Embed Size (px)
Citation preview

AGGREGATION FRAMEWORK
Jeremy Mikola@jmikola
#MONGOBOSTON

State of AggregationPipelineExpressions
Usage and LimitationsShardingLooking Ahead
AGENDA

STATE OF AGGREGATIONWe're storing our data in MongoDB.
We need to do ad-hoc reporting, grouping, common aggregations, etc.
What are we using for this?

DATA WAREHOUSINGSQL for reporting and analyticsInfrastructure complications
Additional maintenanceData duplicationETL processesReal time?

MAPREDUCEExtremely versatile, powerfulIntended for complex data analysisOverkill for simple aggregation tasks
AveragesSummationGrouping

MAPREDUCE IN MONGODBImplemented with JavaScript
Single-threadedDifficult to debug
ConcurrencyAppearance of parallelismWrite locks (without inline or jsMode)

And now for something completely different…

AGGREGATION FRAMEWORKDeclared in BSON, executes in C++Flexible, functional, and simple
Operation pipelineComputational expressions
Plays nice with sharding

PIPELINE

PIPELINEProcess a stream of documents
Original input is a collectionFinal output is a result document
Series of operatorsFilter or transform dataInput/output chain
ps ax | grep mongod | head ‐n 1

PIPELINE OPERATORS$match$project$group$unwind$sort$limit$skip

OUR EXAMPLE DATALibrary Books
{ _id: 375, title: "The Great Gatsby", ISBN: "9781857150193", available: true, pages: 218, chapters: 9, subjects: [ "Long Island", "New York", "1920s" ], language: "English", publisher: { city: "London", name: "Random House" }}

$MATCHFilter documentsUses existing query syntaxNo geospatial operations or $where

►
▼
$MATCHMatching field values
{ title: "The Great Gatsby", pages: 218, language: "English"}
{ title: "War and Peace", pages: 1440, language: "Russian"}
{ title: "Atlas Shrugged", pages: 1088, language: "English"}
{ $match: { language: "Russian"}}
{ title: "War and Peace", pages: 1440, language: "Russian"}
►
▼
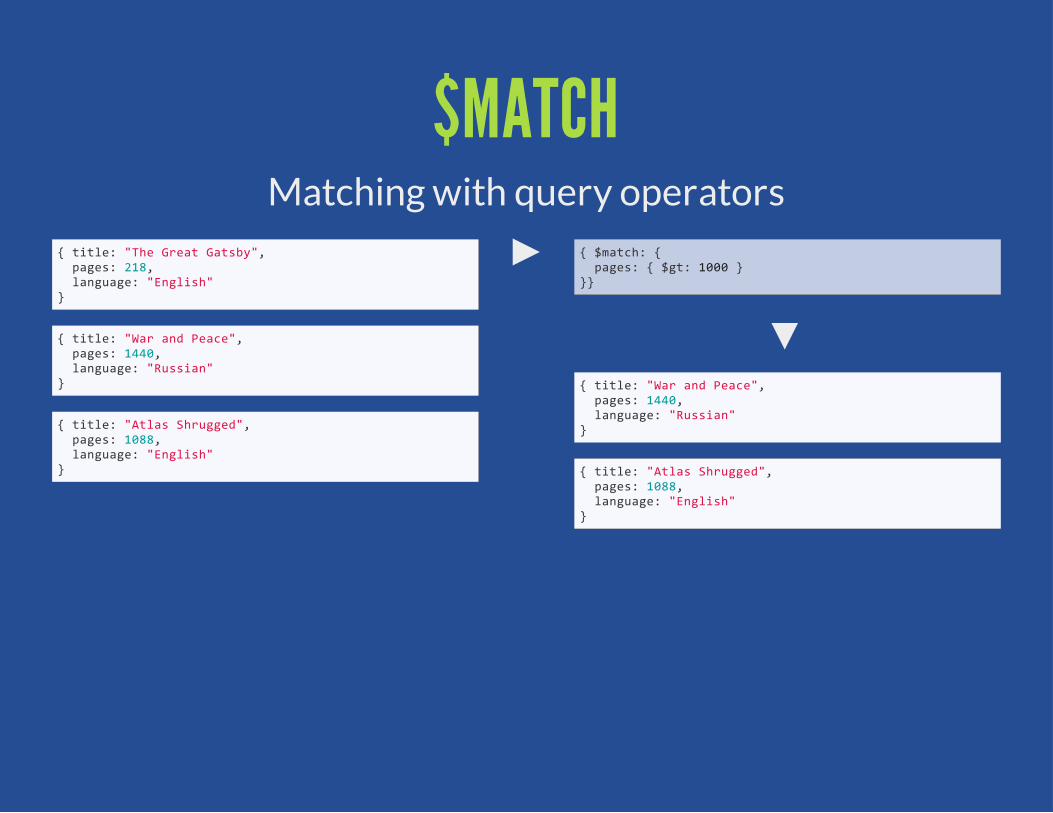
$MATCHMatching with query operators
{ title: "The Great Gatsby", pages: 218, language: "English"}
{ title: "War and Peace", pages: 1440, language: "Russian"}
{ title: "Atlas Shrugged", pages: 1088, language: "English"}
{ $match: { pages: { $gt: 1000 }}}
{ title: "War and Peace", pages: 1440, language: "Russian"}
{ title: "Atlas Shrugged", pages: 1088, language: "English"}

