Embed Size (px)
Citation preview

Packages for Data Wrangling
データ前処理のためのパッケージHiroki

R-bloggers 昨日の記事
把握しておくべきパッケージ
データ取得用
• readr
• rio
• readxl
• RMySQL
• quantmod
データ加工用
• dplyr
• data.table
• tidyr
• sqldf
• zoo
etc…

Data Wrangling用パッケージ群
パッケージ 用途 コメント 解説 作者
plyr data wranglingWhile dplyr is my go-to package for wrangling data frames, the older plyr package still comes in handy when working with other types of R data such as lists. CRAN.
llply(mylist, myfunction) Hadley Wickham
reshape2 data wrangling
Change data row and column formats from "wide" to "long"; turn variables into column names or column names into variables and more. The tidyrpackage is a newer, more focused option, but I still use reshape2. CRAN.
See my tutorial Hadley Wickham
stringr data wrangling
Numerous functions for text manipulation. Some are similar to existing base R functions but in a more standard format, including working with regular expressions. Some of my favorites: str_pad and str_trim. CRAN.
str_pad(myzipcodevector, 5, "left", "0") Hadley Wickham
lubridate data wranglingEverything you ever wanted to do with date arithmetic, although understanding & using available functionality can be somewhat complex. CRAN.
mdy("05/06/2015") + months(1)More examples in the package vignette
Garrett Grolemund, Hadley Wickham & others
sqldfdata wrangling, data analysis
Do you know a great SQL query you'd use if your R data frame were in a SQL database? Run SQL queries on your data frame with sqldf. CRAN.
sqldf("select * from mydf where mycol >
4")G. Grothendieck
dplyrdata wrangling,
data analysis
The essential data-munging R package when working with data frames. Especially useful for operating on data by categories. CRAN.
See the intro vignette Hadley Wickham
data.tabledata wrangling, data analysis
Popular package for heavy-duty data wrangling. While I typically prefer dplyr, data.table has many fans for its speed with large data sets. CRAN.
Useful tutorial Matt Dowle & others
zoodata wrangling, data analysis
Robust package with a slew of functions for dealing with time series data; I like the handy rollmean function for calculating moving averages. CRAN.
rollmean(mydf, 7) Achim Zeileis & others
http://www.computerworld.com/article/2921176/business-intelligence/great-r-packages-for-data-import-wrangling-visualization.html

Data Wrangling
Data munging or data wrangling is loosely the process of manually converting or mapping data from one “raw” form into another format that allows for more convenient consumption of the data with the help of semi-automated tools. This may include further munging, data visualization, data aggregation, training a statistical model, as well as many other potential uses. (Wikipedia)
データを分析可能な形に変換するプロセス
データクレンジング+変換…
≒データ前処理

データ前処理
前処理 解析・他
データ分析の工数のうち7割8割は前処理
閑話休題
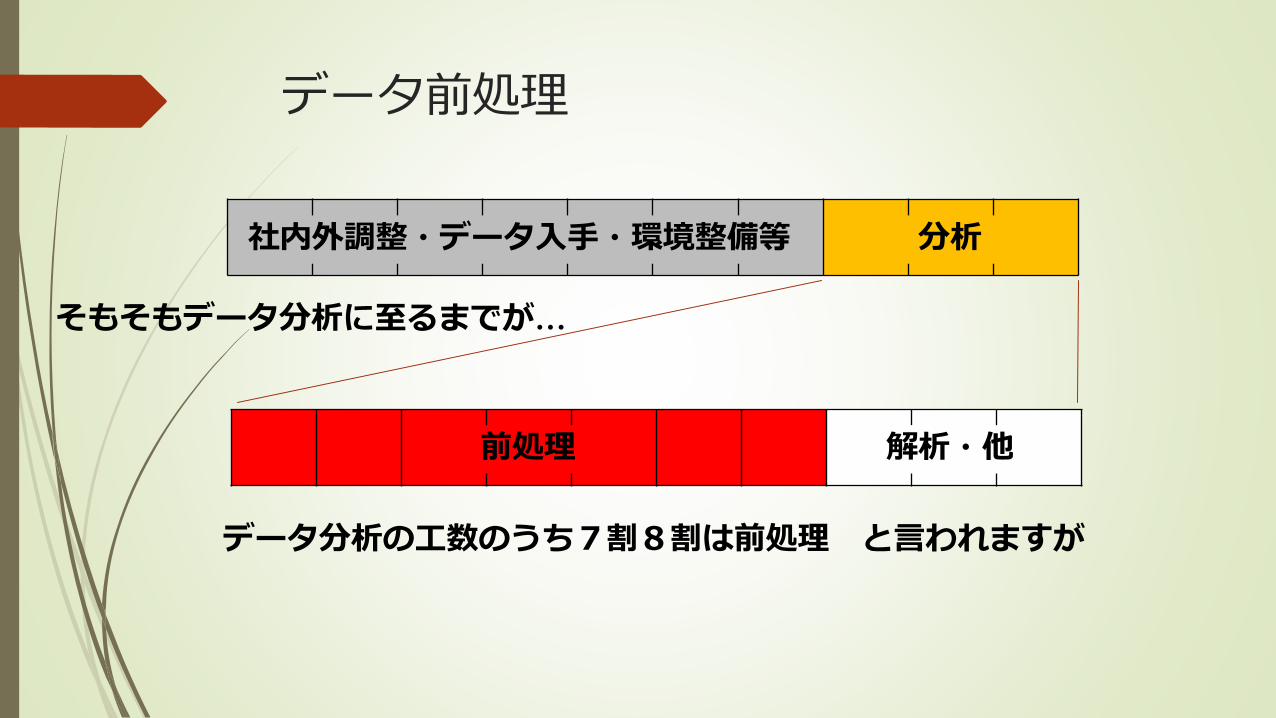
データ前処理
前処理 解析・他
そもそもデータ分析に至るまでが…
社内外調整・データ入手・環境整備等 分析
データ分析の工数のうち7割8割は前処理 と言われますが

