Embed Size (px)
Citation preview

“AÑO DE LA INTEGRACIÓN NACIONAL Y EL RECONOCIMIENTO DE NUESTRA DIVERSIDAD”
FACULTAD DE CIENCIAS ECONÓMICAS
TEMA: MODELO ECONÓMETRICO DEL CONSUMO PRIVADO ENTRE LOS AÑOS 1995 Y 2011 EN EL PERÚ
*ALUMNOS: DELGADO ARAGÓN, RODRIGO 10120132 IBAÑEZ CAMPOS, MARCIA 10120151 PAMPAS OGOSI, LILIANA ELIZABETH 10120174 QUERHUAYO HUAMANÍ, JESSICA 10120181
*PROFESORA: CASTAÑEDA SALDAÑA, BEATRIZ
*CURSO: ECONOMETRÍA I *CICLO: 5° *AULA: 214 *TURNO: MAÑANA
2012

Página 2
INDICE
I.-INDICE ............................................................................................................................................................... 2 II.-RESUMEN ......................................................................................................................................................... 3 III.- PLANTEAMIENTO DEL PROBLEMA ................................................................................................................. 3
3.1.-Formulació del problema IV.-OBJETIVOS ....................................................................................................................................................... 4 4.1.-Objetivos generales
4.2.- Objetivos específicos V.- MARCO TEORICO Y CONCEPTUAL ................................................................................................................... 4
5.1. Consumo privado, producto bruto interno e impuesto VI.-METODOLOGIA ............................................................................................................................................... 5 VII.- RESULTADOS ................................................................................................................................................. 6
7.1.-Estimación por MCO y análisis del modelo ..................................................................................... 6 7.2.-Cumplimiento de los supuestos ...................................................................................................... 7
7.2.1.- No normalidad de las perturbaciones .......................................................................... 7 a. Test Jarque Bera b. Prueba de Kolgomorov-Smirnov
7.2.1.-Multicolinealidad ........................................................................................................... 8 7.2.2.1.-Pruebas para la detección ............................................................................ 8
a. Análisis de la Matriz de correlaciones b. Test Farrar - Glauber c. Regresiones auxiliares
7.2.3.- Heterocedasticidad ...................................................................................................... 9 7.2.3.1.- Predicciones de la Variable Dependiente .................................................... 9 7.2.3.2.- Análisis del Gráfico de los residuos (Errores/ Exógenas) ............................. 9 7.2.3.3.- Pruebas para la detección .......................................................................... 10
a. Prueba de White b. Test de Breusch – Pagan c. Prueba de ARCH
7.2.4.- Autocorrelación ........................................................................................................... 11 7.2.4.1.- Análisis gráfico de los residuos .................................................................. 12 7.2.4.2.- Pruebas para la detección .......................................................................... 12
a. Prueba de Durbin Watson b. Prueba de Q de Ljung y Box c. Prueba de Breush y Godfrey
7.2.4.3.- Corrigiendo la autocorrelación .................................................................. 13 7.2.4.4.- Contrastes individuales sobre los coeficientes .......................................... 16
7.2.5.- Quiebre estructural - Análisis recursivos ................................................................... 17 7.2.5.1.- Pruebas para la detección .......................................................................... 17
a. Test de coeficientes recursivos b. Prueba Cusum c. Prueba Cusum Cuadrado d. Test predictivo de un periodo e. Test predictivo de n periodos f. Test de chow
7.2.5.2.- Corrección del quiebre estructural y análisis de la causa del quiebre. ...... 21 7.3.- Modelo completo ......................................................................................................................... 25
7.4.- Pronóstico .................................................................................................................................... 26 VIII.- CONCLUSIONES .......................................................................................................................................... 27 IX.-BIBLIOGRAFÍA ................................................................................................................................................ 28 X.-ANEXOS .......................................................................................................................................................... 29

Página 3
I. RESUMEN El siguiente trabajo tiene como objetivo presentar un modelo que permita estimar el comportamiento de la función consumo privado en el Perú. Para ello, se ha utilizado las variables producto bruto interno e impuestos con datos trimestrales de los años 1995 y 2011 sustentados en la teoría económica. En la primera parte de este estudio se encuentran el marco teórico del consumo, así como una formulación del modelo. En la segunda parte, utilizamos contrastes para analizar la presencia de multicolinealidad; apreciar si hay normalidad de las perturbaciones gracias a los test de JARQUER-BERA y la prueba de Kolmogorov-Smirnov. Así como también analizar si el modelo presenta heterocedasticidad, para ello utilizamos los diferentes test y pruebas. Además, analizamos si hay presencia de autocorrelación con diferentes contrastes como por ejemplo la prueba de Durbin-Watson. Por otro lado, el test de Chow, la prueba de Cusum, entre otros, nos servirán para saber si hay evidencia de un quiebre estructural. Finalmente, se hace un análisis de todas estas pruebas y se da breves conclusiones. II. PLANTEAMIENTO DEL PROBLEMA Cuando se desarrolla una estimación de función consumo privado para nuestro país, primero debemos elegir las variables que afectarían esta función y en qué modo, nuestra teoría económica por ejemplo nos dice que el ingreso de los peruanos además de los impuestos serian las variables que afectan el consumo privado. Como bien sabemos el aumento del ingreso para los peruanos hará que el consumo en bienes y servicios aumente, pero el pago de impuestos (sean directos e indirectos) tendrán un efecto negativo, porque si recordamos, el pago de impuestos que deben realizar los peruanos disminuye su ingreso y evita que pueda consumir más. Hemos recurrido a estas dos variables, que para nosotros son las principales y con el cual desarrollaremos nuestro modelo econométrico, sin embargo, debemos precisar que no son las únicas variables que afectan el consumo privado de los peruanos, pero que tomamos como prioritarias para nuestra estimación. Prosiguiendo con nuestra base de datos obtenidas de los cuadros estadísticos del BCR (Banco central de Reserva del Perú) empezaremos a estimar nuestro modelo, luego analizarlo y verificar si no cumple los supuestos como por ejemplo no autocorrelación, no multicolinealidad, no heterocedasticidad, etc. Intentaremos luego corregir nuestro modelo si en caso presentara algo como lo anteriormente nombrado y luego haremos una predicción hasta el año 2020 para el consumo privado.

Página 4
IV. OBJETIVOS
4.1.- GENERAL: Analizar por medio de la teoría económica y de algunas herramientas de econometría básicas la dinámica del consumo privado en la historia peruana de manera trimestral comprendida entre los años de 1995-2011, esto es, después del gran fenómeno que generó la hiperinflación y que presentó niveles tan bajos llegando incluso a cero en el consumo privado y el PBI, esta última variable que nos servirá para explicar esta dinámica junto a la otra variable exógena de los impuestos tomados como los ingresos tributarios del gobierno central.
4.2.- ESPECÍFICOS:
Formular un modelo econométrico sobre el consumo privado peruano.
Analizar el impacto de las variables PBI e impuestos sobre el nivel del consumo privado.
Pronosticar el comportamiento del consumo privado en el Perú.
Estimar econométricamente los parámetros de la teoría, es decir, la del PBI y la de los
impuestos.
V. MARCO TEÓRICO
CONSUMO PRIVADO (Cp) Consumo privado es el valor de todas las compras de bienes y servicios realizados por las unidades familiares, las empresas privadas y las instituciones privadas sin ánimo de lucro. Se incluye en su cálculo las remuneraciones en especie recibidas por los asalariados, la producción de bienes para autoconsumo y el valor imputado por las viviendas ocupadas por sus propietarios. Se excluyen las compras de tierra y edificios para viviendas.
PRODUCTO BRUTO INTERNO (PBI) El PIB es el valor monetario de los bienes y servicios finales producidos por una economía en un período determinado, ya sea por nacionales o por extranjeros residentes. En este caso la información que se utiliza es en periodos trimestrales para todas las variables.
IMPUESTO (T)
Es considerado como uno de los ingresos tributarios del Gobierno central, se encuentran aquí los impuestos directos e indirectos, los cuales son cargas obligatorias que se les da a la población para poder financiar los gatos que realizará el Estado.

Página 5
VI. METODOLOGÍA
Modelo macroeconómico:
( ⏞
⏞
)
Donde: CP = Consumo privado. Y = es el ingreso o el Producto Bruto Interno (PBI). T = impuesto o los ingresos tributarios del gobierno central.
Formulación del modelo:
Contrastando el modelo con la teoría económica, esperamos que finalmente nos lleven a concluir una relación positiva entre el nivel de consumo privado y el PBI así como una relación inversa con los ingresos tributarios que genera el gobierno ya que esta representa la retribución obtenida por los impuestos (directos e indirectos). Así mismo el modelo de consumo privado que pretendemos formular trataría de evidenciar el efecto conjunto medido en términos de crecimiento porcentual del PBI y el ingreso tributario sobre el nivel de consumo privado; en este sentido la forma funcional que adopta nuestro modelo es “log - log”, el cual mide el cambio porcentual en nuestra variable endógena ante un cambio porcentual en nuestras variables exógenas. Nuestro modelo seria el siguiente:
Linealizado equivale a:
Donde:
CP: Consumo privado nominal (mill. S/.)
PBI: Producto Bruto interno o Ingreso nominal (mill. S/.)
T: Ingresos tributarios del GC (mill. S/.) (Sumatoria de impuestos directos e
indirectos)

Página 6
VII. RESULTADOS
7.1. Estimación por MCO y análisis del modelo
Interpretación del modelo:
Sustituyendo los valores obtenidos en el modelo:
Nuestro modelo estimado muestra concordancia con la teoría económica que evidencia una relación positiva con la variable del PBI y una relación negativa con los ingresos tributarios del gobierno que representan los impuestos. Además podemos notar que en el modelo todas las variables se presentan como significativas a un nivel del 5% que a su vez conjuntamente también lo son. Interpretación de los coeficientes:
: Es la constante de intercepto o autónomo. Representa que para un caso hipotético de ausencia de variables explicativas, es decir, no tener la participación del PBI y los impuestos la variación porcentual del consumo privado seria 0.694%.
: Representa la elasticidad del consumo privado respecto al PBI. Nos dice que para un cambio de 1% en el PBI el consumo privado aumenta en 1.02%.
: Representa la elasticidad del consumo privado respecto al ingreso tributario que mide los impuestos. Nos dice que ante un aumento en un punto porcentual de T el consumo privado caerá en una tasa de 0.145%.