$PROJECTReshape documentsInclude, exclude or rename fieldsInject computed fieldsManipulate sub-document fields

►
▼
$PROJECTIncluding and excluding fields
{ _id: 375, title: "The Great Gatsby", ISBN: "9781857150193", available: true, pages: 218, chapters: 9, subjects: [ "Long Island", "New York", "1920s" ], language: "English"}
{ $project: { _id: 0, title: 1, language: 1}}
{ title: "The Great Gatsby", language: "English"}
►
▼
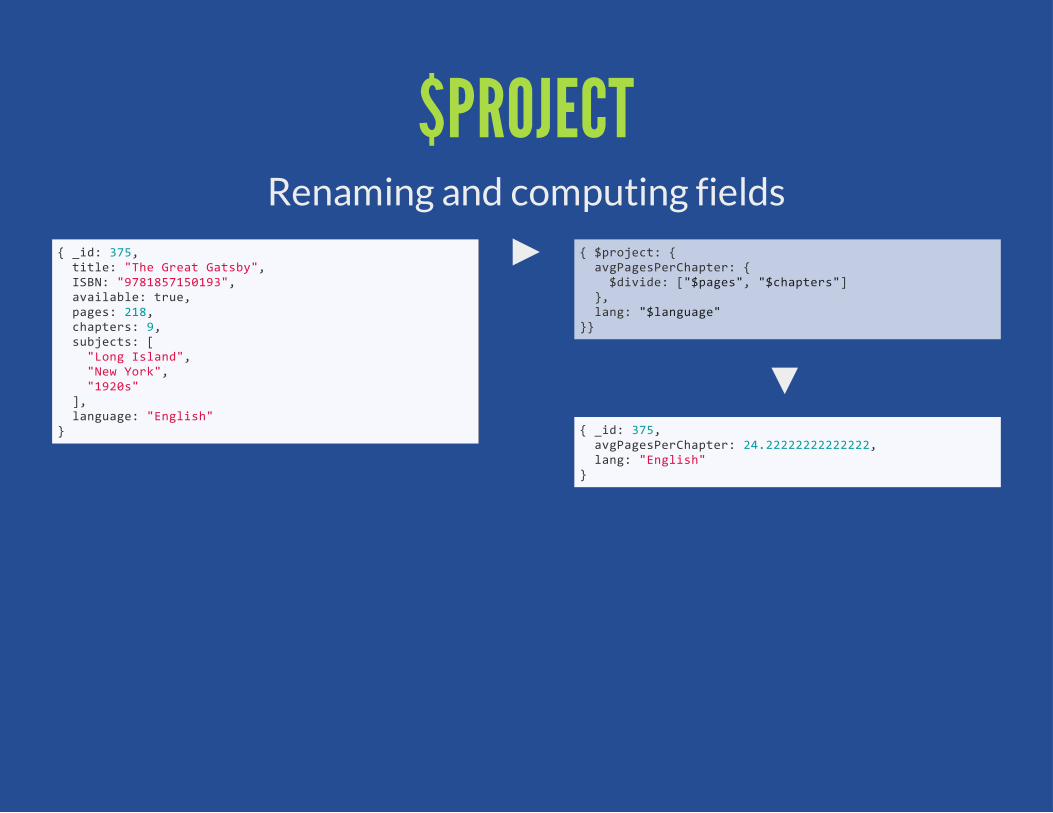
$PROJECTRenaming and computing fields
{ _id: 375, title: "The Great Gatsby", ISBN: "9781857150193", available: true, pages: 218, chapters: 9, subjects: [ "Long Island", "New York", "1920s" ], language: "English"}
