Embed Size (px)
Citation preview

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 1/101
UNIVERSITE DE TUNIS EL MANAR
Département génie électrique
Rapport de Projet de Fin d’Etudes
2002/2003
Réalisé par :Ben Djemâa Ahmed Bassem
Conception d’une chaîne de
transmission :codage source et codage canal
Soutenue le 30 juin 2003 devant le jury composé par :
Présidente : Mme JAIDANE Mériem
Rapporteur : Mme TURKI Monia
Invité : Mr. KALLEL Samir
Encadreurs : Mr. BOUALLEGUE Ammar
Mr. HAMDI Noureddine
Juin 2003

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 2/101
Dédicaces
Je dédie ce travail à mes très chers
parents.
Je ne trouverais jamais les mots qu’il faut
pour vous remercier
Tous mes sentiments de reconnaissance pour
vous.
A mon petit frère.
A mes sœurs.A tous mes amis.
En leurs souhaitant plein de bonheur.
Projet de fin d’étude ENIT 2002-2003

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 3/101
Remerciement
J'adresse mes plus vifs remerciements à mes
encadreurs Mr BOUALLEUE Ammar
et Mr HAMDI Noureddine qui m’ont soigneusement
encadré et prodigué de leurs conseils enrichissants
au cours de la réalisation de ce projet de fin
d’étude. Je tiens également à leur exprimer ma profonde
reconnaissance pour leur disponibilité, leur
confiance et leur assistance technique et morale.
Sans oublier de remercier mes enseignants à
l'ENIT pour la qualité de l'enseignement qu'ils m'ont
offert durant ces trois dernières années.
Mes remerciements les plus vifs vont aussi à
tous ceux qui de prés ou de loin, ont apporté leur
contribution à ce travail.
Projet de fin d’étude ENIT 2002-2003

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 4/101
Que les membres du jury trouvent ici mes
profonds remerciements.
Projet de fin d’étude ENIT 2002-2003

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 5/101
Résumé
Résumé
L’objet de ce projet de fin d’étude consiste à élaborer un algorithme de codage source
appliqué à la transmission d’images et d’un algorithme de codage canal en utilisant le
codage BCH. Les deux problèmes du codage de source et de codage de canal sont
considérés de manière séparée.
Ces deux algorithmes développés seront utilisés pour la transmission d’images.
A la fin de ce projet, nous avons mis en œuvre une chaîne logicielle complète pour la
transmission d’images fixes.
Abstract
The purpose of this project is to elaborate an algorithm of source coding and an
algorithm of channel coding while using the BCH coding.
The two problems of the source coding and channel coding are considered separated.
These two developed algorithms will be used for the transmission of pictures.
At the end this project, we put in work a complete software chain for the picture
transmission.
Projet de fin d’étude ENIT 2002-2003

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 6/101
Sommaire
Sommaire
INTRODUCTION GÉNÉRALE................................................................................7
Chapitre I :Généralité ....................................................................................10I.1Introduction ................................................................................................................ 10I.2Principaux éléments d’une chaîne de communication numérique ............................ 10
I.2.1Source de message ................................................................................................ 11
I.2.2Le codeur de source ..............................................................................................12I.2.3Le codeur de canal ...............................................................................................12I.2.4L’émetteur ou le modulateur .................................................................................12I.2.5Canal de transmission ...........................................................................................13I.2.6Le récepteur ......................................................................................................... 13I.2.7Le décodeur de canal .......................................................................................... 13I.2.8Le décodeur de source ......................................................................................... 13I.2.9 Conclusion ...........................................................................................................14Chapitre II :Codage de source .......................................................................16
II.1 Introduction ..............................................................................................................16II.2Les techniques de compression conservatrice ...........................................................17
II.2.1 Codage de Huffman ............................................................................................17a.Principe de la Méthode de Huffman ..........................................................17 b.Méthode de compression .............................................................................18c.Exemple pratique du codage de Huffman .................................................. 19d.Limites du codage de huffman ................................................................... 21e.Commentaires ..............................................................................................22II.2.2RLE (Run Length Encoding) ............................................................................... 22a.Algorithme de compression .........................................................................22b. Algorithme de decompression ....................................................................23
c.Exemple pratique ........................................................................................ 23d.Commentaire ................................................................................................ 23II.2.3LZW (Lempel-Ziv Welch) .................................................................................. 23a.Algorithme de compression .........................................................................23b.Algorithme de décompression ....................................................................24 c.Commentaires .............................................................................................24
II.3Les techniques de compression non conservatrice ....................................................24II.3.1Introduction .........................................................................................................24II.3.2Qu’est ce qu’une image numérique ? ..................................................................25II.3.3Introduction à la compression d’une image numérique ..................................... 26
II.3.4La compression JPEG ......................................................................................... 27a.Historique 27
Projet de fin d’étude Page 1 ENIT 2002-2003

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 7/101
Sommaire
b. Les différentes étapes de la compression non conservative d'une image . 28c.Exemple de compression .............................................................................35d.Conclusion 37 II.3.5Les ondelettes ......................................................................................................37II.3.6Les fractales ......................................................................................................... 40II.3.7Conclusion .......................................................................................................... 41Chapitre III :Codage de canal .......................................................................43
III.1Introduction ..............................................................................................................43III.2Les codes correcteurs d’erreurs ............................................................................... 44
III.2.1 Les codes en bloc Linéaires .............................................................................. 44III.2.2 Les codes cycliques ........................................................................................... 47III.2.3 Les codes BCH .................................................................................................49III.2.4 Utilisation de la transformé en cosinus discrète dans un codage correcteur d’erreur 51III.2.5 L’algorithme de Berlekamp-Massey et de Forney ............................................ 54III.2.6 L’algorithme de Peterson-Gorenstein-Zierler ...................................................55
Chapitre IV : Conception et Implémentation ................................................ 60IV.1Introduction ..............................................................................................................60IV.2Source de message ...................................................................................................60
IV.2.1Types de données utilise pour modéliser l’image ............................................. 61IV.2.2Fonctions utilisées pour manipuler les images ................................................. 62
IV.3Codage et décodage de source .................................................................................63IV.3.1DCT et IDCT .....................................................................................................65IV.3.2Quantification et déquantification ......................................................................65IV.3.3Lecture en zigzag ...............................................................................................66IV.3.4DPCM et RLE ....................................................................................................66IV.3.5Huffman ............................................................................................................. 67
a.types de données utiliser pour construire l'arbre ....................................... 67 b.Fonctions utilisées pour compresser et decompresser des fichier en
utilisant le codage de hufman ..................................................................67 IV.4Codage et décodage canal ........................................................................................70IV.5Programme principal ...............................................................................................73IV.6Conclusion ..............................................................................................................74
Chapitre V : Résultats et discussion ..............................................................76 V.1Codeur source ..........................................................................................................76V.2Codeur canal .............................................................................................................84V.3Comparaison entre codage source et codage canal indépendant et le codage source
canal conjoint ......................................................................................................90V.3.1Théorème de séparation de Shannon ................................................................... 90V.3.2Solution traditionnelle et limites d’utilisation ..................................................... 91V.3.3Solution conjointe............................................................................................... 91a.Protection des codes sources ...................................................................... 91b.Equilibrage de rendements .......................................................................... 91
V.4Conclusion ................................................................................................................ 91Conclusion Générale ......................................................................................93
Bibliographie 95
Projet de fin d’étude Page 2 ENIT 2002-2003

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 8/101
Liste des figures
Liste des figures
Projet de fin d’étude Page 3 ENIT 2002-2003

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 9/101
Liste des figures
FIGURE 1 : PRINCIPE D'UNE CHAÎNE DE COMMUNICATIONS NUMÉRIQUES......................................................................................................................................11
FIGURE 2 : EXEMPLE MONTRANT COMMENT UN CODE DE HUFFMAN ESTÉTABLIT....................................................................................................................21
FIGURE 3 : PRINCIPE DE LA NORME JPEG....................................................29FIGURE 4 : EXEMPLE DE TABLE DE QUANTIFICATION...........................34
FIGURE 5 : LECTURE EN ZIGZAG.....................................................................34
FIGURE 6 : LENA ORIGINALE............................................................................36
FIGURE 7 : IMAGE DE LENA POUR UN TAUX DE COMPRESSION ÉLEVÉ38
FIGURE 8 : SYSTÈME DE COMPRESSION D'EMPREINTES DIGITALES 40
FIGURE 9 : ALGORITHME DE DÉCODAGE POUR LES CODES DCT.......53
FIGURE 10 : ALGORITHMES DE BERLEKAMP-MASSEY ET DE FORNEY
POUR LES CODES DCT.........................................................................................55FIGURE 11 : ORGANIGRAMME DE L’ALGORITHME DE PETERSON-
GORENSTEIN-ZIERLER........................................................................................58
FIGURE 12 : SCHÉMAS DE PRINCIPE DU CODEUR DE SOURCE..............64
FIGURE 13 : ORGANIGRAMME DE CONSTRUCTION DE L’ARBRE DEHUFFMAN.................................................................................................................69
FIGURE 14 : ORGANIGRAMME SIMPLIFIÉ DE LA COMPRESSION DEHUFFMAN.................................................................................................................70
FIGURE 15 : L’ALGORITHME DE BERLEKAMP_MASSEY ........................72
FIGURE 16 : L’ORGANIGRAMME DE DU PROGRAMME PRINCIPAL.....74
FIGURE 17 : COURBE REPRÉSENTATIVE DE LA VARIATION DE LA TAILLEDU FICHIER COMPRESSÉ EN FONCTION DU FACTEUR DE QUALITÉ..77
FIGURE 18 : COURBE REPRÉSENTATIVE DE LA VARIATION DU NOMBRED’ERREURS NON CORRIGÉES EN FONCTION DE LA PROBABILITÉ
D’ERREUR BINAIRE..............................................................................................85
FIGURE 19 : IMAGE REÇUE SANS UTILISATION DE CODEUR CANAL POUR P= 0.0015.......................................................................................................................86
FIGURE 20 : IMAGE REÇUE EN UTILISANT NOTRE CODEUR CANAL POUR LA MÊME PROBABILITÉ D’ERREUR ..............................................................87
FIGURE 21 : IMAGE TROP BRUITÉ ISSUE D’UNE CHAÎNE QUI NE PRÉSENTEPAS DE CODEUR CANAL......................................................................................88
FIGURE 22 : IMAGE REÇUE CAS D’UN CANAL TROP BRUITÉ.................89
Projet de fin d’étude Page 4 ENIT 2002-2003

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 10/101
Liste des Tableaux
Liste des Tableaux
TABLEAU 1 : TABLES DES OCCURRENCES...................................................19TABLEAU 2: EXEMPLE DE TABLE DE QUANTIFICATION POUR LALUMINANCE ET LA CHROMINANCE...............................................................33
TABLEAU 3: TABLEAU COMPARATIF DES DIFFÉRENTS NIVEAUX DEQUALITÉ...................................................................................................................37
TABLEAU 4 : REPRÉSENTATION DE GF(24) COMME EXTENSION DE GF(2). 50
TABLEAU 5 : TABLE DE MESURE DE LA TAILLE DU FICHIER COMPRESSÉEN FONCTION DU FACTEUR DE QUALITÉ....................................................76
TABLEAU 6 : TABLE DES PROBABILITÉS DE TRANSITION......................84
TABLEAU 7 : QUELQUES ORDRES DE GRANDEUR DE PROBABILITÉD’ERREURS .............................................................................................................89
Liste des Abréviations
Projet de fin d’étude Page 5 ENIT 2002-2003

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 11/101
Liste des Tableaux
Projet de fin d’étude Page 6 ENIT 2002-2003
− JPEG Join Photographic Experts Group− DCT Discrete Cosine Transform− IDCT Inverse Discrete Cosine Transform− RLE Run Length Encoding
− DPCM Differential Pulse Code Modulation− LZW Lempel-Ziv Welch− GF Galois Field− TIFF Tagged Image Format File− CCITT Consultative Committee for International Telegraph and Telephone− ISO Organisation Internationale de Standardisation− CBS Canal Binaire Symétrique− BCH Bose-Chaudhuri-Hockenghem− VLC Variable Length Code− DWT Discrete Wavelet Transform
− IDWT Inverse Discrete Wavelet Transform

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 12/101
Liste des Abréviations
INTRODUCTION GÉNÉRALE
La transmission de contenu multimédia, et particulièrement l'image animée, sur des
réseaux où les débits restent encore relativement faibles, nécessite l’utilisation des
techniques de compression afin de réduire la taille des données à transmettre etd’économiser les ressources des canaux de transmission. Ce besoin a motivé les recherches
en codage source, dans le but de développer de nouveaux algorithmes de compression plus
performants. On distingue deux techniques de compressions : Celles qui sont conservatives,
utilisée pur réduire le poids de données qui doivent rester identiques à leur original et les
techniques de compression destructives, utilisées essentiellement pour compresser les
images fixes et animées, la parole, et la musique.
Un codeur de source peut être la combinaison de plusieurs techniques de compressionafin de réduire au maximum la taille des données à transmettre ou à stocker tout en
conservant une distorsion tolérable.
A cause des perturbations et du bruit introduit par le canal, le signal reçu peut ne pas
être une réplique exacte du signal à la sortie du codeur de source. Ceci peut ne pas être
tolérable, surtout dans le cas ou les données transmises doivent rester identiques à leur
original. La solution est de pouvoir détecter puis éventuellement corriger les erreurs pouvant
altérer le signal a transmettre. Pour cela, des techniques permettant de protéger l’information à émettre contre les perturbations introduites par le canal de transmission sont
utilisées. Cette protection contre les erreurs du canal peut s’effectuer par deux blocs
différents constituants la chaîne.
− Le codeur canal : en recodant l’information à transmettre.
− Le modulateur : en choisissant un qui soit adapté au canal de transmission.
Ces deux techniques de protection sont généralement combinées pour augmenter la performance de la chaîne de transmission.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 13/101
Liste des Abréviations
Ces deux opérations de codage source et de codage canal doivent se faire en respectant
un certain nombre de contraintes :
Il faut d’abord pour un débit visé, évaluer la dégradation apportée au signal et voir si
cette dégradation est acceptable. Il faut ensuite, rendre le degré de complexité inférieur à uncertain seuil. Un degré de complexité important peut être accepté au niveau de l’émission,
mais il doit être beaucoup plus faible à la réception au niveau de l’utilisateur. Enfin, il faut
avoir un délai de reconstitution adapté à l’application. Par exemple, pour les transmission
full duplex, il faut minimiser le plus possible ce délais.
C’est cette double opération de codage source et de codage canal, qui fait l’objet de ce
projet de fin d’étude. En effet, le travail réalisé consiste à élaborer un algorithme de codage
source appliqué à la transmission d’images et d’un algorithme de codage canal en utilisantle codage BCH. Les deux problèmes du codage de source et de codage de canal sont
considérés de manière séparée, selon le « théorème de séparation » de Shannon. Ces deux
algorithmes développés seront utilisés pour la transmission d’images.
Dans ce projet, nous avons mis en œuvre une chaîne logicielle complète pour la
transmission d’images fixes.
L’ensemble de ces idées est développé en cinq chapitres.
− Le premier chapitre présente les différents blocs constituant une chaîne de
communication numérique.
− Dans le deuxième chapitre, nous exposons les techniques de compression
conservatives, ainsi que les techniques de compression non conservatives. Dans laquelle,
nous étudions particulièrement l'algorithme JPEG de compression d'image, qui est la
combinaison de plusieurs techniques de compression.
− Le troisième chapitre introduit les principaux codes correcteurs d'erreur. Nous
finissons ce chapitre par une brève description de l'algorithme de Peterson-Gorenstein-
Zierler et de Berlekamp-Massey.
− Le quatrième chapitre présente les algorithmes que nous avons implémenté en utilisant
le langage C++.
− Le chapitre 5 sera consacré aux résultats de simulation de la chaîne qu’on a pu élaboré.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 14/101
Introduction Générale
Chapitre I
GÉNÉRALITÉ

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 15/101
Introduction Générale
CHAPITRE I : GÉNÉRALITÉ
I.1 Introduction
Dans ce chapitre, nous commençons par une représentation schématique d’une chaîne
de communication numérique. Par la suite nous présentons un à un les différents blocs
constituants la chaîne, en allant de la source du message jusqu’au destinataire.
I.2 Principaux éléments d’une chaîne de communication numérique
Une chaîne de communications numériques est composée généralement des
principaux blocs suivants :
− Source de message
− Codeur de source
− Codeur de canal
− Emetteur
− Canal de transmission
− Récepteur
− Décodeur de canal
− Décodeur de source
− Destinataire
Dans la suite, nous présentons les différents blocs constituant la chaîne.
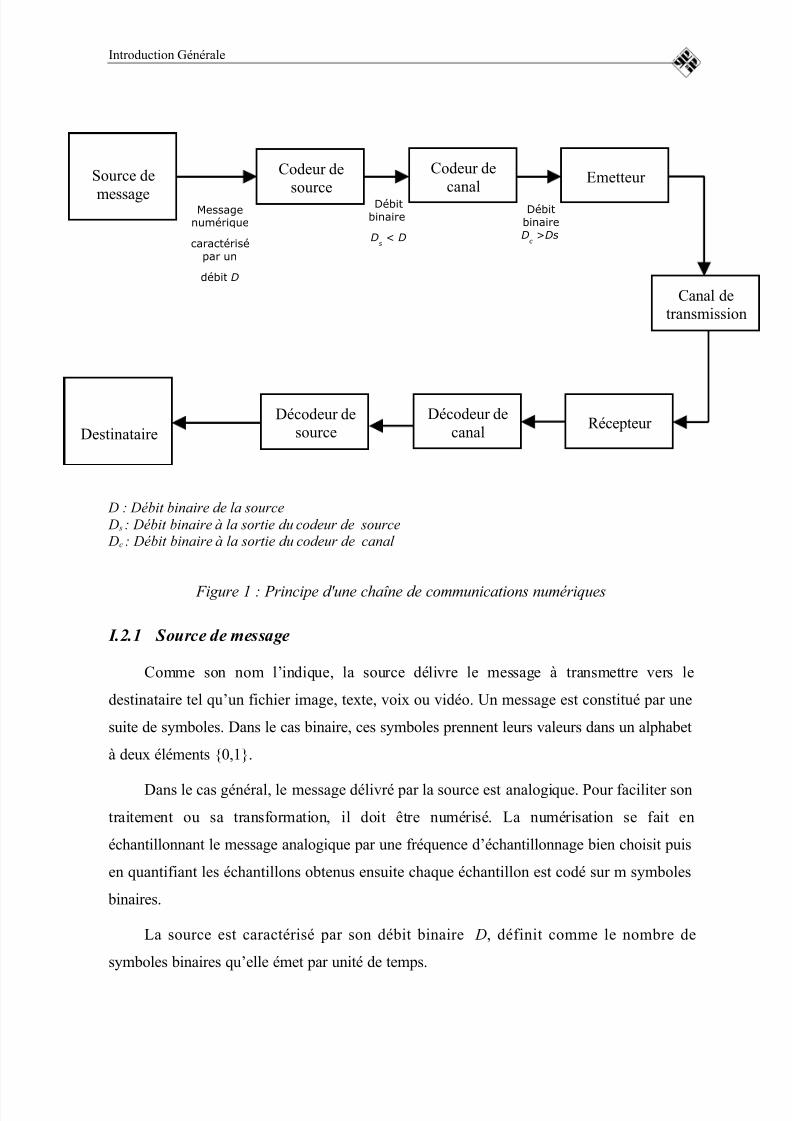
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 16/101
Introduction Générale
D : Débit binaire de la source
D s : Débit binaire à la sortie du codeur de source Dc : Débit binaire à la sortie du codeur de canal
Figure 1 : Principe d'une chaîne de communications numériques
I.2.1 Source de message
Comme son nom l’indique, la source délivre le message à transmettre vers le
destinataire tel qu’un fichier image, texte, voix ou vidéo. Un message est constitué par une
suite de symboles. Dans le cas binaire, ces symboles prennent leurs valeurs dans un alphabet
à deux éléments 0,1.
Dans le cas général, le message délivré par la source est analogique. Pour faciliter sontraitement ou sa transformation, il doit être numérisé. La numérisation se fait en
échantillonnant le message analogique par une fréquence d’échantillonnage bien choisit puis
en quantifiant les échantillons obtenus ensuite chaque échantillon est codé sur m symboles
binaires.
La source est caractérisé par son débit binaire D, définit comme le nombre de
symboles binaires qu’elle émet par unité de temps.
DébitbinaireD
c >Ds
Débitbinaire
Ds< D
Messagenumérique
caractérisépar un
débit D
Source de
message
Codeur desource
Codeur de canal
Emetteur
Canal detransmission
Décodeur desource
Décodeur decanal
Récepteur Destinataire

