Embed Size (px)
Citation preview

50
Lời Mở ĐầuNhận dạng là bài toán xuất hiện cách đây khá lâu và vẫn luôn thu hút
được nhiều sự quan tâm, nghiên cứu. Đặc biệt là trong vài thập niên gần đây,
do sự thúc đẩy của quá trình tin học hoá trong mọi lĩnh vực, bài toán nhận dạng
không còn dừng lại ở mức độ nghiên cứu nữa mà nó trở thành một lĩnh vực để
áp dụng vào thực tế. Các bài toán nhận dạng đang được ứng dụng trong thực
tế hiện nay tập trung vào nhận dạng mẫu, nhận dạng tiếng nói và nhận dạng
chữ. Trong số này, nhận dạng chữ là bài toán được quan tâm rất nhiều và cũng
đã đạt được nhiều thành tựu rực rỡ. Các ứng dụng có ý nghĩa thực tế lớn có thể
kể đến như: nhận dạng chữ in dùng trong quá trình sao lưu sách báo trong thư
viện, nhận dạng chữ viết tay dùng trong việc phân loại thư ở bưu điện, thanh
toán tiền trong nhà băng và lập thư viện sách cho người mù (ứng dụng này có
nghĩa: scan sách bình thường, sau đó cho máy tính nhận dạng và trả về dạng tài
liệu mà người mù có thể đọc được).
Xuất phát từ yêu cầu thực tế, đang rất cần có nhưng nghiên cứu về vấn đề
này. Chính vì vậy tôi đã chọn đề tài nhận dạng ký tự viết tay làm đồ án tốt
nghiệp với mong muốn phần nào áp dụng vào bài toán thực tế.
Bài toán đã đặt ra phải giải quyết được những yêu cầu sau:
Nhận dạng được các ký tự từ ảnh đầu vào
Trích chọn được các đặc trưng của ảnh
Tiến hành nhận dạng với thuật toán Markov ẩn
Với nhưng yêu cầu đã đặt ra ở trên, cấu trúc của khóa luận sẽ bao gồm
những nội dung sau đây:
Chương 1: Giới thiệu đề tài
Giới thiệu về bài toán nhận dạng chữ viết tay, tình hình
nghiên cứu trong và ngoài nước, quy trình chung để giải quyết bài
toán và các phương pháp điển hình trong việc huấn luyện nhận dạng,
phạm vi của đề tài.
Chương 2: Cơ sở lý thuyết về tiền xử lý ảnh ký tự và trích chọn
đặc trưng

51
Trình bày lý thuyết về lọc nhiễu, nhị phân hóa, chuẩn hóa
kích thước, trích chọn đặc trưng ảnh ký tự.
Chương 3: CƠ SỞ LÝ THUYẾT VỀMARKOV ẨN
Trình bày các khái niệm cơ bản, thuật toán của mô hình
Markov
Chương 4: ỨNG DỤNG MÔ HÌNH MARKOV ẨN TRONG
NHẬN DẠNG CHỮ VIẾT TAY
Giới thiệu về thuật toán nhận dạng. Các bước cài đặt thuật
toán. Những khó khăn và giải pháp khắc phục.
Chương 5: CÀI ĐẶT CHƯƠNG TRÌNH VÀ ĐÁNH GIÁ KẾT
QUẢ
Trình bày môi trường cài đặt, giao diện chương trình, một số
class chính của chương trình. Đánh giá kết quả và đưa ra hướng
phát triển trong tương lại.
Phụ lục: Danh mục hình vẽ, bảng biểu và tài liệu tham khảo.
Đồ án này không tránh khỏi sự thiếu sót do hạn chế về thời
gian cũng như kiến thức. Em rất mong nhận được sự đóng góp ý
kiến của thầy hướng dẫn và các bạn để đạt kết quả tốt hơn.

52
CHƯƠNG I : GIỚI THIỆU ĐỀ TÀII.1 Giới thiệu về nhận dạng chữ viết tay
Nhận dạng chữ in: đã được giải quyết gần như trọn vẹn (sản phẩm
FineReader 9.0 của hãng ABBYY có thể nhận dạng chữ in theo 192 ngôn ngữ
khác nhau, phần mềm nhận dạng chữ Việt in VnDOCR 4.0 của Viện Công nghệ
Thông tin Hà Nội có thể nhận dạng được các tài liệu chứa hình ảnh, bảng và
văn bản với độ chính xác trên 98%).
Nhận dạng chữ viết tay: vẫn còn là vấn đề thách thức lớn đối với các nhà
nghiên cứu. Bài toàn này chưa thể giải quyết trọn vẹn được vì nó hoàn toàn phụ
thuộc vào người viết và sự biến đổi quá đa dạng trong cách viết và trạng thái
sức khỏe, tinh thần của từng người viết.
I.1.1 Các giai đoạn phát triển Giai đoạn 1: (1900 – 1980)
- Nhận dạng chữ được biết đến từ năm 1900, khi nhà khoa học người
Nga Tyuring phát triển một phương tiện trợ giúp cho những người mù.
- Các sản phẩm nhận dạng chữ thương mại có từ những năm1950, khi
máy tính lần đầu tiên được giới thiệu tính năng mới về nhập và lưu trữ
dữ liệu hai chiều bằng cây bút viết trên một tấm bảng cảm ứng .Công
nghệ mới này cho phép các nhà nghiên cứu làm việc trên các bài toán
nhận dạng chữ viết tay on-line.
- Mô hình nhận dạng chữ viết được đề xuất từ năm 1951 do phát minh
của M. Sheppard được gọi là GISMO, một robot đọc-viết.
- Năm 1954, máy nhận dạng chữ đầu tiên đã được phát triển bởi J.
Rainbow dùng để đọc chữ in hoa nhưng rất chậm.
- Năm 1967, Công ty IBM đã thương mại hóa hệ thống nhận dạng chữ. Giai đoạn 2: (1980 – 1990)
- Với sự phát triển của các thiết bị phần cứng máy tính và các thiết bị thu
thu nhận dữ liệu, các phương pháp luận nhận dạng đã được phát triển
trong giai đoạn trước đã có được môi trường lý tưởng để triển khai các

53
ứng dụng nhận dạng chữ.
- Các hướng tiếp cận theo cấu trúc và đối sánh được áp dụng trong nhiều
hệ thống nhận dạng chữ.
- Trong giai đoạn này, các hướng nghiên cứu chỉ tập trung vào các kỹ
thuật nhận dạng hình dáng chứ chưa áp dụng cho thông tin ngữ nghĩa.
Điều này dẫn đến sự hạn chế về hiệu suất nhận dạng, không hiệu quả
trong nhiều ứng dụng thực tế. Giai đoạn 3: (Từ 1990 đến nay)
- Các hệ thống nhận dạng thời gian thực được chú trọng trong giai đoạn
này.
- Các kỹ thuật nhận dạng kết hợp với các phương pháp luận trong lĩnh
vực học máy (Machine Learning) được áp dụng rất hiệu quả.
- Một số công cụ học máy hiệu quả như mạng nơ ron, mô hình Markov
ẩn, SVM (Support Vector Machines) và xử lý ngôn ngữ tự nhiên...
I.1.2 Tình hình nghiên cứu trong nước:
Nhận dạng chữ viết tay được chia thành hai lớp bài toán lớn là nhận dạng
chữ viết tay trực tuyến (online) và nhận dạng chữ viết tay ngoại tuyến (offline).
Trong nhận dạng chữ viết tay ngoại tuyến, dữ liệu đầu vào được cho dưới dạng
các ảnh được quét từ các giấy tờ, văn bản. Ngược lại nhận dạng chữ viết tay
trực tuyến là nhận dạng các chữ trên màn hình ngay khi nó được viết. Trong hệ
nhận dạng này máy tính sẽ lưu lại các thông tin về nét chữ như thứ tự nét viết,
hướng và tốc độ của nét…
Tại Việt Nam,
năm 2010, nhóm nghiên
cứu Huỳnh Hữu Lộc,
Lưu Quốc Hải, Đinh
Đức Anh Vũ (Khoa
Khoa học và Kỹ thuật
máy tính, Trường Đại
học Bách khoa TP Hồ

54
Chí Minh) đã đạt được những bước tiến đáng kể trong nhận dạng ký tự viết tay.
Hướng tiếp cận của nhóm nghiên cứu là nhận dạng dựa trên thông tin tĩnh. Dựa
trên nền tảng giải thuật rút trích thông tin theo chiều, nhóm tác giả đã cải tiến đa
số các bước để đạt được độ chính xác cao hơn trong việc nhận dạng ký tự
(khoảng 95%) và có những bước tiến đáng kể trong nhận dạng cả từ. Tuy nhiên
sản phẩm vẫn chưa nhận dạng được chữ viết tay tiếng Việt. Như vậy có thể thấy
nhận dạng chữ viết tay, đặc biệt chữ viết tay tiếng Việt hiện đang là một hướng
nghiên cứu rất được quan tâm hiện nay và đang còn nhiều vấn đề cần phải hoàn
thiện.
I.1.3 Tình hình nghiên cứu ở nước ngoài:
Nhận dạng chữ viết đã được nghiên cứu hơn 40 năm qua. Ngày nay nhận
dạng chữ viết đã nhận được sự quan tâm đáng kể do sự phát triển của các máy
tính cầm tay và điện thoại cầm tay dựa trên các bàn phím, chuột và nhiều dạng
thiết bị định vị khác. Các phương pháp này tỏ ra không hữu hiệu hoặc xử lý
chậm. Do đó người ta cần nghiên cứu phương pháp nghiên cứu phương pháp
nhận dạng chữ viết tay trên các máy Palm Pilot hay các máy TABLET PC.
I.2 Cách tiếp cận giải quyết bài toán
Nhận dạng chữ viết tay thường bao gồm năm giai đoạn: tiền xử lý

55
(preprocessing), tách chữ (segmentation), trích chọn đặc trưng(representation),
huấn luyện và nhận dạng (training and recognition), hậu xử lý (postprocessing).
- Tiền xử lý: giảm nhiễu cho các lỗi trong quá trình quét ảnh, hoạt động
viết của con người, chuẩn hóa dữ liệu và nén dữ liệu.
- Tách chữ: chia nhỏ văn bản thành những thành phần nhỏ hơn ,tách các
từ trong câu hay các kí tự trong từ.
- Biểu diễn, rút trích đặc điểm: giai đoạn đóng vai trò quan trọng nhất
trong nhận dạng chữ viết tay. Để tránh những phức tạp của chữ viết tay
cũng như tăng cường độ chính xác, ta cần phải biểu diễn thông tin chữ
viết dưới những dạng đặc biệt hơn và cô đọng hơn, rút trích các đặc
điểm riêng nhằm phân biệt các ký tự khác nhau.
- Huấn luyện và nhận dạng: phương pháp điển hình so trùng mẫu, dùng
thống kê, mạng nơ-ron ,mô hình markov ẩn ,trí tuệ nhân tạo hay dùng
phương pháp kết hợp các phương pháp trên.
- Hậu xử lý: sử dụng các thông tin về ngữ cảnh để giúp tăng cường độ
chính xác, dùng từ điển dữ liệu.
- Mô tả quá trình trong hệ thống nhận dạng .Sơ đồ gồm hai phần chính:
đường màu đỏ mô tả các bước để huấn luyện cho máy học, đường màu
xanh mô tả các bước trong quá trình nhận dạng:
Ban đầu các hình ảnh này đi qua giai đoạn chuyển ảnh về dạng ảnh nhị
phân (giai đoạn tiền xử lý). Ảnh sẽ được lưu trữ dưới dạng ma trận điểm, vị trí
pixel có nét vẽ sẽ mang giá trị 1, ngược lại có giá trị 0. Sau đó, ảnh được cắt
xén để ký tự nằm trọn trong một khung chữ nhật, các vùng không gian không
có nét vẽ được loại bỏ đi. Giải thuật cắt xén hiện thực đơn giản dựa trên ảnh nhị
phân và thu giảm ảnh đã được cắt xén về một ảnh có kích thước chung đã được
quy định trước.
Tiếp theo, ảnh đã được cắt xén và thu nhỏ được làm mỏng. Quá trình làm
mỏng này giúp ta chỉ lấy những thông tin cần thiết về hình dạng của ký tự và
loại bỏ các pixel dư thừa. Các chấm nhỏ trên hình biểu thị các pixel có giá trị 1
ban đầu. Sau khi làm mỏng, chỉ những pixel có ý nghĩa được giữ lại, và chúng

56
được biểu diễn bằng các chấm to trong hình.
Ảnh sau quá trình làm mỏng chứa hầu hết các thông tin về hình dạng của
ký tự. Những thông tin này sẽ được phân tích để rút trích ra các đặc điểm giúp
việc phân loại các ký tự với nhau. Phương thức này dựa trên thông tin về hình
dạng của ký tự như sự chuyển vị trí và sự chuyển chiều. Kết quả quá trình này
là các véc-tơ đặc điểm chứa thông tin về ký tự. Các thông tin này giúp máy lấy
được các đặc điểm của từng ký tự, phân loại chúng và tạo ra các thông tin cần
thiết để nhận dạng các ký tự có chung ý nghĩa. Do chữ viết mỗi người mỗi khác
nên ta không thể thu thập tất cả các nét chữ của từng người để máy học có thể
nhận diện mà chỉ có thể dựa trên một số mẫu nào đó để nhận ra các nét chữ của
những người viết khác nhau. Mô hình markov ẩn (Hidden Markov Model) có
thể giải quyết vấn đề này.
I.3 Tổng quan về các phương pháp huấn luyệnI.3.1 Mô hình Markov ẩn
Mô hình Markov ẩn (Hiden Markov Model - HMM) được giới thiệu vào
cuối những năm 1960. Cho đến hiện nay nó có một ứng dụng khá rộng như
trong nhận dạng giọng nói, tính toán sinh học (Computational Biology), và xử
lý ngôn ngữ tự nhiên… HMM là mô hình máy hữu hạn trạng thái với các tham
số biểu diễn xác suất chuyển trạng thái và xác suất sinh dữ liệu quan sát tại mỗi
trạng thái.
Mô hình Markov ẩn là mô hình thống kê trong đó hệ thống được mô hình
hóa được cho là một quá trình Markov với các tham số không biết trước, nhiệm
vụ là xác định các tham số ẩn từ các tham số quan sát được. Các tham số của
mô hình được rút ra sau đó có thể sử dụng để thực hiện các phân tích kế tiếp.
Trong một mô hình Markov điển hình, trạng thái được quan sát trực tiếp
bởi người quan sát, và vì vậy các xác suất chuyển tiếp trạng thái là các tham số
duy nhất.

57
Hình 1.4 Mô hình Markov ẩn
xi: Các trạng thái trong mô hình Markov
aij: Các xác suất chuyển tiếp
bij: Các xác suất đầu ra
yi: Các dữ liệu quan sát
Mô hình Markov ẩn thêm vào các đầu ra: mỗi trạng thái có xác suất phân
bố trên các biểu hiện đầu ra có thể. Vì vậy, nhìn vào dãy của các biểu hiện được
sinh ra bởi HMM không trực tiếp chỉ ra dãy các trạng thái. Ta có tìm ra được
chuỗi các trạng thái mô tả tốt nhất cho chuỗi dữ liệu quan sát được bằng cách
tính.
)(/)|()|( XPXYPXYP
Y1 Y2 … … … Yn
X1 X2 … … … Xn
Hình 1.5 Đồ thị vô hướng HMM
Ở đó Yn là trạng thái tại thời điểm thứ t=n trong chuỗi trạng thái Y, Xn là dữ
liệu quan sát được tại thời điểm thứ t=n trong chuỗi X. Do trạng thái hiện tại chỉ
phụ thuộc vào trạng thái ngay trước đó với giả thiết rằng dữ liệu quan sát được tại
thời điểm t chỉ phụ thuộc và trạng thái t. Ta có thể tính:
n
ttttt YXPYYPYXPYPXYP
21111 )|(*)|()|()(),(

