Embed Size (px)
Citation preview

Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in Programmazione I
Cognitive Computing Systems and IBM Watson for Education
Anno Accademico 2016-2017 Candidato: Christian Esposito matr. N46002551


Indice
Indice ............................................................................................................................................ III
Indice delle Figure ........................................................................................................................ IV
Introduzione .................................................................................................................................... 5
Capitolo 1: Scienze Cognitive ......................................................................................................... 6
Capitolo 2: Cognitive Computing System........................................................................................ 8
2.1 Evoluzione ............................................................................................................................ 9
2.2 Scopo .................................................................................................................................... 9
2.3 Question Answering .............................................................................................................. 9
2.3.1 Storia del Question Answering...................................................................................... 10
Capitolo 3: IBM Watson ............................................................................................................... 11
3.1 Jeopardy! Challenge ............................................................................................................ 11
3.2 Open Domain Question Answering ..................................................................................... 12
3.2.1 PIQUANT .................................................................................................................... 12
3.2.2 OpenEphyra .................................................................................................................. 13
3.2.3 DeepQA ....................................................................................................................... 13
3.3 Come ragiona Watson ......................................................................................................... 13
3.3.1 Question Analysis ......................................................................................................... 14
3.3.2 Hypothesis Generation .................................................................................................. 15
3.3.3 Soft Filtering ................................................................................................................ 15
3.3.4 Hypothesis and Evidence Scoring ................................................................................. 15
3.3.5 Answer Merging ........................................................................................................... 16
3.3.6 Ranking & Confidence Estimation ................................................................................ 16
3.3.7 Strategy ........................................................................................................................ 16
3.4 Risultati raggiunti con Watson ............................................................................................. 17
Capitolo 4: Applicazioni di Watson ............................................................................................... 18
4.1 Servizi Watson for Education .............................................................................................. 19
4.1.1 Watson Concept Insights .............................................................................................. 19
4.1.2 Watson Experience Manager ........................................................................................ 19
4.1.3 Watson Analytics .......................................................................................................... 20
4.2 Strumenti Cloud offerti da IBM ........................................................................................... 20 4.2.1 IBM Watson Analytics ................................................................................................. 20
4.2.2 IBM Watson Discovery ................................................................................................ 21
4.2.3 IBM Bluemix & NodeRED ........................................................................................... 22
4.3 Watson Projects in Education .............................................................................................. 24 4.3.1 IBM and Sesame Workshop.......................................................................................... 25
4.3.2 IBM and Pearson .......................................................................................................... 25
4.3.3 Watson Classroom: IBM and Coppel ISD ..................................................................... 26
Conclusioni ................................................................................................................................... 28
Bibliografia ................................................................................................................................... 30

Indice delle Figure
1.1 - Esagramma delle scienze cognitive ......................................................................................... 6
3.1 - Architettura di alto livello DeepQA ...................................................................................... 15
4.1 - Entity relationship ................................................................................................................. 21
4.2 - Watson Discovery: Manage data ........................................................................................... 21 4.3 - Watson Discovery: Overview ................................................................................................ 22
4.4 - Watson Discovery: Query insert box ..................................................................................... 22 4.5 - Natural Language Understanding flow example .................................................................... 23
4.6 - Natural Language Classifier training ..................................................................................... 23 4.7 - Natural Language Classifier .................................................................................................. 24

5
Introduzione
Questo lavoro affronta prima una panoramica del cognitive computing con particolare
riferimento al sistema IBM Watson e si sofferma in particolare sulle applicazioni Education
offerte dal prodotto. Prima di analizzare il sistema e le sue potenzialità si presenta una
introduzione alla storia dell’informatica, che, inevitabilmente, ha subito dei cambiamenti nel
tempo. Essa si può suddividere in tre ere principali: l’era Tabulativa, l’era della
Programmazione e l’era Cognitiva. L’era Tabulativa trova le sue origini intorno al 1900 in cui
i primi sistemi di calcolo erano di tipo meccanico single-purpouse che eseguivano il codice su
schede perforate. La fine dell’era Tabulativa si può collocare negli anni cinquanta quando, in
seguito a necessità di tipo militare e scientifico, si svilupparono i primi digital computers che
erano in grado di eseguire istruzioni logiche di tipo if/then e cicli codificati direttamente in
software. La nascita di queste tecniche di programmazione in concomitanza con l’invenzione
dei transistor e dei microprocessori ha contribuito alla diffusione dei calcolatori e di tutti i
sistemi informatici presenti al giorno d’oggi. L’era Cognitiva ha iniziato a svilupparsi intorno
al 2011 con l’introduzione ufficiale nel mondo di Watson, il primo sistema cognitivo prodotto
da IBM, che rappresenta l’evoluzione del concetto di computer odierno, essendo capace di
“imitare” il modo di pensare dell’uomo. [1] La nascita dei primi sistemi cognitivi è dovuta
anche al continuo sviluppo di forme di dati sempre più eterogene e non strutturate, quali foto,
video e audio che negli ultimi anni sono aumentati esponenzialmente grazie alla diffusione di
internet e di tutti i servizi che esso ci offre.

6
Capitolo 1: Scienze Cognitive
Nel corso della storia, fin dalla antica Grecia, si teorizzava sull’origine del pensiero umano.
La mente umana era oggetto di studio di molti campi come Filosofia e Psicologia. Si può
identificare la nascita delle Scienze Cognitive intorno agli anni Cinquanta quando si iniziò a
concepire l’idea che la mente umana fosse un sistema di elaborazioni di informazioni grazie
agli studi di Turing. Esse rappresentano “l’insieme di discipline che hanno come oggetto di
studio la cognizione di un sistema pensante” e sono: Filosofia, Linguistica, Psicologia,
Informatica, Neuroscienza, Antropologia.
Figura 1.1 - Esagramma delle scienze cognitive

7
In figura è rappresentato un esagramma che collega le discipline che costituiscono le scienze
cognitive. Le linee continue rappresentano i collegamenti tra le discipline prima della nascita
delle scienze cognitive, invece quelle tratteggiate rappresentano i collegamenti che si sono
sviluppati come conseguenza. Tali Scienze si occupano della modalità di formazione del
pensiero basandosi su alcuni concetti base. Grazie alle idee introdotte da Turing si iniziò a
considerare l’idea che la mente possieda delle rappresentazioni simili a quelle presenti nei
computer come procedure di calcolo, elaborazione di simboli. Il primo concetto lo possiamo
ritrovare nella “ragione come calcolo”, in cui il cervello manipola dei simboli ed elabora
informazioni secondo precise regole. Un altro concetto fondamentale è quello di “stato
mentale”, una forma a priori della mente che giustifica concetti mentali che conosciamo a
prescindere dall’esperienza come per esempio l’associazione di espressioni facciali al
sentimento che esse simboleggiano. Secondo vari studi l’architettura cognitiva si può dividere
in tre livelli:
1. Livello delle conoscenze
2. Livello dei simboli
3. Livello materiale
Il livello delle conoscenze permette di veicolare informazioni attraverso i livelli sottostanti,
utilizzando il livello dei simboli (il linguaggio), servendosi del livello materiale (l’uomo). Si
può notare come ogni livello è indipendente da quelli sottostanti in quanto una stessa
informazione può essere trasmessa in un linguaggio differente e addirittura da un differente
livello materiale, come, per esempio, potrebbe essere un automa. [2]

