Embed Size (px)
Citation preview

MODALITA’ DI VALUTAZIONE
DELL’ACCURATEZZA DIAGNOSTICA

Accuratezza diagnostica
E’ definita come la capacità di un test diagnostico di discriminare tra due condizioni cliniche diverse; per esempio: malattia e assenza di malattia, infezione e assenza di infezione, ecc.
Viene chiamata anche: capacità diagnostica, validità o performance.
Un test quindi che discrimina tra malati e sani risulta accurato se vi è concordanza tra positivitàdel test e presenza di malattia (oppure negativitàdel test e assenza di malattia).

I fattori che determinano accuratezza diagnostica sono:
- Sensibilità diagnostica
- Specificità diagnostica
- Predictive Value- Curve ROC
Nota: si parla di condizioni diagnostiche e non analitiche
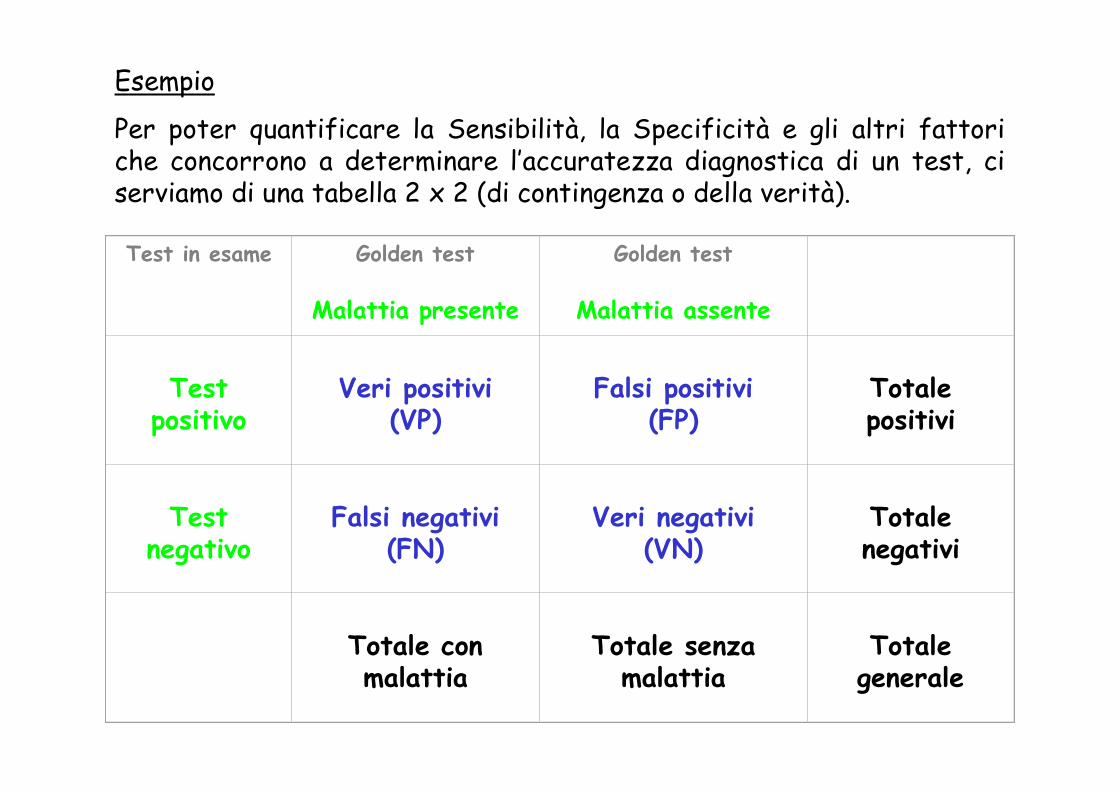
Test in esame Golden test
Malattia presente
Golden test
Malattia assente
Test positivo
Veri positivi(VP)
Falsi positivi(FP)
Totalepositivi
Test negativo
Falsi negativi(FN)
Veri negativi(VN)
Totalenegativi
Totale con malattia
Totale senzamalattia
Totalegenerale
Esempio
Per poter quantificare la Sensibilità, la Specificità e gli altri fattori che concorrono a determinare l’accuratezza diagnostica di un test, ci serviamo di una tabella 2 x 2 (di contingenza o della verità).

Test in esame Golden testMalattia presente
Golden testMalattia assente
Test positivo Veri positivi (VP) Falsi positivi (FP) Totale positivi
Test negativo Falsi negativi (FN) Veri negativi (VN) Totale negativi
Totale con malattia Totale senza malattia Totale generale
( ) VPP VVP FN
+ +| Μ =+
Sensibilità
Specificità ( ) VNP VVN FP
− −| Μ =+
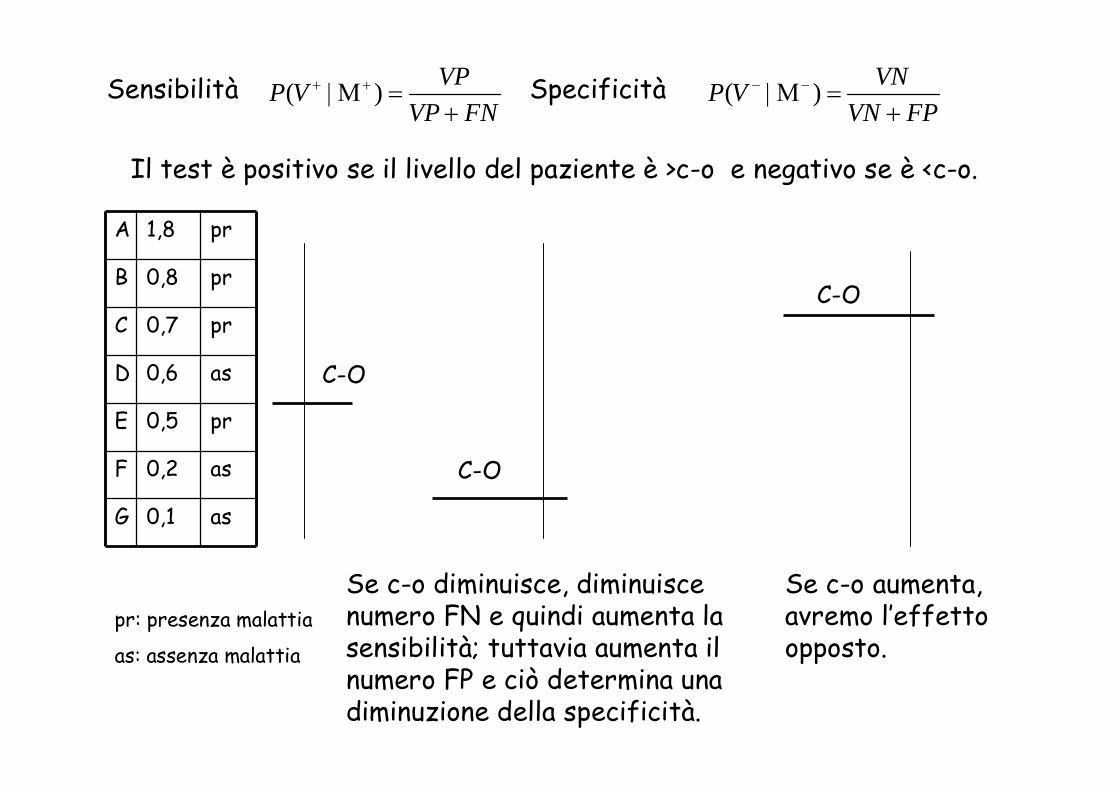
Variando il Cut off di un test una aumenta e contemporaneamente l’altra spesso diminuisce. Es. marker biochimico per l’AMI, Ab anti-virus per infezione virale, ecc.
Prob di essere pos tra i malati
Prob di essere neg tra i sani
( ) VPP VVP FN
+ +| Μ =+
Sensibilità Specificità ( ) VNP VVN FP
− −| Μ =+
Se c-o aumenta, avremo l’effetto opposto.
Il test è positivo se il livello del paziente è >c-o e negativo se è <c-o.
Se c-o diminuisce, diminuisce numero FN e quindi aumenta la sensibilità; tuttavia aumenta il numero FP e ciò determina una diminuzione della specificità.
C-O
C-O
C-O
A 1,8 pr
B 0,8 pr
C 0,7 pr
D 0,6 as
E 0,5 pr
F 0,2 as
G 0,1 as
pr: presenza malattia
as: assenza malattia

Un altro fattore importante per valutare l’accuratezza di un test è la:
( ) VP FNPVP FP VN FN
+ +Μ =
+ + +
I valori di sensibilità, specificità e prevalenza sono
riportati in letteratura
PrevalenzaProb di essere mal
Un buon test diagnostico dovrà quindi bilanciare
Sensibilità e Specificità (Curve ROC)

Lo scopo principale dell’interpretazione di un test diagnostico è quello di
( ) VPP M VVP FP
+ +| =+
( ) VNP M VVN FN
− −| =+
PPV
NPV
Prob di essere mal tra i pos
Prob di essere sano tra i neg
(o Pred +)
(o Pred -)
Predictive value
conoscere la probabilità di avere un’infezione o una malattia in presenza di quel particolare risultato del test:
VP (malati)FPVPFN
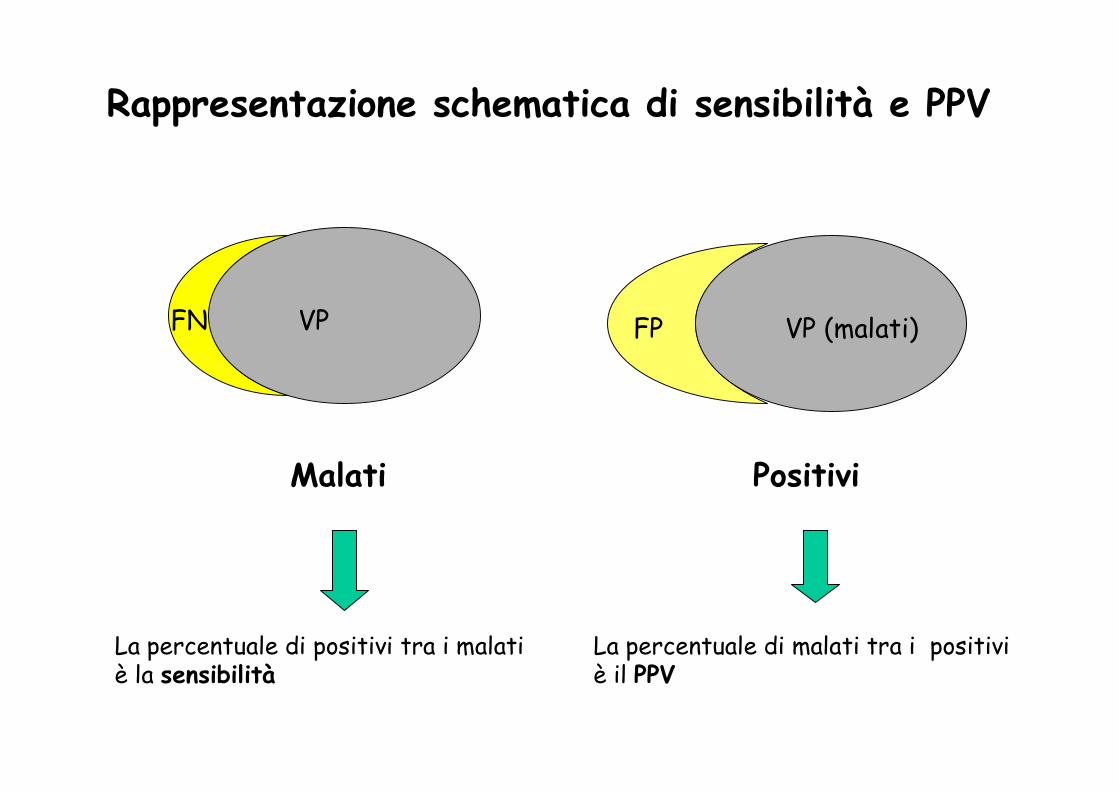
Malati Positivi
La percentuale di positivi tra i malati La percentuale di malati tra i positivi è la sensibilità è il PPV
Rappresentazione schematica di sensibilità e PPV

Esempio 1Nella pratica reumatologica, la prevalenza di Lupus Eritematoso Sistemico (SLE) nei pazienti sottoposti al test ANA (anticorpi antinucleo) è del 2,88%. La sensibilità del test ANA èdel 98%, mentre la specificità è del 93%. Qual’è la probabilità di SLE per un paziente reumatologico che ha il test ANA positivo?

