································································ 140
가. 제공의 ‘허용 사유’의 비교 ··········································································· 140
나. 위탁의 ‘절차’의 비교 ····················································································· 144
다. 국외 이전의 ‘허용 사유’의 비교 ·································································· 145
4. 관리 · 파기 관련 실체적 규제의 비교 ································································ 149
가. ‘파기 사유’의 비교 ························································································· 149
나. ‘개인정보 유효기간 제도’의 비교 ·································································· 151
5. 종합적인 평가 ······································································································· 152
6. 결어 ························································································································ 154
참고문헌 ······················································································································ 155


경희대학교 법학전문대학원 박훤일 교수
2017 NAVER Privacy White Paper
개인정보의 로컬라이제이션에 관한 연구


11
1. 머리말
1. 머리말
ㅇ개인정보의 로컬라이제이션(Data Localization, ‘현지화’ 또는 ‘국지화’)이란 정보통신
을 이용하는 기업이 개인정보의 보관 ・ 처리를 위한 서버를 반드시 국내에 설치하도록
의무화하는 것을 말함
- 데이터 보관 장소라기보다 정보열람에 대한 통제 등 효과적인 관할(Effective
Jurisdiction)에 관한 문제 또는 데이터의 해외 반출에 대한 규제를 의미
- 정보보안, 개인정보 보호, 국가안보, 제품의 안전기준, 자국 산업의 보호 ・ 육성 등을
이유로 소스코드 공개를 요구하거나 데이터의 현지 보관, 로컬 콘텐츠의 이용 등
규제를 강화(Forced Localization Measures; FLMs)하는 경향이 증대
ㅇIoT ・ 빅데이터 시대에 정보의 자유로운 유통을 통해 경제 활성화 기대
- 반면 개인정보 보호 법제의 통일 관점에서 개인정보의 로컬라이제이션 성행
- 미국, 유럽, 일본 등은 2013년부터 데이터 로컬라이제이션 경향에 공동 대응함으로
써 정보의 자유로운 유통과 공평하고 평등한 사이버 공간의 확보를 위해 노력
2. 개인정보 로컬라이제이션의 동기
ㅇ스노든이 미 정보당국의 전 세계 감청활동(PRISM)을 폭로한 것을 계기로 많은 나라
가 국가안보와 국익보호 목적으로 데이터 현지화를 요구
- 독일은 정부 데이터를 국내 저장하는 클라우드 인프라(Bundes-cloud)를 구축하고,
EU 회원국들에 대해서도 범유럽 데이터 네트워크를 갖출 것을 제안
- 브라질은 미국을 우회하는 남미와 유럽 간의 정보통신망을 연결하는 해저 광섬유
케이블 설치 계획을 제안하는가 하면 2014년 4월에는 인터넷 이용자의 권리와 서
비스 제공자의 의무를 규정한 마르코 시빌법을 제정
- 중국에서도 자국민들에 대한 사상통제와 정치적 안정을 위해 정부당국이 인터넷 트
래픽의 국내 유입과 국외 유출을 통제할 수 있는 정보장벽을 설치하고 2017년부터
는 네트워크 안전법으로 보다 구체화
요약문

12
- 안보 목적의 데이터 현지화는 오히려 해킹 등 공격 목표를 명확히 하는 것이 되어
더 위험에 처할 수 있다는 비판이 있음
ㅇ EU의 경우 개인정보의 보호 수준이 낮은 제3국으로의 개인정보의 이전을 불허
- 해외에서 자국민의 개인정보가 침해되는 일이 없도록 개인정보 보호 차원에서 정보
의 국외 이전을 규제
ㅇ 구글, 아마존 등 미국의 IT기업들이 플랫폼을 장악하고 정보유통시장을 지배하는 것
에 대한 경계심으로 데이터 로컬라이제이션 요구 증가
- EU에서는 미국계 플랫폼 기업에 대한 데이터 시장을 탈환하기 위해 정보의 역내
보관을 의무화하기보다 GDPR에 정보이동권(right to data portability)을 규정
- 일부 동남아 국가에서는 자국 내 하이테크 경제활동을 촉진하기 위해 로컬 콘텐츠
를 요구하고 해외 콘텐츠에 대해서는 높은 세율을 부과
ㅇ 여러 나라가 다국적 IT기업들이 국내에서 엄청난 광고 수입을 올리면서도 세금을 거
의 내지 않는 행태를 방지하기 위해 국내에 서버(데이터 센터)를 두도록 유도
- EU에서는 애플, 구글 같은 IT기업들의 ‘Double Irish with Dutch Sandwich’ 전략
을 깨기 위한 방안을 모색 중이며, 프랑스 정부는 구글, 페이스북 같은 IT기업에 대
해 수익이 아닌 매출액(turnover) 기준으로 과세하기로 결정
- 우리나라에서도 구글 등 다국적 기업의 현지 세금회피를 막기 위해 비상장 유한회
사의 경 내용을 공시하도록 하는 관련법 개정안을 발의
- 현지에 서버를 구축하는 것이 단기적으로는 지역경제에 도움이 될지 몰라도 장기적
으로는 외국인투자 의욕을 저상시키고 외국 기업과의 협력사업을 방해하는 등 역효
과 우려
ㅇ 우리나라가 구글의 공간정보 요구를 거절한 것은 이에 응할 경우 보안규정을 적용받
고 있는 국내 기업에 대한 역차별 가능성 때문
- 한국은 국내서버 설치를 조건으로 내걸었으나 구글은 글로벌한 업방침에 반한다
는 이유로 거부함에 따라 최종 불허 결정
- 데이터 로컬라이제이션은 금융권 ・ 제조업 ・ 의료 서비스 업계 클라우딩 서비스의 이
용 증가 추세를 역행하는 것임

13
- 국제적인 정보유통에 로컬라이제이션의 장벽이 설치된다면 경제적으로 심각한 타격,
GDP가 0.7∼1.7% 감소할 것으로 전망(미 IT 분야 씽크탱크 ITIF의 추계)
3. 주요국의 사례
국가 FLMs 조치 주요 내용
중 국
네트워크 안전법
(2017. 6. 1 시행)
•인터넷 공간의 주권과 국가안보의 유지, 공민과 법인, 기
타 조직의 합법적 권익 보호
•개인정보를 비롯한 데이터의 보안 강화
•핵심 정보통신 기반시설(CII) 운 자에 대한 엄격한 책임
과 의무 부과
•중국에서 수집 ・ 창출된 개인정보와 중요 데이터는 현지
서버에 저장하도록 의무화하고, 반대로 데이터를 중국 밖
으로 전송할 경우에는 사이버보안당국 및 국무원의 보안
평가를 거쳐야 함
•필요시 당국에 기술 제공 및 수사에 협력하고, 이용자 게
시정보에 대한 관리를 강화하고, 필요조치를 수행한 후
유관기관에 보고
•네트워크 보안책임 등 불이행시 과징금 부과
은행 ・ 금융기관의 개인정보
보호를 촉구하는
중국인민은행 통지(2011)
•중국 인민의 개인신용정보의 해외 처리 ・ 저장을 금지
은행업 네트워크 보안 및
정보화 건설 강화에 관한
지도의견(2014. 9)
•은행업무의 사이버 안전보장 능력과 정보화 건설 수준을
향상시키는 안전하고 제어 가능한 정보기술의 개발 및 응
용
자율적 가이드라인(2013) •개인정보의 국외 이전에 정보주체의 동의를 받도록 요구
전 인민 건강정보
관리조치(2014)•중국에서 수집된 인구 건강정보의 국외 저장을 금지
베트남
인터넷 통화, SM서비스의
제공 및 이용의 관리에
관한 규정(2013 OTT통달)
•유상 OTT 서비스 제공 해외사업자는 (i) 사업인가를 취득
한 베트남 국내사업자와 동업계약, 또는 (ii) 베트남 국내
에 1개 이상의 호스트 서버를 설치하고 베트남 국내의 사
업자와 업무협약을 체결
정령 72호
(No.72/2013/ND-CP)
•일반 웹사이트나 SNS 웹사이트 사업자는 베트남에 감독
당국의 검사를 받는 하나 이상의 서버 설치 의무
인도네
시아
전자시스템과 거래조직에
관한 규정
(2012년 정부규정 제82호)
•공공서비스 전자시스템 관리자는 데이터 센터를 국내 설
치 의무
•건강정보는 보건부장관이 관리하는 데이터 센터와 연결되
어 있는 국내의 데이터 센터에서 처리 의무화
통신정보부규정
(2015년 정부규정 제27호)
•4G 스마트폰에 대하여 30∼40%의 로컬 콘텐츠 탑재
의무화

14
주: OTT(Over the Top)란 셋톱박스 같은 단말기를 넘어서서 인터넷과 모바일을 이용한 화 ・ 방송 ・ 교육 등 각종
미디어 콘텐츠를 제공하는 서비스를 말함
4. 개인정보 현지화 규제에 대한 평가
ㅇ 데이터 로컬라이제이션의 요구는 IT 발전에 역행하고 디지털 무역장벽(Digital Trade
Barrier)을 쌓는 것으로 인터넷의 본질에 반함
- FLMs 규제는 개방적인 인터넷의 기능과 자원을 조각(fragmentation) 내고 비효율
적으로 만드는 것으로 클라우딩이나 데이터 센터에 의존하는 신생기업 ・ 중소기업의
업에 큰 타격
- 장기적으로 IT산업의 발전을 위축시키고 경제성장에도 차질
- 다만, 개인정보 보호의 수준이 낙후된 제3국에 개인정보의 반출을 일정 조건하에
불허하는 것은 불가피한 조치
ㅇ 오늘날 외국 정보기관에 의한 감시 우려, 개인정보 보호의 필요성으로 인해 증가일
로의 개인정보 로컬라이제이션에 맞설 수 있는 세력은 단독이든 연합이든 가시화되
지 않고 있는 실정
국가 FLMs 조치 주요 내용
OTT 규정•외자계 기업이 OTT 서비스 제공할 때에는 국내에 항구적
시설(BUT)을 두어야 함
인 도 M2M 로드맵
•국가안보의 관점에서 인도 국내의 이용자들에게 서비스를
제공하는 M2M 게이트웨이나 어플용 서버는 모두 인도
국내에 설치
유럽연합
(EU)
개인정보보호지침
(Directive 95/46/EC);
GDPR(2018.5.25 발효)
•개인정보 보호가 미흡한 제3국으로의 개인정보 이전 불
허. 다만, 자율규제, 표준계약서, BCRs 등 안전대책을 갖
춘 경우에는 허용
러시아 연방법 제242호-FZ•러시아 국민의 개인정보는 러시아 국내에 설치된 데이터
베이스로 관리하고, 데이터 센터의 소재를 당국에 신고
한 국 공간정보관리법
•국가안보나 그 밖에 국가의 중대한 이익을 해칠 우려가
있는 경우 기본측량성과를 국외로 반출하는 것을 원칙적
으로 금지
호 주건강기록 시스템
관련 법규
•등록된 포털 운 자 또는 등록된 계약 서비스 제공자인
건강기록(My Health Records) 시스템 운 자는 개인 식
별 가능한 호주시민의 건강기록을 해외에서 보관 ・ 처리하
는 것 금지

15
- 데이터 로컬라이제이션이 심화될수록 이용자들의 데이터 이용범위가 줄어들고 제조
업 ・ 서비스업 종사자들은 유용한 정보에 대한 접근 기회를 상실하게 됨
- 현지 정부가 정보의 자유로운 유통을 정치적인 위협으로 보고 비민주적인 목적을
위해 데이터를 이용하려 들 경우에는 표현의 자유, 프라이버시에 대한 중대한 위협
이 될 가능성
5. 결론
ㅇ 인터넷 시대에 데이터 로컬라이제이션을 요구하는 법제는 나름대로 명분이 있음
- 우리나라도 북한이 장거리 미사일과 무인기를 날리고 있는 현실에 비추어 상세한
지리정보를 공개하는 것은 매우 위험한 처사
- 다른 한편으로는 디지털 공간정보가 유통 ・ 관광산업 및 자율주행차 ・ 드론의 이용에
없어서는 안 될 인프라가 되었음
ㅇ 결국은 서로 충돌하는 가치의 비교형량 문제로 귀결
- 정보의 파편화(fragmentation)를 초래하는 로컬라이제이션을 비판하기보다 다국적
거대 IT기업에 주도권을 뺏기지 않기 위해 국가안보 및 공정과세를 강조하고 국내
IT산업을 보호하자는 식으로 경제적 실리를 취할 수도 있음
ㅇ 장기적으로는 인터넷이 세계의 모든 기업과 개인의 능동적 참여를 통해 시장이 지속
적으로 확대되고 이노베이션이 촉발되었다는 점을 상기할 필요
- 인터넷의 발칸화(Internet Balkanization)를 초래하는 데이터 로컬라이제이션은 바
람직하지 않으며 국경간 정보유통(Transborder Data Flow)의 원활화에 확고한 신
념을 가져야 함
- 세계경제의 고른 성장과 IT발전을 통하여 새로운 시대를 맞기 위해서는 정보의 원
활한 국제유통에 대한 예외 사유는 그것이 안보 목적이든 무엇이든 엄격하게 해석
하는 것이 타당함


17
관한 연구
박훤일 (경희대학교 법학전문대학원 교수)
1. 머리말
개인정보의 로컬라이제이션(data localization)은 개인정보의 ‘현지화’ 또는 ‘국지화’라고 번
역할 수 있는데 정보통신을 이용하는 기업이 개인정보의 보관 ・ 처리를 위한 서버를 반드시 국
내에 설치하도록 의무화하는 것을 일컫는 말이다. 물리적인 데이터 보관 장소(physical data
location)라는 의미보다도 정보열람에 대한 통제 등 효과적인 관할(effective jurisdiction)에
관한 문제라 할 수 있다. 그 연장선상에서 데이터의 해외 반출(data export)에 대한 규제를
뜻하는 말로 쓰이기도 한다.1)
최근 들어 중국, 베트남, 인도네시아, 인도, 러시아 등 여러 나라가 정보보안, 개인정보 보
호, 국가안보, 제품의 안전기준, 자국 산업의 보호 ・ 육성 등을 이유로 소스코드 공개를 요구하
거나 데이터의 현지 보관, 로컬 콘텐츠의 이용 등 규제를 강화(forced localization
measures; FLMs)하는 경향이 늘고 있다.2) IT산업 발전에 따른 이점을 충분히 살리기도 전에
클라우드 컴퓨팅, 사물인터넷(IoT) 산업에 대한 제약요인이 되고 있는 것이다.
<그림 1>에서 보듯이 개인정보의 로컬라이제이션이 전세계적으로 증가하는 추세에 있기
때문에 정보의 자유로운 유통(free flow of data)의 관점에서는 우려를 낳고 있다. 왜냐하면
1) W. Kuan Hon, Data Localization Laws and Policy - The EU Data Protection International Transfers Restriction
Through a Cloud Computing Lens, Edward Elgar, 2017.
2) 베트남, 인도네시아에서는 법률이 아주 추상적으로 규정되어 있고 그 시행세칙인 정령(Decree)과 통달(Circular)에 구체적
인 규정을 두는 경우가 많다. 그러므로 FLMs가 어디에 규정되어 있는지 특정하는 것은 쉽지 않다. 베트남은 2013년 정
령 72호에서 대표자 또는 법인을 베트남 국내에 두도록 요구하고 있다. 엉뚱하게도 정보통신 소관부처 이외의 법률이나
시행세칙에 FLMs 규정을 두기도 한다.
개인정보의 로컬라이제이션에 관한 연구

18
사물인터넷(IoT), 빅데이터 시대에는 정보가 자유롭게 흘러야 이노베이션이 활성화될 터인데
현지 규제에 따라 경제적 고려 없이 무조건 데이터 센터를 설치해야 하고 경우에 따라서는
콘텐츠의 제약도 받을 수 있기 때문이다. 반면 개인정보 보호 법제의 통일이라는 관점에서 살
펴본다면 무엇이 각국의 입법자로 하여금 개인정보의 로컬라이제이션을 택하게 하는지 그 동
기를 알아볼 필요가 있다.
이러한 가운데 미국과 유럽, 일본은 2013년부터 서로 손을 잡고 개인정보의 로컬라이제이
션에 대한 규제에 공동 대응하기로 했다.3) 2016년 5월 일본에서 열린 G7 정상회의에서도
개방적이고 상호운용 가능하며 신뢰할 수 있는 사이버 공간에서 삶의 질을 개선하기 위한 디
지털 경제를 촉진할 것을 공동선언문에 포함시킨 바 있다.4) 한편 일본과 EU는 2015년 정보
의 자유로운 유통과 사이버 공간의 공평하고 평등한 확보를 위해 규제와 협력에 힘을 모으기
로 했다.
이 연구는 모든 것을 인터넷으로 서로 연결하는 시대에 개인정보의 로컬라이제이션 쪽으로
입법 전환을 하는 동기가 무엇인지, 나라마다 FLMs 규제를 어떻게 실시하고 있는지 살펴본
후 국내외의 반응을 알아보고자 한다. 나라마다 특별한 사정이 있기 마련이지만 여러 이점에
도 불구하고 이를 적극적으로 시행할 수 없는 속사정도 있기 때문이다. 마지막으로 우리나라
는 이러한 추세에 어떻게 대응하는 것이 좋을지 생각해 보기로 한다.
3) 일례로 일본의 経済団体連合会(Keidanren)과 在日 미국상공회의소는 양국이 환태평양경제동반자협정(Trans-Pacific
Partnership; TPP)에 참가한 것을 계기로 2016년 2월 25일 “日米 IED民間作業部会共同声明2016”을 내고 Data Localization
과 Cross-border Data Flow 문제를 심도 있게 다루었다. <http://www.keidanren.or.jp/policy/2016/015.html>
4) G7 이세시마 정상회담 자료는 <http://www.mofa.go.jp/ecm/ec/page4e_000457.html> 참조.

19
<그림 1> 데이터 로컬라이제이션의 국가별 현황
지도상의 색 데이터 해외 이전에 대한 제한의 정도 해당 국가
[매우 엄격] 개인정보는 국내 설치된 서버
에 보관되어야 함
러시아, 중국, 인도네시아,
베트남, 브루네이, 나이지리아
[사실상 엄격] 개인정보의 국외 이전을 법
령으로 제한함으로써 사실상 데이터 현지
화가 이루어지고 있음
유럽연합(EU)
[부분적 제한] 국외 이전할 수 없는 정보
의 종류를 지정하거나 정보의 국외 이전
에 정보주체의 동의를 요함
한국, 인도, 말레이시아,
카자흐스탄, 벨라루스
[완 화] 일정한 조건하에서만 정보의 국외
이전을 제한함
아르헨티나, 브라질, 콜롬비아,
페루, 우루과이
[특정분야 제한] 헬스케어, 이동통신, 금
융, 국가안보 등의 분야에 한하여 정보의
국외 이전을 제한함
타이완, 캐나다, 오스트레일리아,
뉴질랜드, 터키, 베네수엘라
[제한 없음] 데이터 현지화 의무가 없음 미국, 일본 등 기타 국가
자료: Albright Stonebridge Group, Data Localization: A Challenge to Global Commerce and the Free Flow of Information, September 2015, p.5.
주: 개인정보의 국외 이전을 제한하고 데이터 현지화를 요구하는 법령은 수시로 바뀔 수 있으므로
명확히 분류하기 어려운 점이 있으며 저자가 작성시점을 기준으로 평가하여 소개한 것임

20
2. 개인정보 로컬라이제이션의 동기
<그림 1>의 세계지도에서 보듯이 정도의 차이는 있지만 데이터 현지화를 요구하는 나라들
이 더 많은 게 사실이다. 그러나 그 동기가 나라마다 조금씩 다른 것을 알 수 있다. 우선 미
국 국가안보국(National Security Agency; NSA)에서 근무했던 에드워드 스노든이 미국 정보
당국의 전 세계를 대상으로 한 정보수집과 감시활동(PRISM)을 폭로한 것을 계기로 국가안보
와 국익보호 목적으로 국내 수집 정보의 국내 보관 및 처리를 요구하는 경우가 많아졌다.
그러나 자국민의 개인정보가 국제교역이나 해외 아웃소싱 등의 목적으로 해외 반출된 경우
에 해외에서 자국민의 개인정보가 침해되는 일이 없도록 하는 개인정보 보호(data protection)
차원에서 정보의 국외 이전을 불허하는 경우도 많다.
최근에는 다국적 IT 거대기업들이 국내에서 많은 수익을 얻음에도 불구하고 세금을 안 내
거나 적게 내는 것을 방지하기 위해 국내에 서버를 설치하고 고정사업장(permanent
establishment)을 두게 하려는 의도도 엿보이고 있다.
가. 국가안보와 질서유지
2013년 7월 스노든의 폭로 이후 독일에서는 연방개인정보감독기구가 나서서 외국의 정보
기관들이 독일 기업들이 전송하는 데이터에 외국의 정보기관이 무단 접근하는 것을 규제할
수 있음을 밝혔다. 이와 함께 독일 정부가 지분을 갖고 있는 도이체 텔레콤에서도 독일 국내
에서의 인터넷 트래픽을 최대한 국내에 유지하려는 방침을 협력업체에 시달하고, 다른 EU 회
원국들에 대해서도 EU만의 유럽 데이터 네트워크를 갖출 것을 제안했다.5) 다만, 이러한 조치
는 외국 정보기관이 독일 데이터를 열람하는 것을 근본적으로 방지하기 위한 대책이 될 수
없다는 비판이 제기되었다.6)
5) 독일 메르켈 정부는 유럽에서 발신되는 이메일과 전기통신의 망을 분리하는 범구주 정보통신망 구축에 앞장서고 있으며,
정부 데이터를 저장하는 클라우드 인프라(Bundes-cloud)를 2022년까지 개통하기로 했다. Albright Stonebridge Group,
Data Localization: A Challenge to Global Commerce and the Free Flow of Information, September 2015, p.8
(이하 “Data Localization”이라 약칭함).
6) 허진성, “데이터 국지화(Data Localization) 정책의 세계적 흐름과 그 법제적 함의”, 언론과 법 제13권 2호, 2014. 295
∼296면.

21
이와 관련하여 브라질의 호세프 대통령도 미국을 우회하는 남미와 유럽 간의 정보통신망을
연결하는 해저 광섬유 케이블 설치 계획을 제안하면서, 브라질 우정국에 암호화된 이메일 시
스템 개발을 지시하 다. 의회에 대해서는 구글, 마이크로소프트 등 미국의 IT기업들이 브라질
이용자에 대한 데이터를 국내 서버에 보관할 것을 의무화하려 했으나 거센 반대에 부딪혀 이
것은 제외한 채 2014년 4월 인터넷 이용자의 권리와 서비스 제공자의 의무를 규정한 마르코
시빌 법(Marco Civil da Internet Law)을 공포하 다.7)
중국에서도 자국민들에 대한 사상통제와 정치적 안정을 위해 외부 인터넷 연결을 막지는 않
아도 일정한 경우 정부당국이 인터넷 트래픽의 국내 유입과 국외 유출을 통제할 수 있는 정보장
벽8)을 설치하 다. 이는 후술하는 2017년의 네트워크 안전법에서 보다 구체화되었다. 이란에서
도 중국에서 전문가들을 불러와 종교적으로 허용되는 인터넷을 구축하는 작업을 진행하 다.
그러나 안보 목적의 데이터 현지화는 오히려 해킹 등 공격 목표를 명확히 하는 것이 되어
더 위험에 처할 수 있다는 비판이 가해지고 있다.
나. IT 거대기업에 대한 종속 탈피
유럽에서는 구글, 아마존, 마이크로소프트, 페이스북 등 미국의 IT기업들이 플랫폼9)을 장악
하고 정보유통 시장을 지배하는 것에 대한 경계심이 고조되었다. 2017년 초까지 유럽의회 의
장을 역임한 독일 사민당 대표 슐츠(Martin Schulz)는 거대 IT기업(Digital Giants)에 의한
데이터 시장의 지배는 경제문제에 한하지 않고 사회질서의 문제로 직결될 것이라고 경고하기
도 했다.10)
7) Dan Cooper, “Brazil Enacts “Marco Civil” Internet Civil Rights Bill”, Covington & Burling LLP April 28, 2014.
<https://www.insideprivacy.com/international/brazil-enacts-marco-civil-internet-civil-rights-bill/>.
8) 중국은 1994년 외부 웹과 연결된 이래 1998년에는 인터넷 트래픽의 유 ・ 출입을 통제할 수 있는 황금방패(Golden
Shield) 시스템을 설치하여 세계에서 가장 정교한 정보장벽 이른바 ‘Great Firewall’(정보의 만리장성)을 구축하 다.
9) 이러한 플랫폼은 중세 시대에는 봉건 주와 교회, 길드조합 등 중간조직에 속하 고 개인의 인권은 도외시되기 일쑤 다.
기본적 인권이 강조되는 21세기의 정보사회에서도 플랫폼을 누가 지배하느냐에 따라 이러한 사정은 마찬가지다. 개인이
정보사회에서 자율적으로 활동하고, 이러저러한 플랫폼에서 조각난 인격을 스스로의 의사로 재통합하기 위해서는 자신의
정보를 소유하고 이전할 수 있는 정보이동권이 앞으로 정보사회의 불가결한 인권으로 인식될 것이다. 生貝直人, “自律 ・ 分
散 ・ 協調社会とデータポータビリティーの権利”, 経済産業省分散戦略ワーキンググループ 第6回, 2016.7.27, 24面.
10) EU의회의 슐츠 전 의장은 2016년 1월 유럽의 CPDP(컴퓨터, 프라이버시, 개인정보보호) 컨퍼런스에서 다음과 같이 말했
다. “만일 개인정보가 21세기의 가장 중요한 상품이 되고 있다면 자신의 정보에 대한 개개인의 소유권을 강화하는 것은
정치인과 사법부의 임무이다. 이러한 상품에 아무도 대가를 지불하지 않고 이용만 하려 드는 상황에서 디지털 자이언츠가
새로운 세계질서를 형성하는 것을 허용하여서는 아니 된다.”

22
이러한 유럽인들의 심리는 EU의 개인정보보호규정(General Data Protection Regulation;
GDPR 2018.5.25 EU회원국내 법률로서 발효)에 정보이동권(Right to Data Portability;
RDP)을 규정함으로써 구체화되었다.11) 만일 정보이동이 안 된다면 어느 한 사람의 개인정보
는 특정 정보처리자의 서버에 갇혀(lock-in) 있거나 다양한 사업자와 정부기관에 분산 보관될
것이다. 인터넷 환경에서는 구글과 페이스북, 애플, 아마존12) 사례에 비추어 플랫폼 기업에
정보가 집중될 것임이 명약관화하다. 특히 인공지능, IoT, 빅데이터, 로봇 등에 의한 4차 산업
혁명 시대에 플랫폼을 장악한 거대 IT기업에 정보가 집중되는 상황은 가상공간뿐만 아니라 이
러한 정보가 이용되는 제조업, 의료 및 교통 서비스 산업, 사회 전반에 걸쳐 중대한 향을
미치게 될 것이라는 점은 쉽게 짐작할 수 있다. 이에 따라 EU에서는 주로 미국계 IT 플랫폼
기업에 대한 데이터 시장을 탈환하기 위한 무기로 EU내 유통 정보의 역내 보관을 의무화하기
보다13) 정보이동권을 강조하고 나왔던 것이다.
그리고 일부 동남아 국가에서는 자국 내 하이테크 경제활동을 촉진한다는 의도하에 로칼
콘텐츠를 요구하고 해외 콘텐츠에 대해서는 높은 세율을 부과하기도 한다. 이를테면 ‘디지털
중상주의(Digital Mercantilism)’의 도래라 할 만하다.14)
다. 공정 과세의 실현
다국적 IT기업들이 국내에서 엄청난 광고 수입을 올리면서도 세금을 내지 않거나 아주 적
은 금액만 납부하는 행태가 많은 나라에서 문제가 되고 있다. 2013년 5월 EU 정상회담에서
도 다국적기업의 조세회피 문제를 거론하고 EU 차원에서 공동대처하기로 의견을 모았다. 실
제로 프랑스 정부는 구글, 페이스북, 아마존과 같은 IT기업에 대해 수익이 아닌 매출액(turnover)
기준으로 과세하기로 한 바 있으며, 2017년 9월 EU 집행위에서도 다국적 IT기업들이 현지법인
11) GDPR Article 20 and para. 68 of Preamble. 박훤일, “정보이동권의 국내 도입 방안 - EU GDPR의 관련 규정을 중심
으로”, 경희법학 제52권 3호, 2017.9.30., 214∼221면 참조.
12) 세계 정보유통시장의 플랫폼을 지배하는 이들 IT기업의 머리글자를 따서 ‘GFAA’라고 부른다.
13) EU의 데이터보관지침(EU Data Retention Directive, Directive 2006/24/EC)은 2014년 4월 유럽사법재판소(Court of
Justice of the European Union; CJEU)로부터 사생활에 대한 기본적 인권 및 개인정보 보호를 광범위하고 심각하게 침
해하므로 소급하여 위법 무효라고 선고받았다. Covington & Burling, “EU Data Retention Directive Declared Invalid by
CJEU”, Inside Privacy, April 8, 2014. <https://www.insideprivacy.com/international/european-union/eu-data-retention-
directive-declared-invalid-by-court-of-justice-of-the-eu/>
14) Stuart Lauchlan, “Data localization rules damage the global digital economy, says US tech thinktank”,
Diginomica, May 3, 2017. <http://diginomica.com/2017/05/03/data-localization-rules-damage-global-digital-economy
-says-us-tech-thinktank/>

23
같은 물리적 실재가 없다는 이유에서 일반 기업의 23.2%에 비해 크게 낮은 10.1% 세율의
법인세만 납부하는 것을 시정하기로 방침을 굳혔다.15) 애플과 구글 같은 IT기업들은 이른바
‘Double Irish with Dutch Sandwich’ 전략16)을 구사하여 미국 외 매출에 대한 원천지 과세
를 회피해 온 것으로 알려져 있다.
이러한 실정에 비추어 정교한 세법 규정을 갖추지 못한 동남아 국가에서는 세계적인 검색 ・
사회관계망 서비스(SNS) 운 기업에 대해 자국 내에 서버를 두도록 하고 이를 근거로 과세하
는 방법을 택하고 있다. 우리나라에서도 구글은 유한회사인 구글 코리아가 소규모 벤처기업으
로 분류되어 있어 외부감사나, 매출액을 공시할 의무가 없다. 2016년 중 구글은 우리나라에
서 구글 플레이 앱을 통한 유료 앱 판매액과 유튜브 동 상 광고 매출, 검색 광고료 등으로
2조 원 이상의 매출을 올린 것으로 추정된다. 그럼에도 한국 내 구글 매출액은 광고 판촉만
벌이는 구글 코리아가 아닌 법인세가 낮은 싱가포르 소재 구글 아시아퍼시픽의 수입으로 잡
히며, 최종적으로는 법인세율이 낮고 조세감면 혜택도 많은 아일랜드에서 세금을 내는 것으로
되어 있다. 정부는 2017년 1월 구글을 비롯한 다국적 기업의 현지 세금회피를 막기 위해 비
상장 유한회사의 경 내용을 공시하도록 하는 관련법 개정안을 발의했지만 법안 심리는 무기
한 연기된 상태이다.17)
그러나 현지에 서버를 구축하게 하는 FLMs 정책이 단기적으로는 데이터 센터의 설치, 정
보통신 기술직 채용의 증가를 가져와 지역경제에 도움이 될 수 있을 것이다. 그러나 장기적으
로는 정보흐름의 단절은 외국인투자 의욕을 저상시키고 유망한 프로젝트에 대한 외국 기업과
의 협력사업을 방해하는 등 역효과가 더 크다는 비판도 만만치 않다.18)
15) The Guardian, “EU to find ways to make Google, Facebook and Amazon pay more tax”, 21 September 2017.
<https://www.theguardian.com/business/2017/sep/21/tech-firms-tax-eu-turnover-google-amazon-apple>
16) 구글(2015. 8.부터는 지주회사인 알파벳)은 아일랜드에 자회사를 설립한 후 연구개발비의 일부만 받기로 하고 지적재산권
을 자회사에 이전한다. 이 자회사는 직접 업을 하지 않고 100% 자회사를 만들어 지재권을 사용하는 업을 유럽과 아
프리카에서 수행하도록 한다. 이때 네덜란드에 세 번째 자회사를 만들어 지재권의 사용과 그 사용료를 중개하는 역할을
맡긴다. 아일랜드 세법 및 조세조약에 따라 EU 역내의 모회사나 자회사에 지급한 사용료에 대해 원천과세를 하지 않는
것을 이용한 편법이다. 그 결과 대부분의 국외 업이익은 구글이 아일랜드에 처음 만든 자회사에 쌓이지만 아일랜드 세
법상 미국 본사(버뮤다에 설립된 또 다른 구글 자회사)의 지배를 받는 비거주자로 취급되므로 아일랜드에서 법인세를 신
고 납부할 필요가 없는 것이다. 안종석, “다국적 IT기업의 조세회피 행태와 시사점; 애플 ・ 구글의 사례를 중심으로”, 재정포
럼 2013. 7, 8∼10면.
17) 조선일보, “한국 게임으로 1兆 챙긴 구글… 세금은 '깜깜'”, 2017. 9. 15; Insight, “'구글', 국내서 2조 버는데 세금은 한
푼도 안 낸다”, 2017. 5. 15. <http://www.insight.co.kr/newsRead.php?ArtNo=105579>
18) Albright Stonebridge Group, Data Localization, p.7.

24
라. 국내 기업의 역차별 방지
우리나라의 경우 한 ・ 미 FTA에서 미국은행 고객의 금융거래 정보를 해외에서 처리하는 문
제를 둘러싸고 논란이 많았다. 그 결과 한 ・ 미 FTA 제13부속서에서 각 당사국은 상대국의 금
융기관이 일상적인 업과정에서 개인정보의 처리가 요구되는 경우 그의 처리를 위해 자국
역 안과 밖으로 정보를 전자적 또는 그 밖의 형태로 이전하는 것을 허용하기로 했다. 다만,
금융정보의 해외 이전을 허용한다고 하여 금융정보의 생성 ・ 저장을 위한 IT 설비, 금융전산망
등 본질적 요소들의 해외 이전까지 허용하는 것은 아니다.19)
한편 구글은 구글 맵 제작을 위해 2007년부터 공간정보의 반출을 줄곧 요구해 왔다.
2016년에도 정식으로 공간정보 반출을 요청하여 외국인투자 담당 부처에서는 긍정적인 의견
을 보 으나20) 최종적으로 국가안보에 지장을 줄 수 있고, 이를 허용하면 엄격한 보안규정을
적용받고 있는 국내 기업들에 대한 역차별이 된다는 이유에서 국내 서버 설치를 조건으로 내
걸었다. 그러나 해외의 클라우드 서비스를 이용하고, 앞서 설명한 바와 같이 글로벌한 관점에
서 세금을 줄이려는 구글 측이 이를 거부함으로써 그 해 11월 최종 불허 결정이 내려졌다.21)
마. 클라우딩 서비스의 이용 추세에서 U턴
세계적인 데이터 로컬라이제이션 추세와는 반대로 우리나라에서는 클라우드 컴퓨팅의 도입
은 이제 거스를 수 없는 대세가 되었다.22) IT 기업은 물론 가장 보수적인 은행들도 클라우드
도입에 적극적이다. 인공지능(AI)과 사물인터넷(IoT), 빅데이터 등 클라우드 인프라 및 플랫폼
이 각광을 받으면서 클라우드 도입율도 현재의 20%대에서 크게 높아질 것으로 보인다.23) 아
마존 같은 해외 클라우딩 서비스 업체를 이용할 경우 데이터는 해외에 소재하는 서버에 보관
될 것이다.
19) 박훤일, 「개인정보의 국제적 유통에 따른 법적 문제와 대책」, 집문당, 2015, 177∼178면.
20) Google Maps가 전 세계적으로 관광산업 및 무인자동차 사업에 널리 이용되고 있음에 비추어 공간정보 분야 국내 기업의 경
쟁력 향상과 외국인투자를 통한 기술제휴 및 협업을 기대할 수 있다는 의견도 있었지만, 그 효과는 일부 하청업체에만 해당되
고 장기적으로는 기술종속의 우려가 있다는 반론도 만만치 않았다. 오마이뉴스, “구글의 지도 국외반출 요구에 포털 ・ 네비 업
체 ‘역차별’ 반발”, 2016.6.20. <http://www.ohmynews.com/NWS_Web/View/at_pg.aspx?CNTN_CD=A0002219482>
21) 2016년 11월 18일 경기도 수원 국토지리원에서 열린 기본측량성과 국외반출협의체 3차 회의에서 협의체는 국가안보를
이유로 구글의 기본측량성과 반출 요청에 대해 불허 결정을 내렸다.
22) 일반적으로 외국에 있는 클라우드컴퓨팅 서비스 업체의 약관에 동의하는 방식으로 서비스 이용이 개시되나 개인정보가 포함되어
있는 경우에는 개인정보보호법, 정보통신망법과 관련하여 주의를 요한다(클라우드컴퓨팅 발전 및 이용자 보호에 관한 법률 제4조).
23) 디지털 데일리, “[주간 클라우드 동향] 2017 국내 클라우드 도입, 어디까지 왔나”, 2017.10.16.
<http://www.ddaily.co.kr/cloud/news/article.html?no=161209>

25
금융권에서도 챗봇과 같은 AI 기반 신기술 수용 사업을 클라우드 기반에서 운 하는 사례
가 늘고 있다. KB국민은행의 경우 2017년 9월에 오픈한 대화형 뱅킹플랫폼 ‘리브똑똑’에 아
마존 웹서비스의 인프라를 이용하고 있으며, 신한금융그룹도 오는 11월부터 아마존의 음성인
식 AI를 통해 파일럿 서비스를 개발하기로 했다.
제조업체들은 스마트 팩토리와 관련하여, 의료부문은 정밀의료나 원격진료 등 여러 분야에
서 클라우드 서비스 및 기술의 도입을 적극 검토하고 있다. 클라우드 주무부처인 과학기술정
보통신부에서도 전국 산업단지에 입주한 기업을 대상으로 다양한 클라우드 서비스 요금을 최
대 70%까지 지원해 중소 규모 제조기업의 경쟁력을 높이기로 했다. 조달청 나라장터의 종합
쇼핑몰에도 2개의 클라우드 인프라 서비스(IaaS)가 정식 등록됨에 따라24) 클라우드 서비스가
확대될 전망이다.
이에 따라 국제적인 정보유통에 로컬라이제이션이라는 장벽이 설치된다면 경제적으로 심각
한 타격을 주게 될 것임이 틀림없다. 미국의 IT분야 씽크탱크인 ITIF (Information Technology
and Innovation Foundation)에 의하면 미국에서는 데이터 로컬라이제이션의 결과 GDP가
0.1∼0.36% 줄어드는 효과가 발생할 것으로 전망했다. 이미 데이터 현지화법을 시행하고 있
는 브라질, 중국, EU, 인도, 인도네시아, 한국, 베트남에서도 정도의 차이는 있지만 GDP가
0.7∼1.7% 감소할 것으로 내다보았다.25)
3. 주요국의 사례
이하에서는 위에서 설명한 정책적 동기에 비추어 우리나라가 참조할 수 있는 데이터 현지화
를 의무화하고 있는 중국, 베트남, 인도네시아, 인도, 러시아 등의 FLMs 규제 현황과 대응책을
살펴보기로 한다.
24) IaaS (Infrastructure as a Service)란 서버, 네트워크 장비, 스토리지 등 인프라 자원을 구매하지 않고 인터넷을 통해 서비
스 형태로 임대해 이용하는 서비스를 말한다. 조달청의 종합쇼핑몰 나라장터에는 NAVER 비즈니스플랫폼과 케이티가 IaaS
를 클라우딩으로 제공하는데 이를 이용하려면 KISA가 발급하는 보안 인증을 받아야 한다. IaaS 사용료는 서비스를 사용한
만큼 청구되며, 웹 방화벽, 데이터관리시스템(DBMS), 백업 등 부가서비스도 함께 제공된다. 전자신문, “나라장터에서 인프
라 클라우드 서비스 이용하세요”, 2017.9.27. <http://www.etnews.com/20170927000385>
25) Stuart Lauchlan, op.cit.,
<http://diginomica.com/2017/05/03/data-localization-rules-damage-global-digital-economy-says-us-tech-thinktank/>

26
가. 중국
1) 규제의 현황
중국은 거대한 인구를 기반으로 알리바바, 바이두, 탄센트와 같은 세계적인 IT 대기업을 둔
나라이지만 개인정보 보호에 관한 한 국제적인 흐름에 크게 뒤져 있다. 그런데 스노든 사건
이후 중국 정부가 국가안보법(國家安全法)과 테러방지법의 제정을 서두르면서 개인정보 보호
관련 규정을 마련하여 주목을 받았다. 지금까지 개인정보 보호를 위한 포괄적인 법 규정이 시
행된 적이 없기에 이들 법안에 들어 있는 개인정보보호에 관한 규정과 다른 한편으로는 이를
제약하는 규정들이 관심을 끌었다.
중국의 입법기관인 전국인민대표대회(全國人民代表大會)26)는 2016년 11월 7일 인터넷에 대
한 통제를 강화하고 네트워크 설비와 시설, 정보데이터 등에 관한 보안조치 등을 망라한 네트워
크 안전법(中國網絡安全法, PRC Cybersecurity Law)을 채택했다. 새 법률은 준비기간을 거쳐
2017년 6월 1일부터 시행되었다.27) 미국의 스노든 사건이 계기가 되었지만 사이버보안을 이유
로 국가기관에 대한 정보제공 및 기술협력 의무, 데이터의 로컬라이제이션 등 개인정보 보호가
뒤로 밀리는 현상이 벌어지게 된 것이다.
네트워크 안전법의 초안은 2015년 6월 발표되었고, 이후 두 차례의 심의 및 의견수렴 과정
을 거쳤다. 2016년 6월 진행된 제2차 심의 및 의견수렴 과정을 거친 최종안에는 인터넷 범죄에
대한 처벌 내용을 담은 4개 조항이 추가되었으며, 이후 최종안은 수정 없이 통과되었다.
2) 주요 내용
① 중국의 네트워크 안전법과 개인정보보호 이슈
네트워크 안전법의 입법 취지는 인터넷 공간의 주권과 국가안보의 유지, 공민과 법인 및
기타 조직의 합법적 권익을 보호하기 위한 것이다. 이 법은 사이버 공간에서의 프라이버시와
보안 관련 사안에 대해 포괄적으로 다룬 중국 최초의 법규라는 점에서 의의가 있다. 개인정보
를 비롯한 데이터의 보안을 강화한 측면도 있으나 시민들의 온라인 활동에 대한 감시 및 해
외기업에 대한 차별을 가져올 수 있는 규정을 포함하고 있다.
26) 중국 전국인민대표대회는 중국의 형식상 최고 권력기관으로서 22개 성 ・ 자치구 ・ 직할시, 홍콩(香港) ・ 마카오(澳門) 특별행
정구(特別行政區), 인민 해방군에서 선출되는 대표로 구성된다.
27) 개인정보보호포럼 ・ 한국인터넷진흥원, 「지능정보사회 선도를 위한 개인정보보호 이슈 및 동향」, 2017. 2.

