Embed Size (px)
Citation preview
第 9 章 抽樣設計
教科書:吳萬益,企業研究方法,華泰書局參考書:古永嘉、楊雪蘭,企業研究方法,華泰書局

2
本章的學習主題
1. 抽樣的基本概念 2. 抽樣的程序
3. 機率抽樣
4. 非機率抽樣
5. 抽樣誤差與非抽樣誤差
6. 樣本大小的決定

3
1 抽樣的基本概念
抽樣的基本意義是「選擇母體或群體 (population) 中一部份的元素,針對抽出之樣本進行研究,並藉由研究的結果推論整個母體」。
一、抽樣的專有名詞簡介 1. 元素 (element) :元素是指研究的基本單位,亦是蒐集資料的根據。 2. 母體 (population) :母體是研究中所有元素的 集合,也是我們藉由樣本想要推論的標的。

4
抽樣的基本概念
3. 抽樣單位 (sampling unit) :抽樣單位是指被抽取樣本中的一個或是一組元素。
4. 樣本 (sample) :經過抽樣方法抽出的元素即為樣本,樣本為母體的一部份,唯有其與母體具有共同的特質,研究結果才有意義,故樣本必須具有代表性。
5. 抽樣架構 (sampling frame) :抽樣架構是元素(element) 的集合名冊,描繪整個抽樣的情形。
6. 抽樣誤差 (sampling error) :所謂抽樣誤差即是所選出的樣本並不能完全代表母體特質。

5
抽樣的種類
6
2 抽樣的程序
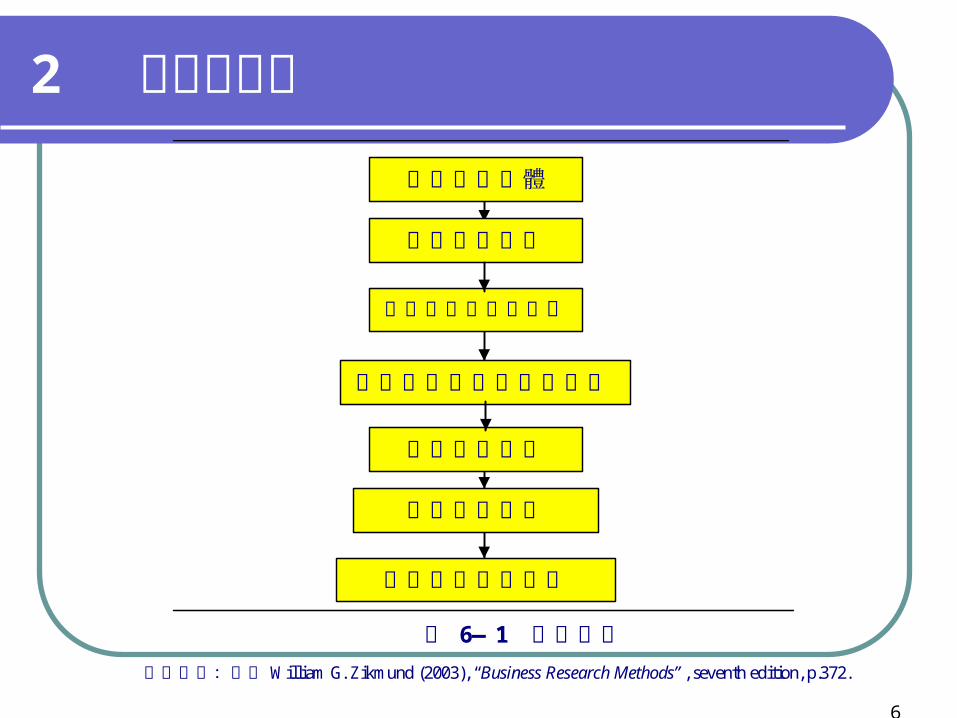
圖 6—1 抽樣程序
資料來源:參考 William G. Zikmund (2003), “Business Research Methods”, seventh edition, p.372.
定義目標母體
選擇抽樣架構
選擇適當的抽樣方法方法
決定樣本大小
選擇抽樣元素
實地進行資料蒐集
規劃選擇抽樣單位的流程

