Embed Size (px)
DESCRIPTION
implantacion
Citation preview

EXCEPCIONES
PL/SQL
Concepto de Excepción
¿Qué es una excepción? Es un identificador de PL/SQL que surge durante la ejecución.
¿Cómo surge? Se produce por un error Oracle o bien puede ser provocada explícitamente.
¿Cómo se gestiona? Interrumpiéndola con un manejador de excepciones o propagándola al entorno de llamadas.
PL/SQL
Interrupción de Excepciones
Sintaxis:
PL/SQL
Excepciones de Oracle8

PL/SQL
Excepciones de Oracle8
PL/SQL
Excepciones de Usuario
Se declaran en la sección declarativa DECLARE.
Se provocan explícitamente en la sección ejecutable utilizando la sentencia RAISE.
Se gestiona la excepción dentro del bloque de excepciones EXCEPTION.

PL/SQL
Excepciones de Usuario
Ejemplo:
PL/SQL
Funciones para Identificar Excepciones
SQLCODE Devuelve el valor numérico del código de error SQL. No se puede referenciar directamente, hay que asignarlo a una variable PL/SQL de tipo NUMBER.
SQLERRM Devuelve el mensaje asociado con el número de error. Tipo VARCHAR2.
PL/SQL
RAISE_APPLICATION_ERROR
Sintaxis:

Utilice el procedimiento RAISE_APPLICATION_ERROR para comunicar de forma interactiva una excepción predefinida, devolviendo un código y un mensaje de error no estándar.
PL/SQL
RAISE_APPLICATION_ERROR
Se utiliza en dos lugares distintos:
o SECCIÓN EJECUTABLE
o SECCIÓN DE EXCEPCIONES
Ejemplos:
SQL Ejercicios
Ejercicios Excepciones
Para un número de empleado dado (por medio de comandos SQL*Plus), incrementarle el salario en un 10%. Controlar dos excepciones predefinidas de ORACLE,

NO_DATA_FOUND y TOO_MANY_ROWS.
Por medio de comandos SQL*Plus, aceptar tres valores que correspondan al número, nombre y localidad de un departamento.Realizar un bloque PL/SQL 9i que inserte en la tabla DEPT los valores aceptados. Controlar los siguientes errores:
o Si el departamento ya existe, insertar en la tabla TEMP un error.
o Si algún dato de los insertados es de mayor longitud que la especificada en la tabla, insertar un error en la tabla TEMP.
o Si se producen otros errores, insertar en la tabla TEMP el número y el mensaje del error producido.Nota: El error ORACLE de longitud del dato fuera del rango es el 1438�
1. Descomposición y NormalizaciónSiempre que un analista de sistemas de base de datos arma una base de datos, queda a su cargo descomponer dicha base en grupos y segmentos de registros. Este proceso es la descomposición; el mismo es necesario independientemente de la arquitectura de la base de datos - relacional, red o jerárquica-. Sin embargo, para la base de datos relacional, la accióncorrespondiente puede dividirse y expresarse en términos formales y se denomina normalización a la misma.La normalización convierte una relación en varias sub-relaciones, cada una de las cuales obedece a reglas. Estas reglas se describen en términos de dependencia. Una vez que hayamos examinado las distintas formas de dependencia, encontraremos procedimientos a aplicar a las relaciones de modo tal que las mismas puedan descomponerse de acuerdo a la dependencia que prevalece. Esto no llevará indefectiblemente a formar varias subrelaciones a partir de la única relación preexistente.2. DependenciaSignificado :Antes de entrar en el tópico principal de dependencia, vamos a rever algunos conceptos acerca de los individuos y acerca de las tuplas que los describen en la base de datos relacional (BDR). Restringiremos la discusión a la BDR, si bien la misma se aplica igualmente a las otras arquitecturas.