Metodo tradizionaleCostruiamo una tabella 2 x 2 considerando un’ipotetica popolazione formata da 100.000 persone. Dobbiamo ora riempire tutte le celle della tabella.
SLE NON SLE
ANA positivo VP FP
ANA negativo FN VN
2880 97120 100.000
VPPPVVP FP
=+
Dobbiamo quindi determinare VP e FP

SLE NON SLE
ANA positivo VP FP
ANA negativo FN VN
2880 97120 100.000
Se la Sensibilità è del 98%, allora possiamo scrivere:
0,98 = VP / 2880 e ricavare VP = 2822.
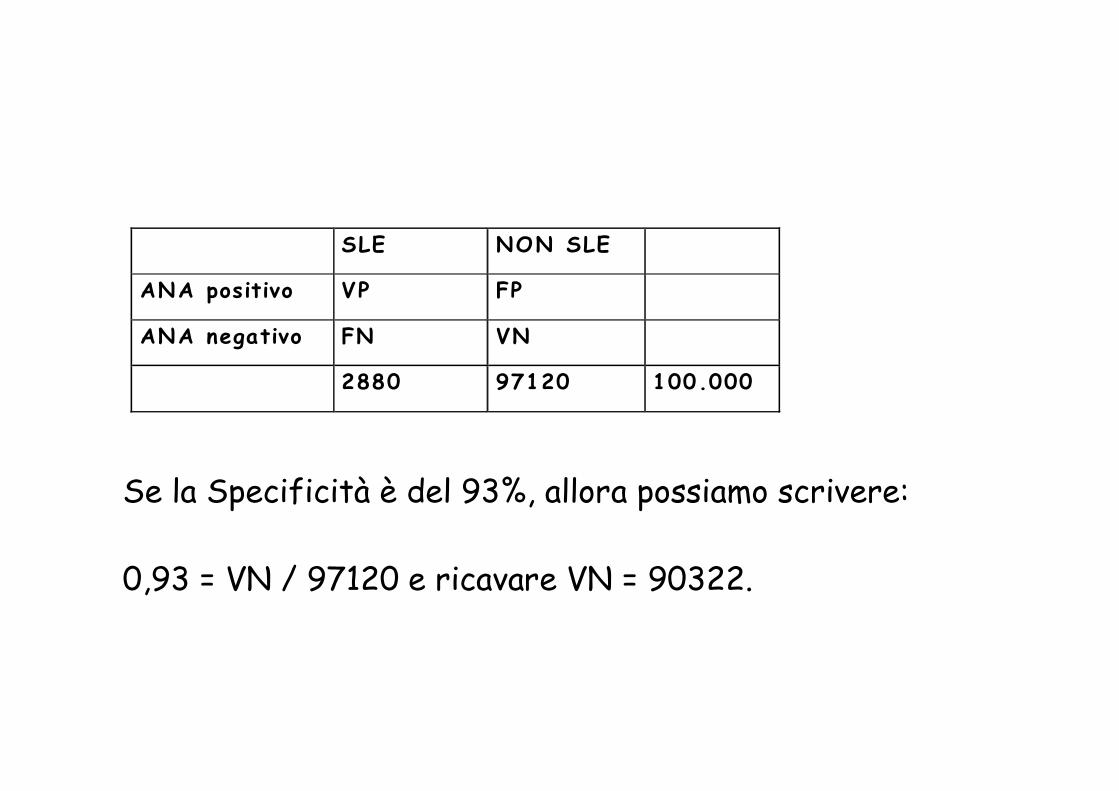
Se la Specificità è del 93%, allora possiamo scrivere:
0,93 = VN / 97120 e ricavare VN = 90322.
SLE NON SLE
ANA positivo VP FP
ANA negativo FN VN
2880 97120 100.000

VPPPVVP FP
=+
PPV = 2822 / 9620 = 0,293
SLE NON SLE
ANA positivo VP = 2822 FP = 6798 9620
ANA negativo FN VN = 90322
2880 97120 100.000

Metodo basato sul Teorema di Bayes
Il Teorema di Bayes definisce la PE(H), cioè la probabilità dell’evento H (presenza di malattia) condizionato da E (test positivo), che corrisponde al PPV:
(1 ) (1 )prevalenza sensibilitàPPV
prevalenza sensibilità prevalenza specificità⋅
=⋅ + − ⋅ −
Prob di essere mal tra i pos
Certe volte il PPV è espresso diversamente:

Metodo basato sul Teorema di BayesIl Teorema di Bayes definisce la PE(H), cioè la probabilità dell’evento H (presenza di malattia) condizionato da E (test positivo), che corrisponde al PPV:
P(H) = Probabilità di essere malati = PrevalenzaPH(E) = Probabilità di avere il test positivo in presenza di malattia =
= VP / (VP + FN) = SensibilitàP(~H) = Probabilità di non essere malati e quindi = 1- PrevalenzaP~H(E) = Probabilità di avere il test positivo in assenza di malattia =
= FP / (FP + VN) = 1 – Specificità.
(1 ) (1 )prevalenza sensibilitàPPV
prevalenza sensibilità prevalenza specificità⋅
=⋅ + − ⋅ −
Prob di essere mal tra i pos
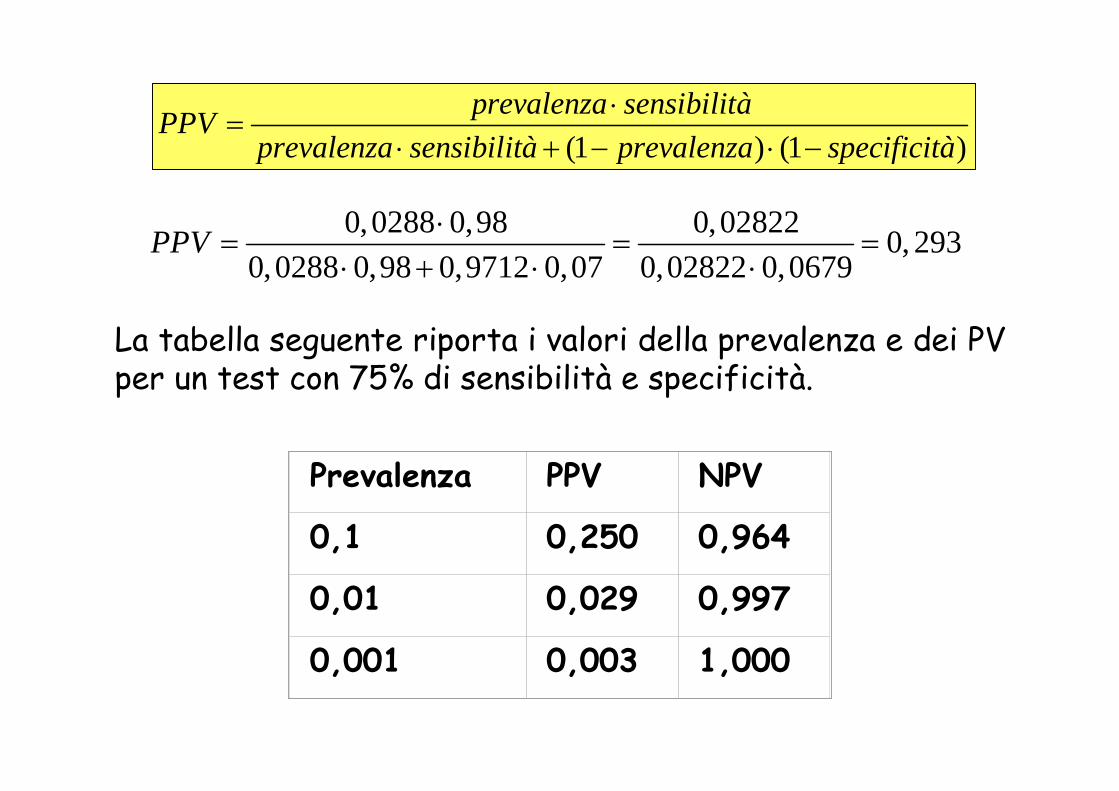
La tabella seguente riporta i valori della prevalenza e dei PV per un test con 75% di sensibilità e specificità.
Prevalenza PPV NPV
0,1 0,250 0,964
0,01 0,029 0,997
0,001 0,003 1,000
(1 ) (1 )prevalenza sensibilitàPPV
prevalenza sensibilità prevalenza specificità⋅
=⋅ + − ⋅ −
0,0288 0,98 0,02822 0, 2930,0288 0,98 0,9712 0,07 0,02822 0,0679
PPV ⋅= = =
⋅ + ⋅ ⋅

Uso dei Rapporti di Probabilità (LR)
VPVP FNLR FPFP VN
+ +=
+
FNVP FNLR VNFP VN
− +=
+
Per calcolare il PPV di un test è possibile anche impiegare i Rapporti di Probabilità (LR), il cui valore èriportato in letteratura.. Essi rappresentano quindi uno strumento per valutare l’accuratezza di un test .
LR = Rapporto tra la Probabilità del risultato di un test nella popolazione con malattia e la Probabilità di quel risultato nella popolazione senza malattia.

Malattia presente Malattia assente Totale
Test positivo 90 90/100 20 20/100 110
Test negativo 10 80 90
Totale 100 100 200
Esempio 2
VPVP FNLR FPFP VN
+ +=
+

Malattia presente Malattia assente Totale
Test positivo 90 90/100 20 20/100 110
Test negativo 10 80 90
Totale 100 100 200
Esempio 2
90 101100 1004,520 80 8
100 100
LR LR+ −= = = =
Significato
Il test ha 4,5 volte più probabilità di essere positivo tra i malati rispetto ai sani (più il valore di LR+ è alto e più il test è accurato). Ha inoltre 8 volte meno probabilità di essere negativo tra i malati rispetto ai sani (1/8), cioè ha 8 volte più probabilità di essere negativo tra i sani rispetto ai malati (più il valore di LR- è basso e più il test è accurato).