7
2 抽樣的程序
一、定義目標母體 (Target Population) 目標母體必須非常明確,後續蒐集得來的資訊才有意義,才
能解決要研究的問題。 如何定義目標母體呢?學者 Davis (2005) 認為詳細的母體定
義應包含: 1. 元素 (elements)、 2. 範圍、 3. 時間。 大學生網路沈迷問題調查
元素:大學生(個人) 範圍:台澎金馬地區,高教、技職、教育與軍事大專院校 時間: 99.1.1—99.3.5

8
6.2 抽樣的程序
二、選擇抽樣架構 (Sample Frame, sampling frame) 抽樣架構是元素 (element) 的集合名冊,而樣本即是從此抽
出。 抽樣架構應與目標母體一致。

9
6.2 抽樣的程序
三、選擇抽樣方法及規劃選擇抽樣單位的流程
如果我們選擇的目標母體是有完整的抽樣架構,那選擇機率抽樣法可能是較適合的。
10
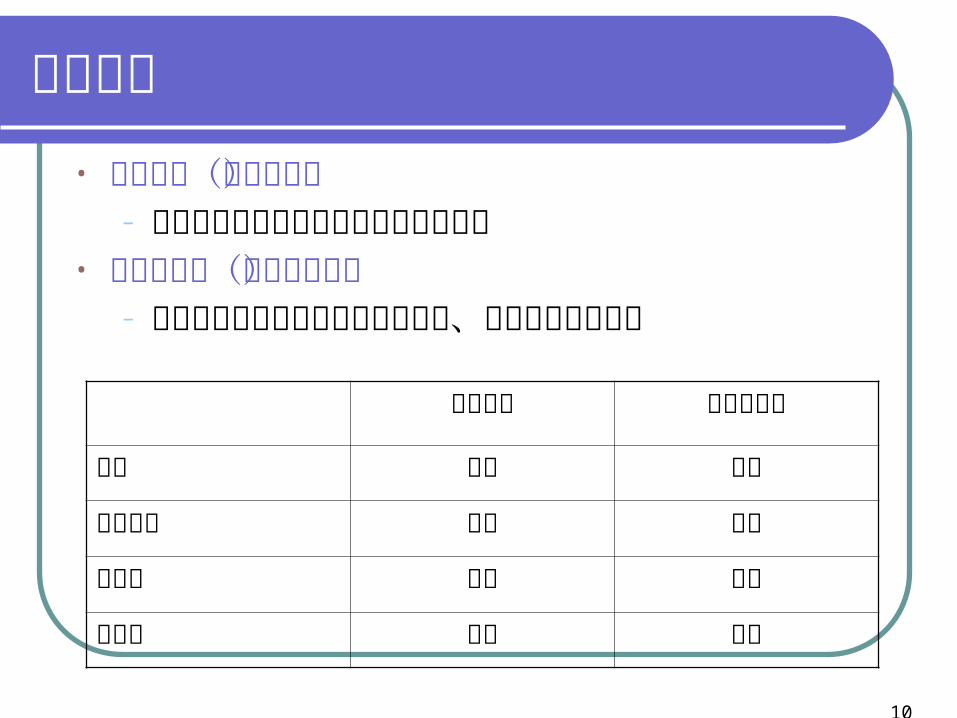
抽樣方法• 隨機抽樣(機率抽樣)
– 每個研究標的被抽出的機率相等且獨立• 非隨機抽樣(非機率抽樣)
– 每個研究標的被抽出的機率不相等、研究標的個數未知
隨機抽樣 非隨機抽樣
成本 較高 較低
所費時間 較多 較少
正確性 較高 較低
嚴謹度 較高 較低

11
2 抽樣的程序
四、決定樣本大小 到底抽多少樣本才足夠呢?必須用統計方法來計算 不同的抽樣方法,其樣本大小也會有所差異。

12
2 抽樣的程序
五、選擇抽樣單位 (Sampling units) 抽樣單位 (Sampling units) 有時和抽樣元素(Sampling element) 是相同的
一般抽樣單位可能為群體或個人,且可以分成好幾階段來進行。 Primary sampling units… Secondary sampling units …

13
2 抽樣的程序
六、進行指定元素的資料蒐集 抽樣過程中最後一個步驟即是實際進行指定元素的資
料蒐集。 以下幾個因素必須慎重考慮:
1. 正確性 2. 資源 3. 時間 4. 對母體的了解 5. 全國型或者是區域型調查 (地理分散程度) 6. 需要統計分析否
14
3 機率抽樣
抽樣的目的在於用樣本來解釋母體的特質。
機率抽樣的基本要點是隨機選取 (random selectio
n) ,即每一個元素被抽出的機率是相同的,且每次抽樣為獨立事件。
一、簡單隨機抽樣 (Simple Random Sampling)
二、系統抽樣 (Systematic Sampling)
三、分層抽樣 (Stratified Sampling)
四、群集抽樣 (Cluster Sampling)

