Embed Size (px)
Citation preview

Apache HadoopПлатформа Примеры использования

Summary
• Актуальность обработки большого объема данных
• Distributed File System, MapReduce
• Apache Hadoop
• : Pig, Apache HiveСмежные технологии
• Column Oriented Database

Объемы данных
• Facebook: 20Tb сжатых данных вдень
• - : 1Tb Нью Йоркская биржа в день
• : Большой андронный коллайдер40Tb в день
• ContextWeb (online advertising): 115Gb в день

DFS/MapReduce
• 1: ?Проблема где хранить данные
• 2: ?Проблема как обрабатывать
• 2003: Google File SystemОктябрь появление
• 2004: MapReduceДекабрь появление

Distributed FS
• FSТребования к распределенной
• Хранить файлы любого размера
• Мягкое масштабирование
• Надежность
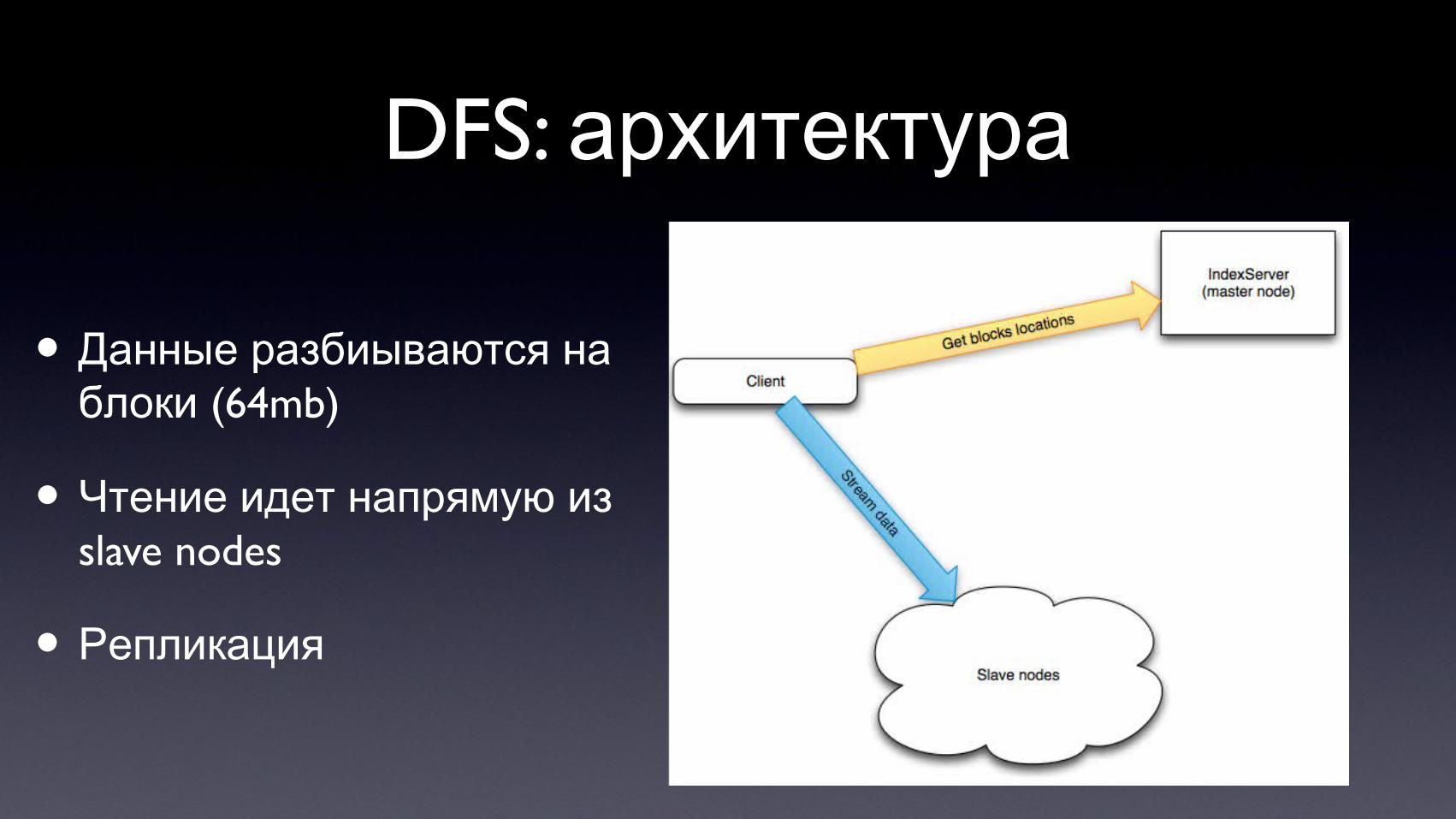
DFS: архитектура
• Данные разбиываются на (64mb)блоки
• Чтение идет напрямую изslave nodes
• Репликация