27
중국 네트워크 안전법은 중국 내 정보통신망의 구축 ・ 운 ・ 유지보호 ・ 사용 및 그의 보안에
대한 감독 및 관리와 관련된 사항을 규정하고 있다. 이에 따라 개인 컴퓨터를 비롯한 정보 단
말기부터 온라인 서비스 제공 기업에 이르기까지 인터넷과 관련된 제반 역이 규제의 대상
이다.
네트워크 안전법은 △총칙(总则), △네트워크 보안 전략 ・ 기획 ・ 촉진(网络安全支持与促进), △
네트워크 운 보안(网络运行安全), △네트워크 정보 보안(网络信息安全), △모니터링 경보와 응
급조치(监测预警与应急处置), △법적 책임(法律责任), △부칙 등 총 7장 79조로 구성되어 있다.
네트워크 안전법은 ‘핵심 정보통신 기반시설(關鍵信息基礎施設, Critical Information
Infrastructures; CII)’ 운 자에게 엄격한 책임과 의무를 부과하고 있다. 이 법 제31조에서
‘핵심 정보통신 기반시설’이란 에너지, 교통, 수리시설, 금융, 의료, 방송, 공공서비스, 전자정
부 등 국가 중점시설 분야와 네트워크의 기능 파괴 또는 데이터 유출 시 국가안전과 공공이
익에 향을 미치는 정보통신 시설을 의미한다’고 정의하 다. 주요 정보통신 기반시설의 운
자는 각종 보안심사와 안전평가를 받아야 하며, 제37조에서는 중국에서의 사업수행 과정 중
수집되거나 창출된 중국 국민들의 개인정보(Citizens' Personal Information)와 중요 데이터
(Important Data)는 반드시 중국 현지에 소재한 서버에 저장하도록 의무화하고 있다. 그러나
합법적인 사업상의 이유로 인해 이 같은 데이터를 중국 외부에 있는 해외 법인이나 조직 등
에게 제공해야 하는 경우에는 중국의 사이버보안관리 당국 및 중국 국무원이 공동으로 마련
한 보안평가(Security Assessment)28)를 거치도록 했다.
② 네트워크 안전법과 개인정보보호 관련 사항
네트워크 안전법은 중국 정보통신산업부(MIIT)가 2011년 12월 정보통신망 보호규정을 제
정한 이래 정부 차원에서 추진해 온 개인정보 보호의 원칙을 법률로써 구체화한 성과물이라
할 수 있다.29) 특히 개인정보 보호와 관련하여 다음 사항들을 규정함으로써 개인정보 보호에
관한 의지를 표명하고 있다.
28) 네트워크 안전법에는 보안평가의 의미와 구체적인 내용이 명시되어 있지 않다. 당초 데이터 현지화 의무도 국내외 비판이
일자 모든 네트워크 운 자에서 CII로 범위를 좁혔는데 최종 시행시기도 18개월 연기한 것으로 알려졌다. Adam
Golodner, et al., China's New Cybersecurity Law Imposes Heightened Restrictions on Company
Computer Networks, Arnold Porter Kaye Scholer, July 20, 2017.
29) Graham Greenleaf and Scott Livingston, “China’s Cybersecurity Law – also a data privacy law?”, Privacy Laws
& Business International Report, December 2016, p. 7.

28
◦ 네트워크 운 자가 법규를 위반하거나 개인정보 수집 ・ 이용과 관련한 계약사항을 위반한
경우 정보주체가 해당 운 자에게 개인정보의 삭제를 요구할 수 있고, 수집되거나 저장된 정
보에 오류가 있을 때에는 이에 대한 수정을 요구할 수 있다(제43조).
◦ 개인이나 조직은 개인정보 획득을 목적으로 불법적인 수단을 동원하거나 개인정보를 절
취해서는 안 되며, 개인정보를 제3자에게 불법적으로 판매하거나 불법적으로 제공해서는 안
된다(제44조).
◦ 네트워크 보안 감사 및 관리 의무를 가진 조직이나 담당자는 업무과정에서 획득한 개인
정보와 상업적 비밀 정보에 대해 엄격한 보안을 유지해야 하며 제3자에게 이를 누설, 판매
또는 불법적으로 제공해서는 안 된다(제45조).
이 법은 기존 법령에 비하면 진일보하여, 이른바 글로벌 스탠더드라 할 수 있는 개인정보
침해 사실의 이용자에 대한 고지의무를 규정하 고 벌칙도 다소 강화되었다. 그러나 이용자의
정보열람권, 정보의 질(quality)이나 민감정보에 관한 규정은 빠져 있으며, 개인정보 보호와
감독을 담당하는 국가기관도 명시되어 있지 않다.30) 더욱이 중요 정보의 국내 처리 ・ 보관을
의무화하고 정보의 반출을 규제하고 있어 국제적인 흐름에 역행하고 있다.
입법취지를 보더라도 네트워크 안전법은 온라인상에서의 검열과 통제를 크게 강화하고 있
으며, 인터넷 활동에 대한 정부의 개입을 합리화하고 있는 것이 특색이다.
◦ 네트워크 안전법은 인터넷 서비스 제공업체에 대해 온라인 서비스를 제공하는 계약관계
를 맺을 때 반드시 실명정보(Real Identity Information)를 요구하도록 했다.
◦ 인터넷 서비스 제공업체 등이 당국에 기술 제공과 수사에 협력하도록 의무화하고, 사용
자가 게시한 정보에 대한 관리를 강화해 불법정보 발견 시 전송 중단, 제거, 확산 방지, 기록
보관 등의 조치를 수행하고 유관기관에 보고하여야 한다.
◦ 인터넷 서비스 제공업체는 수사기관에 대해 의무적으로 협조하도록 했으며 주관부처는
국가안보, 사회질서 유지 등을 위해 인터넷 서비스 제공업체에게 그 사용을 제한하는 임시조
치를 내릴 수 있다.
◦ 네트워크 로그 기록은 데이터 보관 규정에 따라 6개월 이상 보관하여야 한다.
30) Ibid., p. 3.

29
◦ 국가는 네트워크 운 자들이 네트워크 안전에 관한 정보를 수집 ・ 분석 ・ 신고하고 대응능
력을 증진함에 있어서 상호 협력하는 것을 지원한다.
◦ 네트워크 안전법은 법적 책임을 규정하는 제5장에서 법인이나 이와 관련된 책임자가 해
당 법률조항을 준수하지 않을 경우 경고, 과징금 부과, 부당이익 환수, 업정지, 사업면허 박
탈 등의 처벌을 가할 수 있도록 규정하고 있다. 네트워크 보안책임 등을 이행하지 않은 경우
1만 위안∼10만 위안의 과징금이 부과되며, 직접적인 관리 책임자에 대해서는 5천 위안∼5
만 위안의 과징금이 부과된다. 그 밖에 제59조부터 제75조에서는 다양한 상황에 대한 법적
책임을 부여하고 그에 상응한 과징금을 규정하고 있다.
③ 중국의 네트워크 안전법과 데이터의 로컬라이제이션 이슈
시진핑 정부에서는 사이버보안을 강조하면서 개인정보의 국내 보관 ・ 처리를 의무화할 것으
로 예견되었다. 연혁적으로 중국 정부는 국가기밀이나 일정한 금융정보, 의료정보 같은 민감
정보는 외국으로 이전하거나 외국에 보관하는 것을 금지시켜 왔다. 명백히 데이터의 국내 보
관 ・ 처리를 의무화한 것은 아니었지만 그러한 효과를 가져오도록 만들었다.
최근 들어서 중국 정부는 적극적으로 광범위한 개인정보 법제의 중요한 구성요소인 전자정
보의 국내 보관 ・ 처리를 의무화하고 있으며, 이러한 취지로 네트워크 안전법 규정이 마련되었
다. 중국이 이처럼 민감하게 반응한 것은 에드워드 스노든이 미국 정보기관의 PRISM 첩보수
집을 폭로한 것을 계기로 중국 공산당이 사이버보안을 강조하 기 때문이다. 그 당시만 해도
국가의 기간전산망이 외국 업체에 의존하는 사례가 적지 않았다. 스노든 폭로를 계기로 중국
은 인터넷 정책결정기구를 정비하고 시진핑 주석을 위원장으로 하는 중앙 사이버보안 및 정
보화 지도소조(中央网络安全和信息化领导小组, Central Leading Group for Cybersecurity
and Informatization)를 설치하 다. 인터넷 정책을 총괄 조정하는 중앙정부 조직(国家互联网信息办公室, Cyberspace Administration of China; CAC)도 만들었다.
그러니 이들 정부조직이 사이버 주권을 강조하면서 토 안에서 전송되는 인터넷 콘텐츠를
감독하고 통제하는 권한을 갖는 것은 당연한 귀결이었다. 그러니 인터넷 정책은 국내에서 외
국 기술이 안전하고 통제 가능할 것을 요구함과 아울러 정부의 통제와 감독을 기반으로 하는
것이었다. 그 중심은 인터넷 정보를 국외로 이전하는 것을 금하고 국내에 보관하도록 하는 정
보처리의 로컬라이제이션이었다.

30
전통적으로 중국의 인터넷 법령은 정보의 국외 이전을 금하고 일정한 민감정보는 국내에
저장하도록 했다. 중국 국가기밀법(国家机密法, China Secrets Law)에서 광의로 정의되는 국
가기밀(State Secrets)의 국외 이전은 금지되었다. 최근에는 산업별로 특화된 규정이 신설되
어 다른 유형의 민감정보를 여기에 포함시켰다.
◦ 중국 인민의 개인신용정보의 해외 처리 ・ 저장을 금지하는 2011년 은행 및 금융기관의
개인정보 보호를 촉구하는 중국인민은행 통지31)
◦ 은행업무의 사이버 안전보장 능력과 정보화 건설 수준을 향상시키도록 하는 안전하고
제어가능한 정보기술을 응용한 은행업 네트워크 보안 및 정보화 건설 강화에 관한 지도의견32)
◦ 개인정보의 국외 이전에 정보주체의 동의를 요하는 2013년 자율적 가이드라인33)
◦ 중국에서 수집된 인구 건강정보의 국외 저장을 금지하는 2014년 전인민 건강정보 관리
조치34)
④ 중국의 FLMs 규제에 대한 외국의 반응
2014년 테러방지법에서도 국내에서의 정보처리 및 보관을 요구하 다. 이에 따르면 인터
넷 콘텐트 제공자, 즉 웹사이트 또는 스마트폰 앱은 정부가 접속할 수 있는 백도어35)를 만들
고 비밀 암호키를 공안당국에 제출하도록 했다. 더욱이 이 법안에서는 이들 사업자가 중국 내
에 서버를 설치하고 국내 이용자들의 모든 데이터를 보관하도록 했다.
그러자 새 법률안의 의무사항은 외국 정부나 무역단체의 반발을 불러일으켰다. 미국의 오
바마 대통령은 시진핑 주석과 회담할 때 심각한 우려를 표명했다. 이에 따라 중국 정부는
2015년 12월에 제정한 테러방지법(恐怖活动防止法, PRC Anti-Terrorism Law)에서는 논란이
31) 中国人民银行关于金融机构进一步做好客户个人金融信息保护工作的通知 (Notice of the People's Bank of China on
Urging Financial Institutions to Further Effectively Protect Clients' Personal Financial Information) 2011.
32) 2014년 9월 중국은행업감독관리위원회(CBRC), 국가발전개혁위원회, 과학기술부, 공업정보화부가 공포한 关于应用安全可
控信息技术加强银行业网络安全和信息化建设的指导意见(文書番号: 銀監発 [2014] 39号) <http://www.cbrc.gov.cn
/govView_115696B8621049099A0B880DAB133A33.html>
33) Information Security Technology – Guidelines for Personal Information within Public and Commercial Services
Information Systems 2013.
34) 人口健康信息管理办法-试行 (Measures for Administration of Population Health Information – Trial Implementation)
2014.
35) 백도어란 제품, 컴퓨터 시스템, 암호시스템 등에서 정상적인 인증 절차를 우회하여 정식 승인을 받지 않고 시스템에 접속
하는 것을 말한다.

31
많았던 일부 조항을 삭제하거나 수정했다. 최종적으로 데이터의 국내 보관 ・ 처리 조항이 전부
빠졌고, 암호화 요건도 완화되어 공안당국이 요청하면 인터넷 콘텐트 사업자가 암호화 키를
곧바로 제공하는 대신 기술적 지원을 하도록 완화했다.
네트워크 안전법에서도 정보의 국내 보관 ・ 처리를 의무화하는 조항이 들어갔다. 테러방지법
에서 이러한 조항이 빠졌으나 전국인민대표대회에서는 네트워크의 안전을 도모하고 사이버 공
간에서의 주권을 확보하기 위해서는 중요 정보의 국내 보관 ・ 처리가 긴요하다고 여겼다. 그리
하여 중요정보 인프라(CII) 운 자는 중국 국내에서 운 하고 수집 ・ 생성된 개인정보 및 중요
데이터는 중국 국내에서 보관하도록 하고, 업무의 필요성에서 국외로의 제공할 필요가 있는
경우 국가 네트워크 정보부문은 국무원 관련부서에서 제정한 방법에 따라 보안성 평가를 받
도록 했다. 법률, 행정법규로 별도의 규정이 있는 것은 그 규정에 따른다(제37조). 하지만 막
판에 이 조항의 시행시기를 늦춘 것으로 알려졌다.
네트워크 운 자는 치안 및 국가안전 담당기관이 법에 의하여 국가의 안전유지 또는 범죄
수사 활동을 함에 있어 기술적 지원과 협력을 하여야 한다(제28조).
그 밖에 온라인 출판, 자동차 함께 타기(ride sharing), 인터넷 지도 서비스, 인터넷 뱅킹 ・ 증
권 서비스도 관련 규정에 따라 이용자의 개인정보를 중국 내에 보관 ・ 처리할 것을 요구하고 있다.
요컨대 중국 네트워크 안전법은 온라인 데이터의 해외 이전 및 저장에 대한 제약(FLMs)을
강화하고 개인정보 보호를 위한 규정을 명시한 점에서 주목된다.
중국 정부는 스노든의 폭로로 드러난 사이버 위협의 증가 추세를 이유로 사이버보안 강화
및 온라인 정보에 대한 주권 강화의 필요성을 역설하고 있다. 이것은 현재도 중국 정부가 사
이버 공간에서 취하고 있는 여러 조치들의 법적인 근거를 마련한 것이라 볼 수 있다. 개인정
보 보호와 관련하여 글로벌 스탠더드에 따라 정보주체의 권리를 명시하는 등 진일보한 측면
도 있으나 개인의 정보통신망에서의 활동에 대하여 정부의 검열을 강화하겠다는 의지를 표명
하고 있다. 중국 내 정보통신망을 통해 세계 최대의 온라인 시장에 접근하려는 외국의 기업들
로서는 여러 채널을 통해 FLMs는 기업활동을 크게 제약하고 중국경제의 발전에도 유익하지
않다는 점을 설득하는 한편36) 이 법률의 주요 개념과 규제 ・ 시행에 관한 사항, 그에 따른 효
과를 관심 있게 지켜볼 필요가 있다.
36) 野村総合研究所,「EUとの規制協力:サイバー空間及びIoTに係る規制等に関する調査報告書」, 2017.3, 14面.

32
나. 베트남
1) 규제 현황
베트남에서는 다음과 같은 법령에 의하여 서버의 국내설치 의무가 규정되어 있다.
① 인터넷 통화, SM서비스의 제공 및 이용의 관리에 관한 규정(OTT통달)
2013년 이후 인터넷을 이용한 통화 ・ 메시지(Over the Top; OTT)37) 서비스가 발달함에
따라 정보통신부가 처음으로 OTT에 대한 규제를 도입하기로 했다. 업계의 의견수렴도 끝났으
나 아직 정식으로 조문화되어 되어 있지는 않다. 현지 OTT 사업자와 단체들이 일관되게 반대
를 하고 있어 통달의 시행 여부는 불투명한 실정이다.
통달의 주요 내용은 다음과 같다.38)
◦ 국내법인은 OTT 서비스 사업인가를 받은 경우에 한하여 유상으로 서비스를 제공할 수
있다.
◦ 유상의 OTT 서비스를 제공하는 해외사업자는 (i) 유상으로 OTT 서비스 제공에 관한 사
업인가를 취득한 베트남 국내사업자와 계약을 체결하거나 (ii) 베트남 국내에 최소한 하나의
호스트 서버를 설치하고 유상으로 OTT 서비스 제공에 관한 사업인가를 취득한 베트남 국내의
사업자와 업무협약을 체결하여야 한다.
◦ 무상으로 OTT 서비스를 제공하는 사업자는 국내/해외 사업자와 사업인가를 취득할 필요
가 없으나 서비스 가입 이용자 수가 100만을 초과하는 경우에는 그 사업자는 정보통신부
(MIC)에 대하여 본사의 소재지, 도메인이름, 호스트서버의 주소, 취급 통화/메시지 수 등의
정보를 제공하여야 한다.
◦ 인터넷 서비스 제공자는 OTT 서비스 제공자와 그 이용자를 방해해서는 아니 된다.
② 정보기술 서비스 정령
베트남 정보통신부(MIC)가 IT기기 ・ 서비스에 대한 승인 ・ 등록, 데이터의 현지보관을 의무화
하는 정령의 제정을 추진하고 있다.
37) Over the Top에서 Top은 TV셋톱박스 같은 단말기를 뜻하므로 OTT는 셋톱박스 같은 단말기를 넘어서서 인터넷과 모바
일을 이용한 화 ・ 방송 ・ 교육 등 각종 미디어 콘텐츠를 제공하는 서비스를 말한다.
38) 노무라 종합연구소, 앞의 보고서, 15면.

33
③ 정령 72호(No.72/2013/ND-CP)
베트남에서는 2013년 정령 72호에 따라 일반 웹사이트나 사회관계망 웹사이트를 서비스
하는 사업자는 베트남에 감독당국의 검사를 받는 하나 이상의 서버를 두어야 한다.39) 데이터
보관의 요건은 일반 웹사이트의 경우 적어도 일반 정보를 사이트에 게시된 날로부터 90일간,
처리된 정보의 로그 기록은 2년 이상 보관하여야 하며, 사회관계망 웹사이트의 경우 계정 및
로그인-로그아웃 시간, 이용자의 IP주소, 처리된 정보의 로그 기록을 2년 이상 보관하여야 한
다. 그리고 테러, 범죄, 위법행위와 관련이 있는 이용자에 대해서는 관할 행정청의 요구가 있
으면 그의 인적 사항과 사적인 정보를 제공하여야 한다.40)
2015년에는 공개정보의 국경간 제공을 규율하는 통달41)의 시안이 공표되었다. 여기서 공
개정보의 국경간 제공이란 외국의 기관, 기업 또는 개인이 외국에 하드웨어를 설치하거나 외
국의 클라우딩 서비스를 이용하여 베트남 국내 이용자에 대하여 뉴스 웹사이트, 소셜네트워
킹, 검색엔진, 이용자가 열람 또는 다운로드할 수 있는 공개정보에 관한 앱 또는 그와 유사한
것을 제공하는 것을 말한다. 이에 따라 뉴스 사이트, 검색엔진 등을 국외의 하드웨어 또는 클
라우딩 서비스를 통해 운 하는 경우, SNS 가입 회원이 5천명을 넘을 경우에는 법적인 대표
자를 베트남 국내에 두어야 한다.
예외적으로 순전히 상업적인 웹사이트로서 특성화된 응용(specialized application) 사이트
인 경우에는 데이터 처리 및 보관의 현지화 의무가 없다. 통신, 정보기술, 방송, 텔레비전, 상
거래, 금융, 은행, 문화, 헬스케어, 교육 기타 일반적인 정보제공이 아닌 전문 분야에 속한 웹
사이트가 이에 해당한다.42)
2) 국내외의 반응
베트남 IT업계에서는 정부의 현지화 정책에 반대의 입장을 분명히 하 다. 이러한 규제는 베
트남 산업의 경쟁력을 떨어트리고 규제가 없는 싱가포르 등지로 떠나기 때문에 산업 공동화가
39) 정령 72호의 적용범위는 아주 광범위한 바, 베트남에서 등록하고 운 하는 기업은 물론 베트남 밖에 소재하더라도 베트남
이용자들에게 서비스를 하거나 베트남어로 서비스하거나, 베트남 도메인 주소(.vn)를 쓰거나 베트남과 어떤 형태로든 관련
이 있는 사업자들이 그에 해당한다.
40) Scott Livingston and Graham Greenleaf, “Data localisation in China and other APEC jurisdictions”, Privacy Laws
& Business International Report Issue 143, October 2016, pp. 22-26.
41) Draft circular on detailed regulation on cross border provision of public information(No.72/2013/ ND-CP)
42) Livingston and Greenleaf, op.cit.

34
우려된다는 의견을 내놓았다. 이와 관련하여 구글, 이베이 등 미국계 대형 OTT 사업자들도
맹렬히 반대 로비를 펼치고 있다. 다만, 현지법인의 설립을 의무화하는 것에 대하여 외국의
OTT 사업자들이 납세를 회피하려고 반대하는 게 아닌가 하는 의혹을 사고 있다.43)
요컨대 베트남의 FLMs 조치는 크게 국방과 사상통제, 과세, 국내산업의 육성 세 가지 측
면에서 살펴볼 필요가 있다. 국방 ・ 사상통제에 관하여는 국방부가 적극적인 반면 정보통신부,
산업무역부에서는 베트남 경제에 도움이 되지 않는다는 이유에서 이에 소극적이다. 과세 문제는
비단 베트남에 한하지 않고 국가 간의 전자상거래 전반에 관하여 제기되고 있으므로 국제적
논의의 추이를 보아가며 해결될 전망이다. FLMs와 관련 산업의 육성은 산업공동화를 초래할
수 있다는 점에서 특히 주목을 요한다. 베트남에 진출하려는 국내 기업이 늘어나는 추세인 만
큼 우리 정부 차원에서도 기술 및 자금협력을 함에 있어서 FLMs가 상호간에 득이 안 된다는
것을 설명하고 베트남 측의 양해를 구해야 할 것이다.
다. 인도네시아
1) 규제의 현황
① 전자시스템과 거래조직에 관한 규정(2012년 정부규정 제82호)44)
인도네시아 2012년 정부규정 제82호에 따르면 공공서비스 전자시스템 관리자는 데이터
센터를 법 집행 및 국가주권의 보호와 집행을 목적으로 반드시 인도네시아 국내에 두어야 한
다. 공공 서비스와 관련된 정보 외에도 건강정보는 보건부장관이 관리하는 데이터 센터와 연
결되어 있는 국내의 데이터 센터에서 처리해야 한다. 보건부장관의 허가가 있으면 외국에서도
처리할 수 있다. 이러한 현지화 정책은 경제발전에 도움이 안 된다는 반론도 있었으나 공공의
이익을 위한 것이라는 주장에 묻혀버렸다.45)
② 통신정보부 규정(2015년 정부규정 제27호)46)
4G 스마트폰에 대하여 30∼40%의 로컬 콘텐츠를 싣도록 하 다. 이 규정에 의하면 인도
43) 베트남에서 서버의 현지설치 의무화 등 FLMs에 관한 집행사례는 아직 없다. 노무라 연구소, 앞의 보고서, 18면.
44) Organization of Electronic Systems and Transactions Regulation(82/2012)
45) Livingston and Greenleaf, op.cit.
46) Regulation No. 27 of 2015 regarding Technical Requirement of Equipment and/or Telecommunication Devices
in Long Term Evolution Technology Basis(Permenkominfo 27/2015)

35
네시아에서 제조 ・ 이용 또는 수입된 LTE 제품에 대하여 다음과 같은 로칼 콘텐츠 요구를 충
족하여야 한다. 기지국의 송신기는 30%, 스마트폰 수신기는 20%에서 시작하여 2017년부
터는 각각 40%, 30%로 인상되었다. 여기서 로칼 콘텐츠는 소프트웨어를 포함하므로(예컨대
스마트폰의 프리인스톨 소프트웨어) 현지 업계는 반기는 분위기 다.
③ 개인정보보호법
2015년 7월 정부기관에 대한 개인정보보호 규정이 공포되었다. 인도네시아에서는 개인정
보보호에 관한 일반법은 없고 개별 법령에 개인정보보호에 관한 조항이 들어 있다. 일반 사업
자에 대한 규제는 아직 검토된 바 없다.
④ OTT 규정
인도네시아에서도 OTT 서비스가 발전함에 따라 정부가 새로운 규제를 내놓았다. 외자계
기업에 관해서는 OTT 서비스를 제공할 때 인도네시아 국내에 항구적 시설(BUT)을 설치할 의
무가 부과되었다. 이는 외자계 기업의 OTT 서비스 제공에 따른 업수익에 과세를 하기 위한
것으로 풀이된다.
2) 국내외의 반응
인도네시아의 경우 데이터 현지화에 관한 법규정이 복잡하고 예외 규정이 많으므로 현지기
업들이 많이 참여하는 업계단체를 통하여 사정을 파악하는 경우가 많다. 아직은 기업에 대한
FLMs 집행사례도 많지 않다. 인도네시아 정부 역시 과도한 FLMs는 인근 싱가포르 등지로 기
업들이 빠져나갈 가능성을 염두에 두고 있는 것 같다.
현지 기업들은 대체로 정부의 FLMs 시책을 지지하고 있으며, 스마트폰의 로컬 콘텐츠 요
구에 대해서도 적극적으로 받아들이고 있다.
그러나 외국 기업을 비롯하여 일부 현지 기업들은 해외의 클라우드 서비스를 이용하여 사
업을 벌이고 결제를 하는 만큼 지나친 FLMs에 반대하는 입장을 보이고 있다.

36
라. 인도
1) 규제의 현황
현재 인도에 명백히 FLMs와 관련된 법령은 없다. IT산업을 경제발전의 한 축으로 인식하고 있는
인도 정부가 정보의 국외 이전에 대한 규제 강화는 관련 산업의 발전을 저해한다고 보기 때문이다.
예컨대 M2M 로드맵을 보면 2015년 판에는 데이터 현지화와 관련된 기술이 있었으나 그
최종판에서는 그 내용을 수정하 다. 즉, 국가안보의 관점에서 인도 국내의 이용자들에게 서
비스를 제공하는 M2M 게이트웨이나 어플용 서버는 모두 인도 국내에 설치할 필요가 있으
나, 소규모의 고객기반을 가진 MSP로서는 규모의 경제를 누릴 수 없고, 또한 무역정책상의
상호주의, 프라이버시, 비공개조건 등 다른 나라에서도 채택하고 있는 규칙에 따르는 것이 좋
다고 하 다.47)
2) 정보의 자유로운 국제유통을 지향
인도에서는 오히려 정보의 자유로운 유통(data free flow)을 지향하는 움직임이 두드러진다.
인도의 IT법(2000)에 의하면 통신회사는 인도 국내에서의 통신기록 보관이 의무화되어 있다. 이
는 범죄수사 등에 있어서 통신기록을 참조할 가능성이 있기에 인정된 것이지 다른 나라에 비해
특별히 이례적인 것은 아니다.
마. 유럽연합(EU)
1) 규제의 현황
① 제3국의 적절한 개인정보 보호 수준
유럽연합(European Union; EU)에서 역내에서 데이터를 보관 ・ 처리해야 하는 경우란 개인
정보 이전 대상인 정보처리자가 속한 나라의 개인정보 보호의 수준이 EU 기준에 비추어 적절하
지 못할 때이다. 이에 관한 근거는 EU 개인정보보호지침(Data Protection Directive 95/46/EC)
제25조 및 제26조이다. EU 회원국의 개인정보감독기구들로 구성되어 있는 개인정보보호작업반
(Article 29 Working Party)에서는 동 규정에 따른 실무작업보고서(Working Document)48)에
47) 노무라 연구소, 앞의 보고서, 24면.

37
열거되어 있는 12가지 기준49)에 비추어 적절한 보호 수준(adequate level of protection)인
지 여부를 평가하게 된다. 이 기준은 GDPR 제45조에도 그대로 반 되어 있어 GDPR 시행
후에도 정기적으로 재심사를 받는 것 외에는 당분간 계속 적용될 것으로 보인다.
그러므로 개인정보를 수집하고 이를 보관 ・ 처리하는 기업이라면 EU에서 요구하는 개인정보
보호의 안전대책(safeguards)을 갖추지 못한 경우50) 정보를 역외로 반출할 수 없으므로 현지에
서버를 둘 수밖에 없다. EU 입장에서는 EU 역내 시민들의 프라이버시권을 보장하고 미국계
다국적 기업에 의한 정보의 지배를 막기 위한 고육지책이라 할 수 있다. 스노든이 폭로한 대
로 미국 정보당국이 독일, 브라질 등 외국 정상의 통화를 감청하고 있었던 상황에서 다른 대
안이 없었던 것이다.
마침 페이스북의 아일랜드 현지법인에서도 유럽 이용자들의 정보를 세이프하버 협약에 따
라 미국 본사로 전송하여 처리하여 왔는데 유럽사법재판소(CJEU)는 2015년 10월 쉬렘스 사
건51)에서 EU-미국 간 세이프하버 협약을 무효로 선언하 다. 왜냐하면 EU 시민이 페이스북
에 올린 개인정보가 미국 내에서 처리되는 과정에서 미국 정보기관에 제공될 수 있음을 간과
한 협약은 무효라고 한 것이다. 이에 따라 세이프하버 협약을 대체한 프라이버시 방패52)에서
는 미국 기업이 EU 주민의 개인정보를 다룰 때 보다 엄중한 의무를 지게 하고 미국 정부기관
도 명백한 안전조치와 투명한 처리를 약속53)하게 하는 한편 침해를 입은 EU 시민에 대한 구
제에 만전을 기하도록 했다.
그리고 EU 집행위에서도 프라이버시 보호를 최우선 과제로 내세워 데이터의 보관과 소유
문제를 다룰 기관을 설치하고 새로운 직책을 만들었다. 디지털 경제를 담당하는 귄터 외팅어
48) EU Article 29 Working Party, Transfers of personal data to third countries: Applying Articles 25 and 26 of
the EU data protection directive <http://ec.europa.eu/justice/policies/privacy/docs/wpdocs/1998/wp12_en.pdf>.
49) 12개 기준은 다음과 같다. 1) 기본원칙 ① 목적제한의 원칙 ② 정보의 질, 비례성의 원칙 ③ 투명성의 원칙 ④ 안전성의 원
칙 ⑤ 열람 ・ 정정 ・ 거부의 권리 ⑥ 제3자 전송 제한 2) 추가 기준 ⑦ 민감정보 ⑧ 다이렉트 마케팅의 제한 ⑨ 자동화된 의사
결정 3) 절차/집행/구제의 방법 ⑩ 양호한 수준의 준수 ⑪ 정보주체에 대한 지원 ⑫ 피해자에 대한 적절한 구제.
50) 이러한 안전조치에는 자율규제와 표준계약서, 구속력 있는 기업규칙(Binding Corporate Rules; BCRs) 등이 있다. 미국은
EU와 세이프하버 협약(Safe Harbor Agreement)에 의하여 이 문제를 해결하 으나 쉬렘스 판결로 무효가 선언됨에 따라
이를 프라이버시 방패(Privacy Shield)로 대체하 다.
51) Court of Justice of the European Union, Maximilian Schrems v. Data Protection Commissioner, C-362/14, 6
October 2015.
52) EU Commission, “EU Commission and United States agree on new framework for transatlantic data flows:
EU-US Privacy Shield”, Press release, 2 February 2016.
<http://europa.eu/rapid/press-release_IP-16-216_en.htm>
53) 미 정부는 국가안보 목적이라고 했으나 CJEU는 개인정보보호에 대한 예외 사유는 엄격히 해석할 필요가 있다고 보았다.

38
(Günther Oettinger) 집행위원은 미국 기업들로부터 정보 통제권을 되찾는 것이 그의 임무
라고 공언하기도 했다.54)
② 잊힐 권리
2014년 5월 유럽사법재판소의 또 다른 판결55)은 다국적 IT 기업의 유럽 내 콘텐츠를 특별
히 관리할 필요성을 야기했다. 검색 엔진의 결과물이 부적합하고 부적절하거나 더 이상 타당하
지 않은 정보(inadequate, irrelevant or no longer relevant information)라면 그의 삭제를
원하는 이용자의 요구를 들어줘야 한다는 것이다.56) 그 결과 구글은 1백만 건 이상의 신청을
접수하여 독일, 프랑스 등 유럽 도메인에서 40% 이상의 정보를 삭제하지 않을 수 없었다.
프랑스 정보와 자유 국가위원회(CNIL)는 한 걸음 더 나아가 구글 같은 다국적 검색엔진이
잊힐 권리를 제대로 보장하려면 유럽 내 도메인뿐만 아니라 전 세계의 도메인에서 관련 정보
를 삭제해야 한다고 요구하고 나섰다.57)
2) 국내외의 반응
EU에 명시적으로 개인정보의 로컬라이제이션을 요구하는 법규범은 없다. 그러나 개인정보
보호수준이 EU보다 낮은 제3국으로의 개인정보 유출이 금지되는 만큼 복잡한 허가 절차를
밟지 않고 역내에 서버를 설치하여 개인정보를 처리하고 보관하는 것도 개인정보 로컬라이제
이션임에는 틀림없다.
EU에서는 프라이버시권을 기본적 인권의 수준으로 파악하고 있어 개인정보 보호의 수준도
다른 나라에 비해 그 만큼 엄격하다고 볼 수 있다. 그럼에도 EU 회원국들이 세계경제에서 차
지하는 비중이 크기 때문에 EU의 기준에 맞춰 자국의 개인정보보호 법제를 개선하고 복잡한
절차를 거쳐서라도 EU로부터 적정성 평가를 받고자 하는 나라58)가 늘고 있다. 이러한 현상은
2018년 5월 GDPR 발효 후에도 멈추지 않을 것으로 보인다. 이에 따라 OECD의 프라이버시
54) Albright Stonebridge Group, Data Localization, p.6.
55) Court of Justice of the European Union, Google v. Spain AEPD, C-131/12, 13 May 2014.
56) 이것은 GDPR 제17조에 ‘삭제권’(right to erasure) 또는 ‘잊힐 권리’(right to be forgotten)로 성문화되었다.
57) Albright Stonebridge Group, Data Localization, p.8.
58) EU로부터 적정성 평가(adequacy assessment)를 받은 나라를 ‘Whitelisted Countries’라 부르거니와 2017년 6월 현재
역외금융센터 포함하여 12개 나라가 그 판정을 받았으며, 현재 일본과 한국에 대한 EU 측의 적정성평가 작업이 진행 중
이다. <http://ec.europa.eu/justice/data-protection/international-transfers/adequacy/index_en.htm>

39
보호 8원칙59)을 충실히 이어 받은 EU의 개인정보 보호의 기준은 오늘날 개인정보 보호에 관
한 한 글로벌 스탠더드의 하나로 자리잡게 되었다.
바. 러시아
1) 규제의 현황
러시아의 블라디미르 푸틴 대통령은 우크라이나 사태 이후 러시아가 서방 세계에 포위되었
다는 인식하에 외세에 향을 받지 않고 정치적인 비판을 잠재우기 위해 정보에 대한 통제를
강화하고 있다. 러시아 정부는 이러한 정치논리에 입각하여 데이터 로컬라이제이션 정책을 펴
고 있다.
러시아에서는 연방산업기술 ・ 수출관리국(Federal Service for Technical and Export Control;
FSTEC)에서 정보통신 인프라의 안전, 러시아 국내에서 외국인의 산업기술 스파이 활동 단속, 국
가기밀정보의 보호, 정보통신기기의 개발 ・ 제조 ・ 운용 및 폐기기술의 정보보호, 수출관리 등을 담
당하고 있다. 국가안보에 관한 정책운용 및 부처 간의 조정 ・ 협력업무를 수행하기도 한다.
FSTEC는 정부기관, 금융, 정보통신, 전력, 운수, 에너지, 방재 등의 시스템에 이용되는 기
술과 제품에 대한 인증을 담당하며, 요건을 미비한 경우에는 제재를 가하고 집행기관을 감사
할 수 있는 권한을 갖고 있다.60)
2) FSTEC 감독하의 개인정보 보관
FSTEC는 직접적으로 FLMs의 법령이나 규제를 수행하지는 않지만, 정보 시스템 처리에 있
어서 개인정보의 안전 강화를 위한 조직적 ・ 기술적 조건의 확인에 관한 명령(2013.2.18) 제
11조에 의하여 개인정보의 보호를 목적으로 정보 시스템에 대한 검열을 할 수 있다.
2015년에 공표된 “EU와의 규제협력: IT 전자분야에 있어서 제3국의 규제에 관한 조사보고
서”에 의하면 연방법 제242호-FZ61)는 러시아 국민의 개인정보는 러시아 국내에 설치된 데이터
59) OECD Guidelines on the Protection of Privacy and Transborder Flows of Personal Data (1980) <http://www.oecd.org/
internet/ieconomy/oecdguidelinesontheprotectionofprivacyandtransborderflowsofpersonaldata.htm>
60) 노무라 연구소, 앞의 보고서, 27면.
61) 연방법 No.242-FZ는 정보통신망에 의한 개인정보 처리절차 조사에 있어서 개개의 러시아 연방법령의 수정에 관한 연방법
으로 2015년 9월 1일 발효되었다.

40
베이스로 관리하고, 데이터 센터의 소재를 당국에 신고하여야 한다. 구체적으로 초기 데이터
의 수집, 기록, 시스템화, 축약, 집적, 갱신, 복구 등의 작업은 러시아 국내에 설치된 데이터베
이스를 이용하여야 한다. 하지만 개인정보를 동시에 러시아 국외에서도 보관하는 것을 막지는
않고 있다.
FLMs를 직접 관장하는 기관은 전기통신 ・ 매스컴부 산하의 연방통신정보기술 ・ 매스미디아
감독국(Roskomnadzor, 이하 “연방통신감독국”)이다. 러시아 국내의 서버에 모든 개인정보를 수
록한다면 그와 같은 분량 또는 그보다 적은 분량의 개인정보를 국외의 서버에 보관하는 것이
금지되지는 않는다. 요컨대 러시아에 있어서 FLMs는 러시아 국민의 개인정보를 국외에서 관
리하는 것을 금하는 것은 아니지만 러시아 정부의 감독이 미치는 범위에서 반드시 개인정보
를 국내에 보관하도록 하고 있는 것이다.62) 연방통신감독국은 최근 들어 연방법규에 따라 러시아
이용자의 개인정보가 해외 데이터베이스에 보관되고 있는지, 이용자의 동의를 받았는지, 개인
정보처리방침을 제대로 공시하고 있는지 단속과 규제를 강화하고 있는데 러시아 내 SNS 서비
스 길이 막힌 LinkedIn 사례가 대표적이다.63)
사. 그 밖의 나라들
1) TPP 체약국
데이터 보관 ・ 처리의 현지화는 널리 보편화되는 추세에 있다. 인도네시아, 베트남뿐만 아니
라 캐나다, 호주 등지에서도 개인정보보호법 등은 일정 종류의 정보는 반드시 국내 서버에 저
장하고 처리할 것을 의무화하고 데이터를 국외 이전하는 경우에는 일정 조건을 충족할 것을
요구하고 있다.64) 미국의 트럼프 대통령이 철회함으로써 무산되고 말았지만, 환태평양 경제동
반자(Trans-Pacific Partnership; TPP) 조약에서도 일부 APEC 회원국들은 일정한 정보의 국
내 처리를 의무화하고자 하 다.
이와 반대로 유럽회의(Council of Europe) 108호 협약은 체약국 간의 개인정보의 자유로운
62) 노무라 연구소, 앞의 보고서, 28면.
63) 연방통신감독국은 2016년 모스크바 Taganskiy 지방법원에 LinkedIn을 제소하여 승소하 다. LinkedIn은 러시아내 약
600만명의 회원이 현지에서 LinkedIn서비스를 받지 못하게 됨에 따라 항소를 하 으나 항소법원은 1심판결을 그대로 유
지함으로서 러시아 내 LinledIn 접속은 계속 불가능한 실정이다. Dmitry V. Nikiforov, et al, “Russia 2016: Personal
Data & Cybersecurity”, D&P Client Update, Debevoise & Plimpton, February 14, 2017.
64) Livingston and Greenleaf, op.cit.,pp.22-26.

41
이전을 규정65)하고 있는 바 주요 정보를 국내에서 보관 ・ 처리하라고 하는 것은 무슨 문제를
야기하게 되는가?
TPP 조약 전자상거래 편의 제14.13조를 보면 ‘컴퓨터 시설의 소재지’(Location of
Computing Facilities)라는 제하에 각 당사국이 정당한 공공정책목표를 달성할 수 있도록 컴
퓨터 시설의 이용 또는 설치에 대한 제한을 부과할 수 있음을 예외적으로 인정하 다. 그리고
TPP 회원국에서 온 서비스 제공자가 자국에서 업을 하는 조건으로 자국 내에 있는 컴퓨터
시설을 이용하거나 설치할 것을 의무화하는 것을 금지하 다. 일견 자국 내 정보의 보관 ・ 처
리는 금지되고 투자자-국가 분쟁(Investor-State Dispute)에 의해 해결하도록 하고 있으나, 여
기서의 컴퓨터 시설은 상업적 용도로 제한하는 데다 광범한 예외를 인정함으로써 금지를 피
할 수 있게 하 다.
2) 한국
한국에서는 정보처리자가 개인정보를 국외의 제3자에게 이전하려면 정보주체의 동의를 받
도록 하고 있다(개인정보보호법 제17조 3항, 정보통신망법 제63조 2항). 그러므로 정보통신망
이용 계약을 체결함에 있어 약관상으로 이용자, 즉 정보주체의 동의를 받을 수 없다면 예외
사유에도 해당되지 않는 한 당해 정보는 국외의 제3자에게 이전할 수 없고 국내에 보관하여
야 하는 것이다.
앞서 구글 맵과 관련하여 설명한 바와 같이 한국 정부(국토교통부장관)는 국가안보나 그 밖에
국가의 중대한 이익을 해칠 우려가 있다고 인정되는 경우에는 공간정보(기본측량성과 및 기본측량
기록)를 복제하게 하거나 그 사본을 발급할 수 없으며(공간정보의 구축 및 관리 등에 관한 법률 제
14조 3항 1호), 이 경우 기본측량성과를 국외로 반출해서도 안 된다(동법 제16조 2항 본문). 다만,
특정 외국정부와 기본측량성과를 서로 교환하기로 하 거나(동법 제16조 1항 단서에 의한 상호주
의), 국토교통부장관이 국가안보와 관련된 사항에 대하여 과학기술정보통신부장관, 외교부장관, 통
일부장관, 국방부장관, 행정안전부장관, 산업통상자원부장관 및 국가정보원장 등 관계 기관의 장과
협의체66)를 구성하여 국외로 반출하기로 결정한 경우에는 예외로 하 다(동법 제16조 2항 단서).
65) CoE Privacy Convention Article 12(Transborder flows of personal data)
개인정보의 국경간 유통 (1) 각 당사국은 개인정보보호의 한 가지 목적을 위하여 또는 특별허가를 얻는 조건으로 이 협약
의 다른 당사국의 관할에 속하는 제3자에게 개인정보를 이전하는 것을 금지하여서는 아니 된다. 다만, 그 당사국은 지역
적인 국제기구에 속하는 국가들이 공유하는 조화를 이룬 보호규칙에 구속된다면 그리할 수 있다.
66) 이 협의체에는 1인 이상의 민간전문가를 포함하여야 하는데, 새로 개정된 공간정보관리법 제16조의 규정은 2018년 4월
25일 발효한다.