15
3 機率抽樣
一、簡單隨機抽樣 (Simple Random Sampling) 一般讀者最熟悉的可能是簡單隨機抽樣在隨機抽樣中,母體中的每個元素被選出的機會是相
同的 一般實行的隨機抽樣被抽出的樣本是不放回重抽的 研究者可藉由以下的兩個方法來實行。
1. 號碼球取樣法2. 亂數表法 (random number table)

16
3 機率抽樣
程序: 1. 確定研究目的母體名單(抽樣框架) ,並予以編號
2. 決定樣本數 3. 以籤桶(或號碼球)、電腦亂數抽出符合樣本
個數之號碼組 4. 被抽出的號碼即是樣本
特性: 母體不大時較為適用各個研究標的被抽出的機率相等
17
3 機率抽樣
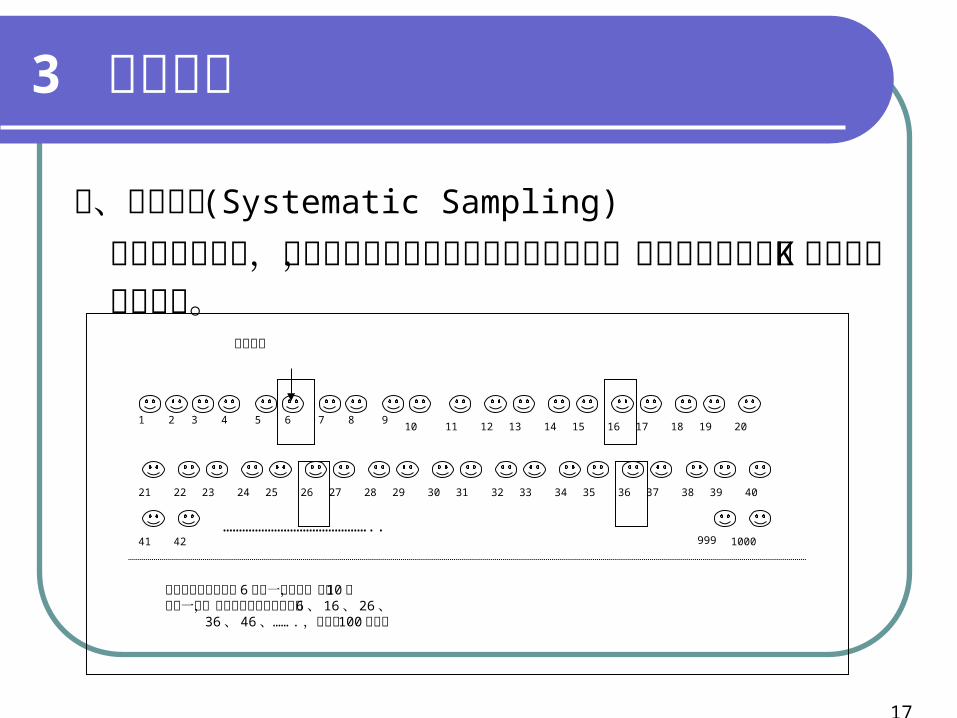
二、系統抽樣 (Systematic Sampling)
所謂系統抽樣法,是把抽樣架構中各元素依次編號分組,選取抽樣架構中第K個元素組成的樣本。
1 2 3 4 5 6 7 8 910 11 12 13 14 15 16 17 18 19 20
隨機開始
21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
41 42 999 1000………………………………………..
如研究者隨機選擇以 6 為第一個元素,每隔 10 個抽取一個,故其選擇的樣本分別為第 6 、 16 、 26 、 36 、 46 、…… . ,共選取 100 個樣本

18
系統抽樣
程序: 1. 確定研究目的母體名單(抽樣框架) ,並予以編號
2. 決定樣本數 ( 根據抽樣比率 ) 3. 決定抽樣區間 n 。 抽樣區間 n=母體大小 / 樣
本數 4. 從名單中前 n筆,隨機選取一個樣本(假設此
樣本編號為 k )後,作為第一個樣本 5. 後續樣本分別為:編號 k+n, k+2n, k+3n…..