Конфигурация
• 40 nodes
• 4Tb/8Gb RAM/4x Xeon per node
• 40*4/2=80Tb общий объем хранилища

MapReduce
• Map: input record (key, value)⇒
• Reduce: (key, {v1, ..., vn}) output record⇒
• Данная парадигма пременима к широкому спектрузадач

Пример
• (Facebook)Как посчитать статистику по браузерам
• Map: log record (Browser, 1)⇒
• Reduce: (Browser, [1, .., 1]) {Browser, sum}⇒
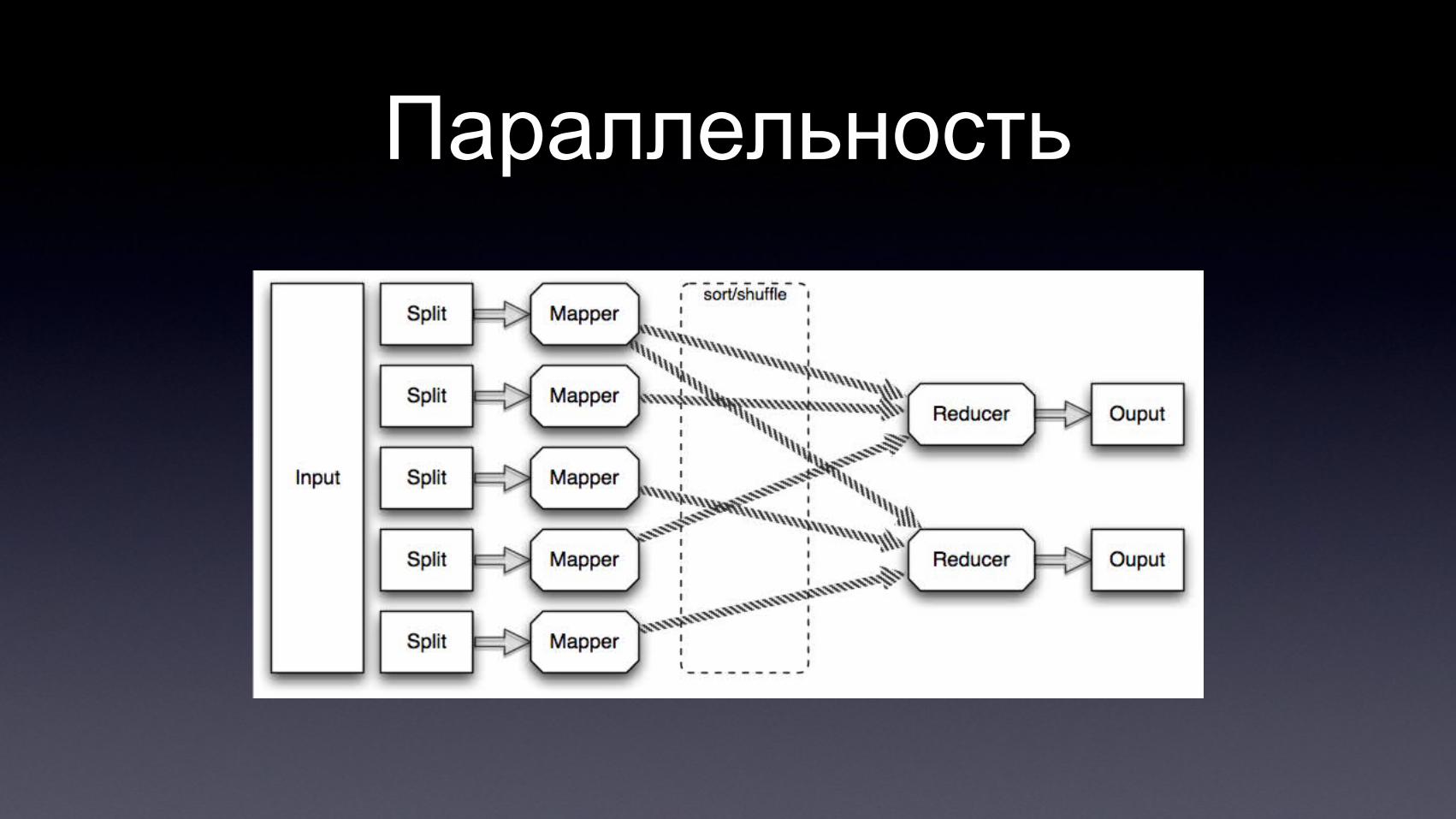
Параллельность

Apache Hadoop• 2004: Nutch - open source search engine
• 2006: Hadoop - отдельный проект
• 2006: Yahoo - research cluster
• 2008: Yahoo WebSearch Hadoop. использует Размер - 4000 кластера машин
• 2009 Hadoop выигрывает соревнование по 100Tb ( Yahoo). 4000 , 173 сортировке на кластере машин
секунды