8
Capitolo 2: Cognitive Computing System
Il Cognitive Computing nasce dall’unione delle scienze cognitive e dell’informatica.
Si basa sulle discipline dell’intelligenza artificiale e del signal processing. Racchiude in sé
numerose caratteristiche quali machine learning, reasoning, natural language processing,
speech recognition, vision recognition, dialog generation. Grazie a queste caratteristiche tali
sistemi non si limitano a rispondere a quello per cui sono stati programmati ma introducono
un fattore non prevedibile basato sull’esperienza e sull’autoapprendimento. I Cognitive
Computing system cercano di simulare i processi neurali propri del cervello umano, cercando
di migliorare le capacità decisionali dell’uomo attraverso algoritimi di autoapprendimento
basati sul data mining, pattern recognition e natural language processing. [3]
IBM definisce i sistemi cognitivi come “sistemi che imparano gradualmente, ragionano ed
interagiscono con l’uomo naturalmente”. [1]
Da un punto di vista generale i sistemi cognitivi devono essere dotati di alcune proprietà:
Adaptive: devono imparare come cambiano le informazioni, risolvere le ambiguità
e tollerare l’imprevedibilità.
Interactive: devono garantire una facile interazione con gli utenti, quali persone o
altri dispositivi.
Iterative and stateful: devono essere capaci di definire un problema facendo
domande aggiuntive per ottenere nuove informazioni mantenendo traccia delle
precedenti iterazioni.
Contextual: devono capire ed estrapolare elementi dal contesto, come significato,
sintassi, tempo, località, dominio utilizzando informazioni sia strutturate che non
strutturate. [4]

9
2.1 Evoluzione
L’evoluzione dei sistemi cognitivi è dovuta anche alla grande capacità di calcolo che permette
di ottenere risultati a complessi algoritmi di calcolo in pochissimo tempo. Un altro fattore che
ha portato il cambio di rotta dai sistemi programmabili a quelli cognitivi è strettamente legato
alla problematica dei Big Data, insiemi di dati eterogenei strutturati e non strutturati. Infatti
secondo il colosso statunitense dell’informatica IBM negli ultimi anni lo sviluppo di dati ha
avuto un’incredibile accelerazione in particolare sotto forma di dati non strutturati quali
immagini, video e audio, rendendo necessario un nuovo modello di computing per
permetterne l’utilizzo ed aumentare la competenza dell’uomo. [5]
2.2 Scopo
Molte persone sono portate a pensare che lo sviluppo di sistemi cognitivi che emulano la
mente umana potrà portare in futuro alla sostituzione stessa dell’uomo con la macchina come
rappresentato da molti film di fantascienza. In realtà lo scopo primo di questi sistemi, come
afferma Alessandro Curioni, Vice Presidente Europe e Direttore del Research – Zurich Lab
di IBM, è quello di “macinare una grande quantità di dati nella loro ‘interezza’, ossia nella
loro ‘forma’ naturale (dati non strutturati), imparando poi a restituire attraverso analisi
avanzate e correlazioni, informazioni utili all’uomo”. Questi sistemi infatti non cercano di
emulare il cervello umano nella sua interezza, sono sistemi che “devono diventare strumenti
in grado di aumentare le capacità umane, non replicarle o sostituirle”. [6]
2.3 Question Answering
Il question answering (QA) è una delle grandi problematiche legate ai sistemi cognitivi. Un
sistema QA è un sistema di recupero automatico delle informazioni che risponde alle
domande in linguaggio naturale, infatti a differenza di un normale motore di ricerca i sistemi
QA forniscono risposte specifiche ottenute analizzando grandi quantità di documenti. I
sistemi Question Answering sono classificati in base al livello di precisione e raffinatezza
della risposta in tre categorie:
1. Slot-filling: il sistema risponde a domande molto semplici.

10
2. Limited-domain: il sistema risponde a domande di media difficoltà relative a
specifiche aree di conoscenza.
3. Open-domain: sistemi più complessi che integrano tecniche di information
extraction, information retrieval e natural language processing [7]
2.3.1 Storia del Question Answering
La storia dei sistemi QA risale agli anni Sessanta quando si iniziò a sviluppare l’idea di
costruire dei sistemi in grado di rispondere a domande poste in linguaggio naturale. I primi
sistemi dotati di questa caratteristica erano sistemi QA limitati ad un determinato domino che
traducevano le domande poste in query su database. Due esempi molto importanti sono
LUNAR e BASEBALL. LUNAR poteva rispondere a domande sulle rocce analizzate durante
la missione Apollo Lunar. BASEBALL era in grado di rispondere a domande sul baseball
relativamente al periodo di un anno. Successivamente tra il 1968-71 al laboratorio di IA del
MIT venne sviluppato da Terry Winograd il sistema SHRDLU capace di sviluppare dialoghi
basati su blocchi di parole. In seguito a numerosi studi nel campo del natural language
processing alla fine degli anni Ottanta venne sviluppato il progetto Unix Consultant capace di
rispondere a domande sul sistema UNIX. Negli anni Novanta venne sviluppato il primo
sistema di QA web based START accompagnato nel 2000 da Open Ephyra un framework
open source che permette di sviluppare sistemi di questo tipo. Nel 2003 iniziò il progetto di
SIRI finanziato da DARPA abbandonato a causa di mancanza di fondi che venne poi ripreso
nel 2008 da Apple. Nel 2007 iniziò il progetto di IBM Watson per partecipare al quiz
televisivo Jeopardy! che vide il successo del team di IBM nel 2011 contro due campioni del
famoso quiz americano. [8]

11
Capitolo 3: IBM Watson
IBM Watson è oggi il più grande esempio di Cognitive Computing System in grado di
elaborare il linguaggio naturale ed utilizzare information retrieval, ragionamento e
apprendimento automatico rappresentando il miglior sistema di Open Domain Question
Answering. È il successore naturale di Deep Blue, il primo sistema capace di battere un
campione di scacchi, rappresentando il simbolo per questo nuovo modo di fare computing.
Watson utilizza dal lato software il sistema di Question Answering DeepQA e il framework
Apache UIMA, per il trattamento e l'analisi di informazioni e il framework Apache Hadoop
per il calcolo distribuito, mentre dal lato Hardware il sistema è composto da una griglia di
Novanta server IBM Power 750 ognuno dei quali è equipaggiato con un processore POWER7
ad otto core da 3.5GHz con quattro threads per core e 16 terabytes di RAM. [9]
3.1 Jeopardy! Challenge
L’obiettivo di IBM era quello di realizzare un sistema capace di partecipare al quiz televisivo
americano Jeopardy! come un concorrente a tutti gli effetti. Il progetto di IBM partì nel 2007
con un team di 15 persone stimando di risolvere il problema nel giro di circa tre o cinque
anni. Questo progetto rappresentava una sfida sotto molti punti di vista in quanto il quiz si
basa su domande e indovinelli molto complessi, rendendo necessario un alto livello di
comprensione del linguaggio naturale e capacità di decomporre le domande, di trovare
relazioni tra entità, di analizzare grandi quantità di dati in poco tempo e di ragionamento per
produrre una risposta che abbia un livello di confidence abbastanza elevato per permettere al
sistema di prenotarsi per rispondere. La natura del quiz introduce alcuni problemi:
Domande: il modo in cui sono scritti gli indizi rende difficile comprendere cosa sia

