Embed Size (px)
DESCRIPTION
Курсовая работа за 7 семестр.
Citation preview

ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ РФ
КАЗАНСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ(ФИЛИАЛ В Г. НАБЕРЕЖНЫЕ ЧЕЛНЫ)
Факультет прикладной математики и информационных технологий
Курсовая работаза VII семестр на тему:
МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ И АНАЛИЗСВОЙСТВ РЕАЛЬНЫХ СЛОЖНЫХ СЕТЕЙ
Студент Сафронов М. А.
Научный руководительк. ф.-м. н., доцент Лернер Э. Ю.
Рецензенты
Набережные Челны2009

Оглавление
1 Введение 3
2 Теория 42.1 Математическая модель . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Распределение степеней . . . . . . . . . . . . . . . . . . . . 52.1.2 Коэффициент кластерности . . . . . . . . . . . . . . . . . . 52.1.3 Эффект «малых миров» . . . . . . . . . . . . . . . . . . . . 5
2.2 Программная реализация модели . . . . . . . . . . . . . . . . . . . 52.2.1 Perl . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3 Реализация 83.1 Формализация модели на языке программирования . . . . . . . . 83.2 Визуализация графа сети . . . . . . . . . . . . . . . . . . . . . . . 10
3.2.1 Pajek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.2.2 Эскпорт данных в Pajek . . . . . . . . . . . . . . . . . . . . 11
3.3 Вывод данных в виде графиков . . . . . . . . . . . . . . . . . . . . 123.3.1 Gnuplot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.3.2 Экспорт данных в Gnuplot . . . . . . . . . . . . . . . . . . 13
3.4 Проведение эксперимента . . . . . . . . . . . . . . . . . . . . . . . 133.4.1 Формализация эксперимента . . . . . . . . . . . . . . . . . 143.4.2 Запуски тестов и полученные результаты . . . . . . . . . . 21
4 Заключение 28
2

Глава 1
Введение
Предметной областью данной работы являются сложные сетевые структу-ры, существующие в реальности, и которые было бы крайне удобно анализиро-вать, пользуясь адекватной математической моделью.
Очевидными примерами таковых структур из реальности являются Интер-нет и World Wide Web, однако можно рассматривать и такие сети, как сетьзнакомств людей, транспортные сети, сеть цитирующих друг друга научныхработ et cetera.
Изучение подобных структур и, более того, моделирование их, представля-ется крайне выгодным. Выгоды выводятся прямо из определения целей моде-лирования как такового.
Во-первых, имея приближённую порождающую модель сети, можно делатьпредположения о динамике её развития.
Во-вторых, построив слепок реальной сети в виде известной формализо-ванной математической модели, возможно оценить её ключевые статическиехарактеристики — такие, например, как устойчивость к изъятию вершин илиминимальное геодезическое расстояние.
В-третьих, появляется возможность делать выводы о возможных взаимодей-ствиях между узлами сети (суть таковых взаимодействий зависит от семантикисамой сети) — например, предсказывать patterns распространения инфекциипри эпидемиях на основе сети знакомств людей, или планировать маршрутыперевозки грузов по транспортным схемам.
Целью работы является разработка порождающей модели сложной сети, еёанализ и подробное описание использованных методов проведения эксперимен-та по моделированию сложных сетей с использованием программных средств.
3

Глава 2
Теория
2.1 Математическая модельМатематическая модель генерации сложной сети основывается на следую-
щих принципах:
• На каждом шаге процесса порождения сети к сети добавляется по одномуновому узлу;
• Каждый узел в сети обладает обобщённой внутренней характеристикой,называемой условно «вес», значение которой влияет на вероятность при-соединения этого узла к новому;
• Сеть считается орграфом;
Алгоритм предложенной модели генерации сети для заданного количестваузлов N следующий.
Для каждого нового узла выполняется два действия:
1 генерируется вес этого нового узла как значение нормально распределён-ной случайной величины, нормализованной в отрезок от 0 до 1;
2 этот новый узел подсоединяется к уже существующему с вероятностьюравной весу того узла, к которому мы устраиваем присоединение.
Предполагается (см. [1]), что реальным сложным сетям присущи следующиетри особенности (свойства):
• распределение степеней вида n(d) ∼ d−γ (степенное);
• коэффициент кластерности сети намного больше средней степени узла;
• существование «эффекта малых миров» — среднее расстояние между уз-лами сети пропорционально логарифму от количества узлов.
Следует проверить, обладают ли этими особенностями сети, порождаемые пред-ложенной моделью.
4

2.1.1 Распределение степенейРаспределение степеней узлов графа — это форма зависимости между зна-
чением степени узла и количеством узлов, этой степенью обладающих. Такимобразом, если d = d(v) — это степень узла v, то распределение степеней
n(d)
описывается некоторой простой функцией f(v).В [2] отмечено, что распределение степеней узлов реальных сложных сетей
имеет видn(d) ∼ d−γ.
2.1.2 Коэффициент кластерностиЕсли β(v) — это количество рёбер между узлами, смежными с узлом v, то
коэффициент кластерности c(v) узла v определяется как
c(v) =β(v)
12d(v)(d(v)− 1)
,
где d(v) — степень узла v.
2.1.3 Эффект «малых миров»Впервые описанный на основе экспериментальных данных эффект «малых
миров» заключается в том, что в реальных сложных сетях кратчайшее рассто-яние sp(v1, v2) между любыми двумя случайно взятыми вершинами v1 и v2 всреднем пропорционально логарифму от количества N узлов в сети:
sp(v1, v2) � logN.
2.2 Программная реализация моделиСеть решено было представлять в виде списка списков смежности. Каждый
элемент списка является тройкой (I,W, L), где I — идентификатор узла, W —вес узла, L — список узлов, смежных к I.
После генерации модели сети в оперативной памяти компьютера предпола-гается её анализ, в том числе внешними приложениями. Для построения гра-фиков использован Gnuplot [5], для визуализации графа сети — Pajek [6]. Дляпередачи сведений о сети во внешние приложения были предусмотрены меха-низмы экспорта данных.
Для программной реализации модели выбран язык программирования Perl [3].Выбор был обусловлен следующими факторами:
5

• интерпретируемый язык позволяет быструю отладку и изменение кода;
• Perl предоставляет на уровне языка возможности по эффективному и про-стому манипулированию списками, в частности, удалению и добавлениюв них элементов, а также быстрый поиск элементов по идентификатору;
• Perl предоставляет на уровне языка возможности по эффективному ма-нипулированию текстом, что важно для удобства экспорта полученныхданных для других приложений.
2.2.1 PerlPerl является интерпретируемым языком программирования, вследствие че-
го программой будет являться простой текстовый документ, в котором описанаформализация изучаемой модели. В случае изменения модели изменения в ал-горитм вносятся без необходимости перекомпиляции программы. Это повышаетпереносимость программы и её компактность.
Традиционный недостаток интерпретируемых языков — необходимость вме-сте с программой переносить и её интерпретатор — смягчается тем фактом, чтосовременные интерпретаторы Perl являются свободным программным обеспе-чением, таким образом, доступ к ним облегчён настолько, насколько это воз-можно (для ОС Windows существует сборка Perl от организации ActiveState,см. [4]). Также многие дистрибутивы GNU\Linux распространяются вместе спредустановленной средой интерпретации Perl.
Для дальнейшего описания формализации математической модели следуетобъяснить некоторые языковые конструкции и связанные с ними возможностиязыка Perl.
Perl использует динамическую типизацию и, таким образом, программистизбавлен от необходимости явно объявлять типы переменных.
Конвертация между строками и числами производится прозрачно; для про-стоты можно считать, что Perl имеет один тип данных, называемый «скаляр»,как для чисел (в любом формате), так и для строк.
Perl предоставляет тип данных, называемый «hash» (везде далее «хэш»),представляющий собой набор элементов, индексированных неким произволь-ным значением. Хэши можно, таким образом, называть «ассоциативными мас-сивами». Синтаксис операции создания хэша:
%hash = (key1 => value1, key2 => value2);
Синтаксис операции извлечения элемента из хэша:
$value1 = $hash{key1};
изменения значения, соответствующего индексу key1:
$hash{key1} = newvalue1;
6