58
Một số hạn chế của mô hình Markov để tính được xác suất P(Y,X) thông
thường ta phải liệt kê hết các trường hợp có thể của chuỗi Y và chuỗi X. Thực tế
thì chuỗi Y là hữu hạn có thể liệt kê được, còn X (các dữ liệu quan sát) là rất
phong phú. Để giải quyết các vấn đề này HMM đưa ra giả thiết về sự độc lập
giữa các dữ liệu quan sát: Dữ liệu quan sát được tại thời điểm t chỉ phụ thuộc vào
trạng thái tại thời điểm đó. Hạn chế thứ hai gặp phải là việc sử dụng xác suất
đồng thời P(Y, X) đôi khi không chính xác vì với một số bài toán thì việc sử dụng
xác suất điều kiện P(Y | X) cho kết quả tốt hơn rất nhiều.
I.3.2 Máy vector hỗ trợ
Có thể mô tả 1 cách đơn giản về bộ phân lớp SVM như sau: Cho trước 2
tập dữ liệu học, mỗi tập thuộc về 1 lớp cho trước, bộ phân lớp SVM sẽ xây dựng
mô hình phân lớp dựa trên 2 tập dữ liệu này. Khi có một mẫu mới được đưa vào,
bộ phân lớp sẽ đưa ra dự đoán xem mẫu này thuộc lớp nào trong 2 lớp đã định.
Phương pháp này được Vapnik và cộng sự đề xuất năm 1992, lấy nền tảng từ lý
thuyết học thống kê của Vapnik & Chervonenkis vào năm 1960.
Đặc trưng cơ bản quyết định khả năng phân loại của một bộ phân loại là
hiệu suất tổng quát hóa, hay là khả năng phân loại những dữ liệu mới dựa vào
những tri thức đã tích lũy được trong quá trình huấn luyện. Thuật toán huấn luyện
được đánh giá là tốt nếu sau quá trình huấn luyện, hiệu suất tổng quát hóa của bộ
phân loại nhận được cao. Hiệu suất tổng quát hóa phụ thuộc vào hai tham số là
sai số huấn luyện và năng lực của máy học. Trong đó sai số huấn luyện là tỷ lệ lỗi
phân loại trên tập dữ liệu huấn luyện. Còn năng lực của máy học được xác định
bằng kích thước Vapnik Chervonenkis (kích thước VC). Kích thước VC là một
khái niệm quan trọng đối với một họ hàm phân tách (hay là bộ phân loại). Đại
lượng này được xác định bằng số điểm cực đại mà họ hàm có thể phân tách hoàn
toàn trong không gian đối tượng, Một bộ phân loại tốt là bộ phân loại đơn giản
nhất và đảm bảo sai số huấn luyện nhỏ. Phương pháp SVM được xây dựng dựa
trên ý tưởng này.Công thức SVM
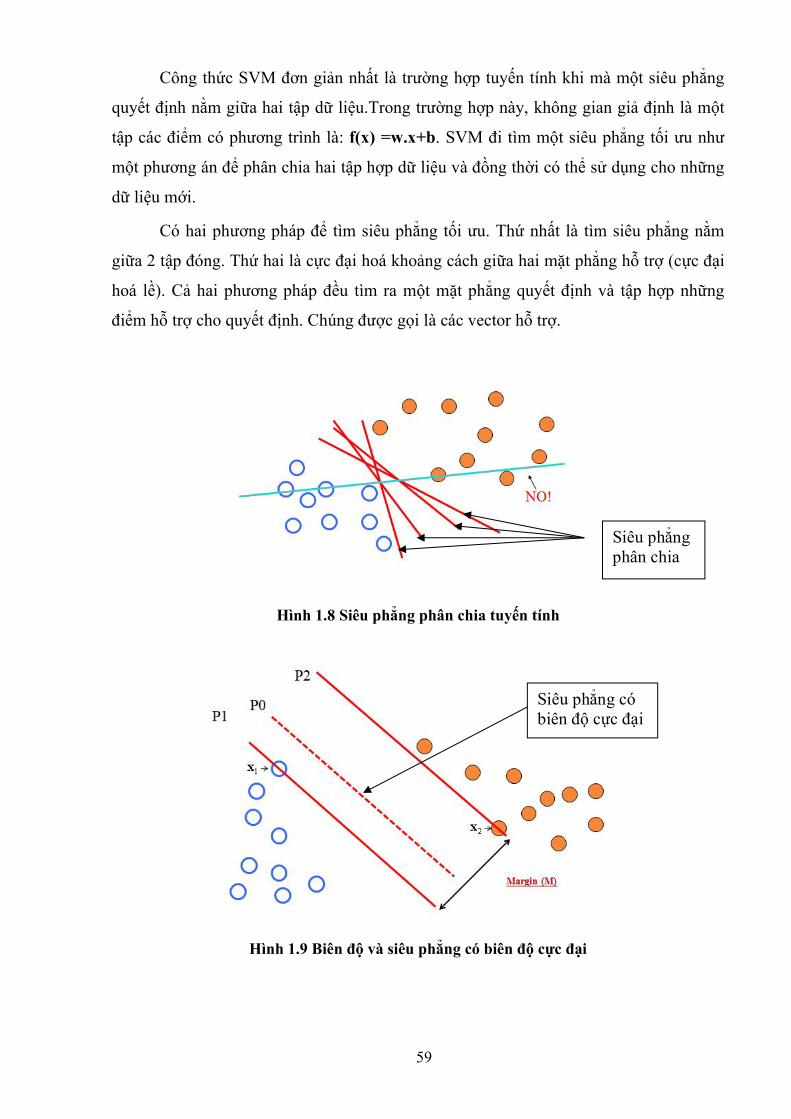
59
Công thức SVM đơn giản nhất là trường hợp tuyến tính khi mà một siêu phẳng
quyết định nằm giữa hai tập dữ liệu.Trong trường hợp này, không gian giả định là một
tập các điểm có phương trình là: f(x) =w.x+b. SVM đi tìm một siêu phẳng tối ưu như
một phương án để phân chia hai tập hợp dữ liệu và đồng thời có thể sử dụng cho những
dữ liệu mới.
Có hai phương pháp để tìm siêu phẳng tối ưu. Thứ nhất là tìm siêu phẳng nằm
giữa 2 tập đóng. Thứ hai là cực đại hoá khoảng cách giữa hai mặt phẳng hỗ trợ (cực đại
hoá lề). Cả hai phương pháp đều tìm ra một mặt phẳng quyết định và tập hợp những
điểm hỗ trợ cho quyết định. Chúng được gọi là các vector hỗ trợ.
Hình 1.8 Siêu phẳng phân chia tuyến tính
Hình 1.9 Biên độ và siêu phẳng có biên độ cực đại
Siêu phẳngphân chia
Siêu phẳng cóbiên độ cực đại
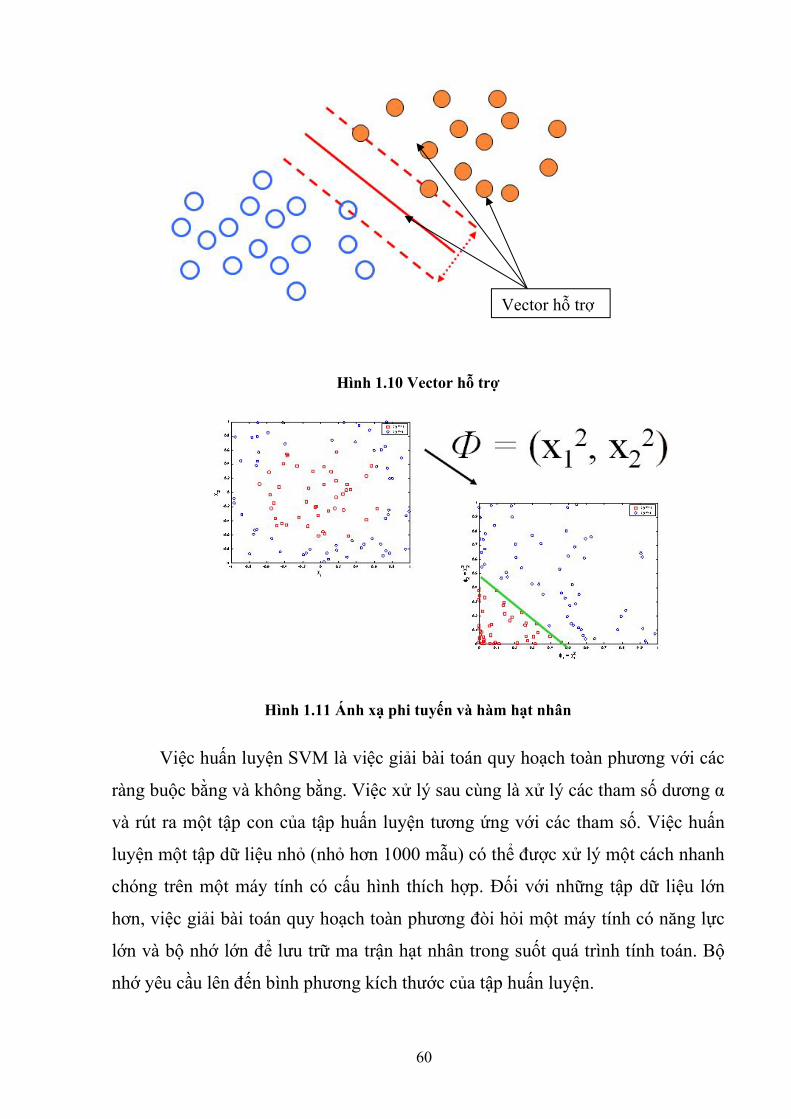
60
Hình 1.10 Vector hỗ trợ
Hình 1.11 Ánh xạ phi tuyến và hàm hạt nhân
Việc huấn luyện SVM là việc giải bài toán quy hoạch toàn phương với các
ràng buộc bằng và không bằng. Việc xử lý sau cùng là xử lý các tham số dương α
và rút ra một tập con của tập huấn luyện tương ứng với các tham số. Việc huấn
luyện một tập dữ liệu nhỏ (nhỏ hơn 1000 mẫu) có thể được xử lý một cách nhanh
chóng trên một máy tính có cấu hình thích hợp. Đối với những tập dữ liệu lớn
hơn, việc giải bài toán quy hoạch toàn phương đòi hỏi một máy tính có năng lực
lớn và bộ nhớ lớn để lưu trữ ma trận hạt nhân trong suốt quá trình tính toán. Bộ
nhớ yêu cầu lên đến bình phương kích thước của tập huấn luyện.
Vector hỗ trợ
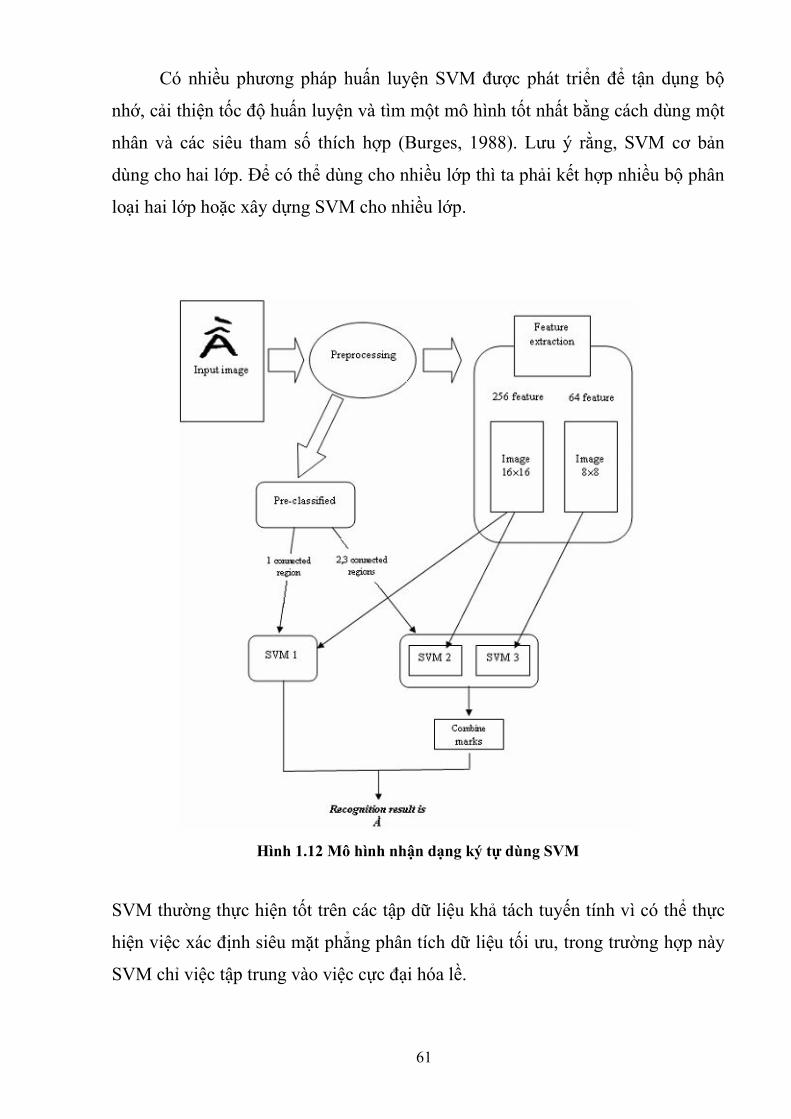
61
Có nhiều phương pháp huấn luyện SVM được phát triển để tận dụng bộ
nhớ, cải thiện tốc độ huấn luyện và tìm một mô hình tốt nhất bằng cách dùng một
nhân và các siêu tham số thích hợp (Burges, 1988). Lưu ý rằng, SVM cơ bản
dùng cho hai lớp. Để có thể dùng cho nhiều lớp thì ta phải kết hợp nhiều bộ phân
loại hai lớp hoặc xây dựng SVM cho nhiều lớp.
Hình 1.12 Mô hình nhận dạng ký tự dùng SVM
SVM thường thực hiện tốt trên các tập dữ liệu khả tách tuyến tính vì có thể thực
hiện việc xác định siêu mặt phẳng phân tích dữ liệu tối ưu, trong trường hợp này
SVM chỉ việc tập trung vào việc cực đại hóa lề.

62
I.3.3 Mạng Neural
Là phương pháp được sử dụng trong đồ án. Quá trình huấn luyện là quá trình học
các tập mẫu để điều chỉnh trọng số liên kết. Giải thuật huấn luyện thường được dùng
nhất là giải thuật lan truyền ngược sai số Back Progration. Nội dung này sẽ được trình
bày chi tiết trong chương 3 và chương 4.
Đồ án sử mạng neural gồm 60 đầu vào được lấy bằng các ký tự đã được tách biên thành
chuỗi Fourier gồm 6 thành phần liên thông và 10 giá trị đối với mỗi thành phần, sử
dụng hàm Sigmoid làm hàm ngưỡng.
Hình 1.13 Sơ đồ một mạng neural nhận dạng ký tự
So với hai phương pháp còn lại, phương pháp sử dụng mạng Neural được lựa chọn là do
những ưu điểm sau đây:
Tính phi tuyến.
Mô hình tổng quát cho ánh xạ từ tập vào đến tập ra.
Có thể yêu cầu sự tiến hóa nhanh của hàm mục tiêu.
Chấp nhận lỗi ở các ví dụ học.
Thích ứng với nhiễu dữ liệu.
I.4 Phạm vi đề tài
Đồ án “Nghiên cứu phương pháp nhận dạng chữ viết tay và cài đặt chương trình thử
nghiệm” được thực hiện với mục đích giải quyết một lớp con các bài toàn nhận dạng
chữ viết tay, tập trung vào bước nhận dạng ký tự tiếng Việt đơn lẻ do đây là bước
mà mọi hệ nhận dạng chữ viết tiếng Việt cần phải có.

63
Từ đó tạo cơ sở để tiếp theo có thể xây dựng và phát triển một sản phẩm nhận dạng
chữ viết tay hoàn chỉnh trên các thiết bị di động, áp dụng vào việc hỗ trợ việc học
tập và sinh hoạt của người khiếm thị.
Đồ án sẽ tập trung vào phân tích 3 thành phần chính của một hệ nhận dạng: Tiền xử
lý, trích chọn đặc trưng và huấn luyện bằng mô hình markov ẩn. Từ đó cài đặt
chương trình mô phỏng trên PC bằng ngôn ngữ C#
CHƯƠNG II
CƠ SỞ LÝ THUYẾT VỀ TIỀN XỬ LÝ ẢNH
VÀ TRÍCH CHỌN ĐẶC TRƯNGII.1 Tổng quan về tiền xử lý ảnh
Đầu vào của quá trình xử lý ảnh là các ảnh gốc ban đầu, thu được qua
scanner. ảnh ban đầu thường có chất lượng thấp do ảnh hưởng của nhiễu, bị
nghiêng, bị đứt nét nên chúng ta cần phải có một quá trình tiền xử lý ảnh để
nâng cao chất lượng ảnh đầu vào trước khi đưa vào nhận dạng. Quá trình này
bao gồm công đoạn khôi phục ảnh và tăng cường ảnh .
Khôi phục ảnh nhằm mục đích loại bỏ hay làm giảm tối thiểu các ảnh
hưởng của môi trường bên ngoài lên ảnh thu nhận được. Công đoạn khôi phục
ảnh bao gồm các bước như lọc ảnh, khử nhiễu, quay ảnh, qua đó giảm bớt các
biến dạng do quá trình quét ảnh gây ra và đưa ảnh về trang thái gần như ban
đầu.
Tăng cường ảnh là một công đoạn quan trọng, tạo tiền đề cho xử lý ảnh.
Tăng cường ảnh không phải làm tăng lượng thông tin trong ảnh mà là làm nổi
bật những đặc trưng của ảnh giúp cho công việc xử lý phía sau được hiệu quả
hơn. Công đoạn này bao gồm các công việc như lọc độ tương phản, làm trơn
ảnh, nhị phân hóa.
Các công đoạn của tiền xử lý ảnh sẽ được trình bày cụ thể trong các phần
tiềp theo.
II.2 Các công đoạn tiền xử lý
Giai đoạn tiền xử lý văn bản là giai đoạn quan trọng, có ảnh hưởng trực
tiếp đến độ chính xác của quá trình nhận dạng, tuy nhiên nó cũng làm tăng thời