42
3) 오스트레일리아
오스트레일리아에서는 ‘나의 건강기록(My Health Records) 시스템’67) 관련 법 규정에 의
하면 시스템 운 자는 등록된 포털 운 자 또는 등록된 계약 서비스 제공자로서 나의 건강기
록 시스템의 목적 상 그 기록을 오스트레일리아 밖에서도 보유하거나 처리하는 것이 금지된
다. 그러나 시스템 운 자는 그 정보가 개인정보 또는 식별정보를 포함하지 않는다면 이를 국
외에서 보유하거나 처리할 수 있다.
보건부 홈페이지에서는 나의 건강기록이 생성된 곳에서 건강기록이 국내에 보관되어야 하
며, 보건부에서는 국민의 건강기록이나 개인정보를 국외에서 밝히지 않는다고 한다. 그 밖의
데이터 처리의 현지화를 명시한 규정은 없다.
4. 개인정보 현지화 규제에 대한 평가
데이터를 보관 ・ 처리함에 있어서 현지에 있는 서버를 이용하도록 요구하는 것은 정보기술
의 발전에 역행하는 처사이다. 국경이 없는 매체(borderless medium)로서 개방적이고 분권
화된 네트워크인 인터넷의 본질에 반하다고 할 수 있다. 정보는 수요처를 찾아 유통하게 마련
이고 이것을 사이버 공간의 참여자들이 신속하고 적은 비용으로 실현 가능하게 만드는 것이
정보통신 기술이기 때문이다. FLMs 규제는 개방적인 인터넷의 기능과 자원을 조각내고 비효
율적으로 만드는 것이다.68) 특히 신생기업 ・ 중소기업은 외부 클라우딩이나 데이터 센터의 컴
퓨터 설비를 빌려서 업을 하는 터에 FLMs 규제는 적잖은 타격이 될 것이다. 데이터 로컬라
이제이션은 IT산업의 발전을 위축시키고 해당 국가는 물론 글로벌한 경제성장에도 차질을 빚
게 된다.69)
다만, 개인정보 보호의 견지에서 보호의 수준이 자국에 비해 뒤떨어지는 나라에 개인정보
를 포함한 데이터의 반출을 일정 조건하에 불허하는 것은 프라이버시권이 기본적 인권으로
보장하는 오늘날에는 당연한 처사라 볼 수 있다. 인터넷의 특성에 비추어 정보가 유통되는
67) 종전에 개인적으로 지배할 수 있는 전자적 건강기록(personally controlled electronic health record) 시스템으로 부르던
것이다. 근거법률의 명칭도 Personally Controlled Electronic Health Records Act.
68) Albright Stonebridge Group, Data Localization, p.3.
69) Ibid., p.9.

43
어느 채널 한 곳이라도 허점이 있으면 데이터의 보안이 제대로 이루어질 수 없다는 점에서
나름대로 정당성을 갖는다.
그러나 아쉽게도 최근 들어 세를 불리고 있는 개인정보 로컬라이제이션에 맞설 수 있는 세
력은 단독이든 연합이든 가시화되지 않고 있다. 그만큼 외국 정보기관에 의한 감시(foreign
surveillance)의 우려, 개인정보 보호의 필요성이 강조되고 있는 탓이다. 외국 기업들이 데이
터 현지화에 반대하는 것 못지않게 국내 기업들은 데이터 현지화에 따른 이익을 양보하려 들
지 않고 있다.70) 그러나 데이터 현지화가 많아질수록 데이터 이용자들은 데이터 이용범위가
그 만큼 줄어들고 제조업이나 서비스업 종사자들은 유용한 정보에 대한 접근 기회를 놓칠 수
있음을 알아야 한다. 만일 현지 정부가 정보의 자유로운 유통을 정치적인 위협으로 간주하고
비민주적인 목적을 위해 데이터를 이용하거나 가공하려 들 경우에는 표현의 자유나 프라이버
시마저 침해될 공산이 크다.
5. 결 론
오늘날 개방된 네트워크인 인터넷을 통해 모든 일이 이루어지는 시대에 데이터의 보관 ・ 처
리의 현지화를 요구하는 법제는 일견 모순되고 시대착오적인 것처럼 보인다. 그러나 이를 시
행하는 각국의 사정을 들여다보면 나름대로 명분이 있다.
우리나라도 구글에 대하여 공간정보의 제공을 불허함으로써 데이터 로컬라이제이션 국가
리스트에 올랐지만 북한이 장거리 미사일과 무인기를 날리고 있는 작금의 현실에 비추어 상
세한 지리정보를 공개하는 것은 매우 위험한 일이 아닐 수 없다. 다른 한편으로 해외여행을
하면서 스마트폰으로 구글이 제공하는 지도 및 교통정보 서비스 <https://maps.google.com>
를 이용해본 사람이라면 그러한 공간정보가 얼마나 유용하며 유통업이나 관광 서비스업 등에
부가가치를 창출하는지 체험적으로 알게 된다. 앞으로 도래할 자율주행차와 드론의 이용에는
없어서는 안 될 인프라가 되고 있다.
결국은 서로 충돌하는 가치를 놓고 선택을 해야 하는 문제로 바뀌게 된다. 어찌 보면 개
방 ・ 협조 ・ 책임을 앞세우는 인터넷의 속성을 강조하는 것이나 정보의 분절화 ・ 파편화를 초래
하는 로컬라이제이션은 원활한 정보의 국제유통을 저해하므로 바람직하지 않다는 주장71)은
70) Ibid., p.3.

44
피상적으로 들릴 수 있다. 그보다는 국가안보 및 공정과세에 중점을 두고 다국적 거대 IT기업
에 주도권을 뺏기지 않는 데 역점을 두거나, 아니면 시대적 조류에 맞게 국내 IT산업을 보호
하고 경제적 실리를 취하자는 것이 피부에 와 닿을 수 있다.
인터넷이 세계의 모든 기업과 개인이 활발히 참여함으로써 그로 인한 시장이 지속적으로
확대되고 이노베이션이 촉발되었다는 점을 감안한다면 이른바 인터넷의 발칸화(Internet
Balkanization)72)를 몰고 오는 데이터 로컬라이제이션은 결코 바람직하지 않다는 결론에 도달
하게 된다. 일단 세계경제의 발전을 도모할 수 있는 국경 간 정보유통의 원활화에 목표를 두
고 그에 대한 예외 사유는 그것이 안보 목적이든 무엇이든 엄격하게 해석되어야 한다. 그리함
으로써 장기적으로 세계경제의 고른 발전을 도모할 수 있고 정보통신 기술의 발전을 통해 새
로운 시대를 맞이할 수 있을 것이다.
71) 월드와이드웹(World Wide Web)의 창시자로 알려진 팀 버너스-리(Tim Berners-Lee)는 최근 모두에게 열려 있는 분권화
된 인터넷(Re-decentralized Web)이라는 처음의 구상을 다시 강조하고 나섰는데, 그는 인터넷의 발전적 미래상에 대한
최대의 위험요소는 이른바 발칸화된 웹의 등장이라고 말했다. 허진성, 앞의 논문, 290면.
72) 인터넷 발칸화(Internet Balkanization)란 인터넷이 국가적으로 지역적으로 폐쇄된 네트워크들로 분열되는 것을 말한다.
19세기 말 오스만 제국이 붕괴되는 과정에서 발칸 반도가 여러 작은 나라들로 분열됨으로써 1차 대전의 원인을 제공한
현상을 사이버 공간에 빗대어 표현한 것이다. 위의 논문, 290∼291면.

45
1. 국내 문헌
문혜정, “느리지만 꾸준히 진화하고 있는 중국의 개인정보 보호법제”, 「언론중재」 2016
가을, 언론중재위원회, 2016.10.
박훤일, “정보이동권의 국내 도입 방안 - EU GDPR의 관련 규정을 중심으로”, 「경희법
학」 제52권 3호, 2017.9.30.
, 「개인정보의 국제적 유통에 따른 법적 문제와 대책」, 집문당, 2015.
안종석, “다국적 IT기업의 조세회피 행태와 시사점: 애플 ・ 구글의 사례를 중심으로”, 「재
정포럼」 2013.7.
허진성, “데이터 국지화(Data Localization) 정책의 세계적 흐름과 그 법제적 함의”,
「언론과 법」 제13권 2호, 2014.
개인정보보호포럼 ・ 한국인터넷진흥원, 「지능정보사회 선도를 위한 개인정보보호 이슈 및
동향」, 2017.2.
2. 외국 문헌
生貝直人, “自律 ・ 分散 ・ 協調社会とデータポータビリティーの権利”, 経済産業省分散戦略
ワーキンググループ 第6回, 2016.7.27.
野村総合研究所,「EUとの規制協力:サイバー空間及びIoTに係る規制等に関する調査報告
書」, 2017.3.
日本経済団体連合会 ・ 在日米國商工會議所, “日米 IED民間作業部会共同声明 2016”,
2016.2.25.
Article 29 Working Party, Transfers of personal data to third countries: Applying Articles
25 and 26 of the EU data protection directive <http://ec.europa.eu/justice/policies
/privacy/docs/wpdocs/1998/wp12_en.pdf>.
Draft circular on detailed regulation on cross border provision of public
information(No.72/2013/ND-CP).
참고문헌

46
Adam Golodner, et al., China's New Cybersecurity Law Imposes Heightened Restrictions
on Company Computer Networks, Arnold Porter Kaye Scholer, July 20, 2017.
<https://www.apks.com/en/perspectives/publications/ 2017/07/chinas-new-
cybersecurity-law-imposes>
Albright Stonebridge Group, Data Localization: A Challenge to Global Commerce
and the Free Flow of Information, September 2015.
Covington & Burling, “EU Data Retention Directive Declared Invalid by CJEU”,
Inside Privacy, April 8, 2014.
Covington & Burling, “Brazil Enacts “Marco Civil” Internet Civil Rights Bill”,
Inside Privacy, April 28, 2014.
<https://www.insideprivacy.com/international/brazil-enacts-marco-civil-int
ernet-civil-rights-bill/>.
Dmitry V. Nikiforov, et al, “Russia 2016: Personal Data & Cybersecurity“, D&P
Client Update, Debevoise & Plimpton, February 14, 2017.
<https://www.debevoise.com/insights> Russia 2016: personal data
EU Commission, “EU Commission and United States agree on new framework
for transatlantic data flows: EU-US Privacy Shield”, Press release, 2
February 2016. <http://europa.eu/rapid/press-release_IP-16-216_en.htm>
Graham Greenleaf and Scott Livingston, “China’s Cybersecurity Law – also a
data privacy law?”, Privacy Laws & Business International Report Issue
144, December 2016.
W. Kuan Hon, Data Localization Laws and Policy - The EU Data Protection
International Transfers Restriction Through a Cloud Computing Lens,
Edward Elgar, 2017.
The Guardian, “EU to find ways to make Google, Facebook and Amazon pay
more tax”, 21 September 2017. <https://www.theguardian.com/ business/2017/sep/
21/tech-firms-tax-eu-turnover-google-amazon-apple>

47
Scott Livingston and Graham Greenleaf, “Data localisation in China and other
APEC jurisdictions”, Privacy Laws & Business International Report Issue
143, October 2016.
Information Security Technology – Guidelines for Personal Information within
Public and Commercial Services Information Systems 2013.
3. 인터넷 자료 (2017.10.25 최종 접속)
디지털 데일리, “[주간 클라우드 동향] 2017 국내 클라우드 도입, 어디까지 왔나”, 2017.10.16.
<http://www.ddaily.co.kr/cloud/news/article.html?no=161209>
오마이뉴스, “구글의 지도 국외반출 요구에 포털 ・ 네비 업체 ‘역차별’ 반발”, 2016.6.20.
<http://www.ohmynews.com/NWS_Web/View/at_pg.aspx?CNTN_CD=A0
002219482>
Insight, “구글, 국내서 2조 버는데 세금은 한 푼도 안 낸다”, 2017.5.15.
<http://www.insight.co.kr/newsRead.php?ArtNo=105579>
전자신문, “나라장터에서 인프라 클라우드 서비스 이용하세요”, 2017.9.27.
<http://www.etnews.com/20170927000385>
조선일보, “한국 게임으로 1兆 챙긴 구글… 세금은 '깜깜'”, 2017.9.15.
<http://biz.chosun.com/site/data/html_dir/2017/09/14/2017091403574.h
tml>
G7 이세시마 정상회담 자료 <http://www.mofa.go.jp/ecm/ec/page4e_000457.html>


서울대학교 통계학과 김용대 교수
2017 NAVER Privacy White Paper
인공지능과 개인정보


51
1. 머리말
1. 인공지능은 빠르게 우리의 생활에 스며들어 산업 전반에 지대한 영향을 미치고 있고
나아가 인공지능의 도래로 인한 노동시장의 재편 및 사회구조의 변화에 대한 진지한
논의가 활발히 진행되고 있음
- 인공지능 기술의 발전을 위해서는 기술의 발전뿐 아니라 관련 법률 및 윤리의 정
비가 필수적임. 또한 기술의 발전을 위해 필요한 다양한 데이터의 수집 및 결합이
여러 법률적 제약과 윤리적 문제로 발전이 저해
- 본 논문에서는 인공지능 기술에 내재하는 프라이버시 침해와 윤리적 딜레마에 대
해서 살펴보고, 이를 해결할 수 있는 방법을 찾아보고자 함
2. 현재 인공지능 기술에서 빅데이터가 핵심역할을 하고 있는 현상을 이해하기 위해 인
공지능의 역사를 개관
- 1950년대 후기부터 1960년대 초기 실제로 컴퓨터를 사용할 수 있게 되면서 인공
지능 연구의 개척기가 시작, 1956년도에 다트머스 학회에서 이 연구 분야의 이름
을 “Artificial Intelligence(AI), 인공지능”이라고 최초로 명명
- 인공지능 역사의 황금기인 1956년부터 1974년, 다트머스 학회 이후 인공지능의
여러 분야에서 기초가 다져지며 대수학을 풀거나 기하학의 이론들을 증명하거나
영어로 질문응답을 하는 프로그램들이 학습됨
- 1974년부터 1980년대는 인공지능의 암흑기, 인공지능 낙관론이 약속한 능력이
사실상 불가능하다는 것을 깨닫고 인공지능 프로젝트에 대한 자금이 회수되었음
- 1980년대부터 인공지능 프로그램은 특정 지식 영역에 대한 문제를 해결해 주는
전문가 시스템의 형태로 다시 각광을 받게 되나 1980년대 후반에 다시 인기를 잃
게 됨
- 1990년대 후반부터 데이터를 기반으로 새로운 지식을 창출하는 기계학습법을 바
탕으로 이미지, 언어, 음성의 인식 분야에서 큰 성공을 거두고 있음
요약문

52
3. 현재 인공지능 기술의 핵심이 되는 기계학습법은 크게 지도학습, 비지도학습, 강화
학습으로 구분
- 지도학습은 주어진 입력자료에 대해 출력변수가 존재하여, 입력자료로 출력변수를
가장 잘 표현하도록 기계에 학습시키는 것을 의미, 간단한 예로 주어진 인물사진
(픽셀별 정보)에 대해 남성인지 여성인지 분류할 수 있도록 학습시키는 방법. 지도
학습법에는 고차원 회귀모형, 앙상블 그리고 신경망 모형을 바탕으로 한 딥러닝
알고리즘 등이 있음
- 지도학습과 비지도학습의 가장 큰 차이점은 출력변수의 유무이며, 비지도학습의 경
우 출력변수가 없고 주어진 자료만을 가지고 분석하는 기계학습 분야 중 하나로
군집분석, 차원축소법 등이 있음
- 강화학습이란 각 행동에 대해 서로 다른 보상이 주어지는 문제에서 어떠한 행동을
취해야 최대한의 보상을 얻을 수 있는지를 학습하는 분야로 각각 요소들 간의 상
호관계에 대해 학습한다는 점에서 한 요소를 통해 다른 요소를 파악하는 지도학습
과는 차이가 있음
4. 최근 딥러닝 기법을 비롯한 인공지능 알고리즘의 발전과 연산속도, 자료처리량 등의
하드웨어 측면에서의 비약적인 향상에 힘입어 산업 전 분야에서 인공지능 응용사례
급증
- 방대한 양의 의료정보를 저장하고 처리할 수 있는 인공지능 시스템은 현대 의학에
서 점점 그 필요성이 높아지고 있음. 의료 분야의 가장 대표적인 인공지능 응용사례
는 인공지능 컴퓨터 시스템 IBM 왓슨을 활용한 질병 진단 및 치료법 제공 시스템
- 금융 분야의 인공지능 응용사례는 투자자문, 신용평가, 금융범죄 탐지 등이 있음.
투자자문 서비스는 경제 및 금융시장의 현재 상황을 분석하고 미래를 예측함으로써
투자방향을 제공, 신용평가는 대출신청자의 신용도를 판단하고 채무불이행 가능성
등을 예측, 금융범죄의 탐지는 카드의 부정사용을 포함한 결제사기 탐지 등에 응용
- 지능형 개인비서는 인간의 음성을 인식하고 그에 맞는 응답을 제공하는 인공지능
서비스로 기존에는 정해진 질문에 대해 간단한 답만 제공하는 정도의 서비스에 그
쳤으나 딥러닝 기술의 등장으로 인공지능의 발달과 사물인터넷(IoT)에 대해 높아진
관심 등이 맞물려 빠르게 발전하고 있는 새로운 첨단산업 분야

53
- 기계번역은 컴퓨터를 통해 서로 다른 언어 간의 번역을 하는 것으로 최근 딥러닝
기술을 통해 과거보다 우수해진 시스템 구현
5. 인공지능의 발달을 통해 인류는 지금까지 누릴 수 없었던 편리함을 느낄 수 있게
되었으나 급격한 기술발전의 부작용으로 프라이버시 및 인권을 침해하는 윤리적 문
제 대두
- 미국에서는 주(州) 차원에서 소유하고 있는 진료기록들을 유료로 공개하고 있음.
하버드대의 연구진은 이러한 진료기록들이 신문기사와 같은 손쉽게 손에 넣을 수
있는 다른 정보와 결합함으로써 인물을 특정할 수 있음을 밝혀내었음
- 현대인의 필수품이 된 스마트폰을 통해 개인정보들이 다양한 곳으로 유출되고 있
는 상황, 인기 있는 101개의 앱을 대상으로 한 조사에서 56개의 앱이 사용자의
동의 없이 제3자에게 기기의 ID를 제공, 47개의 앱이 제3자에게 기기의 위치정보
를 제공
- Google에서 인명(人名)을 검색하는 경우 Google Ad는 개인의 범죄기록을 조사
할 수 있는 사이트의 광고를 종종 제시하곤 하는데 이때 검색하는 이름이 흑인이
주로 사용하는 이름인 경우 백인이 주로 사용하는 이름을 검색하는 경우에 비해
범죄기록 조회 사이트의 광고 문구가 악의적으로 생성된다는 사실이 연구로 밝혀
졌음
- 얼굴 사진을 통해 성적 지향을 추정하는 신경망 모형이 개발됨. 주어진 사진의 남
자(여자)가 동성애자인지 여부를 맞추는 문제에 적용시킨 결과 81%(71%)의 정
확도를 얻을 수 있었음. 하지만 이러한 연구결과에 많은 성소수자들은 많은 염려
를 드러내었음. 역사적으로도 성소수자를 골라내려는 많은 시도들은 그들의 말살,
투옥, 성적 지향 전환치료 등 부정적인 결과를 초래했기 때문임
6. 프라이버시를 보호하면서 빅데이터를 기반으로 인공지능 기술을 구현할 수 있는 기
술적 방법의 개발
- 데이터 자체를 변환하여 프라이버시를 보호하는 방법으로 익명화 방법, 교란방법,
랜덤화 방법, 압축방법 등이 사용되고 있음

54
- 인공지능 기술로 구축된 모형을 변환하여 프라이버시를 보호하는 방법도 관심을
끌고 있음. 차등 정보 보호라는 개념을 도입, 구축된 모형의 적절한 변형을 사용자
에게 제공하여 모형으로부터 프라이버시 침해를 방지하고자 하는 방법
7. 인공지능 기술이 인종차별이나 범죄 등과 같이 반사회적으로 사용되지 않아야 하는
것은 물론이고, 인공지능 기술의 사용에 나타나는 감정이입과 이에 따르는 사회적 ・
문화적 새로운 현상에 대한 고찰 필요
- 인공지능 윤리에 대한 공론화 작업이 진행되고 있는데 다수의 연구자들이 앞으로
인공지능 기술의 발전이 사회의 이익을 위해서 이루어져야 한다는 공개서한을 만
들었으며, 2015년 국제인공지능학회에서 자동살상무기에 대한 반대를 위한 공개
서한에 연구자들이 서명
- 인공지능 윤리에 대한 다양한 교육프로그램들이 개발 중임. 그 중에서도 ‘SF을 통
한 컴퓨터 윤리학’ 코스가 최근 몇 년간 컴퓨터 과학과 인공지능 전공자들에 윤리
를 가르치는 방법으로 주목받고 있음

55
관한 연구
김용대 (서울대학교 통계학과 교수)
1. 서론
인공지능의 약진은 인류의 미래를 걱정할 정도로 빠르게 우리의 생활에 스며들고 있다. 자
동청소기부터 시작하여 무인자동차, 인공지능 의사의 등장은 인공지능이 단순한 호기심 차원
의 연구를 지나서 산업 전반에 지대한 영향을 미치고 있다는 것을 반증한다. 나아가 단순한
산업의 발전을 넘어서서 인공지능의 도래로 인한 노동시장의 재편 및 사회구조의 변화에 대
한 진지한 논의가 활발히 진행되고 있다.
2016년도 다보스포럼에서는 이러한 기술혁신을 4차 산업혁명이라 명명하였다. 4차 산업혁
명핵심은 “모든 것이 연결되고 지능적인 사회로의 진화”이다.1) 즉, 4차 산업혁명은 지능정보
화 사회로의 진입을 의미하는데 지능정보화 사회의 핵심기술은 빅데이터와 인공지능이다. 그
리고 이러한 기술을 이용하여 제조업, 서비스업, 농업 등 산업 전반에 걸쳐서 생산성을 향상
시키고 새로운 시장 및 문화를 창출하는 것이 지능정보화 사회에서 추구하는 방향으로 인식
되고 있다.
<표 1>은 미국의 시가총액 기준 2006년도 10대 기업과 2016년 10대 기업을 비교하고
있다. 2006년도 10대 기업의 대부분이 에너지와 금융과 관련이 있다면, 2016년 10대 기업
의 경우 정보통신기술(ICT) 관련 회사들이 대부분이며, 이 중 애플, 구글, 마이크로소프트, 아
마존, 페이스북, 텐센트 등의 기업들은 직접적으로 인공지능과 빅데이터 관련 기술을 중심으로
사업을 수행하고 있다. 이러한 시장의 변화는 현재 4차 산업혁명이 얼마나 거세게 진행되고
1) 장필성(2016)
인공지능과 개인정보에 관한 연구

56
있는지를 잘 보여주고 있다. 우리나라도 이러한 조류에 합류하지 않으면 국제경쟁력을 상실하
게 될 것이고 경제적으로 큰 어려움에 봉착하게 될 것이다.
우리나라도 과학기술정보통신부, 산업부 등 정부 유관부처와 삼성전자, 네이버 등의 IT선도
기업들을 중심으로 4차 산업혁명의 흐름에 합류하기 위하여 노력을 하고 있다. 삼성전자는 갤
럭시 S8에 음성인식 기반 개인비서인 빅스비를 탑재하였다. 특히 삼성페이와 연동하여 음성
으로 쇼핑을 할 수 있는 기능이 내장되어 있다. 네이버는 무인자동차 관련하여 국내 최초로
임시운행허가를 국토부로부터 받았다. 하지만 애플의 시리, 아마존의 에코, 그리고 2009년부
터 주행을 시작한 구글 무인자동차에 비하면 조금 늦은 감이 없지 않다.
인공지능 기술의 발전을 위해서는 기술의 발전 뿐 아니라 관련 법률 및 윤리의 정비가 필
수적이다. 인공지능 기술의 발전을 위해서는 다양한 데이터의 수집 및 결합이 필수적이다. 예
를 들면, 구글 어시스턴트나 애플 시리와 같은 첨단 인공지능 비서의 구현에는 개인의 다양한
자료(예: 쇼핑 히스토리, 이동 히스토리, 검색 히스토리 등)를 바탕으로 각각의 상황에 최적의
판단을 내려주는 알고리즘의 개발이 핵심이다. 무인자동차의 개발에도 운전자의 운정정보가 필
수요소이다. 이러한 이유로 최근에는 무인자동차의 최초 개발자인 구글보다는 무인자동차를 판
매하는 테슬라가 무인자동차 기술에서 앞서가고 있다고 평가받는다. 하지만, 이런 다양한 종류
의 데이터 결합은 여러 가지 법률적 제약으로 그 발전의 속도가 매우 느리게 진행되고 있다.
그 이유는, 데이터의 수집 및 결합 시 발생하는 프라이버시 침해를 방지하는 다양한 법률규제
가 존재하기 때문이다. 개인정보 보호법, 정보통신망법, 신용정보법 등의 법률은 다양한 종류
의 자료의 결합에 따르는 개인정보 유출의 위험을 전적으로 기술을 개발하고 이용하는 기업에
게 전가하고 있기 때문에, 인공지능에 대한 기업들의 과감한 투자 결정에 걸림돌이 되고 있다.
프라이버시 이슈와 함께 사회적 관심이 고조되고 있는 것은 인공지능 기술과 관련된 윤리
문제이다. 무인자동차 운행 중 탑승자의 안전과 다수 보행자의 안전 사이에서 한 가지를 선택
해야 하는 상황에 처할 경우 어떤 선택을 해야 하는가 하는 윤리적 딜레마에 대해서 많은 연
구 및 논의가 진행 중이다. 어떤 비용을 치르더라도 탑승자의 안전을 보호하는 “자기방어형
무인자동차”와, 탑승자가 다치더라도 최대한 많은 사람들의 안전을 우선시하는 “공리주의적
무인자동차” 가운데 하나를 선택해야 하는 윤리적 딜레마가 있다. 미국의 한 여론조사에서 다
수의 응답자들이 후자가 더 윤리적이지만 구입은 전자로 할 것이라고 답했다. 미국에서는 후
자를 강제하려는 정부 규제에 소비자들은 강한 거부 반응을 보이고 있다. 이러한 윤리적 딜레
마의 해결 없이는 무인자동차의 상용화는 요원해 보인다.

57
순위2006년 10대 기업 2016년 10대 기업
기업(업종) 시가총액 기업(업종) 시가총액
1 액손모빌(에너지) 4510억 애플(IT) 6120억
2 GE(산업기기) 3860억 구글(IT) 5390억
3 마이크로소프트(IT) 2950억 마이크로소프트(IT) 4430억
4 씨티그룹(금융) 2750억 아마존(IT) 3700억
5 가스프롬(에너지) 2720억 페이스북(IT) 3690억
6 페트로차이나(에너지) 2570억 버크셔 해서웨이(금융) 3580억
7 뱅크오브아메리카(금융) 2410억 액손모빌(에너지) 3420억
8 도요타(자동차) 2410억 존슨&존슨(소비재) 3230억
9 IND&COMM뱅크(금융) 2400억 GE(산업기기) 2660억
10 로열더치셸 2280억 텐센트(IT) 2550억
자료:블룸버그
(단위:달러)
<표 1> 미국의 시가총액 기준 2006년도 10대 기업과 2016년 10대 기업
4차 산업혁명 시대를 맞이하여 국가경쟁력 확보를 위한 인공지능과 빅데이터 관련 핵심기
술의 보유 및 이용이 시급히 요청되고 있지만 개인정보 보호관련 규정과 다양한 윤리적 딜레
마가 큰 장애물이 되고 있다. 본 논문에서는 인공지능 기술에 내재하는 프라이버시 침해와 윤
리적 딜레마에 대해서 살펴보고, 이를 해결할 수 있는 방법을 살펴보고자 한다.
본 논문은 다음과 같이 구성되어 있다. 2장에서는 인공지능 기술의 역사를 살펴본다. 3장
에서는 다양한 인공지능 기술들을 정리한다. 특히, 인공지능 기술에서 빅데이터의 중요성을
설명한다. 4장에서는 인공지능의 산업적 응용사례들을 정리하고, 5장에서는 인공지능과 빅데
이터 기술로 생기는 프라이버시 침해와 윤리적 문제들에 대해서 살펴본다. 6장과 7장에서는
각각 프라이버시 침해의 방지를 위한 법률적 체계와 기술적 접근법을 소개하고, 8장에서 인공
지능 기술의 바람직한 발전 방향에 대한 제언으로 본 논문을 마무리 한다.

58
2. 인공지능의 역사
본 장에서는 인종지능의 역사를 간략하게 살펴본다. 특히, 인공지능 기술에 빅데이터가 중
심적 역할을 하게 된 역사적 배경을 살펴본다. 본 장은 위키백과의 “인공지능”의 내용을 바탕
으로 작성되었다.
가. 개척기(1952~1956)
인공지능이란 인간의 인식, 판단, 추론, 문제해결, 그 결과로 자연어 처리나 행동지령, 학습
기능과 같은 인간의 두뇌작용을 이해하는 것을 연구 대상으로 하는 학문으로 1950년대부터
수학, 공학, 철학, 정치학 등 여러 분야의 학자들에 의해 연구가 이루어지고 있다. 1950년대
후기부터 1960년대 초기에 미국의 주요대학과 연구소에서 컴퓨터를 실제로 사용할 수 있게
되면서 인공지능 연구의 개척기가 시작되었다. 해당 시대는 인공지능의 본격적인 연구가 처음
으로 이루어진 시기이며, 여러 가지 AI에 대한 이론들이 발표되었다. 그 중에서도 앨런 튜링
이 1950년도에 제안한 튜링 테스트(Turing’s test)가 가장 대표적인 연구이다.2) 튜링 테스트
는 기계가 인간의 사고를 얼마나 이해하고 생각, 행동할 수 있는지 판단하는 테스트이다. 또
한 1950년대 중반부터 1960년대 초기에 IBM의 사무엘은 체커라는 게임 인공지능을 개발하
였다.3) 사람들의 대전기록과 실제 게임에서 승패 경험을 프로그램에 반영시켜 학습하였고, 그
결과 체스 아마추어와 동등한 수준을 가지는 체커 프로그램을 개발하였다. 1956년도에 개최
된 다트머스 학회4)에서 존 매카시가 이 연구 분야의 이름을 “Artificial Intelligence (AI), 인
공지능” 이라고 최초로 명명하였다.
나. 황금기(1956~1974)
인공지능 역사의 황금기인 1956년도~1974년도에서는 다트머스 학회 이후 인공지능의 여
러 분야에서 기초가 다져졌다. 이 시기에는 대수학을 풀거나 기하학의 이론들을 증명하거나
영어로 질문응답을 하는 프로그램들이 학습되었다. 1957년 매카시는 LISP라 불리는 프로그램을
2) Turing(1950)
3) Schaeffer와 Jonathan(1997)
4) McCorduck(2004), Crevier(1993), Russell와 Norving(2002)

59
개발하였으며, 그 후에 MIT 대학원생인 테리 위노그라드는 자연어 처리 프로그램인 SHRDLU
을 개발하였는데 블록 세계에서 사용자가 주어진 여러 개의 물체들의 이동을 지시하면 처리
하는 프로그램이다. 블록 세계에 있는 물체들의 이름과 배열을 기억하여, 사용자의 질문에 응
답하고 새로운 물체를 생성하기도 한다.5)
The dialog that was used as a SHRDLU demo :Person:PICK UP A BIG RED BLOCK.Computer:OK.(does it)Person:GRASP THE PYPAMID.Computer:I DON’T UNDERSTAND WHICH PYRAMID YOU MEAN.Person:FIND A BLOCK WHICH IS TALLER THAN THE ONE YOU ARE HOLDING AND PUT IT INTO THE BOX.Computer:BY “IT”, I ASSUME YOU MEAN THE BLOCK WHICH IS TALLER THAN THE ONE I AM HOLDING.Computer:OK.(does it)Person:WHAT DOES THE BOX CONTAIN?Computer:THE BLUE PYRAMID AND THE BLUE BLOCK.Person:WHAT IS THE PYRAMID SUPPORTED BY?Computer:THE BOX.Person:HOW MANY BLOCKS ARE NOT IN THE BOX?Computer:FOUR OF THEM.Person:IS AT LEAST ONE OF THEM NARROWER THAN THE ONE WHICH I TOLD YOU TO PICK UP?Computer:YES, THE RED CUBE.Person:IS IT SUPPORTED?Computer:YES, BY THE TABLE.
Original screen display Later color rendering(Univ. of Utah)
PICK UP A BIG RED BLOCK. OK.
<그림 1> SHRDLU의 데모 그림
(자료: http://hci.stanford.edu/winograd/shrdlu/)
또한 이 시기에 첫 번째 사람과 대화를 주고받는 챗봇 ELIZA가 개발되었지만6) 실제로 프
로그램이 생각하여 대화를 주고받기보다는 입력된 내용을 그대로 말하거나 상대방의 한 말을
다시 말해달라고 요청하거나, 상대방의 말에 몇 가지 문법을 적용하여 바꾸어 응답을 하였다.
그리고 1967년도에 인공지능에 지식을 학습시키려는 몇 가지 시도들이 있었고, 그 중 성공적
인 프로그램은 과학적 추론을 하는 지식 기반 프로그램 DENDRAL, 지식 기반 체스 플레이
프로그램 MacHack 등이 있다.7) 이와 같이 자연어 처리 및 기하학 문제를 증명하는 등 기계
의 지능적 사고로 인공지능이 최대 20년 내에 사람이 하는 모든 일을 기계가 처리할 수 있을
것이라는 낙관론이 만연하였다.
5) Ward(2003)
6) McCorduck(2004), Creivier(1993)
7) McCorduck(2004)

60
다. 암흑기(1974-1980)
주어진 환경을 보고 인식하고 반응하는 능력, 더 나아가 실제 사람처럼 대화하고 반응하는
능력 등 낙관론이 약속한 능력이 사실상 불가능하다는 것을 깨닫고, 인공지능 프로젝트에 대
한 자금이 회수되면서 처음으로 암흑기를 맞이하였다. 인공지능 프로그램 수행능력에 대한 여
러 가지의 문제점과 한계점에 직면하였다. 첫 번째 이유로는 컴퓨터 성능의 한계이다. 의미
있는 결과를 얻기 위해서는 상당한 데이터를 수용하고 처리해야 했는데 당시 컴퓨터의 메모
리는 이러한 데이터를 다루는 데에 턱없이 부족하였다. 두 번째 이유로는 상식과 추론을 위한
데이터가 존재하지 않았다. 자연어 처리나 시각 분야로 인공지능 프로그램을 개발하기 위해
실제로는 상식 수준의 지식을 학습하는 데에도 어마어마한 자료의 양을 필요로 한다. 하지만
이 당시 이러한 자료가 포함된 데이터베이스를 구축하지 못하여 단순 수행능력만 가진 장난
감 수준의 프로그램만 개발되었다. 세 번째는 모라벡의 패러독스8)로 수학 정리들을 증명하고
난해한 기하학 문제를 푸는 것은 컴퓨터 프로그램에 있어서 비교적 쉬운 문제에 속하지만, 얼
굴을 인식하는 문제나 로봇을 장애물에 부딪치지 않으면서 원하는 목적지에 도착시키는 일은
극도로 어려운 문제에 속한다. 이러한 어려움으로 당시 시각 분야의 연구가 매우 더디게 진행
되었다.
라. 개화기(1980년대)
1980년대에 들어서면서 인공지능 프로그램은 특정 지식 영역에 대한 문제를 해결해 주는
전문가 시스템의 형태로 활용되었다. 이러한 전문가 시스템을 이용하여 에드워드와 그의 제자
는 분광계를 이용하여 화합물을 식별하는 Dendral을 개발하였고, 또한 전염성 있는 혈액 질
병을 진단할 수 있는 MYCIN(1974)이 개발되었다.9) 전문가 수준의 지식을 포함한 전문가 시
스템은 1980년대 AI 연구의 주요 쟁점인 지식 기반 시스템과 지식 공학 분야의 기반이 되었
다. 1981년도부터 AI의 상업화가 시작되면서 일본 정부에서는 5세대 프로젝트라는 이름으로
인공지능 프로젝트에 매우 적극적인 투자를 하였다. 투자 목적은 인간처럼 대화를 원활히 진
행하거나, 번역이 가능하거나, 주어진 사진을 해석하는 것이다. 일본뿐만 아니라 영국, 미국
등 여러 나라에서도 인공지능 프로그램 개발을 위한 투자를 늘렸다.
8) McCorduck(2004), Moravec(1988)
9) McCorduck(2004), Crevier(1993), Russell와 Norvig(2002)

61
1982년도에 물리학자 존 홉필드는 신경망 네트워크가 정보를 학습하고 처리할 수 있다는
것을 증명하였다. 또한 비슷한 시기에 데이비드 루멜허트는 파울이 제안한 신경망 네트워크를
학습하는 새로운 방법인 역전파(Backpropagation) 알고리즘을 대중화하였다. 이러한 두 개의
방법들은 1970년도에 제안되었다가 버려진 신경망 이론을 부활시켰고, 신경망은 1990년도부
터 광학 문자 판독(Optical Character Recognition, OCR)과 음성 인식 분야에서 사용되면서
상업적 성공을 이루었다.10) 그러나 1980년대 후반부터 1990년대 초반까지는 인공지능의 두
번째 암흑기가 찾아왔는데, 프로그램의 유지비용과 프로젝트를 시작한 목적의 성과를 현실적
으로 얻기 힘들다는 판단으로 자금지원이 잠시 중단되었다.
마. 1990년대부터 현재까지의 인공지능
컴퓨터 메모리, 성능 등 계산능력의 급속한 발달은 딥러닝의 눈부신 발전을 이끌었으며 실
제 산업에 적용되면서 인공지능의 초창기 목표를 달성하고 있다. 1997년 IBM의 딥블루 게임
AI는 체스 세계 챔피언인 게리 카스파로프를 상대로 승리를 거두었고11), 2000년도에는 C.
브리젤은 감정을 나타낼 수 있는 로봇 장난감을 시판하였다. 2011년도에는 IBM에서 자연언
어 이해 및 처리를 위해 생성한 왓슨 프로그램은 제퍼디 퀴즈쇼에서 이전 두 명의 챔피언들
을 상대로 승리를 거두었다.12) 1988년도에 쥬디어 펄이 쓴 책은 인공지능에 확률론과 의사
결정론을 도입할 수 있게 하였다. 베이지안 네트워크, 은닉 마코프 모형, 확률 모형, 최적화
연구와 함께 여러 가지 신경망 구조와 새로운 알고리즘들이 개발되었다.
데이터를 저장해 둘 수 있는 저장 공간이 발달하고, 앞에 언급한 연구들로 이전보다 프로
그램 학습능력이 향상되었고, 데이터 마이닝, 산업 로봇, 음성 인식, 금융 서비스 소프트웨어,
의학 진단 분야 등에 인공지능이 유용히 활용되었다. 특히 인공 신경망 네트워크는 이미지 분
류, 인식 문제에 압도적인 성능을 나타내고 있으며,13) 이를 이용하여 이미지 검색이나 주어진
사진의 인물이나 물체를 판단하는 프로그램 개발에 사용되었다. 페이스북에서 개발한 얼굴 인
식 인공지능 딥페이스는 이 중 성공한 대표적인 예이다.
10) Crevier(1993), Russell와 Norvig(2002)
11) McCorduck(2004)
12) Markoff(2011)
13) LeCun 외(1998), Krzhevsky 외(2012), He 외(2016)

62
자연언어 처리 분야에서도 인공지능은 강점을 보이고 있다. 사용자가 아랍어를 입력하면
영어로 자동 번역해주는 기계번역 시스템도 최근 눈부신 발전을 이루었다.14) 또한 구글 딥마
인드에서 개발한 인공지능 바둑 프로그램 알파고15)는 2015년도 유럽 바둑 챔피언과 대결하
여 5:0 승리를 거두고, 2016년도에는 이세돌 9단과의 대국에서 4승 1패를 기록하며 전 세계
적으로 인공지능의 발전을 알렸으며, 프로기사 9단을 부여받았다. 구글 딥마인드는 바둑에서
큰 승리를 거둔 알파고 인공지능 알고리즘을 이용하여 의학 분야, 무인 자율주행, 인공지능
개인비서 등 다양한 서비스 사업에 활용될 수 있는 인공지능을 개발한다는 계획을 밝혔다. 페
이스북과 아마존도 인공지능을 이용한 개인비서 또는 자동 서비스 시스템을 개발하였고 현재
서비스업에서 활발히 사용되고 있다.
3. 인공지능 기술들
인공지능 구현을 위한 방법론으로는 1) 논리적 추론, 2) 전문가 시스템, 그리고 3) 기계학
습이 있다. 기계학습이란 데이터를 기반으로 컴퓨터가 자동으로 새로운 지식을 학습하고 알고
리즘을 구현하게 하는 방법론이다. 최근의 인공지능의 대부분의 기술은 기계학습을 기반으로
구현되고 있다. 본 장에서는 기계학습의 다양한 방법론들에 대해서 정리한다.
기계학습은 문제의 종류에 따라 지도학습, 비지도학습, 강화학습으로 나뉜다. 지도학습은
입력변수를 기반으로 출력변수를 예측하는 것을 목적으로 하며 기계학습의 핵심 분야이다. 번
역, 질병예측 등이 모두 지도학습과 관련이 있다. 비지도학습은 주어진 데이터들의 관계를 규
명하는 것을 목적으로 하며 차원축소, 군집생성 등의 방법론들이 있다. 데이터의 압축 또는
새로운 데이터의 생성 등에 응용된다. 강화학습은 변화하는 환경에서 최적의 의사결정을 하는
것을 목표로 하는 기계학습법이다. 바둑과 같은 게임에서 최적의 의사결정을 자동으로 학습하
는 문제에 응용된다.
14) Brants 외(2007), Wu 외(2016)
15) Silver 외(2016)