Los individuos tienen muchos atributos que pueden ser de interés a diferentes personas en diferentes momentos. Nuestro problema actual es con una sola aplicación o conjunto de aplicaciones: solemne son de interés algunos de los atributos.Los símbolos aplicables a la relación han sido introducidos previamente.• R es una tupla general o vector que describe a un individuo;• R es una relación, una matriz o un conjunto de vectores que pertenecen la población de interés.• U es el universo consistente en todas las posibles descripciones individuales, obtenido mediante una combinación exhaustiva de los valores a atributos.La tupla general toma la siguiente formaR = (a, b, c, ...., n) La pertenencia con respecto a relaciones, tuplas y universos se indica mediante. Con respecto a los atributos:• A es el símbolo del nombre de un atributo• a es el símbolo de un valor del atributo.Dominio (A) es el dominio para el atributo cuyo nombre es A.Campo de aplicaciónEstamos interesados en relaciones dependientes entre atributos de los individuos en una o varias poblaciones. Consideramos a los atributos D, E, y F. La dependencia es una relación funcional tal que los valores de una (o más de una) de las variables determina y fija el valor de las otras variables en la relación dependiente. Consideramos el caso en el que E y F dependen de D. Esto se describe más brevemente en forma simbólica:e = e (d) f = f(d)Existen tres tipos distintos de dependencia.
Total uno-uno-sinónimo Completa - subtupla Transitiva - múltiple.
La dependencia es una relación funcional que penetra en el universo de posibilidades. La dependencia no puede deducirse solamente de los datos de nuestra, ya que éstos son necesariamente incompletos, sino que debe ser inherente al comportamiento del sistema. Por ejemplo, si los datos revelan que cada uno de nuestros proveedores tiene exactamente una planta y que todas estas plantas están en diferentes ciudades, podemos asumir una dependencia total entre proveedor, planta y ciudad. Es decir, dada una ciudad, la misma está asociada con un proveedor; y dado este proveedor estará asociado con una ciudad. En la práctica, solamente cuando un nuevo proveedor se incorpore con una planta en la misma ciudad que uno de nuestro antiguos proveedores, resultará claro que no existe dicha dependencia total, Esto no podría ser deducido a partir de los datos previos.Dependencia Total

Consideremos los atributos x e y. Cada valor de x tiene uno y solo un valor de y asociados a el; e inversamente, dado un valor de y existe solamente un valor de x asociado a éste. Se trata de una función unitaria de una variable tanto en sentido directo como inverso y por o tanto se denomina dependencia total. Otra forma de expresar lo mismo es decir que x e y son sinónimos; ambas expresiones son equivalentes.Ejemplo con claveSi una de las variables es al mismo tiempo la clave, como consecuencia todo valor de ambas variables es único en cualquier tupla de la relación. Por ejemplo, consideremos un archivo de personal donde cada uno de los empleados es identificado de tres maneras.• Su nombre• Su número de seguridad social• Su número de empleadoLos tres pueden representar una dependencia total. Tanto el número de seguridad social como el número de empleado identifican al individuo en forma única. El número de seguridad social atañe a la población completa de trabajadores de los Estados Unidos. El número de empleado se aplica solamente al personal de una empresa en particular. El nombre puede no ser totalmente único y la dependencia total existe solamente cuando cada empleado tiene un nombre único.Si el número de empleado es al clave de la relación, el número de seguridad social es sinónimo de aquel. Podemos en consecuencia decir que el número de seguridad social, el campo no clave, es totalmente dependiente de la clave, y es una clave candidata.Si los nombres de todos nuestros empleados son únicos, también pueden, ser claves candidatas. Sin embargo puede existir alguna duplicación, dos personas llamadas John Smith, por ejemplo. Dado que esta es una posibilidad, no puede establecerse una dependencia total con respecto total con respecto al nombre. Puede incorporarse a la firma un nuevo empleado y este puede tener el mismo nombre que uno de nuestros empleados actuales.Ejemplo con estado Consideremos una relación que contiene información sobre estado en dos formas :• Una identificación de estado con dos letras, tal como CA para California.• Una designación con un número de dos dígitos tal como 12 paraCalifornia.Estas dos formas de información sobre estado ilustran una dependencia total. Debe notarse sin embargo que muchas tuplas pueden contener la misma identificación de Estado, dado que muchos de nuestros clientes pueden provenir de California. En consecuencia resulta claro que la dependencia total no significa unicidad.Dependencia CompletaEl concepto de dependencia completa se aplica solamente cuando:

• Tenemos más de dos variables, y• Una variable dependiente depende de dos o más variablesindependientes.Consideramos una relación que abarca las variables P, Q y R. Supongamos que P es la variable dependiente. Si el valor de P está determinado por una función de Q y R combinados, se trata de una dependencia completa. Esto es, el valor de P no depende únicamente ni de Q ni de R.Vamos a repetir esto simbólicamente. El valor de P es completamente dependiente de los valores de q y r.p = p (q,r)Ejemplo con orden de compraComo un ejemplo de dependencia completa, consideremos el caso de una orden de compra. Supongamos que esta orden de compra describe mediante tres variables que son de interés para nosotros:• El número de orden de compra (PON) designa la orden completa;• El número de parte de pieza designa una de las partes ordenadas por el pedido;• La cantidad de piezas es el número de unidades de dicha pieza requerida para satisfacer el pedido.Los pedidos describen en consecuencia una orden por medio de varias partes diferentes, y para cada una distinta asociada. El sistema contable ve varios pedidos diferentes. La misma parte puede aparecer en distintos pedidos y, cuando ello sucede, puede estar asociadas distintas cantidades con la misma parte.Un tupla de la base de datos relacional contendrá un PON un número de parte y una cantidad. La cantidad es completamente dependiente del PON y del número de parte. Resulta claro que el número de pedido no es suficiente para determinar la cantidad todas las partes de un determinado pedido no tiene la misma cantidad). Análogamente, un número de parte no es suficiente para determinar la cantidad ordenada, dado que diferentes pedidos pueden requerir distintas cantidades de dicha parte. Por lo tanto, es nuestro ejemplo, la cantidad no es dependiente solamente del PON o del número de parte; es completamente dependiente de ambos.Puede imaginarse, aunque no es muy probable el caso de que cada vez ordenados una parte la ordenamos solamente por una cantidad como una docena, o tres gruesas o cualquier otro valor fijo. Si esto ocurre para todas las partes y para todos los pedidos de nuestro sistema, en consecuencia no existirá dependencia completa. En efecto podemos decir que hay dependencia total entre cantidad y número de partes - condición improbable-.Hemos examinado anteriormente un ejemplo académico y las variables profesor, clase y sección. Tenemos en esta caso una dependencia completa de profesor respecto de clase y sección. Si en nuestra facultad está establecido existirá dependencia completa. Esto existiría que un profesor enseñe siempre a todas

las secciones de una clase particular - una condición no muy factible con un curso de 20 secciones-.Dependencia transitivaLa dependencia transitiva se aplica o tres o más variables. Consideremos el caso de solo tres variables y llamémoslas S, T y V.Diremos que S es la variable independiente si los valores de S determinan tanto a T como a V, y se simbolizará así:S ----> T; S ----> VSin embargo, sería deseable encontrar una relación más restrictiva o definida.Tenemos dependencia transitiva cuando S determina a T y V, pero los valores de V pueden considerarse siempre como dependiendo de los valores de T. Esto puede escribirse comoS ----> T; T ---->o alternativamente comov = v(t); t = t(s) v = v(t(s))ReducciónSi podemos manejar las dependencias transitivas, podremos reducir el espacio total requerido para almacenar los datos. Varios valores de S pueden generar un único valor de T. De modo similar, pueden existir varios valores de T asociados solamente con un valor de V. La separación de estas relaciones permite conservar espacios. Esto puede observarse mejor con respecto al ejemplo que se describe más abajo.EjemploConsideramos un ejemplo que asocia cursos con departamento y con escuela. En consecuencia, canto será dictado por el departamento de música en la escuela de Artes y Ciencias; hidráulica será dictada por ingeniería civil en la Escuela de Ingeniería; impuestos será dictado por el departamento contable en la Escuela de Administración.Llamemos• S al curso• T al departamento• V a la escuelaPor lo tantoS ----> T ----> Vla descomposición consiste en la asociación de un curso con un departamento en una relación. Otras relación identifica a cada departamento con una escuela. Esta segunda relación es necesariamente menor tanto en grado como en cardinalidad y aquí reside el ahorro de espacio.3. Normalizacion¿Qué es normalización?Normalización es un proceso que clasifica relaciones, objetos, formas de relación y demás elementos en grupos, en base a las características que cada uno posee. Si se