64
gian chung của cả hệ thống. Vì vậy, tùy theo chất lượng ảnh thu nhận được của
từng trường hợp cụ thể, mà chúng ta chọn sử dụng một hoặc một số thủ tục tiền
xử lý. Thậm chí, trong trường hợp văn bản đầu vào có chất lượng tốt và cần ưu
tiên tốc độ xử lý, chúng ta có thể bỏ qua giai đoạn tiền xử lý này. Thông thường,
chúng ta vẫn phải thực hiện một số thủ tục quan trọng nhất.
Các thủ tục này bao gồm :
Chuyển xám
Phân ngưỡng,
Lọc nhiễu,
Căn chỉnh độ lệch trang,
Làm trơn ảnh.
II.2.1 Chuyển xám ảnh.
Đơn vị tế bào của ảnh số là pixel. Tùy theo mỗi định dạng là ảnh màu hay
ảnh xám mà từng pixel có thông số khác nhau. Đối với ảnh màu từng pixel sẽ
mang thông tin của ba màu cơ bản tạo ra bản màu khả kiến là Đỏ (R), Xanh lá
(G) và Xanh biển (B) [Thomas 1892]. Trong mỗi pixel của ảnh màu, ba màu cơ
bản R, G và B được bố trí sát nhau và có cường độ sáng khác nhau. Thông
thường, mổi màu cơ bản được biểu diễn bằng tám bit tương ứng 256 mức độ
màu khác nhau. Như vậy mỗi pixel chúng ta sẽ có màu (khoảng 16.78
triệu màu). Đối với ảnh xám, thông thường mỗi pixel mang thông tin của 256
mức xám (tương ứng với tám bit) như vậy ảnh xám hoàn toàn có thể tái hiện
đầy đủ cấu trúc của một ảnh màu tương ứng thông qua tám mặt phẳng bit theo
độ xám.
Trong hầu hết quá trình xử lý ảnh, chúng ta chủ yếu chỉ quan tâm đến cấu
trúc của ảnh và bỏ qua ảnh hưởng của yếu tố màu sắc. Do đó bước chuyển từ
ảnh màu thành ảnh xám là một công đoạn phổ biến trong các quá trình xử lý
ảnh vì nó làm tăng tốc độ xử lý là giảm mức độ phức tạp của các thuật toán trên
ảnh.
Chúng ta có công thức chuyển các thông số giá trị màu của một pixel
thành mức xám tương ứng như sau:

65
G = ỏ.CR + õ.CG + ọ.CB
Trong đó các giá trị CR, CG và CB lần lượt là các mức độ màu Đỏ, Xanh
lá và Xanh biển của pixel màu.
II.2.2 Phân ngưỡng ảnh (Nhị phân ảnh)
Phân ngưỡng hay còn gọi là nhị phân hóa. Mục đích của nó là chuyển từ
ảnh mầu, ảnh đa cấp xám sang ảnh nhị phân (ảnh 2 cấp xám, ảnh đen trắng).
Thuật toán phân ngưỡng cài đặt ở đây sử dụng hàm phân ngưỡng :
1 if Source(x,y) >= T
Dest(x,y)=
0 if Source(x,y) < T
Trong đó, Source(x,y) là giá trị điểm ảnh ở vị trí (x,y) của ảnh nguồn,
Dest(x,y) là giá trị điểm ảnh tương ứng ở vị trí (x,y) của ảnh đích. T là giá trị
ngưỡng.
Giá trị cụ thể của ngưỡng phụ thuộc vào từng ảnh, vùng ảnh đầu vào đang
xét và không thể lấy cố định. Ví dụ như trên hình 3.2.2, hình a) là ảnh ban đầu,
hình e) thể hiện biểu đồ histogram (biểu đồ tần suất), hình b,c,d thể hiện ảnh đã
được nhị phân hóa với cùng ngưỡng thấp, trung bình và ngưỡng cao. Chúng ta
có thể thấy là giá trị ngưỡng trong hình 3.2.2d là thích hợp hơn cả.
a) ảnh gốc ban đầu b) Ngưỡng thấp (90)
c ) Ngưỡng trung bình (128) d ) Ngưỡng cao (225)
Hình 3.2.2 - Phương pháp lấy ngưỡng
Người ta đã đề xuất nhiều phương pháp để xác định giá trị ngưỡng.

66
Một phương pháp là thiết lập ngưỡng sao cho số lượng các điểm đen đạt một
ngưỡng chấp nhận được theo phân phối xác suất mức xám. Ví dụ, chúng ta có
thể biết rằng các kí tự chiếm 25% diện tích của một trang văn bản thông thường.
Vì thế chúng ta có thể thiết lập ngưỡng sao cho số lượng điểm đen còn lại
chiếm 1/4 trang văn bản. Một cách tiếp cận khác là chọn ngưỡng nằm ở vị trí
thấp nhất trên biểu đồ histogram giữa hai đỉnh của nó . Tuy nhiên việc xác
định vị trí này thường rất khó khăn do hình dạng của histogram thường lởm
chởm. Một giải pháp để giải quyết vấn đề này là xấp xỉ giá trị của histogram
giữa hai đỉnh với một hàm giải tích và sử dụng vi phân để xác định điểm thấp
nhất. Ví dụ, coi x và y lần lượt là hoành độ và tung độ trên histogram.
Chúng ta có thể sử dụng hàm : y = ax 2 + bx + c. Với a,b,c là các hằng số
làm hàm xấp xỉ đơn giản cho histogram ở vị trí giữa hai đỉnh của nó. Vị trí
thấp nhất sẽ có tọa độ x = -b/2a.
Phương pháp xấp xỉ các giá trị của histogram và tìm vị trí thấp nhất cho
giá trị ngưỡng tốt hơn nhưng lại yêu cầu nhiều tài nguyên về tính toán để thực
hiện cũng độ phức tạp trong việc cài đặt nên trong phạm vi khóa luận này
chúng tôi chọn giải pháp tìm ngưỡng theo phân phối xác suất. Phương pháp
này đơn giản hơn và kết quả của nó tương đối đáp ứng được các yêu cầu cho
việc nhận dạng.
II.2.3 Nhiễu ảnh
Trong xử lý ảnh các ảnh đầu vào thường được thu thập từ các nguồn ảnh
khác nhau và các ảnh thu thập đươc thường có nhiễu và cần loại bỏ nhiễu hay
ảnh thu được không sắc nét, bị mờ cần làm rõ các chi tiết trước khi đưa vào xử
lý.
Một số loại nhiễu ảnh thường gặp:
Nhiễu cộng : nhiễu cộng thường phân bố khắp ảnh. Nếu ta gọiảnh quan sát( ảnh thu được) là X_qs, ảnh gốc la X_gốc vànhiễu là #. ảnh thu được có thể biểu diễn bởi:
X_qs = X_gốc + #.

67
Nhiễu nhân : Nhiễu nhân thường phân bố khắp ảnh. Nếu ta gọiảnh quan sát( ảnh thu được) là X_qs, ảnh gốc la X_gốc vànhiễu là #. ảnh thu được có thể biểu diễn bởi:
X_qs = X_gốc # #.
Nhiễu xung : Nhiễu xung thường gây đột biến ở một số điểmcủa ảnh. Trong hầu hết các trường hợp thừa nhận nhiễu là tuầnhoàn. Các phương pháp lọc đề cập trong báo cáo xét với cáctrường hợp ảnh chỉ có sự xuất hiện của nhiễu.
II.2.4 Một số phương pháp lọc nhiễuII.2.4.1 Bộ lọc Mean
Mạch lọc là một mặt nạ có kích thước NxN, trong đó tất cả các hệ số đều
bằng 1. Đáp ứng là tổng các mức xám của NxN pixels chia cho NxN. Ví dụ mặt nạ
3x3 thì đáp ứng là tổng mức xám của 9 pixels chia cho 9. Ví dụ mặt nạ 1/9x
Nhân chập mặt nạ với tất cả các pixel của ảnh gốc chúng ta sẽ thu được ảnh
kết quả qua bộ lọc Mean theo công thức sau:
Hình 3.2.4.1 ảnh thu được khi qua bộ lọc Mean
Với f[i,j] là giá trị pixel kết quả, s(k,l) là các giá trị pixel ảnh gốc được mặt
nạ chập lên và S là kích thước mặt nạ. Bộ lọc Mean có vai trò làm trơn ảnh có
thể xem như bộ lọc thông cao, nhưng lại làm mờ đường biên của các đối tượng
bên trong ảnh, làm mất tín hiệu cận nhiễu và không lọc được nhiễu xung.II.2.4.2 Bộ lọc Median
Để thực hiện lọc Median trong lân cận của một pixel chúng ta sắp xếp các
1 1 1
1 1 1
1 1 1

68
giá trị của pixel và các lân cận, xác định trung vị Median và định giá trị pixel. Ví
dụ như một lân cận 3x3 có các giá trị: 10, 20, 20, 20, 15, 20, 20, 25, 100. Các giá
trị này được sắp xếp lại theo thứ tự từ thấp đến cao: 10, 15, 20, 20, 20, 20, 20, 25,
100. Giá trị median là 20. Do đó về nguyên lý thì mạch median có thể tách được
các điểm có cường độ sáng lớn như nhiễu xung và lọc các điểm có cường độ sáng
tức thì (xung) hay còn gọi là các nhiễu muối tiêu. Ví dụ về ảnh sau khi lọc nhiễu
Hình 3.2.4.2 ảnh sau khi qua bộ lọc Median
II.2.4.3 Bộ lọc GaussVề bản chất bộ lọc Gauss có phương thức tiến hành tương đồng với bộ lọc
trung bình nhưng có thêm tác động của các trọng số. Các trọng số này được tính tỷ
lệ với hàm Gauss theo khoảng cách tới điểm tính toán. Công thức tính giá trị cho
từng pixel ảnh gốc theo lọc Gauss như sau:
Trong đó g(i,j) là giá trị độ xám pixel kết quả, N là kích thước cửa sổ, f(m,n)
là giá trị độ xám của pixel đang tác động,G(i-m,j-n) là các trọng số. Các trọng số
được tính toán tỷ lệ theo hàm Gauss bằng khoảng cách tới điểm tính toán.
Thực hiện phép nhân chập giữa mặt nạ Gauss và ảnh gốc chúng ta thu được
ảnh kết quả được xử lý bằng mạch lọc Gauss. Vai trò của bộ lọc Gauss cũng làm
trơn ảnh như bộ lọc trung bình, tuy nhiên bộ lọc Gauss cho chất lượng ành kết quả
cao hơn vì có sự tập trung trong số vào pixel đang xét tại vị trí trung tâm.
Hình 3.2.4.3 ảnh thu được sau khi xử lý qua bộ lọc Gauss

69
II.2.5 Làm trơn ảnh, tách biên đối tượngSau quá trình lọc nhiễu, các từ, kí tự trên ảnh thu được thường bị đứt nét
do ảnh hưởng của bộ lọc nhiễu. Vì thế cần có một bước để nối lại các nét bị
đứt này.
Phương pháp Canny Là một phương pháp tách biên ảnh doFrancis Canny tìm ra tại phòng thí nghiệm ảnh thuộc MIT.Quá trình tiến hành thuật toán trải qua một số bước như sau:
Làm trơn ảnh bằng bộ lọc Gauss nhằm giảm thiểu
ảnh hưởng của nhiễu và các chi tiết không mong
nuôn trong cấu trúc ảnh.
Tính gradient của ảnh nhờ một trong các toán
tử:Roberts, Sobel hay Prewitt…
và
Xác định ngưỡng:
Với T được chọn là các phần tử cạnh
Dựa vào hướng của dradient để loại bỏ những điểm không thực sự là biên.
Chúng ta kiểm tra các điểm MT(i,j) nếu có giá trị lớn hơn hai điểm lân cận dọc
theo phương gradient (i,j) thì giữ nguyên và ngược lại thì gán giá trị bằng 0.
Dùng ngưỡng kép ụ1 và ụ2 (ụ1< ụ2) tạo ra các điểm trung gian nhằm nối
liến các điểm biên đã xác định được từ trước theo phương thức sau:
Những điểm M(i,j) có giá trị gradient lớn hơn ụ2 thì được xem là điểm
biên. Những điểm M(i,j) có giá trị gradient nhỏ hơn ụ1 thì loại bỏ. Với những
điểm có giá trị gradient nằm trong khoảng ụ1 và ụ2 thì kiểm tra thêm nếu nó
liền kề với một điểm có gradient lớn hơn ụ1 thì điểm này được xem là điểm biên.
Kết quả chúng ta sẽ thu được các đường biên tạo từ vô số các điểm biên liền kề
liên tục.

70
II.3 Căn chỉnh độ lệch trangViệc căn chỉnh độ lệch trang là cần thiết vì ảnh nhận được sau quá trình
scan thường bị lệch một góc nghiêng so với phương ban đầu. Công việc này
bao gồm hai thao tác cơ bản :
Thao tác xác định góc nghiêng của trang văn bản Thao tác xoay trang văn bản theo góc nghiêng đã xác định.
Trong đó, xác định góc nghiêng là thao tác quan trong nhấttrong việc căn chỉnh độ lệch trang. Để xác định góc nghiêng,người ta thường dùng 3 phương pháp : Sử dụng biến đổiHough (Line fitting), phương pháp láng giềng gần nhất(nearest neighbours) và sử dụng tia quay (project profile) .
Biến đổi Hough rất hữu ích cho việc dò tìm đường thẳng trong trang văn bản
vì thế rất thích hợp cho việc xác định góc nghiêng của trang văn bản gồm các
thành phần là các dòng văn bản. Tuy nhiên, biến đổi Hough sử dụng rất nhiều
tính toán do phải thao tác trên từng điểm ảnh riêng lẻ. Người ta đã cải tiến để tăng
tốc độ thực hiện bằng cách thực hiện tính toán trên chùm điểm ảnh. Những
chùm điểm ảnh này là các dải liên tục các điểm đen liên tiếp nhau theo chiều
ngang hoặc chiều doc. Mỗi chùm được mã hóa bởi độ dài của và vị trí kết thúc
của nó. Với cải tiến này thì thuật toán này thích hợp với các góc nghiêng ~15o và
cho độ chính xác rất cao. Tuy nhiên, cải tiến này làm tăng tốc độ thuật toán
nhưng vẫn rất chậm so với các phương pháp khác. Hơn nữa, trong trường hợp
văn bản là thưa thớt, thuật toán này tỏ ra không hiệu quả.
Phương pháp láng giềng gần nhất (nearest neighbours) dựa trên một nhận
xét rằng trong một trang văn bản, khoảng cách giữa các kí tự trong một từ và
giữa các kí tự của từ trên cùng một dòng là nhỏ hơn khoảng cách giữa hai dòng
văn bản, vì thế đối với mỗi kí tự, láng giềng gần nhất của nó sẽ là các kí tự liền kề
trên cùng một dòng văn bản.
Bước đầu tiên trong thuật toán này là xác định các thành phần liên
thông trên ảnh. Bước tiếp theo, tìm láng giềng gần nhất của mỗi thành phần
liên thông này, đó là miền liên thông có khoảng cách Ơclit ngắn nhất giữa tâm
của hai miền liên thông. Sau đó, thực hiên tính góc của các vector nối tâm của
các thành phần láng giềng gần nhất. Tất cả các vector cùng phương được nối

71
với nhau và tích lũy thanh biểu đồ histogram về số lượng các vector theo các
phương. Khi đó, trên biểu đồ histogram xuất hiện một vị trí có số lượng
vector nhiều nhất và cũng chính là đỉnh của biểu đồ.Vị trí đó chính là góc
nghiêng của trang văn bản.
Chi phí tính toán của phương pháp này đã giảm đi nhiều so với phương
pháp sử dụng biến đổi Hough tuy nhiên vẫn còn rất cao. Độ chính xác của
phương pháp này phụ thuộc rất nhiều vào số thành phần của một kí tự trong
văn bản. Đối với các kí tự có nhiều thành phần ví dụ như chữ ẩ có 3 thành
phần gồm thân, mũ và dấu hỏi. Khi đó, láng giềng gần nhất của mỗi phần sẽ là
một trong hai thành phần còn lại chứ không phải là kí tự liền kề với nó. Điều đó
làm giảm đi độ chính xác của thuật toán, đồng thời khiến cho nó không thích
hợp với chữ tiếng việt.
L’O Gorman đã phát triển thuật toán với ý tưởng là với mỗi thành phần
lấy k láng giềng (k có thể là 4 hoặc 5) thay vì lấy một láng giềng duy nhất. Và
góc thu được được sử dụng như là góc nghiêng ước lượng. Góc nghiêng
ước lượng này được sử dụng để loại bỏ các liên kết mà góc của nó không gần
với góc ước lương. Sau đó, thực hiện xác định lại góc nghiêng theo các liên
kết được giữ lại. ý tưởng này đã cải thiện được độ chính xác của thuật toán
nhưng lại đòi hỏi chi phí tính toán cao hơn. Trên thực tế, phương pháp này
được gọi là phương pháp docstrum – thực hiện cả việc xác định góc nghiêng
và phân tích cấu trúc trang .
Phương pháp sử dụng tia quay (project profile) là phương pháp thường
được sử dụng trong các hệ thống thương mại. Project profile là biểu đồ các
giá trị điểm đen được tích lũy theo các dòng quét song song với một phương
xác định trên toàn bộ ảnh. Biểu đồ này thường được ghi theo phương ngang và
dọc của ảnh, gọi là các histogram chiếu ngang và histogram chiếu dọc
Để sử dụng project profile để dò tìm độ nghiêng của văn bản, đòi hỏi phải
có sự đính hướng cho trước Postl. Đầu tiên, văn bản được xoay với một số
góc nghiêng trong khoảng cho trước và tính biểu đồ histogram theo chiều
ngang ở mỗi vị trí đó. Tính độ biến thiên của histogram, vị trí góc nghiêng có