12
stato effettivamente chiesto e quali siano gli elementi chiave per rispondere
correttamente alla domanda: infatti spesso conviene scomporre la domanda in più
parti per trovare la risposta.
Puzzle: in questa categoria sono presenti domande molto particolari dove la risposta
deve essere la composizione di due risposte ai sotto-indizi presenti nella domanda
che hanno in comune una o più parole.
Dominio: la generalità delle domande introduce una complessità aggiuntiva nella
progettazione del sistema di Question Answering poiché deve essere istruito con una
grande quantità di informazioni tale da garantirgli un adeguato livello di precisione
delle risposte.
Metrica: in aggiunta alla precisione il sistema deve garantire caratteristiche quali
velocità, capacità di assegnare livelli di confidence adeguati per decidere se
rispondere, di selezionare le domande e di scommettere sulle relative domande.
3.2 Open Domain Question Answering
Analizzando numerose puntate dello show si è stimato che la maggior parte dei campioni di
Jeopardy! rispondeva alle domande con una percentuale che varia tra il 40% e il 50% con un
livello di precisione tra il 85% e il 95%. Considerando che un concorrente tipicamente non
può rispondere a tutte le domande che vuole, in quanto c’è da considerare la competizione per
il “buzz” si è stimato un possibile livello di performance desiderato per Watson, in test che
non prevedevano la prenotazione per rispondere, di 70% di domande risposte con 80% di
precisione elaborate in massimo 3 secondi.
3.2.1 PIQUANT
Il primo approccio alla componente question answering di Watson è avvenuto cercando di
adattare il sistema PIQUANT (Practical Intelligent Question Answering Technology)
precedentemente sviluppato per la TREC (Text Retrieval Conference). PIQUANT è un
sistema basato su pipeline con tecniche all’avanguardia che miravano alla valutazione della
TREC QA in cui il sistema aveva a disposizione una settimana per rispondere a 500 domande

13
e aveva a disposizione una connessione internet. Il sistema rispondeva a domande molto più
semplici rispetto a quelle di Jeopardy!. Dopo aver adattato il sistema i test svolti con 500
domande estrapolate da precedenti puntate del quiz le performance del sistema furono molto
deludenti raggiungendo il 5% di domande risposte con una precisione del 47% mentre per il
resto delle domande la precisione raggiunta era il 13%
3.2.2 OpenEphyra
OpenEphyra è framework Question Answering open-source sviluppato dalla Carnegie Mellon
University (CMU). Il sistema è stato sviluppato, come PIQUANT, per rispondere alle
domande della TREC utilizzando una connessione internet. IBM, in collaborazione con la
CMU, ha adattato OpenEphyra per rispondere alle domande di Jeopardy!, ma come previsto
anche in questo caso i risultati furono molto sotto gli standard posti per poter competere
contro i campioni del quiz.
3.2.3 DeepQA
In seguito ai fallimenti ottenuti cercando di adattare sistemi sviluppati per il TREC QA seguì
una serie di studi su noti algoritmi in letteratura cercando di integrarli nella classica pipeline
del question answering. IBM e CMU collaborarono in una iniziativa chiamata Open
Advancement of Question Answering (OAQA) a cui presero parte numerosi ricercatori ed
esperti. L’insieme di tutti gli studi svolti ha così portato a DeepQA, un sistema probabilistico
fortemente parallelizzato in cui sono stati integrati più di cento differenti tecniche per
analizzare il linguaggio naturale, identificare le fonti, trovare e generare ipotesi, raggruppare e
classificare ipotesi per contribuire a migliorare la precisione, il livello di confidence e la
velocità nel generare risposte
3.3 Come ragiona Watson
Prima di analizzare l’algoritmo DeepQA che permette a Watson di ragionare dobbiamo
soffermarci sulla acquisizione di informazioni in quanto tutto il necessario per gareggiare
deve essere contenuto all’interno del sistema. L’acquisizione avviene sia in modo manuale

14
che automatico. Prima di tutto si analizzano delle domande di esempio per produrre una
descrizione delle domande a cui il sistema dovrà rispondere, compito manuale, mentre il
sistema svolgerà una analisi sul dominio di appartenenza come la ricerca di un LAT (lexical
answer type), una parola che caratterizza il tipo di risposta, compito automatico. A causa
dell’ampiezza dei domini trattati da Jeopardy! le risorse inserite in Watson contengono una
gran parte di enciclopedie, dizionari, articoli, opere letterarie e molto altro. In aggiunta
Watson viene provvisto di informazioni di tipo strutturato e semi-strutturato organizzate in
database per velocizzare le ricerche in caso si riconoscano delle entità nelle domande.
Figura 3.1 - Architettura di alto livello DeepQA
3.3.1 Question Analysis
In questa fase il sistema cerca di capire cosa è richiesto dalla domanda utilizzando analisi
superficiali e profonde sulle parole, forme logiche, semantica, relazioni tra entità e specifici
tipi di analisi per il question answering. Alcune di queste sono:
Question Classification: è un processo che identifica il tipo di domanda e la presenza
di possibili parole o modi di dire con un doppio significato o con un significato
retorico. Questo processo identifica l’ambito della domanda, come di tipo puzzle,
matematico e riconosce i giochi di parole, i vincoli, le definizioni e i sotto-indizi.
Focus and LAT Detection: il Lexical Answer Type è una parola che si riferisce alla
risposta che può aiutare a trovarla anche senza analizzarne la semantica. Il Focus