Página 7
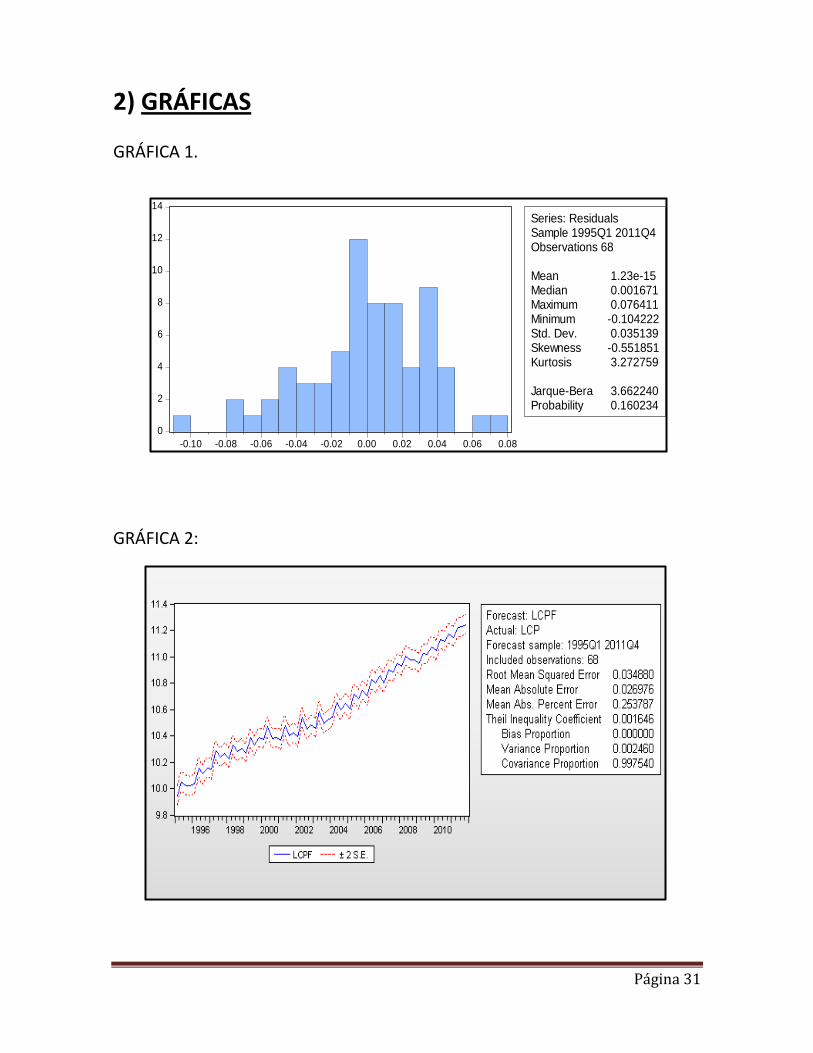
Por último dado el coeficiente de determinación lineal de 0.990207 se entiende que el 99.02% de la variabilidad del consumo privado es explicado por el modelo en análisis. 7.2. CUMPLIMIENTO DE LOS SUPUESTOS 7.2.1 Prueba de Normalidad de los errores
a) Test de JARQUE - BERA
Para contrastar la hipótesis nula de que la serie residual se distribuye como una Normal ya que esta expresión (JB) se distribuye como una con dos grados de libertad.
Prueba de hipótesis:
H0: Las perturbaciones tienen una distribución normal.
H1: Las perturbaciones no tienen una distribución normal.
En la gráfica 1 (anexo), el JB es 3.662240 que es menor a 5.99 (
( )) no se rechaza la
hipótesis nula. Además la probabilidad asociada al rechazo de la hipótesis nula: valores pequeños para esa probabilidad (inferiores a 0.05) indicarían, por tanto, ausencia de normalidad en la distribución de valores de la variable analizada. Decimos entonces que existe una probabilidad de 16.02% (mayor a 5%) de no rechazar la hipótesis nula de normalidad. Por lo tanto aceptamos que los errores se distribuyen normalmente.
b) Prueba de kolmogorov – Smirnov
Es una prueba no paramétrica que se utiliza para determinar la bondad de ajuste de dos distribuciones de probabilidad entre sí; siendo más sensible a los valores cercanos a la mediana que a los extremos de la distribución. Aquí analizamos el valor absoluto de la máxima discrepancia entre la probabilidad acumulada teórica y la frecuencia relativa acumulada (probabilidad acumulada estimada) de la serie residual.
Prueba de hipótesis:
H0: Las perturbaciones tienen una distribución normal.
H1: Las perturbaciones no tienen una distribución normal.
En el cuadro1 (anexo) se observan los siguientes resultados y analizamos: Regla de Decisión:
Con esta prueba afirmamos con una de probabilidad de 43.79% de no rechazar la hipótesis nula y la distribución normal que presentan los residuos.

Página 8
7.2.2 Multicolinealidad La multicolinealidad es un grado de relación lineal existente entre las observaciones de las variables explicativas. Se da cuando algunas de ellas están correlacionadas, incumpliendo uno de los supuestos de partida. Si observamos una alta correlación podría ser señal de multicolinealidad aproximada. 7.2.2.1 Pruebas para la detección
a) Análisis de la Matriz de correlaciones: Se puede observar que hay una fuerte correlación entre las variables regresoras LPBI Y LT lo cual nos da indicio de multicolinealidad aproximada ahora pasamos a ver la determinante de la matriz de correlación entre las variables endógenas:
Determinante c = 0 multicolinealidad
Determinante c =1 no multicolinealidad
El valor que se muestra en Eviews es de 0.030207 que es muy cercano a cero lo que es indicativo que existe multicolinealidad imperfecta.
b) Test de FARRAR-GLAUBER: Test de Ortogonalidad
H0: Las Xi son ortogonales entre si H1: Las Xi no son ortogonales entre si ( multicolinealidad)
Analizando el p valor ofrecido por Eviews podemos decir que se acepta la hipótesis alternativa de que existe multicolinealidad aproximada.

Página 9
c) Regresiones auxiliares Al realizar estas regresiones tendremos una regresión de una de las variables explicativas en función de las otras. Así se muestran en la siguiente tabla los coeficientes de determinación que se obtienen en estas estimaciones:
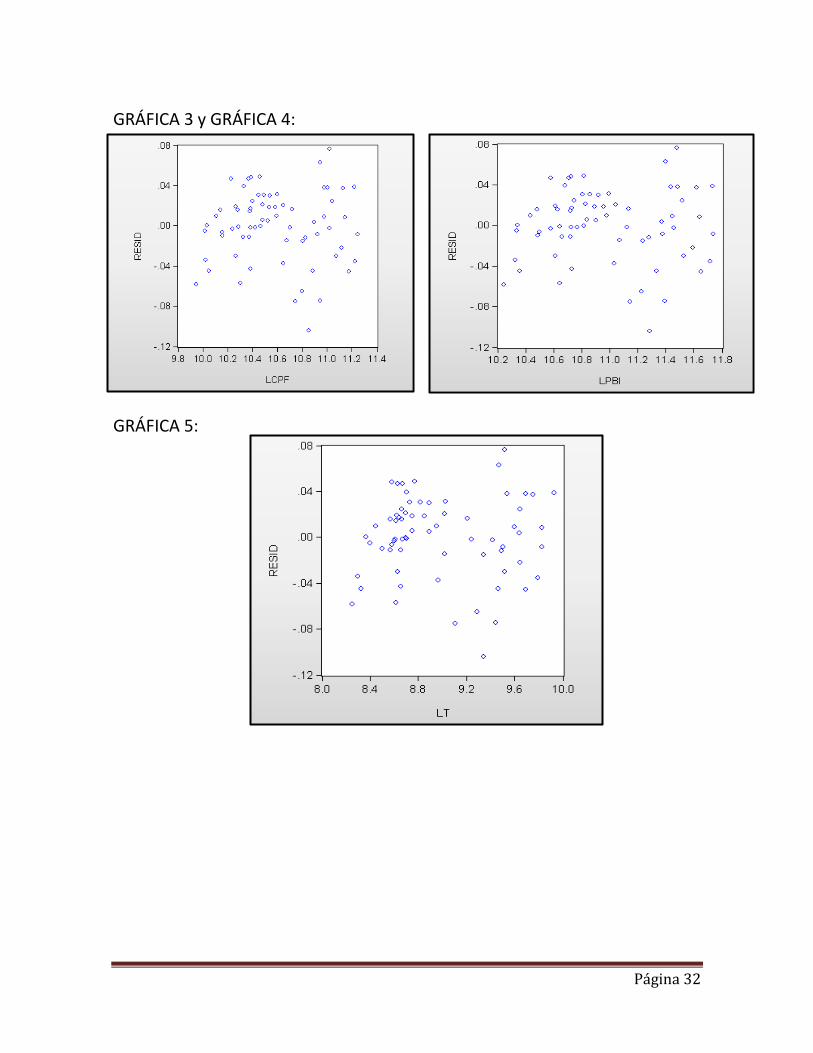
Teniendo en cuenta el alto valor de R2 en las regresiones auxiliares, sigue evidenciando una fuerte presencia de multicolinealidad. Sin embargo si aplicamos la regla practica de Klein la cual nos dice que “no debe haber duda de la presencia de multicolinealidad cuando los valores R2 obtenidos en las regresiones auxiliares exceden el valor general de R2, es decir, el que se obtuvo de la regresión del modelo completo” y siendo que en ninguna de las regresiones auxiliares el R2 supera al general R2 de 0.99, entonces suponemos para nuestro caso practico que no hay suficiente evidencia estadística para afirmar que existe grave presencia de multicolinealidad entre las variables explicativas de nuestro modelo. 7.2.3 Heterocedasticidad Se dice que un modelo de regresión lineal presenta heterocedasticidad cuando la varianza de sus perturbaciones no es constante a lo largo de las observaciones. Esto implica el incumplimiento de una de las hipótesis básicas sobre las que se asienta el modelo de regresión lineal. La presencia de heterocedasticidad no destruye las propiedades de insesgamiento y consistencia de los estimadores de MCO; pero si los estimadores dejan de ser eficientes. 7.2.3.1.-Predicciones de la Variable Dependiente En la gráfica 2 (anexo) es una representación de una predicción dinámica desde el periodo 1995 hasta el 2011, sin embargo, debemos verificar el valor del coeficiente de Theil que debe ser cercano a O, en este caso es 0.001646, esto nos da indicaciones de una buena predicción. 7.2.3.2.-Análisis del Gráfico de los residuos (Errores/ Exógenas): Para detectar qué variables son responsables de la posible heterocedasticidad realizaremos los gráficos de residuos:
Gráfica de LCPF y Resid (anexo: Gráfica3) Parece que LCPF presenta una estructura
aleatoria.