Крайне удобной является возможность создания новой пары «ключ-значение»в хэше в естественном виде:
$hash{$newkey} = $newvalue;
Если указанный ключ существует в хэше, ассоциированное с ним значение будетперезаписано. В противном случае в хэш будет добавлена новая пара «ключ-значение». При этом увеличение размеров хэша производится автоматически.
Perl предоставляет возможность манипулировать указателями на перемен-ные. Это позволяет использовать в программе хэши хэшей.
Для упрощения работы с массивами на уровне языка определены функ-ции для добавления новых элементов в массивы, push(@array, $newelem), иshift(@array, $newelem). Манипуляция с размерами массива при выполненииданных функций производится автоматически.
7

Глава 3
Реализация
3.1 Формализация модели на языке программи-рования
Было сделано принципиальное архитектурное решение использовать гло-бальные переменные для хранения некоторых ключевых объектов, манипуля-ции с которыми будет производить программа. При адаптации кода к муль-типроцессорной среде с параллельными вычислениями или его значительномрасширении совершенно необходимо отказаться от глобальных переменных впользу передачи данных в подпрограммы с помощью указателей и/или реали-зации той или иной объектной модели.
Для генерации сети алгоритму требуется два параметра: размер сети (ко-личество узлов для генерации) и указание на то, генерировать ли орграф илиненаправленный граф.
Для генерации весов узлов как значений нормально распределённой слу-чайной величины используется дополнительный генерируемый заранее массивчисел того же размера, что и размер сети. Значения традиционно используемоговстроенного генератора случайных чисел конвертируются в значения стандарт-но нормально распределённой случайной величины методом полярных коорди-нат Бокса, Мюллера и Марсалья. Метод генерирует значения парами, поэтомунеобходимо несколько изощряться для того, чтобы получить нужное количе-ство значений. Код для предварительной генерации списка значений стандарт-но нормально распределённой случайной величины (длина списка передаётся вкачестве единственного аргумента подпрограммы):sub generate_normal_values {
my $quantity = shift \or die "Normally distributed values \
generator was called without arguments!\n";unless ($quantity > 0)
{ die "Incorrect quantity of numbers to generate!\n";};$quantity = (($quantity && 1) ? $quantity +1 : $quantity) >> 1;my $R;my @NV;for (my $i = 0; $i < $quantity; ++$i) {
my $x1;
8

my $x2;do {
$x1 = rand(1) * 2.0 - 1.0;$x2 = rand(1) * 2.0 - 1.0;$R = $x1 * $x1 + $x2 * $x2;
} until ($R < 1);my $S = sqrt( -2 * (log($R) / $R));push @NV, $x1 * $S;push @NV, $x2 * $S;
} # end forreturn \@NV;
};
Результатом работы подпрограммы generate_normal_values($network_size)является указатель на список чисел. Длина списка равна $network_size.
Для нормализации пресозданных значений Ni стандартно нормально рас-пределённой случайной величины в отрезок [0, 1] используется следующее вы-числение:
w = max(0, min((Ni + 0.5) ∗ 1
4), 1);
Реализующая это подпрограмма выглядит следующим образом:sub generate_weight {
my $node_id = shiftor die "Weight generator called without arguments!\n";
my $raw_value = ${$pregenerated_normal_values}[$node_id];return max(0, min(($raw_value + 0.5) / 4, 1));
};
sub min {my $a = shift;my $b = shift;return ($a < $b)?$a:$b;
}
sub max {my $a = shift;my $b = shift;return ($a > $b)?$a:$b;
}
Здесь были переопределены функции min/2 и max/2, иначе для их доступностипришлось бы надеяться на дополнительные модули Perl, жертвуя переносимо-стью.
Результатом функции generate_weight($node_id) является нормализован-ное значение случайной величины, гарантированно лежащее между 0 и 1. Пред-полагается, что в программе существует, определена и содержит сведения пе-ременная $pregenerated_normal_values, являющаяся указателем на массивчисел. Аргумент $node_id является индексом числа в массиве пресозданныхзначений; таким образом, для каждого узла заранее создано случайное число,являющееся базисом для его веса.
Процесс создания нового узла выделен в отдельную подпрограмму:sub new_node {
my $id = shift
9

or die "Node constructor called without arguments!\n";my $node = {
’weight’ => generate_weight($id),’id’ => $id,’neighbors’ => [ ]
};return $node;
};
Результатом выполнения new_node($id) является указатель на хэш, содержа-щий идентификатор узла, ассоциированный с ключом «id», вес узла, ассоции-рованный с ключом «weight» и изначально пустой список смежных узлов, ас-социированный с ключом «neighbors». Генерация сети будет заключаться, фак-тически, в манипуляциях со списками смежностей узлов сети.
Процедура создания узла пользуется процедурой генерации веса узлаgenerate_weight($id).
Для генерации сети используется следующий код:
my %network;my $pregenerated_normal_values = generate_normal_values($network_size);for (my $counter = 1; $counter < $network_size; ++$counter) {
my $node = new_node($counter);foreach my $existing_node_id ( keys(%network) ) {
if (rand(1) < $network{$existing_node_id}{’weight’}) {push @{${$node}{’neighbors’}}, $existing_node_id;unless ($is_orgraph) {
push @{$network{$existing_node_id}{’neighbors’}}, $counter;} # end unless
} # end if} # end foreach$network{$counter} = $node;
} # end for;
Здесь значение $network_size контролирует число итераций создания и до-бавления нового узла (а также размер вспомогательного массива случайныхчисел). Параметр $is_orgraph указывает на то, является ли граф ориентиро-ванным, в противном случае при добавлении в список смежности нового узла$node идентификатора смежного с ним существующего в сети узла$network{$existing_node_id} необходимо также модифицировать и списоксмежности этого существующего узла, добавив в него идентификатор новогоузла.
Вышеописанный алгоритм полагается на существование хэша %network (ко-торый для этого был объявлен в первой строчке) и модифицирует его в процессевыполнения себя. По окончании последней итерации алгоритма хэш %networkхранит в себе полное описание сгенерированной сети в виде списков смежности.
3.2 Визуализация графа сетиДля представления сети в виде изображения узлов, соединённых дугами
использовано приложение Pajek [6]. Данные из основной программы формати-
10