データ前処理
前処理 解析・他
そもそもデータ分析に至るまでが…
社内外調整・データ入手・環境整備等 分析
30% * 30% < 10%
1割未満

データ前処理
前処理 解析・他
そもそもデータ分析に至るまでが…
社内外調整・データ入手・環境整備等 分析
30% * 30% < 10%
1割未満今回はこのプロセスのためのパッケージ

今回取り上げるパッケージ
パッケージ 用途 コメント 解説 作者
plyr data wranglingWhile dplyr is my go-to package for wrangling data frames, the older plyr package still comes in handy when working with other types of R data such as lists. CRAN.
llply(mylist, myfunction) Hadley Wickham
reshape2 data wrangling
Change data row and column formats from "wide" to "long"; turn variables into column names or column names into variables and more. The tidyrpackage is a newer, more focused option, but I still use reshape2. CRAN.
See my tutorial Hadley Wickham
stringr data wrangling
Numerous functions for text manipulation. Some are similar to existing base R functions but in a more standard format, including working with regular expressions. Some of my favorites: str_pad and str_trim. CRAN.
str_pad(myzipcodevector, 5, "left", "0") Hadley Wickham
lubridate data wranglingEverything you ever wanted to do with date arithmetic, although understanding & using available functionality can be somewhat complex. CRAN.
mdy("05/06/2015") + months(1)More examples in the package vignette
Garrett Grolemund, Hadley Wickham & others
sqldfdata wrangling, data analysis
Do you know a great SQL query you'd use if your R data frame were in a SQL database? Run SQL queries on your data frame with sqldf. CRAN.
sqldf("select * from mydf where mycol >
4")G. Grothendieck
dplyrdata wrangling,
data analysis
The essential data-munging R package when working with data frames. Especially useful for operating on data by categories. CRAN.
See the intro vignette Hadley Wickham
data.tabledata wrangling, data analysis
Popular package for heavy-duty data wrangling. While I typically prefer dplyr, data.table has many fans for its speed with large data sets. CRAN.
Useful tutorial Matt Dowle & others
zoodata wrangling, data analysis
Robust package with a slew of functions for dealing with time series data; I like the handy rollmean function for calculating moving averages. CRAN.
rollmean(mydf, 7) Achim Zeileis & others
http://www.computerworld.com/article/2921176/business-intelligence/great-r-packages-for-data-import-wrangling-visualization.html