Página 10
Gráfica de LPBI y Resid (anexo: Gráfica4): Parece que LPBI presenta una estructura aleatoria.
Gráfica de LT y Resid(anexo: Gráfica5): Parece que LT presenta una estructura aleatoria.
7.2.3.3.-Pruebas para la detección:
Prueba de hipótesis:
H0: El modelo es homocedástico H1: El modelo presenta problemas de heterocedasticidad
a. Prueba de White
La regresión de White, efectuada para los residuos cuadráticos en función de las variables exógenas, sus cuadrados y sus productos cruzados resulta ser: Como vemos en el (anexo: cuadro 2):
En este caso aceptamos la hipótesis de homocedasticidad, ya que la probabilidad del F - contraste es 0,1641. Se encontraría en la región de rechazo a nivel de significancia de 5% .
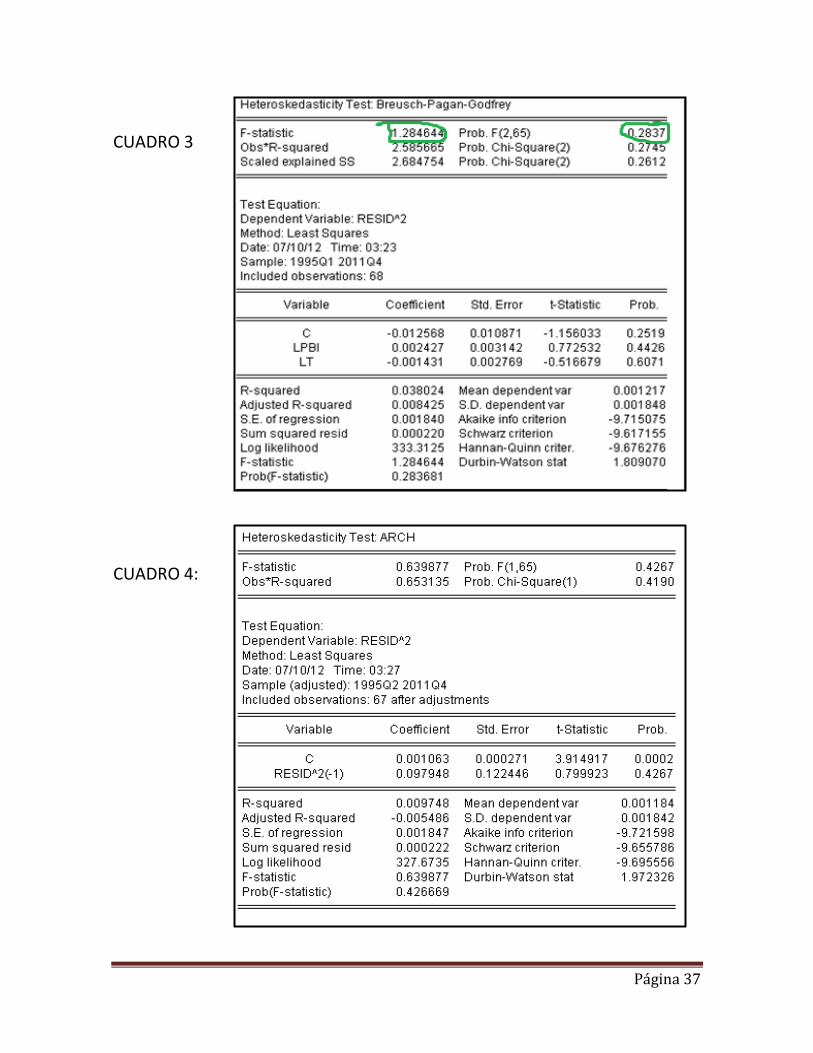
b. Contraste de Breusch-Pagan
La regresión estándar propuesta por BP es:
De modo que en nuestro caso, dado que los residuos están almacenados en la variable RESID, observamos el cuadro 3 (de anexos) y analizamos: El valor del estadístico de contraste para la hipótesis nula de homocedasticidad resulta:
El valor crítico de una Chi cuadrado con k-1 (2) grados de libertad para la nula de homocedasticidad está en torno a 6, de modo que aceptamos la hipótesis nula y rechazamos la hipótesis alternativa de heterocedasticidad.

Página 11
7.2.3.4.-Prueba de heterocedasticidad autorregresiva:
a. Test de ARCH:
Se trata de un test para heterocedasticidad autorregresiva condicionada. Se debe de proveer el número de rezagos. El test es basado en:
Prueba de hipótesis:
Observamos el cuadro 4 (de anexos) El valor del estadístico de contraste para la hipótesis nula de ausencia de ARCH resulta:
0.653116 ( )
El valor critico de una Chi cuadrado con grados de libertad igual al número de residuos al cuadrado rezagados, está en torno a 3.84, de modo que aceptamos la hipótesis nula y rechazamos la hipótesis alternativa. Por lo tanto, el modelo no tiene ARCH, es decir los coeficientes de los errores rezagados al cuadrado son todos iguales a cero. 7.2.4 Autocorrelación La autocorrelación es un problema que se presenta en una regresión cuando existe relación entre los errores de las diferentes observaciones. Simbólicamente se presenta de la siguiente manera: El primer paso para detectar algún tipo de problema, es el análisis gráfico de los residuos. En el gráfico de los residuos, puede verse como los residuos muestran un comportamiento sistemático (línea azul). Se observa un comportamiento de “rachas” tanto positivas como negativas. Este comportamiento es típico de unos residuos correlacionados.
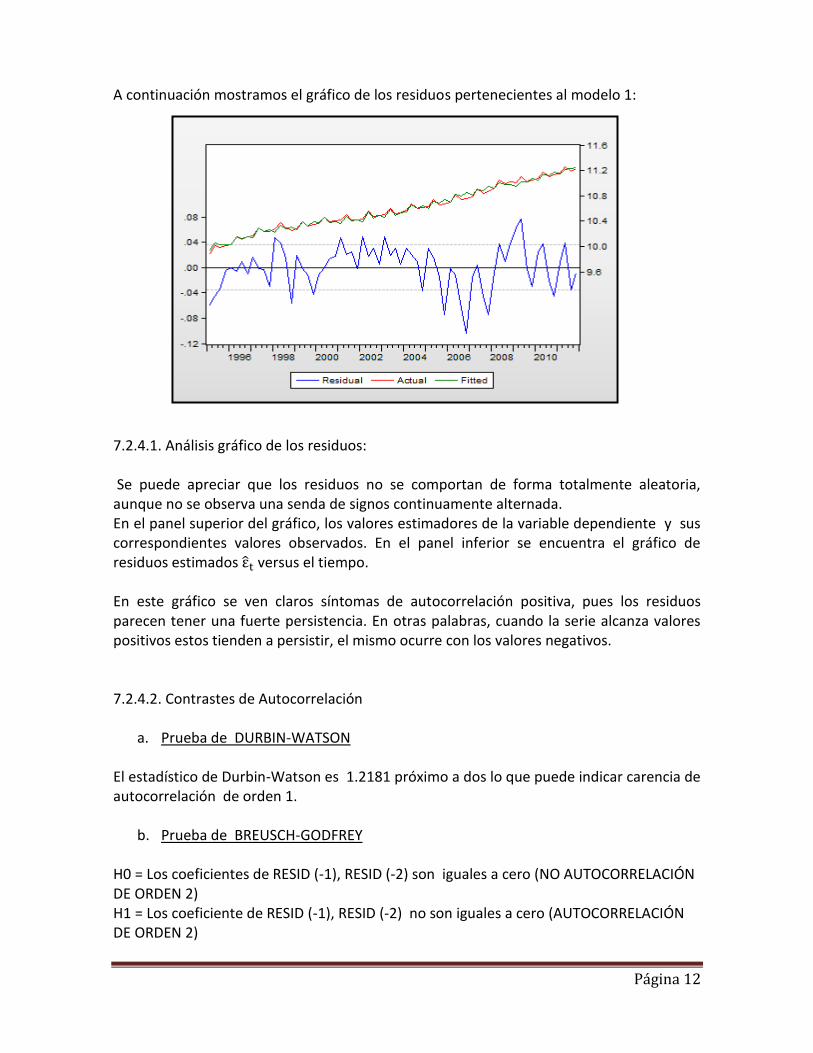
Página 12
A continuación mostramos el gráfico de los residuos pertenecientes al modelo 1: 7.2.4.1. Análisis gráfico de los residuos: Se puede apreciar que los residuos no se comportan de forma totalmente aleatoria, aunque no se observa una senda de signos continuamente alternada. En el panel superior del gráfico, los valores estimadores de la variable dependiente y sus correspondientes valores observados. En el panel inferior se encuentra el gráfico de residuos estimados versus el tiempo. En este gráfico se ven claros síntomas de autocorrelación positiva, pues los residuos parecen tener una fuerte persistencia. En otras palabras, cuando la serie alcanza valores positivos estos tienden a persistir, el mismo ocurre con los valores negativos. 7.2.4.2. Contrastes de Autocorrelación
a. Prueba de DURBIN-WATSON
El estadístico de Durbin-Watson es 1.2181 próximo a dos lo que puede indicar carencia de autocorrelación de orden 1.
b. Prueba de BREUSCH-GODFREY
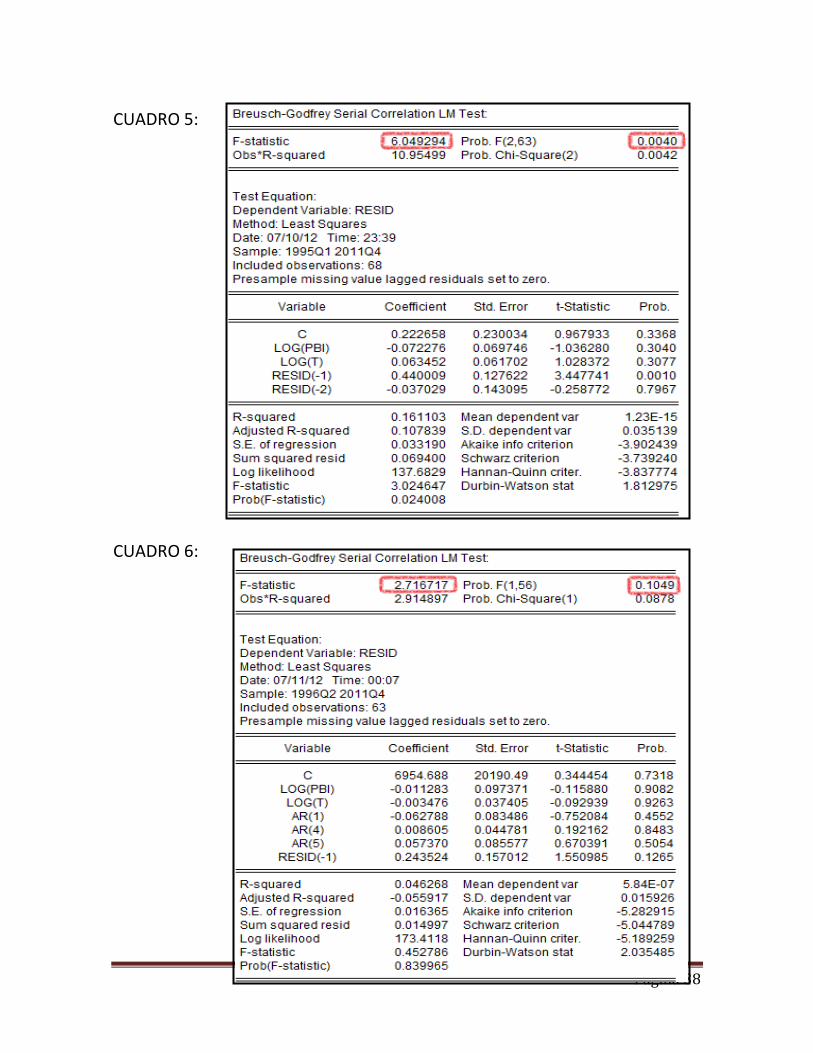
H0 = Los coeficientes de RESID (-1), RESID (-2) son iguales a cero (NO AUTOCORRELACIÓN DE ORDEN 2) H1 = Los coeficiente de RESID (-1), RESID (-2) no son iguales a cero (AUTOCORRELACIÓN DE ORDEN 2)