руются согласно внутреннему синтаксису Pajek и экспортируются в текстовыйфайл, который в дальнейшем обрабатывает Pajek.
3.2.1 PajekPajek является приложением для визуализации графов, обладающее воз-
можностями визуального редактирования и анализа (выделение компонент связ-ности, добавление/удаление узлов/рёбер, различные варианты позиционирова-ния графа в пространстве). Это свободно распространяемое приложение с за-крытым исходным кодом.
3.2.2 Эскпорт данных в PajekПростейший файл, содержащий сведения о графе, и который принимает для
в качестве входных данные Pajek, выглядит так:
*Vertices 240127 12732 32
...далее ещё 238 точек...*Arcs127 33 1127 90 1
...далее список всех остальных дуг...*Edges
В первой строчке объявляется начало раздела описания узлов (в данном случае,«вертексов») и количество узлов. Далее в каждой последующей строке первоезначение является внутренним идентификатором узла для Pajek, второе значе-ние — подписью, выводимой рядом с этим узлом.
В разделе «Arcs» перечислены все дуги (направленные рёбра) в графе. Пер-вое число в определении дуги является идентификатором начального узла, вто-рое — идентификатором конечного узла, третье — весом дуги, для случая взве-шенных графов. Для данной сети веса всех дуг будут равны 1.
Раздел «Edges» перечисляет все рёбра (ненаправленные) в графе. Приведён-ный пример описывает орграф, поэтому этот раздел пуст, однако его объявлениевсё равно обязательно.
Функция на Perl, формирующая корректный файл входных данных дляPajek на основе сведений о сети, сгенерированной нашей моделью, выглядиттак:
sub output_pajek_file {my $pajek_file = shift || "test-network.net";print "Composing the input file for pajek processor...\n";print "File is $pajek_file\n";open PJK,>> $pajek_file" or die "Cannot open file for writing: $!\n";print PJK "*Vertices $network_size\r\n";foreach my $node_id ( keys %network ) {
printf PJK "%4d %4d\r\n", $node_id, $node_id;};
11

print PJK "*Arcs\r\n";foreach my $node_id ( keys %network ) {
foreach my $neighbor_id ( @{$network{$node_id}{’neighbors’}} ) {printf PJK "%4d %4d %d\r\n", $node_id, $neighbor_id, 1;
}; # end foreach}; # end foreachprint PJK "*Edges\r\n";close PJK or die "Cannot close file: $!\n";print "Finished composing file for pajek processor\n";
}; # end sub
В качестве входного аргумента функция принимает имя выходного файла. Вслучае отсутствия значения аргумента используется предопределённое имя фай-ла «test-network.net». При выводе вне зависимости от того, представлена ли сетьв виде ориентированного или неориентированного графа, заполняется толькораздел Arcs.
Экспортированный файл загружается в Pajek с помощью графического поль-зовательского интерфейса программы.
3.3 Вывод данных в виде графиковДля вывода графика распределения степеней используется внешняя утили-
та Gnuplot, для которой формируется файл с исходными данными на основесгенерированной моделью сети. Черчению на экране подлежит график в ло-гарифмическом масштабе по обеим осям, по оси абсцисс отложены значениястепени, по оси ординат — количество узлов, обладающих соответствующейстепенью.
3.3.1 GnuplotGnuplot технически является интерпретатором своего встроенного языка.
Он принимает последовательности команд из стандартного потока ввода (напр.,консоли) или из файла, что позволяет использовать его для обработки заранееэкспортированных данных.
Двумя ключевыми возможностями Gnuplot, которые будут использованыдля получения изображения графика распределения степеней, является коман-да plot, которая чертит на экране график по указанным исходным данным, ивозможность передать в качестве параметра этой команды имя внешнего фай-ла, в котором сохранены эти данные. Таким образом, для вывода графика будетиспользоваться в точности следующая команда Gnuplot:plot datafile using (log($1)):(log($2)) smooth bezier;
Вместо datafile подставляется имя файла с данными для отображения.Указанная команда чертит сглаженный в виде кривой Безье график в декар-товых координатах на плоскости в логарифмическом масштабе по обеим осям.Если распределение степеней узлов окажется степенным, оно будет выглядетьв логарифмическом масштабе по обеим осям как прямая линия.
12

3.3.2 Экспорт данных в GnuplotИсходным файлом данных для Gnuplot в простейшем случае может быть
текстовый файл, в котором в две колонки перечислены координаты точек гра-фика (разделитель колонок — пробел).
Следует учесть, что для экспорта данных в Gnuplot в данном случае требу-ется записать два файла: один с командами, второй с данными для отображенияв виде графика. Процедура экспорта данных выглядит следующим образом:
sub output_gnuplot_file {my $gplot_file = shift || "network.gp";my $gplot_data_file = "network-outdegrees.dat";print "Composing the input file for gnuplot processor...\n";print "File is $gplot_file\n";open GPT, > $gplot_file" or die "Cannot open file for writing: $!\n";print GPT "plot \’$gplot_data_file\’ using (log(\$1)):(log(\$2)) smooth bezier\n";print GPT "pause -1";close GPT or die "Cannot properly close $gplot_file: $!\n";open GPTF, > $gplot_data_file" or die "Cannot open file for writing: $!\n";foreach my $od ( sort {$a <=> $b} keys( %{$outdegree_list_ref} ) ) {
print GPTF $od." ".$outdegree_list_ref->{$od}."\n";};close GPTF or die "Cannot properly close $gplot_data_file: $!\n";
}; # end sub
В качестве единственного аргумента процедура принимает имя файла, в кото-рый следует записать команды для Gnuplot. В случае отсутствия этого аргу-мента используется предопределённое значение «network.gp». В качестве именифайла с данными всегда используется предопределённое значение «network-outdegrees.dat».
После команды отобразить график указана команда “pause -1”, выполняякоторую, Gnuplot будет ожидать нажатия на Enter, прежде, чем закрыть окнос графиком.
Подразумевается, что в окружающем пространстве имён существует указа-тель $outdegree_list_ref, содержащий ассоциации вида:’outdegree_value’=>$number_of_nodes. Здесь outdegree_value это значениестепени узла, $number_of_nodes— количество узлов, обладающих такой степе-нью.
3.4 Проведение экспериментаДля проведения законченного эксперимента по генерации сети и анализу её
свойств следует объединить все описанные ранее отдельные процедуры — гене-рации сети и экспорта данных о ней — в единую программу а также дополнитьэту программу процедурами для анализа ключевых свойств сети.
Таким образом, экспериментом будет считаться выполнение следующих дей-ствий.
1 Генерация сети из N узлов согласно модели;
13