今回取り上げるパッケージ
パッケージ 用途 コメント 解説 作者
plyr data wranglingWhile dplyr is my go-to package for wrangling data frames, the older plyr package still comes in handy when working with other types of R data such as lists. CRAN.
llply(mylist, myfunction) Hadley Wickham
reshape2 data wrangling
Change data row and column formats from "wide" to "long"; turn variables into column names or column names into variables and more. The tidyrpackage is a newer, more focused option, but I still use reshape2. CRAN.
See my tutorial Hadley Wickham
stringr data wrangling
Numerous functions for text manipulation. Some are similar to existing base R functions but in a more standard format, including working with regular expressions. Some of my favorites: str_pad and str_trim. CRAN.
str_pad(myzipcodevector, 5, "left", "0") Hadley Wickham
lubridate data wranglingEverything you ever wanted to do with date arithmetic, although understanding & using available functionality can be somewhat complex. CRAN.
mdy("05/06/2015") + months(1)More examples in the package vignette
Garrett Grolemund, Hadley Wickham & others
sqldfdata wrangling, data analysis
Do you know a great SQL query you'd use if your R data frame were in a SQL database? Run SQL queries on your data frame with sqldf. CRAN.
sqldf("select * from mydf where mycol >
4")G. Grothendieck
dplyrdata wrangling,
data analysis
The essential data-munging R package when working with data frames. Especially useful for operating on data by categories. CRAN.
See the intro vignette Hadley Wickham
data.tabledata wrangling, data analysis
Popular package for heavy-duty data wrangling. While I typically prefer dplyr, data.table has many fans for its speed with large data sets. CRAN.
Useful tutorial Matt Dowle & others
zoodata wrangling, data analysis
Robust package with a slew of functions for dealing with time series data; I like the handy rollmean function for calculating moving averages. CRAN.
rollmean(mydf, 7) Achim Zeileis & others
http://www.computerworld.com/article/2921176/business-intelligence/great-r-packages-for-data-import-wrangling-visualization.html
個人的に最も役立つのはdplyr、その補助(出力形式変換)としてのtidyrだが、以前に紹介したので今回は割愛
http://www.slideshare.net/kawaharahiroki/r-45226370

今回取り上げるパッケージ
パッケージ 用途 コメント 解説 作者
plyr data wranglingWhile dplyr is my go-to package for wrangling data frames, the older plyr package still comes in handy when working with other types of R data such as lists. CRAN.
llply(mylist, myfunction) Hadley Wickham
reshape2 data wrangling
Change data row and column formats from "wide" to "long"; turn variables into column names or column names into variables and more. The tidyrpackage is a newer, more focused option, but I still use reshape2. CRAN.
See my tutorial Hadley Wickham
stringr data wrangling
Numerous functions for text manipulation. Some are similar to existing base R functions but in a more standard format, including working with regular expressions. Some of my favorites: str_pad and str_trim. CRAN.
str_pad(myzipcodevector, 5, "left", "0") Hadley Wickham
lubridate data wranglingEverything you ever wanted to do with date arithmetic, although understanding & using available functionality can be somewhat complex. CRAN.
mdy("05/06/2015") + months(1)More examples in the package vignette
Garrett Grolemund, Hadley Wickham & others
sqldfdata wrangling, data analysis
Do you know a great SQL query you'd use if your R data frame were in a SQL database? Run SQL queries on your data frame with sqldf. CRAN.
sqldf("select * from mydf where mycol >
4")G. Grothendieck
dplyrdata wrangling,
data analysis
The essential data-munging R package when working with data frames. Especially useful for operating on data by categories. CRAN.
See the intro vignette Hadley Wickham
data.tabledata wrangling, data analysis
Popular package for heavy-duty data wrangling. While I typically prefer dplyr, data.table has many fans for its speed with large data sets. CRAN.
Useful tutorial Matt Dowle & others
zoodata wrangling, data analysis
Robust package with a slew of functions for dealing with time series data; I like the handy rollmean function for calculating moving averages. CRAN.
rollmean(mydf, 7) Achim Zeileis & others
http://www.computerworld.com/article/2921176/business-intelligence/great-r-packages-for-data-import-wrangling-visualization.html
データ全体の処理
データ要素の処理

{plyr}
dplyrの前身(まだまだ人気)
http://www.slideshare.net/teramonagi/tokyo-r30-20130420

{plyr}
関数
http://www.slideshare.net/teramonagi/tokyo-r30-20130420

apply family {base}
一つの関数を複数のオブジェクトに適用して得られた結果を一括で返す
(例1) iris {base}の各項目の平均
> apply(iris[,-5], 2, mean, na.rm=T)
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.843333 3.057333 3.758000 1.199333
(例2)データフレーム内のファクタを文字列に一括変換
> df <- data.frame(X=LETTERS, x=letters)
> df[] <- lapply(df, as.character)

apply family {base}
(例2)データフレーム内のファクタを文字列に一括変換
> df <- data.frame(X=LETTERS, x=letters)
> str(df)
'data.frame': 26 obs. of 2 variables:
$ X: Factor w/ 26 levels "A","B","C","D",..: 1 2 3 4 5 6 7 8 9 10 ...
$ x: Factor w/ 26 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ...
> df[] <- lapply(df, as.character)
> str(df)
'data.frame': 26 obs. of 2 variables:
$ X: chr "A" "B" "C" "D" ...
$ x: chr "a" "b" "c" "d" ...