63
가. 지도학습(Supervised Learning)
지도학습은 주어진 자료 에 대해 레이블 가 존재하여, 로 를 가장 잘 표현하도록
기계에 학습시키는 것을 의미하며, 간단한 예로 주어진 인물 사진 (픽셀별 정보)에 대해,
남성( )인지 여성( )인지 분류할 수 있도록 학습시키는 방법이다. 앞의 예처럼 가
이산형 또는 범주형인 경우에는 분류(Classification) 문제라고 하고 연속형인 경우에는 회귀
(Regression) 문제라고 한다. 기계학습의 경우 모형을 학습하기 위한 학습자료(Training
Data)와 학습된 모형의 성능을 평가하고 예측하기 위한 예측자료(Test Data)로 이루어져 있
으며, 학습자료는 입력변수 와 의 여러 개의 쌍으로 이루어진다. 앞으로는 번째 학습자
료를 로 표기하고, 은 차원의 실수 벡터, ⋯ ⋯ 은 ×
차원인 행렬로 표기하겠다.
다양한 지도학습 알고리즘들은 크게 3개의 분야로 나눌 수 있는데 1) 선형모형, 2) 의사결
정나무 및 앙상블 그리고 3) 신경모형망 및 딥러닝이다. 본 절에서는 이 3가지 분야의 여러
방법론들에 대해서 간단히 살펴본다.
1) 선형모형
회귀분석은 출력값 또는 반응변수 ⋯이 실수인 값들은 가지는 문제로, 일반적
인 형태식인 …을 가정하고, 여기서 는 알려져 있진 않은 의
관계 함수이고, …은 평균이 이고 와 독립인 랜덤 에러이다. 회귀분석 중 가장
단순한 방법은 주어진 들의 선형관계식으로 을 표현하는 선형회귀분석이다. 즉
을 가정하는데 여기서 β은 차원의 벡터로 우리가 추정해야 하는 값이다. 일반
적으로 회귀분석에서는 잔차제곱합인 …들의 합을 최소화하도록 함수
을 추정하며, 선형회귀분석의 경우 ∑ 을 최소화하는 을 추정한다. 이와
같은 방법을 최소제곱법이라하며, 이렇게 추정된 는 최소제곱추정량이라 한다. 잔차제곱
합을 최소화하는 은 의 역행렬이 존재한다는 가정하에 선형대수학을 이용하면
로 구할 수 있다. 이와 같이 추정된 을 이용하여 새로운 입력자료
가 들어왔을 때에 로 예측할 수 있고, 예측에 대한 정확도를 높이기 위한, 즉

64
새로운 자료가 들어왔을 때에
을 실제 에 충분히 가깝게 예측하기 위한 여러 가지의
모형들이 연구되었다.
하지만 선형회귀분석의 경우 의 두 개 또는 그 이상의 열들끼리 강한 음의 관계 또는
양의 관계를 가질 경우, 변수의 수 가 에 비해 매우 큰 경우 의 역행렬이 존재하지
않거나 굉장히 큰 값을 가지게 되어 추정량 의 분산이 커지고, 따라서 예측 정확도가 낮
아지게 된다. 따라서 기계학습에서는 에 제약조건을 더하여 어느 정도의 편차는 감안하더
라도 분산을 줄이는 방향을 택한다. 이 중 가장 일반적으로 사용하는 방법은 축소회귀 또는
벌점화 회귀분석이라고 하며, 잔차제곱합에 에 대한 벌점화 함수 가 추가된
∑ 을 최소화하는 을 추정한다. 여기서 은 보다 큰 조율
모수이며 추정량의 성질을 결정한다. ∑ 인 경우 능형(Ridge) 회귀라고 하고,
∑ 이면 라쏘(Lasso) 회귀16)라고 한다. 여기서 조율모수 가 증가하면,
을 최소화하는 해를 찾을 때 벌점화 함수에 더 많은 가중치가 들어가게 되어 추정되는 의
크기가 에 가깝게 되고, 추정된 의 분산은 작아지고 편차는 커지게 된다. 따라서 벌점화
회귀분석을 사용하기 위해서는 데이터를 이용하여 적절한 조율모수를 선택해야 하는데 일반적
으로 겹 교차검증법을 이용하여 조율모수 을 선택한다.
출력값이 특정한 범주에 속하는 분류문제에서는, 여기서는 편의상 ∈ …인 경우를 고려한다. 분류문제에서는 주어진 자료 에 대해 번째 개체의 출력값이 에 속할
지, 또는 1에 속할지에 대한 확률을 추정한다. 이를 모형화하면 아래와 같이 표현할 수 있다.
│
여기서 는 연결함수(Link Function)라고 하며, 과 사이의 값을 가지고 증가함수를 고려한다.
연결함수의 형태에 따라 ① expexp
이면 로지스틱 모형, ② expexp이면 검벨(Gumbell) 모형, ③ 가 표준정규분포의 분포함수인 경우는 프로빗 모형이라 하
고, 이 중 로지스틱 모형이 계산의 편리성으로 가장 많이 사용된다.
16) Tibshirani(1996)

65
분류문제에서 회귀계수의 추정은 일반적으로 가능도함수를 최대로 하는 최대가능도추정법
을 이용하고, 가능도함수는
×
으로 정의하고 가능
도함수에 로그를 취한 로그가능도함수 log을 최대화하는 추정량을 수치적 방법을
이용하여 찾는다. 선형회귀분석 문제에서 잔차에 대해 …~ 가정을 추가하
면 로그가능도함수는
∑ 가 되어 로그가능도함수를 최대화하는 것
은 잔차제곱합을 최소화하는 문제와 동일하다. 선형회귀분석에서 다루었던 최소제곱추정법은 최대
가능도추정법의 특별한 경우로 이해할 수 있고, 따라서 최소화할 목적함수를
을 고려하면 분류문제에서 벌점화 기법을 바로 적용할 수 있다. 마찬가지로 라쏘 벌점함수를
고려할 경우 변수선택이 이루어진다.
2) 의사결정나무(Decision Tree) 및 앙상블
의사결정나무는 <그림 2>와 같이 변수들의 영역을 여러 개의 직사각형으로 분할하며 규칙
을 생성해나가는 방법으로 반응값이 연속형인 경우와 범주형인 경우에 둘 다 사용하고, 예측
자료에서의 성능은 떨어지지만 해석력은 좋다.
≤
≤ ≤
≤
<그림 2> 의사결정나무 모형의 예(Friedman 외, 2001)
나무를 어떤 기준으로 분리해 나갈지 기준을 선택하고, 언제 분리과정을 멈출지 결정한 뒤
제일 아래 노드(<그림 2>에서 …)에서 예측값을 할당하여 의사결정나무를 형성한다.
먼저 나무를 분할할 때에는 순수도(Purity) 또는 불순도(Impurity)을 이용하여 어떤 변수를
이용하여 어떤 기준 값으로 분리할지 결정한다. 순수도가 크다는 것은 나무가 한 번 분리를

66
하기 전보다 분리 후의 각 마디에 있는 자료들의 특성이 어느 하나의 그룹에만 해당할 비율
이 높다는 것으로, 순수도를 최대화하거나 불순도를 최소화하여 나무를 분할한다. 불순도는
반응값이 연속형인 경우 잔차제곱합의 감소량을 사용하고, 범주형인 경우 카이제곱 통계량,
지니 계수, Cross-entropy를 이용한다. 나무가 너무 많이 분리된 경우, 즉 나무의 크기가 큰
경우에는 자료에 대해 과적합할 수 있기 때문에, 일반적으로는 각 노드의 최소 크기(노드에
들어가는 개체 수)를 설정하여 최소 크기 이하로 되는 경우 나무 분리를 멈추고, 비용 복잡도
가지치기(Cost-complexity Pruning)를 이용하여 불필요한 나무의 가지를 제거한다.
의사결정나무는 자료를 약간 변형시켰을 때 전혀 다른 결과가 나올 수 있는 방법으로, 즉
분산이 굉장히 큰 방법이다. 따라서 이러한 불안정성을 줄이기 위해 앙상블 기법을 사용한 배
깅, 랜덤포레스트, 부스팅 등이 있다.17) 배깅과 랜덤포레스트는 부스트랩을 이용하여 여러 개
의 나무 모형을 적합한 뒤 앙상블을 하는 방법으로 나무모형을 적합할 때 배깅에서는 전체
변수를 랜덤포레스트는 몇 개의 변수를 랜덤하게 선택한다. 부스팅은 여러 개의 약한 예측 모
형(weak learner)을 결합하여 매우 정확한 예측모형을 만드는 방법이다. Freund와 Schapire
이 1997년도에 AdaBoost(Adaptive Boost)라는 부스팅 알고리즘을 개발하였다. 그 뒤
Friedman(2001)은 부스팅을 기울기 강하 알고리즘으로 해석하여 다양한 손실함수에 대한 부
스팅 알고리즘을 개발하였고 이런 알고리즘을 Gradient Boosting이라 부른다.
3) 신경망 모형(Neural Network)
신경망 모형은 생물의 뇌 구조를 모방하여 만든 수학적 모형으로 입력값과 출력값 사이의
복잡한 형태의 비선형 함수를 가정한다. 1943년도에 W. S. McCulloch와 W. Pitts에 의해 모
형이 구축되었고, 1957년도에 F. Rosenblatt에 의해 단층신경망 알고리즘이 제안되었지만, 당
시 컴퓨터의 성능 한계로 많이 사용되지 않다가 역전파(Backpropagation) 알고리즘과 다층
신경망 모형의 결합으로 1980년대에 주목받기 시작하였다.18)
신경망 모형은 <그림 3>과 같다. 입력값을 받는 입력층(Input Layer)와 중간층 또는 은닉층
(Hidden Layer), 마지막 출력값을 내는 출력층(Output Layer)으로 구성되며, 원으로 표시한
부분은 각 층의 노드들을 의미한다. 일반적으로 입력층의 노드의 수는 입력변수의 차원 이고,
17) 박창이 와 김용대(2011), Friedman 외(2001)
18) Russell와 Norvig(2002)

67
출력층의 노드의 수는 출력값이 실수 형태의 값을 가질 경우 1개, 출력값이 범주형인 경우에
는 범주의 수만큼 설정한다. <그림 3>과 같이 다음 층의 노드들이 바로 아래층의 전체 노드
들에 영향을 받는 경우를 ‘fully-conneted’라 표현한다. <그림 3>에 나타나 있는 단층신경망
모형은 다음과 같이 수식으로 표현이 가능하다.
입력층의 노드를 ′, 중간층의 노드를 ′, 출력층의 노드를
′라고 표기할 때,
으로 나타낼 수 있고 여기서
은 입력층과 중간층 사이의
편차들과 가중치들이고
은 중간층과 출력층 사이의 편차들과
가중치들을 나타낸다.
Input Layer Input LayerHidden Layer Hidden Layer1 Hidden Layer2
Output Layer
Output Layer
<그림 3> 신경망 모형의 예, 단층신경망 모형(왼쪽), 다층신경망 모형(오른쪽)
자료: http://cs231n.github.io/neural-networks-1
또한 ∙은 활성함수(Activation Function)로 일반적으로 sigmoid, tanh, ReLU을 사용
한다.
tanh
max

68
그리고 ∙은 출력함수(Output Function)로 ① 가 1차원의 실수의 값을 가질 경우에는
, ② 가 이산형인 경우에는 로지스틱 함수를 고려하고, ③ 가 범주형인 경우, 즉 분류문제
에서 의 범주가 개인 경우에는 softmax 함수 ∑
…를 사용한다.
주어진 신경망 모형에서의 가중치들과 편차들의 모수들을 라고 하면, 을 추정하기 위한
목적함수는 분류문제의 경우 cross-entropy 손실함수 ∑ ∑ log 을
사용하고, 회귀문제의 경우에는 제곱 손실함수 ∑ 을 사용하여 각 목적
함수를 최소화하는 을 추정하고 이때 모수추정에는 역전파 알고리즘을 이용한다. 신경망 모
형의 경우 앞서 다룬 선형회귀 또는 로지스틱 회귀분석보다 추정해야 할 모수들의 수가 훨씬
많고, 과적합 문제가 발생하기 쉽다.19) 과적합이란 학습자료의 에러는 굉장히 작지만 새로운
자료 또는 예측자료의 에러는 굉장히 커지는 것을 의미한다. 따라서 이와 같은 과적합을 피하
기 위한 방법들로는 알고리즘을 일찍 종료시키거나, 앞서 능형 회귀, 라쏘 회귀와 비슷하게
벌점화 기법을 고려하여 목적함수를 손실함수와 벌점함수의 합을 이용하는 방법이다. 또는
Srivastava, N이 2014년도에 제안한 drop-out 방법을 이용할 수 있다. <그림 4>는 2개의 중
간층을 가지는 신경망 모형에 drop-out을 적용한 예로, 매번 역전파를 할 때마다 의도적으로
출력층의 노드를 제외한 나머지 노드들의 절반을 랜덤하게 선택하여 끄고(drop-out) 학습하
여, 노드들끼리의 상관관계를 줄이기 위해 제안된 방법이다.
(a) Standard Neural Net (b) After Applying Drop-out
<그림 4> 신경망 모형에서의 drop-out을 적용한 예(Srivastava, 2014)
19) Hawkins(2004)

69
① 이미지 분류에서의 신경망 모형의 응용: Convolutional Neural Network, CNN20)
CNN은 동물의 시각인지과정을 모방한 신경망 모형 중 하나로 이미지 분류문제 또는 분석
에서 기존의 기계학습법을 크게 뛰어넘었다. 1998년 LeCun에 의해 convolutional layer
(이하 conv. layer)를 포함한 LeNet-5 모형이 개발되었다. 구조는 <그림 5>와 같이 입력층,
conv. layer, pooling layer, conv. layer, pooling layer, conv. Layer, fully-connected
layer, 출력층의 순서로 구성되어 있다. Pooling layer의 경우 LeNet-5는 average
pooling을 사용하였고 활성함수로는 sigmoid와 tanh을 이용하였다.
LeNet-5는 conv. layer의 모수들을 공유하는 성질과 down sampling의 일종인 pooling
layer를 이용하여 모수의 수를 줄여 과적합을 방지하도록 하였다. 또한 <그림 3>의 신경
망 모형처럼 이전 층과 그 다음 층의 노드들끼리 다 연결되어 있지 않기 때문에 sparse
connected 인공신경망의 일종이다. 일반적으로 주어진 이미지자료에 대해 속하는 범주
를 찾는 것이 목적이기 때문에 손실함수로는 cross-entropy를 이용하며, 역전파 알고리
즘을 통해 모수를 추정한다.
숫자를 수기로 작성한 이미지 자료가 입력값으로 들어가면 어떤 숫자가 적혀있는지 분류
하는 문제인 MNIST 데이터셋(60,000개의 학습자료와 10,000개의 예측자료로 구성)을
이용하여 LeNet-5를 학습시키고 예측자료를 이용하여 기존에 사용하던 기계학습 방법
들과 성능을 비교하였을 때 더 좋은 성능을 확인할 수 있었다. 이후 CNN에 대한 연구
가 활발히 이루어져 크기가 큰, 그리고 속하는 범주가 많은 이미지 분류문제를 위한 여러
20) LeCun(1998)
INPUT32×32
C1:feature maps6@ 28×28
C3:f. maps 16@ 10×10
S2:f maps6@ 14×14
S4:f. maps 16@ 5×5
C5:layer120
F6:layer84
OUTPUT10
Convolutions Subsampling Convolutions SubsamplingFull connection
Full connection
Gaussian connections
<그림 5> LeNet-5 모형의 구조(LeCun, 1998)

70
CNN 모형이 개발되었는데, 그 중 대표적인 모형들로는 AlexNet21), VGGNet22),
GoogLeNet23), ResNet24) 등이 있다.
② 시계열 자료를 위한 신경망 모형: Recurrent Neural Network, RNN
RNN은 언어 모형화 또는 텍스트 생성, 기계번역, 음성 인식, 이미지 캡션 등에 사용되는
자료로, 일반적인 신경망 모형과 달리 입력값이 순차적으로 주어지는 시계열 자료문제에
주로 사용되는 신경망 모형 중 하나이다. 1980년대에 John Hopfield에 의해 처음으로
제안되었으며, 기존에 사용되었던 은닉 마코프 모형보다 월등히 좋은 성능을 가졌다.
⋯ ⋯, ⋯ ⋯, … …은 각각 시간에 따
른 입력값, 중간노드의 값, 출력값을 나타내는데 시간에 따른 중간층 노드끼리 연결이
되어 있고, 는 각각 입력층과 중간층 사이의 모수, 이전 시점과 다음 시점의
중간층 사이의 모수, 중간층과 출력층 사이의 모수을 나타낸다. 시점의 출력결과는 이
전 시간의 중간층에 영향을 받는다. 시간에 따라 들어오는 입력에 대하여 동일한 task를
적용하고, 즉 모든 시점에 대해 모수( )를 전부 공유한다. 이와 같은 구조를 사용
함으로써 학습시켜야 하는 모수의 수를 줄여 과적합을 피한다. 하지만 실제 구현에서는
너무 먼 과거의 시점에 일어난 일들은 기억하지 못하는 문제가 있다. 이에 대한 해결방
안으로 중간층의 구조를 변형시키는 LSTM25)와 GRU26) 등이 있다.
<그림 6> RNN의 구조(LeCun 외, 2015)
21) Krizhevsky 외(2012)
22) Simonyan와 Zisserman(2014)
23) Szegedy 외(2015)
24) He 외(2016)
25) Hochreiter와 Schmidhuber(1997)
26) Cho 외(2014)

71
나. 비지도학습(Unsupervised Learning)
지도학습과 비지도학습의 가장 큰 차이점은 데이터 라벨의 유무이며, 비지도학습의 경우
반응변수 또는 라벨 가 없고 주어진 자료 만을 가지고 분석하는 기계학습의 분야 중 하
나이다. 비지도학습 내에서도 군집분석, 차원 축소법(주성분분석, 인자분석 등) 여러 개의 분
야가 있다.
1) 군집분석
모집단에 대한 사전 정보가 없는 경우 주어진 관측값들 사이의 거리 또는 비유사성을 이용
하여 전체를 몇 개의 군집으로 군집화하는 방법으로 계층적, 비계층적 군집분석 등이 있다.
계층적 군집분석은 처음 관측치당 하나의 군집을 이루고 있다고 가정하고 가까운 자료끼리
순차적으로 군집 ・ 병합해나가는 방법으로 한번 병합된 자료들은 다시 분리되지 않고, 나무구
조인 덴드로그램을 이용하여 표현한다. 비계층적 군집분석의 경우 관측 자료들을 몇 개의 군
집으로 나눌지를 먼저 설정하고 주어진 군집분석 판정기준을 최적화하는 분리기법을 사용한
다. 대표적인 비계층적 군집분석의 방법으로는 K-means 군집분석, 가우시안 혼합 모형 등이
있다.
2) 차원 축소법
주어진 자료 내 변수들의 선형변환 또는 비선형변환을 이용하여 고차원의 자료를 저차원으
로 환원시키는 방법으로 차원의 단순화를 통하여 자료의 구조를 파악하는 것이 목적이다.
① 선형결합을 이용한 차원 축소27)
선형결합을 이용하여 차원을 축소하는 기법은 주성분분석(Principal Component Analysis),
인자분석(Factor Analysis) 등이 있다. 주성분분석은 주성분이라는 변수를 생성하는 방법
으로 첫 번째로 생성된 주성분은 자료의 분산을 가장 많이 설명하는 선형결합이고 두
번째 주성분은 첫 번째 주성분과 독립이면서 첫 번째 주성분이 설명할 수 없는 나머지
분산을 최대한 설명하는 선형결합으로 주성분의 수는 전체 자료의 수만큼 생성할 수 있
지만, 자료의 차원을 낮추기 위해 전체 분산의 대부분을 설명하는 몇 개의 주성분만을
27) 박창이와 김용대(2011), Friedman 외(2001)

72
고려한다. 인자분석은 관측되지 않은 중요한 몇 개의 잠재적 인자들의 선형결합으로 자
료의 변수가 이루어져있다고 가정하고, 그 잠재적 인자들을 찾아내는 분석법으로 이러
한 잠재적 인자를 이용하여 전체 변수의 상관관계를 파악하고, 그룹화를 할 수 있기 때
문에 차원 축소에 주로 사용된다.
② 신경망 모형을 이용한 차원 축소
주어진 자료에 대한 최소한의 비선형결합으로 자료의 전체 분포를 표현하는 모형으로 주로
이미지 차원 축소 및 복원, 가상 이미지 생성 등에 사용된다. 먼저 입력값들의 확률 분포
에 대해 학습하는 모형인 RBM(Restricted Boltzmann Machine)은 확률 모형으로, 1986
년도에 Paul Smolensky에 의해 제안되었으며, 2006년도에 Geoffrey Hinton에 의해 학
습 알고리즘이 개발되었다. RBM은 입력층과 하나의 중간층으로 이루어져 있으며, 중간층
을 이용하여 입력층의 분포를 표현하는 모형이며 <그림 7>의 왼쪽과 같다. 모수 추정은
CD(Contrastive Divergence) 알고리즘을28) 사용한다. 두 개 이상의 중간층을 이용하여 입
력층의 분포를 표현하는 모형인 DBN(Deep Belief Network)은 2006년도 Geoffrey
Hinton에 의해 제안되었으며 <그림 7>의 오른쪽 모형과 같다. DBN은 가장 위의 층만
RBM을 따르고 나머지 층들은 모두 위에서 아래로 가는 Directed Belief Network을 가정
한다. 모수 추정은 층마다 RBM을 이용하여 모수를 추정하여 모수들의 초기값으로 설정하고,
모든 모수를 지도학습을 이용하여 학습한다.29) 이 외에도 차원 축소 및 데이터 압축을 위
한 신경망 모형에는 Auto-encoder, Stacked Auto-encoder 등이 있다.30)
HiddenLayer
HiddenLayer
InputLayer
<그림 7> RBM(왼쪽), DBN(오른쪽) 구조(Wang 외, 2014)
28) Hinton(2006)
29) Bengio 외(2007)
30) Bourlard와 Kamp(1988), Hinton와 Zemel(1994)

73
다. 강화학습(Reinforcement Learning)
강화학습(Reinforcement Learning)은 기계학습 분야의 한 갈래로, 각 행동에 대해 서로
다른 보상이 주어지는 문제 상태에서 어떠한 행동을 취해야 최대한의 보상을 얻을 수 있는지
를 학습한다.31) 강화학습의 3요소는 상태(State), 행동(Action), 보상(Reward)이다. 강화학습
은 각각 요소들 간의 상호관계에 대해 학습한다는 점에서 한 요소를 통해 다른 요소를 파악
하는 지도학습과는 차이가 있다.
예를 들어, 자율주행 자동차의 움직임에 강화학습 모형을 적용할 경우 가능한 상태는 현재
차의 위치, 속도, 주위 차의 움직임 등이 있고 이 상태에서 가능한 행동으로는 손잡이를 좌우
로 돌린다거나 엑셀이나 브레이크를 밟는 것이 있을 수 있다. 이러한 행동의 보상으로는 목적
지까지의 소요시간이 빠를수록 큰 값을 줄 수 있을 것이고, 사고가 일어난다면 매우 작은 값
(음의 값)이 보상으로 주어지게 될 것이다.
관찰 시점을 기준으로 상태와 행동, 보상은 순서대로 발생하게 된다. 시점에서의 상태, 행
동, 보상을 각각 라고 하면, 시점 부터 관측을 시작하면 ⋯ 와
같은 수열을 관측할 수 있다. 이러한 일련의 행동과 보상 간의 관계를 탐구하기 위해서는 확
률적인 모형이 필요하다. Markov Decision Process는 강화학습에서 주로 사용하는 모형으로,
시간에 따른 각 요소들 간의 상관관계를 나타내는 모형이라고 할 수 있다. Markov Decision
Process는 상태공간 , 행동공간 , 전이확률 , 보상함수 , 감소율 의 모임 <, , ,
, >로 표현되며, 각 공간의 의미는 다음과 같다.
•는 가능한 상태를 모두 모은 집합이다.
•는 가능한 행동을 모두 모은 집합이다.
•는 상태와 행동에 대한 함수로, 현 상태에서 특정 행동을 할 때 나올 수 있는 다음 상
태에 대한 확률적인 모형이다. 이를 식으로 표현하면 다음과 같다.
′ ℙ ′│
31) Sutton과 Barto(1998)

74
•은 상태와 행동에 대한 함수로, 현 상태에서 특정 행동을 할 때 기대할 수 있는 보상
을 나타낸다. 이를 식으로 표현하면 다음과 같다.
E│
•감소율 는 과 사이의 값으로, 계산상의 편의를 위해 추가되었다.
즉, Markov Decision Process는 확률론에서의 Markov 모형과 마찬가지로 시점에서의
상태와 보상이 직전의 상태, 행동에만 영향을 받는다는 가정을 내포하는 모형이라고 할 수 있다.
강화학습의 3요소인 상태, 행동, 보상 중 우리가 결정할 수 있는 사항은 행동뿐이다. 따라
서 강화학습 문제를 해결한다는 것은 어떠한 행동을 할지를 결정하는 것이라고 할 수 있다.
엄밀하게 말하자면 현재 상태에서 어떠한 행동을 취할지를 선택해야 한다고 할 수 있다. 이러
한 선택은 고정되어 있을 수도 있지만, 확률적으로 표현할 수도 있다. 이와 같이 주어진 상태
에 대해 어떤 행동을 취할지를 선택하는 방식을 정책(Policy)이라 하며, 수식으로는 다음과 같
이 정의된다.
π│ℙ │
위와 같은 정의를 이용하면, 강화학습은 최적의 정책을 찾는 문제라고 말할 수 있다. 서로
다른 정책들을 비교하기 위해서는 정책을 평가하는 기준이 필요하다. 강화학습에서 시점 이
후의 총 보상의 합은 반환값(Return)이라고 하며, 다음과 같이 정의된다.
γ ⋯
현재 상황에서 고정된 정책을 따라 행동을 선택하는 경우에, 반환값의 기댓값을 가치함수
(Value Function)이라고 한다. 주어지는 값이 상태뿐인지 혹은 다음 행동까지 주어졌는지에 따
라 상태-가치함수(State-Value Function), 행동-가치함수(Action-Value Function)라 하며, 각각
다음과 같이 정의된다.
Eπ
π Eπ

75
따라서 강화학습의 궁극적인 목표는 모든 상태에서 가장 큰 가치함수를 갖는 정책을 찾는
것이라고 할 수 있다.
그러나 임의의 정책 에 대해 각 상태에 대해 가치함수를 계산하는 것은 불가능하다. 가치
함수를 계산하기 위해서는 전이확률 와 보상함수 을 알아야 하는데, 이는 우리가 알 수
없기 때문이다. 최적의 정책을 찾기 위한 가장 직접적인 방식으로는 가치함수를 추정하는 것이
다. 이러한 상황에서 사용되는 알고리즘으로 몬테카를로 기법이 있다. 몬테카를로 기법은 많은
횟수의 시뮬레이션을 통해 각 행동의 보상을 확인함으로써 실제 행동-가치함수를 추정하고, 가
장 높은 행동-가치함수값을 갖는 행동을 최적 행동으로 선택하는 방법이라고 할 수 있다.
현재의 주어진 정책에 대해서 이를 개선시키는 방안으로 최적의 정책을 찾는 방식도 생각
해 볼 수 있다. 이러한 방식으로 최적 정책을 추정하는 알고리즘 중 하나가 Q-learning이
다.32) Q-learning은 행동-가치함수를 학습하는 알고리즘으로, 현재 π 을 바탕으로 단
한번만 행동을 실행한 후 얻은 보상을 이용해서 행동-가치함수를 학습하는 알고리즘이다.
Q-learning은 반환값 가
을 만족한다는 점을 이용해서 의 기댓값인 π 을 추정하는데 한번의 시뮬레이션 결과
얻은 보상을 이용해서 을 추정하는 알고리즘이다.
가치함수를 모형화함으로써 추정하는 방법도 있다. 이 경우에는 일반적인 지도학습과 유사
한 방식으로 모수 의 추정이 이루어진다. 특정한 목적함수 를 최적화하는 를 추정하
기 위해서 인공 신경망 모형에서도 많이 사용되는 경사강하기법을 이용한다. 이때 J로는 가
치함수가 주로 사용된다. DeepMind에서는 가치함수를 모형화하는 모형으로 인공 신경망 모
형을 사용하는 알고리즘을 개발했으며,33) 이를 이용해서 다양한 비디오 게임의 해법을 성공적
으로 찾아냈으며, 이와 몬테카를로 알고리즘을 결합해서 인간보다 뛰어난 바둑 프로그램을 개
발해냈다.34)
32) Watkins(1989)
33) Mnih 외(2015)
34) Silver 외(2016)

76
4. 인공지능 응용사례
최근 딥러닝 기법을 비롯한 인공지능 알고리즘의 발전과 연산속도, 자료처리량 등의 하드
웨어 측면에서의 비약적인 향상에 힘입어 산업 전 분야에서 인공지능 응용사례가 급증하고
있다. 특히 의료, 금융, 교육 등의 산업 분야에서는 기존에 해당 분야 전문가가 필요했던 영
역들을 인공지능이 상당수 대체하고 있다. 뿐만 아니라, 기존의 인공지능 기술로는 거의 불가
능했던 자율주행, 개인비서 등의 새로운 첨단 산업이 창출되고 있다. 이 장에서는 여러 산업
분야에서의 대표적인 인공지능 응용사례를 살펴보고 각 사례에 대한 구체적인 인공지능 기술
의 활용방법에 대해 알아보도록 한다.
가. 의료 분야
의료정보는 매년 그 양이 두 배로 늘어나고 있으며, 빠르게 변화하는 필드에서 수많은 의
학 지식을 계속적으로 학습해야 하는 과제를 안고 있다.35) 이러한 환경 속에서, 방대한 양의
자료를 저장하고 처리할 수 있는 인공지능 시스템은 현대 의학에서 점점 그 필요성이 높아지
고 있다.
의료 분야의 가장 대표적인 인공지능 응용사례는 인공지능 컴퓨터 시스템 IBM 왓슨을 활
용한 질병 진단 및 치료법 제공 시스템이다. IBM 왓슨은 주어진 질문에 대한 답을 하도록 설계
된 인공지능 시스템으로, 2011년 미국의 퀴즈쇼인 제퍼디에 출연하여 기존의 프로그램 챔피
언들과의 대결에서 승리한 바 있다. IBM은 세계 최고의 암 병원인 뉴욕의 메모리얼 슬로언
케터링 암센터(MSKCC)와의 협동연구 등을 기반으로 암 진단 솔루션인 왓슨 포 온콜로지
(Watson for Oncology)와 암 치료법 제공 프로그램인 왓슨 포 지노믹스(Watson for
Genomics)를 IBM 왓슨에 탑재하였다. 플로리다 주의 주피터 메디컬 센터(Jupiter Medical
Center)를 비롯한 여러 병원에서 위 솔루션들을 진단 및 치료에 활용하고 있다. 국내의 경우
가천대 길병원이 처음으로 왓슨 포 온콜로지를 도입한 이후, 부산대병원에서 왓슨 포 온콜로
지와 왓슨 포 지노믹스를 모두 도입하는 등 점차 그 활용 사례가 늘어나는 추세이다.
35) Lee 와 Kim(2016)

77
나. 금융 분야
금융 분야의 인공지능 응용사례는 투자자문, 신용평가, 금융범죄 탐지 등의 소분야로 나눌
수 있다. 투자자문 서비스는 경제 및 금융시장의 현재 상황을 분석하고 미래를 예측함으로써
투자방향을 제공한다. 신용평가는 대출신청자의 신용도를 판단하고 채무불이행 가능성 등을 예
측하는 것이며, 금융범죄 탐지는 카드부정사용을 포함한 결제사기 탐지 등을 예로 들 수 있다.
투자자문 분야에서는 기존에 여러 핀테크 기업들이 기존의 금융공학과 머신러닝 기법들을
활용하여 투자자문 서비스를 제공해왔다. 최근 딥러닝 기술을 기반으로 하여 보다 방대한 자
료에 대한 효율적인 분석이 가능해졌고, 이에 따라 딥러닝 기술을 활용한 투자자문 서비스를
제공하는 핀테크 기업들이 늘어나고 있다. 대표적으로 Dataminr은 실시간으로 SNS 자료를
분석하여 투자 관련 의사결정에 필요한 시장정보와 동향을 제공한다. 다른 대표적인 투자자문
핀테크 기업으로는 Sentient Technologies, Renaissance Technologies 등이 있다.
신용평가 분야에서는 기존의 머신러닝 기법과 딥러닝 기법을 사용하여 개인 혹은 기업의 신
용을 평가하는 인공지능 프로그램이 다수 개발되었다. 핀테크 기업 TrustingSocial의 경우, 기
존의 직업, 지출내역 등의 정보에 SNS 활동 정보와 같은 웹 자료를 추가하여 개인의 신용평가
점수를 산출하는 Credit Scoring 2.0 프로그램을 제공하고 있다. 기존의 신용평가는 대부분 확
인된 지출 내역 등의 한정된 자료만으로 이루어져 상환능력이 충분함에도 불구하고 대출이 불
가능한 고객들이 많았다. 반면 Credit Scoring 2.0에서는 풍부한 웹 자료를 바탕으로 신용을
평가함으로써 기존의 정보만으로는 대출이 어려웠던 개인들에 대해서 대출기회를 열어주는
역할을 한다. 그리고 소파이(SoFi), 아반트(Avant) 등으로 대표되는 P2P 금융 핀테크 기업들의
경우, 대출을 원하는 개인 혹은 기업의 신용을 정확히 평가하는 것이 회사의 수익률에 직결되
므로 이를 위한 자체적인 인공지능 신용평가 프로그램을 구축하고 있다.
마지막으로 금융범죄 탐지는 온라인 결제서비스 회사인 페이팔이 사용하는 ‘이상 금융거래
탐지 시스템’이 대표적이다. 페이팔은 자사 결제자료를 분석하여 피싱에 해당하는 건들을 탐지
하는 시스템을 구축하였으며, 이 시스템에 딥러닝 기술이 활용되었다. 국내의 많은 회사에서
도 이상 금융거래 탐지 시스템을 자체적으로 구축하여 사용 중이며, 특히 신한카드를 비롯한
여러 회사에서 딥러닝 기술을 활용한 이상 금융거래 탐지 시스템을 구축하고 있다.
이 외에 금융 관련 검색서비스를 제공하는 Alphasense와 같이 인공지능 기술을 활용하여
금융 분야에 간접적인 서비스를 제공하는 사례도 있다.

78
다. 교육 분야
모든 학생들에게 동등한 교육의 기회를 제공하려는 취지하에 온라인 서비스를 통해 여러
교육 프로그램을 제공하는 사례가 증가하고 있다. 이에 따라 개별 학생이 강의를 듣는 동안
성취도를 판단하여 맞춤형 강의를 제공하거나 관심 있는 분야의 강의를 추천해주는 서비스의
수요 또한 늘어나고 있으며 이를 위해 인공지능 기술이 필수적이다.
미국의 대표적인 온라인 수학 교육 사이트 드림박스 러닝은 인공지능 기술을 활용함으로써
학생이 강의를 수강할 때마다 이해 정도를 지속적으로 측정하여 부족한 개념을 보충해주고
적절한 다음 강의를 실시간으로 제공하고 있다. 같은 목적으로 인공지능 기술을 사용하고 있
는 다른 온라인 교육 사이트로는 뉴턴(Knewton) 등이 있다. 온라인 교육 사이트의 개인별
맞춤 교육 서비스가 큰 인기를 끌면서 애리조나 주립 대학교에서는 같은 방식의 개인별 맞춤
교육 시스템을 일부 대학 강의에 적용하고 있다.
한편, 코세라(Coursera)는 스탠포드, 듀크 등 약 100여 개 대학과 제휴하여 해당 대학들
의 많은 강의를 무료로 제공하는 Mooc(Massive Open Online Course)이다. 국내에서는 연
세대학교와 Kaist가 코세라와 제휴를 맺고 있다. 제공하는 강의의 수와 범위가 워낙 많고 넓
기 때문에 인공지능 기술을 활용하여 개인의 관심사와 관심 수준에 맞는 강의를 추천해주는
서비스를 제공하고 있다. 유사한 서비스를 제공하는 MOOC로는 하버드와 MIT 등이 제휴하
고 있는 에덱스(edX)가 있다.
라. 쇼핑 분야
온라인 쇼핑 역시 인공지능 기술을 활용한 개인별 맞춤 추천서비스가 제공되는 대표적인
산업 분야이다. 대표적인 온라인 쇼핑 기업 아마존에서는 구매이력, 사용자가 매긴 평점 등을
종합하여 개인별 맞춤 추천 상품을 제공하고 있다. 아마존의 추천시스템은 초기에는 사용자들
이 입력한 평점 자료를 바탕으로 비슷한 평점 패턴을 보이는 다른 사용자의 상품구매이력을
통해 새 상품을 추천하였으나, 쇼핑몰의 규모가 확장되어 상품의 종류가 급격히 증가하면서
전체 자료의 극히 일부만 관측되는 평점 자료만으로 새로운 상품을 추천하는 데 어려움이 생
기게 되었다. 최근에는 구매이력, 상품클릭정보, 평점, 상품정보, 사용자정보 등으로 이루어진
빅데이터와 여러 인공지능 기법들을 활용하여 추천 시스템을 구축하고 있다. 이러한 추천시스
템은 한 번도 구매해본 적 없는 종류의 상품도 추천이 가능하고, 상품에 대한 평점을 거의

79
매기지 않은 사용자에게도 추천이 가능하다는 점에서 많은 사용자들에게 편의를 제공한다. 현
재는 국내외의 많은 온라인 쇼핑몰에서도 사용하는 자료의 종류와 형태는 다르지만 비슷한 인
공지능 기술들을 활용하여 자체적인 추천 시스템을 구축하고 이를 사용자에게 제공하고 있다.
마. 지능형 개인비서
지능형 개인비서는 인간의 음성을 인식하고 그에 맞는 응답을 제공하는 인공지능 서비스이
다. 기존에는 정해진 질문에 대한 간단한 답만 제공하는 정도의 서비스에 그쳤지만, 딥러닝
기술의 등장으로 대두된 인공지능의 발달과 사물인터넷(IoT)에 대한 관심 등이 맞물려 빠르게
발전하고 있는 새로운 첨단 산업 분야이다. 현재 개발된 대부분의 지능형 개인비서 서비스는
인간의 음성을 인식하여 분석 가능한 자료로 변환하는 음성인식과 변환된 입력자료에 대한
응답을 제공하는 질의응답에 모두 첨단 인공지능 기술이 필요한 고도의 서비스이다.
대표적인 지능형 개인비서 소프트웨어로는 애플의 시리, 구글의 나우, 페이스북의 M 등이
있으며 지능형 개인비서 소프트웨어 대부분은 스마트폰에 탑재되어 제공되어왔다. 최근에는
아마존의 에코, 애플의 홈팟 등 스마트 스피커의 형태로 제공되는 지능형 개인비서 하드웨어
도 다수 개발되고 있으며 이 외에도 자동차를 비롯하여 세탁기, 냉장고 등의 각종 가전제품에
도 지능형 개인비서가 탑재되어 출시되고 있다. 국내의 많은 기업들에서도 지능형 개인비서
서비스를 개발 ・ 제공하고 있는데 소프트웨어로는 삼성전자의 빅스비가 대표적이고 하드웨어로
는 SK텔레콤의 누구, KT의 기가지니, 네이버의 프렌즈 등의 스마트스피커가 있다.
수많은 지능형 개인비서 서비스가 출시되었고 각 소프트웨어의 기술적인 부분은 큰 차이가
없지만, 개발회사에서 모형 학습에 사용한 자료와 개발 목적에 따라 강점을 보이는 분야가 서
로 다르다. 구글의 나우는 스마트폰 사용자의 사용패턴을 분석하여, 질문을 던지지 않아도 사
용자에게 필요할 것 같은 정보를 제공해주는 점에서 타 서비스와 차별성이 있다. 예를 들면,
현재 사용자가 있는 위치정보를 기반으로 주변 맛집정보를 제공해주는 것이다. 한편, 아마존
의 에코는 자사에서 개발한 지능형 개인비서 소프트웨어 알렉사가 내장된 스마트 스피커로
아마존에서 상품주문을 하는 기능이 탑재되어있다.
그 외 회사의 고객상담 서비스에서도 인공지능 기술을 활용한 자동응답 시스템이 점차 적
용되고 있으며, 자동응답 시스템도 좁은 의미의 지능형 개인비서 시스템으로 볼 수 있다.

80
바. 기계번역
기계번역은 컴퓨터를 통해 서로 다른 언어 간 번역을 하는 것이다. 초기의 기계번역은 주
로 언어학자들이 만든 규칙들을 기반으로 구축되었다. 이는 규칙 내 범위에서는 우수한 성능
을 보여주지만 규칙에 벗어나는 문장이 입력된 경우에는 번역이 불가능하다는 단점이 있었다.
특히 위의 규칙화는 해당 언어의 전문가를 필요로 하며 많은 시간이 소요되는 일이므로 현실
적으로 많은 언어 간의 기계번역 시스템을 구축하는 데는 한계가 있었다. 하지만 최근에는 딥
러닝 기술을 통해 두 언어의 문장이 쌍으로 이루어진 자료만 충분히 많이 주어지면 기존의
기계번역 시스템보다도 우수한 성능을 낼 수 있게 되었다. 하지만 한국어를 비롯한 몇 가지
언어의 경우 기계번역이 좋은 성능을 내기 위해서는 형태소를 분해하는 자료의 전처리과정이
필요하다는 한계점이 남아 있다. 형태소 분해과정은 언어학자의 규칙화를 통해 구축된 프로그
램을 사용하므로 아직 완전한 인공지능 기계번역 시스템이 완성되었다고는 볼 수 없다.
구글은 딥러닝 기술을 이용한 기계번역 서비스를 제공하는 대표적인 기업으로, 수십 가지
언어 간 기계번역을 제공하고 있다. 이는 기존에 딥러닝 기술을 활용하기 전 제공되던 번역기
에 비해 월등한 성능을 보이는 것으로 알려져 있다. 국내에서는 네이버와 카카오 등에서 각각
인공지능 기계번역 서비스를 개발하여 제공 중이다.
사. 자율주행
자율주행은 실시간으로 관측되는 주변 상황을 분석하여 매 시점마다 운전자 입장에서 최
선의 판단을 내리고 수행하는 인공지능 시스템이다. 자율주행 연구의 초기에는 자동차 회사
의 주도로 발전해왔으나, 인공지능 기술이 발전하면서 최근에는 구글, 엔비디아 등의 IT 기업
들이 이 분야를 선도하고 있다.
자율주행 시스템에서 주변 상황에 대한 영상은 자동차에 부착된 센서를 통해 실시간 자료
로 입력되며, 영상의 윤곽선을 탐지하여 각 부분이 사람, 사물, 배경 등 여러 카테고리 중 어
느 것에 해당되는지 분류한다. 이때 분류기준은 사전에 축적된 자료와 인공지능 기술을 통해
학습된다. 그리고 분석된 영상을 토대로 핸들, 액셀러레이터, 브레이크 등을 스스로 조종하여
현재 상황에 맞는 의사결정을 한다.