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 17/101
Introduction Générale
I.2.2 Le codeur de source
Le message délivré par la source est ensuite traité par le codeur de source. Son rôle est
de réduire le débit binaire de la source. Cela se fait en représentant le message numérique
issu de la source sous une forme beaucoup plus compacte, c'est-à-dire en utilisant leminimum de symboles binaires. A la sortie du codeur de source le débit binaire D s est
nettement inférieur au débit D à la sortie de la source.
I.2.3 Le codeur de canal
Le codage canal appelé aussi codage correcteur d’erreurs. Comme son nom l’indique,
son rôle est de protéger les donnés numériques contre les erreurs introduites par le canal de
transmission. Ce qui permet d’améliorer les performances d’une chaîne de communicationnumérique. La littérature propose plusieurs algorithmes de codage pour assurer ce besoin.
La réalisation de ces algorithmes est possible grâce aux progrès techniques des circuits
intégrés.
A la sortie du codeur de canal, le débit Dc est strictement supérieur au débit D s à la
sorti du codeur de source. En effet, le codage canal consiste à insérer dans le message issu
du codeur de source des symboles de redondance suivant une loi donnée. On appelle
rendement du code ou encore le taux de codage le rapport :
c
s
D
D R =
I.2.4 L’émetteur ou le modulateur
L’émetteur assure l’opération de modulation qui consiste à associer au message
numérique issu du codeur de canal, un signal analogique compatible avec le milieu de
transmission utilisé. Le choix de ce signal analogique dépend des propriétés physiques dumilieu de transmission. L’émetteur assure donc une fonction d’adaptation au milieu de
transmission.
L’émetteur assure d’autres traitements tel que le filtrage du signal pour limiter sa
bande. Ce qui permet à plusieurs utilisateurs de partager le même milieu de transmission
sans risque d’interférence. L’émetteur peut assurer aussi une fonction de changement de
fréquence ce qui permet de centrer le signal autour de la fréquence f 0 alloué à la
transmission.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 18/101
Introduction Générale
I.2.5 Canal de transmission
Un canal peut être un câble coaxial, une liaison radioélectrique, un câble bifilaire, une
fibre optique ou un support d’enregistrement comme la bande magnétique. En traversant le
milieu de transmission, le signal issu de l’émetteur peut être affecté par des perturbations.Par mis ces perturbations, on peut citer le bruit additif généré par les dispositifs situés dans
le récepteur ainsi que les interférences causées par le milieu de transmission. Ces
interférences proviennent des autres utilisateurs du milieu, des interférences dues aux effets
climatiques ou du bruits industriels.
I.2.6 Le récepteur
Le récepteur a pour fonction de reconstituer le message à la sortie du codeur de canal à partir du signal reçu. Le récepteur comprend des circuits permettant d’amplifier le signal
reçu et d’effectuer des opérations de changement de fréquence et de démodulation.
I.2.7 Le décodeur de canal
Le décodeur de canal reçoit le message fourni par le récepteur et exploite la
redondance introduite par le codeur de canal, pour essayer de détecter puis éventuellement
de corriger les erreurs pouvant affecter le message reçu. Des algorithmes de décodage
assurent ce besoin.
I.2.8 Le décodeur de source
Le décodeur de source reçoit la séquence de symboles provenant du décodeur de
canal. Connaissant le traitement réalisé par le codeur de source, il reconstitue le message
original.
La qualité du message reconstitué peut être mesuré en évaluant la probabilité d’erreur
par symbole à la sortie du décodeur source en le comparant avec celui à la sortie de la
source du message.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 19/101
Introduction Générale
I.2.9 Conclusion
Nous venons d’introduire les différents blocs constituants une chaîne de transmission
numérique. Nous avons également présenté l’intérêt de chaque bloc dans la chaîne.
Nous proposons dans le prochain chapitre une présentation du codage source adapté à
la transmission d’images appelé encore compression d’images.
Nous présentons également chaque technique de compression et nous finissons par
une comparaison entre ces différents types de compression.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 20/101
Chapitre I Généralité
Chapitre II
CODAGE DE SOURCE

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 21/101
Chapitre I Généralité
CHAPITRE II : CODAGE DE SOURCE
II.1 Introduction
Le codage de source à pour rôle de résoudre le problème causé par la taille du fichier à
transmettre. En effet, l’utilisation du codage de source permet une réduction importante de
la quantité de données. La transmission sur des réseaux, ou le débit est relativement faible,
devient beaucoup plus lente que le poids des données est important. D’où l’utilité de
l’installation d’un codeur de source dans une chaîne de transmission [5].
Exemples d'utilisation de la compression pour le transport :
• Réseaux par câbles (Minitel, Internet dont la bande passante est très faible…).
• Réseaux sans fil (communication par satellite, télévision par satellite, le téléphone
portable ...).
La littérature propose plusieurs algorithmes de codage source qu’on peut appelés aussi
algorithmes de compression [12]. Ces algorithmes sont réalisés en réduisant toutes les
formes possibles de redondance. Nous distinguons deux techniques de compression :
- Les techniques de compression conservatrices (RLE, LZW, Huffman) qui permettent
de reconstituer, en fin de la chaîne, un signal identique au signal à l’entrée du codeur de
source. Ce type de compression est utilisé dans le cas ou les données informatiques doivent
rester identiques à leur original (textes, programmes informatiques, ...).
- Les techniques de compression non conservatrices. Dans ce cas, les données
reconstituées en fin de processus diffèrent de leur original, mais la différence n’est
pratiquement pas perçue par l’utilisateur. Ce type de compression est utilisé pour les images
fixes et animées ( JPEG, ondelettes, fractales, MPEG, ...), la parole et la musique.
Les différents algorithmes de compression sont choisis en fonction de :
• Leur taux de compression (rapport de la taille du fichier compressé sur la taille du
fichier initial).

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 22/101
Chapitre I Généralité
• La qualité de compression (dans le cas de compression avec perte).
• La vitesse de compression et de décompression.
Dans les paragraphes suivants, nous présentons les deux techniques de compression
conservatives et non conservatives. Nous étudions particulièrement l’algorithme JPEG de
compression d’image qui est la combinaison de plusieurs techniques de compression.
II.2 Les techniques de compression conservatrice
L’objectif de ce paragraphe est d’introduire les importants algorithmes de
compression conservative :
II.2.1 Codage de Huffman
Une source d’information émet des messages qu’on peut déterminer la probabilité
d’apparition. Pour améliorer l’efficacité de la transmission, il faut coder les messages en
mots dont la longueur varie en sens inverse de leur fréquence.
Le premier code basé sur les résultats de la théorie de l’information était le code
Shannon-Fano. Huffman a après introduit le code qui porte son nom, et dont il a démontré
que l’efficacité est toujours supérieure à celle du code Shannon-Fano.
Ce paragraphe est une présentation générale du codage de Huffman.
A . P RINCIPE DE LA M ÉTHODE DE H UFFMAN
Le codage de Huffman est une méthode de compression statistique de données qui
permet de réduire la longueur du codage d'un alphabet.
Ce codage est utilisé en particulier pour la transmission de messages par télécopie et
sur minitel.
C’est un procédé de codage dans lequel la longueur des mots codés varie en sens
inverse de leur probabilité d’apparition. En d’autres termes les données qui ont une
occurrence très faible sont recodées sur une longueur binaire supérieure à la moyenne, alors
que les données très fréquentes sont recodées sur une longueur binaire très courte.
Ainsi, pour les données rares, nous perdons quelques bits regagnés pour les données
répétitives. Par exemple, dans un fichier ASCII le "w" apparaissant 10 fois aura un code très
long 101000001000. Ici la perte est de 40 bits (10 x 4 bits), car sans compression, il serait

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 23/101
Chapitre I Généralité
codé sur 8 bits au lieu de 12. Par contre, le caractère le plus fréquent comme le "e" avec 200
apparitions aura un code à 1. Le gain sera de 1400 bits (7 x 200 bits).
De plus, le codage de Huffman a une propriété de préfixe : une séquence binaire ne
peut jamais être à la fois représentative d'un élément codé et constituer le début du code d'unautre élément. Cette propriété permet de décoder sans ambiguïté toute séquence, ce qui évite
d’avoir à inclure des séparateurs entre les mots.
Par exemple, si un caractère est représenté par la combinaison binaire 100 alors la
combinaison 10001 ne peut être le code d'aucune autre information. Dans ce cas,
l'algorithme de décodage interpréterait les 5 bits comme une succession du caractère codé
100 puis du caractère codé 01. Cette caractéristique du codage de Huffman permet une
codification à l'aide d'une structure d'arbre binaire.
B . M ÉTHODE DE COMPRESSION
L'algorithme se décompose en deux phases. La première consiste à lire entièrement
l'ensemble des données source et à comptabiliser le nombre d'apparitions de chaque
information : on bâtit ainsi une table des occurrences. Cette table est ordonnée suivant
l'ordre décroissant des fréquences.
Ensuite, on procède à des réductions successives jusqu'à la fin de la table. Une
réduction consiste à prendre les deux éléments de la table ayant les plus petites fréquences
(ou probabilités) et à les assembler. A ce nouvel élément ainsi constitué, on associe une
fréquence résultante de la somme des deux fréquences associées. Puis, il est reclassé dans la
table. Les deux membres initiaux en ont été éliminés.
L'assemblage se fait par l'intermédiaire d'un arbre binaire. On construit un noeud (ou
racine pour le premier) avec deux branches. L'élément de plus faible fréquence est placé sur
la branche de droite (appelée feuille droite), l'autre sur la branche de gauche (appelée feuille
gauche). On peut inverser la répétition des deux feuilles. Seul le codage sera différent avec
des "0" à la place des "1" et des "1" à la place des "0", mais la longueur du code sera la
même.
Feuille gaucheF
1F
2
noeud (ou racine)
Feuille droite

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 24/101
Chapitre I Généralité
Ainsi, deux éléments n'en font plus qu'un, et le nombre d'éléments total de la liste
diminue de un à chaque itération. Cette opération est répétée jusqu'à ce qu'il n'y ait plus
qu'un seul élément. Ce dernier noeud sera précisément la racine de l'arbre final.
Une fois l'arbre est terminé, nous pouvons attribuer aux feuilles (donc les informationssource) des valeurs dictées par la structure de l'arbre.
Pour chaque élément, pour atteindre sa feuille correspondante, on commence la
recherche à partir de la racine de l'arbre. A chaque pas à droite, on ajoute "0" à une chaîne
représentative du codage qui sera initialement nulle. A chaque pas à gauche, on ajoute "1" et
cela jusqu'à ce qu'on atteigne la feuille.
Il est évident qu'une fois le codage effectué, il faut relire l'ensemble des données pour
les coder. Aussi, pour que le codeur et le décodeur soient en phase, il faut transmettre la
table codage/décodage avant de coder les informations.
C . E XEMPLE PRATIQUE DU CODAGE DE H UFFMAN
Il s’agit de construire la table de codage de Huffman des éléments présenté dans le
tableau suivant :
Tableau 1 : Tables des occurrences

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 25/101
Chapitre I Généralité

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 26/101
Chapitre I Généralité
Figure 2 : Exemple montrant comment un code de Huffman est établit
D. L IMITES DU CODAGE DE HUFFMAN
Malgré son efficacité, cet algorithme comporte quelques inconvénients :
− Premièrement, afin de constituer la table des fréquences et le codage de
l'information, il faut lire une première fois l'ensemble des données sources. En fonction de
sa dimension, on perd plus ou moins de temps.
− Deuxièmement, lors de la transmission d'information, il faut copier cette table de
décodage pour que le décodeur restitue l'ensemble des données sources. C'est-à-dire que l'ondevra faire figurer en tête de fichier les clés de décodage des octets. Pour les petits fichiers,
cet en-tête prend proportionnellement beaucoup de place et le gain peut être négatif.
Ces deux défauts sont liés à la méconnaissance de la table de codage/décodage. Cet
algorithme peut être amélioré en compilant une statistique décrivant la répartition des
données susceptibles d'être rencontrées. Dans le cas de la compression de fichier texte, il
existe des tables de statistiques pour l'alphabet lexical. Ces probabilités d'apparition
changent suivant la langue utilisée dans le fichier source. Ces tables statistiques intégrées

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 27/101
Chapitre I Généralité
dans un compresseur/décompresseur limitent l'utilisation d'un tel programme à la
compression de fichier texte uniquement. Pour la compression d’image, la méthode de
compression JPEG utilise des tables prédéfinies optimisées pour être utilisé pour tout type
d’images.
De plus cet algorithme de compression est très sensible à la perte d'un bit, toutes les
valeurs qui suivront un bit perdu seront fausses lors de la décompression.
E . C OMMENTAIRES
Lors de l'étude de la méthode de Huffman, nous avons mis en évidence le problème de
connaissance de la table de correspondance codage binaire, probabilité d'apparition d'un
message.
Ce principe de compression est aussi utilisé dans le codage d'image TIFF (Tagged
Image Format File) spécifié par Microsoft Corporation et Aldus Corporation. Par Ailleurs,
le codage d'image est fait en retranscrivant exactement le contenu d'une image, en utilisant
les méthodes traditionnelles de compression. Il existe des méthodes qui ne conservent pas
exactement le contenu d'une image (méthodes non conservatives). Mais, dont la
représentation visuelle reste correcte. Par exemple, la méthode JPEG ( Join Photographic
Experts Group), qui utilise la compression de type Huffman pour coder les informations
d'une image, est une combinaison de techniques de compression ne conservant pas
exactement le contenue de l’image : elle est dite méthode de compression « destructive ».
Malgré son ancienneté, cette méthode est toujours utilisée, et offre des performances
appréciables. En effet, beaucoup de recherches en algorithmiques ont permis d'améliorer les
fonctionnalités de la méthode Huffman de base, comme avec les arbres binaires, arbres
équilibrés, etc.
II.2.2 RLE (Run Length Encoding)
Cet algorithme exploite les répétitions successives de caractères.
A . A LGORITHME DE COMPRESSION
L’algorithme de compression suit les étapes suivantes :

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 28/101
Chapitre I Généralité
− Recherche des caractères répétés plus de n fois, avec n est un nombre fixé par
l'utilisateur. Ce nombre n doit être au moins égal à 3. Sinon, on risque d’augmenter la taille
de la chaîne.
− Remplacement de l'itération de ce caractères par : un caractère spécial identifiant unecompression suivi par le nombre de fois où le caractère est répété puis le caractère répété.
B. A LGORITHME DE DECOMPRESSION
Durant la lecture du fichier compressé, lorsque le caractère spécial est reconnu, on
effectue l'opération inverse de la compression tout en supprimant ce caractère spécial [5].
C. E XEMPLE
PRATIQUE
Par exemple, on cherche à compresser la chaîne suivante :
AAAAARRRRRROLLLLBBBBBUUTTTTTT
On choisit comme caractère spécial : @ et comme seuil de répétition : 3.
Après compression : on aura @5A@6RO@4L@5BUU@6T.
On gagne 11 caractères soit 38%.
D . C OMMENTAIRE
Cet algorithme est essentiellement utilisé pour la compression des images. Il est très
simple à implémenter. Le seul inconvenant est son taux de compression qui est relativement
faible en le comparant avec les autres algorithmes de compression. Généralement, il est
utilisé avec d’autres techniques de compressions. Citons comme exemple, la compression
JPEG qui utilise la RLE .
II.2.3 LZW (Lempel-Ziv Welch)
Cet algorithme réduit la taille des chaînes de caractères [5].
A . A LGORITHME DE COMPRESSION
Cet algorithme utilise une bibliothèque, c'est-à-dire une table de données contenant
des chaînes de caractères.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 29/101
Chapitre I Généralité
Au cours du traitement de l'information, les chaînes de caractères sont placées une par
une dans la bibliothèque. Lorsqu'une chaîne est déjà présente dans la bibliothèque, son code
de fréquence d'utilisation est incrémenté.
Les chaînes de caractères ayant des codes de fréquence élevés sont remplacées par unmot ayant un nombre de caractères le plus petit possible et le code de correspondance est
inscrit dans la bibliothèque. On obtient ainsi une information encodée et sa bibliothèque.
B . A LGORITHME DE DÉCOMPRESSION
Lors de la lecture de l'information encodée, les mots codés sont remplacés dans le
fichier par leur correspondance lue dans la bibliothèque. Ainsi, le fichier original est
reconstitué.
C. C OMMENTAIRES
Cette méthode est peu efficace pour les images. Mais, elle donne de bons résultats
pour les textes et les données informatiques.
II.3 LES TECHNIQUES DE COMPRESSION NON CONSERVATRICE
II.3.1 Introduction
Ce type de technique de compression est utilisé essentiellement pour les images fixes
et animées ( JPEG, ondelettes, fractales, MPEG, DivX ...) en utilisant une transformation du
contenue de l’image.
Il a été démontré qu'il n'est pas possible d'obtenir des taux de compression intéressants
à partir du contenu de l'image, c'est-à-dire en travaillant dans l'espace pixel, en raison de la
faible corrélation spatiale des points.
Il faut transformer ce contenu soit pour éliminer la corrélation spatiale, dans le cas de
la DCT , soit pour l'augmenter par séparation en plusieurs espaces, dans le cas des
ondelettes.
Il existe de très nombreux formats compressés : compression JPEG, fractale ou par
ondelettes pour les images, norme MPEG et format DivX pour les séquences vidéos.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 30/101
Chapitre I Généralité
Dans les paragraphes suivants, on présente les principales techniques de compression
d’images. On commence par définir qu’est ce qu’une image numérique, puis on présente La
compression JPEG, la compression d'images par ondelettes et nous finissons par la
technique de compression fractale.
II.3.2 Qu’est ce qu’une image numérique ?
On peut séparer les images numériques en deux grandes familles : les images
numérisées d’origine extérieure et les images de synthèse qui sont produites sur un
ordinateur.
Les images sont décomposées géométriquement en petites surfaces élémentaires
appelés les pixels. Chaque pixel est défini par ses abscisses et ordonnées précisant son
emplacement dans l’image.
Le stockage de l’image en mémoire est réalisé en conservant les données concernant
chaque pixel dans une matrice ou à chaque pixel correspondra une case de la matrice.
Une image en noir et blanc ne nécessitera que l’intervention de deux types de pixels
différents pour être décrite. Un seul bit suffira donc pour coder la valeur d’un pixel. Les
images à plusieurs niveaux de gris sont définies avec 256 niveaux de gris, mais seuls 128
sont reconnaissables par l’œil. La quantité d’information est de 8 bits par point.
Une image colorée est toujours le mélange de trois images de couleurs données, donc
le mélange de trois images monochromes. Par combinaison linéaire on peut alors réaliser
environ 16 millions de couleurs différentes. Ces couleurs sont indépendantes entre elles. Ces
trois couleurs sont nécessaires pour restituer l’ensemble des couleurs observables par le
système visuel humain. Elles forment un espace vectoriel de trois dimensions
Les principaux paramètres utilisés pour la description d’un fichier image sont les
suivants :
- Dimension de l’image qui est définie par le nombre de pixels par ligne et le nombre de
lignes constituant l’image.
- Méthode de rangement des pixels.
- Méthode de rangement des bits d’un pixel.
- Algorithme de compression.
- Nombre de bits par pixel.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 31/101
Chapitre I Généralité
- Structure d’un pixel : codage de la couleur.
II.3.3 Introduction à la compression d’une image numérique
Une image sous forme numérique est constituée d'une matrice de pixels contenant des
informations sur la couleur de chacun d'entre eux. Cette information peut être codée sur 1
bit, 8 bits, 16 ou 24 bits dans ce dernier cas, chaque octet code l'une des couleurs
fondamentales, le rouge, le vert ou le bleu. Il est même possible de rajouter un octet
contenant une information de transparence: l'information de couleur sera donc codée sur 32
bits.
La taille en octets de l'image est proportionnelle à la précision sur la couleur, et à sa
taille en pixels. La taille en octets d'une image 24 bits est considérable: une image 300x200
est d’environ 176 Ko de taille. D'où l'intérêt des algorithmes de compression pour une
transmission via le Web par exemple. Ceci est encore plus vrai pour une séquence de 25
images (300x200, 24 bits) par seconde d'une durée d'une minute, dont la taille est d'environ
258 Mo.
La compression d’images utilise les deux techniques de compression :
- Les techniques de compression conservatrice, qui permettent de reconstituer, en fin de
processus, une image identique à l’image initiale. Une présentation de ces technique estl’objet du paragraphe précèdent.
- Les techniques de compression non conservatrice. Dans ce cas l’image reconstituée en
fin de processus diffère de l’image initiale, mais la différence de qualité n’est pratiquement
pas perçue par l’œil de l’utilisateur.
La compression est réalisée en réduisant toutes les formes possibles de redondance
qu’une image peut présenter :
- Redondance spatiale: tous les pixels sont identiques à l’intérieur d’une plage
uniforme de l’image. Il suffit d’en coder un pour caractériser la plage considérée. La
technique de la Transformée en Cosinus Discrète ( DCT ) utilisée dans l’algorithme JPEG,
met en évidence cette redondance spatiale à l’intérieur de chaque image.
- Redondance statistique : certaines données se répètent beaucoup plus fréquemment
que d’autres. La compression sera réalisée en attribuant des codes d’autant plus courts que
la fréquence est élevée.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 32/101
Chapitre I Généralité
- Redondance subjective, mise à profit dans la compression non conservatrice : elle
découle des imperfections de l‘œil humain. Des pixels présentant des caractéristiques assez
proches pour être perçus de manière identique peuvent être traités comme des pixels
identiques.
On peut noter que l’œil est beaucoup plus sensible aux variations d’intensité
lumineuse (luminance) qu’à celles de la couleur (chrominance) : les informations sur la
couleur peuvent donc être davantage compressées que celles sur la luminance. De même,
des pixels trop proches pour être distingués par l‘œil peuvent être regroupés.
II.3.4 La compression JPEG
Nous allons étudier l’un des algorithmes les plus célèbres, créé il y a maintenant plus
de vingt ans, la norme JPEG.
Le format JPEG ( Joint Photographic Experts Group) permet d'atteindre des taux de
compression (sans perte notable de qualité) jusqu'à un facteur 25. La compression JPEG est
très répandue sur le Web. La compression d'images par la norme JPEG est une méthode
« destructrice », c'est à dire que lors de la compression, des informations sont
définitivement perdues par rapport à l'image originale [2].
Cette technique repose sur une transformation matricielle appelée Discrete Cosine
Transform ( DCT ).
La norme JPEG est née de la recherche d'une norme pour la compression des données
graphiques. Cette norme comprend des spécifications pour le codage conservatif et non
conservatif . Mais, la partie la plus intéressante de la spécification JPEG est celle traitant de
la compression non conservative.
Nous présenterons dans ce paragraphe la norme JPEG et nous détaillerons pas à pas
les différentes étapes de cette méthode. Pour finir nous présentons un exemple pratique.
A . H ISTORIQUE
A la fin des années 80, deux importants groupes de normalisation, le CCITT
(Consultative Committee for International Telegraph and Telephone) et l’ ISO
(Organisation Internationale de Standardisation), appuyés par divers groupes industriels et
universitaires, décidèrent de créer une norme internationale pour la compression d’images
fixes [2].