ddply {plyr}
> library(plyr)
Warning message:
パッケージ ‘plyr’ はバージョン 3.1.3 の R の下で造られました
> df <- data.frame(
+ group = c(rep('A', 8), rep('B', 15), rep('C', 6)),
+ sex = sample(c("M", "F"), size = 29, replace = TRUE),
+ age = runif(n = 29, min = 18, max = 54)
+ )
> ddply(df, .(group, sex), summarize,
+ mean = mean(age),
+ sd = sd(age))
Error in withCallingHandlers(tryCatch(evalq((function (i) :
object '.rcpp_warning_recorder' not found
R3.1.1以降でエラー?

ddply {plyr}
install.packages("plyr", type = "source")
library(plyr)
> ddply(df, .(group, sex), summarize,
+ mean = mean(age),
+ sd = sd(age))
group sex mean sd
1 A F 42.43033 8.996826
2 A M 30.09450 13.311536
3 B F 35.64277 11.060713
4 B M 38.96056 6.731923
5 C F 25.01813 4.588658
6 C M 49.29878 NA
> head(df)
group sex age
1 A M 20.23535
2 A F 34.10908
3 A M 45.23656
4 A F 52.72067
5 A M 24.81160
6 A F 37.51441

ddply {plyr}
install.packages("plyr", type = "source")
library(plyr)
> ddply(df, .(group, sex), summarize,
+ mean = mean(age),
+ sd = sd(age))
group sex mean sd
1 A F 42.43033 8.996826
2 A M 30.09450 13.311536
3 B F 35.64277 11.060713
4 B M 38.96056 6.731923
5 C F 25.01813 4.588658
6 C M 49.29878 NA
> head(df)
group sex age
1 A M 20.23535
2 A F 34.10908
3 A M 45.23656
4 A F 52.72067
5 A M 24.81160
6 A F 37.51441
{dplyr}を使った場合
> df %>% group_by(sex) %>% summarise(mean=mean(age), sd=sd(age))
Source: local data frame [2 x 3]
sex mean sd
1 F 34.51422 10.940603
2 M 37.60556 9.497813

{reshape2}
主にデータ形式の変換に使用
melt: 縦長(long)⇨ 横長(wide)
cast: 縦長(long)⇦ 横長(wide)
> names(airquality) <- tolower(names(airquality))
> head(airquality)
ozone solar.r wind temp month day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
melt> aqm <- melt(airquality, id=c("month", "day"), na.rm=TRUE)
> head(aqm)month day variable value
1 5 1 ozone 412 5 2 ozone 363 5 3 ozone 124 5 4 ozone 186 5 6 ozone 287 5 7 ozone 23
cast> acast(aqm, month ~ variable, mean)
ozone solar.r wind temp5 23.61538 181.2963 11.622581 65.548396 29.44444 190.1667 10.266667 79.100007 59.11538 216.4839 8.941935 83.903238 59.96154 171.8571 8.793548 83.967749 31.44828 167.4333 10.180000 76.90000

{reshape2}
主にデータ形式の変換に使用
melt: 縦長(long)⇨ 横長(wide)
cast: 縦長(long)⇦ 横長(wide)
> names(airquality) <- tolower(names(airquality))
> head(airquality)
ozone solar.r wind temp month day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
melt> aqm <- melt(airquality, id=c("month", "day"), na.rm=TRUE)
> head(aqm)month day variable value
1 5 1 ozone 412 5 2 ozone 363 5 3 ozone 124 5 4 ozone 186 5 6 ozone 287 5 7 ozone 23
cast> acast(aqm, month ~ variable, mean)
ozone solar.r wind temp5 23.61538 181.2963 11.622581 65.548396 29.44444 190.1667 10.266667 79.100007 59.11538 216.4839 8.941935 83.903238 59.96154 171.8571 8.793548 83.967749 31.44828 167.4333 10.180000 76.90000
個人的には、{tidyr} spread, gatherの方が使いやすい

