Embed Size (px)
Citation preview

文献紹介(2015/4/16)Automatic Retrieval and
Clustering of Similar Words
長岡技術科学大学 電気電子情報工学専攻
自然言語処理研究室 高橋寛治

文献について
•Automatic Retrieval and Clustering of
Similar Words
•Dekang Lin, Department of Computer
Science University of Manitoba, 1998,
ACL’98,Coling’98, Vol.2, pp.768-774
文献紹介:A Baseline System for Chinese Near-Synonym Choice 2

概要
•Dependency tripleを用いた単語類似度を定義
•定義した類似度測定手法を用いてシソーラスを作成
•自動構築したシソーラスと既存のシソーラスの類似度
を測る方法を提案
文献紹介:A Baseline System for Chinese Near-Synonym Choice 3

はじめに
•A bottle of tezguino is on the table.
•Everyone likes tezguino.
•Tezguino makes you drunk.
•We make tezguino out of corn.
文献紹介:A Baseline System for Chinese Near-Synonym Choice 4
「tezguino」が「beer,wine,vodka」と似ていると分かることが、本研究のゴール

はじめに
•ブートストラップ法によりテキストから意味を取
得することがゴール
≒自動的にシソーラスを構築する
•統計的自然言語処理のデータスパースネス問題を
軽減する手段の一つとなる
文献紹介:A Baseline System for Chinese Near-Synonym Choice 5

単語の類似度
•Dependecy triplesを利用(broad-coverage parser Lin,1993)
•文中の2つの単語の文法関係を記述
“I have a brown dog”
(have subj I), (I subj-of have), (dog obj-of
have),(dog adj-mod brown), (brown adj-mod-of
dog), (dog, det a), (a det-of dog)
文献紹介:A Baseline System for Chinese Near-Synonym Choice 6

Dependency triples
• ||w,r,w‘||は(w,r,w’)の総数を示す
•ワイルドカードを使用する
• ||*,*,*||はコーパスから解析された全てのdependency
triplesを含む
• dependency triplesの頻度はそれぞれ独立と仮定
文献紹介:A Baseline System for Chinese Near-Synonym Choice 7

出現しない組み合わせは共起情報から推定
•無作為に選択したそれぞれの要素をもとに最尤推定を
行う
• 𝑃𝑀𝐿𝐸 𝐴, 𝐵, 𝐶 = 𝑃𝑀𝐿𝐸 𝐵 𝑃𝑀𝐿𝐸 𝐴|𝐵 𝑃𝑀𝐿𝐸 𝐶|𝐵
• 𝑃𝑀𝐿𝐸 𝐵 =||∗,𝑟,∗||
||∗,∗,∗||, 𝑃𝑀𝐿𝐸 𝐴|𝐵 =
||𝑤,𝑟,∗||
||∗,𝑟,∗||, 𝑃𝑀𝐿𝐸 𝐶|𝐵 =
||∗,𝑟,𝑤′||
||∗,𝑟,∗||
文献紹介:A Baseline System for Chinese Near-Synonym Choice 8

相互情報量を求め、類似度を計算
• 𝐼 𝑤, 𝑟, 𝑤′
= − log 𝑃𝑀𝐿𝐸 𝐵 𝑃𝑀𝐿𝐸 𝐴|𝐵 𝑃𝑀𝐿𝐸 𝐶|𝐵 − − log 𝑃𝑀𝐿𝐸 𝐴, 𝐵, 𝐶
単語1と単語2の類似度
文献紹介:A Baseline System for Chinese Near-Synonym Choice 9

使用するコーパス
•全6400万語
•Wall Street Journal(2400万語)
• San Jose Mercury(2100万語)
• AP Newswire(1900万語)
•5650万のdependency triplesを取得
• 各語は頻度100で足切り
文献紹介:A Baseline System for Chinese Near-Synonym Choice 10

類似度を計算しシソーラスを構築
•w(pos):w1,s1,w2,s2,…,wN,sN
• brief(noun):affidavit 0.13, petition 0.05,
memorandum 0.05
• brief(verb):tell 0.09, urge 0.07, ask 0.07, meet
0.06
•最も似ている単語対を取得
• 名詞543ペア、動詞212ペア、形容詞・副詞382ペア
文献紹介:A Baseline System for Chinese Near-Synonym Choice 11

別の類似度計算でシソーラスの構築
•単語の類似度
•w(pos):w1,s1,w2,s2,…,wN,sN
• 提案手法と既存の類似度計算で比較
文献紹介:A Baseline System for Chinese Near-Synonym Choice 12