15
invece è la parte della domanda che sostituito dalla risposta la rende una definizione.
Relation Detection: Molte domande contengono delle relazioni di tipo soggetto-
predicato-oggetto o di tipo semantico. Watson usa queste relazione per svolgere query
su database per generare delle possibili risposte.
Decomposition: DeepQA utilizza una profonda analisi e metodi di classificazione
statistica per decomporre al meglio le domande. Questo permette di generare risposte
con un livello di confidence maggiore molto velocemente analizzando i sotto-indizi in
modo parallelo.
3.3.2 Hypothesis Generation
A questo punto si producono delle possibili risposte ricercando tra le informazioni del
sistema. Una ipotesi è la sostituzione della risposta all’interno della domanda per generare
una affermazione. La generazione di una risposta avviene in due step:
Ricerca Primaria: durante questa ricerca l’obiettivo è quello di raccogliere più
contenuti possibili che hanno a che fare con la domanda che successivamente
verranno ridotti da successivi filtraggi.
Generazione di candidati: i risultati delle ricerche del passaggio precedente,
attraverso delle tecniche appropriate, vengono rielaborate per generare delle risposte
candidate.
3.3.3 Soft Filtering
Questo tipo di filtraggio applica degli algoritmi di assegnazione di punteggi di tipo
superficiale in modo da ridurre il numero delle possibili risposte per procedere con delle
analisi più accurate nelle fasi successive.
3.3.4 Hypothesis and Evidence Scoring
Le risposte che avranno superato la prima fase di filtraggio verranno sottoposte ad una
seconda fase più rigorosa in cui verranno utilizzati degli algoritmi di analisi più sofisticati per
assegnare i livelli di confidence adeguati.
Evidence Retrieval: permette al sistema di raccogliere dati aggiuntivi sulla validità

16
delle risposte. In particolare un metodo utilizzato è quello di svolgere nuovamente
l’analisi primaria aggiungendo alla ricerca la risposta selezionata in modo da
recuperare tra le risorse i passaggi che contengono la risposta nel contesto della
domanda originale.
Scoring: Gli algoritmi di scoring determinano il grado di certezza di una particolare
risposta. DeepQA considera differenti fattori su cui svolgere l’analisi per assegnare un
punteggio alle risposte, come il grado di compatibilità tra la struttura della domanda e
il passaggio da cui si è estrapolata la risposta, la relazione temporale, geospaziale,
lessicale e semantica.
3.3.5 Answer Merging
Dopo lo scoring ci saranno centinaia di ipotetiche risposte a cui saranno assegnati diversi
punteggi. Il Merging serve per associare tra loro le risposte che sono equivalenti tra loro.
L’obbiettivo è quello di migliorare le fasi successive dell’algoritmo evitando di dover
classificare risposte molto simili tra loro
3.3.6 Ranking & Confidence Estimation
In seguito al Merging l’insieme delle risposte viene analizzato per stilare una classifica delle
risposte ed il relativo livello di confidence. In entrambe le fasi si raggruppano i punteggi in
base al dominio generando dei modelli intermedi da cui il sistema produrrà dei punteggi
intermedi che verranno utilizzati per selezionare correttamente la risposta. [10]
3.3.7 Strategy
Watson per partecipare e vincere al quiz doveva essere capace di fare alcune scelte molto
importanti come decidere quando prenotarsi per rispondere ad una domanda, scegliere un
riquadro dal tabellone e scommettere sulle domande speciali. La decisione di prenotarsi è
determinata da una soglia per il livello di confidence desiderato dalla risposta al di sotto del
quale il sistema evita di rispondere. La scelta di un riquadro avviene basata sulle caselle già
rivelate e sulle posizioni più probabili in cui trovare i Daily Double. Determinare quanto
scommettere dipende dallo stato del gioco e dal punteggio degli altri concorrenti. [11]

17
3.4 Risultati raggiunti con Watson
La sfida di creare un sistema artificiale capace di partecipare ad un quiz così complesso come
Jeopardy! ha portato durante i tre anni di intense ricerche una innovazione senza precedenti in
questo campo migliorando le tecniche di Natural Language Processing e sviluppando
complessi algoritmi di Question Answering che hanno portato il sistema Watson a
raggiungere già nel 2008 prestazioni pari a 70% precisione al 70% delle domande risposte per
poi arrivare, qualche anno dopo, al suo apice con 85% precisione al 70% delle domande
poste. Questo ha incoraggiato IBM a continuare gli studi in questa direzione portando a
cambiare il paradigma del computing moderno. Grazie a queste ricerche gli esperti di IBM
sono riusciti a realizzare un sistema capace di vincere ad un quiz televisivo complesso basato
sulle sfumature di significato del linguaggio naturale. [10]

18
Capitolo 4: Applicazioni di Watson
Il sistema e le capacità uniche di Watson sono state facilmente adattate a moltissimi settori
differenti grazie alle enormi abilità che esso possiede. Watson è capace di capire domande
poste in linguaggio naturale, di svolgere analisi su grandi moli di dati strutturati e non
strutturati ed ha la capacità di dare risposte specifiche alle domande poste. IBM ha deciso di
mettere a disposizione del mondo le capacità di Watson adattandolo a diversi campi, come in
campo industriale, sanitario, finanziario e molto altro. Nel settore industriale si sta
sviluppando sempre di più il concetto di industria 4.0 che indica la tendenza ad integrare i
nuovi sistemi cognitivi per migliorare le condizioni di lavoro e aumentare sia la produttività
che la qualità degli impianti. [12] IBM ha investito molto nel campo sanitario cercando di
sfruttare le capacità di calcolo di Watson per aiutare i medici nella lotta contro il cancro.
Infatti il sistema di IBM ha impiegato solo 10 minuti nel produrre una terapia mentre i medici
ci avrebbero impiegato giorni migliorando così le aspettative di vita del paziente in quanto in
questo settore il fattore tempo risulta determinate. Per il campo finanziario IBM ha rilasciato
una serie di servizi per personalizzare il rapporto con i clienti e migliorare la gestione dei
rischi. Watson è stato utilizzato anche per migliorare i servizi di help desk, in alcune città per
fornire informazioni a turisti e cittadini, per aiutare i viaggiatori identificando il percorso
ideale in base allo stato d’animo. Per contribuire allo sviluppo di questa nuova era del
computing IBM ha messo a disposizione di tutti delle API per interfacciarsi a Watson in
cloud e sfruttare le sue abilità cognitive per dare la possibilità a tutti di impiegare le capacità
del sistema per produrre una nuova categoria di applicazioni. [13] Un altro campo molto
promettente è quello dell’istruzione in cui le abilità delle nuove tecnologie di cognitive
computing possono essere di aiuto sia per l’amministrazione che per le attività di