81
아. 기타
인공지능 기술은 지능형 개인비서, 자율주행 외에도 다양하고 새로운 산업을 창출하고 있
다. 그 중 대표적인 예로, 우버(Uber)는 사용자가 현재 위치와 목적지를 입력하면 가까운 위
치의 택시를 연결시켜주는 모바일 차량예약 서비스 회사이다. 우버에서는 우버풀(Uber
POOL)이라는 택시 합승 시스템을 개발하여 제공 중인데, 각 고객들의 현재 위치와 목적지의
동선을 고려하여 최적의 합승경로를 계산하기 위해 인공지능 기술을 사용한다. 또한 택시 중
개 서비스를 제공하면서 축적된 빅데이터를 기반으로 여러 관련 산업에 뛰어들고 있어 전 세
계 주요 도시의 교통정보를 분석하여 제공하는 무브먼트(Movement) 서비스를 출시하였고,
자율주행 시스템을 구축하는 데에도 힘을 쏟고 있다.
그 외에도 택배 회사에서 물류 운송비용의 절감을 위한 최적화를 하거나, 무인 매장을 운영하기
위한 인공지능 로봇의 개발 등 인공지능 기술은 우리 일상생활 전 분야에 걸쳐 활용되고 있다.
5. 프라이버시 침해와 인공지능 윤리
인공지능의 발달을 통해 인류는 지금까지 누릴 수 없었던 편리함을 느낄 수 있게 되었다.
4차 산업혁명이라 불리는 이러한 기술의 발전은 다양한 분야에서 우리의 삶을 풍요롭게 만들
어주고 있다. 인공지능을 통해 우리는 간단한 자가진단을 받을 수도 있게 되었고, 생소한 외
국어도 손쉽게 번역할 수 있게 되었으며, 번거로운 심사 없이 간편하게 출국심사를 받는 것도
가능해졌다. 그러나 급격한 기술의 발전의 부작용으로써 지금까지 찾아볼 수 없었던 여러 문
제점들이 나타나고 있다.
인공지능의 발달로 인해 발생하는 가장 대표적인 문제점으로 프라이버시 침해와 인권 침해
등의 윤리적 문제를 들 수 있다. 이는 4차 산업혁명의 특성과도 밀접한 연관이 있다. 4차 산
업혁명을 한 문장으로 요약하자면 산업구조가 소품종 대량생산을 통한 대중 중심에서 다품종
소량생산을 통한 개인 중심으로 변화하는 과정으로 설명할 수 있다. 따라서 각 개개인의 정보
에 대한 관심이 유례없이 증가하게 되었으며 이에 대한 반대급부로 프라이버시 침해나 인권
침해 등이 사회의 큰 문제점으로 대두되고 있다.
기술의 발달로 인한 프라이버시 침해는 크게 두 종류로 나뉜다. 가장 흔한 경우로써 개인
정보 자체가 누출되는 경우를 들 수 있다. 이러한 문제는 주로 해킹 등을 통한 DB 유출을

82
통해 일어나곤 하나 이외에도 다양한 방법으로 발생되고 있다. 흔히 생각하기 어려운 문제는
정보 제공자도 모르는 사이에 개인정보가 누출되는 경우이다. 정보 제공자에게 충분한 동의
없이 정보를 빼가거나, 연구 등 공익을 위해 비식별화 과정을 거쳐 공개된 자료가 식별되는
경우가 이런 예에 속하게 된다.
분석 기술의 발달로 인해 과거에는 경험하지 못했던 새로운 윤리문제도 발생하고 있다. 다
양한 지도학습분석 기술의 발달로 인해 주어진 자료를 바탕으로 새로운 정보를 추출하는 것
이 가능해졌다. 문제는 이를 통해서 개개인이 밝히고 싶지 않은 정보들(개인의 성적 취향과
같은) 또한 밝혀질 수 있다는 점이다. 이와 같이 인공지능은 기존에는 상상할 수조차 없었던
규칙들을 찾아내면서, 이러한 규칙들이 인종차별이나 특정 집단에 대한 증오와 같은, 현대 사
회에서 용납할 수 없는 윤리적 문제를 초래하게 되었다.
본 장에서는 실제 프라이버시 침해와 윤리적 문제들에 대해서 살펴볼 것이다. 각각의 사례
들 중 현재는 문제점을 발견하고 시정된 사례도 있지만, 예시를 통해 인공지능 기술이 얼마나
예기치 못한 방식으로 사회적 문제를 발생시킬 수 있는지 확인할 수 있을 것이다.
가. 비식별화된 연구용 진료기록의 재식별화
미국에서는 주(州) 차원에서 소유하고 있는 진료기록들을 유료로 공개하고 있다. 이러한 진
료기록들은 연구용으로 공개되고 있으며, 각 주에 위치한 병원에 입원한 환자들에 대해 그들
의 인구통계학적 정보, 진단명, 입원수속과정, 의료행위 등 광범위한 정보들을 포함하고 있다.
각각의 정보들은 비식별화 과정을 거침으로써 각 정보를 어느 인물로 특정하는 것은 불가능
하게 되어 있었다. 그러나 하버드대의 L. Sweeny 교수는 연구를 통해 이러한 진료기록들이 신문
기사와 같은 손쉽게 손에 넣을 수 있는 다른 정보와 결합함으로써 인물을 특정할 수 있음을 밝
혀내었다.36)
주정부 차원에서 공개하는 진료기록은 보건 분야의 다양한 연구에서 매우 유용하게 사용되
고 있다. 병원과의 접근성과 병원이용의 차이,37) 오토바이 사고 시 헬멧 착용이 끼치는 영
향,38) 환자의 안전39) 등 다양한 연구가 이러한 자료를 기반으로 이루어져왔다. 주정부 차원의
36) Sweeny(2015)
37) Ohm(2009)
38) Yakowitz(2011)

83
기록은 자료의 신뢰성이 매우 우수하며 결측값이 매우 적기 때문에 분석에 사용하기에 알맞
은 자료라고 할 수 있다.
그러나 이와 같은 진료기록은 환자의 의료정보부터 병원비 지불내역과 같은 재무정보까지
한 개인에 대한 막대한 정보를 제공할 수 있기 때문에 악용될 수 있는 여지 또한 크다. 실제
로 1996년의 Fortune 선정 글로벌 500대 기업 대상 설문조사에서 84명의 응답자 중 28명
의 응답자(33%)가 종업원에 대한 고용, 해고 등의 의사결정에 의료정보를 이용한다고 밝혔
는데40) 이는 법으로 보호된 환자의 의료정보 비공개 권리를 침해한 것이다.
따라서 학문적인 발전과 개인정보 보호를 함께 이룩하기 위해서는 진료기록을 원본 그대로
공개하는 것이 아닌 가공을 통해 각 정보를 특정화하지 못하게 하는 과정이 필요하다. 이러한
과정을 비식별화(De-identification)라고 하며, 비식별화된 자료를 다시 특정화하는 과정을 재
식별화(Re-identification)라 한다. 가장 직관적인 비식별화 방법으로는 인물을 특정하기 쉬운
변수인 이름, 주소 등의 변수를 삭제하는 방법이 있다. 미국에서는 1996년에 건강보험 정보의
이전과 책임에 관한 법(HIPAA; Health Insurance Portability and Accountability Act of
1996)을 제정해서 진료기록과 같은 의료정보를 공개하는데 있어서 비식별화를 의무화하였다.
그러나 주정부 차원에서의 정보공개는 위 법안의 적용대상이 아니기 때문에 훨씬 단순한 수
준의 비식별화 기법(이름, 주소를 삭제하는 정도의 가공)을 거쳐서 공개되었다.
Sweeny 교수는 이와 같은 단순한 비식별화를 거친 자료는 지역 신문기사와 같은 손쉽게
얻을 수 있는 추가 자료를 이용해서 재식별화할 수 있음을 실험을 통해 입증하였다.41) 그녀는
뉴스 아카이브 LexisNexis을 통해 검색 가능한 2011년 미국 워싱턴주의 지역 신문기사를 통
해 입원 여부가 확인된 사람 중 이름 혹은 주소가 기재된 81명을 대상으로, 신문기사에 주어
진 정보를 이용해서 진료기록 자료를 재식별화하였다. 개인별 차이는 있으나 신문기사를 통해
서 성별, 혈액형, 나이, 우편번호, 입원한 병원 등의 정보를 얻을 수 있었으며, 이를 주정부가
공개한 진료자료와 수작업으로 비교함으로써 각 개인의 진료기록을 탐색하였다. 탐색한 결과
는 실제 기사를 작성했던 신문기사들에게 부탁해 실제 조사대상자와 인터뷰를 진행함으로써
실제 사실과 일치하는지 여부를 확인하였다.
39) Barth-Jones(2012)
40) Linowes(1996)
41) Sweeny(2015)

84
실험 결과 81명 중 35명(43%)에 대해 특정한 진료기록과 신문에 기재된 그들의 정보를
일치시키는 데 성공하였다. 신문기자가 이 중 14명을 임의로 추출해서 직접 연락을 통해 사실
확인을 시도하였는데, 이 중 실제로 연락이 닿은 8명에 대해 확인한 결과 재식별화를 통해 추
정한 진료기록이 그들의 실제 진료기록과 전부 일치하는 것을 확인할 수 있었다.
위 실험을 통해서 신문기사와 같은 공개적인 자료를 바탕으로 진행하는 재식별화의 정확성
을 확인할 수 있었다. 각 개인의 실제 진료기록을 확인하는 것에 많은 어려움이 따르는 관계
로 재식별화한 35명의 자료 중 8명에 대해서만 사실확인을 진행하였지만, 확인한 8명 전원에
게 예측결과가 사실과 일치한다는 확인을 받을 수 있었다. 전체 입원환자 중 35명은 매우 적
은 수치로 생각될 수 있지만, 다양한 뉴스 아카이브를 이용하거나, 특정 회사의 경우 자신들
이 소유하고 있는 종업원의 개인정보를 이용하면 더 넓은 범위의 사람들에 대해서 진료기록
을 추정할 수 있을 것이다.
실제로 현재 워싱턴주에서는 이러한 문제점을 인식하고 HIPAA 법안이 제안하는 수준과 동
등한 수준의 비식별화 과정을 거쳐 자료를 공개하고 있다. 또한 몇몇 변수에 대해서는 검토
과정을 거쳐 충분한 자격이 있다고 판단되는 사람 ・ 기관에게만 자료를 제공하는 등, 개인정보
누출을 막기 위해 노력하고 있다.
나. 스마트폰 어플리케이션을 통한 개인정보 유출
개인정보의 유출은 우리가 정보를 위탁한 정부기관 및 회사를 통해서 이루어지기도 하지만,
우리 스스로를 통해 일어나기도 한다. 첫 아이폰이 출시된 2007년 이래로 현대인의 필수품이
된 스마트폰을 통해서 개인정보들이 우리들도 모르는 사이에 다양한 곳으로 유출되고 있다.42)
스마트폰은 통칭 앱이라 불리는 여러 어플리케이션을 이용해서 손쉽게 다양한 기능을 사용
할 수 있는 전자통신기기로써 발명된 지 10년이 지난 현재에는 전세계인들에게 없어서는 안
될 필수품목으로 자리잡았다. 실제로 2014년 기준 Google의 Play Store의 경우에는 매달
약 10억 명의 사용자가,43) Apple의 App Store의 경우에는 매달 약 5~6억 명의 사용자가
새로운 앱을 이용하기 위해 방문하였다.44)
42) Zang 외(2015), Thurm와 Kane(2010)
43) Reisinger(2014)
44) Bajarin(2014)

85
대부분의 앱은 사용자에게 편리한 기능들을 제공하기 위해서 스마트폰 사용자의 개인정보,
즉 개인관심사, 검색기록, 위치정보 등을 요청하곤 한다. 그들은 종종 스마트폰 사용자에게 이
러한 정보를 이용하기 위한 권한을 요청하며, 따라서 그들은 많은 앱이 개인정보를 기반으로
작동한다는 사실을 충분히 인지하고 있다. 다양한 설문조사를 통해 대다수의 스마트폰 사용자
들이 앱에 개인정보를 제공하는 것을 꺼려하며, 개인정보를 기반으로 작동하는 앱에 대한 선
호도가 낮다는 사실이 알려져 있다.45) 스마트폰이 제공할 수 있는 많은 개인정보 중에서도 특
히 사용자의 위치정보를 제공하는 것에 많은 거부감을 드러내었다.46)
그러나 2010년 Wall Street Journal의 스마트폰 어플리케이션의 정보 유출에 관한 조사
는 많은 사람들의 기대를 저버리는 결과를 보여주었다.47) Android와 iOS 앱 중 인기 있는
101개의 앱을 대상으로 한 이 조사는 다수의 앱들이 사용자의 허락 없이 개인정보를 사용하
고 있다는 점을 확인하였다. 또한 많은 앱들은 앱 개발자들이 개인정보를 사용하는 것에 그치
지 않고 전혀 무관한 제3자에게 개인정보를 유출하였다. 조사 대상 중 56개의 앱이 사용자
동의 없이 제3자에게 기기의 ID를 제공했으며, 47개의 앱은 기기의 위치정보를 제3자에게 제
공하였다.
Wall Street Journal의 연구는 많은 이들에게 충격을 주었다. 개인정보 유출과 관련해서
미국과 캐나다에서는 Apple과 Pandora 등 몇몇 기업들에 대해 손해배상청구 소송이 제기되
기도 하였으며,48) 미국과 유럽에서는 개인정보의 이용과 제3자에게 개인정보를 제공하는 사항
에 대해 앱 사용자의 허락을 의무화하는 다양한 법안이 제정되는 계기가 되었다.
그러나 다양한 법안들의 제정에도 불구하고 앱을 통한 개인정보 유출은 없어지지 않았다.
Zang 외(2015)는 2014년에 Android와 iOS에서 인기를 끈 무료 앱 110개에 대해 개인정보
유출이 이루어지는지 여부를 조사하였다. 조사 결과 여전히 많은 앱이 사용자의 개인정보를
허락 없이 사용하는 것을 확인할 수 있었으며, 제3자에 대한 정보 유출 또한 빈번하게 일어났
다. 조사 대상 중 Android 기반 앱은 평균적으로 3.1개의 사이트에 개인정보를 전송하였으며
iOS 기반 앱은 평균적으로 2.6개의 사이트에 개인정보를 전송하는 것을 확인할 수 있었다.
45) Boyles 외(2012)
46) Urban 외(2012), Felt 외(2012)
47) Thurm와 Kane(2010)
48) Kane(2010), Mui(2010)

86
전송한 개인정보 중 다수는 이메일 주소나 사용자의 이름과 같은 그다지 중요하지 않은 정보
였다. 그러나 iOS 기반 앱의 47%, Android 기반 앱의 33%는 많은 사용자들이 민감하게 반응
하는 정보인 사용자의 위치정보를 제3자에게 제공하였다. 이외에도 소수의 의료 관련 앱은 질병
에 대한 검색기록과 같이 민감할 수 있는 정보를 제3자에게 제공하는 것을 확인할 수 있었다.
각 앱들이 정보를 제공한 사이트에 대해서 살펴보면, 대부분의 정보를 받은 사이트는
Google 혹은 Apple과 관련된 사이트인 것으로 확인되었다. 이러한 정보 전달의 결과는 앱의
특성보다는 스마트폰의 OS 환경과 밀접한 연관이 있는 것으로 보인다. 두 사이트와 관련된
결과들을 제외하고 보면, 다수의 광고 제공 사이트들이 앱이 무단으로 제공하는 정보를 받는
것을 확인할 수 있었다. 이러한 사이트들은 이와 같이 무단으로 취득한 정보를 바탕으로 개인
화 광고를 제공하는 것이다.
스마트폰을 통한 빈번한 정보유출의 문제를 해결하기 위해서 다양한 방면에서 방안이 제시
되고 있다. 기술적인 해결책으로써 스마트폰 앱이 허가되지 않은 사이트로 개인정보를 유출하
려고 하는 경우 가짜 정보를 생성해서 제공하는 방안이 제시되었다.49) 이러한 방안은 기술적
으로는 개인정보의 유출을 막아주는 효과를 주지만, 이렇게 잘못 제공된 정보를 바탕으로 사
용자가 전혀 엉뚱한 광고를 받을 수 있다는 점에서는 임시방편적 해결책이라고 볼 수 있다.
법률적인 해결책 또한 제시되고 있다. 백악관과 美 연방거래위원회(Federal Trade Commission)
는 다양한 인터넷 브라우저들에게 추적금지기능을 탑재하는 것을 추천하고 있다.50)
이는 법적 강제성이 없어 단순한 권고사항에 불과하지만 Chrome, Firefox, Safari 등 많은
상용 브라우저들이 사용자가 추적금지기능을 선택할 수 있도록 기능을 제공하고 있다.
Google, Apple과 같은 앱 생태계를 제공하는 회사들 또한 정보 유출을 막기 위해 많은
노력을 기울이고 있다. 앱의 정보 접근 권한 요청을 사용자가 좀 더 직관적으로 받아들일 수
있도록 인터페이스를 개선하고 있으며 그들의 자체적인 추적 광고 시스템을 더 이상 사용하
지 않음으로써 사용자 몰래 개인정보를 받는 행위를 줄여나가고 있다.51)
49) Zhou 외(2011), Hornyack 외(2011)
50) California Department of Justice(2014)
51) Dilger(2012)

87
다. 광고 전달 시스템에 의한 인종차별
Google Ad는 Google에서 제공하는 광고 서비스로, 개인의 기존 검색기록과 타인의 반응
을 바탕으로 광고를 제공하는 서비스이다. Google Ad는 Google 내에서의 검색뿐만 아니라
이 서비스를 사용하는 외부 사이트에서도 광고를 제공해준다. 인명(人名)을 검색하는 경우
Google Ad는 개인의 범죄기록을 조사할 수 있는 사이트의 광고를 종종 제시하곤 한다. 이때
검색하는 이름이 흑인이 주로 사용하는 이름인 경우, 백인이 주로 사용하는 이름을 검색하는
경우에 비해 범죄기록 조회 사이트의 광고의 문구가 악의적으로 생성된다는 사실이 연구로
밝혀졌다.52)
개인의 범죄기록은 많은 사람들에게 매우 민감하게 받아들여질 수 있는 정보이다. 예를 들
어 고용주가 지원자를 선발하는 데 있어서 개인의 범죄기록을 확인하게 된다면 범죄기록이
있는 사람이 불이익을 받을 것임을 쉽게 예상할 수 있다. 범죄기록을 바탕으로 고용에 불이익
을 주는 것은 법으로 금지되어 있지만, 현실적으로 이를 적용하는 것에는 많은 어려움이 따른
다. 또한 범죄기록을 검색하는 것은 불법이 아니며 몇몇 사이트에서는 유료로 범죄기록을 조
회할 수 있는 기능을 제공해준다. 따라서 특정 이름을 검색할 때 범죄기록 조회 사이트의 광
고 문구가 악의적으로 생성되는 것은 심각한 불평등을 초래할 수 있는 문제라고 볼 수 있다.
이름과 인종(人種) 간의 상관관계에 대해서는 많은 관련 연구가 존재한다.53) 1960~70년대
에 흑인 인권 운동이 활발해 지면서, 흑인들은 점차 자신들 고유의 정체성을 나타내는, 백인과
구별되는 이름을 많이 사용하게 되었다. 이러한 이름의 특징은 현재에 들어서는 미국 내에서
사회적인 통념으로 받아들여지고 있으며, Bertrand와 Mullainathan(2013)은 연구를 통해
이름이 보여주는 인종 정체성과 고용의 상관관계를 밝히기도 했다.
Sweeny(2013)는 이전의 관련 연구54)에서 확인된 인종 정체성을 잘 드러내는 이름 62가
지를 이용해서 실험을 진행했다. 확인하고자 하는 범죄기록 조회 사이트의 광고는 단순 이름
이 아닌 성명 전체를 검색해야 등장했기 때문에, 각 이름에 대응되는 성(姓)이 추가적으로 필
요하였다. 인터넷 검색을 통해 실제로 존재하는 총 2,184개의 성명을 만들어냈으며, 이는 각
이름 별로 평균 35개 정도의 성명을 만들어내었음을 의미한다.
52) Sweeny(2013)
53) Bertrand와 Mullainathan(2013), Levitt와 Dubner(2005)
54) Bertrand와 Mullainathan(2013), Levitt와 Dubner(2005)

88
조사는 다음과 같은 방식으로 진행되었다. Google과 Google Ad를 이용해 광고를 제공하
는 Reutor에서 앞서 생성한 이름을 검색하였다. 검색 결과 범죄기록 조회 사이트의 광고가
등장하는지 여부를 기록하였으며, 추가로 광고 문구 또한 기록하였다.
조사 결과는 다음과 같다. 전체 성명 중 약 78%의 성명을 검색했을 때 범죄기록 조회 사
이트의 광고가 등장한다는 사실을 확인할 수 있었다. 흑인 이름을 가진 성명의 경우 전체의
81%에서 범죄기록 조회 사이트의 광고가 등장했으며, 백인 이름을 가진 성명의 경우 약
68%의 검색 결과에서 범죄기록 조회 사이트의 광고가 등장하였다. 악의적인 광고 문구
“John Doe 씨가 체포되었나요?”와 일반적인 광고 문고 “John Doe 씨에 대한 정보를 제공합
니다.”의 비율 또한 이와 유사한 결과를 나타낸다. 흑인 이름을 검색했을 때 범죄기록 조회
사이트의 광고가 등장한 경우 60%가 악의적인 광고 문구를 보여준 반면 백인 이름을 검색했을
때 범죄기록 조회 사이트의 광고가 등장한 경우에는 48%의 광고만이 악의적인 광고 문구를 보
여주었다.
위의 두 비율의 차이가 얼마나 유의미한지는 단순한 통계적인 검정을 통해서도 확인해 볼
수 있다. 만일 범죄기록 조회 사이트 광고의 등장과 이에 뒤따르는 악의적인 광고 문구의 등
장이 이름이 보여주는 인종적인 특색과 무관하다면 두 종류의 성명에서 동일한 비율로 광고
와 광고 문구가 등장해야 할 것이다. 통계적으로 이러한 경우를 검정하는 방법으로 동질성
검정방법이 있다. 동질성 검정방법을 기반으로 광고 등장 비율을 검정하면 두 검정 모두 유의
확률이 보다 작게 나오는 것을 확인할 수 있다. 따라서 흑인 이름을 가진 성명을 검색했
을 때 범죄기록 조회 사이트 광고가 등장할 확률이 백인 이름을 가진 성명을 검색했을 때 광
고가 등장할 확률보다 통계적으로 유의미하게 높다고 말할 수 있으며 악의적인 광고 문구가
등장할 확률 또한 흑인 이름을 가진 성명을 검색하는 경우가 통계적으로 유의미하게 높다고
말할 수 있는 것이다.
이러한 결과는 Google Ad가 흑인 이름을 가진 사람이 범죄자일 확률이 높다고 추정했기
때문에 나오는 것이 아니다. Google Ad는 단지 기존에 유사한 문구로 검색한 사람들이 어떠
한 광고와 어떠한 광고 문구를 보여줬을 때 광고를 클릭했는지 여부만을 이용해서 새로운 사용
자에게 광고와 광고 문구를 제시한다. 따라서 흑인 이름을 가진 성명을 검색했을 때 범죄기록
조회 사이트의 광고가 자주 등장했다는 사실은 다른 사용자들이 흑인 이름을 가진 성명을 검색
했을 때 등장한 범죄기록 조회 사이트 광고를 클릭했던 경우가 많다는 것을 의미하게 된다.

89
앞서 살펴본 바와 같이 Google Ad의 인종차별적인 광고 제공이 인종에 대한 가치판단을
통해 이뤄지지는 않았지만, 결과적으로 인종에 대한 차별적인 결과를 촉진하게 되었으므로 이
또한 인종차별의 한 예임은 자명하다. 이와 같은 인종차별을 구조적인 인종차별이라고 한
다.55) 이와 유사한 예로 Facebook의 유대인 혐오자 대상 타겟 마케팅 해프닝이 있다.56)
이는 Facebook의 광고 시스템이 유대인 혐오 포스팅을 업로드한 사람들만을 대상으로 광
고를 제공할 수 있다는 점이 밝혀져서 물의를 빚은 사건이다. Facebook의 창립자인 마크 주
커버그가 유대인임을 감안하면 이는 명백히 의도되지 않은 하나의 해프닝으로 간주할 수 있
다. 하지만 여기서 주목해야 할 점은 인공지능을 이용해 자동으로 광고 카테고리를 생성하는
Facebook의 광고 시스템이 이러한 결과를 초래했다는 점이다. 이는 위의 Google Ad의 예
와 매우 흡사한 것으로 볼 수 있다. 두 예를 통해서 인공지능 개발자는 인공지능이 의도치 않
게 초래할 수 있는 문제에 대해서도 충분히 고려해야 한다는 점을 생각해 볼 수 있다.
라. 얼굴 인식을 이용한 개인의 성적 지향 판별
인공신경망 모형의 발전은 이미지 자료 분석에서 어마어마한 진보를 가능하게 하였다. 인공
지능을 이용한 이미지 자료 분석 모형은 인간의 시각보다 더욱 뛰어난 성능을 보여줄 정도로 발
전되었다.57) 이미지 자료 분석의 응용 분야로써 얼굴을 이용한 다양한 분석방법이 개발되었다.
얼굴 인식을 이용한 보안, 출입국 관리, 감정 인식 등 다양한 분야에서 얼굴이 보여주는 풍부한
정보들을 이용하고 있다. Kosinski와 Wang(2017)은 여기에서 더 나아가서 인공신경망 모형
을 통해 얼굴에서부터 개인의 성적 지향을 밝히는 모형을 개발하였다.
Kosinski와 Wang(2017)은 인터넷 데이트 사이트에서 다양한 사람들의 얼굴 사진과 그들
의 성적 지향을 취합함으로써 얼굴 사진을 통해 성적 지향을 추정하는 신경망 모형을 개발하
였다. 그들이 개발한 모형을 사진의 남자(여자)가 동성애자인지 여부를 맞추는 문제에 적용시
킨 결과 81%(71%)의 정확도를 얻을 수 있었다. 이는 매우 높은 수치로, 실제 사람이 눈으
로 동일한 사진을 보고 동성애자인지 여부를 판별한 결과 남자의 경우 61%, 여자의 경우
54%의 정확도를 보였다.
55) Barker(2003)
56) Angwin 외(2017)
57) LeCun 외(2015)

90
이와 같은 연구결과는 상업적으로도 유용하게 사용할 수 있다. 성소수자들을 대상으로 그
들의 취향에 맞는 상품들을 광고한다면, 더욱 효과적인 마케팅을 진행할 수 있게 된다. 실제
로 이와 같은 타겟마케팅 기법은 현재 전세계의 마케팅 시장을 선도하고 있는 Google과
Facebook같은 기업들의 기법이기도 하다. 이를 통해서 성소수자들은 그들의 취향에 맞으리라
고 예상되는 상품들 위주의 광고를 받아볼 수 있을 것이다.
그러나 Kosinski와 Wang(2017)의 연구결과가 발표되자 많은 성소수자들이 염려를 드러내
었다. 역사적으로도 성소수자를 골라내려는 많은 시도들은 그들의 말살, 투옥, 성적 지향 전환
치료 등 부정적인 결과를 초래했기 때문이다. 현대에 들어서 성소수자의 인권이 지속적으로
신장되고 있는 추세이지만, 아직까지도 사회의 대다수 분야에서는 성소수자임이 밝혀지는 것
은 막대한 불이익이 초래될 수 있는 문제이기 때문이다.
이와 같은 사례는 기술의 발달이 사회의 의식의 발달속도보다 빨라짐에 따라 생기는 문제
로 볼 수 있다. 개인의 성적 지향을 어떻게 받아들일지에 대한 사회적인 합의가 존재한다면
이 같은 연구결과는 큰 문제없이 유용하게 사용 가능할 것이다. 인공지능의 발달이 제공하는
새로운 지식에 대해 인공지능은 어떠한 가치적인 판단도 제공하지 않지만, 그 결과에 대한 도
덕적인 선택은 인간의 몫임을 알 수 있다.
지금까지 다양한 사례들을 통해 인공지능 기술의 발달이 개인정보를 어떻게 침해할 수 있
는지를 알아보았다. 비록 인공지능 기술의 발달로 인해 이와 같이 다양한 부작용이 발생하고
있지만, 이로 인해 인공지능의 기술을 발달시키지 않아야 한다고 주장하는 것은 아니다. 이러
한 문제점을 지적하고 해결방안을 도출해냄으로써 새로운 기술의 발전 방향에 대해서 고민할
수 있는 기회를 제공하고 기술의 발달로 얻을 수 있는 혜택을 풍요롭게 누릴 수 있다고 본다.
6. 프라이버시 보호 관련 법률체계 고찰
1장에서 언급하였듯이 빅데이터 분석의 활성화는 개인 프라이버시의 침해 가능성을 크게
증대시켰고, 이를 위한 법률적인 보호망이 요청되고 있다. 이에 각국에서는 개인의 프라이버
시를 보호하기 위한 법률장치를 도입하고 있으며, 한국의 경우에도 2011년 개인정보 보호에
관한 일반법으로 “개인정보 보호법”이 제정되었다. 개인정보 보호 법률은 개인정보 보호와 빅
데이터 분석 기술의 발전이라는 두 가치 사이에서 적절한 균형을 추구하여야 한다. 빅데이터

91
분석 기술과 관련 산업의 발전 및 성장을 위해 개인정보 피해를 묵과해서도 안 되지만, 개인
정보 보호를 명목으로 관련 기술과 산업을 무조건 규제해서도 안 될 것이다. 이 장에서는 개
인정보의 개념과, 개인정보 침해를 방지하기 위한 국내외의 법률체계를 살펴본다. 본 장은 김
용대와 장원철58)의 내용을 기반으로 작성되었다.
가. 개인정보의 개념
법률적 보호의 대상으로서 개인정보를 어떻게 정의하느냐에 따라 해당 개인정보의 수집 및
이용에 대한 규제의 적용 여부가 달라지기 때문에, 법률체계 내에서 개인정보의 정의가 중요
하다고 볼 수 있다. 김경환 외(2014)는 각국의 개인정보 보호 법률에서 정의하는 개인정보의
개념을 점검하고 이를 바탕으로 개인정보의 법률적 정의에는 1) 개인에 관한 정보, 2) 살아
있는 개인에 관한 정보, 3) 개인을 식별할 수 있게 하는 정보라는 3가지 공통된 개념적 요소가
존재한다고 요약하였다. 먼저 개인에 관한 정보란 국가와 사회를 구성하는 개개의 자연인에
관한 정보로 이러한 관점에서 법인 혹은 단체에 관한 정보는 개인정보 보호의 테두리에서 제
외된다고 본다. 또한 개인정보 보호의 대상이 되는 개인은 생존한 자에 한정하는데, 이는 사
망한 자의 정보는 권리를 행사할 수 있는 주체가 존재하지 않기 때문에 권리 주체의 인격적
이익의 보장이라는 개인정보의 보호법익이 성립하지 않기 때문이다. 마지막으로 개인정보는
개인을 특정한 개인을 알아볼 수 있는 정보(식별정보), 혹은 그 자체만으로는 식별가능성이
매우 낮지만 다른 정보와 결합하여 개인을 알아볼 수 있는 정보(식별가능정보)로 한정하는데,
식별가능성이 존재하지 않는 정보까지 보호하는 경우 알권리나 정보분석을 통해 얻을 수 있
는 여러 이익 등을 과도하게 침해할 수 있다고 보기 때문이다.
정보 자체가 식별성을 가지고 있는 식별정보로는 특정인의 성명, ID와 비밀번호, 전화번호
의 전부 또는 일부, 주소 등과 같은 신원정보가 있다. 또한 통신회사에서 사용하는 개인의
IMEI(International Mobile Equipment Identity)나 IMSI(International Mobile Subscriber
Identity) 정보, 회사에서 사용자에게 임의로 부여한 일련번호와 같이 특정 기관이 개인을 식
별하기 위해 도입한 정보가 있다. 식별가능정보의 예로는 핸드폰 어플리케이션 개발회사가 어
플리케이션을 통해 통신회사의 IMEI나 IMSI를 수집함과 동시에 성명, 전화번호 등의 개인정보를
58) 김용대와 장원철(2016). 인공지능 산업 육성을 위한 개인정보 보호 규제 발전 방향

92
수집하여 저장하는 경우를 들 수 있다. 또한, 국가기관에서 공표하는 지역별 통계를 그 지역
에서 개인정보를 수집하는 회사의 정보와 결합하여 개인을 식별하는 경우도 생각할 수 있다.
예컨대 특정 지역의 학원이 학원 수강생의 정보를 정부의 지역별 교육 통계자료와 결합하면
학원 수강생의 다양한 개인정보를 식별할 수 있는 경우가 있다. 식별정보와 식별가능정보 이
외의 정보와 비식별 처리된 개인정보를 비식별정보라고 지칭하고 법률적 보호대상에서 제외하
고 있다. 그러나 기술발전으로 인하여 비식별정보의 식별가능성이 커짐에 따라 개인 프라이버
시를 보호하기 위한 개선된 법적 조치가 요구되는 상황이다.
나. 주요 국가의 개인정보 보호를 위한 법률체계
이 절에서는 미국, 유럽연합, 일본, 한국의 개인정보 보호를 위한 법률체계를 간략히 정리
하도록 한다.
1) 미국
미국의 개인정보 보호를 위한 법률체계의 가장 큰 특징으로 ① 분야별 법제의 형식을 띄고
있다는 점, ② 보호와 규제보다 활용에 방점을 찍고 있다는 점을 들 수 있다. 미국은 개인정
보의 이용을 포괄적으로 규제하는 일반법을 제정하기보다는 산업에서의 자율규제를 원칙으로
하고 있으며, 심각한 개인정보의 침해를 발생시킬 수 있는 사안에 대해서는 기존 법상의 불
법행위로 간주하여 규제하거나 개별법을 제정하여 대응하려는 구조를 가지고 있다. 기본적으
로 공공 부문은 연방프라이버시법(Privacy Act of 1974)이 기본법의 역할을 하며, 민간 부
문의 경우 정보통신, 금융, 의료정보 등 개별 분야에서 개인정보 이용에 관한 법률이 제정되
어 역할을 하고 있다.59)
또한 미국은 개인의 프라이버시가 침해되지 않는 한, 그 이전 단계에서 개인정보를 수집,
공유 및 분석하는 등의 빅데이터 처리를 일관되게 규제하는 법적 시도는 최대한 자제하고 있
다는 특징이 있다. 개인정보 보호와 관련된 규제는 옵트인(opt-in)과 옵트아웃(opt-out) 방식
으로 구분하는데, 옵트인은 개인이 동의해야만 개인정보를 사용할 수 있는 방식이고, 옵트아
웃은 개인의 동의가 없어도 개인정보를 사용할 수 있지만 해당 당사자가 요구하면 개인정보
사용을 금지하는 방식이다. 미국은 공공 부문에서는 옵트인 방식을 적용하여 규제하지만 민간
59) 김경환 외(2014)

93
부문에서는 옵트아웃 방식을 인정하며 자율규제를 허용하고 있는데, 이는 산업발전의 촉진을
위해서이다. 개인정보를 모아서 판매하는 엑시엄(Acxiom)이나 인포USA(InforUSA)같은 개인
정보를 판매하는 회사가 미국에서 크게 성공한 것도 이러한 법률체계와 무관하지 않다.
수많은 회사가 경쟁적으로 개인정보 수집하고 이를 활용하는 상황에서 다양한 부작용이 나
타나고 있다. 2013년에 미국 상원은 개인정보를 수집하고 판매하는 ‘데이터 브로커’ 회사의
역할과 부작용을 비판한 보고서를 내놓기도 하였다. 미국 정부는 이러한 상황을 인식하여 개
인정보를 보호하기 위한 다양한 대책을 내놓고 있는데, 상무부는 2010년 12월에 “인터넷
경제의 상용데이터 개인정보화와 혁신”이라는 보고서에서 ‘개인정보 보호 권리장전’의 채택과
‘개인정보 보호 정책국’의 창설을 제안하였다. 그리고 2012년 2월에는 ‘소비자 개인정보 보호
권리장전’이 발표되었다. 이러한 노력에도 불구하고, 미국에는 아직 민간부분의 개인정보를 보
호하기 위한 일관된 법률체계가 존재하지 않는다.
2) 유럽연합
유럽연합의 경우에는 회원국 국민의 개인정보 처리와 관련한 프라이버시를 보호하며 회원
국 간의 개인정보의 자유로운 유통을 촉진하기 위하여 다양한 지침을 채택하였다. 1995년
“개인정보의 처리와 유통에 관한 개인정보 보호지침”, 1997년 “정보통신부문의 개인정보 처리
와 프라이버시 보호에 관한 지침”, 1999년 “정보고속도로에서 신상정보의 수집 처리와 관련
한 개인정보 보호 지침”, 2002년 “전자통신 분야에서의 개인정보처리 및 프라이버시 보호와
관련된 유럽의회 및 유럽위원회 지침안”, 2011년 “유럽연합에서 개인정보 보호에 관한 종합
적 접근” 등을 채택하였다. 2016년에는 1995년에 채택된 개인정보 보호지침을 대폭 개정하
여 “개인정보 보호일반규칙”(General Data Protection Regulation; GDPR)을 채택하였다.
이와 같이 유럽연합은 미국과 달리 분야별 보호법률 외에도 개인정보 보호에 관한 일반법을
두어 개인 프라이버시 침해에 관하여 보다 엄격한 입장을 견지하고 있다.
가장 최근에 제정된 지침인 GDPR의 중요한 특징을 살펴보자. GDPR은 개인정보의 익명처
리(Anonymisation)와 구분되는 가명처리(Pseudonymisation)의 개념을 새로이 도입하고 가
명처리에 관한 지침을 상세하게 제시하였다. GDPR이 가명처리라는 개념을 도입한 것은 개인
정보의 익명처리를 위한 여러 방법들에 내재하고 있는 기술적 문제, 개인정보 처리자가 개인
정보 처리의 용이성을 어느 정도 포기해야 하는 익명처리를 자발적으로 수행하도록 기대할
수 없다는 현실적인 이유 등으로 인하여 정보의 완전한 익명처리가 가능하지 않을 수 있다는

94
인식 때문이다. 이러한 인식하에서, 개인을 식별할 수 있는 정보의 완전한 삭제를 요구하는
것보다, 식별 정보를 별도로 관리하고 이에 대한 의무를 부과하는 것이 더 바람직하다고
GDPR은 판단한 것이다.60) GDPR은 가명처리에 있어 처리자의 안전조치 의무, 금지되는 사항
등을 상세히 명시함과 동시에 이러한 요건이 충족된 상태에서는 개인정보 처리자의 개인정보
활용 및 분석을 자유롭게 허용하여 빅데이터 분석 및 활용의 유연성을 보장하고 있다.
3) 일본
2003년에 개인정보 보호 법률체계를 정비하기 전에 일본은 공공 부문의 경우 1988년 제
정된 “개인정보 보호법”이, 민간 부문의 경우 각 부문의 개별법 혹은 정부 가이드라인이 개인
정보 보호의 역할을 수행하였다. 미국의 경우와 유사하게 개인정보 보호에 관한 일반법이 존
재하지 않고 개별법이 개인정보에 관한 규제를 포함하고 있던 이러한 체계는 2003년에 개인
정보 보호법률을 대폭 정비하여 민간 부문과 공공 부문 모두에서 일반법의 역할을 하는 법률
이 존재하는 체계로 변경되었다. 이때 일본은 5개의 법률을 제정하였는데 그 중 “개인정보의
보호에 관한 법률”이 민간 부문과 공공 부문에서 일반법의 역할을 하며, 나머지 4개의 법률
“행정기관이 보유한 개인정보 보호에 관한 법률”, “독립행정법인 등이 보유한 개인정보 보호에
관한 법률”, 정보공개 ・ 개인정보심사회 설치법”, “행정기관이 보유하는 개인정보의 보호에 관
한 법률 등의 시행에 따른 관계 법률의 정비 등에 관한 법률”이 공공 부문의 개인정보 보호에
관한 법률이다.61)
4) 한국
한국의 경우 개인정보 보호법이 제정되기 전에는 미국과 유사하게 “신용정보의 이용 및 보
호에 관한 법률”(이하 신용정보법), “금융실명거래 및 비밀보장에 관한 법률”, “정보통신망이용
촉진 등에 관한 법률”(이하 정보통신망법), “통신비밀보호법”, “의료법” 등의 분야별 필요성에
따라 제정된 개별법으로 개인정보를 보호하였다. 그러던 것이 개인정보 보호 침해 사례와 규
모가 증대하는 사회적 변화에 대응하기 위하여 2011년 개인정보 보호법이 제정되어 개인정
보 보호를 위한 일반법으로 기능하고 있다. 그런데 일반법과 개별법이 동시에 존재하고 있는
60) 박노형(2016)
61) 김상미(2012)

95
상황에서 규제의 중첩 및 충돌의 문제가 발생하고 있다. 예컨대 보험회사가 동일한 보험계약
자와 계약을 체결함에 있어서도 거래 경로나 수집하는 정보의 종류에 따라 다양한 법률이 적
용되는데, 오프라인으로 수집한 신용정보에는 신용정보법이, 오프라인으로 수집한 정보 중 신
용정보가 아닌 개인정보에는 개인정보 보호법이, 온라인으로 수집한 보험정보에는 신용정보법
외에 정보통신망법이 중복 적용되며, 마지막으로 수집경로와 관계없이 개별법에 규정되지 않
는 사항에는 개인정보 보호법이 적용된다.62) 이와 같은 규제의 중첩 및 규율 범위의 복잡성은
산업현장에서 큰 혼란을 초래하고 있으며, 개인정보 처리자들이 적용되는 법률규정에 대해
명확하게 인지할 수 없게 하여 제재와 처벌을 최대한 회피하기 위해 여러 규정 중 가장 강한
규정을 적용하여 개인정보의 활용을 스스로 제약하게 되는 상황이다. 또한 개인정보 보호법이
매우 상세하고 강하게 개인정보 이용을 규제하고 있다는 점은 상황을 더욱 악화시키는 요인
이다.
다. 주요 국가의 개인정보 비식별처리에 관한 접근
이 절에서는 주요 국가의 개인정보 비식별처리에 관한 접근에 대해 살펴보도록 한다. 개인
정보를 빅데이터 분석에 이용하기 위해서는 개인정보를 비식별처리하여 해당정보가 개인정보
보호법에 적용을 받지 않도록 하여야 한다. 적절한 비식별처리는 개인정보의 활용성을 높일
뿐만 아니라 개인정보 유출의 가능성도 최소화할 수 있다. 따라서 개인정보 보호와 활용이라는
두 가지 가치를 동시에 달성하기 위해서는 비식별처리에 관한 접근이 매우 중요하다고 볼 수
있다.
미국의 경우 비식별처리에 관하여 두 가지 대표적인 입법례가 있는데, 1966년 “건강보험
이동성 및 책임의 법”(Health Insurance Portability and Accountability Act; HIPAA)의 프
라이버시 규칙과 미국 연방통신위원회가 인터넷 서비스 제공자들에게 제시한 지침인 “브로드
밴드 소비자 프라이버시 규칙”(Broadband Consumer Privacy Rules; BCPR)이 그것이다.63)
HIPPA는 개인 건강정보의 비식별화를 위해 전문가결정 방식과 세이프하버 방식(Safe Harbor
Method)의 두 가지 접근을 채택하고 있다. 전문가결정 방식은 전문가들이 개인정보 데이터
를 확인하여 적절한 비식별화의 범위와 수단을 정하는 방식이다. 반면 세이프하버 방식은 비
62) 김경환 외(2014)
63) 박노형(2016)