{data.table}
大規模データ用
http://www.slideshare.net/sfchaos/datatable
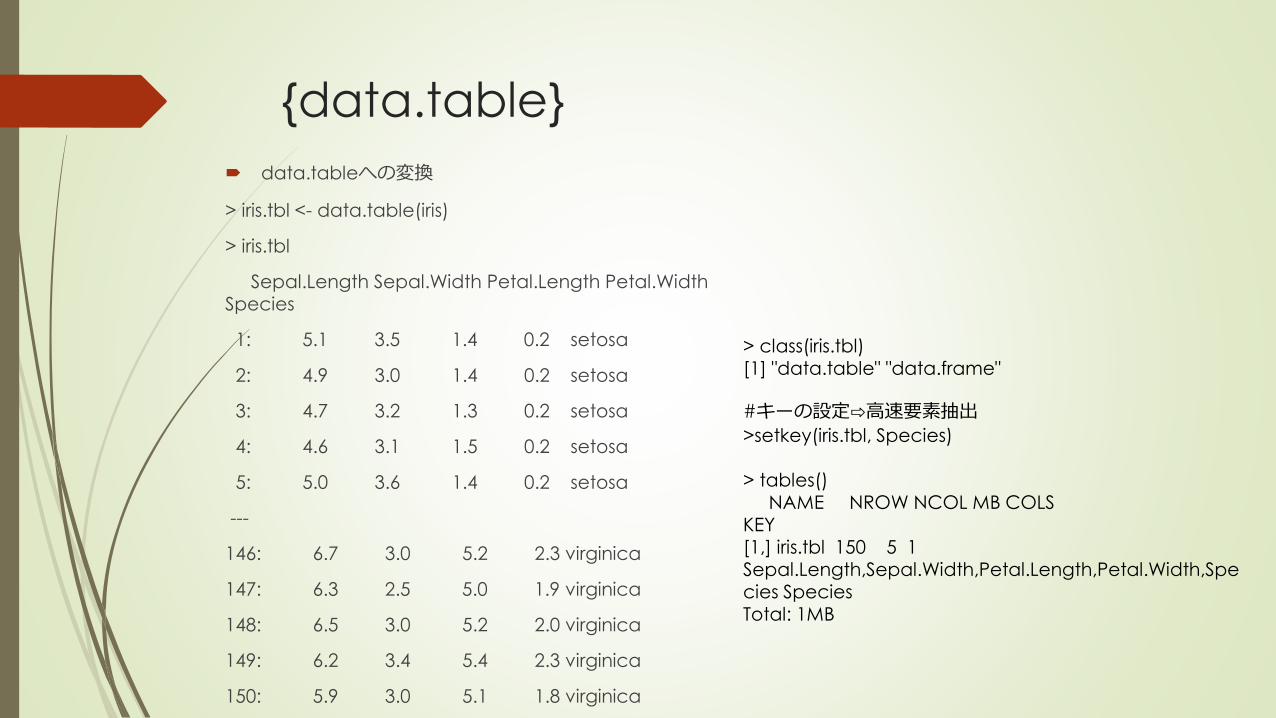
{data.table}
data.tableへの変換
> iris.tbl <- data.table(iris)
> iris.tbl
Sepal.Length Sepal.Width Petal.Length Petal.WidthSpecies
1: 5.1 3.5 1.4 0.2 setosa
2: 4.9 3.0 1.4 0.2 setosa
3: 4.7 3.2 1.3 0.2 setosa
4: 4.6 3.1 1.5 0.2 setosa
5: 5.0 3.6 1.4 0.2 setosa
---
146: 6.7 3.0 5.2 2.3 virginica
147: 6.3 2.5 5.0 1.9 virginica
148: 6.5 3.0 5.2 2.0 virginica
149: 6.2 3.4 5.4 2.3 virginica
150: 5.9 3.0 5.1 1.8 virginica
> class(iris.tbl)[1] "data.table" "data.frame"
#キーの設定⇨高速要素抽出
>setkey(iris.tbl, Species)
> tables()NAME NROW NCOL MB COLS
KEY
[1,] iris.tbl 150 5 1 Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Species SpeciesTotal: 1MB

{stringr}
文字列操作
文字列の結合: str_c
> str_c("ABC", "123")
[1] “ABC123” ⇦スペース無し結合
> paste("ABC", "123")
[1] "ABC 123“
> paste("ABC", "123“, sep=‘’)
[1] "ABC123“

{stringr}
文字列操作
文字列の結合: str_c
> str_c("ABC", "123")
[1] “ABC123” ⇦スペース無し結合
> paste("ABC", "123")
[1] "ABC 123“
> paste("ABC", "123“, sep=‘’)
[1] "ABC123“
文字列の長さ: str_length
> str_length("KOBER")
[1] 5
文字列の抽出: str_sub
> str_sub('this is a hampen', start = 3, end = 5)
[1] "is “
> str_sub('これははんぺんです', start = 3, end = 5)
[1] "ははん"
文字列の反復: str_dup
> str_dup('this is a hampen', times = 2)
[1] "this is a hampenthis is a hampen"
文字列の置換: str_replace> str_replace("これははんぺんです", "はんぺん", "ちくわ")
[1] "これはちくわです"