2 Замер времени, затраченного на генерацию;
3 В случае явного указания на необходимость этого, вывод всех сгенериро-ванных сведений;
4 Вычисление и вывод средней степени вершин по сети;
5 Вычисление и вывод коэффициента кластерности сети;
6 Вычисление и вывод коэффициента отношения среднего кратчайшего рас-стояния между узлами сети к логарифму отN — «коэффициента эффектамалых миров»;
7 Экспорт данных для Gnuplot;
8 Экспорт данных для Pajek;
9 Замер времени, затраченного на анализ и экспорт данных;
Вывод подразумевается в стандартный поток вывода (обычно — консоль).
3.4.1 Формализация экспериментаТеперь последовательно формализуем каждый из шагов проведения экспе-
римента на языке Perl.
Вычисление степеней узлов сети
Степени узлов сети, будучи производными данными, вычисляются отдель-но. Процедура, выполняющая это вычисление, модифицирует хэш %network,содержащий все узлы сети, приписывая к каждому узлу дополнительную пару«ключ-значение» вида ’outdegree’=>$od, где $od — вычисленная степень уз-ла. Параллельно с этой обработкой аккумулируется значение средней степениузлов по всей сети. Текст процедуры:
sub network_mean_degree {# Mean node degree
my %outdegrees_list = check_nodes_degrees($is_verbose);my $network_edges_count = count_edges(\%outdegrees_list, $is_orgraph);print "Total edges in network: $network_edges_count\n";my $mean_degree = ($network_edges_count / ($network_size * ($network_size - 1)/ 2));print "Mean node degree: $mean_degree\n";return ($mean_degree, \%outdegrees_list);
};
Функция network_mean_degree возвращает пару значений. Значение$mean_degree является вычисленной средней степенью узлов сети. Второе воз-вращаемое значение является указателем на хэш %outdegrees_list, содержа-щий значения степеней, встречающиеся в сети, связанные с количествами узлов,обладающими соответствующими степенями.
14

Подразумевается, что в окружающем пространстве имён существует и опре-делено значение $is_verbose, указывающее на необходимость подробного вы-вода хода вычислений, а также значения $network_size (размер сети)и $is_orgraph (является ли граф ориентированным).
Для построения хэша %outdegrees_list используется дополнительная под-процедура check_nodes_degrees. Используя этот хэш, дополнительная подпро-цедура count_edges производит подсчёт рёбер в сети, что необходимо для вы-числения средней степени узлов сети.
Текст дополнительной функции check_nodes_degrees:
sub check_nodes_degrees {my $is_verbose = shift or 0;print "Marking each node with it’s outdegree...\n";
# hash of outdegree value => number of nodes pairs, just a data for a histogrammy %outdegrees_list;foreach my $n ( keys(%network) ) {
my $outdegree = get_and_mark_node_degree($n);# number of nodes with gotten outdegree was just increased by one...
$outdegrees_list{$outdegree} += 1;};if ($is_verbose) {
print "Number of nodes for various value of outdegree:\n";foreach my $od ( sort keys(%outdegrees_list) ) {
print "$od: $outdegrees_list{$od} nodes\n";}
};return %outdegrees_list;
};
В случае, если этой функции был передан ненулевой аргумент, функция допол-нительно выведет в стандартный поток вывода список степеней узлов и соот-ветствующие им количества узлов.
Функция возвращает хэш %outdegrees_list, описанный выше. Для каждо-го узла, принадлежащего сети, вычисляется его степень, которая затем сохра-няется во внутреннем представлении этого узла. Эту задачу выполняет вспо-могательная подпроцедура get_and_mark_node_degree.
Функция check_nodes_degrees полагается на то, что в окружающем про-странстве имён определён хэш %network, описанный ранее.
Текст функции get_and_mark_node_degree, вычисляющей степень узла, вы-глядит так:
sub get_and_mark_node_degree {my $node_id = shift
or die "Marking node degree was called without arguments!\n";my $outdegree = $#{$network{$node_id}{’neighbors’}} + 1;$network{$node_id}{’outdegree’} = $outdegree;return $outdegree;
}; # end sub
В качестве единственного входного аргумента функция ожидает идентифика-тор узла в хэше %network. Этот хэш должен существовать в окружающем про-странстве имён.
15

Функция get_and_mark_node_degree возвращает вычисленную степень уз-ла а также сохраняет её в самом хэше, описывающем узел, в виде пары’outdegree’=>$outdegree, где $outdegree — это вычисленная степень узла.
Функция count_edges, подсчитывающая количество рёбер в сети, выглядиттак:
sub count_edges {print "Calculating edges\n";my $outdegree_list = shift;my $is_digraph = shift;my $edge_number = 0;foreach my $od ( keys(%{$outdegree_list}) ) {
$edge_number += ${$outdegree_list}{$od} * $od;};return ($is_digraph)?($edge_number >> 1):$edge_number;
}; # end sub
В качестве первого аргумента функция ожидает указатель на хэш%outdegree_list, описанный ранее, в качестве второго — указание на то, яв-ляется ли анализируемая сеть орграфом.
Подсчёт рёбер производится элементарным сложением произведений зна-чений степени узлов на количество узлов, имеющих такую степень, для всехзначений степеней, встречающихся среди степеней узлов сети.
Вывод данных о сети
Для вывода всех сгенерированных моделью данных о сети используется сле-дующая подпрограмма:
sub output_network_data {print "Here is statistical data about the network:\n";foreach my $n ( keys(%network) ) {
printf "%4s: % 4d % 5.4f", $n, $network{$n}{’id’}, $network{$n}{’weight’};print " [ ";foreach my $neighbor ( @{$network{$n}{’neighbors’}} ) {
print $neighbor." ";};print "]\n";
};}; # end sub
Подпрограмма полагается на существование хэша %network в окружающемпространстве имён, описанного выше.
Для каждого узла в сети выводится идентификатор, вес и список смежности.
Вычисление коэффициента кластерности
Коэффициент кластерности сети вычисляется как среднее арифметическоекоэффициентов кластерности всех узлов сети. Текст подпрограммы:
sub output_network_clustering_coeff {my $is_verbose = shift or 0;my $accumulator = 0;
16

foreach my $node ( keys(%network) ) {my $node_cluster_coeff = node_clustering_coeff($node);print "c($node) = $node_cluster_coeff\n" if $is_verbose;$accumulator += $node_cluster_coeff;
};my $network_cluster_coeff = $accumulator / $network_size;print "Network clustering coefficient = $network_cluster_coeff\n";
};
Подпрограмма output_network_clustering_coeff полагается на существова-ние хэша %network в окружающем пространстве имён. В случае передачи нену-левого аргумента подпрограмма после вычисления коэффициента кластерностиочередного узла выведет полученные данные в стандартный поток вывода.
В конце работы подпрограмма выводит вычисленный коэффициент кластер-ности сети в стандартный поток вывода.
Для получения коэффициента кластерности очередного узла используетсявспомогательная подпрограмма node_clustering_coeff. Её текст:
sub node_clustering_coeff {my $node_id = shift
or die "Node clustering coefficient was called without arguments!\n";my $Dv;if (exists($network{$node_id}->{’outdegree’})) {
$Dv = $network{$node_id}->{’outdegree’};} else {
$Dv = get_and_mark_node_degree($node_id);};my $edges_between_neighbors = count_edges_between_neighbors($node_id);print "Edges # between neighbors of $node_id: $edges_between_neighbors\n" if $is_verbose;if ($Dv > 1) {
return $edges_between_neighbors / ( ($Dv * ($Dv - 1)) / 2 );} else {
return 0;};
};
В качестве единственного аргумента функция node_clustering_coeff прини-мает идентификатор узла.
Для вычисления коэффициента кластерности узла используется количестворёбер между смежными с ним узлами. Это количество вычисляет вспомогатель-ная функция count_edges_between_neighbors.
В случае, если в окружающем пространстве имён определено ненулевое зна-чение переменной $is_verbose, то информация о количестве рёбер между со-седями рассматриваемого узла будет выведена в стандартный поток вывода.
В случае, если степень рассматриваемого узла равна 0, то его коэффициенткластерности тоже принимается равным нулю.
Подсчёт количества рёбер между узлами, смежными с заданным узлом, вы-полняется так:
sub count_edges_between_neighbors {my $node_id = shift
or die "Counting edges between node’s neighbors \was called without arguments!\n";
my $counter = 0;
17