19
系統抽樣
例:里民滿意度調查 1. 假設某里有 1000里民,將此些里民予以編號 2. 欲抽出樣本數 100 ( 抽樣比率 10%) 3. 抽樣區間: 1000/100= 10 4. 前 10筆中,隨機選取一筆,假設為第 5筆,此
為第一個樣本 5. 後續樣本:編號 15, 25, 35,….995
20
3 機率抽樣
三、分層抽樣 (Stratified Sampling)
分層抽樣為簡單隨機抽樣與系統抽樣的修正後混合模式。
特點:由母體內同質的次集合中抽出適當數目樣本

21
分層抽樣
母 體 樣 本
一年級
二年級
三年級
四年級
一年級
二年級
三年級
四年級
2000 人
1500 人
1000 人
500 人
200 人
150 人
100 人
50 人
圖 6—3 分層抽樣圖例

22
分層抽樣
程序: 1. 研究者將母體按某些特質區分成數類 2. 計算各類在母體之比率 3. 決定總樣本數,再根據上述比率,計算出各類應需多少樣本
4. 針對各個分類,進行隨機抽樣取得樣本
• 例:某高中學生學習行為調查– 1. 按年級分類,分成高一、高二、高三– 2. 在母體之比率分別為: 35 %、 33 %、 32 %– 3. 決定總樣本數為 200 時,根據上述比率,各年級相對應抽出 70 、 66 、
64 位學生– 4. 針對各個年級學生,分別進行隨機抽樣

23
分層抽樣
選擇此抽樣方法的理由: 應用此方法時,應注意三項問題:
樣本大小 層數 分層依據
層內元素同質性高,層間異質性高
24
3 機率抽樣
四、群集抽樣 (Cluster Sampling) 為了節省研究時間及財力,可實施群集抽樣。 所謂群集抽樣是「將母體依特質分成若干類,每一類稱為一個團體 (group) ,再以隨機的方式抽取若干小團體,然後對這些小團體中的元素全部訪問」。

25
群集抽樣
特性: 母體很大時適用 抽樣架構不是很完整
程序: 1. 研究者將母體按某些特質區分成數群 2. 決定欲抽出之群數 3. 以隨機方式抽出數群 4. 各群內的所有研究標的即是樣本

26
群集抽樣
例:市政滿意度調查 1. 可以『村里』加以分群 2. 假設欲抽取 15 個村里 3. 隨機方式抽出 4. 針對此 15村里內的全部研究標的進行資料收集


28
4 非機率抽樣
非機率抽樣的特點是無法估計母體中每一個元素被選入樣本的機會或機率,且也不能保證每個元素有機會被選入樣本。
非機率抽樣相較於機率抽樣較節省成本,且應用較方便,但其缺點是所抽出的樣本可能較不具有代表性。

29
非機率抽樣
一、便利抽樣 (Convenience Sampling)
便利抽樣又稱為偶遇抽樣 (accidental sample) 。
是以選樣的便利為基礎的一種抽樣方式。
研究者在路上或其他地方如速食店或便利商店等,攔下行人進行訪問即是一種便利抽樣。
30
非機率抽樣
二、配額抽樣 (Quota Sampling)
類似分層隨機抽樣的非機率抽樣
此法可改善樣本的代表性。 方法:藉由選擇樣本,使樣本中具有某種特質的比率和母體具
有某種特質的比率大約是一致的。 程序:
1. 研究者將母體按某些特質區分成數類 2. 計算各類在母體之比率 3. 決定總樣本數,再根據上述比率,計算出各類應需多少樣本 4. 針對各個分類,以便利抽樣或判斷抽樣取得樣本