Página 13
Lo vemos en el cuadro 5 (de anexos): Con un 95% de confianza podemos decir que existe autocorrelación de orden 2, por lo que podemos concluir que nuestro modelo 1, presenta problemas de autocorrelación. Podemos concluir basándonos en los test anteriores, con un α = 0.05 que existe suficiente evidencia empírica como para afirmar la existencia de autocorrelación. Para confirmarlo, podemos hacer una breve inspección gráfica con el correlograma de los residuos y se observa cómo claramente el primer retardo se sale de las bandas de confianza. Es decir, presentan estructura autorregresiva.
c. Correlograma de los residuos
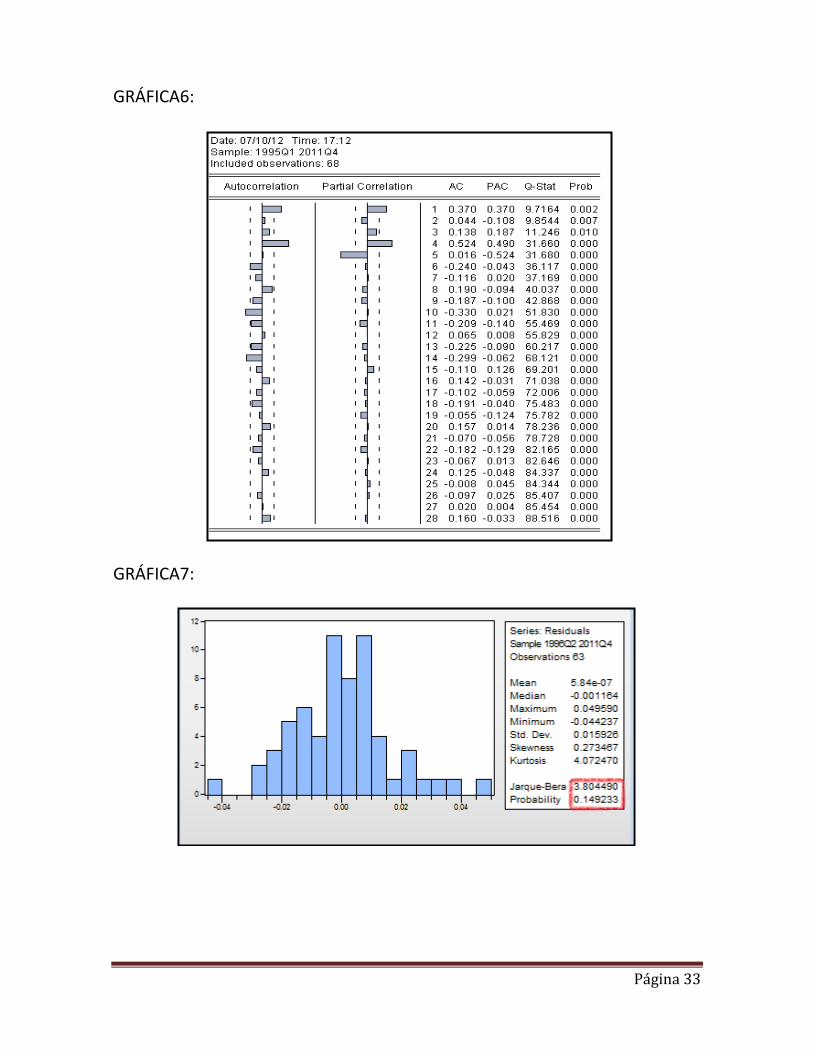
Esto nos servirá para identificar la autocorrelación de orden (p). Así sí el valor estimado se encuentra dentro del límite, este no es significativamente distinto de cero para un nivel de confianza del 95%. (Gráfica 6 de anexos) Las bandas del correlograma están representada por:
√
√
= ± 0.2425 los valores que sean iguales o mayor ha este valor nos indicara el orden de AR (p), por eso escogemos AR(1), AR(4) y AR(5) Una vez visto los contrastes, podemos concluir que nuestro modelo presenta autocorrelación. Por lo tanto lleva consigo las principales consecuencias teóricas de que los estadísticos t y F, quedan invalidados, no podemos hacer contrastes de significatividad sobre los coeficientes. Con el fin de describir lo mejor posible nuestro modelo, trataremos de corregir nuestro modelo 1 introduciendo retardos. 7.2.4.3 Corrigiendo la Autocorrelación: Con el fin de conseguir la mejor descripción de nuestra modelo de consumo privado en función del resto de variables. Introduciremos los 3 retardos AR (1), AR (4) y AR (5) para los datos que se salen de la banda de confianza.
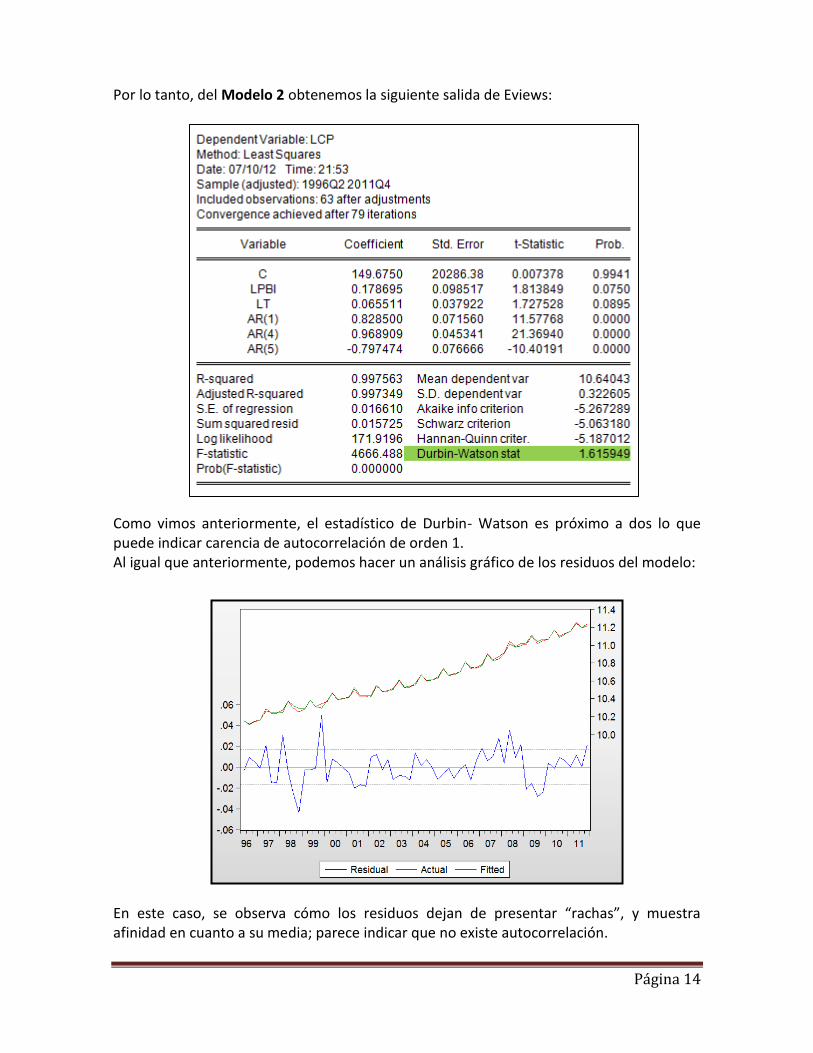
Página 14
Por lo tanto, del Modelo 2 obtenemos la siguiente salida de Eviews: Como vimos anteriormente, el estadístico de Durbin- Watson es próximo a dos lo que puede indicar carencia de autocorrelación de orden 1. Al igual que anteriormente, podemos hacer un análisis gráfico de los residuos del modelo: En este caso, se observa cómo los residuos dejan de presentar “rachas”, y muestra afinidad en cuanto a su media; parece indicar que no existe autocorrelación.

Página 15
Para verificar que se ha corregido la autocorrelación primero veremos si los residuos dejan de presentar algún tipo de estructura autorregresiva. Utilizamos el correlograma de los residuos y parece indicar que no existe autocorrelación, sin embargo lo contrastaremos mediante los utilizados en el modelo 1(modelo original).
Contraste de la autocorrelación de orden 1 usando la Prueba de BREUSCH-GODFREY para el modelo 2.
Se observa claramente en el cuadro6 (de anexos) cómo se acerca la hipótesis de no autocorrelación en el modelo 2 con un 95% de confianza. Ya que el valor del estadístico de contraste es mayor a 0.05.Podemos decir que no existe autocorrelación en el modelo 2, por lo que podemos hacer contrastes de hipótesis acerca de los coeficientes de las variables de nuestro modelo 2.