Esempio 3Presenza di malattia Assenza di malattia Totale
Test fortemente positivo 60 60/100 5 5/100 75
Test debolmente positivo 30 30/100 15 15/100 35
Test negativo 10 80 90
Totale 100 100 200
VPVP FNLR FPFP VN
+ +=
+

Esempio 3Presenza di malattia Assenza di malattia Totale
Test fortemente positivo 60 60/100 5 5/100 75
Test debolmente positivo 30 30/100 15 15/100 35
Test negativo 10 80 90
Totale 100 100 200
60100 125100
LR++ = =
30100 215100
LR+ = =
Nota
Un test è utile se determina un incremento o un decremento di probabilità di malattia dal pre-test al post-test.
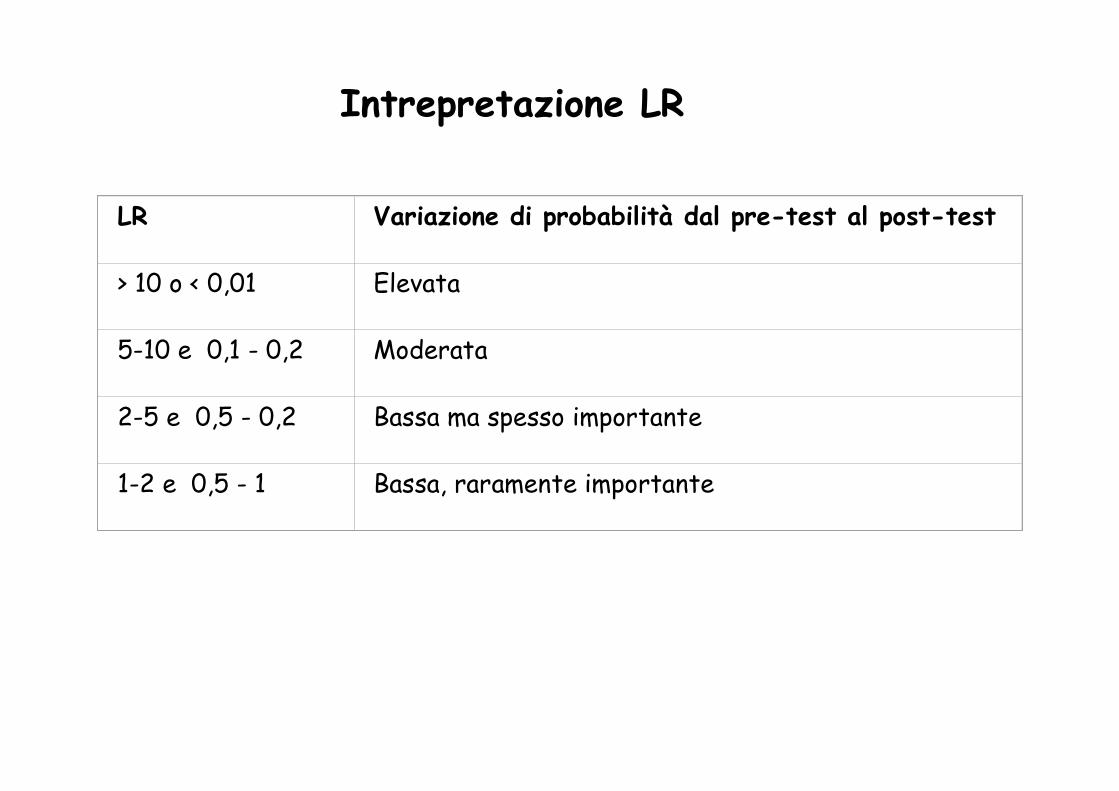
LR Variazione di probabilità dal pre-test al post-test
> 10 o < 0,01 Elevata
5-10 e 0,1 - 0,2 Moderata
2-5 e 0,5 - 0,2 Bassa ma spesso importante
1-2 e 0,5 - 1 Bassa, raramente importante
Intrepretazione LR
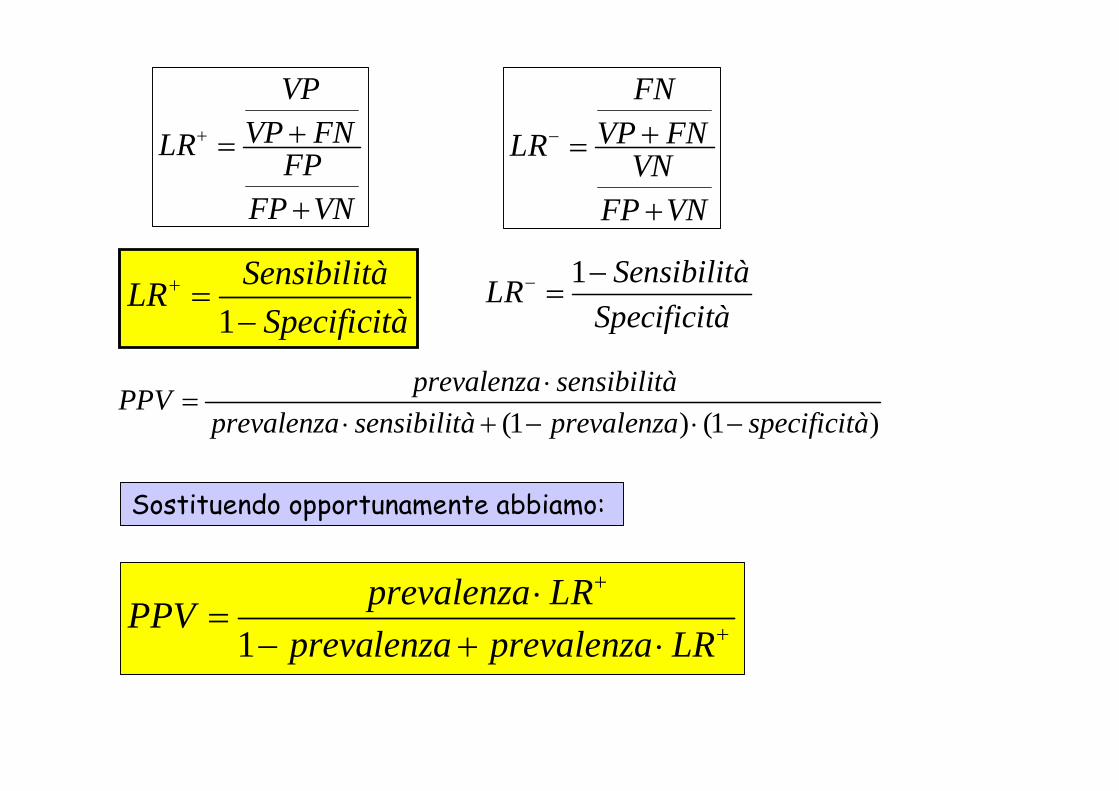
1SensibilitàLR
Specificità+ =
−1 SensibilitàLR
Specificità− −
=
1prevalenza LRPPV
prevalenza prevalenza LR
+
+
⋅=
− + ⋅
VPVP FNLR FPFP VN
+ +=
+
FNVP FNLR VNFP VN
− +=
+
(1 ) (1 )prevalenza sensibilitàPPV
prevalenza sensibilità prevalenza specificità⋅
=⋅ + − ⋅ −
Sostituendo opportunamente abbiamo:

1prevalenza LRPPV
prevalenza prevalenza LR
+
+
⋅=
− + ⋅
LR+ = 0,98 / 0,07 = 14
0,0288 14 0, 2930,9712 0,0288 14
PPV ⋅= =
+ ⋅
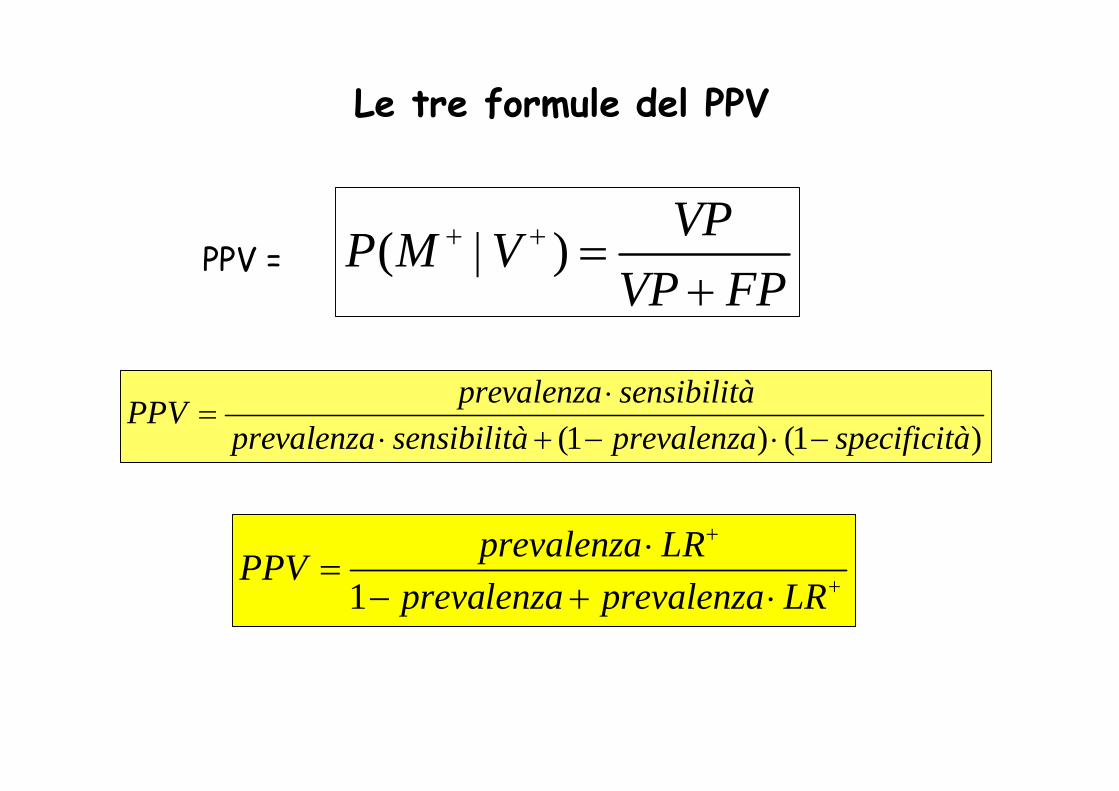
1prevalenza LRPPV
prevalenza prevalenza LR
+
+
⋅=
− + ⋅
(1 ) (1 )prevalenza sensibilitàPPV
prevalenza sensibilità prevalenza specificità⋅
=⋅ + − ⋅ −
( ) VPP M VVP FP
+ +| =+
PPV =
Le tre formule del PPV
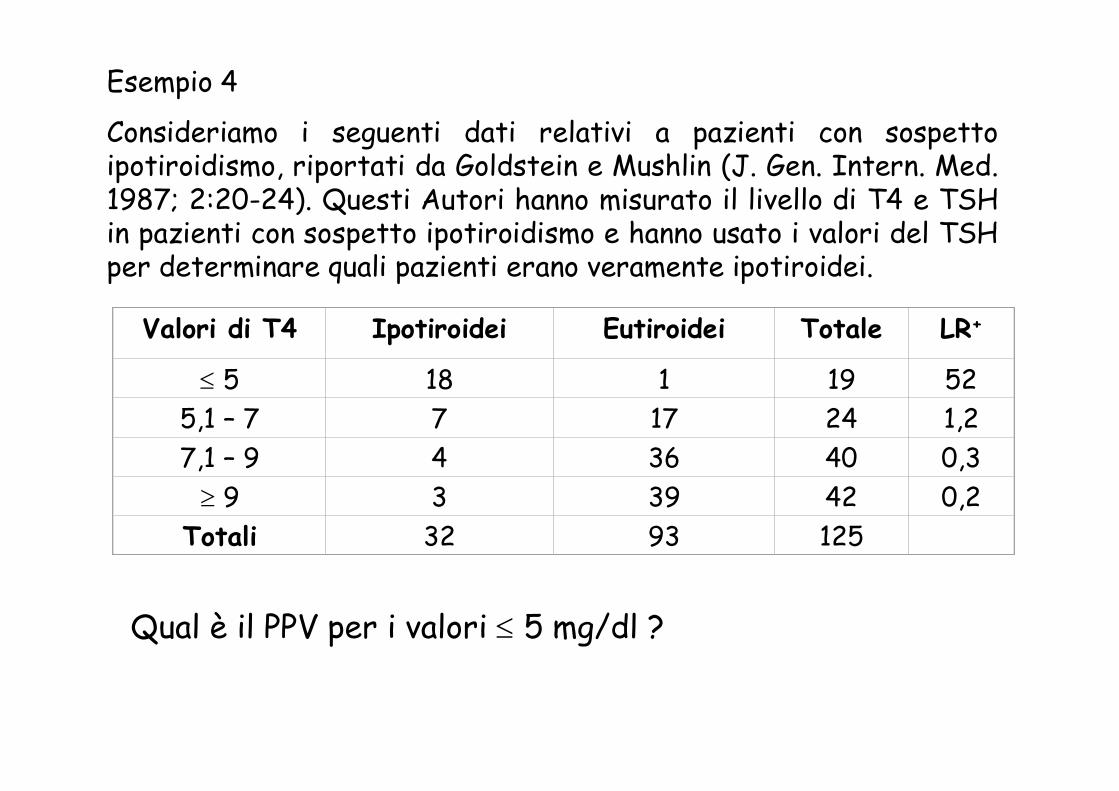
Esempio 4
Consideriamo i seguenti dati relativi a pazienti con sospetto ipotiroidismo, riportati da Goldstein e Mushlin (J. Gen. Intern. Med. 1987; 2:20-24). Questi Autori hanno misurato il livello di T4 e TSH in pazienti con sospetto ipotiroidismo e hanno usato i valori del TSH per determinare quali pazienti erano veramente ipotiroidei.
Valori di T4 Ipotiroidei Eutiroidei Totale LR+
≤ 5 18 1 19 525,1 – 7 7 17 24 1,27,1 – 9 4 36 40 0,3
≥ 9 3 39 42 0,2Totali 32 93 125
Qual è il PPV per i valori ≤ 5 mg/dl ?
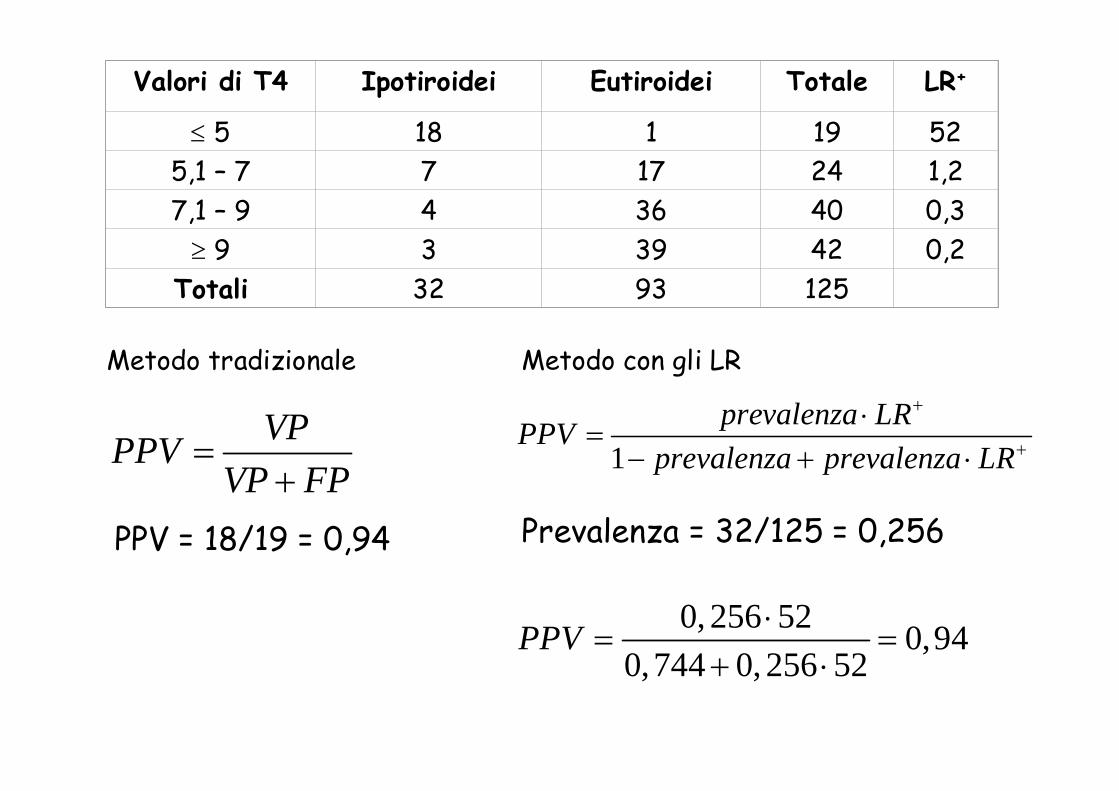
Valori di T4 Ipotiroidei Eutiroidei Totale LR+
≤ 5 18 1 19 525,1 – 7 7 17 24 1,27,1 – 9 4 36 40 0,3
≥ 9 3 39 42 0,2Totali 32 93 125
VPPPVVP FP
=+
PPV = 18/19 = 0,94
1prevalenza LRPPV
prevalenza prevalenza LR
+
+
⋅=
− + ⋅
0, 256 52 0,940,744 0, 256 52
PPV ⋅= =
+ ⋅
Metodo tradizionale Metodo con gli LR
Prevalenza = 32/125 = 0,256