foreach my $neighbor (@{$network{$node_id}{’neighbors’}}) {foreach my $neighbor_neighbor (@{$network{$neighbor}{’neighbors’}}) {
if (grep( /^$neighbor_neighbor$/, @{$network{$node_id}{’neighbors’}} )) {unless ($neighbor_neighbor == $neighbor) {
$counter += 1;}; # end unless
}; # end if}; # end foreach neighbor_neighbor
}; # end foreach neighborreturn $counter;
}; # end sub
Функция возвращает количество рёбер между узлами, смежными с узлом, иден-тификатор которого передан функции в качестве единственного аргумента.Подразумевается, что в окружающем пространстве имён определён хэш %network.
Проверка наличия эффекта малых миров
Будем считать, что эффект малых миров присутствует в сети, если коэф-фициент, полученный в результате деления среднего минимального расстояниямежду узлами сети на натуральный логарифм от количества узлов в сети, до-статочно мал (порядка 100).
Среднее минимальное расстояние будем считать так: для каждого узла всети найдём расстояние от него до какого-нибудь случайно взятого узла, а затемнайдём среднее арифметическое всех полученных ненулевых расстояний. Привычислении расстояния между двумя узлами в случае, если пути между нимине существует, расстояние между ними принимается равным 0.
Для получения пути между двумя заданными узлами используется функцияfind_path. Её исходный код выглядит так:
sub find_path {my $me = $_[0];my $dest = $_[1];my $network = $_[2];
return ($me) if $me eq $dest;
my @queue = ($me);my %route = ($me => [$me]);
while(my $ob = shift @queue) {foreach my $i (@{$network->{$ob}->{’neighbors’}}) {
if(!$route{$i}) {$route{$i} = [ @{$route{$ob}}, $i ];return \$route{$i} if($i eq $dest);push @queue, $i;
}; # end if}; # end foreach
}; # end while}; # end sub
Функция принимает три аргумента: идентификатор узла — начала пути, иден-тификатор узла — окончания пути и хэш, описывающий сеть. В качестве вы-ходного значения функция возвращает указатель на список идентификаторов
18

узлов, входящих в путь, включая начальный узел и конечный. Таким образом,длина пути на 1 меньше длины этого списка. Путь ищется с помощью поиска вширину.
Подпрограмма, выполняющая вычисление «коэффициента эффекта малыхмиров», выглядит так:
sub output_network_small_world_effect_coeff {# utilizing knowledge about network generation algorithm: \# assuming that nodes’ IDs are numbers from 1 to network sizemy $accumulator = 0;my $paths_counter = 0;foreach my $from_node_id ( @{[ 1..$network_size ]} ) {
my $to_node_id = int(rand($network_size)) + 1;while ($from_node_id == $to_node_id) {
$to_node_id = int(rand($network_size)) + 1;}; # end whilemy $path_ref = find_path($from_node_id, $to_node_id, \%network);next unless $path_ref;my $distance = $#{${$path_ref}};if ($distance) {
$paths_counter += 1;$accumulator += $distance;
}; # end if}; #end foreachmy $mean_distance = $accumulator / $paths_counter;print "Mean distance between nodes in network \
(based on limited sample!): $mean_distance\n";my $logsize = log($network_size);print "Log of network size: $logsize\n";my $small_world_coeff = $logsize / $mean_distance;print "So, small world coefficient would be $small_world_coeff\n";
}; # end sub
Подпрограмма output_network_small_world_effect_coeff полагается на то,что в окружающем пространстве имён определено значение $network_size,хранящее в себе количество узлов в сети, и хэш %network.
Сборка основной процедуры
Основная процедура программы принимает до трёх аргументов. Первыйаргумент указывает количество узлов в сети, которое следует сгенерировать.Наличие ненулевого второго аргумента указывает на то, что генерируемая сетьявляется орграфом. Наличие ненулевого третьего аргумента указывает на то,что в процессе работы следует выводить дополнительную информацию, такую,как текстовое представление всей сети etc.
Перед началом генерации сети следует засечь время и определить, сколькосекунд займёт генерация. Затем следует таким же образом определить продол-жительность анализа сети.
Конечный текст основной процедуры программы следующий:
#!perl -w
use warnings;use strict;
19

# Getting input arguments - network size and whether it is a digraphmy $network_size = shift or die "Network size should be supplied!\n";my $is_orgraph = shift or 0;my $is_verbose = shift or 0;
# Declaring empty networkmy %network;
# List of pregenerated values, taken from standard normal random distributionmy $pregenerated_normal_values = generate_normal_values($network_size);
print "Network generation started for $network_size nodes\n";my $starttime = time();(my $sec,my $min,my $hour,my $mday,my $mon,my $year,my $wday,my $yday,my $isdst) \
= localtime($starttime);print "Time of start: $hour:$min:$sec\n";print "Network is ".($is_orgraph)?"":" not"." oriented\n";
my $milestone_time = $starttime;for (my $counter = 1; $counter < $network_size; ++$counter) {
unless ($counter % 250) {print "Processing node: $counter\n";my $cur_time = time();print "Seconds elapsed from start: ".($cur_time - $starttime)."\n";print "Seconds elapsed from last 250 nodes: ".($cur_time - $milestone_time)."\n";$milestone_time = $cur_time;
}my $node = new_node($counter);foreach my $existing_node_id ( keys(%network) ) {
if (rand(1) < $network{$existing_node_id}{’weight’}) {push @{${$node}{’neighbors’}}, $existing_node_id;unless ($is_orgraph) {
push @{$network{$existing_node_id}{’neighbors’}}, $counter;} # end unless
} # end if} # end foreach$network{$counter} = $node;
} # end for;
# Fixation of generation end timemy $endtime = time();($sec, $min, $hour, $mday, $mon, $year, $wday, $yday, $isdst) \
= localtime($endtime);
# Reporting of end of generationprint "Network generation completed, end time: $hour:$min:$sec\n";print "Seconds elapsed since start: ".($endtime - $starttime)."\n";print "Network analysis started\n";
# Fixation of processing start time$starttime = time();($sec, $min, $hour, $mday, $mon, $year, $wday, $yday, $isdst) \
= localtime($starttime);
# Reporting of start of processingprint "Network analysis began at $hour:$min:$sec\n";
# All network nodes listing - if called as verboseoutput_network_data() if $is_verbose;
20