Página 16
7.2.4.4 Contrastes de significancia para los coeficientes del modelo 2 Significancia Individual:
H0 = βi = 0, donde i = 0,..,5 Los coeficientes individualmente no son significativos H1 = βi ≠ 0, donde i = 0,…,5 Los coeficientes individualmente son significativos
Lo que podemos observar, parece indicar que individualmente todos los coeficientes son iguales a cero con un nivel de un 95% de confianza. Todos presentan la probabilidad del estadístico t mayor al 0.05, a excepción de los coeficientes AR (1), AR (4) y AR (5). No parece que sea un problema muy grave, porque si hacemos un contraste de los coeficientes del modelo con el estadístico F, obtenemos que las variables del modelo sean explicativas. Es decir, plantearíamos: Significancia Conjunta:
H0 = Los coeficientes conjuntamente no son significativo. El modelo “NO explica nada” H1 = Los coeficientes conjuntamente son significativos. El modelo “SI explica a la variable endógena”
Si vemos la probabilidad del estadístico F, es igual a cero. Por lo que con un 95% de confianza los coeficientes de las variables explicativas del modelo 3 aceptamos la hipótesis alternativa, es decir, son significativamente distintos de cero conjuntamente. Podemos concluir que nuestro modelo 2 si es explicativo, y que las conclusiones de los contrastes individuales pueden haberse a la transformación del modelo original. No obstante, cabe destacar que el contraste conjunto indica que el modelo SI es explicativo. TEST DE NORMALIDAD DE LOS RESIDUOS
Para contrastar normalidad en los residuos, utilizamos el test de JARQUE-BERA disponible en Eviews (Gráfica7 de anexos). Las hipótesis de contraste son las siguientes:
Los resultados obtenidos del contraste indican que aceptamos la hipótesis nula con un α = 0.05 de que los residuos se distribuyen como una Normal. Por otro lado, hay que resaltar que para que se distribuyeran como una Normal el coeficiente de Asimetría debería ser próximo a cero (Skewness = 0.273467) y el de apuntamiento debería ser próximo a 3 (Kurtosis = 4.072470) lo cual cumple.

Página 17
7.2.5.-Quiebre estructural Queremos observar si nuestro modelo presenta en algún año quiebre estructural, ya que sabemos que por las políticas económicas, el cambio tecnológico u otros evento de impacto social, ocurridos en el tiempo pueden ocasionar un cambio en la estructura de la relación entre la variable dependiente y la variable independiente, ocasionando así que los parámetros no serán constantes para todo el periodo muestral. 7.2.5.1. Pruebas para el Análisis del modelo de CONSUMO PRIVADO: a. Test de RESIDUOS RECURSIVOS El gráfico que es reportado por Eviews considera la evolución de los residuos recursivos normalizados. Entonces debemos recordar que la varianza del error de predicción esta dado por:
( ) (
( )
)
Por lo que el residuo recursivo vendría dado por:
√( (
)
El error normalizado se distribuye como una normal con media cero y varianza constante (
) y es independiente de s ≠ t, el Eviews reporta su evolución alrededor de cero.
Incluye también una banda de confianza calculada como ±2 veces la desviación estándar en cada observación. Podemos esperar que los valores que se encuentren dentro de la banda de confianza, tengan su valor medio igual a cero.
Análisis del Gráfico:
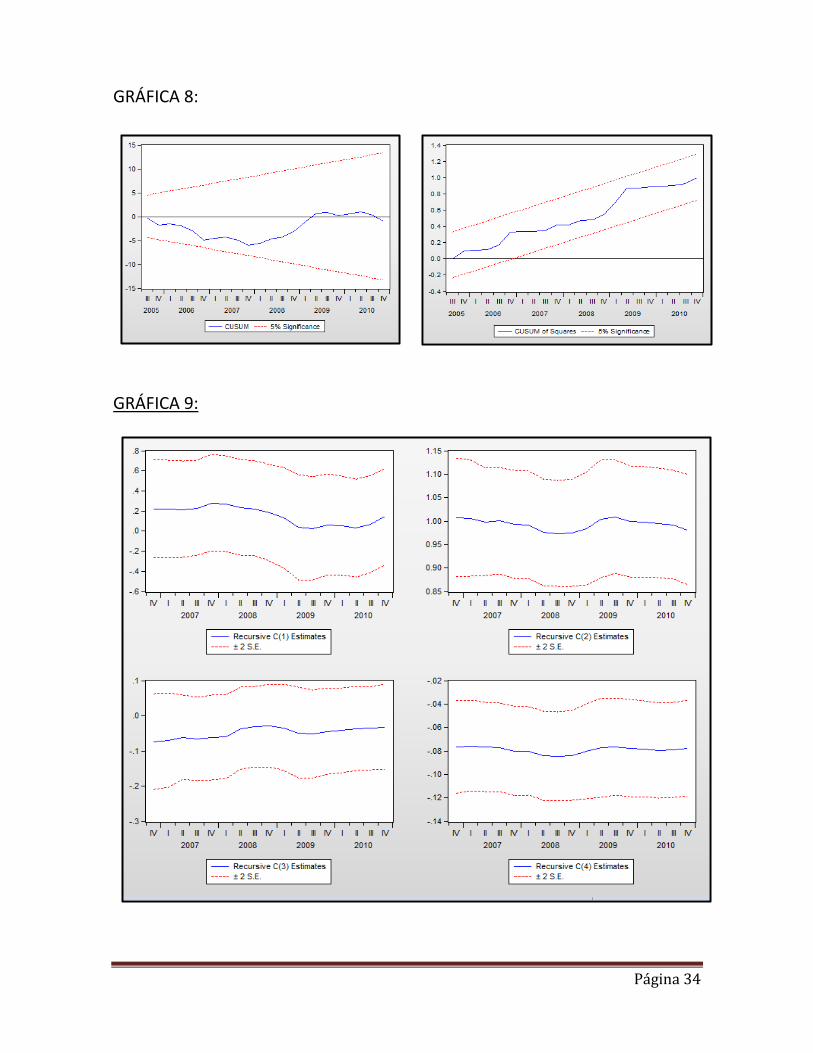
Observamos que tenemos 3 puntos posibles de quiebre que están entre los años 04, 05 y 06 que corresponden a los años 2004, 2005 y 2006, ya que se encuentran fuera de la banda de confianza. Pero daremos cuenta que un rompimiento de banda no asociado a quiebres persistentes o un ensanchamiento de banda nos dará un testimonio débil acerca de presencia de un quiebre estructural, por lo que no estamos en posición de definir aún si existe o no quiebre en esos años o en alguno de esos años observados, pero podría existir inestabilidad en los parámetros. En todo caso debemos desarrollar los demás test.
Página 18
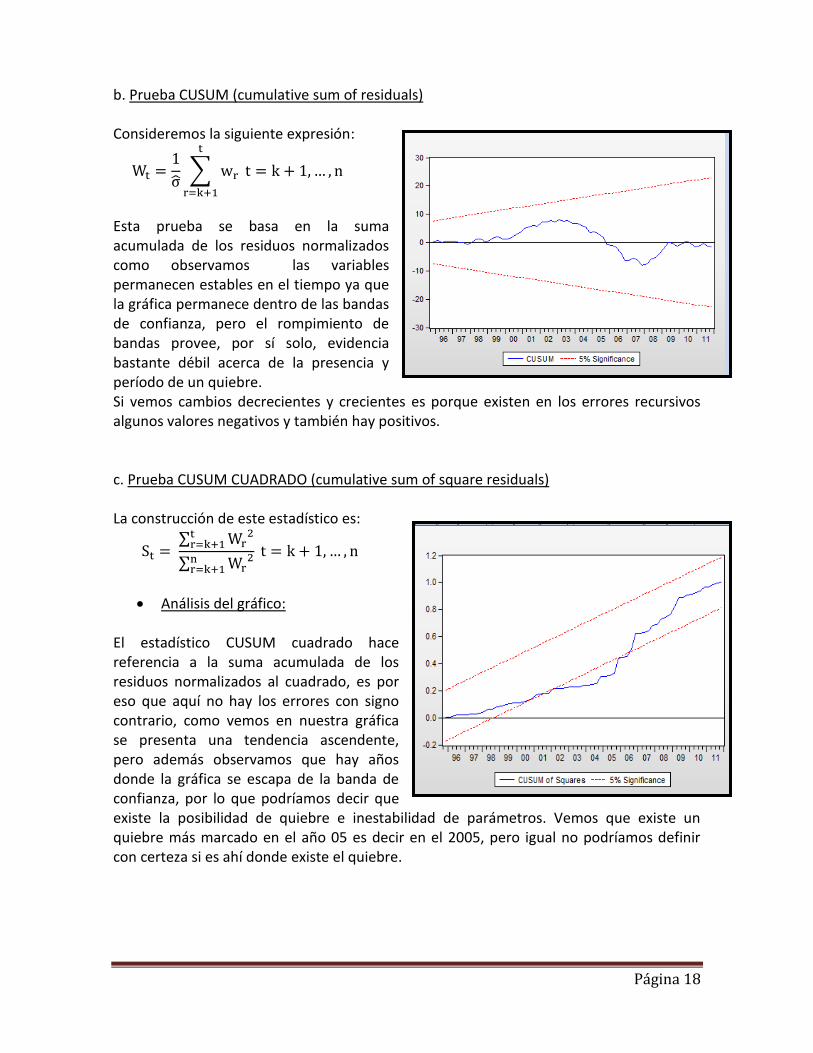
b. Prueba CUSUM (cumulative sum of residuals) Consideremos la siguiente expresión:
∑
Esta prueba se basa en la suma acumulada de los residuos normalizados como observamos las variables permanecen estables en el tiempo ya que la gráfica permanece dentro de las bandas de confianza, pero el rompimiento de bandas provee, por sí solo, evidencia bastante débil acerca de la presencia y período de un quiebre. Si vemos cambios decrecientes y crecientes es porque existen en los errores recursivos algunos valores negativos y también hay positivos. c. Prueba CUSUM CUADRADO (cumulative sum of square residuals) La construcción de este estadístico es:
∑
∑
Análisis del gráfico: El estadístico CUSUM cuadrado hace referencia a la suma acumulada de los residuos normalizados al cuadrado, es por eso que aquí no hay los errores con signo contrario, como vemos en nuestra gráfica se presenta una tendencia ascendente, pero además observamos que hay años donde la gráfica se escapa de la banda de confianza, por lo que podríamos decir que existe la posibilidad de quiebre e inestabilidad de parámetros. Vemos que existe un quiebre más marcado en el año 05 es decir en el 2005, pero igual no podríamos definir con certeza si es ahí donde existe el quiebre.
Página 19
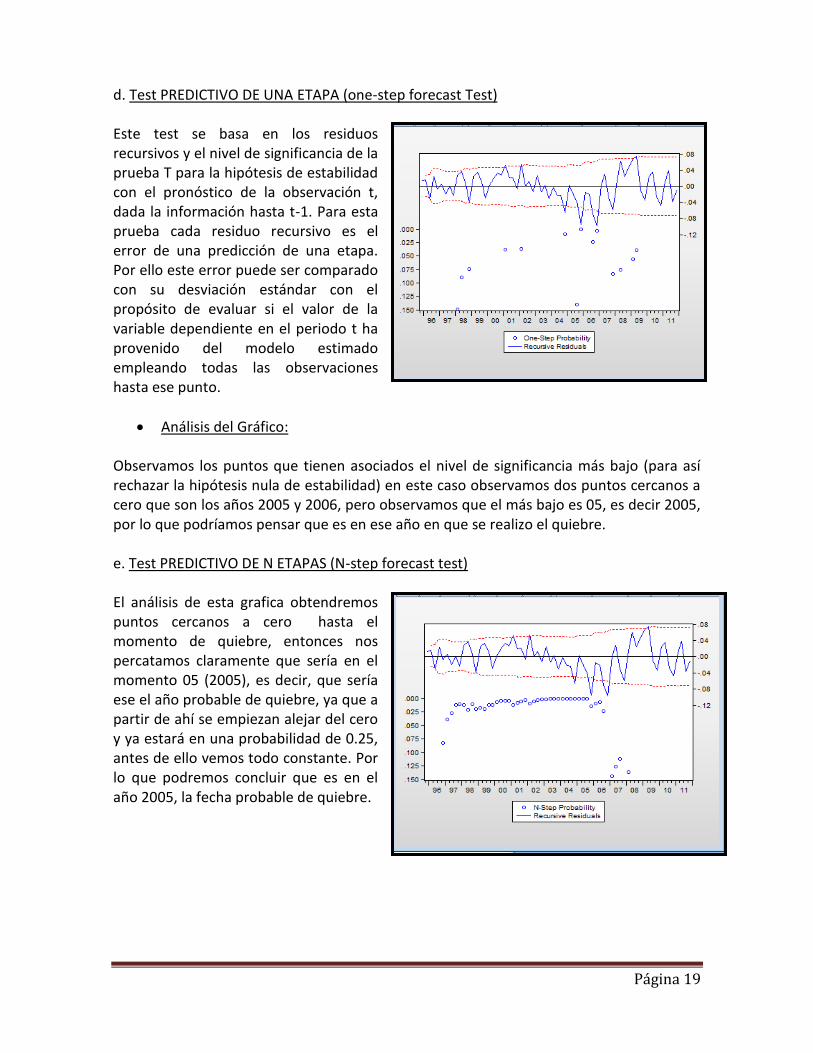
d. Test PREDICTIVO DE UNA ETAPA (one-step forecast Test) Este test se basa en los residuos recursivos y el nivel de significancia de la prueba T para la hipótesis de estabilidad con el pronóstico de la observación t, dada la información hasta t-1. Para esta prueba cada residuo recursivo es el error de una predicción de una etapa. Por ello este error puede ser comparado con su desviación estándar con el propósito de evaluar si el valor de la variable dependiente en el periodo t ha provenido del modelo estimado empleando todas las observaciones hasta ese punto.
Análisis del Gráfico: Observamos los puntos que tienen asociados el nivel de significancia más bajo (para así rechazar la hipótesis nula de estabilidad) en este caso observamos dos puntos cercanos a cero que son los años 2005 y 2006, pero observamos que el más bajo es 05, es decir 2005, por lo que podríamos pensar que es en ese año en que se realizo el quiebre. e. Test PREDICTIVO DE N ETAPAS (N-step forecast test) El análisis de esta grafica obtendremos puntos cercanos a cero hasta el momento de quiebre, entonces nos percatamos claramente que sería en el momento 05 (2005), es decir, que sería ese el año probable de quiebre, ya que a partir de ahí se empiezan alejar del cero y ya estará en una probabilidad de 0.25, antes de ello vemos todo constante. Por lo que podremos concluir que es en el año 2005, la fecha probable de quiebre.