{ $project: { avgPagesPerChapter: { $divide: ["$pages", "$chapters"] }, lang: "$language"}}
{ _id: 375, avgPagesPerChapter: 24.22222222222222, lang: "English"}
►
▼
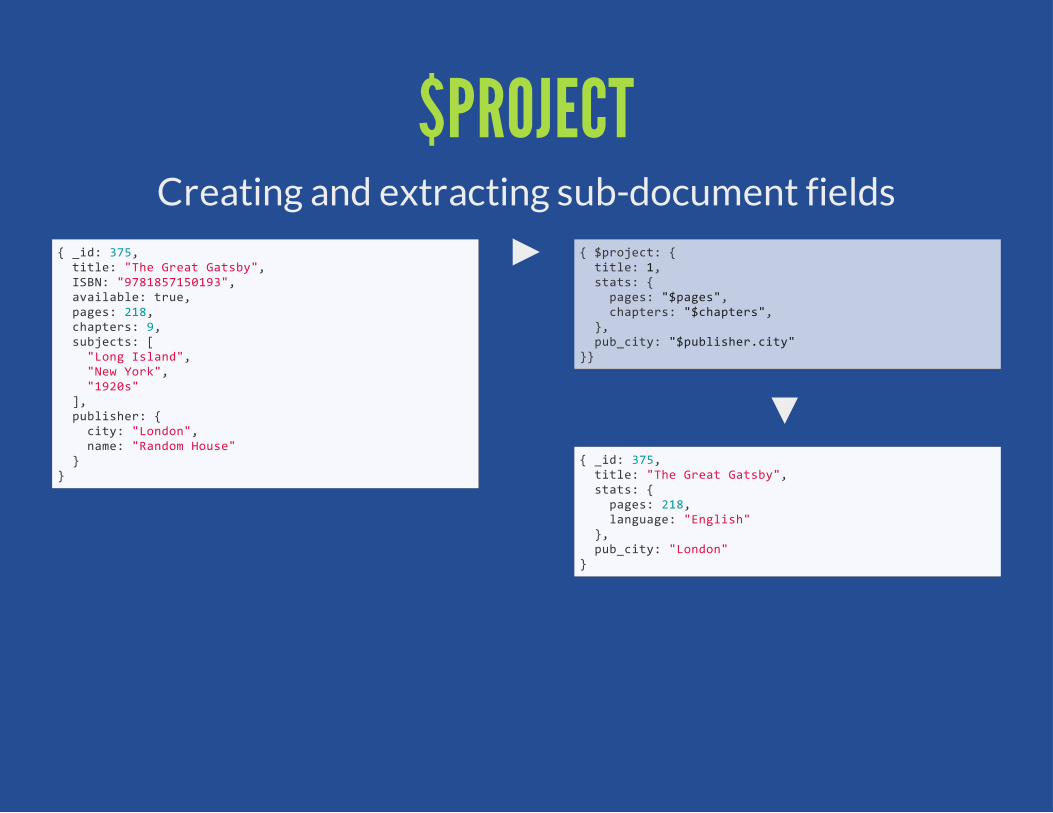
$PROJECTCreating and extracting sub-document fields
{ _id: 375, title: "The Great Gatsby", ISBN: "9781857150193", available: true, pages: 218, chapters: 9, subjects: [ "Long Island", "New York", "1920s" ], publisher: { city: "London", name: "Random House" }}
{ $project: { title: 1, stats: { pages: "$pages", chapters: "$chapters", }, pub_city: "$publisher.city"}}
{ _id: 375, title: "The Great Gatsby", stats: { pages: 218, language: "English" }, pub_city: "London"}