identifican ciertas reglas, se aplica un categoría; si se definen otras reglas, se aplicará otra categoría.Estamos interesados en particular en la clasificación de las relaciones BDR. La forma de efectuar esto es a través de los tipos de dependencias que podemos determinar dentro de la relación. Cuando las reglas de clasificación sean más y más restrictivas, diremos que la relación está en una forma normal más elevada. La relación que está en la forma normal más elevada posible es que mejor se adapta a nuestras necesidades debido a que optimiza las condiciones que son de importancia para nosotros:• La cantidad de espacio requerido para almacenar los datos es la menor posible;• La facilidad para actualizar la relación es la mayor posible;• La explicación de la base de datos es la más sencilla posible.
Disparadores o TriggersW R I T T E N B Y : A D M I N - M A R • 2 5 • 1 0
Los Triggers o Disparadores son objetos que se asocian con tablas y se almacenan en la base de datos. Su nombre se deriva por el comportamiento que presentan en su funcionamiento, ya que se ejecutan cuando sucede algún evento sobre las tablas a las que se encuentra asociado. Los eventos que hacen que se ejecute un trigger son las operaciones de inserción (INSERT), borrado (DELETE) o actualización (UPDATE), ya que modifican los datos de una tabla.
La utilidad principal de un trigger es mejorar la administración de la base de datos, ya que no requieren que un usuario los ejecute. Por lo tanto, son empleados para implementar las REGLAS DE NEGOCIO (tipo especial de integridad) de una base de datos. Una Regla de Negocio es cualquier restricción, requerimiento, necesidad o actividad especial que debe ser verificada al momento de intentar agregar, borrar o actualizar la información de una base de datos. Un trigger puede prevenir errores en los datos, modificar valores de una vista, sincronizar tablas, entre otros.
Un trigger presenta la siguiente estructura básica:
Una llamada de activación, la cual es una sentencia que permite la ejecución del código.
Una condición necesaria para que se realice el código. La secuencia de instrucciones a ejecutar una vez que se han
cumplido las condiciones iniciales.
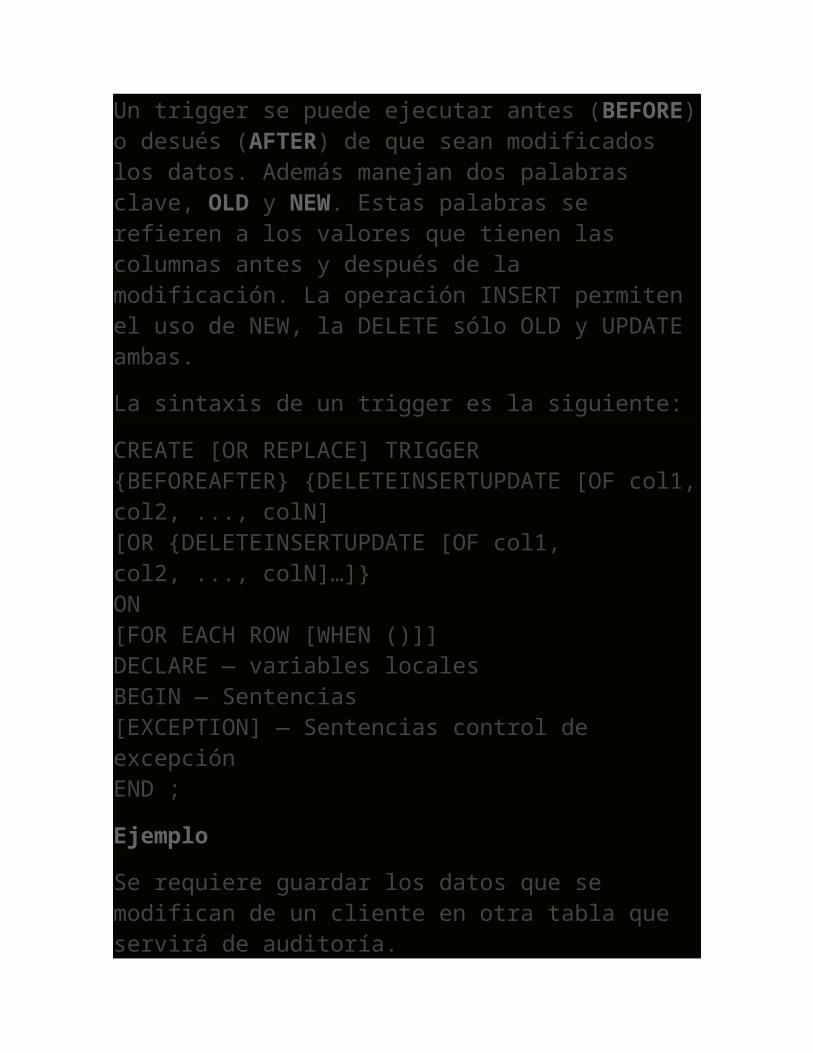
Un trigger se puede ejecutar antes (BEFORE) o desués (AFTER) de que sean modificados los datos. Además manejan dos palabras clave, OLD y NEW. Estas palabras se refieren a los valores que tienen las columnas antes y después de la modificación. La operación INSERT permiten el uso de NEW, la DELETE sólo OLD y UPDATE ambas.
La sintaxis de un trigger es la siguiente:
CREATE [OR REPLACE] TRIGGER{BEFOREAFTER} {DELETEINSERTUPDATE [OF col1, col2, ..., colN][OR {DELETEINSERTUPDATE [OF col1, col2, ..., colN]…]}ON[FOR EACH ROW [WHEN ()]]DECLARE — variables localesBEGIN — Sentencias[EXCEPTION] — Sentencias control de excepciónEND ;
Ejemplo
Se requiere guardar los datos que se modifican de un cliente en otra tabla que servirá de auditoría.
1. Crea la tabla de clientesCREATE TABLE clientes( id int not null auto_increment,