{stringr}
文字列操作
文字列の結合: str_c
> str_c("ABC", "123")
[1] “ABC123” ⇦スペース無し結合
> paste("ABC", "123")
[1] "ABC 123“
> paste("ABC", "123“, sep=‘’)
[1] "ABC123“
文字列の長さ: str_length
> str_length("KOBER")
[1] 5
文字列の抽出: str_sub
> str_sub('this is a hampen', start = 3, end = 5)
[1] "is “
> str_sub('これははんぺんです', start = 3, end = 5)
[1] "ははん"
文字列の反復: str_dup
> str_dup('this is a hampen', times = 2)
[1] "this is a hampenthis is a hampen"
文字列の置換: str_replace> str_replace("これははんぺんです", "はんぺん", "ちくわ")
[1] "これはちくわです"
半角⇔全角
> library(Nippon)> zen2han("12345ABC")
[1] "12345ABC"> x <- "12345ABC"
> x[1] "12345ABC"
> zen2han(x)
[1] "12345ABC"

{lubridate}
時間を扱う
{base}
as.Date("19810322", format = "%Y%m%d")
{lubridate}
ymd("19810322")

{lubridate}
時間を扱う
{base}
as.Date("19810322", format = "%Y%m%d")
{lubridate}
ymd("19810322")
> library(lubridate, type = ‘source’)
> ymd("19810322")
Error in gsub("+", "*", fixed = T, gsub(">", "_e>", num)) :
invalid multibyte string at
'<8c>)<28>?![[:alpha:]]))|((?<H_s_e>2[0-
4]|[01]?¥d)¥D+(?<M_s_e>[0-
5]?¥d)¥D+((?<OS_s_S_e>[0-5]?¥d¥.¥d+)|(?<S_s_e>[0-
6]?¥d))))'
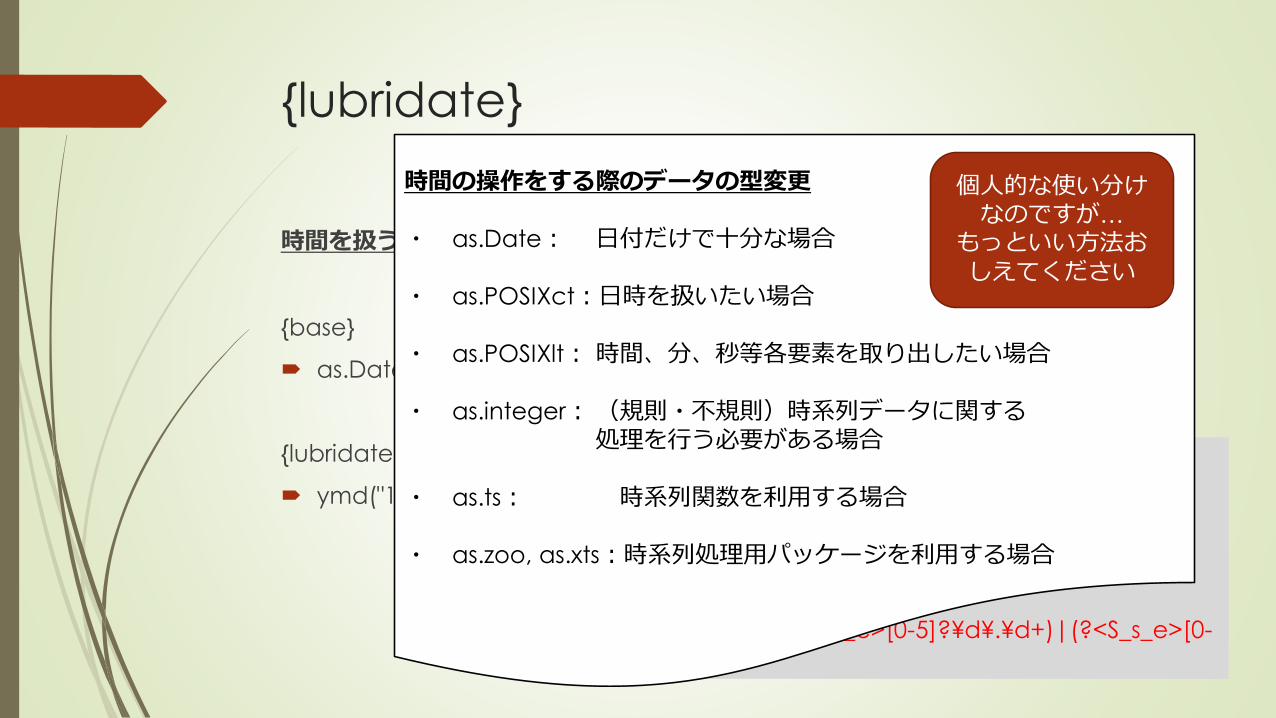
{lubridate}
時間を扱う
{base}
as.Date("19810322", format = "%Y%m%d")
{lubridate}
ymd("19810322")
> library(lubridate, type = ‘source’)
> ymd("19810322")
Error in gsub("+", "*", fixed = T, gsub(">", "_e>", num)) :
invalid multibyte string at
'<8c>)<28>?![[:alpha:]]))|((?<H_s_e>2[0-
4]|[01]?¥d)¥D+(?<M_s_e>[0-
5]?¥d)¥D+((?<OS_s_S_e>[0-5]?¥d¥.¥d+)|(?<S_s_e>[0-
6]?¥d))))'
時間の操作をする際のデータの型変更
・ as.Date: 日付だけで十分な場合
・ as.POSIXct:日時を扱いたい場合
・ as.POSIXlt: 時間、分、秒等各要素を取り出したい場合
・ as.integer:(規則・不規則)時系列データに関する処理を行う必要がある場合
・ as.ts: 時系列関数を利用する場合
・ as.zoo, as.xts:時系列処理用パッケージを利用する場合
個人的な使い分けなのですが…
もっといい方法おしえてください