Esempio 5
E’ stato condotto uno studio (Lakemann F. et al. J. Infect. Dis. 1995; 171:857-863) su un gruppo di pazienti con sospetta encefalite da herpes simplex (HSE), al fine di misurare la sensibilità, la specificità e i PV del test diagnostico PCR per HSV-DNA su liquor. La diagnosi di HSE si basava sulla coltura cellulare del virus da biopsie cerebrali. La PCR sul liquor era positiva su 53 di 54 pazienti. La specificità è risultata pari a 0,94 e il PPV pari a 0,95. Determinare la sensibilità e l’NPV.
Presenza di malattia Assenza di malattia
Test positivo 53 (VP)
Test negativo 1 (FN)
Totale 54
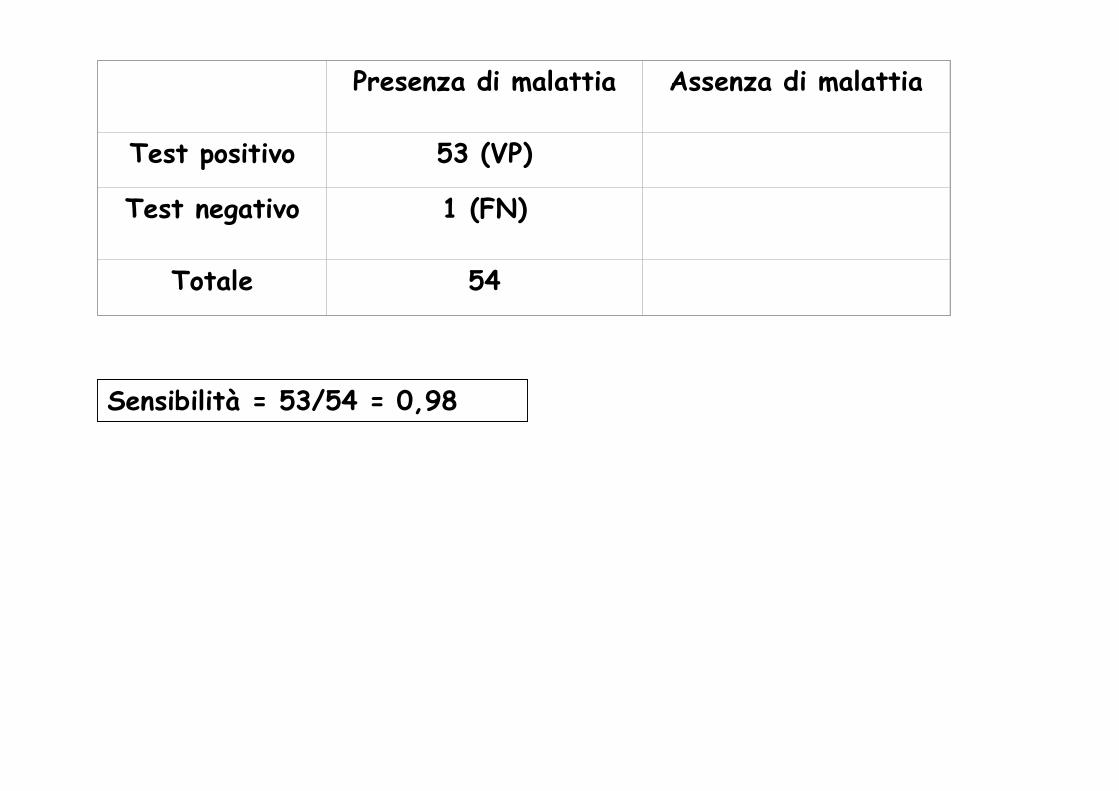
Presenza di malattia Assenza di malattia
Test positivo 53 (VP)
Test negativo 1 (FN)
Totale 54
Sensibilità = 53/54 = 0,98