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 33/101
Chapitre I Généralité
La mise en place d’un standard international était devenue nécessaire pour archiver ou
pour faciliter l’échange des images dans des domaines aussi variés que les photos satellites,
l’imagerie médicale, la télécopie couleur, ou la cartographie…
C’est ainsi que fut créé le groupe JPEG (Joint Photographic Experts Group) à l’originede la norme qui porte son nom. Cette norme comprend des spécifications pour les codages
conservateurs (l’image est restituée identique à elle-même à la suite du codage) et non
conservateurs (l’image est modifiée pendant le cycle de compression mais cette
modification reste imperceptible pour l’œil) de l’image.
Le JPEG est aujourd’hui largement utilisé dans les secteurs de l’informatique et de la
communication (appareils photo numériques, scanners, imprimantes, télécopieurs…). Cette
norme offre l’un des meilleurs rapports qualité/taille de l’image disponible.
B. L ES DIFFÉRENTES ÉTAPES DE LA COMPRESSION NON CONSERVATIVE D' UNE IMAGE
La figure suivante représente schématiquement le principe de la norme JPEG. Nous
allons détaller par la suite pas à pas chaque étape de la compression [10].
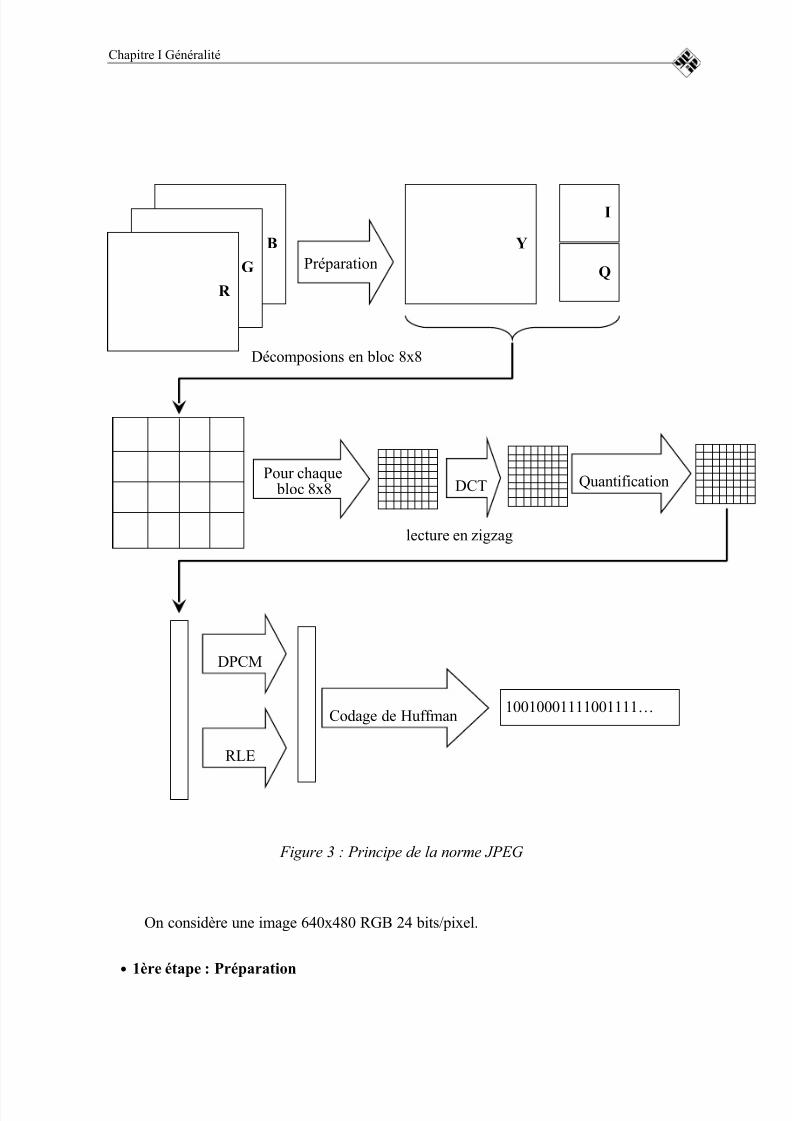
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 34/101
Chapitre I Généralité
Figure 3 : Principe de la norme JPEG
On considère une image 640x480 RGB 24 bits/pixel.
• 1ère étape : Préparation
Décomposions en bloc 8x8
B
G
R
PréparationY
I
Q
Pour chaque bloc 8x8 DCT Quantification
lecture en zigzag
DPCM
RLE
Codage de Huffman10010001111001111…

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 35/101
Chapitre I Généralité
Il est préférable, afin d'obtenir une meilleure compression, de convertir avant
d’effectuer la transformation DCT l'image RGB en image YIQ. Il est très facile d’effectuer
une telle transformation.
En effet, les informations sur la luminance (paramètre Y) et la chrominance (I et Q)sont des combinaisons linéaires des intensités de rouge (R ), vert (G), et bleu (B) :
Y = 0.30 R + 0.59 G + 0.11 B I = 0.60 R - 0.28 G - 0.32 BQ = 0.21 R - 0.52 G + 0.31 B
Chacune des ces trois variables est reprise sous forme de matrice 640x480. Cependant,
les matrices de I et de Q (information sur la chrominance) peuvent être réduites à des
matrices 320x240 en prenant les moyennes des valeurs des pixels regroupés par carré dequatre.
Cela ne nuit pas à la précision des infos sur l'image car nos yeux sont moins sensibles
aux écarts de couleurs qu'aux différences d'intensités lumineuses. Comme chaque point de
chaque matrice est une information codée sur 8 bits, il y a chaque fois 256 niveaux possibles
(de 0 à 255). En soustrayant 128 à chaque élément, on met à zéro le milieu de l’intervalle
des valeurs possibles (de -128 à +127). Enfin chaque matrice est partagée en blocs de 8x8.
• 2ème étape: DCT
La clé du processus de compression est la DCT .
La DCT ( Discret Cosine Transform) qui est au coeur de la méthode a été proposée en
1974 par le professeur Rao de l’université du Texas en 1974 [9].
En théorie, la transformation DCT est sans perte. Cette transformation ne compresse
pas les données : elle modifie simplement les coefficients de la matrice initiale [15].
En pratique, les arrondis vont venir la fausser.
Le but est analogue à celui de la transformée de Fourier d'un signal. Elle prend un
ensemble de points d'un domaine spatial et les transforme en une représentation équivalente
dans le domaine fréquentiel. La matrice initiale donne par DCT une matrice dont les
coefficients en haut à gauche sont les coefficients des basses fréquences et les coefficients
en bas à droite ceux des hautes fréquences.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 36/101
Chapitre I Généralité
Dans le cas présent, nous allons opérer la DCT sur un signal en trois dimensions. En
effet, le signal est une image graphique, les axes X et Y étant les deux dimensions de
l'écran, et l’axe des Z reprenant l'amplitude du signal, la valeur du pixel en un point
particulier de l'écran. La DCT permet de convertir une information spatiale en une
information spectrale dont les axes X et Y représentent les fréquences du signal en deux
dimensions.
La transformation est réalisée, non pas sur l’image entière, mais sur des fractions de
l’image, des blocs de 8 x 8 pixels. Car en augmentant la taille des blocs nous obtiendrions
une meilleure compression, mais au détriment du temps de traitement.
La DCT, effectuée sur chaque matrice 8x8 de valeurs de pixels, donne une matrice 8x8
de coefficients de fréquence: l'élément (0,0) représente la valeur moyenne du bloc, les autres
indiquent la puissance spectrale pour chaque fréquence spatiale. Généralement, plus qu’on
s’éloigne du coin supérieur gauche plus les valeurs de la matrice résultante s’approche de 0.
Cela traduit le fait que l’information effective de l’image est concentrée dans les basses
fréquences. C’est le cas de la majorité des images.
Appliqué à une matrice carrée de dimension N x N la DCT bidimensionnelle s’écrit :
+
+= ∑∑
−
=
−
= 2
1cos.
2
1cos).,()().(
2),(
1
0
1
0
yv N
xu N
y x f vcuc N
vu F N
x
N
y
π π
Avec f(x, y) représentent les éléments de la matrice sur laquelle on va effectuer la
transformation [15].
c (u) est définit part :
1,....2,11)(
2
1)0(
−==
=
N w siwc
c
F(u,v)f(i,j)
DCT

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 37/101
Chapitre I Généralité
La transformation inverse est donnée par :
+
+= ∑∑
−
=
−
= 2
1cos.
2
1cos).,().().(
2),(
1
0
1
0
v y N
u x N
y x F yc xc N
vu f N
x
N
y
π π
La DCT est conservative si l'on ne tient pas compte des erreurs d'arrondis qu'elle
introduit.
• 3ème étape : La quantification
Une fois la transformation DCT effectuée, la première étape de la compression
proprement dite est la quantification des coefficients DCT .
En effet, la quantification représente la phase non conservatrice du processus de
compression JPEG. Elle permet, en diminuant la précision de l’image, de réduire le nombre
de bits nécessaires au stockage. Pour cela, elle réduit chaque valeur de la matrice DCT en la
divisant par un nombre fixé par une table de quantification, que l’on appelle encore une
matrice de quantification (matrice 8 x 8).
Ces 64 quantificateurs sont soit calculés en fonction d'un paramètre de compression,
soit donnés par des tables standards construites en fonction de critères psycho visuels,
optimisées par les concepteurs du format JPEG.
Il existe une table de quantification pour l'information de luminance et une autre pour
l'information de chrominance.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 38/101
Chapitre I Généralité
Luminance Chrominance
16 11 10 16 24 40 51 61
12 12 14 19 26 58 60 55
14 13 16 24 40 57 69 56
14 17 22 29 51 87 80 62
18 22 37 56 68 109 103 77
24 35 55 64 81 104 113 92
49 64 78 87 103 121 120 101
72 92 95 98 112 100 103 99
17 18 24 47 99 99 99 99
18 21 26 66 99 99 99 99
24 26 56 99 99 99 99 99
47 66 99 99 99 99 99 99
99 99 99 99 99 99 99 99
99 99 99 99 99 99 99 99
99 99 99 99 99 99 99 99
99 99 99 99 99 99 99 99
Tableau 2: Exemple de table de quantification pour la luminance et la chrominance
De ce fait, chaque coefficient DCT est divisé par le quantificateur correspondant, puis
arrondi à l'entier le plus proche. L'étape de quantification est donc l'étape de perte
d'information.
) ji,(quantum
) ji,(DCTvaleur ) j,i(quantifiéeValeur = arrondie à l’entier le plus proche.
Ces 64 quantificateurs peuvent être calculés en fonction d'un paramètre de
compression en utilisant une formule mathématique.
Pour simplifier on peut prendre ( ) Fqn jni μi,jquantum ×
+++= 11
avec 1== n µ ce qui donne ( ) ( ) Fq jii,jquantum ×+++= 11
F q est le facteur de qualité. C’est le paramètre qu’on modifie quand on choisit la
qualité de restitution dans un logiciel comme « Paint Shop Pro ».
Les nombreux tests réalisés ont conduit à retenir en pratique des facteurs de qualité
compris entre 1 (l’image reste excellente) et 25 (dégradation maximale acceptable).
Voici la matrice de quantification que nous obtenons en fixant le facteur de qualité F q = 5 :

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 39/101
Chapitre I Généralité
7671666156514641
71666156514641366661565146413631
6156514641363126
5651464136312621
5146413631262116
4641363126211611
41363126211611 6
Figure 4 : Exemple de table de quantification
Ultérieurement, lors de la restitution de l’image (décompression), il suffira de réaliser
l’opération inverse (déquantification) en multipliant chaque valeur de la matrice quantifiée
par le quantum correspondant, pour retrouver une matrice DCT déquantifiée, à partir de
laquelle sera établie la matrice des pixels de sortie. La valeur du quantum peut être d’autant
plus élevée que l’élément correspondant de la matrice DCT contribue peu à la qualité de
l’image, donc qu’il se trouve éloigné du coin supérieur gauche.
• 4ème étape : linéarisation
La matrice 8x8 est transformé en une suite de 64 nombres en s'arrangeant pour que les
éléments les moins importants soit regroupés en fin de liste, on parle de méthode zigzag. Ce
balayage particulier appeler lecture en zigzag permet d’obtenir des suites de 0 les plus
grandes.
Figure 5 : Lecture en ZIGZAG

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 40/101
Chapitre I Généralité
Ceci permettra par la suite d'améliorer encore plus la compression des données.
• 5ème étape : Differential Pulse Code Modulation (DPCM)
On remplace chaque premier élément (0,0) des blocs (8x8) par sa différence avec
l'élément correspondant du bloc précédent. Comme ces éléments sont les moyennes de leur
bloc respectif, ils varient lentement. Ce seront donc de plus petits nombres qui prendront
moins de place mémoire.
• 6ème étape : Run Length Encode (RLE)
Le vecteur 1x64 contient beaucoup de zéros. On code des paires ( skip, value), ou skip
est le nombre de zéros et value est la valeur de la composante AC non nulle suivantimmédiatement la chaîne de zéros dans l'ordre de la lecture en Zigzag .
Pour les derniers 0 du bloc, non suivis d'une valeur non nulle, un End Of Block est
envoyé.
• 7ème étape : Codage Entropique (sans perte)
Après l'encodage DPCM et RLE , les valeurs obtenues sont codés à l'aide d'un Variable
Length Code : codage de Huffman.
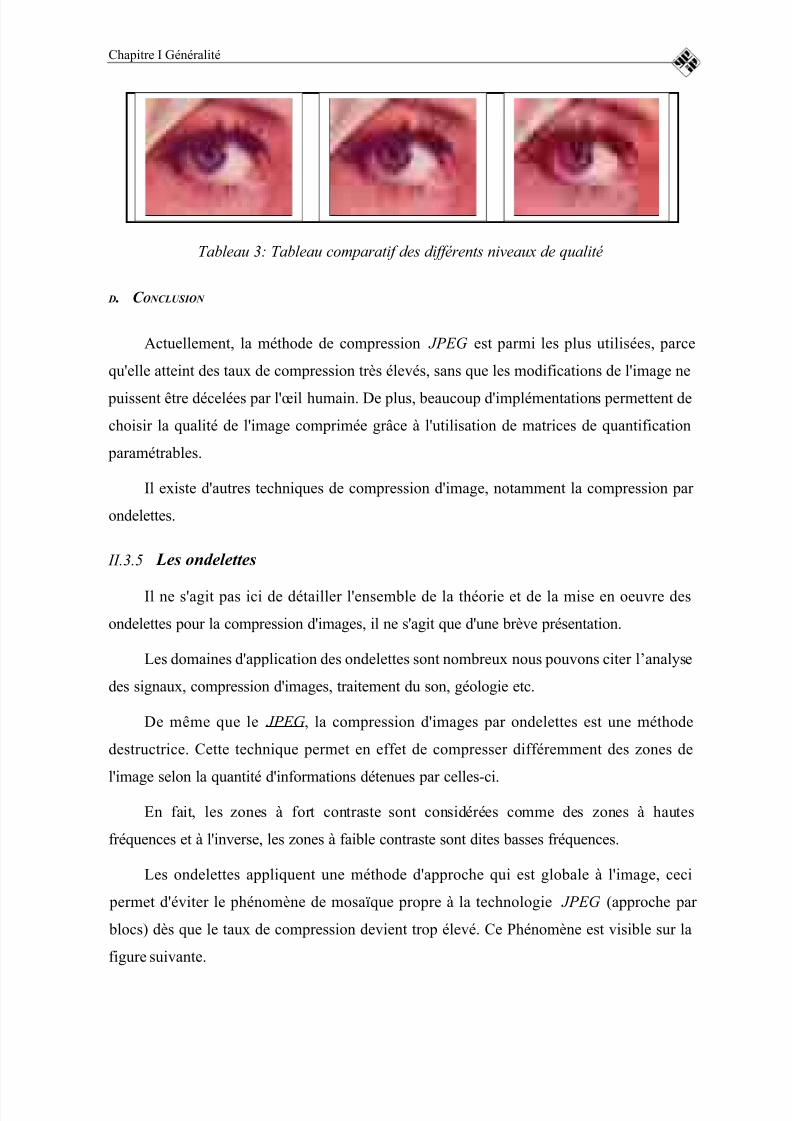
C . E XEMPLE DE COMPRESSION
Voici une comparaison des différents niveaux de qualité que l'on peut obtenir, lorsque
l'on compresse une image avec JPEG. Il faut préciser que la qualité obtenue est un facteur
tout à fait subjectif qui dépendra aussi du type d'image utilisée.
Les niveaux de compressions correspondent à ceux du logiciel « Paint Shop Pro ».1 correspond à un facteur de qualité donnant le moins de perte et 90 à la moins bonne
qualité.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 41/101
Chapitre I Généralité
Figure 6 : LENA originale
Nous allons agir sur l'image ci-dessous. Nous avons agrandi la représentation d’un
détail de l’image afin de bien visualiser l'effet de la compression.
On voit apparaître les macro blocs au fur et à mesure que le taux de compression
augmente.
1 20 40
60 80 90
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 42/101
Chapitre I Généralité
Tableau 3: Tableau comparatif des différents niveaux de qualité
D . C ONCLUSION
Actuellement, la méthode de compression JPEG est parmi les plus utilisées, parce
qu'elle atteint des taux de compression très élevés, sans que les modifications de l'image ne
puissent être décelées par l'œil humain. De plus, beaucoup d'implémentations permettent de
choisir la qualité de l'image comprimée grâce à l'utilisation de matrices de quantification
paramétrables.
Il existe d'autres techniques de compression d'image, notamment la compression par
ondelettes.
II.3.5 Les ondelettes
Il ne s'agit pas ici de détailler l'ensemble de la théorie et de la mise en oeuvre des
ondelettes pour la compression d'images, il ne s'agit que d'une brève présentation.
Les domaines d'application des ondelettes sont nombreux nous pouvons citer l’analyse
des signaux, compression d'images, traitement du son, géologie etc.
De même que le JPEG, la compression d'images par ondelettes est une méthode
destructrice. Cette technique permet en effet de compresser différemment des zones de
l'image selon la quantité d'informations détenues par celles-ci.
En fait, les zones à fort contraste sont considérées comme des zones à hautes
fréquences et à l'inverse, les zones à faible contraste sont dites basses fréquences.
Les ondelettes appliquent une méthode d'approche qui est globale à l'image, ceci
permet d'éviter le phénomène de mosaïque propre à la technologie JPEG (approche par
blocs) dès que le taux de compression devient trop élevé. Ce Phénomène est visible sur la
figure suivante.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 43/101
Chapitre I Généralité
Figure 7 : Image de LENA pour un taux de compression élevé
L'idée est de construire une représentation qui fait à la fois apparaître des informationstemporelles et fréquentielles. Ce type de représentation peut par exemple aider à représenter
la structure physique de la structure géologique à l'origine du signal, c'est d'ailleurs dans ce
domaine que les ondelettes ont démarré.
Dans ce type de graphique les variations de fréquence vont représenter les zones,
contrastées ou pas. Selon le type de zone détectée, la compression ne sera pas appliquée de
la même façon.
On dit que l'analyse d'un signal par les ondelettes est similaire à l'analyse de Fourier
puisqu'elle transforme aussi un signal en ses principaux constituants afin de l'analyser.
Cependant, la transformée de Fourier ne suffit plus ici. Elle est en effet incapable de
détecter quelles portions du signal varient lentement ou rapidement, or nous avons besoin de
distinguer les zones riches en information de celles qui ne le sont pas.
Avec les ondelettes le signal est découpé en différents morceaux qui sont des versions
translatées et dilatées d'une même fonction appelée « ondelette mère ». Le concept d'échelle
apparaît. Il en résulte une superposition d'ondelettes décalées et dilatées qui ne différent
entre elles que par leur taille. On obtient une « transformée en ondelettes », fonction
composée de deux variables : le temps et l'échelle (la dilatation).
Le point fort de cette technique est que les ondelettes s'adaptent en fonction des
caractéristiques recherchées : Hautes fréquences (l'ondelette est très fine) ou basses
fréquences (l'ondelette s'étire). Cette particularité a un nom : « Multi résolution ».
Pour l’analyse de l'image, on utilise une gamme étendue d'échelles. On remplacel'image par l'approximation la plus adéquate possible : on passe donc des échelles les plus