Data Wrangling用パッケージ群
パッケージ 用途 コメント 解説 作者
plyr data wranglingWhile dplyr is my go-to package for wrangling data frames, the older plyr package still comes in handy when working with other types of R data such as lists. CRAN.
llply(mylist, myfunction) Hadley Wickham
reshape2 data wrangling
Change data row and column formats from "wide" to "long"; turn variables into column names or column names into variables and more. The tidyrpackage is a newer, more focused option, but I still use reshape2. CRAN.
See my tutorial Hadley Wickham
stringr data wrangling
Numerous functions for text manipulation. Some are similar to existing base R functions but in a more standard format, including working with regular expressions. Some of my favorites: str_pad and str_trim. CRAN.
str_pad(myzipcodevector, 5, "left", "0") Hadley Wickham
lubridate data wranglingEverything you ever wanted to do with date arithmetic, although understanding & using available functionality can be somewhat complex. CRAN.
mdy("05/06/2015") + months(1)More examples in the package vignette
Garrett Grolemund, Hadley Wickham & others
sqldfdata wrangling, data analysis
Do you know a great SQL query you'd use if your R data frame were in a SQL database? Run SQL queries on your data frame with sqldf. CRAN.
sqldf("select * from mydf where mycol >
4")G. Grothendieck
dplyrdata wrangling,
data analysis
The essential data-munging R package when working with data frames. Especially useful for operating on data by categories. CRAN.
See the intro vignette Hadley Wickham
data.tabledata wrangling, data analysis
Popular package for heavy-duty data wrangling. While I typically prefer dplyr, data.table has many fans for its speed with large data sets. CRAN.
Useful tutorial Matt Dowle & others
zoodata wrangling, data analysis
Robust package with a slew of functions for dealing with time series data; I like the handy rollmean function for calculating moving averages. CRAN.
rollmean(mydf, 7) Achim Zeileis & others
http://www.computerworld.com/article/2921176/business-intelligence/great-r-packages-for-data-import-wrangling-visualization.html
時間の操作をする際のデータの型変更
・ as.Date: 日付だけで十分な場合
・ as.POSIXct:日時を扱いたい場合
・ as.POSIXlt: 時間、分、秒等各要素を取り出したい場合
・ as.integer:(規則・不規則)時系列データに関する処理を行う必要がある場合
・ as.ts: 時系列関数を利用する場合
・ as.zoo, as.xts:時系列処理用パッケージを利用する場合
個人的な使い分けなのですが…
もっといい方法おしえてください
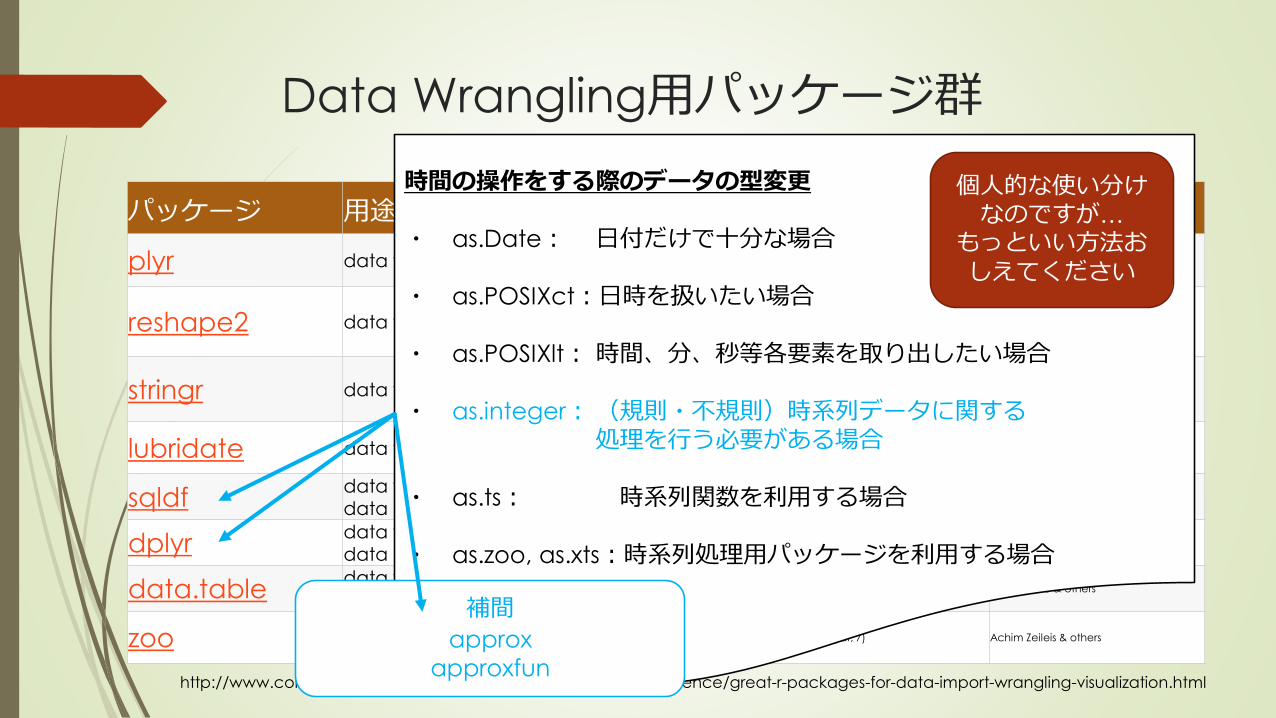
Data Wrangling用パッケージ群
パッケージ 用途 コメント 解説 作者