VPPPVVP FP
=+
530,9553 FP
=+
53 53 0,95 30,95
FP − ⋅= =
VNSpecificitàVN FP
=+
0,943
VNVN
=+
( )1 0,94 3 0,94VN − = ⋅
2,82 470,06
VN = =
47 0,9848
NPV = =
FP = 3
PPV = 0,95
Specificità = 0,94
NPV = 0,98
VN = 47
Presenza di malattia Assenza di malattia
Test positivo 53 (VP)
Test negativo 1 (FN)
Totale 54
( ) VNP M VVN FN
− −| =+
NPV =
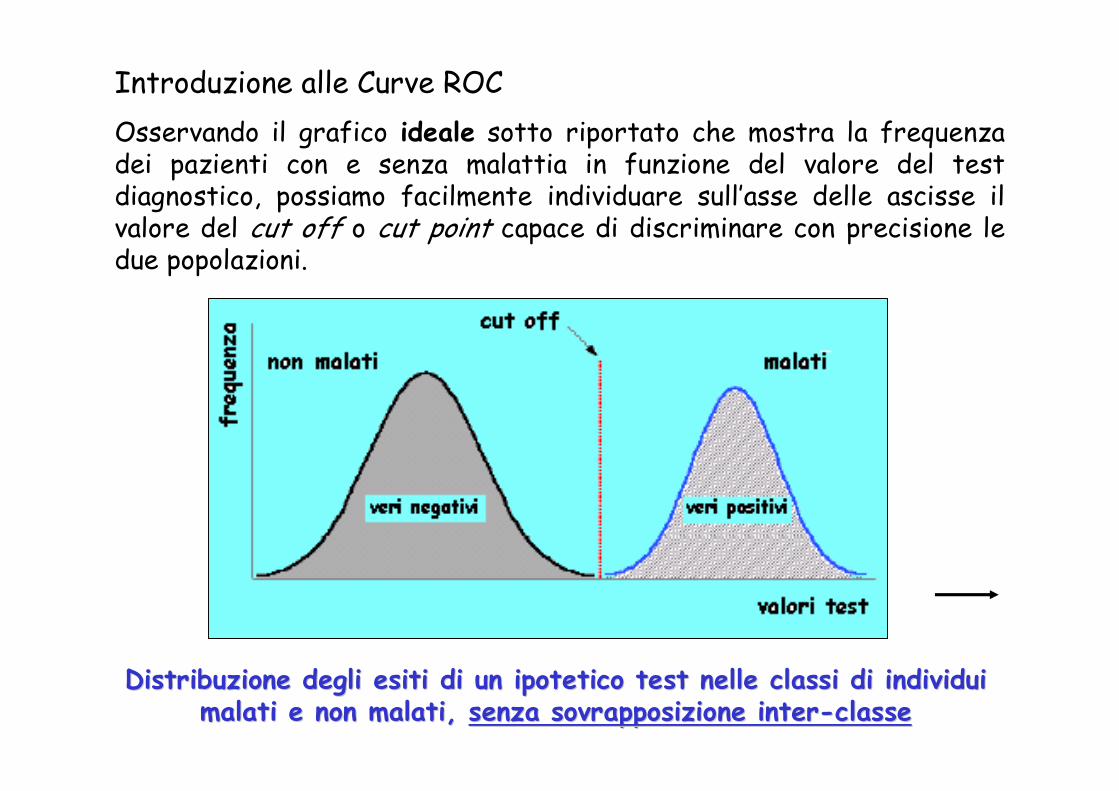
Introduzione alle Curve ROCOsservando il grafico ideale sotto riportato che mostra la frequenza dei pazienti con e senza malattia in funzione del valore del test diagnostico, possiamo facilmente individuare sull’asse delle ascisse il valore del cut off o cut point capace di discriminare con precisione le due popolazioni.
Distribuzione degli esiti di un ipotetico test nelle classi di iDistribuzione degli esiti di un ipotetico test nelle classi di individui ndividui malati e non malati, malati e non malati, senza sovrapposizione intersenza sovrapposizione inter--classeclasse
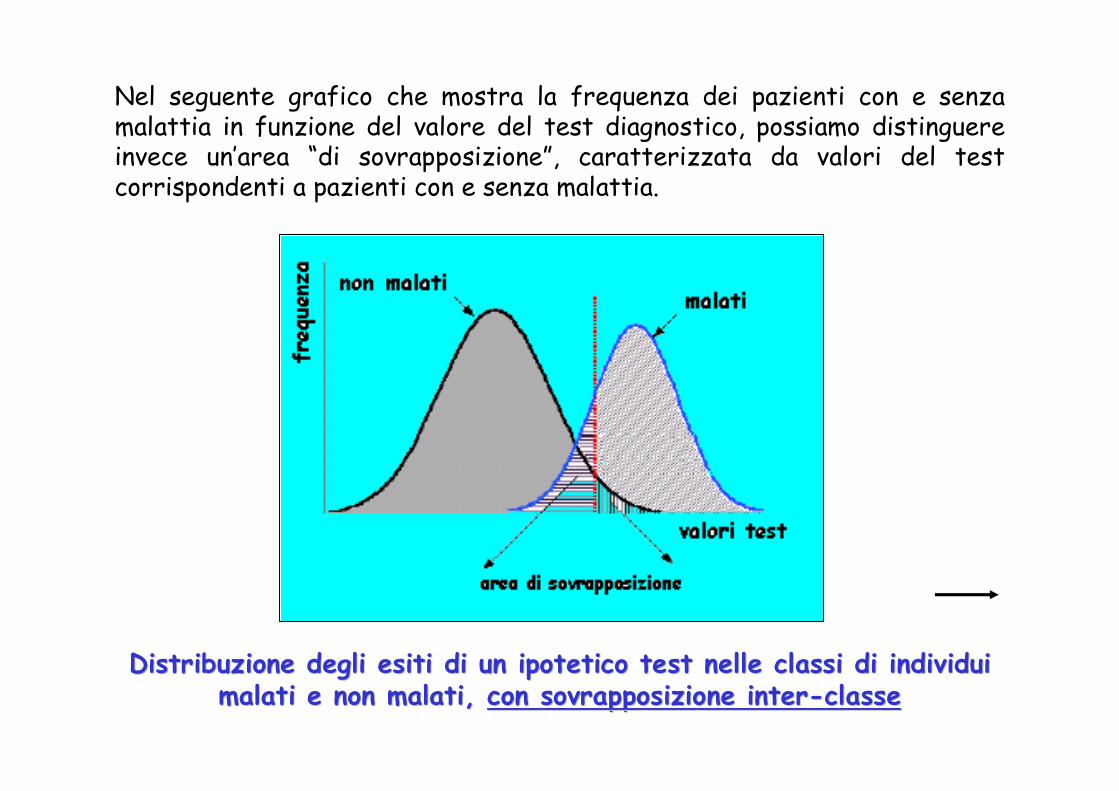
Nel seguente grafico che mostra la frequenza dei pazienti con e senza malattia in funzione del valore del test diagnostico, possiamo distinguere invece un’area “di sovrapposizione”, caratterizzata da valori del test corrispondenti a pazienti con e senza malattia.
Distribuzione degli esiti di un ipotetico test nelle classi di iDistribuzione degli esiti di un ipotetico test nelle classi di individui ndividui malati e non malati, malati e non malati, con sovrapposizione intercon sovrapposizione inter--classeclasse
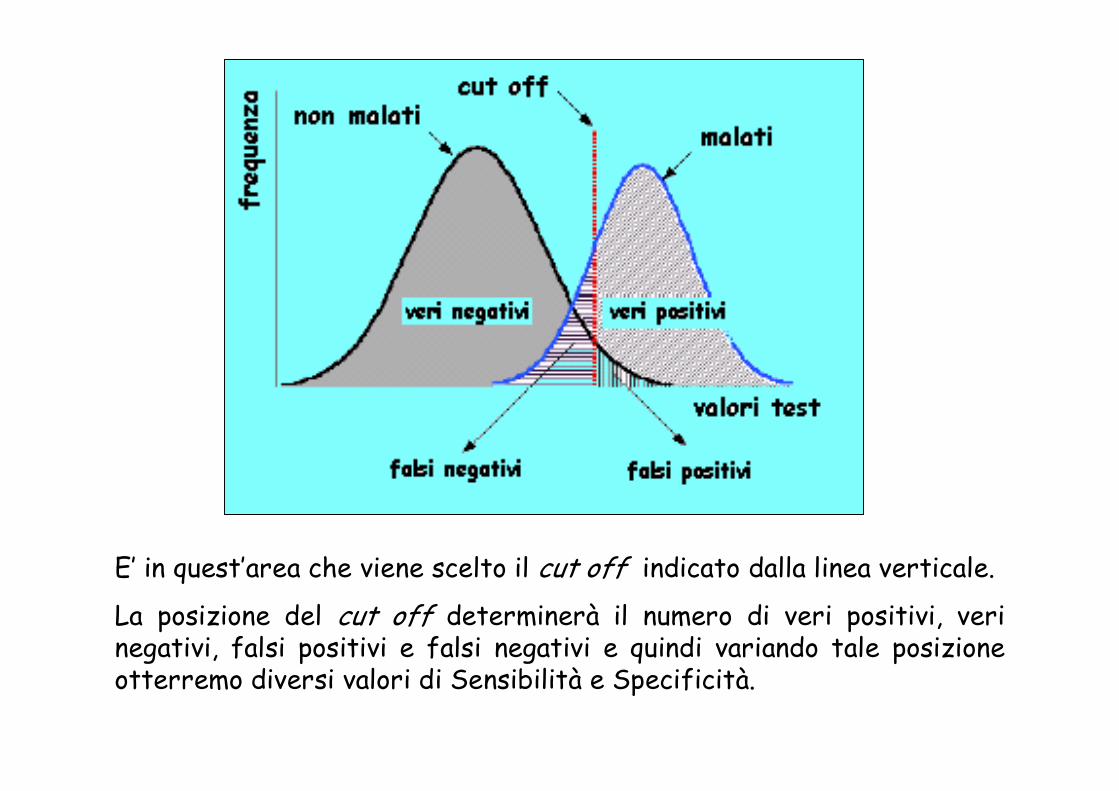
E’ in quest’area che viene scelto il cut off indicato dalla linea verticale.
La posizione del cut off determinerà il numero di veri positivi, veri negativi, falsi positivi e falsi negativi e quindi variando tale posizione otterremo diversi valori di Sensibilità e Specificità.