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 44/101
Chapitre I Généralité
fines vers les plus grossières et on accède à des représentations de plus en plus grossières de
l'image donnée. L'analyse s'effectue en calculant ce qui diffère d'une échelle à l'autre, c'est-
à-dire les détails qui permettent, en corrigeant une approximation encore assez grossière,
d'accéder à une représentation d'une qualité meilleure.
La DWT ( Discrete Wavelet Transform) est une méthode de compression, à base
d'ondelettes, utilisée par le format JPEG 2000, successeur du JPEG, qui lui est à base de
DCT ( Discrete Cosine Transform).
Grâce à l'utilisation des ondelettes, ce format bénéficie d'une compression 50 à 100
fois supérieure à son ancêtre JPEG, tout en conservant une bien meilleure définition des
détails sur l'image finale. Celle-ci peut de plus être téléchargée de manière progressive. Si
les résultats théoriques semblent encourageants, la mise en oeuvre de tels algorithmes resteencore très lourde à l'heure actuelle.
Un exemple d'utilisation des ondelettes pour la compression d'images est donné par la
figure suivante, il s'agit d'archivage d'empreintes digitales.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 45/101
Chapitre I Généralité
Figure 8 : Système de compression d'empreintes digitales
II.3.6 Les fractales
Pour beaucoup, les fractales ne sont pas seulement un moyen de compresser des
images, mais aussi un moyen d'expression, un art capable de générer des paysages
improbables.
Contrairement aux autres techniques de compression habituelles, la compression
fractale ne tente pas de réduire le nombre de couleurs comme pour le format gif ou de
compresser de manière classique les octets composant l'image. Le principe est ici de
remplacer l'image par des formules mathématiques.
La compression fractale a pour principe qu'une image n'est qu'un ensemble de motifs
identiques en nombre limité, auxquels on applique des transformations géométriques
(rotations, symétries, agrandissements, réductions). Evidemment, plus l'image possède cette
propriété plus le résultat sera meilleur.
Comme pour le format JPEG, l'image est découpée en blocs de pixel, mais ils sont ici
de tailles variables. Il faut ensuite détecter les redondances entre ces blocs à diverses
résolutions. On parle de transformations fractales basées sur un opérateur contractant. Ces
transformations décrivent l'image de plus en plus finement.
A la fin de ce processus, on stocke seulement les équations mathématiques permettant
de représenter le contenu de ces carrés.
Au final, on obtient une structure présentant des caractéristiques similaires à des
échelles différentes. Pour retrouver l'image il suffira de décrire les transformations qui ont
été appliquées aux blocs initiaux.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 46/101
Chapitre I Généralité
Ce processus rend la compression indépendante de la taille de l'image. De plus,
l'image produite est vectorisée et ne subit pas les effets de la pixelisation, contrairement au
JPEG.
Ce phénomène est surtout visible lors d'un zoom par exemple, l'image fractale peutdevenir floue mais ne pixelise pas. Ceci est dû au fait que lors de l'agrandissement, ce ne
sont pas les pixels qui sont élargis, mais toute l'image qui est recalculée mathématiquement.
Le problème lié à cette technique est la lenteur du procédé de compression, de l'ordre
de 50 fois plus lent que pour une image JPEG. La décompression quant à elle est aussi
rapide que pour les autres formats.
Il existe un certain flou au niveau de la standardisation de cette technique de
compression. En effet le format « .FIF » qui est un format compressé par cette technique
n'est pas reconnu par les navigateurs. Pour pouvoir visionner ce type d’image il faut donc
télécharger une visionneuse adaptée.
II.3.7 Conclusion
La compression fractale est moins puissante que les ondelettes (format « .wi ») mais
supérieure au JPEG. Et par conséquent constitue une solution intermédiaire.
Pour les forts taux de compression, les fractales obtiennent de meilleurs résultats que
la norme JPEG.
Outil mathématique puissant, la compression par ondelettes offre de meilleurs résultats
que le JPEG. Inclue dans le nouveau format " JPEG 2000", cette technologie est de plus en
plus utilisée.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 47/101
Chapitre II Codage de source
Chapitre III
CODAGE
DE
CANAL

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 48/101
Chapitre II Codage de source
CHAPITRE III : CODAGE DE CANAL
III.1 Introduction
Dans un système de transmission numérique, la probabilité d’erreur qui peut affecter
le signal à la réception est fonction du rapport signal à bruit à la réception.
Pour réduire la probabilité d’erreur, il faut donc soit accroître la puissance d’émission
de l’émetteur soit affaiblir le bruit. Or cela n’est pas toujours réalisable. Car, d’une part la
puissance émise est généralement limitée par l’énergie disponible pour les équipements à la
source. D’autre par le bruit qui affecte le signal est la conséquence de plusieurs paramètres
difficile à modifier dans la plupart des cas.
Pour améliorer les performances de la chaîne de communication numérique, la
solution consiste à recoder le message numérique à transmettre. Ceci est possible est
ajoutant un codeur de canal au niveau de l’émission et un décodeur de canal au niveau de la
réception pour retrouver le message original.
L’opération de codage de canal, contrairement à celle du codage de source, consiste à
ajouter de la redondance au message numérique à transmettre. Cette redondance structuré
permet au niveau du décodeur de canal de détecter puis éventuellement de corriger les
erreurs de transmission.
Ce chapitre sera consacré à la présentation des principaux codes correcteurs d’erreur.
Nous finissons ce chapitre par une brève description de l’algorithme de Peterson-Gorenstein-Zierler et de Berlekamp-Massey.
Il ne s’agit pas ici de détailler toute la théorie des codes correcteurs d’erreurs.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 49/101
Chapitre II Codage de source
III.2 Les codes correcteurs d’erreurs
III.2.1 Les codes en bloc Linéaires
Un code correcteur d'erreurs est généralement défini par des symboles appartenant àun alphabet fini A. Par exemple, A est l'ensemble des q symboles GF (q) = 0,1,2,…,q-1
[4] [6].
Un code en bloc de taille M et de longueur n, défini sur un alphabet de q symboles, est
un ensemble de M séquences q-aires de longueur n appelées mots de code. Si q = 2, ces
symboles sont des bits. Généralement, M = qk , k étant un entier [7] [6].
Le codage en bloc consiste à associer à chaque séquence de k symboles d'information
un mot de code constitué de n symboles tel que n > k . k est appelé dimension du code.
Le code sera désigné par C (n,k ).
On appelle rendement R d’un code en blocs C (n,k ) le rapport :n
k R = .
Lorsqu'un message est constitué d'un grand nombre de bits, il est plus efficace
d'utiliser un seul mot d’un code relativement long plutôt qu'une succession de mots d'un
code plus court. Vue que, les mots de code longs sont moins sensibles aux erreurs aléatoires
que les mots de code courts. Mais la complexité du codeur et du décodeur risque de
s'accroître. En plus, de tels codes sont difficiles à chercher théoriquement et nécessitent des
circuits compliqués pour réaliser les opérations de codage et de décodage.
Les codes en blocs sont caractérisés par trois paramètres : leur longueur n, leur
dimension k et leur distance minimale d min qui mesure la différence entre les deux mots de
code les plus similaires. Cette distance est la distance de Hamming entre les deux mots de
code les plus proches. C’est aussi le poids minimal du code C :
( ( )cW jiM jiccd d c
ji H 0
min min,,1,,;min≠
=≠=∀=
Supposons que le canal ajoute t erreurs au bloc transmis. La distance entre le mot émis
et le mot reçu est donc égale à t . Si la distance entre le mot reçu et tous les autres mots de
code est strictement supérieure à t , le décodeur va pouvoir corriger les t erreurs en
appliquant l'hypothèse du voisin le plus proche. Cette hypothèse reste valable tant que t
vérifie l'inégalité : 2 t + l < d min.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 50/101
Chapitre II Codage de source
−=
2
1mind t est appelé la capacité de correction du code. Il s’agit du nombre
maximal d’erreurs que peut corriger un décodeur.
La détermination de la distance minimale d’un code en bloc n’est pas toujours simplesurtout si le nombre de mots de code est grand.
Description matricielle des codes linéaires
Un code linéaire C est un sous-espace vectoriel de GF (q)n. Cette structure d’espace
vectoriel nous permet de représenter la procédure de codage sous forme matricielle. Les k
vecteurs constituant une base du sous-espace C sont utilisés pour former les lignes d’une
matrice G de taille k × n. Tout mot de code est une combinaison linéaire de lignes de G .
Cette matrice G est une matrice génératrice du code C .
Soit i un mot d'information : un k -uple de symboles d'information (un vecteur ligne à k
composantes, éléments de GF (q) ), et c est le mot de code correspondant formé de n
symboles, alors c = i .G . Cette dernière expression définit l'opération de codage qui dépend
du choix de la base du sous-espace. Mais quel que soit ce choix, l'ensemble des mots de
code reste toujours le même. Seul la correspondance entre mots d’information et mots de
code change.
Par exemple, soient C un code linéaire binaire et G sa matrice génératrice définie par:
G =
11100
10010
01001
Le vecteur d’information i = [0 1 1] est codé en un mot de code c :
c = [ ] [ ]01110
11100
10010
01001
110 =
Code dual et matrice de contrôle de parité
On a, C est un sous-espace vectoriel, il possède donc un complément orthogonal, noté
C ⊥ . Ce dernier n'est autre que l'ensemble de tous les vecteurs de GF (q)n orthogonaux à C .
C’est donc un sous-espace vectoriel. Il peut former donc un code. Ce code est appelé le
code dual de C . La dimension de C ⊥ est égale à n-k . Soit H sa matrice génératrice, formée
par un choix de ces n-k vecteurs comme lignes. H est une matrice de parité du code C . Un
mot c appartient au code C si est seulement si cH T =0.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 51/101
Chapitre II Codage de source
Cette propriété est un moyen simple de test de l’appartenance d’un mot à un code.
Pour cette raison la matrice H est appelé matrice de contrôle.
Puisque tout mot de code de C est une combinaison linéaire de lignes de G , la relation
précédente entraîne : GH T
= 0.
Une matrice de parité associée à la matrice génératrice du code défini à l’exemple
précèdent est : H =
10110
01101.
Cette matrice de parité est également utilisée pour la détermination de la distance
minimale du code qui est égale au plus petit nombre de colonne linéairement indépendant de
la matrice de contrôle H .
Puisque les k lignes de G sont indépendantes, il existe au moins k colonnes de G
indépendantes ; par permutations des colonnes et par opérations élémentaires sur les lignes
on peut transformer G à une matrice de la forme : G = [ ]PI .
Où I est la matrice identité k × k et P est une matrice quelconque k × (n-k ). La forme
[ ]PI de la matrice génératrice s'appelle forme systématique.
Dans ce cas la matrice de parité s’écrit : H = [ ]IP T −
Où I est ici une matrice identité (n-k )× (n-k ).
Principe de la détection et de la correction d’erreurs
Soit c un mot de code formé après codage d’un vecteur d'information i . Le vecteur c
est transmis sur le canal reliant la source à la destination. Une erreur peut affecter un ou
plusieurs symboles des n symboles de c. On définit donc un vecteur d'erreurs e. Une erreur
sur la composante j de c se traduit par une j-ème composante non nulle de e. Ainsi, le mot
reçu par le récepteur est v = c + e. Le vecteur défini par s = v.H T ne dépend pas du mot c il
dépend uniquement l'erreur e. Ce vecteur s est appelé le syndrome du mot reçu v. Ce
syndrome est un vecteur ligne à n-k composantes. Si s ≠ 0 on détecte la présence d'erreurs
dans v. Par contre, si s est nul v est un mot de code. Mais, un syndrome nul ne signifie pas
nécessairement l’absence d’erreurs de transmission.
En présence d’erreurs de transmission, la règle de décodage consiste à rechercher mot
de code c’ le plus vraisemblable, C'est-à-dire celui qui est à la distance de Hamming

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 52/101
Chapitre II Codage de source
minimale du mot reçu v. Mais, cette façon de décodage devient difficile à mettre en oeuvre
lorsque le nombre de mots du code est important.
La correction peut aussi être réalisée à partir du syndrome s dont le nombre de
configurations est k n−
2 . La règle de décodage consiste à faire correspondre pour chaquevaleur non nulle du syndrome s la configuration d’erreur e de poids minimal. Ce poids est
inférieur ou égal à la capacité de correction t du code. Une table constituée de deux
colonnes est formée. La première colonne comporte les polynômes d’erreurs et la deuxième
contient tous les syndromes possibles. Le mot de code le plus vraisemblable est v - e avec e
l’erreur correspondante au syndrome s.
III.2.2 Les codes cycliques
Les codes cycliques représentent la classe la plus importante des codes en blocs
linéaires, obtenue en imposant une condition sur la structure du code. La théorie des corps
de Galois a été utilisée comme outil mathématique fondamental pour la recherche de bons
codes. De plus, les codes cycliques offrent, grâce à leur description dans les corps de Galois,
des procédures de codage et de décodage spécifiques très efficaces.
Définition et représentation polynomiale
Un code linéaire cyclique C(n,k) est définit de la manière suivante :
Si c = [ c0…c j ... cn-1] est un mot du code, alors c1 = [ c1…c j ... cn-1 c0], obtenu par
permutation circulaire à gauche d’un élément de c est aussi un mot du code.
De ce fait, Un code cyclique est un cas particulier de sous-espace de GF(q)n où le
décalage des composantes de ses vecteurs est une opération interne.
Ces codes sont généralement représentés d’une manière polynomiale. Ainsi au mot c
on associe :c(x) = c0 +c1 x+………+c j x j+………cn-1 xn-1 c j∈GF(q)
Le produit x -1 c(x) s’écrit :
x -1 c(x) = c0x -1 + c1x +…+ c j x j-1+…+cn-1xn-2
En introduisant le mot c1(x) = c1 +c2 x+…+c j x j+…+cn-1 xn-2 + c0xn-1 obtenu par
permutation circulaire à gauche d’un élément de c(x), le polynôme x -1 c(x) peut s’écrire
sous la forme suivante :

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 53/101
Chapitre II Codage de source
x -1 c(x) = c0 x -1 (xn -1) + c1(x) = c1(x) modulo (xn -1)
Par conséquent, les mots de code d’un code cyclique peuvent être représentés par des
polynômes dans l’anneau GF(q)[x]/(xn-1). L’ensemble de ces polynômes a une structure
d’espace vectoriel identique à celle de GF(q)n
de plus il possède la structure d’anneau.
Choisissons un polynôme non nul de C unitaire de degré le plus petit possible. Notons
(n-k) son degré. Ce polynôme est unique, il divise x n-1, il est noté g (x), et il est appelé le
polynôme générateur du code C. Le code cyclique C est formé de tous les polynômes
produits de g (x) par un polynôme de degré inférieur ou égal à k-1.
Soit h(x) le quotient xn -1 par g(x) donc xn - l = g(x) h(x). Le polynôme h(x) est appelé
polynôme de parité. C’est le polynôme générateur du code dual.
En effet, pour tout c(x) de C , nous avons : h(x) c(x)=h(x) g(x) a(x) = (xn - l) a(x).
La séquence des symboles d'information est représentée par le polynôme i(x) de degré
inférieur ou égal à k-1. La correspondance entre l'information i(x) et les mots c(x) consiste
à calculer c(x) = g(x) i(x). Ce code n'est pas systématique puisque i(x) n'est pas directement
visible dans c(x). L’opération de codage systématique s'écrit :
c(x) = xn-k i(x) + t (x)avec deg[t(x)] < n-k.
Soit c(x) un polynôme d'un code cyclique C. Le mot c(x) est transmis sur un canal.
Les coefficients de c(x) sont les symboles du vecteur c transmis. Notons le mot reçu par
v(x). Soit e(x)=v(x)-c(x). e(x) est le polynôme d'erreur. Il a un coefficients non nul à la
position où une erreur a été introduite par le canal.
Le polynôme syndrome s(x) est indispensable pour l'opération du décodage d'un code
cyclique. Le syndrome est défini comme le reste de la division Euclidienne de v(x) par g(x).
Il est donc égal au reste de la division Euclidienne de e(x) par g(x). Par conséquent, Le polynôme syndrome dépend uniquement de e(x), mais pas de c(x) ni de i(x). Ce polynôme
est indispensable pour l’opération de décodage.
Il est possible de décoder un code cyclique par une procédure identique à celle du code
en bloc linéaire. Il existe d’autres méthodes de décodage algorithmiques. Ces méthodes
nous évitent ce décodage par table.
Le paragraphe suivant est une présentation générale des codes BCH.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 54/101
Chapitre II Codage de source
III.2.3 Les codes BCH
La classe des codes BCH (Bose-Chaudhuri-Hockenghem) est une classe très large de
codes cycliques correcteurs d'erreurs multiples. Des techniques simples de codage et de
décodage sont disponibles pour les codes BCH. Cette classe contient une sous-classe decodes très populaires, les codes Reed-Solomon.
Les codes BCH primitif sont définis sur GF(q) par la construction d'un polynôme
générateur g (x) de forme particulière. Leur longueur est de n=Q-1=qm-1 et ils ont une
capacité de correction de t erreurs.
Le polynôme générateur d'un code cyclique s'écrit sous la forme :
g (x) = PPCM[ f 1(x), f 2(x),…, f r (x)]
où les f i(x) sont les polynômes minimaux des racines de g (x).
Considérons un cas particulier de codes BCH : les Codes BCH binaires primitifs.
Ce type de code est dit primitif car les racines de son polynôme générateur sont des
puissances successives croissantes d’un élément primitif du corps de Galois considéré. Le
polynôme générateur de ce code cyclique s'écrit sous la forme :
)(m)...,(m),(m PPCMg(x) 123 x x x t −=α α α
Où α est un élément primitif du corps de Galois GF(2m) et les )( xm iα
sont les
polynômes minimaux à coefficients dans le corps GF(2) ayant iα comme racine.
Les codes BCH sont conçus à partir des spécifications de n et t . La valeur de k n’est
pas connue avant la construction de g (x).
Les paramètres d’un code BCH primitif construit sur un corps de Galois GF(2 m), de
distance construite d = 2t+1 sont les suivants :
n = 2m – 1 ; k ≥ n -1 – mt ; dmin ≥ 2t + 1;2
nt <
Pour t = 1 un code BCH primitif est un code de Hamming ayant )( xmα comme
polynôme générateur.
Donnons un exemple simple : Calculons le polynôme générateur du code BCH
2)t?,k 15,(n === , défini sur GF(2), de longueur 15 et de capacité de correction 2 :
On a n = 2m -1 = 15 m = 4
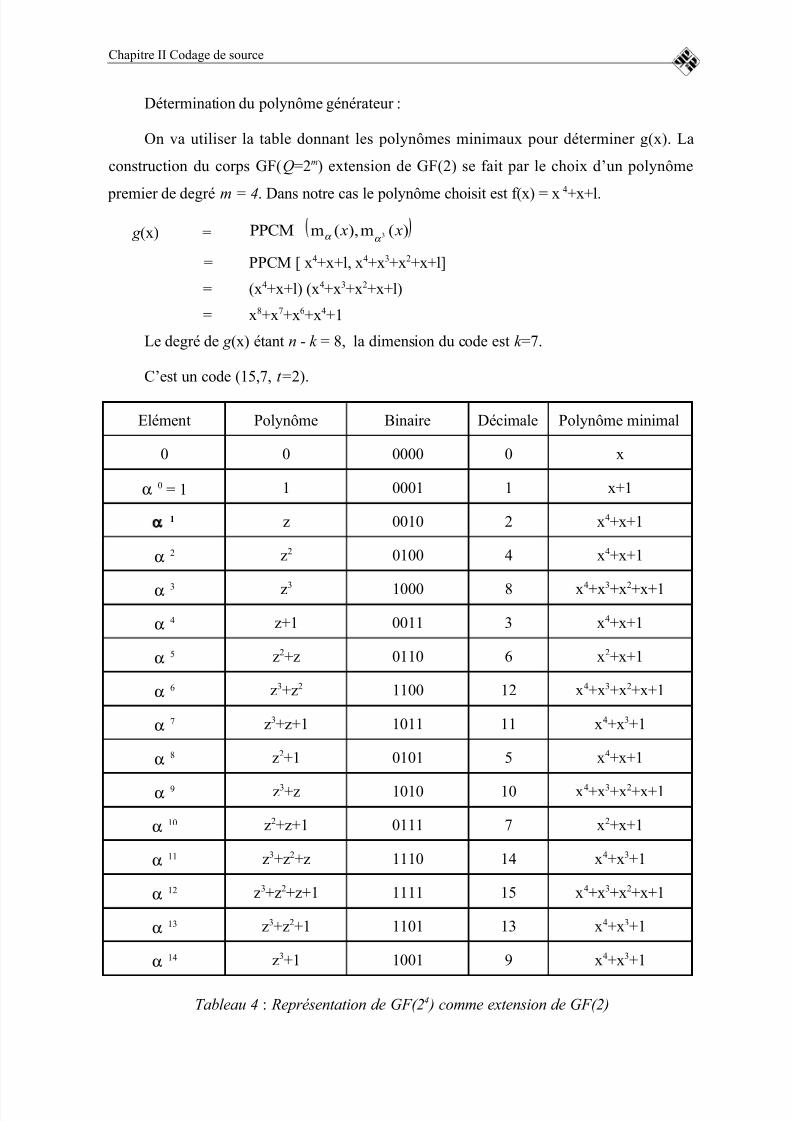
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 55/101
Chapitre II Codage de source
Détermination du polynôme générateur :
On va utiliser la table donnant les polynômes minimaux pour déterminer g(x). La
construction du corps GF(Q=2m) extension de GF(2) se fait par le choix d’un polynôme
premier de degré m = 4. Dans notre cas le polynôme choisit est f(x) = x4
+x+l.
g (x) = )(m),(m PPCM 3 x xα α
= PPCM [ x4+x+l, x4+x3+x2+x+l]
= (x4+x+l) (x4+x3+x2+x+l)
= x8+x7+x6+x4+1
Le degré de g (x) étant n - k = 8, la dimension du code est k =7.
C’est un code (15,7, t=2).
Elément Polynôme Binaire Décimale Polynôme minimal
0 0 0000 0 x
α0 = 1 1 0001 1 x+1
α1 z 0010 2 x4+x+1
α2 z2 0100 4 x4+x+1
α 3 z3 1000 8 x4+x3+x2+x+1
α4 z+1 0011 3 x4+x+1
α5 z2+z 0110 6 x2+x+1
α6 z3+z2 1100 12 x4+x3+x2+x+1
α7 z3+z+1 1011 11 x4+x3+1
α8 z2+1 0101 5 x4+x+1
α 9 z3+z 1010 10 x4+x3+x2+x+1
α10 z2+z+1 0111 7 x2+x+1
α11 z3+z2+z 1110 14 x4+x3+1
α12 z3+z2+z+1 1111 15 x4+x3+x2+x+1
α13 z3+z2+1 1101 13 x4+x3+1
α14 z3+1 1001 9 x4+x3+1
Tableau 4 : Représentation de GF(24 ) comme extension de GF(2)