$GROUPGroup documents by an ID
Field reference, object, constantOther output fields are computed
$max, $min, $avg, $sum$addToSet, $push$first, $last
Processes all data in memory

►
▼
$GROUPCalculating an average
{ title: "The Great Gatsby", pages: 218, language: "English"}
{ title: "War and Peace", pages: 1440, language: "Russian"}
{ title: "Atlas Shrugged", pages: 1088, language: "English"}
{ $group: { _id: "$language", avgPages: { $avg: "$pages" }}}
{ _id: "Russian", avgPages: 1440}
{ _id: "English", avgPages: 653}

►
▼
$GROUPSummating fields and counting
{ title: "The Great Gatsby", pages: 218, language: "English"}
{ title: "War and Peace", pages: 1440, language: "Russian"}
{ title: "Atlas Shrugged", pages: 1088, language: "English"}
{ $group: { _id: "$language", numTitles: { $sum: 1 }, sumPages: { $sum: "$pages" }}}
{ _id: "Russian", numTitles: 1, sumPages: 1440}
{ _id: "English", numTitles: 2, sumPages: 1306}
►
▼
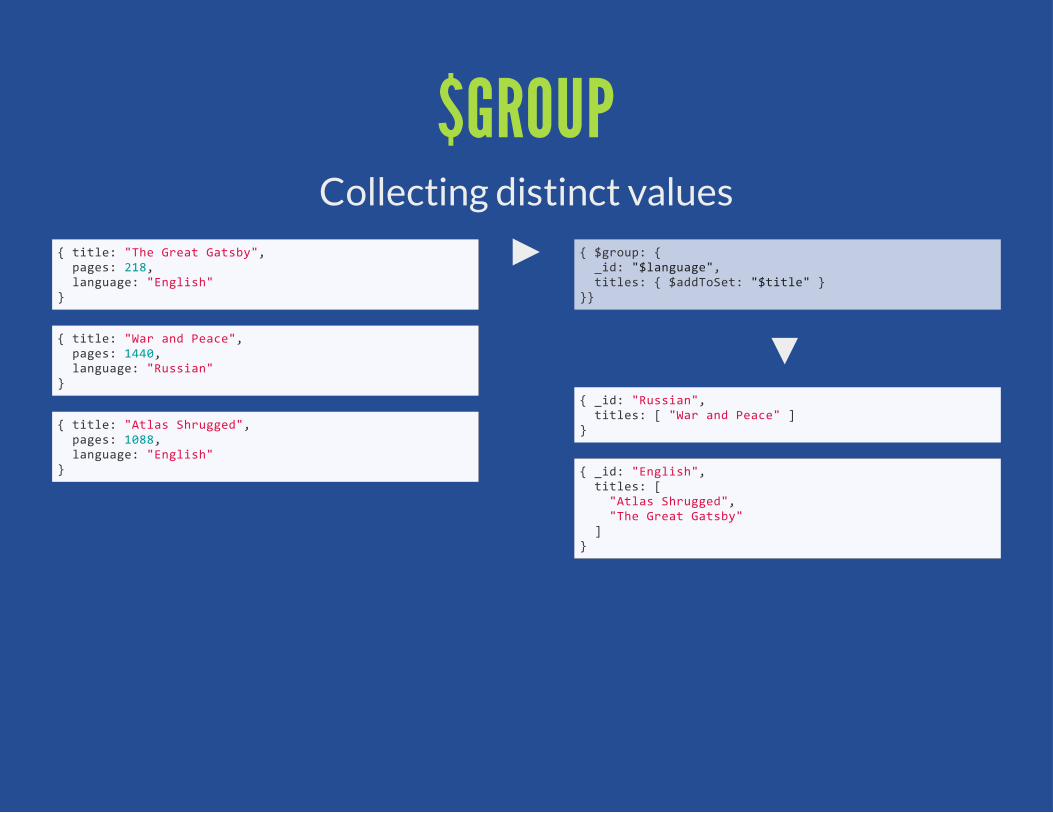
$GROUPCollecting distinct values
{ title: "The Great Gatsby", pages: 218, language: "English"}
{ title: "War and Peace", pages: 1440, language: "Russian"}
{ title: "Atlas Shrugged", pages: 1088, language: "English"}
{ $group: { _id: "$language", titles: { $addToSet: "$title" }}}
{ _id: "Russian", titles: [ "War and Peace" ]}
{ _id: "English", titles: [ "Atlas Shrugged", "The Great Gatsby" ]}