Scelta del valore Cut offE’ possibile dimostrare che, quando la distribuzione del valore nelle due classi sani-malati è di tipo normale, la “soglia discriminante ottimale”, ossia il valore di cut off che minimizza gli errori di classificazione, è pari al valore in ascissa corrispondente al punto di intersezione delle due classi.
Bisogna valutare anche l’impatto di tipo sanitario, economico, sociale, ecc.Infatti, per malattie ad alta contagiosità, è opportuno minimizzare i FN e quindi privilegiare la Sensibilità, mentre per malattie non contagiose trattabili con terapie molto costose si tende a minimizzare i FP e quindi a privilegiare la Specificità.
Tutte queste problematiche vengono affrontate attraverso l’analisi ROC.
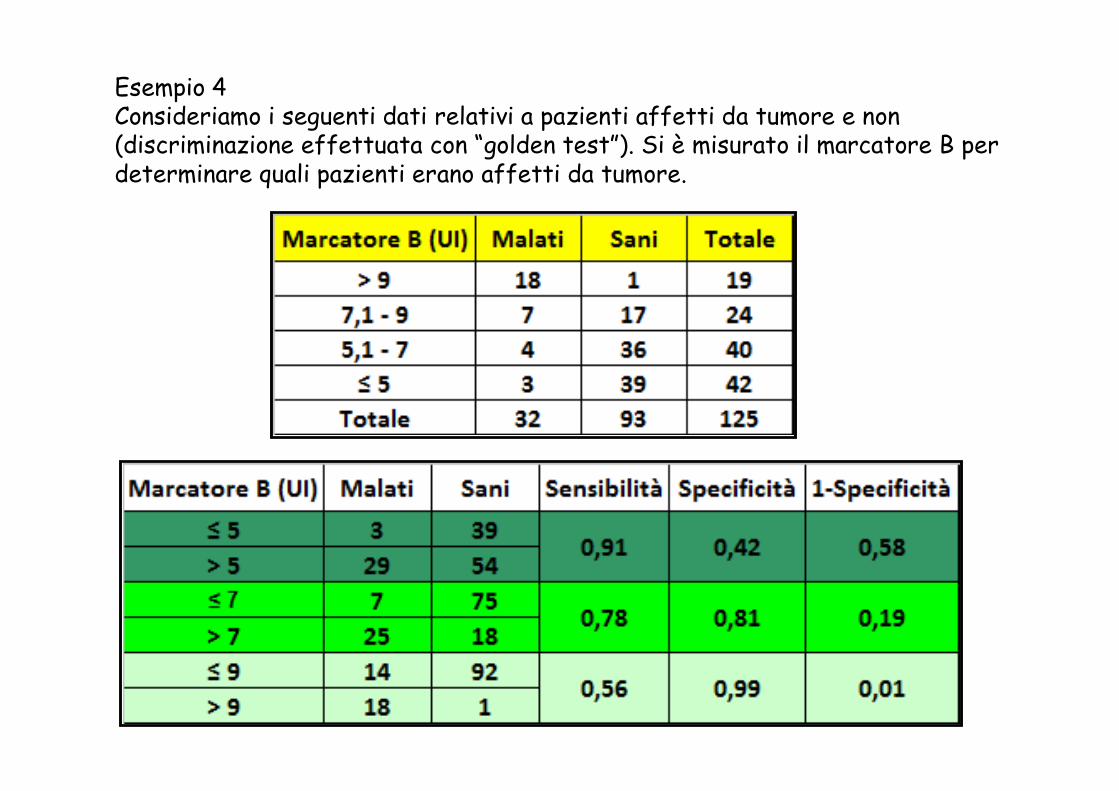
Esempio 4Consideriamo i seguenti dati relativi a pazienti affetti da tumore e non (discriminazione effettuata con “golden test”). Si è misurato il marcatore B per determinare quali pazienti erano affetti da tumore.
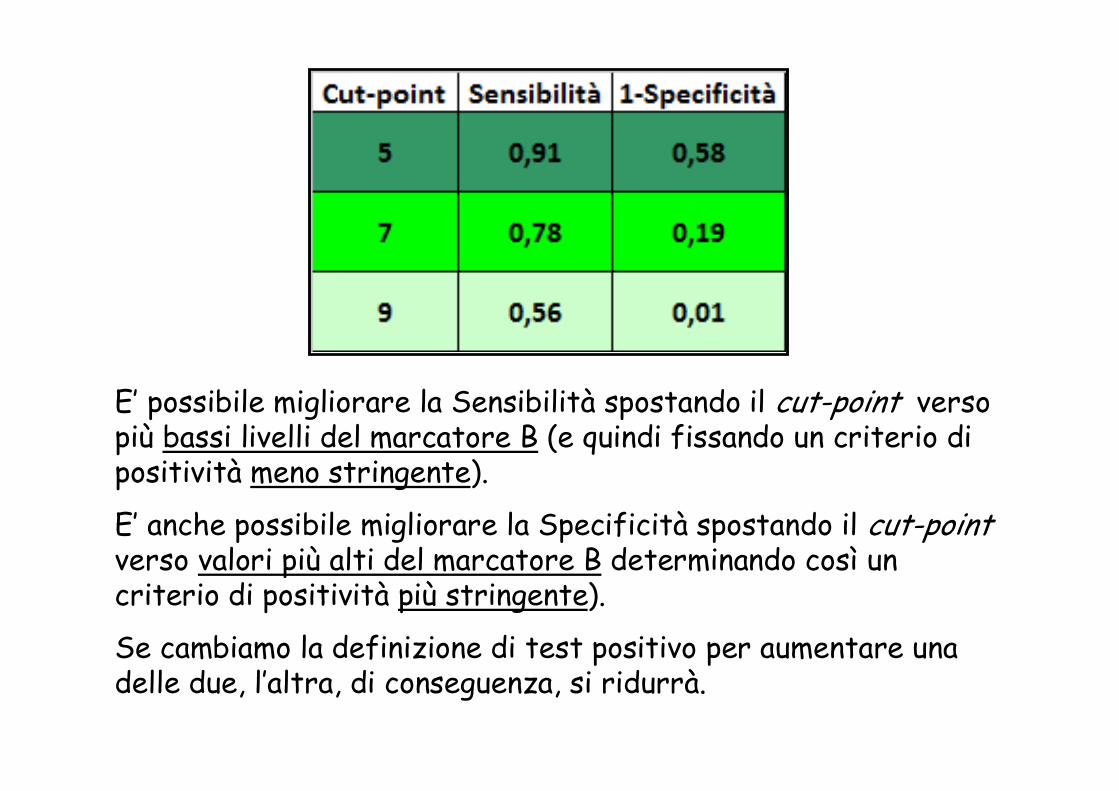
E’ possibile migliorare la Sensibilità spostando il cut-point verso più bassi livelli del marcatore B (e quindi fissando un criterio di positività meno stringente).
E’ anche possibile migliorare la Specificità spostando il cut-pointverso valori più alti del marcatore B determinando così un criterio di positività più stringente).
Se cambiamo la definizione di test positivo per aumentare una delle due, l’altra, di conseguenza, si ridurrà.
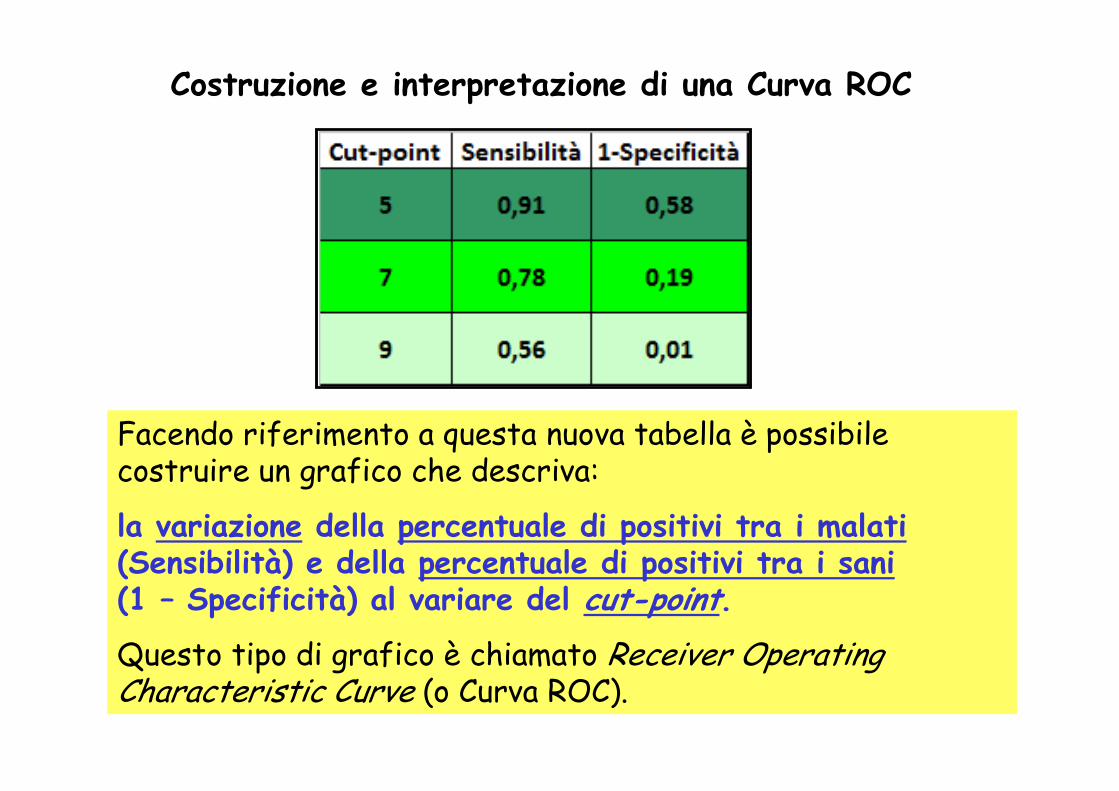
Costruzione e interpretazione di una Curva ROC
Facendo riferimento a questa nuova tabella è possibile costruire un grafico che descriva:
la variazione della percentuale di positivi tra i malati(Sensibilità) e della percentuale di positivi tra i sani(1 – Specificità) al variare del cut-point.Questo tipo di grafico è chiamato Receiver OperatingCharacteristic Curve (o Curva ROC).
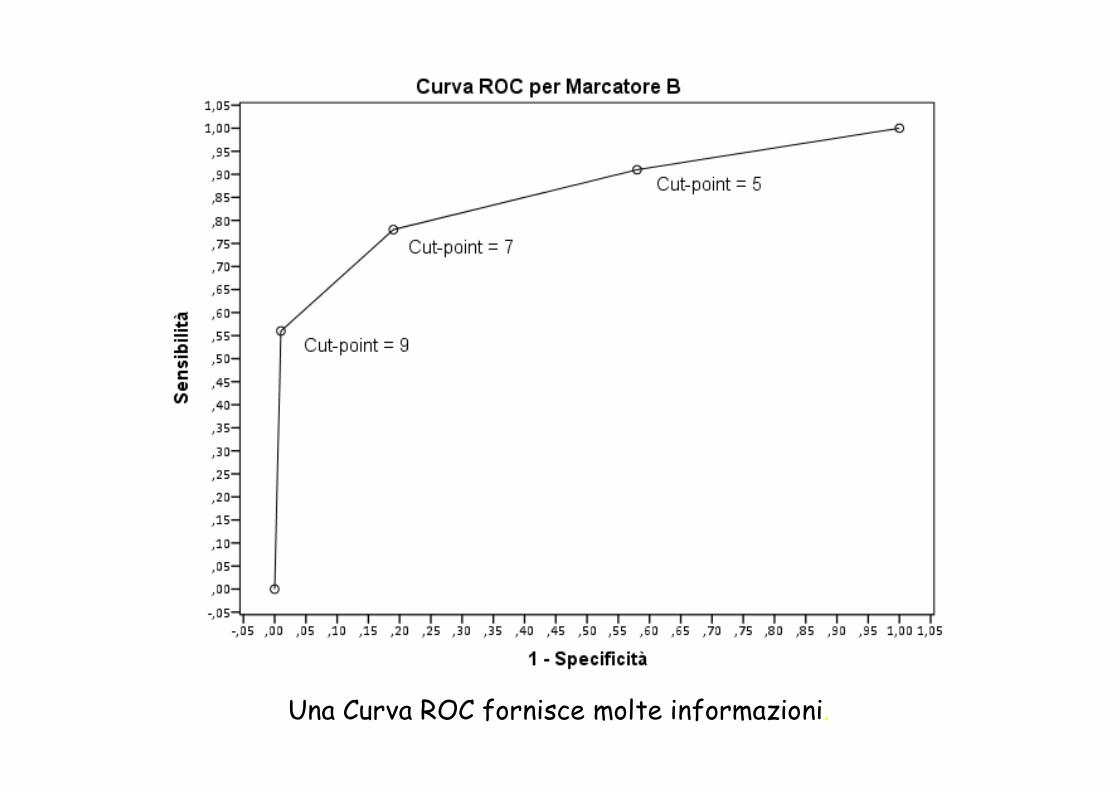
Una Curva ROC fornisce molte informazioni.
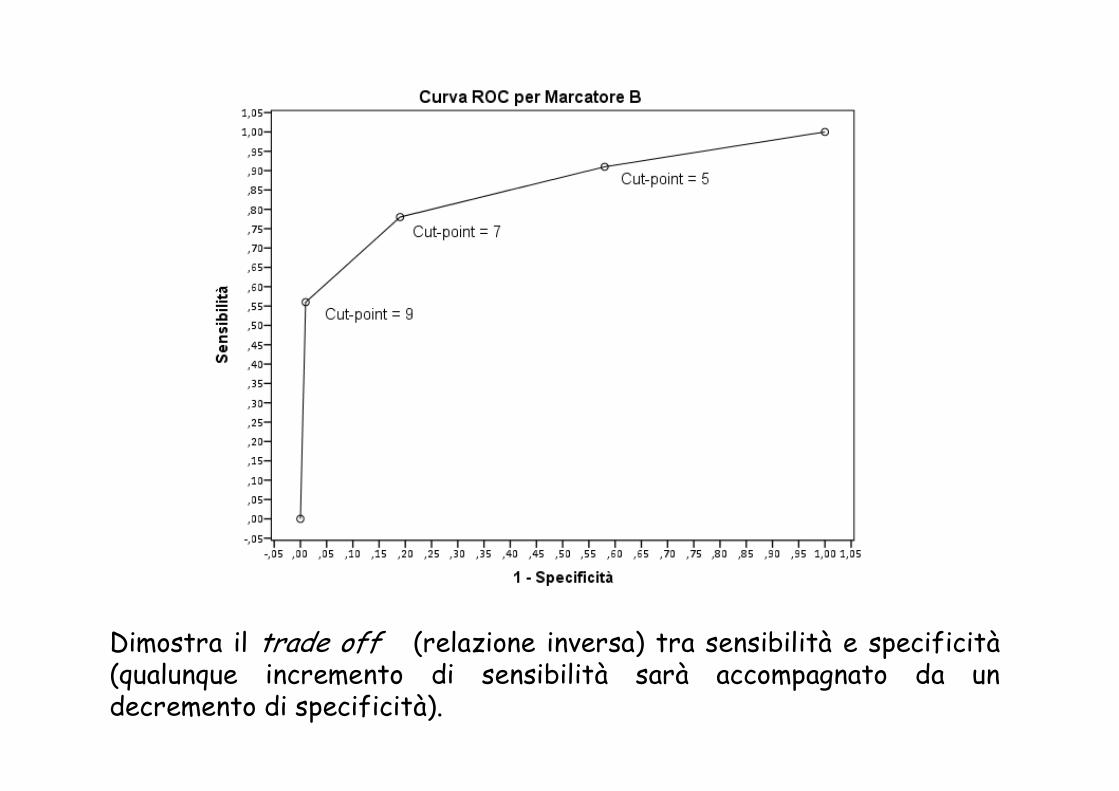
Dimostra il trade off (relazione inversa) tra sensibilità e specificità(qualunque incremento di sensibilità sarà accompagnato da un decremento di specificità).
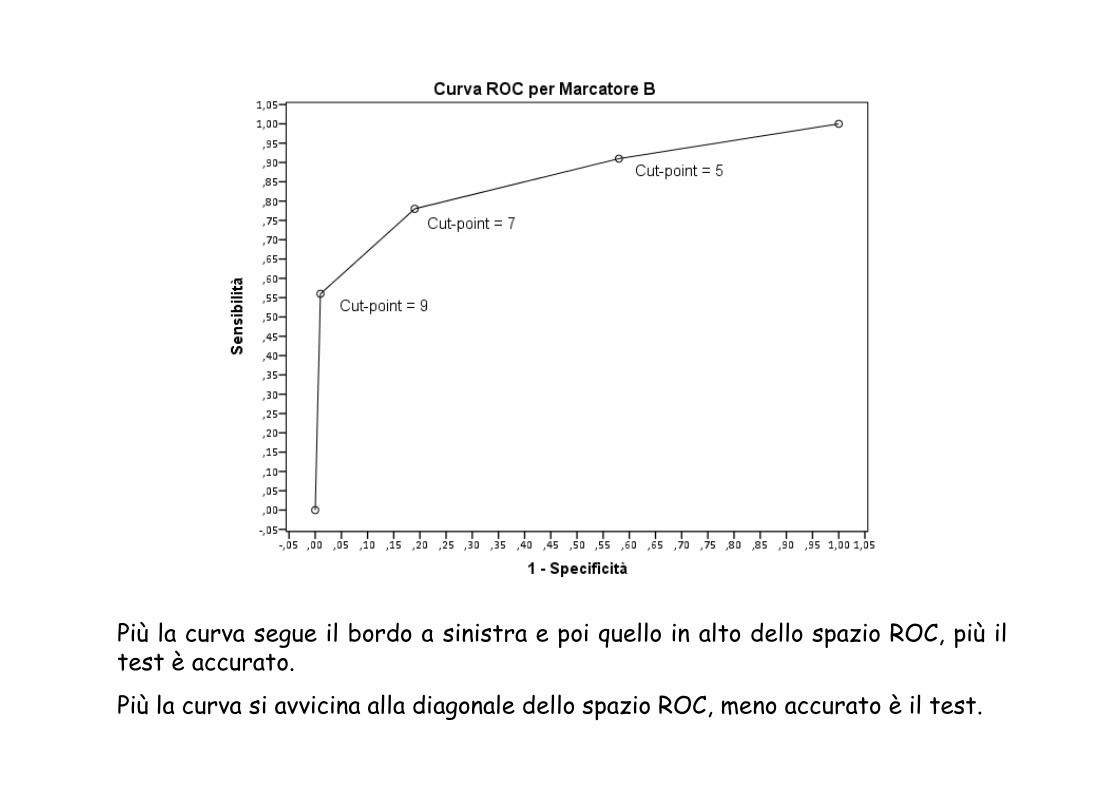
Più la curva segue il bordo a sinistra e poi quello in alto dello spazio ROC, più il test è accurato.
Più la curva si avvicina alla diagonale dello spazio ROC, meno accurato è il test.
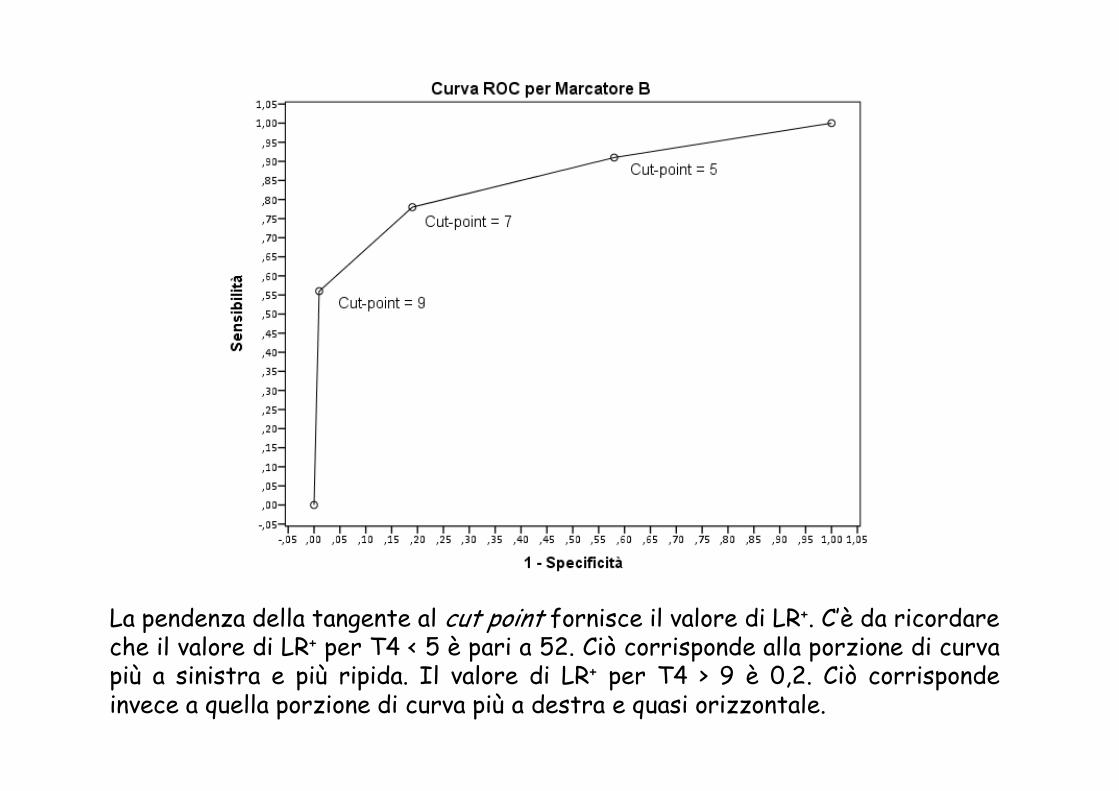
La pendenza della tangente al cut point fornisce il valore di LR+. C’è da ricordare che il valore di LR+ per T4 < 5 è pari a 52. Ciò corrisponde alla porzione di curva più a sinistra e più ripida. Il valore di LR+ per T4 > 9 è 0,2. Ciò corrisponde invece a quella porzione di curva più a destra e quasi orizzontale.
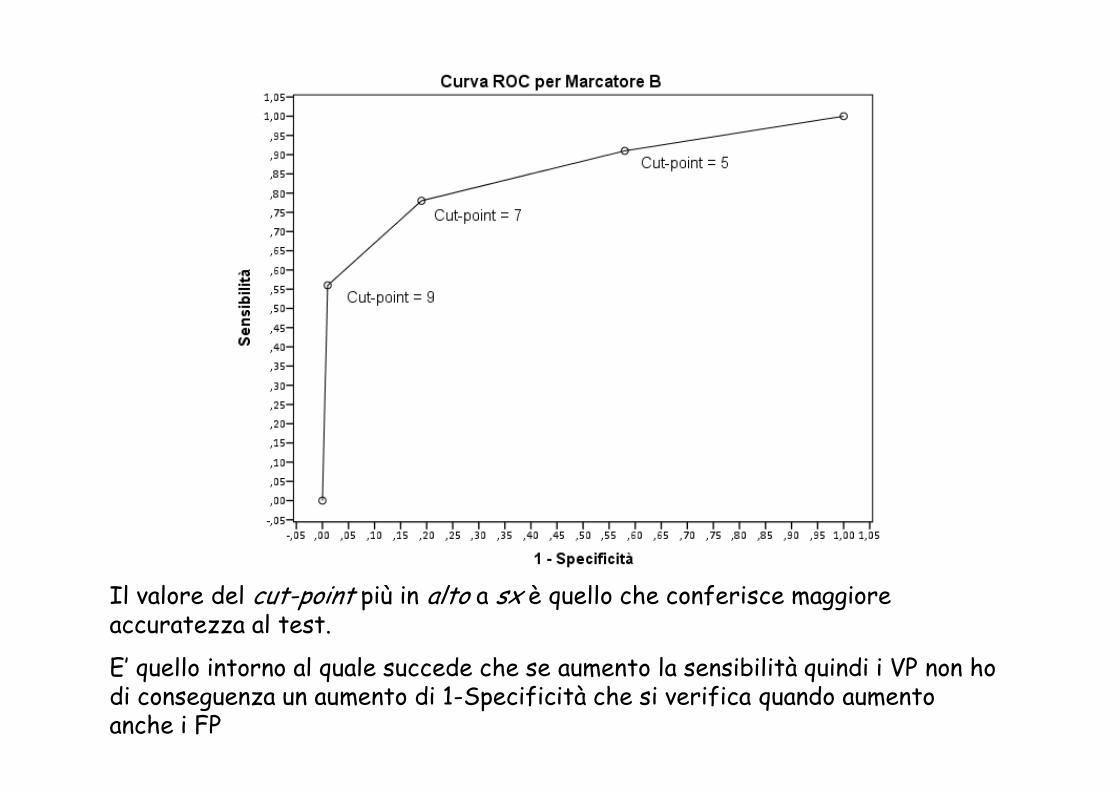
Il valore del cut-point più in alto a sx è quello che conferisce maggiore accuratezza al test.
E’ quello intorno al quale succede che se aumento la sensibilità quindi i VP non ho di conseguenza un aumento di 1-Specificità che si verifica quando aumento anche i FP
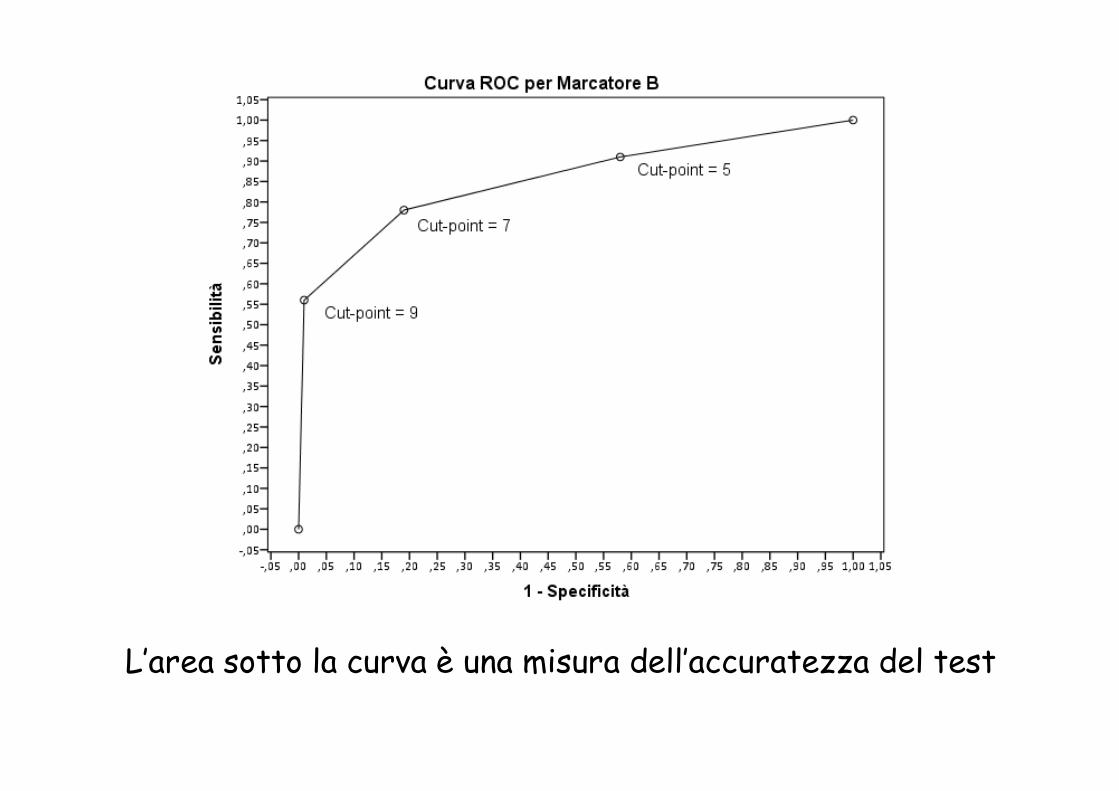
L’area sotto la curva è una misura dell’accuratezza del test
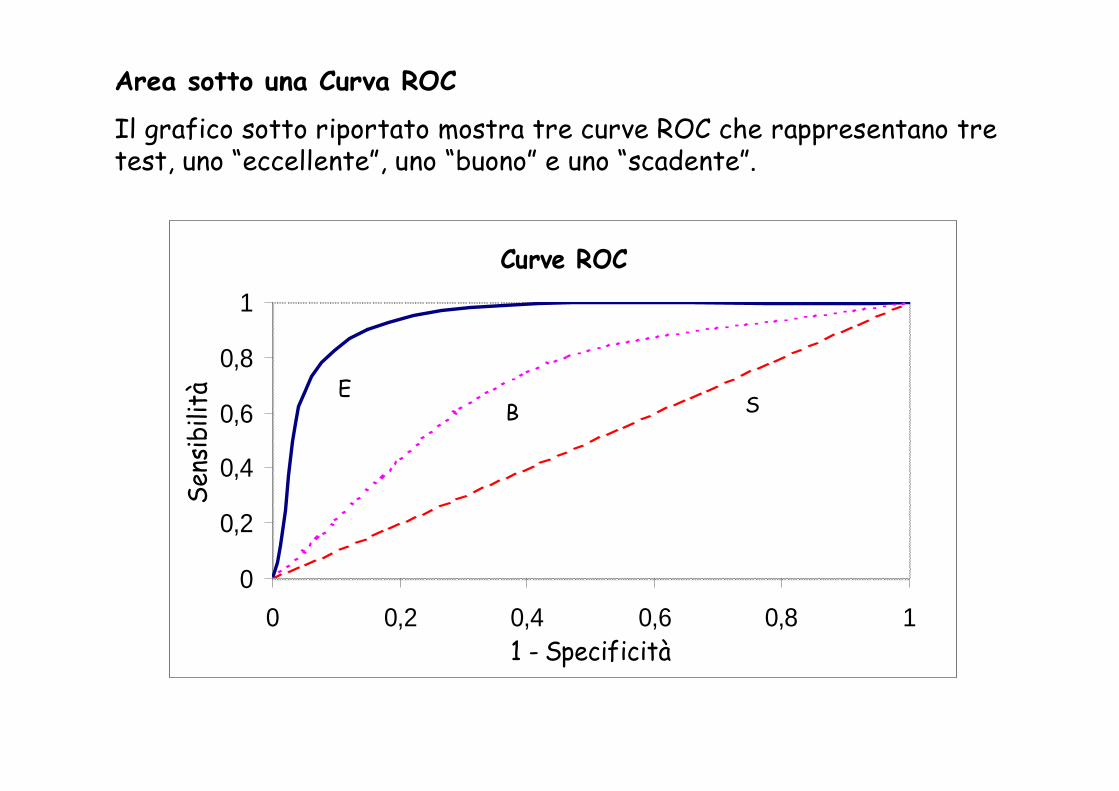
Area sotto una Curva ROC
Il grafico sotto riportato mostra tre curve ROC che rappresentano tre test, uno “eccellente”, uno “buono” e uno “scadente”.
Curve ROC
0
0,2
0,4
0,6
0,8
1
0 0,2 0,4 0,6 0,8 11 - Specificità
Sens
ibili
tà EB S