72
độ biến thiên lớn nhất sẽ là góc nghiêng văn bản cần tìm
Hình 3.3 – Phương pháp Postl tính góc nghiêng
H.S.Braid đã tiến hành cải biến phương pháp project profile. Theo đó,
người ta tiến hành tìm các thành phần liên thông, mỗi thành phần liên thông
được đại diện bởi tâm ở đáy của hình chữ nhật bao quanh nó. Tiếp theo, các
thành phần liên thông được nối với nhau. Tiến hành xoay văn bản ở một
số vị trí và tiến hành tính biểu đồ histogram ở mỗi vị trí. Vị trí có độ biến
thiên lớn nhất của histogram chính là vị trí góc nghiêng cần tìm. Cải biến này
đã làm tăng đáng kể tốc độ của phương pháp Project profile, đồng thời độ
chính xác của nó đạt khá cao (~0.50), thích hợp với các trang có độ nghiêng
trong khoảng ~100
Trong phạm vi khóa luận này, tôi đã chọn thực hiên phương pháp project
profile vì nó tương đối đơn giản, tốc độ nhanh đồng thời có độ chính xác khá
cao. Phù hợp với bài toán đã đặt ra.
II.4 Trích chọn đặc trưng
Trích chọn đặc trưng là quá trình tìm ra các thông tin hữu ích và đặc trưng
nhất cho mẫu đầu vào để sử dụng cho quá trình nhận dạng. Trong lĩnh vực nhận
dạng, trích chọn đặc trưng là một bước rất quan trọng, nó có ảnh hưởng lớn đến
tốc độ và chất lượng nhận dạng. Trích chọn đặc trưng như thế nào để vẫn đảm
bảo không mất mát thông tin và thu gọn kích thước đầu vào là điều vẫn đang
được các nhà nghiên cứu quan tâm.
II.4.1 Một số đặc trưng cơ bản của mẫu Đặc trưng thống kê
73
Hình 2.7 Phân vùng
Hình 2.8 Lược đồ mức xám (histogram)

74
Đặc trưng hình học và hình thái: là các đặc trưng dựa trêncác yếu tố nguyên thủy (đoạn thẳng, cung) tạo ra các ký tự.Các ký tự có thể được phân biệt bằng độ đo của các đại lượnghình học như tỉ số giữa chiều rộng và chiều cao của khungchứa ký tự, quan hệ khoảng cách giữa hai điểm, độ dài một nét,độ dài tương quan giữa hai nét, tỉ lệ giữa các chữ hoa và chữthường trong một từ, độ dài từ…Vì thế các ký tự được tổ chứcthành các tập hợp của các yếu tố nguyên thủy, sau đó đưa cácyếu tố nguyên thủy vào các đồ thị liên quan.
Đặc trưng hướng : Các ký tự được mô tả như các vector màcác phần tử của nó là các giá trị thống kê về hướng. Việc chọnđặc trưng để nâng cao độ chính xác của bài tốn nhận dạng làhết sức khó khăn, đòi hỏi rất nhiều thời gian và quyết định rấtnhiều đến độ chính xác. Hơn nữa, do biến dạng khá lớn trongchữ viết tay nên để hạn chế người ta thường chia ô trên ảnh vàđặc trưng được rút trong các ô đó.
Hình 2.9 Đặc trưng hướng
II.4.2 Một số phương pháp trích chọn đặc trưng
Ta có một số phương pháp trích chọn đặc trưng đơn giản nhưng hiệu quả
sau, có thể áp dụng cho các tập chữ viết tay rời rạc.
Trọng số vùng: Ảnh ký tự sau khi tiền xử lý kích thước được chuẩn hoá về mn
điểm ảnh. Đây là cách được áp dụng trong đồ án.
n
m

75
Hình 2.10 Cách chia ô ký tự
Hình 2.11 Ký tự đã được chia ô
Trích chọn chu tuyến (Contour profiles): Phần được trích chọn là
khoảng cách từ biên của khung chứa đến điểm đen đầu tiên của chữ
trên cùng một dòng quét.
Phương pháp trích chọn này mô tả tốt các khối bên ngoài của chữ
và cho phép phân biệt một số lượng lớn các ký tự. Ví dụ như đối
với ảnh có kích thước 14*9, có 14 trên, 14 dưới, 9 trái, 9 phải, tổng
cộng là 46 đặc trưng.
Hình 2.12 Trích chọn chu tuyến
Trích chọn đặc trưng wavelet Haar
Từ ảnh nhị phân kích thước 2n x 2n , quá trình trích chọn đặc trưng được
mô tả theo thuật toán sau:Input : Ma trận vuông (A, n) cấp 2nKhởi tạo: Queue = NULLBegin
Tính Fi = Tổng các điểm đen trong toàn bộ ma trận (A, n),PUSH ((A,n), Queue),
End,

76
BeginWhile Queue != NULL Do{
POP (Queue,(A,n)),If(n>1){
Chia ảnh thành 4 phần: A1, A2, A3, A4,For (j=1, i<=4, j++)
PUSH((Aj, n div 2), Queue),}
Gọi S1, S2, S3, S4 là tổng các điểm đen tương ứng với A1, A2, A3,A4
Tính Fi+1 = S1 + S2,Fi+2 = S2 + S3,Fi+3 = S4,
i = i+3,}
Hình 2.13 Trích chọn đặc trưng wavelet Haar
Hình 2.14 Dãy đặc trưng wavelet Haar
Phương pháp trích chọn đặc trưng này sẽ tạo ra một dãy số các đặc trưng giảm dần.
Với cùng một chữ thì các giá trị lớn ở đầu dãy tương đối ổn định, và có thể đại diện cho
hình dạng khái quát của chữ. Còn các giá trị ở cuối dãy nhỏ dần và không ổn định, thể
hiện sự đa dạng trong từng chi tiết của chữ.
Trích chọn đặc trưng chuỗi Fourier

77
Biên của ảnh là một trong những đặc trưng quan trọng nhất trong việc mô tả ảnh.
Trong đồ án này sẽ sử dụng phương pháp trích chọn đặc trưng bằng cách dùng biến đổi
Fourier của biên ảnh. Giả sử biên hình dạng được trích chọn trong quá trình tiền xử lý là:
(x(t), y(t)), t = 0,1,…,N-1.
Nếu ta xem xét hình dạng trên một mặt phẳng phức, ta có thể thu được hàm phức
một chiều f(t) bằng các lần theo biên của nó, f(t) là một số phức được tổng quát hóa từ
hệ tọa độ đường bao.
( ) [ ( ) ] [ ( ) ]c cf t x t x j y t y
Với (xc, yc) là trọng tâm của hình được bao bởi biên, được tính theo công thức:
1
0
1 ( )N
tc Nx x t
,
1
0
1 ( )N
tc Ny y t
f(t) miêu tả biên và là dấu hiệu bất biến đối với phép dịch chuyển. Biến đổi Fourier
rời rạc DFT của f(t) được cho bởi:
21
0
1 ( )utN
Nut
F f t eN
Với u từ 0 đến M-1, với M là số mẫu f(t) thu thập được.
II.5 Kết luận chươngTrong chương này, khóa luận đã trình bày một số bước cơ bản trong quá
trình tiền xử lý ảnh đầu vào, phục vụ cho nhận dạng. Đó là nhị phân hóa, căn
chỉnh độ lệch trang. Khóa luận đã trình bày một số phương pháp thường dùng
trong việc nhị phân hóa và căn chỉnh độ lệch trang văn bản. Chỉ ra những ưu,
nhược của mỗi phương pháp, đồng thời chọn cài đặt những phương pháp thích
hợp nhất cho bài toán đã đặt ra.

78
CHƯƠNG III: CƠ SỞ LÝ THUYẾT VỀ MARKOV ẨN
III.1 Giới thiệuMô hình Markov ẩn (Hidden Markov Model) là mô hình thống kê trong
đó hệ thống được mô hình hóa được cho là quá trình Markov với các tham số
không biết trước và nhiệm vụ là xác định các tham số ẩn từ các tham số quan
sát được dựa trên sự thừa nhận này .Các trham số của mô hình được rút ra sau
đó có thể sử dụng được để thực hiện các phân tích kế tiếp ,ví dụ cho các ứng
dụng nhận dạng mẫu.
Trong một mô hình Markov điển hình , trang thái được quan sát trực tiếp
bởi người quan sát và vì vậy các xác suất chuyển tiếp trạng thái là các là các
tham số duy nhất ,mô hình Markov ẩn thêm vào các đầu ra : mỗi trạng thái có
xác suất phân bố trên các biểu hiện đầu ra có thể .Vì vậy, nhìn vào dãy các biểu
hiện được sinh ra bởi HMM không trực tiếp chỉ ra dãy các trạng thái .Đây là
một mô hình toán thống kê có ứng dụng rộng rãi trong Tin sinh học.
Mô hình Markov ẩn đã được sử dụng rất thành công trong lĩnh vực nhận
dạng tiếng nói. Chính sự thành công này đã mở ra một hướng tiếp cận mới
trong lĩnh vực nhận dạng ảnh văn bản. Có thể nói, thời gian gần đây đã xuất
nhiều những công trình nghiên cứu nhận dạng ảnh văn bản bao gồm cả chữ in
và chữ viết tay, online và offline sử dụng mô hình này. Một trong những điểm
mạnh nhất của mô hình Markov ẩn là nó cho phép tích hợp các bước phân đoạn,
nhận dạng và xử lý văn phạm trong một tiến trình. Chương trình này sẽ trình
bày về cơ sở lý thuyết cũng như một số bài toán điển hình của mô hình Markov
ẩn.
Về bản chất, mô hình Markov là một phương pháp mô hình tín hiệu như
một chuỗi kết xuất có thể quan sát, được sinh ra bởi một số tiến trình được gọi
là nguồn (source). Việc mô hình tín hiệu theo cách này cho phép chúng ta khả
năng nghiên cứu về nguồn tạo ra tín hiệu mà không cần phải kiểm tra một cách
trực tiếp lên nguồn đó. Với mô hình như vậy, chúng ta có khả năng nhận dạng
tín hiệu được sinh bởi nguồn hoặc tiên đoán chuỗi quan sát trong tương lai gần

79
đúng nhất khi cho được cho trước một dãy quan sát cục bộ nào đó. Mô hình
Markov ẩn dựa trên giả thiết rằng tín hiệu được sinh bởi một nguồn Markov –
đó là một kiểu nguồn mà các mẫu tượng đang được sinh chỉ phụ thuộc vào một
số cố định các mẫu tượng đã được sinh trước đó. Bậc của mô hình chính là con
số cố định này. Do độ phức tạp của mô hình tỷ lệ với bậc của nó nên các mô
hình bậc một và hai thường được sử dụng nhiều nhất trong các ứng dụng.
Các kết xuất tương ứng với một mẫu tượng có thể được mô tả ở dạng rời
rạc hoặc liên tục. Dạng rời rạc như các ký tự từ bảng chữ cái, các vector được
lượng hóa từ codebook trong dạng liên tục có thể là các mẫu tiếng nói hoặc bản
nhạc được biểu diễn dạng sóng liên tục.
Trong trường hợp tổng quát một tín hiệu có thể được phân làm hai loại:
loại có các đặc tính thống kê thay đỏi theo thời gian và ngược lại. Một tín hiệu
bất biến với thời gian có thể là một sóng sine mf tất cả các tham số của nó (biên
độ, tần số và pha) là không thay đổi trong khi tín hiệu thay đổi theo thời gian có
thể là dạng tổ hợp các sóng sine với biên độ, tần số và pha thay đổi theo thời
gian. Một cách tiếp cận phổ biến thường thấy trong mô hình Markov ẩn là biểu
diễn tín hiệu thay đổi theo thời gian bằng một số ngắn các phân đoạn bất biến
theo thời gian. Những phân đoạn này chính là cái tạo nên chuỗi kết xuất.
Hình 1 Tiến trình Markov rời rạc theo thời gian với các trạng thái rời rạc
Ta sẽ xem xét biểu đồ trạng thái được cho trong hình 2 dưới đây

80
Đây là phương pháp dùng để mô hình một tiến trình xảy ra trong thế giới
thực bao gồm các trạng thái rời rạc cùng với những phép dịch chuyển tương ứng.
Hình vẽ minh họa 4 trạng thái liên kết đầy đủ. Xét một ví dụ cụ thể. Giả thiết rằng
biểu đồ trạng thái này biểu diễn màu sắc của hệ thống đèn giao thông. Có 4 màu
sắc thường thấy trên các hệ thống đèn bao gồm: đỏ (red), đỏ vàng (red_amber),
vàng (amber) và xanh (green). Chuỗi dịch chuyển trạng thái được định nghĩa theo
chu kỳ: red red_amber green amber red … Giả sử rằng hệ thống thay
đổi trạng thái theo chuỗi này tại mỗi bước thời gian rời rạc. Do đó nếu đánh nhẵn
mỗi cung với xác suất dịch chuyển trạng thái tương ứng thì sẽ có 4 cung với xác
suất bằng 1 và phần không thể dịch chuyển còn lại – có xác suất bằng 0.0. Có thể
biểu diễn các xác suất này dạng ma trận aij. Cho trước trạng thái qi ở thời điểm t
và gọi S0, S1, …, SN-1 là N trạng thái tương ứng:
aij = P[qi = S | qi-1 = Si] 0 N (1)

81
Các hệ số dịch chuyển trạng thái aij tuân theo qui ước thống kê chuẩn:
không âm và có tổng theo j tại một giá trị i cố định bằng 1.
Theo như các mô tả ở trên, các phép dịch chuyển là đã xác định, tuân theo
một chuỗi không đổi. Bây giờ giả sử rằng hệ thống đèn giao thông này bị lỗi theo
đó trật tự thay đổi trạng thái của nó là ngẫu nhiên và ta muốn lượng giá các tham
số của mô hình, aij, sao cho phù hợp với những gì thu nhận được. Mô hình hoạt
động của hệ thống đèn giao thông theo cách này chính là dạng Markov bậc nhất –
trạng thái của mô hình tại thời điểm t chỉ phụ thuộc vào trạng thái ở thời điểm t-1.
Một cách tổng quát hơn, ta có thể viết:
P[qi = S | qi-1 = Si, qi-1 = Sk, …] = P[qi = S | qi-1 = Si] (2)
Mở rộng hơn, ta giả thiết rằng hệ thống đèn thay đổi trạng thái tại mỗi
bước thời gian nhưng nó cũng có thể ở trong một trạng thái cố định với số bước
thời gian không biết trước. Khi đó mô hình được thay đổi tương ứng với khoảng
thời gian mà nó ở lại trong mỗi trạng thái bằng cách lượng giá xác suất aij. Ví dụ
giả sử sau khi chuyển sang trạng thái red, xác suất để dịch chuyển sang trạng thái
red_amber là 0,6 và xác suất ở lại trạng thái red là 0,4 ta có thể lượng giá a10 =
0,6 và a00 = 0,4. Mô hình bây giờ sẽ dự đoán rằng xác suất ở nguyên trạng thái
red cho hai bước tiếp theo sẽ là 0.42 = 0,16, 0,43 = 0,064 cho ba bước tiếp theo…
Đây là dạng mật độ xác suất theo số mũ.
Raviv mô hình tri thức ngữ cảnh để nhận dạng văn bản bằng cách xấp xỉ sự
phụ thuộc giữa các chữ liên tiếp nhau như một chuỗi Markov bậc n. Tuy nhiên
những mô hình loại này bị giới hạn về độ chính xác khi được sử dụng để mô hình
các tiến trình trong thế giới thực. Một dạng phức tạp hơn là mô hình Markov ẩn
(HMM).
HMM rất giống với mô hình Markov ngoại trừ các trạng thái trong HMM
không biểu diễn các quan sát của hệ thống. Thay vào đó, có một phân bố xác suất
kết hợp với mỗi trạng thái, được định nghĩa trên tất cả các quan sát có thể. Do đó
việc biểu diễn này mang tính thống kê hai lần – chuỗi quan sát được sinh ra như
một hàm thống kê tại các trạng thái của mô hình và mô hình thay đổi trạng thái ở

82
mỗi bước thời gian như một hàm thống kê các phép dịch chuyển trước đó. Như
vậy một HMM – N trạng thái, bậc một với dãy quan sát rời rạc có thể được định
nghĩa bởi: = (A, B, ) trong đó:
- A: tập aij, xác suất thay đổi từ trạng thái Si sang trạng thái Sj
- B: tập bi(k), xác suất quan sát mẫu tượng k ở trạng thái Sj.
- : phân bố xác suất ở trạng thái ban đầu.
Các thao tác của HMM được minh họa bằng một ví dụ trong hình 3. Có ba
chiếc cốc chứa một hỗn hợp các hình vuông và hình tròn. Tại mỗi thời điểm,
người ta sẽ đi đến chiếc cốc tiếp theo để lấy ra một đối tượng từ nó: hình tròn
hoặc hình vuông. Như vậy ta có thể mô hình chuỗi quan sát này bằng một HMM
3 trạng thái. Mỗi trạng thái tượng trưng cho một cái cốc với các tham số {aij}3x3
biểu diễn dự báo cách mà người ta sẽ di chuyển. Tham số {bj(k)}3x2 biểu diễn xác
suất lấy ra được hình tròn hoặc hình vuông từ một trong số ba chiếc cốc trên. Rõ
ràng các xác suất này là khác nhau ứng với từng chiếc cốc.
Hình 5.2 Ví dụ về hình vuông và hình tròn
Có 3 bài toán cơ bản đối với HMM:
Bài toán 1: Cho dãy quan sát O = (o1o2…oi) và mô hình = (A, B, ). Cần
phải tính xác suất của chuỗi quan O cho bởi mô hình, P(O|) như thế nào là hiệu
quả?
Bài toán 2: Cho chuỗi quan sát O = (o1o2…oi) và mô hình = (A, B, ), làm
thế nào để chọn được một dãy trạng thái tương ứng q = (q1q2…qi) sao cho dãy
trạng thái này là tối ưu theo ý nghĩa nào đó?
Bài toán 3: Cần phải hiệu chỉnh các tham số của mô hình = (A, B, ) như
thế nào để tìm cực đại xác suất P(O|)?
Phần sau sẽ trình bày tóm lược lời giải cho ba bài toán này