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 56/101
Chapitre II Codage de source
III.2.4 Utilisation de la transformé en cosinus discrète dans un codage correcteur
d’erreur
Définition [3]
La DCT appliqué à une séquence [ ]110 ,...,, −= N x x x x de données donne :
[ ]110 ,...,, −= N X X X X avec ∑−
=
=1
0
)( N
n
k nk nT x X k = 0,1,…,N-1 (1)
)(nT k est définit par :
( ) 1...,2,12
12cos2
01
)(
−=+
==
N k nk n
N
k pour N
nT k π
(2)
Notons T la matrice N x N définit par T=
−
−
−− )1(...)0(
.....
.....
.....
)1(..)1()0(
11
000
N T T
N T T T
N N
La transformé en cosinus discrète est orthogonale en effet :
∑−
= ≠
==
1
0 0
1)().(
N
n
q pq p si
q p sinT nT (3)
D’après cette propriété, toutes les ligne de la matrice T sont deux à deux
orthogonales, en plus elles sont normées (de module égal à 1).
Les N équations définies par (1) peuvent être écrites sous forme matricielle :
−
−
=
−−−− 1
1
0
11
1
000
1
1
0
.
..
)1(...)0(
.....
.....
....)0()1(..)1()0(
.
.
N N N N x
x x
N T T
T N T T T
X
X X
(4)
On choisit k ligne de la matrice T (N x N) on obtient un matrice G (d x N), qui va
représenter la matrice génératrice du code correcteur. Cette matrice a pour rang égal
à d. Les N – d lignes restantes vont former la matrice de parié H (N-d x N).
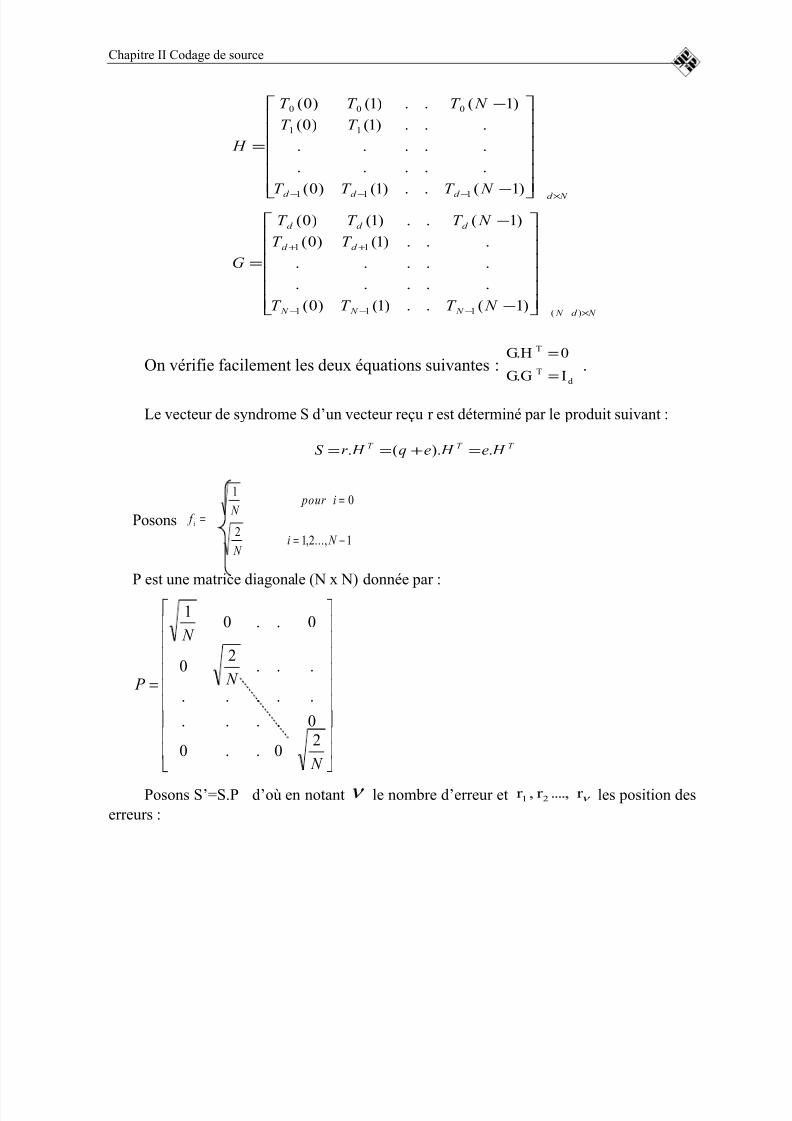
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 57/101
Chapitre II Codage de source
N d N N N N
d d
d d d
N d d d d
N T T T
T T
N T T T
G
N T T T
T T
N T T T
H
×−−−−
++
×−−−
−
−
=
−
−
=
)(111
11
111
11
000
)1(..)1()0(
.....
.....
...)1()0(
)1(..)1()0(
)1(..)1()0(
.....
.....
...)1()0(
)1(..)1()0(
On vérifie facilement les deux équations suivantes :IG.G
0G.H
d
T
T
=
=.
Le vecteur de syndrome S d’un vecteur reçu r est déterminé par le produit suivant :
T T T H e H eq H r S .).(. =+==
Posons1...,2,1
2
01
−=
=
=
N i N
i pour N
f i
P est une matrice diagonale (N x N) donnée par :
=
N
N
N
P
20..0
0....
.....
...2
0
0..01
Posons S’=S.P d’où en notant ν le nombre d’erreur et ν r ....,r ,r 21 les position des
erreurs :

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 58/101
Chapitre II Codage de source
[ ]
=
+=
−=+
==
∑ ∑
∑
= =
−
=
ii
i
i
i
i
i
n
l
i
n
l
nirl
N
r
r i
i
i
C
C
C
X X X
X X X
X X X
Y Y Y
N
r C e
N i pour N
ir eS
f S
,
1,
0,
2
2
2
22
1
2
11
21
1 0
,
1
0
.
.1
.....
.....
.1
.1
...
2
)12(cos.
1,...,2,12
)12(cos..
1'
ν ν ν
ν
ν π
π
Avec : pour rl l eY l == ν ,...,2,1 qui est l’amplitude de l’erreur à la position r l et
N
r X l
l 2
)12(cos
π += .
L’écriture des N – d syndromes comme un vecteur donne :
C
X X
X X
X X
Y
C
C C
C C
X X X
X X X
X X X
Y S
d
d
d
d d d
d
d
.
..1
.....
.....
..1
..1
.
0..0
0....
...0.
.00
.00
.
.1
.....
.....
.1
.1
.'
1
1
22
1
11
1,1
1,31,1
0,20,0
12
1
2
2
22
1
1
2
11
=
=
−
−
−
−−−
−
−
ν ν ν ν ν
Posons
==
−
−
−
−
1
1
22
111
1
..1
.....
.....
..1
..1
.'.''
d
d
d
X X
X X
X X
Y C S S
ν ν
Le décodage s’effectue en utilisant l’algorithme suivant :
Figure 9 : Algorithme de décodage pour les codes DCT

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 59/101
Chapitre II Codage de source
A la suite on présente deux importants algorithmes de décodage celui de
Berlekamp-Massey et de Peterson-Gorenstein-Zierler.
III.2.5 L’algorithme de Berlekamp-Massey et de Forney
Cet algorithme est basé sur le polynôme localisateur d’erreur et le polynôme
évaluateur d’erreur. Ces deux polynômes permettent de déterminer respectivement : la
position des erreurs et l’amplitude de chacun de ces erreurs [8].
Rappelons que le polynôme localisateur d’erreur est donné par :
( ) ( )( ) ( ) 1111 1
1
111 +Λ++Λ+Λ=−−−=Λ −− x x x xX xX xX x
ν
ν
ν
ν ν
Défini par ses ν racines qui sont les inverses des positions X des erreurs. C’est pour
cette raison qu’il est appelé polynôme localisateur d’erreur. La connaissance des
coefficients de ( ) xΛ nous permet d’obtenir ses racines et par conséquent les positions X
des erreurs.
Le polynôme des syndromes est définit par : ∑=
−=t
j
j
j xS xS 2
1
1)( .
Le polynôme évaluateur d’erreur est définit par : ( ) )(mod )()( 2t x x xS x Λ=Ω .
Ce polynôme peut s’écrire de la manière suivante : ∑ ∏= ≠
−=Ων
1
)1()(i il
l ii x X X Y x .
Le polynôme localisateur est déterminé par l’algorithme de Berlekamp-Massey.
L’amplitude des erreurs est déduite d’une manière simple qui ne fait pas appel à
aucune inversion matricielle, en utilisant l’algorithme de Forney.
L’algorithme est représenté par son organigramme à la figure ci dessous.
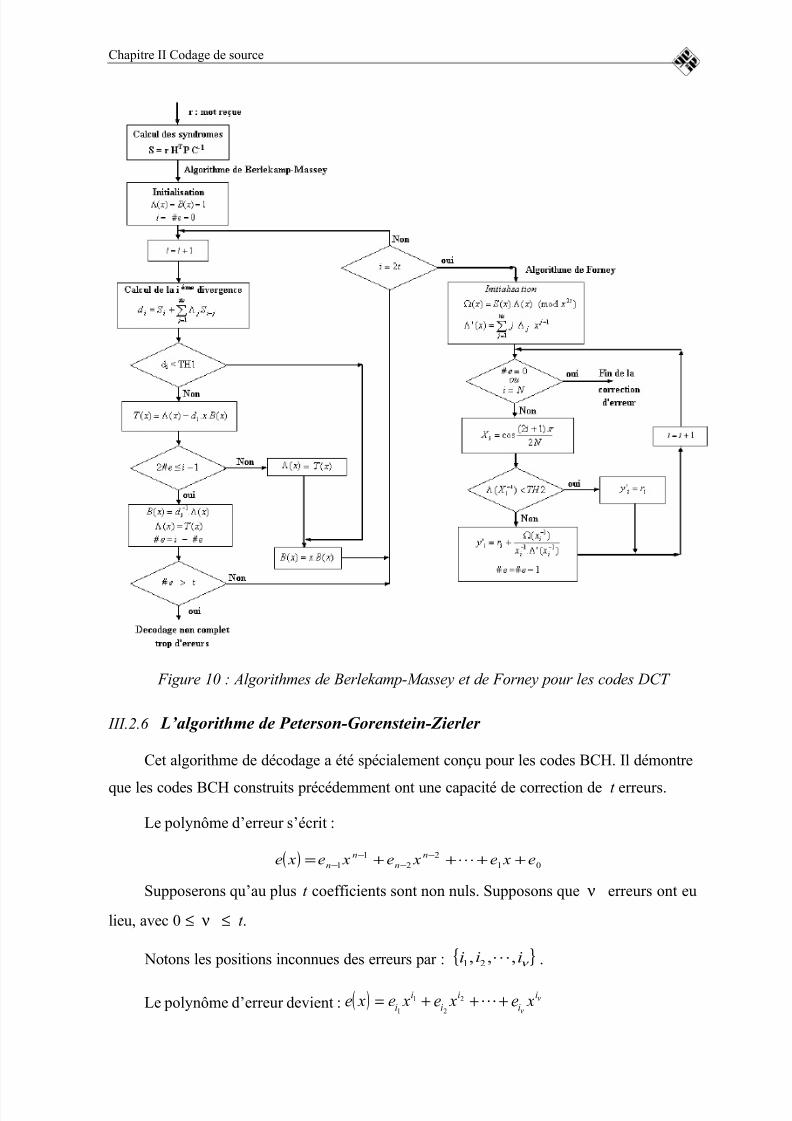
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 60/101
Chapitre II Codage de source
Figure 10 : Algorithmes de Berlekamp-Massey et de Forney pour les codes DCT
III.2.6 L’algorithme de Peterson-Gorenstein-Zierler
Cet algorithme de décodage a été spécialement conçu pour les codes BCH. Il démontre
que les codes BCH construits précédemment ont une capacité de correction de t erreurs.
Le polynôme d’erreur s’écrit :
( ) 01
2
2
1
1 e xe xe xe xe n
n
n
n ++++= −−
−−
Supposerons qu’au plus t coefficients sont non nuls. Supposons que ν erreurs ont eu
lieu, avec 0 ≤ ν ≤ t .
Notons les positions inconnues des erreurs par : ν
iii ,,, 21 .
Le polynôme d’erreur devient : ( ) ν
ν
i
i
i
i
i
i xe xe xe xe +++= 2
2
1
1

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 61/101
Chapitre II Codage de source
Oùi
e représente la valeur de la -ième erreur qui est à la position i . Pour les
codes binaires,i
e est toujours égal à 1.
Les inconnues qui doivent être déterminées par le décodeur de canal sont : Le nombre
d’erreurs, les positions de ces erreurs et les amplitudes de ces erreurs pour un code non
binaire.
Evaluons le polynôme reçu sur toutes les puissances de α qui sont racines de g(x).
Le premier syndrome s’écrit :
( ) ( ) ( ) ( ) ν
ν
α α α α α α α i
i
i
i
i
i eeeeecS +++==+== 2
2
1
1v
1
Pour simplifier, on note
i X α = et ieY = pour 1≤ ≤ ν .
Avec ces nouvelles notations, le premier syndrome s’écrit :
ν ν X Y X Y X Y S +++=
22111
On obtient alors un système (P1) de 2t équations non linéaires à 2 ν inconnues (les
positions et amplitudes des erreurs) qu’il nous faut résoudre :
(P1)
+++=
+++=
+++=+++=
t t t
t X Y X Y X Y S
X Y X Y X Y S
X Y X Y X Y S
X Y X Y X Y S
22
22
2
112
33
22
3
113
2
22
2
112
22111
2
ν ν
ν ν
ν ν
ν ν
On définit le polynôme ( ) ( )( ) ( )ν
xX xX xX x −−−=Λ 111 11 dit polynôme
localisateur d’erreurs défini par ses ν racines qui sont les inverses des positions X des
erreurs.
La connaissance des coefficients de ( ) 11
1
1 +Λ++Λ+Λ=Λ −− x x x x
ν
ν
ν
ν permet
d’obtenir ses racines, et par inversion, les positions X des erreurs.
On a ( 01 =Λ −
X pour 1≤ ≤ ν

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 62/101
Chapitre II Codage de source
011
1
2
21
1
=+Λ+Λ+Λ+Λ −−−
− −
X X X X
ν
ν
ν
ν
( ) 011
1
2
21
1
=+Λ+Λ+Λ+Λ −−−
− −+
X X X X X
j ν ν
ν
ν
ν
( ) 010
1
1
2
21
1
=+Λ+Λ+Λ+Λ∑=
−−−
− −+ν
ν
ν
ν
ν ν
X X X X X
j
( ) 00
1
1
2
2
1
1 =+Λ+Λ+Λ+Λ∑=
−+−++−
− +ν
ν ν
ν ν
ν
j
X X X X X j j j j
ν ν ν ν ν +−+−++− −=Λ++Λ+Λ+Λ j j j j j S S S S S 112211
On obtient un système (P2) d’équations linéaires reliant les syndromes aux
coefficients du polynôme localisateur d’erreurs :
(P2)
−
−
−
−
=
Λ
Λ
Λ
Λ
+
+
+
−
−
−−++
++
+
−
ν
ν
ν
ν
ν
ν
ν
ν ν ν ν ν
ν ν
ν ν
ν ν
2
3
2
1
1
2
1
122221
21543
1432
1321
S
S
S
S
S S S S S
S S S S S
S S S S S
S S S S S
Posons
=
−+
+
121
132
21
µ µ µ
µ
µ
S S S
S S S
S S S
M
appelée matrice des syndromes.
Le système (P2) devient pour ν µ = :
−
−−−
=
Λ
ΛΛΛ
+
+
+
−
−
ν
ν
ν
ν
ν
ν
ν
2
3
2
1
1
2
1
S
S
S
S
M
On a la matrice des syndromes est inversible si ν µ = , donc Le système (P2) possède
une unique solution.
D’où l’algorithme de décodage de Peterson-Gorenstein-Zierler :
1. Calcul des 2t syndromes.
2. Initialisation de ν à t .
3. Construction de la matrice M et calcul du déterminant. S’il est nul, on diminue ν et
on recommence.4. Détermination des coefficients du polynôme localisateur d’erreurs en résolvant (P2).
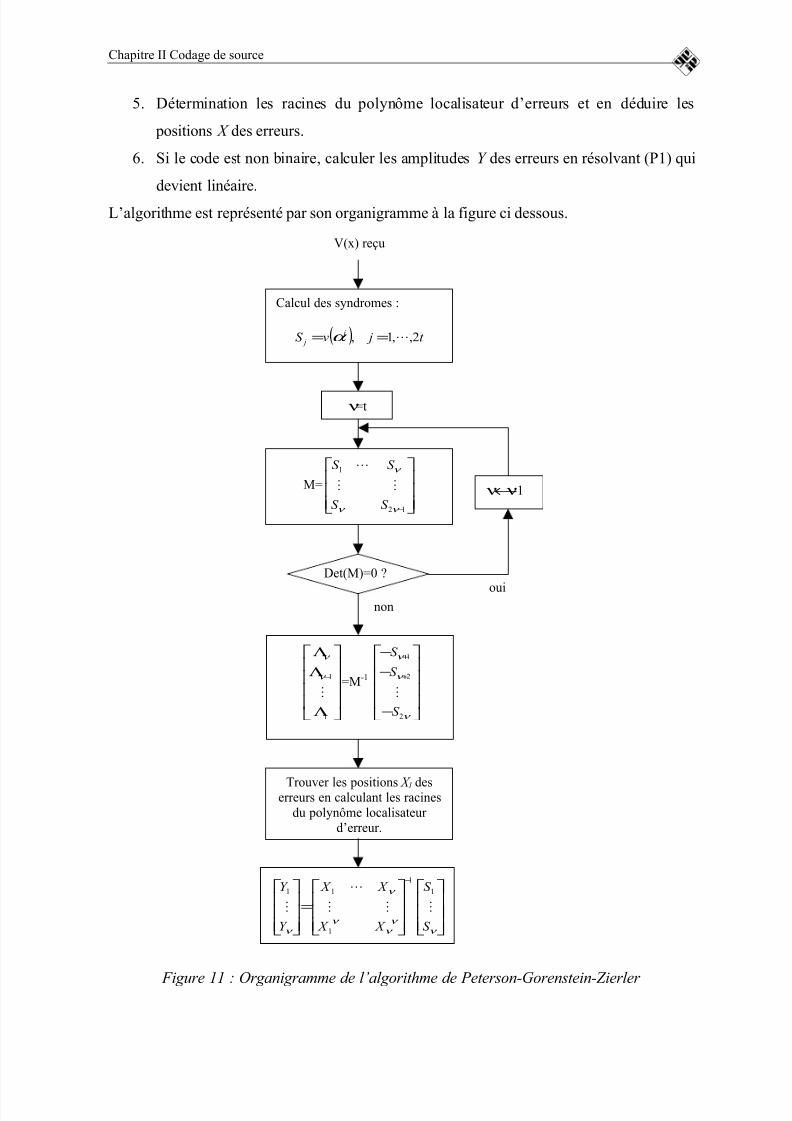
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 63/101
Chapitre II Codage de source
5. Détermination les racines du polynôme localisateur d’erreurs et en déduire les
positions X des erreurs.
6. Si le code est non binaire, calculer les amplitudes Y des erreurs en résolvant (P1) qui
devient linéaire.
L’algorithme est représenté par son organigramme à la figure ci dessous.
oui
V(x) reçu
Calcul des syndromes :
( ) t jvS j
j 2,,1, == α
M=
−12
1
ν ν
ν
S S
S S
ν=t
Det(M)=0 ?
ν←ν-1
non
Λ
Λ
Λ
−
1
1
ν
ν
=M-1
−
−
−
+
+
ν
ν
ν
2
2
1
S
S
S
Trouver les positions X l deserreurs en calculant les racines
du polynôme localisateur d’erreur.
=
−
ν
ν
ν
ν
ν
ν S
S
X X
X X
Y
Y
1
1
1
11
Figure 11 : Organigramme de l’algorithme de Peterson-Gorenstein-Zierler