nombre varchar(20), seccion varchar(10), PRIMARY KEY(id) ) ENGINE = InnoDB;
2. Agrega algunos registrosINSERT INTO clientes (nombre, seccion) VALUES (‘Miguel’,'informatica’), (‘Rosa’,'comida’), (‘Maria’,'ropa’), (‘Albert’,'informatica’), (‘Jordi’,'comida’);
3. Crea la tabla auditoria_clientes que guardará los registros modificadosCREATE TABLE auditoria_clientes (id int not null auto_increment, nombre varchar(20), anterior_seccion varchar(10), usuario varchar(40), modificado datetime, primary key(id) ) ENGINE = InnoDB;
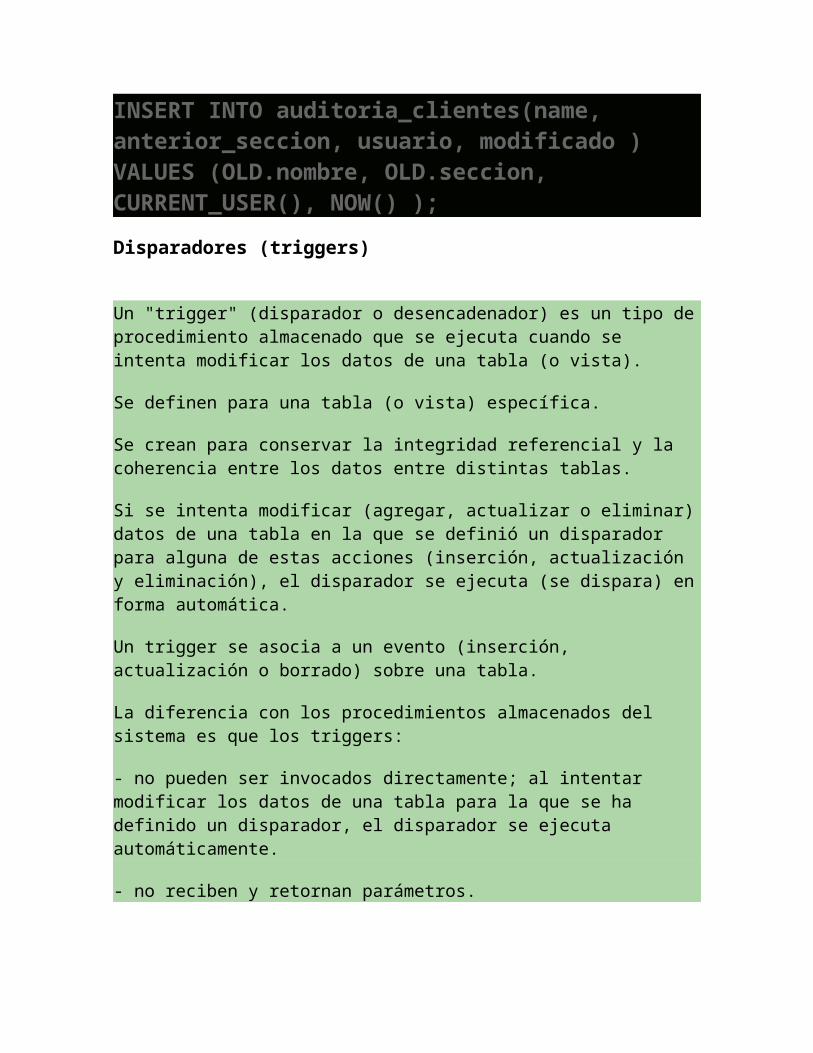
Crea el trigger que se disparará cada vez que alguien modifique un dato de la tabla clientes y lo guardará en la tabla auditoria_clientes junto al nombre del usuario y la fecha.CREATE TRIGGER trigger_auditoria_clientes AFTER UPDATE ON clientesFOR EACH ROWINSERT INTO auditoria_clientes(name, anterior_seccion, usuario, modificado )VALUES (OLD.nombre, OLD.seccion, CURRENT_USER(), NOW() );
Disparadores (triggers)
Un "trigger" (disparador o desencadenador) es un tipo de procedimiento almacenado que se ejecuta cuando se intenta modificar los datos de una tabla (o vista).
Se definen para una tabla (o vista) específica.
Se crean para conservar la integridad referencial y la coherencia entre los datos entre distintas tablas.
Si se intenta modificar (agregar, actualizar o eliminar) datos de una tabla en la que se definió un disparador para alguna de estas acciones (inserción, actualización y eliminación), el disparador se ejecuta (se dispara) en forma automática.
Un trigger se asocia a un evento (inserción, actualización o borrado) sobre una tabla.
La diferencia con los procedimientos almacenados del sistema es que los triggers:
- no pueden ser invocados directamente; al intentar modificar los datos de una tabla para la que se ha definido un disparador, el disparador se ejecuta automáticamente.
- no reciben y retornan parámetros.
- son apropiados para mantener la integridad de los datos, no para obtener resultados de consultas.
Los disparadores, a diferencia de las restricciones "check", pueden hacer referencia a campos de otras tablas. Por ejemplo, puede crearse un trigger de inserción en la tabla "ventas" que compruebe el campo "stock" de un artículo en la tabla "articulos"; el disparador controlaría que, cuando el valor de "stock" sea menor a la cantidad que se intenta vender, la inserción del nuevo registro en "ventas" no se realice.
Los disparadores se ejecutan DESPUES de la ejecución de una instrucción "insert", "update" o "delete" en la tabla en la que fueron definidos. Las restricciones se comprueban ANTES de la ejecución de una instrucción "insert", "update" o "delete". Por lo tanto, las restricciones se comprueban primero, si se infringe alguna restricción, el desencadenador no llega a ejecutarse.
Los triggers se crean con la instrucción "create trigger". Esta instrucción especifica la tabla en la que se define el disparador, los eventos para los que se ejecuta y las instrucciones que contiene.
Sintaxis básica:
create triggre NOMBREDISPARADOR on NOMBRETABLA for EVENTO- insert, update o delete