Página 20
f. Test de COEFICIENTES RECURSIVOS (recursive Coefficients)
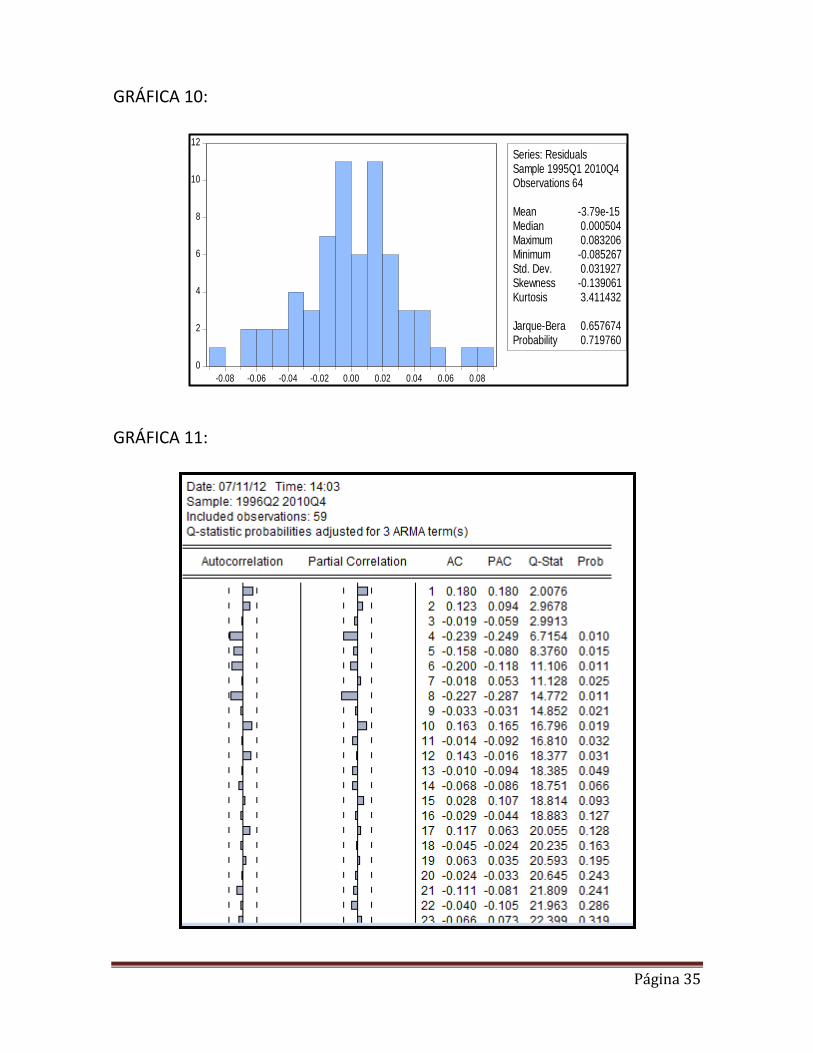
En este test se estiman los coeficientes del modelo de manera recursiva, si el modelo es estable entonces los coeficientes deberían converger y la varianza del estimador debería reducirse conforme aumente la muestra. Podemos observar en nuestras gráficas que el tamaño de las bandas van variando en lo que el tamaño de muestra va creciendo lo que podremos concluir que podría existir quiebre estructural, debemos ver las fluctuaciones abruptas de los coeficientes recursivos y el ensanchamiento de bandas, es por ello que también podemos decir que el caso más preocupante es del C(3) ya que experimenta una fluctuación abrupta y la convergencia se desvía hacia un valor menor.

Página 21
g. Test de CHOW Ya que debemos escoger un año para verificar el quiebre, seleccionaremos el 2005 ya que ha sido el año que más cambios ha presentado en los test anteriores y aquí comprobaremos si nuestra teoría es correcta, que en ese año hubo quiebre estructural. El test consiste en dividir a la muestra en dos submuestras separadas por el punto en el cual suponemos que existe quiebre. La hipótesis de la siguiente forma:
H0: Existe estabilidad estructural en el modelo. H1: Existe un comportamiento distinto en cada grupo.
La hipótesis nula (estabilidad estructural) y alternativa (cambio estructural) se expresan en términos de parámetros: Vemos que la hipótesis nula no hay cambio estructural, en cambio en la hipótesis alternativa si lo hay, verificamos con el estadístico F:
' '
1 1 2 2( , 2 )' '
1 1 2 2
[ ´ ( )] /[ ( ) ( )] /
( ) / ( 2 ) ( ) / ( 2 )k T k
e e e e e e kSCE MR SCE MSR Kes F
SCE MSR T k e e e e T k
La probabilidad asociada al estadístico F obtenido indica claramente (en el cuadro7 de anexos) con un nivel de significancia del 5%, que se encuentra con la evidencia suficiente para rechazar la hipótesis nula de estabilidad. Fcalc ˃ F observado además que 0.0138 < 0.025 entonces rechazamos hipótesis nula y aceptamos que existe quiebre estructural en el año 2005. 7.2.5.2. CORRECCIÓN DEL QUIEBRE ESTRUCTURAL Para la corrección del quiebre estructural de la función de consumo privado se genera una variable dicotómica (variable Dummy) con las siguientes características:
Dummy = 0 si ≤ primer trimestre del 2005 Dummy =1 si ˃ primer trimestre del 2005
2
2
1
2
0
1
1
1
1
0
0 :
kk
H
2
2
1
2
0
1
1
1
1
0
1 :
kk
H

Página 22
Nuestro modelo ahora estaría representado por:
Estimación por MCO e interpretación del modelo: La función de regresión poblacional se puede expresar como:
( )
Modelo estimado:
Donde se puede observar que a diferencia del modelo anterior solo los regresores LOG (PBI) y la DUMMY son significativos para la explicación del modelo y la estimación del promedio del consumo privado en el Perú. Esto con una significancia del 5% y constatándolo con las probabilidades de cada coeficiente que son menores.

Página 23
Interpretación de los coeficientes:
: Es la constante de intercepto o autónomo. Representa que para un caso hipotético de ausencia de variables explicativas, es decir, no tener la participación del PBI y los impuestos la variación porcentual del consumo privado seria 0.066% para el periodo de 2005Q2 hasta el 2011Q4.
Representa que para un caso hipotético de ausencia de variables explicativas, es decir, no tener la participación del PBI y los impuestos la variación porcentual del consumo privado seria 0.1436% para el periodo de 1995Q1 hasta el 2005Q1.
: Representa la elasticidad del consumo privado respecto al PBI. Nos dice que para un cambio de 1% en el PBI el consumo privado aumenta en 0.9806%.
: Representa la elasticidad del consumo privado respecto al ingreso tributario que mide los impuestos. Nos dice que ante un aumento en un punto porcentual de T el consumo privado caerá en una tasa de 0.0321%.
: Es el efecto diferencial en el consumo privado en el Perú para el periodo del segundo trimestre del 2005 hasta el último trimestre del año 2011. Se estima que la variación porcentual del consumo medio por ese periodo será 0.08% menos que el periodo anterior.
Por ultimo dado el coeficiente de determinación lineal de 0.990581 se entiende que el 99.06% de la variabilidad del consumo privado es explicado por el modelo en análisis. Además que hay significancia conjunta con una prueba F (F-statistic) de 2103.448.
Análisis del modelo corregido por quiebre estructural Como observamos en la Grafica 8 (de anexos) en los test de CUSUM y CUSUM cuadrado la gráfica no se sale de la banda por lo que podemos decir que los errores recursivos son normalizados y podemos observar que ya no hay quiebre. Además en la Gráfica 9 (anexos) de los coeficientes recursivos se encuentran todos dentro de la banda, además observamos que no existen cambios bruscos en la grafica de cada coeficiente ni cambios bruscos en la anchura de la banda, por lo que también podemos decir que no hay presencia de quiebre estructural.