$UNWINDOperate on an array fieldYield new documents for each array element
Array replaced by element valueMissing/empty fields → no outputNon-array fields → error
Pipe to $group to aggregate array values
►▼
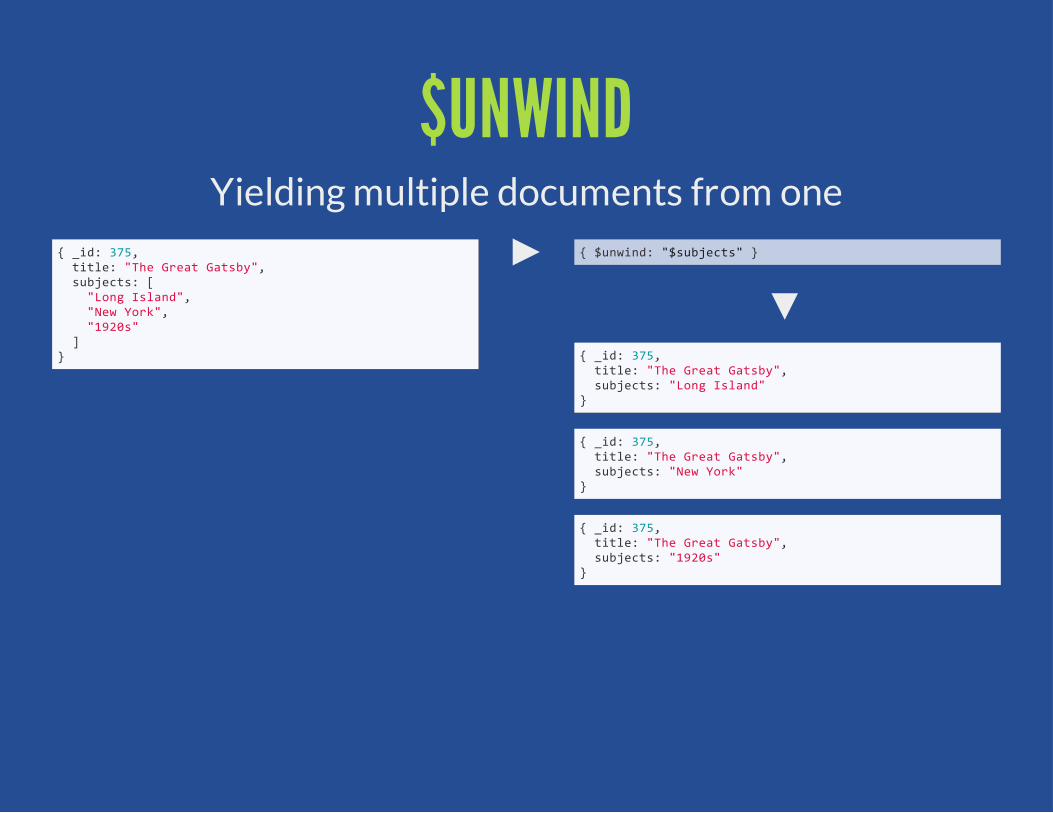
$UNWINDYielding multiple documents from one
{ _id: 375, title: "The Great Gatsby", subjects: [ "Long Island", "New York", "1920s" ]}
{ $unwind: "$subjects" }
{ _id: 375, title: "The Great Gatsby", subjects: "Long Island"}
{ _id: 375, title: "The Great Gatsby", subjects: "New York"}
{ _id: 375, title: "The Great Gatsby", subjects: "1920s"}