83
III.2 HUẤN LUYỆN VÀ CHO ĐIỂM HMMIII.2.1 Các tiêu chuẩn huấn luyện
Tất cả các phương pháp huấn luyện và cho điểm được phác hoạ ở đây dựa
trên tiêu chuẩn xác suất cực đại – ML (Maximun Likelihood). Cho trước một dãy
huấn luyện của các quan sát, một mô hình bắt đầu với các tham số ban đầu, sau
đó được ước lượng một cách lặp lại sao cho xác suất mà mô hình đưa ra những
huấn luyện tăng. Khi xác suất đạt đến cực đại, quá trình huấn luyện dựng. Tối ưu
xác suất cực đại tiêu chuận được cho bởi:= (2)
trong đó , v= 1,2,…,V chỉ các HMM khác nhau và Ov là dãy huấn luyện cho mô hình .
Tuy nhiên, ta sẽ chỉ ra rằng tiếp cận ML không tối ưu một cách cần thiết
khi tín hiệu được lấy mẫu không tuân theo những ràng buộc của HMM hoặc
ngược lại các tham số của HMM khó ước lượng được một cách đáng tín cậy – có
lẽ do dữ liệu không đầy đủ. Trong trường hợp này, những tiêu chuẩn huấn luyện
khác có thể cải tiến hiệu suất của hệ thống.
Tiêu chuẩn thông tin tương hỗ cực đại – MMI (Maximun Mutual
Information) dành cho trường hợp trong đó một số mô hình được thiết kế và mục
tiêu là cực đại khả năng của mỗi mô hình để phân biệt giữa các dãy quan sát tự
phát sinh và các dãy được phát sinh bởi các mô hình khác.
Một khả năng có thể thi hành tiêu chuẩn MMI là:
= (4)
Cách này nhằm mục đích phân biệt chính xác mô hình từ tất cả các mô
hình khác trên dãy huấn luyện . Bằng cách tính tổng tất cả các dãy huấn luyện,
tập phân biệt nhất không khả thi vì cần các thủ tục tối ưu tổng quát. Lớp HMM
của Krogh là một tổng quát hóa của tiêu chuẩn MMI. Lớp này bao gồm một
HMM với một phân bố output trên các nhãn lớp công việc phát ra (emission).
Quá trình huấn luyện tối ưu xác suất gán nhãn, có thể được xem như huấn luyện
giám sát.
Một tiêu chuẩn huấn luyện khác giả thiết rằng tín hiệu được mô hình không
cần thiết phải được sinh ra từ nguồn Markov. Một lời giải thông tin phân biệt cực

84
đại – MDI (Maximum Discrimination Information) sẽ cực tiểu entropi chéo (cross
entropy) giữa tập hợp các mật độ xác suất của tín hiệu hợp lệ và tập hợp các mật
độ xác suất của HMM. Dưới đây là một số lời giải cho các bài toán đã được nêu ở
phần trước.
III.2.2 Giải thuật tiến – lùi (forward-backward algorithm)
Giải thuật tiến lùi đã được xem là cơ sở cho những lời giải đối với ba bài
toán của mô hình Markov ẩn. Thuật toán này bao gồm việc tính toán hai biến,
biến tiến i(i) và biến lùi i(i) là các hàm biểu thị thời gian và trạng thái. Bài toán 1
có thể được giải quyết sử dụng biến tiến, tìm xác suất để mô hình mô hình đưa ra
một dãy quan sát. Bài toán 2, tìm trạng thái có khả năng nhất của hệ thống tại mỗi
khoảng thời gian, mà có thể nhận được từ thuật toán. Một thủ tục có thể được sử
dụng làm lời giải cho bài toán 3.
Biến tiến i(i) biểu diễn xác suất của một dãy quan sát riêng phần O0,O1, …,
Oi được quan sát trong khi mô hình đang ở trong trạng thái Si tại thời điểm t. Có
N trạng thái được định nghĩa cho mô hình trong đó qi là trạng thái mà nó đang
đứng và có thể sinh ra bất kỳ một trong K ký hiệu quan sát Oi ở mỗi khoảng thời
gian t, t=0,1,2,… T-1
i(i) = P[O0O1…Oi, qi = Si] (5)
Phương trình này có thể được giải bằng quy nạp.
Giá trị khởi đầu:
0(j) = (Oi) 0 N (6)
Bước quy nạp tiếp theo:
i+1(j) = []bj(Oi+1) 0 T-2 0 N (7)
Giá trị kết thúc:
P[O|] = (8)
Biến lùi i(i) biểu diễn xác suất của dãy quan sát từng phần được quan sát từ thời
điểm t đến khi kết thúc. Nó được cho khi mô hình đang ở trong trạng thái Si vào
thời điểm t:
i(i) = P[Oi+1Oi+2…| qi = Si] (9)
Một lần nữa, phương trình này có thể được giải bằng quy nạp.

85
Giá trị ban đầu có thể chọn tùy ý:
(i) = 1 0 N (10)
Bước quy nạp tiếp theo:
(i) = = (11)
Hình 3 minh họa tính toán tiến lùi với biểu đồ lưới mắt cáo. Mắt cáo là một
đồ thị có hướng trong đó cá nút biểu diễn các trạng thái của mô hình và các cung
biểu diễn tất cả các trạng thái có thể của mô hình trong một khoảng thời gian. Các
cột được sắp xếp theo thời gian tăng lên từ trái sang phải.
Hình 3a. Sơ đồ lưới cho 3 trạng thái kết nối đầy đủ
Hình 3b. Thao tác cơ bản của tính toán tiến
Hình 3: Biểu đồ lưới minh họa tính toán tiến lùi. Có 3 trạng thái liên thông đầy
đủ được biểu diễn bởi lưới dạng mắt cáo, như một đường đi được minh họa từ
mỗi trạng thái đến tất cả các trạng thái khác nhau trong mỗi bước thời gian.
Hoạt động cơ bản được trình bày như sau: giá trị của mỗi được tính cho trạng
thái bằng cách lấy tổng cho tất cả các trạng thái i, nhân với xác suất biến đổi ,
sau đó nhân với xác suất phát ra (Oi+1)

86
Quá trình tìm kiếm dãy các trạng thái mà mô hình có khả năng đi qua nhất
để đưa ra dãy quan sát có thể được thực hiện theo một số cách. Để tìm trạng thái
có xác suất cực đại qi tại thời điểm t đòi hỏi định nghĩa một biến i(i) khác:
i(i) = (12)
qi = arg 0 t < T (13)
Biến này tìm trạng thái xác suất cao nhất vì i(i) tính xác suất của dãy quan
sát từng phần O0, O1, …, Oi và trạng thái Si tại thời điểm t trong khi i(i) tính
những quan sát còn lại được cho trong trạng thái ở thời điểm t. Hệ số chuẩn hóa
trên mẫu số làm cho biến này là một độ đo xác suất.
Dù tìm kiếm trạng thái có khả năng nhất tại mỗi thời điểm là một cách tiếp
cận có thể chấp nhận được với các mô hình liên thông đầy đủ, nó có thể đạt các
kết quả mâu thuẫn nhau với các mô hình trong đó không phải tất cả các biến đổi
đều được phép. Bởi vì ước lượng một trạng thái riêng lẻ qi không xem xét nó có
hợp lệ hay không trong ngữ cảnh của trạng thái được ước lượng tại những vị trí
thời gian kề nhau. Thuật toán Viterbi, được trình bày chi tiết trong phần sau cho
phép ước lượng dãy các trạng thái đạt xác suất cực đại, sẽ là một tiếp cận khác
cho bài toán ước lượng trạng thái này.
III.2.3 Ước lượng lại tham số - Giải thuật Baum-Welch
Những phương trình ước lượng lại của Baum-Welch được sử dụng để đưa
ra một ước lượng tốt hơn cho các tham số từ mô hình hiện thời. Ước lượng mô
hình là một hệ thống đóng sao cho quá trình huấn luyện được thực hiện trước khi
nhận dạng. Một dãy quan sát huấn luyện được sử dụng để cải tiến một cách lặp
lại đến khi xác suất mà mô hình đưa ra dãy quan sát đạt đến một cực đại mà tại
điểm đó các tham số của mô hình hội tụ. Người ta đã chứng tỏ rằng sự hội tụ này
ít nhất sẽ là một cực đại cục bộ của bề mặt tối ưu. Bởi vì bề mặt này phức tạp và
có nhiều cực đại cục bộ, việc lựa chọn cẩn thận những giá trị ban đầu của các
tham số là cần thiết để đảm bảo rằng các cực đại cục bộ này trên thực tế nằm
trong một cực đại toàn cục.

87
Các phương trình ước lượng lại cho HMM rời rạc dựa trên việc đếm những
lần xảy ra các biến cố. được ước lượng như số các biến đổi kỳ vọng từ trạng thái
Si sang trạng thái Sj chia số các biến đổi kỳ vọng từ trạng thái Si. Cuối cùng, bj(k)
được ước lượng như số lần kỳ vọng trong trạng thái Sj và ký hiệu quan sát k chia
cho số lần kỳ vọng trong trạng thái Sj. = ().
Cần định nghĩa thêm một biến nữa, (i,j) là xác suất nằm trong trạng thái Si
tại thời điểm t và trạng thái Sj tại thời điểm t+1, cho trước mô hình và dãy quan
sát.
(i,j) = (14)
ta có phương trình ước lượng như sau:
= tần số kỳ vọng ở trạng thái Si tại thời điểm t=0 (15)
= (i) (16)
= (kỳ vọng số dịch chuyển từ trạng thái Si sang trạng thái Sj) / (kỳ vọng số dịch
chuyển từ trạng thái Si) (17)
= (18)
(k) = (kỳ vọng số lần ở trạng thái Sj, ký hiệu quan sát k) / (số lần kỳ vọng ở trạng
thái Sj) (5.19)
= (20)
III.2.4 Các mô hình huấn luyện liên tục và bán liên tục
Với một mô hình mật độ hỗn hợp liên tục, những quan sát là những vector
thực tế thay vì những ký hiệu rời rạc, và xác suất phát ra là:
bj() = (21)
trong đó F là một đoạn log-concave bất kỳ hoặc mật độ đối xứng dạng ellipse
(Gausse) có vector trung bình và ma trận hợp biến covariance cho hỗn hợp thứ
m trong trạng thái Sj.
Rabiner bày một phương pháp ước lượng lại tham số theo các dòng giống
nhau tương tự như với mô hình rời rạc, ngoại trừ thay vì bj(k), các biến cjm, và
phải được ước lượng lại. Ước lượng lại sự biến đổi trạng thái và các phân bố
trạng thái ban đầu tương tự với dạng rời rạc. Rõ ràng các biến tiến và lùi được
tính toán sử dụng mật độ phát ra ở dạng liên tục của nó trong trường hợp này. Để

88
trình bày phương trình ước lượng lại cho các tham số phát ra, ta định nghĩa một
biến tạm:
i(i,m) =[ | ] (22)
Đây là xác suất ở trạng thái Sj tại thời điểm t với thành phần hỗn hợp thứ m
tính cho vector quan sát Oi. Tổng của biến này trên toàn bộ M hỗn hợp có dạng i(j)
được cho trong phương trình (12) cũng dùng cho trường hợp một hỗn hợp
Bây giờ các phương trình ước lượng lại có thể được phát biểu theo giá trị
i(j,m):
= (23)
= (24)
= (25)
Những phương trình này có thể được giải thích như sau: là tỷ lệ giữa số
lần kỳ vọng mô hình trong trạng thái Sj sử dụng hỗn hợp thứ m và số lần kỳ vọng
mô hình nằm trong trạng thái Sj. Phương trình tính số lần kỳ vọng mô hình nằm
trong trạng thái Sj sử dụng hỗn hợp thứ m trong vector quan sát, đưa đến giá trị
kỳ vọng của các vector quan sát được, tính bởi hỗn hợp thứ m. Một đối số tương
tự dẫn đến kết quả .
Huang trình bày một phương thức ước lượng lại các tham số của mô hình
và codebook chung cho trường hợp HMM bán liên tục. Một lần nữa công thức
ước lượng lại và tương tự trường hợp rời rạc, với sự khác biệt là các biến tiến và
lùi tính theo giá trị bj(k) được thay bởi giá trị bj() cho những quan sát liên tục .
Để ước lượng lại các tham số của codebook và các tham số phát ra của mô
hình, ngoài biến , định nghĩa trong phương trình (12) cần thêm hai biến tạm khác:
và
(27)
là xác suất mô hình ở trong trạng thái Si tại thời điểm t với quan sát được lượng
hóa thành mẫu tượng vk – nghĩa là xác suất mà codeword thứ k có thể sinh ra
quan sát thứ t kết hợp với xác suất mà codeword thứ k có thể được quan sát trong
trạng thái Si – cho trước quan sát và mô hình.

89
Bây giờ, các phương trình ước lượng lại có thể được phát biểu cho tham số
mô hình bi(k) và các vector trung bình của codebook cùng với các ma trận hợp
biến :
= (28)
= (29)
= (30)
III.2.5 Thuật toán Viterbi
Thuật toán Viterbi là phương pháp để ước lượng xác suất chuỗi trạng thái
cực đại xác suất của mô hình đưa ra dãy các quan sát. Biến cho điểm xác suất
của chuỗi quan sát O0, O1, …, Oi đã được đưa ra bởi dãy các trạng thái của mô
hình có nhiều khả năng nhất, kết thúc ở trạng thái i vào thời điểm t. Biến lưu một
bản tin (record) mà trạng thái cực đại hóa xác suất tại mỗi thời điểm sao cho khi
một đường đi xác suất cực đại được xác định tại thời điểm T-1, mảng có thể
được sử dụng để tìm ra dãy trạng thái.
Xác suất thu được bằng cách cực đại , khác với xác suất tìm thấy bằng cách
tính tổng với mọi i. Giá trị đầu tiên là xác suất mà dãy trạng thái cực đại xác suất
của mô hình có thể đưa ra những quan sát. Giá trị thứ 2 là xác suất mà tất cả các
dãy trạng thái của mô hình có thể đưa ra những quan sát. Thường thì giá trị đầu là
một xấp xỉ gần với giá trị sau.
Thuật toán Viterbi tìm dãy trạng thái tốt nhất có thể được trình bày như sau:
1) Khởi tạo:
= , (31)
= 0
2) Đệ qui:
= bj(Ot), , (32)
3) Kết thúc:
P* = (33)
=
4) Lần ngược lại đường đi (dãy trạng thái):

90
= , i = T-2, T-3, … , 0 (34)
Cũng như khi tính toán biến tiến và lùi, trong trường hợp các mô hình liên tục
và bán liên tục giá trị xác suất phát xạ rời rạc bj(Oi) được thay bằng giá trị mật độ
xác suất liên tục thích hợp.
Hình 4a. Sơ đồ lưới cho 3 trạng thái kết nối đầy đủ
Hình 4b. Thao tác cơ bản của tính toán Viterbi
Hình 4: Biểu đồ lưới mắt cáo minh họa tính toán Viterbi. Mặc dù rất giống với
giải thuật tiến lùi như minh họa trong hình (3) nhưng thao tác cơ sở thì lại khác:
phép dò tìm cực đại thay thế phép tính tổng trong giải thuật tiến – lùi.
Hình 4. Minh họa tính toán của thuật toán Viterbi. Phần tính toán giả sử
rằng mật độ quan sát là không cần bộ nhớ. Trong trường hợp này, với mọi con
đường đi vào một trạng thái (được biểu diễn bởi một nút trong mắt cáo), tất cả
đều có thể bị loại bỏ trừ một con đường có xác suất cao nhất. Điều này chỉ cho
phép một con đường đi ra khỏi mỗi nút, so với N con đường đi vào, giữ cho
độphức tạp không tăng theo cấp số nhân với thời gian.