評価
• 自動で構築したシソーラスと、WordNet1.5・Roget
Thesaurusを比較
• それぞれのシソーラスでの類似度の計算(1997,Lin)
• S(w)はWordNetの同じsynsetの語,super(c)はcの上位クラス
• R(w)は同じRogetカテゴリーに属する語
文献紹介:A Baseline System for Chinese Near-Synonym Choice 13

シソーラス間の類似度
•シソーラス内での類似度を以下のように示す
•W:w1,s1,w2,s2,…,wN,sN
• W:w’1,s’1,w’2,s’2,…,w’N,s’N
•WordNet,Rogetを同じフォーマットに変更
•右の式で計算を行う
文献紹介:A Baseline System for Chinese Near-Synonym Choice 14

結果
•類似度の平均と標準偏差
•データ数のルートで平均を
割ったもの
•sim,Hindle rとcosineは
WordNetで高いスコア
文献紹介:A Baseline System for Chinese Near-Synonym Choice 15
評価結果

よく似た3つを比較
•統計的に優位かどうか確
認するために、類似度の
差を調査
•Simが他よりいい
文献紹介:A Baseline System for Chinese Near-Synonym Choice 16
相違点の分布

今後の課題
•信頼性の高い類似度を
抽出することが今後の
課題
文献紹介:A Baseline System for Chinese Near-Synonym Choice 17

まとめ
•自動で構築されたシソーラスの評価法を提案
•自動構築と手動構築の比較を行える
•自動で構築したシソーラスはRoget Thesaurus
よりWordNetに近い
文献紹介:A Baseline System for Chinese Near-Synonym Choice 18
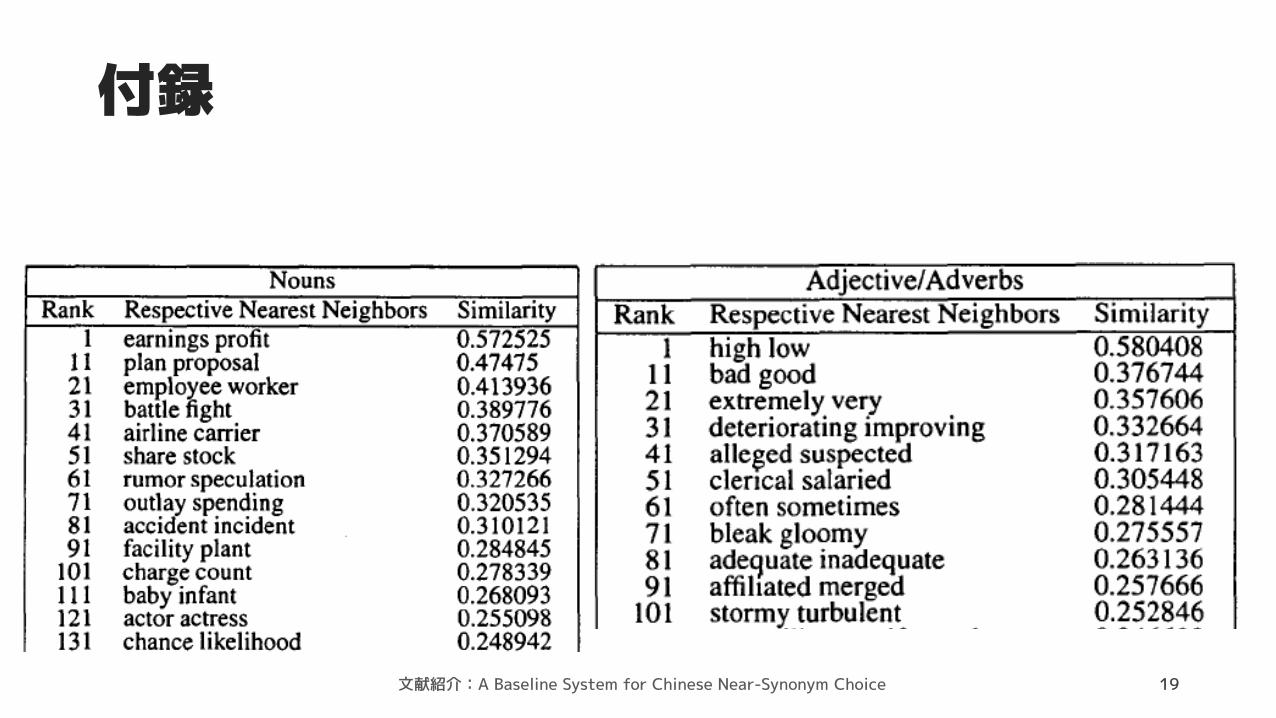
付録
文献紹介:A Baseline System for Chinese Near-Synonym Choice 19





