96
식별화가 필요한 18가지 유형의 데이터를 지정하고 이에 따라 개인정보 관리기관이 비식별화
조치를 하도록 한 것이다. 세이프하버 방식은 지침에 따라 비식별화를 수행하는 방식이므로
전문가결정 방식에 비해 즉각적이고 예측가능하나 비식별조치를 수행하는 기관이 비식별화된
개인정보를 재식별할 수 있는 능력과 지식이 없음을 보장할 수 없다는 문제가 있다. BCPR은
인터넷서비스 제공자가 비식별화된 개인정보를 이용하기 위한 몇 가지 조건을 제시하는데 우
선 미국 연방통신위원회가 고안한 시험을 통과하고, 개별적으로 식별될 수 없는 형식으로 비식
별화를 수행하며 비식별처리된 정보를 재식별하지 않는다는 약속을 공개적으로 선언하며, 비식
별처리된 정보에 접근하는 자가 재식별화를 시도하지 못하도록 적절한 감시를 수행하여야 한다.
일본의 경우 익명처리된 개인정보에 대해서 옵트아웃 방식을 채택하여 해당 정보를 이용할
수 있게 하고 있다. 일본은 익명처리에 대하여 몇 가지 지침을 제시하고 있는데, 익명처리시
특정 개인을 식별할 수 없도록 처리하여야 하며, 개인정보 보호위원회 규칙에 따라 안전관리
조치를 이행하여야 한다. 또한 익명처리된 정보를 재식별화하는 행위를 금지하고 있다.
이러한 미국과 일본에서 비식별화는 개인정보를 가공하여 특정 개인과 해당 정보를 연결하
지 못하도록 한다는 점에서 GDPR의 익명처리와 유사하다고 볼 수 있다. 또한 미국과 일본은
완전한 익명처리를 불가능한 것으로 보고 재식별화를 위한 행위를 금지하고 있다는 공통점이
있다. 반면 유럽연합의 GDPR은 개인정보를 가명처리하도록 권고한다는 점에서 양국과는 그
접근이 다르다고 할 수 있다.64)
라. 빅데이터 산업발전을 위한 법률체계 정비
가장 기본적으로는 개인정보 보호법과 분야별 개별법 사이의 중복 및 충돌되는 요소를 분
석하여 합리적인 해석과 적용을 가능하게 하는 가이드라인을 제시할 필요가 있으며 나아가
중첩 및 충돌되는 규정들을 재정비하여야 한다. 또한 개인정보 보호법률을 통합하여 일원화하
는 것도 하나의 방법이 될 수 있다.
개인정보법의 내용과 관련해서는 유럽연합의 GDPR을 참조할 필요가 있다. 개인정보 보호
일반규칙은 개인정보의 비식별처리에 관하여 기술적, 현실적 이유로 불완전할 수밖에 없는
익명처리가 아닌 가명처리를 권고하고 이에 대한 상세한 지침을 제시함과 동시에 규정 외의
64) 박노형(2016)

97
개인정보 활용은 최대한 보장함으로써 개인정보의 보호와 활용을 균형적으로 추구하고 있다.
이와 같이 기술적 발전을 반영하여 개인정보의 보호범위와 의무를 명확하고 간결하게 규정한
유럽연합의 GDPR을 국내에서도 참고할 만하다.
또 한편으로는 데이터과학자들의 법률적 위험을 분산시킬 수 있는 제도적 장치가 도입될
필요가 있다. 데이터를 통합하거나 분석할 때 발생할 수 있는 개인정보 유출의 위험은 이를
방지하는 통계적 ・ 기술적 방법이 정교하게 발전하더라도 완전히 제거될 수 없다. 따라서 개인
정보 유출에 따르는 법률적 위험 역시도 항상 존재하게 된다. 개인정보 유출에 따른 법률적
위험은 빅데이터 분석을 통하여 새로운 가치를 창출하고자 하는 데이터 과학자들의 입지를
제약할 수밖에 없으며, 이는 빅데이터 활용을 저해하는 중요한 요인 중 하나이다. 이런 상황
을 해결하기 위해서는 특히 개인정보의 유출에 관한 법률적 책임을 면제하거나 최소화하는
방법을 고려하여야 한다.
이를 위한 정책적 대안으로 고려해볼 수 있는 것은 여러 기관의 데이터를 통합할 때 개인
정보 보호를 위한 기술적 지원을 제공하고 인증 과정을 수행하는 소위 ‘데이터 거래소’를 정부
조직 또는 산하기관으로 만드는 것이다. 데이터 거래소에서 승인된 통합 데이터를 분석하는
데이터 과학자에게는 개인정보유출로 인한 법률적 위험을 일부 감면하도록 하는 제도를 고려
해 볼 만하다. 이미 세계 각국에서는 데이터 거래소를 도입하고 있다. 중국은 2015년부터 빅
데이터 거래소를 개설하여 운영하고 있으며, 영국은 기업이 분석에 필요한 개인데이터를 제공
하도록 하는 프로그램을 운영하고 있다. 미국의 경우 앞서 언급했던 데이터 브로커 기업들이
활성화되어 있어 민간 시장에서 데이터 거래가 이루어지고 있다.65) 반면에 개인정보 보호에
대한 매우 엄격한 법을 가지고 있는 한국에서는 개인 혹은 기업 간의 데이터 거래에서 발생
할 수 있는 개인정보유출에 대한 책임이 데이터 거래 당사자인 개인과 기업에 전적으로 부과
되기 때문에, 미국의 경우와 같은 민간 중심의 데이터 거래소가 형성되기 매우 어려운 조건에
처해있다고 할 수 있다. 법률적 책임을 일정 부분 부담하는 정부 산하의 데이터 거래소가 설
립된다면 민간주도의 데이터 거래소 시장이 성장하는데 도움이 될 것이며 이는 빅데이터 분
석을 통한 산업발전에 밑거름이 될 것이다.
65) 파이낸셜뉴스, 2016. 12. 15.

98
7. 프라이버시 보호를 위한 기술들
가. 데이터 변환을 통한 프라이버시 보호
데이터의 변환을 통한 프라이버시 보호는 “개인정보 보호 데이터 마이닝(PPDM; Privacy
Preserving Data Mining)”이란 이름으로 2000년도 초반부터 연구가 되었다.66) 즉, PPDM은
일반적인 기계학습기법과 마찬가지로 데이터를 이용하여 규칙 및 패턴 발견(Pattern
Discovery), 군집 찾기(Clustering), 분류(Classification) 등을 목표로 하되, 날 것의 데이터를
그대로 사용하는 것이 아닌 개인의 식별이 불가능한 수정된 데이터(Modified Data)를 사용하
는 것이 차이점이라 할 수 있겠다.
1) PPDM의 프레임워크
PPDM 기법은 ① 데이터 셋, ② 개인정보 보호 기술, ③ 기계학습 알고리즘 이렇게 세 가
지의 구성요소로 이루어져 있다.67) 이 3가지 구성요소의 관계를 그림으로 나타내면 <그림 8>
과 같다. 일반적으로 PPDM에서 3번째 구성요소인 기계학습 알고리즘(데이터마이닝 알고리
즘)은 어떠한 데이터 가공과정을 거쳤는지에 따라 기존 알고리즘을 사용할 수도, 새로운 알고
리즘을 개발하여 사용할 수도 있다. 따라서 개인정보 보호를 위한 데이터 가공과정이 더 중요
한 요소라고 할 수 있다. 따라서 다음으로 이어지는 소주제에서는 첫 번째와 두 번째의 구성
요소에 대하여 자세하게 다루도록 한다.
OUTPUT
INPUT
PRIVACYPRESERVINGTECHNIQUE
DATA MININGTECHNIQUES
<그림 8> PPDM의 세 가지 구성요소의 관계(Vinoth와 Santhi, 2016)
66) 홍선경 외(2013), Bertino 외(2008)
67) Vinoth와 Santhi(2016)

99
① 데이터 셋
데이터 셋은 문자 그대로 기계학습기법 등을 통하여 유의미한 정보를 추출하고 싶은 대
상이 되는 데이터를 뜻하며, 이 데이터에는 수많은 개인정보 또는 회사의 기밀정보가
포함되어 있다. 데이터 셋은 크게 중앙 서버에 집중되어 저장되어 있거나, 분산 저장되
어있다. 중앙 서버에 집중되어 있는 경우를 ‘Central Server Scenario’라 하고, 분산 저
장되어 있는 경우를 ‘Distributed Server Scenario’라 한다. 특히 ‘Distributed Server
Scenario’의 경우 각 저장 서버마다 다른 설명 변수를 저장하고 있는 경우를 ‘Vertically
Distributed’, 서로 같은 설명 변수를 저장하되 다른 샘플들을 저장하고 있는 경우를
‘Horizontally Distributed’로 정의한다.68)
② 개인정보 보호 기술
두 번째 구성요소인 개인정보 보호 기술은 데이터를 가공, 변형하여 개인정보 또는 회사
고유의 정보를 식별하지 못하도록 하는 기법들을 총칭하며 PPDM의 핵심이 되는 기술
요소를 대부분 포함하고 있다. 개인정보를 보호하는 방법에 따라서 a) 익명화 기반의
PPDM, b) 교란 기반의 PPDM, c) 랜덤화된 응답 기반의 PPDM, d) 압축 기반의
PPDM, e) 암호 기반의 PPDM 이렇게 크게 5가지로 나뉜다.69) 여기서 5번째 암호 기반
의 PPDM은 개인정보 보호의 측면보다는 다자 간의 데이터 공개를 꺼리는 상황에서
모두의 데이터를 이용하여 유의미한 정보를 추출하는 것을 목적으로 하는 기법이기 때문
에 앞의 4가지 PPDM 방법들과 결을 달리 하는 방법이라 할 수 있겠다. 따라서 여기서
는 앞의 4가지의 PPDM 방법에 대해서만 설명하도록 한다.
2) 익명화 기반의 PPDM(Anonymization based PPDM)
익명화 기반의 PPDM이란 가명 처리, 총계 처리, 데이터 삭제 등을 이용하여 데이터의 개
인을 익명화하여 개인정보가 누구의 것인지 식별하지 못하게 하는 것을 의미한다. 개인의 수
많은 정보 중 민감한 정보(예: 질병의 유무 또는 병명)를 분류하는 것을 목표로 하는 경우에,
이를 설명하기 위해 필요한 다른 정보들을 가공하지 않은 채 그대로 사용한다면 개인정보 누
출이 심각해질 것이다. 이런 경우에 데이터를 다양한 방식으로 가공하여 가공된 데이터를 통
해 어떤 개인인지 유추할 수 없게끔 하는 과정이 필요하다. 간단한 방법으로는 앞에서 언급한
68) Malik 외(2012)
69) Malik 외(2012)

100
가명 처리(Pseudonymiztion), 총계 처리(Aggregation), 데이터 삭제(Data Reduction) 등이
존재하며, 고급 방법론으로는 k-익명성70), l-다양성71) 등이 있다. 다음의 대부분의 설명은 한
국신용정보원의 ‘개인정보 비식별 조치 가이드라인’72)을 참조하였다.
가명처리(Pseudonymization)는 성명, 출신학교, 근무처 등 개인 식별이 가능한 데이터를
직접적으로 식별할 수 없는 다른 값으로 대체하는 기법으로, 데이터의 변형 또는 변질 수준이
적은 편에 속하지만 대체 값을 부여한 후에도 식별 가능한 고유의 속성이 계속 유지되기 때
문에 개인의 ID를 유추할 수 있다는 단점이 있다. 대표적인 가명 처리 기법으로는 식별자에
해당하는 값들을 몇 가지 정해진 규칙으로 대체하거나 사람의 판단에 따라 가공하여 자세한
개인정보를 숨기는 방법인 휴리스틱 가명화 방법(Heuristic Pseudonymization), 기존의 데이
터베이스의 레코드를 사전에 정해진 외부의 변수값과 연계하여 교환하는 교환 방법(Swapping)
등이 존재한다.
총계 처리(Aggregation)는 개인을 식별하기 쉬운 신체정보, 소비기록 등 각각의 값 대신
평균 등 통계값을 적용하여 특정 개인을 식별할 수 없도록 하는 기법들을 의미하며, 민감한
수치 정보에 대해 식별이 불가능하도록 할 수 있다는 장점이 있지만 정밀한 분석이 어렵다는
단점이 존재한다. 대표적인 총계 처리 기법으로는 데이터 전체를 총계 처리하는 방법과 일부
민감한 샘플들만 총계 처리하는 부분 총계 방법(Micro Aggregation), 값들을 올림하거나 내
림하는 라운딩(Rounding) 기법 등이 존재한다.
데이터 삭제(Data Reduction)는 이름, 전화번호, 주민등록번호 등 개인식별이 가능한 데이
터를 삭제 처리하는 방법으로 민감한 설명 변수 전체를 삭제하거나 부분만 삭제, 또는 다른
샘플들과 뚜렷하게 구별되는 샘플 전체를 삭제하는 방법이 존재한다.
k-익명성 방법(k-anonymity)73)은 공개된 데이터에 대한 연결공격(linkage attack)에 대한
취약점을 방어하기 위해 제안된 보호 모델이며 여기서 연결 공격은 해당 데이터가 다른 공개
된 데이터와 결합하여 개인의 민감한 정보를 알 수 있는 공격 방법을 말한다. 주어진 데이터
집합에서 같은 값이 적어도 k개 이상 존재하도록 수정하여 모든 샘플이 적어도 자기 자신과
70) Samarati와 Sweeney(1998)
71) Aggarwal과 Philip(2008)
72) 한국신용정보원(2016). 개인정보 비식별 조치 가이드라인
73) Samarati와 Sweeney(1998)

101
구별되지 않는 k-1개의 샘플을 갖도록 한다. 따라서 k-익명성 방법을 통해 가공된 데이터에
대해서는 공격자가 정확이 어떤 샘플이 공격 대상인지 알아낼 수 없다는 장점이 다.
l-다양성 방법(l-diversity)74)은 k-익명성 방법의 취약점을 보완하기 위해 나온 보호 모델로
k-익명성 방법에 대해 동질성 공격 등을 방어하기 위하여 개발되었다. 동질성 공격이란 k-익
명성 방법을 통해 가공된 데이터가 일부 정보들이 모두 같은 민감한 값을 가질 경우에 이를
이용하여 공격 대상의 정보를 알아낼 수 있는 경우를 뜻한다. 따라서 l-다양성 방법은 주어진
데이터에서 비식별되는 샘플들은 적어도 l개의 서로 다른 민감한 정보를 가지도록 가공하는
방법을 말하며, 비식별되는 샘플들마다 충분한 다양성을 가지므로 다양성의 부족으로 인한 공
격에 방어가 가능하다는 장점이 존재한다.
위에서 언급한 방법론들 외에도 t-근접성75), M-불변성76) 등 다양한 방법론들이 존재하지만
여기서는 설명을 생략하였다.
3) 교란 기반의 PPDM(Perturbation based PPDM)
데이터 교란은 프라이버시 누출 방지를 위해 가장 많이 사용되는 기법으로, 민감한 원본
자료를 감추기 위해 원본 데이터에 교란을 주어 개인의 식별이 힘들도록 하는 기법이다.77)
이를 목적으로 원래 데이터를 노이즈 생성을 통한 왜곡(Distortion), 또는 PCA 등의 기법을
이용한 변환(Transformation) 등의 가공을 하고, 가공된 데이터를 바탕으로 기계학습기법을
이용하여 유용한 정보를 추출한다. 결국 교란 기반의 PPDM은 원 자료의 통계적 성질을 크게
잃지 않으면서도 기존 자료를 유추해낼 수 없게끔 가공하는 것이 핵심이라 할 수 있겠다.78)
가장 간단한 방법으로는 랜덤 노이즈를 이용하여 데이터를 가공하는 것이 있으며, 랜덤 노
이즈를 더하거나(Simple Additive Noise) 곱하는 방법(Multiplicative Noise)이 존재한다. 여
기서 랜덤 노이즈는 사전에 정해놓은 분포에서 샘플링하며, 분포의 분산이 작으면 원 데이터의
정보를 크게 잃지 않는 대신 개인의 식별이 가능할 위험이 높고, 반대로 분산이 크면 개인의
74) Aggarwal와 Philip(2008)
75) Li 외(2007)
76) Xiao와 Tao(2007)
77) 홍선경 외(2013)
78) Fung 외(2010)

102
식별이 거의 불가능해지는 대신 원 데이터의 정보를 잃을 가능성이 높다.79) 따라서 적당한 정
도의 노이즈를 섞어서 데이터를 가공하는 것이 필요하다. 분석가가 분석을 위해 가공된 자료
를 받을 경우 원 자료의 정확한 값을 알 수는 없고, 노이즈의 분포로부터 각 샘플마다 각 자
료의 분포를 유추하여 얻을 수 있다. 따라서 이렇게 노이즈를 섞은 자료는 기존에 존재하는
기계학습기법이 아닌 분포 기반의 기계학습기법을 새로 개발하여 유용한 정보를 추출해야 한
다.80)
이를 위해 Agrawal과 Srikant(2000)는 분류 문제를 해결할 수 있는 분포 기반의 새로운
알고리즘을 개발하였고, Kantarcioglu와 Clifton(2002)는 연관 법칙문제를 해결할 수 있는
분포 기반의 알고리즘을 개발하였다. 이처럼 노이즈를 이용한 데이터 교란 기법은 데이터 가
공이 간편하다는 장점이 있지만 설명변수 간의 상관관계를 변화시킬 수 있고, 분포 기반의 기
계학습 알고리즘을 새롭게 개발해야 한다는 단점이 있다.
데이터 변환을 이용한 교란 기법은 위에서 언급한 노이즈를 이용한 교란 기법의 단점 중
하나인 결과에 영향을 주는 설명변수 간의 상관관계를 무시하는 점을 보완하는 방법이다. 샘
플 간의 거리 및 상관관계를 최대한 보존하면서 회전, 평행 이동, 스케일링 또는 푸리에 변환
등 여러 변환 방법들을 이용하여 데이터를 변환하며 기존에 존재하는 기계학습기법을 사용하
기가 용이하다. 특히 거리가 보존되는 경우에는 거리를 이용하여 분석하는 대표적인 방법 중
하나인 군집분석이 가능하고, 상관관계가 보존되는 경우에는 다차원의 상관관계를 이용하여
분류하는 의사결정나무 등의 모형을 사용할 수 있다. 시계열 자료의 경우 이산 푸리에 변환
(Discrete Fourier Transform), 이산 웨이블릿 변환(Discrete Wavelet Transform) 등을 이
용하면 높은 정확도로 유클리디안 거리를 보존한다는 특성이 있어 시계열 데이터의 프라이버
시 보호에 자주 이용되고 있다.81)
79) Moon 외(2010)
80) Nayak와 Devi(2011)
81) 홍선경 외(2013), Papadimitriou 외(2007), Mukherjee 외(2006)

103
4) 랜덤화된 응답 기반의 PPDM(Randomized Response base PPDM)
랜덤화된 응답(Randomized Response)은 원래 전통적인 설문조사기법 중의 하나이다. 랜
덤화된 응답은 설문조사 대상자가 대답하기 민감한 질문(예: 범죄전과 유무, 마약흡입 유무,
성 취향 등)에 대답하기 어려울 경우에 대답을 랜덤화 할 수 있는 질문을 추가하여 응답자가
솔직하게 설문지를 작성할 수 있도록 유도하는 방법으로 1965년 S. L. Warner에 의해 처음으
로 고안되었다. 랜덤화된 응답 기반의 PPDM은 이를 응용한 개인정보 보호방법으로 원 데이
터를 특정 분포 또는 확률로 랜덤화하여 가공하는 것을 의미한다. 기계학습기법을 사용할 때
는 가공된 데이터를 이용하여 원 데이터의 분포를 유추하여 사용한다. 이를 도식화하면 <그림
9>와 같다.
Randomize Reconstruct
OriginalDataset
RandomizedDataset
OriginalDistribution
<그림 9> 랜덤화된 응답 기반의 PPDM의 과정(Vinoth와 Santhi, 2016)
랜덤화된 응답 기반의 방법은 매우 간편하다는 장점이 있지만 이상값이 존재하는 샘플이
그렇지 않은 샘플에 비해 공격자의 공격에 매우 취약하다는 단점을 가지고 있다.
교란 기반의 PPDM과 마찬가지로 가공된 데이터를 이용하여 기계학습 알고리즘을 적용 할
때에 기존의 방법이 아닌 새로운 알고리즘이 필요하다. 때문에 많은 경우에 대해서 다양한 알
고리즘들이 개발되었다. 2000년에 Agrawal과 Srikant는 랜덤화된 응답 기반의 분류문제를
풀 수 있는 알고리즘을 개발하였고, Evfimievski와 Philip(2004)과 Rizvi와 Haritsa(2002)는
연관성 규칙 분석이 가능하도록 하는 알고리즘을 각각 개발하였다.
5) 압축 기반의 PPDM(Condensation approach based PPDM)
압축 기반의 PPDM82)은 위에서 언급한 세 가지 방법의 단점을 보완하기 위해 개발된 새로
운 프레임워크이다. 대부분의 경우에는 개인정보 보호를 위해 원 데이터를 가공하고, 교란된
82) Aggarwal와 Philip(2004)

104
데이터를 훈련 자료로 사용하여 기계학습기법을 통해 유의미한 정보를 추출한다. 가공된 데이
터는 원래 데이터에 비해 ① 손실되는 정보의 양이 크고, ② 정확한 값이 아닌 분포를 이용한
기계학습 알고리즘을 새로 개발해야 하는 번거로움이 존재하며, ③ 가공과정 속에서 다차원
간의 상관관계를 무시하게 될 수도 있고, ④ 마지막으로 변형된 데이터로부터의 기계학습기법
은 예측력이 약할 수 있다.
압축 기반의 PPDM 방법은 위에서 언급한 기존 방법들의 단점들을 대부분 극복할 수 있게
끔 개발되었다. 본 방법의 핵심 아이디어는 가지고 있는 원 데이터를 이용하여 원 데이터와
거의 같은 통계적 성질을 갖는 인공의 익명화된 데이터(synthetic data)를 만드는 것이다. 익
명화된 데이터는 기존의 데이터와 형태가 동일하기 때문에 기계학습기법을 이용할 때 설명
변수에 대한 설명력이 유지될 수 있고, 교란 기반의 PPDM처럼 샘플들의 값의 분포를 유추할
필요가 없기 때문에 분석을 위한 별개의 알고리즘을 개발할 필요 없이 기존의 기계학습기법을
이용하면 된다는 장점이 있다. 이 방법에서는 익명화된 인공 데이터가 원 데이터의 성질과 거
의 유사해야 한다는 것이 가장 중요한 문제인데, Aggarwal과 Philip(2004)은 인공 데이터가
원본 데이터와 거의 비슷한 특성을 가지고 있다는 것을 실험적으로 증명하였다.
나. 차등 정보 보호(Differential Privacy)
대부분 정보의 노출은 자료의 결합을 통하여 발생하였지만 최근에는 공개되는 자료와 정보
가 많아지고 통계분석 서버의 이용이 증가하면서 자료 공격의 형태가 변하고 있다. 더 나아가
빅데이타가 출현한 환경에서 모형노출의 가능성이 상대적으로 높아질 것으로 예상된다. 모형
노출이란 기계학습으로 학습된 예측모형으로부터 개인정보가 노출되는 경우를 지칭한다. 예를
들어 개인의 인구 경제학적 특성을 알고 있고 여러 공개된 자료를 이용하여 소득에 대한 제
법 정확한 회귀모형을 추정할 수 있다면 개인의 소득을 모형을 통하여 예측할 수 있는 가능
성이 있다. “Terry Gross는 리투아니아(Lithuanian) 여자의 평균키보다 2인치가 작다”는 사실
을 알고 있다고 하자. 어떤 자료가 국가별 남녀 평균키에 대한 정보를 줄 수 있다면 Terry
Gross의 정확한 키가 노출된다. 공개되는 자료가 증가하고 빅데이터와 같이 자료의 크기가
커지는 경우 전통적인 노출의 도구인 자료 연결(data matching)과 함께 추론과 모형을 통한
노출도 증가할 수 있다. 따라서 추론과 모형을 통한 노출을 기반으로 하는 노출 위험의 측도
가 필요하다. 차등 정보 보호는 이러한 모형노출의 가능성을 제어하기 위한 기법이다. 본 절
의 내용은 이용희(2013)의 논문을 바탕으로 작성되었다.

105
Dalenius(1977)는 통계적 노출제한 기법의 목표를 다음과 같이 정의하였다.
“자료를 통하지 않으면 알 수 없는 개인의 정보를 자료를 통하여 알아내는 것을 방지한
다. Access to statistical database should not enable one to learn anything about an
individual that could not be learned without access to the database.”
Dwork(2006)은 Dalenius의 목표가 실현될 수 없는 명제임을 보고 차등 정보 보호
(Differential Privacy)라는 개념을 제안하였다. 차등 정보 보호의 개념은 한 개의 개체가 자료
에 추가로 포함될 때 증가하는 위험을 측정하는 것이다. 따라서 차등 정보 보호는 자료의 전
체를 보호하는 의미에서 위험을 측정하기 보다는 자료가 변화함에 따라 증가하는 위험을 상
대적으로 측정하고 이를 제어하는 방법이라고 할 수 있다. 차등 정보 보호의 확률적 정의는
다음과 같다.
[정의 1] 데이터베이스 와 를 고려하고 두 데이터베이스는 자료에 포함된 개체 수의
차이가 한 개라고 하자. 임의의 노출제한 방법을 확률함수 라고 하면 는 노출제한
방법이 적용된 공개 데이터베이스이다. 이러한 가정하에서 -차등 정보 보호(-Differential
Privacy)는 다음과 같은 조건을 만족하는 것이다.
∈ ≤ exp× ∈ for ⊆
위에서 정의된 -차등 정보 보호는 공개된 자료에서 하나의 개인 또는 개체가 제외되어도
자료로부터 얻은 정보가 유의하게 변하지 않는다는 것을 의미한다. -차등 정보 보호는 매우
강한 정도의 정보 보호를 의미하며 절대적인 개념이 아니라 자료의 크기의 차이에서 발생하
는 노출위험의 변화를 측정하는 상대적인 개념이다. 또한 외부 자료의 유무나 가용한 계산능
력을 고려하지 않아도 되는 개념이다.
Dwork(2006)은 -차등 정보 보호의 구현을 위하여 데이터베이스의 쿼리에 대한 민감도
(Sensitivity)를 정의하였다. 데이터베이스 에 대한 쿼리를 함수 로 정의한다면 는 쿼
리에 대한 결과이다.
∶→
만약 쿼리의 결과가 히스토그램이라고 한다면 ⋯이다. 이때 는 각 구
간에 속하는 도수(Frequency) 또는 상대도수이다. 이러한 가정하에서 쿼리 의 민감도 ∆는

106
다음과 같이 정의된다.
[정의 2] 와 를 고려하고 두 데이터베이스는 자료에 포함된 개체 수의 차이가 한 개
라고 하자.
∆ max∥∥
여기서 ∥∥은 -거리(Norm)이며 벡터 의 성분 중 최대값이다.
예를 들어 쿼리의 결과가 히스토그램이라고 한다면 민감도는 이다(∆ ). 왜냐하면 개
체 한 개한 자료에 포함되는 경우 히스토그램은 첨가된 개체가 포함된 도수가 한 개 증가하
고 나머지 도수는 변하지 않기 때문이다. 많은 경우 민감도의 값은 크지 않지만 쿼리의 종류에
따라 그 크기가 상한(Upper Bound)를 가지는 경우도 있고 아닌 경우도 있다.
쿼리의 민감도가 계산되었을 때 -차등 정보 보호를 구현하는 방법은 쿼리의 결과에 표준편
차의 크기가 ∆을 가지는 이중지수분포(Double Exponential Distribution; Laplace
Distribution)에서 생성된 잡음을 첨가하는 것이다. 예를 들어 히스토그램에 잡음을 첨가할 경
우 이중지수분포에서 발생된 개의 독립인 잡음들( )을 각 도수에 첨가하는 것이다.
histogram output =
⋯ ⋯ ⋯
이러한 결과는 만약 의 값이 이중지수분포를 따른다고 가정하고 -차등 정보 보호의
기준에 계산하면 쉽게 유도할 수 있다.
-차등 정보 보호의 개념은 원격접속을 통하여 자료의 요약 통계를 제공해주는 통계분석
서버에 적합한 개념이다. 지금까지는 통계분석 서버를 제공하는 경우 마이크로 자료의 공개보
다는 정보 노출의 위험성이 작았다. 하지만 제공 항목이 다양해지고 제공 서비스가 증가하면
자료 공격자가 계획된 쿼리를 지속적으로 사용하여 정보 노출의 가능성이 높아진다. 또한 계
획된 쿼리가 지능화하거나 자동화될 수 있는 기능성이 증분하기 때문에 추정유출이나 모형유
출의 위험이 증가할 것이다. 이러한 환경에서 -차등 정보 보호는 노출위험을 수량화할 수 있
는 기준을 제공한다는 데 큰 의미가 있다. 하지만 실제로 이를 구현하려면 더 많은 연구가 필
요하다.

107
8. 맺음말
4차 산업혁명 시대에서 인공지능과 빅데이터 기술은 국가의 생존을 위해서 놓쳐서는 안 되
는 중요한 기술이다. 하지만, 개인정보 이용에 따르는 프라이버시 침해에 대한 우려와 인공지
능 서비스와 관련된 윤리적 문제 등이 인공지능 기술 발전에 걸림돌이 되고 있다. 프라이버시
보호를 위한 법률적 체계와 알고리즘들에 대해서 많은 연구 및 논의가 되고 있으며, 윤리적
문제의 해결을 위한 논의가 활발하게 진행 중이다. 본 절에서는 프라이버시 보호와 윤리적 문
제 해결을 위한 발전방향에 대해서 논의한다.
가. 프라이버시 보호를 위한 법률적 ・ 기술적 측면
프라이버시 보호를 위한 다양한 법률체계와 기술적 방법론들이 개발되었음에도 불구하고,
100% 프라이버시를 보호하면서 인공지능 기술을 발전시키는 것은 불가능하다. 따라서, 인공지
능 기술이 가져오는 사회적 득과 실을 따져서 적절한 선에서 프라이버시를 보호하는 사회적 합
의가 필요하다. 최근에 원자력발전에 관한 공론화위의 활동은 사회적으로 건전한 기술의 발전이
라는 대의 명분에 맞는 매우 바람직한 방향이라고 평가할 수 있다. 인공지능 기술과 프라이버시
보호라는 상호 충돌되는 가치에 대해서도 사회적 공론화 과정이 시급히 요청되고 있다. 나아가
기술적으로 프라이버시 침해를 방지하는 인공지능 기술의 연구에도 많은 투자가 필요하다.
나. 윤리적 측면
인공지능의 윤리적 문제의 해결을 위해서는 바람직한 인공지능 기술과 사용이란 무엇인가
를 논의해야 한다. 인공지능 기술이 인종차별이나 범죄 등과 같이 반사회적으로 사용되지 않
아야 하는 것은 물론이고, 인공지능 기술의 사용에 나타나는 감정이입과 이에 따르는 사회적/
문화적 새로운 현상에 대한 고찰도 필요하다. 2005년도 개 로봇의 장례식, 페페의 제스처 및
사용방법 규약, 섹스로봇 등은 이러한 새로운 현상을 잘 보여준다.
인공지능 윤리문제의 해결을 위해서는 사회적 합의를 위한 공론화 작업, 관련 교육프로그
램의 개발, 그리고 윤리문제 해결을 위한 행정시스템의 정비 등이 필요하다. 인공지능 윤리에
대한 공론화 작업이 조금씩 진행되고 있는데 MIT의 맥스 테그마크 교수 필두로 다수의 연구자
들이 앞으로 인공지능의 기술의 발전이 사회의 이익을 위해서 이루어져야 한다는 공개서한을

108
만들어 많은 학자와 관련자들이 온라인 서명을 하도록 했으며, 2015년 국제인공지능학회에서
자동살상무기에 대한 반대를 위한 공개서한에 연구자들이 서명하였다.
인공지능 윤리에 대한 다양한 교육프로그램들도 개발 중이다. 최근 몇 년간 컴퓨터 과학과
인공지능 전공자들에 윤리를 가르치는 방법으로 주목받고 있는 방안은 ‘SF을 통한 컴퓨터 윤리
학’ 코스이다. 이미 2008년부터 유니온 칼리지의 아나스타시아 피스(Pease)는 이에 대한 시
도와 경험을 논문으로 발표했는데 참여 학생이 인문학, 공학, 사회과학 등으로 다양했다. 그녀
는 SF를 실용 윤리학을 가르치는 관문으로 활용해 학생들이 가질 거부감이나 저항을 없앴다.
시카고 대학의 임마뉴엘 버튼, 켄터키 대학의 쥬디 골드스미스, 호주의 뉴 사우스 웨일스 대
학의 니콜라스 마테이 등은 SF를 이용해 인공지능 윤리학을 가르치는 방안에 대해 2015년
미국 인공지능학회의 AI, 윤리학과 사회 워크숍에서 발표했고, 2016년에는 E. M. 포스터의
1909년 SF 명작인 『기계가 멈추다』를 활용한 수업에 대한 결과를 발표했다.83)
인공지능 윤리문제의 해결을 위한 행정시스템의 구축 또한 시급히 요청되고 있다. 인공지
능 기술은 인간에게 직접적으로 적용되기 때문에, 의약, 식품, 환경 등의 문재와 같은 선에서
논의되어야 할 것이다. 의학연구에서 실험을 관리하고 통제하는 IRB(Iternal Review Board)
같은 행정조직을 인공지능 연구에도 적용할 수 있을 것이다.
다. 결어
인공지능의 바람직한 발전이 매우 중요하다. 인공지능의 산업적인 면을 너무 강조하면 부
작용으로 프라이버시 침해가 발생할 수 있으며, 차별, 범죄, 전쟁 등에 인공지능 기술이 사용
되면 큰 사회적 문제를 야기할 수 있다. 인공지능 사회로의 본격적인 진입을 위해서는 기술적
요소와 더불어 법률적 ・ 윤리적 측면 모두를 고려하는 생태계 구축이 필요하다.
하지만 규제일변도의 논의는 인공지능 사회의 바람직한 발전을 저해할 수 있다, 자동차는
영국에서 처음 개발되었지만 교통사고로 인한 피해를 너무 강조하며 매우 강력한 사용 규정을
만든 덕분에 영국에서는 산업적으로 성공하지 못했다. 자율규제에 무게를 둔 미국에서 자동차
산업이 꽃피운 것도 필요 이상의 규제가 나은 결과이다. 인공지능 기술과 이를 통한 건전한
사회발전을 위해서는 솔로몬의 지혜가 필요하다.
83) 한상기(2016)

109
1. 국내 문헌
김경환 ・ 강민규 ・ 이해랑. (2014). “보험개인정보 보호법제 개선방안”, 조사보고서, 2014(8),
1-203.
김상미. (2012). “일본의 개인정보 보호 법제”, KISO Journal. 제7호, 32-39.
김용대 ・ 장원철. (2016). 인공지능산업 육성을 위한 개인정보 보호 규제 발전 방향.
박노형. (2016). 빅데이터 관련 주요 국가의 개인정보 보호 법제도 분석에 따른 한국
개인정보 보호법 개선의 검토, NAVER Privacy White Paper.
박창이 ・ 김진석. (2011). R을 이용한 데이터마이닝.
이용희. (2013). 정보공개 환경에서 개인정보 보호와 노출 위험의 측정에 대한 통계적
방법. 한국데이터정보과학회지, 24(5), 1029-1041.
장필성. (2016). [EU] 2016 다보스포럼: 다가오는 4 차 산업혁명에 대한 우리의 전략
은?. 과학기술정책, 26(2), 12-15.
한국신용정보원. (2016). “개인정보 비식별 조치 가이드라인”.
홍선경 ・ 문양세 ・ 김혜숙. (2013). 프라이버시 보호 시계열 데이터 마이닝. 정보과학회논
문지: 데이타베이스, 40(2), 124-133.
2. 외국문헌
Aggarwal, C. C., & Philip, S. Y. (2008). A general survey of privacy-preserving
data mining models and algorithms. In Privacy-preserving data mining
(pp. 11-52). Springer US.
Aggarwal, C. C., & Yu, P. S. (2004, March). A condensation approach to privacy
preserving data mining. In EDBT (Vol. 4, pp. 183-199).
Agrawal, R., & Srikant, R. (2000, May). Privacy-preserving data mining. In
ACM Sigmod Record (Vol. 29, No. 2, pp. 439-450). ACM.
참고문헌

110
Barker, R. L. (2003). The social work dictionary.
Bengio, Y., Lamblin, P., Popovici, D., & Larochelle, H. (2007). Greedy layer-wise
training of deep networks. In Advances in neural information processing
systems (pp. 153-160).
Bertino, E., Lin, D., & Jiang, W. (2008). A survey of quantification of privacy
preserving data mining algorithms. In Privacy-preserving data mining
(pp. 183-205). Springer US.
Boser, B. E., Guyon, I. M., & Vapnik, V. N. (1992, July). A training algorithm
for optimal margin classifiers. In Proceedings of the fifth annual
workshop on Computational learning theory (pp. 144-152). ACM.
Bourlard, H., & Kamp, Y. (1988). Auto-association by multilayer perceptrons and
singular value decomposition. Biological cybernetics, 59(4), 291-294.
Boyles, J. L., Smith, A., & Madden, M. (2012). Privacy and data management
on mobile devices. Pew Internet & American Life Project, 4.
Brants, T., Popat, A. C., Xu, P., Och, F. J., & Dean, J. (2007). Large language
models in machine translation. In In Proceedings of the Joint Conference
on Empirical Methods in Natural Language Processing and Computational
Natural Language Learning.
Cervier, D. (1993). AI: The Tumultuous Search for Artificial Intelligence.
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H.,
& Bengio, Y. (2014). Learning phrase representations using RNN encoder -
decoder for statistical machine translation. arXiv preprint arXiv: 1406.1078.
Clifton, C., Kantarcioglu, M., Vaidya, J., Lin, X., & Zhu, M. Y. (2002). Tools for privacy
preserving distributed data mining. ACM Sigkdd Explorations Newsletter, 4(2),
28-34.
D. Bajarin. (2014). “iOS, Android, and the Dividing of Business Models”. Tech
Opinions.

111
D. Barth-Jones. (2012). “The debate over re-identification of health information:
what do we risk”. healthaffairs. org.
D. Reisinger. (2014). “Android by the Numbers: 1B Monthly Active Users”. CNET.
Dalenius, T. (1977). Towards a methodology for statistical disclosure control.
statistik Tidskrift, 15(429-444), 2-1.
Dwork, C. (2006). Differential privacy. In 33rd International Colloquium on
Automata, Languages and Programming, Part Ⅱ (ICALP 2006), Springer,
Venice, Italy, 1-12.
Evfimievski, A., Srikant, R., Agrawal, R., & Gehrke, J. (2004). Privacy preserving
mining of association rules. Information Systems, 29(4), 343-364.
Felt, A. P., Egelman, S., & Wagner, D. (2012, October). I've got 99 problems,
but vibration ain't one: a survey of smartphone users' concerns. In
Proceedings of the second ACM workshop on Security and privacy in
smartphones and mobile devices (pp. 33-44). ACM.
Fryer Jr, R. G., & Levitt, S. D. (2004). The causes and consequences of distinctively
black names. The Quarterly Journal of Economics, 119(3), 767-805.
Fung, B., Wang, K., Chen, R., & Yu, P. S. (2010). Privacy-preserving data publishing:
A survey of recent developments. ACM Computing Surveys (CSUR), 42(4), 14.
Google. (2015)“Opt out – Ads Help”. Accessed September 22, 2015.
Hastie, T., Tibshirani, R., & Friedman, J. J. H. (2001). The Elements of Statistical
Learning. Vol. 1. Np.
Hawkins, D. M. (2004). The problem of overfitting. Journal of chemical information
and computer sciences, 44(1), 1-12.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image
recognition. In Proceedings of the IEEE conference on computer vision
and pattern recognition (pp. 770-778).
Hinton, G. E. (2006). Training products of experts by minimizing contrastive
divergence. Training, 14(8).

112
Hinton, G. E., & Zemel, R. S. (1994). Autoencoders, minimum description length
and Helmholtz free energy. In Advances in neural information processing
systems (pp. 3-10).
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural
computation, 9(8), 1735-1780.
Hornyack, P., Han, S., Jung, J., Schechter, S., & Wetherall, D. (2011, October).
These aren't the droids you're looking for: Retrofitting android to
protect data from imperious applications. In Proceedings of the 18th ACM
conference on Computer and communications security (pp. 639-652).
ACM.
J. Urban, C. Hoofnagle, S. Li. (2012). “Mobiles Phones and Privacy”. BCLT
Research Paper Series.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to
statistical learning (Vol. 112). New York: springer.
K.J.Vinoth and V.Santhi. (2016). “A Brief Survey on Privacy Preserving
Techniques in Data Mining”. IOSR Journal of Comuter Engineering.
47-51.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification
with deep convolutional neural networks. In Advances in neural
information processing systems (pp. 1097-1105).
Lavergne, M., & Mullainathan, S. (2004). Are Emily and Greg more
employable than Lakisha and Jamal? A field experiment on labor
market discrimination. The American Economic Review, 94(4),
991-1013.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature,
521(7553), 436-444.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553),
436-444.