91
Giải thuật Viterbi đối sánh một mô hình với một chuỗi quan sát theo cách
tìm xác suất lớn nhất của chuỗi trạng thái ứng với mô hình sinh ra chuỗi quan sát
này.
III.2.6. Giải thuật Level Building
Giải thuật Level Building – LB hoạt động giống như VA nhưng nó đối
sánh một chuỗi quan sát sinh ra bởi một số mô hình.
Mục đích của giải thuật LB là đối sánh các mô hình với chuỗi quan sát mà
không cần phải phân đoạn chuỗi quan sát này ra thành các chuỗi con. Trong lĩnh
vực nhận dạng tiếng nói, nó được sử dụng để nhận dạng các từ phát âm liên tục
trong đó mỗi HMM đực sử dụng để biểu diễn một từ. Cách tiếp cận LB cho phép
nhận dạng cụm từ mà không cần phân đoạn nó ra thành từng từ. Thực tế, giải
thuật LB cực đại xác suất kết nối giữa phân đoạn và nhận dạng.
Tại mức l=0, mỗi mô hình được đối sánh với chuỗi quan sát tính từ thời
điểm t=0. Các mô hình được giả thiết có cấu trúc trái-phải, bắt đầu ở trạng thái 0
và kết thúc ở trạng thái N-1.
1. Khởi tạo:
= () (35)
= (36)
2. Đệ qui:
= (Ot), , (37)
Kết thúc:
P(l,t,w) = , (38)
B(l,t,w) = -1 (39)
Sau khi mảng P(l,t,w) đã được tính toán đầy đủ tại mức này cho tất cả các
mô hình, nó sẽ được giảm mức để chỉ ra mô hình phù hợp nhất tại mỗi thời điểm
ở mức này:
(l,t) = (40)
(l,t) = B(l, t, arg ) (41)
(l,t) = arg (42)

92
Mảng chỉ ra xác suất của mô hình phù hợp nhất tại mức này, lưu nhãn của
mô hình và cuối cùng, là con trỏ tới mức trước đó.
Đối với mức cao hơn, việc tính toán sẽ khác với thủ tục khởi tạo, theo đó
các mô hình ở mức thứ hai (mức cao hơn) sẽ nhận kết quả từ mức mô hình ở mức
thấp nhất:
= (43)
= max[ t-1), ].() (44)
Một mảng con trỏ quay lui cũng được tạo để lưu thời gian mà mức trước
được đối sánh bởi mô hình trước đã kết thúc:
= {t-1 nếu t-1) > ), } (45)
Trong quá trình đệ qui, mảng được cập nhật như sau:
= arg (46)
Khi đến mức cuối cùng, mảng con trỏ quay lui B sẽ được cập nhật:
B(l,t,w) = , (47)
Tại mức cuối này, thao tác giảm mức được thực hiện và các tính toán có
thể được xử lý cho mức tiếp theo. Tiến trình này tiếp tục lặp lại cho đến khi vượt
số mức giới hạn trước. Đối sánh tốt nhất của L mô hình với chuỗi quan sát có xác
suất T-1) và có thể tìm thấy được bằng cách lần ngược, sử dụng mảng B. Chuỗi
đối sánh tốt nhất là cực đại của trên tất cả các mức.
Hình 5. Biểu đồ minh họa giải thuật Level Building

93
III.3 LƯỢNG HÓA VECTOR VÀ PHÂN NHÓM
III.3.1 Lượng hóa vector
Trong phần trước, nhiều kiểu mô hình Markov ẩn được trình bày. HMM
rời rạc thích hợp cho mô hình hóa các tiến trình với những chuỗi quan sát có giá
trị rời rạc. Ngược lại, HMM liên tục mô hình chuỗi quan sát có giá trị liên tục. Để
thực hiện, thông thường mô hình biểu diễn chuỗi quan sát như một hỗn hợp các
phân bố Gauss. Điều này dẫn đến một số lớn các tham số tự do cần được ước
lượng trong quá trình huấn luyện. Vì vậy nhu cầu về dữ liệu huấn luyện là rất lớn.
Quá trình lượng hóa vector (VQ) cho phép các mô hình rời rạc biểu diễn những
quan sát liên tục bằng cách ánh xạ mỗi quan sát liên tục thành một mẫu tượng
nằm trong bảng ký hiệu rời rạc. Cụ thể, các vector liên tục N- chiều được phân bố
thành một số tế bào (codebook) và ánh xạ một quan sát liên tục thành một nhãn
của tế bào mà nó nằm trong đó. Tiến trình VQ cho phép mô hình rời rạc, với dữ
liệu huấn luyện không lớn, biểu diễn những quan sát liên tục.
VQ đã được sử dụng rộng rãi trong lĩnh vực xử lý tiếng nói: trong HMM
dùng để nhận dạng tiếng nói cũng như trong mã hóa tiếng nói với tỷ lệ bit thấp.
Trong tài liệu của Makhoul, vector được lượng hóa là một tập các tham số, tính từ
mỗi frame của tiếng nói (mỗi frame ~ 20ms). Một cách sử dụng khác của VQ là
dùng để nén ảnh trong đó mỗi block chẳng hạn 4x4 pixel được định lượng thành
một vector 16-chiều để lợi dụng sự dư thừa trong các block của ảnh nhằm giảm
bớt lượng thông tin cần để truyền ảnh.
III.3.1.1 Phép lượng hóa vô hướng
Lượng hóa một đại lượng vô hướng thì không mới. Như minh họa trong
hình 5.6, dòng số thực biểu diễn một đại lượng đo được, chia thành các phần Ci –
codebook. Khi đó lượng hóa là tiến trình ánh xạ mỗi số thực vào nhãn (label) của
phần chứa điểm tương ứng trên dòng. Sai lệch được biết đến khi tất cả các điểm
trong một phần được ánh xạ vào cùng một nhãn. Sai lệch trung bình trên toàn bộ,
D, có thể được tính khi cho trước độ đo sai lệch d(x,y) theo đó giá trị x được
lượng hóa thành y:
D= [d(x,y)] (48)
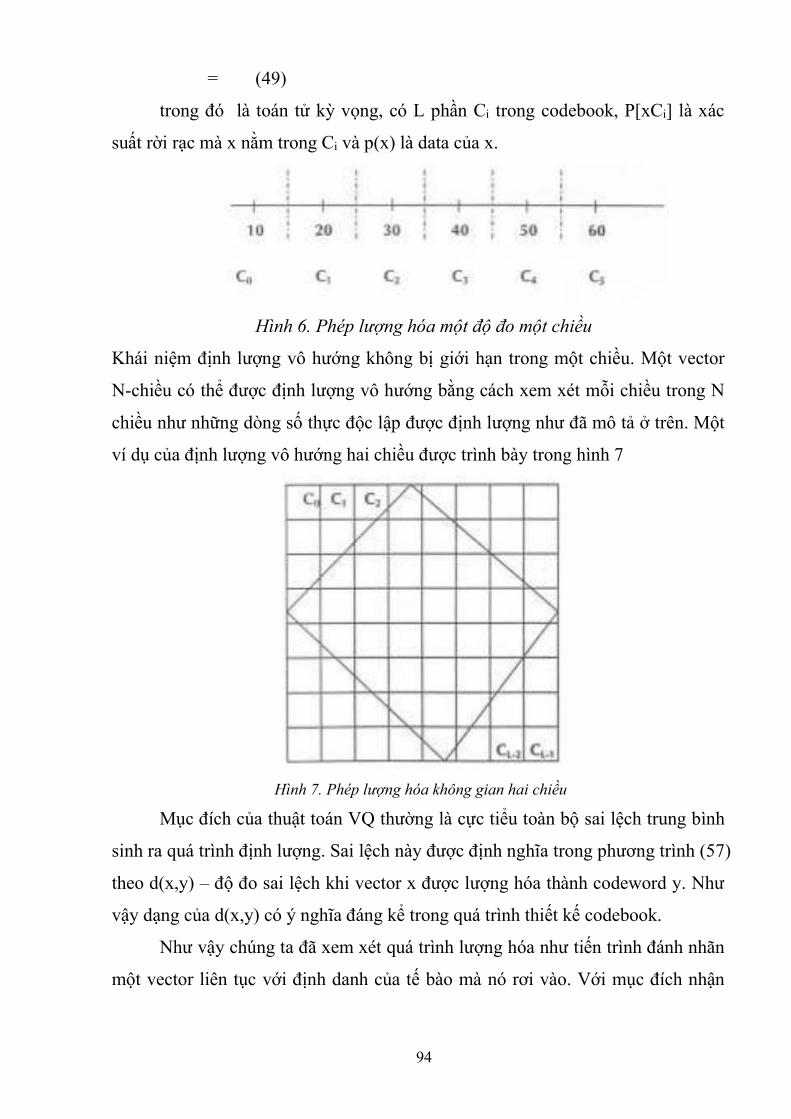
94
= (49)
trong đó là toán tử kỳ vọng, có L phần Ci trong codebook, P[xCi] là xác
suất rời rạc mà x nằm trong Ci và p(x) là data của x.
Hình 6. Phép lượng hóa một độ đo một chiều
Khái niệm định lượng vô hướng không bị giới hạn trong một chiều. Một vector
N-chiều có thể được định lượng vô hướng bằng cách xem xét mỗi chiều trong N
chiều như những dòng số thực độc lập được định lượng như đã mô tả ở trên. Một
ví dụ của định lượng vô hướng hai chiều được trình bày trong hình 7
Hình 7. Phép lượng hóa không gian hai chiều
Mục đích của thuật toán VQ thường là cực tiểu toàn bộ sai lệch trung bình
sinh ra quá trình định lượng. Sai lệch này được định nghĩa trong phương trình (57)
theo d(x,y) – độ đo sai lệch khi vector x được lượng hóa thành codeword y. Như
vậy dạng của d(x,y) có ý nghĩa đáng kể trong quá trình thiết kế codebook.
Như vậy chúng ta đã xem xét quá trình lượng hóa như tiến trình đánh nhãn
một vector liên tục với định danh của tế bào mà nó rơi vào. Với mục đích nhận

95
dạng, tế bào nên được đánh nhãn bằng một vector đại diện – code vector (điển
hình là trọng tâm của nó) cùng với một định danh
Gọi y là code vector mà x được lượng hóa thành và yk là chiều thứ k của y.
Có một số độ đo sai lệch thông thường gồm:
-Sai số bình phương trung bình:
dl(x,y) = (50)
- Dạng tổng quát hơn là:
dt(x,y) = (51)
Thông thường, r = l hay r = , d1 biểu diễn sai số tuyệt đối trung bình và
tiến về sai số cực đại. Cực tiểu hóa D với r = sẽ tương đương với cực tiểu hóa
sai số định lượng cực đại.
Sai số bình phương trung bình giả thiết rằng mỗi chiều của vector góp phần
như nhau vào sai số. Một sai số bình phương trung bình có trọng được định nghĩa
như sau:
- Sai số bình phương trung bình có trọng:
dw(x,y) = W(x-y) (52)
trong đó W là ma trận định nghĩa trọng số dương. Nếu W= l, trong đó là ma
trận hợp biến của vector ngẫu nhiên x thì dw trở thành khoảng cách Mahalanobis.
Cách tiếp trên đã chia không gian vector thành một số tế bào N – chiều, và
lượng hóa mỗi vector liên tục thành một vector đại diện cho tế bào mà nó nằm
trong đó.
Như vậy thiết kế codebook là quá trình điều chỉnh phân bố để cực tiểu sai
lệch trung bình tổng thể.
Một cách tiếp cận khác là biểu diễn mỗi tế bào như một img N- chiều.
Thao tác lượng hóa sau đó gồm ước lượng mỗi img cho vector liên tục để xác
định xác suất mà mỗi img có thể đưa ra vector. Vector đại diện của tế bào với xác
suất cực đại sau đó được chọn làm kết quả định lượng. Ưu điểm của phương pháp
này là các img có thể chồng lên nhau trong khi trước đây chúng ta chỉ có thể xem
xét một phân bố hạn chế trong các tế bào. Điều này phản ánh cấu trúc của quần
thể gần gũi hơn bằng những phân bố giới hạn. Một ưu điểm chủ yếu khác của

96
cách tiếp cận này là khả năng thực hiện định lượng mềm (Soft Quantisation).
Bằng cách ước lượng xác suất mỗi img tạo ra vector, các codeword có thể được
lưu thay vì xác suất. Như vậy một quyết định cứng là không cần và như thế sẽ giữ
lại nhiều thông tin hơn cho những giai đoạn xử lý tiếp theo.
Kết quả của cách tiếp cận cực đại xác suất là tập hợp các vector liên tục
được mô hình hóa như một hàm mật độ hỗn hợp, và quá trình lượng hóa là xác
định thành phần hỗn hợp nào tạo ra vector. Quá trình thiết kết codebook sau đó
cực đại hóa xác suất của hàm mật độ hỗn hợp biểu diễn toàn bộ tập hợp.
III.3.1.2 Thiết kế codebook
Chia một không gian vector thành nhiều tế bào có thể được thực hiện với
các tế bào đồng nhất hoặc có kích thước khác nhau. Cách tiếp cận đồng nhất tăng
theo số mũ khi số chiều tăng – chia mỗi tham số của vector N-chiều thành M
phần được MN tế bào. Cách tiếp cận đồng nhất cũng không khả thi nếu có ít nhất
một chiều có giá trị không bị ràng buộc.
Như vậy ta có thuận lợi khi xây dựng một codebook trong đó các tế bào chỉ
phủ không gian tham số giốn như được phân bố với các vector xuất hiện trong
tiến trình VQ thông thường. Codebook này cũng đảm bảo rằng các phần tử của
không gian tham số có xác suất phân bố cao sẽ được phủ bởi các tế bào nhỏ hơn
các phần có xác suất thấp. Trong trường hợp này mục tiêu của thiết kế codebook
là cực tiểu hóa sai lệch trung bình toàn cục của quá trình VQ.
Để thiết kế một codebook như vậy, cần một tập vector đại diện và một
phân bố các vector xuất hiện trong VQ- tập huấn luyện. Quá trình phát sinh
codebook sau đó sẽ tiến hành phân nhóm các vector này thành tế bào. Tiến trình
này được lặp lại trên từng phần cho đến khi sai lệch trung bình toàn cục đạt đến
một cực tiểu. Với một phân bố cụ thể các vector huấn luyện, để tính toán các
vector này, trước hết cần tính vector đại diện cho mỗi tế bào mà các vector trong
tế bào đó sẽ được lượng hóa. Với các độ đo sai lệch bình phương trung bình hoặc
sai số bình phương trung bình có trọng số, toàn bộ sai lệch được cực tiểu hóa nếu
vector đại diện của một tế bào là trung bình mẫu của các vector huấn luyện được
phân bố vào tế bào đó.

97
Một thuật toán thiết kế codebook thường sử dụng là thuật toán LBG –
Linder, Buzo, Gray mà thực chất là giải thuật phân nhóm k-means. Đôi khi nó
còn được gọi là thuật toán Lloyd tổng quát tài liệu về lý thuyết thông tin. Tên
“LBG” sau khi Linde, Buzo và Gray, những người đã chứng minh rằng thuật toán
hoạt động với phạm vi độ đo sai lệch rộng. Nội dung của nó như sau:
1. Khởi tạo:
Đặt m=0. Chọn một tập hợp các codeword khởi đầu.
2. Phân lớp:
Phân lớp tập hợp các vector huấn luyện thành các nhóm Ci theo qui tắc lân cận
gần nhất:
x Ci(m), nếu d(x,yi(m)) d(x,yj(m)) với mọi j i (53)
3. Cập nhật code vector: m m + 1.
Code vector của mỗi nhóm được tính như trung bình mẫu của các vector huấn
luyện.
4. Kết thúc:
Nếu khác biệt trong toàn bộ sai lệch trung bình giữa lần lặp lại m và lần cuối
cùng là dưới một ngưỡng thì dừng, ngược lại đến bước 2.
Bất kỳ một phép kiểm tra kết thúc hợp lý nào cũng có thể được áp dụng thay vì
bước 4.
Trong trường hợp codebook được biểu diễn như một hỗn hợp các img –
thay vì phân bố không gian vector thành các tế bào – quá trình phân nhóm tương
tự nhưng được điều khiển bởi xác suất của mỗi vector huấn luyện trong tế bào.
Phân nhóm tiếp tục đến khi toàn bộ xác suất của tất cả các vector huấn luyện
được phát sinh bởi các img tương ứng là cực đại hóa. Thay vì tính toán vector đại
diện các tham số của img phải được ước lượng cho một tập hợp các vector huấn
luyện cho trước. Với một mô hình hỗn hợp Gauss, quá trình này gồm tính toán
trung bình mẫu và hợp biến cho mỗi nhóm các vector huấn luyện.
Một cách phân nhóm các vector huấn luyện khác để tạo codebook là lượng
hóa vector theo kiểu thống kê – Stochastic Vector Quantisation. Phương pháp này
cần một mô hình định nghĩa trước cho các vector mã hóa. Các vector nhiễu White

98
Gauss được truyền qua bộ lọc trạng thái để biểu diễn mô hình và các kết quả
chuẩn được sử dụng làm codeword. Cách tiếp cận này tính toán đơn giản hơn
phân nhóm.
Khi codebook đã được thiết kế, cách tiếp cận để định lượng mỗi vector mới
là so sánh nó với mọi codeword để tìm codeword cực tiểu sai lệch lượng hóa
(theo một độ sai lệch nào đó) hoặc cực đại xác suất (theo một mật độ xác suất
tham số nào đó). Cách tiếp cận này có hiệu suất tối ưu với chi phí là một khối
lượng tính toán đáng kể - các thao tác là tuyến tính theo trong số chiều và kích
thước của codebook. Bằng cách phân bố codebook theo cách thích hợp nào đó, có
thể giảm độ phức tạp, chỉ tỷ lệ với kích thước của codebook.
Một codebook tìm kiếm nhị phân hoạt động theo cách phân nhóm có thứ
bậc các vector huấn luyện. Trong quá trình phát sinh codebook, thuật toán phân
nhóm được sử dụng để phân nhóm các vector huấn luyện thành 2 nhóm, và vector
đại diện được tìm thấy như trọng tâm của mỗi nhóm. Sau đó quá trình lặp lại một
cách đệ qui cho mỗi nhóm này, xây dựng thành một cây nhị phân như hình 8.
Quá trình đệ qui kết thúc khi mức thấp nhất của cây biểu diễn số codeword cần L,
trong đó L là lũy thừa của 2. Sau đó quá trình định lượng gồm tìm kiếm cây từ
gốc xuống lá sao cho sai lệch được cực tiểu hóa tại mỗi nút. Trong trường hợp
này số tính toán sai lệch bằng với 2log2L, nhỏ hơn đáng kể so với L tính toán khi
tìm kiếm đầy đủ với bất kỳ giá trị L lớn hợp lý nào.
Hình 8. Cây nhị phân tìm kiếm VQ
III.3.2 Phân nhóm