as SENTENCIAS
Analizamos la sintaxis:
- "create trigger" junto al nombre del disparador.
- "on" seguido del nombre de la tabla o vista para la cual se establece el trigger.
- luego de "for", se indica la acción (evento, el tipo de modificación) sobre la tabla o vista que activará el trigger. Puede ser "insert", "update" o "delete". Debe colocarse al menos UNA acción, si se coloca más de una, deben separarse con comas.
- luego de "as" viene el cuerpo del trigger, se especifican las condiciones y acciones del disparador; es decir, las condiciones que determinan cuando un intento de inserción, actualización o borrado provoca las acciones que el trigger realizará.
Consideraciones generales:
- "create trigger" debe ser la primera sentencia de un bloque y sólo se puede aplicar a una tabla.
- un disparador se crea solamente en la base de datos actual pero puede hacer referencia a objetos de otra base de datos.
- Las siguientes instrucciones no están permitidas en un desencadenador: create database, alter database, drop database, load database, restore database, load log, reconfigure, restore log, disk init, disk resize.
- Se pueden crear varios triggers para cada evento, es decir, para cada tipo de modificación (inserción, actualización o borrado) para una misma tabla. Por ejemplo, se puede crear un "insert trigger" para una tabla que ya tiene otro "insert trigger".
A continuación veremos la creación de un disparador para el suceso de inserción: "insert triger".
Ventajas
Centralización del control: Los accesos, recursos y la integridad de los datos son
controlados por el servidor de forma que un programa cliente defectuoso o no autorizado no pueda dañar el sistema. Esta centralización también facilita la tarea de poner al día datos u otros recursos (mejor que en las redes P2P).
Escalabilidad: Se puede aumentar la capacidad de clientes y servidores por separado. Cualquier elemento puede ser aumentado (o mejorado) en cualquier momento, o se pueden añadir nuevos nodos a la red (clientes y/o servidores).
Fácil mantenimiento: Al estar distribuidas las funciones y responsabilidades entre varios ordenadores independientes, es posible reemplazar, reparar, actualizar, o incluso trasladar un servidor, mientras que sus clientes no se verán afectados por ese cambio (o se afectarán mínimamente). Esta independencia de los cambios también se conoce comoencapsulación.
Existen tecnologías, suficientemente desarrolladas, diseñadas para el paradigma de C/S que aseguran la seguridad en las transacciones, la amigabilidad del interfaz, y la facilidad de empleo.
Desventajas
La congestión del tráfico ha sido siempre un problema en el paradigma de C/S. Cuando una gran cantidad de clientes envían peticiones simultaneas al mismo servidor, puede ser que cause muchos problemas para éste (a mayor número de clientes, más problemas para el servidor). Al contrario, en las redes P2P como cada nodo en la red hace también de servidor, cuantos más nodos hay, mejor es el ancho de banda que se tiene.
El paradigma de C/S clásico no tiene la robustez de una redP2P. Cuando un servidor está caído, las peticiones de los clientes no pueden ser satisfechas. En la mayor parte de redes P2P, los recursos están generalmente distribuidos en varios nodos de la red. Aunque algunos salgan o abandonen la descarga; otros pueden todavía acabar de descargar consiguiendo datos del resto de los nodos en la red.
El software y el hardware de un servidor son generalmente muy determinantes. Un hardware regular de un computador personal puede no poder servir a cierta cantidad de clientes. Normalmente se necesita software y hardware específico, sobre todo en el lado del servidor, para satisfacer el trabajo. Por supuesto, esto aumentará el costo.
Ventajas y desventajas del modelo cliente/servidor Ventajas: * Centralización del control de los recursos, datos y accesos. * Facilidad de mantenimiento y actualización del lado del servidor: Esto es porque el lado del servidor se puede mantener o actualizar fácilmente. Por ejemplo, una actualización se aplica a un único servidor, pero los beneficios los obtienen múltiples clientes generalmente sin necesidad de que éstos actualicen nada. * Toda la información es almacenada en el lado del servidor, que suele tener mayor seguridad que los clientes. * Hay muchas herramientas cliente-servidor probadas, seguras y amigables para usar. Desventajas:

* Si el número de clientes simultáneos es elevado, el servidor puede saturarse. Esto sucede con menor frecuencia en las redes P2P. * Frente a fallas del lado del servidor, el servicio queda paralizado para los clientes. Algo que no sucede en una red P2P. - See more at:
as desventajas de la tecnología cliente-servidor
Share on facebookShare on emailShare on twitterShare on
printMore Sharing Services0
tecnología de servidor de cliente se utiliza para muchos sistemas , incluyendo las
aplicaciones de Internet . En una red cliente-servidor , los recursos de
aplicaciones se almacenan en el servidor y pueden ser solicitadas por un número
de otros equipos, los clientes. Un ejemplo típico de la tecnología de servidor de
cliente es un navegador Web visualiza una página Web solicitada desde un
servidor Web. La tecnología de servidor de cliente tiene muchas ventajas pero
también un número de desventajas cuando se compara con los sistemas
alternativos . Los sistemas son dependientes en el servidor
Una aplicación cliente-servidor es totalmente dependiente del servidor. Los
recursos de la aplicación , tales como datos y el código de programación , se
almacenan en el servidor. Si una máquina servidor se cae , la aplicación en su
conjunto se hunde con él y deja de estar disponible para los clientes. Sistemas de
redes alternativas, como de igual a igual , a menudo tienen la ventaja de ser más
robusto que los sistemas cliente-servidor , ya que las responsabilidades se
comparten entre los diferentes nodos de la red . Para un sistema cliente-servidor ,