plyr data wranglingWhile dplyr is my go-to package for wrangling data frames, the older plyr package still comes in handy when working with other types of R data such as lists. CRAN.
llply(mylist, myfunction) Hadley Wickham
reshape2 data wrangling
Change data row and column formats from "wide" to "long"; turn variables into column names or column names into variables and more. The tidyrpackage is a newer, more focused option, but I still use reshape2. CRAN.
See my tutorial Hadley Wickham
stringr data wrangling
Numerous functions for text manipulation. Some are similar to existing base R functions but in a more standard format, including working with regular expressions. Some of my favorites: str_pad and str_trim. CRAN.
str_pad(myzipcodevector, 5, "left", "0") Hadley Wickham
lubridate data wranglingEverything you ever wanted to do with date arithmetic, although understanding & using available functionality can be somewhat complex. CRAN.
mdy("05/06/2015") + months(1)More examples in the package vignette
Garrett Grolemund, Hadley Wickham & others
sqldfdata wrangling, data analysis
Do you know a great SQL query you'd use if your R data frame were in a SQL database? Run SQL queries on your data frame with sqldf. CRAN.
sqldf("select * from mydf where mycol >
4")G. Grothendieck
dplyrdata wrangling,
data analysis
The essential data-munging R package when working with data frames. Especially useful for operating on data by categories. CRAN.
See the intro vignette Hadley Wickham
data.tabledata wrangling, data analysis
Popular package for heavy-duty data wrangling. While I typically prefer dplyr, data.table has many fans for its speed with large data sets. CRAN.
Useful tutorial Matt Dowle & others
zoodata wrangling, data analysis
Robust package with a slew of functions for dealing with time series data; I like the handy rollmean function for calculating moving averages. CRAN.
rollmean(mydf, 7) Achim Zeileis & others
http://www.computerworld.com/article/2921176/business-intelligence/great-r-packages-for-data-import-wrangling-visualization.html
時間の操作をする際のデータの型変更
・ as.Date: 日付だけで十分な場合
・ as.POSIXct:日時を扱いたい場合
・ as.POSIXlt: 時間、分、秒等各要素を取り出したい場合
・ as.integer:(規則・不規則)時系列データに関する処理を行う必要がある場合
・ as.ts: 時系列関数を利用する場合
・ as.zoo, as.xts:時系列処理用パッケージを利用する場合
補間
approx
approxfun
個人的な使い分けなのですが…
もっといい方法おしえてください



















![[EF] Summer packages 14](https://img.pdfslide.tips/doc/110x75/568c553f1a28ab4916c20543/ef-summer-packages-14.jpg)