113
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based
learning applied to document recognition. Proceedings of the IEEE,
86(11), 2278-2324.
Lee, K. Y., & Kim, J. (2016). Artificial Intelligence Technology Trends and IBM
Watson References in the Medical Field. Korean Medical Education
Review, 18(2), 51-57.
Levitt, S. D., & Dubner, S. J. (2005). Freaknomics. New York: William Morrow.
Li, N., Li, T., & Venkatasubramanian, S. (2007, April). t-closeness: Privacy beyond
k-anonymity and l-diversity. In Data Engineering, 2007. ICDE 2007.
IEEE 23rd International Conference on (pp. 106-115). IEEE.
Linowes, D. (1996). A Research Survey of Privacy in the workplace. an
unpublished white paper available from the University of Illinois at
Urbana-Champaign.
Malik, M. B., Ghazi, M. A., & Ali, R. (2012, November). Privacy preserving data
mining techniques: current scenario and future prospects. In Computer
and Communication Technology (ICCCT), 2012 Third International
Conference on (pp. 26-32). IEEE.
Markoff, J. (2011). On ‘Jeopardy!’ Watson win is all but trivial. The New York
Times, 16.
McCulloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas
immanent in nervous activity. The bulletin of mathematical biophysics,
5(4), 115-133.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G.,
... & Petersen, S. (2015). Human-level control through deep reinforcement
learning. Nature, 518(7540), 529-533.
Moravec, H. (1988). Mind children: The future of robot and human intelligence.
Harvard University Press.

114
Mukherjee, S., Chen, Z., & Gangopadhyay, A. (2006). A privacy-preserving
technique for Euclidean distance-based mining algorithms using
Fourier-related transforms. The VLDB Journal—The International Journal
on Very Large Data Bases, 15(4), 293-315.
Narayanan, A., & Shmatikov, V. (2006). How to break anonymity of the
netflix prize dataset. arXiv preprint cs/0610105.
Nayak, G., & Devi, S. (2011). A survey on privacy preserving data mining:
approaches and techniques. International Journal of Engineering
Science and Technology, 3(3).
Nissim, K., Raskhodnikova, S., & Smith, A. (2007, June). Smooth sensitivity
and sampling in private data analysis. In Proceedings of the
thirty-ninth annual ACM symposium on Theory of computing (pp.
75-84). ACM.
Office of the Attorney General. (2014). “Making Your Privacy Practices Public:
Recommendations on Developing a Meaningful Privacy Policy”.
California Department of Justice.
Ohm, P. (2009). Broken promises of privacy: Responding to the surprising
failure of anonymization.
Papadimitriou, S., Li, F., Kollios, G., & Yu, P. S. (2007, September). Time series
compressibility and privacy. In Proceedings of the 33rd international
conference on Very large data bases (pp. 459-470). VLDB Endowment.
Rizvi, S. J., & Haritsa, J. R. (2002, August). Maintaining data privacy in
association rule mining. In Proceedings of the 28th international
conference on Very Large Data Bases (pp. 682-693). VLDB Endowment.
Rosenblatt, F. (1958). The perceptron: A probabilistic model for information
storage and organization in the brain. Psychological review, 65(6), 386.
Ross, T. (1933). Machines that think. Scientific American, 148(4), 206-208.

115
Russell, S. J., & Norvig, P. (2002). Artificial intelligence: a modern approach
(International Edition).
Samarati, P., & Sweeney, L. (1998). Protecting privacy when disclosing
information: k-anonymity and its enforcement through generalization
and suppression. Technical report, SRI International.
Schaeffer, J. (2013). One jump ahead: challenging human supremacy in
checkers. Springer Science & Business Media. Silver, David, et al.
“Mastering the game of Go with deep neural networks and tree
search.” Nature 529.7587 (2016): 484-489.
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche,
G., ... & Dieleman, S. (2016). Mastering the game of Go with deep
neural networks and tree search. Nature, 529(7587), 484-489.
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for
large-scale image recognition. arXiv preprint arXiv:1409.1556.
Srivastava, Nitish, et al. "Dropout: a simple way to prevent neural
networks from overfitting." Journal of machine learning research15.1
(2014): 1929-1958.
Sutton, R. S., & Barto, A. G. (1998). Reinforcement learning: An introduction
(Vol. 1, No. 1). Cambridge: MIT press.
Sweeney, L. (2013). Discrimination in online ad delivery. Queue, 11(3), 10.
Sweeney, L. (2015). Only you, your doctor, and many others may know. Technology
Science, 2015092903.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., ... &
Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings
of the IEEE conference on computer vision and pattern recognition
(pp. 1-9).
Thurm, S., & Kane, Y. I. (2010). Your apps are watching you. The Wall
Street Journal, 17, 1.

116
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal
of the Royal Statistical Society. Series B (Methodological), 267-288.
Turing, A. M. (1950). Computing machinery and intelligence. Mind, 59(236),
433-460.
Wang, H., Cai, Y., & Chen, L. (2014). A vehicle detection algorithm based
on deep belief network. The scientific world journal, 2014.
Wang, Y., & Kosinski, M. (2017). Deep neural networks are more accurate
than humans at detecting sexual orientation from facial images.
Ward, N. (2003). SHRDLU. John Wiley & Sons, Ltd.
Warner, S. L. (1965). Randomized response: A survey technique for eliminating
evasive answer bias. Journal of the American Statistical Association,
60(309), 63-69.
Watkins, C. J. C. H. (1989). Learning from delayed rewards (Doctoral dissertation,
King's College, Cambridge).
Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., ... & Klingner,
J. (2016). Google's neural machine translation system: Bridging the gap
between human and machine translation. arXiv preprint arXiv:1609.08144.
Xiao, X., & Tao, Y. (2007, June). M-invariance: towards privacy preserving
re-publication of dynamic datasets. In Proceedings of the 2007 ACM
SIGMOD international conference on Management of data (pp.
689-700). ACM.
Y Moon, Y. S., Kim, H. S., Kim, S. P., & Bertino, E. (2010, August). Publishing
time-series data under preservation of privacy and distance orders. In
International Conference on Database and Expert Systems Applications
(pp. 17-31). Springer, Berlin, Heidelberg.
Y. Kane. (2010). “Apple Sued Over Mobile App Privacy”. The Wall Street
Journal.

117
Y. Mui. (2010). “Apple, app makers hit with privacy lawsuits”. The Washington
Post.
Yakowitz, J. (2011). Tragedy of the data commons. Harv. JL & Tech., 25, 1.
Zang, J., Dummit, K., Graves, J., Lisker, P., & Sweeney, L. (2015). Who
knows what about me? A survey of behind the scenes personal data
sharing to third parties by mobile apps. Technology Science, 30.
Zhou, Y., Zhang, X., Jiang, X., & Freeh, V. W. (2011, June). Taming information-
stealing smartphone applications (on android). In International conference
on Trust and trustworthy computing (pp. 93-107). Springer, Berlin,
Heidelberg.
3. 인터넷 자료
한상기. (2016). 마지막 빨간 버튼: 인공지능 윤리 연구의 과제. SlowNews, 2016. 8. 1,
<http://slownews.kr/56435>
허준. (2016). “누구나 빅데이터 사고파는 ‘데이터 거래소’ 생긴다”, 파이낸셜 뉴스,
2016. 12. 15, <http://www.fnnews.com/news/201612151729028466>
Angwin, J., Varner, M., Tobin, A. (2017) “Facebook Enabled Advertisers to
Reach ‘Jew Haters’ ”. Propublica.org.
<https://www.propublica.org/article/facebook-enabled-advertisers-to-reach-
jew-haters>
Dilger, D. E. (2012). Apple adds new “Limit Ad Tracking” feature to iOS 6.
Retrieved from Apple Insider:
<http://appleinsider.com/articles/12/09/13/apple_adds_newJimit_ad_track
ing_feature_tojos_, 6>
LexisNexis. <http://www.lexisnexis.com/en-us/product-finder.page>


법무법인 민후 김경환 변호사
2017 NAVER Privacy White Paper
규제 측면에서의 한국 ・EU ・일본의
개인정보보호 법령의 비교


121
1. 머리말
o 개인정보에 대한 규제는 정보주체에 대한 규제와 개인정보처리자 또는 정보통신서비
스제공자 등 정보처리자에 대한 규제가 있고, 정보처리자에 대한 규제는 개인정보
처리 자체를 하지 못하게 하는 실체적 규제와 개인정보 처리는 가능하지만 일정한
절차적 부담을 주는 절차적 규제로 나눌 수 있음
o 본 연구에서는 정보처리자의 영업의 자유를 제한하는 정보처리자에 대한 실체적 규
제를 중심으로, 한국의 개인정보보호법과 정보통신망법, EU의 GDPR, 일본의 개인정
보보호법을 상호 비교하고, 이를 토대로 우리나라의 규제가 어느 정도 되는지 및 상
대적인 순위가 어떻게 되는지에 대하여 파악하고자 함
o 실체적 규제는 수집 ・ 이용 ・ 제공 ・ 위탁 ・ 관리 ・ 파기의 생명주기 순서로 검토하되, 수
집 ・ 이용 단계에서는 일반 개인정보 수집 ・ 이용의 허용 사유, 민감정보 수집 ・ 이용의
허용 사유, 목적 외 이용의 허용 사유를 비교 ・ 검토하고, 제공 ・ 위탁 단계에서는 제
공의 허용 사유, 위탁의 절차 사유를 비교 ・ 검토하며, 관리 ・ 파기 단계에서는 파기
사유와 개인정보 유효기간 제도에 대하여 각각 비교 및 검토하였음
o 그 결과 대체로 EU GDPR이 가장 허용 사유가 많았고, 우리나라의 입법들이 허용
사유가 적었는바, EU GDPR이 우리 입법들에 비하여 유연한 태도를 취하고 있었음
o 한국의 개인정보보호법과 정보통신망법, EU의 GDPR, 일본의 개인정보보호법에 나타
난 실체적 규제를 비교하고 각각의 허용 사유에 대한 순위를 더하여 총점을 낸 결
과, EU의 GDPR이 가장 낮은 점수가 나와 실체적 규제가 가장 낮음이 밝혀졌으며,
한국의 정보통신망법이 가장 높은 점수가 나와 실체적 규제가 가장 높음이 밝혀짐.
일본의 개인정보보호법은 한국의 개인정보보호법보다는 실체적 규제의 정도가 낮은
것으로 드러남
o EU GDPR을 기준으로 비교하면, 일본 개인정보보호법은 1.4배의 규제가 더 있고,
우리나라 개인정보보호법은 2.6배, 우리나라 정보통신망법은 3.4배의 규제가 더 존재
(2.6배 ~ 3.4배). 일본 개인정보보호법을 기준으로 비교하면, 우리나라 개인정보보호법은
1.8배, 우리나라 정보통신망법은 2.4배의 규제가 더 존재하는 것으로 나타남(1.8배
~ 2.4배)
요약문

122
o 다른 입법에 비하여 상대적으로 높게 나타난 우리나라 개인정보보호 법령의 실체적
규제는 기업의 규제 비용을 증대시키고 개인정보의 활용도를 낮추는 역할을 하고 있
는바, 실체적 규제를 다른 입법 수준에 맞추어 조절하는 노력이 필요할 것으로 보임

123
관한 연구
김경환 (법무법인 민후 변호사)
1. 서설
가. 규제의 개념
규제란 ‘국가나 지방자치단체가 특정한 행정 목적을 실현하기 위하여 국민(국내법을 적용받
는 외국인을 포함한다)의 권리를 제한하거나 의무를 부과하는 것’을 의미한다(행정규제기본법
제2조 제1호).
따라서 국민의 권리제한 또는 의무부과에 관한 사항이 아닌 경우나 국민의 권리를 제한하
거나 의무를 부과하는 사항이기는 하지만 그것이 특정한 행정목적 실현을 위한 것이 아닌 경
우에는 규제가 될 수 없다.
이러한 규제는 법률에 근거하여야 하며, 그 내용은 알기 쉬운 용어로 구체적이고 명확하게 규
정되어야 한다. 다만, 규제의 세부적인 내용은 법률 또는 상위법령(上位法令)에서 구체적으로 범
위를 정하여 위임한 바에 따라 하위법령으로 정할 수 있다(행정규제기본법 제4조 참조).
우리 행정규제기본법 제5조는 규제를 도입함에 있어 반드시 지켜야 할 몇 가지 원칙을 제
시하고 있는데, ① 국가나 지방자치단체는 국민의 자유와 창의를 존중하여야 하며, 규제를 정
하는 경우에도 그 본질적 내용을 침해하지 아니하도록 하여야 하고, ② 국가나 지방자치단체
가 규제를 정할 때에는 국민의 생명 ・ 인권 ・ 보건 및 환경 등의 보호와 식품 ・ 의약품의 안전을
위한 실효성이 있는 규제가 되도록 하여야 하며, ③ 규제의 대상과 수단은 규제의 목적 실현
에 필요한 최소한의 범위에서 가장 효과적인 방법으로 객관성 ・ 투명성 및 공정성이 확보되도
록 설정되어야 한다.
규제 측면에서의 한국 ・ EU ・ 일본의
개인정보보호 법령의 비교

124
나. 개인정보 규제의 특징
개인정보 영역에서도 규제는 존재한다. 개인정보 영역에서의 규제는 두 가지가 있는데, 국가
등의 민간기업(개인정보보호법 적용대상 중 민간의 ‘개인정보처리자’ 및 정보통신망법의 ‘정보통
신서비스제공자등’이 여기에 해당함. 이하 민간기업을 ‘정보처리자’라고 표현함)의 영업의 자유에
대한 제한이 있으며, 또 다른 규제로는 국가 등의 정보주체의 자기결정권 제한이 존재한다.
전자를 정보처리자 규제로 칭한다면, 후자는 정보주체 규제로 부를 수 있다. 예컨대 정보처
리자가 ‘정보주체의 동의를 받은 경우’에 개인정보를 수집할 수 있는 것이 전자의 예이고, 공
공기관이 ‘법령 등에서 정하는 소관 업무의 수행을 위하여 불가피한 경우’에 개인정보를 수집
할 수 있는 것이 후자의 예이다.
본 연구에서는 전자의 경우, 즉 국가 등이 정보처리자의 영업의 자유를 제한하는 경우에
한하여 살펴보도록 할 것인바, 이하 규제라 하면 정보처리자 규제, 즉 정보처리자의 영업의
자유가 제한받는 경우를 의미한다.
참고로 본 연구에서는 정보처리자의 영업의 자유를 중심으로 살펴볼 것이지만, 아래에서
볼 수 있는 바와 같이 정보주체의 권리인 ‘개인정보 자기결정권’과 충돌되는 권리 또는 이익으
로는 정보처리자의 영업의 자유만 있는 것이 아니다.
예컨대 공개된 개인정보의 영리 목적의 이용에 관한 대법원 2016. 8. 17. 선고 2014다
235080 판결에서, 대법원은 ‘개인정보 자기결정권’과 충돌 또는 형량되는 이익으로서 정보처
리자의 영업의 자유, 사회 전체의 경제적 효율성 등의 가치’ 뿐만 아니라 ‘정보처리 행위로 인
하여 얻을 수 있는 이익, 즉 정보처리자의 알 권리와 이를 기반으로 한 정보수용자의 알 권리
및 표현의 자유도 함께 언급하였다.

125
정보주체
개인정보자기결정권
•알 권리•영업의 자유
(3) 사회 전체의 경제적 효율성
•알 권리•표현의 자유
(2) 정보수용자
(1) 정보처리자
<그림 1> 개인정보에 관련된 권리 또는 이익
한편 정보처리자의 영업의 자유를 제한하는 개인정보 규제가 추구하는 특정한 행정 목적이
무엇인지 문제되는데, 개인정보보호법은 ‘개인의 자유와 권리를 보호하고, 나아가 개인의 존엄
과 가치를 구현함을 목적으로’ 규정하고 있는바(제1조), 결국 규제의 목적, 즉 특정한 행정 목
적은 ‘정보주체의 개인정보 자기결정권 보호’라고 볼 수 있다.
즉, 정보처리자는 개인정보보호 법령이 존재하지 않았을 때는 아무런 제한 없이 정보주체
의 개인정보를 수집 ・ 처리할 수 있었으나, 개인정보 자기결정권 보호를 목적으로 하는 개인정
보보호 법령이 제정된 이후에는 그 법령이 정한 절차에 따라서, 그 법령이 정한 요건을 충족
한 경우에만 개인정보를 수집 ・ 처리할 수 있게 된 것이다.
개인정보보호 법령의 제정으로 인하여, 정보처리자의 영업의 자유는 그만큼 제한되었고 의
무를 부과받게 되었는바, 정보처리자 입장에서는 그만큼 규제를 받는 것이다.
그리고 정보처리자의 영업의 자유가 제한받는 개인정보 규제에서 추구하는 그 목적 또는
특정한 행정 목적에 해당하는 ‘개인정보 자기결정권’의 정체가 문제되는데, 우리 헌법재판소는
개인정보 자기결정권에 대하여 아래와 같이 설명하고 있다.
인간의 존엄과 가치, 행복추구권을 규정한 헌법 제10조 제1문에서 도출되는 일반적 인격권
및 헌법 제17조의 사생활의 비 과 자유에 의하여 보장되는 개인정보 자기결정권은 자신에
관한 정보가 언제 누구에게 어느 범위까지 알려지고 또 이용되도록 할 것인지를 그 정보
주체가 스스로 결정할 수 있는 권리이다. 즉, 정보주체가 개인정보의 공개와 이용에 관하여

126
스스로 결정할 권리를 말한다.
개인정보 자기결정권의 보호대상이 되는 개인정보는 개인의 신체, 신념, 사회적 지위, 신분
등과 같이 개인의 인격주체성을 특징짓는 사항으로서 그 개인의 동일성을 식별할 수 있게
하는 일체의 정보라고 할 수 있고, 반드시 개인의 내 한 영역이나 사사(私事)의 영역에 속
하는 정보에 국한되지 않고 공적 생활에서 형성되었거나 이미 공개된 개인정보까지 포함한
다. 또한 그러한 개인정보를 대상으로 한 조사 ・ 수집 ・ 보관 ・ 처리 ・ 이용 등의 행위는 모두 원
칙적으로 개인정보 자기결정권에 대한 제한에 해당한다(헌재 2005. 5. 26. 99헌마513등,
공보 105, 666, 672).
헌법재판소가 파악하는 개인정보 자기결정권을 요약하면, 첫째, 정보주체에게 부여되는 권
리이며, 둘째, 헌법상 명문의 규정은 없지만 헌법상 도출되는 기본권이라는 것이며, 셋째, 정
보주체는 이 권리에 의하여 자신의 개인정보에 대하여 공개 ・ 이용 등의 여부와 범위를 결정할
수 있다는 것이다.
정리하면 개인정보 규제는 정보주체의 개인정보 자기결정권 보호를 위하여 정보처리자의
영업의 자유를 제한한 것인바, 결국 개인정보 규제는 기본권의 충돌의 문제를 형량하여 규정
화한 것이라 볼 수 있다.
다. 본 연구에서의 규제 비교의 방법
본 연구는 한국의 개인정보보호법과 정보통신망법, 2018년 5월 시행 예정인 EU의 GDPR,
2017년 5월 시행된 일본의 개인정보보호법을 정보처리자 규제 측면에서 비교하고자 한다.
즉, 정보처리자의 영업의 자유가 정보주체의 개인정보 자기결정권에 의하여 어느 정도 제한되
는지 상대적으로 비교함으로써 우리 개인정보보호 법령의 현재 실태를 파악하고자 한다.
한편 정보처리자의 영업의 자유를 제한하는 개인정보 규제, 즉 정보처리자 규제는 여러 가
지 유형으로 구분할 수 있는데, 예컨대 아래 표와 같이 유형화할 수 있다.

127
유 형 내 용 예 시
실체적
규제
규제 내용을 만족하지 않으면
개인정보 처리가 허용되지 않
는 경우
• 수집 ・ 이용의 허용 사유
• 제공의 허용 사유
• 개인정보 국외 제공의 허용 사유
• 파기의 사유
• 개인정보 유효기간 제도
절차적
규제
규제가 있더라도 정보처리자의
개인정보 처리는 가능하나 절
차적 부담이 있는 경우
• 개인정보 처리방침의 제정 및 공개
• 개인정보 보호책임자의 지정 의무
• 안전성 확보조치 기준의 준수
• 개인정보 파일의 등록 및 공개
• 개인정보보호 인증
• 개인정보 영향 평가
• 개인정보 유출 통지
• 정보주체의 권리
• 개인정보 이용내역 통지제도
<표 1> 정보처리자 규제 유형
실체적 규제는 정보처리자의 개인정보 처리 자체를 못하게 하는 규제로서, 규제 내용을 만
족하지 않으면 개인정보 처리가 허용되지 않는 경우를 의미한다.
절차적 규제는 정보처리자의 개인정보 처리 자체를 불가능하게 하는 규제는 아닌 것으로
서, 규제가 있더라도 정보처리자의 개인정보 처리는 가능하나 절차적 부담이 있는 경우를 의
미한다.
실체적 규제의 예시로는, 수집 ・ 이용의 허용 사유, 제공의 허용 사유, 개인정보 국외 제공
의 허용 사유, 파기의 사유, 개인정보 유효기간 제도 등이 존재한다.
절차적 규제의 예시로는, 개인정보 처리방침의 제정 및 공개, 개인정보 보호책임자의 지정 의
무, 안전성 확보조치 기준의 준수, 개인정보 파일의 등록 및 공개, 개인정보 보호 인증, 개인정보
영향 평가, 개인정보 유출 통지, 정보주체의 권리, 개인정보 이용내역 통지제도 등이 존재한다.
본 연구에서는 절차적 규제보다는 실체적 규제 중심으로 살펴보고자 한다. 그 이유는 절차
적 규제는 상호 비교가 쉽지 않으며 절차적 규제가 있다고 하더라도 정보처리자 입장에서는
개인정보 처리 자체가 불가능한 것이 아니기 때문이다.
절차적 규제에 대한 상호 비교나 평가는 앞으로의 과제로 남겨두고, 본 연구에서는 실체적
규제를 비교 ・ 평가하되, 비교 순서는 수집 ・ 이용 ・ 제공 ・ 위탁 ・ 관리 ・ 파기의 개인정보의 생명주
기 순서대로 진행하며, 각 생명주기에 해당하는 규제 또는 권리제한 ・ 의무부과 규정을 소개하고,

128
그 규제를 상호 비교함으로써 우리나라 개인정보보호법과 정보통신망법의 개인정보 규제를 외
국 입법에 대응시켜 상대적으로 평가한다.
2. 수집 ・ 이용 관련 실체적 규제의 비교
가. 일반 개인정보 수집 ・ 이용의 ‘허용 사유’의 비교
1) 각 법의 허용 사유
우리나라 개인정보보호법은 수집 ・ 이용이 가능한 사유로서 아래와 같이 6가지의 허용 사유
를 인정하고 있다(제15조 제1항). 6가지의 사유 중 3호는 공공기관에게 적용되어 정보처리자
에게 적용할 수 없으므로 이를 제외하면, 5가지의 허용 사유를 보유하고 있다. 이 중에서 특
히 제6호는 일반조항으로서 규정되어 있다.
1. 정보주체의 동의를 받은 경우
2. 법률에 특별한 규정이 있거나 법령상 의무를 준수하기 위하여 불가피한 경우
3. 공공기관이 법령 등에서 정하는 소관 업무의 수행을 위하여 불가피한 경우
4. 정보주체와의 계약의 체결 및 이행을 위하여 불가피하게 필요한 경우
5. 정보주체 또는 그 법정대리인이 의사표시를 할 수 없는 상태에 있거나 주소불명 등으로
사전 동의를 받을 수 없는 경우로서 명백히 정보주체 또는 제3자의 급박한 생명, 신체,
재산의 이익을 위하여 필요하다고 인정되는 경우
6. 개인정보처리자의 정당한 이익을 달성하기 위하여 필요한 경우로서 명백하게 정보주체의
권리보다 우선하는 경우. 이 경우 개인정보처리자의 정당한 이익과 상당한 관련이 있고
합리적인 범위를 초과하지 아니하는 경우에 한한다.
반면 우리나라 정보통신망법은 수집 ・ 이용이 허용되는 사유로서 아래와 같이 4가지의 허용
사유를 인정하고 있다(제22조 참조).
1. 이용자의 동의를 받은 경우
2. 정보통신서비스의 제공에 관한 계약을 이행하기 위하여 필요한 개인정보로서 경제적 ・ 기
술적인 사유로 통상적인 동의를 받는 것이 뚜렷하게 곤란한 경우

129
3. 정보통신서비스의 제공에 따른 요금정산을 위하여 필요한 경우
4. 이 법 또는 다른 법률에 특별한 규정이 있는 경우
EU GDPR1)은 개인정보의 수집 ・ 이용이 허용되는 사유로서 아래와 같이 6가지를 제시하고
있다(제6조 제1항). 1 ~ 6호 중에서 5호는 공공기관에만 적용되어 정보처리자에게는 적용되지
않는 사유이므로 제외하였다.
1. 정보주체가 하나 이상의 특정한 목적을 위해 자신의 개인정보 처리에 동의한 경우
2. 정보주체가 당사자인 계약의 이행을 위하여 또는 계약 체결 전에 정보주체의 요청에 따
른 조치를 취하기 위하여 처리가 필요한 경우
3. 컨트롤러에게 적용되는 법적 의무의 준수를 위하여 처리가 필요한 경우
4. 정보주체 또는 다른 자연인의 중대한 이익을 보호하기 위하여 처리가 필요한 경우
5. 공익을 위하여 수행되는 직무의 실행을 위하여 또는 컨트롤러에게 부여된 공적 권한의
행사에 처리가 필요한 경우
6. 컨트롤러나 제3자가 추구하는 정당한 이익의 목적을 위하여 처리가 필요한 경우로서, 다
만, 특히 정보주체가 아동인 경우와 같이 개인정보 보호를 요구하는 정보주체의 이익이나
기본권과 자유가 해당 이익에 우선하는 경우에는 그러하지 아니하다. 6호는 공공당국이
자신의 직무 수행을 위하여 실행하는 처리에 적용되지 아니한다.
일본 개인정보보호법의 경우, 민감정보(일본 개인정보보호법은 ‘배려필요정보’로 표현하고
있음)가 아닌 일반적인 개인정보에 대하여는 우리나라 ・ EU와 달리 옵트 아웃 체제이기 때문
에 수집 ・ 이용에 있어 허용 사유는 존재하지 않는다(제17조 참조). 다만, 수집 이후 정보주체
에게 미리 그 이용목적을 공표하고 있는 경우를 제외하고는 절차적으로 신속하게 그 이용목
적을 통지 또는 공표하여야 한다(제18조 제1항).
2) 각 법의 비교 평가
일단 각국의 수집 ・ 이용의 허용 사유를 비교하되 유사한 사유끼리 대응하여 표로 정리하면
아래와 같다.
1) 본 논문에서 EU GDPR의 조문 해석은 박노형 저 ‘EU 개인정보보호법’을 참조하였음
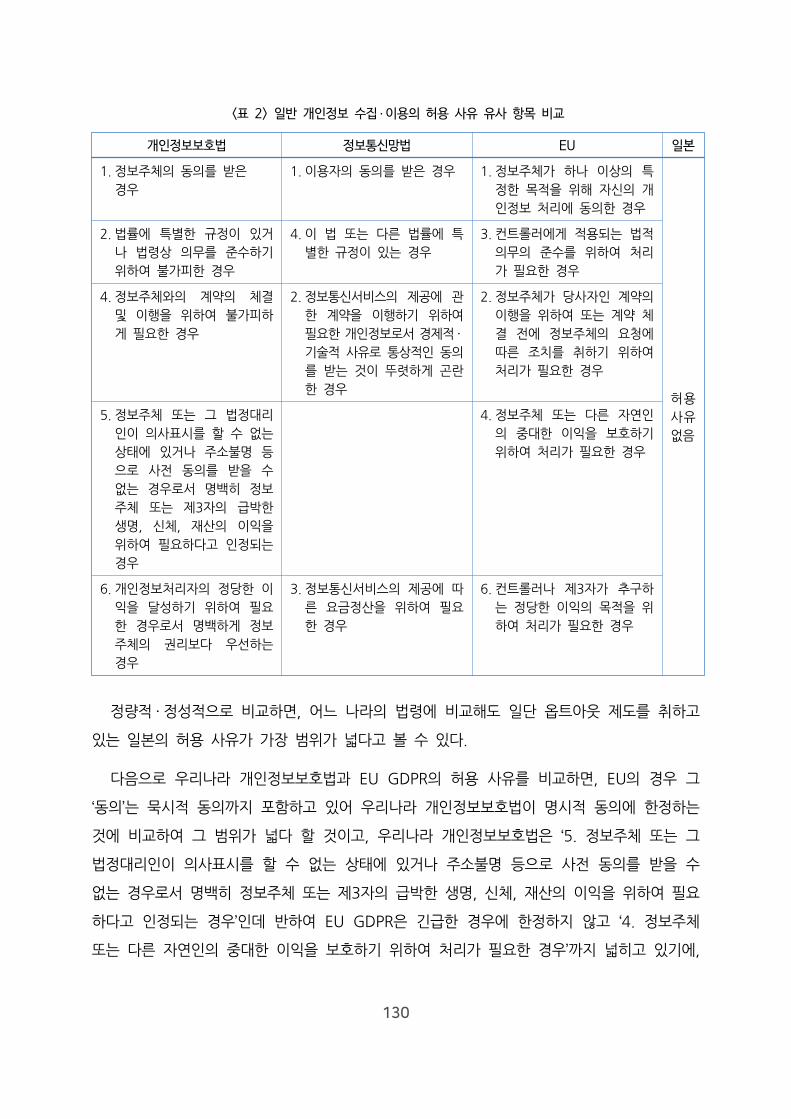
130
개인정보보호법 정보통신망법 EU 일본
1. 정보주체의 동의를 받은
경우
1. 이용자의 동의를 받은 경우 1. 정보주체가 하나 이상의 특
정한 목적을 위해 자신의 개
인정보 처리에 동의한 경우
허용
사유
없음
2. 법률에 특별한 규정이 있거
나 법령상 의무를 준수하기
위하여 불가피한 경우
4. 이 법 또는 다른 법률에 특
별한 규정이 있는 경우
3. 컨트롤러에게 적용되는 법적
의무의 준수를 위하여 처리
가 필요한 경우
4. 정보주체와의 계약의 체결
및 이행을 위하여 불가피하
게 필요한 경우
2. 정보통신서비스의 제공에 관
한 계약을 이행하기 위하여
필요한 개인정보로서 경제적 ・
기술적 사유로 통상적인 동의
를 받는 것이 뚜렷하게 곤란
한 경우
2. 정보주체가 당사자인 계약의
이행을 위하여 또는 계약 체
결 전에 정보주체의 요청에
따른 조치를 취하기 위하여
처리가 필요한 경우
5. 정보주체 또는 그 법정대리
인이 의사표시를 할 수 없는
상태에 있거나 주소불명 등
으로 사전 동의를 받을 수
없는 경우로서 명백히 정보
주체 또는 제3자의 급박한
생명, 신체, 재산의 이익을
위하여 필요하다고 인정되는
경우
4. 정보주체 또는 다른 자연인
의 중대한 이익을 보호하기
위하여 처리가 필요한 경우
6. 개인정보처리자의 정당한 이
익을 달성하기 위하여 필요
한 경우로서 명백하게 정보
주체의 권리보다 우선하는
경우
3. 정보통신서비스의 제공에 따
른 요금정산을 위하여 필요
한 경우
6. 컨트롤러나 제3자가 추구하
는 정당한 이익의 목적을 위
하여 처리가 필요한 경우
<표 2> 일반 개인정보 수집 ․이용의 허용 사유 유사 항목 비교
정량적 ・ 정성적으로 비교하면, 어느 나라의 법령에 비교해도 일단 옵트아웃 제도를 취하고
있는 일본의 허용 사유가 가장 범위가 넓다고 볼 수 있다.
다음으로 우리나라 개인정보보호법과 EU GDPR의 허용 사유를 비교하면, EU의 경우 그
‘동의’는 묵시적 동의까지 포함하고 있어 우리나라 개인정보보호법이 명시적 동의에 한정하는
것에 비교하여 그 범위가 넓다 할 것이고, 우리나라 개인정보보호법은 ‘5. 정보주체 또는 그
법정대리인이 의사표시를 할 수 없는 상태에 있거나 주소불명 등으로 사전 동의를 받을 수
없는 경우로서 명백히 정보주체 또는 제3자의 급박한 생명, 신체, 재산의 이익을 위하여 필요
하다고 인정되는 경우’인데 반하여 EU GDPR은 긴급한 경우에 한정하지 않고 ‘4. 정보주체
또는 다른 자연인의 중대한 이익을 보호하기 위하여 처리가 필요한 경우’까지 넓히고 있기에,

131
결론적으로 EU GDPR의 허용 사유가 우리나라 개인정보보호법의 허용 사유보다 더 넓다고
판단할 수 있다.
우리나라 개인정보호보법과 정보통신망법을 비교하면, 개인정보보호법이 ‘4. 정보주체와의
계약의 체결 및 이행을 위하여 불가피하게 필요한 경우’라고 규정하고 있는 것과 달리 정보통
신망법은 ‘2. 정보통신서비스의 제공에 관한 계약을 이행하기 위하여 필요한 개인정보로서 경
제적 ・ 기술적인 사유로 통상적인 동의를 받는 것이 뚜렷하게 곤란한 경우’로 규정되어 있어
정보통신망법의 허용 사유의 범위가 좁다 할 것이며, 개인정보보호법의 ‘5. 정보주체 또는 그
법정대리인이 의사표시를 할 수 없는 상태에 있거나 주소불명 등으로 사전 동의를 받을 수
없는 경우로서 명백히 정보주체 또는 제3자의 급박한 생명, 신체, 재산의 이익을 위하여 필요
하다고 인정되는 경우’에 해당하는 정보통신망법의 허용 사유가 존재하지 않고, 가장 중요한
점은 정보통신망법은 개인정보보호법이 가지는 일반적인 허용 사유를 보유하고 있지 않다는
점에서, 정보통신망법의 허용 사유는 개인정보보호법의 허용 사유보다 그 범위가 좁다고 단언
할 수 있다.
결론적으로 허용 사유가 가장 넓은 순서 또는 규제가 낮은 순서대로 정리하면, 일본의 개
인정보보호법 → EU GDPR → 우리나라 개인정보보호법 → 우리나라 정보통신망법이 된다.
구 분 개인정보보호법 정보통신망법 EU 일본
수집 ・ 이용의
허용 사유
규제의 완화순위
3 4 2 1
<표 3> 일반 개인정보 수집 ․이용의 허용 사유 규제 완화순위
나. 민감정보 수집 ․이용의 ‘허용 사유’의 비교
1) 각 법의 허용 사유
민감정보의 경우, 우리나라 개인정보보호법은 제23조 제1항에 규정하고 있다. 우리나라 개
인정보보호법은 민감정보의 수집 ・ 이용의 허용 사유로서 아래와 같이 2가지를 규정하고 있다.
1. 다른 개인정보의 처리에 대한 동의와 별도로 동의를 받은 경우
2. 법령에서 민감정보의 처리를 요구하거나 허용하는 경우

132
위 허용 사유가 적용되는 민감정보에 대하여는 아래와 같이 정의하고 있다(제23조 제1항,
같은 법 시행령 제18조).
1. 사상 ・ 신념, 노동조합 ・ 정당의 가입 ・ 탈퇴, 정치적 견해, 건강, 성생활 등에 관한 정보
2. 유전자검사 등의 결과로 얻어진 유전정보
3. 범죄경력자료에 해당하는 정보
한편 우리나라 정보통신망법은 민감정보의 수집 ・ 이용에 있어, 그 허용 사유로서 2가지를
규정하고 있다(제23조 제1항).
1. 이용자의 동의를 받은 경우
2. 다른 법률에 따라 특별히 수집 대상 개인정보로 허용된 경우
위 허용 사유가 적용되는 민감정보의 범위는 아래와 같다(제23조 제1항).
사상, 신념, 가족 및 친인척관계, 학력(學歷) ・ 병력(病歷), 기타 사회활동 경력 등 개인의 권
리 ・ 이익이나 사생활을 뚜렷하게 침해할 우려가 있는 개인정보
EU GDPR 제9조 제2항은 아래와 같이 민감정보(EU GDPR은 ‘특수한 범주의 개인정보’로
표현하고 있음)의 10가지의 허용 사유를 열거하고 있다.
1. 정보주체가 명시적 동의를 한 경우(다만, EU 또는 회원국 법이 금지하지 않아야 함)
2. 고용과 사회보장 및 사회보호법 영역에서 필요한 경우
3. 정보주체 또는 다른 자연인의 중대한 이익을 보호하기 위하여 필요한 경우
4. 비영리기관이 그 기관의 구성원 또는 과거 구성원 또는 그 목적과 관계되어 정보주체의
동의 없이 그 기관 밖으로 공개되지 않는 조건으로 처리가 수행되는 경우
5. 정보주체가 명백하게 공개한 개인정보에 대한 처리
6. 법적 청구권의 설정, 행사 또는 방어를 위하거나 법원이 사법적 지위에서 행동하는 데 필
요한 경우
7. EU 또는 회원국 법에 근거하여 중대한 공익 실현에 필요한 경우

133
8. 예방의학이나 직업병의학의 목적으로, 건강이나 사회복지 시스템과 서비스의 관리를 위하
여 필요한 경우
9. EU 또는 회원국 법에 근거하여 공중보건 영역에서 공익을 이유로 필요한 경우
10. 적절한 보호조치가 있고 공익을 위한 기록보존 목적, 과학적 또는 역사적 연구 또는 통
계적 목적으로 필요한 경우
위 10가지의 허용 사유가 적용되는 민감정보의 범위는 아래와 같다.
1. 인종이나 민족 기원, 정치적 견해, 종교나 철학적 믿음, 노조 가입을 드러내는 개인정보
2. 유전정보
3. 자연인을 고유하게 식별할 수 있는 바이오정보
4. 건강 관련 정보
5. 자연인의 성생활 또는 성적 취향에 관한 데이터
일본 개인정보보호법은 일반 개인정보에 대하여 옵트 아웃 체제가 적용되는 것과는 달리,
민감정보에 대하여는 옵트 인 체제가 적용된다. 따라서 민감정보의 수집 ・ 이용에 있어서는 허
용 사유가 열거되어 있는데, 일본 개인정보보호법 제17조 제2항은 아래와 같이 7가지의 허용
사유를 규정하고 있다. 7가지의 사유 중 5호와 6호는 공공기관에만 적용되는 조항이므로 제
외하였는바, 정보처리자에게는 5가지의 사유가 존재한다.
1. 본인2)의 동의를 얻은 경우
2. 법령에 근거한 경우
3. 사람의 생명, 신체 또는 재산의 보호를 위해서 필요가 있는 경우로서 본인의 동의를 얻는
것이 곤란한 경우
4. 공중위생의 향상 또는 아동의 건전한 육성의 추진을 위하여 특히 필요한 경우로서 본인
의 동의를 얻는 것이 곤란한 경우
5. 국가기관 혹은 지방공공단체 또는 그 위탁을 받은 자가 법령이 정한 사무를 수행하는 것에
대해서 협력할 필요가 있는 경우로서 본인의 동의를 얻은 것이 해당 업무 수행에 지장을
2) 「본인」은 개인정보에 의해 식별되는 특정의 개인을 말한다(일본 개인정보보호법 제2조 제8항). 따라서 우리 법의 정보주
체에 해당한다.