$SORT, $LIMIT, $SKIPSort documents by one or more fields
Same order syntax as cursorsWaits for earlier pipeline operator to returnIn-memory unless early and indexed
Limit and skip follow cursor behavior

►▼
$SORTSort all documents in the pipeline
{ title: "The Great Gatsby" }
{ title: "Brave New World" }
{ title: "The Grapes of Wrath" }
{ title: "Animal Farm" }
{ title: "Lord of the Flies" }
{ title: "Fathers and Sons" }
{ title: "Invisible Man" }
{ title: "Fahrenheit 451" }
{ $sort: { title: 1 }}
{ title: "Animal Farm" }
{ title: "Brave New World" }
{ title: "Fahrenheit 451" }
{ title: "Fathers and Sons" }
{ title: "Invisible Man" }
{ title: "Lord of the Flies" }
{ title: "The Grapes of Wrath" }
{ title: "The Great Gatsby" }

►▼
$LIMITLimit documents through the pipeline
{ title: "Animal Farm" }
{ title: "Brave New World" }
{ title: "Fahrenheit 451" }
{ title: "Fathers and Sons" }
{ title: "Invisible Man" }
{ title: "Lord of the Flies" }
{ title: "The Grapes of Wrath" }
{ title: "The Great Gatsby" }
{ $limit: 5 }
{ title: "Animal Farm" }
{ title: "Brave New World" }
{ title: "Fahrenheit 451" }
{ title: "Fathers and Sons" }
{ title: "Invisible Man" }

►▼
$SKIPSkip over documents in the pipeline
{ title: "Animal Farm" }
{ title: "Brave New World" }
{ title: "Fahrenheit 451" }
{ title: "Fathers and Sons" }
{ title: "Invisible Man" }
{ $skip: 2 }
{ title: "Fahrenheit 451" }
{ title: "Fathers and Sons" }
{ title: "Invisible Man" }

EXPRESSIONSExpressionsUsage and LimitationsShardingLooking Ahead
State of AggregationPipeline

EXPRESSIONSReturn computed valuesUsed with $project and $groupReference fields using $ (e.g. "$x")Expressions may be nested

EXPRESSIONSLogic
$and, $or, $not…
Comparison$cmp, $eq, $gt…
Arithmetic$add, $divide…
String$strcasecmp, $substr…
Date$year, $dayOfMonth…
Conditional$cond, $ifNull…

USAGE
Usage and LimitationsShardingLooking Ahead
State of AggregationPipelineExpressions

USAGEaggregate database commandcollection.aggregate() method
Mongo shellMost drivers