31
配額抽樣
• 例:顧客滿意度調查 1000 位顧客。以性別、居住區域分類 1000 位顧客在各類之比率:(男生,住都市)為 12%,(男生,住鄉下)為 18%,(女生,住都市)為50%,(女生,住鄉下)為 20%
樣本數: 100 ,則分別針對此四類抽出12、 18、 50、 20 之樣本
以便利抽樣或判斷抽樣取得樣本
32
非機率抽樣
三、判斷抽樣 (Judgment Sampling)
依研究者本身判斷選擇樣本,挑選最符合研究目的的樣本。
使用此法時,研究者必須對母體十分了解,才能做出最適合的抽樣。
容易因研究者之偏差,產生抽樣誤差
四、雪球抽樣 (Snowball Sampling)
在特定的母體成員難以找到時,是最適合採用的方式
此法對找出遊民、外勞等樣本頗為適用。 程序:
1. 先找到幾個研究標的 2. 針對此些研究標的進行資料收集 3. 再請此些研究標的,介紹其他研究標的…
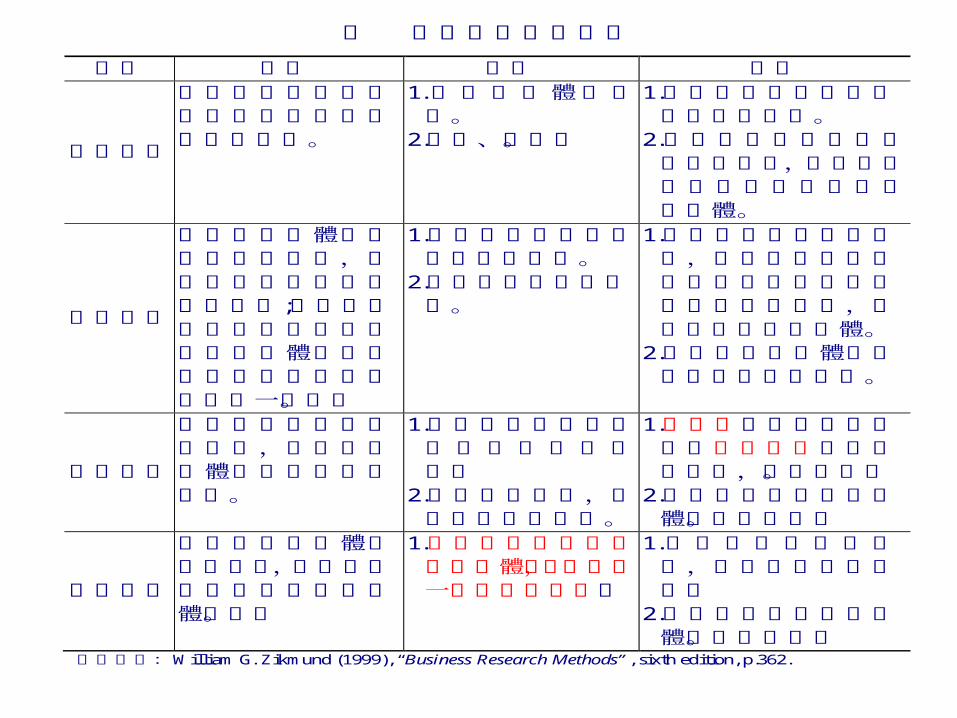
表 非機率抽樣的類型
類型 敘述 優點 缺點
便利抽樣
研究者使用最方便或是最經濟的方法來進行抽樣。
1.不需要母體的名冊。
2.快速、便利。
1.正確性和估計偏差不能衡量或控制。
2.研究者的主觀意識可能影響抽樣,選出的樣本可能不是很適合代表母體。
配額抽樣
研究者將母體依特質區分為數類,而抽樣時按比例從各類中抽出;其樣本元素具有某種特質的比率和母體元素具有某種特質的比率大約是一致的。
1.較機率抽樣中的分層抽樣成本低。
2.具有分層抽樣的效果。
1.雖採用配額的方式抽樣,但在抽樣時若不是隨機選取,選出的樣本也會有誤差,而不能代表整個母體。
2.在研究者將母體分類時可能會產生偏誤。
判斷抽樣
依研究者的判斷進行抽樣,研究者對母體必須有深入的了解。
1.在某種類型如選舉預測上是很有用的。
2.在蒐集樣本時,較節省成本及時間。
1.研究者在抽樣時可能會因主觀因素而影響了抽樣,造成偏差。
2.由抽樣資料來推估母體時較不適合。
雪球抽樣
先蒐集目標母體的少數成員,再由這些成員引出其他的母體成員。
1.在尋找少數難以尋找的母體時,此法是一個很好的方法。
1.因為抽樣單位不獨立,會產生較高的偏差。
2.由抽樣資料來推估母體時較不適合。
資料來源:William G. Zikmund (1999), “Business Research Methods”, sixth edition, p.362.