19
apprendimento. In questo contesto le abilità dei sistemi cognitivi possono aiutare sia studenti
che professori sotto molti punti di vista. Sicuramente l’integrazione di questi servizi può
accelerare il raggiungimento degli obiettivi per gli studenti, in particolare può migliorare le
performance negli studi scientifici e può contribuire, grazie alla collaborazione tra uomo e
macchina, a ottenere nuovi risultati nei campi di intelligenza artificiale e cognitive system
fornendo soluzioni prima impensabili, e fornire supporto ai professori attraverso una
piattaforma digitale che faciliti l’organizzazione delle classi e del materiale scolastico. [14]
4.1 Servizi Watson for Education
In particolare vedremo in maggior dettaglio alcuni servizi offerti da IBM per utilizzare il
sistema nel campo dell’istruzione.
4.1.1 Watson Concept Insights
Il suo scopo è quello di facilitare la ricerca di documenti testuali. Il suo funzionamento si basa
sulla definizione di un dizionario di concetti associati ai documenti che ne definiscono la
rilevanza per una data domanda. Ogni documento viene inserito nel sistema e viene
analizzato per creare un corpus su cui svolgere le analisi successive. L’analisi del documento
avviene attraverso un algoritmo che ne estrapola i concetti fondamentali. In seguito all’analisi
si andrà a realizzare una versione vettorizzata del documento che terrà traccia dei concetti in
esso contenuti. Ogni dimensione del vettore generato rappresenta il livello di rilevanza di quel
concetto per lo specifico documento attraverso un punteggio. Questo vettore è inserito in un
indice che permette di recuperare i documenti più pertinenti in base ad una ricerca
concettuale. Dall’associazione di documento e vettore è quindi possibile risalire facilmente al
documento fornendo risultati in tempi molto brevi. [15]
4.1.2 Watson Experience Manager
Watson Experience Manager (WEM) è un tool browser-based che permette di interagire con
Watson attraverso il Watson Developer Cloud e attraverso le Watson Question & Answer
API. Offre servizi differenti in base al ruolo assegnato all’utente, dando la possibilità di
inserire nuovi documenti, cancellarli, creare un corpus dove Watson “organizza” la propria

20
conoscenza, testare il livello di conoscenza sviluppato su un dato argomento. Il primo passo
per usufruire dei servizi di Watson è quello di caricare dei contenuti per lo specifico dominio
di applicazione. Dopo il caricamento si procede con l’analisi dei contenuti per creare un
corpus che permette a Watson di trovare le risposte alle domande poste. Watson per garantire
un alto livello di performance nelle risposte dovrà avere una base di conoscenza definita
attraverso coppie di domande e risposte. L’attività di training è svolta inserendo domande e/o
risposte nell’apposita sezione del WEM. In questo caso si hanno due tipi di training, uno low-
impact associando la domanda posta ad una già esistente e uno high-impact inserendo la
risposta alla specifica domanda evidenziando dove si trova all’interno di un particolare
documento. [16]
4.1.3 Watson Analytics
Watson riuscendo a capire il linguaggio naturale e sfruttando la sua elevata velocità di calcolo
permette di svolgere analisi avanzate su elevate moli di dati rendendo disponibile a tutti gli
utenti la capacità di visualizzare relazioni nascoste tra dati o analisi predittive di trends
permettendo di comprendere il “perché” di alcuni andamenti. Il Content Analytics fornisce un
nuovo livello di comprensione dei contenuti in relazione al contesto estrapolato dalle
informazioni testuali. [17]
4.2 Strumenti Cloud offerti da IBM
IBM mette a disposizione la piattaforma OnTheHub che garantisce accesso a numerosi
software e servizi offerti dall’azienda. Attraverso tale piattaforma si sono analizzati alcuni
strumenti utilizzabili nel capo dell’istruzione.
4.2.1 IBM Watson Analytics
É un servizio di analisi che consente di scoprire modelli, relazioni tra dati organizzati sotto
forma tabellare. Fornisce strumenti di upload di documenti e interazione con piattaforme di
storage cloud. Permette di scoprire le relazioni tra i dati e di rappresentarle graficamente in
modo da garantire una rapida comprensione da parte dell’utilizzatore. Si riporta di seguito un
esempio di utilizzo svolto Sfruttando un Simple Data già presente tra i dati di Watson
21
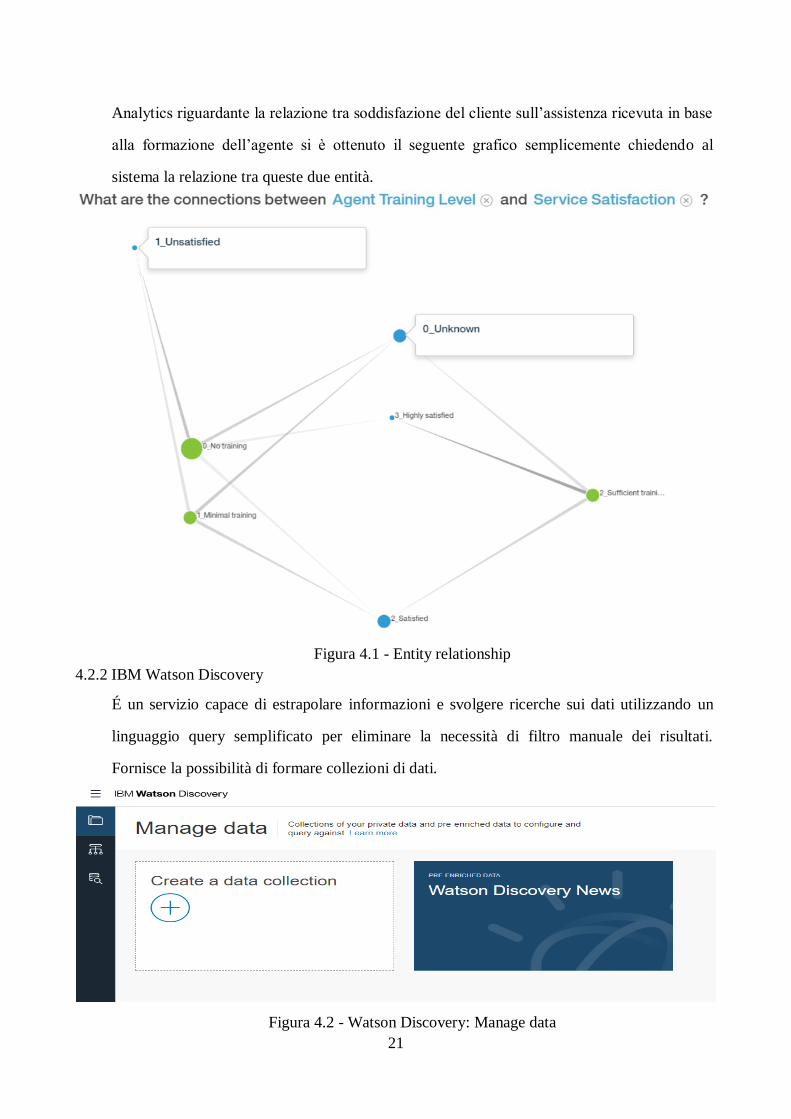
Analytics riguardante la relazione tra soddisfazione del cliente sull’assistenza ricevuta in base
alla formazione dell’agente si è ottenuto il seguente grafico semplicemente chiedendo al
sistema la relazione tra queste due entità.
Figura 4.1 - Entity relationship
4.2.2 IBM Watson Discovery
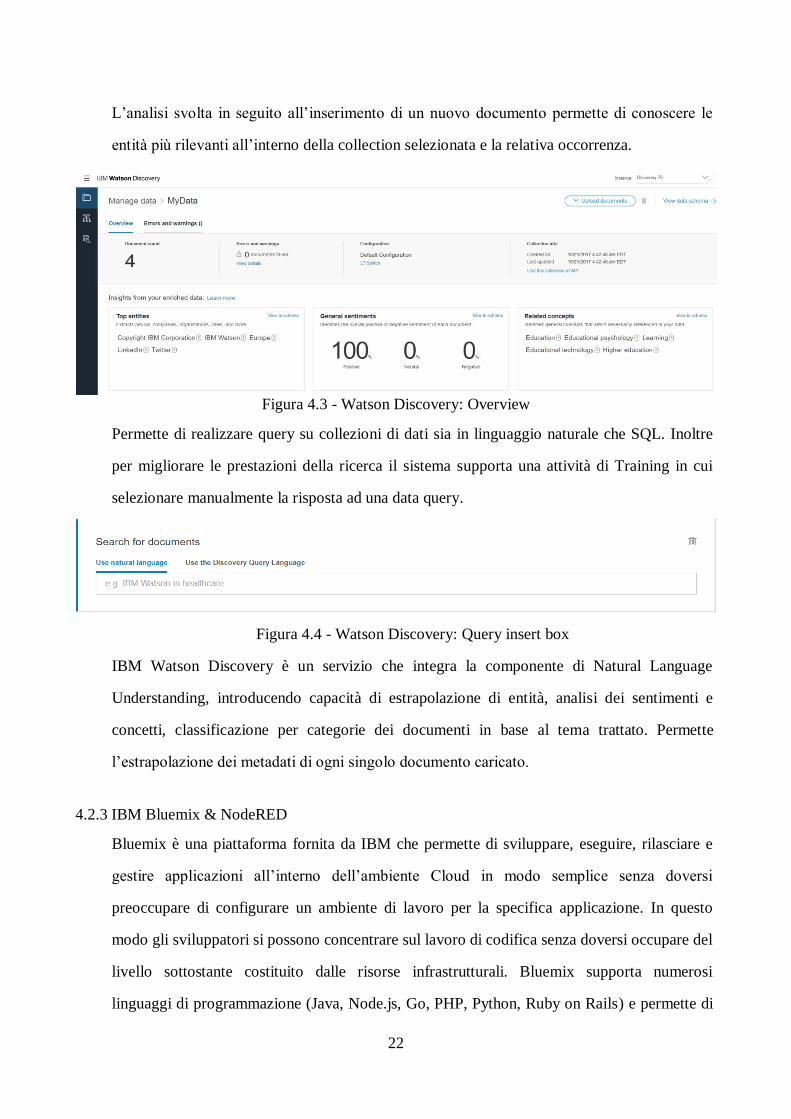
É un servizio capace di estrapolare informazioni e svolgere ricerche sui dati utilizzando un
linguaggio query semplificato per eliminare la necessità di filtro manuale dei risultati.
Fornisce la possibilità di formare collezioni di dati.
Figura 4.2 - Watson Discovery: Manage data
22
L’analisi svolta in seguito all’inserimento di un nuovo documento permette di conoscere le
entità più rilevanti all’interno della collection selezionata e la relativa occorrenza.
Figura 4.3 - Watson Discovery: Overview
Permette di realizzare query su collezioni di dati sia in linguaggio naturale che SQL. Inoltre
per migliorare le prestazioni della ricerca il sistema supporta una attività di Training in cui
selezionare manualmente la risposta ad una data query.
Figura 4.4 - Watson Discovery: Query insert box
IBM Watson Discovery è un servizio che integra la componente di Natural Language
Understanding, introducendo capacità di estrapolazione di entità, analisi dei sentimenti e
concetti, classificazione per categorie dei documenti in base al tema trattato. Permette
l’estrapolazione dei metadati di ogni singolo documento caricato.
4.2.3 IBM Bluemix & NodeRED
Bluemix è una piattaforma fornita da IBM che permette di sviluppare, eseguire, rilasciare e
gestire applicazioni all’interno dell’ambiente Cloud in modo semplice senza doversi
preoccupare di configurare un ambiente di lavoro per la specifica applicazione. In questo
modo gli sviluppatori si possono concentrare sul lavoro di codifica senza doversi occupare del
livello sottostante costituito dalle risorse infrastrutturali. Bluemix supporta numerosi
linguaggi di programmazione (Java, Node.js, Go, PHP, Python, Ruby on Rails) e permette di