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 64/101
Chapitre III Codage de canal
Chapitre IV
CONCEPTION ET IMPLÉMENTATION

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 65/101
Chapitre III Codage de canal
CHAPITRE IV : CONCEPTION ET IMPLÉMENTATION
IV.1 Introduction
Le travail réalisé dans le cadre de ce projet de fin d’étude consiste à élaborer un
algorithme de codage source appliqué à la transmission d’images et d’un algorithme de
codage canal en utilisant le codage BCH . Les deux problèmes du codage de source et de
codage de canal sont considérés suivant le théorème de séparation de Shannon.
Ces deux algorithmes développés, en utilisant le langage C++, seront utilisés pour la
transmission d’images. Dans ce projet nous avons mis en œuvre une chaîne logicielle
complète pour la transmission d’images fixes. La première étape est de compresser l’image
à transmettre en réduisant sa taille et la deuxième étape revient à ajouter de la redondance
structurée pour corriger les erreurs introduites par le canal.
IV.2 Source de message
Notre source est une image de type targa dont le nom de fichier présente l’extension
« .tga ». On a choisit ce type de fichier pour plusieurs raisons : D’une part, c’est un format
non compressé, qui nous à permis de comprendre comment une image est stocké en
mémoire. D’autre part, l’information utile sur chaque pixel est facile à extraire et à
transformer par un programme écrit en langage C++.
Chaque image de ce type présente une entête qui fournit des informations sur l’image.
Cette entête est composé de plusieurs champs. Les champs qui nous intéressent sont :
- Les dimensions, en pixel, de l’images ; C'est-à-dire le nombre de pixels par ligne et le
nombre de lignes constituant l’image.
- Le nombre de bits utilisé pour coder les pixels constituants l’image ; Ce nombre peut
avoir l’une des valeurs suivantes : 16, 24 ou 32.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 66/101
Chapitre III Codage de canal
Dans notre projet, nous allons nous intéresser aux images dont l’information sur
chaque pixel est codée sur 24 bits. Chaque octet code l'une des couleurs fondamentales, le
rouge, le vert ou le bleu. Dans ce cas, l’image est dite sous forme RGB.
Deux cas se présentent : soit qu’on choisit d’utiliser l’image par défaut qui est l’image
de Léna ou utiliser une autre image dont le nom est introduit manuellement par l’utilisateur.
Le nom de l’image est introduit, il est mémoriser dans une variable de type chaîne de
caractère. Puis plusieurs tests seront effectués sur cette image avant le passage au codeur de
source. Ces tests seront effectués sur l’entête pour voir si cette image correspond au format
considéré. L’entête est donc considéré comme une carte d’identité pour l’image ; Si elle est
conforme, l’image passe à l’étape suivante, sinon, un message d’erreur est retourné etl’image sera ignorée.
La lecture de l’entête nous permet de dégager les dimensions, en pixel, de l’images.
Trois matrices, évidemment de même dimension que l’image, vont contenir temporairement
les données concernant chaque proportion de couleur pour chaque pixel.
IV.2.1 Types de données utilise pour modéliser l’image
On a définit trois structures : une structure tga_image qui va contenir les données et
quelques informations sur l’image, une structure img qui est simplifié par rapport à la
première et qui ne garde que les champs qui nous intéressent pour la suite et une autre
structure tga_header qui va contenir touts les informations qu’on trouve dans l’entête de
l’image.
Structure tga_image
typedef struct byte *data;word width, height;
byte bits_per_pixel;tga_line_order line_order;tga_color_order color_order;
tga_image;
Structure imgtypedef struct
int width, height;

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 67/101
Chapitre III Codage de canal
byte *data; img;
Définition de l’entête tga_header d'une imagetypedef struct
byte id_length; byte color_map_type; byte data_type_code;word color_map_origin;word color_map_length;
byte color_map_depth;word origin_x;word origin_y;word width;
word height; byte bits_per_pixel; byte image_descriptor;
tga_header;
IV.2.2 Fonctions utilisées pour manipuler les images
Dans la suite, on présente les principales fonctions utilisées pour la lecture et l’écriture
de ce type d’images.
tga_header_read(FILE *fp, tga_header *hdr) : fonction permettant de lire l'entête de
l'image.
tga_header_write(FILE *fp, const tga_header *hdr) : fonction permettant d'écrire
l'entête de l'image.
tga_write(const char *filename,const tga_image *img) : fonction permettant d’écrireune structure tga_image dans un fichier image.
tga_read(const char *filename) : fonction permettant de retourner une structure
tga_image à partir des données d’un fichier image. C'est-à-dire cette fonction effectue
l’opération inverse de la fonction tga_write.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 68/101
Chapitre III Codage de canal
IV.3 Codage et décodage de source
Le codeur de source qu’on a réalisé est inspiré de la compression JPEG. Plusieurs
techniques de compressions sont assemblées pour la réalisation de notre codeur de source.
Le schéma de principe de notre codeur est similaire à celui de la compression JPEG. Il
comprend trois principaux opérations : la transformé en cosinus discrète, la quantification et
la compression de Huffman.
Dans ce qui suit, on va présenter en détail les différentes opérations réalisées par le
codeur de source.
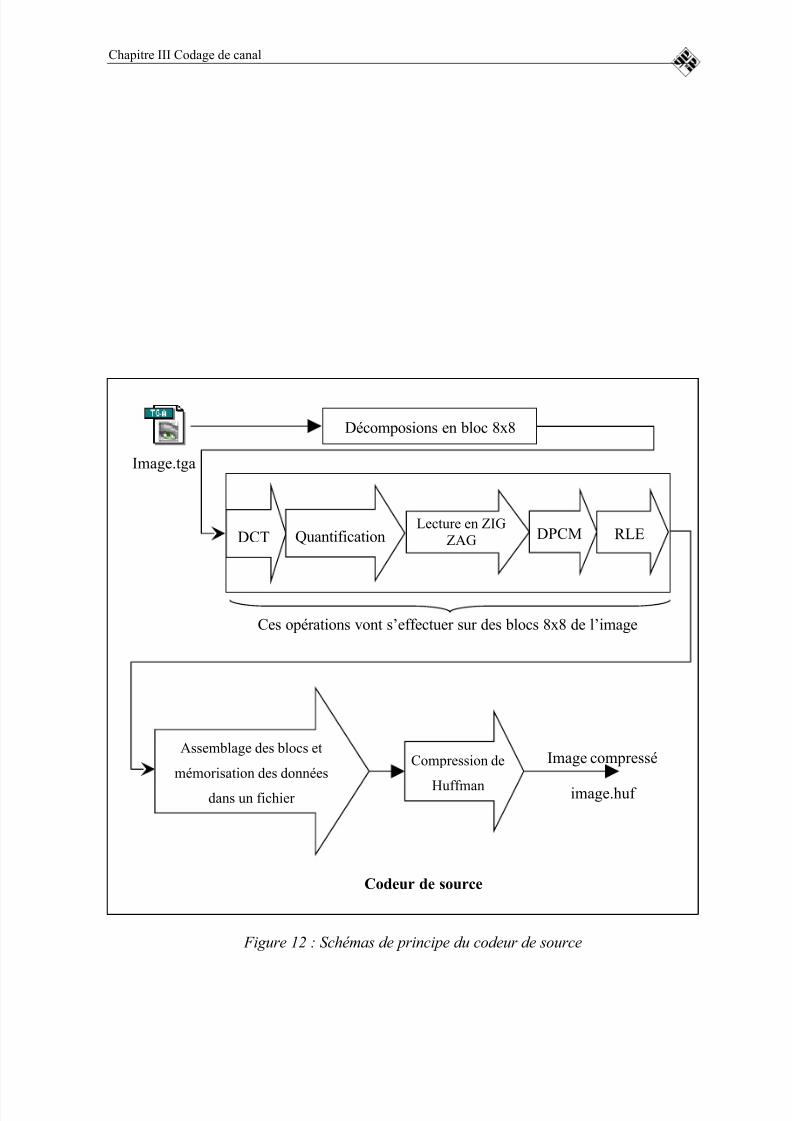
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 69/101
Chapitre III Codage de canal
Figure 12 : Schémas de principe du codeur de source
Compression de
Huffman
Codeur de source
Image.tga
Décomposions en bloc 8x8
DCT QuantificationLecture en ZIG
ZAG DPCM RLE
Ces opérations vont s’effectuer sur des blocs 8x8 de l’image
Assemblage des blocs et
mémorisation des données
dans un fichier
Image compressé
image.huf

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 70/101
Chapitre III Codage de canal
IV.3.1 DCT et IDCT
La procédure permettant de réaliser la transformation DCT est donnée par :
Dct (const img *im, double *data, const int xpos, const int ypos)
Avec img est l’image considérée, data est un tableau de 64 éléments qu’on considère
comme une matrice 8x8 qui va contenir le résultat de la transformation et xpos et ypos
définit le bloc 8x8 sur lequel on va effectuer la transformation.
La procédure permettant de réaliser la transformation IDCT inverse de la
transformation DCT est donnée par :
Idct (const img *im, double *data, const int xpos, const int ypos)
Avec, data est un tableau de 64 éléments qu’on considère comme une matrice 8x8 sur
laquelle on va effectuer la transformation. Le résultat de la transformation inverse IDCT est
rangé directement dans la structure img de l’image considérée. xpos et ypos définit la
position du bloc considéré dans l’image.
IV.3.2 Quantification et déquantification
La qualification utilisé est une quantification scalaire : qui consiste à diviser élément
par élément les éléments du bloc 8x8 résultat de la transformé DCT par les éléments de lamatrice de quantification. Par contre, la déquantification se fait en multipliant élément par
élément les éléments du bloc 8x8 résultat de la quantification par les éléments de la matrice
de quantification.
) ji,(mat_quant
) ji,(dct_out) j,i(Quanti_out = arrondie à l’entier le plus proche.
) ji,(mat_quant) ji,(quanti_out) j,i(utdequanti_o ×=
Cette matrice est paramétrable suivant le facteur de qualité fixé par l’utilisateur.
Les éléments de la matrice de quantification sont donnés par :
( ) tfact_quali11mat_quant ×
+++= n jni μi,j
Pour simplifier, on a pris 1==n µ ce qui donne :
( ) ( ) tfact_quali11mat_quant ×+++= jii,j
Avec fact_qualit est le facteur de qualité.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 71/101
Chapitre III Codage de canal
La procédure permettant de construire cette matrice est donnée par :
Matrice_Quantification(int *mat_quant,const int fact_qualit )
La procédure permettant de réaliser la quantification est donnée par :
Quantification (const double *dct_out, const int xpos, const int ypos,const int
fact_qualit,short int *Quanti_out)
La procédure permettant de réaliser la déquantification est donnée par :
Dequantification(const short *quanti_out, const int xpos, const int ypos,const int
fact_qualit,double *dequanti_out)
IV.3.3 Lecture en zigzag
La procédure permettant de réaliser la lecture en zigzag est donnée par :
void lect_ZIGZAG (short int **quanti_out, short int **ZIGZAG, int *comp_z)
IV.3.4 DPCM et RLE
Le premier élément (0,0) de chaque bloc (8x8) est remplacé par sa différence avec
l'élément correspondant du bloc précédent. Ces éléments sont les moyennes de leur bloc
respectif, par conséquent ils varient lentement.
Le vecteur 1x64 contient beaucoup de zéros. On code des paires ( skip, value), ou skip
est le nombre de zéros et value est la valeur de la composante non nulle suivant
immédiatement la chaîne de zéros dans l'ordre de la lecture Zigzag . Pour les derniers 0 du
bloc, non suivis d'une valeur non nulle, un End Of Block est envoyé.
La procédure permettant de réaliser la modulation par impulsion codé différentielle
( Differential Pulse Code Modulation) DPCM et la RLE est donnée par :
lect_DPCM_RLE (double *ZIGZAG_out, double **DPCM_RLE, double *preced,
int *comp,const int comp_zigzag)

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 72/101
Chapitre III Codage de canal
IV.3.5 Huffman
A . TYPES DE DONNÉES UTILISER POUR CONSTRUIRE L' ARBRE
Définition d'une feuille
typedef struct S_Feuille
bool Noeud; /* vrai = noeud, faux = feuille */union
unsigned char Data; /* donnee d'une feuille */struct S_Noeud * Ptr; /* ptr sur un autre noeud */
U_Feuille; T_Feuille;
Définition d'un noeud de l'arbretypedef struct S_Noeud
T_Feuille FDroite; /* feuille droite de l'arbre */T_Feuille FGauche; /* feuille gauche de l'arbre */char CodeNoeud[MAXCODE]; /* codage jusqu'au noeud */
T_Noeud;
Définition d’un élément de la table de codagetypedef structlong Cumul; /* fréquence d'apparition des caractères */T_Feuille Donnee; /* donnée ou noeud pour calculer l'arbre */char Code[MAXCODE]; /* code trouve pour le caractère */bool Codifie; /* true = codification existante */
T_ASCII;
B. F ONCTIONS UTILISÉES POUR COMPRESSER ET DECOMPRESSER DES FICHIER EN UTILISANT LE CODAGE DE HUFMAN
Dans la suite on présente les principales fonctions utiliser pour construire l’arbre.
MAZ_Table (T_ASCII * Ptr_Ascii) : est une fonction permettant de mettre à zéro la
table de codage.
Swap (T_ASCII *a, T_ASCII *b) : permet de permuter deux éléments de la table de
codage cette procure est utile pour trier cette table.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 73/101
Chapitre III Codage de canal
TriTable(T_ASCII *Ptr_Ascii) : permet réarranger les éléments de la table des
fréquence qu’on appelle aussi table de codage par ordre décroissant.
CalculFrequence(FILE *f,T_ASCII *Ptr_Ascii) : a pour but de calculer les fréquences
d'apparition des symboles du fichier source. A la fin de cette procédure, cette table est triéeen utilisant la procédure TriTable (T_ASCII *Ptr_Ascii).
Creation_Arbre(T_ASCII * Ptr_Ascii) : procédure permettant de construire l’arbre de
Huffman permettant d'élaborer les codes. Cette procédure a pour argument la table des
fréquences triée et elle a comme résultat un pointeur appelé racine de l’arbre.
L’organigramme de cette procédure est présenté dans la figure 13.
Creation_Codage(T_ASCII *Ptr_Ascii,T_Noeud * Ptr) : a pour but de parcourir
l'arbre, et d’élaborer le codage.
Ecriture_Table(FILE *f,T_ASCII *Ptr_Ascii): effectue l’écriture de la table de
correspondance dans le fichier cible.
Compresse_Donnees(FILE *FSource, FILE*FCible,T_ASCII *Ptr_Ascii) : effectue
l’écriture des données caractère par caractère dans le fichier.
Compression_Huffman(FILE *FSource, FILE *FCible) : procédure réalisant
l’opération de compression. La figure 14 présente l’organigramme de cette procédure.
Creer_Arbre_Decodage(FILE *FSource) procédure réalisant la reconstitution de
l'arbre pour décoder les données.
Decodage_Donnees(FILE *FSource,FILE *FCible): permet de décompresser les
données en parcourant l'arbre.
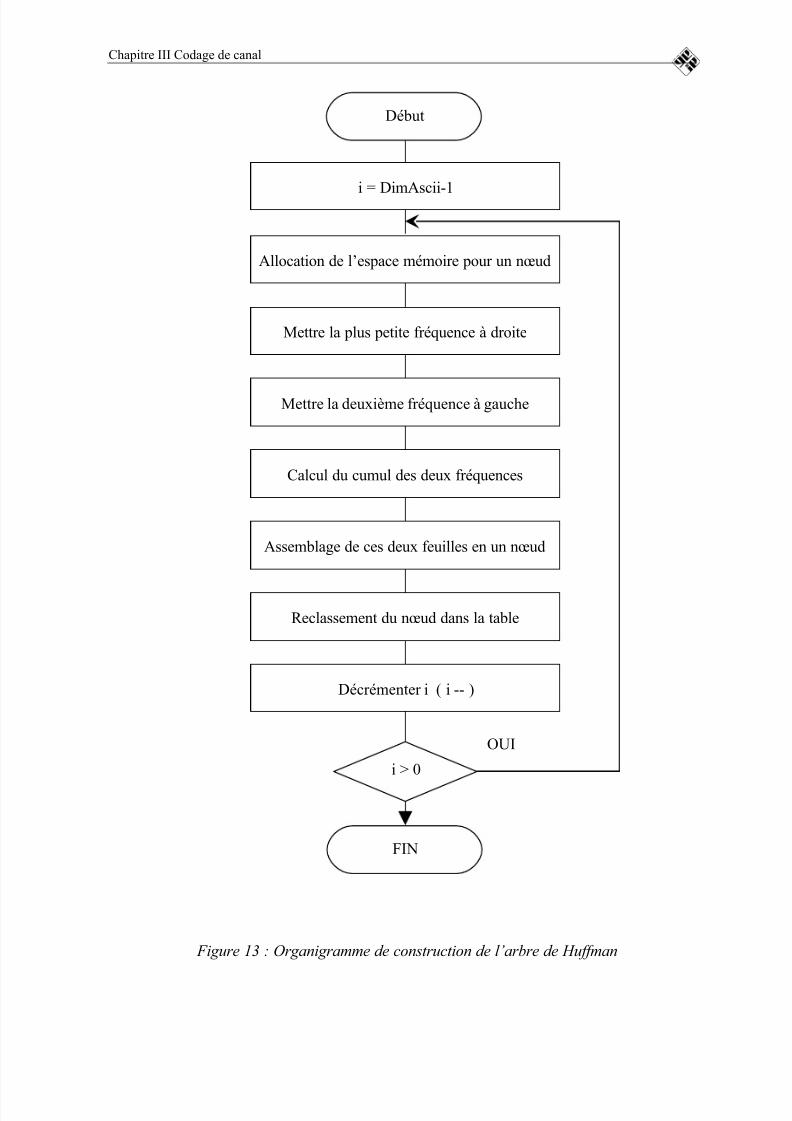
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 74/101
Chapitre III Codage de canal
Figure 13 : Organigramme de construction de l’arbre de Huffman
i = DimAscii-1
Mettre la plus petite fréquence à droite
Mettre la deuxième fréquence à gauche
Calcul du cumul des deux fréquences
Assemblage de ces deux feuilles en un nœud
Reclassement du nœud dans la table
Décrémenter i ( i -- )
i > 0
OUI
Début
FIN
Allocation de l’espace mémoire pour un nœud
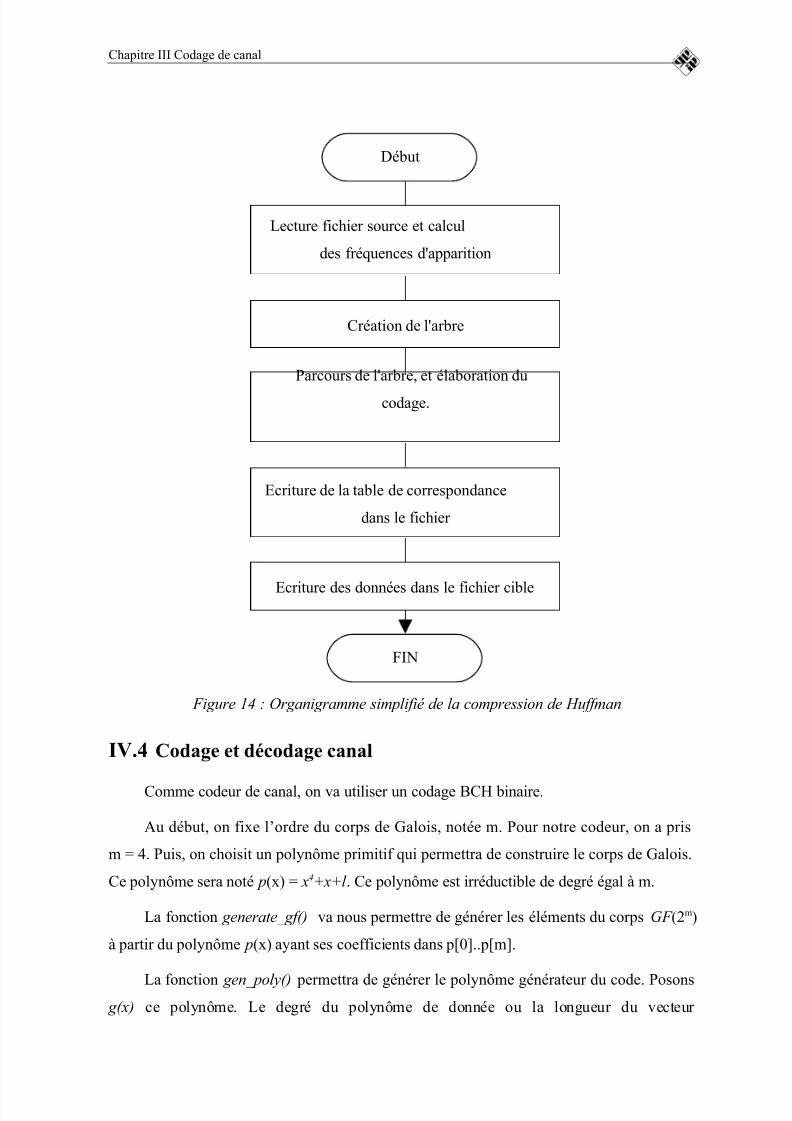
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 75/101
Chapitre III Codage de canal
Figure 14 : Organigramme simplifié de la compression de Huffman
IV.4 Codage et décodage canal
Comme codeur de canal, on va utiliser un codage BCH binaire.
Au début, on fixe l’ordre du corps de Galois, notée m. Pour notre codeur, on a pris
m = 4. Puis, on choisit un polynôme primitif qui permettra de construire le corps de Galois.
Ce polynôme sera noté p(x) = x4+x+l . Ce polynôme est irréductible de degré égal à m.
La fonction generate_gf() va nous permettre de générer les éléments du corps GF (2m)
à partir du polynôme p(x) ayant ses coefficients dans p[0]..p[m].
La fonction gen_poly() permettra de générer le polynôme générateur du code. Posons g(x) ce polynôme. Le degré du polynôme de donnée ou la longueur du vecteur
Lecture fichier source et calcul
des fréquences d'apparition
Création de l'arbre
Parcours de l'arbre, et élaboration du
codage.
Ecriture de la table de correspondance
dans le fichier
Ecriture des données dans le fichier cible
Début
FIN