COLLECTION METHOD
▼
db.books.aggregate([ { $sort: { created: 1 }}, { $unwind: "$subjects" }, { $group: { _id: "$subjects", n: { $sum: 1 }, fc: { $first: "$created" } }}, { $project: { _id: 1, n: 1, fc: { $year: "$fc" }}}]);
{ result: [ { "_id": "Fantasy", "num": 6, "fc": 2008 }, { "_id": "Historical", "num": 7, "fc": 2012 }, { "_id": "World Literature", "n": 2, "fc": 2009 } // Other results follow… ], ok: 1}
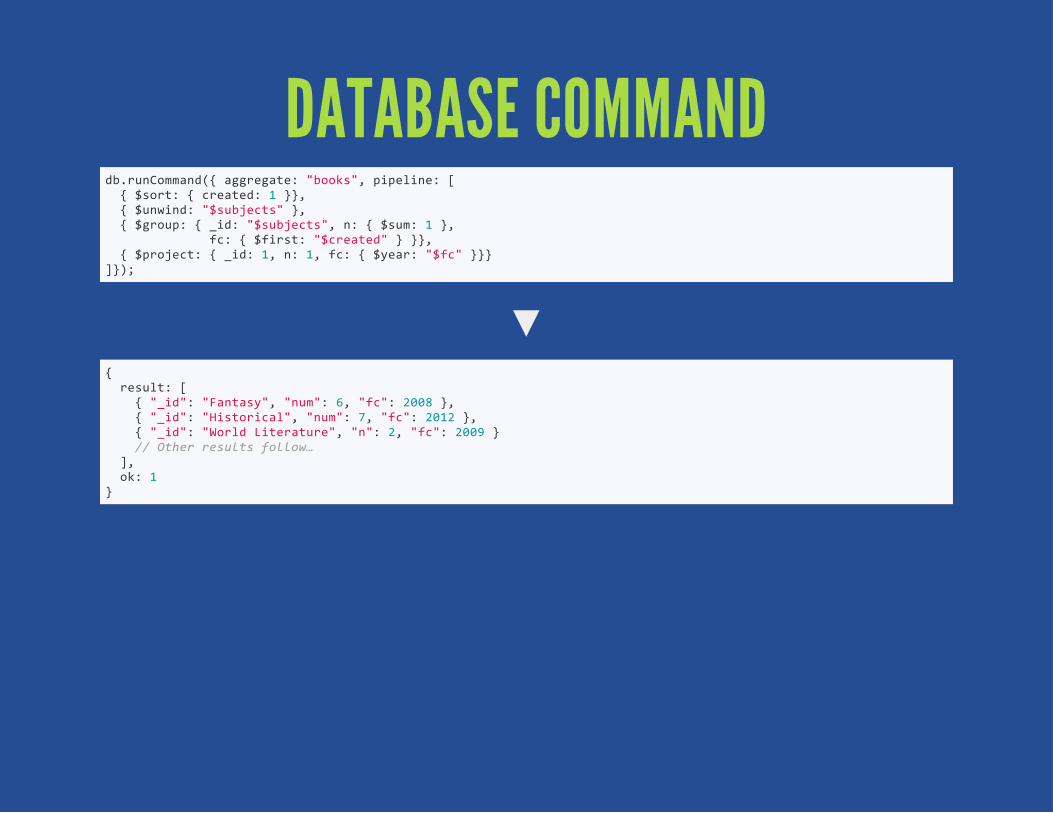
DATABASE COMMAND
▼
db.runCommand({ aggregate: "books", pipeline: [ { $sort: { created: 1 }}, { $unwind: "$subjects" }, { $group: { _id: "$subjects", n: { $sum: 1 }, fc: { $first: "$created" } }}, { $project: { _id: 1, n: 1, fc: { $year: "$fc" }}}]});
{ result: [ { "_id": "Fantasy", "num": 6, "fc": 2008 }, { "_id": "Historical", "num": 7, "fc": 2012 }, { "_id": "World Literature", "n": 2, "fc": 2009 } // Other results follow… ], ok: 1}

LIMITATIONSResult limited by BSON document size
Final command resultIntermediate shard results
Pipeline operator memory limitsSome BSON types unsupported
Binary, Code, deprecated types

SHARDING
ShardingLooking Ahead
State of AggregationPipelineExpressionsUsage and Limitations

SHARDINGSplit the pipeline at first $group or $sort
Shards execute pipeline up to that pointmongos merges results and continues
Early $match may excuse shardsCPU and memory implications for mongos