# Network mean degreemy ($mean_degree, $outdegree_list_ref) = network_mean_degree();
# Network properties calculation and output# Network clustering coefficientoutput_network_clustering_coeff();
# Network small-world effect coefficientoutput_network_small_world_effect_coeff();
# Data export to gnuplot and pajekoutput_gnuplot_file("test-network.gp");output_pajek_file("test-network.net");
# Fixation of processing end time$endtime = time();($sec, $min, $hour, $mday, $mon, $year, $wday, $yday, $isdst) \
= localtime($endtime);
# Reporting of end of processingprint "Network processing completed, end time: $hour:$min:$sec\n";print "Seconds elapsed since start: ".($endtime - $starttime)."\n";
Для Gnuplot и Pajek данные экспортируются в файлы «test-network.gp» и «test-network.net» соответственно.
Только что приведённый исходный код и следующие за ним отдельные опре-деления подпрограмм, последовательно описанные в предыдущих подразделах,составляют полный текст единственного файла исходного кода для программ-ной реализации изучаемой модели.
3.4.2 Запуски тестов и полученные результатыПри условии, что исходный код программы сохранён в файле model.pl,
запуск программы через командную строку осуществляется следующей коман-дой:
> perl model.pl 1250 digraph verbose
Где 1250 — размер сети — заменяется на требуемый размер сети. Наличие второ-го аргумента (в данном примере ’digraph’, допускается любое ненулевое значе-ние) указывает программе, что следует генерировать орграф. Наличие третьегоаргумента (в данном примере ’verbose’, допускается любое ненулевое значе-ние) указывает программе, что следует выводить дополнительные сообщения опромежуточных результатах работы.
В результате работы программа выведет на консоль следующий текст (при-мер с выводом всех сообщений):
> perl model.pl 20 digraph verboseNetwork generation started for 20 nodesTime of start: 15:31:28Network generation completed, end time: 15:31:28Seconds elapsed since start: 0Network analysis startedNetwork analysis began at 15:31:28
21