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 76/101
Chapitre III Codage de canal
d’information k n’est déterminé qu’à ce niveau k=length – rdncy. Avec, length la longueur
du code donnée par length = 2m – 1 et rdncy étant le degrés du polynôme générateur g(x) qui
présente aussi le nombre de bits de redondance ajouté au vecteur de données.
En fixant m = 4 et le pouvoir de détection d= 5 on aura k = 7 et rdncy = 8. On aura uncode BCH (length = 15, k = 7, d = 5).
Posons data(x) le polynôme de donnée à l’entré du codeur, La fonction encode_bch()
permettra d’effectuer le codage en calculant les coefficients du polynôme b(x) qui est le
reste de la division de xlength-k .data(x) par le polynôme générateur g(x).
La fonction decode_bch() est la plus importante elle permet à partir du vecteur reçu de
générer le mot de donnée à l’entrée du codeur de canal, après correction et détection
éventuelle des erreurs.
L’algorithme utiliser pour la détection et la correction des erreurs est celui de
Berlekamp-Massey qui va permettre de déterminer le nombre de ces erreurs et leurs
positions et par conséquent les corriger.
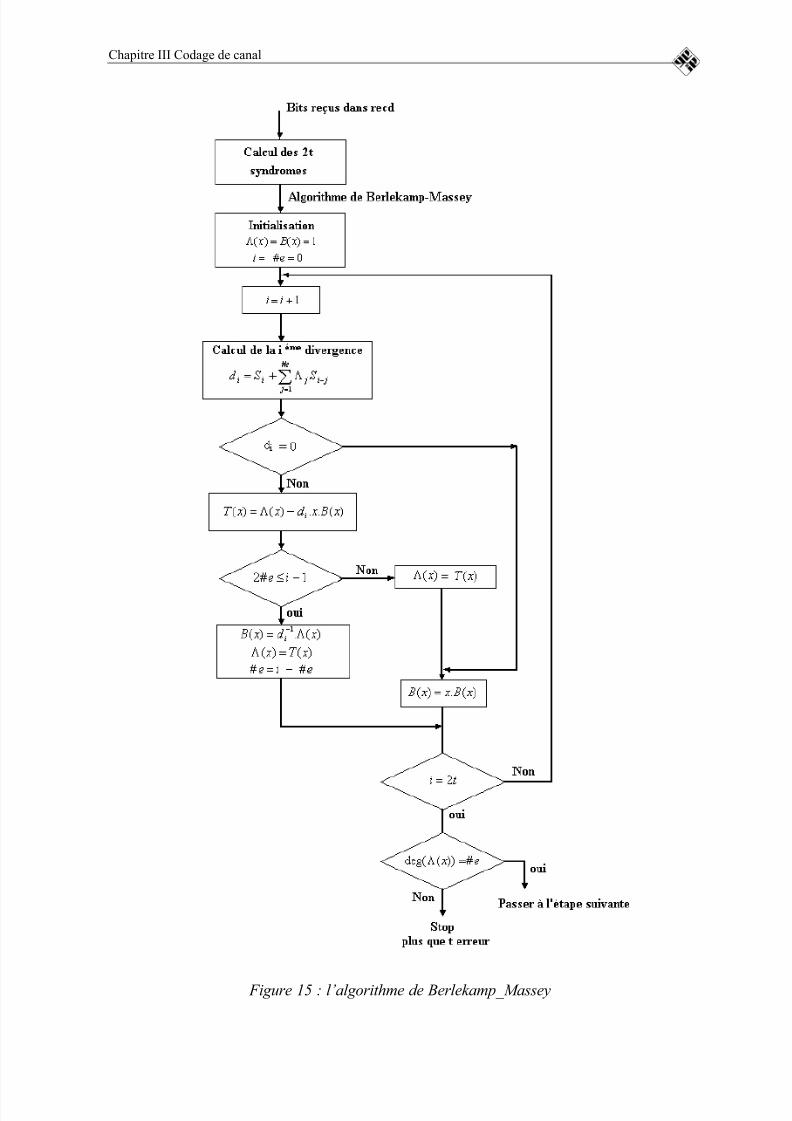
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 77/101
Chapitre III Codage de canal
Figure 15 : l’algorithme de Berlekamp_Massey
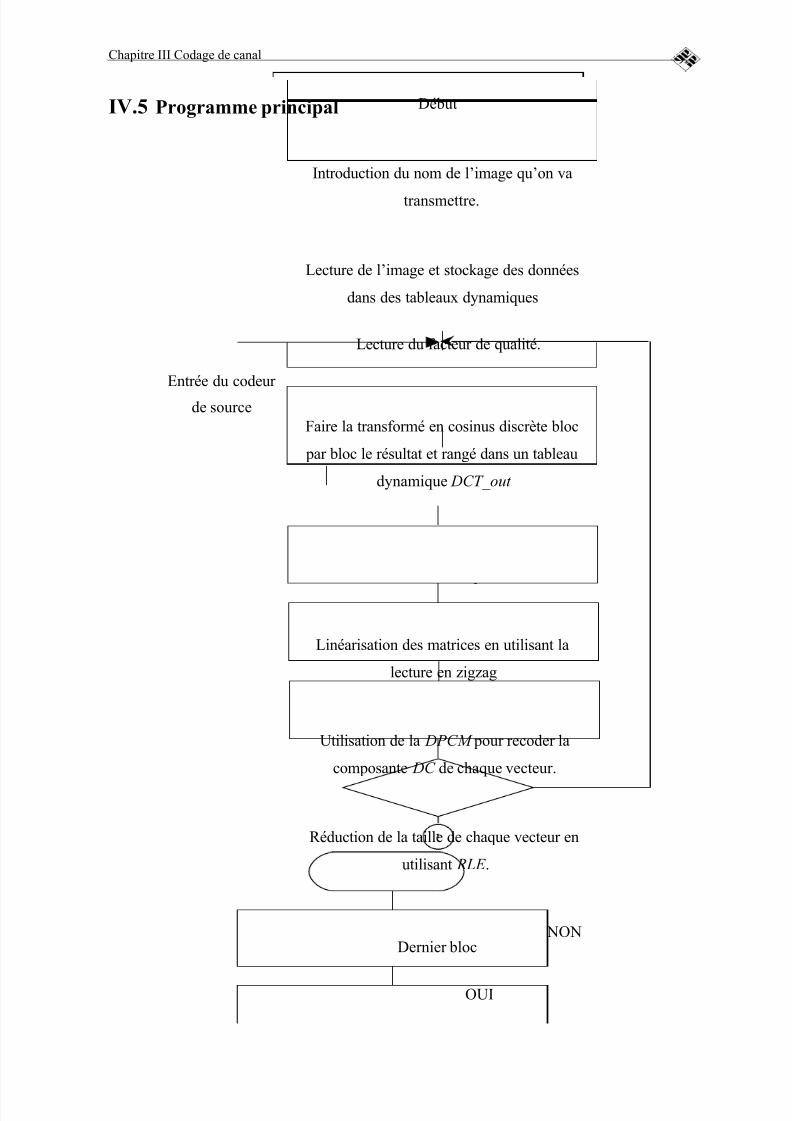
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 78/101
Chapitre III Codage de canal
IV.5 Programme principal
Entrée du codeur
de source
Introduction du nom de l’image qu’on va
transmettre.
Lecture de l’image et stockage des données
dans des tableaux dynamiques
Lecture du facteur de qualité.
Faire la transformé en cosinus discrète bloc
par bloc le résultat et rangé dans un tableau
dynamique DCT_out
Faire la quantification de chaque bloc 8x8 en
utilisant la matrice de quantification
Début
OUI
Linéarisation des matrices en utilisant la
lecture en zigzag
Utilisation de la DPCM pour recoder la
composante DC de chaque vecteur.
Réduction de la taille de chaque vecteur en
utilisant RLE .
Dernier bloc NON
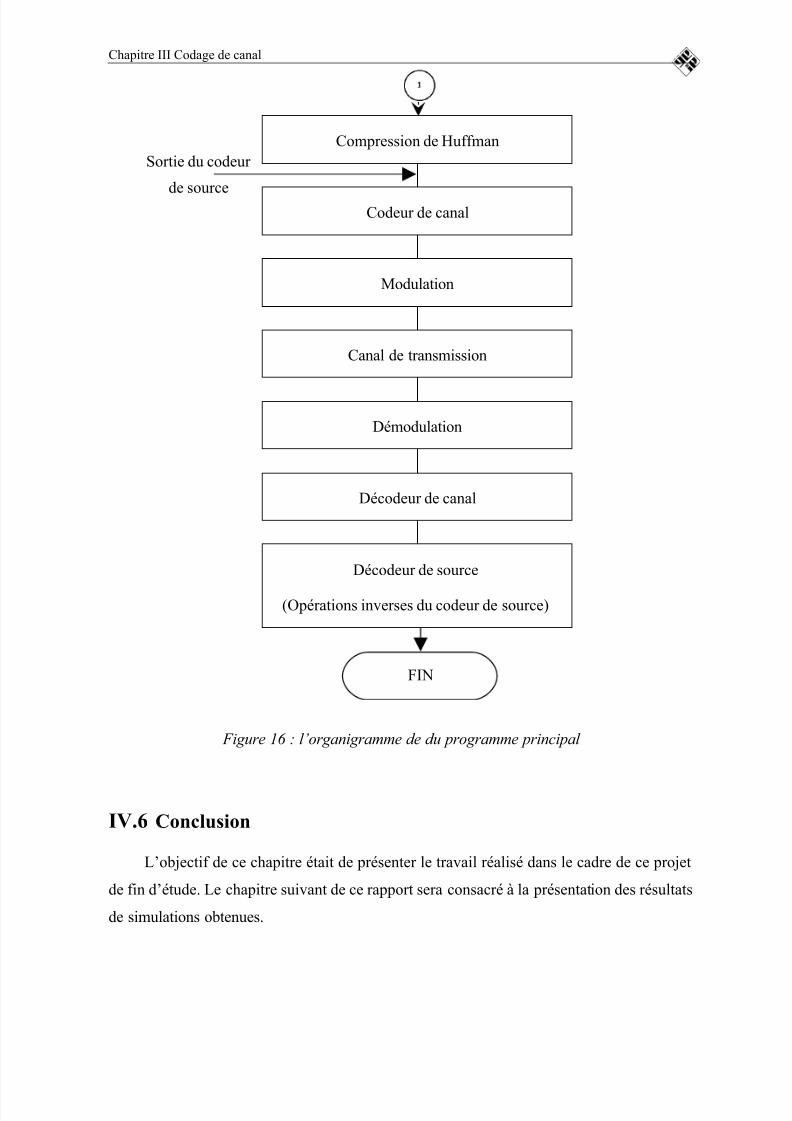
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 79/101
Chapitre III Codage de canal
Figure 16 : l’organigramme de du programme principal
IV.6 Conclusion
L’objectif de ce chapitre était de présenter le travail réalisé dans le cadre de ce projet
de fin d’étude. Le chapitre suivant de ce rapport sera consacré à la présentation des résultats
de simulations obtenues.
Sortie du codeur
de source
FIN
Compression de Huffman
Codeur de canal
Modulation
Canal de transmission
Démodulation
Décodeur de canal
Décodeur de source
(Opérations inverses du codeur de source)

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 80/101
Chapitre IV Conception et Implémentation
Chapitre V
R ÉSULTATS ET DISCUSSION

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 81/101
Chapitre IV Conception et Implémentation
CHAPITRE V : R ÉSULTATS ET DISCUSSION
V.1 Codeur source
L’image choisit pour la simulation est celle de Lena dont les dimensions en pixel est
512x512. On peut déterminer facilement la taille en octet de l’image originale :
Ko7863512512 =×× .
On fait varier le facteur de qualité et on mesure pour chaque valeur la taille du fichier
compressé.
Facteur de qualité 1 2 3 4 5 6
Taille du fichier compressé (Ko)
311 273 259 250 245 241
7 8 9 10 11 12 13 14
238 235 233 231 230 229 228 227
15 16 17 18 19 20 21 22
226 225 225 224 224 223 223 222
23 24 25 30 35 40 50 60
222 221 221 220 219 218 217 216
80 100 150 200 300 600 10000
215 214 213 212 212 212 212
Tableau 5 : Table de mesure de la taille du fichier compressé en fonction du facteur de
qualité
La figure 17 représente la variation de la taille du fichier compressé en fonction du
facteur de qualité.
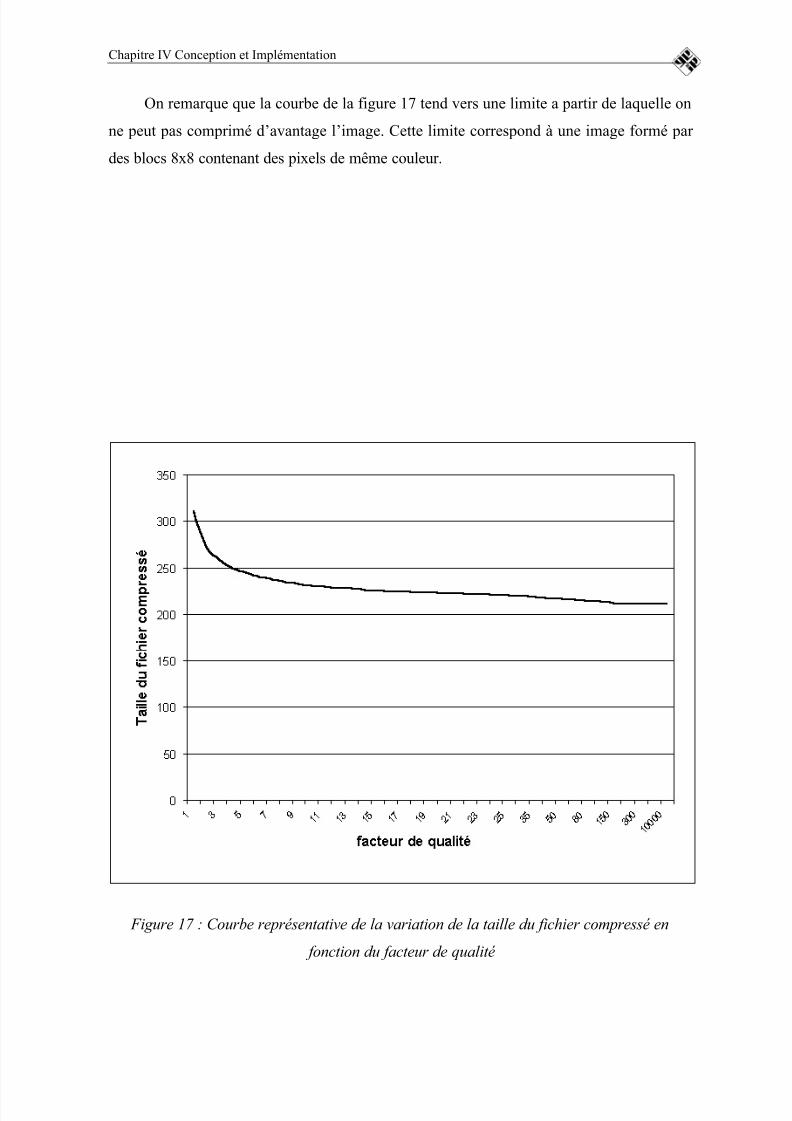
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 82/101
Chapitre IV Conception et Implémentation
On remarque que la courbe de la figure 17 tend vers une limite a partir de laquelle on
ne peut pas comprimé d’avantage l’image. Cette limite correspond à une image formé par
des blocs 8x8 contenant des pixels de même couleur.
Figure 17 : Courbe représentative de la variation de la taille du fichier compressé en
fonction du facteur de qualité