M Hadoopодули
• HDFS: Hadoop distributed file system
• MapReduce

Yahoo: web graph
• Map: page (Target URL, {sourceURL, link text})⇒
• Reduce: {Target URL, SourceURL, Link Text}
Target URL SourceURL Texthadoop.apache.org reddit.com MapReduce OpenSource
hadoop.apache.org wikipedia.org/MapReduce MapReduce OpenSource
hadoop.apache.org sun.java.com MapReduce
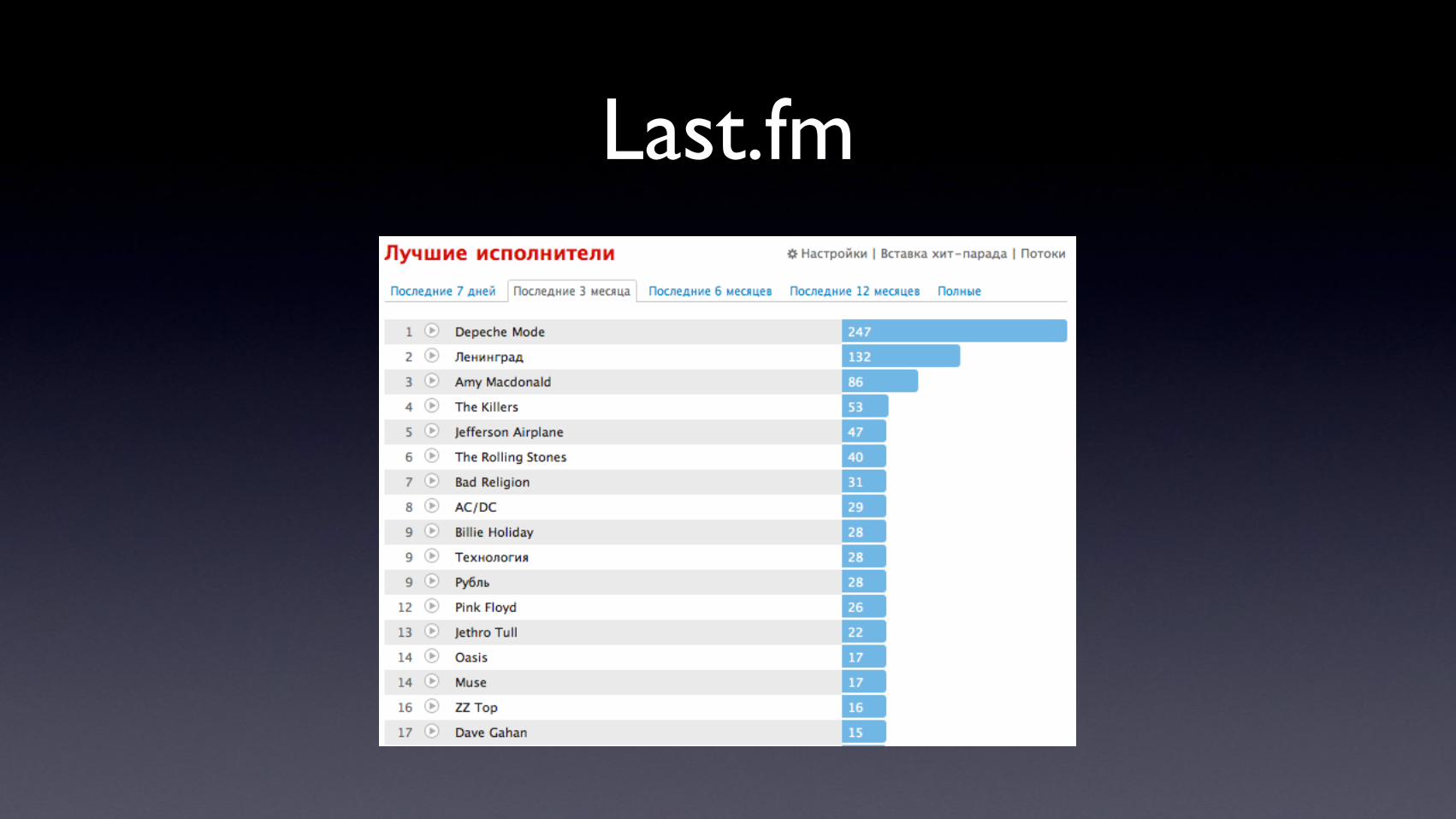
Last.fm

Last.fm
• Пользователь слушает песню
• HDFS: Информация о прослушивании записывается в{user, band, track} ( log- )строчка в файле
• Map: {userId, band, track} (user_band, 1)⇒
• Reduce (user_band, [1, ... , 1]) (user_band, sum)⇒