23
integrarne altri attraverso dei buildpacks, insiemi di script per preparare l’esecuzione del
codice sul cloud. [18] NodeRED è una piattaforma messa a disposizione da Bluemix per la
programmazione Flow-Based che integra dei pacchetti per utilizzare le API di Watson. La
strategia cloud offerta da Bluemix è formata da numerose componenti tra cui spiccano il
Natural Language Undersanting e il Natural Language Classifier presentati brevemente di
seguito.
Natural Language Understanding
Si è sviluppata una semplice applicazione che estrapola da una pagina web le principali entità,
parole chiave, concetti, relazioni e ruoli semantici all’interno di una frase. Di seguito viene
riportato il Flusso dell’applicazione.
Figura 4.5 - Natural Language Understanding flow example
La comunicazione avviene attraverso una richiesta HTTP di tipo GET in cui viene inserito
come parametro l’URL della pagina web da analizzare ed eventualmente il formato della
richiesta nel caso di rappresentazione JSON. La richiesta viene inviata attraverso un
messaggio al Natural Language Undestanding (NLU). Il NLU è il nodo fondamentale per la
comunicazione con il servizio omonimo di Watson fornito da Bluemix. In base al formato
richiesto i risultati dell’analisi verranno rappresentati in formato JSON o in forma di tabelle
grazie al tamplate inserito nel nodo Display Content Analysis. [19]
Natural Language Classifier
É una semplice applicazione che utilizza la capacità di Watson di analizzare dati in forma
tabellare per estrapolare l’appartenenza ad una data categoria del messaggio inviato. Di
seguito è riportato il Flusso dell’applicazione.
Figura 4.6 - Natural Language Classifier training

24
Il primo passo è quello di aggiungere i dati relativi all’argomento su cui interrogare il sistema
in formato CSV. Il caricamento è stato fatto direttamente collegando il sistema alla cartella
dropbox che conteneva il file. In seguito alla richiesta il Natural Language Classifier (NCU)
processa il documento creando un Classifier a cui è associato un ID.
Figura 4.7 - Natural Language Classifier
il nodo NCU è il componente che permette la richiesta del servizio e il confornto con il
Classifier creato al passo precedente ottenuto associandone l’ID. L’input è scritto sotto forma
di String mentre l’output è mostrato a video all’interno della piattaforma Node-RED.
4.3 Watson Projects in Education
In molte parti del mondo il settore scolastico è in uno stato di fallimento non fornendo le
abilità necessarie ai giovani per addentrarsi nel mondo del lavoro. Lo scopo di IBM è quello
di introdurre nuovi tool come supporto per l’insegnamento che aiutino l’insegnante a capire i
pattern di apprendimento di ogni studente in modo da modificare il modo di insegnare a
favore di una migliore fruizione dei contenuti [20] affiancando alla figura dell’insegnante
quella di un assistente virtuale in grado di fornire un supporto per studenti e professori e
sollevando questi ultimi da attività onerose come la correzione di test facendo guadagnare
tempo per seguire gli studenti. In alcune università del mondo sono già presenti sistemi di
analisi in grado di segnalare gli studenti che abbandonano gli studi o sono a rischio di
abbandono. Con l’introduzione dei sistemi cognitivi e di Watson si potrebbe cambiare il
paradigma di insegnamento, da “one-to-many” a “one-to-one” permettendo di seguire
singolarmente gli studenti e di sviluppare metodi di insegnamento su misura in base a
specifici bisogni. In questo modo si ridurrà l’abbandono degli studi mantenendo gli studenti
motivati. Per usufruire delle potenzialità di Watson il sistema deve essere educato da un
ampio pool di dati. Da qui l’idea di organizzare una banca dati contenente informazioni
riguardanti il percorso educativo degli studenti. [21] Di seguito si presentano alcuni dei
progetti già avviati nel campo dell’istruzione da IBM.