SHARDING[ { $match: { /* filter by shard key */ }}, { $group: { /* group by some field */ }}, { $sort: { /* sort by some field */ }}, { $project: { /* reshape result */ }}]
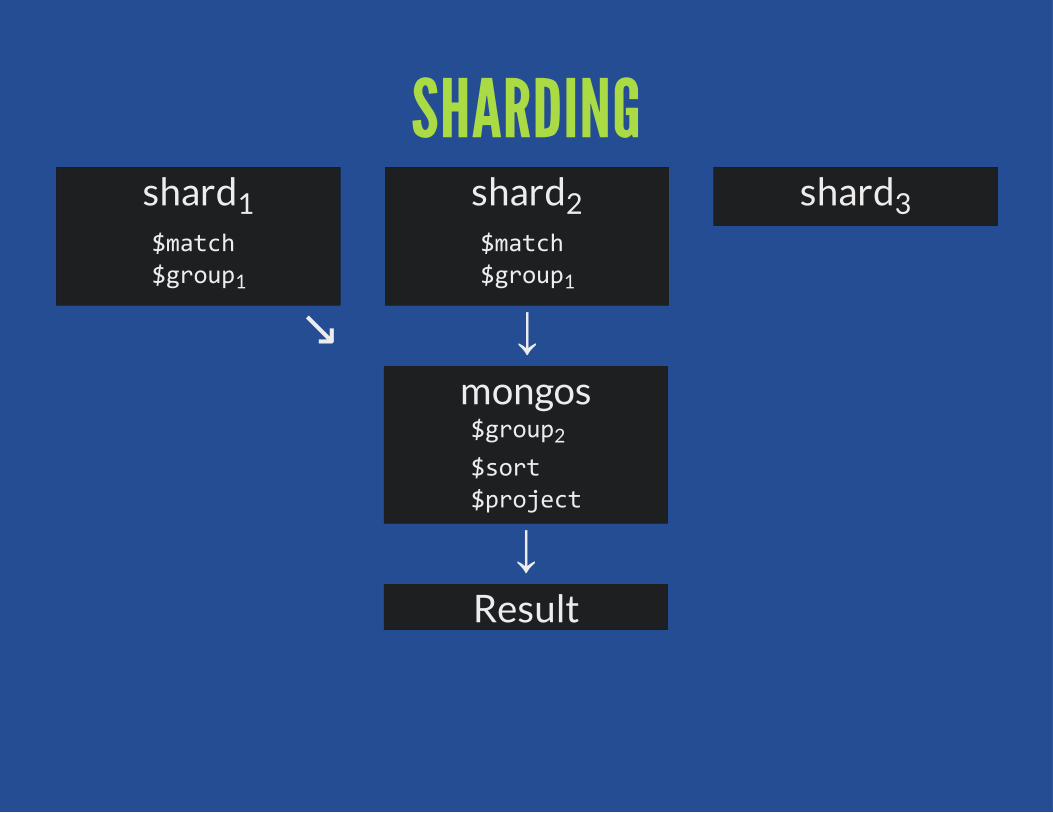
SHARDINGshard1$match$group1
↘
shard2$match$group1
↓
shard3
mongos$group2
$sort$project
↓Result

LOOKING AHEAD
Looking Ahead
State of AggregationPipelineExpressionsUsage and LimitationsSharding

FRAMEWORK USE CASESBasic aggregation queriesAd-hoc reportingReal-time analyticsVisualizing time series data

EXTENDING THE FRAMEWORKAdding new pipeline operators, expressions$out and $tee for output control
https://jira.mongodb.org/browse/SERVER-3253

FUTURE ENHANCEMENTSMove $match earlier when possiblePipeline explain facilityMemory usage improvements
Grouping input sorted by _idSorting with limited output (top k)

ENABLING DEVELOPERSDoing more within MongoDB, fasterRefactoring MapReduce and groupings
Replace pages of JavaScriptLonger aggregation pipelines
Quick aggregations from the shell

THANKS!http://goo.gl/G3cmD
QUESTIONS?

PHOTO CREDITShttp://dilbert.com/strips/comic/2012-09-05http://www.flickr.com/photos/toolstop/4324416999http://www.ristart.ee/web2/files/Product/large/13443203307.jpghttp://www.flickr.com/photos/vascorola/3164882131http://www.flickr.com/photos/capcase/4970062156http://img.timeinc.net/time/photoessays/2009/monty_python/monty_python_02.jpg





