34
抽樣方法案例
討論:教育部打算針對全國 DOC (數位機會中心)
進行整體效益評估研究目的:
瞭解社區民眾對『數位機會中心』效益感受與滿意度 瞭解當地數位落差情況 瞭解社區民眾未使用當地『數位機會中心』原因
全國目前有 160處 DOC
元素、母體、抽樣方法(可行性)、樣本框架、抽樣單位

35
研究誤差
抽樣誤差 抽樣中所產生的誤差造成原因:
樣本太小 抽樣方法
理想的抽樣設計可降低抽樣誤差 非抽樣誤差
非抽樣中所產生的誤差訪員素質、訪員疏忽、登錄錯誤、回答者故意錯誤回答
抽樣前完整準備、嚴格訓練訪員、事後嚴格審查等可降低非抽樣誤差
統計分析時常假設此誤差不存在
36
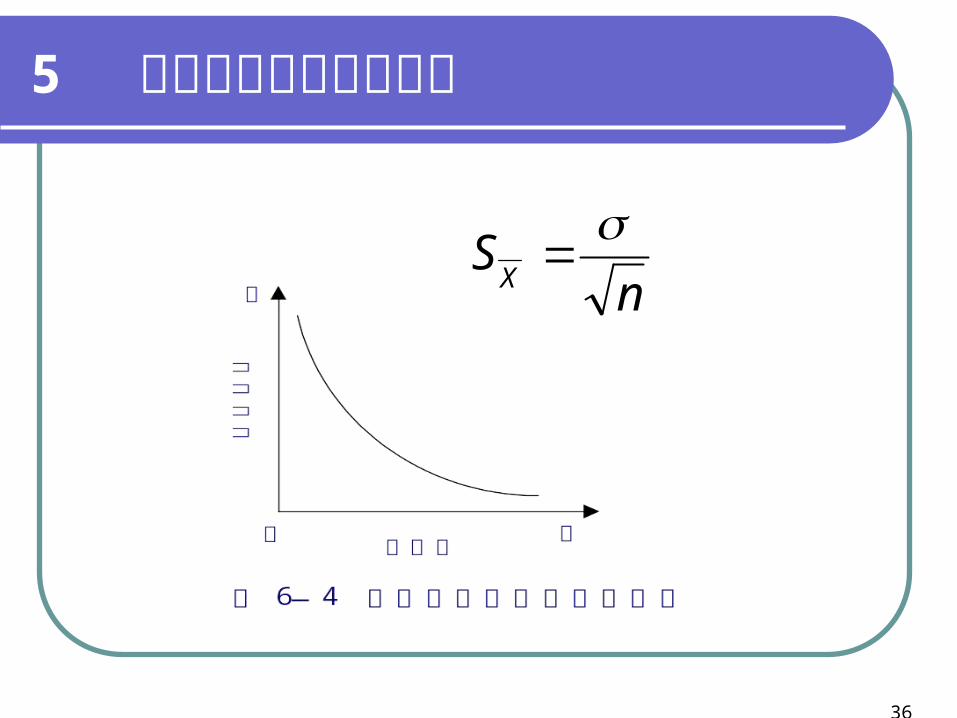
5 抽樣誤差與非抽樣誤差
nS
X

37
抽樣誤差
1. 涵蓋性誤差 (noncoverage) :樣本框架問題、樣本代表性問題

38
非抽樣誤差
2. 回覆性誤差 (nonresponse) :拒答、樣本代表性問題。3. 資料蒐集誤差 (data-collection errors) :填答不實內容、訪員解說錯誤
4. 研究室中處理過程誤差 (office processing
errors) :編碼錯誤

39
6 樣本大小的決定
一、基本的統計概念簡介
1. 母體參數 (population parameter) : 是指母體中變項特質的總括性敘述。
2. 統計值 (statistics) :統計值是由樣本計算出的數值,用來推估母數之用。
3. 樣本誤差 (sample error) :樣本的估計值與母體參數兩者的差。
4.信賴水準與信賴區間 (confidence interval) :信賴水準是用來表示樣本估計母體的正確性。