Per quanto riguarda l’interpretazione del valore dell’area sotto la curva (AUC), si può tener presente la classificazione proposta da Swets (1998).
AUC Tipo di Test- accuratezza
• 1,0 test perfetto
• 0,90 – 1,0 test altamente accurato
• 0,70 – 0,90 test moderatamente accurato
• 0,50 – 0,70 test poco accurato
• 0,50 test non informativo
L’area sotto la curva ROC per MB è 0,86.
Il test basato sul dosaggio del marcatore B deve essere quindi considerato moderatamente accurato (per separare i pazienti affetti da tumore da quelli sani).

Significato di Area sotto la Curva ROCLa capacità del test di classificare correttamente i soggetti malati da quelli sani è proporzionale all’estensione dell’AUC ed equivale alla:
probabilità che il risultato di un test su un individuo estratto a caso dal gruppo dei malati sia superiore (o inferiore) a quello di uno estratto a caso dal gruppo dei non malati.
Esiste una relazione che lega la AUC alla statistica U di Wilcoxon e Mann-Whitney, utilizzata per testare l’ipotesi nulla che i due gruppi abbiano la stessa mediana. Tale ipotesi è del tutto equivalente a testare che un soggetto estratto a caso da un gruppo X abbia la stessa probabilità di presentare un valore della variabile superiore (o inferiore) ad un valore predefinito di quello di un soggetto estratto a caso dall’altro gruppo Y.

Calcolo e confronto tra Aree
Due metodi sono comunemente usati:
1. un metodo non parametrico (metodo di De Long) basato sulla costruzione di un “trapezoide” sotto la curva come approssimazione dell’area (da notare che l’area è sicuramente < 1);
2. un metodo parametrico che fornisce una curva che si avvicina ai punti dati con la massima probabilità (vedi sotto).
Per il confronto tra Aree si utilizza un test statistico simile al test t (basato sulla distribuzione normale standardizzata):
1 2
1 2
( )A A
A AZSE
−
−=
Se Z è sopra un certo livello critico, comunemente pari a 1,96 in quanto si fa riferimento alle tabelle per il t di Student con infiniti GL, allora accettiamo il fatto che le due aree siano differenti.
Metodo di Hanley e McNeil

1 2 1 2
2 2( ) ( ) ( )A A A ASE SE SE− = +
1 2 1 2 1 2
2 2( ) ( ) ( ) ( ) ( )2A A A A A ASE SE SE rSE SE− = + − ⋅
( )2
n am
r rr +=
1 2( )2m
A AA +=
Due test applicati a due gruppi diversi
Due test applicati allo stesso gruppo
Il coefficiente di correlazione tra le due aree, r, si ottiene con i seguenti passaggi:
a) calcolo del coefficiente di correlazione tra i pazienti non malati con i due test: rn;
b) calcolo del coefficiente di correlazione tra i pazienti malati con i due test: ra;
c) calcolo della correlazione media:
d) calcolo dell’area media:
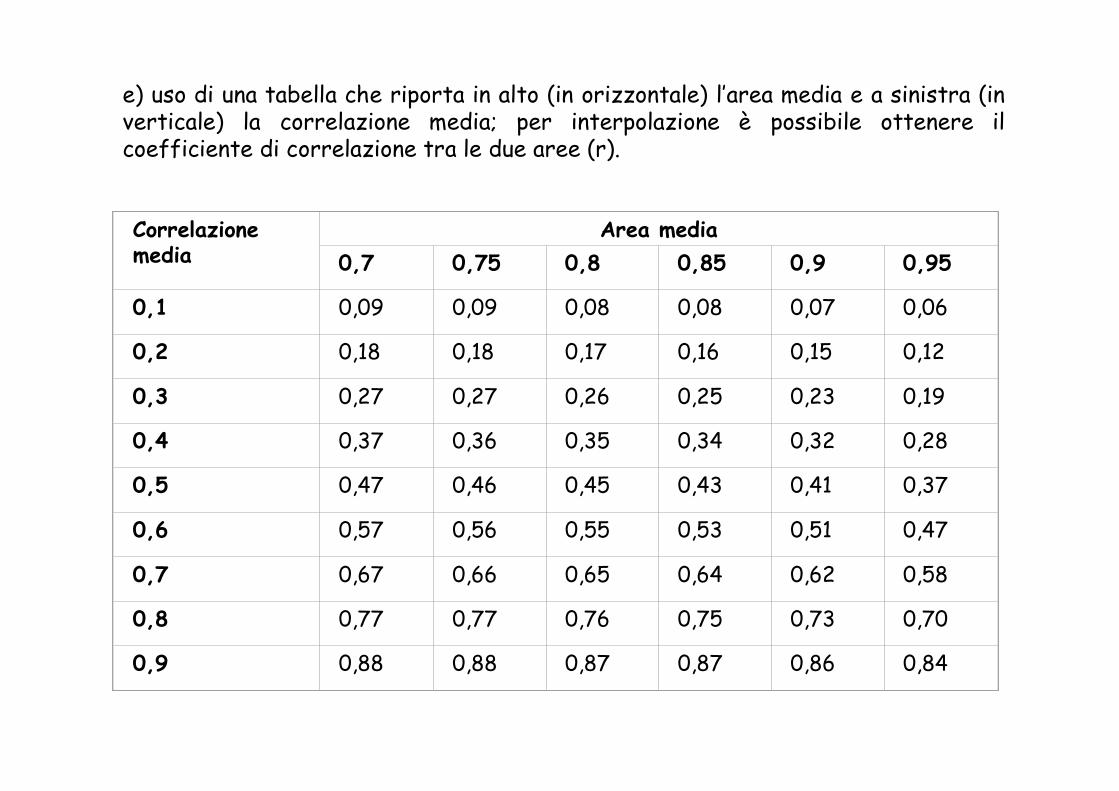
Correlazionemedia
Area media0,7 0,75 0,8 0,85 0,9 0,95
0,1 0,09 0,09 0,08 0,08 0,07 0,06
0,2 0,18 0,18 0,17 0,16 0,15 0,12
0,3 0,27 0,27 0,26 0,25 0,23 0,19
0,4 0,37 0,36 0,35 0,34 0,32 0,28
0,5 0,47 0,46 0,45 0,43 0,41 0,37
0,6 0,57 0,56 0,55 0,53 0,51 0,47
0,7 0,67 0,66 0,65 0,64 0,62 0,58
0,8 0,77 0,77 0,76 0,75 0,73 0,70
0,9 0,88 0,88 0,87 0,87 0,86 0,84
e) uso di una tabella che riporta in alto (in orizzontale) l’area media e a sinistra (in verticale) la correlazione media; per interpolazione è possibile ottenere il coefficiente di correlazione tra le due aree (r).

2 21 2
( )(1 ) ( 1) ( ) ( 1) ( )a n
Aa n
A A n Q A n Q ASEn n
⋅ − + − ⋅ − + − ⋅ −=
⋅
1 2AQ
A=
−
2
221
AQA
=+
1 2
1 2
( )A A
A AZSE
−
−=
Se Z è sopra un certo livello critico, comunemente pari a 1,96 in quanto si fa riferimento alle tabelle per il t di Student con infiniti GL, allora accettiamo il fatto che le due aree siano differenti.
Calcolo di SE(A)


Nota di interesse storico
L’analisi ROC è una metodologia (Signal Detection Theory) sviluppata per la prima volta durante la Seconda Guerra Mondiale per l’analisi delle immagini radar e lo studio del rapporto segnale/disturbo.
Serviva agli operatori di ricezione radar per distinguere il nemico.
Segue

Oggetto in avvicinamento su uno schermo radarE’ un mezzo militare (navale) nemico o un rumore di fondo ?

Era quindi necessario analizzare accuratamente i segnali di ricezione radar per poter discriminare tra “oggetto” in avvicinamento nemico (VP) e rumore di fondo.
Questo tipo di analisi dei segnali fu denominato:Receiver Operating Characteristic o
Relative Operating Characteristic .





