Página 24
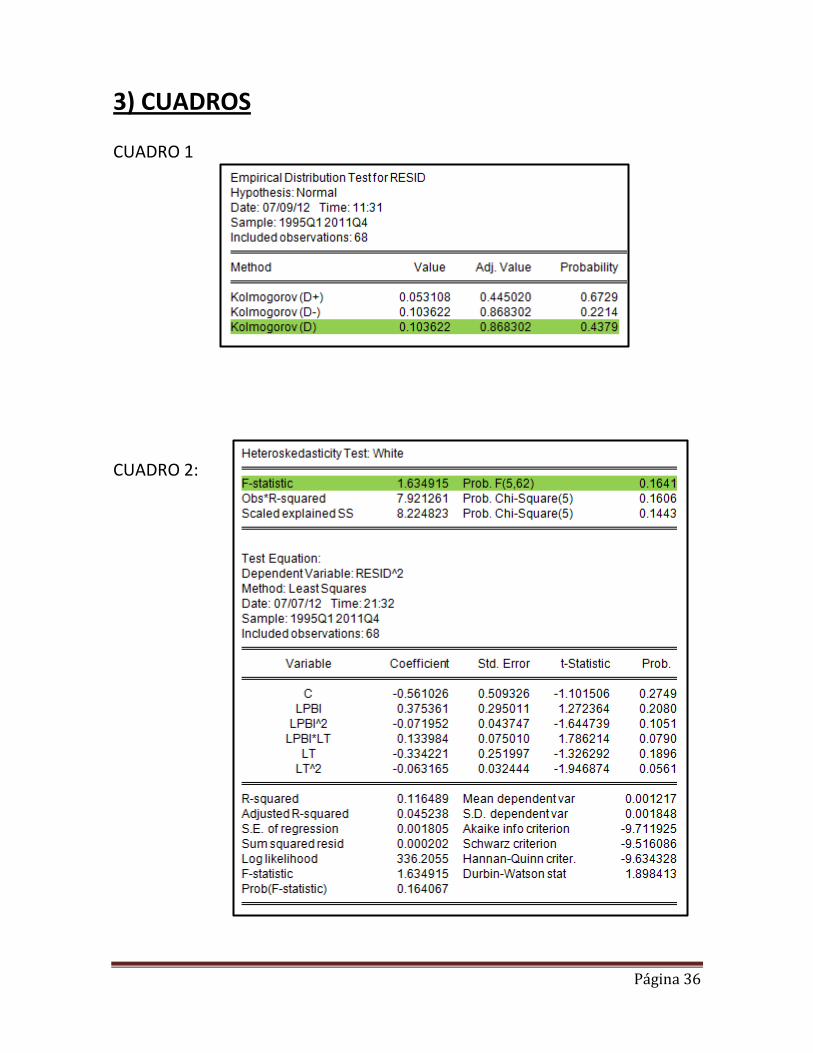
Normalidad de los residuos Para contrastar normalidad en los residuos, utilizamos el test de JARQUE-BERA disponible en Eviews (Gráfica 10 de anexos) Las hipótesis de contraste son las siguientes:
Los resultados obtenidos del contraste indican que aceptamos a hipótesis nula con un α = 0.05 de que los residuos se distribuyen como una Normal. Por otro lado, hay que resaltar que para que se distribuyeran como una Normal el coeficiente de Asimetría debería ser próximo a cero (Skewness = -0.139061) y el de apuntamiento debería ser próximo a 3 (Kurtosis =3.411432) lo cual cumple. Además existe una alta probabilidad de 71.98% (mayor al 5%) de no rechazar la hipótesis nula de normalidad.
¿Por qué ocurrió este cambio estructural en el Perú? El año del quiebre fue en el 2005 y es que en ese año se produce un “BOOM” algunos sectores lo llaman “boom del consumo”. El crecimiento económico en el país permitió que los peruanos tengan mayor acceso a los bienes y servicios. Revisando los datos tenemos que en algunas industrias tienen altas tasas de PBI y del consumo privado. La compra de automóviles aumentó en un 37 % en el año 2005, así que es ahí en que se basa en este aumento tan grande en el consumo privado. ¿Cómo se explicaría este aumento del consumo?
En primer lugar: La existencia del crecimiento económico y del ingreso familiar, lo que nos dará también un aumento en el ingreso disponible per cápita en promedio 6.2% entren2005 y 2011, lo que se refleja en un aumento del consumo privado de 4.6 %. La pobreza disminuyó desde 48.6% en 2004 a 31.3% en 2010. Esto logró que la clase media aumentara.
En segundo lugar: La mayor competencia en los mercados mediante menores precios e inversiones que aparecieron para satisfacer a los consumidores.
A pesar que existe un bajo nivel de penetración a ciertas industrias, se tiene potencial para desarrollar. El ejemplo más claro es el automovilístico que ha ido aumentando a través de los años incluso ahora se espera que se vendan 185 mil unidades nuevos.
Véase más en: Noticias (anexos)

Página 25
7.3 .MODELO COMPLETO: En este modelo estamos eliminando la autocorrelación y el quiebre estructural producido en el 2005.
En este último modelo observamos que las variables se vuelven insignificantes pero a pesar de ello nuestro modelo sigue siendo significativo y podemos comprobar que ya no existe autocorrelación por la siguiente gráfica (gráfica 11 de anexos) demás ya no hay presencia de quiebre estructural porque se corrige por la variable Dummy.
Página 26
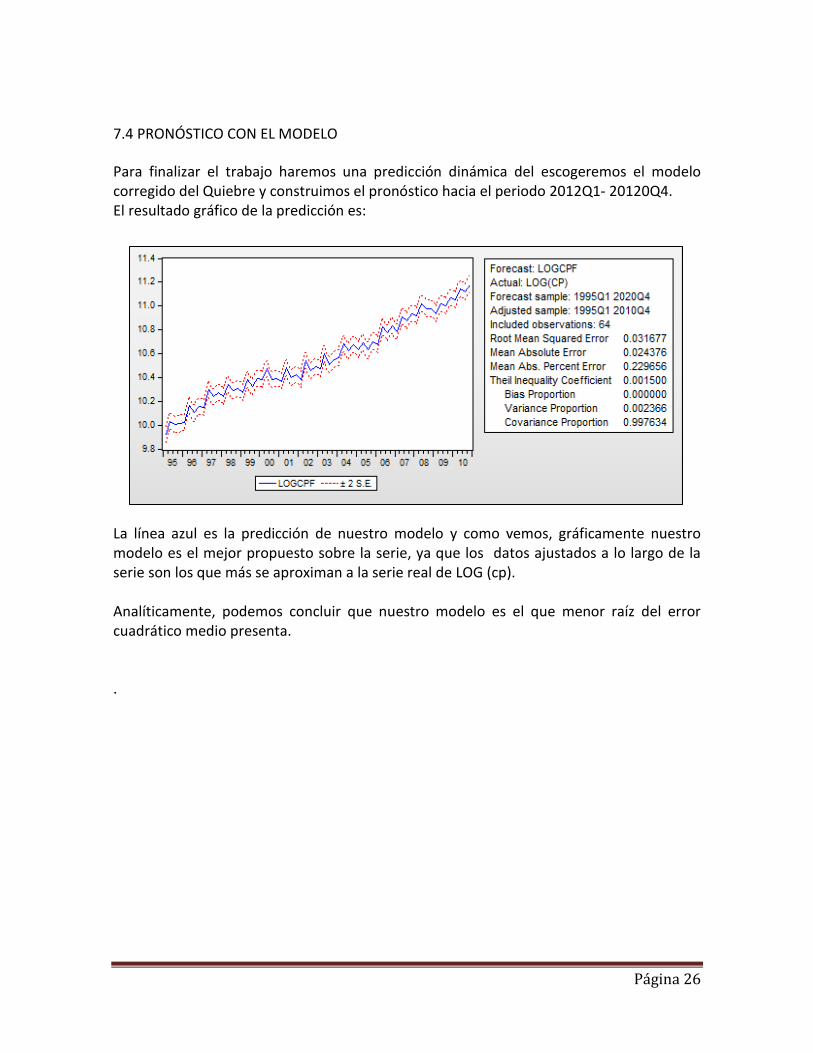
7.4 PRONÓSTICO CON EL MODELO
Para finalizar el trabajo haremos una predicción dinámica del escogeremos el modelo corregido del Quiebre y construimos el pronóstico hacia el periodo 2012Q1- 20120Q4. El resultado gráfico de la predicción es:
La línea azul es la predicción de nuestro modelo y como vemos, gráficamente nuestro modelo es el mejor propuesto sobre la serie, ya que los datos ajustados a lo largo de la serie son los que más se aproximan a la serie real de LOG (cp). Analíticamente, podemos concluir que nuestro modelo es el que menor raíz del error cuadrático medio presenta. .

Página 27
CONCLUSIONES
A partir del modelo consumo privado podemos decir que varía de forma directa con el PBI, pero de forma indirecta con los impuestos. Nuestro modelo presentó homocedasticidad, además no presentó multicolinealidad, los problemas que ocurrieron fue el quiebre estructural producido en el año 2005. Lo cual pudimos arreglarlo en base al aumento de una variable Dummy, aquello fue ocasionado por el aumento del consumo privado, ya que en esos años el ingreso disponible aumentó considerablemente, es por eso que ocasionó aquel BOOM y se vio reflejado en nuestro modelo. El siguiente problema en cuestión fue la autocorrelación que presentaron las variables, lo cual pudimos corregir por nuestros Ar(1), Ar(4) y Ar(5) y al final pudimos crear un modelo que ya no tuviera ni quiebre estructural, ni autocorrelación, además es homocedástico. Este modelo será significativo así que aquí podemos comprobar que tenemos un modelo que puede representar la función del consumo privado en el Perú entre los años 1995 y 2011.