99
Mục đích phân nhóm là tìm một cấu trúc nào đó trong phân bố của tập hợp
các vector trong không gian Euclide N-chiều. Với một hoặc hai chiều, có thể dễ
dàng hình dung bằng trực giác – chẳng hạn trong hình 9 – các vector mẫu được
phân bố rõ ràng thành 3 nhóm. Trong nhiều bài toán nhận dạng mẫu số chiều cao
hơn nhiều và việc biểu diễn bằng hình vẽ là không thể.
Hình 9. Ba nhóm cluster trong mặt phẳng hai chiều
Để phát triển một thuật toán phân nhóm, cần thiết phải có một độ đo
khoảng cách nào đó giữa hai vector x và y. Độ đo khoảng cách thông thường nhất
là khoảng cách Euclide:
D = ||x-y|| (54)
Thuật toán phân nhóm sau đó có thể được xem như bài toán cực tiểu hóa
hoặc cực đại hóa một hàm tiêu chuẩn. Một ví dụ thường gặp là cực tiểu hóa tổng
tiêu chuẩn sai số trung bình:
J = (55)
trong đó k là số nhóm, Cj là tập hợp các mẫu tạo thành nhóm thứ j và là vector
trung bình của nhóm Cj:
= (56)
Nj là số mẫu trong nhóm Cj
Nhiều độ đo khoảng cách khác và các hàm tiêu chuẩn khác đã được đề
nghị. Tuy nhiên phần tử này chỉ tóm tắt hai phương pháp phân nhóm thông
thường nhất – thuật toán k-means và thuật toán ISODATA
Thuật toán –means

100
Thuật toán k-means dựa trên cực tiểu hóa tổng các khoảng cách bình
phương của tất cả các điểm từ tâm nhóm tương ứng của chúng. Các bước của
thuật toán như sau:
1. Chọn k tâm nhóm ban đầu tùy ý. Thường là k mẫu đầu tiên trong tập hợp huấn
luyện.
2. Phân bố mẫu x trong k nhóm theo quan hệ:
x Ci(m), nếu ||x-yi(m)|| ||x-yj(m)|| với mọi j i (57)
trong đó Ci(m) là nhóm i, có tâm yi(m), trong lần lặp thứ m của thuật toán.
3. Tính từ tâm nhóm mới từ trung bình mẫu của các mẫu huấn luyện đã được
đánh nhãn như thành viên của mỗi nhóm. Quá trình này cực tiểu hóa tổng các
bình phương khoảng cách từ mỗi mẫu đến tâm nhóm của nó.
4. Nếu nhóm không thay đổi thừ lần lặp cuối cùng, thì thuật toán hội tụ, ngược lại
đến bước 2.
Thuật toán ISODATA
Thuật toán ISODATA tương tự thuật toán k-means, nhưng kết hợp thêm
một số thủ thuật heuristic để kiểm soát hoạt động của nó. Bắt đầu là số tâm nhóm
k’ được đặc tả. k’ không cần giốn như số nhóm mong muốn k và có thể được
thiết lập lại bằng cách lấy mẫu dữ liệu huấn luyện. Các bước của thuật toán như
sau:
1. Đặc tả các tham số:
k = số nhóm cần
N = tham số cho số mẫu trong một nhóm
S = tham số độ lệch chuẩn
C = tham số gộp (lumping)
L = số các cặp cực đại của nhóm có thể gộp lại
l = số lần lặp cực đại
2. Phân bố tất cả mẫu huấn luyện trong số k’ nhóm hiện diện theo cùng quy luật
như bước 2 của thuật toán k-means.
3. Nếu một nhóm có ít hơn Nthành viên thì loại nó và giảm k’ đi một.
4. Cập nhật mỗi tâm nhóm theo trung bình mẫu của các thành viên của nó.

101
5. Với mỗi nhóm Ci, tính khoảng cách trung bình i của các thành viên từ trung
bình nhóm.
6. Tính khoảng cách trung bình toàn bộ (overall average distance) với mọi mẫu
huấn luyện từ các trung bình nhóm tương ứng của chúng.
7.
Nếu đây là lần lặp cuối cùng, đặt c = 0 và đi đến bước 11.
Nếu k’ k/ 2 đến bước 8
Nếu đây là lần lặp chẵn, hoặc nếu k’ > 2k thì đến bước 11
Ngược lại tiếp tục
8. Tìm một vector lệch chuẩn = (, ,…, )x’cho mỗi nhóm sử dụng quan hệ:
= i=1,2,…,k (58)
trong đó n là số chiều của mẫu, xik là thành phần thứ I của mẫu thứ l trong nhóm
Cj, yij là thành phần thứ i của tâm nhóm Cj và Nj là số các mẫu trong nhóm Cj.
Mỗi thành phần của biểu diễn độ lệch chuẩn của các mẫu trong nhóm Ci theo
trục tọa độ chính.
9. Tìm thành phần cực đại của cho mỗi nhóm.
10. Với nhóm Cj bất kỳ, >j, nếu (i>và Ni >2(N+1)) hoặc k’ k/ 2 thì chia Cj thành
2 nhóm Cj’ và Cj-, xóa Cj và tăng k thêm 1.
11. Tính các khoảng cách Dij theo từng cặp giữa tất cả các tâm nhóm.
12. Sắp xếp theo thứ tự tăng các khoảng cách L nhỏ nhất mà nhỏ hơn c
13. Các khoảng cách Dij có thứ tự nhỏ nhất được xem xét một cách liên tục để kết
các nhóm lại với nhau. Nếu cả Ci lẫn Cj được thu gọn theo một khoảng cách nhỏ
nhất trong lần lặp này, thì một tâm nhóm mới y* được tính toán theo:
y*= [ + ] (59)
Sau đó xóa các nhóm Ci và Cj và giảm k’. Lưu ý rằng chỉ xem xét kết theo từng
cặp – theo kinh nghiệm lumping phức tạp hơn có thể cho những kết quả không
thỏa mãn – và mỗi nhóm chỉ có thể được kết một lần trong mỗi lần lặp.
14. Nếu đây là lần lặp cuối cùng thuật toán kết thúc. Ngược lại một lần lặp mới
có thể bắt đầu tại bước thứ 1 nếu các tham số bất kỳ cần thay đổi tại bước thứ 2

102
nếu chúng vẫn như nhau. Một vòng lặp mới được đếm khi nào thuật toán trở về
bước 1 hoặc 2.
Thuật toán k-means và ISODATA cực tiểu hóa sự khác biệt của dữ liệu
mẫu trong mỗi nhóm. Tuy nhiên, khi ma trận hợp biến của mỗi nhóm không phải
là ma trận đồng nhất, những sai sót không mong muốn có thể xuất hiện. Do đó,
mục đích chính của việc sử dụng các mô hình kết nhóm phức tạp là để giảm bớt
số tối ưu cục bộ trong hàm tiêu chuẩn với hy vọng rằng điều này sẽ cho phép
thuật toán tìm một tối ưu toàn cục. Trong thực tế, phân nhóm tập hợp dữ liệu có
thể được thực hiện theo một số cách đánh nhãn ban đầu khác nhau và phân nhóm
đưa đến những giá trị tốt nhất của hàm tiêu chuẩn sau đó được chọn làm kết quả.
Kittler và Pairman trình bày một luật gán lại nhiều điểm tối ưu sử dụng mô
hình mật đô phân số Gauss của các nhóm. Mô hình Gauss cho phép biểu diễn các
nhóm với các ma trận hợp biến không phải ma trận đồng nhất, và số điểm trong
nhóm cũng có thể được kết hợp. Thêm vào đó, nếu dữ liệu được biết lấy từ một
phân bố hỗn hợp, mô hình Gauss cho phép các tham số hỗn hợp được khôi phục
một cách xấp xỉ.
Quá trình mà phương pháp Kittler – Pairman dựa trên là cực tiểu hóa phần
chồng lên nhau của các hàm mật độ điều kiện p[x/Ci], tính trọng bằng mối liên hệ
giữa kích thước nhóm tương ứng của chúng: Ni/N. Như vậy hàm tiêu chuẩn cực
đại hóa sẽ được định nghĩa như sau:
J = []^(1/N), xj Ci (60)
Định nghĩa mô hình nhóm như là Gauss với vector trung bình N- chiều và
ma trận hợp biến nxn:
p[x|Ci] = [(2)N | ]^(-1/2) exp[- (x - )^] (61)
Bằng cách lấy logarithm (60) và tiếp tục đơn giản, một tiêu chuẩn sau khi
được sửa đổi sẽ cực tiểu hóa có dạng như sau:
J = n + [ log|| - 2 log] (62)
Kittler đưa ra một luật quyết định được rút ra để cực đại hóa biến đổi J
bằng cách xem xét việc di chuyển tất cả p điểm đồng nhất x từ Cj đến nhóm Cj-.
Gán xi Ci cho nhóm Cj chỉ khi:

103
(xi, Cp) = log|| + log[1 + (xi, Cp)]
- 2 log – (n+2) log (64)
và (xi, Cp) là khoảng cách Mahalanobis của nhiều điểm xi từ trung bình
nhóm:
(xi, Cp) = (xi - )^ (65)
Luật quyết định này được rút ra từ sự khác biệt trong tiêu chuẩn phân
nhóm tạo nên bằng cách di chuyển nhiều điểm từ nhóm này sang nhóm khác,
thay vì luật tương tự điểm nhóm của Symons. hai phương pháp này được so sánh
trên dữ liệu tổng hợp trong và luật Post Transfer Advantage chứng tỏ có những
tính chất tốt hơn – khởi tạo của hàm tiêu chuẩn không cần gần với tối ưu toàn cục
để đảm bảo hội tụ. Luật gán lại, có thể được sử dụng với kiểu k-means hoặc
ISODATA của thuật toán, mô hình các nhóm như những mật độ Gauss hợp biến
đầy đủ (full-covariance) và xem xét nhiều điểm để giảm bớt số tối ưu cục bộ
trong hàm tiêu chuẩn với mục đích tìm tối ưu toàn cục dễ dàng hơn. Luật chỉ tối
ưu với giả thuyết rằng các mô hình nhóm được cập nhật sau khi mỗi (nhiều) điểm
đã được di chuyển. Chuyển p điểm đồng nhất xj từ nhóm Ci sang nhóm Cj tạo nên
những thay đổi sau đối với các tham số nhóm:
i’ = i+ (i-i) (66)
j’ = j - (j-j) (67)
Vì mô hình Gauss của mỗi nhóm cần một ước lượng của ma trận hợp biến,
nên việc quan trọng là gán lại các điểm không xảy ra đối với phần mở rộng mà số
điểm trong nhóm nằm dưới số chiều. Nếu rơi vào trường hợp đó, ma trận sẽ duy
nhất và nó sẽ không thể tìm số nghịch đảo của nó để tính khoảng cách
Mahalanobis của một điểm từ trung bình nhóm.
Young tổng kết một số điều kiện khác đã được rút ra liên quan đến số điểm
cực tiểu trong một nhóm theo số chiều. Ông xem xét khoảng cách mahalanobis
được tính với ma trận hợp biến đã được ước lượng với một số mẫu giới hạn như
một biến ngẫu nhiên. Bằng cách xác định phân bố của biến này, một quan hệ
được rút ra giữa số mẫu trong nhóm và số chiều cao thu được một khoảng tin cậy
cho trước. Về số điểm cực đại trong nhóm, Cohn mô tả những giả lập theo kinh

104
nghiệm nhằm ra những đề nghị thực tế trên lượng dữ liệu huấn luyện cần để đạt
được một quá trình tổng quát hóa tốt từ codebook VQ.
Một ví dụ của nghiên cứu hiện nay trong việc sử dụng các mô hình Gauss
để phân nhóm là Celeux và Govaert. Họ đề nghị tham số hóa ma trận hợp biến
của nhóm bằng một phân tích eigenvalue: = , trong đó định nghĩa thể tích của
nhóm, là ma trận trực giao xác định hướng của nó và là ma trận đường chéo với
định thức 1, xác định hình dạng của nó. Bằng cách cố định những tham số này,
các tác giả rút ra một số tiêu chuẩn phân nhóm khác.
III.3.3 Tổng kết
Tổng kết chương này giới thiệu lý thuyết cơ sở về HMM cũng như lượng
hóa vector và phân nhóm.
Chủ đề quan trọng nhất là các mô hình Markov ẩn, vì những mô hình thống
kê nằm trong phần chủ yếu của phương pháp đã được phát triển để biểu diễn các
ảnh văn bản. Những mô hình khác đã được trình bày, và những thuật toán cụ thể
để huấn luyện, cho điểm đã được mô tả. Một số phần mở rộng của những thuật
toán đã được đưa ra liên quan đến việc thực hiện một bộ phân lớp dựa trên HMM.
Phần định lượng vector, đã được trình bày cùng với phân nhóm: mô hình
các vector đặc trưng có giá trị liên tục với một HMM rời rạc. Mỗi vector đặc
trưng được xác định lượng với mục gần nhất trong codebook. Codebook được
đưa ra bằng cách phân nhóm một số vector huấn luyện.
CHƯƠNG IV
ỨNG DỤNG MÔ HÌNH MARKOV ẨN
TRONG NHẬN DẠNG CHỮ VIẾT TAY
IV.1 Cấu trúc một hệ nhận dạng chữ viết khi dùng mô hình Markov ẩn

105
Hình 4.1. Mô hình nhận dạng chữviết.
Hệ thống được chia làm 2 phần: phần huấn luyện và phần nhận dạng.
Phần huấn luyện: ảnh ký tự được scan và đưa vào hệ thống. Hệ thống sẽ
tiến hành giai đoạn tiền xử lý và trích chọn đặc trưng từ dữ liệu đưa vào. Sau đó
một dãy các vector đặc trưng sẽ được đưa vào mô hình cần huấn luyện tương
ứng với ký tự đưa vào. Ở đây mô hình huấn luyện được chọn sẽ là một trong
các mô hình Markov ẩn đã được đề cập bên trên (được thực hiện bằng cách giải
quyết bài toán 3 trong những bài toán cơ bản của mô hình Markov ẩn). Các
vector đặc trưng chính là dãy quan sát đầu vào của mô hình Markov ẩn. Các đặc
trưng có thể lấy bằng cách: ảnh ký tự sẽ chia theo chiều ngang thành các khung.
Những khung này có kích thước bằng nhau và chồng lên nhau (khoảng 1/3).
Đặc trưng rút ra từ một khung sẽ tạo thành 1 vector đặc trưng. Phần nhận dạng:
cũng tương tự như phần huấn luyện. Anh scan sẽ được lấy đặc trưng. Dãy
vector đặc trưng lần lượt sẽ đưa vào các mô hình Markov ẩn đã được huấn
luyện. Mô hình nào đạt giá trị lớn nhất P(O|) thì ký tự ứng với mô hình đó
chính là kết quả nhận dạng (được thực hiện bằng cách giải quyết bài toán 1
trong những bài toán cơ bản của mô hình Markov ẩn).
Hệ thống có thể có thêm phần hậu xử lý gồm chức năng như: kiểm tra
chính tả dùng để tăng độ tin cậy hay sửa lỗi chính tả trong kết quả nhận dạng.
IV.2 Các vấn đề khó khăn và hướng giải quyết đối vời bài toán nhận dạng
chữ viết tay tiếng Việt
IV.2.1 Khó khăn về dấu trong tiếng Việt

106
Cấu tạo của một ký tự tiếng Việt gồm 2 phần: phần chữ và phần dấu.Dấu tầng trênChữDấu tầng dướiHình 2.2. Cấu trúc ký tự tiếng Việt.
Vì xuất hiện các dấu tầng trên và dấu tầng dưới nên việc nhận dạng chữ
viết tiếng Việt sẽ có một số đặc điểm khác với việc nhận dạng chữ trên các hệ
thống ngôn ngữ la tinh khác.
Tập hợp các chữ trong tiếng Việt:a ă â b c d đ e ê g h i k l m n o ô ơ p q r s t u ư v x y
á à ả ã ạ ắ ằ ẳ ẵ ặ ấ ầ ẩ ẫ ậ é è ẻ ẽ ẹ ế ề ể ễ ệ í ì ỉ ĩ ị
ó ò ỏ õ ọ ố ồ ổ ỗ ộ ớ ờ ở ỡ ợ ú ù ủ ũ ụ ứ ừ ử ữ ự ý ỳ ỷ ỹ ỵ
A Ă Â B C D Đ E Ê G H I K L M N O Ô Ơ P Q R S T U Ư V X Y
Á À Ả Ã Ạ Ắ Ằ Ẳ Ẵ Ặ Ấ Ầ Ẩ Ẫ Ậ É È Ẻ Ẽ Ẹ Ế Ề Ể Ễ Ệ Í Ì Ỉ Ĩ ỊÓ
Ò Ỏ Õ Ọ Ố Ồ Ổ Ỗ Ộ Ớ Ờ Ở Ỡ Ợ Ú Ù Ủ Ũ Ụ Ứ Ừ Ử Ữ Ự
Ý Ỳ Ỷ ỸỴ
Tổng cộng: 178 chữ.
Bảng 2.1. Bảng ký tự tiếng Việt.