Here is statistical data about the network:11: 11 0.0000 [ 5 ]7: 7 0.2121 [ 5 ]17: 17 0.5581 [ 6 15 ]2: 2 0.0000 [ ]1: 1 0.0026 [ ]18: 18 0.4182 [ 5 ]16: 16 0.2066 [ 5 ]13: 13 0.1702 [ 12 5 ]6: 6 0.2236 [ 5 ]3: 3 0.0000 [ ]9: 9 0.0333 [ 5 ]12: 12 0.1468 [ ]14: 14 0.0000 [ 5 ]15: 15 0.2707 [ 6 7 ]8: 8 0.0000 [ ]4: 4 0.0000 [ ]19: 19 0.2127 [ 17 13 9 ]10: 10 0.0000 [ 6 5 ]5: 5 0.3333 [ ]
Marking each node with it’s outdegree...Number of nodes for various value of outdegree:0: 7 nodes1: 7 nodes2: 4 nodes3: 1 nodesCalculating edgesTotal edges in network: 9Mean node degree: 0.0473684210526316Edges # between neighbors of 11: 0Edges # between neighbors of 7: 0Edges # between neighbors of 17: 1Edges # between neighbors of 2: 0Edges # between neighbors of 1: 0Edges # between neighbors of 18: 0Edges # between neighbors of 16: 0Edges # between neighbors of 13: 0Edges # between neighbors of 6: 0Edges # between neighbors of 3: 0Edges # between neighbors of 9: 0Edges # between neighbors of 12: 0Edges # between neighbors of 14: 0Edges # between neighbors of 15: 0Edges # between neighbors of 8: 0Edges # between neighbors of 4: 0Edges # between neighbors of 19: 0Edges # between neighbors of 10: 1Edges # between neighbors of 5: 0Network clustering coefficient = 0.1Mean distance between nodes in network (based on limited sample!): 1Log of network size: 2.99573227355399So, small world coefficient would be 2.99573227355399Composing the input file for gnuplot processor...File is test-network.gpComposing the input file for pajek processor...File is test-network.netFinished composing file for pajek processorNetwork processing completed, end time: 15:31:28Seconds elapsed since start: 0
22
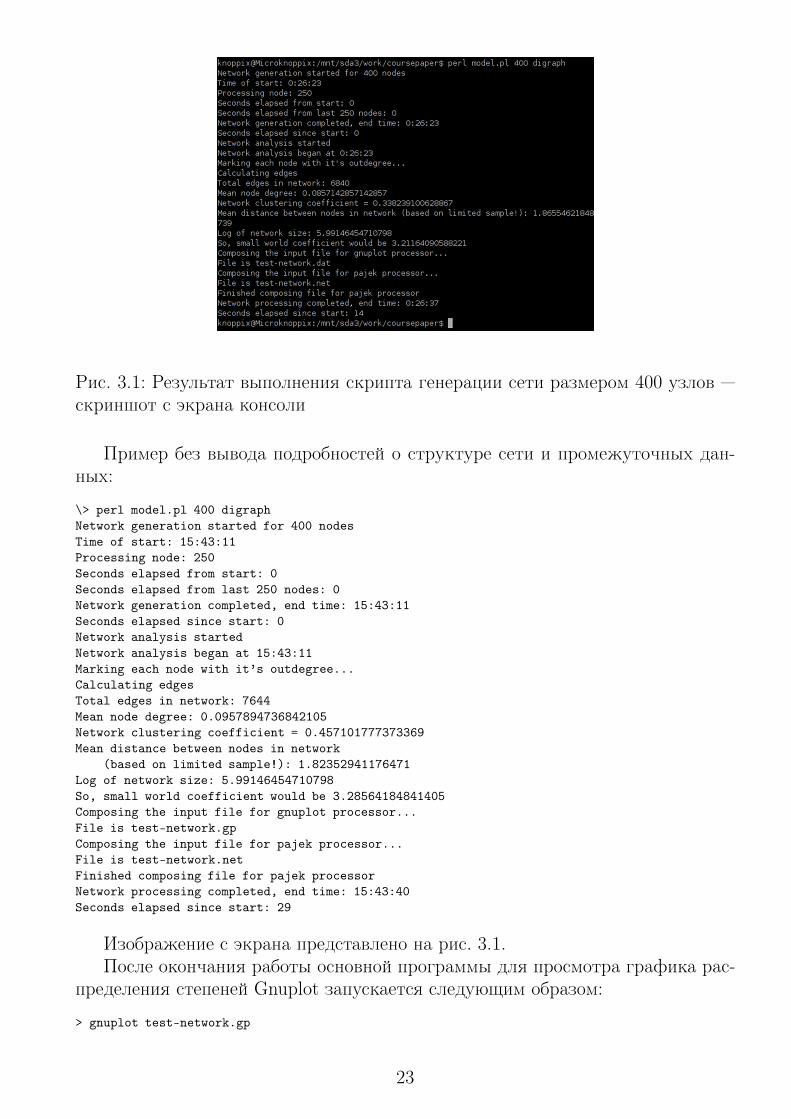
Рис. 3.1: Результат выполнения скрипта генерации сети размером 400 узлов —скриншот с экрана консоли
Пример без вывода подробностей о структуре сети и промежуточных дан-ных:
\> perl model.pl 400 digraphNetwork generation started for 400 nodesTime of start: 15:43:11Processing node: 250Seconds elapsed from start: 0Seconds elapsed from last 250 nodes: 0Network generation completed, end time: 15:43:11Seconds elapsed since start: 0Network analysis startedNetwork analysis began at 15:43:11Marking each node with it’s outdegree...Calculating edgesTotal edges in network: 7644Mean node degree: 0.0957894736842105Network clustering coefficient = 0.457101777373369Mean distance between nodes in network
(based on limited sample!): 1.82352941176471Log of network size: 5.99146454710798So, small world coefficient would be 3.28564184841405Composing the input file for gnuplot processor...File is test-network.gpComposing the input file for pajek processor...File is test-network.netFinished composing file for pajek processorNetwork processing completed, end time: 15:43:40Seconds elapsed since start: 29
Изображение с экрана представлено на рис. 3.1.После окончания работы основной программы для просмотра графика рас-
пределения степеней Gnuplot запускается следующим образом:
> gnuplot test-network.gp
23
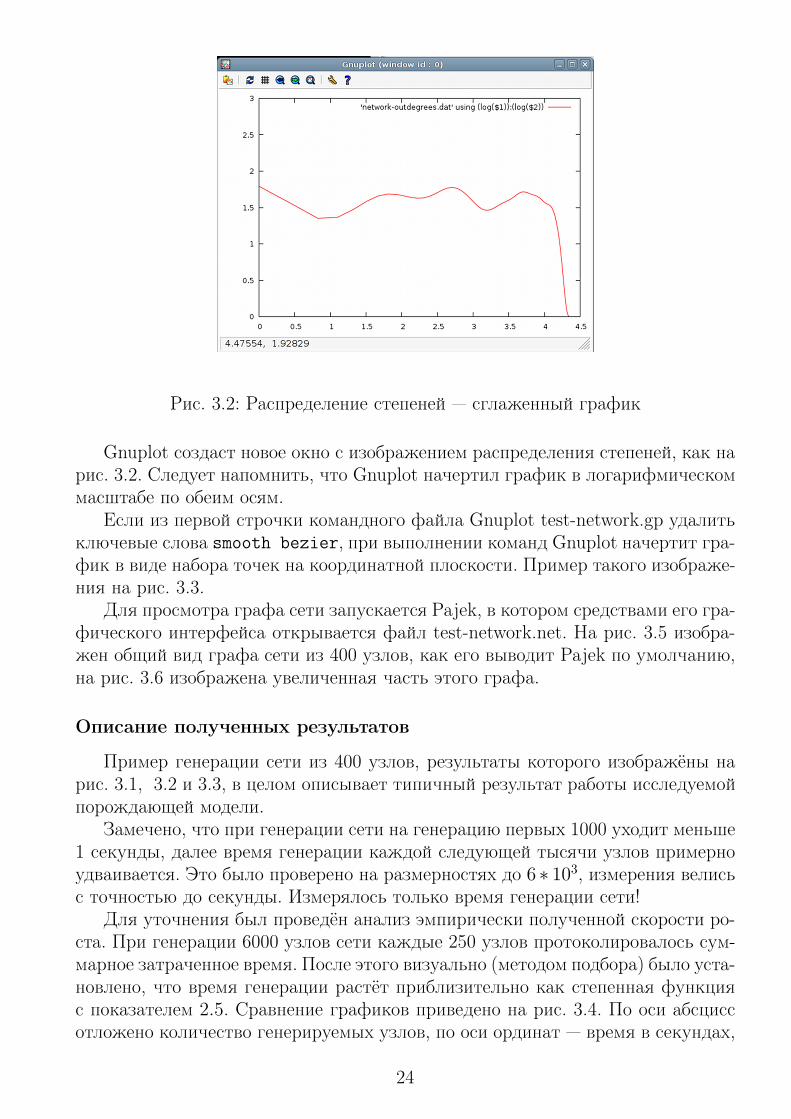
Рис. 3.2: Распределение степеней — сглаженный график
Gnuplot создаст новое окно с изображением распределения степеней, как нарис. 3.2. Следует напомнить, что Gnuplot начертил график в логарифмическоммасштабе по обеим осям.
Если из первой строчки командного файла Gnuplot test-network.gp удалитьключевые слова smooth bezier, при выполнении команд Gnuplot начертит гра-фик в виде набора точек на координатной плоскости. Пример такого изображе-ния на рис. 3.3.
Для просмотра графа сети запускается Pajek, в котором средствами его гра-фического интерфейса открывается файл test-network.net. На рис. 3.5 изобра-жен общий вид графа сети из 400 узлов, как его выводит Pajek по умолчанию,на рис. 3.6 изображена увеличенная часть этого графа.
Опиcание полученных результатов
Пример генерации сети из 400 узлов, результаты которого изображёны нарис. 3.1, 3.2 и 3.3, в целом описывает типичный результат работы исследуемойпорождающей модели.
Замечено, что при генерации сети на генерацию первых 1000 уходит меньше1 секунды, далее время генерации каждой следующей тысячи узлов примерноудваивается. Это было проверено на размерностях до 6 ∗ 103, измерения велисьс точностью до секунды. Измерялось только время генерации сети!
Для уточнения был проведён анализ эмпирически полученной скорости ро-ста. При генерации 6000 узлов сети каждые 250 узлов протоколировалось сум-марное затраченное время. После этого визуально (методом подбора) было уста-новлено, что время генерации растёт приблизительно как степенная функцияс показателем 2.5. Сравнение графиков приведено на рис. 3.4. По оси абсциссотложено количество генерируемых узлов, по оси ординат — время в секундах,
24
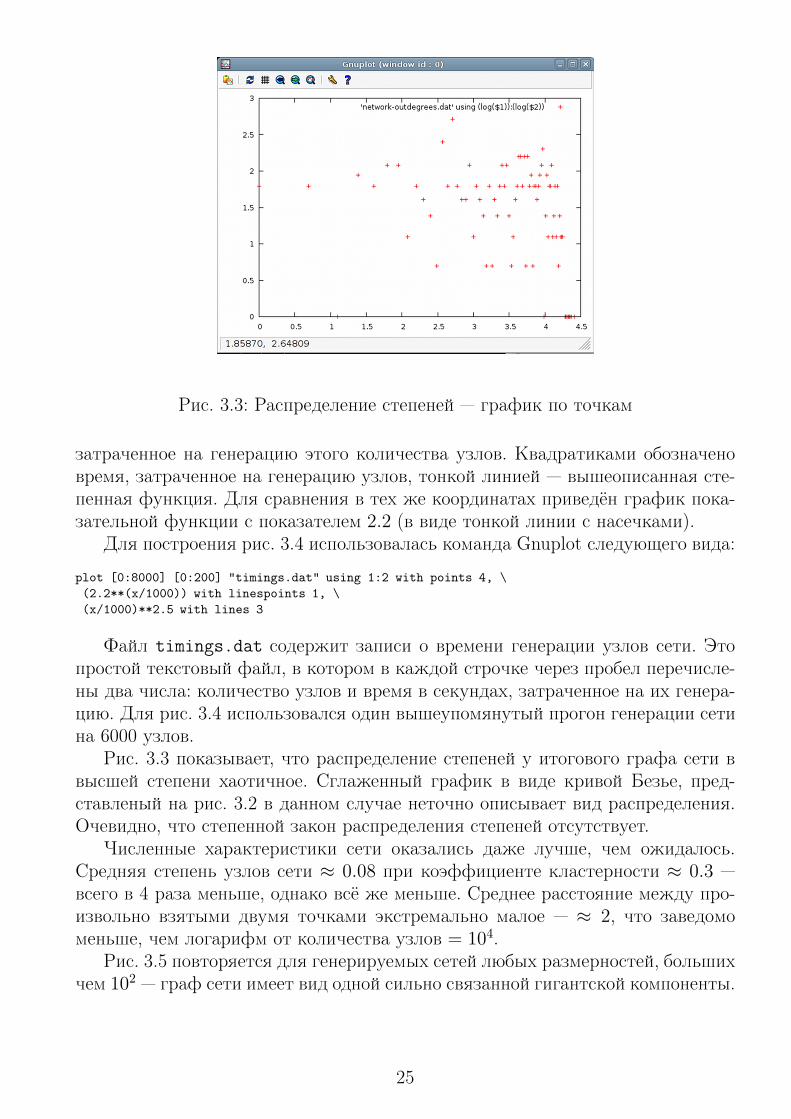
Рис. 3.3: Распределение степеней — график по точкам
затраченное на генерацию этого количества узлов. Квадратиками обозначеновремя, затраченное на генерацию узлов, тонкой линией — вышеописанная сте-пенная функция. Для сравнения в тех же координатах приведён график пока-зательной функции с показателем 2.2 (в виде тонкой линии с насечками).
Для построения рис. 3.4 использовалась команда Gnuplot следующего вида:
plot [0:8000] [0:200] "timings.dat" using 1:2 with points 4, \(2.2**(x/1000)) with linespoints 1, \(x/1000)**2.5 with lines 3
Файл timings.dat содержит записи о времени генерации узлов сети. Этопростой текстовый файл, в котором в каждой строчке через пробел перечисле-ны два числа: количество узлов и время в секундах, затраченное на их генера-цию. Для рис. 3.4 использовался один вышеупомянутый прогон генерации сетина 6000 узлов.
Рис. 3.3 показывает, что распределение степеней у итогового графа сети ввысшей степени хаотичное. Сглаженный график в виде кривой Безье, пред-ставленый на рис. 3.2 в данном случае неточно описывает вид распределения.Очевидно, что степенной закон распределения степеней отсутствует.
Численные характеристики сети оказались даже лучше, чем ожидалось.Средняя степень узлов сети ≈ 0.08 при коэффициенте кластерности ≈ 0.3 —всего в 4 раза меньше, однако всё же меньше. Среднее расстояние между про-извольно взятыми двумя точками экстремально малое — ≈ 2, что заведомоменьше, чем логарифм от количества узлов = 104.
Рис. 3.5 повторяется для генерируемых сетей любых размерностей, большихчем 102 — граф сети имеет вид одной сильно связанной гигантской компоненты.
25
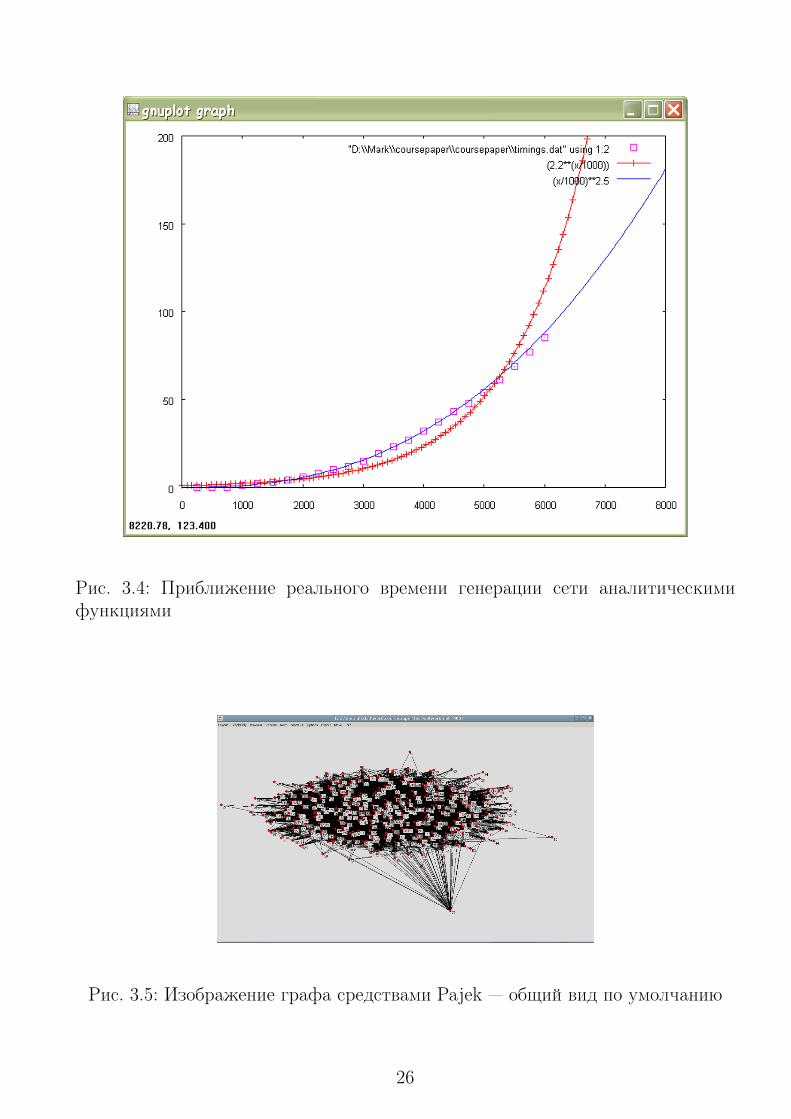
Рис. 3.4: Приближение реального времени генерации сети аналитическимифункциями
Рис. 3.5: Изображение графа средствами Pajek — общий вид по умолчанию
26