134
줄 우려가 있는 경우
6. 해당 배려필요정보가 본인, 국가기관, 지방공공단체, 제76조 제1항 각 호에 해당하는 자,
그 밖에 개인정보보호위원회 규칙으로 정한 사람에 의해 공개된 경우
7. 그 밖에 전 각 호에 준한 것으로서 정령으로 정한 경우
위 허용 사유가 적용되는 민감정보의 범위는 아래와 같다(일본 개인정보보호법 제2조 제3항).
‘배려필요정보’란 본인의 인종, 신조, 사회적 신분, 병력, 범죄경력, 범죄로 인하여 피해를 입
은 사실 그 밖에 본인에 대한 부당한 차별, 편견, 그 밖의 불이익이 생기지 않도록 그 취급
에 특히 배려를 필요로 하는 것으로서 정령으로 정한 기술(記述) 등이 포함된 개인정보를
말한다.
2) 각 법의 비교 평가
각국의 민감정보에 대한 실체적 규제를 유사한 항목끼리 대응 및 비교하여 정리한 표는 아
래와 같다.
개인정보보호법 정보통신망법 EU 일본
1. 다른 개인정보의 처리
에 대한 동의와 별도
로 동의를 받은 경우
1. 이용자의 동의를 받은
경우
1. 정보주체가 명시적 동의
를 한 경우
1. 본인의 동의를 얻은
경우
2. 법령에서 민감정보의
처리를 요구하거나 허
용하는 경우
2. 다른 법률에 따라 특
별히 수집 대상 개인
정보로 허용된 경우
7. EU 또는 회원국 법에 근
거하여 중대한 공익 실현
에 필요한 경우
9. EU 또는 회원국 법에 근
거하여 공중보건 영역에
서 공익을 이유로 필요한
경우
2. 법령에 근거한 경우
3. 정보주체 또는 다른 자연
인의 중대한 이익을 보호
하기 위하여 필요한 경우
3. 사람의 생명, 신체 또
는 재산의 보호를 위해
서 필요가 있는 경우로
서 본인의 동의를 얻는
것이 곤란한 경우
8. 예방의학이나 직업병의
학의 목적으로, 건강이나
4. 공중위생의 향상 또는
아동의 건전한 육성의
<표 4> 민감정보에 대한 실체적 규제 유사 항목 비교

135
일단 민감정보의 범위에 ‘바이오정보’가 포함되어 있는 입법은 EU밖에는 없다. 따라서 민감
정보의 범위에 있어 가장 엄격한 규제는 EU GDPR이라 할 수 있다.
하지만 이러한 점을 감안하더라도, 실체적 규제끼리 비교하면 단연 허용 사유가 월등하게
많은 EU GDPR의 규제가 가장 약하다고 볼 수 있다.
일본은 우리나라의 개인정보보호법이나 정보통신망법에 비하여, 그 허용 사유가 광범위하다.
한편 우리나라의 개인정보보호법은 ‘법령’에만 근거하면 민감정보의 처리가 허용되는 반면,
정보통신망법은 ‘법률’에 근거하여야만 민감정보의 처리가 허용된다.
결국 각국의 민감정보 처리에 대한 실체적 규제를 비교하면, EU GDPR → 일본 개인정보
보호법 → 우리나라 개인정보보호법 → 우리나라 정보통신망법 순서로 정리할 수 있다.
개인정보보호법 정보통신망법 EU 일본
사회복지 시스템과 서비
스의 관리를 위하여 필
요한 경우
추진을 위하여 특히 필
요한 경우로서 본인의
동의를 얻는 것이 곤란
한 경우
2. 고용과 사회보장 및 사회
보호법 영역에서 필요한
경우
4. 비영리기관이 그 기관의
구성원 또는 과거 구성원
또는 그 목적과 관계되어
정보주체의 동의 없이 그
기관 밖으로 공개되지 않
는 조건으로 처리가 수행
되는 경우
5. 정보주체가 명백하게 공개
한 개인정보에 대한 처리
6. 법적 청구권의 설정, 행
사 또는 방어를 위하거나
법원이 사법적 지위에서
행동하는 데 필요한 경우
10. 적절한 보호조치가 있고
공익을 위한 기록보존
목적, 과학적 또는 역사
적 연구 또는 통계적 목
적으로 필요한 경우
7. 그 밖에 전 각 호에
준한 것으로서 정령으
로 정한 경우

136
구분 개인정보보호법 정보통신망법 EU 일본
민감정보 처리의
허용 사유 규제의
완화순위
3 4 1 2
<표 5> 민감정보 처리의 허용 사유 규제 완화순위
다. 목적 외 이용의 ‘허용 사유’의 비교
1) 각 법의 허용 사유
우리나라 개인정보보호법이나 정보통신망법, EU의 GDPR, 일본 개인정보보호법은 공히 개
인정보 이용에 있어 ‘목적제한성’ 원칙을 적용하고 있다. 따라서 목적을 벗어난 개인정보의 이
용은 원칙적으로 허용되지 않는다. 하지만 모든 법은 일정한 사유가 있는 경우에는 목적 외
이용을 허용하고 있다.
우리나라 개인정보보호법 제18조 제2항은 목적 외 이용이 가능한 사유로서 9가지를 규정
하고 있으며, 이 9가지의 사유는 모두 ‘정보주체 또는 제3자의 이익을 부당하게 침해할 우려
가 없는 경우’에 한하여 목적 외 이용이 허용된다(제18조 제2항 본문). 9가지 사유 중 4호는
이용을 제외하고 제공의 경우에만 적용되고, 5호부터 9호까지는 공공기관에만 적용되므로 제
외하면, 정보처리자의 목적 외 이용이 허용되는 경우는 3가지이다.
1. 정보주체로부터 별도의 동의를 받은 경우
2. 다른 법률에 특별한 규정이 있는 경우
3. 정보주체 또는 그 법정대리인이 의사표시를 할 수 없는 상태에 있거나 주소불명 등으로
사전 동의를 받을 수 없는 경우로서 명백히 정보주체 또는 제3자의 급박한 생명, 신체,
재산의 이익을 위하여 필요하다고 인정되는 경우
4. 통계작성 및 학술연구 등의 목적을 위하여 필요한 경우로서 특정 개인을 알아볼 수 없는
형태로 개인정보를 제공하는 경우
5. 개인정보를 목적 외의 용도로 이용하거나 이를 제3자에게 제공하지 아니하면 다른 법률
에서 정하는 소관 업무를 수행할 수 없는 경우로서 보호위원회의 심의 ・ 의결을 거친 경우
6. 조약, 그 밖의 국제협정의 이행을 위하여 외국정부 또는 국제기구에 제공하기 위하여 필
요한 경우

137
7. 범죄의 수사와 공소의 제기 및 유지를 위하여 필요한 경우
8. 법원의 재판업무 수행을 위하여 필요한 경우
9. 형(刑) 및 감호, 보호처분의 집행을 위하여 필요한 경우
우리나라 정보통신망법은 목적 외 이용을 허용하는 사유를 규정하지 않고 있다.
EU GDPR은 제5조 제1항 (b) 및 제6조 제4항에 목적 외 이용이 가능한 사유를 규정하고
있는바, 이를 정리하면 아래와 같다. 이 중에서 4호는 목적 외 이용이 가능한 일반규정으로
규정되어 있다.
1. 적절한 보호조치가 있고 공익 목적의 기록 보존 ・ 과학적 또는 역사적 연구 또는 통계 목
적의 추가처리를 하는 경우
2. 정보주체의 동의를 얻은 경우
3. EU 또는 회원국 법에 근거하고 있는 경우
4. 다음을 고려하여 초기 목적과 일치한다고 판단한 경우
(a) 초기 목적과 추가 처리의 목적 사이의 관련성
(b) 정보주체와 컨트롤러의 관계와 관련하여 개인정보가 수집된 맥락
(c) 개인정보의 성격
(d) 추가 처리가 정보주체에 대하여 야기할 수 있는 결과
(e) 암호화 또는 가명처리를 포함하여 적절한 안전장치의 존재
일본 개인정보보호법은 제15조 제2항, 제16조 제1항 및 제3항에 규정되어 있는바, 이를
정리하면 아래 6가지가 된다. 이 중에서 1호는 정확하게는 이용 목적의 변경 사유이나 목적
외 이용 사유로도 기능하므로 여기에 포함시켰고, 6호는 공공기관에 적용되는 사유이므로 제
외하면, 정보처리자는 5가지의 목적 외 이용 사유를 가진다.
1. 변경 전의 이용 목적과 관련성을 가졌다고 합리적으로 인정되는 경우
2. 본인의 동의를 얻은 경우
3. 법령에 근거하는 경우
4. 사람의 생명, 신체 또는 재산의 보호를 위해서 필요가 있는 경우로서 본인의 동의를 얻는
것이 곤란한 경우

138
5. 공중위생의 향상 또는 아동의 건전한 육성의 추진을 위하여 특히 필요한 경우로서 본인
의 동의를 얻는 것이 곤란한 경우
6. 국가기관 혹은 지방공공단체 또는 그 위탁을 받은 자가 법령이 정한 사무를 수행하는 것
에 대해서 협력할 필요가 있는 경우로서 본인의 동의를 얻은 것이 해당 업무 수행에 지
장을 줄 우려가 있는 경우
2) 각 법의 비교 평가
각국의 목적 외 이용의 허용 사유를 유사한 항목끼리 대응시켜 비교하면 아래 표와 같다.
개인정보보호법 정보통신망법 EU 일본
1. 정보주체로부터 별도의
동의를 받은 경우
2. 정보주체의 동의를 얻
은 경우
2. 본인의 동의를 얻은 경
우
2. 다른 법률에 특별한 규
정이 있는 경우
3. EU 또는 회원국 법에
근거하고 있는 경우
3. 법령에 근거하는 경우
3. 정보주체 또는 그 법정
대리인이 의사표시를
할 수 없는 상태에 있거
나 주소불명 등으로 사
전 동의를 받을 수 없는
경우로서 명백히 정보
주체 또는 제3자의 급
박한 생명, 신체, 재산
의 이익을 위하여 필요
하다고 인정되는 경우
4. 사람의 생명, 신체 또
는 재산의 보호를 위해
서 필요가 있는 경우로
서 본인의 동의를 얻는
것이 곤란한 경우
1. 적절한 보호조치가 있
고 공익 목적의 기록
보존 ・ 과학적 또는 역
사적 연구 또는 통계
목적의 추가처리를 하
는 경우
5. 공중위생의 향상 또는
아동의 건전한 육성의
추진을 위하여 특히 필
요한 경우로서 본인의
동의를 얻는 것이 곤란
한 경우
4. 다음을 고려하여 초기
목적과 일치한다고 판
단한 경우
(a) 초기 목적과 추가 처
리 목적 사이 관련성
1. 변경 전의 이용 목적과
관련성을 가졌다고 합리
적으로 인정되는 경우
<표 6> 목적 외 이용의 허용 사유 유사 항목 비교

139
EU GDPR과 일본의 개인정보보호법을 비교하면, EU GDPR에 있는 일반적인 목적 외 처
리 사유가 일본의 개인정보보호법에 존재하지 않지만, 일본에는 유사한 ‘1. 변경 전의 이용
목적과 관련성을 가졌다고 합리적으로 인정되는 경우’의 사유를 가지고 있기 때문에 쉽게 어
느 입법의 규제가 가볍다고 단정할 수는 없어 보인다. 다만, EU GDPR의 ‘1. 적절한 보호조
치가 있고 공익 목적의 기록 보존 ・ 과학적 또는 역사적 연구 또는 통계 목적의 추가처리를 하
는 경우’의 사유는 일본 개인정보보호법의 ‘4. 공중위생의 향상 또는 아동의 건전한 육성의 추
진을 위하여 특히 필요한 경우로서 본인의 동의를 얻는 것이 곤란한 경우’의 사유보다는 확연
히 넓어 보이기 때문에 전체적으로 EU GDPR의 허용 사유가 가장 넓다고 볼 수 있다.
우리나라의 개인정보보호법은 정량적으로 또는 정성적으로 보아도 EU GDPR과 일본 개인
정보보호법보다는 허용 사유가 넓지 않아 보인다. 다만, 우리나라의 정보통신망법은 허용 사
유가 존재하지 않기 때문에 우리나라 개인정보보호법은 우리나라 정보통신망법보다는 그 허용
사유가 넓다고 볼 수 있다.
결국 각국의 목적 외 처리에 대한 실체적 규제를 비교하면, EU GDPR → 일본 개인정보보
호법 → 우리나라 개인정보보호법 → 우리나라 정보통신망법 순서로 정리할 수 있다.
구분 개인정보보호법 정보통신망법 EU 일본
목적 외 처리의
허용 사유 규제의
완화순위
3 4 1 2
<표 7> 목적 외 처리의 허용 사유 규제의 완화순위
(b) 정보주체와 컨트롤
러의 관계와 관련하
여 개인정보가 수집
된 맥락
(c) 개인정보의 성격
(d) 추가 처리가 정보주
체에 대하여 야기할
수 있는 결과
(e) 암호화 또는 가명처
리를 포함하여 적절
한 안전장치의 존재

140
3. 제공 ・ 위탁 관련 실체적 규제의 비교
가. 제공의 ‘허용 사유’의 비교
1) 각 법의 허용 사유
우리나라 개인정보보호법은 개인정보의 제공이 허용되는 경우로서 4가지를 규정하고 있다
(제17조 제1항). 4가지 중 3호는 공공기관에만 적용되는 사유인바 이를 제외하면 정보처리자
에는 3가지의 제공 사유가 적용된다.
1. 정보주체의 동의를 받은 경우
2. 법률에 특별한 규정이 있거나 법령상 의무를 준수하기 위하여 불가피한 경우
3. 공공기관이 법령 등에서 정하는 소관 업무의 수행을 위하여 불가피한 경우
4. 정보주체 또는 그 법정대리인이 의사표시를 할 수 없는 상태에 있거나 주소불명 등으로
사전 동의를 받을 수 없는 경우로서 명백히 정보주체 또는 제3자의 급박한 생명, 신체,
재산의 이익을 위하여 필요하다고 인정되는 경우
우리나라 정보통신망법은 아래 3가지의 제공의 허용 사유를 규정하고 있다(제24조의2 제1항).
1. 이용자의 동의를 얻은 경우
2. 정보통신서비스의 제공에 따른 요금정산을 위하여 필요한 경우
3. 이 법 또는 다른 법률에 특별한 규정이 있는 경우
EU GDPR은 제공의 허용 사유를 별도로 규정하고 있지 않고 모든 형태의 처리의 허용 사
유를 동일하게 규정하고 있는바, 앞서 살펴본 수집 ・ 이용의 적법 사유가 그대로 제공의 적법
사유에 적용된다. 앞서 살펴본 바와 같이 EU GDPR은 개인정보의 수집 ・ 이용이 허용되는 사
유로서 아래와 같이 6가지를 제시하고 있고(제6조 제1항), 1~6호 중에서 5호의 후단은 공공
기관에만 적용되고 정보처리자에게 적용되지 않는 사유이므로 제외하였다.
1. 정보주체가 하나 이상의 특정한 목적을 위해 자신의 개인정보 처리에 동의한 경우
2. 정보주체가 당사자인 계약의 이행을 위하여 또는 계약 체결 전에 정보주체의 요청에 따
른 조치를 취하기 위하여 처리가 필요한 경우

141
3. 컨트롤러에게 적용되는 법적 의무의 준수를 위하여 처리가 필요한 경우
4. 정보주체 또는 다른 자연인의 중대한 이익을 보호하기 위하여 처리가 필요한 경우
5. 공익을 위하여 수행되는 직무의 실행을 위하여 또는 컨트롤러에게 부여된 공적 권한의
행사에 처리가 필요한 경우
6. 컨트롤러나 제3자가 추구하는 정당한 이익의 목적을 위하여 처리가 필요한 경우로서, 다
만, 특히 정보주체가 아동인 경우와 같이 개인정보 보호를 요구하는 정보주체의 이익이나
기본권과 자유가 해당 이익에 우선하는 경우에는 그러하지 아니하다. 6호는 공공당국이
자신의 직무 수행을 위하여 실행하는 처리에 적용되지 아니한다.
일본 개인정보보호법은 제공의 적법 사유로 5가지를 규정하고 있다(제23조 1항 및 제2항,
5호는 제외함). 다만, 아래 제공의 적법 사유는 ‘개인정보’가 아닌 ‘개인 데이터’에 적용되는데,
여기서 ‘개인 데이터’란 개인정보 데이터베이스 등을 구성하는 개인정보를 의미한다(제2조 제
6항).
1. 미리 본인의 동의를 얻은 경우
2. 법령에 근거한 경우
3. 사람의 생명, 신체 또는 재산의 보호를 위해서 필요가 있는 경우로서 본인의 동의를 얻는
것이 곤란한 경우
4. 공중위생의 향상 또는 아동의 건전한 육성의 추진을 위하여 특히 필요한 경우로서 본인
의 동의를 얻는 것이 곤란한 경우
5. 국가기관 혹은 지방공공단체 또는 그 위탁을 받은 자가 법령이 정한 사무를 수행하는 것
에 대해서 협력할 필요가 있는 경우로서 본인의 동의를 얻은 것이 해당 업무 수행에 지
장을 줄 우려가 있는 경우
6. 일정한 사항에 대하여 개인정보 보호위원회 규칙으로 정한 바에 따라 미리 본인에게 통
지하거나 또는 본인이 쉽게 파악하는 상태로 두는 동시에 개인정보 보호위원회에 신고한
경우

142
2) 각 법의 비교 평가
각국의 제공의 허용 사유를 유사한 항목끼리 대응시켜 비교하면 아래 표와 같다.
개인정보보호법 정보통신망법 EU 일본
1. 정보주체의 동의를 받
은 경우
1. 이용자의 동의를 얻은
경우
1. 정보주체가 하나 이상
의 특정한 목적을 위해
자신의 개인정보 처리
에 동의한 경우
1. 미리 본인의 동의를 얻
은 경우
2. 법률에 특별한 규정이
있거나 법령상 의무를
준수하기 위하여 불가
피한 경우
3. 이 법 또는 다른 법률
에 특별한 규정이 있는
경우
3. 컨트롤러에게 적용되는
법적 의무의 준수를 위하
여 처리가 필요한 경우
2. 법령에 근거한 경우
4. 정보주체 또는 그 법정
대리인이 의사표시를 할
수 없는 상태에 있거나
주소불명 등으로 사전
동의를 받을 수 없는 경
우로서 명백히 정보주체
또는 제3자의 급박한 생
명, 신체, 재산의 이익을
위하여 필요하다고 인정
되는 경우
4. 정보주체 또는 다른 자
연인의 중대한 이익을
보호하기 위하여 처리
가 필요한 경우
3. 사람의 생명, 신체 또
는 재산의 보호를 위해
서 필요가 있는 경우로
서 본인의 동의를 얻는
것이 곤란한 경우
2. 정보통신서비스의 제공
에 따른 요금정산을 위
하여 필요한 경우
6. 컨트롤러나 제3자가
추구하는 정당한 이익
의 목적을 위하여 처
리가 필요한 경우
4. 공중위생의 향상 또는
아동의 건전한 육성의
추진을 위하여 특히 필
요한 경우로서 본인의
동의를 얻는 것이 곤란
한 경우
2. 정보주체가 당사자인
계약의 이행을 위하여
또는 계약체결 전에 정
보주체의 요청에 따른
조치를 취하기 위하여
처리가 필요한 경우
6. 일정한 사항에 대하여
개인정보 보호위원회 규
칙으로 정한 바에 따라 미
리 본인에게 통지하거나
<표 8> 개인정보 제공 허용 사유 유사 항목 비교

143
EU GDPR과 일본 개인정보보호법의 규제는 서로 유사하여 그 우열을 판단하기 어렵다. 다
만, EU GDPR의 ‘4. 정보주체 또는 다른 자연인의 중대한 이익을 보호하기 위하여 처리가 필
요한 경우’가 일본 개인정보보호법의 ‘4. 공중위생의 향상 또는 아동의 건전한 육성의 추진을
위하여 특히 필요한 경우로서 본인의 동의를 얻는 것이 곤란한 경우’보다는 넓어 보이고, 일
본 개인정보보호법에는 없는 ‘2. 정보주체가 당사자인 계약의 이행을 위하여 또는 계약 체결
전에 정보주체의 요청에 따른 조치를 취하기 위하여 처리가 필요한 경우’의 사유가 존재한다
는 점을 고려하면, EU GDPR이 일본 개인정보보호법보다는 그 실체적 규제가 약하고 허용
사유가 넓다고 판단할 수 있다.
우리나라의 개인정보보호법과 정보통신망법의 허용 사유는 일본 개인정보보호법에 비하여
허용 사유가 많지 않음이 명백한 것으로 보인다.
우리나라의 개인정보보호법과 정보통신망법의 허용 사유에 대한 비교 판정은 쉽지 않지만,
외견상 개인정보보호법의 허용 사유가 약간 더 넓어 보인다.
결국 각국의 제공 사유에 대한 실체적 규제를 비교하면, EU GDPR → 일본 개인정보보호
법 → 우리나라 개인정보보호법 → 우리나라 정보통신망법의 순서로 정리할 수 있다.
구분 개인정보보호법 정보통신망법 EU 일본
제공의 허용 사유
규제의 완화순위3 4 1 2
<표 9> 개인정보 제공의 허용 사유 규제 완화순위
개인정보보호법 정보통신망법 EU 일본
또는 본인이 쉽게 파악
하는 상태로 두는 동시
에 개인정보 보호위원회
에 신고한 경우

144
나. 위탁의 ‘절차’의 비교
1) 각 법의 절차
개인정보의 위탁을 규율하는 규정은 위탁 절차 그 자체에 대하여 규율하고 있는 규정과 위
탁으로 인하여 발생하는 법률관계에 대하여 규율하는 규정으로 구별할 수 있다. 예컨대 위탁시
정보주체의 동의를 얻도록 하는 것이 전자의 규정이라면, 위탁 이후 위탁자가 수탁자에 대한
감독의무를 부담하는 것, 위탁을 문서로 해야 하는 것, 적절한 기술적 및 관리적 조치를 이행
한다는 충분한 보증을 제공하는 수탁자를 이용하는 것 등이 후자의 규정이라 할 수 있다.
후자, 즉 위탁으로 인하여 발생하는 법률관계에 대하여 규율하는 규정은 위탁 그 자체를
어렵게 하는 것은 아니므로, 여기서는 전자, 즉 위탁 절차 그 자체에 대하여 규율하고 있는
규정으로 한정하여 살펴보기로 한다. 위탁 절차 그 자체에 대하여 규율하고 있는 규정은 실질
적으로 실체적 규제의 기능도 하고 있다.
우리나라 개인정보보호법은 위탁의 절차에 대하여 ‘정보주체가 언제든지 쉽게 확인할 수
있도록 대통령령으로 정하는 방법에 따라 공개하여야 한다.’라고 규정하고 있다(제26조 제2
항). 여기서 정보주체에 대한 ‘공개’란 불특정 다수에게 일방적으로 정보를 제공하는 것을 의
미하는 것으로서, 정보주체의 승낙을 전제로 하는 ‘동의’나 특정 다수에게 일방적으로 정보를
제공하는 ‘통지 ・ 고지’보다는 간이한 절차에 해당한다.
우리나라 정보통신망법은 위탁의 절차에 대하여 원칙적으로 이용자의 ‘동의’를 전제로 한다
(제25조 제1항). 다만, 정보통신서비스의 제공에 관한 계약을 이행하고 이용자 편의 증진 등
을 위하여 필요한 경우로서 일정한 사항을 공개하거나 전자우편 등으로 이용자에게 알린 경
우에는 동의를 얻지 않아도 된다(같은 조 제2항).
EU GDPR의 경우 컨트롤러와 프로세서의 관계가 우리나라 법의 위탁의 절차와 가장 유사
한바, 컨트롤러의 프로세서에 대한 위탁의 절차에 대하여 별도로 규정한 것은 없다.
일본 개인정보보호법 제23조 제5항은 개인정보 취급사업자가 이용 목적에 필요한 범위 내
에서 개인 데이터 취급의 전부 또는 일부를 위탁하는 경우 그에 수반하여 해당 개인 데이터
가 제공되는 경우에 해당 개인 데이터를 제공받는 사람은 개인정보 제공의 제3자에 해당하지
않는다고 규정되어 있는바, 이 규정에 따르면 위탁의 절차에 대하여 별도의 규제는 존재하지
않는다.

145
2) 각 법의 비교 평가
각국의 위탁의 허용 사유를 유사한 항목끼리 대응시켜 비교하면 아래 표와 같다.
개인정보보호법 정보통신망법 EU 일본
정보 주체에 대한 공개 이용자의 동의 없음 없음
<표 10> 개인정보의 위탁 허용 사유 유사항목 비교
위탁의 경우 실체적 규제를 비교하면 아래와 같은 순서로 정리할 수 있다. 아무런 규제가
없는 EU GDPR이나 일본 개인정보보호법에 비하여 우리 개인정보보호법은 ‘공개’라는 절차를
준수하여야 하며, 정보통신망법은 예외는 있지만 원칙적으로 ‘이용자의 동의’를 전제로 이루어
져야 하기 때문이다.
구분 개인정보보호법 정보통신망법 EU 일본
위탁 허용 사유
규제의 완화순위3 4 1 1
<표 11> 개인정보의 위탁 허용 사유 규제의 완화순위
다. 국외 이전의 ‘허용 사유’의 비교
1) 각 법의 허용 사유
개인정보의 국외 이전은 개인정보의 국외 제공을 포함하여 개인정보가 국경을 넘는 일체의
행위를 지칭한다.
우리나라 개인정보보호법은 개인정보 국외 이전에 대하여 규정하지 않고 단지 개인정보의
국외 제공에 대하여만 규정하고 있으며, 개인정보의 국외 제공의 허용 사유는 유일하게 아래
1가지를 정하고 있다(제17조 제3항).
정보주체의 동의를 얻은 경우

146
우리나라 정보통신망법 역시 개인정보의 국외 이전3)의 허용 사유에 대하여 이용자의 동의
를 원칙으로 하고 있다(제63조 제2항 본문). 다만, 정보통신서비스의 제공에 관한 계약을 이
행하고 이용자 편의 증진 등을 위하여 필요한 경우로서 일정한 사항을 공개하거나 전자우편
등으로 이용자에게 알린 경우에는 처리위탁 ・ 보관시 이용자의 동의를 얻지 않아도 된다(같은
항 단서).
정보주체의 동의를 얻은 경우(예외가 있음)
EU GDPR은 제5장에서 여러 가지의 국외 이전 허용 사유를 규정하고 있다. 이를 정리하
면 아래와 같다.
1. EU집행위원회가 적정한 보호수준에 대하여 평가한 후 적정성 결정을 한 경우
2. 적절한 안전장치가 있는 경우(적절한 안전장치의 예 : 공공당국 또는 기관 사이의 법적
구속력 있고 집행가능한 문서, 소관 감독당국이 승인한 구속력 있는 기업규칙, EU집행위
원회가 채택한 표준개인정보보호조항, 감독당국이 채택하고 EU집행위원회가 승인한 표준
개인정보보호조항, 승인된 행동강령, 승인된 인증 메커니즘 등)
3. 적정성 결정과 적절한 안전장치가 없음을 고지받고, 정보주체가 이전에 명시적으로 동의
한 경우
4. 계약의 이행이나 이행 준비를 위하여 이전이 필요한 경우
5. 정보주체의 이익을 위해 컨트롤러와 다른 법인 등과 체결된 계약 이행을 위해 필요한 경우
6. 공익 달성이 중요한 경우(EU 또는 회원국 법에 의하여 인정된 공익이어야 함)
7. 법적 청구권의 설정, 행사, 방어를 위해 필요한 경우
8. 정보주체의 동의가 불가능하고, 정보주체 또는 다른 사람의 중대한 이익 보호를 위한 경우
9. EU 또는 회원국 법에 따라 의도되고 공개된 등록부로부터 일부가 이전되는 경우
10. 반복적인 이전이 아니고, 정보주체의 수가 제한적이며, 컨트롤러의 정당한 이익을 위해
필요하고, 이전을 둘러싼 모든 환경에 대한 평가를 고려한 적절한 보호조치에 따른 이
전인 경우
3) 정보통신망법은 이전에 대하여 ‘제공(조회되는 경우를 포함한다) ・ 처리위탁 ・ 보관’으로 정의하고 있는바, 본 연구에서 규정한
‘개인정보가 국경을 넘는 일체의 행위’보다는 범위가 협소함을 알 수 있다.

147
일본 개인정보보호법 제24조는 개인 데이터를 국외에 제공할 수 있는 사유를 규정하고 있
는바, 그 허용 사유는 정리하면 6가지이지만, 공공기관에만 적용되는 5호를 제외하면 정보처
리자는 5가지의 개인 데이터 국외 제공의 허용 사유를 보유한다.
1. 미리 본인의 동의를 얻은 경우
2. 법령에 근거한 경우
3. 사람의 생명, 신체 또는 재산의 보호를 위해서 필요가 있는 경우로서 본인의 동의를 얻는
것이 곤란한 경우
4. 공중위생의 향상 또는 아동의 건전한 육성의 추진을 위하여 특히 필요한 경우로서 본인
의 동의를 얻는 것이 곤란한 경우
5. 국가기관 혹은 지방공공단체 또는 그 위탁을 받은 자가 법령이 정한 사무를 수행하는 것
에 대해서 협력할 필요가 있는 경우로서 본인의 동의를 얻는 것이 해당 업무 수행에 지
장을 줄 우려가 있는 경우
6. 개인 데이터 취급에 대해서 제4장 제1절의 규정에 따라 개인정보 취급사업자가 취해야
하는 조치에 상당하는 조치로서, 국외의 개인 데이터를 제공받는 자가 계속적으로 취하기
위하여 필요한 것으로서 개인정보 보호위원회 규칙으로 정한 기준에 적합한 체제를 정비
한 경우
2) 각 법의 비교 평가
각국의 국외 이전의 허용 사유를 유사한 항목끼리 대응시켜 비교하면 아래 표와 같다.
개인정보보호법 정보통신망법 EU 일본
정보주체의 동의를 얻은
경우(제공)
정보주체의 동의를 얻은
경우
3. 적정성 결정과 적절한
안전장치가 없음을 고
지 받고, 정보주체가 이
전에 명시적으로 동의
한 경우
1. 미리 본인의 동의를 얻
은 경우
1. EU집행위원회가 적정한
보호수준에 대하여 평
가한 후 적정성 결정을
한 경우
2. 법령에 근거한 경우
3. 사람의 생명, 신체 또는
재산의 보호를 위해서
필요가 있는 경우로서
<표 12> 개인정보 국외 이전 허용 사유 유사항목 비교

148
개인정보보호법 정보통신망법 EU 일본
2. 적절한 안전장치가 있
는 경우(적절한 안전장
치의 예 : 공공당국 또
는 기관 사이의 법적
구속력 있고 집행가능
한 문서, 소관 감독당국
이 승인한 구속력 있는
기업규칙, EU집행위원
회가 채택한 표준개인
정보보호조항, 감독당국
이 채택하고 EU집행위
원회가 승인한 표준개
인정보보호조항, 승인된
행동강령, 승인된 인증
메커니즘 등)
4. 계약의 이행이나 이행
준비를 위하여 이전이
필요한 경우
5. 정보주체의 이익을 위해
컨트롤러와 다른 법인
등과 체결된 계약 이행
을 위해 필요한 경우
6. 공익 달성이 중요한 경
우(EU 또는 회원국 법
에 의하여 인정된 공익
이어야 함)
7. 법적 청구권의 설정, 행
사, 방어를 위해 필요한
경우
8. 정보주체의 동의가 불
가능하고, 정보주체 또
는 다른 사람의 중대한
이익 보호를 위한 경우
9. EU 또는 회원국 법에
따라 의도되고 공개된
등 록 부 로 부 터 일 부 가
이전되는 경우
10. 반복적인 이전이 아니
고, 정보주체의 수가 제
한적이며, 컨트롤러의 정
당한 이익을 위해 필요할
하고, 이전을 둘러싼 모
든 환경에 대한 평가를
고려한 적절한 보호조치
에 따른 이전인 경우
본인의 동의를 얻는 것
이 곤란한 경우
4. 공중위생의 향상 또는
아동의 건전한 육성의
추진을 위하여 특히 필
요한 경우로서 본인의
동의를 얻는 것이 곤란
한 경우
6. 개인 데이터 취급에 대
해서 제4장 제1절의 규
정에 따라 개인정보 취
급사업자가 취해야 하는
조치에 상당하는 조치로
서, 국외의 개인 데이터
를 제공받는 자가 계속
적으로 취하기 위하여
필요한 것으로서 개인정
보 보호위원회 규칙으로
정한 기준에 적합한 체
제를 정비한 경우

149
정량적으로 또는 정성적으로 판단하더라도, EU GDPR의 허용 사유가 다른 나라의 입법보
다 월등이 많다. 그 다음으로 일본 개인정보보호법의 허용 사유가 많다고 판단할 수 있다.
한편 우리나라의 개인정보보호법이나 정보통신망법은 일본 개인정보보호법보다는 적은 허
용 사유를 보이고 있다. 그리고 우리나라의 개인정보보호법이나 정보통신망법을 비교하면, 개
인정보보호법은 ‘제공’의 사유만 규정하고 있다는 점, 정보통신망법은 ‘동의’를 받지 않고 국외
이전을 할 수 있다는 점을 고려하여, 정보통신망법의 허용 사유가 개인정보보호법의 허용 사
유보다 넓다고 볼 수 있다.
그 허용 사유 또는 실체적 규제의 순서를 정리하면 아래와 같다.
구분 개인정보보호법 정보통신망법 EU 일본
국외 이전의
허용 사유 규제의
완화순위
4 3 1 2
<표 13> 개인정보 국외 이전 허용 사유 규제의 완화순위
4. 관리 ・ 파기 관련 실체적 규제의 비교
가. ‘파기 사유’의 비교
1) 각 법의 사유
우리나라 개인정보보호법은 파기 사유에 대하여 아래와 같이 보유기간의 경과, 개인정보의
처리 목적 달성 등 그 개인정보가 불필요하게 되었을 때로 규정하고 있다(제21조 참조). 파기
를 할 때는 복구 또는 재생되지 아니하도록 조치하여야 하나, 다만 법령에 따라 보존해야 하
는 경우에는 파기를 하지 않아도 된다(제21조 참조).
보유기간의 경과, 개인정보의 처리 목적 달성 등 그 개인정보가 불필요하게 되었을 때
우리나라 정보통신망법은 파기 사유에 대하여 아래 4가지를 들고 있다(제29조). 파기의 방
법은 동일하고, 다만 법령에 따라 보존해야 하는 경우에는 파기를 하지 않아도 된다(제29조).

150
1. 동의를 받은 개인정보의 수집 ・ 이용 목적이나 해당 목적을 달성한 경우
2. 동의를 받은 개인정보의 보유 및 이용 기간이 끝난 경우
3. 이용자의 동의를 받지 아니하고 수집 ・ 이용한 경우에는 개인정보처리방침에서 정한 개인
정보의 보유 및 이용 기간이 끝난 경우
4. 사업을 폐업하는 경우
EU GDPR은 제5조 제1항 (e)에서 ‘개인정보가 처리되는 목적에 필요한 기간’ 동안만 개인정
보를 정보주체의 식별을 허용하는 형태로 저장할 수 있도록 하고 있다. 다만, 예외적으로 개인정
보는 정보주체의 권리와 자유를 보호하기 위해 본 규칙에서 요구하는 적절한 기술적 및 관리적
조치의 이행을 조건으로 공익적 기록보존 목적, 과학적 및 역사적 연구 목적이나 통계적 목적에
한해 개인정보가 처리되는 한, 해당 개인정보는 더 오랜 기간 저장될 수 있다.
개인정보가 처리되는 목적에 필요한 기간이 경과했을 경우
일본 개인정보보호법은 제19조에서 ‘이용할 필요가 없어졌을 경우’ 개인정보를 지체 없이 소
거하도록 규정하고 있다.
이용할 필요가 없어졌을 경우
2) 각 법의 비교 평가
파기 사유는 수집 ・ 이용 ・ 제공의 허용 사유와 달리 그 사유가 적을수록 실체적 규제가 적
다고 볼 수 있다. 각국의 파기 사유를 정리 또는 비교하면 아래 표와 같다.
개인정보보호법 정보통신망법 EU 일본
보유기간의 경과, 개인정
보의 처리 목적 달성 등
그 개인정보가 불필요하
게 되었을 때
1. 동의를 받은 개인정보의
수집 ・ 이용 목적이나 해
당 목적을 달성한 경우
2. 동의를 받은 개인정보의
보유 및 이용 기간이 끝
난 경우
개인정보가 처리되는 목
적에 필요한 기간이 경
과했을 경우
이용할 필요가 없어졌을
경우
<표 14> 각국의 개인정보 파기 사유

151
각국의 파기 사유는 대체로 유사한 범위를 가지고 있다. 다만, EU GDPR의 경우 파기 대
신에 정보주체의 식별을 허용하는 형태로 보관할 수 있기 때문에 파기나 소거를 의무화하는
국가에 대하여 비교적 규제가 낮다고 볼 수 있다.
한국의 개인정보보호법이나 정보통신망법, 일본의 개인정보보호법은 대체로 유사한 파기
사유를 보유하고 있으나, 파기 사유의 개수를 비교하면 일본의 개인정보보호법이 가장 규제가
약하고, 한국의 개인정보보호법, 정보통신망법 순서로 규제의 순서를 정리할 수 있다.
구분 개인정보보호법 정보통신망법 EU 일본
파기 사유
규제의 완화순위3 4 1 2
<표 15> 개인정보 파기 사유 규제의 완화순위
나. ‘개인정보 유효기간 제도’의 비교
1) 각 법의 제도
개인정보 유효기간 제도란 정보주체가 1년의 기간 이상 서비스를 이용하지 않을 경우 보관
중인 개인정보에 대하여 파기 등의 조치를 취해야 하는 의무를 말한다.
우리나라 개인정보보호법은 파기 제도 외에 개인정보 유효기간 제도를 규정하고 있지 않고
우리나라 정보통신망법은 제29조 제2항에서 개인정보 유효기간 제도를 규정하고 있다.
정보통신서비스 제공자등은 정보통신서비스를 1년의 기간 동안 이용하지 아니하는 이용자의
개인정보를 보호하기 위하여 대통령령으로 정하는 바에 따라 개인정보의 파기 등 필요한 조
치를 취하여야 한다. 다만, 그 기간에 대하여 다른 법령 또는 이용자의 요청에 따라 달리 정
한 경우에는 그에 따른다.
3. 이용자의 동의를 받지
아니하고 수집 ・ 이용한
경우에는 개인정보처리
방침에서 정한 개인정보
의 보유 및 이용 기간
이 끝난 경우
4. 사업을 폐업하는 경우

152
EU GDPR이나 일본 개인정보보호법은 개인정보 유효기간 제도를 보유하고 있지 않다.
2) 각 법의 비교 평가
개인정보 유효기간 제도는 오직 우리나라의 정보통신망법에만 존재하고 다른 입법에서는
존재하지 않는다. 따라서 실체적 규제 순서를 표로 정리하면 아래와 같다.
구분 개인정보보호법 정보통신망법 EU 일본
개인정보 유효기간
제도 규제의 완화순위1 4 1 1
<표 16> 개인정보 유효기간 제도 규제의 완화순위
5. 종합적인 평가
지금까지 각국의 실체적 규제 내용을 살펴보았다. 이상의 비교 내용을 정리하면 아래 표와
같다.
규제완화 순위 평가대상 개인정보보호법 정보통신망법 EU 일본
일반 개인정보 수집 ・
이용의 허용 사유3 4 2 1
민감정보의 수집 ・
이용의 허용 사유3 4 1 2
목적 외 이용의
허용 사유3 4 1 2
제공의 허용 사유 3 4 1 2
위탁의 절차 3 4 1 1
국외 이전 허용 사유 4 3 1 2
파기 사유 3 4 1 2
개인정보의
유효기간 제도1 4 1 1
상대적 규제 총점 23 31 9 13
<표 17> 개인정보에 대한 실체적 규제 내용 비교

153
각 입법의 규제 완화의 순위를 더한 것을 ‘상대적 규제 총점’이라 정하고 각 사유에 대한
순위를 더하면, 상대적 규제 총점은 EU GDPR의 경우는 9, 일본 개인정보보호법은 13, 우리
나라의 개인정보보호법은 23, 우리나라의 정보통신망법은 31의 수치가 나온다.
따라서 상대적 규제 총점에 따르면, 우리나라 정보통신망법이 가장 실체적 규제가 강한 입
법이며 EU GDPR이 실체적 규제가 가장 낮은 입법에 해당한다.
상대적 규제 총점에 의하여 단순 비교하면, EU GDPR은 우리나라 개인정보보호법에 비하
여 규제가 9/23 = 39%밖에 되지 않고, 우리나라 정보통신망법에 비하면 규제가 9/31 =
29%밖에 되지 않는다.
일본 개인정보보호법과 비교하더라도, 일본 개인정보보호법은 우리나라 개인정보보호법에
비하여 규제가 13/23 = 56%, 우리나라 정보통신망법에 비하여 규제가 13/31 = 42%밖에
되지 않는다.
EU GDPR을 기준으로 하여 상대적 규제 총점을 비교하면, 일본 개인정보보호법은 1.4배
의 규제가 더 있는 셈이고, 우리나라 개인정보보호법은 2.6배, 우리나라 정보통신망법은 3.4
배의 규제가 더 존재하는 것이다. EU의 정보처리자가 개인정보 처리를 할 때 받는 규제보다
우리나라 정보처리자가 받는 규제가 2.6배 ~ 3.4배 정도 더 많다는 의미이다.
그리고 일본 개인정보보호법을 기준으로 상대적 규제 총점을 비교하면, 우리나라 개인정보
보호법은 1.8배, 우리나라 정보통신망법은 2.4배의 규제가 더 존재하는 것으로 나타났다. 일
본의 정보처리자가 개인정보 처리를 할 때 받는 규제보다 우리나라 정보처리자가 받는 규제
가 1.8배 ~ 2.4배 정도 더 많다는 의미이다.
상대적 규제 총점 기준 개인정보보호법 정보통신망법 EU 일본
EU 기준 2.6배 3.4배 1 1.4배
일본 기준 1.8배 2.4배 0.7배 1
<표 18> 상대적 규제 총점 비교

154
6. 결어
그간 우리나라 개인정보 법령의 규제가 일본이나 EU보다 더 강하고 엄격하다는 평가가 많
았다. 하지만 그 구체적인 통계 자료는 제시하지 못하였다.
이번 연구로 그간의 평가가 틀리지 않았음을 알 수 있었고, 본 연구에서 제시한 상대적 규
제 총점을 기준으로 하면, EU GDPR을 기준으로 우리나라 개인정보보호법은 2.6배, 우리나라
정보통신망법은 무려 3.4배의 실체적 규제가 존재함을 밝혔다. 그 만큼 정보처리자 입장에서
는 개인정보의 처리가 쉽지 않다는 것을 의미한다.
물론 정당한 사유가 존재하면 실체적 규제가 더 강해질 수 있다. 하지만 우리나라 개인정
보 환경이 EU나 일본의 개인정보 환경에 비하여 그 규제가 더 강해야 하는 사유는 특별하게
발견되지 않는다.
무거운 실체적 규제는 기업의 규제 비용을 증가시키고 개인정보의 활용이나 산업에도 부정적
영향을 줄 수밖에 없다. 정보주체의 자기결정권을 보호한다는 원래적 취지는 감소할 수밖에 없다.
정당한 사유가 없음에도 무거운 개인정보 규제를 가지는 점에 대한 진지한 재검토와 고민
을 해야 할 것이고, 적어도 다른 나라와 유사한 규제 수준을 유지함으로써 우리 기업의 개인
정보 활용의 길을 만들어 주고, 나아가 개인정보의 보호와 활용이라는 개인정보 영역에서의
영원한 숙제를 현명하게 해결해 갈 수 있는 실마리를 제공하는 것이 필요하다고 본다.

155
개인정보보호 법령 및 지침 ・ 고시 해설, 행정안전부, 2016.
박노형 외 8인, EU 개인정보보호법, 박영사, 2017.
정보통신서비스 제공자를 위한 개인정보보호 법령 해설서, 방송통신위윈회, 2012.
한은영, “일본 개인정보보호법의 개정 내용 및 평가”, 「정보통신정책동향」 제27권 17호
통권 608호, 2016.
참고문헌


❚박훤일
경희대 법학전문대학원 교수
KoreanLII.or.kr Managing Director
한국상사법학회, 국제거래법학회, 은행법학회 임원
행정안전부, KISA, 통일부 자문교수
법무부 국제거래법연구단 연구위원(UNCITRAL, Unidroit 참석)
한국산업은행 법무팀장 역임
❚김용대
서울대학교 통계학과 교수
한국통계학회 학술이사
한국 BI 데이터마이닝 학회 이사
자료분석학회 국제이사
Journal of Korean Statistical Society 편집위원
Statistical Analysis and Data Mining 편집위원
Computational Statistics and Data Analysis 편집위원
㈜바이오인프라, NHN엔터테인먼트 자문교수
셀트리온 DSMB
금융보안원/ 한국신용정보원 금융분야 개인정보 비식별 조치 적정성평가단 전문가
저자소개

❚김경환
법무법인 민후 대표변호사
과학기술정보통신부 고문변호사
방송통신위원회 법령자문위원
공공데이터제공분쟁조정위원회 조정위원
온라인광고분쟁조정위원회 조정위원
방송통신위원회 자율주행차 관련 개인 ․ 위치정보 보호제도 개선 연구반 연구위원
비금융분야 블록체인 기술 적용 확산을 위한 법제도 연구 전문가 위원회 위원
공정거래위원회 기업거래정책 자문위원
개인정보보호법학회 국제학술이사
개인정보분쟁조정위원회 조정위원
개인정보보호협의회 자문위원
산업기술분쟁조정위원회 조정위원
한국인터넷진흥원 개인정보침해신고센터 법률자문위원
고려대학교 법학전문대학원 사이버법센터 자문위원
한국인터넷진흥원 민원처리심사위원회 위원
한국포스트휴먼학회 대외협력이사

2017 NAVER Privacy White Paper
발 행 일 2017년 12월 12일 인쇄
2017년 12월 12일 발행
저 자 박훤일, 김용대, 김경환
발 행 인 한성숙
발 행 처 NAVER Corp.
경기도 성남시 분당구 불정로 6 NAVER 그린팩토리
Privacy&Security 전화 031-784-1201
http://privacy.naver.com
ⓒ NAVER Corp. All rights reserved.