40
6 樣本大小的決定
二、平均值與標準差
1. 平均值
2. 標準差
nX n ...21
1
)( 2
n
XXS
i
41
6 樣本大小的決定
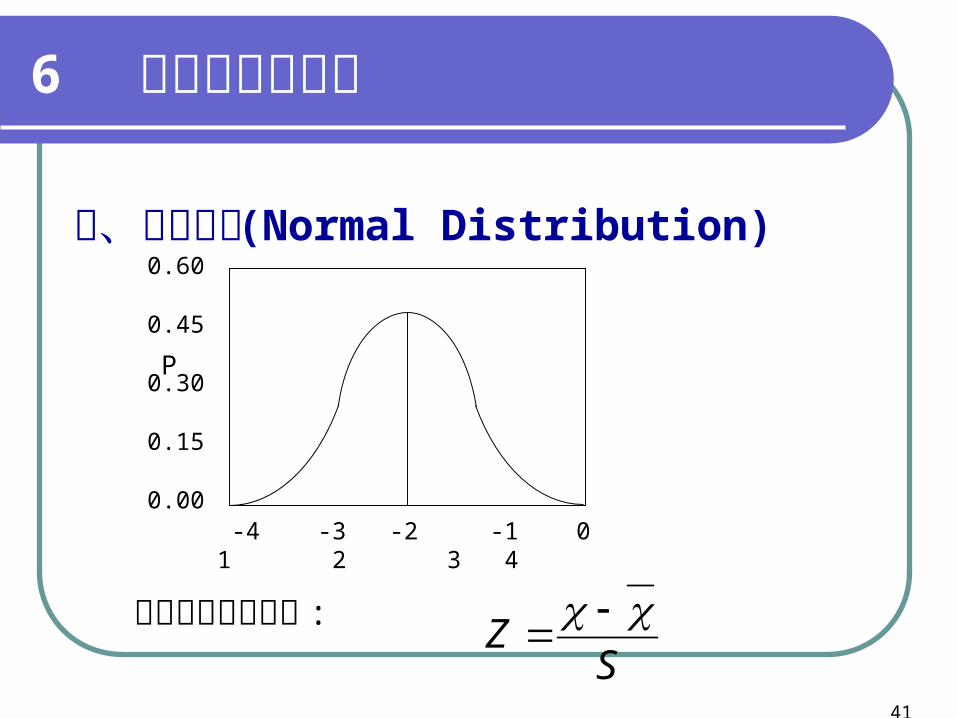
三、常態分配 (Normal Distribution)
標準化值計算方式 :
SZ
-4 -3 -2 -1 0 1 2 3 4
0.60
0.45
0.30
0.15
0.00
P

42
6 樣本大小的決定
四、中央極限定理
中央極限定理是統計中很常用的定理,尤其在抽樣中扮演很重要的角色,其意義為「從一個母體中抽出 n筆資料,並且計算樣本平均數 ,如果 n很大,則 Χ 平均數的分配會趨於常態分配,且 Χ 的平均數仍為母體平均數。
數學表示 :
標準差表示 :
),(~2
nNX
n
nS
X

43
6 樣本大小的決定
五、信賴區間
信賴區間表示以樣本計算出的估計值與母數的相似程度。
若已知樣本數為 n ,樣本平均數為 Χ ,則 在 1-α (α
稱為顯著水準 ) 的信賴區間為 Χ-μ ,而去絕對值展開後得 (Χ-e, Χ+e)
e稱為可容忍的誤差。
44
6 樣本大小的決定
七、分層抽樣樣本大小的決定
分層抽樣有兩個主要的方法:
1. 比例分配法:按各層數量的比例把樣本配置於各層。各層抽出之樣本數量如下:
%10.....2
2
1
1 N
n
N
n
N
n
N
n
L
L

45
6 樣本大小的決定
2. 最適分配法:在某些情況下,可能各層的抽樣 單位成本均不同。故在總樣本數已知,各層抽樣成本不同,各層變異數不同時,適合採用最適分配。其公式如下:
n :為總樣本數 ni :為第 i 層之最適樣本數Ni :為第 i 層所含母體數
σi :為第 i 層的標準差
ii
ii
N
Nnn
1

46
6 樣本大小的決定 以上例而言,設其總樣本數為 1000。第一、二、 三層的數量分別為 1000、 2000、 3000,由先前
的調查知道各層的標準差分別為 10、 20、 30。層數 各層母體數量 各層標準差1 1000 102 2000 203 3000 30
則第三層的樣本數 =
則第一層的樣本數 =
則第二層的樣本數 =)3000*302000*201000*10(
)1000*10(1000
)3000*302000*201000*10(
)2000*20(1000
)3000*302000*201000*10(
)3000*30(1000
=71
=286
=643