Рис. 3.6: Изображение графа средствами Pajek — укрупнённое изображениечасти графа
27

Глава 4
Заключение
Таким образом, в результате выполнения работы была построена взаимосвя-занная цепь инструментов, реализующая генерацию и анализ модели сложнойсети. Для проверки работоспособности цепи инструментов предложена простаяпорождающая модель сложной сети. Удалось сгенерировать сети размером до104 узлов, анализировать за приемлемое время — до 103 узлов. Анализ свойствпорождённой сети показал следующее:
1 Основные затраты по времени приходятся на анализ сети, по сравнениюсо временем, которое тратится на её генерацию.
2 Время на генерацию сети растёт приблизительно как степенная функ-ция с показателем 2.5: t(n) ≈ n2.5, что вытекает из необходимости придобавлении нового узла проверять условие присоединения для всех ужесуществующих узлов сети.
3 У порождаемой сети отсутствует степенной закон распределения степенейузлов. Более того, сложно вообще выявить какую-либо закономерность враспределении степеней.
4 Наблюдается эффект малых миров, причём при рассматриваемых раз-мерностях (≤ 103 узлов) вместо ожидаемых 5 степеней отделимости на-блюдается всего 2.
5 Коэффициент кластерности фактически удовлетворяет характеристиче-скому неравенству, однако, с менее значительным коэффициентом, чеможидалось.
Полученные результаты и цепь инструментов могут быть использованы длядальнейших исследований математических моделей реальных сложных сетей.
28

Литература
[1] The Structure and Functions of Complex Networks, M. E. J. Newman, 2003,SIAM Review, vol. 45, No. 2, pp. 167–256.
[2] Statistical Mechanics of Complex Networks, Reka Albert and Albert-LaszloBarabasi, 2001, arXiv:cond-mat/0106096v.
[3] The Perl Programming Language [В Интернете] // Веб-узел Perl. — 4 марта2010. — http://www.perl.org.
[4] The Dynamic Languages Company: Perl, Python and Tcl — ActiveState [ВИнтернете] / ActiveState Software // Веб-узел ActiveState Perl. — 4 марта2010. — http://www.activestate.com/
[5] Gnuplot homepage [В Интернете] // Веб-узел Gnuplot. — 4 марта 2010. —http://www.gnuplot.info.
[6] start — Pajek wiki [В Интернете] // Pajek wiki. — 4 марта 2010. —http://pajek.imfm.si/doku.php.
29





