Página 28
BIBLIOGRAFIA
LIBROS:
• GUJARATI, DAMODAR (2010): Econometría. McGraw Hill, 5ra Edición, México.
• NOVALES, ALFONSO (1998): Econometría, McGraw Hill 2da Edición, Madrid.
• Mankiw N. Gregory (2004): ‘Principios de Economía´. McGraw Hill. 3º Edición. España.
• Castro, Juan Francisco “Econometría aplicada”. Lima: Universidad del Pacífico. Centro de Investigación, 2003.
• Banco Central de Reserva del Perú.
• Castro, Juan Francisco y Rivas-Llosa Roddy, “Econometría aplicada”.
• Casas Tragodara, Carlos “Econometría Moderna”
WEB:
http://estadisticas.bcrp.gob.pe/index.asp?sFrecuencia=A
http://www.bcrp.gob.pe/estadisticas/cuadros-anuales-historicos.html

Página 29
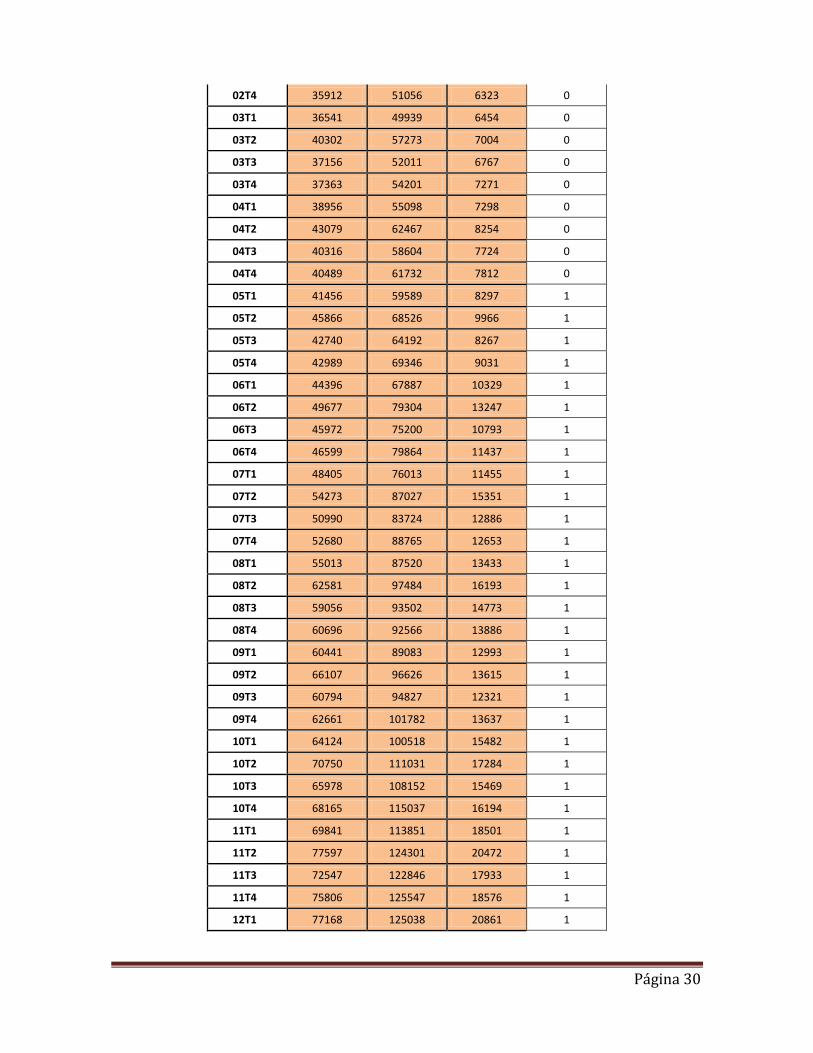
ANEXOS 1) Base de datos
Año/Trim.
Consumo privado
nominal (mill. S/.)
PBI nominal (mill. S/.)
Ingresos tributarios
del GC (mill. S/.)
DUMMY
95T1 19687 28094 3838 0
95T2 22193 31512 4137 0
95T3 21761 30475 4031 0
95T4 22362 30846 4452 0
96T1 22776 31112 4311 0
96T2 25614 36214 5341 0
96T3 24825 33925 4665 0
96T4 25535 35830 4939 0
97T1 25861 35683 5249 0
97T2 29349 41876 6015 0
97T3 27878 39336 5443 0
97T4 27952 40639 5597 0
98T1 28946 39247 5824 0
98T2 31893 43653 6006 0
98T3 29602 41315 5779 0
98T4 28228 42066 5534 0
99T1 29295 40522 5564 0
99T2 32324 45480 5496 0
99T3 30197 42702 5280 0
99T4 31011 45717 5731 0
00T1 31688 45316 5760 0
00T2 35112 49831 5970 0
00T3 32690 45305 5527 0
00T4 32970 45689 5655 0
01T1 33350 44842 5603 0
01T2 36339 50461 5971 0
01T3 33606 46371 5768 0
01T4 33527 47538 5842 0
02T1 34158 45494 5323 0
02T2 38396 53837 6315 0
02T3 35579 49263 6208 0
Página 30
02T4 35912 51056 6323 0
03T1 36541 49939 6454 0
03T2 40302 57273 7004 0
03T3 37156 52011 6767 0
03T4 37363 54201 7271 0
04T1 38956 55098 7298 0
04T2 43079 62467 8254 0
04T3 40316 58604 7724 0
04T4 40489 61732 7812 0
05T1 41456 59589 8297 1
05T2 45866 68526 9966 1
05T3 42740 64192 8267 1
05T4 42989 69346 9031 1
06T1 44396 67887 10329 1
06T2 49677 79304 13247 1
06T3 45972 75200 10793 1
06T4 46599 79864 11437 1
07T1 48405 76013 11455 1
07T2 54273 87027 15351 1
07T3 50990 83724 12886 1
07T4 52680 88765 12653 1
08T1 55013 87520 13433 1
08T2 62581 97484 16193 1
08T3 59056 93502 14773 1
08T4 60696 92566 13886 1
09T1 60441 89083 12993 1
09T2 66107 96626 13615 1
09T3 60794 94827 12321 1
09T4 62661 101782 13637 1
10T1 64124 100518 15482 1
10T2 70750 111031 17284 1
10T3 65978 108152 15469 1
10T4 68165 115037 16194 1
11T1 69841 113851 18501 1
11T2 77597 124301 20472 1
11T3 72547 122846 17933 1
11T4 75806 125547 18576 1
12T1 77168 125038 20861 1
Página 31
2) GRÁFICAS GRÁFICA 1. GRÁFICA 2:
0
2
4
6
8
10
12
14
-0.10 -0.08 -0.06 -0.04 -0.02 0.00 0.02 0.04 0.06 0.08
Series: ResidualsSample 1995Q1 2011Q4Observations 68
Mean 1.23e-15Median 0.001671Maximum 0.076411Minimum -0.104222Std. Dev. 0.035139Skewness -0.551851Kurtosis 3.272759
Jarque-Bera 3.662240Probability 0.160234
Página 32
GRÁFICA 3 y GRÁFICA 4:
GRÁFICA 5:
Página 33
GRÁFICA6: GRÁFICA7:
Página 34
GRÁFICA 8:
GRÁFICA 9:
Página 35
GRÁFICA 10: GRÁFICA 11:
0
2
4
6
8
10
12
-0.08 -0.06 -0.04 -0.02 0.00 0.02 0.04 0.06 0.08
Series: ResidualsSample 1995Q1 2010Q4Observations 64
Mean -3.79e-15Median 0.000504Maximum 0.083206Minimum -0.085267Std. Dev. 0.031927Skewness -0.139061Kurtosis 3.411432
Jarque-Bera 0.657674Probability 0.719760
Página 36
3) CUADROS CUADRO 1 CUADRO 2:
Página 37
CUADRO 3
CUADRO 4:
Página 38
CUADRO 5: CUADRO 6:

Página 39
CUADRO 7:
4) NOTICIAS:
EL BOOM DEL CONSUMO EN EL PERÚ
El modelo económico ha permitido reducir la pobreza en el país y engrosar los segmentos de la clase media. El crecimiento económico de los últimos años ha permitido que los peruanos tengan mayor acceso a bienes y servicios; incluso, en algunos sectores se puede hablar de un boom de consumo. Una forma de contrastar esta afirmación es revisar el crecimiento de ciertas industrias con tasas muy superiores al aumento del Producto Bruto Interno (PBI) y del Consumo Privado. La estrella en el Perú es la venta de automóviles nuevos, que ha crecido 37% anual desde 2005 y tiene aún espacio para seguir haciéndolo. Un informe de Macroconsult analiza dos fundamentos del consumo en el Perú y las perspectivas del mercado de automóviles nuevos y los servicios de transporte doméstico. ¿Qué factores explican el boom de consumo? De acuerdo a la consultora, en términos macroeconómicos, existen tres grandes factores que explican el boom de consumo. En primer lugar, se tiene al crecimiento económico y el crecimiento del ingreso familiar. En términos macroeconómicos, el ingreso nacional disponible per cápita ha crecido en promedio 6.2% entre 2005 y 2011, lo que se refleja en un incremento del consumo privado de 4.6%. Parte del incremento del ingreso nacional disponible se debe al crecimiento de los términos de intercambio del comercio, lo que ha elevado la capacidad de compra de la economía. El crecimiento económico tiene un espejo a nivel de los hogares, pues permitió que la pobreza de los peruanos disminuya de manera significativa desde 48.6% en 2004 a 31.3% en 2010. Así, en el periodo 2004 – 2010, el número de hogares que se encontraba por debajo de línea de la pobreza disminuyó en más de un cuarto (790 mil hogares) y para los que se encontraban por encima de esta línea, en el mismo periodo, se triplicó (se incrementó en dos millones de hogares). Esto ha significado un ensanchamiento importante de la clase media en el Perú.

Página 40
En segundo lugar se tiene la baja penetración de ciertos mercados y la mayor competencia generada en los mismos mediante menores precios e inversiones surgidas para satisfacer a los consumidores. En Perú existe un bajo nivel de penetración en ciertas industrias, pero con un potencial para desarrollar. En el mercado automovilístico, se espera que este año se vendan 185 mil unidades nuevas (19% más que en 2011) debido a los menores precios ofertados por marcas asiáticas, la apreciación del tipo de cambio, la introducción de vehículos pequeños y el incremento del crédito vehicular.
Alza vuelo Otro sector que ha crecido de forma importante es el transporte aéreo doméstico. Esto se debe a una expansión de rutas aéreas, una mayor oferta de promociones y la disminución de tarifas, que incluso llega a competir con el transporte terrestre. Para 2012 proyectamos un crecimiento de 14% con respecto al año pasado, llegando a 14.5 millones de entradas y salidas domésticas este año (1.8 millones más que en 2011). El crecimiento del transporte aéreo doméstico repercutirá sobre el terrestre, que en los dos últimos años ha crecido a tasas inferiores que las registradas entre 2005 y 2009. Sin embargo, proyectamos que este sector recibirá 1.3 millones más de pasajeros en comparación a 2011 (1.8% de crecimiento).
Fuente:http://www.expreso.pe/noticia/2012/03/18/el-boom-del-consumo-en-el-peru
El expreso





