25
4.3.1 IBM and Sesame Workshop
Per quanto riguarda l’educazione infantile IBM è in collaborazione con Sesame Workshop,
un’organizzazione non profit la cui missione è quella di aiutare i bambini a crescere più
intelligenti, forti e buoni [22], per trasformare l’educazione dei bambini. Questa partnership è
volta ad integrare il sistema IBM Watson e la tecnologia di cognitive computing con le
ricerche e la competenza nel campo della prima infanzia di Sesame sviluppando la tecnologia
necessaria per trasformare il modo in cui i bambini apprendono, sia a scuola che fuori. Con
questo supporto Sesame Workshop può sviluppare app, giochi e giocattoli educativi
sfruttando la potenza delle abilità cognitive di Watson per rendere l’apprendimento più
divertente e stimolante. Il primo frutto di questa associazione è una nuova cognitive app per
tablet che include contenuti e metodi alternativi di apprendimento come video educativi e
giochi basati sulle parole caratterizzate dai personaggi di Sesame Street come Grover e Elmo.
L’obbiettivo è quello di ampliare il vocabolario dei bambini dando la possibilità ai professori
di riportare i progressi raggiunti dagli alunni. [23] L’applicazione è stata inserita in un
esperimento condotto nelle scuole pubbliche di Gwinnett in Georgia dove la collaborazione
tra bambini e professori nell’utilizzo di questo diverso e stimolante sistema di insegnamento
sta portando risultati positivi nel processo di ampliamento del vocabolario dei bambini.
4.3.2 IBM and Pearson
Per quanto riguarda il campo universitario IBM collabora con Pearson, azienda impegnata nel
campo dell’editoria scolastica, per fornire un supporto tecnologico per aiutare gli studenti nel
loro percorso di studi. Avvicinando le capacità cognitive sviluppate dai sistemi di IBM al
mondo universitario di tutti i giorni si cerca di dare agli studenti una nuova esperienza di
apprendimento ottenuta affiancando al classico lavoro di studio un tutor artificiale, che
sfruttando le capacità cognitive di Watson, potrà comunicare in linguaggio naturale con lo
studente proprio come si farebbe un compagno di studi o un professore. IBM e Pearson
stanno producendo con delle API per Watson strumenti specifici di diagnostica per
l’educazione e capacità di recupero. Grazie ad esse Watson sarà in grado di cercare attraverso
un proprio set di risorse informazioni utili per rispondere alle domande degli studenti. Watson
potrà definire le conoscenze dello studente in base al dialogo identificando dubbi e

26
fraintendimenti, e ampliarle suggerendo le tematiche da approfondire. Con uno strumento del
genere lo studente avrà anche un metro per comprendere il proprio livello di preparazione. In
base al percorso di studi scelto Watson potrà aiutare lo studente nell’organizzare il proprio
studio, risolvere le lacune riducendo sia il tempo necessario a completare gli studi sia il
rischio di abbandono che negli ultimi tempi è sempre più frequente. Dal punto di vista dei
professori Watson potrà fornire consigli su come impostare le lezioni in base ai dati raccolti,
ai punti di forza e di debolezza degli studenti. [24]
4.3.3 Watson Classroom: IBM and Coppel ISD
Una delle collaborazioni più promettenti è quella tra IBM e Coppel ISD. La Coppel
Indpendent School District è una scuola pubblica ad alto rendimento situata nei pressi di
Dallas che conta circa 12.500 studenti di tutte le età di molte comunità etniche differenti.
Quello che caratterizza la Coppel ISD come partner ideale per IBM nella sua missione è
proprio l’impegno della scuola allo sviluppo di metodi innovativi per l’insegnamento. Prima
di introdurre Watson nel percorso scolastico la scuola ha svolto una serie di sondaggi e
interviste ad insegnanti e amministratori scolastici per capire le principali difficoltà che i
professori devono affrontare giornalmente. Da queste indagini è emerso, secondo i professori,
che, a causa della grande velocità con cui si sviluppano le informazioni, esse risultano
ingestibili e che l’utilizzo della tecnologia come supporto all’insegnamento risulta
inutilizzabile a causa della mancanza di un sistema di raccolta dati e integrazione con sistemi
cartacei o con altre tecnologie, oltre alla mancanza di interfacce intuitive e di conseguenza la
necessità di corsi di training per utilizzarle. L’introduzione del progetto di IBM Watson
Education calza perfettamente con ciò che è emerso dai sondaggi poiché utilizzando la
tecnologia cognitiva è possibile comunicare con il sistema in linguaggio naturale, ottimizzare
e personalizzare il percorso degli studenti utilizzando un unico tool che, grazie alle sue
capacità di “deep learning”, propone soluzioni in pochissimo tempo, permettendo al
professore di scegliere in realtime senza più bisogno di ore e ore di studio e approfondimento.
Per introdurre le abilità di Watson, IBM e Coppell hanno previsto un set di app in modo da
aiutare i professori. Il progetto IBM Watson Education è iniziato nel 2013 con Watson

27
Classroom e ha avuto una grande accelerazione grazie alla partnership con Apple nel 2014. Si
sono così sviluppati due tool fondamentali: IBM Watson Element e IMB Watson Enlight con
lo scopo di:
Avvisare gli insegnanti di cambiamenti nelle performance degli studenti.
Condivide informazioni tra classi e insegnanti.
Migliorare l’apprendimento delle classi e trovare più tempo per gli studenti.
Permettere alla scuola di individuare e personalizzare più facilmente il programma.
IBM Watson Element
IBM Watson Element è un’app iOS sviluppata per iPad che dà la possibilità all’insegnante di
monitorare costantemente i progressi dei singoli studenti in modo da poter intervenire subito
in base ai loro bisogni. Permette di inserire osservazioni sugli studenti come interessi o
progressi condividendoli con gli altri professori.
IBM Watson Enlight
IBM Watson Enlight è un servizio browser che integra capacità cognitive e di analisi per
identificare un percorso su misura per ogni studente utilizzando dati accademici, demografici
e quelli raccolti mediante l’applicazione Watson Element.
Watson Education Insights Cloud
Tutti i dati prodotti da Watson Element e Watson Enlight sono depositati in un cloud comune
per migliorare l’analisi svolte dal sistema. Lo scopo è quello di creare un cloud unico a tutte
le applicazioni create da IBM Watson for Education, comprese quelle in collaborazione con
Sesame Street e Pearson, per connettere tutte le fasi del percorso di apprendimento degli
studenti in modo da rendere l’apprendimento cognitivo più efficiente e conveniente dando la
possibilità di sviluppare biblioteche e tutoraggi cognitivi. [25]