SQL
• SELECT f1, f2, sum(a) WHERE expr GROUP BY f1, f2
• Map: line ({f1, f2}, a) if expr⇒
• Reduce: ({f1, f2}, [a1, ..., an]) ({f1, f2}, sum)⇒

SQL: Принцип• GROUP BY: Mapкак ключ в
• WHERE: Mapвычисляется в фазе
• SUM/AVG Mapкак значение в
• SUM/AVG: окончательное значение вычисляется вReduce
• JOIN: Reduce Mapили
• HAVING: как фильтрация в окончательной фазеReduce

SQL: partitioning
• WHERE: для ключевых полей имеет смысл делатьpartitioning
• partitioning В случае анализа исторических обычно делается по дате
• WHERE, Часть условия имеющее отношение к дате вычисляется до запуска и ограничивает объем
входных данных

Apache Hive
• Apache HadoopФреймворк на базе
• SQL MapReduce jobsТранслирует запросы в
• R&D Используется как основной инструмент вFacebook

Apache Pig• Researchers Javaне привыкли писать на
• Java: 3 , 200 Аналог данного скрипта да класса строк

Области применения
• Research: , как фронтенд для людей занимающихся исследованием данных
• Data mining: построение моделей для дальнейшего Real Timeиспользования
• Reporting: построение отчетов

Достоинства
• : 2 Гладкая масштабируемость для х 2x произвоительности досточно оборудования
( )почти
• softwareНулевая стоимость
• on-demand Amazon Cloud Service Доступность как — research удобно для задач

Недостатки
• Высокая стоимость поддержки и администрирования
• SQL, В отличие от необходим штат Java-developer’квалифицированных ов
• Нестабильность
• ,Низкая скорость
• real-timeНе

Real-Time?
• Окончательный результат можно загружать вSQL/MemCache
• , SQL/MemCache Однако не будет работать если , Real-Time объем данных к которому необходим доступ остается большим
• : column oriented database (HBase)Другое решение

Column oriented databases
• SQL- В подходе хранения данных есть определенныепроблемы
• , Данные должны быть хорошо структурированыALTER TABLE - “ ” дорогая операция
• Структурированность данных в многих случаях . , , является плюсом Но когда она не нужна можно
хранить данные более эффективно

BigTable• Google 2004- Дизайн представлен компанией в омгоду
• 1: Принцип на всю таблицу есть одно индексное поле row key ( primary key)называемое аналог
• 2: Принцип данные во всех остальных полях не. индексируются Таблица может иметь сколько угодно
, — полей добавление нового поля затрагивает row.только отдельные

BigTable
• Удобнее представлять хранилище не как таблицу
• : (row key, column name) valueА как соответствие ⇒
• Так же во многих реализациях данные имеют версионность по времени
• (row key, column name, timestamp) value⇒

BigTable: пример• : Задача хранить информацию о посетителях сайта
• : CookieПростое решение
• : Cookie Недостаток размер ограничен
• BigTable: (UserUID, ) поле ⇒ значение
• Cookie UserUIDВ хранится только
• : , Возможные поля дата последнего визита история, . посещений история показа рекламных объявлений
Новое поле добавить очень легко

BigTable: дизайн
• Row keys , сортируются данные храняться на кластере
• (region server) Каждый сервер хранит определенный диапазон ключей
• master node Клиент обращается к и определяет на каком сервере лежат интересующие его данные
• region serverЧтение идет напрямую с

HBase• e Apache HadoopПостроен на платформ
• HDFSДля хранения данных используется
• Map Reduce процессы могут быть использованы для загрузки большого объма данных
• Reduce На этапе выполняется загрузка данных втаблицу
• Reduce процесс выполняется на соответствующемregion server — происходит исключительно локальная
запись данный

HBase: производительность
• 7 server cluster (16Gb RAM, 8x core CPU, 10K RPM HD)
• 3 rows, 1 5 Таблица из миллиардов от до колонок
• row — 300 Размер каждого около байт
• 300 параллельных запросов
• : 18ms — , 8ms — Средние чтение запись

HBase: недостатки
• 1% Около процента запросов работают сильно ( 300ms)больше среднего порядка
• Возможность индексировать только по одному полю(row key)
• : Нестабильность в последней самой производительной версии возможна потеря данных

Hadoop: областииспользования
• MapReduce — , там где некритична скорость : - , получения результата обработка лог файлов , построение стаитстических моделей построение
, researchиндексов
• HBase — , там где некритична небольшая потеря данных и не обязательно гарантированое время
( , ответа например хранение информации о online advertising)пользователе в

Где не стоит использоватьHadoop
• Точные вычисления
• Биллинг
• Трейдинг
• Банковские операции

!Спасибо за внимание





