si un servidor falla, los clientes no tendrán sus peticiones cumplidas , lo que
socava todo el sistema.
Servidor sobrecarga
Una aplicación cliente-servidor puede poner una carga sustancial en el servidor .
El patrón básico para una red de servidor de cliente es varios clientes por servidor
, y el número de clientes puede aumentar en una medida tal que se convierte en
inmanejable para el servidor . En una red cliente-servidor , la mayor parte de las
responsabilidades que se llevan a cabo de manera desproporcionada por el
servidor , que puede tener un efecto negativo en el rendimiento y la eficiencia.
Restricciones de ancho de banda
En un sistema de servidor de cliente, el servidor tendrá típicamente una cantidad
designada de ancho de banda disponible , que puede llegar a ser agotado cuando
muchos clientes están solicitando los recursos . En una red peer-to -peer , todos
los nodos están contribuyendo al ancho de banda disponible para el sistema en su
conjunto , y pueden beneficiarse de un aumento en los participantes . Para un
sistema cliente-servidor , más clientes significan menos ancho de banda disponible
por cada nodo.
Gastos de funcionamiento
sistemas de servidor de cliente puede ser costoso para correr, principalmente

como consecuencia de la técnica requisitos en el lado del servidor . El
mantenimiento de una red cliente-servidor se requieren recursos importantes, ya
que las aplicaciones deben ser capaces de tratar con múltiples tecnologías
diferentes que interactúan entre sí . Aplicaciones de servidor de cliente implican
un recurso en el servidor intenta ponerse a disposición de una variedad de
capacidades en el lado del cliente , que puede ser una fuente de problemas de
mantenimiento en curso .


