28
Conclusioni
Il cognitive computing sta cambiando il modo di approcciarsi al mondo entrando, sempre di
più, a far parte della realtà di tutti i giorni. I sistemi cognitivi con le innumerevoli capacità di
cui sono dotati possono risolvere problemi di analisi utilizzando dati in formati eterogenei
sollevando l’uomo dall’onere di doverli allineare per sfruttare i sistemi di analisi odierni,
fornendo interfacce in linguaggio naturale rendendo l’utilizzo di questi servizi semplice come
parlare con qualcuno. Dalla prima comparsa del sistema Watson nel 2011, l’introduzione dei
sistemi cognitivi si è diffusa a macchia d’olio nelle aziende e nei servizi pubblici dando vita
ad una “collaborazione” tra uomo e macchina senza precedenti. L’obiettivo più recente di
IBM è quello di introdurre le capacità dei sistemi cognitivi nell’istruzione avviando progetti
con diverse scuole per valutarne i risultati, già abbastanza positivi, per migliorare il campo
dell’istruzione cambiando il paradigma tradizionale di insegnamento. Si è discusso di
numerosi servizi che possono affiancare studenti e insegnanti portando allo sviluppo di una
società sempre più preparata a risolvere problemi. Si sono presentati diversi strumenti che
permettono di analizzare dati strutturati e non strutturati per aiutare lo sviluppo delle capacità
negli studenti rimandando ad uno strumento il compito di catalogare, correggere e analizzare
contenuti. A titolo di esempio si sono analizzate due semplici applicazioni che utilizzano i
servizi di Natural Language Understanding e Classifier di Watson per analizzare i dati
sfruttando le API Watson. Questi sistemi sono alla base delle applicazioni presentate
precedentemente di Watson Analysis e Discovery. L’utilizzo di questi strumenti nell’ambito

29
scolastico/universitario può aprire a nuove opportunità. Infatti l’utilizzo della comprensione
del linguaggio naturale di Watson introduce numerose applicazioni che permetteranno di:
analizzare diversi tipi di fonti sottolineando le relazioni tra le entità in gioco
permettendo a studenti ed insegnanti di scorgere diverse relazioni tra concetti ed
entità.
usare i dati sociali e studenteschi per migliorare le prestazioni degli studenti e
monitorare quelli ad alto rischio
analizzare le statistiche delle performance degli studenti nei test per comprendere se è
necessario soffermarsi di più su alcuni argomenti invece che su altri in base ai risultati
ottenuti in uno specifico esame o in un arco di tempo più lungo.
L’innovazione nell’istruzione raggiunta con questi nuovi tool consentirà di sviluppare
persone sempre più preparate e porterà a una richiesta sempre maggiore di personale che
sappia utilizzare i nuovi strumenti dando la possibilità di sviluppare nuovi corsi che
introducano Watson e i sistemi cognitivi agli studenti, ampliandone le conoscenze e
risolvendo il gap tra ciò che viene insegnato al giorno d’oggi e quello che è richiesto dal
mondo del lavoro, aumentando le possibilità lavorative per lo sviluppo di una società
migliore.

30
Bibliografia
[1] J. E. Kelly III, “Computing, cognition and the future of knowing.”, pagine 2-4,
10/2015
[2] “Scienze Cognitive” https://it.wikipedia.org/wiki/Scienze_cognitive,
Accessed 05/11/2017
[3] Roberto Vergani, “Cognitive Computing: che cos’è?”, 03/08/2016
[4] “Cognitive computing” https://en.wikipedia.org/wiki/Cognitive_computing,
Accessed 05/11/2017
[5] “IBM”, http://www.research.ibm.com/cognitive-computing/, Accessed 10/09/2017
[6] Nicoletta Boldrini, “Intelligenza Artificiale e Cognitive Computing: i nuovi
orizzonti”, ZeroUno, 26/09/2016
[7] “QUESTION-ANSWERING SYSTEMS”
http://di.unipi.it/~cappelli/seminari/brinchigiusti2.pdf, Accessed 11/09/2017
[8] “A Survey on Question Answering System”, pagine 7-11,
http://www.cfilt.iitb.ac.in/resources/surveys/Question%20Answering%20Survey-
biplab.pdf
[9] “Watson (intelligenza artificiale)”,
https://it.wikipedia.org/wiki/Watson_(intelligenza_artificiale), Accessed 05/11/2017
[10] Ferrucci, Brown, Chu-Carroll, Fan, Gondek, Kalyanpur, Lally, Murdock, Nyberg,
Prager, Schlaefer, Welty, “Building Watson: An Overview of the DeepQA Project”
[11] Ferrucci, “Introduction to “This is Watson””, volume 56, pagina 10, 05-07/2012
[12] “Industria 4.0”, https://it.wikipedia.org/wiki/Industria_4.0, Accessed 05/11/2017
[13] “La nuova frontiera del cognitive computing”,

31
https://www.wired.it/attualita/tech/2014/05/23/la-nuova-frontiera-del-cognitive-
computing/, Accessed 05/11/2017
[14] Coccoli, Maresca, Stanganelli, “Cognitive Computing in Education”, volume 12,
pagine 62-63, 05/2016
[15] Franceschini, Soares, Montaño, “Watson Concept Insights a Conceptual Association
Framework”, pagine 179-180, 04/2016
[16] “IBM Watson Ecosystem Getting Started Guide”, pagine 1-16, 07/2014
[17] “IBM Watson Analytics”, https://www.ibm.com/watson-analytics, 05/11/2017
[18] “Bluemix” https://it.wikipedia.org/wiki/Bluemix, Accessed 05/11/2017
[19] Bisson, “Natural Language Understanding in Node-RED”
[20] “EDUCATION IN THE COGNITIVE ERA”,
https://www-01.ibm.com/common/ssi/cgi-bin/ssialias?htmlfid=EDI03007USEN&
[21] King, Cave, Foden, Stent, “Personalized Education white paper”, 04/2016
[22] “sesameworkshop”,
http://www.sesameworkshop.org/about-us/workshop-at-a-glance/,
Accessed 11/09/2017
[23] “IBM Education Industry Blog”,
https://www.ibm.com/blogs/insights-on-business/education/cognitive-education-
announcement/, Accessed 12/09/2017
[24] “IBM Watson Education and Pearson to Drive Cognitive Learning Experiences for
College Students”, http://www-03.ibm.com/press/us/en/pressrelease/50842.wss,
Accessed 12/09/2017
[25] Brooks, McCarthy, “IBM Watson at Coppell White Paper”, 07/2017





