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 83/101
Chapitre IV Conception et Implémentation
Voici les résultats que l’on peut obtenir en compressant une image avec notre codeur
de source :
Image de départFacteur de qualité : 0
24 bits par pixel
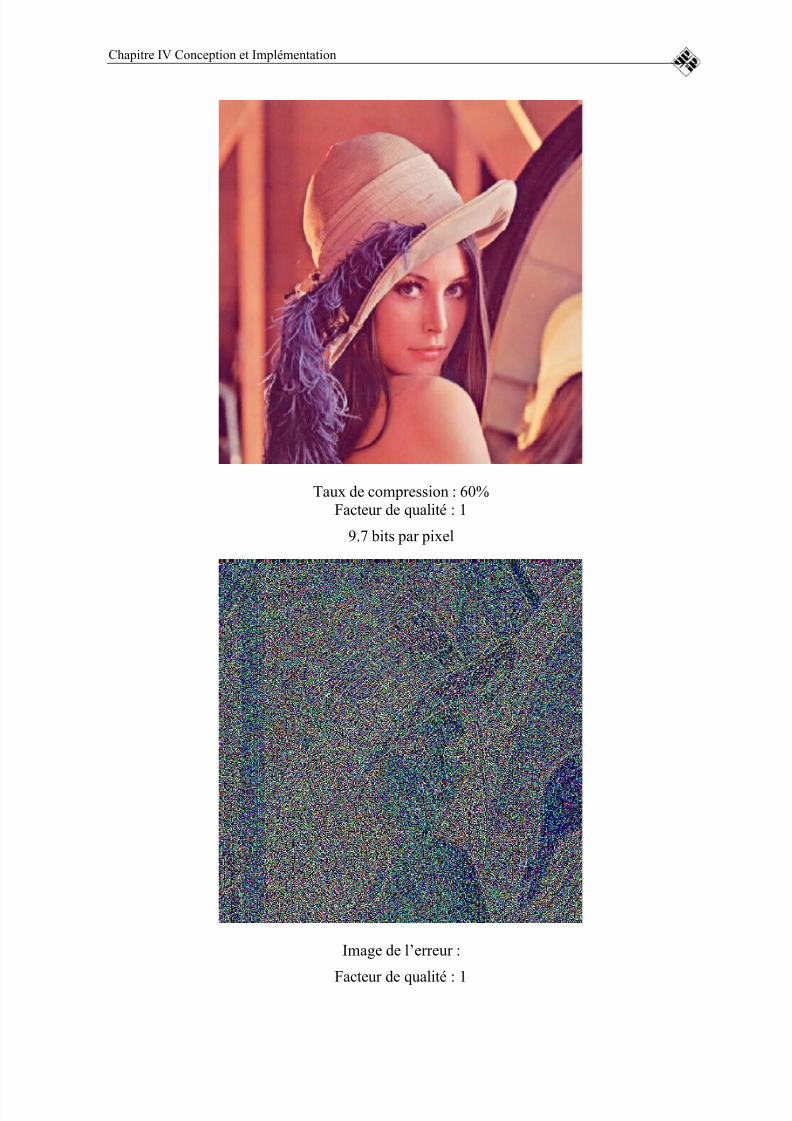
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 84/101
Chapitre IV Conception et Implémentation
Taux de compression : 60%Facteur de qualité : 1
9.7 bits par pixel
Image de l’erreur :
Facteur de qualité : 1
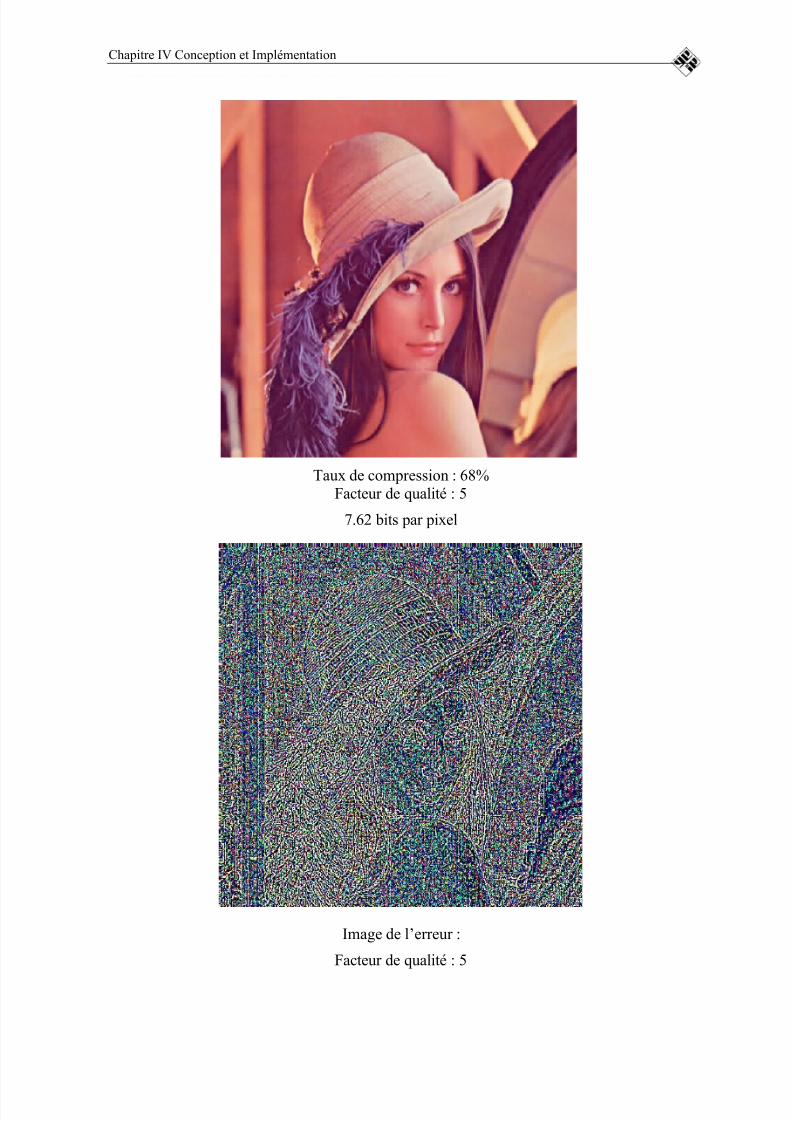
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 85/101
Chapitre IV Conception et Implémentation
Taux de compression : 68%Facteur de qualité : 5
7.62 bits par pixel
Image de l’erreur :
Facteur de qualité : 5

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 86/101
Chapitre IV Conception et Implémentation
Taux de compression : 71%Facteur de qualité : 20
6.95 bits par pixel
Image de l’erreur :
Facteur de qualité : 20

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 87/101
Chapitre IV Conception et Implémentation
Taux de compression : 73%Facteur de qualité : 150
6.63 bits par pixel
Image de l’erreur :
Facteur de qualité : 150

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 88/101
Chapitre IV Conception et Implémentation
On remarque qu’à partir d’un certain taux de compression l’image devient
méconnaissable, et semble être composée de blocs de 8x8 pixels d’une couleur unique. Et
lorsque l’image est agrandie cet effet est amplifié. Plus qu’on augmente le facteur de qualité
plus l’image de l’erreur devient claire et les contours deviennent de plus en plus visibles.
Les taux de compression obtenus sont impressionnants, mais, restent difficiles à
interpréter, car ils dépendent de la nature de l’image. Mais, on peut définir les niveaux de
qualité d’image selon le taux de compression en indiquant le nombre de bits nécessaire au
codage d’un pixel :
• entre 6.8 et 7 bits par pixel, l’image est de qualité moyenne et peut suffire à certaines
applications
• entre 7 et 7.5 bits par pixel, l’image est de bonne qualité
• entre 7.5 et 8 bits par pixel, l’image est d’excellente qualité et répond à tous les
besoins
• entre 10 et 8 bits par pixel, l’image est visuellement indifférentiable de l’originale
La caractéristique la plus importante est le paramétrage de la qualité de l’image, qui
est fait lors du choix de la matrice de quantification. Ce qui donne à l’utilisateur une très
grande flexibilité sur le choix de la qualité de l’image en fonction des contraintes et decapacité de stockage.
Défauts
Premièrement, sur la plupart des images un facteur de qualité égal à 5 pour la matrice
de quantification produit une perte de définition qui se ressent sur la qualité de l’image. En
outre, si ce facteur est dépassé l’image a tendance à apparaître comme une composition de
blocs de 8x8 pixels.
Deuxièmement, l’algorithme de compression nécessite une puissance de traitement
égale pour la compression et la décompression ce qui impose une implémentation matérielle
importante. Or, les applications multimédia de diffusion d’images ont besoin de moyens de
décompression peu coûteux.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 89/101
Chapitre IV Conception et Implémentation
V.2 Codeur canal
Pour évaluer les performances d’un système de transmission il est indispensable de
savoir déterminer la probabilité d’erreur introduite par le canal de transmission.
L’image choisit pour la simulation et celle de Lena. A la sortie du codeur source cette
image est bruitée par un bruit blanc gaussien additif dont la puissance est fixé. Le modèle de
canal considéré est un canal discret sans mémoire, qu’on appelle dans le cas binaire canal
binaire symétrique dont les probabilités de transition sont données par le tableau suivant :
i \ j 0 1
0 1 – p p
1 p 1 – p
Tableau 6 : Table des probabilités de transition
p étant la probabilité d’erreur binaire.
On fait varier la puissance du bruit, ce qui entraîne une variation de la probabilité
d’erreur sur un bit p, afin de montrer visiblement l’importance d’un codeur canal dans une
chaîne de transmission numérique et d’évaluer les performances de notre codeur canal pour
différents niveaux de puissance du bruit.
La figure suivante représente la variation du nombre d’erreurs non corrigées en fonction
de la probabilité d’erreur binaire.
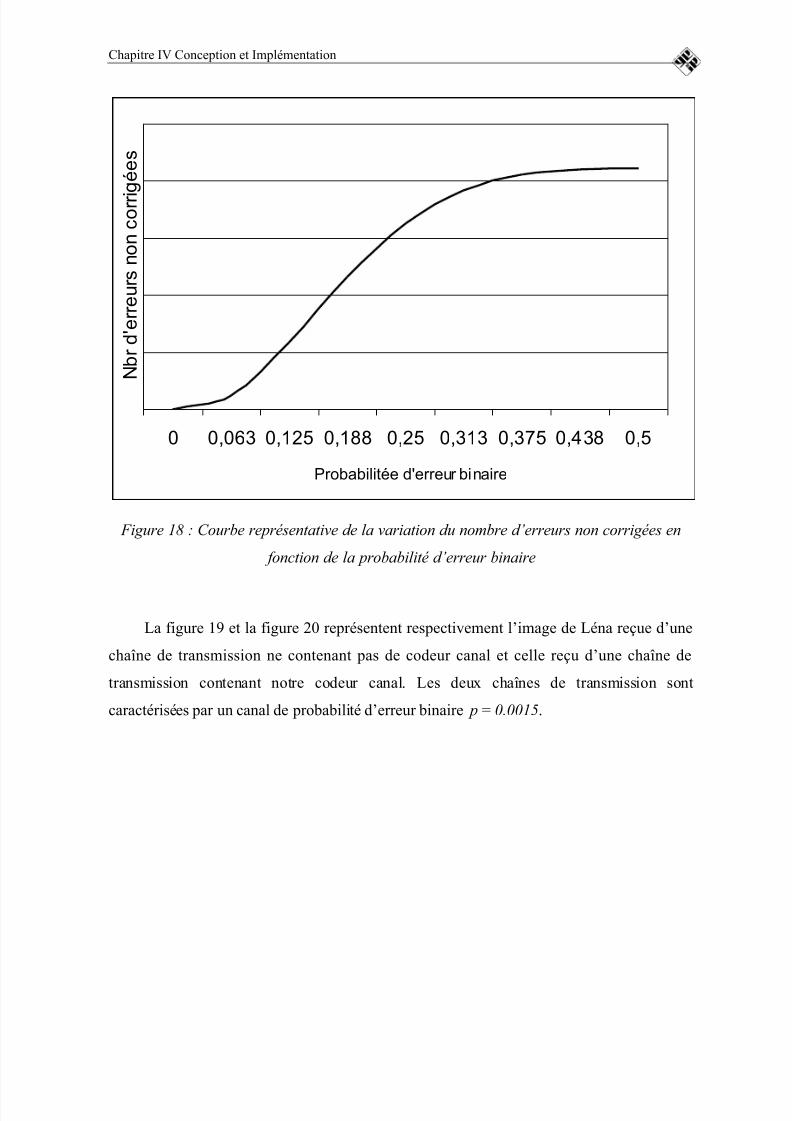
8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 90/101
Chapitre IV Conception et Implémentation
0 0,063 0,125 0,188 0,25 0,313 0,375 0,438 0,5
Probabilitée d'erreur binaire
N b r d ' e r r e u r s n o n c o r r i
g é e s
Figure 18 : Courbe représentative de la variation du nombre d’erreurs non corrigées en
fonction de la probabilité d’erreur binaire
La figure 19 et la figure 20 représentent respectivement l’image de Léna reçue d’une
chaîne de transmission ne contenant pas de codeur canal et celle reçu d’une chaîne de
transmission contenant notre codeur canal. Les deux chaînes de transmission sont
caractérisées par un canal de probabilité d’erreur binaire p = 0.0015.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 91/101
Chapitre IV Conception et Implémentation
Figure 19 : Image reçue sans utilisation de codeur canal pour p = 0.0015.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 92/101
Chapitre IV Conception et Implémentation
Figure 20 : Image reçue en utilisant notre codeur canal pour la même probabilité d’erreur
On remarque que l’image reçue après le décodage est semblable à celle transmit. En
effet, l’impact des erreurs de transmission est supprimé après la correction des erreurs. D’où
l’importance du codeur canal dans une chaîne de transmission.
Sans utilisation de codeur canal, une image reçue peut être trop bruité qu’on ne peut
pas voir ses détails. L’utilisation du codeur canal va permettre de détecter puis de corriger quelques erreurs ce qui éclaircit un peu l’image.
L’image représentée par la figure suivante montre visiblement l’impact des erreurs sur
une image reçue d’une chaîne de transmission présentant un canal trop bruité et ne
présentant pas un codeur canal.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 93/101
Chapitre IV Conception et Implémentation
Figure 21 : Image trop bruité issue d’une chaîne qui ne présente pas de codeur canal
Sur la figure suivante, on a l’image reçue de la même chaîne en ajoutant un codeur
canal au niveau de l’émission et un décodeur canal au niveau de la réception. On remarque
que malgré la présence d’erreurs non corrigées qu’on peut voir qu’il s’agit bien de l’image
de Léna.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 94/101
Chapitre IV Conception et Implémentation
Figure 22 : Image reçue cas d’un canal trop bruité
Pour le codeur canal qu’on a utilisé dans la simulation, on peut déterminer quelques
ordres de grandeurs de probabilités d’erreur qui reflètent la qualité de l’image reçue.
10-1 Mauvais, mais peut donné une idée sur l’image reçue.
10-2
Qualité acceptable, en ajoutant un dispositif de débruitage on peut diminuer le
nombre d’erreurs voir les éliminer pour s’approcher de l’image originale
< 10-3Bonne qualité de transmission. L’image reçue est nette ne présentant aucun
bruit.
Tableau 7 : Quelques ordres de grandeur de probabilité d’erreurs
D’après cette table, on peut tirer la conclusion suivante : Les performances d’un code
dépendent du canal sur lequel il est utilisé.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 95/101
Chapitre IV Conception et Implémentation
V.3 Comparaison entre codage source et codage canal indépendant
et le codage source canal conjoint
V.3.1 Théorème de séparation de ShannonShannon est plus connue en traitement de signal par son théorème de séparation. En
plus, c’est celui, grâce à sa théorie de l’information, a donné les limites possibles tant pour
le codage de source tant pour le codage de canal :
− Pour le codage source, Shannon affirme qu’il existe un débit binaire *
s R , vers lequel
on peut tendre, et qu’on ne peut pas dépasser pour comprimer une source d’information,
pour une distorsion D bien fixé suivant l’application. Cette distorsion est uniquement celle
introduite par le codage de source.
− Pour le codage canal, Shannon montre que pour avoir une transmission fiable dans un
canal bruité, il existe un débit binaire *
c R appelé capacité du canal qu’on peut tendre vers,
mais jamais dépasser.
Shannon affirme, qu’on peut tendre vers une limite infranchissable de débit
source/canal *
*
*
c
s
R R R = avec un système ou codage source et canal sont séparé. Ce débit
global est notéc
s
R
R R = exprimé en nombre moyen de symbole émis par symbole de
source.
Ceci nous donne la borne en débit pour le codage conjoint source/canal.
Il est alors clair qu’on peut s’approcher théoriquement de cette limite de la manière
suivante :
− Le codeur source garantie un débit )(* D R R s = pour une distorsion D donnée.
− Le codeur canal s’impose à une fiabilité quasiment parfaite (Pe 0) tout en
garantissant un débit c R proche de *
c R .
De la sorte qu’on obtient un débit global proche de la limite de Shannon avec une
distorsion totale égale à D [11].

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 96/101
Chapitre IV Conception et Implémentation
V.3.2 Solution traditionnelle et limites d’utilisation
La stratégie traditionnelle consiste à comprimer au maximum la source pour un niveau
de distorsion donnée. Ceci rend les données plus sensibles aux erreurs de transmission.
L’utilisation d’un codeur canal très sophistiqué résout ce problème. Mais en pratique, ilexiste toujours des contraintes de complexité matérielle et de délai qui limite la possibilité
d’utiliser de tel codeur.
V.3.3 Solution conjointe.
Il s’agit de résoudre les deux problèmes de codage source et de codage conjoint
ensemble. Afin de réduire la complexité tout en gardant un bon niveau de performance [1].
A . P ROTECTION DES CODES SOURCES
Dans ce cas, le codeur de source assure les deux fonctions de compression et de
protection contre les erreurs de transmission. Ceci s’effectue en réglant le codeur source de
telle manière que les erreurs éventuelles de transmission aient un impact moins néfaste au
décodage. On dit que le codeur source est plus robuste aux erreurs [11].
B . E QUILIBRAGE DE RENDEMENTS
Cette solution propose un équilibrage du rendement entre codeur source et canal, afin
de trouver un point de fonctionnement compatible avec l’application.
V.4 Conclusion
Les algorithmes développés dans le chapitre 4 ont été implémentés en utilisant le
langage C++. Les résultats de simulation montre le bon fonctionnement de ces algorithmes.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 97/101
Chapitre V Résultats et discussion
CONCLUSION GÉNÉRALE

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 98/101
Chapitre V Résultats et discussion
Conclusion Générale
Dans ce projet de fin d’étude, nous avons élaborer un algorithme de codage source
appliqué à la transmission d’images et d’un algorithme de codage canal en utilisant le
codage BCH. Les deux problèmes du codage de source et de codage de canal sont
considérés de manière séparée. A la fin de ce projet, nous avons pu mettre en œuvre une
chaîne de simulation complète pour la transmission d’images fixes.
Ce travail nous a été fructueux dans la mesure où il nous a permis de découvrir un
domaine en plein essor, celui du codage source canal. Il nous a permis de prendre
conscience de la nécessité de développer des techniques de codage pour représenté le signal
à transmettre sous une forme plus compacte afin de gagner en vitesse de transmission, et destechniques de codage pour protéger le signal contre les erreurs de transmission qui peuvent
altérer la qualité de la transmission. Ces deux techniques sont appelées dans la littérature
codage source et codage canal.
Nous avons montré à la fin de ce travail que traiter ces deux problèmes séparément
peut ne pas vérifier les contraintes de complexité matérielle et de délais de reconstitution.
En effet, comprimer au maximum un signal numérique prend du temps tant au niveau de
l’émetteur que pour le récepteur. En plus, ces données compressées deviennent plus
sensibles aux erreurs de transmission. Dans ce cas, l’utilisation de codeur canal très
sophistiqué devient indispensable, mais il n’est pas toujours réalisable en pratique. Afin de
réduire la complexité et le temps de traitement des données tout en gardant un bon niveau de
performance, La solution et de traiter ces deux problèmes ensembles. Cette solution est
appelée solution conjointe.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 99/101
Conclusion Générale
BIBLIOGRAPHIE

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 100/101
Conclusion Générale
Bibliographie
[1] François-Xavier Bergot, « Dualité entre codage de source et codagede canal », Thèse présentée pour obtenir le grade de docteur del'Ecole nationale supérieure des télécommunications Spécialité :Electronique et Communications soutenue le 16 juin 2000.
[2] Mathieu ASTOUL, Sébastien BARRIA, Xavier DUFLOS, EmericVIRTON, « MPEG/JPEG Compression de données », Mai 1994.
[3] Ja-Ling Wu and Jiun Shiu, « Discrete cosine transform in errorControl coding », IEEE transactions on communication, vol 43, NO 5,MAY 1995.
[4] Alain GALVIEUX, « Introduction à la théorie de l’information et aucodage canal », mai 1996.
[5] BENOIT Christophe, DUSSON Alexandre, « La compression dedonnées informatiques », Juin 1999.
[6] O. Pothier, « Codage de canal et turbo-codes », septembre 2000.
[7] Joseph Boutros, « Techniques de communications numériques », 3ème
Partie : Codage correcteur d’erreur 1994.
[8] Fatma ABdelkefi, « Les codes Reed-Solomon Complexes pour lacorrection des erreurs impulsives dans les systèmesmultiporteuses ».
[9] Andrew B. Watson, «Image Compression Using the Discrete CosineTransform», NASA Ames Research Center 1994.
[10] Gregory K. Wallace «The JPEG Still Picture Compression Standard»,Multimedia Engineering Digital Equipment Corporation December1991.

8/4/2019 RAP_PFE
http://slidepdf.com/reader/full/rappfe 101/101
Conclusion Générale
[11] Pierre Duhamel, Olivier Rioul «Codage conjoint source canal : enjeuxet approches», Septembre 1997.
[12] Nicolas Moreau « Techniques de compression des signaux »,MASSON 1995.





