107
Tiến trình nhận dạng chính là quá trình phân loại giữa các lớp, có độ chính
xác tỷ lệ nghịch với số lượng lớp. Nếu số lớp cần nhận dạng càng nhiều thì tỷ lệ
nhận dạng đúng càng thấp. Nếu xem mỗi chữ trong tiếng Việt là một lớp thì
178 chữ sẽ tạo thành 178 lớp. Một số lượng lớp quá lớn, do đó kết quả nhận
dạng sẽ bị ảnh hưởng.
Một hướng tiếp cận để giảm số lượng lớp cần nhận dạng trong
tiếng Việt chính là dùng một thuật toán nào đó để tách vùng chữ và vùng dấu.
Lúc đó tiến trình nhận dạng sẽ gồm 2 phần: nhận dạng chữ và nhận dạng dấu.
Lúc đó tập hợp các mẫu chữ gồm:a b c d đ e g h i k l m n o ơ p q r s t u ư v x y
A B C D Đ E G H I K L M N O Ơ P Q R S T U Ư V X YBảng 2.2. Bảng ký tự tiếng Việt không dấu.
Tổng cộng: 50 chữ.
Như vậy số lượng lớp đã giảm chỉ còn 1/3 so với số lượng lớp đã đề cập ở
trên. Do đó kết quả nhận dạng sẽ nâng cao.
Hơn nữa số lượng dấu trong tiếng Việt không nhiều, và giữa các
dấu có những đặc trưng rất riêng biệt nên hướng tiếp cận này hoàn toàn
có thể làm được.
IV.3 Khó khăn về sự biến dạng chữ
Mỗi người đều có một nét chữ riêng, cho nên các bài toán về nhận dạng
chữ viết tay đều gặp khó khăn.
Ví dụ về 2 mẫu chữ viết tay chữ A được thể hiện bằng hình dưới đây.
Hình 2.3. Mẫu ký tự chữ A viết tay.

108
Nhìn trên hình vẽ ta thấy sự khác nhau giữa 2 chữ A về hình dạng thì
nhiều. Do đó nếu dùng phương pháp đối sánh để nhận dạng chữ viết tay thì rất
khó
vì so với mẫu, ảnh cần nhận dạng quá khác xa so với mẫu. Hơn nữa các
phương pháp đối sánh rất nhạy cảm với độ lệch, độ nghiêng giữa mẫu và ảnh
cần nhận dạng. Trong những trường hợp lệch hay nghiêng thì kết quả nhận
dạng bằng đối sánh sẽ giảm đi rất nhiều. Nhìn ví dụ trên ta thấy rằng kích
thước giữa 2 chữ không đồng nhất với nhau, vị trí các nét chữ cũng thay đổi.
Do đó nếu dùng hướng tiếp cận đối sánh để giải quyết bài toán nhận dạng chữ
viết tay là một điều rất khó.
Ví dụ về 2 mẫu chữ viết tay chữ G được thể hiện bằng hình dưới đây.
Hình 2.4. Mẫu ký tự chữ G viết tay.
Nhìn hình vẽ những đặc trưng trên 2 chữ G không rõ ràng. Chữ G trái bị
mất thành phần ngang, chữ G phải thì thành phần ngang không rõ ràng.
Do đó nếu dùng phương pháp nhận dạng bằng đặc trưng trên các chữ viết
tay thì vấn đề chọn đặc trưng bất biến giữa các nét chữ khác nhau là một điều
khó. Những đặc trưng thông dụng thường hay dùng để nhận dạng các chữ in
như: thành phần đứng, thành phần ngang, thành phần kín,…đều khó hay không
thể dùng trong bài toán nhận dạng chữ viết tay.
Ví dụ một số mẫu chữ N được thể hiện bằng hình dưới đây.
Hình 2.5. Mẫu ký tự chữ N viết tay.

109
Hình trên là 4 chữ N được lấy một cách hoàn toàn ngẫu nhiên, không có
sự lựa chọn trong tập dữ liệu thử. Tất cả các chữ N ở trên đều có nhiều nét khác
biệt đặc trưng cho nhiều loại nét chữ.
Nếu dùng mạng Neural làm mô hình huấn luyện và nhận dạng thì
vấn đề chọn được đặc trưng để học là một vấn đề khó giải quyết. Điều này xảy
ra bởi vì quá trình học của mạng Neural một lần chỉ học một mẫu chữ của một
hay nhiều lớp. Do đó mạng Neural sẽ nhận dạng tốt những mẫu vừa mới
học và không nhận dạng tốt những mẫu học trong những lần lặp quá xa so với
lần lặp hiện tại nếu đặc trưng được chọn không tốt. Điều này sẽ dẫn đến quá
trình hội tụ khi huấn luyện mạng Neural sẽ rất lâu. Hơn nữa khi dùng mạng
Neural huấn luyện, kích thước về số chiều của vector đầu vào của các mẫu chữ
phải là như nhau. Do đó trước khi đưa vào mạng Neural để huấn luyện, mẫu
học phải qua quá trình chuẩn hoá. Ngoài ra mạng Neural có một nhược điểm
khi dùng để nhận dạng chữ viết tay đó là không thể nhận dạng các ký tự dính,
mà vấn đề ký tự dính xảy ra rất nhiều đối với bài toán nhận dạng chữ viết tay.
Tất cả những vấn đề trên đều có thể phần nào được giải quyết khi dùng
mô hình Markov ẩn nhờ các tính chất sau:
- Đầu vào của mô hình Markov ẩn không cần các mẫu có số
lượng các khung bằng nhau.
- Quá trình học của mô hình Markov ẩn có thể tổng hợp tất cả các
mẫu khác nhau của cùng một lớp để đưa ra một mô hình chung cho các mẫu
học.
- Với thuật toán Level Building khi áp dụng với mô hình Markov ẩn
có thể dùng để nhận dạng các ký tự dính, ngoài ra còn có thể tích hợp các luật
văn phạm.
IV.4 Mô hình nhận dạng và huấn luyện
Gọi N là số phân lớp trong hệ thống cần nhận dạng (ở đây chính là tập
các chữ hoa in đã tách dấu được liệt kê bên trên, và N=25).
Ta xây dựng N mô hình Markov ẩn, mỗi mô hình đại diện cho một phân

110
lớp.
Gọi tên các mô hình lần lượclà:
1 , 2 ,..., N .
Gọi O là dãy các vector nhận được trong quá trình trích chọn đặc trưng
trên một chữ.
Quá trình huấn luyện sẽ được thực hiện bằng thuật toán Baum-Welch
hay thuật toán Segmental K means, hay kết hợp cả hai bằng cách tạo một
khởi tạo tốt bằng thuật toán Segmental K means và dùng thuật toán Baum-
Welch để tối ưu các tham số vừa khởi tạo.
Quá trình nhận dạng: O sẽ thuộc lớp v* với:
v* argmax[P(O|
1 v Nv )] . (2.8)
Việc tính P(O|
v ) sẽ dựa vào việc giải quyết bài toán 1 trong các bài toáncơ

111
bản của mô hình Markov ẩn.Khi xây dựng các mô hình Markov ẩn, các thông số cần quan tâm đó là:
số trạng thái, số thành phần hợp trong một trạng thái đối với mô hình
Markov ẩn liên tục hay số thành phần hợp thành không gian quan sát
đối với mô hình Markov ẩn bán liên tục hay số ký hiệu quan sát phân
biệt đối với mô hình Markov ẩn rời rạc.
Khi chọn lựa số trạng thái của mô hình trong nhận dạng tiếng nói, có
nhiều ýkiến khác nhau. Một ý tưởng hợp lý có thể chấp nhận trong ngữ cảnh
nhận dạng chữ viết tay chính là xây dựng mô hình Markov ẩn với 4 trạng
thái tương ứng với sự biến đổi trong cấu trúc đường nét chữ cái.
Cuối cùng cần chú ý đến loại mô hình Markov ẩn phù hợp, do tính
chất chuyển đổi của các đường nét từ trái sang phải nên mô hình Markov
ẩn được
chọn là mô hình Markov ẩn của Bakis.
1 2 3 4
Hình 2.12. Mô hình Markov ẩn nhận dạng chữ viết tay.
Sau khi nhận dạng các chữ hoa, ta tiến hành nhận dạng dấu (sẽ trình
bày ởchương sau). Và sau đó có thể dùng mô hình văn phạm để hiệu chỉnh
kết quả.
IV.5 Mô hình văn phạm
IV.5.1.Mô hình cây tự điển

112
Cây tự điển là một mảng cây đa phân, được tạo thành với dữ liệu tại
mỗi node là một ký tự sao cho mỗi từ trong tự điển tiếng Việt sẽ tạo
thành một đường đi trên cây [1]. Ví dụ chữ “anh” như trên hình sẽ được tạo
bởi node gốc làchữ “a”, node con ở cấp 1 là chữ “n”, và node con ở cấp 2 là
chữ “h”.
Vì cấu trúc của một từ đơn tiếng Việt chỉ có tối đa 7 chữ nên cây từ điển sẽcó
tối đa 7 mức.
ba
cá
...
...m
gb n
h...
mức 1 mưc 2 mức 3 ... mức 6
Hình 2.13. Mô hình cây tự điển.
Vì cấu trúc của một từ đơn tiếng Việt chỉ có tối đa 7 chữ nên cây từ điển
sẽ cótối đa 7 mức.
Tiếng Việt có gần 8000 từ đơn. Nếu lưu trực tiếp 8000 từ đơn này
không những không được lợi về không gian lưu trữ mà còn khó khăn trong
quá trình tìm kiếm (phải duyệt tuần tự). Mục đích tổ chức cây tự điển nhằm
tối ưu không gian lưu trữ và khả năng tìm kiếm cao do tổ chức cây ở mỗi
mức là tăng dần theo trật tự alphabe.
Cây tự điển có 2 chức năng chính: kiểm tra lỗi chính tả và sửa lỗi chính tả.
Quá trình kiểm tra lỗi chính tả có thể thực hiện bằng cách duyệt từ trái
sang
phải các ký tự trong từ nếu các ký tự tạo thành một đường đi trên cây tự
điển thì từ đó đúng chính tả, ngược lại từ đó sai lỗi chính tả.

113
Quá trình sửa lỗi chính tả có thể thực hiện bằng cách dùng mô hình tri-
grammar. Ý tưởng của mô hình chính là dùng các chữ liên kết ở trước và các
chữliên kết ở sau ở một chữ trong từ để hiệu chỉnh lại chữ đó trong trường
hợp sai lỗi ngữ pháp. Trong ngữ cảnh bài toán nhận dạng họ tên người Việt,
việc sửa lỗi chính tả bằng cây từ điển không đủ mạnh bởi không tận dụng
được một số tính chất đặc biệt của bài toán.
IV.5.2 Mô hình lớp từ đơn
Vì cấu trúc một từ tiếng Việt gồm tối đa 7 chữ nên có thể tổ chức các từ tiếng
Việt thành 7 lớp: lớp 1 chữ, lớp 2 chữ,…, lớp 7 chữ [1].
1 ký tự
2 ký tự
a á ...
...
Từ cần phân lớp 3 ký tự
4 ký tự
5 ký tự
anh
...
...
6 ký tự ...
Hình 2.13. Mô hình lớp từ đơn.
Mô hình lớp từ đơn được dùng chủ yếu để hiệu chỉnh lỗi chính tả, quá
trình được thực hiện như sau:
Khi một từ không có trong tự điển (nghĩa là sai lỗi chính tả) thì ta sẽ tìm
trong lớp từ tương ứng một từ sai ít nhất so với từ đưa vào (sai ít ký tự nhất).
Trong ngữ cảnh bài toán nhận dạng họ tên người Việt, mô hình này
hiệu chỉnh lỗi sai chính tả khá tốt. Bởi vì họ người Việt chỉ có khoảng 150 họ,
và tần số xuất hiện của các họ thay đổi khá lớn, nên khi tìm từ gần đúng
với từ đang

114
xét ta có thể chọn từ sai ít nhất có tần số xuất hiện cao nhất. Ngoài ra các chữlót
và tên cũng có thể được thực hiện tương tự.
IV.6 Tổng kết chương
Tóm lại, trong chương này, chúng ta đã điểm qua một số vấn đề cơ bản
vàcách xây dựng một hệ nhận chữ viết tay đơn giản. Mô hình nhận dạng
được nhấn mạnh ở đây là mô hình Markov ẩn bởi có thể thay đổi đặc trưng
trên chữmột cách dễ dàng. Trong ngữ cảnh bài toán nhận dạng chữ viết tay
họ tên người Việt Nam, có thể dùng một mô hình văn phạm nào đó (ở đây
dùng mô hình lớp từ đơn) để nâng cao kết quả nhận dạng.
CHƯƠNG V
CÀI ĐẶT CHƯƠNG TRÌNH VÀ ĐÁNH GIÁ KẾT QUẢV.1 Môi trường thực nghiệm
Chương trình được cài đặt trên ngôn ngữ Visual C# và được thử
nghiệm trên hệ điều hành Windows XP SP2, máy tính PC tốc độ 1,6
GHz, bộ nhớ 256MB RAM.
Toàn bộ cơ sở dữ liệu mẫu được thiết kế và lưu trữ trên Microsoft
Office 2007
V.2 Tạo cơ sở dữ liệu mẫu
Trước tiên trương trình cần học qua bộ dữ liệu mẫu. Trong quá trình sử
dụng, nếu người dùng cần định nghĩa một ký tự mới thì chương trình có thêm
chức năng cho người dùng tự định nghĩa.
Giao diện làm việc chính của trương trình :
115
Hình 5.1: giao diện chính của chương trình
V.2.1 Tạo CSDL mẫu cho nhận dạng online
Để tạo csdl mẫu cho quá trình nhận dạng online ta chọn nút Nhận dạng
Online tại form chính. Sau khi chọn form nhận dạng online hiển thị như sau:
Hình 5.2: Gao diện form nhận dạng online
Sử dụng chuột để vẽ các ký tự vào ô Pain. Sau khi vẽ xong, click vào
Học mới để tiến hành huấn luyện cho chương trình
116
Hình 5.3: giao diện form huấn luyện online
Chọn chữ cái tương ứng với ký tự vừa vẽ từ dropdown list sau đó click vào
Khởi tạo để lưu dữ liệu mẫu vào db.
V.2.2 Tạo CSDL mẫu cho nhận dạng offline
Từ form giao diện chính chọn Nhận dạng Offline. Form nhận dạng
offline hiển thị như sau:
117
Hinnh 5.4: Giao diện form huấn luyện OfflineChọn Open Image để mở file ảnh mẫu ký tự. Sau đó click vào Học mẫu.
Form học mẫu sẽ hiển thị nhu trên hình. Chọn vào checkbox Nhận dạng
Offline sau đó click vào khởi tạo
V.3 Hướng phát triển tiếp theo
Từ quá trình thực nghiệm cho thấy, trương trình đã có những thành công
nhất định. Song bên cạnh đó cũng còn khá nhiều nhược điểm cần cải tiến. Trong
quá trình hoàn thành đồ án tôi nhận thấy mình khá tâm huyết với bài toán này và
nhận thấy đây là bài toán có khả năng phát triển cao. Tôi rất mong muốn sẽ phát
triển nó thành một trương trình có thể ứng dụng trong thực tế. Tôi xin đưa ra một
số hướng phát triển tiếp theo cho bài toán
Phát triển để trương trình có thể tích hợp với các trương trình quản lý
sinh viên, học sinh. Phát triển thêm về mặt dữ liệu để trương trình có

118
thể hoạt động tốt với dữ liệu của các trương trình quản ly.
Cải tiến một số thuật toán tiền xử lý để chương trình có tốc độ tốt
hơn.
Phát triển giao diện thân thiện hơn với người sử dụng.
TÀI LIỆU THAM KHẢO
Tài liệu tham khảo tiếng Việt:
[1] Nguyễn Đức Dũng, Nguyễn Minh Tuấn. Một số phương pháp nhận dạng vàứng dụng trong nhận dạng chữ viết tay. Khoá luận tốt nghiệp Đại học 2003,Khoa Công nghệ - Đại học Quốc gia Hà nội, tr.17-43
[2] Hoàng Kiếm, Nguyễn Hồng Sơn, Đào Minh Sơn (2001). ứng dụng mạngneuron nhân tạo trong hệ thống xử lý biểu mẫu tự động. Kỷ yếu hội nghị kỉniệm 25 thành lập Viện Công nghệ Thông tin, tr.1-3.
[3] Nguyễn Thị Thanh Tân. Nhận dạng chữ viết tay hạn chế dựa trên mô hìnhmạng neuron kết hợp với thống kê ngữ cảnh. Luận văn thạc sỹ, ĐHQGHN,tr.3-83
Tài liệu tham khảo tiếng Anh:
[4] Anil K. Jain, Jianchang Mao, K.M. Mohiuddin (1996). Artificial NeuralNetworks A Tutorial. IEEE, tr.31-44
[5] Baret O. and Simon J.C. (1992). Cursive Words Recognition. From Pixels toFeatures III Frontiers in Handwriting Recognition, tr.1-2.
[6] Behnke S., Pfister M. and Rojas, R. (2000). Recognition of Handwritten ZIPCodes in a Real-World Non-Standard-Letter Sorting System. KluwerAcademic Publishers, tr.95-115.
[7] Dave Anderson and George McNeill (1992). Artificial Neural Networks

119
Technology. Prepared for Rome Laboratory RL/C3C Griffiss AFB, NY 13441-5700, tr 2-17.
[8] www.codeproject.com





























